HTML
現行標準 — 最終更新 2026年7月20日
現行標準 — 最終更新 2026年7月20日
a
要素em
要素strong要素small
要素s
要素cite
要素q
要素dfn
要素abbr
要素ruby
要素rt
要素rp
要素data
要素time
要素code
要素var
要素samp
要素kbd
要素sub要素とsup要素i
要素b
要素u
要素mark
要素bdi
要素bdo
要素span
要素br
要素wbr
要素a要素およびarea要素によって
作成されるリンクa要素およびarea要素のAPIalternate」
author」
bookmark」canonical」dns-prefetch」expect」
external」
help」icon」license」manifest」modulepreload」nofollow」
noopener」
noreferrer」opener」
pingback」preconnect」prefetch」preload」privacy-policy」search」
stylesheet」tag」terms-of-service」picture要素
source要素img
要素source、
img、
およびlink
要素に共通する属性
iframe要素embed
要素object要素video 要素audio 要素track
要素TrackEvent
インターフェイスmap
要素area
要素form
要素label
要素input
要素
type属性の状態
type=hidden)
type=text)状態および検索状態(type=search)type=tel)
type=url)type=email)type=password)type=date)type=month)type=week)type=time)type=datetime-local)type=number)
type=range)
type=color)type=checkbox)type=radio)
type=file)type=submit)
type=image)
type=reset)type=button)
input要素の
属性
input要素APIbutton
要素select
要素datalist 要素
optgroup 要素
option
要素
textarea 要素
output
要素
progress 要素
meter
要素fieldset 要素
legend
要素
selectedcontent 要素script要素
noscript要素
template要素
slot
要素canvas要素
Path2D オブジェクト
ImageBitmap
レンダリングコンテキスト
OffscreenCanvas
インターフェイス
canvas
要素のセキュリティWindow、
WindowProxy、および Location オブジェクトのセキュリティ基盤
Window オブジェクト
WindowProxy
エキゾチックオブジェクト
Location インターフェイス
History インターフェイス
NotRestoredReasons
インターフェイスX-Frame-Options` ヘッダー
Refresh` ヘッダーWindowOrWorkerGlobalScope
ミックスインbutton 要素
details および
summary
要素input
要素input
要素input 要素input 要素input
要素input
要素input
要素marquee 要素
meter 要素
progress 要素select 要素
textarea 要素この仕様は、ウェブプラットフォームの大部分を詳細に定義する。ウェブプラットフォームの仕様体系における、 他の仕様との相対的な位置付けは、次のように要約するのが最も適切である:
この節は非規範的である。
簡潔に言えば:そうである。
より詳しく言えば、「HTML5」という用語は、現代のウェブ技術を指す流行語として広く使用されており、 その多く(ただし、決してすべてではない)が WHATWG で開発されている。この文書はそのような仕様の 1 つであり、その他の仕様は WHATWG 標準の 概要から入手できる。
この節は非規範的である。
HTML は World Wide Web の中核となるマークアップ言語である。HTML は当初、主に科学文書を 意味論的に記述するための言語として設計された。しかし、その汎用的な設計により、その後の年月を通じて、 その他のさまざまな種類の文書、さらにはアプリケーションを記述するためにも適応されてきた。
この節は非規範的である。
この仕様は、この仕様で定義される機能を使用する文書およびスクリプトの作者、 この仕様で定義される機能を使用するページを処理するツールの実装者、ならびに この仕様の要件に照らして文書または実装の正しさを確認しようとする人を対象としている。
この文書は、ウェブ技術について少なくとも多少の知識をすでに持っていない読者には、 おそらく適していない。これは、箇所によっては明瞭さよりも正確さを、簡潔さよりも完全性を 優先しているためである。より親しみやすいチュートリアルやオーサリングガイドによって、 この主題をより穏やかに紹介できる。
特に、この仕様のより技術的な部分を完全に理解するには、DOM の基本に関する知識が必要である。 Web IDL、HTTP、XML、Unicode、文字エンコーディング、JavaScript、および CSS に関する理解も、 箇所によっては役立つが、必須ではない。
この節は非規範的である。
この仕様は、静的文書から動的アプリケーションまでの、ウェブ上のアクセシブルなページを作成するための 意味論レベルのマークアップ言語と、それに関連する意味論レベルのスクリプト API を提供することに限定される。
この仕様の適用範囲には、メディア固有の表示のカスタマイズ機構を提供することは含まれない (ただし、ウェブブラウザー向けの既定のレンダリング規則はこの仕様の末尾に含まれ、 CSS と連携するためのいくつかの機構が言語の一部として提供される)。
この仕様の目的は、オペレーティングシステム全体を記述することではない。特に、 ハードウェア構成ソフトウェア、画像操作ツール、およびユーザーが高性能ワークステーションで 日常的に使用することが想定されるアプリケーションは適用範囲外である。アプリケーションに関して、 この仕様は、ユーザーが時折使用することが想定されるか、または定期的ではあるが異なる場所から使用され、 CPU 要件が低いアプリケーションを特に対象としている。そのようなアプリケーションの例には、 オンライン購入システム、検索システム、ゲーム(特にマルチプレイヤーオンラインゲーム)、 公開電話帳または住所録、通信ソフトウェア(電子メールクライアント、インスタントメッセージング クライアント、ディスカッションソフトウェア)、文書編集ソフトウェアなどが含まれる。
この節は非規範的である。
最初の 5 年間(1990~1995 年)、HTML は多数の改訂と拡張を経た。それらは主として、 最初は CERN で、その後は IETF で管理された。
W3C の設立に伴い、HTML の開発場所は再び変更された。1995 年に HTML 3.0 として知られる HTML 拡張の最初の試みが頓挫した後、HTML 3.2 として知られる、より実用的なアプローチへと移行し、 これは 1997 年に完成した。同年後半には、すぐに HTML4 が続いた。
翌年、W3C 会員は HTML の発展を停止し、代わりに XHTML と呼ばれる XML ベースの同等物の 作業を開始することを決定した。この取り組みは、XHTML 1.0 として知られる、HTML4 の XML による 再定式化から始まった。これは新しいシリアライズ以外の新機能を追加せず、2000 年に完成した。 XHTML 1.0 の後、W3C の焦点は、XHTML Modularization の名の下で、他の作業グループが XHTML を拡張しやすくすることへ移った。これと並行して、W3C は以前の HTML および XHTML 言語と 互換性のない新しい言語にも取り組み、それを XHTML2 と呼んだ。
HTML の発展が 1998 年に停止された頃、ブラウザーベンダーによって開発された HTML 用 API の一部は、 DOM Level 1(1998 年)、DOM Level 2 Core、および DOM Level 2 HTML(2000 年に開始され、 2003 年に完了)の名称で仕様化され公開された。これらの取り組みはその後衰退し、2004 年には いくつかの DOM Level 3 仕様が公開されたものの、Level 3 のすべての草案が完成する前に 作業グループは閉鎖された。
2003 年、次世代ウェブフォームとして位置付けられた技術である XForms の公開により、 HTML の代替物を探すのではなく、HTML 自体を発展させることへの関心が再燃した。この関心は、 ウェブ技術としての XML の展開が、既存の展開済み技術(HTML など)の代替ではなく、 完全に新しい技術(RSS や後の Atom など)に限定されているとの認識から生じた。
ブラウザーに既存の HTML ウェブページと互換性のないレンダリングエンジンの実装を要求せずに、 HTML4 のフォームを拡張して XForms 1.0 が導入した多くの機能を提供できることを示す概念実証が、 この再燃した関心の最初の成果であった。この初期段階では、草案はすでに一般公開され、 あらゆる方面から意見が募集されていたものの、仕様の著作権は Opera Software のみに帰属していた。
HTML の発展を再開すべきであるという考えは、2004 年の W3C ワークショップで検討された。 そこでは、HTML5 の作業を支えるいくつかの原則(後述)と、前述したフォーム関連機能のみを扱う 初期草案提案が、Mozilla と Opera によって共同で W3C に提示された。この提案は、 ウェブの発展について以前に選択された方向性と衝突するという理由で却下され、 W3C のスタッフと会員は、代わりに XML ベースの代替物の開発を継続することを決議した。
その直後、Apple、Mozilla、および Opera は、WHATWG と呼ばれる新しい場の下で、 この取り組みを継続する意向を共同で発表した。公開メーリングリストが作成され、 草案は WHATWG のサイトへ移された。その後、著作権は 3 社すべての共同所有となるよう修正され、 仕様の再利用が許可された。
WHATWG は、いくつかの中核原則に基づいていた。特に、技術は後方互換性を持つ必要があること、 たとえ実装ではなく仕様を変更することになっても、仕様と実装は一致する必要があること、 そして実装同士が相互にリバースエンジニアリングを行わなくても完全な相互運用性を達成できるほど、 仕様は十分に詳細である必要があることが挙げられる。
特に最後の要件により、HTML5 仕様の適用範囲には、それまで 3 つの別個の文書、 すなわち HTML4、XHTML1、および DOM2 HTML で仕様化されていた内容を含める必要があった。 また、以前に標準と考えられていたものよりも、はるかに多くの詳細を含める必要もあった。
2006 年、W3C は最終的に HTML5 の開発への参加に関心を示し、2007 年には WHATWG と協力して HTML5 仕様を開発することを任務とする作業グループを設立した。Apple、Mozilla、および Opera は、 WHATWG サイト上ではより制限の少ないライセンスの版を維持しながら、W3C が W3C の著作権の下で 仕様を公開することを許可した。
その後、両グループは数年間にわたって共同作業を行った。しかし 2011 年、両グループは 目標が異なるとの結論に達した。W3C は「HTML5」の「完成」版を公開することを望んだ一方、 WHATWG は HTML の現行標準に引き続き取り組み、既知の問題がある状態で仕様を凍結するのではなく 継続的に保守し、プラットフォームを発展させるため必要に応じて新機能を追加することを望んだ。
2019 年、WHATWG と W3C は、今後 HTML の単一の版、すなわちこの文書について協力するための 合意に署名した。
この節は非規範的である。
HTML の多くの側面が、一見すると無意味で一貫性がないように見えることは認めなければならない。
HTML、その補助 DOM API、および多くの補助技術は、異なる優先事項を持ち、 多くの場合は互いの存在を知らなかった多種多様な人々によって、数十年にわたって開発されてきた。
そのため、機能は多くの情報源から生まれ、必ずしも特に一貫した方法で設計されてきたわけではない。 さらに、ウェブの独特な特性により、実装のバグは、修正される前にコンテンツが意図せずそれらに 依存する形で記述されることが多いため、しばしば事実上の標準となり、現在では法的な標準となっている。
それにもかかわらず、一定の設計目標に従うための努力がなされてきた。 これらについては、次のいくつかの小節で説明する。
この節は非規範的である。
ウェブ作者をマルチスレッドの複雑さにさらすことを避けるため、HTML および DOM API は、 いかなるスクリプトも他のスクリプトの同時実行を検出できないように設計されている。 ワーカーを使用する場合でも、 実装の動作は、すべてのグローバルにおけるすべてのスクリプトの実行を完全に直列化するものとして 考えられることが意図されている。
この一般的な設計原則の例外は、JavaScript の SharedArrayBuffer
クラスである。SharedArrayBuffer
オブジェクトを使用すると、他の
エージェント内のスクリプトが同時に実行されていることを実際に観測できる。
さらに、JavaScript のメモリモデルにより、直列化されたスクリプト実行では表現できないだけでなく、
それらのスクリプト間で直列化された文の実行でも表現できない状況が存在する。
この節は非規範的である。
HTML には、意味論を安全な方法で追加するために使用できる、幅広い拡張機構がある:
作者は、class 属性を使用して要素を拡張し、
事実上独自の要素を作成できる。その際、最も適切な既存の「実際の」HTML 要素を使用することで、
その拡張を認識しないブラウザーやその他のツールでも、ある程度適切にサポートできる。
これは、たとえば microformats で使用される方法である。
作者は、インラインのクライアント側スクリプトまたはサーバー側のサイト全体のスクリプトが処理する
データを、data-*=""
属性を使用して含めることができる。これらはブラウザーによって一切変更されないことが保証されており、
スクリプトが後で検索して処理できるデータを HTML 要素に含められる。
作者は、<meta name="" content="">
機構を使用して、ページ全体のメタデータを含めることができる。
作者は、rel=""
機構を使用し、事前定義されたリンク型の集合への拡張を登録することで、
リンクに特定の意味を注釈として付けることができる。これは microformats でも使用される。
作者は、カスタム型を指定した <script type="">
機構を使用して、生データを埋め込み、インラインまたはサーバー側のスクリプトでさらに処理できる。
作者は、JavaScript のプロトタイピング機構を使用して API を拡張できる。 これは、たとえばスクリプトライブラリーで広く使用されている。
作者は、マイクロデータ機能(itemscope="" および
itemprop=""
属性)を使用して、他のアプリケーションやサイトと共有する、入れ子になった名前と値のペアの
データを埋め込むことができる。
作者は、HTML の語彙を拡張するために、カスタム 要素を定義、共有、および使用できる。有効なカスタム要素名の要件は、前方互換性を保証する (将来、ハイフンを含むローカル名を持つ要素が HTML、SVG、または MathML に追加されることはないため)。
この節は非規範的である。
この仕様は、文書およびアプリケーションを記述するための抽象言語と、 この言語を使用するリソースのメモリ内表現と対話するためのいくつかの API を定義する。
このメモリ内表現は「DOM HTML」、略して「DOM」と呼ばれる。
この抽象言語を使用するリソースを転送するために使用できる具体的な構文はいくつかあり、 そのうち 2 つがこの仕様で定義される。
最初の具体的な構文は HTML 構文である。これは、ほとんどの作者に推奨される形式である。
ほとんどの旧来のウェブブラウザーと互換性がある。文書が
text/html MIME 型で転送された場合、
ウェブブラウザーによって HTML 文書として処理される。この仕様は、単に「HTML」と呼ばれる
最新の HTML 構文を定義する。
2 番目の具体的な構文は XML である。文書が XML MIME
型、たとえば application/xhtml+xml
で転送された場合、ウェブブラウザーでは XML 文書として扱われ、XML プロセッサーによって構文解析される。
作者は、XML と HTML では処理が異なることに注意する必要がある。特に、XML として示された文書では、
わずかな構文エラーであっても文書全体のレンダリングを妨げるが、HTML 構文では無視される。
HTML の XML 構文は、以前は「XHTML」と呼ばれていたが、この仕様ではその用語を使用しない (理由の 1 つは、MathML および SVG の HTML 構文に対してそのような用語が使用されていないためである)。
DOM、HTML 構文、および XML 構文は、すべて同じ内容を表現できるわけではない。
たとえば、名前空間は HTML 構文では表現できないが、DOM および XML 構文ではサポートされる。
同様に、noscript 機能を使用する文書は
HTML 構文では表現できるが、DOM または XML 構文では表現できない。
文字列「-->」を含むコメントは、DOM でのみ表現でき、HTML および XML 構文では表現できない。
この節は非規範的である。
この仕様は、次の主要な節に分かれている:
EventSource
として知られるサーバープッシュイベントストリーム機構と、Web Sockets として知られる
スクリプト用の双方向全二重ソケットプロトコルも紹介する。
さらに、廃止された機能および IANA に関する考慮事項を 列挙するいくつかの附属書と、複数の索引がある。
この仕様は、他のすべての仕様と同様に読むべきである。まず、最初から最後まで複数回読む。 次に、少なくとも一度は逆順に読む。その後、目次から無作為に節を選び、すべての相互参照をたどりながら読む。
後述する適合性要件の節で説明するように、この仕様はさまざまな適合性クラスに対する 適合性基準を記述する。特に、作者や作者が作成する文書などの生成者に適用される 適合性要件と、ウェブブラウザーなどの消費者に適用される適合性要件がある。 これらは、何を要求しているかによって区別できる。生成者に対する要件は何が許可されるかを示し、 消費者に対する要件はソフトウェアがどのように動作するかを示す。
たとえば、「foo 属性の値は
有効な
整数でなければならない」という記述は、許可される値を示しているため、生成者に対する要件である。
これに対して、「foo 属性の値は
整数を
構文解析する規則を使用して構文解析しなければならない」という要件は、
コンテンツをどのように処理するかを説明しているため、消費者に対する要件である。
生成者に対する要件は、消費者には一切影響しない。
上記の例を続けると、特定の属性値が 有効な 整数に制約されるという要件は、消費者に対する要件について何も意味しない。 実際には、消費者が、その値が要件に適合するかどうかにまったく影響されず、 その属性を不透明な文字列として扱うよう要求される可能性がある。または、前の例のように、 無効な値(この場合は数値でない値)をどのように処理するかを定義する特定の規則を使用して、 値を構文解析するよう消費者に要求される可能性もある。
これは定義、要件、または説明である。
これは注記である。
これは例である。
これは未解決の Issue である。
これは警告である。
[Exposed =Window ]
interface Example {
// this is an IDL definition
};variable = object.method([optionalArgument])
これは、インターフェイスの使用方法を説明する作者向けの注記である。
/* this is a CSS fragment */ 用語を定義する箇所は、このようにマークアップされる。その用語の使用箇所は、 このように、または このようにマークアップされる。
要素、属性、または API を定義する箇所は、このようにマークアップされる。
その要素、属性、または API への参照は、
このようにマークアップされる。
その他のコード断片は、このようにマークアップされる。
変数は、このようにマークアップされる。
アルゴリズムでは、同期 セクション内の手順には ⌛ が付けられる。
場合によっては、要件は条件とそれに対応する要件を含むリストの形式で示される。 そのような場合、ある条件に適用される要件は、その要件に複数の条件群がある場合であっても、 常にその条件の後に続く最初の要件群である。そのような場合は、次のように示される:
この節は非規範的である。
基本的な HTML 文書は、次のようになる:
<!DOCTYPE html>
< html lang = "en" >
< head >
< title > Sample page</ title >
</ head >
< body >
< h1 > Sample page</ h1 >
< p > This is a < a href = "demo.html" > simple</ a > sample.</ p >
<!-- this is a comment -->
</ body >
</ html > HTML 文書は、要素とテキストのツリーから構成される。各要素は、ソース内で
「<body>」などの
開始タグと、
「</body>」などの
終了タグによって示される。
(特定の開始タグおよび終了タグは、場合によっては
省略でき、
他のタグによって暗黙的に補われる。)
タグは、要素同士が重なることなく、すべて完全に互いの内側に収まるように入れ子にしなければならない:
< p > This is < em > very < strong > wrong</ em > !</ strong ></ p > < p > This < em > is < strong > correct</ strong > .</ em ></ p > この仕様は、HTML で使用できる要素の集合と、要素を入れ子にできる方法に関する規則を定義する。
要素は、その動作を制御する属性を持つことができる。次の例には、a 要素とその href 属性を
使用して形成された ハイパーリンクがある:
< a href = "demo.html" > simple</ a > 属性は開始タグの内側に配置され、
「=」文字で区切られた
名前と
値から構成される。
属性値に ASCII
空白、または "、'、`、=、<、
> のいずれも含まれない場合、属性値は
引用符なしのままにできる。それ以外の場合は、単一引用符または二重引用符で
囲まなければならない。値が空文字列の場合、値は「=」文字とともに完全に省略できる。
<!-- empty attributes -->
< input name = address disabled >
< input name = address disabled = "" >
<!-- attributes with a value -->
< input name = address maxlength = 200 >
< input name = address maxlength = '200' >
< input name = address maxlength = "200" > HTML ユーザーエージェント(たとえばウェブブラウザー)は、このマークアップを構文解析し、 DOM(Document Object Model)ツリーへ変換する。DOM ツリーは、文書のメモリ内表現である。
DOM ツリーには複数の種類のノードが含まれ、特に DocumentType
ノード、
Element
ノード、Text
ノード、Comment
ノード、および場合によっては
ProcessingInstruction
ノードが含まれる。
この節の冒頭にあるマークアップ断片は、 次の DOM ツリーへ変換される:
このツリーの 文書要素は html 要素であり、
HTML 文書では常にこの位置にある要素である。これは、head と body の 2 つの要素と、
それらの間にある Text
ノードを含む。
DOM ツリーには、最初に予想されるよりもはるかに多くの Text
ノードが含まれる。これは、ソースに多数の空白(ここでは「␣」で表す)と改行(「⏎」)が含まれ、
それらがすべて DOM 内の Text
ノードになるためである。ただし、歴史的な理由により、元のマークアップ内のすべての空白と改行が
DOM に現れるわけではない。特に、head 開始タグの前の
すべての空白は黙って破棄され、body 終了タグの後の
すべての空白は、body
の末尾に配置される。
head 要素は
title
要素を含み、その要素自体がテキスト「Sample page」を持つ
Text
ノードを含む。同様に、body
要素は、
h1
要素、p 要素、
およびコメントを含む。
この DOM ツリーは、ページ内のスクリプトから操作できる。スクリプト(通常は JavaScript)は、
script
要素または イベント
ハンドラーコンテンツ属性を使用して埋め込める小さなプログラムである。たとえば次は、
フォームの output
要素の値を
「Hello World」に設定するスクリプトを持つフォームである:
< form name = "main" >
Result: < output name = "result" ></ output >
< script >
document. forms. main. elements. result. value = 'Hello World' ;
</ script >
</ form > DOM ツリー内の各要素はオブジェクトによって表され、これらのオブジェクトには操作のための API がある。
たとえば、リンク(上記のツリー内の a
要素など)は、
その「href」属性を
複数の方法で変更できる:
var a = document. links[ 0 ]; // obtain the first link in the document
a. href = 'sample.html' ; // change the destination URL of the link
a. protocol = 'https' ; // change just the scheme part of the URL
a. setAttribute( 'href' , 'https://example.com/' ); // change the content attribute directly DOM ツリーは、実装(特にウェブブラウザーのようなインタラクティブな実装)が HTML 文書を処理し、 表示するときの表現方法として使用されるため、この仕様は、上記のマークアップではなく、 主として DOM ツリーを基準として記述されている。
HTML 文書は、インタラクティブなコンテンツをメディアに依存せず記述する。 HTML 文書は、画面、音声合成装置、または点字ディスプレイにレンダリングされる可能性がある。 そのようなレンダリングが正確にどのように行われるかへ影響を与えるため、作者は CSS などの スタイル言語を使用できる。
次の例では、CSS を使用してページを青地に黄色としている。
<!DOCTYPE html>
< html lang = "en" >
< head >
< title > Sample styled page</ title >
< style >
body { background : navy ; color : yellow ; }
</ style >
</ head >
< body >
< h1 > Sample styled page</ h1 >
< p > This page is just a demo.</ p >
</ body >
</ html > HTML の使用方法に関する詳細については、作者はチュートリアルおよびガイドを参照することが推奨される。 この仕様に含まれるいくつかの例も役立つ可能性があるが、この仕様は必然的に、最初は理解するのが 難しい可能性のある詳細さで言語を定義しているため、初心者の作者は注意する必要がある。
この節は非規範的である。
HTML を使用してインタラクティブなサイトを作成する場合、攻撃者がサイト自体またはサイトのユーザーの 完全性を侵害できる脆弱性を持ち込まないよう注意する必要がある。
この問題の包括的な研究は、この文書の適用範囲を超えているため、作者にはこの問題をさらに詳細に 学習することを強く推奨する。ただし、この節では、HTML アプリケーション開発における一般的な落とし穴の 一部を簡単に紹介する。
ウェブのセキュリティモデルは「オリジン」の概念に基づいており、それに対応して、 ウェブ上の潜在的な攻撃の多くはクロスオリジンの操作を伴う。[ORIGIN]
テキストコメントなどのユーザー生成コンテンツ、URL パラメーター内の値、第三者サイトからの メッセージなど、信頼できない入力を受け入れる場合、データを使用前に検証し、表示時に適切に エスケープすることが不可欠である。これを怠ると、悪意のあるユーザーは、負の年齢などの偽の ユーザー情報を提供する比較的無害なものから、その情報を含むページをユーザーが見るたびに スクリプトを実行し、その過程で攻撃を拡散する可能性のある深刻なもの、さらにはサーバー上の すべてのデータを削除するような壊滅的なものまで、さまざまな攻撃を実行できる。
ユーザー入力を検証するフィルターを記述する場合、フィルターは常にセーフリストに基づき、 安全であることが既知の構造のみを許可し、その他すべての入力を禁止することが不可欠である。 既知の悪い入力を禁止して、それ以外をすべて許可するブロックリストベースのフィルターは安全ではない。 悪いもののすべてがまだ知られているわけではないためである(たとえば、将来発明される可能性がある)。
たとえば、あるページが URL のクエリー文字列を確認して何を表示するかを決定し、 サイトがメッセージを表示するためにユーザーをそのページへリダイレクトするとする:
< ul >
< li >< a href = "message.cgi?say=Hello" > Say Hello</ a >
< li >< a href = "message.cgi?say=Welcome" > Say Welcome</ a >
< li >< a href = "message.cgi?say=Kittens" > Say Kittens</ a >
</ ul > メッセージがエスケープされずにそのままユーザーへ表示される場合、 悪意のある攻撃者は script 要素を含む URL を作成できる:
https://example.com/message.cgi?say=%3Cscript%3Ealert%28%27Oh%20no%21%27%29%3C/script%3E
攻撃者が被害ユーザーを説得してこのページへアクセスさせた場合、攻撃者が選んだスクリプトが ページ上で実行される。そのようなスクリプトは、サイトが提供する機能によってのみ制限される、 あらゆる数の悪意ある操作を実行できる。たとえばサイトが電子商取引店であれば、 そのようなスクリプトによって、ユーザーが知らないうちに任意の数の不要な購入を行わされる可能性がある。
これは、クロスサイトスクリプティング攻撃と呼ばれる。
サイトにコードを実行させるために使用できる構造は多数ある。次は、作者がセーフリストフィルターを 作成するときに考慮することが推奨されるものの一部である:
img
のような無害に見える要素を許可する場合、指定される属性もセーフリストに登録することが重要である。
すべての属性を許可すると、攻撃者は、たとえば onload
属性を使用して任意のスクリプトを実行できる。javascript:」
であるが、ユーザーエージェントはその他のスキームも実装できる(実際、歴史的に実装してきた)。base
要素の挿入を許可すると、相対リンクを持つページ内のすべての script
要素が乗っ取られる可能性があり、同様に、すべてのフォーム送信を悪意のあるサイトへ
リダイレクトできる。サイトが、ユーザー名でフォーラムへメッセージを投稿する、購入を行う、パスポートを申請するなど、 ユーザー固有の副作用を伴うフォーム送信をユーザーに許可する場合、その要求が、別のサイトに だまされてユーザーが知らずに行ったものではなく、ユーザーが意図的に行ったものであることを 検証することが重要である。
この問題は、HTML フォームを他のオリジンへ送信できるために存在する。
サイトは、フォームにユーザー固有の非表示トークンを設定するか、
すべての要求で `Origin`
ヘッダーを検査することで、このような攻撃を防止できる。
ユーザーが実行したくない可能性のある操作を実行するためのインターフェイスを提供するページは、 ユーザーがだまされてそのインターフェイスを作動させる可能性を避けるよう設計する必要がある。
ユーザーがこのようにだまされる方法の 1 つとして、悪意のあるサイトが被害サイトを小さな
iframe
内に配置し、その後、たとえば反応ゲームをプレイさせることで、ユーザーにクリックするよう促す方法がある。
ユーザーがゲームをプレイし始めた後、悪意のあるサイトは、ユーザーがクリックしようとする直前に
iframe をマウスカーソルの下へすばやく配置し、被害サイトのインターフェイスをクリックさせることができる。
これを避けるため、フレーム内で使用されることを想定していないサイトは、
自身がフレーム内にないことを検出した場合にのみインターフェイスを有効にすることが推奨される
(たとえば、window
オブジェクトと
top 属性の値を比較する)。
この節は非規範的である。
HTML 内のスクリプトには「完了まで実行」のセマンティクスがある。これは、ブラウザーが通常、 その後のイベントの発火や文書の構文解析の継続など、他の処理を行う前に、スクリプトを中断せずに 実行することを意味する。
一方、HTML ファイルの構文解析は段階的に行われる。つまり、構文解析器は任意の時点で一時停止して、 スクリプトを実行させることができる。これは一般に良いことであるが、イベントがすでに発火している 可能性がある後でイベントハンドラーを接続しないよう、作者が注意する必要があることを意味する。
これを確実に行うための技法は 2 つある。イベントハンドラー コンテンツ属性を使用するか、同じスクリプト内で要素を作成してイベントハンドラーを追加する。 後者は、前述したように、その後のイベントが発火する前にスクリプトが完了まで実行されるため安全である。
これが現れる場合の 1 つは、img
要素と load
イベントである。特に画像がすでにキャッシュされている場合(よくあることだが)、
要素が構文解析されるとすぐにイベントが発火する可能性がある。
ここで作者は、img
要素の onload
ハンドラーを使用して、load
イベントを捕捉する:
< img src = "games.png" alt = "Games" onload = "gamesLogoHasLoaded(event)" > 要素がスクリプトによって追加される場合、イベントハンドラーが同じスクリプト内で追加される限り、 イベントを取り逃すことはない:
< script >
var img = new Image();
img. src = 'games.png' ;
img. alt = 'Games' ;
img. onload = gamesLogoHasLoaded;
// img.addEventListener('load', gamesLogoHasLoaded, false); // would work also
</ script > しかし、作者が最初に img
要素を作成し、その後、別のスクリプトでイベントリスナーを追加した場合、その間に load
イベントが発火し、取り逃す可能性がある:
<!-- Do not use this style, it has a race condition! -->
< img id = "games" src = "games.png" alt = "Games" >
<!-- the 'load' event might fire here while the parser is taking a
break, in which case you will not see it! -->
< script >
var img = document. getElementById( 'games' );
img. onload = gamesLogoHasLoaded; // might never fire!
</ script > この節は非規範的である。
作者は、一般的な誤りを検出するため、適合性チェッカー(バリデーターとも呼ばれる)を 使用することが推奨される。WHATWG は、そのようなツールの一覧を次の場所で管理している:https://whatwg.org/validator/
この節は非規範的である。
以前の版の HTML 仕様とは異なり、この仕様は、有効な文書だけでなく無効な文書に必要な処理も ある程度詳細に定義する。
しかし、無効なコンテンツの処理がほとんどの場合に明確に定義されていても、 文書の適合性要件は依然として重要である。実際には、相互運用性(すべての実装が特定のコンテンツを 信頼性のある、同一または同等の方法で処理する状況)は、文書の適合性要件の唯一の目標ではない。 この節では、適合する文書とエラーを含む文書を依然として区別する、より一般的な理由の一部を詳述する。
この節は非規範的である。
以前の版の HTML に存在した表現用機能の大部分は、もはや許可されていない。 表現用マークアップには、一般に多数の問題があることが判明している:
支援技術(AT)のユーザーに許容可能な体験を提供する方法で表現用マークアップを使用することは可能だが (たとえば ARIA を使用する)、意味論的に適切なマークアップを使用する場合よりも著しく困難である。 さらに、そのような技法を使用しても、テキストモードブラウザーのユーザーなど、 AT を使用しない非グラフィカルユーザーにとってページをアクセシブルにする助けにはならない。
一方、メディアに依存しないマークアップを使用すると、より多くのユーザー (たとえばテキストブラウザーのユーザー)が利用できるよう文書を作成するための簡単な方法が得られる。
マークアップがスタイルに依存しない形で作成されたサイトは、著しく保守しやすい。
たとえば、サイト全体で <font color=""> を使用するサイトの色を変更するには、
サイト全体にわたる変更が必要になる。一方、CSS に基づくサイトでは、単一のファイルを変更するだけで
同様の変更を行える。
表現用マークアップは、はるかに冗長になる傾向があり、その結果、文書サイズが大きくなる。
これらの理由により、この版の HTML から表現用マークアップは削除された。この変更は驚くべきものではない。 HTML4 は何年も前に表現用マークアップを非推奨とし、作者が表現用マークアップから移行するのを支援する モード(HTML4 Transitional)を提供した。その後、XHTML 1.1 はさらに進んで、 これらの機能を完全に廃止した。
HTML に残っている表現用マークアップ機能は、style 属性と
style 要素のみである。
style 属性の使用は、
本番環境では多少推奨されないが、迅速なプロトタイピング(後でその規則を別のスタイルシートへ
直接移動できる場合)や、別のスタイルシートが不便な特殊な場合に特定のスタイルを提供するために役立つ。
同様に、style 要素は、
配信時またはページ固有のスタイルに役立つ可能性があるが、一般に、スタイルが複数のページに適用される場合は
外部スタイルシートの方が便利である可能性が高い。
以前は表現用であったいくつかの要素が、この仕様ではメディアに依存しないよう再定義されたことにも
注目する価値がある:b、i、hr、s、small、および u。
この節は非規範的である。
HTML の構文は、さまざまな問題を回避するため制約されている。
特定の無効な構文構造を構文解析すると、非常に直感に反する DOM ツリーが生成される。
ユーザーエージェントが、より奇妙で複雑なエラー処理規則を実装せずに制御された環境で 使用できるようにするため、ユーザーエージェントは 構文解析エラーに遭遇した場合、 処理を失敗させることが許可される。
上記の <table><hr>... の例における動作など、一部のエラー処理動作は、
ストリーミングユーザーエージェント(状態を保存せず、HTML ファイルを 1 回の処理で扱う
ユーザーエージェント)と互換性がない。そのようなユーザーエージェントとの相互運用性の問題を
回避するため、そのような動作を引き起こす構文は無効と見なされる。
XML に基づくユーザーエージェントが HTML 構文解析器へ接続される場合、要素名または属性名に 複数のコロンが含まれないなど、XML が強制する特定の不変条件が HTML ファイルによって 違反される可能性がある。これを処理するには、構文解析器が HTML DOM を XML 互換の情報集合へ 強制変換する必要がある場合がある。そのような処理を必要とする構文構造の大部分は無効と見なされる。 (連続する 2 つのハイフンを含むコメント、またはハイフンで終わるコメントは、 HTML 構文で許可される例外である。)
特定の構文構造は、不釣り合いに低いパフォーマンスをもたらす可能性がある。 そのような構造の使用を抑止するため、通常は非適合とされる。
たとえば、次のマークアップは低いパフォーマンスをもたらす。閉じられていないすべての
i 要素を各段落で
再構築する必要があり、各段落の要素数が次第に増加するためである:
< p >< i > She dreamt.
< p >< i > She dreamt that she ate breakfast.
< p >< i > Then lunch.
< p >< i > And finally dinner.この断片から生成される DOM は次のようになる:
歴史的な理由により、比較的壊れやすい構文構造が存在する。 ユーザーが誤ってそのような問題に遭遇する数を減らすため、これらは非適合とされる。
たとえば、属性内の特定の名前付き文字参照は、終了セミコロンが省略されていても構文解析される。 名前付き文字参照を形成しない文字列がアンパサンドの後に続く場合は安全だが、 文字列が名前付き文字参照を形成するものへ変更されると、代わりにその文字として解釈される。
この断片では、属性値は「?bill&ted」である:
< a href = "?bill&ted" > Bill and Ted</ a > しかし、次の断片では、属性値は意図された「?art©」ではなく、
実際には「?art©」である。これは、最後のセミコロンがなくても、
「©」が「©」と同様に処理され、
「©」として解釈されるためである:
< a href = "?art©" > Art and Copy</ a > この問題を避けるため、すべての名前付き文字参照はセミコロンで終わることが要求され、 セミコロンを伴わない名前付き文字参照の使用はエラーとして示される。
したがって、上記の場合を正しく表現する方法は次のとおりである:
< a href = "?bill&ted" > Bill and Ted</ a > <!-- &ted is ok, since it's not a named character reference --> < a href = "?art&copy" > Art and Copy</ a > <!-- the & has to be escaped, since © is a named character reference --> 特定の構文構造は、旧来のユーザーエージェントで特に微妙または深刻な問題を引き起こすことが 知られているため、作者がそれらを避けられるよう非適合として示される。
たとえば、U+0060 GRAVE ACCENT 文字(`)が引用符なし属性で許可されないのは、このためである。 特定の旧来のユーザーエージェントでは、引用符文字として扱われる場合がある。
もう 1 つの例は DOCTYPE であり、これは 非互換モードでない モードを作動させることが要求される。これは、旧来のユーザーエージェントの 互換モード における動作が、多くの場合ほとんど文書化されていないためである。
特定の制限は、既知のセキュリティ問題を避けることだけを目的として存在する。
たとえば、UTF-7 の使用制限は、作者が UTF-7 を使用する既知のクロスサイトスクリプティング攻撃の 被害を受けることを避けるためだけに存在する。[UTF7]
作者の意図が非常に不明確なマークアップは、しばしば非適合とされる。 これらのエラーを早期に修正することで、その後の保守が容易になる。
ユーザーが単純なタイプミスをした場合、エラーを早期に検出できれば、 作者のデバッグ時間を大幅に節約できる。そのため、この仕様では通常、 この仕様で定義された名前と一致しない要素名、属性名などを使用することをエラーと見なす。
たとえば、作者が <caption> の代わりに <capton> と入力した場合、
エラーとして示され、作者はタイプミスを直ちに修正できる。
将来、言語の構文を拡張できるようにするため、それ以外では無害な特定の機能が禁止される。
たとえば、終了タグ内の「属性」は現在無視されるが、将来の言語変更で、 すでに展開されている(かつ有効な)コンテンツと衝突せずにその構文機能を使用できるように、 無効とされる。
一部の作者は、すべての属性を常に引用符で囲み、すべての省略可能なタグを常に含める習慣が有益だと考える。 そのような慣習から得られる一貫性を、HTML 構文の柔軟性を利用して得られるわずかな簡潔さよりも 優先するためである。そのような作者を支援するため、適合性チェッカーは、そのような慣習を 強制する動作モードを提供できる。
この節は非規範的である。
言語の構文に加えて、この仕様は要素および属性をどのように指定できるかにも制限を設ける。 これらの制限は、同様の理由で存在する:
定義された意味を持つ要素の誤用を避けるため、そのような入れ子が疑わしい価値しか持たない場合に、 要素をどのように入れ子にできるかを制限するコンテンツモデルが定義される。
たとえば、この仕様では、section
要素を kbd
要素の内側に入れ子にすることを禁止している。これは、作者がセクション全体をキー入力すべきことを
示そうとする可能性が非常に低いためである。
同様に、要素の使用における誤りへ作者の注意を向けるため、 表現されたセマンティクスの明確な矛盾も適合性エラーと見なされる。
たとえば、次の断片ではセマンティクスが無意味である。 区切りを同時にセルとすることはできず、ラジオボタンをプログレスバーとすることもできない。
< hr role = "cell" > < input type = radio role = progressbar > もう 1 つの例は、ul
要素のコンテンツモデルに対する制限であり、これは子として li
要素のみを許可する。リストは定義上、0 個以上のリスト項目のみから構成されるため、
ul
要素が li
要素以外のものを含む場合、何を意図したのかが不明確になる。
特定の要素には、特定の組み合わせが混乱を招く可能性を高くする既定のスタイルまたは動作がある。 この問題のない同等の代替手段が存在する場合、混乱を招く組み合わせは禁止される。
たとえば、div
要素は ブロック
ボックスとしてレンダリングされ、span
要素は インライン
ボックスとしてレンダリングされる。ブロックボックスを
インラインボックス内に
配置することは不必要に混乱を招く。div
要素だけを入れ子にする、span
要素だけを入れ子にする、または div
要素の内側に span
要素を入れ子にすることはすべて、span
要素の内側に div
要素を入れ子にすることと同じ目的を果たすが、最後のものだけが
インラインボックス内に
ブロックボックスを
含むため、最後の組み合わせは禁止される。
もう 1 つの例は、インタラクティブコンテンツ
を入れ子にできないことに関するものである。たとえば、button
要素は textarea
要素を含むことができない。これは、そのようなインタラクティブ要素を入れ子にした場合の既定の動作が、
ユーザーにとって非常に混乱を招くためである。これらの要素を入れ子にする代わりに、
並べて配置できる。
何かを許可すると作者の混乱を招く可能性が高いため、それが禁止される場合がある。
たとえば、disabled
属性を値「false」に設定することは禁止される。見た目上は要素が有効であることを
意味するように見えるが、実際には要素が無効であることを意味するためである
(実装にとって重要なのは、属性の値ではなく属性の存在である)。
一部の適合性エラーは、作者が学ぶ必要のある言語を単純化する。
たとえば、area
要素の shape
属性は、実際には circ
と circle
の両方を同義語として受け入れるが、チュートリアルやその他の学習資料を単純化するため、
circ
値の使用を禁止する。両方を許可しても利益はないが、言語を教える際に余計な混乱を招くためである。
特定の要素は、多少特殊な方法で構文解析される(通常は歴史的な理由による)。 そのコンテンツモデルの制限は、作者がこれらの問題にさらされないようにすることを目的としている。
たとえば、form
要素は、フレージングコンテンツ
の内側では許可されない。HTML として構文解析される場合、form
要素の開始タグによって、p
要素の終了タグが暗黙的に補われるためである。したがって、次のマークアップは、
1 つではなく 2 つの 段落を生成する:
< p > Welcome. < form >< label > Name:</ label > < input ></ form > これは、次のものとまったく同じように構文解析される:
< p > Welcome. </ p >< form >< label > Name:</ label > < input ></ form > 一部のエラーは、デバッグが困難なスクリプトの問題を防ぐことを目的としている。
これが、たとえば、同じ値を持つ 2 つの id
属性を持つことが非適合とされる理由である。重複する ID は誤った要素を選択させ、
場合によっては原因の特定が困難な壊滅的影響を引き起こす。
一部の構造は、歴史的に多くのオーサリング時間を浪費する原因となってきたため禁止される。 作者がそのような構造を避けることを促すことで、将来の作業時間を節約できる。
たとえば、script
要素の src
属性により、要素の内容は無視される。しかし、特に要素の内容が実行可能なスクリプトに見える場合、
これは明らかではない。そのため、作者はインラインスクリプトが実行されていないことに気付かず、
デバッグに多くの時間を費やす可能性がある。この問題を減らすため、この仕様では、src
属性が存在する場合に、script
要素内に実行可能なスクリプトを含めることを非適合としている。これにより、
文書を検証する作者は、この種の誤りで時間を浪費する可能性が低くなる。
一部の作者は、XML と HTML の両方として解釈した場合に同様の結果となるファイルを作成することを好む。 この慣行は、特にスクリプト処理、スタイル処理、またはあらゆる種類の自動シリアライズが関係する場合、 無数の微妙な複雑さを伴うため一般には推奨されないが、この仕様には、少なくともある程度 困難を軽減することを意図した制限がいくつかある。これにより、作者は HTML 構文と XML 構文の間を 移行する際の移行段階として、これを使用しやすくなる。
たとえば、lang と
xml:lang
属性を同期した状態に保つことを意図した、多少複雑な規則がある。
もう 1 つの例は、HTML シリアライズにおける xmlns 属性の値に対する制限であり、
適合する文書内の要素が、HTML または XML のどちらとして処理される場合でも同じ名前空間に
属することを保証することを意図している。
将来の言語改訂で新しい構文を使用できるようにすることを意図した構文上の制限と同様に、 要素のコンテンツモデルおよび属性値に対する一部の制限は、HTML の語彙を将来拡張できるようにすることを 意図している。
たとえば、U+005F LOW LINE 文字(_)で始まる target
属性の値を特定の事前定義された値のみに制限することで、作者定義の値と衝突せずに、
将来新しい事前定義値を導入できる。
特定の制限は、他の仕様によって設けられた制限を支援することを意図している。
たとえば、メディアクエリーリストを取る属性に有効なメディアクエリーリストのみを 使用するよう要求することで、その仕様の適合性規則に従うことの重要性が強化される。
この節は非規範的である。
次の文書は、この仕様の読者にとって参考になる可能性がある。
このアーキテクチャ仕様は、Unicode 標準と ISO/IEC 10646 によって共同で定義される Universal Character Set を基盤として、World Wide Web 上で相互運用可能なテキスト操作を行うための 共通の参照を、仕様の作者、ソフトウェア開発者、およびコンテンツ開発者に提供する。扱う主題には、 「文字」、「エンコーディング」、および「文字列」という用語の使用、参照処理モデル、 文字エンコーディングの選択と識別、文字のエスケープ、および文字列のインデックス付けが含まれる。
Unicode には非常に多数の文字が含まれ、世界中の多様な書記体系が取り込まれているため、 誤った使用によってプログラムまたはシステムがセキュリティ攻撃を受ける可能性がある。 製品の国際化がますます進むにつれて、これは特に重要となる。この文書では、 プログラマー、システムアナリスト、標準開発者、およびユーザーが考慮すべき セキュリティ上の事項について説明し、問題のリスクを軽減するための具体的な推奨事項を示す。
ウェブコンテンツアクセシビリティガイドライン(WCAG)は、ウェブコンテンツを よりアクセシブルにするための幅広い推奨事項を扱う。これらのガイドラインに従うことで、 全盲およびロービジョン、聴覚障害および難聴、学習障害、認知上の制約、運動制限、 発話障害、光過敏症、ならびにこれらを併せ持つ人々を含む、より幅広い障害者が コンテンツを利用できるようになる。また、これらのガイドラインに従うことで、 一般のユーザーにとってもウェブコンテンツが使いやすくなる場合が多い。
この仕様は、障害者にとってよりアクセシブルなウェブコンテンツオーサリングツールを 設計するためのガイドラインを提供する。これらのガイドラインに適合するオーサリングツールは、 障害のある作者にアクセシブルなユーザーインターフェイスを提供するとともに、 すべての作者によるアクセシブルなウェブコンテンツの制作を可能にし、支援し、促進することで、 アクセシビリティを推進する。
この文書は、障害者にとってのウェブアクセシビリティ上の障壁を軽減する ユーザーエージェントを設計するためのガイドラインを提供する。ユーザーエージェントには、 ブラウザーや、ウェブコンテンツを取得してレンダリングするその他の種類のソフトウェアが含まれる。 これらのガイドラインに適合するユーザーエージェントは、それ自身のユーザーインターフェイスと、 他の技術、特に支援技術と通信する能力を含むその他の内部機能を通じて、 アクセシビリティを推進する。さらに、障害のあるユーザーだけでなく、すべてのユーザーにとって、 適合するユーザーエージェントはより使いやすいものとなるべきである。
この仕様は Infra に依存する。[INFRA]
この仕様では、HTML および XML の属性と IDL 属性の両方を、多くの場合同じ文脈で参照する。 どちらを参照しているかが明確でない場合、HTML および XML の属性は コンテンツ属性と呼ばれ、 IDL インターフェイスで定義されるものは IDL 属性と呼ばれる。同様に、 「プロパティ」という用語は、JavaScript オブジェクトのプロパティと CSS プロパティの両方に使用される。 これらが曖昧な場合、それぞれ オブジェクトプロパティおよび CSS プロパティと限定して呼ばれる。
一般に、ある機能が HTML 構文または XML 構文に適用されると 仕様に記載されている場合、もう一方も含まれる。機能が 2 つの言語のうち一方のみに特に適用される場合は、 「HTML の場合、……(これは XML には適用されない)」のように、もう一方の形式には適用されないことを 明示することで示される。
この仕様では、短い静的文書から、豊富なマルチメディアを含む長い論文や報告書、
さらには本格的なインタラクティブアプリケーションに至るまで、HTML のあらゆる使用を指すために
文書という用語を使用する。この用語は、文脈に応じて、Document
オブジェクトとその子孫 DOM ツリーの両方、および HTML 構文または XML 構文を使用するシリアライズされたバイトストリームの両方を
指すために使用される。
DOM 構造の文脈では、HTML
文書および XML 文書という用語は、
DOM で定義されているとおりに使用され、Document
オブジェクトが取り得る
2 つの異なるモードを特に指す。[DOM](このような使用箇所は、常にその定義への
ハイパーリンクになっている。)
バイトストリームの文脈では、HTML 文書という用語は
text/html とラベル付けされたリソースを指し、
XML 文書という用語は XML
MIME 型でラベル付けされたリソースを指す。
簡潔さのため、文書がユーザーにレンダリングされる方法を指す場合に、 示される、表示される、および 可視であるなどの用語が使用されることがある。これらの用語は視覚媒体を意味するものではなく、 他の媒体にも同等の方法で適用されるものと見なさなければならない。
手順を 並列に実行するとは、それらの手順を順番に実行しつつ、 標準内の他のロジックと同時に実行することを意味する(たとえば、イベント ループと同時に実行する)。この標準は、これを実現する正確な機構を定義しない。 それは、時分割協調型マルチタスク、ファイバー、スレッド、プロセス、異なるハイパースレッド、 コア、CPU、マシンなどの使用であってもよい。これに対して、 直ちに実行される操作は、現在実行中のタスクを中断し、自身を実行した後、 それまで実行されていたタスクを再開しなければならない。
並列処理を活用する仕様の記述方法に関する指針については、 他の仕様からイベントループを扱うを参照。
同じデータを操作する異なる 並列 アルゴリズム間の競合状態を避けるため、並列キューを使用できる。
並列キューは、直列に実行しなければならない アルゴリズム手順のキューを表す。
並列キューは、初期状態では空の アルゴリズムキュー(キュー)を持つ。
並列 キューに 手順をエンキューするには、 そのアルゴリズム手順を、並列キューの アルゴリズム キューへ エンキューする。
新しい並列キューを開始するには、次の手順を実行する:
parallelQueue を新しい 並列キューとする。
次の手順を 並列に実行する:
true である間:
steps を、parallelQueue の アルゴリズム キューから デキューした結果とする。
steps が nothing でない場合、steps を実行する。
実装がこれを継続的に実行されるループとして実装することは想定されていない。 標準内のアルゴリズムは理解しやすいことを目的としており、必ずしもバッテリー寿命や パフォーマンスに優れているとは限らない。
parallelQueue を返す。
並列に実行される手順は、 それ自体が他の手順を 並列に実行できる。 たとえば、並列キュー内では、 一連の手順をそのキューと並列に実行すると役立つ場合がある。
ある標準が nameList(リスト)と、 nameList がすでに name を 含む場合には拒否し、そうでなければ nameList に name を追加するメソッドを定義しているとする。
次の解決策には競合状態がある:
global を、this の 関連するグローバル オブジェクトとする。
次の手順を 並列に実行する:
nameList が name を
含む場合、
global を指定して DOM 操作
タスクソース上に グローバルタスクをキューに追加し、
p を TypeError
で拒否して、これらの手順を中止する。
時間がかかる可能性のある処理を行う。
name を nameList に 付加する。
global を指定して DOM 操作 タスクソース上に グローバルタスクをキューに追加し、 p を undefined で解決する。
p を返す。
上記の処理が 2 回同時に呼び出されると、手順 3.1 の時点では name が nameList に含まれていないものの、手順 3.3 が実行される前に 追加される可能性がある。その結果、name が nameList に 2 回含まれることになる。
並列キューはこの問題を解決する。標準では、nameListQueue を 新しい並列キューを 開始した結果とし、名前を追加する手順を次のように定義する:
global を、this の 関連するグローバル オブジェクトとする。
nameListQueue に 次の手順をエンキューする:
nameList が name を
含む場合、
global を指定して DOM
操作タスクソース上に グローバルタスクをキューに追加し、
p を TypeError
で拒否して、これらの手順を中止する。
時間がかかる可能性のある処理を行う。
name を nameList に 付加する。
global を指定して DOM 操作 タスクソース上に グローバルタスクをキューに追加し、 p を undefined で解決する。
p を返す。
これにより、手順はキューに追加され、競合が回避される。
この仕様では、ユーザーエージェントが外部リソースのセマンティクスをデコードできる実装を 備えているかどうかを指す場合に、サポートされるという用語を使用する。ある形式または 型の外部リソースを、そのリソースの重要な側面を無視することなく実装が処理できる場合、その形式または 型はサポートされるという。特定のリソースがサポートされるかどうかは、そのリソースの 形式のどの機能が使用されているかに依存する場合がある。
例えば、PNG 画像のピクセルデータをデコードしてレンダリングできる場合、その画像に 実装が認識していないアニメーションデータも含まれていたとしても、その PNG 画像はサポートされる形式で あると見なされる。
MPEG-4 動画ファイルで使用されている圧縮形式がサポートされていない場合、実装が ファイルのメタデータから動画の寸法を判断できたとしても、そのファイルはサポートされる形式であるとは 見なされない。
一部の仕様、特に HTTP 仕様で 表現と呼ばれるものは、この仕様では リソースと呼ばれる。 [HTTP]
リソースの 重要なサブリソースとは、そのリソースを正しく処理するために 利用可能である必要があるリソースをいう。どのリソースが重要であると見なされるか、または見なされないかは、 そのリソースの形式を定義する仕様によって定義される。
CSS スタイルシートについては、その重要なサブリソースを、
@import 規則を介してインポートされる他のスタイルシートと、インポートされた他の
スタイルシートによって間接的にインポートされるスタイルシートを含むものとして、ここで暫定的に定義する。
この定義には完全な相互運用性がない。さらに、一部のユーザーエージェントは、 背景画像やウェブフォントなどのリソースを重要なサブリソースとして数えているようである。理想的には CSS Working Group がこれを定義すべきである。この点に関する進捗を追跡するには、w3c/csswg-drafts issue #1088 を参照されたい。
HTML から XML への移行を容易にするため、この仕様に適合する
ユーザーエージェントは、少なくとも DOM および
CSS の目的において、HTML 内の要素を http://www.w3.org/1999/xhtml
名前空間に配置する。「HTML 要素」という用語は、
XML 文書内であっても、その名前空間内のあらゆる要素を指す。
別途記載されている場合を除き、この仕様で定義または言及されるすべての要素は
HTML 名前空間(「http://www.w3.org/1999/xhtml」)に属し、この仕様で
定義または言及されるすべての属性は名前空間を持たない。
要素型という用語は、特定の
ローカル名および名前空間を持つ要素の集合を指すために使用される。例えば、button 要素は、要素型
button を持つ要素であり、ローカル名
「button」と、
(上記で定義されているように暗黙的に)HTML 名前空間を持つ。
ある要素または属性が 無視される、別の値として 扱われる、または別のものであるかのように処理されると記載されている場合、これは、そのノードが DOM に入った後の処理のみを指す。ユーザーエージェントは、このような状況で DOM を変更してはならない。
コンテンツ属性の値は、その新しい値が 以前の値と異なる場合にのみ変更されるという。属性をすでに持っている値に設定しても、その値は 変更されない。
属性値、Text
ノード、
または文字列について使用される場合、空という用語は、テキストの長さがゼロであることを意味する(すなわち、制御文字や
U+0020 SPACE さえ含まない)。
HTML 要素には、その要素のローカル 名について定義された、特定の HTML 要素挿入手順、HTML 要素 接続後手順、HTML 要素削除手順、および HTML 要素移動 手順をすべて設定できる。
insertedNode が与えられたときの HTML 標準の挿入手順は、次のように定義される:
insertedNode が、名前空間が HTML 名前空間である要素であり、 この標準が insertedNode のローカル名について HTML 要素挿入手順を定義している場合、 insertedNode を与えて、対応する HTML 要素挿入手順を実行する。
insertedNode が フォーム関連要素、または フォーム関連要素の祖先である場合:
フォーム関連 要素の パーサー挿入 フラグが設定されている場合、 戻る。
insertedNode が、HTML パーサーの
開いている要素のスタック上にない
Element
である場合、insertedNode の
ノード文書を与えて、
内部
リソースリンクを処理する。
insertedNode が与えられたときの HTML 標準の接続後手順は、次のように定義される:
insertedNode が、名前空間が HTML 名前空間である要素であり、 この標準が insertedNode のローカル 名について HTML 要素接続後 手順を定義している場合、insertedNode を与えて、対応する HTML 要素接続後手順を実行する。
removedNode、isSubtreeRoot、および oldAncestor が与えられたときの HTML 標準の削除手順は、次のように定義される:
document を、removedNode の ノード文書とする。
document の フォーカス領域が removedNode である場合、document の フォーカス領域を document の ビューポートに設定し、 document の 関連する グローバルオブジェクトの ナビゲーション APIの 進行中の ナビゲーション中にフォーカスが変更されたを false に設定する。
これは、フォーカス解除手順、
フォーカス手順、または
フォーカス更新手順を実行しないため、blur または change イベントは
発火されない。
removedNode が、名前空間が HTML 名前空間である要素であり、 この標準が removedNode のローカル名について HTML 要素削除手順を定義している場合、 removedNode、isSubtreeRoot、および oldAncestor を与えて、 対応する HTML 要素削除手順を実行する。
removedNode が、null でない フォーム所有者を持つ フォーム関連要素であり、removedNode とその フォーム所有者が同じ ツリー内に存在しなくなった場合、removedNode の フォーム所有者をリセットする。
removedNode の popover
属性が
ポップオーバーなし状態でない場合、
removedNode、false、false、false、および null を与えて、
ポップオーバーを
非表示にするアルゴリズムを実行する。
movedNode、isSubtreeRoot、および oldAncestor が与えられたときの HTML 標準の移動手順は、次のように定義される:
movedNode が、名前空間が HTML 名前空間である要素であり、この 標準が movedNode のローカル名について HTML 要素 移動手順を定義している場合、movedNode、isSubtreeRoot、および oldAncestor を与えて、対応する HTML 要素移動手順を実行する。
movedNode が、null でない フォーム所有者を持つ フォーム関連要素であり、movedNode とその フォーム所有者が同じ ツリー内に存在しなくなった場合、movedNode の フォーム所有者をリセットする。
あるノードを引数として 挿入手順が 呼び出され、そのノードが現在 文書 ツリー内にある場合、その ノードは文書に挿入される。同様に、あるノードを引数として 削除手順が呼び出され、そのノードが現在 文書 ツリー内になくなった場合、その ノードは文書から削除される。
あるノードを引数として 挿入手順が呼び出され、そのノードが現在 接続されている場合、そのノードは 接続状態になる。同様に、あるノードを引数として 削除 手順が呼び出され、そのノードが現在 接続されている状態でなくなった場合、そのノードは 切断状態になる。
ノードが 接続されており、その シャドウを含むルートの 閲覧コンテキストが null でない場合、そのノードは 閲覧コンテキストに接続されている。あるノードを 引数として 挿入手順が呼び出され、そのノードが現在 閲覧コンテキストに 接続されている場合、そのノードは 閲覧コンテキスト接続状態になる。あるノードを引数として 削除手順が呼び出され、そのノードが現在 閲覧コンテキストに接続されている状態でなくなった場合、 またはその シャドウを含む ルートの 閲覧コンテキストが null になった場合、そのノードは 閲覧コンテキスト切断状態になる。
Foo が実際にはインターフェイスである場合に、より正確な「Foo
インターフェイスを実装するオブジェクト」の代わりに、「Foo オブジェクト」という
構文が使用されることがある。
IDL 属性の値が取得されている場合(例えば、作者のスクリプトによって)、 その IDL 属性は取得されているといい、新しい値が代入されている場合は 設定されているという。
DOM オブジェクトが ライブであるとされる場合、そのオブジェクトの属性およびメソッドは、 データのスナップショットではなく、実際の基礎となるデータに対して 動作しなければならない。
プラグインという用語は、ユーザーエージェントが使用する実装定義のコンテンツ
ハンドラーの集合であって、ユーザーエージェントによる
Document オブジェクトのレンダリングに参加できるが、
Document の子
ナビガブルとして動作することも、
Document の DOM に
Node
オブジェクトを導入することもないものを指す。
通常、このようなコンテンツハンドラーは第三者によって提供されるが、ユーザーエージェントが 組み込みのコンテンツハンドラーをプラグインとして指定することもできる。
ユーザーエージェントは、型 text/plain
および
application/octet-stream
に登録済みのプラグインがあると見なしてはならない。
プラグインの一例は、ユーザーが PDF ファイルへナビゲートしたときに ナビガブル内でインスタンス化される PDF ビューアーである。 PDF ビューアーのコンポーネントを実装した主体が、ユーザーエージェント自体を実装した主体と 同一であるかどうかにかかわらず、これはプラグインとして数えられる。ただし、同じインターフェイスを 使用するのではなく、ユーザーエージェントとは別に起動する PDF ビューアーアプリケーションは、この 定義におけるプラグインではない。
プラグインとの対話はユーザーエージェントおよびプラットフォームに固有であると 想定されるため、この仕様はそのための機構を定義しない。一部の UA は Netscape Plugin API のような プラグイン機構をサポートすることを選択する場合があり、別の UA はリモートコンテンツコンバーターを 使用したり、特定の型に対する組み込みサポートを持ったりする場合がある。実際、この仕様は ユーザーエージェントにプラグインのサポートをまったく要求しない。[NPAPI]
ブラウザーは、プラグイン向けの外部コンテンツと 対話する際に細心の注意を払うべきである。第三者ソフトウェアがユーザーエージェント自体と同じ 権限で実行される場合、第三者ソフトウェアの脆弱性はユーザーエージェントの脆弱性と同じほど 危険になる。
![]() ユーザーごとに異なるプラグインの集合を持つことは、
ユーザーが一意に識別される可能性を高めるトラッキングベクトルとなるため、ユーザーエージェントには、
各ユーザーについてまったく同じプラグインの集合を
サポートすることが推奨される。
ユーザーごとに異なるプラグインの集合を持つことは、
ユーザーが一意に識別される可能性を高めるトラッキングベクトルとなるため、ユーザーエージェントには、
各ユーザーについてまったく同じプラグインの集合を
サポートすることが推奨される。
文字 エンコーディング、または曖昧でない場合は単にエンコーディングとは、 Encoding で定義されている、バイトストリームと Unicode 文字列との間を変換する 定義済みの方法である。エンコーディングには、エンコーディング 名と、1 つ以上の エンコーディングラベルがあり、 Encoding 標準ではそれぞれエンコーディングの名前およびラベルと呼ばれる。 [ENCODING]
この仕様は、ユーザーエージェント(実装者に関連する)および 文書(作者およびオーサリングツールの実装者に関連する)に対する 適合基準を説明する。
適合文書とは、文書に対するすべての適合基準に 従う文書である。読みやすさのため、これらの適合要件の一部は作者に対する 適合要件として表現される。このような要件は暗黙的に文書に対する要件である。 定義上、すべての文書には作者が存在したものと仮定される。(場合によっては、その作者自体が ユーザーエージェントであることがあり、そのようなユーザーエージェントには、以下で説明する 追加の規則が適用される。)
例えば、「作者は foobar 要素を
使用してはならない」という要件がある場合、文書に foobar という名前の要素を
含めることは許可されないことを意味する。
文書の適合要件と実装の適合要件との間に、暗黙の関係はない。 ユーザーエージェントは、不適合な文書を自由に処理してよいわけではない。この仕様で説明される 処理モデルは、入力文書の適合性にかかわらず、実装に適用される。
ユーザーエージェントはいくつかの(相互に重複する)分類に分かれ、それぞれ異なる 適合要件を持つ。
XML 構文をサポートするウェブブラウザーは、他の仕様によって要素のセマンティクスが 上書きされていない限り、ユーザーが対話できるように、XML 文書内にある HTML 名前空間の要素および属性を、この仕様で説明されるとおりに 処理しなければならない。
適合するウェブブラウザーは、XML 文書内で script 要素を
見つけると、その要素に含まれるスクリプトを実行する。ただし、その要素が XSLT で表現された
変換内に見つかった場合(ユーザーエージェントが XSLT もサポートしているものとする)、
プロセッサーは代わりに script
要素を、
変換の一部を形成する不透明な要素として扱う。
HTML 構文をサポートするウェブブラウザーは、 ユーザーが対話できるように、HTML MIME 型でラベル付けされた文書を、この仕様で説明されるとおりに 処理しなければならない。
スクリプティングをサポートするユーザーエージェントは、Web IDL で説明されているとおり、 この仕様内の IDL 断片の適合実装でもなければならない。[WEBIDL]
明示的に記載されていない限り、HTML 要素のセマンティクスを上書きする仕様は、
その要素を表す DOM オブジェクトに対する要件を上書きしない。例えば、上記の例の script
要素は、引き続き
HTMLScriptElement
インターフェイスを実装する。
HTML および XML 文書を、非対話型の版としてレンダリングする目的だけで処理する ユーザーエージェントは、ユーザーインタラクションに関する要件を免除されることを除き、 ウェブブラウザーと同じ適合基準に従わなければならない。
非対話型提示ユーザーエージェントの典型例は、プリンター (静的 UA)およびオーバーヘッドディスプレイ(動的 UA)である。ほとんどの静的な 非対話型提示ユーザーエージェントは、スクリプティングを サポートしないことも選択すると予想される。
非対話型ではあるが動的な提示 UA は、引き続きスクリプトを実行し、 フォームを動的に送信できるようにするなどする。ただし、ユーザーが文書と対話できない場合、 「フォーカス」という概念は無関係であるため、UA はフォーカスに関連する DOM API を サポートする必要がない。
ユーザーエージェントは、対話型かどうかにかかわらず、この仕様で定義される 推奨される既定のレンダリングをサポートするものとして(ユーザーオプションとしての場合も含め) 指定されてもよい。
これは必須ではない。特に、推奨される既定のレンダリングを実装するユーザーエージェントであっても、 ユーザー体験を向上させるため、例えば色のコントラストを変更したり、異なるフォーカススタイルを 使用したり、その他の方法でユーザーにとってよりアクセシブルかつ使いやすくしたりする、 この既定値を上書きする設定を提供することが推奨される。
推奨される既定のレンダリングをサポートするものとして指定されたユーザーエージェントは、 そのように指定されている間、レンダリングの節がユーザーエージェントに 実装することを期待する動作として定義する規則を実装しなければならない。
スクリプティングをサポートしない実装(またはスクリプティング機能が完全に 無効化されている実装)は、この仕様で言及されるイベントおよび DOM インターフェイスを サポートする義務を免除される。この仕様のうち、イベントモデルまたは DOM によって 定義される部分について、そのようなユーザーエージェントは、イベントおよび DOM が サポートされているかのように動作しなければならない。
スクリプティングはアプリケーションの不可欠な部分を形成することがある。 スクリプティングをサポートしない、またはスクリプティングが無効化されている ウェブブラウザーは、作者の意図を完全には伝えられない場合がある。
適合性チェッカーは、文書がこの仕様で説明される適用可能な適合基準に従っていることを
検証しなければならない。自動化された適合性チェッカーは、作者の意図の解釈を必要とする
エラーの検出を免除される(例えば、blockquote
要素の内容が引用ではない場合、その文書は不適合であるが、人間の判断を入力せずに動作する
適合性チェッカーは、blockquote
要素に引用された内容だけが含まれることを確認する必要はない)。
適合性チェッカーは、入力文書が閲覧コンテキストなしで構文解析された場合 (すなわち、スクリプトが実行されず、パーサーのスクリプティングモードが無効である場合)に 適合することを確認しなければならず、また、スクリプトが実行される閲覧コンテキスト内で 構文解析された場合にも入力文書が適合し、スクリプトの実行中に一時的に発生する場合を除いて、 スクリプトによって不適合な状態が発生しないことも確認すべきである。 (これは不可能であることが証明されているため、「MUST」要件ではなく「SHOULD」要件に とどまる。[COMPUTABLE])
「HTML バリデーター」という用語は、それ自体がこの仕様の適用可能な要件に適合する 適合性チェッカーを指すために使用できる。
XML DTD は、この仕様のすべての適合要件を表現できない。したがって、 検証を行う XML プロセッサーと DTD の組み合わせは適合性チェッカーを構成できない。また、 この仕様で定義される 2 つのオーサリング形式はいずれも SGML の応用ではないため、 検証を行う SGML システムも適合性チェッカーを構成できない。
別の言い方をすれば、適合基準には次の 3 種類がある:
適合性チェッカーは、最初の 2 つを確認しなければならない。単純な DTD ベースのバリデーターは、 最初の種類のエラーだけを確認するため、この仕様によれば適合する適合性チェッカーではない。
文書をレンダリングするため、または適合性を確認するため以外の理由で HTML および XML 文書を 処理するアプリケーションおよびツールは、処理する文書のセマンティクスに従って 動作すべきである。
文書アウトラインを生成するが、 各段落について入れ子レベルを増加させ、見出しについて入れ子レベルを増加させないツールは、 適合しない。
オーサリングツールおよびマークアップジェネレーターは、適合文書を生成しなければならない。 作者に適用される適合基準は、適切な場合、オーサリングツールにも適用される。
オーサリングツールは、要素を指定された目的のためだけに使用するという厳格な要件を、 オーサリングツールが作者の意図をまだ判断できない範囲に限って免除される。ただし、 オーサリングツールは、自動的に要素を誤用したり、ユーザーに誤用を促したりしてはならない。
例えば、任意の連絡先情報に address 要素を
使用することは適合しない。この要素は、最も近い article または
body 要素の祖先に
関する連絡先情報をマークアップするためだけに使用できる。ただし、オーサリングツールは
その違いを判断できない可能性が高いため、オーサリングツールはその要件を免除される。
しかしこれは、オーサリングツールが、例えば斜体テキストの任意のブロックに address
要素を使用できるという意味ではない。単に、ユーザーが article 要素の
連絡先情報を挿入するためのツールを使用するとき、実際にその目的で使用しており、代わりに別のものを
挿入していないことをオーサリングツールが検証する必要はない、という意味である。
適合性確認の観点では、エディターは、適合性チェッカーが検証するのと同じ範囲で 適合する文書を出力しなければならない。
オーサリングツールを使用して不適合な文書を編集する場合、編集セッション中に編集されなかった 文書の部分にある適合性エラーを保持してもよい(すなわち、編集ツールには、誤った内容を ラウンドトリップすることが許可される)。ただし、エラーがそのように保持された場合、 オーサリングツールは出力が適合していると主張してはならない。
オーサリングツールには、大きく分けて 2 種類あると想定される。構造またはセマンティックデータを 基に動作するツールと、メディア固有の What-You-See-Is-What-You-Get 編集方式 (WYSIWYG)で動作するツールである。
前者は、ソース情報内の構造を使用して、どの HTML 要素および属性が最も適切であるかを 情報に基づいて選択できるため、HTML を作成するツールに推奨される機構である。
ただし、WYSIWYG ツールも正当である。WYSIWYG ツールは、適切であることが分かっている要素を
使用すべきであり、適切であることが分からない要素を使用すべきではない。極端な場合には、
フロー要素の使用を div、b、i、および span のような
少数の要素だけに制限し、style 属性を多用することを意味する場合がある。
WYSIWYG であるかどうかにかかわらず、すべてのオーサリングツールは、ユーザーが 適切に構造化され、セマンティクスが豊富で、メディアに依存しないコンテンツを作成できるようにするため、 最善の努力を払うべきである。
既存のコンテンツおよび以前の仕様との互換性のため、この仕様では 2 つのオーサリング形式を 説明する。一方は XML に基づく形式であり、もう一方は SGML に着想を得た カスタム形式を使用する形式である(HTML 構文と呼ばれる)。 実装はこれら 2 つの形式のうち少なくとも一方をサポートしなければならないが、両方を サポートすることが推奨される。
一部の適合要件は、要素、属性、メソッド、またはオブジェクトに対する要件として表現される。 このような要件は、コンテンツモデルの制限を説明するものと、実装の動作を説明するものの 2 つの分類に分かれる。前者の分類に属するものは、文書およびオーサリングツールに対する要件である。 後者の分類に属するものは、ユーザーエージェントに対する要件である。同様に、一部の適合要件は 作者に対する要件として表現される。このような要件は、作者が作成する文書に対する適合要件として 解釈される。(言い換えれば、この仕様は、作者に対する適合基準と文書に対する 適合基準を区別しない。)
この仕様は、基礎となるいくつかの他の仕様に依存する。
次の用語は Infra で定義される:[INFRA]
Unicode 文字集合はテキストデータを表すために使用され、Encoding は 文字エンコーディングに関する要件を定義する。 [UNICODE]
前述のとおり、この仕様は、それらの仕様で定義される用語に基づいて 用語を導入する。
次の用語は Encoding で定義されるとおりに使用される: [ENCODING]
HTML の XML 構文をサポートする実装は、何らかの版の XML と、それに対応する名前空間仕様を サポートしなければならない。これは、その構文が名前空間を伴う XML シリアライゼーションを 使用するためである。[XML] [XMLNS]
スクリプトを実行せず、CSS または XPath 式を評価せず、その他の方法で結果の DOM を 任意のコンテンツに公開せずにコンテンツを操作するデータマイニングツールおよびその他の ユーザーエージェントは、実際に名前空間文字列を公開することなく、対応する DOM ノードが 特定の名前空間内にあると表明するだけで、「名前空間をサポート」してもよい。
HTML 構文では、名前空間接頭辞および 名前空間宣言は XML と同じ効果を持たない。例えば、コロンは HTML 要素名において 特別な意味を持たない。
XML 名前空間内の、space という名前の属性は、
Extensible Markup Language(XML)によって定義される。
[XML]
この仕様は、Associating Style Sheets with XML documents で定義される
<?xml-stylesheet?>
処理命令も参照する。
[XMLSSPI]
この仕様は、XSLTProcessor
インターフェイス、およびその transformToFragment() メソッドと
transformToDocument() メソッドにも
非規範的に言及する。[XSLTP]
次の用語は URL で定義される:[URL]
application/x-www-form-urlencoded
形式application/x-www-form-urlencoded
シリアライザーこの仕様は、いくつかのスキームおよびプロトコルも参照する:
about: スキーム
[ABOUT]
blob: スキーム
[FILEAPI]
data: スキーム
[RFC2397]
http: スキーム
[HTTP]
https: スキーム
[HTTP]
mailto:
スキーム [MAILTO]sms: スキーム
[SMS]
urn: スキーム
[URN]
メディア フラグメント 構文は Media Fragments URI で定義される。 [MEDIAFRAG]
次の用語は URL Pattern で定義される: [URLPATTERN]
次の用語は HTTP 仕様で定義される:[HTTP]
Accept` ヘッダーAccept-Language`
ヘッダーCache-Control`
ヘッダーContent-Disposition` ヘッダーContent-Language`
ヘッダーContent-Range`
ヘッダーLast-Modified`
ヘッダーRange` ヘッダーReferer` ヘッダー次の用語は HTTP State Management Mechanism で定義される: [COOKIES]
次の用語は Web Linking で定義される:[WEBLINK]
Link`
ヘッダーLink` フィールド値を構文解析する次の用語は Structured Field Values for HTTP で定義される: [STRUCTURED-FIELDS]
次の用語は MIME Sniffing で定義される: [MIMESNIFF]
次の用語は Fetch で定義される:[FETCH]
about:blankSec-Purpose`User-Agent` 値Origin`
ヘッダーCross-Origin-Resource-Policy`
ヘッダーRequestCredentials
列挙型RequestDestination
列挙型fetch()
メソッド次の用語は Referrer Policy で定義される: [REFERRERPOLICY]
Referrer-Policy`
HTTP ヘッダーReferrer-Policy` ヘッダーから
リファラーポリシーを
構文解析するアルゴリズム
no-referrer」、
「no-referrer-when-downgrade」、
「origin-when-cross-origin」、
および
「unsafe-url」
リファラーポリシー次の用語は Mixed Content で定義される:[MIX]
次の用語は Subresource Integrity で定義される:[SRI]
次の用語は No-Vary-Search HTTP レスポンスヘッダーフィールドで定義される: [NOVARYSEARCH]
次の用語は Paint Timing で定義される:[PAINTTIMING]
次の用語は Navigation Timing で定義される: [NAVIGATIONTIMING]
NavigationTimingType
およびその
「navigate」、
「reload」、
および
「back_forward」
値。次の用語は Resource Timing で定義される: [RESOURCETIMING]
次の用語は Performance Timeline で定義される: [PERFORMANCETIMELINE]
PerformanceEntry
およびその
name、
entryType、
startTime、
および
duration
属性。
次の用語は Long Animation Frames で定義される:[LONGANIMATIONFRAMES]
次の用語は Long Tasks で定義される:[LONGTASKS]
この仕様の IDL 断片は、Web IDL で説明されるとおり、適合する IDL 断片に要求される方法で解釈しなければならない。[WEBIDL]
次の用語は Web IDL で定義される:
[Global][LegacyFactoryFunction]
[LegacyLenientThis][LegacyNullToEmptyString]
[LegacyOverrideBuiltIns]
[LegacyTreatNonObjectAsNull]
[LegacyUnenumerableNamedProperties]
[LegacyUnforgeable]Web IDL は、この仕様で使用される次の型も定義する:
ArrayBufferArrayBufferView
boolean
DOMStringdouble
Float16ArrayFunctionlongobject
Promise
Uint8ClampedArray
unrestricted double
unsigned longUSVStringVoidFunctionQuotaExceededErrorこの仕様における スローする
という用語は、Web IDL で定義されるとおりに使用される。DOMException
型および次の例外名は Web IDL によって定義され、この
仕様で使用される:
IndexSizeError"HierarchyRequestError"
InvalidCharacterError"
NoModificationAllowedError"
NotFoundError"NotSupportedError"InvalidStateError"SyntaxError"InvalidAccessError"
SecurityError"NetworkError"AbortError"DataCloneError"EncodingError"NotAllowedError"この仕様が、特定の時刻(特殊値 Not-a-Number の場合もある)を表す
Date オブジェクトを作成することを
ユーザーエージェントに要求する場合、その時刻にミリ秒成分があるなら、それを整数に
切り捨てなければならず、新しく作成される Date
オブジェクトの時刻値は、切り捨て後の時刻を表さなければならない。
例えば、2000 年 1 月 1 日 01:00 UTC から 1 秒の 23045 百万分の 1 後の時刻、
すなわち 2000-01-01T00:00:00.023045Z が与えられた場合、その時刻を表すために作成された Date
オブジェクトは、
45 百万分の 1 秒前の時刻 2000-01-01T00:00:00.023Z を表すために作成されたものと同じ時刻を表す。
与えられた時刻が NaN の場合、結果は時刻値 NaN を表す Date
オブジェクトとなる(これは、そのオブジェクトが特定の時点を
表していないことを示す)。
この仕様で説明される言語の一部は、基礎となるスクリプティング言語として JavaScript のみを サポートする。[JAVASCRIPT]
「JavaScript」という用語は、公式名称である ECMAScript ではなく、 ECMA-262 を指すために使用される。これは JavaScript という用語の方が広く知られているためである。
次の用語は JavaScript 仕様で定義され、この 仕様で使用される:
Atomics
オブジェクトAtomics.waitAsync オブジェクト
Date クラス
FinalizationRegistry
クラスRegExp
クラスSharedArrayBuffer
クラスSyntaxError
クラスTypeError
クラスRangeError
クラスWeakRef
クラスeval() 関数
WeakRef.prototype.deref()
関数import()
import.metatypeof
演算子delete
演算子JavaScript をサポートするユーザーエージェントは、Dynamic Code Brand Checks 提案も実装しなければならない。次の用語はそこで定義され、この仕様で使用される: [JSDYNAMICCODEBRANDCHECKS]
JavaScript をサポートするユーザーエージェントは、Import Text 提案も 実装しなければならない。次の用語はそこで定義され、この仕様で使用される:[JSIMPORTTEXT]
JavaScript をサポートするユーザーエージェントは、ECMAScript Internationalization API も実装しなければならない。[JSINTL]
JavaScript をサポートするユーザーエージェントは、Temporal 提案も 実装しなければならない。次の用語はそこで定義され、この仕様で使用される:[JSTEMPORAL]
次の用語は WebAssembly JavaScript Interface で定義される: [WASMJS]
Document Object Model(DOM)は、文書およびその内容の表現、すなわちモデルである。 DOM は単なる API ではない。この仕様では、HTML 実装の適合基準が DOM 上の操作によって 定義される。[DOM]
この仕様は DOM によって定義され、一部の機能は DOM インターフェイスの拡張として 定義されるため、実装は DOM および UI Events で定義されるイベントをサポートしなければならない。 [DOM] [UIEVENTS]
特に、次の機能は DOM で定義される:[DOM]
Attr
インターフェイス
CharacterData
インターフェイスComment インターフェイスDOMImplementation
インターフェイスDocument インターフェイスおよびその
doctype 属性
DocumentOrShadowRoot
インターフェイスDocumentFragment
インターフェイスDocumentType
インターフェイス
ChildNode インターフェイスElement
インターフェイスattachShadow()
メソッド。Node
インターフェイス
NodeList インターフェイスProcessingInstruction
インターフェイスおよびその
ターゲット
概念
ShadowRoot
インターフェイス
Text
インターフェイス
Range
インターフェイスHTMLCollection
インターフェイス、その
length 属性、
およびその
item() メソッドと
namedItem()
メソッド
DOMTokenList
インターフェイス、ならびにその
value 属性および
supports 演算
createDocument()
メソッドcreateHTMLDocument()
メソッドcreateElement()
メソッドcreateElementNS()
メソッドgetElementById()
メソッドgetElementsByClassName()
メソッドappend() メソッドappendChild() メソッド
cloneNode() メソッドmoveBefore() メソッド
importNode() メソッド
preventDefault()
メソッドid
属性setAttribute()
メソッドtextContent 属性
children 属性
slotchange
イベントCharacterData
ノードの データおよびその
データを置換する
アルゴリズム
Event
インターフェイスEvent および派生インターフェイスの
コンストラクター動作EventTarget
インターフェイス
EventInit 辞書型
type
属性currentTarget
属性bubbles 属性cancelable 属性
composed 属性isTrusted 属性initEvent() メソッドaddEventListener()
メソッドEventListener
コールバックインターフェイスDocument の
エンコーディング
(ここでは文字エンコーディング)、
モード、
カスタム要素レジストリ、
宣言的
シャドウルートを許可する、および
コンテンツ型
is 値
MutationObserver
インターフェイス、および一般的な 変更オブザーバーAbortControllerおよびその
シグナル
AbortSignal次の機能は UI Events で定義される:[UIEVENTS]
FocusEvent インターフェイスFocusEvent
インターフェイスの relatedTarget
属性UIEvent
インターフェイスUIEvent
インターフェイスの view 属性beforeinput
イベント
contextmenu
イベント
input イベントkeydown イベントkeypress イベントkeyup イベント次の機能は Touch Events で定義される:[TOUCH]
次の機能は Pointer Events で定義される: [POINTEREVENTS]
MouseEvent
インターフェイス
MouseEvent
インターフェイスの relatedTarget
属性MouseEvent
インターフェイスの button
属性MouseEventInit
辞書型PointerEvent
インターフェイスPointerEvent
インターフェイスの pointerType
属性auxclick イベントclick
イベントdblclick イベントmousedown イベントmouseenter イベントmouseleave イベントmousemove イベントmouseout イベントmouseover イベントmouseup イベントpointerdown
イベントpointerup
イベント
pointercancel
イベントwheel
イベント次のイベントは Clipboard API and events で定義される: [CLIPBOARD-APIS]
この仕様では、イベントの型を指すために、
名前という用語を使用することがある。例えば、「click という名前のイベント」、
または「イベント名が keypress である場合」のように使用する。イベントについて、
「名前」と「型」という用語は同義である。
次の機能は DOM Parsing and Serialization で定義される: [DOMPARSING]
次の機能は Selection API で定義される:[SELECTION]
ユーザーエージェントには、execCommand で説明される機能を 実装することが推奨される。[EXECCOMMAND]
次の機能は Fullscreen API で定義される: [FULLSCREEN]
High Resolution Time は次の機能を提供する:[HRT]
この仕様は、File API で定義される次の機能を使用する: [FILEAPI]
Blob
インターフェイスおよびその
type
属性
File
インターフェイス、ならびにその
name 属性および
lastModified 属性
FileList
インターフェイスBlob
の
スナップショット状態という概念
次の用語は Indexed Database API で定義される: [INDEXEDDB]
次の用語は Media Source Extensions で定義される: [MEDIASOURCE]
MediaSource
インターフェイス次の用語は Media Capture and Streams で定義される: [MEDIASTREAM]
MediaStream
インターフェイスMediaStreamTrack
getUserMedia()
次の用語は Reporting で定義される:[REPORTING]
次の機能および用語は XMLHttpRequest で定義される: [XHR]
XMLHttpRequest
インターフェイス、およびその
responseXML
属性
ProgressEvent
インターフェイス、ならびにその
lengthComputable、
loaded、および
total 属性
FormData
インターフェイス、およびそれに関連する
エントリー
リスト
次の機能は Battery Status API で定義される:[BATTERY]
getBattery()
メソッド実装は Media Queries をサポートしなければならない。<media-condition> 機能はそこで定義される。[MQ]
CSS 全体のサポートは、この仕様の実装に必須ではない (ただし、少なくともウェブブラウザーには推奨される)が、一部の機能は 特定の CSS 要件に基づいて定義される。
この仕様が、何かを特定の CSS 文法に従って 構文解析することを要求する場合、エラー処理規則を含め、 CSS Syntax の関連するアルゴリズムに従わなければならない。 [CSSSYNTAX]
例えば、ユーザーエージェントは、スタイルシートの終端が予期せず
見つかった場合、開いているすべての構文を閉じることを要求される。したがって、
色の値として文字列「rgb(0,0,0」(閉じ括弧が欠落している)を構文解析する場合、
このエラー処理規則によって閉じ括弧が暗黙的に補われ、値(色「black」)が得られる。
しかし、類似した構文「rgb(0,0,」(括弧と「blue」の値の両方が欠落している)は、
開いている構文を閉じても有効な値にならないため、構文解析できない。
次の用語および機能は Cascading Style Sheets (CSS)で定義される:[CSS]
'display' プロパティの基本版は CSS で定義され、このプロパティは他の CSS モジュールによって拡張される。 [CSS] [CSSRUBY] [CSSTABLE]
次の用語および機能は CSS Box Model で定義される: [CSSBOX]
次の機能は CSS Logical Properties で定義される: [CSSLOGICAL]
次の用語および機能は CSS Color で定義される: [CSSCOLOR]
次の用語は CSS Images で定義される:[CSSIMAGES]
ペイント ソースという用語は、特定の HTML 要素と CSS の 'element()' 関数との相互作用を 定義するため、CSS Images Level 4 で定義されるとおりに使用される。 [CSSIMAGES4]
次の機能は CSS Backgrounds and Borders で定義される: [CSSBG]
CSS Backgrounds and Borders は、次のボーダープロパティも定義する: [CSSBG]
次の機能は CSS Box Alignment で定義される:[CSSALIGN]
次の用語および機能は CSS Display で定義される: [CSSDISPLAY]
次の機能は CSS Flexible Box Layout で定義される: [CSSFLEXBOX]
次の用語および機能は CSS Fonts で定義される: [CSSFONTS]
次の機能は CSS Forms で定義される: [CSSFORMS]
次の機能は CSS Gaps で定義される: [CSSGAPS]
次の機能は CSS Grid Layout で定義される:[CSSGRID]
次の用語は CSS Inline Layout で定義される:[CSSINLINE]
次の用語および機能は CSS Box Sizing で定義される: [CSSSIZING]
次の機能は CSS Lists and Counters で定義される。 [CSSLISTS]
次の機能は CSS Overflow で定義される。[CSSOVERFLOW]
次の用語および機能は CSS Positioned Layout で定義される: [CSSPOSITION]
次の機能は CSS Multi-column Layout で定義される。 [CSSMULTICOL]
'display' プロパティの 'ruby-base' 値は CSS Ruby Layout で定義される。 [CSSRUBY]
次の機能は CSS Table で定義される:[CSSTABLE]
次の機能は CSS Text で定義される:[CSSTEXT]
次の機能は CSS Writing Modes で定義される:[CSSWM]
次の機能は CSS Basic User Interface で定義される: [CSSUI]
アニメーションを 更新してイベントを送信するアルゴリズムは Web Animations で定義される。 [WEBANIMATIONS]
スクリプティングをサポートする実装は、CSS Object Model をサポートしなければならない。 次の機能および用語は CSSOM 仕様で定義される:[CSSOM] [CSSOMVIEW]
Screen
インターフェイス
LinkStyle
インターフェイスCSSStyleDeclaration
インターフェイスstyle IDL
属性CSSStyleDeclaration
の cssText
属性
StyleSheet
インターフェイスCSSStyleSheet
インターフェイスCSSStyleSheet を作成するCSSStyleSheet
の規則を同期的に置換するresize
イベント
scroll
イベント
scrollend
イベント次の機能および用語は CSS Syntax で定義される: [CSSSYNTAX]
次の用語は Selectors で定義される:[SELECTORS]
<selector-list>
:focus-visible
疑似クラス次の機能は CSS Values and Units で定義される: [CSSVALUES]
次の機能は CSS View Transitions で定義される: [CSSVIEWTRANSITIONS]
ViewTransition
style 属性という用語は CSS Style Attributes で定義される。[CSSATTR]
次の用語は CSS Cascading and Inheritance で定義される: [CSSCASCADE]
CanvasRenderingContext2D
オブジェクトによるフォントの使用は、CSS の Fonts および Font Loading
仕様で説明される機能に依存する。これには特に FontFace
オブジェクトおよび フォントソース概念が含まれる。
[CSSFONTS] [CSSFONTLOAD]
次のインターフェイスおよび用語は Geometry Interfaces で定義される: [GEOMETRY]
DOMMatrix インターフェイス、
および関連する
m11 要素、
m12 要素、
m21 要素、
m22 要素、
m41 要素、
および
m42 要素
DOMMatrix2DInit
および
DOMMatrixInit
辞書
DOMMatrix2DInit
または DOMMatrixInit
用の、辞書から
DOMMatrix を作成するアルゴリズム、および 2D 辞書から
DOMMatrix を作成するアルゴリズム
DOMPointInit
辞書、および関連する
x と
y メンバー
次の用語は CSS Scoping で定義される:[CSSSCOPING]
次の用語および機能は CSS Color Adjustment で定義される: [CSSCOLORADJUST]
次の用語は CSS Pseudo-Elements で定義される:[CSSPSEUDO]
次の用語は CSS Containment で定義される:[CSSCONTAIN]
次の用語は CSS Anchor Positioning で定義される:[CSSANCHOR]
次の用語は Intersection Observer で定義される: [INTERSECTIONOBSERVER]
次の用語は Resize Observer で定義される: [RESIZEOBSERVER]
次のインターフェイスは WebGL 仕様で定義される:[WEBGL]
WebGLRenderingContext
インターフェイスWebGL2RenderingContext
インターフェイスWebGLContextAttributes
辞書次のインターフェイスは WebGPU で定義される:[WEBGPU]
GPUCanvasContext
インターフェイス
実装は、メディアリソースの字幕、キャプション、メタデータなどのテキストトラック形式として WebVTT をサポートしてもよい。[WEBVTT]
この仕様で使用される次の用語は、WebVTT で定義される:
role 属性は
Accessible Rich Internet Applications(ARIA)で定義され、
次のロールも同様に定義される:[ARIA]
さらに、次の aria-* コンテンツ属性は
ARIA で定義される:[ARIA]
最後に、次の用語は ARIA で定義される:[ARIA]
ARIAMixin
インターフェイス、それに関連付けられた
ARIAMixin ゲッター
手順および
ARIAMixin セッター
手順フック、ならびにその
role 属性および
aria*
属性
次の用語は Content Security Policy で定義される:[CSP]
report-uri
ディレクティブframe-ancestors
ディレクティブsandbox
ディレクティブSecurityPolicyViolationEvent
インターフェイスsecuritypolicyviolation
イベント次の用語は Service Workers で定義される:[SW]
次のアルゴリズムは Secure Contexts で定義される: [SECURE-CONTEXTS]
次の用語は Permissions Policy で定義される: [PERMISSIONSPOLICY]
次の機能は Payment Request API で定義される: [PAYMENTREQUEST]
PaymentRequest
インターフェイスMathML 全体のサポートはこの仕様で要求されない (ただし、少なくともウェブブラウザーには推奨される)が、一部の機能は MathML の 小さな部分が実装されていることに依存する。[MATHML]
次の機能は Mathematical Markup Language (MathML)で定義される:
a
要素annotation-xml 要素math 要素merror 要素mfrac 要素mi 要素mmultiscripts 要素mn 要素mo 要素mover 要素mpadded 要素mphantom 要素mprescripts 要素mroot 要素mrow 要素ms 要素mspace 要素msqrt 要素mstyle 要素msub 要素msubsup 要素msup 要素mtable 要素mtd 要素mtext 要素mtr 要素munder 要素munderover 要素semantics 要素accent 属性accentunder 属性columnspan 属性depth 属性fence 属性form 属性height 属性largeop 属性lspace 属性maxsize 属性minsize 属性movablelimits 属性rowspan 属性rspace 属性separator 属性stretchy 属性symmetric 属性voffset 属性width 属性displaystyle 属性mathbackground 属性mathcolor 属性mathsize 属性scriptlevel 属性SVG 全体のサポートはこの仕様で要求されない (ただし、少なくともウェブブラウザーには推奨される)が、一部の機能は SVG の一部が 実装されていることに依存する。
SVG を実装するユーザーエージェントは、以前の改訂版ではなく、 SVG 2 仕様を実装しなければならない。
次の機能は SVG 2 仕様で定義される: [SVG]
SVGElement
インターフェイスSVGImageElement
インターフェイスSVGScriptElement
インターフェイスSVGSVGElement
インターフェイスa 要素animate 要素animateTransform 要素circle 要素defs 要素desc 要素ellipse 要素foreignObject 要素g 要素image 要素line 要素marker 要素metadata 要素path 要素polygon 要素polyline 要素rect 要素script 要素set 要素svg 要素text 要素textPath 要素title 要素tspan 要素use 要素action 属性attributeName 属性cx 属性cy 属性d 属性dx 属性dy 属性formaction 属性height 属性href 属性hreflang 属性lengthAdjust 属性markerHeight 属性markerUnits 属性markerWidth 属性method 属性orient 属性path 属性pathLength 属性points 属性preserveAspectRatio 属性r 属性refX 属性refY 属性rotate 属性rx 属性ry 属性side 属性spacing 属性startOffset 属性textLength 属性type 属性viewBox 属性width 属性x 属性x1 属性x2 属性y 属性y1 属性y2 属性text-rendering プロパティalignment-baseline プロパティbaseline-shift プロパティclip-path プロパティclip-rule プロパティcolor プロパティcolor-interpolation プロパティcursor プロパティdirection プロパティdisplay プロパティdominant-baseline プロパティfill プロパティfill-opacity プロパティfill-rule プロパティfont-family プロパティfont-size プロパティfont-size-adjust プロパティfont-stretch プロパティfont-style プロパティfont-variant プロパティfont-weight プロパティletter-spacing プロパティmarker-end プロパティmarker-mid プロパティmarker-start プロパティopacity プロパティpaint-order プロパティpointer-events プロパティshape-rendering プロパティstop-color プロパティstop-opacity プロパティstroke プロパティstroke-dasharray プロパティstroke-dashoffset プロパティstroke-linecap プロパティstroke-linejoin プロパティstroke-miterlimit プロパティstroke-opacity プロパティstroke-width プロパティtext-anchor プロパティtext-decoration プロパティtext-overflow プロパティtransform プロパティtransform-origin プロパティunicode-bidi プロパティvector-effect プロパティvisibility プロパティwhite-space プロパティword-spacing プロパティwriting-mode プロパティ次の機能は Filter Effects で定義される:[FILTERS]
次の機能は Compositing and Blending で定義される: [COMPOSITE]
次の機能は Cooperative Scheduling of Background Tasks で定義される:[REQUESTIDLECALLBACK]
次の用語は Screen Orientation で定義される: [SCREENORIENTATION]
次の用語は Storage で定義される:[STORAGE]
次の機能は Web App Manifest で定義される:[MANIFEST]
次の用語は WebAssembly JavaScript Interface: ESM Integration で定義される:[WASMESM]
次の機能は WebCodecs で定義される:[WEBCODECS]
VideoFrame
インターフェイス。次の用語は WebDriver で定義される:[WEBDRIVER]
次の用語は WebDriver BiDi で定義される:[WEBDRIVERBIDI]
次の用語は Web Cryptography API で定義される: [WEBCRYPTO]
次の用語は WebSockets で定義される:[WEBSOCKETS]
次の用語は WebTransport で定義される:[WEBTRANSPORT]
次の用語は Web Authentication: An API for accessing Public Key Credentials で定義される:[WEBAUTHN]
次の用語は Credential Management で定義される:[CREDMAN]
次の用語は Console で定義される:[CONSOLE]
次の用語は Web Locks API で定義される:[WEBLOCKS]
この仕様は、Trusted Types で定義される次の機能を使用する: [TRUSTED-TYPES]
次の用語は WebRTC API で定義される:[WEBRTC]
次の用語は Picture-in-Picture API で定義される:[PICTUREINPICTURE]
次の用語は Idle Detection API で定義される:
次の用語は Web Speech API で定義される:
次の用語は WebOTP API で定義される:
次の用語は Web Share API で定義される:
次の用語は Web Smart Card API で定義される:
次の用語は Web Background Synchronization で定義される:
次の用語は Web Periodic Background Synchronization で定義される:
次の用語は Background Fetch で定義される:
次の用語は Keyboard Lock で定義される:
次の用語は Web MIDI API で定義される:
次の用語は Generic Sensor API で定義される:
次の用語は WebHID API で定義される:
次の用語は WebXR Device API で定義される:
この仕様は、上記の一覧で要求されるものを超えて、特定のネットワークプロトコル、スタイル シート言語、スクリプティング言語、または DOM 仕様のサポートを要求しない。ただし、 この仕様で説明される言語は、スタイル言語として CSS、スクリプティング言語として JavaScript、 ネットワークプロトコルとして HTTP を使用することを前提としており、いくつかの機能はそれらの 言語およびプロトコルが使用されていることを想定している。
HTTP プロトコルを実装するユーザーエージェントは、HTTP State Management Mechanism(Cookie)も実装しなければならない。[HTTP] [COOKIES]
この仕様は、それぞれの節において、文字エンコーディング、画像形式、 音声形式、および動画形式に関する追加要件を定めることがある。
この仕様に対するベンダー固有の独自ユーザーエージェント拡張は強く非推奨とされる。 文書はそのような拡張を使用してはならない。使用すると相互運用性が低下し、 ユーザー基盤が分断され、特定のユーザーエージェントの利用者だけが対象のコンテンツに アクセスできるようになるためである。
すべての拡張は、その使用が仕様で定義された機能と矛盾せず、またその機能を 不適合にしないように定義しなければならない。
例えば、強く非推奨ではあるが、実装はコントロールに新しい IDL
属性「typeTime」を追加し、ユーザーがコントロールの現在の値を
選択するのに要した時間を返すようにしてもよい。一方、フォームの elements
配列に現れる新しいコントロールを定義することは、上記の要件に違反する。
これは、この仕様で与えられた elements
の定義に
違反するためである。
この仕様に対するベンダー中立な拡張が必要な場合、この仕様をそれに応じて 更新するか、この仕様の要件を上書きする拡張仕様を作成できる。この仕様を自らの活動に 適用する者が、そのような拡張仕様の要件を認めると決定した場合、その拡張仕様は、 この仕様における適合性要件のための適用可能な仕様となる。
任意のバイトストリームを適合すると定義する仕様を誰かが作成し、 その上で無作為な無意味データが適合していると主張することもできる。しかし、それは その無作為な無意味データがすべての人の目的に対して実際に適合していることを意味しない。 別の者がその仕様は自らの作業には適用されないと判断した場合、前述の無作為な無意味データは 単なる無意味データであり、まったく適合していないと正当に述べることができる。適合性に関して、 特定のコミュニティで重要なのは、そのコミュニティが何を適用可能であると合意するかである。
ユーザーエージェントは、理解できない要素および属性を意味論的に中立なものとして 扱わなければならない。すなわち、DOM プロセッサーではそれらを DOM に残し、CSS プロセッサーでは CSS に従ってスタイルを適用するが、それらからいかなる意味も推論してはならない。
機能のサポートが無効化されている場合(例えば、セキュリティ問題を軽減するための緊急措置、 開発支援、またはパフォーマンス上の理由による場合)、ユーザーエージェントは、その機能を まったくサポートしておらず、その機能がこの仕様に記載されていないかのように動作しなければならない。 例えば、特定の機能が Web IDL インターフェイスの属性を通じてアクセスされる場合、その属性自体を そのインターフェイスを実装するオブジェクトから省略しなければならない。属性をオブジェクト上に残したまま null を返すようにしたり、例外をスローするようにしたりするだけでは不十分である。
この仕様で説明される方法により構文解析または作成された
HTML
文書に対して動作する XPath 1.0 の実装(例えば document.evaluate() API
の一部として)は、XPath 1.0 仕様に次の編集が適用されたかのように動作しなければならない。
まず、次の段落を削除する:
ノードテスト内の QName は、 式コンテキストの名前空間宣言を使用して 展開名に展開される。 これは、開始タグおよび終了タグ内の要素型名の展開方法と同じであるが、
xmlnsで宣言された既定の名前空間は使用されない。すなわち、 QName に接頭辞がない場合、 名前空間 URI は null となる(これは属性名が展開される方法と同じである)。 QName に、式コンテキスト内に 名前空間宣言が存在しない接頭辞がある場合はエラーとなる。
次に、その位置に以下を挿入する:
ノードテスト内の QName は、式コンテキストの名前空間宣言を使用して展開名に展開される。 QName に接頭辞がある場合、式コンテキスト内にその接頭辞に対応する名前空間宣言が 存在しなければならず、対応する名前空間 URI がその接頭辞に関連付けられる。 QName に、式コンテキスト内に名前空間宣言が存在しない接頭辞がある場合はエラーとなる。
QName に接頭辞がなく、軸の主ノード型が要素である場合、既定の要素名前空間が使用される。 それ以外の場合、QName に接頭辞がなければ、名前空間 URI は null となる。 既定の要素名前空間は XPath 式のコンテキストの一部である。DOM3 XPath API を通じて XPath 式を実行する際の既定の要素名前空間の値は、次の方法で決定される:
- コンテキストノードが HTML DOM に由来する場合、既定の要素名前空間は "http://www.w3.org/1999/xhtml" である。
- それ以外の場合、既定の要素名前空間 URI は null である。
これは、XPath 2.0 の既定の要素名前空間機能を XPath 1.0 に追加し、 HTML 文書について HTML 名前空間を既定の要素名前空間として使用することと同等である。 これは、HTML 要素に使用される名前空間に関してこの仕様が HTML に導入する変更を 引き続きサポートしながら、実装をレガシー HTML コンテンツと互換にしたいという要望、 および XPath 2.0 ではなく XPath 1.0 を使用したいという要望に基づく。
この変更は XPath 1.0 仕様に対する 意図的な違反 であり、HTML 要素にどの名前空間が使用されるかに関してこの仕様が HTML に導入する変更を 引き続きサポートしながら、実装をレガシーコンテンツと互換にしたいという要望に基づく。 [XPATH10]
出力方式が "html" である場合 (明示的に指定された場合、または XSLT 1.0 の既定規則による場合)に DOM へ出力する XSLT 1.0 プロセッサーは、次のような影響を受ける:
変換プログラムが名前空間に属さない要素を出力する場合、プロセッサーは対応する DOM 要素ノードを構築する前に、その要素の名前空間を HTML 名前空間に変更し、要素のローカル名を ASCII 小文字化し、さらに要素上の名前空間に 属さないすべての属性名を ASCII 小文字化しなければならない。
この要件は XSLT 1.0 仕様に対する 意図的な違反 であり、この仕様が HTML の名前空間および大文字小文字の区別に関する規則を、 DOM ベースの XSLT 変換と互換性がなくなるような形で変更するために必要とされる。 (出力をシリアライズするプロセッサーは影響を受けない。)[XSLT10]
この仕様は、XSLT 処理が HTML
パーサー基盤とどのように相互作用するかを厳密には規定しない
(例えば、XSLT プロセッサーが要素を 開いている要素の
スタックに入れるかのように動作するかどうか)。ただし、XSLT プロセッサーは、
正常に完了した場合は構文解析を停止しなければならず、
中止された場合は、まず現在の文書の
準備状態を更新して「interactive」とし、その後「complete」と
しなければならない。
この仕様は、XSLT が ナビゲーションアルゴリズムとどのように相互作用するか、 イベントループにどのように 組み込まれるか、またエラーページをどのように処理するか (例えば、XSLT エラーが増分 XSLT 出力を置換するのか、インラインでレンダリングされるのかなど)を 規定しない。
XSLT と HTML の相互作用については
script 要素の節に、
XSLT、XPath、および HTML の相互作用については
template 要素の節に、
追加の非規範的な注記がある。
Headers/Permissions-Policy/document-domain
1 つのエンジンのみでサポートされています。
この文書は、次の ポリシー制御機能を定義する:
Headers/Feature-Policy/autoplay
Headers/Permissions-Policy/autoplay
1 つのエンジンのみでサポートされています。
autoplay」。その既定の
許可リストは 'self' である。cross-origin-isolated」。その既定の
許可リストは 'self' である。focus-without-user-activation」。その
既定の
許可リストは 'self' である。
HTML には、日付や数値など、特定のデータ型を受け入れるさまざまな箇所がある。 この節では、それらの形式のコンテンツに対する適合性基準と、それらを構文解析する方法について 説明する。
実装者には、以下で説明する構文の構文解析を実装するために使用を検討する サードパーティーライブラリーを、慎重に調査することが強く求められる。例えば、日付 ライブラリーは、この仕様で要求されるものとは異なるエラー処理動作を実装している可能性が高い。 これは、この仕様で使用されるものと類似した日付構文を説明する仕様では、エラー処理動作が 定義されていないことが多く、そのため実装によってエラーの処理方法が大きく異なる傾向があるためである。
以下で説明するマイクロパーサーの一部は、構文解析対象の文字列を保持する input 変数と、input 内で次に構文解析する文字を指す position 変数を持つというパターンに従う。
多くの属性はブール属性である。 要素上にブール属性が存在することは真の値を表し、その属性が存在しないことは 偽の値を表す。
属性が存在する場合、その値は空文字列、または属性の正規名と ASCII 大文字小文字不区別で一致する値のいずれかでなければならず、 先頭または末尾に空白があってはならない。
ブール属性では、値「true」および「false」は許可されない。 偽の値を表すには、その属性自体を完全に省略しなければならない。
以下は、チェックされ、かつ無効化されたチェックボックスの例である。checked 属性と disabled
属性がブール属性である。
< label >< input type = checkbox checked name = cheese disabled > Cheese</ label > これは、次のように同等に記述できる:
< label >< input type = checkbox checked = checked name = cheese disabled = disabled > Cheese</ label > 記法を混在させることもできる。次の例も同等である:
< label >< input type = 'checkbox' checked name = cheese disabled = "" > Cheese</ label > 列挙 属性と呼ばれる一部の属性は、有限個の状態のいずれかを取る。このような 属性の状態は、属性の値、キーワードと状態の対応関係の集合、およびその属性の仕様で 指定することもできる 3 つの特別な状態を組み合わせて導出される。これらの特別な状態は、 無効値の既定状態、欠落値の 既定状態、および 空値の既定状態である。
複数のキーワードが同じ状態に対応してもよい。
属性の状態を決定するには、次の手順を使用する:
作者の適合性に関して、列挙属性が指定されている場合、その属性の値は 次のいずれかでなければならない:
その属性の適合キーワードのいずれかと ASCII 大文字小文字不区別で一致し、先頭または末尾に空白を含まない値。
空文字列であり、かつ属性に 空値の 既定状態が定義されていること。
反映のため、対応するキーワードが 1 つ以上ある状態は、正規キーワードを持つという。これは次のように決定される:
指定された状態に対応するキーワードが 1 つだけである場合、それが正規キーワードである。
指定された状態に対応する適合キーワードが 1 つだけである場合、 その適合キーワードが正規キーワードである。
指定された状態に対応する適合キーワードが 2 つあり、その一方が空文字列である場合、 空文字列ではない適合キーワードが正規キーワードとなる。
それ以外の場合、その状態の正規キーワードは、属性の仕様で明示的に 指定される。
文字列は、1 個以上の ASCII 数字からなり、 任意で先頭に U+002D HYPHEN-MINUS 文字(-)が付く場合、妥当な整数である。
U+002D HYPHEN-MINUS(-)接頭辞を持たない 妥当な整数は、その数字列によって 10 進数で表される数を表す。U+002D HYPHEN-MINUS(-)接頭辞を 持つ 妥当な整数は、 U+002D HYPHEN-MINUS の後に続く数字列が 10 進数で表す数を、ゼロから減算した数を表す。
整数を構文解析する規則は、次の アルゴリズムで示すとおりである。呼び出された場合、値を返す最初の手順で中止しながら、 指定された順序で手順に従わなければならない。このアルゴリズムは整数またはエラーを返す。
input を構文解析対象の文字列とする。
position を input 内へのポインターとし、最初は 文字列の先頭を指すものとする。
sign の値を「positive」とする。
position を与えて、input 内の ASCII 空白をスキップする。
position が input の末尾を越えている場合、エラーを返す。
position が示す文字(最初の文字)が U+002D HYPHEN-MINUS 文字(-)である場合:
それ以外で、position が示す文字(最初の文字)が U+002B PLUS SIGN 文字(+)である場合:
+」は
無視されるが、適合ではない。)position が示す文字が ASCII 数字でない場合、エラーを返す。
position を与えて、input から ASCII 数字である 符号位置の列を収集し、 結果の列を 10 進整数として解釈する。value をその整数とする。
sign が「positive」である場合は value を返し、それ以外の場合は value をゼロから減算した結果を返す。
文字列は、1 個以上の ASCII 数字からなる場合、妥当な非負整数である。
妥当な非負 整数は、その数字列によって 10 進数で表される数を表す。
非負整数を構文解析する規則は、 次のアルゴリズムで示すとおりである。 呼び出された場合、値を返す最初の手順で中止しながら、指定された順序で 手順に従わなければならない。このアルゴリズムは、ゼロ、正の整数、またはエラーを返す。
input を構文解析対象の文字列とする。
value を、input に 整数を構文解析する 規則を適用した結果とする。
value がエラーである場合、エラーを返す。
value がゼロ未満である場合、エラーを返す。
value を返す。
文字列は、次のものから構成される場合、妥当な浮動小数点数である:
妥当な 浮動小数点数は、仮数に 10 の指数乗を乗算して得られる数を表す。ここで仮数は、 最初の数を 10 進数として解釈したものである(小数点および小数点後の数があればそれらを含み、 文字列全体が U+002D HYPHEN-MINUS 文字(-)で始まり、かつ数がゼロでない場合は、 仮数を負の数として解釈する)。指数は、E の後に数がある場合はその数である (E と数の間に U+002D HYPHEN-MINUS 文字(-)があり、かつ数がゼロでない場合は 負の数として解釈し、E と数の間に U+002B PLUS SIGN 文字(+)がある場合はそれを無視する)。 E がない場合、指数はゼロとして扱われる。
Infinity および Not-a-Number(NaN)の値は、妥当な浮動小数点数ではない。
妥当な浮動小数点数という概念は通常、
作者に許可される内容を制限するためにのみ使用され、ユーザーエージェント要件では以下の
浮動小数点数値を
構文解析する規則が使用される(例えば、max 属性は progress 要素の属性である)。
ただし、場合によっては、ユーザーエージェント要件に、文字列が 妥当な
浮動小数点数であるかを検査することが含まれる(例えば、input 要素の
Number 状態に対する
値のサニタイズアルゴリズム、または
srcset
属性を構文解析するアルゴリズム)。
数 n の浮動小数点数としての 最適な表現は、ToString(n) を実行して得られる文字列である。抽象演算 ToString は一意には決定されない。特定の値について ToString から得られる可能性のある文字列が複数ある場合、 ユーザーエージェントは、その値に対して常に同じ文字列を返さなければならない (ただし、他のユーザーエージェントが使用する値とは異なってもよい)。
浮動小数点数値を構文解析する 規則は、次のアルゴリズムで示すとおりである。このアルゴリズムは、 何かを返す最初の手順で中止しなければならない。このアルゴリズムは数またはエラーを返す。
input を構文解析対象の文字列とする。
position を input 内へのポインターとし、最初は 文字列の先頭を指すものとする。
value の値を 1 とする。
divisor の値を 1 とする。
exponent の値を 1 とする。
position を与えて、input 内の ASCII 空白をスキップする。
position が input の末尾を越えている場合、エラーを返す。
position が示す文字が U+002D HYPHEN-MINUS 文字(-)である場合:
それ以外で、position が示す文字(最初の文字)が U+002B PLUS SIGN 文字(+)である場合:
+」は
無視されるが、適合ではない。)position が示す文字が U+002E FULL STOP(.)であり、それが input の最後の文字ではなく、かつ position が示す文字の次の文字が ASCII 数字である場合、 value をゼロに設定し、fraction とラベル付けされた手順へ移る。
position が示す文字が ASCII 数字でない場合、エラーを返す。
position を与えて、input から ASCII 数字である 符号位置の列を収集し、 結果の列を 10 進整数として解釈する。value にその整数を乗算する。
Fraction:position が示す文字が U+002E FULL STOP(.)である場合、次の下位手順を実行する:
position を次の文字へ進める。
position が input の末尾を越えている場合、または position が示す文字が ASCII 数字、 U+0065 LATIN SMALL LETTER E(e)、または U+0045 LATIN CAPITAL LETTER E(E)の いずれでもない場合、conversion とラベル付けされた手順へ移る。
position が示す文字が U+0065 LATIN SMALL LETTER E 文字(e)または U+0045 LATIN CAPITAL LETTER E 文字(E)である場合、 これらの下位手順の残りをスキップする。
Fraction loop:divisor に 10 を乗算する。
position を次の文字へ進める。
position が input の末尾を越えている場合、 conversion とラベル付けされた手順へ移る。
position が示す文字が ASCII 数字である場合、これらの下位手順内の fraction loop とラベル付けされた手順へ戻る。
position が示す文字が U+0065(e)または U+0045(E)である場合:
position を次の文字へ進める。
position が input の末尾を越えている場合、 conversion とラベル付けされた手順へ移る。
position が示す文字が U+002D HYPHEN-MINUS 文字 (-)である場合:
position が input の末尾を越えている場合、 conversion とラベル付けされた手順へ移る。
それ以外で、position が示す文字が U+002B PLUS SIGN 文字(+)である場合:
position が input の末尾を越えている場合、 conversion とラベル付けされた手順へ移る。
position が示す文字が ASCII 数字でない場合、 conversion とラベル付けされた手順へ移る。
position を与えて、input から ASCII 数字である 符号位置の列を収集し、 結果の列を 10 進整数として解釈する。exponent にその整数を乗算する。
value に、10 の exponent 乗を乗算する。
Conversion:S を、−0 を除く有限の IEEE 754 倍精度 浮動小数点値の集合に、2 つの特殊値 21024 および −21024 を 加えたものとする。
rounded-value を、S 内で value に最も近い数とし、同じ距離の値が 2 つある場合は仮数が偶数の数を選択する。 (2 つの特殊値 21024 および −21024 は、この目的では 偶数の仮数を持つものとみなす。)
rounded-value が 21024 または −21024 である場合、エラーを返す。
rounded-value を返す。
寸法値を構文解析する規則は、次の アルゴリズムで示すとおりである。呼び出された場合、値を返す最初の手順で中止しながら、 指定された順序で手順に従わなければならない。このアルゴリズムは 0.0 以上の数または 失敗を返す。数が返された場合、その数はさらにパーセンテージまたは長さのいずれかに分類される。
input を構文解析対象の文字列とする。
position を input の 位置 変数とし、 最初は input の先頭を指すものとする。
position を与えて、input 内の ASCII 空白をスキップする。
position が input の末尾を越えているか、 input 内の position にある符号位置が ASCII 数字でない場合、失敗を返す。
position を与えて、input から ASCII 数字である 符号位置の列を収集し、 結果の列を 10 進整数として解釈する。value をその数とする。
position が input の末尾を越えている場合、 value を長さとして返す。
input 内の position にある符号位置が U+002E(.)である場合:
value、input、および position を用いて 現在の寸法値を返す。
value、input、および position が与えられた場合、現在の寸法値は 次のように決定される:
position が input の末尾を越えている場合、 value を長さとして返す。
input 内の position にある符号位置が U+0025(%)である場合、 value をパーセンテージとして返す。
value を長さとして返す。
0 でない寸法値を構文解析する 規則は、次のアルゴリズムで示すとおりである。呼び出された場合、値を返す最初の 手順で中止しながら、指定された順序で手順に従わなければならない。このアルゴリズムは 0.0 より大きい数またはエラーを返す。数が返された場合、その数はさらに パーセンテージまたは長さのいずれかに分類される。
input を構文解析対象の文字列とする。
value を、input に 寸法値を 構文解析する規則を適用した結果とする。
value がエラーである場合、エラーを返す。
value がゼロである場合、エラーを返す。
value がパーセンテージである場合、value をパーセンテージとして返す。
value を長さとして返す。
妥当な浮動小数点数のリストは、複数の 妥当な 浮動小数点数を U+002C COMMA 文字で区切ったものであり、 その他の文字(例えば ASCII 空白)を 含まない。さらに、指定できる浮動小数点数の個数または許可される値の範囲に 制限が設けられることがある。
浮動小数点数のリストを構文解析する 規則は、次のとおりである:
input を構文解析対象の文字列とする。
position を input 内へのポインターとし、最初は 文字列の先頭を指すものとする。
numbers を、最初は空である浮動小数点数のリストとする。このリストが このアルゴリズムの結果となる。
position を与えて、input から ASCII 空白、U+002C COMMA、または U+003B SEMICOLON 文字である 符号位置の列を収集する。 これにより、先頭の区切り文字を読み飛ばす。
position が input の末尾を越えていない間:
position を与えて、input から ASCII 空白、U+002C COMMA、U+003B SEMICOLON、ASCII 数字、 U+002E FULL STOP、または U+002D HYPHEN-MINUS 文字のいずれでもない 符号位置の列を収集する。 これにより、先頭の不要な文字を読み飛ばす。
position を与えて、input から ASCII 空白、U+002C COMMA、または U+003B SEMICOLON 文字のいずれでもない 符号位置の列を収集し、 結果を unparsed number とする。
number を、unparsed number に 浮動小数点数値を 構文解析する規則を適用した結果とする。
number がエラーである場合、number をゼロに設定する。
number を numbers に付加する。
position を与えて、input から ASCII 空白、U+002C COMMA、または U+003B SEMICOLON 文字である 符号位置の列を収集する。 これにより、区切り文字を読み飛ばす。
numbers を返す。
寸法のリストを構文解析する規則は、次のとおりである。 これらの規則は、数と単位からなる 0 個以上の組のリストを返す。単位は percentage、relative、および absolute のいずれかである。
raw input を構文解析対象の文字列とする。
raw input の最後の文字が U+002C COMMA 文字(,)である場合、 その文字を raw input から削除する。
文字列 raw input を コンマで分割する。raw tokens を、結果として得られるトークンのリストとする。
result を、数と単位の組からなる空のリストとする。
raw tokens 内の各トークンについて、次の下位手順を実行する:
input をそのトークンとする。
position を input 内へのポインターとし、 最初は文字列の先頭を指すものとする。
value を数 0 とする。
unit を absolute とする。
position が input の末尾を越えている場合、 unit を relative に設定し、最後の下位手順へ移る。
position にある文字が ASCII 数字である場合、 position を与えて、input から ASCII 数字である 符号位置の列を収集し、結果の列を 10 進整数として解釈し、その整数だけ value を増加させる。
position にある文字が U+002E(.)である場合:
position を与えて、input から ASCII 空白および ASCII 数字からなる 符号位置の列を収集する。 s を結果の列とする。
s 内のすべての ASCII 空白を削除する。
s が空文字列でない場合:
length を、s 内の文字数 (空白を削除した後の文字数)とする。
fraction を、s を 10 進整数として解釈し、 その数を 10length で除算した結果とする。
value を fraction だけ増加させる。
position を与えて、input 内の ASCII 空白をスキップする。
position にある文字が U+0025 PERCENT SIGN 文字(%)である場合、 unit を percentage に設定する。
それ以外で、position にある文字が U+002A ASTERISK 文字 (*)である場合、unit を relative に設定する。
value で与えられる数と unit で与えられる単位からなる エントリーを result に追加する。
リスト result を返す。
以下のアルゴリズムにおいて、年 year の月 month の日数は、month が 1、3、5、7、8、 10、または 12 の場合は 31、month が 4、6、9、または 11 の場合は 30、 month が 2 で、year が 400 で割り切れる数である場合、または year が 4 で割り切れるが 100 では割り切れない数である場合は 29、 それ以外の場合は 28 である。これはグレゴリオ暦の閏年を考慮している。 [GREGORIAN]
この節で定義される日付および時刻の構文で ASCII 数字が使用される場合、それらは 10 進数を表す。
ここで説明する形式は、対応する ISO8601 形式の部分集合となることを意図しているが、 この仕様では ISO8601 よりもはるかに詳細な構文解析規則を定義する。 したがって実装者には、以下で説明する構文解析規則を実装するために日付構文解析ライブラリーを 使用する前に、それらを慎重に調査することが推奨される。ISO8601 ライブラリーは、日付および 時刻をまったく同じ方法では構文解析しない可能性がある。[ISO8601]
この仕様で先発グレゴリオ暦という場合、 現代のグレゴリオ暦を西暦 1 年まで遡って拡張したものを意味する。 先発 グレゴリオ暦の日付は、明示的に先発グレゴリオ暦の 日付と呼ばれることもあり、対象となる時代または場所でその暦が使用されていなかった場合でも、 その暦を使用して記述される日付である。[GREGORIAN]
この仕様で通信形式としてグレゴリオ暦を使用することは、
決定に関わった者の文化的偏向に起因する恣意的な選択である。フォームにおける
日付、時刻、および数値の形式に関する節
(作者向け)、フォームコントロールのローカライズに関する
実装上の注記、および time 要素も参照のこと。
月は、タイムゾーン情報を持たず、年および月を超える 日付情報も持たない、特定の 先発グレゴリオ暦の 日付からなる。 [GREGORIAN]
文字列は、年 year および月 month を表し、 次の構成要素を指定された順序で含む場合、妥当な月文字列である:
月文字列を構文解析する規則は次のとおりである。 これは年と月、または何も返さない。アルゴリズムのいずれかの時点で「失敗する」とされている場合、 その時点で中止し、何も返さないことを意味する。
input を構文解析対象の文字列とする。
position を input 内へのポインターとし、最初は 文字列の先頭を指すものとする。
月構成要素を構文解析して year および month を得る。これが何も返さない場合、失敗する。
position が input の末尾を越えていない場合、失敗する。
year および month を返す。
input 文字列および position が与えられた場合の、 月構成要素を構文解析する規則は次のとおりである。 これは年と月、または何も返さない。アルゴリズムのいずれかの時点で「失敗する」とされている場合、 その時点で中止し、何も返さないことを意味する。
position を与えて、input から ASCII 数字である 符号位置の列を収集する。 収集された列が少なくとも 4 文字の長さでない場合、失敗する。それ以外の場合、 結果の列を 10 進整数として解釈する。year をその数とする。
year がゼロより大きい数でない場合、失敗する。
position が input の末尾を越えている場合、または position にある文字が U+002D HYPHEN-MINUS 文字でない場合、失敗する。 それ以外の場合、position を 1 文字先へ進める。
position を与えて、input から ASCII 数字である 符号位置の列を収集する。 収集された列が正確に 2 文字の長さでない場合、失敗する。それ以外の場合、 結果の列を 10 進整数として解釈する。month をその数とする。
month が範囲 1 ≤ month ≤ 12 内の数でない場合、失敗する。
year および month を返す。
日付は、タイムゾーン情報を持たず、年、月、および日からなる、 特定の 先発グレゴリオ暦の 日付である。 [GREGORIAN]
文字列は、年 year、月 month、および日 day を表し、次の構成要素を指定された順序で含む場合、 妥当な日付文字列である:
日付文字列を構文解析する規則は次のとおりである。 これは日付、または何も返さない。アルゴリズムのいずれかの時点で「失敗する」とされている場合、 その時点で中止し、何も返さないことを意味する。
input を構文解析対象の文字列とする。
position を input 内へのポインターとし、最初は 文字列の先頭を指すものとする。
日付構成要素を構文解析して year、month、および day を得る。 これが何も返さない場合、失敗する。
position が input の末尾を越えていない場合、失敗する。
date を、年が year、月が month、日が day である日付とする。
date を返す。
input 文字列および position が与えられた場合の、 日付構成要素を構文解析する規則は次のとおりである。 これは年、月、および日、または何も返さない。アルゴリズムのいずれかの時点で 「失敗する」とされている場合、その時点で中止し、何も返さないことを意味する。
月構成要素を構文解析して year および month を得る。これが何も返さない場合、失敗する。
maxday を、年 year の月 month の日数とする。
position が input の末尾を越えている場合、または position にある文字が U+002D HYPHEN-MINUS 文字でない場合、失敗する。 それ以外の場合、position を 1 文字先へ進める。
position を与えて、input から ASCII 数字である 符号位置の列を収集する。 収集された列が正確に 2 文字の長さでない場合、失敗する。それ以外の場合、 結果の列を 10 進整数として解釈する。day をその数とする。
day が範囲 1 ≤ day ≤ maxday 内の数でない場合、失敗する。
year、month、および day を返す。
年のない日付は、グレゴリオ暦の月および その月内の日からなり、関連付けられた年を持たない。[GREGORIAN]
文字列は、月 month および日 day を表し、 次の構成要素を指定された順序で含む場合、 妥当な年のない日付文字列である:
言い換えると、month が 2 月を意味する
「02」である場合、年が閏年であるかのように、日には 29 を指定できる。
年のない日付文字列を構文解析する規則は次のとおりである。 これは月と日、または何も返さない。アルゴリズムのいずれかの時点で「失敗する」とされている場合、 その時点で中止し、何も返さないことを意味する。
input を構文解析対象の文字列とする。
position を input 内へのポインターとし、最初は 文字列の先頭を指すものとする。
年のない 日付構成要素を構文解析して month および day を得る。 これが何も返さない場合、失敗する。
position が input の末尾を越えていない場合、失敗する。
month および day を返す。
input 文字列および position が与えられた場合の、 年のない日付構成要素を構文解析する規則は 次のとおりである。これは月と日、または何も返さない。アルゴリズムのいずれかの時点で 「失敗する」とされている場合、その時点で中止し、何も返さないことを意味する。
position を与えて、input から U+002D HYPHEN-MINUS 文字(-)である 符号位置の列を収集する。 収集された列が正確に 0 文字または 2 文字の長さでない場合、失敗する。
position を与えて、input から ASCII 数字である 符号位置の列を収集する。 収集された列が正確に 2 文字の長さでない場合、失敗する。それ以外の場合、 結果の列を 10 進整数として解釈する。month をその数とする。
month が範囲 1 ≤ month ≤ 12 内の数でない場合、失敗する。
maxday を、任意の閏年(例えば 4 または 2000)の月 month における 日数とする。
position が input の末尾を越えている場合、または position にある文字が U+002D HYPHEN-MINUS 文字でない場合、失敗する。 それ以外の場合、position を 1 文字先へ進める。
position を与えて、input から ASCII 数字である 符号位置の列を収集する。 収集された列が正確に 2 文字の長さでない場合、失敗する。それ以外の場合、 結果の列を 10 進整数として解釈する。day をその数とする。
day が範囲 1 ≤ day ≤ maxday 内の数でない場合、失敗する。
month および day を返す。
時刻は、タイムゾーン情報を持たず、時、分、秒、 および秒の小数部からなる特定の時刻である。
文字列は、時 hour、分 minute、および秒 second を表し、次の構成要素を指定された順序で含む場合、 妥当な時刻文字列である:
second 構成要素を 60 または 61 にすることはできない。 閏秒は表現できない。
時刻文字列を構文解析する規則は次のとおりである。 これは時刻、または何も返さない。アルゴリズムのいずれかの時点で「失敗する」とされている場合、 その時点で中止し、何も返さないことを意味する。
input を構文解析対象の文字列とする。
position を input 内へのポインターとし、最初は 文字列の先頭を指すものとする。
時刻構成要素を構文解析して hour、minute、および second を得る。 これが何も返さない場合、失敗する。
position が input の末尾を越えていない場合、失敗する。
time を、時が hour、分が minute、秒が second である時刻とする。
time を返す。
input 文字列および position が与えられた場合の、 時刻構成要素を構文解析する規則は次のとおりである。 これは時、分、および秒、または何も返さない。アルゴリズムのいずれかの時点で 「失敗する」とされている場合、その時点で中止し、何も返さないことを意味する。
position を与えて、input から ASCII 数字である 符号位置の列を収集する。 収集された列が正確に 2 文字の長さでない場合、失敗する。それ以外の場合、 結果の列を 10 進整数として解釈する。hour をその数とする。
position が input の末尾を越えている場合、または position にある文字が U+003A COLON 文字でない場合、失敗する。 それ以外の場合、position を 1 文字先へ進める。
position を与えて、input から ASCII 数字である 符号位置の列を収集する。 収集された列が正確に 2 文字の長さでない場合、失敗する。それ以外の場合、 結果の列を 10 進整数として解釈する。minute をその数とする。
second を 0 とする。
position が input の末尾を越えておらず、 position にある文字が U+003A(:)である場合:
position を input 内の次の文字へ進める。
position が input の末尾を越えている場合、 input の最後の文字にある場合、または position から始まる input 内の次の2 文字がともに ASCII 数字でない場合、失敗する。
position を与えて、input から ASCII 数字または U+002E FULL STOP 文字のいずれかである 符号位置の列を収集する。 収集された列が 3 文字の長さである場合、3 文字より長く第 3 文字が U+002E FULL STOP 文字でない場合、または U+002E FULL STOP 文字を複数含む場合、 失敗する。それ以外の場合、結果の列を 10 進数 (小数部を含む可能性がある)として解釈する。second をその数に設定する。
second が範囲 0 ≤ second < 60 内の数でない場合、失敗する。
hour、minute、および second を返す。
ローカル日付と時刻は、年、月、および日からなる 特定の 先発グレゴリオ暦の 日付と、時、分、秒、および秒の小数部からなる時刻で構成されるが、 タイムゾーンなしで表現される。[GREGORIAN]
文字列は、日付と時刻を表し、次の構成要素を指定された順序で含む場合、 妥当なローカル日付と時刻の文字列である:
文字列は、日付と時刻を表し、次の構成要素を指定された順序で含む場合、 妥当な 正規化済みローカル日付と時刻の文字列である:
ローカル日付と時刻の文字列を構文解析する規則は 次のとおりである。これは日付と時刻、または何も返さない。アルゴリズムのいずれかの時点で 「失敗する」とされている場合、その時点で中止し、何も返さないことを意味する。
input を構文解析対象の文字列とする。
position を input 内へのポインターとし、最初は 文字列の先頭を指すものとする。
日付構成要素を構文解析して year、month、および day を得る。 これが何も返さない場合、失敗する。
position が input の末尾を越えている場合、または position にある文字が U+0054 LATIN CAPITAL LETTER T 文字 (T)でも U+0020 SPACE 文字でもない場合、失敗する。それ以外の場合、 position を 1 文字先へ進める。
時刻構成要素を構文解析して hour、minute、および second を得る。 これが何も返さない場合、失敗する。
position が input の末尾を越えていない場合、失敗する。
date を、年が year、月が month、日が day である日付とする。
time を、時が hour、分が minute、秒が second である時刻とする。
date および time を返す。
タイムゾーンオフセットは、符号付きの時数および 分数からなる。
文字列は、タイムゾーンオフセットを表し、次のいずれかからなる場合、 妥当なタイムゾーンオフセット文字列である:
U+005A LATIN CAPITAL LETTER Z 文字(Z)。タイムゾーンが UTC である場合にのみ許可される
または、次の構成要素を指定された順序で:
この形式では、-23:59 から +23:59 までのタイムゾーンオフセットが許可される。 現在、実際のタイムゾーンのオフセット範囲は実務上 -12:00 から +14:00 までであり、 実際のタイムゾーンのオフセットの分構成要素は常に 00、30、または 45 のいずれかである。 ただし、タイムゾーンは政治的な争点として利用され、そのため非常に気まぐれな政策決定の 対象となるので、この状態が永遠に続く保証はない。
正式なタイムゾーンが形成される以前の歴史的な時刻で タイムゾーンオフセットを使用する方法の詳細については、以下の グローバル 日付と時刻の節にある使用上の注記および例も参照のこと。
タイムゾーンオフセット文字列を構文解析する規則は 次のとおりである。これはタイムゾーンオフセット、または何も返さない。アルゴリズムの いずれかの時点で「失敗する」とされている場合、その時点で中止し、何も返さないことを意味する。
input を構文解析対象の文字列とする。
position を input 内へのポインターとし、最初は 文字列の先頭を指すものとする。
タイムゾーン オフセット構成要素を構文解析して timezonehours および timezoneminutes を得る。これが 何も返さない場合、失敗する。
position が input の末尾を越えていない場合、失敗する。
UTC から timezonehours 時間および timezoneminutes 分のタイムゾーンオフセットを返す。
input 文字列および position が与えられた場合の、 タイムゾーンオフセット構成要素を構文解析する規則は 次のとおりである。これはタイムゾーンの時数およびタイムゾーンの分数、または何も返さない。 アルゴリズムのいずれかの時点で「失敗する」とされている場合、その時点で中止し、 何も返さないことを意味する。
position にある文字が U+005A LATIN CAPITAL LETTER Z 文字 (Z)である場合:
timezonehours を 0 とする。
timezoneminutes を 0 とする。
position を input 内の次の文字へ進める。
それ以外で、position にある文字が U+002B PLUS SIGN(+) または U+002D HYPHEN-MINUS(-)のいずれかである場合:
position にある文字が U+002B PLUS SIGN(+)である場合、 sign を「positive」とする。それ以外の場合は U+002D HYPHEN-MINUS(-)であり、 sign を「negative」とする。
position を input 内の次の文字へ進める。
position を与えて、input から ASCII 数字である 符号位置の列を収集する。 s を収集された列とする。
s が正確に 2 文字の長さである場合:
s を 10 進整数として解釈する。 timezonehours をその数とする。
position が input の末尾を越えている場合、または position にある文字が U+003A COLON 文字でない場合、失敗する。 それ以外の場合、position を 1 文字先へ進める。
position を与えて、input から ASCII 数字である 符号位置の列を収集する。 収集された列が正確に 2 文字の長さでない場合、失敗する。それ以外の場合、 結果の列を 10 進整数として解釈する。 timezoneminutes をその数とする。
s が正確に 4 文字の長さである場合:
s の最初の 2 文字を 10 進整数として解釈する。 timezonehours をその数とする。
s の最後の 2 文字を 10 進整数として解釈する。 timezoneminutes をその数とする。
それ以外の場合、失敗する。
それ以外の場合、失敗する。
timezonehours および timezoneminutes を返す。
グローバル日付と時刻は、年、月、および日からなる 特定の 先発グレゴリオ暦の 日付と、時、分、秒、および秒の小数部からなり、 符号付きの時数および分数からなるタイムゾーンオフセットを伴って表現される時刻からなる。 [GREGORIAN]
文字列は、日付、時刻、およびタイムゾーンオフセットを表し、次の構成要素を 指定された順序で含む場合、妥当なグローバル日付と時刻の 文字列である:
20 世紀半ばに UTC が成立する以前の日付における時刻は、UTC (SI 秒単位で刻む UT1 の近似)ではなく、UT1(経度 0° における当時の地球太陽時)を基準として 表現および解釈しなければならない。タイムゾーンが形成される以前の時刻は、適切な現地時刻と ロンドンのグリニッジで観測された時刻との当時の差を近似する明示的なタイムゾーンを伴う UT1 時刻として表現および解釈しなければならない。
次に、妥当なグローバル日付と時刻の文字列として 記述された日付の例をいくつか示す。
0037-12-13 00:00Z"1979-10-14T12:00:00.001-04:00"8592-01-01T02:09+02:09"これらの日付については、いくつか注目すべき点がある:
T」を空白に置き換える場合、それは単一の空白文字でなければならない。
文字列「2001-12-21 12:00Z」
(構成要素間に 2 個の空白がある)は正常に構文解析されない。グローバル日付と時刻の文字列を構文解析する規則は 次のとおりである。これは UTC の時刻と、往復変換または表示のために関連付けられた タイムゾーンオフセット情報、または何も返さない。アルゴリズムのいずれかの時点で 「失敗する」とされている場合、その時点で中止し、何も返さないことを意味する。
input を構文解析対象の文字列とする。
position を input 内へのポインターとし、最初は 文字列の先頭を指すものとする。
日付 構成要素を構文解析して year、month、および day を得る。 これが何も返さない場合、失敗する。
position が input の末尾を越えている場合、または position にある文字が U+0054 LATIN CAPITAL LETTER T 文字 (T)でも U+0020 SPACE 文字でもない場合、失敗する。それ以外の場合、 position を 1 文字先へ進める。
時刻 構成要素を構文解析して hour、minute、および second を得る。 これが何も返さない場合、失敗する。
position が input の末尾を越えている場合、 失敗する。
タイムゾーンオフセット構成要素を 構文解析して timezonehours および timezoneminutes を得る。これが何も返さない場合、失敗する。
position が input の末尾を越えていない場合、失敗する。
time を、年 year、月 month、日 day、時 hour、分 minute、秒 second から timezonehours 時間および timezoneminutes 分を減算した時点とする。その時点は UTC タイムゾーン内の時点である。
timezone を、UTC から timezonehours 時間および timezoneminutes 分とする。
time および timezone を返す。
週は、月曜日に始まる 7 日間を表す週年番号および週番号からなる。 この暦法における各週年は、以下で定義するように、そのような 7 日間を 52 個または 53 個持つ。 グレゴリオ暦の日付 1969 年 12 月 29 日月曜日(1969-12-29)に始まる 7 日間を、 週年 1970 の第 1 週と定義する。連続する週には順番に番号が付けられる。 ある週年の第 1 週の前の週は、直前の週年の最終週であり、その逆も同様である。 [GREGORIAN]
番号 year を持つ週年は、先発グレゴリオ暦における年 year の最初の日(1 月 1 日)が木曜日である場合、または 先発 グレゴリオ暦における年 year の最初の日(1 月 1 日)が水曜日であり、 かつ year が 400 で割り切れる数、または 4 で割り切れるが 100 では 割り切れない数である場合、53 週を持つ。それ以外のすべての週年は 52 週を持つ。
53 週を持つ週年の最終日の週番号は 53 であり、 52 週を持つ週年の最終日の週番号は 52 である。
特定の日の週年番号は、その日を含む 先発グレゴリオ暦の 年の番号とは異なる場合がある。週年 y の最初の週は、グレゴリオ暦の年 y の最初の木曜日を含む週である。
現代の目的では、ここで定義される 週は、ISO 8601 で定義される ISO 週と同等である。 [ISO8601]
文字列は、週年 year および週 week を表し、 次の構成要素を指定された順序で含む場合、妥当な週文字列である:
週文字列を構文解析する規則は次のとおりである。 これは週年番号および週番号、または何も返さない。アルゴリズムのいずれかの時点で 「失敗する」とされている場合、その時点で中止し、何も返さないことを意味する。
input を構文解析対象の文字列とする。
position を input 内へのポインターとし、最初は 文字列の先頭を指すものとする。
position を与えて、input から ASCII 数字である 符号位置の列を収集する。 収集された列が少なくとも 4 文字の長さでない場合、失敗する。それ以外の場合、 結果の列を 10 進整数として解釈する。year をその数とする。
year がゼロより大きい数でない場合、失敗する。
position が input の末尾を越えている場合、または position にある文字が U+002D HYPHEN-MINUS 文字でない場合、失敗する。 それ以外の場合、position を 1 文字先へ進める。
position が input の末尾を越えている場合、または position にある文字が U+0057 LATIN CAPITAL LETTER W 文字(W)でない場合、 失敗する。それ以外の場合、position を 1 文字先へ進める。
position を与えて、input から ASCII 数字である 符号位置の列を収集する。 収集された列が正確に 2 文字の長さでない場合、失敗する。それ以外の場合、 結果の列を 10 進整数として解釈する。week をその数とする。
maxweek を、年 year の 最終日の週番号とする。
week が範囲 1 ≤ week ≤ maxweek 内の数でない場合、失敗する。
position が input の末尾を越えていない場合、失敗する。
週年番号 year および週番号 week を返す。
期間は、秒数からなる。
月と秒は比較できないため(月は正確な秒数ではなく、測定を開始する具体的な日に 応じて正確な長さが変わる期間である)、この仕様で定義される 期間には月 (または 12 か月に相当する年)を含めることはできない。具体的な秒数を表す期間だけを記述できる。
文字列は、期間 t を表し、次のいずれかからなる場合、 妥当な期間文字列である:
リテラル U+0050 LATIN CAPITAL LETTER P 文字の後に、次の下位構成要素を 指定された順序で 1 個以上続けたもの。日、時、分、および秒の数は、 t と同じ秒数に対応する:
日数を表す、1 個以上の ASCII 数字の後に U+0044 LATIN CAPITAL LETTER D 文字を続けたもの。
U+0054 LATIN CAPITAL LETTER T 文字の後に、次の下位構成要素を 指定された順序で 1 個以上続けたもの:
これは、この仕様で定義される他の多くの日付および時刻関連の マイクロ構文と同様に、ISO 8601 で定義される形式の 1 つに基づいている。 [ISO8601]
それぞれ異なる 期間時刻構成要素の 尺度を持つ 1 個以上の 期間時刻 構成要素を任意の順序で並べたもの。表される秒数の合計は t の秒数と等しくなる。
期間時刻構成要素は、次の構成要素からなる文字列である:
0 個以上の ASCII 空白。
時間単位の数を表す 1 個以上の ASCII 数字。指定された 期間時刻 構成要素の尺度(以下を参照)によって倍率を掛け、秒数を表す。
指定された 期間時刻 構成要素の尺度が 1(すなわち単位が秒)である場合、任意で U+002E FULL STOP 文字(.)の後に、秒の小数部を表す 1 個、2 個、または 3 個の ASCII 数字を続ける。
0 個以上の ASCII 空白。
期間時刻構成要素の数値部分で使用される 時間単位の期間時刻 構成要素の尺度を表す、次の文字のいずれか:
0 個以上の ASCII 空白。
これは ISO 8601 のいずれの形式にも基づいていない。 ISO 8601 の期間形式に代わる、より人間が読みやすい形式として意図されている。
期間文字列を構文解析する規則は次のとおりである。 これは期間または何も返さない。 アルゴリズムのいずれかの時点で「失敗する」とされている場合、その時点で中止し、 何も返さないことを意味する。
input を構文解析対象の文字列とする。
position を input 内へのポインターとし、最初は 文字列の先頭を指すものとする。
months、seconds、および component count をすべてゼロとする。
M-disambiguator を minutes とする。
このフラグのもう 1 つの値は months である。これは、月と分に 同じ単位を使用する ISO8601 の期間における「M」単位を区別するために使用される。 月は許可されないが、将来の互換性のため、および他のコンテキストでは妥当となる ISO8601 の期間を誤って解釈することを避けるために構文解析される。
position を与えて、input 内の ASCII 空白をスキップする。
position が input の末尾を越えている場合、 失敗する。
position が指す input 内の文字が U+0050 LATIN CAPITAL LETTER P 文字である場合、position を次の文字へ進め、 M-disambiguator を months に設定し、position を与えて input 内の ASCII 空白をスキップする。
永久に繰り返す:
units を未定義とする。これには次の値のいずれかが代入される: years、months、weeks、days、hours、minutes、 および seconds。
next character を未定義とする。これは input から文字を処理するために使用される。
position が input の末尾を越えている場合、中断する。
position が指す input 内の文字が U+0054 LATIN CAPITAL LETTER T 文字である場合、position を次の文字へ進め、 M-disambiguator を minutes に設定し、position を与えて input 内の ASCII 空白をスキップし、続行する。
next character を、position が指す input 内の文字に設定する。
next character が U+002E FULL STOP 文字(.)である場合、 N を 0 とする。(position は進めない。これは以下で処理される。)
それ以外で、next character が ASCII 数字である場合、 position を与えて、input から ASCII 数字である 符号位置の列を収集し、結果の列を 10 進整数として解釈し、N をその数とする。
それ以外の場合、next character は数の一部ではないので、失敗する。
position が input の末尾を越えている場合、 失敗する。
next character を、position が指す input 内の文字に設定し、今回は position を次の文字へ進める。 (next character が以前 U+002E FULL STOP 文字(.)であった場合、 今回もその文字のままである。)
next character が U+002E(.)である場合:
position を与えて、input から ASCII 数字である 符号位置の列を収集する。 s を結果の列とする。
s が空文字列である場合、失敗する。
length を s 内の文字数とする。
fraction を、s を 10 進整数として解釈し、 その数を 10length で除算した結果とする。
N を fraction だけ増加させる。
position を与えて、input 内の ASCII 空白をスキップする。
position が input の末尾を越えている場合、 失敗する。
next character を、position が指す input 内の文字に設定し、position を次の文字へ進める。
next character が U+0053 LATIN CAPITAL LETTER S 文字でも U+0073 LATIN SMALL LETTER S 文字でもない場合、失敗する。
units を seconds に設定する。
それ以外の場合:
next character が ASCII 空白である場合、position を与えて input 内の ASCII 空白をスキップし、next character を position が指す input 内の文字に設定し、position を次の文字へ進める。
next character が U+0059 LATIN CAPITAL LETTER Y 文字、または U+0079 LATIN SMALL LETTER Y 文字である場合、units を years に設定し、 M-disambiguator を months に設定する。
next character が U+004D LATIN CAPITAL LETTER M 文字または U+006D LATIN SMALL LETTER M 文字であり、M-disambiguator が months である場合、units を months に設定する。
next character が U+0057 LATIN CAPITAL LETTER W 文字または U+0077 LATIN SMALL LETTER W 文字である場合、units を weeks に設定し、 M-disambiguator を minutes に設定する。
next character が U+0044 LATIN CAPITAL LETTER D 文字または U+0064 LATIN SMALL LETTER D 文字である場合、units を days に設定し、 M-disambiguator を minutes に設定する。
next character が U+0048 LATIN CAPITAL LETTER H 文字または U+0068 LATIN SMALL LETTER H 文字である場合、units を hours に設定し、 M-disambiguator を minutes に設定する。
next character が U+004D LATIN CAPITAL LETTER M 文字または U+006D LATIN SMALL LETTER M 文字であり、M-disambiguator が minutes である場合、units を minutes に設定する。
next character が U+0053 LATIN CAPITAL LETTER S 文字または U+0073 LATIN SMALL LETTER S 文字である場合、units を seconds に設定し、 M-disambiguator を minutes に設定する。
それ以外で、next character が上記のいずれの文字でもない場合、 失敗する。
component count を 1 増加させる。
multiplier を 1 とする。
units が years である場合、multiplier に 12 を乗算し、units を months に設定する。
units が months である場合、N と multiplier の積を months に加算する。
それ以外の場合:
units が weeks である場合、multiplier に 7 を乗算し、units を days に設定する。
units が days である場合、multiplier に 24 を乗算し、units を hours に設定する。
units が hours である場合、multiplier に 60 を乗算し、units を minutes に設定する。
units が minutes である場合、multiplier に 60 を乗算し、 units を seconds に設定する。
この時点で、units は必ず seconds である。 N と multiplier の積を seconds に加算する。
position を与えて、input 内の ASCII 空白をスキップする。
component count がゼロである場合、 失敗する。
months がゼロでない場合、失敗する。
seconds 秒からなる 期間を返す。
文字列は、次のいずれかでもある場合、任意の時刻を伴う妥当な日付文字列である:
日付または時刻の文字列を構文解析する規則は次のとおりである。 このアルゴリズムは、日付、 時刻、 グローバル日付と時刻、 または何も返さない。アルゴリズムのいずれかの時点で「失敗する」とされている場合、 その時点で中止し、何も返さないことを意味する。
input を構文解析対象の文字列とする。
position を input 内へのポインターとし、最初は 文字列の先頭を指すものとする。
start position を position と同じ位置に設定する。
date present フラグおよび time present フラグを true に設定する。
日付 構成要素を構文解析して year、month、および day を得る。 これが失敗した場合、date present フラグを false に設定する。
date present が true で、position が input の末尾を越えておらず、position にある文字が U+0054 LATIN CAPITAL LETTER T 文字(T)または U+0020 SPACE 文字のいずれかである場合、 position を input 内の次の文字へ進める。
それ以外で、date present が true であり、 position が input の末尾を越えているか、または position にある文字が U+0054 LATIN CAPITAL LETTER T 文字(T)でも U+0020 SPACE 文字でもない場合、time present を false に設定する。
それ以外で、date present が false である場合、 position を start position と同じ位置に戻す。
time present フラグが true である場合、 時刻 構成要素を構文解析して hour、minute、および second を得る。これが何も返さない場合、失敗する。
date present フラグおよび time present フラグが ともに true であるにもかかわらず、position が input の末尾を越えている場合、失敗する。
date present フラグおよび time present フラグが ともに true である場合、タイムゾーンオフセット構成要素を構文解析して timezonehours および timezoneminutes を得る。 これが何も返さない場合、失敗する。
position が input の末尾を越えていない場合、失敗する。
date present フラグが true で、time present フラグが false である場合、date を、年が year、 月が month、日が day である日付とし、date を返す。
それ以外で、time present フラグが true で、date present フラグが false である場合、time を、時が hour、分が minute、秒が second である時刻とし、 time を返す。
それ以外の場合、time を、年 year、月 month、日 day、時 hour、分 minute、秒 second から、 timezonehours 時間および timezoneminutes 分を 減算した時点とする。その時点は UTC タイムゾーン内の時点である。timezone を、 UTC から timezonehours 時間および timezoneminutes 分とし、time および timezone を返す。
一部の廃止されたレガシー属性は、文字列 input が与えられた場合、 レガシーカラー値を構文解析する 規則を使用して色を構文解析する。これは CSS カラーまたは失敗を返す。
input が空文字列である場合、失敗を返す。
input から先頭および末尾の ASCII 空白を除去する。
input が「transparent」と
ASCII
大文字小文字不区別で一致する場合、失敗を返す。
input が、名前付きカラーのいずれかと ASCII 大文字小文字不区別で一致する場合、そのキーワードに対応する CSS カラーを返す。 [CSSCOLOR]
CSS2 System Colors は認識されない。
input の符号位置 長が 4 であり、input の最初の文字が U+0023(#)であり、 input の最後の 3 文字がすべて ASCII 16 進数字である場合:
result を CSS カラーとする。
input の 2 番目の文字を 16 進数字として解釈し、 result の赤成分を、結果の数に 17 を乗算した値とする。
input の 3 番目の文字を 16 進数字として解釈し、 result の緑成分を、結果の数に 17 を乗算した値とする。
input の 4 番目の文字を 16 進数字として解釈し、 result の青成分を、結果の数に 17 を乗算した値とする。
result を返す。
input 内の U+FFFF より大きい
符号位置
(すなわち基本多言語面に含まれないすべての文字)を「00」に置換する。
input の符号位置 長が 128 より大きい場合、input を切り詰め、最初の 128 文字だけを残す。
input の最初の文字が U+0023(#)である場合、それを削除する。
input 内の ASCII 16 進数字でないすべての文字を U+0030(0)に置換する。
input の符号位置 長がゼロであるか 3 の倍数でない間、input に U+0030(0)を付加する。
input を等しい符号位置 長を持つ 3 個の文字列に分割し、3 個の成分を得る。length を、それらすべての 成分が持つ符号位置 長(input の符号位置 長の 3 分の 1)とする。
length が 8 より大きい場合、各成分から先頭の length-8 文字を削除し、length を 8 とする。
length が 2 より大きく、かつ各成分の最初の文字が U+0030(0)である間、 その文字を削除し、length を 1 減少させる。
length が依然として 2 より大きい場合、各成分を切り詰め、 各成分の最初の 2 文字だけを残す。
result を CSS カラーとする。
最初の成分を 16 進数として解釈し、result の赤成分を結果の数とする。
2 番目の成分を 16 進数として解釈し、result の緑成分を結果の数とする。
3 番目の成分を 16 進数として解釈し、result の青成分を結果の数とする。
result を返す。
空白区切りトークンの集合は、 1 個以上の ASCII 空白で 区切られた 0 個以上の単語(トークンと呼ばれる)を含む文字列である。各単語は、 いずれも ASCII 空白ではない 1 個以上の文字からなる任意の文字列である。
空白区切りトークンの集合を含む文字列は、 先頭または末尾に ASCII 空白を持つことができる。
一意な空白区切りトークンの 順序なし集合は、トークンが重複しない 空白区切りトークンの集合である。
一意な空白区切りトークンの順序付き集合は、 トークンが重複せず、かつトークンの順序に意味がある 空白区切り トークンの集合である。
空白区切りトークンの集合には、 許可される値の集合が定義されることがある。許可される値の集合が定義されている場合、 すべてのトークンはその許可値の一覧に含まれていなければならず、その他の値は不適合である。 そのような許可値の集合が提供されていない場合、すべての値が適合する。
空白区切りトークンの集合内の トークンをどのように比較するか(例えば大文字小文字を区別するかどうか)は、 集合ごとに定義される。
コンマ区切りトークンの集合は、 それぞれが単一の U+002C COMMA 文字(,)によって次のトークンから区切られた 0 個以上のトークンを含む文字列である。各トークンは、先頭および末尾が ASCII 空白ではなく、 U+002C COMMA 文字(,)を含まない 0 個以上の文字からなる任意の文字列であり、 任意で周囲を ASCII 空白で囲むことができる。
例えば、文字列「 a ,b,,d d 」は 4 個のトークン、
「a」、「b」、空文字列、および「d d」からなる。各トークンの周囲にある先頭および末尾の
空白はトークンの一部として数えられず、空文字列もトークンになり得る。
コンマ区切りトークンの集合には、 妥当なトークンを構成するものについて追加の制限が設けられることがある。そのような制限が 定義されている場合、すべてのトークンはそれらの制限に従わなければならず、その他の値は 不適合である。そのような制限が指定されていない場合、すべての値が適合する。
型 type の要素に対する妥当なハッシュ名参照は、
U+0023 NUMBER SIGN 文字(#)の後に、同じ
ツリー内にある型 type の要素の
name 属性値と正確に一致する文字列を続けた文字列である。
コンテキストノード scope が与えられた場合の、型 type の要素に対する ハッシュ名参照を構文解析する規則は 次のとおりである:
構文解析対象の文字列が U+0023 NUMBER SIGN 文字を含まない場合、または 文字列内で最初に現れるその文字が文字列の最後の文字である場合、null を返す。
s を、構文解析対象の文字列内で最初に現れる U+0023 NUMBER SIGN 文字の 直後から、その文字列の末尾までの文字列とする。
scope のツリー内で、
ツリー順における最初の型 type の要素で、
値が s である id
または
name 属性を持つものを返す。そのような要素がない場合は null を返す。
id 属性は
構文解析時には考慮されるが、値が
妥当なハッシュ名
参照であるかどうかの判定には使用されない。すなわち、id に基づいて
要素を参照するハッシュ名参照は適合性エラーである
(その要素が同じ値を持つ name 属性も持つ場合を除く)。
文字列は、Media Queries の
<media-query-list> 生成規則に一致する場合、
妥当なメディアクエリーリストである。
[MQ]
文字列は、空文字列、ASCII 空白のみからなる文字列、または Media Queries で与えられた定義に従ってユーザーの環境に一致する メディアクエリーリストである場合、ユーザーの環境に 一致する。[MQ]
一意な内部値は、シリアライズ可能で、値によって比較可能であり、 スクリプトに公開されることのない値である。
新しい一意な内部値を作成するには、 このアルゴリズムによって以前に返されたことのない 一意な内部値を返す。
文字列は、妥当な URL 文字列であり、かつ空文字列でない場合、 妥当な空でない URLである。
文字列は、そこから 先頭および末尾の ASCII 空白を除去した後に、妥当な URL 文字列で ある場合、空白で囲まれている可能性のある 妥当な URLである。
文字列は、そこから 先頭および末尾の ASCII 空白を除去した後に、妥当な 空でない URLである場合、空白で 囲まれている可能性のある妥当な空でない URLである。
この仕様は、URL about:legacy-compat を、
解決不能ではあるが予約された about: URL として定義する。
これは、XML ツールとの互換性のために必要な場合、HTML 文書内の
DOCTYPEで使用される。
[ABOUT]
この仕様は、URL about:html-kind を、
解決不能ではあるが予約された about: URL として定義する。
これは、メディアトラックの種類の識別子として使用される。[ABOUT]
この仕様は、URL about:srcdoc を、
解決不能ではあるが予約された about: URL として定義する。
これは、iframe
srcdoc 文書の
URLとして使用される。
[ABOUT]
URLは、その
スキームが「about」であり、その
パスが単一の文字列「blank」を含み、その
ユーザー名および
パスワードが空文字列であり、その
ホストが null である場合、
about:blank に一致する。
そのような URL の
クエリーおよび
フラグメントは
null でなくてもよい。例えば、「about:blank?foo#bar」を
構文解析して作成された
URL
レコードは、about:blank
に一致する。
URLは、その
スキームが「about」であり、その
パスが単一の文字列「srcdoc」を含み、その
クエリーが null であり、その
ユーザー名および
パスワードが空文字列であり、その
ホストが null である場合、
about:srcdoc に一致する。
about:srcdoc
に一致することによって
URLの
クエリーが null であることを
保証する理由は、URL に null でない
クエリーを持つ
iframe
srcdoc 文書を作成することは、
URL が about:blank に一致する
Documentとは異なり、
不可能だからである。言い換えると、about:srcdoc
に
一致するすべての URLの集合は、
フラグメントだけが異なる。
URL の構文解析とは、文字列を受け取り、それが表す URL レコードを得る処理である。この処理は URL で定義されるが、HTML 標準では基底 URL およびエンコーディングを抽象化する 複数のラッパーを定義する。[URL]
新しい API の大部分は、URL を構文解析するを使用する。 古い API および HTML 要素には、URL をエンコーディング付きで 構文解析するを使用する理由がある場合がある。独自の基底 URL が必要な場合、または 基底 URL を使用しない場合は、もちろん URL パーサーを直接使用することもできる。
文字列 url と、それに対する
Document オブジェクトまたは
環境設定
オブジェクト environment が与えられた場合、
URL を構文解析するには、次の手順を実行する。
これらは失敗または
URLを返す。
environment が
Document オブジェクトである場合、
baseURL を environment の
基底
URLとし、それ以外の場合は environment の
API 基底 URLとする。
baseURL を用いて、url に URL パーサーを適用した結果を返す。
文字列 url と、それに対する
Document オブジェクトまたは
環境
設定オブジェクト environment が与えられた場合、
URL をエンコーディング付きで構文解析するには、
次の手順を実行する。これらは失敗または
URLを返す。
encoding を UTF-8とする。
environment が
Document オブジェクトである場合、
encoding を environment の
文字
エンコーディングに設定する。
それ以外で、environment の
関連するグローバルオブジェクトが
Window オブジェクトである場合、
encoding を、environment の
関連する
グローバルオブジェクトの
関連付けられた
Documentの
文字
エンコーディングに設定する。
environment が
Document オブジェクトである場合、
baseURL を environment の
基底
URLとし、それ以外の場合は environment の
API 基底 URLとする。
baseURL および encoding を用いて、 url に URL パーサーを適用した結果を返す。
文字列 url と、それに対する
Document オブジェクトまたは
環境設定
オブジェクト environment が与えられた場合、
URL をエンコーディング付きで構文解析して
シリアライズするには、次の手順を実行する。これらは失敗または文字列を返す。
url を、environment に対して url を エンコーディング付きで構文解析した結果とする。
url が失敗である場合、失敗を返す。
url に URL シリアライザーを適用した結果を返す。
Document オブジェクト
document のフォールバック基底 URLは、
次の手順を実行して得られる
URL レコードである:
document が
iframe
srcdoc 文書である場合:
表明:document の about 基底 URLは null でない。
document の about 基底 URLを返す。
document の
URLが
about:blank に一致し、
かつ document の
about 基底
URLが null でない場合、
document の
about 基底
URLを返す。
document の URLを返す。
Document
document のURL を設定するには、
URL
レコード url に設定する:
document の URLを url に設定する。
document を与えて、 基底 URL の変更に応答する。
Document
document について基底 URL の変更に応答するには:
ユーザーエージェントは、影響を受ける URL、またはその URL から導出されたデータを
ユーザーに表示しているユーザーインターフェイス要素を更新するべきである。
そのようなユーザーインターフェイス要素の例としては、
ハイパーリンクの
urlを表示する
ステータスバーや、q、
blockquote、
ins、または
del 要素の
cite 属性によって指定された URL を表示するユーザーインターフェイスがある。
document の シャドウを含む子孫である descendant ごとに:
descendant が、結果として
投機規則の構文解析結果を持つ
script
要素である場合:
oldResult を element の 結果とする。
newResult を、element の 子テキスト内容および element の ノード文書が与えられた場合に 投機規則の構文解析結果を 作成した結果とする。
element の 関連するグローバル オブジェクト、oldResult、および newResult を与えて、 投機規則を更新する。
document を与えて、 投機的読み込みを検討する。
これは、基底 URL を変更しても、例えば
img 要素によって
表示される画像には影響しないことを意味する。したがって、その後スクリプトから
src IDL 属性にアクセスすると、
表示中の画像にはもはや対応しない可能性のある新しい
絶対 URLが返される。
url、destination、 corsAttributeState、および任意の 同一オリジンフォールバックフラグが与えられた場合に、 潜在的 CORS 要求を作成するには、 次の手順を実行する:
corsAttributeState が
CORS なしである場合は
mode を「no-cors」とし、それ以外の場合は
「cors」とする。
同一オリジンフォールバックフラグが設定されており、かつ
mode が「no-cors」である場合、
mode を「same-origin」に設定する。
credentialsMode を「include」とする。
corsAttributeState が
匿名である場合、
credentialsMode を「same-origin」に設定する。
要求を新たに返す。その URLは url、 宛先は destination、 モードは mode、 資格情報モードは credentialsMode であり、その URL 資格情報使用フラグが設定されている。
リソースのContent-Type メタデータは、 MIME Sniffing の要件と整合する方法で取得および解釈しなければならない。 [MIMESNIFF]
リソースの算出済み MIME 型は、MIME Sniffing で与えられた要件と整合する方法で特定しなければならない。 [MIMESNIFF]
画像を 特定してスニッフィングする規則、リソースがテキストか バイナリーかを区別する規則、および 音声および 動画を特定してスニッフィングする規則も MIME Sniffing で定義される。 これらの規則は、結果として MIME 型を返す。[MIMESNIFF]
MIME Sniffing の規則に厳密に従うことが不可欠である。 ユーザーエージェントが、サーバーの想定とは異なるヒューリスティックをコンテンツ型の検出に 使用すると、セキュリティ上の問題が発生する可能性がある。詳細については MIME Sniffing を参照のこと。 [MIMESNIFF]
meta
要素からの文字エンコーディングの抽出文字列 s が与えられた場合の、
meta 要素から
文字エンコーディングを抽出するアルゴリズムは次のとおりである。
これは文字エンコーディングまたは何も返さない。
position を s 内へのポインターとし、最初は 文字列の先頭を指すものとする。
ループ:position より後の s 内で、
単語「charset」と
ASCII
大文字小文字不区別で一致する
最初の 7 文字を見つける。そのような一致が見つからない場合、何も返さない。
単語「charset」の直後にある
ASCII
空白をすべてスキップする
(空白がない場合もある)。
次の文字が U+003D EQUALS SIGN(=)でない場合、 position をその次の文字の直前を指すように移動し、 ループとラベル付けされた手順へ戻る。
等号の直後にある ASCII 空白をすべてスキップする (空白がない場合もある)。
次の文字を以下のように処理する:
このアルゴリズムは HTTP 仕様内のアルゴリズムとは異なる (例えば、HTTP では単一引用符の使用を許可せず、このアルゴリズムがサポートしない バックスラッシュエスケープ機構のサポートを要求する)。 このアルゴリズムは歴史的に HTTP と関係していたコンテキストで使用されるが、 実装がサポートする構文は以前から分岐している。[HTTP]
現在のすべてのエンジンでサポートされています。
CORS 設定属性は、次のキーワードおよび状態を持つ 列挙属性である:
| キーワード | 状態 | 概要 |
|---|---|---|
anonymous
|
匿名 | この要素に対する
要求では、その
モードが「cors」に設定され、
資格情報モードが
「same-origin」に設定される。
|
use-credentials
|
資格情報を使用 | この要素に対する
要求では、その
モードが「cors」に設定され、
資格情報モードが
「include」に設定される。
|
CORS 設定 属性によって制御される取得の大部分は、 潜在的 CORS 要求を作成する アルゴリズムを通じて行われる。
要求の
モードが常に「cors」となる
より新しい機能では、一部の
CORS 設定
属性が、わずかに異なる意味を持つよう転用されており、
要求の
資格情報モードだけに影響する。
この変換を行うため、指定された
CORS
設定属性の
CORS 設定属性資格情報
モードを、属性の状態に応じて次のように決定すると定義する:
リファラーポリシー属性は 列挙属性である。空文字列を含む各 リファラーポリシーは、この属性のキーワードであり、 同じ名前の状態に対応する。
これらの状態がさまざまな 取得の処理モデルに与える影響は、この仕様全体、 Fetch、および Referrer Policy でさらに詳しく定義される。 [FETCH] [REFERRERPOLICY]
特定の 取得に使用される処理モデルの決定には複数のシグナルが 寄与する可能性があり、 リファラーポリシー属性は そのうちの 1 つにすぎない。一般に、これらのシグナルが処理される順序は次のとおりである:
最初に、noreferrer リンク種別の存在。
次に、リファラーポリシー属性の値。
最後に、`Referrer-Policy`
HTTP ヘッダー。
現在のすべてのエンジンでサポートされています。
nonce コンテンツ属性は、
特定の取得の続行を許可するかどうかを Content
Security Policy が判断するために使用できる暗号学的 nonce
(「一度だけ使用される数」)を表す。値はテキストである。[CSP]
nonce コンテンツ属性を持つ
要素は、コンテンツ属性から値を取得し、それを
[[CryptographicNonce]] という名前の内部スロットへ移動し、
HTMLOrSVGOrMathMLElement
インターフェイスミックスインを通じてスクリプトに公開し、コンテンツ属性を空文字列に設定することで、
暗号学的 nonce がスクリプトにだけ公開され、CSS 属性セレクターなどのサイドチャネルには
公開されないことを保証する。特に指定がない限り、スロットの値は空文字列である。
element.nonce
element の暗号学的 nonce に設定された値を返す。設定子が使用されていない場合、
これは元々 nonce
コンテンツ属性内にあった値となる。
element.nonce = value
element の暗号学的 nonce 値を更新する。
nonce IDL 属性は、取得時に、
この要素の [[CryptographicNonce]] の値を返し、
設定時に、この要素の
[[CryptographicNonce]] を
指定された値に設定しなければならない。
nonce IDL 属性の設定子が、
対応するコンテンツ属性を更新しないことに注意されたい。これは、要素が
閲覧コンテキストに接続される際に、
以下で nonce コンテンツ属性を
空文字列に設定することと同様に、セレクターのようにコンテンツ属性を容易に読み取れる機構を通じた
nonce 値の流出を防ぐことを意図している。この動作が導入された
issue #2369 で詳細を確認できる。
次の
属性変更
手順は、nonce コンテンツ属性に使用される:
element が
HTMLOrSVGOrMathMLElement を
組み込んでいない場合、戻る。
localName が nonce でないか、
namespace が null でない場合、戻る。
value が null である場合、element の [[CryptographicNonce]] を 空文字列に設定する。
それ以外の場合、element の [[CryptographicNonce]] を value に設定する。
HTMLOrSVGOrMathMLElement を
組み込む要素が
閲覧コンテキストに
接続されるたびに、ユーザーエージェントは element に対して
次の手順を実行しなければならない:
CSP list を、element の シャドウを含むルートの ポリシー コンテナーの CSP リストとする。
CSP list が
ヘッダーによって配信された
Content Security Policy を含み、かつ
element が、値が空文字列でない
nonce コンテンツ属性を持つ場合:
nonce を element の [[CryptographicNonce]] とする。
element の [[CryptographicNonce]] を nonce に設定する。
element の [[CryptographicNonce]] が復元されなければ、 この時点では空文字列となる。
node、copy、および subtree が与えられた場合の、
HTMLOrSVGOrMathMLElement を
組み込む要素に対する
複製手順は、
copy の
[[CryptographicNonce]] を、
node の
[[CryptographicNonce]] に設定することである。
現在のすべてのエンジンでサポートされています。
遅延読み込み属性は、次のキーワードおよび状態を持つ 列挙属性である:
| キーワード | 状態 | 概要 |
|---|---|---|
lazy
|
遅延 | 一定の条件が満たされるまで、リソースの取得を延期するために使用される。 |
eager
|
即時 | リソースを直ちに取得するために使用される。既定の状態である。 |
この属性は、その現在の状態に従い、リソースを直ちに取得するか、 要素に関連する一定の条件が満たされるまで取得を延期するよう、ユーザーエージェントに指示する。
要素 element が与えられた場合の 要素を遅延読み込みするかどうかの手順は、 次のとおりである:
element について スクリプトが無効化されている場合、 false を返す。
これは追跡防止措置である。スクリプトが無効化されているときにも ユーザーエージェントが遅延読み込みをサポートすると、サーバーが要求された画像の数と その時点を追跡できるように、ページのマークアップ内へ画像を戦略的に配置することで、 サイトがセッション全体を通じてユーザーのおおよそのスクロール位置を追跡できてしまうためである。
false を返す。
各 img、audio、video、および iframe 要素には、関連付けられた
遅延読み込み再開手順があり、初期値は null である。
各 video 要素には、関連付けられた
ポスター遅延読み込み再開手順もあり、
初期値は null である。
遅延
読み込みされる img、audio、video、および iframe 要素について、これらの手順は
遅延読み込み
交差オブザーバーのコールバックから、またはそれらの
遅延読み込み
属性が
即時状態に設定されたときに実行される。
これにより、要素の読み込みが続行される。video 要素については、
ポスター遅延読み込み
再開手順も同時に実行される。
各 Document は
遅延読み込み交差オブザーバーを持つ。
これは初期状態では null に設定されているが、
IntersectionObserver
インスタンスに設定できる。
遅延読み込み要素 element の 交差監視を開始するには、 次の手順を実行する:
doc を、element の ノード文書とする。
doc の
遅延読み込み交差オブザーバーが
null である場合、次のように初期化された新しい
IntersectionObserver
インスタンスに設定する:
IntersectionObserver
コンストラクターの元の値を使用することを意図している。しかし、
Intersection Observer が仕様で使用するための低レベルフックを公開するまでは、
この仕様では JavaScript に公開されたコンストラクターを使用せざるを得ない。
これを追跡するバグ
w3c/IntersectionObserver#464
を参照のこと。[INTERSECTIONOBSERVER]
callback は、引数 entries および observer を取る次の手順である:
entries 内の各 entry について 開発者が変更可能な配列アクセサーまたは反復フックを 呼び出さない反復方法を使用して:
resumptionSteps を null とする。
entry.isIntersecting
が true である場合、resumptionSteps を
entry.targetの
遅延
読み込み再開手順に設定する。
posterResumptionSteps を null とする。
entry.isIntersecting
が true であり、かつ entry.target
が video 要素である場合、
posterResumptionSteps を、その video 要素の
ポスター遅延読み込み再開
手順に設定する。
resumptionSteps が null であり、かつ posterResumptionSteps が null である場合、戻る。
entry.target
について、
遅延読み込み要素の
交差監視を停止する。
resumptionSteps が null でない場合:
entry.targetの
遅延読み込み再開
手順を null に設定する。
resumptionSteps を呼び出す。
posterResumptionSteps が null でない場合:
video 要素の
ポスター遅延読み込み再開
手順を null に設定する。
posterResumptionSteps を呼び出す。
isIntersecting
および
target
取得子の元の値を使用することを意図している。
w3c/IntersectionObserver#464
を参照のこと。
[INTERSECTIONOBSERVER]
options は、次の辞書メンバーを持つ
IntersectionObserverInit
辞書である:«[「scrollMargin」→
遅延読み込みスクロール
マージン ]»
これにより、画像がまだビューポートと交差していないが、 まもなく交差するスクロール中に、その画像を取得できる。
遅延読み込みスクロールマージンに関する
提案は値が動的に変化することを示唆するが、
IntersectionObserver
API はスクロールマージンの変更をサポートしていない。issue
w3c/IntersectionObserver#428
を参照のこと。
element を引数として、doc の
遅延読み込み交差オブザーバーの
observe
メソッドを呼び出す。
observe
メソッドの元の値を使用することを意図している。
w3c/IntersectionObserver#464
を参照のこと。
[INTERSECTIONOBSERVER]
遅延読み込み要素 element の 交差監視を停止するには、 次の手順を実行する:
doc を、element の ノード文書とする。
表明:doc の 遅延読み込み交差オブザーバーは null ではない。
element を引数として、doc の
遅延読み込み交差オブザーバーの
unobserve
メソッドを呼び出す。
unobserve
メソッドの元の値を使用することを意図している。
w3c/IntersectionObserver#464
を参照のこと。
[INTERSECTIONOBSERVER]
![]() 遅延読み込みスクロールマージンは
実装定義の値であるが、
次の提案を考慮する:
遅延読み込みスクロールマージンは
実装定義の値であるが、
次の提案を考慮する:
指定されたデバイスの通常の使用パターンにおいて、リソースがビューポートと交差する前に 読み込まれる結果となることが最も多い最小値を設定する。
一般的なスクロール速度:一般的なスクロール速度が速いデバイスでは値を増加させる。
現在のスクロール速度または勢い:ユーザーエージェントはスクロールが停止する可能性の高い 位置を予測し、それに応じて値を調整できる。
ネットワーク品質:低速または高遅延の接続では値を増加させる。
ユーザー設定が値に影響してもよい。
遅延読み込みスクロールマージンが 追加情報を漏洩しないことは、プライバシーにとって重要である。例えば、 新しいフィンガープリンティングベクトルを導入しないよう、現在のデバイスにおける 一般的なスクロール速度を不正確な値にしてもよい。
ブロッキング属性は、外部リソースを取得する際に、 特定の処理をブロックするべきであることを明示的に示す。ブロックできる処理は、 次の表に掲載される文字列である 使用可能なブロッキングトークンによって表される:
| 使用可能なブロッキングトークン | 説明 |
|---|---|
「render」
|
要素は レンダリングをブロックする可能性がある。 |
将来、さらに多くの 使用可能な ブロッキングトークンが追加される可能性がある。
ブロッキング属性の値は、 各トークンが 使用可能な ブロッキングトークンである 一意な空白区切りトークンの 順序なし集合でなければならない。 ブロッキング属性の サポート対象トークンは、 使用可能なブロッキング トークンである。各要素は ブロッキング属性を 最大 1 個だけ持つことができる。
要素 el の ブロッキングトークン集合は、 次の手順の結果である:
value を、el の ブロッキング属性の値とする。 そのような属性が存在しない場合は空文字列とする。
value を、value を ASCII 小文字に変換したものに設定する。
rawTokens を、value を ASCII 空白で 分割した結果とする。
rawTokens の要素のうち、 使用可能なブロッキングトークンである ものを含む集合を返す。
要素は、その
ブロッキングトークン集合が
「render」を含む場合、または
暗黙的にレンダリングをブロックする可能性がある
場合、レンダリングをブロックする可能性がある。
後者は個々の要素で定義される。既定では、要素は
暗黙的にレンダリングを
ブロックする可能性があるものではない。
取得優先度属性は、次のキーワードおよび状態を持つ 列挙属性である:
| キーワード | 状態 | 概要 |
|---|---|---|
high
|
高 | 同じ 宛先を持つ他のリソースと比べて、 高優先度の 取得であることを示す。 |
low
|
低 | 同じ 宛先を持つ他のリソースと比べて、 低優先度の 取得であることを示す。 |
auto
|
自動 | 同じ 宛先を持つ他のリソースと比べて、 取得優先度を自動的に決定することを示す。 |
反映の構成要素は次のとおりである:
反映対象は、要素または ElementInternals
オブジェクトである。通常はコンテキストから明らかであり、通常は
反映 IDL 属性の
インターフェイスと同一である。それが
ElementInternals
オブジェクトである場合は、常にそのインターフェイスと同一である。
反映 IDL 属性は、属性インターフェイスメンバーである。
反映コンテンツ属性名は文字列である。反映
対象が要素である場合、名前空間が null であるコンテンツ属性のローカル名を表す。反映対象が ElementInternals
オブジェクトである場合、それは
反映対象の
対象
要素の 内部コンテンツ属性
マップのキーを表す。
反映 IDL 属性は、 反映対象の 反映コンテンツ属性 名を反映するように定義できる。一般にこれは、 IDL 属性の取得子がコンテンツ属性の現在の値を返し、設定子がコンテンツ属性の値を 指定された値に変更することを意味する。
反映 対象には、次の関連付けられたアルゴリズムがある:
要素 element である 反映対象について、 これらは次のように定義される:
element を返す。
attribute を、null、 反映 コンテンツ属性名、および element が与えられた場合に 名前空間およびローカル名によって 属性を取得した結果とする。
attribute が null である場合、null を返す。
attribute の 値を返す。
element、 反映 コンテンツ属性名、および value が与えられた場合に 属性値を設定する。
null、反映 コンテンツ属性名、および element が与えられた場合に、 名前空間およびローカル名によって 属性を削除する。
ElementInternals
オブジェクト elementInternals である
反映対象について、
これらは次のように定義される:
elementInternals の 対象要素の 内部コンテンツ 属性マップ[反映 コンテンツ属性名]が 存在しない場合、null を返す。
elementInternals の 対象 要素の 内部コンテンツ 属性マップ[反映 コンテンツ 属性名]を返す。
elementInternals の 対象要素の 内部コンテンツ 属性マップ[反映 コンテンツ属性名]を value に 設定する。
elementInternals の 対象要素の 内部コンテンツ 属性マップ[反映 コンテンツ属性名]を 削除する。
これにより、
ElementInternals
オブジェクトでは、その
対象
要素の 内部コンテンツ属性
マップを直接操作できず、そのため反映が一方向でのみ行われるので、多少冗長なデータ構造となる。
それでもこの手法は、複数の
反映対象間で共有され、
共通の API セマンティクスの恩恵を受ける IDL 属性を、より誤りにくく定義できるようにするために
選択された。
列挙コンテンツ属性を
反映する、
型が DOMString
または
DOMString?
である IDL 属性は、既知の値のみに制限できる。
以下の処理モデルに従い、そのような IDL 属性の取得子は、それらの列挙属性のキーワード、
空文字列、または null だけを返す。
取得子の手順は次のとおりである:
contentAttributeValue を、 thisの コンテンツ属性を 取得するを実行した結果とする。
attributeDefinition を、名前空間が null で、ローカル名が 反映 コンテンツ 属性名である、element のコンテンツ属性の属性定義とする。
attributeDefinition が 列挙属性であることを 示し、かつ 反映 IDL 属性が 既知の値のみに 制限されるよう定義されている場合:
contentAttributeValue が null である場合、空文字列を返す。
contentAttributeValue を返す。
設定子の手順は、指定された値を用いて thisの コンテンツ属性を 設定するを実行することである。
反映 IDL 属性の型が
DOMString?
である場合:
取得子の手順は次のとおりである:
contentAttributeValue を、 thisの コンテンツ属性を 取得するを実行した結果とする。
attributeDefinition を、名前空間が null で、ローカル名が 反映 コンテンツ 属性名である、element のコンテンツ属性の属性定義とする。
attributeDefinition が 列挙属性であることを 示す場合:
表明: 反映 IDL 属性は 既知の値のみに 制限されている。
表明: contentAttributeValue は attributeDefinition の状態に対応する。
contentAttributeValue が、関連付けられたキーワード値を持たない attributeDefinition の状態に対応する場合、null を返す。
contentAttributeValue が対応する attributeDefinition の状態の 正規キーワードを 返す。
contentAttributeValue を返す。
設定子の手順は次のとおりである:
指定された値が null である場合、 thisの コンテンツ属性を 削除するを実行する。
それ以外の場合、指定された値を用いて thisの コンテンツ属性を 設定するを実行する。
反映 IDL 属性の型が
USVString
であり、任意でURL として扱われる場合:
取得子の手順は次のとおりである:
contentAttributeValue を、 thisの コンテンツ属性を 取得するを実行した結果とする。
反映 IDL 属性が URL として扱われる場合:
contentAttributeValue が null である場合、空文字列を返す。
urlString を、element の ノード 文書に対して、contentAttributeValue が与えられた場合に URL を エンコーディング付きで構文解析して シリアライズした結果とする。
urlString が失敗でない場合、urlString を返す。
contentAttributeValue を スカラー値文字列に変換して返す。
設定子の手順は、指定された値を用いて thisの コンテンツ属性を 設定するを実行することである。
取得子の手順は次のとおりである:
contentAttributeValue を、 thisの コンテンツ属性を 取得するを実行した結果とする。
contentAttributeValue が null である場合、false を返す。
true を返す。
設定子の手順は次のとおりである:
指定された値が false である場合、 thisの コンテンツ属性を 削除するを実行する。
指定された値が true である場合、空文字列を用いて thisの コンテンツ属性を 設定するを実行する。
これは ブールコンテンツ 属性の規則に対応する。
反映 IDL 属性の型が
long
であり、任意で非負数のみに制限され、
任意で既定
値 defaultValue を持つ場合:
取得子の手順は次のとおりである:
contentAttributeValue を、 thisの コンテンツ属性を 取得するを実行した結果とする。
contentAttributeValue が null でない場合:
反映 IDL 属性が 非負数の みに制限されていない場合、parsedValue を contentAttributeValue の 整数 構文解析の結果とし、それ以外の場合は contentAttributeValue の 非負 整数 構文解析の結果とする。
parsedValue がエラーでなく、かつ long
の範囲内にある場合、parsedValue を返す。
0 を返す。
設定子の手順は次のとおりである:
反映 IDL
属性が
非負数の
みに制限されており、指定された値が負である場合、
"IndexSizeError" DOMException
を投げる。
指定された値を、数を 妥当な 整数として表す可能な限り短い文字列に変換し、それを用いて thisの コンテンツ属性を 設定するを実行する。
反映 IDL 属性の型が
unsigned long
であり、任意で正の数のみに
制限されるか、フォールバック
付きで正の数のみに制限されるか、または
範囲にクランプされ
[clampedMin,
clampedMax]、任意で
既定値
defaultValue を持つ場合:
取得子の手順は次のとおりである:
contentAttributeValue を、 thisの コンテンツ属性を 取得するを実行した結果とする。
minimum を 0 とする。
反映 IDL 属性が 正の 数のみに制限されているか、または フォールバック 付きで正の数のみに制限されている場合、minimum を 1 に設定する。
反映 IDL 属性が 範囲にクランプされない 場合は maximum を 2147483647 とし、それ以外の場合は clampedMax とする。
contentAttributeValue が null でない場合:
minimum を返す。
設定子の手順は次のとおりである:
反映 IDL
属性が
正の
数のみに制限されており、指定された値が 0 である場合、
"IndexSizeError" DOMException
を投げる。
minimum を 0 とする。
反映 IDL 属性が 正の 数のみに制限されているか、または フォールバック 付きで正の数のみに制限されている場合、minimum を 1 に設定する。
newValue を minimum とする。
指定された値が 2147483647 以下かつ minimum 以上の範囲にある場合、 newValue をその値に設定する。
newValue を、数を 妥当な非負 整数として表す可能な限り短い文字列に変換し、それを用いて thisの コンテンツ属性を 設定するを実行する。
範囲へのクランプは、 設定子の手順には影響しない。
反映 IDL 属性の型が
double
であり、任意で
正の数のみに制限され、
任意で 既定値
defaultValue を持つ場合:
取得子の手順は次のとおりである:
contentAttributeValue を、 thisの コンテンツ属性を 取得するを実行した結果とする。
contentAttributeValue が null でない場合:
parsedValue を、contentAttributeValue の 浮動小数点 数構文解析の結果とする。
parsedValue がエラーでなく、かつ 0 より大きい場合、 parsedValue を返す。
parsedValue がエラーでなく、かつ 反映 IDL 属性が 正の 数のみに制限されていない場合、parsedValue を返す。
0 を返す。
設定子の手順は次のとおりである:
指定された値を 数の 浮動小数点数としての最適な 表現に変換し、それを用いて thisの コンテンツ属性を 設定するを実行する。
Infinity および Not-a-Number(NaN)の値は、 Web IDL で定義されるように、設定時に例外を投げる。 [WEBIDL]
反映 IDL 属性の型が
DOMTokenList
である場合、その取得子の手順は、関連付けられた要素が
thisであり、関連付けられた属性のローカル名が
反映コンテンツ
属性名である DOMTokenList
オブジェクトを返すことである。仕様の作者は、この型の IDL 属性を
ElementInternals
上で反映できない。
反映 IDL 属性の型が
T? であり、T が
Element
または
Element
を継承するインターフェイスのいずれかである場合、attr を
反映コンテンツ
属性名として:
その 反映対象は、 要素への弱い参照または null である 明示的に設定された attr 要素を持つ。初期値は null である。
その 反映対象 reflectedTarget は、 attr に関連付けられた要素を 取得するアルゴリズムを持ち、これは次の手順を実行する:
element を、reflectedTarget の 要素を 取得するを実行した結果とする。
contentAttributeValue を、 reflectedTarget の コンテンツ属性を 取得するを実行した結果とする。
reflectedTarget の 明示的に設定された attr 要素が null でない場合:
reflectedTarget の 明示的に設定された attr 要素が、element の シャドウを含む祖先のいずれかの 子孫である場合、 reflectedTarget の 明示的に設定された attr 要素を返す。
null を返す。
それ以外で、contentAttributeValue が null でない場合、 次の基準を満たす最初の要素 candidate を ツリー順で返す:
そのような要素が存在しない場合、null を返す。
null を返す。
取得子の手順は、 thisの attr に 関連付けられた要素を取得するを実行した結果を返すことである。
設定子の手順は次のとおりである:
指定された値が null である場合:
thisの 明示的に設定された attr 要素を null に設定する。
thisの コンテンツ属性を 削除するを実行する。
戻る。
空文字列を用いて thisの コンテンツ属性を 設定するを実行する。
thisの 明示的に設定された attr 要素を、指定された値への弱い参照に設定する。
要素である 反映対象のみについて: element、localName、oldValue、 value、および namespace が与えられた場合、 コンテンツ属性と IDL 属性との間を同期するために、次の 属性変更手順を使用する:
localName が attr でないか、 namespace が null でない場合、戻る。
element の 明示的に設定された attr 要素を null に設定する。
一貫性のため、この型の
反映 IDL 属性では、
その識別子を「Element」で終わらせることを強く推奨する。
反映 IDL 属性の型が
FrozenArray<T>? であり、T が
Element
または Element
を継承するインターフェイスのいずれかである場合、attr を
反映コンテンツ
属性名として:
その 反映対象は、 要素への弱い参照の リストまたは null である 明示的に設定された attr 要素群を持つ。初期値は null である。
その
反映対象は、
FrozenArray<T>? である
キャッシュされた attr 関連要素
オブジェクトを持つ。初期値は null である。
その 反映対象 reflectedTarget は、 attr に関連付けられた要素群を 取得するアルゴリズムを持ち、これは次の手順を実行する:
elements を空の リストとする。
element を、reflectedTarget の 要素を 取得するを実行した結果とする。
reflectedTarget の 明示的に設定された attr 要素群が null でない場合:
reflectedTarget の 明示的に設定された attr 要素群内の各 attrElement について 反復する:
attrElement が、element の シャドウを含む 祖先のいずれの 子孫でもない場合、 続行する。
attrElement を elements に 付加する。
それ以外の場合:
contentAttributeValue を、 reflectedTarget の コンテンツ属性を 取得するを実行した結果とする。
contentAttributeValue が null である場合、null を返す。
tokens を、contentAttributeValue を ASCII 空白で分割したものとする。
tokens の各 id について 反復する:
elements を返す。
取得子の手順は次のとおりである:
elements を、 thisの attr に 関連付けられた要素群を取得するを実行した結果とする。
elements の内容が、 thisの キャッシュされた attr 関連要素群の内容と等しい場合、 thisの キャッシュされた attr 関連要素オブジェクトを返す。
elementsAsFrozenArray を、elements を
FrozenArray<T>? に
変換したものとする。
thisの キャッシュされた attr 関連要素群を elements に設定する。
thisの キャッシュされた attr 関連要素オブジェクトを elementsAsFrozenArray に設定する。
elementsAsFrozenArray を返す。
この追加のキャッシュ層は、
element.reflectedElements === element.reflectedElements
という不変条件を維持するために必要である。
設定子の手順は次のとおりである:
指定された値が null である場合:
thisの 明示的に設定された attr 要素群を null に設定する。
thisの コンテンツ属性を 削除するを実行する。
戻る。
空文字列を用いて thisの コンテンツ属性を 設定するを実行する。
elements を空の リストとする。
指定された値内の各 element について 反復する:
element への弱い参照を elements に 付加する。
thisの 明示的に設定された attr 要素群を elements に設定する。
要素である 反映対象のみについて: element、localName、oldValue、 value、および namespace が与えられた場合、 コンテンツ属性と IDL 属性との間を同期するために、次の 属性変更手順を使用する:
localName が attr でないか、 namespace が null でない場合、戻る。
element の 明示的に設定された attr 要素群を null に設定する。
一貫性のため、この型の
反映 IDL 属性では、
その識別子を「Elements」で終わらせることを強く推奨する。
反映は、IDL から
拡張属性を介して使用できる。
[Reflect]、[ReflectSetter]、[ReflectURL]、
[ReflectNonNegative]、[ReflectPositive]、および
[ReflectPositiveWithFallback]は、いずれも
反映を発生させる。
これらは引数を取らないか文字列を取らなければならず、インターフェイスメンバー属性以外に
出現してはならず、一度に使用できるのはこれらのうち 1 つだけである。
これらの主要な反映 拡張属性のいずれかについて、その 反映コンテンツ属性 名は、文字列値が指定されている場合はその値であり、それ以外の場合は IDL 属性名を ASCII 小文字に変換したものである。
[Reflect]
拡張
属性を持つ IDL 属性は、[Reflect]の
反映コンテンツ属性
名を反映しなければならない。
[ReflectSetter]
拡張
属性を持つ IDL 属性は、設定時に [ReflectSetter]の
反映コンテンツ属性
名を反映しなければならない。
[ReflectURL]
拡張
属性は、型が USVString
である属性にのみ出現しなければならない。
[ReflectURL]
拡張
属性を持つ IDL 属性は、[ReflectURL]の
反映コンテンツ属性
名を、URL として
反映しなければならない。
[ReflectNonNegative]
拡張
属性は、型が long
である属性にのみ出現しなければならない。
[ReflectNonNegative]
拡張
属性を持つ IDL 属性は、[ReflectNonNegative]の
反映コンテンツ属性
名を、非負数のみに制限して
反映しなければならない。
[ReflectPositive]
および [ReflectPositiveWithFallback]
拡張
属性は、型が double
または unsigned
long
である属性にのみ出現しなければならない。
[ReflectPositive]
拡張
属性を持つ IDL 属性は、[ReflectPositive]の
反映
コンテンツ属性名を、
正の数の
みに制限して、
反映しなければならない。
[ReflectPositiveWithFallback]
拡張
属性を持つ IDL 属性は、[ReflectPositiveWithFallback]の
反映
コンテンツ属性名を、
フォールバック
付きで正の数のみに制限して、
反映しなければならない。
上記の
拡張
属性を補うため、[ReflectRange]および
[ReflectDefault]も導入する。これらは
反映の動作を拡張し、
またインターフェイスメンバー属性にのみ出現しなければならない。
[ReflectRange]
拡張
属性は、2 個の値に制限された整数リストを取らなければならない。これは、型が
unsigned long
である属性にのみ使用しなければならない。さらに、[Reflect]
と併せてのみ出現しなければならない。
[ReflectRange]
拡張
属性を持つ IDL 属性は、範囲
[clampedMin,
clampedMax] に
クランプされる。ここで
clampedMin は [ReflectRange]
に指定されたリストの第 1 引数であり、clampedMax は第 2 引数である。
[ReflectDefault]
拡張
属性は、型が double、
long、
または unsigned long
である属性にのみ使用しなければならない。型が double
である属性に使用する場合、10 進数を取らなければならず、それ以外の場合は整数を
取らなければならない。さらに、[Reflect]、
[ReflectNonNegative]、
[ReflectPositive]、
または [ReflectPositiveWithFallback]
と併せてのみ出現しなければならない。
[ReflectDefault]
拡張
属性を持つ IDL 属性は、[ReflectDefault]
に指定された引数によって提供される
既定
値を持つ。
反映は、主として 反映 IDL 属性を通じて コンテンツ属性への型付きアクセスを提供することにより、ウェブ開発者の使いやすさを向上させるための ものである。ウェブプラットフォームが構築される上での最終的な信頼できる情報源は、 コンテンツ属性そのものである。すなわち、仕様の作者は 反映 IDL 属性の取得子または設定子の手順を使用してはならず、代わりにコンテンツ属性の存在および値を 使用しなければならない。(または、 列挙 属性の状態など、その上位の抽象化を使用する。)
これに対する 2 つの重要な例外は、型が次のいずれかである 反映 IDL 属性である:
これらについて、仕様の作者は 反映対象の attr に関連付けられた要素を取得するおよび attr に関連付けられた要素群を取得するを、それぞれ使用しなければならない。 コンテンツ属性の存在および値は、 反映 IDL 属性と完全に同期できないため、使用してはならない。
反映 対象の 明示的に設定された attr 要素、 明示的に 設定された attr 要素群、 キャッシュされた attr 関連要素群、および キャッシュされた attr 関連要素オブジェクトは、内部実装の詳細として扱わなければならず、 その上に機能を構築してはならない。
HTMLFormControlsCollection
および HTMLOptionsCollection
インターフェイスは、
HTMLCollection
インターフェイスから派生した
コレクションである。HTMLAllCollection
インターフェイスは
コレクションではあるが、そのように派生したものではない。
HTMLAllCollection
インターフェイスHTMLAllCollection
インターフェイスは、レガシーな document.all
属性に使用される。これは
HTMLCollection
と同様に動作する。主な違いは、そのメソッドの非常に多様な異なる(誤)用法のすべてが
何らかの値を返すこと、およびプロパティアクセスの代わりに関数として呼び出せることである。
すべての HTMLAllCollection
オブジェクトは Document
をルートとし、すべての要素に一致するフィルターを持つため、HTMLAllCollection
オブジェクトの
コレクションによって表される要素は、
ルートである Document
のすべての子孫要素からなる。
HTMLAllCollection
インターフェイスを実装するオブジェクトは、
レガシー
プラットフォームオブジェクトであり、以下の節で説明する
追加の [[Call]] 内部メソッドを持つ。また、
[[IsHTMLDDA]] 内部スロットも持つ。
HTMLAllCollection
インターフェイスを実装するオブジェクトは、
[[IsHTMLDDA]]
内部スロットを持つため、いくつかの通常とは異なる動作をする:
JavaScript の
ToBoolean 抽象演算は、HTMLAllCollection
インターフェイスを実装するオブジェクトが与えられた場合、false を返す。
IsLooselyEqual 抽象演算は、
HTMLAllCollection
インターフェイスを実装するオブジェクトが与えられた場合、undefined および
null 値と比較すると true を返す。
(IsStrictlyEqual 抽象演算を使用する比較、および
文字列やオブジェクトなどの他の値との IsLooselyEqual 比較には影響しない。)
JavaScript の typeof
演算子は、HTMLAllCollection
インターフェイスを実装するオブジェクトに適用された場合、文字列
"undefined" を返す。
これらの特殊な動作は、2 種類のレガシーコンテンツとの互換性を求めることに由来する。
1 つは、レガシーユーザーエージェントを検出する方法として document.all
の存在を使用するもの、もう 1 つは、それらのレガシーユーザーエージェントだけをサポートし、
document.all
オブジェクトの存在を最初に検査せずに使用するものである。
[JAVASCRIPT]
[Exposed =Window ,
LegacyUnenumerableNamedProperties ]
interface HTMLAllCollection {
readonly attribute unsigned long length ;
getter Element (unsigned long index );
getter (HTMLCollection or Element )? namedItem (DOMString name );
(HTMLCollection or Element )? item (optional DOMString nameOrIndex );
// Note: HTMLAllCollection objects have a custom [[Call]] internal method and an [[IsHTMLDDA]] internal slot.
};このオブジェクトの
サポート対象プロパティインデックスは、
HTMLCollection
オブジェクトについて定義されるものと同じである。
サポート対象プロパティ名は、
コレクションによって表されるすべての要素の
id
属性の空でないすべての値と、
「all」名前付き
要素のうち、
コレクションによって表されるすべての要素の
name 属性の空でないすべての値からなり、
ツリー順で、後の重複を無視し、要素の id と
name の両方が寄与し、互いに異なり、いずれも以前の項目の重複でない場合は、
id を name より前に置く。
length 取得子の手順は、
コレクションによって表されるノードの数を返すことである。
インデックス付きプロパティ取得子は、渡されたインデックスを指定して this から 「all」インデックス付き要素を取得した結果を 返さなければならない。
namedItem(name) メソッドの手順は、
name を指定して
this から
「all」名前付き
要素を取得した結果を返すことである。
item(nameOrIndex) メソッドの手順は
次のとおりである:
nameOrIndex が指定されていない場合、null を返す。
nameOrIndex を指定して、 this から 「all」インデックス付きまたは 名前付き要素を取得した結果を返す。
次の要素は「all」名前付き要素である:
a、
button、
embed、
form、
frame、
frameset、
iframe、
img、
input、
map、
meta、
object、
select、および
textarea
インデックス index が与えられた場合に、HTMLAllCollection
collection から
「all」インデックス付き要素を取得するには、
collection 内の index番目の要素を返し、そのような
index番目の要素がない場合は null を返す。
名前 name が与えられた場合に、HTMLAllCollection
collection から
「all」名前付き要素を取得するには、
次の手順を実行する:
name が空文字列である場合、null を返す。
subCollection を、collection と同じ
Document
をルートとし、次のいずれかである要素だけに一致するフィルターを持つ HTMLCollection
オブジェクトとする:
name と等しい name 属性を持つ
「all」名前付き
要素、または
name と等しい IDを持つ要素。
subCollection 内に要素が正確に 1 個ある場合、その要素を返す。
それ以外で、subCollection が空である場合、null を返す。
それ以外の場合、subCollection を返す。
nameOrIndex が与えられた場合に、HTMLAllCollection
collection から
「all」インデックス付きまたは名前付き
要素を取得するには:
nameOrIndex を JavaScript String 値に 変換したものが 配列インデックスプロパティ名である場合、 nameOrIndex が表す数を指定して collection から 「all」インデックス付き 要素を取得した結果を返す。
nameOrIndex を指定して collection から 「all」名前付き 要素を取得した結果を返す。
argumentsList の サイズがゼロである場合、 または argumentsList[0] が undefined である場合、null を返す。
result を、nameOrIndex を指定してこの HTMLAllCollection
から
「all」インデックス付きまたは名前付き
要素を取得した結果とする。
result を ECMAScript 値に 変換した結果を返す。
thisArgument は無視されるため、
Function.prototype.call.call(document.all, null, "x") のようなコードでも引き続き
要素を検索する。(document.all は Function.prototype を継承しないため、
document.all.call は存在しない。)
HTMLFormControlsCollection
インターフェイスHTMLFormControlsCollection
インターフェイスは、form
要素内の
リスト対象
要素の
コレクションに使用される。
現在のすべてのエンジンでサポートされている。
現在のすべてのエンジンでサポートされている。
[Exposed =Window ]
interface HTMLFormControlsCollection : HTMLCollection {
// inherits length and item()
getter (RadioNodeList or Element )? namedItem (DOMString name ); // shadows inherited namedItem()
};
[Exposed =Window ]
interface RadioNodeList : NodeList {
attribute DOMString value ;
};collection.length
collection 内の要素数を返す。
element = collection.item(index)
element = collection[index]collection 内のインデックス index にある項目を返す。項目は ツリー順に並べられる。
element = collection.namedItem(name)
HTMLFormControlsCollection/namedItem
現在のすべてのエンジンでサポートされている。
radioNodeList = collection.namedItem(name)
element = collection[name]radioNodeList = collection[name]collection から、
IDまたは
nameが
name である項目を返す。
一致する項目が複数ある場合、それらすべての要素を含む RadioNodeList
オブジェクトを返す。
radioNodeList.value
radioNodeList によって表される、チェックされた最初のラジオボタンの値を返す。
radioNodeList.value = value
radioNodeList によって表されるラジオボタンのうち、値が value である最初のものをチェックする。
このオブジェクトの
サポート対象プロパティインデックスは、
HTMLCollection
オブジェクトについて定義されるものと同じである。
サポート対象プロパティ名は、
コレクションによって表されるすべての
要素の id
および name
属性の空でないすべての値からなり、
ツリー順で、後の
重複を無視し、要素の id と
name の両方が
寄与し、互いに異なり、いずれも以前の項目の重複でない場合は、
id を name より前に置く。
namedItem(name) メソッドは、
次のアルゴリズムに従って動作しなければならない:
id
属性または name
属性のいずれかを持つノードが正確に 1 個ある場合、そのノードを返し、アルゴリズムを停止する。
id
属性または name
属性の
いずれかを持つノードがない場合、null を返し、アルゴリズムを停止する。HTMLFormControlsCollection
オブジェクトの
ライブビューを表す新しい
RadioNodeList
オブジェクトを作成し、さらにフィルターを適用して、RadioNodeList
オブジェクト内のノードを、name と等しい id
属性または name
属性の
いずれかを持つものだけにする。RadioNodeList
オブジェクト内のノードは、
ツリー順に
並べなければならない。
RadioNodeList
オブジェクトを返す。NodeList
インターフェイスから継承された RadioNodeList
インターフェイスのメンバーは、NodeList
オブジェクト上で動作する場合と同様に動作しなければならない。
現在のすべてのエンジンでサポートされている。
RadioNodeList
オブジェクト上の
value
IDL 属性は、取得時に、
次の手順を実行して返される値を返さなければならない:
設定時に、value
IDL 属性は、次の手順を実行しなければならない:
新しい値が文字列「on」である場合:element を、RadioNodeList
オブジェクトによって表される要素のうち、
ツリー順で最初に
ある、input
要素で、その
type
属性が ラジオボタン状態にあり、
その value
コンテンツ属性が存在しないか、存在して新しい値と等しいものとする。そのような要素が存在しない場合は、
代わりに element を null とする。
それ以外の場合:element を、RadioNodeList
オブジェクトによって表される要素のうち、
ツリー順で最初に
ある、input
要素で、その
type
属性が ラジオボタン状態にあり、
その value
コンテンツ属性が存在し、新しい値と等しいものとする。そのような要素が存在しない場合は、
代わりに element を null とする。
element が null でない場合、その チェック状態を true に設定する。
HTMLOptionsCollection
インターフェイス現在のすべてのエンジンでサポートされている。
HTMLOptionsCollection
インターフェイスは、option
要素のコレクションに
使用される。これは常に select
要素をルートとし、その要素の子孫を操作する属性およびメソッドを持つ。
[Exposed =Window ]
interface HTMLOptionsCollection : HTMLCollection {
// inherits item(), namedItem()
[CEReactions ] attribute unsigned long length ; // shadows inherited length
[CEReactions ] setter undefined (unsigned long index , HTMLOptionElement ? option );
[CEReactions ] undefined add ((HTMLOptionElement or HTMLOptGroupElement ) element , optional (HTMLElement or long )? before = null );
[CEReactions ] undefined remove (long index );
attribute long selectedIndex ;
};collection.length
collection 内の要素数を返す。
collection.length = value
既存の長さより小さい数に設定すると、collection に対応するコンテナー内の
option
要素数を切り詰める。
既存の長さより大きい数に設定すると、その数が 100000 以下である場合、
collection に対応するコンテナーへ新しい空の option
要素を追加する。
element = collection.item(index)
element = collection[index]collection 内のインデックス index にある項目を返す。項目は ツリー順に並べられる。
collection[index] = elementindex が collection 内の項目数より大きい場合、
対応するコンテナーへ新しい空の option
要素を追加する。
null に設定すると、インデックス index にある項目を collection から削除する。
option
要素に設定すると、collection 内のインデックス index に
その要素を追加するか、既存の要素を置換する。
element = collection.namedItem(name)
element = collection[name]collection から、IDまたは nameが
name である項目を返す。
一致する項目が複数ある場合、最初の項目を返す。
collection.add(element[, before])
before によって指定されたノードの前へ element を挿入する。
before 引数には数を指定できる。この場合、element は その番号を持つ項目の前へ挿入される。または collection 内の要素を指定でき、 この場合、element はその要素の前へ挿入される。
before が省略されるか null である場合、または範囲外の数である場合、 element はリストの末尾へ追加される。
element が挿入先となる要素の祖先である場合、
"HierarchyRequestError" DOMException
を投げる。
collection.remove(index)
インデックス index を持つ項目を collection から削除する。
collection.selectedIndex
選択された項目がある場合は最初の項目のインデックスを返し、 選択された項目がない場合は −1 を返す。
collection.selectedIndex = index
選択項目を、collection 内のインデックス index にある option
要素へ変更する。
このオブジェクトの
サポート対象プロパティインデックスは、
HTMLCollection
オブジェクトについて定義されるものと同じである。
length 取得子の手順は、
コレクションによって表されるノード数を返すことである。
length
設定子の手順は次のとおりである:
current を、 コレクションによって表されるノード数とする。
指定された値が current より大きい場合:
指定された値が 100,000 より大きい場合、戻る。
n を value − current とする。
n を指定して、
this がルートとする select
要素へ
新しい option 要素を付加する。
指定された値が current より小さい場合:
n を current − value とする。
コレクション内の最後の n 個のノードを、その親ノードから削除する。
length
を設定しても、optgroup
要素が削除または追加されることはなく、既存の
optgroup
要素へ新しい子が追加されることもない(ただし、その子が削除されることはある)。
サポート対象プロパティ名は、
コレクションによって表されるすべての
要素の id および
name
属性の空でないすべての値からなり、ツリー順で、後の
重複を無視し、要素の id と
name の両方が
寄与し、互いに異なり、いずれも以前の項目の
重複でない場合は、id を name より前に置く。
非負整数 count が与えられた場合に、select
要素 select へ
新しい option 要素を付加するには:
fragmentを、selectのノード 文書を与えて文書フラグメントを 作成した結果とする。
count個の新しい option
要素をfragmentに追加する。
fragmentを selectに追加する。
プロパティインデックス index および
新しい値 value が与えられた場合に、HTMLOptionsCollection
collection の
新しいインデックス付きプロパティの値を
設定する、または
既存のインデックス付き
プロパティの値を設定するには:
value が null である場合、index を指定して collection から option を 削除し、戻る。
length を、collection によって 表されるノード数とする。
delta を index − length とする。
delta が 0 より大きい場合、delta を指定して、
collection がルートとする select
要素へ
新しい option 要素を付加する。
delta が 0 以上である場合、value を、
collection がルートとする select
要素へ
付加する。それ以外の場合、
collection 内の index 番目の要素を value で
置換する。
add(element, before)
メソッドの手順は次のとおりである:
element が、
this がルートとする select
要素の祖先である場合、
"HierarchyRequestError"
DOMException
を投げる。
before が要素であるが、その要素が
this がルートとする
select
要素の子孫でない場合、
"NotFoundError" DOMException
を投げる。
element と before が同じ要素である場合、戻る。
reference を null とする。
before がノードである場合、reference を before に設定する。それ以外で、before が整数であり、 this 内に before 番目のノードがある場合、 reference をそのノードに設定する。
reference が null でない場合、parent を
reference の親ノードとし、それ以外の場合は
this がルートとする
select
要素とする。
element を、parent ノード内の reference の前へ 事前挿入する。
整数 index が与えられた場合に、HTMLOptionsCollection
collection から
option を削除するには:
remove(index) メソッドの手順は、
index を指定して
this から
option を
削除することである。
selectedIndex 取得子の手順は、
this がルートとする select
要素の
選択済みインデックスを返すことである。
selectedIndex
設定子の手順は、
this がルートとする select
要素の
選択済みインデックスを設定することであり、
その値を指定された値に設定する。
DOMStringList インターフェイス現在のすべてのエンジンでサポートされている。
DOMStringList
インターフェイスは、文字列のリストを表す、時代遅れでレトロな方法である。
[Exposed =(Window ,Worker )]
interface DOMStringList {
readonly attribute unsigned long length ;
getter DOMString ? item (unsigned long index );
boolean contains (DOMString string );
};新しい API は、DOMStringList ではなく、
sequence<DOMString> または同等のものを使用しなければならない。
strings.length
strings 内の文字列数を返す。
strings[index]strings.item(index)
strings から、インデックス index を持つ文字列を返す。
strings.contains(string)
strings が string を含む場合は true を返し、 それ以外の場合は false を返す。
各 DOMStringList
オブジェクトには、関連付けられた
リストがある。
DOMStringList
インターフェイスは
インデックス付きプロパティをサポートする。
サポート対象プロパティインデックスは、
this に
関連付けられたリストの
インデックスである。
現在のすべてのエンジンでサポートされている。
現在のすべてのエンジンでサポートされている。
item(index) メソッドの手順は、
this に
関連付けられたリスト内の index 番目の項目を返すことであり、
index に 1 を加えた値が
this に
関連付けられたリストの
サイズより大きい場合は null を返す。
現在のすべてのエンジンでサポートされている。
プラットフォームオブジェクトを含む JavaScript オブジェクトを、
レルム境界を越えて渡すことをサポートするため、この仕様では、
オブジェクトをシリアライズおよびデシリアライズするための次の基盤を定義する。
場合によっては、基礎となるデータをコピーする代わりに転送することも含まれる。
このシリアライズ/デシリアライズ処理は総称して「構造化クローン」と呼ばれるが、
ほとんどの API はシリアライズとデシリアライズを別々の手順として実行する。
(注目すべき例外は structuredClone()
メソッドである。)
この節では、JavaScript 仕様の用語および表記規約を使用する。 [JAVASCRIPT]
/developer.mozilla.org/en-US/docs/Glossary/Serializable_object
/developer.mozilla.org/en-US/docs/Glossary/Serializable_object
/developer.mozilla.org/en-US/docs/Glossary/Serializable_object
/developer.mozilla.org/en-US/docs/Glossary/Serializable_object
/developer.mozilla.org/en-US/docs/Glossary/Serializable_object
/developer.mozilla.org/en-US/docs/Glossary/Serializable_object
/developer.mozilla.org/en-US/docs/Glossary/Serializable_object
シリアライズ可能なオブジェクトは、 特定の レルムに依存しない方法でシリアライズし、 後でデシリアライズすることをサポートする。これにより、ディスクに保存して後で復元したり、 エージェント境界、さらには エージェントクラスター境界を越えてクローンしたりできる。
すべてのオブジェクトが シリアライズ可能な オブジェクトであるわけではなく、 シリアライズ可能なオブジェクトである オブジェクトのすべての側面が、シリアライズ時に必ず保持されるわけでもない。
プラットフォームオブジェクトは、その
主要インターフェイスに
[Serializable]
IDL
拡張属性が付与されている場合、
シリアライズ可能なオブジェクトになれる。
そのようなインターフェイスは、次のアルゴリズムも定義しなければならない:
value 内のデータを serialized のフィールドへ シリアライズする一連の手順。serialized へシリアライズされた結果のデータは、 どの レルムにも依存してはならない。
シリアライズできない場合、これらの手順は例外を投げてもよい。
これらの手順は、ネストされたデータ構造をシリアライズするために サブシリアライズを実行してもよい。 重要な memory 引数が省略されるため、 StructuredSerialize を 直接呼び出すべきではない。
forStorage 引数がアルゴリズムに関係しない場合、 これらの手順の導入文ではその引数への言及を省略するべきである。
serialized 内のデータをデシリアライズし、それを使用して value を適切に設定する一連の手順。value は、対象となる プラットフォームオブジェクト型の 新たに作成されたインスタンスであり、その内部データはまだ何も設定されていない。 それを設定するのがこれらの手順の役割である。
デシリアライズできない場合、これらの手順は例外を投げてもよい。
これらの手順は、ネストされたデータ構造をデシリアライズするために サブデシリアライズを実行してもよい。 重要な targetRealm および memory 引数が省略されるため、 StructuredDeserialize を 直接呼び出すべきではない。
これらの手順によってどのデータをシリアライズおよびデシリアライズするかは、 個々のプラットフォームオブジェクトの定義に委ねられる。通常、これらの手順は非常に対称的である。
[Serializable]
拡張属性は引数を取ってはならず、インターフェイスにのみ出現しなければならない。
1 つのインターフェイスに複数回出現してはならない。
指定された
プラットフォームオブジェクトについて、
(デ)シリアライズ処理中に考慮されるのは、そのオブジェクトの
主要インターフェイスだけである。
したがって、インターフェイスの定義に継承が関係する場合、継承チェーン内で
[Serializable] が
注釈された各インターフェイスは、継承したインターフェイスに由来する重要なデータも考慮に入れた、
独立した
シリアライズ手順および
デシリアライズ手順を
定義する必要がある。
2 つの関連データが関連付けられたプラットフォームオブジェクト
Person を定義すると仮定する:
文字列である名前値、および
別の Person インスタンスまたは null のいずれかである
親友値。
この場合、Person インターフェイスに
[Serializable]
拡張属性を付与し、次の付随アルゴリズムを定義することで、
Person インスタンスを
シリアライズ可能な
オブジェクトとして定義できる:
value および serialized が与えられた場合の、それらの シリアライズ手順:
serialized.[[Name]] を、value に関連付けられた名前値に 設定する。
serializedBestFriend を、value に関連付けられた親友値の サブシリアライズとする。
serialized.[[BestFriend]] を serializedBestFriend に設定する。
serialized、value、および targetRealm が与えられた場合の、それらの デシリアライズ 手順:
value に関連付けられた名前値を serialized.[[Name]] に設定する。
deserializedBestFriend を、 serialized.[[BestFriend]] の サブデシリアライズとする。
value に関連付けられた親友値を deserializedBestFriend に設定する。
JavaScript 仕様で定義されるオブジェクトは、 StructuredSerialize 抽象演算によって 直接処理される。
当初、 この仕様では、ある レルムから別のレルムへクローンできる 「クローン可能なオブジェクト」という概念を定義していた。しかし、より複雑な特定の状況の動作を より適切に規定するため、シリアライズおよびデシリアライズを明示するようモデルが更新された。
転送可能なオブジェクトは、 エージェント間での転送をサポートする。転送とは、基礎となるデータへの 参照を共有しながらオブジェクトを実質的に再作成し、その後、転送されるオブジェクトを切り離すことである。 これは、高コストなリソースの所有権を移転する場合に有用である。すべてのオブジェクトが 転送可能な オブジェクトであるわけではなく、 転送可能なオブジェクトであるオブジェクトの すべての側面が、転送時に必ず保持されるわけでもない。
転送は、不可逆かつ非冪等な操作である。オブジェクトが一度転送されると、 再度転送することも、実際に使用することもできない。
プラットフォームオブジェクトは、その
主要インターフェイスに
[Transferable]
IDL
拡張
属性が付与されている場合、
転送可能なオブジェクトになれる。
そのようなインターフェイスは、次のアルゴリズムも定義しなければならない:
value 内のデータを dataHolder のフィールドへ転送する一連の手順。 dataHolder に保持される結果のデータは、どの レルムにも依存してはならない。
転送できない場合、これらの手順は例外を投げてもよい。
dataHolder 内のデータを受け取り、それを使用して value を 適切に設定する一連の手順。value は、対象となる プラットフォームオブジェクト型の新たに作成された インスタンスであり、その内部データはまだ何も設定されていない。それを設定するのが これらの手順の役割である。
転送を受信できない場合、これらの手順は例外を投げてもよい。
これらの手順によってどのデータを転送するかは、個々のプラットフォームオブジェクトの定義に 委ねられる。通常、これらの手順は非常に対称的である。
[Transferable]
拡張属性は引数を取ってはならず、インターフェイスにのみ出現しなければならない。
1 つのインターフェイスに複数回出現してはならない。
指定された
プラットフォーム
オブジェクトについて、転送処理中に考慮されるのは、そのオブジェクトの
主要
インターフェイスだけである。したがって、インターフェイスの定義に継承が関係する場合、
継承チェーン内で
[Transferable] が
注釈された各インターフェイスは、継承したインターフェイスに由来する重要なデータも考慮に入れた、
独立した
転送手順および
転送受信手順を
定義する必要がある。
プラットフォームオブジェクトであり、 転送可能な オブジェクトであるものは、 [[Detached]] 内部スロットを持つ。これは、プラットフォームオブジェクトが一度転送された後、 再度転送されないことを保証するために使用される。
JavaScript 仕様で定義されるオブジェクトは、 StructuredSerializeWithTransfer 抽象演算によって 直接処理される。
StructuredSerializeInternal 抽象演算は、 JavaScript 値 value を入力として受け取り、それを レルムに依存しない形式へ シリアライズする。ここでは、その形式を Recordとして 表す。このシリアライズ済み形式には、後で異なるレルム内の新しい JavaScript 値へ デシリアライズするために必要なすべての情報が含まれる。
この処理は、例えばシリアライズ不可能なオブジェクトをシリアライズしようとした場合に、 例外を投げることがある。
memory が指定されていない場合、memory を空の マップとする。
memory マップの目的は、オブジェクトを二重にシリアライズしないことである。 これにより、グラフ内の循環および重複オブジェクトの同一性が保持される。
memory[value] が 存在する場合、 memory[value] を返す。
deep を false とする。
value が undefined、null、 Boolean、 Number、 BigInt、または Stringである場合、 { [[Type]]: "primitive", [[Value]]: value } を返す。
value が
Symbol である場合、
"DataCloneError" DOMException
を投げる。
serialized を未初期化の値とする。
value が [[BooleanData]] 内部スロットを持つ場合、 serialized を { [[Type]]: "Boolean", [[BooleanData]]: value.[[BooleanData]] } に設定する。
それ以外で、value が [[NumberData]] 内部スロットを持つ場合、 serialized を { [[Type]]: "Number", [[NumberData]]: value.[[NumberData]] } に設定する。
それ以外で、value が [[BigIntData]] 内部スロットを持つ場合、serialized を { [[Type]]: "BigInt", [[BigIntData]]: value.[[BigIntData]] } に設定する。
それ以外で、value が [[StringData]] 内部スロットを持つ場合、 serialized を { [[Type]]: "String", [[StringData]]: value.[[StringData]] } に設定する。
それ以外で、value が [[DateValue]] 内部スロットを持つ場合、 serialized を { [[Type]]: "Date", [[DateValue]]: value.[[DateValue]] } に設定する。
それ以外で、value が [[RegExpMatcher]] 内部スロットを持つ場合、 serialized を { [[Type]]: "RegExp", [[RegExpMatcher]]: value.[[RegExpMatcher]], [[OriginalSource]]: value.[[OriginalSource]], [[OriginalFlags]]: value.[[OriginalFlags]] } に設定する。
それ以外で、value が [[ArrayBufferData]] 内部スロットを持つ場合:
IsSharedArrayBuffer(value) が true である場合:
現在の設定オブジェクトの
クロスオリジン
分離機能が false である場合、
"DataCloneError"
DOMException
を投げる。
この検査は、デシリアライズ時ではなくシリアライズ時にのみ必要である。
これは、
クロスオリジン
分離機能は時間の経過によって変化できず、SharedArrayBuffer
は
エージェント
クラスターを離れられないためである。
forStorage が true である場合、
"DataCloneError" DOMException
を投げる。
value が [[ArrayBufferMaxByteLength]] 内部スロットを持つ場合、 serialized を { [[Type]]: "GrowableSharedArrayBuffer", [[ArrayBufferData]]: value.[[ArrayBufferData]], [[ArrayBufferByteLengthData]]: value.[[ArrayBufferByteLengthData]], [[ArrayBufferMaxByteLength]]: value.[[ArrayBufferMaxByteLength]], [[AgentCluster]]: 周囲の エージェントの エージェントクラスター } に設定する。
それ以外の場合、serialized を { [[Type]]: "SharedArrayBuffer", [[ArrayBufferData]]: value.[[ArrayBufferData]], [[ArrayBufferByteLength]]: value.[[ArrayBufferByteLength]], [[AgentCluster]]: 周囲の エージェントの エージェントクラスター } に設定する。
それ以外の場合:
IsDetachedBuffer(value) が true である場合、
"DataCloneError" DOMException
を投げる。
size を value.[[ArrayBufferByteLength]] とする。
dataCopy を ? CreateByteDataBlock(size) とする。
割り当てに失敗した場合、これは RangeError
例外を投げることがある。
CopyDataBlockBytes(dataCopy, 0, value.[[ArrayBufferData]], 0, size) を実行する。
value が [[ArrayBufferMaxByteLength]] 内部スロットを持つ場合、 serialized を { [[Type]]: "ResizableArrayBuffer", [[ArrayBufferData]]: dataCopy, [[ArrayBufferByteLength]]: size, [[ArrayBufferMaxByteLength]]: value.[[ArrayBufferMaxByteLength]] } に設定する。
それ以外の場合、serialized を { [[Type]]: "ArrayBuffer", [[ArrayBufferData]]: dataCopy, [[ArrayBufferByteLength]]: size } に設定する。
それ以外で、value が [[ViewedArrayBuffer]] 内部スロットを持つ場合:
IsArrayBufferViewOutOfBounds(value) が
true である場合、
"DataCloneError" DOMException
を投げる。
buffer を、value の [[ViewedArrayBuffer]] 内部スロットの値とする。
bufferSerialized を ? StructuredSerializeInternal(buffer, forStorage, memory) とする。
表明:bufferSerialized.[[Type]] は "ArrayBuffer"、 "ResizableArrayBuffer"、"SharedArrayBuffer"、または "GrowableSharedArrayBuffer" である。
value が [[DataView]] 内部スロットを持つ場合、 serialized を { [[Type]]: "ArrayBufferView", [[Constructor]]: "DataView", [[ArrayBufferSerialized]]: bufferSerialized, [[ByteLength]]: value.[[ByteLength]], [[ByteOffset]]: value.[[ByteOffset]] } に設定する。
それ以外の場合:
表明:value は [[TypedArrayName]] 内部スロットを持つ。
serialized を { [[Type]]: "ArrayBufferView", [[Constructor]]: value.[[TypedArrayName]], [[ArrayBufferSerialized]]: bufferSerialized, [[ByteLength]]: value.[[ByteLength]], [[ByteOffset]]: value.[[ByteOffset]], [[ArrayLength]]: value.[[ArrayLength]] } に設定する。
それ以外で、value が [[MapData]] 内部スロットを持つ場合:
serialized を { [[Type]]: "Map", [[MapData]]: 新しい空の List } に設定する。
deep を true に設定する。
それ以外で、value が [[SetData]] 内部スロットを持つ場合:
serialized を { [[Type]]: "Set", [[SetData]]: 新しい空の List } に設定する。
deep を true に設定する。
それ以外で、value が [[ErrorData]] 内部スロットを持ち、かつ value が プラットフォーム オブジェクトでない場合:
name を ? Get(value, "name") とする。
name が "Error"、"EvalError"、"RangeError"、"ReferenceError"、 "SyntaxError"、"TypeError"、または "URIError" のいずれでもない場合、 name を "Error" に設定する。
valueMessageDesc を ?
value.[[GetOwnProperty]]("message") とする。
IsDataDescriptor(valueMessageDesc) が false の場合、 message を undefined とし、それ以外の場合は ? ToString(valueMessageDesc.[[Value]]) とする。
stack を、value.[[Stack]] を表す 実装定義の文字列とする。 [JSERRORSTACKACCESSOR] [JSERRORSTACKS]
serialized を { [[Type]]: "Error", [[Name]]: name, [[Message]]: message, [[Stack]]: stack } に設定する。
ユーザーエージェントは、まだ規定されていない重要な付随データがある場合、 そのシリアライズ済み表現を serialized に付加するべきである。
それ以外で、value が Array エキゾチックオブジェクトである場合:
valueLenDescriptor を ?
OrdinaryGetOwnProperty(value,
"length") とする。
valueLen を valueLenDescriptor.[[Value]] とする。
serialized を { [[Type]]: "Array", [[Length]]: valueLen, [[Properties]]: 新しい空の List } に設定する。
deep を true に設定する。
それ以外で、value が プラットフォーム オブジェクトであり、かつ シリアライズ可能なオブジェクトである場合:
value が、値が true である
[[Detached]]
内部スロットを持つ場合、
"DataCloneError" DOMException
を投げる。
typeString を、value の 主要 インターフェイスの識別子とする。
serialized を { [[Type]]: typeString } に設定する。
deep を true に設定する。
それ以外で、value が
プラットフォーム
オブジェクトである場合、
"DataCloneError" DOMException
を投げる。
それ以外で、
IsCallable(value) が true である場合、
"DataCloneError" DOMException
を投げる。
それ以外で、value が [[Prototype]]、[[Extensible]]、または
[[PrivateElements]] 以外の内部スロットを持つ場合、
"DataCloneError"
DOMException
を投げる。
例えば、[[PromiseState]] または [[WeakMapData]] 内部スロット。
それ以外で、value がエキゾチックオブジェクトであり、かつ
value が、いずれかの
レルムに関連付けられた
%Object.prototype% 組み込みオブジェクトでない場合、
"DataCloneError" DOMException
を投げる。
例えば、プロキシオブジェクト。
それ以外の場合:
serialized を { [[Type]]: "Object", [[Properties]]: 新しい空の List } に設定する。
deep を true に設定する。
%Object.prototype% は、この手順および後続の手順によって 処理されることになる。最終的に、そのエキゾチック性は無視され、デシリアライズ後の結果は 空のオブジェクトとなる( 不変プロトタイプエキゾチックオブジェクトではない)。
memory[value] を serialized に 設定する。
deep が true である場合:
value が [[MapData]] 内部スロットを持つ場合:
copiedList を新しい空の Listとする。
value.[[MapData]] の Record { [[Key]], [[Value]] } entry ごとに:
copiedList の Record { [[Key]], [[Value]] } entry ごとに:
serializedKey を ? StructuredSerializeInternal(entry.[[Key]], forStorage, memory) とする。
serializedValue を ? StructuredSerializeInternal(entry.[[Value]], forStorage, memory) とする。
{ [[Key]]: serializedKey, [[Value]]: serializedValue } を serialized.[[MapData]] に 付加する。
それ以外で、value が [[SetData]] 内部スロットを持つ場合:
それ以外で、value が プラットフォーム オブジェクトであり、かつ シリアライズ可能なオブジェクトである場合、 value、serialized、および forStorage を指定して、 value の 主要 インターフェイスの シリアライズ 手順を実行する。
シリアライズ 手順では、 サブシリアライズを実行する必要がある場合がある。 これは値 subValue を入力として受け取り、 StructuredSerializeInternal(subValue, forStorage, memory) を返す操作である。 (言い換えると、 サブシリアライズは、この呼び出し内で 一貫するように特殊化された StructuredSerializeInternalである。)
それ以外の場合、! EnumerableOwnProperties(value, key) 内の 各 key について:
! HasOwnProperty(value, key) が true である場合:
inputValue を ? value.[[Get]](key, value) とする。
outputValue を ? StructuredSerializeInternal(inputValue, forStorage, memory) とする。
{ [[Key]]: key, [[Value]]: outputValue } を serialized.[[Properties]] に 付加する。
serialized を返す。
StructuredSerializeInternal が生成する Recordには、 循環参照を作る別のレコードへの「ポインター」が含まれることがある点を理解することが重要である。 例えば、次の JavaScript オブジェクトを StructuredSerializeInternal に渡す場合:
const o = {};
o. myself = o; 次の結果が生成される:
{
[[Type]]: "Object",
[[Properties]]: «
{
[[Key]]: "myself",
[[Value]]: <この構造全体へのポインター>
}
»
}
? StructuredSerializeInternal(value, false) を返す。
? StructuredSerializeInternal(value, true) を返す。
StructuredDeserialize 抽象演算は、以前に StructuredSerialize または StructuredSerializeForStorage によって生成された Record serialized を入力として受け取り、それを targetRealm 内に作成される 新しい JavaScript 値へデシリアライズする。
この処理は、例えば新しいオブジェクト、特に ArrayBuffer オブジェクトのための
メモリーを割り当てようとした場合に、例外を投げることがある。
memory が指定されていない場合、memory を空の マップとする。
memory マップの目的は、オブジェクトを二重にデシリアライズしないことである。 これにより、グラフ内の循環および重複オブジェクトの同一性が保持される。
memory[serialized] が 存在する場合、 memory[serialized] を返す。
deep を false とする。
value を未初期化の値とする。
serialized.[[Type]] が "primitive" である場合、 value を serialized.[[Value]] に設定する。
それ以外で、serialized.[[Type]] が "Boolean" である場合、 value を、[[BooleanData]] 内部スロットの値が serialized.[[BooleanData]] である、targetRealm 内の新しい Boolean オブジェクトに設定する。
それ以外で、serialized.[[Type]] が "Number" である場合、 value を、[[NumberData]] 内部スロットの値が serialized.[[NumberData]] である、targetRealm 内の新しい Number オブジェクトに設定する。
それ以外で、serialized.[[Type]] が "BigInt" である場合、 value を、[[BigIntData]] 内部スロットの値が serialized.[[BigIntData]] である、targetRealm 内の新しい BigInt オブジェクトに設定する。
それ以外で、serialized.[[Type]] が "String" である場合、 value を、[[StringData]] 内部スロットの値が serialized.[[StringData]] である、targetRealm 内の新しい String オブジェクトに設定する。
それ以外で、serialized.[[Type]] が "Date" である場合、 value を、[[DateValue]] 内部スロットの値が serialized.[[DateValue]] である、targetRealm 内の新しい Date オブジェクトに設定する。
それ以外で、serialized.[[Type]] が "RegExp" である場合、 value を、[[RegExpMatcher]] 内部スロットの値が serialized.[[RegExpMatcher]]、[[OriginalSource]] 内部スロットの値が serialized.[[OriginalSource]]、[[OriginalFlags]] 内部スロットの値が serialized.[[OriginalFlags]] である、targetRealm 内の新しい RegExp オブジェクトに設定する。
それ以外で、serialized.[[Type]] が "SharedArrayBuffer" である場合:
targetRealm に対応する
エージェントクラスターが
serialized.[[AgentCluster]] でない場合、
"DataCloneError" DOMException
を投げる。
それ以外の場合、value を、[[ArrayBufferData]] 内部スロットの値が serialized.[[ArrayBufferData]] であり、[[ArrayBufferByteLength]] 内部スロットの値が serialized.[[ArrayBufferByteLength]] である、 targetRealm 内の新しい SharedArrayBuffer オブジェクトに設定する。
それ以外で、serialized.[[Type]] が "GrowableSharedArrayBuffer" である場合:
targetRealm に対応する
エージェントクラスターが
serialized.[[AgentCluster]] でない場合、
"DataCloneError" DOMException
を投げる。
それ以外の場合、value を、[[ArrayBufferData]] 内部スロットの値が serialized.[[ArrayBufferData]]、[[ArrayBufferByteLengthData]] 内部スロットの値が serialized.[[ArrayBufferByteLengthData]]、 [[ArrayBufferMaxByteLength]] 内部スロットの値が serialized.[[ArrayBufferMaxByteLength]] である、 targetRealm 内の新しい SharedArrayBuffer オブジェクトに設定する。
それ以外で、serialized.[[Type]] が "ArrayBuffer" である場合、 value を、[[ArrayBufferData]] 内部スロットの値が serialized.[[ArrayBufferData]] であり、[[ArrayBufferByteLength]] 内部スロットの値が serialized.[[ArrayBufferByteLength]] である、 targetRealm 内の新しい ArrayBuffer オブジェクトに設定する。
これが例外を投げる場合、その例外を捕捉し、
"DataCloneError" DOMException
を投げる。
この手順は、そのような ArrayBuffer オブジェクトを作成するために利用可能な メモリーが十分にない場合、例外を投げることがある。
それ以外で、serialized.[[Type]] が "ResizableArrayBuffer" である場合、 value を、[[ArrayBufferData]] 内部スロットの値が serialized.[[ArrayBufferData]]、[[ArrayBufferByteLength]] 内部スロットの値が serialized.[[ArrayBufferByteLength]]、 [[ArrayBufferMaxByteLength]] 内部スロットの値が serialized.[[ArrayBufferMaxByteLength]] である、 targetRealm 内の新しい ArrayBuffer オブジェクトに設定する。
これが例外を投げる場合、その例外を捕捉し、
"DataCloneError" DOMException
を投げる。
この手順は、そのような ArrayBuffer オブジェクトを作成するために利用可能な メモリーが十分にない場合、例外を投げることがある。
それ以外で、serialized.[[Type]] が "ArrayBufferView" である場合:
deserializedArrayBuffer を ? StructuredDeserialize(serialized.[[ArrayBufferSerialized]], targetRealm, memory) とする。
serialized.[[Constructor]] が "DataView" である場合、 value を、[[ViewedArrayBuffer]] 内部スロットの値が deserializedArrayBuffer、[[ByteLength]] 内部スロットの値が serialized.[[ByteLength]]、[[ByteOffset]] 内部スロットの値が serialized.[[ByteOffset]] である、targetRealm 内の新しい DataView オブジェクトに設定する。
それ以外の場合、value を、serialized.[[Constructor]] によって 指定されたコンストラクターを使用する、targetRealm 内の新しい型付き配列 オブジェクトに設定する。その [[ViewedArrayBuffer]] 内部スロットの値は deserializedArrayBuffer、[[TypedArrayName]] 内部スロットの値は serialized.[[Constructor]]、[[ByteLength]] 内部スロットの値は serialized.[[ByteLength]]、[[ByteOffset]] 内部スロットの値は serialized.[[ByteOffset]]、[[ArrayLength]] 内部スロットの値は serialized.[[ArrayLength]] である。
それ以外で、serialized.[[Type]] が "Map" である場合:
value を、[[MapData]] 内部スロットの値が新しい空の Listである、 targetRealm 内の新しい Map オブジェクトに設定する。
deep を true に設定する。
それ以外で、serialized.[[Type]] が "Set" である場合:
value を、[[SetData]] 内部スロットの値が新しい空の Listである、 targetRealm 内の新しい Set オブジェクトに設定する。
deep を true に設定する。
それ以外で、serialized.[[Type]] が "Array" である場合:
outputProto を targetRealm.[[Intrinsics]].[[%Array.prototype%]] とする。
value を ! ArrayCreate(serialized.[[Length]], outputProto) に設定する。
deep を true に設定する。
それ以外で、serialized.[[Type]] が "Object" である場合:
value を targetRealm 内の新しい Object に設定する。
deep を true に設定する。
それ以外で、serialized.[[Type]] が "Error" である場合:
prototype を %Error.prototype% とする。
serialized.[[Name]] が "EvalError" である場合、 prototype を %EvalError.prototype% に設定する。
serialized.[[Name]] が "RangeError" である場合、 prototype を %RangeError.prototype% に設定する。
serialized.[[Name]] が "ReferenceError" である場合、 prototype を %ReferenceError.prototype% に設定する。
serialized.[[Name]] が "SyntaxError" である場合、 prototype を %SyntaxError.prototype% に設定する。
serialized.[[Name]] が "TypeError" である場合、 prototype を %TypeError.prototype% に設定する。
serialized.[[Name]] が "URIError" である場合、 prototype を %URIError.prototype% に設定する。
message を serialized.[[Message]] とする。
value を OrdinaryObjectCreate(prototype, « [[ErrorData]], [[Stack]] ») に設定する。
messageDesc を PropertyDescriptor { [[Value]]: message, [[Writable]]: true, [[Enumerable]]: false, [[Configurable]]: true } とする。
message が undefined でない場合、!
OrdinaryDefineOwnProperty(value,
"message",
messageDesc) を実行する。
value.[[Stack]] を serialized.[[Stack]] に設定する。
serialized に付加された重要な付随データがある場合、 それをデシリアライズして value に付加するべきである。
それ以外の場合:
interfaceName を serialized.[[Type]] とする。
interfaceName によって識別されるインターフェイスが
targetRealm で
公開されていない場合、
"DataCloneError" DOMException
を投げる。
value を、targetRealm 内に作成された、 interfaceName によって識別されるインターフェイスの新しいインスタンスに設定する。
deep を true に設定する。
memory[serialized] を value に 設定する。
deep が true である場合:
serialized.[[Type]] が "Map" である場合:
serialized.[[MapData]] の Record { [[Key]], [[Value]] } entry ごとに:
deserializedKey を ? StructuredDeserialize(entry.[[Key]], targetRealm, memory) とする。
deserializedValue を ? StructuredDeserialize(entry.[[Value]], targetRealm, memory) とする。
{ [[Key]]: deserializedKey, [[Value]]: deserializedValue } を value.[[MapData]] に 付加する。
それ以外で、serialized.[[Type]] が "Set" である場合:
serialized.[[SetData]] の各 entry について 反復する:
deserializedEntry を ? StructuredDeserialize(entry, targetRealm, memory) とする。
deserializedEntry を value.[[SetData]] に 付加する。
それ以外で、serialized.[[Type]] が "Array" または "Object" である場合:
serialized.[[Properties]] の Record { [[Key]], [[Value]] } entry ごとに:
deserializedValue を ? StructuredDeserialize(entry.[[Value]], targetRealm, memory) とする。
result を ! CreateDataProperty(value, entry.[[Key]], deserializedValue) とする。
表明:result は true である。
それ以外の場合:
serialized、value、および targetRealm を指定して、serialized.[[Type]] によって識別される インターフェイスの適切な デシリアライズ手順を実行する。
デシリアライズ手順では、 サブデシリアライズを実行する必要がある場合がある。 これは、以前にシリアライズされた Record subSerialized を入力として受け取り、 StructuredDeserialize(subSerialized, targetRealm, memory) を返す操作である。 (言い換えると、 サブデシリアライズは、この呼び出し内で 一貫するように特殊化された StructuredDeserializeである。)
value を返す。
memory を空の マップとする。
StructuredSerializeInternal による 通常の使用方法に加えて、このアルゴリズムでは memory は、 StructuredSerializeInternal が transferList 内の項目を無視し、 代わりにここで独自に処理できるようにするためにも使用される。
各 transferList の transferable について:
transferable が [[ArrayBufferData]] 内部スロットも
[[Detached]] 内部スロットも
持たない場合、
"DataCloneError" DOMException
を投げる。
transferable が [[ArrayBufferData]] 内部スロットを持ち、
IsSharedArrayBuffer(transferable) が true である場合、
"DataCloneError" DOMException
を投げる。
memory[transferable] が 存在する場合、
"DataCloneError" DOMException
を投げる。
設定する memory[transferable] を { [[Type]]: 未初期化の値 } に。
転送には副作用があり、 StructuredSerializeInternal が 先に例外を投げられる必要があるため、transferable はまだ転送されない。
serialized を ? StructuredSerializeInternal(value, false, memory) とする。
transferDataHolders を新しい空の List とする。
各 transferList の transferable について:
transferable が [[ArrayBufferData]] 内部スロットを持ち、
IsDetachedBuffer(transferable) が true である場合、
"DataCloneError" DOMException
を投げる。
transferable が [[Detached]] 内部スロットを持ち、
transferable.[[Detached]] が true である場合、
"DataCloneError" DOMException
を投げる。
dataHolder を memory[transferable] とする。
transferable が [[ArrayBufferData]] 内部スロットを持つ場合:
transferable が [[ArrayBufferMaxByteLength]] 内部スロットを持つ場合:
dataHolder.[[Type]] を "ResizableArrayBuffer" に設定する。
dataHolder.[[ArrayBufferData]] を transferable.[[ArrayBufferData]] に設定する。
dataHolder.[[ArrayBufferByteLength]] を transferable.[[ArrayBufferByteLength]] に設定する。
dataHolder.[[ArrayBufferMaxByteLength]] を transferable.[[ArrayBufferMaxByteLength]] に設定する。
それ以外の場合:
dataHolder.[[Type]] を "ArrayBuffer" に設定する。
dataHolder.[[ArrayBufferData]] を transferable.[[ArrayBufferData]] に設定する。
dataHolder.[[ArrayBufferByteLength]] を transferable.[[ArrayBufferByteLength]] に設定する。
? DetachArrayBuffer(transferable) を実行する。
仕様は、[[ArrayBufferDetachKey]] 内部スロットを使用して
ArrayBuffer
が
切り離されるのを防ぐことができる。これは、例えば
WebAssembly JavaScript Interface で使用されている。[WASMJS]
それ以外の場合:
表明:transferable は プラットフォームオブジェクトであり、 転送可能なオブジェクトである。
interfaceName を、transferable の 主要インターフェイスの識別子とする。
dataHolder.[[Type]] を interfaceName に設定する。
transferable および dataHolder を指定して、 interfaceName によって識別されるインターフェイスの適切な 転送手順を実行する。
transferable.[[Detached]] を true に設定する。
付加する dataHolder を transferDataHolders に。
{ [[Serialized]]: serialized, [[TransferDataHolders]]: transferDataHolders } を返す。
memory を空の マップとする。
StructuredSerializeWithTransfer と同様に、 StructuredDeserialize による通常の 使用方法に加えて、このアルゴリズムでは memory は、 StructuredDeserialize が serializeWithTransferResult.[[TransferDataHolders]] 内の項目を無視し、 代わりにここで独自に処理できるようにするためにも使用される。
transferredValues を新しい空の List とする。
各 serializeWithTransferResult.[[TransferDataHolders]] の transferDataHolder について:
value を未初期化の値とする。
transferDataHolder.[[Type]] が "ArrayBuffer" である場合、value を、 [[ArrayBufferData]] 内部スロットの値が transferDataHolder.[[ArrayBufferData]] であり、[[ArrayBufferByteLength]] 内部スロットの値が transferDataHolder.[[ArrayBufferByteLength]] である、 targetRealm 内の新しい ArrayBuffer オブジェクトに設定する。
[[ArrayBufferData]] が占有していた元のメモリーにデシリアライズ中も アクセスできる場合、この手順が例外を投げる可能性は低い。新しいメモリーを割り当てる必要はなく、 [[ArrayBufferData]] が占有するメモリーが新しい ArrayBuffer へ単に転送されるためである。 例えば、ソースレルムとターゲットレルムの両方が同じプロセス内にある場合が該当し得る。
それ以外で、transferDataHolder.[[Type]] が "ResizableArrayBuffer" である場合、 value を、targetRealm 内の新しい ArrayBuffer オブジェクトに設定する。その [[ArrayBufferData]] 内部スロットの値は transferDataHolder.[[ArrayBufferData]]、 [[ArrayBufferByteLength]] 内部スロットの値は transferDataHolder.[[ArrayBufferByteLength]]、さらに [[ArrayBufferMaxByteLength]] 内部スロットの値は transferDataHolder.[[ArrayBufferMaxByteLength]] である。
前の手順と同じ理由により、この手順も例外を投げる可能性は低い。
それ以外の場合:
interfaceName を transferDataHolder.[[Type]] とする。
interfaceName によって識別されるインターフェイスが
targetRealm で公開されていない場合、"DataCloneError"
DOMException
を投げる。
value を、targetRealm 内に作成された、 interfaceName によって識別されるインターフェイスの新しいインスタンスに設定する。
transferDataHolder および value を指定して、 interfaceName によって識別されるインターフェイスの適切な 転送受信手順を実行する。
設定する memory[transferDataHolder] を value に。
付加する value を transferredValues に。
deserialized を ? StructuredDeserialize(serializeWithTransferResult.[[Serialized]], targetRealm, memory) とする。
{ [[Deserialized]]: deserialized, [[TransferredValues]]: transferredValues } を返す。
他の仕様は、ここで定義されている抽象操作を使用できる。以下では、 各抽象操作が通常どのような場合に有用であるかについて、例とともにいくつかの指針を示す。
転送リストを使用して値を別のレルムにクローンするが、 ターゲット レルムが事前には分からない場合。この場合、シリアライズ手順は直ちに実行でき、 デシリアライズ手順はターゲットレルムが判明するまで遅延できる。
messagePort.postMessage()
は、この一対の抽象操作を使用する。これは、宛先レルムが、
MessagePort
が移送
されるまで判明しないためである。
指定された値について、レルムに依存しないスナップショットを 作成し、それを無期限に保存した後、 後で JavaScript 値として、場合によっては 複数回実体化する場合。
StructuredSerializeForStorage
は、シリアライズ結果をレルム間で渡すのではなく、
永続的な方法で保存することが想定される場合に使用できる。共有メモリーを保存することには
意味がないため、SharedArrayBuffer
オブジェクトをシリアライズしようとすると例外を投げる。同様に、
独自のシリアライズ手順を持つ
プラットフォーム
オブジェクトが指定され、
forStorage 引数が true である場合、例外を投げたり、異なる動作をしたりする可能性がある。
history.pushState()
および history.replaceState()
は、
StructuredSerializeForStorage
を作者によって提供された状態オブジェクトに使用し、それらを適切な
シリアライズ済み状態として、
セッション履歴エントリーに保存する。
その後、
StructuredDeserialize
が使用され、history.state
プロパティが、最初に提供された状態オブジェクトの
クローンを返せるようにする。
broadcastChannel.postMessage()
は、
StructuredSerialize を
その入力に使用し、その結果に対して StructuredDeserialize
を複数回使用して、ブロードキャスト先ごとに新しいクローンを生成する。
複数の宛先がある場合、転送は意味をなさないことに注意する。
JavaScript 値をファイルシステムに永続化する API も、 StructuredSerializeForStorage をその入力に使用し、StructuredDeserialize をその出力に使用する。
一般に、呼び出し箇所は JavaScript 値の代わりに Web IDL 値を渡すことができる。これは、 これらのアルゴリズムを呼び出す前に JavaScript 値への暗黙的な変換を 実行するものと理解される。
作者コードがユーザーエージェントのメソッドを同期的に呼び出した結果として呼び出されるのではない 呼び出し箇所は、任意のオブジェクトに対してこれらを実行する場合、スクリプトを実行する準備を行い、コールバックを 実行する準備を行ってから、StructuredSerialize、 StructuredSerializeForStorage、 または StructuredSerializeWithTransfer 抽象操作を呼び出すよう注意しなければならない。これは、 シリアライズ処理が最終的なディープシリアライズ手順の一部として作者定義のアクセサーを呼び出す可能性があり、 これらのアクセサーが、エントリーおよびインカンベントの概念が 適切に設定されていることに依存する操作を呼び出す可能性があるため、必要となる。
window.postMessage()
は、その引数に
StructuredSerializeWithTransfer
を実行するが、アルゴリズムの同期部分の内部で
直ちに実行するよう注意している。したがって、
スクリプトを実行する準備を行うことや、
コールバックを実行する
準備を行うことなく、このアルゴリズムを使用できる。
対照的に、作者によって提供されたオブジェクトを定期的にシリアライズするために、StructuredSerialize を 使用し、イベントループ上のタスクから直接実行する仮想的な API は、 事前に適切な準備を行うことを 保証する必要がある。現時点では、プラットフォーム上にそのような API は存在しないと認識している。 通常は、作者コードの同期的な結果として、あらかじめシリアライズを実行する方が簡単である。
result = self.structuredClone(value[, { transfer }])
入力値を受け取り、構造化クローンアルゴリズムを実行してディープコピーを返す。
転送可能なオブジェクトとして
transfer
配列に列挙されたものは、単に
クローンされるのではなく転送される。これは、それらが入力値では使用できなくなることを意味する。
入力値のいずれかの部分が
シリアライズ可能でない場合、"DataCloneError" DOMException
を投げる。
現在のすべてのエンジンでサポートされている。
structuredClone(value,
options) メソッドの手順は次のとおりである:
serialized を ?
StructuredSerializeWithTransfer(value,
options["transfer"])
とする。
deserializeRecord を ? StructuredDeserializeWithTransfer(serialized, this の 関連レルム) とする。
deserializeRecord.[[Deserialized]] を返す。
HTML UA 内のすべての XML および HTML 文書は、Document
オブジェクトによって表される。
[DOM]
Document オブジェクトの URL は、
DOM で
定義されている。これは、Document オブジェクトの作成時に最初に設定されるが、
Document オブジェクトの存続期間中に
変更される可能性がある。例えば、
ユーザーがページ上のフラグメントへナビゲートしたとき、および pushState() メソッドが
新しい URL を指定して
呼び出されたときに変更される。[DOM]
対話型ユーザーエージェントは通常、そのユーザーインターフェイスに Document オブジェクトの
URL を公開する。これは、サイトが別のサイトになりすまそうとしているかどうかを
ユーザーが判断するための主要な仕組みである。
Document オブジェクトの オリジンは、
DOM で
定義されている。これは、Document オブジェクトの作成時に最初に設定され、
document.domain を設定した場合にのみ、
Document の存続期間中に変更される可能性がある。Document のオリジンは、その オリジンと、その URL のものとで異なる場合がある。
例えば、子ナビゲーション可能が作成されると、そのアクティブ文書のオリジンは、その親のアクティブ文書の
オリジンから継承される。ただし、そのアクティブ文書の URL は
about:blank である。[DOM]
Document が、スクリプトによって
createDocument()
または createHTMLDocument()
メソッドを使用して作成された場合、その
Document は直ちに読み込み後タスクの準備が整う。
文書のリファラーは、Document の作成時に設定できる文字列(URL を表す)である。明示的に
設定されていない場合、その値は
空文字列である。
Document オブジェクト現在のすべてのエンジンでサポートされている。
DOM は Document
インターフェイスを定義しており、
この仕様はそれを大幅に拡張する。
enum DocumentReadyState { "loading" , "interactive" , "complete" };
enum DocumentVisibilityState { "visible" , "hidden" };
typedef (HTMLScriptElement or SVGScriptElement ) HTMLOrSVGScriptElement ;
[LegacyOverrideBuiltIns ]
partial interface Document {
static Document parseHTMLUnsafe ((TrustedHTML or DOMString ) html , optional ParseHTMLUnsafeOptions options = {});
static Document parseHTML (DOMString html , optional SetHTMLOptions options = {});
// resource metadata management
[PutForwards =href , LegacyUnforgeable ] readonly attribute Location ? location ;
attribute USVString domain ;
readonly attribute USVString referrer ;
attribute USVString cookie ;
readonly attribute DOMString lastModified ;
readonly attribute DocumentReadyState readyState ;
// DOM tree accessors
getter object (DOMString name );
[CEReactions ] attribute DOMString title ;
[CEReactions ] attribute DOMString dir ;
[CEReactions ] attribute HTMLElement ? body ;
readonly attribute HTMLHeadElement ? head ;
[SameObject ] readonly attribute HTMLCollection images ;
[SameObject ] readonly attribute HTMLCollection embeds ;
[SameObject ] readonly attribute HTMLCollection plugins ;
[SameObject ] readonly attribute HTMLCollection links ;
[SameObject ] readonly attribute HTMLCollection forms ;
[SameObject ] readonly attribute HTMLCollection scripts ;
NodeList getElementsByName (DOMString elementName );
readonly attribute HTMLOrSVGScriptElement ? currentScript ; // classic scripts in a document tree only
// dynamic markup insertion
[CEReactions ] Document open (optional DOMString unused1 , optional DOMString unused2 ); // both arguments are ignored
WindowProxy ? open (USVString url , DOMString name , DOMString features );
[CEReactions ] undefined close ();
[CEReactions ] undefined write ((TrustedHTML or DOMString )... text );
[CEReactions ] undefined writeln ((TrustedHTML or DOMString )... text );
// user interaction
readonly attribute WindowProxy ? defaultView ;
boolean hasFocus ();
[CEReactions ] attribute DOMString designMode ;
[CEReactions ] boolean execCommand (DOMString commandId , optional boolean showUI = false , optional DOMString value = "");
boolean queryCommandEnabled (DOMString commandId );
boolean queryCommandIndeterm (DOMString commandId );
boolean queryCommandState (DOMString commandId );
boolean queryCommandSupported (DOMString commandId );
DOMString queryCommandValue (DOMString commandId );
readonly attribute boolean hidden ;
readonly attribute DocumentVisibilityState visibilityState ;
// special event handler IDL attributes that only apply to Document objects
[LegacyLenientThis ] attribute EventHandler onreadystatechange ;
attribute EventHandler onvisibilitychange ;
// also has obsolete members
};
Document includes GlobalEventHandlers ;各 Document は ポリシーコンテナー(ポリシーコンテナー)を持つ。これは最初、新しいポリシー
コンテナーであり、Document に適用されるポリシーを含む。
各 Document は 権限ポリシーを持つ。これは
権限
ポリシーであり、最初は
空である。
各 Document は モジュールマップを持つ。
これは モジュールマップであり、最初は空である。
各 Document は オープナーポリシーを持つ。
これは オープナー
ポリシーであり、最初は新しいオープナーポリシーである。
各 Document は 初期 about:blank であるかを持つ。これは
ブール値であり、最初は false である。
各 Document は WebDriver BiDi 用の読み込み中
ナビゲーション ID を持つ。これは ナビゲーション ID または null
であり、最初は
null である。
その名前が示すとおり、これは WebDriver
BiDi 仕様とのインターフェイスに使用される。この仕様は、Document の
ライフサイクル初期に発生する特定の事象について、
この Document を作成したナビゲーションが
進行中のナビゲーションであったときに使用された元の
ナビゲーション IDと関連付ける形で
通知される必要がある。最終的に、WebDriver
BiDi が読み込み処理の完了を認識した後、これは再び null に設定される。[BIDI]
各 Document は about ベース
URL を持つ。これは URL または null であり、最初は null である。
これは、スキームが "about:" である
Document に対してのみ設定される。
各 Document は bfcache ブロック詳細を持つ。これは、
集合であり、
復元されなかった理由の詳細を含み、
最初は空である。
各 Document は 開いているダイアログのリストを持つ。これは、
dialog 要素の
リストであり、
最初は空である。
DocumentOrShadowRoot
インターフェイスDOM は DocumentOrShadowRoot
ミックスインを定義しており、この仕様は
それを拡張する。
partial interface mixin DocumentOrShadowRoot {
readonly attribute Element ? activeElement ;
};Document オブジェクトは、関連付けられた 内部
祖先オリジンオブジェクト
リストを持ち、最初は null である。
Document オブジェクト
document と リファラーポリシー
referrerPolicy が指定されたときの、内部祖先オリジンオブジェクトリスト作成
手順は次のとおりである:
output を « » とする。
parentDoc を document のコンテナー文書とする。
parentDoc が null である場合、output を返す。
ancestorOrigins を parentDoc の内部祖先オリジンオブジェクト リストとする。
container を document のノードナビゲーション可能のコンテナーとする。
masked を false とする。
referrerPolicy が "no-referrer" である場合、
masked を true に設定する。
それ以外で、referrerPolicy が "same-origin" であり、
parentDoc のオリジンが
document のオリジンと同一
オリジンでない場合、
masked を true に設定する。
混合
コンテンツの検査により、セキュアコンテキストの環境内にある非セキュア
コンテキストの
環境が防止されるため、
"strict-origin"、"strict-origin-when-cross-origin"、
"no-referrer-when-downgrade" についてセキュアコンテキストを検査する必要はない。また、
ここで公開されるのは最大でもオリジンであるため、
"origin" および "origin-when-cross-origin" の値も特別に扱う必要はない。
各 ancestorOrigins の ancestorOrigin について:
masked が true であり、ancestorOrigin が parentDoc のオリジンと同一オリジン である場合、新しい不透明 オリジンを output に付加し、続行する。
ancestorOrigin を output に付加し、 masked を false に設定する。
ここで masked を false に設定しても、それ以降の すべての祖先のオリジンが必ず公開されることを意味するわけではない。それらは、祖先文書が これらの手順を実行した際に既にマスクされている可能性があり、その結果のリストは 子文書が作成されるときの開始点として使用される(上記の手順 5 を参照)。
output を返す。
Document オブジェクトは、関連付けられた 祖先オリジンリストを持ち、
最初は null である。
Document オブジェクト
document が指定されたときの、祖先オリジンリスト作成手順は
次のとおりである:
ancestorOrigins を document の内部祖先オリジンオブジェクト リストとする。
表明:ancestorOrigins は null ではない。
output を « » とする。
各 ancestorOrigins の origin について:
関連付けられたリストが
output である、新しい DOMStringList
オブジェクトを返す。
URL が https://a.example/top であるトップレベル
閲覧コンテキスト文書について考える:
<!doctype html>
< title > top</ title >
< iframe referrerpolicy = "no-referrer" src = "https://a.example/child" ></ iframe > 子文書:
<!doctype html>
< title > child</ title >
< iframe src = "https://b.example/grandchild" ></ iframe >
< script >
console. log([... location. ancestorOrigins]);
</ script > 孫文書:
<!doctype html>
< title > grandchild</ title >
< script >
console. log([... location. ancestorOrigins]);
</ script > 子の Document オブジェクトが
作成されるとき、文書同士が同一オリジンであっても、その親のオリジンは
iframe
要素の referrerpolicy
属性の値が "no-referrer" であるためマスクされる。記録される値は
« "null" » である。
孫の Document オブジェクトが
作成されるとき、子の
Document オブジェクトの内部祖先オリジンオブジェクト
リスト(単一の不透明オリジンを含む)が
開始点として使用され、子のオリジンが
リストに追加される。したがって、記録される値は « "https://a.example",
"null" » である。
前の例において、トップ
文書内の iframe 要素に
referrerpolicy
属性がなく、代わりに子文書内の
iframe 要素が
referrerpolicy="no-referrer" を持つ場合を考える。
この場合、トップ文書のオリジンが、
子の Document オブジェクトの内部祖先オリジンオブジェクト
リストに追加される。記録される値は « "https://a.example" » である。
孫については、子のオリジンが
不透明オリジンとしてマスクされる。
トップ文書のオリジンは、子
文書のオリジンと同一オリジンであるため、それも
マスクされる。したがって、記録される値は
« "null", "null" » である。
この例では、同一オリジンである子孫文書のオリジンがマスクされている場合でも、 その間にクロスオリジン文書が存在するため、トップレベル文書のオリジンはマスクされないことを示す。
URL が https://a.example/top であるトップレベル
< iframe src = "https://b.example/child" ></ iframe > 祖先オリジンリストに 関連付けられたリストは « » である。
URL が https://b.example/child である子
< iframe src = "https://a.example/grandchild" ></ iframe > 祖先オリジンリストに
関連付けられたリストは « "https://a.example" » である。
URL が https://a.example/grandchild である孫
< iframe src = "https://c.example/great-grandchild"
referrerpolicy = "no-referrer" ></ iframe > 祖先オリジンリストに
関連付けられたリストは « "https://b.example", "https://a.example" » である。
URL が https://c.example/great-grandchild であるひ孫
祖先オリジンリストに
関連付けられたリストは « "null", "https://b.example",
"https://a.example" » である。トップレベルのオリジンはマスクされない。
前の例において、トップレベル文書の iframe も
referrerpolicy="no-referrer" を持つ場合、各文書について結果として得られる祖先オリジンリストに関連付けられたリストは
次のようになる:
トップレベル:« »
子:« "null" »
孫:« "https://b.example", "null"
»
ひ孫:« "null", "https://b.example", "null" »。トップレベルの
オリジンは、子文書が内部祖先オリジン
オブジェクトリスト作成手順を実行したときにマスクされ、その結果が孫文書の
内部祖先オリジン
オブジェクトリスト作成手順へ渡され、以降も同様に渡されるため、マスクされる。
document.referrer
現在のすべてのエンジンでサポートされている。
ユーザーが現在の文書へナビゲートする前にいた Document
の URL を
返す。ただし、それがブロックされた場合、またはそのような文書が存在しなかった場合は、
空文字列を返す。
noreferrer
リンク型を使用して、リファラーを
ブロックできる。
referrer
属性は、文書のリファラーを返さなければならない。
document.cookie [ = value ]
Document に適用される HTTP Cookie を
返す。Cookie が存在しない場合、または
このリソースに Cookie を適用できない場合は、空文字列を返す。
設定することで、要素の HTTP Cookie の集合に新しい Cookie を追加できる。
内容が不透明オリジンへ
サンドボックス化されている場合(例えば、iframe の
sandbox
属性による場合)、取得時および設定時に
"SecurityError" DOMException
が投げられる。
現在のすべてのエンジンでサポートされている。
cookie
属性は、文書の URL
によって識別されるリソースの Cookie を表す。
同期的な document.cookie
API の使用は、パフォーマンス上の問題の原因となる可能性がある。代わりに Cookie Store API を使用できる。
これは、パフォーマンス上の問題を回避するため、Cookie を非同期に処理する方法を提供する。詳細については、
Cookie Store API の概要を参照すること。
[COOKIESTORE]
次のいずれかの条件に該当する Document
オブジェクトは、
Cookie 非対応 Document オブジェクトである:
![]() 取得時に、文書が Cookie 非対応
取得時に、文書が Cookie 非対応 Document
オブジェクトである場合、
ユーザーエージェントは空文字列を返さなければならない。それ以外で、Document の オリジン
が不透明
オリジンである場合、ユーザーエージェントは "SecurityError"
DOMException
を投げなければならない。それ以外の場合、ユーザーエージェントは文書の URL に対する
「非 HTTP」API 用の Cookie 文字列を、
BOM
なし UTF-8 デコードを使用してデコードして返さなければならない。
[COOKIES]
設定時に、文書が Cookie 非対応 Document
オブジェクトである場合、
ユーザーエージェントは何もしてはならない。それ以外で、Document の オリジン
が不透明
オリジンである場合、ユーザーエージェントは "SecurityError"
DOMException
を投げなければならない。それ以外の場合、ユーザーエージェントは、文書の
URL に対して
「非 HTTP」API を介してSet-Cookie 文字列を受信した場合と同様に動作しなければならない。
その文字列は、新しい値を
UTF-8 としてエンコードしたものからなる。
[COOKIES] [ENCODING]
cookie 属性は
フレーム間でアクセス可能であるため、Cookie のパス制限は、どの Cookie をサイトのどの部分へ
送信するかを管理するための補助にすぎず、いかなる意味でもセキュリティ機能ではない。
cookie
属性のゲッターと
セッターは、共有状態へ同期的にアクセスする。ロック機構が存在しないため、マルチプロセスの
ユーザーエージェントでは、スクリプトの実行中に他の閲覧コンテキストが Cookie を変更できる。
例えば、サイトが Cookie を読み取り、その値を増加させ、書き戻し、その Cookie の新しい値を
セッションの一意な識別子として使用しようとする場合がある。サイトがこれを二つの異なる
ブラウザーウィンドウで同時に行うと、両方のセッションに同じ「一意な」識別子を使用してしまい、
壊滅的な影響が生じる可能性がある。
document.lastModified
現在のすべてのエンジンでサポートされている。
サーバーによって報告された文書の最終変更日時を、ユーザーのローカルタイムゾーンにおける
「MM/DD/YYYY hh:mm:ss」形式で返す。
最終変更日時が不明な場合は、代わりに現在時刻を返す。
lastModified 属性は、取得時に、
Document のソースファイルの
最終変更日時を、ユーザーの
ローカルタイムゾーンにおける次の形式で返さなければならない:
日付の月の構成要素。
U+002F SOLIDUS 文字(/)。
日付の日の構成要素。
U+002F SOLIDUS 文字(/)。
日付の年の構成要素。
U+0020 SPACE 文字。
時刻の時の構成要素。
U+003A COLON 文字(:)。
時刻の分の構成要素。
U+003A COLON 文字(:)。
時刻の秒の構成要素。
上記の数値構成要素は、年を除き、十進数で数値を表す二つの ASCII 数字として示し、必要に応じてゼロで埋めなければならない。年は、 十進数で数値を表す四つ以上の ASCII 数字からなる 可能な限り短い文字列として示し、 必要に応じてゼロで埋めなければならない。
Document のソースファイルの
最終変更日時は、使用されるネットワークプロトコルの
関連機能から導出しなければならない。例えば、文書の HTTP `Last-Modified`
ヘッダーの値、またはローカルファイルについては
ファイルシステム内のメタデータから導出する。最終変更日時が不明な場合、属性は
上記の形式で現在の日時を返さなければならない。
document.readyState
Document の読み込み中は
「loading」を、構文解析が完了したがサブリソースを読み込み中の場合は
「interactive」を、読み込みが完了すると
「complete」を返す。
この値が変更されると、Document
オブジェクトで
readystatechange
イベントが発生する。
DOMContentLoaded
イベントは、「interactive」への移行後、「complete」への移行前に、
async
script
要素以外のすべてのサブリソースが読み込まれた時点で発生する。
現在のすべてのエンジンでサポートされている。
各 Document は、
文字列である 現在の文書準備状態を持ち、最初は
「complete」である。
Document オブジェクトを
作成して初期化する
アルゴリズムを介して作成された Document
オブジェクトでは、いかなるスクリプトも document.readyState
の値を観測できるようになる前に、これは直ちに「loading」へリセットされる。
この
既定値は、初期
about:blank Document、または
閲覧コンテキストを
持たない Document
など、その他の場合にも適用される。
Document
document の現在の文書準備状態を更新するには、
それを readinessValue にする:
document の 現在の文書準備状態が readinessValue と等しい場合、戻る。
document の 現在の文書準備状態を readinessValue に設定する。
document が HTML パーサーに関連付けられている場合:
now を、document の 関連グローバルオブジェクトによる 現在の高分解能時刻とする。
readinessValue が「complete」であり、
document の 読み込みタイミング情報の
DOM 完了時刻
が 0 である場合、
document の 読み込みタイミング情報の
DOM 完了
時刻を
now に設定する。
それ以外で、readinessValue が「interactive」であり、
document の 読み込みタイミング情報の
DOM 対話可能
時刻が 0 である場合、
document の 読み込みタイミング情報の
DOM
対話可能
時刻を now に設定する。
document で、readystatechange
という名前のイベントを
発火する。
Document は、
文書読み込み
タイミング情報である 読み込みタイミング情報を持つ。
Document は、
文書
アンロードタイミング情報である 前の
文書のアンロードタイミングを持つ。
Document は、
最初は false であるブール値
クロスオリジンリダイレクトを介して作成されたかを持つ。
DOMHighResTimeStamp
値DOMHighResTimeStamp
値各 Document は、
要素の集合である
レンダリングブロック要素集合を持ち、
最初は空集合である。
Document
document は、次の
両方が true である場合、レンダリングブロック中である:
document の レンダリングブロック要素集合が空でないか、 document がレンダリングブロック要素の 追加を許可する。
document の 関連 グローバルオブジェクトによる現在の高分解能時刻が、 実装定義のタイムアウト値を超えていない。
要素 el は、el の ノード文書 document がレンダリングブロック中であり、かつ el が document の レンダリングブロック要素集合内にある場合、 レンダリングブロック要素である。
要素 el でレンダリングをブロックするには:
document を el のノード文書とする。
document がレンダリングブロック要素の 追加を許可する場合、 el を document の レンダリングブロック要素集合に 付加する。
要素 el でレンダリングのブロックを解除するには:
document を el のノード文書とする。
el を document の レンダリングブロック要素集合から 除去する。
レンダリングブロック要素 el が 閲覧コンテキストから切断された状態になった場合、 または el の blocking 属性の値が変更され、 el がもはや 潜在的な レンダリングブロック要素でなくなった場合、el でレンダリングのブロックを 解除する。
document.head
現在のすべてのエンジンでサポートされている。
head
要素を返す。
document.title [ = value ]
HTML ではtitle
要素によって、
SVG では SVG
title 要素によって指定された文書のタイトルを返す。
文書のタイトルを更新するために設定できる。更新するための適切な要素が存在しない場合、 新しい値は無視される。
現在のすべてのエンジンでサポートされている。
title 属性は、
取得時に次の
アルゴリズムを実行しなければならない:
設定時には、次のリストで最初に一致する条件に対応する手順を 実行しなければならない:
document.body [ = value ]
現在のすべてのエンジンでサポートされている。
body 要素を返す。
body 要素を置換するために設定できる。
新しい値が body 要素または frameset 要素でない場合、
"HierarchyRequestError" DOMException
を投げる。
body
属性は、
取得時に、文書のbody
要素(body
要素、frameset 要素、または null)を返さなければならない。
設定時には、次のアルゴリズムを
実行しなければならない:
body 要素または frameset 要素でない場合、
"HierarchyRequestError" DOMException
を投げる。
HierarchyRequestError" DOMException
を投げる。
body ゲッターによって
返される値は、必ずしもセッターに渡された値ではない。
この例では、セッターは body
要素の挿入に成功する
(ただし、SVG は body を
SVG
svg の子として許可しないため、これは非適合である)。しかし、文書要素が
html でないため、
ゲッターは null を返す。
< svg xmlns = "http://www.w3.org/2000/svg" >
< script >
document. body = document. createElementNS( "http://www.w3.org/1999/xhtml" , "body" );
console. assert( document. body === null );
</ script >
</ svg > document.images
現在のすべてのエンジンでサポートされている。
Document 内の
img 要素からなる
HTMLCollection
を返す。
document.embeds
現在のすべてのエンジンでサポートされている。
document.plugins
現在のすべてのエンジンでサポートされている。
Document 内の
embed 要素からなる
HTMLCollection
を返す。
document.links
現在のすべてのエンジンでサポートされている。
Document 内で
href
属性を持つ a 要素および
area 要素からなる
HTMLCollection
を返す。
document.forms
現在のすべてのエンジンでサポートされている。
Document 内の
form 要素からなる
HTMLCollection
を返す。
document.scripts
現在のすべてのエンジンでサポートされている。
Document 内の
script 要素からなる
HTMLCollection
を返す。
images
属性は、Document ノードを
ルートとし、フィルターが img 要素のみに一致する
HTMLCollection
を返さなければならない。
embeds
属性は、Document ノードを
ルートとし、フィルターが embed
要素のみに一致する
HTMLCollection
を返さなければならない。
plugins
属性は、embeds
属性によって返されるものと
同じオブジェクトを返さなければならない。
links
属性は、Document ノードを
ルートとし、フィルターが href
属性を持つ a
要素、および href
属性を持つ area
要素のみに一致する HTMLCollection
を返さなければならない。
forms
属性は、Document ノードを
ルートとし、フィルターが form
要素のみに一致する
HTMLCollection
を返さなければならない。
scripts
属性は、Document ノードを
ルートとし、フィルターが script
要素のみに一致する
HTMLCollection
を返さなければならない。
collection = document.getElementsByName(name)
現在のすべてのエンジンでサポートされている。
getElementsByName(elementName) メソッドの
手順は、その文書内で、値が elementName 引数と
同一である name 属性を持つすべての
HTML
要素をツリー順で含む、ライブな
NodeList
を返すことである。同じ引数を使用して同じ Document オブジェクトで
メソッドが再度呼び出された場合、ユーザーエージェントは
以前の呼び出しによって返されたオブジェクトと同じものを返してもよい。それ以外の場合、新しい
NodeList
オブジェクトを返さなければならない。
document.currentScript
現在のすべてのエンジンでサポートされている。
現在実行中の要素がクラシックスクリプトを表す場合、その
script
要素、または SVG
script 要素を返す。
再入的なスクリプト実行の場合、まだ実行を完了していないもののうち、最後に実行を開始したものを返す。
Document が現在
script 要素または
SVG
script 要素を実行していない場合(例えば、実行中のスクリプトがイベント
ハンドラーまたはタイムアウトであるため)、あるいは現在実行中の script 要素または
SVG
script 要素がモジュールスクリプトを表す場合、null を返す。
currentScript 属性は、取得時に、
最後に設定された値を返さなければならない。Document
が作成されるとき、currentScript
は null に初期化されなければならない。
この API は、script 要素または
SVG
script 要素をグローバルに公開するため、
実装者および標準化コミュニティでは支持されなくなっている。そのため、
モジュール
スクリプトの実行時、またはシャドウツリー内で
スクリプトを実行する場合など、より新しいコンテキストでは利用できない。現在、そのようなコンテキストで
実行中のスクリプトを、グローバルに利用可能にすることなく識別するための新しい解決策を検討している。
issue #1013 を参照すること。
Document インターフェイスは、
名前付き
プロパティをサポートする。任意の時点における
Document オブジェクト
document のサポート対象プロパティ名は、
それらを提供した要素に従ったツリー順で、後に現れる重複を無視し、
同じ要素が両方を提供する場合には id 属性の値を
name 属性の値より前に置いた、次のものからなる:
空でない name コンテンツ属性を持ち、document を
ルートとする
文書
ツリー内にある、すべての公開状態の
embed、
form、
iframe、
img、および
公開状態の
object 要素の
name コンテンツ属性の値。
空でない id
コンテンツ属性を持ち、document を
ルートとする
文書ツリー内にある、すべての
公開状態の
object 要素の
id
コンテンツ属性の値。および
空でない id
コンテンツ属性と、空でない name コンテンツ属性の両方を持ち、
document を ルートとする
文書
ツリー内にある、すべての
img 要素の
id
コンテンツ属性の値。
Document の
名前付きプロパティ name の値を決定するには、
ユーザーエージェントは次の手順によって得られた値を返さなければならない:
elements を、Document を
ルートとする文書
ツリー内にある、名前 name の名前付き
要素のリストとする。
このアルゴリズムは、それ以外の場合には Web IDL によって呼び出されないため、 そのような要素は少なくとも一つ存在する。
elements が一つの要素のみを持ち、その要素が iframe
要素であり、その iframe
要素の
コンテンツナビゲーション可能が
null でない場合、その要素の
コンテンツナビゲーション可能の
アクティブな WindowProxyを返す。
それ以外で、elements が一つの要素のみを持つ場合、その要素を返す。
それ以外の場合、Document ノードを
ルートとし、フィルターが名前 name の名前付き要素のみに一致する
HTMLCollection
を返す。
上記のアルゴリズムにおいて、名前 name の名前付き要素とは、 次のいずれかである:
embed 要素または
object 要素は、
公開状態の
object 祖先を持たず、
さらに object 要素の場合は、
そのフォールバック
コンテンツを表示していないか、object または
embed の子孫を
持たない場合、公開状態であるという。
Document インターフェイスの
dir
属性は、dir
コンテンツ属性とともに定義される。
HTML の要素、属性、および属性値は、(この仕様によって)特定の意味
(セマンティクス)を持つものとして定義される。例えば、ol
要素は順序付きリストを表し、
lang 属性はコンテンツの言語を表す。
これらの定義により、ウェブブラウザーや検索エンジンなどの HTML 処理系は、 作者が考慮していなかった可能性のある多種多様なコンテキストで、文書およびアプリケーションを 提示して使用できる。
単純な例として、デスクトップコンピューターのウェブブラウザーのみを考慮した作者によって 作成されたウェブページについて考える:
<!DOCTYPE HTML>
< html lang = "en" >
< head >
< title > My Page</ title >
</ head >
< body >
< h1 > Welcome to my page</ h1 >
< p > I like cars and lorries and have a big Jeep!</ p >
< h2 > Where I live</ h2 >
< p > I live in a small hut on a mountain!</ p >
</ body >
</ html > HTML は表示方法ではなく意味を伝えるため、同じページを 携帯電話上の小型ブラウザーでも、ページを変更することなく使用できる。 例えば、デスクトップのように見出しを大きな文字で表示する代わりに、携帯電話上のブラウザーは ページ全体で同じ大きさのテキストを使用し、見出しのみを太字にする可能性がある。
しかし、これは単なる画面サイズの違いにとどまらない。同じページを、 音声合成を中心とするブラウザーを使用する視覚障害のあるユーザーが利用することもできる。 このブラウザーはページを画面に表示する代わりに、例えばヘッドフォンを使用してページを ユーザーに読み上げる。見出しに大きなテキストを使用する代わりに、音声ブラウザーは 異なる音量またはより遅い音声を使用する可能性がある。
それだけではない。ブラウザーはページのどの部分が見出しであるかを認識しているため、 ユーザーが文書内をすばやく移動するために使用できる文書アウトラインを作成できる。 例えば、「次の見出しへ移動」または「前の見出しへ移動」のキーを使用できる。 このような機能は、そうでなければページ内をすばやく移動することが非常に困難な 音声ブラウザーで特に一般的である。
ブラウザー以外でも、ソフトウェアはこの情報を利用できる。検索エンジンは、 見出しを使用してページをより効果的にインデックス化したり、検索結果からページの 小節へのクイックリンクを提供したりできる。ツールは見出しを使用して目次を作成できる (実際に、この仕様の目次もそのように生成される)。
この例では見出しに焦点を当てたが、同じ原則が HTML のすべてのセマンティクスに適用される。
作者は、要素、属性、または属性値を、それらに適した意図されたセマンティックな目的以外に 使用してはならない。そのように使用すると、ソフトウェアがページを正しく処理できなくなるためである。
例えば、企業サイトの見出しを表すことを意図した次の断片は、 2 行目が小節の見出しではなく、単なる副見出しまたはサブタイトル (同じ節に対する従属見出し)を意図しているため、非適合である。
< body >
< h1 > ACME Corporation</ h1 >
< h2 > The leaders in arbitrary fast delivery since 1920</ h2 >
...この種の状況には、hgroup 要素を使用できる:
< body >
< hgroup >
< h1 > ACME Corporation</ h1 >
< p > The leaders in arbitrary fast delivery since 1920</ p >
</ hgroup >
...次の例の文書も、構文的には正しいものの、セルに置かれたデータが明らかに
表形式データではなく、cite
要素が誤用されているため、同様に非適合である:
<!DOCTYPE HTML>
< html lang = "en-GB" >
< head > < title > Demonstration </ title > </ head >
< body >
< table >
< tr > < td > My favourite animal is the cat. </ td > </ tr >
< tr >
< td >
—< a href = "https://example.org/~ernest/" >< cite > Ernest</ cite ></ a > ,
in an essay from 1992
</ td >
</ tr >
</ table >
</ body >
</ html > これにより、これらのセマンティクスに依存するソフトウェアは正しく動作しなくなる。 例えば、視覚障害のあるユーザーが文書内の表を移動できる音声ブラウザーは、 上記の引用を表として報告し、ユーザーを混乱させる。同様に、ページから作品名を抽出する ツールは、「Ernest」が実際には作品名ではなく人名であるにもかかわらず、 それを作品名として抽出する。
この文書の修正版は、次のようになる可能性がある:
<!DOCTYPE HTML>
< html lang = "en-GB" >
< head > < title > Demonstration </ title > </ head >
< body >
< blockquote >
< p > My favourite animal is the cat. </ p >
</ blockquote >
< p >
—< a href = "https://example.org/~ernest/" > Ernest</ a > ,
in an essay from 1992
</ p >
</ body >
</ html > 作者は、この仕様またはその他の適用可能な仕様によって許可されていない 要素、属性、または属性値を使用してはならない。そのように使用すると、将来言語を拡張することが 著しく困難になるためである。
次の例には、この仕様で許可されていない非適合な属性値(「carpet」)と 非適合な属性(「texture」)が存在する:
< label > Carpet: < input type = "carpet" name = "c" texture = "deep pile" ></ label > これをマークアップする代替的かつ正しい方法は次のとおりである:
< label > Carpet: < input type = "text" class = "carpet" name = "c" data-texture = "deep pile" ></ label > ノード文書の 閲覧コンテキストが null である DOM ノードは、HTML 構文要件および XML 構文要件を除く、すべての文書 適合要件を免除される。
特に、template 要素の
テンプレート内容の
ノード
文書の 閲覧コンテキストは
null である。例えば、
コンテンツ
モデル要件および
属性値のマイクロ構文要件は、template
要素の
テンプレート内容には適用されない。
この例では、img 要素が、
template 要素の外部では
無効となるプレースホルダーの属性値を持つ。
< template >
< article >
< img src = "{{src}}" alt = "{{alt}}" >
< h1 ></ h1 >
</ article >
</ template > ただし、上記のマークアップで </h1> 終了タグを省略した場合、
それは HTML 構文への違反となり、適合性チェッカーによって
エラーとして報告される。
スクリプトおよびその他の機構を介して、ユーザーエージェントが文書を処理している間に、 属性、テキスト、さらには文書構造全体の値が動的に変更される可能性がある。ある時点における 文書のセマンティクスは、その時点における文書の状態によって表されるものであり、 したがって文書のセマンティクスは時間の経過とともに変化し得る。ユーザーエージェントは、 この変化に応じて文書の表示を更新しなければならない。
HTML には、進行状況バーを記述する progress 要素がある。
その「value」属性がスクリプトによって動的に更新される場合、UA は進行状況の変化を示すように
レンダリングを更新する。
DOM 内の HTML 要素を表すノードは、 この仕様の関連する節でそれぞれについて列挙されたインターフェイスを実装し、 スクリプトに公開しなければならない。これには、別のコンテキスト (例えば XSLT 変換内)にある場合でも、XML 文書内の HTML 要素も含まれる。
DOM 内の要素は、物事を表す。すなわち、 セマンティクスとも呼ばれる固有の意味を持つ。
例えば、ol 要素は順序付き
リストを表す。
要素は、明示的または暗黙的に、何らかの方法で参照される
(言及される)ことができる。DOM 内の要素を明示的に参照する一つの方法は、
要素に id 属性を
指定し、その id 属性の値を
ハイパーリンクの
href 属性値の
フラグメントとして使用して、
ハイパーリンクを作成することである。
ただし、参照にハイパーリンクは必要ではない。対象の要素を指し示す任意の方法で十分である。
id 属性が指定された、
次の figure 要素について考える:
< figure id = "module-script-graph" >
< img src = "module-script-graph.svg"
alt = "Module A depends on module B, which depends
on modules C and D." >
< figcaption > Figure 27: a simple module graph</ figcaption >
</ figure > ハイパーリンクに基づく
参照は、
a 要素を使用して、
次のように作成できる:
As we can see in < a href = "#module-script-graph" > figure 27</ a > , ...ただし、figure 要素を
参照する方法は、他にも多数ある。例えば:
「モジュール A、B、C、および D の図に示されているように……」
「図 27 では……」(ハイパーリンクなし)
「『単純なモジュールグラフ』の図の内容から……」
「下の図では……」(ただし、これは 推奨されない)
すべての HTML
要素のインターフェイスが継承し、追加要件を持たない要素が使用しなければならない基本インターフェイスは、
HTMLElement インターフェイスである。
現在のすべてのエンジンでサポートされている。
現在のすべてのエンジンでサポートされている。
現在のすべてのエンジンでサポートされている。
現在のすべてのエンジンでサポートされている。
現在のすべてのエンジンでサポートされている。
現在のすべてのエンジンでサポートされている。
[Exposed =Window ]
interface HTMLElement : Element {
[HTMLConstructor ] constructor ();
// metadata attributes
[CEReactions , Reflect ] attribute DOMString title ;
[CEReactions , Reflect ] attribute DOMString lang ;
[CEReactions ] attribute boolean translate ;
[CEReactions ] attribute DOMString dir ;
// user interaction
[CEReactions ] attribute (boolean or unrestricted double or DOMString )? hidden ;
[CEReactions , Reflect ] attribute boolean inert ;
undefined click ();
[CEReactions , Reflect ] attribute DOMString accessKey ;
readonly attribute DOMString accessKeyLabel ;
[CEReactions ] attribute boolean draggable ;
[CEReactions ] attribute boolean spellcheck ;
[CEReactions , ReflectSetter ] attribute DOMString writingSuggestions ;
[CEReactions , ReflectSetter ] attribute DOMString autocapitalize ;
[CEReactions ] attribute boolean autocorrect ;
[CEReactions ] attribute [LegacyNullToEmptyString ] DOMString innerText ;
[CEReactions ] attribute [LegacyNullToEmptyString ] DOMString outerText ;
ElementInternals attachInternals ();
// The popover API
undefined showPopover (optional ShowPopoverOptions options = {});
undefined hidePopover ();
boolean togglePopover (optional (TogglePopoverOptions or boolean ) options = {});
[CEReactions ] attribute DOMString ? popover ;
[CEReactions , Reflect , ReflectRange=(0, 8)] attribute unsigned long headingOffset ;
[CEReactions , Reflect ] attribute boolean headingReset ;
};
dictionary ShowPopoverOptions {
HTMLElement source ;
};
dictionary TogglePopoverOptions : ShowPopoverOptions {
boolean force ;
};
HTMLElement includes GlobalEventHandlers ;
HTMLElement includes ElementContentEditable ;
HTMLElement includes HTMLOrSVGOrMathMLElement ;
[Exposed =Window ]
interface HTMLUnknownElement : HTMLElement {
// Note: intentionally no [HTMLConstructor]
};HTMLElement インターフェイスは、
多数の互いに異なる機能に関連するメソッドおよび属性を保持する。そのため、
このインターフェイスのメンバーは、この仕様のさまざまな節で説明される。
HTML 名前空間内の名前 name を持つ要素の 要素インターフェイスは、次のように決定される:
name が applet、
bgsound、
blink、
isindex、
keygen、
multicol、
nextid、または
spacer である場合、
HTMLUnknownElement
を返す。
name が acronym、
basefont、
big、
center、
nobr、
noembed、
noframes、
plaintext、
rb、
rtc、
strike、または
tt である場合、
HTMLElement を返す。
name が listing または
xmp である場合、
HTMLPreElement を返す。
それ以外で、この仕様がローカル名 name に対応する 要素型に適したインターフェイスを定義している場合、 そのインターフェイスを返す。
その他の 適用可能な仕様が name に適したインターフェイスを定義している場合、 それらが定義するインターフェイスを返す。
name が妥当なカスタム要素名である場合、
HTMLElement を返す。
HTMLUnknownElement
を返す。
妥当なカスタム要素名の場合に、
HTMLUnknownElement ではなく
HTMLElement を使用するのは、
将来発生する可能性のあるアップグレードによって、
要素のプロトタイプチェーンが、HTMLUnknownElement から
無関係なサブクラスへの横方向の遷移ではなく、HTMLElement
からサブクラスへの
線形遷移のみを生じさせるためである。
HTML、SVG、および MathML 要素間で共有される機能は、
HTMLOrSVGOrMathMLElement
インターフェイスミックスインを使用する:[SVG] [MATHML]
一つのエンジンのみでサポートされている。
interface mixin HTMLOrSVGOrMathMLElement {
[SameObject ] readonly attribute DOMStringMap dataset ;
attribute DOMString nonce ; // intentionally no [CEReactions]
[CEReactions , Reflect ] attribute boolean autofocus ;
[CEReactions , ReflectSetter ] attribute long tabIndex ;
undefined focus (optional FocusOptions options = {});
undefined blur ();
};HTML 要素、SVG 要素、MathML 要素のいずれでもない要素の例は、 次のように作成されるものである:
const el = document.createElementNS("some namespace", "example");
console.assert(el.constructor === Element);カスタム要素機能をサポートするため、すべてのHTML要素には
特別なコンストラクタ動作があります。これは、[HTMLConstructor] IDL
拡張属性によって示されます。これは、指定されたインターフェースの
インターフェースオブジェクトが呼び出されたときに、以下で詳しく定義する特定の動作を行うことを
示します。
[HTMLConstructor]
拡張属性は引数を取ってはならず、コンストラクタ
操作にのみ現れなければなりません。コンストラクタ操作には1回だけ現れなければならず、インターフェースには
注釈が付けられた単一のコンストラクタ操作のみが含まれ、その他のコンストラクタ操作が含まれてはなりません。注釈が
付けられたコンストラクタ操作は、引数を取らないものとして宣言されなければなりません。
[HTMLConstructor]
拡張属性で注釈が付けられたコンストラクタ操作を伴って宣言されたインターフェースには、次の
オーバーライドされたコンストラクタ手順があります:
NewTargetがアクティブ関数
オブジェクトと等しい場合、TypeErrorをスローします。
これは、カスタム要素が要素 インターフェースをそのコンストラクタとして使用して 定義された場合に発生することがあります:
customElements. define( "bad-1" , HTMLButtonElement);
new HTMLButtonElement(); // (1)
document. createElement( "bad-1" ); // (2) この場合、HTMLButtonElement
の実行中((1)のように明示的に実行される場合、または
(2)のように暗黙的に実行される場合のいずれでも)、アクティブ
関数オブジェクトと
NewTargetの両方がHTMLButtonElementになります。
この検査が存在しなければ、ローカル名が
bad-1であるHTMLButtonElementのインスタンスを
作成できることになります。
registryをnullとします。
周囲のエージェントのアクティブなカスタム要素コンストラクター マップ[NewTarget] が存在する場合、 registryを周囲の エージェントのアクティブなカスタム要素 コンストラクターマップ[NewTarget]に設定する。
それ以外の場合、registryを現在のグローバルオブジェクトの関連付けられた
Documentのカスタム要素レジストリに設定する。
definitionを、registryのカスタム要素
定義集合内で、コンストラクターが
NewTargetに等しい項目とする。そのような項目がない場合、TypeErrorをスローする。
registryのカスタム要素 定義集合には、undefined であるコンストラクターを持つ項目は存在し得ないため、この 手順は、HTML 要素コンストラクターが関数として呼び出されることも防止する(その場合、 NewTargetは undefined になるため)。
isValueをnullとします。
definitionのローカル 名が、definitionの名前と等しい場合(すなわち、definitionが 自律 カスタム要素のものである場合):
アクティブ
関数オブジェクトがHTMLElementでない場合、
TypeErrorをスローします。
これは、カスタム要素がいずれのローカル名も拡張しないものとして定義されている一方で、
HTMLElement以外のクラスを継承する場合に発生することがあります:
customElements. define( "bad-2" , class Bad2 extends HTMLParagraphElement {}); この場合、Bad2のインスタンスを
構築するときに行われる(暗黙的な)super()呼び出し中、アクティブ
関数
オブジェクトはHTMLParagraphElementであり、
HTMLElementではありません。
それ以外の場合(すなわち、definitionがカスタマイズされた組み込み 要素のものである場合):
valid local namesを、この 仕様またはその他の適用可能な仕様で定義され、 アクティブ 関数オブジェクトを要素インターフェースとして使用する要素のローカル名のリストとします。
valid local namesがdefinitionのローカル名を含まない場合、
TypeErrorをスローします。
これは、カスタム要素が指定されたローカル名を拡張するものとして定義されている一方で、 誤ったクラスを継承する場合に発生することがあります:
customElements. define( "bad-3" , class Bad3 extends HTMLQuoteElement {}, { extends : "p" }); この場合、Bad3のインスタンスを
構築するときに行われる(暗黙的な)super()呼び出し中、valid local namesは
qとblockquoteを含むリストですが、
definitionのローカル名はpであり、
そのリストには含まれていません。
isValueをdefinitionの名前に設定します。
definitionの構築スタックが 空の場合:
elementを、インターフェースを実装する新しい オブジェクトを内部的に作成し、 アクティブ 関数オブジェクトが対応するインターフェースを、現在の レルムおよびNewTargetを指定して実装した結果とします。
elementのノード
文書を、現在のグローバル
オブジェクトの関連付けられた
Documentに設定します。
elementの名前空間 接頭辞をnullに設定します。
elementのカスタム要素 レジストリをregistryに設定します。
elementのカスタム要素状態を「custom」に設定します。
elementのカスタム 要素定義をdefinitionに設定します。
elementのis値をisValueに設定します。
elementを返します。
これは、作成者スクリプトが新しいカスタム要素を直接構築する場合、たとえば
new MyCustomElement()を使用する場合に発生します。
prototypeがObjectでない場合:
realmを ? GetFunctionRealm(NewTarget)とします。
prototypeを、インターフェースがアクティブ 関数 オブジェクトのインターフェースと同じであるrealmのインターフェースプロトタイプオブジェクトに設定します。
アクティブ 関数オブジェクトのレルムは realmではない可能性があるため、レルムをまたいだ「同じインターフェース」という、より一般的な概念を 使用しています。インターフェース オブジェクトの同一性を調べているわけではありません。NewTargetのレルムを使用し、 そこで適切なプロトタイプを検索することを含むこのフォールバック動作は、 JavaScriptの組み込みオブジェクトおよびWeb IDLのインターフェースを実装する新しいオブジェクトを 内部的に作成するアルゴリズムの類似した動作と一致するように設計されています。
elementを、definitionの構築 スタックの最後のエントリとします。
elementが既に
構築済みマーカーである場合、TypeErrorをスローします。
これは、カスタム要素
コンストラクタ内の作成者コードが、super()を呼び出す前に、構築中のクラスの別の
インスタンスを不適合に作成する場合に発生することがあります:
let doSillyThing = true ;
class DontDoThis extends HTMLElement {
constructor() {
if ( doSillyThing) {
doSillyThing = false ;
new DontDoThis();
// Now the construction stack will contain an already constructed marker.
}
// This will then fail with a TypeError:
super ();
}
} これはまた、カスタム要素コンストラクタ内の作成者コードが
super()を2回不適合に呼び出す場合にも発生することがあります。
JavaScript仕様によれば、これは実際にはエラーをスローする前に、スーパークラスの
コンストラクタ(すなわち、このアルゴリズム)を2回実行するためです:
class DontDoThisEither extends HTMLElement {
constructor() {
super ();
// This will throw, but not until it has already called into the HTMLElement constructor
super ();
}
} ? element.[[SetPrototypeOf]](prototype)を実行します。
definitionの構築スタックの 最後のエントリを 既に構築済み マーカーに置き換えます。
elementを返します。
この手順には通常、カスタム要素をアップグレードするときに到達します。既存の要素が
返されるため、カスタム要素
コンストラクタ内のsuper()呼び出しは、その既存の要素をthisに割り当てます。
[HTMLConstructor]によって暗黙に示されるコンストラクタ動作に加えて、一部の
要素には名前付きコンストラクタもあります(実際には
変更されたprototypeプロパティを持つファクトリ関数です)。
HTML要素の名前付きコンストラクタは、カスタム
要素コンストラクタを定義するとき、extends
句でも使用できます:
class AutoEmbiggenedImage extends Image {
constructor( width, height) {
super ( width * 10 , height * 10 );
}
}
customElements. define( "auto-embiggened" , AutoEmbiggenedImage, { extends : "img" });
const image = new AutoEmbiggenedImage( 15 , 20 );
console. assert( image. width === 150 );
console. assert( image. height === 200 ); この仕様の各要素には、次の 情報を含む定義があります:
要素を使用できる場所についての非規範的な説明です。この情報は、 この要素を子として許可する要素のコンテンツモデルと重複しており、便宜のためにのみ 提供されています。
簡潔にするため、最も具体的な要件のみを示します。
たとえば、すべてのフレージング コンテンツはフローコンテンツです。したがって、 フレージングコンテンツである要素は、 より具体的な要件であるため、「フレージング コンテンツが期待される場所」とのみ記載されます。 フローコンテンツを期待する場所では、フレージングコンテンツも期待されるため、 この要件も満たします。
要素の子および子孫としてどのようなコンテンツを含めなければならないかについての 規範的な説明です。
text/html構文で、
開始タグおよび終了タグを
省略できるかどうかについての非規範的な説明です。この情報は、省略可能なタグの節で示される規範的要件と重複しており、
便宜のために要素の定義にも記載されています。
要素に指定できる属性(別途禁止されている場合を除く)の規範的なリストと、 それらの属性に関する非規範的な説明です。(ダッシュの左側の内容は規範的であり、右側の内容は 非規範的です。)
作成者向け:ARIAのroleおよびaria-*属性を使用するための適合要件は、
ARIA in HTMLで定義されています。[ARIA] [ARIAHTML]
実装者向け:アクセシビリティAPIのセマンティクスを実装するためのユーザーエージェント要件は、 HTML Accessibility API Mappingsで定義されています。[HTMLAAM]
各要素のサニタイズ情報は、その要素のサニタイズ カテゴリーを定義します。これは、サニタイズ中に要素がどのように 処理されるかに影響します。また、要素の1つ以上の属性をナビゲーションURL 属性として定義することもできます。
そのような要素が実装しなければならないDOMインターフェースの規範的な定義です。
その後に、要素が何を表すかについての説明と、 作成者および実装に適用される可能性がある追加の規範的な適合基準が続きます。例が含まれる場合も あります。
属性値は文字列です。別途指定されている場合を除き、 HTML要素の属性値には空文字列を含む任意の文字列値を 使用でき、そのような属性値に指定できるテキストには制限がありません。
この仕様で定義される各要素にはコンテンツモデル、すなわち要素に期待される 内容の説明があります。HTML 要素は、その要素のコンテンツモデルに記述された要件に一致する内容を持たなければなりません。 要素の内容とは、DOMにおけるその要素の子です。
要素間では常にASCII空白が許可されます。ユーザーエージェントは、ソースマークアップ内の
要素間にあるこれらの文字を、DOM内のText
ノードとして表します。空のText
ノード、およびこれらの文字の列のみからなる
Text
ノードは、要素間空白と見なされます。
要素の内容が要素のコンテンツモデルに一致するかどうかを判定するとき、および 文書と要素のセマンティクスを定義するアルゴリズムに従うときは、要素間空白、 コメントノード、および処理命令ノードを無視しなければなりません。
したがって、要素Aと要素Bが
同じ親ノードを持ち、その間に他の要素ノードまたはText
ノード(要素間空白を除く)が存在しない場合、
要素Aは要素Bの前または後にあるといいます。同様に、ある要素に
要素間
空白、コメントノード、および処理命令ノード以外のノードが含まれていない場合、そのノードは
その要素の唯一の子です。
作成者は、各要素について定義された明示的に許可される場所、または他の仕様によって明示的に 要求される場所以外で、HTML要素を使用してはなりません。 XML複合文書では、他の名前空間の要素が関連するコンテキストを提供するものとして定義されている場合、 そのようなコンテキストがそれらの要素内に存在することがあります。
The Atom Syndication Formatはcontent要素を定義しています。その
type属性の値が
xhtmlの場合、The Atom Syndication Formatは、単一のHTML
div要素を含むことを要求します。したがって、
この仕様で明示的かつ規範的に記述されていなくても、そのコンテキストでは
div要素が許可されます。[ATOM]
さらに、HTML要素は孤立ノード (すなわち、親ノードを持たないノード)であっても構いません。
たとえば、td要素を
作成し、スクリプトのグローバル変数に格納することは適合しています。これは、通常
td要素が
tr要素内でのみ使用されることを想定している場合でも同様です。
var data = {
name: "Banana" ,
cell: document. createElement( 'td' ),
}; 要素のコンテンツモデルが何も含まないである場合、その
要素には、要素間空白以外のText
ノード、および要素ノードが含まれてはなりません。
コンテンツモデルが「何も含まない」であるほとんどのHTML要素は、便宜上、 空要素(HTML構文において終了タグを持たない要素)でもあります。 ただし、これらは完全に別の概念です。
HTMLの各要素は、類似した特性を持つ要素をまとめる0個以上の カテゴリーに属します。この仕様では、次の広範なカテゴリーを 使用します:
一部の要素は、この仕様の他の部分で定義される別のカテゴリーにも 属します。
これらのカテゴリーの関係は次のとおりです:
区分化コンテンツ、見出しコンテンツ、フレージングコンテンツ、埋め込みコンテンツ、および インタラクティブコンテンツは、すべてフローコンテンツの一種です。メタデータはフローコンテンツである場合があります。 メタデータおよびインタラクティブコンテンツは、フレージングコンテンツである場合があります。埋め込みコンテンツも フレージングコンテンツの一種であり、インタラクティブコンテンツである場合もあります。
特定の目的のために他のカテゴリーも使用されます。たとえば、フォームコントロールでは、共通の 要件を定義するために複数のカテゴリーが指定されます。一部の要素には固有の要件があり、 特定のカテゴリーには該当しません。
メタデータコンテンツとは、残りのコンテンツの表示や 動作を設定するコンテンツ、文書と他の文書との関係を設定するコンテンツ、または その他の「帯域外」情報を伝達するコンテンツです。
主にメタデータに関連するセマンティクスを持つ他の名前空間の要素(たとえばRDF)も、 メタデータコンテンツです。
したがって、XMLシリアル化では、次のようにRDFを使用できます:
< html xmlns = "http://www.w3.org/1999/xhtml"
xmlns:r = "http://www.w3.org/1999/02/22-rdf-syntax-ns#" xml:lang = "en" >
< head >
< title > Hedral's Home Page</ title >
< r:RDF >
< Person xmlns = "http://www.w3.org/2000/10/swap/pim/contact#"
r:about = "https://hedral.example.com/#" >
< fullName > Cat Hedral</ fullName >
< mailbox r:resource = "mailto:hedral@damowmow.com" />
< personalTitle > Sir</ personalTitle >
</ Person >
</ r:RDF >
</ head >
< body >
< h1 > My home page</ h1 >
< p > I like playing with string, I guess. Sister says squirrels are fun
too so sometimes I follow her to play with them.</ p >
</ body >
</ html > ただし、HTMLシリアル化ではこれは不可能です。
文書およびアプリケーションの本文で使用されるほとんどの要素は、 フローコンテンツに分類されます。
aabbraddressarea(map要素の子孫である場合)
articleasideaudiobbdibdoblockquotebrbuttoncanvascitecodedatadatalistdeldetailsdfndialogdivdlemembedfieldsetfigurefooterformh1
h2
h3
h4
h5
h6
headerhgrouphriiframeimginputinskbdlabellink(本文で許可される場合)main(階層的に
正しいmain要素である場合)mapmarkmathmenumeta(itemprop
属性が存在する場合)meternavnoscriptobjectoloutputppicturepreprogressqrubyssampscriptsearchsectionselectslotsmallspanstrongsubsupsvgtabletemplatetextareatimeuulvarvideowbr区分化コンテンツとは、headerおよび
footer要素のスコープを定義するコンテンツです。
見出しコンテンツは、節の見出しを定義します( 区分化コンテンツ要素を使用して明示的に マークアップされる場合、または見出しコンテンツ自体によって暗黙に示される場合があります)。
フレージングコンテンツとは、文書のテキスト、および そのテキストを段落内のレベルでマークアップする要素です。連続するフレージングコンテンツは段落を形成します。
aabbrarea(map要素の子孫である場合)audiobbdibdobrbuttoncanvascitecodedatadatalistdeldfnemembediiframeimginputinskbdlabellink(本文で許可される場合)mapmarkmathmeta(itemprop
属性が存在する場合)meternoscriptobjectoutputpictureprogressqrubyssampscriptselectselectedcontent
(select内の
buttonの子孫である場合)
slotsmallspanstrongsubsupsvgtemplatetextareatimeuvarvideowbrフレージングコンテンツとして分類されるほとんどの要素には、フローコンテンツではなく、 それ自体がフレージングコンテンツとして分類される要素のみを含めることができます。
コンテンツモデルのコンテキストにおけるテキストとは、何もないか、
またはText
ノードを意味します。テキストは単独でコンテンツ
モデルとして使用される場合がありますが、フレージング
コンテンツでもあり、Text
ノードが空であるか、ASCII
空白のみを含む場合は、要素間
空白になることがあります。
Text
ノードおよび属性値は、非文字と、制御文字(ASCII空白を除く)を除外した、スカラー
値で構成されなければなりません。
この仕様には、正確なコンテキストに応じて、Text
ノードおよび属性値の正確な値に関する追加の制約が含まれています。
埋め込みコンテンツとは、別のリソースを 文書にインポートするコンテンツ、または別の語彙から文書に挿入される コンテンツです。
HTML名前空間以外の 名前空間に属し、メタデータではなくコンテンツを伝達する要素は、この仕様で定義される コンテンツモデルの目的上、埋め込みコンテンツです。(たとえば、MathMLまたはSVGです。)
一部の埋め込みコンテンツ要素はフォールバックコンテンツ、すなわち 外部リソースを使用できない場合(たとえば、サポートされていない形式である場合)に 使用されるコンテンツを持つことができます。フォールバックがある場合、要素の定義にその内容が記載されます。
インタラクティブコンテンツとは、ユーザーとの インタラクションを特に意図したコンテンツです。
a(href属性が
存在する場合)audio(controls属性が
存在する場合)buttondetailsembediframeimg(usemapまたはcontrols属性が
存在する場合)input(type属性が
状態では
ない場合)
labelselecttextareavideo(controls属性が
存在する場合)一般的な規則として、任意のフローコンテンツまたは フレージングコンテンツを許可するコンテンツモデルを持つ要素は、 その内容に、属性が指定されていない 触知可能なコンテンツであるノードを少なくとも1つ持つべきです。
触知可能なコンテンツは、
空でない子孫テキスト、ユーザーが
聞くことができるもの(audio要素)、
見ることができるもの(video、
img、または
canvas要素)、あるいは
その他の方法で操作できるもの(たとえば、インタラクティブなフォーム
コントロール)を提供することで、要素を空でないものにします。
ただし、この要件は厳格な要件ではありません。要素が正当に空である場合が数多くあるためです。 たとえば、後でスクリプトによって内容が設定されるプレースホルダーとして使用される場合や、 要素がテンプレートの一部であり、ほとんどのページでは内容が設定されるものの、一部のページでは 関係しない場合などです。
適合性チェッカーは、作成支援として、この要件を満たしていない要素を作成者が 検出できる仕組みを提供することが推奨されます。
次の要素は触知可能なコンテンツです:
aabbraddressarticleasideaudio(controls属性が
存在する場合)bbdibdoblockquotebuttoncanvascitecodedatadeldetailsdfndivdl(要素の子に少なくとも
1つの名前と値のグループが含まれる場合)emembedfieldsetfigurefooterformh1
h2
h3
h4
h5
h6
headerhgroupiiframeimginput(type属性が
状態では
ない場合)
inskbdlabelmainmapmarkmathmenu(要素の子に少なくとも
1つのli
要素が含まれる場合)meternavobjectol(要素の子に少なくとも
1つのli要素が含まれる場合)
outputppicturepreprogressqrubyssampsearchsectionselectsmallspanstrongsubsupsvgtabletextareatimeuul(要素の子に少なくとも
1つのli要素が含まれる場合)
varvideoスクリプト支援要素とは、それ自体は何も表さない(すなわち、レンダリングされない)ものの、 たとえばユーザーに機能を提供するために、スクリプトを支援する目的で使用される要素です。
次の要素はスクリプト支援要素です:
一部の要素は透過として記述されます。そのコンテンツモデルの 説明には「透過」が含まれます。透過要素のコンテンツモデルは、 その親要素のコンテンツモデルから導出されます。コンテンツモデル内の「透過」である部分で 要求される要素は、透過要素が置かれている、その親要素のコンテンツモデルの部分で 要求される要素と同じです。
たとえば、ruby要素内のins
要素には、rt要素を
含めることができません。これは、ruby要素のコンテンツモデルで
ins要素を
許可する部分が、フレージング
コンテンツを許可する部分であり、rt要素はフレージングコンテンツではないためです。
透過要素が互いに入れ子になっている場合、この処理を 反復して適用しなければならないことがあります。
次のマークアップ断片について考えます:
< p >< object >< ins >< map >< a href = "/" > Apples</ a ></ map ></ ins ></ object ></ p > 「Apples」がa要素内で許可されるかどうかを
検査するため、コンテンツモデルを調べます。a
要素のコンテンツモデルは透過であり、map
要素のコンテンツモデルも、ins要素のコンテンツモデルも、
object
要素のコンテンツモデルも透過です。object要素は、
コンテンツモデルがフレージングコンテンツであるp要素内にあります。したがって、
テキストはフレージングコンテンツであるため、「Apples」は許可されます。
透過要素に親がない場合、そのコンテンツモデルの「透過」である部分は、代わりに 任意のフローコンテンツを受け入れるものとして扱わなければなりません。
この節で定義する段落という用語は、
p要素の定義以外にも使用されます。ここで
定義する段落の概念は、
文書をどのように解釈するかを説明するために使用されます。p要素は、段落をマークアップする
複数の方法のうちの1つにすぎません。
段落は通常、組版における段落と同様に、特定の話題について述べる 1つ以上の文からなるテキストのブロックを形成する、連続したフレージングコンテンツですが、より一般的な 主題上のグループ化にも使用できます。たとえば、住所、フォームの一部、署名行、 または詩の連も段落です。
次の例では、1つのセクション内に2つの段落があります。また、 段落ではないフレージングコンテンツを含む見出しもあります。コメントおよび 要素間空白が 段落を形成しないことに注意してください。
< section >
< h2 > Example of paragraphs</ h2 >
This is the < em > first</ em > paragraph in this example.
< p > This is the second.</ p >
<!-- This is not a paragraph. -->
</ section > フローコンテンツ内の段落は、
a、ins、del、およびmap要素によって
複雑化されていない文書の外観を基準に定義されます。これらの要素は混合コンテンツモデルを持つため、
以下の最初の2つの例に示すように、段落の境界をまたぐことができます。
一般に、要素が段落の境界をまたぐことは避けるのが最善です。 そのようなマークアップを保守するのは困難になる場合があります。
次の例では、先の例のマークアップを使用し、テキストが変更されたことを示すために
マークアップの一部をinsおよび
del要素で囲んでいます
(もっとも、この場合の変更にはあまり意味がありません)。この例には、insおよびdel要素があるにもかかわらず、
直前の例とまったく同じ段落があることに注意してください。ins要素は
見出しと最初の段落をまたぎ、del要素は
2つの段落間の境界をまたいでいます。
< section >
< ins >< h2 > Example of paragraphs</ h2 >
This is the < em > first</ em > paragraph in</ ins > this example< del > .
< p > This is the second.</ p ></ del >
<!-- This is not a paragraph. -->
</ section > viewを、文書内のすべてのa、
ins、del、およびmap要素をその
内容で置き換えたDOMのビューとします。
次に、viewにおいて、フレージングコンテンツ以外のコンテンツとフレージング
コンテンツの両方を受け入れる要素内にある、他の種類のコンテンツによって中断されていない
兄弟フレージングコンテンツノードの
各連続部分について、firstをその連続部分の最初のノード、lastをその連続部分の最後の
ノードとします。埋め込みコンテンツでも要素間
空白でもないノードを少なくとも1つ含む各連続部分について、元のDOMには
firstの直前からlastの直後まで段落が存在します。(したがって、段落はa、
ins、del、およびmap要素をまたぐことができます。)
適合性チェッカーは、互いに重なり合う段落がある場合、作成者に警告しても構いません
(これは、object、video、audio、および
canvas要素で発生することがあり、
また、SVG
svgやMathML
mathのように、その内部へHTMLをさらに埋め込むことを許可する他の名前空間の要素を介して
間接的に発生することもあります)。
p要素は、
それ以外には段落を互いに分離するフレージングコンテンツ以外のコンテンツが存在しない場合に、
個々の段落を囲むために使用できます。
次の例では、リンクが最初の段落の半分、2つの段落を分ける見出し全体、 および2番目の段落の半分にわたっています。リンクは段落および見出しをまたいでいます。
< header >
Welcome!
< a href = "about.html" >
This is home of...
< h1 > The Falcons!</ h1 >
The Lockheed Martin multirole jet fighter aircraft!
</ a >
This page discusses the F-16 Fighting Falcon's innermost secrets.
</ header > 次は、この内容をマークアップする別の方法です。今回は段落を明示的に示し、 1つのリンク要素を3つに分割しています:
< header >
< p > Welcome! < a href = "about.html" > This is home of...</ a ></ p >
< h1 >< a href = "about.html" > The Falcons!</ a ></ h1 >
< p >< a href = "about.html" > The Lockheed Martin multirole jet
fighter aircraft!</ a > This page discusses the F-16 Fighting
Falcon's innermost secrets.</ p >
</ header > フォールバックコンテンツを定義する特定の要素を使用すると、段落が重なり合うことがあります。 たとえば、次のセクションでは:
< section >
< h2 > My Cats</ h2 >
You can play with my cat simulator.
< object data = "cats.sim" >
To see the cat simulator, use one of the following links:
< ul >
< li >< a href = "cats.sim" > Download simulator file</ a >
< li >< a href = "https://sims.example.com/watch?v=LYds5xY4INU" > Use online simulator</ a >
</ ul >
Alternatively, upgrade to the Mellblom Browser.
</ object >
I'm quite proud of it.
</ section > 段落は5つあります:
object要素です。最初の段落には、他の4つの段落が重なっています。「cats.sim」リソースをサポートする ユーザーエージェントは最初の段落だけを表示しますが、フォールバックを表示するユーザーエージェントは、 最初の段落の最初の文を2番目の段落と同じ段落にあるかのように紛らわしく表示し、 最後の段落を最初の段落の2番目の文の冒頭にあるかのように表示します。
この混乱を避けるため、明示的なp
要素を使用できます。たとえば:
< section >
< h2 > My Cats</ h2 >
< p > You can play with my cat simulator.</ p >
< object data = "cats.sim" >
< p > To see the cat simulator, use one of the following links:</ p >
< ul >
< li >< a href = "cats.sim" > Download simulator file</ a >
< li >< a href = "https://sims.example.com/watch?v=LYds5xY4INU" > Use online simulator</ a >
</ ul >
< p > Alternatively, upgrade to the Mellblom Browser.</ p >
</ object >
< p > I'm quite proud of it.</ p >
</ section > 次の属性は、すべてのHTML 要素(この仕様で定義されていないものを含む)に共通しており、指定できます:
accesskey
autocapitalizeautocorrectautofocuscontenteditable
dirdraggableenterkeyhintheadingoffsetheadingresetinertinputmodeisitemiditemprop
itemrefitemscopeitemtypelangnoncepopoverspellcheckstyletabindextitletranslatewritingsuggestions
これらの属性は、この仕様ではHTML 要素の属性としてのみ定義されています。この仕様が、これらの属性を持つ要素に言及する場合、 これらの属性を持つものとして定義されていない名前空間の要素を、これらの属性を持つ 要素と見なしてはなりません。
たとえば、次のXML断片では、「bogus」要素は、リテラル名が
「dir」である属性を持っているにもかかわらず、この仕様で定義されるdir属性を
持っていません。したがって、最も内側のspan要素の方向性は「rtl」であり、「bogus」要素を
間接的に介してdiv要素から継承されます。
< div xmlns = "http://www.w3.org/1999/xhtml" dir = "rtl" >
< bogus xmlns = "https://example.net/ns" dir = "ltr" >
< span xmlns = "http://www.w3.org/1999/xhtml" >
</ span >
</ bogus >
</ div > 現在のすべてのエンジンでサポートされています。
DOMは、任意の名前空間の任意の要素に対するclass、id、およびslot属性についてのユーザーエージェント要件を定義します。
[DOM]
class、id、およびslot属性は、すべてのHTML要素に指定できます。
HTML要素に指定する場合、class
属性は、その要素が属するさまざまなクラスを表す空白区切りトークンの集合である値を
持たなければなりません。
要素にクラスを割り当てると、CSSのセレクターにおけるクラス照合、DOMのgetElementsByClassName()
メソッド、およびその他の同様の機能に影響します。
作成者がclass属性で使用できるトークンには
追加の制限はありませんが、コンテンツの望ましい表示を説明する値ではなく、
コンテンツの性質を説明する値を使用することが推奨されます。
HTML要素に指定する場合、id属性の値は、
その要素のツリー内にあるすべてのIDの中で一意であり、
少なくとも1文字を含まなければなりません。値にはいかなる
ASCII空白も含めてはなりません。
IDが取り得る形式には、その他の制限はありません。特に、IDは数字のみで構成したり、 数字で始めたり、アンダースコアで始めたり、句読点のみで構成したりできます。
要素の一意識別子は、さまざまな 目的に使用できます。特に、フラグメントを使用して文書の特定部分へリンクする方法、 スクリプト処理時に要素を対象とする方法、およびCSSから特定の要素にスタイルを適用する方法として使用できます。
識別子は不透明な文字列です。id属性の値から
特定の意味を導出するべきではありません。
slot属性には、
HTML要素に固有の適合要件はありません。
slot属性は、
要素にスロットを
割り当てるために使用されます。slot属性を持つ要素は、
そのslot属性の値と
name属性の値が一致するslot要素によって作成されたスロットに割り当てられます。ただし、そのslot要素が、
対応するslot属性値を持つホストを
ルートが持つシャドーツリー内にある場合に限ります。
支援技術製品が、HTML要素および属性だけでは不可能な、より細粒度のインターフェースを
公開できるようにするため、支援技術製品向けの
注釈の集合を指定できます(ARIAのroleおよびaria-*属性)。
[ARIA]
次のイベントハンドラーコンテンツ属性は、 任意のHTML要素に指定できます:
onauxclickonbeforeinput
onbeforematch
onbeforetoggle
onblur*oncanceloncanplayoncanplaythrough
onchangeonclickoncloseoncommandoncontextlost
oncontextmenu
oncontextrestored
oncopyoncuechangeoncutondblclickondragondragendondragenterondragleaveondragoverondragstartondropondurationchange
onemptiedonendedonerror*onfocus*onformdataoninputoninvalidonkeydownonkeypressonkeyuponload*onloadeddataonloadedmetadata
onloadstartonmousedownonmouseenteronmouseleaveonmousemoveonmouseoutonmouseoveronmouseuponpasteonpauseonplayonplayingonprogressonratechangeonresetonresize*onscroll*onscrollend*onsecuritypolicyviolation
onseekedonseekingonselectonslotchangeonstalledonsubmitonsuspendontimeupdateontoggleonvolumechange
onwaitingonwheelアスタリスクが付いた属性は、body要素に指定された場合、
それらの要素が同じ名前を持つWindowオブジェクトのイベントハンドラーを公開するため、
異なる意味を持ちます。
これらの属性はすべての要素に適用されますが、すべての要素で有用なわけではありません。
たとえば、ユーザーエージェントによって発生するvolumechange
イベントを受信するのは、メディア要素だけです。
カスタムデータ属性(たとえば
data-foldernameまたはdata-msgid)は、ページに固有の
カスタムデータ、状態、注釈、および同様の情報を格納するため、任意の
HTML要素に指定できます。
HTML文書では、HTML名前空間の要素に、
値が正確に「http://www.w3.org/1999/xhtml」である場合に限り、
xmlns属性を指定できます。これはXML
文書には適用されません。
HTMLでは、xmlns属性にはまったく効果がありません。
基本的にはお守りです。XMLとの間の移行を多少容易にするためだけに許可されています。
HTMLパーサーによって解析されると、
この属性はいずれの名前空間にも属しません。XMLでは、この属性は名前空間宣言機構の一部であり、
常に「http://www.w3.org/2000/xmlns/」名前空間に属します。
XMLでは、XML
文書内の任意の要素で、XML名前空間のxml:space
属性を使用することも許可されています。HTMLの既定の動作は空白を保持することであるため、
この属性はHTML
要素には影響しません。[XML]
text/html構文では、
HTML要素のxml:space
属性をシリアル化する方法はありません。
title属性現在のすべてのエンジンでサポートされています。
title属性は、
ツールチップに適した情報など、要素に関する助言情報を表します。リンクでは、これは対象リソースのタイトルまたは説明となり得ます。
画像では、画像のクレジットまたは画像の説明となり得ます。段落では、脚注または
テキストに関する解説となり得ます。引用では、出典に関する追加情報となり得ます。
インタラクティブコンテンツでは、
要素を使用するためのラベルまたは説明となり得ます。その他の場合も同様です。値はテキストです。
現在、title
属性に依存することは推奨されません。多くのユーザーエージェントが、この仕様で要求される
アクセシブルな方法で属性を公開していないためです(たとえば、ツールチップを表示するために
マウスなどのポインティングデバイスを必要とし、キーボードのみを使用するユーザーや、
最新の携帯電話またはタブレットを使用する人など、タッチのみを使用するユーザーが
除外されます)。
この属性を要素から省略した場合、title属性が設定された最も近い祖先のHTML要素のtitle属性も、
この要素に関連することを意味します。この属性を設定するとそれを上書きし、祖先の
助言情報がこの要素には関連しないことを明示します。属性を空文字列に設定すると、
要素に助言情報がないことを示します。
title属性の値に
U+000A LINE FEED(LF)文字が含まれる場合、内容は複数行に分割されます。
各U+000A LINE FEED(LF)文字は改行を表します。
title属性で
改行を使用する際には注意が必要です。
たとえば、次の断片は実際には略語の展開形を途中に改行を含むものとして 定義します:
< p > My logs show that there was some interest in < abbr title = "Hypertext
Transport Protocol" > HTTP</ abbr > today.</ p > link、
abbr、およびinputなどの一部の要素は、
上述のセマンティクスに加えて、title属性に
追加のセマンティクスを定義します。
要素の助言情報は、次のアルゴリズムが返す値です。 値が返された時点でアルゴリズムを中止します。アルゴリズムが空文字列を返す場合、 助言情報はありません。
要素に助言情報がある場合、 ユーザーエージェントはユーザーにそのことを知らせるべきです。そうしなければ、 その情報を発見できないためです。
lang属性およびxml:lang
属性現在のすべてのエンジンでサポートされています。
名前空間に属さないlang属性は、要素の内容および
テキストを含む要素のすべての属性の主要言語を指定します。その値は有効なBCP 47言語タグ、
または空文字列でなければなりません。属性を空文字列に設定すると、主要言語が不明であることを
示します。[BCP47]
XML名前空間のlang属性はXMLで定義されています。
[XML]
これらの属性を要素から省略した場合、この要素の言語は、親要素があれば
その親要素の言語と同じです(シャドーツリー内のslot要素を除きます)。
名前空間に属さないlang属性は、任意のHTML
要素で使用できます。
XML
名前空間のlang属性は、XML文書内のHTML要素で使用できます。
また、関連する仕様が許可する場合は、他の名前空間の要素でも使用できます(特に、
MathMLおよびSVGは、それらの要素にXML名前空間の
lang属性を指定することを許可しています)。名前空間に属さないlang属性と、XML名前空間のlang属性の両方を同じ
要素に指定する場合、ASCII
大文字・小文字不区別で比較したとき、両者はまったく同じ値でなければなりません。
作成者は、HTML
文書内のHTML要素で、XML名前空間の
lang属性を使用してはなりません。XMLとの間の移行を容易にするため、作成者は
HTML文書内のHTML要素に、
名前空間に属さず、接頭辞を持たず、リテラルのローカル名が「xml:lang」である属性を
指定しても構いません。ただし、そのような属性は、名前空間に属さないlang
属性も指定されている場合にのみ指定しなければならず、両方の属性はASCII
大文字・小文字不区別で比較したとき同じ値でなければなりません。
名前空間に属さず、接頭辞を持たず、リテラルのローカル名が「xml:lang」である
属性は、言語処理に影響しません。
ノードの言語を決定するには、 ユーザーエージェントは次のリストから最初に該当する手順を使用しなければなりません:
lang属性が設定された要素である場合その属性の値を使用します。
lang属性が
設定されている場合
その属性の値を使用します。
プラグマで設定された既定言語が 設定されている場合、それがノードの言語です。プラグマで設定された既定言語が 設定されていない場合、上位レベルのプロトコル(HTTPなど)からの言語情報があれば、 代わりに最後のフォールバック言語として使用しなければなりません。そのような言語情報がない場合、 および上位レベルのプロトコルが複数の言語を報告する場合、ノードの言語は不明であり、 対応する言語タグは空文字列です。
結果の値が認識される言語タグでない場合、その値は、指定された言語タグを持つ、 他のすべての言語とは異なる不明な言語として扱わなければなりません。ラウンドトリップや、 言語タグを期待する他のサービスとの通信のため、ユーザーエージェントは不明な言語タグを 変更せずに渡し、それがBCP 47言語タグであることを示すべきです。これにより、後続のサービスが データを別の種類の言語記述として解釈しないようにします。 [BCP47]
したがって、たとえばlang="xyzzy"を持つ要素は、
(CSSなどの)セレクター:lang(xyzzy)に一致しますが、両方が同じように無効であっても、
:lang(abcde)には一致しません。同様に、ウェブブラウザーとスクリーンリーダーが
協調して要素の言語について通信する場合、ブラウザーは、その値が無効であると認識していても、
スクリーンリーダーが実際にはそのタグを持つ言語をサポートしている可能性に備えて、
言語が「xyzzy」であるとスクリーンリーダーに伝えます。スクリーンリーダーがBCP 47と
言語名を符号化する別の構文の両方をサポートし、その別の構文では文字列「xyzzy」が
ベラルーシ語を表す方法であったとしても、スクリーンリーダーがテキストをベラルーシ語として
扱い始めることは誤りです。「xyzzy」はBCP 47コードでベラルーシ語を表す方法ではないためです
(BCP 47ではベラルーシ語にコード「be」を使用します)。
結果の値が空文字列である場合、ノードの言語が明示的に不明であることを意味するものとして解釈しなければなりません。
ユーザーエージェントは、要素の言語を使用して適切な処理またはレンダリングを決定しても構いません (たとえば、適切なフォントや発音の選択、辞書の選択、または日付選択コントロールなどの フォームコントロールのユーザーインターフェース)。
translate属性現在のすべてのエンジンでサポートされています。
translate属性は、ページをローカライズするときに、
要素の属性値およびその子であるText
ノードの値を翻訳するか、または変更せずに残すかを指定するために使用します。これは、
次のキーワードおよび状態を持つ列挙属性です:
| キーワード | 状態 | 簡単な説明 |
|---|---|---|
yes
|
はい | 翻訳モードを翻訳有効に設定します。 |
no
|
いいえ | 翻訳モードを翻訳なしに設定します。 |
この属性の欠損値の デフォルトおよび無効値のデフォルトは、いずれも継承状態であり、空値のデフォルトは はい状態です。
各要素(HTML以外の要素を含む)には翻訳モードがあり、
翻訳有効状態または
翻訳なし状態のいずれかです。HTML要素のtranslate
属性がはい状態である場合、その要素の
翻訳モードは翻訳有効状態です。
それ以外で、要素のtranslate
属性がいいえ状態である場合、その要素の翻訳
モードは翻訳なし状態です。それ以外の場合、
要素のtranslate属性が
継承状態であるか、
または要素がHTML要素ではないため、translate属性を
持ちません。いずれの場合も、その要素の翻訳モードは、親要素があればその親要素と同じ状態になり、
要素の親要素が
nullである場合は、翻訳有効状態になります。
要素が翻訳有効状態にある場合、ページをローカライズするときに、
要素の翻訳可能な
属性およびその子であるText
ノードの値を翻訳します。
要素が翻訳なし状態にある場合、ページをローカライズするときに、
要素の属性値およびその子であるText
ノードの値をそのまま残します。たとえば、要素に人名やコンピュータープログラムの名前が
含まれている場合です。
次の属性は翻訳可能な属性です:
abbr(th要素上)alt(area、
img、および
input要素上)
content(meta要素上で、name属性が、
値を翻訳可能であることが分かっているメタデータ名を指定する場合)
download(
aおよび
area要素上)
label(optgroup、
option、および
track要素上)
lang(HTML要素上)。
翻訳で使用される言語に一致するように「翻訳」しなければならないplaceholder(inputおよび
textarea
要素上)
srcdoc(iframe要素上)。
解析し、再帰的に処理しなければならないstyle(HTML要素上)。解析し、
再帰的に処理しなければならない(たとえば、'content'プロパティの値)
title(すべてのHTML要素上)value(input要素上で、その
type属性が
ボタン状態またはリセットボタン状態にある場合)
他の仕様が、同様に翻訳可能な
属性となる別の属性を定義することもあります。たとえば、ARIAはaria-label
属性を翻訳可能なものとして定義します。
translate
IDL属性は、取得時に、要素の翻訳モードが
翻訳有効である場合はtrueを返し、
それ以外の場合はfalseを返さなければなりません。設定時には、新しい値がtrueである場合、
コンテンツ属性の値を「yes」に設定し、それ以外の場合はコンテンツ
属性の値を「no」に設定しなければなりません。
この例では、ページをローカライズするとき、キーボード入力の例とプログラム出力の例を除いて、 文書内のすべてが翻訳されます:
<!DOCTYPE HTML>
< html lang = en > <!-- default on the document element is translate=yes -->
< head >
< title > The Bee Game</ title > <!-- implied translate=yes inherited from ancestors -->
</ head >
< body >
< p > The Bee Game is a text adventure game in English.</ p >
< p > When the game launches, the first thing you should do is type
< kbd translate = no > eat honey</ kbd > . The game will respond with:</ p >
< pre >< samp translate = no > Yum yum! That was some good honey!</ samp ></ pre >
</ body >
</ html > dir属性現在のすべてのエンジンでサポートされています。
dir属性は、
次のキーワードおよび状態を持つ列挙属性です:
| キーワード | 状態 | 簡単な説明 |
|---|---|---|
ltr
|
LTR | 要素の内容は、左から右へ記述されるテキストとして明示的に方向分離されます。 |
rtl
|
RTL | 要素の内容は、右から左へ記述されるテキストとして明示的に方向分離されます。 |
auto
|
自動 | 要素の内容は明示的に方向分離されたテキストですが、その方向は要素の内容を 使用してプログラムによって決定されます(以下で説明します)。 |
自動状態で使用される ヒューリスティックは非常に粗雑です(双方向アルゴリズムにおける段落レベルの決定と同様の方法で、 強い方向性を持つ最初の文字を調べるだけです)。作成者には、テキストの方向が本当に不明であり、 より適切なサーバー側ヒューリスティックを適用できない場合の最後の手段としてのみ、 この値を使用することが強く推奨されます。[BIDI]
この属性の欠損値の デフォルトおよび無効値の デフォルトは、いずれも未定義状態です。
要素(HTML要素に限らない任意の要素)の
方向性は、「ltr」または「rtl」のいずれかです。
要素elementを指定して方向性を算出するには、
elementのdir属性の状態に応じて分岐します:
dir属性は
HTML要素に対してのみ定義されているため、
他の名前空間の要素には存在できません。したがって、他の名前空間の要素は常に親の方向性を使用することになります。
自動方向性フォーム関連要素は 次のとおりです:
要素elementを指定して自動方向性を算出するには:
elementが自動方向性フォーム関連 要素である場合:
elementが、ルートがシャドールートであり、elementの割り当てられたノードが空でないslot要素である場合:
elementの割り当てられたノードの各ノードchildについて反復します:
childDirectionをnullとします。
childがText
ノードである場合、childDirectionをchildのテキストノードの
方向性に設定します。
それ以外の場合:
childDirectionを、canExcludeRootを trueに設定したchildの内包テキストの自動方向性に 設定します。
childDirectionがnullでない場合、 childDirectionを返します。
nullを返します。
canExcludeRootを falseに設定したelementの内包テキストの自動方向性を 返します。
要素elementおよびブール値canExcludeRootを指定して、 要素の内包テキストの自動方向性を算出するには:
Text
ノードtextを指定してテキストノードの方向性を算出するには:
要素elementを指定して親の方向性を算出するには:
この属性には、双方向アルゴリズムに関わる レンダリング要件があります。
HTML要素の 属性の方向性は、その属性のテキストを 何らかの方法でレンダリングに含めるときに使用され、次のリストから最初に該当する 一連の手順に従って決定されます:
次の属性は方向性対応属性です:
document.dir [ = value ]「ltr」、「rtl」、または「auto」のいずれかに設定して、html要素の
dir属性の値を置き換えることができます。
html要素がない場合、
空文字列を返し、新しい値を無視します。
現在のすべてのエンジンでサポートされています。
要素のdir
IDL属性は、その要素のdirコンテンツ属性を、
既知の値のみに制限して反映しなければなりません。
現在のすべてのエンジンでサポートされています。
Documentオブジェクトのdir IDL属性は、html要素が
あれば、そのdirコンテンツ属性を、既知の値のみに制限して反映しなければなりません。そのような要素が
ない場合、この属性は空文字列を返し、設定時には何も行わなければなりません。
作成者には、CSSを使用するのではなく、dir
属性を使用してテキストの方向を示すことが強く推奨されます。そうすることで、CSSがない場合でも
(たとえば、検索エンジンによって解釈される場合でも)、文書が正しくレンダリングされ続けるためです。
このマークアップ断片は、インスタントメッセージの会話を表しています。
< p dir = auto class = "u1" >< b >< bdi > Student</ bdi > :</ b > How do you write "What's your name?" in Arabic?</ p >
< p dir = auto class = "u2" >< b >< bdi > Teacher</ bdi > :</ b > ما اسمك؟</ p >
< p dir = auto class = "u1" >< b >< bdi > Student</ bdi > :</ b > Thanks.</ p >
< p dir = auto class = "u2" >< b >< bdi > Teacher</ bdi > :</ b > That's written "شكرًا".</ p >
< p dir = auto class = "u2" >< b >< bdi > Teacher</ bdi > :</ b > Do you know how to write "Please"?</ p >
< p dir = auto class = "u1" >< b >< bdi > Student</ bdi > :</ b > "من فضلك", right?</ p > 適切なスタイルシート、およびp要素の既定の配置スタイル、
すなわちテキストを段落の開始端に揃えるスタイルが指定されている場合、
結果のレンダリングは次のようになります:

先に述べたように、auto値は万能ではありません。
この例の最後の段落はアラビア文字で始まるため、右から左へ記述されるテキストであると
誤って解釈され、その結果「right?」がアラビア語テキストの左側に配置されます。
style属性現在のすべてのエンジンでサポートされています。
すべてのHTML要素には、styleコンテンツ属性を
設定できます。これは、CSS Style
Attributesで定義されるスタイル属性です。
[CSSATTR]
CSSをサポートするユーザーエージェントでは、属性が追加されたとき、またはその値が変更されたときに、 スタイル属性について 定められた規則に従って、属性値を解析しなければなりません。 [CSSATTR]
ただし、属性の要素、「style attribute」、および属性値を指定して
要素のインライン動作を
コンテンツセキュリティポリシーによってブロックするべきか?アルゴリズムを実行した結果が
「Blocked」である場合、属性値で定義されたスタイル規則を要素に適用してはなりません。[CSP]
いずれかの要素でstyle属性を使用する
文書は、それらの属性を削除した場合でも理解可能かつ使用可能でなければなりません。
特に、コンテンツを非表示または表示するため、あるいは文書内に他の方法で
含まれていない意味を伝えるためにstyle属性を使用することは
不適合です。(コンテンツを非表示または表示するには、
属性を使用してください。)
element.style
要素のstyle属性に対応する
CSSStyleDeclaration
オブジェクトを返します。
style
IDL属性は、CSS Object
Modelで定義されています。[CSSOM]
次の例では、色を表す単語をspan要素およびstyle属性を使用してマークアップし、
視覚媒体でそれらの単語が対応する色で表示されるようにしています。
< p > My sweat suit is < span style = "color: green; background:
transparent" > green</ span > and my eyes are < span style = "color: blue;
background: transparent" > blue</ span > .</ p > data-*
属性によるカスタムの非表示データの埋め込み
現在のすべてのエンジンでサポートされています。
カスタムデータ属性とは、名前空間に属さず、その名前が文字列
「data-」で始まり、ハイフンの後に少なくとも1文字があり、
有効な属性ローカル名であり、ASCII大文字を含まない属性です。
HTML文書内のHTML要素にある すべての属性名は、自動的にASCII小文字化されるため、ASCII大文字に関する制限は そのような文書には影響しません。
カスタムデータ属性は、 より適切な属性または要素が存在しない、ページまたはアプリケーションに固有のカスタムデータ、 状態、注釈、および同様の情報を格納することを目的としています。
これらの属性は、その属性を使用するサイトの管理者に知られていないソフトウェアによる 使用を意図していません。複数の独立したツールで使用される汎用拡張については、 この仕様を拡張してその機能を明示的に提供するか、またはマイクロデータのような 技術を標準化された語彙とともに使用するべきです。
たとえば、音楽に関するサイトでは、アルバム内のトラックを表すリスト項目に、 各トラックの長さを含むカスタムデータ属性で注釈を付けることができます。この情報を サイト自体で使用し、ユーザーがトラックの長さでリストを並べ替えたり、 特定の長さのトラックに絞り込んだりできるようにできます。
< ol >
< li data-length = "2m11s" > Beyond The Sea</ li >
...
</ ol > ただし、ユーザーがその音楽サイトと関係のない汎用ソフトウェアを使用し、 このデータを調べて特定の長さのトラックを検索することは不適切です。
これは、これらの属性がサイト自身のスクリプトによる使用を意図しており、 公開利用可能なメタデータの汎用拡張機構ではないためです。
同様に、ページ作成者は、使用する予定の翻訳ツールに情報を提供する マークアップを記述できます:
< p > The third < span data-mytrans-de = "Anspruch" > claim</ span > covers the case of < span
translate = "no" > HTML</ span > markup.</ p > この例では、「data-mytrans-de」属性が、MyTrans製品が語句「claim」を
ドイツ語へ翻訳するときに使用する特定のテキストを指定しています。ただし、標準のtranslate
属性は、すべての言語で「HTML」を変更せずに残すよう伝えるために使用されています。
標準属性が利用可能な場合、カスタムデータ
属性を使用する必要はありません。
この例では、PaymentRequestの
機能検出結果を格納するためにカスタムデータ属性を使用しています。この結果は、CSSで
決済ページのスタイルを異なるものにするために使用できます。
< script >
if ( 'PaymentRequest' in window) {
document. documentElement. dataset. hasPaymentRequest = '' ;
}
</ script > ここでは、data-has-payment-request属性が実質的にブール属性として
使用されており、属性の存在を確認するだけで十分です。ただし、作成者が望む場合、
後で何らかの値を設定し、たとえば機能が限定的であることを示すこともできます。
すべてのHTML要素には、 任意の値を持つ任意の数のカスタムデータ 属性を指定できます。
作成者は、属性が無視され、関連するCSSが削除された場合でもページを使用できるよう、 このような拡張を慎重に設計するべきです。
ユーザーエージェントは、これらの属性または値から実装動作を導出してはなりません。 ユーザーエージェント向けの仕様は、これらの属性に意味のある値を定義してはなりません。
JavaScriptライブラリは、使用されるページの一部と見なされるため、カスタムデータ 属性を使用できます。多くの作成者によって再利用されるライブラリの作成者には、 衝突の危険を減らすため、属性名に自らの名前を含めることが推奨されます。適切な場合、 ライブラリ作成者には、属性名で使用する正確な名前をカスタマイズ可能にすることも推奨されます。 これにより、作成者が知らずに同じ名前を選んだライブラリを同じページで使用でき、 また、特定のライブラリの相互に互換性のない複数のバージョンを同じページで使用できます。
たとえば、「DoQuery」というライブラリはdata-doquery-rangeのような属性名を使用でき、
「jJo」というライブラリはdata-jjo-rangeのような属性名を使用できます。
jJoライブラリは、使用する接頭辞を設定するAPIも提供できます(たとえば、
J.setDataPrefix('j2')とすると、属性名が
data-j2-rangeのようになります)。
element.dataset
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
要素のdata-*
属性に対応するDOMStringMap
オブジェクトを返します。
ハイフン区切りの名前はキャメルケースになります。たとえば、data-foo-bar=""は
element.dataset.fooBarになります。
dataset IDL
属性は、要素上のすべてのdata-*
属性への便利なアクセサーを提供します。取得時、dataset
IDL属性は、関連付けられた要素がこの要素であるDOMStringMap
を返さなければなりません。
DOMStringMap
インターフェースは、dataset
属性で使用されます。各DOMStringMap
には関連付けられた要素があります。
[Exposed =Window ,
LegacyOverrideBuiltIns ]
interface DOMStringMap {
getter DOMString (DOMString name );
[CEReactions ] setter undefined (DOMString name , DOMString value );
[CEReactions ] deleter undefined (DOMString name );
};DOMStringMapの名前と値の
ペアを取得するには、次のアルゴリズムを実行します:
listを名前と値のペアの空のリストとします。
DOMStringMapの
関連付けられた
要素上の各コンテンツ属性のうち、最初の5文字が文字列「data-」であり、
残りの文字が存在する場合にASCII大文字を含まないものについて、要素の属性
リストに列挙されている順で、名前が属性名から最初の5文字を削除したもの、
値が属性値である名前と値のペアをlistに追加します。
list内の各名前について、その名前内の各U+002D HYPHEN-MINUS文字(-)のうち、 後にASCII 小文字が続くものについて、U+002D HYPHEN-MINUS文字(-)を削除し、 その直後の文字を同じ文字のASCII大文字に変換したもので置き換えます。
listを返します。
任意の時点におけるDOMStringMap
オブジェクトのサポートされるプロパティ名は、その時点でDOMStringMapの
名前と値のペアを取得したときに返される各ペアの名前であり、返される順序と同じです。
DOMStringMapについて、
名前付きプロパティnameの値を決定するには、DOMStringMapの
名前と値のペアを取得して返されたリスト内で、名前部分がnameである
名前と値のペアの値部分を返します。
DOMStringMapについて、
新しい名前付きプロパティの値を設定するか、
既存の名前付きプロパティの値を設定するには、
プロパティ名nameおよび新しい値valueを指定して、次の手順を実行します:
nameに、後にASCII
小文字が続くU+002D HYPHEN-MINUS文字(-)が含まれる場合、「SyntaxError」
DOMExceptionを
スローします。
name内の各ASCII 大文字について、その文字の前にU+002D HYPHEN-MINUS文字(-)を挿入し、その文字を 同じ文字のASCII小文字に変換したもので置き換えます。
文字列data-をnameの先頭に挿入します。
nameが有効な属性ローカル名でない場合、「InvalidCharacterError」 DOMExceptionを
スローします。
nameおよびvalueを使用して、DOMStringMapの
関連付けられた
要素の属性値を設定します。
DOMStringMapについて、
既存の名前付きプロパティnameを削除するには、次の手順を実行します:
name内の各ASCII 大文字について、その文字の前にU+002D HYPHEN-MINUS文字(-)を挿入し、その文字を 同じ文字のASCII小文字に変換したもので置き換えます。
文字列data-をnameの先頭に挿入します。
nameおよびDOMStringMapの
関連付けられた
要素を指定して、名前によって属性を削除します。
このアルゴリズムは、先のDOMStringMapの
名前と値のペアを取得するアルゴリズムによって与えられる名前についてのみ、
Web IDLによって呼び出されます。[WEBIDL]
ウェブページで、たとえばゲームの一部として、要素に宇宙船を表させる場合、class
属性をdata-*
属性とともに使用する必要があります:
< div class = "spaceship" data-ship-id = "92432"
data-weapons = "laser 2" data-shields = "50%"
data- x = "30" data-y = "10" data-z = "90" >
< button class = "fire"
onclick = "spaceships[this.parentNode.dataset.shipId].fire()" >
Fire
</ button >
</ div > ハイフン区切りの属性名がAPIではキャメルケースになることに注意してください。
次の断片および同様の構造を持つ要素が与えられたとします:
< img class = "tower" id = "tower5" data- x = "12" data-y = "5"
data-ai = "robotarget" data-hp = "46" data-ability = "flames"
src = "towers/rocket.png" alt = "Rocket Tower" > ……いくつかの引数を取り、その最初の引数が処理対象の要素である
splashDamage()関数を想定できます:
function splashDamage( node, x, y, damage) {
if ( node. classList. contains( 'tower' ) && // checking the 'class' attribute
node. dataset. x == x && // reading the 'data-x' attribute
node. dataset. y == y) { // reading the 'data-y' attribute
var hp = parseInt( node. dataset. hp); // reading the 'data-hp' attribute
hp = hp - damage;
if ( hp < 0 ) {
hp = 0 ;
node. dataset. ai = 'dead' ; // setting the 'data-ai' attribute
delete node. dataset. ability; // removing the 'data-ability' attribute
}
node. dataset. hp = hp; // setting the 'data-hp' attribute
}
} innerTextおよびouterTextプロパティ現在のすべてのエンジンでサポートされています。
element.innerText [ = value ]
要素のテキスト内容を「レンダリングされたとおり」に返します。
設定すると、要素の子を指定された値で置き換えますが、改行はbr
要素に変換されます。
element.outerText [ = value ]
要素のテキスト内容を「レンダリングされたとおり」に返します。
設定すると、要素を指定された値で置き換えますが、改行は
br要素に
変換されます。
HTMLElement elementを指定したテキストを取得する手順は 次のとおりです:
elementがレンダリングされていない場合、または ユーザーエージェントがCSS非対応ユーザーエージェントである場合、elementの子孫テキスト内容を返します。
この手順は意外な結果を生じることがあります。innerTextゲッターを
レンダリングされていない
要素で呼び出すと、そのテキスト内容が返されますが、レンダリングされている要素でアクセスすると、
レンダリングされていない
すべての子のテキスト内容は無視されます。
resultsを新しい空のリストとします。
elementの各子ノードnodeについて:
currentを、nodeを指定してレンダリング済み テキスト収集手順を実行した結果のリストとします。 results内の各項目は、文字列または正の整数(必須改行数)のいずれかです。
直感的には、必須改行数項目は、その位置に特定数の改行が 現れることを意味しますが、CSSのマージンの相殺を思わせる方法で、隣接する 必須改行数項目によって生じる改行と相殺できます。
current内の各項目itemについて、itemを resultsに追加します。
resultsから空文字列である項目をすべて削除します。
resultsの先頭または末尾にある、連続する必須改行数項目の並びを すべて削除します。
残りの連続する各必須改行数項目の並びを、その必須改行数項目の値の最大値と 同数のU+000A LFコードポイントからなる文字列で置き換えます。
results内の文字列項目を連結したものを返します。
現在のすべてのエンジンでサポートされています。
innerTextおよび
outerTextのゲッター手順は、thisを指定してテキストを取得する手順を実行した結果を
返すことです。
ノードnodeを指定したレンダリング済みテキスト収集手順は、 次のとおりです:
itemsを、nodeの各子ノードについてツリー順でレンダリング済みテキスト収集 手順を実行し、その結果を単一のリストに連結した結果とします。
nodeの'visibility'の算出値が 'visible'でない場合、itemsを返します。
nodeがレンダリングされていない場合、 itemsを返します。この手順の目的上、次の要素は、'display'プロパティの算出値が'none'でない場合、次に記すように動作しなければなりません:
select
要素には、子ボックスとしてoptgroup
およびoption
要素の子孫ノードのボックスのみを含む、置換されないインラインのCSSボックスが関連付けられます。
optgroup
要素には、子ボックスとしてoption
要素の子孫ノードのボックスのみを含む、置換されないブロックレベルのCSS
ボックスが関連付けられます。および
option
要素には、子ボックスが置換されないブロックレベルのCSSボックスとして通常どおりである、置換されない
ブロックレベルのCSS
ボックスが関連付けられます。
'display:contents'により、itemsが空でない場合があります。
nodeがText
ノードである場合、nodeによって生成される各CSSテキストボックスについて、
コンテンツ順で、CSSの'white-space'処理規則および'text-transform'規則を適用した後のボックスのテキストを
算出し、itemsを結果の文字列からなるリストに設定して、itemsを返します。
CSSの'white-space'処理規則はわずかに変更されます。行末の
折り畳み可能な空白は常に折り畳まれますが、その行がブロックの最後の行であるか、
br要素で
終わる場合にのみ削除されます。ソフトハイフンは保持するべきです。
[CSSTEXT]
nodeの'display'の算出値が'table-cell'であり、nodeのCSSボックスが、それを囲む'table-row'ボックスの最後の'table-cell'ボックスでない場合、単一のU+0009 TABコードポイントを 含む文字列をitemsに追加します。
nodeの'display'の算出値が'table-row'であり、nodeのCSSボックスが、最も近い祖先の'table'ボックスの最後の'table-row'ボックスでない場合、単一のU+000A LFコードポイントを 含む文字列をitemsに追加します。
nodeの'display'の使用値がブロックレベルまたは'table-caption'である場合、itemsの先頭および末尾に 1(必須改行数)を追加します。[CSSDISPLAY]
浮動要素および絶対配置要素はこのカテゴリーに該当します。
itemsを返します。
厳密に言えば、ほとんどの置換要素(たとえば、textarea、
input、および
video。
ただし、buttonは除く)の
子孫ノードはCSSによってレンダリングされないため、このアルゴリズムの目的上、CSSボックスを持たないことに
注意してください。
このアルゴリズムは、範囲で動作するよう一般化できます。そうすれば、これをSelectionの
文字列化子の基礎として使用でき、おそらく範囲上に直接公開することもできます。Bugzillaバグ10583を参照してください。
HTMLElement elementおよび文字列valueを指定した内部テキストを設定する手順は 次のとおりです:
fragmentを、elementのノード文書を指定したvalueのレンダリング済みテキスト断片とします。
element内のすべてをfragmentで置き換えます。
innerTextの
セッター手順は、thisおよび指定された値を使用して内部テキストを設定する
手順を実行することです。
outerTextの
セッター手順は次のとおりです:
thisの親がnullである場合、「NoModificationAllowedError」 DOMExceptionを
スローします。
fragmentを、thisのノード文書を指定した、指定された値のレンダリング済みテキスト断片とします。
fragmentに子がない場合、thisのノード文書をノード文書とし、空文字列をデータとする新しいText
ノードをfragmentに追加します。
nextがnullでなく、nextの前の兄弟がText
ノードである場合、nextの前の兄弟を指定して次のテキストノードとマージします。
previousがText
ノードである場合、previousを指定して次のテキスト
ノードとマージします。
Document
documentを指定した文字列inputのレンダリング済みテキスト断片は、次の手順を実行した結果です:
fragmentを、documentを与えて文書フラグメントを 作成した結果とする。
positionを、inputの位置 変数とし、 初期状態ではinputの先頭を指すものとする。
textを空文字列とする。
positionがinputの末尾を越えていない間:
fragmentを返す。
Text
ノードnodeを指定して次のテキストノードとマージするには:
HTML
要素のうち、その内容に
Text
ノードを持つもののテキスト
内容、および自由形式のテキストを許可するHTML
要素の属性内のテキストには、U+202AからU+202Eまで、およびU+2066からU+2069までの範囲の文字
(双方向アルゴリズムの書式制御文字)を含めることができます。[BIDI]
作成者には、双方向アルゴリズムの書式制御文字を手動で管理するのではなく、dir
属性、bdo
要素、およびbdi
要素を使用することが推奨されます。双方向アルゴリズムの書式制御文字は、CSSとの相互作用が不十分です。
ユーザーエージェントは、文書および文書の一部をレンダリングするときに文字の適切な順序を決定するため、 Unicode双方向アルゴリズムを実装しなければなりません。[BIDI]
HTMLからUnicode双方向アルゴリズムへの対応付けは、3つの方法のいずれかで行わなければなりません。 ユーザーエージェントは、特にCSSの'unicode-bidi'、'direction'、および'content'プロパティを含むCSSを実装し、 そのユーザーエージェントスタイルシートに、この仕様のレンダリング節で示される、 それらのプロパティを使用した規則を持たなければなりません。あるいは、ユーザーエージェントは、 前述のプロパティだけを実装し、前述のすべての規則を含むユーザーエージェントスタイルシートを 持っているかのように動作しなければなりません。ただし、文書で指定されたスタイルシートが それらを上書きできるようにしてはなりません。あるいは、ユーザーエージェントは、 同等のセマンティクスを持つ別のスタイル言語を実装しなければなりません。[CSSGC]
次の要素および属性には、レンダリング節によって定義される要件があり、 この節の要件により、すべてのユーザーエージェントに対する要件となります (推奨される既定のレンダリングをサポートするものだけではありません):
HTML 要素にアクセシビリティAPIのセマンティクスを実装するためのユーザーエージェント要件は、 HTML Accessibility API Mappingsで定義されています。そこにある規則に加えて、 カスタム要素elementについて、 既定のARIAロールのセマンティクスは次のように決定されます:[HTMLAAM]
mapを、elementの内部コンテンツ属性 マップとします。
map["role"]が存在する場合、
それを返します。
ロールなしを返します。
同様に、カスタム要素elementについて、 stateOrPropertyという名前の状態またはプロパティに対する、既定のARIA状態および プロパティのセマンティクスは、次のように決定されます:
elementの付加された内部が nullでない場合:
elementの付加された 内部の stateOrPropertyに関連付けられた要素を取得が存在する場合、 それを実行した結果を返します。
elementの付加された 内部の stateOrPropertyに関連付けられた要素群を取得が存在する場合、 それを実行した結果を返します。
elementの内部コンテンツ属性 マップ[stateOrProperty]が存在する場合、 それを返します。
stateOrPropertyの既定値を返します。
ここでいう「既定のセマンティクス」は、ARIAでは「ネイティブ」、 「暗黙的」、または「ホスト言語」のセマンティクスとも呼ばれることがあります。[ARIA]
これらの定義が意味することの1つは、既定のセマンティクスが時間とともに
変化し得るということです。これにより、カスタム要素は組み込み要素と同じ表現力を持てます。
たとえば、a要素の
href属性が
追加または削除されたときに、既定のARIAロールのセマンティクスがどのように変化するかと比較してください。
この動作例については、カスタム要素の節を参照してください。
HTML要素上でのARIAのrole属性およびaria-*属性の使用を検査するための
適合性チェッカー要件は、ARIA in HTMLで定義されています。
[ARIAHTML]
html
要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
head要素の後に
body要素。
html要素内の
最初のものがコメントでない場合、
html要素の開始タグを省略できます。
html要素の直後に
コメントがない場合、html要素の終了タグを省略できます。
[Exposed =Window ]
interface HTMLHtmlElement : HTMLElement {
[HTMLConstructor ] constructor ();
// also has obsolete members
};作成者には、ルートのhtml要素に、
文書の言語を示すlang
属性を指定することが推奨されます。これにより、音声合成ツールは使用する発音を決定し、
翻訳ツールは使用する規則を決定するなどできます。
次の例のhtml要素は、
文書の言語が英語であることを宣言しています。
<!DOCTYPE html>
< html lang = "en" >
< head >
< title > Swapping Songs</ title >
</ head >
< body >
< h1 > Swapping Songs</ h1 >
< p > Tonight I swapped some of the songs I wrote with some friends, who
gave me some of the songs they wrote. I love sharing my music.</ p >
</ body >
</ html > head
要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
html要素内の最初の要素として。iframeのsrcdoc文書である場合、または上位レベルのプロトコルから
タイトル情報を利用できる場合:0個以上のメタデータコンテンツの要素。そのうちtitle要素は最大1つ、
base要素も最大1つ。
title要素であり、
base要素は最大1つ。
head要素内の最初のものが
要素である場合、head要素の開始タグを省略できます。head要素の直後に
ASCII空白または
コメントがない場合、
head要素の終了タグを省略できます。
[Exposed =Window ]
interface HTMLHeadElement : HTMLElement {
[HTMLConstructor ] constructor ();
};head要素は、
Documentのメタデータの集合を表します。
head要素内の
メタデータの集合は、大きい場合も小さい場合もあります。次は非常に短い例です:
<!doctype html>
< html lang = en >
< head >
< title > A document with a short head</ title >
</ head >
< body >
...次はより長い例です:
<!DOCTYPE HTML>
< HTML LANG = "EN" >
< HEAD >
< META CHARSET = "UTF-8" >
< BASE HREF = "https://www.example.com/" >
< TITLE > An application with a long head</ TITLE >
< LINK REL = "STYLESHEET" HREF = "default.css" >
< LINK REL = "STYLESHEET ALTERNATE" HREF = "big.css" TITLE = "Big Text" >
< SCRIPT SRC = "support.js" ></ SCRIPT >
< META NAME = "APPLICATION-NAME" CONTENT = "Long headed application" >
</ HEAD >
< BODY >
...title
要素はほとんどの状況で必須の子ですが、上位レベルのプロトコルがタイトル情報を提供する場合、
たとえばHTMLを電子メール作成形式として使用するときの電子メールの件名行では、title要素を省略できます。
title
要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
title要素を
含まないhead要素内。[Exposed =Window ]
interface HTMLTitleElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions ] attribute DOMString text ;
};title要素は、
文書のタイトルまたは名前を表します。
作成者は、ユーザーの履歴やブックマーク、検索結果など、文脈から切り離して使用される場合でも
文書を識別できるタイトルを使用するべきです。文書のタイトルは、最初の見出しとは異なることが
よくあります。最初の見出しは、文脈から切り離されたときに単独で意味を成す必要がないためです。
文書ごとにtitle要素は
1つ以下でなければなりません。
Documentにタイトルがなくても
妥当である場合、title要素は
おそらく必須ではありません。要素が必須となる場合の説明については、head要素の
コンテンツモデルを参照してください。
title.text [ = value ]
要素の子テキスト内容を返します。
設定すると、要素の子を指定された値で置き換えます。
次に、適切なタイトルの例を、同じページで使用され得る最上位の見出しと対比して示します。
< title > Introduction to The Mating Rituals of Bees</ title >
...
< h1 > Introduction</ h1 >
< p > This companion guide to the highly successful
< cite > Introduction to Medieval Bee-Keeping</ cite > book is...次のページは、同じサイトの一部かもしれません。タイトルが主題を曖昧さなく説明している一方で、 最初の見出しは読者が文脈を知っていることを前提としているため、その踊りがサルサなのか ワルツなのかと疑問に思うことがない点に注意してください:
< title > Dances used during bee mating rituals</ title >
...
< h1 > The Dances</ h1 > 文書のタイトルとして使用する文字列は、document.title
IDL属性によって
与えられます。
ユーザーエージェントは、ユーザーインターフェースで文書を参照するときに、
文書のタイトルを使用するべきです。title要素の内容が
この方法で使用される場合、そのtitle要素の方向性を使用して、
ユーザーインターフェース内の文書タイトルの方向性を設定するべきです。
base
要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
base要素を
含まないhead要素内。href — 文書基底URL
target — ハイパーリンクのナビゲーションおよびフォーム送信に使用する既定のナビゲーション可能
[Exposed =Window ]
interface HTMLBaseElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , ReflectSetter ] attribute USVString href ;
[CEReactions , Reflect ] attribute DOMString target ;
};base要素により、
作成者はURLを解析するための文書基底URLと、ハイパーリンクをたどるための
既定のナビゲーション可能の名前を指定できます。
この要素は、この情報以外の内容を表しません。
文書ごとにbase要素は
1つ以下でなければなりません。
base要素には、
href属性、
target属性、
またはその両方がなければなりません。
hrefコンテンツ属性を指定する場合、その値には空白で囲まれている可能性のある有効なURLを
含めなければなりません。
base要素に
href属性がある場合、
URLを取るものとして定義された属性を持つツリー内の他のすべての要素より
前になければなりません。
href属性を持つbase要素が複数ある場合、
最初のもの以外はすべて無視されます。
target属性を指定する場合、その値には有効なナビゲーション可能ターゲット名または
キーワードを含めなければなりません。これは、Document内のハイパーリンクおよびフォームがナビゲーションを引き起こすときに、
どのナビゲーション可能を既定として
使用するかを指定します。
base要素に
target属性がある場合、
ハイパーリンクを表すツリー内の
すべての要素より前になければなりません。
target属性を持つbase要素が複数ある場合、
最初のもの以外はすべて無視されます。
文書ツリー内で、hrefコンテンツ属性を持つ
最初のbase要素である
base要素には、
凍結基底URLがあります。次のいずれかの状況が発生した場合、
要素の凍結基底URLを直ちに設定しなければなりません:
base要素が、
そのDocument内で、
hrefコンテンツ属性を持つ
ツリー
順で最初のbase
要素になった場合。
base要素が、
そのDocument内で、
hrefコンテンツ属性を持つ
ツリー
順で最初のbase
要素であり、そのhrefコンテンツ属性が
変更された場合。
要素elementの凍結基底URLを設定するには:
documentを、elementのノード文書とします。
urlRecordを、elementのhrefコンテンツ属性の値を、
documentのフォールバック基底URLおよび
documentの文字エンコーディングを使用して解析した結果とします。
(したがって、base要素は
自身の影響を受けません。)
次のいずれかがtrueである場合:
urlRecordが失敗である。
urlRecordのスキームが
「data」または「javascript」である。または
urlRecordおよびdocumentに対してDocumentに対してbaseは許可されるか?を
実行した結果が「Blocked」である。
その場合、elementの凍結基底 URLをdocumentのフォールバック基底URLに設定し、返ります。
elementの凍結基底 URLをurlRecordに設定します。
documentを指定して基底URLの変更に応答します。
href
IDL属性は、取得時に、次のアルゴリズムを
実行した結果を返さなければなりません:
documentを、elementのノード文書とします。
urlを、この要素にhref属性があれば
その値、なければ空文字列とします。
urlRecordを、urlをdocumentのフォールバック基底URLおよび
documentの文字エンコーディングを使用して解析した結果とします。
(したがって、base要素は、他のbase要素または
自身の影響を受けません。)
urlRecordが失敗である場合、urlを返します。
urlRecordの直列化を返します。
この例では、base
要素を使用して文書基底
URLを設定しています:
<!DOCTYPE html>
< html lang = "en" >
< head >
< title > This is an example for the < base> element</ title >
< base href = "https://www.example.com/news/index.html" >
</ head >
< body >
< p > Visit the < a href = "archives.html" > archives</ a > .</ p >
</ body >
</ html > 上の例のリンクは、「https://www.example.com/news/archives.html」へのリンクになります。
link
要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
head要素の子であるnoscript要素内。href — ハイパーリンクのアドレス
crossorigin —
要素がオリジン間リクエストを処理する方法
rel — ハイパーリンクを含む文書と宛先リソースとの関係
media — 適用対象の媒体
integrity —
Subresource Integrityの検査で使用される完全性メタデータ [SRI]
hreflang —
リンク先リソースの言語
type —
参照先リソースの型に関するヒント
referrerpolicy —
要素によって開始されるフェッチに使用するリファラーポリシー
sizes — アイコンのサイズ
(rel="icon"の場合)
imagesrcset —
高解像度ディスプレイ、小型モニターなど、さまざまな状況で使用する画像(rel="preload"の場合)
imagesizes —
異なるページレイアウトにおける画像サイズ(rel="preload"の場合)
as —
プリロードリクエストの宛先(rel="preload"およびrel="modulepreload"の場合)
blocking —
要素が潜在的に
レンダリングをブロックするかどうか
color —
サイトのアイコンをカスタマイズするときに使用する色(rel="mask-icon"の場合)
disabled —
リンクが無効かどうか
fetchpriority
— 要素によって開始されるフェッチの優先度を設定
title属性には、
この要素上で特別なセマンティクスがあります:
リンクのタイトル、CSS
スタイルシート集合名
[Exposed =Window ]
interface HTMLLinkElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , ReflectURL ] attribute USVString href ;
[CEReactions ] attribute DOMString ? crossOrigin ;
[CEReactions , Reflect ] attribute DOMString rel ;
[CEReactions ] attribute DOMString as ;
[SameObject , PutForwards =value , Reflect="rel"] readonly attribute DOMTokenList relList ;
[CEReactions , Reflect ] attribute DOMString media ;
[CEReactions , Reflect ] attribute DOMString integrity ;
[CEReactions , Reflect ] attribute DOMString hreflang ;
[CEReactions , Reflect ] attribute DOMString type ;
[SameObject , PutForwards =value , Reflect ] readonly attribute DOMTokenList sizes ;
[CEReactions , Reflect ] attribute USVString imageSrcset ;
[CEReactions , Reflect ] attribute DOMString imageSizes ;
[CEReactions ] attribute DOMString referrerPolicy ;
[SameObject , PutForwards =value , Reflect ] readonly attribute DOMTokenList blocking ;
[CEReactions , Reflect ] attribute boolean disabled ;
[CEReactions ] attribute DOMString fetchPriority ;
// also has obsolete members
};
HTMLLinkElement includes LinkStyle ;link要素により、作成者は
文書を他のリソースにリンクできます。
リンクのアドレスは、href属性によって与えられます。href属性が存在する場合、その値は
空白で囲まれている可能性のある
有効な空でないURLでなければなりません。href属性またはimagesrcset
属性の一方または両方が存在しなければなりません。
href属性とimagesrcset属性の
両方が存在しない場合、要素はリンクを定義しません。
示されるリンクの種類(関係)は、rel属性の値によって与えられます。
この属性が存在する場合、その値は一意な空白区切りトークンの
順序なし集合でなければなりません。許可されるキーワードとその意味は、
後の節で定義されます。rel
属性が存在しない場合、キーワードを持たない場合、または使用されたキーワードのいずれも
この仕様の定義に従って許可されていない場合、要素はリンクを作成しません。
relのサポートされるトークンは、link要素で許可され、
処理モデルに影響を与え、ユーザーエージェントによってサポートされる、HTMLリンク型で
定義されたキーワードです。可能なサポートされるトークンは、
alternate、
dns-prefetch、
expect、
icon、
manifest、
modulepreload、
next、
pingback、
preconnect、
prefetch、
preload、
search、および
stylesheetです。
relのサポートされる
トークンには、ユーザーエージェントが処理モデルを実装している、このリスト内のトークンだけを
含めなければなりません。
理論上、ユーザーエージェントがJavaScriptを実行する検索エンジンである場合、canonicalキーワードの
処理モデルをサポートすることがあり得ます。しかし、実際にはその可能性はかなり低いです。
したがって、ほとんどの場合、canonicalをrelのサポートされる
トークンに含めるべきではありません。
link要素には、
rel属性またはitemprop
属性のいずれか一方がなければならず、両方があってはなりません。
link要素にitemprop
属性がある場合、またはrel属性がbody-okであるキーワードだけを含む場合、その要素はbody内で許可されるといいます。これは、要素をフレージングコンテンツが期待される場所で使用できることを
意味します。
rel属性を
使用する場合、要素をページのbody内で使用できるのは
一部の場合に限られます。itemprop
属性とともに使用する場合、マイクロデータモデルの制約に従うことを条件に、要素をhead要素内とページのbody内の両方で使用できます。
link要素を使用すると、
2つのカテゴリーのリンク、すなわち外部リソースへのリンクとハイパーリンクを作成できます。リンク型の節では、特定のリンク型が外部リソースであるかハイパーリンクであるかを
定義します。1つのlink要素で複数のリンクを
作成できます(その一部は外部リソースへのリンクで、一部はハイパーリンクである場合があります)。
正確にどのリンクがいくつ作成されるかは、rel属性で指定される
キーワードによって決まります。ユーザーエージェントは、要素ごとではなくリンクごとにリンクを
処理しなければなりません。
link要素について作成される
各リンクは個別に処理されます。たとえば、rel="stylesheet"を持つlink要素が2つある場合、
それぞれが別個の外部リソースとして数えられ、それぞれが独自の属性によって個別に影響を受けます。
同様に、1つのlink要素のrel属性の値が
next stylesheetである場合、nextキーワードについてのハイパーリンクと、stylesheet
キーワードについての外部リソースへのリンクの両方を作成し、それらはmediaやtitleなどの他の属性によって
異なる影響を受けます。
たとえば、次のlink要素は、
同じページへの2つのハイパーリンクを作成します:
< link rel = "author license" href = "/about" > この要素によって作成される2つのリンクのうち、一方は、対象ページに現在のページの作成者に 関する情報があるというセマンティクスを持ち、もう一方は、対象ページに現在のページが 提供されるライセンスに関する情報があるというセマンティクスを持ちます。
link要素とその
rel属性によって作成される
ハイパーリンクは、文書全体に適用されます。
これは、a要素およびarea要素のrel属性とは対照的です。
これらの属性は、文書内のリンクの位置によって文脈が与えられるリンクの型を示します。
a要素およびarea要素によって作成される
ものとは異なり、link要素によって作成される
ハイパーリンクは、推奨される既定のレンダリングをサポートするユーザーエージェントでは、
既定で文書の一部として表示されません。また、CSSを使用して強制的に表示しても、活性化動作を持ちません。代わりに、主としてページや
ページの内容を利用する他のソフトウェアによって使用され得るセマンティック情報を提供します。
さらに、ユーザーエージェントはそのような
ハイパーリンクをたどるための独自のUIを提供できます。
外部リソースへのリンクの 正確な動作は、関連するリンク型について定義される正確な関係によって異なります。
crossorigin属性は、CORS設定属性です。
外部リソースへのリンクでの使用を意図しています。
media属性は、リソースが適用される媒体を示します。
値は有効なメディアクエリーリストでなければなりません。
現在のすべてのエンジンでサポートされています。
integrity属性は、この要素が担当するリクエストの完全性
メタデータを表します。値はテキストです。この属性は、stylesheet、
preload、または
modulepreload
キーワードを含むrel属性を持つlink要素にのみ
指定しなければなりません。[SRI]
link要素上のhreflang属性は、a要素上の
hreflang属性と同じセマンティクスを持ちます。
type属性は、リンク先リソースのMIME型を示します。これは純粋に助言的なものです。値は有効なMIME型文字列でなければなりません。
外部リソースへのリンクでは、type属性は、
ユーザーエージェントがサポートしていないリソースのフェッチを避けられるようにするための
ヒントとして使用されます。
referrerpolicy属性は、リファラーポリシー属性です。これは外部リソースへのリンクでの使用を意図しており、リンク先リソースをフェッチして処理するときに
使用するリファラーポリシーの設定に役立ちます。
[REFERRERPOLICY]
title属性は、リンクのタイトルを示します。
1つの例外を除き、これは純粋に助言的なものです。値はテキストです。例外は、文書ツリー内にあるスタイルシートリンクであり、
その場合、title属性はCSS
スタイルシート集合を定義します。
link要素上の
title属性は、
タイトルを持たないリンクが親要素のタイトルを継承しない点で、他のほとんどの要素のグローバルな
title属性とは異なります。
そのリンクには単にタイトルがありません。
imagesrcset属性を指定しても構いません。これはsrcset属性です。
imagesrcset属性と
href属性は、幅
記述子が使用されていない場合、合わせてソース集合に画像
ソースを提供します。
imagesrcset
属性が存在し、幅記述子を使用する画像候補文字列を
1つでも含む場合、imagesizes属性も存在しなければならず、これはsizes属性です。imagesizes属性は、
ソース集合にソースサイズを提供します。
imagesrcset属性と
imagesizes属性は、
preloadキーワードを
指定するrel属性と、
「image」状態にあるas属性の両方を持つlink要素にのみ
指定しなければなりません。
これらの属性により、後で対応するsrcset属性およびsizes属性の値を持つimg要素によって使用される、
適切なリソースをプリロードできます:
< link rel = "preload" as = "image"
imagesrcset = "wolf_400px.jpg 400w, wolf_800px.jpg 800w, wolf_1600px.jpg 1600w"
imagesizes = "50vw" >
<!-- ... later, or perhaps inserted dynamically ... -->
< img src = "wolf.jpg" alt = "A rad wolf"
srcset = "wolf_400px.jpg 400w, wolf_800px.jpg 800w, wolf_1600px.jpg 1600w"
sizes = "50vw" > href属性を省略している点に
注意してください。この属性はimagesrcsetを
サポートしないブラウザーにのみ関係しますが、その場合は誤った画像がプリロードされる可能性が
高いためです。
imagesrcset
属性は、media属性と
組み合わせて、アートディレクションのために、
picture要素の
ソースから選択される適切なリソースをプリロードできます:
< link rel = "preload" as = "image"
imagesrcset = "dog-cropped-1x.jpg, dog-cropped-2x.jpg 2x"
media = "(max-width: 800px)" >
< link rel = "preload" as = "image"
imagesrcset = "dog-wide-1x.jpg, dog-wide-2x.jpg 2x"
media = "(min-width: 801px)" >
<!-- ... later, or perhaps inserted dynamically ... -->
< picture >
< source srcset = "dog-cropped-1x.jpg, dog-cropped-2x.jpg 2x"
media = "(max-width: 800px)" >
< img src = "dog-wide-1x.jpg" srcset = "dog-wide-2x.jpg 2x"
alt = "An awesome dog" >
</ picture > sizes属性は、視覚媒体用アイコンのサイズを示します。
その値が存在する場合でも、単なる助言です。複数のアイコンを利用できる場合、ユーザーエージェントは
この値を使用して、使用するアイコンを決定しても構いません。属性を指定する場合、その値は一意な空白区切りトークンの
順序なし集合でなければならず、それらはASCII大文字・小文字不区別です。各値は、文字列「any」にASCII大文字・小文字不区別で一致するか、先頭に
U+0030 DIGIT ZERO(0)文字を持たない2つの有効な非負整数を、単一のU+0078 LATIN SMALL LETTER X
またはU+0058 LATIN CAPITAL LETTER X文字で区切った値でなければなりません。この属性は、iconキーワードまたは
apple-touch-iconキーワードを指定するrel属性を持つlink要素にのみ
指定しなければなりません。
apple-touch-iconキーワードは、定義済みリンク型集合の拡張として登録されていますが、
ユーザーエージェントはこれをいかなる方法でもサポートする必要はありません。
as属性は、href属性によって与えられる
リソースのプリロードリクエストについて、プリロード宛先またはモジュールプリロード
宛先のいずれかを指定します。これは列挙属性です。プリロード宛先とモジュールプリロード宛先の和集合の各項目は、
この属性のキーワードであり、同じ名前の状態に対応付けられます。この属性は、preloadキーワードを含む
rel属性を持つlink要素に
指定しなければなりません。そのような場合、その値はプリロード宛先でなければなりません。modulepreload
キーワードを含むrel属性を持つlink要素に指定しても
構いません。そのような場合、その値はモジュールプリロード宛先でなければなりません。
その他のlink要素には
指定してはなりません。
as属性が使用される方法の
処理モデルは、各リンク型のリンク先リソースをフェッチして処理する
アルゴリズムで示されます。
この属性には欠損値の
デフォルトも無効値の
デフォルトもありません。これは、この属性の無効な値または欠損値が、どの状態にも
対応付けられないことを意味します。これは処理モデルで考慮されます。preloadリンクでは、
どちらの条件もエラーです。modulepreload
リンクでは、欠損値は「script」として扱われます。
blocking属性は、ブロッキング属性です。これは
リンク型stylesheetおよび
expectで使用され、
これらのキーワードを含むrel属性を持つlink要素にのみ
指定しなければなりません。
color属性は、mask-iconリンク型とともに
使用されます。この属性は、mask-iconキーワードを含むrel属性を持つlink要素にのみ
指定しなければなりません。値は、CSSの<color>生成規則に一致する文字列でなければならず、
ユーザーがサイトをピン留めしたときに表示されるアイコンの表示をカスタマイズするため、
ユーザーエージェントが使用できる推奨色を定義します。
この仕様には、color属性に関する
ユーザーエージェント要件はありません。
mask-iconキーワードは、定義済みリンク型集合の拡張として登録されていますが、
ユーザーエージェントはこれをいかなる方法でもサポートする必要はありません。
link要素には、
関連付けられた明示的に有効というブール値があります。
初期値はfalseです。
disabled属性は、stylesheetリンク型と
ともに使用されるブール属性です。この属性は、stylesheet
キーワードを含むrel属性を持つlink要素にのみ
指定しなければなりません。
たとえばdocument.querySelector("link").removeAttribute("disabled")を使用して、
disabled属性を
動的に削除すると、スタイルシートがフェッチされ、適用されます:
< link disabled rel = "alternate stylesheet" href = "css/pooh" > fetchpriority属性は、フェッチ優先度属性です。これは外部リソースへのリンクでの使用を意図しており、リンク先リソースをフェッチして処理するときに
使用する優先度を設定するために使用されます。
color属性を反映するIDL属性は
ありませんが、後で追加される可能性があります。
現在のすべてのエンジンでサポートされています。
as IDL属性は、asコンテンツ属性を、既知の値のみに制限して反映しなければなりません。
crossOrigin IDL属性は、crossorigin
コンテンツ属性を、既知の値のみに制限して反映しなければなりません。
HTMLLinkElement/referrerPolicy
現在のすべてのエンジンでサポートされています。
referrerPolicy IDL属性は、referrerpolicy
コンテンツ属性を、既知の値のみに制限して反映しなければなりません。
fetchPriority IDL属性は、fetchpriority
コンテンツ属性を、既知の値のみに制限して反映しなければなりません。
relList
属性は、そのsupports()
メソッドを呼び出して、どのリンク型がサポートされているかを確認することにより、
機能検出に使用できます。
media属性の処理リンクがハイパーリンクである場合、media
属性は純粋に助言的なものであり、対象の文書がどの媒体向けに設計されたかを説明します。
ただし、リンクが外部リソースへのリンクである場合、media属性は
規範的です。ユーザーエージェントは、media属性の値が
環境に一致し、
その他の関連条件が適用される場合に外部リソースを適用しなければならず、それ以外の場合は
適用してはなりません。
media属性を省略した
場合のデフォルトは「all」です。これは、デフォルトではリンクがすべての媒体に
適用されることを意味します。
外部リソース自体に、その適用可能性を制限するさらなる制約が定義されている場合があります。
たとえば、CSSスタイルシートにいくつかの@mediaブロックが含まれている場合があります。
この仕様は、そのような追加の制約または要件を上書きしません。
type属性の処理type
属性が存在する場合、ユーザーエージェントは、そのリソースが指定された型であると
仮定しなければなりません(それが有効なMIME型
文字列でない場合、たとえば空文字列である場合も含みます)。属性が省略されているものの、外部リソースへのリンクの型にデフォルトの型が
定義されている場合、ユーザーエージェントはリソースがその型であると仮定しなければなりません。
UAが指定されたリンク関係について指定されたMIME型を
サポートしていない場合、UAはリンク先リソースをフェッチして
処理するべきではありません。UAが指定されたリンク関係について指定されたMIME型を
サポートしている場合、UAは外部リソースへのリンクの特定の型について
指定された適切な時点で、リンク先リソースをフェッチして
処理するべきです。属性が省略され、外部リソースへのリンクの型にデフォルトの型が
定義されていないものの、型が既知でサポートされていればユーザーエージェントがリンク先リソースをフェッチして
処理する場合、ユーザーエージェントは、それがサポートされるという仮定のもとでリンク先リソースをフェッチして
処理するべきです。
ユーザーエージェントは、type属性を
権威あるものと見なしてはなりません。リソースをフェッチした際、ユーザーエージェントは、その実際の型を
決定するためにtype属性を
使用してはなりません。リソースを適用するかどうかを決定するために使用されるのは、
前述の仮定された型ではなく、実際の型(次の段落で定義されます)だけです。
外部リソースへのリンクの型が、リソースのContent-Type メタデータを処理するための規則を定義している場合、その規則が適用されます。それ以外で、 リソースが画像であることが期待される場合、ユーザーエージェントは、リソースのContent-Typeメタデータから決定された型を official typeとして、画像スニッフィング規則を適用し、その結果得られるリソースの算出型を実際の型であるかのように使用しても 構いません。それ以外で、これらの条件のいずれも適用されない場合、またはユーザーエージェントが 画像スニッフィング規則を適用しないことを選択した場合、ユーザーエージェントは、リソースのContent-Typeメタデータを 使用してリソースの型を決定しなければなりません。型メタデータが存在しないものの、外部リソースへのリンクの型にデフォルトの型が 定義されている場合、ユーザーエージェントは、リソースがその型であると仮定しなければなりません。
stylesheet
リンク型は、リソースのContent-Typeメタデータを処理するための規則を
定義します。
ユーザーエージェントがリソースの型を確定した後、その型がサポートされており、 その他の関連条件が適用される場合はリソースを適用しなければならず、それ以外の場合は リソースを無視しなければなりません。
文書に次のようにラベル付けされたスタイルシートリンクが含まれている場合:
< link rel = "stylesheet" href = "A" type = "text/plain" >
< link rel = "stylesheet" href = "B" type = "text/css" >
< link rel = "stylesheet" href = "C" > ……CSSスタイルシートだけをサポートする適合UAは、BおよびCのファイルをフェッチし、
Aのファイルをスキップします(text/plainは
CSSスタイルシートのMIME型ではないためです)。
BおよびCのファイルについては、次にサーバーから返された実際の型を確認します。text/cssとして送信されたものには
スタイルを適用しますが、text/plain
またはその他の型としてラベル付けされたものには適用しません。
2つのファイルのいずれかがContent-Typeメタデータなしで返された場合、
またはContent-Type: "null"のような構文的に不正な型で返された場合、
stylesheet
リンクのデフォルトの型が適用されます。そのデフォルトの型はtext/cssであるため、
それでもスタイルシートは適用されます。
link
要素からのリソースのフェッチと処理すべての外部リソースへの
リンクには、link
要素elを取るリンク先リソースをフェッチして
処理するアルゴリズムがあります。また、link
要素elおよびリクエストrequestを取るリンク先リソースのフェッチ設定手順もあります。
個々のリンク型は、独自のリンク先
リソースをフェッチして処理するアルゴリズムを提供できますが、明示的に記載されていない限り、
既定の
リンク先リソースをフェッチして処理するアルゴリズムを使用します。同様に、個々のリンク型は
独自のリンク先リソースの
フェッチ設定手順を提供できますが、明示的に記載されていない限り、これらの手順は単にtrueを返します。
link
要素elを指定した既定のリンク先リソースをフェッチして処理する
手順は、次のとおりです:
optionsを、elからリンク オプションを作成した結果とします。
requestを、optionsを指定してリンクリクエストを 作成した結果とします。
requestがnullである場合、返ります。
requestの同期フラグを設定します。
elおよびrequestを指定して、リンク先 リソースのフェッチ設定手順を実行します。結果がfalseである場合、返ります。
elのrel
属性がキーワードstylesheetを
含む場合、requestの開始元の型を「css」に設定し、
それ以外の場合は「link」に設定します。
processResponseConsumeBodyを、 レスポンスresponseおよびnull、失敗、またはバイト列bodyBytesを指定した次の手順に設定して、 requestをフェッチします:
successをtrueとします。
次のいずれかがtrueである場合:
その場合、successをfalseに設定します。
CSS解析エラーやPNGデコードエラーなど、コンテンツ固有のエラーは successに影響しないことに注意してください。
それ以外の場合、リンク リソースの重要な サブリソースの読み込みが完了するまで待ちます。
リンク型の重要な サブリソースを定義する仕様(たとえばCSS)は、これらのサブリソースをどのように フェッチして処理するかを説明することが期待されています。ただし、これは現在明示的ではないため、 この仕様では、リンク リソースの重要な サブリソースがフェッチされ処理されるのを待つことを説明し、これが正しく行われることを 期待しています。
el、success、response、および bodyBytesを指定して、リンク先 リソースを処理します。
リンク処理 オプションoptionsを指定してリンクリクエストを作成するには:
urlを、optionsのhrefを、 optionsの基底URLに対して URLを エンコーディング解析した結果とします。
文書または環境の代わりに基底URLを渡すことは、issue #9715で追跡されています。
urlが失敗である場合、nullを返します。
requestを、url、optionsの宛先、および optionsのcrossoriginを 指定して、潜在的CORS リクエストを作成した結果とします。
requestのポリシーコンテナーを、 optionsのポリシー コンテナーに設定します。
requestの暗号学的nonceメタデータを、 optionsの暗号学的nonce メタデータに設定します。
requestのリファラーポリシーを、 optionsのリファラー ポリシーに設定します。
requestを返します。
ユーザーエージェントは、適用されないすべての外部リソースを 先行してフェッチする代わりに、そのようなリソースが必要になったときにだけフェッチして 処理することを選択しても構いません。
リンク先
リソースをフェッチして処理するアルゴリズムと同様に、すべての外部リソースへの
リンクには、link
要素el、ブール値success、レスポンスresponse、およびバイト列bodyBytesを取るリンク先リソースを処理するアルゴリズムがあります。個々のリンク型は、
独自のリンク先リソースを
処理するアルゴリズムを提供できますが、明示的に記載されていない限り、そのアルゴリズムは
何も行いません。
指定されたrel
キーワードについて別途指定されていない限り、要素は、リンク先
リソースをフェッチして処理するすべての試行と、その重要な
サブリソースが完了するまで、要素のノード文書のloadイベントを
遅延しなければなりません。(ユーザーエージェントがまだフェッチおよび処理を試みていないリソース、
たとえばリソースが必要になるのを待っているために未処理のリソースは、loadイベントを
遅延しません。)
Link`
ヘッダーの処理外部リソースへのリンクとなり得るすべてのリンク型は、
リンク処理オプションを取るリンクヘッダーを処理するアルゴリズムを定義します。このアルゴリズムは、
HTTPレスポンスの`Link`
ヘッダーに現れた場合に、リンク型が反応するかどうか、およびどのように反応するかを定義します。
ほとんどのリンク型では、このアルゴリズムは何も行いません。リンク型にリンクヘッダーを 処理する手順が定義されているかを素早く確認するには、概要表が 役立ちます。
リンク処理オプションは構造体です。これには次の項目があります:
link」)DocumentDocumentを受け取るアルゴリズム自動)
リンク処理オプションが、解析済みURLではなく基底URLとhrefを持つのは、 URLがオプションのソース集合の結果である可能性があるためです。
link要素
elを指定して要素からリンクオプションを
作成するには:
documentをelのノード文書とします。
optionsを、次を持つ新しいリンク処理オプションとします。
crossorigin
コンテンツ属性の状態referrerpolicy
コンテンツ属性の状態fetchpriority
コンテンツ属性の状態elにintegrity
属性がある場合、optionsのintegrityを、
elのintegrity
コンテンツ属性の値に設定します。
表明:optionsのhrefは空文字列ではないか、または optionsのソース集合はnullではありません。
link要素に
href属性も
imagesrcset
属性もない場合、リンクを表しません。
optionsを返します。
ヘッダーリストheadersを指定して、ヘッダーからリンクを抽出するには:
Documentdoc、
レスポンスresponse、および
「pre-media」または「media」であるphaseを指定して、
リンクヘッダーを処理するには:
links内の各linkObjectについて反復します:
relをlinkObject["relation_type"]とします。
attribsをlinkObject["target_attributes"]とします。
「srcset」、
「imagesrcset」、
または「media」の
いずれかがattribsに存在する場合、
expectedPhaseを「media」とし、それ以外の場合は
「pre-media」とします。
expectedPhaseがphaseでない場合、続行します。
optionsを、次を持つ新しいリンク処理オプションとします。
target_uri"]attribsおよびrelを指定して、optionsに解析済みヘッダー属性から リンクオプションを適用します。それがfalseを返した場合、返ります。
attribs["imagesrcset"]が
存在し、かつattribs["imagesizes"]も
存在する場合、optionsのソース集合を、
linkObject["target_uri"]、attribs["imagesrcset"]、
attribs["imagesizes"]、
およびnullを指定してソース集合を作成した結果に設定します。
optionsを指定して、relのリンクヘッダーを処理する手順を実行します。
attribsおよび文字列relを指定して、リンク処理オプションoptionsに解析済みヘッダー属性からリンクオプションを 適用するには:
relが「preload」である場合:
attribs["crossorigin"]が
存在し、かつCORS設定属性のキーワードのいずれかにASCII大文字・小文字不区別で一致する場合、
optionsのcrossoriginを、そのキーワードに対応するCORS設定属性の状態に設定します。
attribs["integrity"]が存在する場合、optionsのintegrityを
attribs["integrity"]に
設定します。
attribs["referrerpolicy"]が
存在し、かつ何らかのリファラーポリシーにASCII大文字・小文字不区別で一致する場合、
optionsのリファラーポリシーを、そのリファラーポリシーに設定します。
attribs["nonce"]が存在する場合、optionsのnonceをattribs["nonce"]に設定します。
attribs["fetchpriority"]が
存在し、かつフェッチ優先度属性のキーワードにASCII大文字・小文字不区別で一致する場合、
optionsのフェッチ優先度を、そのフェッチ優先度属性のキーワードに設定します。
trueを返します。
Early Hintsにより、ユーザーエージェントは、ナビゲーションリクエストが サーバーによって完全に処理され、レスポンスコードが返される前に、文書で使用される可能性が高い リソースを投機的に読み込むなどの操作を実行できます。サーバーは、最終的なレスポンスを返す前に、103ステータスコードを持つレスポンスを返すことで、Early Hintsを示すことができます。[RFC8297]
互換性上の理由から、Early Hintsは通常HTTP/2以上で 配信されますが、読みやすさのため、以下ではHTTP/1.1形式の表記を使用します。
たとえば、次のレスポンス列が与えられた場合:
103 Early Hint Link: </image.png>; rel=preload; as=image
200 OK Content-Type: text/html <!DOCTYPE html> ... <img src="/image.png">
HTMLコンテンツが到着する前に画像の読み込みが開始されます。
ナビゲーション中に返された最初のEarly Hintレスポンスだけが処理され、 その後にオリジン間リダイレクトが続いた場合は破棄されます。
`Link`
ヘッダーに加えて、103レスポンスにContent Security Policyヘッダーが含まれる場合があり、
これはEarly Hintを処理するときに適用されます。
たとえば、次のレスポンス列が与えられた場合:
103 Early Hint Content-Security-Policy: style-src: self; Link: </style.css>; rel=preload; as=style
103 Early Hint Link: </image.png>; rel=preload; as=image
302 Redirect Location: /alternate.html
200 OK Content-Security-Policy: style-src: none; Link: </font.ttf>; rel=preload; as=font
最終的なリダイレクトチェーン内の最初のEarly Hintレスポンスだけが尊重されるため、 フォントとスタイルは読み込まれ、画像は破棄されます。後のContent Security Policyヘッダーは、 スタイルをフェッチするリクエストがすでに実行された後に到着しますが、スタイルは文書から アクセスできません。
レスポンスresponseおよび環境reservedEnvironmentを指定して、 Early Hintヘッダーを処理するには:
Early Hintの`Link`
ヘッダーは、常に最終的なレスポンスの`Link`
ヘッダーより先に処理され、その後にlink要素が処理されます。
これは、Early Hintおよび最終レスポンスの`Link`
ヘッダーの内容を、それぞれの順序でDocumentのhead要素の先頭に追加することと
同等です。
earlyPolicyContainerを、responseおよび reservedEnvironmentを指定してフェッチレスポンスから ポリシーコンテナーを作成した結果とします。
これにより、Early HintのレスポンスにContent Security Policyを含めることができ、 Early Hintのリクエストをフェッチするときに、そのポリシーが適用されます。
earlyHintsを空のリストとします。
links内の各linkObjectについて反復します:
Early Hintのリンクヘッダーを受信した時点で、earlyRequestのフェッチを開始します。Documentが作成される前にレスポンスが
返された場合、earlyResponseをそのフェッチのレスポンスに設定し、Documentが作成された時点で、
link要素であるかのように
プリロード済みリソースのマップで利用可能にすることで
コミットします。Documentが先に作成された場合、
レスポンスは利用可能になり次第コミットされます。
relをlinkObject["relation_type"]とします。
optionsを、次を持つ新しいリンク処理オプションとします。
attribsをlinkObject["target_attributes"]とします。
Early Hintの処理の一部として扱われるのは、as、crossorigin、integrity、およびtype属性だけです。
その他の属性、特にblocking、imagesrcset、imagesizes、および
mediaは、Documentが作成された後にのみ
適用されます。
attribsおよびrelを指定して、optionsに解析済みヘッダー属性から リンクオプションを適用します。それがfalseを返した場合、返ります。
optionsを指定して、relのリンクヘッダーを処理する手順を実行します。
optionsをearlyHintsに追加します。
link
要素を使用して作成されたハイパーリンクをたどる手段のユーザーへの提供
対話型ユーザーエージェントは、文書内の各link
要素を使用して作成されたハイパーリンクを
たどる
手段を、そのユーザーインターフェース内のどこかでユーザーに提供しても構いません。このようなハイパーリンクを
たどるアルゴリズムの呼び出しでは、userInvolvement引数を「browser UI」に
設定しなければなりません。正確なインターフェースはこの仕様では定義されませんが、何らかの形式で
(場合によっては簡略化して)、次の情報(以下で再び定義されるように、要素の属性から取得されます)を
含めることができます:
rel
属性によって与えられます)title
属性によって与えられます)。href
属性によって与えられます)。hreflang
属性によって与えられます)。media
属性によって与えられます)。ユーザーエージェントは、リソースの型(type
属性によって与えられます)など、その他の情報を含めることもできます。
meta
要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
itemprop
属性が存在する場合:フローコンテンツ。itemprop
属性が存在する場合:フレージングコンテンツ。
charset属性が
存在する場合、または要素のhttp-equiv属性が
エンコーディング宣言状態である場合:head要素内。
http-equiv
属性が存在するものの、エンコーディング宣言状態でない場合:head要素内。http-equiv
属性が存在するものの、エンコーディング宣言状態でない場合:head要素の子であるnoscript要素内。
name属性が
存在する場合:メタデータコンテンツが期待される場所。itemprop
属性が存在する場合:メタデータコンテンツが期待される場所。itemprop
属性が存在する場合:フレージングコンテンツが期待される場所。name — メタデータ名
http-equiv —
プラグマ指令
content — 要素の値
charset — 文字エンコーディング宣言
media — 適用対象の媒体
[Exposed =Window ]
interface HTMLMetaElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute DOMString name ;
[CEReactions , Reflect="http-equiv"] attribute DOMString httpEquiv ;
[CEReactions , Reflect ] attribute DOMString content ;
[CEReactions , Reflect ] attribute DOMString media ;
// also has obsolete members
};meta要素は、title、base、link、style、および
script要素を使用して
表現できないさまざまな種類のメタデータを表します。
meta要素は、name属性によって文書レベルの
メタデータを、http-equiv属性によって
プラグマ指令を、HTML文書が文字列形式に直列化される場合(たとえば、ネットワーク経由での送信または
ディスクへの保存のため)には、charset属性によって
ファイルの文字エンコーディング宣言を表すことができます。
name、http-equiv、charset、およびitemprop
属性のうち、正確に1つを指定しなければなりません。
name、http-equiv、または
itemprop
のいずれかを指定する場合、content属性も
指定しなければなりません。それ以外の場合は、省略しなければなりません。
charset属性は、文書によって使用される文字エンコーディングを指定します。これは文字エンコーディング宣言です。属性が存在する場合、
その値は文字列「utf-8」にASCII大文字・小文字不区別で一致しなければなりません。
meta要素の
charset属性は、
XML文書では効果を持ちませんが、XMLとの間の移行を容易にするため、XML文書でも許可されています。
文書ごとに、charset属性を持つmeta要素は、
1つを超えて存在してはなりません。
content属性は、要素がこれらの目的で使用される場合に、
文書メタデータまたはプラグマ指令の値を与えます。許可される値は、この仕様の後続の節で説明されるように、
正確な文脈によって異なります。
meta要素がname属性を持つ場合、
文書メタデータを設定します。文書メタデータは名前と値のペアとして表現され、meta要素のname属性が名前を与え、
同じ要素のcontent属性が値を与えます。
名前は、メタデータのどの側面を設定するかを指定します。有効な名前とその値の意味は、後続の節で
説明されます。meta
要素にcontent属性がない場合、
メタデータの名前と値のペアの値部分は空文字列です。
media属性は、メタデータがどの媒体に適用されるかを示します。
値は有効なメディアクエリーリストでなければなりません。
nameがtheme-colorでない限り、media属性は処理モデルに
影響せず、作成者は使用してはなりません。
現在のすべてのエンジンでサポートされています。
この仕様は、meta要素のname属性について、
いくつかの名前を定義します。
名前は大文字・小文字を区別しません。また、ASCII大文字・小文字不区別で比較しなければなりません。
application-name値は、ページが表すウェブアプリケーションの名前を与える短い自由形式の文字列でなければなりません。
ページがウェブアプリケーションでない場合、application-name
メタデータ名を使用してはなりません。ウェブアプリケーション名の翻訳を指定することができ、
lang属性を使用して、
各名前の言語を指定します。
文書ごとに、特定の言語を持ち、name属性値が
application-nameに
ASCII大文字・小文字不区別で一致するmeta要素は、
1つを超えて存在してはなりません。
タイトルには特定の時点におけるページの状態に関連するステータスメッセージなどが含まれ、
単なるアプリケーション名ではない場合があるため、ユーザーエージェントはUIでページのtitleよりも
アプリケーション名を優先して使用しても構いません。
言語の順序付きリスト(たとえば、イギリス英語、アメリカ英語、英語)を指定して、 使用するアプリケーション名を見つけるには、ユーザーエージェントは次の手順を実行しなければなりません:
languagesを言語のリストとします。
default languageを、Documentの文書要素の言語が存在し、かつその言語が不明でない場合、
その言語とします。
default languageが存在し、それがlanguages内のどの言語とも 同じでない場合、それをlanguagesに追加します。
winning languageを、languages内の最初の言語のうち、Document内に、
name属性値が
application-nameに
ASCII大文字・小文字不区別で一致し、その言語が対象の言語であるmeta要素が
存在する言語とします。
どの言語にもそのようなmeta要素が
ない場合、返ります。指定されたアプリケーション名はありません。
Document内で、
name属性値が
application-nameに
ASCII大文字・小文字不区別で一致し、その言語がwinning
languageである、ツリー順で最初のmeta要素の
content属性の
値を返します。
このアルゴリズムは、たとえばブックマークのラベル付けなど、ブラウザーがページ名を 必要とする場合に使用されます。アルゴリズムに渡される言語は、ユーザーの優先言語です。
author値は、ページの作成者の1人の名前を与える自由形式の文字列でなければなりません。
description
値は、ページを説明する自由形式の文字列でなければなりません。値は、たとえば検索エンジンなど、
ページのディレクトリーで使用するのに適切でなければなりません。文書ごとに、name属性値が
descriptionに
ASCII大文字・小文字不区別で一致するmeta要素は、
1つを超えて存在してはなりません。
generator値は、文書の生成に使用されたソフトウェアパッケージの1つを識別する自由形式の文字列で なければなりません。この値は、マークアップがソフトウェアによって生成されていないページ、 たとえばユーザーがテキストエディターでマークアップを記述したページでは使用してはなりません。
「Frontweaver」というツールは、ページの生成に使用されたツールとして自身を識別するため、
ページのhead要素内の出力に
次のようなものを含めることができます:
< meta name = generator content = "Frontweaver 8.2" > keywords値はコンマ区切りトークンの集合で なければならず、それぞれがページに関連するキーワードです。
イギリスの高速道路で使用される書体に関するこのページでは、ユーザーがページを探すために
使用する可能性があるいくつかのキーワードを、meta要素を
使用して指定しています:
<!DOCTYPE HTML>
< html lang = "en-GB" >
< head >
< title > Typefaces on UK motorways</ title >
< meta name = "keywords" content = "british,type face,font,fonts,highway,highways" >
</ head >
< body >
...この機能は歴史的に信頼できない方法で使用され、ユーザーの役に立たない方法で 検索エンジンの結果をスパムするために、誤解を招くように使用されることさえあったため、 多くの検索エンジンはこのようなキーワードを考慮しません。
作成者がページに適用されるものとして指定したキーワードのリストを取得するには、 ユーザーエージェントは次の手順を実行しなければなりません:
値の信頼性について十分な確信がない場合、ユーザーエージェントはこの情報を使用するべきでは ありません。
たとえば、コンテンツ管理システムがシステム内のページのキーワード情報を使用して、 サイト固有の検索エンジンの索引を作成することは合理的です。しかし、この情報を使用する大規模な コンテンツ集約サービスでは、一部のユーザーが不適切なキーワードを使用して、そのランキング機構を 操作しようとする可能性が高いでしょう。
referrer値は、Documentの
既定のリファラーポリシーを定義するリファラーポリシーでなければなりません。[REFERRERPOLICY]
いずれかのmeta要素
elementが文書に挿入された場合、または
そのname属性もしくは
content属性が
変更された場合、ユーザーエージェントは次のアルゴリズムを実行しなければなりません:
elementが文書ツリー内にない場合、返ります。
elementが、値が「referrer」にASCII大文字・小文字不区別で一致するname属性を
持たない場合、返ります。
elementがcontent
属性を持たない場合、またはその属性値が空文字列である場合、返ります。
valueを、elementのcontent
属性の値をASCII小文字に変換したものとします。
valueが次の表の第1列に示されたいずれかの値である場合、 valueを第2列に示された値に設定します:
| 旧来の値 | リファラーポリシー |
|---|---|
never
|
no-referrer
|
default
|
既定のリファラーポリシー |
always
|
unsafe-url
|
origin-when-crossorigin
|
origin-when-cross-origin
|
valueがリファラーポリシーである場合、elementのノード文書のポリシーコンテナーのリファラーポリシーを policyに設定します。
歴史的な理由により、他の標準メタデータ名とは異なり、referrerの処理モデルは
要素の削除に反応せず、ツリー順を使用しません。この状態では、最も最近挿入された、
または最も最近変更されたmeta要素だけが
効果を持ちます。
theme-color
値は、CSSの<color>生成規則に一致する文字列でなければならず、 ユーザーエージェントがページまたは周囲のユーザーインターフェースの表示をカスタマイズするために 使用するべき推奨色を定義します。たとえば、ブラウザーはページのタイトルバーを指定された値で 色付けしたり、タブバーやタスクスイッチャーの強調色として使用したりできます。
HTML文書内では、name属性値が
theme-colorに
ASCII大文字・小文字不区別で一致するすべてのmeta要素の間で、
media属性値は
一意でなければなりません。
この標準自体は、そのテーマ色として「WHATWG green」を使用しています:
<!DOCTYPE HTML>
< title > HTML Standard</ title >
< meta name = "theme-color" content = "#3c790a" >
...media属性は、
提供された色を使用するべき文脈を説明するために使用できます。
ダークモードでのみ「WHATWG green」をこの標準のテーマ色として使用する場合、
prefers-color-schemeメディア機能を使用できます:
<!DOCTYPE HTML>
< title > HTML Standard</ title >
< meta name = "theme-color" content = "#3c790a" media = "(prefers-color-scheme: dark)" >
...ページのテーマ色を取得するには、ユーザーエージェントは次の手順を実行しなければなりません:
candidate elementsを、次の基準を満たすすべてのmeta要素の
ツリー順のリストとします:
要素が文書ツリー内にある。
要素が、値がtheme-colorに
ASCII大文字・小文字不区別で一致するname属性を
持つ。かつ
要素がcontent
属性を持つ。
candidate elements内の各elementについて:
何も返しません(ページにテーマ色はありません)。
いずれかのmeta要素が文書に挿入された場合、または文書から削除された場合、既存のmeta要素のname、content、または
media属性が
変更された場合、あるいは、いずれかのmeta要素のmedia属性値が、
現在環境に一致する可能性がある、または
一致しなくなる可能性があるように環境が変化した場合、ユーザーエージェントは上記のアルゴリズムを
再実行し、その結果を影響を受けるUIに適用しなければなりません。
UIでテーマ色を使用するとき、ユーザーエージェントは対象のUIにより適したものにするため、 実装固有の方法で色を調整しても構いません。たとえば、ユーザーエージェントがテーマ色を背景として 使用し、その上に白いテキストを表示する場合、十分なコントラストを確保するため、そのUI部分では より暗いテーマ色の変種を使用することがあります。
color-scheme
ページ内のすべてのCSSが読み込まれるのを待つのではなく、目的のカラースキームでページ背景を
直ちにレンダリングする際にユーザーエージェントを支援するため、'color-scheme'値をmeta要素で
提供できます。
値は、CSSの'color-scheme'プロパティ値の構文に一致する文字列で なければなりません。これはページがサポートするカラースキームを決定します。
文書ごとに、name属性値が
color-schemeに
ASCII大文字・小文字不区別で一致するmeta要素は、
1つを超えて存在してはなりません。
次の宣言は、ページが暗い背景色と明るい前景色を持つカラースキームを認識し、 処理できることを示します:
< meta name = "color-scheme" content = "dark" > ページがサポートするカラースキームを取得するには、 ユーザーエージェントは次の手順を実行しなければなりません:
candidate elementsを、次の基準を満たすすべてのmeta要素の
ツリー順のリストとします:
要素が文書ツリー内にある。
要素が、値がcolor-schemeに
ASCII大文字・小文字不区別で一致するname属性を
持つ。かつ
要素がcontent
属性を持つ。
candidate elements内の各elementについて:
content
属性の値を指定してコンポーネント値のリストを解析した結果とします。
nullを返します。
いずれかのmeta要素が文書に挿入された場合、または文書から削除された場合、あるいは
既存のmeta要素の
name属性または
content属性が
変更された場合、ユーザーエージェントは上記のアルゴリズムを再実行しなければなりません。
これらの規則は一致するものを見つけるまで後続の要素を検査するため、作成者は旧来の ユーザーエージェント向けのフォールバックを処理するため、複数の値を提供できます。プロパティに 対するCSSのフォールバックの動作とは逆に、複数のmeta要素は、新しい値の後に旧来の値を配置する 必要があります。
誰でも独自の定義済みメタデータ名集合の拡張を作成して 使用できます。そのような拡張を登録する要件はありません。
ただし、次のいずれかの場合には、新しいメタデータ名を作成するべきではありません:
名前自体がURLである場合、または付随するcontent属性の値がURLである場合。このような場合、新しいメタデータ名を作成する代わりに、
定義済みリンク型集合の拡張として登録することが
推奨されます。
名前が、ユーザーエージェントに処理要件があると期待されるもののためである場合。 この場合は標準化されるべきです。
また、新しいメタデータ名を作成して使用する前に、すでに使用されているメタデータ名を選択すること、 すでに使用されているメタデータ名の目的を重複させること、および新しい標準化名が選択した名前と 衝突することを避けるため、WHATWG WikiのMetaExtensionsページを 参照することが推奨されます。[WHATWGWIKI]
誰でもいつでもWHATWG WikiのMetaExtensionsページを編集して、メタデータ名を追加できます。 新しいメタデータ名は、次の情報を使用して指定できます:
定義される実際の名前です。名前は、他の定義済みの名前と紛らわしく似ているべきではありません (たとえば、大文字・小文字だけが異なるなど)。
値に要求される形式を含む、メタデータ名の意味についての短い非規範的な説明です。
正確に同じ処理要件を持つ他の名前のリストです。作成者は、同義語として定義された名前を 使用するべきではありません(これらは、ユーザーエージェントが旧来のコンテンツをサポートできる ようにすることだけを目的としています)。実際に使用されていない同義語は誰でも削除できます。 旧来のコンテンツとの互換性のために同義語として処理する必要がある名前だけを、この方法で 登録します。
次のいずれかです:
メタデータ名が既存の値と重複していることが判明した場合、その名前を削除し、 既存の値の同義語として記載するべきです。
メタデータ名が「提案済み」状態で追加され、1か月以上使用も仕様化もされない場合、 WHATWG WikiのMetaExtensionsページから削除しても構いません。
メタデータ名が「提案済み」状態で追加され、既存の値と重複していることが判明した場合、 削除して既存の値の同義語として記載するべきです。メタデータ名が「提案済み」状態で追加され、 有害であることが判明した場合、「廃止」状態に変更するべきです。
誰でもいつでも状態を変更できますが、上記の定義に従ってのみ変更するべきです。
http-equiv属性が
meta要素に指定されている場合、
その要素はプラグマ指令です。
http-equiv
属性は、次のキーワードと状態を持つ列挙属性です:
| キーワード | 適合 | 状態 | 簡潔な説明 |
|---|---|---|---|
content-language
|
いいえ | コンテンツ言語 | プラグマ設定による既定の言語を設定します。 |
content-type
|
エンコーディング宣言 | charsetを設定する別形式。
|
|
default-style
|
既定のスタイル | 既定のCSSスタイルシート集合の名前を 設定します。 | |
refresh
|
更新 | 時間指定リダイレクトとして動作します。 | |
set-cookie
|
いいえ | Set-Cookie | 効果はありません。 |
x-ua-compatible
|
X-UA-Compatible | 実際には、Internet Explorerが仕様により厳密に従うことを促します。 | |
content-security-policy
|
コンテンツセキュリティポリシー | DocumentにContent Security Policyを適用します。
|
meta要素が文書に挿入されたとき、そのhttp-equiv属性が
存在し、上記の状態のいずれかを表す場合、ユーザーエージェントは、次のリストで説明されるように、
その状態に適したアルゴリズムを実行しなければなりません:
http-equiv="content-language")
この機能は非適合です。作成者には代わりにlang属性を使用することが推奨されます。
このプラグマはプラグマ設定による既定の言語を設定します。 このようなプラグマが正常に処理されるまでは、プラグマ設定による既定の言語はありません。
要素のcontent属性に
U+002C COMMA文字(,)が含まれる場合、返ります。
inputを、要素のcontent属性の値と
します。
positionをinputの最初の文字に向けます。
positionを指定して、input内のASCII空白をスキップします。
positionを指定して、inputからASCII空白でないコードポイント列を収集します。
candidateを、前の手順の結果として得られた文字列とします。
candidateが空文字列である場合、返ります。
プラグマ設定による既定の言語を candidateに設定します。
値が空白区切りの複数のトークンで構成されている場合、最初のトークン以降は 無視されます。
このプラグマは、同じ名前のHTTP`Content-Language`
ヘッダーとほぼ、しかし完全には異なります。
[HTTP]
http-equiv="content-type")
エンコーディング宣言状態は、
charset属性を
設定する別形式にすぎません。これは文字エンコーディング宣言です。
この状態に関するユーザーエージェント要件は、すべて仕様の解析節で処理されます。
エンコーディング宣言状態にあるhttp-equiv属性を
持つmeta要素では、
content属性は、
「text/html;」の後に任意の数のASCII空白が任意で続き、さらに
「charset=utf-8」が続く文字列にASCII大文字・小文字不区別で一致する値を
持たなければなりません。
文書には、エンコーディング宣言状態にあるhttp-equiv属性を
持つmeta要素と、
charset属性が
存在するmeta要素の
両方を含めてはなりません。
エンコーディング宣言状態は
HTML文書で使用できますが、その状態にあるhttp-equiv属性を
持つ要素をXML文書で使用してはなりません。
http-equiv="default-style")
1つのエンジンでのみサポートされています。
このプラグマは、既定のCSSスタイルシート集合の名前を設定します。
要素のcontent属性の値を
名前として、優先CSSスタイルシート集合名を
変更します。[CSSOM]
http-equiv="refresh")
このプラグマは時間指定リダイレクトとして動作します。
Documentオブジェクトには、
関連付けられた宣言的に更新する予定
(ブール値)があります。初期値はfalseです。
inputを、要素のcontent属性の値と
します。
Documentオブジェクト
document、文字列input、および省略可能なmeta要素
metaを指定した共有宣言的更新手順は、
次のとおりです:
documentの宣言的に更新する予定がtrueである場合、 返ります。
positionをinputの最初のコードポイントに向けます。
positionを指定して、input内のASCII空白をスキップします。
timeを0とします。
positionを指定して、inputからASCII数字であるコードポイント列を収集し、 timeStringをその結果とします。
timeStringが空文字列である場合:
positionが指すinput内のコードポイントがU+002E(.)でない場合、返ります。
それ以外の場合、timeStringを非負整数を解析する規則で 解析した結果をtimeに設定します。
positionを指定して、inputからASCII数字およびU+002E FULL STOP文字(.)であるコードポイント列を収集します。 収集した文字は無視します。
urlRecordを、documentのURLとします。
positionがinputの末尾を越えていない場合:
positionが指すinput内のコードポイントがU+003B(;)、U+002C(,)、またはASCII空白でない場合、返ります。
positionを指定して、input内のASCII空白をスキップします。
positionが指すinput内のコードポイントがU+003B(;)またはU+002C(,)である場合、 positionを次のコードポイントへ進めます。
positionを指定して、input内のASCII空白をスキップします。
positionがinputの末尾を越えていない場合:
urlStringを、positionにあるコードポイントから文字列の末尾までの inputの部分文字列とします。
positionが指すinput内のコードポイントがU+0055(U)またはU+0075(u)である場合、 positionを次のコードポイントへ進めます。それ以外の場合、 引用符をスキップとラベル付けされた手順へ移動します。
positionが指すinput内のコードポイントがU+0052(R)またはU+0072(r)である場合、 positionを次のコードポイントへ進めます。それ以外の場合、 解析とラベル付けされた手順へ移動します。
positionが指すinput内のコードポイントがU+004C(L)またはU+006C(l)である場合、 positionを次のコードポイントへ進めます。それ以外の場合、 解析とラベル付けされた手順へ移動します。
positionを指定して、input内のASCII空白をスキップします。
positionが指すinput内のコードポイントがU+003D(=)である場合、 positionを次のコードポイントへ進めます。それ以外の場合、 解析とラベル付けされた手順へ移動します。
positionを指定して、input内のASCII空白をスキップします。
引用符をスキップ:positionが指すinput内のコードポイントがU+0027(')またはU+0022(")である場合、 quoteをそのコードポイントとし、positionを次のコードポイントへ進めます。それ以外の場合、 quoteを空文字列とします。
urlStringを、positionにあるコードポイントから文字列の末尾までの inputの部分文字列に設定します。
quoteが空文字列でなく、urlString内にquoteと等しいコードポイントがある場合、そのコードポイントでurlStringを切り詰め、 それとそれ以降のすべてのコードポイントを削除します。
解析:urlStringをdocumentに対してURLをエンコーディング解析した結果を urlRecordに設定します。
urlRecordが失敗である場合、返ります。
urlRecordのスキームが「javascript」である場合、
返ります。
documentの宣言的に更新する予定をtrueに設定します。
次の手順の1つ以上を実行します:
更新の期限が到来した後(以下で定義)、ユーザーがリダイレクトをキャンセルしておらず、
かつmetaが指定されている場合はdocumentの有効なサンドボックス化フラグ集合にサンドボックス化された
自動機能閲覧コンテキストフラグが設定されていない場合、documentを使用して
documentのノードナビゲーション可能を
urlRecordへナビゲートし、historyHandlingを
「replace」に
設定します。
前の段落の目的上、次の2つの条件のうち遅い方が発生した時点で、 更新の期限が到来したものとします:
ここではmetaのノード文書ではなく、documentを使用することが
重要です。最初の手順群から更新期限の到来までの間に、そのノード文書が変わっている可能性があり、
またmetaは常に指定されるわけではないためです(HTTP`Refresh`ヘッダーの場合)。
選択されたときに、documentを使用してdocumentのノードナビゲーション可能を urlRecordへナビゲートするインターフェースをユーザーに提供します。
何もしません。
さらに、ユーザーエージェントは、他のあらゆる場合と同様に、タイマーの状態、 時間指定リダイレクトの宛先など、その動作のあらゆる側面をユーザーに知らせても構いません。
更新状態にあるhttp-equiv属性を
持つmeta要素では、
content属性は、
次のいずれかで構成される値を持たなければなりません:
URL」にASCII大文字・小文字不区別で一致する部分文字列、
U+003D EQUALS SIGN文字(=)、そしてリテラルのU+0027 APOSTROPHE(')または
U+0022 QUOTATION MARK(")文字で始まらない有効なURL文字列が続くもの。前者の場合、整数はページが再読み込みされるまでの秒数を表します。後者の場合、整数は ページが指定されたURLのページに置き換えられるまでの秒数を表します。
ニュース組織のトップページでは、ページが5分ごとにサーバーから自動的に再読み込みされるように、
ページのhead要素に
次のマークアップを含めることができます:
< meta http-equiv = "Refresh" content = "300" > 一連の各ページを次のページへ更新させることで、ページの列を自動スライドショーとして 使用できます。たとえば次のようなマークアップを使用します:
< meta http-equiv = "Refresh" content = "20; URL=page4.html" > http-equiv="set-cookie")
このプラグマは非適合であり、効果はありません。
ユーザーエージェントはこのプラグマを無視する必要があります。
http-equiv="x-ua-compatible")
実際には、このプラグマはInternet Explorerが仕様により厳密に従うことを促します。
X-UA-Compatible状態にあるhttp-equiv属性を
持つmeta要素では、
content属性は、
文字列「IE=edge」にASCII大文字・小文字不区別で一致する値を
持たなければなりません。
ユーザーエージェントはこのプラグマを無視する必要があります。
http-equiv="content-security-policy")
このプラグマは、Documentに
Content Security Policyを適用します。[CSP]
policyを、meta要素の
content
属性値に対して、ソースを「meta」、処置を「enforce」としてContent Security Policyの直列化されたContent Security Policyを
解析するアルゴリズムを実行した結果とします。
policyから、report-uri、
frame-ancestors、
およびsandbox
指令のすべての出現を削除します。
policyというポリシーを適用します。
コンテンツセキュリティポリシー
状態にあるhttp-equiv属性を
持つmeta要素では、
content属性は、
有効なContent Security Policyで構成される値を
持たなければなりませんが、report-uri、
frame-ancestors、
またはsandbox
指令を含めてはなりません。
content属性で
指定されたContent Security Policyは、現在の文書に適用されます。[CSP]
meta要素を文書に
挿入する時点で、一部のリソースがすでにフェッチされている可能性があります。たとえば、コンテンツセキュリティポリシー
状態にあるhttp-equiv
属性を持つmeta要素を動的に
挿入する前に、画像が利用可能な画像のリストに格納されている場合が
あります。すでにフェッチされたリソースは、後からContent Security Policyが適用されても、ブロックされる保証はありません。
ページは、インラインJavaScriptの実行を防ぎ、すべてのプラグインコンテンツをブロックすることで、 クロスサイトスクリプティング攻撃のリスクを軽減することを選択できます。たとえば次のような ポリシーを使用します:
< meta http-equiv = "Content-Security-Policy" content = "script-src 'self'; object-src 'none'" > 文書内には、特定の状態ごとにmeta要素を同時に
1つを超えて存在させてはなりません。
文字エンコーディング宣言は、文書の保存または送信に使用される 文字エンコーディングを指定する機構です。
Encoding標準は、UTF-8文字エンコーディングの使用と、それを識別するための
「utf-8」エンコーディングラベルの使用を要求します。これらの要件により、
文書の文字エンコーディング宣言が存在する場合は、
「utf-8」にASCII大文字・小文字不区別で一致するエンコーディングラベルを指定する必要があります。
文字エンコーディング宣言が存在するかどうかにかかわらず、
文書をエンコードするために実際に使用される文字エンコーディングはUTF-8でなければなりません。[ENCODING]
上記の規則を強制するため、作成ツールは新しく作成する文書に対してUTF-8を既定で使用しなければなりません。
次の制約も適用されます:
さらに、meta要素に関する
いくつかの制約により、文書ごとにmetaベースの文字エンコーディング宣言は
1つしか存在できません。
HTML文書がBOMで始まらず、そのエンコーディングがContent-Typeメタデータによって明示的に与えられておらず、かつ文書がiframeのsrcdoc文書でない場合、
エンコーディングは、charset属性を持つmeta要素、またはエンコーディング宣言状態にあるhttp-equiv属性を持つmeta要素を使用して指定しなければなりません。
すべての文字がASCII範囲内にある場合でも、文字エンコーディング宣言は必要です (Content-Typeメタデータ内、またはファイル内で 明示的に指定)。フォームにユーザーが入力した非ASCII文字、スクリプトによって生成されたURLなどを 処理するために、文字エンコーディングが必要であるためです。
UTF-8以外のエンコーディングを使用すると、既定で文書の文字エンコーディングを使用するフォーム送信や URLエンコーディングで、予期しない結果になる可能性があります。
文書がiframeのsrcdoc文書である場合、
文書は文字エンコーディング宣言を持ってはなりません。
(この場合、ソースはiframeを含む文書の一部であるため、
すでにデコードされています。)
XMLでは、必要に応じて、インラインの文字エンコーディング情報にはXML宣言を使用するべきです。
HTMLで文字エンコーディングがUTF-8であることを宣言するには、作成者は文書の上部付近
(head要素内)に
次のマークアップを含めることができます:
< meta charset = "utf-8" > XMLでは、代わりにマークアップの最上部でXML宣言を使用します:
<?xml version="1.0" encoding="utf-8"?> style
要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
head要素の子である
noscript要素内。
media — 適用対象の媒体
blocking —
要素が潜在的にレンダリングをブロックするかどうか
title属性には
この要素上で特別なセマンティクスがあります:CSSスタイルシート集合名
[Exposed =Window ]
interface HTMLStyleElement : HTMLElement {
[HTMLConstructor ] constructor ();
attribute boolean disabled ;
[CEReactions , Reflect ] attribute DOMString media ;
[SameObject , PutForwards =value , Reflect ] readonly attribute DOMTokenList blocking ;
// also has obsolete members
};
HTMLStyleElement includes LinkStyle ;style要素により、
作成者はCSSスタイルシートを文書に埋め込むことができます。style要素は、
スタイリング処理モデルへの複数の入力の1つです。この要素はユーザー向けのコンテンツを表しません。
現在のすべてのエンジンでサポートされています。
disabledゲッターの手順は次のとおりです:
thisに関連付けられたCSSスタイルシートがない場合、 falseを返します。
thisの関連付けられたCSSスタイルシートの無効化フラグが設定されている場合、 trueを返します。
falseを返します。
disabledセッターの
手順は次のとおりです:
thisに関連付けられたCSSスタイルシートがない場合、 返ります。
指定された値がtrueである場合、thisの関連付けられたCSSスタイルシートの無効化フラグを設定します。 それ以外の場合、thisの関連付けられたCSSスタイルシートの無効化フラグを解除します。
重要な点として、disabled属性への代入は、
style要素に関連付けられたCSSスタイルシートがある場合にのみ
効果を持ちます:
const style = document. createElement( 'style' );
style. disabled = true ;
style. textContent = 'body { background-color: red; }' ;
document. body. append( style);
console. log( style. disabled); // false media属性は、スタイルがどの媒体に適用されるかを示します。
値は有効なメディアクエリーリストでなければなりません。
ユーザーエージェントは、media属性の値が環境に一致し、その他の関連条件が適用される場合に
スタイルを適用しなければならず、それ以外の場合は適用してはなりません。
スタイルの適用範囲は、たとえばCSSで@mediaブロックを使用することにより、
さらに制限される場合があります。この仕様は、そのような追加の制約または要件を上書きしません。
media属性を省略した場合の
デフォルトは「all」です。これは、既定ではスタイルがすべての媒体に適用されることを
意味します。
blocking属性はブロッキング属性です。
1つのエンジンでのみサポートされています。
style要素上のtitle属性はCSSスタイルシート集合を定義します。style要素にtitle属性がない場合、
タイトルはありません。祖先のtitle属性はstyle要素には
適用されません。style要素が文書ツリー内にない場合、title属性は無視されます。[CSSOM]
style要素上のtitle属性は、link要素上のtitle属性と同様に、
タイトルを持たないstyleブロックが
親要素のタイトルを継承しない点で、グローバルなtitle属性とは異なります。
そのブロックには単にタイトルがありません。
style要素の子テキスト内容は、適合するスタイルシートのものでなければなりません。
style要素が、
そのノード文書のパーサーによって作成された場合、その要素は暗黙的に潜在的なレンダリングブロッキングです。
ユーザーエージェントは、次のいずれかの条件が発生するたびに、styleブロックを
更新するアルゴリズムを実行しなければなりません:
要素がHTMLパーサーまたはXMLパーサーの開いている要素のスタックから取り出された場合。
要素がHTMLパーサーまたはXMLパーサーの開いている要素のスタック上になく、かつ接続状態になった場合、または切断状態になった場合。
要素がHTMLパーサーまたはXMLパーサーの開いている要素のスタック上になく、かつその子変更手順が実行された場合。
styleブロックを更新するアルゴリズムは
次のとおりです:
elementをstyle要素とします。
elementに関連付けられたCSSスタイルシートがある場合、 対象のCSSスタイルシートを削除します。
elementが接続されていない場合、返ります。
elementのtype属性が存在し、
その値が空文字列でも「text/css」にASCII大文字・小文字不区別で一致するものでもない場合、
返ります。
特に、「text/css; charset=utf-8」のようなパラメーターを持つtype値は、
このアルゴリズムを早期に終了させます。
要素のインライン
動作はContent Security Policyによってブロックされるべきか?アルゴリズムを、style要素、
「style」、およびstyle要素の子テキスト内容に対して実行した結果が
「Blocked」である場合、返ります。[CSP]
次のプロパティを持つCSSスタイルシートを作成します:
element
elementのmedia属性。
これは属性の現在の値のコピーではなく、(現時点では存在しない可能性がある) 属性への参照です。CSSOMは、属性が動的に設定、変更、または削除された場合に 何が起こるかを定義します。
elementが文書ツリー内にある場合は、
elementのtitle属性、
それ以外の場合は空文字列。
ここでも、これは属性への参照です。
未設定。
設定済み。
null
既定値のまま。
未初期化のまま。
これは正しくないように思われます。おそらく要素の子テキスト内容を使用するべきでしょうか? issue #2997として追跡されています。
elementがスクリプトブロッキング スタイルシートに寄与する場合、elementをそのノード文書のスクリプトブロッキングスタイルシート集合に追加します。
elementのmedia属性の値が環境に一致し、elementが潜在的にレンダリングをブロックする場合、
elementでレンダリングをブロックします。
スタイルシートの重要なサブリソースがある場合、その取得試行が 完了した後、またはスタイルシートに重要なサブリソースがない場合は、 スタイルシートが解析および処理された後、ユーザーエージェントは次の手順を実行しなければなりません:
重要なサブリソースのフェッチは明確に定義されていません。
おそらくissue #968が、その最善の解決策です。
それまでは、あらゆる重要なサブリソースのリクエストについて、そのレンダリングブロッキングを、style要素が現在レンダリングをブロックしているかどうかに
設定するべきです。
elementを、対象のスタイルシートに関連付けられたstyle要素とします。
successをtrueとします。
スタイルシートのいずれかの重要なサブリソースの取得試行が何らかの理由 (たとえばDNSエラー、HTTP 404レスポンス、接続の早期終了、サポートされていないContent-Type)で 失敗した場合、successをfalseに設定します。
CSS解析エラーやPNGデコードエラーなど、コンテンツ固有のエラーは successに影響しないことに注意してください。
elementおよび次の手順を指定して、ネットワーキングタスクソース上に要素タスクをキューに入れます:
elementがスクリプトブロッキング スタイルシートに寄与する場合:
表明:elementのノード文書のスクリプトブロッキング スタイルシート集合はelementを含みます。
elementを、そのノード文書のスクリプトブロッキング スタイルシート集合から削除します。
elementでレンダリングのブロックを解除します。
要素は、スタイルシートの重要なサブリソースがある場合、その取得試行がすべて 完了するまで、要素のノード文書のloadイベントを遅延しなければなりません。
この仕様はスタイルシステムを指定しませんが、ほとんどのウェブブラウザーがCSSを サポートすることが期待されます。[CSS]
LinkStyle
インターフェースもこの要素によって実装されます。[CSSOM]
次の文書では、作品のタイトルとラテン語の単語を既定の斜体のままにしつつ、 強調箇所を斜体ではなく明るい赤色のテキストとしてスタイル設定しています。 適切な要素を使用することで文書の再スタイル設定が容易になることを示しています。
<!DOCTYPE html>
< html lang = "en-US" >
< head >
< title > My favorite book</ title >
< style >
body { color : black ; background : white ; }
em { font-style : normal ; color : red ; }
</ style >
</ head >
< body >
< p > My < em > favorite</ em > book of all time has < em > got</ em > to be
< cite > A Cat's Life</ cite > . It is a book by P. Rahmel that talks
about the < i lang = "la" > Felis catus</ i > in modern human society.</ p >
</ body >
</ html > スタイルシートが他のリソースを参照していない場合(たとえば、@import規則を持たない
style
要素によって与えられる内部スタイルシートであった場合)、スタイル規則はスクリプトから直ちに利用可能に
しなければなりません。それ以外の場合、スタイル規則は、イベントループがレンダリングを
更新する手順に到達した時点でのみ、スクリプトから利用可能にしなければなりません。
HTMLパーサーまたはXMLパーサーのDocumentの文脈にある要素
elは、次のすべてがtrueである場合、スクリプトブロッキングスタイルシートに
寄与します:
elは、そのDocumentのパーサーに
よって作成された。
elは、style
要素、またはelがパーサーによって作成された時点でスタイル設定処理モデルに寄与する
外部リソースリンクであったlink
要素のいずれかである。
elのmedia属性の値が
環境に
一致する。
要素がパーサーによって作成された時点で、elのスタイルシートが有効であった。
ユーザーエージェントが、その特定のスタイルシートの読み込みをまだ断念していない。 ユーザーエージェントは、いつでもスタイルシートの読み込みを断念しても構いません。
スタイルシートが読み込まれる前にその読み込みを断念し、その後も最終的には スタイルシートが読み込まれた場合、スクリプトが誤った情報を使用して動作する可能性があります。 たとえば、スタイルシートが要素の色を緑に設定していても、結果のスタイルを検査するスクリプトが シートの読み込み前に実行された場合、スクリプトは要素が黒(または既定の色)であると判断し、 その結果、不適切な選択を行う可能性があります(たとえば、ページ上の別の場所の色として緑ではなく 黒を使用することを決定するなど)。実装者は、スクリプトが誤った情報を使用する可能性と、 低速なネットワークリクエストの完了を待つ間何もしないことによる性能への影響とのバランスを 取らなければなりません。
上記の規則に対応する規則が
<?xml-stylesheet?>
処理命令にも適用されることが予想されます。しかし、これはまだ十分に
調査されていません。
Documentは、初期状態で
空である順序付き集合であるスクリプトブロッキングスタイルシート集合を持ちます。
Document
documentは、次の手順がtrueを返す場合、スクリプトをブロックするスタイルシートを
持ちます:
documentのスクリプトブロッキング スタイルシート集合が空でない場合、 trueを返します。
documentのノードナビゲーション可能がnullである場合、 falseを返します。
containerDocumentを、documentのノードナビゲーション可能の コンテナー文書とします。
containerDocumentがnullでなく、containerDocumentの スクリプトブロッキング スタイルシート集合が空でない場合、 trueを返します。
falseを返します。
Documentは、スクリプトをブロックする
スタイルシートを持たない場合、スクリプトをブロックするスタイルシートを持ちません。
Introduction_to_HTML/Document_and_website_structure#HTML_for_structuring_content
現在のすべてのエンジンでサポートされています。
body
要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
html要素内の2番目の要素として。body要素の開始タグは、
要素が空である場合、またはbody要素内の最初のものが
ASCII空白でもコメントでもない場合に省略できます。ただし、
body要素内の最初のものが
meta、noscript、
link、script、style、またはtemplate要素である場合を
除きます。
body要素の終了タグは、
body要素の直後に
コメントが続かない場合に省略できます。
onafterprint
onbeforeprint
onbeforeunload
onhashchange
onlanguagechange
onmessage
onmessageerror
onoffline
ononlineonpageswap
onpagehide
onpagereveal
onpageshow
onpopstate
onrejectionhandled
onstorage
onunhandledrejection
onunload[Exposed =Window ]
interface HTMLBodyElement : HTMLElement {
[HTMLConstructor ] constructor ();
// also has obsolete members
};
HTMLBodyElement includes WindowEventHandlers ;適合文書には、body要素は1つだけ存在します。
document.body IDL属性は、
文書のbody要素へ
スクリプトが容易にアクセスできるようにします。
一部のDOM操作(たとえば、ドラッグ&
ドロップモデルの一部)は、「body要素」を用いて定義されています。これは、
用語の定義に従ったDOM内の特定の要素を指し、任意のbody要素を指すものでは
ありません。
body要素は、Windowオブジェクトの多数のイベントハンドラーをイベントハンドラーコンテンツ属性として公開します。
また、それらのイベントハンドラーIDL属性もミラーリングします。
Windowを反映するbody要素上のイベントハンドラー集合によって
名前が付けられ、body
要素上で公開されるWindowオブジェクトのイベントハンドラーは、通常HTML要素がサポートする同じ名前の汎用イベントハンドラーを置き換えます。
したがって、たとえばDocumentのbody要素の子で送出された、バブリングするerrorイベントは、最初にその要素のonerrorイベントハンドラーコンテンツ属性を
トリガーし、次にルートhtml要素のものをトリガーし、
その後にbody要素上のonerrorイベントハンドラーコンテンツ属性を
トリガーします。これは、イベントがターゲットからbodyへ、htmlへ、Documentへ、Windowへとバブルし、body上のイベントハンドラーがbodyではなくWindowを監視しているためです。しかし、
addEventListener()を使用してbodyに付加された通常の
イベントリスナーは、イベントがbodyを通過してバブルした
ときに実行され、Windowオブジェクトに
到達したときには実行されません。
このページは、ユーザーがオンラインかどうかを示すインジケーターを更新します:
<!DOCTYPE HTML>
< html lang = "en" >
< head >
< title > Online or offline?</ title >
< script >
function update( online) {
document. getElementById( 'status' ). textContent =
online ? 'Online' : 'Offline' ;
}
</ script >
</ head >
< body ononline = "update(true)"
onoffline = "update(false)"
onload = "update(navigator.onLine)" >
< p > You are: < span id = "status" > (Unknown)</ span ></ p >
</ body >
</ html > article要素
現在のすべてのエンジンでサポートされています。
HTMLElementを使用します。article要素は、
文書、ページ、アプリケーション、またはサイト内の完全な、または自己完結した構成物であり、原則として
独立して配布または再利用できるもの、たとえばシンジケーションで利用できるものを表します。これは、フォーラムの投稿、
雑誌または新聞の記事、ブログのエントリー、ユーザーが投稿したコメント、対話型ウィジェットまたは
ガジェット、あるいはその他の独立したコンテンツ項目である可能性があります。
article
要素が入れ子になっている場合、内側のarticle要素は、
原則として外側の記事の内容に関連する記事を表します。たとえば、ユーザー投稿コメントを受け付ける
サイトのブログエントリーでは、コメントをブログエントリーのarticle要素内に
入れ子にしたarticle要素として
表すことができます。
article要素に
関連付けられた作成者情報(address要素を参照)は、
入れ子になったarticle要素には
適用されません。
シンジケーションで再配布されるコンテンツに特に使用する場合、
article要素は、
Atomのentry要素と目的が似ています。[ATOM]
schema.orgマイクロデータ語彙は、CreativeWorkのサブタイプの1つを使用して、article要素の
公開日を提供するために使用できます。
ページの主要コンテンツ(すなわち、フッター、ヘッダー、ナビゲーションブロック、および
サイドバーを除く)がすべて単一の自己完結した構成物である場合、そのコンテンツをarticleで
マーク付けしても構いませんが、その場合は技術的には冗長です(ページは単一の文書であるため、
単一の構成物であることが自明だからです)。
この例は、いくつかのschema.org注釈とともにarticle要素を
使用したブログ投稿を示しています:
< article itemscope itemtype = "http://schema.org/BlogPosting" >
< header >
< h2 itemprop = "headline" > The Very First Rule of Life</ h2 >
< p >< time itemprop = "datePublished" datetime = "2009-10-09" > 3 days ago</ time ></ p >
< link itemprop = "url" href = "?comments=0" >
</ header >
< p > If there's a microphone anywhere near you, assume it's hot and
sending whatever you're saying to the world. Seriously.</ p >
< p > ...</ p >
< footer >
< a itemprop = "discussionUrl" href = "?comments=1" > Show comments...</ a >
</ footer >
</ article > 同じブログ投稿で、コメントの一部を表示したものを次に示します:
< article itemscope itemtype = "http://schema.org/BlogPosting" >
< header >
< h2 itemprop = "headline" > The Very First Rule of Life</ h2 >
< p >< time itemprop = "datePublished" datetime = "2009-10-09" > 3 days ago</ time ></ p >
< link itemprop = "url" href = "?comments=0" >
</ header >
< p > If there's a microphone anywhere near you, assume it's hot and
sending whatever you're saying to the world. Seriously.</ p >
< p > ...</ p >
< section >
< h1 > Comments</ h1 >
< article itemprop = "comment" itemscope itemtype = "http://schema.org/Comment" id = "c1" >
< link itemprop = "url" href = "#c1" >
< footer >
< p > Posted by: < span itemprop = "creator" itemscope itemtype = "http://schema.org/Person" >
< span itemprop = "name" > George Washington</ span >
</ span ></ p >
< p >< time itemprop = "dateCreated" datetime = "2009-10-10" > 15 minutes ago</ time ></ p >
</ footer >
< p > Yeah! Especially when talking about your lobbyist friends!</ p >
</ article >
< article itemprop = "comment" itemscope itemtype = "http://schema.org/Comment" id = "c2" >
< link itemprop = "url" href = "#c2" >
< footer >
< p > Posted by: < span itemprop = "creator" itemscope itemtype = "http://schema.org/Person" >
< span itemprop = "name" > George Hammond</ span >
</ span ></ p >
< p >< time itemprop = "dateCreated" datetime = "2009-10-10" > 5 minutes ago</ time ></ p >
</ footer >
< p > Hey, you have the same first name as me.</ p >
</ article >
</ section >
</ article > 各コメントの情報(誰がいつ書いたかなど)を提供するためにfooterが使用されている
ことに注目してください。この場合のように適切であれば、footer要素は
セクションの先頭に現れることができます。(この場合にheaderを使用しても
誤りではありません。主に作成者の好みの問題です。)
この例では、article要素が
ポータルページ上でウィジェットをホストするために使用されています。ウィジェットは、特定のスタイルと
スクリプトによる動作を得るため、カスタマイズされた組み込み要素として
実装されています。
<!DOCTYPE HTML>
< html lang = en >
< title > eHome Portal</ title >
< script src = "/scripts/widgets.js" ></ script >
< link rel = stylesheet href = "/styles/main.css" >
< article is = "stock-widget" >
< h2 > Stocks</ h2 >
< table >
< thead > < tr > < th > Stock < th > Value < th > Delta
< tbody > < template > < tr > < td > < td > < td > </ template >
</ table >
< p > < input type = button value = "Refresh" onclick = "this.parentElement.refresh()" >
</ article >
< article is = "news-widget" >
< h2 > News</ h2 >
< ul >
< template >
< li >
< p >< img > < strong ></ strong >
< p >
</ template >
</ ul >
< p > < input type = button value = "Refresh" onclick = "this.parentElement.refresh()" >
</ article > section要素
現在のすべてのエンジンでサポートされています。
HTMLElementを使用します。section要素は、
文書またはアプリケーションの一般的なセクションを表します。この文脈におけるセクションとは、通常は見出しを伴う、
テーマ別にまとめられたコンテンツです。
セクションの例には、章、タブ付きダイアログボックス内の各タブページ、または 論文の番号付きセクションがあります。ウェブサイトのホームページは、導入、ニュース項目、 連絡先情報のセクションに分割できます。
要素の内容をシンジケーションすることが妥当な場合、作成者には
section要素の
代わりにarticle要素を使用する
ことが推奨されます。
section要素は、
汎用コンテナー要素ではありません。スタイル設定の目的だけ、またはスクリプト処理を便利にするためだけに
要素が必要な場合、作成者には代わりにdiv要素を使用することが
推奨されます。一般的な規則として、section要素は、
その要素の内容が文書のアウトラインに明示的に
掲載される場合にのみ適切です。
次の例では、2つの短いセクションを含む、リンゴに関する記事(より大きなウェブページの一部)を 示します。
< article >
< hgroup >
< h2 > Apples</ h2 >
< p > Tasty, delicious fruit!</ p >
</ hgroup >
< p > The apple is the pomaceous fruit of the apple tree.</ p >
< section >
< h3 > Red Delicious</ h3 >
< p > These bright red apples are the most common found in many
supermarkets.</ p >
</ section >
< section >
< h3 > Granny Smith</ h3 >
< p > These juicy, green apples make a great filling for
apple pies.</ p >
</ section >
</ article > 次に、2つのセクションを持つ卒業式プログラムを示します。1つは卒業生のリスト用で、 もう1つは式典の説明用です。(この例のマークアップでは、要素間空白の量を最小限に抑えるために ときどき使用される、一般的ではないスタイルを採用しています。)
<!DOCTYPE Html>
< Html Lang = En
>< Head
>< Title
> Graduation Ceremony Summer 2022</ Title
></ Head
>< Body
>< H1
> Graduation</ H1
>< Section
>< H2
> Ceremony</ H2
>< P
> Opening Procession</ P
>< P
> Speech by Valedictorian</ P
>< P
> Speech by Class President</ P
>< P
> Presentation of Diplomas</ P
>< P
> Closing Speech by Headmaster</ P
></ Section
>< Section
>< H2
> Graduates</ H2
>< Ul
>< Li
> Molly Carpenter</ Li
>< Li
> Anastasia Luccio</ Li
>< Li
> Ebenezar McCoy</ Li
>< Li
> Karrin Murphy</ Li
>< Li
> Thomas Raith</ Li
>< Li
> Susan Rodriguez</ Li
></ Ul
></ Section
></ Body
></ Html > この例では、書籍の著者が一部のセクションを章として、一部を付録としてマーク付けし、 CSSを使用してこの2種類のセクションの見出しを異なる方法でスタイル設定しています。
< style >
section { border : double medium ; margin : 2 em ; }
section . chapter h2 { font : 2 em Roboto , Helvetica Neue , sans-serif ; }
section . appendix h2 { font : small-caps 2 em Roboto , Helvetica Neue , sans-serif ; }
</ style >
< header >
< hgroup >
< h1 > My Book</ h1 >
< p > A sample with not much content</ p >
</ hgroup >
< p >< small > Published by Dummy Publicorp Ltd.</ small ></ p >
</ header >
< section class = "chapter" >
< h2 > My First Chapter</ h2 >
< p > This is the first of my chapters. It doesn't say much.</ p >
< p > But it has two paragraphs!</ p >
</ section >
< section class = "chapter" >
< h2 > It Continues: The Second Chapter</ h2 >
< p > Bla dee bla, dee bla dee bla. Boom.</ p >
</ section >
< section class = "chapter" >
< h2 > Chapter Three: A Further Example</ h2 >
< p > It's not like a battle between brightness and earthtones would go
unnoticed.</ p >
< p > But it might ruin my story.</ p >
</ section >
< section class = "appendix" >
< h2 > Appendix A: Overview of Examples</ h2 >
< p > These are demonstrations.</ p >
</ section >
< section class = "appendix" >
< h2 > Appendix B: Some Closing Remarks</ h2 >
< p > Hopefully this long example shows that you < em > can</ em > style
sections, so long as they are used to indicate actual sections.</ p >
</ section > nav
要素現在のすべてのエンジンでサポートされています。
HTMLElementを使用します。nav要素は、他のページまたは
ページ内の部分へリンクするページのセクション、すなわちナビゲーションリンクを持つセクションを表します。
ページ上のすべてのリンク群をnav要素内に置く必要はありません。
この要素は主として、主要なナビゲーションブロックで構成されるセクションを対象としています。
特に、フッターには利用規約、ホームページ、著作権ページなど、サイト内の各種ページへの短いリンク一覧を
含めることがよくあります。このような場合にはfooter要素だけで十分です。
このような場合にnav要素を使用することも
できますが、通常は不要です。
最初のレンダリング時にナビゲーション情報が省略されることで恩恵を受けるユーザー、 またはナビゲーション情報を直ちに利用できることで恩恵を受けるユーザーを対象とするユーザーエージェント (スクリーンリーダーなど)は、この要素を、ページ上で最初にスキップするコンテンツ、要求時に提供する コンテンツ、またはその両方を決定する方法として使用できます。
次の例には2つのnav要素があります。
1つはサイト全体の主要ナビゲーション用、もう1つはページ自体の副次的ナビゲーション用です。
< body >
< h1 > The Wiki Center Of Exampland</ h1 >
< nav >
< ul >
< li >< a href = "/" > Home</ a ></ li >
< li >< a href = "/events" > Current Events</ a ></ li >
...more...
</ ul >
</ nav >
< article >
< header >
< h2 > Demos in Exampland</ h2 >
< p > Written by A. N. Other.</ p >
</ header >
< nav >
< ul >
< li >< a href = "#public" > Public demonstrations</ a ></ li >
< li >< a href = "#destroy" > Demolitions</ a ></ li >
...more...
</ ul >
</ nav >
< div >
< section id = "public" >
< h2 > Public demonstrations</ h2 >
< p > ...more...</ p >
</ section >
< section id = "destroy" >
< h2 > Demolitions</ h2 >
< p > ...more...</ p >
</ section >
...more...
</ div >
< footer >
< p >< a href = "?edit" > Edit</ a > | < a href = "?delete" > Delete</ a > | < a href = "?Rename" > Rename</ a ></ p >
</ footer >
</ article >
< footer >
< p >< small > © copyright 1998 Exampland Emperor</ small ></ p >
</ footer >
</ body > 次の例では、ページ上の複数の場所にリンクが存在しますが、そのうちナビゲーションセクションと 見なされる場所は1つだけです。
< body itemscope itemtype = "http://schema.org/Blog" >
< header >
< h1 > Wake up sheeple!</ h1 >
< p >< a href = "news.html" > News</ a > -
< a href = "blog.html" > Blog</ a > -
< a href = "forums.html" > Forums</ a ></ p >
< p > Last Modified: < span itemprop = "dateModified" > 2009-04-01</ span ></ p >
< nav >
< h2 > Navigation</ h2 >
< ul >
< li >< a href = "articles.html" > Index of all articles</ a ></ li >
< li >< a href = "today.html" > Things sheeple need to wake up for today</ a ></ li >
< li >< a href = "successes.html" > Sheeple we have managed to wake</ a ></ li >
</ ul >
</ nav >
</ header >
< main >
< article itemprop = "blogPosts" itemscope itemtype = "http://schema.org/BlogPosting" >
< header >
< h2 itemprop = "headline" > My Day at the Beach</ h2 >
</ header >
< div itemprop = "articleBody" >
< p > Today I went to the beach and had a lot of fun.</ p >
...more content...
</ div >
< footer >
< p > Posted < time itemprop = "datePublished" datetime = "2009-10-10" > Thursday</ time > .</ p >
</ footer >
</ article >
...more blog posts...
</ main >
< footer >
< p > Copyright ©
< span itemprop = "copyrightYear" > 2010</ span >
< span itemprop = "copyrightHolder" > The Example Company</ span >
</ p >
< p >< a href = "about.html" > About</ a > -
< a href = "policy.html" > Privacy Policy</ a > -
< a href = "contact.html" > Contact Us</ a ></ p >
</ footer >
</ body > 上記の例には、schema.org語彙を使用してブログ投稿の公開日およびその他のメタデータを提供する マイクロデータ注釈もあります。
nav要素はリストを
含まなければならないわけではなく、他の種類のコンテンツも含めることができます。この
ナビゲーションブロックでは、文章中にリンクが提供されています:
< nav >
< h1 > Navigation</ h1 >
< p > You are on my home page. To the north lies < a href = "/blog" > my
blog</ a > , from whence the sounds of battle can be heard. To the east
you can see a large mountain, upon which many < a
href = "/school" > school papers</ a > are littered. Far up thus mountain
you can spy a little figure who appears to be me, desperately
scribbling a < a href = "/school/thesis" > thesis</ a > .</ p >
< p > To the west are several exits. One fun-looking exit is labeled < a
href = "https://games.example.com/" > "games"</ a > . Another more
boring-looking exit is labeled < a
href = "https://isp.example.net/" > ISP™</ a > .</ p >
< p > To the south lies a dark and dank < a href = "/about" > contacts
page</ a > . Cobwebs cover its disused entrance, and at one point you
see a rat run quickly out of the page.</ p >
</ nav > この例では、メールアプリケーションでユーザーがフォルダーを切り替えられるように、navが使用されています:
< p >< input type = button value = "Compose" onclick = "compose()" ></ p >
< nav >
< h1 > Folders</ h1 >
< ul >
< li > < a href = "/inbox" onclick = "return openFolder(this.href)" > Inbox</ a > < span class = count ></ span >
< li > < a href = "/sent" onclick = "return openFolder(this.href)" > Sent</ a >
< li > < a href = "/drafts" onclick = "return openFolder(this.href)" > Drafts</ a >
< li > < a href = "/trash" onclick = "return openFolder(this.href)" > Trash</ a >
< li > < a href = "/customers" onclick = "return openFolder(this.href)" > Customers</ a >
</ ul >
</ nav > aside
要素現在のすべてのエンジンでサポートされています。
HTMLElementを使用します。aside要素は、
aside要素の周囲の
コンテンツと間接的に関連し、そのコンテンツから分離して考えることができるコンテンツで構成される
ページのセクションを表します。
このようなセクションは、印刷タイポグラフィではサイドバーとして表されることがよくあります。
この要素は、プルクォートやサイドバーなどのタイポグラフィ効果、広告、nav要素のグループ、および
ページの主要コンテンツから分離していると見なされるその他のコンテンツに使用できます。
括弧書きは文書の主要な流れの一部であるため、括弧書きのためだけにaside要素を使用するのは
適切ではありません。
次の例は、ヨーロッパに関するはるかに長いニュース記事内で、スイスについての背景資料を マーク付けするためにasideがどのように使用されるかを示しています。
< aside >
< h2 > Switzerland</ h2 >
< p > Switzerland, a land-locked country in the middle of geographic
Europe, has not joined the geopolitical European Union, though it is
a signatory to a number of European treaties.</ p >
</ aside > 次の例は、より長い記事内でプルクォートをマーク付けするためにasideがどのように使用されるかを 示しています。
...
< p > He later joined a large company, continuing on the same work.
< q > I love my job. People ask me what I do for fun when I'm not at
work. But I'm paid to do my hobby, so I never know what to
answer. Some people wonder what they would do if they didn't have to
work... but I know what I would do, because I was unemployed for a
year, and I filled that time doing exactly what I do now.</ q ></ p >
< aside >
< q > People ask me what I do for fun when I'm not at work. But I'm
paid to do my hobby, so I never know what to answer.</ q >
</ aside >
< p > Of course his work — or should that be hobby? —
isn't his only passion. He also enjoys other pleasures.</ p >
...次の抜粋は、ブログ上でブログロールやその他の補助コンテンツにasideを
どのように使用できるかを示しています:
< body >
< header >
< h1 > My wonderful blog</ h1 >
< p > My tagline</ p >
</ header >
< aside >
<!-- this aside contains two sections that are tangentially related
to the page, namely, links to other blogs, and links to blog posts
from this blog -->
< nav >
< h2 > My blogroll</ h2 >
< ul >
< li >< a href = "https://blog.example.com/" > Example Blog</ a >
</ ul >
</ nav >
< nav >
< h2 > Archives</ h2 >
< ol reversed >
< li >< a href = "/last-post" > My last post</ a >
< li >< a href = "/first-post" > My first post</ a >
</ ol >
</ nav >
</ aside >
< aside >
<!-- this aside is tangentially related to the page also, it
contains twitter messages from the blog author -->
< h1 > Twitter Feed</ h1 >
< blockquote cite = "https://twitter.example.net/t31351234" >
I'm on vacation, writing my blog.
</ blockquote >
< blockquote cite = "https://twitter.example.net/t31219752" >
I'm going to go on vacation soon.
</ blockquote >
</ aside >
< article >
<!-- this is a blog post -->
< h2 > My last post</ h2 >
< p > This is my last post.</ p >
< footer >
< p >< a href = "/last-post" rel = bookmark > Permalink</ a >
</ footer >
</ article >
< article >
<!-- this is also a blog post -->
< h2 > My first post</ h2 >
< p > This is my first post.</ p >
< aside >
<!-- this aside is about the blog post, since it's inside the
<article> element; it would be wrong, for instance, to put the
blogroll here, since the blogroll isn't really related to this post
specifically, only to the page as a whole -->
< h2 > Posting</ h2 >
< p > While I'm thinking about it, I wanted to say something about
posting. Posting is fun!</ p >
</ aside >
< footer >
< p >< a href = "/first-post" rel = bookmark > Permalink</ a >
</ footer >
</ article >
< footer >
< p >< a href = "/archives" > Archives</ a > -
< a href = "/about" > About me</ a > -
< a href = "/copyright" > Copyright</ a ></ p >
</ footer >
</ body > h1、h2、h3、h4、h5、およびh6
要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
hgroup
要素の子として。[Exposed =Window ]
interface HTMLHeadingElement : HTMLElement {
[HTMLConstructor ] constructor ();
// also has obsolete members
};これらの要素は、それぞれのセクションの見出しを表します。
これらの要素のセマンティクスおよび意味は、見出しと アウトラインに関する節で定義されています。
これらの要素は、その名前の数字によって与えられる見出し
レベルを持ちます。見出しレベルは、
入れ子になったセクションのレベルに対応します。h1
要素は最上位セクション用、h2
はサブセクション用、h3
は
サブサブセクション用、以下同様です。
それぞれの文書アウトライン(見出しおよびセクション構造)に関する限り、次の2つの断片は 意味的に同等です:
< body >
< h1 > Let's call it a draw(ing surface)</ h1 >
< h2 > Diving in</ h2 >
< h2 > Simple shapes</ h2 >
< h2 > Canvas coordinates</ h2 >
< h3 > Canvas coordinates diagram</ h3 >
< h2 > Paths</ h2 >
</ body > < body >
< h1 > Let's call it a draw(ing surface)</ h1 >
< section >
< h2 > Diving in</ h2 >
</ section >
< section >
< h2 > Simple shapes</ h2 >
</ section >
< section >
< h2 > Canvas coordinates</ h2 >
< section >
< h3 > Canvas coordinates diagram</ h3 >
</ section >
</ section >
< section >
< h2 > Paths</ h2 >
</ section >
</ body > 作成者は、簡潔さを理由に前者のスタイルを好む場合も、追加のスタイル設定用フックを理由に 後者のスタイルを好む場合もあります。どちらが最善かは、純粋に作成スタイルの好みの問題です。
hgroup要素現在のすべてのエンジンでサポートされています。
p要素に続いて、
1個のh1、
h2、
h3、
h4、
h5、
またはh6
要素、その後に0個以上の
p要素。任意でスクリプト支援
要素を混在させることができます。
HTMLElementを使用します。hgroup要素は、見出しと
関連コンテンツを表します。この要素は、
h1–h6
要素を、副見出し、代替タイトル、または
タグラインを表すコンテンツを含む1個以上のp要素とグループ化するために
使用できます。
hgroup要素内に含まれる
有効な見出しの例を次に示します。
< hgroup >
< h1 > The reality dysfunction</ h1 >
< p > Space is not the only void</ p >
</ hgroup > < hgroup >
< h1 > Dr. Strangelove</ h1 >
< p > Or: How I Learned to Stop Worrying and Love the Bomb</ p >
</ hgroup > header要素現在のすべてのエンジンでサポートされています。
headerまたはfooter要素の
子孫を含みません。HTMLElementを使用します。header要素は、
導入補助またはナビゲーション補助のグループを表します。
header
要素は、通常は見出し
(h1–h6
要素またはhgroup
要素)を含むことを意図していますが、これは
必須ではありません。header
要素は、セクションの目次、検索フォーム、または関連するロゴを
包むためにも使用できます。
いくつかのheaderの例を示します。最初の例はゲーム用です:
< header >
< p > Welcome to...</ p >
< h1 > Voidwars!</ h1 >
</ header > 次の断片は、仕様のヘッダーをマーク付けするためにこの要素をどのように使用できるかを 示しています:
< header >
< hgroup >
< h1 > Fullscreen API</ h1 >
< p > Living Standard — Last Updated 19 October 2015< p >
</ hgroup >
< dl >
< dt > Participate:</ dt >
< dd >< a href = "https://github.com/whatwg/fullscreen" > GitHub whatwg/fullscreen</ a ></ dd >
< dt > Commits:</ dt >
< dd >< a href = "https://github.com/whatwg/fullscreen/commits" > GitHub whatwg/fullscreen/commits</ a ></ dd >
</ dl >
</ header > header
要素はセクショニング
コンテンツではなく、新しいセクションを
導入しません。
この例では、ページはh1
要素によって与えられるページ見出しと、h2
要素によって見出しが与えられる2つの
サブセクションを持ちます。header要素の後の
コンテンツも、header要素内で開始された
最後のサブセクションの一部です。これは、header要素が
アウトラインアルゴリズムに関与しないためです。
< body >
< header >
< h1 > Little Green Guys With Guns</ h1 >
< nav >
< ul >
< li >< a href = "/games" > Games</ a >
< li >< a href = "/forum" > Forum</ a >
< li >< a href = "/download" > Download</ a >
</ ul >
</ nav >
< h2 > Important News</ h2 > <!-- this starts a second subsection -->
<!-- this is part of the subsection entitled "Important News" -->
< p > To play today's games you will need to update your client.</ p >
< h2 > Games</ h2 > <!-- this starts a third subsection -->
</ header >
< p > You have three active games:</ p >
<!-- this is still part of the subsection entitled "Games" -->
...footer要素現在のすべてのエンジンでサポートされています。
headerまたはfooter要素の
子孫を含みません。HTMLElementを使用します。footer要素は、
最も近い祖先のセクショニングコンテンツ要素、またはそのような
祖先がない場合はbody要素の
フッターを表します。フッターには通常、
誰がそのセクションを書いたか、関連文書へのリンク、著作権データなど、そのセクションに関する情報が
含まれます。
footer要素が
セクション全体を含む場合、それらは付録、索引、長い奥付、詳細なライセンス
契約、およびその他の同様のコンテンツを表します。
セクションの作成者または編集者の連絡先情報は、場合によってはfooter内にある
address要素に
含めます。署名欄や、headerまたはfooterのどちらにも
適し得るその他の情報は、どちらか一方(またはどちらにも置かず)に配置できます。これらの要素の主な
目的は、作成者が保守およびスタイル設定しやすい自己説明的なマークアップを書くのを支援することに
すぎず、作成者に特定の構造を課すことを意図していません。
フッターは通常はセクションの末尾に現れますが、必ずしも末尾に現れる必要はありません。
祖先にセクショニングコンテンツ要素がない場合、 ページ全体に適用されます。
footer
要素自体はセクショニングコンテンツではなく、
新しいセクションを導入しません。
同じ内容を持つフッターが上部と下部に1つずつあるページを次に示します:
< body >
< footer >< a href = "../" > Back to index...</ a ></ footer >
< hgroup >
< h1 > Lorem ipsum</ h1 >
< p > The ipsum of all lorems</ p >
</ hgroup >
< p > A dolor sit amet, consectetur adipisicing elit, sed do eiusmod
tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim
veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex
ea commodo consequat. Duis aute irure dolor in reprehenderit in
voluptate velit esse cillum dolore eu fugiat nulla
pariatur. Excepteur sint occaecat cupidatat non proident, sunt in
culpa qui officia deserunt mollit anim id est laborum.</ p >
< footer >< a href = "../" > Back to index...</ a ></ footer >
</ body > footer要素が
サイト全体のフッターとセクションのフッターの両方に使用されている例を次に示します。
<!DOCTYPE HTML>
< HTML LANG = "en" >< HEAD >
< TITLE > The Ramblings of a Scientist</ TITLE >
< BODY >
< H1 > The Ramblings of a Scientist</ H1 >
< ARTICLE >
< H1 > Episode 15</ H1 >
< VIDEO SRC = "/fm/015.ogv" CONTROLS PRELOAD >
< P >< A HREF = "/fm/015.ogv" > Download video</ A > .</ P >
</ VIDEO >
< FOOTER > <!-- footer for article -->
< P > Published < TIME DATETIME = "2009-10-21T18:26-07:00" > on 2009/10/21 at 6:26pm</ TIME ></ P >
</ FOOTER >
</ ARTICLE >
< ARTICLE >
< H1 > My Favorite Trains</ H1 >
< P > I love my trains. My favorite train of all time is a Köf.</ P >
< P > It is fun to see them pull some coal cars because they look so
dwarfed in comparison.</ P >
< FOOTER > <!-- footer for article -->
< P > Published < TIME DATETIME = "2009-09-15T14:54-07:00" > on 2009/09/15 at 2:54pm</ TIME ></ P >
</ FOOTER >
</ ARTICLE >
< FOOTER > <!-- site wide footer -->
< NAV >
< P >< A HREF = "/credits.html" > Credits</ A > —
< A HREF = "/tos.html" > Terms of Service</ A > —
< A HREF = "/index.html" > Blog Index</ A ></ P >
</ NAV >
< P > Copyright © 2009 Gordon Freeman</ P >
</ FOOTER >
</ BODY >
</ HTML > 一部のサイト設計には、「ファットフッター」と呼ばれることがあるものがあります。これは、 画像、他の記事へのリンク、フィードバック送信用ページへのリンク、特別提供など、多量の素材を 含むフッターで、ある意味ではフッター内の完全な「フロントページ」です。
この断片は、「ファットフッター」を持つサイトのページ下部を示しています:
...
< footer >
< nav >
< section >
< h1 > Articles</ h1 >
< p >< img src = "images/somersaults.jpeg" alt = "" > Go to the gym with
our somersaults class! Our teacher Jim takes you through the paces
in this two-part article. < a href = "articles/somersaults/1" > Part
1</ a > · < a href = "articles/somersaults/2" > Part 2</ a ></ p >
< p >< img src = "images/kindplus.jpeg" > Tired of walking on the edge of
a clif<!-- sic --> ? Our guest writer Lara shows you how to bumble
your way through the bars. < a href = "articles/kindplus/1" > Read
more...</ a ></ p >
< p >< img src = "images/crisps.jpeg" > The chips are down, now all
that's left is a potato. What can you do with it? < a
href = "articles/crisps/1" > Read more...</ a ></ p >
</ section >
< ul >
< li > < a href = "/about" > About us...</ a >
< li > < a href = "/feedback" > Send feedback!</ a >
< li > < a href = "/sitemap" > Sitemap</ a >
</ ul >
</ nav >
< p >< small > Copyright © 2015 The Snacker —
< a href = "/tos" > Terms of Service</ a ></ small ></ p >
</ footer >
</ body > address要素
現在のすべてのエンジンでサポートされています。
header、footer、または
address要素の
子孫を含みません。
HTMLElementを使用します。address要素は、
最も近いarticle
またはbody要素の祖先の
連絡先情報を表します。それがbody
要素である場合、連絡先情報は文書全体に適用されます。
たとえば、HTMLに関連するW3Cウェブサイトのページには、次の連絡先情報が 含まれる場合があります:
< ADDRESS >
< A href = "../People/Raggett/" > Dave Raggett</ A > ,
< A href = "../People/Arnaud/" > Arnaud Le Hors</ A > ,
contact persons for the < A href = "Activity" > W3C HTML Activity</ A >
</ ADDRESS > address要素は、
それらの住所が実際に関連する連絡先情報である場合を除き、任意の住所(たとえば郵便
住所)を表すために使用してはなりません。(一般に郵便住所をマーク付けするための適切な要素は
p要素です。)
address要素には、
連絡先情報以外の情報を含めてはなりません。
たとえば、次はaddress要素の
不適合な使用です:
< ADDRESS > Last Modified: 1999/12/24 23:37:50</ ADDRESS > 通常、address要素は、
他の情報とともにfooter要素内に
含まれます。
ノードnodeの連絡先情報は、次のリストで最初に適用される項目によって定義される
address要素の
コレクションです:
ユーザーエージェントは、ノードの連絡先情報をユーザーに公開しても、セクションの連絡先情報に基づいて セクションを索引付けするなど、その他の目的に使用しても構いません。
この例では、フッターに連絡先情報と著作権表示が含まれています。
< footer >
< address >
For more details, contact
< a href = "mailto:js@example.com" > John Smith</ a > .
</ address >
< p >< small > © copyright 2038 Example Corp.</ small ></ p >
</ footer > h1–h6
要素には、要素の算出見出しレベルを
取得することによって与えられる見出しレベルがあります。
これらの要素は見出しを表します。見出しの見出しレベルが低いほど、その見出しが持つ祖先 セクションは少なくなります。
アウトラインは、たとえば目次を生成するときに、 文書アウトラインを生成するために使用するべきです。対話型の目次を作成する場合、各項目はユーザーを 関連する見出しへ移動させる べきです。
文書に1個以上の見出しがある場合、アウトライン内の少なくとも1つの見出しは、 見出しレベル1を持つべきです。
次の例は不適合です:
< body >
< h1 > Apples</ h1 >
< p > Apples are fruit.</ p >
< section >
< h3 > Taste</ h3 >
< p > They taste lovely.</ p >
</ section >
</ body > 次のように記述すれば、適合するようになります:
< body >
< h1 > Apples</ h1 >
< p > Apples are fruit.</ p >
< section >
< h2 > Taste</ h2 >
< p > They taste lovely.</ p >
</ section >
</ body > headingoffset
コンテンツ属性により、作成者は子孫の見出しレベルをオフセットできます。
headingoffset
属性が指定されている場合、その値は0以上8以下の有効な非負整数でなければなりません。
headingreset
コンテンツ属性はブール
属性です。これにより作成者は、見出し
オフセットの計算が、その属性を持つ要素を越えて走査することを防止できます。
要素elementが与えられたとき、要素の算出見出しレベルを取得するには:
levelを0とします。
elementのローカル名がh1である場合、
levelを1に設定します。
elementのローカル名がh2である場合、
levelを2に設定します。
elementのローカル名がh3である場合、
levelを3に設定します。
elementのローカル名がh4である場合、
levelを4に設定します。
elementのローカル名がh5である場合、
levelを5に設定します。
elementのローカル名がh6である場合、
levelを6に設定します。
表明:levelは0ではありません。
elementが与えられたとき、要素の算出見出し オフセットを取得する結果だけlevelを増加させます。
levelが9より大きい場合、9を返します。
levelを返します。
要素elementが与えられたとき、要素の算出見出しオフセットを取得するには、 次の手順を実行します。これらは非負整数を返します。
offsetを0とします。
inclusiveAncestorをelementとします。
inclusiveAncestorがnullでない間:
nextOffsetを0とします。
inclusiveAncestorがHTML要素であり、headingoffset
属性を持つ場合、非負整数を構文解析する
規則を使用してその値を構文解析します。
値を構文解析した結果がエラーでない場合、nextOffsetをその値に設定します。
offsetをnextOffsetだけ増加させます。
inclusiveAncestorがHTML要素であり、headingreset
属性を持つ場合、offsetを返します。
inclusiveAncestorの親がシャドールートで ある場合、inclusiveAncestorをそのシャドールートの ホストに設定し、続行します。
inclusiveAncestorをinclusiveAncestorの親 要素に設定します。
offsetを返します。
この例は、headingoffset、
headingreset、
およびaria-level
属性の組み合わせを、それぞれの見出しレベルを示すコメントとともに示しています。この例はさまざまな
組み合わせを説明するものであり、ベストプラクティスの例ではありません。
< body >
< main >
< h1 > This is a heading level 1</ h1 >
< article headingoffset = "1" >
< h1 > This is a heading level 2</ h1 >
< section headingoffset = "1" >
< h1 > This is a heading level 3</ h1 >
< dialog headingreset >
< h1 > This is a heading level 1</ h1 >
</ dialog >
</ section >
</ article >
< h1 aria-level = "2" > This is a heading level 2</ h1 >
</ main >
</ body > 次のマークアップ断片:
< body >
< hgroup id = "document-title" >
< h1 > HTML: Living Standard</ h1 >
< p > Last Updated 12 August 2016</ p >
</ hgroup >
< p > Some intro to the document.</ p >
< h2 > Table of contents</ h2 >
< ol id = toc > ...</ ol >
< h2 > First section</ h2 >
< p > Some intro to the first section.</ p >
</ body > …は3つの文書見出しを生成します:
<h1>HTML: Living Standard</h1>
<h2>Table of contents</h2>。
<h2>First section</h2>。
アウトラインをレンダリングした表示は、次のように なる可能性があります:

まず、非常に短い章とサブセクションを持つ書籍である文書を次に示します:
<!DOCTYPE HTML>
< html lang = en >
< title > The Tax Book (all in one page)</ title >
< h1 > The Tax Book</ h1 >
< h2 > Earning money</ h2 >
< p > Earning money is good.</ p >
< h3 > Getting a job</ h3 >
< p > To earn money you typically need a job.</ p >
< h2 > Spending money</ h2 >
< p > Spending is what money is mainly used for.</ p >
< h3 > Cheap things</ h3 >
< p > Buying cheap things often not cost-effective.</ p >
< h3 > Expensive things</ h3 >
< p > The most expensive thing is often not the most cost-effective either.</ p >
< h2 > Investing money</ h2 >
< p > You can lend your money to other people.</ p >
< h2 > Losing money</ h2 >
< p > If you spend money or invest money, sooner or later you will lose money.
< h3 > Poor judgement</ h3 >
< p > Usually if you lose money it's because you made a mistake.</ p > そのアウトラインは、次のように表示できます:
文書には複数の最上位見出しを含めることができます:
<!DOCTYPE HTML>
< html lang = en >
< title > Alphabetic Fruit</ title >
< h1 > Apples</ h1 >
< p > Pomaceous.</ p >
< h1 > Bananas</ h1 >
< p > Edible.</ p >
< h1 > Carambola</ h1 >
< p > Star.</ p > 文書のアウトラインは、次のように表示できます:
<!DOCTYPE HTML>
< html lang = "en" >
< title > We're adopting a child! — Ray's blog</ title >
< h1 > Ray's blog</ h1 >
< article >
< header >
< nav >
< a href = "?t=-1d" > Yesterday</ a > ;
< a href = "?t=-7d" > Last week</ a > ;
< a href = "?t=-1m" > Last month</ a >
</ nav >
< h2 > We're adopting a child!</ h2 >
</ header >
< p > As of today, Janine and I have signed the papers to become
the proud parents of baby Diane! We've been looking forward to
this day for weeks.</ p >
</ article >
</ html > 文書のアウトラインは、次のように表示できます:
次の例は適合していますが、見出しレベルが1である見出しを持たないため、推奨されません:
<!DOCTYPE HTML>
< html lang = en >
< title > Alphabetic Fruit</ title >
< section >
< h2 > Apples</ h2 >
< p > Pomaceous.</ p >
</ section >
< section >
< h2 > Bananas</ h2 >
< p > Edible.</ p >
</ section >
< section >
< h2 > Carambola</ h2 >
< p > Star.</ p >
</ section > 文書のアウトラインは、次のように表示できます:
次の例は適合していますが、最初の見出しの見出しレベルが1ではないため、推奨されません:
<!DOCTYPE HTML>
< html lang = en >
< title > Feathers on The Site of Encyclopedic Knowledge</ title >
< h2 > A plea from our caretakers</ h2 >
< p > Please, we beg of you, send help! We're stuck in the server room!</ p >
< h1 > Feathers</ h1 >
< p > Epidermal growths.</ p > 文書のアウトラインは、次のように表示できます:
ユーザーエージェントには、ナビゲーションを支援するため、ページのアウトラインをユーザーに公開することが推奨されます。 これは、スクリーンリーダーなどの非視覚メディアに特に当てはまります。
たとえば、ユーザーエージェントは矢印キーを次のように割り当てることができます:
この節は非規範的です。
| 要素 | 目的 |
|---|---|
| 例 | |
body
|
文書の内容。 |
|
|
article
|
文書、ページ、アプリケーション、またはサイト内の完全な、または自己完結した 構成物であり、原則として独立して配布または再利用できるもの、たとえばシンジケーションで 利用できるもの。これはフォーラムの投稿、雑誌または新聞の記事、ブログのエントリー、 ユーザーが投稿したコメント、対話型ウィジェットまたはガジェット、あるいはその他の独立した コンテンツ項目である可能性があります。 |
|
|
section
|
文書またはアプリケーションの一般的なセクション。この文脈におけるセクションとは、 通常は見出しを伴う、テーマ別にまとめられたコンテンツです。 |
|
|
nav
|
他のページまたはページ内の部分へリンクするページのセクション、すなわち ナビゲーションリンクを持つセクション。 |
|
|
aside
|
aside要素の周囲の
コンテンツと間接的に関連し、そのコンテンツから分離して考えることができるコンテンツで
構成されるページのセクション。このようなセクションは、印刷タイポグラフィでは
サイドバーとして表されることがよくあります。
|
|
|
h1–h6
|
見出し |
|
|
hgroup
|
見出しと関連コンテンツ。この要素は、h1–h6
要素を、副見出し、代替タイトル、または
タグラインを表すコンテンツを含む1個以上のp要素とグループ化するために
使用できます。
|
|
|
header
|
導入補助またはナビゲーション補助のグループ。 |
|
|
footer
|
最も近い祖先のセクショニングコンテンツ要素、またはそのような 祖先がない場合はbody要素のフッター。フッターには通常、 誰がそのセクションを書いたか、関連文書へのリンク、著作権データなど、そのセクションに関する 情報が含まれます。 |
|
この節は非規範的です。
sectionは、
何か別のものの一部を形成します。articleは、それ自体で
1つのものです。しかし、どちらがどちらであるかをどう判断するのでしょうか。実際の答えは、ほとんどの
場合「作成者の意図による」です。
たとえば、「Granny Smith」という章があり、「These juicy, green apples make a great filling for
apple pies.」とだけ書かれた書籍を想像できます。この場合、(おそらく)他の種類のリンゴについても
多数の章があるため、それはsectionになります。
一方、「Granny Smith. These juicy, green apples make a great filling for apple pies.」とだけ書かれた
ツイート、redditコメント、tumblr投稿、または新聞の案内広告を想像できます。その場合、それが全体である
ため、それらはarticleになります。
記事に対するコメントは、それがコメントしているarticleの一部では
ないため、それ自体がarticleです。
p
要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
hgroup要素の子として。p要素の終了タグは、p要素の直後に
address、article、
aside、blockquote、details、dialog、
div、dl、fieldset、figcaption、
figure、footer、form、h1、
h2、
h3、
h4、
h5、
h6、
header、
hgroup、hr、main、menu、nav、
ol、p、pre、search、section、
table、またはul要素が続く場合、あるいは親
要素にそれ以上のコンテンツがなく、親要素がa、audio、del、ins、map、
noscript、またはvideo要素でも、自律カスタム
要素でもないHTML要素である場合に
省略できます。
[Exposed =Window ]
interface HTMLParagraphElement : HTMLElement {
[HTMLConstructor ] constructor ();
// also has obsolete members
};段落は通常、視覚メディアでは空行によって隣接するブロックから物理的に分離された テキストブロックとして表されますが、スタイルシートまたはユーザーエージェントが、たとえば インラインの段落記号(¶)を使用するなど、別の方法で段落区切りを表示することも同様に正当です。
次の例は適合するHTML断片です:
< p > The little kitten gently seated herself on a piece of
carpet. Later in her life, this would be referred to as the time the
cat sat on the mat.</ p > < fieldset >
< legend > Personal information</ legend >
< p >
< label > Name: < input name = "n" ></ label >
< label >< input name = "anon" type = "checkbox" > Hide from other users</ label >
</ p >
< p >< label > Address: < textarea name = "a" ></ textarea ></ label ></ p >
</ fieldset > < p > There was once an example from Femley,< br >
Whose markup was of dubious quality.< br >
The validator complained,< br >
So the author was pained,< br >
To move the error from the markup to the rhyming.</ p > p要素は、より具体的な要素が
より適切である場合には使用するべきではありません。
次の例は技術的には正しいものです:
< section >
<!-- ... -->
< p > Last modified: 2001-04-23</ p >
< p > Author: fred@example.com</ p >
</ section > しかし、次のようにマーク付けする方が適切です:
< section >
<!-- ... -->
< footer > Last modified: 2001-04-23</ footer >
< address > Author: fred@example.com</ address >
</ section > または:
< section >
<!-- ... -->
< footer >
< p > Last modified: 2001-04-23</ p >
< address > Author: fred@example.com</ address >
</ footer >
</ section > リスト要素(特にol
およびul要素)は、p要素の子にできません。したがって、
文に箇条書きリストが含まれる場合、それをどのように
マーク付けするべきか疑問に思うかもしれません。
たとえば、この素晴らしい文には、次に関する箇条書きがあります
そして、以下でさらに説明します。
解決策は、HTMLの用語における段落が、 論理的な概念ではなく構造的な概念であると理解することです。上記の素晴らしい例には、この仕様で 定義される段落が実際には5つあります。 リストの前に1つ、各箇条書きに1つずつ、リストの後に1つです。
したがって、上記の例のマークアップは次のようにできます:
< p > For instance, this fantastic sentence has bullets relating to</ p >
< ul >
< li > wizards,
< li > faster-than-light travel, and
< li > telepathy,
</ ul >
< p > and is further discussed below.</ p > 複数の「構造的」段落から構成されるこのような「論理的」段落を便利にスタイル設定したい作成者は、
p要素の代わりにdiv要素を使用できます。
したがって、たとえば上記の例は次のようにできます:
< div > For instance, this fantastic sentence has bullets relating to
< ul >
< li > wizards,
< li > faster-than-light travel, and
< li > telepathy,
</ ul >
and is further discussed below.</ div > この例にも構造的な段落は5つありますが、作成者は例の各部分を個別に考慮する代わりに、
divだけを
スタイル設定できるようになりました。
hr
要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
select要素の子孫として。[Exposed =Window ]
interface HTMLHRElement : HTMLElement {
[HTMLConstructor ] constructor ();
// also has obsolete members
};hr要素は、段落レベルの主題上の
区切り、たとえば物語における場面転換や、参考書のセクション内で別の話題へ移行することを表します。あるいは、select要素の
一連の選択肢間の区切りを表します。
次の架空のプロジェクトマニュアルからの抜粋は、セクション内の話題を区切るために
hr要素を使用する
2つのセクションを示しています。
< section >
< h1 > Communication</ h1 >
< p > There are various methods of communication. This section
covers a few of the important ones used by the project.</ p >
< hr >
< p > Communication stones seem to come in pairs and have mysterious
properties:</ p >
< ul >
< li > They can transfer thoughts in two directions once activated
if used alone.</ li >
< li > If used with another device, they can transfer one's
consciousness to another body.</ li >
< li > If both stones are used with another device, the
consciousnesses switch bodies.</ li >
</ ul >
< hr >
< p > Radios use the electromagnetic spectrum in the meter range and
longer.</ p >
< hr >
< p > Signal flares use the electromagnetic spectrum in the
nanometer range.</ p >
</ section >
< section >
< h1 > Food</ h1 >
< p > All food at the project is rationed:</ p >
< dl >
< dt > Potatoes</ dt >
< dd > Two per day</ dd >
< dt > Soup</ dt >
< dd > One bowl per day</ dd >
</ dl >
< hr >
< p > Cooking is done by the chefs on a set rotation.</ p >
</ section > セクション自体の間にhr
要素を置く必要はありません。これは、
section要素と
h1
要素自体が主題の変更を
暗示するためです。
次のPeter F. Hamilton著Pandora's Starからの抜粋は、場面転換に先行する2つの
段落と、それに続く段落を示しています。印刷された書籍では、第2段落と第3段落の間に
中央揃えの星印を1つ含む空白として表される場面転換を、ここではhr要素を使用して表しています。
< p > Dudley was ninety-two, in his second life, and fast approaching
time for another rejuvenation. Despite his body having the physical
age of a standard fifty-year-old, the prospect of a long degrading
campaign within academia was one he regarded with dread. For a
supposedly advanced civilization, the Intersolar Commonwealth could be
appallingly backward at times, not to mention cruel.</ p >
< p >< i > Maybe it won't be that bad</ i > , he told himself. The lie was
comforting enough to get him through the rest of the night's
shift.</ p >
< hr >
< p > The Carlton AllLander drove Dudley home just after dawn. Like the
astronomer, the vehicle was old and worn, but perfectly capable of
doing its job. It had a cheap diesel engine, common enough on a
semi-frontier world like Gralmond, although its drive array was a
thoroughly modern photoneural processor. With its high suspension and
deep-tread tyres it could plough along the dirt track to the
observatory in all weather and seasons, including the metre-deep snow
of Gralmond's winters.</ p > pre
要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
[Exposed =Window ]
interface HTMLPreElement : HTMLElement {
[HTMLConstructor ] constructor ();
// also has obsolete members
};pre要素は、要素ではなく
タイポグラフィ上の慣例によって構造が表される、整形済みテキストのブロックを表します。
HTML構文では、
pre要素の開始タグの
直後にある先頭の改行文字は削除されます。
pre要素を使用できる場合の例:
作成者には、整形が失われたときに整形済みテキストがどのように体験されるかを 検討することが推奨されます。音声合成装置、点字ディスプレイなどの利用者については、 まさにそのようになります。ASCIIアートのような場合、テキストによる説明などの 代替表現の方が、文書の読者にとってより広くアクセシブルになる可能性があります。
コンピューターコードのブロックを表すには、pre要素を
code要素とともに使用できます。
コンピューター出力のブロックを表すには、pre要素を
samp要素とともに使用できます。
同様に、kbd要素を
pre要素内で使用して、
ユーザーが入力するテキストを示すことができます。
この要素には、双方向アルゴリズムに関する レンダリング要件があります。
次の断片では、コンピューターコードの例が提示されています。
< p > This is the < code > Panel</ code > constructor:</ p >
< pre >< code > function Panel(element, canClose, closeHandler) {
this.element = element;
this.canClose = canClose;
this.closeHandler = function () { if (closeHandler) closeHandler() };
}</ code ></ pre > 次の断片では、samp要素とkbd要素が、Zork Iの
セッションを示すために、pre要素の
内容内で混在しています。
< pre >< samp > You are in an open field west of a big white house with a boarded
front door.
There is a small mailbox here.
></ samp > < kbd > open mailbox</ kbd >
< samp > Opening the mailbox reveals:
A leaflet.
></ samp ></ pre > 次に示すのは、詩そのものの本質的な一部を形成する特異な書式を保持するために、pre要素を使用した
現代詩です。
< pre > maxling
it is with a heart
heavy
that i admit loss of a feline
so loved
a friend lost to the
unknown
(night)
~cdr 11dec07</ pre > blockquote要素
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
cite —
引用元または編集に関する詳細情報へのリンク
cite。[Exposed =Window ]
interface HTMLQuoteElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , ReflectURL ] attribute USVString cite ;
};HTMLQuoteElementインターフェースは、
q
要素でも使用されます。
blockquote要素は、
別の情報源から引用されたセクションを表します。
blockquote内の
コンテンツは別の情報源から引用されなければならず、その情報源にアドレスがある場合は、
cite属性で引用元を示すことができます。
cite
属性が存在する場合、その値は
前後に空白を含む可能性がある
有効なURLでなければなりません。対応する引用リンクを得るには、属性の値を要素のノード文書を基準として構文解析しなければなりません。ユーザーエージェントは、
ユーザーがそのような引用リンクをたどれるようにしても構いませんが、これらは主として私的利用
(たとえば、サイトでの引用の利用統計を収集するサーバー側スクリプト)を意図したものであり、
読者向けではありません。
blockquoteの
コンテンツは、テキストの言語における慣例的な方法で省略したり、文脈を追加したりできます。
たとえば英語では、これは伝統的に角括弧を使用して行われます。「Jane ate the cracker. She then said she liked apples and fish.」という文を含むページを考えると、次のように引用できます:
< blockquote >
< p > [Jane] then said she liked [...] fish.</ p >
</ blockquote > 引用の帰属情報がある場合、それはblockquote
要素の外側に配置しなければなりません。
たとえば、ここでは引用後の段落に帰属情報が示されています:
< blockquote >
< p > I contend that we are both atheists. I just believe in one fewer
god than you do. When you understand why you dismiss all the other
possible gods, you will understand why I dismiss yours.</ p >
</ blockquote >
< p > — Stephen Roberts</ p > 以下の他の例は、帰属情報を示す別の方法を示しています。
ここでは、blockquote
要素をfigure
要素およびそのfigcaptionと
組み合わせて使用し、引用とその帰属情報を明確に関連付けています(帰属情報は
引用の一部ではないため、blockquote
自体の内部には属しません):
< figure >
< blockquote >
< p > The truth may be puzzling. It may take some work to grapple with.
It may be counterintuitive. It may contradict deeply held
prejudices. It may not be consonant with what we desperately want to
be true. But our preferences do not determine what's true. We have a
method, and that method helps us to reach not absolute truth, only
asymptotic approaches to the truth — never there, just closer
and closer, always finding vast new oceans of undiscovered
possibilities. Cleverly designed experiments are the key.</ p >
</ blockquote >
< figcaption > Carl Sagan, in "< cite > Wonder and Skepticism</ cite > ", from
the < cite > Skeptical Inquirer</ cite > Volume 19, Issue 1 (January-February
1995)</ figcaption >
</ figure > 次の例は、citeをblockquoteとともに使用する例を示しています:
< p > His next piece was the aptly named < cite > Sonnet 130</ cite > :</ p >
< blockquote cite = "https://quotes.example.org/s/sonnet130.html" >
< p > My mistress' eyes are nothing like the sun,< br >
Coral is far more red, than her lips red,< br >
...この例は、フォーラムの投稿でblockquoteを使用して、
ユーザーがどの投稿に
返信しているかを示す方法を示しています。各投稿にはarticle要素を
使用して、スレッド構造を
マークアップしています。
< article >
< h1 >< a href = "https://bacon.example.com/?blog=109431" > Bacon on a crowbar</ a ></ h1 >
< article >
< header >< strong > t3yw</ strong > 12 points 1 hour ago</ header >
< p > I bet a narwhal would love that.</ p >
< footer >< a href = "?pid=29578" > permalink</ a ></ footer >
< article >
< header >< strong > greg</ strong > 8 points 1 hour ago</ header >
< blockquote >< p > I bet a narwhal would love that.</ p ></ blockquote >
< p > Dude narwhals don't eat bacon.</ p >
< footer >< a href = "?pid=29579" > permalink</ a ></ footer >
< article >
< header >< strong > t3yw</ strong > 15 points 1 hour ago</ header >
< blockquote >
< blockquote >< p > I bet a narwhal would love that.</ p ></ blockquote >
< p > Dude narwhals don't eat bacon.</ p >
</ blockquote >
< p > Next thing you'll be saying they don't get capes and wizard
hats either!</ p >
< footer >< a href = "?pid=29580" > permalink</ a ></ footer >
< article >
< article >
< header >< strong > boing</ strong > -5 points 1 hour ago</ header >
< p > narwhals are worse than ceiling cat</ p >
< footer >< a href = "?pid=29581" > permalink</ a ></ footer >
</ article >
</ article >
</ article >
</ article >
< article >
< header >< strong > fred</ strong > 1 points 23 minutes ago</ header >
< blockquote >< p > I bet a narwhal would love that.</ p ></ blockquote >
< p > I bet they'd love to peel a banana too.</ p >
< footer >< a href = "?pid=29582" > permalink</ a ></ footer >
</ article >
</ article >
</ article > この例は、短い断片にblockquoteを
使用する方法を示し、blockquote
要素内で必ずしもp
要素を使用する必要がないことを示しています:
< p > He began his list of "lessons" with the following:</ p >
< blockquote > One should never assume that his side of
the issue will be recognized, let alone that it will
be conceded to have merits.</ blockquote >
< p > He continued with a number of similar points, ending with:</ p >
< blockquote > Finally, one should be prepared for the threat
of breakdown in negotiations at any given moment and not
be cowed by the possibility.</ blockquote >
< p > We shall now discuss these points...会話を表現する方法の例は
後のセクションで示します。この目的でcite要素とblockquote
要素を使用することは適切ではありません。
ol
要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
li要素が含まれる場合:知覚可能コンテンツ。li要素およびスクリプト支援
要素。reversed — リストを
逆順に番号付けする
start — リストの開始値
type — リストマーカーの種類
reversed、start、type。
[Exposed =Window ]
interface HTMLOListElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute boolean reversed ;
[CEReactions , Reflect , ReflectDefault=1] attribute long start ;
[CEReactions , Reflect ] attribute DOMString type ;
// also has obsolete members
};ol要素は、項目が意図的に
順序付けられており、その順序を変更すると文書の意味が変わる項目のリストを表します。
リストの項目は、ol
要素の子ノードであるli
要素をツリー順に並べたものです。
現在のすべてのエンジンでサポートされています。
reversed属性は
真偽属性です。存在する場合、
リストが降順のリスト(...、3、2、1)であることを示します。属性が省略されている場合、
リストは昇順のリスト(1、2、3、...)です。
start属性が
存在する場合、その値は有効な整数でなければなりません。
この属性は、リストの開始値を
決定するために使用されます。
ol要素には、次のように
決定される整数である開始値があります:
parsedを、属性の値を整数として構文解析した結果とします。
parsedがエラーでない場合、parsedを返します。
ol要素にreversed
属性がある場合、所有される
li
要素の数を返します。
1を返します。
type属性は、
それが重要となる場合(たとえば、項目が番号または文字によって参照される場合)に、リストで使用するマーカーの種類を
指定するために使用できます。属性が指定される場合、その値は次の表のいずれかの行の
最初のセルに示される文字の1つと同一で
なければなりません。type属性は、最初のセルが
属性の値と一致する行の第2列のセルに示される状態を表します。どのセルも一致しない場合、または
属性が省略されている場合、属性はdecimal状態を表します。
| キーワード | 状態 | 説明 | 値1~3および3999~4001の例 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
1
(U+0031)
|
decimal | 10進数 | 1. | 2. | 3. | ... | 3999. | 4000. | 4001. | ... |
a (U+0061)
|
lower-alpha | 小文字のラテンアルファベット | a. | b. | c. | ... | ewu. | ewv. | eww. | ... |
A (U+0041)
|
upper-alpha | 大文字のラテンアルファベット | A. | B. | C. | ... | EWU. | EWV. | EWW. | ... |
i (U+0069)
|
lower-roman | 小文字のローマ数字 | i. | ii. | iii. | ... | mmmcmxcix. | i̅v̅. | i̅v̅i. | ... |
I (U+0049)
|
upper-roman | 大文字のローマ数字 | I. | II. | III. | ... | MMMCMXCIX. | I̅V̅. | I̅V̅I. | ... |
ユーザーエージェントは、ol要素のtype属性の状態と一貫した方法で、
リストの項目をレンダリングするべきです。0以下の数値は、type属性にかかわらず、
常に10進法を使用するべきです。
CSSユーザーエージェントについては、この属性から 'list-style-type' CSSプロパティへの対応付けが、 レンダリングのセクションに示されています(対応付けは単純で、上記の状態は対応するCSS値と 同じ名前を持ちます)。
CSSユーザーエージェントでこの属性を実装するために使用されるデフォルトのCSSリストスタイルを 再定義することができます。再定義すると、リスト項目のレンダリング方法に影響します。
[ReflectDefault]により、
start IDL属性は、startコンテンツ属性が
省略され、reversedコンテンツ属性が
指定されている場合、必ずしもリストの開始値と一致しません。
次のマークアップは順序が重要なリストを示しているため、ol
要素が適切です。同じ項目にul要素を使用した例を確認するには、
このリストをul
セクションの同等のリストと比較してください。
< p > I have lived in the following countries (given in the order of when
I first lived there):</ p >
< ol >
< li > Switzerland
< li > United Kingdom
< li > United States
< li > Norway
</ ol > リストの順序を変更すると、文書の意味が変わることに注意してください。次の例では、 最初の2つの項目の相対的な順序を変更したことで、著者の出生地が変わっています:
< p > I have lived in the following countries (given in the order of when
I first lived there):</ p >
< ol >
< li > United Kingdom
< li > Switzerland
< li > United States
< li > Norway
</ ol > ul
要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
li要素が含まれる場合:知覚可能コンテンツ。li要素およびスクリプト支援
要素。[Exposed =Window ]
interface HTMLUListElement : HTMLElement {
[HTMLConstructor ] constructor ();
// also has obsolete members
};ul要素は、項目の順序が
重要ではない、すなわち順序を変更しても文書の意味が実質的に変わらない項目のリストを表します。
次のマークアップは順序が重要ではないリストを示しているため、
ul要素が
適切です。同じ項目にol要素を使用した例を確認するには、
このリストをolセクションの
同等のリストと比較してください。
< p > I have lived in the following countries:</ p >
< ul >
< li > Norway
< li > Switzerland
< li > United Kingdom
< li > United States
</ ul > リストの順序を変更しても文書の意味が変わらないことに注意してください。上の断片では項目を アルファベット順に示していますが、下の断片では2007年時点の当座預金残高の大きさの順に 示しています。それでも文書の意味はまったく変わりません:
< p > I have lived in the following countries:</ p >
< ul >
< li > Switzerland
< li > Norway
< li > United Kingdom
< li > United States
</ ul > menu要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
li要素が含まれる場合:知覚可能コンテンツ。li要素およびスクリプト支援
要素。[Exposed =Window ]
interface HTMLMenuElement : HTMLElement {
[HTMLConstructor ] constructor ();
// also has obsolete members
};menu要素は、その内容から
構成されるツールバーを、項目の順序なしリスト(li要素で表される)の形で表します。各項目は、ユーザーが実行または
起動できるコマンドを表します。
menu要素は、
コマンドの順序なしリスト(「ツールバー」)を表現するためのulの単なる意味的な代替です。
この例では、テキスト編集アプリケーションがmenu要素を使用して、
一連の編集コマンドを提供しています:
< menu >
< li >< button onclick = "copy()" >< img src = "copy.svg" alt = "Copy" ></ button ></ li >
< li >< button onclick = "cut()" >< img src = "cut.svg" alt = "Cut" ></ button ></ li >
< li >< button onclick = "paste()" >< img src = "paste.svg" alt = "Paste" ></ button ></ li >
</ menu > これを従来型のツールバーメニューのように見せるためのスタイル設定は、 アプリケーションに委ねられていることに注意してください。
li
要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
ol要素内。ul要素内。menu要素内。li要素の終了タグは、li要素の直後に別のli要素が続く場合、または親要素内に
それ以上コンテンツがない場合に省略できます。
ul要素またはmenu要素の子でない場合:value — リスト項目の序数値
value。
[Exposed =Window ]
interface HTMLLIElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute long value ;
// also has obsolete members
};li要素はリスト項目を表します。その親要素がol要素、ul要素、またはmenu要素である場合、
この要素は、それらの要素について定義されている親要素のリストの項目です。それ以外の場合、
このリスト項目には、他のどのli要素とも定義された
リスト関連の関係がありません。
value属性が
存在する場合、その値は有効な整数でなければなりません。
この属性は、liのリスト所有者がol要素である場合に、
リスト項目の序数値を
決定するために使用されます。
指定されたリスト 所有者ownerが所有する各要素の序数値を決定するには、 次の手順を実行します:
iを1とします。
ownerがol
要素である場合、numberingを
ownerの開始値とします。
それ以外の場合、
numberingを1とします。
ループ:iがownerが所有するリスト項目の数より大きい場合、 戻ります。ownerの所有するすべてのリスト項目に序数値が割り当てられました。
parsedを、属性の値を整数として構文解析した結果とします。
parsedがエラーでない場合、numberingを parsedに設定します。
itemの序数値は numberingです。
ownerがol
要素であり、ownerにreversed属性がある場合、
numberingを1減らします。
それ以外の場合、numberingを1増やします。
iを1増やします。
ループというラベルが付いた手順に移動します。
要素のvalue IDL属性は、
その序数値に直接対応しません。
単にコンテンツ属性を反映するだけです。
たとえば、次のリストがあるとします:
< ol >
< li > Item 1
< li value = "3" > Item 3
< li > Item 4
</ ol > 次の例では、上位10本の映画が逆順で一覧表示されています。figure要素とそのfigcaption
要素を使用して、リストにタイトルを付けている方法に注意してください。
< figure >
< figcaption > The top 10 movies of all time</ figcaption >
< ol >
< li value = "10" >< cite > Josie and the Pussycats</ cite > , 2001</ li >
< li value = "9" >< cite lang = "sh" > Црна мачка, бели мачор</ cite > , 1998</ li >
< li value = "8" >< cite > A Bug's Life</ cite > , 1998</ li >
< li value = "7" >< cite > Toy Story</ cite > , 1995</ li >
< li value = "6" >< cite > Monsters, Inc</ cite > , 2001</ li >
< li value = "5" >< cite > Cars</ cite > , 2006</ li >
< li value = "4" >< cite > Toy Story 2</ cite > , 1999</ li >
< li value = "3" >< cite > Finding Nemo</ cite > , 2003</ li >
< li value = "2" >< cite > The Incredibles</ cite > , 2004</ li >
< li value = "1" >< cite > Ratatouille</ cite > , 2007</ li >
</ ol >
</ figure > このマークアップは、ol要素にreversed属性を使用して、
次のように記述することもできます:
< figure >
< figcaption > The top 10 movies of all time</ figcaption >
< ol reversed >
< li >< cite > Josie and the Pussycats</ cite > , 2001</ li >
< li >< cite lang = "sh" > Црна мачка, бели мачор</ cite > , 1998</ li >
< li >< cite > A Bug's Life</ cite > , 1998</ li >
< li >< cite > Toy Story</ cite > , 1995</ li >
< li >< cite > Monsters, Inc</ cite > , 2001</ li >
< li >< cite > Cars</ cite > , 2006</ li >
< li >< cite > Toy Story 2</ cite > , 1999</ li >
< li >< cite > Finding Nemo</ cite > , 2003</ li >
< li >< cite > The Incredibles</ cite > , 2004</ li >
< li >< cite > Ratatouille</ cite > , 2007</ li >
</ ol >
</ figure > li要素内に見出し要素(たとえばh1)
を含めることは適合しますが、作成者が意図したセマンティクスを伝えない可能性があります。
見出しは新しいセクションを開始するため、リスト内の見出しは暗黙的にリストを複数の
セクションにまたがるよう分割します。
dl
要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
dt要素と、それに続く1個以上の
dd要素からなるグループが
0個以上。任意で
スクリプト支援要素を混在させることができます。
div要素。
任意でスクリプト支援要素を混在させることができます。[Exposed =Window ]
interface HTMLDListElement : HTMLElement {
[HTMLConstructor ] constructor ();
// also has obsolete members
};dl要素は、0個以上の
名前と値のグループからなる関連付けリスト(説明リスト)を表します。名前と値のグループは、1個以上の名前
(dt要素で、
子のdiv要素の
子である場合もあります)と、それに続く1個以上の値(dd要素で、子のdiv要素の
子である場合もあります)からなります。dt要素およびdd要素の子以外のノードと、
子のdiv要素の子である
dt要素およびdd要素以外のノードは
無視されます。単一のdl
要素内では、各名前について複数のdt要素を置くべきではありません。
名前と値のグループは、用語と定義、メタデータの項目と値、質問と回答、またはその他の 名前と値のデータのグループである場合があります。
グループ内の値は代替です。同じ値の一部を形成する複数の段落は、すべて同じdd要素内に置かなければなりません。
グループのリストの順序、および各グループ内の名前と値の順序は、重要である場合があります。
グループ全体に適用されるマイクロデータ属性、
その他のグローバル
属性でグループに注釈を付けるため、または単にスタイル設定のために、dl要素内の各グループをdiv要素で囲むことができます。
これはdl要素の
セマンティクスを変更しません。
dl要素
dlの名前と値のグループは、次のアルゴリズムを使用して決定されます。
名前と値のグループには、名前(dt要素のリストで、
初期状態では空)と値(dd
要素のリストで、初期状態では空)があります。
groupsを名前と値のグループの空のリストとします。
currentを新しい名前と値のグループとします。
seenDdをfalseとします。
childをdlの最初の 子とします。
grandchildをnullとします。
childがnullでない間:
childがdiv要素である場合:
grandchildをchildの最初の 子とします。
grandchildがnullでない間:
grandchildについてdtまたは
ddを処理します。
grandchildをgrandchildの次の 兄弟に設定します。
それ以外の場合、childについてdtまたは
ddを処理します。
childをchildの次の 兄弟に設定します。
currentが空でない場合、currentを groupsに付加します。
groupsを返します。
名前と値のグループの名前または値が空のリストである場合、多くは
dt要素の代わりに
誤ってdd要素を使用したり、
その逆を行ったりしたことが原因です。適合性チェッカーは、そのような誤りを検出し、
マークアップを正しく使用する方法を作成者に助言できる場合があります。
次の例では、1つの項目(「Authors」)が2つの値(「John」と 「Luke」)に関連付けられています。
< dl >
< dt > Authors
< dd > John
< dd > Luke
< dt > Editor
< dd > Frank
</ dl > 次の例では、1つの定義が2つの用語に関連付けられています。
< dl >
< dt lang = "en-US" > < dfn > color</ dfn > </ dt >
< dt lang = "en-GB" > < dfn > colour</ dfn > </ dt >
< dd > A sensation which (in humans) derives from the ability of
the fine structure of the eye to distinguish three differently
filtered analyses of a view. </ dd >
</ dl > 次の例は、一種のメタデータをマークアップするためにdl要素を使用する方法を
示しています。例の最後では、1つのグループに2つのメタデータラベル(「Authors」と「Editors」)と
2つの値(「Robert Rothman」と「Daniel Jackson」)があります。この例では、スタイル設定を
容易にするため、dt要素と
dd要素のグループを
div要素で囲んでいます。
< dl >
< div >
< dt > Last modified time </ dt >
< dd > 2004-12-23T23:33Z </ dd >
</ div >
< div >
< dt > Recommended update interval </ dt >
< dd > 60s </ dd >
</ div >
< div >
< dt > Authors </ dt >
< dt > Editors </ dt >
< dd > Robert Rothman </ dd >
< dd > Daniel Jackson </ dd >
</ div >
</ dl > 次の例は、一連の指示を示すためにdl要素を使用しています。
ここでは指示の順序が重要です(他の例では、ブロックの順序は重要ではありませんでした)。
< p > Determine the victory points as follows (use the
first matching case):</ p >
< dl >
< dt > If you have exactly five gold coins </ dt >
< dd > You get five victory points </ dd >
< dt > If you have one or more gold coins, and you have one or more silver coins </ dt >
< dd > You get two victory points </ dd >
< dt > If you have one or more silver coins </ dt >
< dd > You get one victory point </ dd >
< dt > Otherwise </ dt >
< dd > You get no victory points </ dd >
</ dl > 次の断片は、dl
要素を用語集として使用する方法を示しています。定義される語を示すためにdfnを
使用していることに注意してください。
< dl >
< dt >< dfn > Apartment</ dfn > , n.</ dt >
< dd > An execution context grouping one or more threads with one or
more COM objects.</ dd >
< dt >< dfn > Flat</ dfn > , n.</ dt >
< dd > A deflated tire.</ dd >
< dt >< dfn > Home</ dfn > , n.</ dt >
< dd > The user's login directory.</ dd >
</ dl > この例は、dl要素内でdiv要素とともにマイクロデータ属性を使用し、
フランス料理店のアイスクリームデザートに注釈を付けています。
< dl >
< div itemscope itemtype = "http://schema.org/Product" >
< dt itemprop = "name" > Café ou Chocolat Liégeois
< dd itemprop = "offers" itemscope itemtype = "http://schema.org/Offer" >
< span itemprop = "price" > 3.50</ span >
< data itemprop = "priceCurrency" value = "EUR" > €</ data >
< dd itemprop = "description" >
2 boules Café ou Chocolat, 1 boule Vanille, sauce café ou chocolat, chantilly
</ div >
< div itemscope itemtype = "http://schema.org/Product" >
< dt itemprop = "name" > Américaine
< dd itemprop = "offers" itemscope itemtype = "http://schema.org/Offer" >
< span itemprop = "price" > 3.50</ span >
< data itemprop = "priceCurrency" value = "EUR" > €</ data >
< dd itemprop = "description" >
1 boule Crème brûlée, 1 boule Vanille, 1 boule Caramel, chantilly
</ div >
</ dl > div要素を使用しない場合、
データを項目と関連付けるため、マークアップではdd要素内のデータをitemref属性で
次のようにリンクする必要があります。
< dl >
< dt itemscope itemtype = "http://schema.org/Product" itemref = "1-offer 1-description" >
< span itemprop = "name" > Café ou Chocolat Liégeois</ span >
< dd id = "1-offer" itemprop = "offers" itemscope itemtype = "http://schema.org/Offer" >
< span itemprop = "price" > 3.50</ span >
< data itemprop = "priceCurrency" value = "EUR" > €</ data >
< dd id = "1-description" itemprop = "description" >
2 boules Café ou Chocolat, 1 boule Vanille, sauce café ou chocolat, chantilly
< dt itemscope itemtype = "http://schema.org/Product" itemref = "2-offer 2-description" >
< span itemprop = "name" > Américaine</ span >
< dd id = "2-offer" itemprop = "offers" itemscope itemtype = "http://schema.org/Offer" >
< span itemprop = "price" > 3.50</ span >
< data itemprop = "priceCurrency" value = "EUR" > €</ data >
< dd id = "2-description" itemprop = "description" >
1 boule Crème brûlée, 1 boule Vanille, 1 boule Caramel, chantilly
</ dl > dl要素は、
対話のマークアップには不適切です。対話をマークアップする方法の例を参照してください。
dt
要素現在のすべてのエンジンでサポートされています。
dl要素内のdd要素またはdt要素の前。dl要素の子であるdiv要素内のdd要素またはdt要素の前。
header、footer、セクショニングコンテンツ、
または見出しコンテンツを含まないもの。dt要素の終了タグは、dt要素の直後に別のdt要素またはdd要素が続く場合に省略できます。
HTMLElementを使用します。dt要素は、
説明リスト(dl要素)内の
用語と説明のグループにおける用語または名前の部分を表します。
dt要素自体は、
dl要素内で使用されても、
その内容が定義される用語であることを示しませんが、これはdfn要素を使用して示すことができます。
この例は、質問にdt要素を、回答にdd要素を使用して
マークアップした、よくある質問(FAQ)のリストを示しています。
< article >
< h1 > FAQ</ h1 >
< dl >
< dt > What do we want?</ dt >
< dd > Our data.</ dd >
< dt > When do we want it?</ dt >
< dd > Now.</ dd >
< dt > Where is it?</ dt >
< dd > We are not sure.</ dd >
</ dl >
</ article > dd
要素現在のすべてのエンジンでサポートされています。
dl要素内のdt要素またはdd要素の後。dl要素の子であるdiv要素内のdt要素またはdd要素の後。
dd要素の終了タグは、dd要素の直後に別のdd要素またはdt要素が続く場合、
または親要素内にそれ以上コンテンツがない場合に省略できます。
HTMLElementを使用します。dd要素は、
説明リスト(dl要素)内の用語と説明の
グループにおける説明、定義、または値の部分を表します。
dlは、辞書のような
語彙リストを定義するために使用できます。次の例では、dfnを含むdtによって示される各項目に、
定義のさまざまな部分を示す複数のddがあります。
< dl >
< dt >< dfn > happiness</ dfn ></ dt >
< dd class = "pronunciation" > /ˈhæpinəs/</ dd >
< dd class = "part-of-speech" >< i >< abbr > n.</ abbr ></ i ></ dd >
< dd > The state of being happy.</ dd >
< dd > Good fortune; success. < q > Oh < b > happiness</ b > ! It worked!</ q ></ dd >
< dt >< dfn > rejoice</ dfn ></ dt >
< dd class = "pronunciation" > /rɪˈdʒɔɪs/</ dd >
< dd >< i class = "part-of-speech" >< abbr > v.intr.</ abbr ></ i > To be delighted oneself.</ dd >
< dd >< i class = "part-of-speech" >< abbr > v.tr.</ abbr ></ i > To cause one to be delighted.</ dd >
</ dl > figure要素現在のすべてのエンジンでサポートされています。
figcaption要素と、
それに続くフローコンテンツ。figcaption
要素。HTMLElementを使用します。figure要素は表します、任意でキャプションを伴い、
自己完結しており(完全な文のように)、通常は文書の主要なフローから単一の単位として参照されるフローコンテンツを。
この文脈における「自己完結」は、必ずしも独立していることを意味しません。
たとえば、段落内の各文は自己完結しています。文の一部である画像にはfigureは
不適切ですが、画像で構成された文全体には
適しています。
したがって、この要素はイラスト、図、写真、コードリストなどに注釈を付けるために 使用できます。
figureが、
キャプション(たとえば図番号)によって識別され、文書の主要なコンテンツから
参照される場合、そのコンテンツを主要なコンテンツから離れた場所、たとえばページの横、
専用ページ、または付録へ、文書のフローに影響を与えることなく容易に移動できます。
figure要素が
相対的な位置、たとえば「上の写真」や「次の図が示すように」によって参照される場合、図を移動するとページの意味が損なわれます。
ページの意味に影響を与えずに容易にスタイルを変更できるように、作成者には、そのような
相対的参照ではなく、ラベルを使用して図を参照することを検討するよう推奨されます。
要素の最初の子であるfigcaption要素が
存在する場合、それはfigure要素の内容の
キャプションを表します。子の
figcaption
要素がない場合、キャプションはありません。
figure要素の
内容は周囲のフローの一部です。ページの目的が、たとえば画像共有サイト上の写真のように
図を表示することである場合、figure要素とfigcaption要素を
使用して、その図に明示的な
キャプションを提供できます。周囲のフローとの関連が間接的にすぎないコンテンツ、または
周囲のフローとは別の目的を果たすコンテンツには、aside要素を使用するべきです
(その内部に
figureを
含めることもできます)。たとえば、articleの内容を
繰り返す抜粋引用は、aside内に置く方が、
figure内に置くより
適切です。これはコンテンツの一部ではなく、読者を引き付けたり主要な話題を強調したりする
目的でコンテンツを繰り返したものだからです。
この例は、コードリストをマークアップするためのfigure要素を
示しています。
< p > In < a href = "#l4" > listing 4</ a > we see the primary core interface
API declaration.</ p >
< figure id = "l4" >
< figcaption > Listing 4. The primary core interface API declaration.</ figcaption >
< pre >< code > interface PrimaryCore {
boolean verifyDataLine();
undefined sendData(sequence< byte> data);
undefined initSelfDestruct();
}</ code ></ pre >
</ figure >
< p > The API is designed to use UTF-8.</ p > ここでは、(ギャラリーのように)ページの主要なコンテンツである写真をマークアップするための
figure
要素を示しています。
<!DOCTYPE HTML>
< html lang = "en" >
< title > Bubbles at work — My Gallery™</ title >
< figure >
< img src = "bubbles-work.jpeg"
alt = "Bubbles, sitting in his office chair, works on his
latest project intently." >
< figcaption > Bubbles at work</ figcaption >
</ figure >
< nav >< a href = "19414.html" > Prev</ a > — < a href = "19416.html" > Next</ a ></ nav > この例では、図ではない画像と、図である画像および
動画を示しています。最初の画像は文字どおり例の第2文の一部であるため、
自己完結した単位ではなく、したがってfigureは
不適切です。
< h2 > Malinko's comics</ h2 >
< p > This case centered on some sort of "intellectual property"
infringement related to a comic (see Exhibit A). The suit started
after a trailer ending with these words:
< blockquote >
< img src = "promblem-packed-action.png" alt = "ROUGH COPY! Promblem-Packed Action!" >
</ blockquote >
< p > ...was aired. A lawyer, armed with a Bigger Notebook, launched a
preemptive strike using snowballs. A complete copy of the trailer is
included with Exhibit B.
< figure >
< img src = "ex-a.png" alt = "Two squiggles on a dirty piece of paper." >
< figcaption > Exhibit A. The alleged < cite > rough copy</ cite > comic.</ figcaption >
</ figure >
< figure >
< video src = "ex-b.mov" ></ video >
< figcaption > Exhibit B. The < cite > Rough Copy</ cite > trailer.</ figcaption >
</ figure >
< p > The case was resolved out of court.ここでは、詩の一部がfigureを使用して
マークアップされています。
< figure >
< p > 'Twas brillig, and the slithy toves< br >
Did gyre and gimble in the wabe;< br >
All mimsy were the borogoves,< br >
And the mome raths outgrabe.</ p >
< figcaption >< cite > Jabberwocky</ cite > (first verse). Lewis Carroll, 1832-98</ figcaption >
</ figure > この例は、城について論じるより大きな作品の一部となり得るもので、入れ子になった
figure要素を
使用して、グループ全体のキャプションと、グループ内の各図の個別キャプションの両方を
提供しています:
< figure >
< figcaption > The castle through the ages: 1423, 1858, and 1999 respectively.</ figcaption >
< figure >
< figcaption > Etching. Anonymous, ca. 1423.</ figcaption >
< img src = "castle1423.jpeg" alt = "The castle has one tower, and a tall wall around it." >
</ figure >
< figure >
< figcaption > Oil-based paint on canvas. Maria Towle, 1858.</ figcaption >
< img src = "castle1858.jpeg" alt = "The castle now has two towers and two walls." >
</ figure >
< figure >
< figcaption > Film photograph. Peter Jankle, 1999.</ figcaption >
< img src = "castle1999.jpeg" alt = "The castle lies in ruins, the original tower all that remains in one piece." >
</ figure >
</ figure > 前の例は、次のようにより簡潔に記述することもできます(入れ子になったfigure/figcaptionの組の
代わりにtitle属性を使用します):
< figure >
< img src = "castle1423.jpeg" title = "Etching. Anonymous, ca. 1423."
alt = "The castle has one tower, and a tall wall around it." >
< img src = "castle1858.jpeg" title = "Oil-based paint on canvas. Maria Towle, 1858."
alt = "The castle now has two towers and two walls." >
< img src = "castle1999.jpeg" title = "Film photograph. Peter Jankle, 1999."
alt = "The castle lies in ruins, the original tower all that remains in one piece." >
< figcaption > The castle through the ages: 1423, 1858, and 1999 respectively.</ figcaption >
</ figure > 図は、コンテンツから暗黙的にのみ参照されることもあります:
< article >
< h1 > Fiscal negotiations stumble in Congress as deadline nears</ h1 >
< figure >
< img src = "obama-reid.jpeg" alt = "Obama and Reid sit together smiling in the Oval Office." >
< figcaption > Barack Obama and Harry Reid. White House press photograph.</ figcaption >
</ figure >
< p > Negotiations in Congress to end the fiscal impasse sputtered on Tuesday, leaving both chambers
grasping for a way to reopen the government and raise the country's borrowing authority with a
Thursday deadline drawing near.</ p >
...
</ article > figcaption要素
現在のすべてのエンジンでサポートされています。
figure要素の最初または
最後の子として。HTMLElementを使用します。figcaption要素は、
親のfigure要素がある場合、
そのfigcaption
要素以外の残りの内容に対するキャプションまたは凡例を表します。
この要素には、出典に関する追加情報を含めることができます:
< figcaption >
< p > A duck.</ p >
< p >< small > Photograph courtesy of 🌟 News.</ small ></ p >
</ figcaption > < figcaption >
< p > Average rent for 3-room apartments, excluding non-profit apartments</ p >
< p > Zürich’s Statistics Office — < time datetime = 2017-11-14 > 14 November 2017</ time ></ p >
</ figcaption > main
要素現在のすべてのエンジンでサポートされています。
main要素である場合に限ります。HTMLElementを使用します。文書には、属性が
指定されていないmain要素を
2個以上含めてはなりません。
階層的に正しいmain要素とは、
祖先要素がhtml、body、div、アクセシブル名を持たないform、および自律カスタム要素に
限定されているものです。各main要素は、階層的に正しいmain
要素でなければなりません。
この例では、作成者はページの各構成要素がボックス内にレンダリングされる表示形式を
使用しています。ヘッダー、フッター、ナビゲーションバー、およびサイドバーとは異なる
ページの主要なコンテンツを囲むために、main要素を使用しています。
<!DOCTYPE html>
< html lang = "en" >
< title > RPG System 17</ title >
< style >
header , nav , aside , main , footer {
margin : 0.5 em ; border : thin solid ; padding : 0.5 em ;
background : #EFF ; color : black ; box-shadow : 0 0 0.25 em #033 ;
}
h1 , h2 , p { margin : 0 ; }
nav , main { float : left ; }
aside { float : right ; }
footer { clear : both ; }
</ style >
< header >
< h1 > System Eighteen</ h1 >
</ header >
< nav >
< a href = "../16/" > ← System 17</ a >
< a href = "../18/" > RPXIX →</ a >
</ nav >
< aside >
< p > This system has no HP mechanic, so there's no healing.
</ aside >
< main >
< h2 > Character creation</ h2 >
< p > Attributes (magic, strength, agility) are purchased at the cost of one point per level.</ p >
< h2 > Rolls</ h2 >
< p > Each encounter, roll the dice for all your skills. If you roll more than the opponent, you win.</ p >
</ main >
< footer >
< p > Copyright © 2013
</ footer >
</ html > 次の例では、複数のmain要素を使用し、
サーバーとの往復なしでナビゲーションを機能させ、現在のものではない要素に属性を設定するために、
スクリプトを使用しています:
<!doctype html>
< html lang = en-CA >
< meta charset = utf-8 >
< title > … </ title >
< link rel = stylesheet href = spa.css >
< script src = spa.js async ></ script >
< nav >
< a href = / > Home</ a >
< a href = /about > About</ a >
< a href = /contact > Contact</ a >
</ nav >
< main >
< h1 > Home</ h1 >
…
</ main >
< main hidden >
< h1 > About</ h1 >
…
</ main >
< main hidden >
< h1 > Contact</ h1 >
…
</ main >
< footer > Made with ❤️ by < a href = https://example.com/ > Example 👻</ a > .</ footer > search要素現在のエンジンではサポートされていません。
HTMLElementを使用します。search要素は、
検索またはフィルタリング操作の実行に関連するフォームコントロールの集合やその他の
コンテンツを含む、文書またはアプリケーションの一部を表します。これは、ウェブサイトまたはアプリケーションの検索、
現在のウェブページ上の検索結果を検索またはフィルタリングする手段、あるいはグローバルまたは
インターネット全体を対象とする検索機能である場合があります。
search要素を、
単に検索結果を表示するためだけに使用することは適切ではありません。ただし、「クイック検索」の
結果の一部としての候補やリンクは、検索機能の一部として含めることができます。検索結果として
返されたウェブページは、代わりにそのウェブページの主要なコンテンツの一部として表示されることが
想定されます。
次の例では、作成者はウェブページのheader内に検索フォームを
含めています:
< header >
< h1 >< a href = "/" > My fancy blog</ a ></ h1 >
...
< search >
< form action = "search.php" >
< label for = "query" > Find an article</ label >
< input id = "query" name = "q" type = "search" >
< button type = "submit" > Go!</ button >
</ form >
</ search >
</ header > この例では、作成者はウェブアプリケーションの検索機能をすべてJavaScriptで実装しています。
サーバー側への送信を行うためのform要素は使用されて
いませんが、コンテナーとなるsearch要素が、
子孫コンテンツの目的が検索機能を表すことであると意味的に識別します。
< search >
< label >
Find and filter your query
< input type = "search" id = "query" >
</ label >
< label >
< input type = "checkbox" id = "exact-only" >
Exact matches only
</ label >
< section >
< h3 > Results found:</ h3 >
< ul id = "results" >
< li >
< p >< a href = "services/consulting" > Consulting services</ a ></ p >
< p >
Find out how can we help you improve your business with our integrated consultants, Bob and Bob.
</ p >
</ li >
...
</ ul >
<!--
when a query returns or filters out all results
render the no results message here
-->
< output id = "no-results" ></ output >
</ section >
</ search > 次の例では、ページに2つの検索機能があります。1つ目はウェブページのheader内にあり、
ウェブサイトのコンテンツを検索するグローバルな仕組みとして機能します。その目的は、
指定されたtitle属性によって
示されます。2つ目は、現在のページのコンテンツを検索およびフィルタリングする仕組みを
表すため、ページの主要なコンテンツの一部として含まれています。その目的を示す見出しが
含まれています。
< body >
< header >
...
< search title = "Website" >
...
</ search >
</ header >
< main >
< h1 > Hotels near your location</ h1 >
< search >
< h2 > Filter results</ h2 >
...
</ search >
< article >
<!-- search result content -->
</ article >
</ main >
</ body > div
要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
dl要素の子として。option要素、optgroup要素、または
select要素の子孫として。
dl要素の子である場合:1個以上の
dt要素と、それに続く1個以上の
dd要素。任意でスクリプト支援
要素を混在させることができます。
option要素、optgroup要素、または
select要素の子孫で
ある場合:透過的。
[Exposed =Window ]
interface HTMLDivElement : HTMLElement {
[HTMLConstructor ] constructor ();
// also has obsolete members
};div要素には、特別な
意味はまったくありません。これはその子を表します。連続する要素のグループに共通するセマンティクスを
マークアップするために、class、lang、およびtitle属性とともに使用できます。また、
dl要素内で、dt要素とdd要素のグループを囲むためにも
使用できます。
作成者には、他に適切な要素がない場合の最後の手段としてdiv要素を捉えることが
強く推奨されます。div要素の代わりに
より適切な要素を使用することで、読者にとってのアクセシビリティが向上し、作成者にとっての
保守性も高まります。
たとえば、ブログ投稿はarticleを使用して、
章はsectionを
使用して、ページのナビゲーション支援はnavを使用して、
フォームコントロールのグループはfieldsetを使用して
マークアップします。
一方、div要素は、
スタイル設定の目的や、同様の方法で注釈を付ける必要があるセクション内の複数の段落を囲むために
役立つ場合があります。次の例では、2つの段落要素それぞれに言語を設定する代わりに、div要素を使用して
2つの段落の言語を一度に設定しています:
< article lang = "en-US" >
< h1 > My use of language and my cats</ h1 >
< p > My cat's behavior hasn't changed much since her absence, except
that she plays her new physique to the neighbors regularly, in an
attempt to get pets.</ p >
< div lang = "en-GB" >
< p > My other cat, coloured black and white, is a sweetie. He followed
us to the pool today, walking down the pavement with us. Yesterday
he apparently visited our neighbours. I wonder if he recognises that
their flat is a mirror image of ours.</ p >
< p > Hm, I just noticed that in the last paragraph I used British
English. But I'm supposed to write in American English. So I
shouldn't say "pavement" or "flat" or "colour"...</ p >
</ div >
< p > I should say "sidewalk" and "apartment" and "color"!</ p >
</ article > a
要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
href属性がある場合:インタラクティブコンテンツ。a要素、またはtabindex属性が指定された要素を
含めてはなりません。
href —
ハイパーリンクのアドレス
target —
ハイパーリンクのナビゲーションに使用するナビガブル
download —
リソースへナビゲートする代わりにダウンロードするかどうか、およびその場合のファイル名
ping — pingするURL
rel —
ハイパーリンクを含む文書内の位置と
宛先リソースとの関係
hreflang —
リンク先リソースの言語
type —
参照先リソースの種類に関するヒント
referrerpolicy
— 要素によって開始されるフェッチのリファラーポリシー
href属性がある場合:作成者向け、
実装者向け。href、hreflang、
およびtype。
また、ナビゲーションURL属性は
href。
[Exposed =Window ]
interface HTMLAnchorElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute DOMString download ;
[CEReactions , Reflect ] attribute USVString ping ;
[CEReactions , Reflect ] attribute DOMString rel ;
[SameObject , PutForwards =value , Reflect="rel"] readonly attribute DOMTokenList relList ;
[CEReactions ] attribute DOMString text ;
[CEReactions ] attribute DOMString referrerPolicy ;
// also has obsolete members
};
HTMLAnchorElement includes HyperlinkElementUtils ;
HTMLAnchorElement includes HTMLHyperlinkElementUtils ;a要素にhref属性がある場合、
その内容によってラベル付けされたハイパーリンク(ハイパーテキストアンカー)を表します。
a要素にhref属性がない場合、
要素は、その内容のみから構成され、関連性があればリンクが置かれていた可能性のある場所の
プレースホルダーを表します。
target、download、ping、rel、hreflang、type、およびreferrerpolicy
属性は、href属性が
存在しない場合、省略しなければなりません。
itemprop
属性がa要素に指定される場合、
href属性も
指定しなければなりません。
サイトがすべてのページで一貫したナビゲーションツールバーを使用している場合、
通常はページ自体へリンクするリンクを、a要素を使用して
マークアップできます:
< nav >
< ul >
< li > < a href = "/" > Home</ a > </ li >
< li > < a href = "/news" > News</ a > </ li >
< li > < a > Examples</ a > </ li >
< li > < a href = "/legal" > Legal</ a > </ li >
</ ul >
</ nav > href、target、download、ping、およびreferrerpolicy
属性は、ユーザーがa要素を使用して
作成されたハイパーリンクをたどる、
またはハイパーリンクをダウンロードする際の動作に影響します。
rel、hreflang、および
type属性は、
ユーザーがリンクをたどる前に、宛先リソースの予想される性質をユーザーに示すために使用できます。
a.texttextContentと
同じです。
HTMLAnchorElement/referrerPolicy
現在のすべてのエンジンでサポートされています。
IDL属性referrerPolicyは、referrerpolicy
コンテンツ属性を、既知の値のみに制限して反映しなければなりません。
text
属性の取得子は、この要素の子孫テキスト内容を返さなければなりません。
a要素は、その内部に
インタラクティブコンテンツ(たとえばボタンや他のリンク)がない限り、段落、リスト、表などの
全体、さらにはセクション全体を囲むことができます。この例は、広告ブロック全体をリンクにするために
これを使用する方法を示しています:
< aside class = "advertising" >
< h1 > Advertising</ h1 >
< a href = "https://ad.example.com/?adid=1929&pubid=1422" >
< section >
< h1 > Mellblomatic 9000!</ h1 >
< p > Turn all your widgets into mellbloms!</ p >
< p > Only $9.99 plus shipping and handling.</ p >
</ section >
</ a >
< a href = "https://ad.example.com/?adid=375&pubid=1422" >
< section >
< h1 > The Mellblom Browser</ h1 >
< p > Web browsing at the speed of light.</ p >
< p > No other browser goes faster!</ p >
</ section >
</ a >
</ aside > 次の例は、少量のスクリプトを使用して、求人一覧表の行全体を実質的に ハイパーリンクにする方法を示しています:
< table >
< tr >
< th > Position
< th > Team
< th > Location
< tr >
< td >< a href = "/jobs/manager" > Manager</ a >
< td > Remotees
< td > Remote
< tr >
< td >< a href = "/jobs/director" > Director</ a >
< td > Remotees
< td > Remote
< tr >
< td >< a href = "/jobs/astronaut" > Astronaut</ a >
< td > Architecture
< td > Remote
</ table >
< script >
document. querySelector( "table" ). onclick = ({ target }) => {
if ( target. parentElement. localName === "tr" ) {
const link = target. parentElement. querySelector( "a" );
if ( link) {
link. click();
}
}
}
</ script > em
要素現在のすべてのエンジンでサポートされています。
HTMLElementを使用します。特定のコンテンツが持つ強勢のレベルは、その祖先であるem要素の数によって示されます。
強勢による強調の位置は、文の意味を変えます。したがって、この要素はコンテンツの 不可欠な部分を形成します。この方法で強勢が使用される正確な方法は、言語によって異なります。
これらの例は、強勢による強調を変更すると意味がどのように変わるかを示しています。 まず、強勢のない一般的な事実の記述です:
< p > Cats are cute animals.</ p > 最初の語を強調すると、話題となっている動物の種類に疑問があることを暗示します (おそらく誰かが犬はかわいいと主張しているのでしょう):
< p >< em > Cats</ em > are cute animals.</ p > 強勢を動詞へ移すと、文全体が真であるかどうかに疑問があることを強調します (おそらく誰かが猫はかわいくないと言っているのでしょう):
< p > Cats < em > are</ em > cute animals.</ p > 形容詞へ移すと、猫の正確な性質が改めて主張されます(おそらく誰かが猫は 意地悪な動物だと示唆したのでしょう):
< p > Cats are < em > cute</ em > animals.</ p > 同様に、誰かが猫は野菜だと主張した場合、それを訂正する人は最後の語を 強調するでしょう:
< p > Cats are cute < em > animals</ em > .</ p > 文全体を強調すると、話者がその主張を伝えるために懸命になっていることが明らかになります。 この種の強勢による強調は、通常、句読点にも影響するため、ここでは感嘆符が使用されています。
< p >< em > Cats are cute animals!</ em ></ p > かわいさの強調に怒りが混じると、次のようなマークアップになる場合があります:
< p >< em > Cats are < em > cute</ em > animals!</ em ></ p > strong要素現在のすべてのエンジンでサポートされています。
HTMLElementを使用します。strong要素は、
その内容の強い重要性、重大性、または緊急性を表します。
重要性:strong要素は、
見出し、キャプション、または段落内で、本当に重要な部分を、より詳細な部分、より陽気な部分、
または単なる定型文から区別するために使用できます。(これは小見出しをマークアップすることとは
異なり、その目的にはhgroup要素が適切です。)
たとえば、前の段落の最初の語は、段落の残りのより詳細なテキストから
区別するために、strongで
マークアップされています。
重大性:strong要素は、
警告または注意書きをマークアップするために使用できます。
緊急性:strong要素は、
ユーザーが文書の他の部分よりも先に確認する必要がある内容を示すために使用できます。
コンテンツの一部の相対的な重要性のレベルは、その祖先であるstrong要素の数によって
示されます。各strong要素は、
その内容の重要性を高めます。
strong要素で
テキストの一部の重要性を変更しても、文の意味は変わりません。
ここでは、「chapter」という語と実際の章番号は単なる定型文であり、章の実際の名前がstrongで
マークアップされています:
< h1 > Chapter 1: < strong > The Praxis</ strong ></ h1 > 次の例では、キャプション内の図の名前が、前にある定型文と後にある説明から区別するために、
strongで
マークアップされています:
< figcaption > Figure 1. < strong > Ant colony dynamics</ strong > . The ants in this colony are
affected by the heat source (upper left) and the food source (lower right).</ figcaption > この例では、見出しは実際には「Flowers, Bees, and Honey」ですが、作成者は見出しに
軽妙な付け足しを加えています。したがって、後半部分と区別するために、最初の部分を
マークアップする目的でstrong要素が
使用されています。
< h1 >< strong > Flowers, Bees, and Honey</ strong > and other things I don't understand</ h1 > ゲーム内の警告通知の例を次に示します。さまざまな部分が、その重要度に応じて マークアップされています:
< p >< strong > Warning.</ strong > This dungeon is dangerous.
< strong > Avoid the ducks.</ strong > Take any gold you find.
< strong >< strong > Do not take any of the diamonds</ strong > ,
they are explosive and < strong > will destroy anything within
ten meters.</ strong ></ strong > You have been warned.</ p > この例では、strong要素を使用して、
ユーザーが最初に読むことを意図したテキストの部分を示しています。
< p > Welcome to Remy, the reminder system.</ p >
< p > Your tasks for today:</ p >
< ul >
< li >< p >< strong > Turn off the oven.</ strong ></ p ></ li >
< li >< p > Put out the trash.</ p ></ li >
< li >< p > Do the laundry.</ p ></ li >
</ ul > small
要素現在のすべてのエンジンでサポートされています。
HTMLElementを使用します。細則には通常、免責事項、注意事項、法的制約、または著作権表示が含まれます。 細則は、帰属表示やライセンス要件を満たすために使用される場合もあります。
small
要素は、em要素によって
強調されたテキストの強調を弱めたり、strong要素によって
重要と示されたテキストの重要性を下げたりしません。テキストを強調されていない、または
重要でないものとして示すには、それぞれem要素またはstrong要素で
マークアップしないだけです。
small要素は、
複数の段落、リスト、またはテキストのセクションなど、長い範囲のテキストに使用するべきでは
ありません。短い範囲のテキストのみを対象としています。たとえば、利用規約を列挙するページの
テキストは、small要素の
適切な候補ではありません。その場合、そのテキストは補足コメントではなく、ページの主要な
コンテンツだからです。
small要素を
小見出しに使用してはなりません。その目的には、hgroup要素を使用します。
この例では、small要素を使用して、
ホテルの客室料金に付加価値税が含まれていないことを示しています:
< dl >
< dt > Single room
< dd > 199 € < small > breakfast included, VAT not included</ small >
< dt > Double room
< dd > 239 € < small > breakfast included, VAT not included</ small >
</ dl > この2番目の例では、small要素を、
記事内の補足コメントに使用しています。
< p > Example Corp today announced record profits for the
second quarter < small > (Full Disclosure: Foo News is a subsidiary of
Example Corp)</ small > , leading to speculation about a third quarter
merger with Demo Group.</ p > これは、複数の段落にわたる場合があり、テキストの主要なフローから除外されるサイドバーとは 異なります。次の例では、同じ記事のサイドバーを示しています。このサイドバーにも細則があり、 サイドバー内の情報の出典を示しています。
< aside >
< h1 > Example Corp</ h1 >
< p > This company mostly creates small software and Web
sites.</ p >
< p > The Example Corp company mission is "To provide entertainment
and news on a sample basis".</ p >
< p >< small > Information obtained from < a
href = "https://example.com/about.html" > example.com</ a > home
page.</ small ></ p >
</ aside > この最後の例では、small要素が、
重要な細則であるとマークされています。
< p >< strong >< small > Continued use of this service will result in a kiss.</ small ></ strong ></ p > s
要素現在のすべてのエンジンでサポートされています。
HTMLElementを使用します。s要素は、もはや正確でない、
またはもはや関連性がない内容を表します。
s要素は、
文書の編集を示す場合には適切ではありません。文書から削除されたテキスト範囲をマークするには、
del要素を使用します。
この例では、対象の商品に新しい特別価格が設定されたため、希望小売価格がもはや 関連性のないものとしてマークされています。
< p > Buy our Iced Tea and Lemonade!</ p >
< p >< s > Recommended retail price: $3.99 per bottle</ s ></ p >
< p >< strong > Now selling for just $2.99 a bottle!</ strong ></ p > cite
要素現在のすべてのエンジンでサポートされています。
HTMLElementを使用します。cite要素は、作品
(たとえば、書籍、
論文、
随筆、
詩、
楽譜、
楽曲、
脚本、
映画、
テレビ番組、
ゲーム、
彫刻、
絵画、
演劇制作、
戯曲、
オペラ、
ミュージカル、
展覧会、
判例報告、
コンピュータープログラム
など)の題名を表します。これは、引用または
詳細に参照されている作品
(すなわち出典表記)である場合も、単に言及されただけの作品である場合もあります。
人物の名前は作品の題名ではありません。その人物が「大した人物」だと呼ばれている場合であっても
同様です。したがって、この要素を人物の名前のマークアップに使用してはなりません。
(場合によっては、名前にb要素が適切なことがあります。
たとえば、有名人の名前が注意を引くために異なるスタイルでレンダリングされるキーワードとなる
ゴシップ記事などです。別の場合で、要素が本当に必要であれば、span要素を使用できます。)
次の例は、cite 要素の典型的な使用法を示す:
< p > My favorite book is < cite > The Reality Dysfunction</ cite > by
Peter F. Hamilton. My favorite comic is < cite > Pearls Before
Swine</ cite > by Stephan Pastis. My favorite track is < cite > Jive
Samba</ cite > by the Cannonball Adderley Sextet.</ p > これは正しい使用法である:
< p > According to the Wikipedia article < cite > HTML</ cite > , as it
stood in mid-February 2008, leaving attribute values unquoted is
unsafe. This is obviously an over-simplification.</ p > しかし、次は誤った使用法である。ここでの cite
要素には、
作品のタイトルをはるかに超える内容が含まれているためである:
<!-- do not copy this example, it is an example of bad usage! -->
< p > According to < cite > the Wikipedia article on HTML</ cite > , as it
stood in mid-February 2008, leaving attribute values unquoted is
unsafe. This is obviously an over-simplification.</ p > cite 要素は、参考文献における
あらゆる引用の重要な部分であるが、
タイトルを示すためにのみ使用される:
< p >< cite > Universal Declaration of Human Rights</ cite > , United Nations,
December 1948. Adopted by General Assembly resolution 217 A (III).</ p > 引用情報は
引用文ではない(引用文には q
要素
が適切である)。
これは誤った使用法である。cite
は引用文のためのものではないためである:
< p >< cite > This is wrong!</ cite > , said Ian.</ p > これも誤った使用法である。人物は作品ではないためである:
< p >< q > This is still wrong!</ q > , said < cite > Ian</ cite > .</ p > 正しい使用法では cite 要素を使用しない:
< p >< q > This is correct</ q > , said Ian.</ p > 前述のとおり、b 要素は、
特定の種類の文書で名前を
キーワードとして示すために適切な場合がある:
< p > And then < b > Ian</ b > said < q > this might be right, in a
gossip column, maybe!</ q > .</ p > 作品のタイトルを慣習的に
句読記号で区切る場合(たとえば、英語の記事タイトルを囲む引用符や、日本語の書籍タイトルを囲む隅付き括弧(『』))、
その句読記号はタイトルの一部ではなく、
cite 要素の外側に置かれる。
これは正しい使用法である:
< p > My review of 『< cite lang = "ja" > 阪急電車</ cite > 』 was titled “< cite > A cute series of short stories</ cite > ”.</ p > q
要素現在のすべてのエンジンでサポートされています。
cite — 引用元、または編集に関する
詳細情報へのリンク
HTMLQuoteElementを使用します。q要素は、別の出典から引用された
フレージングコンテンツを表します。
要素の内容を引用する引用符などの引用用句読点は、q要素の直前、直後、または内部に
記述してはなりません。これらはユーザーエージェントによってレンダリングに挿入されます。
q要素内の内容は、
別の出典から引用されたものでなければなりません。その出典にアドレスがある場合は、cite属性で示すことができます。小説や脚本の登場人物を
引用する場合のように、出典は架空のものであってもかまいません。
cite属性が存在する場合、その値は
前後に空白を含む可能性のある有効な
URLでなければなりません。対応する引用リンクを取得するには、属性の値を要素のノード文書を
基準として解析しなければなりません。ユーザーエージェントは、
ユーザーがそのような引用リンクをたどれるようにしてもかまいませんが、これらは主として
読者向けではなく、私的な用途(たとえば、サイトにおける引用の使用状況を収集する
サーバー側スクリプト)を意図しています。
q要素は、
引用を表さない引用符の代わりに使用してはなりません。たとえば、皮肉な発言をマークアップするために
q要素を使用することは
不適切です。
引用をマークアップするためにq要素を使用するかどうかは
完全に任意です。q要素を
使用せず、明示的な引用符を使用することも同様に正しい方法です。
q要素の簡単な使用例を示します:
< p > The man said < q > Things that are impossible just take
longer</ q > . I disagreed with him.</ p > 次に、q要素内に明示的な引用リンクがあり、
さらにその外側にも明示的な出典表記がある例を示します:
< p > The W3C page < cite > About W3C</ cite > says the W3C's
mission is < q cite = "https://www.w3.org/Consortium/" > To lead the
World Wide Web to its full potential by developing protocols and
guidelines that ensure long-term growth for the Web</ q > . I
disagree with this mission.</ p > 次の例では、引用自体の中に別の引用が含まれています:
< p > In < cite > Example One</ cite > , he writes < q > The man
said < q > Things that are impossible just take longer</ q > . I
disagreed with him</ q > . Well, I disagree even more!</ p > 次の例では、q要素の代わりに引用符を使用しています:
< p > His best argument was ❝I disagree❞, which
I thought was laughable.</ p > 次の例には引用はありません。引用符は単語を示すために使用されています。この場合にq要素を使用することは
不適切です。
< p > The word "ineffable" could have been used to describe the disaster
resulting from the campaign's mismanagement.</ p > dfn
要素現在のすべてのエンジンでサポートされています。
dfn要素を含めてはなりません。title属性は
この要素において特別なセマンティクスを持ちます:
完全な用語または略語の展開形
HTMLElementを使用します。dfn要素は、
用語を定義する箇所を表します。dfn要素に最も近い祖先である
段落、説明リストグループ、またはセクションには、dfn要素によって示される
用語の定義も含まれていなければなりません。
定義される用語:dfn要素にtitle属性がある場合、
その属性の正確な値が定義される用語です。それ以外で、要素が要素子ノードをちょうど1つだけ含み、
子のText
ノードを含まず、その子要素がtitle属性を持つabbr要素である場合、
その属性の正確な値が定義される用語です。それ以外の場合、dfn要素の子孫テキスト内容が定義される用語を示します。
dfn要素のtitle属性が存在する場合、
その属性には定義される用語だけを含めなければなりません。
dfn要素へリンクするa要素は、dfn要素によって定義された
用語の使用例を表します。
次の断片では、「Garage Door Opener」という用語が最初の段落で最初に定義され、 2番目の段落で使用されています。どちらの場合も、実際に表示されるのはその略語です。
< p > The < dfn >< abbr title = "Garage Door Opener" > GDO</ abbr ></ dfn >
is a device that allows off-world teams to open the iris.</ p >
<!-- ... later in the document: -->
< p > Teal'c activated his < abbr title = "Garage Door Opener" > GDO</ abbr >
and so Hammond ordered the iris to be opened.</ p > < p > The < dfn id = gdo >< abbr title = "Garage Door Opener" > GDO</ abbr ></ dfn >
is a device that allows off-world teams to open the iris.</ p >
<!-- ... later in the document: -->
< p > Teal'c activated his < a href = #gdo > < abbr title = "Garage Door Opener" > GDO</ abbr > </ a >
and so Hammond ordered the iris to be opened.</ p > abbr
要素現在のすべてのエンジンでサポートされています。
title属性は
この要素において特別なセマンティクスを持ちます:
完全な用語または略語の展開形
HTMLElementを使用します。abbr要素は、
任意でその展開形を伴う略語または頭字語を表します。title属性は、略語の展開形を提供するために使用できます。
この属性を指定する場合、その値には略語の展開形だけを含めなければなりません。
次の段落には、abbr要素でマークアップされた
略語が含まれています。この段落は、「Web Hypertext Application Technology Working Group」という
用語を定義しています。
< p > The < dfn id = whatwg >< abbr
title = "Web Hypertext Application Technology Working Group" > WHATWG</ abbr ></ dfn >
is a loose unofficial collaboration of web browser manufacturers and
interested parties who wish to develop new technologies designed to
allow authors to write and deploy Applications over the World Wide
Web.</ p > 別の記述方法は次のとおりです:
< p > The < dfn id = whatwg > Web Hypertext Application Technology
Working Group</ dfn > (< abbr
title = "Web Hypertext Application Technology Working Group" > WHATWG</ abbr > )
is a loose unofficial collaboration of web browser manufacturers and
interested parties who wish to develop new technologies designed to
allow authors to write and deploy Applications over the World Wide
Web.</ p > この段落には2つの略語があります。定義されているのは一方だけであることに注目してください。
もう一方には関連付けられた展開形がないため、abbr要素を使用していません。
< p > The
< abbr title = "Web Hypertext Application Technology Working Group" > WHATWG</ abbr >
started working on HTML5 in 2004.</ p > この段落では、略語をその定義へリンクしています。
< p > The < a href = "#whatwg" >< abbr
title = "Web Hypertext Application Technology Working Group" > WHATWG</ abbr ></ a >
community does not have much representation from Asia.</ p > この段落では、展開形を与えずに略語をマークアップしています。これは、略語にスタイル (たとえばスモールキャピタル)を適用するためのフックとして使用することを意図している可能性があります。
< p > Philip` and Dashiva both denied that they were going to
get the issue counts from past revisions of the specification to
backfill the < abbr > WHATWG</ abbr > issue graph.</ p > 略語が複数形である場合、展開形の文法上の数(複数形または単数形)は、要素の内容の 文法上の数と一致しなければなりません。
ここでは複数形を表す文字が要素の外側にあるため、展開形は単数形です:
< p > Two < abbr title = "Working Group" > WG</ abbr > s worked on
this specification: the < abbr > WHATWG</ abbr > and the
< abbr > HTMLWG</ abbr > .</ p > ここでは複数形を表す文字が要素の内側にあるため、展開形は複数形です:
< p > Two < abbr title = "Working Groups" > WGs</ abbr > worked on
this specification: the < abbr > WHATWG</ abbr > and the
< abbr > HTMLWG</ abbr > .</ p > 略語は必ずしもこの要素を使用してマークアップする必要はありません。次の場合に役立つことが 想定されています:
abbr要素をtitle属性とともに使用することは、
展開形を行内(たとえば括弧内)に含める方法の代替となります。
abbr要素とtitle属性を使用してマークアップするか、
略語が最初に使用されるときに展開形をテキスト内に含めることが推奨されます。abbr要素をtitle属性なしで使用できます。
title属性で展開形を一度提供しても、
同じ文書内で同じ内容を持つもののtitle属性を持たない他のabbr要素が、
同じ展開形を持つかのように動作するとは限りません。各abbr要素は独立しています。
ruby
要素現在のすべてのエンジンでサポートされています。
HTMLElementを使用します。ruby要素を使用すると、
1つ以上のフレージングコンテンツの範囲にルビ注釈を付けることができます。ルビ注釈とは、
親文字と並べて表示される短いテキストで、主として東アジアの組版で発音の手引きやその他の
注釈を含めるために使用されます。日本語では、この組版形式は「ふりがな」とも呼ばれます。
ruby要素の
コンテンツモデルは、次のシーケンスを1つ以上並べたものです:
次のいずれか:
フレージングコンテンツ。
ただし、ruby要素を
含まず、子孫にもruby要素を含まないもの
次のいずれか:
ruby要素とrt要素は、特に以下に説明するものを
含む(ただし決してこれらに限定されない)さまざまな種類の注釈に使用できます。特に日本語のルビと、
日本語のルビをレンダリングする方法の詳細については、日本語組版処理の要件を
参照してください。[JLREQ]
執筆時点では、CSSにはHTMLのruby要素のレンダリングを
完全に制御する方法がまだありません。将来的に、以下で説明するスタイルをサポートするようCSSが
拡張されることが期待されています。
各表意文字(親文字)に、1文字以上のひらがなまたはカタカナ(ルビ注釈)を配置します。 これは漢字の読みを示すために使用されます。
< ruby > B< rt > annotation</ ruby > この例では、各注釈が単一の親文字に対応していることに注目してください。
< ruby > 君< rt > くん</ ruby >< ruby > 子< rt > し</ ruby > は< ruby > 和< rt > わ</ ruby > して< ruby > 同< rt > どう</ ruby > ぜず。君子は和して同 ぜず。
この例は、親文字の各セグメントとそれぞれに対応する2つの注釈を含む1個のruby要素を使用して、
次のように記述することもできます。これは、上のマークアップのように、親文字セグメントと
注釈を1つずつ持つ2個のruby要素を
連続して使用する代わりとなります:
< ruby > 君< rt > くん</ rt > 子< rt > し</ ruby > は< ruby > 和< rt > わ</ ruby > して< ruby > 同< rt > どう</ ruby > ぜず。これは前の事例と似ています。熟語内の各表意文字(親文字)に、その読みをひらがなまたは カタカナ(ルビ注釈)で示します。違いは、親文字の各セグメントが互いに独立しているのではなく、 熟語を形成している点です。
< ruby > B< rt > annotation</ rt > B< rt > annotation</ ruby > この例でも、各注釈が単一の親文字に対応していることに注目してください。この例では、
各熟語が単一のruby要素に対応します。
ここでは、各注釈が対応する親文字の上(縦書きでは横)に配置され、隣接する文字には はみ出さないようにレンダリングされることが想定されています。
< ruby > 鬼< rt > き</ rt > 門< rt > もん</ rt ></ ruby > の< ruby > 方< rt > ほう</ rt > 角< rt > がく</ rt ></ ruby > を< ruby > 凝< rt > ぎょう</ rt > 視< rt > し</ rt ></ ruby > する鬼門の方角を凝視する
意味上は前の事例と同一です(親文字である熟語内の各表意文字に、ひらがなまたはカタカナによる 読みを注釈として示します)が、レンダリングには、より複雑な熟語ルビのレンダリングを使用します。
これは、上の熟語用モノルビと同じ例です。異なるレンダリングは、異なるスタイル (たとえばCSS)を使用して実現されることが想定されており、ここには示していません。
< ruby > 鬼< rt > き</ rt > 門< rt > もん</ rt ></ ruby > の< ruby > 方< rt > ほう</ rt > 角< rt > がく</ rt ></ ruby > を< ruby > 凝< rt > ぎょう</ rt > 視< rt > し</ rt ></ ruby > する熟語ルビの レンダリングの詳細については、日本語組版処理の要件の附属書Fを 参照してください。[JLREQ]
注釈は、発音の代わりに(または発音に加えて)親文字の意味を説明します。そのため、 親文字と注釈のどちらも複数の文字で構成できます。
< ruby > BASE< rt > annotation</ ruby > ここでは、表意文字からなる熟語に対応するカタカナを注釈として示しています。
< ruby > 境界面< rt > インターフェース</ ruby > 境界面
ここでは、表意文字からなる熟語の英訳を注釈として示しています。
< ruby lang = "ja" > 編集者< rt lang = "en" > editor</ ruby > 編集者
1対1の対応付けが困難であるため、複数の親文字に対応する音声的な読みを示します。 (英語の「Colonel」や「Lieutenant」は、方言によっては個々の文字と発音を直接対応付けることが かなり不明瞭な単語の例です。)
この例では、花の一種の名前にグループルビを使用して音声的な読みを示しています:
< ruby > 紫陽花< rt > あじさい</ ruby > 紫陽花
上で説明したルビのスタイルを組み合わせることがあります。
その結果、同じ単一の親文字セグメントを対象とする2つの注釈が生じる場合、注釈を単に 連続して配置できます。
< ruby > BASE< rt > annotation 1< rt > annotation 2</ ruby > < ruby > B< rt > a< rt > a</ ruby >< ruby > A< rt > a< rt > a</ ruby >< ruby > S< rt > a< rt > a</ ruby >< ruby > E< rt > a< rt > a</ ruby > この作為的な例では、いくつかの記号に英語とフランス語の名前を付けています。
< ruby >
♥ < rt > Heart < rt lang = fr > Cœur </ rt >
☘ < rt > Shamrock < rt lang = fr > Trèfle </ rt >
✶ < rt > Star < rt lang = fr > Étoile </ rt >
</ ruby > 次の例のような、より複雑な状況では、入れ子になったruby要素を使用して
内側の注釈を示し、そのruby全体に
「外側」のレベルで注釈を付けます。
< ruby >< ruby > B< rt > a</ rt > A< rt > n</ rt > S< rt > t</ rt > E< rt > n</ rt ></ ruby >< rt > annotation</ ruby > ここでは、音声的な読みと意味の両方をルビ注釈で示しています。入れ子になったruby要素の注釈は、
各親文字に対するモノルビの音声注釈を示し、外側のruby要素の子である
rt要素内の注釈は、
ひらがなを使用して意味を示します。
< ruby >< ruby > 東< rt > とう</ rt > 南< rt > なん</ rt ></ ruby >< rt > たつみ</ rt ></ ruby > の方角東南 の方角
これは同じ例ですが、意味を日本語ではなく英語で示しています:
< ruby >< ruby > 東< rt > とう</ rt > 南< rt > なん</ rt ></ ruby >< rt lang = en > Southeast</ rt ></ ruby > の方角東南 の方角
ruby要素の祖先を持たない
ruby要素内では、
コンテンツがセグメント化され、各セグメントは親文字セグメント、注釈セグメント、無視される
セグメントの3つのカテゴリーに分類されます。無視されるセグメントは文書のセマンティクスの
一部を形成しません(これらは一部の要素間空白とrp要素で構成されます。
後者はルビをまったくサポートしない旧来のユーザーエージェント向けに使用されます)。
親文字セグメントは重複できます(DOM内の任意の位置で重複するセグメントは最大2つまでで、
重複するセグメントより開始点が早いセグメントは、その重複するセグメントと同じかそれより後の
終了点を持ち、重複するセグメントより終了点が遅いセグメントは、その重複するセグメントと同じか
それより前の開始点を持ちます)。注釈セグメントはrt要素に対応します。
各注釈セグメントは親文字セグメントに関連付けることができ、各親文字セグメントには注釈セグメントを
関連付けることができます。(適合する文書では、各親文字セグメントは少なくとも1つの注釈セグメントに
関連付けられ、各注釈セグメントは1つの親文字セグメントに関連付けられます。)ruby要素は、そこに含まれる
親文字セグメントの和集合と、それらの親文字セグメントから注釈セグメントへの対応付けを表します。セグメントはDOM範囲によって記述され、
注釈セグメントの範囲は常に要素をちょうど1つだけ含みます。[DOM]
任意の時点におけるruby要素のコンテンツの
セグメント化とカテゴリー分類は、次のアルゴリズムを実行して得られる結果です:
base text segmentsを、親文字セグメントの空のリストとします。各セグメントは、 親文字サブセグメントのリストを持つ可能性があります。
annotation segmentsを、注釈セグメントの空のリストとします。各セグメントは、 親文字セグメントまたはサブセグメントに関連付けられる可能性があります。
rootを、このアルゴリズムの対象となるruby要素とします。
rootにruby要素の祖先が
ある場合、endと付されたステップへ移ります。
current parentをrootとします。
indexを0とします。
start indexをnullとします。
saved start indexをnullとします。
current base textをnullとします。
Start mode:indexがcurrent parent内の子ノード数以上である場合、 end modeと付されたステップへ移ります。
current parent内のindex番目のノードがrt要素またはrp要素である場合、
annotation modeと付されたステップへ移ります。
start indexをindexの値に設定します。
Base mode:current parent内のindex番目のノードがruby要素であり、
かつcurrent parentがrootと同じ要素である場合、ルビレベルをプッシュし、start modeと付された
ステップへ移ります。
current parent内のindex番目のノードがrt要素またはrp要素である場合、現在の親文字を
設定し、annotation modeと付されたステップへ移ります。
indexを1増やします。
Base mode post-increment:indexがcurrent parent内の 子ノード数以上である場合、end modeと付されたステップへ移ります。
base modeと付されたステップへ戻ります。
Annotation mode:current parent内のindex番目のノードがrt要素である場合、ルビ注釈をプッシュし、
annotation mode incrementと付されたステップへ移ります。
current parent内のindex番目のノードがrp要素である場合、
annotation mode incrementと付されたステップへ移ります。
current parent内のindex番目のノードがText
ノードでないか、または要素間空白ではないText
ノードである場合、base modeと付されたステップへ移ります。
Annotation mode increment:lookahead indexをindexに 1を加えた値とします。
Annotation mode white-space skipper:lookahead indexが current parent内の子ノード数と等しい場合、end modeと付されたステップへ 移ります。
current parent内のlookahead index番目のノードがrt要素またはrp要素である場合、
indexをlookahead indexに設定し、annotation modeと付された
ステップへ移ります。
current parent内のlookahead index番目のノードがText
ノードでないか、または要素間空白ではないText
ノードである場合、base modeと付されたステップへ移ります(indexは
それ以上増やさないため、ここまでに確認した要素間空白は次の親文字セグメントの
一部になります)。
lookahead indexを1増やします。
annotation mode white-space skipperと付されたステップへ移ります。
End mode:current parentがrootと同じ要素でない場合、ルビレベルをポップし、 base mode post-incrementと付されたステップへ移ります。
End:base text segmentsとannotation
segmentsを返します。これらのいずれのリストのセグメントによっても記述されないruby要素の内容は、
暗黙的に無視されるセグメントに属します。
上記のステップで現在の親文字を設定すると述べている場合、 アルゴリズムのその時点で次のステップを実行することを意味します:
上記のステップでルビレベルをプッシュすると述べている場合、 アルゴリズムのその時点で次のステップを実行することを意味します:
current parentを、current parent内のindex番目の ノードとします。
indexを0とします。
saved start indexをstart indexの値に設定します。
start indexをnullとします。
上記のステップでルビレベルをポップすると述べている場合、 アルゴリズムのその時点で次のステップを実行することを意味します:
indexを、root内におけるcurrent parentの位置とします。
current parentをrootとします。
indexを1増やします。
start indexをsaved start indexの値に設定します。
saved start indexをnullとします。
上記のステップでルビ注釈をプッシュすると述べている場合、 アルゴリズムのその時点で次のステップを実行することを意味します:
rtを、current parentのindex番目のノードであるrt要素とします。
annotation rangeを、始点が境界点 (current parent、index)であり、終点が境界点 (current parent、indexに1を加えた値)であるDOM範囲とします (つまり、rtだけを含む範囲です)。
new annotation segmentを、範囲annotation rangeによって 記述される注釈セグメントとします。
current base textがnullでない場合、new annotation segmentをcurrent base textに関連付けます。
new annotation segmentをannotation segmentsに追加します。
この例では、日本語のテキスト漢字内の各表意文字に、ひらがなによる読みを 注釈として付けています。
...
< ruby > 漢< rt > かん</ rt > 字< rt > じ</ rt ></ ruby >
...これは次のようにレンダリングされる可能性があります:

この例では、繁体字中国語のテキスト漢字内の各表意文字に、 注音符号による読みを注釈として付けています。
< ruby > 漢< rt > ㄏㄢˋ</ rt > 字< rt > ㄗˋ</ rt ></ ruby > これは次のようにレンダリングされる可能性があります:

この例では、簡体字中国語のテキスト汉字内の各表意文字に、 ピンインによる読みを注釈として付けています。
...< ruby > 汉< rt > hàn</ rt > 字< rt > zì</ rt ></ ruby > ...これは次のようにレンダリングされる可能性があります:

この、より作為的な例では、頭字語「HTML」に4つの注釈があります。1つは頭字語全体に対して、 それが何であるかを簡潔に説明するもの、1つは「HT」という文字を「Hypertext」に展開するもの、 1つは「M」という文字を「Markup」に展開するもの、もう1つは「L」という文字を 「Language」に展開するものです。
< ruby >
< ruby > HT< rt > Hypertext</ rt > M< rt > Markup</ rt > L< rt > Language</ rt ></ ruby >
< rt > An abstract language for describing documents and applications
</ ruby > rt
要素現在のすべてのエンジンでサポートされています。
ruby要素の子として。
rt要素の終了タグは、rt要素の直後にrt要素またはrp要素が続く場合、
または親要素内にそれ以上の内容がない場合に省略できます。
HTMLElementを使用します。rt要素は、ルビ注釈の
ルビテキスト部分をマークします。ruby要素の子である場合、
それ自体は何も表しませんが、ruby要素は、その要素が
何を表すかを決定する一部として、この要素を
使用します。
ruby要素の子ではない
rt要素は、その子と同じものを
表します。
rp
要素現在のすべてのエンジンでサポートされています。
ruby要素の子として、
rt要素の直前または直後。
rp要素の終了タグは、rp要素の直後にrt要素またはrp要素が続く場合、
または親要素内にそれ以上の内容がない場合に省略できます。
HTMLElementを使用します。rp要素は、ルビ注釈を
サポートしないユーザーエージェントで表示するために、ルビ注釈のルビテキスト部分の周囲へ
括弧またはその他の内容を提供するために使用できます。
ruby要素の子である
rp要素は何も表しません。親要素がruby要素ではないrp要素は、その子を表します。
テキスト漢字内の各表意文字に音声的な読みを注釈として付けた上の例は、
旧来のユーザーエージェントで読みが括弧内に表示されるように、rpを使用して次のように
拡張できます:
...
< ruby > 漢< rp > (</ rp >< rt > かん</ rt >< rp > )</ rp > 字< rp > (</ rp >< rt > じ</ rt >< rp > )</ rp ></ ruby >
...適合するユーザーエージェントでは上記のようにレンダリングされますが、ルビをサポートしない ユーザーエージェントでは次のようにレンダリングされます:
... 漢(かん)字(じ)...
1つのセグメントに複数の注釈がある場合、rp要素を注釈の間に配置することも
できます。次に、英語とフランス語による名前が付けられたいくつかの記号を示した以前の作為的な
例を、今回はrp要素も使用して再掲します:
< ruby >
♥< rp > : </ rp >< rt > Heart</ rt >< rp > , </ rp >< rt lang = fr > Cœur</ rt >< rp > .</ rp >
☘< rp > : </ rp >< rt > Shamrock</ rt >< rp > , </ rp >< rt lang = fr > Trèfle</ rt >< rp > .</ rp >
✶< rp > : </ rp >< rt > Star</ rt >< rp > , </ rp >< rt lang = fr > Étoile</ rt >< rp > .</ rp >
</ ruby > これにより、ルビをサポートしないユーザーエージェントでは、例が次のように レンダリングされます:
♥: Heart, Cœur. ☘: Shamrock, Trèfle. ✶: Star, Étoile.
data
要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
value — 機械可読な値
valueを持つデフォルト。[Exposed =Window ]
interface HTMLDataElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute DOMString value ;
};data要素は、その内容と、
value属性に含まれる
その内容の機械可読な形式をあわせて表します。
value属性は
存在しなければなりません。その値は、要素の内容を機械可読な形式で表現したものでなければなりません。
値が日付または時刻に関連する場合は、代わりに、より具体的なtime要素を使用できます。
この要素は、複数の目的に使用できます。
マイクロフォーマット、またはこの仕様で定義されるマイクロデータ属性と
組み合わせた場合、この要素は、データプロセッサー向けの機械可読な値と、ウェブブラウザーで
レンダリングするための人間可読な値の両方を提供します。この場合、value属性で使用する形式は、
使用中のマイクロフォーマットまたはマイクロデータの語彙によって決定されます。
ただし、この要素は、スクリプトが人間可読な値とともにリテラル値を保存する必要がある場合に、
ページ内のスクリプトと組み合わせて使用することもできます。そのような場合、使用する形式は
スクリプトの必要性だけによって決まります。(data-*属性も、このような状況で
役立つことがあります。)
ここでは、短い表の数値をdata要素を使用して
エンコードしています。これにより、一方の列では数値がテキスト形式で、もう一方の列では
分解された形式で示されているにもかかわらず、表の並べ替え用JavaScriptライブラリーが
各列に並べ替え機能を提供できます。
< script src = "sortable.js" ></ script >
< table class = "sortable" >
< thead > < tr > < th > Game < th > Corporations < th > Map Size
< tbody >
< tr > < td > 1830 < td > < data value = "8" > Eight</ data > < td > < data value = "93" > 19+74 hexes (93 total)</ data >
< tr > < td > 1856 < td > < data value = "11" > Eleven</ data > < td > < data value = "99" > 12+87 hexes (99 total)</ data >
< tr > < td > 1870 < td > < data value = "10" > Ten</ data > < td > < data value = "149" > 4+145 hexes (149 total)</ data >
</ table > time
要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
datetime属性がある場合:
フレージングコンテンツ。
datetime —
機械可読な値
datetimeを持つデフォルト。
[Exposed =Window ]
interface HTMLTimeElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute DOMString dateTime ;
};time要素は、その内容と、
datetime属性に
含まれるその内容の機械可読な形式をあわせて表します。内容の種類は、以下で説明するさまざまな種類の日付、
時刻、タイムゾーンオフセット、および期間に限定されます。
datetime属性を指定してもかまいません。指定する場合、
その値は要素の内容を機械可読な形式で表現したものでなければなりません。
datetime
コンテンツ属性を持たないtime要素は、
要素の子孫を持ってはなりません。
time要素の日時値は、次の構文のいずれかに
一致しなければなりません。
< time > 2011-11</ time > < time > 2011-11-18</ time > < time > 11-18</ time > < time > 14:54</ time > < time > 14:54:39</ time > < time > 14:54:39.929</ time > < time > 2011-11-18T14:54</ time > < time > 2011-11-18T14:54:39</ time > < time > 2011-11-18T14:54:39.929</ time > < time > 2011-11-18 14:54</ time > < time > 2011-11-18 14:54:39</ time > < time > 2011-11-18 14:54:39.929</ time > 日付を伴うがタイムゾーンオフセットを伴わない時刻は、1日を通じて、 各タイムゾーンの同じ特定の時刻に行われるイベントを指定する場合に役立ちます。たとえば、 2020年の新年は、すべてのタイムゾーンで同一の正確な瞬間ではなく、各タイムゾーンの 2020-01-01 00:00に祝われます。ビデオ会議など、すべてのタイムゾーンで同一の時刻に 発生するイベントには、有効なグローバル日時文字列の方が 役立つ可能性があります。
< time > Z</ time > < time > +0000</ time > < time > +00:00</ time > < time > -0800</ time > < time > -08:00</ time > 日付を伴わない時刻(または複数の日付で繰り返されるイベントを指す時刻)では、 通常、タイムゾーンオフセットを指定するよりも、その時刻を制御する地理的位置を指定する方が 役立ちます。これは、地理的位置では夏時間に応じてタイムゾーンオフセットが変化するためです。 場合によっては、地理的位置自体がタイムゾーンを変更することもあります。たとえば、 2011年末のサモアで起きたように、タイムゾーンの境界が引き直される場合です。タイムゾーンの 境界と各ゾーン内で適用される規則を記述する、タイムゾーンデータベースとして知られる データベースが存在します。[TZDATABASE]
< time > 2011-11-18T14:54Z</ time > < time > 2011-11-18T14:54:39Z</ time > < time > 2011-11-18T14:54:39.929Z</ time > < time > 2011-11-18T14:54+0000</ time > < time > 2011-11-18T14:54:39+0000</ time > < time > 2011-11-18T14:54:39.929+0000</ time > < time > 2011-11-18T14:54+00:00</ time > < time > 2011-11-18T14:54:39+00:00</ time > < time > 2011-11-18T14:54:39.929+00:00</ time > < time > 2011-11-18T06:54-0800</ time > < time > 2011-11-18T06:54:39-0800</ time > < time > 2011-11-18T06:54:39.929-0800</ time > < time > 2011-11-18T06:54-08:00</ time > < time > 2011-11-18T06:54:39-08:00</ time > < time > 2011-11-18T06:54:39.929-08:00</ time > < time > 2011-11-18 14:54Z</ time > < time > 2011-11-18 14:54:39Z</ time > < time > 2011-11-18 14:54:39.929Z</ time > < time > 2011-11-18 14:54+0000</ time > < time > 2011-11-18 14:54:39+0000</ time > < time > 2011-11-18 14:54:39.929+0000</ time > < time > 2011-11-18 14:54+00:00</ time > < time > 2011-11-18 14:54:39+00:00</ time > < time > 2011-11-18 14:54:39.929+00:00</ time > < time > 2011-11-18 06:54-0800</ time > < time > 2011-11-18 06:54:39-0800</ time > < time > 2011-11-18 06:54:39.929-0800</ time > < time > 2011-11-18 06:54-08:00</ time > < time > 2011-11-18 06:54:39-08:00</ time > < time > 2011-11-18 06:54:39.929-08:00</ time > 日付とタイムゾーンオフセットを伴う時刻は、特定のイベント、または時刻が 特定の地理的位置に固定されていない、繰り返し行われる仮想イベントを指定する場合に役立ちます。 たとえば、小惑星が衝突した正確な時刻や、世界の特定地域で夏時間が実施されているかどうかに 関係なく毎日UTC 1400に行われる一連の会議の特定の1回などです。正確な時刻が特定の地理的位置の ローカルタイムゾーンオフセットによって変化するイベントには、その地理的位置と組み合わせた 有効なローカル日時文字列の方が 役立つ可能性があります。
< time > 2011-W47</ time > < time > 2011</ time > < time > 0001</ time > < time > PT4H18M3S</ time > < time > 4h 18m 3s</ time > 要素の内容の機械可読な等価物は、 次のアルゴリズムを使用して、要素の日時値から取得しなければなりません:
要素の日時値から日付文字列を解析することで 日付が返される場合、それが機械可読な 等価物です。返ります。
要素の日時値から年なし日付文字列を 解析することで年なし日付が返される場合、それが機械可読な 等価物です。返ります。
要素の日時値から時刻文字列を解析することで 時刻が返される場合、それが機械可読な 等価物です。返ります。
要素の日時値からローカル日時文字列を解析することで ローカル日時が 返される場合、それが機械可読な等価物です。返ります。
要素の日時値からタイムゾーンオフセット文字列を解析することで タイムゾーンオフセットが 返される場合、それが機械可読な等価物です。返ります。
要素の日時値からグローバル日時文字列を解析することで グローバル日時が返される場合、 それが機械可読な等価物です。返ります。
要素の日時値がASCII数字だけで構成され、そのうち少なくとも1桁が U+0030 DIGIT ZERO (0)ではない場合、機械可読な等価物は、それらの数字を年として表す 10進数として解釈した値です。返ります。
要素の日時値から期間文字列を解析することで 期間が返される場合、それが 機械可読な等価物です。返ります。
機械可読な等価物はありません。
上で参照されているアルゴリズムは、任意の文字列sに対して、 いずれか1つのアルゴリズムだけが値を返すように設計されることを意図しています。より効率的な 方法として、これらすべてのデータ型を1回の処理で解析する単一のアルゴリズムを作成できる可能性が あります。そのようなアルゴリズムの開発は、読者への演習として残されています。
time要素は、
たとえばマイクロフォーマットで日付をエンコードするために使用できます。次の例は、time要素を使用する
hCalendarの変種によって、イベントをエンコードする仮想的な方法を示しています:
< div class = "vevent" >
< a class = "url" href = "http://www.web2con.com/" > http://www.web2con.com/</ a >
< span class = "summary" > Web 2.0 Conference</ span > :
< time class = "dtstart" datetime = "2005-10-05" > October 5</ time > -
< time class = "dtend" datetime = "2005-10-07" > 7</ time > ,
at the < span class = "location" > Argent Hotel, San Francisco, CA</ span >
</ div > ここでは、Atomの語彙に基づく架空のマイクロデータ語彙をtime要素とともに使用し、
ブログ投稿の公開日をマークアップしています。
< article itemscope itemtype = "https://n.example.org/rfc4287" >
< h1 itemprop = "title" > Big tasks</ h1 >
< footer > Published < time itemprop = "published" datetime = "2009-08-29" > two days ago</ time > .</ footer >
< p itemprop = "content" > Today, I went out and bought a bike for my kid.</ p >
</ article > この例では、別の記事の公開日をtimeを使用して
マークアップしています。今回はschema.orgのマイクロデータ語彙を使用しています:
< article itemscope itemtype = "http://schema.org/BlogPosting" >
< h1 itemprop = "headline" > Small tasks</ h1 >
< footer > Published < time itemprop = "datePublished" datetime = "2009-08-30" > yesterday</ time > .</ footer >
< p itemprop = "articleBody" > I put a bike bell on her bike.</ p >
</ article > 次の断片では、time要素を使用して
日付をISO8601形式でエンコードし、後でスクリプトによって処理できるようにしています:
< p > Our first date was < time datetime = "2006-09-23" > a Saturday</ time > .</ p > 次の2番目の断片では、値に時刻も含まれています:
< p > We stopped talking at < time datetime = "2006-09-24T05:00-07:00" > 5am the next morning</ time > .</ p > ページによって読み込まれたスクリプト(したがって、time要素を使用して
日付と時刻をマークアップするというページ内部の規則を把握しているスクリプト)は、ページ内を
走査して、そこに含まれるすべてのtime要素を調べ、
日付と時刻の索引を作成できます。
たとえば、この要素は文字列「Friday」を伝えると同時に、2011年11月18日が「Friday」に 対応する意味であるという追加のセマンティクスも伝えます:
Today is < time datetime = "2011-11-18" > Friday</ time > .この例では、太平洋標準時のタイムゾーンにおける特定の時刻を指定しています:
Your next meeting is at < time datetime = "2011-11-18T15:00-08:00" > 3pm</ time > .code
要素現在のすべてのエンジンでサポートされています。
HTMLElementを使用します。code要素は、
コンピューターコードの断片を表します。
これは、XML要素名、ファイル名、コンピュータープログラム、またはコンピューターが認識する
その他の任意の文字列である場合があります。
マークアップされるコンピューターコードの言語を示す正式な方法はありません。たとえば、
構文強調表示スクリプトが適切な規則を使用できるよう、使用されている言語をcode要素に
マークしたい作成者は、class属性を
使用できます。たとえば、要素に「language-」という接頭辞を持つクラスを追加します。
次の例は、段落内で要素名とコンピューターコードを、句読点も含めてマークアップするために、 この要素を使用する方法を示しています。
< p > The < code > code</ code > element represents a fragment of computer
code.</ p >
< p > When you call the < code > activate()</ code > method on the
< code > robotSnowman</ code > object, the eyes glow.</ p >
< p > The example below uses the < code > begin</ code > keyword to indicate
the start of a statement block. It is paired with an < code > end</ code >
keyword, which is followed by the < code > .</ code > punctuation character
(full stop) to indicate the end of the program.</ p > 次の例は、pre要素とcode要素を使用して、
コードブロックをマークアップする方法を示しています。
< pre >< code class = "language-pascal" > var i: Integer;
begin
i := 1;
end.</ code ></ pre > この例では、使用されている言語を示すためにクラスを使用しています。
詳細については、pre要素を参照してください。
var
要素現在のすべてのエンジンでサポートされています。
HTMLElementを使用します。var要素は変数を表します。これは、数式またはプログラミングの文脈に
おける実際の変数、定数を表す識別子、物理量を識別する記号、関数のパラメーター、または単に文章内で
プレースホルダーとして使用される用語である場合があります。
次の段落では、文字「n」が文章内の変数として使用されています:
< p > If there are < var > n</ var > pipes leading to the ice
cream factory then I expect at < em > least</ em > < var > n</ var >
flavors of ice cream to be available for purchase!</ p > 数学、特に最も単純な式を超えるものには、MathMLの方が適切です。ただし、var要素は、MathMLの式で
その後言及される特定の変数を参照するために引き続き使用できます。
この例では、方程式と、その方程式内の変数を参照する凡例が示されています。式自体はMathMLで
マークアップされていますが、図の凡例内の変数にはvarを使用しています。
< figure >
< math >
< mi > a</ mi >
< mo > =</ mo >
< msqrt >
< msup >< mi > b</ mi >< mn > 2</ mn ></ msup >
< mi > +</ mi >
< msup >< mi > c</ mi >< mn > 2</ mn ></ msup >
</ msqrt >
</ math >
< figcaption >
Using Pythagoras' theorem to solve for the hypotenuse < var > a</ var > of
a triangle with sides < var > b</ var > and < var > c</ var >
</ figcaption >
</ figure > ここでは、質量とエネルギーの等価性を表す方程式を文中で使用し、var要素を使用して、その
方程式内の変数と定数をマークしています:
< p > Then she turned to the blackboard and picked up the chalk. After a few moment's
thought, she wrote < var > E</ var > = < var > m</ var > < var > c</ var >< sup > 2</ sup > . The teacher
looked pleased.</ p > samp
要素現在のすべてのエンジンでサポートされています。
HTMLElementを使用します。samp要素は、別の
プログラムまたはコンピューティングシステムからのサンプル出力または引用された出力を表します。
詳細については、pre要素およびkbd要素を参照してください。
この要素は、ウェブアプリケーションで即時の出力を提供するために使用できるoutput要素と対比できます。
この例は、samp
要素を行内で使用する方法を示しています:
< p > The computer said < samp > Too much cheese in tray
two</ samp > but I didn't know what that meant.</ p > この2番目の例は、コンソールプログラムからのサンプル出力のブロックを示しています。入れ子にした
samp要素とkbd要素により、
スタイルシートを使用してサンプル出力の特定部分にスタイルを適用できます。また、非常に精密な
スタイル設定を可能にするため、sampの一部には、
さらに詳細なマークアップで注釈が付けられています。これを実現するため、span要素が使用されています。
< pre >< samp >< span class = "prompt" > jdoe@mowmow:~$</ span > < kbd > ssh demo.example.com</ kbd >
Last login: Tue Apr 12 09:10:17 2005 from mowmow.example.com on pts/1
Linux demo 2.6.10-grsec+gg3+e+fhs6b+nfs+gr0501+++p3+c4a+gr2b-reslog-v6.189 #1 SMP Tue Feb 1 11:22:36 PST 2005 i686 unknown
< span class = "prompt" > jdoe@demo:~$</ span > < span class = "cursor" > _</ span ></ samp ></ pre > この3番目の例は、入力のブロックと、それに対応する出力を示しています。この例では、code要素とsamp要素の両方を
使用しています。
< pre >
< code class = "language-javascript" > console.log(2.3 + 2.4)</ code >
< samp > 4.699999999999999</ samp >
</ pre > kbd
要素現在のすべてのエンジンでサポートされています。
HTMLElementを使用します。kbd要素は、ユーザー入力
(通常はキーボード入力ですが、音声コマンドなどの他の入力を表すために使用することもできます)を表します。
kbd要素がsamp要素内に入れ子になっている
場合、システムによってエコーされた入力を表します。
kbd要素がsamp要素を含む場合、
メニュー項目を呼び出す場合など、システム出力に基づく入力を表します。
kbd要素が別のkbd要素内に入れ子になっている
場合、入力機構に応じた実際のキーまたはその他の単一の入力単位を表します。
ここでは、押すべきキーを示すためにkbd要素を使用しています:
< p > To make George eat an apple, press < kbd >< kbd > Shift</ kbd > + < kbd > F3</ kbd ></ kbd ></ p > この2番目の例では、ユーザーに特定のメニュー項目を選択するよう伝えています。外側のkbd要素は入力のブロックを
マークし、内側のkbd要素は入力の各手順を
表します。また、その内部のsamp要素は、その手順が
システムによって表示されたもの(この場合はメニューのラベル)に基づく入力であることを示します:
< p > To make George eat an apple, select
< kbd >< kbd >< samp > File</ samp ></ kbd > |< kbd >< samp > Eat Apple...</ samp ></ kbd ></ kbd >
</ p > このような精密さは必須ではありません。次の記述も同様に適切です:
< p > To make George eat an apple, select < kbd > File | Eat Apple...</ kbd ></ p > sub要素とsup要素
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
sub
要素:作成者向け、実装者向け。sup
要素:作成者向け、実装者向け。HTMLElementを使用します。sup
要素は上付き文字を表し、sub
要素は下付き文字を表します。
これらの要素は、単なる視覚的な表示のためではなく、特定の意味を持つ組版上の慣例を
マークアップするためだけに使用しなければなりません。たとえば、LaTeX文書作成システムの名称に
sub要素や
sup
要素を使用することは不適切です。一般に作成者は、これらの要素が存在しないと内容の意味が
変わる場合に限って使用するべきです。
特定の言語では、一部の略語における組版上の慣例として上付き文字が使用されます。
< p > Their names are
< span lang = "fr" >< abbr > M< sup > lle</ sup ></ abbr > Gwendoline</ span > and
< span lang = "fr" >< abbr > M< sup > me</ sup ></ abbr > Denise</ span > .</ p > sub
要素は、下付き文字を持つ変数について、var要素の内部で
使用できます。
ここでは、sub
要素を使用して、変数群の中で変数を識別する下付き文字を表しています:
< p > The coordinate of the < var > i</ var > th point is
(< var > x< sub >< var > i</ var ></ sub ></ var > , < var > y< sub >< var > i</ var ></ sub ></ var > ).
For example, the 10th point has coordinate
(< var > x< sub > 10</ sub ></ var > , < var > y< sub > 10</ sub ></ var > ).</ p > 数式では下付き文字と上付き文字がよく使用されます。作成者には、数学をマークアップするために
MathMLを使用することが推奨されますが、詳細な数学的マークアップが必要でない場合は、sub要素と
sup
要素を使用することもできます。[MATHML]
< var > E</ var > =< var > m</ var >< var > c</ var >< sup > 2</ sup > f(< var > x</ var > , < var > n</ var > ) = log< sub > 4</ sub >< var > x</ var >< sup >< var > n</ var ></ sup > i
要素現在のすべてのエンジンでサポートされています。
HTMLElementを使用します。i要素は、別の声調や雰囲気に
あるテキスト、または分類学上の名称、専門用語、別の言語からの慣用句、音訳、思考、西洋の文章に
おける船名など、異なる性質のテキストであることを示す方法で通常の文章から区別されたテキストの
範囲を表します。
本文と異なる言語の用語には、lang属性(XMLでは、XML名前空間内のlang属性)で注釈を
付けるべきです。
次の例は、i要素の使用例を示しています:
< p > The < i class = "taxonomy" > Felis silvestris catus</ i > is cute.</ p >
< p > The term < i > prose content</ i > is defined above.</ p >
< p > There is a certain < i lang = "fr" > je ne sais quoi</ i > in the air.</ p > 次の例では、夢の場面をi要素を使用してマークアップしています。
< p > Raymond tried to sleep.</ p >
< p >< i > The ship sailed away on Thursday</ i > , he
dreamt. < i > The ship had many people aboard, including a beautiful
princess called Carey. He watched her, day-in, day-out, hoping she
would notice him, but she never did.</ i ></ p >
< p >< i > Finally one night he picked up the courage to speak with
her—</ i ></ p >
< p > Raymond woke with a start as the fire alarm rang out.</ p > 作成者は、i要素のclass属性を使用して、その要素が使用されている
理由を識別できます。これにより、特定用途のスタイル(たとえば、分類学上の用語ではなく夢の場面)を
後日変更する場合でも、作成者が文書全体(または関連する一連の文書)を調べて各使用箇所に注釈を
付け直す必要がなくなります。
作成者には、i要素よりも他の要素の方が
適切でないか検討することが推奨されます。たとえば、強勢をマークアップするにはem要素を、用語を定義する箇所を
マークアップするにはdfn要素を使用します。
他の要素と同様に、スタイルシートを使用してi要素の書式を設定できます。
したがって、i要素内の内容が必ず斜体で
表示されるとは限りません。
b
要素現在のすべてのエンジンでサポートされています。
HTMLElementを使用します。b要素は、追加の重要性を
伝えることも、別の声調や雰囲気を暗示することもなく、実用上の目的で注意を引くテキストの範囲を表します。たとえば、文書の要約内のキーワード、
レビュー内の商品名、対話型のテキスト駆動ソフトウェアにおける操作可能な語句、記事のリード文などです。
次の例は、キーワードを重要なものとしてマークアップせずに強調するためのb要素の使用例を示しています:
< p > The < b > frobonitor</ b > and < b > barbinator</ b > components are fried.</ p > 次の例では、テキストアドベンチャー内のオブジェクトを、b要素を使用して特別なものとして
強調しています。
< p > You enter a small room. Your < b > sword</ b > glows
brighter. A < b > rat</ b > scurries past the corner wall.</ p > b要素が適切となる別の事例は、
リード文またはリード段落をマークアップする場合です。次の例は、子猫がウサギを母親代わりに
受け入れたことに関するBBCの記事をマークアップする方法を示しています:
< article >
< h2 > Kittens 'adopted' by pet rabbit</ h2 >
< p >< b class = "lede" > Six abandoned kittens have found an
unexpected new mother figure — a pet rabbit.</ b ></ p >
< p > Veterinary nurse Melanie Humble took the three-week-old
kittens to her Aberdeen home.</ p >
[...]i要素と同様に、作成者はb要素のclass属性を使用して、その要素が使用されている
理由を識別できます。これにより、特定用途のスタイルを後日変更する場合でも、作成者が各使用箇所に
注釈を付け直す必要がなくなります。
b要素は、他に適切な要素が
ない場合の最後の手段として使用するべきです。特に、見出しにはh1
からh6
までの要素を使用し、強勢にはem要素を使用し、重要性はstrong要素で示し、
マークまたは強調表示するテキストにはmark要素を使用するべきです。
他の要素と同様に、スタイルシートを使用してb要素の書式を設定できます。
したがって、b要素内の内容が必ず太字で
表示されるとは限りません。
u
要素現在のすべてのエンジンでサポートされています。
HTMLElementを使用します。u要素は、明確には言語化されて
いないものの明示的にレンダリングされる非テキスト注釈を伴うテキストの範囲を表します。たとえば、中国語の文章でテキストが固有名詞であることを
示す場合(中国語の固有名詞記号)や、テキストの綴りが誤っていることを示す場合です。
ほとんどの場合、別の要素の方が適切です。強勢をマークするにはem要素を使用するべきです。
キーワードや語句をマークするには、文脈に応じてb要素またはmark要素を使用するべきです。
書籍名をマークするにはcite要素を使用するべきです。
明示的なテキスト注釈を付けるにはruby要素を使用するべきです。
専門用語、分類学上の名称、音訳、思考、または西洋の文章における船名を示すにはi要素を使用するべきです。
視覚的な表示におけるu要素のデフォルトのレンダリングは、
ハイパーリンクの慣例的なレンダリング(下線)と衝突します。作成者には、ハイパーリンクと
混同される可能性がある場所でu要素を使用しないことが
推奨されます。
この例では、単語の綴りが誤っていることを示すためにu要素を使用しています:
< p > The < u > see</ u > is full of fish.</ p > mark
要素現在のすべてのエンジンでサポートされています。
HTMLElementを使用します。mark要素は、別の文脈に
おける関連性のために、ある文書内で参照目的で
マークまたは強調表示された一連のテキストを表します。文章から参照される引用またはその他のテキストブロックで
使用する場合、元々は存在しなかった強調表示であり、そのブロックが最初に書かれた時点では元の作成者が
重要と考えていなかった可能性があるものの、現在は予想外の観点から精査されている部分へ読者の注意を
向けるために追加されたことを示します。文書の主要な文章で使用する場合、ユーザーの現在の活動との
関連性が高い可能性があるため強調表示された文書の一部を示します。
この例は、引用の特定部分へ注意を向けるためにmark要素を使用する方法を
示しています:
< p lang = "en-US" > Consider the following quote:</ p >
< blockquote lang = "en-GB" >
< p > Look around and you will find, no-one's really
< mark > colour</ mark > blind.</ p >
</ blockquote >
< p lang = "en-US" > As we can tell from the < em > spelling</ em > of the word,
the person writing this quote is clearly not American.</ p > (ただし、その要素の綴りが誤っていることを示すことが目的である場合は、場合によっては
クラスを伴うu要素の方が適切です。)
mark要素の別の例は、
何らかの検索文字列に一致する文書の一部を強調表示する場合です。誰かが文書を閲覧し、サーバーが
ユーザーが「kitten」という語を検索していることを認識している場合、サーバーは1つの段落を
次のように変更した文書を返すことがあります:
< p > I also have some < mark > kitten</ mark > s who are visiting me
these days. They're really cute. I think they like my garden! Maybe I
should adopt a < mark > kitten</ mark > .</ p > 次の断片では、テキストの段落がコード断片の特定部分を参照しています。
< p > The highlighted part below is where the error lies:</ p >
< pre >< code > var i: Integer;
begin
i := < mark > 1.1</ mark > ;
end.</ code ></ pre > これは構文強調表示とは別のものであり、構文強調表示にはspanの方が適切です。
両方を組み合わせると、次のようになります:
< p > The highlighted part below is where the error lies:</ p >
< pre >< code >< span class = keyword > var</ span > < span class = ident > i</ span > : < span class = type > Integer</ span > ;
< span class = keyword > begin</ span >
< span class = ident > i</ span > := < span class = literal >< mark > 1.1</ mark ></ span > ;
< span class = keyword > end</ span > .</ code ></ pre > これは、元々は強調されていなかった引用文の一部を強調表示するためにmarkを使用する別の例です。
この例では、一般的な組版上の慣例に従い、作成者は引用内のmark要素が斜体で
レンダリングされるよう明示的にスタイルを設定しています。
< style >
blockquote mark , q mark {
font : inherit ; font-style : italic ;
text-decoration : none ;
background : transparent ; color : inherit ;
}
. bubble em {
font : inherit ; font-size : larger ;
text-decoration : underline ;
}
</ style >
< article >
< h1 > She knew</ h1 >
< p > Did you notice the subtle joke in the joke on panel 4?</ p >
< blockquote >
< p class = "bubble" > I didn't < em > want</ em > to believe. < mark > Of course
on some level I realized it was a known-plaintext attack.</ mark > But I
couldn't admit it until I saw for myself.</ p >
</ blockquote >
< p > (Emphasis mine.) I thought that was great. It's so pedantic, yet it
explains everything neatly.</ p >
</ article > なお、この例における、引用される元のテキストの一部であるem要素と、コメント対象の
一部を強調表示するmark要素との違いにも
注意してください。
次の例は、テキスト範囲の重要性を示す場合(strong)と、
テキスト範囲の関連性を示す場合(mark)との違いを
示しています。これは教科書からの抜粋であり、試験に関連する部分が強調表示されています。
安全上の警告は重要ではあるものの、試験には関連しないようです。
< h3 > Wormhole Physics Introduction</ h3 >
< p >< mark > A wormhole in normal conditions can be held open for a
maximum of just under 39 minutes.</ mark > Conditions that can increase
the time include a powerful energy source coupled to one or both of
the gates connecting the wormhole, and a large gravity well (such as a
black hole).</ p >
< p >< mark > Momentum is preserved across the wormhole. Electromagnetic
radiation can travel in both directions through a wormhole,
but matter cannot.</ mark ></ p >
< p > When a wormhole is created, a vortex normally forms.
< strong > Warning: The vortex caused by the wormhole opening will
annihilate anything in its path.</ strong > Vortexes can be avoided when
using sufficiently advanced dialing technology.</ p >
< p >< mark > An obstruction in a gate will prevent it from accepting a
wormhole connection.</ mark ></ p > bdi
要素現在のすべてのエンジンでサポートされています。
dirグローバル属性は、
この要素において特別なセマンティクスを持ちます。HTMLElementを使用します。bdi要素は、双方向テキストの
書式設定のために周囲から分離されるテキストの範囲を表します。[BIDI]
dirグローバル属性の
デフォルトは、この要素ではautoです(他の要素のように
親要素から継承されることはありません)。
この要素には、双方向アルゴリズムに関係するレンダリング要件が あります。
この要素は、方向性が不明なユーザー生成コンテンツを埋め込む場合に特に役立ちます。
この例では、ユーザー名と、そのユーザーが投稿した件数を示しています。bdi要素を使用しなかった
場合、アラビア語ユーザーのユーザー名がテキストを混乱させることになります(双方向アルゴリズムは、
コロンと数字「3」を「posts」の隣ではなく「User」という語の隣に配置します)。
< ul >
< li > User < bdi > jcranmer</ bdi > : 12 posts.
< li > User < bdi > hober</ bdi > : 5 posts.
< li > User < bdi > إيان</ bdi > : 3 posts.
</ ul > 
bdi要素を
使用すると、ユーザー名は期待どおりに機能します。
bdi要素を
b要素に置き換えると、
ユーザー名が双方向アルゴリズムを混乱させ、3番目の箇条書きは「User 3 :」に続いてアラビア語の
名前(右から左)、その後に「posts」とピリオドが表示されることになります。
bdo
要素現在のすべてのエンジンでサポートされています。
dirグローバル属性は、
この要素において特別なセマンティクスを持ちます。HTMLElementを使用します。bdo要素は、その子に対する
明示的なテキスト方向の書式制御を表します。これにより作成者は、方向の上書きを明示的に指定して、
Unicode双方向アルゴリズムを上書きできます。[BIDI]
作成者は、この要素にdir属性を指定しなければなりません。
左から右への上書きを指定するには値ltrを、右から左への上書きを
指定するには値rtlを使用します。値autoを指定してはなりません。
この要素には、双方向アルゴリズムに関係するレンダリング要件が あります。
span
要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
[Exposed =Window ]
interface HTMLSpanElement : HTMLElement {
[HTMLConstructor ] constructor ();
};span要素は、それ自体では
何の意味も持ちませんが、グローバル属性、
たとえばclass、
lang、またはdirとともに使用すると便利です。これは、
その子を表します。
この例では、コード断片をspan要素とclass属性を使用してマークアップし、
キーワードと識別子をCSSで色分けできるようにしています:
< pre >< code class = "lang-c" >< span class = "keyword" > for</ span > (< span class = "ident" > j</ span > = 0; < span class = "ident" > j</ span > < 256; < span class = "ident" > j</ span > ++) {
< span class = "ident" > i_t3</ span > = (< span class = "ident" > i_t3</ span > & 0x1ffff) | (< span class = "ident" > j</ span > << 17);
< span class = "ident" > i_t6</ span > = (((((((< span class = "ident" > i_t3</ span > >> 3) ^ < span class = "ident" > i_t3</ span > ) >> 1) ^ < span class = "ident" > i_t3</ span > ) >> 8) ^ < span class = "ident" > i_t3</ span > ) >> 5) & 0xff;
< span class = "keyword" > if</ span > (< span class = "ident" > i_t6</ span > == < span class = "ident" > i_t1</ span > )
< span class = "keyword" > break</ span > ;
}</ code ></ pre > br
要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
[Exposed =Window ]
interface HTMLBRElement : HTMLElement {
[HTMLConstructor ] constructor ();
// also has obsolete members
};改行は通常、視覚メディアにおいて後続のテキストを物理的に新しい行へ移動することで 表されますが、スタイルシートまたはユーザーエージェントが、たとえば緑色の点や追加の間隔など、 異なる方法で改行をレンダリングすることも同様に正当です。
br要素は、詩や住所のように、
実際に内容の一部である改行にのみ使用しなければなりません。
次の例は、br要素の正しい使用方法です:
< p > P. Sherman< br >
42 Wallaby Way< br >
Sydney</ p > br要素は、段落内の主題的な
グループを分離するために使用してはなりません。
次の例は、br要素を誤用しているため、
非適合です:
< p >< a ...> 34 comments.</ a >< br >
< a ...> Add a comment.</ a ></ p > < p >< label > Name: < input name = "name" ></ label >< br >
< label > Address: < input name = "address" ></ label ></ p > 上記に代わる正しい記述は次のとおりです:
< p >< a ...> 34 comments.</ a ></ p >
< p >< a ...> Add a comment.</ a ></ p > < p >< label > Name: < input name = "name" ></ label ></ p >
< p >< label > Address: < input name = "address" ></ label ></ p > 段落が単一のbr要素だけで構成される場合、
それはプレースホルダーとなる空行(たとえばテンプレート内のもの)を表します。このような空行を
表示上の目的で使用してはなりません。
br要素内のいかなる内容も、
周囲のテキストの一部とみなしてはなりません。
この要素には、双方向アルゴリズムに関係するレンダリング要件が あります。
wbr
要素現在のすべてのエンジンでサポートされています。
HTMLElementを使用します。次の例では、効果を狙って1つの長い単語として記述された発言が引用されています。ただし、
テキストを読みやすい形で折り返せるようにするため、引用内の個々の単語をwbr要素で区切っています。
< p > So then she pointed at the tiger and screamed
"there< wbr > is< wbr > no< wbr > way< wbr > you< wbr > are< wbr > ever< wbr > going< wbr > to< wbr > catch< wbr > me"!</ p > wbr要素内のいかなる内容も、
周囲のテキストの一部とみなしてはなりません。
var wbr = document. createElement( "wbr" );
wbr. textContent = "This is wrong" ;
document. body. appendChild( wbr); この要素には、双方向アルゴリズムに関係するレンダリング要件が あります。
この節は非規範的です。
| 要素 | 目的 | 例 |
|---|---|---|
a
|
ハイパーリンク |
|
em
|
強勢 |
|
strong
|
重要性 |
|
small
|
付記 |
|
s
|
不正確なテキスト |
|
cite
|
作品の題名 |
|
q
|
引用 |
|
dfn
|
定義箇所 |
|
abbr
|
略語 |
|
ruby、rt、rp
|
ルビ注釈 |
|
data
|
機械可読な等価物 |
|
time
|
日付または時刻に関連するデータの機械可読な等価物 |
|
code
|
コンピューターコード |
|
var
|
変数 |
|
samp
|
コンピューター出力 |
|
kbd
|
ユーザー入力 |
|
sub
|
下付き文字 |
|
sup
|
上付き文字 |
|
i
|
別の声調 |
|
b
|
キーワード |
|
u
|
注釈 |
|
mark
|
強調表示 |
|
bdi
|
テキスト方向の分離 |
|
bdo
|
テキスト方向の書式設定 |
|
span
|
その他 |
|
br
|
改行 |
|
wbr
|
改行可能位置 |
|
リンクは、a、area、
form、およびlink要素によって作成される概念的な構成物であり、2つのリソース間の接続を表します。
そのうちの1つは現在のDocumentです。HTMLには
3種類のリンクがあります:
これらは、現在の文書を補強するために使用されるリソースへのリンクであり、通常は ユーザーエージェントによって自動的に処理されます。すべての外部リソースへのリンクには、リソースの取得方法を 説明するリンクされたリソースをフェッチして 処理するアルゴリズムがあります。
これらは、通常ユーザーエージェントによってユーザーに提示され、ユーザーがユーザーエージェントを それらのリソースへナビゲートさせることが できるようにする、他のリソースへのリンクです。たとえば、ブラウザーで訪問したり、 ダウンロードしたりするために使用されます。
これらは、現在の文書内のリソースへのリンクであり、それらのリソースに特別な意味または 動作を与えるために使用されます。
href属性および
rel属性を持つlink要素では、
rel属性のキーワードについて、
リンク種別の節でそのキーワードに対して定義されているとおりにリンクを
作成しなければなりません。
同様に、href属性と
rel属性を持つa要素およびarea要素では、
rel属性の
キーワードについて、リンク種別の節でそのキーワードに対して定義されている
とおりにリンクを作成しなければなりません。ただし、link要素とは異なり、
href属性を持つ
a要素およびarea要素は、rel属性を持たない場合、
またはそのrel属性に
ハイパーリンクを指定するものとして定義された
キーワードがない場合にも、ハイパーリンクを作成しなければなりません。
この暗黙のハイパーリンクには、要素のノード文書を、
要素のhref属性で指定された
リソースへリンクすること以外に、特別な意味(リンク種別)はありません。
同様に、rel属性を持つform要素では、
rel属性のキーワードについて、
リンク種別の節でそのキーワードに対して定義されているとおりにリンクを
作成しなければなりません。form要素は、rel属性を持たない場合、
またはそのrel属性に
ハイパーリンクを指定するものとして定義された
キーワードがない場合にも、ハイパーリンクを作成しなければなりません。
ハイパーリンクは、そのハイパーリンクの 処理セマンティクスを変更する1つ以上のハイパーリンク注釈を持つことができます。
a要素およびarea要素によって
作成されるリンクa要素および
area
要素のhref属性の値は、前後に空白を含む可能性が
ある有効なURLでなければなりません。
a要素および
area
要素のhref
属性は必須ではありません。これらの要素がhref
属性を持たない場合、ハイパーリンクを作成しません。
target属性が存在する場合、その値は有効なナビゲーション可能な
ターゲット名またはキーワードでなければなりません。これは使用されるナビゲーション可能の名前を指定します。
ユーザーエージェントは、ハイパーリンクをたどる際にこの名前を
使用します。
download属性が存在する場合、作成者がそのハイパーリンクを
リソースのダウンロードに使用する
意図があることを示します。この属性は値を持つことができます。値がある場合、ローカルファイル
システム上でリソースに名前を付ける際に使用することを作成者が推奨するデフォルトのファイル名を
指定します。許可される値に制限はありませんが、ほとんどのファイルシステムではファイル名に使用
できる句読点に制限があり、ユーザーエージェントはそれに応じてファイル名を調整する可能性がある
ことに、作成者は注意する必要があります。
現在のすべてのエンジンでサポートされています。
ping属性が存在する場合、
ユーザーがハイパーリンクをたどったときに通知を受けることを希望するリソースのURLを指定します。
値は空白区切りのトークンの集合で
なければならず、その各トークンは、スキームが
HTTP(S)スキームである有効な空でないURLでなければなりません。
この値は、ユーザーエージェントがハイパーリンク監査を行うために使用します。
a要素および
area
要素のrel属性は、要素が作成するリンクの種類を制御します。
属性の値は、一意な空白区切り
トークンの順序なし集合でなければなりません。許可されるキーワードと
その意味は以下で定義します。
relの
サポートされるトークンは、HTMLリンク種別で定義されたキーワードのうち、a要素および
area
要素で許可され、処理モデルに影響を与え、ユーザーエージェントによってサポートされているものです。
使用可能なサポートされるトークンは、noreferrer、
noopener、
およびopenerです。
relの
サポートされるトークンには、この一覧のうち、
ユーザーエージェントが処理モデルを実装しているトークンだけを含めなければなりません。
rel
属性にはデフォルト値がありません。属性が省略されている場合、または属性内のどの値も
ユーザーエージェントによって認識されない場合、文書とリンク先リソースとの間には、
両者の間にハイパーリンクが存在すること以外の特定の関係はありません。
referrerpolicy属性は、リファラーポリシー属性です。
その目的は、ハイパーリンクをたどる際に使用する
リファラーポリシーを設定することです。[REFERRERPOLICY]
a要素または
area
要素の活性化動作が呼び出されたとき、ユーザーエージェントは、
ハイパーリンクをナビゲーションに使用するか、それとも指定された
リソースをダウンロードするかについて、ユーザーが希望を示せるようにしてもかまいません。
ユーザーの希望がない場合、要素にdownload
属性がなければデフォルトはナビゲーションとするべきであり、この属性があれば指定されたリソースの
ダウンロードとするべきです。
イベントeventが与えられたa要素または
area
要素elementの活性化動作は、次のとおりです:
elementにhref
属性がない場合、返ります。
hyperlinkSuffixをnullとします。
userInvolvementを、eventのユーザーのナビゲーション関与とします。
ユーザーがハイパーリンクをダウンロードする希望を示している場合、
userInvolvementを「ブラウザーUI」
に設定します。
つまり、ユーザーがダウンロードするという明確な希望を示している場合、これは
単なる「活性化」
とはみなされなくなります。
elementにdownload
属性がある場合、またはユーザーがハイパーリンクをダウンロードする希望を示している場合、
hyperlinkSuffixをhyperlinkSuffixに設定し、
userInvolvementをuserInvolvementに設定して、
elementによって作成されたハイパーリンクをダウンロードします。
それ以外の場合、hyperlinkSuffixをhyperlinkSuffixに設定し、 userInvolvementをuserInvolvementに設定して、 elementによって作成されたハイパーリンクをたどります。
interface mixin HyperlinkElementUtils {
readonly attribute USVString origin ;
[CEReactions ] attribute USVString protocol ;
[CEReactions ] attribute USVString username ;
[CEReactions ] attribute USVString password ;
[CEReactions ] attribute USVString host ;
[CEReactions ] attribute USVString hostname ;
[CEReactions ] attribute USVString port ;
[CEReactions ] attribute USVString pathname ;
[CEReactions ] attribute USVString search ;
[CEReactions ] attribute USVString hash ;
[CEReactions , Reflect ] attribute DOMString hreflang ;
[CEReactions , Reflect ] attribute DOMString type ;
};hyperlink.origin
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
ハイパーリンクのURLのオリジンを返します。
hyperlink.protocol
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
ハイパーリンクのURLのスキームを返します。
設定して、URLのスキームを変更できます。
hyperlink.username
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
ハイパーリンクのURLのユーザー名を返します。
設定して、URLのユーザー名を変更できます。
hyperlink.password
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
ハイパーリンクのURLのパスワードを返します。
設定して、URLのパスワードを変更できます。
hyperlink.host
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
ハイパーリンクのURLのホストとポート(スキームのデフォルトポートと異なる場合)を返します。
設定して、URLのホストとポートを変更できます。
hyperlink.hostname
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
ハイパーリンクのURLのホストを返します。
設定して、URLのホストを変更できます。
hyperlink.port
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
ハイパーリンクのURLのポートを返します。
設定して、URLのポートを変更できます。
hyperlink.pathname
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
ハイパーリンクのURLのパスを返します。
設定して、URLのパスを変更できます。
hyperlink.search
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
ハイパーリンクのURLのクエリーを返します(空でない場合は先頭の「?」を
含みます)。
設定して、URLのクエリーを変更できます(先頭の「?」は無視されます)。
hyperlink.hash
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
ハイパーリンクのURLのフラグメントを返します(空でない場合は先頭の「#」を
含みます)。
設定して、URLのフラグメントを変更できます(先頭の「#」は無視されます)。
HyperlinkElementUtils
ミックスインを実装する要素は、ハイパーリンク要素です。
ハイパーリンク要素には、 関連付けられたurl(nullまたはURL)があります。初期値はnullです。
ハイパーリンク要素は、 関連付けられたurlを設定するアルゴリズムを持たなければなりません。
ハイパーリンク要素には、 関連付けられたurlを再初期化するアルゴリズムがあり、次の手順を 実行します:
ハイパーリンク要素は、
関連付けられたhrefを更新するアルゴリズムを
持たなければなりません。
ハイパーリンクを作成するハイパーリンク要素のhreflang属性が存在する場合、リンク先リソースの
言語を指定します。これは単なる助言です。値は有効なBCP 47言語タグでなければなりません。[BCP47] ユーザーエージェントは、この属性を信頼できる情報とみなしては
なりません。リソースをフェッチした際、ユーザーエージェントはリソースの言語を決定するために、
リソースへのリンクに含まれるメタデータではなく、リソースに関連付けられた言語情報だけを
使用しなければなりません。
ハイパーリンク要素の
type属性が存在する場合、リンク先リソースのMIMEタイプを指定します。これは単なる助言です。値は有効なMIMEタイプ文字列でなければなりません。
ユーザーエージェントは、type属性を
信頼できる情報とみなしてはなりません。リソースをフェッチした際、ユーザーエージェントはその
タイプを決定するために、リソースへのリンクに含まれるメタデータを使用してはなりません。
protocol
の設定手順は次のとおりです:
username
の設定手順は次のとおりです:
urlがnullであるか、urlがユーザー名、パスワード、ポートを持てない場合、 返ります。
urlと与えられた値を指定して、ユーザー名を設定します。
passwordの取得手順は次のとおりです:
urlがnullの場合、空文字列を返します。
urlのパスワードを返します。
password
の設定手順は次のとおりです:
urlがnullであるか、urlがユーザー名、パスワード、ポートを持てない場合、 返ります。
urlと与えられた値を指定して、パスワードを設定します。
hostの取得手順は次のとおりです:
host
の設定手順は次のとおりです:
hostnameの取得手順は次のとおりです:
hostname
の設定手順は次のとおりです:
portの取得手順は次のとおりです:
port
の設定手順は次のとおりです:
pathnameの取得手順は次のとおりです:
urlがnullの場合、空文字列を返します。
urlをURLパスシリアル化した結果を返します。
pathname
の設定手順は次のとおりです:
a要素およびarea要素のAPIinterface mixin HTMLHyperlinkElementUtils {
[CEReactions , ReflectSetter ] stringifier attribute USVString href ;
[CEReactions , Reflect ] attribute DOMString target ;
};hyperlink.toString()hyperlink.href
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
ハイパーリンクのURLを返します。
設定して、URLを変更できます。
hrefの取得手順は次のとおりです:
a要素およびarea要素に対する、
insertedNodeが与えられたHTML要素の挿入手順は次のとおりです:
insertedNodeが接続されていない場合、 返ります。
insertedNodeのノード文書を指定して、投機的読み込みを検討します。
a要素およびarea要素に対する、
removedNode、isSubtreeRoot、およびoldAncestorが与えられたHTML要素の
除去手順は次のとおりです:
oldAncestorが接続されていない場合、 返ります。
oldAncestorのノード文書を指定して、投機的読み込みを検討します。
a要素およびarea要素に対する、
movedNodeが与えられたHTML要素の移動手順は次のとおりです:
movedNodeのノード文書を指定して、投機的読み込みを検討します。
element、localName、oldValue、
value、およびnamespaceが与えられた、次の属性変更手順は、すべてのa要素およびarea要素に
使用されます:
namespaceがnullでない場合、返ります。
oldValueがvalueと等しい場合、返ります。
localNameがhrefの場合、
elementを指定してurlを設定します。
これはblob:
URLでのみ観察できます。これは、それらの解析にBlob URLストアの検索が伴うためです。
localNameがhref、
referrerpolicy、
またはrelの場合、
elementのノード文書を指定して、投機的読み込みを検討します。
HTMLAnchorElement
またはHTMLAreaElement要素の
hrefを更新するには、
要素のhref
コンテンツ属性の値を、要素のurlをシリアル化したものに設定します。
HTMLAnchorElement
要素およびHTMLAreaElement要素の
urlを
設定するアルゴリズムは次のとおりです:
これは、form要素のフォーム送信でも使用されます。
a要素に対する例外は、
ウェブコンテンツとの互換性のためです。
a、area、またはform要素
element、URLレコード
url、および文字列targetが与えられたとき、要素のnoopenerを取得するには、次の手順を実行します。
これらはブール値を返します。
elementのリンク種別にnoopenerまたはnoreferrer
キーワードが含まれる場合、trueを返します。
elementのリンク種別にopenerキーワードが
含まれず、かつtargetが「_blank」とASCII大文字小文字不区別で一致する場合、trueを返します。
urlのblob URLエントリーがnullでない場合:
blobOriginを、urlのblob URLエントリーの環境のオリジンとします。
topLevelOriginを、elementの関連設定オブジェクトのトップレベルオリジンとします。
blobOriginがtopLevelOriginと同一サイトでない場合、trueを返します。
falseを返します。
要素subjectによって作成されたハイパーリンクをたどるには、任意のhyperlinkSuffix(デフォルトはnull)と任意のuserInvolvement(デフォルトは「なし」)が与えられたとき:
subjectがナビゲートできない場合、返ります。
targetAttributeValueを空文字列とします。
subjectがa要素またはarea要素の場合、
targetAttributeValueを、subjectを指定して要素のターゲットを
取得した結果に設定します。
urlRecordを、subjectのhref属性値と、
subjectのノード文書を指定して、URLをエンコーディング解析した結果とします。
urlRecordが失敗の場合、返ります。
noopenerを、subject、urlRecord、および targetAttributeValueを使用して要素のnoopenerを取得した結果とします。
targetNavigableを、targetAttributeValue、subjectのノードナビガブル、および noopenerを指定してナビガブルを選択する規則を 適用した最初の戻り値とします。
targetNavigableがnullの場合、返ります。
urlStringを、urlRecordにURLシリアライザーを適用した結果とします。
hyperlinkSuffixがnullでない場合、それをurlStringに付加します。
subjectのノード文書を使用して、targetNavigableを urlStringへナビゲートします。 このとき、referrerPolicyをsubjectのハイパーリンクリファラーポリシーに、 userInvolvementをuserInvolvementに、 sourceElementをsubjectに設定します。
他の多くの種類のナビゲーションとは異なり、ハイパーリンクをたどる場合、
文書が完全に読み込まれていないときの特別な「置換」
動作はありません。これは、ユーザーが開始したハイパーリンクをたどる処理と、たとえば
aElement.click()を介してスクリプトによって起動された処理の両方に当てはまります。
要素subjectのハイパーリンクリファラーポリシーは、次の手順によって 返される値です:
subjectのリンク種別にnoreferrer
キーワードが含まれる場合、「no-referrer」を返します。
subjectのreferrerpolicy
コンテンツ属性の現在の状態を返します。
現在のすべてのエンジンでサポートされています。
場合によっては、リソースは直ちに表示するのではなく、後で使用することを目的としています。
リソースが直ちに使用されるのではなく、後で使用するためにダウンロードされることを意図していると
示すには、そのリソースへのハイパーリンクを作成するa要素またはarea要素にdownload
属性を指定できます。
さらに、この属性には値を指定して、ユーザーエージェントがリソースをファイルシステムに
保存するときに使用するファイル名を指定できます。この値は、`Content-Disposition`
HTTPヘッダーのfilenameパラメーターによって上書きできます。
[RFC6266]
クロスオリジンの場合、悪意のある可能性がある動作についてユーザーが警告されることを
避けるため、download
属性を`Content-Disposition`
HTTPヘッダー、具体的にはattachment処理種別と組み合わせる必要があります。
(これは、ユーザーが十分に理解しないまま、機密性の高い個人情報または秘密情報をダウンロード
させられることから保護するためです。)
要素subjectによって作成されたハイパーリンクをダウンロードするには、任意のhyperlinkSuffix(デフォルトはnull)と任意のuserInvolvement(デフォルトは
「なし」)が与えられたとき:
subjectがナビゲートできない場合、返ります。
subjectのノード文書のアクティブなサンドボックス化フラグ集合にサンドボックス化された ダウンロード閲覧コンテキストフラグが設定されている場合、返ります。
urlStringを、subjectのhref属性値と、
subjectのノード文書を指定して、URLをエンコーディング解析して
シリアル化した結果とします。
urlStringが失敗の場合、返ります。
hyperlinkSuffixがnullでない場合、それをurlStringに付加します。
userInvolvementが「ブラウザーUI」でない場合:
navigationを、subjectの関連グローバルオブジェクトのナビゲーションAPIとします。
filenameを、subjectのdownload
属性の値とします。
continueを、navigationでダウンロード要求の
navigateイベントを発火した結果とします。このとき、destinationURLをurlStringに、
userInvolvementを
userInvolvementに、sourceElementをsubjectに、filenameをfilenameに設定します。
continueがfalseの場合、返ります。
subjectのノードナビガブルを指定して、ナビゲーションの 中止についてナビゲーションAPIに通知します。
次の手順を並行に実行します:
ユーザーエージェントは、潜在的に敵対的なダウンロードからユーザーを保護できると 判断した場合、任意でこれらの手順を中止してもかまいません。
requestを、URLがurlString、クライアントがエントリー設定オブジェクト、起動元が「download」、宛先が空文字列であり、同期フラグおよびURL資格情報使用フラグが設定された新しい要求とします。
responseを、requestをフェッチした結果とします。
subjectのノードナビガブルとnullを使用して、 responseをダウンロードとして処理します。
応答 responseを、ナビガブルnavigableおよびナビゲーションIDまたはnullである navigationIdとともにダウンロードとして処理するには:
suggestedFilenameを、responseについて推奨ファイル名を取得した結果とします。
download behaviorを、navigableおよび新しいWebDriver BiDiナビゲーション状態を使用してWebDriver BiDiダウンロード開始を
実行した結果とします。このナビゲーション状態のidはnavigationId、statusは「pending」、
urlはresponseのURL、suggestedFilenameは
suggestedFilenameです。
download behaviorがnullでなく、かつdownload behaviorのallowedがfalseの場合:
navigableおよび新しいWebDriver BiDiナビゲーション状態を使用してWebDriver BiDiダウンロード終了を呼び出します。
このナビゲーション状態のidはnavigationId、statusは「canceled」、
urlはresponseのURLです。
返ります。
download behaviorがnullでない場合、destinationFolderを download behaviorのdestinationFolderとします。
次の手順を並行に実行します:
responseを後で使用するために保存する実装定義の手順を実行します。 destinationFolderがnullでない場合、ユーザーエージェントはファイルをそのパスに 保存するべきです。ユーザーエージェントがファイル名を必要とする場合、 suggestedFilenameを使用するべきです。
次のいずれかが真の場合:
ダウンロードがユーザーによってキャンセルされた。
ダウンロードがユーザーエージェントによってキャンセルされた。
エラーが発生した(たとえば、ネットワークエラー、ストレージ不足、使用できない 保存先フォルダー)。
その場合:
navigableおよび新しいWebDriver BiDiナビゲーション状態を
使用してWebDriver BiDiダウンロード終了を
呼び出します。このナビゲーション状態のidはnavigationId、statusは「canceled」、
urlはresponseのURLです。
返ります。
ダウンロードが正常に完了したとき、navigableおよび新しいWebDriver BiDiナビゲーション状態を使用してWebDriver BiDiダウンロード終了を呼び出します。
このナビゲーション状態のidはnavigationId、statusは「complete」、
downloadedFilepathは、利用可能な場合は
ダウンロードされたファイルの絶対パス、そうでない場合はnull、urlはresponseのURLです。
応答 responseについて推奨ファイル名を取得するには:
このアルゴリズムは、信頼されていないサイトからファイルをダウンロードする際の セキュリティ上の危険を軽減することを目的としており、ユーザーエージェントにはこれに従うことが 強く求められます。
filenameをundefined値とします。
responseが`Content-Disposition`
ヘッダーを持ち、そのヘッダーがattachment処理種別を指定し、かつファイル名情報を
含む場合、filenameをそのヘッダーによって指定された値とし、以下の
サニタイズとラベル付けされた手順へ移ります。[RFC6266]
interface originを、ダウンロードをもたらしたダウンロードまたはナビゲート操作が開始されたDocumentのオリジンとします(存在する場合)。
response originを、responseのURLのオリジンとします。ただし、
そのURLのスキーム成分がdataの場合、
response originをinterface originと同じものとします(存在する場合)。
interface originがない場合、trusted operationをtrueとします。 それ以外の場合、response originがinterface originと同一オリジンであれば trusted operationをtrueとし、そうでなければfalseとします。
trusted operationがtrueであり、responseが`Content-Disposition`
ヘッダーを持ち、そのヘッダーがファイル名情報を含む場合、filenameをそのヘッダーで
指定された値とし、以下のサニタイズとラベル付けされた手順へ移ります。[RFC6266]
ダウンロードがa要素またはarea要素によって
作成されたハイパーリンクから開始されたものでない場合、または
ダウンロードの開始時に、開始元となったハイパーリンクの要素がdownload
属性を持たなかった場合、またはそのような属性があってもダウンロード開始時の値が空文字列で
あった場合、提案されたファイル名なしとラベル付けされた手順へ移ります。
proposed filenameを、ダウンロード開始時にダウンロードを開始したハイパーリンクの要素のdownload
属性の値とします。
trusted operationがtrueの場合、filenameを proposed filenameの値とし、以下のサニタイズとラベル付けされた手順へ 移ります。
responseが`Content-Disposition`
ヘッダーを持ち、そのヘッダーがattachment処理種別を指定する場合、
filenameをproposed filenameの値とし、以下のサニタイズと
ラベル付けされた手順へ移ります。
[RFC6266]
提案されたファイル名なし:trusted operationがtrueである場合、または ユーザーが対象の応答をダウンロードする希望を示した場合、filenameを responseのURLから実装定義の方法で導出した値とし、以下の サニタイズとラベル付けされた手順へ移ります。
filenameを、ユーザーが希望するファイル名またはユーザーエージェントが選択した ファイル名に設定し、以下のサニタイズとラベル付けされた手順へ移ります。
アルゴリズムがこの手順に到達した場合、ダウンロードはresponseとは異なる
オリジンから開始され、そのオリジンはファイルがダウンロードに適していると示さず、
ダウンロードはユーザーによって開始されていません。これは、download
属性がダウンロードを起動するために使用されたか、responseが
ユーザーエージェントのサポートするタイプではないためである可能性があります。
これは危険となる可能性があります。たとえば、敵対的なサーバーが、データが敵対的な サーバーからのものであるとユーザーに思わせることで、ユーザーに気付かれずに個人情報を ダウンロードさせ、その後その情報を敵対的なサーバーへ再アップロードさせようとしている 可能性があります。
したがって、responseがまったく異なる出所からのものであることを何らかの方法で ユーザーに通知し、混乱を防ぐため、潜在的に敵対的なinterface originから 提案されたファイル名は無視することがユーザーの利益になります。
サニタイズ:任意で、ユーザーがfilenameに影響を与えられるようにします。 たとえば、ユーザーエージェントはユーザーにファイル名を尋ね、その際、上記で決定された filenameの値をデフォルト値として提示できます。
filenameをローカルファイルシステムに適したものになるよう調整します。
たとえば、ファイル名で使用できない文字を削除したり、先頭および末尾の 空白を取り除いたりすることが考えられます。
プラットフォームの慣例がファイルシステム上のファイルの種類を決定するために拡張子を一切使用しない場合、 filenameをファイル名として返します。
claimed typeを、既知である場合はresponseのContent-Typeメタデータによって 指定されたタイプとします。named typeを、既知である場合はfilenameの拡張子によって指定されたタイプとします。 この手順において、タイプとは、MIMEタイプから拡張子への対応付けです。
named typeがユーザーの設定と一致する場合(たとえば、 filenameの値がユーザーへの問い合わせによって決定された場合)、 filenameをファイル名として返します。
claimed typeとnamed typeが同じタイプである場合(つまり、 responseのContent-Typeメタデータによって指定されたタイプが filenameの拡張子によって指定されたタイプと一致する場合)、 filenameをファイル名として返します。
claimed typeが既知の場合、filenameを変更して claimed typeに対応する拡張子を追加します。
それ以外で、named typeが潜在的に危険であることが分かっている場合
(たとえば、プラットフォームの慣例によってネイティブ実行可能ファイル、シェルスクリプト、
HTMLアプリケーション、または実行可能なマクロを含む文書として扱われる場合)、任意で
filenameを変更して、既知の安全な拡張子(たとえば「.txt」)を
追加します。
この最後の手順により実行可能ファイルをダウンロードできなくなる可能性があり、 これは望ましくない場合があります。常にそうであるように、実装者はこの点について セキュリティと使いやすさのバランスを取らざるを得ません。
filenameをファイル名として返します。
このアルゴリズムにおいて、ファイルの拡張子は、
プラットフォームの慣例によってファイルの種類を識別するために使用される、ファイル名の任意の部分で
構成されます。たとえば、多くのオペレーティングシステムは、ファイル名の最後のドット
(「.」)に続く部分を使用してファイルの種類を決定し、それに基づいてファイルを
開く方法または実行する方法を決定します。
ユーザーエージェントは、生成されるファイルをユーザーのファイルシステム内のどこに保存するかを
決定する際、応答自体、そのURL、およびdownload
属性によって提供されるディレクトリまたはパス情報をすべて無視するべきです。
a要素またはarea要素によって作成されたハイパーリンクがping属性を持ち、ユーザーがそのハイパーリンクをたどり、
要素のhref属性の値を、要素のノード文書を基準として、失敗せずに解析できる場合、
ユーザーエージェントはping属性の値を取得し、その文字列をASCII空白で分割し、結果として得られた各トークンを、
要素のノード文書を
基準として解析し、その後、結果として得られた各URL
ping URLについて、解析が失敗を返した場合は無視して、次の手順を
実行しなければなりません:
ping URLのスキームが HTTP(S)スキームでない場合、返ります。
任意で、返ります。(たとえば、ユーザーエージェントは、ユーザーが明示した設定に従って、 一部またはすべてのping URLを無視することを望む場合があります。)
settingsObjectを、要素のノード文書の関連設定オブジェクトとします。
requestを、URLが
ping URL、メソッドが`POST`、ヘッダーリストが« (`Content-Type`,
`text/ping`) »、本体が`PING`、クライアントが
settingsObject、宛先が空文字列、資格情報モードが「include」、リファラーが
「no-referrer」であり、URL資格情報使用フラグが設定され、かつ起動元タイプが「ping」である新しい要求とします。
target URLを、要素のhref属性の値と、
要素のノード文書を指定して、URLをエンコーディング解析してシリアル化した
結果とし、次のようにします:
DocumentオブジェクトのURLと
ping URLが同一オリジンを持つ場合
DocumentのURLのスキームが「https」でない場合
Ping-From`ヘッダーと、
target URLを値とする`Ping-To`
HTTPヘッダーを含まなければ
なりません。
Ping-To` HTTPヘッダーを含まなければ
なりません。requestは`Ping-From`ヘッダーを
含みません。
requestをフェッチします。
これは主要なフェッチと並行に実行してもよく、そのフェッチの結果とは独立しています。
ユーザーエージェントは、たとえばHTTPの`Referer`
(原文どおり)ヘッダーの送信を無効にする設定と組み合わせるなどして、ユーザーがこの動作を
調整できるようにするべきです。ユーザーの設定に基づき、UAはping属性を完全に無視するか、一覧内のURLを選択的に無視しても
かまいません(たとえば、すべての第三者URLを無視するなど)。これは上記の手順で明示的に
考慮されています。
ユーザーエージェントは、応答で返されたエンティティ本体をすべて無視しなければなりません。 ユーザーエージェントは、応答本体の受信を開始した後、接続を途中で閉じてもかまいません。
![]() ハイパーリンクを作成し、
ハイパーリンクを作成し、ping属性を持つa要素またはarea要素が存在する場合、
ユーザーエージェントは、ハイパーリンクをたどるとバックグラウンドで副次的な要求も送信されることを、
実際のターゲットURLの一覧を表示することを含め、ユーザーに示してもかまいません。
たとえば、視覚的なユーザーエージェントは、ステータスバーまたはツールチップに、 ハイパーリンクの実際のURLとともにターゲットping URLのホスト名を表示できます。
ping属性は、ウェブページがどのサイト外
リンクが最も人気であるかを追跡したり、広告主がクリックスルー率を追跡したりできる点で、HTTP
リダイレクトやJavaScriptなどの既存技術と重複しています。
ただし、ping属性は、それらの代替手段と
比較して、ユーザーに次の利点を提供します:
Ping-From`ヘッダーおよび`Ping-To`ヘッダー`Ping-From`および`Ping-To` HTTP要求ヘッダーは、ハイパーリンク監査要求に含まれます。
これらの値はURLをシリアル化したものです。
現在のすべてのエンジンでサポートされています。
次の表は、この仕様で定義されているリンク種別を、対応するキーワードごとに要約したものです。 この表は非規範的です。リンク種別の実際の定義は、後続のいくつかの節で示します。
この節では、参照先文書という用語は、リンクを表す要素によって識別されるリソースを指し、 現在の文書という用語は、リンクを表す要素が含まれているリソースを指します。
link、a、area、またはform要素に適用されるリンク種別を
決定するには、要素のrel属性をASCII空白で分割しなければ
なりません。結果として得られたトークンが、その要素に適用されるリンク種別のキーワードです。
特に指定がない限り、1つのrel属性内で、同じキーワードを
複数回指定してはなりません。
以下の表に続くいくつかの節では、特定のキーワードの同義語を列挙しています。示された同義語は、
ユーザーエージェントが指定どおりに処理しなければなりませんが、文書では使用してはなりません
(たとえば「copyright」キーワード)。
キーワードは常にASCII大文字小文字不区別であり、そのように比較しなければ なりません。
したがって、rel="next"はrel="NEXT"と同じです。
body-okであるキーワードは、link要素がbody内で許可されるかどうかに影響します。
body-okキーワードは、dns-prefetch、
modulepreload、
pingback、
preconnect、
prefetch、
preload、および
stylesheetです。
ウェブブラウザーによって実装される新しいリンク種別は、この標準に追加されます。それ以外は拡張として登録できます。
| リンク種別 | 次に対する効果... | body-ok | `Link`
処理を持つ |
簡単な説明 | ||
|---|---|---|---|---|---|---|
link |
aおよびarea |
form |
||||
alternate |
ハイパーリンク | 許可されない | · | · | 現在の文書の代替表現を示します。 | |
canonical |
ハイパーリンク | 許可されない | · | · | 現在の文書の優先URLを示します。 | |
author |
ハイパーリンク | 許可されない | · | · | 現在の文書または記事の作成者へのリンクを示します。 | |
bookmark |
許可されない | ハイパーリンク | 許可されない | · | · | 最も近い祖先の節の恒久リンクを示します。 |
dns-prefetch |
外部リソース | 許可されない | はい | · | ユーザーエージェントがターゲットリソースのオリジンについて先行してDNS解決を 実行するべきであることを指定します。 | |
expect |
内部リソース | 許可されない | · | · | ターゲットIDを持つ要素が現在の文書に現れることを期待します。 | |
external |
許可されない | 注釈 | · | · | 参照先文書が現在の文書と同じサイトの一部ではないことを示します。 | |
help |
ハイパーリンク | · | · | 文脈依存のヘルプへのリンクを提供します。 | ||
icon |
外部リソース | 許可されない | · | · | 現在の文書を表すアイコンをインポートします。 | |
manifest |
外部リソース | 許可されない | · | · | アプリケーションマニフェストをインポートまたはリンクします。 [MANIFEST] | |
modulepreload
|
外部リソース | 許可されない | はい | · | ユーザーエージェントが先行してモジュールスクリプトをフェッチし、後で評価するために 文書のモジュールマップへ格納しなければならないことを 指定します。任意で、モジュールの依存関係もフェッチできます。 | |
license |
ハイパーリンク | · | · | 現在の文書の主要コンテンツが、参照先文書で説明される著作権ライセンスの対象であることを 示します。 | ||
next |
ハイパーリンク | · | · | 現在の文書がシリーズの一部であり、シリーズ内の次の文書が参照先文書であることを示します。 | ||
nofollow |
許可されない | 注釈 | · | · | 現在の文書の元の作成者または発行者が参照先文書を支持していないことを示します。 | |
noopener |
許可されない | 注釈 | · | · | ハイパーリンクが本来なら補助的なものを作成する場合(つまり、適切なtarget属性値を持つ場合)、
非補助閲覧コンテキストを持つトップレベル走査可能を作成します。 |
|
noreferrer |
許可されない | 注釈 | · | · | `Referer`
(原文どおり)ヘッダーは含まれません。
さらに、noopenerと同じ効果を
持ちます。 |
|
opener |
許可されない | 注釈 | · | · | ハイパーリンクが本来なら非補助閲覧コンテキストを持つトップレベル走査可能を作成する場合
(つまり、target属性値として
「_blank」を持つ場合)、補助閲覧コンテキストを作成します。 |
|
pingback |
外部リソース | 許可されない | はい | · | 現在の文書へのpingbackを処理するpingbackサーバーのアドレスを示します。 | |
preconnect |
外部リソース | 許可されない | はい | はい | ユーザーエージェントがターゲットリソースのオリジンへ先行して接続するべきであることを指定します。 | |
prefetch |
外部リソース | 許可されない | はい | · | 後続のナビゲーションで必要になる可能性が高いため、 ユーザーエージェントがターゲットリソースを先行してフェッチし、キャッシュするべきである ことを指定します。 | |
preload |
外部リソース | 許可されない | はい | はい | as属性によって指定されたプリロード宛先(および対応する宛先に
関連付けられた優先度)に従って、
ユーザーエージェントが現在のナビゲーション用にターゲットリソースを先行してフェッチし、キャッシュしなければ
ならないことを指定します。 |
|
prev |
ハイパーリンク | · | · | 現在の文書がシリーズの一部であり、シリーズ内の前の文書が参照先文書であることを示します。 | ||
privacy-policy
|
ハイパーリンク | 許可されない | · | · | 現在の文書に適用されるデータ収集および利用慣行に関する情報へのリンクを示します。 | |
search |
ハイパーリンク | · | · | 現在の文書および関連ページ内を検索するために使用できるリソースへのリンクを示します。 | ||
stylesheet |
外部リソース | 許可されない | はい | · | スタイルシートをインポートします。 | |
tag |
許可されない | ハイパーリンク | 許可されない | · | · | 現在の文書に適用されるタグ(指定されたアドレスによって識別される)を示します。 |
terms-of-service
|
ハイパーリンク | 許可されない | · | · | 現在の文書の提供者と、その文書を利用しようとするユーザーとの間の合意に関する情報への リンクを示します。 | |
alternate」1つのエンジンのみでサポートされています。
alternateキーワードは、link、
a、およびarea要素で使用できます。
このキーワードの意味は、他の属性の値によって異なります。
link要素であり、
rel属性にキーワードstylesheetも
含まれている場合
alternateキーワードは、
stylesheetキーワードの
意味を、そのキーワードについて説明されている方法で変更します。alternateキーワードは、それ自体では
リンクを作成しません。
ここでは、一連のlink要素がいくつかの
スタイルシートを提供します:
<!-- a persistent style sheet -->
< link rel = "stylesheet" href = "default.css" >
<!-- the preferred alternate style sheet -->
< link rel = "stylesheet" href = "green.css" title = "Green styles" >
<!-- some alternate style sheets -->
< link rel = "alternate stylesheet" href = "contrast.css" title = "High contrast" >
< link rel = "alternate stylesheet" href = "big.css" title = "Big fonts" >
< link rel = "alternate stylesheet" href = "wide.css" title = "Wide screen" > alternateキーワードが、値
application/rss+xmlまたは値application/atom+xmlに設定されたtype属性とともに使用される場合
このキーワードは、配信フィードを参照するハイパーリンクを作成します(ただし、必ずしも現在のページと 完全に同じコンテンツを配信するとは限りません)。
フィード自動検出の目的では、ユーザーエージェントは、文書内でalternateキーワードが使用され、
type属性が値
application/rss+xmlまたは値application/atom+xmlに設定されているすべての
link要素を考慮するべき
です。ユーザーエージェントにデフォルトの配信フィードという概念がある場合、最初のそのような要素
(ツリー順で)をデフォルトとして使用するべきです。
次のlink要素は、
ブログの配信フィードを示します:
< link rel = "alternate" type = "application/atom+xml" href = "posts.xml" title = "Cool Stuff Blog" >
< link rel = "alternate" type = "application/atom+xml" href = "posts.xml?category=robots" title = "Cool Stuff Blog: robots category" >
< link rel = "alternate" type = "application/atom+xml" href = "comments.xml" title = "Cool Stuff Blog: Comments" > このようなlink要素は、フィード自動検出を
行うユーザーエージェントによって使用され、最初のものがデフォルトになります(該当する場合)。
次の例では、a要素を使用して、さまざまな
配信フィードをユーザーに提供しています:
< p > You can access the planets database using Atom feeds:</ p >
< ul >
< li >< a href = "recently-visited-planets.xml" rel = "alternate" type = "application/atom+xml" > Recently Visited Planets</ a ></ li >
< li >< a href = "known-bad-planets.xml" rel = "alternate" type = "application/atom+xml" > Known Bad Planets</ a ></ li >
< li >< a href = "unexplored-planets.xml" rel = "alternate" type = "application/atom+xml" > Unexplored Planets</ a ></ li >
</ ul > これらのリンクはフィード自動検出には使用されません。
このキーワードは、現在の文書の代替表現を参照するハイパーリンクを作成します。
参照先文書の性質は、hreflang属性および
type属性によって
示されます。
alternateキーワードがhreflang属性と
ともに使用され、その属性の値が文書要素の言語と異なる場合、参照先文書が翻訳であることを示します。
alternateキーワードがtype属性とともに
使用される場合、参照先文書が指定された形式で現在の文書を再構成したものであることを示します。
hreflang
属性およびtype属性は、alternateキーワードとともに指定する
場合、組み合わせて使用できます。
次の例は、代替形式を使用し、他の言語を対象とし、他のメディア向けに意図されたページの版を 指定する方法を示しています:
< link rel = alternate href = "/en/html" hreflang = en type = text/html title = "English HTML" >
< link rel = alternate href = "/fr/html" hreflang = fr type = text/html title = "French HTML" >
< link rel = alternate href = "/en/html/print" hreflang = en type = text/html media = print title = "English HTML (for printing)" >
< link rel = alternate href = "/fr/html/print" hreflang = fr type = text/html media = print title = "French HTML (for printing)" >
< link rel = alternate href = "/en/pdf" hreflang = en type = application/pdf title = "English PDF" >
< link rel = alternate href = "/fr/pdf" hreflang = fr type = application/pdf title = "French PDF" > この関係は推移的です。つまり、文書がリンク種別「alternate」で他の2つの文書に
リンクしている場合、それらの文書が最初の文書の代替表現であることを示すだけでなく、その2つの
文書が互いの代替表現であることも示します。
author」authorキーワードは、link、
a、およびarea要素で使用できます。この
キーワードはハイパーリンクを作成します。
a要素およびarea要素の場合、authorキーワードは、
ハイパーリンクを定義する要素に最も近い祖先のarticle要素がある場合は
その作成者について、そうでない場合はページ全体の作成者について、参照先文書が追加情報を提供することを
示します。
link要素の場合、authorキーワードは、
参照先文書がページ全体の作成者について追加情報を提供することを示します。
「参照先文書」は、作成者の電子メールアドレスを示すmailto:
URLである場合があり、実際にそうであることがよくあります。[MAILTO]
同義語:歴史的な理由により、ユーザーエージェントは、値「made」の
rev属性を持つlink、a、およびarea要素も、リンク関係として
authorキーワードが
指定されているものとして扱わなければなりません。
bookmark」bookmarkキーワードは、
a要素および
area要素で使用できます。
このキーワードはハイパーリンクを作成します。
bookmarkキーワードは、
対象のリンク要素に最も近い祖先のarticle要素、または祖先に
article要素がない
場合は、リンク要素が最も密接に関連付けられている節の恒久リンクを示します。
次の断片には3つの恒久リンクがあります。ユーザーエージェントは、恒久リンクが指定されている 場所を見ることで、どの恒久リンクが仕様のどの部分に適用されるかを判断できます。
...
< body >
< h1 > Example of permalinks</ h1 >
< div id = "a" >
< h2 > First example</ h2 >
< p >< a href = "a.html" rel = "bookmark" > This permalink applies to
only the content from the first H2 to the second H2</ a > . The DIV isn't
exactly that section, but it roughly corresponds to it.</ p >
</ div >
< h2 > Second example</ h2 >
< article id = "b" >
< p >< a href = "b.html" rel = "bookmark" > This permalink applies to
the outer ARTICLE element</ a > (which could be, e.g., a blog post).</ p >
< article id = "c" >
< p >< a href = "c.html" rel = "bookmark" > This permalink applies to
the inner ARTICLE element</ a > (which could be, e.g., a blog comment).</ p >
</ article >
</ article >
</ body >
...canonical」canonicalキーワードは
link要素で使用できます。
このキーワードはハイパーリンクを作成します。
canonicalキーワードは、
href属性によって指定された
URLが現在の文書の優先URLであることを示します。これは、The Canonical
Link Relationで詳しく説明されているように、検索エンジンが重複コンテンツを減らすのに
役立ちます。[RFC6596]
dns-prefetch」dns-prefetch
キーワードはlink要素で使用できます。
このキーワードは外部リソースへのリンクを作成します。このキーワードは
body-okです。
dns-prefetch
キーワードは、ユーザーが指定されたリソースのオリジンにあるリソースを必要とする可能性が
非常に高く、DNS解決に伴う遅延コストを先取りすることでユーザー体験が改善されるため、そのオリジンに
対して先行してDNS解決を実行することが有益である可能性が高いことを示します。
dns-prefetch
キーワードによって指定されるリソースにはデフォルトのタイプはありません。
この種類のリンクをフェッチして処理する適切な時点は、 次のとおりです:
すでに閲覧コンテキストに接続されているlink要素上に外部リソースへのリンクが作成されたとき。
すでに閲覧コンテキストに接続されている外部リソースへのリンクのlink要素のhref属性が変更されたとき。
この種類のリンクされたリソースについて、link要素
elが与えられた場合の、リンクされたリソースをフェッチして処理する
手順は次のとおりです:
urlを、elのhref属性の値と、
elのノード文書を指定して、URLをエンコーディング解析した結果とします。
urlが失敗の場合、返ります。
partitionKeyを、elのノード文書の関連設定オブジェクトを指定して、ネットワークパーティションキーを決定した結果と します。
ユーザーエージェントは、partitionKeyとurlのオリジンを指定して、オリジンを解決するべきです。
このアルゴリズムの結果はキャッシュできるため、将来のフェッチが高速になる可能性が あります。
expect」expectキーワードは
link要素で使用できます。
このキーワードは内部リソースへのリンクを作成します。
expectキーワードによって
作成された内部リソースへのリンクは、それが示す要素が文書に接続され、完全に解析されるまで
レンダリングをブロックするために使用できます。
expectキーワードによって
指定されるリソースにはデフォルトのタイプはありません。
link要素
elについて、次の条件のいずれかが発生したとき:
expect内部リソースへのリンクが、すでに閲覧コンテキストに接続されているel上に
作成されたとき。
expect内部リソースへのリンクがel上に作成され、
elが閲覧コンテキストに接続された状態になるとき。
expect内部リソースへのリンクがel上に作成され、
elがすでに閲覧コンテキストに接続されており、
elのhref属性が設定、変更、または
削除されたとき、または
expect内部リソースへのリンクがel上に作成され、
elがすでに閲覧コンテキストに接続されており、
elのmedia属性が設定、変更、または
削除されたとき。
その場合、elを処理します。
link要素
elが与えられたとき、内部リソースへのリンクを処理するには、次の手順を実行します:
docを、elのノード文書とします。
urlを、elのhref属性の値と
docを指定して、URLをエンコーディング解析した結果とします。
これが失敗した場合、またはurlが、フラグメントを除外をtrueに 設定してもdocのURLと等しくない場合、 elでレンダリングのブロックを解除し、返ります。
indicatedElementを、docとurlを指定して示された部分を選択した結果とします。
次のすべてが真の場合:
docの現在の文書準備状態が
「loading」である。
elが内部リソースへのリンクを作成する。
elが閲覧コンテキストに接続されている。
indicatedElementが要素でないか、または関連付けられたDocumentがdocであるHTMLパーサーの開いている要素のスタック上にある。
その場合、elでレンダリングをブロックします。
それ以外の場合、elでレンダリングのブロックを解除します。
Document
docが与えられたとき、内部リソースへのリンクを処理するには:
docのレンダリングブロック要素集合に含まれる各expectlink要素
linkについて、それぞれlinkを処理します。
element、localName、oldValue、
value、およびnamespaceが与えられた、次の属性変更手順は、expectlink要素が動的なidおよびnameの変更に応答することを保証するために
使用されます:
namespaceがnullでない場合、返ります。
elementがHTMLパーサーの開いている要素のスタック内にある場合、返ります。
次のいずれかが真の場合:
その場合、elementのノード文書を指定して、内部リソースへのリンクを処理します。
external」externalキーワードは、
a、area、およびform要素で使用できます。この
キーワードはハイパーリンクを作成しませんが、要素によって作成される他の
ハイパーリンク(他のキーワードが作成しない場合は暗黙のハイパーリンク)に注釈を付けます。
externalキーワードは、
リンクが現在の文書が属するサイトの一部ではない文書へ通じていることを示します。
help」helpキーワードは、link、
a、area、およびform要素で使用できます。この
キーワードはハイパーリンクを作成します。
a、area、およびform要素の場合、helpキーワードは、参照先文書が
ハイパーリンクを定義する要素の親およびその子について、追加のヘルプ情報を提供することを示します。
次の例では、フォームコントロールに文脈依存のヘルプが関連付けられています。ユーザーエージェントは、 たとえばユーザーが「Help」または「F1」キーを押したときに参照先文書を表示するなど、この情報を 使用できます。
< p >< label > Topic: < input name = topic > < a href = "help/topic.html" rel = "help" > (Help)</ a ></ label ></ p > link要素の場合、helpキーワードは、参照先文書が
ページ全体のヘルプを提供することを示します。
a要素およびarea要素の場合、一部の
ブラウザーでは、helpキーワードによりリンクで
異なるカーソルが使用されます。
icon」現在のすべてのエンジンでサポートされています。
iconキーワードはlink要素で使用できます。
このキーワードは外部リソースへのリンクを作成します。
指定されたリソースはページまたはサイトを表すアイコンであり、ユーザーエージェントが ユーザーインターフェースでページを表す際に使用するべきです。
アイコンは、聴覚的アイコン、視覚的アイコン、またはその他の種類のアイコンである場合があります。
複数のアイコンが提供された場合、ユーザーエージェントはtype、media、およびsizes属性に従って最も適切なアイコンを
選択しなければなりません。同等に適切なアイコンが複数ある場合、ユーザーエージェントはアイコン一覧を
収集した時点でツリー順に最後に宣言されたものを使用しなければなりません。
ユーザーエージェントがアイコンを使用しようとしたものの、詳しく調べた結果、実際には不適切であると
判断された場合(たとえば、サポートされていない形式を使用しているため)、ユーザーエージェントは
属性によって決定される次に適切なアイコンを試さなければなりません。
ユーザーエージェントは、アイコン一覧が変更されたときにアイコンを更新する必要は ありませんが、更新することが推奨されます。
iconキーワードによって指定される
リソースにはデフォルトのタイプはありません。ただし、リソースのタイプを決定する目的では、ユーザーエージェントは
リソースが画像であると想定しなければなりません。
sizesキーワードは、アイコンの
サイズを生のピクセル単位で表します(CSSピクセルとは異なります)。
デバイスピクセル密度が1CSSピクセルあたり2デバイスピクセル(2x、192dpi)のディスプレイ向けで、 幅が50CSSピクセルのアイコンは、生のピクセルでは幅100ピクセルに なります。この機能は、小さい高解像度アイコンと大きい低解像度アイコンで異なるリソースを使用すること (たとえば50×50 2xと100×100 1x)を示すことをサポートしません。
属性値を解析して処理するには、ユーザーエージェントはまず属性値をASCII空白で分割し、その後、結果として得られた各キーワードを 解析して、それが何を表すかを決定しなければなりません。
anyキーワードは、リソースに、たとえばSVG画像によって
提供されるような拡大縮小可能なアイコンが含まれていることを表します。
その他のキーワードが何を表すかを決定するには、次のようにさらに解析しなければなりません:
キーワードにU+0078 LATIN SMALL LETTER XまたはU+0058 LATIN CAPITAL LETTER X文字が ちょうど1つ含まれていない場合、このキーワードは何も表しません。そのキーワードについて 返ります。
width stringを「x」または「X」の前の文字列とします。
height stringを「x」または「X」の後の文字列とします。
width stringまたはheight stringのいずれかがU+0030 DIGIT ZERO (0)文字で 始まるか、ASCII数字以外の文字を含む場合、このキーワードは何も 表しません。そのキーワードについて返ります。
width stringに非負整数を解析する規則を適用して widthを取得します。
height stringに非負整数を解析する規則を適用して heightを取得します。
このキーワードは、リソースに幅widthデバイスピクセル、高さ heightデバイスピクセルのビットマップアイコンが含まれていることを表します。
sizes属性で指定されるキーワードは、
リンクされたリソースで実際には利用できないアイコンサイズを表してはなりません。
この種類のリンクされたリソースについて、link要素elおよび要求requestが与えられた
場合の、リンクされたリソースのフェッチ設定手順は次のとおりです:
requestの宛先を「image」に設定します。
trueを返します。
この種類のリンクされたリソースについてのリンクヘッダーを処理する手順は、何もしません。
iconキーワードを持つlinkが存在しない場合、URLのスキームがHTTP(S)スキームであるDocumentオブジェクトについて、ユーザーエージェントは
代わりに次の手順を並行に実行してもかまいません:
次の断片は、複数のアイコンを持つアプリケーションの先頭部分を示しています。
<!DOCTYPE HTML>
< html lang = "en" >
< head >
< title > lsForums — Inbox</ title >
< link rel = icon href = favicon.png sizes = "16x16" type = "image/png" >
< link rel = icon href = windows.ico sizes = "32x32 48x48" type = "image/vnd.microsoft.icon" >
< link rel = icon href = mac.icns sizes = "128x128 512x512 8192x8192 32768x32768" >
< link rel = icon href = iphone.png sizes = "57x57" type = "image/png" >
< link rel = icon href = gnome.svg sizes = "any" type = "image/svg+xml" >
< link rel = stylesheet href = lsforums.css >
< script src = lsforums.js ></ script >
< meta name = application-name content = "lsForums" >
</ head >
< body >
...歴史的な理由により、iconキーワードの前に
キーワード「shortcut」を置いてもかまいません。「shortcut」キーワードが
存在する場合、rel属性の値全体は文字列
「shortcut icon」(トークン間に単一のU+0020 SPACE文字があり、それ以外のASCII空白はない)とASCII大文字小文字不区別で一致しなければなりません。
license」licenseキーワードは、
link、
a、area、およびform要素で使用できます。この
キーワードはハイパーリンクを作成します。
licenseキーワードは、
現在の文書の主要コンテンツが提供される著作権ライセンスの条件を、参照先文書が示すことを表します。
この仕様では、文書の主要コンテンツと、その主要コンテンツの一部とはみなされないコンテンツを 区別する方法を指定しません。この区別はユーザーに明確に示すべきです。
写真共有サイトを考えます。そのサイトのページでは写真を説明して表示し、ページを次のように マークアップできます:
<!DOCTYPE HTML>
< html lang = "en" >
< head >
< title > Exampl Pictures: Kissat</ title >
< link rel = "stylesheet" href = "/style/default" >
</ head >
< body >
< h1 > Kissat</ h1 >
< nav >
< a href = "../" > Return to photo index</ a >
</ nav >
< figure >
< img src = "/pix/39627052_fd8dcd98b5.jpg" >
< figcaption > Kissat</ figcaption >
</ figure >
< p > One of them has six toes!</ p >
< p >< small >< a rel = "license" href = "http://www.opensource.org/licenses/mit-license.php" > MIT Licensed</ a ></ small ></ p >
< footer >
< a href = "/" > Home</ a > | < a href = "../" > Photo index</ a >
< p >< small > © copyright 2009 Exampl Pictures. All Rights Reserved.</ small ></ p >
</ footer >
</ body >
</ html > この場合、licenseは写真
(文書の主要コンテンツ)だけに適用され、文書全体には適用されません。特に、ページ自体のデザインには
適用されません。ページ自体のデザインには、文書末尾に示された著作権が適用されます。これは
スタイル設定によってより明確にできます(たとえば、ライセンスへのリンクを写真の近くに目立つよう
配置し、ページの著作権をページ下部の薄い小さな文字で表示するなど)。
同義語:歴史的な理由により、ユーザーエージェントはキーワード
「copyright」もlicenseキーワードと
同様に扱わなければなりません。
manifest」1つのエンジンのみでサポートされています。
manifestキーワードはlink要素で使用できます。この
キーワードは外部リソースへのリンクを作成します。
manifestキーワードは、
現在の文書に関連付けられたメタデータを提供するマニフェストファイルを示します。
manifestキーワードによって
指定されるリソースにはデフォルトのタイプはありません。
ウェブアプリケーションがインストールされていない場合、このリンク種別のリンクされたリソースをフェッチして処理する 適切な時点は、ユーザーエージェントが必要と判断したときです。たとえば、ユーザーがウェブアプリケーションをインストールすることを選択したときです。
インストールされたウェブアプリケーションについて、この リンク種別のリンクされたリソースをフェッチして処理する 適切な時点は次のとおりです:
すでに閲覧コンテキストに接続されているlink要素上に外部リソースへのリンクが作成されたとき。
すでに閲覧コンテキストに接続されている外部リソースへのリンクのlink要素のhref属性が変更されたとき。
いずれの場合も、rel属性にトークンmanifestが含まれる、
ツリー順で最初のlink要素だけを使用できます。
ユーザーエージェントは、このリンク種別によってloadイベントを遅延させては なりません。
この種類のリンクされたリソースについて、link要素elおよび
要求requestが
与えられた場合の、リンクされたリソースのフェッチ設定手順は
次のとおりです:
navigableがnullの場合、falseを返します。
navigableがトップレベル走査可能でない場合、falseを返します。
requestの起動元を「manifest」に設定します。
requestの宛先を「manifest」に設定します。
requestのモードを「cors」に設定します。
requestの資格情報モードを、elのcrossorigin
コンテンツ属性に対するCORS設定属性の資格情報モードに
設定します。
trueを返します。
link要素
el、ブール値success、応答response、
およびバイト列bodyBytesが与えられたとき、この種類のリンクされたリソースを処理するには:
responseのContent-TypeメタデータがJSON MIMEタイプでない場合、successをfalseに設定します。
successがtrueの場合:
manifest URLを、responseのURLとします。
clientを、elのノード文書の関連設定オブジェクトとします。
document URL、manifest URL、bodyBytes、および clientを指定して、マニフェストを処理します。[MANIFEST]
この種類のリンクされたリソースについてのリンクヘッダーを処理する手順は、何もしません。
modulepreload」modulepreload
キーワードは
link要素で使用できます。
このキーワードは外部リソースへのリンクを作成します。この
キーワードはbody-okです。
modulepreload
キーワードは、preloadキーワードに対する特化された代替であり、
モジュールスクリプトのプリロード向けに調整された処理モデルを備えています。具体的には、
モジュールスクリプト固有の
フェッチ動作(たとえば、crossorigin
属性の異なる解釈を含む)を使用し、その結果を
後で評価するために適切なモジュール
マップへ配置します。これに
対して、preloadキーワードを使用する同様の外部
リソースへのリンクは、
文書のモジュールマップに影響を与えることなく、
結果をプリロードキャッシュへ配置します。
さらに、実装は、モジュールスクリプトが依存関係を宣言するという事実を
利用して、指定されたモジュールの依存関係もフェッチできます。ユーザーエージェントは、それらの
依存関係も後で必要になる可能性が非常に高いことを認識しているため、これは最適化の機会として
意図されています。通常、サービスワーカーなどの技術を使用するか、サーバー側で監視しない限り、
観察できません。特に、適切なloadイベントまたは
errorイベントは、指定された
モジュールがフェッチされた後に発生し、依存関係を待ちません。
ユーザーエージェントは、このリンク種別によってloadイベントを遅延させてはなりません。
モジュールプリロード宛先は、「json」、
「style」、「text」、またはスクリプト様の宛先です。
このようなリンクについてリンクされたリソースをフェッチして 処理する適切な時点は次のとおりです:
すでに閲覧コンテキストに接続されているlink要素上に外部リソースへのリンクが作成されたとき。
すでに閲覧コンテキストに接続されている外部リソースへのリンクのlink要素のhref属性が変更されたとき。
他の一部のリンク関係とは異なり、このようなlinkの関連属性
(as、crossorigin、
およびreferrerpolicy
など)を変更しても、新しいフェッチは起動されません。これは、文書のモジュールマップが以前のフェッチによって
すでに設定されているため、再フェッチしても意味がないからです。
link要素
elが与えられた場合の、modulepreload
リンクに対するリンクされたリソースをフェッチして
処理するアルゴリズムは次のとおりです:
elのhref属性の値が
空文字列の場合、返ります。
destinationがモジュールプリロード宛先でない場合、
elを指定してネットワークタスクソースに要素タスクを
キューに追加し、elでerrorという名前の
イベントを発火して、返ります。
urlを、elのhref属性の値と、
elのノード文書を指定して、URLをエンコーディング解析した結果とします。
urlが失敗の場合、返ります。
settings objectを、elのノード文書の関連設定オブジェクトとします。
credentials modeを、elのcrossorigin
属性に対するCORS設定属性の資格情報モードと
します。
cryptographic nonceを el.[[CryptographicNonce]]とします。
integrity metadataを、elのintegrity属性が
指定されている場合はその値とし、そうでない場合は空文字列とします。
elがintegrity属性を
持たない場合、integrity metadataを、urlとsettings objectを使用してモジュール完全性メタデータを
解決した結果に設定します。
referrer policyを、elのreferrerpolicy
属性の現在の状態とします。
fetch priorityを、elのfetchpriority
属性の現在の状態とします。
optionsを、暗号学的ノンスが
cryptographic nonce、完全性メタデータが
integrity metadata、パーサーメタデータが
「not-parser-inserted」、資格情報モードが
credentials mode、リファラーポリシーが
referrer policy、およびフェッチ優先度が
fetch priorityであるスクリプトフェッチオプションとします。
url、destination、settings object、options、および resultが与えられた次の手順を指定して、modulepreloadモジュール スクリプトグラフをフェッチします:
この種類のリンクされたリソースについてのリンクヘッダーを処理する手順は、何もしません。
次の断片は、複数のモジュールがプリロードされたアプリケーションの先頭部分を示しています:
<!DOCTYPE html>
< html lang = "en" >
< title > IRCFog</ title >
< link rel = "modulepreload" href = "app.mjs" >
< link rel = "modulepreload" href = "helpers.mjs" >
< link rel = "modulepreload" href = "irc.mjs" >
< link rel = "modulepreload" href = "fog-machine.mjs" >
< script type = "module" src = "app.mjs" >
... アプリケーションのモジュールグラフが次のようになっていると仮定します:

ここでは、アプリケーション開発者がmodulepreload
を使用してモジュールグラフ内のすべてのモジュールを宣言し、ユーザーエージェントがそれらすべての
フェッチを開始するようにしています。このようなプリロードがなく、HTTP/2 Server Pushなどの技術が
使用されていない場合、ユーザーエージェントはhelpers.mjsを発見するまでに複数回の
ネットワーク往復を行う必要があるかもしれません。このように、modulepreload
link要素は、
アプリケーションのモジュールの一種の「マニフェスト」として使用できます。
次のコードは、modulepreload
リンクをimport()
と組み合わせて使用し、ネットワークフェッチを事前に完了させることで、import()
が呼び出されたときに、モジュールがモジュールマップ内ですでに準備済み
(ただし未評価)となるようにする方法を示しています:
< link rel = "modulepreload" href = "awesome-viewer.mjs" >
< button onclick = "import('./awesome-viewer.mjs').then(m => m.view())" >
View awesome thing
</ button > nofollow」nofollowキーワードは、
a、area、およびform要素で使用できます。この
キーワードはハイパーリンクを作成しませんが、要素によって作成される他の
ハイパーリンク(他のキーワードが作成しない場合は暗黙のハイパーリンク)に注釈を付けます。
nofollowキーワードは、
リンクがページの元の作成者または発行者によって支持されていないこと、または参照先文書へのリンクが
主として2つのページに関係する人々の商業的関係を理由として含められていることを示します。
noopener」現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
noopenerキーワードは、
a、area、およびform要素で使用できます。この
キーワードはハイパーリンクを作成しませんが、要素によって作成される他の
ハイパーリンク(他のキーワードが作成しない場合は暗黙のハイパーリンク)に注釈を付けます。
このキーワードは、ハイパーリンクをたどった結果として新しく作成されるトップレベル走査可能が、補助閲覧コンテキストを含まないことを示します。
たとえば、結果として得られるWindowのopenerゲッターはnullを返します。
処理モデルも参照してください。
これは通常、補助閲覧コンテキストを持つトップレベル走査可能を作成します
(ターゲット名が「example」である
既存のナビガブルがないと仮定します):
< a href = help.html target = example > Help!</ a > これは、非補助閲覧コンテキストを持つトップレベル走査可能を作成します (同じことを仮定します):
< a href = help.html target = example rel = noopener > Help!</ a > これらは同等であり、親ナビガブルのみをナビゲートします:
< a href = index.html target = _parent > Home</ a > < a href = index.html target = _parent rel = noopener > Home</ a > noreferrer」
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
noreferrerキーワードは、
a、area、およびform要素で使用できます。この
キーワードはハイパーリンクを作成しませんが、要素によって作成される他の
ハイパーリンク(他のキーワードが作成しない場合は暗黙のハイパーリンク)に注釈を付けます。
これは、リンクをたどる際にリファラー情報が漏洩しないことを示し、同じ条件下でnoopenerキーワードの
動作も暗示します。
リファラーが直接操作される処理モデルも参照してください。
<a href="..." rel="noreferrer" target="_blank">は、
<a href="..." rel="noreferrer noopener" target="_blank">と同じ動作をします。
opener」openerキーワードは、a、area、およびform要素で使用できます。この
キーワードはハイパーリンクを作成しませんが、要素によって作成される他の
ハイパーリンク(他のキーワードが作成しない場合は暗黙のハイパーリンク)に注釈を付けます。
このキーワードは、ハイパーリンクをたどった結果として新しく作成されるトップレベル走査可能が、補助閲覧コンテキストを含むことを示します。
処理モデルも参照してください。
次の例では、openerを使用して、ヘルプ
ページのポップアップがそのオープナーをナビゲートできるようにしています。たとえば、ユーザーが
探しているものが別の場所にある場合に利用できます。別の方法として、_blankの代わりに
名前付きターゲットを使用できますが、既存の名前と衝突する可能性があります。
< a href = "..." rel = opener target = _blank > Help!</ a > pingback」pingbackキーワードは
link要素で使用できます。
このキーワードは外部リソースへのリンクを作成します。このキーワードは
body-okです。
pingbackキーワードの
セマンティクスについては、Pingback 1.0を参照してください。[PINGBACK]
preconnect」
現在のすべてのエンジンでサポートされています。
preconnectキーワードは
link要素で使用できます。
このキーワードは外部リソースへのリンクを作成します。このキーワードは
body-okです。
preconnectキーワードは、
ユーザーが指定されたリソースのオリジンにあるリソースを必要とする可能性が
非常に高く、接続確立に伴う遅延コストを先取りすることでユーザー体験が改善されるため、そのオリジンへの
接続を先行して開始することが有益である可能性が高いことを示します。
preconnectキーワード
によって指定されるリソースにはデフォルトのタイプはありません。
ユーザーエージェントは、このリンク種別によってloadイベントを遅延させてはなりません。
この種類のリンクをフェッチして処理する適切な時点は 次のとおりです:
すでに閲覧コンテキストに接続されているlink要素上に外部リソースへのリンクが作成されたとき。
すでに閲覧コンテキストに接続されている外部リソースへのリンクのlink要素のhref属性が変更されたとき。
すでに閲覧コンテキストに接続されている外部リソースへのリンクのlink要素の
crossorigin
属性が設定、変更、または削除されたとき。
この種類のリンクされたリソースについて、link要素
elが与えられた場合の、リンクされたリソースをフェッチして処理する
手順は、elからリンクオプションを作成し、その結果を指定して
事前接続することです。
この種類のリンクされたリソースについて、リンク処理オプションoptionsが与えられた 場合のリンクヘッダーを処理する手順は、optionsを 指定して事前接続することです。
リンク処理オプションoptionsが与えられた とき、事前接続するには:
optionsの hrefが空文字列の場合、返ります。
urlを、optionsのhrefと、 optionsの基底URLを指定して、URLをエンコーディング解析した結果とします。
文書または環境の代わりに基底URLを渡すことは、issue #9715で追跡されています。
urlが失敗の場合、返ります。
urlのスキームがHTTP(S)スキームでない場合、返ります。
partitionKeyを、optionsの環境を指定して、ネットワークパーティションキーを決定した結果と します。
useCredentialsをtrueとします。
optionsのcrossoriginがAnonymousであり、かつ optionsのオリジンがurlのオリジンと同一オリジンでない場合、useCredentialsをfalseに 設定します。
ユーザーエージェントは、partitionKey、urlのオリジン、およびuseCredentialsを指定して、接続を取得するべきです。
この接続は取得されますが、直接使用されません。その後の使用のために接続プール内に残ります。
ユーザーエージェントは、可能な場合には常に事前接続を開始し、完全な接続ハンドシェイク (HTTPではDNS+TCP、HTTPSオリジンではDNS+TCP+TLS)を実行するよう試みるべきですが、 リソース制約またはその他の理由により、部分的なハンドシェイク(HTTPではDNSのみ、 HTTPSオリジンではDNSまたはDNS+TCP)を実行するか、完全に省略することを選択できます。
オリジンごとの最適な接続数は、交渉されたプロトコル、ユーザーの現在の接続性プロファイル、 利用可能なデバイスリソース、グローバル接続制限、およびその他の文脈固有の変数に依存します。 そのため、いくつの接続を開くべきかの決定はユーザーエージェントに委ねられます。
prefetch」prefetchキーワードは
link要素で使用できます。
このキーワードは外部リソースへのリンクを作成します。このキーワードは
body-okです。
prefetchキーワードは、
ユーザーが将来のナビゲーションでこのリソースを必要とする可能性が非常に高いため、指定された
リソースまたは同一サイトの文書を先行してフェッチし、キャッシュすることが
有益である可能性が高いことを示します。
prefetchキーワードによって
指定されるリソースにはデフォルトのタイプはありません。
この種類のリンクをフェッチして処理する適切な時点は 次のとおりです:
すでに閲覧コンテキストに接続されているlink要素上に外部リソースへのリンクが作成されたとき。
すでに閲覧コンテキストに接続されている外部リソースへのリンクのlink要素のhref属性が変更されたとき。
すでに閲覧コンテキストに接続されている外部リソースへのリンクのlink要素の
crossorigin
属性が設定、変更、または削除されたとき。
link要素
elが与えられた場合の、prefetchリンクに対する
リンクされたリソースをフェッチして処理する
アルゴリズムは次のとおりです:
elのhref属性の値が空文字列の場合、
返ります。
optionsを、elからリンクオプションを作成した結果とします。
requestを、optionsを指定してリンク要求を作成した結果と します。
requestがnullの場合、返ります。
requestの起動元を「prefetch」に設定します。
processPrefetchResponseを、応答responseおよびnull、失敗、またはバイト列bytesOrNullが与えられた次の手順とします:
ユーザーエージェントは、processResponseConsumeBodyを processPrefetchResponseに設定して、requestをフェッチするべきです。 ユーザーエージェントは、現在の文書に必要な他の要求を優先するため、requestのフェッチを 遅延してもかまいません。
この種類のリンクされたリソースについてのリンクヘッダーを処理する手順は、何もしません。
preload」1つのエンジンのみでサポートされています。
preloadキーワードは
link要素で使用できます。
このキーワードは外部リソースへのリンクを作成します。このキーワードは
body-okです。
preloadキーワードは、
ユーザーが現在のナビゲーションでこのリソースを必要とする可能性が非常に高いため、ユーザーエージェントが
as属性によって指定されたプリロード宛先と、fetchpriority属性に
よって指定された優先度に従って、指定されたリソースを先行してフェッチし、キャッシュすることを示します。
ユーザーエージェントは、リソースが読み込まれるときに、画像を先行してデコードしたり、スタイルシートを作成したりするなど、追加の処理を実行する 場合があります。ただし、これらの追加処理には観察可能な効果があってはなりません。
preloadキーワードによって
指定されるリソースにはデフォルトのタイプはありません。
ユーザーエージェントは、このリンク種別によってloadイベントを遅延させてはなりません。
このようなリンクについてリンクされたリソースをフェッチして処理する 適切な時点は次のとおりです:
すでに閲覧コンテキストに接続されているlink要素上に外部リソースへのリンクが作成されたとき。
すでに閲覧コンテキストに接続されている外部リソースへのリンクのlink要素のhref属性が変更されたとき。
すでに閲覧コンテキストに接続されている外部リソースへのリンクのlink要素のas属性が変更されたとき。
すでに閲覧コンテキストに接続されているものの、以前は
type属性が要求の宛先に対してサポートされていないタイプを指定していたため
取得されなかった外部リソースへのリンクのlink要素のtype属性が設定、削除、または
変更されたとき。
すでに閲覧コンテキストに接続されているものの、以前は
media属性が環境に一致しなかったため取得されなかった外部リソースへのリンクのlink要素のmedia属性が変更または
削除されたとき。
Documentは、初期状態で空の順序付きマップであるプリロード済みリソースのマップを持ちます。
same-origin」、「cors」、または
「no-cors」のいずれかである要求モード
Windowwindowについて、
URLurl、文字列destination、文字列
mode、文字列credentialsMode、文字列integrityMetadata、および応答を受け入れるアルゴリズムである
onResponseAvailableが与えられたとき、プリロード済みリソースを消費するには:
keyを、URLがurl、宛先がdestination、モードがmode、および資格情報モードが credentialsModeであるプリロードキーとします。
preloadsを、windowの関連付けられたDocumentのプリロード済みリソースのマップとします。
keyがpreloads内に存在しない場合、falseを返します。
entryをpreloads[key]とします。
consumerIntegrityMetadataを、integrityMetadataを解析した結果とします。
次の条件のいずれも該当しない場合:
consumerIntegrityMetadataがno metadataである。
consumerIntegrityMetadataがpreloadIntegrityMetadataと等しい。または
この比較では、未知の完全性オプションが無視されます。issue #116を 参照してください。
その場合、falseを返します。
プリロードとコンシューマーの完全性メタデータが一致しない場合、両方がデータと 一致していても、ネットワークから追加のフェッチが行われます。
ネットワークエラーをプリロードキャッシュに追加することは 重要です。これにより、プリロード要求でエラーが発生した場合、誤った応答が後でネットワークから 再要求されなくなります。これにはセキュリティ上の影響もあります。開発者がプリロード要求には サブリソース完全性メタデータを指定するものの、その後のリソース要求には指定しない場合を 考えてください。プリロード要求がサブリソース完全性検証に失敗して破棄された場合、リソース要求は 完全性を検証せずに、潜在的に悪意のある応答をネットワークからフェッチして消費します。 [SRI]
preloads[key]を削除します。
entryの応答がnullの場合、entryの応答が利用可能になったときを onResponseAvailableに設定します。
それ以外の場合、entryの応答を指定して onResponseAvailableを呼び出します。
trueを返します。
この節の目的では、文字列typeは、次のアルゴリズムがtrueを返す場合にプリロード宛先destinationと 一致します:
typeが空文字列の場合、trueを返します。
destinationが「fetch」の場合、trueを返します。
mimeTypeRecordを、typeを解析した結果とします。
mimeTypeRecordが失敗の場合、falseを返します。
mimeTypeRecordがユーザーエージェントによってサポートされて いない場合、falseを返します。
次のいずれかが真の場合:
destinationが「script」であり、
mimeTypeRecordがJavaScript MIMEタイプである。
destinationが「image」であり、
mimeTypeRecordが画像MIMEタイプである。
destinationが「font」であり、
mimeTypeRecordがフォントMIMEタイプである。
destinationが「style」であり、
mimeTypeRecordのエッセンスがtext/cssである。または
その場合、trueを返します。
falseを返します。
要求requestについてプリロードキーを作成するには、URLがrequestのURL、宛先がrequestの宛先、モードがrequestのモード、および資格情報モードがrequestの資格情報モードである新しいプリロードキーを返します。
プリロード宛先は、「fetch」、「font」、
「image」、「script」、「style」、または
「track」です。
リンク処理オプションoptionsと、任意の processResponse(応答を受け入れるアルゴリズム)が与えられたとき、プリロードするには:
optionsの宛先が「image」であり、
optionsのソース集合がnullでない場合、
optionsのhrefを、optionsのソース集合から画像ソースを選択した結果に設定します。
requestを、optionsを指定してリンク要求を作成した結果と します。
requestがnullの場合、返ります。
unsafeEndTimeを0とします。
entryを、完全性メタデータがoptionsのintegrityである新しいプリロードエントリーとします。
keyを、requestを指定してプリロードキーを作成した結果とします。
controllerをnullとします。
Document
documentが与えられたreportTimingを、documentの関連グローバルオブジェクトを指定して
controllerのタイミングを報告することとします。
controllerを、processResponseConsumeBodyを、 応答responseおよびnull、失敗、またはバイト列bodyBytesが与えられた次の手順に設定して、 requestをフェッチした結果に設定します:
bodyBytesがバイト列の場合、responseの本体を、bodyBytesを本体として使用したものに設定します。
processResponseConsumeBody を使用することで、本体全体を抽出しています。これは、プリロードが消費されるかどうか (現時点では不確定)に関係なく、プリローダーが本体全体をネットワークから読み込むことを 保証するために必要です。その後、この手順は要求の本体を同じバイトを含む新しい本体に リセットします。これにより、すでに一度読み取っていても、他の仕様が実際の消費時にそこから 読み取れます。
それ以外の場合、responseをネットワークエラーに設定します。
unsafeEndTimeを安全でない共有現在時刻に設定します。
entryの応答が利用可能になったときがnullの場合、 entryの応答をresponseに設定します。 それ以外の場合、responseを指定してentryの応答が利用可能になったときを呼び出します。
processResponseが与えられている場合、responseを指定して processResponseを呼び出します。
Document
documentが与えられたcommitを、次の手順とします:
entryの応答がnullでない場合、documentを指定して reportTimingを呼び出します。
documentのプリロード済みリソースのマップ [key]をentryに設定します。
optionsの文書がnullの場合、optionsの文書準備完了時をcommitに設定します。 それ以外の場合、optionsの文書を指定してcommitを呼び出します。
この種類のリンクされたリソースについて、link要素
elが与えられた場合の、リンクされたリソースをフェッチして処理する
手順は次のとおりです:
elのソース集合を更新します。
optionsを、elからリンクオプションを作成した結果とします。
destinationがnullの場合、返ります。
optionsの宛先をdestinationに設定します。
この種類のリンクについて、リンク処理オプションoptionsが与えられた 場合のリンクヘッダーを処理する手順は、optionsをプリロードすることです。
privacy-policy」privacy-policy
キーワードは
link、a、およびarea要素で使用できます。この
キーワードは
ハイパーリンクを作成します。
privacy-policy
キーワードは、Additional Link Relation
Typesでさらに詳しく説明されているように、参照先文書に現在の文書に適用されるデータ収集および利用慣行に
関する情報が含まれていることを示します。参照先文書は独立したプライバシーポリシーである場合も、
より一般的な文書の特定の節である場合もあります。[RFC6903]
search」searchキーワードは
link、
a、area、およびform要素で使用できます。この
キーワードは
ハイパーリンクを作成します。
searchキーワードは、
参照先文書が、その文書および関連リソースを検索するための専用インターフェースを提供することを示します。
OpenSearch記述文書は、link要素および
searchリンク種別とともに
使用して、ユーザーエージェントが検索インターフェースを自動検出できるようにできます。
[OPENSEARCH]
stylesheet」
stylesheet
キーワードはlink
要素で使用できます。このキーワードは、スタイル処理モデルに寄与する外部リソースへの
リンクを作成します。このキーワードは
body-okです。
指定されたリソースは、文書をどのように表示するかを記述するCSSスタイルシートです。
1つのエンジンのみでサポートされています。
alternateキーワードも
link要素に指定されている
場合、そのリンクは代替スタイルシートです。この場合、title属性を、空でない値とともに
link要素に
指定しなければなりません。
stylesheet
キーワードによって指定されるリソースのデフォルトのタイプは、text/cssです。
この種類のlink要素は、その要素が
ノード文書のパーサーによって作成された場合、暗黙的にレンダリングをブロックする可能性が
あります。
stylesheet
キーワードを持つlink要素のdisabled属性が設定された
とき、無効化し、
関連付けられたCSSスタイルシートを無効にします。
この種類のリンクをフェッチして 処理する適切な時点は次のとおりです:
すでに閲覧コンテキストに接続されているlink要素上に外部リソースへのリンクが作成されたとき。
すでに閲覧コンテキストに接続されている外部リソースへのリンクのlink要素のhref属性が変更されたとき。
すでに
閲覧コンテキストに接続されている外部リソースへのリンクの
link要素の
disabled属性が
設定、変更、または削除されたとき。
すでに閲覧コンテキストに接続されている外部リソースへのリンクの
link要素の
crossorigin
属性が設定、変更、または削除されたとき。
すでに閲覧コンテキストに接続されている外部リソースへのリンクのlink要素のtype属性が、以前に取得した
外部リソースがある場合、そのContent-Typeメタデータと一致しない、または一致しなくなった
値に設定または変更されたとき。
すでに閲覧コンテキストに接続されているものの、
以前はtype属性がサポートされて
いないタイプを指定していたため取得されなかった外部リソースへのリンクのlink要素のtype属性が削除または
変更されたとき。
すでに閲覧コンテキストに接続されている外部リソースへのリンクが、代替スタイルシートである状態から そうでない状態へ、またはその逆へ変化したとき。
クワーク:文書がクワークモードに
設定され、外部リソースのURLと同一オリジンを持ち、外部リソースのContent-Typeメタデータがサポートされている
スタイルシートタイプでない場合、ユーザーエージェントは代わりにそれをtext/cssであると仮定しなければ
なりません。
この種類のリンクされたリソースについて、link要素
elおよび要求
requestが与えられた場合の、リンクされたリソースのフェッチ設定手順は
次のとおりです:
elのdisabled属性が
設定されている場合、falseを返します。
elがスクリプトをブロックするスタイル シートに寄与する場合、elを、そのノード文書のスクリプトをブロックする スタイルシート集合に追加します。
elのmedia属性の値が環境に一致し、かつelがレンダリングをブロックする可能性がある場合、
elでレンダリングをブロックします。
elが現在レンダリングをブロックしている場合、 requestのレンダリングブロックをtrueに設定します。
trueを返します。
デフォルトのリンクされたリソースを
フェッチして処理するアルゴリズムの代わりに、CSSOMのCSSスタイルシートをフェッチする
アルゴリズムを使用する計画については、issue #968を参照してください。それまでの間、
すべての重要なサブリソースの要求は、そのレンダリングブロックを、link要素が現在レンダリングをブロックしているかどうかに
設定するべきです。
link要素
el、ブール値success、応答response、
およびバイト列
bodyBytesが与えられたとき、この種類のリンクされたリソースを処理するには:
リソースのContent-Typeメタデータが
text/cssでない場合、
successをfalseに設定します。
elがスタイル処理モデルに寄与する外部リソースへのリンクを作成しなくなった場合、 または問題のリソースがフェッチされて以降、それを再びフェッチすることが適切になった場合:
elを、elのノード文書のスクリプトをブロックする スタイルシート集合から削除します。
返ります。
elが関連付けられたCSSスタイルシートを持つ場合、CSSスタイルシートを削除します。
successがtrueの場合:
次のプロパティを使用してCSSスタイルシートを作成します:
responseのURLリスト[0]
w3c/csswg-drafts issue #9316が 修正されるという前提で、ここではURLを提供しています。
el
elのmedia属性。
これは、属性の現在の値のコピーではなく、属性 (この時点では存在しない可能性があります)への参照です。CSSOMは、 属性が動的に設定、変更、または削除されたときに何が起こるかを定義します。
elが文書ツリー内にある場合はelのtitle属性、
そうでない場合は空文字列。
これも同様に、属性の現在の値のコピーではなく、属性への参照です。
そのリンクが代替スタイル シートであり、かつelの明示的に有効がfalseの場合に設定し、 それ以外の場合は設定しません。
リソースがCORS同一オリジンの場合に設定し、 それ以外の場合は設定しません。
null
デフォルト値のままにします。
初期化しないままにします。
これは正しくないように見えます。おそらくbodyBytesを使用するべき でしょうか?issue #2997として 追跡されています。
CSSの環境エンコーディングは、次の手順を実行した結果です: [CSSSYNTAX]
elがcharset属性を
持つ場合、その属性の値からエンコーディングを取得します。成功した場合、
結果として得られたエンコーディングを返します。[ENCODING]
それ以外の場合、文書の文字エンコーディングを返します。 [DOM]
elがスクリプトをブロックするスタイル シートに寄与する場合:
表明:elのノード文書のスクリプトをブロックする スタイルシート集合はelを含みます。
elを、そのノード文書のスクリプトをブロックする スタイルシート集合から削除します。
elでレンダリングのブロックを解除します。
この種類のリンクされたリソースについてのリンクヘッダーを処理する手順は、何もしません。
tag」tagキーワードはa要素および
area要素で使用できます。この
キーワードはハイパーリンクを作成します。
tagキーワードは、参照先文書が
表すタグが現在の文書に適用されることを示します。
タグが現在の文書に適用されることを示すため、一連のページ全体で人気のタグを 一覧表示するタグクラウドのマークアップでこのキーワードを使用することは 不適切です。
この文書は宝石についてのものであるため、「https://en.wikipedia.org/wiki/Gemstone」で
タグ付けし、米国の町、Rubyパッケージ形式、またはスイスの機関車形式などではなく、
「宝飾品」の種類の宝石に適用されるものとして明確に分類しています:
<!DOCTYPE HTML>
< html lang = "en" >
< head >
< title > My Precious</ title >
</ head >
< body >
< header >< h1 > My precious</ h1 > < p > Summer 2012</ p ></ header >
< p > Recently I managed to dispose of a red gem that had been
bothering me. I now have a much nicer blue sapphire.</ p >
< p > The red gem had been found in a bauxite stone while I was digging
out the office level, but nobody was willing to haul it away. The
same red gem stayed there for literally years.</ p >
< footer >
Tags: < a rel = tag href = "https://en.wikipedia.org/wiki/Gemstone" > Gemstone</ a >
</ footer >
</ body >
</ html > この文書には2つの記事があります。ただし、「tag」リンクはページ全体に適用されます
(article要素内を含め、
どこに配置されていても同様です)。
<!DOCTYPE HTML>
< html lang = "en" >
< head >
< title > Gem 4/4</ title >
</ head >
< body >
< article >
< h1 > 801: Steinbock</ h1 >
< p > The number 801 Gem 4/4 electro-diesel has an ibex and was rebuilt in 2002.</ p >
</ article >
< article >
< h1 > 802: Murmeltier</ h1 >
< figure >
< img src = "https://upload.wikimedia.org/wikipedia/commons/b/b0/Trains_de_la_Bernina_en_hiver_2.jpg"
alt = "The 802 was red with pantographs and tall vents on the side." >
< figcaption > The 802 in the 1980s, above Lago Bianco.</ figcaption >
</ figure >
< p > The number 802 Gem 4/4 electro-diesel has a marmot and was rebuilt in 2003.</ p >
</ article >
< p class = "topic" >< a rel = tag href = "https://en.wikipedia.org/wiki/Rhaetian_Railway_Gem_4/4" > Gem 4/4</ a ></ p >
</ body >
</ html > terms-of-service」terms-of-service
キーワードは
link、a、およびarea要素で使用できます。この
キーワードは
ハイパーリンクを作成します。
terms-of-service
キーワードは、Additional Link Relation Typesでさらに詳しく説明されているように、
参照先文書に、現在の文書の提供者と現在の文書を利用しようとするユーザーとの間の合意に関する情報が
含まれていることを示します。[RFC6903]
一部の文書は、文書の連続体の一部を形成します。
文書の連続体とは、各文書が前の兄弟および次の兄弟を持つことができるものです。 前の兄弟を持たない文書はその連続体の先頭であり、次の兄弟を持たない文書はその連続体の末尾です。
文書は複数の連続体の一部である場合があります。
next」nextキーワードは
link、
a、area、およびform要素で使用できます。この
キーワードはハイパーリンクを作成します。
nextキーワードは、文書が
連続体の一部であり、リンクがその連続体内で論理的に次の文書へ通じていることを示します。
nextキーワードがlink要素とともに使用される場合、
ユーザーエージェントは、そのようなリンクをdns-prefetch、preconnect、または
prefetchキーワードの
いずれかを使用しているかのように処理するべきです。ユーザーエージェントがどのキーワードを使用するかは
実装依存です。たとえば、ユーザーエージェントは、データ、バッテリー電力、または処理能力を節約しようと
するときに、より低コストなpreconnect処理モデルを
使用したり、類似の状況における過去のユーザー動作をヒューリスティックに分析した結果に応じて
キーワードを選択したりする場合があります。
prev」prevキーワードは
link、
a、area、およびform要素で使用できます。この
キーワードはハイパーリンクを作成します。
prevキーワードは、文書が
連続体の一部であり、リンクがその連続体内で論理的に前の文書へ通じていることを示します。
同義語:歴史的な理由により、ユーザーエージェントはキーワード
「previous」もprevキーワードと同様に扱わなければ
なりません。
定義済みリンク種別集合の拡張は、既存のrel値に関する microformatsページで登録できます。[MFREL]
誰でも、種別を追加するために既存のrel値に関するmicroformatsページをいつでも自由に 編集できます。拡張種別には、次の情報を指定しなければなりません:
実際に定義される値。値は、他の定義済みの値と紛らわしいほど似ているべきではありません (たとえば、大文字小文字だけが異なるなど)。
値にU+003A COLON文字(:)が含まれる場合、それは絶対URLでもなければなりません。
link次のいずれか:
link要素に指定しては
なりません。link要素に指定できます。
これはハイパーリンクを作成します。
link要素に指定できます。
これは外部リソースへのリンクを作成します。
aおよびarea次のいずれか:
a要素およびarea要素に指定しては
なりません。a要素およびarea要素に指定できます。
これはハイパーリンクを作成します。
a要素およびarea要素に指定できます。
これは外部リソースへのリンクを作成します。
a要素およびarea要素に指定できます。
これは、要素によって作成される他のハイパーリンクに注釈を付けます。form次のいずれか:
form要素に指定しては
なりません。form要素に指定できます。
これはハイパーリンクを作成します。
form要素に指定できます。
これは外部リソースへのリンクを作成します。
form要素に指定できます。
これは、要素によって作成される他のハイパーリンクに注釈を付けます。キーワードの意味についての短い非規範的な説明。
キーワードのセマンティクスおよび要件についての、より詳細な説明へのリンク。これはwiki上の 別のページ、または外部ページへのリンクである場合があります。
処理要件が完全に同一である他のキーワード値の一覧。作成者は、同義語として定義された値を 使用するべきではありません。それらは、ユーザーエージェントがレガシーコンテンツをサポートできる ようにすることだけを意図しています。実際には使用されていない同義語は誰でも削除できます。 レガシーコンテンツとの互換性のために同義語として処理する必要がある名前だけを、この方法で 登録します。
次のいずれか:
キーワードが既存の値と重複していることが判明した場合、そのキーワードを削除し、既存の値の 同義語として一覧に記載するべきです。
キーワードが「提案済み」の状態で1か月以上登録されているものの、使用も仕様化もされていない場合、 レジストリーから削除できます。
キーワードが「提案済み」の状態で追加され、既存の値と重複していることが判明した場合、それを 削除し、既存の値の同義語として一覧に記載するべきです。キーワードが「提案済み」の状態で追加され、 有害であることが判明した場合、その状態を「廃止済み」に変更するべきです。
誰でもいつでも状態を変更できますが、上記の定義に従う場合にのみ変更するべきです。
適合性チェッカーは、値が許可されるかどうかを確定するために、既存のrel値に関する microformatsページで提供される情報を使用しなければなりません。この仕様で定義された値、 または「提案済み」もしくは「承認済み」と記された値は、「次に対する効果...」フィールドで説明される 適用対象の要素で使用された場合に受け入れなければなりません。一方、「廃止済み」と記された値、 またはこの仕様にも前述のページにも記載されていない値は、無効として拒否しなければなりません。 適合性チェッカーは、この情報をキャッシュしてもかまいません(たとえば、性能上の理由、または信頼性の 低いネットワーク接続の使用を避けるため)。
作成者が、この仕様にもwikiページにも定義されていない新しい種別を使用した場合、適合性チェッカーは、 上記で説明した詳細と「提案済み」の状態を使用して、その値をwikiへ追加することを提案するべきです。
既存のrel値に関する
microformatsページで「提案済み」または「承認済み」の状態を持つ拡張として定義された種別は、
「次に対する効果...」フィールドに従って、rel属性をlink、a、およびarea
要素で使用できます。[MFREL]
ins要素現在のすべてのエンジンでサポートされています。
cite — 引用元、または編集に
関する詳細情報へのリンク
datetime — 変更の日付と
(任意で)時刻
cite、datetimeを持つデフォルト。HTMLModElementを使用します。次は、単一の段落の追加を表します:
< aside >
< ins >
< p > I like fruit. </ p >
</ ins >
</ aside > 次も同様です。ここではaside要素内のすべてがフレージングコンテンツとして数えられるため、段落は1つだけです:
< aside >
< ins >
Apples are < em > tasty</ em > .
</ ins >
< ins >
So are pears.
</ ins >
</ aside > 次の例は2つの段落の追加を表しており、そのうち2つ目は2つの部分に分けて挿入されています。そのため、
この例の最初のins要素は段落境界を
またいでおり、これは望ましくない形式とみなされます。
< aside >
<!-- don't do this -->
< ins datetime = "2005-03-16 00:00Z" >
< p > I like fruit. </ p >
Apples are < em > tasty</ em > .
</ ins >
< ins datetime = "2007-12-19 00:00Z" >
So are pears.
</ ins >
</ aside > これをマークアップするより良い方法を次に示します。より多くの要素を使用しますが、どの要素も 暗黙の段落の境界をまたぎません。
< aside >
< ins datetime = "2005-03-16 00:00Z" >
< p > I like fruit. </ p >
</ ins >
< ins datetime = "2005-03-16 00:00Z" >
Apples are < em > tasty</ em > .
</ ins >
< ins datetime = "2007-12-19 00:00Z" >
So are pears.
</ ins >
</ aside > del要素現在のすべてのエンジンでサポートされています。
cite — 引用元、または編集に
関する詳細情報へのリンク
datetime — 変更の日付と
(任意で)時刻
cite、datetimeを持つデフォルト。HTMLModElementを使用します。次は、完了した項目が、その完了日時とともに取り消し線で消されている「やること」リストを示しています。
< h1 > To Do</ h1 >
< ul >
< li > Empty the dishwasher</ li >
< li >< del datetime = "2009-10-11T01:25-07:00" > Watch Walter Lewin's lectures</ del ></ li >
< li >< del datetime = "2009-10-10T23:38-07:00" > Download more tracks</ del ></ li >
< li > Buy a printer</ li >
</ ul > ins要素および
del
要素に共通する属性
cite属性は、変更について説明する文書のURLを指定するために使用できます。その文書が長い場合、
たとえば会議の議事録である場合、作成者は、その文書内で変更について論じている特定の部分を指すフラグメントを含めることが推奨されます。
cite属性が
存在する場合、その値は、変更について説明する空白で囲まれている
可能性がある妥当なURLでなければなりません。対応する引用リンクを取得するには、属性の値を要素のノード文書を基準として解析しなければなりません。
ユーザーエージェントは、ユーザーがそのような引用リンクをたどれるようにしてもかまいませんが、
それらは主として非公開の用途(たとえば、サイトの編集に関する統計を収集するサーバー側スクリプト)
のためのものであり、読者向けではありません。
datetime属性は、変更の時刻および日付を指定するために
使用できます。
存在する場合、datetime
属性の値は、
任意の時刻を伴う妥当な
日付文字列でなければなりません。
ユーザーエージェントは、datetime
属性を日付または時刻文字列を解析する
アルゴリズムに従って解析しなければなりません。それが日付またはグローバル日時を返さない場合、
変更には関連付けられたタイムスタンプがありません(値は不適合であり、任意の時刻を伴う妥当な
日付文字列ではありません)。それ以外の場合、変更には、指定された日付またはグローバル日時に行われたことが
記録されます。指定された値がグローバル日時である場合、
ユーザーエージェントは、関連付けられたタイムゾーンオフセット情報を使用して、指定された日時を
どのタイムゾーンで表示するかを決定するべきです。
この値はユーザーに表示してもかまいませんが、主として非公開の用途を意図しています。
ins要素
および
del
要素は、
HTMLModElement
インターフェースを実装しなければなりません:
現在のすべてのエンジンでサポートされています。
[Exposed =Window ]
interface HTMLModElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , ReflectURL ] attribute USVString cite ;
[CEReactions , Reflect ] attribute DOMString dateTime ;
};この節は非規範的です。
ins要素およびdel要素は段落化に影響を与えないため、段落が
(明示的なp要素なしで)
暗黙に形成される場合には、ins要素またはdel要素が、段落全体もしくは
その他の非フレージングコンテンツ要素と、別の段落の一部の両方に
またがることが可能な場合があります。例:
< section >
< ins >
< p >
This is a paragraph that was inserted.
</ p >
This is another paragraph whose first sentence was inserted
at the same time as the paragraph above.
</ ins >
This is a second sentence, which was there all along.
</ section > 一部の段落だけをp要素で囲むことで、
1つの段落の末尾、2つ目の段落全体、および3つ目の段落の先頭を、同じins要素またはdel要素で覆うことさえ
できます(ただし、これは非常に紛らわしく、良い慣行とはみなされません):
< section >
This is the first paragraph. < ins > This sentence was
inserted.
< p > This second paragraph was inserted.</ p >
This sentence was inserted too.</ ins > This is the
third paragraph in this example.
<!-- (don't do this) -->
</ section > ただし、暗黙の段落の定義方法により、同じins要素またはdel要素を使用して、
1つの段落の末尾と、その直後の段落の先頭をマークアップすることはできません。代わりに、
次の例のように、1つ(または2つ)のp要素と、2つのins要素または
del要素を使用する
必要があります:
< section >
< p > This is the first paragraph. < del > This sentence was
deleted.</ del ></ p >
< p >< del > This sentence was deleted too.</ del > That
sentence needed a separate < del> element.</ p >
</ section > 上記で説明した混乱も一因として、作成者には、暗黙の段落の境界をまたぐins要素または
del要素を使用する
代わりに、すべての段落を常にp要素でマークアップすることが
強く推奨されます。
この節は非規範的です。
ol要素および
ul要素のコンテンツモデルでは、
ins要素およびdel要素を子として許可しません。
リストは、そうでなければ削除済みとしてマークされる項目を含め、常にすべての項目を表します。
項目が挿入または削除されたことを示すには、ins要素またはdel要素を、li要素の内容の周囲に配置できます。
項目が別の項目に置き換えられたことを示すには、単一のli要素に、1つ以上のdel要素と、それに続く1つ以上の
ins要素を含めることが
できます。
次の例では、最初は空だったリストに、時間の経過とともに項目が追加および削除されています。 例の強調された部分は、リストの「現在」の状態に当たる部分を示します。ただし、リスト項目の番号は 編集を考慮しません。
< h1 > Stop-ship bugs</ h1 >
< ol >
< li >< ins datetime = "2008-02-12T15:20Z" > Bug 225:
Rain detector doesn't work in snow</ ins ></ li >
< li >< del datetime = "2008-03-01T20:22Z" >< ins datetime = "2008-02-14T12:02Z" > Bug 228:
Water buffer overflows in April</ ins ></ del ></ li >
< li >< ins datetime = "2008-02-16T13:50Z" > Bug 230:
Water heater doesn't use renewable fuels</ ins ></ li >
< li >< del datetime = "2008-02-20T21:15Z" >< ins datetime = "2008-02-16T14:25Z" > Bug 232:
Carbon dioxide emissions detected after startup</ ins ></ del ></ li >
</ ol > 次の例では、最初は果物だけだったリストが、色だけのリストに置き換えられています。
< h1 > List of < del > fruits</ del >< ins > colors</ ins ></ h1 >
< ul >
< li >< del > Lime</ del >< ins > Green</ ins ></ li >
< li >< del > Apple</ del ></ li >
< li > Orange</ li >
< li >< del > Pear</ del ></ li >
< li >< ins > Teal</ ins ></ li >
< li >< del > Lemon</ del >< ins > Yellow</ ins ></ li >
< li > Olive</ li >
< li >< ins > Purple</ ins ></ li >
</ ul > この節は非規範的です。
表モデルの一部を形成する要素には、ins要素およびdel要素を許可しない複雑な
コンテンツモデル要件があるため、表への編集を示すことは困難な場合があります。
行全体または列全体が追加または削除されたことを示すには、その行または列の各セルの内容全体を、
それぞれins要素またはdel要素で囲むことができます。
ここでは、表に行が追加されています:
< table >
< thead >
< tr > < th > Game name < th > Game publisher < th > Verdict
< tbody >
< tr > < td > Diablo 2 < td > Blizzard < td > 8/10
< tr > < td > Portal < td > Valve < td > 10/10
< tr > < td > < ins > Portal 2</ ins > < td > < ins > Valve</ ins > < td > < ins > 10/10</ ins >
</ table > ここでは列が削除されています(削除された時刻と、その理由を説明するページへのリンクも示されて います):
< table >
< thead >
< tr > < th > Game name < th > Game publisher < th > < del cite = "/edits/r192" datetime = "2011-05-02 14:23Z" > Verdict</ del >
< tbody >
< tr > < td > Diablo 2 < td > Blizzard < td > < del cite = "/edits/r192" datetime = "2011-05-02 14:23Z" > 8/10</ del >
< tr > < td > Portal < td > Valve < td > < del cite = "/edits/r192" datetime = "2011-05-02 14:23Z" > 10/10</ del >
< tr > < td > Portal 2 < td > Valve < td > < del cite = "/edits/r192" datetime = "2011-05-02 14:23Z" > 10/10</ del >
</ table > 一般的に言えば、より複雑な編集(たとえば、セルが削除され、それ以降のすべてのセルが上または左へ 移動したこと)を示す良い方法はありません。
picture要素
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
source
要素と、それに続く1個のimg
要素。
任意でスクリプト支援要素を混在させることができます。[Exposed =Window ]
interface HTMLPictureElement : HTMLElement {
[HTMLConstructor ] constructor ();
};picture要素は、
その内部のimg要素に複数のソースを提供する
コンテナーであり、画面のピクセル密度、ビューポートの大きさ、画像形式、
その他の要因に基づいて、使用する画像リソースを作成者が宣言的に制御したり、ユーザーエージェントへ
ヒントを与えたりできるようにします。
これはその子を表します。
picture要素は、
外見が似ている
video要素およびaudio要素とは多少異なります。
これらはすべてsource
要素を含みますが、source
要素のsrc属性は、
要素がpicture要素内に
入れ子にされている場合には意味を持たず、リソース
選択アルゴリズムも異なります。また、picture要素自体は
何も表示しません。これは単に、内部のimg要素が複数のURLから選択できるようにする文脈を提供するだけです。
source要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
picture要素の子として、
img要素より前。
track要素より前。
type — 埋め込み
リソースのタイプ
media — 適用可能なメディア
src(audioまたはvideo内)— リソースの
アドレス
srcset(picture内)— さまざまな
状況、たとえば高解像度ディスプレイ、小型モニターなどで使用する画像
sizes(picture内)— 異なる
ページレイアウトに対応する画像サイズ
width(picture内)— 水平
寸法
height(picture内)— 垂直
寸法
[Exposed =Window ]
interface HTMLSourceElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , ReflectURL ] attribute USVString src ;
[CEReactions , Reflect ] attribute DOMString type ;
[CEReactions , Reflect ] attribute USVString srcset ;
[CEReactions , Reflect ] attribute DOMString sizes ;
[CEReactions , Reflect ] attribute DOMString media ;
[CEReactions , Reflect ] attribute unsigned long width ;
[CEReactions , Reflect ] attribute unsigned long height ;
};source要素を使用すると、
作成者はimg要素に対して複数の代替
ソース集合を指定したり、メディア
要素に対して複数の代替
メディアリソースを指定したりできます。これは
単独では何も表しません。
type属性を
指定してもかまいません。指定する場合、その値は妥当なMIMEタイプ
文字列でなければなりません。
media
属性も指定してもかまいません。指定する場合、その値には妥当なメディアクエリー
リストを含めなければなりません。値が環境に一致しない場合、ユーザーエージェントは次のsource要素へ進みます。
media
属性は、メディア要素のリソース選択アルゴリズム中に
一度だけ評価されます。これに対して、picture要素を使用する場合、
ユーザーエージェントは環境の変化に
反応します。
残りの要件は、親がpicture
要素であるか、メディア要素であるかに
依存します:
source要素の
親がpicture
要素である場合srcset
属性は存在しなければならず、これはsrcset
属性です。
srcset
属性は、source要素が選択された
場合、画像ソースをソース集合に提供します。
srcset
属性に、幅
記述子を使用する画像
候補文字列が含まれている場合、sizes属性も
指定してもかまいません。さらに、
後続の兄弟であるimg
要素が自動サイズを
許可しない場合、sizes属性は存在しなければ
なりません。
sizes
属性はsizes属性であり、source要素が選択された
場合、ソースサイズを
ソース集合に提供します。
img
要素が自動サイズを許可する場合、
それより前の兄弟である
source要素では
sizes属性を省略
できます。この場合、autoを指定することと
同等です。
source要素は
寸法属性をサポートします。
img要素は、
自身のimg要素上の
属性の代わりに、source要素の
width属性およびheight属性を使用して、
レンダリングされる寸法およびアスペクト比を決定できます。これはレンダリングの節で定義されているとおりです。
type属性は、
ソース集合内の画像のタイプを示し、
ユーザーエージェントが指定されたタイプをサポートしていない場合に、次のsource要素へ
進めるようにします。
type属性が
指定されていない場合、ユーザーエージェントは、画像をフェッチした後でその画像形式を
サポートしていないことが判明しても、別のsource要素を
選択しません。
source
要素に、後続の兄弟であるsource要素または
img要素があり、
その要素にsrcset属性が指定されている
場合、少なくとも次のいずれかを持たなければなりません:
media属性が
指定されており、その値が先頭および末尾の
ASCII空白を除去した後に空文字列ではなく、かつ文字列「all」とASCII
大文字小文字不区別で一致しないこと。
type属性が
指定されていること。
src属性は
存在してはなりません。
source
要素の親がメディア要素である場合src
属性は、メディア
リソースのURLを示します。その値は空白で囲まれている可能性がある
妥当な空でないURLでなければなりません。この属性は存在しなければなりません。
type属性は、
メディア
リソースのタイプを示し、ユーザーエージェントがフェッチする前にこのメディア
リソースを再生できるかどうかを判断する助けになります。特定のMIMEタイプで定義される
codecsパラメーターは、リソースがどのようにエンコードされているかを正確に指定するために
必要となる場合があります。
[RFC6381]
source要素が
すでにvideo要素またはaudio要素に挿入されて
いるときに、そのsrc属性またはtype属性を動的に変更しても
効果はありません。再生対象を変更するには、メディア要素上のsrc属性を直接使用してください。
利用可能なリソースから選択するために、canPlayType()
メソッドを使用してもかまいません。一般に、文書が解析された後でsource要素を
手動で操作することは、不必要に複雑な方法です。
次の一覧は、type属性でcodecs=MIME
パラメーターを使用する方法の例を示しています。
< source src = 'video.mp4' type = 'video/mp4; codecs="avc1.42E01E, mp4a.40.2"' > < source src = 'video.mp4' type = 'video/mp4; codecs="avc1.58A01E, mp4a.40.2"' > < source src = 'video.mp4' type = 'video/mp4; codecs="avc1.4D401E, mp4a.40.2"' > < source src = 'video.mp4' type = 'video/mp4; codecs="avc1.64001E, mp4a.40.2"' > < source src = 'video.mp4' type = 'video/mp4; codecs="mp4v.20.8, mp4a.40.2"' > < source src = 'video.mp4' type = 'video/mp4; codecs="mp4v.20.240, mp4a.40.2"' > < source src = 'video.3gp' type = 'video/3gpp; codecs="mp4v.20.8, samr"' > < source src = 'video.ogv' type = 'video/ogg; codecs="theora, vorbis"' > < source src = 'video.ogv' type = 'video/ogg; codecs="theora, speex"' > < source src = 'audio.ogg' type = 'audio/ogg; codecs=vorbis' > < source src = 'audio.spx' type = 'audio/ogg; codecs=speex' > < source src = 'audio.oga' type = 'audio/ogg; codecs=flac' > < source src = 'video.ogv' type = 'video/ogg; codecs="dirac, vorbis"' > sourceのHTML要素挿入
手順は、
insertedNodeが与えられたとき、次のとおりです:
parentをinsertedNodeの親とします。
parentが、src属性を持たず、かつその
networkStateの
値がNETWORK_EMPTY
であるメディア要素の場合、そのメディア
要素のリソース選択
アルゴリズムを呼び出します。
parentがpicture要素の場合、
parentの子のchildごとに反復し、childがimg要素である場合、
これをchildに対する関連する
変異として数えます。
sourceのHTML要素移動
手順は、movedNode、
isSubtreeRoot、およびoldAncestorが与えられたとき、次のとおりです:
sourceのHTML要素削除
手順は、
removedNode、isSubtreeRoot、およびoldAncestorが与えられたとき、
次のとおりです:
提供されたメディアリソースをすべてのユーザーエージェントがレンダリングできるかどうか作成者が
確信できない場合、最後のsource要素上の
errorイベントを待ち受けて、
フォールバック動作を起動できます:
< script >
function fallback( video) {
// replace <video> with its contents
while ( video. hasChildNodes()) {
if ( video. firstChild instanceof HTMLSourceElement)
video. removeChild( video. firstChild);
else
video. parentNode. insertBefore( video. firstChild, video);
}
video. parentNode. removeChild( video);
}
</ script >
< video controls autoplay >
< source src = 'video.mp4' type = 'video/mp4; codecs="avc1.42E01E, mp4a.40.2"' >
< source src = 'video.ogv' type = 'video/ogg; codecs="theora, vorbis"'
onerror = "fallback(parentNode)" >
...
</ video > img
要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
usemap属性またはcontrols属性を持つ場合:インタラクティブコンテンツ。picture要素の子として、
すべてのsource要素の後。
alt — 画像が利用できない場合に
使用する代替テキスト
src — リソースのアドレス
srcset — さまざまな
状況、たとえば高解像度ディスプレイ、小型モニターなどで使用する画像
sizes — 異なる
ページレイアウトに対応する画像サイズ
crossorigin — 要素が
クロスオリジン要求をどのように処理するか
usemap — 使用する
イメージマップの名前
ismap — 画像が
サーバー側イメージマップであるかどうか
controls — ユーザー
エージェントのコントロールを表示
width — 水平寸法
height — 垂直寸法
referrerpolicy
— 要素によって開始されるフェッチのリファラーポリシー
decoding — この画像を
表示用に処理するときに使用するデコードのヒント
loading — 読み込みの
延期を決定するときに使用
fetchpriority —
要素によって開始されるフェッチの優先度を設定
alt
属性を持つ場合:作成者向け;実装者向け。[Exposed =Window ,
LegacyFactoryFunction =Image (optional unsigned long width , optional unsigned long height )]
interface HTMLImageElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute DOMString alt ;
[CEReactions , ReflectURL ] attribute USVString src ;
[CEReactions , Reflect ] attribute USVString srcset ;
[CEReactions , Reflect ] attribute DOMString sizes ;
[CEReactions ] attribute DOMString ? crossOrigin ;
[CEReactions , Reflect ] attribute DOMString useMap ;
[CEReactions , Reflect ] attribute boolean isMap ;
[CEReactions , Reflect ] attribute boolean controls ;
[CEReactions , ReflectSetter ] attribute unsigned long width ;
[CEReactions , ReflectSetter ] attribute unsigned long height ;
readonly attribute unsigned long naturalWidth ;
readonly attribute unsigned long naturalHeight ;
readonly attribute boolean complete ;
readonly attribute USVString currentSrc ;
[CEReactions ] attribute DOMString referrerPolicy ;
[CEReactions ] attribute DOMString decoding ;
[CEReactions ] attribute DOMString loading ;
[CEReactions ] attribute DOMString fetchPriority ;
Promise <undefined > decode ();
// also has obsolete members
};img要素は画像を表します。
img要素には寸法
属性ソースがあり、初期値は要素自身です。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
src属性およびsrcset属性によって指定される画像と、親がpicture要素である場合に、
それ以前の兄弟であるすべてのsource要素のsrcset属性によって指定される
画像が埋め込みコンテンツです。alt属性の値は、画像を処理できない人、または画像の読み込みを
無効にしている人のために同等のコンテンツを提供します(すなわち、これはimg要素のフォールバックコンテンツです)。
alt
属性の値に関する要件は、別の節で説明されています。
src属性およびsrcset属性の少なくとも一方は
存在しなければなりません。
src属性が存在する場合、
その値には、ページ化もスクリプト化もされていない、非インタラクティブで任意にアニメーション化された
画像リソースを参照する空白で囲まれている可能性がある
妥当な空でないURLを含めなければなりません。
上記の要件は、画像が静的ビットマップ(たとえばPNG、GIF、 JPEG)、単一ページのベクター文書(単一ページPDF、SVG文書要素を持つXMLファイル)、 アニメーションビットマップ(APNG、アニメーションGIF)、アニメーションベクターグラフィックス (宣言的SMILアニメーションを使用するSVG文書要素を持つXMLファイル)などであり得ることを意味します。 ただし、これらの 定義は、スクリプトを含むSVGファイル、複数ページPDFファイル、インタラクティブMNGファイル、HTML 文書、プレーンテキスト文書などを除外します。[PNG] [GIF] [JPEG] [PDF] [XML] [APNG] [SVG] [MNG]
srcset属性および
src属性(幅
記述子が使用されていない場合)は、source要素が選択されなかった
場合に、画像
ソースをソース集合に提供します。
srcset属性が
存在し、幅
記述子を使用する画像候補
文字列が含まれている場合、sizes属性も存在しなければなりません。
srcset属性が
指定されておらず、かつ
loading属性が遅延状態である場合、sizes属性に値「auto」
(ASCII
大文字小文字不区別)を指定してもかまいません。sizes属性はsizes属性であり、source要素が選択されなかった
場合に、ソースサイズをソース集合に提供します。
img要素が自動サイズを許可するのは、次の場合です:
loading属性が
遅延状態であり、かつ
sizes属性の値が
「auto」(ASCII
大文字小文字不区別)であるか、「auto,」で始まる(ASCII
大文字小文字不区別)場合。現在のすべてのエンジンでサポートされています。
crossorigin
属性はCORS設定
属性です。その目的は、クロスオリジンアクセスを許可する第三者サイトの画像をcanvasとともに使用できる
ようにすることです。
referrerpolicy属性はリファラー
ポリシー属性です。その目的は、画像をフェッチするときに使用されるリファラー
ポリシーを設定することです。[REFERRERPOLICY]
decoding
属性は、この画像をデコードする望ましい方法を示します。この属性が存在する場合、
画像デコードのヒントでなければなりません。この属性の欠損値のデフォルトおよび無効値のデフォルトは、
いずれも自動状態です。
HTMLImageElement/fetchPriority
fetchpriority属性はフェッチ
優先度属性です。その目的は、画像をフェッチするときに使用される優先度を設定する
ことです。
loading属性は
遅延
読み込み属性です。その目的は、ビューポート外にある画像を読み込むためのポリシーを示すことです。
loading属性の
状態が即時状態に変更されたとき、ユーザーエージェントは
次の手順を実行しなければなりません:
resumptionStepsをimg要素の遅延読み込み
再開手順とします。
resumptionStepsがnullの場合、戻ります。
imgの遅延読み込み再開
手順をnullに設定します。
resumptionStepsを呼び出します。
< img src = "1.jpeg" alt = "1" >
< img src = "2.jpeg" loading = eager alt = "2" >
< img src = "3.jpeg" loading = lazy alt = "3" >
< div id = very-large ></ div > <!-- Everything after this div is below the viewport -->
< img src = "4.jpeg" alt = "4" >
< img src = "5.jpeg" loading = lazy alt = "5" > 上記の例では、画像は次のように読み込まれます:
1.jpeg、2.jpeg、
4.jpeg
画像は即時に読み込まれ、ウィンドウのloadイベントを遅延させます。
3.jpeg画像はビューポート内にあるため、レイアウトが判明したときに読み込まれますが、 ウィンドウのloadイベントを遅延させません。
5.jpeg画像はビューポート内へスクロールされたときにのみ読み込まれ、ウィンドウの loadイベントを遅延させません。
CSSが画像の幅と高さのプロパティを設定する場合でも、画像の読み込み後にページ
レイアウトがずれるのを防ぐため、開発者には、遅延読み込みされる画像上のwidth属性およびheight属性を介して、
望ましいアスペクト比を指定することが推奨されます。
imgのHTML要素挿入
手順は、insertedNodeが与えられたとき、
次のとおりです:
imgのHTML要素移動手順は、
movedNode、
isSubtreeRoot、およびoldAncestorが与えられたとき、次のとおりです:
imgのHTML要素削除
手順は、removedNode、
oldAncestor、およびisSubtreeRootが与えられたとき、次のとおりです:
img要素を
レイアウト用の道具として使用してはなりません。特に、img
要素を透明画像の表示に使用するべきではありません。そのような画像は意味を伝えることがほとんどなく、
文書に有用なものを追加することもほとんどないためです。
img要素が
何を表すかは、src
属性およびalt
属性に依存します。
src属性が設定され、
alt属性が
空文字列に設定されている場合
画像は装飾的であるか、残りのコンテンツを補足するものであり、文書内の 他の情報と重複しています。
画像が利用可能で、ユーザーエージェントが その画像を表示するよう設定されている場合、要素は要素の画像データを表します。
それ以外の場合、要素は何も表さず、 レンダリングから完全に省略してもかまいません。ユーザーエージェントは、画像が存在するものの レンダリングから省略されたことをユーザーへ通知してもかまいません。
src属性が設定され、
alt属性が空でない値に
設定されている場合
画像はコンテンツの重要な部分です。alt属性は、
画像と同等のテキストまたは画像の代替を示します。
画像が利用可能で、ユーザー エージェントがその画像を表示するよう設定されている場合、要素は要素の画像データを表します。
それ以外の場合、要素はalt属性によって与えられるテキストを表します。ユーザーエージェントは、
画像が存在するもののレンダリングから省略されたことをユーザーへ通知してもかまいません。
src属性が設定され、
alt属性が設定されて
いない場合
画像はコンテンツの重要な部分である可能性がありますが、利用可能な画像のテキストによる 同等物はありません。
適合文書では、alt属性が存在しないことは、
画像がコンテンツの重要な部分であるものの、画像が生成された時点では画像の代替テキストが
利用できなかったことを示します。
画像が利用可能で、ユーザー エージェントがその画像を表示するよう設定されている場合、要素は要素の画像データを表します。
画像に、値が空文字列であるsrc属性がある場合、要素は何も表しません。
それ以外の場合、ユーザーエージェントは、レンダリングされていない画像が存在することを示す 何らかの標識を表示するべきであり、ユーザーから要求された場合、そうするよう設定されている場合、 またはナビゲーションに応じて文脈情報を提供する必要がある場合には、次のように導出される画像の キャプション情報を提供してもかまいません:
画像に、値が空文字列でないtitle属性がある場合、その属性の値を返します。
画像が、子としてfigcaption
要素を持つfigure要素の子孫であり、
figcaption
要素およびその子孫を無視したとき、figure要素に、
要素間空白およびimg要素以外のフローコンテンツの子孫がない場合、
そのような最初のfigcaption
要素の内容を返します。
何も返しません。(キャプション情報はありません。)
src属性が設定されて
おらず、alt属性が
空文字列に設定されているか、alt属性がまったく設定されていない場合要素は何も表しません。
alt属性は助言的情報を
表しません。ユーザーエージェントは、alt属性の内容を、
title属性の内容と同じ方法で
提示してはなりません。
ユーザーエージェントは、任意の画像を表示するか、任意の画像が表示されないようにする選択肢を、 常にユーザーへ提供してもかまいません。また、視覚障害があるため、またはグラフィックス機能のない テキスト端末を使用しているためなど、ユーザーが画像を見ることができない場合に、ユーザーが画像を 利用できるようにするためのヒューリスティックを適用してもかまいません。そのようなヒューリスティックには、 たとえば画像内で見つかったテキストの光学文字認識(OCR)が含まれる場合があります。
ユーザーエージェントには、alt属性が欠落している場合を修復する
ことが推奨されますが、作成者はそのような動作に依存してはなりません。画像の代替として機能するテキストを提供するための要件は、以下で詳しく説明されています。
img
要素の内容は、存在する場合でも、レンダリングの目的では無視されます。
usemap
属性が存在する場合、画像に関連付けられたイメージマップがあることを示せます。
ismap属性は、
href属性を持つ
a要素の子孫である要素上で
使用された場合、その存在によって、要素がサーバー側イメージマップへのアクセスを提供することを示します。
これは、対応するa要素上でイベントがどのように処理されるかに影響します。
ismap属性は
ブール属性です。この属性は、
href属性を持つ
祖先のa要素がない要素に
指定してはなりません。
usemap属性およびismap属性を、
picture要素内で
media属性が指定された
source要素とともに
使用すると、混乱を招く動作になる可能性があります。
controls
属性はブール属性です。存在する場合、ユーザーエージェントが
ユーザーインターフェースをユーザーへ公開してもよいことを示します。この属性は、alt属性を持たない要素、または
alt属性の値が空文字列である
要素に指定してはなりません。
controls属性が
存在する場合、ユーザーエージェントは画像に対するコントロール(たとえば、全画面表示用のコントロール)を
公開してもかまいません。提供される具体的なコントロールは実装定義であり、プラットフォーム固有であるか、
ユーザーの設定に基づく場合があります。
ユーザーエージェントがimg
要素上にコントロールを表示することによってユーザーインターフェースを公開する場合、
ユーザーエージェントがそのインターフェースと対話している間、ユーザー操作イベントを抑制するべきです。
Issue #12318では、 画像コントロールとアニメーション画像との相互作用を追跡しています。そのissueが解決されるまで、 ユーザーエージェントは画像のアニメーションコントロールを公開するべきではありません。
現在のすべてのエンジンでサポートされています。
crossOrigin IDL属性は、crossorigin
コンテンツ属性を、既知の値のみに
制限して反映しなければなりません。
HTMLImageElement/referrerPolicy
現在のすべてのエンジンでサポートされています。
referrerPolicy IDL属性は、referrerpolicy
コンテンツ属性を、既知の
値のみに制限して反映しなければなりません。
現在のすべてのエンジンでサポートされています。
decoding
IDL属性は、decoding
コンテンツ属性を、既知の値のみに制限して反映しなければなりません。
現在のすべてのエンジンでサポートされています。
loading
IDL属性は、loadingコンテンツ属性を、
既知の値のみに
制限して反映しなければなりません。
fetchPriority IDL属性は、fetchpriority
コンテンツ属性を、既知の値のみに
制限して反映しなければなりません。
image.width [ = value ]
現在のすべてのエンジンでサポートされています。
image.height [ = value ]
現在のすべてのエンジンでサポートされています。
これらの属性は、画像の実際にレンダリングされた寸法を返します。寸法が不明な場合は0を返します。
対応するコンテンツ属性を変更するために、これらを設定できます。
image.naturalWidth
現在のすべてのエンジンでサポートされています。
image.naturalHeight
HTMLImageElement/naturalHeight
現在のすべてのエンジンでサポートされています。
これらの属性は、画像の密度補正済みの自然な幅と 高さを返します。画像が利用可能でない場合は0を返します。
image.complete
現在のすべてのエンジンでサポートされています。
画像が完全にダウンロード済みであるか、画像が指定されていない場合はtrueを返します。 それ以外の場合はfalseを返します。
image.currentSrc
現在のすべてのエンジンでサポートされています。
画像の絶対URLを返します。
image.decode()
現在のすべてのエンジンでサポートされています。
このメソッドは、ユーザーエージェントに画像を並行してデコードさせ、デコードが完了すると履行されるpromiseを 返します。
画像をデコードできない場合、promiseは「EncodingError」
DOMException
で拒否されます。
image = new Image([ width [, height ] ])
現在のすべてのエンジンでサポートされています。
新しいimg要素を返します。
該当する場合、そのwidth属性
およびheight属性は、
対応する引数で渡された値に設定されます。
img要素
imageの寸法を決定するには:
imageがレンダリングされている場合、そのレンダリングされた幅および 高さをCSSピクセル単位で返します。[CSS]
imageが利用可能で、 密度補正済みの自然な幅と 高さを持つ場合、その 密度補正済みの自然な幅と 高さをCSS ピクセル単位で返します。
幅0、高さ0を返します。
naturalWidthおよびnaturalHeightの取得
手順は次のとおりです:
画像が利用可能でない場合、 0を返します。
画像の密度補正済みの自然な幅と 高さの対応する成分を、CSSピクセル単位で返します。[CSS]
画像の密度補正済みの自然な幅と高さは、
そのメタデータで指定された向きを考慮するため、naturalWidthおよび
naturalHeightは、
'image-orientation'プロパティの値に関係なく、画像を正しく
配向するために必要な回転を適用した後の寸法を反映します。
completeの取得手順は次のとおりです:
decode()
メソッドは、呼び出されたとき、次の手順を実行しなければなりません:
promiseを新しいpromiseとします。
次の手順を実行するマイクロタスクをキューに追加します:
これは、画像データの更新もマイクロタスク内で行われるためです。 したがって、次のようなコードで
img. src = "stars.jpg" ;
img. decode(); stars.jpgを正しくデコードするには、すべての処理を1つのマイクロタスク分
遅延させる必要があります。
globalをthisの関連するグローバル オブジェクトとします。
次のいずれかがtrueの場合:
promiseを「EncodingError」
DOMException
で拒否します。
それ以外の場合、並行して、次のいずれかが発生するまで待ち、 対応する処理を実行します:
img要素の
ノード文書が完全に
アクティブでなくなる
img要素の
現在の要求が変更または
変異する
img要素の
現在の要求の状態が壊れているになる
globalを用いて、DOM操作タスクソース上に、
promiseを「EncodingError」 DOMException
で拒否するグローバルタスクをキューに追加します。
img要素の
現在の要求の状態が完全に
利用可能になる
画像をデコードします。
この画像についてデコードを実行する必要がない場合(たとえばベクターグラフィックスであるため)、 またはデコード処理が正常に完了した場合、globalを用いてDOM操作タスクソース上に、 promiseをundefinedで解決するグローバル タスクをキューに追加します。
デコードが失敗した場合(たとえば画像データが無効であるため)、globalを用いて
DOM操作タスクソース上に、
promiseを「EncodingError」
DOMException
で拒否するグローバル
タスクをキューに追加します。
ユーザーエージェントは、少なくともイベントループ内の次の成功したレンダリングを更新する手順の終了時までは、 デコード済みのメディアデータが容易に利用可能な状態を維持するべきです。これはAPI契約の 重要な部分であり、可能な限り破られるべきではありません。(通常、これに違反するのは、 デコード済み画像データを破棄する必要がある低メモリー状況、またはこの期間中デコード済み 形式で保持するには画像が大きすぎる場合だけです。)
アニメーション画像は、すべてのフレームが読み込まれた後にのみ完全に 利用可能になります。したがって、実装がその時点より前に最初のフレームをデコードできる 場合でも、上記の手順はそうせず、代わりにすべてのフレームが利用可能になるまで待ちます。
promiseを返します。
decode()メソッドを
使用しない場合、img要素を読み込んでから
表示する処理は、次のようになります:
const img = new Image();
img. src = "nebula.jpg" ;
img. onload = () => {
document. body. appendChild( img);
};
img. onerror = () => {
document. body. appendChild( new Text( "Could not load the nebula :(" ));
}; ただし、画像をDOMへ挿入した後に行われる描画によってメインスレッド上で同期デコードが発生するため、 これは目立つフレーム落ちを引き起こす可能性があります。
代わりに、decode()
メソッドを使用して次のように書き換えられます:
const img = new Image();
img. src = "nebula.jpg" ;
img. decode(). then(() => {
document. body. appendChild( img);
}). catch (() => {
document. body. appendChild( new Text( "Could not load the nebula :(" ));
}); 後者の形式では、ユーザーエージェントが画像を並行してデコードし、デコード処理が完了してから初めて DOMへ挿入する(したがって描画させる)ことができるため、元の形式で生じるフレーム落ちを回避できます。
decode()メソッドは、
デコード済み画像データが少なくとも1フレーム分利用可能であることを保証しようとするため、requestAnimationFrame()
APIと組み合わせることができます。
これは、すべてのDOM変更がアニメーションフレーム
コールバックとしてまとめて処理されることを保証するコーディングスタイルまたはフレームワークと
ともに使用できることを意味します:
const container = document. querySelector( "#container" );
const { containerWidth, containerHeight } = computeDesiredSize();
requestAnimationFrame(() => {
container. style. width = containerWidth;
container. style. height = containerHeight;
});
// ...
const img = new Image();
img. src = "supernova.jpg" ;
img. decode(). then(() => {
requestAnimationFrame(() => container. appendChild( img));
}); HTMLImageElementオブジェクトを
作成するために、DOMのcreateElement()などのファクトリーメソッドに加えて、
レガシーファクトリー関数Image(width, height)が提供されます。
呼び出されたとき、レガシーファクトリー関数は次の手順を実行しなければなりません:
documentを現在のグローバルオブジェクトの関連付けられたDocumentとします。
imgを返します。
単一の画像でも、文脈に応じて適切な代替テキストが異なる場合があります。
次の各場合では同じ画像が使用されていますが、altテキストは毎回異なります。
この画像は、スイスのジュネーヴ州にあるカルージュ自治体の紋章です。
ここでは補助的なアイコンとして使用されています:
< p > I lived in < img src = "carouge.svg" alt = "" > Carouge.</ p > ここでは町を表すアイコンとして使用されています:
< p > Home town: < img src = "carouge.svg" alt = "Carouge" ></ p > ここでは町についての文章の一部として使用されています:
< p > Carouge has a coat of arms.</ p >
< p >< img src = "carouge.svg" alt = "The coat of arms depicts a lion, sitting in front of a tree." ></ p >
< p > It is used as decoration all over the town.</ p > ここでは、説明が画像の代替としてではなく画像とともに提供されている、類似の文章を補助する方法として 使用されています:
< p > Carouge has a coat of arms.</ p >
< p >< img src = "carouge.svg" alt = "" ></ p >
< p > The coat of arms depicts a lion, sitting in front of a tree.
It is used as decoration all over the town.</ p > ここでは物語の一部として使用されています:
< p > She picked up the folder and a piece of paper fell out.</ p >
< p >< img src = "carouge.svg" alt = "Shaped like a shield, the paper had a
red background, a green tree, and a yellow lion with its tongue
hanging out and whose tail was shaped like an S." ></ p >
< p > She stared at the folder. S! The answer she had been looking for all
this time was simply the letter S! How had she not seen that before? It all
came together now. The phone call where Hector had referred to a lion's tail,
the time Maria had stuck her tongue out...</ p > ここでは、公開時点では画像が何になるかは不明で、何らかの紋章になることだけが分かっています。
そのため代替テキストを提供できず、代わりに画像の短いキャプションだけがtitle属性で提供されています:
< p > The last user to have uploaded a coat of arms uploaded this one:</ p >
< p >< img src = "last-uploaded-coat-of-arms.cgi" title = "User-uploaded coat of arms." ></ p > 理想的には、この場合でも、たとえば前のユーザーに尋ねることによって、作成者は実際の代替テキストを 提供する方法を見つけるでしょう。代替テキストを提供しないと、画像を見ることができない人、たとえば 盲目のユーザー、非常に低帯域幅の接続を使用するユーザー、バイト単位で料金を支払うユーザー、 またはテキスト専用ウェブブラウザーを使用せざるを得ないユーザーにとって、文書が利用しにくくなります。
次に、同じ画像を異なる文脈で使用し、その都度適切な代替テキストが異なる例をさらに示します。
< article >
< h1 > My cats</ h1 >
< h2 > Fluffy</ h2 >
< p > Fluffy is my favorite.</ p >
< img src = "fluffy.jpg" alt = "She likes playing with a ball of yarn." >
< p > She's just too cute.</ p >
< h2 > Miles</ h2 >
< p > My other cat, Miles just eats and sleeps.</ p >
</ article > < article >
< h1 > Photography</ h1 >
< h2 > Shooting moving targets indoors</ h2 >
< p > The trick here is to know how to anticipate; to know at what speed and
what distance the subject will pass by.</ p >
< img src = "fluffy.jpg" alt = "A cat flying by, chasing a ball of yarn, can be
photographed quite nicely using this technique." >
< h2 > Nature by night</ h2 >
< p > To achieve this, you'll need either an extremely sensitive film, or
immense flash lights.</ p >
</ article > < article >
< h1 > About me</ h1 >
< h2 > My pets</ h2 >
< p > I've got a cat named Fluffy and a dog named Miles.</ p >
< img src = "fluffy.jpg" alt = "Fluffy, my cat, tends to keep itself busy." >
< p > My dog Miles and I like go on long walks together.</ p >
< h2 > music</ h2 >
< p > After our walks, having emptied my mind, I like listening to Bach.</ p >
</ article > < article >
< h1 > Fluffy and the Yarn</ h1 >
< p > Fluffy was a cat who liked to play with yarn. She also liked to jump.</ p >
< aside >< img src = "fluffy.jpg" alt = "" title = "Fluffy" ></ aside >
< p > She would play in the morning, she would play in the evening.</ p >
</ article > この節は非規範的です。
単一の画像リソースしかない場合にHTMLへ画像を埋め込むには、img
要素とそのsrc属性を使用します。
< h2 > From today's featured article</ h2 >
< img src = "/uploads/100-marie-lloyd.jpg" alt = "" width = "100" height = "150" >
< p >< b >< a href = "/wiki/Marie_Lloyd" > Marie Lloyd</ a ></ b > (1870–1922)
was an English < a href = "/wiki/Music_hall" > music hall</ a > singer, ...ただし、作成者がユーザーエージェントによる選択が可能な複数の画像リソースを使用したいと考える 状況がいくつかあります:
ユーザーごとに異なる環境特性を持つ可能性があります:
ユーザーの物理的な画面サイズが互いに異なる可能性があります。
携帯電話の画面は対角4インチである一方、ノートパソコンの画面は対角14インチである 可能性があります。
これは、画像のレンダリングサイズが ビューポートのサイズに依存する場合にのみ関係します。
ユーザーの画面ピクセル密度が互いに異なる可能性があります。
物理的な画面サイズに関係なく、ある携帯電話の画面は、別の携帯電話の画面と比較して 1インチ当たり3倍の物理ピクセルを持つ可能性があります。
ユーザーのズームレベルが互いに異なる可能性、または単一のユーザーについて時間の経過と ともに変化する可能性があります。
ユーザーは、より詳細に見るために特定の画像を拡大する可能性があります。
ズームレベルと画面ピクセル密度(前項)は、いずれもCSSピクセル当たりの物理画面ピクセル数に影響する可能性があります。 この比率は通常、デバイスピクセル比と呼ばれます。
ユーザーの画面の向きが互いに異なる可能性、または単一のユーザーについて時間の経過と ともに変化する可能性があります。
タブレットは直立させて持つことも、90度回転させて持つこともできるため、画面は 「縦向き」または「横向き」になります。
ユーザーのネットワーク速度、ネットワーク遅延、および帯域幅コストが互いに異なる可能性、 または単一のユーザーについて時間の経過とともに変化する可能性があります。
ユーザーは、職場では高速、低遅延、定額の接続を使用し、 自宅では低速、低遅延、定額の接続を使用し、それ以外の場所では 速度可変、高遅延、従量制の接続を使用する可能性があります。
作成者は、通常はビューポートの幅に応じて、同じ画像内容を異なるレンダリングサイズで 表示したい場合があります。これは通常、 ビューポートに基づく選択と呼ばれます。
ウェブページの上部に、常にビューポート 全体の幅にわたるバナーがある可能性があります。この場合、画像のレンダリングサイズは 画面の物理的なサイズに依存します(ブラウザーウィンドウが最大化されているものと仮定します)。
別のウェブページでは、小さい物理サイズの画面には1列、中程度の物理サイズの画面には2列、 大きい物理サイズの画面には3列で画像を配置し、それぞれの場合に画像のレンダリングサイズを変えて ビューポートを埋める可能性があります。この場合、画面が小さいにも かかわらず、1列レイアウトの画像のレンダリングサイズが2列レイアウトと比較して 大きくなる可能性があります。
作成者は、画像のレンダリングサイズに応じて異なる画像内容を表示したい場合があります。 これは通常、アートディレクションと呼ばれます。
ウェブページが物理サイズの大きい画面で表示される場合(ブラウザーウィンドウが最大化されている ものと仮定します)、作成者は画像の重要な部分を囲む、それほど重要でない部分も含めたいと考える 可能性があります。同じウェブページが物理サイズの小さい画面で表示される場合、作成者は画像の 重要な部分のみを表示したいと考える可能性があります。
作成者は、ユーザーエージェントがどの画像形式をサポートするかに応じて、同じ画像内容を 異なる画像形式で表示したい場合があります。これは通常、 画像形式に基づく選択と呼ばれます。
ウェブページには、JPEG、WebP、およびJPEG XRの画像形式による画像があり、 後者2つはJPEGと比較して優れた圧縮能力を持つ可能性があります。異なるユーザーエージェントは 異なる画像形式をサポートでき、一部の形式はより優れた圧縮率を提供するため、作成者はそれらを サポートするユーザーエージェントにはより優れた形式を提供し、サポートしないユーザーエージェントには JPEGによるフォールバックを提供したいと考えます。
上記の状況は相互に排他的ではありません。たとえば、異なるデバイスピクセル比用の異なるリソースと、 アートディレクション用の異なるリソースを 組み合わせることは合理的です。
スクリプトを使用してこれらの問題を解決することは可能ですが、そうすると別の問題が生じます:
一部のユーザーエージェントは、ウェブページの読み込みをより早く完了させるため、 スクリプトを実行できるようになる前にHTMLマークアップで指定された画像を積極的にダウンロードします。 スクリプトがダウンロードする画像を変更すると、ユーザーエージェントは2つの別々のダウンロードを 開始する可能性があり、かえってページの読み込み性能を悪化させる可能性があります。
作成者がHTMLマークアップで画像をまったく指定せず、代わりにスクリプトから単一のダウンロードを 開始する場合、上記の二重ダウンロードの問題は回避されますが、スクリプトを無効にしているユーザーには 画像がまったくダウンロードされず、積極的な画像ダウンロードの最適化も無効になります。
これを考慮し、この仕様では上記の問題に宣言的な方法で対処するための機能をいくつか導入します。
img要素上の
src属性およびsrcset
属性を、x記述子とともに使用して、サイズだけが異なる複数の画像を提供できます
(小さい画像は大きい画像を縮小したものです)。
画像のレンダリングサイズがビューポートの幅に依存する
場合(ビューポートに基づく選択)、
x記述子は適切ではありませんが、
アートディレクションとともに
使用できます。
< h2 > From today's featured article</ h2 >
< img src = "/uploads/100-marie-lloyd.jpg"
srcset = "/uploads/150-marie-lloyd.jpg 1.5x, /uploads/200-marie-lloyd.jpg 2x"
alt = "" width = "100" height = "150" >
< p >< b >< a href = "/wiki/Marie_Lloyd" > Marie Lloyd</ a ></ b > (1870–1922)
was an English < a href = "/wiki/Music_hall" > music hall</ a > singer, ...ユーザーエージェントは、ユーザーの画面のピクセル密度、ズームレベル、および場合によっては ユーザーのネットワーク状態などのその他の要因に応じて、指定されたリソースのいずれかを 選択できます。
srcset属性を
まだ理解しない古いユーザーエージェントとの後方互換性のため、URLの1つが
img要素のsrc属性に指定されます。
これにより、古いユーザーエージェントでも有用なものが表示されます(ただし、ユーザーが望むより
低解像度である可能性があります)。新しいユーザーエージェントでは、src
属性は、1x記述子とともにsrcsetに指定されたかの
ように、リソース選択に参加します。
画像のレンダリングサイズは、width属性および
height属性で
指定され、これによりユーザーエージェントは画像がダウンロードされる前に画像用の空間を
割り当てられます。
srcset属性およびsizes属性を、
w記述子とともに使用して、サイズだけが異なる複数の画像を提供できます
(小さい画像は大きい画像を縮小したものです)。
この例では、バナー画像が(適切なCSSを使用して)ビューポートの幅全体を 占めます。
< h1 >< img sizes = "100vw" srcset = "wolf-400.jpg 400w, wolf-800.jpg 800w, wolf-1600.jpg 1600w"
src = "wolf-400.jpg" alt = "The rad wolf" ></ h1 > ユーザーエージェントは、指定されたw記述子とsizes属性で指定された
レンダリングサイズから各画像の実効ピクセル密度を計算します。その後、ユーザーの画面の
ピクセル密度、ズームレベル、および場合によってはユーザーのネットワーク状態などのその他の
要因に応じて、指定されたリソースのいずれかを選択できます。
ユーザーの画面の幅が320CSSピクセルの場合、これは
wolf-400.jpg 1.25x, wolf-800.jpg 2.5x, wolf-1600.jpg 5xを指定することと同等です。
一方、ユーザーの画面の幅が1200CSSピクセルの場合、
これはwolf-400.jpg 0.33x, wolf-800.jpg 0.67x, wolf-1600.jpg 1.33xを指定することと
同等です。w記述子およびsizes
属性を使用することにより、ユーザーエージェントはユーザーのデバイスの大きさに関係なく、
ダウンロードする正しい画像ソースを選択できます。
後方互換性のため、URLの1つがimg要素の
src属性に指定されます。
新しいユーザーエージェントでは、srcset属性が
w記述子を使用する場合、src属性は無視されます。
この例では、ウェブページはビューポートの幅に応じて3つのレイアウトを持ちます。
狭いレイアウトは画像が1列(各画像の幅は約100%)、中間のレイアウトは画像が2列
(各画像の幅は約50%)、最も広いレイアウトは画像が3列で、ページ余白もあります
(各画像の幅は約33%)。これらのレイアウトの切り替えは、ビューポートの幅が
それぞれ30emおよび50emのときに行われます。
< img sizes = "(max-width: 30em) 100vw, (max-width: 50em) 50vw, calc(33vw - 100px)"
srcset = "swing-200.jpg 200w, swing-400.jpg 400w, swing-800.jpg 800w, swing-1600.jpg 1600w"
src = "swing-400.jpg" alt = "Kettlebell Swing" > sizes属性は、
30emおよび50emにレイアウトのブレークポイントを設定し、
これらのブレークポイント間の画像サイズを100vw、50vw、または
calc(33vw - 100px)と宣言します。これらのサイズは、CSSで指定される実際の
画像幅と必ずしも完全に一致する必要はありません。
ユーザーエージェントは、trueと評価される<media-condition>(括弧内の部分)を持つ最初の項目を使用し、
すべてがfalseと評価される場合は最後の項目(calc(33vw -
100px))を使用して、sizes
属性から幅を選択します。
たとえば、ビューポートの幅が29emの場合、
(max-width: 30em)はtrueと評価され、100vwが使用されるため、
リソース選択の目的における画像サイズは29emです。一方、
ビューポートの幅が32emの場合、
(max-width: 30em)はfalseと評価されますが、
(max-width: 50em)はtrueと評価され、
50vwが使用されるため、リソース選択の目的における画像サイズは
16em(ビューポート幅の半分)です。レイアウトが異なるため、
わずかに広いビューポートの方が小さい画像になることに注意してください。
その後、ユーザーエージェントは前の例と同様に実効ピクセル密度を計算し、適切なリソースを 選択できます。
この例は前の例と同じですが、画像が遅延読み込みされます。この場合、sizes属性でautoキーワードを
使用でき、ユーザーエージェントはwidth属性
(またはCSSで指定された幅)をソースサイズとして使用します。
< img loading = "lazy" width = "200" height = "200" sizes = "auto"
srcset = "swing-200.jpg 200w, swing-400.jpg 400w, swing-800.jpg 800w, swing-1600.jpg 1600w"
src = "swing-400.jpg" alt = "Kettlebell Swing" > autoキーワードを
サポートしない旧来のユーザーエージェントとの後方互換性を向上させるため、必要に応じて
フォールバックサイズを指定できます。
< img loading = "lazy" width = "200" height = "200"
sizes = "auto, (max-width: 30em) 100vw, (max-width: 50em) 50vw, calc(33vw - 100px)"
srcset = "swing-200.jpg 200w, swing-400.jpg 400w, swing-800.jpg 800w, swing-1600.jpg 1600w"
src = "swing-400.jpg" alt = "Kettlebell Swing" > picture要素および
source要素を、
media
属性とともに使用して、画像内容が異なる複数の画像を提供できます
(たとえば、小さい画像は大きい画像を切り抜いたものにできます)。
< picture >
< source media = "(min-width: 45em)" srcset = "large.jpg" >
< source media = "(min-width: 32em)" srcset = "med.jpg" >
< img src = "small.jpg" alt = "The wolf runs through the snow." >
</ picture > ユーザーエージェントは、media属性内の
メディアクエリーが一致する最初のsource要素を選択し、
その後、そのsrcset属性から
適切なURLを選択します。
画像のレンダリングサイズは、どのリソースが選択されるかに応じて異なります。 画像がダウンロードされる前にユーザーエージェントが使用できる寸法を指定するには、 CSSを使用できます。
img { width : 300 px ; height : 300 px }
@media ( min-width: 32em) { img { width: 500px; height:300px } }
@media (min-width: 45em) { img { width: 700px; height:400px } }この例では、アートディレクションに基づく選択と、 デバイスピクセル比に基づく選択を組み合わせます。 ビューポートの半分を占めるバナーが、広い画面用と狭い画面用の 2つの版で提供されます。
< h1 >
< picture >
< source media = "(max-width: 500px)" srcset = "banner-phone.jpeg, banner-phone-HD.jpeg 2x" >
< img src = "banner.jpeg" srcset = "banner-HD.jpeg 2x" alt = "The Breakfast Combo" >
</ picture >
</ h1 > source要素上の
type属性を使用して、
異なる形式による複数の画像を提供できます。
< h2 > From today's featured article</ h2 >
< picture >
< source srcset = "/uploads/100-marie-lloyd.webp" type = "image/webp" >
< source srcset = "/uploads/100-marie-lloyd.jxr" type = "image/vnd.ms-photo" >
< img src = "/uploads/100-marie-lloyd.jpg" alt = "" width = "100" height = "150" >
</ picture >
< p >< b >< a href = "/wiki/Marie_Lloyd" > Marie Lloyd</ a ></ b > (1870–1922)
was an English < a href = "/wiki/Music_hall" > music hall</ a > singer, ...この例では、ユーザーエージェントは、サポートされるMIMEタイプを値とするtype属性を持つ
最初のソースを選択します。ユーザーエージェントがWebP画像をサポートする場合、最初のsource要素が
選択されます。そうではなく、JPEG XR画像をサポートする場合、2番目のsource要素が
選択されます。どちらの形式もサポートされない場合、img要素が選択されます。
この節は非規範的です。
CSSとメディアクエリーを使用して、ユーザーの環境、特に異なるビューポートの寸法および
ピクセル密度へ動的に適応するグラフィカルなページレイアウトを構築できます。しかしコンテンツについては、
CSSは役立ちません。代わりに、img要素の
srcset属性およびpicture要素があります。
この節では、これらの機能の使用方法を示す例を順に説明します。
広い画面(600CSS
ピクセルより広い)では、a-rectangle.pngという名前の300×150画像を使用し、
小さい画面(600CSSピクセル以下)では、
a-square.pngという名前の小さい100×100画像を使用する状況を考えます。
このマークアップは次のようになります:
< figure >
< picture >
< source srcset = "a-square.png" media = "(max-width: 600px)" >
< img src = "a-rectangle.png" alt = "Barney Frank wears a suit and glasses." >
</ picture >
< figcaption > Barney Frank, 2011</ figcaption >
</ figure > alt
属性に何を入れるかの詳細については、画像の代替として機能するテキストを提供するための
要件の節を参照してください。
これには、画像の読み込み中にどの寸法を使用すべきかをユーザーエージェントが必ずしも把握できない という問題があります。ページの読み込み中にレイアウトを何度もリフローする必要をなくすため、 CSSおよびCSSメディアクエリーを使用して寸法を提供できます:
< style >
# a { width : 300 px ; height : 150 px ; }
@ media ( max-width : 600px ) { # a { width : 100 px ; height : 100 px ; } }
</ style >
< figure >
< picture >
< source srcset = "a-square.png" media = "(max-width: 600px)" >
< img src = "a-rectangle.png" alt = "Barney Frank wears a suit and glasses." id = "a" >
</ picture >
< figcaption > Barney Frank, 2011</ figcaption >
</ figure > あるいは、source要素
およびimg要素上で
width属性およびheight属性を使用して、
幅と高さを提供できます:
< figure >
< picture >
< source srcset = "a-square.png" media = "(max-width: 600px)" width = "100" height = "100" >
< img src = "a-rectangle.png" width = "300" height = "150"
alt = "Barney Frank wears a suit and glasses." >
</ picture >
< figcaption > Barney Frank, 2011</ figcaption >
</ figure >
img要素は、
src属性とともに使用されます。
この属性は、picture要素を
サポートしない旧来のユーザーエージェントで使用する画像のURLを示します。これにより、src属性にどの画像を提供するかという
問題が生じます。
作成者が旧来のユーザーエージェントで最大の画像を使用したい場合、マークアップは次のように できます:
< picture >
< source srcset = "pear-mobile.jpeg" media = "(max-width: 720px)" >
< source srcset = "pear-tablet.jpeg" media = "(max-width: 1280px)" >
< img src = "pear-desktop.jpeg" alt = "The pear is juicy." >
</ picture > ただし、旧来のモバイルユーザーエージェントの方が重要である場合、3つすべての画像を
source要素に
列挙し、src属性を完全に
上書きできます。
< picture >
< source srcset = "pear-mobile.jpeg" media = "(max-width: 720px)" >
< source srcset = "pear-tablet.jpeg" media = "(max-width: 1280px)" >
< source srcset = "pear-desktop.jpeg" >
< img src = "pear-mobile.jpeg" alt = "The pear is juicy." >
</ picture > この時点で、src属性は、
pictureを
サポートするユーザーエージェントによって実際には完全に無視されるため、src属性のデフォルトには、
最小でも最大でもない画像を含め、任意の画像を使用できます:
< picture >
< source srcset = "pear-mobile.jpeg" media = "(max-width: 720px)" >
< source srcset = "pear-tablet.jpeg" media = "(max-width: 1280px)" >
< source srcset = "pear-desktop.jpeg" >
< img src = "pear-tablet.jpeg" alt = "The pear is juicy." >
</ picture > 上記ではmax-widthメディア機能を使用し、画像が対象とする最大の
(ビューポート)寸法を指定しています。代わりに
min-widthを使用することもできます。
< picture >
< source srcset = "pear-desktop.jpeg" media = "(min-width: 1281px)" >
< source srcset = "pear-tablet.jpeg" media = "(min-width: 721px)" >
< img src = "pear-mobile.jpeg" alt = "The pear is juicy." >
</ picture > source、
img、
およびlink
要素に共通する属性
srcset属性は、この節で要件が定義される属性です。
存在する場合、その値は1つ以上の画像 候補文字列で構成されなければならず、それぞれは次のものとU+002C COMMA文字(,)で 区切られます。画像候補文字列が記述子を含まず、URLの後に ASCII空白も 含まない場合、後続の画像 候補文字列が存在するなら、それは1つ以上のASCII空白で始まらなければなりません。
画像候補文字列は、次の構成要素でこの順序に従って構成され、 この一覧の後に説明する追加の制約を受けます:
0個以上のASCII 空白。
U+002C COMMA文字(,)で始まらず、また終わらない妥当な空でないURLであり、ページ化も スクリプト化もされていない、非インタラクティブで任意にアニメーション化された画像リソースを 参照するもの。
0個以上のASCII 空白。
0個、または次のいずれか1つ:
幅記述子。これは、ASCII空白、0より大きい数を与えて 幅記述子値を表す妥当な非負整数、および U+0077 LATIN SMALL LETTER W文字で構成されます。
ピクセル密度記述子。これは、ASCII空白、0より大きい数を与えて ピクセル密度記述子値を表す妥当な 浮動小数点数、およびU+0078 LATIN SMALL LETTER X文字で構成されます。
0個以上のASCII 空白。
同じ要素について、別の画像候補 文字列の幅記述子値と同じ幅記述子値を持つ 画像 候補文字列が存在してはなりません。
同じ要素について、別の画像候補文字列の
ピクセル密度
記述子値と同じピクセル密度
記述子値を持つ画像
候補文字列が存在してはなりません。この要件の目的では、記述子を持たない画像候補
文字列は、1x記述子を持つ画像候補文字列と同等です。
ある要素の画像候補文字列に幅記述子が指定されている場合、 その要素の他のすべての画像 候補文字列にも幅記述子が指定されなければなりません。
画像候補文字列の幅記述子で指定された幅は、 画像候補文字列のURLによって指定されるリソースに 自然な幅がある場合、その自然な幅と一致しなければなりません。
要素にsizes属性が存在する場合、その要素のすべての画像候補文字列には 幅 記述子が指定されなければなりません。
sizes属性は、この節で要件が定義される属性です。
存在する場合、その値は妥当なソースサイズリストでなければなりません。
妥当なソースサイズリストは、次の文法に一致する文字列です: [CSSVALUES] [MQ]
< source-size-list > = < source-size > #? , < source-size-value >
< source-size > = < media-condition > < source-size-value > | auto
< source-size-value > = < length > | auto<source-size-value>が<length>である場合、負であってはならず、数学関数以外のCSS関数を使用してはなりません。
キーワードautoは、sizes属性を解析するで
計算される幅です。存在する場合、これは最初の項目でなければならず、<source-size-list>値全体が
文字列「auto」(ASCII大文字小文字不区別)であるか、文字列
「auto,」(ASCII大文字小文字不区別)で始まらなければなりません。
画像の読み込みを開始したimg要素が、
(画像データを更新するまたは
環境の変化に
反応するアルゴリズムによって)自動サイズを許可し、かつレンダリングされている場合、
autoは
具体的オブジェクトサイズの幅です。
それ以外の場合、auto値は無視され、存在する場合は次の
ソースサイズが代わりに使用されます。
次の条件が満たされる場合、autoキーワードを、source要素のsizes属性およびimg要素のsizes属性に指定できます。
それ以外の場合、autoを指定してはなりません。
要素がimg
要素である。
上記いずれかの条件で参照されるimg要素が自動サイズを
許可する。
さらに、width属性およびheight属性、またはCSSを使用して
寸法を指定することが強く推奨されます。寸法が指定されていない場合、sizes="auto"は
レンダリングの節でcontain-intrinsic-size: 300px
150pxを意味するため、画像は300x150の寸法でレンダリングされる可能性があります。
<source-size-value>は、意図される画像の レイアウト幅を示します。作成者は、<media-condition>を使用して、異なる環境に対して 異なる幅を指定できます。
<source-size-value>では、 何に対する割合なのかという混乱を避けるため、パーセンテージは許可されません。 'vw'単位は、ビューポートの幅に 相対的なサイズに使用できます。
img要素には、
現在の要求および保留中の要求があります。
現在の要求は、初期状態では
新しい画像要求に設定されます。
保留中の要求は、初期状態では
nullに設定されます。
画像要求には、状態、現在のURL、および画像 データがあります。
img要素の現在の要求が利用可能である場合、そのimg要素は、
幅が画像の密度補正済みの自然な幅
(存在する場合)、高さが画像の密度補正済みの自然な高さ
(存在する場合)で、外観が画像の自然な外観である描画
ソースを提供します。
各img要素には
最後に選択されたソースがあり、初期状態ではnullでなければなりません。
各画像要求には 現在のピクセル密度があり、初期状態では1でなければなりません。
各画像要求には 優先される密度補正済み寸法があり、 これは幅と高さで構成される構造体またはnullのいずれかです。初期状態ではnullでなければなりません。
img要素
imgの密度補正済みの
自然な幅と高さを決定するには:
densityを、imgの現在の要求の現在の ピクセル密度とします。
dimensionsを、imgの現在の要求の 優先される密度補正済み 寸法とします。
優先される密度補正済み 寸法は、画像内のメタ情報に基づいて、表示用に画像を準備する アルゴリズムで設定されます。
dimensionsがnullでない場合、dimensionsの幅を dimensionsの幅をdensityで割った値に設定し、 dimensionsの高さをdimensionsの高さをdensityで割った値に 設定して、dimensionsを返します。
intrinsicWidth、intrinsicHeight、および intrinsicRatioを、それぞれimgの固有の 幅、固有の高さ、および固有のアスペクト比(存在する場合)とします。
intrinsicWidthが存在しない状態でない場合、intrinsicWidthを intrinsicWidthをdensityで割った値に設定します。
intrinsicHeightが存在しない状態でない場合、intrinsicHeightを intrinsicHeightをdensityで割った値に設定します。
intrinsicWidth、intrinsicHeight、およびintrinsicRatioを 使用し、300×150のデフォルトオブジェクトサイズでデフォルトサイズ設定アルゴリズムを適用した結果を 返します。
たとえば、現在のピクセル密度が3.125である場合、 これはCSSインチ当たり300デバイスピクセルが 存在することを意味します。したがって、画像データが300x600の場合、その画像は 96CSSピクセル×192CSSピクセルの密度補正済みの自然な幅と 高さを持ちます。
すべてのimg要素およびlink要素は、
ソース集合に関連付けられます。
ソース集合は、0個以上の画像ソースからなる順序付き集合および ソースサイズです。
画像ソースは、URLと、任意でピクセル密度 記述子または幅記述子のいずれかです。
ソースサイズは、<source-size-value>です。
ソースサイズがビューポートに相対的な単位を持つ場合、
それはimg要素のノード文書の
ビューポートに相対的に解釈されなければなりません。
その他の単位は、Media Queriesと同じように解釈されなければなりません。
[MQ]
この節のアルゴリズムにおけるパースエラーは、 入力と要件との致命的でない不一致を示します。ユーザーエージェントには、パースエラーを何らかの方法で 公開することが推奨されます。
画像の種類およびそれが妥当な画像であるかどうかを決定するとき、画像のフェッチが成功したか どうか(たとえば、応答ステータスが正常ステータスであったかどうか)は無視されなければなりません。
これにより、サーバーはエラー応答とともに画像を返し、それを表示させることができます。
ユーザーエージェントは、画像の関連付けられたContent-Typeヘッダーを 公式タイプとして、画像の種類を決定するために画像スニッフィング規則を適用するべきです。 これらの規則が適用されない場合、画像の種類は、画像の関連付けられたContent-Typeヘッダーによって 指定された種類でなければなりません。
ユーザーエージェントは、img要素で
画像以外のリソース(たとえば、文書要素がHTML要素であるXMLファイル)をサポートしてはなりません。
ユーザーエージェントは、画像リソースに埋め込まれた実行可能コード(たとえばスクリプト)を
実行してはなりません。ユーザーエージェントは、複数ページのリソース(たとえばPDFファイル)の
最初のページのみを表示しなければなりません。ユーザーエージェントは、リソースがインタラクティブに
動作することを許可してはなりませんが、リソース内のアニメーションは尊重するべきです。
この仕様では、どの画像形式をサポートすべきかは規定しません。
デフォルトでは、画像は直ちに取得されます。ユーザーエージェントは、代わりにオンデマンドで 画像を取得するオプションをユーザーに提供してもよいです。(たとえば、オンデマンドオプションは、 帯域幅に制約のあるユーザーによって使用される可能性があります。)
画像を直ちに取得する場合、ユーザーエージェントは、その要素が作成されたとき、または関連する変異が生じたときは
常に、そうするよう記載されている場合にはアニメーションを再開するフラグを設定して、img
要素の画像データを
更新しなければなりません。
画像をオンデマンドで取得する場合、ユーザーエージェントは、画像データが必要になるたび
(すなわちオンデマンドで)、ただしimg要素の現在の要求の状態が利用不可である場合に限り、
img要素の画像データを更新しなければなりません。img要素に関連する変異が生じた場合、
ユーザーエージェントが画像をオンデマンドでのみ取得するなら、img要素の現在の要求の状態は利用不可に戻らなければなりません。
img要素に対する
関連する変異は、次のとおりです:
要素のsrc
属性が、以前の値と同じ値に設定された。
これは、画像データを更新するアルゴリズムの
アニメーションを再開するフラグを設定しなければなりません。
要素のcrossorigin
属性の状態が変更された。
要素のreferrerpolicy
属性の
状態が変更された。
imgまたはsourceのHTML
要素挿入手順、
HTML要素
削除手順、およびHTML要素移動手順が、その変異を関連する
変異として数える。
要素の親がpicture要素で
あり、以前の兄弟であるsource要素の
srcset、
sizes、
media、
type、
width、または
height属性が
設定、変更、または削除された。
要素の採用 手順が実行された。
要素が自動サイズを 許可する場合:要素がレンダリング されるようになるか、されなくなる、またはその具体的オブジェクトサイズの幅が変化する。これは、画像データを更新するアルゴリズムの イベントを省略する可能性があるフラグを設定しなければなりません。
各Documentオブジェクトは、
利用可能な画像のリストを持たなければなりません。このリスト内の
各画像は、絶対URL、CORS
設定属性モード、およびそのモードがCORS
なしでない場合はオリジンから構成されるタプルによって識別されます。
さらに各画像には、上位層キャッシュを無視するフラグがあります。
ユーザーエージェントは、あるDocument
オブジェクトの利用可能な画像の
リストから別のオブジェクトへ、いつでもエントリーをコピーしてもよいです(たとえば、
Documentが作成されたとき、
ユーザーエージェントは、他のDocumentで読み込まれている
すべての画像を追加できます)が、その際、この方法でコピーされたエントリーのキーを変更してはならず、
コピーされたエントリーの上位層キャッシュを無視するフラグを
設定解除しなければなりません。
ユーザーエージェントは、そのようなリストから画像をいつでも削除してもよいです(たとえば、
メモリーを節約するため)。
ユーザーエージェントは、上位層キャッシュを
無視するフラグが設定されていない場合、リソースに対する上位層キャッシュの意味論
(たとえば、HTTPの`Cache-Control`
応答ヘッダー)に応じて、利用可能な画像のリスト内の
エントリーを適切に削除しなければなりません。
利用可能な画像のリストは、
src属性を、
以前に読み込まれたURLへ変更するときの同期的な切り替えを可能にし、またHTTPによるキャッシュを
許可しない場合でも、同じ文書内で画像を再ダウンロードすることを避けることを意図しています。
以前の画像がまだ読み込み中である間に同じ画像を再ダウンロードすることを避けるためには使用されません。
ユーザーエージェントは、画像データを利用可能な画像のリストとは別に 保存することもできます。
たとえば、リソースにHTTP応答ヘッダー
`Cache-Control: must-revalidate`があり、その上位層キャッシュを
無視するフラグが設定されていない場合、ユーザーエージェントはそのリソースを利用可能な
画像のリストから削除しますが、画像データを別に保持し、サーバーが
304 Not Modifiedステータスで応答した場合にそれを使用できます。
画像データは通常、ファイルサイズを削減するためにエンコードされています。これは、 ユーザーエージェントが画像を画面に表示するには、データをデコードする必要があることを意味します。 デコードとは、画像のメディアデータを、画面への表示に適した ビットマップ形式へ変換する処理です。この処理は、コンテンツの表示に関わる他の処理と比較して 遅い可能性があることに注意してください。そのため、ユーザーエージェントは最良のユーザー体験を 作り出すために、デコードをいつ実行するかを選択できます。
画像のデコードが完了するまで他のコンテンツの表示を妨げる場合、画像のデコードは同期的であると いいます。通常、これは画像とその他のコンテンツを同時に不可分に表示する効果があります。 ただし、この表示はデコードの実行にかかる時間だけ遅延します。
画像のデコードが他のコンテンツの表示を妨げない場合、画像のデコードは非同期的であるといいます。 これは画像以外のコンテンツをより速く表示する効果があります。ただし、デコードが完了するまで、 画像コンテンツは画面に表示されません。デコードが完了すると、画面が画像で更新されます。
同期デコードモードと非同期デコードモードのどちらでも、同じ時間が経過した後に最終的なコンテンツが 画面に表示されます。主な違いは、ユーザーエージェントが最終的なコンテンツの表示に先立って、 画像以外のコンテンツを表示するかどうかです。
ユーザーエージェントが同期デコードまたは非同期デコードのどちらを実行するかを決定するのを
支援するため、decoding属性を
img要素に設定できます。
decoding属性に
使用できる値は、次の画像デコード
ヒントキーワードです:
| キーワード | 状態 | 説明 |
|---|---|---|
sync
|
同期 | 他のコンテンツと不可分に表示するため、この画像を同期的にデコードすることを優先する旨を示します。 |
async
|
非同期 | 他のコンテンツの表示を遅延させないため、この画像を非同期的にデコードすることを優先する旨を示します。 |
auto
|
自動 | デコードモードに優先事項がないことを示します(デフォルト)。 |
画像をデコードするとき、ユーザーエージェントは
decoding
属性の状態によって示される優先事項を尊重するべきです。示された状態が自動である場合、ユーザーエージェントは
任意のデコード動作を自由に選択できます。
decode()メソッドを使用して、
デコード動作を制御することもできます。decode()メソッドは、
コンテンツを画面へ表示する処理とは独立してデコードを実行するため、decoding属性の影響を
受けません。
このアルゴリズムは、並行して実行されている手順から呼び出すことは できません。ユーザーエージェントが、並行して実行されている手順からこのアルゴリズムを 呼び出す必要がある場合、そうするためのタスクをキューに追加する必要があります。
ユーザーエージェントがimg要素の
画像データを更新するとき、任意で
アニメーションを再開するフラグを設定し、任意でイベントを省略する可能性がある
フラグを設定して、次の手順を実行しなければなりません:
このアルゴリズムの実行を並行して続行します。
このimg要素に対する
このアルゴリズムの別のインスタンスが、このインスタンスの後に開始された場合
(中止され、もはや実行中でない場合も含む)、返します。
このアルゴリズムを続行するため、マイクロタスクをキューに追加します。
ユーザーエージェントが画像をサポートできない場合、または画像のサポートが無効にされている場合、 現在の 要求および保留中の 要求に対する画像要求を 中止し、現在の 要求の状態を利用不可に設定し、保留中の要求をnullに設定して、 返します。
selected sourceをnullとし、selected pixel densityを未定義とします。
要素がsrcsetまたは
pictureを使用せず、空文字列ではない値を持つsrc属性が指定されている
場合、selected sourceを要素のsrc属性の値に設定し、
selected pixel densityを
1.0に設定します。
要素の最後に 選択されたソースをselected sourceに設定します。
selected sourceがnullでない場合:
urlStringを、要素のノード 文書を基準として、selected sourceを指定してURLをエンコーディング解析して シリアル化する結果とします。
urlStringが失敗の場合、この内側の一連の手順を中止します。
keyを、urlString、img
要素のcrossorigin
属性のモード、およびそのモードがCORS
なしでない場合はノード
文書のオリジンから構成されるタプルとします。
利用可能な 画像のリストにkeyのエントリーが含まれる場合:
そのエントリーの上位層キャッシュを無視するフラグを 設定します。
保留中の要求を nullに設定します。
img要素を
指定して、現在の
要求を
表示用に準備します。
img要素と
次の手順を指定して、DOM操作タスクソース上で要素
タスクをキューに追加します:
画像データを 更新するアルゴリズムを中止します。
このアルゴリズムを呼び出したタスクが続行できるように、このアルゴリズムの 残りを実行するためのマイクロタスクをキューに追加します。
このimg要素に対する
このアルゴリズムの別のインスタンスが、このインスタンスの後に開始された場合
(中止され、もはや実行中でない場合も含む)、返します。
たとえば、src、srcset、
およびcrossorigin
属性がすべて連続して設定された場合に複数の要求が発生することを避けるため、最後のインスタンスだけが
効果を持ちます。
selected sourceおよびselected pixel densityを、それぞれ画像ソースを選択する結果であるURLおよび ピクセル密度とします。
selected sourceがnullの場合:
urlStringを、要素のノード 文書を基準として、selected sourceを指定してURLをエンコーディング解析して シリアル化する結果とします。
urlStringが失敗の場合:
urlStringが現在の要求の現在のURLと同じであり、現在の要求の状態が部分的に利用可能である場合:
アニメーションを再開するが設定されている場合、img要素を
指定して、DOM
操作タスクソース上で要素タスクをキューに追加し、アニメーションを
再開します。
返します。
現在の要求の状態が利用不可または壊れている場合、現在の要求をimage requestに設定します。それ以外の場合、保留中の 要求をimage requestに設定します。
requestを、urlString、「image」、および要素のcrossorigin
コンテンツ属性の現在の状態を指定して、潜在的CORS要求を作成する結果とします。
requestのクライアントを、 要素のノード 文書の関連設定オブジェクトに設定します。
要素がsrcsetまたは
pictureを使用する場合、requestの起動元を「imageset」に設定します。
requestのリファラー
ポリシーを、要素のreferrerpolicy
属性の現在の状態に設定します。
requestの優先度を、要素のfetchpriority
属性の現在の状態に設定します。
delay load eventを、imgの遅延読み込み
属性が即時状態である場合、または
imgについて
スクリプトが無効である場合はtrueとし、
それ以外の場合はfalseとします。
imgを指定した要素を遅延読み込みするかどうかの
手順がtrueを返す場合:
imgの
遅延読み込み
再開手順を、画像をフェッチするとラベル付けされた手順から始まるこの
アルゴリズムの残りに設定します。
img要素について、遅延読み込み要素の
交差監視を開始します。
返します。
画像をフェッチする:requestをフェッチします。 このアルゴリズムから返し、残りの手順を、応答responseに対するフェッチのprocessResponseの一部として実行します。
この方法で取得されたリソースがある場合、それがimage requestの画像データです。これはCORS同一オリジンまたは
CORSクロスオリジンのいずれかであり、
これは画像と他のAPIとの相互作用に影響します(たとえば、canvasで
使用される場合)。
delay load eventがtrueの場合、画像のフェッチは、リソースがフェッチされた後に ネットワークタスク ソースによってキューに追加されるタスク(以下で定義)が 実行されるまで、要素のノード文書の loadイベントを 遅延しなければなりません。
残念ながら、これはユーザーのローカルネットワークの簡易的なポートスキャンを 実行するために使用できます(特にスクリプトと組み合わせた場合。ただし、このような攻撃を 実行するためにスクリプトが実際に必要なわけではありません)。ユーザーエージェントは、この攻撃を 軽減するため、上記より厳格なクロスオリジンアクセス制御ポリシーを 実装してもよいですが、残念ながらそのようなポリシーは通常、既存のウェブコンテンツと 互換性がありません。
可能な限り早く、次のリストから最初に該当するエントリーへ移動します:
multipart/x-mixed-replace
の場合
画像がフェッチされている間にネットワークタスク ソースによってキューに追加される次のタスクは、次の手順を実行しなければなりません:
image requestが保留中の要求 であり、少なくとも1つのボディ部分が完全にデコードされている場合、 現在の要求に対する画像要求を 中止し、保留中の要求を 現在の要求へ昇格します。
それ以外の場合、image requestが保留中の要求であり、 ユーザーエージェントが、画像の寸法を取得できないほど致命的な方法で image requestの画像が破損していると判断できる場合、現在の要求に対する画像 要求を中止し、保留中の 要求を 現在の要求へ昇格し、現在の要求の状態を壊れているに設定します。
それ以外の場合、image requestが現在の要求であり、その状態が利用不可であり、 ユーザーエージェントがimage requestの画像の幅と高さを判断できる場合、現在の要求の状態を部分的に利用可能に設定します。
それ以外の場合、image requestが現在の要求であり、その状態が利用不可であり、 ユーザーエージェントが、画像の寸法を取得できないほど致命的な方法で image requestの画像が破損していると判断できる場合、現在の 要求の状態を壊れているに設定します。
画像がフェッチされている間にネットワークタスク
ソースによってキューに追加される各タスクは、画像の表示を更新しなければなりません。
ただし、新しいボディ部分が到着するたび、ユーザーエージェントが画像の幅と高さを
判断できる場合、img要素を
指定して、img要素の
現在の要求を
表示用に準備し、以前の画像を置き換えなければなりません。
1つのボディ部分が完全にデコードされたら、次の手順を実行します:
イベントを省略する可能性があるが設定されていないか、または
previousURLがurlStringと等しくない場合、img要素を
指定して、DOM
操作タスクソース上で要素タスクをキューに追加し、
loadという
名前のイベントを
発火します。
画像がフェッチされている間にネットワークタスク ソースによってキューに追加される次のタスクは、次の手順を実行しなければなりません:
ユーザーエージェントがimage requestの画像の幅と高さを判断でき、 image requestが保留中の要求である場合、image requestの状態を部分的に 利用可能に設定します。
それ以外の場合、ユーザーエージェントがimage requestの画像の幅と高さを
判断でき、image requestが現在の要求である場合、img要素を
指定して、image requestを
表示用に準備し、image requestの
状態を部分的に
利用可能に設定します。
それ以外の場合、ユーザーエージェントが、画像の寸法を取得できないほど致命的な方法で image requestの画像が破損していると判断でき、かつ image requestが保留中の要求である場合:
それ以外の場合、ユーザーエージェントが、画像の寸法を取得できないほど致命的な方法で image requestの画像が破損していると判断でき、かつ image requestが現在の要求である場合:
そのタスク、および画像がフェッチされている間に ネットワークタスク ソースによってキューに追加される後続の各タスクは、image requestが現在の 要求である場合、画像の表示を適切に更新しなければなりません (たとえば、画像がプログレッシブJPEGである場合、各パケットによって画像の解像度を 改善できます)。
さらに、リソースがフェッチされた後にネットワークタスク ソースによってキューに追加される最後のタスクは、追加で次の手順を実行しなければ なりません:
image requestが保留中の要求である場合、
現在の要求に対する画像要求を
中止し、保留中の
要求を現在の要求へ昇格し、img要素を
指定して、image requestを
表示用に準備します。
image requestを完全に 利用可能状態に設定します。
上位層キャッシュを無視するフラグを 設定して、キーkeyを使用して画像を利用可能な画像のリストに追加します。
イベントを省略する可能性があるが設定されていないか、または
previousURLがurlStringと等しくない場合、img要素で、
loadという
名前のイベントを
発火します。
画像データはサポートされるファイル形式ではありません。ユーザーエージェントは、
image requestの状態を壊れているに設定し、現在の
要求および保留中の
要求に対する画像
要求を中止し、image requestが保留中の要求である場合は保留中の
要求を
現在の要求へ昇格し、その後、イベントを省略する可能性があるが設定されていないか、
またはpreviousURLがurlStringと等しくない場合、img要素を
指定して、DOM
操作タスク
ソース上で要素タスクをキューに追加し、img要素で
errorという名前の
イベントを
発火します。
画像要求またはnullのimage requestについて、画像要求を中止するとは、 次の手順を実行することを意味します:
img要素について
保留中の要求を現在の
要求へ昇格するとは、次の手順を実行することを意味します:
画像要素imgが与えられたとき、画像要求 reqについて表示用の画像を準備するには:
exifTagMapを、関連するコーデックによって定義される、reqの画像データから取得したEXIFタグとします。 [EXIF]
physicalWidthおよびphysicalHeightを、関連するコーデックによって 定義される、reqの画像データから取得した幅および高さと します。
dimXを、exifTagMapのタグ0xA002
(PixelXDimension)の値とします。
dimYを、exifTagMapのタグ0xA003
(PixelYDimension)の値とします。
resXを、exifTagMapのタグ0x011A
(XResolution)の値とします。
resYを、exifTagMapのタグ0x011B
(YResolution)の値とします。
resUnitを、exifTagMapのタグ0x0128
(ResolutionUnit)の値とします。
次のすべてがtrueの場合:
dimXが正の整数である;
dimYが正の整数である;
resXが正の浮動小数点数である;
resYが正の浮動小数点数である;
physicalWidth × 72 / resXが dimXである;
physicalHeight × 72 / resYが dimYである;
resUnitが2(Inch)である、
その場合:
reqの画像 データが CORSクロスオリジンである場合、 imgの自然な寸法を dimXおよびdimYに設定し、それに応じてimgのピクセルデータを 拡縮します。
それ以外の場合、reqの優先される 密度補正済み寸法を、幅がdimXに設定され、高さがdimYに設定された 構造体に設定します。
reqのimg要素の
表示を適切に更新します。
EXIFの解像度は1インチ当たりのCSSポイントに 相当するため、解像度からサイズを計算する際の基数は72です。
画像がすでに表示された後にEXIFが到着した場合にどうなるかは、まだ規定されていません。 issue #4929を参照してください。
img要素elが
与えられたとき、画像ソースを選択するには:
ソース集合 sourceSetが与えられたとき、ソース集合から 画像ソースを選択するには:
sourceSet内のエントリーbが、sourceSet内の以前のエントリー aと同じ関連付けられたピクセル 密度記述子を持つ場合、エントリーbを削除します。sourceSet内の どのエントリーも以前のエントリーと同じ関連付けられたピクセル密度記述子を持たなくなるまで、 この手順を繰り返します。
実装定義の方法で、sourceSetから1つの画像ソースを選択します。 selectedSourceをこの選択とします。
selectedSourceおよびそれに関連付けられたピクセル密度を返します。
文字列default source、文字列 srcset、文字列sizes、および要素またはnullのimgが与えられて、 ソース集合を作成するよう求められた場合:
指定されたimgまたは
link要素
elについてソース集合を更新するよう求められた場合、
ユーザーエージェントは次を行わなければなりません:
elementsを« el »とします。
elが、親ノードが
picture
要素であるimg要素の場合、
相対的な順序を維持したまま、elementsの内容をelの親ノードの子要素で置換します。
elがimg要素の場合は
imgをelとし、それ以外の場合はnullとします。
elements内の各childについて反復します:
childがelである場合:
default sourceを空文字列とします。
srcsetを空文字列とします。
sizesを空文字列とします。
それ以外の場合、elがimagesrcset
属性を持つlink要素で
ある場合、srcsetをその属性の値に設定します。
それ以外の場合、elがimagesizes
属性を持つlink要素で
ある場合、sizesをその属性の値に設定します。
それ以外の場合、elがhref属性を持つ
link要素である場合、
default sourceをその属性の値に設定します。
elのソース集合を、 default source、srcset、 sizes、およびimgを指定してソース集合を作成する結果に設定します。
返します。
elがlink要素で
ある場合、elementsにはelのみが含まれるため、この手順には直ちに
到達し、アルゴリズムの残りは実行されません。
childのsrcset属性を解析し、 返されたソース集合をsource setとします。
imgを使用してchildのsizes属性を解析し、 返された値をsource setのソースサイズとします。
childがtype属性を持ち、
その値が未知またはサポートされていないMIMEタイプで
ある場合、次の子へ続行します。
childがwidthまたはheight属性を持つ場合、
elの寸法属性ソースを
childに設定します。それ以外の場合、elの寸法属性ソースを
elに設定します。
source setのソース密度を正規化します。
elのソース集合を source setに設定します。
返します。
各img
要素は、画像
ソースを選択するため、以前の兄弟である
source要素と、
img要素自体を
独立して考慮し、同じpicture要素内の
他のimg要素や、
関連するimg要素の後続の兄弟で
あるsource要素を含む、
その他の(無効な)要素を無視します。
要素からsrcset属性を解析するよう求められた場合、 要素のsrcset属性の値を次のように解析します:
inputを、このアルゴリズムに渡された値とします。
positionを、初期状態では文字列の先頭を指す、 input内のポインターとします。
candidatesを、初期状態では空のソース集合とします。
分割ループ:positionを指定して、inputからASCII 空白またはU+002C COMMA文字である符号位置の列を収集します。 U+002C COMMA文字が1つでも収集された場合、それはパースエラーです。
positionがinputの末尾を越えている場合、 candidatesを返します。
descriptorsを新しい空のリストとします。
urlがU+002C(,)で終わる場合:
urlの末尾にあるすべてのU+002C COMMA文字を削除します。 これによって複数の文字が削除された場合、 それはパースエラーです。
それ以外の場合:
記述子トークナイザー:positionを指定して、input内のASCII空白をスキップします。
current descriptorを空文字列とします。
stateを記述子内とします。
cをpositionにある文字とします。 stateの値に応じて、次を行います。 この手順の目的では、「EOF」はpositionがinputの末尾を越えたことを表す 特別な文字です。
cの値に応じて、次を行います:
current descriptorが空でない場合、 current descriptorをdescriptorsに付加し、 current descriptorを空文字列とします。 stateを記述子の後に設定します。
positionをinput内の次の文字へ進めます。 current descriptorが空でない場合、 current descriptorをdescriptorsに付加します。 記述子パーサーとラベル付けされた手順へ移動します。
cをcurrent descriptorに付加します。 stateを括弧内に設定します。
current descriptorが空でない場合、 current descriptorをdescriptorsに付加します。 記述子パーサーとラベル付けされた手順へ移動します。
cをcurrent descriptorに付加します。
cの値に応じて、次を行います:
cをcurrent descriptorに付加します。 stateを記述子内に設定します。
current descriptorをdescriptorsに付加します。 記述子パーサーとラベル付けされた手順へ移動します。
cをcurrent descriptorに付加します。
cの値に応じて、次を行います:
この状態にとどまります。
記述子パーサーとラベル付けされた手順へ移動します。
stateを記述子内に設定します。 positionをinput内の前の文字に設定します。
positionをinput内の次の文字へ進めます。この手順を 繰り返します。
将来の追加との互換性を保つため、 このアルゴリズムは複数の記述子および括弧を持つ記述子をサポートします。
記述子パーサー:errorをいいえとします。
widthを存在しないとします。
densityを存在しないとします。
future-compat-hを存在しないとします。
descriptors内の各記述子について、 次の一覧から適切な一連の手順を実行します:
ユーザーエージェントがsizes属性を
サポートしない場合、errorをはいとします。
適合するユーザーエージェントはsizes
属性をサポートします。
ただし実際には、ユーザーエージェントは通常、機能を段階的に実装して提供します。
widthおよびdensityが 両方とも存在しない状態でない場合、 errorをはいとします。
記述子に非負整数を解析する 規則を適用します。結果が0の場合、errorをはいとします。 それ以外の場合、widthをその結果とします。
width、density、およびfuture-compat-hが すべて存在しない状態でない場合、 errorをはいとします。
記述子に浮動小数点数値を 解析する規則を適用します。 結果が0未満の場合、errorをはいとします。それ以外の場合、 densityをその結果とします。
densityが0の場合、自然な寸法は無限大になります。 ユーザーエージェントには、画像をどの程度の大きさまでレンダリングできるかについて制限があることが期待されます。
これはパースエラーです。
future-compat-hおよびdensityが 両方とも存在しない状態でない場合、 errorをはいとします。
記述子に非負整数を解析する 規則を適用します。結果が0の場合、errorをはいとします。 それ以外の場合、future-compat-hをその結果とします。
errorをはいとします。
future-compat-hが存在しない状態ではなく、widthが 存在しない場合、errorをはいとします。
errorが依然としていいえである場合、 URLがurlであり、widthが存在しない状態でなければ幅 widthに関連付けられ、densityが存在しない状態でなければ ピクセル密度densityに関連付けられた新しい画像ソースをcandidatesに付加します。 それ以外の場合、パースエラーです。
分割ループとラベル付けされた手順に戻ります。
要素elementから、img要素またはnullの
imgを使用して、sizes属性を解析するよう求められた場合:
unparsed sizes listを、elementのsizes 属性の値(属性が存在しない場合は空文字列)からコンポーネント値のコンマ区切りリストを 解析する結果とします。[CSSSYNTAX]
sizeをnullとします。
unparsed sizes list内の各unparsed sizeについて:
unparsed sizeの末尾から、連続するすべての<whitespace-token>を削除します。 unparsed sizeが空になった場合、 それはパースエラーです; 続行します。
unparsed size内の最後のコンポーネント 値が妥当な非負の<source-size-value>である場合、 sizeをその値に設定し、 unparsed sizeからそのコンポーネント 値を削除します。 数学 関数以外のCSS関数は無効です。 それ以外の場合、パースエラーです; 続行します。
sizeがautoであり、
imgがnullでなく、imgがレンダリングされており、かつimgが
自動サイズを許可する場合、
sizeを、CSSピクセル単位による
imgの具体的オブジェクト
サイズの幅に設定します。
sizeが依然としてautoで
ある場合、それは無視されます。
unparsed sizeの末尾から、連続するすべての<whitespace-token>を削除します。 unparsed sizeが空になった場合:
unparsed size内に残っているコンポーネント値を <media-condition>として解析します。 正しく解析されない場合、または正しく解析されても<media-condition>がfalseと評価される場合、 続行します。[MQ]
sizeがautoでない場合、
sizeを返します。それ以外の場合、続行します。
100vwを返します。
<media-condition>を伴わない、<length>である単独の<source-size-value>を、
<source-size-list>内の最後ではないエントリーとして
使用することは無効です。
ただし、解析アルゴリズムは<source-size-list>内の任意の位置でそれを許可し、
リスト内の先行するエントリーが使用されなかった場合は、
直ちにそれをサイズとして受け入れます。
これは、将来の拡張を可能にし、
末尾の余分なコンマなどの単純な作成者の誤りから保護するためです。
単独のautoキーワードの後には、
旧来のユーザーエージェント向けのフォールバックを提供するため、他のエントリーを続けることが
許可されます。
画像ソースは、そのURLに伴って ピクセル密度 記述子、幅 記述子、またはまったく記述子を持たない場合があります。ソース 集合を正規化すると、すべての画像ソースにピクセル密度 記述子が与えられます。
ソース集合 source setのソース 密度を正規化するよう求められた場合、ユーザーエージェントは 次を行わなければなりません:
ユーザーエージェントは、環境の変化に
反応するため、いつでも次のアルゴリズムを実行して、img
要素の画像を更新してもよいです。(ユーザーエージェントは、このアルゴリズムを実行することを
要求されません。たとえば、ユーザーがもうページを見ていない場合、その間に環境が
再び変化する可能性に備えて、どの画像を使用するかを決定する前に、ユーザーがページへ戻るまで
待つことをユーザーエージェントが望む可能性があります。)
ユーザーエージェントには、特にユーザーがビューポートのサイズを変更したとき
(たとえば、ウィンドウのサイズ変更またはページのズーム変更によって)、およびimg要素が
文書へ
挿入されたときに、このアルゴリズムを実行することが推奨されます。これにより、密度補正済みの自然な
幅と高さが新しいビューポートに一致し、またアートディレクションが関与する場合に
正しい画像が選択されます。
安定状態を待機します。同期区間は、 アルゴリズムが同期 区間が終了したと述べるまでの、このアルゴリズムの残りのすべての手順で構成されます。 (同期区間内の手順には⌛が付けられます。)
⌛ img要素が
srcsetまたは
pictureを使用しない場合、そのノード文書が
完全にアクティブでない場合、
リソースタイプがmultipart/x-mixed-replaceである画像データを持つ場合、
またはその保留中の
要求がnullでない場合、返します。
⌛ selected sourceおよびselected pixel densityを、それぞれ画像ソースを選択する結果であるURLと ピクセル密度とします。
⌛ selected sourceがnullの場合、返します。
⌛ selected sourceおよびselected pixel densityが、要素の最後に選択されたソースおよび現在の ピクセル密度と同じ場合、返します。
⌛ urlStringを、要素のノード 文書を基準として、selected sourceを指定してURLをエンコーディング解析して シリアル化する結果とします。
⌛ urlStringが失敗の場合、返します。
⌛ corsAttributeStateを、要素のcrossorigin
コンテンツ属性の状態とします。
⌛ clientを、img要素の
ノード
文書の関連設定オブジェクトとします。
⌛ keyを、urlString、 corsAttributeState、およびcorsAttributeStateがCORSなしでない場合は originから構成されるタプルとします。
⌛ 要素の保留中の 要求をimage requestに設定します。
利用可能な画像のリストに keyのエントリーが含まれる場合、 image requestの画像データをそのエントリーのデータに 設定します。次の手順へ続行します。
それ以外の場合:
requestを、urlString、「image」、および
corsAttributeStateを指定して潜在的CORS
要求を作成する結果とします。
requestのクライアントを
clientに設定し、requestの起動元を「imageset」に設定し、
requestの同期
フラグを設定します。
requestの
リファラーポリシーを、要素のreferrerpolicy
属性の現在の状態に設定します。
requestの優先度を、要素のfetchpriority
属性の現在の状態に設定します。
responseを、requestをフェッチする結果とします。
responseの安全でない応答がネットワーク
エラーである場合、画像形式がサポートされていない場合
(前述のように、画像スニッフィング規則を適用して判断)、
ユーザーエージェントが、画像の寸法を取得できないほど致命的な方法で
image requestの画像が破損していると判断できる場合、またはリソースタイプが
multipart/x-mixed-replaceである場合、
保留中の
要求をnullに設定し、これらの手順を中止します。
それ以外の場合、responseの安全でない応答がimage
requestの画像
データです。これは
CORS同一オリジンまたは
CORSクロスオリジンのいずれかであり、
これは画像と他のAPIとの相互作用に影響します(たとえば、canvasで使用される場合)。
img要素と
次の手順を指定して、DOM操作タスクソース上で要素
タスクをキューに追加します:
このアルゴリズムが開始されてから、img要素に
関連する変異が生じた場合、
保留中の要求をnullに設定し、
これらの手順を中止します。
img
要素の最後に
選択されたソースをselected
sourceに設定し、img
要素の現在のピクセル密度を
selected pixel densityに設定します。
上位層キャッシュを無視するフラグを 設定して、キーkeyを使用して画像を利用可能な画像のリストに 追加します。
保留中の 要求を現在の要求へ昇格します。
img
要素を指定して、image requestを
表示用に準備します。
別途規定されている場合を除き、alt属性を指定しなければならず、
その値は空であってはなりません。その値は画像の適切な代替でなければなりません。alt属性に対する具体的な要件は、
次の各節で説明するように、画像が何を表すことを意図しているかによって異なります。
代替テキストを記述するときに考慮すべき最も一般的な規則は次のとおりです:すべての画像を
そのalt
属性のテキストで置換しても、ページの意味が変わらないようにすることが意図されています。
したがって一般に、画像を含められなかった場合に何を記述したかを考えることで、 代替テキストを記述できます。
この帰結として、alt属性の値には、
画像のキャプション、タイトル、または凡例と見なされる可能性のある
テキストを決して含めるべきではありません。これは、ユーザーが画像の代わりに使用できる
代替テキストを含むことを想定しており、画像を補足することを意図していません。title属性は補足情報に使用できます。
もう1つの帰結として、alt属性の値は、
画像の隣の文章ですでに提供されている情報を繰り返すべきではありません。
代替テキストについて考える1つの方法は、画像が存在することに言及せず、 画像を含むページを電話越しに誰かへどのように読み上げるかを考えることです。 画像の代わりに述べる内容は、通常、代替テキストを記述するうえでの良い出発点になります。
ハイパーリンクを作成するa要素、またはbutton
要素がテキスト内容を持たず、1つ以上の画像を含む場合、alt
属性には、合わせてリンクまたはボタンの目的を伝えるテキストを含めなければなりません。
この例では、ユーザーは3色の一覧から好みの色を選ぶよう求められます。各色は画像によって 示されますが、画像を表示しないようユーザーエージェントを設定しているユーザーには、 代わりに色の名前が使用されます:
< h1 > Pick your color</ h1 >
< ul >
< li >< a href = "green.html" > < img src = "green.jpeg" alt = "Green" > </ a ></ li >
< li >< a href = "blue.html" > < img src = "blue.jpeg" alt = "Blue" > </ a ></ li >
< li >< a href = "red.html" > < img src = "red.jpeg" alt = "Red" > </ a ></ li >
</ ul > この例では、各ボタンが、ユーザーの望む色出力の種類を示す一連の画像を持ちます。 いずれの場合も、最初の画像が代替テキストを提供するために使用されます。
< button name = "rgb" > < img src = "red" alt = "RGB" >< img src = "green" alt = "" >< img src = "blue" alt = "" > </ button >
< button name = "cmyk" > < img src = "cyan" alt = "CMYK" >< img src = "magenta" alt = "" >< img src = "yellow" alt = "" >< img src = "black" alt = "" > </ button > 各画像がテキストの一部を表すため、次のように記述することもできます:
< button name = "rgb" > < img src = "red" alt = "R" >< img src = "green" alt = "G" >< img src = "blue" alt = "B" > </ button >
< button name = "cmyk" > < img src = "cyan" alt = "C" >< img src = "magenta" alt = "M" >< img src = "yellow" alt = "Y" >< img src = "black" alt = "K" > </ button > ただし、他の代替テキストではこれは機能しない場合があり、それぞれの場合にすべての代替 テキストを1つの画像に入れる方が適切である可能性があります:
< button name = "rgb" > < img src = "red" alt = "sRGB profile" >< img src = "green" alt = "" >< img src = "blue" alt = "" > </ button >
< button name = "cmyk" > < img src = "cyan" alt = "CMYK profile" >< img src = "magenta" alt = "" >< img src = "yellow" alt = "" >< img src = "black" alt = "" > </ button > フローチャート、図、グラフ、または道順を示す単純な地図など、何かをグラフィカルな形式で
より明確に表現できる場合があります。そのような場合、img
要素を使用して画像を提供できますが、画像を表示できないユーザー
(たとえば、接続が非常に遅い、テキスト専用ブラウザーを使用している、ハンズフリーの自動車用音声
ウェブブラウザーによるページの読み上げを聞いている、または単に視覚障害があるため)でも伝えられる
メッセージを理解できるように、より簡略なテキスト版も提供しなければなりません。
テキストはalt
属性で提供しなければならず、src
属性で指定された画像と同じメッセージを伝えなければなりません。
代替テキストは画像の説明ではなく、画像の代替であることを理解することが重要です。
次の例では、画像形式のフローチャートがあり、
alt
属性内のテキストがフローチャートを文章形式で言い換えています:
< p > In the common case, the data handled by the tokenization stage
comes from the network, but it can also come from script.</ p >
< p > < img src = "images/parsing-model-overview.svg" alt = "The Network
passes data to the Input Stream Preprocessor, which passes it to the
Tokenizer, which passes it to the Tree Construction stage. From there,
data goes to both the DOM and to Script Execution. Script Execution is
linked to the DOM, and, using document.write(), passes data to the
Tokenizer." > </ p > 別の例を示します。これは、説明に画像を含める問題に対する良い解決策と悪い解決策を示します。
最初に、良い解決策を示します。この例は、画像が存在しなかった場合に文章へ記述した内容そのものを 代替テキストにすべきであることを示しています。
<!-- This is the correct way to do things. -->
< p >
You are standing in an open field west of a house.
< img src = "house.jpeg" alt = "The house is white, with a boarded front door." >
There is a small mailbox here.
</ p > 次に、悪い解決策を示します。この誤った方法では、代替テキストは画像のテキストによる代替ではなく、 単なる画像の説明です。画像が表示されない場合、最初の例ほどテキストが自然に流れないため、 これは悪い方法です。
<!-- This is the wrong way to do things. -->
< p >
You are standing in an open field west of a house.
< img src = "house.jpeg" alt = "A white house, with a boarded front door." >
There is a small mailbox here.
</ p > 「板張りのドアがある白い家の写真」のようなテキストも、同様に悪い代替テキストです
(ただし、title
属性、またはこの画像を持つfigure
のfigcaption
要素には適している可能性があります)。
文書にはアイコン形式の情報を含められます。アイコンは、視覚ブラウザーのユーザーが機能を 一目で認識できるようにすることを意図しています。
場合によっては、アイコンは同じ意味を伝えるテキストラベルを補足します。そのような場合、
alt
属性は存在しなければなりませんが、空でなければなりません。
ここでは、アイコンの隣に同じ意味を伝えるテキストがあるため、空のalt
属性を持ちます:
< nav >
< p >< a href = "/help/" > < img src = "/icons/help.png" alt = "" > Help</ a ></ p >
< p >< a href = "/configure/" > < img src = "/icons/configuration.png" alt = "" >
Configuration Tools</ a ></ p >
</ nav > 他の場合、アイコンの隣にその意味を説明するテキストはなく、アイコン自体が説明不要であることを
想定しています。そのような場合、同等のテキストラベルをalt
属性で提供しなければなりません。
ここでは、ニュースサイトの投稿に、そのトピックを示すアイコンが付けられています。
< body >
< article >
< header >
< h1 > Ratatouille wins < i > Best Movie of the Year</ i > award</ h1 >
< p > < img src = "movies.png" alt = "Movies" > </ p >
</ header >
< p > Pixar has won yet another < i > Best Movie of the Year</ i > award,
making this its 8th win in the last 12 years.</ p >
</ article >
< article >
< header >
< h1 > Latest TWiT episode is online</ h1 >
< p > < img src = "podcasts.png" alt = "Podcasts" > </ p >
</ header >
< p > The latest TWiT episode has been posted, in which we hear
several tech news stories as well as learning much more about the
iPhone. This week, the panelists compare how reflective their
iPhones' Apple logos are.</ p >
</ article >
</ body > 多くのページには、会社、組織、プロジェクト、バンド、ソフトウェアパッケージ、国などの 特定の主体を表すロゴ、記章、旗、または紋章が含まれます。
ロゴが、たとえばページ見出しとして主体を表すために使用されている場合、alt
属性には、ロゴによって表される主体の名前を含めなければなりません。alt
属性には「ロゴ」という語のようなテキストを含めてはなりません。伝えられているのは、
それがロゴであるという事実ではなく、主体そのものだからです。
ロゴが、それが表す主体の名前の隣で使用されている場合、ロゴは補足的なものであり、そのalt
属性は代わりに空でなければなりません。
ロゴが単に装飾素材として使用されている場合(ブランド表示として、または、たとえばロゴが属する 主体に言及する記事の脇の画像として)、純粋に装飾的な画像に関する以下の項目が適用されます。 ロゴ自体が実際に論じられている場合、それは代替のグラフィカル表現(ロゴ自体)を持つ句または段落 (ロゴの説明)として使用されており、上記の最初の項目が適用されます。
次の断片には、上記4つのすべての場合が示されています。最初に、会社を表すために使用される ロゴを示します:
< h1 > < img src = "XYZ.gif" alt = "The XYZ company" > </ h1 > 次に、会社名のすぐ隣でロゴを使用している段落を示します。そのため、代替テキストはありません:
< article >
< h2 > News</ h2 >
< p > We have recently been looking at buying the < img src = "alpha.gif"
alt = "" > ΑΒΓ company, a small Greek company
specializing in our type of product.</ p > この3番目の断片では、買収について論じるより大きな記事の一部として、ロゴがasideで 使用されています:
< aside >< p >< img src = "alpha-large.gif" alt = "" ></ p ></ aside >
< p > The ΑΒΓ company has had a good quarter, and our
pie chart studies of their accounts suggest a much bigger blue slice
than its green and orange slices, which is always a good sign.</ p >
</ article > 最後に、ロゴについて論じる論説があり、そのためロゴは代替テキストで詳細に説明されています。
< p > Consider for a moment their logo:</ p >
< p >< img src = "/images/logo" alt = "It consists of a green circle with a
green question mark centered inside it." ></ p >
< p > How unoriginal can you get? I mean, oooooh, a question mark, how
< em > revolutionary</ em > , how utterly < em > ground-breaking</ em > , I'm
sure everyone will rush to adopt those specifications now! They could
at least have tried for some sort of, I don't know, sequence of
rounded squares with varying shades of green and bold white outlines,
at least that would look good on the cover of a blue book.</ p > この例は、画像が利用可能でなく、代わりにテキストが使用される場合に、 そもそも画像が存在しなかったかのように、そのテキストが周囲のテキストへ途切れなく流れ込むよう、 代替テキストを記述すべきであることを示しています。
画像が単にテキストで構成され、その目的がテキストのレンダリングに使用された実際の組版効果を 強調することではなく、単にテキストそのものを伝えることである場合があります。
そのような場合、alt
属性は存在しなければならず、画像自体に記述されているものと同じテキストで構成されなければなりません。
「Earth Day」というテキストを含み、すべての文字が花や植物で装飾されたグラフィックを考えます。 テキストが単に見出しとして使用され、グラフィカルなユーザー向けにページを華やかにするだけであれば、 正しい代替テキストは単に同じ「Earth Day」というテキストであり、装飾について言及する必要は ありません:
< h1 > < img src = "earthdayheading.png" alt = "Earth Day" > </ h1 > 彩飾写本では、一部の文字にグラフィックを使用する場合があります。そのような状況における 代替テキストは、画像が表す文字そのものです。
< p >< img src = "initials/o.svg" alt = "O" > nce upon a time and a long long time ago, late at
night, when it was dark, over the hills, through the woods, across a great ocean, in a land far
away, in a small house, on a hill, under a full moon...外字、異体字、または新しい通貨記号など、Unicodeでは他の方法で表せない文字を表すために 画像が使用される場合、代替テキストは、たとえば文字の発音を示すひらがなまたはカタカナを使用するなど、 同じものをより一般的な方法で記述したものにするべきです。
1997年のこの例では、中央に1本ではなく2本の線がある、曲がったEのように見える新奇な 通貨記号が画像を使用して表されています。代替テキストは文字の発音を示します。
< p > Only < img src = "euro.png" alt = "euro " > 5.99!文字が同一の目的を果たせる場合、画像を使用するべきではありません。装飾のため、または適切な文字が 存在しないため(外字の場合など)、テキストを直接テキストとして表現できない場合に限り、 画像が適切です。
デフォルトのシステムフォントが特定の文字をサポートしないために作成者が画像を 使用したくなる場合、画像よりウェブフォントの方が優れた解決策です。
多くの場合、画像は実際には単なる補足であり、その存在は周囲のテキストを強調するだけです。
このような場合、alt
属性は存在しなければなりませんが、その値は空文字列でなければなりません。
一般に、画像を削除してもページの有用性が少しも低下せず、画像を含めることで視覚ブラウザーの ユーザーが概念をはるかに理解しやすくなる場合、その画像はこのカテゴリーに該当します。
前の段落をグラフィカルな形式で繰り返すフローチャート:
< p > The Network passes data to the Input Stream Preprocessor, which
passes it to the Tokenizer, which passes it to the Tree Construction
stage. From there, data goes to both the DOM and to Script Execution.
Script Execution is linked to the DOM, and, using document.write(),
passes data to the Tokenizer.</ p >
< p >< img src = "images/parsing-model-overview.svg" alt = "" ></ p > このような場合、単なるキャプションで構成される代替テキストを含めるのは誤りです。
キャプションを含める場合、title
属性を使用するか、figure
要素およびfigcaption
要素を使用できます。後者の場合、画像は実際には代替のグラフィカル表現を持つ句または段落となり、
したがって代替テキストが必要になります。
<!-- Using the title="" attribute -->
< p > The Network passes data to the Input Stream Preprocessor, which
passes it to the Tokenizer, which passes it to the Tree Construction
stage. From there, data goes to both the DOM and to Script Execution.
Script Execution is linked to the DOM, and, using document.write(),
passes data to the Tokenizer.</ p >
< p > < img src = "images/parsing-model-overview.svg" alt = ""
title = "Flowchart representation of the parsing model." > </ p > <!-- Using <figure> and <figcaption> -->
< p > The Network passes data to the Input Stream Preprocessor, which
passes it to the Tokenizer, which passes it to the Tree Construction
stage. From there, data goes to both the DOM and to Script Execution.
Script Execution is linked to the DOM, and, using document.write(),
passes data to the Tokenizer.</ p >
< figure >
< img src = "images/parsing-model-overview.svg" alt = "The Network leads to
the Input Stream Preprocessor, which leads to the Tokenizer, which
leads to the Tree Construction stage. The Tree Construction stage
leads to two items. The first is Script Execution, which leads via
document.write() back to the Tokenizer. The second item from which
Tree Construction leads is the DOM. The DOM is related to the Script
Execution." >
< figcaption > Flowchart representation of the parsing model.</ figcaption >
</ figure > <!-- This is WRONG. Do not do this. Instead, do what the above examples do. -->
< p > The Network passes data to the Input Stream Preprocessor, which
passes it to the Tokenizer, which passes it to the Tree Construction
stage. From there, data goes to both the DOM and to Script Execution.
Script Execution is linked to the DOM, and, using document.write(),
passes data to the Tokenizer.</ p >
< p >< img src = "images/parsing-model-overview.svg"
alt = "Flowchart representation of the parsing model." ></ p >
<!-- Never put the image's caption in the alt="" attribute! --> 前の段落をグラフィカルな形式で繰り返すグラフ:
< p > According to a study covering several billion pages,
about 62% of documents on the web in 2007 triggered the Quirks
rendering mode of web browsers, about 30% triggered the Almost
Standards mode, and about 9% triggered the Standards mode.</ p >
< p >< img src = "rendering-mode-pie-chart.png" alt = "" ></ p > 画像がコンテンツにとって重要ではないものの、純粋に装飾的でもテキストと完全に重複しているわけでも
ない場合があります。このような場合、alt属性は存在しなければならず、
その値は空文字列、または画像が伝える情報のテキストによる表現のいずれかにするべきです。画像に
そのタイトルを示すキャプションがある場合、alt
属性の値は空であってはなりません(空だと非視覚的な読者を大いに混乱させるためです)。
政治家についてのニュース記事で、その人物の顔が画像に表示されている場合を考えます。 画像は記事に関連するため、純粋に装飾的ではありません。政治家の外見を示すため、記事と完全に 重複しているわけでもありません。代替テキストを提供する必要があるかどうかは、画像が文章の解釈に 影響するかどうかによって決定される、作成者の判断です。
この最初の変形では、画像は文脈なしで表示され、代替テキストは提供されません:
< p > < img src = "president.jpeg" alt = "" > Ahead of today's referendum,
the President wrote an open letter to all registered voters. In it, she admitted that the country was
divided.</ p > 写真が単なる顔である場合、それを説明することに価値がない可能性があります。その人物が赤毛か 金髪か、白い肌か黒い肌か、片目か両目かは、読者にとって重要ではありません。
ただし、写真がより動的で、たとえば政治家が怒っている、特に幸せそうである、または打ちのめされて いる様子を示す場合、記事の調子を伝えるために何らかの代替テキストが役立ちます。その調子は、 そうでなければ見落とされる可能性があります:
< p > < img src = "president.jpeg" alt = "The President is sad." >
Ahead of today's referendum, the President wrote an open letter to all
registered voters. In it, she admitted that the country was divided.
</ p > < p > < img src = "president.jpeg" alt = "The President is happy!" >
Ahead of today's referendum, the President wrote an open letter to all
registered voters. In it, she admitted that the country was divided.
</ p > その人物が「悲しい」のか「幸せ」なのかは、段落の残りをどのように解釈するかに違いを もたらします。彼女は国が分裂していることを不幸に思っていると言っている可能性が高いのか、 それとも分裂した国という見通しが自身の政治的経歴にとって好都合だと言っているのか。 解釈は画像によって異なります。
画像にキャプションがある場合、代替テキストを含めることで、キャプションが何を指しているのか 非視覚的なユーザーが混乱することを避けられます。
< p > Ahead of today's referendum, the President wrote an open letter to
all registered voters. In it, she admitted that the country was divided.</ p >
< figure >
< img src = "president.jpeg"
alt = "A high forehead, cheerful disposition, and dark hair round out the President's face." >
< figcaption > The President of Ruritania. Photo © 2014 PolitiPhoto. </ figcaption >
</ figure > 画像が装飾的ではあるものの、特にページ固有ではない場合、たとえばサイト全体のデザイン体系の 一部を形成する画像の場合、その画像は文書のマークアップではなく、サイトのCSSで指定するべきです。
ただし、周囲のテキストでは論じられていないものの、何らかの関連性を持つ装飾画像は、img
要素を使用してページへ含められます。そのような画像は装飾的ですが、依然としてコンテンツの一部を
形成します。このような場合、alt
属性は存在しなければなりませんが、その値は空文字列でなければなりません。
関連性があるにもかかわらず画像が純粋に装飾的である例には、Burning Manのイベントに関する ブログ投稿内のBlack Rock Cityの風景写真や、詩を朗読するページ上の、その詩に着想を得た 絵画の画像などがあります。次の断片は後者の例を示します(この断片には最初の詩節のみが 含まれています):
< h1 > The Lady of Shalott</ h1 >
< p >< img src = "shalott.jpeg" alt = "" ></ p >
< p > On either side the river lie< br >
Long fields of barley and of rye,< br >
That clothe the wold and meet the sky;< br >
And through the field the road run by< br >
To many-tower'd Camelot;< br >
And up and down the people go,< br >
Gazing where the lilies blow< br >
Round an island there below,< br >
The island of Shalott.</ p > 1つの画像が複数の小さな画像ファイルに分割され、それらを一緒に表示して
再び完全な画像を形成する場合、画像のうち1つは、画像全体に適用される関連規則に従って、そのalt
属性を設定しなければならず、残りのすべての画像は、そのalt
属性を空文字列に設定しなければなりません。
次の例では、XYZ Corpの会社ロゴを表す画像が2つの部分に分割されており、最初の部分には「XYZ」という文字が、 2番目の部分には「Corp」という語が含まれています。代替テキスト(「XYZ Corp」)は、すべて最初の画像にあります。
< h1 > < img src = "logo1.png" alt = "XYZ Corp" >< img src = "logo2.png" alt = "" > </ h1 > 次の例では、評価が3つの塗りつぶされた星と2つの空の星で示されています。 代替テキストを「★★★☆☆」とすることもできましたが、作成者は 代わりに、より役立つよう「5段階中3」という形式で評価を示すことにしました。これは 最初の画像の代替テキストであり、残りの画像は空の代替テキストを持ちます。
< p > Rating: < meter max = 5 value = 3 > < img src = "1" alt = "3 out of 5"
>< img src = "1" alt = "" >< img src = "1" alt = "" >< img src = "0" alt = ""
>< img src = "0" alt = "" > </ meter ></ p > 一般に、リンクのために画像を分割する代わりに、イメージ マップを使用するべきです。
ただし、画像が実際に分割され、その分割画像の構成部分のいずれかが
リンクの唯一の内容である場合、リンクごとに1つの画像が、リンクの目的を表す代替テキストをそのalt
属性に持たなければなりません。
次の例では、空飛ぶスパゲッティ・モンスターの紋章を表す画像が、 左側の麺状の付属肢と右側の麺状の付属肢で別々の画像になっており、 ユーザーが冒険の中で左側または右側を選択できるようになっています。
< h1 > The Church</ h1 >
< p > You come across a flying spaghetti monster. Which side of His
Noodliness do you wish to reach out for?</ p >
< p >< a href = "?go=left" >< img src = "fsm-left.png" alt = "Left side. " ></ a
>< img src = "fsm-middle.png" alt = ""
>< a href = "?go=right" >< img src = "fsm-right.png" alt = "Right side." ></ a ></ p > 場合によっては、画像がコンテンツの不可欠な部分であることがあります。これは、たとえば フォトギャラリーの一部であるページなどに当てはまります。画像こそが、それを含むページの 主目的です。
コンテンツの重要な部分である画像に代替テキストを提供する方法は、 画像の由来によって異なります。
詳細な代替テキストを提供できる場合、たとえば画像が
雑誌レビューの一連のスクリーンショットの一部、漫画の一部、または
その写真について述べるブログ記事内の写真である場合、画像の代わりとして機能できるテキストを
alt属性の内容として指定しなければなりません。
新しいOSのスクリーンショットギャラリー内の、代替テキストを持つスクリーンショット:
< figure >
< img src = "KDE%20Light%20desktop.png"
alt = "The desktop is blue, with icons along the left hand side in
two columns, reading System, Home, K-Mail, etc. A window is
open showing that menus wrap to a second line if they
cannot fit in the window. The window has a list of icons
along the top, with an address bar below it, a list of
icons for tabs along the left edge, a status bar on the
bottom, and two panes in the middle. The desktop has a bar
at the bottom of the screen with a few buttons, a pager, a
list of open applications, and a clock." >
< figcaption > Screenshot of a KDE desktop.</ figcaption >
</ figure > 財務報告書内のグラフ:
< img src = "sales.gif"
title = "Sales graph"
alt = "From 1998 to 2005, sales increased by the following percentages
with each year: 624%, 75%, 138%, 40%, 35%, 9%, 21%" > 売上グラフの代替テキストとして「売上グラフ」では不十分であることに注意してください。 良いキャプションとなるテキストが、一般に代替テキストとして適切であるとは限りません。
場合によっては、画像の性質上、詳細な代替テキストを提供することが現実的でないことがあります。 たとえば、画像が不鮮明であったり、複雑なフラクタルであったり、 詳細な地形図であったりする場合です。
このような場合、alt
属性には適切な代替テキストを含めなければなりませんが、
多少簡潔であってもかまいません。
画像を十分に表現できるテキストが、単純に存在しない場合もあります。たとえば、 ロールシャッハ・インクブロット・テストを有用に説明するために言えることはほとんどありません。 ただし、簡潔であっても、説明がある方が何もないよりはましです:
< figure >
< img src = "/commons/a/a7/Rorschach1.jpg" alt = "A shape with left-right
symmetry with indistinct edges, with a small gap in the center, two
larger gaps offset slightly from the center, with two similar gaps
under them. The outline is wider in the top half than the bottom
half, with the sides extending upwards higher than the center, and
the center extending below the sides." >
< figcaption > A black outline of the first of the ten cards
in the Rorschach inkblot test.</ figcaption >
</ figure > 次の例は、代替テキストの非常に悪い使用方法であることに注意してください:
<!-- This example is wrong. Do not copy it. -->
< figure >
< img src = "/commons/a/a7/Rorschach1.jpg" alt = "A black outline
of the first of the ten cards in the Rorschach inkblot test." >
< figcaption > A black outline of the first of the ten cards
in the Rorschach inkblot test.</ figcaption >
</ figure > このようにキャプションを代替テキストへ含めることは役に立ちません。 画像を利用できないユーザーに対して実質的にキャプションを重複させ、 2回同じことを聞かせるだけで、キャプションを1度だけ読んだり聞いたりした場合より 役立つわけではないためです。
完全な説明が困難な画像の別の例は、定義上、細部が無限に続くフラクタルです。
次の例は、マンデルブロ集合の画像全体に対する代替テキストを提供する方法の1つを示します。
< img src = "ms1.jpeg" alt = "The Mandelbrot set appears as a cardioid with
its cusp on the real axis in the positive direction, with a smaller
bulb aligned along the same center line, touching it in the negative
direction, and with these two shapes being surrounded by smaller bulbs
of various sizes." > 同様に、人物の伝記などにおける顔写真は、 コンテンツに非常に関連し重要であると考えられますが、テキストで完全に代替することは困難です:
< section class = "bio" >
< h1 > A Biography of Isaac Asimov</ h1 >
< p > Born < b > Isaak Yudovich Ozimov</ b > in 1920, Isaac was a prolific author.</ p >
< p >< img src = "headpics/asimov.jpeg" alt = "Isaac Asimov had dark hair, a tall forehead, and wore glasses.
Later in life, he wore long white sideburns." ></ p >
< p > Asimov was born in Russia, and moved to the US when he was three years old.</ p >
< p > ...</ p >
</ section > このような場合、代替テキスト内で画像自体の存在に言及する必要はなく、 実際、そのような記述は推奨されません。ブラウザー自体が画像の存在を報告するため、 そのテキストは重複するからです。たとえば、代替テキストが「アイザック・アシモフの写真」であれば、 適合するユーザーエージェントは、より有用な「(画像)アイザック・アシモフは黒髪で、額が広く、 眼鏡をかけていました……」ではなく、「(画像)アイザック・アシモフの写真」と読み上げる可能性があります。
残念ながら、代替テキストをまったく利用できない場合があります。これは、 関連する代替テキストなしに何らかの自動的な方法で画像が取得されるため (たとえばウェブカメラ)、ユーザーが提供した画像を使用してスクリプトがページを生成しているものの ユーザーが適切または使用可能な代替テキストを提供しなかったため (たとえば写真共有サイト)、または作成者自身が画像が何を表すかを知らないため (たとえば視覚障害のある写真家がブログで画像を共有する場合)です。
このような場合、alt
属性を省略してもかまいませんが、さらに
次の条件のいずれかを満たさなければなりません:
img要素が、
要素間空白以外の内容を持つfigcaption
要素を含む
figure
要素内にあり、かつ、
figcaption
要素とその子孫を無視したとき、figure
要素が、要素間空白および
img要素以外の
フローコンテンツの子孫を
持たないこと。
title属性が
存在し、空でない値を持つこと。
title属性に依存することは、
多くのユーザーエージェントが、この仕様で要求されているようなアクセシブルな方法で
属性を公開していないため、現在は推奨されません(たとえばツールチップを表示するために
マウスなどのポインティングデバイスを必要とし、キーボードのみを使用するユーザーや、
最新の電話またはタブレットを使用する人など、タッチのみを使用するユーザーを除外します)。
このような場合は、絶対的な最小限に抑えなければなりません。作成者が
実際の代替テキストを提供できる可能性が少しでもある場合、alt属性を省略することは
許容されません。
写真共有サイト上の写真について、サイトがキャプション以外のメタデータを持たない画像を 受信した場合、次のようにマークアップできます:
< figure >
< img src = "1100670787_6a7c664aef.jpg" >
< figcaption > Bubbles traveled everywhere with us.</ figcaption >
</ figure > ただし、画像の重要な部分に関する詳細な説明をユーザーから取得し、 ページに含める方が望ましいでしょう。
視覚障害のあるユーザーのブログに、そのユーザーが撮影した写真が表示される場合。 当初、ユーザーは自分が撮影した写真に何が写っているかまったく分からない可能性があります:
< article >
< h1 > I took a photo</ h1 >
< p > I went out today and took a photo!</ p >
< figure >
< img src = "photo2.jpeg" >
< figcaption > A photograph taken blindly from my front porch.</ figcaption >
</ figure >
</ article > ただし、最終的には、ユーザーが友人から画像の説明を得て、 代替テキストを含められるようになる可能性があります:
< article >
< h1 > I took a photo</ h1 >
< p > I went out today and took a photo!</ p >
< figure >
< img src = "photo2.jpeg" alt = "The photograph shows my squirrel
feeder hanging from the edge of my roof. It is half full, but there
are no squirrels around. In the background, out-of-focus trees fill the
shot. The feeder is made of wood with a metal grate, and it contains
peanuts. The edge of the roof is wooden too, and is painted white
with light blue streaks." >
< figcaption > A photograph taken blindly from my front porch.</ figcaption >
</ figure >
</ article > 画像の要点そのものが、テキストによる説明を利用できず、
ユーザーが説明を提供することにある場合もあります。たとえば、CAPTCHA画像の目的は、
ユーザーが実際にグラフィックを読めるかどうかを確認することです。CAPTCHAをマークアップする
方法の1つを次に示します(title属性に注意してください):
< p >< label > What does this image say?
< img src = "captcha.cgi?id=8934" title = "CAPTCHA" >
< input type = text name = captcha ></ label >
(If you cannot see the image, you can use an < a
href = "?audio" > audio</ a > test instead.)</ p > 別の例として、正しい代替テキストを持つページを作成することを目的として、 画像を表示し、代替テキストの入力を求めるソフトウェアがあります。このようなページは、 次のような画像の表を持つことができます:
< table >
< thead >
< tr > < th > Image < th > Description
< tbody >
< tr >
< td > < img src = "2421.png" title = "Image 640 by 100, filename 'banner.gif'" >
< td > < input name = "alt2421" >
< tr >
< td > < img src = "2422.png" title = "Image 200 by 480, filename 'ad3.gif'" >
< td > < input name = "alt2422" >
</ table > この例でも、可能な限り多くの有用な情報が、依然としてtitle属性に
含まれていることに注意してください。
一部のユーザーは画像をまったく利用できないため
(たとえば接続が非常に遅い、テキスト専用ブラウザーを使用している、
ハンズフリーの自動車用音声ウェブブラウザーによるページの読み上げを聞いている、
または単に視覚障害があるため)、alt属性を
代替テキストとともに提供する代わりに省略することが許可されるのは、上記の例のように、
代替テキストを利用できず、かつ利用可能にすることもできない場合に限られます。作成者が
努力を怠ったことは、alt属性を省略する
許容可能な理由ではありません。
一般に、作成者は画像を表示する以外の目的でimg要素を
使用することを避けるべきです。
img
要素が画像を表示する以外の目的、たとえば
ページビューを数えるサービスの一部として使用される場合、alt属性は
空文字列でなければなりません。
このような場合、width属性とheight属性は、
どちらも0に設定するべきです。
この節は、一般にアクセス可能な文書、またはウェブサイト上の文書、 公開メーリングリストに送信されるメール、ソフトウェア文書など、 対象読者が必ずしも作成者に個人的に知られているわけではない文書には適用されません。
画像を表示できることが分かっている特定の人物を対象とする
私的な通信(HTMLメールなど)に画像が含まれる場合、alt
属性を省略してもかまいません。ただし、このような場合でも、画像をサポートしないメールクライアントを
ユーザーが使用する場合、または文書が画像を容易に見ることができない他のユーザーへ転送される場合でも
メールを使用できるようにするため、作成者には代替テキスト
(上記の項目で説明した、関係する画像の種類に応じて適切なもの)を含めることを強く推奨します。
マークアップ生成器(WYSIWYG作成ツールなど)は、可能な限り、 ユーザーから代替テキストを取得するべきです。ただし、多くの場合、 それが不可能であることも認識されています。
リンクの唯一の内容である画像について、マークアップ生成器はリンク先を調べ、 リンク先のタイトルまたはURLを判断し、この方法で取得した情報を 代替テキストとして使用するべきです。
キャプションを持つ画像について、マークアップ生成器はfigure要素と
figcaption
要素、またはtitle
属性を使用して、
画像のキャプションを提供するべきです。
最後の手段として、実装者は、画像が情報を何も追加しないものの周囲のコンテンツに固有である
純粋に装飾的な画像であると仮定して、alt
属性を空文字列に設定するか、画像がコンテンツの重要な部分であると仮定して、
alt属性を
完全に省略するべきです。
マークアップ生成器は、代替テキストを取得できず、そのためalt属性を省略した
img
要素に、generator-unable-to-provide-required-alt
属性を指定してもかまいません。この属性の値は空文字列でなければなりません。このような属性を含む文書は
適合しませんが、適合性チェッカーはこのエラーを黙って
無視します。
これは、最新の自動適合性チェッカーが偽の代替テキストと正しい代替テキストを
区別できないため、マークアップ生成器がalt属性を省略する
エラーを、偽の代替テキストを提供するというさらに
悪質なエラーに置き換えるよう圧力を受けることを避けるためのものです。
マークアップ生成器は一般に、画像自体のファイル名を代替テキストとして使用することを 避けるべきです。同様に、マークアップ生成器は、表示用ユーザーエージェント (たとえばウェブブラウザー)でも同じように利用できる内容から代替テキストを生成することを 避けるべきです。
これは、ページが一度生成されると通常は更新されない一方、 後でページを読み取るブラウザーはユーザーによって更新できるため、 ブラウザーの方が、マークアップ生成器がページを生成した時点よりも 最新かつ精密に調整されたヒューリスティックを持つ可能性が高いためです。
適合性チェッカーは、次に示す条件のいずれかが適用されない限り、alt
属性がないことをエラーとして報告しなければなりません:
適合性チェッカーが、文書を、画像を表示できることが分かっている特定の人物向けの メールまたは文書であると仮定するよう設定されている。
img
要素が、値が空文字列である(不適合な)generator-unable-to-provide-required-alt
属性を持つ。alt
属性がないことをエラーとして報告しない適合性チェッカーは、
空のgenerator-unable-to-provide-required-alt
属性が存在することもエラーとして報告してはなりません。(この場合は、文書が適合している場合を
表すものではなく、生成器が適切な代替テキストを判断できなかったことのみを表します。
バリデーターはこの場合にエラーを表示する必要はありません。そのようなエラーは、
バリデーターを黙らせることのみを目的として、マークアップ生成器が偽の代替テキストを
含めることを助長する可能性があるためです。当然、適合性チェッカーは、generator-unable-to-provide-required-alt
属性が存在する場合でも、alt属性がないことを
エラーとして報告してもかまいません。たとえば、マークアップ生成器を使用したことによる
多かれ少なかれ避けられない結果である可能性のあるものも含め、すべての適合性エラーを
報告するユーザーオプションが存在する場合があります。)
iframe要素
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
src — リソースの
アドレス
srcdoc — iframe内で
レンダリングする文書
name — コンテンツナビガブルの名前
sandbox — 入れ子の
コンテンツに対するセキュリティ規則
allow — iframeの内容に適用される権限
ポリシー
allowfullscreen
— iframeの内容による
requestFullscreen()の使用を
許可するかどうか
width — 水平方向の寸法
height — 垂直方向の寸法
referrerpolicy
— 要素によって開始されるフェッチに対するリファラーポリシー
loading — 読み込みの
延期を決定するときに使用
[Exposed =Window ]
interface HTMLIFrameElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , ReflectURL ] attribute USVString src ;
[CEReactions ] attribute (TrustedHTML or DOMString ) srcdoc ;
[CEReactions , Reflect ] attribute DOMString name ;
[SameObject , PutForwards =value , Reflect ] readonly attribute DOMTokenList sandbox ;
[CEReactions , Reflect ] attribute DOMString allow ;
[CEReactions , Reflect ] attribute boolean allowFullscreen ;
[CEReactions , Reflect ] attribute DOMString width ;
[CEReactions , Reflect ] attribute DOMString height ;
[CEReactions ] attribute DOMString referrerPolicy ;
[CEReactions ] attribute DOMString loading ;
readonly attribute Document ? contentDocument ;
readonly attribute WindowProxy ? contentWindow ;
Document ? getSVGDocument ();
// also has obsolete members
};iframe要素は、そのコンテンツナビガブルを表します。
src属性は、
要素のコンテンツナビガブルに
含めるページのURLを指定します。この属性が存在する場合、空白で囲まれている可能性がある
妥当な空でない
URLでなければなりません。itemprop
属性が
iframe要素に指定されている場合、
src属性も
指定しなければなりません。
現在のすべてのエンジンでサポートされています。
srcdoc
属性は、要素のコンテンツナビガブルに
含めるページの内容を指定します。属性の値は、Documentであり、
そのURLがabout:srcdocに一致するiframe srcdoc文書を構築するために使用されます。
上記の要件は、XML文書にも適用されます。
ここではブログが、以下で説明するsandbox
属性と組み合わせてsrcdoc属性を使用し、
この機能をサポートするユーザーエージェントのユーザーに対して、ブログ投稿のコメント内の
スクリプトインジェクションからの追加の保護層を提供しています:
< article >
< h1 > I got my own magazine!</ h1 >
< p > After much effort, I've finally found a publisher, and so now I
have my own magazine! Isn't that awesome?! The first issue will come
out in September, and we have articles about getting food, and about
getting in boxes, it's going to be great!</ p >
< footer >
< p > Written by < a href = "/users/cap" > cap</ a > , 1 hour ago.
</ footer >
< article >
< footer > Thirteen minutes ago, < a href = "/users/ch" > ch</ a > wrote: </ footer >
< iframe sandbox srcdoc = "<p>did you get a cover picture yet?" ></ iframe >
</ article >
< article >
< footer > Nine minutes ago, < a href = "/users/cap" > cap</ a > wrote: </ footer >
< iframe sandbox srcdoc = "<p>Yeah, you can see it <a href="/gallery?mode=cover&amp;page=1">in my gallery</a>." ></ iframe >
</ article >
< article >
< footer > Five minutes ago, < a href = "/users/ch" > ch</ a > wrote: </ footer >
< iframe sandbox srcdoc = "<p>hey that's earl's table.
<p>you should get earl&amp;me on the next cover." ></ iframe >
</ article > 引用符をエスケープする必要があること(そうしないとsrcdoc属性が
途中で終了します)、およびサンドボックス化された内容内で言及される生の
アンパサンド(たとえばURLまたは文章内のもの)を
二重にエスケープする必要があることに注意してください。最初は、
srcdoc属性を
最初に解析するときにアンパサンドを保持するためであり、もう1回は、
サンドボックス化された内容を解析するときにアンパサンドが誤って解釈されることを防ぐためです。
さらに、iframe
srcdoc文書ではDOCTYPE
が任意であり、html、
head、およびbody要素には省略可能な
開始タグと終了タグがあり、iframe
srcdoc
文書ではtitle要素も任意であるため、
srcdoc属性内の
マークアップは、文書全体を表すにもかかわらず比較的簡潔にできます。構文上、文字どおりに現れる必要があるのは
body要素の内容だけだからです。
その他の要素も依然として
存在しますが、暗黙的に存在するだけです。
HTML構文では、作成者は、
属性の内容を囲むためにU+0022
QUOTATION MARK文字(")を使用し、すべてのU+0026
AMPERSAND(&)文字とU+0022 QUOTATION MARK(")文字をエスケープし、さらにsandbox属性を指定して、
内容を安全に埋め込むことだけを覚えておけばよいです。(また、
引用符が&quot;ではなく"となるように、引用符より先にアンパサンドを
エスケープすることを忘れないでください。)
XMLでは、U+003C LESS-THAN SIGN文字(<)もエスケープする必要があります。 属性値の 正規化を防ぐため、XMLの空白文字の一部、具体的にはU+0009 CHARACTER TABULATION(タブ)、U+000A LINE FEED(LF)、およびU+000D CARRIAGE RETURN(CR)も エスケープする必要があります。[XML]
src
属性とsrcdoc
属性が両方とも指定された場合、srcdoc属性が
優先されます。これにより作成者は、srcdoc属性をサポートしない
旧来のユーザーエージェント向けに、フォールバックとなるURLを提供できます。
insertedNodeが与えられたとき、iframeのHTML
要素接続後手順は
次のとおりです:
insertedNodeがsandbox
属性を持つ場合、その属性の値とinsertedNodeの
iframe
サンドボックスフラグ集合を指定して、サンドボックス化
ディレクティブを解析します。
insertedNodeのために新しい 子ナビガブルを作成します。
initialInsertionをtrueに設定して、
insertedNodeの
iframe属性を処理します。
removedNodeが与えられたとき、iframeのHTML要素削除
手順は、
removedNodeを指定して子ナビガブルを破棄することです。
これは、unloadイベントが一切発火することなく
発生します(要素のコンテンツ
文書は、アンロードされるのではなく、破棄されます)。
上記のとおり、iframeは
シャドウツリー内にある間も処理されますが、
その動作の他のいくつかの側面は、シャドウツリーに関して十分に定義されていません。
詳細については、issue #763を参照してください。
nullでないコンテンツ
ナビガブルを持つiframe
要素の
srcdoc属性が設定、
変更、または削除されるたびに、ユーザー
エージェントはiframe属性を処理しなければなりません。
同様に、nullでないコンテンツ
ナビガブルを持つものの、srcdoc属性が
指定されていないiframe要素の
src属性が設定、
変更、または削除されるたびに、ユーザー
エージェントはiframe属性を処理しなければなりません。
要素elementについて、任意のブール値initialInsertion
(デフォルトは
false)を使用して、iframe属性を処理するには:
elementのsrcdoc属性が
指定されている場合:
elementの現在のナビゲーションは遅延読み込みされた ブール値を falseに設定します。
elementを指定した要素を 遅延読み込みするかどうかの手順がtrueを返す場合:
elementの遅延読み込み再開手順を、 srcdocリソースへナビゲートとラベル付けされた手順から始まる、この アルゴリズムの残りに設定します。
elementの現在のナビゲーションは遅延読み込みされた ブール値を trueに設定します。
elementについて遅延読み込み要素の 交差監視を開始します。
返します。
srcdocリソースへナビゲート:element、about:srcdoc、空文字列、
およびelementのsrcdoc
属性の値を指定して、iframeまたは
frameをナビゲートします。
結果のDocumentは、
iframe
srcdoc文書と見なさなければなりません。
それ以外の場合:
urlを、elementおよび
initialInsertionを指定してiframe要素と
frame要素に共通する属性処理
手順を実行した結果とします。
urlがnullの場合、返します。
urlが
about:blankに一致し、
initialInsertionがtrueの場合:
elementを指定してiframe loadイベント手順を実行します。
返します。
referrerPolicyを、elementのreferrerpolicy
コンテンツ属性の現在の状態とします。
elementの現在のナビゲーションは遅延読み込みされた ブール値を falseに設定します。
elementを指定した要素を遅延読み込みするかどうかの手順が trueを返す場合:
elementの遅延読み込み再開手順を、 ナビゲートとラベル付けされた手順から始まる、この アルゴリズムの残りに設定します。
elementの現在のナビゲーションは遅延読み込みされた ブール値を trueに設定します。
elementについて遅延読み込み要素の 交差監視を開始します。
返します。
ナビゲート:element、url、および
referrerPolicyを指定して、iframeまたは
frameをナビゲートします。
要素
elementとブール値initialInsertionが与えられたとき、iframe要素と
frame要素に共通する属性処理手順は次のとおりです:
urlを、URLレコードabout:blankとします。
elementにsrc属性が指定されており、
その値が空文字列でない場合:
maybeURLを、その属性の値を指定し、 elementのノード 文書を基準としてURLをエンコーディング解析した結果とします。
maybeURLが失敗でない場合、urlを maybeURLに設定します。
elementのノード ナビガブルの包括的祖先ナビガブルに、 そのアクティブ 文書のURLが、 フラグメントを除外をtrueに設定して urlと等しいナビガブルが含まれる場合、 nullを返します。
urlが
about:blankに一致し、
initialInsertionがtrueの場合、elementのコンテンツ
ナビガブルのアクティブ
文書とurlを指定して、URLおよび履歴更新手順を実行します。
これは、urlがabout:blank?fooのようなものである場合に必要です。
urlが単なるabout:blankであれば、これは何もしません。
urlを返します。
要素
element、URLurl、リファラーポリシー
referrerPolicy、任意の文字列またはnullのsrcdocString(デフォルトは
null)、および任意のブール値initialInsertion(デフォルトはfalse)が与えられたとき、
iframeまたはframeをナビゲートするには:
historyHandlingを「auto」とします。
elementのコンテンツ
ナビガブルのアクティブ文書が完全に読み込まれていない場合、
historyHandlingを「replace」に設定します。
elementがiframeである場合:
elementの保留中のリソースタイミング開始時刻を、 elementの ノード文書の関連するグローバルオブジェクトを指定した 現在の高分解能時刻に設定します。
elementの保留中のリソースタイミングURLを urlに設定します。
elementのノード文書を 使用して、elementのコンテンツ ナビガブルをurlへナビゲートし、 historyHandlingを historyHandlingに、referrerPolicyをreferrerPolicyに、documentResourceを srcdocStringに、initialInsertionをinitialInsertionに設定します。
各Documentは、iframe読み込み進行中フラグとiframe
読み込み抑制フラグを持ちます。Documentが
作成されるとき、これらのフラグは、その
Documentについて設定解除されなければなりません。
iframe要素
elementが与えられたとき、iframe loadイベント手順を実行するには:
表明:elementのコンテンツナビガブルは nullではありません。
childDocumentを、elementのコンテンツナビガブルの アクティブ文書とします。
childDocumentのiframe 読み込み抑制フラグが設定されている場合、 返します。
elementの保留中のリソースタイミング開始時刻が nullでない場合:
表明:elementの保留中のリソースタイミングURLは nullではありません。
globalを、elementのノード 文書の 関連するグローバル オブジェクトとします。
fallbackTimingInfoを、その開始時刻がelementの保留中のリソースタイミング開始 時刻であり、その応答 終了時刻が、globalを指定した 現在の高分解能時刻である、新しいフェッチタイミング情報とします。
fallbackTimingInfo、elementの
保留中のリソースタイミングURLを解析した結果、
「iframe」、
global、空文字列、新しい
応答本文情報、および0を指定して、リソースタイミングを記録します。
elementの保留中のリソースタイミング開始 時刻を nullに設定します。
elementの保留中のリソースタイミングURLを nullに設定します。
childDocumentのiframe読み込み進行中フラグを設定します。
childDocumentのiframe読み込み進行中フラグを設定解除します。
これはスクリプトと組み合わせることで、ローカルネットワーク上の HTTPサーバーのURL空間を調査するために使用できます。ユーザーエージェントは、この攻撃を軽減するため、 上記よりも厳格なクロスオリジン アクセス制御ポリシーを実装してもかまいませんが、残念ながら、そのようなポリシーは通常、 既存のウェブコンテンツと互換性がありません。
要素型がloadイベントを遅延させる可能性がある場合、 その型の各要素 elementについて、elementのコンテンツ ナビガブルがnullでなく、次のいずれかがtrueである場合、ユーザーエージェントは elementのノード文書のloadイベントを遅延させなければなりません:
elementのコンテンツ ナビガブルのアクティブ 文書が読み込み後タスクの準備ができていない;
elementのコンテンツ
ナビガブルの
loadイベントを遅延させているがtrueである;または
何かが、elementのコンテンツ ナビガブルのアクティブ 文書のload イベントを遅延させている。
loadイベントの処理中に、
elementのコンテンツ
ナビガブルが再びナビゲートされた場合、
それによってさらにloadイベントが遅延します。
各iframe要素は、
初期値がfalseである、関連付けられた現在のナビゲーションは遅延
読み込みされたブール値を持ちます。これはiframe属性を
処理するアルゴリズムで設定および設定解除されます。
現在のナビゲーションは遅延読み込みされたブール値が
falseであるiframe要素は、
loadイベントを遅延させる可能性があります。
各 iframe 要素には、
null または
DOMHighResTimeStamp である、関連付けられた 保留中のリソースタイミング開始時刻があり、
初期状態では null に設定される。
各iframe要素は、
初期値がnullである、関連付けられたnullまたは
URLの保留中のリソースタイミングURLを持ちます。
要素が作成されたとき、srcdoc属性が
設定されておらず、src属性も
設定されていないか、設定されていてもその値を解析できない場合、
要素のコンテンツ
ナビガブルは、初期
about:blankのDocumentに
とどまります。
ユーザーがこのページから別の場所へナビゲートした場合、
iframeのコンテンツナビガブルのアクティブな
WindowProxyオブジェクトは、新しい
Documentオブジェクトに対する新しいWindowオブジェクトをプロキシしますが、
src属性は
変更されません。
name
属性が存在する場合、妥当なナビガブルターゲット名でなければなりません。
指定された値は、要素のコンテンツ
ナビガブルが作成されるときに存在する場合、
その名前として使用されます。
現在のすべてのエンジンでサポートされています。
このsandbox
属性は、指定されると、iframeによってホストされるすべてのコンテンツに対して追加の制限一式を
有効にします。その値は、一意なスペース区切り
トークンの順序なし集合でなければならず、トークンはASCII
大文字・小文字不区別です。許可される値は次のとおりです:
allow-downloads
allow-forms
allow-modals
allow-orientation-lock
allow-pointer-lock
allow-popups
allow-popups-to-escape-sandbox
allow-presentation
allow-same-origin
allow-scripts
allow-top-navigation
allow-top-navigation-by-user-activation
allow-top-navigation-to-custom-protocols
この属性が設定されると、コンテンツは一意な不透明オリジンからのものとして扱われ、フォーム、
スクリプト、および迷惑となる可能性のあるさまざまなAPIが無効になり、リンクが他のナビガブルをターゲットにすることが防止されます。allow-same-origin
キーワードは、コンテンツを不透明オリジンへ強制する代わりに、
実際のオリジンからのものとして扱わせます;allow-top-navigation
キーワードは、コンテンツがその走査可能なナビガブルをナビゲートすることを許可します;
allow-top-navigation-by-user-activation
キーワードも同様に動作しますが、閲覧コンテキストのアクティブウィンドウが一時的
活性化を持つ場合に限り、そのようなナビゲーションを許可します;allow-top-navigation-to-custom-protocols
は、非フェッチスキームへの
ナビゲーションが外部ソフトウェアへ
引き渡されることを再び有効にします;また、allow-forms、
allow-modals、
allow-orientation-lock、
allow-pointer-lock、
allow-popups、
allow-presentation、
allow-scripts、
およびallow-popups-to-escape-sandbox
キーワードは、それぞれフォーム、モーダルダイアログ、画面方向のロック、ポインターロックAPI、
ポップアップ、プレゼンテーションAPI、スクリプト、およびサンドボックス化されていない補助閲覧コンテキストの作成を再び有効にします。allow-downloads
キーワードは、コンテンツが
ダウンロードを実行することを許可します。[POINTERLOCK] [SCREENORIENTATION] [PRESENTATION]
allow-top-navigation
およびallow-top-navigation-by-user-activation
キーワードを両方指定してはなりません。そうすることは冗長であるためです;そのような不適合な
マークアップでは、allow-top-navigation
のみが効果を
持ちます。
同様に、allow-top-navigation-to-custom-protocols
キーワードは、allow-top-navigation
またはallow-popups
のいずれかが指定されている場合、指定してはなりません。そうすることは
冗長であるためです。
サンドボックス化されたコンテンツ内でalert()、confirm()、およびprompt()を許可するには、allow-modals
およびallow-same-origin
の両方のキーワードを
指定する必要があり、読み込まれるURLはトップレベル
オリジンと同一
オリジンである必要があります。allow-same-origin
キーワードがない場合、コンテンツは
常にクロスオリジンとして扱われ、クロスオリジンコンテンツは単純
ダイアログを表示できません。
埋め込まれたページがiframeを含むページと
同一オリジンである場合に、allow-scripts
およびallow-same-origin
キーワードを一緒に設定すると、
埋め込まれたページは単にsandbox
属性を削除してから自身を再読み込みでき、事実上サンドボックスから完全に脱出できます。
これらのフラグは、iframe要素のコンテンツナビガブルがナビゲートされるときにのみ効果を持ちます。
これらを削除すること、またはsandbox属性全体を
削除することは、すでに読み込まれたページには
影響しません。
敵対的である可能性のあるファイルは、iframe要素を含む
ファイルと同じサーバーから提供するべきではありません。攻撃者が、敵対的なコンテンツをiframe内ではなく
直接訪問するようユーザーを説得できる場合、敵対的なコンテンツをサンドボックス化しても
ほとんど役に立ちません。敵対的なHTMLコンテンツによって引き起こされ得る損害を制限するため、
そのコンテンツは専用の別ドメインから提供するべきです。異なるドメインを使用することで、
ユーザーがだまされて、sandbox属性による
保護なしにそれらのページを直接訪問した場合でも、ファイル内のスクリプトがサイトを攻撃できなくなります。
非nullのコンテンツナビガブルを持つ間に、iframe要素のsandbox属性が設定または
変更された場合、ユーザーエージェントは、その属性値とiframe要素のiframe
サンドボックス化フラグ集合を指定して、サンドボックス化指令を
解析しなければなりません。
非nullのコンテンツナビガブルを持つ間に、iframe要素のsandbox属性が
削除された場合、ユーザーエージェントは、iframe要素のiframeサンドボックス化フラグ集合を
空にしなければなりません。
この例では、内容が完全に不明で、敵対的である可能性のあるユーザー提供のHTMLコンテンツが ページに埋め込まれています。別のドメインから提供されるため、通常のすべてのクロスサイト制限の 影響を受けます。さらに、埋め込まれたページではスクリプト、プラグイン、およびフォームが無効化され、 自身以外のフレームまたはウィンドウ(あるいは自身が埋め込んだフレームまたはウィンドウ)を ナビゲートできません。
< p > We're not scared of you! Here is your content, unedited:</ p >
< iframe sandbox src = "https://usercontent.example.net/getusercontent.cgi?id=12193" ></ iframe > 別のドメインを使用することが重要です。攻撃者がそのページを直接訪問するよう ユーザーを説得した場合でも、そのページがサイトのオリジンのコンテキストで実行されず、 ページ内で見つかった攻撃に対してユーザーが脆弱にならないようにするためです。
この例では、別のサイトのガジェットが埋め込まれています。このガジェットではスクリプトと フォームが有効であり、オリジンに関するサンドボックス制限も解除されているため、ガジェットは 元のサーバーと通信できます。それでもサンドボックスは、プラグインとポップアップを無効にし、 ユーザーがマルウェアやその他の迷惑行為にさらされる危険を減らすため、有用です。
< iframe sandbox = "allow-same-origin allow-forms allow-scripts"
src = "https://maps.example.com/embedded.html" ></ iframe > ファイルAに次の断片が含まれているとします:
< iframe sandbox = "allow-same-origin allow-forms" src = B ></ iframe > ファイルBにもiframeが含まれているとします:
< iframe sandbox = "allow-scripts" src = C ></ iframe > さらに、ファイルCにリンクが含まれているとします:
< a href = D > Link</ a > この例では、すべてのファイルがtext/htmlとして提供されるものとします。
このシナリオのページCでは、すべてのサンドボックス化フラグが設定されています。スクリプトは
無効です。これは、A内のiframeで
スクリプトが無効にされており、B内のiframeに設定された
allow-scripts
キーワードよりも優先されるためです。フォームも無効です。これは、内側のiframe(B内)に
allow-forms
キーワードが
設定されていないためです。
ここで、A内のスクリプトがAおよびB内のすべてのsandbox属性を
削除するとします。
これによって直ちに何かが変化することはありません。ユーザーがC内のリンクをクリックして、
ページDがB内のiframeへ読み込まれると、
ページDは、B内のiframeに
allow-same-origin
およびallow-forms
キーワードが設定されているかのように動作します。これは、ページBが
読み込まれた時点で、A内のiframeにあるコンテンツナビガブルがその状態で
あったためです。
一般に、sandbox属性を動的に
削除または変更することは推奨されません。何が許可され、何が許可されないかを判断することが非常に
困難になる可能性があるためです。
このallow
属性は、指定されると、iframeのコンテンツナビガブル内の
Documentについて権限ポリシーが初期化されるときに使用される
コンテナー
ポリシーを決定します。その値は、シリアル化された権限
ポリシーでなければなりません。[PERMISSIONSPOLICY]
この例では、iframeを使用して、
オンラインナビゲーションサービスの地図を埋め込んでいます。allow属性を使用して、
入れ子になったコンテキスト内でGeolocation APIを有効にしています。
< iframe src = "https://maps.example.com/" allow = "geolocation" ></ iframe > このallowfullscreen属性はブール
属性です。指定されると、iframe要素のコンテンツナビガブル内の
Documentオブジェクトが、任意のオリジンから
「fullscreen」機能を使用できるようにする権限ポリシーで初期化されることを示します。
これは、権限ポリシー
属性を処理するアルゴリズムによって強制されます。[PERMISSIONSPOLICY]
ここでは、iframeを使用して、動画サイトのプレーヤーを埋め込んでいます。allowfullscreen
属性は、プレーヤーが動画を全画面表示できるようにするために必要です。
< article >
< header >
< p >< img src = "/usericons/1627591962735" > < b > Fred Flintstone</ b ></ p >
< p >< a href = "/posts/3095182851" rel = bookmark > 12:44</ a > — < a href = "#acl-3095182851" > Private Post</ a ></ p >
</ header >
< p > Check out my new ride!</ p >
< iframe src = "https://video.example.com/embed?id=92469812" allowfullscreen ></ iframe >
</ article > allowもallowfullscreen
も、iframe要素のコンテンツナビガブル内の機能へのアクセスを、その要素のノード
文書がその機能の使用をまだ許可されていない場合に付与することはできません。
Documentオブジェクト
documentが、ポリシー制御機能featureの使用を許可されているかどうかを判断するには、次の
手順を実行します:
documentの閲覧 コンテキストがnullの場合、falseを返します。
documentが完全にアクティブでない場合、 falseを返します。
feature、document、およびdocumentのオリジンについて、オリジンについて文書内で
機能が有効かを実行した結果が「Enabled」の場合、
trueを返します。
falseを返します。
allow属性とallowfullscreen
属性は、iframeのコンテンツナビガブルのアクティブ文書の権限ポリシーにのみ影響するため、
コンテンツ
ナビガブルがナビゲートされるときにのみ
効果を持ちます。これらを追加または削除しても、すでに読み込まれた
文書には影響しません。
このiframe要素は、埋め込まれたコンテンツが特定の寸法を持つ場合
(たとえば、広告ユニットは明確に定義された寸法を持ちます)のために、寸法属性をサポートします。
iframe要素は、指定された初期コンテンツが正常に使用されるか
どうかにかかわらず、常に新しい子
ナビガブルを作成するため、フォールバックコンテンツを持つことはありません。
このreferrerpolicy属性は、
リファラーポリシー
属性です。その目的は、iframe
属性を処理するときに使用されるリファラー
ポリシーを設定するとともに、内部祖先オリジンオブジェクトリスト
作成手順において、一部のオリジンのマスクを可能にすることです。[REFERRERPOLICY]
このloading属性は、遅延
読み込み属性です。その目的は、ビューポートの外側にあるiframe
要素を読み込むためのポリシーを示すことです。
loading属性の状態が即時状態へ変更された場合、
ユーザーエージェントは次の
手順を実行しなければなりません:
resumptionStepsを、iframe要素の遅延読み込み
再開手順とします。
resumptionStepsがnullの場合、返します。
iframeの遅延読み込み
再開手順をnullに設定します。
resumptionStepsを呼び出します。
iframe要素の子孫は何も表しません。(iframe要素を
サポートしない旧来のユーザーエージェントでは、その内容はフォールバックコンテンツとして機能し得る
マークアップとして解析されます。)
HTMLパーサーは、iframe要素内の
マークアップをテキストとして扱います。
現在のすべてのエンジンでサポートされています。
このsrcdocの取得手順は次のとおりです:
attributeを、null、srcdocのローカル
名、およびthisを指定して、名前空間とローカル
名で属性を取得する結果とします。
attributeがnullの場合、空文字列を返します。
attributeの値を返します。
srcdocの設定手順は
次のとおりです:
compliantStringを、TrustedHTML、
thisの関連するグローバル
オブジェクト、指定された値、「HTMLIFrameElement srcdoc」、および
「script」を使用して、Trusted Type
準拠文字列を取得するアルゴリズムを呼び出した結果とします。
sandboxのDOMTokenListについてサポートされるトークンは、sandbox属性で定義され、
ユーザーエージェントによってサポートされる許可された
値です。
HTMLIFrameElement/referrerPolicy
現在のすべてのエンジンでサポートされています。
このreferrerPolicy IDL属性は、referrerpolicy
コンテンツ
属性を、既知の値のみに
制限して反映しなければなりません。
このloading IDL属性は、loadingコンテンツ
属性を、既知の
値のみに制限して反映しなければなりません。
HTMLIFrameElement/contentDocument
現在のすべてのエンジンでサポートされています。
HTMLIFrameElement/contentWindow
現在のすべてのエンジンでサポートされています。
このcontentWindowの取得手順は、thisのコンテンツウィンドウを返すことです。
次は、広告仲介業者からの広告を含めるためにiframeを使用する
ページの例です:
< iframe src = "https://ads.example.com/?customerid=923513721&format=banner"
width = "468" height = "60" ></ iframe > embed
要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
src — リソースのアドレス
type — 埋め込まれる
リソースの種別
width — 水平方向の寸法
height — 垂直方向の寸法
[Exposed =Window ]
interface HTMLEmbedElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , ReflectURL ] attribute USVString src ;
[CEReactions , Reflect ] attribute DOMString type ;
[CEReactions , Reflect ] attribute DOMString width ;
[CEReactions , Reflect ] attribute DOMString height ;
Document ? getSVGDocument ();
// also has obsolete members
};embed要素は、
外部アプリケーションまたはインタラクティブコンテンツの統合点を提供します。
src属性は、
埋め込まれるリソースのURLを示します。この属性が存在する場合、その値には
前後を空白で囲まれている可能性がある
妥当な空でないURLを含めなければなりません。
itemprop
属性がembed要素に指定されている場合、src属性も
指定しなければなりません。
type属性が
存在する場合、インスタンス化するプラグインを選択する際に用いるMIMEタイプを示します。その値は妥当なMIMEタイプ
文字列でなければなりません。type属性とsrc属性の両方が存在する場合、
type属性は、src属性によって指定される
リソースの明示的なContent-Typeメタデータと
同じタイプを指定しなければなりません。
次のいずれかの条件が成立している間、要素についてインスタンス化されたすべてのプラグインを削除しなければならず、embed要素は
何も表しません:
要素が祖先にメディア要素を持つ。
要素が、フォールバックコンテンツを表示していない
祖先のobject要素を持つ。
embed要素は、次の条件がすべて同時に満たされる場合、
潜在的に
アクティブであるといいます:
潜在的に
アクティブではなかったembed要素が潜在的に
アクティブになるたび、また、潜在的にアクティブなままであるembed要素のsrc属性が設定、変更、または
削除されるか、そのtype属性が設定、変更、または
削除されるたびに、ユーザーエージェントは、その要素についてembed要素の
セットアップ手順を実行するため、その要素を指定してembedタスクソース上で要素タスクをキューに追加しなければ
なりません。
指定されたembed要素
elementについてのembed要素の
セットアップ手順は次のとおりです:
その後、elementについてembed要素の
セットアップ手順を実行する別のタスクがキューに追加されている場合、返します。
elementにsrc属性が設定されている場合:
urlを、elementのノード
文書を基準として、elementのsrc属性の値を指定して
URLをエンコーディング解析する結果とします。
urlが失敗の場合、返します。
requestを、URLがurl、クライアントが
elementのノード
文書の関連設定オブジェクト、宛先が「embed」、
資格情報モードが「include」、モードが「navigate」、起動元
タイプが「embed」であり、URL資格情報使用フラグが
設定された新しい要求とします。
requestをフェッチし、processResponseを、応答 responseが与えられた次の手順に設定します:
その後、elementについてembed要素の
セットアップ手順を実行する別のタスクがキューに追加されている場合、
返します。
responseがネットワーク
エラーの場合、elementでloadという名前のイベントを発火し、返します。
typeを、elementおよびresponseを指定してコンテンツの種別を決定した結果とします。
typeに応じて切り替えます:
elementについてプラグインなしを表示します。
elementのコンテンツナビガブルがnullの場合、 elementについて新しい子ナビガブルを作成します。
elementのノード
文書を使用し、responseをresponseに設定し、
historyHandlingを「replace」に設定して、
elementのコンテンツ
ナビガブルをresponseのURLへナビゲートします。
elementのコンテンツナビガブルがさらに他の場所へ
ナビゲートされた場合でも、elementのsrc属性は更新されません。
elementは、ここでそのコンテンツ ナビガブルを表します。
リソースのフェッチは、elementのノード文書のloadイベントを遅延しなければなりません。
それ以外の場合、elementについてプラグインなしを表示します。
embed要素elementおよび応答
responseが与えられたとき、コンテンツの種別を決定するには、次の手順を実行します:
elementがtype属性を持ち、
その属性の値がプラグインによってサポートされる
タイプである場合、type属性の値を返します。
responseのURLのパス構成要素が、プラグインによってサポートされるパターンに一致する場合、 そのプラグインが処理できるタイプを返します。
たとえば、プラグインは、末尾が4文字の文字列
「.swf」であるパス構成要素を持つURLを処理できると宣言する場合があります。
responseに明示的なContent-Type メタデータがあり、その値がプラグインによってサポートされるタイプである場合、その 値を返します。
nullを返します。
上記のアルゴリズムが、responseに非okステータスを持たせることを許可しているのは意図的です。 これにより、サーバーはエラー応答であってもプラグイン用データを返すことができます (たとえば、HTTP 500 Internal Server Errorコードにもプラグイン用データを含められます)。
embed要素elementについてプラグインなしを表示するには:
embed要素にはフォールバックコンテンツがなく、その子孫は無視されます。
潜在的に
アクティブであったembed要素が潜在的に
アクティブではなくなるたび、その要素についてインスタンス化されていたすべてのプラグインをアンロードしなければなりません。
embed要素は、loadイベントを遅延させる可能性があります。
object要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
data — リソースの
アドレス
type — 埋め込まれる
リソースの種別
name — コンテンツナビガブルの名前
form — 要素をform要素に関連付ける
width — 水平方向の寸法
height — 垂直方向の寸法
[Exposed =Window ]
interface HTMLObjectElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , ReflectURL ] attribute USVString data ;
[CEReactions , Reflect ] attribute DOMString type ;
[CEReactions , Reflect ] attribute DOMString name ;
readonly attribute HTMLFormElement ? form ;
[CEReactions , Reflect ] attribute DOMString width ;
[CEReactions , Reflect ] attribute DOMString height ;
readonly attribute Document ? contentDocument ;
readonly attribute WindowProxy ? contentWindow ;
Document ? getSVGDocument ();
readonly attribute boolean willValidate ;
readonly attribute ValidityState validity ;
readonly attribute DOMString validationMessage ;
boolean checkValidity ();
boolean reportValidity ();
undefined setCustomValidity (DOMString error );
// also has obsolete members
};object要素によってインスタンス化されるコンテンツの種別に応じて、
ノードはその他のインターフェースもサポートします。
object要素は外部リソースを表すことができ、そのリソースは、
その種別に応じて画像または子
ナビガブルとして扱われます。
data属性は、
リソースのURLを指定します。この属性は存在しなければならず、その値には
前後を空白で囲まれている可能性がある
妥当な空でないURLを含めなければなりません。
type
属性が存在する場合、
リソースの種別を指定します。この属性が存在する場合、その値は妥当な
MIMEタイプ文字列でなければなりません。
name
属性が存在する場合、その値は妥当なナビガブルターゲット名でなければなりません。
指定された値は、該当する場合、要素のコンテンツ
ナビガブルに名前を付けるために使用され、要素のコンテンツナビガブルが作成されるときに
存在している場合に適用されます。
次のいずれかの条件が発生するたびに:
object要素が、
フォールバックコンテンツを表示する状態へ、または
その状態から変化した、
classid属性が
設定、変更、または削除された、
classid属性が
存在せず、そのdata属性が設定、変更、または削除された、
classid属性も
data属性も
存在せず、そのtype属性が設定、変更、または削除された、
...ユーザーエージェントは、object
要素を指定して、
DOM 操作タスクソースで
要素タスクをキューに入れ、
object
要素が何を表すかを(再)決定するために、次の手順を実行しなければならない。この
タスクが
キューに入れられているか、
または実行中である間は、要素のノード文書の
load
イベントを遅延させなければならない。
ユーザーが、このobject要素の通常の
動作の代わりに、そのフォールバック
コンテンツを表示することを希望すると示した場合、下のフォールバックとラベル付けされた
手順へ移動します。
たとえば、そのコンテンツがユーザーにとってよりアクセシブルな形式を使用しているため、 要素のフォールバックコンテンツを表示するよう ユーザーが要求する場合があります。
要素が祖先にメディア
要素を持つ場合、またはフォールバックコンテンツを表示していない
祖先のobject要素を持つ場合、または要素が非nullの閲覧
コンテキストを持つ文書内にない場合、または要素のノード文書が完全に
アクティブでない場合、または要素が依然としてHTMLパーサーもしくはXMLパーサーの開いている要素のスタック内にある場合、または要素が
レンダリングされていない場合、下の
フォールバックとラベル付けされた手順へ移動します。
data属性が
存在し、その値が空文字列ではない場合:
type属性が存在し、その値が
ユーザーエージェントによってサポートされるタイプではない場合、ユーザーエージェントは、
コンテンツをフェッチして実際のタイプを調べることなく、下のフォールバックと
ラベル付けされた手順へ移動してもよいです。
urlを、要素のノード
文書を基準として、data属性の値を
指定してURLをエンコーディング解析する結果とします。
urlが失敗の場合、要素でerrorという名前のイベントを発火し、下の
フォールバックとラベル付けされた手順へ移動します。
requestを、URLがurl、クライアントが要素のノード
文書の関連設定
オブジェクト、宛先が「object」、
資格情報モードが「include」、モードが「navigate」、起動元
タイプが「object」であり、URL資格情報使用
フラグが設定された新しい要求とします。
requestをフェッチします。
リソースのフェッチは、リソースがフェッチされた後にネットワークタスクソースによってキューに追加されるタスク(次に定義)が実行されるまで、 要素のノード 文書のloadイベントを遅延しなければなりません。
リソースがまだ利用可能でない場合(たとえば、リソースがキャッシュ内で利用できず、 リソースを読み込むためにネットワーク経由で要求を行う必要があった場合)、下の フォールバックとラベル付けされた手順へ移動します。リソースが利用可能になった時点で ネットワークタスク ソースによってキューに追加されるタスクは、この手順からこのアルゴリズムを 再開しなければなりません。リソースは段階的に読み込むことができます。ユーザーエージェントは、 リソースの処理を開始するのに十分なデータが取得された時点で、リソースを「利用可能」と 見なしてもよいです。
読み込みに失敗した場合(たとえば、HTTP 404エラーまたはDNSエラーが発生した場合)、
要素でerrorという名前のイベントを発火し、下の
フォールバックとラベル付けされた手順へ移動します。
次のようにresource typeを決定します:
resource typeを不明とします。
ユーザーエージェントが、このリソースについてContent-Typeヘッダーに厳密に従うよう 構成されており、リソースに関連付けられた Content-Typeメタデータがある場合、resource typeをリソースのContent-Typeメタデータで指定された タイプとし、下のハンドラーとラベル付けされた手順へ移動します。
これは脆弱性を生じさせる可能性があります。サイトが特定のタイプを使用する リソースを埋め込もうとしているにもかかわらず、リモートサイトがその指定を上書きし、 異なるセキュリティ特性を持つ別の種類のコンテンツを起動するリソースを ユーザーエージェントへ提供できるためです。
次の一覧から適切な一連の手順を 実行します:
binaryをfalseとします。
リソースのContent-Type
メタデータで指定されたタイプが「text/plain」であり、
リソースにリソースが
テキストかバイナリーかを区別する規則を適用した結果、そのリソースが
text/plainではない
場合、binaryをtrueに設定します。
リソースのContent-Type
メタデータで指定されたタイプが「application/octet-stream」
である場合、binaryをtrueに設定します。
binaryがfalseの場合、resource typeをリソースの Content-Typeメタデータで指定されたタイプとし、下のハンドラーと ラベル付けされた手順へ移動します。
object要素にtype属性が存在し、その値がapplication/octet-stream
ではない場合、次の手順を実行します:
属性値が「image/」で始まるタイプであり、かつXML MIMEタイプではない場合、
resource typeをそのtype属性で指定されたタイプとします。
下のハンドラーとラベル付けされた手順へ移動します。
object要素にtype属性が存在する場合、tentative
typeをそのtype属性で指定されたタイプとします。
それ以外の場合、tentative typeをリソースの計算済みタイプとします。
tentative typeがapplication/octet-stream
でない場合、resource typeを
tentative typeとし、下のハンドラーとラベル付けされた手順へ
移動します。
指定されたリソースのURL(リダイレクト後)にURLパーサーアルゴリズムを適用した結果、URLレコードが得られ、そのパス構成要素がプラグインによってサポートされるパターンに一致する場合、 resource typeをそのプラグインが処理できるタイプとします。
たとえば、プラグインは、末尾が4文字の文字列
「.swf」であるパス構成要素を持つリソースを処理できると
宣言する場合があります。
この手順が終了した時点、または上記のいずれかの下位手順から次の手順へ 直接移動した時点で、resource typeが依然として不明である可能性があります。 どちらの場合も、次の手順によってフォールバックが開始されます。
ハンドラー:次のうち最初に一致する場合に従ってコンテンツを処理します:
image/」で始まらない場合object要素のコンテンツ
ナビガブルがnullの場合、要素について新しい子ナビガブルを作成します。
responseのURLがabout:blankに一致しない場合、要素のノード文書を使用し、historyHandlingを「replace」に設定して、要素のコンテンツナビガブルをresponseのURLへナビゲートします。
object要素の
コンテンツナビガブルがさらに他の場所へナビゲートされた場合でも、そのdata属性は更新されません。
object要素は、そのコンテンツ
ナビガブルを表します。
image/」で始まり、画像のサポートが
無効化されていない場合object要素を指定して子
ナビガブルを破棄します。
画像の種別を決定するため、画像スニッフィング規則を適用します。
画像が不正である、またはサポートされていない形式であるなどの理由でレンダリングできない 場合、下のフォールバックとラベル付けされた手順へ移動します。
指定されたresource typeはサポートされていません。下の フォールバックとラベル付けされた手順へ移動します。
前の手順がresource typeを不明のまま終了した場合、 この場合が適用されます。
要素の内容は、object要素が
表すものの一部ではありません。
object要素がそのコンテンツ
ナビガブルを表していない場合、リソースが完全に読み込まれた時点で、object要素を指定してDOM
操作タスクソース上で要素タスクをキューに追加し、要素でloadという名前のイベントを発火します。
要素がそのコンテンツナビガブルを実際に表す場合、
作成されたDocumentの読み込みが完全に完了したときに、
同様のタスクがキューに追加されます。
返します。
フォールバック:object要素は、
要素の子を表します。これが要素のフォールバックコンテンツです。要素を指定して子
ナビガブルを破棄します。
上記のアルゴリズムにより、object要素の内容は、
参照されたリソースを表示できない場合(たとえば、404エラーが返された場合)にのみ使用されるフォールバック
コンテンツとして機能します。これにより、異なる能力を持つ複数のユーザーエージェントを
対象として、複数のobject要素を互いに
入れ子にでき、ユーザーエージェントは自身がサポートする最初のものを選択できます。
object要素は、loadイベントを遅延させる可能性があります。
form属性は、
object要素をそのフォーム所有者に明示的に関連付けるために使用されます。
HTMLObjectElement/contentDocument
現在のすべてのエンジンでサポートされています。
HTMLObjectElement/contentWindow
現在のすべてのエンジンでサポートされています。
contentWindowの取得手順は、thisのコンテンツウィンドウを返すことです。
willValidate、validity、およびvalidationMessage属性、ならびにcheckValidity()、reportValidity()、およびsetCustomValidity()メソッドは、制約検証APIの一部です。formIDL属性は、
要素のフォームAPIの一部です。
この例では、object要素を使用して、
HTMLページを別のHTMLページ内に埋め込んでいます。
< figure >
< object data = "clock.html" ></ object >
< figcaption > My HTML Clock</ figcaption >
</ figure > video 要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
controls 属性を持つ場合:
インタラクティブコンテンツ。
src
属性を持つ場合:
0 個以上の track
要素、その後に
透過的コンテンツ。ただし、子孫に メディア要素を含めてはならない。
src 属性を持たない場合: 0 個以上の
source 要素、その後に
0 個以上の track
要素、その後に
透過的コンテンツ。ただし、子孫に メディア要素を含めてはならない。
src — リソースのアドレス
crossorigin —
要素がオリジン間リクエストを処理する方法
poster — 動画再生前に
表示するポスターフレーム
preload — メディアリソースに必要になる可能性が高い
バッファリング量を示すヒント
autoplay —
ページの読み込み時にメディアリソースを
自動的に開始できることを示すヒント
playsinline —
ユーザーエージェントに、要素の再生領域内で動画コンテンツを表示するよう促す
loop — メディアリソースを繰り返し再生するかどうか
muted — デフォルトで
メディアリソースをミュートするかどうか
controls —
ユーザーエージェントのコントロールを表示する
loading —
読み込みの遅延を決定するときに使用される
width — 水平方向の寸法
height — 垂直方向の寸法
[Exposed =Window ]
interface HTMLVideoElement : HTMLMediaElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute unsigned long width ;
[CEReactions , Reflect ] attribute unsigned long height ;
readonly attribute unsigned long videoWidth ;
readonly attribute unsigned long videoHeight ;
[CEReactions , ReflectURL ] attribute USVString poster ;
[CEReactions , Reflect ] attribute boolean playsInline ;
};video 要素は、
動画や映画、およびキャプション付きの音声ファイルを再生するために使用される。
video 要素内にコンテンツを
提供してもよい。ユーザーエージェントは、このコンテンツをユーザーに表示するべきではない。このコンテンツは、
video をサポートしない
古いウェブブラウザーを対象とし、そのような古いブラウザーのユーザーに動画コンテンツへアクセスする方法を
説明するテキストを表示できるようにすることを意図している。
特に、このコンテンツはアクセシビリティ上の問題に対処することを意図したものではない。
弱視者、盲人、難聴者、ろう者、およびその他の身体的または認知的障害を持つ人々が動画コンテンツを
利用できるようにするため、さまざまな機能が利用できる。キャプションは、動画ストリームに埋め込むか、
track 要素を使用して
外部ファイルとして提供できる。手話トラックは動画ストリームに埋め込むことができる。音声解説は、
動画ストリームに埋め込むか、track
要素から参照される
WebVTT ファイルを使用して
テキスト形式で提供し、ユーザーエージェントに音声として合成させることができる。
WebVTT は章タイトルの提供にも使用できる。メディア要素をまったく使用したくないユーザー向けには、
video 要素の近くの本文から
トランスクリプトまたはその他のテキストによる代替にリンクするだけで提供できる。[WEBVTT]
video 要素は、
メディアデータが、関連する音声データを伴う場合もある
動画データであると想定されるメディア要素である。
video 要素は、
slot 要素を含まない内部
シャドーツリーを持つ。
src、crossorigin、
preload、autoplay、
loop、muted、および controls 属性は、すべてのメディア要素に共通する
属性である。
poster
属性は、動画データが利用できない間にユーザーエージェントが表示できる画像ファイルの
URLを指定する。この属性が存在する場合、その値は空白で囲まれている可能性がある
妥当な空でない URLでなければならない。
指定されたリソースを使用する場合、要素が作成されたとき、または poster 属性が設定、
変更、もしくは削除されたとき、ユーザーエージェントは、要素のポスター表示フラグの値にかかわらず、要素の
ポスターフレームを決定するため、次の手順を実行しなければならない。
この video 要素について
実行中のこのアルゴリズムの既存のインスタンスがある場合、ポスター
フレームを変更せずに、そのアルゴリズムのインスタンスを中止する。
poster
属性の値が空文字列であるか、属性が存在しない場合:
video
要素のポスター遅延読み込み再開手順を
null に設定する。
ポスターフレームは存在しない。 return。
urlを、poster 属性の値を、
要素のノード文書を
基準として与え、URL
をエンコーディング解析した結果とする。
urlが失敗である場合、return。ポスター フレームは存在しない。
requestを新しいリクエストとする。その
URLはurl、クライアントは要素の
ノード文書の
関連する設定
オブジェクト、宛先は「image」、開始元の種類は「video」、
資格情報モードは「include」であり、
URL 資格情報使用フラグが設定されているものとする。
video を与えた
要素を遅延
読み込みするかの手順が true を返す場合:
posterResumptionStepsを、フェッチとラベル付けされた手順から始まる このアルゴリズムの残りの部分とする。
video
要素のポスター遅延読み込み再開手順を
posterResumptionStepsに設定する。
Return。
requestをフェッチする。これは要素の ノード文書の load イベントを遅延させなければならない。
poster
属性によって与えられる
画像、すなわちポスターフレームは、
動画がどのようなものかをユーザーに伝える、動画を代表するフレーム(通常は最初の空白でないフレームの
いずれか)であることを意図している。
playsinline
属性はブール
属性である。この属性が存在する場合、デフォルトでは動画を全画面または独立したサイズ変更可能な
ウィンドウで表示するのではなく、要素の再生領域に制約された状態で、文書内に「インライン」で表示するべき
であることをユーザーエージェントに示すヒントとして機能する。
playsinline
属性が存在しないことは、デフォルトで動画が全画面表示されることを意味しない。実際、ほとんどの
ユーザーエージェントは、デフォルトですべての動画をインライン再生することを選択しており、そのような
ユーザーエージェントでは playsinline 属性は
効果を持たない。
poster 属性が存在し、
loading
属性が遅延
状態にある場合、ユーザーエージェントは、要素の遅延読み込み再開手順が呼び出されるまで、ポスター画像の
ソースデータの読み込みを遅延させなければならない。
< video src = "1.mp4" poster = "1.jpg" type = "video/mp4" >
< video src = "2.mp4" type = "video/mp4" loading = "eager" >
< video src = "3.mp4" type = "video/mp4" loading = "lazy" >
< video src = "4.mp4" type = "video/mp4" loading = "lazy" autoplay >
< div id = "very-large" ></ div > <!-- Everything after this div is below the viewport -->
< video src = "5.mp4" type = "video/mp4" >
< video src = "6.mp4" type = "video/mp4" loading = "lazy" >
< video src = "7.mp4" type = "video/mp4" autoplay loading = "lazy" >
< video src = "8.mp4" type = "video/mp4" poster = "8.jpg" loading = "lazy" >
< video src = "9.mp4" type = "video/mp4" preload = "none" poster = "9.jpg" loading = "lazy" >
< video src = "10.mp4" type = "video/mp4" preload = "metadata" loading = "lazy" >
< video src = "11.mp4" type = "video/mp4" poster = "11.jpg" preload = "none" loading = "eager" > 上の例では、動画は次のように読み込まれる。
1.mp4動画とポスター画像は即時に読み込まれ、ウィンドウの load イベントを遅延させる。
2.mp4, 5.mp4動画は即時に読み込まれ、ウィンドウの load イベントを遅延させる。
3.mp4動画はビューポート内にあるため、レイアウトが判明した時点で読み込まれるが、 ウィンドウの load イベントは遅延させない。
4.mp4動画はビューポート内にあるため、レイアウトが判明した時点で読み込まれ、自動再生が開始されるが、 ウィンドウの load イベントは遅延させない。
6.mp4動画はスクロールによってビューポート内に入った時点でのみ読み込まれ、ウィンドウの load イベントは遅延させない。
7.mp4動画はスクロールによってビューポート内に入った時点でのみ読み込まれ、自動再生が開始され、 ウィンドウの load イベントは遅延させない。
8.mp4動画とポスター画像はスクロールによってビューポート内に入った時点でのみ読み込まれ、 ウィンドウの load イベントは遅延させない。
9.mp4動画は再生されるまで読み込まれない。ポスター画像はスクロールによってビューポート内に 入った時点でのみ読み込まれ、ウィンドウの load イベントは遅延させない。
10.mp4動画のメタデータはスクロールによってビューポート内に入った時点でのみ読み込まれ、 ウィンドウの load イベントは遅延させない。
11.mp4動画は再生されるまで読み込まれない。ポスター画像は即時に読み込まれ、ウィンドウの load イベントを遅延させる。
video 要素は、
次の一覧のうち最初に一致する条件について指定されたものを表現する。
readyState 属性が
HAVE_NOTHINGであるか、
または HAVE_METADATA
であるものの動画データがまだまったく取得されていないか、要素の readyState 属性が
それ以降のいずれかの値であるものの、メディアリソースが動画チャンネルを持たない場合)
video 要素は、
存在する場合はそのポスターフレームを表現し、それ以外の場合は透明な黒を、自然寸法を
持たない状態で表現する。video
要素が一時停止されており、現在の再生
位置が動画の最初のフレームで、要素のポスター表示フラグが設定されている場合video 要素は、
存在する場合はそのポスターフレームを表現し、それ以外の場合は動画の最初のフレームを表現する。video
要素が一時停止されており、
現在の再生
位置に対応する動画フレームが利用できない場合(たとえば、動画がシーク中またはバッファリング中であるため)
video
要素が再生可能な状態でも
一時停止状態でもない場合
(たとえば、シーク中または停止中の場合)
video 要素は、
最後にレンダリングされた動画フレームを表現する。video
要素が一時停止されている場合video 要素は、
現在の再生
位置に対応する動画フレームを表現する。
video
要素が動画チャンネルを持ち、再生可能な
状態である場合)video 要素は、
継続的に増加する「現在」の位置にある動画フレームを表現する。
現在の再生
位置が変化し、最後にレンダリングされたフレームが動画内の現在の再生位置に対応するフレームではなくなった場合、
新しいフレームをレンダリングしなければならない。
動画フレームは、イベントループが最後に 手順 1に到達したときに選択されていた動画トラックから取得しなければならない。
動画ストリーム内のどのフレームが特定の再生位置に対応するかは、 動画ストリームの形式によって定義される。
video 要素はさらに、
テキストトラックキューのアクティブフラグが設定され、
そのテキストトラックが
表示中モードにあるすべての
テキストトラックキューと、現在の再生
位置におけるメディアリソースの音声も表現する。
メディアリソースに関連付けられた音声は、 再生される場合、要素の実効メディア音量で、現在の再生位置と同期して再生されなければならない。 ユーザーエージェントは、イベントループが最後に手順 1 に到達したときに有効化されていた音声トラックの音声を再生しなければならない。
上記に加えて、ユーザーエージェントは、動画または要素の再生領域内のその他の領域にテキストやアイコンを 重ねるか、別の適切な方法を使用して、「バッファリング中」「動画が読み込まれていない」「エラー」などの メッセージ、またはより詳細な情報をユーザーに提供してもよい。
動画をレンダリングできないユーザーエージェントは、代わりに、要素に外部の動画再生ユーティリティまたは 動画データ自体へのリンクを表現させてもよい。
video 要素の
メディアリソースが動画チャンネルを
持つ場合、要素は描画ソースを提供する。その幅は
メディアリソースの
自然幅、高さは
メディアリソースの自然高であり、
その外観は、利用できる場合は現在の再生位置に対応する動画フレーム、それ以外の場合
(たとえば動画がシーク中またはバッファリング中の場合)は以前の外観があればそれを、さらにそれもない場合
(たとえば動画がまだ最初のフレームを読み込み中であるため)は黒色となる。
video.videoWidth
現在のすべてのエンジンでサポートされています。
video.videoHeight
現在のすべてのエンジンでサポートされています。
これらの属性は動画の自然寸法を返し、その寸法が不明な場合は 0 を返す。
メディアリソースの自然幅および自然高は、リソースが使用する形式で定義される、リソースの寸法、 アスペクト比、クリーンアパーチャ、解像度などを考慮した後のCSS ピクセル単位の寸法である。アナモルフィック形式が、動画データの寸法に アスペクト比を適用して「正しい」寸法を得る方法を定義していない場合、ユーザーエージェントは、一方の寸法を 増加させ、他方を変更しないことで、その比率を適用しなければならない。
videoWidth の取得手順は次のとおりである。
thisの
readyState
属性が HAVE_NOTHING
である場合、0 を返す。
videoHeight の取得手順は次のとおりである。
thisの
readyState
属性が HAVE_NOTHING
である場合、0 を返す。
動画の自然幅または
自然高が
変化するたびに(たとえば、選択された動画
トラックが変更された場合を含む)、要素の readyState
属性が HAVE_NOTHING
でない場合、ユーザーエージェントは、メディア要素を与えてメディア要素
タスクをキューに入れ、メディア要素で resize という名前の
イベントを発火しなければならない。
これに反するスタイル規則がない場合、動画コンテンツは、そのアスペクト比を維持しながら、再生領域内に 完全に収まる最大の大きさで、再生領域の中央に配置されるよう、要素の再生領域内でレンダリングされるべきである。 したがって、再生領域のアスペクト比が動画のアスペクト比と一致しない場合、動画はレターボックスまたは ピラーボックスとして表示される。動画を含まない要素の再生領域の部分は何も表現しない。
CSS を実装するユーザーエージェントでは、上記の要件は、 レンダリングの節で提案されるスタイル規則を使用して実装できる。
video 要素の再生領域の
自然幅は、ポスターフレームが利用でき、要素が現在そのポスターフレームを
表現している場合、そのポスターフレームの
自然幅である。それ以外の場合、動画リソースの
自然幅が利用できればその値であり、
それ以外の場合、自然幅は
欠落している。
video 要素の再生領域の
自然高は、ポスターフレームが利用でき、要素が現在そのポスターフレームを
表現している場合、そのポスターフレームの
自然高である。それ以外の場合、動画リソースの
自然高が利用できればその値であり、
それ以外の場合、自然高は
欠落している。
デフォルトオブジェクトサイズは、幅が 300 CSS ピクセル、高さが 150 CSS ピクセルである。[CSSIMAGES]
ユーザーエージェントは、クローズドキャプション、音声解説トラック、および動画ストリームに関連付けられた その他の追加データの表示を有効または無効にするためのコントロールを提供するべきである。ただし、このような 機能も、ページの通常のレンダリングを妨げるべきではない。
ユーザーエージェントは、全画面表示や独立したサイズ変更可能なウィンドウなど、ユーザーにとってより適切な
方法で動画コンテンツを表示できるようにしてもよい。ユーザーエージェントは、動画の再生時にデフォルトで
このような表示モードを開始してもよいが、playsinline 属性が
指定されている場合は、そのようにするべきではない。他のユーザーインターフェイス機能と同様に、この機能を
有効にするコントロールは、ユーザーエージェントがユーザーにユーザー
インターフェイスを公開している場合を除き、ページの通常のレンダリングを妨げるべきではない。ただし、
このような独立した表示モードでは、controls 属性が
存在しない場合でも、ユーザーエージェントは完全なユーザーインターフェイスを表示してもよい。
ユーザーエージェントは、動画再生がユーザー体験を妨げる可能性のあるシステム機能に影響を与えることを 許可してもよい。たとえば、動画再生中にスクリーンセーバーを無効にしてもよい。
この例は、動画が正しく再生できなかったことを検出する方法を示している。
< script >
function failed( e) {
// video playback failed - show a message saying why
switch ( e. target. error. code) {
case e. target. error. MEDIA_ERR_ABORTED:
alert( 'You aborted the video playback.' );
break ;
case e. target. error. MEDIA_ERR_NETWORK:
alert( 'A network error caused the video download to fail part-way.' );
break ;
case e. target. error. MEDIA_ERR_DECODE:
alert( 'The video playback was aborted due to a corruption problem or because the video used features your browser did not support.' );
break ;
case e. target. error. MEDIA_ERR_SRC_NOT_SUPPORTED:
alert( 'The video could not be loaded, either because the server or network failed or because the format is not supported.' );
break ;
default :
alert( 'An unknown error occurred.' );
break ;
}
}
</ script >
< p >< video src = "tgif.vid" autoplay controls onerror = "failed(event)" ></ video ></ p >
< p >< a href = "tgif.vid" > Download the video file</ a > .</ p > audio 要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
controls 属性を持つ場合:
インタラクティブコンテンツ。
controls
属性を持つ場合: 可触コンテンツ。src
属性を持つ場合:
0 個以上の track
要素、その後に
透過的コンテンツ。ただし、子孫に メディア要素を含めてはならない。
src 属性を持たない場合: 0 個以上の
source 要素、その後に
0 個以上の track
要素、その後に
透過的コンテンツ。ただし、子孫に メディア要素を含めてはならない。
src — リソースのアドレス
crossorigin —
要素がオリジン間リクエストを処理する方法
preload —
メディアリソースに必要になる可能性が高い
バッファリング量を示すヒント
autoplay —
ページの読み込み時にメディアリソースを
自動的に開始できることを示すヒント
loop — メディアリソースを繰り返し再生するかどうか
muted — デフォルトで
メディアリソースをミュートするかどうか
controls —
ユーザーエージェントのコントロールを表示する
loading —
読み込みの遅延を決定するときに使用される
[Exposed =Window ,
LegacyFactoryFunction =Audio (optional DOMString src )]
interface HTMLAudioElement : HTMLMediaElement {
[HTMLConstructor ] constructor ();
};audio 要素内にコンテンツを
提供してもよい。ユーザーエージェントは、このコンテンツをユーザーに表示するべきではない。このコンテンツは、
audio をサポートしない
古いウェブブラウザーを対象とし、そのような古いブラウザーのユーザーに音声コンテンツへアクセスする方法を
説明するテキストを表示できるようにすることを意図している。
特に、このコンテンツはアクセシビリティ上の問題に対処することを意図したものではない。
ろう者や、その他の身体的または認知的障害を持つ人々が音声コンテンツを利用できるようにするため、
さまざまな機能が利用できる。キャプションまたは手話動画が利用できる場合、audio 要素の代わりに
video 要素を使用して
音声を再生でき、ユーザーは視覚的な代替を有効にできる。ナビゲーションを支援する章タイトルは、
track 要素と
WebVTT ファイルを使用して提供できる。そして当然ながら、
audio 要素の近くの
本文からトランスクリプトまたはその他のテキストによる代替にリンクするだけで提供できる。
[WEBVTT]
audio 要素は、
メディアデータが音声データであると想定される
メディア要素である。
audio 要素は、
slot 要素を含まない内部
シャドーツリーを持つ。
src、crossorigin、
preload、autoplay、
loop、muted、controls、および loading 属性は、すべてのメディア要素に共通する
属性である。
audio
要素に controls 属性がない場合、
ユーザーエージェントによって表示されないため、遅延読み込みできない。
< audio src = "1.mp3" type = "audio/mpeg" controls >
< audio src = "2.mp3" type = "audio/mpeg" controls loading = "eager" >
< audio src = "3.mp3" type = "audio/mpeg" controls loading = "lazy" >
< audio src = "4.mp3" type = "audio/mpeg" controls loading = "lazy" autoplay >
< div id = "very-large" ></ div > <!-- Everything after this div is below the viewport -->
< audio src = "5.mp3" type = "audio/mpeg" controls >
< audio src = "6.mp3" type = "audio/mpeg" controls loading = "lazy" >
< audio src = "7.mp3" type = "audio/mpeg" controls autoplay loading = "lazy" >
< audio src = "8.mp3" type = "audio/mpeg" controls preload = "metadata" loading = "lazy" > 上の例では、音声ファイルは次のように読み込まれる。
1.mp3, 2.mp3, 5.mp3音声ファイルは即時に読み込まれ、ウィンドウの load イベントを遅延させる。
3.mp3音声はビューポート内にあるため、レイアウトが判明した時点で読み込まれるが、 ウィンドウの load イベントは遅延させない。
4.mp3音声はビューポート内にあるため、レイアウトが判明した時点で読み込まれ、自動再生が開始されるが、 ウィンドウの load イベントは遅延させない。
6.mp3音声はスクロールによってビューポート内に入った時点でのみ読み込まれ、ウィンドウの load イベントは遅延させない。
7.mp3音声はスクロールによってビューポート内に入った時点でのみ読み込まれ、自動再生が開始され、 ウィンドウの load イベントは遅延させない。
8.mp3音声のメタデータはスクロールによってビューポート内に入った時点でのみ読み込まれ、 ウィンドウの load イベントは遅延させない。
audio = new Audio([ url ])
現在のすべてのエンジンでサポートされています。
HTMLAudioElement オブジェクトを
作成するため、DOM の createElement() などの
ファクトリーメソッドに加えて、旧来のファクトリー関数
Audio(src)が提供される。呼び出されたとき、
旧来のファクトリー関数は次の手順を実行しなければならない。
documentを、現在のグローバルオブジェクトの関連付けられた Documentとする。
srcが与えられている場合、「src」および
srcを使用して、audioの属性値を設定する。
(これにより、返す前にユーザーエージェントがオブジェクトのリソース選択アルゴリズムを呼び出すことになる。)
audioを返す。
track
要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
kind — テキストトラックの種類
src — リソースのアドレス
srclang —
テキストトラックの言語
label —
ユーザーに表示されるラベル
default —
他のテキストトラックのほうが適切でない場合に
トラックを有効にする
[Exposed =Window ]
interface HTMLTrackElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions ] attribute DOMString kind ;
[CEReactions , ReflectURL ] attribute USVString src ;
[CEReactions , Reflect ] attribute DOMString srclang ;
[CEReactions , Reflect ] attribute DOMString label ;
[CEReactions , Reflect ] attribute boolean default ;
const unsigned short NONE = 0;
const unsigned short LOADING = 1;
const unsigned short LOADED = 2;
const unsigned short ERROR = 3;
readonly attribute unsigned short readyState ;
readonly attribute TextTrack track ;
};track 要素を使用すると、
著者はメディア要素に明示的な外部の時間指定
テキストトラックを指定できる。
この要素自体は何も表現しない。
kind 属性は、
次のキーワードおよび状態を持つ列挙属性である。
| キーワード | 状態 | 簡単な説明 |
|---|---|---|
subtitles
|
字幕 | 音声は利用できるものの理解できない場合(たとえば、ユーザーがメディアリソースの音声トラックの言語を理解できないため)に 適した、会話の書き起こしまたは翻訳。 動画上に重ねて表示される。 |
captions
|
キャプション | 音声が利用できない、または明瞭に聞き取れない場合(たとえば、ミュートされている、周囲の雑音に かき消されている、またはユーザーがろう者であるため)に適した、会話、効果音、関連する音楽上の 合図、およびその他の関連する音声情報の書き起こしまたは翻訳。 動画上に重ねて表示され、難聴者向けであることを適切に示すラベルが付けられる。 |
descriptions
|
解説 | 視覚コンポーネントが遮られている、利用できない、または使用できない場合(たとえば、ユーザーが 運転中に画面を使用せずアプリケーションを操作している、またはユーザーが盲人であるため)に音声合成する ことを意図した、メディアリソースの動画コンポーネントのテキストによる解説。 音声として合成される。 |
chapters
|
章メタデータ | スクリプトから使用することを意図したトラック。 ユーザーエージェントによって表示されない。 |
metadata
|
メタデータ |
この属性の欠落値の デフォルトは字幕状態であり、その無効値のデフォルトは メタデータ状態である。
src 属性は、
テキストトラックデータのURLを指定する。その値は空白で囲まれている可能性がある
妥当な空でない URLでなければならない。この属性は存在しなければならない。
要素には、関連付けられたトラック URL(文字列)があり、初期値は空文字列である。
要素の src
属性が設定されたとき、次の手順を実行する。
trackURLを失敗とする。
valueを、要素の src
属性値とする。
valueが空文字列でない場合、trackURLを、valueを要素の ノード文書を基準として与え、URL をエンコーディング解析して シリアル化した結果に設定する。
trackURLが失敗でない場合、要素のトラック URLをtrackURLに設定し、 それ以外の場合は空文字列に設定する。
要素のトラック URLが WebVTT リソースを識別し、
要素の kind 属性が
章メタデータ状態または
メタデータ状態でない場合、WebVTT ファイルは
キューテキストを使用する WebVTT ファイルでなければならない。
[WEBVTT]
srclang
属性は、テキストトラックデータの言語を指定する。
その値は妥当な BCP 47 言語タグでなければならない。要素の kind 属性が
字幕状態にある場合、この属性は存在しなければならない。
[BCP47]
label 属性は、
ユーザーが読み取れるトラックのタイトルを指定する。このタイトルは、ユーザーエージェントがユーザー
インターフェイス内に字幕、キャプション、および
音声解説トラックを一覧表示するときに使用される。
label
属性が存在する場合、その値は空文字列であってはならない。さらに、同じメディア要素の子である 2
つの track 要素について、
それらの kind 属性が
同じ状態にあり、それらの srclang
属性がともに
欠落しているか同じ言語を表す値を持ち、かつそれらの label 属性がともに欠落しているか
同じ値を持つことがあってはならない。
default 属性はブール属性であり、指定された場合、ユーザーの設定が
別のトラックのほうが適切であることを示していない場合に、そのトラックを有効にすることを示す。
各メディア要素には、kind 属性が
字幕状態または
キャプション状態にあり、かつ default 属性が指定された
track 要素の子を
2 つ以上含めてはならない。
各メディア要素には、kind 属性が
解説状態にあり、かつ default 属性が指定された
track 要素の子を
2 つ以上含めてはならない。
各メディア要素には、kind 属性が
章メタデータ状態にあり、かつ default 属性が指定された
track 要素の子を
2 つ以上含めてはならない。
kind 属性が
メタデータ状態にあり、かつ default 属性が指定された
track 要素の数には
制限がない。
track.readyState次の一覧の数値で表されるテキストトラックの準備状態を返す。
track.NONE (0)track.LOADING (1)track.LOADED (2)track.ERROR (3)track.trackreadyState 属性は、次の一覧で定義されるとおり、track 要素の
テキストトラックのテキストトラックの準備状態に対応する数値を
返さなければならない。
NONE
(数値 0)LOADING
(数値 1)LOADED
(数値 2)ERROR
(数値 3)この動画には、複数の言語の字幕がある。
< video src = "brave.webm" >
< track kind = subtitles src = brave.en.vtt srclang = en label = "English" >
< track kind = captions src = brave.en.hoh.vtt srclang = en label = "English for the Hard of Hearing" >
< track kind = subtitles src = brave.fr.vtt srclang = fr lang = fr label = "Français" >
< track kind = subtitles src = brave.de.vtt srclang = de lang = de label = "Deutsch" >
</ video > (最後の 2 つにある lang 属性は、
字幕自体の言語ではなく、label 属性の言語を示す。
字幕の言語は srclang 属性によって
指定される。)
HTMLMediaElement オブジェクト
(この仕様では audio および video)は、単に
メディア要素と呼ばれる。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
enum CanPlayTypeResult { "" /* empty string */, " maybe " , " probably " };
typedef (MediaStream or MediaSource or Blob ) MediaProvider ;
[Exposed =Window ]
interface HTMLMediaElement : HTMLElement {
// error state
readonly attribute MediaError ? error ;
// network state
[CEReactions , ReflectURL ] attribute USVString src ;
attribute MediaProvider ? srcObject ;
readonly attribute USVString currentSrc ;
[CEReactions ] attribute DOMString ? crossOrigin ;
const unsigned short NETWORK_EMPTY = 0;
const unsigned short NETWORK_IDLE = 1;
const unsigned short NETWORK_LOADING = 2;
const unsigned short NETWORK_NO_SOURCE = 3;
readonly attribute unsigned short networkState ;
[CEReactions ] attribute DOMString preload ;
readonly attribute TimeRanges buffered ;
undefined load ();
CanPlayTypeResult canPlayType (DOMString type );
// ready state
const unsigned short HAVE_NOTHING = 0;
const unsigned short HAVE_METADATA = 1;
const unsigned short HAVE_CURRENT_DATA = 2;
const unsigned short HAVE_FUTURE_DATA = 3;
const unsigned short HAVE_ENOUGH_DATA = 4;
readonly attribute unsigned short readyState ;
readonly attribute boolean seeking ;
// playback state
attribute double currentTime ;
undefined fastSeek (double time );
readonly attribute unrestricted double duration ;
object getStartDate ();
readonly attribute boolean paused ;
attribute double defaultPlaybackRate ;
attribute double playbackRate ;
attribute boolean preservesPitch ;
readonly attribute TimeRanges played ;
readonly attribute TimeRanges seekable ;
readonly attribute boolean ended ;
[CEReactions , Reflect ] attribute boolean autoplay ;
[CEReactions , Reflect ] attribute boolean loop ;
Promise <undefined > play ();
undefined pause ();
// controls
[CEReactions , Reflect ] attribute boolean controls ;
attribute double volume ;
attribute boolean muted ;
[CEReactions , Reflect="muted"] attribute boolean defaultMuted ;
[CEReactions ] attribute DOMString loading ;
// tracks
[SameObject ] readonly attribute AudioTrackList audioTracks ;
[SameObject ] readonly attribute VideoTrackList videoTracks ;
[SameObject ] readonly attribute TextTrackList textTracks ;
TextTrack addTextTrack (TextTrackKind kind , optional DOMString label = "", optional DOMString language = "");
};メディア要素の属性である src、crossorigin、preload、autoplay、
loop、muted、controls、および loading は、すべての
メディア要素に適用される。これらはこの節で定義する。
loading
属性は遅延読み込み
属性である。その目的は、ビューポート外にあるメディアリソースを読み込むための方針を示すことである。
loading
属性の状態が即時状態に変更されたとき、ユーザーエージェントは
次の手順を実行しなければならない。
resumptionStepsを、メディア要素の遅延読み込み再開手順とする。
posterResumptionStepsを null とする。
メディア要素が video 要素である場合、
posterResumptionStepsを、その video 要素のポスター遅延
読み込み再開手順に設定する。
resumptionStepsが null で、かつ posterResumptionStepsも null である場合、 return。
resumptionStepsが null でない場合:
メディア要素の遅延読み込み再開手順を null に設定する。
resumptionStepsを呼び出す。
posterResumptionStepsが null でない場合:
video
要素のポスター遅延読み込み再開手順を
null に設定する。
posterResumptionStepsを呼び出す。
loading 属性が
遅延状態にある場合、
データのフェッチを遅延させることによって、preload
属性よりも優先される。
autoplay 属性が存在し、
loading 属性が
遅延状態にある場合、ユーザーエージェントは、要素の
遅延読み込み再開手順が呼び出されるまで、再生の開始
(および自動再生によって生じる可能性のある関連するネットワークリクエスト)も遅延させなければならない。
メディア要素は、音声データ、または動画と 音声のデータをユーザーに提示するために使用される。この節は音声用および動画用の メディア 要素に等しく適用されるため、この節ではこれを メディアデータと呼ぶ。 メディアリソースという用語は、メディアデータの完全な集合、たとえば 完全な動画ファイルまたは完全な音声ファイルを指すために使用される。
メディアリソースには、関連付けられた
オリジンがある。これは
「none」「multiple」「rewritten」のいずれか、または
オリジンである。初期値は
「none」である。
メディアリソースは、複数の音声トラック
および動画トラックを持つことができる。メディア要素に関して、メディアリソースの動画データは、
イベントループが最後に
手順 1に到達したときに、要素の videoTracks 属性に
よって示される、現在選択されているトラックがあればそのトラックの動画データのみである。また、
メディアリソースの音声データは、
イベントループが最後に
手順 1に到達したときに、要素の audioTracks 属性に
よって示される、現在有効なすべてのトラックがあれば、それらをミキシングした結果である。
audio 要素と
video 要素はどちらも、
音声と動画の両方に使用できる。両者の主な違いは、audio
要素には、動画や
キャプションなどの視覚コンテンツ用の再生領域がない一方で、video 要素にはそれがある、
という点だけである。
各メディア要素は、一意の メディア要素イベントタスクソースを持つ。
メディア要素 elementおよび一連の手順stepsを使用して メディア要素タスクをキューに入れるには、 elementおよびstepsを与え、メディア要素のメディア要素イベント タスクソース上で要素タスクをキューに入れる。
現在のすべてのエンジンでサポートされています。
media.error
現在のすべてのエンジンでサポートされています。
要素の現在のエラー状態を表す MediaError
オブジェクトを返す。
エラーがない場合は null を返す。
すべてのメディア要素には、関連付けられたエラー状態があり、
これは要素のリソース選択アルゴリズムが最後に呼び出されて以降に要素が
遭遇した最後のエラーを記録する。error 属性は、取得時に、この最後のエラーについて作成された
MediaError オブジェクトを返さなければ
ならず、エラーが発生していない場合は null を返さなければならない。
[Exposed =Window ]
interface MediaError {
const unsigned short MEDIA_ERR_ABORTED = 1;
const unsigned short MEDIA_ERR_NETWORK = 2;
const unsigned short MEDIA_ERR_DECODE = 3;
const unsigned short MEDIA_ERR_SRC_NOT_SUPPORTED = 4;
readonly attribute unsigned short code ;
readonly attribute DOMString message ;
};media.error.code
現在のすべてのエンジンでサポートされています。
以下の一覧から、現在のエラーのエラーコードを返す。
media.error.message
現在のすべてのエンジンでサポートされています。
遭遇したエラー状態について、具体的で有用な診断メッセージを返す。メッセージおよび メッセージ形式は、通常、異なるユーザーエージェント間で統一されていない。そのような メッセージが利用できない場合は、空文字列を返す。
各 MediaError オブジェクトは、文字列である
メッセージと、次のいずれかである コードを持つ。
MEDIA_ERR_ABORTED(数値 1)MEDIA_ERR_NETWORK(数値 2)MEDIA_ERR_DECODE(数値 3)MEDIA_ERR_SRC_NOT_SUPPORTED(数値 4)src 属性または
割り当てられた
メディアプロバイダーオブジェクトによって示されるメディアリソースが適切でなかった。
上記の値のいずれかであるエラーコードを与えて、MediaError を作成するには、コードが与えられたエラーコードであり、メッセージが、
エラー状態の原因についてユーザーエージェントが提供できる任意の詳細を含む文字列、またはユーザー
エージェントがそのような詳細を提供できない場合は空文字列である、新しい MediaError オブジェクトを返す。
このメッセージ文字列には、与えられたエラーコードによってすでに利用できる情報だけを含めてはならない。
たとえば、コードを単に文字列形式へ翻訳したものだけであってはならない。エラーコードによって提供される
情報を超える追加情報が利用できない場合、メッセージは空文字列に設定しなければならない。
メディア要素の
src
コンテンツ属性は、表示するメディアリソース
(動画、音声)のURLを与える。この属性が存在する場合、その値は
空白で囲まれている
可能性がある妥当な空でない URLでなければならない。
メディア要素に
itemprop
属性が指定されている場合、src 属性も指定
しなければならない。
メディア要素の
crossorigin コンテンツ属性は、
CORS 設定属性である。
メディア要素が
src 属性を
持つ状態で作成された場合、ユーザーエージェントは直ちに、メディア要素の
リソース選択アルゴリズムを
呼び出さなければならない。
メディア要素の
src
属性が設定または変更された場合、ユーザーエージェントはメディア要素の
メディア要素読み込みアルゴリズムを
呼び出さなければならない。(source
要素が存在する場合でも、src
属性を
削除しても、この処理は行われない。)
現在のすべてのエンジンでサポートされています。
crossOrigin IDL 属性は、
crossorigin
コンテンツ属性を、既知の値のみに制限して
反映しなければならない。
メディアプロバイダーオブジェクトは、
URLとは別に、メディアリソースを表現できるオブジェクトである。
MediaStream
オブジェクト、MediaSource
オブジェクト、および Blob
オブジェクトはすべてメディアプロバイダーオブジェクトである。
各メディア要素には、 割り当てられたメディアプロバイダーオブジェクトがあり、 これはメディアプロバイダーオブジェクトまたは null であり、初期値は null である。
media.srcObject [ = source ]
1 つのエンジンでのみサポートされています。
メディア要素に メディアプロバイダーオブジェクトを 割り当てられるようにする。
media.currentSrc
現在のすべてのエンジンでサポートされています。
currentSrc IDL 属性は、初期状態では空文字列に設定
しなければならない。その値は、以下で定義するリソース選択アルゴリズムによって
変更される。
srcObject の取得手順は、
thisの割り当てられたメディアプロバイダー
オブジェクトを返すことである。
srcObject
の設定手順は次のとおりである。
thisの割り当てられたメディアプロバイダー オブジェクトを、与えられた値に設定する。
thisのメディア要素読み込みアルゴリズムを 呼び出す。
メディアリソースを指定する方法は 3
つある。
srcObject
IDL 属性、src
コンテンツ属性、および source
要素である。IDL 属性が最も優先され、次にコンテンツ属性、最後に要素が優先される。
メディアリソースは、そのタイプ、
具体的にはMIME タイプによって記述でき、場合によっては codecs
パラメーターを伴う。(codecs パラメーターが許可されるかどうかは、MIME タイプによって
異なる。)[RFC6381]
通常、タイプはやや不完全な記述である。たとえば「video/mpeg」はコンテナータイプ以外の
情報を何も示さず、「video/mp4; codecs="avc1.42E01E, mp4a.40.2"」のようなタイプでも、
実際のビットレートなどの情報は含まれない(最大ビットレートのみ)。したがって、あるタイプが与えられた場合、
ユーザーエージェントは多くの場合、そのタイプのメディアを再生できる可能性があるか
(確信度には幅がある)、またはそのタイプのメディアを確実に再生できないかしか判断できない。
ユーザーエージェントがレンダリングできないと 認識しているタイプとは、たとえばコンテナータイプを認識しない、または列挙されたコーデックを サポートしていないため、ユーザーエージェントが確実にサポートしていないリソースを記述するタイプである。
パラメーターを持たない MIME タイプ「application/octet-stream」は、
決してユーザーエージェントがレンダリング
できないと認識しているタイプではない。潜在的なメディアリソースのラベル付けに使用される場合、ユーザーエージェントは
そのタイプを、明示的なContent-Type
メタデータがない場合と同等に扱わなければならない。
ここで特別扱いされるのは、パラメーターを持たない MIME タイプ「application/octet-stream」
だけである。何らかのパラメーターが付いている場合は、他のMIME タイプと同様に
扱われる。これは、不明なMIME タイプの
パラメーターを無視するべきであるという規則からの逸脱である。
media.canPlayType(type)
現在のすべてのエンジンでサポートされています。
ユーザーエージェントが指定されたタイプのメディアリソースを再生できるとどの程度確信しているかに 基づいて、空文字列(否定的な応答)、「maybe」、または「probably」を返す。
canPlayType(type) メソッドは、
typeがユーザーエージェントが
レンダリングできないと認識しているタイプであるか、タイプ「application/octet-stream」
である場合、空文字列を返さなければならない。
ユーザーエージェントが、そのタイプがこの audio または
video 要素で使用した場合に
レンダリングできるメディアリソースを
表すと確信している場合は、「probably」を返さなければならず、それ以外の場合は
「maybe」を返さなければならない。実装者には、
タイプがサポートされるかされないかを確実に判定できない限り、「maybe」を
返すことが推奨される。一般に、ユーザーエージェントは、codecs パラメーターを許可する
タイプについて、そのパラメーターが存在しない場合に「probably」
を返すべきではない。
このスクリプトは、ユーザーエージェントが(架空の)新しい形式をサポートしているかを検査し、
video 要素を
使用するかどうかを動的に決定する。
< section id = "video" >
< p >< a href = "playing-cats.nfv" > Download video</ a ></ p >
</ section >
< script >
const videoSection = document. getElementById( 'video' );
const videoElement = document. createElement( 'video' );
const support = videoElement. canPlayType( 'video/x-new-fictional-format;codecs="kittens,bunnies"' );
if ( support === "probably" ) {
videoElement. setAttribute( "src" , "playing-cats.nfv" );
videoSection. replaceChildren( videoElement);
}
</ script > source
要素の type 属性により、
ユーザーエージェントは、レンダリングできない形式を使用するリソースのダウンロードを回避できる。
media.networkState
現在のすべてのエンジンでサポートされています。
以下の一覧のコードから、要素の現在のネットワーク活動状態を返す。
メディア要素がネットワークとやり取りする際、
その現在のネットワーク活動は networkState 属性によって表される。取得時には、
要素の現在のネットワーク状態を返さなければならず、その値は次のいずれかでなければならない。
NETWORK_EMPTY(数値 0)NETWORK_IDLE(数値 1)NETWORK_LOADING(数値 2)NETWORK_NO_SOURCE(数値 3)以下で定義するリソース選択アルゴリズムは、
networkState
属性の値がいつ変化するか、およびこの状態の変化を示すためにどのイベントが発火するかを正確に記述する。
media.load()
現在のすべてのエンジンでサポートされています。
要素をリセットし、新しいメディアリソースを最初から選択して読み込む処理を 開始させる。
すべてのメディア要素には、 自動再生可能フラグがあり、その初期状態は true でなければならない。 また、load イベント遅延フラグがあり、その初期状態は false でなければならない。load イベント遅延フラグが true の間、 要素はその文書のload イベントを遅延させなければならない。
メディア要素で
load()
メソッドが呼び出されたとき、ユーザーエージェントは
次の手順を実行しなければならない。
resumptionStepsを、メディア要素の 遅延読み込み再開手順とする。
resumptionStepsが null でない場合:
メディア要素の 遅延読み込み再開手順を null に設定する。
resumptionStepsを呼び出す。
メディア要素読み込みアルゴリズムを 実行する。
メディア要素には、関連付けられた ブール値 現在停止しているがあり、初期値は false である。
メディア要素読み込みアルゴリズムは、次の手順からなる。
この要素の現在停止しているを false に設定する。
この要素についてすでに実行中のリソース選択アルゴリズムの インスタンスをすべて中止する。
pending tasksを、いずれかのタスクキューにある、 メディア要素の メディア要素イベントタスクソースからの すべてのタスクのリストとする。
pending tasks内の、保留中の再生 promise を解決するか、 保留中の再生 promise を却下する 各タスクについて、対応するタスクがキューに入れられた順序で、それらの promise を直ちに解決または 却下する。
pending tasks内の各タスクを、その タスクキューから削除する。
基本的に、メディア要素が新しいリソースの読み込みを開始すると、保留中のイベントと コールバックは破棄され、解決または却下される途中の promise は直ちに解決または却下される。
メディア要素の
networkState
が NETWORK_LOADING
または NETWORK_IDLE
に設定されている場合、メディア要素を与えて
メディア要素タスクをキューに入れ、
メディア要素で
abort
という名前のイベントを発火する。
メディア要素の
networkState
が NETWORK_EMPTY
に設定されていない場合:
メディア要素を与えて
メディア要素タスクをキューに入れ、
メディア要素で
emptied
という名前のイベントを発火する。
メディア要素について フェッチ処理が進行中である場合、ユーザーエージェントはそれを停止するべきである。
メディア要素の
割り当てられたメディアプロバイダー
オブジェクトが MediaSource
オブジェクトである場合、それを切り離す。
readyState
が HAVE_NOTHING
に設定されていない場合は、その状態に設定する。
paused 属性が
false の場合:
paused
属性を true に設定する。
保留中の
再生 promise を取得し、その結果と "AbortError"
DOMException
を使用して、保留中の再生 promise を却下する。
seeking
が true の場合、false に設定する。
現在の再生位置を 0 に設定する。
公式再生位置を 0 に設定する。
これによって公式再生位置が変更された場合、
メディア要素を与えて
メディア要素タスクをキューに入れ、
メディア要素で
timeupdate
という名前のイベントを発火する。
タイムラインオフセットを 非数(NaN)に設定する。
duration
属性を非数(NaN)に更新する。
ユーザーエージェントは、この特定の duration の変更については
durationchange
イベントを発火しない。
playbackRate
属性を、defaultPlaybackRate
属性の値に設定する。
メディア要素の リソース選択アルゴリズムを 呼び出す。
この要素で以前に再生されていたメディアリソースの再生は停止する。
メディア要素の リソース選択アルゴリズムは次のとおりである。この アルゴリズムは常にタスクの一部として呼び出されるが、アルゴリズムの 最初の手順の 1 つは、残りの手順を並行して実行し続けるために return することである。 さらに、このアルゴリズムはイベントループ機構と密接に連携する。特に、 イベントループアルゴリズムの 一部としてトリガーされる同期区間を持つ。そのような区間内の手順には ⌛ が付けられている。
要素の networkState
属性を NETWORK_NO_SOURCE
値に設定する。
要素のポスター表示フラグを true に設定する。
メディア要素の 遅延読み込み属性が 即時状態にあるか、 スクリプティングが無効である場合、 メディア要素の load イベント遅延フラグを true に設定する(これによりload イベントが遅延する)。
このアルゴリズムを呼び出したタスクが続行できるようにしながら、 安定状態を待つ。 同期区間は、このアルゴリズムが 同期区間の終了を示すまでの、この アルゴリズムの残りのすべての手順からなる。(同期区間内の手順には ⌛ が付けられている。)
⌛ メディア要素の パーサー待機フラグが false の場合、保留中のテキストトラックの リストを設定する。
⌛ modeを null とする。
⌛ candidateを null とする。
⌛ メディア要素の 割り当てられたメディアプロバイダー オブジェクトが null でない場合、modeをオブジェクトに設定する。
⌛ それ以外の場合、メディア要素が
source
要素の子を持つ場合、modeを子に設定し、candidateを
ツリー順で最初の
source
要素の子に設定する。
⌛ それ以外の場合:
⌛ networkState
を NETWORK_EMPTY
に設定する。
⌛ 要素のload イベント遅延フラグを false に設定する。これにより、load イベントの遅延が停止する。
同期区間を終了して return。
⌛ メディア要素の
networkState
を NETWORK_LOADING
に設定する。
⌛ メディア要素を与えて
メディア要素タスクをキューに入れ、
メディア要素で
loadstart
という名前のイベントを発火する。
次の一覧から適切な手順を実行する。
⌛ currentSrc
属性を空文字列に設定する。
割り当てられたメディアプロバイダー オブジェクトを用いてリソースフェッチアルゴリズムを 実行する。そのアルゴリズムがこのアルゴリズムを中止せずに return した場合、 読み込みは失敗した。
メディアプロバイダーによる失敗: この手順に到達したことは、メディアリソースの 読み込みに失敗したことを示す。保留中の再生 promise を取得し、 メディア要素を与えて メディア要素タスクをキューに入れ、 その結果を用いて専用メディアソース失敗手順を 実行する。
前の手順でキューに入れられたタスクが実行されるまで待つ。
Return。要素は、このアルゴリズムが再びトリガーされるまで、別のリソースの読み込みを 試みない。
⌛ urlRecordを、src
属性が最後に変更された時点のメディア要素の
ノード文書を基準として、src
属性の値を与えてURL
をエンコーディング解析した
結果とする。
⌛ urlRecordが失敗でない場合、currentSrc
属性を、urlRecordにURL
シリアライザーを適用した結果に設定する。
urlRecordが失敗でない場合、urlRecordを用いて リソースフェッチアルゴリズムを 実行する。そのアルゴリズムがこのアルゴリズムを中止せずに return した場合、 読み込みは失敗した。
属性による失敗: この手順に到達したことは、メディアリソースの読み込みに失敗したか、 urlRecordが失敗であることを示す。保留中の再生 promise を取得し、 メディア要素を与えて メディア要素タスクをキューに入れ、 その結果を用いて専用メディアソース失敗手順を 実行する。
前の手順でキューに入れられたタスクが実行されるまで待つ。
Return。要素は、このアルゴリズムが再びトリガーされるまで、別のリソースの読み込みを 試みない。
⌛ pointerを、メディア要素の子リスト内の隣接する 2 つのノードによって定義される位置とする。リストの先頭(リストに最初の子がある場合は その前)およびリストの末尾(リストに最後の子がある場合はその後)も、それ自体をノードとして 扱う。一方のノードはpointerの前のノードであり、もう一方のノードは pointerの後のノードである。初期状態では、candidateノードと、 存在する場合は次のノードとの間、またはそれが最後のノードである場合はリストの末尾との間の 位置をpointerとする。
ノードが挿入、削除、または移動されてメディア要素内に入る際、 pointerは次のように更新しなければならない。
その他の変更はpointerに影響しない。
⌛ 候補を処理: candidateが
src
属性を持たないか、その src
属性の値が空文字列である場合、同期区間を終了し、以下の
要素による失敗手順へ移動する。
⌛ candidateが、値が環境に一致しない
media
属性を持つ場合、同期区間を終了し、以下の
要素による失敗手順へ移動する。
⌛ urlRecordを、candidateの src
属性が最後に変更された時点のcandidateの
ノード文書を基準として、その src
属性の値を与えてURL
をエンコーディング解析した
結果とする。
⌛ urlRecordが失敗である場合、同期区間を終了し、以下の 要素による失敗手順へ移動する。
⌛ candidateが type
属性を持ち、その値をMIME
タイプとして解析したとき
(そのパラメーターを定義するタイプについては、codecs パラメーターによって
記述される任意のコーデックを含む)、ユーザー
エージェントがレンダリングできないと認識しているタイプを表す場合、
同期区間を終了し、以下の
要素による失敗手順へ移動する。
⌛ currentSrc
属性を、urlRecordにURL シリアライザーを適用した結果に設定する。
urlRecordを用いてリソースフェッチアルゴリズムを 実行する。そのアルゴリズムがこのアルゴリズムを中止せずに return した場合、 読み込みは失敗した。
要素による失敗: メディア要素を与えて
メディア要素タスクをキューに入れ、
candidateで error
という名前のイベントを発火する。
安定状態を待つ。 同期区間は、このアルゴリズムが 同期区間の終了を示すまでの、 このアルゴリズムの残りのすべての手順からなる。(同期区間内の手順には ⌛ が 付けられている。)
⌛ 次の候補を探す: candidateを null とする。
⌛ 検索ループ: pointerの後のノードがリストの末尾である場合、 以下の待機手順へ移動する。
⌛ pointerの後のノードが source
要素である場合、candidateをその要素とする。
⌛ pointerを進め、pointerの前のノードが、以前 pointerの後にあったノードとなり、pointerの後のノードが、存在する場合は 以前pointerの後にあったノードの次のノードとなるようにする。
⌛ candidateが null の場合、検索ループ手順へ戻る。それ以外の場合、 候補を処理手順へ戻る。
⌛ 待機: 要素の networkState
属性を NETWORK_NO_SOURCE
値に設定する。
⌛ 要素のポスター表示フラグを true に設定する。
⌛ メディア要素を与えて メディア要素タスクをキューに入れ、 要素のload イベント遅延フラグを false に設定する。これにより、load イベントの遅延が停止する。
pointerの後のノードが、リストの末尾以外のノードになるまで待つ。 (この手順は永久に待ち続ける可能性がある。)
安定状態を待つ。 同期区間は、このアルゴリズムが 同期区間の終了を示すまでの、 このアルゴリズムの残りのすべての手順からなる。(同期区間内の手順には ⌛ が 付けられている。)
⌛ 要素のload イベント遅延フラグを 再び true に設定する(これにより、まだ発火していない場合はload イベントが再び遅延する)。
⌛ networkState
を再び NETWORK_LOADING
に設定する。
⌛ 上の次の候補を探す手順へ戻る。
promise のリストpromisesを用いる 専用メディアソース失敗手順は次のとおりである。
error
属性を、MEDIA_ERR_SRC_NOT_SUPPORTED
を用いてMediaError を作成した結果に
設定する。
要素の networkState
属性を NETWORK_NO_SOURCE
値に設定する。
要素のポスター表示フラグを true に設定する。
promisesおよび「NotSupportedError」
DOMException
を用いて保留中の再生 promise を却下する。
要素のload イベント遅延フラグを false に設定する。これにより、load イベントの遅延が停止する。
レスポンスresponse、メディアリソースresource、および
「entire resource」または(数値、数値もしくは「until end」)の
タプルbyteRangeを与えて、メディアレスポンスを検証するには:
responseがネットワークエラーである場合、false を返す。
byteRangeが「entire resource」である場合、true を返す。
internalResponseを、responseの 安全でないレスポンスとする。
internalResponseのステータスが 200 の場合、true を返す。
internalResponseのステータスが 206 でない場合、false を返す。
internalResponseからcontent-range 値を抽出した結果が失敗である場合、 false を返す。
抽出された値は使用されず、特にbyteRangeと比較されないことに注意。
したがって、この手順は「Content-Range」
ヘッダーの構文検証として機能するが、レスポンスの「Content-Range」
値がリクエストの「Range」
値と一致しない場合でも、失敗とは見なされない。
originを、internalResponseの
URLが null
の場合は「rewritten」、
それ以外の場合はinternalResponseの
URLの
オリジンとする。
previousOriginを、resourceの オリジンとする。
次のいずれかが true の場合:
previousOriginが「none」である。
originとpreviousOriginが「rewritten」である。
originとpreviousOriginがオリジンであり、originが previousOriginと同一オリジンである。
その場合、resourceのオリジンをoriginに設定する。
それ以外の場合、responseがCORS オリジン間である場合、false を返す。
それ以外の場合、resourceのオリジンを
「multiple」に設定する。
これにより、Range ヘッダーを持つ不透明なレスポンスが、異なるオリジンからの 他のレスポンスと連結されることで情報を漏えいしないことが保証される。
true を返す。
メディア要素および、 与えられたURL レコードまたは メディアプロバイダーオブジェクトについての リソースフェッチアルゴリズムは次のとおりである。
メディア要素を与えた 要素を遅延読み込みするかの手順が true を返す場合:
resumptionStepsを、mode を remote とするとラベル付けされた手順から始まる このアルゴリズムの残りの部分とする。
メディア要素の 遅延読み込み再開手順を resumptionStepsに設定する。
メディア要素について 遅延読み込み 要素の交差監視を開始する。
Return。
modeをremoteとする。
アルゴリズムがメディアプロバイダーオブジェクトを用いて 呼び出された場合、modeをlocalに設定する。
それ以外の場合:
isTopLevelSelfFetchを false とする。
settingsObjectを、メディア要素の ノード文書の 関連する設定オブジェクトとする。
globalを、メディア要素の ノード文書の 関連するグローバルオブジェクトとする。
次の条件がすべて true の場合:
その場合、isTopLevelSelfFetchを true に設定する。
stringOrEnvironmentを、isTopLevelSelfFetchが true の場合は
「top-level-self-fetch」、それ以外の場合はsettingsObjectとする。
objectを、URL レコードの blob URL エントリーおよび stringOrEnvironmentを使用してblob オブジェクトを取得した結果とする。
objectがメディアプロバイダーオブジェクトである場合、 modeをlocalに設定する。
modeがremoteの場合、current media resourceを、このアルゴリズムに渡された URL レコードによって与えられるリソースとする。 それ以外の場合、current media resourceをメディアプロバイダーオブジェクトによって 与えられるリソースとする。いずれの場合も、current media resourceはここで要素の メディアリソースとなる。
メディア要素の 保留中のテキストトラックのリストから、 すべてのメディアリソース固有 テキストトラックがあれば、それらを削除する。
次の一覧から適切な手順を実行する。
必要に応じて、次の下位手順を実行する。これは、ユーザーエージェントが、ユーザーが明示的に
要求するまでリソースのフェッチを試みないことを意図している場合に想定される動作である
(たとえば、preload
属性の none
キーワードを実装する方法として)。
networkState
を NETWORK_IDLE
に設定する。
メディア要素を与えて
メディア要素タスクを
キューに入れ、要素で suspend
という名前のイベントを発火する。
メディア要素を与えて メディア要素タスクを キューに入れ、要素のload イベント遅延フラグを false に設定する。これにより、load イベントの遅延が停止する。
タスクが実行されるまで待つ。
実装定義のイベント (たとえば、ユーザーがメディア要素の再生開始を要求すること)を待つ。
要素のload イベント遅延フラグを 再び true に設定する(これにより、まだ発火していない場合はload イベントが再び遅延する)。
networkState
を NETWORK_LOADING
に設定する。
destinationを、メディア要素が
audio
要素である場合は「audio」、それ以外の場合は「video」とする。
requestを、current media resourceの
URL レコード、destination、および
メディア要素の
crossorigin
コンテンツ属性の現在の状態を与えて潜在的 CORS リクエストを作成
した結果とする。
requestのクライアントを、 メディア要素の ノード文書の 関連する設定オブジェクトに 設定する。
requestの開始元の種類を destinationに設定する。
「entire resource」または(数値、数値もしくは
「until end」)のタプルであるbyteRangeを、
メディアデータ内の不足データを
満たすために必要なバイト範囲とする。この値は実装定義であり、コーデック、ネットワーク状態、
またはその他のヒューリスティックに依存してもよい。ユーザーエージェントは、リソース全体を
フェッチすると判断してもよく、その場合byteRangeは
「entire resource」となる。バイトオフセットから末尾までフェッチすると
判断してもよく、その場合byteRangeは(数値、「until end」)となる。
また、2 つのバイトオフセット間の範囲をフェッチすると判断してもよく、その場合
byteRangeは 2 つのオフセットを表す(数値、数値)のタプルとなる。
byteRangeが「entire resource」でない場合:
byteRange[1]が「until end」である場合、
byteRange[0]を与えてrequestに
Range ヘッダーを追加する。
それ以外の場合、byteRange[0]およびbyteRange[1]を与えて requestにRange ヘッダーを追加する。
requestをフェッチする。その processResponseは、 レスポンスresponseを与えて実行する次の手順に 設定する。
globalを、メディア要素の ノード文書の 関連するグローバルオブジェクトとする。
updateMediaを、メディア要素を与えて メディア要素タスクを キューに入れ、以下のメディアデータ処理手順の リストから最初に適切な手順を実行することとする。(以下に記述する処理が ネットワーキングタスクソースを 使用するのではなく、適切なメディア要素イベント タスクソースに対して行われるよう、新しいタスクを使用する。)
processEndOfMediaを次の手順とする。メディアデータのデコードを含む フェッチ処理がエラーなしで完了し、すべてのデータがネットワークアクセスなしで ユーザーエージェントに利用可能である場合、ユーザーエージェントは以下の 最終手順へ進まなければならない。これは、ウェブラジオなどの無限リソースを ストリーミングしている場合や、リソースがユーザーエージェントのデータキャッシュ能力より 長い場合などには、決して発生しない可能性がある。
responseをcurrent media resourceおよび byteRangeを用いて検証した結果が false の場合、 これらの手順を中止する。
それ以外の場合、updateMedia、processEndOfMedia、 空のアルゴリズム、およびglobalを与えて、responseの 本体を 逐次的に読み取る。
この方法で取得したresponseの安全でないレスポンスの内容を用いて、
メディアデータを
更新する。responseはCORS 同一オリジンまたは
CORS
オリジン間であり得る。
これは、メディアデータで参照される字幕が API に
公開されるかどうか、および video
要素について、動画を canvas
に描画したときに canvas が汚染されるかどうかに影響する。
メディア要素停止タイムアウトは、 実装定義の時間であり、約 3 秒であるべきである。 メディアデータを積極的に 取得しようとしているメディア要素が、 メディア要素停止タイムアウトに等しい時間、 データをまったく受信できなかった場合、ユーザーエージェントは メディア要素を与えて メディア要素タスクを キューに入れ、次を実行しなければならない。
ユーザーエージェントは、ユーザーがメディアデータのダウンロードを選択的に ブロックしたり低速化したりできるようにしてもよい。メディア要素のダウンロードが完全に ブロックされた場合、ユーザーエージェントは、接続が閉じられたかのようにではなく、 停止したかのように動作しなければならない。ユーザーエージェントは、たとえば同じ帯域幅を 共有する他の接続とダウンロードを均衡させるため、ダウンロード速度を自動的に制限してもよい。
ユーザーエージェントは、たとえば 1 時間のメディアリソースの
5 分間をバッファリングした後、ユーザーがリソースを再生するかどうかを決定するのを待っている間、
インタラクティブなリソースでユーザー入力を待っている間、またはユーザーがページから離れた場合など、
いつでも追加コンテンツをダウンロードしないと判断してもよい。メディア要素のダウンロードが一時停止された場合、
ユーザーエージェントはメディア要素を与えて
メディア要素タスクを
キューに入れ、networkState
を NETWORK_IDLE
に設定し、要素で suspend
という名前のイベントを発火しなければならない。リソースの
ダウンロードが再開された場合、ユーザーエージェントはメディア要素を与えて
メディア要素タスクを
キューに入れ、networkState
を NETWORK_LOADING
に設定しなければならない。これらのタスクがキューに入れられる間、読み込みは一時停止される
(したがって、上記のとおり progress
イベントは発火しない)。
preload
属性は、autoplay
属性がない場合でも、著者がどの程度のバッファリングを推奨すると考えているかについての
ヒントを提供する。
ユーザーエージェントがダウンロードを完全に一時停止すると判断した場合、たとえばユーザーが 再生を開始するまで追加コンテンツをダウンロードせず待機する場合、ユーザーエージェントは メディア要素を与えて メディア要素タスクを キューに入れ、要素のload イベント遅延フラグを false に設定しなければならない。これにより、load イベントの遅延が停止する。
上記の手順はリクエストを発行するためのアルゴリズムを示しているが、ユーザーエージェントは、 特にエラー状態に直面した場合、それらの正確な手順以外の方法を使用してもよい。たとえば、 ユーザーエージェントはサーバーに再接続したり、ストリーミングプロトコルに切り替えたりしてもよい。 ユーザーエージェントは、リソースのフェッチを試みることを断念した場合に限り、そのリソースを エラーと見なし、上記の手順のエラー分岐へ進まなければならない。
メディアリソースの形式を判定するため、 ユーザーエージェントは音声および動画を特にスニッフィングする規則を 使用しなければならない。
読み込みが一時停止されていない間(以下を参照)、350 ミリ秒(±200 ミリ秒)ごと、 または受信した各バイトごとのうち、頻度の低いほうで、 メディア要素を与えて メディア要素タスクを キューに入れ、次を実行する。
ユーザーエージェントがメディアリソースの一部を取得するために 依然としてネットワークアクセスを必要とする可能性がある間、ユーザーエージェントはこの手順に 留まらなければならない。
たとえば、ユーザーエージェントが動画の前半を破棄した場合、
再生が終了した後でも、
ユーザーが先頭へシークし直す可能性が常にあるため、ユーザーエージェントはこの手順に留まる。
実際、この状況では、再生が終了すると、前述のとおり、
ユーザーエージェントは最終的に suspend
イベントを発火することになる。
current media resourceによって記述されるリソースがある場合、それには メディアデータが含まれる。 これはCORS 同一オリジンである。
current media resourceが生のデータストリーム
(たとえば File
オブジェクトからのもの)である場合、メディアリソースの形式を判定するため、
ユーザーエージェントは音声および動画を特にスニッフィングする規則を
使用しなければならない。それ以外の場合、データストリームが事前にデコードされているなら、
形式は関連する仕様によって与えられる形式である。
current media resourceの新しいデータが利用可能になるたびに、 メディア要素を与えて メディア要素タスクをキューに入れ、 以下のメディアデータ処理手順の リストから最初に適切な手順を実行する。
current media resourceが恒久的に使い果たされたとき
(たとえば Blob
のすべてのバイトが処理されたとき)、デコードエラーがなかった場合、ユーザーエージェントは
以下の最終手順へ進まなければならない。これは、current media resourceが
MediaStream
である場合などには、決して発生しない可能性がある。
メディアデータ処理手順のリストは次のとおりである。
DNS エラー、HTTP 4xx および 5xx エラー(および他のプロトコルにおける同等のエラー)、 ユーザーエージェントがcurrent media resourceを使用可能かどうか確認する前に発生する その他の致命的なネットワークエラー、サポートされていないコンテナー形式を使用するファイル、 またはすべてのデータでサポートされていないコーデックを使用するファイルは、ユーザーエージェントに 次の手順を実行させなければならない。
ユーザーエージェントはフェッチ処理を取り消すべきである。
このサブアルゴリズムを中止し、リソース選択アルゴリズムへ 戻る。
音声トラックを表現する AudioTrack
オブジェクトを作成する。
メディア要素の
audioTracks
属性の AudioTrackList
オブジェクトを、新しい AudioTrack
オブジェクトで更新する。
enableを不明とする。
メディアリソースまたは current media resourceのURLのいずれかが、 有効にする特定の音声トラックの集合を示している場合、またはユーザーエージェントが ユーザー体験を改善するための特定の音声トラックの選択を容易にする情報を持っている場合、 この音声トラックが有効にするものの 1 つであればenableをtrueに設定し、 それ以外の場合はenableをfalseに設定する。
これはメディアフラグメント構文によって トリガーされる可能性があるが、たとえばユーザーエージェントがステレオ音声トラックより 5.1 サラウンド音声トラックを選択することによってもトリガーされ得る。
enableがまだ不明である場合、メディア要素がまだ 有効化された音声トラックを 持っていなければ、enableをtrueに設定し、それ以外の場合は enableをfalseに設定する。
enableがtrueの場合、この音声トラックを有効化し、それ以外の場合は この音声トラックを有効化しない。
この AudioTrackList
オブジェクトで、track
属性を新しい AudioTrack
オブジェクトに初期化した TrackEventを使用して、
addtrack
という名前のイベントを発火する。
動画トラックを表現する VideoTrack
オブジェクトを作成する。
メディア要素の
videoTracks
属性の VideoTrackList
オブジェクトを、新しい VideoTrack
オブジェクトで更新する。
enableを不明とする。
メディアリソースまたは current media resourceのURLのいずれかが、 有効にする特定の動画トラックの集合を示している場合、またはユーザーエージェントが ユーザー体験を改善するための特定の動画トラックの選択を容易にする情報を持っている場合、 この動画トラックがそのような最初の動画トラックであればenableをtrueに 設定し、それ以外の場合はenableをfalseに設定する。
これもメディアフラグメント構文によって トリガーされる可能性がある。
enableがまだ不明である場合、メディア要素がまだ 選択された動画トラックを 持っていなければ、enableをtrueに設定し、それ以外の場合は enableをfalseに設定する。
enableがtrueの場合、このトラックを選択して、以前に選択されていた
動画トラックの選択を解除する。それ以外の場合、この動画トラックを選択しない。他のトラックの
選択が解除された場合、change イベントが発火する。
この VideoTrackList
オブジェクトで、track
属性を新しい VideoTrack
オブジェクトに初期化した TrackEventを使用して、
addtrack
という名前のイベントを発火する。
これは、リソースが使用可能であることを示す。ユーザーエージェントは次の下位手順に 従わなければならない。
メディアデータに基づいて、 現在の再生位置および 最も早い可能な位置のための メディアタイムラインを確立する。
タイムラインオフセットを、 存在する場合、前の手順で確立されたメディアタイムラインの時刻 0 に対応する 日時に更新する。メディアリソースによって明示的な時刻と 日付が与えられていない場合、タイムラインオフセットを非数(NaN)に 設定しなければならない。
duration
属性を、既知である場合、上で確立されたメディアタイムライン上のリソースの
最後のフレームの時刻で更新する。未知である場合(たとえば、原理上無限であるストリーム)、
duration
属性を正の無限大の値に更新する。
この時点で、ユーザーエージェントはメディア要素を与えて
メディア要素タスクを
キューに入れ、要素で durationchange
という名前のイベントを発火する。
video
要素について、videoWidth
属性および videoHeight
属性を設定し、メディア要素を与えて
メディア要素タスクを
キューに入れ、メディア要素で
resize
という名前のイベントを発火する。
その後、寸法が変更された場合、さらに resize
イベントが発火する。
readyState
属性を HAVE_METADATA
に設定する。
readyState
属性を新しい値に設定する処理の一部として、
loadedmetadata
DOM イベントが発火する。
jumpedを false とする。
メディア要素の デフォルト再生開始位置が 0 より大きい場合、その時刻へシークし、jumpedを true とする。
メディア要素の デフォルト再生開始位置を 0 に設定する。
initial playback positionを 0 とする。
メディアリソースまたは current media resourceのURLのいずれかが 特定の開始時刻を示している場合、initial playback positionをその時刻に設定し、 jumpedがまだ false であれば、その時刻へシークする。
たとえば、メディアフラグメント構文をサポートするメディア形式では、 フラグメントを使用して開始位置を示すことができる。
有効化された音声トラックがない場合、
音声トラックを 1 つ有効化する。これによりchange
イベントが発火する。
選択された動画トラックがない場合、
動画トラックを 1 つ選択する。これによりchange
イベントが発火する。
readyState
属性が HAVE_CURRENT_DATA
に達した後、loadeddata イベントが発火した後に、
要素のload イベント遅延フラグを
false に設定する。これにより、load イベントの遅延が停止する。
各メディアリソースのメタデータを引き続き
フェッチしながらネットワーク使用量を削減しようとするユーザーエージェントは、この時点で
バッファリングも停止し、前述の規則に従うことになる。この規則には、
networkState
属性が NETWORK_IDLE
値へ切り替わること、および suspend
イベントが発火することが含まれる。
ユーザーエージェントは、再生前にメディアリソースの継続時間を判定し、 この手順を実行することが要求される。
メディア要素で progress
という名前のイベントを発火する。
networkState
を NETWORK_IDLE
に設定し、メディア要素で suspend
という名前のイベントを発火する。
ユーザーエージェントがメディアデータを破棄し、その後それを再取得するために
ネットワーク活動を再開する必要が生じた場合、メディア要素を与えて
メディア要素タスクをキューに入れ、
networkState
を NETWORK_LOADING
に設定しなければならない。
ユーザーエージェントがメディアリソースを読み込んだ状態で保持できる場合、 アルゴリズムは以下の最終手順へ進み、そこでアルゴリズムを中止する。
ユーザーエージェントがcurrent media resourceを使用可能かどうか確認した後
(すなわち、メディア要素の
readyState
属性が HAVE_NOTHING
でなくなった後)に発生する致命的なネットワークエラーは、ユーザーエージェントに次の手順を
実行させなければならない。
ユーザーエージェントはフェッチ処理を取り消すべきである。
error
属性を、MEDIA_ERR_NETWORK
を用いてMediaError を作成した
結果に設定する。
要素の networkState
属性を NETWORK_IDLE
値に設定する。
要素のload イベント遅延フラグを false に設定する。これにより、load イベントの遅延が停止する。
全体のリソース選択アルゴリズムを 中止する。
ユーザーエージェントがcurrent media resourceを使用可能かどうか確認した後
(すなわち、メディア要素の
readyState
属性が HAVE_NOTHING
でなくなった後)に発生するメディアデータのデコードにおける致命的なエラーは、
ユーザーエージェントに次の手順を実行させなければならない。
ユーザーエージェントはフェッチ処理を取り消すべきである。
error
属性を、MEDIA_ERR_DECODE
を用いてMediaError を作成した
結果に設定する。
要素の networkState
属性を NETWORK_IDLE
値に設定する。
要素のload イベント遅延フラグを false に設定する。これにより、load イベントの遅延が停止する。
全体のリソース選択アルゴリズムを 中止する。
たとえばユーザーが「停止」ボタンを押したため、フェッチ処理がユーザーによって中止された場合、
ユーザーエージェントは次の手順を実行しなければならない。これらの手順の実行中に
load()
メソッド自体が呼び出された場合は、上の手順がその特定の種類の中止を処理するため、これらの手順には
従わない。
ユーザーエージェントはフェッチ処理を取り消すべきである。
error
属性を、MEDIA_ERR_ABORTED
を用いてMediaError を作成した
結果に設定する。
メディア要素の
readyState
属性が HAVE_NOTHING
に等しい値を持つ場合、要素の networkState
属性を NETWORK_EMPTY
値に設定し、要素のポスター表示フラグを
true に設定し、
要素で emptied
という名前のイベントを発火する。
それ以外の場合、要素の networkState
属性を NETWORK_IDLE
値に設定する。
要素のload イベント遅延フラグを false に設定する。これにより、load イベントの遅延が停止する。
全体のリソース選択アルゴリズムを 中止する。
サーバーが、部分的には使用可能だが最適にはレンダリングできないデータを返した場合、 ユーザーエージェントは処理できる部分だけをレンダリングし、残りを無視しなければならない。
メディアデータが CORS 同一オリジンである場合、 関連するデータを用いてメディアリソース 固有テキストトラックを公開する手順を実行する。
オリジン間動画は字幕を公開しない。公開すると、悪意のあるサイトがユーザーの イントラネット上にある機密動画から字幕を読み取るなどの攻撃が可能になるためである。
最終手順: ユーザーエージェントがこの手順に到達した場合 (これはリソース全体が読み込まれ、利用可能な状態に保持された場合に限り発生する)、 全体のリソース選択アルゴリズムを 中止する。
メディア要素が
メディア要素のメディアリソース固有
トラックを破棄するとき、ユーザーエージェントはメディア要素の
テキストトラックのリストから、すべての
メディアリソース固有
テキストトラックを削除し、次にメディア要素の
audioTracks
属性の AudioTrackList
オブジェクトを空にし、次にメディア要素の
videoTracks
属性の VideoTrackList
オブジェクトを空にしなければならない。この処理の一部としてイベント
(特に removetrack
イベント)は発火しない。その代わりに、このアルゴリズムを呼び出すアルゴリズムによって発火する
error
イベントおよび emptied
イベントを使用できる。
preload
属性は、次のキーワードおよび状態を持つ
列挙属性である。
| キーワード | 状態 | 簡単な説明 |
|---|---|---|
auto
|
自動 | リソース全体を楽観的にダウンロードすることまで含めて、サーバーに負担を与える危険なしに ユーザーエージェントがユーザーのニーズを優先できることを、ユーザーエージェントに示す。 |
none
|
なし | 著者がユーザーにメディアリソースが必要になるとは想定していないか、サーバーが不要なトラフィックを 最小限に抑えたいことを、ユーザーエージェントに示す。 この状態は、何らかの理由でバッファリングが開始された場合(たとえばユーザーが「再生」を押した後)に、 実際にメディアリソースをどの程度積極的にダウンロードするかについてのヒントは提供しない。 |
metadata
|
メタデータ | 著者がユーザーにメディアリソースが必要になるとは想定していないものの、リソースのメタデータ
(寸法、トラック一覧、継続時間など)、および場合によっては最初の数フレームをフェッチすることは
妥当であると、ユーザーエージェントに示す。ユーザーエージェントがメタデータを超えるデータを
正確にフェッチしない場合、メディア要素の
readyState
属性は最終的に HAVE_METADATA
に設定される。ただし、通常はいくつかのフレームも取得されるため、おそらく
HAVE_CURRENT_DATA
または HAVE_FUTURE_DATA
になる。メディアリソースの再生中は、帯域幅を希少なものとして考慮するべきであることを
ユーザーエージェントに示す。たとえば、一貫した再生を維持できる最も遅い速度でメディアデータを
取得するよう、ダウンロードを制限することを示唆する。
|
この属性の欠落値の デフォルトおよび無効値のデフォルトは、どちらも 実装定義である。ただし、サーバー負荷の削減と最適な ユーザー体験の提供との妥協点として、メタデータ状態が推奨される。
この属性は、メディアリソースがバッファリング中または再生中に なった後でも変更できる。上の表の説明は、そのことを考慮して解釈する。
著者は、ユーザーが再生を開始した時点で、属性を「none」
または「metadata」
から「auto」へ
動的に切り替えてもよい。たとえば、多数の動画を含むページでは、多数の動画は要求されるまで
ダウンロードしないが、そのうち 1 つが要求された後は積極的にダウンロードすることを示すために
使用できる。
preload
属性は、著者が最適なユーザー体験につながると考えているものについて、ユーザーエージェントにヒントを
提供することを意図している。たとえば、明示的なユーザー設定または利用可能な接続性に基づいて、
この属性は完全に無視されてもよい。
autoplay
属性は、preload
属性より優先され得る(メディアが再生される場合、preload
属性によるヒントにかかわらず、その前に当然バッファリングする必要があるため)。ただし、両方を含めても
エラーではない。
audio 要素および
video 要素で
スクリプティングが有効な場合、
loading
属性は、要素の遅延読み込み再開手順が実行されるまで、
preload
属性によって示された動作を延期できる。
media.buffered
現在のすべてのエンジンでサポートされています。
ユーザーエージェントがバッファリングしたメディアリソースの範囲を表す
TimeRanges
オブジェクトを返す。
buffered の取得手順は、
thisのメディアリソースがある場合、そのうち
ユーザーエージェントがバッファリングした範囲を表す、新しい
正規化済み
TimeRanges オブジェクトを返すことである。ユーザーエージェントは、面倒な検査に
よってしか判定できないメディアストリームについても、利用可能な範囲を正確に判定しなければならない。
通常、これは時刻 0 を起点とする単一の範囲となるが、たとえばユーザーエージェントが シークに応じて HTTP Range リクエストを使用する場合、複数の範囲が存在することがある。
ユーザーエージェントは、以前にバッファリングしたデータを破棄してもよい。
したがって、ある時点で buffered
属性によって返されたオブジェクトの範囲内に含まれていた時刻位置が、後の時点で同じ属性によって返された
オブジェクトの範囲に含まれなくなることがある。
取得するたびに新しいオブジェクトを返すことは、属性の getter として不適切なパターンであり、 変更するには高いコストがかかるため、ここでは既定のものとして残されているにすぎない。新しい API で 模倣してはならない。
media.duration
現在のすべてのエンジンでサポートされています。
メディア リソースの開始が時刻 0 であると仮定して、メディアリソースの長さを秒単位で返す。
継続時間が利用できない場合は NaN を返す。
境界のないストリームの場合は Infinity を返す。
media.currentTime [ = value ]
現在のすべてのエンジンでサポートされています。
公式再生位置を秒単位で返す。
設定して、指定された時刻へシークできる。
メディアリソースには、 時刻(秒単位)をメディアリソース内の位置へ対応付ける メディアタイムラインがある。タイムラインの原点は、その最も早く定義された 位置である。タイムラインの継続時間は、その最後に定義された位置である。
メディアタイムラインの確立: メディアリソースが、原点が負でない明示的な
タイムラインを何らかの方法で指定する場合(すなわち、各フレームに特定の時間オフセットを与え、
最初のフレームに 0 または正のオフセットを与える場合)、メディアタイムラインはそのタイムラインであるべきである。
(メディアリソースが
タイムラインを指定できるかどうかは、メディアリソースの形式に依存する。)
メディアリソースが
明示的な開始時刻と日付を指定する場合、その時刻と日付は
メディアタイムラインの
ゼロ地点と見なすべきである。タイムラインオフセットはその時刻と日付となり、
getStartDate()
メソッドを使用して公開される。
メディアリソースが 不連続なタイムラインを持つ場合、ユーザーエージェントはリソースの開始時に使用されたタイムラインを リソース全体にわたって延長しなければならない。これにより、基礎となるメディアデータに順序が前後したタイムコードや 重複するタイムコードがあっても、メディアリソースの メディア タイムラインは、以下で定義する最も早い可能な位置から始まり、 線形に増加する。
たとえば、2 つのクリップが 1 つの動画ファイルに連結されているものの、 動画形式が 2 つのクリップの元の時刻を公開している場合、動画データが公開するタイムラインは、 たとえば 00:15..00:29 の後に 00:05..00:38 が続くものとなり得る。しかし、ユーザーエージェントは それらの時刻を公開せず、代わりに単一の動画として 00:15..00:29 および 00:29..01:02 を公開する。
![]() 明示的なタイムラインを持たないメディアリソースというまれな場合、
メディアタイムライン上の
時刻 0 は、メディアリソースの最初のフレームに対応する
べきである。フレーム継続時間すら含め、いかなる種類の明示的なタイミングも持たない
メディアリソースという
さらにまれな場合、ユーザーエージェントは各フレームの時刻を
実装定義の方法で自ら決定しなければならない。
明示的なタイムラインを持たないメディアリソースというまれな場合、
メディアタイムライン上の
時刻 0 は、メディアリソースの最初のフレームに対応する
べきである。フレーム継続時間すら含め、いかなる種類の明示的なタイミングも持たない
メディアリソースという
さらにまれな場合、ユーザーエージェントは各フレームの時刻を
実装定義の方法で自ら決定しなければならない。
明示的なタイムラインを持たないが、明示的なフレーム継続時間を持つファイル形式の例として、
Animated GIF 形式がある。明示的なタイミングをまったく持たないファイル形式の例として、
JPEG-push 形式(JPEG フレームを含む multipart/x-mixed-replace。
MJPEG ストリームの形式としてよく使用される)がある。
タイミング情報を持たないリソースの場合でも、ユーザーエージェントがサーバーによって最初に提供された フレームより前の位置へシークできるなら、時刻 0 はメディアリソースの最も早くシーク可能な時刻に 対応するべきである。それ以外の場合は、サーバーから受信した最初のフレーム (ユーザーエージェントがストリームの受信を開始したメディアリソース内の地点)に対応するべきである。
執筆時点では、明示的なフレーム時間オフセットを持たないにもかかわらず、 サーバーが送信した最初のフレームより前のフレームへのシークをサポートする既知の形式はない。
10 月の晴れた金曜日の午後にストリーミングを開始し、接続するユーザーエージェントに対して常に
同じメディアタイムライン上のメディアデータを送信し、その時刻 0 をこのストリームの開始時点に
設定しているテレビ放送事業者からのストリームを考える。数か月後、このストリームに接続した
ユーザーエージェントは、最初に受信するフレームの時刻が数百万秒になっていることに気付く。
getStartDate()
メソッドは常に放送開始日を返す。これにより、コントローラーは、放送開始からの相対時刻
(「8 か月、4 時間、12 分、23 秒」)ではなく、実際の時刻(たとえば「午後 2:30」)を
スクラバーに表示できる。
複数の連結された断片からなる動画を運ぶストリームを考える。サーバーはユーザーエージェントが
特定の時刻を要求することを許可せず、あらかじめ定められた順序で動画データをストリーミングするだけであり、
最初に配信されるフレームは常に時刻 0 のフレームとして識別される。ユーザーエージェントがこの
ストリームに接続し、タイムスタンプ 2010-03-20 23:15:00 UTC から 2010-03-21 00:05:00 UTC、
および 2010-02-12 14:25:00 UTC から 2010-02-12 14:35:00 UTC を覆うものとして定義された断片を
受信した場合、ユーザーエージェントはこれを 0 秒から始まり 3,600 秒(1 時間)まで延びる
メディアタイムラインとして公開する。
ストリーミングサーバーが 2 番目のクリップの終端で切断したと仮定すると、duration
属性は 3,600 を返す。getStartDate()
メソッドは、2010-03-20 23:15:00 UTC に対応する時刻を持つ Date
オブジェクトを返す。しかし、別のユーザーエージェントが 5 分後に接続した場合、その
ユーザーエージェントは(おそらく)タイムスタンプ 2010-03-20 23:20:00 UTC から
2010-03-21 00:05:00 UTC、および 2010-02-12 14:25:00 UTC から 2010-02-12 14:35:00 UTC を覆う
断片を受信し、これを 0 秒から始まり 3,300 秒(55 分)まで延びる
メディアタイムラインとして公開する。
この場合、getStartDate()
メソッドは、2010-03-20 23:20:00 UTC に対応する時刻を持つ Date
オブジェクトを返す。
これら両方の例で、seekable
属性は、コントローラーが実際に UI に表示したい範囲を与える。通常、サーバーが任意の時刻への
シークをサポートしない場合、これはユーザーエージェントがストリームに接続した瞬間から、
ユーザーエージェントが取得した最新フレームまでの時間範囲となる。ただし、ユーザーエージェントが
より以前の情報を破棄し始めた場合、実際の範囲はより短くなる可能性がある。
いずれの場合も、ユーザーエージェントは、確立されたメディアタイムラインを使用した 最も早い可能な位置 (以下で定義)が 0 以上であることを保証しなければならない。
メディアタイムラインには、 関連付けられたクロックもある。どのクロックを使用するかはユーザーエージェント定義であり、 メディアリソースに 依存してもよいが、ユーザーの実時間時計を近似するべきである。
メディア要素には 現在の再生位置があり、初期状態 (すなわちメディアデータが ない状態)では 0 秒でなければならない。現在の再生位置は メディアタイムライン上の 時刻である。
メディア要素には 公式再生位置もあり、初期状態では 0 秒に設定 しなければならない。公式再生位置は、 スクリプトの実行中に安定した状態に保たれる現在の再生位置の近似値である。
メディア要素には デフォルト再生開始位置もあり、初期状態では 0 秒に設定しなければならない。この時刻は、メディアが読み込まれる前でも要素をシークできるようにするために 使用される。
各メディア要素には
ポスター表示フラグがある。メディア要素が作成されたとき、このフラグは
true に設定しなければならない。このフラグは、video 要素で
動画コンテンツの代わりにポスターフレームを表示する時点を制御するために使用される。
currentTime 属性は、取得時に、
メディア要素の
デフォルト再生開始位置が
0 でない限り、それを返さなければならない。0 である場合は、要素の
公式再生位置を返さなければならない。
返される値は秒単位で表さなければならない。設定時に、メディア要素の readyState
が HAVE_NOTHING
である場合、メディア要素の
デフォルト再生開始位置を
新しい値に設定しなければならない。それ以外の場合、公式再生位置を新しい値に設定し、
その後その新しい値へシークしなければならない。
新しい値は秒単位として解釈しなければならない。
メディアリソースが ストリーミングリソースである場合、ユーザーエージェントは、リソースの特定の部分がバッファーから 期限切れになった後、それらを取得できない可能性がある。同様に、一部のメディアリソースは、0 から始まらない メディアタイムラインを 持つ可能性がある。最も早い可能な位置とは、 ユーザーエージェントが再び取得できる可能性のあるストリームまたはリソース内の最も早い位置である。 これはメディアタイムライン上の時刻でもある。
最も早い可能な位置は API で
明示的に公開されない。存在する場合は seekable
属性の TimeRanges
オブジェクト内の最初の範囲の開始時刻に対応し、存在しない場合は
現在の再生位置に対応する。
最も早い可能な位置が変化したとき:
現在の再生位置が
最も早い可能な位置より前である場合、
ユーザーエージェントは最も早い可能な位置へ
シークしなければならない。
それ以外の場合、ユーザーエージェントが過去 15~250 ミリ秒以内に要素で
timeupdate
イベントを発火しておらず、かつそのようなイベントのイベントハンドラーをまだ実行していない場合、
ユーザーエージェントはメディア要素を与えて
メディア要素タスクをキューに入れ、
要素で timeupdate
という名前のイベントを発火しなければならない。
上記の要件、およびクリップのメタデータが判明したときに適用される リソースフェッチアルゴリズムの 要件により、現在の再生位置が 最も早い可能な位置より小さくなることは 決してない。
ユーザーエージェントが、音声トラックまたは動画トラックが終了し、そのトラックに関連するすべての メディアデータが、 最も早い可能な位置より 前にあるメディアタイムラインの部分に対応することを いつでも認識した場合、ユーザーエージェントはメディア要素を与えて メディア要素タスクをキューに入れ、 次の手順を実行してもよい。
必要に応じて、audioTracks
属性の AudioTrackList
オブジェクト、または videoTracks
属性の VideoTrackList
オブジェクトからトラックを削除する。
前述の AudioTrackList
または VideoTrackList
オブジェクトで、トラックを表す AudioTrack または
VideoTrack オブジェクトに
track
属性を初期化した TrackEventを使用して、
removetrack
という名前のイベントを発火する。
duration 属性は、メディアタイムライン上の
メディアリソースの
終端時刻を秒単位で返さなければならない。メディアデータが利用できない場合、
属性は非数(NaN)値を返さなければならない。メディアリソースに境界があることが
分かっていない場合(たとえば、ストリーミングラジオ、または終了時刻が発表されていないライブイベント)、
属性は正の Infinity 値を返さなければならない。
ユーザーエージェントは、メディアデータの一部を再生する前、および
readyState
を HAVE_METADATA
以上の値に設定する前に、たとえそのためにリソースの複数の部分をフェッチする必要があっても、
メディアリソースの
継続時間を決定しなければならない。
メディアリソースの長さが既知の値へ変化したとき
(たとえば、未知から既知へ変化した場合、または以前に確立された長さから新しい長さへ変化した場合)、
ユーザーエージェントはメディア要素を与えて
メディア要素タスクをキューに入れ、
メディア要素で
durationchange
という名前のイベントを発火しなければならない。
(新しいメディアリソースの読み込みの一部として継続時間がリセットされたときは、イベントは発火しない。)
継続時間の変更により現在の再生位置が
メディアリソースの
終端時刻より大きくなった場合、ユーザーエージェントは
メディアリソースの
終端時刻へシークもしなければならない。
「無限」のストリームが何らかの理由で終了した場合、継続時間は正の Infinity から
ストリーム内の最後のフレームまたはサンプルの時刻へ変化し、durationchange
イベントが発火する。同様に、ユーザーエージェントが最初に
メディアリソースの
継続時間を正確に決定する代わりに推定し、後で新しい情報に基づいてその推定を修正した場合、
継続時間は変化し、durationchange
イベントが発火する。
一部の動画ファイルには、メディアタイムライン上の時刻 0 に対応する 明示的な日付と時刻もあり、これはタイムラインオフセットと呼ばれる。 初期状態では、タイムラインオフセットを 非数(NaN)に設定しなければならない。
getStartDate() メソッドは、現在の
タイムラインオフセットを表す
新しい Date
オブジェクトを
返さなければならない。
loop
属性は真偽属性であり、指定された場合、
メディア要素が
メディアリソースの
終端に達したときに、先頭へシークして戻ることを示す。
media.readyState
現在のすべてのエンジンでサポートされています。
以下の一覧のコードから、現在の再生位置をレンダリングすることに関する 要素の現在の状態を表す値を返す。
メディア要素には、現在の 現在の再生位置でレンダリングできる準備がどの程度 整っているかを記述する準備状態がある。可能な値は次のとおりであり、特定の時点における メディア要素の準備状態は、要素の状態を記述する最大の値である。
HAVE_NOTHING(数値 0)メディアリソースに関する情報は
利用できない。現在の再生位置のデータは利用できない。
networkState
属性が NETWORK_EMPTY
に設定されているメディア要素は、
常に HAVE_NOTHING
状態にある。
HAVE_METADATA(数値 1)リソースの継続時間を利用できるだけのリソースが取得されている。
video 要素の場合、
動画の寸法も利用できる。直近の現在の再生位置については、
メディアデータを利用できない。
HAVE_CURRENT_DATA(数値 2)直近の現在の再生位置のデータは利用できるが、
ユーザーエージェントが再生方向に現在の再生位置を少しでも正常に進めると、
直ちに HAVE_METADATA
状態へ戻ってしまうほどしかデータを利用できないか、または再生方向に取得できるデータがそれ以上存在しない。
たとえば動画では、現在の再生位置が現在のフレームの終端にあるとき、
ユーザーエージェントが現在のフレームのデータを持つが次のフレームのデータを持たない場合、
および再生が終了した場合に相当する。
HAVE_FUTURE_DATA(数値 3)直近の現在の再生位置のデータに加え、
HAVE_METADATA
状態へ直ちに戻ることなく、ユーザーエージェントが再生方向に現在の再生位置を少なくとも少し進められるだけの
データも利用でき、かつテキストトラックの準備ができている。
たとえば動画では、現在の再生位置が 2
つのフレーム間の瞬間にあるときに、
ユーザーエージェントが少なくとも現在のフレームと次のフレームのデータを持つ場合、または
現在の再生位置がフレームの途中にあるときに、
ユーザーエージェントが現在のフレームの動画データと、少なくとも少し再生を継続できる音声データを
持つ場合に相当する。再生が終了している場合、現在の再生位置は決して進められないため、
ユーザーエージェントはこの状態になることができない。
HAVE_ENOUGH_DATA(数値 4)HAVE_FUTURE_DATA
状態について記述されたすべての条件が満たされ、さらに次のいずれかの条件も true である。
playbackRate
で進んだとしても、再生がメディアリソースの終端に到達する前に、利用可能なデータを
追い越すことはないと推定している。
実際には、HAVE_METADATA と
HAVE_CURRENT_DATA
の違いはごくわずかである。この違いが実際に関係するほぼ唯一の場面は、video 要素を
canvas に描画するときであり、
何かが描画される場合(HAVE_CURRENT_DATA
以上)と、何も描画されない場合(HAVE_METADATA
以下)を区別する。同様に、HAVE_CURRENT_DATA
(現在のフレームのみ)と HAVE_FUTURE_DATA
(少なくともこのフレームと次のフレーム)の違いも、ごくわずかになり得る
(極端な場合、わずか 1 フレーム)。この区別が実際に重要になる唯一の場面は、ページが
「フレーム単位」のナビゲーション用インターフェイスを提供するときである。
networkState が
NETWORK_EMPTY
でないメディア要素の準備状態が
変化したとき、ユーザーエージェントは以下の手順に従わなければならない。
次の一覧から最初に適用可能な一連の下位手順を適用する。
HAVE_NOTHING
で、新しい準備状態が HAVE_METADATA
の場合
メディア要素を与えて
メディア要素タスクをキューに入れ、
要素で loadedmetadata
という名前のイベントを発火する。
このタスクが実行される前に、イベントループ機構の一部としてレンダリングが更新され、
必要に応じて video 要素の
サイズが変更される。
HAVE_METADATA
で、新しい準備状態が HAVE_CURRENT_DATA
以上の場合このメディア要素について、load() アルゴリズムが最後に
呼び出されてからこれが初めて発生する場合、ユーザーエージェントは
メディア要素を与えて
メディア要素タスクをキューに入れ、
要素で loadeddata
という名前のイベントを発火しなければならない。
新しい準備状態が HAVE_FUTURE_DATA
または HAVE_ENOUGH_DATA
である場合、以下の関連する手順も続いて実行しなければならない。
HAVE_FUTURE_DATA
以上で、新しい準備状態が
HAVE_CURRENT_DATA
以下の場合
メディア要素の
readyState 属性が
HAVE_FUTURE_DATA
より低い値へ変化する前に、その要素が再生可能状態であり、要素の
再生が終了しておらず、
再生がエラーにより停止しておらず、
ユーザー操作のために一時停止しておらず、
帯域内コンテンツのために一時停止していない場合、
ユーザーエージェントはメディア要素を与えて
メディア要素タスクをキューに入れ、
要素で timeupdate
という名前のイベントを発火し、さらに
メディア要素を与えて
メディア要素タスクをキューに入れ、
要素で waiting
という名前のイベントを発火しなければならない。
HAVE_CURRENT_DATA
以下で、新しい準備状態が
HAVE_FUTURE_DATA
の場合
ユーザーエージェントはメディア要素を与えて
メディア要素タスクをキューに入れ、
要素で canplay
という名前のイベントを発火しなければならない。
要素の paused
属性が false の場合、ユーザーエージェントは要素について
再生中であることを通知しなければならない。
HAVE_ENOUGH_DATA
の場合
以前の準備状態が HAVE_CURRENT_DATA
以下である場合、ユーザーエージェントはメディア要素を与えて
メディア要素タスクをキューに入れ、
要素で canplay
という名前のイベントを発火しなければならず、要素の
paused 属性が
false の場合は、要素について再生中であることを通知しなければならない。
ユーザーエージェントはメディア要素を与えて
メディア要素タスクをキューに入れ、
要素で canplaythrough
という名前のイベントを発火しなければならない。
要素が自動再生の対象でない場合、ユーザーエージェントは これらの下位手順を中止しなければならない。
ユーザーエージェントは次の下位手順を実行してもよい。
paused
属性を false に設定する。play
という名前のイベントを発火する。
別の方法として、要素が video
要素である場合、
ユーザーエージェントは要素がビューポートと交差するかどうかの監視を開始してもよい。
要素がビューポートと交差し始めたとき、要素が依然として
自動再生の対象であれば、上記の下位手順を実行する。
任意で、要素がビューポートと交差しなくなったとき、
自動再生可能フラグが依然として
true であり、autoplay
属性が
依然として指定されている場合、次の下位手順を実行する。
pause
という名前のイベントを発火する。
要素がビューポートと交差し始めたり交差しなくなったりする たびに、自動再生可能フラグが true である限り、 再生と一時停止の下位手順は複数回実行され得る。
ユーザーエージェントは自動再生をサポートする必要はなく、この点に関する
ユーザー設定を尊重することが推奨される。著者には、スクリプトを使用して動画を強制的に
再生するのではなく、autoplay
属性を
使用することが強く推奨される。これにより、ユーザーが望む場合にその動作を上書きできる。
メディア要素の準備状態は、これらの状態間を不連続に移動する可能性がある。
たとえば、メディア要素の状態は、HAVE_CURRENT_DATA
および HAVE_FUTURE_DATA
状態を経由せずに、HAVE_METADATA から
HAVE_ENOUGH_DATA
へ直接移動する可能性がある。
readyState IDL 属性は、取得時に、
メディア要素の現在の準備状態を記述する、
上で説明した値を返さなければならない。
autoplay
属性は
真偽属性である。
存在する場合、ユーザーエージェントは(ここで説明するアルゴリズムに従い)停止せずに実行できるように
なり次第、メディアリソースの再生を
自動的に開始する。
著者には、自動再生をトリガーするためにスクリプトを使用するのではなく、
autoplay
属性を使用することが強く推奨される。これにより、たとえばスクリーンリーダーを使用している場合など、
自動再生が望ましくないときにユーザーがそれを上書きできる。著者には、自動再生の動作をまったく使用せず、
ユーザーエージェントがユーザーによる明示的な再生開始を待つようにすることも推奨される。
media.paused
現在のすべてのエンジンでサポートされています。
再生が一時停止中の場合は true を返し、それ以外の場合は false を返す。
media.ended
現在のすべてのエンジンでサポートされています。
再生がメディアリソースの終端に達している場合は true を返す。
media.defaultPlaybackRate [ = value ]
HTMLMediaElement/defaultPlaybackRate
現在のすべてのエンジンでサポートされています。
ユーザーがメディアリソースを早送りまたは逆再生していない ときの、デフォルト再生速度を返す。
設定して、デフォルト再生速度を変更できる。
デフォルト速度は再生に直接影響しないが、ユーザーが早送りモードへ切り替え、その後通常の 再生モードへ戻ったとき、再生速度はデフォルト再生速度へ戻ることが期待される。
media.playbackRate [ = value ]
現在のすべてのエンジンでサポートされています。
現在の再生速度を返す。1.0 が通常速度である。
設定して、再生速度を変更できる。
media.preservesPitch
HTMLMediaElement/preservesPitch
playbackRate
が 1.0 でないときに、ピッチを維持するアルゴリズムが使用される場合は true を返す。
デフォルト値は true である。
false に設定すると、playbackRate
に応じてメディアリソースの音声ピッチを上げ下げできる。
これは美的理由およびパフォーマンス上の理由で有用である。
media.playedユーザーエージェントが再生したメディアリソースの範囲を表す
TimeRanges
オブジェクトを返す。
media.play()
現在のすべてのエンジンでサポートされています。
paused
属性を false に設定し、必要に応じてメディアリソースを読み込んで再生を開始する。
再生が終了していた場合は、先頭から再開する。
media.pause()
現在のすべてのエンジンでサポートされています。
paused
属性は、メディア要素が
一時停止中かどうかを表す。この属性は初期状態で true でなければならない。
メディア要素は、その
readyState
属性が HAVE_NOTHING
状態、HAVE_METADATA
状態、または HAVE_CURRENT_DATA
状態である場合、または要素がユーザー操作のために一時停止しているか、
帯域内コンテンツのために一時停止している
場合、ブロックされたメディア要素である。
メディア要素は、その
paused 属性が
false であり、要素の再生が終了しておらず、再生が
エラーにより停止しておらず、
要素がブロックされたメディア要素でない場合、
再生可能状態にあるという。
再生可能状態にある要素が、その
readyState
属性が HAVE_FUTURE_DATA
より低い値へ変化したため再生を停止した結果として、waiting
DOM イベントが発火することがある。
メディア要素は、 次のすべてが true の場合、自動再生の対象であるという。
その自動再生可能フラグが true である。
その paused
属性が true である。
その autoplay
属性が指定されている。
それが audio または
video 要素である
場合、その遅延読み込み属性が
即時状態にあるか、
遅延状態にある間に読み込みを開始しているか、
または要素についてスクリプティングが無効である。
そのノード文書の 有効なサンドボックス化フラグ集合に、 サンドボックス化された 自動機能閲覧コンテキストフラグが設定されていない。
そのノード文書が「autoplay」
機能の使用を許可されている。
メディア要素は、 ユーザーエージェントおよびシステムが現在のコンテキストでメディア再生を許可している場合、 再生を許可されているという。
たとえば、ユーザーエージェントはメディア要素の Window オブジェクトが
一時的な有効化を持つ場合にのみ再生を許可しつつ、
ミュート中は例外として再生を許可してもよい。
メディア要素は、 次の場合に再生が終了したという。
要素の readyState
属性が HAVE_METADATA
以上であり、かつ
次のいずれかである。
または:
ended
属性は、イベントループが最後に
手順 1へ到達した時点で、メディア要素の
再生が終了しており、
再生方向が順方向であった場合は true
を返し、
それ以外の場合は false を返さなければならない。
メディア要素は、
要素の readyState
属性が HAVE_METADATA
以上であり、ユーザーエージェントがメディアデータの処理中に
致命的でないエラーに遭遇し、そのエラーのために
現在の再生位置のコンテンツを
再生できない場合、エラーにより停止したという。
メディア要素は、その
paused
属性が false で、readyState
属性が HAVE_FUTURE_DATA
または HAVE_ENOUGH_DATA
であり、ユーザーエージェントがメディアリソースを続行するためにユーザーが選択を
行う必要のある地点に達した場合、ユーザー操作のために
一時停止しているという。
メディア要素は、 再生が終了していると同時に、 ユーザー操作のために一時停止している 可能性がある。
再生可能状態にある
メディア要素が、
ユーザー操作のために一時停止したことに
よって再生を停止した場合、ユーザーエージェントはメディア要素を与えて
メディア要素タスクをキューに入れ、
要素で timeupdate
という名前のイベントを発火しなければならない。
メディア要素は、その
paused
属性が false で、readyState
属性が HAVE_FUTURE_DATA
または HAVE_ENOUGH_DATA
であり、ユーザーエージェントがメディアリソースに時間的に固定され、
長さが 0 でないコンテンツを再生するため、またはメディアリソースの一部分に時間的に固定されているが、
その部分より長いコンテンツを再生するために、メディアリソースの再生を中断している場合、
帯域内コンテンツのために一時停止しているという。
メディア要素が 帯域内コンテンツのために一時停止する 場合の一例は、ユーザーエージェントが外部 WebVTT ファイルの 音声解説を再生しており、 キューに対して生成された合成音声がテキストトラックキュー開始時刻と テキストトラックキュー終了時刻の間の時間より 長い場合である。
再生方向が順方向のときに、 現在の再生位置が メディアリソースの 終端に達した場合、ユーザーエージェントは次の手順に従わなければならない。
メディア要素に
loop
属性が指定されている場合、メディアリソースの
最も早い可能な位置へ
シークして return。
メディア要素および次の手順を与えて、 メディア要素タスクをキューに入れる。
メディア要素で
timeupdate
という名前のイベントを発火する。
メディア要素の 再生が終了しており、 再生方向が順方向であり、 pausedが false の場合:
paused
属性を true に設定する。
保留中の再生 promise を取得し、
その結果と 「AbortError」
DOMException
を用いて保留中の再生 promise を却下する。
再生方向が逆方向のときに、
現在の再生位置が
メディアリソースの
最も早い可能な位置に達した場合、
ユーザーエージェントはメディア要素を与えて
メディア要素タスクをキューに入れ、
要素で timeupdate
という名前のイベントを発火することだけを行わなければならない。
ここでいう「達する」という語は、現在の再生位置が通常の再生中に変化する 必要があることを意味しない。たとえば、シークによって達することもある。
defaultPlaybackRate 属性は、
メディアリソースを
その固有速度の何倍で再生するかという、望ましい速度を与える。この属性は変更可能である。
取得時には最後に設定された値を返さなければならず、まだ設定されていない場合は 1.0 を返さなければならない。
設定時には属性を新しい値に設定しなければならない。
defaultPlaybackRate
は、ユーザーエージェントがユーザーにユーザーインターフェイスを
公開するときに使用される。
playbackRate 属性は、実効再生速度、すなわち
メディアリソースが
その固有速度の何倍で再生されるかを与える。これが defaultPlaybackRate
と等しくない場合、ユーザーが早送りまたはスローモーション再生などの機能を使用していることを意味する。
この属性は変更可能である。取得時には最後に設定された値を返さなければならず、まだ設定されていない場合は
1.0 を返さなければならない。設定時には、ユーザーエージェントは次の手順に従わなければならない。
指定された値がユーザーエージェントによってサポートされていない場合、
「NotSupportedError」
DOMException
を投げる。
playbackRate
を新しい値に設定し、要素が再生可能状態である場合、再生速度を変更する。
defaultPlaybackRate
または playbackRate
属性の値が変化したとき(スクリプトによって設定された場合、またはたとえばユーザー操作に応じて
ユーザーエージェントが直接変更した場合)、ユーザーエージェントはメディア要素を与えて
メディア要素タスクをキューに入れ、
メディア要素で
ratechange
という名前のイベントを発火しなければならない。
ユーザーエージェントは属性の変更を滑らかに処理し、その変更に応じて知覚可能な空白や再生の
ミュートを発生させてはならない。
preservesPitch の取得手順は、再生中に
ピッチを維持するアルゴリズムが有効である場合に true を返すことである。設定手順は、知覚可能な
空白や再生のミュートを発生させることなく、対応してピッチを維持するアルゴリズムを有効または
無効に切り替えることである。デフォルトでは、そのようなピッチを維持するアルゴリズムを
有効にしなければならない(すなわち、getter は初期状態で true を返す)。
played
の取得手順は、通常の再生中に
thisの現在の再生位置が通常どおり単調に
増加することで到達した、存在する場合の、thisの
メディアリソースの
メディアタイムライン上の
点の範囲を表す、新しい正規化済み
TimeRanges オブジェクトを返すことである。
取得するたびに新しいオブジェクトを返すことは、属性の getter として不適切なパターンであり、 変更するには高いコストがかかるため、ここでは既定のものとして残されているにすぎない。新しい API で 模倣してはならない。
各メディア要素には、 保留中の再生 promise のリストがあり、 初期状態では空でなければならない。
メディア要素について 保留中の再生 promise を取得するには、 ユーザーエージェントは次の手順を実行しなければならない。
promisesを promise の空のリストとする。
メディア要素の 保留中の再生 promise のリストを promisesへコピーする。
メディア要素の 保留中の再生 promise のリストを 空にする。
promise のリストpromisesを持つメディア要素について 保留中の再生 promise を解決するには、 ユーザーエージェントはpromises内の各 promise を undefined で解決しなければならない。
promise のリストpromisesおよび例外名errorを持つ メディア要素について 保留中の再生 promise を却下するには、 ユーザーエージェントはpromises内の各 promise をerrorで却下しなければならない。
メディア要素について 再生中であることを通知するには、ユーザーエージェントは 次の手順を実行しなければならない。
保留中の再生 promise を取得し、 promisesをその結果とする。
要素および次の手順を与えてメディア要素タスクをキューに入れる。
promisesを用いて保留中の再生 promise を解決する。
メディア要素で
play()
メソッドが呼び出されたとき、
ユーザーエージェントは次の手順を実行しなければならない。
メディア要素が
再生を許可されていない場合、
「NotAllowedError」
DOMException
で却下された promiseを返す。
メディア要素の
error 属性が
null でなく、そのコードが
MEDIA_ERR_SRC_NOT_SUPPORTED
である場合、「NotSupportedError」
DOMException
で却下された promiseを返す。
これは、専用メディアソース失敗手順が
実行されたことを意味する。メディア要素読み込みアルゴリズムが
error
属性をクリアするまで、再生はできない。
resumptionStepsを、メディア要素の 遅延読み込み再開手順とする。
resumptionStepsが null でない場合:
メディア要素の 遅延読み込み再開手順を null に設定する。
resumptionStepsを呼び出す。
promiseを新しい promise とし、promiseを 保留中の再生 promise のリストに 付加する。
promiseを返す。
メディア要素の 内部再生手順は次のとおりである。
メディア要素の
networkState
属性の値が NETWORK_EMPTY
である場合、メディア要素の
リソース選択アルゴリズムを呼び出す。
再生が終了しており、 再生方向が順方向である場合、 メディアリソースの 最も早い可能な位置へ シークする。
これにより、ユーザーエージェントはメディア要素を与えて
メディア要素タスクをキューに入れ、
メディア要素で
timeupdate
という名前のイベントを発火することになる。
paused
の値を false に変更する。
ポスター表示フラグが true の場合、 要素のポスター表示フラグを false に設定し、 時が進む手順を 実行する。
メディア要素を与えて
メディア要素タスクをキューに入れ、
要素で play
という名前のイベントを発火する。
メディア要素の
readyState
属性の値が HAVE_NOTHING、
HAVE_METADATA、
または HAVE_CURRENT_DATA
である場合、メディア要素を与えて
メディア要素タスクをキューに入れ、
要素で waiting
という名前のイベントを発火する。
それ以外の場合、メディア要素の
readyState
属性の値は HAVE_FUTURE_DATA
または HAVE_ENOUGH_DATA
であるため、要素について再生中であることを通知する。
それ以外の場合、メディア要素の
readyState
属性の値が HAVE_FUTURE_DATA
または HAVE_ENOUGH_DATA
である場合、保留中の再生 promise を取得し、
メディア要素を与えて
メディア要素タスクをキューに入れ、
その結果を用いて保留中の再生 promise を解決する。
メディア要素はすでに再生中である。ただし、キューに入れられたタスクが実行される前に promiseが却下される可能性がある。
pause()
メソッドが呼び出されたとき、および
ユーザーエージェントがメディア要素を一時停止する必要があるとき、
ユーザーエージェントは次の手順を実行しなければならない。
メディア要素の
networkState
属性の値が NETWORK_EMPTY
である場合、メディア要素の
リソース選択アルゴリズムを呼び出す。
メディア要素の 内部一時停止手順は次のとおりである。
メディア要素の
paused
属性が false の場合、次の手順を実行する。
paused
の値を true に変更する。
保留中の再生 promise を取得し、 promisesをその結果とする。
メディア要素および次の手順を与えて、 メディア要素タスクをキューに入れる。
要素で timeupdate
という名前のイベントを発火する。
promisesおよび
「AbortError」
DOMException
を用いて保留中の再生 promise を却下する。
要素の playbackRate
が正または 0 である場合、再生方向は順方向である。
それ以外の場合は逆方向である。
メディア要素が
再生可能状態にあり、その
Document が
完全にアクティブな
Document である場合、
その現在の再生位置は、
メディアタイムラインの
クロックの単位時間あたり、要素の playbackRate
単位のメディア時間で単調に増加しなければならない。(この仕様では常にこれを増加と呼ぶが、
要素の playbackRate
が負である場合、その増加は実際には減少となり得る。)
要素の playbackRate
は 0.0 にできる。この場合、再生が一時停止していないにもかかわらず、
現在の再生位置は移動しない
(paused は
true にならず、pause
イベントも発火しない)。
この仕様は、ユーザーエージェントが適切な再生速度をどのように実現するかを定義しない。 利用可能なプロトコルおよびメディアによっては、ユーザーエージェントがサーバーと交渉し、 適切な速度でメディアデータを提供させることも考えられる。その場合 (速度が変更されてからサーバーがストリームの再生速度を更新するまでの期間を除き)、 クライアントは実際にはフレームを破棄したり補間したりする必要がない。
要素の playbackRate
が 1.0 でなく、preservesPitch
が true である場合、ユーザーエージェントは音声の元のピッチを維持するためにピッチ調整を
適用しなければならない。それ以外の場合、ユーザーエージェントはピッチ調整を行わずに音声を
高速化または低速化しなければならない。
メディア要素が 再生可能状態にある場合、再生される音声データは、 要素の実効メディア音量で、 現在の再生位置と同期しなければならない。 ユーザーエージェントは、イベントループが最後に 手順 1へ到達したときに有効化されていた音声トラックの音声を再生しなければならない。
再生可能状態にありながら 文書内にない メディア要素は、 動画を再生してはならないが、音声コンポーネントは再生するべきである。メディア要素へのすべての参照が 削除されたという理由だけで、メディア要素は再生を停止してはならない。メディア要素が、それ以上 いかなる音声も再生できない状態になった後にのみ、その要素をガベージコレクションしてもよい。
明示的な参照が存在しない要素でも、その要素が依然として積極的に再生中でなくても、
音声を再生する可能性がある。たとえば、一時停止されていないがコンテンツのバッファリングを待って
停止している場合や、まだバッファリング中だが、再生を開始する
suspend
イベントリスナーを持つ場合がある。メディアリソースに音声トラックがない
メディア要素であっても、メディアリソースを変更するイベントリスナーを
持っていれば、最終的に再び音声を再生する可能性がある。
各メディア要素には、 新たに導入されたキューのリストがあり、 初期状態では空でなければならない。メディア要素の テキストトラックのリストにある テキストトラックの キューのリストへ テキストトラックキューが 追加されるたびに、そのキューを メディア要素の 新たに導入されたキューのリストへ 追加しなければならない。メディア要素の テキストトラックのリストへ テキストトラックが 追加されるたびに、そのテキストトラックの キューのリスト内のすべての キューを メディア要素の 新たに導入されたキューのリストへ 追加しなければならない。メディア要素の 新たに導入されたキューのリストへ 新しいキューが追加されたとき、メディア要素の ポスター表示フラグが設定されていない場合、 ユーザーエージェントは時が進む手順を実行しなければならない。
メディア要素の テキストトラックのリストにある テキストトラックの キューのリストから テキストトラックキューが削除されたとき、および メディア要素の テキストトラックのリストから テキストトラックが削除されたとき、 メディア要素の ポスター表示フラグが設定されていない場合、 ユーザーエージェントは時が進む手順を実行しなければならない。
メディア要素の 現在の再生位置が変化したとき (たとえば、再生またはシークにより)、ユーザーエージェントは 時が進む手順を 実行しなければならない。動画内のショットの切り替わりと字幕を同期させるなど、キューイベントの 発火タイミングの正確性に依存するユースケースをサポートするため、ユーザーエージェントは、 キューイベントをメディアタイムライン上の位置にできる限り近い時点で発火するべきであり、 理想的には 20 ミリ秒以内であるべきである。手順の実行中に 現在の再生位置が変化した場合、 ユーザーエージェントは手順が完了するまで待ち、その後直ちに手順を再実行しなければならない。 したがって、これらの手順は可能な限り頻繁に、または必要に応じて実行される。
1 回の反復に長い時間がかかると、ユーザーエージェントが「追いつく」ために先へ急ぐ際、
継続時間の短いキューが飛ばされる可能性がある。そのため、
それらのキューは activeCues
リストに現れない。
時が進む手順は次のとおりである。
current cuesを、メディア要素のすべての または 表示中の テキストトラック (無効なものを除く)のうち、 開始時刻が 現在の再生位置以下であり、 終了時刻が 現在の再生位置より大きい、すべての キューを含むように 初期化されたキューのリストとする。
other cuesを、current cuesに存在しない、 メディア要素の および 表示中の テキストトラックのすべての キューを含むように 初期化されたキューのリストとする。
このアルゴリズムがこのメディア要素について以前にも実行されている場合、 last timeを、このアルゴリズムが最後に実行された時点の 現在の再生位置とする。
現在の再生位置が、このアルゴリズムが 最後に実行されてから、通常の再生中の通常どおりの単調な増加によってのみ変化した場合、 missed cuesを、other cues内の キューのうち、 開始時刻が last time以上で、終了時刻が 現在の再生位置以下であるものの リストとする。それ以外の場合、missed cuesを空のリストとする。
missed cues内のキューのうち、 メディア要素の 新たに導入されたキューのリスト にも含まれるものをすべて削除し、その後、要素の 新たに導入されたキューのリストを 空にする。
その時刻が、通常の再生中に現在の再生位置が通常どおり
単調に増加することによって到達され、ユーザーエージェントが過去 15~250 ミリ秒以内に要素で
timeupdate
イベントを発火しておらず、かつそのようなイベントのイベントハンドラーをまだ実行していない場合、
ユーザーエージェントはメディア要素を与えて
メディア要素タスクをキューに入れ、
要素で timeupdate
という名前のイベントを発火しなければならない。
(明示的なシークなど、それ以外の場合には、関連するイベントは
現在の再生位置を変更する
全体的な処理の一部として発火する。)
したがって、このイベントは約 66 Hz より速く、または 4 Hz より遅く発火してはならない (イベントハンドラーの実行に 250 ミリ秒より長くかからないと仮定する)。 ユーザーエージェントには、動画のデコード中にユーザーエージェントが無理なく処理できる頻度より UI 更新が頻繁にならないよう、システム負荷およびイベントを毎回処理する平均コストに基づいて イベント頻度を変化させることが推奨される。
current cues内のすべてのキューの テキストトラックキュー有効フラグが 設定され、other cues内のどのキューにも テキストトラックキュー有効フラグが 設定されておらず、missed cuesが空である場合、return。
その時刻が、通常の再生中に現在の再生位置が通常どおり 単調に増加することによって到達され、other cues内に、 テキストトラックキューの 終了時一時停止フラグが設定され、かつ テキストトラックキュー有効フラグが 設定されているか、missed cuesにも含まれる キューがある場合、 メディア要素を 直ちに 一時停止する。
明示的なシークなど、それ以外の場合には、 キューの テキストトラックキューの 終了時一時停止フラグが設定されていても、その キューの終了時刻を 通過することによって再生は一時停止されない。
eventsを、初期状態では空のタスクのリストとする。このリスト内の各 タスクは、 テキストトラック、 テキストトラックキュー、および時刻に 関連付けられる。これらは、タスクがキューに入れられる前にリストを ソートするために使用される。
affected tracksを、初期状態では空のテキストトラックのリストとする。
以下の手順で、時刻timeを持つテキストトラックキュー targetについて、eventという名前の イベントを準備すると記述されている場合、 ユーザーエージェントは次の手順を実行しなければならない。
trackを、テキストトラックキュー targetが関連付けられているテキストトラックとする。
新たに作成したタスクを、時刻time、 テキストトラック track、およびテキストトラックキュー targetに関連付けてeventsへ追加する。
trackをaffected tracksへ追加する。
missed cues内の各テキストトラックキューについて、
テキストトラックキュー開始時刻を
持つ TextTrackCue
オブジェクトについて、enter
という名前のイベントを準備する。
other cues内の各テキストトラックキューのうち、
テキストトラックキュー有効フラグが
設定されているか、missed cues内にあるものについて、
テキストトラックキュー終了時刻と
テキストトラックキュー開始時刻の
遅いほうを持つ TextTrackCue
オブジェクトについて、exit
という名前のイベントを準備する。
current cues内の各テキストトラックキューのうち、
テキストトラックキュー有効フラグが
設定されていないものについて、テキストトラックキュー開始時刻を持つ
TextTrackCue
オブジェクトについて、enter
という名前のイベントを準備する。
events内のタスクを時刻の昇順 (より早い時刻のタスクを先)にソートする。
events内で同じ時刻を持つタスクを、これらの タスクに関連付けられた テキストトラックキューの相対的な テキストトラックキュー順によって さらにソートする。
最後に、events内で同じ時刻および同じ
テキストトラックキュー順を持つ
タスクを、
enter
イベントを発火するタスクが、
exit
イベントを発火するものより前になるようにソートする。
events内の各タスクについて、リスト順に メディア要素を与えて メディア要素タスクをキューに入れる。
affected tracksを、メディア要素の テキストトラックのリストに テキストトラックが現れる順と 同じ順序にソートし、重複を削除する。
affected tracks内の各テキストトラックについて、リスト順に
メディア要素を与えて
メディア要素タスクをキューに入れ、
TextTrack オブジェクトで
cuechange
という名前のイベントを発火し、さらに
テキストトラックに対応する
track 要素が
ある場合、その track
要素でも cuechange
という名前のイベントを発火する。
current cues内のすべてのキューの テキストトラックキュー有効フラグを 設定し、other cues内のすべてのキューの テキストトラックキュー有効フラグを 設定解除する。
affected tracks内の表示中の各 テキストトラックについて、 テキストトラックの言語が空文字列でない場合は それをフォールバック言語として提供し、テキストトラックの レンダリングを更新する規則を実行する。たとえば、WebVTT に基づく テキストトラックでは、 WebVTT テキストトラックの 表示を更新する規則を実行する。[WEBVTT]
上記のアルゴリズムの目的上、テキストトラックキューは、単に テキストトラックに 関連付けられているだけでなく、テキストトラックのキューのリストに 掲載されている場合に限り、テキストトラックの一部と見なされる。
メディア要素の ノード文書が 完全にアクティブな文書でなくなった場合、 文書が再びアクティブになるまで再生は停止する。
メディア要素が
Document から
削除されたとき、ユーザーエージェントは次の手順を実行しなければならない。
media.seekingユーザーエージェントが現在シーク中である場合は true を返す。
media.seekable
現在のすべてのエンジンでサポートされています。
ユーザーエージェントがシークできるメディア
リソースの範囲を表す TimeRanges オブジェクトを返す。
media.fastSeek(time)
精度より速度を優先し、指定された time の近くへ可能な限り高速にシークする。
(正確な時刻へシークするには、currentTime
属性を使用する。)
メディアリソースが読み込まれていない場合、これは何もしない。
seeking
属性の初期値は false でなければならない。
fastSeek(time) メソッドは、
速度優先近似フラグを設定して、timeで指定された時刻へ
シークしなければならない。
ユーザーエージェントがメディアリソース内の 特定の新しい再生位置へ、任意で速度優先近似フラグを設定して シークする必要がある場合、それはユーザーエージェントが 次の手順を実行しなければならないことを意味する。このアルゴリズムは イベントループ機構と密接に連携する。 特に、イベントループアルゴリズムの一部として トリガーされる同期区間を持つ。その区間内の手順には ⌛ が付けられている。
メディア要素の readyState
が HAVE_NOTHING
である場合、return。
要素の seeking IDL
属性が true である場合、このアルゴリズムの別のインスタンスがすでに実行中である。
その別のアルゴリズムインスタンスが現在実行している手順の完了を待たずに中止する。
seeking IDL 属性を
true に設定する。
シークが DOM メソッド呼び出しまたは IDL 属性の設定に応じて行われた場合、 スクリプトを続行する。これらの手順の残りは並行して実行しなければならない。⌛ が付けられた手順を除き、 このアルゴリズムの別のインスタンスが呼び出されることにより、いつでも中止され得る。
新しい再生位置が最も早い可能な位置より小さい場合、 代わりにその位置とする。
(この時点で変更されている可能性のある)新しい再生位置が、seekable 属性で
与えられる範囲のいずれにも含まれていない場合、それを seekable 属性で
与えられる範囲のいずれかにある位置のうち、新しい再生位置に最も近い位置とする。
2 つの位置がともこの制約を満たす場合(すなわち、新しい再生位置が seekable 属性内の
2 つの範囲のちょうど中間にある場合)、現在の再生位置に最も近い位置を使用する。
seekable 属性で
範囲がまったく与えられていない場合、seeking IDL
属性を
false に設定して return。
速度優先近似フラグが設定されている場合、再生を速やかに再開できる値へ 新しい再生位置を調整する。この手順の前の新しい再生位置が 現在の再生位置より前であった場合、 調整後の新しい再生位置も現在の再生位置より前でなければならない。 同様に、この手順の前の新しい再生位置が現在の再生位置より後であった場合、 調整後の新しい再生位置も現在の再生位置より後でなければならない。
たとえば、ユーザーエージェントは近くのキーフレームに合わせることができる。 これにより、再生を再開する前に中間フレームをデコードしてから破棄するための時間を 費やさずに済む。
メディア要素を与えて
メディア要素タスクをキューに入れ、要素で
seeking
という名前のイベントを発火する。
現在の再生位置を新しい再生位置に設定する。
メディア要素がシークを開始する
直前に再生可能状態であったが、シークによってその
readyState
属性が HAVE_FUTURE_DATA
より低い値へ変化した場合、要素で waiting
イベントが
発火する。
この手順は現在の再生位置を設定するため、ユーザーエージェントが その位置のメディアデータを実際にレンダリングできるようになる前 (次の手順で決定される)であっても、再生が「メディアリソースの終端に達する」時点に関する規則 (ループを処理するロジックの一部)など、他の条件を直ちにトリガーし得る。
currentTime 属性は
現在の再生位置ではなく、
公式再生位置を返すため、このアルゴリズムとは別に、
スクリプト実行前に更新される。
ユーザーエージェントが、新しい再生位置のメディアデータを利用できるかどうかを確定するまで待ち、 利用できる場合は、その位置を再生するのに十分なデータをデコードするまで待つ。
安定状態を待つ。 同期区間は、 このアルゴリズムの残りのすべての手順からなる。 (同期区間内の手順には ⌛ が付けられている。)
⌛ seeking IDL
属性を false に設定する。
⌛ 時が進む手順を実行する。
⌛ メディア要素を与えて
メディア要素タスクをキューに入れ、要素で
timeupdate
という名前のイベントを発火する。
⌛ メディア要素を与えて
メディア要素タスクをキューに入れ、要素で
seeked
という名前のイベントを発火する。
seekable の取得手順は、
ユーザーエージェントがシークできる、存在する場合の
thisのメディアリソースの範囲を表す、新しい
正規化済み
TimeRanges オブジェクトを返すことである。
たとえば、単純な動画ファイルであり、ユーザーエージェントとサーバーが HTTP Range
リクエストをサポートしているため、ユーザーエージェントがメディアリソース内のどこへでもシークできる場合、
属性は 1 つの範囲を持つオブジェクトを返す。その範囲の開始は最初のフレームの時刻
(最も早い可能な位置、通常は 0)であり、
終了は最初のフレームの時刻に duration 属性の値を
加えたものと同じである(これは最後のフレームの時刻に等しく、正の Infinity の場合もある)。
たとえば、ユーザーエージェントが無限ストリーム上のスライディングウィンドウを バッファリングしている場合など、範囲が継続的に変化する可能性がある。これは、たとえば DVR でライブテレビを視聴するときに見られる動作である。
取得するたびに新しいオブジェクトを返すことは、属性の getter として不適切な パターンであり、変更するには高いコストがかかるため、ここでは既定のものとして残されているにすぎない。 新しい API で模倣してはならない。
ユーザーエージェントは、何がシーク可能であるかについて非常に寛容かつ楽観的な見方を 採用するべきである。ユーザーエージェントは、シークを高速化できるよう、可能な場合は 最近のコンテンツもバッファリングするべきである。
たとえば、HTTP Range リクエストをサポートしない HTTP サーバーから配信される 大きな動画ファイルを考える。ブラウザーは、現在のフレームおよび後続フレームについて取得された データのみをバッファリングし、再生を再開することによって最初へシークする場合を除いて、 シークを決して許可しない方法でこれを実装できる。しかし、これは質の低い実装となる。 高品質な実装では、コンテンツの直近数分間 (十分なストレージ容量が利用できる場合はそれ以上)をバッファリングし、ユーザーが待ち時間なしで 戻って驚くような場面を再視聴できるようにする。さらに、必要に応じてファイルを先頭から 再読み込みすることによる任意のシークも許可する。この方法は遅いものの、以前のバッファリングされていない 地点へ到達するためだけに動画を文字どおり再開し、最初から最後まで視聴し直すよりは便利である。
メディアリソースは、内部的にスクリプト化 されていたり、インタラクティブであったりする可能性がある。したがって、 メディア要素は非線形に再生される可能性がある。 これが発生した場合、ユーザーエージェントは、現在の再生位置が不連続に変化するたびに、 シークのアルゴリズムが使用されたかのように 動作しなければならない(これにより、関連するイベントが発火する)。
メディアリソースは、 複数の埋め込み音声トラックおよび動画トラックを持つことができる。たとえば、主要な動画トラックおよび 音声トラックに加えて、メディアリソースは、 外国語による吹き替え会話、監督による解説、音声解説、別のアングル、または手話の重ね合わせを 持つことができる。
media.audioTracks
現在のすべてのエンジンでサポートされています。
メディアリソース内で利用可能な
音声トラックを表す AudioTrackList
オブジェクトを返す。
media.videoTracks
現在のすべてのエンジンでサポートされています。
メディアリソース内で利用可能な
動画トラックを表す VideoTrackList
オブジェクトを返す。
メディア要素の
audioTracks 属性は、
メディア要素の
メディアリソース内で利用可能な
音声トラックを表す、ライブな
AudioTrackList
オブジェクトを返さなければならない。
メディア要素の
videoTracks 属性は、
メディア要素の
メディアリソース内で利用可能な
動画トラックを表す、ライブな
VideoTrackList
オブジェクトを返さなければならない。
別のメディアリソースが要素に
読み込まれた場合でも、各メディア要素につき、
AudioTrackList
オブジェクトは常に 1 つだけ、VideoTrackList
オブジェクトも常に 1 つだけであり、これらのオブジェクトは再利用される。
(ただし、AudioTrack
および VideoTrack
オブジェクトは再利用されない。)
AudioTrackList
および VideoTrackList
オブジェクト現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
AudioTrackList
および VideoTrackList
インターフェイスは、前節で定義された属性によって使用される。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
[Exposed =Window ]
interface AudioTrackList : EventTarget {
readonly attribute unsigned long length ;
getter AudioTrack (unsigned long index );
AudioTrack ? getTrackById (DOMString id );
attribute EventHandler onchange ;
attribute EventHandler onaddtrack ;
attribute EventHandler onremovetrack ;
};
[Exposed =Window ]
interface AudioTrack {
readonly attribute DOMString id ;
readonly attribute DOMString kind ;
readonly attribute DOMString label ;
readonly attribute DOMString language ;
attribute boolean enabled ;
};
[Exposed =Window ]
interface VideoTrackList : EventTarget {
readonly attribute unsigned long length ;
getter VideoTrack (unsigned long index );
VideoTrack ? getTrackById (DOMString id );
readonly attribute long selectedIndex ;
attribute EventHandler onchange ;
attribute EventHandler onaddtrack ;
attribute EventHandler onremovetrack ;
};
[Exposed =Window ]
interface VideoTrack {
readonly attribute DOMString id ;
readonly attribute DOMString kind ;
readonly attribute DOMString label ;
readonly attribute DOMString language ;
attribute boolean selected ;
};media.audioTracks.length
現在のすべてのエンジンでサポートされています。
media.videoTracks.length
現在のすべてのエンジンでサポートされています。
リスト内のトラック数を返す。
audioTrack = media.audioTracks[index]
videoTrack = media.videoTracks[index]
指定された AudioTrack
または VideoTrack
オブジェクトを返す。
audioTrack = media.audioTracks.getTrackById(id)
現在のすべてのエンジンでサポートされています。
videoTrack = media.videoTracks.getTrackById(id)
現在のすべてのエンジンでサポートされています。
指定された識別子を持つ AudioTrack
または VideoTrack
オブジェクトを返す。その識別子を持つトラックがない場合は null を返す。
audioTrack.id
現在のすべてのエンジンでサポートされています。
videoTrack.id
現在のすべてのエンジンでサポートされています。
指定されたトラックの ID を返す。形式がメディアフラグメント構文をサポートしている場合、
これはフラグメントで使用できる ID であり、
getTrackById() メソッドでも使用できる。
audioTrack.kind
現在のすべてのエンジンでサポートされています。
videoTrack.kind
現在のすべてのエンジンでサポートされています。
指定されたトラックが属するカテゴリーを返す。可能なトラック カテゴリーは以下に示す。
audioTrack.label
現在のすべてのエンジンでサポートされています。
videoTrack.label
現在のすべてのエンジンでサポートされています。
指定されたトラックのラベルが分かっている場合はそれを返し、それ以外の場合は空文字列を返す。
audioTrack.language
現在のすべてのエンジンでサポートされています。
videoTrack.language
現在のすべてのエンジンでサポートされています。
指定されたトラックの言語が分かっている場合はそれを返し、それ以外の場合は空文字列を返す。
audioTrack.enabled [ = value ]
現在のすべてのエンジンでサポートされています。
指定されたトラックが有効な場合は true を返し、それ以外の場合は false を返す。
設定して、トラックを有効にするかどうかを変更できる。複数の音声トラックが同時に有効にされている場合、 それらはミックスされる。
media.videoTracks.selectedIndex
現在のすべてのエンジンでサポートされています。
存在する場合は現在選択されているトラックのインデックスを返し、それ以外の場合は −1 を返す。
videoTrack.selected [ = value ]
現在のすべてのエンジンでサポートされています。
指定されたトラックが有効な場合は true を返し、それ以外の場合は false を返す。
設定して、トラックを選択するかどうかを変更できる。選択される動画トラックは 0 個または 1 個である。 以前のトラックが選択されている間に新しいトラックを選択すると、以前のトラックの選択は解除される。
AudioTrackList
オブジェクトは、0 個以上の音声トラックからなる動的なリストを表し、そのうち 0 個以上を同時に
有効にできる。各音声トラックは AudioTrack
オブジェクトによって表される。
VideoTrackList
オブジェクトは、0 個以上の動画トラックからなる動的なリストを表し、そのうち 0 個または 1 個を
同時に選択できる。各動画トラックは VideoTrack
オブジェクトによって表される。
AudioTrackList
および VideoTrackList
オブジェクト内のトラックは、一貫した順序で並べなければならない。
メディアリソースが順序を定義する
形式である場合、その順序を使用しなければならない。それ以外の場合、順序は
メディアリソース内でトラックが
宣言される相対的な順序でなければならない。使用される順序をリストの自然順序と呼ぶ。
したがって、これらのオブジェクト内の各トラックにはインデックスがある。 最初のトラックのインデックスは 0 であり、後続の各トラックには前のトラックより 1 大きい番号が付く。 メディアリソースが音声トラックまたは 動画トラックを動的に追加または削除する場合、トラックのインデックスも動的に変化する。 メディアリソース全体が変更された場合、 以前のすべてのトラックは削除され、新しいトラックに置き換えられる。
AudioTrackList
の length 属性、および VideoTrackList
の length 属性の getter は、取得時にそれぞれの
オブジェクトによって表されているトラック数を返さなければならない。
任意の時点における AudioTrackList
および VideoTrackList
オブジェクトのサポートされるプロパティインデックスは、
トラックが表されている場合、それぞれのオブジェクトによって表されるトラック数から 1 を引いた数までの
0 以上の数である。AudioTrackList
または VideoTrackList
オブジェクトがトラックをまったく表していない場合、そのオブジェクトには
サポートされるプロパティインデックスはない。
AudioTrackList
または VideoTrackList
オブジェクトlist内の指定されたインデックスindexについて
インデックス付きプロパティの値を決定するには、
ユーザーエージェントはlist内のindex番目のトラックを表す
AudioTrack
または VideoTrack
オブジェクトを返さなければならない。
AudioTrackList
の getTrackById(id) メソッド、および
VideoTrackList
の getTrackById(id) メソッドは、それぞれ
AudioTrackList
または VideoTrackList
オブジェクト内で、識別子がid引数の値と等しい最初の
AudioTrack
または VideoTrack
オブジェクトを、それぞれ上で定義したリストの自然順序で返さなければならない。
指定された引数に一致するトラックがない場合、メソッドは null を返さなければならない。
AudioTrack
および VideoTrack
オブジェクトは、メディアリソースの特定のトラックを
表す。各トラックは識別子、カテゴリー、ラベル、および言語を持つことができる。
トラックのこれらの側面は、トラックの存続期間中は永続的である。トラックが
メディアリソースの
AudioTrackList
または VideoTrackList
オブジェクトから削除された場合でも、これらの側面は変化しない。
さらに、各 AudioTrack
オブジェクトは有効または無効にできる。これが音声トラックの有効状態である。
AudioTrack
が作成されたとき、その有効状態は false(無効)に設定しなければならない。
リソースフェッチ
アルゴリズムはこれを上書きできる。
同様に、各 VideoTrackList
オブジェクトにつき、1 つの VideoTrack
オブジェクトを選択できる。これが動画トラックの選択状態である。
VideoTrack
が作成されたとき、その選択状態は false(未選択)に設定しなければならない。
リソースフェッチアルゴリズムは
これを上書きできる。
AudioTrack の
id 属性、および VideoTrack の
id
属性は、トラックに識別子がある場合はそれを返し、
それ以外の場合は空文字列を返さなければならない。メディアリソースが
メディアフラグメント構文をサポートする形式である場合、
特定のトラックについて返される識別子は、そのような
フラグメントのトラック次元におけるトラック名として
使用した場合に、そのトラックを有効にする識別子と同じでなければならない。
[INBAND]
たとえば Ogg ファイルでは、これはトラックの Name ヘッダーフィールドとなる。 [OGGSKELETONHEADERS]
AudioTrack の
kind 属性、および
VideoTrack の
kind
属性は、トラックにカテゴリーがある場合はそれを返し、
それ以外の場合は空文字列を返さなければならない。
トラックのカテゴリーは、メディアリソース内のトラックに
含まれるメタデータに基づいて決定され、下表の第 2 列および第 3 列の定義に照らしてそのトラックに
最も適した、第 1 列に示される文字列である。各行の第 3 列のセルは、その行の第 1 列のセルで
示されたカテゴリーが何に適用されるかを示す。カテゴリーは、音声トラックに適用される場合にのみ
音声トラックに適切であり、動画トラックに適用される場合にのみ動画トラックに適切である。
カテゴリーは、音声に適切な場合にのみ AudioTrack
オブジェクトについて返さなければならず、動画に適切な場合にのみ VideoTrack
オブジェクトについて返さなければならない。
Ogg ファイルでは、トラックの Role ヘッダーフィールドが関連するメタデータを与える。
DASH メディアリソースでは、Role 要素がその情報を伝達する。WebM では、現在のところ
FlagDefault 要素だけが値へ対応付けられる。メディアコンテナーから HTML への
帯域内メディアリソーストラックの取り込みに、さらなる詳細がある。
[OGGSKELETONHEADERS] [DASH] [WEBMCG] [INBAND]
| カテゴリー | 定義 | 適用対象... | 例 |
|---|---|---|---|
"alternative"
|
主要トラックの代替となり得るもの。たとえば、曲の別テイク(音声)や別アングル(動画)。 | 音声および動画。 | Ogg: "audio/alternate" または "video/alternate"; DASH: "main" および "commentary" ロールを 伴わない "alternate"。音声の場合は "dub" ロールも伴わない(その他のロールは無視される)。 |
"captions"
|
キャプションが焼き込まれた主要動画トラックのバージョン。 (従来のコンテンツ用。新しいコンテンツではテキストトラックを使用する。) | 動画のみ。 | DASH: "caption" および "main" ロールを同時に持つ(その他のロールは無視される)。 |
"descriptions"
|
動画トラックの音声解説。 | 音声のみ。 | Ogg: "audio/audiodesc"。 |
"main"
|
主要な音声トラックまたは動画トラック。 | 音声および動画。 | Ogg: "audio/main" または "video/main"; WebM: "FlagDefault" 要素が設定されている; DASH: "caption"、"subtitle"、および "dub" ロールを伴わない "main" ロール (その他のロールは無視される)。 |
"main-desc"
|
音声解説がミックスされた主要音声トラック。 | 音声のみ。 | MPEG-2 TS 内の AC3 音声: bsmod=2 かつ full_svc=1。 |
"sign"
|
音声トラックの手話通訳。 | 動画のみ。 | Ogg: "video/sign"。 |
"subtitles"
|
字幕が焼き込まれた主要動画トラックのバージョン。 (従来のコンテンツ用。新しいコンテンツではテキストトラックを使用する。) | 動画のみ。 | DASH: "subtitle" および "main" ロールを同時に持つ(その他のロールは無視される)。 |
"translation"
|
主要音声トラックの翻訳版。 | 音声のみ。 | Ogg: "audio/dub"。DASH: "dub" および "main" ロールを同時に持つ (その他のロールは無視される)。 |
"commentary"
|
主要な音声トラックまたは動画トラックに対する解説。たとえば、監督による解説。 | 音声および動画。 | DASH: "main" ロールを伴わない "commentary" ロール(その他のロールは無視される)。 |
" |
明示的な種類がない、またはトラックのメタデータによって示された種類を ユーザーエージェントが認識しない。 | 音声および動画。 |
AudioTrack の
label 属性、および
VideoTrack の
label
属性は、トラックにラベルがある場合はそれを返し、
それ以外の場合は空文字列を返さなければならない。[INBAND]
AudioTrack の
language
属性、および
VideoTrack の
language
属性は、トラックに言語がある場合はその言語の
BCP 47 言語タグを返し、それ以外の場合は空文字列を返さなければならない。
ユーザーエージェントがその言語を BCP 47 言語タグとして表現できない場合
(たとえば、メディアリソースの形式内の
言語情報が、定義された解釈を持たない自由形式の文字列である場合)、メソッドは、トラックに言語が
ないかのように空文字列を返さなければならない。[INBAND]
AudioTrack の
enabled
属性は、取得時に、トラックが現在有効である
場合は true を返し、それ以外の場合は false を返さなければならない。設定時には、新しい値が
true の場合はトラックを有効にし、それ以外の場合は無効にしなければならない。
(トラックがすでに AudioTrackList
オブジェクト内にない場合、トラックの有効化または無効化は、AudioTrack
オブジェクト上の属性値を変更すること以外には影響を持たない。)
AudioTrackList
内で無効であった音声トラックが有効にされるたび、および有効であった音声トラックが無効にされるたびに、
ユーザーエージェントはメディア要素を与えて
メディア要素タスクを
キューに入れ、AudioTrackList
オブジェクトで change
という名前のイベントを発火しなければならない。
メディアタイムライン上の特定の位置に データを持たない音声トラック、またはその位置に存在しない音声トラックは、そのタイムライン上の その地点では無音であると解釈しなければならない。
VideoTrackList
の selectedIndex 属性は、存在する場合は現在選択されている
トラックのインデックスを返さなければならない。VideoTrackList
オブジェクトが現在トラックをまったく表していない場合、またはいずれのトラックも選択されていない場合は、
代わりに −1 を返さなければならない。
VideoTrack の
selected
属性は、取得時に、トラックが現在選択されている
場合は true を返し、それ以外の場合は false を返さなければならない。設定時には、新しい値が
true の場合はトラックを選択し、それ以外の場合は選択を解除しなければならない。
トラックが VideoTrackList
内にある場合、そのリスト内の他のすべての VideoTrack
オブジェクトの選択を解除しなければならない。
(トラックがすでに VideoTrackList
オブジェクト内にない場合、トラックの選択または選択解除は、VideoTrack
オブジェクト上の属性値を変更すること以外には影響を持たない。)
VideoTrackList
内で以前選択されていなかったトラックが選択されるたび、および VideoTrackList
内で選択されていたトラックが、その代わりとなる新しいトラックが選択されることなく選択解除されるたびに、
ユーザーエージェントはメディア要素を与えて
メディア要素タスクを
キューに入れ、VideoTrackList
オブジェクトで change
という名前のイベントを発火しなければならない。この
タスクは、存在する場合、
resize
イベントを発火するタスクより前に
キューに入れなければならない。
メディアタイムライン上の特定の位置に データを持たない動画トラックは、そのタイムライン上のその地点では 透明な黒であると解釈しなければならない。 その寸法は、その位置より前の最後のフレームと同じものとし、その位置がそのトラックのすべての データより前である場合は、そのトラックの最初のフレームと同じものとする。現在の位置にまったく存在しない トラックは、存在するがデータを持たないものとして扱わなければならない。
たとえば、動画に再生開始から 1 時間後に初めて導入されるトラックがあり、 ユーザーがそのトラックを選択してから先頭へ戻った場合、ユーザーエージェントは、そのトラックが メディアリソースの先頭から 始まっていたが、1 時間経過するまでは単に透明であったかのように動作する。
以下は、AudioTrackList
および VideoTrackList
インターフェイスを実装するすべてのオブジェクトが、イベントハンドラー IDL 属性
としてサポートしなければならないイベントハンドラー
(および対応するイベントハンドラーイベント型)
である。
| イベントハンドラー | イベントハンドラーイベント型 |
|---|---|
onchange
現在のすべてのエンジンでサポートされています。 Firefox🔰 33+Safari7+Chrome🔰 37+
Opera?Edge🔰 79+ Edge(レガシー)いいえInternet Explorer10+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? 現在のすべてのエンジンでサポートされています。 Firefox31+Safari7+Chrome33+
Opera?Edge79+ Edge(レガシー)18Internet Explorerいいえ Firefox Android?Safari iOS?Chrome Android?WebView Android4.4+Samsung Internet?Opera Android? 現在のすべてのエンジンでサポートされています。 Firefox🔰 33+Safari7+Chrome🔰 37+
Opera?Edge🔰 79+ Edge(レガシー)いいえInternet Explorer10+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
change
|
onaddtrack
現在のすべてのエンジンでサポートされています。 Firefox🔰 33+Safari7+Chrome🔰 37+
Opera?Edge🔰 79+ Edge(レガシー)いいえInternet Explorer10+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? 現在のすべてのエンジンでサポートされています。 Firefox31+Safari6+Chrome23+
Opera12.1+Edge79+ Edge(レガシー)12+Internet Explorer11 Firefox Android?Safari iOS7+Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ 現在のすべてのエンジンでサポートされています。 Firefox🔰 33+Safari7+Chrome🔰 37+
Opera?Edge🔰 79+ Edge(レガシー)いいえInternet Explorer10+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
addtrack
|
onremovetrack
AudioTrackList/removetrack_event 現在のすべてのエンジンでサポートされています。 Firefox🔰 33+Safari7+Chrome🔰 37+
Opera?Edge🔰 79+ Edge(レガシー)いいえInternet Explorer10+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? TextTrackList/removetrack_event 現在のすべてのエンジンでサポートされています。 Firefox31+Safari7+Chrome33+
Opera20+Edge79+ Edge(レガシー)18Internet Explorerいいえ Firefox Android?Safari iOS?Chrome Android?WebView Android4.4+Samsung Internet?Opera Android20+ VideoTrackList/removetrack_event 現在のすべてのエンジンでサポートされています。 Firefox🔰 33+Safari7+Chrome🔰 37+
Opera?Edge🔰 79+ Edge(レガシー)いいえInternet Explorer10+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
removetrack
|
audioTracks
および videoTracks
属性を使用すると、どのトラックを再生するかをスクリプトで選択できるが、
メディアリソースの
URLの
フラグメントで特定のトラックを指定することにより、
特定のトラックを宣言的に選択することもできる。フラグメントの形式は、
メディア
リソースのMIME タイプに依存する。
[RFC2046] [URL]
この例では、メディアフラグメント構文をサポートする形式を使用する動画を、 デフォルトの動画トラックの代わりに「Alternative」というラベルの付いた別アングルが有効になるように 埋め込んでいる。
< video src = "myvideo#track=Alternative" ></ video > メディア要素は、関連付けられた テキストトラックのグループを持つことができ、これは メディア要素の テキストトラックのリストと呼ばれる。 テキストトラックは、次のように並べ替えられる。
addTextTrack()
メソッドを使用して追加されたテキストトラックを、追加された順に古いものから並べる。
メディアリソース固有テキストトラック (メディアリソース内のデータに対応する テキストトラック)を、 メディアリソースの形式仕様で 定義された順序で並べる。
テキストトラックは
TextTrack オブジェクトであり、
次のものから構成される。
これは、ユーザーエージェントがトラックをどのように処理するかを決定する。 種類は文字列で表される。使用可能な文字列は次のとおりである。
subtitles
captions
descriptions
chapters
metadata
これは、ユーザーがトラックを識別できるようにすることを意図した、人間が読める文字列である。
track
要素に対応するテキストトラックの場合、
トラックのラベルは動的に変化し得る。
テキストトラックのラベルが空文字列である場合、 ユーザーエージェントは、ユーザーインターフェイスで使用するために、 テキストトラックの他のプロパティ(たとえば、テキストトラックの種類や言語)から適切なラベルを 自動的に生成するべきである。この自動生成されたラベルは API には公開されない。
これは、帯域内メタデータトラックを文書内の異なるスクリプトへ振り分けられるようにするために、 メディアリソースから 特に帯域内メタデータトラック用として抽出される文字列である。
たとえば、従来のテレビ局の放送をウェブ上でストリーミングし、 ウェブ固有のインタラクティブ機能で拡張する場合、広告ターゲティング用メタデータ、 クイズ番組中のトリビアゲームデータ、スポーツ中継中の選手の状態、料理番組中のレシピ情報などを 含むテキストトラックを持つことができる。各番組の開始および終了に伴って、新しいトラックが ストリームに追加または削除される可能性があり、各トラックが追加されるたびに、 ユーザーエージェントはこの属性の値を使用して専用のスクリプトモジュールに結び付けることができる。
帯域内メタデータテキストトラック以外では、帯域内メタデータトラック ディスパッチ型は空文字列である。異なるメディア形式について、この値をどのように設定するかは、 メディアリソース固有 テキストトラックを公開する手順で説明する。
これは、テキストトラックのキューの言語を表す文字列(BCP 47 言語タグ)である。 [BCP47]
track
要素に対応するテキストトラックの場合、
テキストトラックの言語は動的に変化し得る。
文字列。
次のいずれか。
テキストトラックのキューがまだ取得されていないことを示す。
テキストトラックが読み込み中であり、これまでに致命的なエラーが発生していないことを示す。 パーサーによって、さらにキューがトラックへ追加される可能性がある。
テキストトラックが致命的なエラーなしで読み込まれたことを示す。
テキストトラックは有効にされたが、ユーザーエージェントが取得を試みた際に、 何らかの理由で失敗したことを示す(たとえば、URLを 解析できなかった、ネットワークエラー、 未知のテキストトラック形式など)。一部またはすべてのキューが欠落している可能性が高く、 それらは取得されない。
次のいずれか。
テキストトラックがアクティブではないことを示す。トラックを DOM に公開する目的を除き、 ユーザーエージェントはテキストトラックを無視する。アクティブなキューはなく、 イベントは発火せず、ユーザーエージェントはトラックのキューを取得しようとしない。
テキストトラックはアクティブだが、ユーザーエージェントがキューを積極的に表示していないことを 示す。トラックのキューを取得する試みがまだ行われていない場合、ユーザーエージェントは まもなくその試みを行う。ユーザーエージェントはどのキューがアクティブかのリストを維持し、 それに応じてイベントを発火する。
テキストトラックがアクティブであることを示す。トラックのキューを取得する試みがまだ
行われていない場合、ユーザーエージェントはまもなくその試みを行う。ユーザーエージェントは
どのキューがアクティブかのリストを維持し、それに応じてイベントを発火する。さらに、
種類が
subtitles
または captions
であるテキストトラックでは、必要に応じてキューが動画に重ねて表示される。
種類が
descriptions
であるテキストトラックでは、ユーザーエージェントはキューを非視覚的な方法でユーザーが利用できる
ようにする。また、種類が
chapters
であるテキストトラックでは、ユーザーエージェントはキューを選択することによって
メディアリソース内の任意の地点へ移動できる仕組みを
ユーザーに提供する。
テキストトラックキューのリストと、 テキストトラックのレンダリングを更新する規則。 たとえば WebVTT では、WebVTT テキストトラックの表示を 更新する規則。[WEBVTT]
テキストトラックが まだ読み込まれていないか、 依然として読み込み中であること、または DOM 操作により、 テキストトラックのキューのリストは動的に変化し得る。
各メディア要素は、 初期状態で空でなければならない保留中のテキストトラックのリスト、 初期状態で false でなければならないパーサーでブロック中フラグ、 および同様に初期状態で false でなければならない 自動トラック選択実行済みフラグを持つ。
ユーザーエージェントがメディア要素の 保留中のテキストトラックのリストを設定する 必要がある場合、ユーザーエージェントは、要素の テキストトラックのリスト内にある各 テキストトラックのうち、 テキストトラックモードが 無効ではなく、かつ テキストトラック準備状態が 読み込み中であるものを、要素の 保留中のテキストトラックのリストへ追加しなければ ならない。
track
要素の親ノードが変更されるたびに、ユーザーエージェントは、その要素に対応する
テキストトラックを、それが含まれている
すべての保留中のテキストトラックのリストから
削除しなければならない。
テキストトラックの テキストトラック準備状態が、 読み込み済みまたは 読み込み失敗のいずれかへ変化するたびに、 ユーザーエージェントは、そのトラックを、それが含まれているすべての 保留中のテキストトラックのリストから 削除しなければならない。
メディア要素が HTML パーサーまたは XML パーサーによって作成された場合、 ユーザーエージェントは、要素のパーサーでブロック中フラグを true に設定しなければ ならない。メディア要素が、 HTML パーサーまたは XML パーサーの 開いている要素のスタックから取り出された場合、 ユーザーエージェントは、自動テキストトラック選択に 関するユーザー設定を尊重し、保留中のテキストトラックのリストを 設定し、要素のパーサーでブロック中フラグを false に設定しなければ ならない。
メディア要素の テキストトラックは、要素の 保留中のテキストトラックのリストが空であり、 かつ要素のパーサーでブロック中フラグが false である場合に 準備完了となる。
各メディア要素は、 初期状態で未設定でなければならない 保留中のテキストトラック変更通知フラグを持つ。
メディア要素の テキストトラックのリストに含まれる テキストトラックの テキストトラックモードの値が変化するたびに、 ユーザーエージェントはメディア要素について次の手順を実行しなければならない。
メディア要素の 保留中のテキストトラック変更通知 フラグが設定されている場合、return。
メディア要素の 保留中のテキストトラック変更通知 フラグを設定する。
メディア要素を与えて メディア要素タスクをキューに入れ、 次の手順を実行する。
メディア要素の 保留中のテキストトラック変更通知 フラグを未設定にする。
メディア要素の
textTracks
属性の TextTrackList
オブジェクトで、change
という名前のイベントを発火する。
この節に列挙されるタスクの タスクソースは、 DOM 操作タスクソースである。
テキストトラックキューは、 テキストトラック内の時間依存データの 単位であり、たとえば字幕やキャプションでは、ある時刻に表示され、別の時刻に消えるテキストに対応する。
各テキストトラックキューは、次のものから構成される。
任意の文字列。
キューが適用されるメディアデータの範囲の開始を表す、 秒および秒の小数部で示される時刻。
キューが適用されるメディアデータの範囲の終了を表す、 秒および秒の小数部で示される時刻。または、 無制限テキストトラックキューの場合は 正の Infinity。
キューが適用される範囲の終端に達したときに、メディアリソースの再生を一時停止するかどうかを示す ブール値。
キューの実データを含む、その形式で必要とされる追加フィールド。たとえば WebVTT には、 テキストトラックキューの書字方向などがある。 [WEBVTT]
無制限テキストトラックキューは、 テキストトラックキュー終了時刻が正の Infinity に 設定されたテキストトラックキューである。アクティブな 無制限テキストトラックキューは、 通常の再生中に現在の再生位置が通常どおり単調に増加することでは、 非アクティブになり得ない(たとえば、終了時刻が告知されていないライブイベントの章用メタデータキュー)。
テキストトラックキュー開始時刻および テキストトラックキュー終了時刻は負の値になり得る。 (ただし、現在の再生位置が負になることはないため、 時刻 0 より前に完全に位置するキューはアクティブになれない。)
各テキストトラックキューには、対応する
TextTrackCue オブジェクト
(より具体的には、TextTrackCueを継承する
オブジェクト。たとえば WebVTT キューは VTTCue インターフェイスを使用する)がある。
テキストトラックキューの
メモリー内表現は、この TextTrackCue API を介して
動的に変更できる。[WEBVTT]
テキストトラックキューには、その特定の種類の
テキストトラックキューの仕様で定義される
テキストトラックのレンダリングを更新する
規則が関連付けられる。これらの規則は、キューを表すオブジェクトが
addCue()
メソッドを使用して TextTrack オブジェクトへ追加された場合に
特に使用される。
さらに、各テキストトラックキューは、2 つの動的情報を持つ。
このフラグは初期状態で未設定でなければならない。このフラグは、キューがアクティブまたは 非アクティブになったときにイベントが適切に発火することを保証し、正しいキューがレンダリングされる ようにするために使用される。
ユーザーエージェントは、テキストトラックキューが、その
テキストトラックの
テキストトラックキューのリストから
削除されるたび、テキストトラック自体が、その
メディア要素の
テキストトラックのリストから削除されるたび、
またはそのテキストトラックモードが
無効へ変更されるたび、および
メディア要素の
readyStateが
HAVE_NOTHING
へ戻されるたびに、このフラグを同期的に未設定にしなければならない。この方法により、
関連する事象の前に表示中であった
テキストトラック内の
1 つ以上のキューについてフラグが未設定になった場合、ユーザーエージェントは、影響を受ける
すべてのキューについてフラグを未設定にした後、それらの
テキストトラックの
テキストトラックのレンダリングを
更新する規則を適用しなければならない。たとえば、WebVTT に基づく
テキストトラックでは、
WebVTT テキストトラックの表示を
更新する規則。[WEBVTT]
これは、キューを一貫した位置に保つために、レンダリングモデルの一部として使用される。 初期状態では空でなければならない。テキストトラックキュー有効フラグが 未設定になるたびに、ユーザーエージェントは テキストトラックキュー表示状態を 空にしなければならない。
メディア要素の テキストトラックに属する テキストトラックキューは、 テキストトラックキュー順で互いに対して並べられる。 この順序は次のように決定される。まず、キューを、それぞれの テキストトラックごとにグループ化し、 そのグループを、それぞれのテキストトラックが メディア要素の テキストトラックのリストに現れる順序と同じ順序にする。 次に、各グループ内でキューを 開始時刻の早い順に並べる。次に、同じ 開始時刻を持つ キューを、 終了時刻の遅い順に並べる。最後に、同一の 終了時刻を持つ キューを、それぞれの テキストトラックキューのリストへ最後に追加された 順に、古いものから並べる(したがって、たとえば WebVTT ファイルのキューでは、 初期状態ではファイルに列挙された順序となる)。[WEBVTT]
メディアリソース固有テキストトラックは、 メディアリソース内で見つかったデータに対応する テキストトラックである。
そのようなデータを処理およびレンダリングする規則は、関連する仕様によって定義される。 たとえば、メディアリソースが動画である場合は、 動画形式の仕様によって定義される。一部の従来形式の詳細は、 メディアコンテナーから HTML への帯域内メディアリソーストラックの取り込みにある。 [INBAND]
メディアリソースが、ユーザーエージェントによって テキストトラックと同等であると認識され、 サポートされるデータを含む場合、ユーザーエージェントは、関連データを使用して メディアリソース固有テキストトラックを 公開する手順を次のように実行する。
関連データを新しいテキストトラックに関連付ける。その テキストトラックは メディアリソース固有 テキストトラックである。
関連する仕様で定義される関連データの意味に基づいて、新しい テキストトラックの 種類、 ラベル、 言語、および 識別子を設定する。 そのデータにラベルがない場合、ラベルを空文字列に設定しなければならない。
メディアリソースが メディアフラグメント構文をサポートする形式である場合、 識別子は、そのような フラグメントのトラック次元におけるトラック名として 使用した場合に、そのトラックを有効にする識別子と同じでなければならない。
テキストトラックキューのリストを、 対象となる形式に適したテキストトラックの レンダリングを更新する規則に関連付ける。
新しいテキストトラックの
種類が
chapters
または metadata
である場合、メディアリソースの型に基づいて、
テキストトラックの
帯域内メタデータトラックディスパッチ型を次のように設定する。
CodecID 要素の値に設定しなければ
ならない。[WEBMCG]moov box にある
テキストトラックの
trak box の最初の mdia box の最初の minf box の
最初の stbl box の最初の stsd box とし、そのような
stsd box が存在しない場合は null とする。
stsd boxが null である場合、またはstsd boxが
mett box も metx box も持たない場合、
テキストトラックの
帯域内メタデータトラックディスパッチ型を空文字列に設定しなければならない。
それ以外で、stsd boxが mett box を持つ場合、
テキストトラックの
帯域内メタデータトラックディスパッチ型を、文字列 "mett"、
U+0020 SPACE 文字、およびstsd boxの最初の mett box にある
最初の mime_format フィールドの値を連結したものに設定するか、
その box にそのフィールドがない場合は空文字列に設定しなければならない。
それ以外で、stsd boxが mett box を持たず、
metx box を持つ場合、テキストトラックの
帯域内メタデータトラックディスパッチ型を、文字列 "metx"、
U+0020 SPACE 文字、およびstsd boxの最初の metx box にある
最初の namespace フィールドの値を連結したものに設定するか、
その box にそのフィールドがない場合は空文字列に設定しなければならない。
[MPEG4]
キューを 公開するためのガイドラインに従って、これまでに解析されたキューで、新しい テキストトラックの キューのリストを設定し、 必要に応じて動的な更新を開始する。
新しいテキストトラックの モードを、ユーザー設定およびそのデータに 関する関連仕様の要件と整合するモードに設定する。
たとえば、他にアクティブな字幕がなく、これが強制字幕トラック (音声トラックの主要言語による字幕トラックだが、実際に別の言語で話される音声に対してのみ字幕を 提供するもの)である場合、ここでその字幕を有効にできる。
新しいテキストトラックを、 メディア要素の テキストトラックのリストに追加する。
メディア要素の
textTracks
属性の TextTrackList
オブジェクトで、TrackEventを使用し、
track
属性をテキストトラックに初期化して、
addtrack
という名前のイベントを発火する。
テキストトラックの種類は、要素の
kind
属性の状態から、次の表に従って決定される。第 1 列のセルに示された状態について、
種類は第 2 列に示された文字列となる。
| 状態 | 文字列 |
|---|---|
| 字幕 | subtitles
|
| キャプション | captions
|
| 解説 | descriptions
|
| 章メタデータ | chapters
|
| メタデータ | metadata
|
テキストトラックのラベルは、要素の トラックラベルである。
テキストトラックの言語は、 存在する場合は要素のトラック言語であり、 それ以外の場合は空文字列である。
テキストトラックの識別子は、
存在する場合は要素の id
属性値であり、それ以外の場合は空文字列である。
kind、
label、
srclang、
および id 属性が
設定、変更、または削除されると、テキストトラックは、上記の定義に従って
更新されなければならない。
トラック URLの変更は、以下のアルゴリズムで処理される。
テキストトラック準備状態の初期値は 未読み込みであり、 テキストトラックモードの初期値は 無効である。
テキストトラックキューのリストは 初期状態で空である。参照されるファイルが解析されると、動的に変更される。このリストには、 対象となる形式に適したテキストトラックの レンダリングを更新する規則が関連付けられる。WebVTT では、これは WebVTT テキストトラックの表示を 更新する規則である。[WEBVTT]
track
要素の親要素が変更され、新しい親がメディア要素である場合、
ユーザーエージェントは、その track
要素に対応するテキストトラックを、
メディア要素の
テキストトラックのリストへ追加し、
次にメディア要素を与えて
メディア要素タスクをキューに入れ、
メディア要素の
textTracks
属性の TextTrackList
オブジェクトで、TrackEventを使用し、
track
属性をテキストトラックに初期化して、
addtrack
という名前のイベントを発火しなければならない。
track
要素の親要素が変更され、以前の親がメディア要素であった場合、
ユーザーエージェントは、その track
要素に対応するテキストトラックを、
メディア要素の
テキストトラックのリストから削除し、
次にメディア要素を与えて
メディア要素タスクをキューに入れ、
メディア要素の
textTracks
属性の TextTrackList
オブジェクトで、TrackEventを使用し、
track
属性をテキストトラックに初期化して、
removetrack
という名前のイベントを発火しなければならない。
track
要素に対応するテキストトラックが、
メディア要素の
テキストトラックのリストに
追加された場合、ユーザーエージェントはメディア要素を与えて
メディア要素タスクをキューに入れ、
メディア要素について次の手順を
実行しなければならない。
要素のパーサーでブロック中フラグが true である場合、return。
要素の自動トラック選択実行済み フラグが true である場合、return。
この要素について、自動 テキストトラック選択に関するユーザー設定を尊重する。
ユーザーエージェントがメディア要素について 自動テキストトラック選択に関する ユーザー設定を尊重する必要がある場合、ユーザーエージェントは次の手順を実行しなければ ならない。
subtitles
および captions
について、自動テキストトラック選択を
実行する。
descriptions
について、自動テキストトラック選択を
実行する。
メディア要素の
テキストトラックのリストに、
テキストトラックの種類が
chapters
または metadata
であり、default
属性が設定された track
要素に対応し、かつテキストトラックモードが
無効に設定されている
テキストトラックがある場合、
そのようなすべてのトラックのテキストトラックモードを
に設定する。
要素の自動トラック選択実行済み フラグを true に設定する。
上記の手順で、1 つ以上のテキストトラックの種類について 自動テキストトラック選択を実行すると記されている 場合、それは次の手順を実行することを意味する。
candidatesを、メディア要素の テキストトラックのリスト内にある テキストトラックのうち、 テキストトラックの種類が、 存在する場合はアルゴリズムに渡された種類のいずれかであるものからなるリストとし、 テキストトラックのリストに 示される順序で並べる。
candidatesが空である場合、return。
candidates内のいずれかの テキストトラックの テキストトラックモードが 表示中に設定されている場合、return。
ユーザーが、candidates内のトラックについて、その テキストトラックの種類、 テキストトラックの言語、および テキストトラックのラベルに基づいて 有効にすることを希望している場合、そのトラックの テキストトラックモードを 表示中に設定する。
たとえば、ユーザーは「可能な場合は常にフランス語のキャプションを使用する」、 「タイトルに『Commentary』を含む字幕トラックがある場合は有効にする」、 または「音声解説トラックが利用可能な場合は 1 つ有効にする。理想的にはスイスドイツ語、 それがなければ標準スイスドイツ語または標準ドイツ語」といったブラウザー設定を行える。
それ以外で、candidates内に、default
属性が設定された track
要素に対応し、かつテキストトラックモードが
無効に設定されている
テキストトラックがある場合、
そのような最初のトラックのテキストトラックモードを
表示中に設定する。
track
要素に対応するテキストトラックで、次のいずれかの状況が
発生した場合、ユーザーエージェントは、その
テキストトラックおよびその
track
要素について、track 処理モデルを
開始しなければならない。
track
要素が作成された。track
要素の親要素が変更され、新しい親がメディア要素になった。
ユーザーエージェントが、テキストトラックおよびその
track
要素についてtrack 処理モデルを開始する
場合、次のアルゴリズムを実行しなければならない。このアルゴリズムは
イベントループ機構と密接に連携する。
特に、イベントループアルゴリズムの一部として
トリガーされる同期区間を持つ。
その区間内の手順には ⌛ が付けられている。
このテキストトラックおよびその
track
要素について、このアルゴリズムの別の実行がすでに進行中である場合、その別のアルゴリズムに
この要素を処理させて return。
テキストトラックの テキストトラックモードが または 表示中のいずれにも 設定されていない場合、return。
これらの手順を実行する原因となった処理を続行できるようにし、残りの手順を 並行して実行する。
⌛ テキストトラック準備状態を 読み込み中に設定する。
⌛ track
要素の親がメディア要素である場合、
corsAttributeStateを、親のメディア要素の
crossorigin
コンテンツ属性の状態とする。それ以外の場合、corsAttributeStateを
CORS なしとする。
URLが空文字列ではない場合、
requestを、URL、"track"、
corsAttributeStateを与え、同一オリジンフォールバックフラグを設定して
潜在的 CORS リクエストを
作成した結果とする。
requestの
クライアントを、
track
要素のノード文書の
関連する設定オブジェクトに
設定する。
requestの
開始元の型を
"track" に設定する。
requestを フェッチする。
フェッチアルゴリズムが、データのフェッチ中にそのデータを処理するために ネットワークタスクソースで キューに入れる タスクは、 リソースの型を決定しなければならない。リソースの型がサポートされるテキストトラック形式でない場合、 以下で説明するように読み込みは失敗する。それ以外の場合、受信したリソースのデータを、 適切なパーサー(たとえば WebVTT パーサー)へ渡し、そのパーサーの出力には テキストトラックキューのリストを 使用しなければならない。[WEBVTT]
適切なパーサーは、これらの ネットワークタスクソースの タスク中に、 各タスクがネットワークから受信済みのデータを使用して実行されるたびに、 テキストトラックキューのリストを 増分的に更新する。
この仕様は現在、テキストトラックの MIME タイプを確認するかどうか、 またはどのように確認するか、あるいは実際のファイルデータを使用してファイル型スニッフィングを 行うかどうか、またはどのように行うかを規定していない。この点に関する実装者の意図は異なっており、 正しい解決策は不明確である。ここに要件がないため、Content-Type ヘッダーに従うという HTTP 仕様の厳格な要件が優先される (「Content-Type は基礎となるデータのメディア型を指定する。」…… 「メディア型が Content-Type フィールドによって与えられていない場合に限り、 受信者は、その内容および/またはリソースを識別するために使用された URI の名前拡張子を 調べることにより、メディア型を推測しようとしてもよい。」)。
何らかの理由でフェッチが失敗した場合(ネットワークエラー、サーバーがエラーコードを返す、
CORS が失敗するなど)、またはURLが空文字列である場合、
メディア要素を与えて
DOM
操作タスクソースで
要素タスクをキューに入れ、
まずテキストトラック準備状態を
読み込み失敗へ変更し、
次に track
要素で、error
という名前のイベントを発火する。
フェッチは失敗しなかったが、リソースの型がサポートされるテキストトラック形式ではない場合、
またはファイルの処理に成功しなかった場合
(たとえば、対象となる形式が XML 形式であり、ファイルに
XMLが検出してアプリケーションへ報告することを要求する整形式エラーが含まれていた場合)、
前述の問題が見つかった
ネットワークタスクソースで
キューに入れられた
タスクは、
テキストトラック準備状態を
読み込み失敗へ変更し、
track
要素で、error
という名前のイベントを発火しなければならない。
フェッチが失敗せず、ファイルの処理に成功した場合、データの解析完了後に
ネットワークタスクソースによって
キューに入れられる最後の
タスクは、
テキストトラック準備状態を
読み込み済みへ変更し、
track
要素で、load
という名前のイベントを発火しなければならない。
フェッチの進行中に、次のいずれかが発生した場合、
……その場合、ユーザーエージェントは
フェッチを中止し、そのアルゴリズムによって生成された
保留中のタスクをすべて破棄し
(特に、URL が変更された時点以降は、テキストトラックキューのリストへ
キューを追加しない)、次に track
要素を与えて、DOM 操作タスクソースで
要素タスクをキューに入れ、
まずテキストトラック準備状態を
読み込み失敗へ変更し、
次に track
要素で、error
という名前のイベントを発火しなければならない。
テキストトラック準備状態が 読み込み中ではなくなるまで待つ。
テキストトラックモードが または 表示中に設定されているのと同時に、 トラック URLが URLと等しくなくなるまで待つ。
先頭とラベル付けされた手順へ移動する。
track
要素の src
属性が設定、変更、または削除されるたびに、ユーザーエージェントは
直ちに、要素の
テキストトラックの
テキストトラックキューのリストを
空にしなければならない。(存在する場合、これにより、以前に与えられた URL を使用して取得中の
リソースからキューを追加する上記のアルゴリズムも停止する。)
特定の形式のテキストトラックキューを、HTML ユーザーエージェントによる処理のためにどのように 解釈するかは、その形式によって定義される。そのような仕様がない場合、この節は、実装がそのような形式を 一貫して公開しようとする際に従うことのできる制約を示す。
HTML のテキストトラック モデルをサポートするために、時間指定データの各単位は テキストトラック キューへ変換される。この仕様で定義される テキストトラック キューの各側面に、形式の機能をどのように対応付けるかが定義されていない場合、実装は、 その対応付けが上記で定義されたテキストトラック キューの各側面の定義、および次の制約と整合することを保証しなければならない。
形式にキューごとの識別子に明確に相当するものがない場合、空文字列に設定するべきである。
false に設定するべきである。
現在のすべてのエンジンでサポートされています。
[Exposed =Window ]
interface TextTrackList : EventTarget {
readonly attribute unsigned long length ;
getter TextTrack (unsigned long index );
TextTrack ? getTrackById (DOMString id );
attribute EventHandler onchange ;
attribute EventHandler onaddtrack ;
attribute EventHandler onremovetrack ;
};media.textTracks.length
現在のすべてのエンジンでサポートされています。
メディア要素に関連付けられている
テキストトラックの数
(たとえば、track 要素からのもの)を
返す。これは、メディア要素の
テキストトラックのリストに含まれる
テキストトラックの数である。
media.textTracks[ n ]
メディア要素の テキストトラックのリストにある n 番目のテキストトラックを返す。
textTrack = media.textTracks.getTrackById(id)
現在のすべてのエンジンでサポートされています。
指定された識別子を持つ TextTrack オブジェクトを返す。
その識別子を持つトラックがない場合は null を返す。
TextTrackList オブジェクトは、
指定された順序で動的に更新されるテキストトラックのリストを表す。
メディア要素の
textTracks 属性は、
メディア要素の
テキストトラックのリスト内の
テキストトラックを、
テキストトラックのリストと同じ順序で表す
TextTrackList オブジェクトを
返さなければならない。
現在のすべてのエンジンでサポートされています。
TextTrackList
オブジェクトの length 属性は、
TextTrackList
オブジェクトによって表されるリスト内のテキストトラックの数を返さなければならない。
TextTrackList オブジェクトの
任意の時点におけるサポートされるプロパティインデックスは、
存在する場合、0 から、TextTrackList
オブジェクトによって表されるリスト内のテキストトラックの数から 1 を引いた数までである。
リスト内にテキストトラックがない場合、
サポートされるプロパティインデックスは存在しない。
指定されたインデックス indexについて、
TextTrackList
オブジェクトのインデックス付きプロパティの値を決定するには、
ユーザーエージェントは、TextTrackList
オブジェクトによって表されるリスト内の index 番目の
テキストトラックを返さなければならない。
getTrackById(id) メソッドは、
TextTrackList
オブジェクト内にある TextTrack のうち、その
id IDL 属性が
id 引数の値と等しい値を返す最初のものを返さなければならない。
指定された引数と一致するトラックがない場合、メソッドは null を返さなければならない。
現在のすべてのエンジンでサポートされています。
enum TextTrackMode { " disabled " , " hidden " , " showing " };
enum TextTrackKind { " subtitles " , " captions " , " descriptions " , " chapters " , " metadata " };
[Exposed =Window ]
interface TextTrack : EventTarget {
readonly attribute TextTrackKind kind ;
readonly attribute DOMString label ;
readonly attribute DOMString language ;
readonly attribute DOMString id ;
readonly attribute DOMString inBandMetadataTrackDispatchType ;
attribute TextTrackMode mode ;
readonly attribute TextTrackCueList ? cues ;
readonly attribute TextTrackCueList ? activeCues ;
undefined addCue (TextTrackCue cue );
undefined removeCue (TextTrackCue cue );
attribute EventHandler oncuechange ;
};textTrack = media.addTextTrack(kind [, label [, language ] ])
新しい TextTrack オブジェクトを作成して返す。
このオブジェクトは、メディア要素の
テキストトラックのリストにも追加される。
textTrack.kind
現在のすべてのエンジンでサポートされています。
テキストトラックの種類を表す文字列を返す。
textTrack.label
現在のすべてのエンジンでサポートされています。
存在する場合はテキストトラックのラベルを返し、 それ以外の場合は空文字列を返す (オブジェクトがユーザーに公開される場合、オブジェクトの他の属性からカスタムラベルを 生成する必要がある可能性が高いことを示す)。
textTrack.language
現在のすべてのエンジンでサポートされています。
テキストトラックの言語を表す文字列を返す。
textTrack.id
現在のすべてのエンジンでサポートされています。
指定されたトラックの ID を返す。
帯域内トラックの場合、これは、形式が
メディアフラグメント構文をサポートしている場合に
フラグメントと共に使用でき、
getTrackById()
メソッドでも使用できる ID である。
textTrack.inBandMetadataTrackDispatchType
TextTrack/inBandMetadataTrackDispatchType
テキストトラックの帯域内メタデータ トラックディスパッチ型を表す文字列を返す。
textTrack.mode [ = value ]
現在のすべてのエンジンでサポートされています。
次のリストの文字列によって表される テキストトラックモードを返す。
disabled"
テキストトラック無効モード。
モード。
showing"テキストトラック表示中モード。
モードを変更するために設定できる。
textTrack.cues
現在のすべてのエンジンでサポートされています。
テキストトラックキューのリストを、
TextTrackCueList
オブジェクトとして返す。
textTrack.activeCues
現在のすべてのエンジンでサポートされています。
テキストトラックキューのリストに含まれる
テキストトラックキューのうち、現在アクティブなもの
(すなわち、現在の再生位置より前に開始し、
その位置より後に終了するもの)を、TextTrackCueList
オブジェクトとして返す。
textTrack.addCue(cue)
現在のすべてのエンジンでサポートされています。
指定されたキューを textTrack の テキストトラックキューのリストに追加する。
textTrack.removeCue(cue)
現在のすべてのエンジンでサポートされています。
指定されたキューを textTrack の テキストトラックキューのリストから削除する。
メディア要素の
addTextTrack(kind, label,
language) メソッドが呼び出された場合、次の手順を実行しなければならない。
新しいテキストトラックを作成し、その テキストトラックの種類を kindに、そのテキストトラックのラベルを labelに、そのテキストトラックの言語を languageに、そのテキストトラック準備状態を テキストトラック読み込み済み状態に、その テキストトラックモードを モードに、その テキストトラックキューのリストを空のリストに 設定する。
初期状態では、テキストトラックキューのリストは、 いかなるテキストトラックのレンダリングを 更新する規則にも関連付けられていない。 テキストトラックキューが追加されると、 テキストトラックキューのリストには、 それに応じた規則が永続的に設定される。
新しいテキストトラックを、 メディア要素の テキストトラックのリストへ追加する。
メディア要素を与えて
メディア要素タスクをキューに入れ、
メディア要素の
textTracks 属性の
TextTrackList オブジェクトで、
TrackEventを使用し、
track
属性を新しいテキストトラックに初期化して、
addtrack
という名前のイベントを発火する。
新しいテキストトラックを返す。
inBandMetadataTrackDispatchType
の取得手順は、thisの
帯域内メタデータトラック
ディスパッチ型を返すことである。
mode の取得手順は、
thisの
モードに応じて次の文字列を返すことである。
disabled"hidden"showing"mode
の設定手順は、指定された値に応じたモードを
thisのモードに設定することである。
disabled"
showing"cues
の取得手順は次のとおりである。
thisのモードが テキストトラック無効モードである場合、 null を返す。
thisの
テキストトラックキューのリストのうち、
終了時刻が
スクリプト開始時の
最も早い可能な位置以後であるものの部分集合を、
テキストトラックキュー順で表す
ライブな
TextTrackCueList
オブジェクトを返す。
各 TextTrack オブジェクトについて、
オブジェクトを返す場合は、毎回同じ TextTrackCueList
オブジェクトを返さなければならない。
activeCues の取得手順は次のとおりである。
thisのモードが テキストトラック無効モードである場合、 null を返す。
thisの
テキストトラックキューのリストのうち、
スクリプト開始時に有効フラグが
設定されていたものの部分集合を、
テキストトラックキュー順で表す
ライブな
TextTrackCueList
オブジェクトを返す。
各 TextTrack オブジェクトについて、
オブジェクトを返す場合は、毎回同じ TextTrackCueList
オブジェクトを返さなければならない。
テキストトラックキューは、その テキストトラックキュー有効フラグが、 イベントループが最後に 手順 1へ到達した時点で設定されていた場合、 スクリプト開始時に有効フラグが設定されていた ものとする。
addCue(cue) メソッドの手順は次のとおりである。
listを、thisの テキストトラックキューのリストとする。
listに、関連付けられた テキストトラックのレンダリングを 更新する規則がまだない場合、listを、cueに適した テキストトラックのレンダリングを 更新する規則に関連付ける。
listに関連付けられた
テキストトラックのレンダリングを
更新する規則が、cueに適した
テキストトラックのレンダリングを
更新する規則と同じでない場合、
"InvalidStateError"
DOMExceptionをスローする。
指定されたcueが テキストトラックキューのリストに 含まれている場合、そのテキストトラックキューのリストから cueを削除する。
cueをlistに追加する。
removeCue(cue) メソッドの手順は次のとおりである。
指定されたcueが
thisの
テキストトラックキューのリストに
含まれていない場合、
"NotFoundError"
DOMExceptionをスローする。
cueを、thisの テキストトラックキューのリストから削除する。
この例では、audio 要素を使用して、
多数の効果音を含む音声ファイルから特定の効果音を再生する。ブラウザーが何らかのスクリプトの実行で
ビジー状態であっても、クリップの終端で正確に終了するように、キューを使用して音声を一時停止する。
ページが音声の一時停止をスクリプトに依存していた場合、ブラウザーが指定された正確な時刻に
スクリプトを実行できなければ、次のクリップの冒頭が聞こえる可能性がある。
var sfx = new Audio( 'sfx.wav' );
var sounds = sfx. addTextTrack( 'metadata' );
// add sounds we care about
function addFX( start, end, name) {
var cue = new VTTCue( start, end, '' );
cue. id = name;
cue. pauseOnExit = true ;
sounds. addCue( cue);
}
addFX( 12.783 , 13.612 , 'dog bark' );
addFX( 13.612 , 15.091 , 'kitten mew' );
function playSound( id) {
sfx. currentTime = sounds. getCueById( id). startTime;
sfx. play();
}
// play a bark as soon as we can
sfx. oncanplaythrough = function () {
playSound( 'dog bark' );
}
// meow when the user tries to leave,
// and have the browser ask them to stay
window. onbeforeunload = function ( e) {
playSound( 'kitten mew' );
e. preventDefault();
} 現在のすべてのエンジンでサポートされています。
[Exposed =Window ]
interface TextTrackCueList {
readonly attribute unsigned long length ;
getter TextTrackCue (unsigned long index );
TextTrackCue ? getCueById (DOMString id );
};cuelist.length
リスト内のキューの数を返す。
cuelist[index]リスト内でインデックス indexを持つ テキストトラックキューを返す。 キューはテキストトラックキュー順で並べられる。
cuelist.getCueById(id)
テキストトラックキュー識別子が idである最初のテキストトラックキューを (テキストトラックキュー順で)返す。
指定された識別子を持つキューがない場合、または引数が空文字列である場合は null を返す。
TextTrackCueList
オブジェクトは、指定された順序で動的に更新される
テキストトラックキューのリストを表す。
現在のすべてのエンジンでサポートされています。
length 属性は、
TextTrackCueList
オブジェクトによって表されるリスト内のキューの数を返さなければならない。
TextTrackCueList
オブジェクトの任意の時点における
サポートされるプロパティインデックスは、
存在する場合、0 から、TextTrackCueList
オブジェクトによって表されるリスト内のキューの数から 1 を引いた数までである。
リスト内にキューがない場合、
サポートされるプロパティインデックスは存在しない。
指定されたインデックス indexについて
インデックス付きプロパティの値を決定するには、
ユーザーエージェントは、TextTrackCueList
オブジェクトによって表されるリスト内の index 番目の
テキストトラックキューを返さなければならない。
現在のすべてのエンジンでサポートされています。
getCueById(id) メソッドは、
空文字列以外の引数を指定して呼び出された場合、TextTrackCueList
オブジェクトによって表されるリスト内にある
テキストトラックキューのうち、
テキストトラックキュー識別子が
idである最初のものを、存在する場合は返し、それ以外の場合は null を返さなければ
ならない。引数が空文字列である場合、メソッドは null を返さなければならない。
現在のすべてのエンジンでサポートされています。
[Exposed =Window ]
interface TextTrackCue : EventTarget {
readonly attribute TextTrack ? track ;
attribute DOMString id ;
attribute double startTime ;
attribute unrestricted double endTime ;
attribute boolean pauseOnExit ;
attribute EventHandler onenter ;
attribute EventHandler onexit ;
};cue.trackこのテキストトラックキューが属する
TextTrack オブジェクトを、
存在する場合は返し、それ以外の場合は null を返す。
cue.id [ = value ]
テキストトラックキュー識別子を返す。
設定できる。
cue.startTime [ = value ]
テキストトラックキュー開始時刻を秒単位で返す。
設定できる。
cue.endTime [ = value ]
テキストトラックキュー終了時刻を秒単位で返す。
無制限テキストトラックキューの場合は、 正の Infinity を返す。
設定できる。
cue.pauseOnExit [ = value ]
テキストトラックキューの終了時一時停止フラグが 設定されている場合は true を返し、それ以外の場合は false を返す。
設定できる。
現在のすべてのエンジンでサポートされています。
track
の取得手順は、
thisの
テキストトラックキューが、その
キューのリスト内に含まれている
テキストトラックを、存在する場合は返し、
それ以外の場合は null を返すことである。
現在のすべてのエンジンでサポートされています。
id
属性は、取得時には、
TextTrackCue
オブジェクトが表すテキストトラックキューの
テキストトラックキュー識別子を
返さなければならない。設定時には、
テキストトラックキュー識別子を
新しい値に設定しなければならない。
現在のすべてのエンジンでサポートされています。
startTime 属性は、取得時には、
TextTrackCue
オブジェクトが表すテキストトラックキューの
テキストトラックキュー開始時刻を
秒単位で返さなければならない。設定時には、
テキストトラックキュー開始時刻を、
秒単位として解釈した新しい値に設定しなければならない。その後、
TextTrackCue
オブジェクトのテキストトラックキューが、
テキストトラックの
キューのリストに含まれ、
そのテキストトラックが
メディア要素の
テキストトラックのリストに含まれ、かつ
メディア要素の
ポスター表示フラグが設定されていない場合、
そのメディア要素について
時が進む手順を実行する。
現在のすべてのエンジンでサポートされています。
endTime 属性は、取得時には、
TextTrackCue
オブジェクトが表すテキストトラックキューの
テキストトラックキュー終了時刻を、
秒単位または正の Infinity として返さなければならない。設定時に、新しい値が負の Infinity または
非数(NaN)値である場合、
TypeError
例外をスローする。それ以外の場合、
テキストトラックキュー終了時刻を新しい値に
設定しなければならない。その後、TextTrackCue
オブジェクトのテキストトラックキューが、
テキストトラックの
キューのリストに含まれ、その
テキストトラックが
メディア要素の
テキストトラックのリストに含まれ、かつ
メディア要素の
ポスター表示フラグが設定されていない場合、
そのメディア要素について
時が進む手順を実行する。
現在のすべてのエンジンでサポートされています。
pauseOnExit 属性は、取得時には、
TextTrackCue
オブジェクトが表すテキストトラックキューの
テキストトラックキューの終了時一時停止フラグが
設定されている場合は true を返し、それ以外の場合は false を返さなければならない。設定時には、
新しい値が true である場合は
テキストトラックキューの終了時一時停止フラグを
設定し、それ以外の場合は未設定にしなければならない。
TextTrackList インターフェイスを
実装するすべてのオブジェクトが、イベントハンドラー IDL
属性として
サポートしなければならないイベントハンドラー
(および対応するイベントハンドラーイベント型)は次のとおりである。
| イベントハンドラー | イベントハンドラーイベント型 |
|---|---|
onchange |
change
|
onaddtrack |
addtrack
|
onremovetrack |
removetrack
|
TextTrack インターフェイスを実装する
すべてのオブジェクトが、イベントハンドラー IDL
属性として
サポートしなければならないイベントハンドラー
(および対応するイベントハンドラーイベント型)は次のとおりである。
| イベントハンドラー | イベントハンドラーイベント型 |
|---|---|
oncuechange
現在のすべてのエンジンでサポートされています。 Firefox31+Safari6+Chrome23+
Opera12.1+Edge79+ Edge(レガシー)12+Internet Explorer10+ Firefox Android?Safari iOS7+Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ |
cuechange
|
TextTrackCue インターフェイスを
実装するすべてのオブジェクトが、イベントハンドラー IDL
属性として
サポートしなければならないイベントハンドラー
(および対応するイベントハンドラーイベント型)は次のとおりである。
| イベントハンドラー | イベントハンドラーイベント型 |
|---|---|
onenter
現在のすべてのエンジンでサポートされています。 Firefox31+Safari6+Chrome23+
Opera12.1+Edge79+ Edge(レガシー)12+Internet Explorer10+ Firefox Android?Safari iOS7+Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ |
enter
|
onexit
現在のすべてのエンジンでサポートされています。 Firefox31+Safari6+Chrome23+
Opera12.1+Edge79+ Edge(レガシー)12+Internet Explorer10+ Firefox Android?Safari iOS7+Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ |
exit
|
この節は非規範的である。
テキストトラックは、インタラクティブな表示または拡張表示のために、 メディアデータに関連するデータを格納するために使用できる。
たとえば、スポーツ中継を表示するページには、現在の得点に関する情報を含めることができる。 ロボット競技がライブストリーミングされているとする。次のように、画像に得点を重ねて表示できる。
ユーザーが動画内の任意の地点へシークした場合でも得点表示を正しくレンダリングするには、 メタデータテキストトラックキューを、得点に適した長さにする必要がある。たとえば、上のフレームでは、 試合番号を示し、試合全体の長さにわたって継続するキューが 1 つ、青チームの得点が変化するまで 継続するキューが 1 つ、赤チームの得点が変化するまで継続するキューが 1 つある可能性がある。 動画が単にライブイベントのストリームである場合、右下の時刻はキューに基づくのではなく、 現在の動画時刻から自動的に導出されると考えられる。しかし、動画がハイライトのみである場合は、 それもキューで指定できる。
次に、これらの断片が WebVTT ファイル内でどのように見えるかを示す。
WEBVTT ... 05:10:00.000 --> 05:12:15.000 matchtype:qual matchnumber:37 ... 05:11:02.251 --> 05:11:17.198 red:78 05:11:03.672 --> 05:11:54.198 blue:66 05:11:17.198 --> 05:11:25.912 red:80 05:11:25.912 --> 05:11:26.522 red:83 05:11:26.522 --> 05:11:26.982 red:86 05:11:26.982 --> 05:11:27.499 red:89 ...
ここで重要なのは、関連するイベントが適用される時間の長さにわたるキューとして情報が 与えられている点である。代わりに、たとえば得点が変化したときに、05:11:17.198 で "red+2"、05:11:25.912 で "red+3" などのように、長さが 0 の (または非常に短く、ほぼ長さが 0 の)キューとして得点を指定すると問題が生じる。 主に、通知の見落としがないことを確認するためにスクリプトがキューのリスト全体をたどる必要があるため、 シークの実装がはるかに困難になる。また、キューが短い場合、スクリプトがそれらを明示的に監視しない限り、 キューがアクティブになったことを認識できない可能性もある。
この方法でキューを使用する場合、作成者は現在の注釈を更新するために
cuechange
イベントを使用することが推奨される。(特に、timeupdate
イベントを使用することは、キューが変更されていない場合でも処理を行う必要があり、
さらに重要なこととして、メタデータキューがアクティブになってから表示が更新されるまでの遅延が
大きくなるため、あまり適切ではない。これは、timeupdate
イベントの発生頻度が制限されているためである。)
AudioTrackの
kind
IDL 属性または VideoTrackの
kind
IDL 属性の返り値を識別するため、または
テキストトラックの種類を識別するために
URLを必要とする他の仕様または
形式は、about:html-kind
URLを使用しなければならない。
controls
属性は
ブール属性である。
存在する場合、作成者がスクリプトによるコントローラーを提供しておらず、ユーザーエージェントに
独自のコントロール一式を提供してほしいことを示す。
属性が存在する場合、またはメディア要素について スクリプトが無効である場合、 ユーザーエージェントはユーザーに ユーザーインターフェイスを公開するべきである。このユーザーインターフェイスには、 再生の開始、再生の一時停止、コンテンツ内の任意の位置へのシーク (コンテンツが任意位置へのシークをサポートしている場合)、音量の変更、クローズドキャプションまたは 埋め込み手話トラックの表示変更、別の音声トラックの選択または音声解説の有効化、 およびユーザーにより適した方法でのメディアコンテンツの表示 (たとえば、全画面動画または独立したサイズ変更可能なウィンドウ)が含まれるべきである。 その他のコントロールも利用可能にしてよい。
ただし、属性が存在しない場合でも、ユーザーエージェントはメディアリソースの再生に影響を与える
コントロール(たとえば、再生、一時停止、シーク、トラック選択、および音量コントロール)を
提供してよいが、そのような機能はページの通常のレンダリングを妨げるべきではない。たとえば、
そのような機能は、メディア要素のコンテキストメニュー、
プラットフォームのメディアキー、またはリモートコントロールで公開できる。
ユーザーエージェントは、上記のように
ユーザーにユーザーインターフェイスを公開する
ことで、これを単純に実装してよい
(controls
属性が存在するかのように)。
ユーザーエージェントが、メディア要素上にコントロールを表示することによって
ユーザーにユーザーインターフェイスを
公開する場合、ユーザーエージェントは、このインターフェイスを操作している間、
ユーザー操作イベントを抑制するべきである。(たとえば、ユーザーが動画の再生コントロールを
クリックした場合、mousedown
イベントなどが、ページ上の要素で同時に発火することはない。)
可能な場合、具体的には、再生の開始、停止、一時停止、および再開、シーク、再生速度の変更、 早送りまたは巻き戻し、テキストトラックの列挙、有効化、および無効化、ならびに音声のミュートまたは 音量変更について、ユーザーエージェントが公開するユーザーインターフェイス機能は、 たとえば同じイベントがすべて発火するように、上記の DOM API を使用して実装しなければならない。
早送りや巻き戻しなどの機能は、playbackRate 属性のみを変更することで
(defaultPlaybackRate 属性を変更せずに)実装しなければならない。
シークは、メディア要素の メディアタイムライン内の要求された位置へ シークすることによって実装しなければならない。 任意の位置へのシークが遅くなるメディアリソースについて、ユーザーエージェントは、 シークバーなどのおおよその位置を指定するインターフェイスをユーザーが操作したことに応じて シークする場合、速度優先近似フラグを使用することが推奨される。
media.volume [ = value ]
現在のすべてのエンジンでサポートされています。
現在の再生音量を、0.0 から 1.0 の範囲の数値として返す。0.0 が最も小さく、 1.0 が最も大きい。
音量を変更するために設定できる。
新しい値が 0.0 .. 1.0 の範囲内にない場合、
"IndexSizeError"
DOMExceptionをスローする。
media.muted [ = value ]
現在のすべてのエンジンでサポートされています。
volume
属性を上書きして音声がミュートされている場合は true を返し、
volume
属性が尊重されている場合は false を返す。
音声をミュートするかどうかを変更するために設定できる。
メディア要素は、 0.0(無音)から 1.0(最大音量)の範囲の割合である 再生音量を持つ。初期状態では音量を 1.0 とするべきだが、 ユーザーエージェントは、サイトごとまたはその他の単位で、セッションをまたいで最後に設定された値を 記憶してよいため、音量は別の値で開始されることがある。
メディア要素 elementの再生音量を設定して数値valueにするには、次の手順を実行する。
elementの再生音量が valueと等しい場合、return。
elementの再生音量を valueに設定する。
elementが再生を許可されていない場合、 elementについて内部一時停止手順を実行する。
elementを与えて
メディア要素タスクをキューに入れ、
elementで volumechange
という名前のイベントを発火する。
volume
の設定手順は次のとおりである。
指定された値が 0.0 以上 1.0 以下の範囲内にない場合、
"IndexSizeError"
DOMExceptionをスローする。
メディア要素は、 次のいずれかが true である場合にミュートされている。
そのミュート状態が true である。
再生方向が逆方向である。
その playbackRate
が低すぎるか高すぎるため、ユーザーエージェントが音声を有用な形で再生できない。
各メディア要素は、
true、false、または "default" のいずれかである
ミュート状態を持ち、初期状態では
"default" である。ユーザーエージェントは、メディア要素の
ミュート状態を設定して true または false にしてよい
(たとえば、サイトごとまたはその他の単位で、セッションをまたいで最後に設定された値を記憶する)。
メディア要素 elementのミュート状態を設定してブール値valueにするには、次の手順を実行する。
elementのミュート状態が valueと等しい場合、return。
elementのミュート状態を valueに設定する。
elementが再生を許可されていない場合、 elementについて内部一時停止手順を実行する。
elementを与えて
メディア要素タスクをキューに入れ、
elementで volumechange
という名前のイベントを発火する。
ユーザーエージェントには、関連付けられた 音量ロック(ブール値)がある。その値は 実装定義であり、 再生音量が有効になるかどうかを決定する。
要素の実効メディア音量は次のように決定される。
メディア要素の
muted
コンテンツ属性は、
ミュートのデフォルト値を指定するブール属性である。
muted
の設定手順が呼び出された後、またはユーザーが設定を指定した後、この属性はそれ以上の効果を持たない。
この動画(広告)は自動再生されるが、ユーザーを不快にさせないように無音で再生され、 ユーザーが音声を有効にできる。ユーザー操作なしでミュートが解除された場合、 ユーザーエージェントは動画を一時停止できる。
< video src = "adverts.cgi?kind=video" controls autoplay loop muted ></ video > 現在のすべてのエンジンでサポートされています。
TimeRanges インターフェイスを実装する
オブジェクトは、時間の範囲(期間)のリストを表す。
[Exposed =Window ]
interface TimeRanges {
readonly attribute unsigned long length ;
double start (unsigned long index );
double end (unsigned long index );
};media.length
現在のすべてのエンジンでサポートされています。
オブジェクト内の範囲の数を返す。
time = media.start(index)
現在のすべてのエンジンでサポートされています。
指定されたインデックスを持つ範囲の開始時刻を返す。
インデックスが範囲外である場合、
"IndexSizeError" DOMExceptionをスローする。
time = media.end(index)
現在のすべてのエンジンでサポートされています。
指定されたインデックスを持つ範囲の終了時刻を返す。
インデックスが範囲外である場合、
"IndexSizeError" DOMExceptionをスローする。
TimeRanges オブジェクトは、
0 個以上の時間範囲からなる
リストである範囲を持つ。
開始。秒単位の数値。
終了。秒単位の数値。
start(index) メソッドの手順は次のとおりである。
indexが、thisの
範囲の
サイズ以上である場合、
"IndexSizeError" DOMExceptionをスローする。
end(index) メソッドの手順は次のとおりである。
indexが、thisの
範囲の
サイズ以上である場合、
"IndexSizeError" DOMExceptionをスローする。
TimeRanges オブジェクトの
範囲に含まれる各
時間範囲について、
次が true である場合、そのオブジェクトは
正規化済み
TimeRanges オブジェクトである。
言い換えると、そのようなオブジェクト内の 時間範囲は順序付けられ、重複せず、接してもいない (隣接する範囲は、より大きな 1 つの時間範囲へまとめられる)。 時間範囲は空でもよい (時間上の単一の瞬間だけを参照してもよい)。たとえば、メディア要素が一時停止され、ユーザーエージェントが 現在のフレーム以外のメディアリソース全体を破棄した場合に、 現在バッファリングされているのが 1 フレームだけであることを示すために使用できる。
したがって、ある時間範囲の 終了は、それに続く隣接した (接しているが重複していない)時間範囲の 開始と等しくなる。 同様に、0 を基点とするタイムライン全体を覆う時間範囲は、 開始が 0 と等しく、 終了がタイムラインの長さと等しくなる。
メディア要素の
buffered、
seekable、および
played
IDL 属性によって返されるオブジェクトが使用するタイムラインは、その要素の
メディアタイムラインでなければならない。
TrackEvent インターフェイス現在のすべてのエンジンでサポートされています。
[Exposed =Window ]
interface TrackEvent : Event {
constructor (DOMString type , optional TrackEventInit eventInitDict = {});
readonly attribute (VideoTrack or AudioTrack or TextTrack )? track ;
};
dictionary TrackEventInit : EventInit {
(VideoTrack or AudioTrack or TextTrack )? track = null ;
};event.track
現在のすべてのエンジンでサポートされています。
イベントに関連するトラックオブジェクト
(TextTrack、
AudioTrack、または
VideoTrack)を返す。
track 属性は、
初期化された値を返さなければならない。これはイベントの文脈情報を表す。
この節は非規範的である。
次のイベントは、上記の処理モデルの一部として メディア要素で発火する。
| イベント名 | インターフェイス | 発火するタイミング | 前提条件 |
|---|---|---|---|
loadstart
HTMLMediaElement/loadstart_event 現在のすべてのエンジンでサポートされています。 Firefox6+Safari4+Chrome3+
Opera12.1+Edge79+ Edge(レガシー)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ |
Event
|
ユーザーエージェントが、リソース選択アルゴリズムの一部として、 メディアデータの検索を開始する。 | networkStateが
NETWORK_LOADING
と等しい。
|
progress
HTMLMediaElement/progress_event 現在のすべてのエンジンでサポートされています。 Firefox6+Safari3.1+Chrome3+
Opera12.1+Edge79+ Edge(レガシー)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ |
Event
|
ユーザーエージェントが メディアデータを取得している。 | networkStateが
NETWORK_LOADING
と等しい。
|
suspend
HTMLMediaElement/suspend_event 現在のすべてのエンジンでサポートされています。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(レガシー)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
Event
|
ユーザーエージェントが、意図的に現在 メディアデータを取得していない。 | networkStateが
NETWORK_IDLE
と等しい。
|
abort
現在のすべてのエンジンでサポートされています。 Firefox9+Safari3.1+Chrome3+
Opera12.1+Edge79+ Edge(レガシー)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ |
Event
|
ユーザーエージェントが、完全にダウンロードされる前に メディアデータの取得を停止するが、 エラーによるものではない。 | errorが、
コード MEDIA_ERR_ABORTED
を持つオブジェクトである。networkStateは、
ダウンロードが中止された時点に応じて、NETWORK_EMPTY
または NETWORK_IDLE
のいずれかと等しい。
|
error
現在のすべてのエンジンでサポートされています。 Firefox6+Safari3.1+Chrome3+
Opera11.6+Edge79+ Edge(レガシー)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android?Samsung Internet?Opera Android12+ |
Event
|
メディアデータの取得中にエラーが 発生するか、リソースの型がサポートされるメディア形式ではない。 | errorが、
コード MEDIA_ERR_NETWORK
以上を持つオブジェクトである。networkStateは、
ダウンロードが中止された時点に応じて、NETWORK_EMPTY
または NETWORK_IDLE
のいずれかと等しい。
|
emptied
HTMLMediaElement/emptied_event 現在のすべてのエンジンでサポートされています。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(レガシー)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
Event
|
networkStateが
以前は NETWORK_EMPTY
状態ではなかったメディア要素が、ちょうどその状態へ切り替わった
(報告されようとしている読み込み中の致命的エラーによる場合、または
リソース選択アルゴリズムが
すでに実行中である間に load() メソッドが
呼び出された場合)。
|
networkStateが
NETWORK_EMPTY
であり、すべての IDL 属性が初期状態にある。
|
stalled
HTMLMediaElement/stalled_event 現在のすべてのエンジンでサポートされています。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(レガシー)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
Event
|
ユーザーエージェントが メディアデータを取得しようとしているが、 データが予期せず到着しない。 | networkStateが
NETWORK_LOADING
である。
|
loadedmetadata
HTMLMediaElement/loadedmetadata_event 現在のすべてのエンジンでサポートされています。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(レガシー)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
Event
|
ユーザーエージェントが、メディアリソースの長さと寸法を決定し、 テキストトラックの準備が整った。 | readyStateが、
初めて新たに HAVE_METADATA
以上になった。
|
loadeddata
HTMLMediaElement/loadeddata_event 現在のすべてのエンジンでサポートされています。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(レガシー)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
Event
|
ユーザーエージェントが、現在の再生位置にある メディアデータを初めてレンダリングできる。 | readyStateが、
初めて新たに HAVE_CURRENT_DATA
以上へ増加した。
|
canplay
HTMLMediaElement/canplay_event 現在のすべてのエンジンでサポートされています。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(レガシー)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
Event
|
ユーザーエージェントはメディアデータの再生を再開できるが、 今すぐ再生を開始した場合、コンテンツの追加バッファリングのために停止せずに、 メディアリソースを現在の再生速度で終端まで レンダリングすることはできないと推定する。 | readyStateが、
新たに HAVE_FUTURE_DATA
以上へ増加した。
|
canplaythrough
HTMLMediaElement/canplaythrough_event 現在のすべてのエンジンでサポートされています。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(レガシー)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
Event
|
ユーザーエージェントは、今すぐ再生を開始した場合、追加のバッファリングのために停止せずに、 メディアリソースを現在の再生速度で終端まで レンダリングできると推定する。 | readyStateが、
新たに HAVE_ENOUGH_DATA
と等しくなった。
|
playing
HTMLMediaElement/playing_event 現在のすべてのエンジンでサポートされています。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(レガシー)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
Event
|
一時停止またはメディアデータ不足による遅延の後、 再生を開始する準備が整った。 | readyStateが新たに
HAVE_FUTURE_DATA
以上になり、pausedが false であるか、
または pausedが新たに false になり、
readyStateが
HAVE_FUTURE_DATA
以上である。このイベントが発火しても、要素は依然として
再生可能状態ではない可能性がある。
たとえば、要素がユーザー操作のために一時停止しているか、
帯域内コンテンツのために一時停止している場合である。
|
waiting
HTMLMediaElement/waiting_event 現在のすべてのエンジンでサポートされています。 Firefox6+Safari3.1+Chrome3+
Opera12.1+Edge79+ Edge(レガシー)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android12.1+ |
Event
|
次のフレームが利用できないため再生が停止したが、ユーザーエージェントは、 そのフレームがいずれ利用可能になると予測している。 | readyStateが
HAVE_CURRENT_DATA
以下であり、pausedが false である。
seekingが true であるか、
または現在の再生位置が
buffered内の
いずれの範囲にも含まれていない。pausedが false
のまま、
他の理由で再生が停止することもあるが、それらの理由ではこのイベントは発火しない
(また、それらの状況が解消されても、別の playing
イベントも発火しない)。たとえば、再生が終了した場合、再生が
エラーにより停止した場合、または要素が
ユーザー操作のために一時停止した場合や
帯域内コンテンツのために一時停止した場合である。
|
seeking
HTMLMediaElement/seeking_event 現在のすべてのエンジンでサポートされています。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(レガシー)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
Event
|
seeking IDL 属性が
true に変化し、ユーザーエージェントが新しい位置へのシークを開始した。
|
|
seeked
現在のすべてのエンジンでサポートされています。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(レガシー)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
Event
|
現在の再生位置が変更された後、
seeking IDL 属性が
false に変化した。
|
|
ended
現在のすべてのエンジンでサポートされています。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(レガシー)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
Event
|
メディアリソースの終端に達したため、再生が停止した。 | currentTimeが
メディアリソースの終端と等しく、
endedが true である。
|
durationchange
HTMLMediaElement/durationchange_event 現在のすべてのエンジンでサポートされています。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(レガシー)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
Event
|
duration 属性が
更新された。
|
|
timeupdate
HTMLMediaElement/timeupdate_event 現在のすべてのエンジンでサポートされています。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(レガシー)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
Event
|
現在の再生位置が、通常の再生の一部として、 または特に注目すべき方法、たとえば不連続に変化した。 | |
play
現在のすべてのエンジンでサポートされています。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(レガシー)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
Event
|
要素が一時停止されなくなった。play() メソッドが
return した後、または autoplay
属性によって
再生が開始されたときに発火する。
|
pausedが新たに false になった。
|
pause
現在のすべてのエンジンでサポートされています。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(レガシー)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
Event
|
要素が一時停止された。pause() メソッドが
return した後に発火する。
|
pausedが新たに true になった。
|
ratechange
HTMLMediaElement/ratechange_event 現在のすべてのエンジンでサポートされています。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(レガシー)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
Event
|
defaultPlaybackRate
属性または
playbackRate
属性のいずれかが更新された。
|
|
resize
|
Event
|
videoWidth 属性および
videoHeight 属性の
一方または両方が更新された。
|
メディア要素が
video 要素であり、
readyStateが
HAVE_NOTHING
ではない。
|
volumechange
HTMLMediaElement/volumechange_event 現在のすべてのエンジンでサポートされています。 Firefox6+Safari3.1+Chrome3+
Opera12.1+Edge79+ Edge(レガシー)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android12.1+ |
Event
|
volume 属性または
muted 属性のいずれかが
変化した。該当する属性の設定手順が return した後に発火する。
|
次のイベントは、source 要素で発火する。
| イベント名 | インターフェイス | 発火するタイミング |
|---|---|---|
error
|
Event
|
メディアデータの取得中にエラーが 発生するか、リソースの型がサポートされるメディア形式ではない。 |
次のイベントは、AudioTrackList、
VideoTrackList、および
TextTrackList オブジェクトで発火する。
| イベント名 | インターフェイス | 発火するタイミング |
|---|---|---|
change
現在のすべてのエンジンでサポートされています。 Firefox🔰 33+Safari7+Chrome🔰 37+
Opera?Edge🔰 79+ Edge(レガシー)なしInternet Explorer10+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? 現在のすべてのエンジンでサポートされています。 Firefox31+Safari7+Chrome33+
Opera?Edge79+ Edge(レガシー)18Internet Explorerなし Firefox Android?Safari iOS?Chrome Android?WebView Android4.4+Samsung Internet?Opera Android? 現在のすべてのエンジンでサポートされています。 Firefox🔰 33+Safari7+Chrome🔰 37+
Opera?Edge🔰 79+ Edge(レガシー)なしInternet Explorer10+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
Event
|
トラックリスト内の 1 つ以上のトラックが有効化または無効化された。 |
addtrack
現在のすべてのエンジンでサポートされています。 Firefox🔰 33+Safari7+Chrome🔰 37+
Opera?Edge🔰 79+ Edge(レガシー)なしInternet Explorer10+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? 現在のすべてのエンジンでサポートされています。 Firefox31+Safari6+Chrome23+
Opera12.1+Edge79+ Edge(レガシー)12+Internet Explorer11 Firefox Android?Safari iOS7+Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ 現在のすべてのエンジンでサポートされています。 Firefox🔰 33+Safari7+Chrome🔰 37+
Opera?Edge🔰 79+ Edge(レガシー)なしInternet Explorer10+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
TrackEvent
|
トラックリストにトラックが追加された。 |
removetrack
AudioTrackList/removetrack_event 現在のすべてのエンジンでサポートされています。 Firefox🔰 33+Safari7+Chrome🔰 37+
Opera?Edge🔰 79+ Edge(レガシー)なしInternet Explorer10+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? TextTrackList/removetrack_event 現在のすべてのエンジンでサポートされています。 Firefox31+Safari7+Chrome33+
Opera20+Edge79+ Edge(レガシー)18Internet Explorerなし Firefox Android?Safari iOS?Chrome Android?WebView Android4.4+Samsung Internet?Opera Android20+ VideoTrackList/removetrack_event 現在のすべてのエンジンでサポートされています。 Firefox🔰 33+Safari7+Chrome🔰 37+
Opera?Edge🔰 79+ Edge(レガシー)なしInternet Explorer10+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
TrackEvent
|
トラックリストからトラックが削除された。 |
次のイベントは、TextTrack オブジェクトおよび
track 要素で発火する。
| イベント名 | インターフェイス | 発火するタイミング |
|---|---|---|
cuechange
HTMLTrackElement/cuechange_event 現在のすべてのエンジンでサポートされています。 Firefox68+Safari10+Chrome32+
Opera19+Edge79+ Edge(レガシー)14+Internet Explorerなし Firefox Android?Safari iOS?Chrome Android?WebView Android4.4.3+Samsung Internet?Opera Android19+ 現在のすべてのエンジンでサポートされています。 Firefox31+Safari6+Chrome23+
Opera12.1+Edge79+ Edge(レガシー)12+Internet Explorer10+ Firefox Android?Safari iOS7+Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ |
Event
|
トラック内の 1 つ以上のキューがアクティブになったか、アクティブでなくなった。 |
次のイベントは、track 要素で発火する。
| イベント名 | インターフェイス | 発火するタイミング |
|---|---|---|
error
|
Event
|
トラックデータの取得中にエラーが発生するか、リソースの型がサポートされる テキストトラック形式ではない。 |
load
|
Event
|
トラックデータが取得され、正常に処理された。 |
次のイベントは、TextTrackCue オブジェクトで発火する。
| イベント名 | インターフェイス | 発火するタイミング |
|---|---|---|
enter
現在のすべてのエンジンでサポートされています。 Firefox31+Safari6+Chrome23+
Opera12.1+Edge79+ Edge(レガシー)12+Internet Explorer10+ Firefox Android?Safari iOS7+Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ |
Event
|
キューがアクティブになった。 |
exit
現在のすべてのエンジンでサポートされています。 Firefox31+Safari6+Chrome23+
Opera12.1+Edge79+ Edge(レガシー)12+Internet Explorer10+ Firefox Android?Safari iOS7+Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ |
Event
|
キューがアクティブでなくなった。 |
video
要素および
audio
要素における主なセキュリティおよびプライバシー上の影響は、オリジンをまたいでメディアを
埋め込めることから生じる。脅威が流れる方向は 2 つある。敵対的なコンテンツから被害を受けるページへの
方向と、敵対的なページから被害を受けるコンテンツへの方向である。
被害を受けるページが敵対的なコンテンツを埋め込む場合、そのコンテンツに、
コンテンツを埋め込んだ Documentとの
相互作用を試みるスクリプトコードが含まれる可能性が脅威となる。これを回避するため、
ユーザーエージェントは、コンテンツから埋め込み元ページへのアクセスが存在しないことを
保証しなければならない。DOM の概念を使用するメディアコンテンツの場合、埋め込まれたコンテンツは、
独立した無関係のトップレベル走査可能内に
あるかのように扱わなければならない。
たとえば、SVG アニメーションが video
要素に埋め込まれた場合、ユーザーエージェントは外側のページの DOM へのアクセスを与えない。
SVG リソース内のスクリプトから見ると、SVG ファイルは、親を持たない単独のトップレベル走査可能内に
あるように見える。
敵対的なページが被害を受けるコンテンツを埋め込む場合、埋め込み元ページが、
本来であればアクセスできない情報をコンテンツから取得できる可能性が脅威となる。
API は、メディアの存在、その型、長さ、サイズ、およびそのホストの性能特性といった一部の情報を
公開する。このような情報はすでに問題となり得るが、実際には同じ情報を多かれ少なかれ
img 要素を
使用して取得できるため、許容できるものと判断されている。
しかし、ユーザーエージェントが字幕など、コンテンツ内のメタデータをさらに公開する場合、
より機密性の高い情報を取得できる可能性がある。したがって、その情報は動画リソースが CORS を
使用する場合にのみ公開される。crossorigin
属性により、作成者は CORS を有効にできる。[FETCH]
この制限がなければ、攻撃者は企業ネットワーク内で動作しているユーザーを誘導して、 企業のイントラネット上で以前に漏洩した場所から動画を読み込もうとするサイトを訪問させることができる。 そのような動画に新製品の機密計画が含まれていた場合、字幕を読み取れることは重大な機密性の侵害となる。
この節は非規範的である。
セットトップボックスや携帯電話などの小型デバイスで音声および動画リソースを再生する場合、
デバイス内のハードウェアリソースが限られていることによる制約を受けることが多い。たとえば、デバイスが
同時に 3 つの動画しかサポートしない場合がある。このため、再生が完了したときに
メディア
要素が保持するリソースを解放することが推奨される。その方法としては、
要素へのすべての参照を慎重に削除してガベージコレクションされるようにするか、さらに望ましくは、
要素の src
属性を空文字列に設定する。srcObject
が設定されていた場合は、代わりに srcObject
を null に設定する。
同様に、再生速度が厳密に 1.0 ではない場合、ハードウェア、ソフトウェア、または形式上の制限により、 動画フレームが欠落したり、音声が途切れたりミュートされたりすることがある。
この節は非規範的である。
メディア要素 API の各種側面が どの程度正確に実装されるかは、実装品質上の問題とみなされる。
たとえば、buffered
属性を実装する場合、
実装がバッファリング済み範囲をどの程度正確に報告するかは、ユーザーエージェントがデータをどの程度
注意深く調査するかによって決まる。API は範囲を時刻として報告するが、データはバイトストリームとして
取得されるため、可変ビットレートのストリームを受信するユーザーエージェントは、すべてのデータを
実際にデコードしなければ正確な時刻を決定できない場合がある。ただし、ユーザーエージェントに
これを行うことは要求されない。代わりに、たとえばそれまでに確認された平均ビットレートに基づく
推定値を返し、より多くの情報が利用可能になるにつれて修正してもよい。
一般則として、ユーザーエージェントには楽観的ではなく保守的に振る舞うことが推奨される。 たとえば、実際にはすべてがバッファリングされていないのに、すべてがバッファリングされたと 報告するのは望ましくない。
もう 1 つの実装品質上の問題は、前方再生専用に設計されたコーデックで動画を逆再生する場合である (たとえば、キーフレームが少なく互いに離れており、その間のフレームが直前のフレームとの差分しか 持たない場合)。ユーザーエージェントは、たとえばキーフレームだけを表示するなど、質の低い実装を 行うこともできる。しかし、より優れた実装では、さらに多くの処理を行い、より良い結果を提供する。 たとえば、動画の一部を実際に前方へデコードし、完全なフレームを保存した後、それらのフレームを 逆方向に再生する。
同様に、実装はバッファリング済みデータをいつでも破棄できるが (ユーザーエージェントがメディア要素の存続期間中に取得したすべてのメディアデータを保持するという 要件はない)、これも実装品質上の問題である。すべてのデータを保持するのに十分なリソースを持つ ユーザーエージェントには、より良いユーザー体験を可能にするため、そうすることが推奨される。 たとえば、ユーザーがライブストリームを視聴している場合、ユーザーエージェントはライブ映像だけを 視聴できるようにすることもできる。しかし、より優れたユーザーエージェントはすべてを バッファリングし、ユーザーが以前の内容をシークしたり、一時停止したり、前方および後方に再生したり できるようにする。
一時停止中のメディア 要素が文書から 削除され、次にイベント ループがステップ 1に到達する前に再挿入されなかった場合、リソースに制約のある実装には、 その機会を利用してメディア要素が使用している すべてのハードウェアリソース(動画プレーン、ネットワークリソース、データバッファなど)を解放することが 推奨される。(ただし、ユーザーエージェントは、後で再生が再開された場合に備えて、再生位置などを 引き続き追跡しなければならない。)
map
要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
name — usemap 属性から
参照する
イメージマップの名前
[Exposed =Window ]
interface HTMLMapElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute DOMString name ;
[SameObject ] readonly attribute HTMLCollection areas ;
};map 要素は、img 要素およびその子孫である任意の
area 要素とともに、
イメージマップを定義する。この要素は、その子を
表す。
name 属性は、
マップを参照できるように名前を与える。
この属性は存在しなければならず、ASCII 空白を
含まない空でない値を持たなければならない。name 属性の値は、同じ
ツリー内に
ある別の map 要素の
name 属性の値と
等しくてはならない。id
属性も指定されている場合、両方の属性は同じ値を持たなければならない。
map.areasmap 内の area 要素からなる HTMLCollectionを
返す。
areas
属性は、map 要素を
ルートとし、そのフィルターが area 要素のみに一致する
HTMLCollectionを
返さなければならない。
保守を容易にするため、イメージマップはページ上の他のコンテンツと組み合わせて定義できる。 この例は、ページ上部にイメージマップがあり、下部に対応するテキストリンクの集合があるページである。
<!DOCTYPE HTML>
< HTML LANG = "EN" >
< TITLE > Babies™: Toys</ TITLE >
< HEADER >
< H1 > Toys</ H1 >
< IMG SRC = "/images/menu.gif"
ALT = "Babies™ navigation menu. Select a department to go to its page."
USEMAP = "#NAV" >
</ HEADER >
...
< FOOTER >
< MAP NAME = "NAV" >
< P >
< A HREF = "/clothes/" > Clothes</ A >
< AREA ALT = "Clothes" COORDS = "0,0,100,50" HREF = "/clothes/" > |
< A HREF = "/toys/" > Toys</ A >
< AREA ALT = "Toys" COORDS = "100,0,200,50" HREF = "/toys/" > |
< A HREF = "/food/" > Food</ A >
< AREA ALT = "Food" COORDS = "200,0,300,50" HREF = "/food/" > |
< A HREF = "/books/" > Books</ A >
< AREA ALT = "Books" COORDS = "300,0,400,50" HREF = "/books/" >
</ P >
</ MAP >
</ FOOTER > area
要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
map
要素がある場所。alt — 画像が利用できない場合に
使用する代替テキスト
coords —
イメージマップ内に作成する図形の座標
shape —
イメージマップ内に作成する図形の種類
href —
ハイパーリンクのアドレス
target —
ハイパーリンクの
ナビゲーションに使用する
ナビゲーション可能
download —
リソースへナビゲートする代わりにダウンロードするかどうか、およびダウンロードする場合のファイル名
ping — ping する
URL
rel —
ハイパーリンクを含む文書内の場所と
宛先リソースとの関係
referrerpolicy
— 要素によって開始されるフェッチに使用する
リファラーポリシー
hreflang —
リンク先リソースの言語
type —
参照されるリソースの型に関するヒント
href 属性を持つ場合:
作成者向け;
実装者向け。
hrefを伴う。
[Exposed =Window ]
interface HTMLAreaElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute DOMString alt ;
[CEReactions , Reflect ] attribute DOMString coords ;
[CEReactions , Reflect ] attribute DOMString shape ;
[CEReactions , Reflect ] attribute DOMString download ;
[CEReactions , Reflect ] attribute USVString ping ;
[CEReactions , Reflect ] attribute DOMString rel ;
[SameObject , PutForwards =value , Reflect="rel"] readonly attribute DOMTokenList relList ;
[CEReactions ] attribute DOMString referrerPolicy ;
// also has obsolete members
};
HTMLAreaElement includes HyperlinkElementUtils ;
HTMLAreaElement includes HTMLHyperlinkElementUtils ;area要素は、何らかのテキストと
イメージマップ上の対応する領域を持つハイパーリンク、または
イメージマップ上の無効な領域のいずれかを表す。
親ノードを持つarea要素は、
祖先にmap要素を
持たなければならない。
area要素が
href
属性を持つ場合、area
要素はハイパーリンクを表す。この場合、
alt属性が
存在しなければならない。これはハイパーリンクのテキストを指定する。その値は、イメージ
マップ内の他のハイパーリンクに指定されたテキスト、および画像の代替テキストとともに提示され、
ただし画像自体は提示されない場合に、テキストなしで形状を画像に適用してハイパーリンクを使用した場合と
同じ種類の選択肢をユーザーに提供するテキストでなければならない。同じイメージマップ内に、同じリソースを指し、
空でないalt属性を持つ別の
area要素がある場合、
alt属性は空のままでもよい。
area 要素が
href
属性を持たない場合、その要素が表す領域は選択できず、alt
属性を省略しなければならない。
どちらの場合も、shape
属性および coords 属性が
領域を指定する。
shape 属性は、
次のキーワードおよび状態を持つ
列挙属性である。
| キーワード | 適合 | 状態 | 簡単な説明 |
|---|---|---|---|
circle
|
円状態 | coords 属性で
厳密に 3 個の整数を使用して円を指定する。
|
|
circ
|
いいえ | ||
default
|
デフォルト状態 | この領域は画像全体である。(coords
属性は使用されない。)
|
|
poly
|
多角形状態 | coords 属性で
6 個以上の整数を使用して多角形を指定する。
|
|
polygon
|
いいえ | ||
rect
|
長方形状態 | coords 属性で
厳密に 4 個の整数を使用して長方形を指定する。
|
|
rectangle
|
いいえ |
この属性の欠落値の デフォルトおよび無効値の デフォルトは、どちらも長方形状態である。
coords 属性を
指定する場合、その属性には妥当な浮動小数点数のリストが
含まれなければならない。この属性は、shape
属性によって記述される図形の座標を与える。この属性の処理は、イメージ
マップ処理モデルの一部として説明される。
円状態では、
area 要素に
coords 属性が
存在しなければならず、その値は 3 個の整数で、最後の整数は非負でなければならない。最初の整数は、
画像の左端から円の中心までの距離をCSS ピクセル単位で表し、
2 番目の整数は、画像の上端から円の中心までの距離を
CSS
ピクセル単位で表し、3 番目の整数は円の半径を、同じく
CSS
ピクセル単位で表さなければならない。
デフォルト状態では、
area 要素は
coords
属性を持ってはならない。(領域は画像全体である。)
多角形状態では、
area 要素は、
6 個以上の整数を持つ coords 属性を
持たなければならず、整数の個数は偶数でなければならない。各整数の組は、それぞれ画像の左端および
上端からの距離として与えられる座標を
CSS
ピクセル単位で表さなければならず、
すべての座標は、順番に多角形の頂点を表さなければならない。
長方形状態では、
area 要素は、
厳密に 4 個の整数を持つ coords 属性を
持たなければならず、最初の整数は 3 番目の整数より小さく、2 番目の整数は 4 番目の整数より
小さくなければならない。4 個の値は、それぞれ画像の左端から長方形の左辺までの距離、
上端から上辺までの距離、左端から右辺までの距離、および上端から下辺までの距離を、すべて
CSS
ピクセル単位で表さなければならない。
ユーザーエージェントが、area
要素を使用して作成された
ハイパーリンクをユーザーがたどること、または
ダウンロードすることを
許可する場合、href、target、download、および
ping 属性によってリンクをたどる方法が決まる。
rel 属性は、
ユーザーがリンクをたどる前に、対象リソースの性質として予想されるものをユーザーへ示すために
使用できる。
target、download、ping、
rel、referrerpolicy、
hreflang、および
type 属性は、
href
属性が存在しない場合、省略しなければならない。
itemprop
属性が area 要素に
指定されている場合、href 属性も
指定されなければならない。
HTMLAreaElement/referrerPolicy
現在のすべてのエンジンでサポートされています。
IDL 属性 referrerPolicy は、referrerpolicy
コンテンツ属性を、既知の値のみに
制限して反映しなければならない。
イメージマップは、画像上の幾何学的領域を ハイパーリンクに関連付けられるようにする。
img 要素の形式の画像は、
img 要素に
usemap
属性を指定することにより、map 要素の形式のイメージマップに
関連付けることができる。usemap 属性を
指定する場合、その属性は map 要素への
妥当な
ハッシュ名参照でなければならない。
次のような画像について考える。
色の付いた領域だけをクリック可能にする場合、次のようにできる。
< p >
Please select a shape:
< img src = "shapes.png" usemap = "#shapes"
alt = "Four shapes are available: a red hollow box, a green circle, a blue triangle, and a yellow four-pointed star." >
< map name = "shapes" >
< area shape = rect coords = "50,50,100,100" > <!-- the hole in the red box -->
< area shape = rect coords = "25,25,125,125" href = "red.html" alt = "Red box." >
< area shape = circle coords = "200,75,50" href = "green.html" alt = "Green circle." >
< area shape = poly coords = "325,25,262,125,388,125" href = "blue.html" alt = "Blue triangle." >
< area shape = poly coords = "450,25,435,60,400,75,435,90,450,125,465,90,500,75,465,60"
href = "yellow.html" alt = "Yellow star." >
</ map >
</ p > img 要素に
usemap
属性が指定されている場合、ユーザーエージェントは次のように処理しなければならない。
要素を文脈ノードとして、map
要素への
ハッシュ名
参照を解析する規則を使用して、属性の値を解析する。これは要素
(map)または null のいずれかを返す。
null が返された場合、return する。結局、その画像はイメージマップに 関連付けられていない。
それ以外の場合、ユーザーエージェントは map の子孫であるすべての
area 要素を
収集しなければならない。そのリストを areas とする。
イメージマップを形成する area
要素の
リスト(areas)を取得した後、インタラクティブなユーザーエージェントは、
2 つの方法のいずれかでそのリストを処理しなければならない。
ユーザーエージェントが、img
要素が表す
テキストを表示しようとする場合、次の手順を使用しなければならない。
areas 内に、href
属性の値が同じで、空でない alt
属性を持つ別の
area 要素が
ある場合、alt
属性を持たないか、
alt
属性の値が空文字列である、areas 内のすべての area 要素を
削除する。
areas 内に残った各 area 要素は、
ハイパーリンクを表す。
それらのハイパーリンクはすべて、img の
テキストに関連付けられた方法でユーザーが利用できるようにするべきである。
この文脈では、ユーザーエージェントは、area 要素および
img 要素のうち、
alt 属性が指定されていないもの、または alt
属性が空文字列もしくはその他の不可視テキストであるものを、適切な作成者提供テキストが
ないことを示すための
実装定義の方法で表してもよい。
ユーザーエージェントが画像を表示し、その画像との対話によってハイパーリンクを選択できるように
しようとする場合、画像は、areas 内の area 要素から
取得した、逆ツリー順序の
重ね合わせられた図形の集合に関連付けられなければならない(したがって、map 内で最後に
指定された area 要素が
最下層の図形となり、map 内でツリー順序の
最初の要素が最上層の図形となる)。
areas 内の各 area 要素は、
画像上に重ねる図形を取得するために、次のように処理しなければならない。
要素の shape 属性が
表す状態を見つける。
浮動小数点数の
リストを解析する規則を使用して、要素の coords
属性が存在する場合はそれを解析し、結果を coords リストとする。属性が存在しない場合、
coords リストを空のリストとする。
coords リスト内の項目数が、次の表に従って area 要素の
現在の状態に対して与えられた最小数より少ない場合、図形は空である。return する。
| 状態 | 項目の最小数 |
|---|---|
| 円 状態 | 3 |
| デフォルト 状態 | 0 |
| 多角形状態 | 6 |
| 長方形 状態 | 4 |
shape 属性の
状態に対応する次のリストの項目に従って、coords リスト内の余分な項目を確認する。
shape
属性が長方形状態を表し、リスト内の最初の数値が
3 番目の数値より数値的に大きい場合、それら 2 つの数値を入れ替える。
shape
属性が長方形状態を表し、リスト内の 2
番目の数値が
4 番目の数値より数値的に大きい場合、それら 2 つの数値を入れ替える。
ここで、要素が表す図形は、shape 属性の
状態に対応する次のリストの項目で記述される図形である。
xを coords 内の最初の数値、yを 2 番目の数値、 rを 3 番目の数値とする。
図形は、中心が画像の左端から x CSS ピクセル、 画像の上端から y CSS ピクセルの位置にあり、 半径が r CSS ピクセルである円である。
図形は、画像全体を厳密に覆う長方形である。
xiを coords 内の (2i) 番目の項目とし、 yiを coords 内の (2i+1) 番目の項目とする (coords 内の最初の項目のインデックスは 0 である)。
the coordinatesを (xi, yi) とし、 画像の左上から測定した CSS ピクセルとして解釈する。 これは、coords 内の項目数を N としたとき、0 から (N/2)-1 までのすべての整数値 iについて行う。
図形は、頂点が the coordinates によって与えられ、内部が偶奇規則を使用して 確立される多角形である。[GRAPHICS]
x1を coords 内の最初の数値、 y1を 2 番目の数値、x2を 3 番目の数値、 y2を 4 番目の数値とする。
図形は、左上隅が座標 (x1, y1) で与えられ、 右下隅が座標 (x2, y2) で与えられる長方形であり、 これらの座標は画像の左上隅からの CSS ピクセルとして解釈される。
歴史的な理由により、座標は、CSS の
'width' および
'height'
プロパティによって引き伸ばされた後の表示された画像を基準として解釈しなければならない
(CSS 非対応ブラウザーの場合は、画像要素の width 属性および
height 属性を使用する。CSS 対応ブラウザーは、それらの属性を前述の CSS
プロパティに対応付ける)。
ブラウザーのズーム機能および CSS または SVG を使用して適用された変形は、 座標に影響しない。
上記のアルゴリズムに従って重ね合わせられた図形の集合に関連付けられた画像に対する
ポインティングデバイスの操作では、該当する図形がある場合、ポインティングデバイスが示した点を覆う
最上層の図形に対して、関連するユーザー操作イベントが最初に発火しなければならない。その点を覆う
図形がない場合は、画像要素自体に対して発火しなければならない。ユーザーエージェントは、
ハイパーリンクを表す個々の
area 要素を
選択して作動させること(たとえばキーボードを使用すること)も許可してよい。
map 要素
(およびその area 要素)は、
複数の img 要素に
関連付けることができるため、1 つの area
要素が、文書の複数のフォーカス可能領域に対応することがある。
イメージマップはライブである。DOM が変更された場合、 ユーザーエージェントはイメージマップのアルゴリズムを再実行したかのように動作しなければならない。
HTML/HTML5/HTML5_Parser#Inline_SVG_and_MathML_support
現在のすべてのエンジンでサポートされています。
MathML math 要素は、この仕様のコンテンツモデルにおいて、
埋め込みコンテンツ、
フレージングコンテンツ、
フローコンテンツ、および
可触コンテンツの
カテゴリーに属する。
MathML annotation-xml 要素が
HTML 名前空間の要素を含む場合、そのような要素はすべて
フローコンテンツでなければならない。
MathML トークン要素(mi、
mo、
mn、
ms、
および mtext)が
HTML 要素の子孫である場合、それらには
HTML 名前空間の
フレージングコンテンツ要素を
含めてもよい。
ユーザーエージェントは、直接のテキストを許可しないコンテンツモデルを持つ MathML 要素内で
見つかった、要素間空白以外のテキストを、MathML の
コンテンツモデル、レイアウト、およびレンダリングの目的上、そのテキストが実際には
MathML
mtext 要素で囲まれているかのように処理しなければならない。
(ただし、そのようなテキストは適合しない。)
ユーザーエージェントは、内容が要素のコンテンツモデルに一致しない MathML 要素を、
MathML のレイアウトおよびレンダリングの目的上、適切なエラーメッセージを含む
MathML
merror 要素で置き換えたかのように動作しなければならない。
MathML 要素のセマンティクスは、MathMLおよび その他の適用可能な 仕様によって定義される。[MATHML]
HTML 文書内で MathML を使用する例を次に示す。
<!DOCTYPE html>
< html lang = "en" >
< head >
< title > The quadratic formula</ title >
</ head >
< body >
< h1 > The quadratic formula</ h1 >
< p >
< math >
< mi > x</ mi >
< mo > =</ mo >
< mfrac >
< mrow >
< mo form = "prefix" > −</ mo > < mi > b</ mi >
< mo > ±</ mo >
< msqrt >
< msup > < mi > b</ mi > < mn > 2</ mn > </ msup >
< mo > −</ mo >
< mn > 4</ mn > < mo > </ mo > < mi > a</ mi > < mo > </ mo > < mi > c</ mi >
</ msqrt >
</ mrow >
< mrow >
< mn > 2</ mn > < mo > </ mo > < mi > a</ mi >
</ mrow >
</ mfrac >
</ math >
</ p >
</ body >
</ html > HTML/HTML5/HTML5_Parser#Inline_SVG_and_MathML_support
現在のすべてのエンジンでサポートされています。
SVG svg 要素は、この仕様のコンテンツモデルにおいて、
埋め込みコンテンツ、
フレージングコンテンツ、
フローコンテンツ、および
可触コンテンツの
カテゴリーに属する。
SVG foreignObject 要素が
HTML 名前空間の要素を含む場合、そのような要素はすべて
フローコンテンツでなければならない。
HTML
文書内にある SVG
title 要素のコンテンツモデルは、
フレージングコンテンツである。
(これは、SVG 2で与えられる要件をさらに制約する。)
SVG 要素のセマンティクスは、SVG 2および その他の適用可能な 仕様によって定義される。[SVG]
doc = iframe.getSVGDocument()
doc = embed.getSVGDocument()
doc = object.getSVGDocument()
iframe、embed、または object 要素が SVG の
埋め込みに使用されている場合、Document オブジェクトを返す。
getSVGDocument() メソッドの手順は次のとおりである。
documentが null ではなく、ナビゲートアルゴリズム内の
リソースの算出された型が
image/svg+xmlであったために、
XML ファイルのページ
読み込み処理モデルの節によって作成された場合、documentを返す。
null を返す。
作成者の要件:img、iframe、embed、object、video、
親が picture
要素である場合の source、および
type 属性が
画像ボタン状態である場合の
input 要素では、
width 属性および
height 属性を指定して、要素の視覚的コンテンツの
寸法(出力媒体の公称方向を基準とした、それぞれ幅と高さ)を
CSS
ピクセル単位で与えてもよい。これらの属性を指定する場合、その値は
妥当な
非負整数でなければならない。
リソースの解像度が CSS ピクセルの解像度と異なる場合があるため、指定された寸法は、 リソース自体に指定された寸法と異なってもよい。(画面上では、 CSS ピクセルの解像度は 96ppi だが、一般に CSS ピクセルの解像度は視距離に依存する。) 両方の属性が指定されている場合、次の文のいずれかが true でなければならない。
target ratioは、リソース内の
自然幅と
自然高の比率である。specified widthおよび
specified heightは、それぞれ width 属性および height 属性の値である。
対象となるリソースが自然幅および 自然高の両方を持たない場合、2 つの属性を省略しなければならない。
2 つの属性が両方とも 0 である場合、その要素がユーザーを対象としていないことを示す (たとえば、ページビューを数えるサービスの一部である場合がある)。
寸法属性は、画像を引き伸ばすために使用することを意図していない。
ユーザーエージェントの要件:ユーザーエージェントは、これらの属性を レンダリングのヒントとして使用することが期待される。
iframe、embed、および object の IDL
属性は DOMStringである。video および
source の IDL
属性は unsigned
longである。
img 要素および
input 要素に対応する
IDL 属性は、それぞれの要素の他の動作にやや固有であるため、各要素の節で定義される。
table
要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
caption
要素、続いて
0 個以上の colgroup 要素、
続いて任意の thead 要素、続いて
0 個以上の tbody
要素または 1 個以上の tr
要素のいずれか、続いて任意の tfoot
要素。これらには、任意に 1 個以上の
スクリプト支援
要素を混在させてもよい。
[Exposed =Window ]
interface HTMLTableElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions ] attribute HTMLTableCaptionElement ? caption ;
HTMLTableCaptionElement createCaption ();
[CEReactions ] undefined deleteCaption ();
[CEReactions ] attribute HTMLTableSectionElement ? tHead ;
HTMLTableSectionElement createTHead ();
[CEReactions ] undefined deleteTHead ();
[CEReactions ] attribute HTMLTableSectionElement ? tFoot ;
HTMLTableSectionElement createTFoot ();
[CEReactions ] undefined deleteTFoot ();
[SameObject ] readonly attribute HTMLCollection tBodies ;
HTMLTableSectionElement createTBody ();
[SameObject ] readonly attribute HTMLCollection rows ;
HTMLTableRowElement insertRow (optional long index = -1);
[CEReactions ] undefined deleteRow (long index );
// also has obsolete members
};table 要素は、
表の形式で、複数の次元を持つデータを
表す。
table 要素は
表
モデルに関与する。表には、その子孫によって与えられる行、列、およびセルがある。行と
列はグリッドを形成し、表のセルは重複することなくそのグリッド全体を完全に覆わなければならない。
この適合要件が満たされているかどうかを判断する正確な規則は、 表モデルの説明で述べられている。
作成者には、複雑な表をどのように解釈するかを説明する情報を提供することが推奨される。 そのような情報を提供する方法に関するガイダンスを 以下に示す。
表をレイアウトの補助として使用してはならない。歴史的に、一部のウェブ作成者は ページレイアウトを制御する方法として HTML の表を誤用してきた。この使用法は適合しない。 そのような文書から表形式データを抽出しようとするツールが、非常に混乱した結果を得るためである。 特に、スクリーンリーダーなどのアクセシビリティツールのユーザーは、レイアウトに表を使用した ページをナビゲートすることが非常に困難になる可能性が高い。
レイアウトに HTML の表を使用する代わりに、CSS グリッドレイアウト、 CSS フレキシブルボックスレイアウト(「flexbox」)、CSS マルチカラムレイアウト、CSS 配置、 および CSS 表モデルなど、さまざまな代替手段がある。[CSS]
表は理解およびナビゲートが複雑になる場合がある。これをユーザーが行いやすくするため、 ユーザーエージェントがその表を(適合しない)レイアウト表として分類していない限り、 表内の各セルを互いに明確に区別するべきである。
作成者および実装者には、ユーザーが表をより容易にナビゲートできるようにするため、 以下で説明する表設計技法の一部を使用することを 検討するよう推奨される。
ユーザーエージェント、特に任意のコンテンツに対して表分析を行うものには、どの表が実際に データを含み、どの表が単にレイアウトに使用されているかを判断するためのヒューリスティックを 見つけることが推奨される。この仕様では正確なヒューリスティックを定義しないが、可能性のある 指標として次のものを提案する。
| 特徴 | 示唆 |
|---|---|
role
属性を値 presentation
とともに使用している
|
レイアウト表である可能性が高い |
適合しない border 属性を、
適合しない値 0 とともに使用している
|
レイアウト表である可能性が高い |
適合しない cellspacing 属性および
cellpadding
属性を値 0 とともに使用している
|
レイアウト表である可能性が高い |
caption、thead、または th 要素を使用している
|
レイアウト表ではない可能性が高い |
headers 属性および scope 属性を使用している
|
レイアウト表ではない可能性が高い |
適合しない border 属性を、
0 以外の値とともに使用している
|
レイアウト表ではない可能性が高い |
| CSS を使用して明示的な可視境界線を設定している | レイアウト表ではない可能性が高い |
summary 属性を使用している
|
適切な指標ではない(歴史的に、レイアウト表と非レイアウト表の両方にこの属性が付与されてきた) |
上記の提案が誤っている可能性は十分にある。実装者には、レイアウト表を 検出するヒューリスティックを作成しようとした経験について、詳しいフィードバックを 提供することが強く推奨される。
table 要素が
(適合しない)summary
属性を持ち、かつユーザーエージェントがその表をレイアウト表として分類していない場合、
ユーザーエージェントはその属性の内容をユーザーに報告してもよい。
table.caption [ = value ]
現在のすべてのエンジンでサポートされています。
表の caption 要素を返す。
caption 要素を
置き換えるために設定できる。
caption = table.createCaption()
HTMLTableElement/createCaption
現在のすべてのエンジンでサポートされています。
表に caption 要素が
存在することを保証し、それを返す。
table.deleteCaption()
HTMLTableElement/deleteCaption
現在のすべてのエンジンでサポートされています。
表に caption 要素が
存在しないことを保証する。
table.tHead [ = value ]
現在のすべてのエンジンでサポートされています。
表の thead 要素を返す。
thead 要素を
置き換えるために設定できる。新しい値が
thead 要素でない場合、
"HierarchyRequestError"
DOMExceptionを
例外として投げる。
thead = table.createTHead()
現在のすべてのエンジンでサポートされています。
表に thead 要素が
存在することを保証し、それを返す。
table.deleteTHead()
現在のすべてのエンジンでサポートされています。
表に thead 要素が
存在しないことを保証する。
table.tFoot [ = value ]
現在のすべてのエンジンでサポートされています。
表の tfoot 要素を返す。
tfoot 要素を
置き換えるために設定できる。新しい値が
tfoot 要素でない場合、
"HierarchyRequestError"
DOMExceptionを
例外として投げる。
tfoot = table.createTFoot()
現在のすべてのエンジンでサポートされています。
表に tfoot 要素が
存在することを保証し、それを返す。
table.deleteTFoot()
現在のすべてのエンジンでサポートされています。
表に tfoot 要素が
存在しないことを保証する。
table.tBodies
現在のすべてのエンジンでサポートされています。
表の tbody 要素からなる
HTMLCollectionを
返す。
tbody = table.createTBody()
現在のすべてのエンジンでサポートされています。
tbody
要素を作成し、表に挿入して、それを返す。
table.rows
現在のすべてのエンジンでサポートされています。
表の tr 要素からなる
HTMLCollectionを
返す。
tr = table.insertRow([ index ])
現在のすべてのエンジンでサポートされています。
tr 要素と、必要な場合は
tbodyを作成し、
引数によって与えられた位置で表に挿入して、trを返す。
位置は表内の行を基準とする。引数を省略した場合のデフォルトであるインデックス −1 は、 表の末尾への挿入と同等である。
与えられた位置が −1 未満または行数より大きい場合、
"IndexSizeError" DOMExceptionを
例外として投げる。
table.deleteRow(index)
現在のすべてのエンジンでサポートされています。
表内の指定された位置にある tr 要素を削除する。
位置は表内の行を基準とする。インデックス −1 は、表の最後の行を削除することと同等である。
与えられた位置が −1 未満、最後の行のインデックスより大きい、または行が存在しない場合、
"IndexSizeError"
DOMExceptionを
例外として投げる。
table 要素
tableElementおよび文字列 localNameが与えられたときに
表要素を作成するには、tableElementの
ノード
文書、localName、および
HTML 名前空間を
与えて要素を作成した結果を返す。
caption 設定手順は
次のとおりである。
createCaption() メソッドの手順は次のとおりである。
tHead 設定手順は
次のとおりである。
与えられた値が null でも thead 要素でもない場合、
"HierarchyRequestError" DOMExceptionを
例外として投げる。
与えられた値が null でない場合、thisの要素の子のうち、caption 要素でも
colgroup
要素でもない最初のものがあれば、その直前に挿入する。それ以外の場合は、
thisの末尾に挿入する。
createTHead() メソッドの手順は次のとおりである。
tFoot 設定手順は
次のとおりである。
与えられた値が null でも tfoot 要素でもない場合、
"HierarchyRequestError" DOMExceptionを
例外として投げる。
与えられた値が null でない場合、それを thisの末尾に挿入する。
createTFoot() メソッドの手順は次のとおりである。
tBodies
取得手順は、thisをルートとし、フィルターが
thisの子である
tbody 要素のみに一致する
HTMLCollectionを
返すことである。
createTBody() メソッドの手順は次のとおりである。
rows
取得手順は、thisをルートとし、フィルターが
thisの子であるか、またはそれ自体が
thisの子である
thead、tbody、または tfoot 要素の子である
tr 要素のみに一致する
HTMLCollectionを
返すことである。コレクション内の要素は、親が theadである要素を最初に
ツリー
順序で含め、続いて親が thisまたは
tbody 要素である要素を、
同じくツリー順序で含め、最後に親が
tfoot 要素である要素を、
引き続きツリー順序で含むように並べなければならない。
insertRow(index) メソッドの手順は次のとおりである。
indexが −1 未満、または
rows コレクション内の
要素数より大きい場合、
"IndexSizeError" DOMExceptionを
例外として投げる。
それ以外で、indexが −1、または
rows コレクション内の
項目数に等しい場合、trを
rows
コレクション内の最後の tr 要素の親に付加する。
trを返す。
deleteRow(index) メソッドの手順は次のとおりである。
indexが −1 未満、または
rows
コレクション内の要素数以上である場合、
"IndexSizeError" DOMExceptionを
例外として投げる。
indexが −1 である場合、rows コレクション内の
最後の要素をその親から削除する。
rows
コレクションが空の場合は、何もしない。
数独パズルをマークアップするために表を使用する例を次に示す。このような表では不要であるため、 ヘッダーがないことに注目されたい。
< style >
# sudoku { border-collapse : collapse ; border : solid thick ; }
# sudoku colgroup , table # sudoku tbody { border : solid medium ; }
# sudoku td { border : solid thin ; height : 1.4 em ; width : 1.4 em ; text-align : center ; padding : 0 ; }
</ style >
< h1 > Today's Sudoku</ h1 >
< table id = "sudoku" >
< colgroup >< col >< col >< col >
< colgroup >< col >< col >< col >
< colgroup >< col >< col >< col >
< tbody >
< tr > < td > 1 < td > < td > 3 < td > 6 < td > < td > 4 < td > 7 < td > < td > 9
< tr > < td > < td > 2 < td > < td > < td > 9 < td > < td > < td > 1 < td >
< tr > < td > 7 < td > < td > < td > < td > < td > < td > < td > < td > 6
< tbody >
< tr > < td > 2 < td > < td > 4 < td > < td > 3 < td > < td > 9 < td > < td > 8
< tr > < td > < td > < td > < td > < td > < td > < td > < td > < td >
< tr > < td > 5 < td > < td > < td > 9 < td > < td > 7 < td > < td > < td > 1
< tbody >
< tr > < td > 6 < td > < td > < td > < td > 5 < td > < td > < td > < td > 2
< tr > < td > < td > < td > < td > < td > 7 < td > < td > < td > < td >
< tr > < td > 9 < td > < td > < td > 8 < td > < td > 2 < td > < td > < td > 5
</ table > 最初の行と最初の列に見出しがあるセルのグリッドだけでは構成されていないテーブルや、 一般に読者が内容を理解するのが難しい可能性のあるテーブルについては、著者はテーブルを紹介する説明情報を 含めるべきである。この情報はすべてのユーザーにとって有用であるが、スクリーンリーダーのユーザーなど、 テーブルを見ることができないユーザーにとって特に有用である。
このような説明情報では、テーブルの目的を紹介し、その基本的なセル構造を概説し、傾向やパターンを 強調し、一般にテーブルの使用方法をユーザーに説明するべきである。
たとえば、次のテーブルは:
| 否定的 | 特性 | 肯定的 |
|---|---|---|
| 悲しい | 気分 | 幸せ |
| 不合格 | 成績 | 合格 |
...「特性は2列目に示され、否定的側面は左列に、肯定的側面は右列に示される」のように、 テーブルの配置方法を説明する記述があると有益な場合がある。
この情報を含める方法には、次のようなさまざまなものがある:
< p > 次のテーブルでは、特性は2列目に示され、
否定的側面は左列に、肯定的側面は右列に
示されます。</ p >
< table >
< caption > 肯定的側面と否定的側面を持つ特性</ caption >
< thead >
< tr >
< th id = "n" > 否定的
< th > 特性
< th > 肯定的
< tbody >
< tr >
< td headers = "n r1" > 悲しい
< th id = "r1" > 気分
< td > 幸せ
< tr >
< td headers = "n r2" > 不合格
< th id = "r2" > 成績
< td > 合格
</ table > caption内に記述する
< table >
< caption >
< strong > 肯定的側面と否定的側面を持つ特性。</ strong >
< p > 特性は2列目に示され、
否定的側面は左列に、肯定的側面は右列に
示されます。</ p >
</ caption >
< thead >
< tr >
< th id = "n" > 否定的
< th > 特性
< th > 肯定的
< tbody >
< tr >
< td headers = "n r1" > 悲しい
< th id = "r1" > 気分
< td > 幸せ
< tr >
< td headers = "n r2" > 不合格
< th id = "r2" > 成績
< td > 合格
</ table > caption内の
details
要素内に記述する
< table >
< caption >
< strong > 肯定的側面と否定的側面を持つ特性。</ strong >
< details >
< summary > ヘルプ</ summary >
< p > 特性は2列目に示され、
否定的側面は左列に、肯定的側面は右列に
示されます。</ p >
</ details >
</ caption >
< thead >
< tr >
< th id = "n" > 否定的
< th > 特性
< th > 肯定的
< tbody >
< tr >
< td headers = "n r1" > 悲しい
< th id = "r1" > 気分
< td > 幸せ
< tr >
< td headers = "n r2" > 不合格
< th id = "r2" > 成績
< td > 合格
</ table > figure内で記述する< figure >
< figcaption > 肯定的側面と否定的側面を持つ特性</ figcaption >
< p > 特性は2列目に示され、
否定的側面は左列に、肯定的側面は右列に
示されます。</ p >
< table >
< thead >
< tr >
< th id = "n" > 否定的
< th > 特性
< th > 肯定的
< tbody >
< tr >
< td headers = "n r1" > 悲しい
< th id = "r1" > 気分
< td > 幸せ
< tr >
< td headers = "n r2" > 不合格
< th id = "r2" > 成績
< td > 合格
</ table >
</ figure > figureのfigcaption内で記述する
< figure >
< figcaption >
< strong > 肯定的側面と否定的側面を持つ特性</ strong >
< p > 特性は2列目に示され、
否定的側面は左列に、肯定的側面は右列に
示されます。</ p >
</ figcaption >
< table >
< thead >
< tr >
< th id = "n" > 否定的
< th > 特性
< th > 肯定的
< tbody >
< tr >
< td headers = "n r1" > 悲しい
< th id = "r1" > 気分
< td > 幸せ
< tr >
< td headers = "n r2" > 不合格
< th id = "r2" > 成績
< td > 合格
</ table >
</ figure > 著者は、必要に応じて、その他の技術または上記の技術の組み合わせを使用してもよい。
もちろん、テーブルの配置方法を説明する記述を書くよりも最善なのは、説明が不要になるように テーブルを調整することである。
上記の例で使用したテーブルの場合、見出しが上側と左側に配置されるようにテーブルを単純に
再配置すれば、説明が不要になるだけでなく、headers属性を
使用する必要もなくなる:
< table >
< caption > 肯定的側面と否定的側面を持つ特性</ caption >
< thead >
< tr >
< th > 特性
< th > 否定的
< th > 肯定的
< tbody >
< tr >
< th > 気分
< td > 悲しい
< td > 幸せ
< tr >
< th > 成績
< td > 不合格
< td > 合格
</ table > 優れたテーブルデザインは、テーブルをより読みやすく、使いやすくするための鍵である。
視覚メディアでは、列と行の境界線を設け、行の背景を交互に変えることで、複雑なテーブルを より読みやすくするうえで非常に効果的となる場合がある。
大量の数値コンテンツを含むテーブルでは、等幅フォントを使用すると、特にユーザーエージェントが 境界線をレンダリングしない状況で、ユーザーがパターンを見つけやすくなる。(残念ながら、 歴史的な理由により、テーブルの境界線をレンダリングしないことが一般的なデフォルトである。)
音声メディアでは、セルの内容を読み上げる前に対応する見出しを報告し、テーブルの内容全体を ソース順に直列化するのではなく、ユーザーがグリッド形式でテーブル内を移動できるようにすることで、 テーブルセルを区別できる。
著者は、これらの効果を実現するためにCSSを使用することが推奨される。
ユーザーエージェントは、ページがCSSを使用しておらず、テーブルがレイアウトテーブルとして 分類されていない場合、これらの技術を使用してテーブルをレンダリングすることが推奨される。
caption要素
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
table要素の最初の要素子として。table要素を含まないこと。caption要素の
終了タグは、
caption要素の
直後にASCII空白
または
コメントがない場合、省略できる。
[Exposed =Window ]
interface HTMLTableCaptionElement : HTMLElement {
[HTMLConstructor ] constructor ();
// 廃止されたメンバーもある
};caption要素は、
親が存在し、その親がtable要素である場合、その親であるtableの
タイトルを表す。
table要素が、
figure要素内でfigcaption以外の
唯一のコンテンツである場合、caption要素は省略し、
代わりにfigcaptionを使用するべきである。
キャプションはテーブルのコンテキストを提示できるため、テーブルを大幅に理解しやすくできる。
たとえば、次のテーブルについて考える:
| 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
抽象的に見ると、このテーブルは明確ではない。しかし、テーブルの番号(本文で 参照するため)を示し、その使用方法を 説明するキャプションを付けると、より理解しやすくなる:
< caption >
< p > 表1。
< p > このテーブルは、2個の6面サイコロを振って得られる
合計点を示します。最初の行は1個目のサイコロの値を表し、
最初の列は2個目のサイコロの値を表します。合計は、
2個のサイコロの値に対応するセルに示されます。
</ caption > これにより、ユーザーにより多くのコンテキストが提供される:
| 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
colgroup要素
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
table
要素の子として、すべての
caption要素の後、
かつすべてのthead、
tbody、tfoot、およびtr
要素の前。
span
属性が存在する場合:なし。span
属性が存在しない場合:0個以上のcolおよびtemplate要素。
colgroup
要素内の最初のものがcol要素であり、かつその要素の
直前に、終了タグが省略された別のcolgroup要素が
ない場合、colgroup要素の
開始タグを省略できる。(要素が
空の場合は省略できない。)
colgroup
要素の終了タグは、
colgroup
要素の直後にASCII空白
またはコメントがない場合、省略できる。
span —
要素がまたがる列の数
span属性を伴う
デフォルト。
[Exposed =Window ]
interface HTMLTableColElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect , ReflectDefault=1, ReflectRange=(1, 1000)] attribute unsigned long span ;
// 廃止されたメンバーもある
};colgroup
要素は、親が存在し、その親がtable要素である場合、
その親であるtable内の1つ以上の
列のグループを表す。
colgroup
要素がcol
要素を含まない場合、その要素にはspanコンテンツ属性を指定してもよく、その値は0より大きく
1000以下の有効な非負整数でなければならない。
colgroup
要素およびそのspan
属性は、テーブルモデルに関与する。
col要素現在のすべてのエンジンでサポートされています。
colgroup要素が
span属性を持たない場合、その
子として。
span —
要素がまたがる列の数
span属性を伴う
デフォルト。
colgroup要素について
定義されたHTMLTableColElementを使用する。
col要素に親があり、その親が
colgroup
要素であり、さらにその要素にも親があり、その親がtable要素である場合、col要素は、そのcolgroupが表す
列グループ内の1つ以上の
列を
表す。
この要素には、spanコンテンツ属性を指定してもよく、その値は0より大きく
1000以下の有効な非負整数でなければならない。
col要素およびそのspan属性は、
テーブルモデルに関与する。
tbody要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
table
要素の子として、すべての
caption、colgroup、および
thead要素の後。ただし、
table要素の子である
tr要素が存在しない場合に限る。
trおよびスクリプト支援
要素。tbody要素内の
最初のものがtr要素であり、かつその要素の
直前に、終了タグが省略されたtbody、thead、または
tfoot要素がない場合、
tbody要素の
開始タグを省略できる。(要素が
空の場合は省略できない。)
tbody要素の
終了タグは、
tbody要素の直後に
tbodyまたは
tfoot要素がある場合、
あるいは親要素にそれ以上コンテンツがない場合、省略できる。
[Exposed =Window ]
interface HTMLTableSectionElement : HTMLElement {
[HTMLConstructor ] constructor ();
[SameObject ] readonly attribute HTMLCollection rows ;
HTMLTableRowElement insertRow (optional long index = -1);
[CEReactions ] undefined deleteRow (long index );
// 廃止されたメンバーもある
};HTMLTableSectionElement
インターフェースは、theadおよび
tfoot要素にも
使用される。
tbody要素は、
親が存在し、その親がtableである場合、
親であるtable要素のデータ本体を
構成する行のブロックを
表す。
tbody.rowsテーブルセクションのtr要素のHTMLCollectionを
返す。
tr = tbody.insertRow([ index ])
tr要素を作成し、
引数で指定された位置にあるテーブルセクションへ挿入して、そのtrを返す。
位置はテーブルセクション内の行に対する相対位置である。引数を省略した場合のデフォルトである インデックス−1は、テーブルセクションの末尾への挿入と同等である。
指定された位置が−1未満、または行数より大きい場合、"IndexSizeError" DOMExceptionを
スローする。
tbody.deleteRow(index)
テーブルセクション内の指定された位置にあるtr要素を削除する。
位置はテーブルセクション内の行に対する相対位置である。インデックス−1は、テーブルセクションの 最後の行の削除と同等である。
指定された位置が−1未満、最後の行のインデックスより大きい、または行が存在しない場合、
"IndexSizeError"
DOMExceptionを
スローする。
rows属性は、この要素をルートとし、フィルターが
この要素の子であるtr要素のみに一致するHTMLCollectionを
返さなければならない。
insertRow(index)メソッドは、次のように
動作しなければならない:
deleteRow(index)メソッドは、呼び出されたとき、
次のように動作しなければならない:
indexが−1未満、またはrowsコレクション内の
要素数以上である場合、"IndexSizeError" DOMExceptionを
スローする。
indexが−1の場合、rowsコレクション内の
最後の要素をこの要素から削除するか、rowsコレクションが
空の場合は何もしない。
thead要素現在のすべてのエンジンでサポートされています。
table
要素の子として、すべての
captionおよびcolgroup
要素の後、かつすべてのtbody、tfoot、および
tr要素の前。ただし、
table要素の子である
他のthead要素が
存在しない場合に限る。
trおよびスクリプト支援
要素。thead要素の
終了タグは、
thead要素の直後に
tbodyまたは
tfoot要素がある場合、
省略できる。
tbody
要素について定義されたHTMLTableSectionElementを
使用する。thead要素は、
親が存在し、その親がtableである場合、
親であるtable要素の列ラベル
(見出し)および補助的な見出しではないセルで構成される行のブロックを表す。
この例は、thead要素の使用方法を示す。
thead要素内で、
th要素とtd要素の両方が使用されていることに
注意すること。最初の行は見出しであり、2番目の行はテーブルへの入力方法の説明である。
< table >
< caption > 学校オークション申込表 </ caption >
< thead >
< tr >
< th >< label for = e1 > 氏名</ label >
< th >< label for = e2 > 商品</ label >
< th >< label for = e3 > 画像</ label >
< th >< label for = e4 > 価格</ label >
< tr >
< td > ここに氏名を入力
< td > 何を販売しますか?
< td > 画像へのリンク
< td > 最低落札価格
< tbody >
< tr >
< td > ダナスさん
< td > ドーナツ
< td >< img src = "https://example.com/mydoughnuts.png" title = "ダナスさんのドーナツ" >
< td > $45
< tr >
< td >< input id = e1 type = text name = who required form = f >
< td >< input id = e2 type = text name = what required form = f >
< td >< input id = e3 type = url name = pic form = f >
< td >< input id = e4 type = number step = 0.01 min = 0 value = 0 required form = f >
</ table >
< form id = f action = "/auction.cgi" >
< input type = button name = add value = "送信" >
</ form > tfoot要素現在のすべてのエンジンでサポートされています。
table
要素の子として、すべての
caption、colgroup、thead、
tbody、およびtr要素の後。ただし、
table要素の子である
他のtfoot要素が
存在しない場合に限る。
trおよびスクリプト支援
要素。tfoot要素の
終了タグは、親要素にそれ以上
コンテンツがない場合、省略できる。
tbody
要素について定義されたHTMLTableSectionElementを
使用する。tfoot要素は、
親が存在し、その親がtableである場合、
親であるtable要素の列の要約
(フッター)で構成される行のブロックを表す。
tr要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
thead
要素の子として。tbody
要素の子として。tfoot
要素の子として。table
要素の子として、すべての
caption、colgroup、およびthead
要素の後。ただし、table要素の子であるtbody要素が
存在しない場合に限る。
td、th、およびスクリプト支援
要素。tr要素の
終了タグは、
tr要素の直後に別のtr要素がある場合、または
親要素にそれ以上コンテンツがない場合、省略できる。
[Exposed =Window ]
interface HTMLTableRowElement : HTMLElement {
[HTMLConstructor ] constructor ();
readonly attribute long rowIndex ;
readonly attribute long sectionRowIndex ;
[SameObject ] readonly attribute HTMLCollection cells ;
HTMLTableCellElement insertCell (optional long index = -1);
[CEReactions ] undefined deleteCell (long index );
// 廃止されたメンバーもある
};tr.rowIndex
現在のすべてのエンジンでサポートされています。
テーブルのrows
リスト内における行の位置を返す。
要素がテーブル内にない場合は−1を返す。
tr.sectionRowIndex
テーブルセクションのrowsリスト内における
行の位置を返す。
要素がテーブルセクション内にない場合は−1を返す。
tr.cells行のtd要素およびth要素のHTMLCollectionを
返す。
cell = tr.insertCell([ index ])
HTMLTableRowElement/insertCell
現在のすべてのエンジンでサポートされています。
td要素を作成し、
引数で指定された位置にあるテーブル行へ挿入して、そのtdを返す。
位置は行内のセルに対する相対位置である。引数を省略した場合のデフォルトであるインデックス−1は、 行の末尾への挿入と同等である。
指定された位置が−1未満、またはセル数より大きい場合、"IndexSizeError" DOMExceptionを
スローする。
tr.deleteCell(index)
位置は行内のセルに対する相対位置である。インデックス−1は、行の最後のセルの削除と同等である。
指定された位置が−1未満、最後のセルのインデックスより大きい、またはセルが存在しない場合、
"IndexSizeError"
DOMExceptionを
スローする。
rowIndex属性は、この要素が親table要素を持つ場合、または
親tbody、thead、もしくは
tfoot要素と、
祖父母であるtable要素を持つ場合、そのtable要素のrowsコレクション内における、このtr要素のインデックスを返さなければ
ならない。そのようなtable要素が存在しない場合、
この属性は−1を返さなければならない。
sectionRowIndex属性は、この要素が親table、tbody、thead、またはtfoot要素を持つ場合、
親要素のrowsコレクション内におけるtr要素のインデックスを返さなければ
ならない(テーブルの場合はHTMLTableElementのrowsコレクションであり、テーブル
セクションの場合はHTMLTableSectionElementの
rows
コレクションである)。そのような親要素が存在しない場合、この属性は−1を返さなければならない。
cells
属性は、このtr要素を
ルートとし、フィルターがtr要素の子であるtdおよびth要素のみに一致するHTMLCollectionを
返さなければならない。
insertCell(index)メソッドは、次のように
動作しなければならない:
deleteCell(index)メソッドは、次のように
動作しなければならない:
indexが−1未満、またはcellsコレクション内の要素数以上で
ある場合、"IndexSizeError" DOMExceptionを
スローする。
indexが−1の場合、cellsコレクション内の最後の要素を
その親から削除するか、cellsコレクションが空の場合は
何もしない。
td
要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
tr要素の子として。td要素の終了タグは、その
td要素の直後に
td要素またはth要素が続く場合、
または親要素内にそれ以上の内容がない場合、省略できます。
colspan — セルがまたがる
列の数
rowspan — セルがまたがる
行の数
headers — このセルに対応する
見出しセル
colspan、headers、rowspanを伴う既定。
[Exposed =Window ]
interface HTMLTableCellElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect , ReflectDefault=1, ReflectRange=(1, 1000)] attribute unsigned long colSpan ;
[CEReactions , Reflect , ReflectDefault=1, ReflectRange=(0, 65534)] attribute unsigned long rowSpan ;
[CEReactions , Reflect ] attribute DOMString headers ;
readonly attribute long cellIndex ;
[CEReactions ] attribute DOMString scope ; // th要素にのみ適合
[CEReactions , Reflect ] attribute DOMString abbr ; // th要素にのみ適合
// 廃止されたメンバーも持つ
};
HTMLTableCellElement
インターフェイスは、th
要素にも使用されます。
td要素と、そのcolspan、rowspan、およびheaders
属性は、表モデルに関与します。
ユーザーエージェントは、特に非視覚的な環境、または表を二次元グリッドとして表示することが
実用的でない場合、セルの内容をレンダリングするときに、そのセルの文脈をユーザーに提示してもかまいません。たとえば、
表モデル内での位置を示したり、セルの見出しセル
(見出しセルを割り当てるアルゴリズムによって決定されるもの)
を列挙したりできます。セルの見出しセルを列挙するとき、ユーザーエージェントは、見出しセル自体の内容の代わりに、
それらの見出しセルにabbr
属性があれば、その値を使用してもかまいません。
この例では、編集可能なセルのグリッド(実質的には単純なスプレッドシート)からなる
ウェブアプリケーションの断片を示します。セルの1つは、その上にあるセルの合計を表示するように
構成されています。3つのセルは見出しとしてマークされており、th要素を
td要素の代わりに使用します。
スクリプトは、合計を維持するためにこれらの要素へイベントハンドラーを付加します。
< table >
< tr >
< th >< input value = "Name" >
< th >< input value = "Paid ($)" >
< tr >
< td >< input value = "Jeff" >
< td >< input value = "14" >
< tr >
< td >< input value = "Britta" >
< td >< input value = "9" >
< tr >
< td >< input value = "Abed" >
< td >< input value = "25" >
< tr >
< td >< input value = "Shirley" >
< td >< input value = "2" >
< tr >
< td >< input value = "Annie" >
< td >< input value = "5" >
< tr >
< td >< input value = "Troy" >
< td >< input value = "5" >
< tr >
< td >< input value = "Pierce" >
< td >< input value = "1000" >
< tr >
< th >< input value = "Total" >
< td >< output value = "1060" >
</ table > th
要素現在のすべてのエンジンでサポートされています。
tr要素の子として。header、footer、
セクショニングコンテンツ、または見出しコンテンツの子孫を含まないもの。
th要素の終了タグは、その
th要素の直後に
td要素またはth要素が続く場合、
または親要素内にそれ以上の内容がない場合、省略できます。
colspan — セルがまたがる
列の数
rowspan — セルがまたがる
行の数
headers — このセルに対応する
見出しセル
scope — 見出しセルが適用されるセルを
指定する
abbr — 他の文脈でセルを参照するときに
見出しセルに使用する代替ラベル
abbr、colspan、headers、rowspan、scopeを伴う既定。
td要素について定義されている
HTMLTableCellElementを
使用します。
th要素には、scope内容属性を
指定できます。
scope属性は、次のキーワードおよび状態を持つ列挙属性です。
| キーワード | 状態 | 簡単な説明 |
|---|---|---|
row
|
行 | 見出しセルは、同じ行内の後続セルの一部に適用されます。 |
col
|
列 | 見出しセルは、同じ列内の後続セルの一部に適用されます。 |
rowgroup
|
行グループ | 見出しセルは、行グループ内の残りのすべてのセルに適用されます。 |
colgroup
|
列グループ | 見出しセルは、列グループ内の残りのすべてのセルに適用されます。 |
th要素のscope属性は、要素が
行グループに固定されていない場合、
行グループ状態であってはならず、
要素が列グループに固定されていない場合、
列グループ状態であってはなりません。
th要素には、abbr内容属性を
指定できます。その値は、他の文脈でセルを参照するときに使用する、見出しセルの
代替ラベルでなければなりません(たとえば、データセルに適用される見出しセルを説明するとき)。
通常は完全な見出しセルの省略形ですが、展開形、または単に異なる表現であってもかまいません。
th要素と、そのcolspan、rowspan、headers、および
scope属性は、表モデルに関与します。
次の例は、scope属性のrowgroup値が、
見出しセルの適用対象となるデータセルにどのように影響するかを示します。
次に、表を示すマークアップ断片を示します。
< table >
< thead >
< tr > < th > ID < th > Measurement < th > Average < th > Maximum
< tbody >
< tr > < td > < th scope = rowgroup > Cats < td > < td >
< tr > < td > 93 < th > Legs < td > 3.5 < td > 4
< tr > < td > 10 < th > Tails < td > 1 < td > 1
< tbody >
< tr > < td > < th scope = rowgroup > English speakers < td > < td >
< tr > < td > 32 < th > Legs < td > 2.67 < td > 4
< tr > < td > 35 < th > Tails < td > 0.33 < td > 1
</ table > これにより、次の表が生成されます。
| ID | 測定項目 | 平均 | 最大値 |
|---|---|---|---|
| 猫 | |||
| 93 | 脚 | 3.5 | 4 |
| 10 | 尾 | 1 | 1 |
| 英語話者 | |||
| 32 | 脚 | 2.67 | 4 |
| 35 | 尾 | 0.33 | 1 |
最初の行の見出しはすべて、それぞれの列の下方にある行へ直接適用されます。
scope属性が
行グループ
状態である見出しは、最初の列にあるセルを除き、その行グループ内のすべてのセルに適用されます。
残りの見出しは、その右側にあるセルだけに適用されます。

td要素およびth要素に共通する属性td要素および
th要素には、
colspan
内容属性を指定できます。その値は、0より大きく1000以下の
妥当な
非負整数でなければなりません。
td要素および
th要素には、
rowspan内容属性も指定できます。
その値は、65534以下の妥当な非負整数でなければなりません。
この属性では、値0は、セルが行グループ内の残りのすべての行にまたがることを意味します。
これらの属性は、それぞれセルがまたがる列数および行数を指定します。 これらの属性は、表モデルの説明に 記載されているように、セルを重複させるために使用してはなりません。
td要素および
th要素には、
headers
内容属性を指定できます。headers
属性を指定する場合、その値は一意な空白区切りトークンの
順序なし集合からなる文字列でなければなりません。いずれのトークンも他のトークンと同一であってはならず、それぞれは、td要素またはth要素と同じ
表に関与するth要素のIDの値でなければなりません(表モデルによって定義されます)。
ID idを持つ
th
要素は、同じ表内にあり、
headers
属性の値が、そのトークンの1つとしてID idを含む
すべてのtd要素およびth要素から
直接対象とされるといいます。th要素
Aは、th要素またはtd要素
Bによって、AがBから直接対象とされる場合、または要素Bから
それ自体が対象とされる要素Cが存在し、かつAがCから直接
対象とされる場合に、Bから対象とされるといいます。
th
要素は、それ自身から対象とされてはなりません。
colspan、
rowspan、
およびheaders
属性は、表モデルに関与します。
cell.cellIndex行のcellsリスト内における
セルの位置を返します。
先行するセルが複数の行または列を覆っている可能性があるため、これは必ずしも表内のセルの
x位置に対応するとは限りません。
要素が行内にない場合は−1を返します。
cellIndex IDL属性は、要素が親となる
tr要素を
持つ場合、親要素のcellsコレクション内の
セル要素のインデックスを返さなければなりません。そのような親要素がない場合、属性は−1を返さなければなりません。
scope
IDL属性は、同じ名前の内容属性を、既知の値のみに
制限して反映しなければなりません。
さまざまな表要素とその内容属性は、まとめて表モデルを定義します。
表は、座標(x, y)を持つ二次元グリッド上に整列された
スロットから構成されます。グリッドは有限であり、
空であるか、1つ以上のスロットを持ちます。グリッドが1つ以上のスロットを持つ場合、
x座標は常に
0 ≤ x < xwidthの範囲内にあり、
y座標は常に
0 ≤ y < yheightの範囲内にあります。
xwidthとyheightの一方または両方が0である場合、
表は空です(スロットを持ちません)。表はtable要素に対応します。
セルは、スロット(cellx,
celly)に固定され、特定のwidthとheightを持つ
スロットの集合であり、座標(x, y)が
cellx ≤ x < cellx+width
および
celly ≤ y < celly+height
を満たすすべてのスロットを覆います。セルはデータセルまたは
見出しセルのいずれかです。データセルはtd要素に対応し、見出しセルは
th要素に対応します。
どちらの種類のセルにも、関連付けられた見出しセルが0個以上存在できます。
特定のエラーの場合には、2つのセルが同じスロットを占有する可能性があります。
行は、特定のyの値について、
x=0からx=xwidth-1までの完全なスロットの集合です。
行は通常、tr要素に対応しますが、
複数行にまたがるセルが関係する一部の場合、
行グループは末尾に暗黙の
行を持つことがあります。
列は、特定のxの値について、
y=0からy=yheight-1までの完全なスロットの集合です。
列はcol要素に
対応できます。col要素がない場合、列は
暗黙に存在します。
行グループは、スロット(0, groupy)に固定され、
特定のheightを持つ行の集合であり、座標(x, y)が
0 ≤ x < xwidthおよび
groupy ≤ y < groupy+height
を満たすすべてのスロットを覆います。行グループは
tbody、thead、およびtfoot要素に対応します。
すべての行が必ずしも行グループ内にあるとは限りません。
列グループは、スロット(groupx, 0)に固定され、
特定のwidthを持つ列の集合であり、座標(x, y)が
groupx ≤ x < groupx+width
および0 ≤ y < yheightを満たす
すべてのスロットを覆います。列グループはcolgroup要素に対応します。
すべての列が必ずしも列グループ内にあるとは限りません。
行グループ同士を重複させることは できません。同様に、列グループ 同士を重複させることもできません。
セルは、2つ以上の 行グループに属するスロットを 覆うことはできません。ただし、セルが複数の 列グループに属することは 可能です。1つのセルを構成するすべてのスロットは、0個または1個の 行グループと、 0個以上の列グループに 属します。
セル、列、行、行グループ、および列グループに加え、表には、関連付けられたcaption要素を
持たせることができます。これは表に見出し、または凡例を与えます。
表モデルエラーは、table要素および
その子孫によって表されるデータに関するエラーです。文書は表モデルエラーを含んではなりません。
table要素に関連付けられた
表において、どの要素がどのスロットに対応するか、
表の寸法(xwidthおよびyheight)、
および表モデルエラーが存在するかどうかを
決定するため、ユーザーエージェントは次のアルゴリズムを使用しなければなりません。
xwidthを0とします。
yheightを0とします。
表を、table要素によって表される表とします。
xwidth変数およびyheight変数は、表の
寸法を示します。表は初期状態では空です。
table要素に
子要素がない場合、表(空になります)を返します。
table要素の
最初のcaption子要素を
表に関連付けます。そのような子がない場合、関連付けられた
caption要素は
ありません。
現在の要素を、table要素の最初の
子要素とします。
このアルゴリズムのいずれかのステップで、現在の要素をtableの次の子へ進める必要があるにもかかわらず、
そのような次の子がない場合、ユーザーエージェントは、このアルゴリズムの終端付近にある
終了とラベル付けされたステップへ移らなければなりません。
現在の要素がcolgroupである場合、
次の下位ステップに従います。
列グループ: 次の適切な場合に従って現在の要素を処理します。
col子要素を持つ場合次のステップに従います。
xstartをxwidthの値とします。
列: 現在の列であるcol要素が
span属性を持つ場合、
その値を非負整数を構文解析する規則を
使用して構文解析します。
値の構文解析結果がエラーでも0でもない場合、spanをその値とします。
それ以外の場合、col要素が
span属性を持たないか、
属性値の構文解析を試みた結果がエラーまたは0であった場合、spanを1とします。
spanが1000より大きい場合、代わりに1000とします。
xwidthをspanだけ増加させます。
現在の列が、colgroup
要素の最後のcol子要素でない場合、
現在の列を、そのcolgroup
要素の次のcol子要素とし、
列とラベル付けされたステップへ戻ります。
表内の最後の列のうち、
x=xstartから
x=xwidth-1までを、スロット
(xstart, 0)に固定され、幅が
xwidth-xstartであり、colgroup
要素に対応する新しい列グループとします。
col子要素を持たない場合
colgroup
要素がspan属性を持つ場合、
その値を非負整数を構文解析する規則を
使用して構文解析します。
値の構文解析結果がエラーでも0でもない場合、spanをその値とします。
それ以外の場合、colgroup
要素がspan
属性を持たないか、属性値の構文解析を試みた結果がエラーまたは0であった場合、
spanを1とします。
spanが1000より大きい場合、代わりに1000とします。
xwidthをspanだけ増加させます。
表内の最後のspan個の列を、スロット
(xwidth-span, 0)に固定され、幅が
spanであり、colgroup
要素に対応する新しい列グループとします。
現在の要素がcolgroup
要素である場合、上の列グループとラベル付けされたステップへ移ります。
ycurrentを0とします。
下方向に伸長するセルのリストを空のリストとします。
現在の要素がtrである場合、
行を処理する
アルゴリズムを実行し、現在の要素をtableの次の子へ
進め、
行とラベル付けされたステップへ戻ります。
行グループを終了するアルゴリズムを実行します。
現在の要素がtfootである場合、その要素を
保留中のtfoot要素の
リストに追加し、現在の要素をtableの次の子へ
進め、
行とラベル付けされたステップへ戻ります。
行グループを処理するアルゴリズムを実行します。
行とラベル付けされたステップへ戻ります。
終了: 保留中の
tfoot
要素のリスト内にある各tfoot要素について、
ツリー順に、
行グループを処理するアルゴリズムを実行します。
表を返します。
行グループを処理するアルゴリズムは、上記の一連のステップから
thead、
tbody、およびtfoot要素を処理するために
呼び出されるものであり、次のとおりです。
ystartをyheightの値とします。
処理対象の要素の子である各tr要素について、
ツリー順に行を処理するアルゴリズムを実行します。
yheight > ystartである場合、 表内の最後の行のうち、 y=ystartからy=yheight-1までを、 座標(0, ystart)のスロットに固定され、高さが yheight-ystartであり、処理対象の要素に対応する 新しい行グループとします。
行グループを終了するアルゴリズムを実行します。
行グループを終了するアルゴリズムは、行のブロックを開始および 終了するときに上記の一連のステップから呼び出されるものであり、次のとおりです。
ycurrentがyheight未満である間、次のステップに従います。
下方向に伸長するセルを成長させる アルゴリズムを実行します。
ycurrentを1増加させます。
下方向に伸長するセルのリストを空にします。
行を処理するアルゴリズムは、上記の一連のステップから
tr要素を処理するために
呼び出されるものであり、次のとおりです。
yheightがycurrentと等しい場合、 yheightを1増加させます。 (ycurrentがyheightより大きくなることはありません。)
xcurrentを0とします。
下方向に伸長するセルを成長させる アルゴリズムを実行します。
処理対象のtr要素に
tdまたはth子要素がない場合、
ycurrentを1増加させ、この一連のステップを中止し、
上のアルゴリズムへ戻ります。
セル: xcurrentがxwidth未満であり、 座標(xcurrent, ycurrent)のスロットにすでに セルが割り当てられている間、xcurrentを1増加させます。
xcurrentがxwidthと等しい場合、 xwidthを1増加させます。 (xcurrentがxwidthより大きくなることはありません。)
現在のセルがcolspan属性を持つ場合、
その属性値を構文解析し、
colspanをその結果とします。
その値の構文解析に失敗した場合、0が返された場合、または属性が存在しない場合は、 代わりにcolspanを1とします。
colspanが1000より大きい場合、代わりに1000とします。
現在のセルがrowspan属性を持つ場合、
その属性値を構文解析し、
rowspanをその結果とします。
その値の構文解析に失敗した場合、または属性が存在しない場合は、代わりにrowspanを1とします。
rowspanが65534より大きい場合、代わりに65534とします。
セルが下方向に伸長するをfalseとします。
rowspanが0である場合、セルが下方向に伸長するをtrueに設定し、 rowspanを1に設定します。
xwidth < xcurrent+colspanである場合、 xwidthをxcurrent+colspanとします。
yheight < ycurrent+rowspanである場合、 yheightをycurrent+rowspanとします。
座標(x, y)が xcurrent ≤ x < xcurrent+colspan および ycurrent ≤ y < ycurrent+rowspan を満たすスロットを、(xcurrent, ycurrent)に固定され、 幅がcolspan、高さがrowspanであり、現在のセル要素に対応する 新しいセル cで覆います。
現在のセル要素がth要素である場合、
この新しいセルcを見出しセルとし、それ以外の場合はデータセルとします。
どの見出しセルが現在のセル要素に適用されるかを確定するため、 次の節で説明する見出しセルを割り当てるアルゴリズムを 使用します。
関係するスロットのいずれかが、すでにそれを覆うセルを持っていた場合、これは表モデルエラーです。 これらのスロットには、2つのセルが重複することになります。
セルが下方向に伸長するがtrueである場合、タプル {c, xcurrent, colspan}を 下方向に伸長するセルのリストへ追加します。
xcurrentをcolspanだけ増加させます。
現在のセルが、処理対象のtr要素内にある最後の
tdまたはth子要素である場合、
ycurrentを1増加させ、この一連のステップを中止し、
上のアルゴリズムへ戻ります。
セルとラベル付けされたステップへ戻ります。
上記のアルゴリズムがユーザーエージェントに下方向に伸長するセルを成長させるアルゴリズムの 実行を要求するとき、ユーザーエージェントは、下方向に伸長するセルのリスト内の各 {cell, cellx, width}タプルについて、それが存在する場合、 セル cellを、 座標(x, ycurrent)が cellx ≤ x < cellx+width を満たすスロットも覆うように拡張しなければなりません。
각 셀에는 0개 이상의 헤더 셀을 할당할 수 있다. 셀 principal cell에 헤더 셀을 할당하는 알고리즘은 다음과 같다.
header list를 빈 셀 목록으로 둔다.
(principalx, principaly)를 principal cell이 고정된 슬롯의 좌표로 둔다.
headers
속성이 지정된 경우principal cell의 headers
속성 값을 가져와 ASCII 공백에서 분할하고, 얻어진 토큰
목록을 id
list로 둔다.
id list의 각 토큰에 대해,
토큰과 동일한 ID를 가진 Document의
첫 번째 요소가 동일한 표의 셀이고, 그
셀이
principal cell이 아니면 해당 셀을 header list에 추가한다.
headers
속성이 지정되지 않은 경우principalwidth를 principal cell의 너비로 둔다.
principalheight를 principal cell의 높이로 둔다.
principaly부터 principaly+principalheight-1까지의 각 y 값에 대해, principal cell, header list, 초기 좌표 (principalx, y) 및 증가량 Δx=−1과 Δy=0을 사용하여 헤더 셀을 스캔하고 할당하는 내부 알고리즘을 실행한다.
principalx부터 principalx+principalwidth-1까지의 각 x 값에 대해, principal cell, header list, 초기 좌표 (x, principaly) 및 증가량 Δx=0과 Δy=−1을 사용하여 헤더 셀을 스캔하고 할당하는 내부 알고리즘을 실행한다.
principal cell이 행 그룹에 고정되어 있으면, 행 그룹 헤더이고 동일한 행 그룹에 고정되어 있으며, x 좌표가 principalx+principalwidth-1 이하이고 y 좌표가 principaly+principalheight-1 이하인 모든 헤더 셀을 header list에 추가한다.
principal cell이 열 그룹에 고정되어 있으면, 열 그룹 헤더이고 동일한 열 그룹에 고정되어 있으며, x 좌표가 principalx+principalwidth-1 이하이고 y 좌표가 principaly+principalheight-1 이하인 모든 헤더 셀을 header list에 추가한다.
header list에서 모든 빈 셀을 제거한다.
header list에서 모든 중복 항목을 제거한다.
principal cell이 header list에 있으면 제거한다.
header list의 헤더를 principal cell에 할당한다.
principal cell, header list, 초기 좌표 (initialx, initialy) 및 Δx와 Δy 증가량이 주어졌을 때, 헤더 셀을 스캔하고 할당하는 내부 알고리즘은 다음과 같다:
x를 initialx와 같게 둔다.
y를 initialy와 같게 둔다.
opaque headers를 빈 셀 목록으로 둔다.
in header block을 true로 두고, headers from current header block을 principal cell만 포함하는 셀 목록으로 둔다.
in header block을 false로 두고 headers from current header block을 빈 셀 목록으로 둔다.
루프: x를 Δx만큼 증가시키고, y를 Δy만큼 증가시킨다.
이 알고리즘을 호출할 때마다 Δx와 Δy 중 하나는 −1이고 다른 하나는 0이다.
x 또는 y 중 하나라도 0보다 작으면 이 내부 알고리즘을 중단한다.
슬롯 (x, y)을 덮는 셀이 없거나, 슬롯 (x, y)을 덮는 셀이 둘 이상이면 루프라고 표시된 하위 단계로 돌아간다.
current cell을 슬롯 (x, y)을 덮는 셀로 둔다.
in header block을 true로 설정한다.
current cell을 headers from current header block에 추가한다.
blocked를 false로 둔다.
opaque headers 목록에 current cell과 동일한 x 좌표에 고정되고 current cell과 너비가 동일한 셀이 하나라도 있으면 blocked를 true로 둔다.
current cell이 열 헤더가 아니면 blocked를 true로 둔다.
opaque headers 목록에 current cell과 동일한 y 좌표에 고정되고 current cell과 높이가 동일한 셀이 하나라도 있으면 blocked를 true로 둔다.
current cell이 행 헤더가 아니면 blocked를 true로 둔다.
blocked가 false이면 current cell을 header list에 추가한다.
in header block을 false로 설정한다. headers from current header block의 모든 셀을 opaque headers 목록에 추가하고, headers from current header block 목록을 비운다.
루프라고 표시된 단계로 돌아간다.
좌표가 (x, y)인 슬롯에 고정되고 너비가 width, 높이가 height인 헤더 셀은 다음 중 하나가 참이면 열 헤더라고 한다:
좌표가 (x, y)인 슬롯에 고정되고 너비가 width, 높이가 height인 헤더 셀은 다음 중 하나가 참이면 행 헤더라고 한다:
셀에 요소가 없고, 자식 텍스트 콘텐츠가 있는 경우 그것이 ASCII 공백으로만 구성되어 있으면 해당 셀을 빈 셀이라고 한다.
이 절은 비규범적이다.
다음은 Smithsonian physical tables, Volume 71의 표 45 아래쪽 부분을 마크업할 수 있는 한 가지 방법을 보여 준다:
< table >
< caption > Specification values: < b > Steel</ b > , < b > Castings</ b > ,
Ann. A.S.T.M. A27-16, Class B;* P max. 0.06; S max. 0.05.</ caption >
< thead >
< tr >
< th rowspan = 2 > Grade.</ th >
< th rowspan = 2 > Yield Point.</ th >
< th colspan = 2 > Ultimate tensile strength</ th >
< th rowspan = 2 > Per cent elong. 50.8 mm or 2 in.</ th >
< th rowspan = 2 > Per cent reduct. area.</ th >
</ tr >
< tr >
< th > kg/mm< sup > 2</ sup ></ th >
< th > lb/in< sup > 2</ sup ></ th >
</ tr >
</ thead >
< tbody >
< tr >
< td > Hard</ td >
< td > 0.45 ultimate</ td >
< td > 56.2</ td >
< td > 80,000</ td >
< td > 15</ td >
< td > 20</ td >
</ tr >
< tr >
< td > Medium</ td >
< td > 0.45 ultimate</ td >
< td > 49.2</ td >
< td > 70,000</ td >
< td > 18</ td >
< td > 25</ td >
</ tr >
< tr >
< td > Soft</ td >
< td > 0.45 ultimate</ td >
< td > 42.2</ td >
< td > 60,000</ td >
< td > 22</ td >
< td > 30</ td >
</ tr >
</ tbody >
</ table > 이 표는 다음과 같이 보일 수 있다:
| 등급. | 항복점. | 극한 인장 강도 | 연신율. 50.8 mm 또는 2 in. | 단면 감소율. | |
|---|---|---|---|---|---|
| kg/mm2 | lb/in2 | ||||
| 경질 | 극한값의 0.45 | 56.2 | 80,000 | 15 | 20 |
| 중질 | 극한값의 0.45 | 49.2 | 70,000 | 18 | 25 |
| 연질 | 극한값의 0.45 | 42.2 | 60,000 | 22 | 30 |
다음은 Apple, Inc.의 2008 회계연도 10-K 보고서 46페이지에 있는 매출총이익 표를 마크업할 수 있는 한 가지 방법을 보여 준다:
< table >
< thead >
< tr >
< th >
< th > 2008
< th > 2007
< th > 2006
< tbody >
< tr >
< th > Net sales
< td > $ 32,479
< td > $ 24,006
< td > $ 19,315
< tr >
< th > Cost of sales
< td > 21,334
< td > 15,852
< td > 13,717
< tbody >
< tr >
< th > Gross margin
< td > $ 11,145
< td > $ 8,154
< td > $ 5,598
< tfoot >
< tr >
< th > Gross margin percentage
< td > 34.3%
< td > 34.0%
< td > 29.0%
</ table > 이 표는 다음과 같이 보일 수 있다:
| 2008 | 2007 | 2006 | |
|---|---|---|---|
| 순매출 | $ 32,479 | $ 24,006 | $ 19,315 |
| 매출원가 | 21,334 | 15,852 | 13,717 |
| 매출총이익 | $ 11,145 | $ 8,154 | $ 5,598 |
| 매출총이익률 | 34.3% | 34.0% | 29.0% |
다음은 같은 문서의 동일한 페이지 아래쪽에 있는 운영비 표를 마크업할 수 있는 한 가지 방법을 보여 준다:
< table >
< colgroup > < col >
< colgroup > < col > < col > < col >
< thead >
< tr > < th > < th > 2008 < th > 2007 < th > 2006
< tbody >
< tr > < th scope = rowgroup > Research and development
< td > $ 1,109 < td > $ 782 < td > $ 712
< tr > < th scope = row > Percentage of net sales
< td > 3.4% < td > 3.3% < td > 3.7%
< tbody >
< tr > < th scope = rowgroup > Selling, general, and administrative
< td > $ 3,761 < td > $ 2,963 < td > $ 2,433
< tr > < th scope = row > Percentage of net sales
< td > 11.6% < td > 12.3% < td > 12.6%
</ table > 이 표는 다음과 같이 보일 수 있다:
| 2008 | 2007 | 2006 | |
|---|---|---|---|
| 연구 및 개발 | $ 1,109 | $ 782 | $ 712 |
| 순매출 대비 비율 | 3.4% | 3.3% | 3.7% |
| 판매비, 일반관리비 | $ 3,761 | $ 2,963 | $ 2,433 |
| 순매출 대비 비율 | 11.6% | 12.3% | 12.6% |
현재의 모든 엔진에서 지원된다.
이 절은 비규범적이다.
폼은 텍스트, 버튼, 체크박스, 범위 또는 색상 선택기 컨트롤과 같은 폼 컨트롤을 포함하는 웹 페이지의 구성 요소이다. 사용자는 이러한 폼과 상호작용하여 데이터를 제공할 수 있으며, 해당 데이터는 추가 처리를 위해 서버로 전송될 수 있다(예: 검색이나 계산 결과 반환). 많은 경우 클라이언트 측 스크립팅이 필요하지 않지만, 스크립트가 사용자 경험을 보완하거나 서버로 데이터를 제출하는 것 이외의 목적으로 폼을 사용할 수 있도록 API가 제공된다.
폼 작성은 여러 단계로 구성되며, 어떤 순서로든 수행할 수 있다. 사용자 인터페이스 작성, 서버 측 처리 구현 및 서버와 통신하도록 사용자 인터페이스 구성이다.
이 절은 비규범적이다.
이 간략한 소개에서는 피자 주문 폼을 만든다.
모든 폼은 form 요소로
시작하며, 그 안에 컨트롤을 배치한다. 대부분의 컨트롤은 input 요소로
나타내며, 이 요소는 기본적으로 텍스트 컨트롤을 제공한다. 컨트롤에 레이블을 지정하려면 label 요소를
사용한다. 레이블 텍스트와 컨트롤 자체를 label 요소
안에 넣는다. 폼의 각 부분은
단락으로 간주되며, 일반적으로
p 요소를
사용하여 다른 부분과 구분한다.
이를 모두 합치면 고객의 이름을 다음과 같이 요청할 수 있다:
< form >
< p >< label > Customer name: < input ></ label ></ p >
</ form > 사용자가 피자의 크기를 선택할 수 있도록 라디오 버튼 집합을 사용할 수 있다. 라디오 버튼도
input 요소를
사용하지만, 이번에는 type
속성의 값을
radio로
설정한다. 라디오 버튼이 하나의 그룹으로 작동하게 하려면 name 속성을 사용하여
공통 이름을 지정한다. 이 경우의 라디오 버튼처럼 여러 컨트롤을 하나로 묶으려면
fieldset
요소를 사용할 수 있다. 이러한 컨트롤 그룹의 제목은 fieldset
안의 첫 번째 요소로 제공하며, 이 요소는 legend 요소여야
한다.
< form >
< p >< label > Customer name: < input ></ label ></ p >
< fieldset >
< legend > Pizza Size </ legend >
< p >< label > < input type = radio name = size > Small </ label ></ p >
< p >< label > < input type = radio name = size > Medium </ label ></ p >
< p >< label > < input type = radio name = size > Large </ label ></ p >
</ fieldset >
</ form > 이전 단계에서 변경된 부분이 강조 표시되어 있다.
토핑을 선택하려면 체크박스를 사용할 수 있다. 체크박스는 input 요소와
값이 checkbox인
type
속성을 사용한다:
< form >
< p >< label > Customer name: < input ></ label ></ p >
< fieldset >
< legend > Pizza Size </ legend >
< p >< label > < input type = radio name = size > Small </ label ></ p >
< p >< label > < input type = radio name = size > Medium </ label ></ p >
< p >< label > < input type = radio name = size > Large </ label ></ p >
</ fieldset >
< fieldset >
< legend > Pizza Toppings </ legend >
< p >< label > < input type = checkbox > Bacon </ label ></ p >
< p >< label > < input type = checkbox > Extra Cheese </ label ></ p >
< p >< label > < input type = checkbox > Onion </ label ></ p >
< p >< label > < input type = checkbox > Mushroom </ label ></ p >
</ fieldset >
</ form > 이 폼을 작성하는 피자 가게는 항상 실수하므로 고객에게 연락할 방법이 필요하다.
이를 위해 전화번호 전용 폼 컨트롤(input 요소의
type
속성을 tel로
설정)과 이메일 주소 전용 폼 컨트롤
(input
요소의 type 속성을
email로
설정)을 사용할 수 있다:
< form >
< p >< label > Customer name: < input ></ label ></ p >
< p >< label > Telephone: < input type = tel ></ label ></ p >
< p >< label > Email address: < input type = email ></ label ></ p >
< fieldset >
< legend > Pizza Size </ legend >
< p >< label > < input type = radio name = size > Small </ label ></ p >
< p >< label > < input type = radio name = size > Medium </ label ></ p >
< p >< label > < input type = radio name = size > Large </ label ></ p >
</ fieldset >
< fieldset >
< legend > Pizza Toppings </ legend >
< p >< label > < input type = checkbox > Bacon </ label ></ p >
< p >< label > < input type = checkbox > Extra Cheese </ label ></ p >
< p >< label > < input type = checkbox > Onion </ label ></ p >
< p >< label > < input type = checkbox > Mushroom </ label ></ p >
</ fieldset >
</ form > input 요소의
type
속성을 time으로
설정하여 배달 시간을 요청할 수 있다. 이러한 폼 컨트롤 중 다수에는 지정할 수 있는 값을 정확히
제어하는 속성이 있다. 이 경우 특히 중요한 세 속성은 min, max 및 step이다. 이들은
각각 최소 시간, 최대 시간 및 허용되는 값 사이의 간격(초 단위)을 설정한다. 이 피자 가게는 오전
11시부터 오후 9시까지만 배달하고 15분보다 세밀한 간격은 보장하지 않으므로 다음과 같이 마크업할
수 있다:
< form >
< p >< label > Customer name: < input ></ label ></ p >
< p >< label > Telephone: < input type = tel ></ label ></ p >
< p >< label > Email address: < input type = email ></ label ></ p >
< fieldset >
< legend > Pizza Size </ legend >
< p >< label > < input type = radio name = size > Small </ label ></ p >
< p >< label > < input type = radio name = size > Medium </ label ></ p >
< p >< label > < input type = radio name = size > Large </ label ></ p >
</ fieldset >
< fieldset >
< legend > Pizza Toppings </ legend >
< p >< label > < input type = checkbox > Bacon </ label ></ p >
< p >< label > < input type = checkbox > Extra Cheese </ label ></ p >
< p >< label > < input type = checkbox > Onion </ label ></ p >
< p >< label > < input type = checkbox > Mushroom </ label ></ p >
</ fieldset >
< p >< label > Preferred delivery time: < input type = time min = "11:00" max = "21:00" step = "900" ></ label ></ p >
</ form > textarea
요소를 사용하여 여러 줄 텍스트 컨트롤을 제공할 수 있다. 이 예에서는 고객이 배달 지침을
입력할 공간을 제공하는 데 사용한다:
< form >
< p >< label > Customer name: < input ></ label ></ p >
< p >< label > Telephone: < input type = tel ></ label ></ p >
< p >< label > Email address: < input type = email ></ label ></ p >
< fieldset >
< legend > Pizza Size </ legend >
< p >< label > < input type = radio name = size > Small </ label ></ p >
< p >< label > < input type = radio name = size > Medium </ label ></ p >
< p >< label > < input type = radio name = size > Large </ label ></ p >
</ fieldset >
< fieldset >
< legend > Pizza Toppings </ legend >
< p >< label > < input type = checkbox > Bacon </ label ></ p >
< p >< label > < input type = checkbox > Extra Cheese </ label ></ p >
< p >< label > < input type = checkbox > Onion </ label ></ p >
< p >< label > < input type = checkbox > Mushroom </ label ></ p >
</ fieldset >
< p >< label > Preferred delivery time: < input type = time min = "11:00" max = "21:00" step = "900" ></ label ></ p >
< p >< label > Delivery instructions: < textarea ></ textarea ></ label ></ p >
</ form > 마지막으로 폼을 제출할 수 있게 하려면 button 요소를
사용한다:
< form >
< p >< label > Customer name: < input ></ label ></ p >
< p >< label > Telephone: < input type = tel ></ label ></ p >
< p >< label > Email address: < input type = email ></ label ></ p >
< fieldset >
< legend > Pizza Size </ legend >
< p >< label > < input type = radio name = size > Small </ label ></ p >
< p >< label > < input type = radio name = size > Medium </ label ></ p >
< p >< label > < input type = radio name = size > Large </ label ></ p >
</ fieldset >
< fieldset >
< legend > Pizza Toppings </ legend >
< p >< label > < input type = checkbox > Bacon </ label ></ p >
< p >< label > < input type = checkbox > Extra Cheese </ label ></ p >
< p >< label > < input type = checkbox > Onion </ label ></ p >
< p >< label > < input type = checkbox > Mushroom </ label ></ p >
</ fieldset >
< p >< label > Preferred delivery time: < input type = time min = "11:00" max = "21:00" step = "900" ></ label ></ p >
< p >< label > Delivery instructions: < textarea ></ textarea ></ label ></ p >
< p >< button > Submit order</ button ></ p >
</ form > 이 절은 비규범적이다.
서버 측 처리기를 작성하는 정확한 세부 사항은 이 명세의 범위를 벗어난다.
이 소개에서는 https://pizza.example.com/order.cgi의 스크립트가
application/x-www-form-urlencoded
형식을 사용하는 제출을 허용하도록 구성되어 있고, HTTP POST 본문으로 전송되는 다음 매개변수를
예상한다고 가정한다:
custnamecusttelcustemailsizesmall, medium 또는 large 중 하나toppingbacon,
cheese, onion 및 mushroom
deliverycomments이 절은 비규범적이다.
폼 제출은 다양한 방식으로 서버에 노출되며, 가장 일반적으로 HTTP GET 또는 POST 요청으로
노출된다. 사용할 정확한 메서드를 지정하려면 form
요소에 method
속성을 지정한다. 그러나 이 속성은 폼 데이터를 인코딩하는 방법을 지정하지 않는다. 이를
지정하려면 enctype
속성을 사용한다. 또한 action
속성을 사용하여 제출된 데이터를 처리할 서비스의 URL도 지정해야 한다.
제출하려는 각 폼 컨트롤에는 제출 데이터에서 해당 데이터를 참조하는 데 사용할 이름을 지정해야
한다. 라디오 버튼 그룹의 이름은 이미 지정했다. 동일한 속성(name)이
제출 이름도 지정한다. 라디오 버튼에는 value
속성을 사용하여 서로 다른 값을 지정함으로써 제출 데이터에서 각 버튼을 구분할 수 있다.
여러 컨트롤이 동일한 이름을 가질 수 있다. 예를 들어 여기서는 모든 체크박스에 동일한 이름을
지정하고, 서버는 해당 이름으로 어떤 값이 제출되었는지 확인하여 어떤 체크박스가 선택되었는지
구분한다. 라디오 버튼과 마찬가지로 체크박스에도 value
속성을 사용하여 고유한 값을 지정한다.
이전 절의 설정을 적용하면 전체 폼은 다음과 같다:
< form method = "post"
enctype = "application/x-www-form-urlencoded"
action = "https://pizza.example.com/order.cgi" >
< p >< label > Customer name: < input name = "custname" ></ label ></ p >
< p >< label > Telephone: < input type = tel name = "custtel" ></ label ></ p >
< p >< label > Email address: < input type = email name = "custemail" ></ label ></ p >
< fieldset >
< legend > Pizza Size </ legend >
< p >< label > < input type = radio name = size value = "small" > Small </ label ></ p >
< p >< label > < input type = radio name = size value = "medium" > Medium </ label ></ p >
< p >< label > < input type = radio name = size value = "large" > Large </ label ></ p >
</ fieldset >
< fieldset >
< legend > Pizza Toppings </ legend >
< p >< label > < input type = checkbox name = "topping" value = "bacon" > Bacon </ label ></ p >
< p >< label > < input type = checkbox name = "topping" value = "cheese" > Extra Cheese </ label ></ p >
< p >< label > < input type = checkbox name = "topping" value = "onion" > Onion </ label ></ p >
< p >< label > < input type = checkbox name = "topping" value = "mushroom" > Mushroom </ label ></ p >
</ fieldset >
< p >< label > Preferred delivery time: < input type = time min = "11:00" max = "21:00" step = "900" name = "delivery" ></ label ></ p >
< p >< label > Delivery instructions: < textarea name = "comments" ></ textarea ></ label ></ p >
< p >< button > Submit order</ button ></ p >
</ form > 일부 속성의 값에는 따옴표가 있고 다른 속성에는 없다는 점에 특별한 의미는 없다. HTML 구문에서는 구문 절에서 설명한 대로 속성을 지정하는 여러 가지 동등하게 유효한 방식을 허용한다.
예를 들어 고객이 이름으로 "Denise Lawrence", 전화번호로 "555-321-8642"를 입력하고 이메일 주소를 지정하지 않았으며, 중간 크기의 피자를 요청하고 Extra Cheese와 Mushroom 토핑을 선택하고, 배달 시간으로 오후 7시를 입력하고 배달 지침 텍스트 컨트롤을 비워 두었다면 사용자 에이전트는 온라인 웹 서비스에 다음 데이터를 제출한다:
custname=Denise+Lawrence&custtel=555-321-8642&custemail=&size=medium&topping=cheese&topping=mushroom&delivery=19%3A00&comments=현재의 모든 엔진에서 지원된다.
이 절은 비규범적이다.
사용자 에이전트가 폼을 제출하기 전에 사용자의 입력을 검사하도록 폼에 주석을 지정할 수 있다. 적대적인 사용자가 폼 유효성 검사를 쉽게 우회할 수 있으므로 서버는 여전히 입력이 유효한지 확인해야 하지만, 서버만 사용자의 입력을 검사할 때 발생하는 대기 시간을 사용자가 피할 수 있게 한다.
가장 간단한 주석은 required
속성이다. 이 속성을 input
요소에
지정하여 값이 제공될 때까지 폼을 제출하지 않도록 나타낼 수 있다. 이 속성을 고객 이름, 피자 크기 및
배달 시간 필드에 추가하면 사용자가 해당 필드를 채우지 않고 폼을 제출할 때 사용자 에이전트가
사용자에게 알릴 수 있다:
< form method = "post"
enctype = "application/x-www-form-urlencoded"
action = "https://pizza.example.com/order.cgi" >
< p >< label > Customer name: < input name = "custname" required ></ label ></ p >
< p >< label > Telephone: < input type = tel name = "custtel" ></ label ></ p >
< p >< label > Email address: < input type = email name = "custemail" ></ label ></ p >
< fieldset >
< legend > Pizza Size </ legend >
< p >< label > < input type = radio name = size required value = "small" > Small </ label ></ p >
< p >< label > < input type = radio name = size required value = "medium" > Medium </ label ></ p >
< p >< label > < input type = radio name = size required value = "large" > Large </ label ></ p >
</ fieldset >
< fieldset >
< legend > Pizza Toppings </ legend >
< p >< label > < input type = checkbox name = "topping" value = "bacon" > Bacon </ label ></ p >
< p >< label > < input type = checkbox name = "topping" value = "cheese" > Extra Cheese </ label ></ p >
< p >< label > < input type = checkbox name = "topping" value = "onion" > Onion </ label ></ p >
< p >< label > < input type = checkbox name = "topping" value = "mushroom" > Mushroom </ label ></ p >
</ fieldset >
< p >< label > Preferred delivery time: < input type = time min = "11:00" max = "21:00" step = "900" name = "delivery" required ></ label ></ p >
< p >< label > Delivery instructions: < textarea name = "comments" ></ textarea ></ label >
< p >< button > Submit order</ button ></ p >
</ form > maxlength 속성을
사용하여 입력 길이를 제한할 수도 있다. 이를 textarea
요소에 추가하면 사용자를 1000자로 제한하여, 바쁜 배달 기사에게 핵심에서 벗어난 긴 글을 쓰지
못하게 할 수 있다:
< form method = "post"
enctype = "application/x-www-form-urlencoded"
action = "https://pizza.example.com/order.cgi" >
< p >< label > Customer name: < input name = "custname" required ></ label ></ p >
< p >< label > Telephone: < input type = tel name = "custtel" ></ label ></ p >
< p >< label > Email address: < input type = email name = "custemail" ></ label ></ p >
< fieldset >
< legend > Pizza Size </ legend >
< p >< label > < input type = radio name = size required value = "small" > Small </ label ></ p >
< p >< label > < input type = radio name = size required value = "medium" > Medium </ label ></ p >
< p >< label > < input type = radio name = size required value = "large" > Large </ label ></ p >
</ fieldset >
< fieldset >
< legend > Pizza Toppings </ legend >
< p >< label > < input type = checkbox name = "topping" value = "bacon" > Bacon </ label ></ p >
< p >< label > < input type = checkbox name = "topping" value = "cheese" > Extra Cheese </ label ></ p >
< p >< label > < input type = checkbox name = "topping" value = "onion" > Onion </ label ></ p >
< p >< label > < input type = checkbox name = "topping" value = "mushroom" > Mushroom </ label ></ p >
</ fieldset >
< p >< label > Preferred delivery time: < input type = time min = "11:00" max = "21:00" step = "900" name = "delivery" required ></ label ></ p >
< p >< label > Delivery instructions: < textarea name = "comments" maxlength = 1000 ></ textarea ></ label ></ p >
< p >< button > Submit order</ button ></ p >
</ form > 폼이 제출되면 유효하지 않은 각 폼 컨트롤에서 invalid 이벤트가
발생한다. 브라우저 자체는 일반적으로 한 번에 하나의 문제만 보고하므로, 이 이벤트는 폼의 문제를
요약하여 표시하는 데 유용할 수 있다.
이 절은 비규범적이다.
일부 브라우저는 사용자가 매번 정보를 다시 입력하도록 하는 대신 폼 컨트롤을 자동으로 채워 사용자를 돕는다. 예를 들어 사용자의 전화번호를 요청하는 필드는 사용자의 전화번호로 자동으로 채울 수 있다.
이를 사용자 에이전트에 알리기 위해 autocomplete
속성을 사용하여 필드의 목적을 설명할 수 있다. 이 폼에서는 피자를 배달받을 사람에 관한 정보인
세 필드에 이러한 주석을 유용하게 지정할 수 있다. 이 정보를 추가하면 다음과 같다:
< form method = "post"
enctype = "application/x-www-form-urlencoded"
action = "https://pizza.example.com/order.cgi" >
< p >< label > Customer name: < input name = "custname" required autocomplete = "shipping name" ></ label ></ p >
< p >< label > Telephone: < input type = tel name = "custtel" autocomplete = "shipping tel" ></ label ></ p >
< p >< label > Email address: < input type = email name = "custemail" autocomplete = "shipping email" ></ label ></ p >
< fieldset >
< legend > Pizza Size </ legend >
< p >< label > < input type = radio name = size required value = "small" > Small </ label ></ p >
< p >< label > < input type = radio name = size required value = "medium" > Medium </ label ></ p >
< p >< label > < input type = radio name = size required value = "large" > Large </ label ></ p >
</ fieldset >
< fieldset >
< legend > Pizza Toppings </ legend >
< p >< label > < input type = checkbox name = "topping" value = "bacon" > Bacon </ label ></ p >
< p >< label > < input type = checkbox name = "topping" value = "cheese" > Extra Cheese </ label ></ p >
< p >< label > < input type = checkbox name = "topping" value = "onion" > Onion </ label ></ p >
< p >< label > < input type = checkbox name = "topping" value = "mushroom" > Mushroom </ label ></ p >
</ fieldset >
< p >< label > Preferred delivery time: < input type = time min = "11:00" max = "21:00" step = "900" name = "delivery" required ></ label ></ p >
< p >< label > Delivery instructions: < textarea name = "comments" maxlength = 1000 ></ textarea ></ label ></ p >
< p >< button > Submit order</ button ></ p >
</ form > 이 절은 비규범적이다.
일부 기기, 특히 가상 키보드를 사용하는 기기는 사용자에게 여러 입력 방식을 제공할 수 있다. 예를 들어 신용카드 번호를 입력할 때 사용자는 숫자 0~9 키만 보기를 원할 수 있지만, 이름을 입력할 때는 기본적으로 각 단어의 첫 글자를 대문자로 바꾸는 폼 필드를 원할 수 있다.
inputmode
속성을 사용하면 적절한 입력 방식을 선택할 수 있다:
< form method = "post"
enctype = "application/x-www-form-urlencoded"
action = "https://pizza.example.com/order.cgi" >
< p >< label > Customer name: < input name = "custname" required autocomplete = "shipping name" ></ label ></ p >
< p >< label > Telephone: < input type = tel name = "custtel" autocomplete = "shipping tel" ></ label ></ p >
< p >< label > Buzzer code: < input name = "custbuzz" inputmode = "numeric" ></ label ></ p >
< p >< label > Email address: < input type = email name = "custemail" autocomplete = "shipping email" ></ label ></ p >
< fieldset >
< legend > Pizza Size </ legend >
< p >< label > < input type = radio name = size required value = "small" > Small </ label ></ p >
< p >< label > < input type = radio name = size required value = "medium" > Medium </ label ></ p >
< p >< label > < input type = radio name = size required value = "large" > Large </ label ></ p >
</ fieldset >
< fieldset >
< legend > Pizza Toppings </ legend >
< p >< label > < input type = checkbox name = "topping" value = "bacon" > Bacon </ label ></ p >
< p >< label > < input type = checkbox name = "topping" value = "cheese" > Extra Cheese </ label ></ p >
< p >< label > < input type = checkbox name = "topping" value = "onion" > Onion </ label ></ p >
< p >< label > < input type = checkbox name = "topping" value = "mushroom" > Mushroom </ label ></ p >
</ fieldset >
< p >< label > Preferred delivery time: < input type = time min = "11:00" max = "21:00" step = "900" name = "delivery" required ></ label ></ p >
< p >< label > Delivery instructions: < textarea name = "comments" maxlength = 1000 ></ textarea ></ label ></ p >
< p >< button > Submit order</ button ></ p >
</ form > 이 절은 비규범적이다.
type,
autocomplete
및 inputmode
속성은 혼동스러울 정도로 비슷해 보일 수 있다. 예를 들어 세 속성 모두에서 문자열
"email"은 유효한 값이다. 이 절에서는 세 속성의 차이를 설명하고 사용 방법에 관한
조언을 제공한다.
input
요소의 type
속성은 사용자 에이전트가 필드를 노출하는 데 사용할 컨트롤의 종류를 결정한다. 이 속성의 여러 값
중에서 선택하는 것은 input
요소, textarea
요소, select
요소 등을 사용할지 선택하는 것과 같다.
반면 autocomplete
속성은 사용자가 입력할 값이 실제로 무엇을 나타내는지 설명한다. 이 속성의 여러 값 중에서 선택하는
것은 요소의 레이블을 무엇으로 지정할지 선택하는 것과 같다.
먼저 전화번호를 살펴보자. 페이지가 사용자에게 전화번호를 요청하는 경우 사용할 올바른 폼
컨트롤은 <input type=tel>이다.
그러나 사용할 autocomplete
값은 페이지가 어떤 전화번호를 요청하는지, 국제 형식의 전화번호를 예상하는지 아니면 지역 형식만
예상하는지 등에 따라 달라진다.
예를 들어 친구에게 배송할 선물을 구매하는 고객을 위한 전자상거래 사이트의 결제 과정에 포함된 페이지는 구매자의 전화번호(결제 문제에 대비)와 친구의 전화번호(배송 문제에 대비)가 모두 필요할 수 있다. 사이트가 국가 코드 접두사를 포함한 국제 전화번호를 예상한다면 다음과 같이 작성할 수 있다:
< p >< label > Your phone number: < input type = tel name = custtel autocomplete = "billing tel" ></ label >
< p >< label > Recipient's phone number: < input type = tel name = shiptel autocomplete = "shipping tel" ></ label >
< p > Please enter complete phone numbers including the country code prefix, as in "+1 555 123 4567".하지만 사이트가 영국 고객과 수령인만 지원한다면 대신 다음과 같이 작성할 수 있다
(tel이
아니라 tel-national을
사용한다는 점에 유의한다):
< p >< label > Your phone number: < input type = tel name = custtel autocomplete = "billing tel-national" ></ label >
< p >< label > Recipient's phone number: < input type = tel name = shiptel autocomplete = "shipping tel-national" ></ label >
< p > Please enter complete UK phone numbers, as in "(01632) 960 123".이제 개인의 선호 언어를 살펴보자. 올바른 autocomplete
값은 language이다.
그러나 이 목적에는 텍스트 컨트롤(<input type=text>),
드롭다운 목록(<select>),
라디오 버튼(<input
type=radio>) 등 여러 종류의 폼 컨트롤을 사용할 수 있다. 원하는 인터페이스 종류에 따라
선택하면 된다.
마지막으로 이름을 살펴보자. 페이지가 사용자에게 하나의 이름만 요청한다면 관련 컨트롤은
<input type=text>이다.
페이지가 사용자의 전체 이름을 요청한다면 관련 autocomplete
값은 name이다.
< p >< label > Japanese name: < input name = "j" type = "text" autocomplete = "section-jp name" ></ label >
< label > Romanized name: < input name = "e" type = "text" autocomplete = "section-en name" ></ label > 이 예에서 autocomplete
속성 값의 "section-*"
키워드는 두 필드가 서로 다른 이름을 예상한다는 것을 사용자 에이전트에 알린다. 이 키워드가
없으면 사용자가 첫 번째 필드에 값을 입력했을 때 사용자 에이전트가 두 번째 필드를 첫 번째 필드의
값으로 자동으로 채울 수 있다.
키워드의 "-jp"와 "-en" 부분은 사용자 에이전트에
불투명하다. 사용자 에이전트는 이 부분만으로 두 이름이 각각 일본어와 영어로 입력되어야 한다고
추측할 수 없다.
type과
autocomplete에
관한 선택과 별개로, 컨트롤이 텍스트 컨트롤인 경우 inputmode
속성은 사용할 입력 방식(예: 가상 키보드)의 종류를 결정한다.
신용카드 번호를 살펴보자. 적절한 입력 유형은 아래에서
설명하는 것처럼 <input type=number>가
아니며, 대신 <input type=text>이다.
그럼에도 사용자 에이전트가 숫자 입력 방식(예: 숫자만 표시하는 가상 키보드)을 사용하도록
권장하려면 페이지는 다음을 사용한다
< p >< label > Credit card number:
< input name = "cc" type = "text" inputmode = "numeric" pattern = "[0-9]{8,19}" autocomplete = "cc-number" >
</ label ></ p > 이 절은 비규범적이다.
이 피자 배달 예제에서 시간은 "HH:MM" 형식으로 지정된다. 24시간 형식의 시를 나타내는 두 자리와 분을 나타내는 두 자리이다. 초도 지정할 수 있지만 이 예제에서는 필요하지 않다.
그러나 일부 로케일에서는 사용자에게 시간을 표시할 때 다른 방식으로 표현하는 경우가 많다. 예를 들어 미국에서는 "2pm"처럼 am/pm 표시가 있는 12시간제를 여전히 흔히 사용한다. 프랑스에서는 "14h00"처럼 "h" 문자를 사용하여 시와 분을 구분하는 것이 일반적이다.
날짜에도 비슷한 문제가 있으며, 구성 요소의 순서조차 항상 일관되지는 않는다는 문제가 추가된다. 예를 들어 키프로스에서는 2003년 2월 1일을 일반적으로 "1/2/03"으로 쓰지만, 일본에서는 같은 날짜를 일반적으로 "2003年02月01日"로 쓴다. 숫자에서도 로케일마다 소수점 구분 기호와 천 단위 구분 기호로 사용하는 문장 부호가 다르다.
따라서 HTML과 폼 제출에서 사용하는 시간, 날짜 및 숫자 형식과 브라우저가 사용자에게 표시하고 사용자 입력으로 허용하는 시간, 날짜 및 숫자 형식을 구분하는 것이 중요하다. 전자는 항상 이 명세에 정의된 형식이며, 컴퓨터가 읽을 수 있는 날짜와 시간 형식에 관한 확립된 ISO 8601 표준을 기반으로 한다.
HTML 마크업과 폼 제출에서 사용되는 "전송 형식"은 사용자의 로케일과 관계없이 컴퓨터가 읽을 수 있고 일관되도록 의도된다. 예를 들어 날짜는 항상 "2003-02-01"과 같은 "YYYY-MM-DD" 형식으로 작성된다. 일부 사용자는 이 형식을 볼 수 있지만 다른 사용자는 "01.02.2003" 또는 "February 1, 2003"으로 볼 수 있다.
페이지가 전송 형식으로 제공한 시간, 날짜 또는 숫자는 사용자에게 표시되기 전에 사용자 환경설정 또는 페이지 자체의 로케일에 따라 사용자가 선호하는 표시 형식으로 변환된다. 마찬가지로 사용자가 선호하는 형식으로 시간, 날짜 또는 숫자를 입력하면 사용자 에이전트는 이를 DOM에 넣거나 제출하기 전에 다시 전송 형식으로 변환한다.
이를 통해 페이지와 서버의 스크립트는 수십 가지 서로 다른 형식을 지원하지 않고도 시간, 날짜 및 숫자를 일관된 방식으로 처리하면서 사용자의 요구를 지원할 수 있다.
폼 컨트롤의 현지화에 관한 구현 참고 사항도 참조한다.
주로 역사적인 이유로 이 절의 요소는 플로 콘텐츠, 구문 콘텐츠 및 대화형 콘텐츠와 같은 일반적인 범주 외에도 서로 겹치지만 미묘하게 다른 여러 범주에 속한다.
여러 요소는 폼 연관 요소이며, 이는 이러한 요소가 폼 소유자를 가질 수 있음을 의미한다.
폼 연관 요소는 여러 하위 범주로 나뉜다:
form.elements 및
fieldset.elements
API에 나열되는 요소를 나타낸다. 이 요소에는 작성자가 명시적인
폼 소유자를 지정할 수 있게 하는
form 콘텐츠 속성과 이에 대응하는
form IDL 속성도 있다.
form 요소가
제출될 때
엔트리 목록을 구성하는 데 사용할
수 있는 요소를
나타낸다.
일부 제출 가능한 요소는 속성에 따라 버튼이 될 수 있다. 아래의 설명은 요소가 언제 버튼이 되는지 정의한다. 일부 버튼은 특별히 제출 버튼이다.
폼
소유자로부터 autocapitalize
및 autocorrect 속성을
상속하는 요소를 나타낸다.
일부 요소는 모두가 폼 연관 요소인 것은 아니지만
레이블 지정 가능 요소로 분류된다. 이 요소는 label 요소와 연결할 수 있다.
form
要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
form 要素を含めてはならない。accept-charset —
フォーム
送信に使用する文字エンコーディング
action — フォーム送信に使用する URL
autocomplete —
フォーム内のコントロールに対する自動入力機能の既定設定
enctype — フォーム送信に使用するエントリーリストのエンコーディング形式
method — フォーム送信に使用する方式
name — document.forms API で使用する
フォームの名前
novalidate — フォーム送信時にフォームコントロールの
検証を回避する
target — フォーム送信のためのナビゲーション可能
relaction を持つ。[Exposed =Window ,
LegacyOverrideBuiltIns ,
LegacyUnenumerableNamedProperties ]
interface HTMLFormElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect="accept-charset"] attribute DOMString acceptCharset ;
[CEReactions , ReflectSetter ] attribute USVString action ;
[CEReactions ] attribute DOMString autocomplete ;
[CEReactions ] attribute DOMString enctype ;
[CEReactions ] attribute DOMString encoding ;
[CEReactions ] attribute DOMString method ;
[CEReactions , Reflect ] attribute DOMString name ;
[CEReactions , Reflect ] attribute boolean noValidate ;
[CEReactions , Reflect ] attribute DOMString target ;
[CEReactions , Reflect ] attribute DOMString rel ;
[SameObject , PutForwards =value , Reflect="rel"] readonly attribute DOMTokenList relList ;
[SameObject ] readonly attribute HTMLFormControlsCollection elements ;
readonly attribute unsigned long length ;
getter Element (unsigned long index );
getter (RadioNodeList or Element ) (DOMString name );
undefined submit ();
undefined requestSubmit (optional HTMLElement ? submitter = null );
[CEReactions ] undefined reset ();
boolean checkValidity ();
boolean reportValidity ();
};form 要素は、フォーム関連
要素の集合を通じて操作できるハイパーリンクを表します。それらの要素の一部は、編集可能な値を表し、
処理のためにサーバーへ送信できます。
accept-charset 属性は、送信に使用する文字
エンコーディングを指定します。指定する場合、その値は「UTF-8」と ASCII
大文字小文字不区別で一致しなければなりません。[ENCODING]
name 属性は、
forms
コレクション内における form
の名前を表します。値は空文字列であってはならず、存在する場合は、その要素が属する forms コレクション内の
form 要素間で
一意でなければなりません。
autocomplete
属性は、次のキーワードおよび状態を持つ列挙
属性です。
| キーワード | 状態 | 簡単な説明 |
|---|---|---|
on
|
オン | フォームコントロールの自動入力フィールド名は、既定で「on」に設定されます。
|
off
|
オフ | フォームコントロールの自動入力フィールド名は、既定で「off」に
設定されます。
|
action、enctype、
method、novalidate、
および target 属性は、フォーム
送信用の属性です。
form 要素の
rel 属性は、
要素が作成するリンクの種類を制御します。属性値は、一意な空白区切りトークンの
順序なし集合でなければなりません。許可されるキーワードとその意味は、
前の節で定義されています。
rel のサポートされる
トークンは、form
要素で許可され、処理モデルに影響し、ユーザーエージェントがサポートする、HTML リンク型で
定義されたキーワードです。利用可能なサポートされるトークンは、
noreferrer、noopener、および opener です。rel のサポートされるトークンには、この一覧のうち、
ユーザーエージェントが処理モデルを実装しているトークンのみを含めなければなりません。
form.elements
現在のすべてのエンジンでサポートされています。
フォーム内のフォームコントロールの HTMLFormControlsCollection
を返します
(歴史的な理由により画像ボタンは除外されます)。
form.length
現在のすべてのエンジンでサポートされています。
フォーム内のフォームコントロール数を返します(歴史的な理由により画像ボタンは 除外されます)。
form[index]フォーム内の index 番目の要素を返します(歴史的な理由により画像ボタンは 除外されます)。
form[name]指定された ID または name を持つフォーム内のフォームコントロール
(複数ある場合は、それらのフォームコントロールの RadioNodeList)を返します
(歴史的な理由により画像ボタンは除外されます)。該当するものがない場合は、指定された ID を持つ img 要素を返します。
ある要素が特定の名前を使用して参照されると、その要素がツリー内に存在し続ける限り、要素の実際の ID または name が変更されても、その名前は
このメソッドでその要素を参照する方法として引き続き利用できます。
一致する項目が複数ある場合は、それらすべての要素を含む RadioNodeList オブジェクトが返されます。
form.submit()
現在のすべてのエンジンでサポートされています。
form.requestSubmit([ submitter ])
現在のすべてのエンジンでサポートされています。
フォームの送信を要求します。submit()
と異なり、この
メソッドには対話的な制約
検証および submit イベントの発火が含まれ、
そのいずれも送信を取り消すことができます。
submitter 引数を使用すると、特定の送信ボタンを指定できます。その formaction、formenctype、formmethod、formnovalidate、
および formtarget 属性は、
送信に影響を与えることができます。さらに、送信用のエントリーリストを構築する際に、
送信者が含まれます。通常、ボタンは除外されます。
form.reset()
現在のすべてのエンジンでサポートされています。
フォームをリセットします。
form.checkValidity()
フォームのコントロールがすべて妥当である場合は true を返し、それ以外の場合は false を返します。
form.reportValidity()
フォームのコントロールがすべて妥当である場合は true を返し、それ以外の場合は false を返して ユーザーに通知します。
elements
IDL 属性は、form
要素のルートを基点とする HTMLFormControlsCollection
を返さなければなりません。そのフィルターは、フォーム所有者がその form 要素であるリスト対象要素に一致します。ただし、type 属性が画像ボタン
状態である input 要素は、
歴史的な理由により、この特定のコレクションから
除外しなければなりません。
任意の時点におけるサポートされるプロパティインデックスは、その時点で elements 属性が返す
オブジェクトによってサポートされるインデックスです。
form
要素についてインデックス付きプロパティの値を決定するには、
ユーザーエージェントは、指定されたインデックスを引数として elements
コレクションの item
メソッドを呼び出した結果の値を返さなければなりません。
各 form 要素は、
名前から要素へのマッピングである過去の名前
マップを持ちます。これは、コントロールの名前が変更された場合でも名前を保持するために使用されます。
サポートされるプロパティ名は、次の アルゴリズムから得られる名前を、このアルゴリズムで得られた順序で並べたものです。
sourced names を、文字列、要素、ソースからなるタプルの、初期状態では空の順序付きリストとします。 ソースは id、name、または past のいずれかであり、 ソースが past である場合は、さらに経過時間を持ちます。
フォーム所有者が form 要素である各リスト対象要素
candidate について、ただし type 属性が画像
ボタン状態である input
要素は除きます。
過去の名前マップ内の各エントリー past entry について、 past entry の名前を文字列、past entry の要素を要素、past をソース、 past entry が過去の名前マップに存在していた期間を経過時間として、 sourced names にエントリーを追加します。
sourced names を、各タプルの要素エントリーのツリー順で ソートします。同じ要素のエントリーでは、ソースが id のエントリーを最初に、 次にソースが name のエントリー、最後にソースが past のエントリーを配置します。 要素とソースが同じエントリーは、古いものを先にして経過時間でソートします。
sourced names から、名前が空文字列であるエントリーをすべて削除します。
sourced names から、マップ内の先行するエントリーと同じ名前を持つ エントリーをすべて削除します。
sourced names から名前のリストを、相対的な順序を維持して返します。
form
要素の名前付きプロパティ name の値を決定するには、
ユーザーエージェントは次の手順を実行しなければなりません。
candidates を、フォーム
所有者が form
要素であり、name と等しい id 属性または name 属性を持つすべてのリスト対象要素を含む、ライブな RadioNodeList オブジェクトとします。
ただし、type 属性が
画像
ボタン状態である input
要素は除外し、
ツリー順とします。
candidates が空の場合、candidates を、フォーム
所有者が form
要素であり、name と等しい id 属性または name 属性を持つすべての img 要素を含む、ライブな
RadioNodeList オブジェクトとし、
ツリー順とします。
candidates が空で、name が form
要素の過去の名前マップ内の
いずれかのエントリー名である場合、そのマップで name に関連付けられたオブジェクトを
返します。
candidates に複数のノードが含まれる場合は、candidates を返します。
それ以外の場合、candidates には正確に 1 つのノードが含まれます。form
要素の過去の名前マップに、
name から candidates 内のノードへのマッピングを追加し、
同じ名前の以前のエントリーがある場合は置き換えます。
candidates 内のノードを返します。
form 要素の過去の名前マップに記載された要素の
フォーム所有者が変更された場合、
その要素のエントリーをそのマップから削除しなければなりません。
submit()
メソッドの手順は、this から this を送信し、submit()
メソッドから送信されたを true に設定することです。
requestSubmit(submitter) メソッドは、
呼び出されたとき、次の手順を実行しなければなりません。
submitter が null でない場合:
submitter のフォーム所有者が
この form 要素でない場合、
「NotFoundError」 DOMException
をスローします。
それ以外の場合、submitter をこの form 要素に設定します。
reset()
メソッドは、呼び出されたとき、次の手順を実行しなければなりません。
form 要素が
リセット用にロック済みと
マークされている場合は、戻ります。
form 要素を
リセット用にロック済みとマークします。
form
要素のリセット用にロック済み
マークを解除します。
checkValidity() メソッドが呼び出された場合、
ユーザーエージェントは form 要素の制約を静的に検証しなければならず、
制約検証が肯定結果を返した場合は true、否定結果を返した場合は false を
返さなければなりません。
reportValidity() メソッドが呼び出された場合、
ユーザーエージェントは form 要素の制約を対話的に検証しなければならず、
制約検証が肯定結果を返した場合は true、否定結果を返した場合は false を
返さなければなりません。
この例は、2 つの検索フォームを示します。
< form action = "https://www.google.com/search" method = "get" >
< label > Google: < input type = "search" name = "q" ></ label > < input type = "submit" value = "検索..." >
</ form >
< form action = "https://www.bing.com/search" method = "get" >
< label > Bing: < input type = "search" name = "q" ></ label > < input type = "submit" value = "検索..." >
</ form > label
要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
label 要素を
含めてはならない。
for — ラベルを
フォームコントロールに関連付ける
[Exposed =Window ]
interface HTMLLabelElement : HTMLElement {
[HTMLConstructor ] constructor ();
readonly attribute HTMLFormElement ? form ;
[CEReactions , Reflect="for"] attribute DOMString htmlFor ;
readonly attribute HTMLElement ? control ;
};label 要素は、
ユーザーインターフェイス内のキャプションを表します。キャプションは、label 要素の
ラベル付きコントロールと呼ばれる特定のフォームコントロールに、
for 属性を使用するか、
フォームコントロールを label 要素自体の内部に
配置することで関連付けることができます。
次の規則で別途指定されている場合を除き、label
要素には
ラベル付きコントロールはありません。
現在のすべてのエンジンでサポートされています。
for 属性は、
キャプションを関連付けるフォームコントロールを示すために指定できます。この属性を指定する場合、
属性値は label 要素と
同じツリー内にあるラベル付け可能要素の
ID でなければなりません。属性が指定されており、ツリー内に、for 属性値と等しい ID を持つ要素があり、ツリー
順で最初のそのような要素がラベル付け可能要素である場合、その要素が
label 要素の
ラベル付きコントロールです。
label 要素の
正確な既定の表示および動作、特に活性化動作がある場合にそれがどのようなものであるかは、
プラットフォームのラベル動作と一致するべきです。label 要素の対話型コンテンツの子孫、
およびそれらの対話型コンテンツの子孫を対象とするイベントについて、
label 要素の活性化動作は、何もしないものでなければなりません。
フォーム関連カスタム
要素はラベル付け可能要素です。そのため、
label 要素の活性化動作がラベル付き
コントロールに影響するユーザーエージェントでは、組み込み要素とカスタム要素の両方が影響を受けます。
たとえば、ラベルをクリックするとフォームコントロールが活性化されるプラットフォームでは、次の
断片内の label を
クリックすると、要素自体がユーザーによって操作されたかのように、ユーザーエージェントが input 要素でclick イベントを
発火する可能性があります。
< label >< input type = checkbox name = lost > 紛失</ label > 同様に、my-checkbox が(この
例のような)フォーム関連
カスタム要素として宣言されていると仮定すると、次のコード
< label >< my-checkbox name = lost ></ my-checkbox > 紛失</ label > も同じ動作をし、my-checkbox 要素でclick イベントを
発火します。
他のプラットフォームでは、どちらの場合も、コントロールにフォーカスするだけか、 何もしない場合があります。
次の例は、それぞれラベルを持つ 3 つのフォームコントロールを示します。そのうち 2 つには、 ユーザーが使用すべき正しい形式を示す小さなテキストがあります。
< p >< label > 氏名: < input name = fn > < small > 形式: 名 姓</ small ></ label ></ p >
< p >< label > 年齢: < input name = age type = number min = 0 ></ label ></ p >
< p >< label > 郵便番号: < input name = pc > < small > 形式: AB12 3CD</ small ></ label ></ p > label.control
現在のすべてのエンジンでサポートされています。
この要素に関連付けられているフォームコントロールを返します。
label.form
現在のすべてのエンジンでサポートされています。
この要素に関連付けられたフォームコントロールのフォーム所有者を返します。
存在しない場合は null を返します。
control
IDL 属性は、存在する場合は label
要素のラベル付きコントロールを返し、
存在しない場合は null を返さなければなりません。
form
IDL
属性は、次の手順を実行しなければなりません。
label
要素にラベル付きコントロールがない場合、
null を返します。
label
要素のラベル付きコントロールが
フォーム関連要素でない場合、
null を返します。
label
要素のラベル付きコントロールのフォーム
所有者を返します(依然として null の場合があります)。
label
要素の form IDL
属性は、リスト対象のフォーム関連要素の form IDL
属性とは異なり、label
要素には form コンテンツ属性は
ありません。
control.labels
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
ラベル付け可能要素およびすべての input 要素には、
対象要素をラベル付き
コントロールとする label
要素の一覧を
ツリー順で表す、関連付けられたライブな NodeList オブジェクトがあります。フォーム関連
カスタム要素ではないラベル付け可能要素の labels IDL 属性、および input 要素の labels IDL 属性は、取得時に、
その NodeList オブジェクトを返さなければならず、
常に同じ値を返さなければなりません。ただし、この要素が type 属性が状態である
input 要素の場合は、
代わりに null を返さなければなりません。
現在のすべてのエンジンでサポートされています。
フォーム関連カスタム要素には
labels IDL 属性はありません。
代わりに、その ElementInternals
オブジェクトが
labels IDL 属性を持ちます。取得時に、対象要素がフォーム関連カスタム
要素でない場合は、「NotSupportedError」 DOMException をスローしなければなりません。
それ以外の場合、その NodeList オブジェクトを返さなければならず、
常に同じ値を返さなければなりません。
この(非適合の)例は、input 要素の
type 属性が変更されたとき、
NodeList に何が起こり、labels が何を返すかを示します。
<!doctype html>
< p >< label >< input ></ label ></ p >
< script >
const input = document. querySelector( 'input' );
const labels = input. labels;
console. assert( labels. length === 1 );
input. type = 'hidden' ;
console. assert( labels. length === 0 ); // input はもはや label の ラベル付きコントロール ではない
console. assert( input. labels === null );
input. type = 'checkbox' ;
console. assert( labels. length === 1 ); // input は再び label の ラベル付きコントロール になる
console. assert( input. labels === labels); // 最初に返された値と同じ
</ script > input
要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
type 属性が
非表示状態でない場合:対話型コンテンツ。
type 属性が
非表示状態でない場合:リスト対象、ラベル付け可能、送信可能、リセット可能、および自動大文字化と自動修正を継承するフォーム関連要素。
type 属性が
非表示状態の場合:リスト対象、送信可能、リセット可能、および自動大文字化と自動修正を継承するフォーム関連要素。
type 属性が
非表示状態でない場合:知覚可能コンテンツ。
accept — ファイルアップロードコントロールで期待される
ファイル形式のヒント
alpha — 色の
アルファ成分を設定可能にする
alt — 画像を利用できない
場合に使用する代替テキスト
autocomplete —
フォーム自動入力機能のヒント
checked —
コントロールが選択済みであるかどうか
colorspace —
シリアル化された色の色空間
dirname —
フォーム送信時に要素の方向性を送信するために使用する
フォームコントロールの名前
disabled —
フォームコントロールが無効化されているかどうか
form — 要素を form 要素に関連付ける
formaction —
フォーム送信に使用する URL
formenctype —
フォーム送信に使用するエントリーリストのエンコーディング形式
formmethod —
フォーム送信に使用する方式
formnovalidate
— フォーム送信時に
フォームコントロールの検証を回避する
formtarget —
フォーム送信のためのナビゲーション可能
height — 垂直方向の寸法
list — 自動補完候補の一覧
max — 最大値
maxlength —
値の最大長
min — 最小値
minlength —
値の最小長
multiple —
複数の値を許可するかどうか
name —
フォーム送信および form.elements API で使用する
要素の名前
pattern —
フォームコントロールの値が一致すべきパターン
placeholder —
フォームコントロール内に配置されるユーザー可視のラベル
popovertarget —
切り替え、表示、または非表示にするポップオーバー要素を対象とする
popovertargetaction
— 対象のポップオーバー要素を切り替える、表示する、または非表示にするかを示す
readonly —
ユーザーによる値の編集を許可するかどうか
required —
フォーム送信にそのコントロールが
必須であるかどうか
size — コントロールのサイズ
src — リソースのアドレス
step —
フォームコントロールの値が一致すべき粒度
type —
フォームコントロールの種類
value —
フォームコントロールの値
width — 水平方向の寸法
title 属性は
この要素上で特別な意味を持ちます:
パターンの説明(pattern 属性と共に
使用する場合)
type 属性が非表示状態の場合:
著者向け、実装者向け。
type 属性がテキスト状態の場合:
著者向け、実装者向け。
type 属性が検索状態の場合:
著者向け、実装者向け。
type 属性が電話番号状態の場合:
著者向け、実装者向け。
type 属性がURL 状態の場合:
著者向け、実装者向け。
type 属性がメール状態の場合:
著者向け、実装者向け。
type 属性がパスワード状態の場合:
著者向け、実装者向け。
type 属性が日付状態の場合:
著者向け、実装者向け。
type 属性が月状態の場合:
著者向け、実装者向け。
type 属性が週状態の場合:
著者向け、実装者向け。
type 属性が時刻状態の場合:
著者向け、実装者向け。
type 属性がローカル日付と時刻状態の場合:
著者向け、実装者向け。
type 属性が数値状態の場合:
著者向け、実装者向け。
type 属性が範囲状態の場合:
著者向け、実装者向け。
type 属性が色状態の場合:
著者向け、実装者向け。
type 属性がチェックボックス
状態の場合:著者向け、実装者向け。
type 属性がラジオボタン
状態の場合:著者向け、実装者向け。type 属性がファイルアップロード
状態の場合:著者向け、実装者向け。type 属性が送信
ボタン状態の場合:著者向け、実装者向け。type 属性が画像ボタン
状態の場合:著者向け、実装者向け。type 属性がリセットボタン
状態の場合:著者向け、実装者向け。type 属性がボタン状態の場合:
著者向け、実装者向け。
formaction
を持つ。[Exposed =Window ]
interface HTMLInputElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute DOMString accept ;
[CEReactions , Reflect ] attribute boolean alpha ;
[CEReactions , Reflect ] attribute DOMString alt ;
[CEReactions , ReflectSetter ] attribute DOMString autocomplete ;
[CEReactions , Reflect="checked"] attribute boolean defaultChecked ;
attribute boolean checked ;
[CEReactions ] attribute DOMString colorSpace ;
[CEReactions , Reflect ] attribute DOMString dirName ;
[CEReactions , Reflect ] attribute boolean disabled ;
readonly attribute HTMLFormElement ? form ;
attribute FileList ? files ;
[CEReactions , ReflectSetter ] attribute USVString formAction ;
[CEReactions ] attribute DOMString formEnctype ;
[CEReactions ] attribute DOMString formMethod ;
[CEReactions , Reflect ] attribute boolean formNoValidate ;
[CEReactions , Reflect ] attribute DOMString formTarget ;
[CEReactions , ReflectSetter ] attribute unsigned long height ;
attribute boolean indeterminate ;
readonly attribute HTMLDataListElement ? list ;
[CEReactions , Reflect ] attribute DOMString max ;
[CEReactions , ReflectNonNegative ] attribute long maxLength ;
[CEReactions , Reflect ] attribute DOMString min ;
[CEReactions , ReflectNonNegative ] attribute long minLength ;
[CEReactions , Reflect ] attribute boolean multiple ;
[CEReactions , Reflect ] attribute DOMString name ;
[CEReactions , Reflect ] attribute DOMString pattern ;
[CEReactions , Reflect ] attribute DOMString placeholder ;
[CEReactions , Reflect ] attribute boolean readOnly ;
[CEReactions , Reflect ] attribute boolean required ;
[CEReactions , Reflect ] attribute unsigned long size ;
[CEReactions , ReflectURL ] attribute USVString src ;
[CEReactions , Reflect ] attribute DOMString step ;
[CEReactions ] attribute DOMString type ;
[CEReactions , Reflect="value"] attribute DOMString defaultValue ;
[CEReactions ] attribute [LegacyNullToEmptyString ] DOMString value ;
attribute object ? valueAsDate ;
attribute unrestricted double valueAsNumber ;
[CEReactions , ReflectSetter ] attribute unsigned long width ;
undefined stepUp (optional long n = 1);
undefined stepDown (optional long n = 1);
readonly attribute boolean willValidate ;
readonly attribute ValidityState validity ;
readonly attribute DOMString validationMessage ;
boolean checkValidity ();
boolean reportValidity ();
undefined setCustomValidity (DOMString error );
readonly attribute NodeList ? labels ;
undefined select ();
attribute unsigned long ? selectionStart ;
attribute unsigned long ? selectionEnd ;
attribute DOMString ? selectionDirection ;
undefined setRangeText (DOMString replacement );
undefined setRangeText (DOMString replacement , unsigned long start , unsigned long end , optional SelectionMode selectionMode = "preserve");
undefined setSelectionRange (unsigned long start , unsigned long end , optional DOMString direction );
undefined showPicker ();
// 廃止されたメンバーも持つ
};
HTMLInputElement includes PopoverTargetAttributes ;input 要素は、
通常、ユーザーがデータを編集できるフォームコントロールを伴う、型付きデータフィールドを表します。
type 属性は、
要素のデータ型(および関連付けられたコントロール)を制御します。これは、次のキーワードおよび状態を持つ列挙
属性です。
| キーワード | 状態 | データ型 | コントロール型 |
|---|---|---|---|
hidden
|
任意の文字列 | 該当なし | |
text
|
テキスト | 改行を含まないテキスト | テキストコントロール |
search
|
検索 | 改行を含まないテキスト | 検索コントロール |
tel
|
電話番号 | 改行を含まないテキスト | テキストコントロール |
url
|
URL | 絶対 URL | テキストコントロール |
email
|
メール | メールアドレスまたはメールアドレスの一覧 | テキストコントロール |
password
|
パスワード | 改行を含まないテキスト(機密情報) | データ入力を隠すテキストコントロール |
date
|
日付 | タイムゾーンを含まない日付(年、月、日) | 日付コントロール |
month
|
月 | タイムゾーンを含まず、年と月からなる日付 | 月コントロール |
week
|
週 | タイムゾーンを含まず、週年番号と週番号からなる日付 | 週コントロール |
time
|
時刻 | タイムゾーンを含まない時刻(時、分、秒、秒の小数部) | 時刻コントロール |
datetime-local
|
ローカル日付と時刻 | タイムゾーンを含まない日付と時刻(年、月、日、時、分、秒、秒の小数部) | 日付と時刻のコントロール |
number
|
数値 | 数値 | テキストコントロールまたはスピナーコントロール |
range
|
範囲 | 正確な値が重要ではないという追加の意味を持つ数値 | スライダーコントロールまたは類似のコントロール |
color
|
色 | 8 ビットの赤、緑、青成分を持つ sRGB 色 | カラーピッカー |
checkbox
|
チェックボックス | 定義済みの一覧から選択される 0 個以上の値の集合 | チェックボックス |
radio
|
ラジオ ボタン | 列挙値 | ラジオボタン |
file
|
ファイル アップロード | それぞれが MIME 型と、任意で ファイル名を持つ 0 個以上のファイル | ラベルとボタン |
submit
|
送信ボタン | 最後に選択された値でなければならず、フォーム送信を開始するという追加の意味を持つ列挙値 | ボタン |
image
|
画像 ボタン | 特定の画像サイズに対する相対座標であり、最後に選択された値でなければならず、 フォーム送信を開始するという追加の意味を持つ | クリック可能な画像またはボタン |
reset
|
リセット ボタン | 該当なし | ボタン |
button
|
ボタン | 該当なし | ボタン |
次の
accept、
alpha、
alt、
autocomplete、
checked、
colorspace、
dirname、
formaction、
formenctype、
formmethod、
formnovalidate、
formtarget、
height、
list、
max、
maxlength、
min、
minlength、
multiple、
pattern、
placeholder、
readonly、
required、
size、
src、
step、および
width コンテンツ属性、
checked、
files、
valueAsDate、
valueAsNumber、
および
list IDL 属性、
select()
メソッド、
selectionStart、
selectionEnd、
および
selectionDirection
IDL 属性、
setRangeText()
および
setSelectionRange()
メソッド、
stepUp() および
stepDown() メソッド、
ならびに
input
および
change イベントのうち、
どれが input 要素に
適用されるかは、その
type 属性の状態によって
決まります。各型を定義する小節では、規範的な「記録管理」節で、これらの機能のどれが各型に適用され、
どれが適用されないかも明確に定義しています。これらの機能の動作は、
それぞれの節で定義されているとおり、適用されるかどうかによって決まります(コンテンツ属性、API、イベントを参照)。
次の表は非規範的であり、これらのコンテンツ属性、IDL 属性、メソッド、およびイベントのどれが 各状態に適用されるかをまとめたものです。
| テキスト、 検索 | 電話番号、 URL | メール | パスワード | 日付、 月、 週、 時刻 | ローカル日付と時刻 | 数値 | 範囲 | 色 | チェックボックス、 ラジオボタン | ファイル アップロード | 送信ボタン | 画像ボタン | リセットボタン、 ボタン | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| コンテンツ属性 | |||||||||||||||
accept
|
· | · | · | · | · | · | · | · | · | · | · | はい | · | · | · |
alpha
|
· | · | · | · | · | · | · | · | · | はい | · | · | · | · | · |
alt
|
· | · | · | · | · | · | · | · | · | · | · | · | · | はい | · |
autocomplete
|
はい | はい | はい | はい | はい | はい | はい | はい | はい | はい | · | · | · | · | · |
checked
|
· | · | · | · | · | · | · | · | · | · | はい | · | · | · | · |
colorspace
|
· | · | · | · | · | · | · | · | · | はい | · | · | · | · | · |
dirname
|
はい | はい | はい | はい | はい | · | · | · | · | · | · | · | はい | · | · |
formaction
|
· | · | · | · | · | · | · | · | · | · | · | · | はい | はい | · |
formenctype
|
· | · | · | · | · | · | · | · | · | · | · | · | はい | はい | · |
formmethod
|
· | · | · | · | · | · | · | · | · | · | · | · | はい | はい | · |
formnovalidate
|
· | · | · | · | · | · | · | · | · | · | · | · | はい | はい | · |
formtarget
|
· | · | · | · | · | · | · | · | · | · | · | · | はい | はい | · |
height
|
· | · | · | · | · | · | · | · | · | · | · | · | · | はい | · |
list
|
· | はい | はい | はい | · | はい | はい | はい | はい | はい | · | · | · | · | · |
max
|
· | · | · | · | · | はい | はい | はい | はい | · | · | · | · | · | · |
maxlength
|
· | はい | はい | はい | はい | · | · | · | · | · | · | · | · | · | · |
min
|
· | · | · | · | · | はい | はい | はい | はい | · | · | · | · | · | · |
minlength
|
· | はい | はい | はい | はい | · | · | · | · | · | · | · | · | · | · |
multiple
|
· | · | · | はい | · | · | · | · | · | · | · | はい | · | · | · |
pattern
|
· | はい | はい | はい | はい | · | · | · | · | · | · | · | · | · | · |
placeholder
|
· | はい | はい | はい | はい | · | · | はい | · | · | · | · | · | · | · |
popovertarget
|
· | · | · | · | · | · | · | · | · | · | · | · | はい | はい | はい |
popovertargetaction
|
· | · | · | · | · | · | · | · | · | · | · | · | はい | はい | はい |
readonly
|
· | はい | はい | はい | はい | はい | はい | はい | · | · | · | · | · | · | · |
required
|
· | はい | はい | はい | はい | はい | はい | はい | · | · | はい | はい | · | · | · |
size
|
· | はい | はい | はい | はい | · | · | · | · | · | · | · | · | · | · |
src
|
· | · | · | · | · | · | · | · | · | · | · | · | · | はい | · |
step
|
· | · | · | · | · | はい | はい | はい | はい | · | · | · | · | · | · |
width
|
· | · | · | · | · | · | · | · | · | · | · | · | · | はい | · |
| IDL 属性およびメソッド | |||||||||||||||
checked
|
· | · | · | · | · | · | · | · | · | · | はい | · | · | · | · |
files
|
· | · | · | · | · | · | · | · | · | · | · | はい | · | · | · |
value
|
既定 | 値 | 値 | 値 | 値 | 値 | 値 | 値 | 値 | 値 | 既定/on | ファイル名 | 既定 | 既定 | 既定 |
valueAsDate
|
· | · | · | · | · | はい | · | · | · | · | · | · | · | · | · |
valueAsNumber
|
· | · | · | · | · | はい | はい | はい | はい | · | · | · | · | · | · |
list
|
· | はい | はい | はい | · | はい | はい | はい | はい | はい | · | · | · | · | · |
select()
|
· | はい | はい | はい† | はい | はい† | はい† | はい† | · | はい† | · | はい† | · | · | · |
selectionStart
|
· | はい | はい | · | はい | · | · | · | · | · | · | · | · | · | · |
selectionEnd
|
· | はい | はい | · | はい | · | · | · | · | · | · | · | · | · | · |
selectionDirection
|
· | はい | はい | · | はい | · | · | · | · | · | · | · | · | · | · |
setRangeText()
|
· | はい | はい | · | はい | · | · | · | · | · | · | · | · | · | · |
setSelectionRange()
|
· | はい | はい | · | はい | · | · | · | · | · | · | · | · | · | · |
stepDown()
|
· | · | · | · | · | はい | はい | はい | はい | · | · | · | · | · | · |
stepUp()
|
· | · | · | · | · | はい | はい | はい | はい | · | · | · | · | · | · |
| イベント | |||||||||||||||
input
イベント
|
· | はい | はい | はい | はい | はい | はい | はい | はい | はい | はい | はい | · | · | · |
change イベント
|
· | はい | はい | はい | はい | はい | はい | はい | はい | はい | はい | はい | · | · | · |
† コントロールに選択可能なテキストがない場合、select()
メソッドは何も行わず、
"InvalidStateError" DOMExceptionも発生しない。
type
属性の一部の状態では、値の
サニタイズアルゴリズムが定義される。
各input要素には
値があり、これは
value IDL
属性によって公開される。一部の状態では、
文字列を数値に変換するアルゴリズム、
数値を文字列に
変換するアルゴリズム、文字列を
Dateオブジェクトに変換するアルゴリズム、および
Dateオブジェクトを文字列に変換するアルゴリズムが定義され、これらはmax、min、step、valueAsDate、
valueAsNumber、
およびstepUp()によって使用される。
input要素のダーティー値フラグは、ユーザーが
値を変更するような方法でコントロールを操作するたびに、
trueに設定されなければならない。(また、value
IDL
属性の定義で説明されるように、値がプログラムによって変更された場合にもtrueに設定される。)
valueコンテンツ
属性は、input
要素の既定の値を与える。
value
コンテンツ属性が追加、設定、または削除されたとき、コントロールのダーティー値フラグ
がfalseである場合、ユーザーエージェントは、value
コンテンツ属性が存在するならその値に、そうでなければ空文字列に、要素の値を設定し、その後、定義されている場合は、現在の値のサニタイズ
アルゴリズムを実行しなければならない。
各input要素には
チェック状態があり、
これはchecked IDL属性によって公開される。
各input要素には、
ブール値のダーティーチェック状態フラグがある。これがtrueの場合、
要素はダーティーチェック状態を持つという。
ダーティー
チェック状態フラグは、要素が作成されたときに最初は
falseに設定されなければならず、ユーザーがチェック状態を変更するような方法で
コントロールを操作するたびにtrueに設定されなければならない。
現在のすべてのエンジンでサポートされている。
checked
コンテンツ属性は、input要素の
既定のチェック状態を与える
ブール属性である。
checked
コンテンツ属性が追加されたとき、
コントロールがダーティーチェック状態を持たない場合、ユーザー
エージェントは要素のチェック状態を
trueに設定しなければならない。
checked
コンテンツ属性が削除されたとき、
コントロールがダーティーチェック状態を持たない場合、ユーザー
エージェントは要素のチェック状態を
falseに設定しなければならない。
input
要素のリセットアルゴリズムは、
そのユーザー妥当性、
ダーティー値フラグ、および
ダーティー
チェック状態フラグ
をfalseに戻し、value
コンテンツ属性が存在するならその値に、そうでなければ空文字列に、要素の値を設定し、要素がcheckedコンテンツ
属性を持つ場合は要素のチェック状態をtrueに設定し、持たない場合はfalseに設定し、
選択されたファイルのリストを空にし、その後、
type属性の
現在の状態で定義されている場合は、値の
サニタイズアルゴリズムを呼び出すことである。
各input要素は
変更可能になり得る。別段の
指定がない限り、input要素は常に変更可能である。同様に、別段の
指定がない限り、ユーザーエージェントは、ユーザーが要素の値またはチェック状態を変更できるようにすべきではない。
readonly属性も、
場合によっては(例えば、日付状態ではそうだが、チェックボックス状態ではそうではない)input要素が
変更可能になることを妨げることができる。
input要素は
ピッカーをサポートできる。
ピッカーとは、エンドユーザーが値を選択できるユーザーインターフェイス要素である。
input要素がピッカーを
サポートするかどうかは、type
属性の状態および実装定義の
振る舞いに依存する。input要素は、
そのtype属性がファイル
アップロード状態である場合、ピッカーをサポートしなければならない。
本書執筆時点では、一般的なブラウザー実装は、次の場合にこのようなピッカーUIを表示する。
node、copy、およびsubtreeが与えられたときの、input要素の複製手順は、nodeから
copyへ、値、ダーティー値フラグ、
チェック状態、ダーティー
チェック状態フラグ、および不確定状態を伝播することである。
要素の活性化の振る舞いは、ユーザーによって開始された活性化と、
合成された活性化(例えば、el.click()によるもの)の両方で実行されることを思い出されたい。
ユーザーエージェントは、所定のコントロールについて、ここでは規定されていない、真にユーザーによって開始された
活性化によってのみ引き起こされる振る舞いも持つことがある。一般的な選択は、コントロールについて
該当する場合は
ピッカーを表示することである。対照的に、input
活性化の振る舞いがピッカーを表示するのは、歴史的に特別な事例であるファイルアップロード状態と
色状態だけである。
input要素の旧来の事前活性化の振る舞いは、次の手順である。
この要素のtype
属性がチェックボックス状態である場合、この要素のチェック状態をその反対の値
(すなわち、falseであればtrueに、trueであれば
falseに)設定し、この要素の不確定状態をfalseに設定する。
この要素のtype
属性がラジオボタン状態である場合、この要素の
ラジオボタングループ内で、
チェック状態がtrueに
設定されている要素があれば、その要素への参照を取得し、その後、この要素の
チェック状態をtrueに設定する。
input要素の旧来の取り消された活性化の振る舞いは、次の手順である。
要素のtype
属性がチェックボックス状態である場合、要素のチェック状態および要素の不確定状態を、旧来の事前活性化の振る舞いが実行される前の値に戻す。
この要素のtype
属性がラジオボタン状態である場合、旧来の事前活性化の振る舞いで参照を取得した要素があるなら、
その要素が現在もこの要素のラジオ
ボタングループにあり、この要素が依然としてそのグループを持っている場合、その要素の
チェック状態を
trueに設定する。そうでなければ、そのような要素がなかった場合、その要素がこの要素のラジオボタン
グループに存在しなくなった場合、またはこの要素がラジオボタングループを持たなくなった場合、この
要素のチェック状態をfalseに設定する。
input要素が
最初に作成されたとき、要素のレンダリングと振る舞いは、type
属性の状態に対して定義されたレンダリングと振る舞いに設定されなければならず、type属性の状態に対して
値のサニタイズアルゴリズムが定義されている場合、
そのアルゴリズムを呼び出さなければならない。
input
要素のtype属性の
状態が変更されたとき、ユーザーエージェントは次の手順を実行しなければならない。
要素のtype属性の以前の状態が
value IDL
属性をvalueモードにし、要素の値が空文字列ではなく、かつ要素の
type属性の新しい状態が
value IDL属性を
defaultモードまたはdefault/onモードのいずれかにする場合、要素のvalueコンテンツ属性を、
要素の値に設定する。
そうでなく、要素のtype属性の以前の状態が
value
IDL属性をvalueモード以外のモードにし、要素のtype属性の新しい状態が
value IDL属性を
valueモードにする場合、valueコンテンツ属性が
存在するならその値に、そうでなければ空文字列に、要素の値を設定し、その後、コントロールのダーティー値フラグをfalseに設定する。
そうでなく、要素のtype属性の以前の状態が
value IDL属性を
filenameモード以外のモードにし、要素のtype属性の新しい状態が
value IDL属性を
filenameモードにする場合、要素の値を空文字列に設定する。
要素のレンダリングと振る舞いを、新しい状態のものに更新する。
要素について型の変更を通知する。(特に、ラジオ ボタン状態がこれを使用する。)
type
属性の新しい状態について値のサニタイズアルゴリズムが定義されている場合、
それを呼び出す。
以前にsetRangeText()が
要素に適用されていた場合は
previouslySelectableをtrueとし、そうでなければfalseとする。
現在、setRangeText()が
要素に適用される場合は
nowSelectableをtrueとし、そうでなければfalseとする。
previouslySelectableがfalseで、nowSelectableがtrueである場合、
要素のテキスト
入力カーソル位置を
テキストコントロールの先頭に設定し、選択方向を
設定して"none"にする。
name属性は、
要素の名前を表す。
dirname属性は、
要素の方向性が
どのように送信されるかを制御する。
disabled属性は、
コントロールを非対話的にし、その値が送信されることを防ぐために使用される。
form属性は、input要素をそのフォーム所有者に明示的に関連付けるために使用される。
autocomplete
属性は、ユーザーエージェントが自動入力の振る舞いをどのように提供するかを制御する。
各input要素には、
最初はfalseであるブール値の不確定状態がある。
これは、レンダリングおよびアクセシビリティのセマンティクスを含め、チェックボックスコントロールにのみ影響する。
input要素の
不確定状態は、そのチェック状態から独立している。
HTMLInputElement#indeterminate
現在のすべてのエンジンでサポートされている。
indeterminate
セッターの手順は、
thisの不確定状態を、
与えられた値に設定することである。
colorSpace IDL属性は、colorspace
コンテンツ属性を、既知の値のみに
制限して反映しなければならない。type IDL属性は、同じ名前を持つ対応する
コンテンツ属性を、既知の値のみに制限して反映しなければならない。
IDL属性widthおよびheightは、画像がレンダリングされている場合、画像のレンダリングされた
幅および高さを、CSS
ピクセル単位で返さなければならない。そうでなく、画像が利用可能であるがレンダリングされていない場合、画像の自然な幅および高さを、
CSS
ピクセル単位で返さなければならない。そうでなく、画像が利用可能でない場合は、
0を返さなければならない。input
要素のtype属性が
画像ボタン状態でない場合、画像は利用可能ではない。[CSS]
willValidate、
validity、およびvalidationMessage
IDL属性、ならびにcheckValidity()、reportValidity()、および
setCustomValidity()
メソッドは、
制約検証
APIの一部である。labels IDL
属性は、要素のlabel要素のリストを提供する。select()、
selectionStart、
selectionEnd、
selectionDirection、
setRangeText()、
およびsetSelectionRange()
メソッドおよびIDL属性は、
要素のテキスト選択を公開する。disabled、
form、およびname IDL属性は、
要素のフォームAPIの一部である。
type属性の状態type=hidden)現在のすべてのエンジンでサポートされている。
要素の属性が 状態である場合、この節の規則が適用される。
要素は、 ユーザーが調査または操作することを意図していない値を 。
制約検証:要素の 属性が 状態である場合、その要素はである。
属性が 存在し、その値が""と 一致する場合、要素の 属性は省略されなければならない。
および コンテンツ属性は、この要素に。
IDL属性はこの要素に、 モードである。
次のコンテンツ属性を指定してはならず、要素には: 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、および 。
次のIDL属性およびメソッドは要素に: 、 、 、 、 、 、 、 および IDL属性; 、 、 、 、および メソッド。
およびイベントは。
type=text)状態および検索状態(type=search)現在のすべてのエンジンでサポートされている。
現在のすべてのエンジンでサポートされている。
input
要素のtype
属性が
テキスト
状態または検索
状態である場合、この節の規則が適用される。
input
要素は、要素の値のための
1行のプレーンテキスト編集コントロールを表す。
テキスト 状態と 検索 状態の違いは主として外観上のものである。検索コントロールが通常のテキストコントロールと区別される プラットフォームでは、検索 状態は、通常のテキストコントロールのように表示されるのではなく、 プラットフォームの検索コントロールと一貫した外観になることがある。
要素が変更可能である場合、その値は ユーザーが編集できるべきである。ユーザーエージェントは、ユーザーが要素の 値に U+000A LINE FEED(LF)またはU+000D CARRIAGE RETURN(CR)文字を挿入できるようにしてはならない。
要素が変更可能である場合、 ユーザーエージェントは、要素の書字方向を左から右または右から左のいずれかに設定して、 ユーザーが変更できるようにすべきである。ユーザーがこれを行った場合、ユーザーエージェントは 次の手順を実行しなければならない。
ユーザーが左から右の書字方向を選択した場合は、要素のdir
属性を"ltr"に設定し、
ユーザーが右から左の書字方向を選択した場合は
"rtl"に
設定する。
要素を与えて、ユーザー操作
タスクソースに、要素でinput
という名前のイベントを発火する要素タスクをキューに入れる。
このとき、bubbles
およびcomposed
属性をtrueに初期化する。
value
属性が指定される場合、その値にはU+000A LINE FEED(LF)またはU+000D CARRIAGE RETURN(CR)文字を
含めてはならない。
値のサニタイズ アルゴリズムは次のとおりである:改行文字を 除去する処理を値に適用する。
次の共通のinput
要素のコンテンツ属性、IDL属性、およびメソッドは、要素に適用される:
autocomplete、
dirname、
list、
maxlength、
minlength、
pattern、
placeholder、
readonly、
required、
および
size
コンテンツ属性;
list、
selectionStart、
selectionEnd、
selectionDirection、
および
value
IDL属性;
select()、
setRangeText()、
および
setSelectionRange()
メソッド。
次のコンテンツ属性を指定してはならず、要素には適用
されない:
accept、
alpha、
alt、
checked、
colorspace、
formaction、
formenctype、
formmethod、
formnovalidate、
formtarget、
height、
max、
min、
multiple、
popovertarget、
popovertargetaction、
src、
step、
および
width。
次のIDL属性およびメソッドは要素に適用されない:
checked、
files、
valueAsDate、
および
valueAsNumber
IDL属性;
stepDown()
および
stepUp()
メソッド。
type=tel)現在のすべてのエンジンでサポートされている。
input
要素のtype属性が
電話番号
状態である場合、この節の規則が適用される。
input要素は、
要素の値として与えられた
電話番号を編集するためのコントロールを表す。
要素が変更可能である場合、 その値はユーザーが 編集できるべきである。ユーザーエージェントは、ユーザーが入力した値の空白、および注意を払った上で句読点を 変更してもよい。ユーザーエージェントは、ユーザーが要素の値にU+000A LINE FEED(LF)またはU+000D CARRIAGE RETURN(CR)文字を挿入できるようにしてはならない。
value属性が
指定される場合、その値にはU+000A LINE FEED(LF)またはU+000D CARRIAGE RETURN(CR)文字を
含めてはならない。
値のサニタイズアルゴリズムは次のとおりで ある:改行文字を 除去する処理を値に適用する。
URLおよびメールアドレス型とは異なり、電話番号型は、
特定の構文を強制しない。これは意図的なものである。実際には、有効な電話番号には非常に多くの種類が
あるため、電話番号フィールドは自由形式のフィールドとなる傾向がある。特定の形式を強制する必要が
あるシステムでは、pattern属性または
setCustomValidity()
メソッドを使用してクライアント側検証機構に接続することが推奨される。
次の共通のinput要素の
コンテンツ属性、IDL属性、およびメソッドは、要素に適用される:
autocomplete、
dirname、
list、
maxlength、
minlength、
pattern、
placeholder、
readonly、
required、および
sizeコンテンツ
属性;
list、
selectionStart、
selectionEnd、
selectionDirection、
および
value IDL属性;
select()、
setRangeText()、
および
setSelectionRange()
メソッド。
次のコンテンツ属性を指定してはならず、要素には適用
されない:
accept、
alpha、
alt、
checked、
colorspace、
formaction、
formenctype、
formmethod、
formnovalidate、
formtarget、
height、
max、
min、
multiple、
popovertarget、
popovertargetaction、
src、
step、および
width。
次のIDL属性およびメソッドは要素に適用されない:
checked、
files、
valueAsDate、
および
valueAsNumber
IDL属性;
stepDown()および
stepUp()メソッド。
type=url)現在のすべてのエンジンでサポートされている。
input要素の
type属性が
URL状態である場合、
この節の規則が適用される。
input要素は、
要素の値として与えられた単一の
絶対URLを編集するためのコントロールを表す。
要素が変更可能である場合、 ユーザーエージェントは、その値によって表されるURLをユーザーが変更できるように すべきである。ユーザーエージェントは、ユーザーが値を 妥当な絶対URLではない文字列に 設定できるようにしてもよいが、代わりに、またはそれに加えて、ユーザーが入力した文字を自動的に エスケープし、値が常に妥当な 絶対URLになるようにしてもよい(インターフェイス上でユーザーが実際に 見て編集する値がそれとは異なる場合でも)。ユーザーエージェントは、ユーザーが値を空文字列に設定できるようにすべきである。 ユーザーエージェントは、ユーザーが値にU+000A LINE FEED(LF)またはU+000D CARRIAGE RETURN(CR)文字を挿入できるようにしてはならない。
value属性が
指定され、かつ空でない場合、その値は
周囲に空白を含み得る妥当なURLであり、
さらに絶対URLでなければならない。
値の サニタイズアルゴリズムは次のとおりである:改行文字を 除去する処理を値に適用し、次に 先頭および末尾の ASCII空白を除去する処理を値に適用する。
制約検証:要素の値が 空文字列でも妥当な 絶対URLでもない間、その要素は型不一致の状態にある。
次の共通のinput要素のコンテンツ
属性、IDL属性、およびメソッドは、要素に適用される:
autocomplete、
dirname、
list、
maxlength、
minlength、
pattern、
placeholder、
readonly、
required、および
sizeコンテンツ属性;
list、
selectionStart、
selectionEnd、
selectionDirection、
および
value IDL属性;
select()、
setRangeText()、
および
setSelectionRange()
メソッド。
次のコンテンツ属性を指定してはならず、要素には適用
されない:
accept、
alpha、
alt、
checked、
colorspace、
formaction、
formenctype、
formmethod、
formnovalidate、
formtarget、
height、
max、
min、
multiple、
popovertarget、
popovertargetaction、
src、
step、および
width。
次のIDL属性およびメソッドは要素に適用
されない:
checked、
files、
valueAsDate、および
valueAsNumber
IDL属性;
stepDown()および
stepUp()メソッド。
文書に次のマークアップが含まれていたとする。
< input type = "url" name = "location" list = "urls" >
< datalist id = "urls" >
< option label = "MIME: Format of Internet Message Bodies" value = "https://www.rfc-editor.org/rfc/rfc2045" >
< option label = "HTML" value = "https://html.spec.whatwg.org/" >
< option label = "DOM" value = "https://dom.spec.whatwg.org/" >
< option label = "Fullscreen" value = "https://fullscreen.spec.whatwg.org/" >
< option label = "Media Session" value = "https://mediasession.spec.whatwg.org/" >
< option label = "The Single UNIX Specification, Version 3" value = "http://www.unix.org/version3/" >
</ datalist > ……そして、ユーザーが"spec.w"と入力し、ユーザーエージェントが、ユーザーが最近
https://url.spec.whatwg.org/#url-parsingおよび
https://streams.spec.whatwg.org/を訪問したことも検出した場合、レンダリングは
次のようになることがある。

この例の最初の4つのURLは、著者が指定したリスト内でユーザーが入力したテキストと一致する4つのURLを、 何らかの実装定義の方法 (おそらくユーザーがそれらのURLを参照する頻度など)で並べ替えたものである。UAが、値がURLであるという 知識を使用して、ユーザーがスキーム部分を省略し、ドメイン名に対して高度な照合を行えるようにしている点に 注目されたい。
最後の2つのURL(スクロールバーがさらに値を利用できることを示しているため、おそらくさらに多くのURL)は、 ユーザーエージェントのセッション履歴データから得られた一致である。このデータはページのDOMには 公開されない。この特定の場合、UAにはこれらの値に対して提供するタイトルがない。
type=email)現在のすべてのエンジンでサポートされている。
input
要素のtype属性が
メールアドレス状態である場合、
この節の規則が適用される。
メールアドレス
状態がどのように動作するかは、
multiple属性が
指定されているかどうかによって異なる。
multiple属性が
要素に指定されていない場合input
要素は、要素の値として与えられたメールアドレスを編集するための
コントロールを表す。
要素が変更可能である場合、 ユーザーエージェントは、その値によって表されるメールアドレスをユーザーが 変更できるようにすべきである。ユーザーエージェントは、ユーザーが値を 妥当なメール アドレスではない文字列に設定できるようにしてもよい。ユーザーエージェントは、ユーザーが 単一のメールアドレスを提供すると予期するのと一貫した方法で動作すべきである。ユーザーエージェントは、 ユーザーが値を空文字列に設定できるようにすべきである。 ユーザーエージェントは、ユーザーが値にU+000A LINE FEED(LF)またはU+000D CARRIAGE RETURN(CR)文字を挿入できるようにしてはならない。ユーザーエージェントは、表示および 編集のために値を変換してもよい。特に、ユーザーエージェントは、 表示時に値のドメインラベル内のPunycodeをIDNに変換し、 その逆も行うべきである。
制約検証:ユーザーインターフェイスが、ユーザーエージェントがPunycodeに 変換できない入力を表している間、コントロールは不正な入力が 生じている。
value
属性が指定され、かつ空でない場合、その値は単一の妥当なメールアドレスでなければならない。
値のサニタイズアルゴリズムは次のとおりで ある:改行文字を 除去する処理を値に適用し、次に先頭および末尾の ASCII空白を除去する処理を値に適用する。
制約検証:要素の値が 空文字列でも単一の妥当なメールアドレスでもない間、 要素は型の不一致が生じている。
multiple属性が
要素に指定されている場合
input
要素は、要素の複数の値として与えられたメールアドレスを追加、
削除、および編集するためのコントロールを表す。
要素が変更可能である場合、 ユーザーエージェントは、その複数の値によって表されるメールアドレスをユーザーが 追加、削除、および編集できるようにすべきである。ユーザーエージェントは、複数の値のリスト内の各値を、 妥当な メールアドレスではない文字列に設定できるようにしてもよいが、個々の値をU+002C COMMA(,)、 U+000A LINE FEED(LF)、またはU+000D CARRIAGE RETURN(CR)文字を含む文字列に設定できるように してはならない。ユーザーエージェントは、ユーザーが要素の複数の値内のすべてのアドレスを削除できるように すべきである。ユーザーエージェントは、表示および編集のために複数の値を変換してもよい。特に、 ユーザーエージェントは、表示時に値のドメインラベル内のPunycodeをIDNに変換し、 その逆も行うべきである。
制約検証:ユーザーインターフェイスが、個々の値にU+002C COMMA(,)が含まれる状況、 またはユーザーエージェントがPunycodeに変換できない入力を表している間、コントロールは不正な入力が生じている。
ユーザーが要素の複数の値を変更するたびに、ユーザーエージェントは 次の手順を実行しなければならない。
latest valuesを、要素の複数の値のコピーとする。
latest values内の各値から先頭および末尾のASCII空白を 除去する。
リストの順序を維持しながら、latest values内のすべての値を、それぞれの値の間を 単一のU+002C COMMA文字(,)で区切って連結した結果を、要素の値に設定する。
value
属性が指定される場合、その値は妥当な
メールアドレスリストでなければならない。
値のサニタイズアルゴリズムは 次のとおりである:
制約検証:要素の値が 妥当なメールアドレスリストでない間、 要素は型の不一致が 生じている。
multiple属性が
設定または削除されたとき、ユーザーエージェントは値のサニタイズアルゴリズムを
実行しなければならない。
妥当なメールアドレスとは、次のABNFのemail
生成規則に一致する文字列であり、その文字集合はUnicodeである。
このABNFはRFC 1123で説明される拡張を実装する。[ABNF] [RFC5322]
[RFC1034] [RFC1123]
email = 1* ( atext / "." ) "@" label * ( "." label )
label = let-dig [ [ ldh-str ] let-dig ] ; limited to a length of 63 characters by RFC 1034 section 3.5
atext = < as defined in RFC 5322 section 3 .2 .3 >
let-dig = < as defined in RFC 1034 section 3 .5 >
ldh-str = < as defined in RFC 1034 section 3 .5 >この要件はRFC 5322に対する意図的な違反である。 RFC 5322が定義するメールアドレスの構文は、ここで実用的に使用するには、同時に厳格すぎ("@"文字の前)、 曖昧すぎ("@"文字の後)、かつ寛容すぎる(ほとんどのユーザーに馴染みのない方法でコメント、空白文字、 および引用符で囲まれた文字列を許可する)。
次のJavaScriptおよびPerl互換の正規表現は、上記の定義を実装したものである。
/^[a-zA-Z0-9.!#$%&'*+\/=?^_`{|}~-]+@[a-zA-Z0-9](?:[a-zA-Z0-9-]{0,61}[a-zA-Z0-9])?(?:\.[a-zA-Z0-9](?:[a-zA-Z0-9-]{0,61}[a-zA-Z0-9])?)*$/
妥当なメールアドレスリストとは、各トークン自体が 妥当なメールアドレスである コンマ区切りトークンの集合である。 妥当なメールアドレスリストから トークンのリストを取得するため、実装は文字列を コンマで分割しなければならない。
次の共通のinput要素のコンテンツ
属性、IDL属性、およびメソッドは、要素に適用される:
autocomplete、
dirname、
list、
maxlength、
minlength、
multiple、
pattern、
placeholder、
readonly、
required、および
sizeコンテンツ属性;
listおよび
value IDL属性;
select()
メソッド。
次のコンテンツ属性を指定してはならず、要素には適用
されない:
accept、
alpha、
alt、
checked、
colorspace、
formaction、
formenctype、
formmethod、
formnovalidate、
formtarget、
height、
max、
min、
popovertarget、
popovertargetaction、
src、
step、および
width。
次のIDL属性およびメソッドは要素に適用されない:
checked、
files、
selectionStart、
selectionEnd、
selectionDirection、
valueAsDate、
および
valueAsNumber
IDL属性;
setRangeText()、
setSelectionRange()、
stepDown()および
stepUp()メソッド。
type=password)現在のすべてのエンジンでサポートされている。
input
要素のtype
属性が
パスワード状態である場合、
この節の規則が適用される。
input
要素は、要素の値のための1行のプレーンテキスト編集コントロールを
表す。ユーザーエージェントは、
ユーザー以外の人が値を見られないように、その値を隠すべきである。
要素が変更可能である場合、 その値はユーザーが 編集できるべきである。ユーザーエージェントは、ユーザーが値にU+000A LINE FEED(LF)または U+000D CARRIAGE RETURN(CR)文字を挿入できるようにしてはならない。
value
属性が指定される場合、その値にはU+000A LINE FEED(LF)またはU+000D CARRIAGE RETURN(CR)文字を
含めてはならない。
値のサニタイズアルゴリズムは次のとおりで ある:改行文字を 除去する処理を値に適用する。
次の共通のinput要素の
コンテンツ属性、IDL属性、およびメソッドは、要素に適用される:
autocomplete、
dirname、
maxlength、
minlength、
pattern、
placeholder、
readonly、
required、
および
sizeコンテンツ
属性;
selectionStart、
selectionEnd、
selectionDirection、
および
value IDL
属性;
select()、
setRangeText()、
および
setSelectionRange()
メソッド。
次のコンテンツ属性を指定してはならず、要素には適用
されない:
accept、
alpha、
alt、
checked、
colorspace、
formaction、
formenctype、
formmethod、
formnovalidate、
formtarget、
height、
list、
max、
min、
multiple、
popovertarget、
popovertargetaction、
src、
step、および
width。
次のIDL属性およびメソッドは要素に適用されない:
checked、
files、
list、
valueAsDate、
および
valueAsNumber
IDL属性;
stepDown()
および
stepUp()
メソッド。
type=date)現在のすべてのエンジンでサポートされている。
input要素の
type属性が
日付状態である場合、
この節の規則が適用される。
input要素は、
要素の値を、特定の
日付を表す文字列に設定するための
コントロールを表す。
要素が変更可能である場合、 ユーザーエージェントは、その値から日付を 構文解析して得られる、値によって表される日付をユーザーが変更できるようにすべきである。 ユーザーエージェントは、ユーザーが値を妥当な日付 文字列ではない空でない文字列に設定できるようにしてはならない。ユーザーエージェントが 日付を選択するための ユーザーインターフェイスを提供する場合、値は、ユーザーの選択を表す 妥当な日付文字列に 設定されなければならない。ユーザーエージェントは、ユーザーが値を空文字列に設定できるようにすべきである。
制約検証:ユーザーインターフェイスが、ユーザーエージェントが妥当な日付 文字列に変換できない入力を表している間、コントロールは不正な入力が 生じている。
日付、時刻、および数値フォームコントロールの入力形式と送信形式の違いについては 導入節を、フォームコントロールのローカライズについては 実装上の注記を参照されたい。
value属性が
指定され、かつ空でない場合、その値は妥当な日付文字列でなければならない。
値のサニタイズアルゴリズムは 次のとおりである:要素の値が妥当な日付 文字列でない場合、代わりに空文字列に設定する。
min属性が
指定される場合、その値は妥当な日付文字列でなければならない。max属性が
指定される場合、その値は妥当な日付文字列でなければならない。
step属性は
日数で表される。ステップ尺度係数は86,400,000
(他のアルゴリズムで使用されるように、日数をミリ秒に変換する)である。既定のステップは
1日である。
要素にステップの不一致が生じている場合、 ユーザーエージェントは、要素にステップの不一致が生じない最も近い 日付に、要素の値を丸めてもよい。
文字列inputが与えられたときの、文字列を数値に変換する
アルゴリズムは次のとおりである:inputから日付を構文解析した結果がエラーとなる場合、
エラーを返す。そうでなければ、1970-01-01の朝のUTC午前0時(値
"1970-01-01T00:00:00.0Z"によって表される時刻)から、構文解析された日付の朝のUTC午前0時までに
経過したミリ秒数を、うるう秒を無視して返す。
数値inputが与えられたときの、数値を文字列に変換する
アルゴリズムは次のとおりである:UTCにおいて、1970-01-01の朝のUTC午前0時
(値"1970-01-01T00:00:00.0Z"によって表される時刻)からinputミリ秒後に
現在となる日付を表す
妥当な日付文字列を返す。
文字列inputが与えられたときの、文字列を
Dateオブジェクトに変換するアルゴリズムは次のとおりである:
inputから日付を構文解析した結果がエラーとなる場合、
エラーを返す。そうでなければ、構文解析された日付の朝のUTC午前0時を表す新しい
Dateオブジェクトを返す。
Date
オブジェクトinputが与えられたときの、
Dateオブジェクトを文字列に変換するアルゴリズムは
次のとおりである:UTCタイムゾーンにおいてinputによって表される時刻に現在となる
日付を表す妥当な
日付文字列を返す。
日付状態 (および後続の節で説明する他の日付および時刻関連の状態)は、現代の暦との関係で正確な日付と時刻を 確定できない値を入力することを意図していない。例えば、「ビッグバンの1ミリ秒後」、 「ジュラ紀の初期」、または「紀元前250年頃の冬」のような時刻を入力するために使用するのは不適切である。
グレゴリオ暦の導入以前の日付を入力する場合、ユーザーエージェントには以前の時代の日付と時刻を
グレゴリオ暦に変換することが要求されておらず、ユーザーに手動で変換させることは不当な負担となるため、
著者は日付状態(および後続の節で説明する他の
日付および時刻関連の状態)を使用しないことが推奨される。(これは、グレゴリオ暦が国ごとに異なる時期に、
16世紀途中から20世紀初頭まで段階的に導入された方法によって複雑になっている。)
代わりに、著者はselect要素および
数値状態の
input要素を
使用して、きめ細かな入力コントロールを提供することが推奨される。
次の共通のinput要素のコンテンツ
属性、IDL属性、およびメソッドは、要素に適用される:
autocomplete、
list、
max、
min、
readonly、
required、および
stepコンテンツ属性;
list、
value、
valueAsDate、
および
valueAsNumber
IDL属性;
select()、
stepDown()、および
stepUp()メソッド。
次のコンテンツ属性を指定してはならず、要素には適用
されない:
accept、
alpha、
alt、
checked、
colorspace、
dirname、
formaction、
formenctype、
formmethod、
formnovalidate、
formtarget、
height、
maxlength、
minlength、
multiple、
pattern、
placeholder、
popovertarget、
popovertargetaction、
size、
src、および
width。
次のIDL属性およびメソッドは要素に適用されない:
checked、
selectionStart、
selectionEnd、
および
selectionDirection
IDL属性;
setRangeText()、
および
setSelectionRange()
メソッド。
type=month)現在のすべてのエンジンでサポートされている。
input
要素のtype属性が
月状態である場合、
この節の規則が適用される。
input要素は、
要素の値を、特定の
月を表す文字列に設定するための
コントロールを表す。
要素が変更可能である場合、 ユーザーエージェントは、その値から月を 構文解析して得られる、値によって表される月をユーザーが変更できるようにすべきである。 ユーザーエージェントは、ユーザーが値を妥当な月 文字列ではない空でない文字列に設定できるようにしてはならない。ユーザーエージェントが 月を選択するための ユーザーインターフェイスを提供する場合、値は、 ユーザーの選択を表す妥当な月文字列に設定されなければならない。 ユーザーエージェントは、ユーザーが値を空文字列に設定できるようにすべきである。
制約検証:ユーザーインターフェイスが、ユーザーエージェントが妥当な 月文字列に変換できない入力を表している間、コントロールは不正な入力が 生じている。
日付、時刻、および数値フォームコントロールの入力形式と送信形式の違いについては 導入節を、フォームコントロールのローカライズについては 実装上の注記を参照されたい。
value属性が
指定され、かつ空でない場合、その値は妥当な月文字列でなければならない。
値のサニタイズアルゴリズムは 次のとおりである:要素の値が妥当な 月文字列でない場合、代わりに空文字列に設定する。
min属性が
指定される場合、その値は妥当な月文字列でなければならない。max属性が
指定される場合、その値は妥当な月文字列でなければならない。
step属性は
月数で表される。ステップ尺度係数は1である
(アルゴリズムでは月数を使用するため、変換は不要である)。既定のステップは1か月である。
要素にステップの不一致が生じている場合、 ユーザーエージェントは、要素にステップの不一致が生じない最も近い 月に、要素の値を丸めてもよい。
文字列inputが与えられたときの、文字列を数値に変換する アルゴリズムは次のとおりである:inputから月を構文解析した結果がエラーとなる場合、 エラーを返す。そうでなければ、1970年1月と構文解析された月との間の月数を返す。
数値inputが与えられたときの、数値を文字列に変換する アルゴリズムは次のとおりである:1970年1月との間にinputか月ある 月を表す 妥当な月文字列を返す。
文字列inputが与えられたときの、文字列を
Dateオブジェクトに変換するアルゴリズムは次のとおりである:
inputから月を構文解析した結果がエラーとなる場合、
エラーを返す。そうでなければ、構文解析された月の初日の朝のUTC午前0時を表す新しい
Dateオブジェクトを返す。
Date
オブジェクトinputが与えられたときの、
Dateオブジェクトを文字列に変換するアルゴリズムは
次のとおりである:UTCタイムゾーンにおいてinputによって表される時刻に現在となる
月を表す妥当な月文字列を返す。
次の共通のinput要素のコンテンツ
属性、IDL属性、およびメソッドは、要素に適用される:
autocomplete、
list、
max、
min、
readonly、
required、および
stepコンテンツ
属性;
list、
value、
valueAsDate、
および
valueAsNumber
IDL属性;
select()、
stepDown()、および
stepUp()メソッド。
次のコンテンツ属性を指定してはならず、要素には適用
されない:
accept、
alpha、
alt、
checked、
colorspace、
dirname、
formaction、
formenctype、
formmethod、
formnovalidate、
formtarget、
height、
maxlength、
minlength、
multiple、
pattern、
placeholder、
popovertarget、
popovertargetaction、
size、
src、および
width。
次のIDL属性およびメソッドは要素に適用されない:
checked、
files、
selectionStart、
selectionEnd、
および
selectionDirection
IDL属性;
setRangeText()、
および
setSelectionRange()
メソッド。
type=week)input要素の
type属性が
週状態である場合、
この節の規則が適用される。
input要素は、
要素の値を、特定の
週を表す文字列に設定するための
コントロールを表す。
要素が変更可能である場合、 ユーザーエージェントは、その値から週を 構文解析して得られる、値によって表される週をユーザーが変更できるようにすべきである。 ユーザーエージェントは、ユーザーが値を妥当な週 文字列ではない空でない文字列に設定できるようにしてはならない。ユーザーエージェントが 週を選択するための ユーザーインターフェイスを提供する場合、値は、ユーザーの選択を表す 妥当な週文字列に 設定されなければならない。ユーザーエージェントは、ユーザーが値を空文字列に設定できるようにすべきである。
制約検証:ユーザーインターフェイスが、ユーザーエージェントが妥当な週 文字列に変換できない入力を表している間、コントロールは不正な入力が 生じている。
日付、時刻、および数値フォームコントロールの入力形式と送信形式の違いについては 導入節を、フォームコントロールのローカライズについては 実装上の注記を参照されたい。
value属性が
指定され、かつ空でない場合、その値は妥当な週文字列でなければならない。
値のサニタイズアルゴリズムは 次のとおりである:要素の値が妥当な週 文字列でない場合、代わりに空文字列に設定する。
min属性が
指定される場合、その値は妥当な週文字列でなければならない。max属性が
指定される場合、その値は妥当な週文字列でなければならない。
step属性は
週数で表される。ステップ尺度係数は604,800,000
(他のアルゴリズムで使用されるように、週数をミリ秒に変換する)である。既定のステップは
1週間である。既定のステップ基準は−259,200,000
(1970-W01週の開始)である。
要素にステップの不一致が生じている場合、 ユーザーエージェントは、要素にステップの不一致が生じない最も近い 週に、要素の値を丸めてもよい。
文字列inputが与えられたときの、文字列を数値に変換する
アルゴリズムは次のとおりである:inputから週文字列を構文解析した結果が
エラーとなる場合、エラーを返す。そうでなければ、1970-01-01の朝のUTC午前0時
(値"1970-01-01T00:00:00.0Z"によって表される時刻)から、構文解析された
週の月曜日の朝のUTC午前0時までに
経過したミリ秒数を、うるう秒を無視して返す。
数値inputが与えられたときの、数値を文字列に変換する
アルゴリズムは次のとおりである:UTCにおいて、1970-01-01の朝のUTC午前0時
(値"1970-01-01T00:00:00.0Z"によって表される時刻)からinputミリ秒後に
現在となる週を表す
妥当な週文字列を返す。
文字列inputが与えられたときの、文字列を
Dateオブジェクトに変換するアルゴリズムは次のとおりである:
inputから週を構文解析した結果がエラーとなる場合、
エラーを返す。そうでなければ、構文解析された週の月曜日の朝のUTC午前0時を表す新しいDate
オブジェクトを返す。
Date
オブジェクトinputが与えられたときの、
Dateオブジェクトを文字列に変換するアルゴリズムは
次のとおりである:UTCタイムゾーンにおいてinputによって表される時刻に現在となる
週を表す妥当な
週文字列を返す。
次の共通のinput要素のコンテンツ
属性、IDL属性、およびメソッドは、要素に適用される:
autocomplete、
list、
max、
min、
readonly、
required、および
stepコンテンツ属性;
list、
value、
valueAsDate、
および
valueAsNumber
IDL属性;
select()、
stepDown()、および
stepUp()メソッド。
次のコンテンツ属性を指定してはならず、要素には適用されない:
accept、
alpha、
alt、
checked、
colorspace、
dirname、
formaction、
formenctype、
formmethod、
formnovalidate、
formtarget、
height、
maxlength、
minlength、
multiple、
pattern、
placeholder、
popovertarget、
popovertargetaction、
size、
src、および
width。
次のIDL属性およびメソッドは要素に適用されない:
checked、
files、
selectionStart、
selectionEnd、
および
selectionDirection
IDL属性;
setRangeText()、
および
setSelectionRange()
メソッド。
type=time)現在のすべてのエンジンでサポートされている。
input要素の
type属性が
時刻状態である場合、
この節の規則が適用される。
input要素は、
要素の値を、特定の
時刻を表す文字列に設定するための
コントロールを表す。
要素が変更可能である場合、 ユーザーエージェントは、その値から時刻を 構文解析して得られる、値によって表される時刻をユーザーが変更できるようにすべきである。 ユーザーエージェントは、ユーザーが値を妥当な時刻 文字列ではない空でない文字列に設定できるようにしてはならない。ユーザーエージェントが 時刻を選択するための ユーザーインターフェイスを提供する場合、値は、ユーザーの選択を表す 妥当な時刻文字列に 設定されなければならない。ユーザーエージェントは、ユーザーが値を空文字列に設定できるようにすべきである。
制約検証:ユーザーインターフェイスが、ユーザーエージェントが妥当な時刻 文字列に変換できない入力を表している間、コントロールは不正な入力が 生じている。
日付、時刻、および数値フォームコントロールの入力形式と送信形式の違いについては 導入節を、フォームコントロールのローカライズについては 実装上の注記を参照されたい。
value属性が
指定され、かつ空でない場合、その値は妥当な時刻文字列でなければならない。
値のサニタイズアルゴリズムは 次のとおりである:要素の値が妥当な時刻 文字列でない場合、代わりに空文字列に設定する。
フォームコントロールは周期的な領域を持つ。
min属性が
指定される場合、その値は妥当な時刻文字列でなければならない。max属性が
指定される場合、その値は妥当な時刻文字列でなければならない。
step属性は
秒数で表される。ステップ尺度係数は1000
(他のアルゴリズムで使用されるように、秒数をミリ秒に変換する)である。既定のステップは60秒である。
要素にステップの不一致が生じている場合、 ユーザーエージェントは、要素にステップの不一致が生じない最も近い 時刻に、要素の値を丸めてもよい。
文字列inputが与えられたときの、文字列を数値に変換する アルゴリズムは次のとおりである:inputから時刻を構文解析した結果がエラーとなる場合、 エラーを返す。そうでなければ、時刻の変更がない日における午前0時から、構文解析された時刻までに経過したミリ秒数を返す。
数値inputが与えられたときの、数値を文字列に変換する アルゴリズムは次のとおりである:時刻の変更がない日における午前0時から inputミリ秒後となる時刻を表す妥当な時刻文字列を返す。
文字列inputが与えられたときの、文字列を
Dateオブジェクトに変換するアルゴリズムは次のとおりである:
inputから時刻を構文解析した結果が
エラーとなる場合、エラーを返す。そうでなければ、1970-01-01における構文解析された時刻をUTCで表す新しい
Dateオブジェクトを返す。
Date
オブジェクトinputが与えられたときの、
Dateオブジェクトを文字列に変換するアルゴリズムは
次のとおりである:inputによって表されるUTCの時刻成分を表す妥当な時刻文字列を返す。
次の共通のinput要素のコンテンツ
属性、IDL属性、およびメソッドは、要素に適用される:
autocomplete、
list、
max、
min、
readonly、
required、および
stepコンテンツ属性;
list、
value、
valueAsDate、
および
valueAsNumber
IDL属性;
select()、
stepDown()、および
stepUp()メソッド。
次のコンテンツ属性を指定してはならず、要素には適用されない:
accept、
alpha、
alt、
checked、
colorspace、
dirname、
formaction、
formenctype、
formmethod、
formnovalidate、
formtarget、
height、
maxlength、
minlength、
multiple、
pattern、
placeholder、
popovertarget、
popovertargetaction、
size、
src、および
width。
次のIDL属性およびメソッドは要素に適用されない:
checked、
files、
selectionStart、
selectionEnd、
および
selectionDirection
IDL属性;
setRangeText()、
および
setSelectionRange()
メソッド。
type=datetime-local)
現在のすべてのエンジンでサポートされている。
input
要素のtype
属性が
ローカル日付
および時刻状態である場合、この節の規則が適用される。
input
要素は、要素の値を、タイムゾーンオフセット情報を
含まないローカル日付および時刻を表す
文字列に設定するためのコントロールを表す。
要素が変更可能である場合、 ユーザーエージェントは、その値から日付および時刻を 構文解析して得られる、値によって表される日付および時刻を ユーザーが変更できるようにすべきである。ユーザーエージェントは、ユーザーが値を、妥当な 正規化済みローカル日付および時刻文字列ではない空でない文字列に設定できるようにしてはならない。 ユーザーエージェントがローカル日付および時刻を 選択するためのユーザーインターフェイスを提供する場合、値は、ユーザーの選択を表す妥当な 正規化済みローカル日付および時刻 文字列に設定されなければならない。ユーザーエージェントは、ユーザーが 値を 空文字列に設定できるようにすべきである。
制約検証:ユーザーインターフェイスが、ユーザーエージェントが妥当な 正規化済みローカル日付および時刻文字列に変換できない入力を表している間、コントロールは 不正な入力が生じている。
日付、時刻、および数値フォームコントロールの入力形式と送信形式の違いについては 導入節を、フォームコントロールのローカライズについては 実装上の注記を参照されたい。
value
属性が指定され、かつ空でない場合、その値は妥当なローカル日付および
時刻文字列でなければならない。
値のサニタイズ アルゴリズムは次のとおりである:要素の値が妥当なローカル日付および 時刻 文字列である場合、同じ日付および時刻を表す妥当な 正規化済みローカル日付および時刻文字列に設定する。そうでない場合、代わりに空文字列に設定する。
min
属性が指定される場合、その値は妥当なローカル日付および
時刻文字列でなければならない。max
属性が指定される場合、その値は妥当なローカル日付および
時刻文字列でなければならない。
step
属性は秒数で表される。ステップ尺度係数は1000
(他のアルゴリズムで使用されるように、秒数をミリ秒に変換する)である。既定のステップは60秒である。
要素にステップの 不一致が生じている場合、ユーザーエージェントは、要素にステップの 不一致が生じない最も近いローカル 日付および時刻に、要素の値を丸めてもよい。
文字列inputが与えられたときの、文字列を
数値に変換する
アルゴリズムは次のとおりである:inputから日付および
時刻を構文解析した結果がエラーとなる場合、エラーを返す。そうでなければ、1970-01-01の朝の
午前0時(値"1970-01-01T00:00:00.0"によって表される時刻)から、構文解析されたローカル日付および時刻までに
経過したミリ秒数を、うるう秒を無視して返す。
数値inputが与えられたときの、数値を
文字列に変換する
アルゴリズムは次のとおりである:1970-01-01の朝の午前0時
(値"1970-01-01T00:00:00.0"によって表される時刻)から
inputミリ秒後となる日付および時刻を表す妥当な
正規化済みローカル日付および時刻文字列を返す。
日付状態の節にある 歴史上の日付に関する注記を参照されたい。
次の共通のinput
要素のコンテンツ属性、IDL属性、およびメソッドは、要素に適用される:
autocomplete、
list、
max、
min、
readonly、
required、
および
step
コンテンツ属性;
list、
value、
および
valueAsNumber
IDL属性;
select()、
stepDown()、
および
stepUp()
メソッド。
次のコンテンツ属性を指定してはならず、要素には適用
されない:
accept、
alpha、
alt、
checked、
colorspace、
dirname、
formaction、
formenctype、
formmethod、
formnovalidate、
formtarget、
height、
maxlength、
minlength、
multiple、
pattern、
placeholder、
popovertarget、
popovertargetaction、
size、
src、
および
width。
次のIDL属性およびメソッドは要素に適用されない:
checked、
files、
selectionStart、
selectionEnd、
selectionDirection、
および
valueAsDate
IDL属性;
setRangeText()、
および
setSelectionRange()
メソッド。
次の例は、航空券予約アプリケーションの一部を示す。このアプリケーションは、
input
要素のtype
属性を
datetime-localに設定して使用し、
指定された日付および時刻を、選択された空港のタイムゾーンで解釈する。
< fieldset >
< legend > Destination</ legend >
< p >< label > Airport: < input type = text name = to list = airports ></ label ></ p >
< p >< label > Departure time: < input type = datetime-local name = totime step = 3600 ></ label ></ p >
</ fieldset >
< datalist id = airports >
< option value = ATL label = "Atlanta" >
< option value = MEM label = "Memphis" >
< option value = LHR label = "London Heathrow" >
< option value = LAX label = "Los Angeles" >
< option value = FRA label = "Frankfurt" >
</ datalist > type=number)現在のすべてのエンジンでサポートされている。
input
要素のtype属性が
数値
状態である場合、この節の規則が適用される。
input要素は、
要素の値を、数値を表す
文字列に設定するためのコントロールを表す。
要素が変更可能である場合、 ユーザーエージェントは、その値に浮動小数点数値を構文解析する 規則を適用して得られる、値によって表される数値をユーザーが変更できるようにすべきである。 ユーザーエージェントは、ユーザーが値を妥当な浮動小数点数ではない空でない文字列に 設定できるようにしてはならない。ユーザーエージェントが数値を選択するためのユーザーインターフェイスを 提供する場合、値は、ユーザーの選択を表す 数値の浮動小数点数としての最良の表現に設定されなければならない。ユーザーエージェントは、 ユーザーが値を空文字列に設定できるようにすべきである。
制約検証:ユーザーインターフェイスが、ユーザーエージェントが妥当な浮動小数点数に変換できない入力を 表している間、コントロールは不正な入力が 生じている。
この仕様は、ユーザーエージェントがどのようなユーザーインターフェイスを使用するかを 定義しない。ユーザーエージェントのベンダーは、ユーザーのニーズに最も適したものを検討することが 推奨される。例えば、ペルシャ語圏またはアラビア語圏のユーザーエージェントは、ペルシャ数字および アラビア数字による入力をサポートし、それを上記で説明した送信に必要な形式へ変換することができる。 同様に、古代ローマ人向けに設計されたユーザーエージェントは、値を十進数ではなくローマ数字で 表示することができる。あるいは、より現実的には、フランス市場向けに設計されたユーザーエージェントは、 桁区切りにアポストロフィ、小数点にコンマを用いて値を表示し、ユーザーがその形式で値を入力できるようにし、 内部で上記の送信形式に変換することができる。
value属性が
指定され、かつ空でない場合、その値は妥当な浮動小数点数でなければならない。
値のサニタイズアルゴリズムは 次のとおりである:要素の値が妥当な 浮動小数点数でない場合、代わりに空文字列に設定する。
min属性が
指定される場合、その値は妥当な
浮動小数点数でなければならない。max属性が
指定される場合、その値は妥当な浮動小数点数でなければならない。
ステップ尺度 係数は 1である。既定の ステップは1である(ステップ 基準が整数でない値を持つ場合を除き、ユーザーが選択できるのは整数のみとなる)。
要素にステップの不一致が生じている場合、 ユーザーエージェントは、要素にステップの不一致が生じない最も近い 数値に、要素の値を丸めてもよい。そのような数値が2つある場合、 ユーザーエージェントは正の無限大に最も近い方を選ぶことが推奨される。
文字列inputが与えられたときの、文字列を数値に変換する アルゴリズムは次のとおりである:inputに 浮動小数点数値を 構文解析する規則を適用した結果がエラーとなる場合、エラーを返す。そうでなければ、 結果の数値を返す。
数値inputが与えられたときの、数値を文字列に変換する アルゴリズムは次のとおりである:inputを表す 妥当な浮動小数点数を返す。
次の共通のinput要素の
コンテンツ属性、IDL属性、およびメソッドは、要素に適用される:
autocomplete、
list、
max、
min、
placeholder、
readonly、
required、および
stepコンテンツ
属性;
list、
value、および
valueAsNumber
IDL属性;
select()、
stepDown()、および
stepUp()メソッド。
次のコンテンツ属性を指定してはならず、要素には適用されない:
accept、
alpha、
alt、
checked、
colorspace、
dirname、
formaction、
formenctype、
formmethod、
formnovalidate、
formtarget、
height、
maxlength、
minlength、
multiple、
pattern、
popovertarget、
popovertargetaction、
size、
src、および
width。
次のIDL属性およびメソッドは要素に適用されない:
checked、
files、
selectionStart、
selectionEnd、
selectionDirection、
および
valueAsDate
IDL属性;
setRangeText()、
および
setSelectionRange()
メソッド。
数値入力コントロールを使用する例を次に示す。
< label > How much do you want to charge? $< input type = number min = 0 step = 0.01 name = price ></ label > 上記のとおり、ユーザーエージェントはユーザーのローカル形式による数値入力をサポートし、 上記で説明した送信に必要な形式へ変換することができる。これには、桁区切り文字 (「872,000,000,000」など)や各種の小数点区切り文字(「3,99」と「3.99」など)の処理、 またはローカル数字(アラビア数字、デーヴァナーガリー数字、ペルシャ数字、タイ数字など)の 使用が含まれることがある。
type=number状態は、
数字だけで構成されてはいるものの、厳密には数値ではない入力には適していない。例えば、
クレジットカード番号や米国の郵便番号には不適切である。type=numberを使用すべきかを
判断する簡単な方法は、入力コントロールにスピンボックスインターフェイス
(例えば「上」および「下」矢印)があっても意味があるかどうかを考えることである。
クレジットカード番号の最後の桁を1だけ間違えることは軽微な誤りではなく、すべての桁を間違えるのと
同じほど誤っている。したがって、ユーザーが「上」および「下」ボタンを使用してクレジットカード番号を
選択できるようにすることには意味がない。スピンボックスインターフェイスが適切でない場合、
type=textがおそらく正しい選択である(場合によってはinputmodeまたはpattern
属性と共に使用する)。
type=range)現在のすべてのエンジンでサポートされている。
input
要素のtype属性が
範囲状態である場合、
この節の規則が適用される。
input要素は、
要素の値を数値を表す
文字列に設定するためのコントロールを表すが、正確な値は重要ではないという条件があり、
UAは数値状態よりも単純なインターフェイスを
提供できる。
要素が変更可能である場合、 ユーザーエージェントは、その値に 浮動小数点数値を構文解析する 規則を適用して得られる、値によって表される数値をユーザーが変更できるようにすべきである。 ユーザーエージェントは、ユーザーが値を 妥当な浮動小数点数ではない文字列に 設定できるようにしてはならない。ユーザーエージェントが数値を選択するための ユーザーインターフェイスを提供する場合、値は ユーザーの選択を 表す数値の浮動小数点数としての最良の表現に設定されなければならない。ユーザーエージェントは、 ユーザーが値を空文字列に設定できるようにしてはならない。
制約検証:ユーザーインターフェイスが、ユーザーエージェントが妥当な浮動小数点数に変換できない入力を 表している間、コントロールは不正な 入力が生じている。
value属性が
指定される場合、その値は妥当な浮動小数点数でなければならない。
値のサニタイズアルゴリズムは 次のとおりである:要素の値が妥当な浮動小数点数でない場合、 既定値の 浮動小数点数としての 最良の表現に設定する。
要素にアンダーフローが生じている場合、 ユーザーエージェントは要素の値を、最小値の浮動小数点数としての 最良の表現に設定しなければならない。
要素にステップの不一致が生じている場合、 ユーザーエージェントは、そのような制約を満たす数値が存在するならば、要素の値を、要素に ステップの不一致が生じず、 最小値以上であり、さらに最大値が最小値より小さくない場合には 最大値以下である、 最も近い数値に丸めなければならない。 そのような制約を満たす数値が2つある場合、ユーザーエージェントは正の無限大に最も近い方を 使用しなければならない。
例えば、マークアップ
<input type="range" min=0 max=100 step=20 value=50>
は、初期値が60である範囲コントロールを生成する。
次に、list属性で
自動補完リストを使用する範囲コントロールの例を示す。これは、事前設定された照明レベルや、
速度コントロールとして使用される範囲コントロールの一般的な速度制限など、コントロールの
全範囲内に特に重要な値がある場合に有用となり得る。次のマークアップ断片:
< input type = "range" min = "-100" max = "100" value = "0" step = "10" name = "power" list = "powers" >
< datalist id = "powers" >
< option value = "0" >
< option value = "-30" >
< option value = "30" >
< option value = "++50" >
</ datalist > ……に次のスタイルシートを適用すると:
input { writing-mode : vertical-lr; height : 75 px ; width : 49 px ; background : #D5CCBB; color : black; } ……次のようにレンダリングされることがある。
![]()
UAがスタイルシートで指定された高さと幅のプロパティの比率から、コントロールの向きを
決定したことに注目されたい。色も同様にスタイルシートから導出された。一方、目盛りは
マークアップから導出された。特に、step属性は
目盛りの配置には影響しておらず、UAは著者が指定した補完値のみを使用し、その後、両端に
より長い目盛りを追加することを選択している。
無効な値++50が無視されていることにも注目されたい。
別の例として、次のマークアップ断片を考える。
< input name = x type = range min = 100 max = 700 step = 9.09090909 value = 509.090909 > ユーザーエージェントは、例えば次のようにさまざまな方法で表示できる。
あるいは、例えば次のようにも表示できる。

ユーザーエージェントは、スタイルシートで指定された寸法に基づいて、どちらを表示するかを 選択できる。これにより、幅が異なる場合でも、目盛りについて同じ解像度を維持できる。
最後に、ラベル付きの値を2つ持つ範囲コントロールの例を示す。
< input type = "range" name = "a" list = "a-values" >
< datalist id = "a-values" >
< option value = "10" label = "Low" >
< option value = "90" label = "High" >
</ datalist > コントロールを縦方向に描画するスタイルを使用すると、次のように表示されることがある。
この状態では、範囲およびステップの制約はユーザー入力中にも適用され、 値を空文字列に設定する方法はない。
min属性が
指定される場合、その値は妥当な浮動小数点数でなければならない。
既定の
最小値は0である。max属性が指定される場合、
その値は妥当な浮動小数点数でなければならない。
既定の最大値は100である。
ステップ尺度係数は
1である。既定の
ステップは1である(min属性が整数でない
値を持つ場合を除き、整数のみが許可される)。
文字列inputが与えられたときの、文字列を数値に変換する アルゴリズムは次のとおりである:inputに 浮動小数点数値を構文解析する 規則を適用した結果がエラーとなる場合、エラーを返す。そうでなければ、結果の数値を返す。
数値inputが与えられたときの、数値を文字列に変換する アルゴリズムは次のとおりである:inputの浮動小数点数としての 最良の表現を返す。
次の共通のinput要素のコンテンツ
属性、IDL属性、およびメソッドは、要素に適用される:
autocomplete、
list、
max、
min、および
stepコンテンツ
属性;
list、
value、および
valueAsNumber
IDL属性;
stepDown()および
stepUp()メソッド。
次のコンテンツ属性を指定してはならず、要素には適用されない:
accept、
alpha、
alt、
checked、
colorspace、
dirname、
formaction、
formenctype、
formmethod、
formnovalidate、
formtarget、
height、
maxlength、
minlength、
multiple、
pattern、
placeholder、
popovertarget、
popovertargetaction、
readonly、
required、
size、
src、および
width。
次のIDL属性およびメソッドは要素に適用されない:
checked、
files、
selectionStart、
selectionEnd、
selectionDirection、
および
valueAsDate
IDL属性;
select()、
setRangeText()、
および
setSelectionRange()
メソッド。
type=color)現在のすべてのエンジンでサポートされている。
input
要素のtype属性が
色状態である場合、
この節の規則が適用される。
input要素は、
要素の値を、
CSS色のシリアル化を表す文字列に設定するためのカラーウェルコントロールを表す。
この状態では、常にCSS色が選択されており、エンドユーザーが値を空文字列に 設定する方法はない。
alpha属性は
ブール属性である。
存在する場合、CSS色のアルファ成分をエンドユーザーが操作でき、完全に不透明である必要がないことを示す。
colorspace属性は、
シリアル化されたCSS色の色空間を示す。また、CSS色を選択するための望ましいユーザーインターフェイスを
示唆する。これは次のキーワードおよび状態を持つ列挙属性である。
| キーワード | 状態 | 簡単な説明 |
|---|---|---|
limited-srgb
|
制限付きsRGB | CSS色は'srgb'色空間に変換され、
成分ごとに8ビットに制限される。例えば、"#123456"または
"color(srgb 0 1 0 / 0.5)"。
|
display-p3
|
Display P3 | CSS色は'display-p3'色空間に変換される。例えば、
"color(display-p3 1.84 -0.19 0.72 / 0.6)"。
|
要素のalpha属性またはcolorspace
属性が変更されるたびに、ユーザーエージェントは要素を与えて
カラーウェルコントロールの色を更新するを
実行しなければならない。
要素が変更可能である場合、 ユーザーエージェントは、その値を構文解析して得られる、値によって表される色を ユーザーが変更できるようにすべきである。ユーザーエージェントは、要素に対してカラーウェルコントロールの色を更新するを 実行しても設定されない文字列に、ユーザーが値を設定できるようにしてはならない。 ユーザーエージェントがCSS色を選択するためのユーザーインターフェイスを提供する場合、 値は、要素およびエンドユーザーの選択を与えてカラーウェルコントロールの色を シリアル化する結果に設定されなければならない。
そのような要素elementのinputの活性化動作は、 elementに対して該当する場合にピッカーを表示することである。
制約検証:要素の値が空文字列ではなく、その値の構文解析が失敗を返す間、コントロールは不正な入力が生じている。
value属性が
指定され、かつ空文字列でない場合、その値はCSS色でなければならない。
値のサニタイズアルゴリズムは 次のとおりである:要素に対してカラーウェルコントロールの色を 更新するを実行する。
要素elementが与えられたとき、カラーウェルコントロールの色を更新するには:
valueを、次の手順を実行した結果とする。
elementの値のdirtyフラグが
falseである場合、null、"value"、およびelementを与えて名前空間および
ローカル名によって属性を取得する結果を返す。
elementの値を返す。
colorを、valueを 構文解析した結果とする。
colorが失敗である場合、colorを不透明な黒に設定する。
elementおよびcolorを与えてカラーウェルコントロールの 色をシリアル化する結果に、elementの値を設定する。
要素elementおよびCSS色colorが与えられたとき、カラーウェルコントロールの色をシリアル化するには:
htmlCompatibleをfalseとする。
elementのalpha属性が
指定されていない場合、colorのアルファ成分を完全に不透明に設定する。
elementのcolorspace
属性が制限付きsRGB状態である場合:
そうでなければ:
表明:elementのcolorspace
属性はDisplay P3状態である。
colorを、'display-p3'色空間へ変換されたcolorに設定する。
colorをシリアル化した結果を返す。 htmlCompatibleがtrueである場合、HTML互換シリアル化を 要求してこれを行う。
次の共通のinput要素の
コンテンツ属性およびIDL属性は、要素に適用される:
alpha、
autocomplete、
colorspace、
および
listコンテンツ属性;
listおよび
valueIDL属性;
select()
メソッド。
次のコンテンツ属性を指定してはならず、要素には適用されない:
accept、
alt、
checked、
dirname、
formaction、
formenctype、
formmethod、
formnovalidate、
formtarget、
height、
max、
maxlength、
min、
minlength、
multiple、
pattern、
placeholder、
popovertarget、
popovertargetaction、
readonly、
required、
size、
src、
step、および
width。
次のIDL属性およびメソッドは要素に適用されない:
checked、
files、
selectionStart、
selectionEnd、
selectionDirection、
valueAsDate
および
valueAsNumber
IDL属性;
setRangeText()、
setSelectionRange()、
stepDown()、および
stepUp()メソッド。
type=checkbox)現在のすべてのエンジンでサポートされている。
input
要素のtype
属性が
チェックボックス状態である場合、
この節の規則が適用される。
input
要素は、要素のチェック状態を表す二状態コントロールを
表す。
要素のチェック状態がtrueである場合、
コントロールは肯定的な選択を表し、falseである場合は否定的な選択を表す。要素の
不定状態がtrueである場合、
コントロールの選択状態は隠されるべきである。
inputの活性化動作は、次の手順を 実行することである。
制約検証:要素が必須であり、 そのチェック状態がfalseである場合、 要素は値の欠落が 生じている。
input.indeterminate [ = value ]
設定されると、現在の値が見えないようにチェックボックス コントロールのレンダリングを上書きする。
次の共通のinput要素の
コンテンツ属性およびIDL属性は、要素に適用される:
checked、
および
required
コンテンツ属性;
checkedおよび
valueIDL属性。
valueIDL
属性はdefault/onモードである。
次のコンテンツ属性を指定してはならず、要素には適用されない:
accept、
alpha、
alt、
autocomplete、
colorspace、
dirname、
formaction、
formenctype、
formmethod、
formnovalidate、
formtarget、
height、
list、
max、
maxlength、
min、
minlength、
multiple、
pattern、
placeholder、
popovertarget、
popovertargetaction、
readonly、
size、
src、
step、および
width。
次のIDL属性およびメソッドは要素に適用されない:
files、
list、
selectionStart、
selectionEnd、
selectionDirection、
valueAsDate、
および
valueAsNumber
IDL属性;
select()、
setRangeText()、
setSelectionRange()、
stepDown()、
および
stepUp()
メソッド。
type=radio)現在のすべてのエンジンでサポートされている。
input
要素のtype
属性が
ラジオボタン状態である場合、
この節の規則が適用される。
input
要素は、他のinput要素と
組み合わせて使用すると、1つのコントロールだけがチェック状態をtrueに設定できる
ラジオボタン
グループを形成するコントロールを表す。要素のチェック状態がtrueである場合、
コントロールはグループ内で選択されたコントロールを表し、falseである場合、グループ内で
選択されていないコントロールを示す。
ツリーは、その要素のみを含むラジオボタン
グループを持つinput要素を
含んではならない。
次のいずれかの現象が発生したとき、その発生後に要素のチェック状態がtrueである場合、 同じラジオ ボタングループ内の他のすべての要素のチェック状態をfalseに 設定しなければならない。
name属性が
設定、変更、または削除された。inputの活性化動作は、 次の手順を実行することである。
制約検証:ラジオボタン
グループ内の要素が必須であり、そのラジオ
ボタングループ内のすべてのinput
要素のチェック状態がfalseである場合、
要素は値の欠落が生じている。
次の例では、何らかの理由により、子犬が必須かつ無効として指定されている。
< form >
< p >< label >< input type = "radio" name = "dog-type" value = "pupper" required disabled > Pupper</ label >
< p >< label >< input type = "radio" name = "dog-type" value = "doggo" > Doggo</ label >
< p >< button > Make your choice</ button >
</ form > ユーザーが最初に「Doggo」を選択せずにこのフォームを送信しようとした場合、ラジオボタン
グループ内の要素(すなわち最初の要素)が必須であり、ラジオボタン
グループ内の両方の要素のチェック状態がfalseであるため、
両方のinput
要素に値の欠落が生じる。
一方、ユーザーが「Doggo」を選択してからフォームを送信した場合、一方が必須であっても、すべての要素の
チェック状態がfalseではないため、
どちらのinput
要素にも値の欠落は生じない。
ラジオボタングループ内の ラジオボタンがいずれもチェックされていない場合、いずれかが(ユーザーまたはスクリプトによって) チェックされるまで、インターフェイス上ではすべてが初期状態で未チェックとなる。
次の共通のinput要素の
コンテンツ属性およびIDL属性は、要素に適用される:
checkedおよび
required
コンテンツ属性;
checkedおよび
valueIDL属性。
valueIDL
属性はdefault/onモードである。
次のコンテンツ属性を指定してはならず、要素には適用されない:
accept、
alpha、
alt、
autocomplete、
colorspace、
dirname、
formaction、
formenctype、
formmethod、
formnovalidate、
formtarget、
height、
list、
max、
maxlength、
min、
minlength、
multiple、
pattern、
placeholder、
popovertarget、
popovertargetaction、
readonly、
size、
src、
step、および
width。
次のIDL属性およびメソッドは要素に適用されない:
files、
list、
selectionStart、
selectionEnd、
selectionDirection、
valueAsDate、
および
valueAsNumber
IDL属性;
select()、
setRangeText()、
setSelectionRange()、
stepDown()、
および
stepUp()
メソッド。
type=file)現在のすべてのエンジンでサポートされている。
input
要素のtype
属性が
ファイル
アップロード状態である場合、この節の規則が
適用される。
input
要素は、ファイル名、ファイル型、およびファイル本体(ファイルの内容)からそれぞれ構成される
選択されたファイルのリストを表す。
ユーザーがディレクトリ階層全体を選択した場合や、異なるディレクトリから同じ名前の複数の ファイルを選択した場合であっても、ファイル名にパス構成要素を含めてはならない。 ファイルアップロード状態における パス構成要素とは、U+005C REVERSE SOLIDUS文字(\)によって 区切られたファイル名の部分である。
multiple
属性が設定されていない限り、選択された
ファイルのリストには、1つを超えるファイルが存在してはならない。
そのような要素elementのinputの活性化の振る舞いは、 elementについて該当する場合にピッカーを 表示することである。
要素が変更可能である場合、ユーザーエージェントは、 ドラッグアンドドロップによるファイルの追加または削除など、他の方法でもユーザーがリスト内の ファイルを変更できるようにすべきである。ユーザーがこれを行った場合、ユーザーエージェントは 要素についてファイル選択を更新する必要がある。
要素が変更可能でない場合、 ユーザーエージェントは、ユーザーが要素の選択を変更できるようにしてはならない。
要素elementについてファイル選択を更新するには:
elementおよび次の手順を与えて、ユーザー操作タスクソースに 要素タスクを キューする:
制約検証:要素が必須であり、 選択されたファイルのリストが 空である場合、要素には 値の欠落が生じている。
現在のすべてのエンジンでサポートされている。
現在のすべてのエンジンでサポートされている。
accept属性は、受け入れられるファイル型についての
ヒントをユーザーエージェントに提供するために指定してもよい。
指定する場合、この属性はコンマで区切られたトークンの集合で 構成されなければならず、各トークンは次のいずれかとASCII大文字小文字を区別せず一致しなければならない。
audio/*」video/*」image/*」トークンは、他のいずれのトークンともASCII大文字小文字を区別せず一致してはならない (すなわち、重複は許可されない)。属性からトークンのリストを取得するために、 ユーザーエージェントは属性値をコンマで 分割しなければならない。
ユーザーエージェントは、この属性の値を使用して、汎用のファイルピッカーより適切な
ユーザーインターフェイスを表示してもよい。例えば、値がimage/*である場合、
ユーザーエージェントは、ローカルカメラを使用するか、写真コレクションから写真を選択する
オプションをユーザーに提供できる。値がaudio/*である場合、ユーザーエージェントは、
ヘッドセットのマイクを使用して音声クリップを録音するオプションをユーザーに提供できる。
ユーザーエージェントは、これらのトークンの1つ以上によって受け入れられないファイルを ユーザーが選択できないようにすべきである。
特定の形式のデータを求める場合、著者はMIME型と対応する拡張子の両方を 指定することが推奨される。
例えば、Microsoft Word文書をOpen Document Formatファイルに変換するアプリケーションを 考える。Microsoft Word文書は多種多様なMIME型および拡張子で記述されるため、サイトは次のように 複数のものを列挙できる。
< input type = "file" accept = ".doc,.docx,.xml,application/msword,application/vnd.openxmlformats-officedocument.wordprocessingml.document" > ファイル型を記述するためにファイル拡張子のみを使用するプラットフォームでは、ここに 列挙された拡張子を使用して許可される文書を絞り込むことができる。一方、MIME型は、存在する場合、 システムの型登録表(MIME型をシステムが使用する拡張子に対応付けるもの)と共に使用して、 許可すべき他の拡張子を決定できる。同様に、ファイル名や拡張子を持たず、内部的にMIME型で文書に ラベルを付けるシステムでは、MIME型を使用して許可されるファイルを選択できる。一方、システムが 既知の拡張子をシステムが使用するMIME型に対応付ける拡張子登録表を持つ場合、拡張子を使用できる。
拡張子には曖昧さがある傾向がある(例えば、「.dat」拡張子を
使用する形式は数え切れないほどあり、Microsoft Word文書でなくても、ユーザーは通常、
ファイル名を「.doc」拡張子に非常に簡単に変更できる)。また、MIME型は信頼性に
欠ける傾向がある(例えば、多くの形式には正式に登録された型がなく、実際には多くの形式が
複数の異なるMIME型を使用してラベル付けされている)。著者は、通常どおり、クライアントから
受信したデータを慎重に扱う必要があることに留意すべきである。ユーザーに悪意がなく、
ユーザーエージェントがaccept
属性の要件に完全に従っていたとしても、そのデータは期待される形式でない可能性がある。
歴史的な理由により、valueIDL属性は、
ファイル名の先頭に文字列「C:\fakepath\」を付加する。一部の旧来の
ユーザーエージェントは、実際に完全なパスを含めていた(これはセキュリティ上の脆弱性であった)。
この結果、valueIDL属性から
後方互換性のある方法でファイル名を取得することは容易ではない。次の関数は、適切な互換性を
保つ方法でファイル名を抽出する。
function extractFilename( path) {
if ( path. substr( 0 , 12 ) == "C:\\fakepath\\" )
return path. substr( 12 ); // modern browser
var x;
x = path. lastIndexOf( '/' );
if ( x >= 0 ) // Unix-based path
return path. substr( x+ 1 );
x = path. lastIndexOf( '\\' );
if ( x >= 0 ) // Windows-based path
return path. substr( x+ 1 );
return path; // just the filename
} これは次のように使用できる。
< p >< input type = file name = image onchange = "updateFilename(this.value)" ></ p >
< p > The name of the file you picked is: < span id = "filename" > (none)</ span ></ p >
< script >
function updateFilename( path) {
var name = extractFilename( path);
document. getElementById( 'filename' ). textContent = name;
}
</ script > 次の共通のinput要素の
コンテンツ属性およびIDL属性は、要素に適用される:
accept、
multiple、
および
required
コンテンツ属性;
filesおよび
valueIDL属性;
select()
メソッド。
次のコンテンツ属性を指定してはならず、要素には適用されない:
alpha、
alt、
autocomplete、
checked、
colorspace、
dirname、
formaction、
formenctype、
formmethod、
formnovalidate、
formtarget、
height、
list、
max、
maxlength、
min、
minlength、
pattern、
popovertarget、
popovertargetaction、
placeholder、
readonly、
size、
src、
step、および
width。
要素のvalue属性は
省略しなければならない。
次のIDL属性およびメソッドは要素に適用されない:
checked、
list、
selectionStart、
selectionEnd、
selectionDirection、
valueAsDate、
および
valueAsNumber
IDL属性;
setRangeText()、
setSelectionRange()、
stepDown()、
および
stepUp()メソッド。
type=submit)現在のすべてのエンジンでサポートされている。
input要素の
type属性が
送信ボタン状態である場合、
この節の規則が
適用される。
![]()
input
要素は、活性化されるとフォームを送信するボタンを表す。要素がvalue属性を
持つ場合、ボタンのラベルはその属性の値でなければならない。そうでない場合、「送信」または
それに類する意味を持つ実装定義の文字列でなければならない。要素は
ボタンであり、
特に送信ボタンである。
既定のラベルは実装定義であり、ボタンの幅は通常ボタンのラベルに依存するため、 ボタンの幅によってフィンガープリント可能な情報が数ビット漏洩する可能性がある。これらのビットは、 ユーザーエージェントの種類およびユーザーのロケールと強く相関する可能性が高い。
eventが与えられたときの要素のinputの活性化の振る舞いは 次のとおりである。
要素がフォーム所有者を持たない場合、返る。
userInvolvementをeventのユーザーナビゲーション関与に 設定して、要素から要素のフォーム所有者を送信する。
formaction、
formenctype、
formmethod、
formnovalidate、
およびformtarget
属性は、フォーム送信用の
属性である。
formnovalidate
属性は、制約検証を引き起こさない送信ボタンを作るために使用できる。
次の共通のinput要素の
コンテンツ属性およびIDL属性は、要素に適用される:
dirname、
formaction、
formenctype、
formmethod、
formnovalidate、
formtarget、
popovertarget、
および
popovertargetaction
コンテンツ
属性;valueIDL属性。
次のコンテンツ属性を指定してはならず、要素には適用されない:
accept、
alpha、
alt、
autocomplete、
checked、
colorspace、
height、
list、
max、
maxlength、
min、
minlength、
multiple、
pattern、
placeholder、
readonly、
required、
size、
src、
step、および
width。
次のIDL属性およびメソッドは要素に適用されない:
checked、
files、
list、
selectionStart、
selectionEnd、
selectionDirection、
valueAsDate、
および
valueAsNumber
IDL属性;
select()、
setRangeText()、
setSelectionRange()、
stepDown()、
および
stepUp()
メソッド。
type=image)現在のすべてのエンジンでサポートされている。
input
要素のtype
属性が
画像ボタン状態である場合、
この節の規則が
適用される。
input
要素は、ユーザーが座標を選択してフォームを送信できる画像、またはユーザーがフォームを送信できる
ボタンのいずれかを表す。要素はボタンであり、特に送信
ボタンである。
座標は、フォーム送信時に、
コントロールの名前から導出し、その名前に「.x」および「.y」を
それぞれ座標のx成分およびy成分として付加した、要素用の2つのエントリーを
送信することによってサーバーへ送られる。
現在のすべてのエンジンでサポートされている。
画像はsrc属性によって与えられる。src
属性は存在しなければならず、ページ化もスクリプト化もされていない、非対話的で、任意で
アニメーションする画像リソースを参照する空白で囲まれている
可能性がある妥当な空でないURLを含まなければならない。
次のいずれかのイベントが発生した場合:
input
要素のtype属性が
(要素が最初に作成されたときを含め)初めて画像ボタン状態に設定され、
src属性が
存在する場合
input
要素のtype属性が
再び画像ボタン状態に変更され、
src属性が
存在し、かつその値が、type属性が
前回画像ボタン状態であったとき
以降に変更されている場合
input
要素のtype属性が
画像ボタン状態であり、src属性が
設定または変更された場合
その場合、ユーザーエージェントが画像をサポートできない、画像のサポートが無効にされている、
ユーザーエージェントが要求時にのみ画像をフェッチする、またはsrc
属性の値が空文字列である場合を除き、次の手順を実行する。
urlを、src属性の値を、
要素のノード
文書に対して相対的に与えて、URLをエンコーディング構文解析する
結果とする。
urlが失敗である場合、返る。
requestを、URLがurl、クライアントが要素のノード文書の関連する設定オブジェクト、
宛先が「image」、
開始元型が「input」、
資格情報モードが「include」で、
URL資格情報使用フラグが設定された、新しいリクエストとする。
レスポンスresponseが与えられたときの processResponseEndOfBodyを 次の手順に設定して、requestをフェッチする。
ダウンロードが成功し、画像が利用可能である場合、input
要素を与えて、ユーザー操作タスクソースに
要素タスクをキューし、input
要素でloadという名前の
イベントを発火する。
そうでなく、フェッチ処理がリモートサーバーからのレスポンスなしに失敗するか、
完了したものの画像が妥当またはサポートされる画像でない場合、input
要素を与えて、ユーザー操作タスクソースに
要素タスクを
キューし、input
要素でerrorという
名前のイベントを発火する。
画像のフェッチは、リソースがフェッチされた後にネットワーキングタスク ソースによってキューされた(後述する) タスクが実行されるまで、 要素のノード文書のloadイベントを遅延させなければならない。
ネットワークエラーなしに画像が正常に取得され、画像の型がサポートされる画像型であり、 その画像がその型の妥当な画像である場合、その画像は利用可能であるという。画像が完全にダウンロードされる前に これが真となる場合、画像のフェッチ中にネットワーキングタスク ソースによってキューされる各タスクは、 画像の表示を適切に更新しなければならない。
ユーザーエージェントは、画像の関連付けられたContent-Typeヘッダーが 公式の型を与えるものとして、画像の型を決定するために画像スニッフィング 規則を適用すべきである。これらの規則が適用されない場合、画像の型は、画像の関連付けられたContent-Type ヘッダーによって与えられる型でなければならない。
ユーザーエージェントは、input要素で
画像以外のリソースをサポートしてはならない。ユーザーエージェントは、画像リソースに埋め込まれた
実行可能コードを実行してはならない。ユーザーエージェントは、複数ページのリソースの最初のページのみを
表示しなければならない。ユーザーエージェントは、リソースが対話的に動作することを許可してはならないが、
リソース内のアニメーションには従うべきである。
現在のすべてのエンジンでサポートされている。
alt属性は、画像を使用できないユーザーおよび
ユーザーエージェントに対して、ボタンのテキストラベルを提供する。alt属性は
存在しなければならず、画像が利用できない場合に同等のボタンに適切なラベルを与える、
空でない文字列を含まなければならない。
src
属性が設定され、画像が利用可能であり、ユーザーエージェントがその画像を表示するよう
構成されている場合、要素は、src属性によって
指定された画像から座標を選択するための
コントロールを表す。その場合、要素が変更可能であるなら、
ユーザーエージェントはユーザーがこの座標を選択できるように
すべきである。
eventが与えられたときの要素のinputの活性化の振る舞いは 次のとおりである。
要素がフォーム所有者を持たない場合、返る。
ユーザーが座標を明示的に選択しながらコントロールを活性化した場合、要素の選択された座標を その座標に設定する。
これは、要素がそのような座標を選択するためのコントロールを表す場合に、 上記の条件下でのみ可能である。その場合であっても、ユーザーは座標を明示的に選択せずに コントロールを活性化することがある。
userInvolvementをeventのユーザーナビゲーション関与に 設定して、要素から要素のフォーム所有者を送信する。
要素の選択された座標は、 x成分およびy成分から構成される。初期値は(0, 0)である。 座標は要素の画像の端に対する相対位置を表し、座標空間では正のx方向が右、 正のy方向が下である。
x成分は、範囲 −(borderleft+paddingleft) ≤ x ≤ width+borderright+paddingright 内の数値xを表す妥当な整数でなければならない。ここで、 widthは画像のレンダリングされた幅、borderleftは画像の左側の 境界線の幅、paddingleftは画像の左側のパディングの幅、 borderrightは画像の右側の境界線の幅、 paddingrightは画像の右側のパディングの幅であり、すべての寸法は CSSピクセルで与えられる。
y成分は、範囲 −(bordertop+paddingtop) ≤ y ≤ height+borderbottom+paddingbottom 内の数値yを表す妥当な整数でなければならない。ここで、 heightは画像のレンダリングされた高さ、bordertopは画像の上側の 境界線の幅、paddingtopは画像の上側のパディングの幅、 borderbottomは画像の下側の境界線の幅、 paddingbottomは画像の下側のパディングの幅であり、すべての寸法は CSSピクセルで与えられる。
境界線またはパディングが存在しない場合、その幅は0CSS ピクセルである。
formaction、
formenctype、
formmethod、
formnovalidate、
およびformtarget
属性は、フォーム送信用の
属性である。
image.width [ = value ]
image.height [ = value ]
これらの属性は、画像の実際のレンダリング寸法を返す。寸法が不明な場合は0を返す。
これらを設定して、対応するコンテンツ属性を変更できる。
次の共通のinput要素の
コンテンツ属性およびIDL属性は、要素に適用される:
alt、
formaction、
formenctype、
formmethod、
formnovalidate、
formtarget、
height、
popovertarget、
popovertargetaction、
src、および
widthコンテンツ
属性;
valueIDL属性。
次のコンテンツ属性を指定してはならず、要素には適用されない:
accept、
alpha、
autocomplete、
checked、
colorspace、
dirname、
list、
max、
maxlength、
min、
minlength、
multiple、
pattern、
placeholder、
readonly、
required、
size、および
step。
要素のvalue属性は
省略しなければならない。
次のIDL属性およびメソッドは要素に適用されない:
checked、
files、
list、
selectionStart、
selectionEnd、
selectionDirection、
valueAsDate、
および
valueAsNumber
IDL属性;
select()、
setRangeText()、
setSelectionRange()、
stepDown()、
および
stepUp()
メソッド。
この状態の振る舞いの多くの側面は、img要素の
振る舞いと似ている。読者は、その節を読むことが推奨される。そこでは、同じ要件の多くがより詳しく
説明されている。
次のフォームを考える。
< form action = "process.cgi" >
< input type = image src = map.png name = where alt = "Show location list" >
</ form > ユーザーが画像上の座標(127,40)をクリックした場合、フォームの送信に使用されるURLは
「process.cgi?where.x=127&where.y=40」となる。
(この例では、地図を見ることができず、代わりに「Show location list」というラベルの ボタンのみを見るユーザーについて、ボタンをクリックするとサーバーが地図の代わりに選択可能な 場所のリストを表示すると仮定している。)
type=reset)現在のすべてのエンジンでサポートされている。
input
要素のtype
属性が
リセットボタン状態である場合、
この節の規則が
適用される。
![]()
input
要素は、活性化されるとフォームをリセットするボタンを表す。要素がvalue属性を
持つ場合、ボタンのラベルはその属性の値でなければならない。そうでない場合、「リセット」または
それに類する意味を持つ実装定義の文字列でなければならない。要素は
ボタンである。
既定のラベルは実装定義であり、ボタンの幅は通常ボタンのラベルに依存するため、 ボタンの幅によってフィンガープリント可能な情報が数ビット漏洩する可能性がある。これらのビットは、 ユーザーエージェントの種類およびユーザーのロケールと強く相関する可能性が高い。
制約検証:要素は制約検証の 対象外である。
valueIDL属性は
この要素に適用され、defaultモードである。
次の共通のinput要素の
コンテンツ属性は、要素に適用される:
popovertarget
および
popovertargetaction。
次のコンテンツ属性を指定してはならず、要素には適用されない:
accept、
alpha、
alt、
autocomplete、
checked、
colorspace、
dirname、
formaction、
formenctype、
formmethod、
formnovalidate、
formtarget、
height、
list、
max、
maxlength、
min、
minlength、
multiple、
pattern、
placeholder、
readonly、
required、
size、
src、
step、および
width。
次のIDL属性およびメソッドは要素に適用されない:
checked、
files、
list、
selectionStart、
selectionEnd、
selectionDirection、
valueAsDate、
および
valueAsNumber
IDL属性;
select()、
setRangeText()、
setSelectionRange()、
stepDown()、
および
stepUp()
メソッド。
type=button)現在のすべてのエンジンでサポートされている。
input
要素のtype属性が
ボタン状態である場合、
この節の規則が適用される。
input要素は、
既定の振る舞いを持たないボタンを表す。ボタンのラベルはvalue属性で
提供されなければならないが、空文字列でもよい。要素がvalue属性を持つ場合、
ボタンのラベルはその属性の値でなければならない。そうでない場合、空文字列でなければならない。
要素はボタンである。
要素はinputの活性化の振る舞いを持たない。
制約検証:要素は制約検証の 対象外である。
valueIDL属性は
この要素に適用され、defaultモードである。
次の共通のinput要素の
コンテンツ属性は、要素に適用される:
popovertarget
および
popovertargetaction。
次のコンテンツ属性を指定してはならず、要素には適用されない:
accept、
alpha、
alt、
autocomplete、
checked、
colorspace、
dirname、
formaction、
formenctype、
formmethod、
formnovalidate、
formtarget、
height、
list、
max、
maxlength、
min、
minlength、
multiple、
pattern、
placeholder、
readonly、
required、
size、
src、
step、および
width。
次のIDL属性およびメソッドは要素に適用されない:
checked、
files、
list、
selectionStart、
selectionEnd、
selectionDirection、
valueAsDate、
および
valueAsNumber
IDL属性;
select()、
setRangeText()、
setSelectionRange()、
stepDown()、および
stepUp()メソッド。
この節は規範的ではない。
日付、時刻、および数値コントロールでユーザーに表示される形式は、フォーム送信に使用される 形式とは独立している。
ブラウザーは、input要素の
言語によって示されるロケール、または
ユーザーが優先するロケールのいずれかの慣習に従って日付、時刻、および数値を提示する
ユーザーインターフェイスを使用することが推奨される。ページのロケールを使用すると、
ページによって提供されるデータとの一貫性が確保される。
例えば、アメリカ英語のページでCirque De Soleilの公演が02/03に行われると 表示されている一方、イギリス英語のロケールを使用するよう設定されたブラウザーが、チケット購入の 日付ピッカーに03/02としか表示しない場合、ユーザーは混乱するだろう。ページのロケールを使用すれば、 少なくとも日付がどこでも同じ形式で提示されることが保証される。(もちろん、ユーザーが1か月遅れて 到着する危険は依然としてあるが、このような文化的差異に対してできることには限界がある……。)
input要素の
属性これらの属性は、input
要素のtype属性が、
その定義において当該属性が適用されると宣言されている状態に
ある場合にのみ、その要素に適用される。属性がinput要素に
適用されない場合、ユーザーエージェントは、
以下の要件および定義にかかわらず、その属性を無視しなければならない。
maxlength
属性およびminlength
属性現在のすべてのエンジンでサポートされている。
現在のすべてのエンジンでサポートされている。
現在のすべてのエンジンでサポートされている。
現在のすべてのエンジンでサポートされている。
現在のすべてのエンジンでサポートされている。
maxlength属性は、それが適用される場合、
フォームコントロールの
maxlength
属性である。
現在のすべてのエンジンでサポートされている。
minlength属性は、それが適用される場合、
フォームコントロールの
minlength
属性である。
input
要素に許可される値の最大長が
ある場合、要素のvalue
属性の値の長さは、要素の許可される値の
最大長以下でなければならない。
次の抜粋は、メッセージングクライアントのテキスト入力を任意に固定文字数に制限し、 この媒体を通じた会話を簡潔にするよう強制し、知的な議論を妨げる方法を示す。
< label > What are you doing? < input name = status maxlength = 140 ></ label > ここでは、パスワードに最小長が指定されている。
< p >< label > Username: < input name = u required ></ label >
< p >< label > Password: < input name = p required minlength = 12 ></ label > size属性size属性は、視覚的レンダリングにおいて、
要素の値を編集中にユーザーエージェントがユーザーに
表示できるようにする文字数を与える。
size属性が
指定される場合、その値は0より大きい妥当な非負整数でなければならない。
属性が存在する場合、その値は非負整数を構文解析する 規則を使用して構文解析しなければならず、結果が0より大きい数値である場合、 ユーザーエージェントは少なくともその数の文字が表示されることを保証すべきである。
sizeIDL属性は、
正の数値のみに
制限され、既定値は20である。
readonly属性現在のすべてのエンジンでサポートされている。
現在のすべてのエンジンでサポートされている。
現在のすべてのエンジンでサポートされている。
readonly
属性は、ユーザーがフォームコントロールを編集できるかどうかを制御するブール属性である。指定された場合、要素は変更可能ではない。
disabledとreadonlyの違いは、
読み取り専用のコントロールは引き続き機能できるのに対し、無効化されたコントロールは通常、
有効化されるまでコントロールとして機能しないことである。これは、この仕様の別の箇所で、
無効化の概念を参照する
規範的要件とともに、より詳しく規定されている(例えば、要素の活性化の振る舞い、要素がフォーカス可能領域であるかどうか、またはエントリーリストを
構築する場合など)。テキストを選択またはコピーできるかどうかなど、無効化されたコントロールとの
ユーザー操作に関連するその他の振る舞いは、この標準では定義されない。
読み取り専用にできるのはテキストコントロールだけである。チェックボックスやボタンなどの
その他のコントロールでは、読み取り専用であることと無効化されていることの間に有用な違いが
ないため、readonly
属性は適用されない。
次の例では、既存の製品識別子は変更できないが、新しい製品を表す行(まだ識別子が 入力されていない行)との一貫性を保つため、フォームの一部として引き続き表示される。
< form action = "products.cgi" method = "post" enctype = "multipart/form-data" >
< table >
< tr > < th > Product ID < th > Product name < th > Price < th > Action
< tr >
< td > < input readonly = "readonly" name = "1.pid" value = "H412" >
< td > < input required = "required" name = "1.pname" value = "Floor lamp Ulke" >
< td > $< input required = "required" type = "number" min = "0" step = "0.01" name = "1.pprice" value = "49.99" >
< td > < button formnovalidate = "formnovalidate" name = "action" value = "delete:1" > Delete</ button >
< tr >
< td > < input readonly = "readonly" name = "2.pid" value = "FG28" >
< td > < input required = "required" name = "2.pname" value = "Table lamp Ulke" >
< td > $< input required = "required" type = "number" min = "0" step = "0.01" name = "2.pprice" value = "24.99" >
< td > < button formnovalidate = "formnovalidate" name = "action" value = "delete:2" > Delete</ button >
< tr >
< td > < input required = "required" name = "3.pid" value = "" pattern = "[A-Z0-9]+" >
< td > < input required = "required" name = "3.pname" value = "" >
< td > $< input required = "required" type = "number" min = "0" step = "0.01" name = "3.pprice" value = "" >
< td > < button formnovalidate = "formnovalidate" name = "action" value = "delete:3" > Delete</ button >
</ table >
< p > < button formnovalidate = "formnovalidate" name = "action" value = "add" > Add</ button > </ p >
< p > < button name = "action" value = "update" > Save</ button > </ p >
</ form > required属性required
属性はブール属性である。
指定された場合、要素は必須である。
次のフォームには2つの必須フィールドがあり、1つはメールアドレス用、もう1つは パスワード用である。また、ユーザーがパスワードフィールドとこの第3のフィールドに 同じパスワードを入力した場合にのみ妥当と見なされる、第3のフィールドもある。
< h1 > Create new account</ h1 >
< form action = "/newaccount" method = post
oninput = "up2.setCustomValidity(up2.value != up.value ? 'Passwords do not match.' : '')" >
< p >
< label for = "username" > Email address:</ label >
< input id = "username" type = email required name = un >
< p >
< label for = "password1" > Password:</ label >
< input id = "password1" type = password required name = up >
< p >
< label for = "password2" > Confirm password:</ label >
< input id = "password2" type = password name = up2 >
< p >
< input type = submit value = "Create account" >
</ form > ラジオボタンの場合、グループ内のいずれかのラジオボタンが
選択されていれば、required属性の
要件は満たされる。したがって、次の例では、必須と指定されたものだけでなく、いずれの
ラジオボタンをチェックしてもよい。
< fieldset >
< legend > Did the movie pass the Bechdel test?</ legend >
< p >< label >< input type = "radio" name = "bechdel" value = "no-characters" > No, there are not even two female characters in the movie. </ label >
< p >< label >< input type = "radio" name = "bechdel" value = "no-names" > No, the female characters never talk to each other. </ label >
< p >< label >< input type = "radio" name = "bechdel" value = "no-topic" > No, when female characters talk to each other it's always about a male character. </ label >
< p >< label >< input type = "radio" name = "bechdel" value = "yes" required > Yes. </ label >
< p >< label >< input type = "radio" name = "bechdel" value = "unknown" > I don't know. </ label >
</ fieldset > ラジオボタングループが必須であるかどうかに 関する混乱を避けるため、著者はグループ内のすべてのラジオボタンにこの属性を指定することが 推奨される。実際、一般に著者は、初期状態でチェックされたコントロールが1つもない ラジオボタングループを使用しないことが推奨される。これはユーザーが戻ることのできない状態であり、 通常、質の低いユーザーインターフェイスと見なされるためである。
multiple属性現在のすべてのエンジンでサポートされている。
現在のすべてのエンジンでサポートされている。
multiple属性は、ユーザーが複数の値を指定することを
許可されるかどうかを示すブール属性である。
次の抜粋は、メールクライアントの「To」フィールドで複数のメールアドレスを受け入れる方法を示す。
< label > To: < input type = email multiple name = to ></ label > ユーザーの連絡先データベースにいる多くの友人の中に、「Spider-Man」 (アドレス「spider@parker.example.net」)と「Scarlet Witch」 (アドレス「scarlet@avengers.example.net」)という2人の友人がいた場合、 ユーザーが「s」と入力した後、ユーザーエージェントはこれら2つの メールアドレスをユーザーに候補として提示できる。

ページは、サイトからユーザーの連絡先データベースをリンクすることもできる。
< label > To: < input type = email multiple name = to list = contacts ></ label >
...
< datalist id = "contacts" >
< option value = "hedral@damowmow.com" >
< option value = "pillar@example.com" >
< option value = "astrophy@cute.example" >
< option value = "astronomy@science.example.org" >
</ datalist > ユーザーがこのテキストコントロールに「bob@example.net」と入力し、その後、
「s」で始まる2つ目のメールアドレスを入力し始めたとする。ユーザーエージェントは、
前述の2人の友人に加えて、datalist
要素で与えられた「astrophy」および「astronomy」の値も表示できる。

次の抜粋は、メールクライアントの「Attachments」フィールドでアップロード用の複数の ファイルを受け入れる方法を示す。
< label > Attachments: < input type = file multiple name = att ></ label > pattern属性現在のすべてのエンジンでサポートされている。
現在のすべてのエンジンでサポートされている。
pattern属性は、コントロールの値、またはmultiple属性が適用され、かつ設定されている場合は
コントロールの複数の値を
検査するための正規表現を指定する。
指定する場合、属性の値はJavaScriptのPattern[+UnicodeSetsMode, +N]
生成規則に一致しなければならない。
input要素の
コンパイル済みパターン正規表現は、存在する場合、
JavaScriptのRegExp
オブジェクトである。これは次のように決定される。
要素にpattern属性が
指定されていない場合、何も返さない。要素はコンパイル済みパターン
正規表現を持たない。
patternを、要素のpattern属性の
値とする。
regexpCompletionをRegExpCreate(pattern,
"v")とする。
regexpCompletionが突然の 完了である場合、何も返さない。要素はコンパイル済みパターン 正規表現を持たない。
デバッグを支援するため、ユーザーエージェントはこのエラーを開発者コンソールに 記録することが推奨される。
anchoredPatternを、文字列「^(?:」に
patternを続け、さらに「)$」を続けた文字列とする。
! RegExpCreate(anchoredPattern, "v")を返す。
pattern属性の値を
直接使用せず、これらの手順を用いる理由は2つある。第1に、文字列との照合時に、正規表現の先頭を
文字列の先頭に、末尾を文字列の末尾に固定したい。第2に、正規表現が「^(?:」および
「)$」のアンカーで囲まれた後にのみ妥当になるのではなく、単独の形式でも妥当である
ことを保証したい。
RegExp
オブジェクトregexpは、! RegExpBuiltinExec(regexp, input)がnullで
ない場合、文字列inputに一致する。
制約検証:要素の値が空文字列でなく、要素のmultiple属性が
指定されていないか、またはその属性が、type属性の現在の状態に
基づいてinput要素に適用されず、要素がコンパイル済みパターン正規表現を
持つものの、その正規表現が要素の値に一致しない場合、要素にはパターン不一致が生じている。
制約検証:要素の値が空文字列でなく、要素のmultiple属性が
指定され、input要素に適用され、要素がコンパイル済みパターン正規表現を
持つものの、その正規表現が要素の各値に一致しない場合、要素にはパターン不一致が生じている。
input要素に
pattern属性が
指定されている場合、著者はパターンの説明を与えるためにtitle属性を含めるべきである。
ユーザーエージェントは、この属性が存在する場合、パターンが一致しないことをユーザーに通知する際、
またはツールチップとして表示する場合や、コントロールがフォーカスを得たときに支援技術が読み上げる場合など、
その他の適切な時点で、この属性の内容を使用してもよい。
例えば、次の断片:
< label > Part number:
< input pattern = "[0-9][A-Z]{3}" name = "part"
title = "A part number is a digit followed by three uppercase letters." />
</ label > ……により、UAは次のような警告を表示できる。
部品番号は、1桁の数字の後に3文字の大文字を続けたものです。 フィールドが正しくない場合、このフォームを送信できません。
コントロールがpattern属性を持つ場合、
title属性を使用するなら、
その属性はパターンを説明しなければならない。ユーザーがコントロールに入力するのを支援する限り、
追加情報を含めることもできる。そうでなければ、支援技術の利用が損なわれる。
例えば、title属性にコントロールの見出しが含まれている場合、支援技術は 入力したテキストは必要なパターンに一致しません。誕生日のように読み上げる可能性があり、 これは有用ではない。
UAは、エラーでない状況でもtitleを表示することがある
(例えば、コントロール上にポインターを置いたときのツールチップとして)。したがって著者は、
必ずエラーが発生したかのような文言をtitleに
使用しないよう注意すべきである。
min属性およびmax属性現在のすべてのエンジンでサポートされている。
現在のすべてのエンジンでサポートされている。
一部のフォームコントロールには、ユーザーが指定できる値の許容範囲を制限する明示的な制約を 適用できる。通常、このような範囲は線形かつ連続的である。ただし、フォームコントロールは 周期的な定義域を持つことができ、その場合、 フォームコントロールが取り得る最も広い範囲は有限であり、著者は境界をまたぐ明示的な範囲を その内部で指定できる。
具体的には、type=time
コントロールの最も広い範囲は午前0時から翌日の午前0時まで(24時間)であり、著者は
連続した線形範囲(午後9時から午後11時など)と、午前0時をまたぐ不連続な範囲
(午後11時から午前1時など)の両方を設定できる。
min属性およびmax属性は、
要素に許可される値の範囲を示す。
それらの構文は、type属性の現在の状態を
定義する節によって定義される。
要素がmin属性を持ち、
min属性の値に
文字列を数値に変換する
アルゴリズムを適用した結果が数値である場合、その数値が要素の最小値である。そうでなく、type属性の現在の
状態が既定の最小値を定義している場合、それが
最小値である。それ以外の場合、要素は
最小値を持たない。
要素がmax属性を持ち、
max属性の値に
文字列を数値に変換する
アルゴリズムを適用した結果が数値である場合、その数値が要素の最大値である。そうでなく、type属性の現在の
状態が既定の最大値を定義している場合、それが
最大値である。それ以外の場合、要素は
最大値を持たない。
要素が周期的な定義域を持たない場合、
max属性の値
(最大値)は、min属性の値
(その最小値)未満であってはならない。
周期的な定義域を持たない要素の 最大値がその最小値未満である場合、要素に値がある限り、 要素にはアンダーフローが生じているか、 オーバーフローが生じているかの いずれかとなる。
要素が周期的な定義域を持ち、その 最大値がその最小値未満である場合、 その要素は逆転した範囲を持つ。
制約検証:要素が最小値を持ち、逆転した範囲を持たず、要素の値によって与えられる 文字列に文字列を数値に変換する アルゴリズムを適用した結果が数値であり、そのアルゴリズムから得られた数値が 最小値未満である場合、要素にはアンダーフローが生じている。
制約検証:要素が最大値を持ち、逆転した範囲を持たず、要素の値によって与えられる 文字列に文字列を数値に変換する アルゴリズムを適用した結果が数値であり、そのアルゴリズムから得られた数値が 最大値を超える場合、要素にはオーバーフローが生じている。
制約検証:要素が逆転した範囲を持ち、要素の値によって与えられる 文字列に文字列を数値に変換する アルゴリズムを適用した結果が数値であり、そのアルゴリズムから得られた数値が 最大値を超え、かつ最小値未満である場合、 要素には同時にアンダーフローが生じており、 オーバーフローが生じている。
次の日付コントロールは、入力を1980年代より前の日付に制限する。
< input name = bday type = date max = "1979-12-31" > 次の数値コントロールは、入力を0より大きい整数に制限する。
< input name = quantity required = "" type = "number" min = "1" value = "1" > 次の時刻コントロールは、入力を午後9時から午前6時までの間の分に制限し、 既定値を午前0時とする。
< input name = "sleepStart" type = time min = "21:00" max = "06:00" step = "60" value = "00:00" > step属性現在のすべてのエンジンでサポートされている。
step属性は、
許可される値を制限することにより、値または複数の値に期待される(かつ要求される)粒度を示す。
type属性の現在の状態を
定義する節は、以下で説明する属性の処理に使用される既定のステップ、ステップ尺度係数、および一部の場合には既定のステップ基準も定義する。
step属性を指定する場合、
その値は、構文解析すると0より大きい数値に
なる妥当な浮動小数点数であるか、
文字列「any」とASCII大文字小文字を区別せず一致する値でなければならない。
この属性は、要素について次のように許可される値のステップを提供する。
属性が適用されない場合、 許可される値のステップは存在しない。
そうでなく、属性が存在しない場合、許可される値のステップは、既定のステップにステップ尺度 係数を乗じた値である。
そうでなく、属性の値が文字列「any」とASCII大文字小文字を区別せず一致する場合、
許可される値のステップは存在しない。
そうでなく、属性の値に浮動小数点数値を 構文解析する規則を適用したとき、エラー、0、または0未満の数値が返される場合、 許可される値のステップは、既定のステップにステップ尺度係数を乗じた値である。
そうでなければ、許可される値のステップは、属性の値に浮動小数点数値を 構文解析する規則を適用して返された数値に、ステップ尺度係数を乗じた値である。
ステップ基準は、次のアルゴリズムによって返される値である。
要素がmin
コンテンツ属性を持ち、minコンテンツ属性の値に
文字列を数値に変換する
アルゴリズムを適用した結果がエラーでない場合、その結果を返す。
要素がvalueコンテンツ属性を持ち、
valueコンテンツ属性の
値に文字列を数値に変換する
アルゴリズムを適用した結果がエラーでない場合、その結果を返す。
0を返す。
制約検証:要素が許可される値のステップを持ち、要素の値によって与えられる文字列に 文字列を数値に変換するアルゴリズムを 適用した結果が数値であり、その数値からステップ基準を減じた値が許可される値のステップの整数倍でない場合、 要素にはステップ不一致が生じている。
次の範囲コントロールは0から1までの範囲の値のみを受け入れ、その範囲内で256段階を許可する。
< input name = opacity type = range min = 0 max = 1 step = 0.00392156863 > 次のコントロールでは、任意の精度(例えば1000分の1秒以上の精度)で、 1日の任意の時刻を選択できる。
< input name = favtime type = time step = any > 通常、時刻コントロールの精度は1分に制限される。
list属性現在のすべてのエンジンでサポートされている。
list属性は、ユーザーに提案される定義済みの選択肢を
列挙する要素を識別するために使用される。
存在する場合、その値は、同じツリー内にあるdatalist要素の
IDでなければならない。
候補ソース要素は、list属性の値と等しい
IDを持つ、ツリー内のツリー順で最初の要素が、datalist要素で
ある場合、その要素である。list属性が存在しない場合、
そのIDを持つ要素が存在しない場合、
またはそのIDを持つ最初の要素がdatalist要素で
ない場合、候補ソース要素は存在しない。
候補ソース要素が存在する場合、ユーザーエージェントが
ユーザーにinput要素の値を編集させるとき、
ユーザーエージェントは、使用されるコントロールの種類に適した方法で、候補ソース要素によって表される候補をユーザーに
提供すべきである。適切な場合、ユーザーエージェントは、候補のラベルおよび値を使用して、
ユーザーにその候補を識別させるべきである。
候補数が多い場合、ユーザーエージェントは候補ソース要素によって表される候補を絞り込み、 最も関連性の高いものだけを含めることが推奨される(例えば、これまでのユーザー入力に基づく)。 正確なしきい値は定義されないが、リストを4から7個の値に制限するのが妥当である。 ユーザー入力に基づいて絞り込む場合、ユーザーエージェントは候補のラベルと値の両方から一致するものを 検索すべきである。ユーザーエージェントは、入力の差異が照合処理にどのように影響するかを 考慮すべきである。異なるキーボードまたは入力固有の機構によって生じる、基礎となるUnicode コードポイント列の違いが照合処理を妨げないよう、Unicode正規化を適用すべきである。 大文字小文字の違いは無視すべきであり、そのために言語固有の大文字小文字マッピングが必要となる 場合がある。これらの例については、Character Model for the World Wide Web: String Matchingを参照されたい。ユーザーエージェントは、他の照合機能も提供してよい。 例として、異なるかな表記同士(または漢字との)照合、アクセント記号の無視、綴り訂正の適用などが 挙げられる。[CHARMODNORM]
このテキストフィールドでは、JavaScript関数の種類を選択できる。
< input type = "text" list = "function-types" >
< datalist id = "function-types" >
< option value = "function" > function</ option >
< option value = "async function" > async function</ option >
< option value = "function*" > generator function</ option >
< option value = "=>" > arrow function</ option >
< option value = "async =>" > async arrow function</ option >
< option value = "async function*" > async generator function</ option >
</ datalist > 上記の提案に従うユーザーエージェントでは、ラベルと値の両方が 表示される。

次に、「arrow」または「=>」と入力すると、リストは ラベルが「arrow function」および「async arrow function」のエントリーに絞り込まれる。 「generator」または「*」と入力すると、リストはラベルが 「generator function」および「async generator function」のエントリーに絞り込まれる。
いつものように、ユーザーエージェントは、それぞれの要件およびユーザー固有の状況に 適したユーザーインターフェイス上の決定を自由に行える。しかし、歴史的にこれは実装者、 ウェブ開発者、ユーザーのいずれにとっても混乱の原因となってきた領域であるため、 上記ではいくつかの「すべき」という提案を示した。
ユーザーによる候補の選択をどのように処理するかは、その要素が単一の値だけを受け入れる コントロールであるか、複数の値を受け入れるかによって異なる。
multiple属性が
指定されていない場合、またはmultiple属性が適用されない場合ユーザーが候補を選択した場合、input要素の値を、ユーザー自身がその値を
入力したかのように、選択された候補の値に設定しなければならない。
type属性が
メールアドレス状態であり、要素にmultiple属性が
指定されている場合
ユーザーが候補を選択した場合、ユーザーエージェントは、選択された候補の値を値とする新しい
エントリーをinput要素の複数の値に追加するか、
input要素の複数の値内の既存の
エントリーを、選択された候補の値によって与えられる値に変更しなければならない。
これは、ユーザー自身がその値を持つエントリーを追加したか、既存のエントリーをその値に編集した
かのように行う。どちらの振る舞いを適用するかは、ユーザーインターフェイスに応じて実装定義の方法で決まる。
list属性が適用されない場合、候補ソース要素は存在しない。
このURLフィールドはいくつかの候補を提供する。
< label > Homepage: < input name = hp type = url list = hpurls ></ label >
< datalist id = hpurls >
< option value = "https://www.google.com/" label = "Google" >
< option value = "https://www.reddit.com/" label = "Reddit" >
</ datalist > ユーザーの履歴にある他のURLも表示される場合がある。これはユーザーエージェントに委ねられる。
この例は、旧来のユーザーエージェントでも有用に機能低下しつつ、オートコンプリートリスト機能を 使用するフォームの設計方法を示す。
オートコンプリートリストが単なる補助であり、内容にとって重要でない場合は、子としてoption要素を持つ
datalist要素を
使用するだけで十分である。旧来のユーザーエージェントで値がレンダリングされるのを防ぐには、
値をインラインではなくvalue属性内に
配置する必要がある。
< p >
< label >
Enter a breed:
< input type = "text" name = "breed" list = "breeds" >
< datalist id = "breeds" >
< option value = "Abyssinian" >
< option value = "Alpaca" >
<!-- ... -->
</ datalist >
</ label >
</ p > ただし、旧来のUAで値を表示する必要がある場合は、次のようにフォールバックコンテンツを
datalist要素内に
配置できる。
< p >
< label >
Enter a breed:
< input type = "text" name = "breed" list = "breeds" >
</ label >
< datalist id = "breeds" >
< label >
or select one from the list:
< select name = "breed" >
< option value = "" > (none selected)
< option > Abyssinian
< option > Alpaca
<!-- ... -->
</ select >
</ label >
</ datalist >
</ p > フォールバックコンテンツは、datalistを
サポートしないUAでのみ表示される。一方、選択肢はdatalist要素の
子でなくても、すべてのUAによって検出される。
datalistで使用される
option要素がselectedである場合、
旧来のUAでは(select要素に影響するため)
既定で選択されるが、datalistを
サポートするUAでは、input要素には
何の影響も与えないことに注意されたい。
placeholder
属性現在のすべてのエンジンでサポートされている。
Element/input#attr-placeholder
現在のすべてのエンジンでサポートされている。
placeholder属性は、コントロールに値がないとき、
ユーザーのデータ入力を支援することを目的とした短いヒント(単語または短い語句)を表す。
ヒントには、値の例や期待される形式の簡潔な説明を使用できる。属性を指定する場合、その値に
U+000A LINE FEED(LF)文字またはU+000D CARRIAGE RETURN(CR)文字を含めてはならない。
placeholder
属性は、labelの代わりとして
使用すべきではない。より長いヒントやその他の助言的なテキストには、title属性の方が適切である。
これらの仕組みは非常によく似ているが、微妙に異なる。コントロールのlabelによって
与えられるヒントは常に表示される。placeholder属性で与えられる短いヒントは、ユーザーが
値を入力する前に表示される。title属性のヒントは、
ユーザーが追加の助けを求めたときに表示される。
要素の値が空文字列である場合、特にコントロールがフォーカスされていない場合、 ユーザーエージェントは、ヒントから改行を除去した後、そのヒントをユーザーに提示すべきである。
ユーザーエージェントが通常、コントロールがフォーカスされているときにこのヒントを
ユーザーに表示しない場合でも、コントロールがautofocus属性に
よってフォーカスされたのであれば、ユーザーエージェントはそのコントロールのヒントを表示すべきである。
この場合、ユーザーにはフォーカスされる前にコントロールを確認する機会がなかったためである。
次は、placeholder属性を使用するメール設定ユーザーインターフェイスの
例である。
< fieldset >
< legend > Mail Account</ legend >
< p >< label > Name: < input type = "text" name = "fullname" placeholder = "John Ratzenberger" ></ label ></ p >
< p >< label > Address: < input type = "email" name = "address" placeholder = "john@example.net" ></ label ></ p >
< p >< label > Password: < input type = "password" name = "password" ></ label ></ p >
< p >< label > Description: < input type = "text" name = "desc" placeholder = "My Email Account" ></ label ></ p >
</ fieldset > コントロールの内容がある方向性を持つ一方、プレースホルダーには別の方向性が必要な場合、 属性値でUnicodeの双方向アルゴリズム整形文字を使用できる。
< input name = t1 type = tel placeholder = " ‫ رقم الهاتف 1 ‮ " >
< input name = t2 type = tel placeholder = " ‫ رقم الهاتف 2 ‮ " > 少し分かりやすくするため、インラインのアラビア語の代わりに数値文字参照を使用した 同じ例を次に示す。
< input name = t1 type = tel placeholder = " ‫ رقم الهاتف 1 ‮ " >
< input name = t2 type = tel placeholder = " ‫ رقم الهاتف 2 ‮ " > input要素APIinput.value [ = value ]
フォームコントロールの現在の値を返す。
値を変更するために設定できる。
コントロールがファイルアップロードコントロールであるときに空文字列以外の値を設定すると、
"InvalidStateError" DOMExceptionをスローする。
input.checked [ = value ]
フォームコントロールの現在のチェック状態を返す。
チェック状態を変更するために設定できる。
input.files [ = files ]
現在のすべてのエンジンでサポートされている。
現在のすべてのエンジンでサポートされている。
フォームコントロールの選択されたファイルを列挙する
FileListオブジェクトを返す。
コントロールがファイルコントロールでない場合はnullを返す。
フォームコントロールの選択されたファイルを変更するために、
FileListオブジェクトを設定できる。
例えば、ドラッグアンドドロップ操作の結果として設定できる。
input.valueAsDate [ = value ]
該当する場合、フォームコントロールの値を表すDateオブジェクトを返す。
それ以外の場合はnullを返す。
値を変更するために設定できる。
コントロールが日付または時刻に基づくものでない場合、"InvalidStateError" DOMExceptionをスローする。
input.valueAsNumber [ = value ]
該当する場合、フォームコントロールの値を表す数値を返す。 それ以外の場合はNaNを返す。
値を変更するために設定できる。これをNaNに設定すると、基礎となる値は空文字列に設定される。
コントロールが日付または時刻に基づくものでも数値でもない場合、"InvalidStateError" DOMExceptionをスローする。
input.stepUp([ n ])
input.stepDown([ n ])
フォームコントロールの値を、step属性で
与えられる値にnを乗じた値だけ変更する。nの既定値は1である。
コントロールが日付または時刻に基づくものでも数値でもない場合、またはstep属性の値が
「any」である場合、"InvalidStateError" DOMExceptionをスローする。
input.listinput.showPicker()
ユーザーが値を選択できるよう、inputに該当するピッカーUIを表示する。
inputがピッカーをサポートしない場合、 このメソッドは何もしない。
inputが変更可能でない場合、
"InvalidStateError" DOMExceptionをスローする。
一時的なユーザー活性化なしに呼び出された場合、
"NotAllowedError" DOMExceptionをスローする。
inputがオリジンをまたぐiframe内に
あり、inputがファイルアップロード状態または色状態でない場合、
"SecurityError" DOMExceptionをスローする。
valueIDL属性により、スクリプトはinput要素の値を操作できる。
この属性は、振る舞いを定義する次のいずれかのモードになる。
取得時には、要素の現在の値を返す。
設定時:
oldValueを、要素の値とする。
要素の値を新しい値に設定する。
要素のダーティー値フラグをtrueに設定する。
要素のtype属性の
現在の状態が値のサニタイズアルゴリズムを
定義している場合、それを呼び出す。
要素の値が(値のサニタイズアルゴリズムを
適用した後)oldValueと異なり、要素がテキスト入力カーソル位置を
持つ場合、テキスト入力カーソル位置を
テキストコントロールの末尾に移動し、選択されているテキストの選択を解除し、選択方向を
リセットして「none」にする。
取得時には、要素がvalue
コンテンツ属性を持つ場合、その属性の値を返す。そうでなければ空文字列を返す。
設定時には、要素のvalue
コンテンツ属性の値を新しい値に設定する。
取得時には、要素がvalue
コンテンツ属性を持つ場合、その属性の値を返す。そうでなければ文字列「on」を返す。
設定時には、要素のvalue
コンテンツ属性の値を新しい値に設定する。
取得時には、文字列「C:\fakepath\」に、選択されたファイルのリストに
ファイルがあればその最初のファイル名を続けた文字列を返す。リストが空の場合は空文字列を返す。
設定時には、新しい値が空文字列である場合、選択されたファイルのリストを
空にする。そうでなければ、"InvalidStateError" DOMExceptionをスローする。
この「fakepath」要件は、歴史上の不幸な事故である。詳細については、ファイルアップロード状態の節にある例を参照されたい。
選択されたファイルのリスト内の ファイル名にはパス構成要素が許可されないため、 「\fakepath\」がパス構成要素と誤解されることはない。
checkedIDL属性により、スクリプトはinput要素のチェック状態を操作できる。
取得時には、要素の現在のチェック状態を返さなければならない。
設定時には、要素のチェック状態を新しい値に設定し、
要素のダーティーチェック状態
フラグをtrueに設定しなければならない。
filesIDL属性により、スクリプトは要素の選択されたファイルにアクセスできる。
取得時に、IDL属性が適用される場合、現在の選択されたファイルを表すFileListオブジェクトを
返さなければならない。選択されたファイルのリストが
変更されるまでは、同じオブジェクトを返さなければならない。IDL属性が適用されない場合は、代わりにnullを
返さなければならない。[FILEAPI]
valueAsDateIDL属性は、日付として解釈された要素の値を表す。
取得時に、input要素の
type属性の
現在の状態について定義されるとおり、valueAsDate属性が適用されない場合、nullを返す。
そうでなければ、その状態について定義された文字列をDateオブジェクトに
変換するアルゴリズムを要素の値に適用する。アルゴリズムがDateオブジェクトを返した場合、
それを返す。そうでなければnullを返す。
設定時に、input要素の
type属性の
現在の状態について定義されるとおり、valueAsDate属性が適用されない場合、"InvalidStateError" DOMExceptionをスローする。
そうでなく、新しい値がnullでなく、かつDateオブジェクトでもない場合、
TypeError
例外をスローする。そうでなく、新しい値がnullであるか、NaN時刻値を表すDateオブジェクトである場合、
要素の値を空文字列に設定する。
そうでなければ、その状態について定義されたDateオブジェクトを文字列に
変換するアルゴリズムを新しい値に対して実行し、要素の値を結果の文字列に設定する。
valueAsNumberIDL属性は、数値として解釈された要素の値を表す。
取得時に、input要素の
type属性の
現在の状態について定義されるとおり、valueAsNumber属性が適用されない場合、非数(NaN)値を返す。
そうでなければ、その状態について定義された文字列を数値に変換する
アルゴリズムを要素の値に適用する。アルゴリズムが数値を
返した場合はそれを返し、そうでなければ非数(NaN)値を返す。
設定時に、新しい値が無限大である場合、TypeError
例外をスローする。
そうでなく、input要素の
type属性の
現在の状態について定義されるとおり、valueAsNumber属性が適用されない場合、"InvalidStateError" DOMExceptionをスローする。
そうでなく、新しい値が非数(NaN)値である場合、要素の値を空文字列に設定する。
そうでなければ、その状態について定義された数値を文字列に変換するアルゴリズムを
新しい値に対して実行し、要素の値を結果の文字列に設定する。
stepDown(n)メソッドおよびstepUp(n)メソッドは、呼び出されたとき、
次のアルゴリズムを実行しなければならない。
input要素の
type属性の
現在の状態について定義されるとおり、stepDown()メソッドおよびstepUp()メソッドが
適用されない場合、"InvalidStateError" DOMExceptionをスローする。
要素が許可される値のステップを持たない場合、
"InvalidStateError" DOMExceptionをスローする。
要素が最小値および最大値を持ち、要素の最小値以上かつ要素の最大値以下であり、その値からステップ基準を減じた値が許可される値のステップの整数倍となる値が 存在しない場合、返る。
要素の値によって与えられる文字列に文字列を数値に変換する アルゴリズムを適用した結果がエラーでない場合、valueをそのアルゴリズムの 結果とする。そうでなければ、valueを0とする。
valueBeforeSteppingをvalueとする。
valueからステップ基準を減じた値が許可される値のステップの整数倍でない場合、
valueを、そこからステップ基準を減じた値が許可される値のステップの整数倍となる最も近い値に
設定する。呼び出されたメソッドがstepDown()メソッドである場合、その値はvalue未満とし、
それ以外の場合はvalueを超える値とする。
そうでない場合(valueからステップ基準を減じた値が許可される値のステップの整数倍である場合):
nを引数とする。
deltaを、許可される値のステップに nを乗じた値とする。
呼び出されたメソッドがstepDown()メソッドである場合、
deltaの符号を反転する。
valueを、valueにdeltaを加えた結果とする。
要素が最小値を持ち、valueがその最小値未満である場合、valueを、 そこからステップ基準を減じた値が許可される値のステップの整数倍となり、 かつその最小値以上となる最小の値に設定する。
要素が最大値を持ち、valueがその最大値を超える場合、valueを、 そこからステップ基準を減じた値が許可される値のステップの整数倍となり、 かつその最大値以下となる最大の値に設定する。
呼び出されたメソッドがstepDown()メソッドで、valueが
valueBeforeSteppingを超える場合、または呼び出されたメソッドがstepUp()メソッドで、valueが
valueBeforeStepping未満である場合、返る。
value as stringを、input要素のtype属性の
現在の状態について定義された数値を文字列に変換する
アルゴリズムをvalueに対して実行した結果とする。
要素の値をvalue as stringに設定する。
listIDL属性は、現在の候補ソース要素が存在する場合はそれを返し、
そうでなければnullを返さなければならない。
現在のすべてのエンジンでサポートされている。
HTMLInputElementの
showPicker()メソッドおよびHTMLSelectElementのshowPicker()メソッドの手順は次のとおりである。
thisが変更可能でない場合、
"InvalidStateError" DOMExceptionをスローする。
thisの関連する設定オブジェクトのオリジンが、thisの関連する設定オブジェクトのトップレベルオリジンと同一オリジンでなく、かつ
thisがselect要素であるか、または
thisのtype属性が
ファイルアップロード状態でも色状態でもない場合、
"SecurityError" DOMExceptionをスローする。
ファイル入力および色入力は、歴史的理由によりこの検査から 免除される。これらのinputの活性化の振る舞いもピッカーを 表示し、オリジン検査によって保護されたことがないためである。
thisの関連するグローバルオブジェクトが一時的な活性化を持たない場合、
"NotAllowedError"
DOMExceptionをスローする。
thisがselect要素であり、かつthisがレンダリングされていない場合、"NotSupportedError"
DOMExceptionをスローする。
thisについて、該当する場合にピッカーを表示する。
input要素またはselect要素elementについて、該当する場合にピッカーを表示するには:
elementの関連するグローバルオブジェクトが一時的な活性化を持たない場合、返る。
elementが変更可能でない場合、返る。
elementの関連するグローバル オブジェクトを与えて、ユーザー活性化を消費する。
elementがピッカーをサポートしない場合、返る。
elementがinput要素であり、elementのtype属性が
ファイルアップロード状態である場合、
次の手順を並行して実行する。
任意で、このアルゴリズムの以前の実行が終了するまで待つ。
dismissedを、elementを使用してWebDriver BiDi file dialog openedを 実行した結果とする。
dismissedがfalseである場合:
ユーザーにいくつかのファイルを指定するよう求めるプロンプトを表示する。
elementにmultiple属性が設定されていない場合、
選択されるファイルは1つ以下でなければならない。そうでなければ、任意の数を選択してよい。
ファイルはファイルシステムから取得しても、その場で作成してもよい。例えば、
ユーザーのデバイスに接続されたカメラで撮影した写真を使用できる。
ユーザーが選択を行うまで待つ。
dismissedがtrueであるか、ユーザーが選択を変更せずにプロンプトを閉じた場合、
elementを与えてユーザー操作タスク
ソースに要素タスクをキューし、
elementでcancelという名前の
イベントを発火する。bubbles属性はtrueに
初期化する。
そうでなければ、elementについてファイル選択を更新する。
すべてのユーザーインターフェイス仕様と同様に、ユーザーエージェントには、
これらの要件をどのように解釈するかについて大きな自由がある。上記の文章は、
ユーザーがプロンプトを閉じるか、選択を変更するかのいずれか一方だけが真になることを
暗示している。しかし、これらの可能性を特定のユーザーインターフェイス要素にどのように
対応付けるかは、標準によって義務付けられていない。例えば、以前にファイルが選択されていた
ときに「Cancel」ボタンをクリックした場合、ユーザーエージェントはそれをファイル数0への
選択変更と解釈し、inputおよびchangeを発火することが
できる。または、そのクリックを選択を変更しないままプロンプトを閉じたものと解釈し、cancelを発火することも
できる。同様に、以前選択されていたものと同じファイルを再選択することを、プロンプトを
閉じたものと数えるか、選択の変更と数えるかもユーザーエージェントに委ねられる。
そうでなければ、ユーザーエージェントは、ユーザーが通常そのコントロールを操作するときと 同じ方法で、elementの値を選択するための関連するユーザーインターフェイスを 表示すべきである。
そのようなユーザーインターフェイスを表示するとき、elementのtype属性の状態に
基づく振る舞いについて、仕様の関連部分で定められた要件に従わなければならない。
(例えば、さまざまな節で、結果となる値の文字列に対する制限が説明されている。)
この手順には、このアルゴリズムによって以前に表示された他のピッカーを閉じるなどの
副作用が生じる場合がある。(これによってファイル選択ピッカーが閉じられた場合、
上記に従い、inputイベントおよびchangeイベントの
いずれか、またはcancelイベントが
発火される。)
input
およびchangeイベントが適用される
場合(これは、ボタンおよびtype属性が状態にあるものを
除く、すべてのinputコントロールに
該当する)、これらのイベントは、ユーザーがコントロールを操作したことを示すために発火される。input
イベントは、ユーザーがコントロールのデータを変更するたびに発火する。changeイベントは、そのコントロールに
とって意味がある場合は値が確定されたときに、そうでない場合はコントロールがフォーカスを失ったときに発火する。
すべての場合において、input
イベントは、対応する
changeイベント(存在する場合)より前に発火する。
input
要素に定義済みのinputの活性化動作がある場合、これらのイベントが適用されるならば、
それらをディスパッチする規則は、上記のtype属性の
状態を定義する節に示される。(これは、type属性が
チェックボックス状態、ラジオ
ボタン状態、またはファイルアップロード状態にある、すべてのinputコントロールに該当する。)
定義済みのinputの活性化動作を持たないものの、
これらのイベントが適用されるinput要素であり、
そのユーザーインターフェイスに対話的な操作と明示的な確定操作の両方が含まれる場合、ユーザーが
要素の値を変更したとき、ユーザーエージェントは、
そのinput要素を
与えて、ユーザーインタラクションタスクソース上に
要素タスクをキューに入れ、
input
要素において、bubbles
およびcomposed
属性をtrueに初期化して、input
という名前のイベントを発火しなければならない。
また、ユーザーが変更を確定するたびに、ユーザーエージェントは、そのinput要素を与えて、
ユーザーインタラクションタスクソース上に
要素タスクを
キューに入れ、そのユーザー妥当性をtrueに設定した後、
input
要素において、bubbles
属性をtrueに初期化して、changeという名前のイベントを発火しなければならない。
対話的な操作と確定操作の両方を伴うユーザーインターフェイスの例として、
ポインティングデバイスを使用して操作される、スライダーを使用する範囲コントロールが挙げられる。
ユーザーがコントロールのつまみをドラッグしている間、位置が変わるたびにinput
イベントが発火する一方、changeイベントは、
ユーザーがつまみを放して特定の値を確定したときにのみ発火する。
定義済みのinputの活性化動作を持たないものの、
これらのイベントが適用されるinput要素であり、
そのユーザーインターフェイスに明示的な確定操作は含まれるが中間的な操作は含まれない場合、ユーザーが
要素の値に対する変更を確定するたびに、ユーザー
エージェントは、そのinput要素を
与えて、ユーザーインタラクションタスクソース上に
要素
タスクをキューに入れ、まずinput
要素において、bubbles
およびcomposed
属性をtrueに初期化して、input
という名前のイベントを
発火し、次にchangeという名前のイベントを発火しなければならない。後者は、input
要素において、bubbles
属性をtrueに初期化して発火する。
確定操作を伴うユーザーインターフェイスの例として、カラーホイールを 表示する単一のボタンから構成される色コントロールが挙げられる。ダイアログが 閉じられたときにのみ値が変更される場合、それが明示的な確定操作となる。 一方、コントロールの操作によって色が対話的に変更される場合、確定操作が存在しないこともある。
確定操作を伴うユーザーインターフェイスの別の例として、テキストによる ユーザー入力とドロップダウンカレンダーからのユーザー選択の両方を許可する日付コントロールが 挙げられる。テキスト入力には明示的な確定手順がない場合でも、ドロップダウンカレンダーから 日付を選択し、その後ドロップダウンを閉じることは確定操作となる。
定義済みのinputの活性化動作を持たないものの、
これらのイベントが適用されるinput要素について、
ユーザーが明示的な確定操作なしに要素の値を変更させるたびに、ユーザーエージェントは、
そのinput要素を与えて、
ユーザーインタラクションタスク
ソース上に要素タスクをキューに入れ、input
要素において、bubbles
およびcomposed
属性をtrueに初期化して、input
という名前のイベントを
発火しなければならない。対応するchangeイベントが存在する場合、
それはコントロールがフォーカスを失ったときに発火する。
ユーザーが要素の値を変更する例には、テキストコントロールへの入力、 コントロールへの新しい値の貼り付け、またはそのコントロール内の編集の取り消しが含まれる。 一部のユーザー操作は値を変更しない。例えば、空のテキストコントロールで「delete」キーを押すことや、 コントロール内のテキストを、たまたままったく同じ内容であるクリップボード上のテキストに 置き換えることが該当する。
ユーザーがフォーカスし、キーボードで操作しているスライダー形式の範囲コントロールも、確定手順なしにユーザーが 要素の値を変更する別の例である。
input
イベントを発火するだけのタスクの場合、ユーザーエージェントは、タスクをキューに入れる前に、
ユーザーの操作における適切な中断を待ってもよい。例えば、各キーストロークごとに連続してイベントを
発火する代わりに、ユーザーが一時停止したときにのみイベントを発火するよう、ユーザーが100msの間
キーを押していない状態になるまで待つことができる。
ユーザーエージェントが、ユーザーに代わってinput要素の値を変更する場合
(例えば、フォームの事前入力機能の一部として)、ユーザーエージェントは、そのinput要素を与えて、
ユーザーインタラクション
タスクソース上に要素タスクをキューに入れ、まず値をそれに応じて更新し、
次にinput要素において、
bubbles
およびcomposed
属性をtrueに初期化して、input
という名前のイベントを
発火し、その後changeという名前のイベントを発火しなければならない。後者は、input
要素において、bubbles
属性をtrueに初期化して発火する。
これらのイベントは、スクリプトによってフォームコントロールの値に加えられた変更に 応じて発火されることはない。(これは、ユーザーによるコントロールの操作に応じてフォームコントロールの 値を更新する際に、無限ループを避けるためにスクリプト自身による変更を除外する必要がないようにするためである。)
これらのイベントは、ブラウザーがナビゲーション中の 状態復元の一環としてフォームコントロールの値を変更した場合にも発火されない。
button
要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
select要素の最初の子として。tabindex属性が指定された
子孫が存在してはならない。要素がselect要素の最初の子である
場合は、1つの子孫selectedcontent
要素を持つこともできる。command —
ターゲットとされた要素に対して、実行する操作を示す。
commandfor —
呼び出す別の要素をターゲットにする。
disabled —
フォームコントロールが無効かどうか
form —
要素をform要素に関連付ける
formaction —
URL。フォーム送信に使用する
formenctype —
フォーム送信に使用するエントリーリストの符号化方式
formmethod —
フォーム送信に使用する種類
formnovalidate
— フォーム
送信においてフォームコントロールの検証を迂回する
formtarget —
フォーム送信のためのナビゲート可能
name —
フォーム送信およびform.elements APIで使用する
要素の名前
popovertarget —
切り替え、表示、または非表示にするポップオーバー要素をターゲットにする
popovertargetaction
— ターゲットとされたポップオーバー要素を切り替えるか、表示するか、非表示にするかを示す
type —
ボタンの種類
value —
フォーム送信に使用する値
formactionを伴う。
[Exposed =Window ]
interface HTMLButtonElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , ReflectSetter ] attribute DOMString command ;
[CEReactions , Reflect ] attribute Element ? commandForElement ;
[CEReactions , Reflect ] attribute boolean disabled ;
readonly attribute HTMLFormElement ? form ;
[CEReactions , ReflectSetter ] attribute USVString formAction ;
[CEReactions ] attribute DOMString formEnctype ;
[CEReactions ] attribute DOMString formMethod ;
[CEReactions , Reflect ] attribute boolean formNoValidate ;
[CEReactions , Reflect ] attribute DOMString formTarget ;
[CEReactions , Reflect ] attribute DOMString name ;
[CEReactions , ReflectSetter ] attribute DOMString type ;
[CEReactions , Reflect ] attribute DOMString value ;
readonly attribute boolean willValidate ;
readonly attribute ValidityState validity ;
readonly attribute DOMString validationMessage ;
boolean checkValidity ();
boolean reportValidity ();
undefined setCustomValidity (DOMString error );
readonly attribute NodeList labels ;
};
HTMLButtonElement includes PopoverTargetAttributes ;button要素は、その
内容によってラベル付けされたボタンを表す。
この要素はボタンである。
type属性は、ボタンが活性化されたときの動作を制御する。
これは、次のキーワードと状態を持つ列挙
属性である。
| キーワード | 状態 | 簡単な説明 |
|---|---|---|
submit
|
送信ボタン | フォームを送信する。 |
reset
|
リセットボタン | フォームをリセットする。 |
button
|
ボタン | 何もしない。 |
この属性の欠落値の デフォルトおよび無効値の デフォルトは、いずれも自動状態である。
button要素が、
select要素の
要素である最初の子である場合、その要素は不活性である。
指定される場合、commandfor属性値は、そのcommandfor属性を
持つボタンと同じツリー内にある要素のIDでなければならない。
command属性は、次のキーワードと状態を持つ列挙
属性である。
| キーワード | 状態 | 簡単な説明 |
|---|---|---|
toggle-popover
|
ポップオーバー切り替え | ターゲットとされたpopover要素を表示または非表示にする。
|
show-popover
|
ポップオーバー表示 | ターゲットとされたpopover要素を表示する。
|
hide-popover
|
ポップオーバー非表示 | ターゲットとされたpopover要素を非表示にする。
|
close
|
閉じる | ターゲットとされたdialog要素を閉じる。
|
request-close
|
閉じるよう要求 | ターゲットとされたdialog要素を
閉じるよう要求する。
|
show-modal
|
モーダル表示 | ターゲットとされたdialog要素を
モーダルとして開く。
|
| カスタムコマンド キーワード | カスタム | ターゲットとされた要素においてcommandイベントのみを
ディスパッチする。
|
この属性の欠落値の デフォルトおよび無効値のデフォルトは、いずれも不明状態である。
カスタムコマンドキーワードとは、
「--」で始まる文字列である。
command属性commandおよび要素targetが
与えられたとき、コマンドがターゲットに対して有効かどうかを
判定するには、次を実行する。
commandが不明状態である場合、falseを返す。
commandがカスタム状態である場合、trueを返す。
targetがHTML 要素ではない場合、falseを返す。
commandが次のいずれかの状態である場合:
trueを返す。
この標準が、targetのローカル 名について有効コマンド判定ステップを定義していない場合、 falseを返す。
それ以外の場合、commandを与えて、targetに対応する有効 コマンド判定ステップを実行した結果を返す。
button要素
elementに、eventが与えられたときの活性化動作は、次のとおりである。
elementが無効である場合、戻る。
elementがフォーム所有者を持つ場合:
targetを、elementのcommandforに関連付けられた
要素を取得する処理を実行した結果とする。
targetがnullではない場合:
commandをelementのcommand
属性とする。
commandおよびtargetを与えて、コマンドがターゲットに対して 有効かどうかを判定した結果がfalseである場合、戻る。
continueを、targetにおいてcommandという名前の
イベントを
発火した結果とする。CommandEventを使用し、そのcommand
属性をcommandに、そのsource
属性をelementに、そのcancelable
属性をtrueに初期化する。
DOM標準のissue #1328では、イベントにとって意味のある方法で関連イベントデータをより適切に標準化する方法を 追跡している。現在、値に初期化されたイベント属性はgetterも持つことができないため、 これを適切に指定するには内部スロット(または追加フィールドのマップ)が必要になる。
continueがfalseである場合、戻る。
targetが接続されていない場合、戻る。
commandがカスタム状態である場合、戻る。
commandがポップオーバー非表示状態である場合:
validityを、target、true、およびnullを与えてポップオーバーの妥当性を確認する処理を 実行した結果とする。これが例外をスローした場合は捕捉し、validityをfalseとする。
validityがtrueである場合、target、true、true、false、および elementを与えてポップオーバー非表示アルゴリズムを実行する。
それ以外で、commandがポップオーバー切り替え状態である場合:
validityを、target、false、およびnullを与えてポップオーバーの妥当性を確認する処理を 実行した結果とする。これが例外をスローした場合は捕捉し、validityをfalseとする。
validityがtrueである場合、target、false、およびelementを 与えてポップオーバー表示 アルゴリズムを実行する。
それ以外の場合:
validityを、target、true、およびnullを与えてポップオーバーの妥当性を確認する処理を 実行した結果とする。これが例外をスローした場合は捕捉し、validityをfalseとする。
validityがtrueである場合、target、true、true、false、および elementを与えてポップオーバー非表示アルゴリズムを 実行する。
それ以外で、commandがポップオーバー表示状態である場合:
validityを、target、false、およびnullを与えてポップオーバーの妥当性を確認する処理を 実行した結果とする。これが例外をスローした場合は捕捉し、validityをfalseとする。
validityがtrueである場合、target、false、およびelementを 与えてポップオーバー表示 アルゴリズムを実行する。
それ以外で、この標準がtargetのローカル 名についてコマンドステップを定義している場合、 target、element、およびcommandを与えて、対応するコマンドステップを実行する。
それ以外の場合、elementおよびeventのターゲットを与えて、ポップオーバーターゲット属性の 活性化動作を実行する。
HTML要素には、その要素のローカル名について定義された固有の 有効コマンド判定ステップおよびコマンドステップを持たせることができる。
form属性は、button要素をそのフォーム所有者に明示的に関連付けるために使用される。
name属性は要素の名前を表す。
disabled属性は、
コントロールを非インタラクティブにし、その値が送信されないようにするために使用される。formaction、
formenctype、formmethod、formnovalidate、
およびformtarget属性は、フォーム
送信用の属性である。
formnovalidate
属性は、制約検証を引き起こさない送信ボタンを作成するために使用できる。
formaction、formenctype、formmethod、formnovalidate、
およびformtargetは、要素が送信ボタンではない場合、
指定してはならない。
commandの取得手順は、次のとおりである。
value属性は、フォーム送信の目的における要素の値を与える。
要素の値は、要素にvalue属性が存在する場合は
その値であり、それ以外の場合は空文字列である。
要素のオプション
値は、要素にvalue属性が存在する場合は
その値であり、それ以外の場合はnullである。
ボタン(およびその値)は、そのボタン自体がフォーム送信を開始するために 使用された場合にのみ、フォーム送信に含まれる。
typeの取得手順は、次のとおりである。
willValidate、validity、およびvalidationMessage IDL属性、ならびにcheckValidity()、reportValidity()、およびsetCustomValidity()メソッドは、制約検証
APIの一部である。labels IDL属性は、要素のlabelのリストを提供する。
disabled、form、およびname IDL属性は、
要素のフォームAPIの一部である。
次のボタンには「Show hint」というラベルが付けられており、活性化されるとダイアログボックスを ポップアップする。
< button type = button
onclick = "alert('This 15-20 minute piece was composed by George Gershwin.')" >
Show hint
</ button > 次の例は、ボタンが、活性化されたときにpopover属性を持つ要素を
表示または非表示にするため、commandforを使用する方法を示している。
< button type = button
commandfor = "the-popover"
command = "show-popover" >
Show menu
</ button >
< div popover
id = "the-popover" >
< button commandfor = "the-popover"
command = "hide-popover" >
Hide menu
</ button >
</ div >
次の例は、指定されていない動作にカスタムコマンドを使用する方法を示すため、ボタンが要素上の
カスタムコマンド
キーワードとともにcommandforを使用する方法を示している。
< button type = button
commandfor = "the-image"
command = "--rotate-landscape" >
Rotate Left
</ button >
< button type = button
commandfor = "the-image"
command = "--rotate-portrait" >
Rotate Right
</ button >
< img id = "the-image"
src = "photo.jpg" >
< script >
const image = document. getElementById( "the-image" );
image. addEventListener( "command" , ( event) => {
if ( event. command == "--rotate-landscape" ) {
event. target. style. rotate = "-90deg"
} else if ( event. command == "--rotate-portrait" ) {
event. target. style. rotate = "0deg"
}
});
</ script >
select
要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
selectがドロップダウン
ボックスである場合は0個または1個のbutton要素、その後に
0個以上のoption要素、optgroup要素、hr要素、スクリプト支援
要素、noscript要素、
またはdiv要素。
autocomplete —
フォーム自動入力機能へのヒント
disabled —
フォームコントロールが無効かどうか
form —
要素をform要素に関連付ける
multiple —
複数の値を許可するかどうか
name —
フォーム送信およびform.elements APIで使用する
要素の名前
required —
フォーム
送信にコントロールが必須かどうか
size —
コントロールのサイズ
multiple属性、
または値が> 1であるsize属性を持つ場合:
著者向け;
実装者向け。
[Exposed =Window ]
interface HTMLSelectElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , ReflectSetter ] attribute DOMString autocomplete ;
[CEReactions , Reflect ] attribute boolean disabled ;
readonly attribute HTMLFormElement ? form ;
[CEReactions , Reflect ] attribute boolean multiple ;
[CEReactions , Reflect ] attribute DOMString name ;
[CEReactions , Reflect ] attribute boolean required ;
[CEReactions , Reflect , ReflectDefault=0] attribute unsigned long size ;
readonly attribute DOMString type ;
[SameObject ] readonly attribute HTMLOptionsCollection options ;
[CEReactions ] attribute unsigned long length ;
getter HTMLOptionElement ? item (unsigned long index );
HTMLOptionElement ? namedItem (DOMString name );
[CEReactions ] undefined add ((HTMLOptionElement or HTMLOptGroupElement ) element , optional (HTMLElement or long )? before = null );
[CEReactions ] undefined remove (); // ChildNode overload
[CEReactions ] undefined remove (long index );
[CEReactions ] setter undefined (unsigned long index , HTMLOptionElement ? option );
[SameObject ] readonly attribute HTMLCollection selectedOptions ;
attribute long selectedIndex ;
attribute DOMString value ;
readonly attribute boolean willValidate ;
readonly attribute ValidityState validity ;
readonly attribute DOMString validationMessage ;
boolean checkValidity ();
boolean reportValidity ();
undefined setCustomValidity (DOMString error );
undefined showPicker ();
readonly attribute NodeList labels ;
};select要素は、
一連のオプションから選択するためのコントロールを表す。
現在のすべてのエンジンでサポートされています。
multiple属性は論理属性である。この属性が存在する場合、select要素は、オプション
リストから0個以上のオプションを選択するためのコントロールを表す。この属性が存在しない場合、select要素は、オプションリストから単一のオプションを選択するための
コントロールを表す。
現在のすべてのエンジンでサポートされています。
size属性は、ユーザーに表示するオプションの数を与える。size属性が指定される場合、
その値は0より大きい妥当な非負整数でなければならない。
現在のすべてのエンジンでサポートされています。
required属性は論理属性である。指定された場合、ユーザーはフォームを
送信する前に値を選択することを要求される。
form属性は、select要素をそのフォーム所有者に明示的に関連付けるために使用される。
name属性は要素の名前を表す。
disabled属性は、
コントロールを非インタラクティブにし、その値が送信されないようにするために使用される。autocomplete属性は、ユーザーエージェントが自動入力動作を
提供する方法を制御する。
select要素に
required属性が指定され、表示
サイズが1であり、かつselect要素のオプションリスト内の最初のoption要素(存在する場合)の
値が空文字列であり、そのoption要素の親ノードが
select要素であって
optgroup要素ではない場合、そのoptionは、select要素のプレースホルダーラベルオプションである。
select要素に
required属性が指定され、multiple属性が指定されておらず、かつ表示サイズが1である場合、
select要素は
プレースホルダーラベル
オプションを持たなければならない。
実際には、上の段落で述べた要件は、select要素が、
1より大きい値を持つsize属性を持たない場合に
のみ適用され得る。
制約検証: 要素にrequired属性が指定されており、かつselect要素のオプションリスト内のどのoption要素も、その選択状態がtrueに設定されていないか、またはselect要素のオプションリスト内で選択状態がtrueに設定されている唯一のoption要素がプレースホルダーラベル
オプションである場合、要素は欠損状態にある。
select要素
selectElementのリセットアルゴリズムは、次のとおりである。
ユーザーエージェントは、select要素のオプションリストから、ユーザーがoption要素を
選択できるようにするべきである。これは、クリック、値を変更した後に要素からフォーカスを外すこと、
メニューコマンド、またはその他の
任意の仕組みによって、select要素、
option要素、
およびselectの
内容が基本外観でレンダリングされている場合は対応するkeydown
またはmouseup
イベント、それ以外の場合はnullを与えて、オプションを選択するアルゴリズムを実行することによって行う。
select要素
select、option要素
option、およびEvent
またはnullであるeventが与えられたとき、オプションを選択するには、次を実行する。
eventがnullではなく、eventのキャンセル済みフラグが設定されている場合、戻る。
eventがMouseEvent
であり、eventのbutton
属性が1ではない場合、戻る。
optionの選択状態をtrueに設定する。
optionのダーティネスをtrueに設定する。
selectを与えて、select更新通知を
送信する。
selectが基本 外観を持つドロップダウンボックスとしてレンダリングされている場合、 selectのselectポップオーバーを与えて、ポップオーバー非表示アルゴリズムを実行する。
multiple属性が存在しない場合、select要素のオプションリスト内のoption要素の選択状態がtrueに設定されるたび、および選択状態がtrueに設定されたoption要素がselect要素のオプションリストに追加されるたびに、
ユーザーエージェントは、そのオプション
リスト内のほかのすべてのoption要素の選択状態をfalseに設定しなければならない。
multiple属性が存在せず、要素の表示サイズが1より大きい場合、ユーザーエージェントは、
選択状態がtrueであるoptionが存在するなら、
ユーザーがそれを非選択にするよう要求できるようにもするべきである。この要求がユーザーエージェントに
伝えられたとき、関連するユーザーインタラクションイベントがキューに入れられる前
(例えば、click
イベントの前)に、ユーザーエージェントは、そのoption要素の選択状態をfalseに、そのダーティネスをtrueに設定し、その後select更新通知を送信
しなければならない。
selectが基本
外観を持つドロップダウンボックスとしてレンダリングされている場合、
ユーザーエージェントは、対応するselect要素
selectおよび対応するmousedown
またはkeydown
イベントeventが与えられたとき、ユーザーがピッカーを開くことができるようにするべきである。
eventのキャンセル済みフラグが設定されている場合、戻る。
eventのbutton
属性が1ではない場合、戻る。
selectのselect ポップオーバー、false、およびselectを与えて、ポップオーバー表示アルゴリズムを実行する。
selectが基本外観でレンダリングされている場合、ユーザーエージェントは、
フォーカスする新しいoption要素
optionおよびkeydown
イベントeventが与えられたとき、ユーザーが別のオプションにフォーカスすることができるようにするべきである。
eventのキャンセル済みフラグが設定されている場合、戻る。
optionに対してフォーカス手順を実行する。
実装では一般に、上矢印キーおよび下矢印キーによって次または前のオプションに フォーカスし、HomeキーまたはEndキーによって最初または最後のオプションにフォーカスし、 PageUpキーまたはPageDownキーによってピッカーのビューポート内の最初または最後のオプションに フォーカスできるようにしている。
これらの操作を引き起こす具体的なキーボードのキーは、実装およびプラットフォームに よって異なる場合がある。ARIA Authoring Practices Guideには、この動作に関する優れた推奨事項が ある。
multiple属性が存在し、要素が無効ではない場合、
ユーザーエージェントは、要素のオプションリスト内にあり、それ自体が無効ではないoption要素の選択状態をユーザーが切り替えられるようにするべきである。そのような要素がクリック、メニューコマンド、またはその他の
仕組みによって切り替えられたとき、関連するユーザー
インタラクションイベントがキューに入れられる前(例えば、関連するclick
イベントの前)に、option要素の選択状態を変更し
(trueからfalse、またはfalseからtrue)、要素のダーティネスをtrueに設定し、
ユーザーエージェントはselect更新通知を送信しなければならない。
select要素の
表示サイズは、要素にsize属性が存在し、
その構文解析が成功する場合、その属性値に非負整数を構文解析する規則を
適用した結果である。それらの規則を属性値に適用しても成功しない場合、またはsize属性が存在しない場合、
要素のmultipleコンテンツ属性が存在するなら、要素の表示サイズは4であり、
それ以外の場合は1である。
select要素
selectが与えられたとき、オプションリストを取得するには、次を実行する。
オプション
リスト内のoption要素がリセットを要求する場合、そのselect要素の選択状態
設定アルゴリズムを実行する。
select 要素
elementが与えられたとき、選択状態設定アルゴリズムは、
次の手順を実行します。
elementのmultiple 属性が
存在せず、elementの表示サイズが1であり、
elementのオプションリスト内のどのoption
要素も、その選択状態が
trueに設定されていない場合、オプションリスト内で
ツリー順における、無効ではない最初のoption
要素が存在するなら、その選択状態をtrueに設定し、返ります。
elementのmultiple
属性が存在せず、elementのオプションリスト内の2つ以上のoption 要素の
選択状態がtrueに設定されている場合、
オプション
リスト内でツリー順における、
選択状態がtrueに設定された最後のoption
要素を除くすべての要素の選択状態をfalseに設定します。
select 要素
elementについてselect更新通知を
送信するには、elementを指定し、ユーザーインタラクションタスク
ソースに要素タスクをキューに入れ、次の手順を実行します。
elementを指定して、selectの
selectedcontentを更新するを実行します。
elementを指定して、選択されたoptionを
selectボタンに複製するを実行します。
elementで、input
という名前のイベントを発火し、bubbles
およびcomposed
属性をtrueで初期化します。
select.type
現在のすべてのエンジンでサポートされています。
要素にmultiple属性が
ある場合は「select-multiple」を返し、それ以外の場合は「select-one」を
返します。
select.options
現在のすべてのエンジンでサポートされています。
オプションリストのHTMLOptionsCollectionを
返します。
select.length [ = value ]
オプションリスト内の要素数を返します。
element = select.item(index)
現在のすべてのエンジンでサポートされています。
select[index]element = select.namedItem(name)
現在のすべてのエンジンでサポートされています。
オプションリストから、IDまたはnameが
nameである最初の項目を返します。
そのIDを持つ要素が見つからない場合は、 nullを返します。
select.add(element [, before ])
現在のすべてのエンジンでサポートされています。
elementを、beforeによって指定されたノードの前に挿入します。
before引数は数値にすることができ、その場合、elementはその番号を持つ項目の 前に挿入されます。または、オプションリスト内の要素にすることができ、 その場合、elementはその要素の前に挿入されます。
beforeが省略された場合、nullである場合、または範囲外の数値である場合、 elementはリストの末尾に追加されます。
elementが挿入先の要素の祖先である場合、このメソッドは「HierarchyRequestError」
DOMExceptionを
投げます。
select.selectedOptions
HTMLSelectElement/selectedOptions
現在のすべてのエンジンでサポートされています。
選択されているオプションリストのHTMLCollectionを
返します。
select.selectedIndex [ = value ]
HTMLSelectElement/selectedIndex
現在のすべてのエンジンでサポートされています。
選択された最初の項目が存在する場合はそのインデックスを返し、選択された項目がない場合は−1を 返します。
選択を変更するために設定できます。
select.value [ = value ]
選択された最初の項目が存在する場合はその値を返し、選択された項目がない場合は空文字列を 返します。
選択を変更するために設定できます。
select.showPicker()
ユーザーが値を選択できるように、selectに対応するピッカーUIを表示します。
selectが可変ではない場合、「InvalidStateError」 DOMExceptionを
投げます。
一時的なユーザー活性化なしで呼び出された場合、「NotAllowedError」 DOMExceptionを
投げます。
selectがオリジン間iframe内にある場合、
「SecurityError」 DOMExceptionを
投げます。
selectがレンダリング中ではない場合、「NotSupportedError」 DOMExceptionを
投げます。
type
IDL属性は、取得時に、multiple属性が
存在しない場合は文字列「select-one」を返し、multiple
属性が存在する場合は文字列「select-multiple」を返さなければなりません。
options IDL属性は、select
ノードをルートとし、そのフィルターがオプションリスト内の要素と一致するHTMLOptionsCollectionを
返さなければなりません。
options
コレクションは、HTMLSelectElement
オブジェクトにも反映されます。任意の時点におけるサポートされるプロパティインデックスは、その時点で
options属性が返す
オブジェクトによってサポートされるインデックスです。
ユーザーエージェントがselect要素について
新しいインデックス付きプロパティの値を
設定する、または既存のインデックス付きプロパティの値を
設定する場合、代わりにselect要素のoptionsコレクションで
対応するアルゴリズムを実行しなければなりません。
同様に、add(element, before)メソッドは、同じ
options
コレクションの同名メソッドと同様に動作しなければなりません。
現在のすべてのエンジンでサポートされています。
remove()
メソッドは、引数がある場合は同じoptionsコレクションの
同名メソッドと同様に動作し、引数がない場合はHTMLSelectElementの
祖先インターフェイスElementが
実装するChildNode
インターフェイスの同名メソッドと同様に動作しなければなりません。
selectedOptions IDL属性は、select
ノードをルートとし、そのフィルターがオプションリスト内で
選択状態がtrueに設定されている要素と一致する
HTMLCollectionを
返さなければなりません。
select要素の
選択インデックスは、ツリー順において、そのオプションリスト内で
選択状態がtrueに設定されている最初のoption要素の
インデックスです。そのような要素がない場合は−1です。
select要素
selectの選択インデックスを設定して値
valueにするには、次の手順を実行します。
firstMatchingOptionをnullとします。
selectのオプションリスト内の各 optionについて、次を実行します。
firstMatchingOptionがnullでない場合、firstMatchingOptionの 選択状態をtrueに設定し、 firstMatchingOptionのダーティネスをtrueに設定します。
selectを指定して、selectの
selectedcontentを更新するを実行します。
これにより、select要素にmultiple属性がなく、
表示サイズが1である場合でも、どの要素の
選択状態もtrueに設定されないことがあります。
selectedIndexの
設定手順は、thisの選択インデックスを設定して、指定された値にすることです。
valueの取得手順は、ツリー順において、thisの
オプションリスト内で
選択状態がtrueに設定されている最初のoption要素が
存在する場合、その値を返すことです。そのような要素がない場合は、
空文字列を返します。
valueの設定手順は、
次のとおりです。
firstMatchingOptionをnullとします。
firstMatchingOptionがnullでない場合、firstMatchingOptionの 選択状態をtrueに設定し、 firstMatchingOptionのダーティネスをtrueに設定します。
thisを指定して、selectの
selectedcontentを更新するを実行します。
これにより、select要素にmultiple属性がなく、
表示サイズが1である場合でも、どの要素の
選択状態もtrueに設定されないことがあります。
歴史的な理由により、size
IDL属性のデフォルト値は、
実際に使用されるサイズを返しません。sizeコンテンツ属性がない場合、
実際のサイズは、multiple
属性が存在するかどうかに応じて1または4になります。
willValidate、
validity、およびvalidationMessage
IDL属性と、checkValidity()、
reportValidity()、
およびsetCustomValidity()
メソッドは、制約検証APIの一部です。labels IDL属性は、要素の
labelのリストを
提供します。disabled、form、およびname IDL属性は、要素の
フォームAPIの一部です。
次の例は、select要素を使用して、
ユーザーが単一のオプションを選択できるオプションセットを提示する方法を示しています。デフォルトの
オプションは事前に選択されています。
< p >
< label for = "unittype" > ユニットの種類を選択:</ label >
< select id = "unittype" name = "unittype" >
< option value = "1" > Miner </ option >
< option value = "2" > Puffer </ option >
< option value = "3" selected > Snipey </ option >
< option value = "4" > Max </ option >
< option value = "5" > Firebot </ option >
</ select >
</ p > デフォルトのオプションがない場合は、代わりにプレースホルダーを使用できます。
< select name = "unittype" required >
< option value = "" > ユニットの種類を選択 </ option >
< option value = "1" > Miner </ option >
< option value = "2" > Puffer </ option >
< option value = "3" > Snipey </ option >
< option value = "4" > Max </ option >
< option value = "5" > Firebot </ option >
</ select > ここでは、ユーザーは任意の数を選択できるオプションセットを提示されます。デフォルトでは、 5つのオプションすべてが選択されています。
< p >
< label for = "allowedunits" > このマップで有効にするユニットの種類を選択:</ label >
< select id = "allowedunits" name = "allowedunits" multiple >
< option value = "1" selected > Miner </ option >
< option value = "2" selected > Puffer </ option >
< option value = "3" selected > Snipey </ option >
< option value = "4" selected > Max </ option >
< option value = "5" selected > Firebot </ option >
</ select >
</ p > 場合によっては、ユーザーが1つ以上の項目を選択しなければなりません。この例は、そのような インターフェイスを示しています。
< label >
Act IIミックステープに入れたい曲を選択してください:
< select multiple required name = "act2" >
< option value = "s1" > It Sucks to Be Me (Reprise)
< option value = "s2" > There is Life Outside Your Apartment
< option value = "s3" > The More You Ruv Someone
< option value = "s4" > Schadenfreude
< option value = "s5" > I Wish I Could Go Back to College
< option value = "s6" > The Money Song
< option value = "s7" > School for Monsters
< option value = "s8" > The Money Song (Reprise)
< option value = "s9" > There's a Fine, Fine Line (Reprise)
< option value = "s10" > What Do You Do With a B.A. in English? (Reprise)
< option value = "s11" > For Now
</ select >
</ label > 区切りを設けることが役立つ場合もあります。
< label >
次に再生する曲を選択:
< select required name = "next" >
< option value = "sr" > ランダム
< hr >
< option value = "s1" > It Sucks to Be Me (Reprise)
< option value = "s2" > There is Life Outside Your Apartment
…次は、div、legend、
img、button、およびselectedcontent
要素を使用する例です。
< select >
< button >
< selectedcontent ></ selectedcontent >
</ button >
< div class = "border" >
< optgroup >
< legend > WHATWG仕様</ legend >
< option >
< img src = "html.jpg" alt = "" >
HTML
</ option >
< option >
< img src = "dom.jpg" alt = "" >
DOM
</ option >
</ optgroup >
</ div >
< div class = "border" >
< optgroup >
< legend > W3C仕様</ legend >
< option >
< img src = "forms.jpg" alt = "" >
CSSフォームコントロールのスタイル設定
</ option >
< option >
< img src = "pseudo.jpg" alt = "" >
CSS疑似要素
</ option >
</ optgroup >
</ div >
</ select > datalist 要素
現在のすべてのエンジンでサポートされています。
option要素およびスクリプト支援要素.[Exposed =Window ]
interface HTMLDataListElement : HTMLElement {
[HTMLConstructor ] constructor ();
[SameObject ] readonly attribute HTMLCollection options ;
};datalist
要素は、他のコントロール用の事前定義されたオプションを表すoption要素の集合を
表します。レンダリングにおいて、datalist
要素は何も表さず、その子とともに
非表示にするべきです。
datalist
要素は2つの方法で使用できます。最も単純な場合、datalist要素は、
子としてoption
要素だけを持ちます。
< label >
動物:
< input name = animal list = animals >
< datalist id = animals >
< option value = "Cat" >
< option value = "Dog" >
</ datalist >
</ label > より複雑な場合、datalist要素には、
datalistを
サポートしない旧式のクライアントに表示する内容を指定できます。この場合、option要素は、datalist要素内の
select要素の中に
配置されます。
< label >
動物:
< input name = animal list = animals >
</ label >
< datalist id = animals >
< label >
またはリストから選択:
< select name = animal >
< option value = "" >
< option > 猫
< option > 犬
</ select >
</ label >
</ datalist > datalist
要素は、input要素のlist属性を使用して、input要素に関連付けられます。
datalist要素の
子孫であり、無効ではなく、その値が空文字列ではない
文字列である各option要素は、
候補を表します。各候補には値とラベルがあります。
datalist.optionsdatalist要素の
option要素の
HTMLCollectionを
返します。
options IDL属性は、datalistノードを
ルートとし、そのフィルターがoption要素と一致する
HTMLCollectionを
返さなければなりません。
制約検証: 要素がdatalist要素の
祖先を持つ場合、その要素は制約検証から除外されます。
optgroup 要素
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
select要素の子孫として.legend要素の後に、
0個以上のoption要素、スクリプト支援要素、noscript要素、または
div要素が続く.
optgroup
要素の直後に別のoptgroup要素が
続く場合、直後にhr要素が続く場合、または親
要素にそれ以上の内容がない場合、optgroup要素の
終了タグを省略できます.
disabled —
フォームコントロールが無効かどうか
label —
ユーザーに表示されるラベル
[Exposed =Window ]
interface HTMLOptGroupElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute boolean disabled ;
[CEReactions , Reflect ] attribute DOMString label ;
};optgroup
要素は、共通のラベルを持つoption要素のグループを表します。
select要素内に
option要素を
表示するとき、ユーザーエージェントは、このようなグループのoption要素を、
互いに関連し、他のoption要素とは
分離されているものとして表示するべきです。
現在のすべてのエンジンでサポートされています。
disabled属性は論理属性であり、option要素のグループをまとめて無効化するために
使用できます。
label
属性は、optgroupに子の
legend要素が
ない場合、指定しなければなりません。
optgroup
optgroupが与えられたとき、optgroup要素のラベルを取得するには、次の手順を実行します。
optgroupに子のlegend要素が
ある場合、optgroupの最初の子legend要素の
すべてのText
ノード子孫のデータをツリー順に連結したものから、ASCII空白を除去し縮約した結果を返します。ただし、
legendの
子孫の子孫であり、それ自体がscript要素または
SVG
script要素であるものの子孫は除外します。
それ以外の場合、optgroupのlabel属性の値を
返します。
optgroupラベルアルゴリズムの値は、
ユーザーインターフェイスにおけるグループ名を与えます。ユーザーエージェントは、select要素内の
option要素の
グループにラベルを付けるとき、この属性の値を使用するべきです。
optgroup要素を
選択する方法はありません。選択できるのはoption要素だけです。
optgroup要素は、
単にoption要素の
グループにラベルを提供するだけです。
次の断片は、3つの講座に含まれる一連の授業をselectドロップダウン
ウィジェットで提示する方法を示しています。
< form action = "courseselector.dll" method = "get" >
< p > 今日はどの講座を視聴しますか?
< p >< label > 講座:
< select name = "c" >
< optgroup label = "8.01 物理学I:古典力学" >
< option value = "8.01.1" > 講義01:10の累乗
< option value = "8.01.2" > 講義02:1次元運動学
< option value = "8.01.3" > 講義03:ベクトル
< optgroup label = "8.02 電気と磁気" >
< option value = "8.02.1" > 講義01:世界をつなぎ止めているものは何か?
< option value = "8.02.2" > 講義02:電場
< option value = "8.02.3" > 講義03:電束
< optgroup label = "8.03 物理学III:振動と波" >
< option value = "8.03.1" > 講義01:周期現象
< option value = "8.03.2" > 講義02:うなり
< option value = "8.03.3" > 講義03:減衰を伴う強制振動
</ select >
</ label >
< p >< input type = submit value = "▶ 再生" >
</ form > option
要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
select要素の子孫として.datalist要素の
子孫として.optgroup要素の
子孫として.label属性およびvalue属性がある場合: なし.label属性があり、value属性がない場合: テキスト.label属性がなく、datalist要素の
子孫でもない場合: 0個以上のdiv要素またはフレージングコンテンツ。ただし、
インタラクティブコンテンツの子孫、datalist要素の
子孫、object要素の子孫、または
tabindex属性が指定された
子孫があってはなりません
label属性がなく、datalist要素の
子孫である場合: テキスト.option要素の直後に別の
option要素が続く場合、
直後にoptgroup要素が
続く場合、直後にhr要素が続く場合、または親要素に
それ以上の内容がない場合、option要素の終了タグを省略できます.
disabled —
フォームコントロールが無効かどうか
label —
ユーザーに表示されるラベル
selected —
オプションがデフォルトで選択されているかどうか
value — フォーム送信に使用する値
[Exposed =Window ,
LegacyFactoryFunction =Option (optional DOMString text = "", optional DOMString value , optional boolean defaultSelected = false , optional boolean selected = false )]
interface HTMLOptionElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute boolean disabled ;
readonly attribute HTMLFormElement ? form ;
[CEReactions , ReflectSetter ] attribute DOMString label ;
[CEReactions , Reflect="selected"] attribute boolean defaultSelected ;
attribute boolean selected ;
[CEReactions , ReflectSetter ] attribute DOMString value ;
[CEReactions ] attribute DOMString text ;
readonly attribute long index ;
};option要素は、select要素内のオプション、
またはdatalist要素内の
候補リストの一部を表します。
select要素の定義で
説明されている特定の状況では、option要素は、select要素のプレースホルダーラベル
オプションとなることができます。プレースホルダーラベルオプションは実際のオプションを
表さず、代わりにselectコントロールの
ラベルを表します。
現在のすべてのエンジンでサポートされています。
無効であるoption要素は、ユーザーインタラクション
タスクソースにキューに入れられたclick
イベントが、その要素にディスパッチされないようにしなければなりません。
無効であることは、option要素に対する
すべての変更を妨げるわけではありません。たとえば、その選択状態は、
JavaScriptからプログラムによって変更できます。また、select要素内の他の
無効ではないoption要素が変更された
場合など、ユーザー操作によって間接的に変更されることもあります。
label属性は、要素のラベルを提供します。option要素のラベルは、labelコンテンツ属性が
存在し、その値が空文字列ではない場合はその値であり、それ以外の場合は要素のtext IDL属性の値です。
labelコンテンツ
属性を指定する場合、その値は空であってはなりません。
value属性は、要素の値を提供します。option要素の値は、valueコンテンツ属性が
存在する場合はその値であり、存在しない場合はoptionテキストを収集するにthisおよびfalseを指定した結果です。
selected属性は論理属性です。これは要素のデフォルトの選択状態を表します。
option要素のダーティネスは、初期状態がfalseの論理状態です。これは、selectedコンテンツ
属性の追加または削除が効果を持つかどうかを制御します。
option要素の選択状態は、初期状態がfalseの論理状態です。別途指定されている
場合を除き、要素が作成されたとき、その要素にselected属性が
ある場合、その選択状態をtrueに設定しなければなりません。
option要素のselected属性が
追加されるたびに、そのダーティネスがfalseである場合、その選択状態をtrueに設定しなければなりません。option要素のselected属性が
削除されるたびに、そのダーティネスがfalseである場合、その選択状態をfalseに設定しなければなりません。
Option()コンストラクターは、
3個以下の引数で呼び出された場合、第3引数がtrueであっても、選択状態の初期状態を常にfalseに上書きします
(これはselected属性が
設定されることを意味します)。コンストラクターを使用するとき、第4引数を使用して初期の選択状態を明示的に設定できます。
multiple
属性が指定されていないselect要素は、selected属性が
設定された子孫option要素を2つ以上
持ってはなりません。
option要素のインデックスは、同じオプションリストに存在し、ツリー順でその要素より前にあるoption要素の数です。
option要素がオプションリストに存在しない場合、option要素のインデックスは0です。
各option要素は、
キャッシュされた最も近い祖先select
要素を持ちます。これはselect要素またはnullであり、
初期状態ではnullに設定されます。
option
optionが与えられたとき、optionの最も近い祖先
selectを更新するには、次の手順を実行します。
oldSelectを、optionのキャッシュされた最も近い祖先
select要素とします。
newSelectを、optionのoption要素の最も近い祖先
selectとします。
oldSelectがnewSelectではない場合:
oldSelectがnullではない場合、oldSelectを指定して選択状態設定アルゴリズムを実行します。
newSelectがnullではない場合、newSelectを指定して選択状態設定アルゴリズムを実行します。
optionのキャッシュされた最も近い祖先
select要素をnewSelectに設定します。
insertedOptionが与えられたとき、optionのHTML要素挿入手順は、
insertedOptionを指定してoptionの最も近い祖先
selectを更新するを実行することです。
removedNode、isSubtreeRoot、およびoldAncestorが与えられたとき、optionのHTML要素削除手順は、
removedNodeを指定してoptionの最も近い祖先
selectを更新するを実行することです。
movedNode、isSubtreeRoot、およびoldAncestorが与えられたとき、optionのHTML要素移動手順は、
movedNodeを指定してoptionの最も近い祖先
selectを更新するを実行することです。
option
optionが与えられたとき、optionを
selectedcontentに複製する可能性を処理するには、次の手順を実行します。
selectを、optionのoption要素の最も近い祖先
selectとします。
次の条件がすべてtrueである場合:
selectがnullではない;
optionの選択状態がtrueである; および
selectの有効な
selectedcontentがnullではない,
optionおよびselectの有効な
selectedcontentを指定して、optionを
selectedcontentに複製するを実行します。
select要素
selectが与えられたとき、選択されたoptionをselect
ボタンに複製するには、次の手順を実行します。
optionを、selectのオプションリスト内で選択状態がtrueに設定された最初の要素とし、 そのような要素が存在しない場合はnullとします。
textを空文字列とします。
optionがnullではない場合、textをoptionのラベルに設定します。
selectのselectフォールバックボタンテキストを textに設定します。
option要素が、
HTMLパーサーまたはXMLパーサーの開いている要素のスタックから取り出されたとき、
ユーザーエージェントは、そのoption要素を指定して
optionをselectedcontentに複製する
可能性を処理するを実行しなければなりません。
option.selected要素が選択されている場合はtrueを返し、それ以外の場合はfalseを返します。
要素の現在の状態を上書きするために設定できます。
option.indexoption.form要素にform要素がある場合は
その要素を返し、それ以外の場合はnullを返します。
option.text空白が縮約され、script要素が
スキップされる点を除いて、textContentと
同じです。
option = new Option([ text [, value [, defaultSelected [, selected ] ] ] ])
現在のすべてのエンジンでサポートされています。
新しいoption要素を返します。
text引数は要素の内容を設定します。
value引数はvalue属性を設定します。
defaultSelected引数はselected属性を
設定します。
selected引数は、要素が選択されているかどうかを設定します。この引数が省略された場合、 defaultSelected引数がtrueであっても、要素は選択されません。
labelの取得手順は、次のとおりです。
selected IDL属性は、取得時に要素の選択状態がtrueである場合はtrueを返し、
それ以外の場合はfalseを返さなければなりません。設定時には、要素の選択状態を新しい値に設定し、そのダーティネスをtrueに設定してから、要素にリセットを要求させなければなりません。
index
IDL属性は、要素のインデックスを返さなければなりません。
textの取得手順は、thisおよびfalseを指定してoptionテキストを収集するを実行した結果を返すことです。
formの取得手順は、次のとおりです。
selectを、thisのoption要素の最も近い祖先
selectとします。
selectがnullである場合、nullを返します。
selectのフォーム所有者を返します。
HTMLOptionElementオブジェクトを
作成するために、DOMのcreateElement()
などのファクトリーメソッドに加えて、従来のファクトリー関数Option(text, value,
defaultSelected, selected)が提供されます。呼び出されたとき、
従来のファクトリー関数は次の手順を実行しなければなりません。
documentを、現在のグローバルオブジェクトの関連付けられたDocumentとします。
textが空文字列ではない場合、データがtextである新しいText
ノードをoptionに追加します。
defaultSelectedがtrueである場合、「selected」および
空文字列を使用して、optionの属性値を設定します。
selectedがtrueである場合、optionの選択状態をtrueに設定し、それ以外の場合は その選択状態をfalseに設定します (defaultSelectedがtrueであっても同様です)。
optionを返します。
option要素
optionおよび論理値includeAltTextが与えられたとき、optionテキストを収集するには、次の手順を実行します。
textを空文字列とします。
textを指定してASCII空白を除去し縮約するを実行した結果を 返します。
option要素にvalue属性が設定されていない
場合、そのテキスト内容を使用して送信可能な値が生成されます。option要素に子要素が
ある場合、レンダリングは異なるものの同じ値を持つoption要素が生じる
など、予期しない結果につながる可能性があります。これに対処するため、option要素にvalue属性を設定することが
推奨されます。
textarea 要素
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
autocomplete —
フォーム自動入力機能のヒント
cols —
1行当たりの最大文字数
dirname —
フォーム送信で要素の方向性を送信するために使用するフォームコントロールの名前
disabled —
フォームコントロールが無効かどうか
form — 要素をform要素に関連付けます
maxlength
— 値の最大長さ
minlength
— 値の最小長さ
name — フォーム送信およびform.elements APIで
使用する要素の名前
placeholder
— フォームコントロール内に配置するユーザーに表示されるラベル
readonly —
ユーザーによる値の編集を許可するかどうか
required —
フォーム送信にコントロールが必要かどうか
rows —
表示する行数
wrap —
フォーム送信用にフォームコントロールの値を折り返す方法
[Exposed =Window ]
interface HTMLTextAreaElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , ReflectSetter ] attribute DOMString autocomplete ;
[CEReactions , ReflectPositiveWithFallback , ReflectDefault=20] attribute unsigned long cols ;
[CEReactions , Reflect ] attribute DOMString dirName ;
[CEReactions , Reflect ] attribute boolean disabled ;
readonly attribute HTMLFormElement ? form ;
[CEReactions , ReflectNonNegative ] attribute long maxLength ;
[CEReactions , ReflectNonNegative ] attribute long minLength ;
[CEReactions , Reflect ] attribute DOMString name ;
[CEReactions , Reflect ] attribute DOMString placeholder ;
[CEReactions , Reflect ] attribute boolean readOnly ;
[CEReactions , Reflect ] attribute boolean required ;
[CEReactions , ReflectPositiveWithFallback , ReflectDefault=2] attribute unsigned long rows ;
[CEReactions , Reflect ] attribute DOMString wrap ;
readonly attribute DOMString type ;
[CEReactions ] attribute DOMString defaultValue ;
attribute [LegacyNullToEmptyString ] DOMString value ;
readonly attribute unsigned long textLength ;
readonly attribute boolean willValidate ;
readonly attribute ValidityState validity ;
readonly attribute DOMString validationMessage ;
boolean checkValidity ();
boolean reportValidity ();
undefined setCustomValidity (DOMString error );
readonly attribute NodeList labels ;
undefined select ();
attribute unsigned long selectionStart ;
attribute unsigned long selectionEnd ;
attribute DOMString selectionDirection ;
undefined setRangeText (DOMString replacement );
undefined setRangeText (DOMString replacement , unsigned long start , unsigned long end , optional SelectionMode selectionMode = "preserve");
undefined setSelectionRange (unsigned long start , unsigned long end , optional DOMString direction );
};textarea
要素は、要素の生の値に対する複数行のプレーンテキスト編集
コントロールを表します。コントロールの
内容は、コントロールのデフォルト値を表します。
textareaコントロールの
生の値は、初期状態では空文字列でなければなりません。
この要素には、双方向アルゴリズムに関するレンダリング要件があります。
readonly属性は、ユーザーがテキストを編集できるかどうかを
制御するために使用される論理属性です。
この例では、テキストコントロールが読み取り専用ファイルを表すため、読み取り専用として マークされています。
ファイル名: < code > /etc/bash.bashrc</ code >
< textarea name = "buffer" readonly >
# System-wide .bashrc file for interactive bash(1) shells.
# To enable the settings / commands in this file for login shells as well,
# this file has to be sourced in /etc/profile.
# If not running interactively, don't do anything
[ -z "$PS1" ] && return
...</ textarea > 制約検証: textarea要素に
readonly
属性が指定されている場合、その要素は制約検証から除外されます。
textareaが
可変である場合、その生の値はユーザーが編集できるべきです。
ユーザーエージェントは、ユーザーがテキストを編集、挿入、削除できるようにし、U+000A LINE FEED
(LF)文字の形式で改行を挿入および削除できるようにするべきです。ユーザーが要素の生の値を変更するたびに、ユーザーエージェントは
textarea要素を
指定してユーザーインタラクションタスクソースに要素タスクをキューに入れ、textarea要素で
input
という名前のイベントを発火し、bubbles
およびcomposed
属性をtrueで初期化しなければなりません。ユーザーエージェントは、タスクをキューに入れる前にユーザーの
操作が適切に中断されるまで待つことができます。たとえば、各キーストロークごとに継続的にイベントを
発火する代わりに、ユーザーが一時停止したときだけイベントを発火するため、ユーザーが100msの間キーを
押していない状態になるまで待つことができます。
textarea要素が、
HTMLパーサーまたはXMLパーサーの開いている要素のスタックから取り出された場合、
ユーザーエージェントは要素のリセットアルゴリズムを呼び出さなければなりません。
要素が可変である場合、ユーザーエージェントは、ユーザーが 要素の書字方向を左から右または右から左の書字方向に変更できるようにするべきです。ユーザーが変更した 場合、ユーザーエージェントは次の手順を実行しなければなりません。
cols属性は、1行当たりに想定される最大文字数を指定します。
cols属性が指定される
場合、その値は0より大きい妥当な非負整数でなければなりません。属性値に
非負整数を構文解析する規則を適用した
結果が0より大きい数値になる場合、要素の文字幅はその値になり、それ以外の場合は20になります。
ユーザーエージェントは、textarea要素の文字幅を、サーバーが1行当たりに希望する文字数の
ヒントとしてユーザーに示すために使用できます(たとえば、視覚ユーザーエージェントではコントロールの
幅をその文字数にします)。視覚レンダリングでは、ユーザーエージェントは各行がこの文字数より広く
ならないように、ユーザーの入力をレンダリング内で折り返すべきです。
rows属性は、表示する行数を指定します。rows属性が指定される
場合、その値は0より大きい妥当な非負整数でなければなりません。属性値に
非負整数を構文解析する規則を
適用した結果が0より大きい数値になる場合、要素の文字高はその値になり、それ以外の場合は2になります。
視覚ユーザーエージェントは、コントロールの高さを文字高で指定された行数に設定するべきです。
wrap属性は、次のキーワードと状態を持つ列挙属性です。
| キーワード | 状態 | 簡単な説明 |
|---|---|---|
soft
|
ソフト | 送信時にテキストを折り返しません(レンダリングでは引き続き折り返すことができます)。 |
hard
|
ハード | 送信時にテキストが折り返されるように、ユーザーエージェントが改行を追加します。 |
この属性の欠落値の デフォルトおよび無効値のデフォルトは、どちらもソフト状態です。
要素のwrap属性がハード状態である場合、cols属性を
指定しなければなりません。
歴史的な理由により、要素の値は3つの異なる目的のために3つの異なる方法で正規化されます。生の値は、最初に設定されたままの値です。
これは正規化されません。API値は、value IDL属性、
textLength
IDL属性、およびmaxlengthとminlengthコンテンツ属性で
使用される値です。これは、改行がU+000A LINE FEED (LF)文字を使用するように正規化されます。最後に、
フォーム送信およびこの標準の他の処理モデルで使用される値があります。これはAPI値と同様に正規化され、さらに要素のwrap属性に応じて
必要な場合、指定された幅でテキストを折り返すために追加の改行が挿入されます。
要素の値は、要素のAPI値にtextarea折り返し変換を適用したものとして 定義されます。textarea折り返し変換は、文字列に適用される 次のアルゴリズムです。
maxlength属性は、フォームコントロールのmaxlength属性です。
textarea要素に許容される最大値長がある場合、要素の子は、改行を正規化した要素の子孫テキスト内容の値の長さが、要素の許容される最大値長以下になるように
構成されなければなりません。
minlength属性は、フォームコントロールのminlength属性です。
required属性は論理属性です。指定された場合、ユーザーはフォームを
送信する前に値を入力する必要があります。
placeholder属性は、コントロールに値がないときにユーザーの
データ入力を支援することを目的とした短いヒント(単語または短い句)を表します。ヒントには、
値の例や想定される形式の簡単な説明を使用できます。
placeholder
属性は、labelの代わりとして
使用するべきではありません。より長いヒントやその他の助言テキストには、title属性の方が適切です。
これらの仕組みは非常によく似ていますが、微妙に異なります。コントロールのlabelによって
与えられるヒントは常に表示され、placeholder
属性によって与えられる短いヒントは、ユーザーが値を入力する前に表示され、title属性のヒントは、ユーザーが
追加のヘルプを要求したときに表示されます。
ユーザーエージェントは、要素の値が空文字列であり、コントロールがフォーカスされていないときに、このヒントを ユーザーに提示するべきです(たとえば、空でフォーカスされていないコントロール内に表示します)。 ヒント内のすべてのU+000D CARRIAGE RETURN U+000A LINE FEED文字ペア(CRLF)、およびヒント内の その他すべてのU+000D CARRIAGE RETURN(CR)とU+000A LINE FEED(LF)文字は、ヒントをレンダリング するときに改行として扱わなければなりません。
ユーザーエージェントが通常、コントロールがフォーカスされているときにこのヒントをユーザーに表示しない
場合でも、autofocus属性の結果として
コントロールがフォーカスされた場合には、そのコントロールのヒントを表示するべきです。その場合、
ユーザーはフォーカスされる前にコントロールを確認する機会がなかったためです。
name属性は要素の名前を
表します。
dirname属性は、
要素の方向性を送信する方法を制御します。
disabled属性は、
コントロールを非インタラクティブにし、その値が送信されないようにするために使用されます。
form属性は、textarea要素を
そのフォーム所有者に明示的に関連付けるために
使用されます。
autocomplete
属性は、ユーザーエージェントが自動入力動作を提供する方法を制御します。
textarea.type文字列「textarea」を返します。
textarea.value要素の現在の値を返します。
値を変更するために設定できます。
type
IDL属性は、値「textarea」を返さなければなりません。
defaultValue属性の取得は、要素の子テキスト内容を返さなければなりません。
defaultValue
属性の設定は、指定された値を使用してこの要素内のすべてを文字列置換しなければなりません。
value IDL属性は、取得時に要素のAPI値を返さなければなりません。設定時には、次の手順を
実行しなければなりません。
oldAPIValueを、この要素のAPI値とします。
この要素の生の値を新しい値に設定します。
この要素のダーティ値フラグをtrueに設定します。
新しいAPI値がoldAPIValueと異なる場合、
テキスト入力カーソル位置をテキスト
コントロールの末尾に移動し、選択されているテキストの選択を解除し、選択方向を「none」にリセットします。
willValidate、
validity、およびvalidationMessage
IDL属性と、checkValidity()、
reportValidity()、
およびsetCustomValidity()
メソッドは、制約検証APIの一部です。labels IDL属性は、要素の
labelのリストを
提供します。select()、
selectionStart、
selectionEnd、
selectionDirection、
setRangeText()、
およびsetSelectionRange()
メソッドとIDL属性は、要素のテキスト選択を公開します。disabled、form、およびname IDL属性は、要素の
フォームAPIの一部です。
次は、フォーム内で制限のない自由形式のテキスト入力にtextareaを
使用する例です。
< p > ご意見がありましたらお知らせください: < textarea cols = 80 name = comments ></ textarea ></ p > コメントの最大長を指定するには、maxlength
属性を使用できます。
< p > 短いご意見がありましたらお知らせください: < textarea cols = 80 name = comments maxlength = 200 ></ textarea ></ p > デフォルト値を指定するには、要素内にテキストを含めることができます。
< p > ご意見がありましたらお知らせください: < textarea cols = 80 name = comments > 最高です!</ textarea ></ p > 最小長を指定することもできます。ここでは、ユーザーが手紙を完成させる必要があります。テンプレート (最小長より短い)が提供されていますが、フォームを送信するには不十分です。
< textarea required minlength = "500" > 議長殿
日付...の書簡について
...
敬具
...</ textarea > 明示的なテンプレートを提供せずに、基本的な形式をユーザーに示すため、プレースホルダーを指定する こともできます。
< textarea placeholder = "フランシーンへ
今週は公園が閉鎖されたので、そこで会うことはできません。
代わりに夕食を一緒に食べませんか?
愛を込めて
パパ" ></ textarea > ブラウザーが値とともに要素の方向性を送信するようにするには、dirname属性を
指定できます。
< p > ご意見がありましたらお知らせください(英語またはヘブライ語で記入できます):
< textarea cols = 80 name = comments dirname = comments.dir ></ textarea ></ p > output
要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
for — 出力の計算元となった
コントロールを指定する
form — 要素を
form要素に関連付ける
name —
form.elements APIで使用する
要素の名前。
[Exposed =Window ]
interface HTMLOutputElement : HTMLElement {
[HTMLConstructor ] constructor ();
[SameObject , PutForwards =value , Reflect="for"] readonly attribute DOMTokenList htmlFor ;
readonly attribute HTMLFormElement ? form ;
[CEReactions , Reflect ] attribute DOMString name ;
readonly attribute DOMString type ;
[CEReactions ] attribute DOMString defaultValue ;
[CEReactions ] attribute DOMString value ;
readonly attribute boolean willValidate ;
readonly attribute ValidityState validity ;
readonly attribute DOMString validationMessage ;
boolean checkValidity ();
boolean reportValidity ();
undefined setCustomValidity (DOMString error );
readonly attribute NodeList labels ;
};output要素は、アプリケーションによって
実行された計算の結果、またはユーザー操作の結果を表す。
この要素は、以前に実行された別のプログラムの出力を引用するのに適切な要素であるsamp要素と対比できる。
現在のすべてのエンジンでサポートされています。
forコンテンツ
属性を使用すると、計算結果と、その計算に使用された値を表す要素、またはその他の方法で計算に
影響を与えた要素との間に、明示的な関係を設定できる。for属性を指定する場合、その値は、
一意な空白区切りトークンの順序なし集合からなる
文字列でなければならず、どのトークンも別のトークンと同一であってはならず、各トークンは同じツリー内の要素のIDの値でなければならない。
form属性は、
output要素をその
フォーム所有者に明示的に関連付けるために使用される。name属性は要素の名前を表す。output
要素がフォームに関連付けられるのは、フォームコントロールのイベントハンドラーから容易に参照できるようにするためであり、フォームが送信される際に、
要素自体の値が送信されることはない。
この要素は、デフォルト値の オーバーライド(nullまたは文字列)を持つ。初期状態ではnullでなければならない。
要素のデフォルト値は、次の手順によって決定される:
この要素のデフォルト値の オーバーライドがnullでない場合、それを返す。
この要素の子孫テキストコンテンツを返す。
output
要素のリセットアルゴリズムは、
次の手順を実行することである:
この要素のデフォルト値の オーバーライドをnullに設定する。
output.value [ = value ]
要素の現在値を返す。
値を変更するために設定できる。
output.defaultValue [ = value ]
要素の現在のデフォルト値を返す。
デフォルト値を変更するために設定できる。
output.type文字列「output」を返す。
value
取得子の手順は、thisの子孫テキストコンテンツを返すことである。
defaultValue
設定子の手順は次のとおりである:
thisのデフォルト値の オーバーライドがnullの場合、this内の内容を 指定された値ですべて文字列置換し、戻る。
thisのデフォルト値の オーバーライドを指定された値に設定する。
type
取得子の手順は、「output」を返すことである。
willValidate、
validity、およびvalidationMessage
IDL属性、ならびにcheckValidity()、reportValidity()、
およびsetCustomValidity()
メソッドは、制約検証APIの一部である。labels IDL属性は、
要素のlabelの
リストを提供する。formおよびname IDL属性は、
要素のフォームAPIの一部である。
単純な計算機では、計算結果を表示するためにoutputを使用できる:
< form onsubmit = "return false" oninput = "o.value = a.valueAsNumber + b.valueAsNumber" >
< input id = a type = number step = any > +
< input id = b type = number step = any > =
< output id = o for = "a b" ></ output >
</ form > この例では、リモートサーバーによって実行された計算結果を、受信するたびに報告するためにoutput要素が使用されている:
< output id = "result" ></ output >
< script >
var primeSource = new WebSocket( 'ws://primes.example.net/' );
primeSource. onmessage = function ( event) {
document. getElementById( 'result' ). value = event. data;
}
</ script > progress 要素
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
progress要素の
子孫が存在してはならない。
value — 要素の
現在値
max — 範囲の上限
[Exposed =Window ]
interface HTMLProgressElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , ReflectSetter ] attribute double value ;
[CEReactions , ReflectPositive , ReflectDefault=1.0] attribute double max ;
readonly attribute double position ;
readonly attribute NodeList labels ;
};progress
要素は、タスクの完了進捗を表す。
進捗は、作業が進行しているものの、タスクが完了するまでにあとどれほどの作業が残っているかが
明確でないことを示す不確定状態(たとえば、タスクがリモートホストからの応答を待っている場合)か、
0から最大値までの範囲の数値であり、これまでに完了した作業の割合を示す。
現在のすべてのエンジンでサポートされています。
要素が表す現在のタスク完了状態を決定する属性は2つある。value
属性はタスクのうちどれだけが完了したかを指定し、max属性はタスク全体に必要な
作業量を指定する。単位は任意であり、指定されていない。
確定的なプログレスバーを作成するには、現在の進捗を示すvalue属性
(0.0から1.0までの数値、またはmax属性が指定されている場合は、
0からmax属性値までの数値)
を追加する。不確定なプログレスバーを作成するには、value
属性を削除する。
旧来のユーザーエージェントを使用するユーザーにも進捗が提供されるように、著者は現在値と最大値を 要素内のテキストとしてインラインで含めることも推奨される。
次に、自動化されたタスクの進捗を表示するウェブアプリケーションの一部を示す:
< section >
< h2 > タスクの進捗</ h2 >
< p > 進捗: < progress id = p max = 100 >< span > 0</ span > %</ progress ></ p >
< script >
var progressBar = document. getElementById( 'p' );
function updateProgress( newValue) {
progressBar. value = newValue;
progressBar. getElementsByTagName( 'span' )[ 0 ]. textContent = newValue;
}
</ script >
</ section > (この例のupdateProgress()メソッドは、タスクの進行に合わせて実際のプログレスバーを
更新するため、ページ上の別のコードから呼び出される。)
valueおよびmax属性が存在する場合、
その値は妥当な浮動小数点数でなければならない。value属性が存在する場合、
その値は0以上で、max属性が存在する場合はその値以下、存在しない場合は1.0以下でなければならない。max属性が存在する場合、
その値は0より大きくなければならない。
progress要素は、
タスクの進捗ではなく単なるゲージを表すものに使用するには不適切な要素である。たとえば、ディスク領域の
使用量をprogressで示すのは不適切である。そのような用途には、代わりにmeter要素を利用できる。
ユーザーエージェント要件: value
属性が省略されている場合、プログレスバーは不確定プログレスバーである。それ以外の場合は、
確定プログレスバーである。
プログレスバーが確定プログレスバーであり、要素がmax属性を持つ場合、
ユーザーエージェントは、浮動小数点数値を構文解析する
規則に従ってmax属性の値を
構文解析しなければならない。これによってエラーが発生せず、構文解析された値が0より大きい場合、
プログレスバーの最大値はその値である。それ以外の場合、
要素がmax属性を
持たない場合、その属性を持つものの構文解析でエラーが発生した場合、または構文解析された値が0以下である場合、
プログレスバーの最大値は1.0である。
プログレスバーが確定プログレスバーである場合、ユーザーエージェントは、浮動小数点数値を
構文解析する規則に従ってvalue属性の値を
構文解析しなければならない。これによってエラーが発生せず、構文解析された値が0より大きい場合、
プログレスバーの値はその構文解析された値である。それ以外の場合、
value属性値の
構文解析によってエラーまたは0以下の数値が得られた場合、プログレスバーの値は0である。
プログレスバーを表示するためのUA要件: progress要素を
ユーザーに表現する場合、UAは、それが確定プログレスバーであるか不確定プログレスバーであるかを示すべきであり、
前者の場合、現在値の、最大値に対する
相対位置を示すべきである。
progress.position
確定プログレスバー(現在値と最大値が既知であるもの)では、現在値を最大値で割った結果を返す。
不確定プログレスバーでは、−1を返す。
対応するコンテンツ属性が存在しないときに、value IDL属性を
それ自身に設定すると、プログレスバーは不確定プログレスバーから、進捗がない確定プログレスバーに変化する。
labels IDL属性は、
要素のlabelの
リストを提供する。
meter
要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
meter要素の
子孫が存在してはならない。
value — 要素の現在値
min — 範囲の下限
max — 範囲の上限
low — 低域の上限
high — 高域の下限
optimum — ゲージの
最適値
[Exposed =Window ]
interface HTMLMeterElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , ReflectSetter ] attribute double value ;
[CEReactions , ReflectSetter ] attribute double min ;
[CEReactions , ReflectSetter ] attribute double max ;
[CEReactions , ReflectSetter ] attribute double low ;
[CEReactions , ReflectSetter ] attribute double high ;
[CEReactions , ReflectSetter ] attribute double optimum ;
readonly attribute NodeList labels ;
};meter要素は、
既知の範囲内のスカラー測定値、または小数値を表す。たとえば、ディスク使用量、検索結果の
関連度、または特定の候補者を選択した投票者の割合などである。
これはゲージとも呼ばれる。
meter要素は、
進捗(プログレスバーのようなもの)を示すために使用すべきではない。
その役割のために、HTMLは別個のprogress要素を提供する。
meter
要素は、任意の範囲のスカラー値も表さない。たとえば、既知の最大値がない限り、重量や高さを報告するために
この要素を使用するのは誤りである。
要素が表すゲージの意味を決定する属性は6つある。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
min属性は
範囲の下限を指定し、max属性は上限を指定する。value属性は、
ゲージに「測定された」値として示させる値を指定する。
残りの3つの属性は、ゲージの範囲を「低」「中」「高」の部分に分割し、ゲージのどの部分が
「最適」な部分であるかを示すために使用できる。low属性は「低」の部分と
見なされる範囲を指定し、high属性は「高」の部分と見なされる範囲を指定する。
optimum属性は「最適」な位置を示す。
それが「高」の値より高ければ、値が高いほど良いことを示す。それが「低」の境界より低ければ、
値が低いほど良いことを示し、その中間にあれば、当然ながら、高い値も低い値も良くないことを示す。
著者要件: value属性を
指定しなければならない。value、min、low、high、max、およびoptimum属性が
存在する場合、それらの値は妥当な
浮動小数点数でなければならない。
さらに、属性の値には次の制約が適用される:
valueを、value属性の
数値とする。
min属性が
指定されている場合、minimumをその属性の値とし、それ以外の場合は0とする。
max属性が
指定されている場合、maximumをその属性の値とし、それ以外の場合は1.0とする。
該当する場合、次の不等式が成立しなければならない:
最小値または最大値が指定されていない場合、範囲は0..1であると仮定され、 したがって値はその範囲内でなければならない。
meter
要素をサポートしないユーザーエージェントのユーザーのために、著者はゲージの状態をテキストで表現したものを
要素の内容に含めることが推奨される。
マイクロデータとともに使用する場合、meter要素のvalue属性は、
要素の機械可読値を提供する。
次の例は、いずれも4分の3まで満たされた3つのゲージを示す:
ストレージ領域の使用量: < meter value = 6 max = 8 > 6ブロック使用(全8ブロック中)</ meter > 投票率: < meter value = 0.75 >< img alt = "75%" src = "graph75.png" ></ meter > 販売済みチケット: < meter min = "0" max = "100" value = "75" ></ meter > 次の例は、範囲を指定していないため、要素の誤った使用法である (デフォルトの最大値は1なので、どちらのゲージも最大まで満たされたように見える):
< p > グレープフルーツパイの半径は< meter value = 12 > 12cm</ meter >
で、高さは< meter value = 2 > 2cm</ meter > でした。</ p > <!-- 誤り! --> 代わりに、meter要素を含めないか、または定義済みの範囲を持つmeter要素を使用して、 他のパイと比較した文脈で寸法を示す:
< p > グレープフルーツパイの半径は12cmで、高さは
2cmでした。</ p >
< dl >
< dt > 半径: < dd > < meter min = 0 max = 20 value = 12 > 12cm</ meter >
< dt > 高さ: < dd > < meter min = 0 max = 10 value = 2 > 2cm</ meter >
</ dl > meter要素には、
単位を明示的に指定する方法はないが、単位はtitle属性に自由形式のテキストとして
指定できる。
上の例を拡張して単位を記載できる:
< dl >
< dt > 半径: < dd > < meter min = 0 max = 20 value = 12 title = "センチメートル" > 12cm</ meter >
< dt > 高さ: < dd > < meter min = 0 max = 10 value = 2 title = "センチメートル" > 2cm</ meter >
</ dl > ユーザーエージェント要件: ユーザーエージェントは、浮動小数点数値を構文解析する
規則を使用して、min、max、value、low、high、およびoptimum
属性を構文解析しなければならない。
次に、ユーザーエージェントは、これらすべての数値を使用して、次のようにゲージ上の6つの点の 値を取得しなければならない。(一部の値はそれ以前の値を参照するため、評価順序は重要である。)
min属性が
指定されており、そこから値を構文解析できた場合、最小値はその値である。それ以外の場合、
最小値は0である。
max属性が
指定されており、そこから値を構文解析できた場合、最大値候補はその値である。それ以外の場合、
最大値候補は1.0である。
最大値候補が最小値以上である場合、最大値は最大値候補である。それ以外の場合、最大値は 最小値と同じである。
value属性が
指定されており、そこから値を構文解析できた場合、その値が実際の値の候補となる。それ以外の場合、
実際の値の候補は0である。
実際の値の候補が最小値より小さい場合、実際の値は最小値である。
それ以外で、実際の値の候補が最大値より大きい場合、実際の値は最大値である。
それ以外の場合、実際の値は実際の値の候補である。
low属性が
指定されており、そこから値を構文解析できた場合、低域境界候補はその値である。それ以外の場合、
低域境界候補は最小値と同じである。
低域境界候補が最小値より小さい場合、低域境界は最小値である。
それ以外で、低域境界候補が最大値より大きい場合、低域境界は最大値である。
それ以外の場合、低域境界は低域境界候補である。
high属性が
指定されており、そこから値を構文解析できた場合、高域境界候補はその値である。それ以外の場合、
高域境界候補は最大値と同じである。
高域境界候補が低域境界より小さい場合、高域境界は低域境界である。
それ以外で、高域境界候補が最大値より大きい場合、高域境界は最大値である。
それ以外の場合、高域境界は高域境界候補である。
optimum
属性が指定されており、そこから値を構文解析できた場合、最適点候補はその値である。それ以外の場合、
最適点候補は最小値と最大値の中間点である。
最適点候補が最小値より小さい場合、最適点は最小値である。
それ以外で、最適点候補が最大値より大きい場合、最適点は最大値である。
それ以外の場合、最適点は最適点候補である。
これらすべてにより、次の不等式がすべて成立する:
最小値 ≤ 実際の値 ≤ 最大値
最小値 ≤ 低域境界 ≤ 高域境界 ≤ 最大値
最小値 ≤ 最適点 ≤ 最大値
ゲージの領域に関するUA要件: 最適点が低域境界または高域境界と等しい場合、 またはそれらの間の任意の位置にある場合、ゲージの低域境界と高域境界の間の領域を最適領域として 扱わなければならず、低域部分および高域部分がある場合は、それらを準最適として扱わなければならない。 それ以外で、最適点が低域境界より小さい場合、最小値と低域境界の間の領域を最適領域として扱い、 低域境界から高域境界までの領域を準最適領域として扱い、残りの領域をさらに好ましくない領域として 扱わなければならない。最後に、最適点が高域境界より高い場合、状況は逆になる。高域境界と最大値の間の 領域を最適領域として扱い、高域境界から低域境界までの領域を準最適領域として扱い、残りの領域をさらに 好ましくない領域として扱わなければならない。
ゲージを表示するためのUA要件: meter
要素をユーザーに表現する場合、UAは、実際の値の最小値および最大値に対する相対位置と、実際の値と
ゲージの3つの領域との関係を示すべきである。
次のマークアップ:
< h3 > 推奨グループ</ h3 >
< menu >
< li >< a href = "?cmd=hsg" onclick = "hideSuggestedGroups()" > 推奨グループを非表示にする</ a ></ li >
</ menu >
< ul >
< li >
< p >< a href = "/group/comp.infosystems.www.authoring.stylesheets/view" > comp.infosystems.www.authoring.stylesheets</ a > -
< a href = "/group/comp.infosystems.www.authoring.stylesheets/subscribe" > 参加</ a ></ p >
< p > グループの説明: < strong > WWW上のレイアウト/表示。</ strong ></ p >
< p > < meter value = "0.5" > 中程度の活動量、</ meter > Usenet、購読者618人</ p >
</ li >
< li >
< p >< a href = "/group/netscape.public.mozilla.xpinstall/view" > netscape.public.mozilla.xpinstall</ a > -
< a href = "/group/netscape.public.mozilla.xpinstall/subscribe" > 参加</ a ></ p >
< p > グループの説明: < strong > Mozilla XPInstallに関する議論。</ strong ></ p >
< p > < meter value = "0.25" > 低い活動量、</ meter > Usenet、購読者22人</ p >
</ li >
< li >
< p >< a href = "/group/mozilla.dev.general/view" > mozilla.dev.general</ a > -
< a href = "/group/mozilla.dev.general/subscribe" > 参加</ a ></ p >
< p > < meter value = "0.25" > 低い活動量、</ meter > Usenet、購読者66人</ p >
</ li >
</ ul > 次のようにレンダリングされる可能性がある:
ユーザーエージェントは、title属性の値と他の属性を組み合わせて、
実際の値を詳述する文脈依存のヘルプまたはインラインテキストを提供してもよい。
たとえば、次の断片:
< meter min = 0 max = 60 value = 23.2 title = 秒 ></ meter > ……によって、ユーザーエージェントが、1行目に「値: 60中23.2。」、 2行目に「秒」と表示するツールチップ付きのゲージを表示する可能性がある。
labels IDL属性は、
要素のlabelの
リストを提供する。
次の例は、ゲージがローカライズされたテキストまたは読みやすく整形されたテキストに フォールバックする方法を示す。
< p > ディスク使用量: < meter min = 0 value = 170261928 max = 233257824 > 利用可能な233 257 824バイトのうち
170 261 928バイトを使用</ meter ></ p > fieldset 要素
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
legend
要素、その後にフローコンテンツ。disabled —
legend内のものを
除き、子孫フォームコントロールが無効であるかどうか
form — 要素を
form要素に関連付ける
name —
form.elements
APIで使用する要素の名前。
[Exposed =Window ]
interface HTMLFieldSetElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute boolean disabled ;
readonly attribute HTMLFormElement ? form ;
[CEReactions , Reflect ] attribute DOMString name ;
readonly attribute DOMString type ;
[SameObject ] readonly attribute HTMLCollection elements ;
readonly attribute boolean willValidate ;
[SameObject ] readonly attribute ValidityState validity ;
readonly attribute DOMString validationMessage ;
boolean checkValidity ();
boolean reportValidity ();
undefined setCustomValidity (DOMString error );
};fieldset
要素は、任意でキャプションを伴い、まとめてグループ化された一連のフォームコントロール(またはその他の
コンテンツ)を表す。キャプションは、存在する場合、
fieldset要素の
子である最初のlegend要素によって
与えられる。残りの子孫がグループを形成する。
Element/fieldset#attr-disabled
現在のすべてのエンジンでサポートされています。
fieldset
要素は、次のいずれかの条件に一致する場合、無効な
fieldsetである:
form属性は、
fieldset要素を
そのフォーム所有者に明示的に関連付けるために
使用される。name属性は、
要素の名前を表す。
fieldset.type文字列「fieldset」を返す。
fieldset.elements
要素内のフォームコントロールのHTMLCollectionを
返す。
type
IDL属性は、文字列「fieldset」を返さなければならない。
elements IDL属性は、fieldset要素を
ルートとし、フィルターがリスト対象要素に一致するHTMLCollectionを
返さなければならない。
willValidate、
validity、およびvalidationMessage
属性、ならびにcheckValidity()、
reportValidity()、
およびsetCustomValidity()
メソッドは、制約検証APIの一部である。formおよびname IDL属性は、
要素のフォームAPIの一部である。
この例は、関連する一連のコントロールをグループ化するためにfieldset要素を
使用する例を示す:
< fieldset >
< legend > 表示</ legend >
< p >< label >< input type = radio name = c value = 0 checked > 白地に黒</ label >
< p >< label >< input type = radio name = c value = 1 > 黒地に白</ label >
< p >< label >< input type = checkbox name = g > グレースケールを使用</ label >
< p >< label > コントラストを強調 < input type = range name = e list = contrast min = 0 max = 100 value = 0 step = 1 ></ label >
< datalist id = contrast >
< option label = 通常 value = 0 >
< option label = 最大 value = 100 >
</ datalist >
</ fieldset > 次の断片は、fieldsetが有効であるかどうかを制御するチェックボックスをlegend内に持つfieldsetを示す。 fieldsetの内容は、2つの必須テキストコントロールと、任意の年/月コントロールからなる。
< fieldset name = "clubfields" disabled >
< legend > < label >
< input type = checkbox name = club onchange = "form.clubfields.disabled = !checked" >
クラブカードを使用
</ label > </ legend >
< p >< label > カード記載名: < input name = clubname required ></ label ></ p >
< p >< label > カード番号: < input name = clubnum required pattern = "[-0-9]+" ></ label ></ p >
< p >< label > 有効期限: < input name = clubexp type = month ></ label ></ p >
</ fieldset > fieldset要素を
入れ子にすることもできる。次に、前の例を拡張して入れ子にした例を示す:
< fieldset name = "clubfields" disabled >
< legend > < label >
< input type = checkbox name = club onchange = "form.clubfields.disabled = !checked" >
クラブカードを使用
</ label > </ legend >
< p >< label > カード記載名: < input name = clubname required ></ label ></ p >
< fieldset name = "numfields" >
< legend > < label >
< input type = radio checked name = clubtype onchange = "form.numfields.disabled = !checked" >
カードには数字が記載されている
</ label > </ legend >
< p >< label > カード番号: < input name = clubnum required pattern = "[-0-9]+" ></ label ></ p >
</ fieldset >
< fieldset name = "letfields" disabled >
< legend > < label >
< input type = radio name = clubtype onchange = "form.letfields.disabled = !checked" >
カードには文字が記載されている
</ label > </ legend >
< p >< label > カードコード: < input name = clublet required pattern = "[A-Za-z]+" ></ label ></ p >
</ fieldset >
</ fieldset > この例では、外側の「クラブカードを使用」チェックボックスが選択されていない場合、外側のfieldset内の
すべてが無効になる。これには、入れ子になった2つのfieldsetの
legend内にある2つのラジオボタンも含まれる。ただし、チェックボックスが選択されている場合、
両方のラジオボタンが有効になり、内側の2つのfieldsetの
どちらを有効にするかを選択できる。
この例は、legend要素が
グループにラベルを付けると同時に、入れ子になった見出し要素によってグループが文書アウトラインに
表示されるコントロールのグループ化を示す:
< fieldset >
< legend > < h2 >
最適な連絡方法は何ですか?
</ h2 > </ legend >
< p > < label >
< input type = radio checked name = contact_pref >
電話
</ label > </ p >
< p > < label >
< input type = radio name = contact_pref >
テキストメッセージ
</ label > </ p >
< p > < label >
< input type = radio name = contact_pref >
メール
</ label > </ p >
</ fieldset > legend
要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
fieldset要素の
最初の子として。
optgroup要素の
最初の子として。
optgroup要素の
子である場合: フレージングコンテンツ。ただし、インタラクティブコンテンツ、
およびtabindex属性を持つ
子孫が存在してはならない。[Exposed =Window ]
interface HTMLLegendElement : HTMLElement {
[HTMLConstructor ] constructor ();
readonly attribute HTMLFormElement ? form ;
// also has obsolete members
};legend要素は、
存在する場合、その親であるfieldset要素の
残りの内容に対するキャプションを表す。それ以外で、legendが親としてoptgroup要素を持つ場合、
legendはoptgroupの
ラベルを表す。
legend.form存在する場合は要素のform要素を返し、
それ以外の場合はnullを返す。
form
IDL属性の動作は、legend要素がfieldset要素内に
あるかどうかによって異なる。legendが親としてfieldset要素を持つ場合、
form IDL属性は、
そのfieldset要素のform IDL属性と同じ値を
返さなければならない。それ以外の場合はnullを返さなければならない。
selectedcontent 要素select要素の子であるbutton要素の
子孫として。[Exposed =Window ]
interface HTMLSelectedContentElement : HTMLElement {
[HTMLConstructor ] constructor ();
};selectedcontent
要素は、select要素で
現在選択されているoption要素の
内容を反映する。selectedcontent
要素を使用すると、選択されているoption要素の
内容を、select要素の
最初の子であるbutton要素内に
宣言的に表示できる。
option要素の
label
属性を使用してoptionの可視ラベルをレンダリングできるが、selectedcontent
要素はlabel属性の
内容を反映しない。
すべてのselectedcontent
要素は、真偽値の無効状態を持ち、その初期値はfalseである。
select要素selectが与えられたとき、selectのselectedcontentを更新するには:
selectedcontentを、selectを与えてselectの有効な
selectedcontentを取得する結果とする。
selectedcontentがnullの場合、戻る。
optionを、selectのoptionのリスト内で、選択状態がtrueである最初のoptionとする。
そのようなoptionが
存在しない場合はnullとする。
optionがnullの場合、selectedcontentを与えてselectedcontentを空にするを
実行する。
それ以外の場合、optionおよびselectedcontentを与えてoptionを
selectedcontent内に複製するを実行する。
select要素selectが与えられたとき、selectの有効な
selectedcontentを取得するには:
selectがmultiple
属性を持つ場合、nullを返す。
selectedcontentを、存在する場合、ツリー順でselectの子孫である最初のselectedcontent
要素とする。そのような要素が存在しない場合はnullを返す。
selectedcontentの無効状態がtrueの場合、nullを返す。
selectedcontentを返す。
option
要素 option と selectedcontent
要素
selectedcontent が与えられたとき、option を
selectedcontent に複製するには:
selectedcontent
要素
selectedcontentが与えられたとき、selectedcontentを消去するには:
selectedcontent内を null ですべて置換する。
select 要素
selectが与えられたとき、selectの非主要な
selectedcontent 要素を消去するには:
passedFirstSelectedcontentを false とする。
selectの子孫のうち、木順序で
selectedcontent
要素である各 descendantについて:
passedFirstSelectedcontentが false の場合、 passedFirstSelectedcontentを true に設定する。
それ以外の場合、descendantを与えてselectedcontentを消去するを
実行する。
selectedcontentが与えられたとき、selectedcontent
のHTML 要素接続後手順は、
次のとおりである:
nearestSelectAncestorを null とする。
selectedcontentの無効を false に設定する。
selectedcontentの無効が
true、nearestSelectAncestorが null、または nearestSelectAncestorが
multiple
属性を持つ場合、返る。
nearestSelectAncestorを与えて、selectの
selectedcontentを更新するを実行する。
nearestSelectAncestorを与えて、selectの非主要な
selectedcontent
要素を消去するを実行する。
removedNode、isSubtreeRoot、およびoldAncestorが与えられたとき、selectedcontentの
HTML要素の削除手順は、
次のとおりである:
ほとんどのフォームコントロールは、値とチェック状態を持つ。(後者はinput
要素でのみ使用される。)これらは、ユーザーがコントロールをどのように操作するかを記述するために使用される。
コントロールの値は、その内部状態である。 したがって、ユーザーの現在の入力と一致しない場合がある。
たとえば、ユーザーが数字を期待する数値フィールドに
「three」という単語を入力した場合、ユーザーの入力は文字列「three」になるが、コントロールの値は変更されないままである。また、
ユーザーがメールアドレスフィールドに、先頭に空白を含む
メールアドレス「 awesome@example.com」を入力した場合、ユーザーの入力は文字列
「 awesome@example.com」になるが、メールアドレスフィールド用のブラウザーUIは、それを
先頭の空白を含まない「awesome@example.com」という値に変換する場合がある。
input
要素およびtextarea
要素は、値のダーティフラグを持つ。
これは、値とデフォルト値との相互作用を追跡するために使用される。
falseの場合、値は
デフォルト値を反映する。trueの場合、デフォルト値は無視される。
一部のフォームコントロールは、オプション値も持つ。 これは概ね値を反映するが、 空文字列には正規化されない。これは慎重に使用すべきであり、通常は値を使用する。
input、textarea、およびselect要素は、
真偽値のユーザー妥当性を持つ。これは初期状態でfalseに設定される。
input
要素のmultiple
属性が存在する場合の制約検証の動作を定義するために、input要素は、
個別に定義された複数の値を持つこともできる。
maxlength属性およびminlength属性、ならびに
textarea
要素に固有のその他のAPIの動作を定義するため、値を持つすべてのフォームコントロールは、API値を取得するアルゴリズムも持つ。
デフォルトでは、このアルゴリズムは単にコントロールの値を返す。
select要素は、
値を持たない。
代わりに、そのoption
要素の選択状態が使用される。
フォームコントロールは、可変として指定できる。
これは、要素がそのように指定されているかどうかに依存する本仕様の定義および要件によって、 ユーザーがフォームコントロールの値またはチェック状態を変更できるかどうか、あるいはコントロールを 自動的に事前入力できるかどうかを決定する。
フォーム関連要素は、form
要素との関係を持つことができ、この要素をその要素のフォーム所有者と呼ぶ。フォーム関連要素がform
要素に関連付けられていない場合、そのフォーム所有者はnullであるという。
フォーム関連要素には、関連付けられた パーサー挿入済みフラグがある。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
フォーム関連要素は、デフォルトでは、
最も近い祖先のform要素に
関連付けられる(以下で説明する)。ただし、要素がリスト対象である場合、この関連付けを上書きするために
form属性を指定してもよい。
この機能により、著者は入れ子になったform
要素がサポートされていないことを回避できる。
この節の規則が複雑なのは、適合する文書またはツリーには入れ子になったform
要素が含まれることはないものの、そのような要素が入れ子になったツリーを生成することは十分に可能だからである
(たとえば、DOM操作を行うスクリプトを使用する場合)。また、歴史的理由により、フォーム関連要素がその祖先ではないform要素に
関連付けられる結果となり得るHTMLパーサーの規則によっても複雑になっている。
リスト対象のフォーム関連要素のform属性が
設定、変更、または削除されたとき、ユーザーエージェントはその要素のフォーム所有者を
リセットしなければならない。
リスト対象のフォーム関連要素がform属性を持ち、
IDを持つ要素が
Documentに挿入されたか、そこから削除されたか、またはそのHTML要素の
移動手順が実行されたとき、ユーザーエージェントはそのフォーム関連要素のフォーム所有者を
リセットしなければならない。
フォーム所有者は、HTML要素の挿入手順、 HTML要素の削除手順、およびHTML要素の移動手順によってもリセットされる。
フォーム関連要素elementの フォーム所有者をリセットするには:
次の不適合な断片では
...
< form id = "a" >
< div id = "b" ></ div >
</ form >
< script >
document. getElementById( 'b' ). innerHTML =
'<table><tr><td></form><form id="c"><input id="d"></table>' +
'<input id="e">' ;
</ script >
...「d」のフォーム所有者は内側に入れ子になったフォーム 「c」になり、一方で「e」のフォーム所有者は外側のフォーム「a」になる。
これは次のように起こる。まず、「e」ノードがHTMLパーサー内で「c」に関連付けられる。
次に、innerHTML
アルゴリズムが、一時文書から「b」要素へノードを移動する。この時点で、ノードの祖先チェーンが変更されるため、
パーサーによって行われたすべての「特別な」関連付けが、通常の祖先との関連付けにリセットされる。
ただし、この例は不適合な文書である。form要素を
入れ子にすることはコンテンツモデルへの違反であり、</form>タグについて構文解析エラーも発生する。
element.form
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
要素のフォーム所有者を返す。
存在しない場合はnullを返す。
フォーム関連カスタム要素を除く、リスト対象のフォーム関連要素は、form IDL属性を持つ。この属性の取得時には、
要素のフォーム所有者を返さなければならず、
所有者が存在しない場合はnullを返さなければならない。
現在のすべてのエンジンでサポートされています。
フォーム関連カスタム要素は、
form IDL属性を
持たない。代わりに、そのElementInternals
オブジェクトが、form IDL属性を持つ。取得時に、対象要素がフォーム関連カスタム要素でない場合、
"NotSupportedError" DOMExceptionを
投げなければならない。それ以外の場合、要素のフォーム所有者を返さなければならず、
所有者が存在しない場合はnullを返さなければならない。
name属性
現在のすべてのエンジンでサポートされています。
nameコンテンツ属性は、フォーム送信および
form要素のelementsオブジェクトで使用されるフォームコントロールの名前を与える。
属性を指定する場合、その値は空文字列またはisindexであってはならない。
歴史的に、多くのユーザーエージェントは、フォーム内で最初に現れ、名前が
isindexであるテキストコントロールを特別にサポートしており、本仕様も以前はそれに関連する
ユーザーエージェント要件を定義していた。しかし、一部のユーザーエージェントがその後この特別なサポートを
廃止したため、関連する要件も本仕様から削除された。したがって、旧来のユーザーエージェントで問題のある
再解釈が行われることを避けるため、isindexという名前は現在では許可されていない。
isindex以外では、nameに
空でない任意の値を使用できる。名前_charset_とのASCII大文字小文字不区別の一致には特別な意味がある。
value属性を持たないコントロールの名前として
使用された場合、送信時にvalue属性には、送信時の文字エンコーディングからなる値が自動的に与えられる。
DOMクロバーリングは、セキュリティ問題の一般的な原因である。name
コンテンツ属性には、組み込みフォームプロパティの名前を使用しないこと。
この例では、input
要素が組み込みのmethod
プロパティを上書きする:
let form = document. createElement( "form" );
let input = document. createElement( "input" );
form. appendChild( input);
form. method; // => "get"
input. name = "method" ; // DOMクロバーリングがここで発生する
form. method === input; // => true inputの名前は組み込みフォームプロパティより優先されるため、JavaScript参照
form.methodは、組み込みのmethod
プロパティではなく、「method」という名前のinput要素を指す。
dirname
属性
現在のすべてのエンジンでサポートされています。
フォームコントロール要素のdirname属性は、要素の方向性を送信できるようにし、
フォーム送信時にこの値を
格納するコントロールの名前を与える。この属性を指定する場合、その値は空文字列であってはならない。
この例では、フォームにテキストコントロールと送信ボタンが含まれている:
< form action = "addcomment.cgi" method = post >
< p >< label > コメント: < input type = text name = "comment" dirname = "comment.dir" required ></ label ></ p >
< p >< button name = "mode" type = submit value = "add" > コメントを投稿</ button ></ p >
</ form > ユーザーがフォームを送信すると、ユーザーエージェントは「comment」、「comment.dir」、「mode」という 3つのフィールドを含める。したがって、ユーザーが「Hello」と入力した場合、送信本文は次のようになる可能性がある:
comment=Hello&comment.dir=ltr&mode=add
ユーザーが書字方向を手動で右から左に切り替え、「مرحبا」と入力した場合、送信本文は次のようになる可能性がある:
comment=%D9%85%D8%B1%D8%AD%D8%A8%D8%A7&comment.dir=rtl&mode=add
maxlength
属性
値のダーティフラグによって
制御されるフォームコントロールのmaxlength属性は、ユーザーが入力できる
文字数の上限を宣言する。文字数は長さを使用して測定され、
textarea要素の場合、すべての改行はCRLFの組ではなく
1文字に正規化される。
要素にフォームコントロールの
maxlength属性が指定されている場合、その属性値は妥当な
非負整数でなければならない。属性が指定され、その値に非負整数を
構文解析する規則を適用した結果が数値である場合、その数値が要素の許容される値の最大長となる。属性が省略されているか、
その値の構文解析がエラーになる場合、許容される値の
最大長は存在しない。
制約検証: 要素に許容される値の 最大長があり、その値のダーティフラグがtrueであり、 その値が最後にスクリプトではなく ユーザー編集によって変更され、かつ要素のAPI値の長さが要素の許容される値の 最大長より大きい場合、その要素は長すぎる状態にある。
ユーザーエージェントは、要素のAPI値が、その長さが要素の許容される値の 最大長より大きい値に設定されることを、ユーザーが引き起こせないようにしてもよい。
textarea要素の場合、API値と値は異なる。特に、改行の正規化は、許容される値の
最大長を検査する前に適用される(ただし、textareaの
折り返し変換は適用されない)。
minlength
属性値のダーティフラグによって
制御されるフォームコントロールのminlength属性は、ユーザーが入力できる
文字数の下限を宣言する。「文字数」は長さを使用して測定され、
textarea要素の場合、すべての改行はCRLFの組ではなく
1文字に正規化される。
minlength属性は、required属性を暗黙に意味しない。
フォームコントロールがrequired属性を持たない場合、値は引き続き省略できる。minlength属性は、ユーザーが何らかの値を入力した場合にのみ適用される。
空文字列を許可しない場合は、required属性も設定する必要がある。
要素にフォームコントロールの
minlength属性が指定されている場合、その属性値は妥当な
非負整数でなければならない。属性が指定され、その値に非負整数を
構文解析する規則を適用した結果が数値である場合、その数値が要素の許容される値の最小長となる。属性が省略されているか、
その値の構文解析がエラーになる場合、許容される値の
最小長は存在しない。
要素に許容される値の 最大長と許容される値の 最小長の両方がある場合、許容される値の 最小長は、許容される値の 最大長以下でなければならない。
制約検証: 要素に許容される値の 最小長があり、その値のダーティフラグが trueであり、その値が最後に スクリプトではなくユーザー編集によって変更され、その値が 空文字列ではなく、かつ要素のAPI値の長さが要素の許容される値の 最小長より小さい場合、その要素は短すぎる 状態にある。
この例には4つのテキストコントロールがある。最初のコントロールは必須であり、少なくとも5文字の長さが 必要である。他の3つは任意だが、ユーザーがいずれかに入力する場合は、少なくとも10文字を入力する必要がある。
< form action = "/events/menu.cgi" method = "post" >
< p >< label > イベント名: < input required minlength = 5 maxlength = 50 name = event ></ label ></ p >
< p >< label > 朝食の希望があれば記述してください:
< textarea name = "breakfast" minlength = "10" ></ textarea ></ label ></ p >
< p >< label > 昼食の希望があれば記述してください:
< textarea name = "lunch" minlength = "10" ></ textarea ></ label ></ p >
< p >< label > 夕食の希望があれば記述してください:
< textarea name = "dinner" minlength = "10" ></ textarea ></ label ></ p >
< p >< input type = submit value = "リクエストを送信" ></ p >
</ form > disabled
属性
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
disabledコンテンツ属性は、真偽属性である。
option要素のdisabled属性、およびoptgroup要素のdisabled属性は、別個に定義される。
次のいずれかがtrueである場合、フォームコントロールは無効である:
無効な
フォームコントロールは、ユーザー操作
タスクソースにキューされたすべてのclick
イベントが、その要素に配送されることを防がなければならない。
無効であっても、 フォームコントロールに対するすべての変更が防止されるわけではない。たとえば、コントロールの値またはチェック状態は、 JavaScriptからプログラムによって変更できる。また、コントロールのラジオボタングループ内の 他の無効でない要素が変更された場合など、ユーザー操作によって間接的に変更されることもある。
Element/form#Attributes_for_form_submission
現在のすべてのエンジンでサポートされています。
フォーム送信用の属性は、form要素と
送信ボタン
(フォームを送信するボタンを表す要素。たとえば、type属性が
送信ボタン状態であるinput要素)の
両方に指定できる。
form
要素に指定できるフォーム送信用の属性は、action、enctype、method、novalidate、および
targetである。
送信
ボタンに指定できる、対応するフォーム送信用の属性は、formaction、formenctype、formmethod、formnovalidate、
およびformtarget
である。省略された場合は、form要素の
対応する属性に指定された値がデフォルトとなる。
現在のすべてのエンジンでサポートされています。
actionおよび
formaction
コンテンツ属性を指定する場合、その値は空白で囲まれている可能性のある
妥当な空でないURLでなければならない。
要素のアクションは、要素が送信ボタンであり、formaction
属性を持つ場合はその属性の値、それ以外で、そのフォーム所有者がaction属性を
持つ場合はその属性の値、それ以外の場合は空文字列である。
現在のすべてのエンジンでサポートされています。
methodおよび
formmethod
コンテンツ属性は、次のキーワードおよび状態を持つ列挙属性である:
| キーワード | 状態 | 概要 |
|---|---|---|
get
|
GET | formが
HTTP GETメソッドを使用することを示す。
|
post
|
POST | formが
HTTP POSTメソッドを使用することを示す。
|
dialog
|
ダイアログ | formが、
存在する場合はそのフォームを含むdialog
ボックスを閉じるためのものであり、それ以外の場合は送信しないことを示す。
|
method属性の
欠落値の
デフォルトおよび無効値のデフォルトは、どちらもGET状態である。
formmethod
属性には欠落値の
デフォルトがなく、その無効値の
デフォルトはGET状態である。
要素のメソッドは、それらの状態のいずれかである。
要素が送信
ボタンであり、formmethod
属性を持つ場合、要素のメソッドはその属性の状態である。それ以外の場合は、
フォーム
所有者のmethod属性の状態である。
ここでは、method属性を使用して、デフォルト値「get」を明示的に指定し、検索クエリーがURL内で
送信されるようにしている:
< form method = "get" action = "/search.cgi" >
< p >< label > 検索語: < input type = search name = q ></ label ></ p >
< p >< input type = submit ></ p >
</ form > 一方、ここではmethod属性を使用して
値「post」を指定し、ユーザーのメッセージが
HTTPリクエストの本文内で送信されるようにしている:
< form method = "post" action = "/post-message.cgi" >
< p >< label > メッセージ: < input type = text name = m ></ label ></ p >
< p >< input type = submit value = "メッセージを送信" ></ p >
</ form > この例では、formをdialogと
ともに使用する。method属性の「dialog」キーワードを使用して、フォームが送信されたときに
ダイアログが自動的に閉じるようにしている。
< dialog id = "ship" >
< form method = dialog >
< p > 港に船が到着しました。</ p >
< button type = submit value = "board" > 船に乗る</ button >
< button type = submit value = "call" > 船長を呼ぶ</ button >
</ form >
</ dialog >
< script >
var ship = document. getElementById( 'ship' );
ship. showModal();
ship. onclose = function ( event) {
if ( ship. returnValue == 'board' ) {
// ...
} else {
// ...
}
};
</ script > 現在のすべてのエンジンでサポートされています。
enctype
および
formenctype
コンテンツ属性は、次のキーワードおよび状態を持つ列挙属性である:
application/x-www-form-urlencoded」キーワードおよび
対応する状態。multipart/form-data」キーワードおよび対応する
状態。text/plain」キーワードおよび対応する状態。属性の欠落値のデフォルトおよび無効値の
デフォルトは、どちらもapplication/x-www-form-urlencoded状態である。
formenctype
属性には欠落値の
デフォルトがなく、その無効値の
デフォルトはapplication/x-www-form-urlencoded状態である。
要素のenctypeは、それら3つの状態のいずれかである。
要素が送信ボタンであり、formenctype
属性を持つ場合、要素のenctypeはその属性の状態である。それ以外の場合は、
フォーム所有者のenctype属性の
状態である。
現在のすべてのエンジンでサポートされています。
targetおよび
formtarget
コンテンツ属性を指定する場合、その値は妥当なナビゲーション可能ターゲット名または
キーワードでなければならない。
現在のすべてのエンジンでサポートされています。
novalidateおよびformnovalidateコンテンツ属性は、
真偽属性である。存在する場合、
フォームを送信時に検証しないことを示す。
要素の検証なし状態は、要素が送信
ボタンであり、その要素のformnovalidate属性が存在する場合、または要素の
フォーム所有者のnovalidate
属性が存在する場合はtrueであり、それ以外の場合はfalseである。
この属性は、検証制約を持つフォームに「保存」ボタンを含め、ユーザーがフォーム内のデータを 完全に入力していなくても進捗を保存できるようにする場合に有用である。次の例は、2つの必須フィールドを 持つ単純なフォームを示す。ボタンは3つある。1つはフォームを送信するためのもので、両方のフィールドへの 入力が必要である。1つはフォームを保存し、ユーザーが後で戻って入力を続けられるようにするためのもの。 もう1つはフォーム全体をキャンセルするためのものである。
< form action = "editor.cgi" method = "post" >
< p >< label > 名前: < input required name = fn ></ label ></ p >
< p >< label > 作文: < textarea required name = essay ></ textarea ></ label ></ p >
< p >< input type = submit name = submit value = "作文を送信" ></ p >
< p >< input type = submit formnovalidate name = save value = "作文を保存" ></ p >
< p >< input type = submit formnovalidate name = cancel value = "キャンセル" ></ p >
</ form > 現在のすべてのエンジンでサポートされています。
actionの取得手順は、次のとおりである:
formActionの取得手順は、次のとおりである:
attributeを、thisのformaction属性とする。
urlStringを、attributeの値を、thisのノード文書を基準として与え、URLをエンコーディングを用いて 構文解析し直列化する結果とする。
urlStringが失敗でない場合、urlStringを返す。
attributeの値を、スカラー値文字列に変換して返す。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
methodおよび
enctype
IDL属性は、それぞれ同名のコンテンツ属性を、
既知の値のみに制限して反映しなければならない。encoding IDL属性は、enctype
コンテンツ属性を、既知の値のみに
制限して反映しなければならない。formEnctype IDL属性は、formenctypeコンテンツ属性を、既知の値のみに
制限して反映しなければならない。formMethod IDL属性は、formmethodコンテンツ属性を、既知の値のみに
制限して反映しなければならない。
autocomplete属性現在のすべてのエンジンでサポートされています。
ユーザーエージェントには、たとえば以前のユーザー入力に基づいてユーザーの住所を事前入力するなど、
ユーザーによるフォーム入力を支援する機能が備わっている場合がある。autocompleteコンテンツ属性を使用すると、
そのような機能をどのように提供するか、あるいは提供するかどうかをユーザーエージェントに示唆できる。
この属性には2つの使用方法がある。自動入力期待
マントルをまとっている場合、autocomplete属性は、ユーザーにどのような入力が期待されるかを
記述する。自動入力アンカーマントルをまとっている場合、autocomplete属性は、与えられた値の意味を記述する。
type
属性が状態であるinput要素では、autocomplete属性は自動入力アンカー
マントルをまとう。それ以外のすべての場合には、自動入力期待
マントルをまとう。
自動入力期待
マントルをまとっている場合、autocomplete属性を指定するなら、その値は、文字列「off」とのASCII大文字小文字不区別の一致となる単一のトークン、
文字列「on」とのASCII大文字小文字不区別の一致となる単一のトークン、または自動入力詳細トークンから
なる、順序付きの空白区切りトークンの
集合でなければならない。
自動入力アンカー
マントルをまとっている場合、autocomplete属性を指定するなら、その値は、自動入力詳細トークンのみ
からなる、順序付きの空白区切り
トークンの集合でなければならない(つまり、「on」および「off」キーワードは許可されない)。
自動入力詳細トークンは、次に示す順序のとおりである:
任意で、最初の8文字が文字列「section-」とのASCII大文字小文字不区別の一致となるトークン。
これは、そのフィールドが名前付きグループに属することを意味する。
たとえば、フォームに2つの配送先住所がある場合、次のようにマークアップできる:
< fieldset >
< legend > 青い贈り物の配送先...</ legend >
< p > < label > 住所: < textarea name = ba autocomplete = "section-blue shipping street-address" ></ textarea > </ label >
< p > < label > 市区町村: < input name = bc autocomplete = "section-blue shipping address-level2" > </ label >
< p > < label > 郵便番号: < input name = bp autocomplete = "section-blue shipping postal-code" > </ label >
</ fieldset >
< fieldset >
< legend > 赤い贈り物の配送先...</ legend >
< p > < label > 住所: < textarea name = ra autocomplete = "section-red shipping street-address" ></ textarea > </ label >
< p > < label > 市区町村: < input name = rc autocomplete = "section-red shipping address-level2" > </ label >
< p > < label > 郵便番号: < input name = rp autocomplete = "section-red shipping postal-code" > </ label >
</ fieldset > 任意で、次のいずれかの文字列とのASCII大文字小文字不区別の一致となるトークン:
shipping」。
フィールドが配送先住所または連絡先情報の一部であることを意味する
billing」。
フィールドが請求先住所または連絡先情報の一部であることを意味する
次の2つの選択肢のいずれか:
次の自動入力フィールド名の いずれかとのASCII大文字小文字不区別の一致となるトークン。 ただし、その コントロールに不適切なものを除く:
name"
honorific-prefix"
given-name"
additional-name"
family-name"
honorific-suffix"
nickname"
username"
new-password"
current-password"
one-time-code"
organization-title"
organization"
street-address"
address-line1"
address-line2"
address-line3"
address-level4"
address-level3"
address-level2"
address-level1"
country"
country-name"
postal-code"
cc-name"
cc-given-name"
cc-additional-name"
cc-family-name"
cc-number"
cc-exp"
cc-exp-month"
cc-exp-year"
cc-csc"
cc-type"
transaction-currency"
transaction-amount"
language"
bday"
bday-day"
bday-month"
bday-year"
sex"
url"
photo"
(これらの値の説明については、以下の表を参照。)
次に示す順序のもの:
任意で、次のいずれかの文字列とのASCII大文字小文字不区別の一致となるトークン:
home」。
フィールドが居住地にいる人へ連絡するためのものであることを意味する
work」。
フィールドが職場にいる人へ連絡するためのものであることを意味する
mobile」。
フィールドが場所にかかわらず人へ連絡するためのものであることを意味する
fax」。
フィールドがファクシミリの連絡先詳細を記述することを意味する
pager」。
フィールドがポケットベルまたはページャーの連絡先詳細を記述することを意味する
次の自動入力フィールド 名のいずれかとのASCII大文字小文字不区別の一致となるトークン。 ただし、その コントロールに不適切なものを除く:
tel"
tel-country-code"
tel-national"
tel-area-code"
tel-local"
tel-local-prefix"
tel-local-suffix"
tel-extension"
email"
impp"
(これらの値の説明については、以下の表を参照。)
任意で、文字列「webauthn」とのASCII大文字小文字不区別の一致となるトークン。
これは、ユーザーがフォームコントロールを操作するとき、ユーザーエージェントがconditional
仲介を介して利用可能な公開鍵資格情報を表示するべきであることを意味する。webauthnは、input要素およびtextarea要素に対してのみ妥当である。
前述のとおり、この属性およびそのキーワードの意味は、その属性がまとっているマントルによって異なる。
「off」キーワードは、
コントロールの入力データが特に機密性の高いものであること(たとえば核兵器の起動コード)、または
決して再利用されない値であること(たとえば銀行ログイン用のワンタイムキー)を示す。この場合、
ユーザーはUAによる値の事前入力に頼ることができず、毎回明示的にデータを入力する必要がある。
または、文書が独自の自動補完機構を提供しており、ユーザーエージェントに自動補完値を提供してほしくない
ことを示す。
「on」キーワードは、
ユーザーエージェントがユーザーに自動補完値を提供することを許可するが、ユーザーがどのような種類の
データを入力すると期待されるかについて、それ以上の情報を提供しないことを示す。ユーザーエージェントは、
どの自動補完値を提案するかを決定するためにヒューリスティックを使用する必要がある。
上記の自動入力フィールドは、 ユーザーエージェントがユーザーに自動補完値を提供することを許可し、どのような種類の値が期待されるかを 指定する。各キーワードの意味は、以下の表で説明する。
autocomplete属性が省略された場合は、要素のフォーム所有者のautocomplete属性の状態に対応するデフォルト値
(「on」または「off」)が代わりに使用される。フォーム所有者が存在しない場合は、
値「on」が使用される。
上記の自動入力フィールドは、 指定された特定の種類の値について、この要素に与えられた値がその値であることを示す。各キーワードの 意味は、以下の表で説明する。
この例では、ページが取引の通貨と金額を明示的に指定している。フォームは、クレジットカードと その他の請求情報を要求する。ユーザーエージェントは、この情報を使用して、十分な残高があり、 該当する通貨をサポートしていることを把握しているクレジットカードを提案できる。
< form method = post action = "step2.cgi" >
< input type = hidden autocomplete = transaction-currency value = "CHF" >
< input type = hidden autocomplete = transaction-amount value = "15.00" >
< p >< label > クレジットカード番号: < input type = text inputmode = numeric autocomplete = cc-number ></ label >
< p >< label > 有効期限: < input type = month autocomplete = cc-exp ></ label >
< p >< input type = submit value = "続行..." >
</ form > 自動入力フィールドキーワードは、以下の表に示すように互いに関連する。
この表の各行に記載されたフィールド名は、「意味」という見出しの列にある、その行のセルに示された意味に
対応する。一部のフィールドは、他のフィールドの下位部分に対応する。たとえば、クレジットカードの有効期限は、
有効期限の月と年の両方を示す1つのフィールド(「cc-exp」)として表すことも、月を示す1つのフィールド
(「cc-exp-month」)と、年を示す1つのフィールド
(「cc-exp-year」)として表すこともできる。
このような場合、より広いフィールドの名前は、より狭いフィールドが定義されている複数の行にまたがる。
一般に、著者には、より狭いフィールドではなく、より広いフィールドを使用することが推奨される。 より狭いフィールドは、西洋文化に偏った前提を露呈しやすいためである。たとえば、一部の西洋文化では 名と姓をこの順序で持つことが一般的であり、そのためしばしばファーストネームおよび サーネームと呼ばれるが、多くの文化では姓を先に、名を後に置き、また、単一の名前 (単名)のみを持つ文化も多い。したがって、単一のフィールドを使用する方が柔軟である。
一部のフィールドは、特定のフォームコントロールにのみ適している。コントロールが、以下の表でその 自動入力フィールドを 説明する最初の行の第5列に記載されたグループに属さない場合、その自動入力フィールド名は、 そのコントロールに不適切である。各グループに含まれる コントロールについては、表の下で説明する。
| フィールド名 | 意味 | 正規形式 | 正規形式の例 | コントロールグループ | |||
|---|---|---|---|---|---|---|---|
"name"
|
氏名 | 自由形式のテキスト、改行なし | Sir Timothy John Berners-Lee, OM, KBE, FRS, FREng, FRSA | テキスト | |||
"honorific-prefix"
|
敬称または肩書き(例: 「Mr.」、「Ms.」、「Dr.」、「Mlle」) | 自由形式のテキスト、改行なし | Sir | テキスト | |||
"given-name"
|
名(一部の西洋文化ではファーストネームとも呼ばれる) | 自由形式のテキスト、改行なし | Timothy | テキスト | |||
"additional-name"
|
追加の名前(一部の西洋文化ではミドルネーム、すなわち最初の名以外の名とも呼ばれる) | 自由形式のテキスト、改行なし | John | テキスト | |||
"family-name"
|
姓(一部の西洋文化ではラストネームまたはサーネームとも呼ばれる) | 自由形式のテキスト、改行なし | Berners-Lee | テキスト | |||
"honorific-suffix"
|
接尾称号(例: 「Jr.」、「B.Sc.」、「MBASW」、「II」) | 自由形式のテキスト、改行なし | OM, KBE, FRS, FREng, FRSA | テキスト | |||
"nickname"
|
ニックネーム、スクリーンネーム、ハンドル名。通常、氏名の代わりに使用される短い名前 | 自由形式のテキスト、改行なし | Tim | テキスト | |||
"organization-title"
|
職名(例: 「Software Engineer」、「Senior Vice President」、「Deputy Managing Director」) | 自由形式のテキスト、改行なし | Professor | テキスト | |||
"username"
|
ユーザー名 | 自由形式のテキスト、改行なし | timbl | ユーザー名 | |||
"new-password"
|
新しいパスワード(例: アカウントの作成時またはパスワードの変更時) | 自由形式のテキスト、改行なし | GUMFXbadyrS3 | パスワード | |||
"current-password"
|
usernameフィールドで識別されるアカウントの現在の
パスワード(例: ログイン時)
|
自由形式のテキスト、改行なし | qwerty | パスワード | |||
"one-time-code"
|
ユーザーの本人確認に使用されるワンタイムコード | 自由形式のテキスト、改行なし | 123456 | パスワード | |||
"organization"
|
このフィールドに関連付けられた他のフィールド内の人物、住所、または連絡先情報に対応する会社名 | 自由形式のテキスト、改行なし | World Wide Web Consortium | テキスト | |||
"street-address"
|
番地住所(複数行、改行を保持) | 自由形式のテキスト | 32 Vassar Street MIT Room 32-G524 |
複数行 | |||
"address-line1"
|
番地住所(フィールドごとに1行) | 自由形式のテキスト、改行なし | 32 Vassar Street | テキスト | |||
"address-line2"
|
自由形式のテキスト、改行なし | MIT Room 32-G524 | テキスト | ||||
"address-line3"
|
自由形式のテキスト、改行なし | テキスト | |||||
"address-level4"
|
4つの行政区分レベルを持つ住所における、最も細かい行政区分レベル | 自由形式のテキスト、改行なし | テキスト | ||||
"address-level3"
|
3つ以上の行政区分レベルを持つ住所における、第3行政区分レベル | 自由形式のテキスト、改行なし | テキスト | ||||
"address-level2"
|
2つ以上の行政区分レベルを持つ住所における、第2行政区分レベル。2つの行政区分レベルを持つ国では、 通常、該当する番地住所が存在する市、町、村、またはその他の地域となる | 自由形式のテキスト、改行なし | Cambridge | テキスト | |||
"address-level1"
|
住所における最も広い行政区分レベル。つまり、 地域が属する州または県。たとえば、米国では州、スイスではカントン、英国では郵便都市となる | 自由形式のテキスト、改行なし | MA | テキスト | |||
"country"
|
国コード | 妥当なISO 3166-1 alpha-2国コード [ISO3166] | US | テキスト | |||
"country-name"
|
国名 | 自由形式のテキスト、改行なし。場合によってはcountryから導出される
|
US | テキスト | |||
"postal-code"
|
郵便番号、ZIPコード、CEDEXコード(CEDEXの場合は「CEDEX」と、該当する場合はarrondissementをaddress-level2フィールドに追加する)
|
自由形式のテキスト、改行なし | 02139 | テキスト | |||
"cc-name"
|
決済手段に記載された氏名 | 自由形式のテキスト、改行なし | Tim Berners-Lee | テキスト | |||
"cc-given-name"
|
決済手段に記載された名(一部の西洋文化ではファーストネームとも呼ばれる) | 自由形式のテキスト、改行なし | Tim | テキスト | |||
"cc-additional-name"
|
決済手段に記載された追加の名前(一部の西洋文化ではミドルネーム、すなわち最初の名以外の 名とも呼ばれる) | 自由形式のテキスト、改行なし | テキスト | ||||
"cc-family-name"
|
決済手段に記載された姓(一部の西洋文化ではラストネームまたは サーネームとも呼ばれる) | 自由形式のテキスト、改行なし | Berners-Lee | テキスト | |||
"cc-number"
|
決済手段を識別するコード(例: クレジットカード番号) | ASCII数字 | 4114360123456785 | テキスト | |||
"cc-exp"
|
決済手段の有効期限 | 妥当な月文字列 | 2014-12 | 月 | |||
"cc-exp-month"
|
決済手段の有効期限の月部分 | 1..12の範囲の妥当な 整数 | 12 | 数値 | |||
"cc-exp-year"
|
決済手段の有効期限の年部分 | 0より大きい妥当な 整数 | 2014 | 数値 | |||
"cc-csc"
|
決済手段のセキュリティコード(カードセキュリティコード(CSC)、カード検証コード(CVC)、 カード確認値(CVV)、署名欄コード(SPC)、クレジットカードID(CCID)などとも呼ばれる) | ASCII数字 | 419 | テキスト | |||
"cc-type"
|
決済手段の種類 | 自由形式のテキスト、改行なし | Visa | テキスト | |||
"transaction-currency"
|
ユーザーが取引で使用したい通貨 | ISO 4217通貨コード [ISO4217] | GBP | テキスト | |||
"transaction-amount"
|
ユーザーが取引に使用したい金額(例: 入札額または販売価格を入力する場合) | 妥当な浮動小数点 数 | 401.00 | 数値 | |||
"language"
|
優先言語 | 妥当なBCP 47言語タグ [BCP47] | en | テキスト | |||
"bday"
|
生年月日 | 妥当な日付文字列 | 1955-06-08 | 日付 | |||
"bday-day"
|
生年月日の日部分 | 1..31の範囲の妥当な 整数 | 8 | 数値 | |||
"bday-month"
|
生年月日の月部分 | 1..12の範囲の妥当な 整数 | 6 | 数値 | |||
"bday-year"
|
生年月日の年部分 | 0より大きい妥当な 整数 | 1955 | 数値 | |||
"sex"
|
性別の自己認識(例: Female、Fa'afafine) | 自由形式のテキスト、改行なし | Male | テキスト | |||
"url"
|
このフィールドに関連付けられた他のフィールド内の会社、人物、住所、または連絡先情報に対応する ホームページまたはその他のウェブページ | 妥当なURL文字列 | https://www.w3.org/People/Berners-Lee/ | URL | |||
"photo"
|
このフィールドに関連付けられた他のフィールド内の会社、人物、住所、または連絡先情報に対応する 写真、アイコン、またはその他の画像 | 妥当なURL文字列 | https://www.w3.org/Press/Stock/Berners-Lee/2001-europaeum-eighth.jpg | URL | |||
"tel"
|
国番号を含む完全な電話番号 | U+002B PLUS SIGN文字(+)を先頭に付けたASCII数字およびU+0020 SPACE文字 | +1 617 253 5702 | 電話 | |||
"tel-country-code"
|
電話番号の国番号部分 | U+002B PLUS SIGN文字(+)を先頭に付けたASCII数字 | +1 | テキスト | |||
"tel-national"
|
国番号部分を除き、該当する場合は国内用プレフィックスを適用した電話番号 | ASCII数字および U+0020 SPACE文字 | 617 253 5702 | テキスト | |||
"tel-area-code"
|
該当する場合は国内用プレフィックスを適用した、電話番号の市外局番部分 | ASCII数字 | 617 | テキスト | |||
"tel-local"
|
国番号部分および市外局番部分を除いた電話番号 | ASCII数字 | 2535702 | テキスト | |||
"tel-local-prefix"
|
市外局番に続く電話番号部分が2つに分割される場合の、その前半部分 | ASCII数字 | 253 | テキスト | |||
"tel-local-suffix"
|
市外局番に続く電話番号部分が2つに分割される場合の、その後半部分 | ASCII数字 | 5702 | テキスト | |||
"tel-extension"
|
電話番号の内線番号 | ASCII数字 | 1000 | テキスト | |||
"email"
|
メールアドレス | 妥当なメールアドレス | timbl@w3.org | ユーザー名 | |||
"impp"
|
インスタントメッセージングプロトコルのエンドポイントを表すURL(例:
「aim:goim?screenname=example」または「xmpp:fred@example.net」)
|
妥当なURL文字列 | irc://example.org/timbl,isuser | URL | |||
各グループは、次のようにコントロールに対応する:
type属性がHidden状態である
input要素
type属性がText
状態であるinput要素
type属性がSearch
状態であるinput要素
textarea要素
select要素
type属性がHidden状態である
input要素
textarea要素
select要素
type属性がHidden状態である
input要素
type属性がText
状態であるinput要素
type属性がSearch
状態であるinput要素
type属性がPassword状態である
input要素
textarea要素
select要素
type属性がHidden状態である
input要素
type属性がText
状態であるinput要素
type属性がSearch
状態であるinput要素
type属性がURL状態であるinput要素
textarea要素
select要素
type属性がHidden状態である
input要素
type属性がText
状態であるinput要素
type属性がSearch
状態であるinput要素
type属性がEmail状態であるinput要素
textarea要素
select要素
type属性がHidden状態である
input要素
type属性がText
状態であるinput要素
type属性がSearch
状態であるinput要素
type属性がTelephone状態である
input要素
textarea要素
select要素
type属性がHidden状態である
input要素
type属性がText
状態であるinput要素
type属性がSearch
状態であるinput要素
type属性がNumber状態である
input要素
textarea要素
select要素
type属性がHidden状態である
input要素
type属性がText
状態であるinput要素
type属性がSearch
状態であるinput要素
type属性がMonth状態である
input要素
textarea要素
select要素
type属性がHidden状態である
input要素
type属性がText
状態であるinput要素
type属性がSearch
状態であるinput要素
type属性がDate状態である
input要素
textarea要素
select要素
住所レベル: 「address-level1」から「address-level4」までのフィールドは、
番地住所の地域を記述するために使用される。地域ごとにレベル数は異なる。たとえば、米国では2レベル
(州と市町村)、英国では住所に応じて1または2レベル(郵便都市、および場合によっては地域)、
中国では3レベル(省、市、区)を使用できる。「address-level1」フィールドは、最も広い行政区分を
表す。地域によってフィールドの順序は異なる。たとえば、米国では市町村(レベル2)が州(レベル1)より
先に来る一方、日本では都道府県(レベル1)が市区町村(レベル2)より先に来て、その後に地区
(レベル3)が続く。著者には、国の慣習に合った方法で表示されるフォームを提供することが推奨される
(ユーザーが国を変更するのに応じて、フィールドを非表示、表示、および並べ替える)。
autocomplete
属性が適用される各input要素、各select要素、および
各textarea
要素は、自動入力ヒント集合、自動入力スコープ、自動入力フィールド名、
非自動入力資格情報タイプ、およびIDL公開自動入力値を持つ。
自動入力フィールド名は、
フィールドで期待される具体的なデータの種類、たとえば「street-address」または「cc-exp」を指定する。
自動入力ヒント集合は、
ユーザーエージェントが参照すべき住所または連絡先情報の種類、たとえば「shipping
fax」または「billing」を識別する。
非自動入力資格情報タイプは、ユーザーが
フィールドを操作したときに、他の自動入力フィールド値とともにユーザーエージェントが
提示できる資格情報の種類を
識別する。この値がnullではなく「webauthn」である場合、その種類の資格情報を選択すると、
フィールドを自動入力する代わりに、保留中のconditional
仲介によるnavigator.credentials.get()
要求が解決される。
たとえば、サインインページは、保存されたパスワードを自動入力するか、保留中のnavigator.credentials.get()
要求を解決する公開鍵資格情報を表示するよう、ユーザーエージェントに指示できる。
ユーザーは、どちらかを選択してサインインできる。
< input name = password type = password autocomplete = "current-password webauthn" > 自動入力スコープは、同じ対象に
関する情報を持つフィールドのグループを識別し、該当する場合は「section-*」接頭辞を伴う
自動入力ヒント集合から
構成される。たとえば「billing」、「section-parent shipping」、または
「section-child shipping
home」である。
これらの値は、次のアルゴリズムを実行した結果として定義される:
要素にautocomplete
属性がない場合は、デフォルトとラベル付けされた手順へジャンプする。
tokensを、属性の値をASCII空白で分割する結果とする。
tokensが空の場合は、デフォルトとラベル付けされた手順へジャンプする。
indexを、tokens内の最後のトークンのインデックスとする。
fieldを、tokens内のindex番目のトークンとする。
categoryとmaximum tokensの組を、fieldを与えてフィールドのカテゴリーを決定する結果に 設定する。
categoryがnullの場合は、デフォルトとラベル付けされた手順へジャンプする。
tokens内のトークン数がmaximum tokensより大きい場合は、 デフォルトとラベル付けされた手順へジャンプする。
categoryがオフまたは自動であり、要素のautocomplete
属性が自動入力アンカーマントルをまとっている場合は、
デフォルトとラベル付けされた手順へジャンプする。
categoryがオフの場合、要素の自動入力フィールド名を文字列
「off」に設定し、その自動入力ヒント集合を空に設定し、そのIDL公開自動入力値を文字列
「off」に設定する。その後、戻る。
categoryが自動の場合、要素の自動入力フィールド名を文字列
「on」に設定し、その自動入力ヒント集合を空に設定し、そのIDL公開自動入力値を文字列
「on」に設定する。その後、戻る。
scope tokensを空のリストとする。
hint tokensを空の集合とする。
credential typeをnullとする。
IDL valueをfieldと同じ値にする。
categoryが資格情報であり、tokens内のindex番目のトークンが
「webauthn」とのASCII大文字小文字不区別の一致である場合、次の下位手順を
実行する:
credential typeを「webauthn」に設定する。
tokens内のindex番目のトークンが最初の項目である場合は、 完了とラベル付けされた手順へ進む。
indexを1減らす。
categoryとmaximum tokensの組を、tokens内の index番目のトークンを与えてフィールドのカテゴリーを決定する結果に 設定する。
categoryが通常でも連絡先でもない場合は、デフォルトとラベル付けされた手順へ ジャンプする。
indexがmaximum tokensから1を引いた値より大きい場合 (すなわち、残りのトークン数がmaximum tokensより大きい場合)は、 デフォルトとラベル付けされた手順へジャンプする。
IDL valueを、tokens内のindex番目のトークン、 U+0020 SPACE文字、およびIDL valueの直前の値を連結したものに設定する。
tokens内のindex番目のトークンが最初の項目である場合は、 完了とラベル付けされた手順へ進む。
indexを1減らす。
categoryが連絡先であり、tokens内のindex番目のトークンが 次のリスト内の文字列のいずれかとのASCII大文字小文字不区別の一致である場合、次の下位手順を 実行する:
下位手順は次のとおりである:
contactを、上記のリスト内で一致した文字列とする。
contactをscope tokensの先頭に挿入する。
contactをhint tokensに追加する。
IDL valueを、contact、U+0020 SPACE文字、および IDL valueの直前の値を連結したものとする。
tokens内のindex番目の項目が最初の項目である場合は、 完了とラベル付けされた手順へ進む。
indexを1減らす。
tokens内のindex番目のトークンが、次のリスト内の文字列のいずれかとの ASCII大文字小文字不区別の一致である場合、次の下位手順を 実行する:
下位手順は次のとおりである:
modeを、上記のリスト内で一致した文字列とする。
modeをscope tokensの先頭に挿入する。
modeをhint tokensに追加する。
IDL valueを、mode、U+0020 SPACE文字、および IDL valueの直前の値を連結したものとする。
tokens内のindex番目の項目が最初の項目である場合は、 完了とラベル付けされた手順へ進む。
indexを1減らす。
tokens内のindex番目の項目が最初の項目でない場合は、 デフォルトとラベル付けされた手順へジャンプする。
tokens内のindex番目のトークンの最初の8文字が、文字列「section-」とのASCII大文字小文字不区別の一致でない場合は、
デフォルトとラベル付けされた手順へジャンプする。
sectionを、tokens内のindex番目のトークンをASCII小文字に変換したものとする。
sectionをscope tokensの先頭に挿入する。
IDL valueを、section、U+0020 SPACE文字、および IDL valueの直前の値を連結したものとする。
完了: 要素の自動入力ヒント集合をhint tokensに設定する。
要素の非自動入力資格情報タイプを credential typeに設定する。
要素の自動入力 スコープをscope tokensに設定する。
要素の自動入力フィールド名をfieldに 設定する。
要素のIDL公開自動入力値をIDL valueに設定する。
戻る。
デフォルト: 要素のIDL公開自動入力値を空文字列に設定し、 その自動入力ヒント集合および自動入力スコープを空に 設定する。
要素のautocomplete
属性が自動入力アンカーマントルをまとっている場合、
要素の自動入力フィールド名を空文字列に設定して戻る。
formを、存在する場合は要素のフォーム所有者とし、それ以外の場合はnullとする。
formがnullではなく、formのautocomplete属性がオフ状態である場合、要素の自動入力フィールド名を「off」に設定する。
それ以外の場合、要素の自動入力フィールド名を「on」に設定する。
fieldを与えて、フィールドのカテゴリーを決定するには:
fieldが、次の表の第1列に示されたいずれかのトークンとのASCII大文字小文字不区別の一致でない場合、組 (null, null)を返す。
それ以外の場合、maximum tokensおよびcategoryを、それぞれその行の 第2列および第3列のセルの値とする。
組(category, maximum tokens)を返す。
自動入力の目的において、コントロールのデータはコントロールの種類に 応じて異なる:
自動入力ヒント集合、自動入力スコープ、および
自動入力フィールド名をどのように処理するかは、
autocomplete属性がまとっているマントルに依存する。
要素の自動入力フィールド名が「off」である場合、ユーザーエージェントはコントロールのデータを記憶せず、
過去の値をユーザーに提示しないことが望ましい。
さらに、要素の自動入力フィールド名が「off」である場合、文書を再活性化する
ときに値がリセットされる。
銀行は、多くの場合、UAにログイン情報を事前入力してほしくない:
< p >< label > 口座: < input type = "text" name = "ac" autocomplete = "off" ></ label ></ p >
< p >< label > PIN: < input type = "password" name = "pin" autocomplete = "off" ></ label ></ p > 要素の自動入力フィールド名が「off」でない場合、ユーザーエージェントはコントロールのデータを保存し、
以前に保存した値をユーザーに提示してもよい。
たとえば、ユーザーが次のコントロールを持つページを訪問したとする:
< select name = "country" >
< option > アフガニスタン
< option > アルバニア
< option > アルジェリア
< option > アンドラ
< option > アンゴラ
< option > アンティグア・バーブーダ
< option > アルゼンチン
< option > アルメニア
<!-- ... -->
< option > イエメン
< option > ザンビア
< option > ジンバブエ
</ select > これは次のようにレンダリングされる可能性がある:
このページへの最初の訪問時に、ユーザーが「ザンビア」を選択したとする。2回目の訪問では、 ユーザーエージェントはリストの先頭にザンビアの項目を複製し、インターフェイスを代わりに次のように 表示できる:
自動入力フィールド名が「on」である場合、ユーザーエージェントは、たとえば要素の
name値、そのツリー内での要素の位置、フォーム内に存在する他のフィールドなどに基づき、
ユーザーに提示する最も適切な値を決定するため、ヒューリスティックの使用を試みることが望ましい。
自動入力フィールド名が、上記で説明した自動入力フィールド名のいずれかである場合、 ユーザーエージェントは、この節の前の表に示されたフィールド名の意味に一致する候補を提供することが 望ましい。複数の候補から選択するために、自動入力ヒント集合を使用することが望ましい。
たとえば、ユーザーが以前「shipping」キーワードを使用するフィールドに1つの住所を
入力し、「billing」キーワードを使用するフィールドに別の住所を
入力した場合、その後のフォームでは、自動入力ヒント集合に「shipping」キーワードを含むフォームコントロールには、
最初の住所のみが提案される。ただし、自動入力ヒント集合にどちらのキーワードも
含まない住所関連のフォームコントロールには、両方の住所が提案される場合がある。
自動入力フィールド名が空文字列でない場合、 ユーザーエージェントは、指定された自動入力ヒント集合、自動入力スコープ、および 自動入力フィールド名の組み合わせに対して、 ユーザーがコントロールのデータを指定したかのように 動作しなければならない。
ユーザーエージェントがフォームコントロールを自動入力するとき、
同じフォーム所有者および同じ自動入力スコープを持つ要素は、
同じ人物、住所、決済手段、および連絡先詳細に関するデータを使用しなければならない。ユーザーエージェントが、同じフォーム所有者および自動入力スコープを持つ「country」および「country-name」フィールドを自動入力し、かつ
ユーザーエージェントが「country」フィールドの値を持つ場合、「country-name」フィールドには、同じ国の人間が読める
名前を使用して入力しなければならない。ユーザーエージェントが複数のフィールドに同時に入力するとき、
同じ自動入力フィールド名、フォーム所有者、および自動入力スコープを持つすべてのフィールドには、
同じ値を入力しなければならない。
ユーザーエージェントが、+1 555 123 1234および+1 555 666 7777という2つの電話番号を
知っているとする。ユーザーエージェントが、autocomplete="shipping tel-local-prefix"を
持つフィールドに値「123」を入力し、同じフォーム内のautocomplete="shipping tel-local-suffix"
を持つ別のフィールドに値「7777」を入力することは、適合しない。前述の情報に基づく妥当な事前入力値は、
それぞれ「123」と「1234」、または「666」と「7777」のみである。
同様に、何らかの理由でフォームに「cc-exp」フィールドと「cc-exp-month」フィールドの両方が含まれ、
ユーザーエージェントがフォームを事前入力した場合、前者の月部分は後者と一致しなければならない。
この要件は、自動入力アンカーマントルとも相互作用する。 次のマークアップ断片を考える:
< form >
< input type = hidden autocomplete = "nickname" value = "TreePlate" >
< input type = text autocomplete = "nickname" >
</ form > 適合するユーザーエージェントがテキストコントロール内で提案できる唯一の値は、非表示のinput要素に
与えられた値「TreePlate」である。
自動入力スコープ内の
「section-*」トークンは不透明である。ユーザーエージェントは、これらのトークンの具体的な
値から意味を導出しようとしてはならない。
たとえば、ユーザーエージェントが「section-child」にはユーザーの娘の住所と
認識している住所を提示し、「section-spouse」にはユーザーの配偶者の住所と認識している住所を
提示すべきだと判断することは、適合しない。
自動補完機構は、ユーザーがコントロールのデータを変更したかのように ユーザーエージェントが動作することで実装しなければならず、要素が可変である時点(たとえば、要素が文書に挿入された 直後、またはユーザーエージェントが構文解析を停止するとき)に行わなければならない。 ユーザーエージェントは、ユーザーが入力できた値のみを使用してコントロールを事前入力しなければならない。
たとえば、select要素が、
値「Steve」、「Rebecca」、「Jay」、および「Bob」を持つoption要素しか
持たず、自動入力フィールド名が「given-name」であるが、ユーザーエージェントがその
フィールドに事前入力する候補として「Evan」しか持たない場合、ユーザーエージェントはそのフィールドを
事前入力できない。ユーザー自身がそのように設定できないため、何らかの方法でselect要素を
値「Evan」に設定することは適合しない。
フォームコントロールを事前入力するユーザーエージェントは、文書ツリー内にあるフォームコントロールと、接続されているフォームコントロールを区別してはならない。すなわち、
要素のルートがシャドウルートであるか、Documentであるかに基づいて、
自動入力するかどうかを決定することは適合しない。
フォームコントロールの値を事前入力するユーザーエージェントは、その コントロールを型不一致の状態、長すぎる状態、短すぎる状態、アンダーフロー状態、オーバーフロー状態、またはステップ不一致の状態にしてはならない。 フォームコントロールの値を事前入力するユーザーエージェントは、その コントロールをパターン不一致の状態にしてもならない。 コントロールの制約上可能である場合、ユーザーエージェントは前述の表で正規形式として示された形式を 使用しなければならない。正規形式を使用できない場合、ユーザーエージェントは値を使用可能な形式に変換する ため、ヒューリスティックの使用を試みることが望ましい。
たとえば、ユーザーエージェントがユーザーのミドルネームを「Ines」と認識しており、次のような フォームコントロールを事前入力しようとする場合:
< input name = middle-initial maxlength = 1 autocomplete = "additional-name" > ...ユーザーエージェントは「Ines」を「I」に変換し、その形式で事前入力できる。
より複雑な例として、月の値がある。ユーザーエージェントがユーザーの生年月日を2012年7月27日と 認識している場合、この情報に基づいて、次のすべてのコントロールにわずかに異なる値を事前入力しようとする 場合がある:
|
2012-07 |
Month状態は月と年の組み合わせのみを
受け入れるため、日は削除される。(この例は、自動入力フィールド名bdayがMonth状態では許可されていないため、
不適合であることに注意。)
|
|
July | ユーザーエージェントは、12個の選択肢があることを認識して7番目を選択するか、いずれかの文字列 (3文字の「Jul」に改行と空白が続くもの)が、ユーザーエージェントの対応言語のいずれかにおける 月名(July)とよく一致することを認識するか、または他の類似した機構を使用して、一覧の選択肢から 月を選ぶ。 |
|
7 | ユーザーエージェントは、フィールドに合わせて「July」を1..12の範囲の月番号に変換する。 |
|
6 | ユーザーエージェントは、フィールドに合わせて「July」を0..11の範囲の月番号に変換する。 |
|
ユーザーエージェントは、フォームが何を期待しているかを適切に推測できないため、 フィールドに入力しない。 |
ユーザーエージェントは、要素の自動入力フィールド名をユーザーが上書きできる
ようにしてもよい。たとえば、ページ著者の意向に反して値を記憶して事前入力できるように「off」から「on」へ変更したり、値を決して記憶しないよう常に「off」にしたりできる。
より具体的には、ユーザーエージェントは、次の表の第1列に示す説明に一致するフォームコントロールの
自動入力フィールド名が「on」または「off」である場合、それをその行の第2セルに示された値に
置き換えることを特に検討してもよい。この表を使用する場合、最初の行を除くすべての行が先行する要素の
自動入力フィールド名を参照するため、
置換はツリー順で行わなければならない。以下の説明でフォームコントロールが
他のコントロールに先行または後続すると述べる場合、それは同じフォーム所有者を共有するリスト対象要素のリスト内での
順序を意味する。
| フォームコントロール | 新しい自動入力フィールド名 |
|---|---|
type属性が
Text状態であり、
その後にtype属性がPassword状態であるinput要素が
続くinput要素
|
"username"
|
type属性が
Password状態であり、その前に
自動入力フィールド名が「username」であるinput要素が
あるinput要素
|
"current-password"
|
type属性が
Password状態であり、その前に
自動入力フィールド名が「current-password」であるinput要素が
あるinput要素
|
"new-password"
|
type属性が
Password状態であり、その前に
自動入力フィールド名が「new-password」であるinput要素が
あるinput要素
|
"new-password"
|
autocomplete IDL属性は、取得時に要素のIDL公開自動入力値を返さなければならない。
input要素およびtextarea要素は、
その選択範囲を処理するためのいくつかの属性およびメソッドを定義する。それらに共通するアルゴリズムを
ここで定義する。
element.select()
テキストコントロール内のすべてを選択する。
element.selectionStart [ = value ]
選択範囲の開始位置へのオフセットを返す。
設定することで、選択範囲の開始位置を変更できる。
element.selectionEnd [ = value ]
選択範囲の終了位置へのオフセットを返す。
設定することで、選択範囲の終了位置を変更できる。
element.selectionDirection [ = value ]
選択範囲の現在の方向を返す。
設定することで、選択範囲の方向を変更できる。
指定可能な値は「forward」、「backward」、
および「none」である。
element.setSelectionRange(start, end [, direction])
HTMLInputElement/setSelectionRange
現在のすべてのエンジンでサポートされています。
指定された方向で、指定された部分文字列を覆うよう選択範囲を変更する。方向を省略した場合、 プラットフォームのデフォルト(noneまたはforward)にリセットされる。
element.setRangeText(replacement [, start, end [, selectionMode ] ])
現在のすべてのエンジンでサポートされています。
テキスト範囲を新しいテキストに置換する。startおよびend 引数が指定されていない場合、その範囲は選択範囲であるとみなされる。
最後の引数は、テキストの置換後に選択範囲をどのように設定するかを決定する。 指定可能な値は次のとおりである:
select"start"end"preserve"これらのAPIが適用されるすべての
input要素、および
すべてのtextarea要素は、常に(レンダリングされていない要素であっても)選択範囲またはテキスト入力カーソル位置のいずれかを持つ。これは、コントロールの
関連値のコード単位へのオフセットで測定される。初期状態は、コントロールの先頭に
テキスト入力カーソルがある状態でなければならない。
input要素の場合、
これらのAPIは要素の値に対して
動作しなければならない。textarea要素の場合、これらのAPIは要素のAPI値に対して動作しなければ
ならない。以下のアルゴリズムでは、操作対象となる値の文字列を関連値と呼ぶ。
textarea要素に対して生の値ではなくAPI値を使用することは、
U+000D(CR)文字が正規化によって除去されることを意味する。たとえば、
< textarea id = "demo" ></ textarea >
< script >
demo. value = "A\r\nB" ;
demo. setRangeText( "replaced" , 0 , 2 );
assert( demo. value === "replacedB" );
</ script > 「A\r\nB」という生の値に対して操作していた場合、
「A\r」という文字を置換し、結果は「replaced\nB」となっていた。
しかし、「A\nB」というAPI値を使用したため、「A\n」という
文字を置換し、「replacedB」となる。
U+200D ZERO WIDTH JOINERのような、可視レンダリングを持たない文字も文字として数えられる。 したがって、たとえば選択範囲に不可視文字のみを含めることができ、テキスト挿入カーソルをその文字の いずれか一方の側に配置できる。
これらのAPIが適用される要素について関連値が変更されるたびに、 次の手順を実行する:
関連値が変更される一部の場合では、
仕様の他の部分も、上記のクランプ手順に加えてテキスト入力カーソル位置を変更する。
たとえば、textareaのvalueセッターを参照。
可能な場合、input要素およびtextarea要素内の
テキスト選択範囲を変更するユーザー
インターフェイス機能は、たとえばすべて同じイベントが発火するように、選択範囲を設定する
アルゴリズムを使用して実装しなければならない。
input要素および
textarea要素の
選択範囲は、選択方向を持ち、「forward」、「backward」、
または「none」のいずれかである。
選択方向の正確な意味はプラットフォームに依存する。この方向は、ユーザーが選択範囲を操作したときに
設定される。初期選択方向は、プラットフォームがその方向をサポートする
場合は「none」、それ以外の場合は「forward」でなければならない。
要素の選択方向を設定するには、指定された方向へ要素の
選択方向を更新する。
ただし、方向が「none」であり、プラットフォームがその方向をサポートしない場合は、
要素の選択方向を「forward」へ更新する。
Windowsでは、方向は選択範囲に対するキャレットの位置を示す。「forward」の選択範囲は
選択範囲の末尾にキャレットを持ち、「backward」の選択範囲は選択範囲の先頭にキャレットを
持つ。Windowsには「none」方向はない。
Macでは、方向はユーザーがShift修飾キーと矢印キーを使用して選択範囲の大きさを調整するときに、
選択範囲のどちらの端が影響を受けるかを示す。「forward」方向は選択範囲の末尾が変更される
ことを意味し、「backward」方向は選択範囲の先頭が変更されることを意味する。
「none」方向はMacのデフォルトであり、特定の方向がまだ選択されていないことを示す。
ユーザーは選択範囲を最初に調整したとき、使用した方向キーに基づいて暗黙的に方向を設定する。
現在のすべてのエンジンでサポートされています。
select()メソッドは、呼び出されたとき、次の手順を
実行しなければならない:
この要素がinput要素であり、
select()がこの要素に適用されないか、対応するコントロールに
選択可能なテキストがない場合は、戻る。
たとえば、<input type=color>が、16進数カラーコードを受け入れる
テキストコントロールではなく、ピッカーを備えたカラーウェルとしてレンダリングされるユーザー
エージェントでは、選択可能なテキストがないため、メソッドの呼び出しは無視される。
0および無限大を使用して選択範囲を設定する。
selectionStart属性のゲッターは、次の手順を
実行しなければならない:
この要素がinput要素であり、
selectionStartがこの要素に適用されない場合、nullを返す。
選択範囲がない場合、テキスト入力カーソルの直後にある文字への、 関連値内のコード単位オフセットを返す。
selectionStart属性のセッターは、次の手順を
実行しなければならない:
この要素がinput要素であり、
selectionStartがこの要素に適用されない場合、"InvalidStateError" DOMExceptionを投げる。
endを、この要素のselectionEnd属性の値とする。
endが指定された値より小さい場合、endを指定された値に設定する。
指定された値、end、およびこの要素のselectionDirection属性の値を使用して、選択範囲を設定する。
selectionEnd属性のゲッターは、次の手順を
実行しなければならない:
この要素がinput要素であり、
selectionEndがこの要素に適用されない場合、nullを返す。
選択範囲がない場合、テキスト入力カーソルの直後にある文字への、 関連値内のコード単位オフセットを返す。
selectionEnd属性のセッターは、次の手順を
実行しなければならない:
この要素がinput要素であり、
selectionEndがこの要素に適用されない場合、"InvalidStateError" DOMExceptionを投げる。
この要素のselectionStart属性の値、指定された値、および
この要素のselectionDirection属性の値を使用して、選択範囲を設定する。
selectionDirection属性のゲッターは、次の手順を
実行しなければならない:
この要素がinput要素であり、
selectionDirectionがこの要素に適用されない場合、nullを返す。
この要素の選択方向を返す。
selectionDirection属性のセッターは、次の手順を
実行しなければならない:
この要素がinput要素であり、
selectionDirectionがこの要素に適用されない場合、"InvalidStateError" DOMExceptionを投げる。
この要素のselectionStart属性の値、この要素のselectionEnd属性の値、および指定された値を使用して、
選択範囲を設定する。
setSelectionRange(start, end,
direction)メソッドは、呼び出されたとき、次の手順を実行しなければならない:
この要素がinput要素であり、
setSelectionRange()がこの要素に適用されない場合、"InvalidStateError" DOMExceptionを投げる。
start、end、およびdirectionを使用して、選択範囲を設定する。
整数またはnullのstart、整数、null、または特別な値である無限大のend、および 任意の文字列directionを使用して選択範囲を設定するには、次の手順を実行する:
startがnullの場合、startを0とする。
endがnullの場合、endを0とする。
テキストコントロールの選択範囲を、関連値内の、論理順で start番目の位置にあるコード単位から始まり、 (end-1)番目の位置にあるコード単位で終わるコード単位の列に設定する。 テキストコントロールの関連値の長さより大きい引数(特別な値である無限大を含む)は、テキスト コントロールの末尾を指すものとして扱わなければならない。endがstart以下で ある場合、選択範囲の開始位置と終了位置の両方を、オフセットendの文字の直前に配置しなければ ならない。空の選択範囲という概念がないUAでは、これによりカーソルをオフセットendの 文字の直前に設定しなければならない。
directionが「backward」または「forward」のいずれとも
同一でない場合、またはdirection引数が指定されて
いない場合、directionを「none」に設定する。
テキストコントロールの選択方向を設定することで、 directionにする。
前の手順によってテキストコントロールの選択範囲が、範囲または方向のいずれかについて
変更された場合、要素を与えてユーザー操作タスクソース上で要素タスクをキューに入れ、
bubbles属性をtrueに初期化して、
要素においてselectという名前のイベントを発火する。
setRangeText(replacement, start,
end, selectMode)メソッドは、呼び出されたとき、次の手順を
実行しなければならない:
この要素がinput要素であり、
setRangeText()がこの要素に適用されない場合、"InvalidStateError" DOMExceptionを投げる。
この要素の値のダーティフラグをtrueに設定する。
メソッドが引数を1つしか持たない場合、startおよびendを、それぞれselectionStart属性およびselectionEnd属性の値とする。
それ以外の場合、start、endを、それぞれ第2引数および第3引数の値とする。
startがendより大きい場合、"IndexSizeError" DOMExceptionを投げる。
selection startを、selectionStart属性の現在の値とする。
selection endを、selectionEnd属性の現在の値とする。
startがendより小さい場合、要素の関連値内にある、start 番目の位置のコード単位から始まり、 (end-1)番目の位置のコード単位で終わるコード単位の列を削除する。
new lengthを、第1引数の値の長さとする。
new endを、startとnew lengthの合計とする。
次のリストから適切な下位手順の集合を実行する:
select」の場合selection startをstartとする。
selection endをnew endとする。
start」の場合selection startおよびselection endをstartとする。
end」の場合selection startおよびselection endをnew endとする。
preserve」の場合old lengthを、endからstartを引いた値とする。
deltaを、new lengthからold lengthを引いた値とする。
selection startがendより大きい場合、それをdeltaだけ 増加させる。(deltaが負、すなわち新しいテキストが古いテキストより短い場合、 これによりselection startの値は減少する。)
それ以外の場合、selection startがstartより大きければ、それを startに設定する。(これにより、選択範囲の開始位置が置換されたテキストの途中に あった場合、新しいテキストの先頭へスナップする。)
selection endがendより大きい場合、同じ方法でそれを deltaだけ増加させる。
それ以外の場合、selection endがstartより大きければ、それを new endに設定する。(これにより、選択範囲の終了位置が置換されたテキストの途中に あった場合、新しいテキストの末尾へスナップする。)
selection startおよびselection endを使用して、選択範囲を設定する。
setRangeText()メソッドは、次の列挙型を使用する:
enum SelectionMode {
" select " ,
" start " ,
" end " ,
" preserve " // default
};現在選択されているテキストを取得するには、次のJavaScriptで十分である:
var selectionText = control. value. substring( control. selectionStart, control. selectionEnd); テキスト選択範囲を維持しながらテキストコントロールの先頭にテキストを追加するには、 3つの属性を保持しなければならない:
var oldStart = control. selectionStart;
var oldEnd = control. selectionEnd;
var oldDirection = control. selectionDirection;
var prefix = "http://" ;
control. value = prefix + control. value;
control. setSelectionRange( oldStart + prefix. length, oldEnd + prefix. length, oldDirection); 送信可能要素は、何らかの条件によって
要素が制約検証の対象外となっている場合を除き、
制約検証の候補である。(たとえば、要素がdatalist要素の祖先を
持つ場合、その要素は制約検証の対象外となる。)
要素には、カスタム妥当性エラーメッセージを定義できる。
初期状態では、要素のカスタム妥当性エラーメッセージを空文字列に
設定しなければならない。その値が空文字列でない場合、要素はカスタムエラーの状態にある。これは、フォーム関連カスタム要素を除き、setCustomValidity()メソッドを使用して設定できる。フォーム関連カスタム要素では、そのElementInternalsオブジェクトの
setValidity()メソッドを介してカスタム妥当性エラーメッセージを設定できる。
ユーザーエージェントは、コントロールの問題をユーザーに通知するとき、カスタム妥当性エラーメッセージを使用することが望ましい。
要素にはさまざまな制約を課すことができる。次に、フォームコントロールが取り得る妥当性状態の一覧を示す。これらの状態では、制約検証の目的において コントロールが無効となる。(以下の定義は非規範的である。この仕様の他の部分で、それぞれの状態がいつ 適用されるか、または適用されないかをより正確に定義する。)
コントロールに値がないが、
required属性(inputのrequired、textareaのrequired)を持つ場合。
または、それぞれの節で指定されているとおり、select要素およびラジオボタングループ内の
コントロールには、より複雑な規則が適用される。
setValidity()メソッドが、フォーム関連カスタム要素について
valueMissingフラグをtrueに設定した場合。
任意のユーザー入力を許可するコントロールの値が正しい構文ではない場合(Email、URL)。
setValidity()メソッドが、フォーム関連カスタム要素について
typeMismatchフラグをtrueに設定した場合。
setValidity()メソッドが、フォーム関連カスタム要素について
patternMismatchフラグをtrueに設定した場合。
コントロールの値が、フォームコントロールの
maxlength属性(inputのmaxlength、textareaの
maxlength)に対して長すぎる場合。
setValidity()メソッドが、フォーム関連カスタム要素について
tooLongフラグをtrueに設定した場合。
コントロールの値が、フォームコントロールの
minlength属性(inputのminlength、textareaの
minlength)に対して短すぎる場合。
setValidity()メソッドが、フォーム関連カスタム要素について
tooShortフラグをtrueに設定した場合。
コントロールの値が空文字列ではなく、
min属性に対して小さすぎる場合。
setValidity()メソッドが、フォーム関連カスタム要素について
rangeUnderflowフラグをtrueに設定した場合。
コントロールの値が空文字列ではなく、
max属性に対して大きすぎる場合。
setValidity()メソッドが、フォーム関連カスタム要素について
rangeOverflowフラグをtrueに設定した場合。
コントロールの値がstep属性によって指定される規則に
適合しない場合。
setValidity()メソッドが、フォーム関連カスタム要素について
stepMismatchフラグをtrueに設定した場合。
コントロールに不完全な入力があり、ユーザーエージェントが、現在の状態でユーザーがフォームを 送信できるべきではないと判断する場合。
setValidity()メソッドが、フォーム関連カスタム要素について
badInputフラグをtrueに設定した場合。
コントロールのカスタム妥当性エラーメッセージ(要素のsetCustomValidity()メソッドまたはElementInternalsのsetValidity()メソッドによって設定される)が
空文字列でない場合。
要素が無効であっても、これらの状態にある場合がある。したがって、 送信時にフォームを検証してもユーザーに問題が示されない場合でも、これらの状態をDOM内で表現できる。
要素が上記のどの妥当性状態にもない場合、その要素は制約を満たす。
ユーザーエージェントがform要素
formの制約を静的に検証する必要がある場合、
次の手順を実行しなければならない。この手順は、肯定結果(フォーム内のすべてのコントロールが
妥当である)または否定結果(無効なコントロールが存在する)とともに、無効であり、かつ
スクリプトが責任を引き受けていない要素の(空の場合もある)リストを返す:
invalid controlsを、初期状態では空の要素リストとする。
controls内の各要素fieldについて、ツリー順で:
invalid controlsが空の場合、肯定結果を返す。
unhandled invalid controlsを、初期状態では空の要素リストとする。
invalid controls内に要素がある場合、その各要素fieldについて、ツリー順で:
notCanceledを、cancelable属性をtrueに初期化して、
fieldにおいてinvalidという名前の
イベントを
発火する結果とする。
notCanceledがtrueの場合、fieldをunhandled invalid controlsに追加する。
unhandled invalid controlsリスト内の要素のリストとともに否定結果を返す。
ユーザーエージェントがform要素
formの制約を対話的に検証する場合、次の手順を実行しなければならない:
formの制約を静的に検証し、結果が 否定であった場合に返された要素のリストをunhandled invalid controlsとする。
結果が肯定であった場合、その結果を返す。
unhandled invalid controls内にある少なくとも1つの要素について、その制約の問題を ユーザーに報告する。
ユーザーエージェントは、その要素についてフォーカス手順を実行することで、それらの要素の 1つにフォーカスしてもよく、文書のスクロール位置を変更したり、その要素にユーザーの注意を 向ける他の操作を実行したりしてもよい。フォーム関連カスタム要素については、 ユーザーエージェントは、これらの操作の目的において代わりにその検証アンカーを使用することが望ましい。
ユーザーエージェントは、複数の制約違反を報告してもよい。
適切な場合、ユーザーエージェントは関連する制約違反の報告を統合してもよい(たとえば、 グループ内の複数の ラジオボタンが必須としてマークされている場合、報告する必要があるエラーは1つだけである)。
コントロールの1つがレンダリングされていない場合(たとえば、 属性が設定されている場合)、ユーザーエージェントは スクリプトエラーを報告してもよい。
否定結果を返す。
element.willValidate
HTMLObjectElement/willValidate
現在のすべてのエンジンでサポートされています。
フォームの送信時に要素が検証される場合はtrueを返し、それ以外の場合はfalseを返す。
element.setCustomValidity(message)
HTMLObjectElement/setCustomValidity
現在のすべてのエンジンでサポートされています。
HTMLSelectElement/setCustomValidity
現在のすべてのエンジンでサポートされています。
カスタムエラーを設定し、要素が検証に失敗するようにする。指定されたメッセージは、 問題をユーザーに報告するときに表示されるメッセージである。
引数が空文字列の場合、カスタムエラーをクリアする。
element.validity.valueMissing
現在のすべてのエンジンでサポートされています。
要素に値がないが必須フィールドである場合はtrueを返し、それ以外の場合はfalseを返す。
element.validity.typeMismatch
要素の値が正しい構文でない場合はtrueを返し、それ以外の場合はfalseを返す。
element.validity.patternMismatch
要素の値が指定されたパターンに一致しない場合はtrueを返し、それ以外の場合はfalseを返す。
element.validity.tooLong
現在のすべてのエンジンでサポートされています。
要素の値が指定された最大長より長い場合はtrueを返し、それ以外の場合はfalseを返す。
element.validity.tooShort
現在のすべてのエンジンでサポートされています。
要素の値が空文字列でなく、指定された最小長より短い場合はtrueを返し、それ以外の場合はfalseを返す。
element.validity.rangeUnderflow
要素の値が指定された最小値より小さい場合はtrueを返し、それ以外の場合はfalseを返す。
element.validity.rangeOverflow
要素の値が指定された最大値より大きい場合はtrueを返し、それ以外の場合はfalseを返す。
element.validity.stepMismatch
要素の値がstep属性によって指定された規則に適合しない場合はtrueを返し、
それ以外の場合はfalseを返す。
element.validity.badInput
現在のすべてのエンジンでサポートされています。
ユーザーがユーザーインターフェイスで、ユーザーエージェントが値に変換できない入力を指定した場合は trueを返し、それ以外の場合はfalseを返す。
element.validity.customError
要素にカスタムエラーがある場合はtrueを返し、それ以外の場合はfalseを返す。
element.validity.valid
要素の値に妥当性の問題がない場合はtrueを返し、それ以外の場合はfalseを返す。
valid = element.checkValidity()
HTMLInputElement/checkValidity
現在のすべてのエンジンでサポートされています。
HTMLObjectElement/checkValidity
現在のすべてのエンジンでサポートされています。
HTMLSelectElement/checkValidity
現在のすべてのエンジンでサポートされています。
要素の値に妥当性の問題がない場合はtrueを返し、それ以外の場合はfalseを返す。後者の場合、
要素においてinvalidイベントを発火する。
valid = element.reportValidity()
HTMLFormElement/reportValidity
現在のすべてのエンジンでサポートされています。
HTMLInputElement/reportValidity
現在のすべてのエンジンでサポートされています。
要素の値に妥当性の問題がない場合はtrueを返す。それ以外の場合はfalseを返し、要素において
invalidイベントを発火し、イベントがキャンセルされなければ問題を
ユーザーに報告する。
element.validationMessage
HTMLObjectElement/validationMessage
現在のすべてのエンジンでサポートされています。
要素の妥当性を検査する場合にユーザーへ表示されるエラーメッセージを返す。
willValidate属性のゲッターは、
この要素が制約検証の候補である場合は
trueを返し、それ以外の場合はfalseを返さなければならない(すなわち、何らかの条件によって制約検証の対象外となっている
場合はfalse)。
現在のすべてのエンジンでサポートされています。
ElementInternalsインターフェイスのwillValidate属性は、取得時に、対象要素がフォーム関連カスタム要素でない場合、
"NotSupportedError" DOMExceptionを投げなければならない。
それ以外の場合、対象要素が制約検証の候補であれば
trueを返し、それ以外の場合はfalseを返さなければならない。
HTMLInputElement/setCustomValidity
現在のすべてのエンジンでサポートされています。
setCustomValidity(error)メソッドの手順は次のとおりである:
errorを、errorを与えて改行を正規化する結果に設定する。
カスタム妥当性エラーメッセージを errorに設定する。
次の例では、スクリプトがフォームコントロールの値を編集されるたびに確認し、妥当な値でない場合は
setCustomValidity()メソッドを使用して適切なメッセージを
設定する。
< label > 気分: < input name = f type = "text" oninput = "check(this)" ></ label >
< script >
function check( input) {
if ( input. value == "good" ||
input. value == "fine" ||
input. value == "tired" ) {
input. setCustomValidity( '"' + input. value + '" is not a feeling.' );
} else {
// input is fine -- reset the error message
input. setCustomValidity( '' );
}
}
</ script > 現在のすべてのエンジンでサポートされています。
validity属性のゲッターは、この要素の
妥当性状態を表すValidityStateオブジェクトを返さなければならない。このオブジェクトは
ライブである。
現在のすべてのエンジンでサポートされています。
ElementInternalsインターフェイスのvalidity属性は、取得時に、対象要素がフォーム関連カスタム要素でない場合、
"NotSupportedError" DOMExceptionを投げなければならない。
それ以外の場合、対象要素の妥当性状態を表すValidityStateオブジェクトを返さなければならない。このオブジェクトは
ライブである。
[Exposed =Window ]
interface ValidityState {
readonly attribute boolean valueMissing ;
readonly attribute boolean typeMismatch ;
readonly attribute boolean patternMismatch ;
readonly attribute boolean tooLong ;
readonly attribute boolean tooShort ;
readonly attribute boolean rangeUnderflow ;
readonly attribute boolean rangeOverflow ;
readonly attribute boolean stepMismatch ;
readonly attribute boolean badInput ;
readonly attribute boolean customError ;
readonly attribute boolean valid ;
};ValidityStateオブジェクトは、次の属性を持つ。取得時には、次のリストに
示される対応する条件がtrueの場合はtrueを返し、それ以外の場合はfalseを返さなければならない。
valueMissingコントロールが値欠落の状態にある。
typeMismatch
現在のすべてのエンジンでサポートされています。
コントロールが型不一致の状態にある。
patternMismatch
現在のすべてのエンジンでサポートされています。
コントロールがパターン不一致の状態にある。
tooLongコントロールが長すぎる状態にある。
tooShortコントロールが短すぎる状態にある。
rangeUnderflow
現在のすべてのエンジンでサポートされています。
コントロールがアンダーフロー状態にある。
rangeOverflow
現在のすべてのエンジンでサポートされています。
コントロールがオーバーフロー状態にある。
stepMismatch
現在のすべてのエンジンでサポートされています。
コントロールがステップ不一致の状態にある。
badInputコントロールが不正な入力の状態にある。
customErrorコントロールがカスタムエラーの状態にある。
valid他の条件がいずれもtrueでない。
要素elementの妥当性確認手順は次のとおりである:
elementが制約検証の候補であり、 制約を満たさない場合:
cancelable属性をtrueに初期化して、
elementにおいてinvalidという名前のイベントを発火する(ただし、キャンセルしても効果はない)。
falseを返す。
trueを返す。
checkValidity()メソッドは、
呼び出されたとき、この要素について妥当性確認手順を実行しなければならない。
ElementInternals/checkValidity
現在のすべてのエンジンでサポートされています。
ElementInternalsインターフェイスのcheckValidity()メソッドは、次の手順を実行しなければならない:
elementを、このElementInternalsの対象要素とする。
elementがフォーム関連カスタム要素でない場合、
"NotSupportedError" DOMExceptionを投げる。
elementについて妥当性確認手順を実行する。
要素elementの妥当性報告手順は次のとおりである:
elementが制約検証の候補であり、 制約を満たさない場合:
reportを、cancelable属性をtrueに初期化して、
elementにおいてinvalidという名前のイベントを発火する結果とする。
reportがtrueの場合、この要素の制約の問題をユーザーに報告する。制約の問題を ユーザーに報告するとき、ユーザーエージェントはelementについてフォーカス手順を実行してもよく、 文書のスクロール位置を変更したり、elementにユーザーの注意を向ける他の操作を 実行したりしてもよい。elementが同時に複数の問題を持つ場合、ユーザーエージェントは 複数の制約違反を報告してもよい。
falseを返す。
trueを返す。
reportValidity()メソッドは、
呼び出されたとき、この要素について妥当性報告手順を実行しなければならない。
ElementInternals/reportValidity
現在のすべてのエンジンでサポートされています。
ElementInternalsインターフェイスのreportValidity()メソッドは、次の手順を実行しなければならない:
elementを、このElementInternalsの対象要素とする。
elementがフォーム関連カスタム要素でない場合、
"NotSupportedError" DOMExceptionを投げる。
elementについて妥当性報告手順を実行する。
validationMessage属性のゲッターは、次の手順を
実行しなければならない:
この要素が妥当性制約の問題を持つ唯一のフォームコントロールであった場合に、 ユーザーエージェントがユーザーへ表示する、適切にローカライズされたメッセージを返す。 そのような状況でユーザーエージェントが実際にはテキストメッセージを表示しない場合 (たとえば、代わりに視覚的な手掛かりを表示する場合)、コントロールが満たしていない 妥当性制約の1つ以上を表す、適切にローカライズされたメッセージを返す。要素が制約検証の候補であり、 カスタムエラーの状態にある場合、 戻り値にはカスタム妥当性エラーメッセージを 含めることが望ましい。
サーバーはクライアント側検証に依存すべきではない。クライアント側検証は、悪意のある ユーザーによって意図的に迂回される可能性があり、また、これらの機能を実装していない古い ユーザーエージェントまたは自動化ツールのユーザーによって意図せず迂回される可能性もある。 制約検証機能は、ユーザー体験を改善することのみを目的としており、いかなる種類のセキュリティ機構を 提供することも目的としていない。
この節は非規範的である。
フォームが送信されると、フォーム内のデータはenctypeによって指定された構造に変換され、指定されたメソッドを使用して、アクションによって指定された送信先へ 送信される。
たとえば、次のフォームを考える:
< form action = "/find.cgi" method = get >
< input type = text name = t >
< input type = search name = q >
< input type = submit >
</ form > ユーザーが最初のフィールドに「cats」、2番目のフィールドに「fur」と入力し、送信ボタンを押すと、
ユーザーエージェントは/find.cgi?t=cats&q=furを読み込む。
一方、次のフォームを考える:
< form action = "/find.cgi" method = post enctype = "multipart/form-data" >
< input type = text name = t >
< input type = search name = q >
< input type = submit >
</ form > 同じユーザー入力を与えた場合、送信時の結果は大きく異なる。ユーザーエージェントは代わりに、 指定されたURLへHTTP POSTを行い、エンティティ本体として次のようなテキストを使用する:
------kYFrd4jNJEgCervE Content-Disposition: form-data; name="t" cats ------kYFrd4jNJEgCervE Content-Disposition: form-data; name="q" fur ------kYFrd4jNJEgCervE--
ユーザーエージェントが、ユーザーによるフォームの暗黙的な送信をサポートする場合(たとえば、
一部のプラットフォームでは、テキストコントロールがフォーカスされているときに「Enter」キーを押すと、フォームが
暗黙的に送信される)、デフォルトボタンが活性化動作を持ち、かつ無効でないフォームに対して
これを行うと、ユーザーエージェントはそのデフォルトボタンにおいてclickイベントを
発火しなければならない。
暗黙的にフォームを送信する方法がなければ利用できないウェブページが存在するため、 ユーザーエージェントはこれをサポートすることが強く推奨される。
フォームに送信ボタンがない場合、暗黙的な送信機構は 次の手順を実行しなければならない:
フォームに複数の暗黙的な送信を阻止するフィールドが ある場合は、戻る。
userInvolvementを「activation」に設定して、
form要素自体から
form要素を送信する。
前の段落の目的において、要素がinput要素であり、その
フォーム所有者が対象のform要素であり、かつ
そのtype属性が
次のいずれかの状態である場合、その要素はform要素の暗黙的な送信を阻止するフィールドである:
Text、
Search、
Telephone、
URL、
Email、
Password、
Date、
Month、
Week、
Time、
Local Date and Time、
Number
各form要素は、初期値がfalseであるエントリーリスト構築中真偽値を持つ。
各form要素は、初期値がfalseである送信イベント発火中真偽値を持つ。
要素submitter(通常はボタン)からform要素
formを送信するには、省略可能な真偽値submit()メソッドから送信された
(デフォルトはfalse)および省略可能なユーザーナビゲーション関与userInvolvement(デフォルトは「none」)を与えて:
formがナビゲートできない場合は、戻る。
formのエントリーリスト構築中がtrueの場合は、 戻る。
form documentを、formのノード文書とする。
form documentの有効なサンドボックス化フラグ集合に サンドボックス化されたフォーム閲覧 コンテキストフラグが設定されている場合は、戻る。
submit()メソッドから送信されたがfalseの場合:
formの送信イベント発火中がtrueの場合は、 戻る。
formの送信イベント発火中をtrueに設定する。
フォーム所有者が formである送信可能要素のリスト内の各要素 fieldについて、fieldのユーザー妥当性をtrueに設定する。
submitter要素の検証なし状態がfalseの場合、 formの制約を対話的に検証し、 その結果を調べる。結果が否定である場合(すなわち、制約検証によって無効なフィールドがあると 結論付けられ、おそらくユーザーに通知された場合):
formの送信イベント発火中をfalseに 設定する。
戻る。
submitterがformである場合、submitterButtonをnullとする。 それ以外の場合、submitterButtonをsubmitterとする。
shouldContinueを、submitter属性をsubmitterButtonに、
bubbles属性をtrueに、cancelable属性をtrueに初期化して、
SubmitEventを使用し、formにおいてsubmitという名前のイベントを発火する結果とする。
formの送信イベント発火中をfalseに設定する。
shouldContinueがfalseの場合は、戻る。
formがナビゲートできない場合は、戻る。
encodingを、フォームのエンコーディングを選択する 結果とする。
entry listを、form、submitter、およびencodingを 使用してエントリーリストを構築する結果とする。
表明: entry listはnullではない。
formがナビゲートできない場合は、戻る。
エントリーリストを構築する際の
formdataイベントのディスパッチによって結果が変わる可能性があるため、
ナビゲートできないを再度実行する。
methodを、submitter要素のメソッドとする。
methodがdialogである場合:
actionを、submitter要素のアクションとする。
actionが空文字列の場合、actionをform documentのURLとする。
parsed actionを、submitterのノード文書を基準として、actionを与えてURLをエンコーディング解析する結果とする。
parsed actionが失敗の場合は、戻る。
schemeを、parsed actionのスキームとする。
enctypeを、submitter要素のenctypeとする。
formTargetをnullとする。
submitter要素が送信ボタンであり、formtarget属性を持つ場合、formTargetをformtarget属性値に設定する。
targetを、submitterのフォーム所有者およびformTargetを与えて 要素のターゲットを取得する結果とする。
noopenerを、form、parsed action、およびtargetを 使用して要素のnoopenerを取得する結果とする。
targetNavigableを、target、formのノードナビゲーション可能、 およびnoopenerを与えてナビゲーション可能を選択する規則を 適用した最初の戻り値とする。
targetNavigableがnullの場合は、戻る。
historyHandlingを「auto」とする。
form documentがtargetNavigableのアクティブ文書と等しく、かつ
form documentがまだ完全に読み込まれていない場合、
historyHandlingを「replace」に設定する。
各行の最初のセルに示されるschemeに基づき、下の表から適切な行を選択する。 次に、各列の最初のセルに示されるmethodに基づき、その行から適切なセルを選択する。 次に、そのセルに名前が示され、表の下で定義されている手順へジャンプする。
| GET | POST | |
|---|---|---|
http
|
アクションURLを 変更する | エンティティ本体として送信する |
https
|
アクションURLを 変更する | エンティティ本体として送信する |
ftp
|
アクションURLを取得する | アクションURLを取得する |
javascript
|
アクションURLを取得する | アクションURLを取得する |
data
|
アクションURLを 変更する | アクションURLを取得する |
mailto
|
ヘッダー付き メール | 本文としてメール送信 |
schemeがこの表に示されているもののいずれでもない場合、その動作はこの仕様では 定義されない。これを定義する別の仕様がない場合、ユーザーエージェントは、類似したスキームについて この仕様で定義されている方法と同様に動作することが望ましい。
各form要素は、nullまたはタスクのいずれかである予定されたナビゲーションを持つ。formが最初に作成されたとき、その予定されたナビゲーションをnullに設定しなければ
ならない。以下で説明する動作において、ユーザーエージェントが、省略可能なPOSTリソースまたはnullの
postResource(デフォルトはnull)を与えて、URL urlへのナビゲーションを予定する必要がある場合、次の手順を実行しなければならない:
referrerPolicyを空文字列とする。
form要素のリンク型にnoreferrerキーワードが含まれる場合、
referrerPolicyを「no-referrer」に設定する。
formがnullでない予定されたナビゲーションを持つ場合、
それをそのタスクキューから削除する。
form要素および次の手順を与えて、DOM操作タスクソース上で要素タスクをキューに入れる:
formの予定されたナビゲーションをnullに設定する。
form要素のノード文書を使用し、historyHandlingをhistoryHandlingに、userInvolvementをuserInvolvementに、
sourceElementをsubmitterに、referrerPolicyをreferrerPolicyに、
documentResourceをpostResourceに、formDataEntryListをentry
listに設定して、targetNavigableをurlへナビゲートする。
formの予定されたナビゲーションを、直前にキューへ
入れたタスクに設定する。
動作は次のとおりである:
pairsを、entry listを使用して名前と値の組のリストに 変換する結果とする。
queryを、pairsおよびencodingを使用して
application/x-www-form-urlencoded
シリアライザーを実行した結果とする。
parsed actionのクエリコンポーネントをqueryに設定する。
parsed actionへのナビゲーションを予定する。
enctypeに応じて切り替える:
application/x-www-form-urlencoded
pairsを、entry listを使用して名前と値の組のリストに 変換する結果とする。
bodyを、pairsおよびencodingを使用して
application/x-www-form-urlencoded
シリアライザーを実行した結果とする。
bodyを、bodyをエンコードする結果に設定する。
mimeTypeを「application/x-www-form-urlencoded」とする。
multipart/form-data
bodyを、entry listおよびencodingを使用してmultipart/form-data
エンコーディングアルゴリズムを実行した結果とする。
mimeTypeを、「multipart/form-data; boundary=」とmultipart/form-data
エンコーディングアルゴリズムによって生成されたmultipart/form-data
境界文字列を連結したものの同型エンコーディングとする。
text/plain
pairsを、entry listを使用して名前と値の組のリストに 変換する結果とする。
bodyを、pairsを使用してtext/plain
エンコーディングアルゴリズムを実行した結果とする。
bodyを、encodingを使用してbodyをエンコードする結果に設定する。
mimeTypeを「text/plain」とする。
POSTリソースのリクエスト本体が bodyであり、リクエストcontent-typeが mimeTypeであるものを与えて、parsed actionへのナビゲーションを予定する。
parsed actionへのナビゲーションを予定する。
entry listは破棄される。
pairsを、entry listを使用して名前と値の組のリストに 変換する結果とする。
headersを、pairsおよびencodingを使用して
application/x-www-form-urlencoded
シリアライザーを実行した結果とする。
headers内に出現するU+002B PLUS SIGN文字(+)を文字列「%20」に
置換する。
parsed actionのクエリをheadersに設定する。
parsed actionへのナビゲーションを予定する。
pairsを、entry listを使用して名前と値の組のリストに 変換する結果とする。
enctypeに応じて切り替える:
text/plain
bodyを、pairsを使用してtext/plain
エンコーディングアルゴリズムを実行した結果とする。
bodyを、デフォルトエンコード集合を使用してbodyに UTF-8パーセントエンコードを実行した結果に設定する。 [URL]
bodyを、pairsおよびencodingを使用して
application/x-www-form-urlencoded
シリアライザーを実行した結果とする。
parsed actionのクエリがnullの場合、それを空文字列に設定する。
parsed actionのクエリが空文字列でない場合、単一のU+0026 AMPERSAND文字 (&)を追加する。
parsed actionのクエリに「body=」を追加する。
parsed actionのクエリにbodyを追加する。
parsed actionへのナビゲーションを予定する。
エントリーリストは、通常はフォームの内容を表すエントリーのリストである。エントリーは、名前(スカラー値文字列)および値(スカラー値文字列またはFileオブジェクト)からなるタプルである。
文字列name、文字列またはBlobオブジェクトvalue、および
省略可能なスカラー値文字列filenameを与えてエントリーを作成するには:
form、省略可能なsubmitter(デフォルトはnull)、および省略可能な encoding(デフォルトはUTF-8)を与えてエントリーリストを構築するには:
formのエントリーリスト構築中がtrueの場合、 nullを返す。
formのエントリーリスト構築中をtrueに設定する。
entry listを、新しい空のエントリーリストとする。
controls内の各要素fieldについて、ツリー順で:
次のいずれかがtrueである場合:
fieldが祖先となるdatalist要素を持つ。
fieldが無効である。
fieldがボタンであるが、 submitterではない。
fieldが、type属性がCheckbox状態であり、かつ
チェック状態がfalseであるinput要素である。または
fieldが、type属性がRadio Button状態であり、かつ
チェック状態がfalseであるinput要素である。
その場合、継続する。
field要素が、type属性がImage Button状態であるinput要素である場合:
fieldがフォーム関連カスタム要素である場合、 fieldおよびentry listを与えてエントリー構築アルゴリズムを実行し、 その後継続する。
nameを、field要素のname属性の値とする。
field要素がselect要素である場合、select要素の選択肢のリスト内にあり、選択状態がtrueで、かつ無効でない各option要素について、nameおよびoption要素の値を使用してエントリーを作成し、それをentry
listに付加する。
それ以外の場合、field要素が、type属性がCheckbox状態またはRadio Button状態であるinput要素である場合:
それ以外の場合、field要素が、type属性がFile Upload状態であるinput要素である場合:
それ以外の場合、field要素が、type属性が状態であり、かつ
nameが「_charset_」とのASCII大文字小文字不区別の一致であるinput要素である場合:
要素がdirname属性を持ち、その属性の値が空文字列でなく、かつ要素が自動方向性フォーム関連
要素である場合:
form dataを、entry listに関連付けられた新しいFormDataオブジェクトとする。
formData属性をform dataに、bubbles属性をtrueに初期化し、FormDataEventを使用して、formにおいてformdataという名前のイベントを発火する。
formのエントリーリスト構築中をfalseに設定する。
entry listのクローンを返す。
ユーザーエージェントがフォームのエンコーディングを 選択する場合、次の手順を実行しなければならない:
encodingを、文書の文字エンコーディングとする。
form
要素がaccept-charset
属性を持つ場合、encodingを、次の下位手順を実行した戻り値に設定する:
inputを、form
要素のaccept-charset
属性の値とする。
candidate encoding labelsを、inputをASCII空白で分割する結果とする。
candidate encodingsを、空の文字エンコーディングのリストとする。
candidate encoding labels内の各トークンについて順に(input内で 見つかった順序で)、そのトークンの エンコーディングを取得し、失敗にならなければ、そのエンコーディングをcandidate encodingsに追加する。
candidate encodingsが空の場合、UTF-8を返す。
candidate encodings内の最初のエンコーディングを返す。
encodingから出力エンコーディングを取得する結果を返す。
application/x-www-form-urlencoded
およびtext/plain
エンコーディングアルゴリズムは、値が文字列でなければならない名前と値の組のリストを受け取り、値が
File
であり得るエントリーリストは受け取らない。
次のアルゴリズムがその変換を実行する。
エントリーリスト entry listを名前と値の組のリストに変換するには、 次の手順を実行する:
listを、空の名前と値の組のリストとする。
entry list内の各entryについて反復する:
nameを、entryの名前とし、 U+000A(LF)が後続しないU+000D(CR)の各出現、およびU+000D(CR)が先行しない U+000A(LF)の各出現を、U+000D(CR)とU+000A(LF)からなる文字列に置換する。
entryの値が
File
オブジェクトである場合、valueを、entryの値のnameとする。
それ以外の場合、
valueをentryの値とする。
value内の、U+000A(LF)が後続しないU+000D(CR)の各出現、および U+000D(CR)が先行しないU+000A(LF)の各出現を、U+000D(CR)とU+000A(LF)からなる 文字列に置換する。
名前がnameで値がvalueである新しい名前と値の組をlistに 付加する。
listを返す。
application/x-www-form-urlencodedの詳細については
URLを参照。
[URL]
エントリーリストentry listおよび
エンコーディング
encodingを与えたmultipart/form-dataエンコーディングアルゴリズムは、次のとおりである:
entry list内の各entryについて反復する:
次の条件を与えて、RFC 7578『Returning Values from Forms:
multipart/form-data』で説明される規則を使用してentry listを
エンコードした結果のバイト列を返す:
[RFC7578]
entry list内の各エントリーはフィールドであり、エントリーの 名前は フィールド名であり、エントリーの値はフィールド値である。
各パートの順序は、entry list内のフィールドの順序と同じでなければならない。 同じ名前を持つ複数のエントリーは、別個のフィールドとして扱わなければならない。
生成されるmultipart/form-data
リソース内のフィールド名、非ファイルフィールドのフィールド値、およびファイルフィールドの
ファイル名は、対応するエントリーの名前または値をencodingでエンコードし、バイト列へ変換した
結果に設定しなければならない。
フィールド名およびファイルフィールドのファイル名については、前の箇条書きのエンコード結果を、
0x0A(LF)バイトをバイト列「%0A」に、0x0D(CR)を「%0D」に、
0x22(")を「%22」に置換してエスケープしなければならない。
ユーザーエージェントは、その他のエスケープを行ってはならない。
生成されるmultipart/form-data
リソースのうち、非ファイルフィールドに対応するパートには「Content-Type」ヘッダーを
指定してはならない。
このアルゴリズムの戻り値を生成する際にユーザーエージェントが使用する境界は、multipart/form-data境界文字列である。(この値は、
このアルゴリズムによって生成されるフォーム送信ペイロードのMIME型を生成するために使用される。)
multipart/form-data
ペイロードの解釈方法の詳細については、RFC 7578を参照。
[RFC7578]
名前と値の組のリストpairsを与えたtext/plainエンコーディングアルゴリズムは、
次のとおりである:
resultを空文字列とする。
pairs内の各pairについて:
pairの名前をresultに追加する。
単一のU+003D EQUALS SIGN文字(=)をresultに追加する。
pairの値をresultに追加する。
U+000D CARRIAGE RETURN(CR)とU+000A LINE FEED(LF)の文字の組を resultに追加する。
resultを返す。
text/plain
形式を使用するペイロードは、人間が読めることを意図している。この形式は曖昧であるため、コンピューターで
確実に解釈することはできない(たとえば、値内のリテラル改行と値の末尾の改行を区別する方法がない)。
SubmitEventインターフェイス現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
[Exposed =Window ]
interface SubmitEvent : Event {
constructor (DOMString type , optional SubmitEventInit eventInitDict = {});
readonly attribute HTMLElement ? submitter ;
};
dictionary SubmitEventInit : EventInit {
HTMLElement ? submitter = null ;
};submitter属性は、初期化された値を返さなければならない。
FormDataEventインターフェイス現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
[Exposed =Window ]
interface FormDataEvent : Event {
constructor (DOMString type , FormDataEventInit eventInitDict );
readonly attribute FormData formData ;
};
dictionary FormDataEventInit : EventInit {
required FormData formData ;
};event.formData
対象のformに関連付けられた
要素の名前と値を表すFormData
オブジェクトを返す。FormData
オブジェクトに対する操作は、送信されるフォームデータに影響する。
form要素
formがリセットされるとき、次の手順を実行する:
resetを、bubbles属性およびcancelable属性をtrueに初期化して、
formにおいてresetという名前のイベントを発火する結果とする。
resetがtrueの場合、フォーム所有者がformである各リセット可能要素のリセットアルゴリズムを呼び出す。
各リセット可能要素は、それ自体の
リセットアルゴリズムを定義する。これらのアルゴリズムの一部として
フォームコントロールに加えられた変更は、ユーザーによって行われた変更とはみなされない(したがって、
たとえばinputイベントを発火させない)。
details要素
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
summary要素に
続くフローコンテンツ。name — 相互排他的な
details要素のグループ名
open — 詳細が
表示されるかどうか
[Exposed =Window ]
interface HTMLDetailsElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute DOMString name ;
[CEReactions , Reflect ] attribute boolean open ;
};details要素は、
ユーザーが追加情報または追加のコントロールを取得できる開示ウィジェットを表す。
すべてのHTML要素と同様に、別の種類のコントロールを表そうとしてdetails要素を
使用することは適合しない。たとえば、タブウィジェットおよびメニューウィジェットは開示ウィジェットでは
ないため、これらのパターンを実装するためにdetails要素を
誤用することは不正である。
details要素は脚注には
適していない。脚注をマークアップする方法の詳細については、脚注に関する節を参照。
要素の最初の子summary要素が存在する場合、それは詳細の概要または凡例を表す。子summary要素がない場合、
ユーザーエージェントは独自の凡例(たとえば「詳細」)を提供することが望ましい。
要素の残りの内容は、追加情報または追加のコントロールを表す。
nameコンテンツ
属性は、要素が属する、関連するdetails要素の
グループ名を指定する。このグループの1つのメンバーを開くと、グループの他のメンバーが閉じる。
属性が指定される場合、その値は空文字列であってはならない。
この機能を使用する前に、著者は、関連するdetails要素を
排他的なアコーディオンにグループ化することが、ユーザーにとって有益か有害かを検討することが望ましい。
排他的なアコーディオンを使用すると、一連のコンテンツが占め得る最大領域を削減できる一方で、必要なものを
見つけるために多数の項目を開かなければならないユーザーや、複数の項目の内容を同時に見たいユーザーを
苛立たせる可能性もある。
文書は、同じdetails名前グループ内に、open属性を持つdetails要素を
2つ以上含んではならない。著者は、details名前グループが、open属性を持つdetails要素を
2つ以上持つことになる方法で、スクリプトを使用してdetails要素を文書に
追加してはならない。
共通のname属性によって作成される要素のグループは排他的であり、一度に開くことが
できるdetails要素は最大1つである。この排他性はユーザーエージェントに
よって強制されるが、その強制の結果、マークアップ内のopen属性が直ちに変更される。
著者に対するこの要件は、そのような誤解を招くマークアップを禁止する。
文書は、同じdetails名前グループ内の別のdetails要素の
子孫であるdetails要素を含んではならない。
name属性を使用して
複数の関連するdetails要素をグループ化する文書は、それらの関連する要素を、
包含要素(section要素またはarticle要素など)内に
まとめておくことが望ましい。グループを見出しによって導入することが適切な場合、著者はその見出しを
包含要素の先頭にある見出し要素内に配置することが望ましい。
関連する要素を視覚的およびプログラム的にグループ化することは、アクセシブルな ユーザー体験にとって重要な場合がある。これにより、ユーザーはそのような要素間の関係を理解しやすくなる。 関連する要素がグループ化されず、ウェブページの離れた節に存在する場合、要素間の関係は見つけにくく、 理解しにくくなる可能性がある。
openコンテンツ
属性は真偽属性である。存在する場合、概要と追加情報の両方を
ユーザーに表示することを示す。属性が存在しない場合、概要のみを表示する。
要素が作成されたとき、属性が存在しない場合は追加情報を非表示にすることが望ましく、属性が存在する場合は その情報を表示することが望ましい。その後、属性が削除された場合は情報を非表示にすることが望ましく、 属性が追加された場合は情報を表示することが望ましい。
ユーザーエージェントは、追加情報の表示または非表示をユーザーが要求できるようにすることが望ましい。
詳細を表示する要求に従うには、ユーザーエージェントは要素のopen属性を空文字列に設定しなければならない。情報を非表示にする要求に
従うには、ユーザーエージェントは要素からopen属性を削除しなければならない。
追加情報の表示または非表示を要求するこの機能は、適切なsummary要素が存在する
場合には、単にその要素の活性化動作であってもよい。ただし、そのような要素が存在しない
場合でも、ユーザーエージェントは別のユーザーインターフェイス上の手段を通じてこの機能を提供できる。
各details要素は、切替タスク追跡子またはnullであり、初期値がnullである
details切替タスク追跡子を持つ。
element、localName、oldValue、value、および
namespaceを与えた次の属性変更手順は、すべてのdetails要素に使用される:
namespaceがnullでない場合は、戻る。
localNameがnameである場合、
elementを与えて必要に応じて
指定された要素を閉じることによりdetailsの排他性を確保する。
localNameがopenである場合:
oldValueまたはvalueの一方がnullであり、もう一方がnullでない場合、
このdetails要素について、details通知タスク手順として知られる次の手順を実行する:
open属性が連続して複数回切り替えられた場合、結果となるタスクは
実質的にまとめられ、1つのイベントだけが発火する。
oldValueがnullの場合、details要素、「closed」、および
「open」を与えてdetails切替イベントタスクを
キューに入れる。
それ以外の場合、details要素、「open」、および
「closed」を与えてdetails切替イベントタスクを
キューに入れる。
oldValueがnullであり、valueがnullでない場合、 elementを与えて必要に応じて 他の要素を閉じることによりdetailsの排他性を確保する。
insertedNodeを与えたdetailsのHTML要素挿入
手順は、次のとおりである:
insertedNodeを与えて必要に応じて 指定された要素を閉じることによりdetailsの排他性を確保する。
明確にすると、これらの属性変更手順および挿入手順は、属性または要素がパーサーによって 挿入された場合にも実行される。
details要素element、文字列oldState、
および文字列newStateを与えてdetails切替イベントタスクをキューに入れるには:
elementのdetails切替タスク追跡子がnullでない場合:
oldStateを、elementのdetails切替タスク追跡子の旧状態に設定する。
elementのdetails切替タスク追跡子のタスクを、そのタスクキューから削除する。
elementのdetails切替タスク追跡子をnullに設定する。
DOM操作タスクソースおよび elementを与えて、次の手順を実行する要素タスクをキューに入れる:
oldState
属性をoldStateに、newState
属性をnewStateに初期化して、ToggleEventを使用し、
elementにおいてtoggleという名前のイベントを発火する。
elementのdetails切替タスク追跡子をnullに設定する。
elementのdetails切替タスク追跡子を、タスクを直前にキューに入れたタスクに設定し、旧状態を oldStateに設定した構造体に設定する。
details要素elementを与えて、必要に応じて他の要素を閉じることにより
detailsの排他性を確保するには:
groupMembersを、elementを除く、elementのdetails名前グループ内の すべての要素をツリー順に 含む要素のリストとする。
groupMembers内の各要素otherElementについて反復する:
details要素elementを与えて、必要に応じて指定された要素を閉じることに
よりdetailsの排他性を確保するには:
次の例は、進捗報告内の技術的詳細を隠すためにdetails要素を使用する例を示す。
< section class = "progress window" >
< h1 > Copying "Really Achieving Your Childhood Dreams"</ h1 >
< details >
< summary > Copying... < progress max = "375505392" value = "97543282" ></ progress > 25%</ summary >
< dl >
< dt > Transfer rate:</ dt > < dd > 452KB/s</ dd >
< dt > Local filename:</ dt > < dd > /home/rpausch/raycd.m4v</ dd >
< dt > Remote filename:</ dt > < dd > /var/www/lectures/raycd.m4v</ dd >
< dt > Duration:</ dt > < dd > 01:16:27</ dd >
< dt > Color profile:</ dt > < dd > SD (6-1-6)</ dd >
< dt > Dimensions:</ dt > < dd > 320×240</ dd >
</ dl >
</ details >
</ section > 次の例は、details要素を使用して、デフォルトで一部のコントロールを
隠す方法を示す:
< details >
< summary >< label for = fn > Name & Extension:</ label ></ summary >
< p >< input type = text id = fn name = fn value = "Pillar Magazine.pdf" >
< p >< label >< input type = checkbox name = ext checked > Hide extension</ label >
</ details > これをリスト内の他のdetails要素と
組み合わせて使用すると、各項目を開く機能を維持しながら、一連のフィールドを少数の見出しへ折り畳める
ようにすることができる。
これらの例では、概要は実際の値ではなく、コントロールが変更できる内容を単に要約しているだけであり、 理想的とは言い難い。
次の例は、details要素のname属性を使用して
排他的なアコーディオン、すなわち、あるdetails要素を開く
ユーザー操作によって、開いている他のすべてのdetails要素が閉じる
details要素の集合を作成する例を示す。
< section class = "characteristics" >
< details name = "frame-characteristics" >
< summary > Material</ summary >
The picture frame is made of solid oak wood.
</ details >
< details name = "frame-characteristics" >
< summary > Size</ summary >
The picture frame fits a photo 40cm tall and 30cm wide.
The frame is 45cm tall, 35cm wide, and 2cm thick.
</ details >
< details name = "frame-characteristics" >
< summary > Color</ summary >
The picture frame is available in its natural wood
color, or with black stain.
</ details >
</ section > 次の例は、name属性を使用して排他的なアコーディオンを作成する要素集合の一部で
あるdetails要素に、open属性が設定された場合に何が起こるかを示す。
次の初期マークアップがあるとする:
< section class = "characteristics" >
< details name = "frame-characteristics" id = "d1" open > ...</ details >
< details name = "frame-characteristics" id = "d2" > ...</ details >
< details name = "frame-characteristics" id = "d3" > ...</ details >
</ section > および次のスクリプトがあるとする:
document. getElementById( "d2" ). setAttribute( "open" , "" ); この場合、スクリプトの実行後に得られるツリーは、次のマークアップと同等になる:
< section class = "characteristics" >
< details name = "frame-characteristics" id = "d1" > ...</ details >
< details name = "frame-characteristics" id = "d2" open > ...</ details >
< details name = "frame-characteristics" id = "d3" > ...</ details >
</ section > これは、d2にopen属性を設定すると、
d1からその属性が削除されるためである。
ユーザーがd2内のsummary要素を活性化した場合にも、同じことが起こる。
open属性は、
ユーザーがコントロールを操作すると自動的に追加および削除されるため、CSSで要素の状態に基づいて異なる
スタイルを適用するために使用できる。ここでは、要素が開かれたときまたは閉じられたときに概要の色を
アニメーション化するためにスタイルシートを使用している:
< style >
details > summary { transition : color 1 s ; color : black ; }
details [ open ] > summary { color : red ; }
</ style >
< details >
< summary > Automated Status: Operational</ summary >
< p > Velocity: 12m/s</ p >
< p > Direction: North</ p >
</ details > summary要素
現在のすべてのエンジンでサポートされています。
details要素の最初の子として。HTMLElementを使用する。summary要素は、
存在する場合、その親であるdetails要素の
残りの内容についての概要、キャプション、または凡例を表す。
summary要素は、
次のアルゴリズムがtrueを返す場合、親detailsの概要である:
summary要素の活性化動作は、次の手順を実行することである:
このsummary要素が
親detailsの概要でない場合、戻る。
parentを、このsummary要素の
親とする。
parentにopen属性が存在する場合、それを削除する。
それ以外の場合、parentのopen属性を空文字列に設定する。
これにより、details通知タスク手順が実行される。
コマンドは、メニュー項目、ボタン、およびリンクの背後にある抽象概念である。 コマンドが定義されると、インターフェイスの他の部分は同じコマンドを参照できるようになり、1つの機能への 多数のアクセスポイントで、無効状態などのファセットを共有できる。
コマンドは、次のファセットを持つものとして定義される:
ユーザーエージェントは、次の基準を満たすコマンドを公開してもよい:
ユーザーエージェントは、特にアクセスキーを持つコマンドについて、そのキーをユーザーに 周知する方法として、これを行うことが推奨される。
たとえば、そのようなコマンドをユーザーエージェントのメニューバーに一覧表示できる。
a要素を
使用したコマンドの定義コマンドのラベルは、要素の子孫テキストコンテンツである。
コマンドのアクセスキーは、存在する場合、 要素に割り当てられたアクセスキーである。
コマンドのは、要素が属性を 持つ場合はtrue(非表示)であり、それ以外の場合はfalseである。
コマンドのアクションは、要素においてclickイベントを発火する
ことである。
button
要素を使用したコマンドの定義コマンドのラベル、
アクセスキー、、および
アクションファセットは、a要素の
場合と同様に決定される(前の節を参照)。
input
要素を使用したコマンドの定義input
要素のtype
属性が、Submit Button、Reset Button、Image Button、Button、Radio Button、またはCheckbox状態のいずれかで
ある場合、その要素はコマンドを定義する。
コマンドのラベルは、次のように決定される:
type
属性が、Submit Button、
Reset Button、Image Button、
またはButton状態のいずれかで
ある場合、ラベルは、存在する場合は
value属性によって与えられる文字列であり、属性が存在しない場合は、
UAがボタン自体にラベルを付けるために使用する、UA依存かつロケール依存の値である。
それ以外の場合、要素がラベル付きコントロールであれば、
ラベルは、ラベル付きコントロールが対象の
要素である、ツリー順で最初のlabel要素の子孫テキストコンテンツである。(JavaScriptで表すと、
element.labels[0].textContentによって与えられる。)
それ以外の場合、ラベルは空文字列である。
Image Button状態の
input
要素上のvalue
属性は非適合であるが、属性が存在し、Image Buttonのalt属性が
欠落している場合、その属性はラベルの決定に寄与できる。
コマンドのアクセスキーは、存在する場合、 要素に割り当てられたアクセスキーである。
コマンドのは、要素が属性を 持つ場合はtrue(非表示)であり、それ以外の場合はfalseである。
コマンドのアクションは、要素においてclickイベントを発火する
ことである。
option
要素を使用したコマンドの定義コマンドのラベルは、存在する場合はoption要素のlabel属性の値であり、それ以外の場合は、ASCII空白を除去して折り畳んだoption要素の子孫テキストコンテンツである。
コマンドのアクセスキーは、存在する場合、 要素に割り当てられたアクセスキーである。
コマンドのは、要素が属性を 持つ場合はtrue(非表示)であり、それ以外の場合はfalseである。
コマンドの無効状態は、要素が無効である場合、最も近い祖先の
select要素が無効である場合、または要素自身
もしくはその祖先の1つが不活性である場合はtrueであり、それ以外の場合は
falseである。
optionの最も近い祖先であるselect要素がmultiple属性を持つ場合、コマンドのアクションは、option要素を切り替えることである。それ以外の
場合、アクションは、option要素を選択することである。
legend要素のaccesskey属性を
使用したコマンドの定義
次のすべてがtrueである場合、legend要素はコマンドを定義する:
要素に 割り当てられたアクセスキーがある。
要素がfieldset要素の子である。
その親が、label要素でもlegend要素でもなく、コマンドを
定義する子孫を持つ。この要素が存在する場合、それをlegend要素のaccesskey
委譲先と呼ぶ。
コマンドのラベルは、 要素の子孫テキストコンテンツである。
コマンドの アクセスキーは、要素に 割り当てられたアクセスキーである。
コマンドの、
無効状態、およびアクション
ファセットは、
legend要素のaccesskey委譲先の各ファセットと同じである。
この例では、legend要素がaccesskeyを指定しており、それが活性化されると、legend要素内のinput要素へ委譲される。
< fieldset >
< legend accesskey = p >
< label > I want < input name = pizza type = number step = 1 value = 1 min = 0 >
pizza(s) with these toppings</ label >
</ legend >
< label >< input name = pizza-cheese type = checkbox checked > Cheese</ label >
< label >< input name = pizza-ham type = checkbox checked > Ham</ label >
< label >< input name = pizza-pineapple type = checkbox > Pineapple</ label >
</ fieldset > accesskey属性を
使用したコマンドの定義
割り当てられたアクセスキーを持つ要素は、コマンドを定義する。
コマンドを定義する 要素を定義する前の節のいずれかで、この要素がコマンドを定義する と定義されている場合、その節がこの要素に適用され、この節は適用されない。それ以外の場合、この節が その要素に適用される。
コマンドのラベルは、
要素によって異なる。要素が
ラベル付きコントロールである場合、
ラベル付きコントロールが対象の要素である、ツリー順で最初のlabel要素の子孫テキストコンテンツがラベルである
(JavaScriptで表すと、element.labels[0].textContentによって与えられる)。
それ以外の場合、ラベルは、
要素の子孫テキストコンテンツである。
コマンドの アクセスキーは、要素に 割り当てられたアクセスキーである。
コマンドのは、要素が属性を持つ場合はtrue(非表示)であり、それ以外の場合はfalseである。
コマンドのアクションは、 次の手順を実行することである:
clickイベントを発火する。dialog要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
closedby —
ダイアログを閉じるユーザー操作
open — ダイアログ
ボックスが表示されているかどうか
[Exposed =Window ]
interface HTMLDialogElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute boolean open ;
attribute DOMString returnValue ;
[CEReactions , ReflectSetter ] attribute DOMString closedBy ;
[CEReactions ] undefined show ();
[CEReactions ] undefined showModal ();
[CEReactions ] undefined close (optional DOMString returnValue );
[CEReactions ] undefined requestClose (optional DOMString returnValue );
};dialog要素は、
ユーザーがタスクを実行したり情報を取得したりするために操作する、小さなウィンドウ
(「ダイアログボックス」)形式の、アプリケーションの一時的な部分を表す。ユーザーが操作を終えると、
ダイアログはアプリケーションによって自動的に閉じることも、ユーザーによって手動で閉じることもできる。
特に、あらゆる種類のアプリケーションで一般的なパターンであるモーダルダイアログについて、著者は ウェブアプリケーション内のダイアログが、非ウェブアプリケーションのユーザーにとって馴染みのある方法で 動作するよう努めることが望ましい。
すべてのHTML要素と同様に、別の種類のコントロールを表そうとしてdialog要素を使用する
ことは適合しない。たとえば、コンテキストメニュー、ツールチップ、およびポップアップリストボックスは
ダイアログボックスではないため、これらのパターンを実装するためにdialog要素を
誤用することは不正である。
ユーザー向けダイアログの動作における重要な部分は、初期フォーカスの配置である。ダイアログフォーカス手順は、
ダイアログが表示されたときに初期フォーカスの適切な候補を選択しようとするが、特定のダイアログについての
ユーザーの期待に合う正しい選択肢を著者が慎重に検討することの代わりにはならない場合がある。そのため、
著者は、ダイアログが開いた直後にユーザーが操作することが期待されるダイアログの子孫要素にautofocus属性を使用する
ことが望ましい。そのような要素がない場合、著者はdialog要素自体に
autofocus属性を使用することが望ましい。
次の例では、在庫管理ウェブアプリケーションで製品の詳細を編集するためにダイアログを使用している。
< dialog >
< label > Product Number < input type = "text" readonly ></ label >
< label > Product Name < input type = "text" autofocus ></ label >
</ dialog > autofocus属性が存在しなかった場合、ダイアログフォーカス手順は
Product Numberフィールドにフォーカスしたはずである。これは妥当な動作だが、著者は、Product Number
フィールドがreadonlyでユーザー入力を必要としないため、フォーカスするより関連性の高いフィールドは
Product Nameフィールドであると判断した。そのため、著者はautofocusを使用してデフォルトを上書きした。
著者がデフォルトでProduct Numberフィールドにフォーカスしたい場合でも、そのinput要素にautofocusを
使用して明示的に指定するのが最善である。これにより、コードの将来の読者に意図が明確になり、将来の更新に
対してコードの堅牢性が保たれる。(たとえば、別の開発者が閉じるボタンを追加し、それをノードツリー内で
Product Numberフィールドより前に配置した場合。)
ユーザー動作のもう1つの重要な側面は、ダイアログがスクロール可能かどうかである。ユーザーの高いテキスト ズーム設定が原因の場合など、オーバーフロー(したがってスクロール可能性)を避けられない場合もある。 しかし一般に、スクロール可能なダイアログはユーザーに期待されていない。大きなテキストノードを ダイアログ要素に直接追加することは、ダイアログ要素自体がオーバーフローする可能性が高いため、特に 望ましくない。著者はこれを避けるのが最善である。
次の利用規約ダイアログは、上記の提案に従っている。
< dialog style = "height: 80vh;" >
< div style = "overflow: auto; height: 60vh;" autofocus >
< p > By placing an order via this Web site on the first day of the fourth month of the year
2010 Anno Domini, you agree to grant Us a non-transferable option to claim, for now and for
ever more, your immortal soul.</ p >
< p > Should We wish to exercise this option, you agree to surrender your immortal soul,
and any claim you may have on it, within 5 (five) working days of receiving written
notification from this site or one of its duly authorized minions.</ p >
<!-- ... etc., with many more <p> elements ... -->
</ div >
< form method = "dialog" >
< button type = "submit" value = "agree" > Agree</ button >
< button type = "submit" value = "disagree" > Disagree</ button >
</ form >
</ dialog > ダイアログフォーカス
手順は、デフォルトでスクロール可能なdiv要素を選択したはずだが、
前の例と同様に、より明示的にし、将来の変更に対して堅牢にするためにdivにautofocusを配置している
ことに注意。
対照的に、利用規約を表すp要素にそのようなラッパーdiv要素がなかった場合、
dialog自体がスクロール可能になり、上記の助言に反する。さらに、
autofocus属性がない場合、そのようなマークアップパターンは上記の
助言に反し、ダイアログフォーカス手順のデフォルト動作を妨げ、
フォーカスをAgree buttonへ移動させ、好ましくないユーザー体験になる。
このダイアログボックスには小さな注意書きがある。より重要な部分にユーザーの注意を引くためにstrong要素を使用している。
< dialog >
< h1 > Add to Wallet</ h1 >
< p >< strong >< label for = amt > How many gold coins do you want to add to your wallet?</ label ></ strong ></ p >
< p >< input id = amt name = amt type = number min = 0 step = 0.01 value = 100 ></ p >
< p >< small > You add coins at your own risk.</ small ></ p >
< p >< label >< input name = round type = checkbox > Only add perfectly round coins</ label ></ p >
< p >< input type = button onclick = "submit()" value = "Add Coins" ></ p >
</ dialog > open属性は
真偽属性である。指定された場合、
dialog要素が
アクティブであり、ユーザーがそれを操作できることを示す。
closedby
コンテンツ属性は、次のキーワードおよび状態を持つ列挙属性である:
| キーワード | 状態 | 簡単な説明 |
|---|---|---|
any
|
任意 | 閉じる要求または外側のクリックによって ダイアログを閉じる。 |
closerequest
|
閉じる要求 | 閉じる要求によってダイアログを閉じる。 |
none
|
なし | ダイアログを自動的に閉じるユーザー操作はない。 |
closedby属性の
無効値のデフォルト
および欠落値の
デフォルトは、いずれも自動状態である。
自動状態は、dialogがそのshowModal()メソッドを
使用して表示された場合は閉じる要求状態として動作し、それ以外の
場合はなし状態として動作する。
open属性が指定されて
いないdialog要素は、ユーザーに表示しないことが望ましい。この要件は、
スタイル層を通じて間接的に実装してもよい。たとえば、推奨されるデフォルト
レンダリングをサポートするユーザーエージェントは、レンダリングの節で
説明されるCSS規則を使用してこの要件を実装する。
open属性を削除すると、
通常はダイアログが非表示になる。しかし、これを行うと、次のようないくつかの奇妙な追加の結果が生じる:
closeイベントは発火しない。
ダイアログがそのshowModal()
メソッドを使用して表示された場合、Documentは引き続きブロックされたままとなる。
これらの理由から、一般にopen属性を手動で削除しない方がよい。代わりに、ダイアログを閉じるには
requestClose()またはclose()メソッドを使用し、
非表示にするには属性を使用する。
tabindex属性は、dialog要素に指定しては
ならない。
dialog.show()
現在のすべてのエンジンでサポートされています。
dialog要素を表示する。
dialog.showModal()
現在のすべてのエンジンでサポートされています。
dialog要素を表示し、それを最上位のモーダルダイアログにする。
このメソッドはautofocus属性を尊重する。
dialog.close([ result ])
現在のすべてのエンジンでサポートされています。
dialog要素を閉じる。
引数が指定されている場合、それが戻り値を与える。
dialog.requestClose([ result ])
最初にcancelイベントを発火し、そのイベントがpreventDefault()によって取り消されない
場合は、close()メソッドと同じ方法でdialogを閉じる(closeイベントの発火を含む)ことにより、
dialogを対象とする閉じる要求が送信されたかのように動作する。
これは、閉じる要求ではないすべての
閉じる手段にこのメソッドを呼び出させることで、取り消しと閉じるロジックをcancelおよびcloseイベントハンドラーに統合する
ために使用できる補助ユーティリティである。
このメソッドはclosedby属性を無視することに注意。つまり、closedbyが
「none」に設定されている場合でも、同じ動作が適用される。
引数が指定されている場合、それが戻り値を与える。
dialog.returnValue [ = result ]
現在のすべてのエンジンでサポートされています。
dialogの戻り値を返す。
設定することで、戻り値を更新できる。
show()メソッドの手順は次のとおりである:
thisがopen属性を持つ場合、
「InvalidStateError」DOMExceptionを投げる。
cancelable属性をtrueに、oldState属性を「closed」に、newState属性を「open」に初期化し、ToggleEventを使用して、thisにおいてbeforetoggleという名前のイベントを発火する結果がfalseの場合、戻る。
this、「closed」、「open」、およびnullを与えて、
ダイアログ切替イベントタスクをキューに入れる。
thisの以前にフォーカスされていた要素を、フォーカスされている要素に設定する。
hideUntilを、this、null、およびfalseを与えて 最上位のポップオーバー祖先を実行した結果とする。
document、hideUntil、false、およびtrueを与えてそこまでポップオーバーを隠すを 実行する。
thisを与えてダイアログフォーカス手順を実行する。
showModal()メソッドの手順は、thisおよびnullを与えてモーダルダイアログを表示することである。
close(returnValue)メソッドの手順は次のとおりである:
requestClose(returnValue)メソッドの手順は次のとおりである:
次の制約により、dialog要素には、show/hideやopen/closeなど、より一般的に反意語と
考えられる動詞の組とは異なり、show/closeを動詞として使用する:
ダイアログを隠すことは、それを閉じることとは異なる。ダイアログを閉じると、戻り値が与えられ、
イベントが発火し、他のダイアログに対するページのブロックが解除されるなどする。一方、ダイアログを
隠すことは純粋に視覚的なプロパティであり、属性またはopen属性を削除することで既に実行できる。(open属性を削除すること、およびその方法でダイアログを隠すことが
一般に望ましくない理由については、上記の注記も参照。)
ダイアログを表示することは、それを開くこととは異なる。ダイアログを開くことは、そのダイアログを
作成して表示することからなる(window.open()が新しいウィンドウを作成して表示する方法と同様)。
一方、ダイアログを表示することは、既にDOM内にあるdialog要素を取得し、ユーザーが操作可能かつ可視にする処理である。
上記にもかかわらずdialog.open()メソッドを持たせると、dialog.openプロパティと競合する。
さらに、dialog要素の最初の設計と同時期の他の多数のUIフレームワークに
関する調査により、
show/closeという動詞の組がかなり一般的であることが明らかになった。
要約すると、特定の動詞が持つ含意と、それらが技術的な文脈でどのように使用されるかにより、 ダイアログを表示する、閉じるといった対になった操作は、必ずしも反意語として表現できないことが分かる。
returnValue IDL属性は、取得時に、最後に設定された
値を返さなければならない。設定時には、新しい値に設定されなければならない。要素が作成された
ときは、空文字列に設定されなければならない。
closedByゲッター手順は、算出済み
closed-by状態をthisに対して取得し、それに対応するキーワードを返すことである。
各Documentは、ダイアログpointerdownターゲットを持つ。これはHTMLダイアログ要素または
nullであり、初期値はnullである。
各HTML要素は、nullまたは要素であり、
初期値がnullである以前にフォーカスされていた
要素を持つ。showModal()および
show()が
呼び出されたとき、この要素はダイアログフォーカス手順を実行する前に、現在フォーカスされている要素に設定される。popover属性を持つ要素は、
ポップオーバー表示アルゴリズムの間に、
この要素を現在フォーカスされている要素に設定する。
各dialog要素は、
切替タスク追跡子またはnullであり、
初期値がnullであるダイアログ切替タスク追跡子を持つ。
各dialog要素は、
閉じる監視器を持つ。これは閉じる監視器またはnullであり、初期値はnullである。
各dialog要素は、
文字列またはnullであり、初期値がnullである閉じる要求の戻り値を持つ。
各dialog要素は、
閉じる要求のソース要素を持つ。これは
Element
またはnullであり、初期値はnullである。
各dialog要素は、
初期値がfalseである閉じる要求のために閉じる監視器を
有効にする真偽値を持つ。
dialogの
閉じる要求のために閉じる監視器を有効にするは、
ダイアログを閉じるよう要求している間、そのダイアログの閉じる
監視器を強制的に有効にするために使用される。算出済み
closed-by状態がなし状態であるダイアログは、
そうしなければ無効な閉じる監視器を持つことになる。
各dialog要素は、
初期値がfalseであるモーダルである真偽値を持つ。
insertedNodeを与えたdialogのHTML要素挿入
手順は、次のとおりである:
removedNode、isSubtreeRoot、およびoldAncestorを与えたdialogのHTML要素削除
手順は、次のとおりである:
removedNodeがopen属性を持つ場合、
removedNodeを与えてダイアログクリーンアップ手順を実行する。
removedNodeのノード 文書の最上位レイヤーがremovedNodeを含む場合、removedNodeを与えて要素を 最上位レイヤーから直ちに削除する。
removedNodeのモーダルであるをfalseに設定する。
element、localName、oldValue、value、および
namespaceを与えた次の属性変更
手順は、dialog要素に使用される:
namespaceがnullでない場合は、戻る。
localNameがopenでない場合は、
戻る。
valueがnullであり、oldValueがnullでない場合、 elementを与えてダイアログクリーンアップ手順を実行する。
elementが接続されていない場合は、 戻る。
これにより、接続解除されたノードに対してダイアログ設定手順が実行され、 閉じる 監視器が確立されることを防ぐ。ダイアログクリーンアップ手順には、 このようなガードは不要である。
valueがnullでなく、oldValueがnullである場合、 elementを与えてダイアログ設定手順を実行する。
dialog要素
subjectおよびElement
またはnullであるsourceを与えてモーダルダイアログを
表示するには:
subjectがopen属性を持つ場合、
「InvalidStateError」DOMExceptionをスローする。
subjectのノード文書が
完全にアクティブでない場合、
「InvalidStateError」DOMExceptionをスローする。
subjectが接続されていない場合、
「InvalidStateError」DOMExceptionをスローする。
subjectがポップオーバー表示
状態にある場合、「InvalidStateError」DOMExceptionをスローする。
cancelable属性をtrueに、oldState
属性を「closed」に、newState
属性を「open」に、source属性を
sourceに初期化して、ToggleEventを使用し、
subjectにおいてbeforetoggleという
名前のイベントを発火する
結果がfalseの場合は、戻る。
subjectがopen属性を持つ場合は、
戻る。
subjectが接続されていない場合は、戻る。
subjectがポップオーバー表示 状態にある場合は、戻る。
subject、「closed」、「open」、および
sourceを与えてダイアログ切替イベントタスクを
キューに入れる。
subjectに、値が空文字列であるopen属性を追加する。
subjectのモーダルであるをtrueに設定する。
subjectのノード文書を、 モーダルダイアログsubjectによってブロックされるように設定する。
これにより、文書のフォーカス 領域は不活性になる(現在のフォーカス領域が subjectのシャドウを含む子孫である場合を除く)。 このような場合、文書のフォーカス領域は、まもなく リセットされ、ビューポートになる。数手順後に、より適切なフォーカス候補を 見つけることを試みる。
subjectのノード 文書の最上位レイヤーが、まだsubjectを含んでいない場合、subjectを与えて要素を 最上位レイヤーに追加する。
subjectの以前にフォーカスされていた要素を、フォーカスされている要素に設定する。
documentを、subjectのノード文書とする。
hideUntilを、subject、null、およびfalseを与えて最上位のポップオーバー祖先を実行した結果とする。
document、hideUntil、false、およびtrueを与えて指定位置までポップオーバーを 非表示にするを実行する。
subjectを与えてダイアログフォーカス手順を実行する。
dialog要素dialogを与えてダイアログの閉じる監視器を設定するには:
dialogの閉じる監視器を、dialogの関連するグローバルオブジェクトを与え、次を使用して 閉じる監視器を確立する結果に設定する:
canPreventCloseを与えたcancelActionは、cancelable属性を
canPreventCloseに初期化して、dialogにおいてcancelという名前のイベントを発火する結果を返す。
closeActionは、dialog、 dialogの閉じる要求の 戻り値、およびdialogの閉じる要求のソース要素を与えてダイアログを閉じる。
getEnabledStateは、 dialogの閉じる要求のために閉じる監視器を 有効にするがtrueであるか、dialogの算出済みclosed-by状態がなしでない場合はtrueを返し、 それ以外の場合はfalseを返す。
command属性commandを与えたdialog要素の有効なコマンドかどうかの
手順は、次のとおりである:
次のボタンはcommandforを使用し、
活性化されたときに「confirm」dialogをモーダルとして
開閉する:
< button type = button
commandfor = "the-dialog"
command = "show-modal" >
Delete
</ button >
< dialog id = "the-dialog" >
< form action = "/delete" method = "POST" >
< button type = "submit" >
Delete
</ button >
< button commandfor = "the-dialog"
command = "close" >
Cancel
</ button >
</ form >
</ dialog >
dialog要素
subjectが、nullまたは文字列resultおよびElement
またはnullであるsourceを使用して閉じられるとき、
次の手順を実行する:
subjectがopen属性を持たない場合は、
戻る。
oldState
属性を「open」に、newState
属性を「closed」に、source
属性をsourceに初期化して、ToggleEventを使用し、
subjectにおいてbeforetoggleという
名前のイベントを発火する。
subjectがopen属性を持たない場合は、
戻る。
subject、「open」、「closed」、および
sourceを与えてダイアログ切替イベントタスクを
キューに入れる。
subjectのopen属性を削除する。
subjectのモーダルであるがtrueの場合、subjectを与えて要素を 最上位レイヤーから削除するよう要求する。
wasModalを、subjectのモーダルであるフラグの値とする。
subjectのモーダルであるをfalseに設定する。
resultがnullでない場合、subjectのreturnValue属性をresultに設定する。
subjectの閉じる要求の戻り値をnullに設定する。
subjectの閉じる要求のソース要素をnullに設定する。
subjectの以前にフォーカスされていた要素がnullでない場合:
elementを、subjectの以前にフォーカスされていた 要素とする。
subjectの以前にフォーカスされていた要素をnullに設定する。
subjectのノード 文書の文書のフォーカス 領域のDOMアンカーが subjectのシャドウを含む包括的 子孫であるか、wasModalがtrueである場合、elementに対してフォーカス手順を実行する。 この手順を実行することでビューポートをスクロールしないことが望ましい。
subject要素を与えて、ユーザー
インタラクションタスクソース上で、subjectにおいてcloseという名前のイベントを発火する要素タスクをキューに入れる。
nullまたは文字列returnValueおよびnullまたはElement
sourceを与えて、dialog要素subjectを閉じるよう要求するには:
subjectがopen属性を持たない場合は、
戻る。
subjectの閉じる要求のために閉じる監視器を 有効にするをtrueに設定する。
subjectの閉じる要求の戻り値を returnValueに設定する。
subjectの閉じる要求のソース要素を sourceに設定する。
subjectの閉じる監視器をfalseを使用して閉じるよう 要求する。
subjectの閉じる要求のために閉じる監視器を 有効にするをfalseに設定する。
dialog要素
element、文字列oldState、文字列newState、および
Element
またはnullであるsourceを与えてダイアログ切替イベントタスクをキューに入れるには:
elementのダイアログ切替タスク追跡子がnullでない場合:
oldStateを、elementのダイアログ切替タスク 追跡子の旧 状態に設定する。
elementのダイアログ切替タスク追跡子のタスクを、そのタスクキューから削除する。
elementのダイアログ切替タスク追跡子をnullに設定する。
DOM 操作タスクソースおよびelementを与えて、次の手順を実行する要素タスクを キューに入れる:
oldState
属性をoldStateに、newState
属性をnewStateに、source
属性をsourceに初期化して、ToggleEventを使用し、
elementにおいてtoggleという名前のイベントを発火する。
elementのダイアログ切替タスク追跡子をnullに設定する。
elementのダイアログ切替タスク追跡子を、タスクを直前にキューに入れたタスクに設定し、旧状態を oldStateに設定した構造体に設定する。
dialog
dialogを与えて、ダイアログの算出済みclosed-by状態を取得するには:
dialog要素
subjectを与えたダイアログフォーカス手順は、
次のとおりである:
controlをnullとする。
subjectがautofocus属性を持つ場合、
controlをsubjectに設定する。
controlがnullの場合、controlをsubjectのフォーカス 委任先に設定する。
controlがnullの場合、controlをsubjectに設定する。
controlに対してフォーカス手順を実行する。
controlがフォーカス可能でない場合、これは何もしない。これは、
subjectにフォーカス委任先がなく、ユーザーエージェントがdialog要素を
一般にはフォーカス可能でないと判断した場合にのみ発生する。その場合、文書のフォーカス
領域に対する以前の
変更が適用される。
topDocumentを、controlのノードナビゲーション可能のトップレベル走査可能のアクティブ 文書とする。
topDocumentのautofocus候補を空にする。
topDocumentのautofocus処理済みフラグをtrueに設定する。
dialog要素
subjectを与えたダイアログ設定手順は、
次のとおりである:
表明: subjectのノード 文書の開いているダイアログの リストはsubjectを含まない。
subjectを、subjectのノード 文書の開いている ダイアログのリストに追加する。
subjectを使用してダイアログの 閉じる監視器を設定する。
dialog要素
subjectを与えたダイアログクリーンアップ手順は、
次のとおりである:
「ライトディスミス」とは、closedby属性が
任意状態である
dialog要素の外側を
クリックすると、そのdialog要素が閉じられることを意味する。これは、このようなdialogが閉じる要求に応答する方法に加えて行われる。
PointerEvent
eventを与えて、開いているダイアログをライトディスミスするには:
documentの開いている ダイアログのリストが空の場合は、戻る。
ancestorを、eventを与えて最も近いクリックされたダイアログを実行した結果とする。
eventのtypeが
「pointerdown」である場合、
documentのダイアログpointerdown
ターゲットをancestorに設定する。
sameTargetを、ancestorがdocumentの ダイアログ pointerdownターゲットである場合はtrue、それ以外の場合はfalseとする。
documentのダイアログpointerdownターゲットをnullに設定する。
sameTargetがfalseの場合は、戻る。
topmostDialogを、documentの開いている ダイアログのリストの最後の要素とする。
ancestorがtopmostDialogである場合は、戻る。
topmostDialogの算出済みclosed-by状態が任意でない場合は、戻る。
topmostDialogの閉じる監視器をfalseを使用して閉じるよう 要求する。
PointerEvent
eventを与えて、ライトディスミス処理を実行するには:
eventを使用して開いているポップオーバーをライト ディスミスするを実行する。
eventを使用して開いているダイアログをライトディスミスするを実行する。
ライト ディスミス処理を実行するは、ユーザーがページ上の任意の場所をクリックまたはタッチしたときに、Pointer Events仕様によって呼び出される。
PointerEvent
eventを与えて、最も近いクリックされたダイアログを見つけるには:
スクリプトにより、著者は文書に対話性を追加できる。
宣言的な仕組みは保守しやすいことが多く、多くのユーザーがスクリプティングを無効にしているため、 著者は可能な場合、スクリプティングの代わりに宣言的な手段を使用することが推奨される。
たとえば、詳細を追加表示するために節を表示または非表示にするスクリプトを使用する代わりに、
details要素を使用できる。
著者は、スクリプティングがサポートされていない場合でも、アプリケーションが適切に機能低下するように することも推奨される。
たとえば、表を動的に並べ替えるために表の見出し内にリンクを提供する場合、そのリンクは、 並べ替え済みの表をサーバーに要求することで、スクリプトなしでも機能するようにできる。
script要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
src属性がない場合、
type属性の値に依存するが、
スクリプト内容の制限に適合しなければ
ならない。
src属性が
ある場合、要素は空であるか、スクリプト
内容の制限にも適合するスクリプトの文書化のみを含まなければ
ならない。
type —
スクリプトの種類
src —
リソースのアドレス
nomodule —
モジュールスクリプトをサポートする
ユーザーエージェントでの実行を防止する
async —
取得中にブロックせず、利用可能になったときにスクリプトを実行する
defer —
スクリプトの実行を延期する
blocking —
要素がレンダリングをブロックする可能性があるかどうか
crossorigin
— 要素がオリジン間要求を処理する方法
referrerpolicy
— 要素によって開始されたフェッチに対するリファラーポリシー
integrity —
サブリソース完全性チェックで使用される完全性メタデータ [SRI]
fetchpriority
— 要素によって開始されたフェッチの優先度を設定する
[Exposed =Window ]
interface HTMLScriptElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute DOMString type ;
[CEReactions , ReflectURL ] attribute USVString src ;
[CEReactions , Reflect ] attribute boolean noModule ;
[CEReactions ] attribute boolean async ;
[CEReactions , Reflect ] attribute boolean defer ;
[SameObject , PutForwards =value , Reflect ] readonly attribute DOMTokenList blocking ;
[CEReactions ] attribute DOMString ? crossOrigin ;
[CEReactions ] attribute DOMString referrerPolicy ;
[CEReactions , Reflect ] attribute DOMString integrity ;
[CEReactions ] attribute DOMString fetchPriority ;
[CEReactions ] attribute DOMString text ;
static boolean supports (DOMString type );
// also has obsolete members
};script要素により、
著者は文書内に動的スクリプト、ユーザーエージェントへの指示、およびデータブロックを含められる。
この要素はユーザー向けのコンテンツを表さない。
現在のすべてのエンジンでサポートされています。
script要素には、2つの中核となる属性がある。type属性を使用すると、表されるスクリプトの種類を
カスタマイズできる:
属性を省略する、空文字列に設定する、またはJavaScript MIME型エッセンス一致に設定することは、
スクリプトがJavaScriptのScript最上位
生成規則に従って解釈されるクラシック
スクリプトであることを意味する。著者は冗長に設定する代わりに、type属性を省略することが
望ましい。
属性を「module」とASCII
大文字・小文字を区別せず一致する値に設定することは、スクリプトがJavaScriptのModule最上位
生成規則に従って解釈されるJavaScriptモジュール
スクリプトであることを意味する。
属性を「importmap」とASCII
大文字・小文字を区別せず一致する値に設定することは、スクリプトがモジュール指定子の解決の動作を制御するために
使用されるJSONを含むインポートマップであることを意味する。
属性を「speculationrules」とASCII
大文字・小文字を区別せず一致する値に設定することは、スクリプトが投機的読み込みを記述するために使用されるJSONを含む投機ルール
セットを定義することを意味する。
属性をその他の値に設定することは、スクリプトがデータブロックであり、 ユーザーエージェントではなく、著者スクリプトまたはその他のツールによって処理されることを意味する。 著者は、データブロックを示すために、JavaScript MIME型エッセンス 一致ではない妥当なMIME型文字列を使用しなければならない。
データブロックを妥当なMIME型文字列を使用して示さなければならないという要件は、
将来起こり得る衝突を避けるためのものである。「module」や「importmap」のような
MIME型ではないtype属性の値は、ユーザーエージェント内で特別な動作を持つ
スクリプトの種類を示すために標準によって使用される。現在、妥当なMIME型文字列を使用することで、
将来のユーザーエージェントでも、データブロックが別のスクリプトの種類として再解釈されないことを
保証できる。
2つ目の中核属性は、src属性である。これはクラシックスクリプトおよびJavaScriptモジュールスクリプトにのみ指定しなければ
ならず、要素の子テキストコンテンツをスクリプトの内容として使用する代わりに、
指定されたURLからスクリプトをフェッチすることを示す。srcが指定される場合、
それは空白で囲まれている可能性のある
妥当な空でないURLでなければならない。
特定のscript要素に指定できる
その他の属性は、次の表によって決定される:
nomodule
|
async
|
defer
|
blocking
|
crossorigin
|
referrerpolicy
|
integrity
|
fetchpriority
|
|
|---|---|---|---|---|---|---|---|---|
| 外部クラシックスクリプト | 対応 | 対応 | 対応 | 対応 | 対応 | 対応 | 対応 | 対応 |
| インラインクラシックスクリプト | 対応 | · | · | · | 対応* | 対応* | · | ·† |
| 外部モジュールスクリプト | · | 対応 | · | 対応 | 対応 | 対応 | 対応 | 対応 |
| インラインモジュールスクリプト | · | 対応 | · | · | 対応* | 対応* | · | ·† |
| インポートマップ | · | · | · | · | · | · | · | · |
| 投機ルール | · | · | · | · | · | · | · | · |
| データブロック | · | · | · | · | · | · | · | · |
* インラインスクリプトには初期フェッチがないが、インラインスクリプト上の
crossorigin属性
およびreferrerpolicy
属性は、動的なimport()を
含むモジュールインポートで使用される資格情報モードおよびリファラー
ポリシーに影響する。
† crossoriginおよび
referrerpolicyとは異なり、
fetchpriorityは
モジュールインポートに影響しない。issue
#10276の議論を参照。
インラインscript要素の内容または
外部スクリプトリソースは、それぞれクラシックスクリプトおよびJavaScriptモジュールスクリプトについて、
JavaScript仕様のScriptまたはModule生成規則の要件に適合しなければならない。
[JAVASCRIPT]
インポート
マップ用のインラインscript要素の内容は、
インポートマップの作成要件に適合しなければならない。
投機ルールセット用の
インラインscript要素の内容は、
投機ルールセットの作成
要件に適合しなければならない。
データブロックを含めるために使用する場合、
データはインラインに埋め込まれ、データの形式はtype属性を使用して指定され、
script要素の内容は、
使用される形式について定義された要件に適合しなければならない。
nomodule属性は、モジュールスクリプトをサポートするユーザーエージェントで
スクリプトが実行されることを防ぐ真偽属性である。これにより、以下に示すように、最新のユーザーエージェントではモジュールスクリプトを、古い
ユーザーエージェントではクラシックスクリプトを選択的に実行できる。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
async属性および
defer属性は、スクリプトをどのように評価するかを示す
真偽属性である。
スクリプトの種類に応じて、これらの属性を使用して選択できるモードがいくつかある。
外部クラシックスクリプトでは、
async属性が存在する場合、
クラシックスクリプトは構文解析と並行してフェッチされ、利用可能になり次第評価される
(構文解析の完了前である可能性もある)。async属性が存在せず、
defer属性が存在する場合、
クラシックスクリプトは並行してフェッチされ、ページの構文解析が完了したときに評価される。
どちらの属性も存在しない場合、スクリプトは直ちにフェッチおよび評価され、その両方が完了するまで
構文解析をブロックする。
モジュールスクリプトでは、
async属性が存在する場合、
モジュールスクリプトとそのすべての依存関係は構文解析と並行してフェッチされ、モジュールスクリプトは利用可能になり次第
評価される(構文解析の完了前である可能性もある)。それ以外の場合、モジュールスクリプトとその依存関係は
構文解析と並行してフェッチされ、
ページの構文解析が完了したときに評価される。(defer属性は
モジュールスクリプトには影響しない。)
これらはすべて、次の概略図にまとめられている:

これらの属性の正確な処理の詳細は、主として歴史的な理由から多少複雑であり、
HTMLの多くの側面が関係する。そのため、実装要件は必然的に仕様全体に分散している。
以下のアルゴリズムはこの処理の中核を説明するが、
これらのアルゴリズムは、HTML内のscriptの開始タグおよび終了タグ、外来コンテンツ内、ならびにXML内における
構文解析規則、document.write()メソッドの規則、
スクリプティングの処理などを参照し、またそれらから参照される。
document.write()メソッドを
使用して挿入された場合、script要素は
通常実行される(一般に、以後のスクリプト実行または
HTML構文解析をブロックする)。innerHTML属性および
outerHTML属性を
使用して挿入された場合、それらはまったく実行されない。
defer属性は、
async属性が指定されて
いる場合でも指定できる。これは、deferのみをサポートし、
asyncをサポートしない
古いウェブブラウザーが、デフォルトのブロック動作ではなく、defer動作にフォールバック
するようにするためである。
blocking属性は、ブロッキング属性である。
crossorigin属性は、CORS設定
属性である。外部クラシックスクリプトでは、スクリプトが他のオリジンから取得された場合に、
エラー情報を公開するかどうかを制御する。外部モジュールスクリプトでは、オリジン間の場合に、
モジュールソースの初期フェッチに使用される資格情報モードを制御する。クラシックスクリプトとモジュールスクリプトの両方で、
オリジン間モジュールインポートに使用される資格情報モードを制御する。
クラシックスクリプトとは 異なり、モジュールスクリプトは、 オリジン間フェッチにCORSプロトコルを使用する必要がある。
referrerpolicy属性は、リファラー
ポリシー属性である。これは、外部スクリプトの初期フェッチおよびインポートされたモジュール
スクリプトのフェッチに使用されるリファラー
ポリシーを設定する。
[REFERRERPOLICY]
インポートされたスクリプトをフェッチするときには使用されるが、その他のサブリソースをフェッチするとき
には使用されないscript要素の
リファラーポリシーの例:
< script referrerpolicy = "origin" >
fetch( '/api/data' ); // not fetched with <script>'s referrer policy
import ( './utils.mjs' ); // is fetched with <script>'s referrer policy ("origin" in this case)
</ script > integrity属性は、外部スクリプトの初期フェッチに使用される
完全性メタデータを設定する。値はintegrity属性の要件に適合しなければならない。
[SRI]
fetchpriority属性は、フェッチ優先度
属性である。これは、外部スクリプトの初期フェッチに使用される優先度を設定する。
これらの属性を動的に変更しても直接的な効果はない。これらの属性は、処理モデルで説明される特定の時点でのみ使用される。
crossOrigin IDL属性は、crossorigin
コンテンツ属性を既知の値のみに制限して反映しなければならない。
HTMLScriptElement/referrerPolicy
現在のすべてのエンジンでサポートされています。
referrerPolicy IDL属性は、referrerpolicy
コンテンツ属性を既知の値のみに制限して反映しなければならない。
fetchPriority IDL属性は、fetchpriority
コンテンツ属性を既知の値のみに制限して反映しなければならない。
asyncセッター手順は、
次のとおりである:
script.text [ = value ]
要素の子テキストコンテンツを返す。
script.text = value
要素の子を、valueで与えられたテキストに置換する。
HTMLScriptElement.supports(type)与えられたtypeがユーザーエージェントによってサポートされるスクリプトの種類である場合は
trueを返す。この仕様で使用できるスクリプトの種類は「classic」、
「module」、および「importmap」であるが、将来その他の種類が
追加される可能性がある。
textゲッター手順は、thisの子テキストコンテンツを返すことである。
textセッター手順は、
this内で、与えられた値を使用してすべての文字列を
置換することである。
HTMLScriptElement/supports_static
現在のすべてのエンジンでサポートされています。
静的supports(type)メソッドの手順は、次のとおりである:
type引数はこれらの値と完全に一致しなければならない。ASCII
大文字・小文字を区別しない一致は行わない。これは、typeコンテンツ属性の値が
処理される方法、およびDOMTokenListの
supports()
メソッドの動作とは異なるが、Worker()コンストラクターで使用される
WorkerType列挙型とは一致している。
この例では、2つのscript要素が使用される。
一方は外部クラシックスクリプトを埋め込み、もう一方は一部のデータを
データブロックとして含める。
< script src = "game-engine.js" ></ script >
< script type = "text/x-game-map" >
........ U......... e
o............ A.... e
..... A..... AAA.... e
. A.. AAA... AAAAA... e
</ script > この場合、データはスクリプトによってビデオゲームのマップを生成するために使用される可能性がある。 ただし、データをそのように使用する必要はない。マップデータは実際にはページのマークアップ内の別の 部分に埋め込まれ、ここでのデータブロックは、ゲームマップ内の特定の機能を探しているユーザーを支援する サイトの検索エンジンによってのみ使用される可能性もある。
次の例は、script要素を使用して、
クラシックスクリプトの一部として、
文書の他の部分で使用される関数を定義する方法を示す。また、文書の構文解析中にスクリプトを呼び出すために
script要素を使用する方法も示す。この場合は、フォームの出力を
初期化している。
< script >
function calculate( form) {
var price = 52000 ;
if ( form. elements. brakes. checked)
price += 1000 ;
if ( form. elements. radio. checked)
price += 2500 ;
if ( form. elements. turbo. checked)
price += 5000 ;
if ( form. elements. sticker. checked)
price += 250 ;
form. elements. result. value = price;
}
</ script >
< form name = "pricecalc" onsubmit = "return false" onchange = "calculate(this)" >
< fieldset >
< legend > Work out the price of your car</ legend >
< p > Base cost: £52000.</ p >
< p > Select additional options:</ p >
< ul >
< li >< label >< input type = checkbox name = brakes > Ceramic brakes (£1000)</ label ></ li >
< li >< label >< input type = checkbox name = radio > Satellite radio (£2500)</ label ></ li >
< li >< label >< input type = checkbox name = turbo > Turbo charger (£5000)</ label ></ li >
< li >< label >< input type = checkbox name = sticker > "XZ" sticker (£250)</ label ></ li >
</ ul >
< p > Total: £< output name = result ></ output ></ p >
</ fieldset >
< script >
calculate( document. forms. pricecalc);
</ script >
</ form > 次の例は、script要素を使用して、
外部JavaScriptモジュール
スクリプトを含める方法を示す。
< script type = "module" src = "app.mjs" ></ script > このモジュールおよびそのすべての依存関係(ソースファイル内のJavaScript import文で
表される)がフェッチされる。結果として得られるモジュールグラフ全体がインポートされ、文書の構文解析が
完了すると、app.mjsの内容が評価される。
さらに、同じWindow内の別のscript要素のコードが、
app.mjsからモジュールをインポートする場合(たとえばimport
"./app.mjs";を使用して)、前者のscript要素によって
作成された同じJavaScriptモジュールスクリプトがインポートされる。
この例は、最新のユーザーエージェント向けにJavaScriptモジュールスクリプトを、 古いユーザーエージェント向けにクラシックスクリプトを含める方法を示す:
< script type = "module" src = "app.mjs" ></ script >
< script nomodule defer src = "classic-app-bundle.js" ></ script > JavaScriptモジュール
スクリプトをサポートする最新のユーザーエージェントでは、nomodule属性を持つ
script要素は無視され、「module」というtypeを持つscript要素が
(JavaScriptモジュール
スクリプトとして)フェッチおよび評価される。反対に、古いユーザーエージェントは、
「module」というtypeを持つscript要素を、
未知のスクリプトの種類であるため無視するが、nomodule属性を
実装していないため、もう一方のscript要素を
(クラシックスクリプトとして)問題なくフェッチおよび評価する。
次の例は、より興味深い読書体験を提供するために(たとえばニュースサイトで)、文書のテキストに
多数の置換を行うインラインJavaScriptモジュール
スクリプトを記述するためにscript要素を
使用する方法を示す:
[XKCD1288]
< script type = "module" >
import { walkAllTextNodeDescendants } from "./dom-utils.mjs" ;
const substitutions = new Map([
[ "witnesses" , "these dudes I know" ]
[ "allegedly" , "kinda probably" ]
[ "new study" , "Tumblr post" ]
[ "rebuild" , "avenge" ]
[ "space" , "spaaace" ]
[ "Google glass" , "Virtual Boy" ]
[ "smartphone" , "Pokédex" ]
[ "electric" , "atomic" ]
[ "Senator" , "Elf-Lord" ]
[ "car" , "cat" ]
[ "election" , "eating contest" ]
[ "Congressional leaders" , "river spirits" ]
[ "homeland security" , "Homestar Runner" ]
[ "could not be reached for comment" , "is guilty and everyone knows it" ]
]);
function substitute( textNode) {
for ( const [ before, after] of substitutions. entries()) {
textNode. data = textNode. data. replace( new RegExp( `\\b ${ before} \\b` , "ig" ), after);
}
}
walkAllTextNodeDescendants( document. body, substitute);
</ script > JavaScriptモジュールスクリプトを使用することで得られる注目すべき機能には、他のJavaScript
モジュールから関数をインポートできること、デフォルトで厳格モードになること、および最上位宣言が
グローバル
オブジェクトに新しいプロパティを導入しないことが含まれる。また、このscript要素が
文書内のどこに現れても、文書の構文解析が完了し、その依存関係(dom-utils.mjs)が
フェッチおよび評価されるまで評価されないことにも注意する。
次の例は、JavaScriptモジュール スクリプト内からJSON モジュールスクリプトをインポートする方法を示す:
< script type = "module" >
import peopleInSpace from "http://api.open-notify.org/astros.json" with { type: "json" };
const list = document. querySelector( "#people-in-space" );
for ( const { craft, name } of peopleInSpace. people) {
const li = document. createElement( "li" );
li. textContent = ` ${ name} / ${ craft} ` ;
list. append( li);
}
</ script > モジュールスクリプトのMIME型チェックは厳格である。JSON
モジュールスクリプトのフェッチが成功するには、HTTP応答が、たとえば
Content-Type: text/jsonのようなJSON
MIME型を持たなければならない。一方、文の
with { type: "json" }部分を省略した場合、意図はJavaScriptモジュールスクリプトを
インポートすることであると想定され、HTTP応答のMIME型がJavaScript
MIME型でない場合、フェッチは失敗する。
script要素には、
関連付けられたいくつかの状態がある。
script要素は、
nullまたはDocumentであり、
初期値がnullであるパーサー文書を持つ。これは、HTMLパーサーおよびXMLパーサーが挿入するscript要素に対して
設定し、それらの要素の処理に影響する。nullでないパーサー文書を持つscript要素は、
パーサーによって挿入されたものと呼ばれる。
script要素は、
nullまたはDocumentであり、
初期値がnullである準備時文書を持つ。これは、準備中に
文書間を移動するスクリプトが実行されることを防ぐために使用される。
script要素は、
初期値がtrueである強制
async真偽値を持つ。これは、HTMLパーサーおよびXMLパーサーが挿入するscript要素に対して
falseに設定し、また要素にasyncコンテンツ属性が
追加されたときにもfalseに設定される。
script要素は、
初期値がfalseである外部
ファイル由来真偽値を持つ。これは、スクリプトが準備されるとき、その時点における要素の
src属性に基づいて
決定される。
script要素は、
初期値がfalseであるパーサーによる実行準備完了真偽値を持つ。
これは、同時にパーサーによって挿入された要素にのみ使用され、
スクリプトをいつ実行するかをパーサーに知らせる。
script要素は、
初期値がfalseである開始済み真偽値を持つ。
script要素は、
初期値がfalseであるloadイベントを
遅延させている真偽値を持つ。
script要素は、
null、「classic」、「module」、「importmap」、または
「speculationrules」のいずれかであり、初期値がnullである種類を持つ。これは、要素が準備されるとき、その時点における要素の
type属性に基づいて
決定される。
script要素は、
「uninitialized」、null(エラーを表す)、スクリプト、インポートマップ解析結果、または
投機ルール解析結果のいずれかである
結果を持つ。初期値は「uninitialized」である。
script要素は、
一連の手順またはnullであり、初期値がnullである結果の準備ができたときに実行する
手順を持つ。resultを与えてscript要素
elを準備完了としてマークするには:
elの結果を resultに設定する。
elの結果の準備ができたときに実行する手順が nullでない場合、それらを実行する。
elの結果の準備ができたときに実行する 手順をnullに設定する。
elのloadイベントを 遅延させているをfalseに設定する。
script要素
elは、elの種類が「classic」であり、
elがパーサーによって挿入されており、かつ
elがasync属性または
defer属性を
持たない場合、暗黙的にレンダリングを
ブロックする可能性がある。
script要素
elのloadイベントを遅延させているがtrueである間、
ユーザーエージェントはelの準備時文書のloadイベントを遅延させなければならない。
insertedNodeを与えたscriptのHTML
要素接続後手順は、次のとおりである:
insertedNodeがパーサーによって挿入されている場合は、戻る。
insertedNodeを与えてscript要素を準備する。
HTML要素接続後手順は、挿入された要素が
依然として接続されている場合にのみ実行される。これにより、先に挿入された
scriptが、
後から挿入されたscriptを削除する
場合から保護される。たとえば:
< script >
const script1 = document. createElement( 'script' );
script1. innerText = `
document.querySelector('#script2').remove();
` ;
const script2 = document. createElement( 'script' );
script2. id = 'script2' ;
script2. textContent = `console.log('script#2 running')` ;
document. body. append( script1, script2);
</ script > この例では、コンソールには何も出力されない。append()によってアトミックに挿入された
最初のscriptに対して
HTML要素
接続後手順が実行される時点で、2番目のscriptがすでに
DOMに接続されていることを確認でき、それをDOMから削除する。
2番目のscriptはもはや
接続されていないため、そのHTML
要素接続後手順は実行されず、準備されない。
removedNodeを与えたscriptのHTML要素
削除手順は、次のとおりである:
removedNodeの結果が投機ルール解析結果である場合:
removedNodeの関連する グローバルオブジェクトおよびremovedNodeの結果を与えて投機ルールの登録を解除する。
removedNodeの開始済みをfalseに設定する。
removedNodeの結果をnullに設定する。
changedNodeを与えたscriptの子が変更された手順は、次のとおりである:
changedNodeを与えて、scriptのHTML要素接続後手順を実行する。
これは、script要素と、
新たに挿入された子script要素の
実行順序に興味深い影響を与える。次の断片を考える:
< script id = outer-script ></ script >
< script >
const outerScript = document. querySelector( '#outer-script' );
const start = new Text( 'console.log(1);' );
const innerScript = document. createElement( 'script' );
innerScript. textContent = `console.log('inner script executing')` ;
const end = new Text( 'console.log(2);' );
outerScript. append( start, innerScript, end);
// Logs:
// 1
// 2
// inner script executing
</ script > 2番目のスクリプトブロックが実行される時点で、outer-scriptはすでに準備されているが、
空であるため実行されず、したがって開始済みとしてマークされていない。Textノードおよび入れ子になったscript要素を
アトミックに挿入すると、次の効果が生じる:
element、localName、oldValue、value、および
namespaceを与えた次の属性変更
手順は、すべてのscript要素に
使用される:
namespaceがnullでない場合は、戻る。
localNameがsrcであり、
valueがnullでなく、かつelementが接続されている場合、elementを与えてscriptの
HTML要素接続後手順を実行する。
script要素
elを与えてscript要素を準備するには:
elの開始済みがtrueの場合は、戻る。
parser documentを、elのパーサー文書とする。
elのパーサー文書をnullに設定する。
これは、パーサーがパーサーによって挿入されたscript要素を
実行しようとしたとき、たとえば要素が空であるか、サポートされていないスクリプト言語を指定しているため
実行に失敗した場合に、別のスクリプトが後でそれらを変更して再度実行させられるようにするためである。
parser documentがnullでなく、かつelがasync属性を
持たない場合、elの強制
asyncをtrueに設定する。
これは、パーサーによって挿入されたscript要素が
パーサーによる実行時に失敗した後、スクリプトによって動的に更新されて実行される場合、
async属性が設定されていなくても、async方式で実行されるように
するためである。
source textを、elの子テキストコンテンツとする。
elがsrc属性を持たず、
かつsource textが空文字列である場合は、戻る。
elが接続されていない場合は、戻る。
次のいずれかがtrueである場合:
elが、値が空文字列であるtype属性を
持つ。
その場合、このscript要素の
the script block's type stringを「text/javascript」とする。
それ以外で、elがtype属性を持つ場合、
the script block's type stringを、その属性の値から先頭および末尾のASCII空白を
除去したものとする。
それ以外の場合、elは空でないlanguage属性を持つ。the script block's type stringを
「text/」とelのlanguage属性の値を連結したものとする。
the script block's type stringがJavaScript MIME型エッセンス
一致である場合、elの種類を「classic」に設定する。
それ以外で、the script block's type stringが文字列「module」とASCII大文字・小文字を区別せず一致する場合、
elの種類を「module」に設定する。
それ以外で、the script block's type stringが文字列「importmap」とASCII大文字・小文字を区別せず一致する場合、
elの種類を「importmap」に設定する。
それ以外で、the script block's type stringが文字列「speculationrules」とASCII大文字・小文字を区別せず一致する場合、
elの種類を「speculationrules」に設定する。
それ以外の場合は、戻る。(スクリプトは実行されず、elの種類はnullのままとなる。)
parser documentがnullでない場合、elのパーサー 文書をparser documentに戻し、elの強制asyncをfalseに設定する。
elの開始済みをtrueに設定する。
parser documentがnullでなく、かつparser documentが elの準備時文書と等しくない場合は、戻る。
elに対してスクリプティングが 無効である場合は、戻る。
スクリプティングが
無効であるの定義は、とりわけ次のスクリプトが実行されないことを意味する:
XMLHttpRequestのresponseXML文書内のスクリプト、
DOMParserによって作成された
文書内のスクリプト、XSLTProcessorのtransformToDocument機能によって作成された
文書内のスクリプト、およびcreateDocument()
APIを使用して作成されたDocumentに、スクリプトによって
最初に挿入されたスクリプト。[XHR]
[DOMPARSING] [XSLTP] [DOM]
elがnomodule
コンテンツ属性を持ち、その種類が「classic」である場合は、戻る。
これは、モジュールスクリプトにnomoduleを指定しても効果がなく、アルゴリズムはそのまま続行することを
意味する。
elの種類が「speculationrules」である場合、
cspTypeを「script speculationrules」とし、それ以外の場合は
「script」とする。
elがsrcコンテンツ属性を
持たず、el、cspType、およびsource
textを与えたときに、要素のインライン
動作をコンテンツセキュリティポリシーによってブロックすべきか?アルゴリズムが
「Blocked」を返す場合は、戻る。[CSP]
elがevent属性および
for属性を持ち、
elの種類が「classic」である場合:
forを、elのfor属性の値とする。
eventを、elのevent属性の値とする。
eventおよびforから先頭および末尾のASCII 空白を除去する。
forが文字列「window」とASCII大文字・小文字を区別せず一致しない場合は、戻る。
eventが文字列「onload」または文字列「onload()」の
いずれともASCII大文字・小文字を区別せず一致しない場合は、戻る。
elがcharset属性を
持つ場合、encodingを、charset属性の値からエンコーディングを取得した結果とする。
elがcharset属性を
持たないか、エンコーディングの取得に失敗した場合、
encodingを、elのノード
文書のエンコーディングとする。
elの種類が「module」である場合、
このエンコーディングは無視される。
classic script CORS settingを、elのcrossoriginコンテンツ属性の現在の状態とする。
module script credentials modeを、elのcrossoriginコンテンツ属性に対するCORS設定属性の
資格情報モードとする。
cryptographic nonceを、elの[[CryptographicNonce]] 内部スロットの値とする。
elがintegrity属性を持つ場合、
integrity metadataをその属性の値とする。
それ以外の場合、integrity metadataを空文字列とする。
referrer policyを、elのreferrerpolicyコンテンツ属性の現在の状態とする。
fetch priorityを、elのfetchpriorityコンテンツ属性の現在の状態とする。
elがパーサーによって挿入されている場合、
parser metadataを「parser-inserted」とし、それ以外の場合は
「not-parser-inserted」とする。
optionsを、暗号学的ノンスが cryptographic nonce、完全性メタデータが integrity metadata、パーサー メタデータがparser metadata、資格情報モードが module script credentials mode、リファラー ポリシーがreferrer policy、およびフェッチ優先度が fetch priorityであるスクリプトフェッチオプションとする。
settings objectを、elのノード 文書の関連設定オブジェクトとする。
elがsrcコンテンツ属性を
持つ場合:
elの種類が「importmap」または
「speculationrules」である場合、elを与えてDOM操作タスクソース上で、
elにおいてerrorという名前のイベントを発火する要素タスクを
キューに入れ、戻る。
外部インポートマップおよび投機ルールは現在サポートされていない。サポートの追加に 関する議論については、WICG/import-maps issue #235およびWICG/nav-speculation issue #348を 参照。
srcを、elのsrc属性の値とする。
srcが空文字列である場合、elを与えてDOM
操作タスクソース上で、elにおいてerrorという名前のイベントを発火する要素タスクをキューに入れ、戻る。
elの外部ファイル由来をtrueに設定する。
urlを、elのノード 文書を基準として、srcを与えてURLをエンコーディング解析する結果とする。
urlが失敗である場合、elを与えてDOM
操作タスクソース上で、elにおいてerrorという名前のイベントを発火する要素タスクをキューに入れ、戻る。
elがレンダリングをブロックする可能性がある場合、 el上でレンダリングをブロックする。
elのloadイベントを 遅延させているをtrueに設定する。
elが現在レンダリングをブロックしている場合、 optionsの レンダリングブロックをtrueに設定する。
resultを与えたonCompleteを、次の手順とする:
resultを与えてelを準備完了としてマークする。
elの種類に応じて切り替える:
classic」url、settings object、options、 classic script CORS setting、encoding、および onCompleteを与えてクラシック スクリプトをフェッチする。
module」elがintegrity属性を持たない場合、
optionsの完全性メタデータを、
urlおよびsettings objectを使用してモジュール完全性
メタデータを解決する結果に設定する。
url、settings object、options、および onCompleteを与えて外部モジュールスクリプトグラフを フェッチする。
性能上の理由から、ユーザーエージェントは、elが接続されること
(および、その間にcrossorigin属性の値が変更されないこと)を期待して、
src属性が設定された時点で、上記で定義されたクラシックスクリプト
またはモジュールグラフのフェッチを開始してもよい。どちらの場合でも、elが接続された時点までに、
読み込みはこの手順で説明されるとおり開始されていなければならない。UAがこのようなプリフェッチを
行ったものの、elが一度も接続されない、src属性が
動的に変更される、またはcrossorigin属性が動的に変更される場合、
ユーザーエージェントはそのようにして取得したスクリプトを実行せず、フェッチ処理は実質的に
無駄になる。
elがsrcコンテンツ属性を
持たない場合:
elの種類に応じて切り替える:
classic」scriptを、source text、settings object、 base URL、およびoptionsを使用してクラシックスクリプトを作成する結果とする。
scriptを与えてelを準備完了としてマークする。
module」elのloadイベントを 遅延させているをtrueに設定する。
elがレンダリングをブロックする可能性が ある場合:
el上でレンダリングをブロックする。
optionsのレンダリングブロックを trueに設定する。
source text、base URL、settings object、 options、およびresultを与えた次の手順を使用してインラインモジュールスクリプト グラフをフェッチする:
elを与えてネットワークタスクソース上で、 次の手順を実行する要素タスクをキューに入れる:
resultを与えてelを準備完了としてマークする。
ここでタスクをキューに入れることは、インラインモジュールスクリプトに 依存関係がない場合や、同期的に解析エラーが生じる場合でも、script要素を実行する処理へ 同期的に進まないことを意味する。
importmap」resultを、source textおよびbase URLを与えてインポートマップ解析結果を 作成する結果とする。
resultを与えてelを準備完了としてマークする。
speculationrules」resultを、source textおよびelのノード 文書を与えて投機ルール解析結果を 作成する結果とする。
resultを与えてelを準備完了としてマークする。
elの種類が「classic」であり、
elがsrc属性を持つか、またはelの種類が「module」である場合:
elがasync属性を持つか、elの強制
asyncがtrueである場合:
scriptsを、elの準備時文書の可能な限り早く 実行されるスクリプトの集合とする。
elをscriptsに付加する。
elの結果の準備ができたときに実行する 手順を次のとおり設定する:
elをscript要素として実行する。
elをscriptsから削除する。
それ以外で、elがパーサーによって挿入されていない場合:
scriptsを、elの準備時文書の可能な限り 早く順番に実行されるスクリプトのリストとする。
elをscriptsに付加する。
elの結果の準備ができたときに実行する 手順を次のとおり設定する:
scripts[0]がelでない場合、これらの手順を中止する。
scriptsが空でなく、かつscripts[0]の結果が
「uninitialized」でない間:
scripts[0]をscript要素として実行する。
scripts[0]を削除する。
それ以外で、elが
defer属性を持つか、elの種類が「module」である場合:
elの結果の準備ができたときに実行する 手順を次のとおり設定する: elのパーサーによる実行準備完了をtrueに設定する。 (パーサーがスクリプトの実行を処理する。)
それ以外の場合:
elのパーサー 文書の保留中の構文解析ブロックスクリプトを elに設定する。
el上でレンダリングをブロックする。
elの結果の準備ができたときに実行する 手順を次のとおり設定する: elのパーサーによる実行準備完了をtrueに設定する。 (パーサーがスクリプトの実行を処理する。)
それ以外の場合:
次のすべてがtrueである場合:
classic」である。その場合:
elのパーサー 文書の保留中の構文解析ブロックスクリプトを elに設定する。
elのパーサーによる実行準備完了をtrueに設定する。 (パーサーがスクリプトの実行を処理する。)
それ以外の場合、他のスクリプトがすでに実行中であっても、elを直ちにscript要素として実行する。
各Documentは、
script要素または
nullであり、初期値がnullである保留中の構文解析ブロックスクリプトを持つ。
各Documentは、script要素の集合であり、初期状態が空である可能な限り早く実行されるスクリプトの
集合を持つ。
各Documentは、script要素のリストであり、初期状態が空である可能な限り早く順番に
実行されるスクリプトのリストを持つ。
各Documentは、script要素のリストであり、初期状態が空である文書の構文解析が
完了したときに実行されるスクリプトのリストを持つ。
パーサーをブロックするscript要素が、
通常そのパーサーのブロックを停止する時点より前に別のDocumentへ移動された場合でも、
パーサーをブロックする原因となっている条件が適用されなくなるまで、そのパーサーをブロックし続ける
(たとえば、元のDocumentが解析時にスクリプトをブロックしている
スタイルシートを持つため、そのスクリプトが保留中の構文解析ブロックスクリプトであるが、
ブロックしているスタイルシートが読み込まれる前にスクリプトが別のDocumentへ移動された場合でも、
すべてのスタイルシートが読み込まれるまでスクリプトはパーサーをブロックし続け、その時点で
スクリプトが実行され、パーサーのブロックが解除される)。
script要素
elを与えてscript要素を実行するには:
documentを、elのノード文書とする。
elの準備時文書が documentと等しくない場合は、戻る。
el上のレンダリングのブロックを解除する。
elの外部ファイル由来がtrueであるか、
elの種類が「module」である場合、
documentの破壊的書き込み無視
カウンターを増加させる。
elの種類に応じて切り替える:
classic」oldCurrentScriptを、documentのcurrentScriptオブジェクトが最後に設定された値とする。
elのルートがシャドウ
ルートでない場合、documentのcurrentScript属性をelに設定する。
それ以外の場合は、nullに設定する。
ここでは文書ツリー内にあるかどうかの確認を使用しない。
elは実行前に文書から削除されている可能性があり、その場合でもcurrentScriptはそれを指す必要があるためである。
elの結果によって与えられるクラシックスクリプトを実行する。
documentのcurrentScript属性を
oldCurrentScriptに設定する。
module」表明: documentのcurrentScript属性はnullである。
elの結果によって与えられるモジュールスクリプトを実行する。
importmap」elの関連するグローバル オブジェクトおよびelの結果を与えてインポートマップを登録する。
speculationrules」elの関連するグローバル オブジェクトおよびelの結果を与えて投機ルールを登録する。
前の手順で増加させていた場合、documentの破壊的書き込み無視カウンターを 減少させる。
ユーザーエージェントはJavaScriptをサポートする必要はない。JavaScript以外の言語が登場し、
ウェブブラウザーに同程度広く採用された場合、この標準を更新する必要がある。それまでは、
script要素について
定義された処理モデルを考慮すると、他の言語を実装することはこの標準と矛盾する。
サーバーは、ECMAScriptメディア型の更新に従い、JavaScriptリソースに対して
text/javascriptを
使用することが望ましい。サーバーはJavaScriptリソースにその他のJavaScript
MIME型を使用しないことが望ましく、
JavaScript以外のJavaScript MIME型を
使用してはならない。
[RFC9239]
外部JavaScriptリソースの場合、`Content-Type`ヘッダー内の
MIME型パラメーターは通常無視される。(場合によっては`charset`パラメーターが
影響する。)ただし、script要素のtype属性では重要である。
これはJavaScript
MIME型エッセンス一致の概念を使用する。
たとえば、type属性が
「text/javascript; charset=utf-8」に設定されたスクリプトは、それを解析すると
妥当なJavaScript
MIME型であるにもかかわらず、評価されない。
さらに、外部JavaScriptリソースについては、script
要素を準備するアルゴリズムおよびFetchで詳述されているように、
`Content-Type`ヘッダーの
処理に関して特別な考慮事項が適用される。[FETCH]
script
要素の内容に対する制限この節で説明する多少奇妙な制限を回避する最も簡単で安全な方法は、
スクリプト内のリテラル(たとえば文字列、正規表現、またはコメント)にこれらのシーケンスが現れる場合、
「<!--」とのASCII大文字・小文字を区別しない一致を常に
「\x3C!--」として、「<script」を「\x3Cscript」として、
「</script」を「\x3C/script」としてエスケープし、
式でこのような構文を使用するコードを書かないようにすることである。そうすることで、
この節の制限によって引き起こされやすい落とし穴を回避できる。すなわち、歴史的な理由から、
HTML内のscript
ブロックの解析は奇妙で特殊な慣行であり、これらのシーケンスに直面すると直感に反する動作をする。
script
要素の子孫テキストコンテンツは、文字集合がUnicodeである
次のABNF内のscript生成規則に一致しなければならない。
[ABNF]
script = outer * ( comment-open inner comment-close outer )
outer = < any string that doesn 't contain a substring that matches not-in-outer >
not-in-outer = comment-open
inner = < any string that doesn 't contain a substring that matches not-in-inner >
not-in-inner = comment-close / script-open
comment-open = "<!--"
comment-close = "-->"
script-open = "<" s c r i p t tag-end
s = %x0053 ; U+0053 LATIN CAPITAL LETTER S
s =/ %x0073 ; U+0073 LATIN SMALL LETTER S
c = %x0043 ; U+0043 LATIN CAPITAL LETTER C
c =/ %x0063 ; U+0063 LATIN SMALL LETTER C
r = %x0052 ; U+0052 LATIN CAPITAL LETTER R
r =/ %x0072 ; U+0072 LATIN SMALL LETTER R
i = %x0049 ; U+0049 LATIN CAPITAL LETTER I
i =/ %x0069 ; U+0069 LATIN SMALL LETTER I
p = %x0050 ; U+0050 LATIN CAPITAL LETTER P
p =/ %x0070 ; U+0070 LATIN SMALL LETTER P
t = %x0054 ; U+0054 LATIN CAPITAL LETTER T
t =/ %x0074 ; U+0074 LATIN SMALL LETTER T
tag-end = %x0009 ; U+0009 CHARACTER TABULATION (tab)
tag-end =/ %x000A ; U+000A LINE FEED (LF)
tag-end =/ %x000C ; U+000C FORM FEED (FF)
tag-end =/ %x0020 ; U+0020 SPACE
tag-end =/ %x002F ; U+002F SOLIDUS (/)
tag-end =/ %x003E ; U+003E GREATER-THAN SIGN (>) script
要素がスクリプト
文書化を含む場合、以下の節で説明するように、その要素の内容にはさらに制限がある。
次のスクリプトはこの問題を示している。次のように、文字列を含むスクリプトがあるとする:
const example = 'Consider this string: <!-- <script>' ;
console. log( example); この文字列を直接script
ブロックに配置すると、上記の制限に違反する:
< script >
const example = 'Consider this string: <!-- <script>' ;
console. log( example);
</ script > しかし、より大きな問題、そしてこれらの制限に違反する理由は、実際にはスクリプトが奇妙に
解析されることである。上記のスクリプトブロックは終了していない。つまり、この断片で
「</script>」終了タグのように見えるものは、実際にはまだscript
ブロックの一部である。スクリプトは終了していないため実行されない。次のようなマークアップであれば
実行される可能性があるが、何らかの方法で実行されたとしても、ここで強調表示されているスクリプトが
妥当なJavaScriptではないため失敗する:
< script >
const example = 'Consider this string: <!-- <script>' ;
console. log( example);
</ script >
<!-- despite appearances, this is actually part of the script still! -->
< script >
... // this is the same script block still...
</ script > ここで起きていることは、歴史的な理由から、HTML内のscript
要素にある「<!--」および「<script」文字列は、パーサーがブロックを
閉じると判断するために対応が取れている必要があるということである。
この節の冒頭で述べたように問題のある文字列をエスケープすることで、問題を完全に回避できる:
< script >
// Note: `\x3C` is an escape sequence for `<`.
const example = 'Consider this string: \x3C!-- \x3Cscript>' ;
console. log( example);
</ script >
<!-- this is just a comment between script blocks -->
< script >
... // this is a new script block
</ script > 次の例のように、これらのシーケンスがスクリプト式内に自然に現れることもある:
if ( x<!-- y) { ... }
if ( player< script ) { ... } このような場合、文字をエスケープすることはできないが、次のようにシーケンスが現れないように 式を書き換えることができる:
if ( x < !-- y) { ... }
if ( !-- y > x) { ... }
if ( ! ( -- y) > x) { ... }
if ( player < script) { ... }
if ( script > player) { ... } これを行うことで、別の落とし穴も回避できる。関連する歴史的な理由から、クラシック スクリプト内の文字列「<!--」は、実際には「//」と同様に行コメントの開始として扱われる。
script
要素のsrc属性が
指定されている場合、script
要素の内容が存在するなら、その内容から導出されるtext IDL
属性の値が、文字集合がUnicodeである次のABNF内のdocumentation生成規則に一致するもので
なければならない。[ABNF]
documentation = * ( * ( space / tab / comment ) [ line-comment ] newline )
comment = slash star * ( not-star / star not-slash ) 1* star slash
line-comment = slash slash * not-newline
; characters
tab = %x0009 ; U+0009 CHARACTER TABULATION (tab)
newline = %x000A ; U+000A LINE FEED (LF)
space = %x0020 ; U+0020 SPACE
star = %x002A ; U+002A ASTERISK (*)
slash = %x002F ; U+002F SOLIDUS (/)
not-newline = %x0000-0009 / %x000B-10FFFF
; a scalar value other than U+000A LINE FEED (LF)
not-star = %x0000-0029 / %x002B-10FFFF
; a scalar value other than U+002A ASTERISK (*)
not-slash = %x0000-002E / %x0030-10FFFF
; a scalar value other than U+002F SOLIDUS (/) これは、要素の内容をJavaScriptコメント内に配置することに相当する。
この要件は、script
要素の内容の構文に関する先の制限に加えて適用される。
これにより、著者は外部スクリプトファイルを参照しながら、ライセンス情報やAPI情報などの文書を
文書内に含めることができる。著者がsrc属性を
提供しながら、妥当なスクリプトのように見えるものを誤って含めないよう、構文は制約されている。
< script src = "cool-effects.js" >
// create new instances using:
// var e = new Effect();
// start the effect using .play, stop using .stop:
// e.play();
// e.stop();
</ script > script要素とXSLTの相互作用この節は非規範的である。
この仕様は、XSLTがscript要素とどのように
相互作用するかを定義しない。ただし、これを実際に定義する別の仕様がないため、既存の実装に基づく
実装者向けの指針を以下に示す:
XSLT変換プログラムが<?xml-stylesheet?>処理命令によって起動され、
ブラウザーがDOMへの直接変換を実装している場合、XSLTプロセッサーによって作成されたscript要素は、
パーサー文書が正しく設定され、
変換の進行中に、deferまたはasyncとマークされた
スクリプトを除き、文書順に直ちに実行される必要がある。
XSLTProcessorのtransformToDocument()
メソッドは、nullの閲覧コンテキストを持つDocumentオブジェクトに要素を追加する。
したがって、それらが作成するすべてのscript要素は、
script要素を
準備するアルゴリズムにおいて開始済みをtrueに設定する必要があり、決して実行されない
(スクリプティングが
無効である)。ただし、このようなscript要素でも、
パーサー
文書を設定する必要がある。これにより、asyncコンテンツ属性が
ない場合、そのasync IDL属性はfalseを返す。
XSLTProcessorのtransformToFragment()
メソッドは、document.createElementNS()を
使用して要素を作成することにより手動で構築されたものと同等の断片を作成する必要がある。
たとえば、nullのパーサー文書を持ち、その開始済みがfalseに設定されたscript要素を作成し、
断片が文書に挿入されたときに実行されるようにする必要がある。
最初の2つの場合と最後の場合の主な違いは、最初の2つはDocumentを操作し、最後のものは断片を
操作することである。
noscript要素
現在のすべてのエンジンでサポートされています。
noscript要素が
ない場合、HTML文書のhead要素内。
noscript要素が
ない場合、HTML文書内で記述コンテンツが期待される場所。
noscript要素が
ない場合、select要素またはoptgroup要素の子孫。
head要素内では、任意の順序で0個以上のlink要素、0個以上のstyle要素、および
0個以上のmeta要素。
head要素内でなければ、透過的であるが、子孫にnoscript要素が
あってはならない。HTMLElementを使用する。noscript要素は、
スクリプティングが有効である場合は
何も表さず、スクリプティングが無効である
場合はその子を表す。これは文書の解析方法に
影響を与えることで、スクリプティングをサポートするユーザーエージェントとサポートしない
ユーザーエージェントに異なるマークアップを提示するために使用される。
HTML文書で使用する場合、許可されるコンテンツモデルは次のとおりである:
head要素内で、
noscript要素に対してスクリプティングが
無効である場合
head要素内で、
noscript要素に対してスクリプティングが有効である場合
noscript要素はテキストのみを含まなければならない。ただし、
noscript要素をコンテキスト要素とし、テキスト内容を
inputとしてHTML断片解析アルゴリズムを呼び出した結果は、
noscript要素の子であったなら適合するlink、style、およびmeta要素のみからなる
ノードのリストとなり、解析エラーが生じてはならない。
head要素の外側で、
noscript要素に対してスクリプティングが
無効である場合
noscript要素のコンテンツモデルは透過的であり、さらにnoscript要素は祖先にnoscript要素を持ってはならないという制限がある
(つまり、noscriptを入れ子にすることはできない)。
head要素の外側で、
noscript要素に対してスクリプティングが
有効である場合
noscript要素はテキストのみを含まなければならない。ただし、
そのテキストは、次のアルゴリズムを実行した結果が、noscript要素もscript要素もない
適合文書となり、アルゴリズムのどの手順も例外を投げず、HTML
パーサーに解析エラーを通知させないものでなければならない:
これらすべての複雑な処理が必要なのは、歴史的な理由から、noscript要素が、パーサーの呼び出し時にスクリプティングモードが無効であったかどうかに
基づき、HTMLパーサーによって異なる方法で
処理されるためである。
noscript要素はHTML構文でのみ有効であり、XML構文では効果がない。これは、スクリプトが有効な場合に
パーサーを本質的に「オフにする」ことによって動作し、要素の内容を実際の要素ではなく純粋なテキストとして
扱うためである。XMLにはこれを行う仕組みが定義されていない。
noscript要素には、その他の要件はない。特に、要素に対してスクリプティングが有効である場合でも、
noscript要素の子は、フォーム送信、スクリプティングなどから免除されない。
次の例では、noscript要素を使用して、スクリプトのフォールバックを提供している。
< form action = "calcSquare.php" >
< p >
< label for = x > Number</ label > :
< input id = "x" name = "x" type = "number" >
</ p >
< script >
var x = document. getElementById( 'x' );
var output = document. createElement( 'p' );
output. textContent = 'Type a number; it will be squared right then!' ;
x. form. appendChild( output);
x. form. onsubmit = function () { return false ; }
x. oninput = function () {
var v = x. valueAsNumber;
output. textContent = v + ' squared is ' + v * v;
};
</ script >
< noscript >
< input type = submit value = "Calculate Square" >
</ noscript >
</ form > スクリプトが無効な場合、サーバー側で計算を行うためのボタンが表示される。スクリプトが有効な場合は、 代わりに値がその場で計算される。
noscript要素は大ざっぱな手段である。スクリプトが有効であっても、
何らかの理由でページのスクリプトが失敗することがある。そのため、一般にはnoscriptの使用を避け、次の例のように、スクリプトを使用しない
ページからスクリプトを使用するページへ動的に変更するようスクリプトを設計する方がよい:
< form action = "calcSquare.php" >
< p >
< label for = x > Number</ label > :
< input id = "x" name = "x" type = "number" >
</ p >
< input id = "submit" type = submit value = "Calculate Square" >
< script >
var x = document. getElementById( 'x' );
var output = document. createElement( 'p' );
output. textContent = 'Type a number; it will be squared right then!' ;
x. form. appendChild( output);
x. form. onsubmit = function () { return false ; }
x. oninput = function () {
var v = x. valueAsNumber;
output. textContent = v + ' squared is ' + v * v;
};
var submit = document. getElementById( 'submit' );
submit. parentNode. removeChild( submit);
</ script >
</ form > template要素
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
span属性を持たないcolgroup要素の子として。shadowrootmode
— ストリーミング宣言的シャドウルートを有効にする
shadowrootdelegatesfocus
— 宣言的シャドウルートにフォーカスを委任するを設定する
shadowrootslotassignment
— 宣言的シャドウルートにスロット
割り当てを設定する
shadowrootclonable
— 宣言的シャドウルートに複製可能を設定する
shadowrootserializable
— 宣言的シャドウルートに直列化可能を設定する
shadowrootcustomelementregistry
— 宣言的シャドウルートがカスタム要素レジストリを使用することを示せるようにする
[Exposed =Window ]
interface HTMLTemplateElement : HTMLElement {
[HTMLConstructor ] constructor ();
readonly attribute DocumentFragment content ;
[CEReactions ] attribute DOMString shadowRootMode ;
[CEReactions , Reflect ] attribute boolean shadowRootDelegatesFocus ;
[CEReactions ] attribute DOMString shadowRootSlotAssignment ;
[CEReactions , Reflect ] attribute boolean shadowRootClonable ;
[CEReactions , Reflect ] attribute boolean shadowRootSerializable ;
[CEReactions , Reflect ] attribute DOMString shadowRootCustomElementRegistry ;
};template要素は、スクリプトによって複製され文書に挿入できる
HTML断片を宣言するために使用される。
shadowrootmodeコンテンツ属性は、次のキーワードおよび状態を
持つ列挙属性である:
| キーワード | 状態 | 簡単な説明 |
|---|---|---|
open
|
開放 | template要素は開放された宣言的シャドウルートを表す。 |
closed
|
閉鎖 | template要素は閉鎖された宣言的シャドウルートを表す。 |
shadowrootmode
属性の無効値の
デフォルトおよび欠落値の
デフォルトは、いずれもなし状態である。
shadowrootdelegatesfocusコンテンツ属性は、
真偽属性である。
shadowrootslotassignmentコンテンツ属性は、次のキーワードおよび
状態を持つ列挙
属性である:
| キーワード | 状態 | 簡単な説明 |
|---|---|---|
named
|
名前付き | 宣言的シャドウルートは名前付きスロット割り当てを使用する。 |
manual
|
手動 | 宣言的シャドウルートは手動スロット割り当てを使用する。 |
shadowrootslotassignment
属性の無効値の
デフォルトおよび欠落値のデフォルトは、いずれも名前付き状態である。
shadowrootclonableコンテンツ属性は、
真偽属性である。
shadowrootserializableコンテンツ属性は、
真偽属性である。
shadowrootcustomelementregistryコンテンツ属性は、
真偽
属性である。
template要素のテンプレート内容は、要素自体の
子ではない。
DOM操作の結果として、template要素がTextノードおよび要素ノードを含むことも可能で
ある。ただし、そのコンテンツモデルはなしとして定義されているため、いずれかを
持つことはtemplate要素のコンテンツモデルへの違反である。
たとえば、次の文書を考える:
<!doctype html>
< html lang = "en" >
< head >
< title > Homework</ title >
< body >
< template id = "template" >< p > Smile!</ p ></ template >
< script >
let num = 3 ;
const fragment = document. getElementById( 'template' ). content. cloneNode( true );
while ( num-- > 1 ) {
fragment. firstChild. before( fragment. firstChild. cloneNode( true ));
fragment. firstChild. textContent += fragment. lastChild. textContent;
}
document. body. appendChild( fragment);
</ script >
</ html > template内のp要素は、DOM内のtemplateの子ではない。これは、template要素のcontent IDL属性によって返されるDocumentFragmentの子である。
スクリプトがtemplate要素に対してappendChild()を呼び出した場合、
それは他の要素の場合と同様にtemplate要素に子を追加する。ただし、そうすることはtemplate要素のコンテンツモデルへの違反である。
template.content
現在のすべてのエンジンでサポートされています。
テンプレート内容
(DocumentFragment)を返す。
各template要素には、そのテンプレート内容である、関連付けられたDocumentFragmentオブジェクトがある。
テンプレート内容には適合要件がない。template要素が作成されたとき、ユーザーエージェントはテンプレート
内容を確立するために次の手順を実行しなければならない:
documentを、template要素のノード
文書の適切なテンプレート内容所有
文書とする。
ノード文書がdocumentであり、ホストがtemplate要素であるDocumentFragmentオブジェクトを
作成する。
template要素のテンプレート内容を、新たに作成したDocumentFragmentオブジェクトに
設定する。
Document
documentの適切なテンプレート内容所有
文書は、次のアルゴリズムによって返されるDocumentである:
documentが、このアルゴリズムによって作成された Document でない場合:
documentがまだ関連付けられた不活性な template 文書を持たない場合:
documentを、documentの関連付けられた不活性な template 文書に設定する。
したがって、このアルゴリズムによって作成されていない各 Documentは、
そのすべての template
要素のtemplate の内容を所有する
代理として機能する単一の Documentを取得するため、それらは
閲覧コンテキスト内になく、
したがって不活性なままである(たとえば、スクリプトは実行されない)。一方、このアルゴリズムによって
作成された Document オブジェクト内の
template
要素は、その内容について同じ
Document 所有者を再利用する。
documentを返す。
template要素の受け入れ手順
(nodeおよびoldDocumentをパラメーターとする)は次のとおりである:
documentを、nodeのノード 文書の適切なテンプレート内容所有 文書とする。
nodeのテンプレート内容
(DocumentFragmentオブジェクト)を
documentに受け入れる。
shadowRootMode IDL属性は、shadowrootmode
コンテンツ属性を既知の値のみに
制限して反映しなければならない。
shadowRootSlotAssignment IDL属性は、shadowrootslotassignment
コンテンツ属性を既知の値のみに
制限して反映しなければならない。
shadowRootCustomElementRegistry IDL 属性は、拡張できるように意図的に真偽型を持たない。
この例では、スクリプトがデータ構造からのデータで4列の表を埋める際、マークアップから構造を
手動で生成する代わりに、templateを使用して要素構造を提供する。
<!DOCTYPE html>
< html lang = 'en' >
< title > Cat data</ title >
< script >
// Data is hard-coded here, but could come from the server
var data = [
{ name: 'Pillar' , color: 'Ticked Tabby' , sex: 'Female (neutered)' , legs: 3 },
{ name: 'Hedral' , color: 'Tuxedo' , sex: 'Male (neutered)' , legs: 4 },
];
</ script >
< table >
< thead >
< tr >
< th > Name < th > Color < th > Sex < th > Legs
< tbody >
< template id = "row" >
< tr >< td >< td >< td >< td >
</ template >
</ table >
< script >
var template = document. querySelector( '#row' );
for ( var i = 0 ; i < data. length; i += 1 ) {
var cat = data[ i];
var clone = template. content. cloneNode( true );
var cells = clone. querySelectorAll( 'td' );
cells[ 0 ]. textContent = cat. name;
cells[ 1 ]. textContent = cat. color;
cells[ 2 ]. textContent = cat. sex;
cells[ 3 ]. textContent = cat. legs;
template. parentNode. appendChild( clone);
}
</ script > この例では、templateの内容に対してcloneNode()を使用している。
同等に、同じ処理を行うdocument.importNode()を使用することも
できる。この2つのAPIの唯一の違いは、ノード文書が更新される時点である。cloneNode()では、ノードがappendChild()によって付加されたときに
更新され、document.importNode()では、
ノードが複製されたときに更新される。
template要素と
XSLTおよびXPathの相互作用この節は非規範的である。
この仕様は、XSLTおよびXPathがtemplate要素と
どのように相互作用するかを定義しない。ただし、これを実際に定義する別の仕様がないため、
この仕様で説明される他の処理と整合することを意図した、実装者向けの指針を以下に示す:
この仕様で説明されている
とおりに動作するXMLパーサーに基づくXSLTプロセッサーは、変換の目的上、template要素が
そのテンプレート内容を
子孫として含むかのように動作する必要がある。
DOMを出力するXSLTプロセッサーは、template要素に
入るはずのノードが、代わりにその要素のテンプレート
内容に配置されることを保証する必要がある。
この仕様で説明されるHTMLパーサーまたはXMLパーサーを使用して解析されたDocumentにXPath DOM APIを適用して
XPath評価を行う場合、テンプレート内容を無視する必要がある。
slot
要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
name — シャドウツリーの
スロット名
[Exposed =Window ]
interface HTMLSlotElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute DOMString name ;
sequence <Node > assignedNodes (optional AssignedNodesOptions options = {});
sequence <Element > assignedElements (optional AssignedNodesOptions options = {});
undefined assign ((Element or Text )... nodes );
};
dictionary AssignedNodesOptions {
boolean flatten = false ;
};slot要素はスロットを定義する。これは通常、シャドウツリー内で使用される。slot要素は、存在する場合は
その割り当てられたノードを、それ以外の場合はその内容を表す。
nameコンテンツ属性は、
任意の文字列値を含むことができる。これはスロットの名前を表す。
name属性は、
他の要素にスロットを割り当てるために使用される。name属性を持つslot要素は、名前付きスロットを作成する。ある要素が、そのname属性の値と一致する値を持つ
slot属性を持ち、かつslot要素が、そのルートのホストが対応するslot属性値を持つシャドウツリーの子である場合、その要素はその名前付きスロットに割り当てられる。
slot.name
現在のすべてのエンジンでサポートされています。
slot.assignedNodes()
現在のすべてのエンジンでサポートされています。
slot.assignedNodes({ flatten: true })
slot要素に対しても、
slot要素が残らなくなるまで
再帰的に同じ処理を行う。
slot.assignedElements()
HTMLSlotElement/assignedElements
現在のすべてのエンジンでサポートされています。
slot.assignedElements({ flatten: true })
assignedNodes({ flatten: true
})と同じものを、要素のみに限定して返す。slot.assign(...nodes)
slotの手動で割り当てられたノードを、与えられた nodesに設定する。
slot要素は、
assign()によって設定される
スロット可能要素の有順集合である手動で割り当てられた
ノードを持つ。この集合は初期状態では空である。
手動で割り当てられたノードの集合は、 スクリプトから直接アクセスできないため、スロット可能要素への弱い参照を使用して 実装できる。
assignedNodes(options)メソッドの手順は次のとおりである:
options["flatten"]がfalseの場合、thisの割り当てられたノードを返す。
thisを使用して平坦化されたスロット可能要素を見つける結果を返す。
assignedElements(options)メソッドの手順は次のとおりである:
options["flatten"]がfalseの場合、thisの割り当てられたノードを、Elementノードのみを含むように
フィルターして返す。
thisを使用して平坦化されたスロット可能要素を見つける結果を、
Elementノードのみを含むように
フィルターして返す。
現在のすべてのエンジンでサポートされています。
assign(...nodes)メソッドの手順は次のとおりである:
thisの手動で割り当てられたノードの各nodeに ついて、nodeの手動スロット割り当てをnullに設定する。
nodesSetを、新しい有順集合とする。
nodesの各nodeについて:
nodeの手動スロット割り当てがslotを参照する場合、 そのnodeを、そのslotの手動で割り当てられたノードから削除する。
nodeの手動スロット割り当てをthisに設定する。
nodeをnodesSetに付加する。
thisの手動で割り当てられたノードを nodesSetに設定する。
thisのルートに対してツリーのスロット可能要素を割り当てるを実行する。
canvas要素現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
a要素、usemap属性を持つ
img要素、button要素、type属性がチェックボックス状態またはラジオ
ボタン状態にあるinput要素、ボタンであるinput要素、およびmultiple属性を持つか
表示サイズが1より大きいselect要素を除き、
子孫にインタラクティブコンテンツを含まない。
width — 水平方向の
寸法
height — 垂直方向の
寸法
typedef (CanvasRenderingContext2D or ImageBitmapRenderingContext or WebGLRenderingContext or WebGL2RenderingContext or GPUCanvasContext ) RenderingContext ;
[Exposed =Window ]
interface HTMLCanvasElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions ] attribute unsigned long width ;
[CEReactions ] attribute unsigned long height ;
RenderingContext ? getContext (DOMString contextId , optional any options = null );
USVString toDataURL (optional DOMString type = "image/png", optional any quality );
undefined toBlob (BlobCallback _callback , optional DOMString type = "image/png", optional any quality );
OffscreenCanvas transferControlToOffscreen ();
};
callback BlobCallback = undefined (Blob ? blob );canvas要素は、
スクリプトに解像度依存のビットマップキャンバスを提供し、グラフ、ゲームグラフィックス、芸術作品、
またはその他の視覚画像を動的にレンダリングするために使用できる。
より適切な要素が利用できる場合、著者は文書内でcanvas要素を
使用しないことが望ましい。たとえば、ページ見出しをレンダリングするためにcanvas要素を
使用するのは不適切である。見出しの望ましい表示がグラフィックスを多用するものである場合、
適切な要素(通常はh1)
を使用してマークアップし、CSSおよびシャドウツリーなどの支援技術を
使用してスタイルを適用することが望ましい。
著者がcanvas要素を使用する場合、
ユーザーに提示されたときにcanvasのビットマップと
本質的に同じ機能または目的を伝えるコンテンツも提供しなければならない。このコンテンツはcanvas要素の内容として
配置できる。canvas要素の内容が
存在する場合、それは要素のフォールバックコンテンツである。
インタラクティブな視覚媒体において、canvas要素に対してスクリプティングが有効であり、かつ
canvas要素の
サポートが有効になっている場合、canvas要素は、
動的に作成された画像、すなわち要素のビットマップからなる埋め込みコンテンツを表す。
非インタラクティブで静的な視覚媒体において、canvas要素が以前に
レンダリングコンテキストに関連付けられていた場合(たとえば、ページがインタラクティブな視覚媒体で
表示され、現在印刷されている場合や、ページのレイアウト処理中に実行されたスクリプトが要素に
描画した場合)、canvas要素は、
要素の現在のビットマップおよびサイズを持つ埋め込みコンテンツを表す。それ以外の場合、要素は代わりにそのフォールバックコンテンツを表す。
非視覚媒体、および視覚媒体においてcanvas要素に対してスクリプティングが
無効である場合、またはcanvas要素の
サポートが無効になっている場合、canvas要素は、
代わりにそのフォールバック
コンテンツを表す。
canvas要素が埋め込みコンテンツを表す場合でも、ユーザーはcanvas要素の
子孫(フォールバック
コンテンツ内)にフォーカスできる。要素がフォーカスされている場合、それはキーボード操作イベントの対象となる
(要素自体が表示されていない場合でも)。これにより、著者はインタラクティブなcanvasをキーボードで
アクセス可能にできる。著者は、インタラクティブ領域とフォールバックコンテンツ内のフォーカス可能領域との間に
1対1の対応を持たせることが望ましい。(フォーカスはマウス操作イベントには影響しない。)
[UIEVENTS]
最も近い祖先のcanvas要素がレンダリングされており、かつ埋め込みコンテンツを表す要素は、関連するcanvasフォールバックコンテンツとして
使用されている要素である。
canvas要素は、
要素のビットマップのサイズを制御する2つの属性、widthおよびheightを持つ。これらの属性が指定される場合、その値は
妥当な
非負整数でなければならない。その数値を
取得するには、非負整数の解析規則を使用しなければ
ならない。属性が欠落している場合、またはその値の解析がエラーを返す場合は、代わりにデフォルト値を
使用しなければならない。width属性の
デフォルトは300であり、height属性の
デフォルトは150である。
width属性またはheight属性の値を
設定するとき、canvas要素のコンテキストモードがplaceholderに設定されている場合、
ユーザーエージェントは「InvalidStateError」DOMExceptionを投げ、
属性の値を変更せずに残さなければならない。
ユーザーエージェントは、canvasおよびその
レンダリングコンテキストのビットマップに対して、座標空間単位あたり画像データ1ピクセルからなる
正方形のピクセル密度を使用しなければならない。
canvas要素はスタイルシートによって任意のサイズにでき、
そのビットマップには'object-fit' CSSプロパティが適用される。
canvas要素の
ビットマップ、ImageBitmapオブジェクトのビットマップ、および以下のCanvasRenderingContext2D、OffscreenCanvasRenderingContext2D、およびImageBitmapRenderingContextオブジェクトに関する節で説明する
ものなど、一部のレンダリングコンテキストのビットマップは、trueまたはfalseに設定できるオリジンクリーンフラグを持つ。初期状態では、canvas要素またはImageBitmapオブジェクトが作成された
とき、そのビットマップのオリジンクリーンフラグはtrueに設定されなければ
ならない。
canvas要素には、
レンダリングコンテキストを結び付けることができる。初期状態では、結び付けられたレンダリング
コンテキストを持たない。レンダリングコンテキストを持つかどうか、およびそれがどの種類の
レンダリングコンテキストであるかを追跡するため、canvasは
canvasコンテキストモードも持つ。これは初期状態では
noneであるが、この仕様で定義されたアルゴリズムによって
placeholder、2d、
bitmaprenderer、webgl、webgl2、または
webgpuのいずれかに変更できる。
canvas要素のcanvasコンテキストモードがnoneである場合、
レンダリングコンテキストを持たず、そのビットマップは透明な黒でなければならない。その自然幅は、要素のwidth属性の数値と等しく、自然高は、要素のheight属性の数値と等しい。
これらの値はCSSピクセルとして解釈され、属性が設定、変更、
または削除されると更新される。
canvas要素のcanvasコンテキストモードがplaceholderである場合、
レンダリングコンテキストを持たない。これはOffscreenCanvasオブジェクトの
プレースホルダーとして機能し、canvas要素の内容は、
OffscreenCanvasオブジェクトの
レンダリングコンテキストによって更新される。
canvas要素が埋め込み
コンテンツを表す場合、幅が要素の自然幅、高さが要素の自然高、外観が要素のビットマップであるペイントソースを提供する。
widthおよび
heightコンテンツ
属性が設定、削除、変更、またはすでに持っている値に重複して設定されるたびに、
ユーザーエージェントは、canvas要素のコンテキストモードに対応する、次の表の行の
アクションを実行しなければならない。
|
アクション |
|
|---|---|
|
|
|
|
WebGL仕様で定義された動作に従う。[WEBGL] |
|
|
WebGPUで定義された動作に従う。[WEBGPU] |
|
|
コンテキストのビットマップ
モードがblankに設定されている場合、
|
|
|
何もしない。 |
|
|
何もしない。 |
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
widthおよびheight IDL属性は、同じ名前のそれぞれのコンテンツ属性を、
同じデフォルト値で反映しなければならない。
context = canvas.getContext(contextId [, options ])
現在のすべてのエンジンでサポートされています。
canvas上に描画するためのAPIを公開するオブジェクトを返す。contextIdは、希望するAPI、
「2d」、「bitmaprenderer」、「webgl」、「webgl2」、または
「webgpu」を指定する。optionsはそのAPIによって処理される。
この仕様は、以下で「2d」および「bitmaprenderer」コンテキストを定義する。WebGL仕様は
「webgl」および「webgl2」コンテキストを定義する。WebGPUは
「webgpu」コンテキストを定義する。
[WEBGL] [WEBGPU]
contextIdがサポートされていない場合、またはcanvasがすでに別のコンテキスト型で
初期化されている場合(たとえば、「webgl」
コンテキストを取得した後に「2d」
コンテキストを取得しようとする場合)、nullを返す。
canvas要素のgetContext(contextId, options)メソッドは、
呼び出されたとき、次の手順を実行しなければならない:
optionsがオブジェクトでない場合、 optionsをnullに設定する。
optionsをJavaScript値に変換した結果に 設定する。
次の表で、列見出しがこのcanvas要素のcanvasコンテキストモードと一致し、
行見出しがcontextIdと一致するセルの手順を実行する:
| none | 2d | bitmaprenderer | webglまたはwebgl2 | webgpu | placeholder | |
|---|---|---|---|---|---|---|
「2d」
|
|
この同じ第1引数でメソッドが最後に呼び出されたときに返されたものと同じオブジェクトを返す。 | nullを返す。 | nullを返す。 | nullを返す。 |
「InvalidStateError」DOMExceptionを投げる。
|
「bitmaprenderer」
|
|
nullを返す。 | この同じ第1引数でメソッドが最後に呼び出されたときに返されたものと同じオブジェクトを返す。 | nullを返す。 | nullを返す。 |
「InvalidStateError」DOMExceptionを投げる。
|
ユーザーエージェントが現在の構成でWebGL機能をサポートする場合、
「webgl」または「webgl2」
|
nullを返す。 | nullを返す。 | この同じ第1引数でメソッドが最後に呼び出されたときに返されたものと同じオブジェクトを返す。 | nullを返す。 |
「InvalidStateError」DOMExceptionを投げる。
|
|
ユーザーエージェントが現在の構成でWebGPU機能をサポートする場合、
「webgpu」
|
|
nullを返す。 | nullを返す。 | nullを返す。 | この同じ第1引数でメソッドが最後に呼び出されたときに返されたものと同じオブジェクトを返す。 |
「InvalidStateError」DOMExceptionを投げる。
|
| サポートされていない値* | nullを返す。 | nullを返す。 | nullを返す。 | nullを返す。 | nullを返す。 |
「InvalidStateError」DOMExceptionを投げる。
|
* たとえば、ユーザーエージェントがグラフィックスハードウェアの能力を
使い果たし、ソフトウェアによるフォールバック実装もない場合の「webgl」または「webgl2」値。
url = canvas.toDataURL([ type [, quality ] ])
現在のすべてのエンジンでサポートされています。
canvas内の画像に対するdata: URLを返す。
第1引数が指定された場合、返される画像の種類(たとえばPNGまたはJPEG)を制御する。
デフォルトは「image/png」であり、指定された種類がサポートされていない場合も
この種類が使用される。第2引数は、種類が可変品質をサポートする画像形式
(「image/jpeg」など)である場合に適用され、結果の画像に望まれる
品質レベルを示す0.0以上1.0以下の数値である。
「image/png」以外の種類を使用しようとする場合、著者は返された文字列が
厳密な文字列「data:image/png,」または「data:image/png;」のいずれかで
始まるかどうかを確認することで、画像が実際に要求された形式で返されたかを確認できる。
そのように始まる場合、画像はPNGであり、要求された種類はサポートされていなかったことになる。
(唯一の例外は、canvasの高さまたは幅のいずれかがない場合で、その場合、結果は単に
「data:,」となることがある。)
canvas.toBlob(callback [, type [, quality ] ])
現在のすべてのエンジンでサポートされています。
canvas内の画像を含むファイルを表すBlobオブジェクトを作成し、そのオブジェクトへの
ハンドルを使用してコールバックを呼び出す。
第2引数が指定された場合、返される画像の種類(たとえばPNGまたはJPEG)を制御する。
デフォルトは「image/png」であり、指定された種類がサポートされていない場合も
この種類が使用される。第3引数は、種類が可変品質をサポートする画像形式
(「image/jpeg」など)である場合に適用され、結果の画像に望まれる
品質レベルを示す0.0以上1.0以下の数値である。
canvas.transferControlToOffscreen()
HTMLCanvasElement/transferControlToOffscreen
現在のすべてのエンジンでサポートされています。
canvas要素をプレースホルダーとして使用する、新たに作成されたOffscreenCanvasオブジェクトを返す。canvas要素が
OffscreenCanvasオブジェクトのプレースホルダーになると、その自然サイズは
変更できなくなり、レンダリングコンテキストも持てなくなる。プレースホルダーcanvasの内容は、
OffscreenCanvasの関連エージェントのイベントループのレンダリングを更新する手順で
更新される。
toDataURL(type, quality)メソッドは、
呼び出されたとき、次の手順を実行しなければならない:
このcanvas要素のビットマップのオリジンクリーンフラグがfalseに
設定されている場合、「SecurityError」DOMExceptionを投げる。
このcanvas要素のビットマップにピクセルがない場合
(すなわち、水平方向または垂直方向の寸法のいずれかが0の場合)、文字列
「data:,」を返す。(これは最短のdata: URLであり、
text/plainリソース内の空文字列を表す。)
fileを、指定されている場合はtypeおよびqualityを渡して得られる、
このcanvas要素の
ビットマップをファイルとして直列化したものとする。
fileがnullの場合、「data:,」を返す。
toBlob(callback, type,
quality)メソッドは、呼び出されたとき、次の手順を実行しなければならない:
このcanvas要素のビットマップのオリジンクリーンフラグがfalseに
設定されている場合、「SecurityError」DOMExceptionを投げる。
resultをnullとする。
このcanvas要素のビットマップにピクセルがある場合
(すなわち、水平方向の寸法も垂直方向の寸法も0でない場合)、resultをこのcanvas要素の
ビットマップのコピーに設定する。
次の手順を並行して実行する:
resultがnullでない場合、指定されているならtypeおよび qualityを使用して、resultをresultを ファイルとして直列化したものに設定する。
canvas要素を与えて、canvas
blob直列化タスク
ソース上で、次の手順を実行する要素タスクをキューに入れる:
transferControlToOffscreen()メソッドは、
呼び出されたとき、次の手順を実行しなければならない:
このcanvas要素のコンテキスト
モードがnoneに設定されていない場合、「InvalidStateError」DOMExceptionを投げる。
offscreenCanvasを、その幅および高さがこのcanvas要素のwidthおよびheightコンテンツ属性の値と等しい、新しいOffscreenCanvasオブジェクトとする。
offscreenCanvasのプレースホルダーcanvas要素を、
このcanvas要素への弱い参照に設定する。
このcanvas要素のコンテキスト
モードをplaceholderに設定する。
offscreenCanvasを返す。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
typedef (HTMLImageElement or
SVGImageElement ) HTMLOrSVGImageElement ;
typedef (HTMLOrSVGImageElement or
HTMLVideoElement or
HTMLCanvasElement or
ImageBitmap or
OffscreenCanvas or
VideoFrame ) CanvasImageSource ;
enum CanvasColorType { " unorm8 " , " float16 " };
enum CanvasFillRule { " nonzero " , " evenodd " };
dictionary CanvasRenderingContext2DSettings {
boolean alpha = true ;
boolean desynchronized = false ;
PredefinedColorSpace colorSpace = "srgb";
CanvasColorType colorType = "unorm8";
boolean willReadFrequently = false ;
};
enum ImageSmoothingQuality { " low " , " medium " , " high " };
[Exposed =Window ]
interface CanvasRenderingContext2D {
// back-reference to the canvas
readonly attribute HTMLCanvasElement canvas ;
};
CanvasRenderingContext2D includes CanvasSettings ;
CanvasRenderingContext2D includes CanvasState ;
CanvasRenderingContext2D includes CanvasTransform ;
CanvasRenderingContext2D includes CanvasCompositing ;
CanvasRenderingContext2D includes CanvasImageSmoothing ;
CanvasRenderingContext2D includes CanvasFillStrokeStyles ;
CanvasRenderingContext2D includes CanvasShadowStyles ;
CanvasRenderingContext2D includes CanvasFilters ;
CanvasRenderingContext2D includes CanvasRect ;
CanvasRenderingContext2D includes CanvasDrawPath ;
CanvasRenderingContext2D includes CanvasUserInterface ;
CanvasRenderingContext2D includes CanvasText ;
CanvasRenderingContext2D includes CanvasDrawImage ;
CanvasRenderingContext2D includes CanvasImageData ;
CanvasRenderingContext2D includes CanvasPathDrawingStyles ;
CanvasRenderingContext2D includes CanvasTextDrawingStyles ;
CanvasRenderingContext2D includes CanvasPath ;
interface mixin CanvasSettings {
// settings
CanvasRenderingContext2DSettings getContextAttributes ();
};
interface mixin CanvasState {
// state
undefined save (); // push state on state stack
undefined restore (); // pop state stack and restore state
undefined reset (); // reset the rendering context to its default state
boolean isContextLost (); // return whether context is lost
};
interface mixin CanvasTransform {
// transformations (default transform is the identity matrix)
undefined scale (unrestricted double x , unrestricted double y );
undefined rotate (unrestricted double angle );
undefined translate (unrestricted double x , unrestricted double y );
undefined transform (unrestricted double a , unrestricted double b , unrestricted double c , unrestricted double d , unrestricted double e , unrestricted double f );
[NewObject ] DOMMatrix getTransform ();
undefined setTransform (unrestricted double a , unrestricted double b , unrestricted double c , unrestricted double d , unrestricted double e , unrestricted double f );
undefined setTransform (optional DOMMatrix2DInit transform = {});
undefined resetTransform ();
};
interface mixin CanvasCompositing {
// compositing
attribute unrestricted double globalAlpha ; // (default 1.0)
attribute DOMString globalCompositeOperation ; // (default "source-over")
};
interface mixin CanvasImageSmoothing {
// image smoothing
attribute boolean imageSmoothingEnabled ; // (default true)
attribute ImageSmoothingQuality imageSmoothingQuality ; // (default low)
};
interface mixin CanvasFillStrokeStyles {
// colors and styles (see also the CanvasPathDrawingStyles and CanvasTextDrawingStyles interfaces)
attribute (DOMString or CanvasGradient or CanvasPattern ) strokeStyle ; // (default black)
attribute (DOMString or CanvasGradient or CanvasPattern ) fillStyle ; // (default black)
CanvasGradient createLinearGradient (double x0 , double y0 , double x1 , double y1 );
CanvasGradient createRadialGradient (double x0 , double y0 , double r0 , double x1 , double y1 , double r1 );
CanvasGradient createConicGradient (double startAngle , double x , double y );
CanvasPattern ? createPattern (CanvasImageSource image , [LegacyNullToEmptyString ] DOMString repetition );
};
interface mixin CanvasShadowStyles {
// shadows
attribute unrestricted double shadowOffsetX ; // (default 0)
attribute unrestricted double shadowOffsetY ; // (default 0)
attribute unrestricted double shadowBlur ; // (default 0)
attribute DOMString shadowColor ; // (default transparent black)
};
interface mixin CanvasFilters {
// filters
attribute DOMString filter ; // (default "none")
};
interface mixin CanvasRect {
// rects
undefined clearRect (unrestricted double x , unrestricted double y , unrestricted double w , unrestricted double h );
undefined fillRect (unrestricted double x , unrestricted double y , unrestricted double w , unrestricted double h );
undefined strokeRect (unrestricted double x , unrestricted double y , unrestricted double w , unrestricted double h );
};
interface mixin CanvasDrawPath {
// path API (see also CanvasPath)
undefined beginPath ();
undefined fill (optional CanvasFillRule fillRule = "nonzero");
undefined fill (Path2D path , optional CanvasFillRule fillRule = "nonzero");
undefined stroke ();
undefined stroke (Path2D path );
undefined clip (optional CanvasFillRule fillRule = "nonzero");
undefined clip (Path2D path , optional CanvasFillRule fillRule = "nonzero");
boolean isPointInPath (unrestricted double x , unrestricted double y , optional CanvasFillRule fillRule = "nonzero");
boolean isPointInPath (Path2D path , unrestricted double x , unrestricted double y , optional CanvasFillRule fillRule = "nonzero");
boolean isPointInStroke (unrestricted double x , unrestricted double y );
boolean isPointInStroke (Path2D path , unrestricted double x , unrestricted double y );
};
interface mixin CanvasUserInterface {
undefined drawFocusIfNeeded (Element element );
undefined drawFocusIfNeeded (Path2D path , Element element );
};
interface mixin CanvasText {
// text (see also the CanvasPathDrawingStyles and CanvasTextDrawingStyles interfaces)
undefined fillText (DOMString text , unrestricted double x , unrestricted double y , optional unrestricted double maxWidth );
undefined strokeText (DOMString text , unrestricted double x , unrestricted double y , optional unrestricted double maxWidth );
TextMetrics measureText (DOMString text );
};
interface mixin CanvasDrawImage {
// drawing images
undefined drawImage (CanvasImageSource image , unrestricted double dx , unrestricted double dy );
undefined drawImage (CanvasImageSource image , unrestricted double dx , unrestricted double dy , unrestricted double dw , unrestricted double dh );
undefined drawImage (CanvasImageSource image , unrestricted double sx , unrestricted double sy , unrestricted double sw , unrestricted double sh , unrestricted double dx , unrestricted double dy , unrestricted double dw , unrestricted double dh );
};
interface mixin CanvasImageData {
// pixel manipulation
ImageData createImageData ([EnforceRange ] long sw , [EnforceRange ] long sh , optional ImageDataSettings settings = {});
ImageData createImageData (ImageData imageData );
ImageData getImageData ([EnforceRange ] long sx , [EnforceRange ] long sy , [EnforceRange ] long sw , [EnforceRange ] long sh , optional ImageDataSettings settings = {});
undefined putImageData (ImageData imageData , [EnforceRange ] long dx , [EnforceRange ] long dy );
undefined putImageData (ImageData imageData , [EnforceRange ] long dx , [EnforceRange ] long dy , [EnforceRange ] long dirtyX , [EnforceRange ] long dirtyY , [EnforceRange ] long dirtyWidth , [EnforceRange ] long dirtyHeight );
};
enum CanvasLineCap { "butt" , "round" , "square" };
enum CanvasLineJoin { "round" , "bevel" , "miter" };
enum CanvasTextAlign { " start " , " end " , " left " , " right " , " center " };
enum CanvasTextBaseline { " top " , " hanging " , " middle " , " alphabetic " , " ideographic " , " bottom " };
enum CanvasDirection { " ltr " , " rtl " , " inherit " };
enum CanvasFontKerning { " auto " , " normal " , " none " };
enum CanvasFontStretch { " ultra-condensed " , " extra-condensed " , " condensed " , " semi-condensed " , " normal " , " semi-expanded " , " expanded " , " extra-expanded " , " ultra-expanded " };
enum CanvasFontVariantCaps { " normal " , " small-caps " , " all-small-caps " , " petite-caps " , " all-petite-caps " , " unicase " , " titling-caps " };
enum CanvasTextRendering { " auto " , " optimizeSpeed " , " optimizeLegibility " , " geometricPrecision " };
interface mixin CanvasPathDrawingStyles {
// line caps/joins
attribute unrestricted double lineWidth ; // (default 1)
attribute CanvasLineCap lineCap ; // (default "butt")
attribute CanvasLineJoin lineJoin ; // (default "miter")
attribute unrestricted double miterLimit ; // (default 10)
// dashed lines
undefined setLineDash (sequence <unrestricted double > segments ); // default empty
sequence <unrestricted double > getLineDash ();
attribute unrestricted double lineDashOffset ;
};
interface mixin CanvasTextDrawingStyles {
// text
attribute DOMString lang ; // (default: "inherit")
attribute DOMString font ; // (default 10px sans-serif)
attribute CanvasTextAlign textAlign ; // (default: "start")
attribute CanvasTextBaseline textBaseline ; // (default: "alphabetic")
attribute CanvasDirection direction ; // (default: "inherit")
attribute DOMString letterSpacing ; // (default: "0px")
attribute CanvasFontKerning fontKerning ; // (default: "auto")
attribute CanvasFontStretch fontStretch ; // (default: "normal")
attribute CanvasFontVariantCaps fontVariantCaps ; // (default: "normal")
attribute CanvasTextRendering textRendering ; // (default: "auto")
attribute DOMString wordSpacing ; // (default: "0px")
};
interface mixin CanvasPath {
// shared path API methods
undefined closePath ();
undefined moveTo (unrestricted double x , unrestricted double y );
undefined lineTo (unrestricted double x , unrestricted double y );
undefined quadraticCurveTo (unrestricted double cpx , unrestricted double cpy , unrestricted double x , unrestricted double y );
undefined bezierCurveTo (unrestricted double cp1x , unrestricted double cp1y , unrestricted double cp2x , unrestricted double cp2y , unrestricted double x , unrestricted double y );
undefined arcTo (unrestricted double x1 , unrestricted double y1 , unrestricted double x2 , unrestricted double y2 , unrestricted double radius );
undefined rect (unrestricted double x , unrestricted double y , unrestricted double w , unrestricted double h );
undefined roundRect (unrestricted double x , unrestricted double y , unrestricted double w , unrestricted double h , optional (unrestricted double or DOMPointInit or sequence <(unrestricted double or DOMPointInit )>) radii = 0);
undefined arc (unrestricted double x , unrestricted double y , unrestricted double radius , unrestricted double startAngle , unrestricted double endAngle , optional boolean counterclockwise = false );
undefined ellipse (unrestricted double x , unrestricted double y , unrestricted double radiusX , unrestricted double radiusY , unrestricted double rotation , unrestricted double startAngle , unrestricted double endAngle , optional boolean counterclockwise = false );
};
[Exposed =(Window ,Worker )]
interface CanvasGradient {
// opaque object
undefined addColorStop (double offset , DOMString color );
};
[Exposed =(Window ,Worker )]
interface CanvasPattern {
// opaque object
undefined setTransform (optional DOMMatrix2DInit transform = {});
};
[Exposed =(Window ,Worker )]
interface TextMetrics {
// x-direction
readonly attribute double width ; // advance width
readonly attribute double actualBoundingBoxLeft ;
readonly attribute double actualBoundingBoxRight ;
// y-direction
readonly attribute double fontBoundingBoxAscent ;
readonly attribute double fontBoundingBoxDescent ;
readonly attribute double actualBoundingBoxAscent ;
readonly attribute double actualBoundingBoxDescent ;
readonly attribute double emHeightAscent ;
readonly attribute double emHeightDescent ;
readonly attribute double hangingBaseline ;
readonly attribute double alphabeticBaseline ;
readonly attribute double ideographicBaseline ;
};
[Exposed =(Window ,Worker )]
interface Path2D {
constructor (optional (Path2D or DOMString ) path );
undefined addPath (Path2D path , optional DOMMatrix2DInit transform = {});
};
Path2D includes CanvasPath ;既存のウェブコンテンツとの互換性を維持するため、ユーザーエージェントはCanvasRenderingContext2Dオブジェクト上で、stroke()メソッドの
直後にCanvasUserInterfaceで
定義されたメソッドを列挙する必要がある。
context = canvas.getContext('2d' [, { [ alpha: true ] [, desynchronized: false ] [, colorSpace: 'srgb'] [, willReadFrequently: false ]} ])
特定のcanvas要素に永続的に結び付けられたCanvasRenderingContext2Dオブジェクトを返す。
alphaメンバーがfalseの場合、
コンテキストは常に不透明になるよう強制される。
desynchronizedメンバーが
trueの場合、コンテキストは非同期化されることがある。
colorSpaceメンバーは、
レンダリングコンテキストの色空間を指定する。
colorTypeメンバーは、
レンダリングコンテキストの色の型を指定する。
willReadFrequentlyメンバーが
trueの場合、コンテキストは読み戻し最適化の対象としてマークされる。
context.canvas
CanvasRenderingContext2D/canvas
現在のすべてのエンジンでサポートされています。
canvas要素を返す。
attributes = context.getContextAttributes()
次の特性を持つオブジェクトを返す:
alphaメンバーはtrue、
それ以外の場合はfalseである。desynchronizedメンバーは
trueである。colorSpaceメンバーは、
コンテキストの色
空間を示す文字列である。colorTypeメンバーは、
コンテキストの色の
型を示す文字列である。willReadFrequentlyメンバーは
trueである。CanvasRenderingContext2Dの2Dレンダリングコンテキストは、
原点(0,0)が左上隅にあり、右へ進むとx値が増加し、下へ進むとy値が増加する、
平坦な線形デカルト平面を表す。右端のx座標は、レンダリングコンテキストの出力ビットマップの幅をCSSピクセルで表した値と等しい。同様に、下端のy座標は、
レンダリングコンテキストの出力ビットマップの高さをCSSピクセルで表した値と等しい。
座標空間のサイズは、ユーザーエージェントが内部またはレンダリング中に使用する実際の ビットマップのサイズを必ずしも表さない。たとえば高精細ディスプレイでは、レンダリング全体を 高品質に保つため、ユーザーエージェントは内部で座標空間の1単位あたり4デバイスピクセルを持つ ビットマップを使用することがある。同様にアンチエイリアシングは、ディスプレイ上の最終画像より 高解像度のビットマップによるオーバーサンプリングを使用して実装できる。
レンダリングコンテキストの出力ビットマップのサイズをCSSピクセルで記述しても、レンダリング時にcanvasが同等の面積をCSSピクセルで占めることを意味しない。CSSピクセルは、テキストレイアウトなどのCSS機能との統合を容易にするため 再利用される。
言い換えると、以下のcanvas要素のレンダリングコンテキストは、200×200の出力ビットマップを持ち
(CSSとの統合を容易にするため、内部ではCSSピクセルを単位として使用する)、100×100CSSピクセルとしてレンダリングされる:
< canvas width = 200 height = 200 style = width:100px;height:100px > target(canvas要素)および
optionsが渡される2Dコンテキスト作成
アルゴリズムは、次の手順を実行することからなる:
settingsを、optionsを辞書型CanvasRenderingContext2DSettingsに変換した結果とする。
(これは例外を投げることがある。)
contextを、新しいCanvasRenderingContext2Dオブジェクトとする。
contextのcanvas属性を、targetを指すように初期化する。
contextの出力ビットマップを、targetのビットマップと同じ ビットマップに設定する(これにより共有される)。
targetのwidthおよびheightコンテンツ属性の数値にビットマップ寸法を設定する。
contextおよびsettingsを与えて、canvas設定の出力 ビットマップ初期化アルゴリズムを実行する。
contextを返す。
ユーザーエージェントがwidthおよびheightにビットマップ寸法を設定するとき、次の手順を実行しなければ ならない:
次の例では、正方形が1つだけ描画されたように見える:
// canvas is a reference to a <canvas> element
var context = canvas. getContext( '2d' );
context. fillRect( 0 , 0 , 50 , 50 );
canvas. setAttribute( 'width' , '300' ); // clears the canvas
context. fillRect( 0 , 100 , 50 , 50 );
canvas. width = canvas. width; // clears the canvas
context. fillRect( 100 , 0 , 50 , 50 ); // only this square remains canvas属性は、オブジェクトの作成時に初期化された値を
返さなければならない。
CanvasColorType列挙型は、
canvasのバッキングストアの色の型を指定するために使用される。
「unorm8」値は、すべての色成分の型が8ビット符号なし
正規化型であることを示す。
「float16」値は、すべての色成分の型が16ビット
浮動小数点型であることを示す。
CanvasFillRule列挙型は、
点がパスの内側か外側かを判定する塗りつぶし規則アルゴリズムを選択するために
使用される。
「nonzero」値は、非ゼロ巻き数規則を示す。この規則では、
ある点から引いた半無限直線が一方向に図形のパスを横切る回数と、反対方向にパスを横切る回数が
等しい場合、その点は図形の外側にあると見なされる。
「evenodd」値は、偶奇規則を示す。この規則では、
ある点から引いた半無限直線が図形のパスを横切る回数が偶数である場合、その点は図形の外側に
あると見なされる。
点が図形の外側にない場合、その点は図形の内側にある。
ImageSmoothingQuality列挙型は、画像を平滑化するときに使用する
補間品質の優先度を表すために使用される。
「low」値は、低水準の画像補間品質を優先することを示す。
低品質の画像補間は、より高い設定よりも計算効率がよいことがある。
「medium」値は、中程度の画像補間品質を優先することを
示す。
「high」値は、高水準の画像補間品質を優先することを示す。
高品質の画像補間は、より低い設定よりも計算コストが高いことがある。
バイリニアスケーリングは、比較的高速で低品質な画像平滑化アルゴリズムの一例である。 バイキュービックまたはLanczosスケーリングは、より高品質な出力を生成する画像平滑化アルゴリズムの 例である。この仕様は、特定の補間アルゴリズムの使用を義務付けない。
この節は非規範的である。
出力ビットマップが
ユーザーエージェントによって直接表示されない場合、実装はこのビットマップを更新する代わりに、
ビットマップの実際のデータが必要になるまで(たとえばdrawImage()の呼び出し、またはcreateImageBitmap()ファクトリメソッドによって必要になるまで)、
適用された描画操作のシーケンスだけを記憶できる。多くの場合、これはメモリー効率がよりよい。
canvas要素のビットマップは、実際にはほぼ常に必要となる唯一の
ビットマップである。レンダリングコンテキストが出力ビットマップを持つ場合、それは常にcanvas要素のビットマップへの単なる別名である。
追加のビットマップが必要になることもある。たとえば、canvasがその自然サイズとは 異なるサイズで描画されているときに高速な描画を可能にする場合や、canvas描画コマンドの実行中に ページスクロールなどのグラフィックス更新を並行して処理できるよう、ダブルバッファリングを 有効にする場合である。
CanvasSettingsオブジェクトは、オブジェクトの作成時に初期化される
出力ビットマップを持つ。
出力ビットマップは、 trueまたはfalseに設定できるオリジンクリーンフラグを持つ。 初期状態では、これらのビットマップのいずれかが作成されたとき、そのオリジンクリーンフラグはtrueに 設定されなければならない。
CanvasSettingsオブジェクトは、alpha真偽値も持つ。CanvasSettingsオブジェクトのalphaがfalseの場合、
すべてのピクセルについてアルファ成分は1.0(完全に不透明)に固定されなければならず、いずれかの
ピクセルのアルファ成分を変更しようとする試みは暗黙に無視されなければならない。
したがって、このようなコンテキストのビットマップは透明な黒ではなく不透明な黒で開始する。clearRect()は常に不透明な黒のピクセルを生成し、getImageData()から得られる4バイトごとの値は常に255であり、
putImageData()メソッドは入力の4バイトごとの値を
実質的に無視する、などである。ただし、canvas上に描画されるスタイルおよび画像のアルファ成分は、
出力ビットマップのアルファ成分に
影響を与える時点までは引き続き尊重される。たとえば、alphaがfalseに設定された新たに作成された出力ビットマップに50%透明な白い正方形を
描画すると、完全に不透明な灰色の正方形になる。
CanvasSettingsオブジェクトは、desynchronized真偽値も持つ。CanvasSettingsオブジェクトのdesynchronizedがtrueの場合、
ユーザーエージェントは、canvasの描画サイクルをイベントループから非同期化する、通常の
ユーザーエージェントのレンダリングアルゴリズムを迂回する、またはその両方によって、入力イベントから
ラスタライズまでで測定される遅延を低減するようcanvasのレンダリングを最適化してもよい。
このモードが通常の描画機構、ラスタライズ、またはその両方の迂回を伴う限り、目に見える
ティアリングアーティファクトを生じさせることがある。
ユーザーエージェントは通常、表示されていないバッファーにレンダリングし、 それを表示のために走査されているバッファーと迅速に交換する。前者のバッファーをバックバッファー、 後者をフロントバッファーと呼ぶ。遅延を低減する一般的な手法はフロントバッファー レンダリングと呼ばれ、シングルバッファーレンダリングとも呼ばれる。この手法では、 走査処理と並行して競合的にレンダリングが行われる。この手法は、ティアリングアーティファクトを 生じさせる可能性と引き換えに遅延を低減し、desynchronized真偽値の全部または一部を 実装するために使用できる。 [MULTIPLEBUFFERING]
desynchronized真偽値は、 入力からラスタライズまでの遅延が重要となる描画アプリケーションなど、特定の種類の アプリケーションを実装するときに有用となることがある。
CanvasSettingsオブジェクトは、頻繁に読み取る真偽値も持つ。CanvasSettingsオブジェクトの頻繁に読み取るがtrueの場合、
ユーザーエージェントは読み戻し操作向けにcanvasを最適化してもよい。
ほとんどのデバイスでは、ユーザーエージェントはcanvasの出力ビットマップをGPU
(「ハードウェアアクセラレーション」とも呼ばれる)に保存するか、CPU
(「ソフトウェア」とも呼ばれる)に保存するかを決定する必要がある。ほとんどのレンダリング操作は、
アクセラレーションされたcanvasの方が高性能であるが、主な例外はgetImageData()、toDataURL()、またはtoBlob()による読み戻しである。頻繁に読み取るがtrueに等しいCanvasSettingsオブジェクトは、ウェブページが多数の読み戻し操作を
行う可能性が高く、ソフトウェアcanvasを使用することが有利であることをユーザーエージェントに
伝える。
CanvasSettingsオブジェクトは、PredefinedColorSpace型の色空間設定も持つ。CanvasSettingsオブジェクトの色空間は、出力ビットマップの色空間を示す。
CanvasSettingsオブジェクトは、CanvasColorType型の色の型設定も持つ。CanvasSettingsオブジェクトの色の型は、出力ビットマップのピクセルの色成分および
アルファ成分のデータ型を示す。
CanvasSettingsであるcontextおよびCanvasRenderingContext2DSettingsである
settingsが与えられたとき、CanvasSettingsの
出力ビットマップを初期化するには:
contextのalphaを、
settings["alpha"]に設定する。
contextのdesynchronizedを、
settings["desynchronized"]に設定する。
contextの色空間を、
settings["colorSpace"]に設定する。
contextの色の型を、
settings["colorType"]に設定する。
contextの頻繁に
読み取るを、settings["willReadFrequently"]に設定する。
getContextAttributes()メソッドの手順は、
«[「alpha」
→
thisのalpha、「desynchronized」
→
thisのdesynchronized、「colorSpace」
→ thisの色空間、
「colorType」
→ thisの色の型、「willReadFrequently」
→
thisの頻繁に
読み取る
]»を返すことである。
CanvasStateインターフェイスを実装するオブジェクトは、描画状態のスタックを
維持する。描画状態は、次のものからなる:
現在の変換 行列。
現在のクリッピング領域。
現在の文字 間隔、単語間隔、 塗りつぶしスタイル、ストロークスタイル、フィルター、グローバルアルファ、合成およびブレンド演算子、および影の色。
次の属性の現在値: lineWidth、lineCap、lineJoin、miterLimit、
lineDashOffset、
shadowOffsetX、
shadowOffsetY、
shadowBlur、
lang、font、textAlign、textBaseline、
direction、
fontKerning、
fontStretch、
fontVariantCaps、
textRendering、
imageSmoothingEnabled、
imageSmoothingQuality。
現在の破線リスト。
レンダリングコンテキストのビットマップは、レンダリングコンテキストがcanvas要素に結び付けられているかどうか、およびどのように
結び付けられているかに依存するため、描画状態の一部ではない。
CanvasStateミックスインを実装するオブジェクトは、オブジェクトの作成時に
falseへ初期化されるコンテキスト消失真偽値を持つ。
コンテキスト消失値は、コンテキスト消失手順で更新される。
context.save()
現在のすべてのエンジンでサポートされています。
現在の状態をスタックにプッシュする。
context.restore()
CanvasRenderingContext2D/restore
現在のすべてのエンジンでサポートされています。
スタックの先頭状態をポップし、コンテキストをその状態に復元する。
context.reset()バッキングバッファー、描画状態スタック、パス、およびスタイルを含むレンダリングコンテキストを リセットする。
context.isContextLost()
レンダリングコンテキストが失われた場合はtrueを返す。コンテキスト消失は、ドライバーの クラッシュ、メモリー不足などによって発生することがある。この場合、canvasはバッキング ストレージを失い、レンダリングコンテキストを デフォルト状態にリセットするための手順を実行する。
save()メソッドの手順は、現在の描画状態のコピーを描画状態
スタックにプッシュすることである。
restore()メソッドの手順は、描画状態スタックの先頭項目を
ポップし、それが記述する描画状態を復元することである。保存された状態がない場合、メソッドは
何もしてはならない。
CanvasRenderingContext2D/reset
OffscreenCanvasRenderingContext2D#canvasrenderingcontext2d.reset
reset()メソッドの手順は、レンダリングコンテキストを
デフォルト状態にリセットすることである。
レンダリングコンテキストをデフォルト 状態にリセットするには:
canvasのビットマップを透明な黒で消去する。
コンテキストの現在のデフォルトパスにあるサブパスのリストを空にする。
コンテキストの描画状態スタックを消去する。
描画状態を構成するすべてのものを 初期値にリセットする。
CanvasRenderingContext2D/isContextLost
1つのエンジンでのみサポートされています。
context.lineWidth [ = value ]
CanvasRenderingContext2D/lineWidth
現行のすべてのエンジンでサポートされています。
styles.lineWidth [ = value ]
現在の線幅を返します。
線幅を変更するために設定できます。0 より大きい有限値でない値は 無視されます。
context.lineCap [ = value ]
CanvasRenderingContext2D/lineCap
現行のすべてのエンジンでサポートされています。
styles.lineCap [ = value ]
現在の線端スタイルを返します。
線端スタイルを変更するために設定できます。
指定可能な線端スタイルは、"butt"、"round"、および "square" です。その他の
値は無視されます。
context.lineJoin [ = value ]
CanvasRenderingContext2D/lineJoin
現行のすべてのエンジンでサポートされています。
styles.lineJoin [ = value ]
現在の線接合スタイルを返します。
線接合スタイルを変更するために設定できます。
指定可能な線接合スタイルは、"bevel"、"round"、および "miter" です。その他の
値は無視されます。
context.miterLimit [ = value ]
CanvasRenderingContext2D/miterLimit
現行のすべてのエンジンでサポートされています。
styles.miterLimit [ = value ]
現在のマイター限界比を返します。
マイター限界比を変更するために設定できます。0 より大きい有限値でない値は 無視されます。
context.setLineDash(segments)
CanvasRenderingContext2D/setLineDash
現行のすべてのエンジンでサポートされています。
styles.setLineDash(segments)
現在の線の破線パターン(ストローク時に使用されるもの)を設定します。引数は、 線をオンにする距離とオフにする距離を交互に示すリストです。
segments = context.getLineDash()
CanvasRenderingContext2D/getLineDash
現行のすべてのエンジンでサポートされています。
segments = styles.getLineDash()
現在の線の破線パターンのコピーを返します。返される配列の要素数は常に偶数になります (すなわち、パターンは正規化されます)。
context.lineDashOffset
CanvasRenderingContext2D/lineDashOffset
現行のすべてのエンジンでサポートされています。
styles.lineDashOffset
位相オフセット(線の破線パターンと同じ単位)を返します。
位相オフセットを変更するために設定できます。有限値でない値は無視されます。
CanvasPathDrawingStyles
インターフェイスを実装するオブジェクトには、オブジェクトが線をどのように扱うかを制御する
属性およびメソッド(この節で定義されます)があります。
lineWidth 属性は、座標空間単位で線の幅を示します。
取得時には、現在値を返さなければなりません。設定時には、ゼロ、負、無限大、および
NaN の値を無視し、値を変更しないままにしなければなりません。それ以外の値の場合は、
現在値を新しい値に変更しなければなりません。
CanvasPathDrawingStyles
インターフェイスを実装するオブジェクトが作成されたとき、
lineWidth 属性の
初期値は
1.0 でなければなりません。
lineCap 属性は、UA が線の端に配置する
終端の種類を定義します。有効な3つの値は、"butt"、
"round"、および "square" です。
取得時には、現在値を返さなければなりません。設定時には、現在値を 新しい値に変更しなければなりません。
CanvasPathDrawingStyles
インターフェイスを実装するオブジェクトが作成されたとき、
lineCap 属性の
初期値は
"butt" でなければなりません。
lineJoin 属性は、2本の線が交わる箇所に
UA が配置する角の種類を定義します。有効な3つの値は、"bevel"、
"round"、および "miter" です。
取得時には、現在値を返さなければなりません。設定時には、現在値を 新しい値に変更しなければなりません。
CanvasPathDrawingStyles
インターフェイスを実装するオブジェクトが作成されたとき、
lineJoin 属性の
初期値は
"miter" でなければなりません。
lineJoin
属性の値が "miter" の場合、ストロークは接合部のレンダリング方法を決定するためにマイター限界比を使用します。
マイター限界比は、miterLimit
属性を使用して明示的に設定できます。取得時には、現在値を返さなければなりません。設定時には、ゼロ、負、無限大、および
NaN の値を無視し、値を変更しないままにしなければなりません。それ以外の値の場合は、
現在値を新しい値に変更しなければなりません。
CanvasPathDrawingStyles
インターフェイスを実装するオブジェクトが作成されたとき、
miterLimit
属性の初期値は
10.0 でなければなりません。
各 CanvasPathDrawingStyles
オブジェクトには、空であるか、偶数個の非負数からなる 破線リスト があります。
初期状態では、破線リストは
空でなければなりません。
setLineDash(segments) メソッドが呼び出されたときは、
次の手順を実行しなければなりません。
segments 内のいずれかの値が有限でない(たとえば Infinity または NaN 値である)場合、または いずれかの値が負(ゼロ未満)である場合は、戻ります(例外はスローしません。ただし、 デバッグに役立つため、ユーザーエージェントは開発者コンソールにメッセージを表示しても 構いません)。
segments の要素数が奇数の場合は、segments を segments の2つのコピーを連結したものとします。
オブジェクトの 破線リストを segments に設定します。
getLineDash() メソッドが呼び出されたときは、オブジェクトの
破線
リストの値を同じ
順序で含むシーケンスを返さなければなりません。
「行進するアリ」の効果を実現する場合など、破線パターンの「位相」を変更すると便利なことがあります。
位相は、lineDashOffset 属性を使用して設定できます。
取得時には、
現在値を返さなければなりません。設定時には、無限大および NaN の値を無視し、値を
変更しないままにしなければなりません。それ以外の値の場合は、現在値を新しい値に変更しなければなりません。
CanvasPathDrawingStyles
インターフェイスを実装するオブジェクトが作成されたとき、
lineDashOffset
属性の初期値は
0.0 でなければなりません。
ユーザーエージェントが、CanvasPathDrawingStyles
インターフェイスを実装するオブジェクト style を指定して、
パスをトレースするときは、次の
アルゴリズムを実行しなければなりません。このアルゴリズムは新しい パスを返します。
path を、トレースされるパスのコピーとします。
path から、長さがゼロのすべての 線分を 除去します。
path から、線を含まないサブパス(すなわち、 点が1つだけのサブパス)をすべて削除します。
path の各サブパスにある、各サブパスの最初の点と 最後の点以外の各点を、その点へ向かう線とその点から出る線を接続する 接合部に置き換えます。これにより、すべてのサブパスが、2つの点(線が出る 始点と、線が入る終点)、1本以上の線(点と接合部を接続するもの)、および 0個以上の接合部(それぞれが1本の線を別の線に接続するもの)からなり、 各サブパスが、各線の間に接合部があり、両端に点がある1本以上の線の連続となるように 接続されるようにします。
path 内の各閉じたサブパスに、そのサブパスの最後の点と 最初の点を接続する直線の閉じ線を追加します。最後の点を接合部(以前の 最後の線から新たに追加された閉じ線への接合部)に変更し、最初の点を接合部(新たに 追加された閉じ線から最初の線への接合部)に変更します。
style の 破線リストが空の場合は、 変換とラベル付けされた 手順へ移動します。
pattern width を、style の 破線リストのすべての項目を座標空間単位で連結したものとします。
path 内の各サブパス subpath について、 次の副手順を実行します。これらの副手順は、path 内のサブパスをその場で 変更します。
subpath width を、subpath のすべての線の長さを座標空間 単位で表したものとします。
offset を、style の lineDashOffset
の値を座標空間
単位で表したものとします。
offset が pattern width より大きい間、 pattern width だけ減少させます。
offset がゼロ未満である間、pattern width だけ増加させます。
L を、subpath 内のすべての線に沿って定義される 線形座標線として定義します。このとき、サブパス内の最初の線の始点を 座標 0 として定義し、サブパス内の最後の線の終点を座標 subpath width として定義します。
position を 0 から offset を引いた値とします。
index を 0 とします。
current state を off とします(その他の状態は on および zero-on です)。
破線オン: segment length を、 style の 破線 リストの index 番目の項目の値とします。
position を segment length だけ増加させます。
position が subpath width より大きい場合、 このサブパスに対するこれらの副手順を終了し、次のサブパスについて再び開始します。 サブパスがもうない場合は、代わりに 変換とラベル付けされた手順へ移動します。
segment length がゼロでない場合は、current state を on とします。
index を1増加させます。
破線オフ: segment length を、style の 破線 リストの index 番目の項目の値とします。
start を、L 上のオフセット position とします。
position を segment length だけ増加させます。
position がゼロ未満の場合は、 切断後とラベル付けされた手順へ移動します。
start がゼロ未満の場合は、start を ゼロとします。
position が subpath width より大きい場合は、 end を L 上のオフセット subpath width とします。それ以外の場合は、 end を L 上のオフセット position とします。
最初に該当する手順へ移動します。
何もせず、次の手順へ進みます。
end が位置する線を end で切り詰め、そこに点を配置して、 その点が含まれていたサブパスを2つに分割します。 start と end の間にあるすべての線分、接合部、点、およびサブパスを 削除します。最後に、start に、接続する線のない単一の点を配置します。
この点には、線端を描画するための方向性があります(下記参照)。 その方向性は、その点における元の線の方向(すなわち、上記で L が 定義された時点の方向)です。
start が位置する線を start で2つに切断してそこに点を配置し、 その点が含まれていたサブパスを2つに分割します。また同様に、 end が位置する線を end で切り詰めてそこに点を配置し、 その点が含まれていたサブパスを2つに分割します。その後、 start と end の間にあるすべての線分、接合部、点、およびサブパスを 削除します。
start と end が同じ点である場合、この処理では、 線が2つに切断され、そこに2つの点が挿入されるだけで、何も 削除されません。ただし、その点に接合部も存在する場合、その接合部は 削除されなければなりません。
切断後: position が subpath width より大きい場合は、 変換とラベル付けされた手順へ移動します。
index を1増加させます。それが style の 破線リストの項目数と等しい場合は、 index を 0 とします。
破線オンとラベル付けされた手順へ戻ります。
変換: これは、パスをそのストロークを表す新しいパスへ 変換する手順です。
style の
lineWidth
と等しい長さの直線を、
掃引されるパスに対して直交する角度に保ちながら、path 内の各サブパスに沿って
掃引した場合に覆われる領域の縁を記述する、新しい
パスを作成します。
各点は、前述され、下記で詳述されるように、style の lineCap 属性を
満たすために必要な線端に置き換え、各接合部は、下記で定義される
style の lineJoin
型を満たすために必要な接合部に置き換えます。
線端: 各点には、そこから出る線の方向に垂直な平坦な縁があります。
これは、style の lineCap の値に従って拡張されます。
"butt" の値は、追加の線端が加えられないことを意味します。"round" の値は、
直径が style の lineWidth の幅と等しい
半円を、
各点から出る線に追加で配置しなければならないことを意味します。"square" の値は、
長さが style の lineWidth の幅で、
幅が style の lineWidth
の幅の半分である長方形を、
点から出る線の方向に垂直な縁に平らに接するように配置して、各
点に追加しなければならないことを意味します。
そこから出る線がない点には、その点の方向性(上記で定義)に沿った、 無限小の短い直線で互いに接続された2つの点であるかのように、2つの線端を背中合わせに 配置しなければなりません。
接合部: 接合が発生する点に加えて、各接合部には、線ごとに1つずつ、 さらに2つの点が関係します。これは、接合点から線幅の半分だけ離れた位置にある2つの角であり、 それぞれが各線に垂直で、もう一方の線から最も遠い側にあります。
これら2つの反対側の角を直線で接続し、三角形の3つ目の点を接合点とする三角形を、
すべての接合部に追加しなければなりません。lineJoin 属性は、
それ以外のものがレンダリングされるかどうかを
制御します。前述の3つの値には、次の意味があります。
"bevel" の値は、接合部でレンダリングされるものが
これですべてであることを意味します。
"round" の値は、前述の接合部の2つの角を接続し、
前述の三角形に隣接する(重ならない)、直径が線幅と等しく、
原点が接合点にある円弧を、接合部に追加しなければならないことを意味します。
"miter" の値は、マイター長が許す場合、接合部に
2つ目の三角形を追加しなければならないことを意味します。その一辺は前述の2つの角の間の線であり、
最初の三角形に隣接します。その他の2辺は、接合する2本の線の外側の縁を延長したものであり、
マイター長を超えることなく交差するために必要な長さだけ延長されます。
マイター長は、接合が発生する点から、接合部の外側にある線の縁が交差する点までの距離です。
マイター限界比は、マイター長と線幅の半分との比に許可される最大値です。
マイター長によって、style の miterLimit
属性で設定されたマイター限界比を超えることになる場合、この2つ目の
三角形を追加してはなりません。
新たに作成されたパス内のサブパスは、任意の点について、その点から引いた半無限の直線が サブパスを横切る回数が偶数であることと、その同じ点から引いた半無限の直線が 一方向に進むサブパスを横切る回数と、反対方向に進むサブパスを横切る回数が 等しいこととが同値になるように、向きを設定しなければなりません。
新たに作成されたパスを返します。
context.lang [ = value ]
styles.lang [ = value ]
現在の言語設定を返します。
フォントを解決するときに使用する言語を変更するため、BCP 47 言語タグ、空文字列、または "inherit" に
設定できます。"inherit"
は、canvas 要素の
言語を取得し、canvas 要素がない場合は、
関連付けられた 文書
要素の言語を取得します。
既定値は "inherit" です。
context.font [ = value ]
現行のすべてのエンジンでサポートされています。
styles.font [ = value ]
現在のフォント設定を返します。
フォントを変更するために設定できます。構文は CSS の 'font' プロパティと同じです。CSS フォント値として構文解析できない値は無視されます。既定値は "10px sans-serif" です。
相対キーワードおよび長さは、canvas
要素のフォントを基準として計算されます。
context.textAlign [ = value ]
CanvasRenderingContext2D/textAlign
現行のすべてのエンジンでサポートされています。
styles.textAlign [ = value ]
現在のテキスト配置設定を返します。
配置を変更するために設定できます。指定可能な値とその意味を
以下に示します。その他の値は無視されます。既定値は "start" です。
context.textBaseline [ = value ]
CanvasRenderingContext2D/textBaseline
現行のすべてのエンジンでサポートされています。
styles.textBaseline [ = value ]
現在のベースライン配置設定を返します。
ベースライン配置を変更するために設定できます。指定可能な値とその意味を
以下に示します。その他の値は無視されます。既定値は "alphabetic"
です。
context.direction [ = value ]
CanvasRenderingContext2D/direction
現行のすべてのエンジンでサポートされています。
styles.direction [ = value ]
現在の方向性を返します。
方向性を変更するために設定できます。指定可能な値とその意味を
以下に示します。その他の値は無視されます。既定値は "inherit"
です。
context.letterSpacing [ = value ]
styles.letterSpacing [ = value ]
テキスト内の現在の文字間隔を返します。
文字間隔を変更するために設定できます。CSS
<length> として構文解析できない値は無視されます。既定値は "0px" です。
context.fontKerning [ = value ]
styles.fontKerning [ = value ]
現在のフォントカーニング設定を返します。
フォントカーニングを変更するために設定できます。指定可能な値とその意味を
以下に示します。その他の値は無視されます。既定値は "auto"
です。
context.fontStretch [ = value ]
styles.fontStretch [ = value ]
現在のフォント伸縮設定を返します。
フォントの伸縮を変更するために設定できます。指定可能な値とその意味を
以下に示します。その他の値は無視されます。既定値は "normal"
です。
context.fontVariantCaps [ = value ]
styles.fontVariantCaps [ = value ]
現在のフォント異体字キャップ設定を返します。
フォント異体字キャップを変更するために設定できます。指定可能な値とその意味を
以下に示します。その他の値は無視されます。既定値は "normal"
です。
context.textRendering [ = value ]
styles.textRendering [ = value ]
現在のテキストレンダリング設定を返します。
テキストレンダリングを変更するために設定できます。指定可能な値とその意味を
以下に示します。その他の値は無視されます。既定値は "auto"
です。
context.wordSpacing [ = value ]
styles.wordSpacing [ = value ]
テキスト内の現在の単語間隔を返します。
単語間隔を変更するために設定できます。CSS
<length> として構文解析できない値は無視されます。既定値は "0px" です。
CanvasTextDrawingStyles
インターフェイスを実装するオブジェクトには、オブジェクトによってテキストをどのようにレイアウト
(ラスタライズまたはアウトライン化)するかを制御する属性
(この節で定義されます)があります。このようなオブジェクトは、
フォントスタイルソースオブジェクトを持つこともできます。
CanvasRenderingContext2D
オブジェクトの場合、これはコンテキストの canvas
属性の値によって指定される
canvas
要素です。OffscreenCanvasRenderingContext2D
オブジェクトの場合、これは関連付けられた
OffscreenCanvas オブジェクトです。
フォントスタイル
ソースオブジェクトのフォント解決には、フォント
ソースが必要です。これは、CanvasTextDrawingStyles
を実装する特定の object について、次の手順で決定されます。[CSSFONTLOAD]
object の フォント
スタイルソースオブジェクトが canvas
要素である場合、その要素の ノード文書を返します。
それ以外の場合、object の フォントスタイルソースオブジェクトは
OffscreenCanvas オブジェクトです。
global を object の 関連するグローバル オブジェクトとします。
global が Window オブジェクトである場合は、
global の
関連付けられた
Document を返します。
表明:
global は
WorkerGlobalScope
を実装しています。
global を返します。
これは、ID が c1 である通常の canvas 要素を使用した
フォント解決の例です。
const font = new FontFace( "MyCanvasFont" , "url(mycanvasfont.ttf)" );
documents. fonts. add( font);
const context = document. getElementById( "c1" ). getContext( "2d" );
document. fonts. ready. then( function () {
context. font = "64px MyCanvasFont" ;
context. fillText( "hello" , 0 , 0 );
}); この例では、キャンバスは mycanvasfont.ttf を
フォントとして使用してテキストを表示します。
これは、OffscreenCanvas を使用して
フォント解決を行う方法の例です。ID が c2 であり、
次のようにワーカーへ転送される canvas
要素があるものとします。
const offscreenCanvas = document. getElementById( "c2" ). transferControlToOffscreen();
worker. postMessage( offscreenCanvas, [ offscreenCanvas]); 次に、ワーカー内で次のようにします。
self. onmessage = function ( ev) {
const transferredCanvas = ev. data;
const context = transferredCanvas. getContext( "2d" );
const font = new FontFace( "MyFont" , "url(myfont.ttf)" );
self. fonts. add( font);
self. fonts. ready. then( function () {
context. font = "64px MyFont" ;
context. fillText( "hello" , 0 , 0 );
});
}; この例では、キャンバスは myfont.ttf を使用してテキストを表示します。
フォントはワーカー内でのみ読み込まれ、文書コンテキスト内では読み込まれないことに注意してください。
font IDL 属性は、設定時に、CSS <'font'> 値として構文解析されなければなりません
(ただし、'inherit' のようなプロパティ非依存のスタイルシート構文はサポートしません)。その結果のフォントは、
'line-height'
成分を 'normal' に強制し、
'font-size' 成分を CSS ピクセルへ変換し、
システムフォントを明示的な値に計算したうえで、コンテキストに割り当てなければなりません。
新しい値が構文的に不正である場合('inherit' や 'initial' のようなプロパティ非依存の
スタイルシート構文を使用する場合を含む)は、新しいフォント値を割り当てずに、
その値を無視しなければなりません。[CSS]
フォントを使用するとき、フォントファミリー名は フォントスタイルソース
オブジェクトのコンテキストで解釈しなければなりません。したがって、@font-face を使用して
埋め込まれたフォント、または フォントスタイルソースオブジェクトから見える FontFace オブジェクトを使用して読み込まれたフォントは、
読み込みが完了した時点で利用可能にならなければなりません。(各 フォントスタイルソース
オブジェクトには、利用可能なフォントを決定する フォントソースがあります。)フォントが完全に読み込まれる前に
使用された場合、またはフォントを使用する時点で フォントスタイルソースオブジェクトの
スコープ内にそのフォントがない場合、そのフォントは未知のフォントであるかのように扱い、
関連する CSS 仕様に記述されているように別のフォントへフォールバックしなければなりません。
[CSSFONTS] [CSSFONTLOAD]
取得時に、font
属性は、コンテキストの現在のフォントの
シリアル化された形式を
返さなければなりません('line-height' 成分は含みません)。[CSSOM]
たとえば、次の文の後では、
context. font = 'italic 400 12px/2 Unknown Font, sans-serif' ; 式 context.font は、文字列
"italic 12px "Unknown Font", sans-serif" と評価されます。
"400" の font-weight は既定値であるため表示されません。line-height は
既定値である "normal" に強制されるため表示されません。
CanvasTextDrawingStyles
インターフェイスを実装するオブジェクトが作成されたとき、コンテキストの
フォントは 10px sans-serif に設定されなければなりません。'font-size' 成分が、
パーセント、'em' または 'ex'
単位を使用する長さ、あるいは 'larger' または
'smaller' キーワードに設定された場合、属性の設定時にフォントスタイルソースオブジェクトが要素であれば、
フォントスタイルソースオブジェクトの
'font-size' プロパティの 算出値を
基準として解釈しなければなりません。'font-weight'
成分が相対値
'bolder' または 'lighter' に設定された場合、属性の設定時にフォントスタイルソースオブジェクトが
要素であれば、フォントスタイル
ソースオブジェクトの 'font-weight'
プロパティの 算出値を基準として解釈しなければなりません。特定の状況で
算出値が未定義である場合(たとえば、
フォントスタイルソースオブジェクトが
要素でないか、レンダリング
されていない場合)、相対キーワードは、標準ウェイトの
10px sans-serif という既定値を基準として解釈しなければなりません。
textAlign IDL 属性は、取得時には
現在値を返さなければなりません。設定時には、現在値を新しい値に変更しなければなりません。
CanvasTextDrawingStyles
インターフェイスを実装するオブジェクトが作成されたとき、textAlign 属性の
初期値は start
でなければなりません。
textBaseline IDL 属性は、取得時には
現在値を返さなければなりません。設定時には、現在値を新しい値に変更しなければなりません。
CanvasTextDrawingStyles
インターフェイスを実装するオブジェクトが作成されたとき、textBaseline
属性の初期値は
alphabetic
でなければなりません。
CanvasTextDrawingStyles
インターフェイスを実装するオブジェクトには、フォントレンダリングのローカライズに使用される、
関連付けられた 言語値があります。
有効な値は、BCP 47 言語タグ、空文字列、または "inherit" です。"inherit" の場合、言語は
canvas 要素の言語から取得され、
canvas 要素がない場合は、
関連付けられた 文書要素から取得されます。
初期状態では、言語は "inherit"
でなければなりません。
direction IDL 属性は、取得時には
現在値を返さなければなりません。設定時には、現在値を新しい値に変更しなければなりません。
CanvasTextDrawingStyles
インターフェイスを実装するオブジェクトが作成されたとき、direction 属性の
初期値は "inherit"
でなければなりません。
CanvasTextDrawingStyles
インターフェイスを実装するオブジェクトには、文字間および単語間の間隔を
制御する属性があります。このようなオブジェクトには、CSS
<length> 値である、関連付けられた
文字間隔および
単語間隔の値があります。
初期状態では、どちらも "0px" を CSS
<length> として 構文解析した結果でなければなりません。
CanvasRenderingContext2D/letterSpacing
1つのエンジンでのみサポートされています。
letterSpacing の取得子手順は、
this の 文字間隔の
シリアル化された形式を返すことです。
letterSpacing
の設定子手順は次のとおりです。
CanvasRenderingContext2D/wordSpacing
1つのエンジンでのみサポートされています。
wordSpacing の取得子手順は、
this の
単語間隔の
シリアル化された形式を返すことです。
wordSpacing
の設定子手順は次のとおりです。
CanvasRenderingContext2D/fontKerning
fontKerning IDL 属性は、
取得時には現在値を返さなければなりません。設定時には、現在値を新しい
値に変更しなければなりません。CanvasTextDrawingStyles
インターフェイスを実装するオブジェクトが作成されたとき、
fontKerning
属性の初期値は "auto"
でなければなりません。
CanvasRenderingContext2D/fontStretch
1つのエンジンでのみサポートされています。
fontStretch IDL 属性は、
取得時には現在値を返さなければなりません。設定時には、現在値を新しい
値に変更しなければなりません。CanvasTextDrawingStyles
インターフェイスを実装するオブジェクトが作成されたとき、
fontStretch
属性の初期値は "normal"
でなければなりません。
CanvasRenderingContext2D/fontVariantCaps
1つのエンジンでのみサポートされています。
fontVariantCaps IDL 属性は、
取得時には現在値を返さなければなりません。設定時には、現在値を新しい
値に変更しなければなりません。CanvasTextDrawingStyles
インターフェイスを実装するオブジェクトが作成されたとき、
fontVariantCaps
属性の初期値は "normal"
でなければなりません。
CanvasRenderingContext2D/textRendering
1つのエンジンでのみサポートされています。
textRendering IDL 属性は、
取得時には現在値を返さなければなりません。設定時には、現在値を新しい
値に変更しなければなりません。CanvasTextDrawingStyles
インターフェイスを実装するオブジェクトが作成されたとき、
textRendering
属性の初期値は "auto"
でなければなりません。
textAlign
属性で許可されるキーワードは、
次のとおりです。
start
テキストの始端側(左から右へのテキストでは左側、右から左への テキストでは右側)に揃えます。
end
テキストの終端側(左から右へのテキストでは右側、右から左への テキストでは左側)に揃えます。
left
左に揃えます。
right
右に揃えます。
center
中央に揃えます。
textBaseline
属性で許可されるキーワードは、フォント内の
配置点に対応します。

キーワードは、これらの配置点に次のように対応します。
top
hanging
middle
alphabetic
ideographic
bottom
direction
属性で許可されるキーワードは、
次のとおりです。
ltr
テキスト 準備アルゴリズムへの入力を、左から右へのテキストとして扱います。
rtl
テキスト 準備アルゴリズムへの入力を、右から左へのテキストとして扱います。
inherit
テキスト
準備アルゴリズム内の処理を使用して、canvas
要素、プレースホルダーの
canvas 要素、または
文書要素からテキスト方向を取得します。
fontKerning
属性で許可されるキーワードは、
次のとおりです。
auto
ユーザーエージェントの裁量でカーニングが適用されます。
normal
カーニングが適用されます。
none
カーニングは適用されません。
fontStretch
属性で許可されるキーワードは、
次のとおりです。
ultra-condensed
CSS の 'font-stretch' の 'ultra-condensed' 設定と同じです。
extra-condensed
CSS の 'font-stretch' の 'extra-condensed' 設定と同じです。
condensed
CSS の 'font-stretch' の 'condensed' 設定と同じです。
semi-condensed
CSS の 'font-stretch' の 'semi-condensed' 設定と同じです。
normal
グリフの幅が 100% である既定の設定です。
semi-expanded
CSS の 'font-stretch' の 'semi-expanded' 設定と同じです。
expanded
CSS の 'font-stretch' の 'expanded' 設定と同じです。
extra-expanded
CSS の 'font-stretch' の 'extra-expanded' 設定と同じです。
ultra-expanded
CSS の 'font-stretch' の 'ultra-expanded' 設定と同じです。
fontVariantCaps
属性で許可される
キーワードは次のとおりです。
normal
以下に示す機能はいずれも有効になりません。
small-caps
CSS の 'font-variant-caps' の 'small-caps' 設定と同じです。
all-small-caps
CSS の 'font-variant-caps' の 'all-small-caps' 設定と同じです。
petite-caps
CSS の 'font-variant-caps' の 'petite-caps' 設定と同じです。
all-petite-caps
CSS の 'font-variant-caps' の 'all-petite-caps' 設定と同じです。
unicase
CSS の 'font-variant-caps' の 'unicase' 設定と同じです。
titling-caps
CSS の 'font-variant-caps' の 'titling-caps' 設定と同じです。
textRendering
属性で許可される
キーワードは次のとおりです。
auto
SVG text-rendering プロパティの 'auto' と同じです。
optimizeSpeed
SVG text-rendering プロパティの 'optimizeSpeed' と同じです。
optimizeLegibility
SVG text-rendering プロパティの 'optimizeLegibility' と同じです。
geometricPrecision
SVG text-rendering プロパティの 'geometricPrecision' と同じです。
テキスト準備アルゴリズムは次のとおりです。このアルゴリズムは、
文字列 text、
CanvasTextDrawingStyles
オブジェクト target、および省略可能な長さ
maxWidth を入力として受け取ります。共通の座標空間上にそれぞれ配置されたグリフ形状の配列、
値が left、right、または center のいずれかである
physical alignment、および インラインボックスを返します。(このアルゴリズムのほとんどの呼び出し元は、
physical alignment および インラインボックスを無視します。)
maxWidth が指定されているものの、ゼロ以下または NaN と等しい場合は、 空の配列を返します。
text 内のすべての ASCII 空白を U+0020 SPACE 文字に置き換えます。
font を、target の font
属性によって指定される、そのオブジェクトの現在のフォントとします。
language を、target の 言語とします。
language が "inherit"
である場合:
sourceObject を、object の フォントスタイルソース オブジェクトとします。
sourceObject が canvas
要素である場合は、language を sourceObject の
言語に設定します。
それ以外の場合:
表明: sourceObject は
OffscreenCanvas
オブジェクトです。
language を sourceObject の 継承された 言語に設定します。
language が空文字列である場合は、language を 明示的に不明に設定します。
次のリストから適切な手順を適用して、 direction の値を決定します。
direction
属性の値が "ltr"
である場合direction
属性の値が "rtl"
である場合direction
属性の値が "inherit"
である場合
sourceObject を、object の フォントスタイルソース オブジェクトとします。
sourceObject が canvas
要素である場合は、direction を sourceObject の
方向性とします。
それ以外の場合:
表明: sourceObject は
OffscreenCanvas
オブジェクトです。
direction を sourceObject の 継承された方向とします。
テキスト text を含む単一の インラインボックスを含む、仮想的な無限幅の CSS 行ボックスを形成します。CSS コンテンツ言語は language に設定し、 CSS プロパティは 次のように設定します。
| プロパティ | ソース |
|---|---|
| 'direction' | direction |
| 'font' | font |
| 'font-kerning' | target の fontKerning
|
| 'font-stretch' | target の fontStretch
|
| 'font-variant-caps' | target の fontVariantCaps
|
| 'letter-spacing' | target の 文字間隔 |
| SVG text-rendering | target の textRendering
|
| 'white-space' | 'pre' |
| 'word-spacing' | target の 単語間隔 |
その他のすべてのプロパティは初期値に設定します。
maxWidth が指定されており、仮想的な 行ボックス内の仮想的な インラインボックスの幅が maxWidth CSS ピクセルより大きい場合は、 font を、より幅の狭いフォント(利用可能な場合、またはフォントに 水平スケール係数を適用することで適度に読みやすいものを合成できる場合)か、 より小さいフォントに変更し、前の手順へ戻ります。
anchor point は インラインボックス上の点であり、
physical alignment は left、right、または center
のいずれかの値です。これらの変数は、textAlign
および textBaseline
の値によって、次のように決定されます。
水平位置:
textAlign
が
left
の場合
textAlign
が
start
で、direction が
'ltr' の場合
textAlign
が
end
で、direction が 'rtl' の場合
textAlign
が
right
の場合
textAlign
が
end
で、direction が 'ltr' の場合
textAlign が
start
で、direction が
'rtl' の場合
textAlign が
center
の場合
垂直位置:
textBaseline
が top
の場合
textBaseline
が hanging
の場合
textBaseline
が middle
の場合
textBaseline
が alphabetic
の場合
textBaseline
が ideographic
の場合
textBaseline
が bottom
の場合
result を、インラインボックス内の各グリフを、 存在する場合は左から右へ反復し、各グリフについて、インラインボックス内にあるグリフの形状を、 anchor point を原点とし、CSS ピクセルを使用する座標空間上に配置して配列へ追加することによって構築される配列とします。
result、physical alignment、およびインライン ボックスを返します。
CanvasPath
インターフェイスを実装するオブジェクトは、パスを持ちます。パスは、0個以上の
サブパスのリストを持ちます。各サブパスは、直線または曲線の
線分で接続された1個以上の点のリストと、サブパスが閉じているかどうかを示すフラグで構成されます。
閉じたサブパスとは、サブパスの最後の点が直線によってサブパスの最初の点に接続されているものです。
点が1個しかないサブパスは、パスを描画するときには無視されます。
パスには、新しい サブパスが必要フラグがあります。この フラグが設定されている場合、特定のAPIは、以前のサブパスを拡張する代わりに新しいサブパスを作成します。 パスが作成されたとき、その新しいサブパスが必要フラグは 設定されなければなりません。
CanvasPath
インターフェイスを実装するオブジェクトが作成されたとき、そのパスは、サブパスが0個の状態に初期化されなければなりません。
context.moveTo(x, y)
CanvasRenderingContext2D/moveTo
現行のすべてのエンジンでサポートされています。
path.moveTo(x, y)
指定された点を持つ新しいサブパスを作成します。
context.closePath()
CanvasRenderingContext2D/closePath
現行のすべてのエンジンでサポートされています。
path.closePath()
現在のサブパスを閉じたものとしてマークし、新たに閉じられたサブパスの 始点および終点と同じ点を持つ新しいサブパスを開始します。
context.lineTo(x, y)
CanvasRenderingContext2D/lineTo
現行のすべてのエンジンでサポートされています。
path.lineTo(x, y)
指定された点を現在のサブパスに追加し、直線によって前の点に 接続します。
context.quadraticCurveTo(cpx, cpy, x, y)
CanvasRenderingContext2D/quadraticCurveTo
現行のすべてのエンジンでサポートされています。
path.quadraticCurveTo(cpx, cpy, x, y)
指定された点を現在のサブパスに追加し、指定された制御点を持つ2次 ベジェ曲線によって前の点に接続します。
context.bezierCurveTo(cp1x, cp1y, cp2x, cp2y, x, y)
CanvasRenderingContext2D/bezierCurveTo
現行のすべてのエンジンでサポートされています。
path.bezierCurveTo(cp1x, cp1y, cp2x, cp2y, x, y)
指定された点を現在のサブパスに追加し、指定された制御点を持つ3次ベジェ 曲線によって前の点に接続します。
context.arcTo(x1, y1, x2, y2, radius)
CanvasRenderingContext2D/arcTo
現行のすべてのエンジンでサポートされています。
path.arcTo(x1, y1, x2, y2, radius)
指定された制御点および半径を持つ円弧を現在のサブパスに追加し、直線によって 前の点に接続します。
指定された
半径が負の場合は、"IndexSizeError" DOMException をスローします。
context.arc(x, y, radius, startAngle, endAngle [, counterclockwise ])
現行のすべてのエンジンでサポートされています。
path.arc(x, y, radius, startAngle, endAngle [, counterclockwise ])
引数によって記述された円の円周に沿う円弧が、指定された開始角から始まり、 指定された終了角で終わり、指定された方向(既定では時計回り)へ進むように、 サブパスへ点を追加します。円弧はパスへ追加され、直線によって前の点に接続されます。
指定された
半径が負の場合は、"IndexSizeError" DOMException をスローします。
context.ellipse(x, y, radiusX, radiusY, rotation, startAngle, endAngle [, counterclockwise])
CanvasRenderingContext2D/ellipse
現行のすべてのエンジンでサポートされています。
path.ellipse(x, y, radiusX, radiusY, rotation, startAngle, endAngle [, counterclockwise])
引数によって記述された楕円の円周に沿う円弧が、指定された開始角から始まり、 指定された終了角で終わり、指定された方向(既定では時計回り)へ進むように、 サブパスへ点を追加します。円弧はパスへ追加され、直線によって前の点に接続されます。
指定された
半径が負の場合は、"IndexSizeError" DOMException をスローします。
context.rect(x, y, w, h)
現行のすべてのエンジンでサポートされています。
path.rect(x, y, w, h)
指定された長方形を表す、新しい閉じたサブパスをパスに追加します。
context.roundRect(x, y, w, h, radii)
path.roundRect(x, y, w, h, radii)
指定された角丸長方形を表す、新しい閉じたサブパスをパスに追加します。 radii は、長方形の角をピクセル単位で表す半径のリスト、または単一の半径です。 リストが指定された場合、これらの半径の数および順序は、CSS の 'border-radius' プロパティと同じように機能します。 単一の半径は、要素が1個のリストと同じように動作します。
w と h がともに0以上である場合、またはともに0未満である場合、 パスは時計回りに描画されます。それ以外の場合は、反時計回りに描画されます。
w が負の場合、角丸長方形は水平方向に反転します。これは、 通常は左側の角に適用される半径値が右側で使用され、その逆も同様であることを意味します。 同様に、h が負の場合、角丸長方形は垂直方向に反転します。
radii 内の値 r が数値である場合、対応する角は 半径 r の円弧として描画されます。
radii 内の値 r が { x, y
} プロパティを持つオブジェクトである場合、対応する角は、x
半径と y 半径がそれぞれ r.x および r.y に等しい
楕円弧として描画されます。
同じ辺にある2つの角の radii の合計がその辺の長さより大きい場合、 角丸長方形のすべての radii は、length / (r1 + r2) の係数で拡縮されます。複数の辺がこの条件に該当する場合、拡縮係数が最も小さい辺の 拡縮係数が使用されます。これはCSSの動作と一致します。
radii が、要素数が1、2、3、または4ではないリストである場合は、
RangeError
をスローします。
radii 内の値が負数である場合、または
{ x, y } オブジェクトで、その x
または y プロパティが負数である場合は、RangeError
をスローします。
次のメソッドにより、作者は CanvasPath
インターフェイスを実装するオブジェクトのパスを
操作できます。
CanvasDrawPath および CanvasTransform
インターフェイスを実装するオブジェクトの場合、メソッドへ渡される点と、これらのメソッドによって
現在の
既定パスに追加される結果の線は、パスへ追加される前に、
現在の変換行列に従って変換されなければなりません。
moveTo(x,
y) メソッドが呼び出されたときは、次の手順を実行しなければなりません。
いずれかの引数が無限大または NaN である場合は、戻ります。
指定された点を最初の(かつ唯一の)点とする新しいサブパスを作成します。
ユーザーエージェントが、パス上の座標
(x,
y) についてサブパスが存在することを確保するとき、
ユーザーエージェントは、パスの
新しいサブパスが必要フラグが設定されているかどうかを
確認しなければなりません。設定されている場合、ユーザーエージェントは、
moveTo() メソッドが
呼び出されたかのように、点 (x, y) を最初の(かつ唯一の)点とする
新しいサブパスを作成し、その後、パスの
新しい
サブパスが必要フラグを解除しなければなりません。
closePath() メソッドが呼び出されたとき、
オブジェクトのパスにサブパスがない場合は何もしてはなりません。それ以外の場合は、
最後のサブパスを閉じたものとしてマークし、その最初の点が前のサブパスの最初の点と同じである
新しいサブパスを作成し、最後にこの新しいサブパスをパスへ追加しなければなりません。
最後のサブパスの点のリストに複数の点があった場合、これは、 最後の点から最後のサブパスの最初の点へ戻る直線を追加して、サブパスを「閉じる」ことと 同等です。
新しい点と、それらを接続する線は、以下で説明するメソッドを使用してサブパスに追加されます。 すべての場合において、メソッドはオブジェクトのパス内の最後のサブパスのみを変更します。
lineTo(x,
y) メソッドが呼び出されたときは、次の手順を実行しなければなりません。
いずれかの引数が無限大または NaN である場合は、戻ります。
オブジェクトのパスにサブパスがない場合は、 (x, y) について サブパスが存在することを確保します。
それ以外の場合は、サブパスの最後の点を指定された点 (x, y) に直線で接続し、その後、指定された点 (x, y) を サブパスへ追加します。
quadraticCurveTo(cpx, cpy,
x, y) メソッドが呼び出されたときは、次の手順を実行しなければなりません。
いずれかの引数が無限大または NaN である場合は、戻ります。
(cpx, cpy) について、サブパスが存在することを 確保します。
サブパスの最後の点を、制御点 (cpx, cpy) を持つ 2次ベジェ曲線によって、指定された点 (x, y) に接続します。 [BEZIER]
指定された点 (x, y) をサブパスへ追加します。
bezierCurveTo(cp1x, cp1y,
cp2x, cp2y, x, y) メソッドが呼び出されたときは、
次の手順を実行しなければなりません。
いずれかの引数が無限大または NaN である場合は、戻ります。
(cp1x, cp1y) について、サブパスが存在することを 確保します。
サブパスの最後の点を、制御点 (cp1x, cp1y) および (cp2x, cp2y) を持つ3次ベジェ曲線によって、 指定された点 (x, y) に接続します。[BEZIER]
点 (x, y) をサブパスへ追加します。
arcTo(x1,
y1, x2, y2, radius) メソッドが呼び出されたときは、
次の手順を実行しなければなりません。
いずれかの引数が無限大または NaN である場合は、戻ります。
(x1, y1) について、サブパスが存在することを 確保します。
radius が負の場合は、"IndexSizeError"
DOMException をスローします。
点 (x0, y0) を、サブパス内の最後の点に 現在の変換 行列の逆行列を適用して変換したものとします(これにより、メソッドへ渡された点と 同じ座標系になります)。
点 (x0, y0) が点 (x1, y1) と等しい場合、点 (x1, y1) が点 (x2, y2) と等しい場合、または radius が0の場合は、 点 (x1, y1) をサブパスへ追加し、その点を前の点 (x0, y0) に直線で接続します。
それ以外の場合で、点 (x0, y0)、(x1, y1)、 および (x2, y2) がすべて1本の直線上にある場合は、点 (x1, y1) をサブパスへ追加し、その点を前の点 (x0, y0) に直線で接続します。
それ以外の場合は、The Arc を、半径 radius を持つ円の円周によって 与えられる最短の円弧とします。この円は、点 (x0, y0) を通過して 点 (x1, y1) で終わる半無限直線に接する点を1つ持ち、 さらに、点 (x1, y1) で終わり、点 (x2, y2) を通過する半無限直線に接する別の点を1つ持ちます。 この円がこれら2本の線に接する点を、それぞれ開始接点および終了接点と呼びます。 点 (x0, y0) を開始接点に直線で接続し、開始接点をサブパスへ 追加します。その後、開始接点を終了接点に The Arc で接続し、 終了接点をサブパスへ追加します。
arc(x,
y, radius, startAngle, endAngle,
counterclockwise) メソッドが呼び出されたときは、楕円メソッドの
手順を、this、x、y、radius、radius、0、
startAngle、endAngle、および counterclockwise を指定して実行しなければなりません。
これにより、両方の半径が等しく、rotation が0である点を除き、
ellipse()
と同等になります。
ellipse(x,
y, radiusX, radiusY, rotation, startAngle,
endAngle, counterclockwise) メソッドが呼び出されたときは、
楕円メソッドの手順を、
this、
x、y、radiusX、
radiusY、rotation、startAngle、endAngle、および
counterclockwise を指定して実行しなければなりません。
楕円上の点を決定する手順は、 ellipse および angle を指定して、次のとおりです。
eccentricCircle を、原点を ellipse と共有し、 半径が ellipse の半長軸に等しい円とします。
outerPoint を、ellipse の半長軸から時計回りに ラジアン単位で測定した angle にある、eccentricCircle の円周上の点とします。
chord を、ellipse の長軸と outerPoint の間にあり、 この長軸に垂直な線とします。
ellipse の円周と交差する chord 上の点を返します。
楕円メソッドの手順は、canvasPath、x、 y、 radiusX、radiusY、rotation、startAngle、 endAngle、および counterclockwise を指定して、次のとおりです。
いずれかの引数が無限大または NaN である場合は、戻ります。
radiusX または radiusY のいずれかが負の場合は、
"IndexSizeError" DOMException をスローします。
canvasPath のパスにサブパスがある場合は、サブパスの最後の点から 円弧の始点まで直線を追加します。
円弧の始点および終点をサブパスへ追加し、それらを円弧で接続します。 円弧とその始点および終点は、次のように定義されます。
原点が (x, y) にあり、長軸半径が radiusX、 短軸半径が radiusY で、半長軸がx軸から時計回りに rotation ラジアン傾くように原点の周囲で回転した楕円を考えます。
counterclockwise が false で、endAngle − startAngle が 2π 以上である場合、または counterclockwise が true で、startAngle − endAngle が 2π 以上である場合、円弧は この楕円の円周全体となり、始点と終点の両方は、この楕円および startAngle を指定して 楕円上の点を決定する手順を 実行した結果となります。
それ以外の場合、始点は、この楕円および startAngle を指定して 楕円上の点を決定する 手順を実行した結果であり、終点は、この楕円および endAngle を指定して 楕円上の点を決定する手順を 実行した結果です。また、円弧は、この楕円の円周に沿って始点から終点まで進むパスであり、 counterclockwise が true の場合は反時計回り、それ以外の場合は時計回りに進みます。 点は単にゼロからの角度ではなく楕円上にあるため、円弧が 2π ラジアンを超える角度を覆うことはありません。
円弧が楕円の円周全体を覆い、サブパス内に他の点がない場合でも、
closePath()
メソッドが適切に呼び出されない限り、パスは閉じられません。
rect(x,
y, w, h) メソッドが呼び出されたときは、次の
手順を実行しなければなりません。
いずれかの引数が無限大または NaN である場合は、戻ります。
4つの点 (x, y)、 (x+w, y)、(x+w, y+h)、(x, y+h) のみを、 この順序で含み、これら4つの点が直線で接続された新しいサブパスを作成します。
サブパスを閉じたものとしてマークします。
点 (x, y) をサブパス内の唯一の点とする 新しいサブパスを作成します。
CanvasRenderingContext2D/roundRect
現行のすべてのエンジンでサポートされています。
roundRect(x, y, w,
h, radii) メソッドの手順は次のとおりです。
x、y、w、または h のいずれかが 無限大または NaN である場合は、戻ります。
radii が 制限なし
double または DOMPointInit である場合は、
radii を « radii
» に設定します。
radii が、要素数が1、2、3、または4のリストでない場合は、RangeError
をスローします。
normalizedRadii を空のリストとします。
radii の各 radius について、次を実行します。
radius が DOMPointInit である場合:
radius["x"]
または
radius["y"]
が負である場合は、RangeError
をスローします。
それ以外の場合は、radius を normalizedRadii に付加します。
radius が 制限なし
double である場合:
radius が無限大または NaN である場合は、戻ります。
radius が負である場合は、RangeError
をスローします。
それ以外の場合は、«[ "x"
→ radius,
"y"
→ radius ]» を
normalizedRadii に付加します。
upperLeft、upperRight、lowerRight、および lowerLeft を null とします。
normalizedRadii の要素数が4の場合は、upperLeft を normalizedRadii[0] に設定し、upperRight を normalizedRadii[1] に設定し、lowerRight を normalizedRadii[2] に設定し、lowerLeft を normalizedRadii[3] に設定します。
normalizedRadii の要素数が3の場合は、upperLeft を normalizedRadii[0] に設定し、upperRight および lowerLeft を normalizedRadii[1] に設定し、 lowerRight を normalizedRadii[2] に設定します。
normalizedRadii の要素数が2の場合は、upperLeft および lowerRight を normalizedRadii[0] に設定し、 upperRight および lowerLeft を normalizedRadii[1] に設定します。
normalizedRadii の要素数が1の場合は、upperLeft、 upperRight、lowerRight、および lowerLeft を normalizedRadii[0] に設定します。
角の曲線は重なってはなりません。これを防ぐため、すべての半径を拡縮します。
新しいサブパスを作成します。
点 (x + upperLeft["x"],
y) へ移動します。
点 (x + w −
upperRight["x"],
y) まで直線を描画します。
点 (x + w, y +
upperRight["y"]) まで円弧を描画します。
点 (x + w, y +
h − lowerRight["y"]) まで直線を描画します。
点 (x + w −
lowerRight["x"],
y +
h) まで円弧を描画します。
点 (x + lowerLeft["x"],
y + h) まで直線を描画します。
点 (x, y + h −
lowerLeft["y"]) まで円弧を描画します。
点 (x, y +
upperLeft["y"]) まで直線を描画します。
点 (x + upperLeft["x"],
y) まで円弧を描画します。
サブパスを閉じたものとしてマークします。
点 (x, y) をサブパス内の唯一の点とする 新しいサブパスを作成します。
これは、CSS の 'border-radius' プロパティと同様に動作するよう設計されています。
Path2D オブジェクト現行のすべてのエンジンでサポートされています。
Path2D オブジェクトは、後で
CanvasDrawPath インターフェイスを実装する
オブジェクトで使用されるパスを宣言するために使用できます。前の節で説明した多くのAPIに加えて、
Path2D オブジェクトには、
パスを結合するメソッド、およびパスにテキストを追加するメソッドがあります。
path = new Path2D()
現行のすべてのエンジンでサポートされています。
新しい空の Path2D オブジェクトを作成します。
path = new Path2D(path)
path が Path2D オブジェクトである場合、
コピーを返します。
path が文字列である場合、引数をSVGパスデータとして解釈し、 その引数によって記述されるパスを作成します。[SVG]
path.addPath(path [, transform ])
現行のすべてのエンジンでサポートされています。
引数によって指定されたパスをパスに追加します。
Path2D(path)
コンストラクターが呼び出されたときは、
次の手順を実行しなければなりません。
output を新しい Path2D オブジェクトとします。
path が指定されていない場合は、output を返します。
path が Path2D オブジェクトである場合は、
path のすべてのサブパスを output に追加し、output を返します。
(言い換えると、引数のコピーを返します。)
svgPath を、SVG 2 のパスデータに関する規則に従って path を構文解析および解釈した結果とします。[SVG]
結果のパスは空である場合があります。SVGは、パスデータの構文解析および 適用に関するエラー処理規則を定義しています。
(x, y) を svgPath 内の最後の点とします。
svgPath にサブパスがある場合は、そのすべてを output に追加します。
(x, y) をサブパス内の唯一の点とする新しいサブパスを output 内に作成します。
output を返します。
addPath(path,
transform) メソッドが Path2D
オブジェクト
a に対して呼び出されたときは、次の手順を実行しなければなりません。
Path2D オブジェクト
path にサブパスがない場合は、戻ります。
matrix を、2D辞書 transform から
DOMMatrix を作成した結果とします。
matrix の m11 要素、 m12 要素、 m21 要素、m22 要素、 m41 要素、または m42 要素のうち1つ以上が無限大または NaN である場合は、戻ります。
path 内のすべてのサブパスのコピーを作成します。このコピーを c とします。
c 内のすべての座標および線を、変換行列 matrix によって変換します。
(x, y) を、c の最後のサブパス内の 最後の点とします。
c 内のすべてのサブパスを a に追加します。
(x, y) をサブパス内の唯一の点とする新しいサブパスを a 内に作成します。
CanvasTransform インターフェイスを実装する
オブジェクトは、現在の
変換行列と、それを操作するためのメソッド(この節で説明します)を持ちます。
CanvasTransform インターフェイスを実装する
オブジェクトが作成されたとき、その変換行列は単位行列に初期化されなければなりません。
現在の
変換行列は、現在の既定パスを作成するとき、および
CanvasTransform インターフェイスを実装する
オブジェクト上でテキスト、図形、および Path2D オブジェクトを描画するときに、
座標へ適用されます。
変換は逆順で実行されなければなりません。
たとえば、幅を2倍にする拡縮変換をキャンバスに適用し、 続いて描画処理を4分の1回転させる回転変換を適用してから、高さの2倍の幅を持つ 長方形をキャンバス上に描画した場合、実際の結果は正方形になります。
context.scale(x, y)
CanvasRenderingContext2D/scale
現行のすべてのエンジンでサポートされています。
指定された特性を持つ拡縮変換を適用するように、現在の変換行列を変更します。
context.rotate(angle)
CanvasRenderingContext2D/rotate
現行のすべてのエンジンでサポートされています。
指定された特性を持つ回転変換を適用するように、現在の変換行列を変更します。 角度はラジアン単位です。
context.translate(x, y)
CanvasRenderingContext2D/translate
現行のすべてのエンジンでサポートされています。
指定された特性を持つ平行移動変換を適用するように、現在の変換行列を変更します。
context.transform(a, b, c, d, e, f)
CanvasRenderingContext2D/transform
現行のすべてのエンジンでサポートされています。
以下で説明するように、引数によって指定された行列を適用するように 現在の変換行列を変更します。
matrix = context.getTransform()
CanvasRenderingContext2D/getTransform
現行のすべてのエンジンでサポートされています。
context.setTransform(a, b, c, d, e, f)
CanvasRenderingContext2D/setTransform
現行のすべてのエンジンでサポートされています。
以下で説明するように、現在の変換行列を、引数によって指定された 行列に変更します。
context.setTransform(transform)
現在の変換行列を、渡された
DOMMatrix2DInit
辞書によって表される行列に変更します。
context.resetTransform()
CanvasRenderingContext2D/resetTransform
現行のすべてのエンジンでサポートされています。
現在の変換行列を単位行列に変更します。
scale(x,
y) メソッドが呼び出されたときは、次の手順を実行しなければなりません。
いずれかの引数が無限大または NaN である場合は、戻ります。
引数によって記述される拡縮変換を、現在の 変換行列に追加します。x 引数は水平方向の拡縮係数を表し、 y 引数は垂直方向の拡縮係数を表します。係数は倍率です。
rotate(angle) メソッドが呼び出されたときは、
次の手順を実行しなければなりません。
angle が無限大または NaN である場合は、戻ります。
引数によって記述される回転変換を、現在の 変換行列に追加します。angle 引数は、ラジアン単位で表される 時計回りの回転角度を表します。
translate(x, y) メソッドが
呼び出されたときは、次の手順を実行しなければなりません。
いずれかの引数が無限大または NaN である場合は、戻ります。
引数によって記述される平行移動変換を、現在の 変換行列に追加します。x 引数は水平方向の平行移動距離を表し、 y 引数は垂直方向の平行移動距離を表します。引数の単位は座標空間単位です。
transform(a, b, c,
d, e, f) メソッドが呼び出されたときは、次の
手順を実行しなければなりません。
引数 a、b、c、d、 e、および f は、m11、m12、 m21、m22、dx、および dy、または m11、m21、m12、m22、 dx、および dy と呼ばれることがあります。特に、第2引数と 第3引数(b と c)の順序には注意する必要があります。 その順序はAPIごとに異なり、APIによってはこれらの位置に m12/m21 という表記を使用し、別のAPIでは m21/m12 という表記を使用するためです。
返されるオブジェクトはライブではないため、そのオブジェクトを更新しても
現在の
変換行列には影響せず、現在の変換
行列を更新しても、すでに返された DOMMatrix には影響しません。
setTransform(a, b, c,
d, e, f) メソッドが呼び出されたときは、次の
手順を実行しなければなりません。
いずれかの引数が無限大または NaN である場合は、戻ります。
現在の変換行列を、 次によって記述される行列にリセットします。
| a | c | e |
| b | d | f |
| 0 | 0 | 1 |
setTransform(transform)
メソッドが呼び出されたときは、次の手順を実行しなければなりません。
resetTransform() メソッドが呼び出されたときは、
現在の
変換行列を単位行列にリセットしなければなりません。
transform()
および
setTransform()
メソッドによって作成される形式の行列、すなわち、
| a | c | e |
| b | d | f |
| 0 | 0 | 1 |
が指定された場合、変換行列の乗算後に得られる変換済み座標は次のようになります。
xnew = a x + c y + e
ynew = b x + d y + f
CanvasDrawImage
および CanvasFillStrokeStyles
インターフェイスの一部のメソッドは、共用体型 CanvasImageSource
を引数として受け取ります。
この共用体型により、次のいずれかのインターフェイスを実装するオブジェクトを画像ソースとして 使用できます。
HTMLOrSVGImageElement
(img または
SVG
image
要素)
HTMLVideoElement
(video
要素)HTMLCanvasElement
(canvas
要素)OffscreenCanvas
ImageBitmap
VideoFrame
正式にはそのように指定されていませんが、SVG
image
要素は、img
要素と
ほぼ同一に実装されることが期待されます。すなわち、
SVG
image 要素は、img
要素の基本的な概念および機能を共有します。
ImageBitmap
インターフェイスは、ImageData
を含む、
画像を表す多数の他の型から作成できます。
image が CanvasImageSource
オブジェクトである場合に、image
引数の使用可能性を確認するには、次の手順を実行します。
image に応じて切り替えます。
HTMLOrSVGImageElement
image の 現在のリクエストの
状態が
壊れている場合は、
"InvalidStateError" DOMException をスローします。
image が完全に復号可能でない場合は、 bad を返します。
HTMLVideoElement
image の readyState
属性が HAVE_NOTHING
または HAVE_METADATA
のいずれかである場合は、bad を返します。
HTMLCanvasElement
OffscreenCanvas
image の水平寸法または垂直寸法のいずれかが0に等しい場合は、
"InvalidStateError"
DOMException をスローします。
ImageBitmap
VideoFrame
image の [[Detached]] 内部スロットの値が
true に設定されている場合は、"InvalidStateError"
DOMException をスローします。
good を返します。
CanvasImageSource
オブジェクトが HTMLOrSVGImageElement
を表す場合、その要素の画像をソース画像として使用しなければなりません。
具体的には、CanvasImageSource
オブジェクトが HTMLOrSVGImageElement
内のアニメーション画像を表す場合、ユーザーエージェントは、
CanvasRenderingContext2D
APIのために画像をレンダリングするとき、アニメーションの既定画像
(アニメーションがサポートされていないか無効であるときに使用するものとして形式が定義する画像)を
使用しなければならず、そのような画像がない場合は、アニメーションの最初のフレームを
使用しなければなりません。
CanvasImageSource
オブジェクトが HTMLVideoElement
を表す場合、引数を持つメソッドが呼び出された時点の
現在の再生位置にあるフレームを、
CanvasRenderingContext2D
APIのために画像をレンダリングするときのソース画像として使用しなければなりません。また、
ソース画像の寸法は、メディアリソースの
自然幅および
自然高さ
(すなわち、アスペクト比の補正が適用された後の値)でなければなりません。
CanvasImageSource
オブジェクトが HTMLCanvasElement
を表す場合、その要素のビットマップをソース画像として使用しなければなりません。
CanvasImageSource
オブジェクトが、レンダリング
されている要素を表し、その要素のサイズが変更されている場合、
レンダリングされた状態の画像ではなく、ソース画像の元の画像データを使用しなければなりません
(たとえば、ソース要素の width および
height
属性は、CanvasRenderingContext2D
APIのために画像をレンダリングするとき、オブジェクトがどのように解釈されるかには影響しません)。
CanvasImageSource
オブジェクトが ImageBitmap を表す場合、
オブジェクトのビットマップ画像データをソース画像として使用しなければなりません。
CanvasImageSource
オブジェクトが OffscreenCanvas
を表す場合、オブジェクトのビットマップをソース画像として使用しなければなりません。
CanvasImageSource
オブジェクトが VideoFrame を表す場合、
オブジェクトのピクセルデータをソース画像として使用しなければなりません。また、
ソース画像の寸法は、オブジェクトの [[display width]] および [[display height]] でなければなりません。
オブジェクト image は、image の型に応じて切り替えたときに 次の条件を満たす場合、オリジンクリーンではありません。
HTMLOrSVGImageElement
image の 現在のリクエストの 画像 データが CORSクロスオリジンです。
HTMLVideoElement
image の メディア データが CORSクロスオリジンです。
HTMLCanvasElement
ImageBitmap
OffscreenCanvas
image のビットマップの オリジンクリーン フラグが false です。
context.fillStyle [ = value ]
CanvasRenderingContext2D/fillStyle
現行のすべてのエンジンでサポートされています。
図形の塗りつぶしに使用される現在のスタイルを返します。
塗り スタイルを変更するために設定できます。
スタイルには、CSS 色を含む文字列、または CanvasGradient もしくは
CanvasPattern オブジェクトを指定できます。
無効な値は無視されます。
context.strokeStyle [ = value ]
CanvasRenderingContext2D/strokeStyle
現行のすべてのエンジンでサポートされています。
図形のストロークに使用される現在のスタイルを返します。
ストローク スタイルを変更するために設定できます。
スタイルには、CSS 色を含む文字列、または CanvasGradient もしくは
CanvasPattern
オブジェクトを指定できます。
無効な値は無視されます。
CanvasFillStrokeStyles
インターフェイスを実装するオブジェクトは、オブジェクトによる図形の処理方法を制御する
属性およびメソッド(この節で定義します)を持ちます。
このようなオブジェクトには、CSS 色、CanvasPattern、または CanvasGradient のいずれかである、
関連付けられた 塗り
スタイル値および ストロークスタイル値があります。
初期状態では、どちらも文字列「#000000」を
構文解析した
結果でなければなりません。
値がCSS色である場合、ビットマップへの描画に使用されるときに、変換行列の影響を 受けてはなりません。
CanvasPattern
または CanvasGradient オブジェクトに
設定された場合、代入後にそのオブジェクトへ加えられた変更は、その後の図形のストロークまたは
塗りつぶしに影響します。
fillStyle ゲッターの手順は次のとおりです。
fillStyle
セッターの手順は次のとおりです。
指定された値が文字列である場合:
指定された値が、オリジンクリーンでないものとして
マークされた CanvasPattern
オブジェクトである場合は、
this の オリジンクリーンフラグを
false に設定します。
strokeStyle ゲッターの手順は次のとおりです。
this の ストローク スタイルがCSS色である場合は、 HTML互換シリアライズを要求して、 その色のシリアライズを返します。
this の ストローク スタイルを返します。
strokeStyle
セッターの手順は次のとおりです。
指定された値が文字列である場合:
指定された値が、オリジンクリーンでないものとして
マークされた CanvasPattern
オブジェクトである場合は、
this の オリジンクリーンフラグを
false に設定します。
this の ストローク スタイルを指定された値に設定します。
グラデーションには、線形グラデーション、放射グラデーション、および円錐グラデーションの
3種類があり、不透明な CanvasGradient
インターフェイスを実装するオブジェクトによって表されます。
グラデーションが作成されると(以下を参照)、グラデーションに沿った色の 分布を定義するために、カラーストップが配置されます。各ストップにおけるグラデーションの色は、 そのストップに指定された色を変換して、コンテキストの色空間にしたものです。 各ストップの間では、そのオフセットで使用する色を求めるために、アルファ値を事前乗算せずに、 色とアルファ成分をコンテキストの色空間で線形補間しなければなりません。 最初のストップより前では、色は最初のストップの色でなければなりません。最後のストップより後では、 色は最後のストップの色でなければなりません。ストップがない場合、グラデーションは 透明な 黒です。
gradient.addColorStop(offset, color)
現行のすべてのエンジンでサポートされています。
指定されたオフセットに、指定された色を持つカラーストップをグラデーションへ追加します。 0.0はグラデーションの一端のオフセットであり、1.0はもう一方の端のオフセットです。
オフセットが範囲外である場合は、"IndexSizeError" DOMException をスローします。
色を構文解析できない場合は、"SyntaxError" DOMException をスローします。
gradient = context.createLinearGradient(x0, y0, x1, y1)
CanvasRenderingContext2D/createLinearGradient
現行のすべてのエンジンでサポートされています。
引数によって表される座標で指定された線に沿って描画する線形グラデーションを表す
CanvasGradient
オブジェクトを返します。
gradient = context.createRadialGradient(x0, y0, r0, x1, y1, r1)
CanvasRenderingContext2D/createRadialGradient
現行のすべてのエンジンでサポートされています。
引数によって表される円で指定された円錐に沿って描画する放射グラデーションを表す
CanvasGradient
オブジェクトを返します。
いずれかの半径が負の場合は、"IndexSizeError"
DOMException をスローします。
gradient = context.createConicGradient(startAngle, x, y)
CanvasRenderingContext2D/createConicGradient
現行のすべてのエンジンでサポートされています。
引数によって表される中心の周囲を時計回りに回転しながら描画する円錐グラデーションを表す
CanvasGradient
オブジェクトを返します。
CanvasGradient の
addColorStop(offset,
color) メソッドが呼び出されたときは、
次の手順を実行しなければなりません。
offset が0未満または1より大きい場合は、
"IndexSizeError" DOMException をスローします。
parsed color を、color を構文解析した結果とします。
CanvasGradient
オブジェクトは canvas
に依存しないため、
構文解析器には要素が渡されません。つまり、ある
canvas によって
作成された CanvasGradient
オブジェクトを別のものが使用できるため、色を指定した時点でどれが
「対象の要素」であるかを知る方法はありません。
parsed color が失敗である場合は、"SyntaxError"
DOMException をスローします。
グラデーション全体に対するオフセット offset の位置に、 色 parsed color を持つ新しいストップを配置します。
グラデーション上の同じオフセットに複数のストップが追加された場合、それらは追加された 順序で配置されなければなりません。最初のものがグラデーションの始点に最も近く、 後続の各ストップは終点に向かって無限小だけ先に配置されます (実質的には、各点に追加された最初と最後のストップ以外はすべて無視されます)。
createLinearGradient(x0, y0,
x1, y1) メソッドは、グラデーションの始点
(x0, y0) および終点 (x1, y1) を表す
4つの引数を取ります。このメソッドが呼び出されたときは、指定された線で初期化された線形
CanvasGradient を
返さなければなりません。
線形グラデーションは、始点および終点を横切る線に垂直な線上のすべての点が、 それら2本の線が交差する点の色を持つようにレンダリングされなければなりません (色は上記で説明した補間および外挿によって得られます)。 線形グラデーション内の点は、レンダリング時に現在の変換行列によって説明されるように変換されなければなりません。
x0 = x1 かつ y0 = y1 である場合、線形 グラデーションは何も描画してはなりません。
createRadialGradient(x0, y0,
r0, x1, y1, r1) メソッドは6つの
引数を取ります。最初の3つは原点が (x0, y0)、半径が
r0 である開始円を表し、最後の3つは原点が (x1,
y1)、半径が r1 である終了円を表します。値の単位は座標空間単位です。
r0 または r1 のいずれかが負である場合は、
"IndexSizeError" DOMException を
スローしなければなりません。それ以外の場合、このメソッドが呼び出されたときは、
指定された2つの円で初期化された放射
CanvasGradient を
返さなければなりません。
放射グラデーションは、次の手順に従ってレンダリングされなければなりません。
x0 = x1 かつ y0 = y1 かつ r0 = r1 である場合、放射グラデーションは 何も描画してはなりません。戻ります。
x(ω) = (x1-x0)ω + x0 とします。
y(ω) = (y1-y0)ω + y0 とします。
r(ω) = (r1-r0)ω + r0 とします。
ω における色を、グラデーション上のその位置の色とします (色は上記で説明した補間および外挿によって得られます)。
r(ω) > 0 となるすべての ω の値について、 正の無限大に最も近い ω の値から始め、負の無限大に最も近い ω の値で終わる順序で、位置 (x(ω), y(ω)) にある 半径 r(ω) の円の円周を、ω における色で描画します。ただし、 このグラデーションの今回のレンダリングにおいて、この手順内の以前の円によってまだ 描画されていないビットマップの部分にのみ描画します。
これにより実質的に、グラデーションの作成時に定義された2つの円に接する 円錐が作成されます。開始円(0.0)より前の円錐部分には最初のオフセットの色が使用され、 終了円(1.0)より後の円錐部分には最後のオフセットの色が使用され、円錐の外側の領域は グラデーションによって変更されません(透明な 黒)。
その後、結果として得られる放射グラデーションは、レンダリング時に現在の変換行列によって説明されるように変換されなければなりません。
createConicGradient(startAngle,
x, y) メソッドは3つの引数を取ります。最初の引数
startAngle はグラデーションが始まる角度をラジアン単位で表し、最後の
2つの引数 (x, y) はグラデーションの中心をCSS
ピクセル単位で表します。このメソッドが呼び出されたときは、指定された中心および角度で
初期化された円錐 CanvasGradient を
返さなければなりません。
これはCSSの 'conic-gradient' と同じレンダリング規則に従い、 CSSの 'conic-gradient(from adjustedStartAnglerad at xpx ypx, angularColorStopList)' と同等です。ここで:
adjustedStartAngle は startAngle + π/2 で与えられます。
angularColorStopList は、addColorStop()
を使用して CanvasGradient
に
追加されたカラーストップによって与えられ、カラーストップのオフセットは
パーセンテージとして解釈されます。
グラデーションは、関連するストロークまたは塗りつぶしの効果によって描画が必要とされる 場所にのみ描画されなければなりません。
パターンは、不透明な CanvasPattern
インターフェイスを実装するオブジェクトによって表されます。
pattern = context.createPattern(image, repetition)
CanvasRenderingContext2D/createPattern
現行のすべてのエンジンでサポートされています。
指定された画像を使用し、repetition 引数によって指定された方向に繰り返す
CanvasPattern
オブジェクトを返します。
repetition に許可される値は、repeat(両方向)、
repeat-x(水平方向のみ)、repeat-y
(垂直方向のみ)、および no-repeat(どちらも繰り返さない)です。
repetition 引数が空の場合は、値 repeat が使用されます。
画像がまだ完全に復号されていない場合は、何も描画されません。画像がデータを持たない
キャンバスである場合は、"InvalidStateError" DOMException をスローします。
pattern.setTransform(transform)
現行のすべてのエンジンでサポートされています。
塗りまたはストロークの描画処理中にパターンをレンダリングするときに使用される 変換行列を設定します。
createPattern(image,
repetition) メソッドが呼び出されたときは、次の手順を実行しなければなりません。
usability を、image の 使用可能性を確認した 結果とします。
usability が bad である場合は、null を返します。
表明: usability は good です。
repetition が空文字列である場合は、「repeat」に設定します。
repetition が「repeat」、「repeat-x」、
「repeat-y」、または「no-repeat」のいずれとも
同一でない場合は、
"SyntaxError" DOMException をスローします。
pattern を、画像 image と repetition によって指定された
繰り返し動作を持つ新しい CanvasPattern
オブジェクトとします。
image がオリジンクリーンでない場合は、 pattern をオリジンクリーンでないものとして マークします。
pattern を返します。
createPattern()
メソッドを呼び出した後に、CanvasPattern
オブジェクトの
作成時に使用された image を変更しても、CanvasPattern オブジェクトによって
レンダリングされるパターンに影響してはなりません。
パターンには、描画時にパターンをどのように使用するかを制御する変換行列があります。 初期状態では、パターンの変換行列は単位行列でなければなりません。
setTransform(transform) メソッドが
呼び出されたときは、次の手順を実行しなければなりません。
パターンを領域内にレンダリングするとき、ユーザーエージェントは何がレンダリングされるかを 決定するために、次の手順を実行しなければなりません。
無限の透明な 黒のビットマップを作成します。
画像の左上隅が座標空間の原点に位置し、画像のCSS
ピクセルごとに1座標空間単位となるように、画像のコピーをビットマップ上へ配置します。
次に、繰り返し動作が「repeat-x」の場合は、この画像のコピーを水平方向の
左右に繰り返して配置し、繰り返し動作が「repeat-y」の場合は垂直方向の
上下に繰り返して配置し、繰り返し動作が「repeat」の場合は、
ビットマップ全体の4方向に繰り返して配置します。
元の画像データがビットマップ画像である場合、繰り返し領域内の点に描画される値は、
元の画像データをフィルタリングすることで計算されます。拡大時に imageSmoothingEnabled
属性が false に設定されている場合、画像は最近傍補間を使用してレンダリングされなければなりません。
それ以外の場合、ユーザーエージェントは任意のフィルタリングアルゴリズム
(たとえば、双線形補間または最近傍法)を使用できます。複数のフィルタリングアルゴリズムを
サポートするユーザーエージェントは、imageSmoothingQuality
属性の値を使用して、フィルタリングアルゴリズムの選択を決定できます。このような
フィルタリングアルゴリズムが元の画像データの外側にあるピクセル値を必要とする場合、
代わりにピクセルの座標を元の画像の寸法に折り返した位置の値を使用しなければなりません。
(すなわち、フィルターはパターンの繰り返し動作の値に関係なく、「repeat」動作を使用します。)
結果として得られるビットマップを、パターンの変換行列に従って変換します。
結果として得られるビットマップを、今度は現在の変換行列に従って、もう一度変換します。
パターンがレンダリングされる領域の外側にある画像の部分を、 透明な 黒に置き換えます。
結果として得られるビットマップが、同じ原点および同じ スケールでレンダリングされるものとなります。
変換行列が特異であるときに放射グラデーションまたは繰り返しパターンが使用された場合、 結果として得られるスタイルは透明な 黒でなければなりません(そうでなければ、グラデーションまたはパターンが点または線へ 押し潰され、他のピクセルが未定義になります)。線形グラデーションおよび単色は、 特異な変換行列であっても、常にすべての点を定義します。
CanvasRect インターフェイスを実装する
オブジェクトは、ビットマップへ矩形を直ちに描画するための次のメソッドを提供します。
各メソッドは4つの引数を取ります。最初の2つは矩形の左上の x 座標および
y 座標を指定し、後の2つはそれぞれ矩形の幅 w および高さ
h を指定します。
現在の変換 行列は、次の4つの座標に適用されなければなりません。これらの座標によって形成される パスを閉じることで、指定された矩形が得られます。(x, y)、 (x+w, y)、(x+w, y+h)、 (x, y+h)。
図形は現在の既定パスに影響を与えずに描画され、
クリッピング領域の
適用対象となります。また、clearRect()
を除き、影の
効果、グローバルアルファ、および
現在の合成およびブレンド
演算子の適用対象にもなります。
context.clearRect(x, y, w, h)
CanvasRenderingContext2D/clearRect
現行のすべてのエンジンでサポートされています。
指定された矩形内にあるビットマップ上のすべてのピクセルを、 透明な 黒にクリアします。
context.fillRect(x, y, w, h)
CanvasRenderingContext2D/fillRect
現行のすべてのエンジンでサポートされています。
現在の塗りスタイルを使用して、指定された矩形をビットマップ上に描画します。
context.strokeRect(x, y, w, h)
CanvasRenderingContext2D/strokeRect
現行のすべてのエンジンでサポートされています。
現在のストロークスタイルを使用して、指定された矩形の輪郭を形成するボックスを ビットマップ上に描画します。
clearRect(x, y, w,
h) メソッドが呼び出されたときは、次の手順を実行しなければなりません。
高さまたは幅のいずれかが0である場合、ピクセルの集合が空になるため、 このメソッドは何の効果も持ちません。
fillRect(x,
y, w, h) メソッドが呼び出されたときは、次の
手順を実行しなければなりません。
strokeRect(x, y, w,
h) メソッドが呼び出されたときは、次の手順を実行しなければなりません。
いずれかの引数が無限大または NaN である場合は、戻ります。
CanvasPathDrawingStyles
インターフェイスの線のスタイルを使用して、以下で説明する
パスをトレースした
結果を取得し、this の ストローク
スタイルで塗りつぶします。
w と h がともに0である場合、パスは点 (x, y) だけを持ち、線を持たない単一のサブパスとなるため、 このメソッドには効果がありません(この場合、パスをトレースするアルゴリズムは 空のパスを返します)。
w または h の一方だけが0である場合、パスは座標 (x, y) および (x+w, y+h) の2つの点をこの順序で持ち、 それらが1本の直線で接続された単一のサブパスとなります。
それ以外の場合、パスは座標 (x, y)、(x+w, y)、 (x+w, y+h)、および (x, y+h) の 4つの点を持ち、それらがこの順序で直線によって互いに接続された単一のサブパスとなります。
現行のすべてのエンジンでサポートされています。
context.fillText(text, x, y [, maxWidth ])
CanvasRenderingContext2D/fillText
現行のすべてのエンジンでサポートされています。
context.strokeText(text, x, y [, maxWidth ])
CanvasRenderingContext2D/strokeText
現行のすべてのエンジンでサポートされています。
指定された位置に、指定されたテキストをそれぞれ塗りつぶすかストロークします。 最大幅が指定されている場合、必要に応じて、その幅に収まるようにテキストが拡縮されます。
metrics = context.measureText(text)
CanvasRenderingContext2D/measureText
現行のすべてのエンジンでサポートされています。
現在のフォントにおける指定されたテキストの測定値を持つ
TextMetrics
オブジェクトを返します。
metrics.width
現行のすべてのエンジンでサポートされています。
metrics.actualBoundingBoxLeft
TextMetrics/actualBoundingBoxLeft
現行のすべてのエンジンでサポートされています。
metrics.actualBoundingBoxRight
TextMetrics/actualBoundingBoxRight
現行のすべてのエンジンでサポートされています。
metrics.fontBoundingBoxAscent
TextMetrics/fontBoundingBoxAscent
現行のすべてのエンジンでサポートされています。
metrics.fontBoundingBoxDescent
TextMetrics/fontBoundingBoxDescent
現行のすべてのエンジンでサポートされています。
metrics.actualBoundingBoxAscent
TextMetrics/actualBoundingBoxAscent
現行のすべてのエンジンでサポートされています。
metrics.actualBoundingBoxDescent
TextMetrics/actualBoundingBoxDescent
現行のすべてのエンジンでサポートされています。
metrics.emHeightAscent
現行のすべてのエンジンでサポートされています。
metrics.emHeightDescent
現行のすべてのエンジンでサポートされています。
metrics.hangingBaseline
metrics.alphabeticBaseline
TextMetrics/alphabeticBaseline
metrics.ideographicBaseline
TextMetrics/ideographicBaseline
以下で説明する測定値を返します。
CanvasText インターフェイスを実装する
オブジェクトは、テキストをレンダリングするための次のメソッドを提供します。
fillText(text, x, y,
maxWidth) および strokeText(text, x, y,
maxWidth) メソッドは、現在の font、
textAlign、
および textBaseline
の値を使用して、指定された text を指定された (x, y) 座標に
レンダリングし、maxWidth が指定されている場合は、テキストがその値より
幅広くならないようにします。具体的には、これらのメソッドが呼び出されたとき、
ユーザーエージェントは次の手順を実行しなければなりません。
いずれかの引数が無限大または NaN である場合は、戻ります。
text、CanvasText インターフェイスを
実装するオブジェクト、および maxWidth 引数が指定されている場合はその引数を渡して、
テキスト
準備アルゴリズムを実行します。その結果を glyphs とします。
glyphs の座標空間内の各CSS ピクセルを1座標空間単位へ対応付け、現在の変換行列によって変換された glyphs 内の図形を描画します。
fillText()
の場合、this の 塗りスタイルを
図形に適用しなければならず、this の ストローク
スタイルは無視しなければなりません。strokeText()
の場合は逆となります。すなわち、線のスタイルに CanvasText インターフェイスを
実装するオブジェクトを使用して図形をトレースした結果に、
this の ストロークスタイルを
適用しなければならず、this の 塗りスタイルは
無視しなければなりません。
これらの図形は現在のパスに影響を与えずに描画され、影の効果、グローバル アルファ、クリッピング 領域、および 現在の合成およびブレンド 演算子の適用対象となります。
![]()
measureText(text) メソッドの手順は、
text および CanvasText
インターフェイスを
実装するオブジェクトを渡して、テキスト
準備アルゴリズムを実行し、返されたインライン
ボックスを使用して、次のリストで説明するように動作するメンバーを持つ新しい TextMetrics オブジェクトを
返すことです。[CSS]
width
属性actualBoundingBoxLeft 属性textAlign
属性によって指定された揃え位置から、指定されたテキストの境界矩形の左辺までの
ベースラインと平行な距離をCSS ピクセル単位で表します。
正の数は、指定された揃え位置から左向きの距離を示します。
この値と次の値(actualBoundingBoxRight)の
合計は、インラインボックスの幅(width)より
広くなる場合があります。特に、文字がその送り幅からはみ出す斜体フォントで発生します。
actualBoundingBoxRight 属性textAlign
属性によって指定された揃え位置から、指定されたテキストの境界矩形の右辺までの
ベースラインと平行な距離をCSS ピクセル単位で表します。
正の数は、指定された揃え位置から右向きの距離を示します。
fontBoundingBoxAscent 属性textBaseline
属性によって示される水平線から、最初に利用可能なフォントのアセント
メトリックまでの距離をCSS
ピクセル単位で表します。正の数は、指定されたベースラインから上向きの距離を示します。
この値と次の値は、レンダリングされる正確なテキストが変わっても
一貫した高さを持つ必要がある背景をレンダリングするときに役立ちます。actualBoundingBoxAscent
属性(およびディセントに対応する属性)は、特定のテキストの周囲に境界ボックスを描画するときに
役立ちます。
fontBoundingBoxDescent 属性textBaseline
属性によって示される水平線から、最初に利用可能なフォントのディセント
メトリックまでの距離をCSS ピクセル単位で表します。
正の数は、指定されたベースラインから下向きの距離を示します。
actualBoundingBoxAscent 属性textBaseline
属性によって示される水平線から、指定されたテキストの境界矩形の上端までの距離を
CSS ピクセル単位で表します。
正の数は、指定されたベースラインから上向きの距離を示します。
この数値は、最初に指定されたフォントが入力内のすべての文字を
カバーしている場合でも、入力テキストによって大きく異なることがあります。たとえば、
アルファベットベースラインからの小文字「o」の
actualBoundingBoxAscent
は、大文字「F」のものより小さくなります。この値は容易に負になることがあります。
たとえば、指定されたテキストが単一のコンマ「,」だけである場合、
emボックスの上端(textBaseline
の値「top」)
から境界矩形の上端までの距離は、フォントが非常に特殊でない限り、おそらく負になります。
actualBoundingBoxDescent 属性textBaseline
属性によって示される水平線から、指定されたテキストの境界矩形の下端までの距離を
CSS ピクセル単位で表します。
正の数は、指定されたベースラインから下向きの距離を示します。
emHeightAscent 属性textBaseline
属性によって示される水平線から、インラインボックス内のem上端
ベースラインまでの距離をCSS ピクセル単位で表します。
正の数は、指定されたベースラインがem上端
ベースラインより下にあることを示します
(したがって、この値は通常、正になります)。指定されたベースラインがem上端
ベースラインである場合は0となり、指定されたベースラインがem上端
ベースラインとem下端
ベースラインの中間にある場合は、フォントサイズの半分となります。
emHeightDescent 属性textBaseline
属性によって示される水平線から、インラインボックス内のem下端
ベースラインまでの距離をCSS ピクセル単位で表します。
正の数は、指定されたベースラインがem下端
ベースラインより上にあることを示します。
(指定されたベースラインがem下端
ベースラインである場合は0です。)
hangingBaseline 属性textBaseline
属性によって示される水平線から、インラインボックスのハンギング
ベースラインまでの距離をCSS ピクセル単位で表します。
正の数は、指定されたベースラインがハンギング
ベースラインより下にあることを示します。
(指定されたベースラインがハンギング
ベースラインである場合は0です。)
alphabeticBaseline 属性textBaseline
属性によって示される水平線から、インラインボックスのアルファベット
ベースラインまでの距離をCSS ピクセル単位で表します。
正の数は、指定されたベースラインがアルファベット
ベースラインより下にあることを示します。(指定されたベースラインがアルファベットベースラインである場合は0です。)
ideographicBaseline 属性textBaseline
属性によって示される水平線から、インラインボックスの表意文字下端
ベースラインまでの距離をCSS ピクセル単位で表します。
正の数は、指定されたベースラインが表意文字下端
ベースラインより下にあることを示します。(指定されたベースラインが表意文字下端
ベースラインである場合は0です。)
fillText()
および
strokeText()
を使用してレンダリングされたグリフは、フォントサイズおよび measureText()
によって返される幅(テキスト幅)によって指定されるボックスからはみ出す場合があります。
これが問題となる場合、作者は上記で説明した境界ボックスの値を使用することが推奨されます。
2DコンテキストAPIの将来のバージョンでは、CSSを使用してレンダリングされた 文書の断片をキャンバスへ直接レンダリングする方法が提供される可能性があります。 これは、複数行レイアウトを行うための専用の方法よりも優先して提供されることになります。
CanvasDrawPath インターフェイスを
実装するオブジェクトには、現在の既定
パスがあります。現在の既定パスは1つだけであり、
描画状態の一部ではありません。現在の既定パスは、
上記で説明したパスです。
context.beginPath()
CanvasRenderingContext2D/beginPath
現行のすべてのエンジンでサポートされています。
現在の 既定パスをリセットします。
context.fill([ fillRule ])
現行のすべてのエンジンでサポートされています。
context.fill(path [, fillRule ])
指定された塗り規則に従い、現在の既定パスまたは指定されたパスの サブパスを、現在の塗りスタイルで塗りつぶします。
context.stroke()
CanvasRenderingContext2D/stroke
現行のすべてのエンジンでサポートされています。
context.stroke(path)
現在の既定パスまたは指定されたパスの サブパスを、現在のストロークスタイルでストロークします。
context.clip([ fillRule ])
現行のすべてのエンジンでサポートされています。
context.clip(path [, fillRule ])
指定された塗り規則を使用して、どの点がパス内にあるかを決定し、 クリッピング領域を現在の既定パスまたは指定された パスにさらに制限します。
context.isPointInPath(x, y [, fillRule ])
CanvasRenderingContext2D/isPointInPath
現行のすべてのエンジンでサポートされています。
context.isPointInPath(path, x, y [, fillRule ])
指定された塗り規則を使用して、どの点がパス内にあるかを決定し、指定された点が 現在の既定パスまたは指定された パス内にある場合は true を返します。
context.isPointInStroke(x, y)
CanvasRenderingContext2D/isPointInStroke
現行のすべてのエンジンでサポートされています。
context.isPointInStroke(path, x, y)
現在のストロークスタイルを使用した場合に、指定された点が 現在の既定パス または指定されたパスのストロークによって覆われる領域内にあるなら、true を返します。
次のメソッド定義で、Path2D
または null である path に対して対象パスという用語を
使用する場合、それは path が Path2D
オブジェクトであれば
path 自体を意味し、それ以外の場合は現在の既定パスを
意味します。
対象パスが Path2D オブジェクトである場合、
これらのメソッドで使用するとき、そのサブパスの座標および線は、CanvasTransform
インターフェイスを実装するオブジェクト上の現在の変換行列に従って変換されなければなりません
(Path2D オブジェクト自体には
影響しません)。対象パスが現在の
既定パスである場合、変換の影響を受けません。(これは、変換が
現在の
既定パスの構築時にすでに影響しているためであり、描画時にも適用すると
二重に変換されることになるためです。)
CanvasDrawPath
context、Path2D または null
である
path、および塗り規則 fillRule
が指定された場合の
塗り手順は、path の対象パスのすべてのサブパスを、
context の塗りスタイルと、
fillRule によって示される塗り規則を使用して塗りつぶすことです。
開いたサブパスは、塗りつぶすときに暗黙的に閉じられなければなりません
(実際のサブパスには影響しません)。
CanvasDrawPath
context および Path2D または
null である
path が指定された場合のストローク手順は、
context の CanvasPathDrawingStyles
ミックスインによって設定された線のスタイルを使用して、path の
対象パスを
トレースし、
その後、非ゼロ巻き数
規則を使用して、結果のパスを context の
ストローク
スタイルで塗りつぶすことです。
パスをトレースするアルゴリズムの定義方法により、 1回のストローク処理で重なり合うパスの部分は、それらの和集合が描画されるものとして扱われます。
現在の既定 パスが使用される場合でも、ストロークのスタイルは描画時の変換の影響を受けます。
パスを塗りつぶすかストロークするときは、現在の既定
パスまたはいずれの Path2D オブジェクトにも影響を
与えずに描画されなければならず、影の効果、グローバル
アルファ、クリッピング領域、および
現在の合成およびブレンド
演算子の適用対象となります。(変換の効果は上記で説明されており、使用されるパスに
よって異なります。)
CanvasDrawPath
context、Path2D または null
である
path、および塗り規則 fillRule
が指定された場合の
クリップ手順は、context の現在のクリッピング領域と、
fillRule によって示される塗り
規則を使用して path の対象
パスによって表される領域との交差を計算し、新しいクリッピング領域を作成することです。開いたサブパスは、
実際のサブパスに影響を与えずに、クリッピング領域を計算するときに暗黙的に
閉じられなければなりません。新しいクリッピング領域が現在のクリッピング領域を置き換えます。
コンテキストが初期化されたとき、その現在のクリッピング領域は最大の無限平面に 設定されなければなりません(すなわち、既定ではクリッピングは行われません)。
isPointInPath(x, y,
fillRule) メソッドの手順は、this、null、x、y、および
fillRule を指定した点がパス内にあるかを判定する
手順の結果を返すことです。
isPointInPath(path, x,
y, fillRule) メソッドの手順は、this、path、x、y、および
fillRule を指定した点がパス内にあるかを判定する
手順の結果を返すことです。
CanvasDrawPath
context、Path2D または null
である
path、2つの数値 x および y、ならびに
塗り規則
fillRule が指定された場合の点がパス内にあるかを判定する手順は次のとおりです。
isPointInStroke(x, y)
メソッドの手順は、this、null、
x、および y を指定した点がストローク内にあるかを判定する手順の
結果を返すことです。
isPointInStroke(path, x,
y) メソッドの手順は、this、path、x、および
y を指定した
点がストローク内にあるかを判定する
手順の結果を返すことです。
CanvasDrawPath
context、Path2D または null
である
path、および2つの数値 x と y が指定された場合の
点がストローク内にあるかを判定する手順は次のとおりです。
x または y が無限大または NaN である場合は、false を返します。
x および y 座標によって指定される点を、現在の変換の影響を
受けないキャンバス座標空間内の座標として扱ったとき、その点が
context の CanvasPathDrawingStyles
ミックスインによって設定された線のスタイルと、非ゼロ巻き数規則を使用して、
path の対象
パスをトレースした結果のパス内にある場合は、
true を返します。結果のパス上にある点は、パス内にあるものと見なさなければなりません。
false を返します。
この canvas
要素には、2つのチェックボックスがあります。パスに関連するコマンドは
強調表示されています。
< canvas height = 400 width = 750 >
< label >< input type = checkbox id = showA > Show As</ label >
< label >< input type = checkbox id = showB > Show Bs</ label >
<!-- ... -->
</ canvas >
< script >
function drawCheckbox( context, element, x, y, paint) {
context. save();
context. font = '10px sans-serif' ;
context. textAlign = 'left' ;
context. textBaseline = 'middle' ;
var metrics = context. measureText( element. labels[ 0 ]. textContent);
if ( paint) {
context. beginPath();
context. strokeStyle = 'black' ;
context. rect( x- 5 , y- 5 , 10 , 10 );
context. stroke();
if ( element. checked) {
context. fillStyle = 'black' ;
context. fill();
}
context. fillText( element. labels[ 0 ]. textContent, x+ 5 , y);
}
context. beginPath();
context. rect( x- 7 , y- 7 , 12 + metrics. width+ 2 , 14 );
context. drawFocusIfNeeded( element);
context. restore();
}
function drawBase() { /* ... */ }
function drawAs() { /* ... */ }
function drawBs() { /* ... */ }
function redraw() {
var canvas = document. getElementsByTagName( 'canvas' )[ 0 ];
var context = canvas. getContext( '2d' );
context. clearRect( 0 , 0 , canvas. width, canvas. height);
drawCheckbox( context, document. getElementById( 'showA' ), 20 , 40 , true );
drawCheckbox( context, document. getElementById( 'showB' ), 20 , 60 , true );
drawBase();
if ( document. getElementById( 'showA' ). checked)
drawAs();
if ( document. getElementById( 'showB' ). checked)
drawBs();
}
function processClick( event) {
var canvas = document. getElementsByTagName( 'canvas' )[ 0 ];
var context = canvas. getContext( '2d' );
var x = event. clientX;
var y = event. clientY;
var node = event. target;
while ( node) {
x -= node. offsetLeft - node. scrollLeft;
y -= node. offsetTop - node. scrollTop;
node = node. offsetParent;
}
drawCheckbox( context, document. getElementById( 'showA' ), 20 , 40 , false );
if ( context. isPointInPath( x, y) )
document. getElementById( 'showA' ). checked = ! ( document. getElementById( 'showA' ). checked);
drawCheckbox( context, document. getElementById( 'showB' ), 20 , 60 , false );
if ( context. isPointInPath( x, y) )
document. getElementById( 'showB' ). checked = ! ( document. getElementById( 'showB' ). checked);
redraw();
}
document. getElementsByTagName( 'canvas' )[ 0 ]. addEventListener( 'focus' , redraw, true );
document. getElementsByTagName( 'canvas' )[ 0 ]. addEventListener( 'blur' , redraw, true );
document. getElementsByTagName( 'canvas' )[ 0 ]. addEventListener( 'change' , redraw, true );
document. getElementsByTagName( 'canvas' )[ 0 ]. addEventListener( 'click' , processClick, false );
redraw();
</ script > context.drawFocusIfNeeded(element)
CanvasRenderingContext2D/drawFocusIfNeeded
現行のすべてのエンジンでサポートされています。
element がフォーカスされている場合、 フォーカスリングに関するプラットフォームの慣例に従い、現在の 既定パスの周囲にフォーカスリングを描画します。
context.drawFocusIfNeeded(path, element)
element がフォーカスされている場合、 フォーカスリングに関するプラットフォームの慣例に従い、path の周囲に フォーカスリングを描画します。
CanvasUserInterface
インターフェイスを実装するオブジェクトは、フォーカスリングを描画するための次の
メソッドを提供します。
drawFocusIfNeeded(element)
メソッドの手順は、this、element、および
this の
現在の既定パスを
指定して、必要に応じてフォーカスを
描画することです。
drawFocusIfNeeded(path,
element) メソッドの手順は、this、element、および
path を指定して、
必要に応じてフォーカスを
描画することです。
CanvasUserInterface
を実装するオブジェクト context、要素 element、および
パス
path が指定された場合に、必要に応じてフォーカスを描画するには、
次の手順を実行します。
element がフォーカスされていない場合、
または context の canvas
要素の子孫でない場合は、戻ります。
プラットフォームの慣例に従い、path に沿って適切なスタイルの フォーカスリングを描画します。
一部のプラットフォームでは、マウスからフォーカスされた要素ではなく、
キーボードからフォーカスされた要素の周囲にのみフォーカスリングを描画します。
他のプラットフォームでは、関連するアクセシビリティ機能が有効になっていない限り、
一部の要素の周囲にフォーカスリングをまったく描画しません。このAPIは、これらの慣例に
従うことを意図しています。要素がフォーカスされた方法に基づく区別を実装する
ユーザーエージェントは、focus()
メソッドによって引き起こされたフォーカスを、その呼び出しの起点となった
ユーザー操作イベントの種類(存在する場合)に基づいて分類することが推奨されます。
フォーカスリングは、影の効果、
グローバルアルファ、
現在の
合成およびブレンド演算子、塗り
スタイル、ストローク
スタイル、または CanvasPathDrawingStyles、
CanvasTextDrawingStyles
インターフェイス内のいずれのメンバーの適用対象にもなるべきではありませんが、
クリッピング領域の
適用対象にはなるべきです。(変換の効果は上記で説明されており、
使用されるパスによって異なります。)
フォーカスが対象パスによって指定された位置にあることを ユーザーに通知します。ユーザーエージェントは、 イベントループが次に レンダリングを更新する 手順へ到達するまで待ってから、任意でユーザーへ通知できます。
ユーザーエージェントは、フォーカスリングを描画するとき、対象パス内の開いたサブパスを 暗黙的に閉じるべきではありません。
ただし、これは問題にならない場合があります。たとえば、対象パス内の点を 囲む軸に平行な境界矩形としてフォーカスリングが描画される場合、サブパスが閉じられているか どうかは影響しません。この仕様では、フォーカスリングを正確にどのように描画するかを 意図的に規定していません。ユーザーエージェントは、プラットフォーム固有の慣例を 尊重することが期待されます。
この節で使用される「ユーザーに通知する」は、永続的な状態変更を意味しません。 たとえば、拡大ツールなどの支援技術へ通知して、ユーザーの拡大表示をキャンバスの指定された 領域へ移動させるために、システムのアクセシビリティAPIを呼び出すことを意味する場合があります。 ただし、パスを要素に関連付けたり、触覚フィードバックのための領域を提供したりするものではありません。
CanvasDrawImage インターフェイスを
実装するオブジェクトには、画像を描画するための drawImage() メソッドがあります。
このメソッドは、3種類の異なる引数の組み合わせで呼び出すことができます。
drawImage(image, dx, dy)
drawImage(image, dx, dy, dw, dh)
drawImage(image, sx, sy, sw, sh, dx, dy, dw, dh)
context.drawImage(image, dx, dy)
CanvasRenderingContext2D/drawImage
現行のすべてのエンジンでサポートされています。
context.drawImage(image, dx, dy, dw, dh)
context.drawImage(image, sx, sy, sw, sh, dx, dy, dw, dh)
指定された画像をキャンバス上へ描画します。引数は次のように解釈されます。
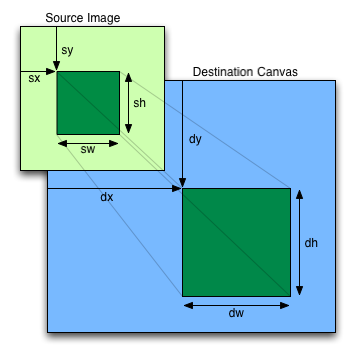
画像がまだ完全に復号されていない場合は、何も描画されません。画像がデータを持たない
キャンバスである場合は、"InvalidStateError" DOMException をスローします。
drawImage()
メソッドが呼び出されたとき、ユーザーエージェントは次の手順を実行しなければなりません。
いずれかの引数が無限大または NaN である場合は、戻ります。
usability を、image の 使用可能性を確認した結果とします。
usability が bad である場合は、何も描画せずに戻ります。
ソース矩形および描画先矩形を次のように確立します。
指定されていない場合、dw および dh 引数は、 画像内の1CSS ピクセルを 出力 ビットマップの座標空間内の1単位として扱うように解釈した、 sw および sh の値を既定値としなければなりません。 sx、sy、sw、および sh 引数が省略された場合は、 それぞれ0、0、画像ピクセル単位での画像の自然幅、および画像ピクセル単位での画像の 自然高さを既定値としなければなりません。 画像に自然 寸法がない場合は、代わりにCSSの「具体的なオブジェクトサイズの 解決」アルゴリズムを使用して決定される、具体的なオブジェクトサイズを 使用しなければなりません。このとき、指定サイズには確定した幅も高さもなく、 追加の制約もなく、オブジェクトの自然プロパティは image 引数のものとし、 既定のオブジェクトサイズは 出力ビットマップのサイズとします。 [CSSIMAGES]
ソース矩形は、4つの点 (sx, sy)、 (sx+sw, sy)、 (sx+sw, sy+sh)、 (sx, sy+sh) を頂点とする矩形です。
描画先矩形は、4つの点 (dx, dy)、 (dx+dw, dy)、 (dx+dw, dy+dh)、 (dx, dy+dh) を頂点とする矩形です。
ソース矩形がソース画像の外側にある場合、ソース矩形はソース画像に合わせて クリップされなければならず、描画先矩形も同じ比率でクリップされなければなりません。
描画先矩形が描画先画像(出力ビットマップ)の外側にある場合、 描画先が無限のキャンバスであり、そのレンダリングが 出力ビットマップの寸法に クリップされる場合と同様に、出力ビットマップの外側に配置されるピクセルは破棄されます。
sw または sh 引数のいずれかが0である場合は、戻ります。 何も描画されません。
描画先矩形に現在の 変換行列を適用した後、ソース矩形によって指定された image 引数の領域を、 描画先矩形によって指定されたレンダリングコンテキストの出力 ビットマップの領域へ描画します。
指定された寸法が負であっても、画像データは元の方向で処理されなければなりません。
拡大時に、imageSmoothingEnabled
属性が true に設定されている場合、ユーザーエージェントは、画像データを拡縮するときに
平滑化アルゴリズムの適用を試みるべきです。複数のフィルタリングアルゴリズムをサポートする
ユーザーエージェントは、imageSmoothingEnabled
属性が true に設定されているとき、imageSmoothingQuality
属性の値を使用して、フィルタリングアルゴリズムの選択を決定できます。
それ以外の場合、画像は最近傍補間を使用してレンダリングされなければなりません。
この仕様では、画像を縮小するとき、または imageSmoothingEnabled
属性が true に設定されている状態で画像を拡大するときに使用する正確なアルゴリズムを
定義していません。
canvas 要素が
自分自身へ描画される場合、描画
モデルでは画像を描画する前にソースをコピーすることが要求されるため、
canvas
要素の一部を、その要素自身の重なり合う部分へコピーできます。
元の画像データがビットマップ画像である場合、描画先矩形内の点に描画される値は、 元の画像データをフィルタリングすることで計算されます。ユーザーエージェントは、 任意のフィルタリングアルゴリズム(たとえば、双線形補間または最近傍法)を使用できます。 フィルタリングアルゴリズムが元の画像データの外側にあるピクセル値を必要とする場合、 代わりに最も近い端のピクセルの値を使用しなければなりません。 (すなわち、フィルターは「clamp-to-edge」動作を使用します。) フィルタリングアルゴリズムがソース矩形の外側であるものの、元の画像データ内にある ピクセル値を必要とする場合、元の画像データの値を使用しなければなりません。
したがって、画像を部分ごとに拡縮しても、全体を拡縮しても同じ効果になります。
これは、単一のスプライトシートから取得したスプライトを拡縮するときに、スプライトシート内の
隣接する画像が干渉する可能性があることを意味します。これは、シート内の各スプライトを
透明な
黒の境界線で囲むか、拡縮するスプライトを一時的な
canvas
要素へコピーし、そこから拡縮されたスプライトを描画することで回避できます。
画像は現在のパスに影響を与えずに描画され、影の効果、グローバル アルファ、クリッピング領域、および 現在の合成およびブレンド 演算子の適用対象となります。
image がオリジンクリーンでない場合は、
CanvasRenderingContext2D
のオリジンクリーンフラグを false
に設定します。
imageData = context.createImageData(imageData)
引数と同じ寸法および色空間を持つ ImageData オブジェクトを返します。
返されるオブジェクト内のすべてのピクセルは透明な
黒です。
imageData = context.createImageData(sw, sh [, settings])
CanvasRenderingContext2D/createImageData
現行のすべてのエンジンでサポートされています。
指定された寸法を持つ ImageData オブジェクトを返します。
settings によって上書きされない限り、返されるオブジェクトの色空間は
context の色空間です。返されるオブジェクト内の
すべてのピクセルは透明な
黒です。
幅または高さの引数のいずれかが0である場合は、"IndexSizeError" DOMException をスローします。
imageData = context.getImageData(sx, sy, sw, sh [, settings])
CanvasRenderingContext2D/getImageData
現行のすべてのエンジンでサポートされています。
ビットマップの指定された矩形の画像データを含む ImageData
オブジェクトを返します。
settings によって上書きされない限り、返されるオブジェクトの色空間は
context の色空間です。
幅または高さの引数のいずれかが0である場合は、"IndexSizeError" DOMException をスローします。
context.putImageData(imageData, dx, dy [, dirtyX, dirtyY, dirtyWidth, dirtyHeight ])
CanvasRenderingContext2D/putImageData
現行のすべてのエンジンでサポートされています。
指定された ImageData オブジェクトのデータを
ビットマップへ描画します。ダーティ矩形が指定されている場合は、その矩形内の
ピクセルだけが描画されます。
globalAlpha
および globalCompositeOperation
プロパティ、ならびに影の属性は、このメソッド呼び出しでは無視されます。
キャンバス内のピクセルは、合成、アルファブレンディング、影などを行わず、全面的に置き換えられます。
imageData オブジェクトの data 属性値の
[[ViewedArrayBuffer]] 内部スロットが切り離されている場合は、"InvalidStateError" DOMException をスローします。
CanvasImageData インターフェイスを
実装するオブジェクトは、ビットマップのピクセルデータを読み書きするための次のメソッドを
提供します。
createImageData(sw, sh,
settings) メソッドの手順は次のとおりです。
sw および sh の一方または両方が0である場合は、
"IndexSizeError" DOMException をスローします。
sw の絶対値、sh の絶対値、settings、および defaultColorSpace を this の色空間に設定したものを指定して、 newImageData を初期化します。
newImageData の画像データを透明な 黒に初期化します。
newImageData を返します。
createImageData(imageData)
メソッドの手順は次のとおりです。
settings を、次の ImageDataSettings
オブジェクトとします。«[
"colorSpace"
→
this
の colorSpace,
"pixelFormat"
→
this
の pixelFormat ]»。
imageData の width
属性の値、imageData の height
属性の値、および settings を指定して、newImageData を
初期化します。
newImageData の画像データを透明な 黒に初期化します。
newImageData を返します。
getImageData(sx, sy, sw,
sh, settings) メソッドの手順は次のとおりです。
sw または sh 引数のいずれかが0である場合は、
"IndexSizeError" DOMException をスローします。
CanvasRenderingContext2D
のオリジンクリーンフラグが
false に
設定されている場合は、"SecurityError" DOMException をスローします。
sw、sh、settings、および defaultColorSpace を this の色空間に設定したものを指定して、 imageData を初期化します。
ソース矩形を、4つの点 (sx, sy)、(sx+sw, sy)、(sx+sw, sy+sh)、(sx, sy+sh) を頂点とする矩形とします。
imageData のピクセル値を、ビットマップの座標空間単位でソース矩形によって
指定された領域内にある、this の出力ビットマップのピクセルに設定します。
その際、'relative-colorimetric'
レンダリングインテントを使用して、this の色空間から
imageData の colorSpace
へ変換します。
imageData を返します。
putImageData(imageData,
dx, dy) メソッドの手順は、
imageData、this の出力
ビットマップ、dx、dy、0、0、
imageData の width、および
imageData の height を
指定して、ImageData のピクセルを
ビットマップ上へ配置することです。
putImageData(imageData,
dx, dy, dirtyX, dirtyY,
dirtyWidth, dirtyHeight) メソッドの手順は、
imageData、this の出力
ビットマップ、dx、dy、dirtyX、dirtyY、
dirtyWidth、および dirtyHeight を指定して、
ImageData の
ピクセルをビットマップ上へ配置することです。
ImageData
imageData、出力ビットマップ
bitmap、および
数値 dx、dy、dirtyX、dirtyY、
dirtyWidth、dirtyHeight が指定された場合に、
ImageData のピクセルを
ビットマップ上へ配置するには、次の手順を実行します。
buffer を、imageData の data 属性値の
[[ViewedArrayBuffer]] 内部スロットとします。
IsDetachedBuffer(buffer) が true である場合は、
"InvalidStateError" DOMException をスローします。
dirtyWidth が負である場合は、dirtyX を dirtyX+dirtyWidth とし、dirtyWidth を dirtyWidth の絶対値に等しくします。
dirtyHeight が負である場合は、dirtyY を dirtyY+dirtyHeight とし、dirtyHeight を dirtyHeight の絶対値に等しくします。
dirtyX が負である場合は、dirtyWidth を dirtyWidth+dirtyX とし、dirtyX を0とします。
dirtyY が負である場合は、dirtyHeight を dirtyHeight+dirtyY とし、dirtyY を0とします。
dirtyX+dirtyWidth が imageData 引数の width 属性より
大きい場合、dirtyWidth を、その width
属性の値から dirtyX の値を引いたものとします。
dirtyY+dirtyHeight が imageData 引数の height 属性より
大きい場合、dirtyHeight を、その height 属性の
値から dirtyY の値を引いたものとします。
これらの変更後、dirtyWidth または dirtyHeight のいずれかが 負または0である場合は、いずれのビットマップにも影響を与えずに戻ります。
dirtyX ≤ x < dirtyX+dirtyWidth
かつ
dirtyY ≤ y < dirtyY+dirtyHeight
を満たすすべての整数値 x および y について、
bitmap 内の座標 (dx+x,
dy+y) のピクセルを、imageData データ構造の
ビットマップ内の座標
(x, y) にあるピクセルの色へ設定します。その際、
'relative-colorimetric'
レンダリングインテントを使用して、imageData の colorSpace
から bitmap の色
空間へ変換します。
色空間間の変換、および事前乗算済み
アルファ色値との相互変換には損失が伴うため、putImageData()
を使用して設定された直後の完全に不透明でないピクセルが、対応する getImageData()
によって異なる値として返される場合があります。
現在のパス、変換行列、影の属性、グローバル アルファ、クリッピング領域、および 現在の合成およびブレンド 演算子は、この節で説明するメソッドに影響してはなりません。
次の例では、スクリプトが描画先として使用できるように ImageData
オブジェクトを
生成します。
// canvas is a reference to a <canvas> element
var context = canvas. getContext( '2d' );
// create a blank slate
var data = context. createImageData( canvas. width, canvas. height);
// create some plasma
FillPlasma( data, 'green' ); // green plasma
// add a cloud to the plasma
AddCloud( data, data. width/ 2 , data. height/ 2 ); // put a cloud in the middle
// paint the plasma+cloud on the canvas
context. putImageData( data, 0 , 0 );
// support methods
function FillPlasma( data, color) { ... }
function AddCloud( data, x, y) { ... } 次は、getImageData()
および putImageData()
を使用してエッジ検出フィルターを実装する例です。
<!DOCTYPE HTML>
< html lang = "en" >
< head >
< title > Edge detection demo</ title >
< script >
var image = new Image();
function init() {
image. onload = demo;
image. src = "image.jpeg" ;
}
function demo() {
var canvas = document. getElementsByTagName( 'canvas' )[ 0 ];
var context = canvas. getContext( '2d' );
// draw the image onto the canvas
context. drawImage( image, 0 , 0 );
// get the image data to manipulate
var input = context. getImageData( 0 , 0 , canvas. width, canvas. height);
// get an empty slate to put the data into
var output = context. createImageData( canvas. width, canvas. height);
// alias some variables for convenience
// In this case input.width and input.height
// match canvas.width and canvas.height
// but we'll use the former to keep the code generic.
var w = input. width, h = input. height;
var inputData = input. data;
var outputData = output. data;
// edge detection
for ( var y = 1 ; y < h- 1 ; y += 1 ) {
for ( var x = 1 ; x < w- 1 ; x += 1 ) {
for ( var c = 0 ; c < 3 ; c += 1 ) {
var i = ( y* w + x) * 4 + c;
outputData[ i] = 127 + - inputData[ i - w* 4 - 4 ] - inputData[ i - w* 4 ] - inputData[ i - w* 4 + 4 ] +
- inputData[ i - 4 ] + 8 * inputData[ i] - inputData[ i + 4 ] +
- inputData[ i + w* 4 - 4 ] - inputData[ i + w* 4 ] - inputData[ i + w* 4 + 4 ];
}
outputData[( y* w + x) * 4 + 3 ] = 255 ; // alpha
}
}
// put the image data back after manipulation
context. putImageData( output, 0 , 0 );
}
</ script >
</ head >
< body onload = "init()" >
< canvas ></ canvas >
</ body >
</ html > 次は、単色を描画し、その結果を getImageData()
を使用して読み戻すときに適用される色空間変換の例です。
<!DOCTYPE HTML>
< html lang = "en" >
< title > Color space image data demo</ title >
< canvas ></ canvas >
< script >
const canvas = document. querySelector( 'canvas' );
const context = canvas. getContext( '2d' , { colorSpace: 'display-p3' });
// Draw a red rectangle. Note that the hex color notation
// specifies sRGB colors.
context. fillStyle = "#FF0000" ;
context. fillRect( 0 , 0 , 64 , 64 );
// Get the image data.
const pixels = context. getImageData( 0 , 0 , 1 , 1 );
// This will print 'display-p3', reflecting the default behavior
// of returning image data in the canvas's color space.
console. log( pixels. colorSpace);
// This will print the values 234, 51, and 35, reflecting the
// red fill color, converted to 'display-p3'.
console. log( pixels. data[ 0 ]);
console. log( pixels. data[ 1 ]);
console. log( pixels. data[ 2 ]);
</ script > context.globalAlpha [ = value ]
CanvasRenderingContext2D/globalAlpha
現行のすべてのエンジンでサポートされています。
レンダリング処理に適用される現在のグローバル アルファ値を返します。
グローバルアルファ値を変更するために 設定できます。0.0~1.0 の範囲外の値は無視されます。
context.globalCompositeOperation [ = value ]
CanvasRenderingContext2D/globalCompositeOperation
現行のすべてのエンジンでサポートされています。
Compositing and Blending で定義されている値のうち、現在の合成およびブレンド演算子を返します。 [COMPOSITE]
現在の合成およびブレンド演算子を 変更するために設定できます。不明な値は無視されます。
CanvasCompositing インターフェイスを
実装するオブジェクトには、グローバルアルファ値と、現在の合成
およびブレンド演算子値があり、どちらもこのオブジェクトに対するすべての描画処理へ
影響します。
グローバルアルファ値は、図形および画像を 出力ビットマップへ合成する前に 適用されるアルファ値を示します。この値の範囲は、0.0(完全に透明)から 1.0(追加の透明度なし)までです。初期値は 1.0 でなければなりません。
globalAlpha の
設定手順は次のとおりです。
指定された値が無限大、NaN、または 0.0~1.0 の範囲外である場合は、 戻ります。
それ以外の場合は、this のグローバル アルファを指定された値に設定します。
現在の合成およびブレンド演算子値は、
グローバルアルファおよび
現在の変換
行列が適用された後、図形および画像を出力ビットマップへどのように描画するかを制御します。
初期値は「source-over」に
設定されなければなりません。
globalCompositeOperation の取得
手順は、this の現在の合成およびブレンド
演算子を返すことです。
globalCompositeOperation
の設定手順は次のとおりです。
指定された値が、<blend-mode> または <composite-mode> プロパティが受け入れるものとして 定義されているどの値とも同一でない場合は、戻ります。 [COMPOSITE]
それ以外の場合は、this の現在の合成およびブレンド演算子を 指定された値に設定します。
context.imageSmoothingEnabled [ = value ]
CanvasRenderingContext2D/imageSmoothingEnabled
現行のすべてのエンジンでサポートされています。
画像を拡大するとき、そのピクセルが表示と正確に一致しない場合に、パターンによる
塗りつぶしおよび drawImage()
メソッドが画像の平滑化を試みるかどうかを返します。
画像を平滑化するか(true)、しないか(false)を変更するために設定できます。
context.imageSmoothingQuality [ = value ]
CanvasRenderingContext2D/imageSmoothingQuality
現在の画像平滑化品質の設定を返します。
画像平滑化の優先品質を変更するために設定できます。指定できる値は、
「low」、
「medium」、
および「high」です。
不明な値は無視されます。
CanvasImageSmoothing
インターフェイスを実装するオブジェクトには、画像の平滑化方法を制御する属性があります。
imageSmoothingEnabled 属性は、取得時には
最後に設定された値を返さなければなりません。設定時には新しい値に設定されなければなりません。
CanvasImageSmoothing
インターフェイスを実装するオブジェクトが作成されたとき、この属性は true に
設定されなければなりません。
imageSmoothingQuality 属性は、取得時には
最後に設定された値を返さなければなりません。設定時には新しい値に設定されなければなりません。
CanvasImageSmoothing
インターフェイスを実装するオブジェクトが作成されたとき、この属性は「low」に
設定されなければなりません。
CanvasShadowStyles
インターフェイスを実装するオブジェクトに対するすべての描画処理は、4つのグローバルな
影属性の影響を受けます。
context.shadowColor [ = value ]
CanvasRenderingContext2D/shadowColor
現行のすべてのエンジンでサポートされています。
現在の影の色を返します。
影の色を変更するために設定できます。CSS 色として解析できない値は無視されます。
context.shadowOffsetX [ = value ]
CanvasRenderingContext2D/shadowOffsetX
現行のすべてのエンジンでサポートされています。
context.shadowOffsetY [ = value ]
CanvasRenderingContext2D/shadowOffsetY
現行のすべてのエンジンでサポートされています。
現在の影のオフセットを返します。
影のオフセットを変更するために設定できます。有限数でない値は無視されます。
context.shadowBlur [ = value ]
CanvasRenderingContext2D/shadowBlur
現行のすべてのエンジンでサポートされています。
影に適用される現在のぼかしレベルを返します。
ぼかしレベルを変更するために設定できます。0 以上の有限数でない値は無視されます。
CanvasShadowStyles インターフェイスを
実装するオブジェクトには、CSS 色である、関連付けられた影の色があります。初期値は
透明な黒でなければなりません。
shadowColor の取得手順は、
this の影の
色を、HTML 互換のシリアライズを
要求してシリアライズした結果を返すことです。
shadowColor
の設定手順は次のとおりです。
shadowOffsetX 属性および
shadowOffsetY 属性は、それぞれ影を正の水平方向および
正の垂直方向へずらす距離を指定します。これらの値は座標空間単位です。
現在の変換行列の影響を受けません。
コンテキストが作成されたとき、影のオフセット属性の初期値は 0 でなければなりません。
取得時には現在の値を返さなければなりません。設定時には、値が無限大または NaN であり、 その場合に新しい値が無視される場合を除き、設定対象の属性を新しい値に設定しなければなりません。
shadowBlur 属性は、ぼかし効果のレベルを指定します。
(単位は座標空間単位に対応せず、現在の変換行列の影響も受けません。)
コンテキストが作成されたとき、shadowBlur
属性の初期値は 0 でなければなりません。
取得時には、この属性は現在の値を返さなければなりません。設定時には、値が負、 無限大、または NaN であり、その場合に新しい値が無視される場合を除き、この属性を 新しい値に設定しなければなりません。
影が描画されるのは、影の
色のアルファ成分の不透明度成分が 0 でなく、かつ shadowBlur、
shadowOffsetX、
または shadowOffsetY の
いずれかが 0 でない場合に限ります。
影が描画される場合、 影は次のようにレンダリングされなければなりません。
A を、影が作成されるソース画像がレンダリングされた、無限の 透明な黒のビットマップとします。
B を、A と同一の座標空間および原点を持つ、無限の 透明な黒のビットマップとします。
A のアルファ成分を B へコピーし、正の x 方向へ
shadowOffsetX、
正の y 方向へ shadowOffsetY
だけオフセットします。
shadowBlur
が 0 より大きい場合は、次の手順を実行します。
σ を shadowBlur の
値の半分とします。
σ を標準偏差として使用し、B に 2D ガウスぼかしを実行します。
ユーザーエージェントは、ガウスぼかし処理中にハードウェアの制限を超えないように、 σ の値を実装固有の最大値へ制限できます。
B 内のすべてのピクセルの赤、緑、および青の成分を、それぞれ 影の色の赤、緑、および青の成分に 設定します。
B 内のすべてのピクセルのアルファ成分に、影の 色のアルファ成分を乗算します。
影はビットマップ B 内にあり、以下で説明する描画モデルの一部としてレンダリングされます。
現在の合成およびブレンド演算子が
「copy」である場合、
図形が影を上書きするため、実質的に影はレンダリングされません。
CanvasFilters
インターフェイスを実装するオブジェクトに対するすべての描画処理は、グローバルな
filter
属性の影響を受けます。
context.filter [ = value ]
CanvasRenderingContext2D/filter
現在のフィルターを返します。
フィルターを変更するために設定できます。値には文字列「none」または
<filter-value-list> として解析可能な文字列を
指定できます。それ以外の値は無視されます。
このようなオブジェクトには、文字列である、関連付けられた現在の
フィルターがあります。現在のフィルターは、初期状態では文字列
「none」に設定されます。現在の
フィルターの値が文字列「none」である場合、コンテキストのフィルターは
無効になります。
filter の設定手順は
次のとおりです。
context. はコンテキストのフィルターを無効にしますが、
filter
= "none"context.、
filter
= ""context.、
および
filter
= nullcontext. はすべて解析不能な入力として扱われ、現在のフィルターの値は変更されません。
filter
=
undefined
現在の フィルターの値で使用される座標は、1ピクセルが1つの SVG ユーザー空間単位および 1つのキャンバス座標空間単位に相当するものとして解釈されます。フィルター座標は 現在の変換行列の影響を受けません。 現在の変換行列は、フィルターへの入力にのみ影響します。フィルターは 出力ビットマップの座標空間で適用されます。
現在の
フィルターの値が、パーセント値、または 'em' 単位もしくは
'ex' 単位を使用して長さを定義する
<filter-value-list> として解析可能な文字列である場合、
これらは属性が設定された時点のフォントスタイルソースオブジェクトの
'font-size' プロパティの算出値を基準として解釈されなければなりません。
特定の場合に算出値が未定義である場合
(たとえば、フォントスタイルソースオブジェクトが要素でないか、
レンダリングされていない場合)、
相対キーワードは font
属性の既定値を基準として解釈されなければなりません。「larger」および「smaller」
キーワードはサポートされません。
現在の フィルターの値が、同じ文書内の SVG フィルターへの参照を含む <filter-value-list> として解析可能な文字列であり、 その SVG フィルターが変更された場合は、変更後のフィルターが次の描画処理で使用されます。
現在の フィルターの値が、外部リソース文書内の SVG フィルターへの参照を含む <filter-value-list> として解析可能な文字列であり、 描画処理が呼び出された時点でその文書が読み込まれていない場合、描画処理は フィルタリングを行わずに続行されなければなりません。
この節は非規範的です。
外部で定義されたフィルターの読み込みが完了するまでは、フィルター値
「none」を使用して描画が行われるため、著者は描画処理を続行する前に、
そのようなフィルターの読み込みが完了しているかどうかを判断したい場合があります。
そのための方法の1つは、同じページ内の別の場所で、load イベントを送信する
何らかの要素(たとえば、SVG
use 要素)に外部で定義されたフィルターを
読み込ませ、load イベントがディスパッチされるまで待機することです。
図形または画像を描画するとき、ユーザーエージェントは次の手順を指定された順序で 実行しなければなりません(または、実行したかのように動作しなければなりません)。
前の各節で説明したように、図形または画像を無限の透明な黒のビットマップへレンダリングし、 画像 A を作成します。図形については、現在の塗り、ストローク、および 線のスタイルを尊重しなければならず、ストローク自体も現在の変換行列の適用対象と しなければなりません。
画像 A をコンテキストの 色空間へ変換します。
色空間が未定義となる 2D コンテキストへの入力は存在しません。 CSS 色の色空間は CSS Color で定義されています。カラープロファイル情報を 指定しない画像の色空間は、CSS Color の タグ付けされていない色の 色空間節で指定されているとおり、'srgb' です。[CSSCOLOR]
A 内のすべてのピクセルのアルファ成分に グローバルアルファを
乗算します。
現在の
フィルターが「none」以外の値に設定され、そのフィルターが参照する
外部で定義されたすべてのフィルター(存在する場合)が現在読み込まれている文書内に
ある場合は、画像 A を現在のフィルターへの入力として使用し、
画像 B を作成します。現在のフィルターが
<filter-value-list> として解析可能な文字列である場合は、
SVG と同じ方法で現在のフィルターを使用して描画します。
それ以外の場合は、B を A の別名とします。
影が描画される場合は、現在の影スタイルを 使用して画像 B から影をレンダリングし、画像 C を作成します。
影が描画される場合は、 現在の 合成およびブレンド演算子を使用して、クリッピング領域内で C を現在の 出力ビットマップの上へ合成します。
現在の合成およびブレンド 演算子を使用して、クリッピング 領域内で B を現在の出力ビットマップの上へ合成します。
出力ビットマップへ合成するとき、 出力ビットマップの外側に 配置されるピクセルは破棄されなければなりません。
キャンバスが対話的である場合、著者は、上の例のように、 キャンバスの各フォーカス可能な部分に 対応するフォーカス可能な要素を、 その要素のフォールバックコンテンツに含めるべきです。
フォーカスリングをレンダリングするとき、フォーカスリングがネイティブの
フォーカスリングの外観を持つようにするため、著者は drawFocusIfNeeded()
メソッドを使用し、リングが描画される要素を渡すべきです。このメソッドは、要素が
フォーカスされている場合にのみ
フォーカスリングを描画するため、要素がフォーカスされているかどうかを最初に確認せず、
要素を描画するたびに単純に呼び出すことができます。
著者は、canvas 要素を使用して
テキスト編集コントロールを実装することを避けるべきです。これには多数の欠点があります。
これは膨大な作業量です。著者には、この作業を行う代わりに、input 要素、
textarea 要素、
または contenteditable 属性を
使用して、このような作業を一切行わないことが強く推奨されます。
この節は非規範的です。
次は、キャンバスを使用して美しく 輝く線を描画するスクリプトの例です。
< canvas width = "800" height = "450" ></ canvas >
< script >
var context = document. getElementsByTagName( 'canvas' )[ 0 ]. getContext( '2d' );
var lastX = context. canvas. width * Math. random();
var lastY = context. canvas. height * Math. random();
var hue = 0 ;
function line() {
context. save();
context. translate( context. canvas. width/ 2 , context. canvas. height/ 2 );
context. scale( 0.9 , 0.9 );
context. translate( - context. canvas. width/ 2 , - context. canvas. height/ 2 );
context. beginPath();
context. lineWidth = 5 + Math. random() * 10 ;
context. moveTo( lastX, lastY);
lastX = context. canvas. width * Math. random();
lastY = context. canvas. height * Math. random();
context. bezierCurveTo( context. canvas. width * Math. random(),
context. canvas. height * Math. random(),
context. canvas. width * Math. random(),
context. canvas. height * Math. random(),
lastX, lastY);
hue = hue + 10 * Math. random();
context. strokeStyle = 'hsl(' + hue + ', 50%, 50%)' ;
context. shadowColor = 'white' ;
context. shadowBlur = 10 ;
context. stroke();
context. restore();
}
setInterval( line, 50 );
function blank() {
context. fillStyle = 'rgba(0,0,0,0.1)' ;
context. fillRect( 0 , 0 , context. canvas. width, context. canvas. height);
}
setInterval( blank, 40 );
</ script > canvas の
2D レンダリングコンテキストは、スプライトベースのゲームによく使用されます。
次の例はこれを示しています。
この例のソースは次のとおりです。
<!DOCTYPE HTML>
< html lang = "en" >
< meta charset = "utf-8" >
< title > Blue Robot Demo</ title >
< style >
html { overflow : hidden ; min-height : 200 px ; min-width : 380 px ; }
body { height : 200 px ; position : relative ; margin : 8 px ; }
. buttons { position : absolute ; bottom : 0 px ; left : 0 px ; margin : 4 px ; }
</ style >
< canvas width = "380" height = "200" ></ canvas >
< script >
var Landscape = function ( context, width, height) {
this . offset = 0 ;
this . width = width;
this . advance = function ( dx) {
this . offset += dx;
};
this . horizon = height * 0.7 ;
// This creates the sky gradient (from a darker blue to white at the bottom)
this . sky = context. createLinearGradient( 0 , 0 , 0 , this . horizon);
this . sky. addColorStop( 0.0 , 'rgb(55,121,179)' );
this . sky. addColorStop( 0.7 , 'rgb(121,194,245)' );
this . sky. addColorStop( 1.0 , 'rgb(164,200,214)' );
// this creates the grass gradient (from a darker green to a lighter green)
this . earth = context. createLinearGradient( 0 , this . horizon, 0 , height);
this . earth. addColorStop( 0.0 , 'rgb(81,140,20)' );
this . earth. addColorStop( 1.0 , 'rgb(123,177,57)' );
this . paintBackground = function ( context, width, height) {
// first, paint the sky and grass rectangles
context. fillStyle = this . sky;
context. fillRect( 0 , 0 , width, this . horizon);
context. fillStyle = this . earth;
context. fillRect( 0 , this . horizon, width, height- this . horizon);
// then, draw the cloudy banner
// we make it cloudy by having the draw text off the top of the
// canvas, and just having the blurred shadow shown on the canvas
context. save();
context. translate( width- (( this . offset+ ( this . width* 3.2 )) % ( this . width* 4.0 )) + 0 , 0 );
context. shadowColor = 'white' ;
context. shadowOffsetY = 30 + this . horizon/ 3 ; // offset down on canvas
context. shadowBlur = '5' ;
context. fillStyle = 'white' ;
context. textAlign = 'left' ;
context. textBaseline = 'top' ;
context. font = '20px sans-serif' ;
context. fillText( 'WHATWG ROCKS' , 10 , - 30 ); // text up above canvas
context. restore();
// then, draw the background tree
context. save();
context. translate( width- (( this . offset+ ( this . width* 0.2 )) % ( this . width* 1.5 )) + 30 , 0 );
context. beginPath();
context. fillStyle = 'rgb(143,89,2)' ;
context. lineStyle = 'rgb(10,10,10)' ;
context. lineWidth = 2 ;
context. rect( 0 , this . horizon+ 5 , 10 , - 50 ); // trunk
context. fill();
context. stroke();
context. beginPath();
context. fillStyle = 'rgb(78,154,6)' ;
context. arc( 5 , this . horizon- 60 , 30 , 0 , Math. PI* 2 ); // leaves
context. fill();
context. stroke();
context. restore();
};
this . paintForeground = function ( context, width, height) {
// draw the box that goes in front
context. save();
context. translate( width- (( this . offset+ ( this . width* 0.7 )) % ( this . width* 1.1 )) + 0 , 0 );
context. beginPath();
context. rect( 0 , this . horizon - 5 , 25 , 25 );
context. fillStyle = 'rgb(220,154,94)' ;
context. lineStyle = 'rgb(10,10,10)' ;
context. lineWidth = 2 ;
context. fill();
context. stroke();
context. restore();
};
};
</ script >
< script >
var BlueRobot = function () {
this . sprites = new Image();
this . sprites. src = 'blue-robot.png' ; // this sprite sheet has 8 cells
this . targetMode = 'idle' ;
this . walk = function () {
this . targetMode = 'walk' ;
};
this . stop = function () {
this . targetMode = 'idle' ;
};
this . frameIndex = {
'idle' : [ 0 ], // first cell is the idle frame
'walk' : [ 1 , 2 , 3 , 4 , 5 , 6 ], // the walking animation is cells 1-6
'stop' : [ 7 ], // last cell is the stopping animation
};
this . mode = 'idle' ;
this . frame = 0 ; // index into frameIndex
this . tick = function () {
// this advances the frame and the robot
// the return value is how many pixels the robot has moved
this . frame += 1 ;
if ( this . frame >= this . frameIndex[ this . mode]. length) {
// we've reached the end of this animation cycle
this . frame = 0 ;
if ( this . mode != this . targetMode) {
// switch to next cycle
if ( this . mode == 'walk' ) {
// we need to stop walking before we decide what to do next
this . mode = 'stop' ;
} else if ( this . mode == 'stop' ) {
if ( this . targetMode == 'walk' )
this . mode = 'walk' ;
else
this . mode = 'idle' ;
} else if ( this . mode == 'idle' ) {
if ( this . targetMode == 'walk' )
this . mode = 'walk' ;
}
}
}
if ( this . mode == 'walk' )
return 8 ;
return 0 ;
},
this . paint = function ( context, x, y) {
if ( ! this . sprites. complete) return ;
// draw the right frame out of the sprite sheet onto the canvas
// we assume each frame is as high as the sprite sheet
// the x,y coordinates give the position of the bottom center of the sprite
context. drawImage( this . sprites,
this . frameIndex[ this . mode][ this . frame] * this . sprites. height, 0 , this . sprites. height, this . sprites. height,
x- this . sprites. height/ 2 , y- this . sprites. height, this . sprites. height, this . sprites. height);
};
};
</ script >
< script >
var canvas = document. getElementsByTagName( 'canvas' )[ 0 ];
var context = canvas. getContext( '2d' );
var landscape = new Landscape( context, canvas. width, canvas. height);
var blueRobot = new BlueRobot();
// paint when the browser wants us to, using requestAnimationFrame()
function paint() {
context. clearRect( 0 , 0 , canvas. width, canvas. height);
landscape. paintBackground( context, canvas. width, canvas. height);
blueRobot. paint( context, canvas. width/ 2 , landscape. horizon* 1.1 );
landscape. paintForeground( context, canvas. width, canvas. height);
requestAnimationFrame( paint);
}
paint();
// but tick every 100ms, so that we don't slow down when we don't paint
setInterval( function () {
var dx = blueRobot. tick();
landscape. advance( dx);
}, 100 );
</ script >
< p class = "buttons" >
< input type = button value = "Walk" onclick = "blueRobot.walk()" >
< input type = button value = "Stop" onclick = "blueRobot.stop()" >
< footer >
< small > Blue Robot Player Sprite by < a href = "https://johncolburn.deviantart.com/" > JohnColburn</ a > .
Licensed under the terms of the Creative Commons Attribution Share-Alike 3.0 Unported license.</ small >
< small > This work is itself licensed under a < a rel = "license" href = "https://creativecommons.org/licenses/by-sa/3.0/" > Creative
Commons Attribution-ShareAlike 3.0 Unported License</ a > .</ small >
</ footer >
ImageBitmap
レンダリングコンテキストImageBitmapRenderingContext
は、ImageBitmap オブジェクトの
内容を表示するためのオーバーヘッドの少ない方法を提供する、パフォーマンス指向の
インターフェイスです。転送のセマンティクスを使用して、全体的なメモリ消費量を削減します。
また、CanvasRenderingContext2D
の drawImage()
メソッドとは異なり、中間合成を回避することでパフォーマンスを効率化します。
たとえば、画像リソースをキャンバスへ取り込むための中間要素として img 要素を使用すると、
復号された画像の2つのコピー、すなわち img 要素のコピーと、
キャンバスのバッキングストア内のコピーが同時にメモリ内へ存在することになります。
非常に大きな画像を扱う場合、このメモリコストが許容できないことがあります。
これは ImageBitmapRenderingContext
を使用することで回避できます。
ImageBitmapRenderingContext
を使用して、メモリおよび CPU を効率的に使用しながら画像を JPEG 形式へ
トランスコードする方法は次のとおりです。
createImageBitmap( inputImageBlob). then( image => {
const canvas = document. createElement( 'canvas' );
const context = canvas. getContext( 'bitmaprenderer' );
context. transferFromImageBitmap( image);
canvas. toBlob( outputJPEGBlob => {
// Do something with outputJPEGBlob.
}, 'image/jpeg' );
}); ImageBitmapRenderingContext
インターフェイス現行のすべてのエンジンでサポートされています。
[Exposed =(Window ,Worker )]
interface ImageBitmapRenderingContext {
readonly attribute (HTMLCanvasElement or OffscreenCanvas ) canvas ;
undefined transferFromImageBitmap (ImageBitmap ? bitmap );
};
dictionary ImageBitmapRenderingContextSettings {
boolean alpha = true ;
};context = canvas.getContext('bitmaprenderer' [, { [ alpha: false ] } ])
特定の canvas
要素へ永続的に関連付けられた ImageBitmapRenderingContext
オブジェクトを返します。
alpha
設定が指定され、false に設定されている場合、キャンバスは常に不透明になるよう強制されます。
context.canvas
コンテキストが関連付けられている canvas
要素を返します。
context.transferFromImageBitmap(imageBitmap)
ImageBitmapRenderingContext/transferFromImageBitmap
現行のすべてのエンジンでサポートされています。
基礎となるビットマップデータを
imageBitmap から context へ転送します。このビットマップは、
context が関連付けられている canvas
要素の内容になります。
context.transferFromImageBitmap(null)
context が関連付けられている canvas
要素の内容を、その canvas
要素の width
および height
内容属性に対応するサイズの透明な黒のビットマップで置き換えます。
canvas 属性は、オブジェクトの作成時に
初期化された値を返さなければなりません。
ImageBitmapRenderingContext
オブジェクトには、ビットマップデータへの
参照である出力ビットマップがあります。
ImageBitmapRenderingContext
オブジェクトには、有効または
空に設定できるビットマップモードがあります。
有効という値は、
コンテキストの出力ビットマップが
transferFromImageBitmap()
によって取得されたビットマップデータを
参照していることを示します。空という値は、
コンテキストの出力
ビットマップが既定の透明なビットマップであることを示します。
ImageBitmapRenderingContext
オブジェクトには、true または false に設定できるアルファフラグもあります。
ImageBitmapRenderingContext
オブジェクトのアルファフラグが
false に設定されている場合、コンテキストが関連付けられている canvas
要素の内容は、source-over 合成演算子を使用して、コンテキストの
出力
ビットマップを同じサイズの不透明な黒のビットマップ上へ合成することで得られます。
アルファフラグが
true に設定されている場合は、出力
ビットマップが、コンテキストの関連付けられている canvas
要素の内容として使用されます。
[COMPOSITE]
他の手段によって同等の結果をより効率的に得られる場合は、 不透明な黒のビットマップ上へ合成する手順を省略するべきです。
ユーザーエージェントが、ImageBitmapRenderingContext
オブジェクトである context 引数と、ビットマップデータを
参照する省略可能な bitmap 引数を使用して、ImageBitmapRenderingContext の
出力ビットマップを設定する必要がある場合は、次の手順を実行しなければなりません。
bitmap 引数が指定されていない場合は、次の手順を実行します。
bitmap 引数が指定されている場合は、次の手順を実行します。
context のビットマップ モードを有効に 設定します。
コピーを作成せずに、context の出力 ビットマップが bitmap と同じ基礎ビットマップデータを参照するように 設定します。
bitmap のオリジンクリーンフラグは、 context の出力 ビットマップが参照するビットマップデータに含まれます。
target および options が渡されるImageBitmapRenderingContext 作成
アルゴリズムは、次の手順から構成されます。
settings を、options を辞書型 ImageBitmapRenderingContextSettings
へ変換した結果とします。
(これは例外をスローする可能性があります。)
context を新しい ImageBitmapRenderingContext
オブジェクトとします。
context の canvas
属性を、target を指すように初期化します。
context の出力 ビットマップを、target のビットマップと同じビットマップに設定します (これにより共有されます)。
context を使用して、ImageBitmapRenderingContext
の
出力ビットマップを設定する手順を実行します。
context のアルファフラグを true に初期化します。
settings の各メンバーを次のように処理します。
alphacontext を返します。
transferFromImageBitmap(bitmap)
メソッドは、呼び出されたときに次の手順を実行しなければなりません。
bitmapContext を、transferFromImageBitmap()
メソッドが呼び出された ImageBitmapRenderingContext
オブジェクトとします。
bitmap が null である場合は、bitmapContext を context 引数として使用し、bitmap 引数を指定せずに、 ImageBitmapRenderingContext の 出力ビットマップを設定する手順を実行してから、戻ります。
bitmap の[[Detached]] 内部スロットの値が
true に設定されている場合は、"InvalidStateError" DOMException をスローします。
context 引数を bitmapContext と等しくし、bitmap 引数が
bitmap の基礎となるビットマップデータを
参照するようにして、ImageBitmapRenderingContext
の
出力ビットマップを設定する手順を実行します。
bitmap の[[Detached]] 内部スロットの値を true に設定します。
bitmap のビットマップ データを未設定にします。
OffscreenCanvas
インターフェイス現行のすべてのエンジンでサポートされています。
typedef (OffscreenCanvasRenderingContext2D or ImageBitmapRenderingContext or WebGLRenderingContext or WebGL2RenderingContext or GPUCanvasContext ) OffscreenRenderingContext ;
dictionary ImageEncodeOptions {
DOMString type = "image/png";
unrestricted double quality ;
};
enum OffscreenRenderingContextId { " 2d " , " bitmaprenderer " , " webgl " , " webgl2 " , " webgpu " };
[Exposed =(Window ,Worker ), Transferable ]
interface OffscreenCanvas : EventTarget {
constructor ([EnforceRange ] unsigned long long width , [EnforceRange ] unsigned long long height );
attribute [EnforceRange ] unsigned long long width ;
attribute [EnforceRange ] unsigned long long height ;
OffscreenRenderingContext ? getContext (OffscreenRenderingContextId contextId , optional any options = null );
ImageBitmap transferToImageBitmap ();
Promise <Blob > convertToBlob (optional ImageEncodeOptions options = {});
attribute EventHandler oncontextlost ;
attribute EventHandler oncontextrestored ;
};OffscreenCanvas は
EventTarget であるため、
OffscreenCanvasRenderingContext2D
と WebGL はどちらも、このオブジェクトへイベントを発生させることができます。
OffscreenCanvasRenderingContext2D
は contextlost
および contextrestored
を発生させることができ、WebGL は webglcontextlost および
webglcontextrestored を発生させることができます。
[WEBGL]
OffscreenCanvas
オブジェクトは、HTMLCanvasElementと
よく似た方法でレンダリングコンテキストを作成するために使用されますが、DOM との接続はありません。
これにより、ワーカー内でキャンバスレンダリングコンテキストを
使用できるようになります。
OffscreenCanvas
オブジェクトは、通常は DOM 内にあり、その埋め込みコンテンツが OffscreenCanvas
オブジェクトによって提供されるプレースホルダー
canvas 要素への弱参照を保持できます。OffscreenCanvas
オブジェクトのビットマップは、OffscreenCanvas の
関連するエージェントの
イベントループの
レンダリングを更新する手順の一部として、
プレースホルダー
canvas 要素へ送られます。
offscreenCanvas = new OffscreenCanvas(width,
height)
OffscreenCanvas/OffscreenCanvas
現行のすべてのエンジンでサポートされています。
プレースホルダー
canvas 要素へ関連付けられておらず、ビットマップのサイズが
width および height 引数によって決定される、新しい OffscreenCanvas
オブジェクトを返します。
context = offscreenCanvas.getContext(contextId [,
options ])
現行のすべてのエンジンでサポートされています。
OffscreenCanvas
オブジェクト上へ描画するための API を公開するオブジェクトを返します。
contextId は、必要な API、すなわち「2d」、
「bitmaprenderer」、
「webgl」、
「webgl2」、
または「webgpu」を
指定します。options はその API によって処理されます。
この仕様では、以下で「2d」
コンテキストを定義します。これは canvas
要素から作成される「2d」
コンテキストに似ていますが、別のものです。WebGL 仕様は「webgl」
および「webgl2」
コンテキストを定義します。WebGPU は「webgpu」
コンテキストを定義します。[WEBGL]
[WEBGPU]
キャンバスがすでに別のコンテキスト型で初期化されている場合は null を返します
(たとえば、「webgl」
コンテキストを取得した後で「2d」
コンテキストを取得しようとする場合)。
OffscreenCanvas
オブジェクトには、オブジェクトの作成時に初期化される内部ビットマップがあります。ビットマップの幅および高さは、
OffscreenCanvas
オブジェクトの width
および height
属性の値と等しくなります。初期状態では、ビットマップのすべてのピクセルは
透明な黒です。
OffscreenCanvas
オブジェクトには、OffscreenCanvas の
作成時に設定される、内部の継承された言語および
継承された方向があります。
OffscreenCanvas
オブジェクトには、レンダリングコンテキストを関連付けることができます。初期状態では、
関連付けられたレンダリングコンテキストはありません。レンダリングコンテキストを持つか
どうか、およびそれがどの種類のレンダリングコンテキストであるかを追跡するため、
OffscreenCanvas
オブジェクトにはコンテキストモードもあります。
初期状態では none ですが、この仕様で定義される
アルゴリズムによって 2d、
bitmaprenderer、
webgl、
webgl2、
webgpu、または
detached のいずれかに変更できます。
new OffscreenCanvas(width,
height) コンストラクターの手順は次のとおりです。
OffscreenCanvas
オブジェクトは転送可能です。
value および dataHolder が指定された場合の転送手順は次のとおりです。
value のコンテキストモードが
none と等しくない場合は、
"InvalidStateError" DOMException をスローします。
width および height を、value のビットマップの寸法とします。
value のビットマップを未設定にします。
dataHolder.[[Width]] を width に設定し、 dataHolder.[[Height]] を height に設定します。
dataHolder.[[Language]] を language に設定し、 dataHolder.[[Direction]] を direction に設定します。
value にプレースホルダー
canvas 要素がある場合は、
dataHolder.[[PlaceholderCanvas]] をその要素への弱参照に設定し、
ない場合は null に設定します。
dataHolder および value が指定された場合の 転送受信手順は次のとおりです。
value のビットマップを、 幅が dataHolder.[[Width]]、高さが dataHolder.[[Height]] である 透明な黒のピクセルの矩形配列に初期化します。
value の継承された 言語を dataHolder.[[Language]] に設定し、その 継承された方向を dataHolder.[[Direction]] に設定します。
dataHolder.[[PlaceholderCanvas]] が null でない場合は、弱参照の
セマンティクスを維持しながら、value のプレースホルダー
canvas 要素を
dataHolder.[[PlaceholderCanvas]] に設定します。
OffscreenCanvas
オブジェクトの getContext(contextId,
options) メソッドは、呼び出されたときに次の手順を実行しなければなりません。
options がオブジェクトでない場合は、 options を null に設定します。
options を、options を JavaScript 値へ 変換した結果に設定します。
次の表で、列見出しがこの OffscreenCanvas
オブジェクトのコンテキスト
モードと一致し、行見出しが contextId と一致するセル内の手順を実行します。
| none | 2d | bitmaprenderer | webgl または webgl2 | webgpu | detached | |
|---|---|---|---|---|---|---|
"2d"
|
|
この同じ第1引数を使用して最後にメソッドが呼び出されたときに返されたものと 同じオブジェクトを返します。 | null を返します。 | null を返します。 | null を返します。 |
"InvalidStateError" DOMException をスローします。
|
"bitmaprenderer"
|
|
null を返します。 | この同じ第1引数を使用して最後にメソッドが呼び出されたときに返されたものと 同じオブジェクトを返します。 | null を返します。 | null を返します。 |
"InvalidStateError" DOMException をスローします。
|
"webgl" または "webgl2"
|
|
null を返します。 | null を返します。 | この同じ第1引数を使用して最後にメソッドが呼び出されたときに返されたものと 同じ値を返します。 | null を返します。 |
"InvalidStateError" DOMException をスローします。
|
"webgpu"
|
|
null を返します。 | null を返します。 | null を返します。 | この同じ第1引数を使用して最後にメソッドが呼び出されたときに返されたものと 同じ値を返します。 |
"InvalidStateError" DOMException をスローします。
|
offscreenCanvas.width [
= value ]
現行のすべてのエンジンでサポートされています。
offscreenCanvas.height [
= value ]
現行のすべてのエンジンでサポートされています。
これらの属性は、OffscreenCanvas
オブジェクトのビットマップの寸法を返します。
指定された寸法を持つ新しい透明な黒のビットマップでビットマップを置き換える (実質的にサイズを変更する)ために設定できます。
OffscreenCanvas
オブジェクトの width 属性または
height 属性のいずれかが設定され
(新しい値または以前と同じ値に設定され)、その OffscreenCanvas
オブジェクトのコンテキスト
モードが2d である場合は、
レンダリング
コンテキストを既定の状態へリセットし、OffscreenCanvas
オブジェクトのビットマップを、
width
および height
属性の新しい値へサイズ変更します。
「webgl」
および「webgl2」
コンテキストのサイズ変更動作は、WebGL 仕様で定義されています。
[WEBGL]
「webgpu」
コンテキストのサイズ変更動作は WebGPU で定義されています。
[WEBGPU]
寸法が変更された OffscreenCanvas
オブジェクトにプレースホルダー
canvas 要素がある場合、そのプレースホルダー
canvas 要素の自然サイズは、OffscreenCanvas の
関連するエージェントの
イベントループの
レンダリングを更新する手順中にのみ
更新されます。
promise = offscreenCanvas.convertToBlob([options])
現行のすべてのエンジンでサポートされています。
OffscreenCanvas
オブジェクト内の画像を含むファイルを表す、新しい Blob オブジェクトによって
履行される Promise を返します。
引数が指定されている場合、その引数は作成される画像ファイルのエンコードオプションを
制御する辞書です。type
フィールドはファイル形式を指定し、既定値は「image/png」です。
要求された形式がサポートされていない場合にも、この形式が使用されます。画像形式が
可変品質をサポートする場合(「image/jpeg」など)、
quality
フィールドは、結果の画像に求められる品質レベルを示す 0.0 以上 1.0 以下の数値です。
canvas.transferToImageBitmap()
OffscreenCanvas/transferToImageBitmap
現行のすべてのエンジンでサポートされています。
OffscreenCanvas
オブジェクト内の画像を持つ、新しく作成された ImageBitmap
オブジェクトを返します。OffscreenCanvas
オブジェクト内の画像は、新しい空の画像で置き換えられます。
convertToBlob(options) メソッドの
手順は次のとおりです。
this の[[Detached]] 内部スロットの値が true である場合は、
"InvalidStateError" DOMException によって
拒否された Promiseを返します。
this のコンテキストモードが
2d
であり、
レンダリングコンテキストの出力
ビットマップのオリジンクリーンフラグが
false に設定されている場合は、"SecurityError" DOMException によって
拒否された Promiseを返します。
this のビットマップにピクセルがない
(すなわち、水平寸法または垂直寸法のいずれかが 0 である)場合は、
"IndexSizeError" DOMException によって
拒否された Promiseを返します。
result を新しい Promise オブジェクトとします。
global を、this の関連するグローバル オブジェクトとします。
次の手順を並行して実行します。
file を、存在する場合は options の
type および
quality を使用した、
bitmap の
ファイルとしてのシリアライズとします。
global を指定して、キャンバス Blob シリアライズタスクソース上に、次の手順を実行するグローバルタスクを キューに追加します。
file が null である場合は、result を
"EncodingError" DOMException によって
拒否します。
それ以外の場合は、global の関連するレルムで作成され、
file を表す新しい Blob オブジェクトによって
result を解決します。[FILEAPI]
result を返します。
transferToImageBitmap() メソッドは、
呼び出されたときに次の手順を実行しなければなりません。
この OffscreenCanvas
オブジェクトの[[Detached]] 内部スロットが true に
設定されている場合は、"InvalidStateError" DOMException をスローします。
この OffscreenCanvas
オブジェクトのコンテキストモードが
none に設定されている場合は、
"InvalidStateError" DOMException をスローします。
image を、この OffscreenCanvas
オブジェクトのビットマップと同じ基礎ビットマップ
データを参照する、新しく作成された ImageBitmap
オブジェクトとします。
この OffscreenCanvas
オブジェクトのビットマップが、
前のビットマップと同じ寸法および色空間を持ち、そのピクセルが透明な黒、またはレンダリングコンテキストの
アルファが false である場合は
不透明な黒に初期化された、新しく作成された
ビットマップを参照するように設定します。
これは、この OffscreenCanvas
のレンダリングコンテキストが WebGLRenderingContext
である場合、preserveDrawingBuffer
の値は効果を持たないことを意味します。
[WEBGL]
image を返します。
次は、OffscreenCanvas
インターフェイスを実装するすべてのオブジェクトが、イベントハンドラー IDL 属性として
サポートしなければならないイベント
ハンドラー(および対応するイベントハンドラーイベント型)です。
| イベントハンドラー | イベントハンドラーイベント型 |
|---|---|
oncontextlost |
contextlost
|
oncontextrestored |
contextrestored
|
OffscreenCanvasRenderingContext2D
現在のすべてのエンジンでサポートされています。
[Exposed =(Window ,Worker )]
interface OffscreenCanvasRenderingContext2D {
readonly attribute OffscreenCanvas canvas ;
};
OffscreenCanvasRenderingContext2D includes CanvasSettings ;
OffscreenCanvasRenderingContext2D includes CanvasState ;
OffscreenCanvasRenderingContext2D includes CanvasTransform ;
OffscreenCanvasRenderingContext2D includes CanvasCompositing ;
OffscreenCanvasRenderingContext2D includes CanvasImageSmoothing ;
OffscreenCanvasRenderingContext2D includes CanvasFillStrokeStyles ;
OffscreenCanvasRenderingContext2D includes CanvasShadowStyles ;
OffscreenCanvasRenderingContext2D includes CanvasFilters ;
OffscreenCanvasRenderingContext2D includes CanvasRect ;
OffscreenCanvasRenderingContext2D includes CanvasDrawPath ;
OffscreenCanvasRenderingContext2D includes CanvasText ;
OffscreenCanvasRenderingContext2D includes CanvasDrawImage ;
OffscreenCanvasRenderingContext2D includes CanvasImageData ;
OffscreenCanvasRenderingContext2D includes CanvasPathDrawingStyles ;
OffscreenCanvasRenderingContext2D includes CanvasTextDrawingStyles ;
OffscreenCanvasRenderingContext2D includes CanvasPath ;OffscreenCanvasRenderingContext2D
オブジェクトは、
OffscreenCanvas
オブジェクトのビットマップに描画するためのレンダリングコンテキストです。
これは CanvasRenderingContext2D
オブジェクトに似ていますが、次の
相違点があります。
ユーザーインターフェイス 機能はサポートされません。
その canvas
属性は、canvas
要素ではなく、
OffscreenCanvas
オブジェクトを参照します。
OffscreenCanvasRenderingContext2D
オブジェクトには、関連付けられた
OffscreenCanvas オブジェクトがあります。これは、OffscreenCanvasRenderingContext2D
オブジェクトが作成された元の OffscreenCanvas
オブジェクトです。
offscreenCanvas = offscreenCanvasRenderingContext2D.canvas
オフスクリーン 2D コンテキスト作成アルゴリズムは、
target(OffscreenCanvas
オブジェクト)および任意でいくつかの引数を渡され、
次の手順を実行することからなります。
アルゴリズムにいくつかの引数が渡された場合、arg をそのような最初の 引数とします。それ以外の場合、arg を undefined とします。
settings を、arg を辞書型
CanvasRenderingContext2DSettings
に変換した結果とします。
(これは例外を投げる可能性があります。)
context を新しい OffscreenCanvasRenderingContext2D
オブジェクトとします。
context の関連付けられた
OffscreenCanvas オブジェクトを
target に設定します。
context と settings を指定して、キャンバス設定出力ビットマップ 初期化アルゴリズムを実行します。
context の出力ビットマップを、target の width
属性および height
属性で指定された寸法を持つ新しく作成されたビットマップに設定し、
target のビットマップを同じビットマップに設定します(これにより共有されます)。
context の アルファフラグが true に設定されている場合、context の出力ビットマップのすべてのピクセルを 透明な 黒に初期化します。それ以外の場合、ピクセルを不透明な 黒に初期化します。
context を返します。
プレースホルダー canvas 要素の内容を
ディスプレイに更新する目的では、実装がウィンドウイベントループの
グラフィックス更新手順を短絡することが推奨されます。これは、たとえばビットマップの内容を、プレースホルダー canvas 要素の
物理的な表示位置にマッピングされたグラフィックスバッファへ直接コピーすることを意味する場合があります。
このような短絡手法または
類似した手法は、特に OffscreenCanvas が
ワーカーイベントループから更新され、
プレースホルダー canvas 要素の
ウィンドウイベントループが
ビジー状態である場合に、表示遅延を大幅に低減できます。
ただし、そのような短絡によって、スクリプトから観測可能な副作用が生じてはなりません。これは、
要素が CanvasImageSource、
ImageBitmapSource
として使用される場合、または
その要素で toDataURL()
もしくは toBlob()
が呼び出される場合に備えて、コミットされたビットマップを引き続きプレースホルダー canvas 要素へ
送信する必要があることを意味します。
canvas 属性は、取得時に、この
OffscreenCanvasRenderingContext2Dの
関連付けられた
OffscreenCanvas
オブジェクトを返さなければなりません。
enum PredefinedColorSpace { " srgb " , " srgb-linear " , " display-p3 " , " display-p3-linear " };PredefinedColorSpace
列挙は、キャンバスのバッキングストアの色空間を指定するために使用されます。
「srgb」値は、「srgb」
色空間を示します。
「srgb-linear」値は、
「srgb-linear」色空間を示します。
「display-p3」値は、
「display-p3」
色空間を示します。
「display-p3-linear」値は、
「display-p3-linear」色空間を示します。
キャンバスを出力デバイスへレンダリングするときは、キャンバスの バッキングストアに色空間 変換を適用しなければなりません。
色空間間を変換するアルゴリズムは、
CSS Color の色の
変換の節にあります。この色空間変換は、
キャンバスのバッキングストアと同じ色
空間を指定するカラープロファイルを持つ img 要素に
適用される色空間変換と同一です。[CSSCOLOR]
ユーザーエージェントが、type および任意の quality を指定して、ビットマップの ファイルとしてのシリアライズを作成するときは、type で指定された形式の画像ファイルを作成しなければなりません。画像ファイルの作成中に エラーが発生した場合(たとえば内部エンコーダーエラー)、シリアライズの 結果は null となります。[PNG]
画像ファイルのピクセルデータは、座標空間単位ごとに 1 画像ピクセルとなるように拡大縮小されたビットマップのピクセルデータでなければならず、 使用するファイル形式が解像度メタデータの符号化をサポートする場合、解像度は 96dpi(CSS ピクセルごとに 1 画像ピクセル)として指定しなければなりません。
type が指定された場合、使用する形式を示すMIME タイプとして解釈しなければなりません。タイプにパラメーターが含まれている場合、そのタイプは サポートされていないものとして扱わなければなりません。
たとえば、値「image/png」は PNG
画像を生成することを意味し、値「image/jpeg」は
JPEG 画像を生成することを意味し、値
「image/svg+xml」は
SVG 画像を生成することを意味します(これには、
ユーザーエージェントがビットマップの生成方法を追跡する必要があり、実現の可能性は低いものの、潜在的には素晴らしい
機能です)。
ユーザーエージェントは PNG(「image/png」)をサポートしなければなりません。ユーザーエージェントは
その他のタイプをサポートしてもかまいません。
ユーザーエージェントが要求されたタイプをサポートしない場合、PNG
形式を使用してファイルを作成しなければなりません。[PNG]
ユーザーエージェントは、そのタイプをサポートしているかどうかを判断する前に、指定されたタイプをASCII 小文字に変換しなければなりません。
アルファ成分をサポートしない画像タイプの場合、シリアライズされた画像は、source-over 合成演算子を使用して、ビットマップ画像を不透明な黒の 背景上に合成したものでなければなりません。
カラープロファイルをサポートする画像タイプの場合、シリアライズされた画像には、基礎となるビットマップの色空間を示す カラープロファイルを含めなければなりません。カラープロファイルをサポートしない画像タイプの場合、シリアライズされた画像は、 「relative-colorimetric」レンダリングインテントを使用して、 「srgb」色空間に変換しなければなりません。
したがって 2D コンテキストでは、適切な寸法を指定して、
toDataURL()
メソッドまたは toBlob()
メソッドの出力をキャンバスにレンダリングするために drawImage()
メソッドを呼び出しても、
最大でもキャンバスの色をより狭い色域にクリッピングすることを除き、目に見える効果はありません。
複数のビット深度をサポートする画像タイプの場合、シリアライズされた画像は、基礎となるビットマップの内容を 最も適切に保持するビット深度を使用しなければなりません。
たとえば、
色タイプが
float16
である 2D コンテキストを、type
「image/png」へシリアライズする場合、結果の
画像はサンプルあたり 16 ビットになります。
このシリアライズでも、依然としてかなりの詳細が失われます(0.5/65535 未満のすべての値は
0 にクランプされ、1 より大きいすべての値は 1 にクランプされます)。
type が可変品質をサポートする画像形式(
「image/jpeg」など)で、
quality が指定され、かつ type が
「image/png」でない場合、
quality が 0.0 以上 1.0 以下の範囲のNumber であるなら、
ユーザーエージェントは quality を目的の
品質レベルとして扱わなければなりません。それ以外の場合、ユーザーエージェントは、
quality 引数が指定されなかった場合と同様に、既定の品質値を使用しなければなりません。
ここで単純に quality を
Web IDL の double と宣言するのではなく型検査を使用しているのは、歴史的な名残です。
「品質」の解釈は、実装によってわずかに異なることがあります。 品質が指定されていない場合、圧縮率、画像品質、およびエンコード 時間の間の妥当な折衷を表す、実装固有の既定値が使用されます。
canvas 要素のセキュリティこの節は非規範的です。
あるオリジンのスクリプトが、別のオリジン(同一ではないオリジン)の画像から情報(たとえばピクセルの読み取り)に アクセスできる場合、情報漏洩が発生する可能性があります。
これを軽減するため、canvas 要素、
OffscreenCanvas
オブジェクト、および ImageBitmap
オブジェクトで使用されるビットマップには、それらが
オリジンクリーンであるかどうかを示すフラグがあるものとして定義されます。すべてのビットマップは、
オリジンクリーンが true
に設定された状態で始まります。クロスオリジン画像が使用されると、
フラグは false に設定されます。
toDataURL()、
toBlob()、および
getImageData()
メソッドはこのフラグを検査し、
クロスオリジンデータを漏洩させる代わりに、「SecurityError」 DOMException
を投げます。
オリジンクリーンフラグの値は、
createImageBitmap()
によって、ソースのビットマップから新しい ImageBitmap オブジェクトへ伝播されます。
逆に、ソース画像が、そのビットマップのオリジンクリーンフラグが false に設定されている
ImageBitmap オブジェクトである場合、
drawImage
によって、宛先の canvas 要素の
ビットマップのオリジンクリーンフラグが false に設定されます。
このフラグは特定の状況でリセットできます。たとえば、
CanvasRenderingContext2D
が結び付けられている canvas 要素の
width または
height 内容
属性の値を変更すると、ビットマップは
クリアされ、そのオリジンクリーンフラグがリセットされます。
ImageBitmapRenderingContext
を使用する場合、オリジンクリーンフラグの値は、
ImageBitmap オブジェクトが
transferFromImageBitmap()
を介して canvasへ
転送されるときに、そのオブジェクトから伝播されます。
乗算済みアルファとは、画像内の透明度を 表現する方法の一つを指し、もう一つは非乗算済みアルファです。
非乗算済みアルファでは、ピクセルの赤、緑、および青の成分がその ピクセルの色を表し、そのアルファ成分がそのピクセルの不透明度を表します。
一方、乗算済みアルファでは、ピクセルの赤、緑、および青の成分が、 そのピクセルが画像に加える色の量を表し、アルファ成分が、 そのピクセルが背後にあるものを覆い隠す量を表します。
たとえば、色成分の範囲が 0(オフ)から 255(最大強度)までであると仮定すると、次の 色の例は以下のように表現されます。
| CSS 色表現 | 乗算済み表現 | 非乗算済み表現 | 色の説明 | ほかの内容の上に合成された色の画像 |
|---|---|---|---|---|
| rgba(255, 127, 0, 1) | 255, 127, 0, 255 | 255, 127, 0, 255 | 完全に不透明なオレンジ | 
|
| rgba(255, 255, 0, 0.5) | 127, 127, 0, 127 | 255, 255, 0, 127 | 半透明の黄色 | 
|
| 表現不可 | 255, 127, 0, 127 | 表現不可 | 加算的な半透明のオレンジ | 
|
| 表現不可 | 255, 127, 0, 0 | 表現不可 | 加算的な完全に透明なオレンジ | 
|
| rgba(255, 127, 0, 0) | 0, 0, 0, 0 | 255, 127, 0, 0 | 完全に透明な(「見えない」)オレンジ | 
|
| rgba(0, 127, 255, 0) | 0, 0, 0, 0 | 255, 127, 0, 0 | 完全に透明な(「見えない」)ターコイズ |
|
色値を非乗算済み表現から 乗算済み表現へ変換することには、その色の赤、緑、および 青の成分にアルファ成分を乗算することが含まれます(アルファ成分の範囲を、 「完全に透明」が 0、「完全に不透明」が 1 となるように再マッピングします)。
色値を乗算済み表現から 非乗算済み表現へ変換することには、その逆、つまり色の赤、 緑、および青の成分をアルファ成分で除算することが含まれます。
特定の色は乗算済みアルファでのみ表現でき(たとえば加算色)、 ほかの色は非乗算済みアルファでのみ表現できる(たとえば、 不透明度がなくても特定の赤、緑、および青の値を保持する「見えない」色)うえ、 有限精度を使用した除算と乗算では精度が失われるため、 乗算済みアルファと非乗算済みアルファの間の変換は、完全に 不透明ではない色に対して損失を伴う処理となります。
CanvasRenderingContext2Dの
出力ビットマップおよび
OffscreenCanvasRenderingContext2Dの
出力ビットマップは、
透明色を表現するために乗算済み
アルファを使用しなければなりません。
キャンバスのビットマップが乗算済みアルファを使用して色を表現することは、
表現可能な色の範囲に影響するため重要です。CSS の色は非乗算済みであり加算色を表現できないため、
現在、加算色をキャンバスへ直接描画することはできませんが、
たとえば加算色を WebGL キャンバスに描画し、その WebGL キャンバスを drawImage()
を介して 2D キャンバスに描画することは可能です。
現在のすべてのエンジンでサポートされています。
この節は非規範的です。
カスタム要素は、作者が 独自の完全な機能を備えた DOM 要素を構築するための方法を提供します。作者は常に、文書内で非標準要素を使用し、 後からスクリプトなどによってアプリケーション固有の動作を追加できましたが、そのような 要素は歴史的に非適合であり、十分な機能を備えていませんでした。カスタム要素を定義することにより、作者は、要素を適切に構築する方法と、 そのクラスの要素が変更にどのように反応すべきかを構文解析器へ知らせることができます。
カスタム要素は、既存のプラットフォーム機能(HTML の要素など)を、 作者に公開されたより低水準の拡張ポイント(カスタム要素定義など)によって説明することで、 「プラットフォームを合理化する」という、より大きな取り組みの一部です。現在、カスタム要素の能力には、 機能面でも意味論面でも多くの制限があり、HTML の既存要素の動作を完全に 説明することはできませんが、この隔たりが時間とともに縮小することを期待しています。
この節は非規範的です。
自律型カスタム要素の作成方法を説明するため、 国旗の小さなアイコンのレンダリングをカプセル化するカスタム要素を 定義してみましょう。目標は、次のように使用できるようにすることです。
< flag-icon country = "nl" ></ flag-icon > これを行うため、まず HTMLElement
を拡張して、カスタム要素のクラスを宣言します。
class FlagIcon extends HTMLElement {
constructor() {
super ();
this . _countryCode = null ;
}
static observedAttributes = [ "country" ];
attributeChangedCallback( name, oldValue, newValue) {
// observedAttributes により、name は常に "country" になります
this . _countryCode = newValue;
this . _updateRendering();
}
connectedCallback() {
this . _updateRendering();
}
get country() {
return this . _countryCode;
}
set country( v) {
this . setAttribute( "country" , v);
}
_updateRendering() {
// 読者への演習として残します。ただし、おそらく
// this.ownerDocument.defaultView を検査して、ブラウジングコンテキストを持つ
// 文書に挿入されているかどうかを確認し、挿入されていない場合は
// 何も処理しないようにする必要があります。
}
} 次に、このクラスを使用して要素を定義する必要があります。
customElements. define( "flag-icon" , FlagIcon); この時点で、上記のコードが動作するようになります。構文解析器は flag-icon タグを見つけるたびに、
FlagIcon クラスの新しいインスタンスを構築し、新しい country
属性についてコードに通知します。そしてその属性を使用して要素の内部状態を設定し、
(適切な場合に)レンダリングを更新します。
DOM API を使用して flag-icon 要素を作成することもできます。
const flagIcon = document. createElement( "flag-icon" )
flagIcon. country = "jp"
document. body. appendChild( flagIcon) 最後に、カスタム要素コンストラクター自体を使用することもできます。つまり、 上記のコードは次と同等です。
const flagIcon = new FlagIcon()
flagIcon. country = "jp"
document. body. appendChild( flagIcon) この節は非規範的です。
true の値を持つ静的な formAssociated プロパティを追加すると、
自律型カスタム
要素がフォーム関連カスタム要素になります。
ElementInternals
インターフェイスは、フォームコントロール要素に共通する機能とプロパティを
実装するのに役立ちます。
class MyCheckbox extends HTMLElement {
static formAssociated = true ;
static observedAttributes = [ 'checked' ];
constructor() {
super ();
this . _internals = this . attachInternals();
this . addEventListener( 'click' , this . _onClick. bind( this ));
}
get form() { return this . _internals. form; }
get name() { return this . getAttribute( 'name' ); }
get type() { return this . localName; }
get checked() { return this . hasAttribute( 'checked' ); }
set checked( flag) { this . toggleAttribute( 'checked' , Boolean( flag)); }
attributeChangedCallback( name, oldValue, newValue) {
// observedAttributes により、name は常に "checked" になります
this . _internals. setFormValue( this . checked ? 'on' : null );
}
_onClick( event) {
this . checked = ! this . checked;
}
}
customElements. define( 'my-checkbox' , MyCheckbox); カスタム要素 my-checkbox は、組み込みのフォーム関連要素と同じように使用できます。
たとえば、これを form または
label
に配置すると、my-checkbox 要素はそれらと関連付けられ、
form を送信すると、
my-checkbox の実装によって提供されたデータが送信されます。
< form action = "..." method = "..." >
< label >< my-checkbox name = "agreed" ></ my-checkbox > 利用規約を読みました。</ label >
< input type = "submit" >
</ form >
この節は非規範的です。
ElementInternals
の適切なプロパティを使用することにより、カスタム要素に
既定のアクセシビリティセマンティクスを持たせることができます。次のコードは、前の節のフォーム関連チェックボックスを拡張し、
アクセシビリティ技術から見た既定のロールとチェック状態を適切に設定します。
class MyCheckbox extends HTMLElement {
static formAssociated = true ;
static observedAttributes = [ 'checked' ];
constructor() {
super ();
this . _internals = this . attachInternals();
this . addEventListener( 'click' , this . _onClick. bind( this ));
this . _internals. role = 'checkbox' ;
this . _internals. ariaChecked = 'false' ;
}
get form() { return this . _internals. form; }
get name() { return this . getAttribute( 'name' ); }
get type() { return this . localName; }
get checked() { return this . hasAttribute( 'checked' ); }
set checked( flag) { this . toggleAttribute( 'checked' , Boolean( flag)); }
attributeChangedCallback( name, oldValue, newValue) {
// observedAttributes により、name は常に "checked" になります
this . _internals. setFormValue( this . checked ? 'on' : null );
this . _internals. ariaChecked = this . checked;
}
_onClick( event) {
this . checked = ! this . checked;
}
}
customElements. define( 'my-checkbox' , MyCheckbox); 組み込み要素の場合と同様に、これらは既定値にすぎず、ページ作者が role 属性および aria-*
属性を使用して上書きできることに注意してください。
<!-- このマークアップは非適合です -->
< input type = "checkbox" checked role = "button" aria-checked = "false" > <!-- このマークアップは、おそらくカスタム要素の作者が意図したものではありません -->
< my-checkbox role = "button" checked aria-checked = "false" > カスタム要素の作者は、そのアクセシビリティセマンティクスのどの側面が
強いネイティブセマンティクス、すなわちカスタム要素の利用者によって上書きされるべきではないものかを明示することが推奨されます。この
例では、my-checkbox 要素の作者は、その
ロールおよび aria-checked
値が強い
ネイティブセマンティクスであると明示し、上記のようなコードを使用しないよう促すことになります。
この節は非規範的です。
カスタマイズされた組み込み要素は、 カスタム要素の 独特な種類であり、自律型カスタム 要素とは少し異なる方法で定義され、非常に異なる方法で使用されます。これらは、 既存の HTML 要素を新しいカスタム機能で拡張することにより、その要素の動作を再利用できるようにするために存在します。残念ながら、 HTML 要素の既存の動作の多くは、純粋な自律型カスタム要素を使用して複製できないため、これは重要です。 代わりに、カスタマイズされた組み込み要素は、 既存の要素にカスタム構築動作、ライフサイクルフック、およびプロトタイプチェーンを インストールし、実質的には、すでに存在する要素の上にこれらの能力を「ミックスイン」できるようにします。
カスタマイズされた組み込み要素には、 自律型カスタム要素とは異なる構文が必要です。 これは、ユーザーエージェントやその他のソフトウェアが、要素のセマンティクスと動作を識別するために、 要素のローカル名を基準とするためです。つまり、既存の動作の上に構築されるカスタマイズされた組み込み要素の 概念は、拡張される要素が元のローカル名を保持することに決定的に依存しています。
この例では、plastic-button という名前のカスタマイズされた組み込み要素を作成します。
この要素は通常のボタンのように動作しますが、クリックするたびに派手なアニメーション
効果が追加されます。前と同様にクラスを定義することから始めますが、
今回は HTMLElement
ではなく HTMLButtonElement
を拡張します。
class PlasticButton extends HTMLButtonElement {
constructor() {
super ();
this . addEventListener( "click" , () => {
// 派手なアニメーション効果を描画します!
});
}
} カスタム要素を定義するときは、extends
オプションも指定する必要があります。
customElements. define( "plastic-button" , PlasticButton, { extends : "button" }); 一般に、拡張される要素の名前は、その要素がどの要素インターフェイスを拡張しているかを見るだけでは
判断できません。多くの要素が同じインターフェイスを共有しているためです(たとえば、
q と blockquote
はどちらも HTMLQuoteElement
を共有しています)。
構文解析された HTML ソーステキストからカスタマイズされた組み込み要素を
構築するには、button
要素で is 属性を使用します。
< button is = "plastic-button" > クリックしてください!</ button > カスタマイズされた組み込み要素を
自律型カスタム
要素として使用しようとしても、動作しません。つまり、<plastic-button>クリック
しますか?</plastic-button> は、特別な
動作を持たない HTMLElement
を単に作成します。
カスタマイズされた組み込み要素をプログラムによって作成する必要がある場合、次の形式の createElement()
を使用できます。
const plasticButton = document. createElement( "button" , { is: "plastic-button" });
plasticButton. textContent = "クリックしてください!" ; 前と同様に、コンストラクターも動作します。
const plasticButton2 = new PlasticButton();
console. log( plasticButton2. localName); // "button" を出力します
console. assert( plasticButton2 instanceof PlasticButton);
console. assert( plasticButton2 instanceof HTMLButtonElement); カスタマイズされた組み込み要素をプログラムによって作成するとき、is 属性は明示的に
設定されていないため、DOM 内には存在しないことに注意してください。ただし、シリアライズ時には出力へ
追加されます。
console. assert( ! plasticButton. hasAttribute( "is" ));
console. log( plasticButton. outerHTML); // '<button is="plastic-button"></button>' を出力します 作成方法にかかわらず、button
が持つすべての特別な性質は、このような「プラスチックボタン」にも適用されます。これには、フォーカス動作、
フォーム
送信に参加する能力、disabled
属性などが含まれます。
カスタマイズされた組み込み要素は、
有用なユーザーエージェント提供の動作または API を持つ既存の HTML
要素を拡張できるよう設計されています。そのため、この仕様で定義された既存の HTML 要素のみを拡張でき、
bgsound、blink、isindex、keygen、
multicol、nextid、または spacer のように、
HTMLUnknownElement
を要素
インターフェイスとして使用するよう定義されたレガシー要素を拡張することはできません。
この要件の理由の一つは、将来互換性です。たとえば combobox のような、
現在は未知の要素を拡張するカスタマイズされた組み込み
要素が定義された場合、この仕様が将来 combobox 要素を定義できなくなります。派生した
カスタマイズされた
組み込み要素の利用者が、その基底要素には注目すべき
ユーザーエージェント提供の動作がないことに依存するようになるためです。
この節は非規範的です。
以下で規定し、上でも触れたように、
taco-button という要素を単に定義して使用しても、そのような要素がボタンを表すことにはなりません。つまり、ウェブブラウザー、
検索エンジン、
またはアクセシビリティ技術などのツールは、その定義された名前だけに基づいて、生成された要素を自動的にボタンとして
扱うことはありません。
引き続き自律型 カスタム要素を使用しながら、さまざまな利用者に目的のボタンセマンティクスを伝えるには、 多数の技法を採用する必要があります。
tabindex
属性を追加すると、
taco-button がフォーカス可能になります。
taco-button が論理的に無効になった場合は、tabindex
属性を削除する必要があることに注意してください。
ARIA ロールとさまざまな ARIA の状態およびプロパティを追加すると、アクセシビリティ技術に
セマンティクスを伝えるのに役立ちます。たとえば、ロールを「button」
に設定すると、これがボタンであるというセマンティクスが伝わり、
利用者はアクセシビリティ技術で通常のボタンと同様の操作を使用して、コントロールを正常に
操作できるようになります。アクセシビリティ技術に子テキストノードをたどらせて
読み上げさせる代わりに、ボタンへアクセシブルな
名前を与えるには、aria-label
プロパティを設定する必要があります。また、ボタンが論理的に無効になっているときに aria-disabled
状態を
「true」に設定すると、ボタンの無効状態がアクセシビリティ
技術に伝わります。
一般に期待されるボタンの動作を処理するイベントハンドラーを追加すると、
ウェブブラウザーの利用者にボタンのセマンティクスを伝えるのに役立ちます。この場合、最も関連性の高いイベントハンドラーは、
適切な keydown
イベントを click
イベントへプロキシーし、キーボードでもクリックでも
ボタンを作動できるようにするものです。
taco-button 要素に提供される既定の視覚的スタイルに加えて、
無効になる場合など、論理状態の変化を反映するように視覚的スタイルも更新する必要があります。つまり、
taco-button の規則を持つスタイルシートには、taco-button[disabled] の規則も
必要になります。
これらの点を考慮すると、ボタンのセマンティクスを伝える責任
(無効化できる機能を含む)を担う、完全な機能を備えた taco-button は、
次のようになります。
class TacoButton extends HTMLElement {
static observedAttributes = [ "disabled" ];
constructor() {
super ();
this . _internals = this . attachInternals();
this . _internals. role = "button" ;
this . addEventListener( "keydown" , e => {
if ( e. code === "Enter" || e. code === "Space" ) {
this . dispatchEvent( new PointerEvent( "click" , {
bubbles: true ,
cancelable: true
}));
}
});
this . addEventListener( "click" , e => {
if ( this . disabled) {
e. preventDefault();
e. stopImmediatePropagation();
}
});
this . _observer = new MutationObserver(() => {
this . _internals. ariaLabel = this . textContent;
});
}
connectedCallback() {
this . setAttribute( "tabindex" , "0" );
this . _observer. observe( this , {
childList: true ,
characterData: true ,
subtree: true
});
}
disconnectedCallback() {
this . _observer. disconnect();
}
get disabled() {
return this . hasAttribute( "disabled" );
}
set disabled( flag) {
this . toggleAttribute( "disabled" , Boolean( flag));
}
attributeChangedCallback( name, oldValue, newValue) {
// observedAttributes により、name は常に "disabled" になります
if ( this . disabled) {
this . removeAttribute( "tabindex" );
this . _internals. ariaDisabled = "true" ;
} else {
this . setAttribute( "tabindex" , "0" );
this . _internals. ariaDisabled = "false" ;
}
}
} このかなり複雑な要素定義を使用しても、この要素は利用者にとって使いやすいものではありません。
要素は自らの判断で tabindex
属性を継続的に「生やす」ことになり、tabindex="0" によるフォーカス可能性の
動作は、現在のプラットフォームにおける button
の動作と一致しない可能性があります。これは、
現時点ではカスタム要素の既定のフォーカス動作を指定する方法がなく、そのため
tabindex
属性を使用せざるを得ないためです(通常、この属性は
利用者が既定の動作を上書きできるようにするために予約されています)。
対照的に、前の節で示した単純なカスタマイズされた組み込み要素は、
button
要素のセマンティクスと動作を自動的に継承し、
これらの動作を手作業で実装する必要はありません。一般に、HTML の既存要素の上に構築される、
自明でない動作とセマンティクスを持つ要素では、カスタマイズされた組み込み要素のほうが、
開発、保守、および利用が容易になります。
この節は非規範的です。
要素の 定義はいつでも行えるため、非カスタム要素が 作成され、 適切な定義が登録された後で、カスタム 要素になることがあります。通常の要素からカスタム 要素へ変化させるこの処理を、要素の「アップグレード」と呼びます。
アップグレードにより、構文解析器などによって関連要素が最初に作成された後で、
カスタム要素定義を
登録するほうが望ましい状況に対応できます。これにより、カスタム要素内の内容を
段階的に拡張できます。たとえば、次の HTML
文書では、img-viewer の要素定義が
非同期に読み込まれます。
<!DOCTYPE html>
< html lang = "en" >
< title > 画像ビューアーの例</ title >
< img-viewer filter = "Kelvin" >
< img src = "images/tree.jpg" alt = "何もないサバンナにそびえ立つ美しい木" >
</ img-viewer >
< script src = "js/elements/img-viewer.js" async ></ script > ここでは、img-viewer 要素の定義は、
マークアップ内の <img-viewer> タグの後に配置された、async
属性が付いた script
要素を使用して読み込まれます。
スクリプトが読み込まれている間、img-viewer 要素は、span と同様に、
未定義の要素として扱われます。スクリプトが
読み込まれると、img-viewer 要素が定義され、ページ上にある既存の img-viewer 要素が
アップグレードされ、カスタム要素の定義が適用されます(この定義にはおそらく、
「Kelvin」という文字列で識別される画像フィルターを適用し、画像の視覚的な
外観を向上させる処理が含まれます)。
アップグレードは、文書ツリー内の 要素にのみ適用されることに注意してください。(正式には、接続されている要素です。)文書に 挿入されていない要素は、アップグレードされないままとなります。次の例はこの点を示しています。
<!DOCTYPE html>
< html lang = "en" >
< title > アップグレードの特殊事例の例</ title >
< example-element ></ example-element >
< script >
"use strict" ;
const inDocument = document. querySelector( "example-element" );
const outOfDocument = document. createElement( "example-element" );
// 要素定義前は、両方とも HTMLElement です。
console. assert( inDocument instanceof HTMLElement);
console. assert( outOfDocument instanceof HTMLElement);
class ExampleElement extends HTMLElement {}
customElements. define( "example-element" , ExampleElement);
// 要素定義後、文書内の要素はアップグレードされています。
console. assert( inDocument instanceof ExampleElement);
console. assert( ! ( outOfDocument instanceof ExampleElement));
document. body. appendChild( outOfDocument);
// 要素を文書内へ移動したため、この要素もアップグレードされています。
console. assert( outOfDocument instanceof ExampleElement);
</ script > 複数のライブラリーが明示的な調整なしに共存できるように、
CustomElementRegistry
はスコープ付きの方法でも使用できます。
const scoped = new CustomElementRegistry();
scoped. define( "example-element" , ExampleElement);
const element = document. createElement( "example-element" , { customElementRegistry: scoped }); スコープ付きの CustomElementRegistry
が関連付けられているノードは、setHTMLUnsafe()
を呼び出す場合など、そのすべての操作でそのレジストリーを使用します。
ユーザーエージェントが提供する組み込み要素には、利用者の操作やその他の要因に応じて
時間とともに変化する特定の状態があり、擬似クラスを通じてウェブ作者に公開されます。たとえば、一部のフォームコントロールには
「無効」という状態があり、これは :invalid
擬似クラスを通じて公開されます。
組み込み要素と同様に、カスタム 要素もさまざまな 状態を持つことができ、カスタム 要素の作者は、組み込み要素と同様の方法でこれらの状態を公開することを望みます。
これは :state()
擬似クラスを介して行われます。
カスタム
要素の作者は、ElementInternals
の states
プロパティを使用してそのようなカスタム状態を追加および削除でき、それらは
:state()
擬似クラスの引数として公開されます。
次の例は、:state()
を使用して
カスタムチェックボックス要素にスタイルを設定する方法を示しています。
LabeledCheckbox は、その「checked」状態を内容属性を介して公開しないものとします。
< script >
class LabeledCheckbox extends HTMLElement {
constructor() {
super ();
this . _internals = this . attachInternals();
this . addEventListener( 'click' , this . _onClick. bind( this ));
const shadowRoot = this . attachShadow({ mode: 'closed' });
shadowRoot. innerHTML =
`<style>
:host::before {
content: '[ ]';
white-space: pre;
font-family: monospace;
}
:host(:state(checked))::before { content: '[x]' }
</style>
<slot>ラベル</slot>` ;
}
get checked() { return this . _internals. states. has( 'checked' ); }
set checked( flag) {
if ( flag)
this . _internals. states. add( 'checked' );
else
this . _internals. states. delete ( 'checked' );
}
_onClick( event) {
this . checked = ! this . checked;
}
}
customElements. define( 'labeled-checkbox' , LabeledCheckbox);
</ script >
< style >
labeled-checkbox { border : dashed red ; }
labeled-checkbox : state ( checked ) { border : solid ; }
</ style >
< labeled-checkbox > これを確認する必要があります</ labeled-checkbox > カスタム擬似クラスは、シャドウパーツを対象にすることもできます。上記の例を拡張すると、 次のようになります。
< script >
class QuestionBox extends HTMLElement {
constructor() {
super ();
const shadowRoot = this . attachShadow({ mode: 'closed' });
shadowRoot. innerHTML =
`<div><slot>質問</slot></div>
<labeled-checkbox part='checkbox'>はい</labeled-checkbox>` ;
}
}
customElements. define( 'question-box' , QuestionBox);
</ script >
< style >
question-box :: part ( checkbox ) { color : red ; }
question-box :: part ( checkbox ) : state ( checked ) { color : green ; }
</ style >
< question-box > 続行しますか?</ question-box > カスタム要素コンストラクターを作成するとき、 作者は次の適合要件に従わなければなりません。
引数を持たない super() の呼び出しは、
それ以降のコードを実行する前に正しいプロトタイプチェーンと this 値を確立するため、
コンストラクター本体の最初の文でなければなりません。
単純な早期リターン(return または return
this)でない限り、コンストラクター本体内のどこにも return 文が
現れてはなりません。
コンストラクターは、document.write()
または document.open()
メソッドを使用してはなりません。
非アップグレードの場合には属性も子も存在せず、 アップグレードに依存すると要素の使いやすさが低下するため、要素の属性や子を検査してはなりません。
createElement
または createElementNS
メソッドを使用する利用者の期待に反するため、要素に属性や子を追加してはなりません。
一般に、処理は可能な限り connectedCallback まで
遅延させるべきです。特に、リソースの取得やレンダリングを伴う処理が該当します。ただし、
connectedCallback は複数回呼び出される可能性があるため、本当に一度だけ行う初期化処理には、
二度実行されることを防ぐためのガードが必要になることに注意してください。
一般に、コンストラクターは初期状態と既定値の設定、 イベントリスナー、および場合によってはシャドウルートの設定に使用すべきです。
これらの要件のいくつかは、直接または間接的に、要素の 作成中に検査されます。これらに従わないと、構文解析器または DOM API からインスタンス化できないカスタム 要素になります。コンストラクターが開始したマイクロタスク内で処理を行った場合でも同様です。 構築直後にマイクロタスク チェックポイントが発生する可能性があるためです。
カスタム要素リアクションを作成するとき、 予期しない結果につながる可能性があるため、作者はノードツリーの操作を避けるべきです。
要素が切断される前に、その要素の connectedCallback がキューに入ることがあります。
ただしコールバックキューは引き続き処理されるため、すでに接続されていない要素に対して
connectedCallback が実行されることになります。
class CParent extends HTMLElement {
connectedCallback() {
this . firstChild. remove();
}
}
customElements. define( "c-parent" , CParent);
class CChild extends HTMLElement {
connectedCallback() {
console. log( "CChild connectedCallback: isConnected =" , this . isConnected);
}
}
customElements. define( "c-child" , CChild);
const parent = new CParent(),
child = new CChild();
parent. append( child);
document. body. append( parent);
// ログ:
// CChild connectedCallback: isConnected = false この節は非規範的です。
DOM ツリーを操作するとき、要素は接続されたままツリー内で移動できます。これはカスタム
要素にも適用されます。既定では、要素に対して「disconnectedCallback」と「connectedCallback」が
順番に呼び出されます。これは、
moveBefore()
メソッドより前から存在する既存のカスタム要素との互換性を維持するために
行われます。つまり既定では、カスタム
要素は、削除されて再挿入されたかのように状態をリセットします。上記の例では、
オブザーバーが切断されて再接続され、タブインデックスがリセットされます。
移動中に状態を保持する動作を選択するには、作者は
「connectedMoveCallback」を実装できます。このコールバックが存在すると、空であっても、
「disconnectedCallback」と「connectedCallback」を呼び出す既定の動作より優先されます。
「connectedMoveCallback」は、
要素の祖先に依存するロジックを実行する適切な場所にもなります。次に例を示します。
class TacoButton extends HTMLElement {
static observedAttributes = [ "disabled" ];
constructor() {
super ();
this . _internals = this . attachInternals();
this . _internals. role = "button" ;
this . _observer = new MutationObserver(() => {
this . _internals. ariaLabel = this . textContent;
});
}
_notifyMain() {
if ( this . parentElement. tagName === "MAIN" ) {
// 祖先に依存するロジックを実行します。
}
}
connectedCallback() {
this . setAttribute( "tabindex" , "0" );
this . _observer. observe( this , {
childList: true ,
characterData: true ,
subtree: true
});
this . _notifyMain();
}
disconnectedCallback() {
this . _observer. disconnect();
}
// この関数を実装すると、この要素が切断されずに DOM 内を移動した場合に、
// タブインデックスのリセットや変更オブザーバーの再登録を回避できます。
connectedMoveCallback() {
// 状態を保持する移動中に、親が変わることがあります。
this . _notifyMain();
}
} カスタム要素とは、カスタムである要素です。 非形式的には、これは、そのコンストラクターと プロトタイプがユーザーエージェントではなく作者によって定義されることを意味します。作者が提供するこの コンストラクター関数を、カスタム要素 コンストラクターと呼びます。
次の 2 種類の異なるカスタム 要素を定義できます。
自律型カスタム要素。これは、
extends
オプションなしで定義されます。この種類のカスタム
要素は、その定義名と等しいローカル名を持ちます。
カスタマイズされた組み込み要素。これは、
extends
オプションを指定して定義されます。この種類のカスタム
要素は、その extends
オプションに渡された値と等しいローカル名を持ち、その定義名が
is 属性の値として使用されます。
したがって、その値は妥当なカスタム要素名でなければなりません。
カスタム要素が作成された後では、
is
属性の値を変更しても
要素の動作は変わりません。この値は要素のis 値として保存されるためです。
自律型カスタム 要素には、次の 要素定義があります。
is 属性を除く、
グローバル属性
form —
要素を form 要素に関連付ける
disabled —
フォームコントロールが無効かどうか
readonly —
willValidate
およびカスタム要素の作者によって追加されるあらゆる動作に影響する
name —
フォーム
送信および form.elements API
で使用する要素の名前
HTMLElement を継承する)自律型 カスタム要素には特別な意味はなく、その子を 表します。カスタマイズされた 組み込み要素は、拡張する要素の セマンティクスを継承します。
要素の作者が要素の機能に関係すると判断した、名前空間を持たない属性は、
属性名が妥当な
属性ローカル名であり、ASCII
大文字を含まない限り、自律型カスタム要素に指定してもかまいません。
例外は is 属性です。この属性は、
自律型カスタム
要素に指定してはなりません(指定しても効果はありません)。
カスタマイズされた
組み込み要素は、拡張する要素に基づいて、
属性に関する通常の要件に従います。属性に基づくカスタム
動作を追加するには、data-* 属性を使用してください。
自律型 カスタム要素は、関連付けられているカスタム要素定義の フォーム関連フィールドが true に設定されている場合、フォーム関連カスタム 要素と呼ばれます。
name 属性は、
フォーム関連
カスタム要素の名前を表します。disabled 属性は、
フォーム関連カスタム要素を
非対話的にし、その
送信値が
送信されないようにするために使用されます。form 属性は、
フォーム関連カスタム要素を、そのフォーム所有者に明示的に関連付けるために使用されます。
フォーム関連カスタム要素の
readonly 属性は、要素が制約
検証の対象外であることを指定します。ユーザーエージェントはこの属性に対してその他の動作を提供しませんが、
カスタム要素の作者は、可能な場合、その存在を利用して、組み込みフォームコントロールの
readonly
属性の動作と同様に、適切な方法でコントロールを
編集不能にすべきです。
制約検証:readonly
属性がフォーム関連
カスタム要素に指定されている場合、その要素は制約検証の対象外となります。
フォーム関連カスタム要素の
リセット
アルゴリズムは、その要素、コールバック名「formResetCallback」、および «
» を指定して、カスタム要素コールバックリアクションを
キューに追加することです。
文字列 name は、次のすべてが true である場合、 妥当なカスタム要素名です。
name が妥当な要素ローカル名である。
これにより、createElement()
でカスタム要素を作成できることが保証されます。
name の 0 番目の符号位置が、ASCII 小文字である。
これにより、HTML 構文解析器がその名前をテキストではなくタグ名として 扱うことが保証されます。
name がASCII 大文字を 一切含まない。
これにより、ユーザーエージェントが HTML 要素を常に ASCII 大文字・小文字不区別で扱えることが保証されます。
name が U+002D (-) を含む。かつ、
これは、名前空間を確保し、将来互換性を保証するために使用されます(今後、 ハイフンを含むローカル名を持つ要素が HTML、SVG、または MathML に追加されることは ないためです)。
name が次のいずれでもない。
annotation-xml」color-profile」font-face」font-face-src」font-face-uri」font-face-format」font-face-name」missing-glyph」上記の名前のリストは、適用可能な仕様、すなわち SVG 2 および MathML に含まれる、ハイフンを含むすべての要素名をまとめたものです。 [SVG] [MATHML]
これらの制限を除けば、<math-α> や <emotion-😍> などの用途に
最大限の柔軟性を与えるため、多種多様な名前が許可されます。
カスタム要素定義は、カスタム要素を記述し、 次のものから構成されます。
CustomElementConstructor
コールバック関数型の値sequence<DOMString>connectedCallback」、「disconnectedCallback」、
「connectedMoveCallback」、「adoptedCallback」、「attributeChangedCallback」、
「formAssociatedCallback」、「formDisabledCallback」、「formResetCallback」、および
「formStateRestoreCallback」であるマップ。対応する値は、Web IDL の Function
コールバック
関数型の値または null です。既定では各項目の値は null です。attachInternals()を制御します。
attachShadow()を制御します。
null または CustomElementRegistry
オブジェクト registry、文字列または null の
namespace、文字列 localName、および文字列または null の is を指定して、
カスタム要素定義を検索するには、次の手順を
実行します。この手順は、カスタム要素定義または null を返します。
registry が null の場合、null を返します。
namespace がHTML 名前空間でない場合、 null を返します。
registry のカスタム要素定義集合が、 名前とローカル名の両方が localName と等しい項目を含む場合、その項目を返します。
registry のカスタム要素定義集合が、 名前が is と等しく、ローカル名が localName と等しい項目を含む場合、その項目を返します。
null を返します。
CustomElementRegistry
インターフェイス現在のすべてのエンジンでサポートされています。
各類似オリジン
ウィンドウエージェントには、関連付けられたアクティブなカスタム要素コンストラクターマップがあります。
これは、コンストラクターから CustomElementRegistry
オブジェクトへのマップです。
現在のすべてのエンジンでサポートされています。
Window の customElements ゲッターの手順は、次のとおりです。
表明:this の関連付けられた
Documentのカスタム要素
レジストリーは、CustomElementRegistry
オブジェクトです。
Window の関連付けられた
Documentは、常に新しい
CustomElementRegistry
オブジェクトとともに作成されます。
this の関連付けられた
Documentのカスタム要素
レジストリーを返します。
[Exposed =Window ]
interface CustomElementRegistry {
constructor ();
[CEReactions ] undefined define (DOMString name , CustomElementConstructor constructor , optional ElementDefinitionOptions options = {});
(CustomElementConstructor or undefined ) get (DOMString name );
DOMString ? getName (CustomElementConstructor constructor );
Promise <CustomElementConstructor > whenDefined (DOMString name );
[CEReactions ] undefined upgrade (Node root );
[CEReactions ] undefined initialize (Node root );
};
callback CustomElementConstructor = HTMLElement ();
dictionary ElementDefinitionOptions {
DOMString extends ;
};各 CustomElementRegistry
には、最初は false であるブール値のスコープ付きかがあります。
各 CustomElementRegistry
には、最初は « » である、Document
オブジェクトの集合であるスコープ付き
文書集合があります。
各 CustomElementRegistry
には、最初は « » である、カスタム要素
定義の集合であるカスタム要素定義集合があります。
この集合内の項目の検索には、その名前、ローカル名、またはコンストラクターを使用します。
各 CustomElementRegistry
には、要素定義の再入呼び出しを防ぐために使用される
要素定義の実行中ブール値もあります。これは
最初は false です。
各 CustomElementRegistry
には、妥当なカスタム
要素名からプロミスへのマップである定義時プロミスマップもあります。
これは、whenDefined()
メソッドを実装するために使用されます。
Node
オブジェクト
node を指定して、カスタム要素レジストリーを検索するには、次の手順を実行します。
node が Element
オブジェクトである場合、node のカスタム要素レジストリーを返します。
node が ShadowRoot
オブジェクトである場合、node の
カスタム要素レジストリーを返します。
node が Document
オブジェクトである場合、node のカスタム要素レジストリーを返します。
null を返します。
registry = window.customElements
Document の CustomElementRegistry
オブジェクトを返します。registry = new CustomElementRegistry()
CustomElementRegistry
オブジェクトを構築します。registry.define(name,
constructor)
現在のすべてのエンジンでサポートされています。
registry.define(name, constructor,
{ extends: baseLocalName })CustomElementRegistry
オブジェクトでない場合、「NotSupportedError」
DOMException
が投げられます。
registry.get(name)
現在のすべてのエンジンでサポートされています。
registry.getName(constructor)
registry.whenDefined(name)
CustomElementRegistry/whenDefined
現在のすべてのエンジンでサポートされています。
SyntaxError」 DOMException
で拒否されたプロミスを返します。
registry.upgrade(root)
現在のすべてのエンジンでサポートされています。
registry.initialize(root)
CustomElementRegistry
オブジェクトに更新します。この
CustomElementRegistry
オブジェクトがスコープ付きで使用するためのものではなく、かつ root が
Document ノードであるか、または
root のノード文書のカスタム要素レジストリーがこの
CustomElementRegistry
オブジェクトでない場合、「NotSupportedError」 DOMException
が投げられます。
要素定義とは、カスタム要素定義を
CustomElementRegistry
に追加する処理です。これは、define()
メソッドによって行われます。
define(name, constructor,
options) メソッドの手順は、次のとおりです。
IsConstructor(constructor) が false の場合、TypeError
を投げます。
name が妥当なカスタム要素名でない場合、
「SyntaxError」 DOMException
を投げます。
this のカスタム要素定義集合が、
名前が name である項目を含む場合、
「NotSupportedError」 DOMException
を投げます。
this のカスタム要素定義集合が、
コンストラクターが
constructor である項目を含む場合、
「NotSupportedError」 DOMException
を投げます。
localName を name とします。
options[「extends」]
が存在する場合、extends をその値とします。それ以外の場合は null とします。
extends が null でない場合:
this のスコープ付きかが
true の場合、
「NotSupportedError」 DOMException
を投げます。
extends が妥当なカスタム要素名である場合、
「NotSupportedError」 DOMException
を投げます。
extends およびHTML
名前空間に対する要素インターフェイスが HTMLUnknownElement
である場合(たとえば、extends がこの仕様内の要素定義を
示していない場合)、
「NotSupportedError」 DOMException
を投げます。
localName を extends に設定します。
this の要素定義の実行中が true の場合、
「NotSupportedError」 DOMException
を投げます。
formAssociated を false とします。
disableInternals を false とします。
disableShadow を false とします。
observedAttributes を空の sequence<DOMString> とします。
あらゆる例外を捕捉しながら、次の手順を実行します。
prototype を ? Get(constructor, "prototype") とします。
lifecycleCallbacks を、次の順序付きマップとします:«[
「connectedCallback」→ null、「disconnectedCallback」→
null、「connectedMoveCallback」→ null、「adoptedCallback」→ null、
「attributeChangedCallback」→
null ]»。
lifecycleCallbacks のキーである各 callbackName について:
lifecycleCallbacks[「attributeChangedCallback」] が
null でない場合:
disabledFeatures を空の sequence<DOMString> とします。
disabledFeaturesIterable を ? Get(constructor, "disabledFeatures") とします。
disabledFeaturesIterable が undefined でない場合、
disabledFeatures を、disabledFeaturesIterable を
sequence<DOMString> に変換した結果に設定します。
変換から生じた例外はすべて再度投げます。
disabledFeatures が「internals」を含む場合、
disableInternals を true に設定します。
disabledFeatures が「shadow」を含む場合、
disableShadow を true に設定します。
formAssociatedValue を ? Get( constructor, "formAssociated") とします。
formAssociated を、formAssociatedValue を
boolean に変換した結果に設定します。
formAssociated が true の場合、«
「formAssociatedCallback」、「formResetCallback」、
「formDisabledCallback」、「formStateRestoreCallback」
» の各 callbackName について:
その後、上記の手順が例外を投げたかどうかにかかわらず、 this の要素定義の実行中を false に設定します。
最後に、手順が例外を投げた場合、その例外を再度投げます。
definition を、名前が name、ローカル名が localName、 コンストラクターが constructor、監視対象属性が observedAttributes、ライフサイクルコールバックが lifecycleCallbacks、 フォーム関連が formAssociated、内部を無効化が disableInternals、およびシャドウを無効化が disableShadow である、新しいカスタム要素定義とします。
definition を this の カスタム 要素定義集合に付加します。
this のスコープ付きかが true の場合、this のスコープ付き文書集合の各 document について、this、document、definition、および localName を指定して、文書内の特定の要素を アップグレードします。
それ以外の場合、this、this の関連するグローバル
オブジェクトの関連付けられた
Document、
definition、
localName、および name を指定して、文書内の特定の要素を
アップグレードします。
this の定義時プロミスマップ[name] が存在する場合:
this の定義時プロミスマップ[name] を constructor で解決します。
this の定義時 プロミス マップ[name] を削除します。
CustomElementRegistry
オブジェクト registry、Document
オブジェクト
document、カスタム要素定義 definition、文字列
localName、および任意で文字列 name(既定値は localName)を指定して、
文書内の特定の要素をアップグレードするには、次の手順を実行します。
upgradeCandidates を、document のシャドウを含む子孫であり、そのカスタム要素レジストリーが registry であり、
名前空間がHTML 名前空間であり、
ローカル名が localName であるすべての要素を、シャドウを含むツリー順序で並べたものとします。さらに、
name が localName でない場合は、is
値が name と等しい要素のみを含めます。
upgradeCandidates の各要素 element について、element と definition を指定して、カスタム要素アップグレードリアクションを キューに追加します。
get(name) メソッドの手順は、次のとおりです。
this のカスタム要素定義集合が、 名前が name である項目を含む場合、その項目のコンストラクターを返します。
undefined を返します。
getName(constructor) メソッドの
手順は、次のとおりです。
this のカスタム要素定義集合が、 コンストラクターが constructor である項目を含む場合、その項目の名前を返します。
null を返します。
whenDefined(name) メソッドの
手順は、次のとおりです。
name が妥当なカスタム要素名でない場合、
「SyntaxError」
DOMException
で拒否された
プロミスを返します。
this のカスタム要素定義集合が、 名前が name である項目を含む場合、その項目のコンストラクターで解決された プロミスを返します。
this の定義時プロミスマップ[name] が存在しない場合、 this の定義時プロミスマップ[name] を 新しいプロミスに設定します。
this の定義時プロミス マップ[name] を返します。
whenDefined()
メソッドは、適切なすべてのカスタム
要素が定義されるまで、
処理を行わないようにするために使用できます。この例では、これを :defined 擬似クラスと組み合わせ、
動的に読み込まれた記事が使用するすべての自律型カスタム要素が定義されたことを確認できるまで、
記事の内容を非表示にします。
articleContainer. hidden = true ;
fetch( articleURL)
. then( response => response. text())
. then( text => {
articleContainer. innerHTML = text;
return Promise. all(
[... articleContainer. querySelectorAll( ":not(:defined)" )]
. map( el => customElements. whenDefined( el. localName))
);
})
. then(() => {
articleContainer. hidden = false ;
}); upgrade(root) メソッドの手順は、次のとおりです。
root の各シャドウを含む広義子孫 candidate について、シャドウを含むツリー順序で、次を実行します。
candidate のカスタム要素 レジストリーが this でない場合、続行します。
candidate をアップグレードしようとします。
upgrade()
メソッドを使用すると、任意の時点で要素をアップグレードできます。通常、要素は接続されたときに自動的にアップグレードされますが、要素を接続する準備が整う前に
アップグレードする必要がある場合は、このメソッドを使用できます。
const el = document. createElement( "spider-man" );
class SpiderMan extends HTMLElement {}
customElements. define( "spider-man" , SpiderMan);
console. assert( ! ( el instanceof SpiderMan)); // まだアップグレードされていません
customElements. upgrade( el);
console. assert( el instanceof SpiderMan); // アップグレードされました! initialize(root) メソッドの
手順は、次のとおりです。
this のスコープ付きかが
false であり、かつ root が
Document ノードであるか、または
root のノード文書のカスタム要素レジストリーが
this でない場合、
「NotSupportedError」
DOMException
を投げます。
root が、そのカスタム要素レジストリーが null である
Document
ノードの場合、root のカスタム要素レジストリーを
this に設定します。
それ以外で、root が、そのカスタム要素レジストリーが null である
ShadowRoot
ノードの場合、root のカスタム要素
レジストリーを this に設定します。
root の各広義子孫 inclusiveDescendant について、 ツリー順序で、次を実行します。
inclusiveDescendant のカスタム 要素レジストリーが null の場合:
inclusiveDescendant のカスタム要素レジストリーを this に設定します。
this のスコープ付きかが true の場合、inclusiveDescendant のノード 文書を、this のスコープ付き文書集合に付加します。
inclusiveDescendant のカスタム要素レジストリーが this でない場合、続行します。
inclusiveDescendant をアップグレードしようとします。
ノードのカスタム要素レジストリーが CustomElementRegistry
オブジェクトに初期化されると、それ以降は意図的に変更できません。これにより、
コードについての推論が簡単になり、実装による最適化が可能になります。
カスタム要素定義 definition および要素 element を入力として与えられたときに、 要素をアップグレードするには、 次の手順を実行します。
element のカスタム要素状態が「undefined」でも
「uncustomized」でもない場合、返します。
このアルゴリズムの再入呼び出しによってこれが発生する状況の一つを、 次の例に示します。
<!DOCTYPE html>
< x-foo id = "a" ></ x-foo >
< x-foo id = "b" ></ x-foo >
< script >
// 定義により、"a" と "b" の両方に対するアップグレードリアクションがキューに追加されます
customElements. define( "x-foo" , class extends HTMLElement {
constructor() {
super ();
const b = document. querySelector( "#b" );
b. remove();
// このコンストラクターが "a" に対して実行されている間、"b" はまだ
// undefined であるため、これを文書へ挿入すると、x-foo の定義によって
// キューに追加されたものに加えて、"b" に対する 2 番目のアップグレード
// リアクションがキューに追加されます。
document. body. appendChild( b);
}
})
</ script > したがって、この手順は「b」を指定して要素をアップグレードする処理が
2 回目に呼び出されたとき、アルゴリズムを早期に終了します。
element のカスタム 要素定義を definition に設定します。
element のカスタム要素状態を「failed」に設定します。
これは、アップグレードが成功した後に
「custom」へ設定されます。ここでは、再入呼び出しが上記の早期終了手順に到達するように、
「failed」へ設定します。
element の属性
リスト内の各 attribute について、その順序で、element、
コールバック名「attributeChangedCallback」、および « attribute のローカル名、
null、attribute の値、attribute の名前空間 » を指定して、
カスタム要素コールバックリアクションをキューに
追加します。
element が接続されている場合、element、
コールバック名「connectedCallback」、および « » を指定して、カスタム要素
コールバックリアクションをキューに追加します。
element を definition の構築スタックの末尾に追加します。
C を definition のコンストラクターとします。
previousRegistryを、周囲の エージェントのアクティブなカスタム 要素コンストラクターマップ[C]を既定値 null で取得したものとする。
設定する。 周囲のエージェントのアクティブなカスタム 要素コンストラクターマップ[C]を、elementのカスタム 要素レジストリに。
例外を捕捉しながら、次の手順を実行する:
definitionのシャドウを無効化が true であり、
elementのシャドウルート
が
null でない場合、「NotSupportedError」
DOMExceptionをスローする。
これは、attachShadow()
がカスタム
要素定義を検索するを使用しない一方、attachInternals()
は使用するため必要である。
elementのカスタム要素状態を「precustomized」に設定する。
constructResultを、引数なしで Cを構築した結果とする。
Cが非適合に
[CEReactions] 拡張
属性で装飾された API を使用する場合、このアルゴリズムの先頭でキューに入れられたリアクションは、
この手順中、Cが完了して制御がこのアルゴリズムへ戻る前に実行される。それ以外の場合、
それらは Cおよび残りのアップグレード処理が完了した後に実行される。
SameValue(constructResult, element)が false の場合、
TypeErrorをスローする。
これは、Cが super()を呼び出す前に同じカスタム
要素の別のインスタンスを構築した場合、または Cが JavaScript の
return オーバーライド機能を使用して任意の HTMLElement
オブジェクトをコンストラクターから返した場合に発生し得る。
次に、上記の手順が例外をスローしたかどうかにかかわらず、次の手順を実行する:
previousRegistryが null の場合、削除する。 周囲のエージェントのアクティブなカスタム要素コンストラクター マップ[C]を。
それ以外の場合、設定する。周囲の エージェントの アクティブなカスタム要素コンストラクター マップ[C]を previousRegistryに。
definitionの構築スタックの末尾から最後の項目を削除する。
Cが super()を呼び出し(適合している場合はそうなる)、かつその呼び出しが成功すると仮定すると、これは、
このアルゴリズムの先頭でプッシュした elementを置き換えたすでに
構築済みマーカーである。(HTML 要素コンストラクターが
この置換を実行する。)
Cが super()を呼び出さない場合(すなわち適合していない場合)、またはHTML
要素コンストラクター内のいずれかの手順が例外をスローする場合、この項目は
引き続き elementである。
最後に、上記の手順が例外をスローした場合:
elementのカスタム 要素定義を null に設定する。
elementのカスタム要素リアクションキューを空にする。
例外を再スローする(これによりこのアルゴリズムを終了する)。
上記の手順が例外をスローした場合、elementのカスタム
要素状態は「failed」または「precustomized」のままとなる。
elementがフォーム関連カスタム要素である場合:
elementのフォーム所有者をリセットする。elementが
form
要素に関連付けられている場合、
element、コールバック
名「formAssociatedCallback」、および « 関連付けられた form
» を指定して、カスタム要素コールバック
リアクションをキューに入れる。
elementが無効である場合、
element、コールバック名
「formDisabledCallback」、および « true » を指定して、カスタム要素コールバック
リアクションをキューに入れる。
elementのカスタム
要素状態を「custom」に設定する。
要素 element が与えられたときに、 要素をアップグレードしようとするには、 次の手順を実行します。
definition を、element のカスタム
要素レジストリー、element の名前空間、element のローカル名、および element のis 値を指定して、カスタム要素定義を検索した結果とします。
definition が null でない場合、element および definition を指定して、カスタム要素アップグレード リアクションをキューに追加します。
カスタム要素は、 作者のコードを実行することにより、特定の事象へ応答する能力を持ちます。
接続されたとき、
引数なしでその connectedCallback が呼び出されます。
切断されたとき、
引数なしでその disconnectedCallback が呼び出されます。
移動されたとき、
引数なしでその connectedMoveCallback が呼び出されます。
新しい文書へ移管されたとき、
古い文書と新しい文書を引数として、その adoptedCallback が呼び出されます。
その属性のいずれかが変更、付加、削除、または置換されたとき、属性のローカル名、古い値、
新しい値、および名前空間を引数として、その attributeChangedCallback
が呼び出されます。(属性が追加または削除された場合、それぞれ属性の古い値または新しい値は null
とみなされます。)
ユーザーエージェントがフォーム関連カスタム要素のフォーム所有者を
リセットし、それによってフォーム所有者が変化したとき、新しいフォーム所有者(所有者がない場合は null)を
引数として、その formAssociatedCallback が呼び出されます。
フォーム関連カスタム要素のフォーム所有者が
リセットされたとき、
その formResetCallback が呼び出されます。
フォーム関連カスタム要素の無効状態が
変化したとき、新しい状態を引数として、その formDisabledCallback が呼び出されます。
ユーザーエージェントが、利用者の代わりに、またはナビゲーションの一部として、フォーム関連カスタム要素の値を更新したとき、
新しい状態と、理由を示す文字列「autocomplete」または「restore」を
引数として、その formStateRestoreCallback が呼び出されます。
これらのリアクションをまとめてカスタム 要素リアクションと呼びます。
カスタム要素リアクションを 呼び出す方法は、慎重さが求められる処理の途中で作者のコードを実行することを避けるため、 特別な注意を払って設計されています。実質的には、「利用者のスクリプトへ戻る直前」まで遅延されます。 これは、ほとんどの場合には同期的に実行されるように見えるものの、複雑な複合操作(複製や範囲の操作など)の場合は、関連するユーザーエージェントの すべての処理手順が完了した後まで遅延され、その後まとめて一括実行されることを意味します。
さらに、これらのリアクションの正確な順序は、以下で説明する、やや複雑な キューのスタックシステムによって管理されます。このシステムの目的は、少なくとも単一のカスタム 要素の局所的なコンテキスト内では、カスタム要素リアクションが常に、 それを引き起こした操作と同じ順序で呼び出されることを保証することです。(カスタム要素 リアクションのコードは独自の変更を行えるため、複数の要素にまたがる大域的な順序を 保証することはできません。)
各類似オリジンウィンドウエージェントには、 最初は空であるカスタム要素リアクションスタックがあります。 類似オリジンウィンドウエージェントの 現在の要素キューとは、そのカスタム要素リアクション スタックの先頭にある要素キューです。スタック内の各項目は 要素キューであり、これも最初は空です。要素キュー内の各項目は要素です。 (このキューはアップグレードにも使用されるため、要素は必ずしもまだ カスタムであるとは限りません。)
各カスタム要素リアクションスタックには、
最初は空の要素キューである、関連付けられた
バックアップ要素キューがあります。DOM に影響する操作が、
[CEReactions] が付けられた
API、または構文解析器のトークン用の要素を作成するアルゴリズムを
経由せずに行われる場合、要素はバックアップ要素キューへ追加されます。
この例として、編集可能な要素の
子孫または属性を変更する、利用者によって開始された編集操作があります。バックアップ要素キューを処理するときの再入を防ぐため、
各カスタム要素リアクションスタックには、
最初は設定されていないバックアップ要素キューを
処理中フラグもあります。
すべての要素には、最初は空である、関連付けられた カスタム要素リアクションキューがあります。 カスタム要素リアクションキュー内の各項目は、 次の 2 種類のいずれかです。
コールバックリアクション。これはライフサイクルコールバックを呼び出し、 コールバック関数と引数のリストを含みます。
これらすべてを次の概略図にまとめます。

要素 element が与えられたときに、適切な要素キューへ要素を キューに追加するには、次の手順を実行します。
reactionsStack を、element の関連するエージェントのカスタム要素リアクションスタックとします。
reactionsStack が空である場合:
element を reactionsStack のバックアップ要素 キューに追加します。
reactionsStack のバックアップ要素 キューを処理中フラグが設定されている場合、返します。
reactionsStack のバックアップ要素 キューを処理中フラグを設定します。
次の手順を実行するマイクロタスクをキューに追加します。
reactionsStack のバックアップ要素 キュー内のカスタム要素リアクションを呼び出します。
reactionsStack のバックアップ要素 キューを処理中フラグを解除します。
それ以外の場合、element を element の関連するエージェントの現在の要素 キューに追加します。
カスタム 要素 element、コールバック名 callbackName、および引数のリスト args が与えられたときに、カスタム要素コールバックリアクションをキューに追加するには、次の手順を実行します。
definition を element のカスタム要素定義とします。
callback を、キーが callbackName である、 definition のライフサイクルコールバックの 項目の値とします。
callbackName が「connectedMoveCallback」であり、
callback が null である場合:
disconnectedCallback を、キーが「disconnectedCallback」である、
definition のライフサイクル
コールバックの項目の値とします。
connectedCallback を、キーが「connectedCallback」である、
definition のライフサイクル
コールバックの項目の値とします。
connectedCallback と disconnectedCallback が null である場合、 返します。
callback を次の手順に設定します。
disconnectedCallback が null でない場合、 引数なしで disconnectedCallback を呼び出します。
connectedCallback が null でない場合、引数なしで connectedCallback を呼び出します。
callback が null である場合、返します。
callbackName が「attributeChangedCallback」である場合:
attributeName を args の最初の要素とします。
definition の監視対象 属性が attributeName を含まない場合、返します。
コールバック関数が callback、引数が args である新しいコールバックリアクションを、 element のカスタム要素 リアクションキューへ追加します。
element を指定して、適切な要素キューへ 要素をキューに追加します。
要素 element およびカスタム要素定義 definition が与えられたときに、カスタム要素アップグレードリアクションをキューに追加するには、 次の手順を実行します。
カスタム要素定義が definition である新しいアップグレードリアクションを、 element のカスタム要素 リアクションキューへ追加します。
element を指定して、適切な要素キューへ 要素をキューに追加します。
要素キュー queue 内の カスタム要素リアクションを呼び出すには、 次の手順を実行します。
queue が空でない間:
element を、queue からデキューした結果とします。
reactions を element のカスタム要素リアクション キューとします。
reactions が空になるまで繰り返します。
reactions の最初の要素を削除し、reaction をその要素とします。 reaction の型に応じて:
reaction のカスタム要素定義を使用して、 element をアップグレードします。
これが例外を投げた場合、その例外を捕捉し、reaction のカスタム要素 定義のコンストラクターに対応する JavaScript オブジェクトの関連付けられたレルムのグローバルオブジェクトについて、 その例外を報告します。
reaction の引数と「report」を指定し、コールバックの this 値
を element に設定して、reaction のコールバック関数を呼び出します。
カスタム要素リアクションが適切に
引き起こされることを保証するため、[CEReactions] IDL 拡張
属性を導入します。これは、カスタム要素
リアクションを適切に追跡して呼び出すため、関連するアルゴリズムに追加の手順を
補足する必要があることを示します。
[CEReactions] 拡張
属性は引数を取ってはならず、操作、属性、セッター、またはデリーター以外のものに現れてはなりません。
さらに、読み取り専用属性に現れてはなりません。
[CEReactions] 拡張属性が付けられた
操作、属性、セッター、またはデリーターは、その説明で指定された手順の代わりに、
次の手順を実行しなければなりません。
新しい要素キューを、このオブジェクトの関連するエージェントのカスタム要素リアクションスタックへプッシュします。
あらゆる例外を捕捉しながら、この構造について元々指定されていた手順を実行します。 手順が値を返した場合、value をその返された値とします。例外を投げた場合、 exception をその投げられた例外とします。
queue を、このオブジェクトの関連するエージェントのカスタム要素リアクションスタックからポップした結果とします。
queue 内のカスタム要素リアクションを呼び出します。
元の手順によって例外 exception が投げられた場合、 exception を再度投げます。
元の手順から値 value が返された場合、 value を返します。
この拡張属性の意図は、いくらか微妙です。その目的を達成する方法の一つは、 プラットフォーム上のすべての操作、属性、セッター、およびデリーターへこれらの手順を 挿入しなければならないと規定したうえで、実装者が不要な場合(カスタム要素リアクションを発生させ得る DOM の変更が不可能な場合)を最適化によって除去できるようにすることです。
しかし実際には、この不正確さにより、カスタム 要素リアクションについて相互運用できない実装につながる可能性があります。一部の実装が、 特定の場合にこれらの手順を呼び出すことを忘れる可能性があるためです。そこで代わりに、 相互運用可能な動作を保証し、実装がこれらの手順を必要とするすべての場合を容易に特定できるよう、 関連するすべての IDL 構造へ明示的に注釈を付ける方法を採用しました。
ユーザーエージェントによって導入された非標準 API のうち、属性または子要素を変更するなど、
カスタム要素コールバック
リアクションをキューに追加するか、カスタム要素アップグレード
リアクションをキューに追加するような方法で DOM を変更できるものには、[CEReactions] 属性も
付けなければなりません。
本稿執筆時点では、次の非標準またはまだ標準化されていない API が、 このカテゴリーに該当することが知られています。
HTMLInputElement
の
webkitdirectory および incremental IDL 属性
HTMLLinkElement の
scope IDL 属性
特定の機能は、カスタム要素の作者には利用可能であるものの、カスタム
要素の利用者には利用できないことが意図されています。これらは、ElementInternals のインスタンスを
返す element.attachInternals()
メソッドによって提供されます。ElementInternals の
プロパティとメソッドにより、ユーザーエージェントがすべての要素へ提供する内部機能を
制御できます。
element.attachInternals()
カスタム要素
element を対象とする ElementInternals オブジェクトを
返します。element がカスタム
要素でない場合、要素定義の一部として「internals」機能が無効化されている場合、
または同じ要素について 2 回呼び出された場合、例外を投げます。
各 HTMLElement には、
最初は null である付加された内部(null または
ElementInternals
オブジェクト)があります。
現在のすべてのエンジンでサポートされています。
attachInternals() メソッドの手順は、次のとおりです。
this
のis
値が null でない場合、「NotSupportedError」
DOMException
を投げます。
definition を、this のカスタム要素レジストリー、this の名前空間、 this のローカル 名、および null を指定して、カスタム要素定義を検索した結果とします。
definition が null である場合、
「NotSupportedError」 DOMException
を投げます。
definition の内部を無効化が true の場合、
「NotSupportedError」 DOMException
を投げます。
this
の付加された内部が null でない場合、
「NotSupportedError」 DOMException
を投げます。
this
のカスタム要素状態が「precustomized」でも
「custom」でもない場合、
「NotSupportedError」 DOMException
を投げます。
this
の付加された内部を、その対象
要素が this である新しい
ElementInternals
インスタンスに設定します。
ElementInternals
インターフェイス現在のすべてのエンジンでサポートされています。
ElementInternals
インターフェイスの IDL は次のとおりです。各種の操作と属性は、
後続の節で定義します。
[Exposed =Window ]
interface ElementInternals {
// シャドウルートへのアクセス
readonly attribute ShadowRoot shadowRoot ;
// フォーム関連カスタム要素
undefined setFormValue ((File or USVString or FormData )? value ,
optional (File or USVString or FormData )? state );
readonly attribute HTMLFormElement ? form ;
undefined setValidity (optional ValidityStateFlags flags = {},
optional DOMString message ,
optional HTMLElement anchor );
readonly attribute boolean willValidate ;
readonly attribute ValidityState validity ;
readonly attribute DOMString validationMessage ;
boolean checkValidity ();
boolean reportValidity ();
readonly attribute NodeList labels ;
// カスタム状態擬似クラス
[SameObject ] readonly attribute CustomStateSet states ;
};
// アクセシビリティセマンティクス
ElementInternals includes ARIAMixin ;
dictionary ValidityStateFlags {
boolean valueMissing = false ;
boolean typeMismatch = false ;
boolean patternMismatch = false ;
boolean tooLong = false ;
boolean tooShort = false ;
boolean rangeUnderflow = false ;
boolean rangeOverflow = false ;
boolean stepMismatch = false ;
boolean badInput = false ;
boolean customError = false ;
};各 ElementInternals には、
カスタム要素である
対象要素があります。
internals.shadowRoot
internals の対象
要素がシャドウホストである場合、
その対象
要素の ShadowRoot
を返します。それ以外の場合は null を返します。
現在のすべてのエンジンでサポートされています。
shadowRoot ゲッターの手順は、次のとおりです。
target がシャドウホストでない場合、 null を返します。
shadow を target のシャドウ ルートとします。
shadow の要素の内部から利用可能かが false の場合、 null を返します。
shadow を返します。
internals.setFormValue(value)
internals の対象要素の状態と送信値の両方を value に設定します。
value が null の場合、要素はフォーム送信に参加しません。
internals.setFormValue(value,
state)internals の対象要素の送信値を value に、その状態を state に設定します。
value が null の場合、要素はフォーム送信に参加しません。
internals.form
internals.setValidity(flags,
message [, anchor ])internals の対象要素を、
flags 引数で示される制約に違反しているものとしてマークし、その要素の
検証メッセージを message に設定します。anchor が指定されている場合、
フォーム所有者が対話的に検証されるか、reportValidity()
が呼び出されたとき、ユーザーエージェントはこれを使用して、internals の対象要素の制約に関する問題を
示すことがあります。
internals.setValidity({})
internals.willValidate
フォームが送信されるときに internals の対象 要素が検証される場合は true を返し、それ以外の場合は false を返します。
internals.validity
internals の対象要素の ValidityState
オブジェクトを返します。
internals.validationMessage
internals の対象要素の妥当性が検査された場合に、 利用者へ表示されるエラーメッセージを返します。
valid = internals.checkValidity()
internals の対象
要素に妥当性の問題がない場合は true を返し、それ以外の場合は false を返します。
後者の場合、その要素で invalid
イベントを発火します。
valid = internals.reportValidity()
internals の対象
要素に妥当性の問題がない場合は true を返します。それ以外の場合は false を返し、
その要素で invalid
イベントを発火し、イベントが取り消されなかった場合は問題を利用者へ報告します。
internals.labels
各フォーム関連カスタム要素には
送信値があります。これは、フォーム送信時に一つ以上の
項目を提供するために使用されます。
送信値の初期値は null であり、
送信値は null、文字列、
File、
または項目のリストにできます。
各フォーム関連カスタム要素には
状態があります。
これは、ユーザーエージェントがその要素に対する利用者の入力を復元するための情報です。
状態の初期値は null であり、
状態は null、文字列、File、
または項目のリストにできます。
setFormValue()
メソッドは、カスタム要素の作者が要素の送信
値と状態を設定し、
それらをユーザーエージェントへ伝えるために使用します。
ユーザーエージェントが、たとえばナビゲーション後や
ユーザーエージェントの再起動後に、フォーム関連カスタム
要素の状態を復元することが適切であると判断した場合、
その要素、コールバック名「formStateRestoreCallback」、および
« 復元する状態、「restore」 » を指定して、カスタム要素
コールバックリアクションをキューに追加してもかまいません。
ユーザーエージェントがフォーム入力支援機能を持つ場合、その機能が呼び出されたとき、
フォーム関連カスタム
要素、コールバック名「formStateRestoreCallback」、および
« 状態値の履歴と何らかのヒューリスティックによって決定された状態値、「autocomplete」 »
を指定して、カスタム要素
コールバックリアクションをキューに追加してもかまいません。
一般に、状態は利用者によって指定された情報であり、 送信 値は、正規化またはサニタイズされた、サーバーへの送信に適した値です。 次の例は、これを具体的に示します。
利用者に日付の指定を求めるフォーム関連カスタム要素が
あるとします。利用者は 「3/15/2019」と指定しますが、コントロールはサーバーへ
「2019-03-15」を送信することを望みます。「3/15/2019」は要素の状態であり、
「2019-03-15」は送信値になります。
既存のチェックボックス input 型の動作を
模倣するカスタム要素を開発するとします。その送信値は、その value
内容属性の値、または文字列 「on」になります。その状態は、
「checked」、「unchecked」、「checked/indeterminate」、または
「unchecked/indeterminate」のいずれかになります。
現在のすべてのエンジンでサポートされています。
setFormValue(value,
state) メソッドの手順は、次のとおりです。
element がフォーム関連カスタム要素でない場合、
「NotSupportedError」 DOMException
を投げます。
value が FormData
オブジェクトでない場合、element の送信値を value に設定します。
それ以外の場合、value の項目
リストの複製に設定します。
それ以外で、state が FormData
オブジェクトである場合、element の状態を、state の項目
リストの複製に設定します。
それ以外の場合、element の状態を state に設定します。
各フォーム関連カスタム要素には、
valueMissing、typeMismatch、
patternMismatch、tooLong、
tooShort、rangeUnderflow、
rangeOverflow、stepMismatch、および
customError という名前の妥当性フラグがあります。これらは最初は false です。
各フォーム関連カスタム要素には、 検証メッセージ文字列があります。これは最初は空文字列です。
各フォーム関連カスタム要素には、 検証アンカー要素があります。これは最初は null です。
現在のすべてのエンジンでサポートされています。
setValidity(flags, message,
anchor) メソッドの手順は、次のとおりです。
element がフォーム関連カスタム要素でない場合、
「NotSupportedError」 DOMException
を投げます。
flags が一つ以上の true 値を含み、message が指定されていないか
空文字列である場合、TypeError
を投げます。
flags の各項目 flag → value について、 element の flag という名前の妥当性フラグを value に設定します。
message が指定されていないか、element のすべての妥当性フラグが false である場合、element の検証メッセージを 空文字列に設定します。それ以外の場合は message に設定します。
element の customError 妥当性フラグが true の場合、
element のカスタム妥当性エラーメッセージを、
element の検証
メッセージに設定します。それ以外の場合、element のカスタム妥当性エラーメッセージを
空文字列に設定します。
anchor が指定されていない場合、これを element に設定します。
それ以外で、anchor が element のシャドウを含む広義
子孫でない場合、「NotFoundError」
DOMException
を投げます。
element の検証アンカーを anchor に設定します。
ElementInternals/validationMessage
現在のすべてのエンジンでサポートされています。
validationMessage ゲッターの手順は、
次のとおりです。
element がフォーム関連カスタム要素でない場合、
「NotSupportedError」 DOMException
を投げます。
element の検証 メッセージを返します。
要素 element および項目リスト entry list が与えられたときの、 フォーム関連カスタム要素の 項目構築アルゴリズムは、次の手順からなります。
internals.role [ = value ]
internals の対象要素の既定の
ARIA ロールを設定または取得します。
これは、ページ作者が role 属性を使用して
上書きしない限り使用されます。
internals.aria* [ = value ]
internals の対象
要素の各種の既定の ARIA 状態またはプロパティ値を設定または取得します。これらは、
ページ作者が aria-*
属性を使用して上書きしない限り使用されます。
各カスタム要素には、 最初は空であるマップである内部内容属性マップがあります。これがプラットフォームの アクセシビリティ API に与える影響については、ARIA およびプラットフォーム アクセシビリティ API に関する要件の節を参照してください。
internals.states.add(value)
擬似クラスとして公開するために、文字列 value を要素の状態集合へ追加します。
internals.states.has(value)
value が要素の状態集合内にある場合は true を返し、 それ以外の場合は false を返します。
internals.states.delete(value)
要素の状態集合が value を持つ場合、これを削除して true を返します。 それ以外の場合は false を返します。
internals.states.clear()
要素の状態 集合からすべての値を削除します。
for (const stateName of internals.states)
for (const stateName of internals.states.entries())
for (const stateName of internals.states.keys())
for (const stateName of internals.states.values())
要素の状態集合内のすべての値を反復処理します。
internals.states.forEach(callback)
各値について callback を一度ずつ呼び出すことにより、 要素の状態集合内のすべての値を反復処理します。
internals.states.size
要素の状態集合内の値の数を返します。
各カスタム要素には、
最初は空である CustomStateSet である
状態集合があります。
[Exposed =Window ]
interface CustomStateSet {
setlike <DOMString >;
};状態集合は、
文字列値の存在または不存在によって表現される真偽状態を公開できます。作者が 3 つの値を
取り得る状態を公開したい場合、それを排他的な 3 つの真偽状態へ変換できます。たとえば、
"loading"、"interactive"、および "complete" の値を持つ
readyState という状態は、排他的な 3 つの真偽状態
"loading"、"interactive"、および "complete" へ対応付けられます。
// readyState を任意の状態から "complete" へ変更します。
this . _readyState = "complete" ;
this . _internals. states. delete ( "loading" );
this . _internals. states. delete ( "interactive" );
this . _internals. states. add( "complete" ); この仕様は、パンくずナビゲーションメニューを機械可読な方法で記述する手段を提供しません。
作者には、段落内で一連のリンクを使用することが推奨されます。nav
要素を使用して、これらの段落を含む節をナビゲーションブロックとしてマークできます。
次の例では、現在のページへ 2 つの経路から到達できます。
< nav >
< p >
< a href = "/" > メイン</ a > ▸
< a href = "/products/" > 製品</ a > ▸
< a href = "/products/dishwashers/" > 食器洗い機</ a > ▸
< a > 中古</ a >
</ p >
< p >
< a href = "/" > メイン</ a > ▸
< a href = "/second-hand/" > 中古</ a > ▸
< a > 食器洗い機</ a >
</ p >
</ nav > この仕様は、ページのグループに適用されるキーワードのリスト(タグクラウドとも
呼ばれます)をマークアップするための特別なマークアップを定義しません。一般に、作者には、
明示的なインラインの個数を含む ul 要素を使用してそのようなリストを
マークアップした後、スタイルシートを使用して個数を非表示にし、視覚的効果へ変換するか、SVG を
使用することが推奨されます。
ここでは、短いタグクラウドに 3 つのタグが含まれています。
< style >
. tag-cloud > li > span { display : none ; }
. tag-cloud > li { display : inline ; }
. tag-cloud-1 { font-size : 0.7 em ; }
. tag-cloud-2 { font-size : 0.9 em ; }
. tag-cloud-3 { font-size : 1.1 em ; }
. tag-cloud-4 { font-size : 1.3 em ; }
. tag-cloud-5 { font-size : 1.5 em ; }
@ media speech {
. tag-cloud > li > span { display : inline }
}
</ style >
...
< ul class = "tag-cloud" >
< li class = "tag-cloud-4" >< a title = "28 件" href = "/t/apple" > りんご</ a > < span > (人気)</ span >
< li class = "tag-cloud-2" >< a title = "6 件" href = "/t/kiwi" > キウイ</ a > < span > (まれ)</ span >
< li class = "tag-cloud-5" >< a title = "41 件" href = "/t/pear" > なし</ a > < span > (非常に人気)</ span >
</ ul > 各タグの実際の頻度は、title
属性を使用して示されています。マークアップを異なる大きさの単語からなるクラウドへ変換する
CSS スタイルシートが提供されていますが、CSS をサポートしない、または視覚的でない
ユーザーエージェント向けに、マークアップには「(人気)」や「(まれ)」などの注釈が含まれ、
各種タグを頻度別に分類しています。これにより、すべての利用者がその情報を活用できます。
ol ではなく
ul 要素が使用されているのは、
順序が特に重要ではないためです。実際にはリストはアルファベット順ですが、たとえばタグの長さで
並べたとしても、同じ情報を伝えます。
これらの a 要素には、
tag rel キーワードは
使用されていません。これは、それらがページ自体に適用されるタグを表すのではなく、
タグ自体を一覧表示する索引の一部にすぎないためです。
この仕様は、会話、会議の議事録、チャットの記録、脚本内の対話、インスタントメッセージのログ、 および複数の話者が交代で発言するその他の状況をマークアップするための特定の要素を定義しません。
代わりに、作者には、p 要素と句読点を使用して会話を
マークアップすることが推奨されます。スタイル付けを目的として話者をマークする必要がある作者には、
span または b の使用が推奨されます。テキストを
i
要素で囲んだ段落は、舞台指示をマークアップするために使用できます。
この例は、アボットとコステロの有名なコント 一塁は誰だからの抜粋を使用して、これを示しています。
< p > コステロ:なあ、一塁手はいるんだろ?
< p > アボット:もちろん。
< p > コステロ:一塁を守っているのは誰だ?
< p > アボット:そのとおり。
< p > コステロはいら立つ。
< p > コステロ:毎月一塁手へ給料を払うとき、誰がその金を受け取るんだ?
< p > アボット:一ドル残らずだ。次の抜粋は、各行の Unix タイムスタンプを提供するために data 要素を使用して、
IM 会話ログをどのようにマークアップできるかを示しています。タイムスタンプは time 要素がサポートしない形式、
すなわち Unix の time_t タイムスタンプで提供されるため、代わりに data 要素が使用されていることに
注意してください。作者が time 要素によってサポートされる
日付および時刻形式のいずれかを使用してデータをマークアップしたい場合は、data の代わりにその要素を
使用できました。これにより、データ分析ツールがページ作者との調整を行わなくても、
タイムスタンプを曖昧さなく検出できるという利点があります。
< p > < data value = "1319898155" > 14:22</ data > < b > egof</ b > そこまでオタクじゃないよ。スタートレックのエピソードは 30% しか見てない
< p > < data value = "1319898192" > 14:23</ data > < b > kaj</ b > スタートレックの何パーセントを見たか知っているなら、間違いなくオタクだよ
< p > < data value = "1319898200" > 14:23</ data > < b > egof</ b > 「間違いなく」だよ
< p > < data value = "1319898228" > 14:23</ data > < i > * kaj はまばたきする</ i >
< p > < data value = "1319898260" > 14:24</ data > < b > kaj</ b > 自分の立場を悪くしているだけだよHTML にはグラフを適切にマークアップする方法がないため、ゲーム内の対話型会話の記述は
マークアップがさらに困難です。この例は、会話の各時点で可能な応答を一覧表示するために
dl 要素を使用する、
考えられる一つの規約を示しています。
考慮できる別の方法は、会話を DOT ファイルの形式で記述し、その結果を文書へ配置する
SVG 画像として出力することです。[DOT]
< p > 次に、漁師と出会います。いくつかの挨拶のうち一つを言えます。
< dl >
< dt > 「こんにちは!」
< dd >
< p > 彼女は「こんにちは、何かお手伝いしましょうか?」と答えます。次のように返答できます。
< dl >
< dt > 「魚を一匹買いたいです。」
< dd > < p > 彼女は魚を売り、会話が終わります。
< dt > 「船を借りてもいいですか?」
< dd >
< p > 彼女は驚いて「代わりに何をくれるの?」と尋ねます。
< dl >
< dt > 「金貨 5 枚。」(十分に持っている場合)
< dt > 「金貨 10 枚。」(十分に持っている場合)
< dt > 「金貨 15 枚。」(十分に持っている場合)
< dd > < p > 彼女は船を貸してくれます。会話が終わります。
< dt > 「魚一匹。」(持っている場合)
< dt > 「新聞。」(持っている場合)
< dt > 「小石。」(持っている場合)
< dd > < p > 「結構です」と彼女は答えます。この時点での会話の選択肢は、
船を借りたいと尋ねた後と同じですが、以前に提案した選択肢は
除かれます。
</ dl >
</ dd >
</ dl >
</ dd >
< dt > 「次の選挙で私に投票してください!」
< dd > < p > 彼女は背を向けます。会話が終わります。
< dt > 「奥さん、魚が逃げていますよ?」
< dd >
< p > 彼女は疑わしげにこちらを見て「魚は走れませんよ、お嬢さん」と言います。
< dl >
< dt > 「ばれました!」
< dd > < p > 漁師はため息をつき、会話が終わります。
< dt > 「冗談です。」
< dd > < p > 「うまいこと言ったわね!」と彼女は言い返します。この時点での会話の選択肢は、
上の「こんにちは!」に続くものと同じです。
< dt > 「では、魚は何をしているのですか?」
< dd > < p > 彼女が魚を見るため、その隙に船を盗みます。会話が終わります。
</ dl >
</ dd >
</ dl > 一部のゲームでは会話はより単純で、各登場人物は単に決まった一連の台詞を話します。 この例では、ゲームの FAQ/攻略ガイドが、各登場人物について知られている応答の一部を 一覧表示しています。
< section >
< h1 > 会話</ h1 >
< p >< small > 一部の登場人物は、対話するたびに台詞を順番に繰り返し、
ほかの登場人物は台詞の中からランダムに選びます。順番に応答する登場人物には、
以下のリストで番号付きの項目があります。</ small >
< h2 > 店主</ h2 >
< ul >
< li > 何かお手伝いしましょうか?
< li > 新鮮なりんごだよ!
< li > 奥様、パンはいかがですか?
</ ul >
< h2 > 操縦士</ h2 >
< p > 事故の前:
< ul >
< li > 今から飛び立つところなんだ、すまない!
< li > すまない、飛行許可を待っているところで、許可が出たら出発するよ!
</ ul >
< p > 事故の後:
< ol >
< li > 今から飛び立つところなんだ、すまない!
< li > わかった、今すぐには出発しない。飛行機を清掃中なんだ。
< li > わかった、清掃中ではない。まず少し修理が必要なんだ。
< li > わかった、わかった、もう邪魔しないでくれ!実は墜落したんだ。
</ ol >
< h2 > 一族の長</ h2 >
< p > 最初の一族会議の間:
< ul >
< li > やあ、娘を見なかったか?また何か悪だくみをしているに違いない……
< li > 今日はいい天気だね?
< li > 名前はベイリー、ジェフ・ベイリーだ。今日はどうしたんだい?
< li > 水を一杯?井戸から汲みたてだよ!
</ ul >
< p > 地震の後:
< ol >
< li > 全員避難所で無事だ。あとは火を消すだけだ!
< li > 消防隊へ知らせてくる。君は放水を続けてくれ!
</ ol >
</ section > HTML には脚注をマークアップするための専用の機構がありません。次の代替方法が推奨されます。
短いインライン注釈には、title 属性を使用できます。
この例では、対話の 2 か所に title 属性を使用して、
脚注のような内容が注釈として付けられています。
< p > < b > 客</ b > :こんにちは!苦情を申し立てたいのですが。もしもし。お嬢さん?
< p > < b > 店主</ b > :< span title = "「What do you」の口語的な発音"
> 何の</ span > ことです、お嬢さん?
< p > < b > 客</ b > :ああ、すみません、風邪をひいていて。苦情を申し立てたいのです。
< p > < b > 店主</ b > :すみません、< span title = "もちろん、これは嘘です。" > 昼食のため
閉店</ span > します。残念ながら、現在は title 属性に依存することは推奨されません。
多くのユーザーエージェントが、この仕様で要求されるアクセシブルな方法で属性を公開していないためです
(たとえば、ツールチップを表示させるためにマウスなどのポインティングデバイスを必要とし、
キーボードのみを使用する利用者や、最新の携帯電話またはタブレットを使用する人など、
タッチのみを使用する利用者を除外します)。
title 属性を使用する場合、
CSS を使用して、その属性を持つ要素へ読者の注意を引くことができます。
たとえば、次の CSS は、title 属性を持つ要素の下に破線を配置します。
[title] { border-bottom : thin dashed; } より長い注釈には、文書内の後方にある要素を指す a 要素を使用するべきです。
慣例では、リンクの内容を角括弧内の数字とします。
この例では、対話内の脚注が、対話の下にある段落へリンクしています。その段落は対話へ 相互にリンクし、利用者が脚注の位置へ戻れるようにしています。
< p > アナウンサー:第 16 番、< i > 手</ i > 。
< p > インタビュアー:こんばんは。今夜スタジオへお招きしたのは、
ここ数年間、人の発言に反論し続けているノーマン・セント・ジョン・ポールヴォルターさんです。
ポールヴォルターさん、なぜ人に< em > 反論する</ em > のですか?
< p > ノーマン:しません。< sup >< a href = "#fn1" id = "r1" > [1]</ a ></ sup >
< p > インタビュアー:すると言ったではありませんか!
...
< section >
< p id = "fn1" >< a href = "#r1" > [1]</ a > これは当然ながら嘘ですが、
逆説的に、もしそれが真実ならば、インタビュアーへ反論して
それを偽にすることなく、そのように言うことはできません。</ p >
</ section > 特定の単語や文だけでなく、テキストの節全体に適用される欄外注などの長い注釈には、aside 要素を使用するべきです。
この例では、対話の後に、その背景を説明するサイドバーがあります。
< p > < span class = "speaker" > 客</ span > :このレコードは傷が付いているので買いません。
< p > < span class = "speaker" > 店主</ span > :何ですって?
< p > < span class = "speaker" > 客</ span > :このレコードは傷が付いているので買いません。
< p > < span class = "speaker" > 店主</ span > :いやいや、ここはたばこ屋ですよ。
< aside >
< p > 1970 年、イギリス帝国は廃墟と化し、外国の
国民が通りを行き交っていました。その多くはハンガリー人でした
(通りではなく、外国人のことです)。残念ながら、アレクサンダー・
ヤルトは出来の悪い会話集を出版し続けていました。
</ aside > 図または表については、脚注を関連する figcaption または
caption 要素、
あるいは周囲の文章に含めることができます。
この例では、表のセルに脚注があり、それらは文章で示されています。figure 要素を使用して、
表とその脚注の組み合わせへ単一の説明を与えています。
< figure >
< figcaption > 表 1. 騎士の代替活動。</ figcaption >
< table >
< tr >
< th > 活動
< th > 場所
< th > 費用
< tr >
< td > 踊り
< td > 可能な場所ならどこでも
< td > £0< sup >< a href = "#fn1" > 1</ a ></ sup >
< tr >
< td > 定番演目、合唱場面< sup >< a href = "#fn2" > 2</ a ></ sup >
< td > 非公開
< td > 非公開
< tr >
< td > 食事< sup >< a href = "#fn3" > 3</ a ></ sup >
< td > キャメロット
< td > ハム、ジャム、スパムの費用< sup >< a href = "#fn4" > 4</ a ></ sup >
</ table >
< p id = "fn1" > 1. 推定。</ p >
< p id = "fn2" > 2. 足運びは完璧。</ p >
< p id = "fn3" > 3. 品質は「良い」と表現されます。</ p >
< p id = "fn4" > 4. かなり高い。</ p >
</ figure > 要素が次のいずれかである場合、その要素は実際に無効化されているといいます。
button 要素
input 要素
select 要素
textarea
要素
disabled 属性を
持つか、その最も近い祖先の
selectが無効である
optgroup 要素
selectが無効である
option 要素
fieldset
要素
この定義は、どの要素がフォーカス可能であるか、およびどの要素が :enabled と
:disabled 擬似
クラスに一致するかを決定するために使用されます。
CSS Values and Units は、「attr()」関数における 属性名の大文字小文字の区別をホスト言語による定義に委ねています。 [CSSVALUES]
CSS の 「attr()」関数の属性名部分を、 HTML 文書内のHTML 要素にある名前空間を持たない 属性の名前と比較するとき、CSS の 「attr()」関数の名前部分は、 まず ASCII 小文字へ変換しなければなりません。同じ関数をその他の属性と比較するときは、元の大文字小文字に 従って比較しなければなりません。どちらの場合も、一致するには値同士が同一でなければなりません (したがって、比較では大文字と小文字が区別されます)。
これは、次の節で指定される CSS の属性 セレクターの名前部分を比較する場合と同じです。
Selectors は、要素名、属性名、および属性値の大文字小文字の区別を ホスト言語による定義に委ねています。[SELECTORS]
CSS の要素型セレクターを、 HTML 文書内のHTML 要素の名前と比較するとき、CSS の要素型セレクターは、 まず ASCII 小文字へ変換しなければなりません。同じセレクターをその他の要素と比較するときは、 元の大文字小文字に従って比較しなければなりません。どちらの場合も、一致するには値同士が同一でなければなりません (したがって、比較では大文字と小文字が区別されます)。
CSS の属性 セレクターの名前部分を、HTML 文書内のHTML 要素にある属性の名前と比較するとき、 CSS の属性 セレクターの名前部分は、まずASCII 小文字へ変換しなければなりません。同じセレクターをその他の属性と比較するときは、 元の大文字小文字に従って比較しなければなりません。どちらの場合も、比較では大文字と小文字が区別されます。
属性 セレクターを、HTML 文書内のHTML 要素に適用するとき、 次の名前を持つ属性の値はASCII 大文字小文字不区別として扱わなければなりません。
accept
accept-charset
align
alink
axis
bgcolor
charset
checked
clear
codetype
color
compact
declare
defer
dir
direction
disabled
enctype
face
frame
hreflang
http-equiv
lang
language
link
media
method
multiple
nohref
noresize
noshade
nowrap
readonly
rel
rev
rules
scope
scrolling
selected
shape
target
text
type
valign
valuetype
vlink
たとえば、セレクター [bgcolor="#ffffff"] は、#ffffff、
#FFFFFF、および #fffFFF を含む値を持つ bgcolor 属性が
指定された任意の HTML 要素に一致します。これは、特定の要素(たとえば div)において
bgcolor が効果を持たない場合でも同様です。
セレクター [type=a s] は、値が a である type 属性を
持つ任意の HTML 要素に一致しますが、s フラグにより、値が A である要素には
一致しません。
セレクターの照合では、その他のすべての属性値およびその他のすべてのものを、互いに完全に同一として扱わなければなりません。これには次のものが含まれます。
Selectors は、互換モードの文書内の要素と照合される
ID およびクラスセレクター
(#foo や .bar など)を、ASCII
大文字小文字不区別で照合することを定義しています。しかし、これは名前部分が
「id」または「class」である属性セレクターには適用されません。
セレクター [class="foobar"] は、互換モードであっても、その値の大文字と小文字を区別します。
HTML で使用できる動的セレクターがいくつかあります。この節では、これらのセレクターが HTML 要素に一致する条件を定義します。[SELECTORS] [CSSUI]
:defined
現在のすべてのエンジンでサポートされています。
:link
現在のすべてのエンジンでサポートされています。
:visited
現在のすべてのエンジンでサポートされています。
href
属性を持つすべての a 要素と、
href 属性を持つすべての
area 要素は、:link と :visited のいずれか一方に
一致しなければなりません。
この要件を単純に実装した場合に生じる一部のプライバシー上の懸念を軽減するため、 その他の仕様が、これらの要素をこれらの擬似クラスへどのように一致させるかについて、 より具体的な規則を適用することがあります。
:active
現在のすべてのエンジンでサポートされています。
:active 擬似クラスは、要素が利用者によって
アクティブ化されている間
、
その要素に一致するものとして定義されます。
:active
擬似クラスを定義する目的に限り、特定の要素がアクティブ化
されているかどうかを決定するために、HTML ユーザーエージェントは次のリストのうち、
最初に該当する項目を使用しなければなりません。
button 要素である場合
type 属性について、
送信ボタン、画像ボタン、リセットボタン、またはボタン状態にある input 要素である場合
href 属性を持つ
a 要素である場合
href 属性を持つ
area 要素である場合
要素が正式なアクティブ化状態にある場合、 その要素はアクティブ化されているものとします。
たとえば、利用者がキーボードのスペースキーを押して button
要素を押す場合、その要素が keydown
イベントを受け取った時点から、keyup
イベントを受け取る時点まで、その要素はこの擬似クラスに一致します。
その要素はアクティブ化されているものとします。
利用者が要素のアクティブ化の動作を引き起こす意図を示し始めた時点から、 利用者がその要素のアクティブ化の 動作を引き起こす意図を示すことをやめた時点、または要素のアクティブ化の動作の実行が完了した時点のうち、 いずれか早い方まで、要素は正式なアクティブ化状態にあるといいます。
利用者が、ポインティングデバイスが「押下」状態にある間、そのポインティングデバイスを 使用して要素を示している場合、その要素は能動的に指し示されているといいます (たとえば、マウスではマウスボタンが押されてから放されるまで、マルチタッチ環境の指では 指が表示面へ触れている間)。
Selectors の定義に従い、:active は、
アクティブ化されている要素のフラットツリーの祖先にも一致します。
[SELECTORS]
さらに、現在 :active に一致している
label 要素のラベル付けされた
コントロールである任意の要素も、:active
に一致します。
(ただし、その要素自体がアクティブ化されているとはみなされません。)
:hover
現在のすべてのエンジンでサポートされています。
:hover 擬似クラスは、利用者がポインティングデバイスを使用して要素を
指示している間
、その要素に一致するものとして
定義されます。:hover
擬似クラスを定義する目的に限り、HTML ユーザーエージェントは、
利用者がポインティングデバイスを使用して示している要素を、利用者が指示している要素とみなさなければなりません。
Selectors の定義に従い、:hover は、
指示されている要素のフラットツリーの祖先にも一致します。
[SELECTORS]
さらに、現在 :hover に一致している
label 要素のラベル付けされた
コントロールである任意の要素も、:hover
に一致します。
(ただし、その要素自体が指示されているとはみなされません。)
特に、次のような断片を考えます。
< p > < label for = c > < input id = a > </ label > < span id = b > < input id = c > </ span > </ p > 利用者がポインティングデバイスを使用して ID が「a」の要素を指示した場合、
p 要素
(および上の断片には示されていないそのすべての祖先)、label 要素、
ID が「a」の要素、および ID が「c」の要素は、:hover 擬似クラスに一致します。ID が「a」の要素は、
指示されているため一致します。label 要素と p 要素は、
フラットツリーの祖先に関する Selectors の条件によって一致します。また、
ID が「c」の要素は、上記のラベル付けされた
コントロールに関する追加条件によって一致します(すなわち、その label 要素が :hover に一致します)。
しかし、ID が「b」の要素は :hover に一致しません。
そのフラットツリーの子孫が :hover に一致していても、
そのフラットツリーの子孫は指示されていないためです。
:focus
現在のすべてのエンジンでサポートされています。
CSS の :focus
擬似クラスの目的において、次の場合に要素がフォーカスを持つといいます。
その要素自体がナビゲーション可能コンテナーではないこと。かつ、
次のいずれかが true であること。
その要素がトップレベル辿可能の現在の フォーカス連鎖に一覧表示される要素の一つである。または、
そのシャドウ ルート shadowRoot が null でなく、shadowRoot が、 フォーカスを持つ少なくとも一つの要素のルートである。
:target
現在のすべてのエンジンでサポートされています。
:popover-open
現在のすべてのエンジンでサポートされています。
:popover-open
擬似クラスは、popover 属性がポップオーバーなし状態ではなく、
かつそのポップオーバー表示状態が表示中である任意のHTML 要素に一致するものとして定義されます。
:enabled
現在のすべてのエンジンでサポートされています。
:enabled 擬似クラスは、実際に無効化されていない任意の
button、
input、
select、
textarea、
optgroup、
option、
fieldset 要素、
またはフォーム関連カスタム要素に一致しなければなりません。
:disabled
現在のすべてのエンジンでサポートされています。
:disabled 擬似クラスは、実際に
無効化されている任意の要素に一致しなければなりません。
:checked
現在のすべてのエンジンでサポートされています。
:indeterminate
現在のすべてのエンジンでサポートされています。
:indeterminate 擬似クラスは、次のカテゴリーのいずれかに該当する任意の要素に
一致しなければなりません。
:default
現在のすべてのエンジンでサポートされています。
:placeholder-shown:placeholder-shown
擬似クラスは、次のカテゴリーのいずれかに該当する任意の要素に
一致しなければなりません。
placeholder
属性を持つ input 要素placeholder
属性を持つ textarea 要素
:valid
現在のすべてのエンジンでサポートされています。
:invalid
現在のすべてのエンジンでサポートされています。
:user-valid:user-valid 擬似クラスは、利用者妥当性が true であり、制約検証の候補であり、
かつその制約を満たす
input、
textarea、および
select 要素に
一致しなければなりません。
:user-invalid:user-invalid
擬似クラスは、利用者妥当性が true であり、制約検証の候補であるものの、
その制約を満たさない
input、
textarea、および
select 要素に
一致しなければなりません。
:in-range
現在のすべてのエンジンでサポートされています。
:in-range 擬似クラスは、制約検証の
候補であり、範囲制限を持ち、かつ下限不足の状態でも上限超過の状態でもない、すべての要素に
一致しなければなりません。
:out-of-range
現在のすべてのエンジンでサポートされています。
:out-of-range
擬似クラスは、制約検証の
候補であり、範囲制限を持ち、かつ下限不足の状態または上限超過の状態のいずれかである、
すべての要素に一致しなければなりません。
:required
現在のすべてのエンジンでサポートされています。
:optional
現在のすべてのエンジンでサポートされています。
:autofill
:-webkit-autofill:autofill および :-webkit-autofill
擬似クラスは、ユーザーエージェントによって自動入力された
input 要素に
一致しなければなりません。利用者が自動入力されたフィールドを編集した場合、これらの擬似クラスは
一致しなくならなければなりません。
このような自動入力が行われる方法の一つは、autocomplete 属性を
介するものですが、ユーザーエージェントはその属性が関与しない場合でも自動入力できます。
:read-only
現在のすべてのエンジンでサポートされています。
:read-write
現在のすべてのエンジンでサポートされています。
:read-write 擬似クラスは、次のカテゴリーのいずれかに該当する任意の要素に
一致しなければなりません。これらは Selectors の目的において利用者が変更可能であると
みなされます。[SELECTORS]
readonly
属性が適用され、かつ変更可能である
(すなわち readonly
属性が指定されておらず、かつ無効ではない)
input 要素
readonly 属性を
持たず、かつ無効ではない
textarea
要素
input 要素でも
textarea 要素でもない
要素
:read-only 擬似クラスは、その他のすべてのHTML 要素に一致しなければなりません。
:modal:dir(ltr)
:dir(rtl):state(identifier)
擬似クラスは、その状態集合の集合の項目が
identifier を含むすべてのカスタム要素に一致しなければなりません。
:heading:heading 擬似クラスは、
すべての
h1、
h2、
h3、
h4、
h5、
および
h6
要素に一致しなければなりません。
:heading(integer#):heading(integer#)
擬似クラスは、見出しレベルが integer であるすべての
h1、
h2、
h3、
h4、
h5、
および h6
要素に一致しなければなりません。[CSSSYNTAX] [CSSVALUES]
:playing:playing 擬似クラスは、paused 属性が false である
すべてのメディア要素に一致しなければなりません。
:paused:seeking:seeking 擬似クラスは、seeking 属性が true である
すべてのメディア要素に一致しなければなりません。
:buffering:buffering 擬似クラスは、paused 属性が false、
networkState 属性が
NETWORK_LOADING、
かつ準備状態が HAVE_CURRENT_DATA
以下である、すべてのメディア要素に一致しなければなりません。
:stalled:stalled 擬似クラスは、:buffering 擬似クラスに一致し、かつその現在停止しているかが true であるすべてのメディア要素に一致しなければなりません。
この擬似クラスは、動画の再生が長時間バッファリングされているときに、
プレーヤー状態の UI を表示するためのものです。これは、再生状態または準備状態にかかわらず、
ネットワークからのダウンロードが停止するたびに発火する stalled イベントとは
異なります。
:muted:volume-locked
:volume-locked 擬似クラスは、ユーザーエージェントの音量ロックが true である場合、
すべてのメディア要素に一致しなければなりません。
:open:open 擬似クラスは、次のカテゴリーのいずれかに該当する任意の要素に
一致しなければなりません。
ドロップダウンボックスであり、
そのドロップダウンボックスが開いている select 要素
ピッカーを
サポートし、そのピッカーが開いている input 要素
この仕様は、要素が :lang() 動的擬似クラスに一致する条件を定義しません。これは
Selectors において、言語に依存しない方法で十分詳細に定義されているためです。
[SELECTORS]
この節は非規範的です。
汎用スクリプトがページに合わせてカスタマイズされたサービスを提供できるようにしたり、 協力関係にあるさまざまな作者のコンテンツを単一のスクリプトによって一貫した方法で処理できるように したりするために、コンテンツへ特定の機械可読ラベルを注釈として付けることが望ましい場合があります。
この目的のために、作者はこの節で説明するマイクロデータ機能を使用できます。マイクロデータを使用すると、 既存のコンテンツと並行して、名前と値のペアからなる入れ子のグループを文書へ追加できます。
この節は非規範的です。
大まかにいえば、マイクロデータは名前と値のペアのグループから構成されます。グループはアイテムと呼ばれ、名前と値の各ペアは プロパティです。アイテムとプロパティは通常の要素によって表されます。
アイテムを作成するには、itemscope
属性を使用します。
アイテムへプロパティを追加するには、アイテムの子孫の一つで itemprop
属性を使用します。
ここには 2 つのアイテムがあり、それぞれが「name」プロパティを持ちます。
< div itemscope >
< p > 私の名前は < span itemprop = "name" > Elizabeth</ span > です。</ p >
</ div >
< div itemscope >
< p > 私の名前は < span itemprop = "name" > Daniel</ span > です。</ p >
</ div > マイクロデータ関連の属性を持たないマークアップは、マイクロデータモデルへ何の影響も与えません。
次の 2 つの例は、マイクロデータの水準では、それぞれ前の 2 つの例とまったく同等です。
< div itemscope >
< p > 私の< em > 名前</ em > は < span itemprop = "name" > E< strong > liz</ strong > abeth</ span > です。</ p >
</ div >
< section >
< div itemscope >
< aside >
< p > 私の名前は < span itemprop = "name" >< a href = "/?user=daniel" > Daniel</ a ></ span > です。</ p >
</ aside >
</ div >
</ section > 通常、プロパティは文字列である値を持ちます。
ここでは、アイテムは 3 つのプロパティを持ちます。
< div itemscope >
< p > 私の名前は < span itemprop = "name" > Neil</ span > です。</ p >
< p > 私のバンドの名前は < span itemprop = "band" > Four Parts Water</ span > です。</ p >
< p > 私は < span itemprop = "nationality" > イギリス人</ span > です。</ p >
</ div > 文字列値が URL
である場合、その値は a 要素とその
href 属性、
img 要素とその
src 属性、または外部リソースへ
リンクするか外部リソースを埋め込むその他の要素を使用して表します。
この例では、アイテムは値が URL である「image」というプロパティを一つ持ちます。
< div itemscope >
< img itemprop = "image" src = "google-logo.png" alt = "Google" >
</ div > 文字列値が人間による利用には適さない何らかの機械可読形式である場合、data 要素の value
属性を使用してその値を表し、人間が読める版を要素の内容として指定します。
ここには、値が製品 ID であるプロパティを持つアイテムがあります。この ID は人間には 分かりやすくないため、人間に表示されるテキストには ID の代わりに製品名を使用しています。
< h1 itemscope >
< data itemprop = "product-id" value = "9678AOU879" > The Instigator 2000</ data >
</ h1 > 数値データには、代わりに meter 要素とその
value 属性を使用できます。
ここでは、meter 要素を使用して
評価を示しています。
< div itemscope itemtype = "http://schema.org/Product" >
< span itemprop = "name" > Panasonic ホワイト 60L 冷蔵庫</ span >
< img src = "panasonic-fridge-60l-white.jpg" alt = "" >
< div itemprop = "aggregateRating"
itemscope itemtype = "http://schema.org/AggregateRating" >
< meter itemprop = "ratingValue" min = 0 value = 3.5 max = 5 > 5 点中 3.5 点</ meter >
(< span itemprop = "reviewCount" > 11</ span > 件の顧客レビューに基づく)
</ div >
</ div > 同様に、日付および時刻に関するデータには、代わりに time
要素とその datetime 属性を使用できます。
この例では、アイテムは値が日付である「birthday」というプロパティを一つ持ちます。
< div itemscope >
私は < time itemprop = "birthday" datetime = "2009-05-10" > 2009 年 5 月 10 日</ time > に生まれました。
</ div > プロパティを宣言する要素へ itemscope
属性を指定することで、
プロパティ自体を名前と値のペアのグループにすることもできます。
ほかのアイテムの一部ではないアイテムは、トップレベルマイクロデータアイテムと呼ばれます。
この例では、外側のアイテムが人物を表し、内側のアイテムがバンドを表します。
< div itemscope >
< p > 名前:< span itemprop = "name" > Amanda</ span ></ p >
< p > バンド:< span itemprop = "band" itemscope > < span itemprop = "name" > Jazz Band</ span > (< span itemprop = "size" > 12</ span > 人の演奏者)</ span ></ p >
</ div > ここで外側のアイテムは、「name」と「band」という 2 つのプロパティを持ちます。「name」は 「Amanda」であり、「band」はそれ自体がアイテムで、「name」と「size」という 2 つの プロパティを持ちます。バンドの「name」は「Jazz Band」で、「size」は「12」です。
この例の外側のアイテムはトップレベルマイクロデータアイテムです。
itemscope 属性を持つ要素の
子孫ではないプロパティは、itemref 属性を使用してアイテムへ関連付けることができます。
この属性は、itemscope
属性を持つ要素の子を走査することに加えて、走査する要素の ID のリストを受け取ります。
この例は前の例と同じですが、すべてのプロパティがそれぞれのアイテムから分離されています。
< div itemscope id = "amanda" itemref = "a b" ></ div >
< p id = "a" > 名前:< span itemprop = "name" > Amanda</ span ></ p >
< div id = "b" itemprop = "band" itemscope itemref = "c" ></ div >
< div id = "c" >
< p > バンド:< span itemprop = "name" > Jazz Band</ span ></ p >
< p > 人数:< span itemprop = "size" > 12</ span > 人</ p >
</ div > これは前の例と同じ結果になります。最初のアイテムは、「Amanda」に設定された「name」と、 別のアイテムに設定された「band」という 2 つのプロパティを持ちます。その 2 番目のアイテムは、 「Jazz Band」に設定された「name」と、「12」に設定された「size」という、さらに 2 つの プロパティを持ちます。
アイテムは、同じ名前で異なる値を持つ 複数のプロパティを持つことができます。
この例は、2 種類の味を持つアイスクリームについて記述しています。
< div itemscope >
< p > 私の好きなアイスクリームの味:</ p >
< ul >
< li itemprop = "flavor" > レモンシャーベット</ li >
< li itemprop = "flavor" > アプリコットシャーベット</ li >
</ ul >
</ div > したがって、これは「flavor」という 2 つのプロパティを持ち、それぞれの値が 「レモンシャーベット」と「アプリコットシャーベット」であるアイテムになります。
一部のプロパティが同じ値を持つ場合の重複を避けるため、プロパティを導入する要素は、 複数のプロパティを一度に導入することもできます。
ここでは、「favorite-color」と「favorite-fruit」という 2 つのプロパティが、ともに 「orange」という値へ設定されたアイテムを示しています。
< div itemscope >
< span itemprop = "favorite-color favorite-fruit" > オレンジ</ span >
</ div > マイクロデータと、マイクロデータがマークアップされている文書の内容との間には関係がないことに 注意することが重要です。
たとえば、次の 2 つの例の間に意味上の違いはありません。
< figure >
< img src = "castle.jpeg" >
< figcaption >< span itemscope >< span itemprop = "name" > 城</ span ></ span > (1986 年)</ figcaption >
</ figure > < span itemscope >< meta itemprop = "name" content = "城" ></ span >
< figure >
< img src = "castle.jpeg" >
< figcaption > 城(1986 年)</ figcaption >
</ figure > どちらもキャプション付きの図を持ち、どちらもその図とはまったく無関係に、名前が「name」で 値が「城」である名前と値のペアを持つアイテムを含みます。唯一の違いは、利用者がキャプションを 文書の外へドラッグした場合、前者ではアイテムがドラッグアンドドロップデータへ含まれることです。 どちらの場合も、画像はアイテムと一切関連付けられていません。
この節は非規範的です。
前の節の例は、そのマイクロデータが再利用されることを想定していないページ上で、情報をどのように マークアップできるかを示しています。しかし、マイクロデータが最も有用なのは、ほかの作者と読者が 協力し、そのマークアップを新たな用途へ利用できる状況で使用される場合です。
この目的のために、各アイテムには、 「https://example.com/person」、「https://example.org/cat」、または 「https://band.example.net/」などの型を与える必要があります。型はURLとして識別されます。
アイテムの型は、itemscope 属性と同じ要素にある
itemtype 属性の値として指定します。
ここでは、アイテムの型は「https://example.org/animals#cat」です。
< section itemscope itemtype = "https://example.org/animals#cat" >
< h1 itemprop = "name" > Hedral</ h1 >
< p itemprop = "desc" > Hedral はアメリカンショートヘアの雄で、
白い足と腹を持つ、ふわふわした黒い毛の猫です。</ p >
< img itemprop = "img" src = "hedral.jpeg" alt = "" title = "Hedral、月齢 18 か月" >
</ section > この例の「https://example.org/animals#cat」アイテムは、「name」(「Hedral」)、 「desc」(「Hedral は……」)、および「img」(「hedral.jpeg」)という 3 つの プロパティを持ちます。
型はプロパティの文脈を与え、それによって語彙を選択します。型
「https://census.example/person」を持つアイテムへ指定された「class」という名前の
プロパティは、個人の経済階級を指す可能性があります。一方、型
「https://example.com/school/teacher」を持つアイテムへ指定された「class」という名前の
プロパティは、教師が割り当てられた教室を指す可能性があります。複数の型が同じ語彙を共有できます。
たとえば、型「https://example.org/people/teacher」と
「https://example.org/people/engineer」は、同じ語彙を使用するように定義できます
(ただし、一部のプロパティは両方の場合で特に有用とは限りません。たとえば、
「https://example.org/people/engineer」型は通常「classroom」
プロパティとともに使用されないかもしれません)。同じ語彙を使用するように定義された複数の型は、
属性値に URL を空白区切りのリストとして列挙することにより、単一のアイテムへ指定できます。
ただし、同じ語彙を使用しない 2 つの型をアイテムへ指定することはできません。
この節は非規範的です。
アイテムが、グローバル識別子を 持つ主題についての情報を与える場合があります。たとえば、書籍は ISBN 番号によって識別できます。
語彙は、itemtype 属性によって
識別されますが、その語彙を、itemid 属性に指定するURLとしてグローバル識別子を表すことにより、アイテムを曖昧さなくその
グローバル識別子へ関連付けられるように設計できます。
itemid 属性で指定される
URLの正確な意味は、使用される語彙によって異なります。
ここでは、アイテムが特定の書籍について記述しています。
< dl itemscope
itemtype = "https://vocab.example.net/book"
itemid = "urn:isbn:0-330-34032-8" >
< dt > 題名
< dd itemprop = "title" > The Reality Dysfunction
< dt > 著者
< dd itemprop = "author" > Peter F. Hamilton
< dt > 出版日
< dd >< time itemprop = "pubdate" datetime = "1996-01-26" > 1996 年 1 月 26 日</ time >
</ dl > この例の「https://vocab.example.net/book」語彙は、itemid
属性が、書籍の ISBN を指す urn:
URLを受け取ることを定義することになります。
この節は非規範的です。
マイクロデータを使用することは、語彙を使用することを意味します。目的によっては、場当たり的な 語彙で十分です。別の目的では、語彙を設計する必要があります。可能な場合、コンテンツの再利用が 容易になるため、作者には既存の語彙を再利用することが推奨されます。
新しい語彙を設計するとき、識別子は URLを使用するか、プロパティについては単純な単語 (ピリオドまたはコロンを含まないもの)として作成できます。URL の場合、作者が管理するページに 対応する識別子だけを使用することで、ほかの語彙との競合を避けられます。
たとえば、Jon と Adam がともに example.com 上の、それぞれ
https://example.com/~jon/... と https://example.com/~adam/... で
コンテンツを作成している場合、それぞれ
「https://example.com/~jon/name」と「https://example.com/~adam/name」の形式の
識別子を選択できます。
名前が単純な単語だけであるプロパティは、その対象として意図された型の文脈内でのみ使用できます。 URL を使用して名前が付けられたプロパティは、任意の型のアイテムで再利用できます。アイテムに型がなく、 かつほかのアイテムの一部でもない場合、そのプロパティ名が単純な単語だけであれば、それらは グローバルに一意であることを意図しておらず、限定的な用途だけを意図しています。一般に、作者には、 グローバルに一意な名前(URL)を持つプロパティを使用するか、アイテムに型が指定されることを 確実にすることが推奨されます。
ここでは、アイテムは「https://example.org/animals#cat」であり、ほとんどのプロパティには、 その型の文脈で定義された単語の名前があります。名前がほかの語彙に由来する追加のプロパティも いくつかあります。
< section itemscope itemtype = "https://example.org/animals#cat" >
< h1 itemprop = "name https://example.com/fn" > Hedral</ h1 >
< p itemprop = "desc" > Hedral はアメリカンショートヘアの雄で、
白い足と腹を持つ、ふわふわした < span
itemprop = "https://example.com/color" > 黒い</ span > 毛の猫です。足と腹は< span
itemprop = "https://example.com/color" > 白</ span > です。</ p >
< img itemprop = "img" src = "hedral.jpeg" alt = "" title = "Hedral、月齢 18 か月" >
</ section > この例には、型が「https://example.org/animals#cat」であり、次のプロパティを持つ 一つのアイテムがあります。
| プロパティ | 値 |
| name | Hedral |
| https://example.com/fn | Hedral |
| desc | Hedral はアメリカンショートヘアの雄で、白い足と腹を持つ、ふわふわした黒い毛の猫です。 |
| https://example.com/color | 黒 |
| https://example.com/color | 白 |
| img | .../hedral.jpeg |
マイクロデータモデルは、アイテムと呼ばれる、名前と値のペアのグループから構成されます。
各グループはアイテムと呼ばれます。 各アイテムは、アイテム型、アイテム型によって指定される語彙がアイテムのグローバル識別子を サポートする場合はグローバル 識別子、および名前と値のペアのリストを持つことができます。名前と値のペアの各名前はプロパティと呼ばれ、各プロパティは一つ以上の値を持ちます。各値は、文字列であるか、 それ自体が名前と値のペアのグループ(アイテム)です。名前同士には順序がありませんが、 特定の名前が複数の値を持つ場合、それらの値には相対的な順序があります。
現在のすべてのエンジンでサポートされています。
すべてのHTML 要素には、itemscope 属性を指定できます。
itemscope 属性は真偽属性です。
itemscope 属性が指定された要素は、
名前と値のペアのグループである新しいアイテムを作成します。
現在のすべてのエンジンでサポートされています。
itemscope 属性を持つ要素には、
アイテムのアイテム型を指定するために、itemtype 属性を指定できます。
itemtype 属性が指定される場合、
その値は一意な空白区切りトークンの順序なし集合で
なければなりません。各トークンはほかのトークンと同一であってはならず、それぞれが絶対 URLである妥当な URL 文字列で
なければならず、すべてが同じ語彙を使用するように定義されていなければなりません。属性値には
少なくとも一つのトークンがなければなりません。
アイテムのアイテム型とは、要素の
itemtype 属性値をASCII 空白で分割して得られるトークンです。itemtype
属性が存在しない場合、またはこの方法で解析してもトークンが見つからない場合、そのアイテムにはアイテム型がないといいます。
アイテム型は、すべて適用可能な仕様で定義される型でなければならず、 すべて同じ語彙を使用するように定義されていなければなりません。
その仕様によって別途指定されている場合を除き、アイテム型として指定されるURLを自動的に参照解決するべきではありません。
たとえば、仕様は、そのアイテム型を参照解決することで、利用者へヘルプ情報を提供できると 定義できます。実際、語彙の作者には、指定されたURLで有用な情報を提供することが 推奨されます。
アイテム型は不透明な識別子であり、 ユーザーエージェントは、それらを使用するアイテムの処理方法を決定するために、未知のアイテム型を参照解決したり、その他の方法で分解したりしてはなりません。
itemtype 属性は、itemscope 属性が指定されていない要素へ
指定してはなりません。
アイテムがアイテム型を持つ場合、または型付きアイテムのプロパティの値である場合、そのアイテムを型付きアイテムといいます。型付きアイテムの関連する型は、 そのアイテムにアイテム型がある場合はそのアイテム型であり、そうでない場合は、 そのアイテムがプロパティの値となっているアイテムの関連する型です。
現在のすべてのエンジンでサポートされています。
itemscope 属性と、アイテムのグローバル識別子をサポートするように定義された
語彙を参照する itemtype 属性を持つ
要素には、アイテムのグローバル識別子を指定し、
ウェブ上の別の場所にあるページ上のほかのアイテムと関連付けられるようにするため、itemid 属性も指定できます。
itemid 属性が指定される場合、その値は空白で囲まれている可能性のある妥当な URLで
なければなりません。
アイテムのグローバル識別子とは、そのアイテムの要素に itemid 属性がある場合、その属性が指定された
要素のノード文書を基準として解析した属性値です。itemid
属性が存在しない場合、またはその解析が失敗を返す場合、そのアイテムにはグローバル
識別子がないといいます。
itemid 属性は、itemscope 属性と itemtype 属性の両方が指定されていない要素へ
指定してはなりません。また、itemscope 属性を持つ要素で、その itemtype 属性が、その語彙の仕様で定義される
アイテムのグローバル識別子をサポートしない語彙を
指定する場合にも、指定してはなりません。
グローバル識別子の正確な意味は、 語彙の仕様によって決定されます。同じグローバル識別子を持つ複数のアイテム (同じページ上か異なるページ上かを問いません)の存在を許可するかどうか、および同じ ID を持つ 複数のアイテムを処理する場合のその語彙の処理規則を定義するのは、そのような仕様です。
現在のすべてのエンジンでサポートされています。
itemscope 属性を持つ要素には、
アイテムの名前と値のペアを見つけるために
走査する追加要素のリストを指定する、itemref 属性を指定できます。
itemref 属性が指定される場合、
その値は一意な空白区切りトークンの順序なし集合で
なければなりません。各トークンはほかのトークンと同一であってはならず、同じツリー内にある要素のIDから構成されなければなりません。
itemref 属性は、itemscope 属性が指定されていない要素へ
指定してはなりません。
itemref 属性は、
マイクロデータのデータモデルの一部ではありません。注釈を付けるデータが扱いやすいツリー構造に
従っていないページへ、作者が注釈を追加するのを支援する単なる構文上の仕組みです。たとえば、
各列が別々のアイテムを定義するように、
セル内にプロパティを保持したまま表のデータをマークアップできます。
この例は、鉄道模型メーカーの製品を記述するために使用される単純な語彙を示しています。 この語彙には、次の 5 つのプロパティ名だけがあります。
この語彙には、定義済みのアイテム型が 4 つあります。
この語彙を使用する各アイテムには、その製品が何であるかに応じて、 これらの型を一つ以上指定できます。
したがって、機関車は次のようにマークアップできます。
< dl itemscope itemtype = "https://md.example.com/loco
https://md.example.com/lighting" >
< dt > 名前:
< dd itemprop = "name" > タンク機関車(DB 80)
< dt > 製品コード:
< dd itemprop = "product-code" > 33041
< dt > 縮尺:
< dd itemprop = "scale" > HO
< dt > デジタル:
< dd itemprop = "digital" > Delta
</ dl > 分岐器ランタンの後付けキットは、次のようにマークアップできます。
< dl itemscope itemtype = "https://md.example.com/track
https://md.example.com/lighting" >
< dt > 名前:
< dd itemprop = "name" > 分岐器ランタンキット
< dt > 製品コード:
< dd itemprop = "product-code" > 74470
< dt > 用途:
< dd > 2 個の < span itemprop = "track-type" > C</ span > 線路用
分岐器の後付け用。< meta itemprop = "scale" content = "HO" >
</ dl > 照明を持たない客車は、次のようにマークアップできます。
< dl itemscope itemtype = "https://md.example.com/passengers" >
< dt > 名前:
< dd itemprop = "name" > 急行列車客車(DB Am 203)
< dt > 製品コード:
< dd itemprop = "product-code" > 8710
< dt > 縮尺:
< dd itemprop = "scale" > Z
</ dl > 新しい語彙を作成するときは、細心の注意が必要です。多くの場合、型に階層的な方法を採用することで、 各アイテムが常に一つの型だけを持つ語彙を作成でき、一般にその方が管理ははるかに簡単です。
itemprop 属性現在のすべてのエンジンでサポートされています。
すべてのHTML 要素には、それによって一つ以上のアイテムへ一つ以上のプロパティが追加される
(以下で定義します)場合、itemprop
属性を指定できます。
itemprop
属性が指定される場合、その値は、それによって追加される名前と値のペアの名前を表す一意な
空白区切りトークンの順序なし集合でなければなりません。各トークンは、ほかのトークンと同一であってはなりません。属性値には少なくとも一つのトークンが
なければなりません。
各トークンは、次のいずれかでなければなりません。
定義済みプロパティ名を導入する仕様は、 そのようなすべてのプロパティ名に、U+002E FULL STOP 文字(.)、U+003A COLON 文字(:)、 およびASCII 空白が含まれないことを確実にしなければなりません。
上の規則が URL ではない値で U+003A COLON 文字(:)を禁止するのは、 そうしなければ URL と区別できないためです。U+002E FULL STOP 文字(.)を持つ値は、 将来の拡張用に予約されています。ASCII 空白が禁止されるのは、そうしなければ値が複数の トークンとして解析されるためです。
itemprop
属性を持つ要素が、複数のアイテムへプロパティを追加する場合、
上記のトークンに関する要件は、各アイテムへ個別に適用されます。
要素のプロパティ名とは、その要素の itemprop
属性値をASCII
空白で分割したときに、その属性に含まれることが
判明したトークンです。順序は保持しますが、重複は削除します
(各名前について最初に現れたものだけを残します)。
アイテム内では、 プロパティ同士に順序はありません。ただし、同じ名前を持つプロパティは例外であり、それらはアイテムのプロパティを定義する アルゴリズムによって与えられた順序に従います。
次の例では、「a」プロパティはこの順序で「1」と「2」という値を持ちますが、 「a」プロパティが「b」プロパティより前に来るかどうかは重要ではありません。
< div itemscope >
< p itemprop = "a" > 1</ p >
< p itemprop = "a" > 2</ p >
< p itemprop = "b" > テスト</ p >
</ div > したがって、次のものは同等です。
< div itemscope >
< p itemprop = "b" > テスト</ p >
< p itemprop = "a" > 1</ p >
< p itemprop = "a" > 2</ p >
</ div > 次のものも同様です。
< div itemscope >
< p itemprop = "a" > 1</ p >
< p itemprop = "b" > テスト</ p >
< p itemprop = "a" > 2</ p >
</ div > そして、次のものも同様です。
< div id = "x" >
< p itemprop = "a" > 1</ p >
</ div >
< div itemscope itemref = "x" >
< p itemprop = "b" > テスト</ p >
< p itemprop = "a" > 2</ p >
</ div > itemprop 属性を
持つ要素によって追加される名前と値のペアのプロパティ値は、次のリストで最初に一致する場合に示す値です。
itemscope
属性も持つ場合値は、その要素によって作成されたアイテムです。
meta 要素である場合
値は、要素に content
属性がある場合はその属性の値であり、そのような属性がない場合は空文字列です。
audio、
embed、
iframe、
img、
source、
track、または
video 要素である場合
値は、その属性が設定された時点で、要素のノード文書を基準として、要素の src 属性値を
与えてURL
をエンコーディング解析して直列化した
結果です。そのような属性がない場合、または結果が失敗である場合は空文字列です。
a、
area、または
link 要素である場合
値は、その属性が設定された時点で、要素のノード文書を基準として、要素の href 属性値を
与えてURL
をエンコーディング解析して直列化した
結果です。そのような属性がない場合、または結果が失敗である場合は空文字列です。
object
要素である場合値は、その属性が設定された時点で、要素のノード文書を基準として、要素の data 属性値を
与えてURL
をエンコーディング解析して直列化した
結果です。そのような属性がない場合、または結果が失敗である場合は空文字列です。
data 要素である場合
値は、要素に value 属性がある場合は
その属性の値であり、それ以外の場合は空文字列です。
meter 要素である場合
値は、要素に value 属性がある場合は
その属性の値であり、それ以外の場合は空文字列です。
time 要素である場合
値は、要素の日時値です。
値は、要素の子孫テキスト内容です。
プロパティの定義によって定義される、そのプロパティの値が絶対 URLである場合、そのプロパティはURL プロパティ要素を使用して 指定しなければなりません。
これらの要件は、プロパティ値がたまたま URL の構文に一致するというだけでは 適用されません。そのプロパティがそのような値を受け取るものとして明示的に定義されている場合にのみ 適用されます。
たとえば、最初の月面着陸についての書籍には「mission:moon」という題名を
付けることができます。題名を文字列として定義する語彙の「title」プロパティでは、その題名が
URLのように見えても、a 要素内で題名が指定されることは
想定されません。一方、「URL のように見える題名を持つ書籍」のための
(かなり限定的な範囲の)語彙が存在し、その「title」プロパティが URL を受け取るものとして
定義されている場合、上記の要件により、そのプロパティは a 要素
(またはその他のURL プロパティ要素の一つ)内で題名が指定されることを
想定します。
要素 root によって定義されるアイテムのプロパティを 検出するために、ユーザーエージェントは次の手順を実行しなければなりません。これらの手順は、マイクロデータエラーを示すためにも使用されます。
results、memory、および pending を、要素の空のリストとします。
要素 root を memory に追加します。
root に子要素がある場合、それらを pending に追加します。
root が itemref 属性を持つ場合、
その itemref 属性の値をASCII
空白で分割します。結果として得られる各トークン
ID について、root のツリー内に、ID が ID である要素が存在する場合、そのような最初の要素を
pending に追加します。
pending が空でない間、次を行います。
pending から要素を一つ取り除き、その要素を current とします。
current がすでに memory 内にある場合、マイクロデータエラーです。続行します。
current を memory に追加します。
current が itemscope
属性を持たない場合、current のすべての子要素を
pending に追加します。
current に itemprop
属性が指定されており、かつ一つ以上のプロパティ名を持つ場合、current を
results に追加します。
results をツリー順に並べ替えます。
results を返します。
文書には、アイテムのプロパティを検出するアルゴリズムが マイクロデータエラーを検出するようなアイテムを含めてはなりません。
Document 内のすべての itemref 属性は、Document 内の各アイテムをグラフ内のノードとして表し、
値が別のアイテムである
アイテムの各プロパティを、それら二つのアイテムを接続する
グラフ内の辺として表すことによって形成されるグラフに、循環が生じないようにしなければなりません。
文書には、その文書内のすべてのアイテムについてプロパティをすべて決定した場合に、
いずれのアイテムのプロパティとしても検出されない itemprop
属性を持つ要素を含めてはなりません。
この例では、著作物を表すアイテムから itemref を使用することで、
単一のライセンス文を二つの著作物へ適用しています。
<!DOCTYPE HTML>
< html lang = "en" >
< head >
< title > 写真ギャラリー</ title >
</ head >
< body >
< h1 > 私の写真</ h1 >
< figure itemscope itemtype = "http://n.whatwg.org/work" itemref = "licenses" >
< img itemprop = "work" src = "images/house.jpeg" alt = "森の中に、板で塞がれた白い家があります。" >
< figcaption itemprop = "title" > 私が見つけた家。</ figcaption >
</ figure >
< figure itemscope itemtype = "http://n.whatwg.org/work" itemref = "licenses" >
< img itemprop = "work" src = "images/mailbox.jpeg" alt = "家の外に郵便受けがあります。中にはチラシが入っています。" >
< figcaption itemprop = "title" > 郵便受け。</ figcaption >
</ figure >
< footer >
< p id = "licenses" > すべての画像は < a itemprop = "license"
href = "http://www.opensource.org/licenses/mit-license.php" > MIT
ライセンス</ a > の下でライセンスされています。</ p >
</ footer >
</ body >
</ html > 上記の結果、型が「http://n.whatwg.org/work」である二つのアイテムが生成されます。
一つは次のプロパティを持ちます。
images/house.jpeg
http://www.opensource.org/licenses/mit-license.php
……もう一つは次のプロパティを持ちます。
images/mailbox.jpeg
http://www.opensource.org/licenses/mit-license.php
現在、itemscope、itemprop、
およびその他のマイクロデータ属性は、HTML
要素についてのみ定義されています。これは、
「itemscope」や「itemprop」などのリテラル名を持つ属性が、SVG などの
その他の名前空間内の要素ではマイクロデータ処理を発生させないことを意味します。
したがって、次の例には二つではなく、一つのアイテムだけがあります。
< p itemscope ></ p > <!-- これはアイテムです(プロパティも型もありません) -->
< svg itemscope ></ svg > <!-- これはアイテムではなく、無効な未知の属性を持つ単なる SVG svg 要素です --> この節の語彙は、主に語彙を指定する方法を実演することを目的としていますが、それ自体を 使用することもできます。
アイテム型が http://microformats.org/profile/hcard であるアイテムは、人物または
組織の連絡先情報を表します。
この語彙はアイテムのグローバル識別子をサポートしません。
次に示すのは、この型の定義済みプロパティ名です。これらは、vCard 形式仕様 (vCard)およびその拡張で定義される語彙に基づいています。値の解釈方法についての 詳細情報は、そこに記載されています。[RFC6350]
kindアイテムがどのような種類の連絡先を表すかを記述します。
値は、種類文字列のいずれかと同一であるテキストでなければなりません。
型が http://microformats.org/profile/hcard である各アイテム内には、kind という名前のプロパティを一つ
含めることができます。
fn人物または組織の名前に対応する整形済みテキストを指定します。
値はテキストでなければなりません。
型が http://microformats.org/profile/hcard である各アイテム内には、fn という名前のプロパティが正確に一つ
存在しなければなりません。
n人物または組織の構造化された名前を指定します。
値は、family-name、given-name、additional-name、honorific-prefix、
および honorific-suffix
の各プロパティをゼロ個以上持つアイテムでなければなりません。
型が http://microformats.org/profile/hcard である各アイテム内には、n という名前のプロパティが正確に一つ
存在しなければなりません。
family-name(n 内)人物の姓、または組織の完全な名前を指定します。
値はテキストでなければなりません。
型が http://microformats.org/profile/hcard であるアイテムの n プロパティの値を形成するアイテム内には、family-name
という名前のプロパティを任意の数だけ含めることができます。
given-name(n 内)人物の名を指定します。
値はテキストでなければなりません。
型が http://microformats.org/profile/hcard であるアイテムの n プロパティの値を形成するアイテム内には、given-name
という名前のプロパティを任意の数だけ含めることができます。
additional-name(n 内)人物の追加の名前を指定します。
値はテキストでなければなりません。
型が http://microformats.org/profile/hcard であるアイテムの n プロパティの値を形成するアイテム内には、additional-name
という名前のプロパティを任意の数だけ含めることができます。
honorific-prefix(n 内)人物の敬称接頭辞を指定します。
値はテキストでなければなりません。
型が http://microformats.org/profile/hcard であるアイテムの n プロパティの値を形成するアイテム内には、honorific-prefix
という名前のプロパティを任意の数だけ含めることができます。
honorific-suffix(n 内)人物の敬称接尾辞を指定します。
値はテキストでなければなりません。
型が http://microformats.org/profile/hcard であるアイテムの n プロパティの値を形成するアイテム内には、honorific-suffix
という名前のプロパティを任意の数だけ含めることができます。
nickname人物または組織のニックネームを指定します。
ニックネームとは、人物、場所、または物に属する名前の代わりに、またはそれに加えて
与えられる説明的な名前です。fn
または n プロパティによって指定された
固有名の親しみやすい形式を指定するためにも使用できます。
値はテキストでなければなりません。
型が http://microformats.org/profile/hcard である各アイテム内には、nickname という名前のプロパティを
任意の数だけ含めることができます。
photo人物または組織の写真を指定します。
型が http://microformats.org/profile/hcard である各アイテム内には、photo という名前のプロパティを
任意の数だけ含めることができます。
bday人物または組織の生年月日を指定します。
型が http://microformats.org/profile/hcard である各アイテム内には、bday という名前のプロパティを一つ
含めることができます。
anniversary人物または組織の生年月日を指定します。
型が http://microformats.org/profile/hcard である各アイテム内には、anniversary
という名前のプロパティを一つ含めることができます。
sex人物の生物学的性別を指定します。
値は、
「女性」を意味する F、
「男性」を意味する M、
「なし、または該当なし」を意味する N、
「その他」を意味する O、または
「不明」を意味する U のいずれかでなければなりません。
型が http://microformats.org/profile/hcard である各アイテム内には、sex という名前のプロパティを一つ
含めることができます。
gender-identity人物の性自認を指定します。
値はテキストでなければなりません。
型が http://microformats.org/profile/hcard である各アイテム内には、gender-identity
という名前のプロパティを一つ含めることができます。
adr人物または組織の配達先住所を指定します。
値は、type、post-office-box、
extended-address、
および street-address
プロパティをそれぞれゼロ個以上持ち、任意で locality プロパティ、
任意で region プロパティ、
任意で postal-code プロパティ、
および任意で country-name
プロパティを持つアイテムでなければなりません。
型が http://microformats.org/profile/hcard であるアイテムの adr プロパティの値を形成するアイテム内に、type プロパティが存在しない場合、
住所型文字列 work が暗黙的に
指定されます。
型が http://microformats.org/profile/hcard である各アイテム内には、adr という名前のプロパティを
任意の数だけ含めることができます。
type(adr 内)配達先住所の型を指定します。
値は、住所型文字列のいずれかと同一であるテキストでなければなりません。
型が http://microformats.org/profile/hcard であるアイテムの adr プロパティの値を形成するアイテム内には、type という名前のプロパティを
任意の数だけ含めることができます。ただし、そのような各 adr プロパティのアイテム内では、異なる値ごとに type プロパティを一つだけ
含めなければなりません。
post-office-box(adr 内)人物または組織の配達先住所における私書箱部分を指定します。
値はテキストでなければなりません。
型が http://microformats.org/profile/hcard であるアイテムの adr プロパティの値を形成するアイテム内には、post-office-box
という名前のプロパティを任意の数だけ含めることができます。
vCard は、作者にこのフィールドを使用しないよう強く勧めています。
extended-address(adr 内)人物または組織の配達先住所の追加部分を指定します。
値はテキストでなければなりません。
型が http://microformats.org/profile/hcard であるアイテムの adr プロパティの値を形成するアイテム内には、extended-address
という名前のプロパティを任意の数だけ含めることができます。
vCard は、作者にこのフィールドを使用しないよう強く勧めています。
street-address(adr 内)人物または組織の配達先住所における通りの住所部分を指定します。
値はテキストでなければなりません。
型が http://microformats.org/profile/hcard であるアイテムの adr プロパティの値を形成するアイテム内には、street-address
という名前のプロパティを任意の数だけ含めることができます。
locality(adr 内)人物または組織の配達先住所における地域部分(都市など)を指定します。
値はテキストでなければなりません。
型が http://microformats.org/profile/hcard であるアイテムの adr プロパティの値を形成するアイテム内には、locality
という名前のプロパティを一つ含めることができます。
region(adr 内)人物または組織の配達先住所における地域部分(州または県など)を指定します。
値はテキストでなければなりません。
型が http://microformats.org/profile/hcard であるアイテムの adr プロパティの値を形成するアイテム内には、region
という名前のプロパティを一つ含めることができます。
postal-code(adr 内)人物または組織の配達先住所における郵便番号部分を指定します。
値はテキストでなければなりません。
型が http://microformats.org/profile/hcard であるアイテムの adr プロパティの値を形成するアイテム内には、postal-code
という名前のプロパティを一つ含めることができます。
country-name(adr 内)人物または組織の配達先住所における国名部分を指定します。
値はテキストでなければなりません。
型が http://microformats.org/profile/hcard であるアイテムの adr プロパティの値を形成するアイテム内には、country-name
という名前のプロパティを一つ含めることができます。
tel人物または組織の電話番号を指定します。
値は、CCITT 仕様 E.163 および
X.121 で定義される電話番号として解釈できるテキスト、またはゼロ個以上の type プロパティと正確に一つの
value プロパティを持つアイテムのいずれかでなければなりません。[E163] [X121]
型が http://microformats.org/profile/hcard であるアイテムの tel プロパティの値を形成するアイテム内に、type プロパティが存在しない場合、
またはそのような tel
プロパティの値がテキストである場合、
電話型文字列
voice が
暗黙的に指定されます。
型が http://microformats.org/profile/hcard である各アイテム内には、tel という名前のプロパティを
任意の数だけ含めることができます。
type(tel 内)電話番号の型を指定します。
値は、電話型文字列のいずれかと同一であるテキストでなければなりません。
型が http://microformats.org/profile/hcard であるアイテムの tel プロパティの値を形成するアイテム内には、type という名前のプロパティを
任意の数だけ含めることができます。ただし、そのような各 tel プロパティのアイテム内では、異なる値ごとに type プロパティを一つだけ
含めなければなりません。
value(tel 内)人物または組織の実際の電話番号を指定します。
値は、CCITT 仕様 E.163 および X.121 で定義される電話番号として解釈できるテキストでなければなりません。[E163] [X121]
型が http://microformats.org/profile/hcard であるアイテムの tel プロパティの値を形成するアイテム内には、value
という名前のプロパティが正確に一つ存在しなければなりません。
email人物または組織のメールアドレスを指定します。
値はテキストでなければなりません。
型が http://microformats.org/profile/hcard である各アイテム内には、email という名前のプロパティを
任意の数だけ含めることができます。
impp人物または組織とのインスタントメッセージングおよびプレゼンスプロトコル通信に使用するURLを指定します。
型が http://microformats.org/profile/hcard である各アイテム内には、impp という名前のプロパティを
任意の数だけ含めることができます。
lang人物または組織が理解する言語を指定します。
値は妥当な BCP 47 言語タグでなければなりません。 [BCP47]
型が http://microformats.org/profile/hcard である各アイテム内には、lang という名前のプロパティを
任意の数だけ含めることができます。
tz人物または組織のタイムゾーンを指定します。
値はテキストでなければならず、 次の構文に一致しなければなりません。
型が http://microformats.org/profile/hcard である各アイテム内には、tz という名前のプロパティを任意の数だけ
含めることができます。
geo人物または組織の地理的位置を指定します。
値はテキストでなければならず、 次の構文に一致しなければなりません。
アスタリスク(*)で示された任意の構成要素は含めるべきであり、それぞれ 6 桁にするべきです。
値は、緯度と経度をこの順序(すなわち「LAT LON」の順序)で、十進度によって 指定します。経度は、本初子午線から東または西の位置を、それぞれ正または負の実数で表します。 緯度は、赤道から北または南の位置を、それぞれ正または負の実数で表します。
型が http://microformats.org/profile/hcard である各アイテム内には、geo という名前のプロパティを任意の数だけ
含めることができます。
title人物または組織の役職、職務上の地位、または職務を指定します。
値はテキストでなければなりません。
型が http://microformats.org/profile/hcard である各アイテム内には、title という名前のプロパティを
任意の数だけ含めることができます。
role人物または組織の役割、職業、または事業分類を指定します。
値はテキストでなければなりません。
型が http://microformats.org/profile/hcard である各アイテム内には、role という名前のプロパティを
任意の数だけ含めることができます。
logo人物または組織のロゴを指定します。
型が http://microformats.org/profile/hcard である各アイテム内には、logo という名前のプロパティを
任意の数だけ含めることができます。
agent人物または組織を代理する別の人物の連絡先情報を指定します。
値は、型が http://microformats.org/profile/hcard であるアイテム、絶対
URL、またはテキストのいずれかでなければなりません。
型が http://microformats.org/profile/hcard である各アイテム内には、agent という名前のプロパティを
任意の数だけ含めることができます。
org組織の名前および部門を指定します。
値は、テキスト、または一つの
organization-name
プロパティとゼロ個以上の organization-unit
プロパティを持つアイテムのいずれかでなければなりません。
型が http://microformats.org/profile/hcard である各アイテム内には、org という名前のプロパティを任意の数だけ
含めることができます。
organization-name(org 内)組織の名前を指定します。
値はテキストでなければなりません。
型が http://microformats.org/profile/hcard であるアイテムの org プロパティの値を形成するアイテム内には、organization-name
という名前のプロパティが正確に一つ存在しなければなりません。
organization-unit(org 内)組織部門の名前を指定します。
値はテキストでなければなりません。
型が http://microformats.org/profile/hcard であるアイテムの org
プロパティの値を形成するアイテム内には、organization-unit
という名前のプロパティを任意の数だけ含めることができます。
memberグループのメンバーを表すURLを指定します。
型が http://microformats.org/profile/hcard である各アイテム内には、そのアイテムが値「group」を持つ kind という名前のプロパティも持つ場合に限り、
member という名前のプロパティを
任意の数だけ含めることができます。
related別のエンティティとの関係を指定します。
値は、一つの url
プロパティと一つの rel
プロパティを持つアイテムでなければなりません。
型が http://microformats.org/profile/hcard である各アイテム内には、related という名前のプロパティを
任意の数だけ含めることができます。
url(related 内)関連するエンティティのURLを指定します。
型が http://microformats.org/profile/hcard であるアイテムの related
プロパティの値を形成するアイテム内には、url
という名前のプロパティが正確に一つ存在しなければなりません。
rel(related 内)エンティティと関連するエンティティとの関係を指定します。
値は、関係文字列のいずれかと同一であるテキストでなければなりません。
型が http://microformats.org/profile/hcard であるアイテムの related
プロパティの値を形成するアイテム内には、rel
という名前のプロパティが正確に一つ存在しなければなりません。
categories人物または組織を分類できるカテゴリーまたはタグの名前を指定します。
値はテキストでなければなりません。
型が http://microformats.org/profile/hcard である各アイテム内には、categories
という名前のプロパティを任意の数だけ含めることができます。
note人物または組織についての補足情報またはコメントを指定します。
値はテキストでなければなりません。
型が http://microformats.org/profile/hcard である各アイテム内には、note という名前のプロパティを
任意の数だけ含めることができます。
rev連絡先情報の改訂日時を指定します。
値は、妥当な グローバル日付時刻文字列であるテキストでなければなりません。
値は、情報の現在の改訂版を、その情報のその他の表現と区別します。
型が http://microformats.org/profile/hcard である各アイテム内には、rev という名前のプロパティを任意の数だけ
含めることができます。
sound人物または組織に関する音声ファイルを指定します。
型が http://microformats.org/profile/hcard である各アイテム内には、sound という名前のプロパティを
任意の数だけ含めることができます。
uid人物または組織に対応するグローバルに一意な識別子を指定します。
値はテキストでなければなりません。
型が http://microformats.org/profile/hcard である各アイテム内には、uid という名前のプロパティを一つ
含めることができます。
url人物または組織に関するURLを指定します。
型が http://microformats.org/profile/hcard である各アイテム内には、url という名前のプロパティを任意の数だけ
含めることができます。
種類文字列は次のとおりです。
individual単一のエンティティ(人物など)を示します。
group複数のエンティティ(メーリングリストなど)を示します。
org人物ではない単一のエンティティ(会社など)を示します。
location地理的な場所(オフィスビルなど)を示します。
住所型文字列は次のとおりです。
home住居の配達先住所を示します。
work勤務先の配達先住所を示します。
電話型文字列は次のとおりです。
home住居用の電話番号を示します。
work勤務先の電話番号を示します。
text電話番号がテキストメッセージ(SMS)をサポートすることを示します。
voice音声通話用の電話番号を示します。
faxファクシミリ用の電話番号を示します。
cell携帯電話番号を示します。
videoビデオ会議用の電話番号を示します。
pagerページング装置の電話番号を示します。
textphone聴覚または発話が困難な人向けの通信装置を示します。
関係文字列は次のとおりです。
emergency緊急連絡先。
agentこのエンティティを代理する別のエンティティ。
XFN で定義される意味を持ちます。[XFN]
Document 内のノードのリスト
nodes が与えられた場合、ユーザーエージェントは、それらのノードによって表される vCard データを抽出するために、
次のアルゴリズムを実行しなければなりません(最初の vCard だけが返されます)。
nodes 内のどのノードも、アイテム型が http://microformats.org/profile/hcard
であるアイテムではない場合、
vCard は存在しません。何も返さずにアルゴリズムを中止します。
nodes 内で、アイテム型が http://microformats.org/profile/hcard
であるアイテムである最初のノードを
node とします。
output を空文字列とします。
型が「BEGIN」、値が「VCARD」であるvCard 行を output に追加します。
型が「PROFILE」、値が「VCARD」であるvCard 行を output に追加します。
型が「VERSION」、値が「4.0」であるvCard 行を output に追加します。
型を「SOURCE」、文書のURLである
vCard テキスト文字列をエスケープした結果を値として、vCard 行を output に
追加します。
title
要素が null でない場合、型を「NAME」、title 要素の子孫テキスト内容から得られた vCard テキスト文字列をエスケープした結果を値として、vCard 行を output に
追加します。
sex を空文字列とします。
gender-identity を空文字列とします。
アイテム node のプロパティである各要素 element について、element のプロパティ名内の各名前 name に対して、 次の下位手順を実行します。
parameters を名前と値のペアの空の集合とします。
次のリストから適切な一連の下位手順を実行します。これらの手順は、次の手順で使用される 変数 value を設定します。
n である場合
value を空文字列とします。
subitem 内の family-name
という名前の最初の vCard
サブプロパティを収集した結果を、value に付加します。
subitem 内の given-name
という名前の最初の vCard
サブプロパティを収集した結果を、value に付加します。
subitem 内の additional-name
という名前の最初の vCard
サブプロパティを収集した結果を、value に付加します。
subitem 内の honorific-prefix
という名前の最初の vCard
サブプロパティを収集した結果を、value に付加します。
subitem 内の honorific-suffix
という名前の最初の vCard
サブプロパティを収集した結果を、value に付加します。
adr
である場合
value を空文字列とします。
subitem 内の post-office-box
という名前のvCard
サブプロパティを収集した結果を、value に付加します。
subitem 内の extended-address
という名前のvCard
サブプロパティを収集した結果を、value に付加します。
subitem 内の street-address
という名前のvCard
サブプロパティを収集した結果を、value に付加します。
subitem 内の locality
という名前の最初の vCard
サブプロパティを収集した結果を、value に付加します。
subitem 内の region
という名前の最初の vCard
サブプロパティを収集した結果を、value に付加します。
subitem 内の postal-code
という名前の最初の vCard
サブプロパティを収集した結果を、value に付加します。
subitem 内の country-name
という名前の最初の vCard
サブプロパティを収集した結果を、value に付加します。
subitem 内に type
という名前のプロパティが存在し、そのような最初のプロパティの値がアイテムではなく、その値がASCII 英数字だけで構成される場合、
名前が「TYPE」、値がそのプロパティの値であるパラメーターを
parameters に追加します。
org
である場合
value を空文字列とします。
subitem 内の organization-name
という名前の最初の vCard
サブプロパティを収集した結果を、value に付加します。
subitem 内の organization-unit
という名前の各プロパティについて、次の手順を実行します。
http://microformats.org/profile/hcard
を持つアイテム
subitem であり、name が related である場合
value を空文字列とします。
subitem 内に url
という名前のプロパティが存在し、その要素がURL プロパティ要素である場合、
そのような最初のプロパティの値によって与えられる
vCard テキスト文字列をエスケープした結果を
value に付加し、名前が「VALUE」、値が「URI」である
パラメーターを parameters に追加します。
subitem 内に rel
という名前のプロパティが存在し、そのような最初のプロパティの値がアイテムではなく、その値がASCII 英数字だけで構成される場合、
名前が「RELATION」、値がそのプロパティの値であるパラメーターを
parameters に追加します。
value を、subitem 内の value という名前の最初の vCard
サブプロパティを収集した結果とします。
subitem 内に type という名前のプロパティが存在し、
そのような最初のプロパティの値がアイテムではなく、その値がASCII 英数字だけで構成される場合、
名前が「TYPE」、値がそのプロパティの値であるパラメーターを
parameters に追加します。
sex である場合これが最初に検出されたそのようなプロパティである場合、sex をプロパティの値に設定します。
gender-identity
である場合
これが最初に検出されたそのようなプロパティである場合、gender-identity を プロパティの値に設定します。
value をプロパティの値とします。
element がURL プロパティ要素の一つである場合、
名前が「VALUE」、値が「URI」であるパラメーターを
parameters に追加します。
それ以外で、name が bday または
anniversary
であり、value が妥当な日付文字列である場合、
名前が「VALUE」、値が「DATE」であるパラメーターを
parameters に追加します。
それ以外で、name が rev であり、
value が妥当なグローバル日付時刻
文字列である場合、名前が「VALUE」、値が「DATE-TIME」である
パラメーターを parameters に追加します。
value 内の各 U+005C REVERSE SOLIDUS 文字(\)の前に、別の U+005C REVERSE SOLIDUS 文字(\)を付けます。
value 内の各 U+002C COMMA 文字(,)の前に、U+005C REVERSE SOLIDUS 文字(\)を付けます。
name が geo でない限り、
value 内の各 U+003B SEMICOLON 文字(;)の前に、U+005C REVERSE
SOLIDUS 文字(\)を付けます。
value 内の各 U+000D CARRIAGE RETURN U+000A LINE FEED 文字ペア(CRLF)を、 U+005C REVERSE SOLIDUS 文字(\)と、それに続く U+006E LATIN SMALL LETTER N 文字(n)に置換します。
value 内の残りの各 U+000D CARRIAGE RETURN(CR)または U+000A LINE FEED(LF)文字を、U+005C REVERSE SOLIDUS 文字(\)と、それに続く U+006E LATIN SMALL LETTER N 文字(n)に置換します。
型を name、パラメーターを parameters、値を value として、vCard 行を output に追加します。
sex または gender-identity のいずれかが空文字列でない値を持つ場合、
型を「GENDER」、sex、U+003B SEMICOLON 文字(;)、および
gender-identity を連結したものを値として、vCard 行を output に追加します。
型が「END」、値が「VCARD」であるvCard 行を output に追加します。
上記のアルゴリズムで、型 type、任意のパラメーター、および値 value からなる vCard 行を文字列 output に追加するよう ユーザーエージェントへ指示された場合、次の手順を実行しなければなりません。
line を空文字列とします。
type をASCII 大文字へ変換し、line に付加します。
パラメーターが存在する場合、それらが追加された順序で各パラメーターについて、 次の下位手順を実行します。
U+003B SEMICOLON 文字(;)を line に付加します。
パラメーターの名前を line に付加します。
U+003D EQUALS SIGN 文字(=)を line に付加します。
パラメーターの値を line に付加します。
U+003A COLON 文字(:)を line に付加します。
value を line に付加します。
maximum length を 75 とします。
line のコードポイント長が maximum length より大きい間、 次を行います。
line の最初の maximum length 個のコードポイントを output に付加します。
line から最初の maximum length 個のコードポイントを取り除きます。
U+000D CARRIAGE RETURN 文字(CR)を output に付加します。
U+000A LINE FEED 文字(LF)を output に付加します。
U+0020 SPACE 文字を output に付加します。
maximum length を 74 とします。
line の残りを output に付加します。
U+000D CARRIAGE RETURN 文字(CR)を output に付加します。
U+000A LINE FEED 文字(LF)を output に付加します。
上記の手順で、subitem 内の subname という名前のvCard サブプロパティを収集した結果を取得するよう ユーザーエージェントへ要求された場合、ユーザーエージェントは次の手順を実行しなければなりません。
上記の手順で、subitem 内の subname という名前の最初の vCard サブプロパティを収集した結果を 取得するようユーザーエージェントへ要求された場合、ユーザーエージェントは次の手順を 実行しなければなりません。
上記のアルゴリズムで、ユーザーエージェントが value というvCard テキスト文字列をエスケープするよう指示された場合、 ユーザーエージェントは次の手順を使用しなければなりません。
value 内の各 U+005C REVERSE SOLIDUS 文字(\)の前に、別の U+005C REVERSE SOLIDUS 文字(\)を付けます。
value 内の各 U+002C COMMA 文字(,)の前に、U+005C REVERSE SOLIDUS 文字(\)を付けます。
value 内の各 U+003B SEMICOLON 文字(;)の前に、U+005C REVERSE SOLIDUS 文字(\)を付けます。
value 内の各 U+000D CARRIAGE RETURN U+000A LINE FEED 文字ペア(CRLF)を、 U+005C REVERSE SOLIDUS 文字(\)と、それに続く U+006E LATIN SMALL LETTER N 文字(n)に置換します。
value 内の残りの各 U+000D CARRIAGE RETURN(CR)または U+000A LINE FEED(LF) 文字を、U+005C REVERSE SOLIDUS 文字(\)と、それに続く U+006E LATIN SMALL LETTER N 文字(n)に置換します。
変更された value を返します。
入力が、http://microformats.org/profile/hcard
アイテム型および定義済みプロパティ名について記述された規則に
適合していない場合、このアルゴリズムは無効な vCard 出力を生成する可能性があります。
この節は非規範的です。
以下は、「Jack Bauer」という架空の人物についての長い vCard の例です。
< section id = "jack" itemscope itemtype = "http://microformats.org/profile/hcard" >
< h1 itemprop = "fn" >
< span itemprop = "n" itemscope >
< span itemprop = "given-name" > Jack</ span >
< span itemprop = "family-name" > Bauer</ span >
</ span >
</ h1 >
< img itemprop = "photo" alt = "" src = "jack-bauer.jpg" >
< p itemprop = "org" itemscope >
< span itemprop = "organization-name" > 対テロ部隊</ span >
(< span itemprop = "organization-unit" > ロサンゼルス支局</ span > )
</ p >
< p >
< span itemprop = "adr" itemscope >
< span itemprop = "street-address" > 10201 W. Pico Blvd.</ span >< br >
< span itemprop = "locality" > ロサンゼルス</ span > ,
< span itemprop = "region" > CA</ span >
< span itemprop = "postal-code" > 90064</ span >< br >
< span itemprop = "country-name" > アメリカ合衆国</ span >< br >
</ span >
< span itemprop = "geo" > 34.052339;-118.410623</ span >
</ p >
< h2 > 各種連絡方法</ h2 >
< ul >
< li itemprop = "tel" itemscope >
< span itemprop = "value" > +1 (310) 597 3781</ span > < span itemprop = "type" > work</ span >
< meta itemprop = "type" content = "voice" >
</ li >
< li >< a itemprop = "url" href = "https://en.wikipedia.org/wiki/Jack_Bauer" > Wikipedia にいます</ a >
ので、利用者トークページにメッセージを残せます。</ li >
< li >< a itemprop = "url" href = "http://www.jackbauerfacts.com/" > Jack Bauer Facts</ a ></ li >
< li itemprop = "email" >< a href = "mailto:j.bauer@la.ctu.gov.invalid" > j.bauer@la.ctu.gov.invalid</ a ></ li >
< li itemprop = "tel" itemscope >
< span itemprop = "value" > +1 (310) 555 3781</ span > < span >
< meta itemprop = "type" content = "cell" > 携帯電話</ span >
</ li >
</ ul >
< ins datetime = "2008-07-20 21:00:00+01:00" >
< meta itemprop = "rev" content = "2008-07-20 21:00:00+01:00" >
< p itemprop = "tel" itemscope >< strong > 更新!</ strong >
新しい < span itemprop = "type" > home</ span > 電話番号は
< span itemprop = "value" > 01632 960 123</ span > です。</ p >
</ ins >
</ section > 不自然な行の折り返しが必要なのは、マイクロデータでは改行に意味があるためです。たとえば、 vCard 形式へ変換する場合、改行は保持されます。
この例は、二つの通り部分を持つ住所を含むサイトの連絡先詳細を(address 要素を使用して)
示しています。
< address itemscope itemtype = "http://microformats.org/profile/hcard" >
< strong itemprop = "fn" >< span itemprop = "n" itemscope >< span itemprop = "given-name" > Alfred</ span >
< span itemprop = "family-name" > Person</ span ></ span ></ strong > < br >
< span itemprop = "adr" itemscope >
< span itemprop = "street-address" > 1600 Amphitheatre Parkway</ span > < br >
< span itemprop = "street-address" > 43 号棟 2 階</ span > < br >
< span itemprop = "locality" > マウンテンビュー</ span > ,
< span itemprop = "region" > CA</ span > < span itemprop = "postal-code" > 94043</ span >
</ span >
</ address > vCard 語彙は、人物名だけをマークアップするためにも使用できます。
< span itemscope itemtype = "http://microformats.org/profile/hcard"
>< span itemprop = fn >< span itemprop = "n" itemscope >< span itemprop = "given-name"
> George</ span > < span itemprop = "family-name" > Washington</ span ></ span
></ span ></ span > これにより、二つの名前と値のペアを持つ単一のアイテムが作成されます。一つは名前が「fn」で、 値が「George Washington」です。もう一つは名前が「n」で、値として 2 番目のアイテムを持ちます。 2 番目のアイテムは、「given-name」と「family-name」という二つの名前と値のペアを持ち、 それぞれの値は「George」と「Washington」です。これは、次の vCard へ対応付けられるものとして 定義されています。
BEGIN:VCARD PROFILE:VCARD VERSION:4.0 SOURCE:文書のアドレス FN:George Washington N:Washington;George;;; END:VCARD
アイテム型が http://microformats.org/profile/hcalendar#vevent であるアイテムは、
イベントを表します。
この語彙はアイテムのグローバル識別子をサポートしません。
次に示すのは、この型の定義済みプロパティ名です。これらは、 インターネットカレンダーおよびスケジューリング中核オブジェクト仕様 (iCalendar)で定義される語彙に基づいています。値の解釈方法についての詳細情報は、 そこに記載されています。[RFC5545]
ここでは、iCalendar 語彙のイベントに関係する部分だけが使用されます。この語彙では、 完全な iCalendar インスタンスを表現できません。
attachイベントに関連付けられた文書のアドレスを指定します。
型が http://microformats.org/profile/hcalendar#vevent
である各アイテム内には、attach という名前のプロパティを
任意の数だけ含めることができます。
categoriesイベントを分類できるカテゴリーまたはタグの名前を指定します。
値はテキストでなければなりません。
型が http://microformats.org/profile/hcalendar#vevent
である各アイテム内には、categories
という名前のプロパティを任意の数だけ含めることができます。
classイベントに関する情報のアクセス区分を指定します。
値は、次の値のいずれかを 持つテキストでなければなりません。
publicprivateconfidentialこれは単なる助言であり、機密性を保護する手段とはみなせません。
型が http://microformats.org/profile/hcalendar#vevent
である各アイテム内には、class という名前のプロパティを
一つ含めることができます。
commentイベントに関するコメントを指定します。
値はテキストでなければなりません。
型が http://microformats.org/profile/hcalendar#vevent
である各アイテム内には、comment という名前のプロパティを
任意の数だけ含めることができます。
descriptionイベントの詳細な説明を指定します。
値はテキストでなければなりません。
型が http://microformats.org/profile/hcalendar#vevent
である各アイテム内には、description
という名前のプロパティを一つ含めることができます。
geoイベントの地理的位置を指定します。
値はテキストでなければならず、 次の構文に一致しなければなりません。
アスタリスク(*)で示された任意の構成要素は含めるべきであり、それぞれ 6 桁にするべきです。
値は、緯度と経度をこの順序(すなわち「LAT LON」の順序)で、十進度によって 指定します。経度は、本初子午線から東または西の位置を、それぞれ正または負の実数で表します。 緯度は、赤道から北または南の位置を、それぞれ正または負の実数で表します。
型が http://microformats.org/profile/hcalendar#vevent
である各アイテム内には、geo という名前のプロパティを一つ
含めることができます。
locationイベントの場所を指定します。
値はテキストでなければなりません。
型が http://microformats.org/profile/hcalendar#vevent
である各アイテム内には、location
という名前のプロパティを一つ含めることができます。
resourcesイベントに必要となるリソースを指定します。
値はテキストでなければなりません。
型が http://microformats.org/profile/hcalendar#vevent
である各アイテム内には、resources
という名前のプロパティを任意の数だけ含めることができます。
statusイベントの確認状態を指定します。
値は、次の値のいずれかを 持つテキストでなければなりません。
tentativeconfirmedcanceled型が http://microformats.org/profile/hcalendar#vevent
である各アイテム内には、status という名前のプロパティを
一つ含めることができます。
summaryイベントの短い要約を指定します。
値はテキストでなければなりません。
ユーザーエージェントは、値を使用するとき、値内の U+000A LINE FEED(LF)文字を U+0020 SPACE 文字に置換するべきです。
型が http://microformats.org/profile/hcalendar#vevent
である各アイテム内には、summary
という名前のプロパティを一つ含めることができます。
dtendイベントが終了する日付および時刻を指定します。
型が http://microformats.org/profile/hcalendar#vevent
であり、値が妥当な日付
文字列である dtstart という名前のプロパティを
持つアイテム内に、dtend という名前のプロパティが
存在する場合、dtend という名前のプロパティの値も、妥当な日付
文字列であるテキストでなければなりません。それ以外の場合、そのプロパティの値は、妥当なグローバル日付時刻文字列であるテキストで
なければなりません。
いずれの場合も、値は、同じアイテムの dtstart プロパティの値より
時間的に後でなければなりません。
dtend プロパティによって指定される
時刻は、その範囲に含まれません。したがって、終日のイベントでは、dtend
プロパティの値は、
イベント終了日の翌日になります。
型が http://microformats.org/profile/hcalendar#vevent
である各アイテム内には、その http://microformats.org/profile/hcalendar#vevent
が duration という名前のプロパティを
持たない限り、dtend という名前のプロパティを
一つ含めることができます。
dtstartイベントが開始する日付および時刻を指定します。
値は、妥当な日付文字列、または妥当なグローバル日付時刻文字列のいずれかである テキストでなければなりません。
型が http://microformats.org/profile/hcalendar#vevent
である各アイテム内には、dtstart
という名前のプロパティが正確に一つ存在しなければなりません。
durationイベントの継続時間を指定します。
値は、妥当な vevent 継続時間文字列であるテキストでなければなりません。
表される継続時間は、値内の整数によって表されるすべての継続時間の合計です。
型が http://microformats.org/profile/hcalendar#vevent
である各アイテム内には、その http://microformats.org/profile/hcalendar#vevent
が dtend という名前のプロパティを
持たない限り、duration
という名前のプロパティを一つ含めることができます。
transp空き時間検索の目的で、イベントがカレンダー上の時間を占有するものとみなされるかどうかを 指定します。
値は、次の値のいずれかを 持つテキストでなければなりません。
opaquetransparent型が http://microformats.org/profile/hcalendar#vevent
である各アイテム内には、transp
という名前のプロパティを一つ含めることができます。
contactイベントの連絡先情報を指定します。
値はテキストでなければなりません。
型が http://microformats.org/profile/hcalendar#vevent
である各アイテム内には、contact
という名前のプロパティを任意の数だけ含めることができます。
urlイベントのURLを指定します。
型が http://microformats.org/profile/hcalendar#vevent
である各アイテム内には、url という名前のプロパティを一つ
含めることができます。
uidイベントに対応するグローバルに一意な識別子を指定します。
値はテキストでなければなりません。
型が http://microformats.org/profile/hcalendar#vevent
である各アイテム内には、uid という名前のプロパティを一つ
含めることができます。
exdate繰り返し規則にかかわらず、イベントが発生しない日付および時刻を指定します。
値は、妥当な日付文字列、または妥当なグローバル日付時刻文字列のいずれかである テキストでなければなりません。
型が http://microformats.org/profile/hcalendar#vevent
である各アイテム内には、exdate
という名前のプロパティを任意の数だけ含めることができます。
rdateイベントが繰り返し発生する日付および時刻を指定します。
値は、次のいずれかである テキストでなければなりません。
型が http://microformats.org/profile/hcalendar#vevent
である各アイテム内には、rdate という名前のプロパティを
任意の数だけ含めることができます。
rruleイベントが発生する日付および時刻を求めるための規則を指定します。
値は、 iCalendar で定義される RECUR 値型に一致するテキストでなければなりません。 [RFC5545]
型が http://microformats.org/profile/hcalendar#vevent
である各アイテム内には、rrule
という名前のプロパティを一つ含めることができます。
createdイベント情報がカレンダーシステム内で最初に作成された日付および時刻を指定します。
値は、妥当なグローバル日付時刻文字列であるテキストで なければなりません。
型が http://microformats.org/profile/hcalendar#vevent
である各アイテム内には、created
という名前のプロパティを一つ含めることができます。
last-modifiedイベント情報がカレンダーシステム内で最後に変更された日付および時刻を指定します。
値は、妥当なグローバル日付時刻文字列であるテキストで なければなりません。
型が http://microformats.org/profile/hcalendar#vevent
である各アイテム内には、last-modified
という名前のプロパティを一つ含めることができます。
sequenceイベント情報の改訂番号を指定します。
型が http://microformats.org/profile/hcalendar#vevent
である各アイテム内には、sequence
という名前のプロパティを一つ含めることができます。
文字列が次のパターンに一致する場合、その文字列は妥当な vevent 継続時間文字列です。
U+0050 LATIN CAPITAL LETTER P 文字(P)。
次のいずれか。
Document 内のノードのリスト
nodes が与えられた場合、ユーザーエージェントは、それらのノードによって表される vEvent データを抽出するために、
次のアルゴリズムを実行しなければなりません。
nodes 内のどのノードも、型が http://microformats.org/profile/hcalendar#vevent
であるアイテムではない場合、
vEvent データは存在しません。何も返さずにアルゴリズムを中止します。
output を空文字列とします。
型が「BEGIN」、値が「VCALENDAR」であるiCalendar 行を
output に追加します。
型が「PRODID」、値がユーザーエージェントを表すユーザーエージェント固有の文字列に
等しいiCalendar 行を
output に追加します。
型が「VERSION」、値が「2.0」であるiCalendar 行を
output に追加します。
nodes 内で、型が http://microformats.org/profile/hcalendar#vevent
であるアイテムである各ノード
node について、次の手順を実行します。
型が「BEGIN」、値が「VEVENT」であるiCalendar 行を
output に追加します。
型が「DTSTAMP」、値が現在の日付および時刻を表す iCalendar DATE-TIME 文字列で、
注釈が「VALUE=DATE-TIME」であるiCalendar 行を
output に追加します。
[RFC5545]
アイテム node のプロパティである各要素 element について、element のプロパティ名内の各名前 name に対して、次のリストから適切な一連の下位手順を実行します。
そのプロパティを飛ばします。
dtend
である場合dtstart である場合
exdate である場合rdate
である場合created である場合
last-modified
である場合
value を、プロパティの値からすべての U+002D HYPHEN-MINUS(-)文字と U+003A COLON(:)文字を取り除いた結果とします。
プロパティの値が妥当な日付
文字列である場合、型を name、値を value、注釈を
「VALUE=DATE」として、iCalendar 行を
output に追加します。
それ以外で、プロパティの値が妥当なグローバル日付時刻
文字列である場合、型を name、値を value、注釈を
「VALUE=DATE-TIME」として、iCalendar 行を
output に追加します。
それ以外の場合、そのプロパティを飛ばします。
型を name、値をプロパティの値として、iCalendar 行を output に追加します。
型が「END」、値が「VEVENT」であるiCalendar 行を
output に追加します。
型が「END」、値が「VCALENDAR」であるiCalendar 行を
output に追加します。
上記のアルゴリズムで、型 type、値 value、および任意の注釈からなる iCalendar 行を文字列 output に追加するよう ユーザーエージェントへ指示された場合、次の手順を実行しなければなりません。
line を空文字列とします。
type をASCII 大文字へ変換し、line に付加します。
注釈が存在する場合、次を行います。
U+003B SEMICOLON 文字(;)を line に付加します。
注釈を line に付加します。
U+003A COLON 文字(:)を line に付加します。
value 内の各 U+005C REVERSE SOLIDUS 文字(\)の前に、別の U+005C REVERSE SOLIDUS 文字(\)を付けます。
value 内の各 U+002C COMMA 文字(,)の前に、U+005C REVERSE SOLIDUS 文字(\)を付けます。
value 内の各 U+003B SEMICOLON 文字(;)の前に、U+005C REVERSE SOLIDUS 文字(\)を付けます。
value 内の各 U+000D CARRIAGE RETURN U+000A LINE FEED 文字ペア(CRLF)を、 U+005C REVERSE SOLIDUS 文字(\)と、それに続く U+006E LATIN SMALL LETTER N 文字(n)に置換します。
value 内の残りの各 U+000D CARRIAGE RETURN(CR)または U+000A LINE FEED(LF) 文字を、U+005C REVERSE SOLIDUS 文字(\)と、それに続く U+006E LATIN SMALL LETTER N 文字(n)に置換します。
value を line に付加します。
maximum length を 75 とします。
line のコードポイント長が maximum length より 大きい間、次を行います。
line の最初の maximum length 個のコードポイントを output に付加します。
line から最初の maximum length 個のコードポイントを取り除きます。
U+000D CARRIAGE RETURN 文字(CR)を output に付加します。
U+000A LINE FEED 文字(LF)を output に付加します。
U+0020 SPACE 文字を output に付加します。
maximum length を 74 とします。
line の残りを output に付加します。
U+000D CARRIAGE RETURN 文字(CR)を output に付加します。
U+000A LINE FEED 文字(LF)を output に付加します。
入力が、http://microformats.org/profile/hcalendar#vevent
アイテム型および定義済みプロパティ名について記述された規則に
適合していない場合、このアルゴリズムは無効な iCalendar 出力を生成する可能性があります。
この節は非規範的です。
以下は、vEvent 語彙を使用してイベントをマークアップするページの例です。
< body itemscope itemtype = "http://microformats.org/profile/hcalendar#vevent" >
...
< h1 itemprop = "summary" > Bluesday Tuesday: Money Road</ h1 >
...
< time itemprop = "dtstart" datetime = "2009-05-05T19:00:00Z" > 5 月 5 日午後 7 時</ time >
(< time itemprop = "dtend" datetime = "2009-05-05T21:00:00Z" > 午後 9 時</ time > まで)
...
< a href = "http://livebrum.co.uk/2009/05/05/bluesday-tuesday-money-road"
rel = "bookmark" itemprop = "url" > このページへのリンク</ a >
...
< p > 場所:< span itemprop = "location" > The RoadHouse</ span ></ p >
...
< p >< input type = button value = "カレンダーに追加"
onclick = "location = getCalendar(this)" ></ p >
...
< meta itemprop = "description" content = "livebrum.co.uk より" >
</ body > getCalendar() 関数の実装は、読者への演習として残されています。
同じページでは、ブログへコピーアンドペーストするために、次のようなマークアップを 提供することもできます。
< div itemscope itemtype = "http://microformats.org/profile/hcalendar#vevent" >
< p > 私は
< strong itemprop = "summary" > Bluesday Tuesday: Money Road</ strong > に、
< time itemprop = "dtstart" datetime = "2009-05-05T19:00:00Z" > 5 月 5 日午後 7 時</ time >
から < time itemprop = "dtend" datetime = "2009-05-05T21:00:00Z" > 午後 9 時</ time > まで、
< span itemprop = "location" > The RoadHouse</ span > で参加します!</ p >
< p >< a href = "http://livebrum.co.uk/2009/05/05/bluesday-tuesday-money-road"
itemprop = "url" > livebrum.co.uk でこのイベントを見る</ a > 。</ p >
< meta itemprop = "description" content = "livebrum.co.uk より" >
</ div > アイテム型が http://n.whatwg.org/work であるアイテムは、著作物
(記事、画像、動画、楽曲など)を表します。この型は主に、作者が著作物のライセンス情報を
含められるようにすることを目的としています。
次に示すのは、この型の定義済みプロパティ名です。
work記述されている著作物を識別します。
型が http://n.whatwg.org/work である各アイテム内には、work
という名前のプロパティが正確に一つ存在しなければなりません。
title著作物の名前を指定します。
型が http://n.whatwg.org/work である各アイテム内には、title
という名前のプロパティを一つ含めることができます。
author著作物の作者または作成者の一人について、名前または連絡先情報を指定します。
値は、型が http://microformats.org/profile/hcard
であるアイテム、またはテキストの
いずれかでなければなりません。
型が http://n.whatwg.org/work である各アイテム内には、author
という名前のプロパティを任意の数だけ含めることができます。
license著作物を利用できるライセンスの一つを識別します。
型が http://n.whatwg.org/work である各アイテム内には、license
という名前のプロパティを任意の数だけ含めることができます。
この節は非規範的です。
この例は、My Pond という題名の埋め込み画像を示しています。この画像には、 Creative Commons Attribution-Share Alike 4.0 International License と MIT license が 同時に適用されています。
< figure itemscope itemtype = "http://n.whatwg.org/work" >
< img itemprop = "work" src = "mypond.jpeg" >
< figcaption >
< p >< cite itemprop = "title" > My Pond</ cite ></ p >
< p >< small > この著作物には、< a itemprop = "license"
href = "https://creativecommons.org/licenses/by-sa/4.0/" > Creative
Commons Attribution-Share Alike 4.0 International License</ a >
および < a itemprop = "license"
href = "http://www.opensource.org/licenses/mit-license.php" > MIT
license</ a > が適用されています。</ small >
</ figcaption >
</ figure > Document 内のノードのリスト
nodes が与えられた場合、ユーザーエージェントは、それらのノードからマイクロデータを JSON 形式へ抽出するために、
次のアルゴリズムを実行しなければなりません。
result を空のオブジェクトとします。
items を空の配列とします。
nodes 内の各 node について、その要素がトップレベル マイクロデータアイテムであるかを確認します。該当する場合、その要素のオブジェクトを取得し、 items に追加します。
result に「items」という名前の項目を追加し、その値を配列
items とします。
result を可能な限り短い方法で JSON へ直列化した結果を返します
(つまり、トークン間に空白を含めず、数値に不要なゼロ桁を含めず、専用のエスケープシーケンスが
ない文字に対してのみ文字列内で Unicode エスケープを使用します)。また、数値の表現では、
適切な場合に小文字の「e」を使用します。[JSON]
このアルゴリズムが単なる配列ではなく、単一のプロパティとして配列を持つ オブジェクトを返すのは、将来必要になった場合にアルゴリズムを拡張できるようにするためです。
ユーザーエージェントが、任意で要素のリスト memory とともに、アイテム item のオブジェクトを取得する場合、次の下位手順を 実行しなければなりません。
result を空のオブジェクトとします。
memory がアルゴリズムへ渡されなかった場合、memory を空のリストとします。
item を memory に追加します。
item が一つ以上のアイテム型を持つ場合、result
に「type」
という名前の項目を追加します。その値は、itemtype 属性に指定された順序で
item のアイテム型を列挙する配列です。
item がグローバル識別子を持つ場合、result
に
「id」という名前の項目を追加し、その値を item のグローバル
識別子とします。
properties を空のオブジェクトとします。
一つ以上のプロパティ名を持ち、 アイテム item のプロパティの一つである各要素 element について、アイテムのプロパティを返すアルゴリズムによって それらの要素が与えられる順序で、次の下位手順を実行します。
value を element のプロパティ値とします。
value がアイテムである場合、
次を行います。value が memory 内にある場合、value を
文字列「ERROR」とします。それ以外の場合、memory のコピーを渡して
value のオブジェクトを取得し、
value をそれらの手順から返されたオブジェクトで置換します。
element のプロパティ名内の各名前 name について、 次の下位手順を実行します。
properties 内に name という名前の項目が存在しない場合、 properties に name という名前の項目を追加し、その値を 空の配列とします。
value を、properties 内の name という名前の項目へ 付加します。
result に「properties」という名前の項目を追加し、その値を
オブジェクト properties とします。
result を返します。
たとえば、次のマークアップを考えます。
<!DOCTYPE HTML>
< html lang = "en" >
< title > 私のブログ</ title >
< article itemscope itemtype = "http://schema.org/BlogPosting" >
< header >
< h1 itemprop = "headline" > 進捗報告</ h1 >
< p >< time itemprop = "datePublished" datetime = "2013-08-29" > 今日</ time ></ p >
< link itemprop = "url" href = "?comments=0" >
</ header >
< p > 全体として、彼は水泳のレッスンを順調にこなしています。最大の問題は頭を
水に入れるのが苦手だったことですが、できるようになりました。</ p >
< section >
< h1 > コメント</ h1 >
< article itemprop = "comment" itemscope itemtype = "http://schema.org/UserComments" id = "c1" >
< link itemprop = "url" href = "#c1" >
< footer >
< p > 投稿者:< span itemprop = "creator" itemscope itemtype = "http://schema.org/Person" >
< span itemprop = "name" > Greg</ span >
</ span ></ p >
< p >< time itemprop = "commentTime" datetime = "2013-08-29" > 15 分前</ time ></ p >
</ footer >
< p > はは!</ p >
</ article >
< article itemprop = "comment" itemscope itemtype = "http://schema.org/UserComments" id = "c2" >
< link itemprop = "url" href = "#c2" >
< footer >
< p > 投稿者:< span itemprop = "creator" itemscope itemtype = "http://schema.org/Person" >
< span itemprop = "name" > Charlotte</ span >
</ span ></ p >
< p >< time itemprop = "commentTime" datetime = "2013-08-29" > 5 分前</ time ></ p >
</ footer >
< p > 「できるようになった」って、誰が……?</ p >
</ article >
</ section >
</ article > 上記のアルゴリズムにより、これは次の JSON へ変換されます
(ページの URL が https://blog.example.com/progress-report であると仮定します)。
{
"items" : [
{
"type" : [ "http://schema.org/BlogPosting" ],
"properties" : {
"headline" : [ "Progress report" ],
"datePublished" : [ "2013-08-29" ],
"url" : [ "https://blog.example.com/progress-report?comments=0" ],
"comment" : [
{
"type" : [ "http://schema.org/UserComments" ],
"properties" : {
"url" : [ "https://blog.example.com/progress-report#c1" ],
"creator" : [
{
"type" : [ "http://schema.org/Person" ],
"properties" : {
"name" : [ "Greg" ]
}
}
],
"commentTime" : [ "2013-08-29" ]
}
},
{
"type" : [ "http://schema.org/UserComments" ],
"properties" : {
"url" : [ "https://blog.example.com/progress-report#c2" ],
"creator" : [
{
"type" : [ "http://schema.org/Person" ],
"properties" : {
"name" : [ "Charlotte" ]
}
}
],
"commentTime" : [ "2013-08-29" ]
}
}
]
}
}
]
} 一つのエンジンでのみサポートされています。
現在のすべてのエンジンでサポートされています。
すべての には、hidden 内容属性を
設定できます。 属性は、
次のキーワードおよび状態を持つです。
| キーワード | 状態 | 簡単な説明 |
|---|---|---|
hidden
|
非表示 | レンダリングされません。 |
until-found
|
検出されるまで非表示 | レンダリングされませんが、内部の内容には およびから アクセスできます。 |
要素の 属性が状態にある場合、その要素がまだページの 現在の状態に直接関係していないか、もはや直接関係していないこと、またはユーザーが直接アクセスするのではなく、 ページのほかの部分で再利用される内容を宣言するために使用されていることを示します。 ユーザーエージェントは、状態にある要素をレンダリングするべきではありません。
状態にある要素をユーザーエージェントが レンダリングしないという要件は、スタイル層を介して間接的に実装できます。たとえば、ウェブブラウザーは、 レンダリングの節で提案されている規則を使用して、これらの要件を実装できます。
要素の 属性が状態にある場合、 その要素が状態と同様に非表示である一方、 要素内部の内容にはおよびからアクセスできることを示します。 これらの機能が要素のサブツリー内にある対象へスクロールしようとすると、ユーザーエージェントは、 対象ノードに対してを実行することにより、 その対象へスクロールする前に内容を表示するため、 属性を削除します。
属性が状態にある場合、 ウェブブラウザーは、レンダリングの節で指定されているように、 'display: none' の代わりに 'content-visibility: hidden' を使用します。
この属性は通常 CSS を使用して実装されるため、CSS を使用して上書きすることもできます。 たとえば、すべての要素へ 'display: block' を適用する規則は、状態の効果を打ち消します。したがって作者は、 スタイルシートを記述するとき、属性が引き続き意図したとおりにスタイル付けされるよう注意する必要があります。 また、状態をサポートしない 旧来のユーザーエージェントでは、'content-visibility: hidden' の代わりに 'display: none' が使用されるため、 作者には、スタイルシートが状態の要素の 'display' または 'content-visibility' プロパティを変更しないよう確認することが推奨されます。
状態にある 属性を持つ要素は、 'display: none' の代わりに 'content-visibility: hidden' を使用するため、状態には、 状態とは異なる二つの注意点があります。
ページ内検索によって表示されるためには、要素がの影響を受けている必要があります。 これは、状態にある要素の 'display' 値が 'none'、'contents'、または 'inline' である場合、その要素はページ内検索によって 表示されないことを意味します。
要素は、状態にあるときも、 を 持ち続けます。つまり、境界線、マージン、およびパディングは、引き続き要素の周囲にレンダリングされます。
次の骨組みだけの例では、ユーザーがログインするまでウェブゲームのメイン画面を非表示にするために この属性を使用しています。
< h1 > サンプルゲーム</ h1 >
< section id = "login" >
< h2 > ログイン</ h2 >
< form >
...
<!-- ユーザーの認証情報が確認された後に login() を呼び出す -->
</ form >
< script >
function login() {
// 画面を切り替える
document. getElementById( 'login' ). hidden = true ;
document. getElementById( 'game' ). hidden = false ;
}
</ script >
</ section >
< section id = "game" hidden >
...
</ section > 属性は、 別の表示方法では正当に表示できる内容を非表示にするために使用してはなりません。たとえば、 タブ付きダイアログ内のパネルを非表示にするために を使用するのは誤りです。 タブ付きインターフェイスは単なるオーバーフロー表示の一種にすぎず、すべてのフォームコントロールを スクロールバー付きの一つの大きなページに表示することも同様に可能だからです。同様に、この属性を、 一つの表示方法からだけ内容を非表示にするために使用することも誤りです。何かが としてマークされている場合、 それは、たとえばスクリーンリーダーを含む、すべての表示方法から非表示になります。
それ自体が ではない要素は、
である要素へ
してはなりません。それ自体が
ではない 要素および 要素の
for 属性も同様に、
である要素を参照してはなりません。
どちらの場合も、そのような参照はユーザーを混乱させます。
ただし、要素およびスクリプトは、ほかの文脈で である要素を参照できます。
たとえば、 属性でマークされた節へ リンクするために 属性を使用するのは誤りです。内容が適用できない、または関連しない場合、その内容へリンクする理由はありません。
ただし、それ自体が である説明を参照するために、 ARIA の 属性を使用することは 問題ありません。説明を非表示にすることは、その説明が単独では有用でないことを意味しますが、 説明対象の要素から参照される特定の文脈では有用になるように記述できます。
同様に、 属性を持つ 要素を、 スクリプト化されたグラフィックスエンジンがオフスクリーンバッファーとして使用でき、フォームコントロールは、 その 属性を使用して、 非表示の 要素を参照できます。
属性によって 非表示にされた節内の要素は、引き続きアクティブです。たとえば、そのような節内のスクリプトおよび フォームコントロールは、それぞれ引き続き実行および送信されます。ユーザーへの表示だけが変化します。
現在のすべてのエンジンでサポートされています。
hidden
の取得手順は次のとおりです。
属性が 状態にある場合、 「」を返します。
属性が 設定されている場合、true を返します。
false を返します。
の設定手順は次のとおりです。
与えられた値が、「」とで一致する文字列である場合、 属性を 「」に設定します。
それ以外で、与えられた値が false である場合、 属性を削除します。
それ以外で、与えられた値が空文字列である場合、 属性を削除します。
それ以外で、与えられた値が null である場合、 属性を削除します。
それ以外で、与えられた値が 0 である場合、 属性を削除します。
それ以外で、与えられた値が NaN である場合、 属性を削除します。
それ以外の場合、 属性を空文字列に 設定します。
祖先表示ペアは、ノードと文字列からなる です。
ノード target が与えられた場合の祖先表示アルゴリズムは次のとおりです。
ancestorsToReveal を « » とします。
ancestor を target とします。
ancestor が内に親ノードを持つ間、次を行います。
ancestor が状態にある
属性を
持つ場合、(ancestor, "until-found")を
ancestorsToReveal にします。
ancestor が、 属性を
持たない
要素の 2 番目のスロットへ割り当てられている場合、(ancestor の親ノード,
"details")を ancestorsToReveal にします。
ancestor を、内における ancestor の親ノードに 設定します。
ancestorsToReveal の各(ancestorToReveal, revealType)について、 次を行います。
ancestorToReveal がいない場合、返します。
revealType が "until-found" である場合、次を行います。
ancestorToReveal の 属性が 状態に ない場合、返します。
ancestorToReveal において、 属性を true に 初期化して、 という名前のします。
ancestorToReveal がいない場合、返します。
ancestorToReveal の 属性が 状態に ない場合、返します。
ancestorToReveal から 属性を 削除します。
それ以外の場合、次を行います。
:revealType は "details" です。
ancestorToReveal が 属性を持つ場合、返します。
ancestorToReveal の 属性を空文字列に設定します。
辿ることができるナビゲーブルのシステム可視性状態は、 作成時の初期値を含めてユーザーエージェントによって決定されます。これは、たとえばブラウザーウィンドウが 最小化されているか、ブラウザータブが現在バックグラウンドにあるか、タスクスイッチャーなどの システム要素がページを覆っているかを表します。
ユーザーエージェントが、辿ることができるナビゲーブル traversable のシステム可視性状態が newState に 変化したと判断した場合、次の手順を実行しなければなりません。
navigables を、traversable のアクティブな文書の包括的子孫ナビゲーブルとします。
navigables の各 navigable について反復します どの順序で?。
document を、navigable のアクティブな文書とします。
document の関連するグローバルオブジェクトが与えられた場合に、 document の可視性状態を更新して newState にするため、ユーザー操作タスクソース上にグローバルタスクを キューに追加します。
Document は、
"hidden" または "visible" のいずれかである可視性状態を持ち、
初期値は "hidden" です。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
Document
document の可視性状態を更新して
visibilityState にするには、次を行います。
document の可視性状態が visibilityState と 等しい場合、返します。
document の可視性状態を visibilityState に 設定します。
可視性状態が
visibilityState であり、タイムスタンプが、
document の関連するグローバルオブジェクトを与えた場合の現在の高精度時刻である、新しい VisibilityStateEntry をキューに追加します。
document を使用して、画面の向き変更手順を実行します。 [SCREENORIENTATION]
document を使用して、ビュー遷移のページ可視性変更手順を 実行します。
可視性状態および document を使用して、 ほかの仕様で定義されている可能性があるページ可視性変更手順を実行します。
仕様間の呼び出し順序が明確に定義されるようにするため、仕様の作者は、 ページ可視性変更手順フックを使用する代わりに、 ここから自身の仕様へ直接呼び出しを追加するプルリクエストを送信する方がよいでしょう。 本稿執筆時点では、次の仕様がページ可視性変更手順を持つことが 知られており、これらは指定されていない順序で実行されます:Device Posture API および Web NFC。[DEVICEPOSTURE] [WEBNFC]
document において、bubbles 属性を true に
初期化して、visibilitychange という名前のイベントを発火します。
Document
document の初期可視性状態を設定して
visibilityState にするには、次を行います。
VisibilityStateEntry インターフェイス一つのエンジンでのみサポートされています。
VisibilityStateEntry インターフェイスは、文書がアクティブになった
時点から、文書の可視性の変化を公開します。
function wasHiddenBeforeFirstContentfulPaint() {
const fcpEntry = performance. getEntriesByName( "first-contentful-paint" )[ 0 ];
const visibilityStateEntries = performance. getEntriesByType( "visibility-state" );
return visibilityStateEntries. some( e =>
e. startTime < fcpEntry. startTime &&
e. name === "hidden" );
} ページを非表示にすると、レンダリングおよびそのほかのユーザーエージェント処理が スロットリングされる可能性があるため、そのようなスロットリングが発生したことを示すものとして 可視性の変化を使用するのが一般的です。ただし、長時間の非アクティブ状態など、ブラウザーによっては ほかの要因でもスロットリングが発生する可能性があります。
[Exposed =(Window )]
interface VisibilityStateEntry : PerformanceEntry {
readonly attribute DOMString name ; // 継承された name を隠蔽する
readonly attribute DOMString entryType ; // 継承された entryType を隠蔽する
readonly attribute DOMHighResTimeStamp startTime ; // 継承された startTime を隠蔽する
readonly attribute unsigned long duration ; // 継承された duration を隠蔽する
};VisibilityStateEntry には、関連付けられた
DOMHighResTimeStamp
タイムスタンプがあります。
VisibilityStateEntry には、関連付けられた
"visible" または "hidden" の可視性状態があります。
entryType の取得手順は、
"visibility-state" を返すことです。
duration の取得手順は、0 を返すことです。
同名の属性についての説明は、inert も参照してください。
ノード(特に要素およびテキストノード)は、不活性になり得ます。 ノードが不活性である場合、次のようになります。
ヒットテストは、'pointer-events' CSS プロパティが 'none' に設定されているかの ように動作しなければなりません。
テキスト選択機能は、'user-select' CSS プロパティが 'none' に設定されているかの ように動作しなければなりません。
ノードが編集可能である場合、そのノードは編集不可能であるかのように動作します。
ユーザーエージェントは、ページ内検索の目的では、そのノードを無視するべきです。
不活性なノードは一般にフォーカスできず、ユーザーエージェントは、不活性なノードを アクセシビリティ API または支援技術へ公開しません。コマンドである不活性なノードは、上記の方法でユーザーが 操作できなくなります。
ただし、ユーザーエージェントは、ページ内検索およびテキスト選択に関する制限を、 ユーザーが上書きできるようにしても構いません。
既定では、ノードは不活性ではありません。
subject が Document
document の最上位層内で最上位にある
dialog 要素である場合、document は
subject によってモーダルダイアログにより
ブロックされている状態です。document がそのようにブロックされている間、
subject 要素およびそのフラットツリー子孫を除き、document に接続されているすべてのノードは、不活性にならなければなりません。
subject は、inert 属性によって追加で不活性になり得ますが、これは
subject 自体に指定された場合に限ります(すなわち、subject は祖先の
不活性状態から逃れます)。subject のフラットツリー子孫も、同様の方法で不活性になり得ます。
dialog 要素の showModal() メソッドは、dialog 要素を、そのノード文書の最上位層へ追加することにより、この仕組みを発動させます。
inert 属性現在のすべてのエンジンでサポートされています。
inert 属性は、その存在によって、要素および別の方法で不活性状態から
逃れないすべてのフラットツリー子孫(モーダルダイアログなど)を、ユーザーエージェントが
不活性にすることを示すブール属性です。
不活性なサブツリーには、不活性状態ではないページの側面を理解または使用するうえで重要な内容や
コントロールを含めるべきではありません。不活性なサブツリー内の内容は、すべてのユーザーに知覚可能または
操作可能とは限りません。作者は、その内容も何らかの方法で視覚的に覆われていない限り、要素を不活性として
指定するべきではありません。ほとんどの場合、作者は個々のフォームコントロールに inert
属性を指定するべきではありません。
このような場合は、disabled 属性の方が適切である可能性があります。
次の例は、「読み込み中」というメッセージによって視覚的に覆われている、部分的に読み込まれた内容を 不活性としてマークする方法を示しています。
< section aria-labelledby = s1 >
< h3 id = s1 > 都市別人口</ h3 >
< div class = container >
< div class = loading >< p > 読み込み中...</ p ></ div >
< div inert >
< form >
< fieldset >
< legend > 日付範囲</ legend >
< div >
< label for = start > 開始</ label >
< input type = date id = start >
</ div >
< div >
< label for = end > 終了</ label >
< input type = date id = end >
</ div >
< div >
< button > 適用</ button >
</ div >
</ fieldset >
</ form >
< table >
< caption > 20-- 年から 20-- 年まで</ caption >
< thead >
< tr >
< th > 都市</ th >
< th > 州</ th >
< th > 20-- 年の人口</ th >
< th > 20-- 年の人口</ th >
< th > 変化率</ th >
</ tr >
</ thead >
< tbody >
<!-- ... -->
</ tbody >
</ table >
</ div >
</ div >
</ section > 
「読み込み中」のオーバーレイは不活性な内容を覆い、不活性な内容へ現在アクセスできないことを
視覚的に明らかにします。見出しおよび「読み込み中」のテキストは、inert
属性を持つ要素の子孫ではないことに
注意してください。これにより、このテキストはすべてのユーザーがアクセスできる一方、不活性な内容は
誰も操作できなくなります。
既定では、要素またはそのサブツリーが不活性であることを示す永続的な視覚表示はありません。
そのような内容に適した視覚スタイルは、多くの場合、文脈に依存します。たとえば、不活性な
オフスクリーンナビゲーションパネルには、そのオフスクリーン位置によって内容が視覚的に覆われるため、
既定のスタイルは必要ありません。同様に、モーダルな dialog 要素の
背景は、不活性な内容自体へ特別にスタイルを適用する代わりに、ウェブページの不活性な内容を視覚的に
覆う手段として機能します。
ただし、そのほかの多くの状況では、ユーザーの混乱を避けるため、文書のどの部分がアクティブで、 どの部分が不活性であるかを明確に示すことが作者に強く推奨されます。特に、すべてのユーザーがページの すべての部分を一度に見られるわけではないことを覚えておく価値があります。たとえば、スクリーンリーダーの ユーザー、小型端末または拡大鏡を使用するユーザー、さらに特に小さなウィンドウを使用するユーザーでさえ、 ページのアクティブな部分を見られず、不活性な節が明らかに不活性でなければ不満を感じる可能性があります。
ユーザーにとって迷惑となり得る特定の API(たとえば、ポップアップを開いたり電話を振動させたりするもの)の 悪用を防ぐため、ユーザーエージェントは、ユーザーがウェブページを能動的に操作している場合、または少なくとも 一度はページを操作したことがある場合にのみ、これらの API を許可します。この「能動的な操作」状態は、 この節で定義される仕組みによって維持されます。
ユーザーアクティベーションを追跡するため、各 Window
W は、関連する二つの
値を持ちます。
最終アクティベーションタイムスタンプ。これは、
DOMHighResTimeStamp、
正の無限大(W が一度もアクティベートされていないことを示します)、または負の無限大
(アクティベーションが消費されたことを示します)のいずれかです。
初期値は正の無限大です。
最終履歴アクションアクティベーションタイムスタンプ。
これは、
DOMHighResTimeStamp
または正の無限大のいずれかであり、初期値は正の無限大です。
ユーザーエージェントは、一時的アクティベーション継続時間も 定義します。これは、特定のユーザーアクティベーションによって 制限される API(たとえば、ポップアップを開くための API)で、ユーザーアクティベーションを利用できる 期間を示す定数です。
一時的アクティベーション継続時間は、 ユーザーがページとの操作と、そのページによるアクティベーション制限付き API の呼び出しとの関連を認識できる ように、長くても数秒程度であることが想定されています。
これにより、W には次のブール型のユーザーアクティベーション状態があります。
W を与えた場合の現在の高精度時刻が、W の最終アクティベーションタイムスタンプ以上で ある場合、W はスティッキーアクティベーションを持つといいます。
これは W の履歴上のアクティベーション状態であり、ユーザーが W 内で一度でも 操作したことがあるかどうかを示します。初期値は false であり、W が最初のアクティベーション通知を受け取ると true に変化し、その後は false に戻りません。
W を与えた場合の現在の高精度時刻が、W の最終アクティベーションタイムスタンプ以上で あり、かつ W の最終アクティベーションタイムスタンプに 一時的アクティベーション継続時間を 加えた値未満である場合、W は一時的アクティベーションを持つといいます。
これは W の現在のアクティベーション状態であり、ユーザーが最近 W 内で 操作したかどうかを示します。初期値は false であり、W が各アクティベーション通知を受け取った後、 限られた期間だけ true のままになります。
一時的アクティベーション状態は、最後の ユーザーアクティベーションから一時的アクティベーション継続時間が 経過したために false になった場合、期限切れになったとみなされます。 なお、アクティベーションの消費によって、 期限切れ時刻より前に false になることもあります。
W の最終履歴アクション アクティベーションタイムスタンプが、W の最終アクティベーションタイムスタンプと 等しくない場合、W は履歴アクションアクティベーションを 持つといいます。
これはユーザーアクティベーションの特殊な変種であり、頻繁に使用するとユーザーがブラウザー UIを使用して戻る操作を行うことが困難になる、特定の セッション履歴 API へのアクセスを許可するために使用されます。初期値は false であり、ユーザーが W を操作するたびに true になりますが、履歴アクション アクティベーションの消費によって false にリセットされます。これにより、途中にユーザー アクティベーションを挟まずに、そのような API を連続して複数回使用できないようにします。ただし、 一時的アクティベーションとは異なり、 そのような API を使用しなければならない時間制限はありません。
最終アクティベーションタイムスタンプおよび最終履歴アクション
アクティベーションタイムスタンプは、Document の完全にアクティブな状態が変化した後も
保持されます(たとえば、ある Document から移動した後、
またはキャッシュされた Document へ移動した後)。
これは、同じ Document が再利用される限り、
スティッキーアクティベーション状態が複数の
ナビゲーションにわたって維持されることを意味します。一時的アクティベーション状態については、元の期限切れ時刻が変更されません
(すなわち、この状態は、元のアクティベーションを引き起こす入力イベント
から一時的アクティベーション継続時間の
制限内で期限切れになります)。特定の事柄をスティッキーアクティベーションまたは一時的アクティベーションのどちらに基づかせるかを
決定する際には、この点を考慮することが重要です。
ユーザー操作によって、Document
document 内でアクティベーションを引き起こす
入力イベントが発火する場合、ユーザーエージェントは、イベントを配送する前に、次のアクティベーション通知手順を実行しなければなりません。
windows を « document の関連するグローバルオブジェクト » とします。
document の各祖先ナビゲーブルのアクティブなウィンドウで windows を拡張します。
document の各子孫ナビゲーブルのアクティブなウィンドウで windows を拡張します。 ただし、ナビゲーブルのうち、 そのアクティブな文書のオリジンが、document のオリジンと同一オリジンであるものだけを含めます。
windows 内の各 window について反復します。
window の最終アクティベーション タイムスタンプを、現在の高精度時刻に設定します。
window を与えて、ユーザー アクティベーションについてクローズウォッチャーマネージャーへ通知します。
アクティベーションを引き起こす入力イベントとは、isTrusted
属性が true であり、かつ type
が次のいずれかであるイベントです。
「keydown」。
ただし、キーが Esc キーでも、ユーザーエージェントによって予約されたショートカットキーでも
ない場合に限ります。
「mousedown」。
「pointerdown」。
ただし、イベントの
pointerType
が「mouse」である場合に限ります。
「pointerup」。
ただし、イベントの
pointerType
が「mouse」でない場合に限ります。または、
「touchend」。
この仕様およびほかの仕様で定義されるアクティベーションを消費する APIは、
Window
W が与えられた場合に次の手順を実行することで、ユーザーアクティベーションを消費できます。
W のナビゲーブルが null である場合、返します。
top を、W のナビゲーブルの最上位の辿ることができるナビゲーブルとします。
navigables を、top のアクティブな文書の包括的子孫ナビゲーブルとします。
windows を、navigables 内の各項目のアクティブなウィンドウを取得することで構築した
Window
オブジェクトのリストとします。
windows 内の各 window について反復し、 window の最終アクティベーション タイムスタンプが正の無限大でない場合、window の最終アクティベーション タイムスタンプを負の無限大に設定します。
履歴アクション
アクティベーションを消費する APIは、Window
W が与えられた場合に次の手順を実行することで、履歴アクションユーザーアクティベーションを消費できます。
W のナビゲーブルが null である場合、返します。
top を、W のナビゲーブルの最上位の辿ることができるナビゲーブルとします。
navigables を、top のアクティブな文書の包括的子孫ナビゲーブルとします。
windows を、navigables 内の各項目のアクティブなウィンドウを取得することで構築した
Window
オブジェクトのリストとします。
windows 内の各 window について反復し、 window の最終履歴アクション アクティベーションタイムスタンプを、window の最終アクティベーション タイムスタンプに設定します。
ページ内でアクティベーション通知とアクティベーションの消費によって影響を受ける
閲覧コンテキストの集合が非対称であることに
注意してください。アクティベーションの消費は、ページ内のすべての閲覧コンテキストの一時的アクティベーション状態を false に
変更しますが、アクティベーション通知は、その閲覧コンテキストの部分集合の状態を true に変更します。
ここで消費が網羅的に行われるのは意図的です。これにより、悪意のあるサイトが一回のユーザー
アクティベーションからアクティベーションを消費する APIを
複数回呼び出すことを防ぎます(場合によっては、iframe の深い階層を悪用する可能性があります)。
ユーザーアクティベーションに依存する API は、次の異なるレベルに分類されます。
これらの API は、スティッキーアクティベーション状態が true であることを 必要とするため、最初のユーザーアクティベーションが発生するまでブロックされます。
これらの API は、一時的アクティベーション状態が true であることを 必要としますが、その状態を消費しません。そのため、一時的状態が期限切れになるまで、 一回のユーザーアクティベーションにつき複数回の呼び出しが許可されます。
これらの API は、一時的アクティベーション状態が true であることを 必要とし、一回のユーザーアクティベーションにつき複数回呼び出されることを防ぐため、呼び出すたびにユーザーアクティベーションを消費します。
これらの API は、履歴アクションアクティベーション状態が true であることを必要とし、一回のユーザーアクティベーションにつき複数回呼び出されることを防ぐため、 呼び出すたびに履歴アクションユーザー アクティベーションを消費します。
UserActivation
インターフェイス各 Window は、UserActivation オブジェクトである、関連付けられた
UserActivation を持ちます。Window オブジェクトの作成時に、
その関連付けられた
UserActivationは、Window オブジェクトの関連するレルム内で
作成された新しい UserActivation オブジェクトに設定されなければなりません。
[Exposed =Window ]
interface UserActivation {
readonly attribute boolean hasBeenActive ;
readonly attribute boolean isActive ;
};
partial interface Navigator {
[SameObject ] readonly attribute UserActivation userActivation ;
};navigator.userActivation.hasBeenActive
ウィンドウがスティッキーアクティベーションを持つかどうかを 返します。
navigator.userActivation.isActive
ウィンドウが一時的アクティベーションを持つかどうかを 返します。
userActivation の取得手順は、このオブジェクトの関連するグローバルオブジェクトの関連付けられた
UserActivationを返すことです。
hasBeenActive の取得手順は、このオブジェクトの関連するグローバルオブジェクトがスティッキーアクティベーションを持つ場合に
true を返し、それ以外の場合に false を返すことです。
isActive の取得手順は、このオブジェクトの関連するグローバルオブジェクトが一時的アクティベーションを持つ場合に
true を返し、それ以外の場合に false を返すことです。
ユーザーエージェントの自動化およびアプリケーションのテストを目的として、この仕様では Web Driver 仕様用に、次の拡張コマンドを定義します。ユーザーエージェントが次の拡張コマンドをサポートすることは任意です。 [WEBDRIVER]
| HTTP メソッド | URI テンプレート |
|---|---|
`POST` |
/session/{session id}/window/consume-user-activation |
リモートエンド手順は次のとおりです。
window を、現在の閲覧コンテキストのアクティブなウィンドウとします。
window が一時的アクティベーションを持つ場合は consume を true とし、それ以外の場合は false とします。
consume が true である場合、window のユーザーアクティベーションを消費します。
データを consume として、成功を返します。
HTML の特定の要素には、アクティベーション動作があります。これは、ユーザーがそれらを
アクティベートできることを意味します。これは常に click イベントによって引き起こされます。
ユーザーエージェントは、たとえばキーボード入力、音声入力、またはマウスクリックを使用して、アクティベーション動作を持つ要素をユーザーが手動で作動できるように
するべきです。ユーザーが、定義されたアクティベーション動作を持つ要素を、クリック以外の方法で
作動させた場合、その操作イベントの既定の動作は、その要素においてclick
イベントを発火することでなければなりません。
element.click()
現在のすべてのエンジンでサポートされています。
要素がクリックされたかのように動作します。
各要素には、関連付けられたクリック処理中フラグがあり、 初期状態では設定されていません。
click()
メソッドは、次の手順を実行しなければなりません。
この要素が無効化されているフォームコントロールである場合、返します。
この要素のクリック処理中フラグが設定されている場合、返します。
この要素のクリック処理中フラグを設定します。
この要素において、非信頼フラグを設定して、click という名前の合成ポインターイベントを発火します。
この要素のクリック処理中フラグを解除します。
ToggleEvent インターフェイス現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
[Exposed =Window ]
interface ToggleEvent : Event {
constructor (DOMString type , optional ToggleEventInit eventInitDict = {});
readonly attribute DOMString oldState ;
readonly attribute DOMString newState ;
readonly attribute Element ? source ;
};
dictionary ToggleEventInit : EventInit {
DOMString oldState = "";
DOMString newState = "";
Element ? source = null ;
};event.oldState
閉じた状態から開いた状態へ遷移するときは「closed」に設定され、開いた状態から
閉じた状態へ遷移するときは「open」に設定されます。
event.newState
閉じた状態から開いた状態へ遷移するときは「open」に設定され、開いた状態から
閉じた状態へ遷移するときは「closed」に設定されます。
event.source切り替えを開始した要素に設定されます。この要素は、popovertarget 属性および commandfor 属性を使用して設定できます。発生元要素がない場合は、
null に設定されます。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
oldState 属性および newState 属性は、それぞれ
初期化された値を返さなければなりません。
source
の取得手順は、source を、このオブジェクトの currentTarget に対して再ターゲット化した結果を返すことです。
DOM 標準 issue #1328では、 イベント上で意味を持つ方法によって、関連付けられたイベントデータをより適切に標準化する方法が追跡されています。 現在、値で初期化されたイベント属性は取得メソッドを同時に持てないため、これを適切に指定するには内部スロット (または追加フィールドのマップ)が必要です。
切り替えタスクトラッカーは、次のものを持つ構造体です。
ToggleEvent を発火するタスク。oldState 属性の値を表す文字列。CommandEvent インターフェイス[Exposed =Window ]
interface CommandEvent : Event {
constructor (DOMString type , optional CommandEventInit eventInitDict = {});
readonly attribute Element ? source ;
readonly attribute DOMString command ;
};
dictionary CommandEventInit : EventInit {
Element ? source = null ;
DOMString command = "";
};event.command
要素が実行できるアクションを返します。
event.source
このイベントを発生させるために操作された Element を返します。
command 属性は、初期化された値を返さなければなりません。
source
の取得手順は、source を、このオブジェクトの currentTarget に対して再ターゲット化した結果を返すことです。
DOM 標準 issue #1328では、 イベント上で意味を持つ方法によって、関連付けられたイベントデータをより適切に標準化する方法が追跡されています。 現在、値で初期化されたイベント属性は取得メソッドを同時に持てないため、これを適切に指定するには内部スロット (または追加フィールドのマップ)が必要です。
この節は非規範的です。
HTML ユーザーインターフェイスは通常、フォームコントロール、スクロール可能領域、リンク、ダイアログボックス、 ブラウザータブなど、複数の対話型ウィジェットで構成されます。これらのウィジェットは階層を形成し、一部の ウィジェット(ブラウザータブやダイアログボックスなど)は、ほかのウィジェット(リンクやフォームコントロール など)を含みます。
キーボードを使用してインターフェイスを操作するとき、キー入力はシステムから対話型ウィジェットの階層を 通って、アクティブなウィジェットへ送られます。このウィジェットはフォーカスされているといいます。
グラフィカル環境内のブラウザータブで実行されている HTML アプリケーションを考えます。この アプリケーションのページに複数のテキストコントロールとリンクがあり、現在、テキストコントロールと ボタンを持つモーダルダイアログが表示されているとします。
この状況でフォーカス可能なウィジェットの階層にはブラウザーウィンドウが含まれ、その子の一つとして HTML アプリケーションを含むブラウザータブがあります。タブ自体は、さまざまなリンクとテキスト コントロール、およびダイアログを子として持ちます。ダイアログ自体は、テキストコントロールとボタンを 子として持ちます。
この例でフォーカスを持つウィジェットが ダイアログボックス内のテキストコントロールである場合、キー入力はグラフィカルシステムから ① ウェブブラウザーへ、次に ② タブへ、次に ③ ダイアログへ、最後に ④ テキストコントロールへ送られます。
キーボードイベントは、常にこのフォーカスされている要素を対象とします。
最上位の辿ることができるナビゲーブルは、オペレーティング システムから送られたキーボード入力を受け取ることができる場合、システムフォーカスを持ちます。この入力は、その アクティブな文書の子孫ナビゲーブルの一つを対象としている可能性があります。
最上位の辿ることができるナビゲーブルは、そのシステム可視性状態が「visible」であり、かつ
システムフォーカスを持つか、それに直接関係する
ユーザーエージェントのウィジェットがオペレーティングシステムから送られたキーボード入力を受け取れる場合、
ユーザーの注意を持ちます。
ブラウザーウィンドウがフォーカスを失うとユーザーの注意が失われますが、 システムフォーカスは、ロケーションバーなど、ブラウザーウィンドウ内のほかのシステムウィジェットに 移動することによっても失われる可能性があります。
Document d が完全にアクティブであり、かつ d のノードナビゲーブルの最上位の辿ることができるナビゲーブルがユーザーの注意を持つ場合、d は
ユーザーの注意を持つ最上位の辿ることができるナビゲーブルの完全にアクティブな子孫です。
フォーカス可能領域という用語は、このようなキーボード入力の対象に さらになることができるインターフェイスの領域を指すために使用されます。フォーカス可能領域は、要素、 要素の一部、またはユーザーエージェントによって管理されるほかの領域である場合があります。
各フォーカス可能領域は、DOM 内における
フォーカス可能領域の位置を表す Node オブジェクトである、DOM
アンカーを持ちます。(フォーカス可能領域自体が Node である場合、そのノード自体が
DOM アンカーです。)DOM アンカーは、フォーカス可能領域を表すほかの DOM オブジェクトがない場合、一部の
API でフォーカス可能領域の代わりに使用されます。
次の表は、どのオブジェクトがフォーカス可能領域になり得るかを説明します。左列のセルは、 フォーカス可能領域になり得るオブジェクトを 説明し、右列のセルは、それらの要素のDOM アンカーを説明します。(両方の列にまたがるセルは非規範的な例です。)
| フォーカス可能領域 | DOM アンカー |
|---|---|
| 例 | |
次の基準をすべて満たす要素。
|
要素自体。 |
|
|
|
レンダリングされている、かつ不活性でない img 要素に関連付けられたイメージマップ内の area 要素の形状。
|
img 要素。
|
|
次の例では、 |
|
| レンダリングされている、かつ実際に無効化されておらず、不活性でもない要素について、ユーザーエージェントによって提供される サブウィジェット。 | フォーカス可能領域がサブウィジェットとなっている 要素。 |
|
|
|
| レンダリングされている、かつ不活性でない要素のスクロール可能領域。 | スクロール可能領域がスクロールするボックスの作成元となった要素。 |
|
CSS の 'overflow' プロパティの 'scroll' 値は、通常、スクロール可能領域を 作成します。 |
|
null でない閲覧コンテキストを持ち、かつ不活性でない Document
のビューポート。
|
ビューポートの作成元となった Document。
|
|
|
|
| 特にアクセシビリティを支援するため、またはプラットフォームの慣例により適切に合わせるために、 ユーザーエージェントによってフォーカス可能領域であると判断された、そのほかの要素または要素の一部。 | その要素。 |
|
ユーザーがリスト内をより簡単に移動できるように、ユーザーエージェントは、すべての リスト項目の箇条書き記号を順次フォーカス可能にできます。 同様に、助言情報へアクセスできるように、ユーザーエージェントは |
|
ナビゲーブルコンテナー(たとえば iframe)はフォーカス可能領域ですが、ナビゲーブルコンテナーへ送られたキーイベントは、直ちにその内容ナビゲーブルのアクティブな文書へ送られます。同様に、順次
フォーカスナビゲーションでは、ナビゲーブルコンテナーは、実質的にはその内容ナビゲーブルのアクティブな文書のプレースホルダーとしてのみ
機能します。
各 Document 内の一つのフォーカス可能領域が、文書のフォーカス領域として指定されます。どのコントロールが
指定されるかは、この仕様のアルゴリズムに基づいて時間の経過とともに変化します。
文書が完全にアクティブでなく、 ユーザーに表示されていない場合でも、その文書は文書のフォーカス領域を持つことができます。文書の完全にアクティブな状態が変化しても、その文書のフォーカス領域は同じままです。
traversable という最上位の辿ることができるナビゲーブルの現在の フォーカス領域は、次のアルゴリズムによって返されるフォーカス可能領域または null です。
traversable がシステムフォーカスを持たない場合、null を返します。
candidate を、traversable のアクティブな文書とします。
candidate のフォーカス領域が、null でない内容ナビゲーブルを持つナビゲーブルコンテナーである間、candidate を、 そのナビゲーブルコンテナーの内容ナビゲーブルのアクティブな文書に設定します。
candidate のフォーカス領域が null でない場合、 candidate を candidate のフォーカス領域に設定します。
candidate を返します。
traversable という最上位の辿ることができるナビゲーブルの現在の フォーカスチェーンは、traversable が null でない場合、traversable の現在のフォーカス領域のフォーカスチェーンであり、それ以外の場合は空のリストです。
フォーカス可能領域のDOM アンカーである要素は、そのフォーカス可能領域が最上位の辿ることができるナビゲーブルの 現在のフォーカス領域になったとき、フォーカスを得るといいます。要素が、 最上位の辿ることができるナビゲーブルの 現在のフォーカス領域であるフォーカス可能領域のDOM アンカーである場合、その要素はフォーカスされている状態です。
フォーカス可能領域 subject のフォーカスチェーンは、次のように構築される順序付きリストです。
output を空のリストとします。
currentObject を subject とします。
true の間、次を行います。
currentObject を output に付加します。
currentObject が area 要素の形状である場合、
その area 要素を output に付加します。
それ以外で、currentObject のDOM アンカーが、currentObject 自体ではない要素である場合、 currentObject のDOM アンカーを output に付加します。
currentObject がフォーカス可能領域である場合、currentObject を、 currentObject のDOM アンカーのノード文書に設定します。
それ以外で、currentObject が、ノードナビゲーブルの親が
null でない Document である場合、
currentObject を currentObject のノードナビゲーブルの親に設定します。
それ以外の場合、中断します。
output を返します。
このチェーンは subject から始まり、subject が最上位の辿ることができるナビゲーブルの
現在のフォーカス領域であるか、そうなり得る場合、フォーカス階層を上へたどって最上位の辿ることができるナビゲーブルの Document まで続きます。
フォーカス可能領域であるすべての要素は、 フォーカス可能であるといいます。
フォーカス可能領域には、二つの特殊な フォーカス可能性があります。
フォーカス可能領域が、その Document の順次フォーカスナビゲーション順序に含まれ、
かつユーザーエージェントがその領域を順次フォーカス可能であると判断する場合、その領域は順次フォーカス可能であるといいます。
ユーザーエージェントがフォーカス可能領域をクリックフォーカス可能であると判断する場合、 その領域はクリックフォーカス可能であるといいます。ユーザーエージェントは、 null でないtabindex 値を持つフォーカス可能領域をクリックフォーカス可能と みなすべきです。
フォーカス可能でない要素はフォーカス可能領域ではないため、順次フォーカス可能でも、クリックフォーカス可能でもありません。
フォーカス可能であることは、要素が、たとえば focus() メソッドまたは autofocus 属性を介して、
プログラムによってフォーカスできるかどうかを表します。これに対し、順次フォーカス可能およびクリックフォーカス可能は、ユーザー操作に対してユーザーエージェントが
どのように応答するか、すなわち、それぞれ順次フォーカスナビゲーションおよびアクティベーション動作に対する応答を制御します。
ユーザーエージェントは、ユーザー設定に従い、要素がフォーカス可能で、その Document の順次フォーカスナビゲーション順序に含まれていても、
その要素が順次フォーカス可能でないと判断する可能性があります。
たとえば、macOS のユーザーは、フォームコントロールでない要素をユーザーエージェントが飛ばすように
設定したり、Option キーと Tab キーの両方を使用する代わりに、Tab
キーだけで順次フォーカスナビゲーションを行うときにリンクを
飛ばすよう設定したりできます。
同様に、ユーザーエージェントは、要素がフォーカス可能であっても、その要素がクリックフォーカス可能でないと判断する可能性があります。 たとえば、一部のユーザーエージェントでは、編集不可能なフォームコントロールをクリックしても フォーカスされません。すなわち、ユーザーエージェントは、そのようなコントロールがクリック フォーカス可能でないと判断しています。
したがって、要素はフォーカス可能でありながら、 順次フォーカス可能でも、クリックフォーカス可能でもない場合があります。たとえば、一部の ユーザーエージェントでは、負の整数のtabindex 値を持つ編集不可能なフォームコントロールは、 ユーザー操作によってはフォーカスできず、プログラム API によってのみフォーカスできます。
ユーザーがクリックフォーカス可能なフォーカス可能領域をアクティベートした場合、
ユーザーエージェントは、そのフォーカス可能領域に対し、フォーカストリガーを
「click」に設定して、フォーカス手順を実行しなければなりません。
フォーカスすることはアクティベーション動作ではないことに注意してください。
すなわち、要素に対して click()
メソッドを呼び出したり、合成 click イベントを配送したりしても、その要素が
フォーカスされることはありません。
ノードが Document、シャドウホスト、slot、またはポップオーバー表示状態にある要素のポップオーバートリガーである要素の場合、そのノードは
フォーカスナビゲーションスコープ所有者です。
各フォーカスナビゲーションスコープ所有者は、要素のリストである フォーカスナビゲーションスコープを持ちます。その内容は次のように 決定されます。
すべての要素 element は、null またはフォーカスナビゲーションスコープ所有者のいずれかである、 関連付けられたフォーカスナビゲーション所有者を 持ちます。これは次のアルゴリズムによって決定されます。
element の親が null である場合、null を返します。
element の親がシャドウホストである場合、element の割り当てられたスロットを返します。
element がポップオーバー表示状態にあり、かつポップオーバートリガーが設定されている場合、 element のポップオーバートリガーを返します。
element の親の関連付けられたフォーカスナビゲーション所有者を 返します。
そして、与えられたフォーカスナビゲーションスコープ所有者 owner のフォーカスナビゲーションスコープの内容は、関連付けられたフォーカスナビゲーション所有者が owner であるすべての要素です。
フォーカスナビゲーションスコープ内の要素の順序は、この仕様の どのアルゴリズムにも影響を与えません。順序が重要になるのは、以下で定義されるtabindex 順フォーカスナビゲーションスコープおよび 平坦化された tabindex 順フォーカス ナビゲーションスコープの概念だけです。
tabindex 順フォーカスナビゲーションスコープは、 フォーカス可能領域およびフォーカスナビゲーションスコープ所有者のリストです。 各フォーカスナビゲーションスコープ所有者 owner はtabindex 順フォーカスナビゲーションスコープを 持ち、その内容は次のように決定されます。
owner のフォーカスナビゲーションスコープ内にあり、それ自体がフォーカスナビゲーションスコープ所有者であるすべての 要素を含みます。ただし、tabindex 値が負の整数である要素を除きます。
DOM アンカーが owner のフォーカスナビゲーションスコープ内の要素である、すべての フォーカス可能領域を含みます。ただし、 tabindex 値が負の整数であるフォーカス可能領域を除きます。
tabindex 順フォーカスナビゲーションスコープ内の 順序は、以下の節で説明するように、各要素のtabindex 値によって決定されます。
そこにある規則は、主に「べき」という記述と相対的な順序で構成されているため、 厳密な順序を定めるものではありません。
平坦化された tabindex 順フォーカス ナビゲーションスコープは、フォーカス可能領域のリストです。各フォーカスナビゲーションスコープ所有者 owner は、個別の平坦化された tabindex 順フォーカス ナビゲーションスコープを所有し、その内容は次のアルゴリズムによって決定されます。
result を、owner のtabindex 順フォーカスナビゲーションスコープの 複製とします。
result の各 item について、次を行います。
item がフォーカスナビゲーションスコープ所有者でない場合、 続行します。
item がフォーカス可能領域でない場合、item を、 item の平坦化された tabindex 順 フォーカスナビゲーションスコープ内のすべての項目で置換します。
それ以外の場合、item の平坦化された tabindex 順 フォーカスナビゲーションスコープの内容を、item の後に挿入します。
tabindex 属性現在のすべてのエンジンでサポートされています。
tabindex
内容属性を使用すると、作者は、要素およびその要素を
DOM アンカーとして持つ領域をフォーカス可能領域にし、それらを順次
フォーカス可能にすることを許可または禁止し、順次フォーカス
ナビゲーションにおける相対的な順序を決定できます。
「tab index」という名前は、フォーカス可能な要素間を移動するために Tab キーが 一般的に使用されることに由来します。「tabbing」という用語は、順次 フォーカス可能なフォーカス可能領域を前方へ移動することを指します。
tabindex 属性を
指定する場合、その値は妥当な整数でなければなりません。正の数は、
順次フォーカス
ナビゲーション順序における要素のフォーカス可能領域の相対位置を指定し、負の数は、
コントロールが順次フォーカス可能でないことを示します。
0 または −1 以外の値を tabindex
属性に使用する場合、
正しく処理することが複雑であるため、開発者は注意するべきです。
次に、可能な tabindex 属性値の動作について、
非規範的な概要を示します。以下の処理モデルでは、より正確な規則を示します。
tabindex 属性値が
大きい要素ほど後になります。
tabindex
属性を使用して、要素をフォーカス不可能にすることはできないことに注意してください。ページの作者が
それを行う唯一の方法は、要素を無効化するか、不活性にすることです。
要素のtabindex 値は、その tabindex 属性の値を、
整数を構文解析する規則を使用して構文解析した
値です。構文解析に失敗した場合、または属性が指定されていない場合、tabindex
値は null です。
要素のtabindex 値は、次のように解釈しなければなりません。
ユーザーエージェントは、要素をフォーカス可能領域とみなすべきかどうかを プラットフォームの慣例に従って判断し、そうみなす場合は、要素およびその要素をDOM アンカーとして持つフォーカス 可能領域が順次 フォーカス可能であるかどうかを判断し、そうである場合は、それらのtabindex 順フォーカスナビゲーション スコープ内における相対位置を判断するべきです。要素がフォーカス ナビゲーションスコープ所有者である場合、その要素がフォーカス可能 領域でなくても、そのtabindex 順フォーカスナビゲーション スコープに含めなければなりません。
同じフォーカスナビゲーションスコープに属し、 tabindex 値が null である要素およびフォーカス可能領域について、 tabindex 順フォーカスナビゲーション スコープ内の相対順序は、シャドウを含むツリー順であるべきです。
ユーザーエージェントは、要素をフォーカス可能領域とみなさなければなりませんが、 要素をすべてのtabindex 順フォーカスナビゲーション スコープから除外するべきです。
順次フォーカスナビゲーションによって作者が要素へ移動できないようにするという要件を
無視する妥当な理由の一つは、ユーザーがフォーカスを移動する唯一の手段が順次フォーカス
ナビゲーションである場合です。たとえば、キーボードのみを使用するユーザーは、負の tabindex を持つ
テキストコントロールをクリックできないため、そのユーザーのユーザーエージェントが、それにもかかわらず
ユーザーによるタブ操作でそのコントロールへ移動できるようにすることには、十分な正当性があります。
ユーザーエージェントは、要素をフォーカス可能領域とみなすことを許可しなければならず、 要素およびその要素をDOM アンカーとして持つフォーカス可能領域を順次 フォーカス可能にすることを許可するべきです。
同じフォーカスナビゲーション スコープに属し、tabindex 値がゼロである要素およびフォーカス可能領域について、tabindex 順フォーカスナビゲーション スコープ内の相対順序は、シャドウを含むツリー順であるべきです。
ユーザーエージェントは、要素をフォーカス可能領域とみなすことを許可しなければならず、 要素およびその要素をDOM アンカーとして持つフォーカス可能領域を順次 フォーカス可能にすることを許可するべきです。また、以下で candidate と呼ぶ要素および 前述のフォーカス可能領域を、要素が属するtabindex 順フォーカスナビゲーション スコープ内に、同じフォーカス ナビゲーションスコープに属するほかの要素およびフォーカス 可能領域との相対関係が次のようになるよう配置するべきです。
tabindex 属性を
省略しているか、またはその値を構文解析するとエラーが返される要素である、すべてのフォーカス可能領域より前。
tabindex 属性値が
ゼロ以下である要素である、すべてのフォーカス可能領域より前。
tabindex 属性値が
ゼロより大きいものの、candidate の tabindex 属性値より
小さい要素である、すべてのフォーカス可能領域より後。
tabindex 属性値が
candidate の tabindex 属性値と
等しいものの、シャドウを含むツリー順で
candidate より前に位置する要素である、すべてのフォーカス可能領域より後。
tabindex 属性値が
candidate の tabindex 属性値と
等しいものの、シャドウを含むツリー順で
candidate より後に位置する要素である、すべてのフォーカス可能領域より前。
tabindex 属性値が、
candidate の tabindex 属性値より
大きい要素である、すべてのフォーカス可能領域より前。
現在のすべてのエンジンでサポートされています。
tabIndex
の取得手順は次のとおりです。
要素型によって既定値が異なるのは、歴史的な事情によるものです。
フォーカス可能領域でない要素、またはナビゲーブルのいずれかである
focus target についてフォーカス可能領域を取得するには、
任意の文字列 focus trigger(既定値は「other」)が与えられた場合、
次のリストから最初に一致する一連の手順を実行します。
area 要素である場合
フラットツリーを先行順かつ深さ優先で走査した場合に最初となる、 要素のスクロール可能領域を返します。[CSSSCOPING]
Document の文書要素である場合
ナビゲーブルコンテナーの内容ナビゲーブルのアクティブな文書を返します。
focusedElement を、最上位の辿ることが できるナビゲーブルの現在のフォーカス領域のDOM アンカーとします。
focus target が focusedElement のシャドウを含む包括的祖先である場合、 focusedElement を返します。
focus trigger が与えられた場合の focus target のフォーカス委任先を返します。
順次フォーカス可能性については、シャドウホストおよびフォーカスを委任するかの処理は、順次フォーカスナビゲーション順序を 構築するときに行われます。すなわち、順次フォーカスナビゲーションの一部として、このようなシャドウホストに対してフォーカス手順が呼び出されることはありません。
null を返します。
任意の文字列 focusTrigger(既定値は「other」)が与えられた場合の
focusTarget のフォーカス委任先は、次の手順によって
求められます。
focusTarget がシャドウホストであり、そのシャドウルートのフォーカスを委任するかが false である場合、 null を返します。
whereToLook を focusTarget とします。
whereToLook がシャドウホストである場合、whereToLook を whereToLook のシャドウ ルートに設定します。
autofocusDelegate を、focusTrigger が与えられた場合の whereToLook のautofocus 委任先とします。
autofocusDelegate が null でない場合、autofocusDelegate を返します。
whereToLook の子孫の各 descendant について、ツリー 順で反復します。
focusableArea を null とします。
focusTarget が dialog 要素であり、descendant が順次フォーカス可能である場合、
focusableArea を descendant に設定します。
それ以外で、focusTarget が dialog ではなく、descendant がフォーカス可能領域である場合、
focusableArea を descendant に設定します。
それ以外の場合、focusableArea を、focusTrigger が与えられた場合の descendant についてフォーカス可能領域を取得した結果に設定します。
この手順では再帰が発生する可能性があります。すなわち、フォーカス可能領域を取得する手順が、 descendant のフォーカス委任先を返す可能性があります。
focusableArea が null でない場合、focusableArea を返します。
ここではシャドウを含む子孫を調べるのではなく、子孫だけを調べることが重要です。シャドウ ホストは、代わりに前述の再帰的な場合によって処理されます。
null を返します。
上記のアルゴリズムは本質的に、focusTarget とDOM アンカーとの間の経路が、すべてのシャドウツリー境界でフォーカスを委任する、最初の適切なフォーカス 可能領域を返します。
focus trigger が与えられた場合の focus target のautofocus 委任先は、次の手順によって求められます。
focus target の各子孫 descendant について、ツリー順で次を行います。
descendant がフォーカス可能領域である場合、 focusable area を descendant とします。それ以外の場合、 focusable area を、focus trigger が与えられた場合の descendant についてフォーカス可能領域を取得した結果とします。
focusable area が null である場合、続行します。
focusable area がクリックフォーカス可能でなく、かつ
focus trigger が「click」である場合、続行します。
focusable area を返します。
null を返します。
フォーカス可能領域、フォーカス可能領域でない要素、 またはナビゲーブルのいずれかである オブジェクト new focus target のフォーカス手順は、次のとおりです。これらは、任意で fallback target および文字列 focus trigger とともに実行できます。
new focus target がフォーカス可能領域でない場合、 focus trigger が渡されていればそれを与えて、new focus target を new focus target についてフォーカス可能領域を取得した結果に 設定します。
new focus target が null である場合、次を行います。
fallback target が指定されていない場合、返します。
それ以外の場合、new focus target を fallback target に設定します。
new focus target が、null でない内容ナビゲーブルを持つナビゲーブルコンテナーである場合、 new focus target を、その内容 ナビゲーブルのアクティブな文書に設定します。
new focus target が最上位の辿ることが できるナビゲーブルの現在のフォーカス領域である場合、返します。
old chain を、new focus target が属する最上位の辿ることができる ナビゲーブルの現在のフォーカス チェーンとします。
new chain を、new focus target のフォーカス チェーンとします。
old chain、new chain、および new focus target をそれぞれ与えて、 フォーカス更新手順を実行します。
ユーザーがフォーカス可能領域またはナビゲーブル candidate へフォーカスを 移動しようとした場合、ユーザーエージェントは、candidate についてフォーカス手順を直ちに実行しなければなりません。
フォーカス可能領域またはフォーカス可能領域でない要素の いずれかであるオブジェクト old focus target のフォーカス解除手順は次のとおりです。
old focus target が、シャドウルートのフォーカスを委任するかが true であるシャドウホストであり、かつ old focus target のシャドウルートが、最上位の辿ることが できるナビゲーブルの現在のフォーカス領域のDOM アンカーのシャドウを含む包括的祖先である場合、 old focus target をその最上位の辿ることが できるナビゲーブルの現在のフォーカス領域に設定します。
old focus target が不活性である場合、返します。
old focus target が area 要素であり、その形状の一つが最上位の辿ることが
できるナビゲーブルの現在のフォーカス領域である場合、または old focus
target が一つ以上のスクロール可能領域を持つ要素であり、その一つが最上位の辿ることが
できるナビゲーブルの現在のフォーカス領域である場合、old focus target をその最上位の辿ることが
できるナビゲーブルの現在のフォーカス領域とします。
old chain を、old focus target が属する最上位の辿ることができる ナビゲーブルの現在のフォーカス チェーンとします。
old focus target が old chain 内の項目の一つでない場合、返します。
old focus target がフォーカス可能領域でない場合、返します。
topDocument を old chain の最後の項目とします。
topDocument のノードナビゲーブルがシステムフォーカスを持つ場合、topDocument の ビューポートについてフォーカス手順を実行します。
それ以外の場合、topDocument のノードナビゲーブルからシステム フォーカスを取り除くため、関連するプラットフォーム固有の慣例を適用し、old chain、 空のリスト、および null を与えてフォーカス 更新手順を実行します。
フォーカス解除手順は、最上位の辿ることが できるナビゲーブルの現在のフォーカス領域へ適用された場合でも、必ずしもフォーカスの変更を 引き起こすとは限りません。たとえば、最上位の辿ることが できるナビゲーブルの現在のフォーカス領域がビューポートである場合、別のフォーカス可能領域がフォーカス手順によって明示的にフォーカスされるまで、 通常はフォーカスを保持します。
old chain、new chain、および new focus target がそれぞれ 与えられた場合のフォーカス更新手順は次のとおりです。
old chain の最後の項目と new chain の最後の項目が同じである場合、 old chain から最後の項目を取り出し、new chain から最後の項目を取り出して、 この手順を再実行します。
old chain 内の各項目 entry について、順番に次の下位手順を実行します。
entry が input 要素であり、change イベントが
その要素に適用され、その要素に定義済みのアクティベーション動作がなく、コントロールがフォーカス
されている間に、ユーザーがその変更を確定せずに要素の値または選択されたファイルのリストを
変更しており、その変更がコントロールを最初にフォーカスしたときの値と異なる場合、次を行います。
entry が要素である場合、blur event target を entry とします。
entry が Document
オブジェクトである
場合、blur event target を、その Document オブジェクトの
関連するグローバルオブジェクトとします。
それ以外の場合、blur event target を null とします。
entry が old chain の最後の項目であり、かつ entry が
Element であり、
new chain の最後の項目も Element である場合、
related blur target を new chain の最後の項目とします。それ以外の場合、
related blur target を null とします。
blur event target が null でない場合、related blur target を
関連ターゲットとして、blur event target において blur という名前のフォーカスイベントを発火します。
一部の場合、たとえば entry が area 要素の形状、スクロール可能領域、またはビューポートである場合、イベントは発火しません。
new focus target をフォーカスするため、関連するプラットフォーム固有の慣例を適用します。 (たとえば、一部のプラットフォームでは、テキストコントロールがフォーカスされると、 そのコントロールの内容が選択されます。)
new chain 内の各項目 entry について、逆順に次の下位手順を実行します。
entry がフォーカス可能領域であり、かつ文書のフォーカス領域が entry でない場合、次を行います。
document の関連するグローバルオブジェクトのナビゲーション APIの進行中のナビゲーション中に フォーカスが変更されたかを true に設定します。
entry を文書のフォーカス領域として 指定します。
entry が要素である場合、focus event target を entry とします。
entry が Document
オブジェクトである
場合、focus event target を、その Document オブジェクトの
関連するグローバルオブジェクトとします。
それ以外の場合、focus event target を null とします。
entry が new chain の最後の項目であり、かつ entry が
Element であり、
old chain の最後の項目も Element である場合、
related focus target を old chain の最後の項目とします。それ以外の場合、
related focus target を null とします。
focus event target が null でない場合、related focus target を
関連ターゲットとして、focus event target において focus という名前のフォーカスイベントを発火します。
一部の場合、たとえば entry が area 要素の形状、スクロール可能領域、またはビューポートである場合、イベントは発火しません。
与えられた関連ターゲット r とともに、要素 t において e という
名前のフォーカスイベントを発火するには、FocusEvent を使用し、relatedTarget 属性を
r に初期化し、view 属性を t のノード文書の関連するグローバルオブジェクトに初期化し、
composed
フラグを設定して、t において e という名前のイベントを発火します。
最上位の辿ることができるナビゲーブル内で キーイベントを送る場合、ユーザーエージェントは次の手順を実行しなければなりません。
target area を、最上位の辿ることが できるナビゲーブルの現在のフォーカス領域とします。
表明:キーイベントはシステム フォーカスを持つ最上位の辿ることができるナビゲーブルにのみ 送られるため、target area は null ではありません。したがって、target area は フォーカス可能領域です。
target node を、target area のDOM アンカーとします。
target node がbody
要素を持つ Document である場合、
target node を、その Document のbody
要素とします。
それ以外で、target node が null でない文書要素を持つ Document オブジェクトである場合、
target node をその文書
要素とします。
target node が不活性でない場合、次を行います。
canHandle を、target node においてキーイベントを配送した結果とします。
canHandle が true である場合、target area にキーイベントを処理させます。
これには、target node においてclick イベントを発火することが
含まれる可能性があります。
Document オブジェクト target が与えられた場合のフォーカスを持つかを判定する手順は次のとおりです。
target のノードナビゲーブルの最上位の辿ることができる ナビゲーブルがシステムフォーカスを持たない場合、false を返します。
candidate を、target のノードナビゲーブルの最上位の辿ることができるナビゲーブルのアクティブな文書とします。
true の間、次を行います。
candidate が target である場合、true を返します。
candidate のフォーカス領域が、null でない内容ナビゲーブルを持つナビゲーブルコンテナーである場合、 candidate を、そのナビゲーブルコンテナーの内容 ナビゲーブルのアクティブな文書に設定します。
それ以外の場合、false を返します。
各 Document は、
Document 内の一部または
すべてのフォーカス可能領域を
相互に順序付ける、順次フォーカスナビゲーション順序を
持ちます。その内容および順序は、Document の平坦化された tabindex 順
フォーカスナビゲーションスコープによって与えられます。
平坦化された tabindex 順
フォーカスナビゲーション
スコープを定義する規則により、その順序は必ずしも Document のツリー順と関連するとは限りません。
フォーカス可能領域が、その
Document の順次フォーカスナビゲーション
順序から除外されている場合、順次フォーカス
ナビゲーションでは到達できません。
順次フォーカスナビゲーション開始 点が存在することもあります。これは初期状態では 未設定です。ユーザーが移動するべきであることを示したとき、ユーザーエージェントはこれを設定できます。
たとえば、ユーザーが文書の内容をクリックした場合、ユーザーエージェントはこれを ユーザーがクリックした位置に設定できます。
ユーザーエージェントは、フラグメントへ ナビゲートするとき、順次フォーカスナビゲーション開始 点を対象要素に設定する必要があります。
順次フォーカス方向は、「forward」または「backward」という二つの値のいずれかです。これらは、
次のアルゴリズムで、ユーザーの要求に応じて順次フォーカスが移動する方向を説明するために使用されます。
選択機構は、「DOM」または
「sequential」という二つの値のいずれかです。
これらは、順次ナビゲーション検索アルゴリズムが、
返すフォーカス可能
領域をどのように見つけるかを説明するために使用されます。
ユーザーが、最上位の辿ることができる ナビゲーブルの現在のフォーカス領域から、次または前のフォーカス可能領域へフォーカスを移動することを 要求した場合(たとえば、tab キーを押したときの既定の動作として)、または ユーザーが最初に最上位の辿ることができるナビゲーブルへ 順次フォーカスを移動することを要求した場合(たとえば、 ブラウザーのロケーションバーから)、ユーザーエージェントは次のアルゴリズムを使用しなければなりません。
ユーザーが最上位の辿ることが できるナビゲーブルの現在のフォーカス領域から順次フォーカスを移動することを要求した場合、 starting point をその領域とします。それ以外で、ユーザーが最上位の辿ることができるナビゲーブルの 外部からフォーカスを移動することを要求した場合、starting point を最上位の 辿ることができるナビゲーブル自体とします。
順次フォーカスナビゲーション 開始点が定義されており、それが starting point の内部にある場合、代わりに starting point を順次 フォーカスナビゲーション開始点とします。
ユーザーが次のコントロールを要求した場合、direction を「forward」とし、
ユーザーが前のコントロールを要求した場合、「backward」とします。
通常、tab を押すと次のコントロールが要求され、 shift + tab を押すと前のコントロールが要求されます。
ループ:starting point がナビゲーブルであるか、または
starting point がその Document の順次フォーカスナビゲーション順序に
含まれている場合、selection mechanism を「sequential」とします。
それ以外の場合、starting point はその Document の順次
フォーカスナビゲーション順序に含まれていません。selection mechanism を「DOM」とします。
candidate を、starting point、direction、および selection mechanism を使用して順次ナビゲーション検索 アルゴリズムを実行した結果とします。
candidate が null でない場合、candidate についてフォーカス手順を実行して返します。
それ以外の場合、順次フォーカスナビゲーション 開始点を設定解除します。
starting point が最上位の辿ることができるナビゲーブルであるか、 または最上位の 辿ることができるナビゲーブル内のフォーカス可能領域である場合、 ユーザーエージェントは direction に従って、フォーカスを自身のコントロール (存在する場合)へ適切に移動してから返すべきです。
たとえば、direction が backward の場合、ブラウザーの レンダリング領域より前にある最後の順次 フォーカス可能なコントロールが、フォーカスされるコントロールになります。
ユーザーエージェントに順次フォーカス可能なコントロールが ない場合(たとえばキオスクモードのブラウザー)、ユーザーエージェントは代わりに、 starting point を最上位の辿ることができるナビゲーブル 自体として、これらの手順を再開できます。
それ以外の場合、starting point は子 ナビゲーブル内のフォーカス可能領域です。 starting point をその子ナビゲーブルの親に設定し、ループとラベル付けされた手順へ 戻ります。
フォーカス可能領域 starting point、順次フォーカス方向 direction、 および選択機構 selection mechanism が与えられた場合の順次ナビゲーション検索アルゴリズムは、 次の手順で構成されます。 これらはフォーカス可能 領域または null を返します。
次の表から適切なセルを選択し、そのセル内の指示に従います。
適切なセルは、その列見出しが direction を説明する列、および starting point と selection mechanism を説明する最初の行に属するセルです。
direction が「forward」の場合
|
direction が「backward」の場合
|
|
|---|---|---|
| starting point がナビゲーブルである場合 | candidate を、starting point のアクティブな文書内で最初の適切な順次フォーカス可能 領域(存在する場合)とし、それ以外の場合は null とします。 | candidate を、starting point のアクティブな文書内で最後の適切な順次 フォーカス可能領域(存在する場合)とし、それ以外の場合は null とします。 |
selection mechanism が「DOM」の場合
|
candidate を、starting point の
この場合、starting point は必ずしもその
|
candidate を、starting point の
Document内で、
シャドウを含むツリー順において
starting point の前に最も近く現れる適切な順次
フォーカス可能領域(存在する場合)とし、それ以外の場合は null とします。
|
selection mechanism が「sequential」の場合
|
candidate を、starting point の Document の
順次フォーカスナビゲーション
順序において、starting point より後にある最初の適切な順次
フォーカス可能領域(存在する場合)とし、それ以外の場合は null とします。
|
candidate を、starting point の Document の
順次フォーカスナビゲーション
順序において、starting point より前にある最後の適切な順次
フォーカス可能領域(存在する場合)とし、それ以外の場合は null とします。
|
適切な順次フォーカス可能領域とは、 DOM アンカーが不活性ではなく、かつ順次 フォーカス可能であるフォーカス可能領域です。
candidate が、null でない内容 ナビゲーブルを持つナビゲーブルコンテナーである場合、次を行います。
recursive candidate を、candidate の内容ナビゲーブル、
direction、および「sequential」を使用して、
順次
ナビゲーション検索アルゴリズムを実行した結果とします。
recursive candidate が null である場合、candidate、 direction、および selection mechanism を使用して順次ナビゲーション検索 アルゴリズムを実行した結果を返します。
それ以外の場合、candidate を recursive candidate に設定します。
candidate を返します。
dictionary FocusOptions {
boolean preventScroll = false ;
boolean focusVisible ;
};documentOrShadowRoot.activeElement
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
documentOrShadowRoot 内で、キーイベントが経由して、または直接送られている最も深い 要素を返します。大まかに言えば、これは文書内のフォーカスされた要素です。
この API では、子ナビゲーブルがフォーカスされているとき、そのコンテナーは、その親のアクティブな
文書内でフォーカスされているものとみなされます。たとえば、
ユーザーが iframe 内のテキストコントロールへフォーカスを移動した場合、
iframe は、その iframe のノード文書内で activeElement
API によって返される要素です。
同様に、フォーカスされた要素が documentOrShadowRoot とは異なるノードツリー内にあり、 documentOrShadowRoot がフォーカスされた要素のシャドウを含む包括的祖先である場合、返される要素は、 documentOrShadowRoot と同じノード ツリー内に位置するホストです。そうでない場合は null です。
document.hasFocus()
現在のすべてのエンジンでサポートされています。
キーイベントが document を経由して、または直接送られている場合は true を返し、 それ以外の場合は false を返します。大まかに言えば、これは document、または document 内に入れ子になった文書がフォーカスされていることに対応します。
window.focus()
現在のすべてのエンジンでサポートされています。
window のナビゲーブルが 存在する場合、そのナビゲーブルへフォーカスを移動します。
element.focus()
現在のすべてのエンジンでサポートされています。
element.focus({ preventScroll, focusVisible })
element へフォーカスを移動します。
element がナビゲーブルコンテナーである場合、代わりにその 内容ナビゲーブルへ フォーカスを移動します。
既定では、このメソッドは element が表示される位置までスクロールします。preventScroll
オプションを指定して true に設定すると、
この動作を防止できます。
既定では、ユーザーエージェントは実装定義のヒューリスティックを使用して、フォーカスリングに
よってフォーカスを示すかどうかを決定します。focusVisible
オプションを指定して true に設定すると、
フォーカスリングが常に表示されるようになります。
element.blur()
現在のすべてのエンジンでサポートされています。
フォーカスをビューポートへ移動します。このメソッドの使用は推奨されません。
ビューポートをフォーカスする場合は、Document の文書要素に対して focus() メソッドを呼び出してください。
フォーカスリングが見栄えに合わないという理由で、フォーカスリングを非表示にするためにこのメソッドを
使用しないでください。代わりに、:focus-visible
擬似クラスを使用して'outline'
プロパティを上書きし、どの要素がフォーカスされているかを示す別の方法を提供してください。代替となる
フォーカススタイルを提供しない場合、主にキーボードを使用してページを移動する人や、ページ内を移動する
ためにフォーカスの輪郭を使用する視力の弱い人にとって、ページの使いやすさが大幅に低下することに
注意してください。
たとえば、textarea 要素の輪郭を非表示にし、代わりに黄色の背景を使用して
フォーカスを示すには、次のように記述できます。
textarea:focus-visible { outline : none; background : yellow; color : black; } DocumentOrShadowRoot
の activeElement の取得手順は次のとおりです。
Document の hasFocus()
メソッド手順は、このオブジェクトを与えてフォーカスを持つかを判定する手順を実行した結果を返すことです。
Window の focus() メソッド手順は次のとおりです。
現在のすべてのエンジンでサポートされています。
Window の blur() メソッド手順では何も行いません。
歴史的には、focus()
および blur() メソッドは、
ナビゲーブルを含むシステムウィジェット
(タブやウィンドウなど)のシステムレベルのフォーカスに実際に影響を与えていましたが、敵対的なサイトが
この動作をユーザーに不利益を与える形で広く悪用していました。
HTMLOrSVGOrMathMLElement
の
focus(options) メソッド手順は次のとおりです。
options["focusVisible"] が true である場合、またはその値が存在しないものの、ユーザーエージェントが実装定義の方法で、そうすることが最適であると判断した場合、
フォーカスを示します。
options["preventScroll"] が false である場合、このオブジェクト、「auto」、「center」、
および「center」を与えて、対象が表示される位置まで
スクロールします。
HTMLOrSVGOrMathMLElement の
blur()
メソッド手順は次のとおりです。
たとえば、blur() メソッドが見栄え上の理由でフォーカスリングを取り除くために不適切に
使用されている場合、ページはキーボードユーザーにとって使用不能になります。そのため、このメソッドの
呼び出しを無視すれば、キーボードユーザーがページを操作できるようになります。
Document オブジェクト
target が与えられた場合のフォーカス許可手順は次のとおりです。
target が「focus-without-user-activation」
機能を使用することを許可されている場合、
true を返します。
target の関連するグローバルオブジェクトが一時的アクティベーションを持つ場合、true を返します。
false を返します。
autofocus 属性autofocus
内容属性を使用すると、作者は、ページが読み込まれた時点ですぐに要素がフォーカスされることを示せます。
これにより、ユーザーは主要な要素を手動でフォーカスすることなく、すぐに入力を開始できます。
autofocus 属性が、dialog 要素の内部、
または popover 属性が
設定されたHTML 要素の内部にある
要素へ指定されている場合、その要素はダイアログまたは
ポップオーバーが表示されたときにフォーカスされます。
Element
element が与えられた場合に、最も近い祖先 autofocus スコープルート
要素を見つけるには、次を行います。
同じ最も近い祖先 autofocus スコープ
ルート要素を持つ二つの要素の両方に、autofocus 属性を
指定してはなりません。
各 Document は、初期状態では
空である、autofocus 候補のリストを持ちます。
各 Document は、初期値が
false であるブール値のautofocus 処理済みフラグを持ちます。
autofocus 属性が指定された要素が文書へ挿入された場合、次の手順を
実行します。
ユーザーが、たとえばフォームコントロールへの入力を開始することにより、フォーカスの変更を 望まないことを示した場合、任意で返します。
target を、要素のノード文書とします。
target が完全にアクティブでない場合、返します。
target のアクティブなサンドボックス化フラグ集合が、 サンドボックス化された 自動機能閲覧コンテキストフラグを持つ場合、返します。
target を与えたフォーカス許可手順が false を返す場合、 返します。
topDocument を、target のノードナビゲーブルの最上位の辿ることができるナビゲーブルのアクティブな 文書とします。
topDocument のautofocus 処理済みフラグが false の場合、 要素を topDocument のautofocus 候補から削除し、要素を topDocument のautofocus 候補へ付加します。
要素をautofocus 候補リストへ格納する前に、その要素が フォーカス可能領域であるかどうかは 確認しません。挿入された時点でフォーカス可能領域でなくても、autofocus 候補をフラッシュする処理が その要素を確認するまでに、フォーカス可能領域になる可能性があるためです。
文書 topDocument のautofocus 候補をフラッシュするには、 次の手順を実行します。
topDocument のautofocus 処理済みフラグが true の場合、 返します。
candidates を、topDocument のautofocus 候補とします。
candidates が空である場合、返します。
topDocument のフォーカス領域が topDocument 自体でないか、topDocument が null でない対象要素を持つ場合、次を行います。
candidates を空にします。
topDocument のautofocus 処理済みフラグを true に 設定します。
返します。
candidates が空でない間、次を行います。
element を candidates[0] とします。
doc を、element のノード 文書とします。
doc のノード ナビゲーブルの最上位の辿ることができる ナビゲーブルが、topDocument のノードナビゲーブルと同じでない場合、 element を candidates から削除し、続行します。
doc のスクリプトをブロックするスタイルシート集合が 空でない場合、返します。
この場合、element は現在最適な候補ですが、doc は autofocus を実行する準備ができていません。次にautofocus 候補をフラッシュする処理が呼び出されたときに、もう一度試行します。
element を candidates から削除します。
inclusiveAncestorDocuments を、doc の包括的 祖先ナビゲーブルのアクティブな文書で構成されるリストとします。
inclusiveAncestorDocuments 内のいずれかの Document が null でない
対象要素を持つ場合、続行します。
target を element とします。
target がフォーカス可能領域でない場合、 target を、target についてフォーカス可能領域を取得した結果に設定します。
autofocus 候補には、フォーカス可能
領域でない要素が含まれる場合があります。フォーカス可能
領域を取得するアルゴリズムで処理される特殊な場合に加えて、これは、autofocus 属性を持つ、フォーカス可能領域でない要素が文書へ挿入され、
一度もフォーカス可能にならなかった場合、または要素はフォーカス可能だったものの、
autofocus
候補へ格納されている間にその状態が変化した場合に発生する可能性があります。
target が null でない場合、次を行います。
candidates を空にします。
topDocument のautofocus 処理済みフラグを true に 設定します。
target についてフォーカス手順を実行します。
これは、文書の読み込み中の自動フォーカスを処理します。dialog 要素の
show() および showModal()
メソッドも、autofocus 属性を処理します。
要素をフォーカスすることは、ブラウザーウィンドウがフォーカスを失っている場合に、 ユーザーエージェントがブラウザーウィンドウをフォーカスしなければならないことを意味しません。
次の断片では、文書が読み込まれたときにテキストコントロールがフォーカスされます。
< input maxlength = "256" name = "q" value = "" autofocus >
< input type = "submit" value = "検索" > autofocus 属性はフォームコントロールだけでなく、
すべての要素に適用されます。これにより、次のような例が可能になります。
< div contenteditable autofocus > < strong > 私を</ strong > 編集してください!< div > この節は非規範的です。
アクティベートまたはフォーカスできる各要素には、accesskey 属性を
使用して、その要素をアクティベートする単一のキーの組み合わせを割り当てることができます。
正確なショートカットは、ユーザーのキーボードに関する情報、プラットフォーム上にすでに存在する
キーボードショートカット、およびページ上で指定されているほかのショートカットに基づいて、
accesskey 属性で提供される情報を手掛かりとして、
ユーザーエージェントが決定します。
さまざまな入力デバイスで関連するキーボードショートカットを使用できるようにするため、作者は
accesskey 属性に複数の代替候補を指定できます。
各代替候補は、文字や数字などの単一の文字で構成されます。
ユーザーエージェントは、キーボードショートカットのリストをユーザーへ提供できますが、作者も
提供することが推奨されます。accessKeyLabel
IDL 属性は、
ユーザーエージェントによって実際に割り当てられたキーの組み合わせを表す文字列を返します。
この例では、作者がショートカットキーを使用して呼び出せるボタンを提供しています。フルキーボードを サポートするため、作者は使用可能なキーとして「C」を指定しています。テンキーのみを備えたデバイスを サポートするため、作者はもう一つの使用可能なキーとして「1」を指定しています。
< input type = button value = 収集 onclick = "collect()"
accesskey = "C 1" id = c > ショートカットキーをユーザーへ伝えるため、ここでは作者がキーの組み合わせをボタンのラベルへ 明示的に追加することを選択しています。
function addShortcutKeyLabel( button) {
if ( button. accessKeyLabel != '' )
button. value += ' (' + button. accessKeyLabel + ')' ;
}
addShortcutKeyLabel( document. getElementById( 'c' )); 異なるプラットフォーム上のブラウザーは、同じキーの組み合わせであっても、そのプラットフォームで 一般的な慣例に基づいて異なるラベルを表示します。たとえば、キーの組み合わせが Control キー、 Shift キー、および文字 C である場合、Windows ブラウザーは「Ctrl+Shift+C」と 表示する可能性がありますが、Mac ブラウザーは「^⇧C」と表示し、 Emacs ブラウザーは単に「C-C」と表示する可能性があります。同様に、キーの組み合わせが Alt キーと Escape キーである場合、Windows は「Alt+Esc」、Mac は 「⌥⎋」、Emacs ブラウザーは「M-ESC」または 「ESC ESC」を使用する可能性があります。
したがって一般に、accessKeyLabel IDL 属性から返された値を構文解析しようとすることは
適切ではありません。
accesskey
属性現在のすべてのエンジンでサポートされています。
すべてのHTML 要素には、accesskey
内容属性を設定できます。accesskey
属性の値は、要素をアクティベートまたはフォーカスするキーボードショートカットを作成するための手掛かりとして、
ユーザーエージェントによって使用されます。
指定する場合、その値は一意なスペース区切りトークンの 順序付き集合でなければなりません。どのトークンも別のトークンと同一であってはならず、各トークンの長さは正確に一つの コードポイントでなければなりません。
次の例では、サイトに慣れているキーボードユーザーが関連するページへより素早く移動できるように、 さまざまなリンクへアクセスキーが指定されています。
< nav >
< p >
< a title = "コンソーシアムの活動" accesskey = "A" href = "/Consortium/activities" > 活動</ a > |
< a title = "技術報告書および勧告" accesskey = "T" href = "/TR/" > 技術報告書</ a > |
< a title = "アルファベット順サイト索引" accesskey = "S" href = "/Consortium/siteindex" > サイト索引</ a > |
< a title = "このサイトについて" accesskey = "B" href = "/Consortium/" > コンソーシアムについて</ a > |
< a title = "コンソーシアムへの問い合わせ" accesskey = "C" href = "/Consortium/contact" > 問い合わせ</ a >
</ p >
</ nav > 次の例では、検索フィールドに使用可能な二つのアクセスキー「s」と「0」が、その順序で指定されています。 フルキーボードを備えたデバイス上のユーザーエージェントは、ショートカットキーとして Ctrl + Alt + S を選択する可能性がありますが、 テンキーしか持たない小型デバイス上のユーザーエージェントは、装飾されていない通常の 0 キーだけを選択する可能性があります。
< form action = "/search" >
< label > 検索:< input type = "search" name = "q" accesskey = "s 0" ></ label >
< input type = "submit" >
</ form > 次の例では、ボタンに使用可能なアクセスキーが指定されています。次に、スクリプトが、 ユーザーエージェントによって選択されたキーの組み合わせを知らせるように、ボタンのラベルを更新しようとします。
< input type = submit accesskey = "N @ 1" value = "作成" >
...
< script >
function labelButton( button) {
if ( button. accessKeyLabel)
button. value += ' (' + button. accessKeyLabel + ')' ;
}
var inputs = document. getElementsByTagName( 'input' );
for ( var i = 0 ; i < inputs. length; i += 1 ) {
if ( inputs[ i]. type == "submit" )
labelButton( inputs[ i]);
}
</ script > あるユーザーエージェントでは、ボタンのラベルが「作成(⌘N)」になる可能性があります。 別のユーザーエージェントでは、「作成(Alt+⇧+1)」になる可能性があります。 ユーザーエージェントがキーを割り当てない場合は、単に「作成」になります。正確な文字列は、 割り当てられたアクセスキーが何であるか、および ユーザーエージェントがそのキーの組み合わせをどのように表すかによって異なります。
要素の割り当てられたアクセスキーは、要素の
accesskey
内容属性から導出されたキーの組み合わせです。初期状態では、要素は割り当てられたアクセス
キーを持ってはなりません。
要素の accesskey
属性が設定、変更、または削除されるたびに、ユーザーエージェントは次の手順を実行して、要素の割り当てられたアクセスキーを更新しなければ
なりません。
要素が accesskey
属性を持たない場合、以下のフォールバック手順へ進みます。
それ以外の場合、属性値をASCII 空白で 分割し、keys をその結果のトークンとします。
keys 内の各値について、トークンが属性値内に現れた順序で、次の下位手順を実行します。
値が、長さが正確に一つのコードポイントである文字列でない場合、この値について残りの手順を スキップします。
値がシステムのキーボード上のキーに対応しない場合、この値について残りの手順をスキップします。
![]() ユーザーエージェントが、属性で指定された値に対応するキーと組み合わせてアクセスキーとして
使用できる、ゼロ個以上の修飾キーの組み合わせを見つけられる場合、ユーザーエージェントはその
キーの組み合わせを要素の割り当てられたアクセスキーとして
割り当てて返すことができます。
ユーザーエージェントが、属性で指定された値に対応するキーと組み合わせてアクセスキーとして
使用できる、ゼロ個以上の修飾キーの組み合わせを見つけられる場合、ユーザーエージェントはその
キーの組み合わせを要素の割り当てられたアクセスキーとして
割り当てて返すことができます。
フォールバック:任意で、ユーザーエージェントは自身が選択したキーの組み合わせを要素の 割り当てられたアクセスキーとして 割り当ててから返すことができます。
この手順に到達した場合、要素は割り当てられたアクセスキーを 持ちません。
ユーザーエージェントが要素のアクセスキーを選択して割り当てた後は、accesskey
内容属性が変更されるか、要素が別の Document
へ移動されない限り、
ユーザーエージェントは要素の割り当てられたアクセスキーを変更するべきでは
ありません。
ユーザーが要素の割り当てられたアクセスキーに対応する キーの組み合わせを押したとき、要素がコマンドを定義し、そのコマンドのファセットが false (表示)であり、そのコマンドの無効状態ファセットも false (有効)であり、要素が null でない閲覧 コンテキストを持つ文書に含まれており、要素およびその祖先のいずれにも 属性が指定されて いない場合、ユーザーエージェントはコマンドのアクションを実行しなければなりません。
ユーザーエージェントは、accesskey
属性を持つ要素を、たとえば特定のキーの組み合わせに応じて表示されるメニューなど、ほかの方法でも
公開する可能性があります。
accessKeyLabel IDL 属性は、要素に割り当てられたアクセスキーがある場合、
それを表す文字列を返さなければなりません。要素がアクセスキーを
持たない場合、IDL 属性は空文字列を返さなければなりません。
contenteditable 内容
属性現在のすべてのエンジンでサポートされています。
interface mixin ElementContentEditable {
[CEReactions ] attribute DOMString contentEditable ;
[CEReactions ] attribute DOMString enterKeyHint ;
readonly attribute boolean isContentEditable ;
[CEReactions ] attribute DOMString inputMode ;
};Global_attributes/contenteditable
現在のすべてのエンジンでサポートされています。
contenteditable 内容属性は、次のキーワードおよび状態を持つ
列挙属性です。
| キーワード | 状態 | 簡単な説明 |
|---|---|---|
true
|
True | 要素は編集可能です。 |
false
|
False | 要素は編集可能ではありません。 |
plaintext-only
|
プレーンテキストのみ | 要素の生のテキスト内容のみを編集でき、リッチ形式は無効になります。 |
たとえば、ユーザーが HTML を使用して記事を書くことを想定し、新しい記事を公開するための form および textarea を持つ
ページについて考えます。
< form method = POST >
< fieldset >
< legend > 新しい記事</ legend >
< textarea name = article > < p>こんにちは、世界。< /p></ textarea >
</ fieldset >
< p >< button > 公開</ button ></ p >
</ form > スクリプトが有効である場合、代わりに contenteditable 属性を使用して、textarea 要素を
リッチテキストコントロールへ置き換えることができます。
< form method = POST >
< fieldset >
< legend > 新しい記事</ legend >
< textarea id = textarea name = article > < p>こんにちは、世界。< /p></ textarea >
< div id = div style = "white-space: pre-wrap" hidden >< p > こんにちは、世界。</ p ></ div >
< script >
let textarea = document. getElementById( "textarea" );
let div = document. getElementById( "div" );
textarea. hidden = true ;
div. hidden = false ;
div. contentEditable = "true" ;
div. oninput = ( e) => {
textarea. value = div. innerHTML;
};
</ script >
</ fieldset >
< p >< button > 公開</ button ></ p >
</ form > リンクの挿入などの機能は、document.execCommand()
API、または
Selection
API およびそのほかの DOM API を使用して実装できます。[EXECCOMMAND]
[SELECTION]
[DOM]
contenteditable
属性は、次のような効果的な使い方もできます。
<!doctype html>
< html lang = en >
< title > CSS をライブ編集!</ title >
< style style = white-space:pre contenteditable >
html { margin : .2 em ; font-size : 2 em ; color : lime ; background : purple }
head , title , style { display : block }
body { display : none }
</ style > element.contentEditable [ = value ]
contenteditable 属性の状態に基づいて、「true」、
「plaintext-only」、「false」、または「inherit」を返します。
設定すると、その状態を変更できます。
新しい値がこれらの文字列のいずれでもない場合、「SyntaxError」 DOMException
をスローします。
element.isContentEditable
現在のすべてのエンジンでサポートされています。
要素が編集可能である場合は true を返し、それ以外の場合は false を返します。
contentEditable IDL 属性は、取得時に、内容属性が
True
状態に設定されている場合は文字列
「true」を、内容属性がプレーンテキストのみ状態に設定されている
場合は「plaintext-only」を、内容属性がFalse 状態に設定されている場合は
「false」を、それ以外の場合は「inherit」を返さなければなりません。設定時に、
新しい値が文字列「inherit」とASCII
大文字小文字を区別せず一致する場合、内容属性を
削除しなければなりません。新しい値が文字列「true」とASCII
大文字小文字を区別せず一致する場合、
内容属性を文字列「true」に設定しなければなりません。新しい値が文字列
「plaintext-only」とASCII
大文字小文字を区別せず一致する場合、
内容属性を文字列「plaintext-only」に設定しなければなりません。新しい値が文字列
「false」とASCII
大文字小文字を区別せず一致する場合、内容属性を文字列
「false」に設定しなければなりません。それ以外の場合、属性の設定子は
「SyntaxError」 DOMException をスローしなければなりません。
designMode
の取得子および設定子
document.designMode [ = value ]
現在のすべてのエンジンでサポートされています。
文書が編集可能である場合は「on」を返し、編集可能でない場合は
「off」を返します。
設定すると、文書の現在の状態を変更できます。これにより文書がフォーカスされ、その文書内の 選択範囲がリセットされます。
Document
オブジェクトには、ブール値であるデザインモード有効が関連付けられます。
初期値は false です。
designMode
の設定手順は次のとおりです。
value を、指定された値をASCII 小文字へ変換した値とします。
value が「on」であり、かつこのオブジェクトのデザインモード
有効が false である場合、次を行います。
value が「off」である場合、このオブジェクトのデザインモード
有効を false に設定します。
作者は、編集ホストおよびこれらの編集機構によって最初に 作成されたマークアップに対して、'white-space' プロパティを 'pre-wrap' に設定することが推奨されます。HTML の既定の空白処理は WYSIWYG 編集には 適しておらず、'white-space' を既定値のままにすると、特定の特殊な場合に行の折り返しが正しく機能しません。
代わりに既定の 'normal' 値を使用した場合に発生する問題の例として、ユーザーが単語の間に 二つのスペース(ここでは「␣」で表します)を入れて「yellow␣␣ball」と入力する場合を 考えます。'white-space' の既定値('normal')に対する編集規則では、 生成されるマークアップは「yellow ball」または 「yellow ball」のいずれかになります。すなわち、通常のスペースに加えて、 二つの単語の間に改行しないスペースが存在します。これは、'white-space' の 'normal' 値では、隣接する通常のスペースを 一つに折り畳む必要があるためです。
前者の場合、「yellow⍽」は、「yellow」だけなら行末に収まる場合でも、 次の行へ折り返される可能性があります(ここでは「⍽」を改行しないスペースとして使用しています)。 後者の場合、「⍽ball」が行頭へ折り返されると、改行しないスペースによる目に見える インデントが生じます。
しかし、'white-space' を 'pre-wrap' に設定すると、編集規則は代わりに単語の間へ通常のスペースを二つ配置するだけになり、 二つの単語が行末で分割された場合、スペースはレンダリングからきれいに取り除かれます。
編集ホストとは、contenteditable 属性が
true 状態または plaintext-only 状態であるHTML
要素、またはデザインモード
有効が true である Document の子であるHTML
要素です。
アクティブ範囲、
編集ホスト、および
編集可能という用語の定義、
編集ホストまたは編集可能な要素のユーザーインターフェイス要件、
execCommand()、
queryCommandEnabled()、
queryCommandIndeterm()、
queryCommandState()、
queryCommandSupported()、
および
queryCommandValue()
メソッド、テキスト選択、および選択範囲を
削除するアルゴリズムは、execCommand で定義されています。[EXECCOMMAND]
ユーザーエージェントは、フォームコントロール(textarea
要素の値など)または編集ホスト内の要素(たとえば contenteditable を使用する要素)にある編集可能なテキストについて、
スペルおよび文法のチェックをサポートできます。
ユーザーエージェントは各要素について、既定値またはユーザーが表明した設定によって、 既定動作を確立しなければなりません。各要素には、次の三つの 既定動作のいずれかがあります。
spellcheck 属性に
よってスペルチェックが明示的に無効化されていない場合、要素のスペルおよび文法がチェックされます。
spellcheck 属性によってスペルチェックが明示的に有効化されない限り、
要素のスペルおよび文法はチェックされません。
現在のすべてのエンジンでサポートされています。
spellcheck
属性は、次のキーワードおよび状態を持つ列挙
属性です。
| キーワード | 状態 | 簡単な説明 |
|---|---|---|
true
|
True | スペルおよび文法がチェックされます。 |
false
|
False | スペルおよび文法はチェックされません。 |
属性の欠損値の既定値および無効な値の
既定値は、どちらも既定状態です。既定状態は、
以下で定義するように、親要素自身の spellcheck 状態に基づく可能性がある既定動作に従って要素が
動作することを示します。属性の空値の既定値は、True 状態です。
element.spellcheck [ = value ]
要素のスペルおよび文法をチェックする場合は true を返し、それ以外の場合は false を返します。
設定すると、既定値を上書きし、spellcheck 内容属性を設定できます。
spellcheck IDL
属性は、取得時に、要素の spellcheck 内容属性がTrue 状態である場合、または要素の
spellcheck 内容属性が既定状態であり、かつ要素の既定動作が既定で
trueである場合、または要素の
spellcheck 内容属性が既定状態であり、要素の既定動作が既定で継承であり、かつ要素の
親要素の spellcheck IDL 属性が true を返す場合は、true を返さなければ
なりません。
それ以外で、これらの条件のいずれも該当しない場合、属性は代わりに false を返さなければなりません。
spellcheck IDL 属性は、spellcheck 内容属性を上書きするユーザー設定の影響を受けないため、
実際のスペルチェック状態を反映しない可能性があります。
設定時に、新しい値が true である場合、要素の spellcheck 内容属性を
「true」に設定しなければならず、それ以外の場合は「false」に設定しなければ
なりません。
ユーザーエージェントは、この機能でチェック可能なテキストとして、次の部分だけを考慮するべきです。
type 属性がテキスト、
検索、
URL、またはメール状態であり、かつ可変である(すなわち readonly 属性が指定されておらず、かつ無効化されていない)input 要素の値。
readonly 属性を持たず、かつ無効化されていない textarea 要素の値。Text ノード内のテキスト。Text ノードの一部であるテキストについて、
そのテキストが関連付けられる要素は、単語、文、またはそのほかのテキスト部分の最初の文字の直接の親である
要素です。属性内のテキストについては、その属性の要素です。input および
textarea 要素の値については、その要素自体です。
該当する要素(上記で定義)内の単語、文、またはそのほかのテキスト部分について、スペルおよび文法の チェックを有効にするかどうかを判定するため、UA は次のアルゴリズムを使用しなければなりません。
spellcheck 内容属性を持つ場合、その属性が
True
状態であればチェックは有効であり、
それ以外で、その属性がFalse
状態であればチェックは無効です。
spellcheck 内容属性を持つ祖先要素がある場合、最も近いそのような
祖先の spellcheck 内容属性がTrue 状態であればチェックは有効であり、
それ以外の場合はチェックが無効です。単語、文、またはテキストのチェックが有効である場合、ユーザーエージェントはそのテキスト内のスペルおよび
文法の誤りを示すべきです。ユーザーエージェントは、スペルおよび文法の修正を提案するときに、
文書内で与えられているそのほかのセマンティクスを考慮するべきです。ユーザーエージェントは、使用する
スペルおよび文法規則を決定するために要素の言語を使用することも、ユーザーが選択した言語設定を使用することも
できます。可能な場合、結果の値が妥当であることを保証するため、UA は pattern などの
input 要素の属性を使用するべきです。
チェックが無効である場合、ユーザーエージェントはそのテキストのスペルまたは文法の誤りを示すべきでは ありません。
次の例で ID が「a」である要素は、単語「Hello」のスペルミスをチェックするかどうかを判定するために 使用される要素です。この例では、チェックされません。
< div contenteditable = "true" >
< span spellcheck = "false" id = "a" > Hell</ span >< em > o!</ em >
</ div > 次の例で ID が「b」である要素では、チェックが有効になります(input 要素の属性値の先頭にあるスペース文字によって属性が
無視されるため、既定値にかかわらず、代わりに祖先の値が使用されます)。
< p spellcheck = "true" >
< label > 名前:< input spellcheck = " false" id = "b" ></ label >
</ p > この仕様では、スペルおよび文法チェッカーのユーザーインターフェイスを定義しません。 ユーザーエージェントは、要求時のチェックを提供したり、チェックが有効である間は継続的にチェックを 実行したり、そのほかのインターフェイスを使用したりできます。
사용자 에이전트는 사용자가 폼 컨트롤(예: textarea 요소)이나
편집 호스트의 요소에 있는 편집 가능한
영역에 입력할 때 쓰기 제안을 제공한다.
writingsuggestions 콘텐츠 속성은 다음 키워드와 상태를 가진
열거형 속성이다.
| 키워드 | 상태 | 간략한 설명 |
|---|---|---|
true
|
참 | 이 요소에 쓰기 제안을 제공하는 것이 좋다. |
false
|
거짓 | 이 요소에 쓰기 제안을 제공하지 않는 것이 좋다. |
이 속성의 누락 값
기본값은 기본 상태이다. 기본 상태는
아래에 정의된 대로 부모 요소 자체의 writingsuggestions
상태를 기반으로 할 수도 있는 기본 동작에 따라 요소가 동작해야 함을 나타낸다.
이 속성의 유효하지 않은 값 기본값과 빈 값 기본값은 모두 참 상태이다.
element.writingSuggestions [ = value ]
사용자 에이전트가 요소의 범위 내에서 쓰기 제안을 제공해야 하면 "true"를 반환하고,
그렇지 않으면 "false"를 반환한다.
기본값을 재정의하고
writingsuggestions 콘텐츠 속성을 설정하도록 지정할 수 있다.
주어진 element의 계산된 쓰기 제안 값은 다음 단계를 실행하여 결정한다.
element의 writingsuggestions
콘텐츠 속성이 거짓 상태이면
"false"를 반환한다.
element의 writingsuggestions
콘텐츠 속성이 기본 상태이고,
element에 부모 요소가 있으며, element의 부모 요소의 계산된 쓰기 제안 값이
"false"이면 "false"를 반환한다.
"true"를 반환한다.
writingSuggestions 게터 단계는 다음과 같다.
this의 계산된 쓰기 제안 값을 반환한다.
writingSuggestions
IDL 속성은 writingsuggestions
콘텐츠 속성을 재정의하는 사용자 환경 설정의 영향을 받지 않으므로 실제 쓰기 제안 상태를 반영하지 않을
수 있다.
사용자 에이전트는 element가 주어졌을 때 다음 알고리즘을 실행한 결과가 true인 경우에만 요소의 범위 내에서 제안을 제공하는 것이 좋다.
사용자가 쓰기 제안을 비활성화했으면 false를 반환한다.
다음 조건 중 어느 것도 true가 아니면 다음을 수행한다.
false를 반환한다.
element에 writingsuggestions
콘텐츠 속성이 기본 상태가 아닌 포괄적
조상이 있고, 그러한 조상 중 가장 가까운 조상의
writingsuggestions
콘텐츠 속성이 거짓 상태이면 false를 반환한다.
그렇지 않으면 true를 반환한다.
이 명세는 쓰기 제안의 사용자 인터페이스를 정의하지 않는다. 사용자 에이전트는 요청 시 제안, 사용자가 입력하는 동안의 지속적인 제안, 인라인 제안, 팝업의 자동 완성과 유사한 제안을 제공하거나 다른 인터페이스를 사용할 수 있다.
모바일 장치의 가상 키보드와 같은 일부 텍스트 입력 방식과 음성 입력은 문장의 첫 글자를 자동으로
대문자로 변환하여 사용자를 돕는 경우가 많다(이 관례를 사용하는 언어로 텍스트를 작성하는 경우).
자동 대문자화를 구현하는 가상 키보드는 자동으로 대문자화해야 하는 문자를 입력하려 할 때 자동으로
대문자를 표시하도록 전환할 수 있다. 단, 사용자는 이를 다시 소문자로 전환할 수 있다. 음성 입력과
같은 다른 유형의 입력은 사용자에게 먼저 개입할 선택권을 주지 않는 방식으로 자동 대문자화를 수행할
수 있다. autocapitalize 속성을
사용하면 작성자가 이러한 동작을 제어할 수 있다.
일반적으로 구현되는 autocapitalize
속성은 물리적 키보드로 입력할 때의 동작에는 영향을 주지 않는다. 이러한 이유와 사용자가 경우에 따라
자동 대문자화 동작을 재정의하거나 처음 입력한 후 텍스트를 편집할 수 있다는 점 때문에, 어떤 종류의
입력 유효성 검사에도 이 속성에 의존해서는 안 된다.
autocapitalize
속성은 호스팅된 편집 가능 영역의 자동 대문자화 동작을 제어하기 위해 편집 호스트에서 사용할
수 있고, 해당 요소에 텍스트를
입력할 때의 동작을 제어하기 위해 input 또는
textarea 요소에서
사용할 수 있으며, form 요소와 연결된 모든
autocapitalize 및 autocorrect 상속
요소의 기본
동작을 제어하기 위해 form 요소에서 사용할
수 있다.
autocapitalize
속성은 type 속성이 URL, 이메일 또는 비밀번호 상태 중 하나인
input 요소에서 자동
대문자화가 활성화되도록 하지 않는다. 이 동작은 아래의 사용되는 자동 대문자화 힌트 알고리즘에
포함되어 있다.
자동 대문자화 처리 모델은 다음과 같이 정의된 다섯 가지 자동 대문자화 힌트 중 하나를 선택하는 것을 기반으로 한다.
사용자 에이전트와 입력 방식은 자동 대문자화를 활성화할지 자체적으로 결정하는 것이 좋다.
자동 대문자화를 적용하지 않는 것이 좋다. 모든 문자는 기본적으로 소문자여야 한다.
각 문장의 첫 글자는 기본적으로 대문자여야 하고, 다른 모든 문자는 기본적으로 소문자여야 한다.
각 단어의 첫 글자는 기본적으로 대문자여야 하고, 다른 모든 문자는 기본적으로 소문자여야 한다.
모든 문자는 기본적으로 대문자여야 한다.
Global_attributes/autocapitalize
현재 모든 엔진에서 지원됨.
autocapitalize 속성은 가능한 자동 대문자화 힌트를 상태로 가지는 열거형 속성이다. 속성의
상태로 지정된 자동 대문자화 힌트는 다른 고려
사항과 결합하여
사용자 에이전트의 동작을 알려 주는 사용되는 자동 대문자화 힌트를 형성한다.
이 속성의 키워드와 상태 매핑은 다음과 같다.
| 키워드 | 상태 |
|---|---|
off
|
없음 |
none
|
|
on
|
문장 |
sentences
|
|
words
|
단어 |
characters
|
문자 |
이 속성의 누락 값 기본값은 기본 상태이고, 유효하지 않은 값 기본값은 문장 상태이다.
element.autocapitalize [ = value ]
요소의 현재 자동 대문자화 상태를 반환하고, 설정되지 않았으면 빈 문자열을 반환한다. 상태를
form 요소에서
상속하는 input 및 textarea
요소의 경우에는 form 요소의 자동
대문자화 상태를 반환하지만, 편집 가능한 영역의 요소에 대해서는 이 요소가 실제로 편집
호스트가 아닌 한 편집
호스트의 자동 대문자화 상태를 반환하지 않는다는 점에 유의하라.
autocapitalize
콘텐츠
속성을 설정하고 이에 따라 요소의 자동 대문자화 동작을 변경하도록 지정할 수 있다.
요소 element의 자체 자동 대문자화 힌트를 계산하려면 다음 단계를 실행한다.
element에 autocapitalize
콘텐츠 속성이 있고 그 값이 빈 문자열이 아니면 속성의 상태를 반환한다.
element가 autocapitalize 및 autocorrect 상속 요소이고 null이 아닌 폼 소유자가 있으면 element의 폼 소유자의 자체 자동 대문자화 힌트를 반환한다.
기본을 반환한다.
autocapitalize 게터 단계는 다음과 같다.
텍스트 입력 방식의 사용자 정의 가능한 자동 대문자화 동작을 지원하고 웹 개발자가 이 기능을 제어하도록 허용하려는 사용자 에이전트는 요소에 텍스트를 입력하는 동안 해당 요소의 사용되는 자동 대문자화 힌트를 계산하는 것이 좋다. 이는 요소에 텍스트를 입력할 때 권장되는 자동 대문자화 동작을 설명하는 자동 대문자화 힌트이다.
사용자 에이전트나 입력 방식은 특정 상황에서 사용되는 자동 대문자화 힌트를 무시하거나 재정의할 수 있다.
요소 element의 사용되는 자동 대문자화 힌트는 다음 알고리즘을 사용하여 계산한다.
일부 텍스트 입력 방식은 입력하는 동안 맞춤법이 틀린 단어를 자동으로 수정하여 사용자를 돕는데,
이 과정을 자동 교정이라고도 한다. 사용자 에이전트는 폼 컨트롤(예: textarea 요소의 값)
또는 편집 호스트의 요소(예: contenteditable 사용)에
있는 편집 가능한 텍스트의 자동 교정을 지원할 수 있다. 자동 교정에는 텍스트가 곧 자동 교정되거나
이미 자동 교정되었음을 나타내는 사용자 인터페이스가 함께 제공될 수 있으며, 일반적으로 맞춤법이 틀린
단어 뒤에 문장 부호, 공백 또는 새 단락을 삽입할 때 수행된다. autocorrect 속성을 사용하면
작성자가 이러한 동작을 제어할 수 있다.
autocorrect 속성은
호스팅된 편집 가능 영역의 자동 교정 동작을 제어하기 위해 편집 호스트에서 사용할 수 있고, 해당
요소에 텍스트를 삽입할 때의 동작을 제어하기 위해 input 또는 textarea 요소에서
사용할 수 있으며, form 요소와 연결된 모든 autocapitalize 및 autocorrect 상속
요소의 기본 동작을
제어하기 위해 form 요소에서 사용할 수
있다.
autocorrect 속성은
type 속성이 URL, 이메일 또는 비밀번호 상태 중 하나인 input 요소에서 자동 교정이
활성화되도록 하지 않는다. 이 동작은 아래의 사용되는 자동
교정 상태 알고리즘에 포함되어 있다.
autocorrect
속성은 다음 키워드와 상태를 가진 열거형
속성이다.
| 키워드 | 상태 | 간략한 설명 |
|---|---|---|
on
|
켜짐 | 사용자 에이전트는 사용자가 입력하는 동안 맞춤법 오류를 자동으로 수정할 수 있다. 입력 중 맞춤법을 자동으로 수정할지는 사용자 에이전트가 결정하며, 요소와 사용자의 환경 설정에 따라 달라질 수 있다. |
off
|
꺼짐 | 사용자 에이전트는 사용자가 입력하는 동안 맞춤법을 자동으로 수정해서는 안 된다. |
이 속성의 유효하지 않은 값 기본값, 누락 값 기본값 및 빈 값 기본값은 모두 켜짐 상태이다.
autocorrect 게터
단계는 요소의 사용되는 자동 교정 상태가 켜짐이면 true를 반환하고, 요소의 사용되는 자동 교정 상태가 꺼짐이면 false를 반환하는 것이다. 세터
단계는
주어진 값이 true이면 요소의 autocorrect
속성을
"on"으로 설정하고, 그렇지 않으면 "off"로 설정하는 것이다.
요소 element의 사용되는 자동 교정 상태를 계산하려면 다음 단계를 실행한다.
element가 input 요소이고 그
type 속성이 URL, 이메일 또는 비밀번호 상태 중
하나이면 꺼짐을 반환한다.
element에 autocorrect 콘텐츠 속성이
있으면 속성의 상태를 반환한다.
element가 autocapitalize 및 autocorrect 상속 요소이고
null이 아닌 폼 소유자가 있으면
element의 폼 소유자의 autocorrect 속성
상태를 반환한다.
켜짐을 반환한다.
autocorrect요소의 자동 교정 동작을 반환한다. 상태를 form 요소에서 상속하는
autocapitalize 및 autocorrect 상속
요소의 경우
form 요소의 자동 교정
동작을 반환하지만, 편집 가능한 영역의 요소에 대해서는 이 요소가 실제로 편집 호스트가
아닌 한 편집 호스트의 자동 교정 동작을 반환하지 않는다는 점에
유의하라.
autocorrect
=
value
autocorrect 콘텐츠
속성을 업데이트하여 요소의 자동 교정 동작을 변경한다.
다음 예시의 input 요소는 autocorrect 콘텐츠 속성이
없으므로 "off"
속성을 가진 form 요소에서 상속하므로
자동 교정을 허용하지 않는다. 그러나 textarea 요소에는
값이 "on"인
autocorrect 콘텐츠
속성이 있으므로 자동 교정을 허용한다.
< form autocorrect = "off" >
< input type = "search" >
< textarea autocorrect = "on" ></ textarea >
</ form > inputmode
속성사용자 에이전트는 폼 컨트롤(예: textarea
요소의 값) 또는 편집 호스트의 요소(예:
contenteditable
사용)에서 inputmode
속성을 지원할 수 있다.
현재 모든 엔진에서 지원됨.
inputmode 콘텐츠
속성은 사용자가 콘텐츠를 입력할 때 어떤
종류의 입력 메커니즘이 가장 유용한지를 지정하는 열거형 속성이다.
| 키워드 | 설명 |
|---|---|
none
|
사용자 에이전트는 가상 키보드를 표시하지 않는 것이 좋다. 이 키워드는 자체 키보드 컨트롤을 렌더링하는 콘텐츠에 유용하다. |
text
|
사용자 에이전트는 사용자의 로케일에서 텍스트를 입력할 수 있는 가상 키보드를 표시하는 것이 좋다. |
tel
|
사용자 에이전트는 전화번호를 입력할 수 있는 가상 키보드를 표시하는 것이 좋다. 여기에는 숫자 0부터 9까지의 키, "#" 문자 및 "*" 문자의 키가 포함되는 것이 좋다. 일부 로케일에서는 알파벳 연상 레이블도 포함될 수 있다. 예를 들어 미국에서는 "2" 레이블이 붙은 키에 역사적으로 A, B 및 C 문자도 함께 표시된다. |
url
|
사용자 에이전트는 사용자의 로케일에서 텍스트를 입력할 수 있고, "/" 및 "." 문자와 "www." 또는 ".com"처럼 도메인 이름에서 흔히 발견되는 문자열을 빠르게 입력하기 위한 키 등 URL 입력을 돕는 키가 있는 가상 키보드를 표시하는 것이 좋다. |
email
|
사용자 에이전트는 사용자의 로케일에서 텍스트를 입력할 수 있고, "@" 문자 및 "." 문자와 같이 이메일 주소 입력을 돕는 키가 있는 가상 키보드를 표시하는 것이 좋다. |
numeric
|
사용자 에이전트는 숫자를 입력할 수 있는 가상 키보드를 표시하는 것이 좋다. 이 키워드는 PIN 입력에 유용하다. |
decimal
|
사용자 에이전트는 소수 숫자를 입력할 수 있는 가상 키보드를 표시하는 것이 좋다. 숫자 키와 로케일의 형식 구분 기호를 표시하는 것이 좋다. |
search
|
사용자 에이전트는 검색에 최적화된 가상 키보드를 표시하는 것이 좋다. |
현재 모든 엔진에서 지원됨.
inputMode IDL 속성은 알려진 값으로만
제한하여 inputmode
콘텐츠 속성을 반영해야 한다.
inputmode가
지정되지 않았거나 사용자 에이전트가 지원하지 않는 상태이면 사용자 에이전트는 표시할 기본 가상
키보드를 결정하는 것이 좋다. 입력의 type
또는 pattern
속성과 같은 문맥 정보를 사용하여 사용자에게 어떤 유형의 가상 키보드를 제공할지 결정하는 것이 좋다.
enterkeyhint
속성사용자 에이전트는 폼 컨트롤(예: textarea
요소의 값) 또는 편집 호스트의 요소(예:
contenteditable
사용)에서 enterkeyhint
속성을 지원할 수 있다.
Global_attributes/enterkeyhint
현재 모든 엔진에서 지원됨.
enterkeyhint
콘텐츠 속성은 가상 키보드의 Enter 키에 어떤
동작 레이블 또는 아이콘을 표시할지 지정하는 열거형 속성이다. 이를 통해
작성자는 사용자에게 더 유용하도록 Enter 키의 표시를 사용자 정의할 수 있다.
| 키워드 | 설명 |
|---|---|
enter
|
사용자 에이전트는 일반적으로 새 줄을 삽입하는 'enter' 작업에 대한 표시를 제공하는 것이 좋다. |
done
|
사용자 에이전트는 일반적으로 더 이상 입력할 내용이 없고 입력기(IME)가 닫힌다는 의미인 'done' 작업에 대한 표시를 제공하는 것이 좋다. |
go
|
사용자 에이전트는 일반적으로 사용자를 입력한 텍스트의 대상으로 이동시키는 의미인 'go' 작업에 대한 표시를 제공하는 것이 좋다. |
next
|
사용자 에이전트는 일반적으로 사용자를 텍스트를 입력받을 다음 필드로 이동시키는 'next' 작업에 대한 표시를 제공하는 것이 좋다. |
previous
|
사용자 에이전트는 일반적으로 사용자를 텍스트를 입력받을 이전 필드로 이동시키는 'previous' 작업에 대한 표시를 제공하는 것이 좋다. |
search
|
사용자 에이전트는 일반적으로 사용자를 입력한 텍스트의 검색 결과로 이동시키는 'search' 작업에 대한 표시를 제공하는 것이 좋다. |
send
|
사용자 에이전트는 일반적으로 텍스트를 대상으로 전달하는 'send' 작업에 대한 표시를 제공하는 것이 좋다. |
현재 모든 엔진에서 지원됨.
enterKeyHint IDL 속성은 알려진 값으로만
제한하여 enterkeyhint
콘텐츠 속성을 반영해야 한다.
enterkeyhint
가 지정되지 않았거나 사용자 에이전트가 지원하지 않는 상태이면 사용자 에이전트는 표시할 기본 동작
레이블 또는 아이콘을 결정하는 것이 좋다. inputmode,
type
또는 pattern
속성과 같은 문맥 정보를 사용하여 가상 키보드에 어떤 동작 레이블 또는 아이콘을 표시할지 결정하는 것이
좋다.
이 절에서는 사용자가 특정 정보를 찾기 위해 페이지 콘텐츠를 검색할 수 있게 하는 일반적인 사용자 에이전트 메커니즘인 페이지 내 찾기를 정의한다.
페이지 내 찾기 기능은 페이지 내 찾기 인터페이스를 통해 제공된다. 이는 사용자가 입력과 검색 매개변수를 지정할 수 있도록 사용자 에이전트가 제공하는 사용자 인터페이스이다. 이 인터페이스는 단축키나 메뉴 선택의 결과로 나타날 수 있다.
페이지 내 찾기 인터페이스의 텍스트 입력과 설정의 조합은 사용자의 쿼리를 나타낸다. 일반적으로 사용자가 검색하려는 텍스트와 선택적 설정(예: 전체 단어로만 검색을 제한하는 기능)이 포함된다.
사용자 에이전트는 주어진 쿼리에 대해 페이지 콘텐츠를 처리하고, 사용자 쿼리를 충족하는 콘텐츠 범위인 0개 이상의 일치 항목을 식별한다.
일치 항목 중 하나가 사용자에게 활성 일치 항목으로 표시된다. 이 항목은 강조 표시되고 보이도록 스크롤된다. 사용자는 페이지 내 찾기 인터페이스를 사용하여 활성 일치 항목을 진행시킴으로써 일치 항목 사이를 이동할 수 있다.
이슈 #3539에서는 페이지 내 찾기가 현재 지정되지 않은
window.find() API의 기반이 되는 방식을 표준화하는 작업을 추적한다.
페이지 내 찾기가 일치 항목 검색을 시작하면 페이지에서 속성이 설정되지 않은 모든 요소는 페이지 내 찾기가 두 번째 슬롯을 검색할 수 있도록 속성을 수정하지 않고 두 번째 슬롯의 에 접근할 수 있게 하는 것이 좋다. 마찬가지로 속성이 상태인 모든 HTML 요소는 페이지 내 찾기가 해당 요소를 검색할 수 있도록 속성을 수정하지 않고 에 접근할 수 있게 하는 것이 좋다. 페이지 내 찾기가 일치 항목 검색을 마치면 요소와 속성이 상태인 요소의 콘텐츠는 다시 건너뛰게 하는 것이 좋다. 이 전체 과정은 동기적으로 이루어져야 하므로 사용자나 작성자 코드가 관찰할 수 없다. [CSSCONTAIN]
페이지 내 찾기가 새 을 선택하면 다음 단계를 수행한다.
node를 의 첫 번째 노드로 설정한다.
node의 가 주어졌을 때 에 하여 node에 대해 을 실행한다.
페이지 내 찾기가 이와 같이 요소를 자동으로 확장하면 이벤트가 발생한다. 페이지 내 찾기가 별도로 발생시키는 이벤트와 마찬가지로, 페이지는 이 이벤트를 사용하여 사용자가 페이지 내 찾기 대화상자에 무엇을 입력하는지 알아낼 수 있다. 페이지가 현재 검색어와 사용자가 다음에 입력할 수 있는 모든 문자를 간격으로 구분하여 포함하는 작은 스크롤 가능 영역을 생성하고 브라우저가 어느 항목으로 스크롤하는지 관찰하면, 해당 문자를 검색어에 추가하고 스크롤 가능 영역을 업데이트하여 검색어를 점진적으로 구성할 수 있다. 가능한 각 다음 일치 항목을 닫힌 요소로 감싸면 페이지는 이벤트 대신 이벤트를 수신할 수 있다. 사용자가 페이지 내 찾기 대화상자에 입력하는 모든 문자에 대해 동작하지 않도록 하면 두 이벤트 모두에서 이 공격을 해결할 수 있다.
페이지 내 찾기 과정은 문서의 문맥에서 호출되며 해당 문서의 선택 영역에 영향을 줄 수 있다. 구체적으로 활성 일치 항목을 정의하는 범위가 현재 선택 영역을 결정할 수 있다. 그러나 이러한 선택 영역 업데이트는 페이지 내 찾기 과정 중 서로 다른 시점에 발생할 수 있다. 예를 들어 페이지 내 찾기 인터페이스가 닫힐 때나 활성 일치 항목 범위가 변경될 때 발생할 수 있다.
구현 정의 방식이며 장치별일 가능성이 높은 방식으로 사용자는 사용자 에이전트에 닫기 요청을 보낼 수 있다. 이는 사용자가 팝오버, 메뉴, 대화상자, 선택기 또는 표시 모드처럼 현재 화면에 표시되는 항목을 닫으려 한다는 것을 나타낸다.
닫기 요청의 몇 가지 예시는 다음과 같다.
데스크톱 플랫폼의 Esc 키.
Android와 같은 특정 모바일 플랫폼의 뒤로 버튼 또는 제스처.
iOS VoiceOver의 두 손가락으로 "z"를 그리는 문지르기 제스처와 같은 보조 기술의 닫기 제스처.
DualShock 게임패드의 원형 버튼과 같은 게임 컨트롤러의 표준 "뒤로" 버튼.
사용자 에이전트가 Document document를 대상으로
하는 잠재적인 닫기 요청을 받을 때마다 document의 관련 전역 객체가 주어졌을 때 사용자 상호작용 태스크 소스에 전역 태스크를 대기열에
추가하여 다음 닫기 요청 단계를 수행해야 한다.
document의 전체 화면 요소가 null이 아니면 다음을 수행한다.
document의 노드 내비게이션 가능 객체의 최상위 순회 가능 객체의 활성 문서가 주어졌을 때 전체 화면을 완전히 종료한다.
반환한다.
이는 keydown
과 같은 관련 이벤트를 발생시키지 않는다. 단지 최종적으로 fullscreenchange
가 발생하도록 할 뿐이다.
선택적으로 대체 처리라고 표시된 단계로 건너뛴다.
예를 들어 사용자 에이전트가 현재 웹 페이지가 닫기 요청을 반복해서 가로채 사용자가 불편해하는 것을 감지하면 이 경로를 선택할 수 있다.
UI Events 또는 기타 관련 명세에 따라 관련 이벤트를 발생시킨다. [UIEVENTS]
UI Events 모델에서 관련 이벤트의 예로는 사용자가 키보드의
Esc 키를 누를 때 UI Events에서 발생시키도록 제안하는
keydown
이벤트가 있다. 키보드가 있는 대부분의 플랫폼에서 이는 닫기 요청으로 처리되므로
이러한 닫기 요청 단계를
트리거한다.
UI Events에서 제공하는 모델 외부의 관련 이벤트 예로는 사용자가
닫기 제스처를 사용하여 닫기 요청을 보낼 때 보조 기술이
Esc keydown
이벤트를 합성하는 경우가 있다.
그러한 이벤트가 발생하지 않으면 event를 null로 설정하고, 그렇지 않으면 발생한
이벤트 중 하나를 나타내는 Event
객체로 설정한다. 여러 이벤트가 발생하면 어떤 이벤트를 선택할지는 구현
정의이다.
event가 null이 아니고 해당 취소됨 플래그가 설정되어 있으면 반환한다.
document가 완전히 활성이 아니면 반환한다.
event가 null이 아니면 이벤트 리스너로 인해 document가 더 이상 완전히 활성이 아닐 수 있으므로 이 단계가 필요하다.
closedSomething을 document의 관련 전역 객체에서 닫기 감시자를 처리한 결과로 설정한다.
closedSomething이 true이면 반환한다.
대체 처리: 그렇지 않으면 닫기 요청을 감시하는 항목이 없었다. 사용자 에이전트는 이 상호작용을 닫기 요청으로 해석하는 대신 다른 동작으로 해석할 수 있다.
Esc 키를 누르는 것이 닫기 요청으로 해석되는 플랫폼에서 사용자
에이전트는 키를
놓는 것이 아니라 키가 눌리는 것을 닫기 요청으로 해석해야 한다. 따라서 위 알고리즘에서
발생시키는 "관련 이벤트"는 단일 keydown
이벤트여야 한다.
Esc가 닫기 요청인 플랫폼에서 사용자
에이전트는 먼저 적절히 초기화된
keydown
이벤트를 발생시킨다. 웹 개발자가 preventDefault()
를 호출하여 이벤트를 취소하면 더 이상 아무 일도 일어나지 않는다. 그러나 이벤트가 취소되지 않고
발생하면 사용자 에이전트는 닫기 감시자 처리를 계속한다.
뒤로 버튼이 잠재적인 닫기 요청인 플랫폼에서는 이벤트가 관여하지 않으므로 뒤로 버튼을 누르면 사용자 에이전트가 직접 닫기 감시자 처리를 진행한다. 활성 닫기 감시자가 있으면 해당 감시자가 트리거된다. 없으면 사용자 에이전트는 뒤로 버튼 누르기를 다른 방식으로 해석할 수 있다. 예를 들어 −1의 델타로 기록을 순회하라는 요청으로 해석할 수 있다.
각 Window에는 다음 항목을 가진 구조체인 닫기
감시자 관리자가 있다.
닫기 감시자 관리자의 복잡성 대부분은 대체 동작이 기록 순회의 주요 메커니즘인 플랫폼에서 개발자가 사용자의 기록 순회 기능을 비활성화하지 못하도록 설계된 악용 방지 보호에서 비롯된다. 구체적으로 다음과 같다.
닫기 감시자 그룹화는 여러 닫기 감시자가 기록 동작 활성화 없이 생성되면 함께 그룹화되도록 설계되었다. 따라서 사용자가 트리거한 닫기 요청은 그룹의 모든 닫기 감시자를 닫는다. 이를 통해 웹 개발자는 닫기 감시자를 생성하여 무제한의 닫기 요청을 가로챌 수 없으며, 대신 최대 1 + 사용자가 페이지를 활성화한 횟수와 같은 수만큼 생성할 수 있다.
다음 사용자 상호작용에서 새 그룹 허용 불리언은 웹 개발자가 개별 사용자 활성화에 연결된 방식으로 닫기 감시자를 생성하도록 권장한다. 이것이 없으면 웹 개발자가 닫기 감시자를 생성하는 데 해당 사용자 활성화를 "사용"하지 않더라도 각 사용자 활성화가 허용된 그룹 수를 증가시킨다. 요약하면 다음과 같다.
허용됨: 사용자 상호작용, 자체 그룹에 닫기 감시자 생성, 사용자 상호작용, 두 번째 독립 그룹에 닫기 감시자 생성.
허용되지 않음: 사용자 상호작용, 사용자 상호작용, 자체 그룹에 닫기 감시자 생성, 두 번째 독립 그룹에 닫기 감시자 생성.
허용됨: 사용자 상호작용, 사용자 상호작용, 자체 그룹에 닫기 감시자 생성, 이전 감시자와 함께 그룹화된 닫기 감시자 생성.
이 보호는 최대 (1 + 사용자가 페이지를 활성화한 횟수)개의 그룹을 생성한다는 원하는 불변 조건을 유지하는 데 중요하지 않다. 악용하려는 사용자는 각 사용자 상호작용마다 닫기 감시자를 하나씩 생성하여 나중의 악용을 위해 "저장"할 수 있다. 그러나 이 시스템은 일반적인 경우에 더 예측 가능한 동작을 제공하며, 악의적이지 않은 개발자가 사용자 상호작용에 직접 응답하여 닫기 감시자를 생성하도록 권장한다.
Window
window가 주어졌을 때 사용자 활성화를 닫기 감시자 관리자에게
알리려면 다음을 수행한다.
manager를 window의 닫기 감시자 관리자로 설정한다.
manager의 다음 사용자 상호작용에서 새 그룹 허용이 true이면 manager의 허용된 그룹 수를 증가시킨다.
manager의 다음 사용자 상호작용에서 새 그룹 허용을 false로 설정한다.
window: Window.
취소 동작: 불리언 인수를 받고 불리언을 반환하는 알고리즘. 인수는 취소 동작 알고리즘이 알고리즘의 반환 값을 통해 닫기 요청의 진행을 막을 수 있는지를 나타낸다. 불리언 인수가 true이면 알고리즘은 호출자가 닫기 동작으로 계속 진행함을 나타내기 위해 true를 반환하거나, 호출자가 중단함을 나타내기 위해 false를 반환할 수 있다. 인수가 false이면 반환 값은 항상 false이다. 이 알고리즘은 예외를 던질 수 없다.
닫기 동작: 인수를 받지 않고 아무것도 반환하지 않는 알고리즘. 이 알고리즘은 예외를 던질 수 없다.
취소 동작 실행 중 불리언.
활성화 상태 가져오기: 인수를 받지 않고 불리언을 반환하는 알고리즘. 이 알고리즘은 예외를 던질 수 없다.
닫기 감시자 closeWatcher의 window의 닫기 감시자 관리자가 closeWatcher를 포함하는 목록을 하나라도 포함하면 closeWatcher는 활성 상태이다.
Window
window, 단계 목록 cancelAction, 단계 목록 closeAction 및 불리언을 반환하는 알고리즘
getEnabledState가 주어졌을 때 닫기 감시자를 설정하려면 다음을 수행한다.
단언: window의 연결된 Document는 완전히 활성이다.
closeWatcher를 다음 값을 가진 새로운 닫기 감시자로 설정한다.
manager를 window의 닫기 감시자 관리자로 설정한다.
manager의 그룹의 크기가 manager의 허용된 그룹 수보다 작으면 « closeWatcher »를 manager의 그룹에 추가한다.
그렇지 않으면 다음을 수행한다.
manager의 다음 사용자 상호작용에서 새 그룹 허용을 true로 설정한다.
closeWatcher를 반환한다.
불리언 requireHistoryActionActivation을 사용하여 닫기 감시자 closeWatcher에 닫기를 요청하려면 다음을 수행한다.
closeWatcher가 활성 상태가 아니면 true를 반환한다.
closeWatcher의 활성화 상태 가져오기를 실행한 결과가 false이면 true를 반환한다.
closeWatcher의 취소 동작 실행 중이 true이면 true를 반환한다.
window를 closeWatcher의 window로 설정한다.
window의 연결된 Document가 완전히 활성이 아니면
true를 반환한다.
requireHistoryActionActivation이 false이거나, window의 닫기 감시자 관리자의 그룹의 크기가 window의 닫기 감시자 관리자의 허용된 그룹 수보다 작고 window에 기록 동작 활성화가 있으면 canPreventClose를 true로 설정하고, 그렇지 않으면 false로 설정한다.
closeWatcher의 취소 동작 실행 중을 true로 설정한다.
shouldContinue를 canPreventClose가 주어졌을 때 closeWatcher의 취소 동작을 실행한 결과로 설정한다.
closeWatcher의 취소 동작 실행 중을 false로 설정한다.
shouldContinue가 false이면 다음을 수행한다.
단언: canPreventClose는 true이다.
window가 주어졌을 때 기록 동작 사용자 활성화를 소비한다.
false를 반환한다.
이 하위 단계는 기록 동작 사용자 활성화를 소비하므로 중간에 사용자 활성화가 없이 닫기 감시자에 두 번 닫기를 요청하면 두 번째에는 canPreventClose가 false가 된다.
closeWatcher를 닫는다.
true를 반환한다.
닫기 감시자 closeWatcher를 닫으려면 다음을 수행한다.
closeWatcher가 활성 상태가 아니면 반환한다.
closeWatcher의 활성화 상태 가져오기를 실행한 결과가 false이면 반환한다.
closeWatcher의 window의 연결된 Document가 완전히 활성이 아니면
반환한다.
closeWatcher를 파기한다.
closeWatcher의 닫기 동작을 실행한다.
닫기 감시자 closeWatcher를 파기하려면 다음을 수행한다.
Window
window가 주어졌을 때 닫기 감시자를 처리하려면 다음을
수행한다.
processedACloseWatcher를 false로 설정한다.
window의 닫기 감시자 관리자의 그룹이 비어 있지 않으면 다음을 수행한다.
group을 window의 닫기 감시자 관리자의 그룹에서 마지막 항목으로 설정한다.
group의 각 closeWatcher에 대해 역순으로 반복하여 다음을 수행한다.
closeWatcher의 활성화 상태 가져오기를 실행한 결과가 true이면 processedACloseWatcher를 true로 설정한다.
shouldProceed를 true를 사용하여 closeWatcher에 닫기를 요청한 결과로 설정한다.
shouldProceed가 false이면 중단한다.
window의 닫기 감시자 관리자의 허용된 그룹 수가 1보다 크면 1만큼 감소시킨다.
processedACloseWatcher를 반환한다.
CloseWatcher インターフェイス[Exposed =Window ]
interface CloseWatcher : EventTarget {
constructor (optional CloseWatcherOptions options = {});
undefined requestClose ();
undefined close ();
undefined destroy ();
attribute EventHandler oncancel ;
attribute EventHandler onclose ;
};
dictionary CloseWatcherOptions {
AbortSignal signal ;
};watcher = new CloseWatcher()
watcher = new CloseWatcher({ signal })
新しい CloseWatcher
インスタンスを作成します。
signal
オプションが指定されている場合、指定された
AbortSignal
を中止することによって、watcher を(watcher.destroy()
を呼び出したかのように)破棄できます。
いずれかのクローズウォッチャーがすでに
アクティブであり、かつ Window が
履歴アクションアクティベーションを持たない場合、
生成される CloseWatcher は、
いずれかの閉じる要求に応答して、
そのすでにアクティブなクローズウォッチャーとともに閉じられます。
(このすでにアクティブなクローズウォッチャーは、必ずしも CloseWatcher オブジェクトである
必要はありません。モーダルな
dialog
要素、または popover 属性を持つ要素によって
生成されたポップオーバーである可能性もあります。)
watcher.requestClose()
まず cancel イベントを
発生させ、そのイベントが preventDefault()
によってキャンセルされなかった場合、close
イベントを発生させてから、
watcher.destroy()
が呼び出されたかのようにクローズウォッチャーを非アクティブ化することによって、watcher を
対象とする閉じる要求が送信された
かのように動作します。
これは、閉じる要求以外のすべての閉じるための操作手段からこのメソッドを呼び出すことにより、
キャンセル処理および閉じる処理のロジックを cancel および close イベントハンドラーに
集約するために使用できる補助ユーティリティです。
watcher.close()
直ちに close イベントを発生させ、
次に watcher.destroy()
が呼び出されたかのようにクローズウォッチャーを非アクティブ化します。
これは、cancel
イベントハンドラー内のすべてのロジックをスキップし、閉じる処理のロジックを close イベントハンドラーで
実行させるために使用できる補助ユーティリティです。
watcher.destroy()
watcher を非アクティブ化し、それ以降 close イベントを受信しないように
するとともに、新しい独立した CloseWatcher インスタンスを
構築できるようにします。
これは、関連する UI 要素が閉じられる以外の方法で破棄された場合に呼び出すことを意図しています。
各 CloseWatcher インスタンスは、
クローズウォッチャーである
内部クローズウォッチャーを持ちます。
new CloseWatcher(options)
コンストラクターの手順は次のとおりです。
このオブジェクトの関連するグローバルオブジェクトの関連付けられた
Documentが完全にアクティブでない場合、「InvalidStateError」
DOMException
をスローします。
closeWatcher を、次を使用して、このオブジェクトの関連するグローバル オブジェクトを与えてクローズウォッチャーを確立した結果とします。
cancelAction は、
canPreventClose を与えられたとき、このオブジェクトで cancel という名前の
イベントを発生させた結果を返すものとし、cancelable
属性は canPreventClose に初期化します。
closeAction は、このオブジェクトで close
という名前のイベントを発生させるものとします。
getEnabledState は true を返すものとします。
このオブジェクトの内部クローズウォッチャーを closeWatcher に設定します。
requestClose() メソッドの手順は、false を使用してこのオブジェクトの内部
クローズウォッチャーを閉じるよう要求することです。
close()
メソッドの手順は、このオブジェクトの
内部クローズ
ウォッチャーを閉じることです。
destroy() メソッドの手順は、このオブジェクトの内部クローズ
ウォッチャーを破棄することです。
次に示すものは、CloseWatcher
インターフェイスを
実装するすべてのオブジェクトが、イベントハンドラー IDL 属性として
サポートしなければならないイベントハンドラー(および対応するイベントハンドラーイベント型)です。
| イベントハンドラー | イベントハンドラー イベント型 |
|---|---|
oncancel |
cancel
|
onclose |
close
|
ユーザーが送信した閉じる要求および閉じるボタンの押下によって
自身を閉じるカスタムピッカーコントロールを実装する場合、次のコードは、閉じる要求を処理するために
CloseWatcher API をどのように使用するかを示します。
const watcher = new CloseWatcher();
const picker = setUpAndShowPickerDOMElement();
let chosenValue = null ;
watcher. onclose = () => {
chosenValue = picker. querySelector( 'input' ). value;
picker. remove();
};
picker. querySelector( '.close-button' ). onclick = () => watcher. requestClose(); 選択された値を収集するロジックが CloseWatcher
オブジェクトの close イベントハンドラーに集約されており、閉じるボタンの click
イベントハンドラーが requestClose() を呼び出すことによって、そのロジックへ
処理を委譲していることに注意してください。
CloseWatcher オブジェクトの cancel イベントを使用すると、
close イベントが発生すること、および
CloseWatcher が破棄されることを防止できます。一般的な使用例は次のとおりです。
watcher. oncancel = async ( e) => {
if ( hasUnsavedData && e. cancelable) {
e. preventDefault();
const userReallyWantsToClose = await askForConfirmation( "本当に閉じますか?" );
if ( userReallyWantsToClose) {
hasUnsavedData = false ;
watcher. close();
}
}
}; 不正使用を防止するため、このイベントが キャンセル可能になるのは、
ページが履歴アクション
アクティベーションを持つ場合のみであり、これはいずれかの閉じる要求の後に失われます。これにより、ユーザーが
途中にユーザーアクティベーションを挟まずに閉じる要求を 2 回連続して送信した場合、要求が確実に成功します。
2 回目の要求は、いずれかの cancel
イベントハンドラーによる
preventDefault() の呼び出しを
無視し、CloseWatcher を閉じます。
上記二つの例を組み合わせると、requestClose()
と close()
の違いが示されます。閉じるボタンの click
イベントハンドラーで requestClose()
を使用したため、そのボタンをクリックすると CloseWatcher の
cancel イベントが
トリガーされ、保存されていないデータがある場合にはユーザーへ確認を求める可能性があります。
close() を使用していた場合、この確認はスキップされます。
それが適切な場合もありますが、ユーザーがトリガーする閉じる要求については、通常は requestClose()
の方が適切な選択肢です。
cancel イベントに対するユーザーアクティベーションの制限に加えて、
CloseWatcher の構築には、より微妙な形のユーザーアクティベーションによる
制限があります。ユーザーアクティベーションなしで複数の
CloseWatcher を作成すると、新しく作成されたものは、直近に作成された
クローズウォッチャーとともにグループ化されるため、
一つの閉じる
要求によって両方が閉じられます。
window. onload = () => {
// これは通常どおり動作します。ユーザーアクティベーションなしで作成された最初のクローズウォッチャーです。
( new CloseWatcher()). onclose = () => { /* ... */ };
};
button1. onclick = () => {
// これは通常どおり動作します。ボタンのクリックはユーザーアクティベーションとして数えられます。
( new CloseWatcher()). onclose = () => { /* ... */ };
};
button2. onclick = () => {
// これらはまとめてグループ化され、一つの閉じる要求に応答して両方とも閉じられます。
( new CloseWatcher()). onclose = () => { /* ... */ };
( new CloseWatcher()). onclose = () => { /* ... */ };
}; これは、destroy()、
close()、
または requestClose()
を適切に呼び出すことが重要であることを意味します。これは、グループ化されていない「無料」の
クローズウォッチャースロットを取り戻す唯一の方法です。ユーザーアクティベーションなしで作成される
このようなクローズウォッチャーは、セッションの非アクティブ状態によるタイムアウトダイアログや、
ユーザーアクティベーションへの応答として生成されない、サーバーによってトリガーされるイベントの
緊急通知などの場合に役立ちます。
現在のすべてのエンジンでサポートされています。
この節では、イベントに基づくドラッグ&ドロップ機構を定義します。
この仕様では、ドラッグ&ドロップ操作が実際に何であるかを厳密には定義しません。
ポインティングデバイスを備えた視覚媒体では、ドラッグ操作は、mousedown イベントの既定アクションであり、
その後に一連の mousemove イベントが続き、
マウスを離すことでドロップがトリガーされる場合があります。
ポインティングデバイス以外の入力モダリティを使用する場合、ユーザーは、何をドラッグし、 どこへドロップするかをそれぞれ指定することで、ドラッグ&ドロップ操作を実行する意図を明示的に 示す必要があるでしょう。
どのように実装される場合でも、ドラッグ&ドロップ操作は開始点(たとえば、マウスがクリックされた場所、 またはドラッグ対象として選択された選択範囲や要素の始点)を持たなければならず、任意の数の中間手順 (ドラッグ中にマウスが通過する要素、またはユーザーが候補を順番に切り替えながら可能なドロップ地点として 選択する要素)を持つことができ、終点(マウスボタンが離された位置の要素、または最終的に選択された要素) を持つか、キャンセルされなければなりません。終点は、ドロップが発生する前に可能なドロップ地点として 最後に選択された要素でなければなりません(したがって、操作がキャンセルされない場合、中間手順に 少なくとも一つの要素が存在しなければなりません)。
この節は非規範的です。
要素をドラッグ可能にするには、その要素に draggable
属性を指定し、ドラッグされるデータを保存する dragstart
のイベントリスナーを設定します。
イベントハンドラーは通常、ドラッグされているものがテキストの選択範囲でないことを確認し、
その後 DataTransfer オブジェクトへ
データを保存して、許可される効果(コピー、移動、リンク、またはそれらの組み合わせ)を設定する必要があります。
例:
< p > どの果物が好きですか?</ p >
< ol ondragstart = "dragStartHandler(event)" >
< li draggable = "true" data-value = "fruit-apple" > リンゴ</ li >
< li draggable = "true" data-value = "fruit-orange" > オレンジ</ li >
< li draggable = "true" data-value = "fruit-pear" > ナシ</ li >
</ ol >
< script >
var internalDNDType = 'text/x-example' ; // サイト固有の値に設定します
function dragStartHandler( event) {
if ( event. target instanceof HTMLLIElement) {
// 要素の data-value="" 属性を移動する値として使用します。
event. dataTransfer. setData( internalDNDType, event. target. dataset. value);
event. dataTransfer. effectAllowed = 'move' ; // 移動のみを許可します
} else {
event. preventDefault(); // 選択範囲のドラッグを許可しません
}
}
</ script > ドロップを受け入れるには、ドロップ対象が次のイベントを待ち受ける必要があります。
dragenter イベントハンドラーは、
イベントをキャンセルすることにより、ドロップ対象がドロップを受け入れる可能性があるかどうかを報告します。dragover イベントハンドラーは、
イベントに関連付けられた
DataTransfer の dropEffect
属性を設定することにより、ユーザーにどのようなフィードバックを表示するかを指定します。
このイベントもキャンセルする必要があります。
drop イベントハンドラーには、
ドロップを受け入れるか拒否するかを決定する最後の機会があります。ドロップを受け入れる場合、
イベントハンドラーは対象上でドロップ操作を実行しなければなりません。このイベントは、dropEffect
属性の値をソースが使用できるように、キャンセルする必要があります。それ以外の場合、ドロップ操作は拒否されます。例:
< p > 好きな果物を下にドロップしてください:</ p >
< ol ondragenter = "dragEnterHandler(event)" ondragover = "dragOverHandler(event)"
ondrop = "dropHandler(event)" >
</ ol >
< script >
var internalDNDType = 'text/x-example' ; // サイト固有の値に設定します
function dragEnterHandler( event) {
var items = event. dataTransfer. items;
for ( var i = 0 ; i < items. length; ++ i) {
var item = items[ i];
if ( item. kind == 'string' && item. type == internalDNDType) {
event. preventDefault();
return ;
}
}
}
function dragOverHandler( event) {
event. dataTransfer. dropEffect = 'move' ;
event. preventDefault();
}
function dropHandler( event) {
var li = document. createElement( 'li' );
var data = event. dataTransfer. getData( internalDNDType);
if ( data == 'fruit-apple' ) {
li. textContent = 'リンゴ' ;
} else if ( data == 'fruit-orange' ) {
li. textContent = 'オレンジ' ;
} else if ( data == 'fruit-pear' ) {
li. textContent = 'ナシ' ;
} else {
li. textContent = '不明な果物' ;
}
event. target. appendChild( li);
}
</ script > 元の要素(ドラッグされた要素)を表示から削除するには、dragend
イベントを使用できます。
この例では、そのイベントを処理するように元のマークアップを更新することを意味します。
< p > どの果物が好きですか?</ p >
< ol ondragstart = "dragStartHandler(event)" ondragend = "dragEndHandler(event)" >
...前と同じ...
</ ol >
< script >
function dragStartHandler( event) {
// ...前と同じ...
}
function dragEndHandler( event) {
if ( event. dataTransfer. dropEffect == 'move' ) {
// ドラッグされた要素を削除します
event. target. parentNode. removeChild( event. target);
}
}
</ script > ドラッグデータストアと呼ばれる、ドラッグ&ドロップ操作の基盤となるデータは、 次の情報で構成されます。
ドラッグデータストア項目リスト。ドラッグされたデータを表す 項目のリストであり、各項目は次の情報で構成されます。
データの種類:
テキスト。
ファイル名を持つバイナリデータ。
データの型または形式を示す Unicode 文字列であり、通常は MIME 型によって示されます。MIME 型でない一部の値は、 後方互換性の理由から特別に処理されます。API は MIME 型の使用を強制しません。 そのほかの値も使用できます。ただし、すべての場合に、値は API によってASCII 小文字へ変換されます。
項目の型文字列ごとに、 テキスト項目は一つに制限されます。
ドラッグデータ項目の種類に従った、 Unicode 文字列またはバイナリ文字列であり、場合によってはファイル名(それ自体も Unicode 文字列)を伴います。
ドラッグデータストア 項目リストは、項目がリストに追加された順序で並べられ、最後に追加された項目が末尾になります。
ドラッグ中の UI フィードバックを生成するために使用される次の情報:
ドラッグデータストアのモード。次のいずれかです。
dragstart
イベント用です。
ドラッグデータストアへ新しいデータを追加できます。
drop イベント用です。
ドラッグされたデータを表す項目のリストを、そのデータを含めて読み取れます。
新しいデータは追加できません。
そのほかのすべてのイベント用です。ドラッグされたデータを表すドラッグデータストアの項目リスト内の形式および種類を 列挙できますが、データ自体は利用できず、新しいデータを追加することもできません。
文字列であるドラッグデータストアの許可される効果の状態。
ドラッグデータストアが
作成されるとき、そのドラッグデータストア項目リストが空であり、
ドラッグデータストアの既定のフィードバックを
持たず、ドラッグデータストアのビットマップおよび
ドラッグデータストアのホットスポット座標を
持たず、そのドラッグデータストアのモードが保護モードであり、そのドラッグデータストアの許可される効果の
状態が文字列「uninitialized」
となるように初期化しなければなりません。
DataTransfer インターフェイス現在のすべてのエンジンでサポートされています。
DataTransfer オブジェクトは、
ドラッグ&ドロップ操作の基盤となるドラッグデータストアを公開するために使用されます。
[Exposed =Window ]
interface DataTransfer {
constructor ();
attribute DOMString dropEffect ;
attribute DOMString effectAllowed ;
[SameObject ] readonly attribute DataTransferItemList items ;
undefined setDragImage (Element image , long x , long y );
/* old interface */
readonly attribute FrozenArray <DOMString > types ;
DOMString getData (DOMString format );
undefined setData (DOMString format , DOMString data );
undefined clearData (optional DOMString format );
[SameObject ] readonly attribute FileList files ;
};dataTransfer = new DataTransfer()
現在のすべてのエンジンでサポートされています。
空のドラッグデータ
ストアを持つ、新しい DataTransfer オブジェクトを
作成します。
dataTransfer.dropEffect [ = value ]
現在のすべてのエンジンでサポートされています。
現在選択されている操作の種類を返します。操作の種類が effectAllowed
属性によって許可されるものの一つでない場合、その操作は失敗します。
設定すると、選択されている操作を変更できます。
dataTransfer.effectAllowed [ = value ]
現在のすべてのエンジンでサポートされています。
許可される操作の種類を返します。
設定すると(dragstart
イベント中)、許可される操作を変更できます。
取り得る値は「none」、
「copy」、
「copyLink」、
「copyMove」、
「link」、
「linkMove」、
「move」、
「all」、
および「uninitialized」です。
dataTransfer.items
現在のすべてのエンジンでサポートされています。
ドラッグデータを持つ DataTransferItemList
オブジェクトを返します。
dataTransfer.setDragImage(element, x, y)
現在のすべてのエンジンでサポートされています。
指定された要素を使用してドラッグのフィードバックを更新し、それ以前に指定されたフィードバックを置き換えます。
dataTransfer.types
現在のすべてのエンジンでサポートされています。
dragstart イベントで設定された形式を列挙する凍結配列を返します。さらに、いずれかのファイルがドラッグされている場合、
型の一つは文字列「Files」になります。
data = dataTransfer.getData(format)
現在のすべてのエンジンでサポートされています。
指定されたデータを返します。そのようなデータがない場合、空文字列を返します。
dataTransfer.setData(format, data)
現在のすべてのエンジンでサポートされています。
指定されたデータを追加します。
dataTransfer.clearData([ format ])
現在のすべてのエンジンでサポートされています。
指定された形式のデータを削除します。引数が省略された場合、すべてのデータを削除します。
dataTransfer.files
現在のすべてのエンジンでサポートされています。
ドラッグされているファイルがある場合、それらの FileList を返します。
ドラッグ&ドロップイベントの一部として作成される DataTransfer オブジェクトは、
それらのイベントが発生している間だけ有効です。
DataTransfer オブジェクトは、
有効である間、ドラッグデータストアに関連付けられます。
DataTransfer オブジェクトは、
初期状態では空である FrozenArray<DOMString> である、
関連付けられた型配列を持ちます。DataTransfer
オブジェクトのドラッグデータ
ストア項目リストの内容が変更されたとき、または
DataTransfer オブジェクトがドラッグデータ
ストアに関連付けられなくなったとき、次の手順を実行します。
L を空のシーケンスとします。
DataTransfer
オブジェクトがまだドラッグデータ
ストアに関連付けられている場合、次を行います。
DataTransfer オブジェクトのドラッグデータストア項目
リスト内にある、種類がテキストである各項目について、
その項目の型文字列で構成される項目を
L へ追加します。
DataTransfer オブジェクトのドラッグデータストア
項目リスト内に、種類がファイルである項目が
一つでもある場合、文字列「Files」で構成される項目を L へ追加します。
(この値は小文字でないため、そのほかの値と区別できます。)
DataTransfer
オブジェクトの型
配列を、L から凍結配列を作成した結果に設定します。
DataTransfer() コンストラクターは、呼び出されたとき、
次のように初期化された、新しく作成された DataTransfer オブジェクトを
返さなければなりません。
ドラッグデータストアの項目 リストを空のリストに設定します。
ドラッグデータストアのモードを 読み書きモードに設定します。
dropEffect および
effectAllowed
を「none」に設定します。
dropEffect 属性は、ドラッグ&ドロップ操作中にユーザーへ
与えられるドラッグ&ドロップのフィードバックを制御します。DataTransfer オブジェクトが
作成されるとき、dropEffect
属性は文字列値に設定されます。取得時には、その現在の値を返さなければなりません。設定時に、新しい値が
「none」、
「copy」、
「link」、または
「move」のいずれかである場合、
属性の現在の値を新しい値に設定しなければなりません。そのほかの値は無視しなければなりません。
effectAllowed 属性は、ドラッグ&ドロップ処理モデルにおいて、
dragenter および
dragover イベント中に dropEffect
属性を初期化するために使用されます。DataTransfer
オブジェクトが作成されるとき、effectAllowed
属性は文字列値に設定されます。取得時には、その現在の値を返さなければなりません。設定時に、
ドラッグデータ
ストアのモードが読み書きモードであり、新しい値が
「none」、
「copy」、
「copyLink」、
「copyMove」、
「link」、
「linkMove」、
「move」、
「all」、または
「uninitialized」のいずれかである場合、
属性の現在の値を新しい値に設定しなければなりません。それ以外の場合、変更せずに残さなければなりません。
items
属性は、DataTransfer オブジェクトに関連付けられた DataTransferItemList オブジェクトを返さなければなりません。
setDragImage(image, x,
y) メソッドは、次の手順を実行しなければなりません。
DataTransfer
オブジェクトがドラッグデータ
ストアに関連付けられなくなっている場合、返します。何も起こりません。
ドラッグデータストアのモードが 読み書きモードでない場合、返します。 何も起こりません。
image が img 要素である場合、
ドラッグデータストアの
ビットマップを、その要素の画像(その自然な
サイズ)に設定します。それ以外の場合、ドラッグデータストアのビットマップを、
指定された要素から生成された画像に設定します(そのための正確な機構は現在指定されていません)。
ドラッグデータストアのホットスポット座標 を、指定された x、y 座標に設定します。
types
属性は、この DataTransfer
オブジェクトの
型配列を返さなければなりません。
getData(format) メソッドは、
次の手順を実行しなければなりません。
DataTransfer
オブジェクトがドラッグデータ
ストアに関連付けられなくなっている場合、空文字列を返します。
ドラッグデータストアのモードが 保護モードである場合、空文字列を返します。
format を、最初の引数をASCII 小文字へ変換したものとします。
convert-to-URL を false とします。
format が「text」と等しい場合、「text/plain」へ変更します。
format が「url」と等しい場合、「text/uri-list」へ変更し、
convert-to-URL を true に設定します。
ドラッグデータストア項目リスト内に、 種類がテキストであり、 型文字列が format と等しい項目がない場合、空文字列を返します。
result を、ドラッグデータストア項目 リスト内にある、種類がプレーン Unicode 文字列であり、型文字列が format と等しい項目のデータとします。
convert-to-URL が true である場合、result を
text/uri-list データに適切な方法で解析し、その後、リストに URL がある場合は
result を最初の URL に設定し、それ以外の場合は空文字列に設定します。
[RFC2483]
result を返します。
setData(format, data) メソッドは、
次の手順を実行しなければなりません。
DataTransfer
オブジェクトがドラッグデータ
ストアに関連付けられなくなっている場合、返します。何も起こりません。
ドラッグデータストアのモードが 読み書きモードでない場合、返します。 何も起こりません。
format を、最初の引数をASCII 小文字へ変換したものとします。
format が「text」と等しい場合、「text/plain」へ変更します。
format が「url」と等しい場合、「text/uri-list」へ変更します。
ドラッグデータストア項目リスト内に、 種類がテキストであり、 型文字列が format と等しい項目がある場合、その項目を削除します。
ドラッグデータストア項目リストへ、 種類がテキストであり、 型文字列が format と等しく、データがメソッドの第 2 引数によって指定された文字列である項目を追加します。
clearData(format) メソッドは、
次の手順を実行しなければなりません。
DataTransfer
オブジェクトがドラッグデータ
ストアに関連付けられなくなっている場合、返します。何も起こりません。
ドラッグデータストアのモードが 読み書きモードでない場合、返します。 何も起こりません。
メソッドが引数なしで呼び出された場合、ドラッグデータストア 項目リスト内にある、種類がプレーン Unicode 文字列である各項目を削除し、返します。
format を、format をASCII 小文字へ変換したものに設定します。
format が「text」と等しい場合、「text/plain」へ変更します。
format が「url」と等しい場合、「text/uri-list」へ変更します。
ドラッグデータストア項目リスト内に、 種類がテキストであり、 型文字列が format と等しい項目がある場合、その項目を削除します。
clearData()
メソッドは、いずれかのファイルがドラッグに含まれていたかどうかには影響しません。そのため、
clearData()
を呼び出した後も、types
属性のリストは空でない場合があります(いずれかのファイルがドラッグに含まれていた場合、
「Files」文字列が引き続き含まれます)。
files
属性は、次の手順によって検出されたファイルを表す File
オブジェクトで構成されるライブな FileList
シーケンスを返さなければなりません。さらに、指定された FileList
オブジェクトおよび指定された基盤となるファイルについて、毎回同じ File
オブジェクトを使用しなければなりません。
空のリスト L から開始します。
DataTransfer
オブジェクトがドラッグデータ
ストアに関連付けられなくなっている場合、FileList
は空です。空のリスト L を返します。
ドラッグデータストアのモードが 保護モードである場合、空のリスト L を返します。
ドラッグデータストア項目リスト内にある、 種類がファイルである各項目について、 その項目のデータ(ファイル、特にその名前および内容、ならびにその型)をリスト L へ追加します。
これらの手順によって検出されたファイルは、リスト L 内のものです。
このバージョンの API は、ドラッグ中にファイルの型を公開しません。
DataTransferItemList
インターフェイス現在のすべてのエンジンでサポートされています。
各 DataTransfer
オブジェクトは、DataTransferItemList
オブジェクトに関連付けられます。
[Exposed =Window ]
interface DataTransferItemList {
readonly attribute unsigned long length ;
getter DataTransferItem (unsigned long index );
DataTransferItem ? add (DOMString data , DOMString type );
DataTransferItem ? add (File data );
undefined remove (unsigned long index );
undefined clear ();
};items.length
現在のすべてのエンジンでサポートされています。
ドラッグデータストア内の項目数を返します。
items[index]ドラッグデータストア内の
index 番目の項目を表す DataTransferItem
オブジェクトを返します。
items.remove(index)
現在のすべてのエンジンでサポートされています。
ドラッグデータストア内の index 番目の項目を削除します。
items.clear()
現在のすべてのエンジンでサポートされています。
ドラッグデータストア内のすべての項目を削除します。
items.add(data)
現在のすべてのエンジンでサポートされています。
items.add(data, type)
指定されたデータの新しい項目をドラッグデータストアへ追加します。 データがプレーンテキストである場合、type 文字列も指定する必要があります。
DataTransferItemList
オブジェクトの DataTransfer オブジェクトが
ドラッグデータストアに関連付けられている間、
DataTransferItemList
オブジェクトの
モードは、ドラッグデータストアのモードと同じです。
DataTransferItemList
オブジェクトの DataTransfer オブジェクトが
ドラッグデータストアに関連付けられて
いない場合、DataTransferItemList
オブジェクトの
モードは無効モードです。この節で参照されるドラッグデータストア(DataTransferItemList
オブジェクトが無効モードでない場合にのみ使用されます)は、DataTransferItemList
オブジェクトの DataTransfer オブジェクトが
関連付けられているドラッグデータストアです。
length 属性は、オブジェクトが無効モードである場合は
0 を返さなければなりません。それ以外の場合は、ドラッグデータストア項目リスト内の
項目数を返さなければなりません。
DataTransferItemList
オブジェクトが無効モードでない場合、そのサポートされるプロパティインデックスは、ドラッグデータストア
項目リストのインデックスです。
DataTransferItemList
オブジェクトのインデックス付きプロパティ i の値を決定するには、ユーザーエージェントは
ドラッグデータストア内の
i 番目の項目を表す DataTransferItem
オブジェクトを返さなければなりません。この DataTransferItemList
オブジェクトから特定の項目が取得されるたびに、同じオブジェクトを返さなければなりません。DataTransferItem
オブジェクトは、最初に作成されたとき、DataTransferItemList
オブジェクトと同じ DataTransfer オブジェクトに
関連付けられなければなりません。
add() メソッドは、次の手順を実行しなければなりません。
DataTransferItemList
オブジェクトが読み書きモードでない場合、null を返します。
次のリストから適切な一連の手順へ進みます。
ドラッグデータストア項目リスト内に、
種類がテキストであり、
型文字列が、メソッドの
第 2 引数の値をASCII 小文字へ変換した値と等しい項目が
すでに存在する場合、「NotSupportedError」 DOMException
をスローします。
それ以外の場合、ドラッグデータストア項目リストへ、 種類がテキストであり、 型文字列が、メソッドの 第 2 引数の値をASCII 小文字へ変換した値と等しく、データが メソッドの第 1 引数によって指定された文字列である項目を追加します。
File
である場合
ドラッグデータストア項目リストへ、
種類がファイルであり、
型
文字列が File
の type をASCII 小文字へ変換した値であり、データが
File
のデータと同じである項目を追加します。
新しく追加された項目に対応するインデックス付きプロパティの値を
決定し、その値(新しく作成された DataTransferItem
オブジェクト)を返します。
remove(index) メソッドは、次の手順を
実行しなければなりません。
DataTransferItemList
オブジェクトが読み書きモードでない場合、「InvalidStateError」 DOMException
をスローします。
ドラッグデータストアに index 番目の項目が含まれていない場合、返します。
ドラッグデータストアから index 番目の項目を削除します。
clear() メソッドは、DataTransferItemList
オブジェクトが読み書き
モードである場合、ドラッグデータストアからすべての項目を
削除しなければなりません。それ以外の場合、何もしてはなりません。
DataTransferItem
インターフェイス現在のすべてのエンジンでサポートされています。
各 DataTransferItem
オブジェクトは、DataTransfer
オブジェクトに関連付けられます。
[Exposed =Window ]
interface DataTransferItem {
readonly attribute DOMString kind ;
readonly attribute DOMString type ;
undefined getAsString (FunctionStringCallback ? _callback );
File ? getAsFile ();
};
callback FunctionStringCallback = undefined (DOMString data );item.kind
現在のすべてのエンジンでサポートされています。
ドラッグデータ項目の種類を返します。 値は「string」または「file」のいずれかです。
item.type
現在のすべてのエンジンでサポートされています。
ドラッグデータ項目の型文字列を返します。
item.getAsString(callback)
現在のすべてのエンジンでサポートされています。
ドラッグデータ項目の種類が テキストである場合、文字列データを引数としてコールバックを呼び出します。
file = item.getAsFile()
現在のすべてのエンジンでサポートされています。
ドラッグデータ項目の種類が
ファイルである場合、File
オブジェクトを返します。
DataTransferItem
オブジェクトの DataTransfer
オブジェクトが
ドラッグデータストアに関連付けられており、かつ
そのドラッグデータストアのドラッグデータストア項目リストに、
DataTransferItem
オブジェクトが表す項目がまだ含まれている間、DataTransferItem
オブジェクトのモードは、ドラッグデータストアの
モードと同じです。DataTransferItem
オブジェクトの DataTransfer
オブジェクトが
ドラッグデータストアに関連付けられて
いない場合、または DataTransferItem
オブジェクトが表す項目が、関連するドラッグデータストア項目リストから
削除されている場合、DataTransferItem
オブジェクトのモードは無効モードです。この節で参照されるドラッグデータストア(DataTransferItem
オブジェクトが無効モードでない場合にのみ使用されます)は、DataTransferItem
オブジェクトの DataTransfer
オブジェクトが
関連付けられているドラッグデータストアです。
kind 属性は、DataTransferItem
オブジェクトが無効モードである場合、空文字列を返さなければなりません。それ以外の場合、
DataTransferItem
オブジェクトが表す項目のドラッグデータ項目の種類を
第 1 列のセルに含む行について、次の表の第 2 列のセルに示された文字列を返さなければなりません。
| 種類 | 文字列 |
|---|---|
| テキスト | 「string」
|
| ファイル | 「file」
|
type 属性は、DataTransferItem
オブジェクトが無効モードである場合、空文字列を返さなければなりません。それ以外の場合、
DataTransferItem
オブジェクトが表す項目のドラッグデータ項目の型文字列を
返さなければなりません。
getAsString(callback) メソッドは、
次の手順を実行しなければなりません。
callback が null である場合、返します。
DataTransferItem
オブジェクトが読み書きモードまたは読み取り専用モードの
いずれでもない場合、返します。コールバックは呼び出されません。
ドラッグデータ項目の種類が テキストでない場合、返します。コールバックは呼び出されません。
それ以外の場合、DataTransferItem
オブジェクトが表す項目の実際のデータを引数として渡し、callback を呼び出すタスクをキューに追加します。
getAsFile() メソッドは、次の手順を
実行しなければなりません。
DataTransferItem
オブジェクトが読み書きモードまたは読み取り専用モードの
いずれでもない場合、null を返します。
ドラッグデータ項目の種類が ファイルでない場合、null を返します。
DataTransferItem
オブジェクトが表す項目の実際のデータを表す、新しい File
オブジェクトを返します。
DragEvent インターフェイス現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
ドラッグ&ドロップ処理モデルには、複数のイベントが関与します。それらはすべて
DragEvent インターフェイスを
使用します。
[Exposed =Window ]
interface DragEvent : MouseEvent {
constructor (DOMString type , optional DragEventInit eventInitDict = {});
readonly attribute DataTransfer ? dataTransfer ;
};
dictionary DragEventInit : MouseEventInit {
DataTransfer ? dataTransfer = null ;
};event.dataTransfer
現在のすべてのエンジンでサポートされています。
イベントの DataTransfer
オブジェクトを返します。
そのほかのイベントインターフェイスとの一貫性を保つため、DragEvent
インターフェイスにはコンストラクターがありますが、特に有用ではありません。特に、スクリプトから
有用な DataTransfer オブジェクトを作成する方法はありません。これは、DataTransfer オブジェクトが、
ドラッグ&ドロップ中にブラウザーによって調整される処理モデルおよびセキュリティモデルを持つためです。
DragEvent インターフェイスの
dataTransfer 属性は、初期化された値を返さなければなりません。
これは、イベントのコンテキスト情報を表します。
ユーザーエージェントが、特定のドラッグデータストアを使用し、任意で特定の related target を指定して、要素で e という名前のDND イベントを発生させる必要がある場合、ユーザーエージェントは 次の手順を実行しなければなりません。
特定の related target が指定されていない場合、related target を null に設定します。
window を、指定された対象要素の Document オブジェクトの関連するグローバルオブジェクトとします。
e が dragstart である
場合、ドラッグデータストアのモードを読み書きモードに設定し、
dataDragStoreWasChanged を true に設定します。
e が drop
である場合、
ドラッグデータストアのモードを読み取り専用モードに設定します。
dataTransfer を、指定されたドラッグデータストアに関連付けられた、
新しく作成された DataTransfer
オブジェクトと
します。
effectAllowed
属性を、ドラッグデータストアのドラッグデータストアの許可される効果の
状態に設定します。
e が dragstart、
drag、または
dragleave である場合、dropEffect
属性を「none」に設定します。e が drop または
dragend である場合、現在のドラッグ操作に対応する値に設定します。
それ以外の場合(すなわち、e が dragenter または
dragover である場合)、次の表に従って、effectAllowed
属性の値およびドラッグ&ドロップのソースに基づく値に設定します。
effectAllowed
|
dropEffect
|
|---|---|
「none」
|
「none」
|
「copy」
|
「copy」
|
「copyLink」
|
「copy」、
または適切な場合は「link」
|
「copyMove」
|
「copy」、
または適切な場合は「move」
|
「all」
|
「copy」、
または適切な場合は「link」
または「move」のいずれか
|
「link」
|
「link」
|
「linkMove」
|
「link」、
または適切な場合は「move」
|
「move」
|
「move」
|
ドラッグされているものがテキストコントロール内の選択範囲である場合の「uninitialized」
|
「move」、
または適切な場合は「copy」
または「link」のいずれか
|
ドラッグされているものが選択範囲である場合の「uninitialized」
|
「copy」、
または適切な場合は「link」
または「move」のいずれか
|
ドラッグされているものが href
属性を持つ a 要素である場合の「uninitialized」
|
「link」、
または適切な場合は「copy」
または「move」のいずれか
|
| そのほかの場合 | 「copy」、
または適切な場合は「link」
または「move」のいずれか
|
上の表で適切である可能性のある代替値が示されている 場合、プラットフォームの慣例により、ユーザーがそれらの代替効果を要求したことが示されるなら、 ユーザーエージェントは代わりに一覧の代替値を使用できます。
たとえば、Windows プラットフォームの慣例では、「alt」キーを押しながらドラッグすると、
データを移動またはコピーするのではなく、リンクすることを優先することが示されます。したがって、
Windows システムで「alt」キーが押されている間、上の表に従って「link」が選択肢である場合、
ユーザーエージェントは「copy」または「move」の代わりに、それを選択できます。
event の type
属性を e に、bubbles
属性を true に、view
属性を window に、relatedTarget
属性を related target に、dataTransfer
属性を dataTransfer に初期化します。
e が dragleave または
dragend で
ない場合、event の cancelable
属性を true に初期化します。
ユーザーインタラクションイベントの場合と同様に、入力デバイスの状態に従って event のマウス属性およびキー属性を初期化します。
関連するポインティングデバイスがない場合、event の screenX、
screenY、clientX、
clientY、
および button 属性を 0 に初期化します。
指定された対象要素で event をディスパッチします。
ドラッグデータストアの許可される
効果の状態を、dataTransfer の effectAllowed
属性の現在の値に設定します。(値が変更される可能性があるのは、e が dragstart である場合のみです。)
dataDragStoreWasChanged が true である場合、ドラッグデータストアの モードを保護モードに戻します。
dataTransfer とドラッグデータストアとの関連付けを解除します。
ユーザーがドラッグ操作を開始しようとするとき、ユーザーエージェントは次の手順を実行しなければなりません。 ドラッグが実際には別の文書またはアプリケーションで開始され、ユーザーエージェントの管理下にある文書と 交差するまで、ユーザーエージェントがドラッグの発生を認識していなかった場合でも、ユーザーエージェントは これらの手順が実行されたかのように動作しなければなりません。
次のように、何がドラッグされているかを決定します。
ドラッグ操作が選択範囲上で呼び出された場合、ドラッグされているものはその選択範囲です。
それ以外の場合、ドラッグ操作が Document
上で呼び出された場合、
ユーザーがドラッグしようとしたノードから祖先チェーンを上方へ辿り、IDL 属性 draggable が
true に設定されている最初の要素がドラッグされているものです。そのような要素がない場合、
何もドラッグされていません。返します。ドラッグ&ドロップ操作は開始されません。
それ以外の場合、ドラッグ操作はユーザーエージェントの管理外で呼び出されました。 ドラッグされているものは、ドラッグが開始された文書またはアプリケーションによって定義されます。
img 要素、および
href 属性を持つ a 要素では、
draggable 属性が既定で true に設定されています。
ドラッグデータストアを作成します。 この節の手順によって後で発生するすべての DND イベントは、このドラッグデータストアを使用しなければなりません。
次のように、どの DOM ノードがソースノードであるかを確立します。
ドラッグされているものが選択範囲である場合、ソースノードは、ユーザーがドラッグを開始した
Text ノード(通常はユーザーが最初に
クリックした Text ノード)です。ユーザーが特定の
ノードを指定しなかった場合、たとえばユーザーが単に「選択範囲」のドラッグを開始するよう
ユーザーエージェントへ指示した場合、ソースノードは、選択範囲の一部を含む最初の
Text ノードです。
それ以外の場合、ドラッグされているものが要素である場合、ソースノードはドラッグされている要素です。
それ以外の場合、ソースノードは別の文書またはアプリケーションの 一部です。この場合に、この仕様がソースノードでイベントをディスパッチすることを 要求するとき、ユーザーエージェントは代わりに、その状況に関連するプラットフォーム固有の慣例に 従わなければなりません。
ドラッグ&ドロップ操作中、ソースノードで複数のイベントが発生します。
次のように、ドラッグされたノードのリストを決定します。
ドラッグされているものが選択範囲である場合、ドラッグされたノードのリストには、 選択範囲に部分的または完全に含まれるすべてのノード(それらのすべての祖先を含みます)が、ツリー順で含まれます。
それ以外の場合、ドラッグされたノードのリストには、 存在する場合、ソースノードだけが含まれます。
ドラッグされているものが選択範囲である場合、次のようにプロパティを設定した項目をドラッグデータストア 項目リストへ追加します。
text/plain」
それ以外の場合、いずれかのファイルがドラッグされている場合、ファイルごとに一つの項目を、 次のようにプロパティを設定してドラッグデータストア項目リストへ 追加します。
application/octet-stream」。
現在、ファイルのドラッグはナビゲーブルの外部、たとえばファイルシステム マネージャーアプリケーションからのみ行えます。
ドラッグがアプリケーションの外部で開始された場合、ユーザーエージェントは、適切な場合には プラットフォームの慣例に従い、ドラッグされているデータに応じた項目をドラッグデータストア項目リストへ 追加しなければなりません。ただし、プラットフォームの慣例がドラッグデータのラベル付けにMIME 型を使用しない場合、ユーザーエージェントは型を MIME 型へ 対応付けるために最善を尽くさなければならず、いずれの場合も、すべてのドラッグデータ項目の型文字列を ASCII 小文字へ変換しなければなりません。
ユーザーエージェントは、選択範囲またはドラッグされた要素を、そのほかの形式、たとえば HTML として 表す一つ以上の項目を追加することもできます。
ドラッグされたノードのリストが 空でない場合、それらのノードからマイクロデータを JSON 形式へ抽出し、 次のようにプロパティを設定した一つの項目をドラッグデータストア項目リストへ 追加します。
application/microdata+json
次の下位手順を実行します。
urls を « » とします。
ドラッグされたノードのリスト内の 各 node について、次を行います。
href
属性を持つ a 要素である場合href
コンテンツ属性の値を、要素のノード文書に相対的なものとして与え、URL をエンコードして
構文解析し直列化した結果を urls へ追加します。src
属性を持つ img 要素である場合src
コンテンツ
属性の値を、要素のノード文書に相対的なものとして与え、URL をエンコードして
構文解析し直列化した結果を urls へ追加します。urls が依然として空である場合、返します。
url string を、urls 内の文字列を追加された順序で、U+000D CARRIAGE RETURN U+000A LINE FEED 文字の組(CRLF)で区切って連結した結果とします。
次のようにプロパティを設定した一つの項目をドラッグデータストア項目リストへ 追加します。
text/uri-list
ユーザーエージェントに適した方法でドラッグデータストアの既定の フィードバックを更新します(ユーザーが選択範囲をドラッグしている場合、その選択範囲が フィードバックの基礎になる可能性があります。ユーザーが要素をドラッグしている場合、その要素の レンダリングが使用されます。ドラッグがユーザーエージェントの外部で開始された場合、ドラッグの フィードバックを決定するためのプラットフォームの慣例を使用するべきです)。
ソースノードで dragstart という名前のDND イベントを発生させます。
イベントがキャンセルされた場合、ドラッグ&ドロップ操作は発生するべきではありません。返します。
イベントリスナーが登録されていないイベントは、ほとんど定義上、決してキャンセルされないため、 作者が明示的に防止しない限り、ドラッグ&ドロップは常にユーザーが利用できます。
ソースノードで pointercancel という名前の
ポインターイベントを発生させ、Pointer Events が
要求するそのほかの後続イベントを発生させます。[POINTEREVENTS]
プラットフォームの慣例と一致し、以下で説明する方法でドラッグ&ドロップ操作を 開始します。
ドラッグ&ドロップのフィードバックは、利用可能な次のソースのうち最初のものから 生成しなければなりません。
ユーザーエージェントがドラッグ&ドロップ操作を開始する 時点からドラッグ&ドロップ操作が終了するまで、デバイス入力イベント(たとえばマウスイベントおよび キーボードイベント)を抑制しなければなりません。
ドラッグ操作中、ユーザーがドロップ対象として直接示した要素を直接のユーザー選択と呼びます。(ユーザーが選択できるのは要素だけです。 そのほかのノードをドロップ対象として利用可能にしてはなりません。)ただし、直接のユーザー選択は、必ずしも 現在の対象要素、すなわちドラッグ&ドロップ操作のドロップ部分について 現在選択されている要素と同じではありません。
直接のユーザー選択は、ユーザーが異なる要素を 選択するにつれて(ポインティングデバイスで要素を指すか、そのほかの方法で選択することによって)変化します。 現在の対象要素は、以下で説明するように、 文書内のイベントリスナーの結果に基づき、直接のユーザー選択が変化したときに変化します。
現在の対象要素および直接のユーザー選択は、どちらも null にでき、 これは対象要素が選択されていないことを意味します。また、どちらもそのほかの(DOM ベースの)文書内の 要素、またはまったく別の(ウェブ以外の)プログラム内の要素にすることもできます。(たとえば、ユーザーが テキストをワードプロセッサーへドラッグする場合があります。)現在の対象要素は、初期状態では null です。
さらに、現在のドラッグ操作もあり、値として「none」、「copy」、「link」、および「move」を取ることができます。初期状態では
「none」の値を持ちます。以下の手順で説明するように、
ユーザーエージェントによって更新されます。
ユーザーエージェントは、ドラッグ操作が開始されると直ちに、 またその後ドラッグ操作が継続している間は 350 ミリ秒(±200 ミリ秒)ごとに、次の手順を順番に実行する タスクをキューに追加しなければなりません。
次の反復を行うべき時点で、ユーザーエージェントがまだ前の反復(存在する場合)を実行している場合、 この反復について返します(実質的には、ドラッグ&ドロップ操作の「欠落したフレームをスキップ」します)。
ソースノードで drag という名前の
DND イベントを発生させます。
このイベントがキャンセルされた場合、ユーザーエージェントは現在のドラッグ操作を「none」(ドラッグ操作なし)に設定しなければなりません。
drag イベントがキャンセルされず、かつユーザーがドラッグ&ドロップ操作を
終了していない場合、次のようにドラッグ&ドロップ操作の状態を確認します。
ユーザーが前の反復時とは異なる直接のユーザー選択を示している場合 (またはこれが最初の反復である場合)、かつこの直接のユーザー選択が現在の対象要素と同じでない場合、 次のように現在の対象要素を更新します。
現在の対象要素も null に設定します。
直接のユーザー選択で dragenter という名前のDND イベントを発生させます。
イベントがキャンセルされた場合、現在の対象要素を直接のユーザー選択に設定します。
それ以外の場合、次のリストから適切な手順を実行します。
textarea、または type 属性がテキスト
状態である input 要素)、編集ホスト、または編集可能な要素であり、かつドラッグデータストア項目リストに、
ドラッグデータ項目の型文字列が
「text/plain」であり、
ドラッグデータ項目の種類が
テキストである項目がある場合
現在の対象要素を変更せずに残します。
body
要素がある場合はそこで、
ない場合は Document オブジェクトで、dragenter という名前のDND イベントを発生させます。
次に、そのイベントがキャンセルされたかどうかにかかわらず、現在の対象要素をbody
要素に設定します。
前の手順によって現在の対象要素が変更され、かつ
前の対象要素が null でも DOM 以外の文書の一部でもなかった場合、前の対象要素で dragleave という名前のDND イベントを発生させ、新しい現在の対象要素を特定の
related target として使用します。
現在の対象要素が DOM 要素である場合、
この現在の対象要素で dragover という名前のDND イベントを発生させます。
dragover イベントがキャンセルされなかった場合、次のリストから
適切な手順を実行します。
textarea、または type 属性がテキスト
状態である input 要素)、編集ホスト、または編集可能な要素であり、かつドラッグデータストア項目リストに、
ドラッグデータ項目の型文字列が
「text/plain」であり、
ドラッグデータ項目の種類が
テキストである項目がある場合
それ以外の場合(dragover イベントがキャンセルされた場合)、
イベントのディスパッチ完了後の DragEvent オブジェクトの
dataTransfer オブジェクトの effectAllowed および dropEffect 属性の値に基づいて、次の表に従い
現在のドラッグ操作を設定します。
effectAllowed
|
dropEffect
|
ドラッグ操作 |
|---|---|---|
「uninitialized」、
「copy」、
「copyLink」、
「copyMove」、
または「all」
|
「copy」
|
「copy」
|
「uninitialized」、
「link」、
「copyLink」、
「linkMove」、
または「all」
|
「link」
|
「link」
|
「uninitialized」、
「move」、
「copyMove」、
「linkMove」、
または「all」
|
「move」
|
「move」
|
| そのほかの場合 | 「none」
|
|
それ以外の場合、現在の対象要素が DOM 要素でないなら、 プラットフォーム固有の機構を使用して、どのドラッグ操作(なし、コピー、リンク、または移動)が 実行されているかを決定し、それに応じて現在のドラッグ操作を設定します。
次のように、ドラッグのフィードバック(たとえばマウスカーソル)を現在のドラッグ操作に一致するよう 更新します。
| ドラッグ操作 | フィードバック |
|---|---|
「copy」
|
ここでドロップすると、データがコピーされます。 |
「link」
|
ここでドロップすると、データがリンクされます。 |
「move」
|
ここでドロップすると、データが移動されます。 |
「none」
|
操作は許可されていません。ここでドロップすると、ドラッグ&ドロップ操作がキャンセルされます。 |
それ以外の場合、ユーザーがドラッグ&ドロップ操作を終了した場合(たとえば、マウスによる
ドラッグ&ドロップインターフェイスでマウスボタンを離した場合)、または drag
イベントがキャンセルされた場合、これが最後の反復になります。次の手順を実行し、その後
ドラッグ&ドロップ操作を停止します。
現在のドラッグ操作が「none」(ドラッグ操作なし)である場合、
ユーザーがドラッグ&ドロップ操作をキャンセルして終了した場合(たとえば
Escape キーを押した場合)、または現在の対象要素が null である場合、
ドラッグ操作は失敗しました。次の下位手順を実行します。
dropped を false とします。
現在の対象要素が DOM 要素である場合、
そこで dragleave という名前のDND イベントを発生させます。
それ以外の場合、null でなければ、ドラッグのキャンセルに関するプラットフォーム固有の慣例を
使用します。
それ以外の場合、ドラッグ操作は成功する可能性があります。次の下位手順を実行します。
dropped を true とします。
現在の対象要素が DOM 要素である場合、
そこで drop という名前のDND イベントを発生させます。
それ以外の場合、ドロップを示すためのプラットフォーム固有の慣例を使用します。
イベントがキャンセルされた場合、現在のドラッグ操作を、
イベントのディスパッチ完了後の DragEvent
オブジェクトの dataTransfer オブジェクトの dropEffect 属性の値に設定します。
それ以外の場合、イベントはキャンセルされていません。正確な対象に応じて、次のように イベントの既定アクションを実行します。
textarea、または type 属性がテキスト
状態である input 要素)、編集ホスト、または編集可能な要素であり、かつドラッグデータストア項目リストに、
ドラッグデータ項目の型文字列が
「text/plain」であり、
ドラッグデータ項目の種類が
テキストである項目がある場合
ドラッグデータストア項目
リスト内にある、ドラッグデータ項目の
型文字列が「text/plain」であり、
ドラッグデータ項目の種類が
テキストである最初の項目の実際のデータを、プラットフォーム固有の慣例と一致する方法
(たとえば、現在のマウスカーソル位置へ挿入するか、フィールドの末尾へ挿入する方法)で、
テキストコントロール、編集ホスト、または編集可能な要素へ挿入します。
ソースノードで dragend という名前のDND イベントを発生させます。
dragend イベントの既定アクションとして、次のリストから適切な
手順を実行します。
move」であり、ドラッグ&ドロップ操作の
ソースが DOM 内の選択範囲で、その全体が編集ホスト内に含まれている場合
選択範囲を削除します。
move」であり、ドラッグ&ドロップ操作の
ソースがテキストコントロール内の選択範囲である場合ユーザーエージェントは、関連するテキストコントロールからドラッグされた選択範囲を 削除するべきです。
none」である場合
ドラッグはキャンセルされました。プラットフォームの慣例により、これをユーザーへ示すことが 求められる場合(たとえば、ドラッグされた選択範囲がドラッグ&ドロップ操作のソースへ戻る アニメーションを表示する場合)、そのようにします。
イベントには既定アクションがありません。
この手順において、テキストコントロールとは、textarea 要素、または type 属性がテキスト、
検索、
電話番号、
URL、
メール、
パスワード、または
数値
状態のいずれかである input 要素です。
ユーザーエージェントは、スクロール可能領域の端付近でのドラッグにどのように反応するかを 考慮することが推奨されます。たとえば、ユーザーが長いページ上のビューポートの下端へリンクをドラッグした場合、ユーザーがページの さらに下へリンクをドロップできるように、ページをスクロールすることが適切な場合があります。
このモデルは、関与するノードがどの Document オブジェクトに
由来するかには依存しません。操作に関与する文書の数に関係なく、イベントは上記のとおりに発生し、
処理モデルの残りの部分も上記のとおりに実行されます。
この節は参考情報です。
次のイベントがドラッグ&ドロップモデルに関与します。
| イベント名 | 対象 | キャンセル可能か | ドラッグデータストアのモード | dropEffect
|
既定アクション |
|---|---|---|---|---|---|
dragstart
現在のすべてのエンジンでサポートされています。 Firefox9+Safari3.1+Chrome1+
Opera12+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android12+ |
ソースノード | ✓ キャンセル可能 | 読み書きモード | "none"
|
ドラッグ&ドロップ操作を開始する |
drag
現在のすべてのエンジンでサポートされています。 Firefox9+Safari3.1+Chrome1+
Opera12+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android12+ |
ソースノード | ✓ キャンセル可能 | 保護モード | "none"
|
ドラッグ&ドロップ操作を継続する |
dragenter
現在のすべてのエンジンでサポートされています。 Firefox9+Safari3.1+Chrome1+
Opera12+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android12+ |
直接のユーザー選択、または body 要素 | ✓ キャンセル可能 | 保護モード | effectAllowed 値に基づく |
潜在的な対象 要素としての直接の ユーザー選択を拒否する |
dragleave
現在のすべてのエンジンでサポートされています。 Firefox9+Safari3.1+Chrome1+
Opera12+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android12+ |
以前の対象要素 | — | 保護モード | "none"
|
なし |
dragover
現在のすべてのエンジンでサポートされています。 Firefox9+Safari3.1+Chrome1+
Opera12+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android12+ |
現在の対象要素 | ✓ キャンセル可能 | 保護モード | effectAllowed 値に基づく |
現在のドラッグ操作を "none" にリセットする |
drop
現在のすべてのエンジンでサポートされています。 Firefox9+Safari3.1+Chrome1+
Opera12+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android12+ |
現在の対象要素 | ✓ キャンセル可能 | 読み取り専用モード | 現在のドラッグ操作 | 場合による |
dragend
現在のすべてのエンジンでサポートされています。 Firefox9+Safari3.1+Chrome1+
Opera12+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android12+ |
ソースノード | — | 保護モード | 現在のドラッグ操作 | 場合による |
これらのイベントはすべてバブリングし、構成されます。また、effectAllowed
属性は常に、dragstart
イベント後に持っていた値を持ちます。dragstart
イベントでは、既定値は
"uninitialized"
です。
draggable 属性現在のすべてのエンジンでサポートされています。
すべてのHTML 要素には、draggable 内容
属性を設定できます。draggable 属性は、次の
キーワードおよび状態を持つ列挙属性です。
| キーワード | 状態 | 簡単な説明 |
|---|---|---|
true
|
真 | 要素はドラッグ可能になります。 |
false
|
偽 | 要素はドラッグ可能になりません。 |
draggable 属性を持つ要素は、
非視覚的インタラクションのために要素へ名前を付ける title
属性も持つべきです。
element.draggable [ = value ]
要素がドラッグ可能な場合は true を返し、それ以外の場合は false を返します。
既定値を上書きして draggable
内容属性を
設定するために、値を設定できます。
draggable IDL
属性は、その値が以下で説明する方法により内容属性に依存し、要素がドラッグ可能かどうかを制御します。
一般に、ドラッグ可能なのはテキスト選択範囲だけですが、draggable IDL 属性が true の
要素もドラッグ可能になります。
要素の draggable 内容属性が
真状態である
場合、draggable IDL 属性は
true を返さなければなりません。
それ以外の場合、要素の draggable
内容属性が
偽状態である場合、draggable IDL 属性は
false を返さなければなりません。
それ以外の場合、要素の draggable
内容属性は
自動状態です。要素が img 要素、画像を表す object 要素、または
href 内容属性を持つ a 要素である場合、draggable IDL 属性は
true を返さなければなりません。それ以外の場合、draggable IDL 属性は
false を返さなければなりません。
draggable IDL
属性が false に設定された場合、draggable 内容属性を
リテラル値 "false" に設定しなければなりません。draggable IDL
属性が true に設定された場合、draggable 内容属性を
リテラル値 "true" に設定しなければなりません。
ユーザーエージェントは、dragstart イベント中に DataTransfer オブジェクトへ追加されたデータを、drop
イベントまでスクリプトから利用可能にしてはなりません。そうしなければ、ユーザーが機密情報をある文書から
2 番目の文書へドラッグする途中で悪意のある第 3 の文書を通過した場合、その悪意のある文書がデータを
傍受できるためです。
同じ理由により、ユーザーエージェントは、ユーザーがドラッグ操作を明示的に終了した場合に限り、
ドロップが成功したとみなさなければなりません。いずれかのスクリプトがドラッグ操作を終了した場合、
失敗(キャンセル)とみなし、drop
イベントを発生させてはなりません。
ユーザーエージェントは、スクリプトの動作に応じてドラッグ&ドロップ操作を開始しないよう注意するべきです。 たとえば、マウスおよびウィンドウを使用する環境で、ユーザーがマウスボタンを押したままの状態でスクリプトが ウィンドウを移動した場合、UA はそれをドラッグの開始とはみなしません。これは重要です。そうしなければ、 UA がユーザーの同意なしに機密性の高いソースからデータをドラッグし、悪意のある文書へドロップさせる 可能性があるためです。
ユーザーエージェントは、潜在的に能動的な(スクリプト化された)内容(たとえば HTML)がドラッグされる とき、およびドロップされるとき、既知の安全な機能の許可リストを使用してその内容をフィルタリングする べきです。同様に、参照先が予期しない形で変化することを避けるため、相対 URLを 絶対 URL へ変換するべきです。この仕様では、これをどのように行うかは規定しません。
悪意のあるページが何らかの内容を提供し、ユーザーにその内容を選択して被害を受けるページの contenteditable 領域へドラッグ&ドロップ(またはコピー&ペースト)
させる場合を考えてください。ブラウザーが安全な内容だけがドラッグされることを保証しない場合、選択範囲内の
スクリプトやイベントハンドラーなどの潜在的に安全でない内容は、被害を受けるサイトへドロップ(または
ペースト)されると、そのサイトの権限を得ます。その結果、クロスサイトスクリプティング攻撃が可能に
なります。
popover 属性現在のすべてのエンジンでサポートされています。
すべてのHTML 要素には、popover 内容
属性を設定できます。指定された場合、要素は表示状態になるまでレンダリングされず、表示状態になると、
ページ内のそのほかの内容の上にレンダリングされます。
popover 属性は、
作者が最も適切なセマンティクスを持つ要素へポップオーバー機能を適用できるようにする柔軟性を提供する
グローバル属性です。
次の例は、ウェブサイトのグローバルナビゲーション内に、リンクのポップオーバー型サブナビゲーション リストを作成する方法を示しています。
< ul >
< li >
< a href = ... > すべての商品</ a >
< button popovertarget = sub-nav >
< img src = down-arrow.png alt = "商品ページ" >
</ button >
< ul popover id = sub-nav >
< li >< a href = ... > シャツ</ a >
< li >< a href = ... > 靴</ a >
< li >< a href = ... > 帽子など</ a >
</ ul >
</ li >
<!-- そのほかのリスト項目およびリンクをここに置く -->
</ ul > アクセシビリティセマンティクスを持たない要素、たとえば div 要素で popover を使用する場合、
作者はポップオーバーをアクセシブルにするため、適切な ARIA 属性を使用するべきです。
次の例は、カスタムメニューポップオーバーを作成するための基本的なマークアップを示しています。
autofocus 属性を使用しているため、ポップオーバーが呼び出されると、最初のメニュー項目が
キーボードフォーカスを受け取ります。矢印キーによるメニュー項目間の移動およびアクティベーション動作には、
依然として作者によるスクリプトが必要です。カスタムメニューウィジェットを構築するための追加要件は、
WAI-ARIA
仕様で定義されています。
< button popovertarget = m > 操作</ button >
< div role = menu id = m popover >
< button role = menuitem tabindex = -1 autofocus > 編集</ button >
< button role = menuitem tabindex = -1 > 非表示</ button >
< button role = menuitem tabindex = -1 > 削除</ button >
</ div > ポップオーバーは、ユーザーが実行した操作を確認するステータスメッセージのレンダリングに役立つ場合が
あります。次の例は、output
要素内でポップオーバーを表示する方法を示しています。
< button id = submit > 送信</ button >
< p >< output >< span popover = manual ></ span ></ output ></ p >
< script >
const sBtn = document. getElementById( "submit" );
const outSpan = document. querySelector( "output [popover=manual]" );
let successMessage;
let errorMessage;
/* 操作が成功したかどうかを決定するロジックと、
使用する適切な成功メッセージまたはエラーメッセージを
決定するロジックを定義する */
sBtn. addEventListener( "click" , ()=> {
if ( success ) {
outSpan. textContent = successMessage;
}
else {
outSpan. textContent = errorMessage;
}
outSpan. showPopover();
setTimeout( function () {
outSpan. hidePopover();
}, 10000 );
});
</ script > output
要素へ
ポップオーバー要素を挿入すると、一般に、その内容が可視になったときスクリーンリーダーがその内容を
読み上げます。内容の複雑さまたは表示頻度によっては、これらの支援技術を使用するユーザーにとって有用な
場合もあれば、煩わしい場合もあります。最良のユーザー体験を確保するため、output 要素または
そのほかの ARIA ライブ領域を使用するときは、この点に留意してください。
popover 属性は、
次のキーワードおよび状態を持つ列挙属性です。
| キーワード | 状態 | 簡単な説明 |
|---|---|---|
auto
|
自動 | 開いたときにそのほかのポップオーバーを閉じます。ライトディスミスを持ち、閉じる要求に応答します。 |
manual
|
手動 | そのほかのポップオーバーを閉じません。ライトディスミスを行わず、閉じる要求にも応答しません。 |
hint |
ヒント | 開いたときにそのほかのヒントポップオーバーを閉じますが、そのほかの自動ポップオーバーは閉じません。 ライトディスミスを持ち、閉じる要求に応答します。 |
現在のすべてのエンジンでサポートされています。
popover IDL 属性は、popover 属性を、既知の値だけに
制限して反映しなければなりません。
すべてのHTML 要素には、 ポップオーバーの可視性状態があり、初期状態は であり、 次の値を取り得ます。
非表示
表示中
すべての Document には、
ポップオーバーの pointerdown 対象があり、これはHTML 要素または null であり、
初期状態は null です。
すべてのHTML 要素には、 ポップオーバートリガーがあり、これはHTML 要素または null であり、初期状態は null です。
すべてのHTML 要素には、 ポップオーバーを非表示にしているかがあり、これは真偽値であり、 初期状態は false です。
すべてのHTML 要素には、 ポップオーバー切り替えタスクトラッカーがあり、 これは切り替えタスクトラッカーまたは null であり、 初期状態は null です。
すべてのHTML 要素には、 ポップオーバーの閉じる監視機能があり、これは閉じる監視機能または null であり、 初期状態は null です。
すべてのHTML 要素には、
ポップオーバーモードで開かれた状態があり、これは
"auto"、"hint"、または null であり、初期状態は null です。
すべての Document には、
ポップオーバー非表示処理の入れ子数があり、これは数値であり、
初期値は 0 です。
すべての Document には、
ポップオーバーを表示中かがあり、これは真偽値であり、初期値は
false です。
すべての Document には、
ヒントスタックの親があり、これはHTML 要素または null であり、初期値は null です。
ヒントスタックの親は、 表示中のヒントポップオーバーリストの最初の項目の 「親」が、表示中の自動ポップオーバーリスト内のどの項目であるかを 追跡します。また、表示中のヒントポップオーバーリストの最初の項目が 表示中の自動ポップオーバーリスト内の項目の「子」でない 場合は、null です。
したがって、ヒントスタックの親が null でない場合、その
ポップオーバーモードで開かれた状態は
"auto" になります。
element、localName、oldValue、value、および namespace を指定して、次の属性変更手順が、すべてのHTML 要素に使用されます。
namespace が null でない場合、返します。
localName が popover でない場合、
返します。
element のポップオーバーの可視性状態が表示中状態であり、oldValue および value が 異なる状態にある場合、element、true、true、 false、および null を指定して、ポップオーバーを非表示にするアルゴリズムを 実行します。
element.showPopover()popover 属性が
自動状態である場合、最上位ポップオーバー祖先アルゴリズムに従って
element の祖先となるものを除き、そのほかのすべての自動ポップオーバーも閉じます。
element.hidePopover()display: none を
適用することで非表示にします。
element.togglePopover()現在のすべてのエンジンでサポートされています。
showPopover(options) メソッドの手順は次のとおりです。
this、true、および source を指定して、ポップオーバーを表示するを実行します。
HTML 要素 element、真偽値 throwExceptions、およびHTML 要素または null の source を指定して、 ポップオーバーを表示するには、次を行います。
document を、element のノード文書とします。
document のポップオーバーを表示中かが true である場合、または document のポップオーバー非表示処理の入れ子数が 0 でない場合、次を行います。
throwExceptions が true である場合、"InvalidStateError" DOMException をスローします。
返します。
これにより、別のポップオーバーを表示または非表示にしている間にポップオーバーが 表示されることを防ぎます。
validityResult を、element、false、および null を指定してポップオーバーの妥当性を確認するを実行した 結果とします。これが例外をスローした場合、その例外を捕捉し、validityResult をその例外に 設定します。
validityResult が true でない場合、次を行います。
throwExceptions が true であり、かつ validityResult が DOMException である場合、
validityResult をスローします。
返します。
表明:element のポップオーバートリガーは null です。
document のポップオーバーを表示中かを true に設定します。
cleanupShowingSteps を次の手順とします。
document のポップオーバーを表示中かを false に設定します。
element で、ToggleEvent を使用し、cancelable 属性を true に、
oldState 属性を "closed" に、newState 属性を "open" に、source
属性を source に初期化して、beforetoggle という名前のイベントを発生させた結果が false である場合、
cleanupShowingSteps を実行して返します。
validityResult を、element、false、および document を指定して ポップオーバーの妥当性を確認するを実行した 結果に設定します。これが例外をスローした場合、その例外を捕捉し、validityResult を その例外に設定します。
beforetoggle イベントの発生によって、この要素が切断されたり、
その popover 属性が変更されたりする可能性があるため、ポップオーバーの妥当性を確認するが再度呼び出されます。
validityResult が true でない場合、次を行います。
cleanupShowingSteps を実行します。
throwExceptions が true であり、かつ validityResult が DOMException である場合、
validityResult をスローします。
返します。
shouldRestoreFocus を false とします。
originalType を、element の popover 属性の
現在の状態とします。
effectiveType を originalType とします。
originalType が自動またはヒントである場合、次を行います。
ancestor を、element、source、および true を指定して最上位ポップオーバー祖先アルゴリズムを 実行した結果とします。
次のすべてが true である場合、次を行います。
ancestor が null でない。
ancestor のポップオーバーモードで開かれた状態が
"hint" である。かつ
effectiveType が自動状態である。
この場合、effectiveType をヒント状態に設定します。
ヒントポップオーバーは自動ポップオーバーより優先度が低いため、 自動ポップオーバーはヒントポップオーバーを「親」として持つことは できません。この場合を解決するため、effectiveType はヒントへ「格下げ」されます。
document、ancestor、ヒント、 shouldRestoreFocus、および true を指定して、指定位置までポップオーバースタックを 非表示にするを実行します。
effectiveType が自動状態である場合、 document、ancestor、自動、 shouldRestoreFocus、および true を指定して、指定位置までポップオーバースタックを 非表示にするを実行します。
originalType が element の popover 属性の値と
等しくない場合、次を行います。
cleanupShowingSteps を実行します。
throwExceptions が true である場合、"InvalidStateError" DOMException をスローします。
返します。
validityResult を、element、false、および document を指定して ポップオーバーの妥当性を確認するを実行した 結果に設定します。これが例外をスローした場合、その例外を捕捉し、validityResult を その例外に設定します。
上記の指定位置までポップオーバースタックを
非表示にするの実行によって、beforetoggle イベントが発生し、イベントハンドラーがこの要素を
切断したり、その popover 属性を変更したりする可能性があるため、ポップオーバーの妥当性を確認するが再度
呼び出されます。
validityResult が true でない場合、次を行います。
cleanupShowingSteps を実行します。
throwExceptions が true であり、かつ validityResult が DOMException である場合、
validityResult をスローします。
返します。
document に対して最上位の自動またはヒントポップオーバーを 実行した結果が null である場合、shouldRestoreFocus を true に設定します。
これにより、スタック内の最初のポップオーバーについてのみ、以前フォーカスされていた 要素へフォーカスが戻されます。
effectiveType が自動である場合、次を行います。
表明:document の表示中の自動ポップオーバーリストは element を含みません。
element のポップオーバーモードで開かれた状態を
"auto" に設定します。
それ以外の場合、次を行います。
表明:document の表示中のヒントポップオーバーリストは element を含みません。
element のポップオーバーモードで開かれた状態を
"hint" に設定します。
element のポップオーバーの閉じる監視機能を、 element の関連するグローバルオブジェクトを指定し、 次の設定で閉じる監視機能を確立した結果に設定します。
cancelAction は true を返します。
closeAction は、element、true、 true、false、および null を指定してポップオーバーを非表示にすることです。
getEnabledState は true を返します。
element の以前フォーカスされていた要素を null に 設定します。
originallyFocusedElement を、document の文書のフォーカス領域のDOM アンカーとします。
element を指定して、要素を最上位レイヤーへ追加します。
effectiveType がヒントであり、ancestor の
ポップオーバーモードで開かれた状態が
"auto" である場合、document のヒントスタックの親を ancestor に
設定します。
element のポップオーバーの可視性状態を表示中に設定します。
element のポップオーバートリガーを source に 設定します。
element の暗黙的アンカー要素を source に設定します。
element を指定して、ポップオーバーのフォーカス手順を実行します。
shouldRestoreFocus が true であり、かつ element の popover 属性が
ポップオーバーなし状態でない場合、
element の以前フォーカスされていた要素を
originallyFocusedElement に設定します。
cleanupShowingSteps を実行します。
element、"closed"、"open"、および
source を指定して、ポップオーバー切り替えイベントタスクを
キューに追加します。
要素 element、文字列 oldState、文字列 newState、および
Element または null の
source を指定して、ポップオーバー切り替えイベントタスクをキューに追加するには、
次を行います。
element のポップオーバー切り替えタスクトラッカーが null でない場合、次を行います。
oldState を、element のポップオーバー切り替えタスク トラッカーの旧状態に設定します。
element のポップオーバー切り替えタスク トラッカーのタスクを、そのタスクキューから削除します。
element のポップオーバー切り替えタスク トラッカーを null に設定します。
DOM 操作タスクソースおよび element を指定して、次の手順を実行する要素タスクをキューに追加します。
element で、ToggleEvent を使用し、oldState 属性を oldState に、newState 属性を newState に、source 属性を source に初期化して、
toggle という名前の
イベントを発生させます。
element のポップオーバー切り替えタスクトラッカーを null に設定します。
element のポップオーバー切り替えタスクトラッカーを、 タスクが今キューに 追加されたタスクに設定され、旧状態が oldState に設定された 構造体に設定します。
現在のすべてのエンジンでサポートされています。
hidePopover()
メソッドの手順は次のとおりです。
this、true、true、true、および null を指定して、ポップオーバーを非表示にするアルゴリズムを 実行します。
HTML 要素 element、真偽値 focusPreviousElement、真偽値 fireEvents、真偽値 throwExceptions、およびHTML 要素または null の source を指定して、 ポップオーバーを非表示にするには、次を行います。
validityResult を、element、true、および null を指定してポップオーバーの妥当性を確認するを実行した 結果とします。これが例外をスローした場合、その例外を捕捉し、validityResult をその例外と します。
validityResult が true でない場合、次を行います。
throwExceptions が true であり、かつ validityResult が DOMException である場合、
validityResult をスローします。
返します。
document を、element のノード文書とします。
nestedHide を、element のポップオーバーを非表示にしているかとします。
element のポップオーバーを非表示にしているかを true に設定します。
nestedHide が true である場合、fireEvents を false に設定します。
document のポップオーバー非表示処理の入れ子数を 1 増やします。
cleanupSteps を次の手順とします。
nestedHide が false である場合、element のポップオーバーを非表示にしているかを false に 設定します。
element のポップオーバーの閉じる監視機能が null でない場合、次を行います。
element のポップオーバーの閉じる監視機能を 破棄します。
element のポップオーバーの閉じる監視機能を null に設定します。
document のポップオーバー非表示処理の入れ子数を 1 減らします。
autoPopoverListContainsElement を、document の表示中の自動ポップオーバーリストが element を含む場合は true とし、それ以外の場合は false とします。
hintPopoverListContainsElement を、document の表示中のヒントポップオーバーリストが element を含む場合は true とし、それ以外の場合は false とします。
element のポップオーバーモードで開かれた状態が
"auto" または "hint" である場合、次を行います。
hintPopoverListContainsElement が true である場合、document、 element、ヒント、 focusPreviousElement、および fireEvents を指定して、指定位置までポップオーバースタックを 非表示にするを実行します。
element が document のヒントスタックの親である場合、 document、null、ヒント、 focusPreviousElement、および fireEvents を指定して、指定位置までポップオーバースタックを 非表示にするを実行します。
document のヒントスタックの親が非表示にされている場合、 すべてのヒントポップオーバーが非表示になります。
autoPopoverListContainsElement が true である場合、document、 element、自動、 focusPreviousElement、および fireEvents を指定して、指定位置までポップオーバースタックを 非表示にするを実行します。
validityResult を、element、true、および null を指定してポップオーバーの妥当性を確認するを実行した 結果に設定します。これが例外をスローした場合、その例外を捕捉し、 validityResult をその例外に設定します。
指定位置までポップオーバースタックを
非表示にするの実行によって、element が切断されたり、その popover 属性が
変更されたりする可能性があるため、ポップオーバーの妥当性を確認するが
再度呼び出されます。
validityResult が true でない場合、次を行います。
cleanupSteps を実行します。
throwExceptions が true であり、かつ validityResult が DOMException である場合、
validityResult をスローします。
返します。
fireEvents が true である場合、次を行います。
element で、ToggleEvent を使用し、
oldState 属性を "open" に、newState 属性を "closed" に、source 属性を source に設定して、beforetoggle という名前のイベントを発生させます。
validityResult を、element、true、および null を指定してポップオーバーの妥当性を確認するを実行した 結果に設定します。これが例外をスローした場合、その例外を捕捉し、 validityResult をその例外に設定します。
beforetoggle イベントの発生によって、
element が切断されたり、その popover 属性が
変更されたりする可能性があるため、ポップオーバーの妥当性を確認するが
再度呼び出されます。
validityResult が true でない場合、次を行います。
cleanupSteps を実行します。
throwExceptions が true であり、かつ validityResult が DOMException である場合、
validityResult をスローします。
返します。
element を指定して、要素を最上位レイヤーから 削除するよう要求します。
element の暗黙的アンカー要素を null に設定します。
それ以外の場合、element を指定して、要素を最上位レイヤーから直ちに 削除します。
element のポップオーバートリガーを null に設定します。
element のポップオーバーモードで開かれた状態を null に 設定します。
element のポップオーバーの可視性状態をに設定します。
element が document のヒントスタックの親である場合、または document の表示中のヒントポップオーバーリストが 空である場合、 document のヒントスタックの親を null に設定します。
fireEvents が true である場合、element、"open"、
"closed"、および source を指定して、ポップオーバー切り替えイベントタスクを
キューに追加します。
previouslyFocusedElement を、element の以前フォーカスされていた要素とします。
previouslyFocusedElement が null でない場合、次を行います。
element の以前フォーカスされていた要素を null に設定します。
focusPreviousElement が true であり、かつ document の文書のフォーカス領域のDOM アンカーが、 element のシャドウを含む包括的子孫である場合、 previouslyFocusedElement に対してフォーカス手順を実行します。この手順によって ビューポートをスクロールするべきではありません。
cleanupSteps を実行します。
現在のすべてのエンジンでサポートされています。
togglePopover(options) メソッドの手順は次のとおりです。
force を null とします。
options が真偽値である場合、force を options に設定します。
それ以外の場合、options["force"] が存在する場合、
force を options["force"] に設定します。
options["source"] が存在する場合、
source をその値とし、それ以外の場合は null とします。
this のポップオーバーの可視性状態が表示中であり、かつ force が null または false である場合、this、true、true、true、 および null を指定して、ポップオーバーを非表示にするアルゴリズムを 実行します。
それ以外の場合、force が null または true である場合、this、true、および source を指定して、ポップオーバーを表示するを実行します。
それ以外の場合、次を行います。
expectedToBeShowing を、this のポップオーバーの可視性状態が表示中である場合は true とし、 それ以外の場合は false とします。
this、expectedToBeShowing、および null を指定して、ポップオーバーの妥当性を確認するを 実行します。
this のポップオーバーの可視性状態が表示中である場合は true を返し、 それ以外の場合は false を返します。
Document
document、HTML 要素または null の
endpoint、真偽値
focusPreviousElement、および真偽値 fireEvents を指定して、
指定位置までポップオーバーを非表示にするには、
次を行います。
endpointIsHint を、document の表示中のヒントポップオーバーリストが endpoint を含む場合は true とし、それ以外の場合は false とします。
document、endpoint、ヒント、 focusPreviousElement、および fireEvents を指定して、指定位置までポップオーバースタックを 非表示にするを実行します。
endpointIsHint が true である場合、返します。
document、endpoint、自動、 focusPreviousElement、および fireEvents を指定して、指定位置までポップオーバースタックを 非表示にするを実行します。
Document
document、HTML 要素または null の
endpoint、自動またはヒントの stackType、真偽値
focusPreviousElement、および真偽値 fireEvents を指定して、
指定位置までポップオーバースタックを非表示にするには、
次を行います。
popoverList を、stackType が自動である場合は document の表示中の自動ポップオーバーリストとし、 それ以外の場合は document の表示中のヒントポップオーバーリストと します。
lastHideIndex を、popoverList が endpoint を含まない場合は 0 とし、それ以外の場合は popoverList 内の endpoint のインデックスに 1 を加えた値とします。
toHide の各 popover について、popover、 focusPreviousElement、fireEvents、false、および null を指定して、ポップオーバーを非表示にするアルゴリズムを 実行します。
newPopoverList を、stackType が自動である場合は document の表示中の自動ポップオーバーリストとし、 それ以外の場合は document の表示中のヒントポップオーバーリストと します。
toCheck を、newPopoverList を逆順にしたものとします。
toCheck の各 popover について、次を行います。
toRemain が popover を含む場合、続行します。
popover、focusPreviousElement、false、false、および null を指定して、 ポップオーバーを非表示にするアルゴリズムを 実行します。
これは、ポップオーバーを非表示にしている間にポップオーバーが表示された場合、
たとえば beforetoggle イベント内で発生します。これは通常、
開発者の誤りであるため、ユーザーエージェントには警告を表示することが推奨されます。この追加の
非表示処理段階では、fireEvents は無視され、代わりに false が使用されます。
指定位置までポップオーバースタックを非表示にする アルゴリズムは、何らかの動作が発生したときに開いたままにならないすべてのポップオーバーを非表示にするため、 複数の場合に使用されます。たとえば、ポップオーバーのライトディスミス中、このアルゴリズムは、ユーザーが クリックしたノードと関係のないポップオーバーだけを閉じることを保証します。
Node
newPopoverOrTopLayerElement、HTML
要素または null の source、および
真偽値 isPopover を指定して、最上位ポップオーバー祖先を見つけるには、次の手順を実行します。これらは
HTML 要素または null を返します。
最上位ポップオーバー祖先アルゴリズムは、 指定されたポップオーバーまたは最上位レイヤー要素について、最上位の祖先ポップオーバーを返します。 ポップオーバーは複数の方法で相互に関連付けられ、ポップオーバーのツリーを形成できます。ある ポップオーバー(「子」ポップオーバーと呼びます)が最上位の祖先ポップオーバー(「親」 ポップオーバーと呼びます)を持つ経路は、次の 2 つです。
ポップオーバーがノードツリー内で相互に入れ子になっている場合。この場合、子孫ポップオーバーが 「子」であり、その最上位の祖先ポップオーバーが「親」です。
要素がポップオーバーの「ソース」である場合(たとえば、command がポップオーバーを表示状態である
button)。この場合、ポップオーバーが「子」であり、
トリガー要素が属するポップオーバー部分ツリーが「親」です。トリガー要素はポップオーバー内にあり、
開いているポップオーバーを参照していなければなりません。
上記で形成される各関係では、親ポップオーバーは、子ポップオーバーよりも表示中の自動ポップオーバーリストまたは表示中のヒントポップオーバーリスト内で 厳密に前になければならず、そうでなければ有効な祖先関係を形成しません。これにより、表示されていない ポップオーバーおよび自己参照(たとえば、自身を含むポップオーバーを指し戻す呼び出し要素を含む ポップオーバー)が除外され、接続の(循環している可能性のある)グラフから整形式のツリーを構築できます。 自動およびヒントポップオーバーだけが考慮されます。
指定された要素が、ポップオーバーとして表示されていない dialog などの
最上位レイヤー要素である場合、最上位ポップオーバー祖先は、最初の
ポップオーバーを見つけるためにノードツリーだけを調べます。
isPopover が true である場合、次を行います。
表明:newPopoverOrTopLayerElement の popover 属性は、
ポップオーバーなし状態または手動状態ではありません。
表明:newPopoverOrTopLayerElement のポップオーバーの可視性状態は、 ポップオーバー表示中状態ではありません。
それ以外の場合、次を行います。
表明:source は null です。
document を、newPopoverOrTopLayerElement のノード文書とします。
combinedPopovers を、document の表示中の自動ポップオーバーリストを document の表示中のヒントポップオーバーリストで 拡張したものとします。
popoverAncestorIndex を、newPopoverOrTopLayerElement がフラットツリーの子孫となっている combinedPopovers 内の最後の項目のインデックスとし、存在しない場合は -1 とします。
sourceAncestorIndex を -1 とします。
source が null でない場合、sourceAncestorIndex を、 source がフラットツリーの子孫となっている combinedPopovers 内の最後の項目のインデックスに設定し、存在しない場合は -1 に設定します。
ancestorIndex を、popoverAncestorIndex および sourceAncestorIndex の最大値とします。
ancestorIndex が -1 である場合、null を返します。
combinedPopovers[ancestorIndex] を返します。
Node node を指定して、
最も近い包括的な開いているポップオーバーを見つけるには、
次の手順を実行します。これらはHTML 要素または null を返します。
currentNode を node とします。
currentNode が null でない間、次を行います。
currentNode のポップオーバーモードで開かれた状態が
"auto" または "hint" であり、かつ currentNode の
ポップオーバーの可視性状態が表示中である場合、
currentNode を返します。
currentNode を、フラットツリー内の currentNode の親に設定します。
null を返します。
Document
document を指定して、最上位の自動またはヒント
ポップオーバーを見つけるには、次の手順を実行します。これらはHTML
要素または null を返します。
document の表示中のヒントポップオーバーリストが 空でない場合、document の表示中のヒントポップオーバーリストの 最後の要素を返します。
document の表示中の自動ポップオーバーリストが空でない場合、 document の表示中の自動ポップオーバーリストの最後の要素を 返します。
null を返します。
HTML 要素 subject に対して、 ポップオーバーのフォーカス手順を実行するには、次を行います。
subject が dialog 要素である
場合、subject を指定してダイアログのフォーカス手順を実行し、返します。
subject が autofocus 属性を
持つ場合、control を subject とします。
それ以外の場合、control を、"other" を指定した
subject のautofocus
委任先とします。
control が null である場合、返します。
control を指定して、フォーカス手順を実行します。
topDocument を、control のノードナビゲーブルの最上位の辿ることができるナビゲーブルのアクティブな文書とします。
topDocument のautofocus 候補を空にします。
topDocument のautofocus 処理済みフラグを true に設定します。
HTML 要素 element について、真偽値
expectedToBeShowing および Document または null の
expectedDocument を指定して、ポップオーバーの妥当性を確認するには、次の手順を実行します。
これらは例外をスローするか、真偽値を返します。
element の popover 属性がポップオーバーなし状態である場合、"NotSupportedError" DOMException をスローします。
次のいずれかが true である場合、次を行います。
expectedToBeShowing が true であり、かつ element のポップオーバーの可視性状態が表示中でない。あるいは
expectedToBeShowing が false であり、かつ element のポップオーバーの可視性状態がでない。
この場合、false を返します。
次のいずれかが true である場合、次を行います。
element が接続されていない。
expectedDocument が null でなく、かつ element のノード文書が expectedDocument でない。
element の全画面フラグが設定されている。
この場合、"InvalidStateError" DOMException をスローします。
true を返します。
Document
document の表示中の自動ポップオーバーリストを取得するには、
次を行います。
popovers を « » とします。
document の最上位レイヤー内の各 Element element について、
次を行います。
次のすべてが true である場合、次を行います。
element がHTML 要素である。
element のポップオーバーモードで開かれた状態が
"auto" である。かつ
element のポップオーバーの可視性状態が表示中である。
この場合、element を popovers へ付加します。
popovers を返します。
Document
document の表示中のヒントポップオーバーリストを
取得するには、次を行います。
popovers を « » とします。
document の最上位レイヤー内の各 Element element について、
次を行います。
次のすべてが true である場合、次を行います。
element がHTML 要素である。
element のポップオーバーモードで開かれた状態が
"hint" である。かつ
element のポップオーバーの可視性状態が表示中である。
この場合、element を popovers へ付加します。
popovers を返します。
ボタンは、次の 内容属性を持つことができます。
popovertarget
popovertargetaction
指定する場合、popovertarget
属性値は、popovertarget
属性を持つボタンと同じツリー内にある、popover 属性を持つ要素の
IDでなければなりません。
popovertargetaction
属性は、次のキーワードおよび状態を持つ列挙属性です。
| キーワード | 状態 | 簡単な説明 |
|---|---|---|
toggle
|
切り替え | 対象のポップオーバー要素を表示または非表示にします。 |
show
|
表示 | 対象のポップオーバー要素を表示します。 |
hide
|
非表示 | 対象のポップオーバー要素を非表示にします。 |
可能な限り、ポップオーバー要素が、そのトリガー要素の直後に DOM 内で配置されるように してください。そうすることで、スクリーンリーダーなどの支援技術を使用するユーザーに対して、 ポップオーバーが論理的なプログラム上の読み上げ順序で公開されるようになります。
次の例は、popovertarget
属性を popovertargetaction
属性と組み合わせて、ポップオーバーを表示および閉じるために使用する方法を示しています。
< button popovertarget = "foo" popovertargetaction = "show" >
ポップオーバーを表示
</ button >
< article popover = "auto" id = "foo" >
これはポップオーバーの記事です!
< button popovertarget = "foo" popovertargetaction = "hide" > 閉じる</ button >
</ article > popovertargetaction
属性が指定されていない場合、既定のアクションは、関連付けられたポップオーバーを切り替えることです。
次の例は、呼び出し元のボタンに popovertarget
属性だけを指定することで、手動ポップオーバーを開いた状態と閉じた状態の間で切り替える方法を示しています。
手動ポップオーバーは、ライトディスミスまたは閉じる要求には応答しません。
< input type = "button" popovertarget = "foo" value = "ポップオーバーを切り替える" >
< div popover = manual id = "foo" >
これはポップオーバーです!
</ div > HTMLButtonElement/popoverTargetElement
現在のすべてのエンジンでサポートされています。
HTMLInputElement/popoverTargetElement
現在のすべてのエンジンでサポートされています。
interface mixin PopoverTargetAttributes {
[CEReactions , Reflect ] attribute Element ? popoverTargetElement ;
[CEReactions ] attribute DOMString popoverTargetAction ;
};HTMLButtonElement/popoverTargetAction
現在のすべてのエンジンでサポートされています。
HTMLInputElement/popoverTargetAction
現在のすべてのエンジンでサポートされています。
popoverTargetAction IDL 属性は、popovertargetaction
属性を、既知の値のみに制限して反映しなければなりません。
Node
node および Node
eventTarget を指定して、ポップオーバーターゲット属性のアクティベーション動作を
実行するには、次を行います。
popover を、node のポップオーバーターゲット要素とします。
popover が null である場合、返します。
eventTarget が popover のシャドウを含む包括的子孫であり、かつ popover が node のシャドウを含む子孫である場合、返します。
node の popovertargetaction
属性が表示状態であり、かつ
popover のポップオーバーの可視性状態が表示中である場合、返します。
node の popovertargetaction
属性が非表示状態であり、かつ
popover のポップオーバーの可視性状態がである場合、返します。
popover のポップオーバーの可視性状態が表示中である場合、 popover、true、true、false、および node を指定して、ポップオーバーを 非表示にするアルゴリズムを実行します。
それ以外の場合、次を行います。
validity を、popover、false、および null を指定してポップオーバーの妥当性を確認するを 実行した結果とします。これが例外をスローした場合、その例外を捕捉し、 validity を false とします。
validity が true である場合、popover、false、および node を指定して、ポップオーバーを表示するを実行します。
Node
node を指定して、ポップオーバーターゲット要素を取得するには、次の手順を実行します。
これらはHTML
要素または null を返します。
node がボタンでない場合、null を返します。
node が無効である場合、null を返します。
popoverElement を、node のpopovertarget に関連付けられた
要素を取得するを実行した結果とします。
popoverElement が null である場合、null を返します。
popoverElement の popover 属性がポップオーバー
なし状態である場合、null を返します。
popoverElement を返します。
「ライトディスミス」とは、popover
属性が自動またはヒント状態である
ポップオーバーの外側をクリックすると、そのポップオーバーが閉じられることを意味します。これは、
そのようなポップオーバーが閉じる要求に応答する方法に加えて行われます。
PointerEvent
event を指定して、開いているポップオーバーをライトディスミスするには、次を行います。
target を、event の対象とします。
document を、target のノード文書とします。
document を指定して最上位の自動またはヒントポップオーバーを 実行した結果が null である場合、返します。
event の type
が「pointerdown」である場合、
document のポップオーバーの
pointerdown 対象を、target を指定してクリックされた最上位ポップオーバーを実行した
結果に設定します。
event の type
が「pointerup」である場合、次を行います。
ancestor を、target を指定してクリックされた最上位ポップオーバーを 実行した結果とします。
sameTarget を、ancestor が document のポップオーバーの pointerdown 対象である 場合は true とします。
document のポップオーバーの pointerdown 対象を null に設定します。
sameTarget が false である場合、返します。
endpointIsHint を、document の表示中のヒントポップオーバーリストが ancestor を含む場合は true とし、 それ以外の場合は false とします。
document、ancestor、ヒント、false、および true を指定して、 指定位置までポップオーバースタックを 非表示にするを実行します。
autoEndpoint を ancestor とします。
endpointIsHint が true である場合、autoEndpoint を document のヒントスタックの親に設定します。
これは、ヒントポップオーバーがクリックされた場合、そのクリックされた ヒントポップオーバーの親である自動ポップオーバーを除き、自動ポップオーバーが閉じられることを 意味します。
document、autoEndpoint、自動、false、および true を指定して、 指定位置までポップオーバースタックを 非表示にするを実行します。
Node
node を指定して、クリックされた最上位ポップオーバーを見つけるには、次を行います。
clickedPopover を、node を指定して最も近い包括的な開いている ポップオーバーを実行した結果とします。
targetPopover を、node を指定して最も近い包括的ターゲット ポップオーバーを実行した結果とします。
clickedPopover を指定してポップオーバースタック内の位置を 取得した結果が、targetPopover を指定してポップオーバースタック内の位置を 取得した結果より大きい場合、clickedPopover を返します。
targetPopover を返します。
HTML 要素 popover を指定して、ポップオーバースタック内の位置を取得するには、次を行います。
hintList を、popover のノード文書の表示中の ヒントポップオーバーリストとします。
autoList を、popover のノード文書の表示中の 自動ポップオーバーリストとします。
popover が hintList 内にある場合、hintList 内の popover のインデックス + autoList のサイズ + 1 を返します。
popover が autoList 内にある場合、autoList 内の popover のインデックス + 1 を返します。
0 を返します。
Node
node を指定して、最も近い包括的ターゲットポップオーバーを見つけるには、
次を行います。
currentNode を node とします。
currentNode が null でない間、次を行います。
targetPopover を、currentNode のターゲットポップオーバーとします。
targetPopover が null でなく、targetPopover の popover 属性が自動状態またはヒント状態であり、かつ
targetPopover のポップオーバーの可視性状態が表示中である場合、
targetPopover を返します。
currentNode を、フラットツリー内の currentNode の祖先に設定します。
Node
node を指定して、ターゲットポップオーバーを取得するには、
次の手順を実行します。これらはHTML 要素または null を返します。
node が button 要素でない
場合、node のポップオーバーターゲット要素を返します。
node が無効である場合、null を返します。
target を、node のcommandfor に関連付けられた
要素を取得するを実行した結果とします。
target が null である場合、node のポップオーバーターゲット要素を返します。
node がフォーム所有者を持つ場合、次を行います。
command を、node の command 属性と
します。
command が、ポップオーバーを切り替え、 ポップオーバーを非表示、または ポップオーバーを表示状態のいずれでも ない場合、null を返します。
target を返します。
この節では、ウェブブラウザーに最も直接的に適用される機能について説明します。ただし、 特に指定されている場合を除き、この節で定義される要件は、ウェブブラウザーであるかどうかにかかわらず、 すべてのユーザーエージェントに実際に適用されます。
オリジンは、ウェブのセキュリティモデルにおける基本的な単位です。ウェブプラットフォーム上で オリジンを共有する二つの主体は、互いを信頼し、同じ権限を持つと想定されます。異なるオリジンを持つ 主体同士は、潜在的に敵対的であるとみなされ、さまざまな程度で互いに分離されます。
たとえば、bank.example.com でホストされている Example Bank の
ウェブサイトが、charity.example.org でホストされている Example Charity のウェブサイトの
DOM を調べようとすると、「SecurityError」
DOMException
が発生します。
オリジンは、次のいずれかです。
再作成に使用できる直列化を持たない内部値です(オリジンの直列化に従い「null」として
直列化されます)。これに対して意味を持つ唯一の操作は、等価性の検査です。
次の要素からなるタプルです。
オリジンは、たとえば複数の
Document オブジェクト間で共有できます。
さらに、オリジンは通常、変更不能です。
タプルオリジンのドメインだけが変更可能であり、
document.domain API を介して
のみ変更できます。
オリジン origin の 実効ドメインは、次のように算出されます。
オリジンの直列化は、指定されたオリジン origin に次のアルゴリズムを 適用して得られる文字列です。
(「https」、「xn--maraa-rta.example」、null、null)の
直列化は
「https://xn--maraa-rta.example」です。
以前は、オリジンの Unicode 直列化も存在していました。しかし、 広く採用されることはありませんでした。
二つのオリジン A および B は、次のアルゴリズムが true を返す場合、同一オリジンであるといいます。
二つのオリジン A および B は、次のアルゴリズムが true を返す場合、同一オリジンドメインであるといいます。
| A | B | 同一オリジン | 同一オリジンドメイン |
|---|---|---|---|
("https", "example.org", null, null)
|
("https", "example.org", null, null)
|
✅ | ✅ |
("https", "example.org", 314, null)
|
("https", "example.org", 420, null)
|
❌ | ❌ |
("https", "example.org", 314, "example.org")
|
("https", "example.org", 420, "example.org")
|
❌ | ✅ |
("https", "example.org", null, null)
|
("https", "example.org", null, "example.org")
|
✅ | ❌ |
("https", "example.org", null, "example.org")
|
("http", "example.org", null, "example.org")
|
❌ | ❌ |
スキームとホストは、スキーム(ASCII 文字列)および ホスト(ホスト)からなるタプルです。
オリジン origin を指定して、サイトを取得するには、次の手順を実行します。
二つのサイト A および B は、 次のアルゴリズムが true を返す場合、同一サイトであるといいます。
サイトの直列化は、指定されたサイト site に次のアルゴリズムを適用して得られる文字列です。
直列化された値がオリジンではなくサイトであることが、文脈から明確である必要があります。
両者には必ずしも構文上の違いがないためです。たとえば、オリジン(「https」、
「shop.example」、null、null)およびサイト(「https」、
「shop.example」)は、同じ直列化「https://shop.example」を持ちます。
二つのオリジン A および B は、次のアルゴリズムが true を返す場合、スキームを無視した同一サイトであるといいます。
二つのオリジン A および B は、次のアルゴリズムが true を返す場合、同一サイトであるといいます。
同一オリジンおよび同一オリジンドメインの概念とは異なり、 スキームを無視した同一サイトおよび同一サイトでは、ポートおよびドメインの構成要素は無視されます。
URL で説明されている 理由により、同一サイトおよびスキームを無視した同一サイトの概念は、可能な場合、同一オリジンの検査を優先して避けるべきです。
wildlife.museum、museum、および com が公開サフィックスであり、example.com はそうではないと
すると、次のようになります。
| A | B | スキームを無視した同一サイト | 同一サイト |
|---|---|---|---|
("https", "example.com")
|
("https", "sub.example.com")
|
✅ | ✅ |
("https", "example.com")
|
("https", "sub.other.example.com")
|
✅ | ✅ |
("https", "example.com")
|
("http", "non-secure.example.com")
|
✅ | ❌ |
("https", "r.wildlife.museum")
|
("https", "sub.r.wildlife.museum")
|
✅ | ✅ |
("https", "r.wildlife.museum")
|
("https", "sub.other.r.wildlife.museum")
|
✅ | ✅ |
("https", "r.wildlife.museum")
|
("https", "other.wildlife.museum")
|
❌ | ❌ |
("https", "r.wildlife.museum")
|
("https", "wildlife.museum")
|
❌ | ❌ |
("https", "wildlife.museum")
|
("https", "wildlife.museum")
|
✅ | ✅ |
("https", "example.com")
|
("https", "example.com.")
|
❌ | ❌ |
document.domain [ = domain ]
セキュリティ検査に使用される現在のドメインを返します。
サブドメインを取り除く値に設定することで、オリジンのドメインを変更し、同じドメインの ほかのサブドメイン上のページも同様の操作を行う場合に、互いへのアクセスを許可できます。これにより、 あるドメインの異なるホスト上のページが、互いの DOM に同期的にアクセスできるようになります。
サンドボックス化された iframe、
不透明なオリジンを持つ
Document、および
閲覧コンテキストを持たない
Documentでは、
セッターは「SecurityError」例外をスローします。crossOriginIsolated
または originAgentCluster
が true を返す場合、セッターは何も行いません。
document.domain
セッターの使用は避けてください。これは、同一オリジンポリシーによって提供されるセキュリティ保護を
弱めます。これは共有ホスティングを使用する場合に特に深刻です。たとえば、信頼できない第三者が同じ
IP アドレスの異なるポートで HTTP サーバーをホストできる場合、document.domain
セッターの使用後はオリジンを比較する際にポートが無視されるため、通常は同じホスト上の異なる二つの
サイトを保護する同一オリジン保護が機能しなくなります。
これらのセキュリティ上の問題のため、この機能はウェブプラットフォームから削除される過程にあります。 (これは何年もかかる長い過程です。)
代わりに、postMessage()
または MessageChannel
オブジェクトを使用して、オリジンをまたいだ通信を安全な方法で行ってください。
domain
ゲッターの手順は次のとおりです。
domain
セッターの手順は次のとおりです。
this の閲覧コンテキストが null である場合、
「SecurityError」 DOMException
をスローします。
this のアクティブなサンドボックス化フラグ
集合にサンドボックス化された
document.domain 閲覧コンテキストフラグが設定されている場合、「SecurityError」 DOMException
をスローします。
effectiveDomain が null である場合、「SecurityError」 DOMException
をスローします。
指定された値が effectiveDomain の登録可能ドメインの
接尾辞ではなく、かつ等しくもない場合、「SecurityError」 DOMException
をスローします。
周囲のエージェントのエージェントクラスターのオリジンキー付きかが true である場合、 返します。
スカラー値文字列 hostSuffixString が、ホスト originalHost の登録可能ドメインの接尾辞であるか、または等しいかを判定するには、 次を行います。
hostSuffixString が空文字列である場合、false を返します。
hostSuffix を、hostSuffixString を構文解析した結果とします。
hostSuffix が失敗である場合、false を返します。
hostSuffix が originalHost と等しくない場合、次を行います。
true を返します。
| hostSuffixString | originalHost | 登録可能 ドメインの接尾辞であるか、または等しいの結果 | 注記 |
|---|---|---|---|
"0.0.0.0" |
0.0.0.0 |
✅ | |
"0x10203" |
0.1.2.3 |
✅ | |
"[0::1]" |
::1 |
✅ | |
"example.com" |
example.com |
✅ | |
"example.com" |
example.com. |
❌ | 末尾のドットには意味があります。 |
"example.com." |
example.com |
❌ | |
"example.com" |
www.example.com |
✅ | |
"com" |
example.com |
❌ | 執筆時点では、com は公開サフィックスです。 |
"example" |
example |
✅ | |
"compute.amazonaws.com" |
example.compute.amazonaws.com |
❌ | 執筆時点では、*.compute.amazonaws.com は公開サフィックスです。
|
"example.compute.amazonaws.com" |
www.example.compute.amazonaws.com |
❌ | |
"amazonaws.com" |
www.example.compute.amazonaws.com |
❌ | |
"amazonaws.com" |
test.amazonaws.com |
✅ | 執筆時点では、amazonaws.com は登録可能ドメインです。 |
Origin
インターフェイスOrigin
インターフェイスはオリジンを表し、堅牢な同一オリジンおよび同一サイトの比較を可能にします。
[Exposed=*]
interface Origin {
constructor ();
static Origin from (any value );
readonly attribute boolean opaque ;
boolean isSameOrigin (Origin other );
boolean isSameSite (Origin other );
};Origin
オブジェクトには、オリジンを保持する、関連付けられたオリジンがあります。
プラットフォームオブジェクトには、 オリジンを抽出する操作があり、特に指定されていない限り null を返します。
静的な from(value) メソッドの手順は次のとおりです。
value がプラットフォームオブジェクトである場合、次を行います。
value が文字列である場合、次を行います。
parsedURL を、value を基本 URL 構文解析した結果とします。
parsedURL が失敗でない場合、オリジンが parsedURL のオリジンに設定された、新しい Origin オブジェクトを返します。
TypeError
をスローします。
isSameOrigin(other) メソッドの手順は、
this
のオリジンが other のオリジンと同一オリジンである場合は true を返し、
それ以外の場合は false を返すことです。
window.originAgentCluster
この Window が、この節で
説明する方法により、オリジンでキー付けされたエージェントクラスターに属する場合、true を返します。
安全なコンテキストを介して配信された Document は、
「Origin-Agent-Cluster」HTTP
応答ヘッダーを使用することで、
オリジンでキー付けされたエージェントクラスターへ配置されることを要求できます。このヘッダーは、
値が真偽値でなければならない構造化ヘッダーです。
[STRUCTURED-FIELDS]
新しい
Document オブジェクトを作成し、
初期化するの処理モデルに従い、構造化ヘッダーの真偽値 true(すなわち「?1」)ではない値は
無視されます。
このヘッダーを使用した結果、生成される Document のエージェントクラスターキーは、対応するサイトではなく、その
オリジンになります。観測可能な影響として、これは、
document.domain を使用して同一オリジン制限を緩和しようとしても何も行われなくなり、
クロスオリジンの Document へ WebAssembly.Module
オブジェクトを送信できなくなることを意味します(それらが同一サイトであってもです)。内部的には、この分離により、
ユーザーエージェントは、プロセスやスレッドなど、エージェントクラスターに対応する実装固有のリソースを、より効率的に
割り当てられる場合があります。
閲覧コンテキストグループ内では、
「Origin-Agent-Cluster」ヘッダーによって、同一オリジンの
Document オブジェクトが、
一方ではヘッダーが送信され、もう一方では送信されない場合でも、異なるエージェントクラスターに配置されることはありません。これは、
履歴エージェントクラスターキーマップに
よって防止されます。
これは、同じ閲覧コンテキストグループ内で以前に読み込まれた
同一オリジンのページからヘッダーが省略されていた場合、ヘッダーが設定されていても originAgentCluster ゲッターが false を返す可能性があることを
意味します。同様に、ヘッダーが設定されていなくても true を返す場合があります。
originAgentCluster ゲッターの手順は、周囲のエージェントのエージェントクラスターのオリジンキー付きかを返すことです。
不透明なオリジンを持つ Document は、無条件に
オリジンキー付きであるとみなすことができます。これらに対してヘッダーは影響を与えず、originAgentCluster ゲッターは常に true を返します。
同様に、エージェントクラスターのクロスオリジン分離モードが
「none」でない Document は、自動的に
オリジンキー付きになります。「Origin-Agent-Cluster」ヘッダーは、同じアドレス空間内のすべてが
そこへ存在することに同意するよう保証することを主な目的とする、クロスオリジン分離の実現に使用される
「Cross-Origin-Opener-Policy」および「Cross-Origin-Embedder-Policy」ヘッダーとは異なり、
リソース割り当てについて実装へ追加のヒントを提供するために役立つ場合があります。ただし、これを追加しても
作者のコードに追加の観測可能な影響はありません。
オープナーポリシー値により、最上位閲覧コンテキストでナビゲーション される文書は、新しい最上位閲覧コンテキストおよび対応する グループを強制的に作成できます。 取り得る値は次のとおりです。
unsafe-none」これは(現在の)既定値であり、先行する文書が異なるオープナーポリシーを指定していない限り、 文書がその先行する文書と同じ最上位閲覧コンテキストを占有することを 意味します。
same-origin-allow-popups」先行する文書が同じオープナーポリシーを指定し、 両者が同一オリジンでない限り、この文書のために新しい 最上位閲覧コンテキストを強制的に 作成します。
same-origin」これは「same-origin-allow-popups」
と同じように動作します。さらに、作成された補助閲覧コンテキストには、同じオープナーポリシーも持つ同一オリジンの文書が含まれている
必要があります。そうでなければ、オープナーからは閉じられているように見えます。
same-origin-plus-COEP」これは「same-origin」と同じように動作します。さらに、(新しい)最上位閲覧コンテキストのグループのクロスオリジン分離モードを、
「logical」または「concrete」のいずれかに設定します。
「same-origin-plus-COEP」は、「Cross-Origin-Opener-Policy」ヘッダーを介して直接設定することは
できません。これは、「Cross-Origin-Opener-Policy: same-origin」と、値がクロスオリジン分離と互換性がある
「Cross-Origin-Embedder-Policy」ヘッダーの両方を設定した
組み合わせによって生じます。
noopener-allow-popups」先行する文書に関係なく、この文書のために新しい最上位閲覧コンテキストを強制的に 作成します。
noopener-allow-popups 値を含めると、それが適用された
文書とそのオープナーとのオープナー関係が切断されますが、それらの同一オリジン文書間に堅牢な
セキュリティ境界が作成されるわけではありません。
同一オリジンのアプリケーションから生じるそのほかのリスクには、次のものがあります。
文書の内容を取得する同一オリジン要求 — Fetch Metadata によるフィルタリングで軽減できる場合が あります。[FETCHMETADATA]
同一オリジンのフレーム化 — X-Frame-Options
または CSP の frame-ancestors
によって軽減できる場合があります。
JavaScript からアクセス可能な Cookie — すべての Cookie を httponly にすることで
軽減できます。
localStorage による機密データへのアクセス。
サービスワーカーのインストール。
機密情報を公開する postMessage または BroadcastChannel メッセージング。
同一オリジン文書ではユーザーインタラクションを必要としない場合がある自動入力。
noopener-allow-popups を使用する開発者は、機密性の高い
アプリケーションが、localStorage やそのほかのクライアント側ストレージ API、
BroadcastChannel や関連する同一オリジン通信機構など、
ほかの同一オリジン文書からアクセスできるクライアント側機能に依存していないことを保証する必要が
あります。また、応答内容へ同一オリジン文書からアクセスできる非ナビゲーション要求に対して、
サーバー側のエンドポイントが機密データを返さないことも保証する必要があります。
オープナーポリシーは、次の要素からなります。
値。これはオープナーポリシー値であり、
初期値は「unsafe-none」です。
報告エンドポイント。これは文字列または null であり、 初期値は null です。
報告専用値。これはオープナーポリシー値であり、
初期値は「unsafe-none」です。
報告専用の報告エンドポイント。これは文字列または null であり、初期値は null です。
オープナーポリシー値 documentCOOP、オリジン documentOrigin、オープナーポリシー値 responseCOOP、およびオリジン responseOrigin を指定して、 オープナーポリシー値を照合するには、次を行います。
documentCOOP が「unsafe-none」であり、かつ responseCOOP が
「unsafe-none」である場合、true を返します。
documentCOOP が「unsafe-none」であるか、responseCOOP が
「unsafe-none」である場合、false を返します。
documentCOOP が responseCOOP であり、かつ documentOrigin が responseOrigin と同一オリジンである場合、true を返します。
false を返します。
Headers/Cross-Origin-Opener-Policy
現在のすべてのエンジンでサポートされています。
Document のクロスオリジンオープナー
ポリシーは、「Cross-Origin-Opener-Policy」および「Cross-Origin-Opener-Policy-Report-Only」HTTP 応答ヘッダーから
導出されます。これらのヘッダーは、値がトークンでなければならない構造化ヘッダーです。
[STRUCTURED-FIELDS]
有効なトークン値は、オープナーポリシー値です。トークンにはパラメーターを付加することもできます。そのうち、
「report-to」パラメーターには、適切な報告エンドポイントを
識別する妥当な URL
文字列を指定できます。[REPORTING]
以下で説明する処理モデルに従い、無効な値を含む場合、ユーザーエージェントはこのヘッダーを 無視します。同様に、値をトークンとして構文解析できない場合も、 ユーザーエージェントはこのヘッダーを無視します。
応答 response および環境 reservedEnvironment を指定して、オープナーポリシーを取得するには、 次を行います。
policy を新しいオープナーポリシーとします。
reservedEnvironment が安全でないコンテキストである場合、 policy を返します。
parsedItem を、response のヘッダーリストから、「Cross-Origin-Opener-Policy」および
「item」を指定して構造化フィールド値を取得した結果とします。
parsedItem が null でない場合、次を行います。
parsedItem[0] が「same-origin」である場合、次を行います。
coep を、response および reservedEnvironment からクロスオリジン埋め込み元ポリシーを取得した結果と します。
coep の値がクロスオリジン分離と互換性がある
場合、policy の値を「same-origin-plus-COEP」に設定します。
それ以外の場合、policy の値を「same-origin」に設定します。
parsedItem[0] が「same-origin-allow-popups」である場合、
policy の値を「same-origin-allow-popups」に設定します。
parsedItem[0] が「noopener-allow-popups」である場合、
policy の値を「noopener-allow-popups」に設定します。
parsedItem[1]["report-to"] が存在し、かつ文字列である場合、policy の報告エンドポイントを
parsedItem[1]["report-to"] に設定します。
parsedItem を、response のヘッダーリストから、「Cross-Origin-Opener-Policy-Report-Only」
および「item」を指定して構造化フィールド値を取得した結果に設定します。
parsedItem が null でない場合、次を行います。
parsedItem[0] が「same-origin」である場合、次を行います。
coep を、response および reservedEnvironment からクロスオリジン埋め込み元ポリシーを取得した結果と します。
coep の値がクロスオリジン分離と互換性がある
か、coep の報告専用値がクロスオリジン分離と互換性がある
場合、policy の報告専用値を「same-origin-plus-COEP」に設定します。
報告専用 COOP は、特別な「same-origin-plus-COEP」値を割り当てる際に、
報告専用 COEP も考慮します。これにより、開発者は COOP と COEP を展開する順序について、
より大きな自由を得られます。
それ以外の場合、policy の報告専用値を「same-origin」に設定します。
parsedItem[0] が「same-origin-allow-popups」である場合、
policy の報告専用値を「same-origin-allow-popups」に設定します。
parsedItem[1]["report-to"] が存在し、かつ文字列である場合、policy の報告専用の報告エンドポイントを
parsedItem[1]["report-to"] に設定します。
policy を返します。
二つのオリジン responseOrigin および activeDocumentNavigationOrigin、ならびに二つのオープナーポリシー 値 responseCOOPValue および activeDocumentCOOPValue を指定して、 ポップアップの COOP 値が閲覧コンテキスト グループの切り替えを必要とするかを検査するには、次を行います。
responseCOOPValue が「noopener-allow-popups」である場合、true を返します。
次のすべてが true である場合、次を行います。
activeDocumentCOOPValue の値が
「same-origin-allow-popups」または
「noopener-allow-popups」である。かつ
responseCOOPValue が「unsafe-none」である。
この場合、false を返します。
activeDocumentCOOPValue、activeDocumentNavigationOrigin、 responseCOOPValue、および responseOrigin を照合した結果が true である場合、false を返します。
true を返します。
真偽値 isInitialAboutBlank、二つのオリジン responseOrigin および activeDocumentNavigationOrigin、ならびに二つのオープナーポリシー 値 responseCOOPValue および activeDocumentCOOPValue を指定して、 COOP 値が閲覧コンテキストグループの切り替えを 必要とするかを検査するには、次を行います。
isInitialAboutBlank が true である場合、responseOrigin、 activeDocumentNavigationOrigin、responseCOOPValue、および activeDocumentCOOPValue を指定してポップアップの COOP 値が閲覧コンテキストグループの切り替えを必要とするかを検査した結果を返します。
ここでは、ポップアップではないナビゲーションを扱っています。
activeDocumentCOOPValue、activeDocumentNavigationOrigin、 responseCOOPValue、および responseOrigin を照合した結果が true である場合、false を返します。
true を返します。
真偽値 isInitialAboutBlank、二つのオリジン responseOrigin、activeDocumentNavigationOrigin、および二つのオープナー ポリシー responseCOOP および activeDocumentCOOP を指定して、 報告専用 COOP を適用した場合に閲覧コンテキストグループの 切り替えが必要になるかを検査するには、次を行います。
isInitialAboutBlank、responseOrigin、 activeDocumentNavigationOrigin、responseCOOP の報告専用 値、および activeDocumentCOOPReportOnly の報告専用 値を指定して、COOP 値が閲覧コンテキストグループの切り替えを必要とするかを検査した結果が false である場合、 false を返します。
報告専用ポリシーが一致していれば、ウェブサイトはすべてのページに同じ報告専用 オープナーポリシーを指定し、それらのページ間のナビゲーションに対する違反報告を受け取らずに済みます。
isInitialAboutBlank、responseOrigin、 activeDocumentNavigationOrigin、responseCOOP の値、および activeDocumentCOOPReportOnly の報告専用 値を指定して、COOP 値が閲覧コンテキストグループの切り替えを必要とするかを検査した結果が true である場合、 true を返します。
isInitialAboutBlank、responseOrigin、 activeDocumentNavigationOrigin、responseCOOP の報告専用 値、および activeDocumentCOOPReportOnly の値を 指定して、COOP 値が閲覧コンテキストグループの切り替えを必要とするかを検査した結果が true である場合、 true を返します。
false を返します。
真偽値 閲覧コンテキストグループの切り替えが必要か。 初期値は false です。
真偽値 報告専用によって閲覧コンテキストグループの 切り替えが必要になるか。初期値は false です。
URL url。
オリジン オリジン。
オープナー ポリシー オープナーポリシー。
真偽値 現在のコンテキストがナビゲーションソースか。 初期値は false です。
閲覧 コンテキスト browsingContext、URL responseURL、オリジン responseOrigin、オープナー ポリシー responseCOOP、オープナー ポリシー適用結果 currentCOOPEnforcementResult、およびリファラー referrer を指定して、 応答のオープナーポリシーを適用するには、次を行います。
newCOOPEnforcementResult を、次の値を持つ新しいオープナー ポリシー適用結果とします。
isInitialAboutBlank を、browsingContext のアクティブな
文書の初期
about:blank かとします。
isInitialAboutBlank が true であり、かつ browsingContext の初期 URLが null である場合、browsingContext の初期 URLを responseURL に設定します。
isInitialAboutBlank、currentCOOPEnforcementResult のオープナー ポリシーの値、 currentCOOPEnforcementResult のオリジン、 responseCOOP の値、 および responseOrigin を指定してCOOP 値が閲覧コンテキストグループの切り替えを必要とするかを検査した結果が true である場合、次を行います。
newCOOPEnforcementResult の閲覧 コンテキストグループの切り替えが必要かを true に設定します。
browsingContext のグループの閲覧 コンテキスト集合のサイズが 1 より大きい場合、次を行います。
responseCOOP、「enforce」、responseURL、
currentCOOPEnforcementResult のurl、
currentCOOPEnforcementResult のオリジン、
responseOrigin、および referrer を指定して、COOP
応答へナビゲーションする際の閲覧コンテキストグループ切り替えについて違反報告をキューに
追加します。
currentCOOPEnforcementResult のオープナー
ポリシー、「enforce」、currentCOOPEnforcementResult のurl、
responseURL、currentCOOPEnforcementResult のオリジン、
responseOrigin、および currentCOOPEnforcementResult の現在の
コンテキストがナビゲーションソースかを指定して、COOP
応答から離れるようナビゲーションする際の閲覧コンテキストグループ切り替えについて違反報告を
キューに追加します。
isInitialAboutBlank、responseOrigin、 currentCOOPEnforcementResult のオリジン、 responseCOOP、および currentCOOPEnforcementResult のオープナー ポリシーを指定して、報告専用 COOP を適用した場合に閲覧コンテキストグループの切り替えが必要になるかを検査した結果が true で ある場合、次を行います。
newCOOPEnforcementResult の報告専用によって 閲覧コンテキストグループの切り替えが必要になるかを true に設定します。
browsingContext のグループの閲覧 コンテキスト集合のサイズが 1 より大きい場合、次を行います。
responseCOOP、「reporting」、responseURL、
currentCOOPEnforcementResult のurl、
currentCOOPEnforcementResult のオリジン、
responseOrigin、および referrer を指定して、COOP
応答へナビゲーションする際の閲覧コンテキストグループ切り替えについて違反報告をキューに
追加します。
currentCOOPEnforcementResult のオープナー
ポリシー、「reporting」、currentCOOPEnforcementResult のurl、
responseURL、currentCOOPEnforcementResult のオリジン、
responseOrigin、および currentCOOPEnforcementResult の現在の
コンテキストがナビゲーションソースかを指定して、COOP
応答から離れるようナビゲーションする際の閲覧コンテキストグループ切り替えについて違反報告を
キューに追加します。
newCOOPEnforcementResult を返します。
ナビゲーション パラメーター navigationParams を指定して、ナビゲーション応答に使用する閲覧コンテキストを取得するには、 次を行います。
browsingContext を、navigationParams のナビゲーブルの アクティブな閲覧 コンテキストとします。
browsingContext が最上位 閲覧コンテキストでない場合、browsingContext を返します。
coopEnforcementResult を、navigationParams のCOOP 適用結果とします。
swapGroup を、coopEnforcementResult の閲覧 コンテキストグループの切り替えが必要かとします。
destinationOrigin を、navigationParams のオリジンと します。
sourceOrigin が destinationOrigin と同一サイトでない 場合、次を行います。
sourceOrigin または destinationOrigin のいずれかが、HTTP(S) スキームでないスキームを 持ち、ユーザーエージェントが実装定義の理由により、sourceOrigin と destinationOrigin を互いに分離する必要があると判断した場合、任意で swapGroup を true に設定します。
たとえば、ユーザーが about:settings から
https://example.com へナビゲーションする場合、ユーザーエージェントは切り替えを
強制できます。
Issue #10842 は、 これを任意のままにするのではなく、ここで相互運用可能な動作を確定する作業を追跡しています。
navigationParams の
ユーザー関与が「ブラウザー UI」である場合、任意で
swapGroup を true に設定します。
Issue #6356 は、 これを任意のままにするのではなく、ここで相互運用可能な動作を確定する作業を追跡しています。
browsingContext のグループの閲覧 コンテキスト集合のサイズが 1 である場合、任意で swapGroup を true に 設定します。
一部の実装は、パフォーマンス上の理由から、ここで閲覧コンテキストグループを 切り替えます。
このコンテキストをスクリプト化できるほかのコンテキストがあるかどうかの検査だけでは、 ウェブページへ影響を与える可能性のある動作の違いを防ぐのに十分ではありません。現在ほかの コンテキストが存在しなくても、遷移先ページがウィンドウを開き、その後ユーザーが戻った場合、 前のページは開かれたウィンドウをスクリプト化できることを期待する可能性があります。ここで 切り替えを行うと、その使用例が機能しなくなります。
swapGroup が false である場合、次を行います。
coopEnforcementResult の報告専用によって 閲覧コンテキストグループの切り替えが必要になるかが true である場合、 browsingContext の仮想 閲覧コンテキストグループ IDを新しい一意の識別子に設定します。
browsingContext を返します。
newBrowsingContext を、新しい 最上位閲覧コンテキストおよび文書を作成した最初の戻り値とします。
この場合、閲覧コンテキストグループの切り替えを実行します。
browsingContext は、これから作成
しようとしている新しい Document によって使用されません。ほかの Document(戻る/進むキャッシュ内のものなど)によっても使用されていない
場合、ユーザーエージェントはこの時点でそれを破棄できます。
navigationCOOP を、navigationParams のクロスオリジン オープナーポリシーとします。
navigationCOOP の値が
「same-origin-plus-COEP」である場合、
newBrowsingContext のグループのクロスオリジン
分離モードを「logical」または「concrete」のいずれかに設定します。どちらを選択するかは
実装定義です。
一部のプラットフォームでは、クロスオリジン
分離機能に必要なセキュリティ特性を提供することが困難です。「concrete」はその機能へのアクセスを許可し、
「logical」は許可しません。
sandboxFlags を、navigationParams の最終的な サンドボックス化フラグ集合の複製とします。
sandboxFlags が空でない場合、次を行います。
表明:
navigationCOOP の値は
「unsafe-none」です。
表明: newBrowsingContext のポップアップ サンドボックス化フラグ集合は空です。
newBrowsingContext のポップアップ サンドボックス化フラグ集合を sandboxFlags に設定します。
newBrowsingContext を返します。
アクセサーとアクセス対象の関係は、アクセスが発生した二つの 閲覧コンテキスト間の関係を説明する 列挙です。これは次の値を取ることができます。
アクセサーの閲覧コンテキストまたはその祖先の一つが、 アクセス対象の閲覧コンテキストの最上位閲覧コンテキストのオープナー閲覧コンテキストです。
アクセス対象の閲覧コンテキストまたはその祖先の一つが、 アクセサーの閲覧コンテキストの最上位閲覧コンテキストのオープナー閲覧コンテキストです。
二つの閲覧コンテキスト accessor および accessed、JavaScript プロパティ名 P、ならびに環境設定オブジェクト environment を指定して、二つの閲覧コンテキスト間のアクセスを報告するべきかを検査するには、 次を行います。
P がクロスオリジンからアクセス可能な Window プロパティ名でない場合、返します。
表明:accessor のアクティブな文書および accessed のアクティブな文書は、どちらも完全にアクティブです。
accessorTopDocument を、accessor の最上位閲覧コンテキストのアクティブな文書とします。
accessorInclusiveAncestorOrigins を、accessor のアクティブな文書の包括的祖先ナビゲーブルのそれぞれについて、その アクティブな文書のオリジンを取得して得られるリストとします。
accessedTopDocument を、accessed の最上位閲覧コンテキストのアクティブな文書とします。
accessedInclusiveAncestorOrigins を、accessed のアクティブな文書の包括的祖先ナビゲーブルのそれぞれについて、その アクティブな文書のオリジンを取得して得られるリストとします。
accessorInclusiveAncestorOrigins のいずれかが accessorTopDocument のオリジンと同一オリジンでない場合、または accessedInclusiveAncestorOrigins のいずれかが accessedTopDocument のオリジンと同一オリジンでない場合、返します。
これにより、オープナーポリシー報告を持つ最上位フレームに対して、 クロスオリジン iframe に関する情報が漏れることを防ぎます。
accessor の最上位閲覧コンテキストの仮想閲覧コンテキストグループ IDが、 accessed の最上位閲覧コンテキストの仮想閲覧コンテキストグループ IDである場合、 返します。
accessorAccessedRelationship を、値がなしである新しいアクセサーとアクセス対象の関係とします。
accessed の最上位閲覧コンテキストのオープナー閲覧コンテキストが accessor であるか、accessor の祖先である場合、 accessorAccessedRelationship をアクセサーがオープナーに設定します。
accessor の最上位閲覧コンテキストのオープナー閲覧コンテキストが accessed であるか、accessed の祖先である場合、 accessorAccessedRelationship をアクセサーがオープン先に設定します。
accessorAccessedRelationship、accessorTopDocument のオープナーポリシー、 accessedTopDocument のオープナーポリシー、 accessor のアクティブな文書のURL、 accessed のアクティブな文書のURL、 accessor の最上位閲覧コンテキストの初期 URL、 accessed の最上位閲覧コンテキストの初期 URL、 accessor のアクティブな文書のオリジン、 accessed のアクティブな文書のオリジン、 accessor の最上位閲覧コンテキストの作成時のオープナーオリジン、 accessed の最上位閲覧コンテキストの作成時のオープナーオリジン、 accessorTopDocument のリファラー、 accessedTopDocument のリファラー、P、および environment を指定して、アクセスについて違反報告をキューに追加します。
URL url を指定して、報告で送信する URL をサニタイズするには、次を行います。
sanitizedURL を url のコピーとします。
sanitizedURL および空文字列を指定して、ユーザー名を設定します。
sanitizedURL および空文字列を指定して、パスワードを設定します。
オープナーポリシー coop、文字列 disposition、URL coopURL、URL previousResponseURL、二つのオリジン coopOrigin および previousResponseOrigin、ならびにリファラー referrer を指定して、COOP 応答へナビゲーションする際の閲覧コンテキストグループ切り替えについて 違反報告をキューに追加するには、次を行います。
coop の報告エンドポイントが null である場合、返します。
coopValue を、coop の値とします。
disposition が「reporting」である場合、coopValue を
coop の報告専用値に設定します。
serializedReferrer を空文字列とします。
referrer がURLである場合、serializedReferrer を referrer の直列化に設定します。
body を、次のプロパティを含む新しいオブジェクトとします。
| キー | 値 |
|---|---|
| disposition | disposition |
| effectivePolicy | coopValue |
| previousResponseURL | coopOrigin および previousResponseOrigin が同一オリジンである場合は previousResponseURL のサニタイズであり、それ以外の場合は null です。 |
| referrer | serializedReferrer |
| type | "navigation-to-response" |
オープナーポリシー coop、文字列 disposition、URL coopURL、URL nextResponseURL、二つのオリジン coopOrigin および nextResponseOrigin、ならびに真偽値 isCOOPResponseNavigationSource を指定して、 COOP 応答から離れるようナビゲーションする際の閲覧コンテキスト グループ切り替えについて違反報告をキューに追加するには、次を行います。
coop の報告エンドポイントが null である場合、返します。
coopValue を、coop の値とします。
disposition が「reporting」である場合、coopValue を
coop の報告専用値に設定します。
body を、次のプロパティを含む新しいオブジェクトとします。
| キー | 値 |
|---|---|
| disposition | disposition |
| effectivePolicy | coopValue |
| nextResponseURL | coopOrigin および nextResponseOrigin が同一オリジンであるか、 isCOOPResponseNavigationSource が true である場合は nextResponseURL のサニタイズであり、それ以外の場合は null です。 |
| type | "navigation-from-response" |
アクセサーとアクセス対象の関係 accessorAccessedRelationship、二つのオープナーポリシー accessorCOOP および accessedCOOP、四つのURL accessorURL、accessedURL、 accessorInitialURL、accessedInitialURL、四つのオリジン accessorOrigin、 accessedOrigin、accessorCreatorOrigin、accessedCreatorOrigin、二つの リファラー accessorReferrer および accessedReferrer、文字列 propertyName、ならびに環境設定オブジェクト environment を指定して、アクセスについて違反報告をキューに追加するには、次を行います。
coop の報告エンドポイントが null である場合、返します。
coopValue を、coop の値とします。
disposition が「reporting」である場合、coopValue を
coop の報告専用値に設定します。
accessorAccessedRelationship がアクセサーがオープナーである場合、次を行います。
accessorCOOP、accessorURL、accessedURL、 accessedInitialURL、accessorOrigin、accessedOrigin、 accessedCreatorOrigin、propertyName、および environment を指定して、開かれたウィンドウへのアクセスについて 違反報告をキューに追加します。
accessedCOOP、accessedURL、accessorURL、 accessedOrigin、accessorOrigin、propertyName、および accessedReferrer を指定して、オープナーからのアクセスについて違反報告を キューに追加します。
それ以外の場合、accessorAccessedRelationship がアクセサーがオープン先である場合、次を行います。
accessorCOOP、accessorURL、accessedURL、 accessorOrigin、accessedOrigin、propertyName、 accessorReferrer、および environment を指定して、オープナーへのアクセスについて違反報告を キューに追加します。
accessedCOOP、accessedURL、accessorURL、 accessorInitialURL、accessedOrigin、accessorOrigin、 accessorCreatorOrigin、および propertyName を指定して、開かれたウィンドウからのアクセスについて 違反報告をキューに追加します。
それ以外の場合、次を行います。
accessorCOOP、accessorURL、accessedURL、 accessorOrigin、accessedOrigin、propertyName、および environment を指定して、別のウィンドウへのアクセスについて 違反報告をキューに追加します。
accessedCOOP、accessedURL、accessorURL、 accessedOrigin、accessorOrigin、および propertyName を指定して、 別のウィンドウからのアクセスについて 違反報告をキューに追加します。
オープナーポリシー coop、二つの URL coopURL および openerURL、二つのオリジン coopOrigin および openerOrigin、文字列 propertyName、リファラー referrer、ならびに環境設定オブジェクト environment を指定して、オープナーへのアクセスについて違反報告をキューに追加するには、 次を行います。
sourceFile、lineNumber、および columnNumber を、この報告を 引き起こした関連するスクリプト URL および問題の位置とします。
serializedReferrer を空文字列とします。
referrer がURLである場合、serializedReferrer を referrer の直列化に設定します。
body を、次のプロパティを含む新しいオブジェクトとします。
| キー | 値 |
|---|---|
| disposition | "reporting" |
| effectivePolicy | coop の報告専用値 |
| property | propertyName |
| openerURL | coopOrigin および openerOrigin が同一オリジンである場合は openerURL のサニタイズであり、それ以外の場合は null です。 |
| referrer | serializedReferrer |
| sourceFile | sourceFile |
| lineNumber | lineNumber |
| columnNumber | columnNumber |
| type | "access-to-opener" |
coopURL および environment を使用して、body を
「coop」として coop の報告エンドポイント向けにキューに追加します。
オープナーポリシー coop、三つのURL coopURL、openedWindowURL、および initialWindowURL、三つのオリジン coopOrigin、 openedWindowOrigin、および openerInitialOrigin、文字列 propertyName、ならびに環境設定オブジェクト environment を指定して、開かれたウィンドウへのアクセスについて違反報告をキューに追加するには、 次を行います。
sourceFile、lineNumber、および columnNumber を、この報告を 引き起こした関連するスクリプト URL および問題の位置とします。
body を、次のプロパティを含む新しいオブジェクトとします。
| キー | 値 |
|---|---|
| disposition | "reporting" |
| effectivePolicy | coop の報告専用値 |
| property | propertyName |
| openedWindowURL | coopOrigin および openedWindowOrigin が同一オリジンである場合は openedWindowURL のサニタイズであり、それ以外の場合は null です。 |
| openedWindowInitialURL | coopOrigin および openerInitialOrigin が同一オリジンである場合は initialWindowURL のサニタイズであり、それ以外の場合は null です。 |
| sourceFile | sourceFile |
| lineNumber | lineNumber |
| columnNumber | columnNumber |
| type | "access-to-opener" |
coopURL および environment を使用して、body を
「coop」として coop の報告エンドポイント向けにキューに追加します。
オープナーポリシー coop、二つのURL coopURL および otherURL、二つのオリジン coopOrigin および otherOrigin、文字列 propertyName、ならびに環境設定オブジェクト environment を指定して、別のウィンドウへのアクセスについて違反報告をキューに追加するには、 次を行います。
sourceFile、lineNumber、および columnNumber を、この報告を 引き起こした関連するスクリプト URL および問題の位置とします。
body を、次のプロパティを含む新しいオブジェクトとします。
| キー | 値 |
|---|---|
| disposition | "reporting" |
| effectivePolicy | coop の報告専用値 |
| property | propertyName |
| otherURL | coopOrigin および otherOrigin が同一オリジンである場合は otherURL のサニタイズであり、それ以外の場合は null です。 |
| sourceFile | sourceFile |
| lineNumber | lineNumber |
| columnNumber | columnNumber |
| type | "access-to-opener" |
coopURL および environment を使用して、body を
「coop」として coop の報告エンドポイント向けにキューに追加します。
オープナーポリシー coop、二つのURL coopURL および openerURL、二つのオリジン coopOrigin および openerOrigin、文字列 propertyName、ならびにリファラー referrer を指定して、オープナーからのアクセスについて違反報告をキューに追加するには、 次を行います。
coop の報告エンドポイントが null である場合、返します。
serializedReferrer を空文字列とします。
referrer がURLである場合、serializedReferrer を referrer の直列化に設定します。
body を、次のプロパティを含む新しいオブジェクトとします。
| キー | 値 |
|---|---|
| disposition | "reporting" |
| effectivePolicy | coop の報告専用値 |
| property | propertyName |
| openerURL | coopOrigin および openerOrigin が同一オリジンである場合は openerURL のサニタイズであり、それ以外の場合は null です。 |
| referrer | serializedReferrer |
| type | "access-to-opener" |
オープナーポリシー coop、三つのURL coopURL、openedWindowURL、および initialWindowURL、三つのオリジン coopOrigin、 openedWindowOrigin、および openerInitialOrigin、ならびに文字列 propertyName を指定して、開かれたウィンドウからのアクセスについて違反報告をキューに追加する には、次を行います。
coop の報告エンドポイントが null である場合、返します。
body を、次のプロパティを含む新しいオブジェクトとします。
| キー | 値 |
|---|---|
| disposition | "reporting" |
| effectivePolicy | coopValue |
| property | coop の報告専用値 |
| openedWindowURL | coopOrigin および openedWindowOrigin が同一オリジンである場合は openedWindowURL のサニタイズであり、それ以外の場合は null です。 |
| openedWindowInitialURL | coopOrigin および openerInitialOrigin が同一オリジンである場合は initialWindowURL のサニタイズであり、それ以外の場合は null です。 |
| type | "access-to-opener" |
オープナーポリシー coop、二つのURL coopURL および otherURL、二つのオリジン coopOrigin および otherOrigin、ならびに文字列 propertyName を指定して、 別のウィンドウからのアクセスについて違反報告をキューに 追加するには、次を行います。
Headers/Cross-Origin-Embedder-Policy
現在のすべてのエンジンでサポートされています。
埋め込み元ポリシー値は、リソース所有者から明示的な 許可を得ずにクロスオリジンリソースを取得することを制御する、三つの文字列のいずれかです。
unsafe-none」
これは既定値です。この値を使用する場合、CORS プロトコルまたは「Cross-Origin-Resource-Policy」
ヘッダーを介した明示的な許可を与えなくても、クロスオリジンリソースを取得できます。
require-corp」この値を使用する場合、クロスオリジンリソースを取得するには、CORS
プロトコルまたは「Cross-Origin-Resource-Policy」
ヘッダーを介したサーバーの明示的な許可が必要です。
credentialless」この値を使用する場合、クロスオリジンの no-CORS リソースを取得するときに資格情報を省略します。
その代わり、明示的な「Cross-Origin-Resource-Policy」
ヘッダーは必要ありません。資格情報とともに送信されるそのほかの要求には、CORS
プロトコルまたは「Cross-Origin-Resource-Policy」
ヘッダーを介したサーバーの明示的な許可が必要です。
「credentialless」をサポートする前に、実装者には次の両方を
サポートすることが強く推奨されます。
そうしなければ、攻撃者はクロスオリジン分離機能を使用して、 クライアントのネットワーク上の位置を利用し、公開されていないリソースを読み取れるようになります。
埋め込み元ポリシー値は、
「credentialless」または「require-corp」である場合、
クロスオリジン分離と互換性があります。
埋め込み元ポリシーは、次の要素からなります。
値。これは埋め込み元ポリシー値であり、初期値は「unsafe-none」です。
報告エンドポイント文字列。初期値は空文字列です。
報告専用値。これは埋め込み元ポリシー値であり、初期値は
「unsafe-none」です。
報告専用の報告エンドポイント文字列。初期値は空文字列です。
「coep」報告種別は、値が
「coep」である報告種別です。これはReportingObserver から可視です。
「Cross-Origin-Embedder-Policy」および
「Cross-Origin-Embedder-Policy-Report-Only」HTTP 応答ヘッダーにより、
サーバーは環境設定オブジェクトの埋め込み元ポリシーを宣言できます。
これらのヘッダーは、値がトークンでなければならない構造化ヘッダーです。
[STRUCTURED-FIELDS]
有効なトークン値は、埋め込み元ポリシー値です。トークンにはパラメーターを付加することもできます。そのうち、
「report-to」パラメーターには、適切な報告エンドポイントを
識別する妥当な URL 文字列を指定できます。
[REPORTING]
処理モデルは、トークンとして構文解析できないヘッダーが
存在する場合、「unsafe-none」を既定値とすることで、制限なしの状態へ移行します。
これには、特定の応答に存在する「Cross-Origin-Embedder-Policy」ヘッダーの複数の
インスタンスを結合することで意図せず作成されたリストも含まれます。
「Cross-Origin-Embedder-Policy」
|
最終的な埋め込み元ポリシー値 |
|---|---|
| ヘッダーが配信されていない | 「unsafe-none」 |
「require-corp」 |
「require-corp」 |
「unknown-value」 |
「unsafe-none」 |
「require-corp, unknown-value」 |
「unsafe-none」 |
「unknown-value, unknown-value」 |
「unsafe-none」 |
「unknown-value, require-corp」 |
「unsafe-none」 |
「require-corp, require-corp」 |
「unsafe-none」 |
(同じことが「Cross-Origin-Embedder-Policy-Report-Only」にも
適用されます。)
応答 response および環境 environment から、埋め込み元ポリシーを取得するには、次を行います。
policy を新しい埋め込み元ポリシーとします。
environment が安全でないコンテキストである場合、 policy を返します。
parsedItem を、response のヘッダーリストから、「Cross-Origin-Embedder-Policy」および
「item」を指定して構造化フィールド値を取得した結果とします。
parsedItem が null でなく、かつ parsedItem[0] がクロスオリジン分離と互換性がある場合、 次を行います。
parsedItem を、response のヘッダーリストから、「Cross-Origin-Embedder-Policy-Report-Only」
および「item」を指定して構造化フィールド値を取得した結果に設定します。
parsedItem が null でなく、かつ parsedItem[0] がクロスオリジン分離と互換性がある場合、 次を行います。
policy を返します。
応答 response、ナビゲーブル navigable、および埋め込み元ポリシー responsePolicy を指定して、ナビゲーション応答がその埋め込み元 ポリシーに準拠しているかを検査するには、次を行います。
navigable が子ナビゲーブルでない場合、true を返します。
parentPolicy の報告専用値がクロスオリジン分離と互換性があり、
かつ responsePolicy の値がそうでない場合、
response、「navigation」、parentPolicy の報告専用の報告
エンドポイント、「reporting」、および navigable のコンテナー文書の関連する設定オブジェクトを指定して、クロスオリジン
埋め込み元ポリシーの継承違反をキューに追加します。
parentPolicy の値がクロスオリジン分離と互換性がない か、responsePolicy の値がクロスオリジン分離と互換性がある 場合、true を返します。
response、「navigation」、parentPolicy の報告エンドポイント、
「enforce」、および navigable のコンテナー文書の関連する設定オブジェクトを指定して、クロスオリジン
埋め込み元ポリシーの継承違反をキューに追加します。
false を返します。
WorkerGlobalScope
workerGlobalScope、環境設定オブジェクト owner、および
応答 response を指定して、グローバルオブジェクトの埋め込み元ポリシーを検査するには、
次を行います。
workerGlobalScope が DedicatedWorkerGlobalScope オブジェクトでない場合、
true を返します。
policy を、workerGlobalScope の埋め込み元ポリシーとします。
ownerPolicy の報告専用値がクロスオリジン分離と互換性があり、
かつ policy の値がそうでない場合、
response、「worker
initialization」、ownerPolicy の報告専用の報告
エンドポイント、「reporting」、および owner を指定して、クロスオリジン
埋め込み元ポリシーの継承違反をキューに追加します。
ownerPolicy の値がクロスオリジン分離と互換性がない か、policy の値がクロスオリジン分離と互換性がある 場合、true を返します。
response、「worker initialization」、ownerPolicy の報告エンドポイント、
「enforce」、および owner を指定して、クロスオリジン
埋め込み元ポリシーの継承違反をキューに追加します。
false を返します。
応答 response、文字列 type、文字列 endpoint、文字列 disposition、および環境設定オブジェクト settings を指定して、クロスオリジン埋め込み元ポリシーの 継承違反をキューに追加するには、次を行います。
serialized を、response を使用して報告用に応答 URL を直列化した結果とします。
body を、次のプロパティを含む新しいオブジェクトとします。
| キー | 値 |
|---|---|
| type | type |
| blockedURL | serialized |
| disposition | disposition |
body を、settings 上の endpoint 向けに、「coep」
報告種別としてキューに追加します。
サンドボックス化フラグ集合は、潜在的に信頼できない リソースが持つ能力を制限するために使用される、次のフラグのうちゼロ個以上からなる集合です。
このフラグは、サンドボックス化された閲覧コンテキスト自体 (またはその中にさらに入れ子になった閲覧コンテキスト)、補助閲覧コンテキスト (次に定義するサンドボックス化された補助ナビゲーション 閲覧コンテキストフラグによって保護されます)、および最上位閲覧コンテキスト (後述するユーザーアクティベーションなしの サンドボックス化された最上位ナビゲーション閲覧コンテキストフラグおよびユーザーアクティベーションありの サンドボックス化された最上位ナビゲーション閲覧コンテキストフラグによって保護されます)を除く閲覧コンテキストへ、 内容がナビゲーションすることを防ぎます。
サンドボックス化された補助ナビゲーション 閲覧コンテキストフラグが設定されていない場合、特定の場合には、制限があってもポップアップ (新しい最上位閲覧コンテキスト)を開くことができます。これらの 閲覧コンテキストには常に、 閲覧コンテキストの作成時に設定される一つの許可されたサンドボックス化ナビゲーターがあり、 それらを作成した閲覧コンテキストが実際にそれらへナビゲーションできるようにします。 (そうでなければ、サンドボックス化されたナビゲーション 閲覧コンテキストフラグにより、それらが開かれた場合でもナビゲーションできなくなります。)
このフラグは、たとえば target
属性や
window.open() メソッドを使用して、
内容が新しい補助閲覧コンテキストを作成することを防ぎます。
このフラグは、内容が自身の最上位閲覧コンテキストへ ナビゲーションすることと、内容が自身の 最上位閲覧コンテキストを閉じることを防ぎます。これは、サンドボックス化された閲覧 コンテキストのアクティブなウィンドウが 一時的アクティベーションを 持たない場合にのみ参照されます。
ユーザー アクティベーションなしのサンドボックス化された最上位ナビゲーション閲覧コンテキストフラグが 設定されていない場合、内容は自身の最上位閲覧コンテキストへナビゲーションできますが、 そのほかの閲覧コンテキストは、 依然としてサンドボックス化されたナビゲーション 閲覧コンテキストフラグと、場合によってはサンドボックス化された補助ナビゲーション 閲覧コンテキストフラグによって保護されます。
このフラグは、内容が自身の最上位閲覧コンテキストへ ナビゲーションすることと、内容が自身の 最上位閲覧コンテキストを閉じることを防ぎます。これは、サンドボックス化された閲覧 コンテキストのアクティブなウィンドウが 一時的アクティベーションを 持つ場合にのみ参照されます。
ユーザー アクティベーションなしのサンドボックス化された最上位ナビゲーション閲覧コンテキスト フラグと同様に、このフラグは最上位閲覧コンテキストにのみ影響します。 これが設定されていない場合でも、そのほかの閲覧コンテキストは、そのほかのフラグによって保護される場合が あります。
このフラグは、内容を不透明なオリジンへ強制的に配置し、 同じオリジンのほかの内容へアクセスすることを 防ぎます。
このフラグは、スクリプトが document.cookie IDL 属性を
読み書きすることも防ぎ、localStorage へのアクセスをブロックします。
このフラグは、フォームの送信をブロックします。
このフラグは Pointer Lock API を無効にします。[POINTERLOCK]
このフラグは、スクリプトの実行をブロックします。
このフラグは、動画の自動再生やフォームコントロールへの自動フォーカスなど、自動的に発動する 機能をブロックします。
document.domain
閲覧コンテキストフラグこのフラグは、内容が
document.domain
セッターを使用することを防ぎます。
このフラグは、内容が作成するすべての 補助閲覧 コンテキストに、内容のアクティブなサンドボックス化フラグ集合を継承させることで、 内容がサンドボックスから脱出することを防ぎます。
このフラグは、内容が次の機能を使用してモーダルダイアログを生成することを防ぎます。
このフラグは、画面の向きをロックする機能を無効にします。 [SCREENORIENTATION]
このフラグは Presentation API を無効にします。[PRESENTATION]
このフラグは、ハイパーリンクによるダウンロードを介するか、ダウンロードとして処理されるナビゲーションを介するかにかかわらず、内容が ダウンロードを開始または生成することを防ぎます。
このフラグは、フェッチスキームではないスキームへの ナビゲーションが、外部ソフトウェアへ引き渡されることを防ぎます。
ユーザーエージェントが、文字列 input およびサンドボックス化フラグ集合 output を指定して、 サンドボックス化ディレクティブを構文解析する 場合、次の手順を実行しなければなりません。
input を ASCII 空白で分割し、 tokens を取得します。
output を空にします。
次のフラグを output に追加します。
tokens が allow-popups キーワードを含まない限り、
サンドボックス化された補助
ナビゲーション閲覧コンテキストフラグ。
tokens が allow-top-navigation キーワードを含まない限り、
ユーザー
アクティベーションなしのサンドボックス化された最上位ナビゲーション閲覧コンテキスト
フラグ。
tokens が allow-top-navigation-by-user-activation
キーワードまたは allow-top-navigation
キーワードのいずれかを含まない限り、ユーザー
アクティベーションありのサンドボックス化された最上位ナビゲーション閲覧コンテキストフラグ。
これは、allow-top-navigation
が存在する場合、allow-top-navigation-by-user-activation
キーワードは何の効果も持たないことを意味します。このため、両方を指定することは文書の適合性
エラーです。
tokens が allow-same-origin キーワードを含まない限り、
サンドボックス化されたオリジン
閲覧コンテキストフラグ。
allow-same-origin
キーワードは、二つの場合を対象としています。
一つ目は、サンドボックス化された内容の DOM へのアクセスを引き続き許可しながら、 同一サイトの内容をサンドボックス化してスクリプトを無効にする場合です。
二つ目は、第三者サイトの内容を埋め込み、そのサイトがポップアップを開くことなどを防ぐために サンドボックス化しながら、埋め込まれたページが元のサイトへ通信したり、データベース API を 使用してデータを保存したりすることを妨げない場合です。
tokens が allow-forms キーワードを含まない限り、
サンドボックス化されたフォーム
閲覧コンテキストフラグ。
tokens が allow-pointer-lock キーワードを含まない限り、
サンドボックス化されたポインターロック
閲覧コンテキストフラグ。
tokens が allow-scripts キーワードを含まない限り、
サンドボックス化されたスクリプト
閲覧コンテキストフラグ。
tokens が allow-scripts
キーワード(上で定義)を含まない限り、サンドボックス化された自動機能
閲覧コンテキストフラグ。
このフラグがスクリプトと同じキーワードによって緩和されるのは、スクリプトが 有効な場合、これらの機能はいずれにしても容易に実現可能であり、サンドボックス内で宣言的機能を 使用することを許可せず、作者にスクリプトの使用を強制するのは望ましくないためです。
tokens が allow-popups-to-escape-sandbox
キーワードを含まない限り、補助閲覧コンテキストへ
サンドボックスを伝播するフラグ。
tokens が allow-modals
キーワードを含まない限り、サンドボックス化されたモーダルフラグ。
tokens が allow-orientation-lock キーワードを含まない限り、
サンドボックス化された画面方向ロック
閲覧コンテキストフラグ。
tokens が allow-presentation キーワードを含まない限り、
サンドボックス化されたプレゼンテーション
閲覧コンテキストフラグ。
tokens が allow-downloads キーワードを含まない限り、
サンドボックス化されたダウンロード
閲覧コンテキストフラグ。
tokens が allow-top-navigation-to-custom-protocols
キーワード、allow-popups
キーワード、または allow-top-navigation
キーワードのいずれも含まない限り、サンドボックス化された
カスタムプロトコルナビゲーション閲覧コンテキストフラグ。
すべての最上位閲覧コンテキストには、ポップアップサンドボックス化フラグ集合があり、これはサンドボックス化フラグ集合です。 閲覧コンテキストが作成されるとき、 そのポップアップサンドボックス化フラグ集合は空でなければ なりません。これは、ナビゲーブルを選択する規則およびナビゲーション応答に使用する閲覧コンテキストを取得する アルゴリズムによって設定されます。
すべての iframe 要素には、iframe
サンドボックス化フラグ集合があり、
これはサンドボックス化フラグ集合です。特定の時点でiframe
サンドボックス化フラグ集合内の
どのフラグが設定されるかは、iframe 要素の sandbox 属性によって決定されます。
すべての Document には、アクティブなサンドボックス化フラグ集合があり、これはサンドボックス化フラグ集合です。
Document が作成されるとき、その
アクティブなサンドボックス化フラグ集合は空でなければ
なりません。これはナビゲーションアルゴリズムによって
設定されます。
すべてのCSP リスト cspList には、CSP 由来のサンドボックス化フラグが あり、これはサンドボックス化フラグ集合です。これは次のアルゴリズムの 戻り値です。
directives を空の有順序集合とします。
cspList 内の各 policy について、次を行います。
directives が空である場合、空のサンドボックス化フラグ集合を返します。
directive を directives[directives のサイズ − 1] とします。
directive のサンドボックス化ディレクティブを構文解析した結果を 返します。
閲覧コンテキスト browsing context について、null または要素 embedder を指定して、作成時のサンドボックス化フラグを決定するには、 次のサンドボックス化フラグ集合に存在するフラグの和集合を返します。
embedder が null である場合、browsing context の ポップアップサンドボックス化フラグ集合に設定された フラグ。
embedder が要素である場合、embedder の
iframe
サンドボックス化フラグ集合に
設定されたフラグ。
embedder が要素である場合、embedder のノード文書のアクティブなサンドボックス化フラグ集合に設定された フラグ。
iframe 要素の
リファラーポリシー要素または null の embedder を指定して、iframe 要素の
リファラーポリシーを決定するには、次を行います。
embedder が iframe
要素である場合、embedder の referrerpolicy
属性の状態に対応するキーワードを返します。
空文字列を返します。
これは、内部祖先オリジン オブジェクトリストの作成手順において、一部のオリジンを秘匿できるようにするために使用されます。
ポリシーコンテナーは、Document、WorkerGlobalScope、または
WorkletGlobalScope に適用されるポリシーを含む構造体です。これには次の項目があります。
CSP リスト。 これはCSP リストです。 初期状態では空です。
リファラーポリシー。これはリファラーポリシーです。初期状態では既定のリファラーポリシーです。
そのほかのポリシーをポリシーコンテナーへ移動します。
ポリシーコンテナー policyContainer を指定して、ポリシーコンテナーを複製するには、次を行います。
URL url が、ポリシーコンテナーを履歴に保存する必要があるかを 判定するには、次を行います。
応答 response および環境または null の environment を指定して、 フェッチ応答から ポリシーコンテナーを作成するには、次を行います。
response のURLのスキームが
「blob」である場合、response のURLのblob URL
エントリーの環境のポリシーコンテナーの複製を返します。
result を新しいポリシーコンテナーとします。
result のCSP リストを、response を指定して 応答の Content Security Policy を構文解析した結果に設定します。
environment が null でない場合、result の埋め込み元ポリシーを、
response および environment を指定して埋め込み元ポリシーを取得した結果に設定します。
それ以外の場合、「unsafe-none」に設定します。
result のリファラーポリシーを、
response を指定して`Referrer-Policy` ヘッダーを
構文解析した結果に設定します。
[REFERRERPOLICY]
response および result を使用して、Integrity-Policy ヘッダーを構文解析します。
result を返します。
URL responseURL および四つのポリシーコンテナーまたは null historyPolicyContainer、initiatorPolicyContainer、 parentPolicyContainer、および responsePolicyContainer を指定して、 ナビゲーションパラメーターの ポリシーコンテナーを決定するには、次を行います。
historyPolicyContainer が null でない場合、次を行います。
表明:responseURL はポリシーコンテナーを履歴に 保存する必要があります。
historyPolicyContainer の複製を返します。
responseURL が about:srcdoc である場合、
次を行います。
responseURL がローカルであり、かつ initiatorPolicyContainer が null でない場合、initiatorPolicyContainer の 複製を返します。
responsePolicyContainer が null でない場合、 responsePolicyContainer を返します。
新しいポリシーコンテナーを返します。
WorkerGlobalScope workerGlobalScope、応答
response、および環境 environment
を指定して、ワーカーグローバルスコープのポリシーコンテナーを初期化する
には、次を行います。
Window、
WindowProxy、および Location オブジェクトのセキュリティ基盤
通常、オブジェクトには異なるオリジンからアクセスできませんが、ウェブプラットフォームには、 ウェブが依存するこの規則の歴史的な例外がいくつか存在しなければ、ウェブプラットフォームらしいとは いえません。
この節では、JavaScript 仕様の用語および表記規則を使用します。 [JAVASCRIPT]
platformObject、identifier、および type を指定して、セキュリティ検査を実行するが呼び出された場合、次の手順を 実行します。
CrossOriginProperties(platformObject) の各 e について、次を行います。
SameValue(e.[[Property]], identifier) が true である場合、次を行います。
type が「method」であり、e が [[NeedsGetter]] も
[[NeedsSetter]] も持たない場合、返します。
それ以外の場合、type が「getter」であり、
e.[[NeedsGetter]] が true である場合、返します。
それ以外の場合、type が「setter」であり、
e.[[NeedsSetter]] が true である場合、返します。
IsPlatformObjectSameOrigin(platformObject)
が false である場合、「SecurityError」 DOMException をスローします。
Window および Location オブジェクトは、どちらも
[[CrossOriginPropertyDescriptorMap]] 内部スロットを持ち、
その値は初期状態では空のマップです。
[[CrossOriginPropertyDescriptorMap]]
内部スロットには、キーが(currentGlobal、objectGlobal、
propertyKey)タプルで、値がプロパティ記述子であるエントリーを持つマップが含まれます。
これは、currentGlobal が objectGlobal の Window または
Location オブジェクトを調べるとき、スクリプトから可視になるものを
メモ化したものです。これはCrossOriginGetOwnPropertyHelper
によって遅延的に設定され、以後の検索で参照されます。
ユーザーエージェントは、値のいずれの部分も参照されていない場合、マップ内に保持された値を、 対応するキーとともにガベージコレクションできるようにするべきです。つまり、ガベージコレクションが 観測可能でない限り、そのようにするべきです。
たとえば、const href =
Object.getOwnPropertyDescriptor(crossOriginLocation, "href").set の場合、マップ内の値とそれに対応する
キーをガベージコレクションすると観測可能になるため、ガベージコレクションできません。
ユーザーエージェントは、document.domain が設定されたとき、マップからキーと値の組を
削除する最適化を行ってもかまいません。document.domain は以前の値へ戻ることができないため、これは
観測できません。
たとえば、www.example.com で document.domain を「example.com」に設定すると、
ユーザーエージェントは、キーの一部が www.example.com であるすべてのキーと値の組をマップから
削除できます。これは、その値が再びオリジンの一部になることは
なく、したがって対応する値をマップから再び取得することもできないためです。
O が Location
オブジェクトである
場合、«
{ [[Property]]: "href", [[NeedsGetter]]: false, [[NeedsSetter]]: true },
{ [[Property]]: "replace" } » を返します。
«
{ [[Property]]: "window", [[NeedsGetter]]: true, [[NeedsSetter]]: false },
{ [[Property]]: "self", [[NeedsGetter]]: true, [[NeedsSetter]]: false },
{ [[Property]]: "location", [[NeedsGetter]]: true, [[NeedsSetter]]: true },
{ [[Property]]: "close" },
{ [[Property]]: "closed", [[NeedsGetter]]: true, [[NeedsSetter]]: false },
{ [[Property]]: "focus" },
{ [[Property]]: "blur" },
{ [[Property]]: "frames", [[NeedsGetter]]: true, [[NeedsSetter]]: false },
{ [[Property]]: "length", [[NeedsGetter]]: true, [[NeedsSetter]]: false },
{ [[Property]]: "top", [[NeedsGetter]]: true, [[NeedsSetter]]: false },
{ [[Property]]: "opener", [[NeedsGetter]]: true, [[NeedsSetter]]: false },
{ [[Property]]: "parent", [[NeedsGetter]]: true, [[NeedsSetter]]: false },
{ [[Property]]: "postMessage" } » を返します。
この抽象操作は、Completion Record を返しません。
インデックス付きプロパティは、WindowProxy オブジェクトに
よって直接処理されるため、このアルゴリズムで許可リストへ登録する必要はありません。
JavaScript プロパティ名 P は、それが「window」、
「self」、「location」、「close」、
「closed」、「focus」、「blur」、
「frames」、「length」、「top」、
「opener」、「parent」、「postMessage」、または配列インデックスプロパティ名である場合、クロスオリジンからアクセス可能な Window プロパティ名
です。
P が「then」、%Symbol.toStringTag%、
%Symbol.hasInstance%、または%Symbol.isConcatSpreadable% である場合、
PropertyDescriptor {
[[Value]]: undefined,
[[Writable]]: false,
[[Enumerable]]: false,
[[Configurable]]: true } を返します。
「SecurityError」 DOMException をスローします。
現在の設定オブジェクトのオリジンが、 O の関連する設定オブジェクトのオリジンと同一オリジンドメインである場合は true を、 それ以外の場合は false を返します。
この抽象操作は、Completion Record を返しません。
ここで、現在の設定オブジェクトは、大まかには
「呼び出し元」に対応します。これは、この検査が、対象のゲッター、セッター、またはメソッドの実行コンテキストがJavaScript 実行コンテキストスタックへ追加される前に
行われるためです。たとえば、コード w.document では、この手順は WindowProxy
w の [[Get]] アルゴリズムの一部として document ゲッターへ
到達する前に呼び出されます。
この抽象操作が undefined を返し、かつカスタム動作がない場合、呼び出し元は
「SecurityError」 DOMException をスローする必要があります。
実際には、これは呼び出し元がCrossOriginPropertyFallback
を呼び出すことで処理されます。
crossOriginKey を、現在の設定オブジェクト、 O の関連する設定オブジェクト、 および P からなるタプルとします。
CrossOriginProperties(O) の各 e について、次を行います。
SameValue(e.[[Property]], P) が true である場合、 次を行います。
O の[[CrossOriginPropertyDescriptorMap]] 内部スロットの値が、キーが crossOriginKey であるエントリーを含む場合、 そのエントリーの値を返します。
originalDesc をOrdinaryGetOwnProperty(O, P) とします。
crossOriginDesc を undefined とします。
e.[[NeedsGetter]] および e.[[NeedsSetter]] が存在しない場合、 次を行います。
value を originalDesc.[[Value]] とします。
IsCallable(value) が true である場合、 value を、現在のレルムで作成され、オブジェクト O 上の IDL 操作 P と同じ手順を実行する無名の組み込み関数に設定します。
crossOriginDesc をPropertyDescriptor { [[Value]]: value, [[Enumerable]]: false, [[Writable]]: false, [[Configurable]]: true } に設定します。
それ以外の場合、次を行います。
crossOriginGetter を undefined とします。
e.[[NeedsGetter]] が true である場合、crossOriginGetter を、 現在のレルムで作成され、オブジェクト O 上の IDL 属性 P のゲッターと同じ手順を実行する無名の 組み込み関数に設定します。
crossOriginSetter を undefined とします。
e.[[NeedsSetter]] が true である場合、crossOriginSetter を、 現在のレルムで作成され、オブジェクト O 上の IDL 属性 P のセッターと同じ手順を実行する無名の 組み込み関数に設定します。
crossOriginDesc をPropertyDescriptor { [[Getter]]: crossOriginGetter, [[Setter]]: crossOriginSetter, [[Enumerable]]: false, [[Configurable]]: true } に設定します。
O の[[CrossOriginPropertyDescriptorMap]] 内部スロットの値に、キーが crossOriginKey、値が crossOriginDesc であるエントリーを作成します。
crossOriginDesc を返します。
undefined を返します。
この抽象操作は、Completion Record を返しません。
ここで生成されるプロパティ記述子が構成可能である理由は、JavaScript 仕様で要求される 基本内部メソッドの不変条件を維持するためです。 特に、プロパティの値はナビゲーションの結果として変化する可能性があるため、そのプロパティは構成可能で なければなりません。(ただし、既存のウェブ内容との互換性のためにこれらの不変条件を維持できない場合に ついては、tc39/ecma262 issue #672 および この仕様内のそれへの参照を参照してください。)[JAVASCRIPT]
プロパティ記述子が、同一オリジンでの動作とは一致しないにもかかわらず列挙不可である理由は、 既存のウェブ内容との互換性のためです。詳細については、issue #3183 を参照してください。
desc を ? O.[[GetOwnProperty]](P) とします。
表明:desc は undefined ではありません。
IsDataDescriptor(desc) が true である場合、 desc.[[Value]] を返します。
表明:IsAccessorDescriptor(desc) は true です。
getter を desc.[[Getter]] とします。
getter が undefined である場合、「SecurityError」
DOMException
をスローします。
? Call(getter, Receiver) を返します。
desc を ? O.[[GetOwnProperty]](P) とします。
表明:desc は undefined ではありません。
desc.[[Setter]] が存在し、その値が undefined でない場合、次を行います。
? Call(desc.[[Setter]], Receiver, « V ») を実行します。
true を返します。
「SecurityError」 DOMException
をスローします。
keys を新しい空のリストとします。
CrossOriginProperties(O) の各 e について、e.[[Property]] を keys に付加します。
keys と « "then",
%Symbol.toStringTag%, %Symbol.hasInstance%, %Symbol.isConcatSpreadable%
» を連結したものを返します。
この抽象操作は、Completion Record を返しません。
Window オブジェクト現在のすべてのエンジンでサポートされています。
[Global =Window ,
Exposed =Window ,
LegacyUnenumerableNamedProperties ]
interface Window : EventTarget {
// 現在の閲覧コンテキスト
[LegacyUnforgeable ] readonly attribute WindowProxy window ;
[Replaceable ] readonly attribute WindowProxy self ;
[LegacyUnforgeable ] readonly attribute Document document ;
attribute DOMString name ;
[PutForwards =href , LegacyUnforgeable ] readonly attribute Location location ;
readonly attribute History history ;
[Replaceable ] readonly attribute Navigation navigation ;
readonly attribute CustomElementRegistry customElements ;
[Replaceable ] readonly attribute BarProp locationbar ;
[Replaceable ] readonly attribute BarProp menubar ;
[Replaceable ] readonly attribute BarProp personalbar ;
[Replaceable ] readonly attribute BarProp scrollbars ;
[Replaceable ] readonly attribute BarProp statusbar ;
[Replaceable ] readonly attribute BarProp toolbar ;
attribute DOMString status ;
undefined close ();
readonly attribute boolean closed ;
undefined stop ();
undefined focus ();
undefined blur ();
// その他の閲覧コンテキスト
[Replaceable ] readonly attribute WindowProxy frames ;
[Replaceable ] readonly attribute unsigned long length ;
[LegacyUnforgeable ] readonly attribute WindowProxy ? top ;
attribute any opener ;
[Replaceable ] readonly attribute WindowProxy ? parent ;
readonly attribute Element ? frameElement ;
WindowProxy ? open (optional USVString url = "", optional DOMString target = "_blank", optional [LegacyNullToEmptyString ] DOMString features = "");
// これはグローバルオブジェクトであるため、IDL の名前付きゲッターはプロトタイプチェーン上に
// NamedPropertiesObject エキゾチックオブジェクトを追加します。これは、グローバルオブジェクト自体をエキゾチックオブジェクトにはしません。
// インデックス付きアクセスは、WindowProxy エキゾチックオブジェクトによって処理されます。
getter object (DOMString name );
// ユーザーエージェント
readonly attribute Navigator navigator ;
[Replaceable ] readonly attribute Navigator clientInformation ; // .navigator の歴史的な別名
readonly attribute boolean originAgentCluster ;
// ユーザーへのプロンプト
undefined alert ();
undefined alert (DOMString message );
boolean confirm (optional DOMString message = "");
DOMString ? prompt (optional DOMString message = "", optional DOMString default = "");
undefined print ();
undefined postMessage (any message , USVString targetOrigin , optional sequence <object > transfer = []);
undefined postMessage (any message , optional WindowPostMessageOptions options = {});
// 廃止されたメンバーも持ちます
};
Window includes GlobalEventHandlers ;
Window includes WindowEventHandlers ;
dictionary WindowPostMessageOptions : StructuredSerializeOptions {
USVString targetOrigin = "/";
};window.window
現在のすべてのエンジンでサポートされています。
window.frames
現在のすべてのエンジンでサポートされています。
window.self
現在のすべてのエンジンでサポートされています。
これらの属性はすべて window を返します。
window.document
現在のすべてのエンジンでサポートされています。
window に関連付けられた Document を返します。
document.defaultView
現在のすべてのエンジンでサポートされています。
document に関連付けられた Window が存在する場合はそれを返し、それ以外の場合は null を返します。
Window オブジェクトには、Document オブジェクトである関連付けられた
Documentがあります。これは Window オブジェクトが作成されるときに設定され、初期
about:blank Document からのナビゲーション中にのみ変更されます。
Window の 閲覧コンテキストは、その関連付けられた
Documentの閲覧コンテキストです。これは null または
閲覧コンテキストです。
document
のゲッター手順は、this の関連付けられた
Documentを返すことです。
Window オブジェクトに
関連付けられた Document オブジェクトが
変更される可能性があるのは、正確に一つの場合だけです。すなわち、ナビゲーションアルゴリズムが、閲覧コンテキストに最初に読み込まれるページのために新しい
Document オブジェクトを作成する場合です。その特定の場合には、初期
about:blank ページの Window オブジェクトが再利用され、新しい Document オブジェクトを取得します。
defaultView のゲッター手順は次のとおりです。
this
の閲覧コンテキストの WindowProxy オブジェクトを返します。
現在のすべてのエンジンでサポートされています。
歴史的な理由から、Window オブジェクトは、
値が Document のインターフェイスオブジェクトである、HTMLDocument
という名前の書き込み可能、構成可能、列挙不可の
プロパティも持たなければなりません。
window = window.open([ url [, target [, features ] ] ])
現在のすべてのエンジンでサポートされています。
url(既定値は「about:blank」)
を表示するウィンドウを開き、それを返します。target(既定値は「_blank」)は、
新しいウィンドウの名前を指定します。その名前を持つウィンドウがすでに存在する場合、それが再利用されます。
features 引数には、コンマで区切られた
トークンの集合を含めることができます。
noopener"noreferrer"これらは、ハイパーリンクにおける
noopener
および noreferrer
リンク型と同等に動作します。
popup"ユーザーエージェントに対し、新しいウィンドウ用の最小限のウェブブラウザーユーザーインターフェイスを
提供するよう促します。(すべての BarProp
オブジェクトの visible
ゲッターにも影響します。)
globalThis. open( "https://email.example/message/CAOOOkFcWW97r8yg=SsWg7GgCmp4suVX9o85y8BvNRqMjuc5PXg" , undefined , "noopener,popup" ); window.name [ = value ]
現在のすべてのエンジンでサポートされています。
ウィンドウの名前を返します。
設定して、名前を変更できます。
window.close()
現在のすべてのエンジンでサポートされています。
ウィンドウを閉じます。
window.closed
現在のすべてのエンジンでサポートされています。
ウィンドウが閉じられている場合は true を返し、それ以外の場合は false を返します。
window.stop()
現在のすべてのエンジンでサポートされています。
文書の読み込みを取り消します。
Document
sourceDocument、有順序マップ
tokenizedFeatures、およびURL レコードまたは null の
url を指定して、ウィンドウを開くための noopener を取得する
には、次の手順を実行します。これらはブール値を返します。
url が null でなく、url のblob URL エントリーが null でない場合、次を行います。
blobOrigin を、url のblob URL エントリーの環境のオリジン とします。
topLevelOrigin を、sourceDocument の関連する設定 オブジェクトの最上位 オリジンとします。
blobOrigin が topLevelOrigin と同一サイトでない場合、 true を返します。
noopener を false とします。
tokenizedFeatures["noopener"] が存在する場合、noopener を、tokenizedFeatures["noopener"]
をブール機能として構文解析した結果に設定します。
noopener を返します。
文字列 url、文字列 target、および文字列 features を指定した ウィンドウを開く手順は、次のとおりです。
sourceDocument を、入口グローバル
オブジェクトの関連付けられた
Documentとします。
urlRecord を null とします。
url が空文字列でない場合、次を行います。
urlRecord を、sourceDocument を基準として url を指定してURL を エンコーディング構文解析した結果に設定します。
urlRecord が失敗である場合、「SyntaxError」
DOMException
をスローします。
target が空文字列である場合、target を「_blank」に設定します。
tokenizedFeatures を、features をトークン化した 結果とします。
noreferrer を false とします。
tokenizedFeatures["noreferrer"] が存在する場合、noreferrer を、tokenizedFeatures["noreferrer"]
をブール機能として構文解析した結果に設定します。
noopener を、sourceDocument、tokenizedFeatures、および urlRecord を使用してウィンドウを 開くための noopener を取得した結果とします。
tokenizedFeatures["noopener"] および
tokenizedFeatures["noreferrer"] を削除します。
referrerPolicy を空文字列とします。
noreferrer が true である場合、noopener を true に設定し、
referrerPolicy を「no-referrer」に設定します。
targetNavigable および windowType を、target、 sourceDocument のノード ナビゲーブル、および noopener を指定してナビゲーブルを 選択する規則を適用した結果とします。
リンクを Control キーを押しながらクリックして新しいタブで開く操作をサポートする
ユーザーエージェントがあり、ユーザーが、onclick
ハンドラーで window.open()
API を使用して iframe
要素内にページを開く要素を Control キーを押しながらクリックした場合、ユーザーエージェントは対象閲覧
コンテキストの選択を上書きし、代わりに新しいタブを対象にすることができます。
targetNavigable が null である場合、null を返します。
windowType が「new and unrestricted」または
「new with no opener」のいずれかである場合、次を行います。
targetNavigable のアクティブな閲覧コンテキストの ポップアップかを、 tokenizedFeatures を指定してポップアップ ウィンドウが要求されているか検査した結果に設定します。
tokenizedFeatures を指定して、targetNavigable のアクティブな閲覧コンテキストの 閲覧コンテキスト機能を設定します。 [CSSOMVIEW]
urlRecord が null である場合、urlRecord を about:blank
を表すURL
レコードに設定します。
urlRecord が about:blank
に一致する場合、targetNavigable のアクティブな文書および
urlRecord を指定して、URL および
履歴の更新手順を実行します。
これは、url が about:blank?foo のようなものである場合に
必要です。url が単なる about:blank である場合、これは何もしません。
それ以外の場合、sourceDocument を使用して targetNavigable を urlRecord へナビゲーションし、 referrerPolicy を referrerPolicy に、 exceptionsEnabled を true に設定します。
それ以外の場合、次を行います。
urlRecord が null でない場合、sourceDocument を使用して targetNavigable を urlRecord へナビゲーションし、 referrerPolicy を referrerPolicy に、 exceptionsEnabled を true に設定します。
noopener が false である場合、targetNavigable のアクティブな閲覧コンテキストの 開始元閲覧 コンテキストを、sourceDocument の閲覧コンテキストに 設定します。
noopener が true であるか、windowType が「new with no
opener」である場合、null を返します。
targetNavigable のアクティブな
WindowProxyを返します。
open(url, target,
features) メソッドの手順は、url、target、および
features を使用してウィンドウを開く手順を
実行することです。
このメソッドは、既存の閲覧コンテキストへナビゲーションするか、補助閲覧 コンテキストを開いてナビゲーションするための機構を提供します。
features 引数をトークン化するには、 次を行います。
tokenizedFeatures を新しい有順序マップとします。
position を features の最初の符号位置に向けます。
position が features の終端を越えていない間、次を行います。
name を空文字列とします。
value を空文字列とします。
position を指定して、features から機能区切り文字である 符号位置の列を収集します。これにより、 名前の前にある先頭の区切り文字を読み飛ばします。
position を指定して、features から機能 区切り文字でない符号位置の列を収集します。name を、 収集された文字をASCII 小文字に変換したものに設定します。
name を、name の機能名を 正規化した結果に設定します。
position が features の終端を越えておらず、かつ features 内の position にある符号位置が U+003D (=) でない間、次を行います。
これは最初の U+003D (=) まで読み飛ばしますが、U+002C (,) または区切り文字でない 文字を越えて読み飛ばすことはありません。
features 内の position にある符号位置が機能 区切り文字である場合、次を行います。
position が features の終端を越えておらず、かつ features 内の position にある符号位置が機能 区切り文字である間、次を行います。
features 内の position にある符号位置が U+002C (,) である場合、 中断します。
position を 1 だけ進めます。
これは最初の区切り文字でない文字まで読み飛ばしますが、U+002C (,) を越えて読み飛ばすことはありません。
position を指定して、features から機能 区切り文字の符号位置でない符号位置の列を収集します。 value を、収集された符号位置をASCII 小文字に変換したものに設定します。
name が空文字列でない場合、 tokenizedFeatures[name] を value に設定します。
tokenizedFeatures を返します。
tokenizedFeatures、featureName、および defaultValue を指定して、 ウィンドウ機能が設定されているか検査するには、次を行います。
tokenizedFeatures[featureName] が存在する場合、tokenizedFeatures[featureName] をブール機能として構文解析した結果を返します。
defaultValue を返します。
tokenizedFeatures を指定して、ポップアップウィンドウが要求されているか検査するには、次を行います。
tokenizedFeatures が空である場合、false を返します。
tokenizedFeatures["popup"] が存在する場合、tokenizedFeatures["popup"]
をブール機能として構文解析した結果を返します。
location を、tokenizedFeatures、「location」、および false を
指定してウィンドウ機能が
設定されているか検査した結果とします。
toolbar を、tokenizedFeatures、「toolbar」、および false を
指定してウィンドウ機能が
設定されているか検査した結果とします。
location および toolbar がどちらも false である場合、true を返します。
menubar を、tokenizedFeatures、「menubar」、および false を
指定してウィンドウ機能が
設定されているか検査した結果とします。
menubar が false である場合、true を返します。
resizable を、tokenizedFeatures、「resizable」、および true を
指定してウィンドウ機能が
設定されているか検査した結果とします。
resizable が false である場合、true を返します。
scrollbars を、tokenizedFeatures、「scrollbars」、および
false を指定してウィンドウ機能が
設定されているか検査した結果とします。
scrollbars が false である場合、true を返します。
status を、tokenizedFeatures、「status」、および false を
指定してウィンドウ機能が
設定されているか検査した結果とします。
status が false である場合、true を返します。
false を返します。
符号位置がASCII 空白、 U+003D (=)、または U+002C (,) である場合、その符号位置は機能区切り文字です。
歴史的な理由から、一部の機能名には別名があります。機能名 name を正規化するには、name に応じて次のように切り替えます。
screenx"
left" を返します。
screeny"
top" を返します。
innerwidth"
width" を返します。
innerheight"
height" を返します。
文字列 value を指定して、ブール機能を構文解析するには、次を行います。
value が空文字列である場合、true を返します。
value が「yes」である場合、true を返します。
value が「true」である場合、true を返します。
parsed を、value を整数として 構文解析した結果とします。
parsed がエラーである場合、0 に設定します。
parsed が 0 である場合は false を返し、それ以外の場合は true を返します。
name
のセッター手順は次のとおりです。
this のナビゲーブルのアクティブなセッション 履歴エントリーの文書状態のナビゲーブルの 対象名を、指定された値に設定します。
ナビゲーブルが別のオリジンへナビゲーションされると、名前はリセットされます。
close()
メソッドの手順は次のとおりです。
thisTraversable が最上位の辿ることが できるナビゲーブルでない場合、返します。
thisTraversable の閉じようとしているかが true である場合、返します。
browsingContext を、thisTraversable のアクティブな閲覧コンテキストと します。
sourceSnapshotParams を、thisTraversable のアクティブな文書を 指定してソースの スナップショットパラメーターをスナップショットした結果とします。
次のすべてが true である場合、次を行います。
thisTraversable がスクリプトで閉じることが できる。
現任の グローバルオブジェクトの閲覧コンテキストが browsingContext を認識している。
現任の グローバルオブジェクトのナビゲーブルが、 sourceSnapshotParams を指定したとき、thisTraversable へナビゲーションすることを サンドボックス化によって許可されている。
その場合、次を行います。
thisTraversable の閉じようとしているかを true に設定します。
thisTraversable を確実に 閉じるため、DOM 操作タスクソース上でタスクをキューに追加します。
ナビゲーブルが最上位の辿ることが できるナビゲーブルであり、次のいずれかが true である場合、そのナビゲーブルはスクリプトで閉じることができるものです。
closed
のゲッター手順は、this の閲覧コンテキストが null であるか、
その閉じようとしているかが true
である場合は true を返し、それ以外の場合は false を返すことです。
stop()
メソッドの手順は次のとおりです。
Window オブジェクトへのインデックス付き
アクセスwindow.length
現在のすべてのエンジンでサポートされています。
文書ツリーの子ナビゲーブルの数を 返します。
window[index]指定された文書ツリーの子ナビゲーブルに
対応する WindowProxy を返します。
length のゲッター手順は、this の関連付けられた
Documentの文書ツリーの子ナビゲーブルのサイズを返すことです。
文書ツリーの子ナビゲーブルへの
インデックス付きアクセスは、WindowProxy オブジェクトの [[GetOwnProperty]]
内部メソッドによって定義されます。
Window オブジェクトの名前付きアクセスwindow[name]指定された要素または要素のコレクションを返します。
一般に、これに依存すると壊れやすいコードになります。たとえば、ウェブプラットフォームに新しい機能が
追加されるにつれて、どの ID がこの API に対応付けられるかは時間の経過とともに変わる可能性があります。
代わりに、document.getElementById() または document.querySelector() を
使用してください。
Window オブジェクト
window の文書ツリーの子ナビゲーブルの対象名プロパティ集合は、
次の手順を実行した戻り値です。
children を、window の関連付けられた
Documentの文書ツリーの子ナビゲーブルとします。
firstNamedChildren を空の有順序集合とします。
children の各 navigable について、次を行います。
names を空の有順序集合とします。
firstNamedChildren の各 navigable について、次を行います。
names を返します。
二つの個別の反復があるため、https://example.org/ でホストされる次の例において、
https://elsewhere.example/ が window.name を
「spices」に設定すると仮定すると、すべての読み込みが完了した後に
window.spices を評価した結果は undefined になります。
< iframe src = https://elsewhere.example.com/ ></ iframe >
< iframe name = spices ></ iframe > Window オブジェクトは名前付きプロパティをサポートします。任意の時点における Window オブジェクト
window のサポートされるプロパティ名は、後に現れる重複を無視し、
それらを提供した要素に従ったツリー順で、次のものからなります。
window の文書ツリーの 子ナビゲーブルの対象名プロパティ集合。
空でない name 内容属性を持ち、window の関連付けられた
Documentをルートとする文書ツリー内にある、すべての embed、
form、
img、
および object
要素の name 内容属性の値。および、
空でない id
内容属性を持ち、window の関連付けられた
Documentをルートとする文書ツリー内にある、すべてのHTML 要素の id
内容属性の値。
Window オブジェクト window 内の名前 name を持つ名前付きプロパティの値を決定するには、
ユーザーエージェントは次の手順を使用して取得した値を返さなければなりません。
objects を、名前が name である window の名前付きオブジェクトのリストとします。
そうでなければこのアルゴリズムはWeb IDL によって呼び出されていないため、 そのようなオブジェクトが少なくとも一つ存在します。
objects がナビゲーブルを含む場合、次を行います。
container を、window の関連付けられた
Documentの子孫のうち、その内容ナビゲーブルが
objects 内にある最初のナビゲーブルコンテナーとします。
container の内容ナビゲーブルのアクティブな WindowProxyを返します。
それ以外の場合、objects に要素が一つだけある場合、その要素を返します。
それ以外の場合、window の関連付けられた
Documentをルートとし、フィルターが名前 name を持つ
window の名前付きオブジェクトのみに
一致する HTMLCollection を返します。
(定義上、これらはすべて要素です。)
上記のアルゴリズムにおいて、名前が name である Window オブジェクト
window の名前付きオブジェクトは、
次のものからなります。
window の関連付けられた
Documentの文書ツリーの子ナビゲーブルのうち、
対象名が
name であるもの。
値が name である name 内容属性を持ち、window の関連付けられた
Documentをルートとする文書ツリー内にある
embed、
form、
img、
または object
要素。および、
値が name である id
内容属性を持ち、window の関連付けられた
Documentをルートとする文書ツリー内にあるHTML 要素。
Window
インターフェイスは [Global] 拡張属性を持つため、その名前付きプロパティは
旧来のプラットフォームオブジェクトではなく、名前付きプロパティオブジェクトの規則に従います。
window.top
現在のすべてのエンジンでサポートされています。
最上位の辿ることができる
ナビゲーブルの WindowProxy を返します。
window.opener [ = value ]
現在のすべてのエンジンでサポートされています。
開始元閲覧コンテキストの
WindowProxy を返します。
開始元閲覧コンテキストが存在しないか、null に設定されている場合は null を返します。
null に設定できます。
window.parent
現在のすべてのエンジンでサポートされています。
親ナビゲーブルの WindowProxy を返します。
window.frameElement
現在のすべてのエンジンでサポートされています。
ナビゲーブルコンテナー要素を返します。
ナビゲーブルコンテナーが存在しない場合、およびクロスオリジンの場合は null を返します。
top のゲッター手順は次のとおりです。
opener のゲッター手順は次のとおりです。
current が null である場合、null を返します。
current の開始元閲覧コンテキストが null である場合、null を返します。
current の開始元閲覧コンテキストの
WindowProxy オブジェクトを返します。
opener のセッター手順は次のとおりです。
指定された値が null であり、かつ this の閲覧コンテキストが null でない場合、this の閲覧コンテキストの開始元閲覧コンテキストを null に設定します。
指定された値が null でない場合、?
DefinePropertyOrThrow(this, "opener", {
[[Value]]: 指定された値, [[Writable]]: true, [[Enumerable]]: true, [[Configurable]]: true
}) を実行します。
window.opener を null に設定すると、開始元閲覧コンテキストへの
参照が消去されます。実際には、これにより、将来のスクリプトが自身の開始元閲覧コンテキストの
Window オブジェクトへアクセスすることを防ぎます。
既定では、スクリプトは window.opener ゲッターを介して、自身の開始元閲覧コンテキストの
Window オブジェクトへアクセスできます。
たとえば、スクリプトは window.opener.location を設定して、開始元閲覧コンテキストを
ナビゲーションさせることができます。
parent のゲッター手順は次のとおりです。
navigable が null である場合、null を返します。
navigable のアクティブな
WindowProxyを返します。
frameElement
のゲッター手順は次のとおりです。
current が null である場合、null を返します。
container を、current のコンテナーとします。
container が null である場合、null を返します。
container のノード文書のオリジンが、現在の設定オブジェクトのオリジンと同一オリジンドメインでない場合、 null を返します。
container を返します。
これらのプロパティが null を返す場合の例は次のとおりです。
<!DOCTYPE html>
< iframe ></ iframe >
< script >
"use strict" ;
const element = document. querySelector( "iframe" );
const iframeWindow = element. contentWindow;
element. remove();
console. assert( iframeWindow. top === null );
console. assert( iframeWindow. parent === null );
console. assert( iframeWindow. frameElement === null );
</ script > ここでは、element が文書から削除されたとき、iframeWindow に対応する
閲覧コンテキストがnull
にされました。
歴史的な理由から、Window インターフェイスには、特定のウェブブラウザーインターフェイス要素の
可視性を表すプロパティがいくつかありました。
プライバシーおよび相互運用性上の理由から、これらのプロパティは現在、Window の閲覧コンテキストのポップアップかプロパティが
true か false かを表す値を返します。
各インターフェイス要素は BarProp オブジェクトによって表されます。
現在のすべてのエンジンでサポートされています。
[Exposed =Window ]
interface BarProp {
readonly attribute boolean visible ;
};window.locationbar.visible
現在のすべてのエンジンでサポートされています。
window.menubar.visible
現在のすべてのエンジンでサポートされています。
window.personalbar.visible
現在のすべてのエンジンでサポートされています。
window.scrollbars.visible
現在のすべてのエンジンでサポートされています。
window.statusbar.visible
現在のすべてのエンジンでサポートされています。
window.toolbar.visible
現在のすべてのエンジンでサポートされています。
Window がポップアップでない場合は
true を返し、それ以外の場合は false を返します。
現在のすべてのエンジンでサポートされています。
visible
のゲッター手順は次のとおりです。
browsingContext を、this の関連するグローバルオブジェクトの閲覧コンテキストとします。
browsingContext が null である場合、true を返します。
browsingContext の最上位閲覧コンテキストのポップアップかの否定を返します。
各 Window オブジェクトには、
次の BarProp オブジェクトが
存在しなければなりません。
BarProp オブジェクトBarProp オブジェクトBarProp オブジェクトBarProp オブジェクトBarProp オブジェクトBarProp オブジェクトlocationbar
属性は、ロケーションバーの
BarProp オブジェクトを返さなければなりません。
menubar 属性は、メニューバーの
BarProp オブジェクトを返さなければなりません。
personalbar
属性は、パーソナルバーの
BarProp オブジェクトを返さなければなりません。
scrollbars
属性は、スクロールバーの
BarProp オブジェクトを返さなければなりません。
statusbar
属性は、ステータスバーの
BarProp オブジェクトを返さなければなりません。
toolbar 属性は、ツールバーの
BarProp オブジェクトを返さなければなりません。
歴史的な理由から、Window オブジェクトの status 属性は、取得時には最後に設定された文字列を返し、
設定時には自身を新しい値に設定しなければなりません。Window
オブジェクトが作成されるとき、
この属性は空文字列に設定されなければなりません。それ以外には何もしません。
Window オブジェクトのスクリプト設定URL creationURL、JavaScript 実行コンテキスト execution context、null または環境 reservedEnvironment、URL topLevelCreationURL、およびオリジン topLevelOrigin を指定して、 ウィンドウ環境設定オブジェクトを設定するには、 次の手順を実行します。
realm を、execution context の Realm コンポーネントの値とします。
window を、realm のグローバルオブジェクトとします。
settings object を、次のようにアルゴリズムが定義される新しい環境設定オブジェクトとします。
execution context を返します。
window の関連付けられた
Documentのモジュールマップを返します。
window の関連付けられた
Documentの現在のベース URLを返します。
window の関連付けられた
Documentのオリジンを返します。
parentDocument の関連する設定オブジェクトのクロスサイトの 祖先を持つかが true である場合、true を返します。
parentDocument のオリジンが、window の関連付けられた
Documentのオリジンと同一サイトでない場合、true を返します。
false を返します。
window の関連付けられた
Documentのポリシーコンテナーを返します。
次の両方が成立する場合は true を返し、それ以外の場合は false を返します。
realm のエージェントクラスターのクロスオリジン分離モードが
「concrete」である。かつ、
window の関連付けられた
Documentが「cross-origin-isolated」機能を使用することを許可されている。
window の関連付けられた
Documentの読み込みタイミング情報のナビゲーション開始時刻を返します。
reservedEnvironment が null でない場合、次を行います。
settings object のIDを reservedEnvironment のIDに、対象閲覧コンテキストを reservedEnvironment の対象閲覧コンテキストに、 アクティブなサービス ワーカーを reservedEnvironment のアクティブなサービス ワーカーに設定します。
reservedEnvironment のIDを空文字列に設定します。
予約済み環境の同一性は、作成された環境設定オブジェクトへ 完全に移譲されたものと見なされます。この時点以降、予約済み環境を環境のIDによって検索することはできません。
それ以外の場合、settings object のIDを新しい一意の不透明な文字列に、 settings object の対象閲覧コンテキストを null に、settings object のアクティブなサービス ワーカーを null に設定します。
settings object の作成 URLを creationURL に、settings object の最上位作成 URLを topLevelCreationURL に、settings object の最上位オリジンを topLevelOrigin に設定します。
realm の [[HostDefined]] フィールドを settings object に設定します。
WindowProxy エキゾチックオブジェクトWindowProxy は、Window 通常オブジェクトを包み込み、
ほとんどの操作を包み込まれたオブジェクトへ間接的に転送するエキゾチックオブジェクトです。
各閲覧コンテキストには、関連付けられた WindowProxy オブジェクトが
あります。閲覧コンテキストがナビゲーションされると、その閲覧コンテキストに関連付けられた WindowProxy オブジェクトが
包み込む Window オブジェクトが
変更されます。
WindowProxy エキゾチックオブジェクトは、以下で明示的に別段の指定がある場合を除き、
通常の内部メソッドを使用しなければなりません。
WindowProxy のインターフェイスオブジェクトは存在しません。
すべての WindowProxy オブジェクトは、包み込まれた Window オブジェクトを表す
[[Window]] 内部スロットを持ちます。
WindowProxy は「プロキシ」と名付けられていますが、WindowProxy と Location オブジェクトの間で機構を
再利用するため、実際のプロキシのように対象の内部メソッドに対して多相ディスパッチを行いません。Window オブジェクトが通常オブジェクトの
ままである限り、これは観測不能であり、どちらの方法でも実装できます。
W を、this の[[Window]] 内部スロットの値とします。
IsPlatformObjectSameOrigin(W) が true である場合、! OrdinaryGetPrototypeOf(W) を返します。
null を返します。
! SetImmutablePrototype(this, V) を返します。
W を、this の[[Window]] 内部スロットの値とします。
P が配列インデックスプロパティ名である場合、次を行います。
index を ! ToUint32(P) とします。
children を、W の関連付けられた
Documentの文書ツリーの子ナビゲーブルとします。
value を undefined とします。
index が children のサイズ未満である場合、次を行います。
navigableA のコンテナーが
navigableB のコンテナーより先に W の関連付けられた
Documentへ挿入された場合に navigableA が
navigableB より小さいものとして、children を昇順に並べ替えます。
value を、children[index] のアクティブな
WindowProxyに設定します。
value が undefined である場合、次を行います。
IsPlatformObjectSameOrigin(W) が true である場合、undefined を返します。
「SecurityError」 DOMException をスローします。
PropertyDescriptor { [[Value]]: value, [[Writable]]: false, [[Enumerable]]: true, [[Configurable]]: true } を返します。
IsPlatformObjectSameOrigin(W) が true である場合、! OrdinaryGetOwnProperty(W, P) を返します。
これは、既存のウェブ内容との互換性を維持するための、JavaScript 仕様の基本内部メソッドの不変条件に対する意図的な違反です。詳細については、tc39/ecma262 issue #672 を参照してください。 [JAVASCRIPT]
property を、CrossOriginGetOwnPropertyHelper(W, P) とします。
property が undefined でない場合、property を返します。
property が undefined であり、かつ P が W の文書ツリーの 子ナビゲーブルの対象名プロパティ集合内にある場合、次を行います。
value を、名前が P である W の名前付きオブジェクトのアクティブな
WindowProxyとします。
PropertyDescriptor { [[Value]]: value, [[Enumerable]]: false, [[Writable]]: false, [[Configurable]]: true } を返します。
同一オリジンでの動作と一致しないにもかかわらずプロパティ記述子が列挙不可である理由は、 既存のウェブ内容との互換性のためです。詳細については、issue #3183 を参照してください。
? CrossOriginPropertyFallback(P) を返します。
W を、this の[[Window]] 内部スロットの値とします。
IsPlatformObjectSameOrigin(W) が true である場合、次を行います。
P が配列インデックスプロパティ名である場合、 false を返します。
? OrdinaryDefineOwnProperty(W, P, Desc) を返します。
これは、既存のウェブ内容との互換性を維持するための、JavaScript 仕様の基本内部メソッドの不変条件に対する意図的な違反です。詳細については、tc39/ecma262 issue #672 を参照してください。 [JAVASCRIPT]
「SecurityError」 DOMException をスローします。
W を、this の[[Window]] 内部スロットの値とします。
現在のグローバルオブジェクトの閲覧コンテキスト、W の閲覧コンテキスト、P、および現在の設定オブジェクトを指定して、二つの閲覧コンテキスト間のアクセスを報告するべきか検査します。
IsPlatformObjectSameOrigin(W) が true である場合、? OrdinaryGet(this, P, Receiver) を返します。
? CrossOriginGet(this, P, Receiver) を返します。
OrdinaryGet および CrossOriginGet は [[GetOwnProperty]] 内部メソッドを呼び出すため、 W ではなく this が渡されます。
W を、this の[[Window]] 内部スロットの値とします。
現在のグローバルオブジェクトの閲覧コンテキスト、W の閲覧コンテキスト、P、 および現在の設定オブジェクトを指定して、二つの閲覧コンテキスト間のアクセスを報告するべきか検査します。
IsPlatformObjectSameOrigin(W) が true である場合、次を行います。
P が配列インデックスプロパティ名である場合、 false を返します。
? OrdinarySet(W, P, V, Receiver) を返します。
? CrossOriginSet(this, P, V, Receiver) を返します。
CrossOriginSet は [[GetOwnProperty]] 内部メソッドを呼び出すため、 W ではなく this が渡されます。
W を、this の[[Window]] 内部スロットの値とします。
IsPlatformObjectSameOrigin(W) が true である場合、次を行います。
P が配列インデックスプロパティ名である場合、次を行います。
desc を ! this.[[GetOwnProperty]](P) とします。
desc が undefined である場合、true を返します。
false を返します。
? OrdinaryDelete(W, P) を返します。
「SecurityError」 DOMException をスローします。
W を、this の[[Window]] 内部スロットの値とします。
maxProperties を、W の関連付けられた
Documentの文書ツリーの子ナビゲーブルのサイズとします。
keys を、0 から maxProperties までの、終端を含まない範囲とします。
IsPlatformObjectSameOrigin(W) が true である場合、keys と OrdinaryOwnPropertyKeys(W) を連結したものを 返します。
keys と ! CrossOriginOwnPropertyKeys(W) を連結したものを返します。
Location インターフェイス現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
各 Window オブジェクトには、
Window オブジェクトが作成されるときに
割り当てられる、一意の Location オブジェクトのインスタンスが関連付けられます。
Location エキゾチックオブジェクトは、IDL、作成後の JavaScript 内部メソッドの
呼び出し、および上書きされた JavaScript 内部メソッドの寄せ集めによって定義されています。
恐ろしいセキュリティポリシーも伴うため、この厄介なものを実装するときは特に注意してください。
Location オブジェクトを作成するには、次の手順を実行します。
location を、新しい Location プラットフォームオブジェクトとします。
valueOf を、location の関連するレルム.[[Intrinsics]].[[%Object.prototype.valueOf%]] とします。
! location.[[DefineOwnProperty]]("valueOf", {
[[Value]]: valueOf,
[[Writable]]: false,
[[Enumerable]]: false,
[[Configurable]]: false }) を実行します。
! location.[[DefineOwnProperty]](%Symbol.toPrimitive%, { [[Value]]: undefined, [[Writable]]: false, [[Enumerable]]: false, [[Configurable]]: false }) を実行します。
location の[[DefaultProperties]] 内部スロットの値を location.[[OwnPropertyKeys]]() に設定します。
location を返します。
valueOf および %Symbol.toPrimitive% 所有データプロパティの追加と、
Location のすべての IDL 属性が
[LegacyUnforgeable] としてマークされることは、Location インターフェイスを参照するか、
それを文字列化して文書
URLを決定し、その後それをセキュリティ上重要な方法で
使用する旧来のコードに必要です。
特に、valueOf、%Symbol.toPrimitive%、および
[LegacyUnforgeable] 文字列化子による緩和策により、
foo[location] = bar や location + "" のようなコードが誤った対象へ
誘導されないことが保証されます。
document.location [ = value ]
window.location [ = value ]
現在のページの場所を持つ Location オブジェクトを返します。
別のページへナビゲーションするために設定できます。
Document オブジェクトの location
のゲッター手順は、this が完全にアクティブである場合は、this の関連するグローバルオブジェクトの Location オブジェクトを返し、
それ以外の場合は null を返すことです。
Location オブジェクトは、
関連付けられた Document のURL
の表現と、関連付けられたナビゲーブルをナビゲーションおよび再読み込みするためのメソッドを提供します。
[Exposed =Window ]
interface Location { // 追加の作成手順および上書きされた内部メソッドも参照
[LegacyUnforgeable ] stringifier attribute USVString href ;
[LegacyUnforgeable ] readonly attribute USVString origin ;
[LegacyUnforgeable ] attribute USVString protocol ;
[LegacyUnforgeable ] attribute USVString host ;
[LegacyUnforgeable ] attribute USVString hostname ;
[LegacyUnforgeable ] attribute USVString port ;
[LegacyUnforgeable ] attribute USVString pathname ;
[LegacyUnforgeable ] attribute USVString search ;
[LegacyUnforgeable ] attribute USVString hash ;
[LegacyUnforgeable ] undefined assign (USVString url );
[LegacyUnforgeable ] undefined replace (USVString url );
[LegacyUnforgeable ] undefined reload ();
[LegacyUnforgeable ] readonly attribute DOMStringList ancestorOrigins ;
};location.toString()location.href
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
Location オブジェクトの URL を返します。
指定された URL へナビゲーションするために設定できます。
location.origin
現在のすべてのエンジンでサポートされています。
Location オブジェクトの URL のオリジンを返します。
location.protocol
現在のすべてのエンジンでサポートされています。
Location オブジェクトの URL のスキームを返します。
スキームを変更した同じ URL へナビゲーションするために設定できます。
location.host
現在のすべてのエンジンでサポートされています。
Location オブジェクトの URL のホストおよびポート
(スキームの既定のポートと異なる場合)を返します。
ホストおよびポートを変更した同じ URL へナビゲーションするために設定できます。
location.hostname
現在のすべてのエンジンでサポートされています。
Location オブジェクトの URL のホストを返します。
ホストを変更した同じ URL へナビゲーションするために設定できます。
location.port
現在のすべてのエンジンでサポートされています。
Location オブジェクトの URL のポートを返します。
ポートを変更した同じ URL へナビゲーションするために設定できます。
location.pathname
現在のすべてのエンジンでサポートされています。
Location オブジェクトの URL のパスを返します。
パスを変更した同じ URL へナビゲーションするために設定できます。
location.search
現在のすべてのエンジンでサポートされています。
Location オブジェクトの URL のクエリーを返します
(空でない場合は先頭の「?」を含みます)。
クエリーを変更した同じ URL へナビゲーションするために設定できます
(先頭の「?」は無視されます)。
location.hash
現在のすべてのエンジンでサポートされています。
Location オブジェクトの URL のフラグメントを返します
(空でない場合は先頭の「#」を含みます)。
フラグメントを変更した同じ URL へナビゲーションするために設定できます
(先頭の「#」は無視されます)。
location.assign(url)
現在のすべてのエンジンでサポートされています。
指定された URL へナビゲーションします。
location.replace(url)
現在のすべてのエンジンでサポートされています。
現在のページをセッション履歴から削除し、指定された URL へナビゲーションします。
location.reload()
現在のすべてのエンジンでサポートされています。
現在のページを再読み込みします。
location.ancestorOrigins
祖先ナビゲーブルのアクティブな文書のオリジンを列挙する DOMStringList オブジェクトを返します。
Location オブジェクトには、関連付けられた関連する
Documentがあります。これは、その Location オブジェクトの関連するグローバルオブジェクトの閲覧コンテキストが null でない場合は、その関連するグローバルオブジェクトの閲覧コンテキストのアクティブな文書であり、
それ以外の場合は null です。
Location オブジェクトには、関連付けられたURLがあります。これは、その Location オブジェクトの関連する
Documentが null でない場合は、その Location オブジェクトの関連する
DocumentのURLであり、それ以外の場合は about:blank です。
Location オブジェクト location をURL url へLocation オブジェクトとしてナビゲーションするには、
任意で NavigationHistoryBehavior historyHandling
(既定値は「auto」)を指定して、次を行います。
navigable を、location の関連するグローバルオブジェクトのナビゲーブルとします。
sourceDocument を、現任のグローバルオブジェクトの関連付けられた
Documentとします。
location の関連する
Documentがまだ完全に読み込まれておらず、かつ現任のグローバルオブジェクトが一時的アクティベーションを持たない場合、
historyHandling を「replace」に設定します。
exceptionsEnabled を true に、historyHandling を historyHandling に設定して、 sourceDocument を使用して navigable を url へナビゲーションします。
href
のゲッター手順は次のとおりです。
this の関連する Documentが null
でなく、そのオリジンが入口設定オブジェクトのオリジンと同一オリジンドメインでない場合、「SecurityError」 DOMException をスローします。
href のセッター手順は次のとおりです。
this の関連する Documentが null である場合、
返します。
url を、指定された値を入口設定オブジェクトを基準としてURL としてエンコーディング構文解析した結果とします。
url が失敗である場合、「SyntaxError」
DOMException をスローします。
this を url へLocation オブジェクトとして
ナビゲーションします。
href セッターには、意図的にセキュリティ検査がありません。
origin
のゲッター手順は次のとおりです。
this の関連する Documentが null
でなく、そのオリジンが入口設定オブジェクトのオリジンと同一オリジンドメインでない場合、「SecurityError」 DOMException をスローします。
protocol
のゲッター手順は次のとおりです。
this の関連する Documentが null
でなく、そのオリジンが入口設定オブジェクトのオリジンと同一オリジンドメインでない場合、「SecurityError」 DOMException をスローします。
protocol のセッター手順は次のとおりです。
this の関連する Documentが null である場合、
返します。
this の関連する Documentのオリジンが入口設定オブジェクトのオリジンと同一オリジンドメインでない場合、「SecurityError」 DOMException をスローします。
possibleFailure を、指定された値と、それに続く「:」を、copyURL を
url、スキーム開始状態を状態上書きとして基本 URL 構文解析した結果とします。
URL パーサーは連続する複数のコロンを無視するため、「https:」
(または「https::::」)という値を指定することは、「https」という値を
指定することと同じです。
possibleFailure が失敗である場合、「SyntaxError」 DOMException をスローします。
copyURL のスキームがHTTP(S) スキームでない場合、これらの手順を終了します。
this を copyURL へLocation オブジェクトとして
ナビゲーションします。
host
のゲッター手順は次のとおりです。
this の関連する Documentが null
でなく、そのオリジンが入口設定オブジェクトのオリジンと同一オリジンドメインでない場合、「SecurityError」 DOMException をスローします。
url のホストが null である場合、空文字列を返します。
host のセッター手順は次のとおりです。
this の関連する Documentが null である場合、
返します。
this の関連する Documentのオリジンが入口設定オブジェクトのオリジンと同一オリジンドメインでない場合、「SecurityError」 DOMException をスローします。
copyURL が不透明パスを持つ場合、返します。
指定された値を、copyURL をurl、ホスト状態を状態上書きとして基本 URL 構文解析します。
this を copyURL へLocation オブジェクトとして
ナビゲーションします。
hostname
のゲッター手順は次のとおりです。
this の関連する Documentが null
でなく、そのオリジンが入口設定オブジェクトのオリジンと同一オリジンドメインでない場合、「SecurityError」 DOMException をスローします。
hostname のセッター手順は次のとおりです。
this の関連する Documentが null である場合、
返します。
this の関連する Documentのオリジンが入口設定オブジェクトのオリジンと同一オリジンドメインでない場合、「SecurityError」 DOMException をスローします。
copyURL が不透明パスを持つ場合、返します。
指定された値を、copyURL をurl、ホスト名状態を状態上書きとして基本 URL 構文解析します。
this を copyURL へLocation オブジェクトとして
ナビゲーションします。
port
のゲッター手順は次のとおりです。
this の関連する Documentが null
でなく、そのオリジンが入口設定オブジェクトのオリジンと同一オリジンドメインでない場合、「SecurityError」 DOMException をスローします。
port のセッター手順は次のとおりです。
this の関連する Documentが null である場合、
返します。
this の関連する Documentのオリジンが入口設定オブジェクトのオリジンと同一オリジンドメインでない場合、「SecurityError」 DOMException をスローします。
copyURL がユーザー名/パスワード/ポートを持つことができない場合、 返します。
指定された値が空文字列である場合、copyURL のポートを null に設定します。
それ以外の場合、指定された値を、copyURL をurl、ポート状態を状態上書きとして基本 URL 構文解析します。
this を copyURL へLocation オブジェクトとして
ナビゲーションします。
pathname
のゲッター手順は次のとおりです。
this の関連する Documentが null
でなく、そのオリジンが入口設定オブジェクトのオリジンと同一オリジンドメインでない場合、「SecurityError」 DOMException をスローします。
この Location オブジェクトのURLをURL パスとして直列化した結果を返します。
pathname のセッター手順は次のとおりです。
this の関連する Documentが null である場合、
返します。
this の関連する Documentのオリジンが入口設定オブジェクトのオリジンと同一オリジンドメインでない場合、「SecurityError」 DOMException をスローします。
copyURL が不透明パスを持つ場合、返します。
copyURL のパスを空のリストに設定します。
指定された値を、copyURL をurl、パス開始状態を状態上書きとして基本 URL 構文解析します。
this を copyURL へLocation オブジェクトとして
ナビゲーションします。
search
のゲッター手順は次のとおりです。
this の関連する Documentが null
でなく、そのオリジンが入口設定オブジェクトのオリジンと同一オリジンドメインでない場合、「SecurityError」 DOMException をスローします。
search のセッター手順は次のとおりです。
this の関連する Documentが null である場合、
返します。
this の関連する Documentのオリジンが入口設定オブジェクトのオリジンと同一オリジンドメインでない場合、「SecurityError」 DOMException をスローします。
指定された値が空文字列である場合、copyURL のクエリーを null に設定します。
それ以外の場合、次の下位手順を実行します。
input を、指定された値から、存在する場合は先頭の「?」を一つ削除したものと
します。
copyURL のクエリーを空文字列に設定します。
input を、null、関連する
Documentの文書の文字エンコーディング、
copyURL をurl、およびクエリー状態を状態上書きとして基本 URL 構文解析します。
this を copyURL へLocation オブジェクトとして
ナビゲーションします。
hash
のゲッター手順は次のとおりです。
this の関連する Documentが null
でなく、そのオリジンが入口設定オブジェクトのオリジンと同一オリジンドメインでない場合、「SecurityError」 DOMException をスローします。
hash のセッター手順は次のとおりです。
this の関連する Documentが null である場合、
返します。
this の関連する Documentのオリジンが入口設定オブジェクトのオリジンと同一オリジンドメインでない場合、「SecurityError」 DOMException をスローします。
thisURLFragment を、copyURL のフラグメントが null でない場合はその値とし、 それ以外の場合は空文字列とします。
input を、指定された値から、存在する場合は先頭の「#」を一つ削除したものと
します。
copyURL のフラグメントを空文字列に設定します。
input を、copyURL をurl、フラグメント状態を状態上書きとして基本 URL 構文解析します。
copyURL のフラグメントが thisURLFragment である場合、返します。
この早期終了は、スクロール時に
location.hash を重複して設定する既存の内容との互換性のために必要です。
location.href セッターや location.assign() など、ほかのフラグメントナビゲーション機構には
適用されません。
this を copyURL へLocation オブジェクトとして
ナビゲーションします。
a および area 要素の同等の API とは異なり、hash セッターは、
既存のスクリプトとの互換性を維持するため、空文字列を特別扱いしません。
assign(url) メソッドの手順は次のとおりです。
this の関連する Documentが null である場合、
返します。
this の関連する Documentのオリジンが入口設定オブジェクトのオリジンと同一オリジンドメインでない場合、「SecurityError」 DOMException をスローします。
urlRecord を、url を入口設定オブジェクトを基準としてURL としてエンコーディング構文解析した結果とします。
urlRecord が失敗である場合、「SyntaxError」
DOMException をスローします。
this を urlRecord へLocation オブジェクトとして
ナビゲーションします。
replace(url) メソッドの手順は次のとおりです。
this の関連する Documentが null である場合、
返します。
urlRecord を、url を入口設定オブジェクトを基準としてURL としてエンコーディング構文解析した結果とします。
urlRecord が失敗である場合、「SyntaxError」
DOMException をスローします。
「replace」を指定して、this を urlRecord へLocation オブジェクトとして
ナビゲーションします。
replace() メソッドには、意図的にセキュリティ検査がありません。
reload()
メソッドの手順は次のとおりです。
document を、this の関連する
Documentとします。
document が null である場合、返します。
document のオリジンが入口設定オブジェクトのオリジンと同一オリジンドメインでない場合、「SecurityError」 DOMException をスローします。
Location オブジェクトには、関連付けられた空の
DOMStringListがあります。これは、関連付けられたリストが空のリストである DOMStringList オブジェクトです。
このオブジェクトは、関連する
Documentがない場合にのみ
返されます。その場合はナビゲーションできず、null でない関連する
Documentへ戻ることも
できないため、このオブジェクトはナビゲーションをまたいで状態を保持できません。
ancestorOrigins のゲッター手順は次のとおりです。
this の関連する Documentが null である場合、
this の空の
DOMStringListを返します。
this の関連する Documentのオリジンが入口設定オブジェクトのオリジンと同一オリジンドメインでない場合、「SecurityError」 DOMException をスローします。
表明:this の関連する Documentの祖先オリジンリストは
null ではありません。
それ以外の場合、this の関連する Documentの祖先オリジンリストを返します。
前述のとおり、Location エキゾチックオブジェクトには、
セキュリティ上の目的から IDL を超える追加のロジックが必要です。Location オブジェクトは、
以下で明示的に別段の指定がある場合を除き、通常の内部メソッドを使用しなければなりません。
また、すべての Location オブジェクトは、作成時における自身のプロパティを表す [[DefaultProperties]] 内部スロットを持ちます。
IsPlatformObjectSameOrigin(this) が true である場合、! OrdinaryGetPrototypeOf(this) を返します。
null を返します。
! SetImmutablePrototype(this, V) を返します。
IsPlatformObjectSameOrigin(this) が true である場合、次を行います。
desc を OrdinaryGetOwnProperty(this, P) とします。
this の [[DefaultProperties]] 内部スロットの値が P を含む場合、desc.[[Configurable]] を true に設定します。
desc を返します。
property を CrossOriginGetOwnPropertyHelper(this, P) とします。
property が undefined でない場合、property を返します。
? CrossOriginPropertyFallback(P) を返します。
IsPlatformObjectSameOrigin(this) が true である場合、次を行います。
this の [[DefaultProperties]] 内部スロットの値が P を含む場合、false を返します。
? OrdinaryDefineOwnProperty(this, P, Desc) を返します。
「SecurityError」 DOMException
をスローします。
IsPlatformObjectSameOrigin(this) が true である場合、? OrdinaryGet(this, P, Receiver) を返します。
? CrossOriginGet(this, P, Receiver) を返します。
IsPlatformObjectSameOrigin(this) が true である場合、? OrdinarySet(this, P, V, Receiver) を返します。
? CrossOriginSet(this, P, V, Receiver) を返します。
IsPlatformObjectSameOrigin(this) が true である場合、? OrdinaryDelete(this, P) を返します。
「SecurityError」 DOMException
をスローします。
IsPlatformObjectSameOrigin(this) が true である場合、 OrdinaryOwnPropertyKeys(this) を返します。
CrossOriginOwnPropertyKeys(this) を返します。
History インターフェイス現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
enum ScrollRestoration { " auto " , " manual " };
[Exposed =Window ]
interface History {
readonly attribute unsigned long length ;
attribute ScrollRestoration scrollRestoration ;
readonly attribute any state ;
undefined go (optional long delta = 0);
undefined back ();
undefined forward ();
undefined pushState (any data , DOMString unused , optional USVString ? url = null );
undefined replaceState (any data , DOMString unused , optional USVString ? url = null );
};history.length
現在のすべてのエンジンでサポートされています。
現在の辿ることができるナビゲーブルの全体のセッション履歴エントリ数を返します。
history.scrollRestoration
現在のすべてのエンジンでサポートされています。
アクティブなセッション履歴エントリのスクロール復元モードを返します。
history.scrollRestoration = value
アクティブなセッション履歴エントリのスクロール 復元モードを value に設定します。
history.state
現在のすべてのエンジンでサポートされています。
アクティブなセッション履歴エントリのクラシック履歴 API 状態を、 JavaScript 値へ逆直列化して返します。
history.go()
現在のページを再読み込みします。
history.go(delta)
現在のすべてのエンジンでサポートされています。
現在の辿ることができるナビゲーブルの全体のセッション履歴エントリリスト内で、 指定されたステップ数だけ後方または前方へ移動します。
デルタがゼロの場合、現在のページを再読み込みします。
デルタが範囲外である場合、何もしません。
history.back()
現在のすべてのエンジンでサポートされています。
現在の辿ることができるナビゲーブルの全体のセッション履歴エントリリスト内で一ステップ戻ります。
前のページが存在しない場合、何もしません。
history.forward()
現在のすべてのエンジンでサポートされています。
現在の辿ることができるナビゲーブルの全体のセッション履歴エントリリスト内で一ステップ進みます。
次のページが存在しない場合、何もしません。
history.pushState(data, "")
現在のすべてのエンジンでサポートされています。
クラシック履歴 API 状態を data の直列化に設定した新しいエントリをセッション履歴へ追加します。アクティブな履歴エントリの URL がコピーされ、新しいエントリの URL として使用されます。
(第二引数は歴史的な理由で存在し、省略できません。空文字列を渡すのが慣例です。)
history.pushState(data, "", url)
クラシック履歴 API 状態を data の直列化に設定し、URL を url に設定した新しいエントリをセッション履歴へ追加します。
現在の Document が
url へURL
を書き換えることができない場合、「SecurityError」
DOMException
がスローされます。
(第二引数は歴史的な理由で存在し、省略できません。空文字列を渡すのが慣例です。)
history.replaceState(data, "")
現在のすべてのエンジンでサポートされています。
アクティブなセッション履歴エントリのクラシック履歴 API 状態を、 data の構造化複製へ更新します。
(第二引数は歴史的な理由で存在し、省略できません。空文字列を渡すのが慣例です。)
history.replaceState(data, "", url)
アクティブなセッション履歴エントリのクラシック履歴 API 状態を、 data の構造化複製へ更新し、そのURL を url へ更新します。
現在の Document が
url へURL を書き換えることができない場合、「SecurityError」
DOMException
がスローされます。
(第二引数は歴史的な理由で存在し、省略できません。空文字列を渡すのが慣例です。)
Document は、履歴オブジェクトである
History オブジェクトを持ちます。
history のゲッター手順は、
this
の関連付けられた
Documentの履歴オブジェクトを返すことです。
各 History オブジェクトは、
初期値が null である状態を持ちます。
各 History オブジェクトは、
初期値が 0 である非負整数の長さを持ちます。
各 History オブジェクトは、
初期値が 0 である非負整数のインデックスを持ちます。
インデックスは直接公開されませんが、同期ナビゲーション中の長さの変化から推測できます。実際、それがこの値の用途です。
length
のゲッター手順は次のとおりです。
this の関連するグローバルオブジェクトの関連付けられた
Documentが完全にアクティブでない場合、「SecurityError」
DOMException
をスローします。
scrollRestoration のゲッター手順は次のとおりです。
this の関連するグローバルオブジェクトの関連付けられた
Documentが完全にアクティブでない場合、「SecurityError」
DOMException
をスローします。
this の関連するグローバルオブジェクトのナビゲーブルのアクティブなセッション履歴エントリのスクロール復元モードを返します。
scrollRestoration
のセッター手順は次のとおりです。
this の関連するグローバルオブジェクトの関連付けられた
Documentが完全にアクティブでない場合、「SecurityError」
DOMException
をスローします。
this の関連するグローバルオブジェクトのナビゲーブルのアクティブなセッション履歴エントリのスクロール復元モードを、 指定された値に設定します。
state のゲッター手順は
次のとおりです。
this の関連するグローバルオブジェクトの関連付けられた
Documentが完全にアクティブでない場合、「SecurityError」
DOMException
をスローします。
整数 delta を指定して、History
オブジェクト
history をデルタ走査するには、次を行います。
document を、history の関連するグローバルオブジェクトの
関連付けられた
Documentとします。
document が完全にアクティブでない場合、「SecurityError」 DOMException
をスローします。
history の関連するグローバルオブジェクトのナビゲーブルのナビゲーションまたは履歴更新を 実行することが許可されているかが ブロック済みを返す場合、返します。
document のノードナビゲーブルの辿ることができるナビゲーブル、delta を指定し、 sourceDocument を document に設定して、デルタによって履歴を走査します。
pushState(data,
unused, url) メソッドの手順は、this、data、url、
および「push」を
指定して、共有履歴 push/replace 状態手順を
実行することです。
replaceState(data, unused,
url) メソッドの手順は、this、data、url、および「replace」を
指定して、共有履歴 push/replace 状態手順を
実行することです。
History
history、値 data、スカラー値
文字列または null の
url、および履歴処理動作 historyHandling を指定した
共有履歴 push/replace 状態手順は、次のとおりです。
document を、history の関連するグローバルオブジェクトの
関連付けられた
Documentとします。
document が完全にアクティブでない場合、「SecurityError」 DOMException
をスローします。
serializedData を StructuredSerializeForStorage(data) とします。すべての例外を再スローします。
newURL を、document のURLとします。
url が null でも空文字列でもない場合、次を行います。
newURL を、history の関連する設定オブジェクトを基準として、 url をURL としてエンコーディング構文解析した結果に 設定します。
newURL が失敗である場合、「SecurityError」
DOMException
をスローします。
document が newURL へURL を書き換えることができない場合、「SecurityError」
DOMException
をスローします。
ここでの空文字列に対する特別扱いは歴史的なものであり、
location.href = ""(空文字列に対して URL 構文解析を行う)と
history.pushState(null, "", "")(構文解析を迂回する)のようなコードを比較すると、
結果の URL が異なることになります。
history の関連するグローバルオブジェクトのナビゲーブルのナビゲーションまたは履歴更新を 実行することが許可されているかが ブロック済みを返す場合、返します。
navigation を、history の関連するグローバルオブジェクトの ナビゲーション APIと します。
continue を、navigationType を
historyHandling に、isSameDocument を
true に、destinationURL を
newURL に、classicHistoryAPIState を
serializedData に設定して、navigation でpush/replace/reload
navigate イベントを発火した結果とします。
continue が false である場合、返します。
document と newURL を指定し、serializedData を serializedData に、historyHandling を historyHandling に設定して、URL および履歴更新手順を実行します。
ユーザーエージェントは、ページごとにセッション履歴へ追加できる状態オブジェクトの数を制限してもかまいません。
ページが実装定義の制限に達した場合、ユーザーエージェントは新しいエントリを
追加した後、セッション履歴内のその Document
オブジェクトの最初のエントリの
直後にあるエントリを削除しなければなりません。(したがって、状態履歴は削除については FIFO バッファとして、
ナビゲーションについては LIFO バッファとして機能します。)
次のアルゴリズムが true を返す場合、Document
document は、
URL
targetURL へURL を書き換えることができます。
documentURL を、document のURLとします。
targetURL と documentURL のスキーム、ユーザー名、 パスワード、ホスト、またはポート コンポーネントが異なる場合、false を返します。
targetURL のスキームが HTTP(S) スキームである場合、true を返します。
targetURL のスキームが
「file」である場合、次を行います。
targetURL と documentURL のパスコンポーネントが異なる場合、false を返します。
true を返します。
targetURL と documentURL のパスコンポーネントまたはクエリーコンポーネントが異なる場合、false を返します。
その他の種類の URL では、フラグメントの相違のみが許可されます。
true を返します。
| document のURL | targetURL | URL を書き換えることができる |
|---|---|---|
https://example.com/home
|
https://example.com/home#about
|
✅ |
https://example.com/home
|
https://example.com/home?page=shop
|
✅ |
https://example.com/home
|
https://example.com/shop
|
✅ |
https://example.com/home
|
https://user:pass@example.com/home
|
❌ |
https://example.com/home
|
http://example.com/home
|
❌ |
file:///path/to/x
|
file:///path/to/x#hash
|
✅ |
file:///path/to/x
|
file:///path/to/x?search
|
✅ |
file:///path/to/x
|
file:///path/to/y
|
❌ |
about:blank
|
about:blank#hash
|
✅ |
about:blank
|
about:blank?search
|
❌ |
about:blank
|
about:srcdoc
|
❌ |
data:text/html,foo
|
data:text/html,foo#hash
|
✅ |
data:text/html,foo
|
data:text/html,foo?search
|
❌ |
data:text/html,foo
|
data:text/html,bar
|
❌ |
data:text/html,foo
|
data:bar
|
❌ |
blob:https://example.com/77becafe-657b-4fdc-8bd3-e83aaa5e8f43
|
blob:https://example.com/77becafe-657b-4fdc-8bd3-e83aaa5e8f43#hash
|
✅ |
blob:https://example.com/77becafe-657b-4fdc-8bd3-e83aaa5e8f43
|
blob:https://example.com/77becafe-657b-4fdc-8bd3-e83aaa5e8f43?search
|
❌ |
blob:https://example.com/77becafe-657b-4fdc-8bd3-e83aaa5e8f43
|
blob:https://example.com/anything
|
❌ |
blob:https://example.com/77becafe-657b-4fdc-8bd3-e83aaa5e8f43
|
blob:path
|
❌ |
Document のURLのみが重要であり、そのオリジンは重要ではないことに注意してください。これらは、
オリジンを継承した about:blank Document、サンドボックス化された
iframe、または document.domain セッターが使用された場合などに一致しないことがあります。
ユーザーが直線上を移動でき、常に何らかの座標に位置し、後で戻れるように特定の座標に対応するページを ブックマークできるゲームを考えます。
このようなゲームで x=5 の位置を実装する静的ページは、次のようになります。
<!DOCTYPE HTML>
<!-- this is https://example.com/line?x=5 -->
< html lang = "en" >
< title > Line Game - 5</ title >
< p > You are at coordinate 5 on the line.</ p >
< p >
< a href = "?x=6" > Advance to 6</ a > or
< a href = "?x=4" > retreat to 4</ a > ?
</ p > このようなシステムの問題は、ユーザーがクリックするたびにページ全体を再読み込みする必要があることです。 代わりに、スクリプトを使用して実装する別の方法を次に示します。
<!DOCTYPE HTML>
<!-- this starts off as https://example.com/line?x=5 -->
< html lang = "en" >
< title > Line Game - 5</ title >
< p > You are at coordinate < span id = "coord" > 5</ span > on the line.</ p >
< p >
< a href = "?x=6" onclick = "go(1); return false;" > Advance to 6</ a > or
< a href = "?x=4" onclick = "go(-1); return false;" > retreat to 4</ a > ?
</ p >
< script >
var currentPage = 5 ; // prefilled by server
function go( d) {
setupPage( currentPage + d);
history. pushState( currentPage, "" , '?x=' + currentPage);
}
onpopstate = function ( event) {
setupPage( event. state);
}
function setupPage( page) {
currentPage = page;
document. title = 'Line Game - ' + currentPage;
document. getElementById( 'coord' ). textContent = currentPage;
document. links[ 0 ]. href = '?x=' + ( currentPage+ 1 );
document. links[ 0 ]. textContent = 'Advance to ' + ( currentPage+ 1 );
document. links[ 1 ]. href = '?x=' + ( currentPage- 1 );
document. links[ 1 ]. textContent = 'retreat to ' + ( currentPage- 1 );
}
</ script > スクリプトがないシステムでも、これは以前の例と同じように動作します。しかし、スクリプトを サポートするユーザーは、同じ体験のためにネットワークアクセスが不要になるため、はるかに高速に ナビゲーションできるようになります。さらに、単純なスクリプトベースの手法だけを使用した場合とは異なり、 ブックマークおよびセッション履歴のナビゲーションも引き続き機能します。
上の例では、pushState()
メソッドの data 引数は、サーバーへ送信される情報と同じですが、より便利な形式になっているため、
ユーザーがナビゲーションするたびにスクリプトが URL を構文解析する必要はありません。
ほとんどのアプリケーションは、すべての履歴エントリに同じスクロール復元モード値を使用しようとします。
これを実現するには、可能な限り早く(たとえば、文書の head 要素内の最初の
script 要素で)
scrollRestoration
属性を設定し、履歴セッションへ追加されるすべてのエントリが目的のスクロール復元モードを取得するようにできます。
< head >
< script >
if ( 'scrollRestoration' in history)
history. scrollRestoration = 'manual' ;
</ script >
</ head >
この節は非規範的です。
グローバルな navigation
プロパティによって提供されるナビゲーション API は、ナビゲーションおよび履歴エントリを管理するための、
ウェブアプリケーションに焦点を当てた現代的な方法を提供します。これは従来の location API および history API の後継です。
この API が提供する機能の一つは、セッション履歴エントリを調べることです。たとえば、 次のコードはエントリの URL を有順序リストとして表示します。
const ol = document. createElement( "ol" );
ol. start = 0 ; // so that the list items' ordinal values match up with the entry indices
for ( const entry of navigation. entries()) {
const li = document. createElement( "li" );
if ( entry. index < navigation. currentEntry. index) {
li. className = "backward" ;
} else if ( entry. index > navigation. currentEntry. index) {
li. className = "forward" ;
} else {
li. className = "current" ;
}
li. textContent = entry. url;
ol. append( li);
} navigation.entries()
配列には、ここで示した url
および index
プロパティに加えて、ほかにも有用なプロパティを持つ NavigationHistoryEntry
インスタンスが含まれます。この配列には、現在のナビゲーブルを表す NavigationHistoryEntry
オブジェクトのみが含まれることに注意してください。したがって、その内容は iframe などのナビゲーブルコンテナー内での
ナビゲーションや、ナビゲーション API 自体が iframe 内で使用される
場合の親ナビゲーブルのナビゲーションによる
影響を受けません。さらに、この配列には同一オリジンのセッション履歴エントリを表す NavigationHistoryEntry
オブジェクトのみが含まれます。つまり、ユーザーが現在のオリジンの前後に別のオリジンを訪問していても、
対応する NavigationHistoryEntry
は存在しません。
ナビゲーション API は、ナビゲーション、再読み込み、または履歴の走査にも使用できます。
< button onclick = "navigation.reload()" > Reload</ button >
< input type = "url" id = "navigationURL" >
< button onclick = "navigation.navigate(navigationURL.value)" > Navigate</ button >
< button id = "backButton" onclick = "navigation.back()" > Back</ button >
< button id = "forwardButton" onclick = "navigation.forward()" > Forward</ button >
< select id = "traversalDestinations" ></ select >
< button id = "goButton" onclick = "navigation.traverseTo(traversalDestinations.value)" > Traverse To</ button >
< script >
backButton. disabled = ! navigation. canGoBack;
forwardButton. disabled = ! navigation. canGoForward;
for ( const entry of navigation. entries()) {
traversalDestinations. append( new Option( entry. url, entry. key));
}
</ script > 走査は同一オリジンの移動先に再び制限されることに注意してください。
たとえば、前のセッション履歴エントリが別のオリジンのページである場合、
navigation.canGoBack
は false になります。
ナビゲーション API の最も強力な部分は navigate
イベントです。これは、
現在のナビゲーブルでほぼすべての
ナビゲーションまたは走査が発生するたびに発火します。
navigation. onnavigate = event => {
console. log( event. navigationType); // "push", "replace", "reload", or "traverse"
console. log( event. destination. url);
console. log( event. userInitiated);
// ... and other useful properties
}; (移動先が新しい文書である場合、ロケーションバーから開始された ナビゲーション、または別のウィンドウから開始されたナビゲーションでは、このイベントは発火しません。)
多くの場合、イベントの cancelable
プロパティは true になります。つまり、preventDefault() を使用してこのイベントを
キャンセルできます。
navigation. onnavigate = event => {
if ( event. cancelable && isDisallowedURL( event. destination. url)) {
alert( `Please don't go to ${ event. destination. url} !` );
event. preventDefault();
}
};
cancelable
プロパティは、子ナビゲーブル内で発生する走査、新しいオリジンへ移動する走査、
または以前の preventDefault() の呼び出しによって
走査が阻止された直後にユーザーが再び走査を試みる場合など、一部の「traverse」ナビゲーションでは false になります。
NavigateEvent の intercept()
メソッドを使用すると、ナビゲーションを横取りして同一文書ナビゲーションへ変換できます。
navigation. addEventListener( "navigate" , e => {
// Some navigations, e.g. cross-origin navigations, we cannot intercept.
// Let the browser handle those normally.
if ( ! e. canIntercept) {
return ;
}
// Similarly, don't intercept fragment navigations or downloads.
if ( e. hashChange || e. downloadRequest !== null ) {
return ;
}
const url = new URL( event. destination. url);
if ( url. pathname. startsWith( "/articles/" )) {
e. intercept({
async handler() {
// The URL has already changed, so show a placeholder while
// fetching the new content, such as a spinner or loading page.
renderArticlePagePlaceholder();
// Fetch the new content and display when ready.
const articleContent = await getArticleContent( url. pathname, { signal: e. signal });
renderArticlePage( articleContent);
}
});
}
}); handler
関数は、ナビゲーションの非同期進行状況および成功または失敗を表すプロミスを返せることに注意してください。
プロミスが保留中である間、ブラウザー UI はナビゲーションが進行中であるものとして扱えます
(たとえば、読み込みスピナーを表示できます)。ナビゲーション API のその他の部分も、navigation.navigate() の戻り値など、これらのプロミスの影響を
受けます。
const { committed, finished } = await navigation. navigate( "/articles/the-navigation-api-is-cool" );
// The committed promise will fulfill once the URL has changed, which happens
// immediately (as long as the NavigateEvent wasn't canceled).
await committed;
// The finished promise will fulfill once the Promise returned by handler() has
// fulfilled, which happens once the article is downloaded and rendered. (Or,
// it will reject, if handler() fails along the way).
await finished; Navigation インターフェイス[Exposed =Window ]
interface Navigation : EventTarget {
sequence <NavigationHistoryEntry > entries ();
readonly attribute NavigationHistoryEntry ? currentEntry ;
undefined updateCurrentEntry (NavigationUpdateCurrentEntryOptions options );
readonly attribute NavigationTransition ? transition ;
readonly attribute NavigationActivation ? activation ;
readonly attribute boolean canGoBack ;
readonly attribute boolean canGoForward ;
NavigationResult navigate (USVString url , optional NavigationNavigateOptions options = {});
NavigationResult reload (optional NavigationReloadOptions options = {});
NavigationResult traverseTo (DOMString key , optional NavigationOptions options = {});
NavigationResult back (optional NavigationOptions options = {});
NavigationResult forward (optional NavigationOptions options = {});
attribute EventHandler onnavigate ;
attribute EventHandler onnavigatesuccess ;
attribute EventHandler onnavigateerror ;
attribute EventHandler oncurrententrychange ;
};
dictionary NavigationUpdateCurrentEntryOptions {
required any state ;
};
dictionary NavigationOptions {
any info ;
};
dictionary NavigationNavigateOptions : NavigationOptions {
any state ;
NavigationHistoryBehavior history = "auto";
};
dictionary NavigationReloadOptions : NavigationOptions {
any state ;
};
dictionary NavigationResult {
Promise <NavigationHistoryEntry > committed ;
Promise <NavigationHistoryEntry > finished ;
};
enum NavigationHistoryBehavior {
" auto " ,
" push " ,
" replace "
};各 Window には、Navigation オブジェクトである、
関連付けられたナビゲーション APIがあります。Window オブジェクトの作成時、そのナビゲーション APIは、
Window オブジェクトの関連するレルムで作成された
新しい Navigation オブジェクトに設定されなければ
なりません。
navigation
のゲッター手順は、this のナビゲーション APIを返すことです。
Navigation インターフェイスを
実装するすべてのオブジェクトが、イベントハンドラー IDL 属性として
サポートしなければならないイベントハンドラー(および対応するイベントハンドラーイベント型)は次のとおりです。
| イベントハンドラー | イベントハンドラーイベント型 |
|---|---|
onnavigate
|
navigate
|
onnavigatesuccess
|
navigatesuccess
|
onnavigateerror
|
navigateerror
|
oncurrententrychange
|
currententrychange
|
各 Navigation には、初期状態で
空である NavigationHistoryEntry
オブジェクトのリストである、関連付けられたエントリリストが
あります。
各 Navigation には、初期値が
−1 である整数の、関連付けられた現在のエントリインデックスが
あります。
Navigation
navigation の現在のエントリは、次の手順を実行した結果です。
navigation のエントリとイベントが無効になっている場合、 null を返します。
表明:navigation の現在のエントリインデックスは −1 ではありません。
navigation のエントリリスト[navigation の現在のエントリインデックス] を返します。
次の手順が true を返す場合、Navigation
navigation の
エントリとイベントが無効になっています。
document を、navigation の関連するグローバルオブジェクトの
関連付けられた
Documentとします。
document が完全にアクティブでない場合、true を返します。
document の初期
about:blank かが true
である場合、true を返します。
false を返します。
Navigation
navigation 内のセッション履歴エントリ she の
ナビゲーション API エントリインデックスを取得するには、
次を行います。
index を 0 とします。
navigation のエントリリストの各 nhe について、次を行います。
nhe のセッション履歴エントリが she と等しい場合、index を返します。
index を 1 増加させます。
−1 を返します。
ナビゲーション API 全体で使用される主要な型は、NavigationType
列挙です。
enum NavigationType {
" push " ,
" replace " ,
" reload " ,
" traverse "
};これは、ウェブ開発者に可視な主要な「ナビゲーション」の種類を表しますが、(別の箇所で述べられているように)この標準の単一のナビゲーションアルゴリズムとは正確には一致しません。 各値の意味は次のとおりです。
push」push」となるナビゲーションの呼び出し、または
history.pushState()
に対応します。
replace」replace」となるナビゲーションの呼び出し、または
history.replaceState()
に対応します。
reload」traverse」NavigationType
列挙の値空間は、
仕様内部の履歴処理動作型の値空間の上位集合です。この標準の
いくつかの部分では、この重なりを利用し、NavigationType を期待する
アルゴリズムへ履歴処理動作を渡します。
Navigation
navigation, 세션
히스토리 항목의 목록 newSHEs 및 세션 히스토리
항목 initialSHE가 주어진 경우 새 문서의
탐색 API 항목을 초기화하려면
다음을 수행한다.
navigation의 항목 및 이벤트가 비활성화되어 있으면 반환한다.
newSHEs의 각 newSHE에 대해 다음을 수행한다.
newNHE를 navigation의 관련
영역에서 생성된 새로운 NavigationHistoryEntry로
설정한다.
newNHE의 세션 히스토리 항목을 newSHE로 설정한다.
newSHEs는 원래 탐색 API용 세션 히스토리 항목 가져오기에서 얻은 것이므로 각 newSHE는 initialSHE와 연속된 동일 출처이다.
navigation의 현재 항목 인덱스를 navigation 내 initialSHE의 탐색 API 항목 인덱스를 가져온 결과로 설정한다.
Navigation
navigation, 세션 히스토리 항목의 목록 newSHEs 및
세션 히스토리
항목 reactivatedSHE가 주어진 경우 재활성화를 위해
탐색 API 항목을
업데이트하려면 다음을 수행한다.
navigation의 항목 및 이벤트가 비활성화되어 있으면 반환한다.
newNHEs를 새로운 빈 목록으로 설정한다.
newSHEs의 각 newSHE에 대해 다음을 수행한다.
newNHE를 null로 설정한다.
oldNHEs가 세션 히스토리 항목이
newSHE인
NavigationHistoryEntry
matchingOldNHE를 포함하면 다음을
수행한다.
newNHE를 matchingOldNHE로 설정한다.
oldNHEs에서 matchingOldNHE를 제거한다.
그렇지 않으면 다음을 수행한다.
newNHE를 navigation의 관련 영역에서 생성된 새로운 NavigationHistoryEntry로
설정한다.
newNHE의 세션 히스토리 항목을 newSHE로 설정한다.
newNHE를 newNHEs에 추가한다.
newSHEs는 원래 탐색 API용 세션 히스토리 항목 가져오기에서 얻은 것이므로 각 newSHE는 reactivatedSHE와 연속된 동일 출처이다.
이 루프가 끝날 때까지 oldNHEs에 남아 있는 모든 NavigationHistoryEntry는
Document가 bfcache에 있는 동안 폐기된 세션 히스토리 항목을 나타낸다.
navigation의 항목 목록을 newNHEs로 설정한다.
navigation의 현재 항목 인덱스를 navigation 내 reactivatedSHE의 탐색 API 항목 인덱스를 가져온 결과로 설정한다.
navigation의 관련 전역 객체가 주어진 상태에서 탐색 및 순회 태스크 소스에 다음 단계를 실행하는 전역 태스크를 큐에 추가한다.
oldNHEs의 각 disposedNHE에 대해 다음을 수행한다.
disposedNHE에서 dispose라는
이름의 이벤트를
발생시킨다.
dispose
이벤트가 pageshow
이벤트
이후에 발생하도록 이 단계를 태스크만큼 지연한다. 이렇게 하면 페이지가 재활성화될 때
pageshow가
페이지가 받는 첫 번째 이벤트가 된다.
(그러나 이 알고리즘의 나머지 부분은 pageshow 이벤트가
발생하기 전에 실행된다. 이렇게 하면 모든 pageshow 이벤트
처리기에서 navigation.entries()
및 navigation.currentEntry가
올바르게 업데이트된 값을 갖게 된다.)
Navigation
navigation, 세션 히스토리 항목
destinationSHE 및 NavigationType
navigationType이 주어진 경우 동일
문서 탐색을 위해 탐색 API 항목을
업데이트하려면 다음을 수행한다.
navigation의 항목 및 이벤트가 비활성화되어 있으면 반환한다.
oldCurrentNHE를 navigation의 현재 항목으로 설정한다.
disposedNHEs를 새로운 빈 목록으로 설정한다.
navigationType이 "traverse"이면
다음을 수행한다.
navigation의 현재 항목 인덱스를 navigation 내 destinationSHE의 탐색 API 항목 인덱스를 가져온 결과로 설정한다.
이 알고리즘은 동일 문서 순회에만 호출된다. 문서 간 순회에서는 대신 새 문서의 탐색 API 항목 초기화 또는 재활성화를 위한 탐색 API 항목 업데이트를 호출한다.
그렇지 않고 navigationType이 "push"이면
다음을 수행한다.
그렇지 않고 navigationType이 "replace"이면
다음을 수행한다.
oldCurrentNHE를 disposedNHEs에 추가한다.
navigationType이 "push"
또는
"replace"이면
다음을 수행한다.
newNHE를 navigation의 관련 영역에서 생성된 새로운 NavigationHistoryEntry로
설정한다.
newNHE의 세션 히스토리 항목을 destinationSHE로 설정한다.
navigation의 진행 중인 API 메서드 추적기가 null이 아니면 navigation의 진행 중인 API 메서드 추적기와 navigation의 현재 항목이 주어진 상태에서 커밋된 대상 항목에 관해 알린다.
이벤트 처리기가 다른 탐색을 시작하거나 navigation의 진행
중인 API 메서드 추적기 값을 변경할 수 있으므로 dispose 또는
currententrychange
이벤트를 발생시키기 전에 이를 수행하는 것이 중요하다.
navigateEvent를 navigation의 진행 중인 navigate 이벤트로
설정한다.
apiMethodTracker를 navigation의 진행 중인 API 메서드 추적기로 설정한다.
navigation의 관련 설정 객체가 주어진 상태에서 스크립트 실행을 준비한다.
이렇게 하는 이유를 이해하려면 다른 탐색 API 이벤트에 관한 설명을 참조한다.
navigation에서 NavigationCurrentEntryChangeEvent를
사용하여 currententrychange라는
이름의 이벤트를
발생시킨다. 이때 해당 navigationType
속성을 navigationType으로 초기화하고 from을
oldCurrentNHE로 초기화한다.
disposedNHEs의 각 disposedNHE에 대해 다음을 수행한다.
disposedNHE에서 dispose라는
이름의 이벤트를
발생시킨다.
navigation, navigateEvent 및 apiMethodTracker가 주어진 상태에서
navigate
이벤트 가로채기 커밋 처리기 단계를 실행한다.
navigation의 관련 설정 객체가 주어진 상태에서 스크립트 실행 후 정리한다.
구현에서 동일 문서 탐색으로 인해 세션 히스토리 항목이 세션 히스토리 항목 목록의 뒤쪽에서 밀려나 폐기될 수 있다. 이는 위 알고리즘이나 이 표준의 다른 어떤 부분에서도 아직 처리되지 않는다. 이러한 경우의 올바른 동작 정의 진행 상황은 이슈 #8620을 참조한다.
NavigationHistoryEntry
인터페이스[Exposed =Window ]
interface NavigationHistoryEntry : EventTarget {
readonly attribute USVString ? url ;
readonly attribute DOMString key ;
readonly attribute DOMString id ;
readonly attribute long long index ;
readonly attribute boolean sameDocument ;
any getState ();
attribute EventHandler ondispose ;
};entry.url
이 탐색 히스토리 항목의 URL이다.
항목이 현재 문서와 다른 Document에
해당하고
(즉, sameDocument가
false이고), 해당 Document가
"no-referrer" 또는 "origin"의 리퍼러
정책으로 가져와졌다면 null을 반환할 수 있다. 이는 해당
Document가 동일
출처의 다른 페이지에서도 자신의 URL을 숨기고 있음을 나타내기 때문이다.
entry.key
탐색 히스토리 목록에서 이 탐색 히스토리 항목의 위치를 나타내는 사용자 에이전트 생성 임의 UUID 문자열이다.
이 값은 "replace"
탐색으로 인해 이 인스턴스를 교체하는 다른 NavigationHistoryEntry
인스턴스에서 재사용되며, 다시 로드 및 세션 복원 이후에도 유지된다.
이는 navigation.traverseTo(key)를
사용하여 탐색 히스토리 목록에서 이 항목으로 돌아가는 데 유용하다.
entry.id
이 특정 탐색 히스토리 항목을 나타내는 사용자 에이전트 생성 임의 UUID 문자열이다. 이 값은 다른 NavigationHistoryEntry
인스턴스에서 재사용되지 않는다. 이 값은 다시 로드 및 세션 복원 이후에도 유지된다.
이는 다른 저장소 API를 사용하여 데이터를 이 탐색 히스토리 항목과 연결하는 데 유용하다.
entry.index
navigation.entries()
내 이 NavigationHistoryEntry의
인덱스이며, 항목이 탐색 히스토리 항목 목록에 없으면 −1이다.
entry.sameDocument
이 탐색 히스토리 항목이 현재 문서와 동일한 Document에 대한 것인지
여부를 나타낸다. 예를 들어 항목이 프래그먼트 탐색 또는 단일 페이지 앱 탐색을 나타내는 경우 true가 된다.
entry.getState()
navigation.navigate()
또는 navigation.updateCurrentEntry()를
사용하여 이 항목에 추가된 저장 상태의 역직렬화를 반환한다. 이 상태는
다시 로드 및 세션 복원 이후에도 유지된다.
일반적으로 상태 값이 원시 값이 아닌 한 매번 새로운 역직렬화가 반환되므로 entry.getState() !== entry.getState()이다.
이 상태는 클래식 히스토리 API의 history.state와
관련이 없다.
각 NavigationHistoryEntry에는
세션 히스토리 항목인
연결된 세션
히스토리 항목이 있다.
NavigationHistoryEntry
nhe의 키는 다음 알고리즘의 반환 값으로
주어진다.
nhe의 관련 전역 객체의 연결된
Document가 완전히 활성 상태가 아니면 빈 문자열을
반환한다.
nhe의 세션 히스토리 항목의 탐색 API 키를 반환한다.
NavigationHistoryEntry
nhe의 ID는 다음 알고리즘의 반환 값으로
주어진다.
nhe의 관련 전역 객체의 연결된
Document가
완전히 활성 상태가
아니면 빈 문자열을 반환한다.
nhe의 세션 히스토리 항목의 탐색 API ID를 반환한다.
NavigationHistoryEntry
nhe의 인덱스는 다음 알고리즘의 반환 값으로
주어진다.
nhe의 관련 전역 객체의 연결된
Document가
완전히 활성 상태가
아니면 −1을 반환한다.
this의 관련 전역 객체의 탐색 API 내에서 this의 세션 히스토리 항목의 탐색 API 항목 인덱스를 가져온 결과를 반환한다.
url 게터 단계는 다음과 같다.
sameDocument 게터 단계는 다음과 같다.
document를 this의 관련
전역 객체의 연결된 Document로
설정한다.
document가 완전히 활성 상태가 아니면 false를 반환한다.
this의 세션 히스토리 항목의 문서가 document와 같으면 true를 반환하고, 그렇지 않으면 false를 반환한다.
getState() 메서드 단계는 다음과 같다.
this의 관련 전역 객체의 연결된
Document가
완전히 활성 상태가
아니면 undefined를 반환한다.
StructuredDeserialize(this의 세션 히스토리 항목의 탐색 API 상태)를 반환한다. 모든 예외를 다시 던진다.
사용 가능한 메모리가 충분하지 않은 상태에서 큰 ArrayBuffer를
역직렬화하려 하면 이론적으로 예외가 발생할 수 있다.
다음은 NavigationHistoryEntry
인터페이스를 구현하는 모든 객체가 이벤트 처리기 IDL 속성으로 지원해야
하는 이벤트
처리기와 그에 대응하는 이벤트 처리기 이벤트 유형이다.
| 이벤트 처리기 | 이벤트 처리기 이벤트 유형 |
|---|---|
ondispose
|
dispose
|
entries = navigation.entries()
현재 탐색 히스토리 항목 목록, 즉 이 내비게이션 가능 객체에 대한 세션 히스토리
항목 중 현재 세션 히스토리
항목과 동일 출처이며 연속된 모든
세션 히스토리 항목을 나타내는 NavigationHistoryEntry
인스턴스의 배열을 반환한다.
navigation.currentEntry
현재 세션 히스토리
항목에 해당하는 NavigationHistoryEntry를
반환한다.
navigation.updateCurrentEntry({ state })
navigation.reload()처럼
탐색을 수행하지 않고 현재 세션
히스토리 항목의 탐색
API 상태를 업데이트한다.
이 메서드는 이미 발생했으며 탐색 API 상태에 반영해야 하는 페이지 업데이트를 캡처할 때 가장 적합하다.
상태 업데이트가 페이지 업데이트를 구동하도록 의도된 경우에는 대신 navigation.navigate()
또는 navigation.reload()를
사용한다. 그러면 navigate 이벤트가
발생한다.
navigation.canGoBack
현재 현재 세션 히스토리
항목(즉, currentEntry)이
탐색 히스토리 항목 목록(즉, entries())의
첫 번째 항목이 아니면 true를 반환한다. 이는 이 내비게이션 가능 객체에 대한
이전 세션 히스토리 항목이
존재하고, 해당 문서 상태의
출처가 현재
Document의 출처와
동일 출처임을 의미한다.
navigation.canGoForward
현재 현재 세션 히스토리
항목(즉, currentEntry)이
탐색 히스토리 항목 목록(즉, entries())의
마지막 항목이 아니면 true를 반환한다. 이는 이 내비게이션 가능 객체에 대한
다음 세션 히스토리 항목이 존재하고,
해당
문서 상태의 출처가 현재
Document의 출처와
동일 출처임을 의미한다.
entries()
메서드 단계는 다음과 같다.
this의 항목 및 이벤트가 비활성화되어 있으면 빈 목록을 반환한다.
Web IDL의 시퀀스 유형 변환 규칙으로 인해 호출할 때마다 새로운 JavaScript 배열 객체가
생성된다는 점을 기억한다. 즉,
navigation.entries() !== navigation.entries()이다.
updateCurrentEntry(options)
메서드 단계는 다음과 같다.
current가 null이면 "InvalidStateError"
DOMException을
던진다.
serializedState를
StructuredSerializeForStorage(options["state"])로
설정하고 모든 예외를 다시 던진다.
current의 세션 히스토리 항목의 탐색 API 상태를 serializedState로 설정한다.
this에서
NavigationCurrentEntryChangeEvent를
사용하여 currententrychange라는
이름의 이벤트를 발생시킨다. 이때 해당 navigationType
속성을 null로 초기화하고 from을
current로 초기화한다.
canGoBack 게터 단계는 다음과 같다.
canGoForward 게터 단계는 다음과 같다.
{ committed, finished } = navigation.navigate(url)
{ committed, finished } = navigation.navigate(url, options)
현재 페이지를 주어진 url로 탐색한다. options에는 다음 값이 포함될 수 있다.
history를
"replace"로
설정하면 새 세션 히스토리 항목을 푸시하는 대신 현재 세션 히스토리 항목을 교체할 수 있다.
info는 임의의
값으로 설정할 수 있으며, 해당 NavigateEvent의
info
속성에 채워진다.
state는
임의의 직렬화
가능한 값으로 설정할 수
있다. 동일 문서 탐색의 경우 탐색이 완료되면 navigation.currentEntry.getState()로
가져오는 상태에 이 값이 채워진다. (문서 간 탐색이 되는 경우에는 무시된다.)
기본적으로 전체 탐색을 수행한다. 즉, 주어진 URL이 현재 URL과 프래그먼트에서만 다른 경우가 아니라면 문서 간 탐색을
수행한다. navigateEvent.intercept()
메서드를 사용하여 이를 동일 문서 탐색으로 변환할 수 있다.
반환된 프로미스는 다음과 같이 동작한다.
중단된 탐색의 경우 두 프로미스 모두 "AbortError" DOMException으로
거부된다.
navigateEvent.intercept()
메서드를 사용하여 생성된 동일 문서 탐색의 경우 committed는
탐색이 커밋된 후 이행되고, finished는
intercept()에
전달된 처리기가 반환한 프로미스에 따라 이행되거나 거부된다.
그 밖의 동일 문서 탐색(예: 가로채지 않은 프래그먼트 탐색)에서는 두 프로미스가 모두 즉시 이행된다.
문서 간 탐색 또는 서버에서 204나 205 상태나 `Content-Disposition: attachment`
헤더 필드가 반환되어 실제로 탐색하지 않는 경우 두 프로미스는 모두 영원히 완료되지 않는다.
모든 경우에 반환된 프로미스가 이행되면 탐색한 대상인 NavigationHistoryEntry로
이행된다.
{ committed, finished } = navigation.reload(options)
현재 페이지를 다시 로드한다.
options에는 위에서 설명한 대로 동작하는 info
및 state가
포함될 수 있다.
현재 페이지를 네트워크 또는 캐시에서 다시 로드하는 기본 동작은 navigateEvent.intercept()
메서드를 사용하여 재정의할 수 있다. 이렇게 하면 이 호출은 상태를 업데이트하거나 적절한 info를
전달하고, navigate 이벤트
처리기가 적절하다고 판단한 동작을 수행하기만 한다.
반환된 프로미스는 다음과 같이 동작한다.
navigateEvent.intercept()
메서드를 사용하여 다시 로드가 가로채진 경우 committed는
탐색이 커밋된 후 이행되고, finished는
intercept()에
전달된 처리기가 반환한 프로미스에 따라 이행되거나 거부된다.
그렇지 않으면 두 프로미스 모두 영원히 완료되지 않는다.
{ committed, finished } = navigation.traverseTo(key)
{ committed, finished } = navigation.traverseTo(key, { info })
주어진 key를 가진 NavigationHistoryEntry와
일치하는 가장 가까운 세션
히스토리 항목으로 순회한다. info는
임의의 값으로 설정할 수 있으며, 해당 NavigateEvent의
info
속성에 채워진다.
해당 세션
히스토리 항목으로의 순회가 이미
진행 중이면 원래 순회의 프로미스를 반환하고 info는
무시된다.
반환된 프로미스는 다음과 같이 동작한다.
navigation.entries()에
key가
key와 일치하는 NavigationHistoryEntry가
없으면 두 프로미스 모두 "InvalidStateError"
DOMException으로
거부된다.
navigateEvent.intercept()
메서드로 가로챈 동일 문서 순회의 경우 committed는
순회가 처리되고 navigation.currentEntry가
업데이트되는 즉시 이행되며, finished는
intercept()에
전달된 처리기가 반환한 프로미스에 따라 이행되거나 거부된다.
가로채지 않은 동일 문서 순회의 경우 두 프로미스는 순회가 처리되고 navigation.currentEntry가
업데이트되는 즉시 이행된다.
문서 간 순회 또는 서버에서 204나 205 상태나 `Content-Disposition: attachment`
헤더 필드가 반환되어 실제로 순회하지 않는 문서 간 순회 시도의 경우 두 프로미스는 모두 영원히 완료되지
않는다.
{ committed, finished } = navigation.back(key)
{ committed, finished } = navigation.back(key, { info })
이 내비게이션 가능 객체가
순회하게 되는 가장 가까운 이전 세션 히스토리 항목, 즉 다른
NavigationHistoryEntry에
해당하여 navigation.currentEntry가
변경되는 항목으로 순회한다. info는
임의의 값으로 설정할 수 있으며, 해당 NavigateEvent의
info
속성에 채워진다.
해당 세션
히스토리 항목으로의 순회가 이미
진행 중이면 원래 순회의 프로미스를 반환하고 info는
무시된다.
반환된 프로미스는 traverseTo()가
반환하는 프로미스와 동일하게 동작한다.
{ committed, finished } = navigation.forward(key)
{ committed, finished } = navigation.forward(key, { info })
이 내비게이션 가능 객체가
순회하게 되는 가장 가까운 다음 세션 히스토리 항목, 즉 다른
NavigationHistoryEntry에
해당하여 navigation.currentEntry가
변경되는 항목으로 순회한다. info는
임의의 값으로 설정할 수 있으며, 해당 NavigateEvent의
info
속성에 채워진다.
해당 세션
히스토리 항목으로의 순회가 이미
진행 중이면 원래 순회의 프로미스를 반환하고 info는
무시된다.
반환된 프로미스는 traverseTo()가
반환하는 프로미스와 동일하게 동작한다.
navigate(url, options) 메서드
단계는 다음과 같다.
urlRecord가 실패이면 "SyntaxError" DOMException에
대한 조기 오류 결과를
반환한다.
urlRecord의 스킴이
"javascript"이면
"NotSupportedError" DOMException에
대한 조기 오류 결과를
반환한다.
document를 this의 관련
전역 객체의 연결된 Document로
설정한다.
options["history"]가
"push"이고,
urlRecord와 document가 주어졌을 때 탐색이 반드시 교체여야
하면 "NotSupportedError" DOMException에
대한 조기 오류 결과를
반환한다.
options["state"]가
존재하면
state를 해당 값으로 설정하고, 그렇지 않으면 undefined로 설정한다.
serializedState를 StructuredSerializeForStorage(state)로 설정한다. 이 과정에서 예외가 발생하면 해당 예외에 대한 조기 오류 결과를 반환한다.
직렬화는 웹 개발자 코드를 호출할 수 있고, 그 코드는 이후 단계에서 검사하는 여러 항목을 변경할 수 있으므로 이 단계를 일찍 수행하는 것이 중요하다.
document가 완전히
활성 상태가 아니면 "InvalidStateError" DOMException에
대한 조기 오류 결과를
반환한다.
document의 언로드
카운터가 0보다 크면
"InvalidStateError" DOMException에
대한 조기 오류 결과를
반환한다.
options["info"]가
존재하면
info를 해당 값으로 설정하고, 그렇지 않으면 undefined로 설정한다.
apiMethodTracker를 info와 serializedState가 주어진 this에 대한 탐색/다시 로드 API 메서드 추적기를 설정한 결과로 설정한다.
document를 사용하여 document의 노드
내비게이션 가능 객체를 urlRecord로 탐색한다. 이때 historyHandling을
options["history"]로,
navigationAPIState를
serializedState로, apiMethodTracker를
apiMethodTracker로 설정한다.
출처-도메인 경계를 넘어 노출되는
location.assign()
및 관련 메서드와 달리 navigation.navigate()에는
window.navigation
속성에 직접 동기적으로 접근할 수 있는 코드만 접근할 수 있다. 따라서 탐색의 소스 문서를 귀속하는 복잡성을
피할 수 있으며, 샌드박싱에
의해 탐색이 허용되는지
검사하거나 그에 수반되는 exceptionsEnabled 플래그를 처리할 필요가 없다. 모든 탐색을 이
Navigation
객체 자체에 해당하는 Document(즉,
document)에서 발생한 것처럼 처리한다.
apiMethodTracker에 대한 탐색 API 메서드 추적기 파생 결과를 반환한다.
reload(options) 메서드 단계는 다음과 같다.
document를 this의 관련 전역
객체의 연결된 Document로
설정한다.
serializedState를 StructuredSerializeForStorage(undefined)로 설정한다.
options["state"]가
존재하면 serializedState를
StructuredSerializeForStorage(options["state"])로
설정한다. 이 과정에서 예외가 발생하면 해당 예외에 대한 조기 오류 결과를
반환한다.
직렬화는 웹 개발자 코드를 호출할 수 있고, 그 코드는 이후 단계에서 검사하는 여러 항목을 변경할 수 있으므로 이 단계를 일찍 수행하는 것이 중요하다.
그렇지 않으면 다음을 수행한다.
current가 null이 아니면 serializedState를 current의 세션 히스토리 항목의 탐색 API 상태로 설정한다.
document가 완전히
활성 상태가 아니면 "InvalidStateError" DOMException에
대한 조기 오류 결과를
반환한다.
document의 언로드 카운터가 0보다 크면
"InvalidStateError" DOMException에
대한 조기 오류 결과를
반환한다.
options["info"]가
존재하면
info를 해당 값으로 설정하고, 그렇지 않으면 undefined로 설정한다.
apiMethodTracker를 info와 serializedState가 주어진 this에 대한 탐색/다시 로드 API 메서드 추적기를 설정한 결과로 설정한다.
document의 노드 내비게이션 가능 객체를 다시 로드한다. 이때 navigationAPIState를 serializedState로, apiMethodTracker를 apiMethodTracker로 설정한다.
apiMethodTracker에 대한 탐색 API 메서드 추적기 파생 결과를 반환한다.
traverseTo(key, options)
메서드 단계는 다음과 같다.
this의 현재 항목
인덱스가 −1이면 "InvalidStateError"
DOMException에
대한 조기 오류 결과를
반환한다.
this의 항목 목록이 세션 히스토리 항목의 탐색
API 키가 key와 같은 NavigationHistoryEntry를
포함하지 않으면 "InvalidStateError" DOMException에
대한 조기 오류 결과를
반환한다.
this, key 및 options가 주어진 상태에서 탐색 API 순회를 수행한 결과를 반환한다.
back(options) 메서드 단계는 다음과 같다.
this의 현재 항목
인덱스가 −1 또는 0이면 "InvalidStateError" DOMException에
대한 조기 오류 결과를
반환한다.
key를 this의 항목 목록[this의 현재 항목 인덱스 − 1]의 세션 히스토리 항목의 탐색 API 키로 설정한다.
this, key 및 options가 주어진 상태에서 탐색 API 순회를 수행한 결과를 반환한다.
forward(options) 메서드 단계는 다음과 같다.
this의 현재 항목
인덱스가 −1이거나 this의 항목
목록의 크기 −
1과 같으면 "InvalidStateError" DOMException에
대한 조기 오류 결과를
반환한다.
key를 this의 항목 목록[this의 현재 항목 인덱스 + 1]의 세션 히스토리 항목의 탐색 API 키로 설정한다.
this, key 및 options가 주어진 상태에서 탐색 API 순회를 수행한 결과를 반환한다.
Navigation
navigation, 문자열 key 및
NavigationOptions
options가 주어진 경우 탐색 API 순회를
수행하려면 다음을 수행한다.
document를 navigation의 관련 전역 객체의
연결된
Document로
설정한다.
document가 완전히
활성 상태가 아니면 "InvalidStateError" DOMException에
대한 조기 오류 결과를
반환한다.
document의 언로드 카운터가 0보다 크면
"InvalidStateError" DOMException에
대한 조기 오류 결과를
반환한다.
current를 navigation의 현재 항목으로 설정한다.
key가 current의 세션 히스토리
항목의 탐색 API 키와 같으면 «[
"committed"
→ current로 해결된
프로미스, "finished"
→ current로 해결된
프로미스 ]»를 반환한다.
navigation의 예정된 순회 API 메서드 추적기[key]가 존재하면 navigation의 예정된 순회 API 메서드 추적기[key]에 대한 탐색 API 메서드 추적기 파생 결과를 반환한다.
options["info"]가
존재하면 info를 해당 값으로 설정하고, 그렇지 않으면
undefined로 설정한다.
apiMethodTracker를 key와 info가 주어진 navigation에 대해 예정된 순회 API 메서드 추적기를 추가한 결과로 설정한다.
navigable을 document의 노드 내비게이션 가능 객체로 설정한다.
traversable을 navigable의 순회 가능 내비게이션 가능 객체로 설정한다.
sourceSnapshotParams를 document가 주어진 상태에서 소스 스냅숏 매개변수를 스냅숏한 결과로 설정한다.
traversable에 다음 세션 히스토리 순회 단계를 추가한다.
navigableSHEs를 navigable이 주어진 상태에서 세션 히스토리 항목을 가져온 결과로 설정한다.
targetSHE를 navigableSHEs에서 탐색 API 키가 key인 세션 히스토리 항목으로 설정한다. 그러한 항목이 없으면 다음을 수행한다.
navigation의 관련 전역 객체가 주어진
상태에서 탐색 및 순회
태스크
소스에 apiMethodTracker의 완료 프로미스를
"InvalidStateError" DOMException으로
거부하는 전역
태스크를 큐에 추가한다.
이 단계를 중단한다.
이 경로는 navigation의 항목 목록이 navigableSHEs에 비해 오래된 경우 사용되며, 이는 히스토리 변경에 대응하여 관련된 모든 스레드와 프로세스가 동기화되는 짧은 기간 동안 발생할 수 있다.
targetSHE가 navigable의 활성 세션 히스토리 항목이면 다음을 수행한다.
navigation의 관련 전역 객체가 주어진
상태에서 탐색 및 순회
태스크
소스에 apiMethodTracker의 완료 프로미스를
"InvalidStateError" DOMException으로
거부하는 전역 태스크를 큐에 추가한다.
이 단계를 중단한다.
이전에 큐에 추가된 순회가 이미 이 세션 히스토리 항목으로 이동시킨 경우 발생할 수 있다.
result를 sourceSnapshotParams,
navigable 및 "none"이 주어진
상태에서 targetSHE의 단계를
traversable에 순회 히스토리 단계로
적용한 결과로 설정한다.
result가 "canceled-by-beforeunload"이면
navigation의 관련 전역 객체가 주어진
상태에서 탐색 및 순회 태스크
소스에 navigation의 관련 영역에서 생성된 새로운
"AbortError" DOMException으로
apiMethodTracker의 완료 프로미스를 거부하는
전역
태스크를 큐에 추가한다.
result가 "initiator-disallowed"이면
navigation의 관련 전역 객체가 주어진
상태에서 탐색 및 순회 태스크
소스에 navigation의 관련 영역에서 생성된 새로운
"SecurityError" DOMException으로
apiMethodTracker의 완료 프로미스를 거부하는
전역
태스크를 큐에 추가한다.
result가 "canceled-by-beforeunload" 또는
"initiator-disallowed"이면 navigate
이벤트가 발생하지 않았으므로 진행 중인 탐색을
중단하는 것은 올바르지 않다. 그렇게 하면 선행 navigate
이벤트 없이 navigateerror
이벤트가 발생한다.
"canceled-by-navigate"의 경우에는 navigate
이벤트가 발생하지만, 내부
navigate 이벤트 발생 알고리즘이 진행 중인 탐색을
중단하는 작업을 처리한다.
apiMethodTracker에 대한 탐색 API 메서드 추적기 파생 결과를 반환한다.
예외 e에 대한 조기 오류 결과는 «[
"committed"
→ e로 거부된
프로미스,
"finished"
→ e로 거부된
프로미스 ]»로 주어진 NavigationResult
사전 인스턴스이다.
탐색 API 메서드 추적기 또는 null인 apiMethodTracker에 대한 탐색 API 메서드 추적기 파생 결과를 계산하려면 다음을 수행한다.
apiMethodTracker가 대기 중이면
"AbortError" DOMException에
대한 조기 오류 결과를
반환한다.
«[ "committed"
→ apiMethodTracker의 커밋 프로미스,
"finished"
→ apiMethodTracker의 완료 프로미스 ]»로
주어진 NavigationResult
사전 인스턴스를 반환한다.
任意のナビゲーション中(この語の広義の
意味において)、Navigation
オブジェクトは、次の事項を追跡する必要があります。
| 状態 | 期間 | 説明 |
|---|---|---|
NavigateEvent
|
イベントの発火中 | イベントの発火中にナビゲーションがキャンセルされた場合、そのイベントをキャンセルできるようにするため |
| イベントの中止コントローラー | intercept()
に渡されたハンドラーから返されたすべてのプロミスが確定するまで
|
ナビゲーションがキャンセルされた場合に、中止を 通知できるようにするため |
| 新しい要素がフォーカスされたかどうか | intercept()
に渡されたハンドラーから返されたすべてのプロミスが確定するまで
|
新しい要素がフォーカスされた場合に、フォーカスがリセットされないようにするため |
ナビゲーション先となるNavigationHistoryEntry
|
それが決定されてから、intercept()
に渡されたハンドラーから返されたすべてのプロミスが確定するまで
|
返されたcommitted
およびfinished
プロミスを何で解決するか把握できるようにするため
|
返されたfinished
プロミス
|
intercept()
に渡されたハンドラーから返されたすべてのプロミスが確定するまで
|
そのプロミスを適切に解決または却下できるようにするため |
| 状態 | 期間 | 説明 |
|---|---|---|
任意のstate
|
イベントの発火中 | イベントがキャンセルされずに発火を 完了した場合、現在のエントリのナビゲーション API 状態を更新できるようにするため |
| 状態 | 期間 | 説明 |
|---|---|---|
任意のinfo
|
navigate
イベントを発火するタスクが
キューに追加されるまで
|
セッション履歴走査キューを経由した後に、
それを使用してnavigate
を発火できるようにするため。
|
返されたcommitted
プロミス
|
セッション履歴が更新されるまで(同じタスク内) | そのプロミスを適切に解決または却下できるようにするため |
intercept()
が呼び出されたかどうか
|
セッション履歴が更新されるまで(同じタスク内) | scroll
オプションで指定された動作を優先して、通常のスクロール復元ロジックを抑制できるようにするため
|
また、次のようなウェブ開発者のコードが存在するため、任意の時点で要求されるナビゲーションが 1 つだけであると仮定することもできません。
const p1 = navigation. navigate( url1). finished;
const p2 = navigation. navigate( url2). finished; つまり、このシナリオでは、url2 へナビゲーションしている間も、却下できるように
p1 プロミスを保持しておく必要があります。2 回目の
navigate()
呼び出しが行われた時点で、進行中のナビゲーションプロミスを単純にすべて破棄することはできません。
最終的に、各
Navigation に次のものを関連付けることで、
これらすべてを実現します。
進行中の navigate イベント。これは
NavigateEvent または
null であり、初期値は null です。
進行中のナビゲーション中にフォーカスが変更された。これは真偽値であり、 初期値は false です。
進行中のナビゲーション中に通常のスクロール復元を 抑制する。これは真偽値であり、 初期値は false です。
進行中の API メソッドトラッカー。これはナビゲーション API メソッドトラッカーまたは null であり、初期値は null です。
今後の traverse API メソッドトラッカー。これは文字列から ナビゲーション API メソッドトラッカーへの順序付きマップであり、初期状態では 空です。
ナビゲーション API メソッドトラッカーに保存されない ここでの状態は、ナビゲーション API メソッドを介して開始されない ナビゲーションについても追跡する必要がある状態です。
ナビゲーション API メソッドトラッカーは、次の項目を持つ構造体です。
ナビゲーションオブジェクト。これは
Navigation です
キー。これは文字列または null です
情報。これは JavaScript 値です
直列化された状態。これは 直列化された状態または null です
コミット先エントリ。これは
NavigationHistoryEntry
または null です
コミット済みプロミス。これは プロミスです
完了済みプロミス。これは プロミスです
保留中。これは真偽値です。
これらすべての状態は、次のアルゴリズムによって管理されます。
Navigation
navigation、JavaScript 値 info、および直列化された
状態または null の serializedState を指定して、navigate/reload API メソッドトラッカーを設定するには、
committedPromise および finishedPromise を、 navigation の関連するレルムで作成された新しいプロミスとします。
finishedPromise を処理済みとして マークします。
次の値を持つ新しいナビゲーション API メソッドトラッカーを返します。
Navigation
navigation、文字列 destinationKey、および JavaScript 値
info を指定して、今後の traverse API
メソッドトラッカーを追加するには、
committedPromise および finishedPromise を、 navigation の関連するレルムで作成された新しいプロミスとします。
finishedPromise を処理済みとして マークします。
これを行う理由については、前述の 説明を参照してください。
apiMethodTracker を、次の値を持つ新しいナビゲーション API メソッドトラッカーとします。
navigation の今後の traverse API メソッド トラッカー[destinationKey] を apiMethodTracker に設定します。
apiMethodTracker を返します。
ナビゲーション API メソッドトラッカー apiMethodTracker をクリーンアップするには、
navigation を、apiMethodTracker のナビゲーションオブジェクトとします。
navigation の進行中の API メソッドトラッカーが apiMethodTracker である場合、navigation の進行中の API メソッド トラッカーを null に設定します。
それ以外の場合は、次を行います。
key を、apiMethodTracker のキーとします。
表明:key は null ではありません。
表明:navigation の今後の traverse API メソッド トラッカー[key] が存在します。
navigation の今後の traverse API メソッドトラッカー[key] を削除します。
ナビゲーション
API メソッド
トラッカー apiMethodTracker およびNavigationHistoryEntry
nhe を指定して、コミット先エントリについて通知するには、
apiMethodTracker のコミット先エントリを nhe に設定します。
apiMethodTracker の直列化された状態が null でない場合、 nhe のセッション履歴エントリのナビゲーション API 状態を、apiMethodTracker の直列化された状態に設定します。
それが null である場合は、navigation.traverseTo()
を介して nhe へ走査しており、このメソッドでは
状態を変更できません。
この時点で、apiMethodTracker の直列化された状態は不要になります。 実装は、ナビゲーション API メソッドトラッカーの 存続期間中にそれを保持し続けることを避けるため、消去することを検討できます。
apiMethodTracker のコミット済みプロミスを nhe で解決します。
この時点で、apiMethodTracker のコミット済みプロミスは、 まだ作者コードに返されていない場合にのみ 必要です。実装は、ナビゲーション API メソッド トラッカーの存続期間中にそれを保持し続けることを避けるため、消去することを検討できます。
ナビゲーション API メソッドトラッカー apiMethodTracker の完了済みプロミスを解決するには、
JavaScript 値 exception を指定して、ナビゲーション API メソッドトラッカー apiMethodTracker の完了済みプロミスを却下するには、
apiMethodTracker のコミット済みプロミスを exception で却下します。
apiMethodTracker のコミット済みプロミスが、以前に コミット先エントリについて 通知することによって解決されている場合、これは何も行いません。
apiMethodTracker の完了済みプロミスを exception で却下します。
apiMethodTracker をクリーンアップします。
Navigation
navigation および省略可能なDOMException
error を指定して、進行中のナビゲーションを中止するには、
event を、navigation の進行中の navigate イベントとします。
表明:event は null ではありません。
navigation の進行中のナビゲーション中に フォーカスが変更されたを false に設定します。
navigation の進行中の ナビゲーション中に通常のスクロール復元を 抑制するを false に設定します。
error が指定されていない場合、error を、
navigation の関連するレルムで作成された新しい
「AbortError」DOMException
とします。
event のディスパッチフラグが設定されている場合、 event のキャンセル済みフラグを true に設定します。
error を指定して、event を中止します。
reason を指定して、event NavigateEvent
を中止するには、
navigation を、event の関連する大域オブジェクトの ナビゲーション APIとします。
navigation の進行中の navigate
イベントを null に設定します。
errorInfo を、reason からエラー情報を 抽出した結果とします。
たとえば、window.stop() の
呼び出しによってこのアルゴリズムに到達した場合、これらのプロパティは、window.stop() を
呼び出したスクリプト行に基づいて初期化される可能性があります。しかし、ユーザーが停止
ボタンをクリックしたことが原因である場合、これらのプロパティは空文字列や
0 などの既定値になる可能性があります。
navigation の進行中の API メソッドトラッカーが null でない場合、 reason を指定して apiMethodTracker の完了済み プロミスを却下します。
errorInfo に従って追加属性を初期化した
ErrorEvent を使用し、
navigation で navigateerror
という名前のイベントを発火します。
navigation の遷移が null である場合、戻ります。
navigation の遷移のコミット済みプロミスを reason で却下します。
navigation の遷移を null に設定します。
ナビゲーション可能 navigable におけるナビゲーションの中止について ナビゲーション API に通知するには、
このアルゴリズムが navigable のアクティブな ウィンドウの関連するエージェントのイベント ループで実行されている場合、次の手順へ進みます。それ以外の場合は、navigable のアクティブなウィンドウを指定し、ナビゲーションおよび走査タスク ソース上で次の手順を実行する大域タスクをキューに追加します。
navigation を、navigable のアクティブな ウィンドウのナビゲーション APIとします。
navigation の進行中の navigate イベントが
null でない間、次を行います。
navigation を指定して、進行中のナビゲーションを中止します。
進行中の文書間ナビゲーションが存在する場合、これは、たとえばnavigateerror
イベントを発火することにより、中止されたものとしてナビゲーション API に通知されることを意味します。
Document が次に経験する
ナビゲーションはこの同一文書ナビゲーションになるため、これはある程度正確です。そのため、
次に完了するナビゲーションが文書間ナビゲーションであると期待していた開発者は、それが
起こらなかったという有用なシグナルを得られます。しかし、ブラウザーは進行中の文書間ナビゲーションの
処理を続行するため、ある程度不正確でもあります(この同一文書ナビゲーションが同期的に完了した後に
適用されます)。
最終的に、文書間ナビゲーションと同一文書ナビゲーションが重複すると、ナビゲーション API は
やや複雑になります。これは、進行中のナビゲーションの追跡
機構および API が、進行中のナビゲーションを 1 つだけ公開するように構築されているためです。ウェブ開発者は、
新しいナビゲーションを開始する前に、navigation.navigate()
から返されたプロミスを await するなどして、このような重複状況を作り出さないことが
最善です。
これはループです。進行中のナビゲーションを中止するは、
JavaScript を実行する可能性があり(たとえば、navigateerror
イベントを介して)、新しいナビゲーションが開始される可能性があるためです。このように新しく開始された
ナビゲーションは、このナビゲーションの完了によって置き換えられるため、中止されたものとして
ナビゲーション API に通知されます。
ナビゲーション可能 navigable を指定して、子 ナビゲーション可能オブジェクトの破棄についてナビゲーション API に通知するには、
navigable におけるナビゲーションの 中止についてナビゲーション API に通知します。
navigation を、navigable のアクティブな ウィンドウのナビゲーション APIとします。
traversalAPIMethodTrackers を、navigation の今後の traverse API メソッド トラッカーのクローンとします。
traversalAPIMethodTrackers の各
apiMethodTracker について、navigation の関連するレルムで作成された新しい「AbortError」
DOMException
を指定して、apiMethodTracker の完了済みプロミスを却下します。
進行中のナビゲーションという概念は、navigation.transition
プロパティを通じてウェブ開発者に最も直接的に公開されます。このプロパティは、
NavigationTransition
インターフェースのインスタンスです。
[Exposed =Window ]
interface NavigationTransition {
readonly attribute NavigationType navigationType ;
readonly attribute NavigationHistoryEntry from ;
readonly attribute NavigationDestination to ;
readonly attribute Promise <undefined > committed ;
readonly attribute Promise <undefined > finished ;
};navigation.transition
存在する場合、まだnavigatesuccess
またはnavigateerror
の段階に到達していない進行中のナビゲーションを表すNavigationTransition。
そのような進行中の遷移が存在しない場合は null です。
navigation.currentEntry
(およびlocation.href
のような
その他のプロパティ)はナビゲーション時に即座に更新されるため、このnavigation.transition
プロパティは、navigateEvent.intercept()
に渡されたハンドラーに従って、そのようなナビゲーションがまだ完全に確定していない時点を判断するのに役立ちます。
navigation.transition.navigationType
「push」、
「replace」、
「reload」、
または「traverse」
のいずれかであり、この遷移が対象とする
ナビゲーションの種類を示します。
navigation.transition.from
遷移元となるNavigationHistoryEntry。
これはnavigation.currentEntry
と比較する際に役立ちます。
navigation.transition.to
遷移のNavigationDestination。
これは、navigate
イベントを監視せずに、
現在のナビゲーションの移動先のurl
を反映する方法として役立ちます。
navigation.transition.committed
navigation.currentEntry
およびURLが
変更されると充足されるプロミスです。これは、すべてのコミット前ハンドラーが
充足された後に発生します。
1 つ以上のコミット前ハンドラーが
却下された場合、プロミスは却下されます。
navigation.transition.finished
navigatesuccess
が発火するのと同時に充足されるか、navigateerror
イベントが発火するのと同時に却下されるプロミスです。
各Navigationは、
NavigationTransition
または null である遷移を持ち、初期値は null です。
各NavigationTransitionには、
NavigationTypeである、
関連付けられたナビゲーション種別があります。
各NavigationTransitionには、
NavigationHistoryEntryである、
関連付けられた遷移元エントリがあります。
各NavigationTransitionには、
NavigationDestinationである、
関連付けられた移動先があります。
各NavigationTransitionには、
プロミスである、関連付けられたコミット済みプロミスがあります。
各NavigationTransitionには、
プロミスである、関連付けられた完了済みプロミスがあります。
navigationType 取得子の手順は、this のナビゲーション
種別を返すことです。
committed 取得子の手順は、this のコミット済み
プロミスを返すことです。
NavigationActivation
接口[Exposed =Window ]
interface NavigationActivation {
readonly attribute NavigationHistoryEntry ? from ;
readonly attribute NavigationHistoryEntry entry ;
readonly attribute NavigationType navigationType ;
};navigation.activation
一个 NavigationActivation,
其中包含有关最近一次跨文档导航的信息,即“激活”此 Document 的导航。
虽然 navigation.currentEntry
和
Document 的 URL
可能会因同文档导航而定期更新,但 navigation.activation
会保持不变,并且只有在该 Document
从历史记录中被重新激活时,
其属性才会更新。
navigation.activation.entry
一个 NavigationHistoryEntry,
等同于该 Document 被激活时
navigation.currentEntry
属性的值。
navigation.activation.from
一个 NavigationHistoryEntry,
表示紧接在当前 Document
之前处于活动状态的
Document。如果前一个
Document 与当前文档并非
同源,或者它是
初始
about:blank
Document,
则此值为 null。
在某些情况下,from
或 entry
NavigationHistoryEntry
对象可能不是 traverseTo()
方法的有效目标,因为它们可能未保留在历史记录中。例如,可以使用 location.replace()
激活该 Document,或者其初始
条目可能会被 history.replaceState()
替换。不过,仍然可以访问这些条目的 url
属性和 getState()
方法。
navigation.activation.navigationType
为“push”、
“replace”、
“reload”
或“traverse”
之一,指示激活此 Document 的导航类型。
每个 Navigation 都有一个
关联的激活,它为 null 或一个
NavigationActivation
对象,初始为 null。
每个 NavigationActivation
都具有:
旧条目,为 null 或一个
NavigationHistoryEntry。
新条目,为 null 或一个
NavigationHistoryEntry。
导航类型,为一个
NavigationType。
navigate 事件导航 API 的一项主要功能是 navigate
事件。此事件会在任何导航(取该词的广义含义)上触发,从而允许 Web
开发者监视此类传出导航。
在许多情况下,该事件是可取消的,因而可以阻止导航发生。
在其他情况下,可以使用 NavigateEvent 类的 intercept()
方法拦截导航,并将其替换为同文档导航。
NavigateEvent 接口[Exposed =Window ]
interface NavigateEvent : Event {
constructor (DOMString type , NavigateEventInit eventInitDict );
readonly attribute NavigationType navigationType ;
readonly attribute NavigationDestination destination ;
readonly attribute boolean canIntercept ;
readonly attribute boolean userInitiated ;
readonly attribute boolean hashChange ;
readonly attribute AbortSignal signal ;
readonly attribute FormData formData ;
readonly attribute DOMString ? downloadRequest ;
readonly attribute any info ;
readonly attribute boolean hasUAVisualTransition ;
readonly attribute Element ? sourceElement ;
undefined intercept (optional NavigationInterceptOptions options = {});
undefined scroll ();
};
dictionary NavigateEventInit : EventInit {
NavigationType navigationType = "push";
required NavigationDestination destination ;
boolean canIntercept = false ;
boolean userInitiated = false ;
boolean hashChange = false ;
required AbortSignal signal ;
FormData ? formData = null ;
DOMString ? downloadRequest = null ;
any info ;
boolean hasUAVisualTransition = false ;
Element ? sourceElement = null ;
};
dictionary NavigationInterceptOptions {
NavigationPrecommitHandler precommitHandler ;
NavigationInterceptHandler handler ;
NavigationFocusReset focusReset ;
NavigationScrollBehavior scroll ;
};
enum NavigationFocusReset {
" after-transition " ,
" manual "
};
enum NavigationScrollBehavior {
" after-transition " ,
" manual "
};
callback NavigationInterceptHandler = Promise <undefined > ();event.navigationType
event.destination
一个 NavigationDestination,
表示导航的目的地。
event.canIntercept
如果可以调用 intercept()
来拦截此导航,并将其转换为同文档导航以替换其常规行为,则为 true;否则为 false。
一般来说,只要当前 Document 的 URL
可以被重写为目的地 URL,此值就会为 true;但跨文档“traverse”
导航除外,在这种情况下它始终为 false。
event.userInitiated
如果此导航是由于用户单击 a 元素、
提交 form
元素,或使用浏览器 UI进行导航而产生的,则为 true;否则为 false。
event.hashChange
对于片段导航为 true; 否则为 false。
event.signal
一个 AbortSignal,如果导航被取消,
例如用户按下浏览器的“停止”按钮,或另一个导航中断了此导航,则该信号会变为已中止。
预期的模式是,开发者会将其传递给处理此导航时所执行的任何异步操作,例如
fetch()。
event.formData
如果此导航是表示 POST 表单提交的“push”
或“replace”
导航,则为表示为此导航提交的表单条目的 FormData;否则为 null。
(值得注意的是,即使是重新访问最初由表单提交创建的会话历史
条目的“reload”
或“traverse”
导航,此值也会为 null。)
event.downloadRequest
表示是否通过使用 a 或 area 元素的 download
属性,请求将此导航作为下载:
如果未请求下载,则此属性为 null。
如果请求了下载,则返回作为 download
属性值提供的文件名。(该值可以是空字符串。)
请注意,请求下载并不总是意味着下载会发生:例如,下载可能会被浏览器安全策略阻止,或因未指定的原因最终被视为“push”
导航。
同样,即使未请求将导航作为下载,导航最终也可能成为下载,这是因为目的地服务器使用
`Content-Disposition: attachment`
标头进行了响应。
最后,请注意,对于使用浏览器 UI 控件发起的下载,例如右键单击并选择保存链接目标所创建的下载,
navigate 事件根本不会
触发。
event.info通过发起此导航的某个导航 API 方法传递的任意 JavaScript 值;如果导航由用户或其他 API 发起,则为 undefined。
event.hasUAVisualTransition
如果用户代理在分派此事件之前为此导航执行了视觉转换,则返回 true。如果为 true, 则作者同步将 DOM 更新为导航后状态时,可提供最佳用户体验。
event.sourceElement
event.intercept({ precommitHandler, handler, focusReset, scroll })
拦截此导航,阻止其常规处理,转而将其转换为指向目的地 URL 的同类型同文档导航。
precommitHandler
选项可以是一个接受 NavigationPrecommitController
并返回 promise 的函数。预提交处理器函数将在 navigate 事件
完成触发之后,但在 navigation.currentEntry
属性更新之前运行。返回一个被拒绝的 promise 将中止导航及其效果,例如更新 URL
和会话历史。在所有预提交处理器均已兑现后,导航可以继续提交并调用其余处理器。只有在事件是可取消的情况下,才能传递 precommitHandler
选项:尝试向不可取消的 NavigateEvent 传递
precommitHandler
将抛出一个
“SecurityError” DOMException。
handler
选项可以是一个返回 promise 的函数。处理器函数将在 navigate 事件
完成触发,并且 navigation.currentEntry
属性已更新后运行。此返回的 promise 用于指示导航的持续时间以及成功或失败。
在其敲定后,浏览器会向用户发出导航已完成的信号(例如通过加载旋转图标 UI 或辅助技术)。
此外,它会根据情况触发 navigatesuccess
或 navigateerror
事件,Web 应用程序的其他部分可以响应这些事件。
默认情况下,使用此方法会在任何处理器返回的 promise 敲定时重置焦点。
焦点将被重置到第一个设置了 autofocus 属性的
元素;如果不存在该属性,则重置到body
元素。可以将 focusReset
选项设置为“manual”
以避免此行为。
默认情况下,对于“traverse”
或“reload”
导航,使用此方法会延迟浏览器的滚动恢复逻辑;对于“push”
或“replace”
导航,则会延迟其重置滚动位置或滚动到片段的逻辑,直到任何处理器返回的 promise 均已敲定。
可以将 scroll
选项设置为“manual”,
以完全关闭此导航中任何由浏览器驱动的滚动行为;也可以在 promise 敲定之前调用 scroll()
以提前触发此行为。
如果 canIntercept
为 false,或者 isTrusted
为 false,则此方法将抛出一个 “SecurityError” DOMException。
如果未在事件分派期间同步调用此方法,则将抛出一个
“InvalidStateError” DOMException。
event.scroll()
对于“traverse”
或“reload”
导航,使用浏览器常规的滚动恢复逻辑恢复滚动位置。
对于“push”
或“replace”
导航,将滚动位置重置到文档顶部;如果 destination.url
指定了片段,则滚动到该片段。
如果多次调用此方法,或者由于 scroll
选项保留为“after-transition”
而已发生自动转换后滚动处理之后调用此方法,或者在导航提交之前调用此方法,则此方法将抛出一个
“InvalidStateError” DOMException。
每个 NavigateEvent
都有一个拦截状态,它为“none”、
“intercepted”、“committed”、
“scrolled”或“finished”之一,初始为“none”。
每个 NavigateEvent
都有一个导航预提交处理器
列表,它是由 NavigationPrecommitHandler
回调组成的列表,初始为空。
每个 NavigateEvent
都有一个导航处理器列表,它是由
NavigationInterceptHandler
回调组成的列表,初始为空。
每个 NavigateEvent
都有一个焦点
重置行为,它为一个可为 null 的 NavigationFocusReset,
初始为 null。
每个 NavigateEvent
都有一个滚动
行为,它为一个可为 null 的 NavigationScrollBehavior,
初始为 null。
每个 NavigateEvent
都有一个中止控制器,它为一个可为 null 的
AbortController,初始为 null。
每个 NavigateEvent
都有一个经典历史记录 API 状态,它为一个
序列化状态或 null。
仅在某些事件的 navigationType
为“push”
或“replace”
的情况下才会使用它,并且会在事件被触发时进行适当设置。
navigationType、destination、canIntercept、userInitiated、
hashChange、signal、formData、downloadRequest、info、hasUAVisualTransition 和
sourceElement 属性
必须返回其初始化时所使用的值。
intercept(options) 方法的步骤
为:
如果 this 的 canIntercept
属性被初始化为 false,则抛出一个 “SecurityError”
DOMException。
如果 this 的分派标志未设置,
则抛出一个
“InvalidStateError” DOMException。
如果 options[“precommitHandler”]
存在:
如果 this 的 cancelable
属性被初始化为 false,则抛出一个 “InvalidStateError”
DOMException。
将 options[“precommitHandler”]
追加到
this 的导航
预提交处理器
列表。
如果 options[“focusReset”]
存在:
如果 this 的焦点重置
行为不为 null,并且它不等于 options[“focusReset”],
则用户代理可以向控制台报告警告,指出先前调用
intercept()
时使用的 focusReset
选项已被此新值覆盖,先前的值将被忽略。
将 this 的焦点重置
行为设置为 options[“focusReset”]。
scroll() 方法的步骤为:
如果 this 的拦截状态不是
“committed”,则抛出一个 “InvalidStateError”
DOMException。
要对一个 NavigateEvent
event执行共享检查:
如果 event 的相关全局对象的关联的
Document不是完全
活动的,则抛出一个 “InvalidStateError”
DOMException。
如果 event 的 isTrusted
属性被初始化为 false,则抛出一个 “SecurityError”
DOMException。
如果 event 的已取消标志已设置,则抛出一个
“InvalidStateError” DOMException。
NavigationPrecommitController
インターフェイス[Exposed =Window ]
interface NavigationPrecommitController {
undefined redirect (USVString url , optional NavigationNavigateOptions options = {});
undefined addHandler (NavigationInterceptHandler handler );
};
callback NavigationPrecommitHandler = Promise <undefined > (NavigationPrecommitController controller );precommitController.redirect(USVString url, NavigationNavigateOptions options)
「push」
または「replace」
ナビゲーションの場合、destination.url
を url に設定します。
options が指定されている場合、info
および結果として得られる
NavigationHistoryEntry
の
状態も、
存在する場合は、それぞれ options のinfo
およびstate
に設定します。history
オプションを使用して、
「push」
と「replace」
のナビゲーション種別を切り替えることもできます。
「reload」
または「traverse」
ナビゲーションの場合、
「InvalidStateError」がスローされます。
現在のDocumentの
URL を
url に書き換えることが
できない場合、「SecurityError」
DOMException
がスローされます。
precommitController.addHandler(NavigationInterceptHandler handler)
このメソッドがnavigateEvent.intercept()
メソッドにhandler
として渡されたかのように、ナビゲーションがコミットされた時点で呼び出される
NavigationInterceptHandler
コールバックを追加します。
各NavigationPrecommitControllerには、
NavigateEvent
イベントがあります。
redirect(url,
options)メソッドの手順は、次のとおりです。
表明:thisのイベントのインターセプト
状態は「none」ではありません。
thisのイベントの
インターセプト
状態が「intercepted」でない場合、「InvalidStateError」
DOMException
をスローします。
thisのイベントの
navigationType
が「push」でも
「replace」でもない場合、
「InvalidStateError」DOMException
をスローします。
documentを、thisの関連する大域オブジェクトの関連付けられた
Documentとします。
destinationURLを、documentを指定して urlを構文解析した結果とします。
destinationURLが失敗である場合、
「SyntaxError」DOMException
をスローします。
documentの URL を destinationURL に書き換えることが
できない場合、
「SecurityError」DOMException
をスローします。
options["history"]
が「push」
または「replace」
である場合、thisのイベントの
navigationType
を options["history"]
に設定します。
options["state"]
が存在する場合は、
次を行います。
serializedStateを、
StructuredSerializeForStorage(options["state"])
を呼び出した結果とします。
これは例外をスローする場合があります。
thisのイベントの
destinationの
状態を
serializedStateに設定します。
thisのイベントの 対象の進行中の API メソッド トラッカーの直列化された 状態を serializedStateに設定します。
thisのイベントの
destinationの
URLを
destinationURLに設定します。
options["info"]
が存在する場合、
thisのイベントの
info
を options["info"]
に設定します。
addHandler(handler,)
メソッドの手順は、次のとおりです。
表明:thisのイベントの
インターセプト
状態は「none」ではありません。
thisのイベントの
インターセプト
状態が「intercepted」でない場合、「InvalidStateError」
DOMException
をスローします。
handlerを、thisのイベントの ナビゲーション ハンドラーリストに付加します。
NavigationDestination
インターフェイス[Exposed =Window ]
interface NavigationDestination {
readonly attribute USVString url ;
readonly attribute DOMString key ;
readonly attribute DOMString id ;
readonly attribute long long index ;
readonly attribute boolean sameDocument ;
any getState ();
};event.destination.url
ナビゲーション先の URL。
event.destination.key
これが「traverse」
ナビゲーションである場合は、移動先のNavigationHistoryEntryの
key
プロパティの値。それ以外の場合は空文字列です。
event.destination.id
これが「traverse」
ナビゲーションである場合は、移動先のNavigationHistoryEntryの
id
プロパティの値。それ以外の場合は空文字列です。
event.destination.index
これが「traverse」
ナビゲーションである場合は、移動先のNavigationHistoryEntryの
index
プロパティの値。それ以外の場合は −1 です。
event.destination.sameDocument
このナビゲーションが現在のものと同じDocumentへのものかどうかを
示します。たとえば、フラグメントナビゲーションまたはhistory.pushState()
ナビゲーションの場合、これは true になります。
このプロパティはナビゲーションの元の性質を示すことに注意してください。文書間ナビゲーションが
navigateEvent.intercept()
を使用して同一文書ナビゲーションに変換された場合でも、
このプロパティの値は変更されません。
event.destination.getState()
「traverse」
ナビゲーションの場合、移動先のセッション履歴エントリーに保存された状態を
逆直列化したものを返します。
「push」
または「replace」
ナビゲーションの場合、そのナビゲーションがnavigation.navigate()
によって開始された場合は、そのメソッドに渡された状態を逆直列化したものを返し、
そうでない場合は undefined を返します。
「reload」
ナビゲーションの場合、その再読み込みがnavigation.reload()
によって開始された場合は、そのメソッドに渡された状態を逆直列化したものを返し、
そうでない場合は undefined を返します。
各NavigationDestinationには、
URLであるURLがあります。
各NavigationDestinationには、
NavigationHistoryEntry
または null であるエントリーがあります。
NavigationDestinationが
「traverse」
ナビゲーションに対応する場合に限り、これは null ではありません。
各NavigationDestinationには、
直列化された
状態である状態があります。
各NavigationDestinationには、
真偽値である同じ文書であるがあります。
getState()メソッドの手順は、
StructuredDeserialize(thisの状態)を返すことです。
この標準の他の部分では、この節で示す一連のラッパーアルゴリズムを通じて、navigateイベントを
発火します。
セッション履歴
エントリー destinationSHEおよび省略可能な
ユーザーナビゲーション
関与 userInvolvement(既定値は
「none」)を指定して、
Navigation
navigationでtraverse navigateイベントを
発火するには、
eventを、navigationの関連するレルムで、
NavigateEventを指定してイベントを
作成した結果とします。
eventの従来の履歴 API 状態を null に設定します。
destinationを、navigationの関連する
レルムで作成された新しいNavigationDestination
とします。
destinationNHEを、navigationのエントリーリスト内にあり、そのセッション履歴エントリーが
destinationSHEであるNavigationHistoryEntry
とします。そのような
NavigationHistoryEntry
が存在しない場合は null とします。
destinationNHEが null でない場合は、次を行います。
destinationのエントリーを destinationNHEに設定します。
destinationの状態を destinationSHEのナビゲーション API 状態に設定します。
それ以外の場合は、次を行います。
destinationのエントリーを null に設定します。
destinationの状態を StructuredSerializeForStorage(null) に設定します。
destinationSHEの文書が、navigationの関連する大域
オブジェクトの関連付けられたDocumentと等しい場合、
destinationの同じ
文書であるを true に設定し、それ以外の場合は false に設定します。
navigation、「traverse」、
event、destination、userInvolvement、null、null、および
null を指定して、内部 navigateイベント発火
アルゴリズムを実行した結果を返します。
NavigationType navigationType、URL destinationURL、真偽値 isSameDocument、省略可能なユーザー
ナビゲーション関与 userInvolvement(既定値は
「none」)、省略可能なElementまたは
null
sourceElement(既定値は null)、省略可能なエントリーリストまたは null formDataEntryList(既定値は null)、省略可能な直列化された状態 navigationAPIState(既定値は
StructuredSerializeForStorage(null))、
省略可能な直列化された
状態または null classicHistoryAPIState
(既定値は
null)、および省略可能なナビゲーション API メソッドトラッカーまたは null apiMethodTrackerを指定して、
Navigation
navigationでpush/replace/reload
navigateイベントを発火するには、
documentを、navigationの関連する大域オブジェクトの関連付けられた
Documentとします。
documentのノードナビゲーション可能におけるナビゲーションの中止について ナビゲーション API に通知します。
navigationがエントリーおよびイベントを無効化されている、 かつapiMethodTrackerが null でない場合は、次を行います。
apiMethodTrackerの保留中を false に設定します。
apiMethodTrackerを null に設定します。
navigationがエントリーおよびイベントを無効化されている場合、
navigate()
およびreload()の
呼び出しは、決して充足されないプロミスを返します。このようなDocumentについて
NavigationHistoryEntry
オブジェクトを作成することはなく、serializedStateを適用する
NavigationHistoryEntry
も存在せず、infoを含めるnavigateイベントも
存在しません。したがって、結局この API メソッド呼び出しを追跡する必要はありません。以前の
ナビゲーションを中止した結果、navigateerror
イベントによってDocumentが完全にアクティブでなくなった場合に備え、
以前のナビゲーションを中止した後にこれを検査する必要があります。
documentが完全に アクティブでない場合、false を返します。
eventを、navigationの関連するレルムで、
NavigateEventを指定してイベントを
作成した結果とします。
eventの従来の履歴 API 状態を classicHistoryAPIStateに設定します。
destinationを、navigationの関連する
レルムで作成された新しいNavigationDestination
とします。
destinationのURLを destinationURLに設定します。
destinationのエントリーを null に設定します。
destinationの状態を navigationAPIStateに設定します。
destinationの同じ 文書であるを isSameDocumentに設定します。
navigation、navigationType、event、destination、
userInvolvement、sourceElement、formDataEntryList、null、および
apiMethodTrackerを指定して、内部 navigateイベント発火
アルゴリズムを実行した結果を返します。
URL
destinationURL、
ユーザー
ナビゲーション関与 userInvolvement、
Elementまたは
null
sourceElement、および文字列
filenameを指定して、
Navigation
navigationでダウンロード要求
navigateイベントを発火するには、
eventを、navigationの関連するレルムで、
NavigateEventを指定してイベントを
作成した結果とします。
eventの従来の履歴 API 状態を null に設定します。
destinationを、navigationの関連する
レルムで作成された新しいNavigationDestination
とします。
destinationのURLを destinationURLに設定します。
destinationのエントリーを null に設定します。
destinationの状態を StructuredSerializeForStorage(null) に設定します。
destinationの同じ 文書であるを false に設定します。
navigation、「push」、
event、
destination、userInvolvement、sourceElement、null、および
filenameを指定して、内部 navigateイベント発火
アルゴリズムを実行した結果を返します。
内部 navigateイベント発火アルゴリズムは、
Navigation
navigation、NavigationType
navigationType、NavigateEvent
event、NavigationDestination
destination、ユーザー
ナビゲーション関与 userInvolvement、Elementまたは
null
sourceElement、エントリーリストまたは null
formDataEntryList、文字列または null の downloadRequestFilename、および省略可能なナビゲーション API
メソッド
トラッカーまたは null の apiMethodTracker(既定値は null)を指定して、次の手順からなります。
navigationがエントリーおよびイベントを無効化されている場合は、 次を行います。
表明:navigationの進行中の API メソッドトラッカーは null です。
表明:navigationの今後の traverse API メソッド トラッカーは空です。
表明:apiMethodTrackerは null です。
true を返します。
これらの表明が成り立つのは、エントリーおよびイベントが無効化されている場合、
traverseTo()、
back()、および
forward()
が直ちに失敗するためです(走査先のエントリーが存在しないためです)。
表明:navigationの進行中の API メソッドトラッカーは null です。
destinationのエントリーが null でない場合は、次を行います。
表明:apiMethodTrackerは null です。
apiMethodTrackerが引数として渡されるのは、navigate()
およびreload()
の呼び出しの場合のみです。
表明:destinationKeyは空文字列ではありません。
navigationの今後の traverse API メソッド トラッカー[destinationKey]が存在する場合は、次を行います。
apiMethodTrackerを、navigationの今後の traverse API メソッドトラッカー[destinationKey]に設定します。
navigationの今後の traverse API メソッドトラッカー[destinationKey]を削除します。
apiMethodTrackerが null でない場合は、次を行います。
navigationの進行中の API メソッドトラッカーを apiMethodTrackerに設定します。
apiMethodTrackerの保留中を false に設定します。
navigableを、navigationの関連する大域オブジェクトの ナビゲーション可能とします。
documentを、navigationの関連する大域オブジェクトの
関連付けられた
Documentとします。
documentの URL を destinationのURLに書き換えることができる、かつ
destinationの同じ文書であるが true であるか、
またはnavigationTypeが「traverse」
でない場合、eventのcanIntercept
を true に初期化します。それ以外の場合は、
false に初期化します。
次のいずれかである場合、
navigationTypeが「traverse」
でない。または、
traverseCanBeCanceledが true である。
eventのcancelable
を true に初期化します。それ以外の場合は false に初期化します。
eventのnavigationType
を
navigationTypeに初期化します。
eventのdestination
を destinationに初期化します。
eventのdownloadRequest
を
downloadRequestFilenameに初期化します。
apiMethodTrackerが null でない場合、eventのinfoを
apiMethodTrackerの情報に初期化します。それ以外の場合は
undefined に初期化します。
この時点で、apiMethodTrackerの情報は不要になり、ナビゲーション API メソッド トラッカーの存続期間中に保持し続ける代わりに、null にできます。
documentの最新の
エントリーのキャッシュされたレンダリング状態を表示する視覚的遷移をユーザーエージェントが
実行した場合、eventのhasUAVisualTransition
を true に初期化します。それ以外の場合は false に初期化します。
eventのsourceElement
を
sourceElementに初期化します。
eventの中止
コントローラーを、navigationの関連するレルムで作成された新しいAbortController
に設定します。
eventのsignalを、
eventの中止
コントローラーのシグナルに初期化します。
currentURLを、documentのURLとします。
次のすべてが true である場合、
eventの従来の履歴 API 状態が null である。
destinationの同じ 文書であるが true である。
eventのhashChange
を true に初期化します。それ以外の場合は
false に初期化します。
ここでの最初の条件は、hashChange
がフラグメント
ナビゲーションでは true になりますが、
history.pushState(undefined, "", "#fragment")のような場合には false になることを意味します。
userInvolvementが「none」でない場合、
eventのuserInitiated
を true に初期化します。それ以外の場合は false に初期化します。
formDataEntryListが null でない場合、eventのformData
を、navigationの関連するレルムで作成され、
formDataEntryListに関連付けられた新しいFormData
に初期化します。それ以外の場合は null に初期化します。
表明:navigationの進行中の navigateイベントは null です。
navigationの進行中の navigate
イベントを eventに設定します。
navigationの進行中のナビゲーション中に フォーカスが変更されたを false に設定します。
navigationの進行中の ナビゲーション中に通常のスクロール復元を 抑制するを false に設定します。
dispatchResultを、navigationで eventをディスパッチした結果とします。
dispatchResultが false である場合は、次を行います。
navigationTypeが「traverse」
である場合、navigationの関連する大域オブジェクトを指定して、
履歴操作のユーザー
アクティブ化を消費します。
eventの中止 コントローラーのシグナルが中止済みでない場合、navigationを指定して、 進行中のナビゲーションを中止します。
false を返します。
eventのインターセプト
状態が「none」でない場合は、次を行います。
fromNHEを、navigationの現在の エントリーとします。
表明:fromNHEは null ではありません。
navigationの遷移を、
navigationの関連するレルムで作成され、
次の値を持つ新しいNavigationTransition
に設定します。
destination
navigationの遷移の完了済みプロミスを処理済みとしてマークします。
これを行う理由については、他の完了済みプロミスに 関する説明を参照してください。
navigationの遷移のコミット済みプロミスを処理済みとしてマークします。
eventのナビゲーションコミット前 ハンドラー リストが空である場合、apiMethodTrackerを指定して eventをコミットします。
それ以外の場合は、次を行います。
precommitControllerを、navigationの関連するレルムで作成され、そのイベントが
eventである新しいNavigationPrecommitController
とします。
precommitPromisesListを空のリストとします。
eventのナビゲーション コミット前ハンドラー リストの各 handlerについて、次を行います。
次の成功手順を使用して、precommitPromisesListのすべてを待機します。成功手順は、 apiMethodTrackerを指定してeventをコミットすることです。また、 reasonを指定した失敗手順は、eventおよび reasonを指定してnavigate イベントハンドラーの 失敗を処理することです。
eventのインターセプト
状態が「none」である場合、true を返します。
false を返します。
navigate イベントのインターセプトコミットハンドラー手順は、
Navigation
navigation、NavigateEventオブジェクト
event、およびナビゲーション
API メソッドトラッカー apiMethodTrackerを指定して、次のとおりです。
promisesListを空のリストとします。
eventのナビゲーションハンドラーリストの 各 handlerについて、次を行います。
promisesListのサイズが 0 である場合、 promisesListを « undefined で解決された プロミス » に設定します。
0 個のプロミスが指定された場合と 1 個以上のプロミスが指定された場合では、
すべてを待機する処理が成功手順および失敗手順を
スケジュールする方法に微妙なタイミングの違いがあります。すべてを待機する処理の
ほとんどの用途では、これは問題になりません。しかし、この API では、ほぼ同時に発火する可能性がある
イベントおよびプロミスハンドラーが非常に多いため、この違いはかなり容易に観測できます。これにより、
イベントとプロミスのハンドラーの順序が変化する可能性があります。(関連するイベントおよびプロミスには、
navigatesuccess
/navigateerror、
currententrychange、
dispose、
apiMethodTrackerのプロミス、およびnavigation.transition.finished
プロミスなどがあります。)
次の成功手順を使用して、promisesListのすべてを待機します。
eventの関連する大域オブジェクトが完全に アクティブでない場合、これらの手順を中止します。
eventの中止 コントローラーのシグナルが中止済みである場合、これらの手順を中止します。
表明:eventは、navigationの進行中の
navigateイベントと等しいです。
navigationの進行中の navigate
イベントを null に設定します。
true を指定してeventを完了します。
apiMethodTrackerが null でない場合、apiMethodTrackerの完了済み プロミスを解決します。
navigationでnavigatesuccess
という名前のイベントを発火します。
navigationの遷移が null でない場合、 navigationの遷移の完了済みプロミスを undefined で 解決します。
navigationの遷移を null に設定します。
また、reasonを指定した失敗手順は、eventおよびreasonを指定して navigate イベントハンドラーの 失敗を処理することです。
NavigateEventオブジェクト
eventおよびナビゲーション API メソッドトラッカー
apiMethodTrackerを指定して、navigate イベントをコミットするには、
navigationを、eventの対象とします。
navigableを、eventの関連する大域オブジェクトのナビゲーション可能とします。
eventの関連する大域オブジェクトの関連付けられた
Documentが完全に
アクティブでない場合、戻ります。
eventの中止 コントローラーのシグナルが中止済みである場合、戻ります。
eventのインターセプト状態が
「none」でないか、またはeventのdestinationの
同じ文書であるが true である場合、
endResultIsSameDocumentを true とします。
navigationの関連する設定 オブジェクトを指定して、スクリプトを実行する準備をします。
eventのインターセプト
状態が「none」でない場合は、次を行います。
eventのインターセプト状態を
「committed」に設定します。
eventのnavigationTypeに
応じて分岐します。
push」
replace」
eventの関連する
大域オブジェクトの関連付けられた
Documentおよびeventのdestinationの
URLを指定し、serializedData
をeventの従来の履歴 API
状態に設定し、
historyHandlingをeventのnavigationType
に設定して、URL および履歴の更新手順を実行します。
reload」
navigation、navigableのアクティブな
セッション履歴エントリー、および「reload」
を指定して、同一文書
ナビゲーションについてナビゲーション API エントリーを更新します。
traverse」
navigationの進行中の ナビゲーション中に通常のスクロール復元を 抑制するを true に設定します。
eventのスクロール
動作が「after-transition」
に設定されていた場合、関連するNavigateEventを完了する処理の一部として、
スクロール復元が行われます。それ以外の場合、スクロール復元は行われません。つまり、
intercept()
によってインターセプトされたナビゲーションは通常のスクロール復元処理を通過せず、
そのようなナビゲーションのスクロール復元は、ウェブ開発者によって手動で行われるか、
遷移後に行われます。
userInvolvementを「none」とします。
eventのuserInitiated
が true である場合、
userInvolvementを「activation」
に設定します。
インターセプト後のこの時点では、アクティブ化がブラウザー UI の結果であったかどうかは 重要ではありません。
navigableの走査可能なナビゲーション可能に、次のセッション 履歴走査手順を付加します。
eventのdestinationの
エントリーのセッション履歴エントリーのステップ、
navigableの走査可能なナビゲーション可能、および
userInvolvementを指定して、履歴走査ステップの
適用を再開します。
navigationの遷移が null でない場合、navigationの遷移のコミット済みプロミスを undefined で 解決します。
endResultIsSameDocumentが false かつapiMethodTrackerが null でない場合、 apiMethodTrackerをクリーンアップします。
navigationの関連する 設定オブジェクトを指定して、スクリプト実行後の クリーンアップを行います。
前述の 注記に従い、これにより潜在的なプロミスハンドラーのマイクロタスクの抑制が終了し、 この時点またはそれ以降に実行されるようになります。
NavigateEventオブジェクト
eventおよびreasonを指定して、navigate
イベントハンドラーの失敗を処理するには、
eventの関連する大域オブジェクトの関連付けられた
Documentが完全に
アクティブでない場合、戻ります。
eventの中止 コントローラーのシグナルが中止済みである場合、戻ります。
表明:eventは、eventの関連する大域
オブジェクトのナビゲーション
APIの進行中の
navigateイベントです。
eventのインターセプト
状態が「intercepted」でない場合、false を指定して
eventを完了します。
reasonを指定してeventを中止します。
navigateEvent.intercept()を呼び出すことにより、
ウェブ
開発者は同一文書ナビゲーションの通常のスクロールおよびフォーカス動作を抑制し、
代わりに後の時点で文書間ナビゲーションに似た動作を呼び出すことができます。この
節のアルゴリズムは、後の適切な時点で呼び出されます。
真偽値didFulfillを指定して、NavigateEvent
eventを完了するには、
eventのインターセプト
状態が「intercepted」である場合は、次を行います。
表明:didFulfillは false です。
表明:eventのナビゲーション コミット前ハンドラー リストは空ではありません。
ナビゲーションがコミットされる前にキャンセルできるのは、コミット前ハンドラーのみです。
eventのインターセプト状態を
「finished」に設定します。
戻ります。
eventのインターセプト
状態が「none」である場合、戻ります。
eventを指定して、必要に応じてフォーカスをリセットします。
didFulfillが true である場合、eventを指定して必要に応じてスクロール動作を処理します。
eventのインターセプト状態を
「finished」に設定します。
NavigateEvent
eventを指定して、必要に応じてフォーカスをリセットするには、
navigationを、eventの関連する大域オブジェクトの ナビゲーション APIとします。
focusChangedを、navigationの進行中のナビゲーション中にフォーカスが 変更されたとします。
navigationの進行中のナビゲーション中にフォーカスが 変更されたを false に設定します。
focusChangedが true である場合、戻ります。
eventのフォーカスリセット
動作が「manual」
である場合、
戻ります。
null のままにされている場合は、「after-transition」
として扱い、
処理を続行します。
documentを、eventの関連する大域オブジェクトの関連付けられた
Documentとします。
focusTargetを、documentのautofocus 委任先とします。
focusTargetが null である場合、focusTargetを documentのbody 要素に設定します。
focusTargetが null である場合、focusTargetを documentの文書 要素に設定します。
documentの ビューポートをフォールバック対象として、 focusTargetに対するフォーカス手順を実行します。
順次フォーカスナビゲーションの 開始点を focusTargetに移動します。
NavigateEvent
eventを指定して、必要に応じてスクロール動作を処理するには、
eventのインターセプト
状態が「scrolled」である場合、戻ります。
eventのスクロール動作が
「manual」
である場合、戻ります。
null のままにされている場合は、「after-transition」
として扱い、
処理を続行します。
eventを指定して、スクロール 動作を処理します。
NavigateEvent
eventを指定して、スクロール動作を処理するには、
eventのインターセプト状態を
「scrolled」に設定します。
eventのnavigationType
が「traverse」
または「reload」
に初期化されている場合、eventの関連する大域オブジェクトのナビゲーション可能のアクティブな
セッション履歴
エントリーを指定して、スクロール位置データを復元します。
それ以外の場合は、次を行います。
documentを、eventの関連する大域オブジェクトの
関連付けられた
Documentとします。
documentの指示された部分が null である場合、 documentを指定して文書の先頭へ スクロールします。[CSSOMVIEW]
それ以外の場合、documentを指定してフラグメントへスクロールします。
NavigateEventインターフェイスには、
その複雑さのため、専用の
節があります。
NavigationCurrentEntryChangeEvent
インターフェイス[Exposed =Window ]
interface NavigationCurrentEntryChangeEvent : Event {
constructor (DOMString type , NavigationCurrentEntryChangeEventInit eventInitDict );
readonly attribute NavigationType ? navigationType ;
readonly attribute NavigationHistoryEntry from ;
};
dictionary NavigationCurrentEntryChangeEventInit : EventInit {
NavigationType ? navigationType = null ;
required NavigationHistoryEntry from ;
};event.navigationType
現在のエントリーを変更させたナビゲーションの種類を返します。変更がnavigation.updateCurrentEntry()
によるものである場合は null を返します。
event.from
現在のエントリーが変更される前のnavigation.currentEntryの
以前の値を返します。
navigationType
が null または「reload」
である場合、この値は
navigation.currentEntryと同じになります。
この場合、
このイベントは、新しいエントリーへ移動したり現在のエントリーを置き換えたりしていなくても、
エントリーの内容が変更されたことを示します。
navigationTypeおよびfrom属性は、初期化された
値を返さなければなりません。
PopStateEventインターフェイス現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
[Exposed =Window ]
interface PopStateEvent : Event {
constructor (DOMString type , optional PopStateEventInit eventInitDict = {});
readonly attribute any state ;
readonly attribute boolean hasUAVisualTransition ;
};
dictionary PopStateEventInit : EventInit {
any state = null ;
boolean hasUAVisualTransition = false ;
};event.state
現在のすべてのエンジンでサポートされています。
pushState()
またはreplaceState()
に提供された情報のコピーを返します。
event.hasUAVisualTransition
ユーザーエージェントがこのイベントをディスパッチする前に、このナビゲーションについて視覚的な遷移を 実行した場合は true を返します。true の場合、作者が DOM をナビゲーション後の状態に 同期的に更新すると、最良のユーザーエクスペリエンスが得られます。
state属性は、初期化された値を
返さなければなりません。これはイベントのコンテキスト情報を表します。表される状態がDocumentの初期状態である場合は null です。
hasUAVisualTransition属性は、初期化された値を返さなければなりません。
HashChangeEvent
インターフェイスHashChangeEvent/HashChangeEvent
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
[Exposed =Window ]
interface HashChangeEvent : Event {
constructor (DOMString type , optional HashChangeEventInit eventInitDict = {});
readonly attribute USVString oldURL ;
readonly attribute USVString newURL ;
};
dictionary HashChangeEventInit : EventInit {
USVString oldURL = "";
USVString newURL = "";
};event.oldURL
現在のすべてのエンジンでサポートされています。
以前に現在であったセッション履歴エントリーのURLを返します。
event.newURL
現在のすべてのエンジンでサポートされています。
現在のセッション履歴エントリーのURLを返します。
oldURL属性は、初期化された値を
返さなければなりません。これはイベントのコンテキスト情報、具体的には走査元である
セッション履歴
エントリーの URL を表します。
newURL属性は、初期化された値を
返さなければなりません。これはイベントのコンテキスト情報、具体的には走査先である
セッション履歴
エントリーの URL を表します。
PageSwapEventインターフェイス[Exposed =Window ]
interface PageSwapEvent : Event {
constructor (DOMString type , optional PageSwapEventInit eventInitDict = {});
readonly attribute NavigationActivation activation ;
readonly attribute ViewTransition viewTransition ;
};
dictionary PageSwapEventInit : EventInit {
NavigationActivation ? activation = null ;
ViewTransition viewTransition = null ;
};event.activation
文書間ナビゲーションの移動先および種類を表すNavigationActivation
オブジェクト。オリジン間ナビゲーションの場合、これは null になります。
event.activation.entry
まもなくアクティブになるDocumentを表す
NavigationHistoryEntry。
event.activation.from
イベントが発火された時点のnavigation.currentEntry
プロパティの値に相当する
NavigationHistoryEntry。
event.activation.navigationType
「push」、
「replace」、
「reload」、
または「traverse」
のいずれかであり、ページの入れ替えを発生させようとしているナビゲーションの
種類を示します。
event.viewTransition
イベントが発火されたときにそのような遷移がアクティブである場合、外向きの文書間ビュー
遷移を表すViewTransition
オブジェクトを返します。それ以外の場合は null を返します。
activationおよびviewTransition属性は、
初期化された
値を返さなければなりません。
PageRevealEvent
インターフェイス[Exposed =Window ]
interface PageRevealEvent : Event {
constructor (DOMString type , optional PageRevealEventInit eventInitDict = {});
readonly attribute ViewTransition viewTransition ;
};
dictionary PageRevealEventInit : EventInit {
ViewTransition viewTransition = null ;
};event.viewTransition
イベントが発火されたときにそのような遷移がアクティブである場合、内向きの文書間ビュー
遷移を表すViewTransition
オブジェクトを返します。それ以外の場合は null を返します。
viewTransition属性は、初期化された
値を返さなければなりません。
PageTransitionEvent
インターフェイスPageTransitionEvent/PageTransitionEvent
現在のすべてのエンジンでサポートされています。
現在のすべてのエンジンでサポートされています。
[Exposed =Window ]
interface PageTransitionEvent : Event {
constructor (DOMString type , optional PageTransitionEventInit eventInitDict = {});
readonly attribute boolean persisted ;
};
dictionary PageTransitionEventInit : EventInit {
boolean persisted = false ;
};event.persisted
現在のすべてのエンジンでサポートされています。
pageshowイベントの場合、
ページが新たに
読み込まれている(かつloadイベントが発火する)場合は
false を返します。それ以外の場合は
true を返します。
pagehideイベントの場合、
ページが最後に
破棄されようとしている場合は false を返します。それ以外の場合は true を返し、ユーザーがこのページへ
戻った場合にページが再利用される可能性があることを意味します(Documentの救済可能状態が true のままである場合)。
ページを救済不可能にする可能性があるものには、次のものがあります。
ユーザーエージェントが、アンロード後にDocumentをセッション
履歴エントリー内で存続させないと決定した場合
アクティブなWebSocket
オブジェクト
persisted属性は、初期化された値を
返さなければなりません。これはイベントのコンテキスト情報を表します。
真偽値persistedを使用して、Window
windowでeventNameという名前のページ遷移イベントを発火するには、
PageTransitionEventを使用し、
persisted
属性をpersistedに初期化し、cancelable
属性を
true に初期化し、bubbles
属性を
true に初期化し、旧来の対象上書きフラグを設定して、windowで
eventNameという名前のイベントを発火します。
cancelable
およびbubbles
の値には意味がありません。イベントをキャンセルしても
何も起こらず、Windowオブジェクトを越えてバブリングすることも
できないためです。歴史的な理由により、これらは true に設定されています。
BeforeUnloadEvent
インターフェイス現在のすべてのエンジンでサポートされています。
[Exposed =Window ]
interface BeforeUnloadEvent : Event {
attribute DOMString returnValue ;
};BeforeUnloadEvent固有の
初期化メソッドはありません。
BeforeUnloadEvent
インターフェイスは、イベントをキャンセルするだけでなく、returnValue
属性を空文字列以外の値に設定することによっても、アンロードがキャンセルされたかどうかの
検査を制御できる旧来のインターフェイスです。作者はreturnValue
を使用する代わりに、preventDefault()
メソッド、またはイベントをキャンセルするその他の手段を使用するべきです。
returnValue属性は、アンロードがキャンセルされたかどうかを検査する
処理を制御します。イベントが作成されたとき、
この属性は空文字列に設定されなければなりません。取得時には、最後に設定された値を返さなければ
なりません。設定時には、この属性を新しい値に設定しなければなりません。
この属性がDOMStringであるのは、歴史的な理由によるものにすぎません。
空文字列以外の値は、ユーザーに
確認を求める要求として扱われます。
NotRestoredReasons
インターフェイス[Exposed =Window ]
interface NotRestoredReasonDetails {
readonly attribute DOMString reason ;
[Default ] object toJSON ();
};
[Exposed =Window ]
interface NotRestoredReasons {
readonly attribute USVString ? src ;
readonly attribute DOMString ? id ;
readonly attribute DOMString ? name ;
readonly attribute USVString ? url ;
readonly attribute FrozenArray <NotRestoredReasonDetails >? reasons ;
readonly attribute FrozenArray <NotRestoredReasons >? children ;
[Default ] object toJSON ();
};notRestoredReasonDetails.reason
文書が戻る/進むキャッシュから提供されることを妨げた理由を説明する文字列を 返します。取り得る文字列値については、bfcache ブロック詳細の 定義を参照してください。
notRestoredReasons.src
文書のノードナビゲーション可能のコンテナーがiframe
要素である場合、そのsrc属性を返します。
設定されていない場合、またはiframe
要素でない場合、これは null になることがあります。
notRestoredReasons.id
文書のノードナビゲーション可能のコンテナーがiframe
要素である場合、そのid属性を返します。
設定されていない場合、またはiframe
要素でない場合、これは null になることがあります。
notRestoredReasons.name
文書の
ノードナビゲーション可能のコンテナーがiframe
要素である場合、そのname属性を
返します。設定されていない場合、またはiframe
要素でない場合、これは null になることがあります。
notRestoredReasons.url
文書のURLを返します。文書がオリジン間iframe内に
ある場合は null を返します。元のsrcが設定されてから
iframeが
ナビゲートした可能性があるため、これはsrc
に加えて報告されます。
notRestoredReasons.reasons
文書についてのNotRestoredReasonDetailsの
配列を返します。文書がオリジン間iframe内に
ある場合、これは null です。
notRestoredReasons.children
文書の子についてのNotRestoredReasonsの
配列を返します。文書がオリジン間iframe内に
ある場合、これは null です。
NotRestoredReasonDetails
オブジェクトには、未復元理由
詳細または null である基礎構造体があり、初期値は null です。
未復元理由
詳細 backingStructおよびレルム realmを指定して、NotRestoredReasonDetailsオブジェクトを作成するには、
notRestoredReasonDetailsを、realmで作成された新しいNotRestoredReasonDetails
オブジェクトとします。
notRestoredReasonDetailsの基礎 構造体を backingStructに設定します。
notRestoredReasonDetailsを返します。
理由。文字列であり、初期値は空です。
理由は、ページが戻る/進むキャッシュから復元されることを妨げた理由を表す文字列です。 この文字列は、次のいずれかです。
fetch"Documentによって開始された
fetch がまだ進行中であり、キャンセルされたため、ページは戻る/進むキャッシュに
保存できる状態ではありませんでした。
navigation-failure"Documentを作成した元のナビゲーションで
エラーが発生したため、結果のエラー文書を戻る/進むキャッシュに
保存することが妨げられました。parser-aborted"Documentが初期 HTML 解析を
完了しなかったため、未完成の文書を戻る/進むキャッシュに保存することが
妨げられました。websocket"WebSocket
接続が切断されたため、ページは戻る/進むキャッシュに保存できる状態ではありませんでした。[WEBSOCKETS]
lock"masked"Documentには
オリジン間iframe内の
子があり、それらが戻る/進むキャッシュを妨げたか、またはこのDocumentを
ユーザーエージェント固有の理由で戻る/進むキャッシュに保存できず、
ユーザーエージェントがユーザーエージェント固有のブロック理由の一覧にある、
より具体的な理由のいずれかを使用しないことを選択しました。
上記の一覧に加えて、ユーザーエージェントは、ユーザーエージェント固有のブロック理由により、ページが戻る/進むキャッシュから復元されることを妨げた理由を公開することを選択する場合があります。 これらは、次の文字列のいずれかです。
audio-capture"Documentが、
Media Capture and
StreamsのgetUserMedia()
を audio とともに使用して、音声キャプチャーの許可を要求しました。[MEDIASTREAM]
background-work"Documentが、
SyncManagerの
register()
メソッド、
PeriodicSyncManagerの
register()
メソッド、または
BackgroundFetchManagerの
fetch()
メソッドを呼び出して、バックグラウンド処理を要求しました。
broadcastchannel-message"BroadcastChannel
接続がメッセージを受信し、messageイベントが発火されました。
idbversionchangeevent"Documentには、アンロード中に保留中の
IDBVersionChangeEvent
がありました。[INDEXEDDB]
idledetector"Documentには、アンロード中に
アクティブなIdleDetector
がありました。
keyboardlock"Keyboardの
lock()
メソッドが呼び出されていたため、キーボードロックがまだアクティブでした。
mediastream"MediaStreamTrack
がlive 状態でした。[MEDIASTREAM]midi"Documentが、
navigator.requestMIDIAccess()
を呼び出して MIDI の許可を要求しました。
modals"navigating"Documentは戻る/進むキャッシュに保存できる状態ではありませんでした。
navigation-canceled"window.stop()を
呼び出すことでナビゲーション要求がキャンセルされ、ページは
戻る/進むキャッシュに保存できる状態ではありませんでした。
non-trivial-browsing-context-group"Documentの閲覧コンテキストグループに複数の
最上位閲覧コンテキストがありました。
otpcredential"Documentが
OTPCredentialを作成しました。
outstanding-network-request"
Documentには
未処理のネットワーク要求があり、戻る/進む
キャッシュに保存できる状態ではありませんでした。
paymentrequest"Documentには、アンロード中に
アクティブなPaymentRequest
がありました。[PAYMENTREQUEST]pictureinpicturewindow"Documentには、アンロード中に
アクティブなPictureInPictureWindow
がありました。[PICTUREINPICTURE]plugins"Documentにプラグインが含まれていました。request-method-not-get"Documentが、
メソッドが
`GET` でない HTTP 要求から作成されました。
[FETCH]
response-auth-required"Documentが、
HTTP 認証を必要とする HTTP
応答から作成されました。response-cache-control-no-store"Documentが、
`Cache-Control`
ヘッダーに「no-store」トークンが含まれる HTTP 応答から作成されました。[HTTP]response-cache-control-no-cache"Documentが、
`Cache-Control`
ヘッダーに「no-cache」トークンが含まれる HTTP 応答から作成されました。[HTTP]response-keep-alive"Documentが、
`Keep-Alive`ヘッダーを含む HTTP 応答から作成されました。response-scheme-not-http-or-https"Documentが、
URLのスキームがHTTP(S)
スキームでない応答から作成されました。[FETCH]
response-status-not-ok"Documentが、
状態がok 状態でない HTTP 応答から作成されました。
[FETCH]
rtc"RTCPeerConnection
または
RTCDataChannel
が終了されたため、ページは戻る/進むキャッシュに保存できる状態ではありませんでした。[WEBRTC]
rtc-used-with-cache-control-no-store"
Documentが、
`Cache-Control`
ヘッダーに
「no-store」トークンが含まれる HTTP 応答から作成され、機密情報の受信に使用される可能性がある
RTCPeerConnection
または
RTCDataChannel
を作成していたため、ページは戻る/進むキャッシュに保存できる状態では
ありませんでした。
[HTTP] [WEBRTC]
sensors"Documentがセンサーへの
アクセスを要求しました。serviceworker-added"Documentのサービスワーカークライアントが
ServiceWorkerによって制御され始めました。[SW]
serviceworker-claimed"Documentのサービスワーカークライアントのアクティブなサービスワーカーが
claim されました。[SW]serviceworker-postmessage"Documentのサービスワーカークライアントのアクティブなサービスワーカーが
メッセージを受信しました。[SW]serviceworker-version-activated"Documentのサービスワーカークライアントのアクティブなサービスワーカーの
バージョンがアクティブ化されました。
[SW]
serviceworker-unregistered"Documentのサービスワーカークライアントのアクティブなサービスワーカーのサービス
ワーカー登録が登録解除されました。[SW]sharedworker"Documentが、
SharedWorkerGlobalScopeの
所有者集合に含まれていました。
共有ワーカーを使用する文書について戻る/進むキャッシュを
サポートするユーザーエージェントは、この一般的な理由の代わりに、"sharedworker-message"
または"sharedworker-with-no-active-client"
などの、より具体的な理由を使用できます。共有ワーカーの使用自体は、それらの理由で説明される
場合を除いてサポートされるためです。
sharedworker-message"Documentを含む所有者集合を持つSharedWorkerGlobalScopeから
メッセージを受信しました。sharedworker-with-no-active-client"Documentが、
アクティブに必要とされていないSharedWorkerGlobalScopeの
所有者集合に含まれていました。
smartcardconnection"Documentには、アンロード中に
アクティブなSmartCardConnection
がありました。speechrecognition"Documentには、アンロード中に
アクティブなSpeechRecognition
がありました。storageaccess"Documentが、
Storage Access
API を使用してストレージアクセスの許可を要求しました。unload-listener"Documentが、
unloadイベントの
イベントリスナーを登録しました。
video-capture"Documentが、
Media Capture and
StreamsのgetUserMedia()
を video とともに使用して、映像キャプチャーの許可を要求しました。[MEDIASTREAM]
webhid"Documentが、
WebHID API のrequestDevice()
メソッドを呼び出しました。webshare"Documentが、Web
Share API のnavigator.share()
メソッドを使用しました。websocket-used-with-cache-control-no-store"Documentが、
`Cache-Control`
ヘッダーに
「no-store」トークンが含まれる HTTP 応答から作成され、機密情報の受信に使用される可能性がある
WebSocket
接続を作成していたため、ページは戻る/進むキャッシュに保存できる状態では
ありませんでした。[HTTP] [WEBSOCKETS]
webtransport"WebTransport
接続が切断されたため、ページは戻る/進むキャッシュに保存できる状態ではありませんでした。[WEBTRANSPORT]webtransport-used-with-cache-control-no-store"Documentが、
`Cache-Control`
ヘッダーに
「no-store」トークンが含まれる HTTP 応答から作成され、機密情報の受信に使用される可能性がある
WebTransport
接続を作成していたため、ページは戻る/進むキャッシュに保存できる状態では
ありませんでした。[HTTP] [WEBTRANSPORT]
webxrdevice"Documentが
XRSystemを作成しました。
NotRestoredReasons
オブジェクトには、未復元理由または null である基礎構造体があり、初期値は
null です。
NotRestoredReasons
オブジェクトには、FrozenArray<
または null である理由配列があり、
初期値は null です。
NotRestoredReasonDetails>
NotRestoredReasons
オブジェクトには、FrozenArray<NotRestoredReasons>
または null である子配列があり、
初期値は null です。
未復元
理由 backingStructおよびレルム realmを指定して、NotRestoredReasons
オブジェクトを作成するには、
notRestoredReasonsを、realmで
作成された新しいNotRestoredReasons
オブジェクトとします。
notRestoredReasonsの基礎構造体を backingStructに設定します。
backingStructの理由が null である場合、 notRestoredReasonsの理由配列を null に設定します。
それ以外の場合は、次を行います。
backingStructの子が null である場合、 notRestoredReasonsの子配列を null に設定します。
それ以外の場合は、次を行います。
notRestoredReasonsを返します。
src。スカラー値 文字列または null であり、初期値は null です。
id。文字列または null であり、初期値は null です。
name。文字列または null であり、初期値は null です。
url。URLまたは null であり、初期値は null です。
Documentの未復元理由は、Documentのノードナビゲーション可能が最上位の走査可能である場合、そのノードナビゲーション可能の
アクティブなセッション
履歴エントリーの文書状態の未復元理由です。
それ以外の場合は null です。
この標準には、文書のシーケンスをグループ化するための関連する概念がいくつか含まれています。 簡潔な非規範的要約として、次のようになります。
ナビゲーション可能は、
文書のシーケンスをユーザー向けに
表現したものです。つまり、文書間をナビゲートできるものを表します。代表的な
例としては、ウェブブラウザーのタブやウィンドウ、iframe、
または
frameset内のframeがあります。
走査可能なナビゲーション可能は、 自身および子孫のナビゲーション可能のセッション履歴を制御する特殊な種類の ナビゲーション可能です。つまり、自身の一連の文書に加えて、さらに別の一連の 文書からなるツリーと、そのツリーを平坦化したビューを通じて前後へ線形に走査する機能を 表します。
閲覧
コンテキストは、一連の文書を開発者向けに
表現したものです。これらはWindowProxy
オブジェクトと 1 対 1 で対応します。各ナビゲーション可能は一連の閲覧コンテキストを提示でき、
特定の明確に定義された状況下では、それらの閲覧コンテキスト間で切り替えが発生します。
この標準の大部分はナビゲーション可能という用語を使用しますが、一部の API は閲覧コンテキストの 切り替えの存在を公開するため、標準の一部では閲覧コンテキストの観点で扱う必要があります。
ナビゲーション可能は、そのアクティブなセッション履歴エントリーを介して、
Documentをユーザーに提示します。各
ナビゲーション可能には、次のものがあります。
ID。新しい一意な内部値です。
親。ナビゲーション可能または null です。
現在のセッション履歴 エントリー。セッション履歴エントリーです。
これは、親の走査可能なナビゲーション可能のセッション履歴走査キュー内でのみ変更できます。
アクティブなセッション履歴エントリー。セッション履歴エントリーです。
これは、アクティブなセッション履歴エントリーの文書のイベントループからのみ変更できます。
真偽値終了中である。初期値は false です。
これは最上位の走査可能なナビゲーション可能についてのみ true に設定されます。
真偽値load
イベントを遅延している。初期値は false です。
これは、ナビゲーション可能の親が null でない場合にのみ true に設定されます。
ナビゲーションまたは履歴更新の実行が 許可されているアルゴリズム。これは実装定義であり、許可またはブロックのいずれかを返します。
たとえば、一定の時間内に過度に多く呼び出された場合、これはブロックを返すことがあります。
現在のセッション履歴エントリーと アクティブなセッション履歴エントリーは通常同じですが、 次の場合には同期しなくなります。
同期ナビゲーションが実行された場合。これにより、アクティブなセッション履歴エントリーが一時的に 現在のセッション履歴エントリーより先に進みます。
履歴ステップを適用するときに、表示不可能かつエラーでない応答を 受信した場合。これにより現在のセッション履歴エントリーは更新されますが、 アクティブなセッション履歴エントリーはそのままです。
ナビゲーション可能のアクティブな 文書は、そのアクティブなセッション履歴 エントリーの文書です。
これは、ナビゲーション可能の最上位の走査可能のセッション履歴走査キュー内から安全に読み取ることができます。
ナビゲーション可能のアクティブな履歴エントリーは同期的に変更される可能性がありますが、
新しいエントリーは常に同じDocumentを持ちます。
ナビゲーション可能のアクティブな閲覧 コンテキストは、そのアクティブな文書の閲覧コンテキストです。このナビゲーション可能が 走査可能なナビゲーション可能である場合、そのアクティブな閲覧コンテキストは 最上位閲覧コンテキストになります。
ナビゲーション可能のアクティブな
WindowProxyは、そのアクティブな閲覧コンテキストに関連付けられたWindowProxyです。
ナビゲーション可能のアクティブなウィンドウは、
そのアクティブなWindowProxyの[[Window]]です。
これは常に、ナビゲーション可能のアクティブな文書の関連する大域 オブジェクトと等しくなります。これはアクティブにするアルゴリズムによって同期されます。
ナビゲーション可能の対象 名前は、そのアクティブなセッション履歴エントリーの 文書状態のナビゲーション可能の対象名です。
ノード nodeのノードナビゲーション可能を取得するには、 そのアクティブな文書がnodeのノード文書であるナビゲーション可能を返します。そのような ナビゲーション可能がない場合は null を返します。
文書状態 documentStateおよび省略可能なナビゲーション可能または null の parent(既定値は null)を指定して、ナビゲーション可能 navigableを初期化するには、
entryを、次の値を持つ新しいセッション履歴エントリーとします。
このアルゴリズムの呼び出し元は、entryのステップを初期化する責任があります。その処理が
完了するまで、これは「pending」のままになります。
navigableの現在のセッション 履歴エントリーをentryに設定します。
navigableのアクティブなセッション履歴 エントリーをentryに設定します。
navigableの親を parentに設定します。
documentStateの文書の初期表示状態を設定し、 navigableの走査可能なナビゲーション可能の システム表示状態にします。
走査可能なナビゲーション可能は、自身およびその子孫のナビゲーション可能について、どの セッション履歴エントリーを現在のセッション履歴エントリーおよびアクティブなセッション履歴 エントリーとするかも制御するナビゲーション可能です。
ナビゲーション可能のプロパティに加えて、 走査可能な ナビゲーション可能には、次のものがあります。
現在のセッション履歴 ステップ。数値であり、初期値は 0 です。
セッション履歴 エントリー。セッション履歴 エントリーのリストであり、初期値は新しいリストです。
セッション履歴走査キュー。 セッション履歴走査並列 キューであり、新しい セッション履歴走査並列キューを開始した結果です。
真偽値入れ子の履歴ステップ適用を 実行中。初期値は false です。
システム表示状態。「hidden」または
「visible」のいずれかです。
この項目に関する要件については、ページの可視性の節を参照してください。
真偽値ウェブコンテンツによって作成された。初期値は false です。
ナビゲーション可能 inputNavigableの走査可能なナビゲーション可能を取得するには、次を行います。
navigableをinputNavigableとします。
navigableが走査可能なナビゲーション可能でない間、 navigableをnavigableの親に設定します。
navigableを返します。
最上位の走査可能は、親が null である走査可能なナビゲーション可能です。
現在、すべての走査可能なナビゲーション可能は 最上位の走査可能です。将来の提案では、 最上位ではない走査可能の導入が想定されています。
ユーザーエージェントは、最上位の 走査可能の集合を保持します。これは集合 形式の最上位の走査可能です。これらは 通常、ブラウザーウィンドウまたはブラウザータブの形式でユーザーに提示されます。
ナビゲーション可能 inputNavigableの最上位の走査可能を取得するには、
閲覧コンテキストまたは null の opener、文字列targetName、および省略可能なナビゲーション可能 openerNavigableForWebDriverを指定して、新しい最上位の走査可能を作成するには、
documentを null とします。
openerが null である場合、documentを 新しい最上位閲覧 コンテキストおよび文書を作成した 2 番目の戻り値に設定します。
それ以外の場合、documentを、openerを指定して新しい補助 閲覧コンテキストおよび文書を作成した 2 番目の戻り値に設定します。
documentStateを、次の値を持つ新しい文書状態とします。
traversableを、新しい走査可能なナビゲーション可能とします。
documentStateを指定して、traversableを初期化します。
initialHistoryEntryを、traversableのアクティブなセッション履歴エントリーとします。
initialHistoryEntryのステップを 0 に設定します。
initialHistoryEntryを、traversableのセッション履歴 エントリーに付加します。
openerが null でない場合、openerの最上位の 走査可能およびtraversableを指定して、走査可能のストレージ領域を旧来方式で 複製します。[STORAGE]
traversableをユーザーエージェントの最上位の 走査可能の集合に付加します。
traversableおよびopenerNavigableForWebDriverを使用して、WebDriver BiDi のナビゲーション可能作成を 呼び出します。
traversableを返します。
URL initialNavigationURLおよび省略可能なPOST リソースまたは null の initialNavigationPostResource(既定値は null)を指定して、新しい最上位の走査可能を作成するには、
traversableを、null および空文字列を指定して新しい最上位の 走査可能を作成した結果とします。
traversableのアクティブな文書を使用し、 documentResourceを initialNavigationPostResourceに設定して、traversableを initialNavigationURLへナビゲートします。
これらの初期ナビゲーションは、traversableが自身をナビゲートするものとして 扱います。これにより、関連するすべてのセキュリティ検査が成功します。
traversableを返します。
特定の要素(たとえば、iframe要素)は、
ナビゲーション可能をユーザーに提示できます。これらの要素は
ナビゲーション可能コンテナーと呼ばれます。
各ナビゲーション可能コンテナーには、ナビゲーション可能または null である内容ナビゲーション可能があります。初期値は null です。
ナビゲーション可能 navigableのコンテナーは、その 内容ナビゲーション可能がnavigableであるナビゲーション可能コンテナーです。そのような要素がない場合は null です。
ナビゲーション可能 navigableのコンテナー 文書は、次の手順を実行した結果です。
Document
documentのコンテナー文書は、次の手順を実行した結果です。
documentのノードナビゲーション可能が null である場合、null を返します。
documentのノード ナビゲーション可能のコンテナー 文書を返します。
ナビゲーション可能 navigableは、その親がpotentialParentであるとき、別のナビゲーション可能 potentialParentの子ナビゲーション可能です。また、単にナビゲーション可能が「子ナビゲーション可能である」とも言えます。これは、 その親が null でないことを意味します。
すべての子ナビゲーション可能は、そのコンテナーの内容ナビゲーション可能です。
ナビゲーション可能 コンテナー containerの内容文書は、次の手順を実行した結果です。
containerの内容 ナビゲーション可能が null である場合、 null を返します。
documentを、containerの内容ナビゲーション可能のアクティブな文書とします。
documentのオリジンと containerのノード 文書のオリジンが 同一オリジンドメインでない場合、 null を返します。
documentを返します。
ナビゲーション可能コンテナー containerの内容ウィンドウは、次の手順を実行した 結果です。
containerの内容 ナビゲーション可能が null である場合、 null を返します。
containerの内容
ナビゲーション可能のアクティブなWindowProxyのオブジェクトを返します。
要素elementを指定して、新しい子 ナビゲーション可能を作成するには、次を行います。
parentNavigableを、elementのノード ナビゲーション可能とします。
groupを、elementのノード 文書の閲覧 コンテキストの最上位閲覧 コンテキストのグループとします。
browsingContextおよびdocumentを、elementのノード文書、element、および groupを指定して新しい 閲覧コンテキストおよび文書を作成した結果とします。
targetNameを null とします。
elementがname内容属性を持つ場合、
targetNameをその属性の値に設定します。
documentStateを、次の値を持つ新しい文書状態とします。
navigableを、新しいナビゲーション可能とします。
documentStateおよびparentNavigableを指定して、 navigableを初期化します。
elementの内容 ナビゲーション可能をnavigableに設定します。
historyEntryを、navigableのアクティブなセッション履歴エントリーとします。
traversableを、parentNavigableの走査可能なナビゲーション可能とします。
traversableに次のセッション 履歴走査手順を付加します。
parentDocStateを、parentNavigableのアクティブなセッション履歴エントリーの文書状態とします。
parentNavigableEntriesを、parentNavigableについてセッション履歴 エントリーを取得した結果とします。
targetStepSHEを、parentNavigableEntries内で、その文書 状態がparentDocStateと等しい最初のセッション履歴エントリーとします。
nestedHistoryを、そのIDがnavigableのIDであり、 エントリーリストが « historyEntry » である新しい入れ子の履歴とします。
traversableを指定して、ナビゲーション可能の 作成/破棄について更新します。
traversableを使用して、WebDriver BiDi のナビゲーション可能作成を 呼び出します。
文書のシーケンス、特にナビゲーション可能とそのセッション 履歴エントリーを視覚化する有用な方法が、Jake 図です。典型的な Jake 図は 次のとおりです。
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
top |
/t-a | /t-a#foo | /t-b | ||
frames[0] |
/i-0-a | /i-0-b | |||
frames[1] |
/i-1-a | /i-1-b | |||
ここでは、番号付きの各列が、走査可能のセッション履歴
ステップの取り得る値を示します。ラベル付きの各行は、異なる URL と文書の間を遷移する
ナビゲーション可能を示します。最初の
topとラベル付けされたものが最上位の走査可能であり、その他は
子ナビゲーション可能です。文書は各セルの
背景色によって示され、新しい背景色はそのナビゲーション可能内の新しい文書を示します。URL はセルの
テキスト内容によって示されます。通常、簡潔にするため相対 URLとして示されますが、オリジン間の事例を
特に検討している場合はその限りではありません。特定のナビゲーション可能が特定のステップで存在しない場合があり、
その場合、対応するセルは空になります。太字斜体のステップ番号は、走査可能の現在のセッション
履歴ステップを示し、太字斜体の URL を持つすべてのセルは、その行の
ナビゲーション可能についての現在のセッション履歴エントリーを表します。
したがって、上記の Jake 図は次の一連のイベントを示しています。
最上位の走査可能が作成され、
URL /t-aから開始し、2 つの子ナビゲーション可能が
それぞれ/i-0-aおよび/i-1-aから開始します。
最初の子ナビゲーション可能が、URL /i-0-bを持つ別の
文書へナビゲートされます。
2 番目の子ナビゲーション可能が、URL /i-1-bを持つ別の
文書へナビゲートされます。
最上位の走査可能が同じ文書へナビゲートされ、その URL が
/t-a#fooに更新されます。
最上位の走査可能が、URL /t-bを持つ別の
文書へナビゲートされます。(当然ながら、この文書には
以前の文書の子ナビゲーション可能は引き継がれません。)
走査可能が −3 のデルタによって 走査され、ステップ 1 に戻ります。
Jake 図は、複数のナビゲーション可能、 ナビゲーション、および走査の相互作用を視覚化するための強力なツールです。あらゆる 可能な相互作用を表現できるわけではありません。たとえば、入れ子は 1 段階にしか対応しません。 しかし、この標準全体を通じて、いくつかの複雑な状況を説明するために使用します。
Jake 図は、その考案者である 比類なき Jake Archibald にちなんで名付けられました。
この標準のアルゴリズムでは、特定のDocumentから始まるナビゲーション可能の集合を調べることが有用な場合がよくあります。この節には、
それらのナビゲーション可能を収集するために選定されたアルゴリズムの集合が含まれています。
これらのアルゴリズムの戻り値は、親が子より前に現れるよう順序付けられています。 呼び出し元はこの順序に依存します。
ナビゲーション可能ではなくDocumentから開始する方が、
呼び出し元が完全にアクティブなDocumentから開始しているかどうかを
意識できるため、一般に適切です。完全にアクティブでない
Documentにも祖先および
子孫のナビゲーション可能は存在しますが、多くの場合、それらが存在しないかのように動作します
(たとえば、window.parent取得子)。
Document
documentの祖先ナビゲーション可能は、次の手順によって得られます。
navigableを、documentのノードナビゲーション可能の親とします。
ancestorsを空のリストとします。
navigableが null でない間、次を行います。
ancestorsを返します。
Document
documentの自身を含む祖先
ナビゲーション可能は、次の手順によって得られます。
navigablesを、documentの祖先 ナビゲーション可能とします。
documentのノード ナビゲーション可能をnavigablesに付加します。
navigablesを返します。
Document
documentの子孫
ナビゲーション可能は、次の手順によって得られます。
navigablesを新しいリストとします。
navigableContainersを、documentのシャドウを含む子孫のうちナビゲーション可能 コンテナーであるすべてのものを、シャドウを含むツリー順に並べたリストとします。
navigableContainersの各 navigableContainerについて、次を行います。
navigableContainerの内容ナビゲーション可能が null である場合、 続行します。
navigablesを、navigableContainerの内容ナビゲーション可能のアクティブな文書の自身を含む子孫 ナビゲーション可能で拡張します。
navigablesを返します。
Document
documentの自身を含む子孫
ナビゲーション可能は、次の手順によって得られます。
navigablesを « documentのノードナビゲーション可能 » とします。
navigablesを、documentの 子孫 ナビゲーション可能で拡張します。
navigablesを返します。
これらの子孫収集アルゴリズムは、子孫のDocumentオブジェクトの DOM ツリーを
調べるものとして説明されています。実際には、DOM
ツリーがアルゴリズムの呼び出し元とは別のプロセスにある可能性があるため、これは多くの場合実現不可能です。
その代わりに、実装は一般に、適切なツリーをプロセス間で複製します。
Document
documentの文書ツリーの子
ナビゲーション可能は、次の手順によって得られます。
documentのノード ナビゲーション可能が null である場合、空の リストを返します。
navigablesを新しいリストとします。
navigableContainersを、documentの子孫のうちナビゲーション可能コンテナーであるすべてのものを、 ツリー順に並べたリストとします。
navigableContainersの各 navigableContainerについて、次を行います。
navigableContainerの内容ナビゲーション可能が null である場合、 続行します。
navigableContainerの内容 ナビゲーション可能をnavigablesに付加します。
navigablesを返します。
ナビゲーション可能コンテナー containerを指定して、子ナビゲーション可能を破棄するには、
navigableを、containerの内容 ナビゲーション可能とします。
navigableが null である場合、戻ります。
containerの内容ナビゲーション可能を null に設定します。
navigableを指定して、子ナビゲーション可能の破棄を ナビゲーション API に通知します。
navigableのアクティブな文書を指定して、文書および その子孫を破棄します。
parentDocStateを、containerのノードナビゲーション可能の アクティブなセッション履歴エントリーの文書 状態とします。
parentDocStateの入れ子の 履歴から、そのIDが navigableのIDと等しい入れ子の履歴を削除します。
traversableを、containerのノードナビゲーション可能の走査可能な ナビゲーション可能とします。
traversableに次の セッション 履歴走査手順を付加します。
traversableを指定して、ナビゲーション可能の 作成/破棄について更新します。
navigableを使用して、WebDriver BiDi のナビゲーション可能破棄を 呼び出します。
最上位の 走査可能 traversableを破棄するには、次を行います。
browsingContextを、traversableのアクティブな閲覧コンテキストとします。
traversableのセッション履歴 エントリー内のどの順序で?各 historyEntryについて次を行います。
documentを、historyEntryの文書とします。
documentが null でない場合、documentを指定して、文書および その子孫を破棄します。
browsingContextを削除します。
traversableをユーザーインターフェイスから削除します(たとえば、タブ式ブラウザーで そのタブを閉じるか非表示にします)。
traversableをユーザーエージェントの 最上位の走査可能の集合から削除します。
traversableを使用して、WebDriver BiDi のナビゲーション可能破棄を 呼び出します。
ユーザーエージェントは、いつでも(通常はユーザーの要求に応じて) 最上位の走査可能を破棄できます。
最上位の 走査可能 traversableを確実に閉じるには、次を行います。
toUnloadを、traversableのアクティブな 文書の自身を含む子孫 ナビゲーション可能とします。
toUnloadについてアンロードが
キャンセルされたかどうかを検査した結果が
「continue」でない場合、戻ります。
traversableに次の セッション履歴 走査手順を付加します。
afterAllUnloadsを、traversableを破棄する アルゴリズム手順とします。
traversableのアクティブな文書、null、および afterAllUnloadsを指定して、文書および その子孫をアンロードします。
閉じると確実に閉じるを
分離することで、他の
仕様が閉じるを呼び出した際、
JavaScript コードがwindow.close()を
呼び出したことによって最上位の走査可能がすでに終了中である場合に、何もしないようにできます。
ナビゲーション可能には対象
名を指定できます。これは、特定の API(window.open()や、a要素のtarget属性など)が、
そのナビゲーション可能をナビゲーションの対象にできるようにする文字列です。
妥当なナビゲーション可能の対象名は、少なくとも 1 文字を持ち、ASCII タブまたは 改行と U+003C (<) の両方を含まず、かつ U+005F (_) で始まらない任意の文字列です。(U+005F (_) で始まる名前は、 特殊なキーワードのために予約されています。)
妥当なナビゲーション可能の
対象名または
キーワードは、妥当なナビゲーション可能の対象名であるか、
_blank、_self、_parent、または
_topのいずれかとASCII
大文字小文字不区別で一致する任意の文字列です。
これらの値は、ページがサンドボックス化されているかどうかに応じて異なる意味を持ちます。
次の(非規範的な)表に要約します。この表で「現在」とは、リンクまたはスクリプトが存在する
ナビゲーション可能を意味し、「親」とは、
リンクまたはスクリプトが存在するナビゲーション可能の親を意味します。
「最上位」とは、リンクまたはスクリプトが存在するナビゲーション可能の最上位の走査可能を意味し、
「新規」とは、親が null である新しい走査可能なナビゲーション可能を意味します(これは、
さまざまなユーザー設定およびユーザーエージェントの方針に従い、補助閲覧
コンテキストを使用する場合があります)。「なし」とは何も起こらないことを意味し、
「新規の可能性あり」とは、allow-popups
キーワードもsandbox属性に指定されている
場合(またはユーザーがサンドボックス化を上書きした場合)は「新規」と同じであり、
それ以外の場合は「なし」と同じであることを意味します。
| キーワード | 通常の効果 | 次を持つiframe内での効果...
|
|
|---|---|---|---|
sandbox=""
|
sandbox="allow-top-navigation"
|
||
| リンクおよびフォーム送信で何も指定されていない | 現在 | 現在 | 現在 |
| 空文字列 | 現在 | 現在 | 現在 |
_blank
|
新規 | 新規の可能性あり | 新規の可能性あり |
_self
|
現在 | 現在 | 現在 |
親が存在しない場合の_parent
|
現在 | 現在 | 現在 |
親が最上位でもある場合の_parent
|
親/最上位 | なし | 親/最上位 |
親が存在し、それが最上位でない場合の_parent
|
親 | なし | なし |
最上位が現在である場合の_top
|
現在 | 現在 | 現在 |
最上位が現在でない場合の_top
|
最上位 | なし | 最上位 |
| 存在しない名前 | 新規 | 新規の可能性あり | 新規の可能性あり |
| 存在し、子孫である名前 | 指定された子孫 | 指定された子孫 | 指定された子孫 |
| 存在し、現在である名前 | 現在 | 現在 | 現在 |
| 存在し、最上位である祖先の名前 | 指定された祖先 | なし | 指定された祖先/最上位 |
| 存在し、最上位でない祖先の名前 | 指定された祖先 | なし | なし |
| 共通の最上位を持つ、存在するその他の名前 | 指定されたもの | なし | なし |
| 異なる最上位に存在する名前で、相知であり、かつ1 つの許可されたサンドボックス化ナビゲーターである場合 | 指定されたもの | 指定されたもの | 指定されたもの |
| 異なる最上位に存在する名前で、相知ではあるが、1 つの許可されたサンドボックス化ナビゲーターでない場合 | 指定されたもの | なし | なし |
| 異なる最上位に存在する名前で、相知でない場合 | 新規 | 新規の可能性あり | 新規の可能性あり |
サンドボックス化された閲覧コンテキストに対する制限の大部分は、 以下に示すナビゲーション可能を選択する 規則ではなく、たとえばナビゲーションアルゴリズムなどの 他のアルゴリズムによって適用されます。
文字列nameおよびナビゲーション可能 currentNavigableを指定して、対象名によってナビゲーション可能を検索するには、次を行います。
currentDocumentを、currentNavigableのアクティブな文書とします。
sourceSnapshotParamsを、currentDocumentを指定してソーススナップショット パラメーターをスナップショット化した結果とします。
subtreesToSearchを、次のいずれかから実装定義で選択したものとします。
« currentNavigableの走査可能な ナビゲーション可能, currentNavigable »
currentDocumentの自身を含む祖先ナビゲーション可能
Issue #10848は、 相互運用性を実現するため、この 2 つの可能性のいずれかに決定することを追跡しています。
subtreesToSearchの各subtreeToSearchについて、逆順に次を行います。
documentToSearchを、subtreeToSearchのアクティブな文書とします。
documentToSearchの自身を含む 子孫ナビゲーション可能の各navigableについて次を行います。
currentNavigableが、sourceSnapshotParamsを指定した navigableへのナビゲーションをサンドボックス化によって許可されていない場合、 任意で続行します。
Issue #10849は、 相互運用性を実現するため、この検査を必須にすることを追跡しています。
navigableの対象 名が nameである場合、navigableを返します。
currentTopLevelBrowsingContextを、currentNavigableのアクティブな閲覧コンテキストの最上位閲覧 コンテキストとします。
groupを、currentTopLevelBrowsingContextのグループとします。
groupの閲覧 コンテキスト集合の各topLevelBrowsingContextについて、実装定義の 順序で次を行います(ユーザーエージェントは、最後に開かれたもの、 最後にフォーカスされたもの、またはより密接に関連するものなど、一貫した順序を選択するべきです)。
Issue #10850は、 相互運用性を実現するため、特定の順序を選択することを追跡しています。
currentTopLevelBrowsingContextがtopLevelBrowsingContextである場合、 続行します。
documentToSearchを、topLevelBrowsingContextのアクティブな 文書とします。
documentToSearchの自身を含む 子孫ナビゲーション可能の各navigableについて次を行います。
currentNavigableのアクティブな 閲覧コンテキストが navigableのアクティブな 閲覧コンテキストと相知でない場合、続行します。
currentNavigableが、sourceSnapshotParamsを指定した navigableへのナビゲーションをサンドボックス化によって許可されていない場合、 任意で続行します。
Issue #10849は、 相互運用性を実現するため、この検査を必須にすることを追跡しています。
navigableの対象 名が nameである場合、navigableを返します。
null を返します。
文字列name、 ナビゲーション可能 currentNavigable、および真偽値noopenerを指定したナビゲーション可能を 選択する規則は、次のとおりです。
chosenを null とします。
windowTypeを「existing or none」とします。
sandboxingFlagSetを、currentNavigableのアクティブな文書のアクティブなサンドボックス化フラグ集合とします。
nameが空文字列であるか、「_self」とASCII
大文字小文字不区別で一致する場合、
chosenを
currentNavigableに設定します。
それ以外で、nameが「_parent」とASCII
大文字小文字不区別で一致する場合、存在すればchosenを
currentNavigableの親に設定し、
存在しなければcurrentNavigableに設定します。
それ以外で、nameが「_top」とASCII
大文字小文字不区別で一致する場合、chosenをcurrentNavigableの
走査可能なナビゲーション可能に設定します。
それ以外で、nameが「_blank」とASCII
大文字小文字不区別で一致せず、かつnoopenerが false である場合、
chosenを、nameおよびcurrentNavigableを指定して対象名によってナビゲーション可能を
検索した結果に設定します。
chosenが null である場合、新しい最上位の走査可能が要求されており、 何が起こるかはユーザーエージェントの構成および能力に依存します。次の一覧で最初に該当する選択肢について 示された規則によって決定されます。
ユーザーエージェントは、ポップアップがブロックされたことをユーザーに通知しても構いません。
ユーザーエージェントは、ポップアップがブロックされたことを開発者コンソールに報告しても構いません。
currentNavigableのアクティブなウィンドウのユーザーアクティブ化を消費します。
windowTypeを「new and unrestricted」に設定します。
currentDocumentを、currentNavigableのアクティブな文書とします。
currentDocumentのオープナー
ポリシーの値が
「same-origin」または
「same-origin-plus-COEP」
であり、かつ
currentDocumentのオリジンが、
currentDocumentの関連する設定
オブジェクトの最上位オリジンと
同一オリジンでない場合、次を行います。
noopenerを true に設定します。
nameを「_blank」に設定します。
windowTypeを「new with no opener」に設定します。
オープナーポリシーが存在する場合、 最上位閲覧コンテキストのアクティブな文書とオリジン間である入れ子の文書は、常に noopenerを true に設定します。
targetNameを空文字列とします。
nameが「_blank」とASCII 大文字小文字不区別で一致しない場合、
targetNameをnameに設定します。
noopenerが true である場合、chosenを、 null、targetName、およびcurrentNavigableを指定して新しい最上位の 走査可能を作成した結果に設定します。
それ以外の場合は、次を行います。
chosenを、currentNavigableのアクティブな 閲覧コンテキスト、targetName、およびcurrentNavigableを指定して新しい最上位の 走査可能を作成した結果に設定します。
sandboxingFlagSetのサンドボックス化されたナビゲーション 閲覧コンテキスト フラグが設定されている場合、chosenのアクティブな閲覧 コンテキストの1 つの許可されたサンドボックス化 ナビゲーターを、 currentNavigableのアクティブな 閲覧 コンテキストに設定します。
sandboxingFlagSetのサンドボックスが 補助閲覧 コンテキストへ伝播するフラグが設定されている場合、sandboxingFlagSetに設定されているすべての フラグを、chosenのアクティブな 閲覧コンテキストの ポップアップ サンドボックス化フラグ集合にも設定しなければなりません。
chosenのウェブコンテンツによって作成されたを true に設定します。
新しく作成されたナビゲーション可能
chosenが直ちにナビゲートされる場合、そのナビゲーションは
「replace」
ナビゲーションとして実行されます。
chosenをcurrentNavigableに設定します。
何もしません。
ユーザーエージェントは、常にcurrentNavigableを選択するよう ユーザーがユーザーエージェントを構成できる手段を提供することが推奨されます。
chosenおよびwindowTypeを返します。
閲覧コンテキストは、一連の
文書をプログラム上で表現したものであり、
その複数が単一のナビゲーション可能内に存在できます。各閲覧
コンテキストには、対応するWindowProxy
オブジェクトと、次のものがあります。
オープナー閲覧コンテキスト。閲覧コンテキストまたは null であり、 初期値は null です。
作成時のオープナーオリジン。オリジンまたは null であり、初期値は null です。
真偽値ポップアップである。初期値は false です。
この仕様において、ポップアップであることによる
必須の影響は、関連する
BarPropオブジェクトの
visible取得子に対するものだけです。
ただし、ユーザーエージェントはユーザーインターフェイス上の考慮事項にも
これを使用することがあります。
真偽値補助である。初期値は false です。
初期 URL。URLまたは null であり、初期値は null です。
整数仮想閲覧コンテキストグループ ID。 初期値は 0 です。これはオープナーポリシーの 報告によって使用され、報告専用ポリシーが適用されていた場合に発生していたはずの 閲覧コンテキストグループの切り替えを追跡します。
閲覧コンテキストのアクティブなウィンドウは、そのWindowProxy
オブジェクトの[[Window]]内部
スロットの値です。閲覧コンテキストのアクティブな文書は、そのアクティブな
ウィンドウの
関連付けられたDocumentです。
閲覧コンテキストの最上位の走査可能は、そのアクティブな文書の ノードナビゲーション可能の最上位の走査可能です。
補助であるが true である閲覧コンテキストは、補助閲覧コンテキストと呼ばれます。補助閲覧コンテキストは常に最上位閲覧コンテキストです。
独立した補助であるという 概念が必要かどうかは不明です。 issue #5680では、オープナー閲覧コンテキストが null であるかどうかを使用することで、これを単純化できる可能性が示されています。
現代の仕様では、ほとんどの場合、
閲覧コンテキストの概念の使用を避けるべきです。ただし、
閲覧コンテキスト
グループの切り替えおよびエージェントクラスターの割り当ての微妙な点を
扱う場合は除きます。代わりに、
Documentおよびナビゲーション可能の概念の方が、通常はより適切です。
Documentの閲覧コンテキストは、閲覧コンテキストまたは null であり、
初期値は null です。
Documentが必ずしも
null でない閲覧コンテキストを持つとは限りません。特に、データ
マイニングツールは閲覧コンテキストを一度もインスタンス化しない可能性があります。createDocument()などの API を
使用して作成されたDocumentは、
null でない閲覧コンテキストを持つことはありません。また、
iframe要素のために最初に
作成され、その後文書から削除されたDocumentには、関連付けられた閲覧コンテキストがありません。その
閲覧コンテキストがnull に設定されたためです。
一般に、Documentオブジェクトが null でない閲覧コンテキストを持つ限り、Windowオブジェクトから
Documentオブジェクトへの対応は 1 対 1 です。
例外が 1 つあります。Windowは、同じ閲覧コンテキスト内で 2 番目のDocumentを提示するために再利用でき、
その場合、対応は 1 対 2 になります。これは、閲覧コンテキストが初期about:blankのDocumentから別の文書へナビゲートされる場合に発生し、これは置換によって行われます。
null またはDocument
オブジェクトcreator、null または要素embedder、および閲覧コンテキスト
グループ groupを指定して、新しい閲覧コンテキストおよび文書を作成するには、
browsingContextを、新しい閲覧コンテキストとします。
unsafeContextCreationTimeを、 安全でない共有現在時刻とします。
creatorOriginを null とします。
creatorBaseURLを null とします。
creatorが null でない場合、次を行います。
creatorOriginを、creatorのオリジンに設定します。
creatorBaseURLを、creatorの文書ベース URLに設定します。
browsingContextの仮想閲覧コンテキストグループ IDを、 creatorの閲覧コンテキストの最上位閲覧コンテキストの仮想閲覧コンテキストグループ IDに設定します。
sandboxFlagsを、browsingContextおよびembedderを指定して作成時の サンドボックス化 フラグを決定した結果とします。
originを、about:blank、
sandboxFlags、および
creatorOriginを指定してオリジンを
決定した結果とします。
permissionsPolicyを、embedderおよびoriginを指定して権限ポリシーを作成した結果とします。 [PERMISSIONSPOLICY]
agentを、origin、group、および false を指定して類似オリジンのウィンドウ エージェントを取得した結果とします。
realm execution contextを、agentおよび次のカスタマイズを指定して新しいレルムを作成した結果とします。
大域オブジェクトについては、新しいWindowオブジェクトを作成します。
大域thisバインディングについては、browsingContextの
WindowProxyオブジェクトを使用します。
topLevelCreationURLを、embedderが
null である場合はabout:blank、
それ以外の場合はembedderの関連する設定オブジェクトの最上位の
作成 URLとします。
topLevelOriginを、embedderが null である場合はorigin、 それ以外の場合はembedderの関連する設定オブジェクトの最上位 オリジンとします。
about:blank、
realm execution context、null、topLevelCreationURL、および
topLevelOriginを使用して、ウィンドウ環境
設定オブジェクトを設定します。
loadTimingInfoを、新しい文書読み込みタイミング情報とし、そのナビゲーション開始 時刻を、unsafeContextCreationTimeおよび新しい環境設定オブジェクトの オリジン間分離 能力を使用して時刻を粗くするを呼び出した結果に設定します。
documentを、次の値を持つ新しいDocumentとします。
html"text/html"quirks"about:blankであるCustomElementRegistry
オブジェクトiframeReferrerPolicyを、embedderを指定してiframe要素の
リファラーポリシーを決定した結果とします。
documentの内部祖先 オリジンオブジェクト リストを、documentおよびiframeReferrerPolicyを指定して内部祖先 オリジンオブジェクトリスト作成 手順を実行した結果に設定します。
documentの祖先 オリジンリストを、documentを指定して祖先オリジンリスト作成 手順を実行した結果に設定します。
creatorが null でない場合、次を行います。
documentのポリシー コンテナーを、 creatorのポリシー コンテナーの複製に設定します。
creatorのオリジンが、 creatorの関連する設定オブジェクトの 最上位オリジンと 同一オリジンである場合、 documentのオープナーポリシーを、creatorの閲覧コンテキストの 最上位 閲覧コンテキストのアクティブな 文書のオープナーポリシーに設定します。
表明:documentのURLと、documentの関連する設定オブジェクトの作成
URLは、
about:blankです。
documentを読み込み後タスクの準備完了としてマークします。
documentを指定して、html/head/bodyを
追加します。
documentをアクティブにします。
documentの読み込みを完全に 完了します。
browsingContextおよびdocumentを返します。
新しい最上位閲覧コンテキストおよび 文書を作成するには、次を行います。
groupおよびdocumentを、新しい 閲覧コンテキストグループおよび文書を作成した結果とします。
groupの閲覧コンテキスト集合[0]および documentを返します。
閲覧コンテキスト openerを指定して、新しい補助閲覧コンテキストおよび 文書を作成するには、
openerTopLevelBrowsingContextを、openerの最上位の走査可能のアクティブな閲覧 コンテキストとします。
groupを、openerTopLevelBrowsingContextのグループとします。
browsingContextおよびdocumentを、openerのアクティブな文書、null、およびgroupを使用して新しい 閲覧コンテキストおよび文書を作成した結果とします。
browsingContextの補助であるを true に設定します。
browsingContextをgroupに付加します。
browsingContextのオープナー閲覧コンテキストを openerに設定します。
browsingContextの仮想 閲覧コンテキストグループ IDを、openerTopLevelBrowsingContextの仮想閲覧コンテキストグループ IDに 設定します。
browsingContextの作成時のオープナー オリジンを、openerのアクティブな文書の オリジンに設定します。
browsingContextおよびdocumentを返します。
URL url、サンドボックス化 フラグ集合 sandboxFlags、および オリジンまたは null の sourceOriginを指定して、オリジンを決定するには、
sandboxFlagsにサンドボックス化されたオリジン閲覧 コンテキストフラグが設定されている場合、新しい不透明な オリジンを返します。
urlが null である場合、新しい不透明な オリジンを返します。
urlがabout:srcdocである場合、次を行います。
表明:sourceOriginは null ではありません。
sourceOriginを返します。
urlがabout:blankに一致し、
sourceOriginが null でない場合、sourceOriginを返します。
urlのオリジンを返します。
sourceOriginを返す場合は、同じ基礎となるオリジンを持つことになる 2 つの
Documentが生成されます。これは、
document.domainが
両方に影響することを意味します。
閲覧コンテキスト potentialDescendantは、次のアルゴリズムが true を返す場合、閲覧コンテキスト potentialAncestorの祖先であるといいます。
最上位閲覧コンテキストは、その アクティブな文書のノードナビゲーション可能が走査可能な ナビゲーション可能である閲覧コンテキストです。
最上位の走査可能であることは必須ではありません。
閲覧コンテキスト startの最上位閲覧コンテキストは、次のアルゴリズムの結果です。
navigableを、startのアクティブな文書のノード ナビゲーション可能とします。
navigableのアクティブな閲覧 コンテキストを返します。
閲覧コンテキスト Aは、次の アルゴリズムが true を返す場合、2 番目の閲覧コンテキスト Bと 相知であるといいます。
Aの最上位閲覧コンテキストが Bである場合、true を返します。
Bが補助閲覧コンテキストであり、Aが Bのオープナー閲覧 コンテキストと相知である場合、 true を返します。
Bの祖先閲覧コンテキストのうち、そのアクティブな 文書が、Aのアクティブな文書と同じオリジンを持つものが存在する場合、true を返します。
これには、AがBの祖先閲覧 コンテキストである場合も含まれます。
false を返します。
最上位 閲覧コンテキストには、関連付けられたグループがあります(null または閲覧コンテキスト グループ)。初期値は null です。
ユーザーエージェントは、閲覧コンテキストグループ集合を保持します (閲覧コンテキストグループの集合)。
閲覧コンテキストグループは、閲覧 コンテキスト集合を保持します(最上位 閲覧コンテキストの集合)。
最上位閲覧コンテキストは、 グループが作成されるとき、 グループに追加されます。その後 グループに追加されるすべての最上位 閲覧コンテキストは、補助 閲覧コンテキストになります。
閲覧コンテキスト グループには、関連付けられたエージェントクラスターマップがあります (エージェントクラスター キーからエージェントクラスターへの弱いマップ)。ユーザーエージェントは、何もアクセスできなくなったと判断した時点で エージェントクラスターを収集する責任を負います。
閲覧コンテキスト グループには、関連付けられた履歴エージェントクラスターキー マップがあります。これは、オリジンからエージェントクラスターキーへのマップです。この マップは、特定のオリジンについて以前に使用されたエージェントクラスターキーを記録することで、オリジンキー付き エージェントクラスター機能の一貫性を確保するために使用されます。
履歴エージェントクラスターキーマップは、 閲覧コンテキストグループの存続期間を通じてエントリーが増えるだけです。
閲覧コンテキスト
グループには、オリジン間分離モードがあります。これはオリジン間
分離モードです。初期値は「none」です。
オリジン間分離モードは、次の 3 つの値のいずれかです。「none」、「logical」、または「concrete」。
「logical」と「concrete」は
類似しています。どちらも、次の条件を満たす閲覧コンテキスト
グループに使用されます。
すべての最上位Documentが
`Cross-Origin-Opener-Policy: same-origin`を持ち、かつ
すべてのDocumentが、その値がオリジン間
分離と互換性がある
`Cross-Origin-Embedder-Policy`
ヘッダーを持ちます。
一部のプラットフォームでは、オリジン間
分離
能力によって制限される API への安全なアクセスを許可するために必要なセキュリティ特性を提供することは困難です。
そのため、その能力へのアクセスを許可できるのは「concrete」だけです。
「logical」は、この能力をサポートしない
プラットフォームで使用されます。この場合もオリジン間分離によるさまざまな制限は適用されますが、
能力は付与されません。
新しい 閲覧コンテキストグループおよび文書を作成するには、次を行います。
groupを、新しい閲覧コンテキストグループとします。
groupをユーザーエージェントの閲覧 コンテキストグループ集合に付加します。
browsingContextおよびdocumentを、null、null、およびgroupを使用して新しい 閲覧コンテキストおよび文書を作成した結果とします。
browsingContextをgroupに付加します。
groupおよびdocumentを返します。
最上位閲覧コンテキスト browsingContextを閲覧コンテキストグループ groupに付加するには、次を行います。
browsingContextをgroupの 閲覧コンテキスト 集合に付加します。
browsingContextのグループを groupに設定します。
最上位閲覧コンテキスト browsingContextを削除するには、次を行います。
groupを、browsingContextのグループとします。
browsingContextのグループを null に設定します。
browsingContextを groupの閲覧コンテキスト集合から削除します。
groupの閲覧コンテキスト集合が空である場合、groupを ユーザーエージェントの閲覧コンテキストグループ集合から削除します。
付加および削除は、閲覧
コンテキストグループの存続期間を定義するのに役立つ基本操作です。これらは、
Documentおよび閲覧コンテキストに対する、より高水準の作成および破棄操作によって呼び出されます。
その閲覧コンテキストが特定の閲覧
コンテキストと等しいDocumentオブジェクトが存在せず
(すなわち、そのようなDocumentがすべて破棄されており)、かつその閲覧コンテキストのWindowProxyが
ガベージコレクションの対象となる場合、その閲覧コンテキストに再びアクセスされることはありません。
それが最上位閲覧コンテキストである場合、この時点で
ユーザーエージェントはそれを削除しなければなりません。
Document
dは、dがナビゲーション可能
navigableのアクティブな
文書であり、かつ
navigableが最上位の
走査可能であるか、navigableのコンテナー
文書が完全にアクティブである場合、完全に
アクティブであるといいます。
子
ナビゲーション可能は要素に関連付けられているため、常にその親ナビゲーション可能内の特定のDocument、すなわち自身のコンテナー文書に結び付けられています。ユーザーエージェントは、そのコンテナー文書自体が完全に
アクティブでない子ナビゲーション可能との対話をユーザーに許可してはなりません。
次の例は、Documentが、そのノードナビゲーション可能のアクティブな文書でありながら、完全にアクティブではない状態になり得る仕組みを示します。ここでは、
a.htmlがブラウザーウィンドウに読み込まれ、
b-1.htmlは示されているように最初はiframe内に読み込まれ、
b-2.htmlおよびc.htmlは省略されています(単なる空の文書で構いません)。
<!-- a.html -->
<!DOCTYPE html>
< html lang = "en" >
< title > Navigable A</ title >
< iframe src = "b-1.html" ></ iframe >
< button onclick = "frames[0].location.href = 'b-2.html'" > Click me</ button >
<!-- b-1.html -->
<!DOCTYPE html>
< html lang = "en" >
< title > Navigable B</ title >
< iframe src = "c.html" ></ iframe > この時点では、a.html、b-1.html、およびc.htmlによる文書はすべて、
それぞれのノードナビゲーション可能のアクティブな文書です。また、すべて完全にアクティブでもあります。
buttonをクリックし、
それによってb-2.htmlから新しいDocumentを
ナビゲーション可能 B に読み込んだ後、次の結果になります。
a.htmlのDocumentは、
ナビゲーション可能 A のアクティブな文書であり、かつ完全に
アクティブである状態を維持します。
b-1.htmlのDocumentは、現在はナビゲーション可能 B のアクティブな文書ではありません。
したがって、これも完全に
アクティブではありません。
新しいb-2.htmlのDocumentは、現在はナビゲーション可能 B のアクティブな文書であり、同時に完全に
アクティブでもあります。
c.htmlのDocumentは、依然として
ナビゲーション可能 C のアクティブな文書です。しかし、C のコンテナー文書は
b-1.htmlの
Documentであり、これ自体が完全にアクティブではないため、
c.htmlのDocumentも現在は完全に
アクティブではありません。
ドラゴンの口へようこそ。ナビゲーション、セッション履歴、およびその セッション履歴の走査は、この標準で最も複雑な部分の一部です。
基本的な概念は、それほど難しく見えないかもしれません。
ユーザーは、アクティブな文書を提示している ナビゲーション可能を見ています。 ユーザーは、それを別の URLへナビゲートします。
ブラウザーは指定された URL をネットワークから取得し、それを使用して、新しく作成された
Documentで新しいセッション履歴
エントリーを設定します。
ブラウザーは、ナビゲーション可能のアクティブなセッション 履歴エントリーを、新しく設定された エントリーに更新し、それによってユーザーに表示しているアクティブな 文書を更新します。
その後のある時点で、ユーザーは前のセッション履歴 エントリーへ戻るために、ブラウザーの 戻るボタンを押します。
ブラウザーは、そのセッション 履歴エントリーに格納されているURLを調べ、それを使用して再取得し、その エントリーの文書を設定します。
ブラウザーは再び、ナビゲーション可能のアクティブなセッション履歴エントリーを更新します。
ここでは、走査がナビゲーション(すなわち、格納された URL へのネットワーク取得)を 引き起こす可能性があることや、ナビゲーションが完了したときにユーザーが正しいものを 見ていることを保証するため、必然的にセッション履歴リストと連携する必要があることから、 絡み合った複雑さの一端が見えます。しかし、本当の問題は、さまざまな境界事例と 相互作用するウェブプラットフォーム機能にあります。
子ナビゲーション可能
(たとえば、
iframe内に
含まれるもの)もナビゲートおよび走査できますが、ユーザーは走査可能な
ナビゲーション可能全体(たとえば、ブラウザータブ)に対して 1 つの戻る/進むインターフェイスしか持たないため、
それらのナビゲーションは単一のセッション履歴リストへ
線形化する必要があります。
ユーザーはセッション履歴を 1 ステップより多く戻って走査できるため(たとえば、 戻るボタンを押し続けることで)、子ナビゲーション可能が関係していると、複数のナビゲーション可能を同時に走査することがあります。 これは関係するすべてのナビゲーション可能の間で同期する必要があり、複数のイベント ループ、さらにはエージェントクラスターが 関係する可能性があります。
ナビゲーション中、サーバーは 204 または 205 ステータスコード、あるいは `Content-Disposition: attachment`
ヘッダーで応答することがあります。これにより
ナビゲーションは中止され、ナビゲーション可能は元のアクティブな
文書に留まります。(走査によって開始された
ナビゲーション中にこれが発生すると、事態はさらに悪化します。)
`Location`、
`Refresh`、`X-Frame-Options`、
および Content Security Policy 用のものなど、さまざまな他の HTTP ヘッダーが、
取得
処理、Document作成
処理、またはその両方に関与します。`Cross-Origin-Opener-Policy`
ヘッダーは、閲覧
コンテキストの選択および作成処理にさえ関与します。
一部のナビゲーション(すなわち、フラグメントナビゲーションおよびシングルページアプリのナビゲーション)は同期的です。これは、 JavaScript コードがナビゲーションの結果を即座に観測することを期待していることを意味します。次に、これを ツリー内の他のすべてのナビゲーション可能が見るセッション履歴の表示と同期する必要がありますが、 これは競合状態の影響を受ける可能性があり、 セッション履歴に対する競合する表示を解決する必要が生じます。
プラットフォームには、javascript:
URL、srcdoc
iframe、
およびbeforeunload
イベントなど、特別扱いが必要なさまざまな興味深いナビゲーション関連機能が蓄積されています。
以下では、これらの複雑さをラベル付きの節およびアルゴリズムへ適切に分離し、可能な場合には 適切な導入説明を与えることで、読者を案内しようと試みています。それでも、ナビゲーションと セッション履歴を真に理解したい場合は、通常の助言が 非常に役立ちます。
ステップ。非負整数または「pending」であり、初期値は
「pending」です。
URL。URLです。
文書状態。文書 状態です。
従来の履歴 API 状態。直列化された 状態であり、初期値は StructuredSerializeForStorage(null) です。
ナビゲーション API 状態。直列化された状態であり、初期値は StructuredSerializeForStorage(undefined) です。
ナビゲーション API キー。文字列であり、 初期値はランダムな UUID を生成した結果に設定されます。
ナビゲーション API ID。文字列であり、初期値は ランダムな UUID を生成した結果に設定されます。
スクロール復元モード。スクロール
復元モードであり、初期値は「auto」です。
スクロール位置データ。文書の復元可能な スクロール可能領域のスクロール位置 データです。
永続化されたユーザー状態。 実装定義であり、初期値は null です。
たとえば、一部のユーザーエージェントはフォーム コントロールの値を永続化したい場合があります。
フォームコントロールの値を永続化するユーザーエージェントは、その方向性
(要素のdir
属性の値)も永続化することが推奨されます。これにより、ユーザーが明示的な既定値ではない
方向性を使用して最初に値を入力した場合に、履歴走査後に値が誤って表示されることを防ぎます。
セッション履歴 エントリーの文書を取得するには、その文書状態の文書を返します。
直列化された状態は、ユーザーインターフェイス状態を表す オブジェクトを(StructuredSerializeForStorageを介して) 直列化したものです。著者によって提供されたユーザーインターフェイス状態を表すオブジェクト、または 直列化された状態を(StructuredDeserializeを介して) 逆直列化することで作成されるオブジェクトを、非公式に「状態オブジェクト」と呼ぶことがあります。
ページは、セッション履歴へ直列化された状態を追加できます。ユーザー (またはスクリプト)が履歴内を戻ると、これらは逆直列化され、スクリプトへ返されます。これにより、著者は 1 ページアプリケーションでも「ナビゲーション」の比喩を使用できます。
直列化された状態は、
主に 2 つの目的で使用することが意図されています。第 1 に、単純な場合に著者が解析を行う必要がないよう、
事前に解析された状態の記述をURLに格納することです
(ただし、ユーザー間で受け渡されるURLを処理するには依然として解析が必要なので、これは小さな最適化にすぎません)。
第 2 に、現在のDocumentインスタンスにのみ適用され、
新しいDocumentが開かれた場合には
再構築する必要があるため URL には格納しないような状態を、著者が格納できるようにすることです。
後者の例としては、ポップアップのdivがアニメーションを
開始した正確な座標を追跡し、ユーザーが戻った場合に同じ位置へ
アニメーションできるようにすることが挙げられます。あるいは、URL内の情報に基づいてサーバーから取得されるデータの
キャッシュへのポインターを保持するために使用することで、戻る/進む際に情報を再び取得する必要が
なくなるようにすることもできます。
スクロール復元モードは、エントリーへ走査するときに、ユーザーエージェントが 永続化されたスクロール位置(存在する場合)を復元するべきかどうかを示します。 スクロール復元モードは、次のいずれかです。
auto"manual"文書状態は、Documentをどのように提示し、必要に応じて
再作成するかに関する状態を、セッション履歴エントリー内に保持します。次のものがあります。
文書。Documentまたは null であり、初期値は null です。
履歴エントリーがアクティブである場合、その文書状態には
Documentがあります。しかし、
Documentが完全にアクティブでない場合、リソースを解放するために
破棄される可能性があります。そのような
場合、この文書項目は
null に設定されます。その後、ユーザー
エージェントがそのエントリーへ走査する必要が生じた場合、セッション履歴エントリーおよび文書状態内のURLとその他のデータを使用して、元のものに代わる
新しいDocumentを生成します。
Documentが破棄されていない場合、
履歴
走査中に再アクティブ化できます。ブラウザーがこのようなDocumentを格納するキャッシュは、
多くの場合、戻る/進む
キャッシュ、またはbfcache(あるいは「blazingly
fast」キャッシュ)と呼ばれます。
履歴ポリシーコンテナー。ポリシーコンテナーまたは null であり、初期値は null です。
要求
リファラー。「no-referrer」、「client」、
またはURLであり、
初期値は「client」です。
要求 リファラーポリシー。リファラーポリシーであり、初期値は既定の リファラーポリシーです。
要求リファラー ポリシーは、履歴ポリシーコンテナーのリファラー ポリシーとは異なります。前者はこの文書の 取得に使用され、後者はこの 文書による取得を制御します。
開始元オリジン。 オリジンまたは null であり、初期値は null です。
オリジン。オリジンまたは null であり、初期値は null です。
これは、「about:」スキームの
Documentのオリジンに設定するオリジンです。これらのDocumentは、走査中にネットワークへ
アクセスせずローカルで再構築されるため、その復元時にも使用されるので、ここに格納します。また、セッション履歴エントリーが再設定される前後の
オリジンを比較するためにも使用されます。オリジンが変化した場合、ナビゲーション可能の
対象名が消去されます。
about ベース URL。 URLまたは null であり、初期値は null です。
これは、「about:」スキームの
Documentについてのみ設定され、
それらのDocumentのフォールバックベース URLになります。
これは、開始元のDocumentの文書
ベース URLのスナップショットです。
リソース。文字列、 POST リソース、または null であり、初期値は null です。
文字列は HTML として扱われます。これはiframe
srcdoc文書のソースを格納するために使用されます。
真偽値再読み込み保留中。初期値は false です。
真偽値設定されたことがある。初期値は false です。
ナビゲーション可能の対象名文字列。初期値は空文字列です。
未復元 理由。未復元理由または null であり、初期値は null です。
ユーザーエージェントは、文書
状態の null でない文書を指定して、文書およびその子孫を破棄しても構いません。ただし、
Documentが完全にアクティブでない場合に限ります。
その制限を除き、この標準は、ユーザーエージェントが文書 状態に格納された文書をいつ破棄するべきか、またはキャッシュしたままにするべきかを 規定しません。
POST リソースには、次のものがあります。
要求本体。バイト列または失敗です。
これは並行にのみアクセスされるため、 メモリーへ格納する必要はありません。ただし、毎回同じバイト列を返さなければなりません。ディスク上のリソースが変更されたためにこれが 不可能な場合、またはリソースへアクセスできなくなった場合は、 これを失敗に設定しなければなりません。
要求
Content-Type。`application/x-www-form-urlencoded`、
`multipart/form-data`、
または`text/plain`です。
入れ子の履歴には、次のものがあります。
ID。一意な内部値です。
エントリー。セッション履歴エントリーのリストです。
これには後で、再読み込みをまたいで子ナビゲーション可能を識別する方法が含まれます。
セッション履歴内の連続する複数のエントリーは、同じ文書状態を共有できます。これは、最初のエントリーへ通常のナビゲーションによって到達し、次のエントリーが
history.pushState()によって
追加された場合に発生する可能性があります。または、フラグメントへのナビゲーションによって発生することもあります。
同じ文書 状態を共有するすべてのエントリー(したがって、特定の 1 つの文書の異なる状態にすぎないもの)は、 構造上連続しています。
Documentには、最新
エントリーがあります。これはセッション履歴
エントリーまたは
null です。
これは、特定の
Documentによって最後に表されたエントリーです。
1 つのDocumentは、時間の経過とともに多くのセッション履歴エントリーを表すことができます。これは、上で説明したように、
連続する多数のセッション履歴
エントリーが同じ文書
状態を共有できるためです。
単一の信頼できる情報源を維持するため、走査可能な ナビゲーション可能のセッション履歴エントリーに対するすべての変更は、 同期する必要があります。これは、セッション履歴がすべての子孫のナビゲーション可能、したがって複数のイベント ループの影響を受けるため、特に重要です。これを実現するため、セッション履歴 走査並列キュー構造を使用します。
セッション履歴走査 並列キューは、並列キューと非常によく似ています。これは、 順序付き集合であるアルゴリズム集合を持ちます。
セッション履歴 走査並列 キューのアルゴリズム 集合内の項目は、アルゴリズム手順、または同期ナビゲーション 手順のいずれかです。後者は、対象 ナビゲーション可能(ナビゲーション可能)が関係する特別な種類のアルゴリズム手順です。
アルゴリズム手順stepsを指定して、走査可能なナビゲーション可能 traversableへセッション履歴走査 手順を付加するには、stepsを traversableのセッション履歴 走査キューのアルゴリズム 集合に付加します。
アルゴリズム手順stepsを指定して、ナビゲーション可能 targetNavigableが関係するセッション履歴同期 ナビゲーション手順を付加するには、stepsを、対象 ナビゲーション可能targetNavigableを対象とする同期 ナビゲーション 手順として、走査可能なナビゲーション可能 traversableのセッション履歴走査 キューのアルゴリズム 集合に付加します。
新しい セッション履歴走査並列キューを開始するには、次を行います。
この節には、セッション履歴を操作するときにこの標準全体で実行する、さまざまな操作が 雑多にまとめられています。それらが何を行うかを把握する最善の方法は、 その呼び出し箇所を確認することです。
ナビゲーション可能 navigableの セッション履歴エントリーを取得するには、次を行います。
traversableを、navigableの走査可能なナビゲーション可能とします。
表明:これはtraversableのセッション履歴走査 キュー内で実行されています。
navigableがtraversableである場合、traversableのセッション履歴エントリーを返します。
traversableのセッション履歴エントリーの各 entryについて、entryの文書状態を docStatesに付加します。
docStatesの各 docStateについて次を行います。
表明:この手順には到達しません。
整数targetStepを指定して、ナビゲーション可能 navigableのナビゲーション API 用のセッション履歴 エントリーを取得するには、次を行います。
rawEntriesを、navigableについてセッション履歴 エントリーを取得した結果とします。
entriesForNavigationAPIを、新しい空のリストとします。
startingIndexを、rawEntries内で、targetStep以下の 最大のステップを持つセッション履歴エントリーの インデックスとします。
なぜtargetStep以下の最大のステップであるのかを 理解するには、この例を参照してください。
rawEntries[startingIndex]を entriesForNavigationAPIに付加します。
iをstartingIndex − 1 とします。
i > 0 の間、次を行います。
iをstartingIndex + 1 に設定します。
i < rawEntriesのサイズの間、次を行います。
entriesForNavigationAPIを返します。
走査可能な ナビゲーション可能 navigableの進むセッション履歴を消去するには、次を行います。
表明:これはnavigableのセッション履歴走査 キュー内で実行されています。
stepを、navigableの現在のセッション履歴 ステップとします。
entryListsを、順序付き集合 « navigableのセッション履歴エントリー » とします。
entryListsの各 entryListについて次を行います。
走査可能なナビゲーション可能 traversableの一部である使用済みのすべての履歴ステップを取得するには、 次を行います。
表明:これはtraversableのセッション履歴走査 キュー内で実行されています。
stepsを、非負整数の空の順序付き集合とします。
entryListsを、順序付き集合 « traversableのセッション履歴 エントリー » とします。
entryListsの各 entryListについて次を行います。
並べ替えた stepsを返します。
特定の操作により、ナビゲーション可能が 新しいリソースへナビゲートします。
たとえば、ハイパーリンクをたどること、
フォーム送信、および
window.open()メソッドとlocation.assign()
メソッドは、いずれもナビゲーションを引き起こす可能性があります。
ナビゲーション アルゴリズム自体へ進む前に、 そのアルゴリズムが使用する重要な構造をいくつか確立する必要があります。
ソーススナップショットパラメーター構造体は、ナビゲーションを開始する
Documentからデータを取得するために使用されます。
これはナビゲーションの開始時にスナップショット化され、
ナビゲーションの存続期間全体を通じて使用されます。次の項目を持ちます。
Documentまたは null の
sourceDocumentを指定して、ソーススナップショットパラメーターをスナップショット化するには、
次を行います。
sourceDocumentが null である場合、次の値を持つ新しいソーススナップショットパラメーターを 返します。
これは、ブラウザー UI によって開始されたナビゲーションの場合にのみ発生します。
次の値を持つ新しいソーススナップショットパラメーターを返します。
対象スナップショットパラメーター構造体は、ナビゲートされる ナビゲーション可能からデータを取得するために使用されます。ソーススナップショット パラメーターと同様に、ナビゲーションの開始時にスナップショット化され、ナビゲーションの存続期間全体を通じて使用されます。 次の項目を持ちます。
iframe要素リファラーポリシーナビゲーション可能 targetNavigableを指定して、対象スナップショットパラメーターをスナップショット化するには、 次の値を持つ新しい対象スナップショット パラメーターを返します。
iframe要素
リファラーポリシーiframe要素の
リファラーポリシーを決定した結果
ナビゲーション処理の多くは、新しい
Documentをどのように作成するかの決定に関係し、
これは最終的にDocument
オブジェクトを作成して初期化する
アルゴリズムで行われます。そのアルゴリズムへのパラメーターは、次の項目を持つナビゲーションパラメーター構造体を介して追跡されます。
Documentを受け入れるアルゴリズム
Document用に予約された環境Documentに使用するオリジン
Documentに使用するポリシーコンテナーDocumentに適用するサンドボックス化フラグ
集合iframe要素
リファラーポリシーDocumentに使用するオープナー
ポリシーDocument用のナビゲーションタイミングエントリーを作成するために使用されるNavigationTimingType
Documentのabout ベース URLを設定するために使用される
URLまたは null
Document用の閲覧コンテキストを取得するときに使用されるユーザーナビゲーション関与
ナビゲーション パラメーター構造体が作成されると、この標準はその項目を変更しません。それらは 他のアルゴリズムへ渡されるだけです。
ナビゲーション IDは、ナビゲーション中に生成される UUID 文字列です。これは WebDriver BiDi仕様と連携するため、および進行中の ナビゲーションを追跡するために使用されます。[WEBDRIVERBIDI]
Documentの作成後、関連する走査可能な
ナビゲーション可能のセッション履歴が更新されます。NavigationHistoryBehavior
列挙は、目的のセッション
履歴更新種別をナビゲートアルゴリズムに示すために使用されます。
次のいずれかです。
push"replace"auto"push」
または「replace」へ
変換されます。通常は「push」になりますが、
特定の状況では、代わりに「replace」になります。
履歴処理動作は、「push」
または「replace」
のいずれかであるNavigationHistoryBehavior、
すなわち、初期の「auto」
値から解決済みのものです。
URL urlおよび
Document
documentを指定したとき、次のいずれかが true である場合、ナビゲーションは置換でなければなりません。
urlのスキームが
「javascript」
である、または
documentの初期about:blankであるが true である。
常にではありませんが、多くの場合に「replace」
ナビゲーションを強制するその他の場合は、次のとおりです。
プラットフォームのさまざまな部分は、ユーザーがナビゲーションに関与しているかどうかを追跡します。ユーザーナビゲーション関与は、次のいずれかです。
browser UI"activation"none"特定の呼び出し箇所での便宜のため、Event
eventのユーザーナビゲーション
関与は、次のように定義されます。
ナビゲーション可能 navigableを
URL
urlへナビゲートするには、オプションのDocumentまたは null のsourceDocument(既定値は null)、オプションのPOST
リソース、文字列、または null のdocumentResource(既定値は null)、オプションの応答または null のresponse(既定値は null)、オプションの真偽値exceptionsEnabled(既定値は false)、オプションの
NavigationHistoryBehavior
historyHandling(既定値は「auto」)、
オプションの直列化された
状態または null のnavigationAPIState(既定値は null)、オプションのエントリーリストまたは
null のformDataEntryList(既定値は null)、オプションのリファラーポリシー
referrerPolicy(既定値は空
文字列)、オプションのユーザーナビゲーション関与userInvolvement(既定値は「none」)、オプションのElement
sourceElement(既定値は null)、オプションの
真偽値initialInsertion(既定値は
false)、および
オプションのナビゲーション API
メソッド追跡子または null のapiMethodTracker(既定値は null)を使用し、
次を行います。
cspNavigationTypeを、formDataEntryListが null でない場合は
「form-submission」、それ以外の場合は「other」とします。
sourceSnapshotParamsを、sourceDocumentを指定してソーススナップショット パラメーターをスナップショット化した結果とします。
initiatorOriginSnapshotを、新しい不透明なオリジンとします。
initiatorBaseURLSnapshotをabout:blankとします。
sourceDocumentが null である場合、次を行います。
表明:userInvolvementは
「browser UI」です。
urlのスキームが「javascript」
である場合、initiatorOriginSnapshotを
navigableのアクティブな
文書のオリジンに設定します。
それ以外の場合は、次を行います。
表明:userInvolvementは「browser UI」ではありません。
sourceDocumentのノード ナビゲーション可能が、sourceSnapshotParamsを指定したnavigableへのナビゲーションをサンドボックス化によって 許可されていない場合、次を行います。
exceptionsEnabledが true である場合、「SecurityError」DOMExceptionを
スローします。
戻ります。
initiatorOriginSnapshotをsourceDocumentのオリジンに設定します。
initiatorBaseURLSnapshotをsourceDocumentの文書 ベース URLに設定します。
navigationIdを、ランダムな UUID を生成した結果とします。 [WEBCRYPTO]
周囲のエージェントがnavigableのアクティブな文書の関連するエージェントと等しい場合、 これらの手順を続行します。それ以外の場合、navigableのアクティブな ウィンドウを指定して、ナビゲーションおよび走査タスク ソースに、これらの手順を続行する大域タスクをキューに入れます。
これは、これからnavigableの アクティブな文書の多数のプロパティを調べるためです。 これらは理論上、適切なイベントループ内でのみアクセス可能です。(ただし、無条件に タスクをキューに入れることは望みません。たとえば、同一イベントループのフラグメントナビゲーションは同期的に効果を生じる必要があるためです。)
別の実装戦略として、関連する情報をイベントループ間、または正規の「ブラウザー処理」内へ複製し、 タスクをキューに入れずに参照できるようにする方法があります。この方法は、対象イベントループ内で 関連するプロパティが変更されたものの、まだ複製されていない境界事例において、ここで規定するものとは 異なる結果を生じる可能性があります。このような競合する境界事例で、どの戦略がブラウザーの 動作と最も一致するかを判断するには、さらなるテストが必要です。
navigableのアクティブな
文書の
アンロードカウンターが 0 より大きい場合、
navigableおよび、IDが
navigationId、状態が
「canceled」、
URLが
urlであるWebDriver BiDi ナビゲーション状態を使用して、WebDriver BiDi ナビゲーション失敗を呼び出し、戻ります。
containerを、navigableのコンテナーとします。
containerがiframe要素であり、
containerを指定した要素を遅延読み込みするかどうかの手順が true を返す場合、
containerについて遅延読み込み要素の
交差監視を停止し、containerの遅延読み込み再開手順を null に設定します。
navigableのナビゲーションまたは
履歴更新の実行が許可されるかが
ブロックを返す場合、navigableおよび、IDが
navigationId、状態が
「canceled」、
URLが
urlであるWebDriver BiDi ナビゲーション状態を使用して、WebDriver BiDi ナビゲーション失敗を呼び出し、戻ります。
urlおよびnavigableのアクティブな文書を指定したとき、ナビゲーションが
置換でなければならない場合、
historyHandlingを「replace」に
設定します。
navigableの親が null でない場合、
navigableのloadイベントを遅延しているを
true に設定します。
targetSnapshotParamsを、navigableを指定して対象スナップショット パラメーターをスナップショット化した結果とします。
navigableおよび、IDが
navigationId、状態が
「pending」、
URLが
urlである新しい
WebDriver BiDi ナビゲーション状態を使用して、WebDriver BiDi ナビゲーション開始を呼び出します。
navigableの進行中の
ナビゲーションが「traversal」である場合、次を行います。
navigableおよび、IDが
navigationId、状態が「canceled」、
URLが
urlである新しい
WebDriver BiDi ナビゲーション状態を使用して、WebDriver BiDi ナビゲーション失敗を呼び出します。
戻ります。
navigableの進行中の ナビゲーションを設定して、 navigationIdとします。
ナビゲーション中の特定の時点では進行中の ナビゲーションが変更されると後続の作業が中止されるため、これは navigableの他の進行中のナビゲーションを中止する効果を持ちます。
urlのスキームが「javascript」
である場合、次を行います。
navigableのアクティブなウィンドウを指定して、ナビゲーションおよび走査タスク
ソースに、navigable、
url、historyHandling、sourceSnapshotParams、
initiatorOriginSnapshot、userInvolvement、
cspNavigationType、initialInsertion、および
navigationIdを指定してjavascript: URL へ
ナビゲートするための大域タスクをキューに入れます。
戻ります。
次のすべてが true である場合、次を行います。
userInvolvementが「browser
UI」でない。
navigableのアクティブな 文書のオリジンが sourceDocumentのオリジンと同一オリジンドメインである。
navigableのアクティブな
文書の初期
about:blankであるが false である。
その場合、次を行います。
navigationを、navigableのアクティブな ウィンドウのナビゲーション APIとします。
entryListForFiringを、documentResourceがPOST リソースである場合はformDataEntryList、それ以外の場合は null とします。
navigationAPIStateForFiringを、navigationAPIStateが null でない場合はnavigationAPIState、それ以外の場合は StructuredSerializeForStorage(undefined)とします。
continueを、navigationで、navigationTypeをhistoryHandling、
isSameDocumentを false、userInvolvementを
userInvolvement、sourceElementを
sourceElement、formDataEntryListを
entryListForFiring、destinationURLを
url、navigationAPIStateを
navigationAPIStateForFiring、およびapiMethodTrackerを
apiMethodTrackerに設定して、push/replace/reload
navigate
イベントを発火した結果とします。
continueが false である場合、戻ります。
userInvolvementが「browser UI」である
ナビゲーション、またはオリジンドメイン間の
sourceDocumentによって開始されたナビゲーションでも、先のフラグメントへ
ナビゲートする経路を通る場合は、navigateイベントを発火できます。
sourceDocumentがnavigableのコンテナー文書である場合、urlのオリジンを指定して、navigableのコンテナー用の遅延取得クォータを 予約します。
並行に、次の手順を実行します。
unloadPromptCanceledを、navigableのアクティブな 文書の自身を含む子孫ナビゲーション可能についてアンロードが キャンセルされたかどうかを検査した結果とします。
unloadPromptCanceledが「continue」でないか、
navigableの進行中のナビゲーションが
navigationIdではなくなった場合、次を行います。
navigableおよび、IDが
navigationId、状態が「canceled」、
URLが
urlである
新しいWebDriver BiDi ナビゲーション状態を使用して、WebDriver BiDi ナビゲーション失敗を呼び出します。
これらの手順を中止します。
navigableのアクティブなウィンドウを指定して、ナビゲーションおよび走査タスク ソースに、navigableのアクティブな 文書を指定して文書およびその子孫を中止するための大域タスクをキューに入れます。
urlがabout:blankに一致するか、
about:srcdocである場合、
次を行います。
documentStateのオリジンを initiatorOriginSnapshotに設定します。
documentStateのabout ベース URLをinitiatorBaseURLSnapshotに設定します。
historyEntryを、URLをurlに、文書状態を documentStateに設定した新しいセッション履歴エントリーとします。
navigationParamsを null とします。
responseが null でない場合、次を行います。
sourcePolicyContainerを、sourceDocumentが null でない場合は sourceDocumentのポリシーコンテナーの複製、それ以外の場合は null とします。
policyContainerを、responseのURL、 null、sourcePolicyContainer、navigableのコンテナー文書のポリシーコンテナー、および null を指定してナビゲーション パラメーターのポリシーコンテナーを決定した結果とします。
finalSandboxFlagsを、targetSnapshotParamsのサンドボックス化 フラグと、policyContainerのCSP リストのCSP 由来のサンドボックス化フラグとの和集合とします。
responseOriginを、responseのURL、 finalSandboxFlags、およびdocumentStateの開始元オリジンを指定してオリジンを決定した結果とします。
coopを、新しいオープナーポリシーとします。
coopEnforcementResultを、次の値を持つ新しいオープナーポリシー適用結果とします。
navigationParamsを、次の値を持つ新しいナビゲーションパラメーターに設定します。
iframe要素
リファラーポリシーiframe
要素リファラー
ポリシーnavigate」
historyEntryについて、navigable、「navigate」、
sourceSnapshotParams、
targetSnapshotParams、userInvolvement、navigationId、
navigationParams、cspNavigationTypeを指定し、allowPOSTを true、completionStepsを次の
手順に設定して、履歴エントリーの文書の
設定を試みます。
navigable、historyHandling、 userInvolvement、およびhistoryEntryを指定して文書間 ナビゲーションを完了するため、navigableの走査可能にセッション履歴 走査手順を付加します。
通常の文書間ナビゲーションの場合は、最初にセッション履歴エントリーの設定へ進み、
Documentを設定しますが、中止されないすべてのナビゲーションは
最終的に、以下のいずれかのアルゴリズムを呼び出すことになります。
ナビゲーション可能 navigable、履歴処理動作 historyHandling、 ユーザーナビゲーション関与 userInvolvement、およびセッション履歴 エントリー historyEntryを指定して、文書間ナビゲーションを完了するには、次を行います。
表明:これはnavigableの走査可能なナビゲーション可能のセッション履歴走査 キュー上で実行されています。
navigableのload
イベントを遅延しているを false に設定します。
historyEntryの文書が null である場合、 戻ります。
これは、たとえば、後続のナビゲーションによってナビゲーションがキャンセルされた場合や、204 No Content 応答などの結果として、履歴エントリーの 文書の設定を試みる処理が、最終的に文書を作成しなかったことを意味します。
次のすべてが true である場合、次を行います。
navigableの親が null である。
historyEntryの文書の閲覧 コンテキストが、オープナー閲覧コンテキストが null でない補助閲覧 コンテキストではない。
その場合、historyEntryの文書状態の ナビゲーション可能の対象名を 空 文字列に設定します。
entryToReplaceを、historyHandlingが「replace」
である場合はnavigableのアクティブなセッション履歴エントリー、
それ以外の場合は null とします。
traversableを、navigableの走査可能なナビゲーション可能とします。
targetStepを null とします。
targetEntriesを、navigableについてセッション履歴 エントリーを取得した結果とします。
entryToReplaceが null である場合、次を行います。
traversableの進む セッション履歴を消去します。
targetStepを、traversableの現在のセッション履歴 ステップ + 1 に設定します。
historyEntryのステップを targetStepに設定します。
historyEntryを targetEntriesに付加します。
それ以外の場合は、次を行います。
targetEntries内の entryToReplaceを historyEntryで置換します。
historyEntryの文書状態の オリジンが entryToReplaceの文書状態のオリジンと同一オリジンである場合、 historyEntryのナビゲーション API キーを entryToReplaceのナビゲーション API キーに設定します。
targetStepを、traversableの現在のセッション履歴 ステップに設定します。
historyHandlingおよびuserInvolvementを指定して、 traversableにtargetStepのpush/replace 履歴ステップを適用します。
javascript: URL
の特殊な場合javascript:
URL には、その仕様に関するさまざまな問題を記録するため、issue tracker 上に専用ラベルがあります。
ナビゲーション可能
targetNavigable、URL url、履歴
処理
動作 historyHandling、ソーススナップショットパラメーター
sourceSnapshotParams、オリジン initiatorOrigin、ユーザー
ナビゲーション関与 userInvolvement、文字列
cspNavigationType、真偽値initialInsertion、およびナビゲーション
ID navigationIdを指定して、javascript: URL
へナビゲートするには、次を行います。
targetNavigableの進行中のナビゲーションが navigationIdではなくなった場合、戻ります。
targetNavigableの進行中の ナビゲーションを設定して null とします。
initiatorOriginが targetNavigableのアクティブな 文書のオリジンと同一オリジンドメインでない場合、戻ります。
requestを、URLが urlであり、ポリシーコンテナーが sourceSnapshotParamsのソース ポリシーコンテナーである新しい要求とします。
これは、次の手順へ渡すためだけの合成要求です。 ネットワークへ送信されることはありません。
requestおよびcspNavigationTypeを指定したその種別の
ナビゲーション要求を Content Security
Policy によってブロックするべきかの結果が「Blocked」である場合、
戻ります。[CSP]
newDocumentを、targetNavigable、
url、initiatorOrigin、およびuserInvolvementを指定してjavascript:
URL を評価した結果とします。
newDocumentが null である場合、次を行います。
initialInsertionが true であり、targetNavigableのアクティブな文書の初期
about:blankであるが true である場合、targetNavigableのコンテナーを指定してiframe 読み込みイベント手順を実行します。
戻ります。
この場合、何らかの JavaScript コードは実行されましたが、新しい
Documentは作成されなかったため、
ナビゲーションは実行しません。
entryToReplaceを、targetNavigableのアクティブなセッション履歴エントリーとします。
oldDocStateを、entryToReplaceの文書状態とします。
documentStateを、次の値を持つ新しい文書状態とします。
historyEntryを、次の値を持つ新しいセッション履歴エントリーとします。
URLには、
url、すなわちナビゲートアルゴリズムが呼び出された実際のjavascript:
URL を使用しません。これは、javascript:
URL がセッション履歴に格納されることはなく、したがって
そこへ走査することもできないことを意味します。
targetNavigable、 historyHandling、userInvolvement、およびhistoryEntryを使用して文書間 ナビゲーションを完了するため、 targetNavigableの走査可能にセッション履歴 走査 手順を付加します。
ナビゲーション可能
targetNavigable、URL url、オリジン
newDocumentOrigin、およびユーザーナビゲーション関与
userInvolvementを指定して、javascript: URL
を評価するには、次を行います。
urlStringを、urlにURL 直列化器を実行した結果とします。
encodedScriptSourceを、urlStringから先頭の「javascript:」を削除した結果とします。
scriptSourceを、 encodedScriptSourceをパーセントデコードしたものをUTF-8 デコードした結果とします。
settingsを、targetNavigableのアクティブな文書の関連する 設定オブジェクトとします。
baseURLを、settingsのAPI ベース URLとします。
scriptを、scriptSource、settings、baseURL、および既定のスクリプト 取得オプションを指定してクラシックスクリプトを作成した結果とします。
evaluationStatusを、scriptのクラシックスクリプトを実行した結果とします。
resultを null とします。
evaluationStatusが正常完了であり、 evaluationStatus.[[Value]]が String である場合、resultを evaluationStatus.[[Value]]に設定します。
それ以外の場合は、null を返します。
responseを、次の値を持つ新しい応答とします。
Content-Type`,
`text/html;charset=utf-8`) »UTF-8 へのエンコードは、HTML パーサーが応答本体をデコードした後、対になっていないサロゲートが 往復変換されないことを意味します。
finalSandboxFlagsを、policyContainerのCSP リストのCSP 由来のサンドボックス化 フラグとします。
coopEnforcementResultを、次の値を持つ新しいオープナー ポリシー適用結果とします。
navigationParamsを、次の値を持つ新しいナビゲーションパラメーターとします。
Documentの
リファラーは null になりますが、これは正しいのでしょうか。iframe要素
リファラーポリシーiframe
要素リファラー
ポリシーnavigate"
navigationParamsを指定してHTML 文書を読み込む処理の結果を返します。
ナビゲーション可能
navigable、URL url、履歴処理動作
historyHandling、ユーザーナビゲーション関与 userInvolvement、
Elementまたは
null の
sourceElement、直列化された
状態または null の
navigationAPIState、およびナビゲーション
ID navigationIdを指定して、フラグメントへナビゲートするには、次を行います。
navigationを、navigableのアクティブな ウィンドウのナビゲーション APIとします。
destinationNavigationAPIStateを、navigableのアクティブなセッション履歴エントリーのナビゲーション API 状態とします。
navigationAPIStateが null でない場合、 destinationNavigationAPIStateをnavigationAPIStateに設定します。
continueを、
navigationで、navigationTypeを
historyHandling、isSameDocumentを
true、userInvolvementを
userInvolvement、sourceElementを
sourceElement、destinationURLを
url、およびnavigationAPIStateを
destinationNavigationAPIStateに設定して、push/replace/reload
navigateイベントを発火した結果とします。
continueが false である場合、次を行います。
navigationの進行中のnavigate
イベントが null でない場合、navigableの進行中のナビゲーションを設定して
navigationIdとします。
これにより、傍受されたハッシュナビゲーションを、ブラウザー UI またはwindow.stop()によってキャンセルできます。
戻ります。
historyEntryを、次の値を持つ新しいセッション履歴エントリーとします。
navigation.navigate()を使用して
実行されるナビゲーションでは、state
オプションによって指定された値が、新しいナビゲーション API 状態に使用されます。(そのオプションに
値が指定されていない場合は、undefined の直列化に設定されます。)ユーザーによって開始されたものを含むその他の
フラグメントナビゲーションでは、ナビゲーション
API 状態は前の
エントリーから引き継がれます。
従来の 履歴 API 状態は 引き継がれません。
entryToReplaceを、historyHandlingが「replace」
である場合はnavigableのアクティブなセッション履歴エントリー、
それ以外の場合は null とします。
scriptHistoryIndexを、historyのインデックスとします。
scriptHistoryLengthを、historyの長さとします。
historyHandlingが「push」
である場合、次を行います。
historyの状態を null に設定します。
scriptHistoryIndexを 1 増加させます。
scriptHistoryLengthをscriptHistoryIndex + 1 に設定します。
navigableのアクティブなセッション履歴 エントリーをhistoryEntryに設定します。
navigableの アクティブな文書、historyEntry、 true、 scriptHistoryIndex、scriptHistoryLength、および historyHandlingを指定して、履歴ステップの 適用用に文書を更新します。
このアルゴリズムは、1 回のフラグメントナビゲーションの結果として 2 回呼び出されます。1 回目は
同期的に呼び出され、最善推定値scriptHistoryIndexおよび
scriptHistoryLengthが設定され、history.stateが
null に設定され、さまざまなイベントが発火されます。2 回目は非同期的に呼び出され、インデックスと長さの最終値が
設定され、history.stateは
変更されず、イベントも発火されません。
navigableのアクティブな文書を指定して、フラグメントへ スクロールします。
Documentが新しく、関連するIDがまだ解析されていないためにスクロールが失敗した場合は、
2 回目の非同期的な履歴ステップの
適用用に文書を更新する呼び出しが
スクロールを処理します。
traversableを、navigableの走査可能なナビゲーション可能とします。
navigableが関係する次のセッション履歴 同期ナビゲーション手順を付加して、 traversableとします。
traversable、 navigable、historyEntry、entryToReplace、 historyHandling、およびuserInvolvementを指定して、同一文書ナビゲーションを完了します。
navigableおよび、IDが
navigationId、URLが
url、状態が
「complete」である
新しいWebDriver BiDi ナビゲーション状態を使用して、WebDriver BiDi フラグメントナビゲート完了を呼び出します。
走査可能なナビゲーション可能 traversable、ナビゲーション可能 targetNavigable、セッション 履歴エントリー targetEntry、セッション履歴エントリーまたは null の entryToReplace、履歴処理動作 historyHandling、 およびユーザーナビゲーション 関与 userInvolvementを指定して、同一文書ナビゲーションを完了するには、次を行います。
これは、フラグメント ナビゲーションと、セッション履歴に対する唯一の同期的な更新であるURL および 履歴更新手順の両方によって使用されます。同期的であるため、これらのアルゴリズムは 最上位の走査可能のセッション 履歴走査キューの外部で実行されます。このため、最上位の 走査可能の現在のセッション履歴 ステップとの同期が外れるため、このアルゴリズムを使用して競合状態による衝突を解決します。
表明:これはtraversableのセッション履歴走査キュー上で実行されています。
targetNavigableのアクティブなセッション 履歴エントリーがtargetEntryでない場合、戻ります。
targetStepを null とします。
targetEntriesを、targetNavigableについてセッション履歴 エントリーを取得した結果とします。
entryToReplaceが null である場合、次を行います。
traversableの進むセッション履歴を消去します。
targetStepを、traversableの現在のセッション履歴ステップ + 1 に設定します。
targetEntryのステップを targetStepに設定します。
targetEntryを targetEntriesに付加します。
それ以外の場合は、次を行います。
targetEntries内のentryToReplaceを targetEntryで置換します。
targetStepを、traversableの現在のセッション履歴ステップに設定します。
historyHandlingおよびuserInvolvementを指定して、 traversableにtargetStepのpush/replace 履歴ステップを適用します。
これは、複数の同期ナビゲーション間の競合状態を解決するため、「replace」
ナビゲーションの場合でも実行されます。
非取得スキーム文書の 作成を試みる処理への入力は、非取得 スキームナビゲーションパラメーター構造体です。これは、 非取得 スキームのナビゲーションの場合に関連するパラメーターだけを保持する、ナビゲーションパラメーターの軽量版です。 次の項目を持ちます。
外部ソフトウェアパッケージの呼び出しを確認するための、ユーザー向けプロンプトで使用される可能性があるオリジン
これは、文書 状態の開始元オリジンとはわずかに異なります。 非取得スキームナビゲーション パラメーターの開始元オリジンは、 非取得 スキームURL で終了するリダイレクト連鎖内の最後の取得スキームURL までリダイレクトに従います。
Document用の
ナビゲーションタイミングエントリーを作成するために使用されるNavigationTimingType
(作成される場合)
Document用の閲覧コンテキストを取得するときに
使用されるユーザーナビゲーション関与
(作成される場合)
urlのスキームが外部で処理されるなどの理由により、 urlがnavigableに影響しない仕組みを使用して処理される場合、次を行います。
url、navigable、 navigationParamsの対象 スナップショットのサンドボックス化フラグ、navigationParamsのソーススナップショットが 一時的な アクティブ化を持つ、およびnavigationParamsの開始元 オリジンを指定して、外部 ソフトウェアへ引き渡します。
null を返します。
指定されたスキームが対応プロトコルの 1 つでないことを示すエラーメッセージや、指定されたスキーム用の登録済み ハンドラーをユーザーが選択できるようにするインラインプロンプトなど、何らかのインラインコンテンツを表示して urlを処理します。navigable、 navigationParamsのID、 navigationParamsのナビゲーション タイミング種別、およびnavigationParamsのユーザー関与を指定してインラインコンテンツを表示した結果を返します。
登録済みハンドラーが使用される場合、ナビゲートは 新しい URL を使用して呼び出されます。
URLまたは応答 resource、ナビゲーション可能 navigable、サンドボックス化フラグ集合 sandboxFlags、真偽値 hasTransientActivation、およびオリジン initiatorOriginを指定して、 ユーザーエージェントが外部ソフトウェアへ引き渡すには、 次を行うべきです。
次のすべてが true である場合、次を行います。
navigableが最上位の走査可能ではない。
sandboxFlagsにサンドボックス化された カスタムプロトコルナビゲーション閲覧 コンテキストフラグが設定されている。
sandboxFlagsにサンドボックス化された ユーザーアクティブ化を伴う最上位ナビゲーション閲覧 コンテキストフラグが設定されているか、hasTransientActivationが false である。
その場合、外部ソフトウェアパッケージを呼び出さずに戻ります。
iframe 内から外部ソフトウェアへ向かうナビゲーションは、新しいポップアップまたは新しい
最上位ナビゲーションとしてユーザーに認識される可能性があります。そのため、サンドボックス化された
iframeでは、
allow-popups、
allow-top-navigation、
allow-top-navigation-by-user-activation、
またはallow-top-navigation-to-custom-protocols
のいずれかが指定されている場合にのみ許可されます。
これが対象ソフトウェアを悪用しようとする試みである危険性を軽減しながら、resourceを適切に 引き渡します。たとえば、ユーザーエージェントは、initiatorOriginが対象の外部 ソフトウェアを呼び出すことを許可するかどうか、ユーザーに確認を求めることができます。特に、 hasTransientActivationが false である場合、ユーザーエージェントは事前にユーザーの確認を得ずに 外部ソフトウェアパッケージを呼び出すべきではありません。
たとえば、対象ソフトウェアの URL ハンドラーに脆弱性が存在し、悪意のあるページがユーザーをだましてリンクをクリックさせることで その脆弱性を悪用しようとする可能性があります。
いくつかのシナリオは、ナビゲーション処理の早い段階で介入し、処理全体を停止させることができる。 セッション履歴のトラバーサルによって、複数のナビゲーション可能が 同時にナビゲートしている場合、これは特に興味深いものとなり得る。
ナビゲーション可能 source は、 ソーススナップショットパラメーター sourceSnapshotParams が与えられたとき、次の手順が true を返す場合、2 つ目のナビゲーション可能 target をナビゲートすることがサンドボックス化によって許可されている:
source が target である場合、true を返す。
source が target の祖先である場合、true を返す。
target が source の祖先である場合:
target がトップレベルトラバーサブルでない場合、true を 返す。
sourceSnapshotParams の一時的なアクティベーションを持つが true であり、 sourceSnapshotParams のサンドボックス化 フラグのユーザー アクティベーションを伴うサンドボックス化されたトップレベルナビゲーション閲覧コンテキスト フラグが設定されている場合、false を返す。
sourceSnapshotParams の一時的なアクティベーションを持つが false であり、 sourceSnapshotParams のサンドボックス化 フラグのユーザー アクティベーションを伴わないサンドボックス化されたトップレベルナビゲーション閲覧コンテキスト フラグが設定されている場合、false を返す。
true を返す。
target がトップレベルトラバーサブルである場合:
source が target の許可された唯一のサンドボックス化ナビゲーターである場合、 true を返す。
sourceSnapshotParams のサンドボックス化フラグのサンドボックス化されたナビゲーション 閲覧コンテキストフラグが設定されている場合、false を返す。
true を返す。
sourceSnapshotParams のサンドボックス化フラグのサンドボックス化されたナビゲーション 閲覧コンテキストフラグが設定されている場合、false を返す。
true を返す。
リストであるナビゲーション可能
navigablesThatNeedBeforeUnload について、任意の
トラバーサブルナビゲーション可能
traversable、任意の整数
targetStep、および任意のユーザーナビゲーション関与
userInvolvementForNavigateEvent が与えられたとき、アンロードがキャンセルされたかを確認するには、次の手順を実行する。
この手順は「canceled-by-beforeunload」、
「canceled-by-navigate」、または
「continue」を返す。
documentsToFireBeforeunload を、 navigablesThatNeedBeforeUnload 内の各項目のアクティブ 文書とする。
unloadPromptShown を false とする。
finalStatus を「continue」とする。
traversable が与えられている場合:
表明:targetStep および userInvolvementForNavigateEvent が与えられている。
targetEntry を、traversable および targetStep が与えられたときに 対象の履歴エントリーを取得した結果とする。
targetEntry が traversable の現在のセッション履歴エントリーではなく、 targetEntry の文書状態のオリジンが、 traversable の現在のセッション履歴 エントリーの文書 状態のオリジンと同一である場合:
この場合、ここで traversable に対して navigate イベントを
発火する。これは、特定の
状況ではキャンセルされる可能性があるため、後で発生する他のトラバーサルの
navigate
イベントとは別に行う必要がある。
さらに、beforeunload
イベントを navigate
イベントより
前に発火させる必要があるため、該当する場合には、以下の
documentsToFireBeforeunload に対するループの一部としてではなく、ここで
traversable に対して beforeunload
を発火する必要がある。
eventsFired を false とする。
navigablesThatNeedBeforeUnload が traversable を 含む場合、needsBeforeunload を true とし、それ以外の場合は false とする。
needsBeforeunload が true の場合、traversable のアクティブ 文書を documentsToFireBeforeunload から削除する。
traversable のアクティブ ウィンドウが与えられたとき、ナビゲーションおよびトラバーサルタスク ソース上にグローバルタスクをキューに追加し、 次の手順を実行する:
needsBeforeunload が true の場合:
(unloadPromptShownForThisDocument,
unloadPromptCanceledByThisDocument) を、
traversable のアクティブ文書および
false が与えられたときに、beforeunload を
発火する手順を実行した結果とする。
unloadPromptShownForThisDocument が true の場合、 unloadPromptShown を true に設定する。
unloadPromptCanceledByThisDocument が true の場合、
finalStatus を「canceled-by-beforeunload」に設定する。
finalStatus が「canceled-by-beforeunload」である場合、
これらの手順を中止する。
navigation を、traversable のアクティブウィンドウのナビゲーション APIとする。
navigateEventResult を、targetEntry および
userInvolvementForNavigateEvent が与えられたときに、
navigation に対してトラバーサルの
navigate
イベントを発火した結果とする。
navigateEventResult が false の場合、finalStatus を
「canceled-by-navigate」に設定する。
eventsFired を true に設定する。
eventsFired が true になるまで待機する。
finalStatus が「continue」でない場合、
finalStatus を返す。
totalTasks を、documentsToFireBeforeunload のサイズとする。
completedTasks を 0 とする。
documentsToFireBeforeunload の各 document に対して、 document の関連するグローバルオブジェクトが与えられたとき、 ナビゲーションおよびトラバーサルタスクソース上に グローバルタスクをキューに追加して、次の手順を実行する:
(unloadPromptShownForThisDocument,
unloadPromptCanceledByThisDocument) を、document および
unloadPromptShown が与えられたときに、beforeunload を
発火する手順を実行した結果とする。
unloadPromptShownForThisDocument が true の場合、 unloadPromptShown を true に設定する。
unloadPromptCanceledByThisDocument が true の場合、
finalStatus を「canceled-by-beforeunload」に設定する。
completedTasks をインクリメントする。
completedTasks が totalTasks になるまで待機する。
finalStatus を返す。
Document document および
ブール値 unloadPromptShown が与えられたときの
beforeunload を発火する手順は、次のとおりである:
unloadPromptCanceled を false とする。
document のアンロード カウンターを 1 増加させる。
document の関連する エージェントのイベント ループの終了ネストレベルを 1 増加させる。
eventFiringResult を、document の関連するグローバルオブジェクトに対し、BeforeUnloadEvent を
使用し、cancelable
属性を true に初期化して、beforeunload
という名前のイベントを
発火した結果とする。
document の関連する エージェントのイベント ループの終了ネストレベルを 1 減少させる。
次のすべてが true である場合:
unloadPromptShown が false である;
document のアクティブなサンドボックス化フラグ集合に サンドボックス化されたモーダル フラグが設定されていない;
document の関連するグローバルオブジェクトがスティッキー アクティベーションを持つ;
eventFiringResult が false であるか、event の returnValue
属性が空文字列でない;かつ
アンロードプロンプトを表示しても、不快、欺瞞的、または無意味となる可能性が低い、
その場合:
unloadPromptShown を true に設定する。
userPromptHandler を、document の関連するグローバルオブジェクト、
「beforeunload」、および "" を使用して、WebDriver BiDi ユーザープロンプトを
開いた結果とする。
userPromptHandler が「dismiss」である場合、
unloadPromptCanceled を true に設定する。
userPromptHandler が「none」である場合:
文書をアンロードすることを希望するかユーザーに確認し、ユーザーの応答を待つ間、 一時停止する。
ユーザーに表示されるメッセージはカスタマイズできず、ユーザーエージェントによって
決定される。特に、returnValue
属性の実際の値は無視される。
ユーザーがページナビゲーションを確認しなかった場合、 unloadPromptCanceled を true に設定する。
document の
関連するグローバル
オブジェクト、「beforeunload」、および
unloadPromptCanceled が false の場合は true、それ以外の場合は false を使用して、
WebDriver BiDi ユーザープロンプトを閉じたを
呼び出す。
document のアンロード カウンターを 1 減少させる。
(unloadPromptShown, unloadPromptCanceled) を返す。
ナビゲーション可能 navigable の 進行中のナビゲーションを設定することによって、 newValue にするには:
navigable の進行中の ナビゲーションが newValue と等しい場合、戻る。
navigable が与えられたとき、ナビゲーションの中止について ナビゲーション API に通知する。
navigable の進行中のナビゲーションを newValue に設定する。
ナビゲーション可能
navigable を再読み込みするには、任意の
直列化された状態または null
navigationAPIState(既定値は null)、
任意のユーザーナビゲーション関与
userInvolvement(既定値は「none」)、および任意のナビゲーション API
メソッド
トラッカーまたは null apiMethodTracker
(既定値は null)が与えられたとき:
userInvolvement が「browser UI」でない場合:
navigation を、navigable のアクティブ ウィンドウのナビゲーション APIとする。
destinationNavigationAPIState を、navigable のアクティブなセッション 履歴エントリーのナビゲーション API 状態とする。
navigationAPIState が null でない場合、 destinationNavigationAPIState を navigationAPIState に設定する。
continue を、navigation において、
navigationType を「reload」に設定し、
isSameDocument を false に設定し、userInvolvement を
userInvolvement に設定し、destinationURL を
navigable のアクティブなセッション履歴
エントリーのURL に設定し、navigationAPIState を
destinationNavigationAPIState に設定し、apiMethodTracker を
apiMethodTracker に設定して、push/replace/reload
navigate
イベントを発火した結果とする。
continue が false の場合、戻る。
navigable のアクティブなセッション履歴 エントリーの文書 状態の再読み込み保留中を true に設定する。
traversable を、navigable のトラバーサブルナビゲーション可能とする。
次のセッション履歴トラバーサル手順を traversable に追加する:
userInvolvement が与えられたとき、traversable に再読み込み履歴ステップを適用する。
トラバーサブルナビゲーション可能
traversable、整数 delta、および任意の Document
sourceDocument が与えられたとき、
差分によって履歴をトラバースするには:
sourceSnapshotParams および initiatorToCheck を null とする。
userInvolvement を「browser
UI」とする。
sourceDocument が与えられている場合:
sourceSnapshotParams を、sourceDocument が与えられたときに ソーススナップショット パラメーターをスナップショットした結果に設定する。
initiatorToCheck を、sourceDocument のノード ナビゲーション可能に設定する。
userInvolvement を「none」に設定する。
次のセッション履歴トラバーサル手順を traversable に追加する:
allSteps を、traversable について使用されているすべての履歴ステップを 取得した結果とする。
currentStepIndex を、allSteps 内における traversable の現在のセッション履歴ステップの インデックスとする。
targetStepIndex を、currentStepIndex に delta を加えた値とする。
allSteps[targetStepIndex] が存在しない場合、これらの手順を中止する。
sourceSnapshotParams、initiatorToCheck、および userInvolvement が与えられたとき、 allSteps[targetStepIndex] を traversable にトラバース履歴ステップとして適用する。
ナビゲートアルゴリズムとは別に、セッション
履歴エントリーは、もう 1 つの仕組みであるURL および
履歴更新手順を介してプッシュまたは置換できる。これらの手順を呼び出すものとして最もよく知られているのは、history.replaceState()
および history.pushState()
API であるが、標準のさまざまな他の部分でもアクティブな
履歴エントリーを更新する必要があり、そのためにこれらの手順が使用される。
Document
document、URL newURL、任意の直列化された
状態または null serializedData(既定値は
null)、および任意の履歴処理動作
historyHandling(既定値は「replace」)が与えられたときの
URL および履歴更新手順は、次のとおりである:
navigable を、document のノードナビゲーション可能とする。
activeEntry を、navigable のアクティブなセッション履歴エントリーとする。
newEntry を、次の値を持つ新しいセッション履歴エントリーとする:
document の初期
about:blank であるが true の場合、
historyHandling を「replace」に設定する。
これは、初期
about:blank
Document に対する pushState() が、replaceState()
の呼び出しとして動作することを意味する。
historyHandling が「replace」である場合、
entryToReplace を activeEntry とし、それ以外の場合は null とする。
historyHandling が「push」である場合:
これらは、即時の同期アクセスのための一時的な最善推定値である。
serializedData が null でない場合、document および newEntry が与えられたときに、履歴オブジェクトの 状態を復元する。
document および newURL が与えられたとき、URL を設定する。
これはナビゲーションでも履歴トラバーサルでもないため、hashchange イベントは発火されない。
document の最新のエントリーを newEntry に設定する。
navigable のアクティブなセッション履歴 エントリーを newEntry に設定する。
document の関連するグローバルオブジェクトのナビゲーション API、 newEntry、および historyHandling が与えられたとき、同一文書 ナビゲーション用のナビゲーション API エントリーを更新する。
traversable を、navigable のトラバーサブルナビゲーション可能とする。
navigable が関与する、次のセッション履歴 同期ナビゲーション手順を traversable に追加する:
traversable、navigable、newEntry、
entryToReplace、historyHandling、および「none」が与えられたとき、
同一文書ナビゲーションを
完了する。
navigable を使用して、WebDriver BiDi 履歴更新を呼び出す。
フラグメント
ナビゲーションと
URL および履歴
更新手順は、どちらも同期的な履歴更新を実行するが、履歴ステップ適用のために
文書を更新する同期的な呼び出しを含むのは、フラグメントナビゲーションだけである。代わりに、URL および履歴更新手順は、上記のアルゴリズム内で
いくつかの選択された更新を実行し、その他の更新を省略する。これは、やや不幸な歴史的偶然であり、一般に、この不整合に関する
ウェブ開発者の
悲しみにつながる。たとえば、これは、フラグメントナビゲーションでは popstate イベントが
発火するが、history.pushState()
の呼び出しでは発火しないことを意味する。
概要で説明したように、ナビゲーションと トラバーサルはいずれも、セッション履歴 エントリーを作成し、その後、その文書 メンバーにデータを設定して、ナビゲーション可能内に表示できるようにする処理を伴う。
これには、すでに与えられている
応答を使用すること、セッション履歴
エントリーに格納されているsrcdoc リソースを使用すること、または
フェッチすることのいずれかが含まれる。
この処理には複数の失敗形態があり、何も行わないこと
(ナビゲーション可能を、現在の
アクティブな Documentのままにすること)になる場合と、
セッション履歴
エントリーにエラー文書を設定することになる場合がある。
セッション履歴
エントリー entryについて、ナビゲーション可能 navigable、
NavigationTimingType
navTimingType、ソーススナップショットパラメーター
sourceSnapshotParams、対象スナップショットパラメーター
targetSnapshotParams、ユーザーナビゲーション関与
userInvolvement、任意のナビゲーション IDまたは null の
navigationId(既定値は null)、任意のナビゲーションパラメーターまたは null の
navigationParams(既定値は null)、任意の文字列 cspNavigationType
(既定値は「other」)、任意のブール値
allowPOST(既定値は false)、および任意の
アルゴリズム手順 completionSteps
(既定値は空のアルゴリズム)が与えられたとき、履歴エントリーの
文書へのデータ設定を試みるには:
表明:navigationParamsが null でない場合、 navigationParamsの応答は null でない。
navigationParamsが null の場合:
documentResourceが文字列である場合、navigationParamsを、 entry、navigable、targetSnapshotParams、 userInvolvement、navigationId、および navTimingTypeが与えられたときに、srcdoc リソースからナビゲーションパラメーターを作成した結果に設定する。
それ以外の場合、次のすべてが true である場合:
documentResourceが null であるか、allowPOSTが true であり、 documentResourceのリクエスト本体が failure でない、
その場合、navigationParamsを、entry、 navigable、sourceSnapshotParams、targetSnapshotParams、 cspNavigationType、userInvolvement、navigationId、および navTimingTypeが与えられたときに、フェッチによって ナビゲーションパラメーターを作成した結果に設定する。
それ以外の場合、entryのURLのスキームがフェッチスキームでない場合、 navigationParamsを、次の値を持つ新しい非フェッチスキーム ナビゲーションパラメーターに設定する:
セッション履歴
エントリー entry、ナビゲーション可能 navigable、対象
スナップショットパラメーター targetSnapshotParams、ユーザーナビゲーション関与
userInvolvement、ナビゲーション IDまたは null の
navigationId、および
NavigationTimingType
navTimingTypeが与えられたとき、srcdoc
リソースからナビゲーションパラメーターを作成するには:
responseを、次の値を持つ新しい応答とする:
about:srcdoc
Content-Type`,
`text/html`) »responseOriginを、responseのURL、 targetSnapshotParamsのサンドボックス化 フラグ、および entryの文書状態の オリジンが与えられたときに、 オリジンを決定した結果とする。
coopを新しいオープナーポリシーとする。
coopEnforcementResultを、次の値を持つ新しいオープナー ポリシー適用結果とする:
policyContainerを、responseのURL、entryの文書状態の履歴ポリシー コンテナー、null、 navigableのコンテナー文書のポリシーコンテナー、および null が与えられたときに、ナビゲーションパラメーターの ポリシーコンテナーを決定した結果とする。
次の値を持つ新しいナビゲーションパラメーターを返す:
iframe
要素のリファラーポリシーiframe
要素のリファラー
ポリシーこのアルゴリズムは entryを変更する。
requestを、次の値を持つ新しいリクエストとする:
document」navigableがコンテナーを持つ場合、
宛先は以下で更新される。include」manual」navigate」navigableがトップレベルトラバーサブルである場合、 requestのトップレベルナビゲーション開始元オリジンを、 entryの文書 状態の開始元オリジンに設定する。
requestのクライアントが null の場合:
これは、ブラウザー UI によって開始されたナビゲーションの場合にのみ発生する。
requestのサービスワーカーモードを
「all」に設定する。
requestのリファラーを
「no-referrer」に設定する。
documentResourceがPOST リソースである場合:
entryの文書状態の再読み込み保留中が true の場合、 requestの再読み込みナビゲーション フラグを設定する。
それ以外の場合、entryの文書 状態の設定されたことがあるが true の場合、requestの履歴ナビゲーションフラグを設定する。
sourceSnapshotParamsの一時的な アクティベーションを持つが true の場合、requestのユーザーアクティベーションを true に設定する。
navigableのコンテナーが null でない場合:
navigableのコンテナーが 閲覧コンテキストスコープオリジンを 持つ場合、requestのオリジンをその閲覧コンテキストスコープ オリジンに設定する。
sourceSnapshotParamsのフェッチ クライアントが、navigableのコンテナー 文書の関連する設定オブジェクトである場合、 requestの開始元の型を、 navigableのコンテナーのローカル 名に設定する。
これにより、コンテナーによって開始されたナビゲーションのみが リソースタイミングに報告されることが保証される。
responseを null とする。
responseOriginを null とする。
fetchControllerを null とする。
coopEnforcementResultを、次の値を持つ新しいオープナー ポリシー適用結果とする:
finalSandboxFlagsを空のサンドボックス化フラグ集合とする。
responsePolicyContainerを null とする。
responseCOOPを新しいオープナーポリシーとする。
locationURLを null とする。
currentURLを、requestの現在の URLとする。
commitEarlyHintsを null とする。
true である間:
requestの予約済み クライアントが null でなく、currentURLのオリジンが、 requestの予約済み クライアントの作成 URLのオリジンと同一でない場合:
requestの予約済みクライアントについて、 環境破棄手順を 実行する。
requestの予約済み クライアントを null に設定する。
commitEarlyHintsを null に設定する。
Early Hints ヘッダーから プリロードされたリンクは、同一オリジンリダイレクト後も プリロードキャッシュに残るが、クロスオリジンリダイレクト時には破棄される。
requestの予約済み クライアントが null の場合:
topLevelCreationURLを currentURLとする。
topLevelOriginを null とする。
navigableがトップレベルトラバーサブルでない場合:
parentEnvironmentを、navigableの親のアクティブ文書の 関連する設定オブジェクトとする。
topLevelCreationURLを、parentEnvironmentの トップレベル 作成 URLに設定する。
topLevelOriginを、parentEnvironmentのトップレベル オリジンに設定する。
requestの予約済み クライアントを、IDが一意な不透明文字列、 対象閲覧 コンテキストが navigableのアクティブ 閲覧コンテキスト、作成 URLが currentURL、 トップレベル 作成 URLが topLevelCreationURL、かつトップレベル オリジンが topLevelOriginである新しい環境に設定する。
作成された環境のアクティブサービス ワーカーは、リクエスト URL がサービスワーカー登録と一致する場合、フェッチ中に フェッチを処理するアルゴリズムで設定される。 [SW]
requestおよび cspNavigationTypeが与えられたときのこの型の
ナビゲーションリクエストを Content Security Policy によってブロックすべきか?の結果が
「Blocked」である場合、responseをネットワーク
エラーに設定して中断する。[CSP]
responseを null に設定する。
fetchControllerが null の場合、fetchControllerを、 requestをフェッチした結果に設定する。このとき、processEarlyHintsResponseを 以下で定義する processEarlyHintsResponseに、processResponseを 以下で定義する processResponseに、useParallelQueueを true に設定する。
応答 earlyResponseが与えられたときの processEarlyHintsResponseを、次のアルゴリズムとする:
commitEarlyHintsが null の場合、commitEarlyHintsを、 earlyResponseおよび requestの予約済みクライアントが与えられたときに、 Early Hints ヘッダーを 処理した結果に設定する。
応答 fetchedResponseが与えられたときの processResponseを、次のアルゴリズムとする:
responseを fetchedResponseに設定する。
それ以外の場合、fetchControllerについて次の手動リダイレクトを処理する。
これにより、ループの最初の反復中に、上記で指定した processResponseが呼び出され、 その結果 responseが設定される。
ナビゲーションは、mailto:
URL などへのリダイレクトを考慮するウェブプラットフォーム上で唯一の場所であるため、
リダイレクトを手動で処理する。
responseが null でなくなるか、navigableの進行中の ナビゲーションが変更されて navigationIdと等しくなくなるまで待機する。
後者の条件が発生した場合、fetchControllerを中止し、戻る。
それ以外の場合、処理を続行する。
requestの本体が null の場合、 entryの文書状態のリソースを null に設定する。
フェッチは、特定のリダイレクトについて本体の設定を解除する。
responsePolicyContainerを、responseおよび requestの予約済みクライアントが与えられたときに、 フェッチ応答から ポリシーコンテナーを作成した結果に設定する。
finalSandboxFlagsを、targetSnapshotParamsのサンドボックス化 フラグと、responsePolicyContainerのCSP リストのCSP 由来のサンドボックス化 フラグとの和集合に設定する。
responseOriginを、responseのURL、 finalSandboxFlags、および entryの文書状態の開始元オリジンが 与えられたときに、オリジンを決定した結果に設定する。
responseがリダイレクトである場合、responseのURLは、responseのLocation URLへのリダイレクトを引き起こした URL となり、Location URLそのものではない。
navigableがトップレベルトラバーサブルである場合:
responseCOOPを、responseおよび requestの予約済みクライアントが与えられたときに、 オープナーポリシーを 取得した結果に設定する。
coopEnforcementResultを、 navigableのアクティブ 閲覧コンテキスト、 responseのURL、 responseOrigin、responseCOOP、coopEnforcementResult、および requestのリファラーが与えられたときに、 応答のオープナーポリシーを適用した結果に 設定する。
finalSandboxFlagsが空でなく、responseCOOPの値が「unsafe-none」でない場合、
responseを適切なネットワーク
エラーに設定して中断する。
これは、オープナーポリシーを使用して応答にクリーンな環境を提供しながら、 同時にその応答へのナビゲーション結果をサンドボックス化することはできないため、 ネットワークエラーとなる。
responseがネットワーク エラーでなく、navigableが 子ナビゲーション可能であり、 navigableのコンテナー文書のオリジン、navigableのコンテナー文書の関連する設定 オブジェクト、requestの宛先、response、および true を使用して クロスオリジンリソース ポリシーチェックを実行した結果が ブロック済みである場合、responseをネットワーク エラーに設定して中断する。
ここでは、navigable自体ではなく、親 ナビゲーション可能に対してクロスオリジンリソースポリシーチェックを 実行している。これは、ナビゲーションソースではなく、埋め込まれたコンテンツと親コンテキストとの 同一オリジン性を問題としているためである。
locationURLを、currentURLのフラグメントが与えられたときの responseのLocation URLに設定する。
locationURLが failure または null の場合、中断する。
entryのクラシック履歴 API 状態を StructuredSerializeForStorage(null) に設定する。
oldDocStateを、entryの文書状態とする。
entryの文書状態を、次の値を持つ新しい 文書状態に設定する:
ナビゲーションの場合、oldDocStateを参照していたのは entryだけであり、これはナビゲートアルゴリズムの 早い段階で作成された。したがって、ナビゲーションの場合、これは機能的には単に entryの文書状態の更新となる。 トラバーサルの場合、隣接するセッション履歴 エントリーも oldDocStateを参照している可能性があり、その場合、 entryの文書 状態を更新した後も、それらは引き続き oldDocStateを参照する。
oldDocStateの履歴ポリシー コンテナーがここで null でないのは、トラバーサルの場合に限られる。これは、 ポリシーコンテナーを 履歴に格納する必要がある URL へのナビゲーション中に、その値を設定した後である。
設定は、次のJake 図によって示される:
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
top |
/a | /a#foo | /a#bar | /b |
また、ステップ 0、1、および 2 のエントリーによって共有される文書状態の文書が null、すなわち bfcacheが関与していないと仮定する。
ここで、ステップ 2 に戻るようトラバースするが、今回 /aをフェッチしたとき、
サーバーが /cを指す `Location`ヘッダーで応答するシナリオを考える。
すなわち、locationURLは /cを指し、そのためループから中断するのではなく、このステップに到達している。
この場合、ステップ 2 を占めるセッション履歴エントリーの文書状態を置き換えるが、 ステップ 0 および 1 を占めるエントリーの文書状態は置き換えない。 結果として得られるJake 図は次のようになる:
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
top |
/a | /a#foo | /c#bar | /b |
最終的に元の URL に戻るリダイレクトチェーンになった場合でも、この置換を行うことに注意。
たとえば、/c自体が /aを指す
`Location`ヘッダーを持っていた場合である。この場合、最終的には
次のようになる:
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
top |
/a | /a#foo | /a#bar | /b |
locationURLのスキームが HTTP(S) スキームでない場合:
currentURLを locationURLに設定する。
entryのURLを currentURLに設定する。
このループの終了時点では、次のいずれかのシナリオに該当する:
解析不能な `Location`ヘッダーにより、locationURLが failure である。
responseがネットワーク
エラーであるか、`Location`ヘッダーを持たない非ネットワーク
エラーの HTTP(S) 応答を正常にフェッチしたことにより、
locationURLが null である。
locationURLが、スキームがフェッチスキームでないURLである場合、次の値を持つ新しい 非フェッチスキーム ナビゲーションパラメーターを返す:
この時点で、requestの現在の URLは、非フェッチスキーム URLへリダイレクトする前の、リダイレクトチェーン内で最後の フェッチスキームを持つURLである。非フェッチスキーム URLへのナビゲーションで開始元オリジンとして使用されるのは、 このURLのオリジンである。
次のいずれかが true である場合:
responseがネットワーク エラーである;
locationURLが failure である;または
その場合、null を返す。
非フェッチスキームのURLへのリダイレクトは許可するが、HTTP(S)ではないフェッチスキームのURLへのリダイレクトは、ネットワークエラーと同様に扱われる。
表明:locationURLは null であり、 responseはネットワーク エラーでない。
resultPolicyContainerを、responseのURL、entryの文書状態の履歴ポリシー コンテナー、 sourceSnapshotParamsのソース ポリシーコンテナー、null、および responsePolicyContainerが与えられたときに、 ナビゲーションパラメーターの ポリシーコンテナーを決定した結果とする。
navigableのコンテナーが
iframeであり、
responseのタイミング許可通過フラグが設定されている場合、
navigableのコンテナーの保留中のリソースタイミング
開始時刻を null に設定する。
iframeが
リソースタイミングへの報告を許可されている場合、通常の報告が行われるため、
そのフォールバック手順を実行する必要はない。
次の値を持つ新しいナビゲーションパラメーターを返す:
要素の Documentの
ノードナビゲーション可能がトップレベル
トラバーサブルであるか、またはその
Documentのすべての祖先ナビゲーション可能が、
要素のノード文書のオリジンと同一オリジンであるオリジンを持つアクティブ文書を持つ場合、その要素は
閲覧コンテキストスコープオリジンを持つ。
要素が閲覧コンテキストスコープオリジンを
持つ場合、その値は要素のノード文書のオリジンである。
この定義は壊れており、何を表現する意図だったのかを調査する必要がある: issue #4703を参照。
ナビゲーションパラメーター
navigationParams、ソーススナップショットパラメーター
sourceSnapshotParams、およびオリジン
initiatorOriginが与えられたとき、文書を読み込むには、
次の手順を実行する。この手順は
Documentまたは
null を返す。
ユーザーエージェントが、指定された typeのリソースを、コンテンツをナビゲーション可能内にレンダリングする以外の 仕組みで処理するよう構成されている場合、このステップを飛ばす。それ以外の場合、 typeが次の型のいずれかである場合:
text/css」text/plain」
text/vtt」multipart/x-mixed-replace」
multipart/x-mixed-replace
文書を読み込んだ結果を返す。
application/pdf」text/pdf」それ以外の場合、処理を続行する。
明示的にサポートされる XML MIME 型とは、
ユーザーエージェントが外部アプリケーションを使用してコンテンツをレンダリングするよう
構成されているか、またはユーザーエージェントが専用の処理規則を持つXML MIME
型である。たとえば、組み込みの Atom
フィードビューアーを持つウェブブラウザーは、application/atom+xml
MIME 型を明示的にサポートしているとみなされる。
明示的にサポートされる JSON MIME 型とは、 ユーザーエージェントが外部アプリケーションを使用してコンテンツをレンダリングするよう 構成されているか、またはユーザーエージェントが専用の処理規則を持つJSON MIME 型である。
どちらの場合も、外部アプリケーションまたはユーザーエージェントは、 navigationParamsのナビゲーション可能内に コンテンツを直接インライン表示するか、 外部ソフトウェアに 引き渡す。どちらも以下の手順で行われる。
それ以外の場合、文書の typeは、そのリソースが navigationParamsのナビゲーション可能に 影響しないような型である。たとえば、リソースが外部アプリケーションに引き渡される場合や、 ダウンロードとして処理するによって 処理される不明な型である場合である。navigationParamsの応答、 navigationParamsのナビゲーション可能、 navigationParamsの最終サンドボックス化フラグ集合、 sourceSnapshotParamsの一時的な アクティベーションを持つ、および initiatorOriginが与えられたとき、 外部ソフトウェアに 引き渡す。
null を返す。
ナビゲーションとトラバーサルのどちらについても、セッション履歴内のどこへ進もうとしているのかが
決まると、その考えをトラバーサブル
ナビゲーブルおよび関連する Documentに適用することが、
処理の大部分を占める。ナビゲーションでは、この処理は通常、処理の終盤で行われるが、
トラバーサルでは、これが処理の始まりとなる。
トラバーサブルが適切な セッション履歴ステップに到達することを保証する処理は、特に複雑である。これは、トラバーサブルの複数の ナビゲーブル子孫を連携させ、 それらに並列でデータを設定し、その後、 全員が結果について同じ見方を持つよう再び同期する必要が生じ得るためである。さらに、 同期的な同一文書ナビゲーションが文書間ナビゲーションと混在すること、およびウェブページが 特定の相対的なタイミングを期待するようになってきたことによって、処理は一層複雑になる。
変更中ナビゲーブル継続状態は、 履歴ステップを適用する アルゴリズムの実行中に情報を格納するために使用され、アルゴリズムの一部が、 他の部分の完了後にのみ続行できるようにする。これは、次のメンバーを持つ構造体である:
Documentトラバーサブルナビゲーブルに対するすべての更新は、 最終的には同じ履歴ステップを適用するアルゴリズムに 到達するが、考えられる各エントリーポイントには、それぞれ若干のカスタマイズが伴う:
トラバーサブル ナビゲーブル traversableが与えられたとき、 ナビゲーブルの作成/破棄に応じて更新するには:
stepを、traversableの現在のセッション履歴ステップとする。
false、null、null、「none」、および null が
与えられたとき、stepを traversableに履歴ステップとして適用した結果を返す。
非負整数 stepをトラバーサブル ナビゲーブル traversableにプッシュ/置換履歴ステップとして適用するには、さらに 履歴処理 動作 historyHandlingおよびユーザーナビゲーション関与 userInvolvementが与えられたとき:
false、null、null、userInvolvement、および historyHandlingが 与えられたとき、stepを traversableに履歴ステップとして適用した結果を返す。
プッシュ/置換履歴ステップを適用するは、 履歴ステップを適用するに、ソース スナップショットパラメーターまたは開始元のナビゲーブルを渡すことはない。これは、それらの確認が ナビゲートアルゴリズムの より早い段階で行われるためである。
トラバーサブルナビゲーブル traversableに再読み込み履歴ステップを適用するには、 ユーザーナビゲーション関与 userInvolvementが与えられたとき:
stepを、traversableの現在のセッション履歴ステップとする。
true、null、null、userInvolvement、および「reload」が与えられたとき、stepを
traversableに履歴ステップとして適用した結果を返す。
再読み込み履歴ステップを適用するは、
履歴ステップを適用するに、ソーススナップショット
パラメーターまたは開始元のナビゲーブルを渡すことはない。これは、
parent.location.reload()のような場合であっても、再読み込みは常にナビゲーブル自身が行ったものとして
扱われるためである。
非負整数 stepをトラバーサブルナビゲーブル traversableにトラバース履歴ステップとして適用するには、ソーススナップショット パラメーター sourceSnapshotParams、ナビゲーブル initiatorToCheck、および ユーザーナビゲーション関与 userInvolvementを使用して:
true、sourceSnapshotParams、initiatorToCheck、
userInvolvement、および「traverse」が与えられたとき、stepを
traversableに履歴ステップとして適用した結果を返す。
非負整数 step、トラバーサブルナビゲーブル
traversable、およびユーザーナビゲーション関与
userInvolvementが与えられたとき、トラバース履歴ステップの適用を再開するには、
false、null、null、userInvolvement、および「traverse」が与えられたものとして、stepを
traversableに適用する。
トラバースを再開する時点では、キャンセル、開始元、およびソーススナップショットの確認は すでに完了しており、このトラバーサルは同一文書トラバーサルであるとすでに判定されている。 したがって、これらの引数には false および null を渡すことができる。
ここからアルゴリズム本体を示す。
非負整数 stepをトラバーサブルナビゲーブル
traversableに履歴ステップとして適用するには、
ブール値 checkForCancelation、ソーススナップショット
パラメーターまたは null の sourceSnapshotParams、ナビゲーブルまたは null の
initiatorToCheck、ユーザーナビゲーション関与
userInvolvement、および NavigationTypeまたは null の
navigationTypeを使用して、次の手順を実行する。
この手順は「initiator-disallowed」、「canceled-by-beforeunload」、
「canceled-by-navigate」、または
「applied」を返す。
表明:これは traversableのセッション履歴トラバーサルキュー内で 実行されている。
targetStepを、traversableおよび stepが与えられたときに 使用されるステップを取得した結果とする。
initiatorToCheckが null でない場合:
表明:sourceSnapshotParamsは null でない。
現在の
セッション履歴エントリーが変更または再読み込みされるすべてのナビゲーブルを取得するの
各 navigableについて、sourceSnapshotParamsが与えられたとき、
initiatorToCheckが navigableをナビゲートすることをサンドボックス化によって
許可されていない場合、「initiator-disallowed」を返す。
navigablesCrossingDocumentsを、traversableおよび targetStepが与えられたときに、文書間 トラバーサルが発生する可能性のあるすべてのナビゲーブルを取得した結果とする。
checkForCancelationが true であり、
navigablesCrossingDocuments、traversable、
targetStep、および userInvolvementが与えられたときに、アンロードがキャンセルされたかを
確認した結果が「continue」でない場合、その結果を返す。
changingNavigablesを、traversableおよび targetStepが与えられたときに、現在の セッション履歴エントリーが変更または再読み込みされるすべてのナビゲーブルを取得した結果とする。
nonchangingNavigablesThatStillNeedUpdatesを、traversableおよび targetStepが与えられたときに、履歴 オブジェクトの長さ/インデックスの更新のみを必要とするすべてのナビゲーブルを取得した結果とする。
changingNavigablesの各 navigableについて:
targetEntryを、navigableおよび targetStepが 与えられたときに対象履歴 エントリーを取得した結果とする。
navigableの現在のセッション 履歴エントリーを targetEntryに設定する。
navigableのアクティブ ウィンドウのナビゲーションおよび トラバーサルタスクソース上にグローバルタスクをキューに追加し、 次の手順を実行する:
navigationを、navigableのアクティブ ウィンドウのナビゲーション APIとする。
navigationの進行中の navigate
イベントを null に設定する。
navigationの進行中の API メソッドトラッカーを null に設定する。
これにより、正常な文書間ナビゲーションの結果として、navigateerrorイベントおよび対応するシグナルが発火することを防ぐ。
navigableの進行中のナビゲーションを設定し、
「traversal」にする。
totalChangeJobsを、changingNavigablesのサイズとする。
completedChangeJobsを 0 とする。
changingNavigableContinuationsを、変更中ナビゲーブル継続状態の 空のキューとする。
このキューは、changingNavigablesに対する操作を 2 つの部分に分割するために 使用される。具体的には、changingNavigableContinuationsは後半部分のデータを保持する。
changingNavigablesの各 navigableについて、 navigableのアクティブ ウィンドウのナビゲーションおよび トラバーサルタスクソース上にグローバルタスクをキューに追加し、 次の手順を実行する:
この一連の手順は、文書がアンロードされる前に同期的なナビゲーションを 処理できるよう、2 つの部分に分割されている。後半 部分のために、状態は changingNavigableContinuationsに格納される。
displayedEntryを、navigableのアクティブなセッション履歴エントリーとする。
targetEntryを、navigableの現在のセッション履歴エントリーとする。
changingNavigableContinuationを、次の値を持つ変更中ナビゲーブル継続 状態とする:
displayedEntryが targetEntryであり、targetEntryの文書状態の再読み込み 保留中が false である場合:
changingNavigableContinuationの更新のみを true に設定する。
changingNavigableContinuationを changingNavigableContinuationsにエンキューする。
これらの手順を中止する。
この場合は、同期的なナビゲーションが アクティブなセッション履歴エントリーを すでに更新しているために発生する。
navigationTypeに応じて切り替える:
targetEntryの文書が null であるか、 targetEntryの文書状態の再読み込み保留中が true である場合:
targetEntryの文書が
null である場合、
navTimingTypeを「back_forward」とし、
それ以外の場合は「reload」とする。
targetSnapshotParamsを、navigableが与えられたときに対象スナップショット パラメーターをスナップショットした結果とする。
potentiallyTargetSpecificSourceSnapshotParamsを sourceSnapshotParamsとする。
potentiallyTargetSpecificSourceSnapshotParamsが null の場合、 navigableのアクティブ文書が与えられたときに、ソーススナップショット パラメーターをスナップショットした結果に設定する。
この場合、トラバーサル/再読み込みの明確なソースは存在しない。この状況は、 navigableが自身をナビゲートしたかのように扱う。ただし、targetEntryの 元の開始元が持つ一部のプロパティは、targetEntryの文書状態に保持されることに注意。 これには、ナビゲーションに適切な影響を与える開始元オリジンおよびリファラーなどが含まれる。
並列に、targetEntryについて、 navigable、potentiallyTargetSpecificSourceSnapshotParams、 targetSnapshotParams、userInvolvementが与えられ、allowPOSTが allowPOSTに設定され、completionStepsが、 navigableのアクティブ ウィンドウが与えられたときに、ナビゲーションおよび トラバーサルタスクソース上にグローバル タスクをキューに追加して afterDocumentPopulatedを実行するよう設定された状態で、 履歴エントリーの 文書へのデータ設定を試みる。
それ以外の場合、afterDocumentPopulatedを直ちに実行する。
どちらの場合も、afterDocumentPopulatedを次の手順とする:
targetEntryの文書が null の場合、 changingNavigableContinuationの更新のみを true に設定する。
これは文書へのデータ設定を試みたものの、たとえばサーバーが 204 を返したため、 実行できなかったことを意味する。
この種の失敗したナビゲーションまたはトラバーサルは、ナビゲーション APIには通知されない。たとえば、ナビゲーション API
メソッドトラッカーのプロミスや、navigateerrorイベントを介して通知されることはない。
そうすると、クロスオリジンの場合に、他のオリジンからの応答のタイミングに関する情報が
漏洩することになる。また、クロスオリジンの場合と同一オリジンの場合とで異なる結果を
提供することは、混乱を招きすぎると判断された。
ただし実装は、この時点で決して実行されないことが保証されている navigation.transition.finished
プロミスのプロミスハンドラーを消去する機会として利用できる。また、ナビゲーション API の
いずれかの部分がこれらのナビゲーションを開始した場合、ウェブ開発者に対して、
プロミスが決して確定せず、イベントも決して発火しない理由を明確にするため、コンソールに警告を報告することもできる。
targetEntryの文書のオリジンが oldOriginでない場合、 targetEntryのクラシック履歴 API 状態を StructuredSerializeForStorage(null) に設定する。
これにより、リダイレクトが発生することなく、以前の targetEntryの読み込み時と比べてオリジンが変更された場合、履歴状態が消去される。 これは CSP サンドボックスヘッダーの変更によって発生し得る。
次のすべてが true である場合:
navigableの親が null である;
targetEntryの文書の閲覧コンテキストが、 オープナー閲覧コンテキストが null でない補助閲覧 コンテキストでない;かつ
その場合、targetEntryの文書 状態のナビゲーブルのターゲット名を 空文字列に設定する。
changingNavigableContinuationを changingNavigableContinuationsにエンキューする。
このジョブの残りの部分は、このアルゴリズム内で後に実行される。
navigablesThatMustWaitBeforeHandlingSyncNavigationを空の 集合とする。
completedChangeJobsが totalChangeJobsと等しくない間:
traversableのネストした 履歴ステップ適用を実行中が false である場合:
changingNavigableContinuationを、 changingNavigableContinuationsからデキューした結果とする。
changingNavigableContinuationが nothing の場合、続行する。
displayedDocumentを、changingNavigableContinuationの表示中の文書とする。
targetEntryを、changingNavigableContinuationの対象エントリーとする。
navigableを、changingNavigableContinuationのナビゲーブルとする。
(scriptHistoryLength, scriptHistoryIndex) を、 traversableおよび targetStepが与えられたときに、履歴オブジェクトの 長さおよびインデックスを取得した結果とする。
これらの値は、最後に算出されてから変更されている可能性がある。
navigableを navigablesThatMustWaitBeforeHandlingSyncNavigationに付加する。
ナビゲーブルがトラバーサル内のこの地点に到達すると、追加でキューに入れられた 同期ナビゲーション手順は、このトラバーサルより前ではなく後に行われることを意図している可能性が 高くなるため、キューの先頭へ移動しなくなる。詳細はこちらを参照。
entriesForNavigationAPIを、navigableおよび targetStepが与えられたときに、ナビゲーション API 用のセッション履歴エントリーを取得した結果とする。
changingNavigableContinuationの更新のみが true であるか、 targetEntryの文書が displayedDocumentである場合:
これは同一文書ナビゲーションであるため、アンロードせずに処理を続行する。
navigableの進行中のナビゲーションを設定し、 null にする。
これにより、トラバーサル中にはブロックされていた navigableの新しいナビゲーションを開始できるようになる。
navigableのアクティブウィンドウが与えられたとき、 ナビゲーションおよび トラバーサルタスクソース上にグローバルタスクをキューに追加して afterPotentialUnloadsを実行する。
それ以外の場合:
どちらの場合も、afterPotentialUnloadsを次の手順とする:
previousEntryを、navigableのアクティブなセッション履歴エントリーとする。
changingNavigableContinuationの更新のみが false の場合、 navigableについて targetEntryを履歴エントリーとしてアクティブ化する。
updateDocumentを、targetEntryの文書、targetEntry、 changingNavigableContinuationの更新のみ、 scriptHistoryLength、scriptHistoryIndex、 navigationType、entriesForNavigationAPI、および previousEntryが与えられたときに、履歴ステップ適用のために 文書を更新するアルゴリズム手順とする。
targetEntryの文書が displayedDocumentと等しい場合、updateDocumentを実行する。
それ以外の場合、targetEntryの文書の 関連する グローバルオブジェクトが与えられたとき、ナビゲーションおよび トラバーサルタスクソース上にグローバルタスクをキューに追加して updateDocumentを実行する。
completedChangeJobsをインクリメントする。
totalNonchangingJobsを、 nonchangingNavigablesThatStillNeedUpdatesのサイズとする。
このステップ以降は、意図的に以前のすべての操作が完了するまで待機する。 以前の操作には、履歴の長さおよびインデックスを更新するためのタスクも送信する同期ナビゲーションの処理が含まれるためである。
completedNonchangingJobsを 0 とする。
(scriptHistoryLength, scriptHistoryIndex) を、 traversableおよび targetStepが与えられたときに、履歴オブジェクトの 長さおよびインデックスを取得した結果とする。
nonchangingNavigablesThatStillNeedUpdatesの各 navigableについて、 navigableのアクティブウィンドウが与えられたとき、 ナビゲーションおよび トラバーサルタスクソース上にグローバルタスクをキューに追加し、 次の手順を実行する:
completedNonchangingJobsが totalNonchangingJobsと等しくなるまで待機する。
traversableの現在の セッション履歴ステップを targetStepに設定する。
「applied」を返す。
Document
displayedDocument、ユーザーナビゲーション関与
userNavigationInvolvement、セッション履歴エントリー
targetEntry、NavigationType
navigationType、および引数を受け取らないアルゴリズム
afterPotentialUnloadsが与えられたとき、文書間ナビゲーションのために文書を
非アクティブ化するには:
navigableを、displayedDocumentの ノードナビゲーブルとする。
potentiallyTriggerViewTransitionを false とする。
userNavigationInvolvementが「browser UI」である場合、
isBrowserUINavigationを true とし、それ以外の場合は false とする。
potentiallyTriggerViewTransitionを、 displayedDocument、targetEntryの文書、navigationType、および isBrowserUINavigationが与えられたときに、ナビゲーションは 文書間ビュー遷移をトリガーできるか?を呼び出した結果に設定する。
potentiallyTriggerViewTransitionが false の場合:
firePageSwapBeforeUnloadを次の手順とする:
displayedDocument、targetEntry、
navigationType、および null が与えられたとき、pageswap
イベントを発火する。
navigableの進行中のナビゲーションを設定し、 null にする。
これにより、トラバーサル中にはブロックされていた navigableの新しいナビゲーションを開始できるようになる。
displayedDocument、targetEntryの文書、 afterPotentialUnloads、および firePageSwapBeforeUnloadが与えられたとき、 文書およびその子孫を アンロードする。
それ以外の場合、navigableのアクティブウィンドウが与えられたとき、 ナビゲーションおよび トラバーサルタスクソース上にグローバルタスクをキューに追加し、 次の手順を実行する:
proceedWithNavigationAfterViewTransitionCaptureを次の 手順とする:
navigableのトラバーサブルナビゲーブルに、 次のセッション 履歴トラバーサル手順を追加する:
navigableの進行中のナビゲーションを設定し、 null にする。
これにより、トラバーサル中にはブロックされていた navigableの新しいナビゲーションを開始できるようになる。
displayedDocument、targetEntryの文書、および afterPotentialUnloadsが与えられたとき、文書およびその子孫を アンロードする。
viewTransitionを、displayedDocument、 targetEntryの文書、navigationType、および proceedWithNavigationAfterViewTransitionCaptureが与えられたときに、文書間ビュー遷移を セットアップした結果とする。
displayedDocument、targetEntry、
navigationType、および viewTransitionが与えられたとき、pageswap
イベントを発火する。
viewTransitionが null の場合、 proceedWithNavigationAfterViewTransitionCaptureを実行する。
ビュー遷移が開始された場合、ビュー遷移アルゴリズムが proceedWithNavigationAfterViewTransitionCaptureを呼び出す役割を担う。
Document
displayedDocument、セッション履歴エントリー
targetEntry、NavigationType
navigationType、および
ViewTransitionまたは
null の
viewTransitionが与えられたとき、pageswapイベントを発火するには:
表明:これは、displayedDocumentの 関連するエージェントのイベントループ上にキューされたタスクの一部として 実行されている。
navigationを、displayedDocumentの 関連するグローバル オブジェクトのナビゲーション APIとする。
activationを null とする。
次のすべてが true である場合:
targetEntryの文書の クロスオリジン リダイレクトを介して作成されたが false であるか、targetEntryの 文書の最新のエントリーが null でない、
その場合:
destinationEntryを、navigationTypeに応じて 次のように決定する:
reload」
navigationの現在のエントリー
traverse」
navigationのエントリーリスト内で、セッション履歴エントリーが
targetEntryである NavigationHistoryEntry
push」
replace」
displayedDocumentの関連するレルム内にある新しい
NavigationHistoryEntryであり、そのセッション履歴エントリーが
targetEntryに設定されたもの
activationを、displayedDocumentの関連する
レルム内で作成された新しい NavigationActivationに設定し、次の値を持たせる:
これは、ナビゲーション中のクロスオリジンリダイレクトにより、新しい文書が
bfcacheから復元されている場合を除き、以前の文書の
PageSwapEvent内の activationが null になることを意味する。
displayedDocumentの
関連するグローバル
オブジェクトに対し、PageSwapEventを使用し、その activationを activationに設定し、
viewTransitionを
viewTransitionに設定して、pageswapという名前のイベントを発火する。
ナビゲーブル navigableについて、セッション履歴エントリー entryを履歴エントリーとしてアクティブ化するには:
newDocumentを、entryの文書とする。
表明:newDocumentの初期
about:blankであるは false である。すなわち、初期 about:blank
Documentから離れてナビゲートすると、常に置換されるため、初期
about:blankに
戻るようトラバースすることはない。
navigableのアクティブなセッション履歴 エントリーを entryに設定する。
newDocumentをアクティブにする。
newDocumentの初期表示状態を設定し、 navigableのトラバーサブル ナビゲーブルのシステム表示状態にする。
トラバーサブル ナビゲーブル traversableおよび非負整数 stepが与えられたとき、 使用されるステップを取得するには、次の手順を実行する。 この手順は非負整数を返す。
stepsを、traversable内で使用されているすべての履歴ステップを 取得した結果とする。
steps内で step以下である最大の項目を返す。
これは、ナビゲーブルが削除されたことにより、 ステップ stepを持つセッション履歴エントリーが 存在しない状況に対応する。
トラバーサブルナビゲーブル traversableおよび非負整数 stepが与えられたとき、 履歴オブジェクトの長さおよび インデックスを取得するには、次の手順を実行する。この手順は、2 つの非負整数からなるタプルを返す。
stepsを、traversable内で使用されているすべての履歴ステップを 取得した結果とする。
scriptHistoryLengthを、stepsのサイズとする。
stepは使用されるステップを 取得することによって調整済みであると仮定する。
scriptHistoryIndexを、steps内の stepのインデックスとする。
(scriptHistoryLength, scriptHistoryIndex) を返す。
トラバーサブル ナビゲーブル traversableおよび非負整数 targetStepが与えられたとき、現在のセッション履歴 エントリーが変更または再読み込みされるすべてのナビゲーブルを取得するには、 次の手順を実行する。この手順はナビゲーブルのリストを返す。
resultsを空のリストとする。
navigablesToCheckを « traversable » とする。
このリストは、以下のループ内で拡張される。
navigablesToCheckの各 navigableについて:
targetEntryを、navigableおよび targetStepが与えられたときに、対象履歴 エントリーを取得した結果とする。
targetEntryが navigableの現在のセッション履歴エントリーでないか、 targetEntryの文書状態の再読み込み保留中が true の場合、 navigableを resultsに付加する。
targetEntryの文書が navigableの文書であり、 targetEntryの文書状態の再読み込み保留中が false の場合、 navigableの子ナビゲーブルを使用して navigablesToCheckを拡張する。
navigablesToCheckに子ナビゲーブルを追加すると、 それらのナビゲーブルもこのループによって確認される。子ナビゲーブルが確認されるのは、 navigableのアクティブ 文書が、このトラバーサルの一部として変更されない場合に限られる。
resultsを返す。
トラバーサブル ナビゲーブル traversableおよび非負整数 targetStepが 与えられたとき、履歴 オブジェクトの長さ/インデックスの更新のみを必要とするすべてのナビゲーブルを取得するには、 次の手順を実行する。この手順はナビゲーブルのリストを返す。
他のナビゲーブルは、トラバーサルの影響を受けない可能性がある。 たとえば、応答が 204 の場合、現在アクティブな文書はそのまま残る。さらに、204 の後に「戻る」と、 現在のセッション履歴エントリーは変更されるが、 アクティブなセッション履歴 エントリーはすでに正しい状態となっている。
resultsを空のリストとする。
navigablesToCheckを « traversable » とする。
このリストは、以下のループ内で拡張される。
navigablesToCheckの各 navigableについて:
targetEntryを、navigableおよび targetStepが与えられたときに、対象履歴 エントリーを取得した結果とする。
targetEntryが navigableの現在のセッション履歴エントリーであり、 targetEntryの文書状態の再読み込み保留中が false の場合:
resultsを返す。
ナビゲーブル navigableおよび 非負整数 stepが与えられたとき、対象履歴エントリーを取得するには、 次の手順を実行する。この手順はセッション履歴エントリーを返す。
entriesを、navigableについてセッション履歴エントリーを 取得した結果とする。
対象履歴エントリーを取得するが、 入力ステップ以下の最大のステップを持つエントリーを返す理由を理解するため、 次のJake 図を考える:
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
top |
/t | /t#foo | ||
frames[0] |
/i-0-a | /i-0-b | ||
入力ステップ 1 の場合、topナビゲーブルの対象履歴エントリーは、
ステップが 0 である
/tエントリーとなる。一方、frames[0]ナビゲーブルの対象履歴エントリーは、
ステップが 1 である
/i-0-bエントリーとなる:
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
top |
/t | /t#foo | ||
frames[0] |
/i-0-a | /i-0-b | ||
同様に、入力ステップ 3 の場合、ステップが 3 である
topエントリーと、
ステップが 1 である
frames[0]エントリーが得られる:
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
top |
/t | /t#foo | ||
frames[0] |
/i-0-a | /i-0-b | ||
トラバーサブル ナビゲーブル traversableおよび非負整数 targetStepが 与えられたとき、文書間トラバーサルが 発生する可能性のあるすべてのナビゲーブルを取得するには、次の手順を実行する。 この手順はナビゲーブルのリストを返す。
traversableのセッション 履歴トラバーサルキューの観点では、これらの文書は、targetStepによって記述される トラバーサル中に文書間で移動する候補である。対象文書のステータスコードが HTTP 204 No Content である場合、文書間トラバーサルは発生しない。
特定のナビゲーブルに文書間トラバーサルが発生する可能性が ある場合、このアルゴリズムはそのナビゲーブルを返すが、その子 ナビゲーブルは返さないことに注意。それらはトラバースされるのではなく、アンロードされることになる。
resultsを空のリストとする。
navigablesToCheckを « traversable » とする。
このリストは、以下のループ内で拡張される。
navigablesToCheckの各 navigableについて:
targetEntryを、navigableおよび targetStepが与えられたときに、対象履歴 エントリーを取得した結果とする。
targetEntryの文書が navigableの文書でないか、 targetEntryの文書状態の再読み込み保留中が true の場合、 navigableを resultsに付加する。
navigableのアクティブな履歴エントリーは
同期的に変更され得るが、新しいエントリーは常に同じ Documentを持つため、
navigableの文書へのアクセスは信頼できる。
それ以外の場合、navigableの子 ナビゲーブルを使用して、navigablesToCheckを拡張する。
navigablesToCheckに子 ナビゲーブルを追加すると、それらのナビゲーブルもこのループによって確認される。子ナビゲーブルが確認されるのは、 navigableのアクティブ 文書が、このトラバーサルの一部として変更されない場合に限られる。
resultsを返す。
Document
document、セッション
履歴エントリー entry、ブール値
doNotReactivate、整数 scriptHistoryLengthおよび
scriptHistoryIndex、NavigationTypeまたは null の
navigationType、任意のリストであるセッション履歴エントリー
entriesForNavigationAPI、および任意のセッション履歴エントリー
previousEntryForActivationが与えられたとき、履歴ステップ適用のために文書を更新するには:
documentの最新のエントリーが null である場合、documentIsNewを true とし、それ以外の場合は false とする。
documentの最新の エントリーが entryでない場合、documentsEntryChangedを true とし、 それ以外の場合は false とする。
navigationを、historyの関連するグローバルオブジェクトの ナビゲーション APIとする。
documentsEntryChangedが true の場合:
documentの最新の エントリーを entryに設定する。
documentおよび entryが与えられたとき、履歴オブジェクトの状態を復元する。
documentIsNewが false の場合:
表明:navigationTypeは null でない。
navigation、entry、および navigationTypeが 与えられたとき、同一文書 ナビゲーション用のナビゲーション API エントリーを更新する。
documentの関連するグローバル
オブジェクトに対し、PopStateEventを使用し、
state
属性を documentの
履歴オブジェクトの状態で初期化し、
ユーザーエージェントが最新の
エントリーのキャッシュされたレンダリング状態を表示するために視覚的遷移を行った場合は、hasUAVisualTransition
を true で初期化して、popstateという
名前のイベントを発火する。
entryが与えられたとき、永続化された状態を復元する。
oldURLのフラグメントが、
entryのURLのフラグメントと等しくない場合、
documentの関連するグローバル
オブジェクトが与えられたとき、DOM
操作タスクソース上にグローバルタスクをキューに追加し、
documentの関連するグローバル
オブジェクトに対し、HashChangeEventを
使用し、oldURL
属性を oldURLの直列化で初期化し、newURL
属性を entryのURLの直列化で初期化して、hashchangeという名前のイベントを発火する。
それ以外の場合:
表明:entriesForNavigationAPIが与えられている。
entryが与えられたとき、永続化された状態を復元する。
navigation、entriesForNavigationAPI、および entryが与えられたとき、新しい文書用の ナビゲーション API エントリーを初期化する。
次のすべてが true である場合:
previousEntryForActivationが与えられている;
navigationTypeが null でない;かつ
navigationTypeが「reload」であるか、
previousEntryForActivationの文書が
documentでない、
その場合:
navigationのアクティベーションが null の場合、
navigationの
アクティベーションを、
navigationの関連するレルム内の新しい
NavigationActivation
オブジェクトに設定する。
previousEntryIndexを、navigation内の previousEntryForActivationについてナビゲーション API エントリーの インデックスを取得した結果とする。
previousEntryIndexが非負の場合、activationの 以前のエントリーを、 navigationのエントリーリスト[previousEntryIndex] に設定する。
それ以外の場合、次のすべてが true である場合:
navigationTypeが「replace」である;
previousEntryForActivationの 文書状態のオリジンが、 documentのオリジンと同一オリジンである;かつ
previousEntryForActivationの文書の
初期
about:blankが
false である、
その場合、activationの以前のエントリーを、
navigationの関連するレルム内にある新しい
NavigationHistoryEntry
に設定し、そのセッション履歴エントリーを
previousEntryForActivationにする。
activationのナビゲーション型を navigationTypeに設定する。
documentIsNewが true の場合:
表明:documentのWebDriver BiDi 用の読み込み中ナビゲーション IDは null でない。
navigableと、新しいWebDriver BiDi ナビゲーション状態を使用して、
WebDriver BiDi ナビゲーションコミットを
呼び出す。この状態のIDは
documentのWebDriver
BiDi 用の読み込み中ナビゲーション ID、状態は「committed」、
URLは
documentのURLである。
documentについてフラグメントへのスクロールを試みる。
この時点で、新しく作成された文書 documentについてスクリプトを実行できる。
それ以外の場合、documentsEntryChangedが false であり、 doNotReactivateが false の場合:
documentsEntryChangedが false となる理由は 2 つある。 bfcacheから復元しているか、または documentの最新の エントリーをすでに同期的に設定した同期ナビゲーションを、非同期的に完了させているかの いずれかである。doNotReactivate引数は、この 2 つの場合を区別する。
Document
documentおよびセッション履歴エントリー
entryが与えられたとき、履歴オブジェクトの状態を復元するには:
targetRealmを、documentの関連するレルムとする。
stateを、StructuredDeserialize(entryのクラシック 履歴 API 状態, targetRealm) とする。 これが例外をスローした場合、それをキャッチして stateを null とする。
Document
documentをアクティブにするには:
windowを、documentの関連するグローバル オブジェクトとする。
documentの閲覧コンテキストの
WindowProxyの[[Window]]内部
スロット値を windowに設定する。
windowの関連する設定オブジェクトの実行準備完了フラグを設定する。
セッション履歴エントリー
reactivatedEntryおよびリストであるセッション履歴エントリー
entriesForNavigationAPIが与えられたとき、Document
documentを再アクティブ化するには:
このアルゴリズムは、documentがbfcacheから復帰した後、すなわち再び完全にアクティブにされた後で、 documentを更新する。この完全に アクティブな状態への変更を監視する必要がある他の仕様には、この変更の結果として発生する イベントの順序が明確になるよう、このアルゴリズムに手順を追加することが推奨される。
document内で自動入力フィールド
名が「off」である各フォームコントロール
formControlについて、formControlのリセットアルゴリズムを呼び出す。
documentの一時停止されたタイマーハンドルが空でない場合:
activeTimersを、documentの関連するグローバル オブジェクトのアクティブなタイマーのマップとする。
documentの一時停止されたタイマー ハンドル内の各 handleについて、 activeTimers[handle] が存在する場合、 activeTimers[handle] を suspendDurationだけ増加させる。
documentの関連するグローバルオブジェクトのナビゲーション API、 entriesForNavigationAPI、および reactivatedEntryが与えられたとき、再アクティブ化用の ナビゲーション API エントリーを更新する。
documentの現在の文書準備状態が
「complete」であり、documentのページを表示中が false の場合:
documentのページを 表示中を true に設定する。
documentの表示されたことがあるを false に設定する。
documentの表示状態を更新し、
「visible」にする。
documentの関連するグローバル
オブジェクトに対し、true を使用して、pageshowという名前のページ遷移イベントを発火する。
Document
documentについてフラグメントへのスクロールを試みるには、
次の手順を並列に実行する:
実装定義の時間だけ待機する。(これは、 パフォーマンス上の懸念がある場合に、ユーザーエージェントがユーザー体験を最適化できるようにすることを 意図している。)
documentの関連するグローバルオブジェクトが 与えられたとき、ナビゲーションおよび トラバーサルタスクソース上にグローバルタスクをキューに追加し、 次の手順を実行する:
documentにパーサーがないか、そのパーサーが構文解析を停止しているか、またはユーザーが フラグメントへのスクロールに関心を持たなくなったと ユーザーエージェントが判断する理由がある場合、これらの手順を中止する。
documentが与えられたとき、フラグメントへスクロールする。
documentの示された部分が依然として null の場合、documentについてフラグメントへのスクロールを試みる。
Document
documentおよび文字列 reasonが与えられたとき、
文書を再利用不能にするには:
detailsを、理由が reasonである新しい復元されなかった理由の詳細とする。
detailsを documentの bfcache ブロック詳細に付加する。
documentの再利用可能状態を false に設定する。
Document
documentが与えられたとき、文書状態の復元されなかった理由を構築するには:
notRestoredReasonsForDocumentを、新しい復元されなかった理由とする。
containerが iframe要素である場合:
srcを空文字列とする。
containerが src属性を持つ場合:
srcを、containerのノード
文書を基準として、containerの src属性の値が与えられたときに、URL を符号化、構文解析、および直列化した結果とする。
srcが failure の場合、srcを
containerの src属性の値に設定する。
notRestoredReasonsForDocumentのsrcを srcに設定する。
notRestoredReasonsForDocumentのidを、
containerの id属性の値に設定し、そのような属性がない場合は空文字列に設定する。
notRestoredReasonsForDocumentのnameを、
containerの name属性の値に設定し、そのような属性がない場合は
空文字列に設定する。
notRestoredReasonsForDocumentの理由を、 documentのbfcache ブロック詳細の複製に設定する。
documentの文書ツリーの子ナビゲーブルの 各 navigableについて:
childDocumentを、navigableのアクティブ文書とする。
childDocumentが与えられたとき、文書状態の復元されなかった理由を 構築する。
childDocumentの復元されなかった理由を、 notRestoredReasonsForDocumentの子に付加する。
documentのノード ナビゲーブルのアクティブなセッション履歴エントリーの文書状態の復元されなかった理由を、 notRestoredReasonsForDocumentに設定する。
トップレベルトラバーサブル topLevelTraversableが与えられたとき、トップレベルトラバーサブルおよび その子孫の復元されなかった理由を構築するには:
topLevelTraversableのアクティブ 文書が与えられたとき、文書状態の復元されなかった理由を 構築する。
crossOriginDescendantsを空のリストとする。
topLevelTraversableのアクティブ 文書の子孫ナビゲーブルの 各 childNavigableについて:
crossOriginDescendantsPreventsBfcacheを false とする。
crossOriginDescendantsの各 crossOriginNavigableについて:
crossOriginDescendantsPreventsBfcacheが true の場合、
topLevelTraversableのアクティブ文書および「masked」が与えられたとき、文書を再利用不能にする。
Documentには、初期値が false である
ブール値の表示されたことがあるがある。これは、
pagerevealイベントが、
Documentのアクティブ化ごとに
1 回(最初にレンダリングされるときに 1 回、および再アクティブ化ごとに 1 回)発火されることを
保証するために使用される。
Document documentを
表示するには:
documentの表示されたことがあるが true の場合、戻る。
documentの表示されたことがあるを true に設定する。
transitionを、documentについて 受信側の文書間 ビュー遷移を解決した結果とする。
documentの
関連するグローバル
オブジェクトに対し、PageRevealEventを使用し、
その viewTransitionを
transitionに設定して、pagerevealという
名前のイベントを発火する。
transitionが null でない場合:
documentの 関連する設定 オブジェクトが与えられたとき、スクリプトを実行する準備をする。
transitionをアクティブ化する。
documentの 関連する 設定オブジェクトが与えられたとき、スクリプト実行後の後片付けをする。
ビュー遷移をアクティブ化するとプロミスが解決または拒否される可能性があるため、 アクティブ化を準備/後片付けで囲むことにより、それらのプロミスが次のレンダリング手順より前に 処理されることを保証する。
pagerevealは、
ページの最新バージョンを表示する最初のレンダリングを更新する手順中に
発火されることが保証されているが、ユーザーエージェントは、それを発火する前にページのキャッシュされた
フレームを自由に表示できる。これにより、pagerevealハンドラーが
存在することで、そのようなキャッシュされたフレームの表示が遅延することを防ぐ。
Document
documentが与えられたとき、フラグメントへスクロールするには:
それ以外の場合、documentの示された部分が文書の 先頭である場合:
documentの対象 要素を null に設定する。
documentについて文書の先頭へスクロールする。 [CSSOMVIEW]
戻る。
それ以外の場合:
targetを、documentの示された部分とする。
documentの対象 要素を targetに設定する。
targetに対して祖先表示アルゴリズムを実行する。
behaviorを「auto」、blockを「start」、inlineを 「nearest」に設定して、targetが表示されるよう スクロールする。[CSSOMVIEW]
シーケンシャルフォーカス ナビゲーションの開始点を targetへ移動する。
Documentの示された部分は、そのURLのフラグメントが識別する部分であり、フラグメントが
何も識別しない場合は null である。ノードへのマッピングに関するフラグメントの意味論は、Documentが使用するMIME
型を定義する仕様によって定義される(たとえば、XML MIME
型におけるフラグメントの処理は
RFC7303 の責任である)。
[RFC7303]
各 Documentには、
対象要素もあり、これは :target
疑似クラスの定義に使用され、上記のアルゴリズムによって更新される。初期値は null である。
HTML 文書 documentについて、その 示された部分は、 documentおよび documentのURLが与えられたときに、示された部分を選択した結果である。
Document
documentおよびURL urlが与えられたとき、示された部分を選択するには:
documentのURLが、フラグメントを除外するを true に設定した状態で urlと等しくない場合、null を返す。
fragmentを、urlのフラグメントとする。
fragmentが空文字列である場合、特殊値文書の 先頭を返す。
potentialIndicatedElementを、documentおよび fragmentが与えられたときに、示された要素の候補を 見つけた結果とする。
potentialIndicatedElementが null でない場合、 potentialIndicatedElementを返す。
fragmentBytesを、fragmentをパーセント復号した結果とする。
decodedFragmentを、fragmentBytesに対してBOM なしの UTF-8 復号を実行した結果とする。
potentialIndicatedElementを、documentおよび decodedFragmentが与えられたときに、示された要素の候補を 見つけた結果に設定する。
potentialIndicatedElementが null でない場合、 potentialIndicatedElementを返す。
decodedFragmentが文字列 topとASCII
大文字・小文字不区別で一致する場合、
文書の先頭を返す。
null を返す。
Document
documentおよび文字列 fragmentが与えられたとき、
示された要素の候補を見つけるには、
次の手順を実行する:
セッション履歴エントリー entryに永続化された状態を保存するには:
entryのスクロール 位置データを、entryの文書のすべての復元可能なスクロール可能領域の スクロール位置を含むように設定する。
任意で、フォームフィールドの値など、ユーザーエージェントが永続化を望む任意の状態を反映するよう、 entryの永続化されたユーザー状態を更新する。
セッション 履歴エントリー entryから永続化された状態を復元するには:
entryのスクロール復元
モードが「auto」であり、
entryの
文書の関連する
グローバルオブジェクトのナビゲーション APIの進行中の
ナビゲーション中に通常のスクロール復元を抑制するが false の場合、
entryが与えられたとき、スクロール位置データを復元する。
ユーザーエージェントがスクロール位置を復元しないことは、スクロール位置が 特定の値(たとえば (0,0))のままになることを意味しない。実際のスクロール位置は、 ナビゲーション型およびユーザーエージェント固有のキャッシュ戦略に依存する。そのため、 ウェブアプリケーションは特定のスクロール位置を想定できず、代わりに希望する位置へ設定することが 強く推奨される。
進行中の
ナビゲーション中に通常のスクロール復元を抑制するが
true の場合でも、関連する NavigateEventの
完了処理の一部として、または
navigateEvent.scroll()
メソッドの呼び出しによって、後の時点でスクロール位置データの復元が
行われる可能性がある。
任意で、ユーザーエージェントが以前に entryの永続化されたユーザー状態に記録した フォームフィールドの値など、entryの文書およびそのレンダリングの その他の側面を更新する。
これには、そのようなコントロールにおけるユーザー入力の方向性が
永続化された状態に含まれている場合、textarea
要素、または type属性が
Text、
Search、
Telephone、
URL、または
Email状態である input
要素の dir属性の更新さえ含まれ得る。
この処理の一部としてフォームコントロールの値を復元しても、input
または changeイベントは
発火しないが、フォーム関連カスタム要素の
formStateRestoreCallbackをトリガーする可能性がある。
各 Documentには、
初期値が false であるブール値のユーザーによってスクロールされたことがあるがある。
ユーザーが文書をスクロールした場合、ユーザーエージェントはその文書のユーザーによって
スクロールされたことがあるを true に設定しなければならない。
Document
documentの復元可能なスクロール可能領域は、
documentのビューポートおよび、ナビゲーション可能コンテナーを除く
documentのすべてのスクロール可能領域である。
子ナビゲーション可能のスクロール復元は、
それらのナビゲーション可能の Documentに対応するセッション履歴エントリーの
状態復元の一部として処理される。
セッション履歴 エントリー entryが与えられたとき、スクロール位置データを復元するには:
documentを、entryの文書とする。
documentのユーザーによって スクロールされたことがあるが true の場合、ユーザーエージェントは戻るべきである。
ユーザーエージェントは、entryのスクロール位置データを使用して、 entryの文書の復元可能なスクロール可能 領域のスクロール位置の復元を試みるべきである。ユーザーエージェントは、 documentのユーザーによって スクロールされたことがあるが true になるまで、定期的に復元を試み続けてもよい。
これは、成功するかユーザーがスクロールするまで繰り返される可能性のある 試みとして記述されている。これは、スクロール位置 データによって示される関連コンテンツをネットワークから読み込むのに時間がかかる可能性が あるためである。
スクロール復元は、スクロールアンカーの影響を受ける可能性がある。 [CSSSCROLLANCHORING]
以下のいずれかのアルゴリズムを使用して文書を読み込むとき、型
type、コンテンツ型 contentType、および
ナビゲーションパラメーター
navigationParamsが与えられたとき、次の手順を使用してDocumentオブジェクトを作成して初期化する:
Document
オブジェクトは、新しい閲覧コンテキストおよび
文書を作成するときにも作成される。そのような初期
about:blank Documentは、
このアルゴリズムによって作成されることはない。また、閲覧
コンテキストを持たない Document
オブジェクトは、document.implementation.createHTMLDocument()など、
さまざまな API を介して作成できる。
browsingContextを、navigationParamsが与えられたときに、ナビゲーション応答に使用する 閲覧コンテキストを取得した結果とする。
これは閲覧コンテキストグループの
切り替えにつながる可能性があり、その場合、browsingContextは
navigationParamsのナビゲーション可能のアクティブな閲覧
コンテキストではなく、新しく作成された閲覧コンテキストとなる。
このような場合、作成された Window、Document、および
エージェントは、最終的に使用されない。作成された Documentの
オリジンは不透明であるため、
新しい Documentに
対応する新しいエージェントおよび Windowを、このアルゴリズムの後の段階で作成することになる。
permissionsPolicyを、navigationParamsのナビゲーション可能のコンテナー、 navigationParamsのオリジン、および navigationParamsの応答が与えられたときに、 応答から権限ポリシーを 作成した結果とする。[PERMISSIONSPOLICY]
応答から権限ポリシーを作成する
アルゴリズムは、渡されたオリジンを使用する。
navigationParamsのナビゲーション可能のコンテナー文書で document.domainが
使用されている場合、そのオリジンは、渡されたオリジンと同一オリジンドメインにはなれない。
これは、これらの手順は documentが作成される前に実行されるため、
document自身はまだ document.domainを
使用できないためである。これは、代わりに同一オリジンチェックを行う場合と比べて、
権限ポリシーのチェックがより制限的になることを意味する。
これが実際にどのように動作するかについては、以下の例を参照。
navigationParamsのリクエストが null でない場合、creationURLを navigationParamsのリクエストの現在の URLに設定する。
windowを null とする。
browsingContextのアクティブ文書の初期
about:blankであるが true であり、browsingContextのアクティブ
文書のオリジンが、
navigationParamsのオリジンと同一
オリジンドメインである場合、windowを
browsingContextのアクティブウィンドウに設定する。
これは、初期
about:blank Documentと、
これから作成される新しい Documentの
両方が、同じ Windowオブジェクトを
共有することを意味する。
それ以外の場合:
oacHeaderを、navigationParamsの応答の
ヘッダーリストから、`Origin-Agent-Cluster`および
「item」が与えられたときに、構造化フィールド値を取得した結果とする。
oacHeaderが null でなく、oacHeader[0]がブール値 true である場合、 requestsOACを true とし、それ以外の場合は false とする。
navigationParamsの予約済み 環境が非セキュア コンテキストである場合、requestsOACを false に設定する。
agentを、navigationParamsのオリジン、 browsingContextのグループ、および requestsOACが与えられたときに、類似オリジンウィンドウ エージェントを取得した結果とする。
realmExecutionContextを、agentおよび次のカスタマイズが 与えられたときに、新しいレルムを 作成した結果とする:
グローバルオブジェクトには、新しい Window
オブジェクトを作成する。
グローバル thisバインディングには、browsingContextの
WindowProxy
オブジェクトを使用する。
windowを、realmExecutionContextの Realm コンポーネントのグローバル オブジェクトに設定する。
topLevelCreationURLを creationURLとする。
topLevelOriginを、navigationParamsのオリジンとする。
navigableのコンテナーが null でない場合:
parentEnvironmentを、navigableのコンテナーの関連する設定オブジェクトとする。
topLevelCreationURLを、parentEnvironmentのトップレベル 作成 URLに設定する。
topLevelOriginを、parentEnvironmentのトップレベル オリジンに設定する。
creationURL、realmExecutionContext、 navigationParamsの予約済み 環境、topLevelCreationURL、および topLevelOriginを使用して、ウィンドウ環境 設定オブジェクトをセットアップする。
loadTimingInfoを、そのナビゲーション 開始時刻が navigationParamsの応答のタイミング情報の開始時刻に設定された、新しい文書読み込みタイミング情報とする。
documentを、次の値を持つ新しい Documentとする:
loading」CustomElementRegistry
オブジェクトwindowの関連付けられた
Documentを documentに設定する。
documentの内部
祖先オリジンオブジェクト
リストを、documentおよび navigationParamsのiframe
要素のリファラー
ポリシーが与えられたときに、内部
祖先オリジンオブジェクトリスト作成
手順を実行した結果に設定する。
documentの祖先 オリジンリストを、documentが与えられたときに、祖先オリジンリスト 作成手順を実行した結果に設定する。
documentが与えられたとき、Documentの CSP 初期化を
実行する。[CSP]
navigationParamsのリクエストが null でない場合:
navigationParamsのフェッチ コントローラーが null でない場合:
fullTimingInfoを、navigationParamsのフェッチコントローラーから 完全なタイミング情報を抽出した結果とする。
redirectCountを 0 とする。
navigationParamsの応答のクロスオリジンリダイレクトを持つが false であるか、次のすべてが true である場合:
fullTimingInfo、redirectCount、navigationTimingType、 navigationParamsの応答の サービスワーカータイミング情報、 および navigationParamsの応答の 本体情報が与えられたとき、 documentについてナビゲーションタイミングエントリーを作成する。
navigationParamsの応答のタイミング情報、redirectCount、 navigationParamsのナビゲーションタイミング 型、および navigationParamsの応答のサービスワーカータイミング情報を使用して、 documentについてナビゲーションタイミングエントリーを作成する。
navigationParamsの応答が
`Refresh`
ヘッダーを持つ場合:
valueを、ヘッダーの値を同型復号した結果とする。
documentおよび valueを使用して、共有宣言的更新 手順を実行する。
現在、複数の `Refresh`
ヘッダーを処理する方法についての仕様はない。これはissue #2900として追跡されている。
navigationParamsのEarly Hints の コミットが null でない場合、navigationParamsのEarly Hints の コミットを documentとともに呼び出す。
document、navigationParamsの応答、および
「pre-media」が与えられたとき、リンクヘッダーを処理する。
navigationParamsのナビゲーション可能が
トップレベルトラバーサブルである場合、
documentおよび navigationParamsの応答が与えられたとき、
`Speculation-Rules`
ヘッダーを処理する。
これは、投機的読み込みがトップレベルトラバーサブルについてのみ 考慮されるための条件であり、それ以外の場合にこれらの規則をフェッチすることは無駄になる。
documentについて遅延フェッチクォータを解放する可能性がある。
documentを返す。
この例では、子文書が使用を試みる時点で同一
オリジンドメインであるにもかかわらず、子文書は PaymentRequestを
使用することを許可されない。子文書が初期化される時点では、親文書だけが document.domainを
設定しており、子文書は設定していない。
<!-- https://foo.example.com/a.html -->
<!doctype html>
< script >
document. domain = 'example.com' ;
</ script >
< iframe src = b.html ></ iframe > <!-- https://bar.example.com/b.html -->
<!doctype html>
< script >
document. domain = 'example.com' ; // This happens after the document is initialized
new PaymentRequest( …); // Not allowed to use
</ script > この例では、子文書が使用を試みる時点で同一オリジンドメインでないにもかかわらず、
子文書は PaymentRequestを
使用することを許可される。子文書が初期化される時点では、どの文書もまだ document.domainを
設定していないため、同一
オリジンドメインは通常の同一オリジンチェックにフォールバックする。
<!-- https://example.com/a.html -->
<!doctype html>
< iframe src = b.html ></ iframe >
<!-- The child document is now initialized, before the script below is run. -->
< script >
document. domain = 'example.com' ;
</ script > <!-- https://example.com/b.html -->
<!doctype html>
< script >
new PaymentRequest( …); // Allowed to use
</ script > Document
documentが与えられたとき、html/
head/bodyを設定するには:
ナビゲーション パラメーター navigationParamsが与えられたとき、HTML 文書を読み込むには:
documentを、「html」、「text/html」、および
navigationParamsが与えられたときに、Document
オブジェクトを作成して初期化した結果とする。
documentのURLが
about:blankである場合、
documentが与えられたとき、
html/head/bodyを設定する。
初期
about:blankでない Documentでさえ、その要素ノードが同期的に
与えられるこの特殊な場合は、展開済みのコンテンツとの互換性のために必要である。言い換えると、
代わりに「それ以外の場合」の分岐へ進み、空のバイト列を
HTML パーサーに供給して、
documentを非同期的に設定することには互換性がない。
それ以外の場合、宣言的シャドウ ルートを許可するが true であるHTML パーサーを作成し、documentに関連付ける。
フェッチの実行中にネットワークタスクソースがタスクキューに配置する各タスクは、その後、取得したバイトをパーサーの 入力バイトストリームに 充填し、HTML パーサーに 入力ストリームの適切な処理を実行させなければならない。
フェッチの実行中にネットワークタスク
ソースがタスクキューに配置する
最初のタスクは、そのタスクがHTML パーサーによって処理された後、
document、navigationParamsの応答、および「media」が与えられたとき、
リンクヘッダーを処理しなければならない。
スクリプトが実行される前に、ユーザーエージェントは、documentについて新しく作成された文書で スクリプトを実行できるが true になるまで待機しなければならない。
入力バイト ストリームは、トークナイザーで使用するために、バイトを文字に変換する。 この処理は、部分的にはリソースの実際のContent-Type メタデータに含まれる文字エンコーディング情報に 依存し、この目的には算出された型は使用されない。
利用できるバイトがなくなったとき、ユーザーエージェントは、
documentの関連するグローバル
オブジェクトが与えられたとき、ネットワークタスクソース上にグローバルタスクをキューに追加し、
パーサーに暗黙の EOF 文字を処理させなければならない。これにより最終的に
loadイベントが発火される。
documentを返す。
XML ファイルをインラインで表示する場合、ナビゲーションパラメーター
navigationParamsおよび文字列 typeが与えられたとき、ユーザーエージェントは、
XML、Namespaces in XML、XML Media
Types、DOM、およびその他の関連仕様で定義された要件に従い、
「xml」、type、および navigationParamsが与えられたとき、
Documentオブジェクトを作成して初期化し、
documentとし、その Documentを返さなければならない。また、対応する
XML パーサーも作成しなければならない。
[XML] [XMLNS] [RFC7303]
[DOM]
執筆時点では、XML 仕様コミュニティは、XML と DOM がどのように相互作用するかを 実際にはまだ規定していなかった。
フェッチの実行中にネットワークタスクソースが
タスクキューに配置する最初のタスクは、そのタスクがXML
パーサーによって処理された後、
document、navigationParamsの応答、および「media」が与えられたとき、
リンクヘッダーを処理しなければならない。
上記の仕様で示された規則に従って文字エンコーディングを決定するときに使用しなければならないのは、 この仕様で示されたアルゴリズムによって変更または暗示されたヘッダーではなく、実際の HTTP ヘッダーおよび その他のメタデータである。文字エンコーディングが確立されたら、文書の文字エンコーディングを、その 文字エンコーディングに設定しなければならない。
スクリプトが実行される前に、ユーザーエージェントは、新しく作成された Documentについて、新しく作成された文書で
スクリプトを実行できるが true になるまで待機しなければならない。
構文解析が完了したら、ユーザーエージェントは documentのWebDriver BiDi 用の読み込み中ナビゲーション IDを null に設定しなければならない。
HTML 文書の場合、これは構文解析が完了し、load イベントが発火された後にリセットされる。
構文解析処理からのエラーメッセージ(たとえば、XML 名前空間の整形式性エラー)は、
Documentを変更することによって
インラインで報告してもよい。
ナビゲーション パラメーター navigationParamsおよび文字列 typeが与えられたとき、 テキスト文書を読み込むには:
documentを、「html」、type、および
navigationParamsが与えられたときに、Document
オブジェクトを作成して初期化した結果とする。
documentのパーサーはモードフラグを変更できないを true に設定する。
documentのモードを
「no-quirks」に設定する。
HTML パーサーを作成し、 documentに関連付ける。トークナイザーがタグ名「pre」の開始タグトークンを発行し、 その後に単一の U+000A LINE FEED (LF) 文字を発行したかのように動作し、HTML パーサーのトークナイザーをPLAINTEXT 状態に切り替える。フェッチの実行中に ネットワークタスクソースが タスクキューに配置する各タスクは、その後、取得したバイトをパーサーの 入力バイト ストリームに充填し、HTML パーサーに入力ストリームの適切な処理を実行させなければならない。
documentのエンコーディングは、 構文解析中に文書を復号するために使用された文字エンコーディングに設定しなければならない。
フェッチの実行中にネットワークタスク
ソースがタスクキューに配置する
最初のタスクは、そのタスクがHTML パーサーによって処理された後、
document、navigationParamsの応答、および「media」が与えられたとき、
リンクヘッダーを処理しなければならない。
スクリプトが実行される前に、ユーザーエージェントは、documentについて新しく作成された文書で スクリプトを実行できるが true になるまで待機しなければならない。
利用できるバイトがなくなったとき、ユーザーエージェントは、
documentの関連するグローバル
オブジェクトが与えられたとき、ネットワークタスクソース上にグローバルタスクをキューに追加し、
パーサーに暗黙の EOF 文字を処理させなければならない。これにより最終的に
loadイベントが発火される。
ユーザーエージェントは、スタイルシートへのリンク、スクリプトの提供、文書への titleの付与など、
documentの head要素にコンテンツを
追加してもよい。
特に、ユーザーエージェントが RFC 3676 の Format=Flowed機能を
サポートする場合、テキストを正しく折り返し、引用機能を処理するために、
追加のスタイルを適用する必要がある。これは、たとえば CSS 拡張を使用して実行できる。
documentを返す。
プレーンテキスト文書のバイトを実際の文字に変換する方法の規則、およびテキストを実際に ユーザーへレンダリングするための規則は、リソースの算出された MIME 型(すなわち type)の仕様によって定義される。
multipart/x-mixed-replace
文書の読み込みナビゲーションパラメーター
navigationParams、ソーススナップショットパラメーター
sourceSnapshotParams、
およびオリジン
initiatorOriginが与えられたとき、
multipart/x-mixed-replace文書を読み込むには:
firstPartNavigationParamsを navigationParamsのコピーとする。
firstPartNavigationParamsの応答を、 navigationParamsの応答の本体のマルチパートストリームの最初の部分を表す 新しい応答に設定する。
documentを、firstPartNavigationParams、 sourceSnapshotParams、および initiatorOriginが与えられたときに、文書を読み込んだ結果とする。
navigationParamsの応答から取得される
追加の各本体部分について、ユーザーエージェントは、documentを使用し、
responseを
navigationParamsの応答に設定し、
historyHandlingを「replace」に設定して、
documentのノード
ナビゲーション可能を navigationParamsのリクエストのURLへナビゲートしなければならない。
documentを返す。
これらの本体部分を完全な独立リソースであるかのように処理するアルゴリズムの目的上、 ユーザーエージェントは、本体部分の後に続く境界へ到達した時点で、それらのリソースに それ以上バイトが存在しないかのように動作しなければならない。
したがって、読み込まれる各本体部分について、load
イベント(さらに言えば、unloadイベント)も
発火する。
navigationParamsおよび文字列 typeが与えられたとき、 メディア文書を読み込むには:
documentを、「html」、type、および
navigationParamsが与えられたときに、Document
オブジェクトを作成して初期化した結果とする。
documentのモードを
「no-quirks」に設定する。
documentが与えられたとき、
html/head/bodyを設定する。
以下で説明するメディア用の要素 host elementを、
body要素に付加する。
以下で説明する要素 host elementの適切な属性を、画像、動画、または音声リソースの アドレスに設定する。
ユーザーエージェントは、スタイルシートへのリンク、スクリプトの提供、文書への titleの付与、または
メディアの自動再生などのために、
documentの head要素にコンテンツを、
または host elementに属性を追加してもよい。
document、navigationParamsの応答、および
「media」が与えられたとき、リンクヘッダーを処理する。
ユーザーエージェントが documentの構文解析を停止したかのように動作する。
documentを返す。
メディア用に作成する要素 host elementは、下表で、最初のセルがそのメディアを説明する 行の 2 番目のセルに示された要素である。設定する適切な属性は、同じ行の 3 番目のセルに 示された属性である。
| メディアの種類 | メディア用の要素 | 適切な属性 |
|---|---|---|
| 画像 | img
|
src
|
| 動画 | video
|
src
|
| 音声 | audio
|
src
|
スクリプトが実行される前に、ユーザーエージェントは、Documentについて、新しく作成された文書で
スクリプトを実行できるが true になるまで待機しなければならない。
ユーザーエージェントが、ナビゲーション可能 navigable、ナビゲーション ID
navigationId、NavigationTimingType
navTimingType、およびユーザーナビゲーション
関与 userInvolvementが与えられたとき、ユーザーエージェントページまたは PDF ビューアーをインラインで表示する文書を
作成する場合、ユーザーエージェントは次のようにすべきである:
originを新しい不透明 オリジンとする。
coopを新しいオープナーポリシーとする。
coopEnforcementResultを、次の値を持つ新しいオープナー ポリシー適用結果とする:
navigationParamsを、次の値を持つ新しいナビゲーションパラメーターとする:
iframe要素のリファラー
ポリシーdocumentを、「html」、「text/html」、および
navigationParamsが与えられたときに、Document
オブジェクトを作成して初期化した結果とする。
documentを、通常の Documentレンダリング規則を使用して
レンダリングされないカスタムレンダリングに関連付けるか、ユーザーエージェントがレンダリングしようとする
コンテンツを表すようになるまで documentを変更する。
ユーザーエージェントが documentの構文解析を停止したかのように動作する。
これは、ナビゲーションが CSP によってブロックされたかどうか、または応答が
ネットワーク
エラーであったかどうかに関する情報が親ページへ漏洩することを避けるために行われる。
コンテナーが iframe要素である場合、
構文解析を
停止することで、iframe
load イベント手順が実行される。
documentを返す。
生成される Documentのオリジンが不透明であり、生成される Documentが DOM にアクセスする
スクリプトを実行できないことを保証しているため、この Documentの存在およびプロパティは、
ウェブ開発者のコードから観測できない。これは、上記の値の大部分、たとえば
text/htmlの型は重要でないことを意味する。
同様に、navigationParams内のほとんどの項目は、Document作成
アルゴリズムが混乱するのを防ぐこと以外に観測可能な効果を持たないため、既定値に設定される。
Documentには、
完全読み込み時刻(時刻または null)があり、
初期値は null である。
Document
documentの読み込みを完全に完了するには:
documentの完全読み込み時刻を現在の 時刻に設定する。
containerを、documentのノードナビゲーション可能のコンテナーとする。
documentが frameまたは iframe内の初期
about:blank Documentである場合、
このアルゴリズムを呼び出す閲覧コンテキストの作成時点では、
コンテナー関係がまだ確立されていないため、これは null となる。(これは新しい子ナビゲーション可能を作成するの
後続の手順で行われる。)
この結果、次の手順は何も行わない。すなわち、このような場合、コンテナー要素に非同期の
loadイベントを発火しない。
代わりに、iframe属性を処理するときの
特殊な初期挿入の場合に、同期的な loadイベントが発火される。
containerが iframe要素である場合、
containerが与えられたとき、DOM 操作タスクソース上に要素タスクをキューに追加し、
containerが与えられたときにiframe load イベント手順を実行する。
それ以外の場合、containerが null でない場合、
containerが与えられたとき、DOM
操作タスクソース上に要素タスクをキューに追加し、
containerに対して loadという名前のイベントを発火する。
Documentには、
初期値が true でなければならない再利用可能状態、および初期値が false である
ページを表示中ブール値がある。ページを
表示中ブール値は、スクリプトが pageshowおよび
pagehideイベントを
一貫した方法で受信すること(たとえば、間に pageshowを挟まずに
2 つの pagehideイベントを
連続して受信したり、その逆になったりしないこと)を保証するために使用される。
Documentには、
初期値が 0 である DOMHighResTimeStamp
一時停止時刻がある。
Documentには、
初期状態が空である一時停止されたタイマーハンドルのリストがある。
イベントループには、 初期値が 0 でなければならない終了ネストレベルカウンターがある。
Documentオブジェクトには、
以下のアルゴリズムの実行中に特定の操作を無視するために使用されるアンロード
カウンターがある。カウンターの初期値は 0 に設定しなければならない。
任意の Document
newDocumentが与えられたとき、Document
oldDocumentをアンロードするには:
表明:これは oldDocumentの関連する エージェントのイベント ループ上にキューされたタスクの一部として実行されている。
unloadTimingInfoを新しい文書アンロードタイミング 情報とする。
newDocumentが与えられていない場合、unloadTimingInfoを null に設定する。
この場合、oldDocumentのアンロードにかかった時間を知る必要がある 新しい文書は存在しない。
それ以外の場合、newDocumentのイベント ループが oldDocumentのイベントループでない場合、 ユーザーエージェントは oldDocumentを並列にアンロードしている可能性がある。 その場合、ユーザーエージェントは unloadTimingInfoを null に設定すべきである。
この場合、newDocumentの読み込みは oldDocumentのアンロードにかかる時間の影響を受けないため、そのタイミング情報を 伝達しても意味がない。
ユーザーエージェントが oldDocumentをセッション履歴エントリー内で存続させ、 後で履歴トラバーサルに使用できるようにする意図がある場合、 intendToKeepInBfcacheを true とする。
oldDocumentが再利用可能でない場合、または oldDocumentの子孫のうち、ユーザーエージェントが同じ方法で存続させる意図のないものが 存在する場合(その再利用可能性がないことに起因する場合を含む)、 これは false でなければならない。
eventLoopを、oldDocumentの関連するエージェントのイベントループとする。
eventLoopの終了ネストレベルを 1 増加させる。
oldDocumentのアンロード カウンターを 1 増加させる。
intendToKeepInBfcacheが false の場合、oldDocumentの再利用可能状態を false に設定する。
oldDocumentのページを表示中が true の場合:
oldDocumentのページを 表示中を false に設定する。
oldDocumentの関連するグローバル
オブジェクトに対し、oldDocumentの再利用可能状態を使用して、pagehideという名前の
ページ遷移イベントを発火する。
oldDocumentの表示状態を更新し、
「hidden」にする。
unloadTimingInfoが null でない場合、 unloadTimingInfoのunload イベント開始 時刻を、newDocumentの関連するグローバルオブジェクトが 与えられたときの現在の高分解能時刻を、 oldDocumentの関連する設定 オブジェクトのクロスオリジン分離 能力が与えられたときに粗くした値に設定する。
oldDocumentの再利用可能
状態が false の場合、従来の対象上書きフラグを設定して、
oldDocumentの関連するグローバル
オブジェクトに対し、unloadという名前のイベントを発火する。
unloadTimingInfoが null でない場合、 unloadTimingInfoのunload イベント終了時刻を、 newDocumentの関連するグローバルオブジェクトが 与えられたときの現在の高分解能時刻を、 oldDocumentの関連する設定 オブジェクトのクロスオリジン分離 能力が与えられたときに粗くした値に設定する。
eventLoopの終了ネストレベルを 1 減少させる。
oldDocumentの一時停止 時刻を、documentの関連するグローバルオブジェクトが 与えられたときの現在の高分解能時刻に設定する。
oldDocumentの一時停止されたタイマーハンドルを、 アクティブなタイマーのマップについて キーを取得した結果に設定する。
oldDocumentのユーザーによってスクロールされたことがあるを false に設定する。
この仕様およびその他の適用可能な仕様によって 定義される、oldDocumentについての文書アンロード後片付け手順を実行する。
oldDocumentのノード ナビゲーション可能がトップレベルトラバーサブルである場合、 oldDocumentのノードナビゲーション可能が与えられたとき、 トップレベル トラバーサブルおよびその子孫の復元されなかった理由を構築する。
oldDocumentのアンロード カウンターを 1 減少させる。
newDocumentが与えられ、newDocumentのクロスオリジンリダイレクトを介して 作成されたが false であり、newDocumentのオリジンが oldDocumentのオリジンと同一である場合、 newDocumentの以前の文書のアンロードタイミングを unloadTimingInfoに設定する。
Document
document、任意の Documentまたは null
の
newDocument(既定値は null)、任意の手順集合 afterAllUnloads、および
任意の手順集合 firePageSwapStepsが与えられたとき、文書およびその子孫をアンロードするには:
表明:これは documentのノード ナビゲーション可能のトラバーサブル ナビゲーション可能のセッション履歴トラバーサルキュー内で 実行されている。
childNavigablesを、documentの子ナビゲーション可能とする。
numberUnloadedを 0 とする。
childNavigablesの各 childNavigableについてどの順序で?、childNavigableのアクティブウィンドウが与えられたとき、 ナビゲーションおよび トラバーサルタスクソース上にグローバルタスクをキューに追加し、 次の手順を実行する:
incrementUnloadedを、 numberUnloadedをインクリメントするアルゴリズム手順とする。
childNavigableの アクティブ文書、null、および incrementUnloadedが与えられたとき、文書およびその子孫を アンロードする。
numberUnloadedが childNavigableのサイズと等しくなるまで待機する。
documentの関連するグローバルオブジェクトが 与えられたとき、ナビゲーションおよび トラバーサルタスクソース上にグローバルタスクをキューに追加し、 次の手順を実行する:
firePageSwapStepsが与えられている場合、 firePageSwapStepsを実行する。
documentをアンロードし、 newDocumentが null でない場合はそれを渡す。
afterAllUnloadsが与えられていた場合、それを実行する。
この仕様は、次の文書アンロード後片付け手順を定義する。
他の仕様は、さらに定義できる。Document
documentが与えられたとき:
windowを、documentの関連するグローバル オブジェクトとする。
関連するグローバル
オブジェクトが windowである各 WebSocket
オブジェクト webSocketについて、webSocketを消滅させる。
これがいずれかの WebSocket
オブジェクトに影響した場合、documentおよび「websocket」が
与えられたとき、文書を再利用不能にする。
関連するグローバル
オブジェクトが windowである各 WebTransport
オブジェクト transportについて、transportが与えられたときにコンテキスト後片付け手順を実行する。
documentの再利用可能 状態が false の場合:
関連する
グローバルオブジェクトが windowと等しい各 EventSourceオブジェクト
eventSourceについて、eventSourceを強制的に閉じる。
windowのアクティブなタイマーのマップをクリアする。
仕様間の呼び出し順序が明確に定義されるよう、仕様の著者は文書アンロード後片付け 手順フックを使用するのではなく、ここから自身の仕様への呼び出しを追加するプルリクエストを 送信する方が望ましい。執筆時点で、次の仕様が文書アンロード後片付け 手順を持つことが知られており、未指定の順序で実行される:Fullscreen API、 Web NFC、WebDriver BiDi、Compute Pressure、 File API、Media Capture and Streams、 Picture-in-Picture、Screen Orientation、 Service Workers、WebLocks API、WebAudio API、WebRTC。[FULLSCREEN] [WEBNFC] [WEBDRIVERBIDI] [COMPUTEPRESSURE] [FILEAPI] [MEDIASTREAM] [PICTUREINPICTURE] [SCREENORIENTATION] [SW] [WEBLOCKS] [WEBAUDIO] [WEBRTC]
Issue #8906は、 これらの手順の順序を明確にする作業を追跡している。
Document
documentを破棄するには:
表明:これは documentの関連する エージェントのイベント ループ上にキューされたタスクの一部として実行されている。
documentを中止する。
documentの再利用可能状態を false に設定する。
portsを、その関連するグローバル
オブジェクトの関連付けられた
Documentが
documentである MessagePortのリストとする。
ports内の各 portについて、 portを切り離す。
この仕様およびその他の適用可能な仕様によって 定義される、documentについての文書アンロード後片付け手順を実行する。
documentの閲覧コンテキストを null に設定する。
documentのノード ナビゲーション可能のアクティブなセッション履歴エントリーの文書状態の文書を null に設定する。
その集合が documentを含む各 WorkerGlobalScope
オブジェクトの所有者集合から、
documentを削除する。
documentのワークレットグローバル スコープ内の各 workletGlobalScopeについて、 workletGlobalScopeを終了する。
子ナビゲーション可能を破棄している場合、
破棄後であっても、Documentオブジェクト自体は、
引き続きスクリプトからアクセスできる可能性がある。
Document
documentおよび任意の手順集合 afterAllDestructionが与えられたとき、
文書およびその子孫を破棄するには、
次の手順を並列に実行する:
documentが完全に アクティブでない場合:
reasonをユーザーエージェント固有のブロック理由の
文字列とする。該当するものがない場合、reasonを「masked」とする。
documentおよび reasonが与えられたとき、文書を再利用不能にする。
documentのノード ナビゲーション可能がトップレベル トラバーサブルである場合、 documentのノードナビゲーション可能が与えられたとき、 トップレベル トラバーサブルおよびその子孫の復元されなかった理由を構築する。
childNavigablesを、documentの子ナビゲーション可能とする。
numberDestroyedを 0 とする。
childNavigablesの各 childNavigableについてどの順序で?、childNavigableのアクティブウィンドウが与えられたとき、 ナビゲーションおよび トラバーサルタスクソース上にグローバルタスクをキューに追加し、 次の手順を実行する:
incrementDestroyedを、 numberDestroyedをインクリメントするアルゴリズム手順とする。
childNavigableの アクティブ文書および incrementDestroyedが与えられたとき、文書およびその 子孫を破棄する。
numberDestroyedが childNavigableのサイズと等しくなるまで待機する。
documentの関連するグローバルオブジェクトが 与えられたとき、ナビゲーションおよび トラバーサルタスクソース上にグローバルタスクをキューに追加し、 次の手順を実行する:
documentを破棄する。
afterAllDestructionが与えられていた場合、それを実行する。
Document
documentを中止するには:
表明:これは documentの関連するエージェントのイベントループ上にキューされたタスクの一部として実行されている。
documentのコンテキスト内にあるフェッチアルゴリズムのすべてのインスタンスをキャンセルし、
それらについてキューに追加されたタスクを破棄し、それらについてネットワークから
さらに受信したデータを破棄する。これにより、いずれかのフェッチアルゴリズムのインスタンスがキャンセルされたか、
キューに追加されたタスクまたはネットワークデータが破棄された場合、
documentおよび「fetch」が与えられたとき、文書を再利用不能にする。
documentのWebDriver BiDi 用の読み込み中 ナビゲーション IDが null でない場合:
documentの
ノードナビゲーション可能および新しいWebDriver BiDi ナビゲーション状態を使用して、
WebDriver BiDi ナビゲーション中止を
呼び出す。この状態のIDは
documentのWebDriver BiDi 用の読み込み中
ナビゲーション ID、状態は「canceled」、
URLは
documentのURLである。
documentのWebDriver BiDi 用の読み込み中 ナビゲーション IDを null に設定する。
documentにアクティブな パーサーがある場合:
documentのアクティブなパーサーが中止されたを true に設定する。
documentおよび「parser-aborted」が与えられたとき、文書を再利用不能にする。
Document
documentが与えられたとき、文書およびその子孫を中止するには:
表明:これは documentの関連するエージェントのイベントループ上にキューされたタスクの一部として実行されている。
descendantNavigablesを、documentの子孫 ナビゲーション可能とする。
descendantNavigablesの各 descendantNavigableについてどの順序で?、descendantNavigableのアクティブ ウィンドウが与えられたとき、ナビゲーションおよび トラバーサルタスクソース上にグローバルタスクをキューに追加し、 次の手順を実行する:
documentを中止する。
ナビゲーション可能 navigableの読み込みを停止するには:
documentを、navigableのアクティブ 文書とする。
documentのアンロード カウンターが 0 であり、navigableの 進行中のナビゲーションがナビゲーション IDである場合、 navigableの進行中のナビゲーションを設定し、 null にする。
ナビゲーション中の特定の時点では、進行中の ナビゲーションを変更すると以降の作業が放棄されるため、これは navigableの進行中のナビゲーションを中止する効果を持つ。
documentが与えられたとき、文書およびその子孫を中止する。
ユーザーエージェントは、そのユーザーインターフェイスを
通じて、進行中のナビゲーションが
「traversal」である場合、すなわちトラバーサルの停止も許可する。上記のアルゴリズムは、
これを考慮していない。(一方、ユーザーエージェントは window.stop()によるトラバーサルの停止を許可しないため、
上記のアルゴリズムは、その呼び出し元に対しては正しい。)issue #6905を参照。
投機的読み込みとは、ナビゲーションが開始する前に、プリフェッチなどの ナビゲーション処理を実行することである。これにより、後続のナビゲーションが高速になる。
開発者は、投機規則を使用して投機的読み込みを開始できる。 ユーザーエージェントも、アドレスバーへの入力など、特定の実装定義の状況で投機的読み込みを実行することがある。
投機規則は、 開発者が有益であると考える投機的読み込み処理について、ブラウザーに指示するためのものである。 これらは、次のいずれかによって JSON 文書として提供される:
`Speculation-Rules`
HTTP
応答ヘッダーで指定された URL からフェッチされたリソース。
次の JSON 文書は、ユーザーエージェントがリファラーによって開始されるナビゲーション プリフェッチを開始するために望まれる複数の条件を指定する投機規則セットとして構文解析される:
{
"prefetch" : [
{
"urls" : [ "/chapters/5" ]
},
{
"eagerness" : "moderate" ,
"where" : {
"and" : [
{ "href_matches" : "/*" },
{ "not" : { "selector_matches" : ".no-prefetch" } }
]
}
}
]
} 投機規則セットを表す JSON 文書は、次の 投機規則セット作成要件を満たさなければならない:
有効な JSON でなければならない。[JSON]
JSON は、キー「tag」、「prefetch」、および
「prerender」を最大 3 つ持つ JSON オブジェクトを表さなければならない。
この標準では、「prerender」は構文解析時に任意で
「prefetch」へ変換される。一部の実装は、Prerendering Revampedで
規定されているように、プリレンダーについて異なる動作を実装することがある。
[PRERENDERING-REVAMPED]
「tag」キーに対応する値は、存在する場合、
投機規則タグでなければならない。
「prefetch」および「prerender」キーに対応する値は、存在する場合、
有効な投機規則の
配列でなければならない。
有効な投機規則とは、次の要件を満たす JSON オブジェクトである:
最大で次のキーを持たなければならない:「source」、「urls」、
「where」、「relative_to」、
「eagerness」、「referrer_policy」、「tag」、
「requires」、「expects_no_vary_search」、または
「target_hint」。
この標準では、
「target_hint」は無視される。
「source」キーに対応する値は、存在する場合、
「list」または「document」のいずれかでなければならない。
「source」キーに対応する値が「list」である場合、
「urls」キーが存在し、「where」キーは存在してはならない。
「source」キーに対応する値が「document」である場合、
「urls」キーは存在してはならない。
「urls」キーと「where」キーの両方が
存在してはならない。
「source」キーに対応する値が「document」であるか、
「where」キーが存在する場合、「relative_to」キーは存在してはならない。
「urls」キーに対応する値は、存在する場合、有効な URL 文字列の配列でなければならない。
「where」キーに対応する値は、存在する場合、
有効な文書規則述語でなければならない。
「relative_to」キーに対応する値は、存在する場合、
「ruleset」または「document」のいずれかでなければならない。
「eagerness」キーに対応する値は、存在する場合、
投機規則の積極度でなければならない。
「referrer_policy」キーに対応する値は、存在する場合、
リファラーポリシーでなければならない。
「tag」キーに対応する値は、存在する場合、
投機規則タグでなければならない。
「requires」キーに対応する値は、存在する場合、
投機規則要件の配列でなければならない。
「expects_no_vary_search」キーに対応する値は、存在する場合、
`No-Vary-Search`
ヘッダー値として構文解析可能な
文字列でなければならない。
有効な文書規則述語とは、次の要件を満たす JSON オブジェクトである:
キー「and」、「or」、「not」、
「href_matches」、または
「selector_matches」のうち、正確に 1 つを含まなければならない。
上記のキーまたは「relative_to」以外のキーを含んではならない。
キー「relative_to」を含む場合、キー
「href_matches」も含まなければならない。
「relative_to」キーに対応する値は、存在する場合、
「ruleset」または「document」のいずれかでなければならない。
「and」または「or」キーに対応する値は、存在する場合、
有効な文書規則述語の配列でなければならない。
「not」キーに対応する値は、存在する場合、
有効な文書規則述語でなければならない。
「href_matches」キーに対応する値は、存在する場合、
有効な URL パターン入力、または有効な URL
パターン入力の配列でなければならない。
「selector_matches」キーに対応する値は、存在する場合、
<selector-list>に
一致する文字列、または
<selector-list>に
一致する文字列の配列でなければならない。
有効な URL パターン入力は、次のいずれかである:
キーが URLPatternInit
辞書のメンバーから選ばれ、値がスカラー値
文字列である JSON オブジェクト。
将来、プリレンダー規則など、他の規則も使用可能になる予定である。 そのような未承認の拡張については、Prerendering Revampedを参照。 [PRERENDERING-REVAMPED]
文書規則述語は、次のいずれかである:
文書規則 URL パターン述語; または
節。文書規則述語
文書規則 URL パターン述語は、次の 項目を持つ構造体である:
投機規則の積極度は、次の文字列のいずれかである:
immediate」開発者は、関連する投機的読み込みを実行することが有益である可能性が非常に高く、 その読み込みを完了するには大幅な先行時間が必要になる可能性もあると考えている。 ユーザーエージェントは通常、ユーザー設定、デバイスの状態、リソース制限などの考慮事項にのみ 従いつつ、実用上可能な限り早く投機的読み込み候補を実行すべきである。
eager」ユーザーエージェントは、ユーザーが将来この URL へナビゲートする可能性をわずかでも示した場合に、 投機的読み込み候補を実行すべきである。たとえば、ユーザーがリンクに向かってカーソルを移動したり、 一瞬でもリンク上にカーソルを置いたり、リンクがビューポート内で比較的目立つものの一つであるときに スクロールを一時停止した場合がある。著者は、可能な限り多くのナビゲーションを、 可能な限り早く捉えようとしている。
moderate」ユーザーの動作から、近い将来この URL へナビゲートする可能性が示される場合、
ユーザーエージェントは候補を実行すべきである。たとえば、ユーザーがリンクをビューポート内へ
スクロールし、しばらくカーソルをその上に置くなど、クリックする可能性が高い兆候を示した場合がある。
開発者は「eager」と
「conservative」の
間のバランスを求めている。
conservative」ユーザーがいつでもこの URL へナビゲートする可能性が非常に高い場合に限り、 ユーザーエージェントは候補を実行すべきである。たとえば、ユーザーがリンクとの操作を 開始した場合がある。開発者は、リソース上の比較的小さな代償と引き換えに、 投機的読み込みの利点の一部を得ようとしている。
投機規則タグは、そのコードポイントがすべて U+0020 から U+007E までの範囲内にあるASCII 文字列、または null のいずれかである。
このコードポイント範囲の制限により、値をエスケープまたは変更せずに HTTP ヘッダーで送信できることが保証される。
投機規則要件は、文字列
「anonymous-client-ip-when-cross-origin」である。
将来、さらに多くの要件が定義される可能性がある。
投機的読み込みは段階的拡張であるため、この標準の構文解析動作はかなり保守的である。 特に、不明なキーまたは無効な値は通常、構文解析の失敗を引き起こす。投機規則を 誤って解釈する可能性があるよりも、何もしない方が安全であるためである。
ただし、単一の投機規則の構文解析に失敗しても、他の投機規則は引き続き処理できる。 投機規則セット全体が破棄されるのは、トップレベルの設定が不正である場合のみである。
文字列 input、
Document
document、およびURL baseURLが与えられたとき、投機規則セット文字列を構文解析するには:
parsedを、inputが与えられたときに、JSON 文字列を Infra 値として構文解析した結果とする。
parsedがマップでない場合、
トップレベルの値が JSON オブジェクトである必要があることを示す TypeErrorを
スローする。
resultを新しい投機規則セットとする。
tagを null とする。
parsed[「tag」]が存在する場合:
typesToTreatAsPrefetchを « 「prefetch」 » とする。
ユーザーエージェントは、typesToTreatAsPrefetchに
「prerender」を付加してもよい。
この仕様には プリフェッチのみが含まれるため、これによりユーザーエージェントはプリレンダーの要求を プリフェッチの要求として扱うことができる。Prerendering Revamped仕様に従って プリレンダーを実装するユーザーエージェントは、代わりにこれらをプリレンダー要求として解釈する。 [PRERENDERING-REVAMPED]
typesToTreatAsPrefetchの各 typeについて:
parsed[type]が存在する場合:
parsed[type]がリストである場合、 parsed[type]の各 ruleについて:
ruleを、rule、tag、 document、および baseURLが与えられたときに、投機規則を 構文解析した結果とする。
ruleが null の場合、続行する。
それ以外の場合、ユーザーエージェントは、typeの規則リストが JSON 配列である必要があることを示す警告をコンソールに報告してもよい。
resultを返す。
マップ
input、投機規則タグ
rulesetLevelTag、Document
document、およびURL baseURLが与えられたとき、投機規則を構文解析するには:
inputがマップでない場合:
ユーザーエージェントは、規則が JSON オブジェクトである必要があることを示す警告をコンソールに報告してもよい。
null を返す。
inputが「source」、「urls」、
「where」、「relative_to」、「eagerness」、
「referrer_policy」、「tag」、「requires」、
「expects_no_vary_search」、または「target_hint」以外のキーを持つ場合:
ユーザーエージェントは、規則に認識されないキーが含まれていることを示す警告をコンソールに報告してもよい。
null を返す。
「target_hint」は、
この標準の処理モデルには影響を与えない。ただし、Prerendering Revampedの
実装ではプリレンダー規則に使用できるため、ユーザーエージェントにそのような規則の
構文解析を失敗させることを要求するのは逆効果となる。
[PRERENDERING-REVAMPED]。
sourceを null とする。
input[「source」]が存在する場合、
sourceを input[「source」]に設定する。
それ以外の場合、input[「urls」]が存在し、
input[「where」]が存在しない場合、
sourceを「list」に設定する。
それ以外の場合、input[「where」]が存在し、
input[「urls」]が存在しない場合、
sourceを「document」に設定する。
sourceが「list」でも「document」でもない場合:
ユーザーエージェントは、ソースを推論できなかったか、無効なソースが指定されたことを 示す警告をコンソールに報告してもよい。
null を返す。
urlsを空のリストとする。
predicateを null とする。
sourceが「list」である場合:
input[「where」]が存在する場合:
ユーザーエージェントは、この規則について競合するソースが存在したことを示す警告をコンソールに報告してもよい。
null を返す。
input[「relative_to」]が存在する場合:
input[「relative_to」]が「ruleset」でも
「document」でもない場合:
ユーザーエージェントは、指定された relative-to 値が無効であることを示す警告をコンソールに報告してもよい。
null を返す。
input[「relative_to」]が「document」である場合、
baseURLを documentの
文書ベース URLに設定する。
input[「urls」]が存在しないか、
リストでない場合:
ユーザーエージェントは、指定された URL リストが無効であることを示す警告をコンソールに報告してもよい。
null を返す。
input[「urls」]の各
urlStringについて:
urlStringが文字列でない場合:
ユーザーエージェントは、指定された URL が文字列でなければならないことを示す警告をコンソールに報告してもよい。
null を返す。
parsedURLを、baseURLを使用して urlStringをURL 構文解析した結果とする。
parsedURLが失敗であるか、parsedURLのスキームがHTTP(S) スキームでない場合:
ユーザーエージェントは、指定された URL 文字列を構文解析できなかったことを示す警告をコンソールに報告してもよい。
続行する。
urlsに parsedURLを付加する。
sourceが「document」である場合:
input[「urls」]または
input[「relative_to」]が存在する場合:
ユーザーエージェントは、この規則について競合するソースが存在したことを示す警告をコンソールに報告してもよい。
null を返す。
input[「where」]が存在しない場合、
predicateを、その節が空のリストである文書規則の
論理積に設定する。
そのような述語は、すべてのリンクに一致する。
それ以外の場合、predicateを、input[「where」]、
document、および baseURLが与えられたときに、文書規則述語を構文解析した結果に設定する。
predicateが null の場合、null を返す。
sourceが「list」である場合、eagernessを
「immediate」とし、
それ以外の場合は「conservative」とする。
input[「eagerness」]が存在する場合:
input[「eagerness」]が投機規則の
積極度でない場合:
ユーザーエージェントは、積極度が無効であることを示す警告をコンソールに報告してもよい。
null を返す。
eagernessを input[「eagerness」]に設定する。
referrerPolicyを空文字列とする。
input[「referrer_policy」]が存在する場合:
input[「referrer_policy」]がリファラー
ポリシーでない場合:
ユーザーエージェントは、リファラーポリシーが無効であることを示す警告をコンソールに報告してもよい。
null を返す。
referrerPolicyを input[「referrer_policy」]に設定する。
tagsを空の順序付き集合とする。
rulesetLevelTagが null でない場合、tagsに rulesetLevelTagを付加する。
input[「tag」]が存在する場合:
input[「tag」]が投機規則
タグでない場合:
ユーザーエージェントは、タグが無効であることを示す警告をコンソールに報告してもよい。
null を返す。
tagsに input[「tag」]を付加する。
requirementsを空の順序付き集合とする。
input[「requires」]が存在する場合:
input[「requires」]がリストでない場合:
ユーザーエージェントは、要件を理解できなかったことを示す警告をコンソールに報告してもよい。
null を返す。
input[「requires」]の各
requirementについて:
requirementが投機規則要件でない場合:
ユーザーエージェントは、その要件を理解できなかったことを示す警告をコンソールに報告してもよい。
null を返す。
requirementsに requirementを付加する。
noVarySearchHintを既定の URL 検索差異とする。
input[「expects_no_vary_search」]が存在する場合:
input[「expects_no_vary_search」]が文字列でない場合:
ユーザーエージェントは、`No-Vary-Search`
ヒントが無効であることを示す警告をコンソールに報告してもよい。
null を返す。
noVarySearchHintを、
input[「expects_no_vary_search」]が与えられたときに、URL 検索差異を構文解析した結果に設定する。
次の値を持つ投機規則を返す:
値 input、Document
document、およびURL baseURLが与えられたとき、文書規則述語を構文解析するには:
inputがマップでない場合:
ユーザーエージェントは、文書規則述語が無効であることを示す警告をコンソールに報告してもよい。
null を返す。
inputが「and」、「or」、
「not」、「href_matches」、または
「selector_matches」のうち正確に 1 つを含まない場合:
ユーザーエージェントは、文書規則述語が空または曖昧であることを示す警告をコンソールに報告してもよい。
null を返す。
predicateTypeを、前の手順で見つかった単一のキーとする。
predicateTypeが「and」または「or」である場合:
inputが predicateType以外のキーを持つ場合:
ユーザーエージェントは、文書規則述語に予期しない追加オプションが含まれていることを 示す警告をコンソールに報告してもよい。
null を返す。
input[predicateType]がリストでない場合:
ユーザーエージェントは、文書規則述語に無効な節リストが含まれていることを示す警告をコンソールに報告してもよい。
null を返す。
clausesを空のリストとする。
input[predicateType]の各 rawClauseについて:
clauseを、rawClause、 document、および baseURLが与えられたときに、文書規則 述語を構文解析した結果とする。
clauseが null の場合、null を返す。
clausesに clauseを付加する。
predicateTypeが「not」である場合:
inputが「not」以外のキーを持つ場合:
ユーザーエージェントは、文書規則述語に予期しない追加オプションが含まれていることを 示す警告をコンソールに報告してもよい。
null を返す。
clauseを、input[predicateType]、 document、および baseURLが与えられたときに、文書規則述語を構文解析した結果とする。
clauseが null の場合、null を返す。
predicateTypeが「href_matches」である場合:
inputが「href_matches」または
「relative_to」以外のキーを持つ場合:
ユーザーエージェントは、文書規則述語に予期しない追加オプションが含まれていることを 示す警告をコンソールに報告してもよい。
null を返す。
input[「relative_to」]が存在する場合:
input[「relative_to」]が「ruleset」でも
「document」でもない場合:
ユーザーエージェントは、指定された relative-to 値が無効であることを示す警告をコンソールに報告してもよい。
null を返す。
input[「relative_to」]が「document」である場合、
baseURLを documentの
文書ベース URLに設定する。
rawPatternsを
input[「href_matches」]とする。
rawPatternsがリストでない場合、 rawPatternsを « rawPatterns » に設定する。
patternsを空のリストとする。
rawPatternsの各 rawPatternについて:
patternを、rawPatternおよび baseURLが与えられたときに、Infra 値から URL パターンを 構築した結果とする。この手順が例外をスローした場合、その例外を捕捉し、 patternを null に設定する。
patternが null の場合:
ユーザーエージェントは、指定された URL パターンが無効であることを示す警告をコンソールに報告してもよい。
null を返す。
patternsに patternを付加する。
パターンが patternsである文書規則 URL パターン 述語を返す。
predicateTypeが「selector_matches」である場合:
inputが「selector_matches」以外のキーを持つ場合:
ユーザーエージェントは、文書規則述語に予期しない追加オプションが含まれていることを 示す警告をコンソールに報告してもよい。
null を返す。
rawSelectorsを
input[「selector_matches」]とする。
rawSelectorsがリストでない場合、 rawSelectorsを « rawSelectors » に設定する。
selectorsを空のリストとする。
rawSelectorsの各 rawSelectorについて:
parsedSelectorListを失敗とする。
rawSelectorが文字列である場合、 parsedSelectorListを、rawSelectorが与えられたときに、セレクターを構文解析した結果に設定する。
parsedSelectorListが失敗である場合:
ユーザーエージェントは、指定されたセレクターリストが無効であることを示す警告をコンソールに報告してもよい。
null を返す。
parsedSelectorListの各 selectorについて、 selectorsに selectorを付加する。
セレクターが selectorsである文書規則セレクター述語を返す。
表明:前の分岐のいずれかが選択されるため、 この手順に到達することはない。
プリフェッチ候補は、次の追加の項目を持つ投機的読み込み候補である:
匿名化ポリシー。プリフェッチ IP 匿名化ポリシー
プリフェッチ IP 匿名化ポリシーは、null またはクロスオリジンプリフェッチ IP 匿名化ポリシーのいずれかである。
クロスオリジンプリフェッチ IP 匿名化ポリシーは、 唯一の項目として、オリジンであるオリジンを持つ構造体である。
投機的読み込み候補 candidateAは、次の手順が true を返す場合、別の投機的読み込み 候補 candidateBと重複する:
candidateAのNo-Vary-Search ヒントが candidateBのNo-Vary-Search ヒントと等しくない場合、false を返す。
candidateAのURLが、 candidateAのNo-Vary-Search ヒントを使用したときに、candidateBのURLと検索差異を法として同等でない場合、false を返す。
true を返す。
No-Vary-Search ヒントが 同等であるという要件は、やや厳格である。これは、理論上は一致として扱える一部の場合が、 そのようには扱われないことを意味する。そのため、重複する投機的読み込みが発生する可能性がある。
しかし、より緩やかな一致を許可すると、このチェックは同値関係ではなくなり、 そのような一致を生成するには、正規化された URL キーを使用するより単純な方式ではなく、 完全な比較を行う実装方式が必要になる。これは、No Vary Search § 6 Comparingにおけるサーバー運用者向けのベストプラクティスおよび 付随する HTTP キャッシュ実装上の注記と一致している。
実際には、サーバー運用者および対応する投機規則を記述するウェブ開発者は
ベストプラクティスに従い、静的な `No-Vary-Search`
ヘッダー値/投機規則ヒントを使用するため、これによって重複する投機的読み込みが
発生するとは予想されない。
3 つの投機的読み込み 候補を考える:
Aは、https://example.com?a=1&b=1というURLと、
params=("a")から構文解析されたNo-Vary-Search ヒントを持つ。
Bは、https://example.com?a=2&b=1というURLと、
params=("b")から構文解析されたNo-Vary-Search ヒントを持つ。
Cは、https://example.com?a=2&b=2というURLと、
params=("a")から構文解析されたNo-Vary-Search ヒントを持つ。
重複するの現在の定義では、 これらの候補はいずれも互いに重複しない。3 つすべてを含む投機規則 セットは、3 つの個別の投機的読み込みを発生させる可能性がある。
同等のNo-Vary-Search ヒントを 要求しない定義では、AのNo-Vary-Search ヒントを使用して Aと Bを一致するとみなし、BのNo-Vary-Search ヒントを使用して Bと Cを一致するとみなせる。しかし、Aと Cを 一致するとみなすことはできないため、推移的ではなく、したがって同値関係ではない。
各 Documentには、
初期状態が空である投機規則セットのリストである投機規則セットがある。
各 Documentには、
初期値が false であるブール値の投機的読み込みを検討するマイクロタスクが
キューに追加済みがある。
Document
documentについて投機的読み込みを検討するには:
documentのノードナビゲーブルがトップレベルトラバーサブルでない場合、 戻る。
子ナビゲーブルへの投機的読み込みの サポートにはいくつかの複雑さがあり、現在は定義されていない。将来定義できる可能性がある。
documentの投機的読み込みを 検討するマイクロタスクがキューに追加済みが true の場合、戻る。
documentの投機的読み込みを 検討するマイクロタスクがキューに追加済みを true に設定する。
documentが与えられたとき、次の手順を実行するマイクロタスクをキューに追加する:
documentの投機的読み込みを 検討するマイクロタスクがキューに追加済みを false に設定する。
documentについて内部の投機的読み込み 検討手順を実行する。
この標準で明示的に示される呼び出し箇所に加えて:
スタイルの再計算によってセレクターの照合結果が変化する場合、ユーザーエージェントは、
関連する Documentについて投機的読み込みを検討しなければならない。
ユーザーエージェントが投機規則の積極度の ヒューリスティックを実装するために使用する実装定義の方法のいずれかで、ユーザーがハイパーリンクに 関心を示した場合、ユーザーエージェントは、そのハイパーリンクのノード文書について投機的読み込みを検討してもよい。
たとえば、pointerdown
イベントを監視することで「conservative」
の積極度を実装するユーザーエージェントは、そのようなイベントへの反応の一部として投機的読み込みを
検討することを望むだろう。
この標準では、投機的読み込みを検討するの各呼び出しには、
Documentのみが
与えられ、アルゴリズムは状態を保持せずにすべての可能な候補を再計算する。
実際の実装では、以前の計算結果をキャッシュし、更新をより効率的にするために呼び出し箇所から
情報を引き渡す可能性が高い。たとえば、a要素の href
属性が変更された場合、その特定の要素を引き渡して、関連する投機的読み込み候補のみを
更新できる。
投機的読み込みを検討するが マイクロタスクをキューに追加する方法により、内部の投機的読み込み 検討手順が実行される時点までに、複数の更新(またはキャンセル)がまとめて処理される可能性が あることに注意。
Document
documentについての内部の投機的読み込み検討手順は次のとおり:
documentが完全にアクティブでない場合、戻る。
prefetchCandidatesを空のリストとする。
documentの投機規則セットの各 ruleSetについて:
anonymizationPolicyを null とする。
ruleの要件が
「anonymous-client-ip-when-cross-origin」を含む場合、anonymizationPolicyを、そのオリジンが
documentのオリジンであるクロスオリジン
プリフェッチ IP 匿名化ポリシーに設定する。
referrerPolicyを、ruleおよび null が与えられたときに、投機的読み込みの リファラーポリシーを算出した結果とする。
prefetchCandidatesに。
ruleの述語が null でない場合:
linksを、documentおよび ruleの述語が与えられたときに、一致するリンクを 見つけた結果とする。
linksの各 linkについて:
referrerPolicyを、ruleおよび linkが 与えられたときに、投機的読み込みの リファラーポリシーを算出した結果とする。
prefetchCandidatesに。
documentのプリフェッチレコードの各 prefetchRecordについて:
prefetchRecordが、prefetchCandidatesが与えられたときに依然として投機対象である状態でない場合、 documentが与えられたときに prefetchRecordをキャンセルして 破棄する。
prefetchCandidateGroupsを空のリストとする。
prefetchCandidatesの各 candidateについて:
groupを « candidate » とする。
candidate自身を除く prefetchCandidates内のすべての項目のうち、candidateと重複し、 その積極度が candidateの積極度と少なくとも同程度に 積極的であるものすべてで、groupを拡張する。
prefetchCandidateGroupsが、順序を無視して項目が groupと同じである別のグループを含む場合、続行する。
prefetchCandidateGroupsに groupを付加する。
次の投機規則は、2 つの重複するプリフェッチ 候補を生成する:
{
"prefetch" : [
{
"tag" : "a" ,
"urls" : [ "next.html" ]
},
{
"tag" : "b" ,
"urls" : [ "next.html" ],
"referrer_policy" : "no-referrer"
}
]
} この手順は、指定された順序で両方を含む単一のグループを作成する。(2 回目の処理では、
内容が最初のグループと同じで順序だけが異なるため、グループは作成されない。)
これは、ユーザーエージェントがグループを実行するために以下の「してもよい」手順を
実行することを選択した場合、最初の候補を実行し、2 番目を無視することを意味する。
したがって、リクエストは「no-referrer」を
使用する代わりに、既定のリファラーポリシーを使用して行われる。
しかし、投機的読み込み候補から
タグを収集するアルゴリズムは、グループ内の両方の候補からタグを収集するため、
`Sec-Speculation-Tags`
ヘッダー値は `"a", "b"` となる。これは、いずれの規則も投機的読み込みを
発生させた可能性があることをサーバー運用者に示す。
prefetchCandidateGroupsの各 groupについて:
ユーザーエージェントは次の手順を実行してもよい:
prefetchCandidateを group[0] とする。
tagsToSendを、groupが与えられたときに、投機的読み込み 候補からタグを収集した結果とする。
prefetchRecordを、次の値を持つ新しいプリフェッチレコードとする:
speculation rules」documentおよび prefetchRecordが与えられたとき、リファラーによって開始される ナビゲーションプリフェッチを開始する。
この「してもよい」手順を実行するかどうかを決定するとき、ユーザーエージェントは、 ユーザーの現在の動作および投機規則の 積極度の定義に従って、prefetchCandidateの積極度を考慮すべきである。
prefetchCandidateのNo-Vary-Search ヒントは、投機規則の積極度の値に 定義されたヒューリスティックを実装する際にも有用となり得る。たとえば、ユーザーが、 そのURLが prefetchCandidateのNo-Vary-Search ヒントを使用したときに prefetchCandidateのURLと検索差異を法として 同等であるリンク上にカーソルを置いた場合、この手順を実行することが有用であると ユーザーエージェントに示す可能性がある。
この「してもよい」手順を実行するかどうかを決定するとき、ユーザーエージェントは、 ウェブ開発者が指定した積極度よりも、ユーザー設定(明示的または、データセーバーモードや バッテリーセーバーモードなどの暗黙的な設定)を優先すべきである。
投機規則
ruleおよび a要素、area要素、
または null の linkが与えられたとき、投機的読み込みのリファラーポリシーを算出するには:
ruleのリファラーポリシーが 空文字列でない場合、ruleのリファラー ポリシーを返す。
linkが null の場合、空文字列を返す。
linkのハイパーリンクリファラーポリシーを返す。
Document
documentおよび文書規則
述語 predicateが与えられたとき、一致するリンクを見つけるには:
linksを空のリストとする。
documentのシャドウを含む子孫 descendantの各について、シャドウを含むツリー順で:
descendantがレンダリングされていないか、スキップされた コンテンツの一部である場合、続行する。
そのようなリンクは、document内に存在していてもユーザーが 操作できないため、適切な候補である可能性は低い。さらに、スタイルまたはレイアウトが 算出されていない可能性があり、これらの要素に対する作業の一部または全部を省略する ユーザーエージェントでは、セレクター照合の効率が低下する可能性がある。
descendantのurlが null であるか、 そのスキームがHTTP(S) スキームでない場合、続行する。
linksを返す。
文書規則述語
predicateは、predicateの型に応じて分岐する次の手順が true を返す場合、
a要素または
area要素 elに一致する:
投機規則機能は、タスクソースである投機規則タスクソースを使用する。
投機的読み込みは一般に、現在の文書のタスク処理より重要度が低いため、 実装は、ここでキューに追加されるタスクに特に低い優先度を 与えることがある。
現時点では、ナビゲーションプリフェッチ処理は Prefetch仕様で定義されている。 この標準へ移動する作業は、issue #11123で追跡されている。 [PREFETCH]
この標準は、そこで定義される次の概念を参照する:
Speculation-Rules`
ヘッダー`Speculation-Rules` HTTP 応答
ヘッダーを使用すると、開発者は、指定された投機規則セットをユーザーエージェントが
フェッチし、現在の Documentに適用するよう要求できる。これは構造化
ヘッダーであり、その値は、すべて有効な URL 文字列である文字列のリストでなければならない。
Document
documentおよび応答
responseが与えられたとき、
`Speculation-Rules` ヘッダーを処理するには:
parsedListを、responseのヘッダーリストから、`Speculation-Rules`
および「list」が与えられたときに、構造化フィールド値を取得した結果とする。
parsedListが null の場合、戻る。
parsedListの各 itemについて:
urlが失敗である場合、続行する。
並列に:
任意で、実装定義の時間だけ待機する。
これにより、実装は投機規則の読み込みよりも他の作業を優先できる。
特に Documentの作成およびヘッダー処理中には、
より重要な処理が多数行われていることが多い。
documentの関連するグローバルオブジェクトが 与えられたとき、投機規則タスクソース上にグローバルタスクをキューに追加し、 次の手順を実行する:
requestを、そのURLが url、宛先が
「speculationrules」、モードが
「cors」である新しいリクエストとする。
応答 responseおよび null、失敗、またはバイト列 bodyBytesが与えられたとき、 次の processResponseConsumeBody 手順を使用して requestをフェッチする:
bodyBytesが null または失敗である場合、これらの手順を中止する。
responseのヘッダーリストからMIME 型を抽出した結果のエッセンスが「application/speculationrules+json」で
ない場合、これらの手順を中止する。
bodyTextを、bodyBytesをUTF-8 復号した結果とする。
ruleSetを、bodyText、 document、および responseのURLが与えられたときに、投機規則セット文字列を 構文解析した結果とする。これが例外をスローした場合、これらの手順を中止する。
documentについて投機的読み込みを検討する。
Sec-Speculation-Tags`
ヘッダー`Sec-Speculation-Tags` HTTP
リクエストヘッダーは、投機的ナビゲーションリクエストに関連付けられた、ウェブ開発者が指定したタグを
指定する。また、`Sec-Purpose`は
両方のカテゴリのリクエストによって送信される可能性があるため、投機的ナビゲーションリクエストと
投機的サブリソースリクエストを区別するためにも使用できる。
このヘッダーは構造化
ヘッダーであり、その値はリストでなければならない。このリストにはトークンまたは文字列の値を含めることができる。文字列値は
開発者が指定したタグを表し、トークン値は事前定義されたタグを表す。現時点で唯一の
事前定義タグは nullであり、開発者定義のタグを持たない投機的ナビゲーション
リクエストを示す。
投機的読み込みは、ウェブページによってクロスサイトの宛先に対して開始できる。ただし、 そのようなクロスサイトの投機的読み込みは、資格情報なしで常に実行されるため、後述するように、環境権限はプラットフォーム上の 他の仕組みによってすでに可能なリクエストに限定される。
`Speculation-Rules`
ヘッダーは、本体が投機規則セット文字列として
構文解析される JSON 文書に対するリクエストを発行するためにも使用できる。ただし、これらは
「same-origin」資格情報モード、
「cors」モードを
使用し、application/speculationrules+json
のMIME 型
エッセンスを使用しない応答は無視されるため、攻撃を仕掛ける用途には役立たない。
文書内のリンクは文書規則述語によって投機的読み込みの
対象として選択できるため、そのようなリンクにユーザー生成のマークアップが含まれる可能性がある場合、
開発者は注意する必要がある。たとえば、リンクの hrefを
あるユーザーが入力でき、他のすべてのユーザーに表示できる場合、悪意のあるユーザーは
「/logout」のような値を選択し、そのリンクが投機的に読み込まれたときに、
他のユーザーのブラウザーをサイトから自動的にログアウトさせる可能性がある。そのような潜在的に
危険なリンクを除外するために文書規則セレクター述語を
使用すること、または安全であることが既知のリンクを許可リストに登録するために文書規則 URL パターン
述語を使用することは、この点で有用な手法である。
script要素のすべての使用と同様に、開発者は
<script type=speculationrules>の子テキスト
コンテンツへユーザー指定のコンテンツを挿入する際に注意する必要がある。特に、エスケープされていない
閉じる </script>タグを挿入すると、script
要素のコンテキストから抜け出し、攻撃者が制御するマークアップを注入するために使用される可能性がある。
<script type=speculationrules>機能は、文書内で見つかったコンテンツに応じて
動作を発生させるため、エスケープされていない HTML を注入できる攻撃者が利用できる選択肢を
検討する価値がある。このような攻撃者は、すでに JavaScript または iframe
要素を注入できる。投機的読み込みは、一般に任意のスクリプト実行よりも危険性が低い。ただし、
文書規則
述語を使用すると、文書内のリンクを投機的に読み込むことができ、それらの読み込みの存在が、
それらのリンクに関する情報を抽出する経路を提供する可能性がある。この可能性に対する多層防御は、
Content Security Policy によって提供される。特に、script-srcディレクティブを
使用して、投機規則の script
要素の構文解析を制限でき、default-srcディレクティブは、そのような投機規則から
発生するナビゲーションプリフェッチリクエストに適用される。投機的読み込みが潜在的に信頼できる URLに対してのみ実行されるという
要件によって、追加の防御が提供されるため、経路上の攻撃者はメタデータおよびトラフィック分析にのみ
アクセスでき、URL を直接見ることはできない。
[CSP]
一般に、ユーザー生成コンテンツが任意の応答ヘッダーとして追加されることは想定されていない。
これが可能である場合、サーバー運用者はすでに重大な問題に直面することになる。したがって、
`Speculation-Rules`
ヘッダーが XSS 攻撃対象領域を有意に拡大する可能性は低い。このため、Content Security Policy は、
そのヘッダーを介した規則セットの読み込みには適用されない。
この標準では、ユーザーエージェントによって提供される IP 匿名化技術を使用して ナビゲーションプリフェッチを実行するよう、開発者が要求できる。この匿名化の詳細は規定されないが、 いくつかの一般的なセキュリティ原則が適用される。
IP 匿名化がプロキシサービスを使用して実装される範囲では、サービス運用者およびネットワーク経路上の 他の主体が利用できる情報を最小限に抑えることが推奨される。これには、少なくとも接続に TLS を 使用することが含まれる可能性が高い。
サイト運用者は、仮想プライベートネットワーク(VPN)技術と同様に、HTTP サーバーから見える クライアント IP アドレスが、ユーザーの実際のネットワークプロバイダーまたは位置と正確に一致しない 可能性があり、複数の異なる加入者のトラフィックが単一のクライアント IP アドレスから発信される 可能性があることを認識する必要がある。これは、サイト運用者のセキュリティおよび不正利用防止対策に 影響を与える可能性がある。IP 匿名化対策は、ユーザーと類似した地理的位置を持つ、または同じ 管轄区域内に位置する出口 IP アドレスを使用しようとすることがあるが、そのような動作は ユーザーエージェント固有であり、保証されない。
投機的読み込みを 検討するアルゴリズムには、重要な「してもよい」手順が含まれており、これは投機規則の 積極度とユーザー環境のその他の特性との組み合わせに基づいて、ユーザーエージェントがリファラーによって開始される ナビゲーションプリフェッチを開始することを推奨する。投機的読み込みが実行されるかどうかは 文書から観測できる可能性があるため、ユーザーエージェントは、そのような決定を行う際に プライバシーを保護するよう注意しなければならない。たとえば、オリジンですでに利用可能な情報のみを 使用する必要がある。これらのヒューリスティックが永続的な状態に依存する場合、その状態は、 ユーザーが他のサイトデータを消去するたびに消去されなければならない。ユーザーエージェントが 他のサイトデータを定期的に自動消去する場合、その永続的な状態も同時に消去しなければならない。
ここでサイトではなくオリジンを使用しているのは 意図的である。同一サイトのオリジンは、望む場合に一般に連携できるものの、ウェブのセキュリティモデルは、 同一サイトのオリジンであっても、オリジンが他のオリジンのデータへアクセスすることを防止することを 前提としている。したがって、ユーザーエージェントは、サイト間だけでなく、オリジン間でもそのような データを意図せず漏洩しないようにする必要がある。
文書がすでに把握している入力の例:
著者が指定した積極度
文書内での出現順序
リンクがビューポート内にあるかどうか
カーソルがリンクの近くにあるかどうか
リンクのレンダリングされたサイズ
オリジンに関連する永続データ(オリジン自身が収集できるもの)であるが、ユーザーの意図に従って 消去されなければならないものの例:
ユーザーが、この文書または同じオリジン上の他の文書で、このリンクまたは類似のリンクを クリックしたことがあるかどうか
投機的読み込みが適切かどうかを判断する際に有用となる可能性があるが、オリジン間でユーザーを より識別しやすくする可能性があるため、ユーザーエージェント全体のプライバシー方針の一部として 検討する必要があるデバイス情報の例:
大まかなデバイスクラス(CPU、メモリー)
大まかなバッテリーレベル
ネットワーク接続が従量制であることが判明しているかどうか
投機的読み込みの切り替え、バッテリーセーバーの切り替え、データセーバーの切り替えなど、 ユーザーが切り替え可能な設定
リファラーによって開始される ナビゲーションプリフェッチを開始するアルゴリズムは、それが発行する HTTP リクエストが、 ユーザーエージェントがストレージキーに 従って資格情報をパーティショニングする方法と一貫して動作することを 保証するよう設計されている。この特性は、次のように、パーティションをまたぐプリフェッチでも維持される。
プリフェッチされた応答を使用する将来のナビゲーションが同じパーティション内に文書を読み込む場合、 プリフェッチ時には、サブリソースリクエストやスクリプトによるフェッチと同様に、パーティショニングされた 資格情報を送信できる。そのような将来のナビゲーションが別のパーティション内に文書を読み込む場合、 宛先パーティションのパーティショニングされた資格情報を使用することは、トップレベルナビゲーションなしで パーティション間の境界を越えることになるため、パーティショニング方式と一貫しない。また、開始元 パーティション内のパーティショニングされた資格情報を使用することも、プリフェッチされていない ナビゲーションとは異なる状態の文書をユーザーに表示することになるため、一貫しない。代わりに、 そのようなリクエストには、初期状態が空である第 3 のパーティションが使用される。したがって、 これらのリクエストは、いずれのパーティションからも資格情報を送信しない。ただし、この初期状態が 空のパーティションを使用して構築された結果のプリフェッチ応答本体は、アクティブ化時に宛先 パーティションに資格情報が含まれていない場合にのみ使用できる。
これは、宛先パーティションに資格情報が含まれていないことが事前に判明している場合にのみ、 そのようなプリフェッチリクエストを送信する動作とやや似ている。ただし、そのような動作が資格情報の 存在を探る手段として使用されることを避けるため、代わりにそのようなプリフェッチリクエストは常に完了し、 資格情報が競合する場合にはその結果が使用されない。
これら 2 種類のリクエスト間でリダイレクトが発生する可能性がある。同一パーティションの URL から クロスパーティションの URL へのリダイレクトには、開始元パーティション内のパーティショニングされた 資格情報から派生した情報が含まれる可能性がある。ただし、これは開始元文書が同一パーティションの URL 自体をフェッチし、その後クロスパーティションの URL に対するリクエストを発行することと同等である。 クロスパーティションの URL から同一オリジンの URL へのリダイレクトは、分離されたパーティションから 資格情報を運ぶ可能性があるが、このパーティションには以前の状態がないため、そのサイトでのユーザーの 過去の閲覧活動に基づく追跡は可能にならず、文書は資格情報なしのリクエストを自身で発行することによって 同じ状態を構築できる。
投機的読み込みは、後続のトップレベルナビゲーションに対する HTTP リクエストを、ユーザージェスチャー なしで行える仕組みを提供する。連携する 2 つのサイトがユーザーの識別情報を関連付けることが可能かどうかを 問うのは自然である。
前の節で説明したように、宛先サイトの既存の資格情報は送信されないため、
そのサイトがナビゲーション前にユーザーを識別する能力は、リファラーサイトが単に fetch()を
使用して資格情報なしのリクエストを行った場合と同様に制限される。ナビゲーション時には、通常の
ナビゲーション(たとえば、投機的に読み込まれていないリンクをクリックすること)と似た状態になる。
ユーザーエージェントが通常のフェッチおよびナビゲーションにおける識別情報の結合を軽減しようとする 範囲では、投機的に読み込まれたナビゲーションにも同様の軽減策を適用できる。
X-Frame-Options` ヘッダー現在のすべてのエンジンでサポートされています。
`X-Frame-Options` HTTP 応答ヘッダーは、
Documentを子ナビゲーブル内に
読み込むことができるか、およびどのように読み込めるかを制御する方法である。CSP を使用するサイトでは、
frame-ancestors
ディレクティブによって、同じ状況をよりきめ細かく制御できる。これは元々
HTTP Header Field X-Frame-Optionsで定義されていたが、ここでの定義および処理モデルが
その文書に優先する。
[CSP] [RFC7034]
特に、HTTP Header Field X-Frame-Optionsでは、このヘッダーの
`ALLOW-FROM`形式が規定されていたが、これは実装してはならない。
以下の処理モデルに従い、CSP の frame-ancestors
ディレクティブと `X-Frame-Options`
ヘッダーの両方が同じ応答で使用される場合、
`X-Frame-Options`は無視される。
ウェブ開発者および適合性チェッカー向けの、その値のABNFは次のとおり:
X-Frame-Options = "DENY" / "SAMEORIGIN" 応答 response、ナビゲーブル navigable、CSP リスト
cspList、およびオリジン
destinationOriginが与えられたとき、ナビゲーション応答が
`X-Frame-Options`に準拠しているかを確認するには:
navigableが子ナビゲーブルでない場合、true を返す。
cspListの各 policyについて:
policyのディレクティブ集合が
frame-ancestors
ディレクティブを含む場合、true を返す。
rawXFrameOptionsを、responseのヘッダーリストから `X-Frame-Options`を取得し、復号し、分割した結果とする。
xFrameOptionsを新しい集合とする。
rawXFrameOptionsの各 valueについて、valueをASCII 小文字に変換し、 xFrameOptionsに付加する。
xFrameOptionsのサイズが 1 より大きく、
xFrameOptionsが「deny」、「allowall」、または
「sameorigin」のいずれかを含む場合、false を返す。
ここでの意図は、有効な処理を行おうとしているものの、混乱しているように見える
`X-Frame-Options`の
適用試行をすべてブロックすることである。
これは、旧来の `ALLOWALL`値が処理モデルに与える唯一の影響である。
xFrameOptionsのサイズが 1 より大きい場合、true を返す。
これは、複数の無効な値が含まれていることを意味し、ヘッダーが完全に省略された場合と 同じように扱う。
xFrameOptions[0]が「deny」である場合、false を返す。
xFrameOptions[0]が「sameorigin」である場合:
true を返す。
この時点に到達した場合、単独の無効な値(旧来の
`ALLOWALL`または `ALLOW-FROM`形式のいずれかである可能性がある)が
存在する。これらは、ヘッダーが完全に省略された場合と同じように扱われる。
次の表は、非適合なものを含む、ヘッダーのさまざまな値の処理を示している:
`X-Frame-Options`
|
有効 | 結果 |
|---|---|---|
`DENY` |
✅ | 埋め込みは禁止される |
`SAMEORIGIN` |
✅ | 同一オリジンの埋め込みが許可される |
`INVALID` |
❌ | 埋め込みが許可される |
`ALLOWALL` |
❌ | 埋め込みが許可される |
`ALLOW-FROM=https://example.com/` |
❌ | 埋め込みが許可される(任意の場所から) |
次の表は、複数の値を含むさまざまな非適合の場合がどのように処理されるかを示している:
`X-Frame-Options`
|
結果 |
|---|---|
`SAMEORIGIN, SAMEORIGIN` |
同一オリジンの埋め込みが許可される |
`SAMEORIGIN, DENY` |
埋め込みは禁止される |
`SAMEORIGIN,` |
埋め込みは禁止される |
`SAMEORIGIN, ALLOWALL` |
埋め込みは禁止される |
`SAMEORIGIN, INVALID` |
埋め込みは禁止される |
`ALLOWALL, INVALID` |
埋め込みは禁止される |
`ALLOWALL,` |
埋め込みは禁止される |
`INVALID, INVALID` |
埋め込みが許可される |
値がカンマ区切りの単一のヘッダーで提供される場合でも、複数のヘッダーで提供される場合でも、 同じ結果が得られる。
Refresh` ヘッダー`Refresh` HTTP 応答ヘッダーは、
Refresh 状態の http-equiv
属性を持つ meta要素に相当する HTTP 版である。これは同じ値を取り、ほぼ同じように動作する。
その処理モデルは、Document
オブジェクトを作成して初期化するで詳述されている。
ブラウザーユーザーエージェントは、そのトップレベルトラバーサブル集合内の任意のトップレベルトラバーサブルをナビゲートする、再読み込みする、および読み込みを停止する機能を提供すべきである。
たとえば、ロケーションバーおよび再読み込み/停止ボタンの UI を介して。
ブラウザーユーザーエージェントは、そのトップレベル トラバーサブル集合内の任意のトップレベルトラバーサブルをデルタによってトラバースする機能を 提供すべきである。
たとえば、戻るボタンおよび進むボタンを介して。デルタを変更するための 長押し機能を含む可能性もある。
このようなユーザーエージェントは、ページがセッション履歴を偽のエントリーで埋めることでユーザーを
「閉じ込める」ことを避けるため、1 より大きいデルタによるトラバーサルを許可することが推奨される。
(たとえば、history.pushState()の
繰り返し呼び出し、またはフラグメントナビゲーションによる。)
一部のユーザーエージェントは、そのような不正利用を克服するために、単一の「戻る」 または「進む」ボタンの押下を、より大きなデルタに変換するヒューリスティックを備えている。 これらのヒューリスティックをissue #7832で規定することを検討している。
ブラウザーユーザーエージェントは、ユーザーが指定した、またはユーザーエージェントが決定した初期URLが与えられたとき、ユーザーが新しいトップレベルトラバーサブルを 作成する機能を提供すべきである。
たとえば、「新しいタブ」または「新しいウィンドウ」ボタンを介して。
ブラウザーユーザーエージェントは、そのトップレベルトラバーサブル 集合内の任意のトップレベルトラバーサブルをユーザーが任意に閉じる機能を提供すべきである。
たとえば、「タブを閉じる」ボタンをクリックすることによって。
ブラウザーユーザーエージェントは、ユーザーが任意のナビゲーブル(トップレベルトラバーサブルだけでなく)を明示的にナビゲートする、再読み込みする、または読み込みを停止する方法を提供してもよい。
たとえば、コンテキストメニューを介して。
ブラウザーユーザーエージェントは、ユーザーがトップレベルトラバーサブルを 破棄する機能を提供してもよい。
たとえば、そのようなトップレベルトラバーサブルを 1 つ以上含む ウィンドウを強制的に閉じることによって。
ユーザーが、そのアクティブなセッション履歴エントリーの文書状態のリソースがPOST リソースであるナビゲーブルの再読み込みを要求した場合、ユーザーエージェントは、そうしなければ トランザクション(たとえば、購入またはデータベースの変更)が繰り返される可能性があるため、 最初に操作を確認するようユーザーに求めるべきである。
ユーザーがナビゲーブルの再読み込みを要求した場合、 ユーザーエージェントは、再読み込み時にすべてのキャッシュを無視する仕組みを提供してもよい。
上記の仕組みによって開始されるナビゲートのすべての呼び出しは、userInvolvement引数を「browser UI」に設定しなければならない。
上記の仕組みによって開始される再読み込みのすべての呼び出しは、userInvolvement引数を「browser UI」に設定しなければならない。
上記の仕組みによって開始されるデルタによって履歴をトラバースするの すべての呼び出しは、sourceDocument引数に値を渡してはならない。
上記の推奨事項およびこの仕様のデータ構造は、ユーザーエージェントがセッション履歴をユーザーに どのように表現するかを制限することを意図していない。
たとえば、トップレベルトラバーサブルのセッション履歴エントリーはリストとして保存および 管理され、ユーザーエージェントはデルタによってそのリストを トラバースするインターフェイスを提供することが推奨されるものの、新しいユーザーエージェントは、 代わりに、または追加で、各ページがユーザーの選択可能な複数の「進む」ページを持つツリー状の表示を 提供することもできる。
同様に、すべての子孫ナビゲーブルのセッション履歴は、そのトラバーサブルナビゲーブルに保存されるものの、 ユーザーエージェントは、ユーザーに対して、よりきめ細かなナビゲーブル単位のナビゲーブルのセッション履歴表示を 提供することもできる。
ブラウザーユーザーエージェントは、トップレベル閲覧コンテキストのポップアップであるブール値を、次の目的で使用してもよい:
対応するトップレベルトラバーサブルに最小限の ウェブブラウザーユーザーインターフェイスを提供するかどうかを決定する。
閲覧コンテキスト機能を設定するの任意の手順を 実行する。
どちらの場合も、ユーザーエージェントは、さらにユーザー設定を考慮したり、 ポップアップとして扱うかどうかの選択肢を提示したりすることがある。
このようなポップアップに最小限のユーザーインターフェイスを提供するユーザーエージェントは、 ブラウザーのロケーションバーを非表示にしないことが推奨される。
さまざまな仕組みによって、著者が提供した実行可能コードが文書のコンテキスト内で実行される。 これらの仕組みには、次のものが含まれるが、おそらくこれらに限定されない:
script
要素の処理。javascript: URLへのナビゲーション。addEventListener()を使用して登録されたもの、明示的なイベントハンドラー
コンテンツ属性によるもの、イベントハンドラー IDL
属性によるもの、またはその他の方法によるイベントハンドラー。
JavaScript はエージェントの概念を定義している。 この節では、その言語レベルの概念をウェブプラットフォームへ対応付ける。
概念的には、エージェントの概念は、 JavaScript コードが実行される、アーキテクチャに依存しない理想化された「スレッド」である。 そのようなコードは、相互に同期的にアクセスできる複数のグローバル/レルムに 関係する可能性があり、したがって単一の実行スレッドで実行する必要がある。
2 つの Windowオブジェクトが同じエージェントを持つことは、
互いのレルムで作成されたすべてのオブジェクトへ直接アクセスできることを示すものではない。
それらは同一オリジンドメインで
なければならない。IsPlatformObjectSameOriginを
参照。
ウェブプラットフォームには、次の種類のエージェントが存在する:
直接、または document.domainを
使用することによって、互いに到達できる可能性があるさまざまな Windowオブジェクトを
含む。
包含するエージェントクラスターのオリジンキー方式で
あるが true の場合、すべての Windowオブジェクトは
同一オリジンとなり、
互いに直接到達でき、document.domainは
何も行わない。
同一オリジンである 2 つの
Windowオブジェクトは、たとえばそれぞれが独自の閲覧コンテキストグループ内に
ある場合、異なる類似オリジンウィンドウ
エージェントに属する可能性がある。
単一の DedicatedWorkerGlobalScopeを
含む。
単一の SharedWorkerGlobalScopeを
含む。
単一の ServiceWorkerGlobalScopeを
含む。
単一の WorkletGlobalScope
オブジェクトを含む。
特定のワークレットは複数のレルムを持つ可能性があるが、各レルムは他のレルムと 独立して同時にコードを実行できるため、そのような各レルムには独自のエージェントが必要である。
JavaScript の Atomics
API の使用によって潜在的にブロックできるのは、共有および専用ワーカーエージェントだけである。
ブール値 canBlockが与えられたとき、エージェントを作成するには:
プラットフォームオブジェクト platformObjectの関連するエージェントは、 platformObjectの関連するレルムのエージェントである。
現在のレルムに相当する エージェントは、周囲のエージェントである。
JavaScript はエージェントクラスターの概念も定義している。この標準は、 類似オリジン ウィンドウエージェントを取得する、またはワーカー/ワークレット エージェントを取得するアルゴリズムを使用してエージェントが作成される際に、エージェントを適切に 配置することによって、その概念をウェブプラットフォームへ対応付ける。
エージェントクラスターの概念は、JavaScript
のメモリーモデルを
定義するうえで重要であり、特に SharedArrayBuffer
オブジェクトの基盤データを、どのエージェント間で共有できるかを定義するうえで重要である。
概念的には、エージェントクラスターの概念は、複数の「スレッド」(エージェント)をまとめる、アーキテクチャに依存しない理想化された 「プロセス境界」である。仕様によって定義されるエージェントクラスターは、一般にユーザーエージェントで実装される 実際のプロセス境界よりも制限が厳しい。仕様レベルでこれらの理想化された分割を強制することにより、 ユーザーエージェントのプロセスモデルが変化し異なる場合でも、共有メモリーに関してウェブ開発者が 相互運用可能な動作を確認できることを保証する。
エージェントクラスターには、関連付けられたクロスオリジン分離モードがあり、これはクロスオリジン分離
モードである。初期値は「none」である。
エージェントクラスターには、関連付けられたオリジンキー方式である(ブール値)があり、初期値は false である。
次に、類似オリジンウィンドウ エージェントのエージェントクラスターの割り当てを定義する。
エージェントクラスターキーは、サイトまたはタプルオリジンである。 オリジンキー方式のエージェントクラスターを実現するための ウェブ開発者による操作がない場合、これはサイトになる。
同等の表現として、エージェントクラスターキーは、 スキームとホストまたはオリジンになり得る。
オリジン origin、閲覧コンテキストグループ group、およびブール値 requestsOACが与えられたとき、類似オリジンウィンドウエージェントを取得するには、 次の手順を実行する:
siteを、originを使用してサイトを取得した結果とする。
keyを siteとする。
groupのクロスオリジン分離
モードが「none」でない場合、
keyを originに設定する。
それ以外の場合、groupの履歴 エージェントクラスターキーマップ[origin]が存在する場合、keyを groupの履歴 エージェントクラスターキーマップ[origin]に設定する。
それ以外の場合:
requestsOACが true の場合、keyを originに設定する。
groupの履歴 エージェントクラスターキーマップ[origin]を keyに設定する。
groupのエージェントクラスター マップ[key]が存在しない場合:
agentClusterを新しいエージェントクラスターとする。
agentClusterのクロスオリジン 分離モードを、groupのクロスオリジン 分離モードに設定する。
keyがオリジンである場合:
表明:keyは originである。
agentClusterのオリジンキー方式で あるを true に設定する。
false が与えられたときにエージェントを 作成した結果を、agentClusterに追加する。
groupのエージェントクラスター マップ[key]を agentClusterに設定する。
groupのエージェントクラスター マップ[key]に含まれる単一の類似オリジン ウィンドウエージェントを返す。
これは、閲覧コンテキストエージェントクラスターごとに類似オリジンウィンドウ エージェントが 1 つだけ存在することを意味する。(ただし、専用 ワーカーおよびワークレットエージェントは、 同じクラスターに属する可能性がある。)
次に、他のすべての種類のエージェントのエージェントクラスターの割り当てを定義する。
環境設定 オブジェクトまたは null の outside settings、ブール値 isTopLevel、およびブール値 canBlockが与えられたとき、ワーカー/ワークレットエージェントを取得するには、 次の手順を実行する:
agentClusterを null とする。
isTopLevelが true の場合:
agentClusterを新しいエージェントクラスターに設定する。
agentClusterのオリジンキー方式で あるを true に設定する。
これらのワーカーは、オリジンキー方式であるとみなせる。ただし、これは
API を通じて公開されない(originAgentClusterが
ウィンドウのオリジンキー方式であることを公開する方法とは異なる)。
それ以外の場合:
agentを、canBlockが与えられたときにエージェントを 作成した結果とする。
agentを agentClusterに追加する。
agentを返す。
環境設定 オブジェクト outside settingsおよびブール値 isSharedが与えられたとき、 専用/共有ワーカーエージェントを取得するには、 outside settings、isShared、および true が与えられたときにワーカー/ワークレット エージェントを取得した結果を返す。
環境設定 オブジェクト outside settingsが与えられたとき、ワークレットエージェントを取得するには、 outside settings、false、および false が与えられたときにワーカー/ワークレット エージェントを取得した結果を返す。
サービスワーカーエージェントを取得するには、 null、true、および false が与えられたときにワーカー/ワークレット エージェントを取得した結果を返す。
JavaScript 仕様は、スクリプトが実行されるグローバル環境を表すレルムの概念を導入している。 各レルムには、実装定義のグローバルオブジェクトが付随する。この仕様の 大部分は、そのグローバルオブジェクトとそのプロパティの定義に充てられている。
ウェブ仕様では、値またはアルゴリズムをレルム/グローバルオブジェクトの組に関連付けると
便利なことが多い。値が特定の種類のレルムに固有である場合、たとえば Windowまたは WorkerGlobalScope
インターフェイスの定義のように、対象のグローバルオブジェクトに直接関連付けられる。
値が複数のレルムにわたって有用である場合、環境設定オブジェクトの概念を使用する。
最後に、レルム/グローバルオブジェクト/環境設定オブジェクトが存在するようになる前に、 関連する値を追跡する必要がある場合がある(たとえば、ナビゲーション中)。これらの値は、環境の概念で追跡される。
環境は、現在または潜在的な実行環境(すなわち、ナビゲーションパラメーターの予約済み環境、またはリクエストの予約済み クライアント)の設定を識別するオブジェクトである。環境には、次のフィールドがある:
この環境を一意に識別する不透明な文字列。
Windowの環境設定
オブジェクトの場合、この URL は、後者を変更する history.pushState()などの
仕組みにより、そのグローバル
オブジェクトの関連付けられた
DocumentのURLとは
異なることがある。
現時点では実装定義の値、null、またはオリジン。「トップレベル」の潜在的な 実行環境では null である(すなわち、まだ応答が存在しない場合)。それ以外では、 「トップレベル」の環境のオリジンである。専用ワーカーまたは ワークレットでは、その作成者のトップレベルオリジンである。 共有ワーカーまたはサービスワーカーでは、実装定義の値である。
サンドボックス化、ワーカー、およびワークレットが関係する場合、これはトップレベル作成 URLのオリジンとは異なる。
null、またはナビゲーションリクエストの対象となる閲覧コンテキスト。
環境の設定が完了しているかどうかを示すフラグ。初期状態では未設定である。
仕様は、環境に対する環境破棄手順を 定義してもよい。この手順は、環境を入力として受け取る。
環境破棄 手順は、たとえば読み込みに失敗したために実行準備完了状態になることが決してない、 選ばれた少数の環境に対してのみ実行される。
環境設定オブジェクトは、さらに次のための アルゴリズムを指定する環境である:
この設定オブジェクトを使用するすべてのスクリプト、すなわち特定のレルム内のすべてのスクリプトによって共有されるJavaScript 実行コンテキスト。古典スクリプトを実行する、またはモジュール スクリプトを実行すると、この実行コンテキストはJavaScript 実行コンテキスト スタックの最上位になり、その上に対象のスクリプトに固有の別の実行コンテキストが プッシュされる。(この設定により、Source Text Module RecordのEvaluateが、どのレルムを使用すべきかを把握できる。)
JavaScript モジュールをインポートするときに使用されるモジュールマップ。
この環境設定 オブジェクトを使用するスクリプトによって呼び出される API が、URL を構文解析するために使用するURL。
セキュリティチェックで使用されるオリジン。
セキュリティチェックで使用されるブール値。
セキュリティチェックで使用されるポリシーを含むポリシーコンテナー。
この環境設定 オブジェクトを使用するスクリプトが、クロスオリジン分離を必要とする API の使用を 許可されているかどうかを表すブール値。
環境設定オブジェクトの担当イベントループは、そのグローバル オブジェクトの関連するエージェントのイベント ループである。
グローバルオブジェクトは、レルムの [[GlobalObject]] フィールドである JavaScript オブジェクトである。
この仕様では、すべてのレルムは、Window、WorkerGlobalScope、
または WorkletGlobalScope
オブジェクトのいずれかであるグローバル
オブジェクトとともに作成される。
グローバルオブジェクトには、 初期値が false であるエラー報告モード中ブール値がある。
グローバルオブジェクトには、
初期状態が空である Promise
オブジェクトの集合である未処理の拒否された Promise の弱い集合がある。
この集合は、そのいずれのメンバーに対しても強参照を作成してはならず、実装は、たとえば新しい
エントリーが追加されたときに古いエントリーを削除することにより、実装定義の方法でそのサイズを制限してよい。
グローバルオブジェクトには、
初期状態が空である Promise
オブジェクトのリストである通知予定の拒否された Promise
のリストがある。
グローバルオブジェクトには、 初期状態が空のインポート マップであるインポートマップがある。
現時点では、Windowのグローバル
オブジェクトだけが、そのインポートマップを
初期状態の空のものから変更する。インポートマップは、
ルートモジュールスクリプトの解決にのみ
アクセスされる。
グローバルオブジェクトには、 初期状態が空である指定子解決レコードの集合である解決済みモジュール集合がある。
解決済みモジュール集合は、
同じ(リファラー、指定子)の組で複数回呼び出されたときに、モジュール指定子の解決が同じ結果を
返すことを保証する。これは、指定子の最初の解決後に、そのリファラーのスコープ内で指定子に影響するインポート
マップ規則を定義できないようにすることで実現される。現時点では、Windowのグローバルオブジェクトだけが、
モジュール集合のデータ構造を初期状態の空のものから変更する。
レルム、グローバルオブジェクト、および環境設定オブジェクトの間には、 常に 1 対 1 対 1 の対応関係がある:
レルムには [[HostDefined]] フィールドがあり、そこにはレルムの設定オブジェクトが格納される。
レルムには [[GlobalObject]] フィールドがあり、そこにはレルムのグローバル オブジェクトが格納される。
この仕様の各グローバルオブジェクトは、 対応するレルムの作成中に作成され、 そのレルムはグローバルオブジェクトのレルムと呼ばれる。
この仕様の各グローバルオブジェクトは、対応する環境設定オブジェクトとともに 作成され、その環境設定オブジェクトは関連する設定オブジェクトと呼ばれる。
環境設定オブジェクトのレルム 実行コンテキストの Realm コンポーネントを、環境設定オブジェクトのレルムという。
その後、環境設定オブジェクトのレルムには [[GlobalObject]] フィールドがあり、そこには環境設定オブジェクトのグローバルオブジェクトが格納される。
エージェント agent内で新しいレルムを 作成するには、任意でグローバルオブジェクトまたはグローバル this バインディング (あるいはその両方)を作成する指示とともに、次の手順を実行する:
グローバルオブジェクトおよびグローバル this バインディングを作成するために 提供されたカスタマイズを使用して、InitializeHostDefinedRealm()を実行する。
realm execution contextを、実行中の JavaScript 実行 コンテキストとする。
これは、前の手順で作成されたJavaScript 実行コンテキストである。
JavaScript 実行コンテキスト スタックから realm execution contextを削除する。
realmを、realm execution contextの Realm コンポーネントとする。
agentのエージェントクラスターのクロスオリジン分離
モードが「none」である場合:
globalを、realmのグローバル オブジェクトとする。
statusを、! global.[[Delete]]("SharedArrayBuffer") とする。
表明:statusは true である。
これはウェブコンテンツとの互換性のために行われるものであり、将来削除できることが
期待されている。ウェブ開発者は、引き続き new WebAssembly.Memory({ shared:true, initial:0, maximum:0
}).buffer.constructorを通じてコンストラクターを取得できる。
realm execution contextを返す。
この仕様全体でアルゴリズム手順を定義するとき、どのレルムを使用するか、または同等に、どのグローバルオブジェクトあるいは環境設定オブジェクトを使用するかを 示すことが重要な場合が多い。一般に、少なくとも次の 4 つの可能性がある:
エントリー、現任、および現在の概念は修飾なしで 使用できる一方、関連の概念は特定のプラットフォームオブジェクトに適用する必要があることに注意。
現任およびエントリーの概念は、 過度に複雑で直感に反しており扱いにくいため、新しい仕様では使用すべきでない。 プラットフォームから既存の使用のほぼすべてを削除する作業を進めている。現任についてはissue #1430、エントリーについてはissue #1431を参照。
一般に、ウェブプラットフォーム仕様は、操作対象のオブジェクト(通常は現在のメソッドの
this 値)に適用した関連の概念を使用すべきである。
これは、一般に現在を既定として使用する
JavaScript 仕様とは一致しない(たとえば、Array.prototype.mapで結果を構築するために
使用すべき Arrayコンストラクターのレルムを決定するとき)。
しかし、この不整合はプラットフォームに深く組み込まれているため、今後も受け入れざるを得ない。
次のページを考える。a.htmlはブラウザーウィンドウ内に読み込まれ、
b.htmlは示されているように iframe内に
読み込まれ、c.htmlと d.htmlは省略されている(単に空の文書でよい):
<!-- a.html -->
<!DOCTYPE html>
< html lang = "en" >
< title > Entry page</ title >
< iframe src = "b.html" ></ iframe >
< button onclick = "frames[0].hello()" > Hello</ button >
<!--b.html -->
<!DOCTYPE html>
< html lang = "en" >
< title > Incumbent page</ title >
< iframe src = "c.html" id = "c" ></ iframe >
< iframe src = "d.html" id = "d" ></ iframe >
< script >
const c = document. querySelector( "#c" ). contentWindow;
const d = document. querySelector( "#d" ). contentWindow;
window. hello = () => {
c. print. call( d);
};
</ script > 各ページには独自の閲覧コンテキストがあり、 したがって独自のレルム、グローバルオブジェクト、および環境設定オブジェクトがある。
a.htmlのボタンを押したことに応じて print()メソッドが
呼び出される場合:
関連の概念が、一般に現在の概念よりも
優れた既定の選択肢である理由の一つは、永続化されて複数回返されるオブジェクトを作成するのに
より適していることである。たとえば、navigator.getBattery()
メソッドは、それが呼び出された Navigatorオブジェクトの関連する
レルム内に Promise を作成する。これは次の影響を持つ:[BATTERY]
<!-- outer.html -->
<!DOCTYPE html>
< html lang = "en" >
< title > Relevant realm demo: outer page</ title >
< script >
function doTest() {
const promise = navigator. getBattery. call( frames[ 0 ]. navigator);
console. log( promise instanceof Promise); // logs false
console. log( promise instanceof frames[ 0 ]. Promise); // logs true
frames[ 0 ]. hello();
}
</ script >
< iframe src = "inner.html" onload = "doTest()" ></ iframe >
<!-- inner.html -->
<!DOCTYPE html>
< html lang = "en" >
< title > Relevant realm demo: inner page</ title >
< script >
function hello() {
const promise = navigator. getBattery();
console. log( promise instanceof Promise); // logs true
console. log( promise instanceof parent. Promise); // logs false
}
</ script > getBattery()
メソッドのアルゴリズムが代わりに現在のレルムを使用していた場合、すべての結果が逆になる。
すなわち、outer.htmlで最初に getBattery()を
呼び出した後、inner.html内の Navigatorオブジェクトは、
outer.htmlのレルムで作成された
Promiseオブジェクトを永続的に
保存することになり、hello()関数内の同様の呼び出しは「誤った」レルムの Promise を
返すことになる。これは望ましくないため、アルゴリズムは代わりに関連するレルムを使用し、
上のコメントに示された妥当な結果を得る。
この節の残りでは、エントリー、現任、現在、および関連の概念を正式に定義する。
スクリプトを呼び出す処理では、他の実行コンテキストを間に挟みながら、レルム実行コンテキストをJavaScript 実行コンテキストスタックにプッシュまたはポップする。
これを踏まえ、エントリー実行コンテキストを、JavaScript 実行コンテキストスタック内で 最も最近プッシュされたレルム実行コンテキストである項目と定義する。 エントリーレルムは、エントリー実行 コンテキストの Realm コンポーネントである。
次に、エントリー設定オブジェクトは、エントリーレルムの環境設定オブジェクトである。
同様に、エントリーグローバルオブジェクトは、エントリー レルムのグローバルオブジェクトである。
すべてのJavaScript 実行コンテキストは、そのコード評価状態の 一部として、初期値が 0 である現任を決定するときにスキップする カウンター値を含まなければならない。コールバックを実行する準備およびコールバック実行後の クリーンアップの処理中に、この値は増減される。
各イベントループには、初期状態が空である予備現任設定オブジェクト スタックが関連付けられている。概略的には、スタック上に著者コードがないものの、 現在のアルゴリズムが何らかの方法で実行される原因が著者コードにある場合に、現任設定オブジェクトを決定するために使用される。コールバックを実行する準備およびコールバック実行後の クリーンアップの処理は、このスタックを操作する。[WEBIDL]
Web IDL が著者コードを呼び出す場合、 またはHostEnqueuePromiseJobが Promise ジョブを呼び出す場合、現任設定オブジェクトを決定するための関連データを 追跡するために、次のアルゴリズムを使用する:
環境設定オブジェクト settingsを使用してコールバックを実行する準備をするには:
settingsを予備現任設定オブジェクト スタックにプッシュする。
contextを最上位のスクリプトを持つ実行 コンテキストとする。
contextが null でない場合、contextの現任を決定するときにスキップする カウンターを 1 増やす。
環境設定 オブジェクト settingsを使用してコールバック実行後にクリーンアップするには:
contextを最上位のスクリプトを持つ実行コンテキストとする。
これは、対応するコールバックを実行する 準備の呼び出し内における最上位のスクリプトを持つ実行 コンテキストと同じになる。
contextが null でない場合、contextの現任を決定するときにスキップする カウンターを 1 減らす。
表明:予備現任設定オブジェクト スタックの最上位のエントリーは settingsである。
予備現任設定オブジェクト スタックから settingsを削除する。
ここで、最上位のスクリプトを持つ実行コンテキストは、 ScriptOrModule コンポーネントが null でないJavaScript 実行コンテキストスタックの 最上位のエントリーであり、JavaScript 実行コンテキストスタックに そのようなエントリーがない場合は null である。
以上を踏まえ、現任設定オブジェクトは次のように決定される:
contextを最上位のスクリプトを持つ実行 コンテキストとする。
contextが null であるか、contextの現任を決定するときにスキップする カウンターが 0 より大きい場合:
表明:予備現任設定オブジェクトスタックは 空でない。
この表明は、スクリプトの呼び出しによっても、 Web IDL によるコールバックの呼び出しによっても引き起こされていない アルゴリズム内から現任設定 オブジェクトを取得しようとすると失敗する。たとえば、著者コードが関与せずにイベントループの一部として定期的に実行される アルゴリズム内で現任設定オブジェクトを取得しようとすると発生する。 そのような場合、現任の概念は使用できない。
予備現任設定オブジェクト スタックの最上位のエントリーを返す。
contextの Realm コンポーネントの設定オブジェクトを返す。
次に、現任レルムは、現任設定オブジェクトのレルムである。
同様に、現任グローバルオブジェクトは、 現任設定オブジェクトのグローバルオブジェクトである。
次の一連の例は、さまざまな仕組みすべてが現任の概念の定義に どのように寄与するかを明確にすることを目的としている:
次の基本的な例を考える:
<!DOCTYPE html>
< iframe ></ iframe >
< script >
frames[ 0 ]. postMessage( "some data" , "*" );
</ script > ここには、windowのものと frames[0]のものという、興味深い 2 つの環境設定
オブジェクトがある。問題は、postMessage()の
アルゴリズムが実行される時点で、現任設定オブジェクトは何か、ということである。
それは windowのものであるべきであり、アルゴリズムを発生させた著者スクリプトが
frames[0]ではなく window内で実行されているという直感的な概念を
捉える。これは理にかなっている。ウィンドウの
postMessage 手順は、結果となる MessageEventの
sourceプロパティを
決定するために現任設定オブジェクトを使用し、この場合
windowが明らかにメッセージの送信元である。
次に、上記の手順によって、直感的に望ましい windowの関連する設定オブジェクトという結果が
どのように得られるかを説明する。
ウィンドウの postMessage
手順が現任設定
オブジェクトを検索するとき、最上位のスクリプトを持つ実行コンテキストは、
script要素に対応するものになる。
これは、古典スクリプトを実行するアルゴリズム中のScriptEvaluationの一部として、JavaScript 実行コンテキストスタックに
プッシュされたためである。Web IDL のコールバック呼び出しは関係していないため、
コンテキストの現任を決定するときにスキップする
カウンターは 0 であり、そのコンテキストが現任設定オブジェクトの決定に使用される。
結果は、windowの環境設定
オブジェクトである。
(frames[0]の環境
設定オブジェクトは、postMessage()メソッドが
呼び出される時点でのthisの関連する設定オブジェクトであり、
したがってメッセージの宛先の決定に関与することに注意。一方、現任は
送信元の決定に使用される。)
次の、より複雑な例を考える:
<!DOCTYPE html>
< iframe ></ iframe >
< script >
const bound = frames[ 0 ]. postMessage. bind( frames[ 0 ], "some data" , "*" );
window. setTimeout( bound);
</ script > この例は前のものと非常によく似ているが、Function.prototype.bindおよび setTimeout()を介した
追加の間接処理がある。しかし、結果は同じであるべきである。アルゴリズムを非同期に呼び出すことで現任の概念が変わるべきではない。
今回は、結果により複雑な仕組みが関係する:
boundが Web IDL コールバック型に変換されるとき、
現任設定オブジェクトは
windowに対応するものである(上の基本例と同じ方法による)。Web IDL はこれを、
結果となるコールバック値のコールバック
コンテキストとして保存する。
setTimeout()によって投稿されたタスクが実行されると、そのタスクのアルゴリズムは
Web IDL を使用して保存されたコールバック値を呼び出す。次に Web
IDL は、上記のコールバックを実行する
準備アルゴリズムを呼び出す。これにより、保存されたコールバックコンテキストが予備
現任設定オブジェクトスタックにプッシュされる。この時点(タイマータスク内)では、
スタック上に著者コードがないため、最上位のスクリプトを持つ実行コンテキストは
null であり、どのコンテキストの現任を決定するときにスキップする
カウンターも増加しない。
次に、コールバックを呼び出すと boundが呼び出され、それによって
frames[0]の postMessage()メソッドが
呼び出される。postMessage()の
アルゴリズムが現任設定
オブジェクトを検索するとき、バインドされた関数は組み込みメソッドを直接呼び出すだけなので、
スタック上には依然として著者コードがない。そのため、最上位のスクリプトを持つ実行コンテキストは
null になる。JavaScript 実行
コンテキストスタックには、postMessage()に
対応する実行コンテキストだけが含まれ、その下にScriptEvaluationコンテキストなどは存在しない。
ここで予備現任設定オブジェクトスタックに
フォールバックする。上で述べたように、その最上位のエントリーには windowの関連する設定オブジェクトが含まれる。
したがって、postMessage()アルゴリズムの
実行中は、それが現任設定
オブジェクトとして使用される。
最後に、さらに複雑な次の例を考える:
<!-- a.html -->
<!DOCTYPE html>
< button > click me</ button >
< iframe ></ iframe >
< script >
const bound = frames[ 0 ]. location. assign. bind( frames[ 0 ]. location, "https://example.com/" );
document. querySelector( "button" ). addEventListener( "click" , bound);
</ script > <!-- b.html -->
<!DOCTYPE html>
< iframe src = "a.html" ></ iframe >
< script >
const iframe = document. querySelector( "iframe" );
iframe. onload = function onLoad() {
iframe. contentWindow. document. querySelector( "button" ). click();
};
</ script > ここでも、a.htmlのものと b.htmlのものという、関係する興味深い
2 つの環境
設定オブジェクトがある。location.assign()メソッドがLocationオブジェクトのナビゲートアルゴリズムを
発生させるとき、現任設定
オブジェクトは何になるだろうか。前と同様、直感的には a.htmlのものであるべきである。
click
リスナーは元々 a.htmlによってスケジュールされたため、b.htmlに関係する
何かがリスナーを発火させたとしても、責任を持つ現任は a.htmlのものである。
コールバックの設定は前の例と同様である。boundが Web IDL コールバック型に変換されるとき、現任設定オブジェクトは
a.htmlに対応するものであり、コールバックのコールバック
コンテキストとして保存される。
b.html内で click()メソッドが
呼び出されると、a.html内のボタンに click
イベントを発火する。今回は、イベントの発火の一部としてコールバックを実行する準備アルゴリズムが実行されるとき、
スタック上に著者コードが存在する。最上位のスクリプトを持つ実行コンテキストは
onLoad関数のものであり、その現任を決定するときにスキップする
カウンターが増加する。さらに、a.htmlの環境設定オブジェクト(EventHandlerのコールバックコンテキストとして保存されたもの)が予備
現任設定オブジェクトスタックにプッシュされる。
ここで、Locationオブジェクトのナビゲートアルゴリズムが
現任設定オブジェクトを検索するとき、最上位のスクリプトを持つ実行
コンテキストは、(コールバックとしてバインドされた関数を使用しているため)依然として
onLoad関数のものである。ただし、その現任を決定するときにスキップする
カウンター値は 1 であるため、予備現任設定
オブジェクトスタックにフォールバックする。これにより、予想どおり a.htmlの環境設定オブジェクトが得られる。
これは、ナビゲートするのが a.html内の iframeであっても、
送信元の Documentとして使用されるのは
a.html自体であり、それによってリクエストクライアントなどが決定されることを意味する。
これはウェブプラットフォームにおける
現任の概念の、おそらく唯一正当化できる使用法である。それ以外の場合、これを使用した結果は
単に混乱を招くだけであり、いつか適切に現在または関連を使用するよう切り替えたいと考えている。
JavaScript 仕様は、「現在の Realm Record」とも呼ばれる現在のレルムを定義している。[JAVASCRIPT]
次に、現在の設定オブジェクトは、現在の レルムの環境設定オブジェクトである。
同様に、現在のグローバルオブジェクトは、現在のレルムのグローバルオブジェクトである。
プラットフォーム オブジェクトの関連するレルムは、その [[Realm]] フィールドの値である。
プラットフォームオブジェクト oの関連する設定オブジェクトは、 oの関連するレルムの環境設定 オブジェクトである。
同様に、プラットフォームオブジェクト oの関連するグローバルオブジェクトは、 oの関連するレルムのグローバル オブジェクトである。
次の条件がすべて true である場合、環境設定オブジェクト settingsについてスクリプト処理が有効である:
Windowオブジェクトでないか、
または settingsのグローバルオブジェクトの関連付けられた
Documentのアクティブな
サンドボックス化フラグ集合に、サンドボックス化された
スクリプト閲覧コンテキストフラグが設定されていない。
環境設定オブジェクトについてスクリプト処理が有効でない場合、 すなわち上記の条件のいずれかが false である場合、その環境設定オブジェクトについてスクリプト処理が無効である。
プラットフォームオブジェクト objectについて、次のいずれかが true である場合、 スクリプト処理が無効である:
objectの関連する設定オブジェクトについてスクリプト処理が無効である。
objectが Windowを実装し、
objectの関連付けられた
Documentの閲覧コンテキストが null である。
プラットフォームオブジェクト objectについて、objectのスクリプト処理が無効でない場合、スクリプト処理が有効である。
環境 environmentは、次の アルゴリズムが true を返す場合、セキュアコンテキストである:
environmentが環境設定オブジェクトである場合:
globalを、environmentのグローバルオブジェクトとする。
globalが WorkerGlobalScopeである場合:
globalの所有者集合[0]の関連する設定 オブジェクトがセキュアコンテキストである場合、true を返す。
これらは必ずすべて一貫するため、0 番目の項目だけを確認すればよい。
false を返す。
globalが WorkletGlobalScopeで
ある場合、true を返す。
ワークレットはセキュアコンテキスト内でのみ作成できる。
environmentのトップレベル作成 URLが
与えられたときのURL は潜在的に信頼できるか?の結果が
「Potentially
Trustworthy」である場合、true を返す。
false を返す。
環境がセキュアコンテキストでない場合、 その環境は非セキュアコンテキストである。
スクリプトは、2 つの可能な構造体 (すなわち、古典スクリプトまたは モジュールスクリプト)のいずれかである。 すべてのスクリプトには次のものがある:
同じコンテキスト内の他のスクリプトと共有されるさまざまな設定を含む環境設定 オブジェクト。
次のいずれか:
CSS モジュール スクリプト、JSON モジュールスクリプト、および テキストモジュールスクリプトの場合は、Synthetic Module Record。
構文解析の失敗を表す null。
レコードが null の場合にのみ意味を持ち、 対応するスクリプトソーステキストを構文解析できなかったことを示す JavaScript 値。
この値は、スクリプトを作成するときに即時の 構文解析エラーを内部的に追跡するために使用され、直接使用するものではない。代わりに、 このスクリプトで「何が問題だったか」を判断するときは、再スローするエラーを参照する。
評価の成功を妨げるエラーを表す JavaScript 値。スクリプトを実行するあらゆる試みによって再スローされる。
これはスクリプトの構文解析 エラーである可能性があるが、モジュールスクリプトの場合は、代わりにその依存関係の 1 つの構文解析エラー、またはモジュール指定子を解決する処理からの エラーである可能性がある。
この例外値は JavaScript 仕様によって提供されるため、null になることは ないと分かっている。そのため、エラーが発生していないことを示すために null を使用する。
null、またはモジュール指定子を解決するために使用される ベースURL。null でない場合、外部スクリプトではスクリプトを取得した URL、インラインスクリプトではそれを含む文書の文書ベース URLのいずれかになる。
古典スクリプトは、次の追加の項目を持つスクリプトの一種である:
true の場合、このスクリプト内のエラーについてエラー情報が提供されないことを意味する ブール値。これは、個人情報が漏洩する可能性があるため、クロスオリジンスクリプトのエラーを ミュートするために使用される。
モジュールスクリプトは、別の種類のスクリプトである。追加の項目はない。
モジュールスクリプトは、次の 4 種類に分類できる:
モジュールスクリプトは、そのレコードがSource Text Module Recordである場合、JavaScript モジュールスクリプトである。
モジュールスクリプトは、そのレコードがSynthetic Module Recordであり、CSS モジュール スクリプトを作成するアルゴリズムによって作成された場合、CSS モジュールスクリプトである。 CSS モジュールスクリプトは、構文解析済みの CSS スタイルシートを表す。
モジュールスクリプトは、そのレコードがSynthetic Module Recordであり、JSON モジュール スクリプトを作成するアルゴリズムによって作成された場合、JSON モジュールスクリプトである。 JSON モジュールスクリプトは、構文解析済みの JSON 文書を表す。
モジュールスクリプトは、そのレコードがSynthetic Module Recordであり、テキストモジュール スクリプトを作成するアルゴリズムによって作成された場合、テキストモジュールスクリプトである。 テキストモジュールスクリプトは、UTF-8 として符号化されたテキストデータを表す。
モジュールスクリプトは、そのレコードがWebAssembly Module Recordである場合、WebAssembly モジュールスクリプトである。
CSS スタイルシート、JSON 文書、およびテキストは依存モジュールをインポートせず、 評価時に例外をスローしないため、CSS モジュールスクリプト、JSON モジュール スクリプト、およびテキストモジュールスクリプトのフェッチ オプションとベース URLは常に null である。
アクティブなスクリプトは、次のアルゴリズムによって決定される:
recordを GetActiveScriptOrModule() とする。
recordが null の場合、null を返す。
record.[[HostDefined]] を返す。
アクティブなスクリプトの概念は、現在のところ
import()
機能だけで使用され、相対モジュール指定子の解決に使用するベース
URLを決定する。
この節では、さまざまな必要な入力を受け取り、古典スクリプトまたはモジュールスクリプトを結果として生成する、 スクリプトをフェッチするための複数のアルゴリズムを導入する。
スクリプトフェッチオプションは、次の項目を持つ構造体である:
最初のフェッチおよびインポートされたモジュールのフェッチに使用される暗号学的 nonce メタデータ
最初のフェッチに使用される完全性メタデータ
最初のフェッチおよびインポートされたモジュールのフェッチに使用されるパーサー メタデータ
最初のフェッチ(モジュールスクリプトの場合)およびインポートされた モジュールのフェッチ(モジュールスクリプトと古典スクリプトの両方の場合)に 使用される資格情報モード
最初のフェッチおよびインポートされたモジュールのフェッチに使用されるリファラーポリシー
このポリシーは、モジュールスクリプトの応答を受信した後に、応答から構文解析されたリファラーポリシーに変更される可能性があり、 モジュールの依存関係をフェッチするときに使用される。
最初のフェッチおよびインポートされたモジュールのフェッチに使用されるレンダリングブロッキングの ブール値。特に明記されない限り、その値は false である。
最初のフェッチに使用される優先度
import()
機能を介して、古典スクリプトがモジュールスクリプトを
インポートできることを思い出してほしい。
既定のスクリプトフェッチオプションは、暗号学的 nonceが空文字列、完全性メタデータが空文字列、
パーサー
メタデータが「not-parser-inserted」、資格情報モードが
「same-origin」、リファラーポリシーが
空文字列、フェッチ優先度が
「auto」であるスクリプトフェッチオプションである。
リクエスト requestおよびスクリプトフェッチオプション optionsが与えられたとき、古典スクリプトリクエストを設定するには、 requestの暗号学的 nonce メタデータを optionsの暗号学的 nonceに、その完全性メタデータを optionsの完全性メタデータに、そのパーサー メタデータを optionsのパーサーメタデータに、そのリファラーポリシーを optionsのリファラーポリシーに、その レンダリングブロッキングを optionsのレンダリングブロッキングに、 その優先度を optionsのフェッチ優先度に設定する。
モジュールスクリプトリクエストを設定するには、 リクエスト requestおよび スクリプトフェッチオプション optionsが与えられたとき、 requestの暗号学的 nonce メタデータを optionsの暗号学的 nonceに、その完全性メタデータを optionsの 完全性メタデータに、そのパーサー メタデータを optionsのパーサーメタデータに、その資格情報モードを optionsの資格情報モードに、そのリファラーポリシーを optionsのリファラーポリシーに、その レンダリングブロッキングを optionsの レンダリングブロッキングに、そしてその 優先度を optionsの フェッチ優先度に設定する。
スクリプトフェッチオプション originalOptions、URL url、および環境設定 オブジェクト settingsObjectが与えられたとき、子孫スクリプトフェッチオプションを取得するには:
newOptionsを originalOptionsのコピーとする。
integrityを、urlおよび settingsObjectを使用してモジュール完全性 メタデータを解決した結果とする。
newOptionsの完全性メタデータを integrityに設定する。
newOptionsのフェッチ優先度を
「auto」に設定する。
newOptionsを返す。
URL urlおよび環境設定 オブジェクト settingsObjectが与えられたとき、モジュール完全性 メタデータを解決するには:
mapを、settingsObjectのグローバルオブジェクトのインポートマップとする。
mapのintegrity[url]を返す。
以下のいくつかのアルゴリズムは、リクエスト、ブール値 isTopLevel、およびprocessCustomFetchResponse
アルゴリズムを受け取るフェッチを実行する
フックアルゴリズムによってカスタマイズできる。このアルゴリズムは、応答および null(失敗時)または応答本体を含むバイト
列を使用して processCustomFetchResponseを実行する。
isTopLevelは、すべての古典
スクリプトのフェッチ、および外部モジュールスクリプトグラフをフェッチする場合やモジュールワーカースクリプトグラフを
フェッチする場合の最初のフェッチでは true になるが、グラフ全体で遭遇する
import文または import()式から発生するフェッチでは false になる。
既定では、フェッチを実行する フックを指定しない場合、以下のアルゴリズムは、アルゴリズム固有のリクエストのカスタマイズと結果の応答の検証を伴って、指定されたリクエストを単にフェッチする。
これらのアルゴリズム固有のカスタマイズの上に独自のカスタマイズを重ねるには、指定されたリクエストを変更してフェッチし、結果となる応答に対して特定の検証を実行する(検証に失敗した場合はネットワークエラーで完了する)フェッチを実行する フックを指定する。
このフックは、応答のキャッシュを保持し、フェッチをまったく実行しないようにするなど、 より微妙なカスタマイズにも使用できる。
Service Workersは、このフックに独自のオプションを指定して これらのアルゴリズムを実行する仕様の一例である。[SW]
ここからはアルゴリズム自体を示す。
URL url、環境設定 オブジェクト settingsObject、スクリプトフェッチ オプション options、CORS 設定 属性状態 corsSetting、符号化 encoding、およびアルゴリズム onCompleteが与えられたとき、古典スクリプトをフェッチするには、次の手順を実行する。 onCompleteは、null(失敗時)または古典 スクリプト(成功時)を受け入れるアルゴリズムでなければならない。
requestを、url、「script」、および
corsSettingが与えられたときに潜在的 CORS リクエストを作成した結果とする。
requestのクライアントを settingsObjectに設定する。
requestの開始元
タイプを「script」に設定する。
requestおよび optionsが与えられたとき、古典スクリプトリクエストを 設定する。
応答 responseおよび null、失敗、またはバイト列 bodyBytesが与えられたとき、 次の processResponseConsumeBody 手順を使用して requestをフェッチする:
responseは、CORS 同一オリジンまたはCORS クロスオリジンのいずれかになり得る。 これはエラー報告の方法にのみ影響する。
responseを responseの安全でない応答に設定する。
次のいずれかが true の場合:
その場合、null を使用して onCompleteを実行し、これらの手順を中止する。
歴史的な理由により、このアルゴリズムには、この節の他の スクリプトフェッチアルゴリズムとは異なり、MIME 型の確認が含まれない。
potentialMIMETypeForEncodingを、responseのヘッダー リストが与えられたときにMIME 型を抽出した結果とする。
encodingを、potentialMIMETypeForEncodingおよび encodingが与えられたときに従来方式で符号化を 抽出した結果に設定する。
これは意図的にMIME 型エッセンスを無視する。
sourceTextを、フォールバック符号化として encodingを使用し、 bodyBytesを Unicode に復号した結果とする。
ファイルに BOM が含まれる場合、復号アルゴリズムは encodingを上書きする。
mutedErrorsを、responseがCORS クロスオリジンであった場合は true、 それ以外の場合は false とする。
scriptを、sourceText、settingsObject、 responseのURL、options、 mutedErrors、および urlが与えられたときに古典スクリプトを作成した結果とする。
URL url、環境設定 オブジェクト fetchClient、宛先 destination、環境設定 オブジェクト settingsObject、アルゴリズム onComplete、および任意のフェッチを 実行するフック performFetchが与えられたとき、古典ワーカースクリプトをフェッチするには、 次の手順を実行する。onCompleteは、null(失敗時)または古典スクリプト(成功時)を 受け入れるアルゴリズムでなければならない。
requestを、そのURLが url、クライアントが
fetchClient、宛先が
destination、開始元タイプが「other」、
モードが「same-origin」、資格情報モードが「same-origin」、パーサー
メタデータが「not parser-inserted」であり、URL 資格情報使用フラグが設定された新しいリクエストとする。
performFetchが与えられた場合、request、true、および以下で 定義する processResponseConsumeBodyを使用して performFetchを実行する。
それ以外の場合、processResponseConsumeBodyを 以下で定義する processResponseConsumeBodyに設定して、requestをフェッチする。
どちらの場合も、応答 responseおよび null、失敗、またはバイト 列 bodyBytesが与えられたときの processResponseConsumeBodyを、 次のアルゴリズムとする:
responseを responseの安全でない応答に設定する。
次のいずれかが true の場合:
その場合、null を使用して onCompleteを実行し、これらの手順を中止する。
次のすべてが true の場合:
responseのURLのスキームがHTTP(S) スキームである。かつ
responseのヘッダーリストからMIME 型を抽出した結果がJavaScript MIME 型でない。
その場合、null を使用して onCompleteを実行し、これらの手順を中止する。
その他のフェッチスキームは、歴史的なウェブ互換性上の理由から MIME 型の確認を免除される。将来これを厳格化できる可能性がある。issue #3255を参照。
sourceTextを、bodyBytesをUTF-8 復号した結果とする。
scriptを、sourceText、settingsObject、 responseのURL、および既定のスクリプトフェッチ オプションを使用して古典スクリプトを作成した結果とする。
scriptを使用して onCompleteを実行する。
URL url、環境設定オブジェクト settingsObject、および任意のフェッチを実行するフック performFetchが与えられたとき、古典ワーカーによってインポートされる スクリプトをフェッチするには、次の手順を実行する。このアルゴリズムは成功時に古典スクリプトを返し、 失敗時に例外をスローする。
responseを null とする。
bodyBytesを null とする。
requestを、そのURLが url、クライアントが
settingsObject、宛先が「script」、
開始元タイプが「other」、パーサーメタデータが
「not parser-inserted」であり、URL 資格情報使用フラグが
設定された新しいリクエストとする。
performFetchが与えられた場合、request、 isTopLevel、および以下で定義する processResponseConsumeBodyを使用して performFetchを実行する。
それ以外の場合、processResponseConsumeBodyを 以下で定義する processResponseConsumeBodyに設定して、requestをフェッチする。
どちらの場合も、応答 resおよび null、失敗、またはバイト列 bbが与えられたときの processResponseConsumeBodyを、次のアルゴリズムとする:
bodyBytesを bbに設定する。
responseを resに設定する。
responseが null でなくなるまで一時停止する。
この節の他のアルゴリズムとは異なり、ここではフェッチ処理は同期的である。
responseを responseの安全でない応答に設定する。
次のいずれかが true の場合:
bodyBytesが null または失敗である。
responseのヘッダーリストからMIME 型を抽出した結果がJavaScript MIME 型でない。
その場合、「NetworkError」 DOMExceptionを
スローする。
sourceTextを、bodyBytesをUTF-8 復号した結果とする。
mutedErrorsを、responseがCORS クロスオリジンであった場合は true、 それ以外の場合は false とする。
scriptを、sourceText、settingsObject、 responseのURL、既定のスクリプトフェッチオプション、 および mutedErrorsが与えられたときに古典スクリプトを作成した結果とする。
scriptを返す。
URL url、環境設定オブジェクト settingsObject、スクリプト フェッチオプション options、およびアルゴリズム onCompleteが与えられたとき、外部モジュールスクリプトグラフをフェッチするには、次の手順を実行する。 onCompleteは、null(失敗時)またはモジュールスクリプト(成功時)を受け入れる アルゴリズムでなければならない。
url、settingsObject、「script」、
options、settingsObject、「client」、true、および
resultが与えられたときの次の手順を使用して、単一のモジュールスクリプトをフェッチする:
resultが null の場合、null を使用して onCompleteを実行し、 これらの手順を中止する。
settingsObject、「script」、および
onCompleteが与えられたとき、resultの子孫をフェッチして
リンクする。
URL url、宛先 destination、環境設定 オブジェクト settingsObject、スクリプトフェッチ オプション options、およびアルゴリズム onCompleteが与えられたとき、 modulepreload モジュールスクリプトグラフを フェッチするには、次の手順を実行する。onCompleteは、null(失敗時)またはモジュール スクリプト(成功時)を受け入れるアルゴリズムでなければならない。
url、settingsObject、destination、
options、settingsObject、「client」、true、および
resultが与えられたときの次の手順を使用して、単一のモジュールスクリプトをフェッチする:
resultを使用して onCompleteを実行する。
表明:settingsObjectのグローバル
オブジェクトは Windowを実装する。
resultが null でない場合、任意で settingsObject、 destination、および空のアルゴリズムが与えられたとき、 resultの子孫をフェッチして リンクする。
一般に、この手順を実行することはパフォーマンス上有益である。 グラフ全体をフェッチする外部モジュールスクリプトグラフを フェッチするなどのアルゴリズムを介して、後で必ず要求されるモジュールを 事前読み込みできるためである。ただし、ユーザーエージェントは、帯域幅が制限された 状況や、関連するフェッチがすでに進行中の状況では、この手順を省略することがある。
文字列 sourceText、URL baseURL、環境設定 オブジェクト settingsObject、スクリプトフェッチオプション options、およびアルゴリズム onCompleteが与えられたとき、インラインモジュールスクリプトグラフをフェッチするには、 次の手順を実行する。onCompleteは、null(失敗時)またはモジュール スクリプト(成功時)を受け入れるアルゴリズムでなければならない。
scriptを、sourceText、settingsObject、 baseURL、および optionsを使用してJavaScript モジュールスクリプトを 作成した結果とする。
settingsObject、「script」、および
onCompleteが与えられたとき、scriptの子孫をフェッチして
リンクする。
URL url、環境設定オブジェクト fetchClient、宛先 destination、資格情報 モード credentialsMode、環境設定オブジェクト settingsObject、およびアルゴリズム onCompleteが与えられたとき、 モジュールワーカースクリプトグラフを フェッチするには、url、fetchClient、destination、 credentialsMode、settingsObject、および onCompleteが 与えられたときにワークレット/モジュール ワーカースクリプトグラフをフェッチする。
URL url、環境設定 オブジェクト fetchClient、宛先 destination、資格情報モード credentialsMode、環境設定オブジェクト settingsObject、モジュール応答 マップ moduleResponsesMap、およびアルゴリズム onCompleteが与えられたとき、 ワークレットスクリプトグラフをフェッチするには、 url、fetchClient、destination、 credentialsMode、settingsObject、onComplete、および requestと processCustomFetchResponseが 与えられたときの次のフェッチを 実行するフックを使用して、ワークレット/モジュール ワーカースクリプトグラフをフェッチする:
requestURLを requestのURLとする。
moduleResponsesMap[requestURL]が「fetching」である場合、
そのエントリーの値が変化するまで並列に待機し、その後、次の手順の実行を続行するタスクをキューに追加する。
moduleResponsesMap[requestURL]が存在する場合:
cachedを moduleResponsesMap[requestURL]とする。
cached[0]および cached[1]を使用して processCustomFetchResponseを実行する。
戻る。
moduleResponsesMap[requestURL]を「fetching」に設定する。
応答 responseおよび null、失敗、またはバイト列 bodyBytesが与えられたときの 次の手順を processResponseConsumeBodyに 設定して、requestをフェッチする:
moduleResponsesMap[requestURL]を (response, bodyBytes) に設定する。
responseおよび bodyBytesを使用して processCustomFetchResponseを実行する。
次のアルゴリズムは、外部モジュールスクリプトグラフを フェッチする処理または上記の類似の概念の一部として、この仕様だけが内部的に使用することを 意図したものであり、他の仕様が直接使用すべきではない。
この図は、これらのアルゴリズムが上記のアルゴリズムおよび相互にどのように関係するかを示す:
URL url、環境設定オブジェクト fetchClient、宛先 destination、資格情報モード credentialsMode、環境設定オブジェクト settingsObject、 アルゴリズム onComplete、および任意のフェッチを実行するフック performFetchが与えられたとき、ワークレット/モジュールワーカー スクリプトグラフをフェッチするには、次の手順を実行する。 onCompleteは、null(失敗時)またはモジュールスクリプト(成功時)を 受け入れるアルゴリズムでなければならない。
optionsを、その暗号学的 nonceが空文字列、完全性メタデータが空文字列、
パーサーメタデータが
「not-parser-inserted」、資格情報モードが
credentialsMode、リファラー
ポリシーが空文字列、フェッチ優先度が
「auto」であるスクリプトフェッチオプションとする。
url、fetchClient、destination、
options、settingsObject、「client」、true、および
以下で定義する onSingleFetchCompleteが与えられたとき、単一のモジュールスクリプトを
フェッチする。performFetchが与えられた場合、それも渡す。
resultが与えられたときの onSingleFetchCompleteは、 次のアルゴリズムである:
resultが null の場合、null を使用して onCompleteを実行し、 これらの手順を中止する。
fetchClient、destination、および onCompleteが与えられたとき、resultの子孫をフェッチして リンクする。performFetchが与えられた場合、それも渡す。
モジュールスクリプト moduleScript、環境 設定オブジェクト fetchClient、宛先 destination、アルゴリズム onComplete、および任意のフェッチを 実行するフック performFetchが与えられたとき、moduleScriptの子孫をフェッチして リンクするには、次の手順を実行する。onCompleteは、null(失敗時)またはモジュール スクリプト(成功時)を受け入れるアルゴリズムでなければならない。
recordを moduleScriptのレコードとする。
recordが null の場合:
moduleScriptの再スローする エラーを moduleScriptの構文解析エラーに設定する。
moduleScriptを使用して onCompleteを実行する。
戻る。
stateを Record { [[ErrorToRethrow]]: null, [[Destination]]: destination, [[PerformFetch]]: null, [[FetchClient]]: fetchClient } とする。
performFetchが与えられた場合、state.[[PerformFetch]]を performFetchに設定する。
loadingPromiseを record.LoadRequestedModules(state) とする。
この手順は、モジュールの推移的な依存関係をすべて再帰的に読み込む。
loadingPromiseが履行されたとき、次の手順を実行する:
record.Link() を実行する。
この手順は、モジュールのリンクされていないすべての依存関係に対してLinkを再帰的に呼び出す。
これが例外をスローした場合、それを捕捉し、moduleScriptの再スローする エラーをその例外に設定する。
moduleScriptを使用して onCompleteを実行する。
loadingPromiseが拒否されたとき、次の手順を実行する:
state.[[ErrorToRethrow]]が null でない場合、moduleScriptの再スローする エラーを state.[[ErrorToRethrow]]に設定し、 moduleScriptを使用して onCompleteを実行する。
それ以外の場合、null を使用して onCompleteを実行する。
loadingPromiseが読み込みエラーにより拒否された場合、 state.[[ErrorToRethrow]]は null である。
URL url、環境設定 オブジェクト fetchClient、宛先 destination、スクリプト フェッチオプション options、環境設定オブジェクト settingsObject、リファラー referrer、オプションのModuleRequest レコード moduleRequest、 ブール値 isTopLevel、アルゴリズム onComplete、およびオプションのフェッチを 実行するフック performFetchが与えられたとき、単一のモジュールスクリプトをフェッチするには、次の手順を実行する。onCompleteは、 null(失敗時)またはモジュール スクリプト(成功時)を受け入れるアルゴリズムでなければならない。
moduleTypeを「javascript-or-wasm」とする。
moduleRequestが与えられた場合、moduleTypeを、 moduleRequestを与えてモジュール要求からのモジュールタイプ手順を 実行した結果に設定する。
表明:moduleTypeとsettingsObjectを 与えて許可されるモジュールタイプ手順を 実行した結果は true である。そうでなければ、 HostLoadImportedModuleまたは単一のインポートされたモジュールスクリプトをフェッチするで moduleRequest.[[Attributes]]を検査した際に失敗が発生していたため、この地点には 到達していないはずである。
moduleMapを、settingsObjectのモジュールマップとする。
moduleMap[(url, moduleType)]が モジュールスクリプトまたは null である場合、 moduleMap[(url, moduleType)]を与えて onCompleteを実行し、返る。
moduleMap[(url, moduleType)]がリストである場合、 onCompleteを moduleMap[(url, moduleType)]に付加し、返る。
moduleMap[(url, moduleType)]を « onComplete » に設定する。
requestを、新しい要求とする。その
URLは url、モードは「cors」、リファラーは
referrer、そしてクライアントは
fetchClientである。
requestの宛先を、 destinationとmoduleTypeを与えてモジュールタイプからのフェッチ宛先手順を実行した 結果に設定する。
destinationが「worker」、「sharedworker」、または
「serviceworker」であり、かつ
isTopLevelが true である場合、requestのモードを「same-origin」に設定する。
requestの開始元
タイプを「script」に設定する。
requestと optionsを与えて、モジュールスクリプト要求を セットアップする。
performFetchが与えられた場合、request、 isTopLevel、および以下で定義するprocessResponseConsumeBodyを用いて、performFetchを実行する。
それ以外の場合、以下で定義する processResponseConsumeBodyに processResponseConsumeBodyを設定して、 requestをフェッチする。
どちらの場合も、応答 responseと、null、失敗、または バイト列 bodyBytesが与えられたprocessResponseConsumeBodyを、次のアルゴリズムとする:
responseは常にCORS 同一オリジンである。
次のいずれかが true である場合:
その場合:
callbacksを moduleMap[(url, moduleType)]とする。
moduleMap[(url, moduleType)]を削除する。
callbacksの各 callbackについて、null を与えて callbackを実行する。
返る。
mimeTypeを、responseのヘッダーリストからMIME タイプを 抽出した結果とする。
moduleScriptを null とする。
referrerPolicyを、responseを与えて`Referrer-Policy`ヘッダーを構文解析した
結果とする。[REFERRERPOLICY]
referrerPolicyが空文字列でない場合、optionsのリファラーポリシーを referrerPolicyに設定する。
mimeTypeのエッセンスが
「application/wasm」であり、かつ
moduleTypeが「javascript-or-wasm」である場合、moduleScriptを、
bodyBytes、
settingsObject、responseのURL、およびoptionsを与えてWebAssembly モジュールスクリプトを作成した
結果に設定する。
それ以外の場合:
sourceTextを、bodyBytesをUTF-8 デコードした結果とする。
moduleTypeが「text」である場合、
moduleScriptを、sourceTextとsettingsObjectを与えてテキストモジュールスクリプトを作成した結果に設定する。
mimeTypeがJavaScript MIME タイプであり、かつmoduleType
が「javascript-or-wasm」である場合、moduleScriptを、
sourceText、
settingsObject、responseのURL、および
optionsを与えてJavaScript モジュールスクリプトを作成した
結果に設定する。
mimeTypeのMIME
タイプエッセンスが「text/css」であり、
かつmoduleTypeが「css」である場合、moduleScriptを、
sourceTextと
settingsObjectを与えてCSS モジュールスクリプトを作成した結果に設定する。
mimeTypeがJSON MIME
タイプであり、
moduleTypeが「json」である場合、moduleScriptを、
sourceTextと
settingsObjectを与えてJSON モジュールスクリプトを作成した結果に設定する。
callbacksを moduleMap[(url, moduleType)]とする。
moduleScriptが null である場合、 moduleMap[(url, moduleType)]を削除する。それ以外の場合、 moduleMap[(url, moduleType)]をmoduleScriptに設定する。
モジュール マップが要求 URLをキーとする一方、 モジュールスクリプトの 基底 URLが 応答 URLに 設定されるのは意図的である。前者は フェッチの重複排除に使用され、後者は URL の解決に使用される。
callbacksの各 callbackについて、moduleScriptを与えて callbackを実行する。
URL url、環境設定オブジェクト fetchClient、宛先 destination、スクリプト フェッチオプション options、環境設定オブジェクト settingsObject、リファラー referrer、ModuleRequest Record moduleRequest、アルゴリズム onComplete、および任意のフェッチを実行するフック performFetchが与えられたとき、単一のインポート済みモジュールスクリプトを フェッチするには、次の手順を実行する。onCompleteは、null(失敗時)または モジュールスクリプト(成功時)を 受け入れるアルゴリズムでなければならない。
表明:HostGetSupportedImportAttributesで
「type」属性だけを要求したため、moduleRequest.[[Attributes]]には、
entry.[[Key]]が「type」でないRecord
entryは含まれない。
moduleTypeを、moduleRequestが与えられたときのモジュールリクエストからモジュールタイプを 取得する手順の結果とする。
moduleTypeおよび settingsObjectが与えられたときのモジュールタイプが許可される手順の結果が false の場合、null を使用して onCompleteを実行し、戻る。
url、fetchClient、destination、 options、settingsObject、referrer、 moduleRequest、false、および onCompleteが与えられたとき、単一のモジュールスクリプトをフェッチする。 performFetchが与えられた場合、それも渡す。
この標準では、そこで定義されている次の概念を参照する:
古典スクリプトを作成するには、 文字列 source、環境設定オブジェクト settings、URL baseURL、スクリプトフェッチオプション options、任意のブール値 mutedErrors(既定値は false)、任意の URLまたは null の sourceURLForWindowScripts(既定値は null)、および任意の ブール値 bypassDisabledScripting(既定値は false)が与えられたとき:
bypassDisabledScriptingパラメーターは、スクリプト処理が無効な場合でもスクリプトを 実行するために使用することを意図している。 これは、WebDriver BiDi コマンド 「script.evaluate」など、 一部の自動化シナリオで必要となる。
bypassDisabledScriptingパラメーターは、スクリプト処理が無効な場合でも スクリプトを実行するために使用することを意図している。これは、一部の自動化シナリオ、 たとえばWebDriver BiDi コマンド 「script.evaluate」で必要となる。スクリプト処理(たとえば WebDriver BiDi コマンドを介したスクリプトの実行)が、bypassDisabledScriptingを true に設定して 呼び出された場合、スクリプト処理が無効であっても、 イベントループは、そのスクリプトによって作成された thenable(Promise 由来)および weakmap の ファイナライゼーションを解決するために実行することを許可される。これは、非同期操作に依存することが 多いテストスクリプトが適切に機能するために必要である。
mutedErrorsが true の場合、baseURLを
about:blankに設定する。
mutedErrorsが true の場合、baseURLはスクリプトの CORS クロスオリジン応答のURLであり、JavaScript に公開すべきではない。したがって、 ここで baseURLを無害化する。
settingsについてスクリプト処理が無効であり、 bypassDisabledScriptingが false の場合、sourceを空文字列に設定する。
scriptを、このアルゴリズムが後で初期化する新しい古典スクリプトとする。
scriptの設定 オブジェクトを settingsに設定する。
scriptのベース URLを baseURLに設定する。
scriptのフェッチ オプションを optionsに設定する。
scriptのミュートされたエラーを mutedErrorsに設定する。
scriptの構文解析エラーおよび 再スローする エラーを null に設定する。
scriptおよび sourceURLForWindowScriptsが与えられたとき、古典スクリプトの作成時刻を記録する。
resultを ParseScript(source, settingsのレルム, script) とする。
ここで最後のパラメーターとして scriptを渡すことにより、 result.[[HostDefined]]が scriptになることが保証される。
resultがエラーのリストである場合:
scriptのレコードを resultに設定する。
scriptを返す。
JavaScript モジュールスクリプトを作成するには、 文字列 source、環境設定 オブジェクト settings、URL baseURL、およびスクリプトフェッチ オプション optionsが与えられたとき:
settingsについてスクリプト処理が無効である場合、 sourceを空文字列に設定する。
scriptを、このアルゴリズムが後で初期化する新しいモジュールスクリプトとする。
scriptの設定 オブジェクトを settingsに設定する。
scriptのベース URLを baseURLに設定する。
scriptのフェッチ オプションを optionsに設定する。
scriptの構文解析エラーおよび 再スローする エラーを null に設定する。
resultを ParseModule(source, settingsのレルム, script) とする。
ここで最後のパラメーターとして scriptを渡すことにより、 result.[[HostDefined]]が scriptになることが保証される。
resultがエラーのリストである場合:
scriptの構文解析エラーを result[0]に設定する。
scriptを返す。
scriptのレコードを resultに設定する。
scriptを返す。
WebAssembly モジュールスクリプトを作成するには、 バイト列 bodyBytes、環境設定 オブジェクト settings、URL baseURL、およびスクリプトフェッチ オプション optionsが与えられたとき:
settingsについてスクリプト処理が無効である場合、 bodyBytesをバイト列 0x00 0x61 0x73 0x6D 0x01 0x00 0x00 0x00 に設定する。
このバイト列は、マジックバイトとバージョン番号だけを持つ空の WebAssembly モジュールに対応する。
scriptを、このアルゴリズムが後で初期化する新しいモジュール スクリプトとする。
scriptの設定 オブジェクトを settingsに設定する。
scriptのベース URLを baseURLに設定する。
scriptのフェッチ オプションを optionsに設定する。
scriptの構文解析エラーおよび 再スローする エラーを null に設定する。
resultを、bodyBytes、 settingsのレルム、および scriptが与えられたときにWebAssembly モジュールを構文解析した結果とする。
ここで最後のパラメーターとして scriptを渡すことにより、 result.[[HostDefined]]が scriptになることが保証される。
前の手順がエラー errorをスローした場合:
scriptの構文解析エラーを errorに設定する。
scriptを返す。
scriptのレコードを resultに設定する。
scriptを返す。
WebAssembly JavaScript Interface: ESM Integrationは、 WebAssembly と ECMA-262 のモジュール読み込みを統合するためのフックを規定する。これには、 直接的な依存関係のインポートだけでなく、仮想化および複数インスタンス化をサポートする ソースフェーズインポートのサポートも含まれる。[WASMESM]
CSS モジュールスクリプトを作成するには、 文字列 sourceおよび環境設定オブジェクト settingsが 与えられたとき:
scriptを、このアルゴリズムが後で初期化する新しいモジュール スクリプトとする。
scriptの設定 オブジェクトを settingsに設定する。
scriptの構文解析エラーおよび 再スローする エラーを null に設定する。
sheetを、空の辞書を引数として構築済み
CSSStyleSheetを作成する手順を実行した結果とする。
sourceが与えられたとき、sheetに対してCSSStyleSheetの規則を
同期的に置換する手順を実行する。
これが例外をスローした場合、それを捕捉し、scriptの構文解析エラーをその例外に設定して、 scriptを返す。
CSSStyleSheetの規則を
同期的に置換する手順は、sourceに @import規則が含まれる場合に
スローする。CSS モジュールスクリプトでこれらをどのように処理するかについてまだ合意が
得られていないため、現時点ではこれは意図的な設計であり、合意に達するまではすべて
ブロックされる。
scriptのレコードを CreateDefaultExportSyntheticModule(sheet) の結果に設定する。
scriptを返す。
JSON モジュールスクリプトを作成するには、 文字列 sourceおよび環境設定オブジェクト settingsが 与えられたとき:
scriptを、このアルゴリズムが後で初期化する新しいモジュール スクリプトとする。
scriptの設定 オブジェクトを settingsに設定する。
scriptの構文解析エラーおよび 再スローする エラーを null に設定する。
resultを ParseJSONModule(source) とする。
これが例外をスローした場合、それを捕捉し、scriptの構文解析エラーをその例外に設定して、 scriptを返す。
scriptのレコードを resultに設定する。
scriptを返す。
テキストモジュールスクリプトを作成するには、 文字列 textおよび環境設定オブジェクト settingsが 与えられたとき:
scriptを、このアルゴリズムが後で初期化する新しいモジュール スクリプトとする。
scriptの設定 オブジェクトを settingsに設定する。
scriptの構文解析エラーおよび 再スローする エラーを null に設定する。
resultを CreateTextModule(text) とする。
scriptのレコードを resultに設定する。
scriptを返す。
ModuleRequest Record moduleRequestが与えられたときのモジュールリクエストからのモジュールタイプ手順は、次のとおり:
moduleTypeを「javascript-or-wasm」とする。
moduleRequest.[[Attributes]]に、entry.[[Key]]が
「type」であるRecord
entryがある場合:
entry.[[Value]]が「javascript-or-wasm」である場合、
moduleTypeを null に設定する。
この仕様では、「javascript-or-wasm」モジュール
タイプをJavaScript
モジュールスクリプトまたは
WebAssembly モジュール
スクリプトのために内部的に使用する。そのため、「javascript-or-wasm」
type 属性を使用してモジュールがインポートされることを防ぐために、この手順が必要となる
(null の moduleTypeは、モジュールタイプが許可されるかの確認を
失敗させる)。
それ以外の場合、moduleTypeを entry.[[Value]]に設定する。
moduleTypeを返す。
文字列 moduleTypeおよび環境設定 オブジェクト settingsが与えられたときのモジュールタイプが許可される手順は、次のとおり:
moduleTypeが「javascript-or-wasm」、「css」、
「json」、または「text」のいずれでもない場合、
false を返す。
moduleTypeが「css」であり、
CSSStyleSheet
インターフェイスが settingsのレルムに公開されていない場合、false を返す。
true を返す。
宛先 defaultDestinationおよび文字列 moduleTypeが与えられたときのモジュールタイプからのフェッチ宛先手順は、次のとおり:
json」である場合、「json」を返す。css」である場合、「style」を返す。text」である場合、「text」を返す。古典スクリプト scriptおよび 任意のブール値 rethrow errors(既定値は false)が与えられたとき、古典スクリプトを実行するには:
settingsを scriptの設定オブジェクトとする。
settingsを使用してスクリプトを実行できるか確認する。 これが「do not run」を返す場合、NormalCompletion(empty) を返す。
scriptが与えられたとき、古典スクリプトの実行開始時刻を記録する。
settingsが与えられたとき、スクリプトを実行する準備をする。
evaluationStatusを null とする。
scriptの再スローする エラーが null でない場合、evaluationStatusを ThrowCompletion(scriptの再スローする エラー) に設定する。
それ以外の場合、evaluationStatusを ScriptEvaluation(scriptのレコード) に設定する。
ユーザーエージェントが実行中のスクリプトを中止したためにScriptEvaluationが完了しない場合、 evaluationStatusを null のままにする。
evaluationStatusが突然の完了である場合:
rethrow errorsが true であり、scriptのミュートされた エラーが false である場合:
settingsを使用してスクリプト実行後のクリーンアップをする。
evaluationStatus.[[Value]]を再スローする。
rethrow errorsが true であり、scriptのミュートされた エラーが true である場合:
settingsを使用してスクリプト実行後のクリーンアップをする。
「NetworkError」 DOMExceptionを
スローする。
それ以外の場合、rethrow errorsは false である。次の手順を実行する:
scriptの設定 オブジェクトのグローバル オブジェクトについて、evaluationStatus.[[Value]]によって与えられる例外を報告する。
settingsを使用してスクリプト実行後のクリーンアップをする。
evaluationStatusを返す。
settingsを使用してスクリプト実行後のクリーンアップをする。
evaluationStatusが通常の完了である場合、evaluationStatusを返す。
この時点に到達した場合、評価中にスクリプトが途中で中止されたため、
evaluationStatusは null のままであった。
ThrowCompletion(新しい QuotaExceededError)
を返す。
モジュールスクリプト scriptおよび 任意のブール値 preventErrorReporting(既定値は false)が与えられたとき、モジュールスクリプトを実行するには:
settingsを scriptの設定 オブジェクトとする。
settingsを使用してスクリプトを実行できるか確認する。 これが「do not run」を返す場合、undefined で解決された Promiseを返す。
scriptが与えられたとき、モジュールスクリプトの実行開始時刻を記録する。
settingsが与えられたとき、スクリプトを実行する準備をする。
evaluationPromiseを null とする。
scriptの再スローする エラーが null でない場合、evaluationPromiseを scriptの再スローする エラーで拒否された Promiseに設定する。
それ以外の場合:
recordを scriptのレコードとする。
evaluationPromiseを record.Evaluate() に設定する。
この手順は、モジュールのすべての依存関係を再帰的に評価する。
ユーザーエージェントが実行中のスクリプトを中止したためにEvaluateが完了しない場合、
evaluationPromiseを新しい
QuotaExceededErrorで拒否された Promiseに設定する。
preventErrorReportingが false の場合、evaluationPromiseが reasonで拒否されたとき、scriptの設定 オブジェクトのグローバルオブジェクトについて、 reasonによって与えられる例外を報告する。
settingsを使用してスクリプト実行後のクリーンアップをする。
evaluationPromiseを返す。
環境設定 オブジェクト settingsを使用してスクリプトを実行できるか確認する手順は次のとおり。 この手順は「run」または「do not run」のいずれかを返す。
settingsによって指定されたグローバル
オブジェクトが Windowオブジェクトであり、
その Documentオブジェクトが
完全にアクティブでない場合、
「do not run」を返す。
settingsについてスクリプト処理が無効である場合、 「do not run」を返す。
「run」を返す。
環境設定 オブジェクト settingsを使用してスクリプトを実行する準備をする手順は、次のとおり:
settingsのレルム実行コンテキストをJavaScript 実行コンテキストスタックにプッシュする。これが新しい実行中の JavaScript 実行 コンテキストとなる。
settingsを、周囲の エージェントのイベント ループの現在実行中の タスクのスクリプト評価環境 設定オブジェクト集合に追加する。
環境設定 オブジェクト settingsを使用してスクリプト実行後のクリーンアップをする手順は、 次のとおり:
表明:settingsのレルム実行コンテキストは、 実行中の JavaScript 実行コンテキストである。
settingsのレルム実行コンテキストを JavaScript 実行コンテキストスタックから削除する。
JavaScript 実行コンテキストスタックが 空になった場合、マイクロタスクチェックポイントを実行する。 (これがスクリプトを実行する場合、これらのアルゴリズムは再入的に呼び出される。)
これらのアルゴリズムは、あるスクリプトが別のスクリプトを直接呼び出すことによっては 呼び出されないが、スクリプトがイベントリスナーの登録されたイベントを発火する場合など、 間接的な方法で再入的に呼び出されることがある。
実行中のスクリプトは、実行中の JavaScript 実行 コンテキストの ScriptOrModule コンポーネントの [[HostDefined]] フィールドにあるスクリプトである。
JavaScript 仕様ではこの可能性を考慮していないが、場合によっては実行中のスクリプトを中止する必要がある。これにより、ScriptEvaluation
またはSource Text Module RecordのEvaluateの呼び出しが
即座に停止し、finallyブロックのような通常の仕組みを発生させることなく、JavaScript 実行コンテキストスタックが空になる。
[JAVASCRIPT]
ユーザーエージェントは、CPU クォータ、メモリー制限、合計実行時間の制限、帯域幅の制限など、
スクリプトにリソース制限を課してもよい。スクリプトが制限を超えた場合、ユーザーエージェントは
QuotaExceededErrorを
スローするか、例外なしでスクリプトを中止するか、ユーザーに確認を求めるか、
スクリプトの実行を抑制してもよい。
たとえば、次のスクリプトは決して終了しない。ユーザーエージェントは数秒待った後、 スクリプトを終了するか続行させるかをユーザーに確認できる。
< script >
while ( true ) { /* loop */ }
</ script > ユーザーエージェントは、スクリプトによって(たとえば window.alert() API
を使用して)
ユーザーに確認を求める場合、またはスクリプトの動作によって(たとえば時間制限を超えたため)
ユーザーに確認を求める場合に、スクリプト処理を無効にできるようにすることが推奨される。
スクリプトの実行中にスクリプト処理が無効になった場合、そのスクリプトは直ちに終了すべきである。
ユーザーエージェントは、閲覧コンテキストを閉じる目的に限って、 スクリプトを明示的に無効にできるようにしてもよい。
たとえば、上の例で述べた確認には、unloadイベントハンドラーを
実行せず、単にページ全体を閉じる仕組みをユーザーに提示することもできる。
現在のすべてのエンジンでサポートされている。
self.reportError(e)処理されなかった例外と同じ方法で、指定された値 eについて、グローバルオブジェクトに
errorイベントを発火する。
JavaScript 値 exceptionからエラー情報を抽出するには:
attributesを、IDL 属性をキーとする空のマップとする。
attributes[error]を
exceptionに設定する。
![]() attributes[
attributes[message]、
attributes[filename]、
attributes[lineno]、および
attributes[colno]を、
exceptionから導出された実装定義の値に設定する。
ブラウザーは、有用な値を収集するために、ここにも JavaScript 仕様にも
規定されていない動作を実装している。これには、特殊な場合(たとえば eval)も
含まれる。将来、これはより詳細に規定される可能性がある。
attributesを返す。
JavaScript 値である exceptionを、特定のグローバルオブジェクト globalについて、 任意のブール値 omitError(既定値は false)を 使用して例外を報告するには:
notHandledを true とする。
errorInfoを、exceptionからエラー 情報を抽出した結果とする。
scriptを、実装定義の方法で見つけられたスクリプト、または null とする。 通常、これは実行中の スクリプトであるべきである(特に古典スクリプトを実行する処理中)。
あまり一般的でない場合に、エラーがミュートされるかどうかを判断するために どのスクリプトを使用するかについて、実装間で相互運用可能な動作はまだ確立されていない。
scriptが古典
スクリプトであり、scriptのミュートされた
エラーが true である場合、errorInfo[error]を null、
errorInfo[message]を
「Script error.」、
errorInfo[filename]を
空文字列、errorInfo[lineno]を 0、
そして
errorInfo[colno]を 0
に設定する。
omitErrorが true の場合、errorInfo[error]を null
に設定する。
globalがエラー報告モード中でない場合:
globalが EventTargetを
実装する場合、notHandledを、globalに ErrorEventを使用して
errorという名前の
イベントを発火した結果に設定する。このとき、
cancelable
属性を true に初期化し、追加の属性を errorInfoに従って初期化する。
イベントハンドラーで true を返すと、イベントハンドラー処理 アルゴリズムに従ってイベントがキャンセルされる。
globalのエラー報告モード中を false に設定する。
notHandledが true の場合:
errorInfo[error]を
null に設定する。
globalが DedicatedWorkerGlobalScopeを
実装する場合、globalに関連付けられた Workerの関連するグローバル
オブジェクトを使用して、DOM 操作タスクソース上に、
次の手順を実行するグローバルタスクをキューに追加する:
workerObjectを、globalに関連付けられた Workerオブジェクトとする。
notHandledを、workerObjectに ErrorEventを使用して
errorという名前のイベントを発火した結果に設定する。このとき、
cancelable
属性を true に初期化し、追加の属性を errorInfoに従って初期化する。
notHandledが true の場合、workerObjectの関連するグローバルオブジェクトについて、 omitErrorを true に設定して exceptionを報告する。
実際の exception値は所有者レルムでは利用できないが、 ユーザーエージェントは、メッセージ、ファイル名、およびその他の属性を設定し、 場合によっては開発者コンソールに報告するのに十分な情報を引き続き保持する。
それ以外の場合、ユーザーエージェントは exceptionを開発者 コンソールに報告してもよい。
ワーカーをその Workerオブジェクトに接続する暗黙の
ポートが切り離されている場合(すなわち、親ワーカーが終了している場合)、ユーザーエージェントは、
Workerオブジェクトに
errorイベントハンドラーがなく、
そのワーカーの onerror
属性が null であるかのように動作しなければならないが、それ以外は上記のとおりに動作しなければならない。
したがって、エラー報告は、その連鎖内の一部のワーカーが終了しガベージコレクション
されていたとしても、専用ワーカーの連鎖を通じて元の Documentまで伝播する。
この標準の以前の改訂版では、例外を報告するアルゴリズムを定義していた。 issue #958の一環として、これは異なる動作をし、 異なる入力を受け取る例外を 報告するによって置き換えられた。Issue #10516では、仕様エコシステムの 更新を追跡している。
ここでミュートが適用されるかどうかは不明である。 Chrome と Safari ではミュートされるが、Firefox ではミュートされない。issue #958も参照。
現在のすべてのエンジンでサポートされている。
ErrorEventインターフェイスは、
次のように定義される:
[Exposed=*]
interface ErrorEvent : Event {
constructor (DOMString type , optional ErrorEventInit eventInitDict = {});
readonly attribute DOMString message ;
readonly attribute USVString filename ;
readonly attribute unsigned long lineno ;
readonly attribute unsigned long colno ;
readonly attribute any error ;
};
dictionary ErrorEventInit : EventInit {
DOMString message = "";
USVString filename = "";
unsigned long lineno = 0;
unsigned long colno = 0;
any error ;
};message属性は、初期化された値を返さなければならない。
これはエラーメッセージを表す。
filename属性は、初期化された値を返さなければならない。
これは、エラーが最初に発生したスクリプトのURLを表す。
lineno属性は、初期化された値を返さなければならない。
これは、スクリプト内でエラーが発生した行番号を表す。
colno属性は、初期化された値を返さなければならない。
これは、スクリプト内でエラーが発生した列番号を表す。
error属性は、初期化された値を返さなければならない。
初期状態では undefined に初期化されなければならない。適切な場合、エラーを表すオブジェクト
(たとえば、捕捉されなかった例外の場合は例外オブジェクト)に設定される。
現在のすべてのエンジンでサポートされている。
同期的な実行時スクリプトエラーに加えて、スクリプトでは
非同期の Promise 拒否が発生する場合があり、これは unhandledrejection
および rejectionhandled
イベントを介して追跡される。これらの
拒否の追跡は、HostPromiseRejectionTracker
抽象操作を介して行われるが、
その報告についてはここで定義する。
グローバルオブジェクト global が与えられたとき、拒否された Promise について通知するには:
list を、global の 通知されようとしている拒否された Promise のリストの複製とする。
list が空である場合、返す。
global の通知されようとしている 拒否された Promise のリストを空にする。
global が与えられたとき、DOM 操作タスクソース上に、 次の手順を実行するグローバルタスクをキューに追加する:
list の各 Promise pについて反復する:
p.[[PromiseIsHandled]] が true の場合、続行する。
notCanceled を、global に
PromiseRejectionEventを使用して、
unhandledrejection
という名前のイベントを発火した結果とする。このとき、cancelable
属性を true に初期化し、promise
属性を
p に初期化し、reason
属性を p.[[PromiseResult]] に初期化する。
notCanceled が true の場合、 ユーザーエージェントは p.[[PromiseResult]] を開発者コンソールに報告してもよい。
p.[[PromiseIsHandled]] が false の場合、p を global の未処理の拒否された Promise の弱集合に付加する。
現在のすべてのエンジンでサポートされている。
PromiseRejectionEvent
インターフェイスは
次のように定義される:
[Exposed=*]
interface PromiseRejectionEvent : Event {
constructor (DOMString type , PromiseRejectionEventInit eventInitDict );
readonly attribute object promise ;
readonly attribute any reason ;
};
dictionary PromiseRejectionEventInit : EventInit {
required object promise ;
any reason ;
};現在のすべてのエンジンでサポートされている。
promise 属性は、初期化された値を返さなければならない。
これは、この通知の対象となる Promise を表す。
Promise<T> 型に対する Web IDL 変換規則は、
常に入力を新しい Promise でラップするため、promise
属性は代わりに object
型である。これは、元の Promise オブジェクトへの不透明な
ハンドルを表すためにより適切である。
現在のすべてのエンジンでサポートされている。
reason 属性は、初期化された値を返さなければならない。
これは Promise の拒否理由を表す。
インポートマップの構文解析結果は、スクリプトに似た構造体であり、script 要素の
結果に格納することもできるが、
その他の目的ではスクリプトとして数えられない。これは次の項目を持つ:
文字列 input および URL baseURL が与えられたとき、インポートマップの構文解析結果を作成するには:
result を、インポートマップが null であり、再スローするエラーが null であるインポートマップの構文解析結果とする。
input および baseURL が与えられたとき、例外を捕捉しながらインポートマップ 文字列を構文解析する。これが例外をスローした場合、result の再スローするエラーを その例外に設定する。それ以外の場合、 result のインポートマップを戻り 値に設定する。
result を返す。
Window global および
インポートマップの構文解析
結果 result が与えられたとき、インポートマップを登録するには:
result の再スローするエラーが null でない場合、global について result の再スローするエラーによって与えられる例外を 報告する。その後、返す。
global および result のインポートマップが与えられたとき、既存および新しいインポート マップをマージする。
投機ルールの構文解析結果は、スクリプトに似た構造体であり、script 要素の
結果に格納することもできるが、
その他の目的ではスクリプトとして数えられない。これは次の項目を持つ:
文字列
input および Document
document が与えられたとき、投機ルールの構文解析結果を作成するには:
result を、投機ルール集合が null であり、再スローする エラーが null である投機ルールの構文解析結果とする。
input、 document、および document の文書ベース URLが与えられたとき、 例外を捕捉しながら投機ルール集合 文字列を構文解析する。これが例外をスローした場合、result の再スローするエラーをその例外に設定する。 それ以外の場合、 result の投機ルール 集合を戻り値に設定する。
result を返す。
Window global、
投機ルールの構文解析結果
result、および任意のブール値
queueErrors(既定値は false)が与えられたとき、投機ルールを登録するには:
result の再スローするエラーが null でない場合:
queueErrors が true の場合、global が与えられたとき、DOM 操作タスクソース上に、次の手順を実行するグローバルタスクをキューに追加する:
返す。
result の投機ルール集合を、
global の関連付けられた
Document の投機ルール集合に付加する。
global の関連付けられた Documentについて、
投機的読み込みを検討する。
Window global および
投機ルールの構文解析結果
result が与えられたとき、投機ルールの登録を解除するには:
result の再スローするエラーが null でない場合、返す。
result の投機ルール集合を、
global の関連付けられた
Document の投機ルール集合から削除する。
global の関連付けられた Documentについて、
投機的読み込みを検討する。
Window global、
投機ルールの構文解析結果
oldResult、および投機ルールの
構文解析結果 newResult が与えられたとき、投機ルールを更新するには:
oldResult の投機ルール集合を、
global の関連付けられた
Document の投機ルール集合から削除する。
global、newResult、および true が与えられたとき、投機ルールを登録する。
投機ルールを最初に登録する場合とは異なり、
更新する場合には、error イベントが
同期的に発火されるのではなく、タスクとしてキューに追加されることを保証する。
script
要素を挿入するときに、error
イベントハンドラーを
同期的に実行しても問題はないが、
その他の変更によってこのような同期的なスクリプト実行が引き起こされないことが望ましい。
モジュール 指定子を解決するアルゴリズムは、モジュール指定子文字列をURLに変換するための主要な入口である。 インポートマップが関与しない場合は比較的単純であり、 URL のようなモジュール指定子を解決することに帰着する。
空でないインポートマップが存在する場合、 動作はより複雑になる。適用可能なすべてのモジュール指定子 マップから、最も具体的なものから最も具体的でないスコープの順に (最上位のスコープなしのimportsにフォールバックする)、さらに 最も具体的なプレフィックスから最も具体的でない プレフィックスの順に、候補エントリーを確認する。各候補について、imports の 一致を解決するアルゴリズムは、次のいずれかの結果を返す:
指定子をURLに正常に解決する。この場合、 モジュール指定子を 解決するアルゴリズムは、その URL を返す。
例外をスローする。この場合、モジュール指定子を解決するアルゴリズムは、 それ以上フォールバックすることなく、その例外を再スローする。
エラーなしで解決に失敗する。この場合、外側のモジュール 指定子を解決するアルゴリズムは、次の候補に進む。
最終的に、候補となるどのモジュール指定子マップからも正常な解決が見つからない場合、 モジュール指定子を 解決するは例外をスローする。したがって、結果は常にURLまたはスローされた例外のいずれかとなる。
scriptまたは null の referringScript および文字列 specifier が与えられたとき、モジュール指定子を解決するには:
settingsObject および baseURL を null とする。
referringScript が null でない場合:
それ以外の場合:
表明:現在の設定オブジェクトが存在する。
settingsObject を現在の設定オブジェクトに設定する。
baseURL を settingsObject のAPI ベース URLに設定する。
importMap を空のインポートマップとする。
settingsObject のグローバル
オブジェクトが Windowを実装する場合、
importMap を
settingsObject のグローバルオブジェクトの
インポートマップに設定する。
serializedBaseURL を、baseURL をシリアル化したものとする。
asURL を、specifier および baseURL が与えられたときにURL のようなモジュール 指定子を解決した結果とする。
normalizedSpecifier を、asURL が null でない場合は asURL のシリアル化とし、それ以外の場合は specifier とする。
result を、初期値が null のURLまたは null とする。
importMap のscopesの各 scopePrefix → scopeImportsについて反復する:
scopePrefix が serializedBaseURL である場合、または scopePrefix が U+002F (/) で終わり、かつ scopePrefix が serializedBaseURL の符号単位プレフィックスである場合:
scopeImportsMatch を、normalizedSpecifier、 asURL、および scopeImports が与えられたときにimports の 一致を解決した結果とする。
scopeImportsMatch が null でない場合、result を scopeImportsMatch に設定し、中断する。
result が null の場合、result を normalizedSpecifier、asURL、および importMap のimportsが与えられたときにimports の一致を 解決した結果に設定する。
result が null の場合、asURL に設定する。
この時点で result が null であった場合、specifier は importMap によって何にも再マッピングされなかったが、 URL に変換できた可能性がある。
result が null でない場合:
settingsObject、 serializedBaseURL、normalizedSpecifier、および asURL が与えられたとき、解決済みモジュール集合に モジュールを追加する。
result を返す。
specifier がベア指定子であったが、
importMap によって何にも再マッピングされなかったことを示す
TypeErrorを
スローする。
文字列 normalizedSpecifier、 URLまたは null の asURL、およびモジュール指定子 マップ specifierMap が与えられたとき、imports の一致を解決するには:
specifierMap の各 specifierKey → resolutionResultについて反復する:
specifierKey が normalizedSpecifier である場合:
resolutionResult が null の場合、specifierKey の解決が
null エントリーによってブロックされたことを示す TypeErrorを
スローする。
これにより、モジュール指定子を解決する アルゴリズム全体が、それ以上フォールバックすることなく終了する。
resolutionResult を返す。
次のすべてが true である場合:
specifierKey が U+002F (/) で終わる。
specifierKey が normalizedSpecifier の符号単位プレフィックスである。かつ
asURL が null であるか、または asURL が特殊である。
その場合:
resolutionResult が null の場合、specifierKey の解決が
null エントリーによってブロックされたことを示す TypeErrorを
スローする。
これにより、モジュール指定子を解決する アルゴリズム全体が、それ以上フォールバックすることなく終了する。
afterPrefix を、先頭の specifierKey プレフィックスより後の normalizedSpecifier の部分とする。
表明:resolutionResult をシリアル化したものは、構文解析時に強制されるとおり、 U+002F (/) で終わる。
url を、resolutionResult を基準として afterPrefix をURL 構文解析した結果とする。
url が failure である場合、normalizedSpecifier の解決が
ブロックされたことを示す TypeErrorを
スローする。その理由は、afterPrefix の部分を、specifierKey
プレフィックスによってマッピングされた resolutionResult を基準として
URL 構文解析できなかったためである。
これにより、モジュール指定子を解決する アルゴリズム全体が、それ以上フォールバックすることなく終了する。
resolutionResult のシリアル化が、
url のシリアル化の符号単位プレフィックスでない場合、
normalizedSpecifier の解決が、そのプレフィックス
specifierKey より上に後戻りしたためブロックされたことを示す TypeErrorを
スローする。
これにより、モジュール指定子を解決する アルゴリズム全体が、それ以上フォールバックすることなく終了する。
url を返す。
null を返す。
モジュール指定子を解決するアルゴリズムは、
可能であれば、より具体的でないスコープまたは
"imports" にフォールバックする。
文字列 specifier およびURL baseURL が与えられたとき、URL のようなモジュール 指定子を解決するには:
specifier が
"/"、"./"、または "../" で始まる場合:
url を、baseURL を基準として specifier をURL 構文解析した結果とする。
url が failure である場合、null を返す。
これが起こり得る一例は、specifier が
"../foo" であり、baseURL が data:
URL である場合である。
url を返す。
これには、specifier が
"//"、すなわちスキーム相対 URL で始まる場合も含まれる。したがって、
url のホストは、
baseURL と異なるものになる可能性がある。
url を、specifier をベース URL なしでURL 構文解析した結果とする。
url が failure である場合、null を返す。
url を返す。
インポートマップを使用すると、モジュール指定子の解決を制御できる。
インポートマップは、type 属性が
"importmap" に設定され、子テキスト内容にインポートマップの JSON 表現を含む、
インラインの script 要素を介して提供される。
Document では、複数のインポートマップを
処理できる。これは、たとえば import()
式や、type 属性が
"module" に設定された script 要素を介して、
モジュールがインポートされる前または後のいずれでも発生し得る。既存および新しいインポートマップをマージするアルゴリズムは、
新しいインポートマップが、過去のインポートマップですでに定義されたモジュール、または
すでに解決されたモジュールについて、モジュール解決を定義できないことを保証する。
インポートマップの最も単純な使用方法は、ベアモジュール指定子をグローバルに再マッピングすることである:
{
"imports" : {
"moment" : "/node_modules/moment/src/moment.js"
}
} これにより、import moment from "moment"; のような文が機能し、
/node_modules/moment/src/moment.js URL の JavaScript モジュールがフェッチおよび評価される。
インポートマップは、次のように末尾の スラッシュを使用して、ある種類のモジュール指定子をある種類の URL に再マッピングできる:
{
"imports" : {
"moment/" : "/node_modules/moment/src/"
}
} これにより、import localeData from
"moment/locale/zh-cn.js"; のような文が機能し、
/node_modules/moment/src/locale/zh-cn.js URL の JavaScript モジュールが
フェッチおよび評価される。このような末尾スラッシュ
マッピングは、ベア指定子のマッピングと組み合わせて使用されることが多い。たとえば:
{
"imports" : {
"moment" : "/node_modules/moment/src/moment.js" ,
"moment/" : "/node_modules/moment/src/"
}
} これにより、"moment" で指定される「メインモジュール」と、
"moment/locale/zh-cn.js" のようなパスで指定される
「サブモジュール」の両方を利用できる。
インポートマップが再マッピングできるモジュール指定子は、ベア指定子だけではない。
絶対 URL として構文解析できるもの、または
"/"、"./"、もしくは "../" で始まる
「URL のような」指定子も再マッピングできる:
{
"imports" : {
"https://cdn.example.com/vue/dist/vue.runtime.esm.js" : "/node_modules/vue/dist/vue.runtime.esm.js" ,
"/js/app.mjs" : "/js/app-8e0d62a03.mjs" ,
"../helpers/" : "https://cdn.example/helpers/"
}
} 再マッピングされる URL と、マッピング先の URL のどちらも、
絶対 URL、または "/"、"./"、もしくは "../" で始まる
相対 URL として指定できることに注意。(これらの先頭記号はベアモジュール指定子との区別に役立つため、
それらを持たない相対 URL として指定することはできない。)また、この文脈でも末尾スラッシュのマッピングが機能することに注意。
このような再マッピングは正規化後の URL に対して動作し、インポートマップのキーに指定された
リテラル文字列と、インポートされたモジュール指定子との一致を必要としない。たとえば、
このインポートマップが https://example.com/app.html に含まれている場合、
import "/js/app.mjs" だけでなく、
import "./js/app.mjs" および
import "./foo/../js/app.mjs" も再マッピングされる。
これまでのすべての例では、インポートマップの最上位の "imports" キーを使用して、
モジュール指定子をグローバルに再マッピングしていた。最上位の "scopes"
キーを使用すると、参照元モジュールが特定の URL プレフィックスに
一致する場合にのみ適用される局所的な再マッピングを提供できる。たとえば:
{
"scopes" : {
"/a/" : {
"moment" : "/node_modules/moment/src/moment.js"
},
"/b/" : {
"moment" : "https://cdn.example.com/moment/src/moment.js"
}
}
} このインポートマップでは、import "moment" 文は、
その文を含む参照元スクリプトによって異なる意味を持つ:
/a/ 以下にあるスクリプト内では、
/node_modules/moment/src/moment.js をインポートする。
/b/ 以下にあるスクリプト内では、
https://cdn.example.com/moment/src/moment.js をインポートする。
/c/ 以下にあるスクリプト内では、解決に失敗し、
その結果、例外をスローする。
スコープの典型的な使用方法は、ウェブアプリケーション内に「同じ」モジュールの複数の バージョンが存在できるようにし、モジュールグラフの一部があるバージョンをインポートし、 別の部分が別のバージョンをインポートできるようにすることである。
スコープ同士は重なり合うことができ、グローバルな "imports"
指定子マップとも重なり合うことができる。解決時には、スコープは最も具体的なものから最も具体的でないものの
順に参照される。具体性は、符号単位の小なり
操作を使用してスコープを並べ替えることで測定される。したがって、たとえば
"/scope2/scope3/" は "/scope2/" より具体的なものとして扱われ、
"/scope2/" は最上位の(スコープなしの)マッピングより具体的なものとして扱われる。
次のインポートマップはこれを示す:
{
"imports" : {
"a" : "/a-1.mjs" ,
"b" : "/b-1.mjs" ,
"c" : "/c-1.mjs"
},
"scopes" : {
"/scope2/" : {
"a" : "/a-2.mjs"
},
"/scope2/scope3/" : {
"b" : "/b-3.mjs"
}
}
} これにより、次の解決結果となる(簡潔にするため相対 URL を使用):
| 指定子 | ||||
|---|---|---|---|---|
"a"
|
"b"
|
"c"
|
||
| 参照元 | /scope1/r.mjs
|
/a-1.mjs
|
/b-1.mjs
|
/c-1.mjs
|
/scope2/r.mjs
|
/a-2.mjs
|
/b-1.mjs
|
/c-1.mjs
|
|
/scope2/scope3/r.mjs
|
/a-2.mjs
|
/b-3.mjs
|
/c-1.mjs
|
|
インポートマップを使用して、サブリソース完全性チェックで使用する 完全性メタデータをモジュールに提供することもできる。[SRI]
次のインポートマップはこれを示す:
{
"imports" : {
"a" : "/a-1.mjs" ,
"b" : "/b-1.mjs" ,
"c" : "/c-1.mjs"
},
"integrity" : {
"/a-1.mjs" : "sha384-Li9vy3DqF8tnTXuiaAJuML3ky+er10rcgNR/VqsVpcw+ThHmYcwiB1pbOxEbzJr7" ,
"/d-1.mjs" : "sha384-MBO5IDfYaE6c6Aao94oZrIOiC6CGiSN2n4QUbHNPhzk5Xhm0djZLQqTpL0HzTUxk"
}
} 上の例では、モジュール /a-1.mjs および
/d-1.mjs に適用される完全性メタデータを提供する。後者が
マップ内でインポートとして定義されていなくても同様である。
インポートマップを表す script 要素の子テキスト内容は、次のインポートマップ作成
要件に一致しなければならない:
有効な JSON でなければならない。[JSON]
JSON は JSON オブジェクトを表さなければならず、キーは最大でも
"imports"、"scopes"、および "integrity" の3つである。
"imports"、"scopes"、および "integrity"
キーに対応する値が存在する場合、それら自体も JSON オブジェクトでなければならない。
"imports" キーに対応する値が存在する場合、それは
有効なモジュール指定子マップでなければならない。
"scopes" キーに対応する値が存在する場合、それは
JSON オブジェクトでなければならない。そのキーは有効な URL 文字列であり、
その値は有効なモジュール指定子
マップでなければならない。
"integrity" キーに対応する値が存在する場合、それは
JSON オブジェクトでなければならない。そのキーは有効な URL 文字列であり、
その値はintegrity
属性の要件を満たさなければならない。
有効なモジュール指定子マップは、次の 要件を満たす JSON オブジェクトである:
すべてのキーは空であってはならない。
すべての値は文字列でなければならない。
各値は、有効な絶対 URL、または
"/"、"./"、もしくは "../" で始まる有効な URL 文字列のいずれかでなければならない。
指定されたキーが "/" で終わる場合、対応する
値も同様でなければならない。
形式的には、インポートマップは、3つの項目を持つ構造体である:
imports。モジュール指定子 マップ。
scopes。URLからモジュール指定子 マップへの順序付きマップ。および
integrity。モジュール完全性 マップ。
モジュール指定子マップは、キーが文字列であり、値がURLまたは null である順序付きマップである。
モジュール完全性マップは、キーがURLであり、値が完全性メタデータとして使用される文字列である順序付きマップである。
空のインポートマップは、importsおよびscopesがどちらも空のマップであるインポートマップである。
実装は、URL としての指定子を、 指定子がベアであるか、または特殊な URL のような指定子であることを示すブール値に置き換えることができる。
環境設定 オブジェクト settingsObject、文字列 serializedBaseURL、文字列 normalizedSpecifier、およびURLまたは null の asURL が与えられたとき、解決済みモジュール集合にモジュールを追加するには:
global を settingsObject のグローバルオブジェクトとする。
global が Windowを実装しない場合、返す。
record を、新しい指定子解決レコードとする。そのシリアル化されたベース URLを serializedBaseURL に、指定子を normalizedSpecifier に、URL としての指定子を asURL に設定する。
record を global の 解決済みモジュール集合に付加する。
文字列 input および URL baseURL が与えられたとき、インポートマップ文字列を構文解析するには:
parsed を、input が与えられたときにJSON 文字列を Infra 値に構文解析した結果とする。
parsed が順序付きマップでない場合、最上位の値は JSON
オブジェクトである必要があることを示す
TypeErrorを
スローする。
sortedAndNormalizedImports を空の順序付きマップとする。
parsed["imports"] が存在する場合:
parsed["imports"] が順序付き
マップでない場合、最上位の "imports" キーの値は JSON オブジェクトである必要があることを示す
TypeErrorを
スローする。
sortedAndNormalizedImports を、
parsed["imports"] および
baseURL が与えられたときにモジュール指定子マップを並べ替えて
正規化した結果に設定する。
sortedAndNormalizedScopes を空の順序付きマップとする。
parsed["scopes"] が存在する場合:
parsed["scopes"] が順序付き
マップでない場合、最上位の "scopes" キーの値は JSON オブジェクトである必要があることを示す
TypeErrorを
スローする。
sortedAndNormalizedScopes を、
parsed["scopes"] および
baseURL が与えられたときにスコープを並べ替えて
正規化した結果に設定する。
normalizedIntegrity を空の順序付きマップとする。
parsed["integrity"] が存在する場合:
parsed["integrity"] が順序付き
マップでない場合、最上位の "integrity" キーの値は JSON オブジェクトである必要があることを示す
TypeErrorを
スローする。
normalizedIntegrity を、
parsed["integrity"] および
baseURL が与えられたときにモジュール
完全性マップを正規化した結果に設定する。
parsed のキーに、
"imports"、"scopes"、または "integrity" 以外の項目が含まれる場合、ユーザーエージェントは、
インポートマップに無効な最上位キーが存在したことを示す警告をコンソールに報告するべきである。
これは入力ミスの検出に役立つ。これはエラーではない。エラーにすると、 将来の拡張を後方互換性を保って追加できなくなるためである。
importsが sortedAndNormalizedImports、 scopesが sortedAndNormalizedScopes、およびintegrityが normalizedIntegrity であるインポートマップを返す。
この構文解析アルゴリズムから得られるインポートマップは高度に正規化される。
たとえば、ベース URL が https://example.com/base/page.html である場合、
入力
{
"imports" : {
"/app/helper" : "node_modules/helper/index.mjs" ,
"lodash" : "/node_modules/lodash-es/lodash.js"
}
} は、次の imports を持つインポートマップを生成する:
«[
"https://example.com/app/helper" → https://example.com/base/node_modules/helper/index.mjs
"lodash" → https://example.com/node_modules/lodash-es/lodash.js
]»モジュール指定子マップ newMap およびモジュール指定子マップ oldMap が与えられたとき、モジュール指定子マップをマージするには:
mergedMap を oldMap のディープコピーとする。
newMap の各 specifier → urlについて反復する:
specifier が oldMap に存在する場合:
ユーザーエージェントは、無視された規則を示す警告をコンソールに報告してもよい。 規則が既存の規則と同一である場合、報告しないことを選択してもよい。
続行する。
mergedMap[specifier] を url に設定する。
mergedMap を返す。
グローバルオブジェクト global およびインポートマップ newImportMap が与えられたとき、既存および新しいインポートマップをマージするには:
newImportMapScopes を newImportMap のscopesのディープコピーとする。
これらのコピーを変更し、スコープ固有の規則を無視するために使用したときに、 それらから項目を削除する。これは newImportMapScopes だけでなく、 以下の newImportMapImports にも当てはまる。
oldImportMap を global のインポートマップとする。
newImportMapImports を newImportMap のimportsのディープコピーとする。
newImportMapScopes の各 scopePrefix → scopeImportsについて反復する:
global の解決済みモジュール 集合の各 recordについて反復する:
scopePrefix が record のシリアル化されたベース URLである場合、または scopePrefix が U+002F (/) で終わり、かつ scopePrefix が record のシリアル化されたベース URLの符号単位プレフィックスである場合:
scopeImports の各 specifierKey → resolutionResultについて反復する:
specifierKey が record の指定子である場合、 または次の 条件がすべて true である場合:
specifierKey が U+002F (/) で終わる。
specifierKey が record の指定子の符号単位プレフィックスである。
record のURL としての 指定子が null であるか、または 特殊である。
その場合:
ユーザーエージェントは、無視された規則を示す警告をコンソールに報告してもよい。 規則が既存の規則と同一である場合、報告しないことを選択してもよい。
scopeImports[specifierKey] を削除する。
実装者には、解決済みモジュール集合を扱うとき、 より効率的な照合 アルゴリズムを実装することが推奨される。目安として、大規模なアプリケーション内の 解決済みまたはマッピング済みモジュールの数は、数千の規模になり得る。
scopePrefix が oldImportMap のscopesに存在する場合、 oldImportMap のscopes[scopePrefix] を、 scopeImports および oldImportMap のscopes[scopePrefix] が与えられたときにモジュール指定子マップをマージした結果に 設定する。
それ以外の場合、oldImportMap のscopes[scopePrefix] を scopeImports に設定する。
newImportMap のintegrityの各 url → integrityについて反復する:
url が oldImportMap の integrityに存在する場合:
ユーザーエージェントは、無視された規則を示す警告をコンソールに報告してもよい。 規則が既存の規則と同一である場合、報告しないことを選択してもよい。
続行する。
oldImportMap のintegrity[url] を integrity に設定する。
global の解決済みモジュール集合の各 recordについて反復する:
newImportMapImports の各 specifier → urlについて反復する:
specifier が record の指定子で始まる場合:
ユーザーエージェントは、無視された規則を示す警告をコンソールに報告してもよい。 規則が既存の規則と同一である場合、報告しないことを選択してもよい。
newImportMapImports[specifier] を削除する。
oldImportMap のimportsを、 newImportMapImports および oldImportMap のimportsが与えられたときにモジュール指定子マップをマージした結果に 設定する。
上のアルゴリズムは、新しいインポートマップを、指定された環境設定 オブジェクトのグローバルオブジェクトのインポートマップにマージする。 いくつかの例を見てみる:
新しいインポートマップがすでに解決されたモジュールに影響を与える場合、その規則は インポートマップから削除される。
したがって、解決済みモジュール
集合に "/app/helper" がすでに含まれている場合、次の新しいインポートマップ:
{
"imports" : {
"/app/helper" : "./helper/index.mjs" ,
"lodash" : "/node_modules/lodash-es/lodash.js"
}
} は、次のものと等価になる:
{
"imports" : {
"lodash" : "/node_modules/lodash-es/lodash.js"
}
} 特定のスコープで定義された、すでに解決済みのモジュールに影響する規則についても同様である。
"/app/main.mjs" から "/app/helper" をすでに解決している場合、次の新しいインポートマップ:
{
"scopes" : {
"/app/" : {
"/app/helper" : "./helper/index.mjs"
}
},
"imports" : {
"lodash" : "/node_modules/lodash-es/lodash.js"
}
} も同様に、次のものと等価になる:
{
"imports" : {
"lodash" : "/node_modules/lodash-es/lodash.js"
}
} 単一の解決済みモジュール指定子が、参照元スクリプトに応じて複数の 解決規則を持つ場合もあり得る。そのような場合、関連する規則だけが マップに追加されない。
たとえば、"/app/vendor/main.mjs" から
"/app/helper" をすでに解決している場合、次の新しいインポートマップ:
{
"scopes" : {
"/app/" : {
"/app/helper" : "./helper/index.mjs"
},
"/app/vendor/" : {
"/app/" : "./vendor_helper/"
},
"/vendor/" : {
"/app/helper" : "./helper/vendor_index.mjs"
}
},
"imports" : {
"lodash" : "/node_modules/lodash-es/lodash.js"
"/app/" : "./general_app_path/"
"/app/helper" : "./other_path/helper/index.mjs"
}
} は、次のものと等価になる:
{
"scopes" : {
"/vendor/" : {
"/app/helper" : "./helper/vendor_index.mjs"
}
},
"imports" : {
"lodash" : "/node_modules/lodash-es/lodash.js"
}
} これは、マージアルゴリズムがすでに解決されたモジュールを追跡し、 それらに影響する規則を、既存のマップにマージする前に新しいインポートマップから 削除することによって実現される。
影響を受ける解決済みモジュールがなく、新しいインポートマップに既存のインポートマップと 競合する規則がある場合、既存のインポートマップの規則が維持される。
たとえば、次の既存および新しいインポートマップ:
{
"imports" : {
"/app/helper" : "./helper/index.mjs" ,
"lodash" : "/node_modules/lodash-es/lodash.js"
}
} {
"imports" : {
"/app/helper" : "./main/helper/index.mjs"
}
} は、次の単一のインポートマップと等価になる:
{
"imports" : {
"/app/helper" : "./helper/index.mjs" ,
"lodash" : "/node_modules/lodash-es/lodash.js" ,
}
} 順序付きマップ originalMap および URL baseURL が与えられたとき、モジュール 指定子マップを並べ替えて正規化するには:
normalized を空の順序付きマップとする。
originalMap の各 specifierKey → valueについて反復する:
normalizedSpecifierKey を、specifierKey および baseURL が与えられたときに指定子 キーを正規化した結果とする。
normalizedSpecifierKey が null の場合、続行する。
value が文字列でない場合:
ユーザーエージェントは、アドレスは文字列である必要があることを示す警告をコンソールに報告してもよい。
normalized[normalizedSpecifierKey] を null に設定する。
続行する。
addressURL を、value および baseURL が与えられたときにURL のようなモジュール 指定子を解決した結果とする。
addressURL が null の場合:
ユーザーエージェントは、アドレスが無効であったことを示す警告をコンソールに報告してもよい。
normalized[normalizedSpecifierKey] を null に設定する。
続行する。
specifierKey が U+002F (/) で終わり、かつ addressURL のシリアル化が U+002F (/) で終わらない場合:
ユーザーエージェントは、指定子キー specifierKey に 無効なアドレスが指定されたことを示す警告をコンソールに報告してもよい。 specifierKey はスラッシュで終わるため、アドレスも同様に終わる必要がある。
normalized[normalizedSpecifierKey] を null に設定する。
続行する。
normalized[normalizedSpecifierKey] を addressURL に設定する。
エントリー a のキーが エントリー b のキーより符号単位で小さい場合に、 エントリー a がエントリー b より小さいものとして、 normalized を降順に並べ替えた結果を返す。
順序付きマップ originalMap およびURL baseURL が与えられたとき、スコープを並べ替えて正規化するには:
normalized を空の順序付きマップとする。
originalMap の各 scopePrefix → potentialSpecifierMapについて反復する:
potentialSpecifierMap が順序付きマップでない場合、
プレフィックス scopePrefix を持つスコープの値は JSON オブジェクトである必要があることを示す
TypeErrorを
スローする。
scopePrefixURL を、baseURL を基準として scopePrefix をURL 構文解析した結果とする。
scopePrefixURL が failure である場合:
ユーザーエージェントは、スコーププレフィックス URL を構文解析できなかったことを示す警告をコンソールに報告してもよい。
続行する。
normalizedScopePrefix を scopePrefixURL のシリアル化とする。
normalized[normalizedScopePrefix] を、 potentialSpecifierMap および baseURL が与えられたときにモジュール指定子マップを並べ替えて 正規化した結果に設定する。
エントリー a のキーが エントリー b のキーより符号単位で 小さい場合に、エントリー a がエントリー b より小さいものとして、normalized を降順に 並べ替えた結果を返す。
上の2つのアルゴリズムでは、キーとスコープを降順に並べ替えることにより、
"foo/bar/" が "foo/" より前に配置される。その結果、
モジュール
指定子の解決時に、"foo/bar/" が "foo/" より高い優先度を持つ。
順序付きマップ originalMap が与えられたとき、モジュール完全性マップを正規化するには:
normalized を空の順序付きマップとする。
originalMap の各 key → valueについて反復する:
resolvedURL を、key および baseURL が与えられたときにURL のようなモジュール 指定子を解決した結果とする。
"imports" とは異なり、完全性マップのキーは
モジュール指定子ではなく URL として扱われる。ただし、モジュール指定子と誤認され得る
foo のような「ベア」相対
URL を禁止するため、URL のようなモジュール
指定子を解決するアルゴリズムを使用する。
resolvedURL が null の場合:
ユーザーエージェントは、キーの解決に失敗したことを示す警告をコンソールに報告してもよい。
続行する。
value が文字列でない場合:
ユーザーエージェントは、完全性メタデータの値は 文字列である必要があることを示す警告をコンソールに報告してもよい。
続行する。
normalized[resolvedURL] を value に設定する。
normalized を返す。
文字列 specifierKey およびURL baseURL が与えられたとき、指定子キーを正規化するには:
specifierKey が空文字列である場合:
ユーザーエージェントは、指定子キーを空文字列にしてはならないことを示す警告をコンソールに報告してもよい。
null を返す。
url を、specifierKey および baseURL が与えられたときにURL のようなモジュール 指定子を解決した結果とする。
url が null でない場合、url のシリアル化を返す。
specifierKey を返す。
JavaScript 仕様には、ホスト環境に応じて異なる、いくつかの実装定義の抽象 操作が含まれている。この節では、ユーザーエージェントホストについてそれらを定義する。
JavaScript には、実装定義のHostEnsureCanAddPrivateElement(O) 抽象操作が含まれている。ユーザーエージェントは、次の実装を使用しなければならない:[JAVASCRIPT]
O が WindowProxy
オブジェクトであるか、または Locationを実装する場合、
ThrowCompletion(新しい
TypeError)
を返す。
NormalCompletion(unused) を返す。
JavaScript のプライベートフィールドは、任意のオブジェクトに適用できる。これは、
特に特殊なホストオブジェクトの実装を劇的に複雑にする可能性があるため、JavaScript
言語仕様は、ホスト定義の基準を満たすオブジェクト上のプライベートフィールドをホストが拒否できるように、
このフックを提供している。HTML の場合、WindowProxy
および
Location は、
特にナビゲーションとセキュリティに関して複雑な意味論を持ち、
プライベートフィールドの意味論を実装することが困難であるため、この実装ではそれらのオブジェクトを単純に拒否する。
JavaScript には、Dynamic Code Brand Checks 提案によって再定義された、実装定義のHostEnsureCanCompileStrings 抽象操作が含まれている。 ユーザーエージェントは、次の実装を使用しなければならない:[JAVASCRIPT] [JSDYNAMICCODEBRANDCHECKS]
? EnsureCSPDoesNotBlockStringCompilation(realm, parameterStrings, bodyString, codeString, compilationType, parameterArgs, bodyArg) を実行する。 [CSP]
Dynamic Code Brand Checks 提案には、 実装定義のHostGetCodeForEval(argument) 抽象操作が含まれている。 ユーザーエージェントは、次の実装を使用しなければならない:[JSDYNAMICCODEBRANDCHECKS]
argument が TrustedScript
オブジェクトである場合、
argument のデータを返す。
それ以外の場合、no-code を返す。
JavaScript には、実装定義のHostPromiseRejectionTracker(promise, operation) 抽象操作が含まれている。ユーザーエージェントは、次の実装を使用しなければならない: [JAVASCRIPT]
script を実行中のスクリプトとする。
script がクラシックスクリプトであり、 script のミュートされた エラーが true の場合、返す。
settingsObject を現在の設定オブジェクトとする。
script が null でない場合、settingsObject を script の設定 オブジェクトに設定する。
global を settingsObject のグローバルオブジェクトとする。
operation が "reject" である場合:
promise を global の 通知されようとしている 拒否された Promise のリストに付加する。
operation が "handle" である場合:
global の通知されようとしている 拒否された Promise のリストに promise が含まれる場合、そのリストから promise を削除し、返す。
global の未処理の 拒否された Promise の弱集合に promise が含まれない場合、返す。
promise を global の 未処理の 拒否された Promise の弱集合から削除する。
global が与えられたとき、DOM 操作タスク
ソース上に、global に PromiseRejectionEventを使用して、
rejectionhandled
という名前のイベントを発火するグローバルタスクをキューに追加する。
このとき、promise
属性を
promise に初期化し、reason
属性を promise.[[PromiseResult]] に初期化する。
Temporal 提案には、実装定義のHostSystemUTCEpochNanoseconds 抽象操作が含まれている。 ユーザーエージェントは、次の実装を使用しなければならない:[JSTEMPORAL]
settingsObject を global の関連する設定 オブジェクトとする。
time を settingsObject の現在の実時間とする。
ns を、Unix エポックから time までのナノ秒数を最も近い整数に丸めたものとする。
ns を nsMinInstant と nsMaxInstant の間にクランプした結果を返す。
Reference/Global_Objects/Promise#Incumbent_settings_object_tracking
1つのエンジンのみでサポートされている。
JavaScript 仕様は、ホストによって後でスケジュールされ実行されるジョブと、
ジョブの一部として呼び出される JavaScript 関数をカプセル化するJobCallback
Recordを定義している。JavaScript 仕様には、
ホストがジョブのスケジュール方法および JobCallback の処理方法を定義できる、いくつかの実装定義の抽象操作が含まれている。HTML はこれらの抽象操作を使用し、
JobCallback 内で現任設定オブジェクトおよび
アクティブスクリプトのためのJavaScript
実行コンテキストを保存および復元することにより、Promise および FinalizationRegistry
コールバック内の現任設定
オブジェクトを追跡する。この節では、
ユーザーエージェントホストについてそれらを定義する。
JavaScript には、ホストがタスク内から JavaScript コールバックを呼び出すときに状態を復元できるようにする、 実装定義のHostCallJobCallback(callback, V, argumentsList) 抽象操作が含まれている。ユーザーエージェントは、次の実装を使用しなければならない: [JAVASCRIPT]
incumbent settings を callback.[[HostDefined]].[[IncumbentSettings]] とする。
script execution context を callback.[[HostDefined]].[[ActiveScriptContext]] とする。
incumbent settings を使用してコールバックを実行する準備をする。
これは、コールバックの実行中に現任の概念に影響する。
script execution context が null でない場合、script execution context をJavaScript 実行 コンテキストスタックにプッシュする。
これは、コールバックの実行中にアクティブ スクリプトに影響する。
result を Call(callback.[[Callback]], V, argumentsList) とする。
script execution context が null でない場合、JavaScript 実行コンテキスト スタックから script execution context をポップする。
incumbent settings を使用してコールバック実行後の クリーンアップをする。
result を返す。
JavaScript には、オブジェクトがガベージコレクションされたことが検出された場合に
クリーンアップ操作をスケジュールするため、オブジェクトを FinalizationRegistry
オブジェクトに登録する機能がある。
JavaScript 仕様には、クリーンアップ操作をスケジュールするための実装定義のHostEnqueueFinalizationRegistryCleanupJob(finalizationRegistry)
抽象操作が含まれている。
クリーンアップ処理のタイミングおよび発生は、JavaScript 仕様では実装定義である。
オブジェクトがいつ、またはそもそもガベージコレクションされるかはユーザーエージェントによって異なる可能性があり、
これは WeakRef.prototype.deref()
メソッドの戻り値が undefined になるかどうかと、FinalizationRegistry
クリーンアップコールバックが発生するかどうかの両方に影響する。一般的なウェブブラウザーでは、
オブジェクトが JavaScript からアクセスできなくなっているにもかかわらず、
ガベージコレクターによって無期限に保持され続ける既知の事例がある。HTML は、
マイクロタスクチェックポイントを実行する
アルゴリズムで、生存状態に保たれている WeakRef
オブジェクトをクリアする。作者は、ガベージコレクション実装のタイミングの詳細に依存しないことが最善である。
クリーンアップ操作は、同期的な JavaScript 実行の途中に挟まれて行われるのではなく、 キューに追加されたタスク内で行われる。 ユーザーエージェントは、次の実装を使用しなければならない:[JAVASCRIPT]
global を finalizationRegistry.[[Realm]] のグローバル オブジェクトとする。
global が与えられたとき、JavaScript エンジンタスクソース上に、 次の手順を実行するグローバルタスクをキューに追加する:
entry を finalizationRegistry.[[CleanupCallback]].[[Callback]].[[Realm]] の環境設定 オブジェクトとする。
entry を使用してスクリプトを実行する準備をする。
これは、クリーンアップコールバックの実行中にエントリーの概念に影響する。
result を CleanupFinalizationRegistry(finalizationRegistry) を実行した結果とする。
entry を使用してスクリプト実行後の クリーンアップをする。
result が突然の完了である場合、 global について result.[[Value]] によって与えられる例外を報告する。
JavaScript には、特定のレルムで汎用ジョブを実行するための
(たとえば、Atomics.waitAsync
の結果として生じる Promise を解決するための)実装定義のHostEnqueueGenericJob(job, realm)
抽象操作が含まれている。ユーザーエージェントは、次の実装を使用しなければならない:
[JAVASCRIPT]
global を realm のグローバル オブジェクトとする。
global が与えられたとき、JavaScript エンジンタスクソース上に、job() を実行するグローバルタスクをキューに追加する。
JavaScript には、Promise 関連の操作をスケジュールするための実装定義のHostEnqueuePromiseJob(job, realm) 抽象操作が含まれている。HTML はこれらの操作を マイクロタスクキュー内にスケジュールする。ユーザーエージェントは、次の実装を使用しなければならない:[JAVASCRIPT]
realm が null でない場合、job settings を realm の設定 オブジェクトとする。それ以外の場合、 job settings を null とする。
realm が null でない場合、これは実行される作者コードのレルムである。
job が NewPromiseReactionJob によって返される場合、
これは Promise のハンドラー関数のレルムである。job が
NewPromiseResolveThenableJob によって返される場合、
これは then
関数のレルムである。
realm が null の場合、作者コードが実行されないか、または作者コードが必ず
スローする。前者では、promise.then(null, null) のように、
作者が実行するコードを渡していない可能性がある。後者では、取り消された Proxy が
渡されたことが理由である。どちらの場合も、そうでなければ job settings を使用する
以下のすべての手順はスキップされる。
NewPromiseResolveThenableJob および NewPromiseReactionJob はどちらも、取り消された Proxy の場合に null でないレルム(現在の Realm Record)を 提供するように見える。以前のテキストは、それを反映するように更新できる。
次の手順を実行するマイクロタスクをキューに追加する:
job settings が null でない場合、job settings を使用してスクリプトを実行する準備をする。
これは、ジョブの実行中にエントリーの概念に影響する。
result を job() とする。
job は、NewPromiseReactionJob またはNewPromiseResolveThenableJob によって返される抽象
クロージャである。job が NewPromiseReactionJob によって返される場合の Promise の
ハンドラー関数、および job が
NewPromiseResolveThenableJob によって返される場合の
then 関数は、JobCallback
Recordでラップされる。HTML は、
HostMakeJobCallback で現任
設定オブジェクトおよびアクティブスクリプトのためのJavaScript 実行コンテキストを保存し、
HostCallJobCallback
でそれらを復元する。
job settings が null でない場合、job settings を使用してスクリプト実行後のクリーンアップをする。
result が突然の完了である場合、 realm のグローバルオブジェクトについて、 result.[[Value]] によって与えられる例外を報告する。
HostEnqueuePromiseJob が null のレルムで呼び出される (たとえば Promise.prototype.then が null のハンドラーで呼び出されたため)一方で、 ジョブも突然返る(Promise capability の resolve または reject ハンドラーがスローしたため。これは、 渡された関数を受け取り、それらをスローする関数でラップしてから、Promise スーパークラスコンストラクターに渡された関数へ渡す Promise のサブクラスであるために起こり得る) という非常に複雑な場合がある。その場合、別のレルムの Promise コンストラクターまたは Promise.prototype.then を使用することで、各手順で現在のレルムが異なり得ることを考慮すると、 どのグローバルを使用すべきか。issue #10526 を参照。
JavaScript には、タイムアウト後に実行される操作をスケジュールするための実装定義のHostEnqueueTimeoutJob(job, milliseconds) 抽象操作が含まれている。HTML は、タイムアウト後に手順を実行するを使用して、 これらの操作をスケジュールする。ユーザーエージェントは、 次の実装を使用しなければならない:[JAVASCRIPT]
global を realm のグローバル オブジェクトとする。
timeoutStep を、global が与えられたとき、JavaScript エンジンタスクソース上に、job() を実行するグローバルタスクをキューに追加するアルゴリズム手順とする。
global、"JavaScript"、milliseconds、および
timeoutStep が与えられたとき、タイムアウト後に手順を実行する。
JavaScript には、ホストがタスク内から呼び出される JavaScript コールバックに状態を 添付できるようにする、実装定義のHostMakeJobCallback(callable) 抽象操作が含まれている。 ユーザーエージェントは、次の実装を使用しなければならない: [JAVASCRIPT]
incumbent settings を現任設定オブジェクトとする。
active script をアクティブ スクリプトとする。
script execution context を null とする。
active script が null でない場合、script execution context を新しい JavaScript 実行コンテキストに設定する。 その Function フィールドを null に、Realm フィールドを active script の設定 オブジェクトのレルムに、そして ScriptOrModule を active script の レコードに設定する。
以下で示すように、これは現在のアクティブ スクリプトを、ジョブコールバックが呼び出される時点まで伝播させるために使用される。
active script が null でなく、この方法で保存することが有用な場合の一例は、 次のとおりである:
Promise. resolve( 'import(`./example.mjs`)' ). then( eval); この手順(および HostCallJobCallback 内でこれを使用する手順)がなければ、
import()
式が評価されるとき、アクティブスクリプトは存在しない。
なぜなら、eval()
は特定のスクリプトに由来しない組み込み関数だからである。
この手順があることで、アクティブスクリプトは上のコードからジョブへ伝播され、
import()
が元のスクリプトのベース
URLを適切に使用できるようになる。
ユーザーが次のボタンをクリックした場合、active script は null になり得る:
< button onclick = "Promise.resolve('import(`./example.mjs`)').then(eval)" > Click me</ button > この場合、イベント ハンドラーの JavaScript 関数は、null の [[ScriptOrModule]] 値を持つ関数を作成するイベントハンドラーの現在の値を取得する アルゴリズムによって作成される。したがって、Promise の仕組みが HostMakeJobCallback を呼び出すとき、 引き渡すアクティブスクリプトは存在しない。
その結果、import()
式が評価されるときにも、
アクティブスクリプトは依然として存在しない。
幸い、これは HostLoadImportedModule の実装で、現在の設定
オブジェクトのAPI ベース
URLの使用にフォールバックすることで処理される。
JobCallback Record { [[Callback]]: callable, [[HostDefined]]: { [[IncumbentSettings]]: incumbent settings, [[ActiveScriptContext]]: script execution context } } を返す。
JavaScript 仕様は、モジュールの構文と、その処理モデルのうちホストに依存しない部分を定義する。
この仕様は、処理モデルの残りの部分、すなわち type
属性が "module" に設定された script
要素を介してモジュールシステムを起動する方法、および
モジュールをフェッチ、解決、実行する方法を定義する。[JAVASCRIPT]
JavaScript 仕様では「スクリプト」と「モジュール」という用語が使われるが、
この仕様では一般にクラシック
スクリプトとモジュールスクリプトという用語を使用する。
これは、どちらも script
要素を使用するためである。
modulePromise = import(specifier)
specifier によって識別されるモジュールスクリプトの
モジュール名前空間オブジェクトに対する Promise を返す。これにより、静的に import
文形式を使用する代わりに、実行時にモジュールスクリプトを動的にインポートできる。指定子は、
アクティブ
スクリプトを基準として解決される。
無効な指定子が与えられた場合、または結果として得られるモジュールグラフのフェッチ中もしくは評価中に 失敗が発生した場合、返された Promise は拒否される。
この構文は、クラシックスクリプトとモジュールスクリプトの両方で使用できる。 したがって、クラシックスクリプトの世界からモジュールスクリプトの世界への橋渡しを提供する。
url = import.meta.url
この構文は、モジュールスクリプト内でのみ使用できる。
url = import.meta.resolve(specifier)
アクティブスクリプトを基準として解決された
specifier を返す。つまり、これは import(specifier)
を使用してインポートされる URL を返す。
無効な指定子が与えられた場合、TypeError
例外をスローする。
この構文は、モジュールスクリプト内でのみ使用できる。
モジュールマップは、マップであり、タプルをキーとし、そのタプルはURL レコードと文字列からなる。
URL レコードは、モジュールが
フェッチされた場所の要求
URLであり、文字列はモジュールのタイプを示す
(たとえば「javascript-or-wasm」)。モジュールマップの値は、モジュール
スクリプト、null(不一致のMIME タイプを表すために使用される)、または
アルゴリズムのリスト(フェッチの完了を待機している)のいずれかである。モジュールマップは、インポートされた
モジュールスクリプトが、Documentまたはワーカーごとに一度だけフェッチ、構文解析、および評価されることを保証するために使用される。
モジュールマップは
(URL, モジュールタイプ) をキーとするため、次のコードは、3つの異なる
(URL, モジュールタイプ) タプル
(すべて "javascript-or-wasm" タイプ)を生成するので、モジュールマップ内に
3つの別個のエントリーを作成する:
import "https://example.com/module.mjs" ;
import "https://example.com/module.mjs#map-buster" ;
import "https://example.com/module.mjs?debug=true" ; つまり、URL のクエリーおよびフラグメントを変化させて、 モジュールマップ内に別個のエントリーを 作成できる。それらは無視されない。したがって、3回の別個のフェッチと3回の別個の モジュール評価が実行される。
対照的に、次のコードはモジュール マップ内に1つのエントリーしか作成しない。これらの入力にURL パーサーを適用した後、結果として得られるURL レコードが等しいためである:
import "https://example.com/module2.mjs" ;
import "https:example.com/module2.mjs" ;
import "https://///example.com\\module2.mjs" ;
import "https://example.com/foo/../module2.mjs" ; したがって、この2番目の例では、1回のフェッチと1回のモジュール評価だけが発生する。
この動作は、共有ワーカーが、 構文解析されたコンストラクター URLをキーとする方法と同じであることに注意。
モジュールタイプもモジュールマップのキーの一部であるため、
次のコードはモジュールマップ内に2つの別個のエントリーを
作成する(最初のタイプは "javascript-or-wasm"、2番目のタイプは
"css" である):
< script type = module >
import "https://example.com/module" ;
</ script >
< script type = module >
import "https://example.com/module" with { type: "css" };
</ script > これにより、2回の別個のフェッチと2回の別個のモジュール評価が実行される可能性がある。
実際には、まだ規定されていないメモリーキャッシュ(issue #6110 を参照)のため、 WebKit および Blink ベースのブラウザーではリソースが一度だけフェッチされる可能性がある。 さらに、すべてのモジュールタイプが互いに排他的である限り、単一のモジュールスクリプトをフェッチする内の モジュールタイプ確認は、少なくとも1つのインポートについて失敗するため、 最大でも1回のモジュール評価しか発生しない。
モジュールマップのキーにタイプを含める目的は、 誤った type 属性を持つインポートによって、同じ指定子を正しいタイプで行う別のインポートの成功が 妨げられないようにすることである。
別の JavaScript モジュールからインポートする場合、JavaScript モジュールスクリプトは既定の
インポートタイプである。つまり、import 文に type インポート属性がない場合、
インポートされるモジュールスクリプトのタイプは JavaScript となる。
type インポート属性を持つ import 文を使用して
JavaScript リソースをインポートしようとすると失敗する:
< script type = "module" >
// All of the following will fail, assuming that the imported .mjs files are served with a
// JavaScript MIME type. JavaScript module scripts are the default and cannot be imported with
// any import type attribute.
import foo from "./foo.mjs" with { type: "javascript" };
import foo2 from "./foo2.mjs" with { type: "js" };
import foo3 from "./foo3.mjs" with { type: "" };
await import ( "./foo4.mjs" , { with : { type: null } });
await import ( "./foo5.mjs" , { with : { type: undefined } });
</ script > Reference/Operators/import.meta/resolve
現在のすべてのエンジンでサポートされている。
Reference/Operators/import.meta
現在のすべてのエンジンでサポートされている。
JavaScript には、実装定義のHostGetImportMetaProperties 抽象操作が含まれている。 ユーザーエージェントは、次の実装を使用しなければならない:[JAVASCRIPT]
moduleScript を moduleRecord.[[HostDefined]] とする。
表明:moduleScript はJavaScript モジュール スクリプトであるため、moduleScript のベース URLは null でない。
steps を、引数 specifier が与えられたときの次の手順とする:
specifier を ? ToString(specifier) に設定する。
url を、moduleScript および specifier が与えられたときにモジュール指定子を 解決した結果とする。
url のシリアル化を返す。
resolveFunction を ! CreateBuiltinFunction(steps,
1, "resolve", « ») とする。
« Record {
[[Key]]: "url", [[Value]]: urlString },
Record {
[[Key]]: "resolve",
[[Value]]: resolveFunction } » を返す。
JavaScript には、実装定義のHostGetSupportedImportAttributes 抽象 操作が含まれている。ユーザーエージェントは、次の実装を使用しなければならない:[JAVASCRIPT]
« "type" » を返す。
JavaScript には、実装定義のHostLoadImportedModule 抽象操作が含まれている。 ユーザーエージェントは、次の実装を使用しなければならない:[JAVASCRIPT]
settingsObject を現在の設定オブジェクトとする。
settingsObject のグローバル
オブジェクトが WorkletGlobalScope
または ServiceWorkerGlobalScopeを実装し、
かつ loadState が undefined である場合:
loadState は、現在のフェッチ処理が動的な import()
呼び出しによって、直接または動的にインポートされたモジュールの
推移的依存関係を読み込むときに開始された場合、undefined となる。
FinishLoadingImportedModule(referrer,
moduleRequest, payload, ThrowCompletion(新しい
TypeError))
を実行する。
返す。
referencingScript を null とする。
originalFetchOptions を既定のスクリプトフェッチ オプションとする。
fetchReferrer を "client" とする。
referrer がScript RecordまたはCyclic Module Recordである場合:
referencingScript を referrer.[[HostDefined]] に設定する。
settingsObject を referencingScript の設定オブジェクトに設定する。
fetchReferrer を referencingScript のベース URLに設定する。
originalFetchOptions を referencingScript のフェッチオプションに設定する。
referrer は通常、Script Recordまたは Cyclic Module Recordであるが、イベントハンドラーの現在の値を取得する アルゴリズムによるイベントハンドラーの場合はそうならない。たとえば、次が与えられたとする:
< button onclick = "import('./foo.mjs')" > Click me</ button > click
イベントが発生した場合、import()
式が実行される時点で、GetActiveScriptOrModule は null を返し、
この操作はフォールバック
referrer として現在のレルムを受け取る。
referrer がCyclic Module Recordであり、かつ moduleRequest が referrer.[[RequestedModules]] の最初の要素と等しい場合:
referrer.[[RequestedModules]] の各ModuleRequest record requestedについて反復する:
requested.[[Attributes]] に、entry.[[Key]] が
"type" でないRecord entry が含まれる場合:
error を新しい SyntaxError
例外とする。
loadState が undefined でなく、かつ loadState.[[ErrorToRethrow]] が null である場合、 loadState.[[ErrorToRethrow]] を error に設定する。
FinishLoadingImportedModule(referrer, moduleRequest, payload, ThrowCompletion(error)) を実行する。
返す。
JavaScript 仕様はこの検証を再度実行するが、検証に失敗した場合に 不必要に依存関係を読み込むことを避けるため、ここでも重複して実行する。
referencingScript および requested.[[Specifier]] が与えられたとき、例外を捕捉しながらモジュール 指定子を解決する。これが例外をスローした場合、 resolutionError をスローされた例外とする。
前の手順が例外をスローした場合:
loadState が undefined でなく、かつ loadState.[[ErrorToRethrow]] が null である場合、 loadState.[[ErrorToRethrow]] を resolutionError に設定する。
FinishLoadingImportedModule(referrer, moduleRequest, payload, ThrowCompletion(resolutionError)) を実行する。
返す。
moduleType を、requested が与えられたときにモジュールリクエストからのモジュールタイプ 手順を実行した結果とする。
moduleType および settingsObject が与えられたときにモジュールタイプが許可される手順を実行した結果が false の場合:
error を新しい TypeError
例外とする。
loadState が undefined でなく、かつ loadState.[[ErrorToRethrow]] が null である場合、 loadState.[[ErrorToRethrow]] を error に設定する。
FinishLoadingImportedModule(referrer, moduleRequest, payload, ThrowCompletion(error)) を実行する。
返す。
この手順は本質的に、静的モジュール依存関係リストに対する最初の HostLoadImportedModule 呼び出しが行われたとき、 要求されたすべてのモジュール指定子および type 属性を検証する。これは、 依存関係のいずれか1つに静的エラーがある場合に、それ以上の読み込み操作を避けるためである。 解決不能なモジュール指定子またはサポートされていない type 属性を持つモジュールは、 構文解析できないモジュールと同様に扱う。どちらの場合も、構文上の問題により、 後でそのモジュールをリンクすることを検討することすら不可能になる。
url を、referencingScript および moduleRequest.[[Specifier]] が与えられたとき、例外を捕捉しながらモジュール 指定子を解決した結果とする。これが例外をスローした場合、 resolutionError をスローされた例外とする。
前の手順が例外をスローした場合:
loadState が undefined でなく、かつ loadState.[[ErrorToRethrow]] が null である場合、 loadState.[[ErrorToRethrow]] を resolutionError に設定する。
FinishLoadingImportedModule(referrer, moduleRequest, payload, ThrowCompletion(resolutionError)) を実行する。
返す。
fetchOptions を、originalFetchOptions、url、および settingsObject が与えられたときに子孫スクリプトフェッチ オプションを取得した結果とする。
destination を "script" とする。
fetchClient を settingsObject とする。
loadState が undefined でない場合:
destination を loadState.[[Destination]] に設定する。
fetchClient を loadState.[[FetchClient]] に設定する。
url、 fetchClient、destination、fetchOptions、 settingsObject、fetchReferrer、moduleRequest、および 以下で定義される onSingleFetchComplete が与えられたとき、単一のインポートされたモジュールスクリプトをフェッチする。 loadState が undefined でなく、かつ loadState.[[PerformFetch]] が null でない場合、 loadState.[[PerformFetch]] も一緒に渡す。
moduleScript が与えられたときの onSingleFetchComplete は、 次のアルゴリズムである:
completion を null とする。
moduleScript が null である場合、completion を
ThrowCompletion(新しい TypeError)
に設定する。
それ以外の場合、moduleScript の構文解析 エラーが null でない場合:
parseError を moduleScript の構文解析エラーとする。
completion を ThrowCompletion(parseError) に設定する。
loadState が undefined でなく、かつ loadState.[[ErrorToRethrow]] が null である場合、 loadState.[[ErrorToRethrow]] を parseError に設定する。
それ以外の場合、completion を NormalCompletion(moduleScript のレコード) に設定する。
FinishLoadingImportedModule(referrer, moduleRequest, payload, completion) を実行する。
イベント、ユーザー操作、スクリプト、レンダリング、ネットワーク処理などを調整するため、 ユーザーエージェントは、この節で説明するイベントループを使用しなければならない。各エージェントには、そのエージェントに固有のイベントループが関連付けられている。
類似オリジンウィンドウエージェントのイベントループは、ウィンドウイベントループと呼ばれる。専用ワーカーエージェント、共有ワーカーエージェント、またはサービスワーカーエージェントのイベントループは、ワーカー イベントループと呼ばれる。また、ワークレットエージェントのイベントループは、ワークレットイベントループと呼ばれる。
イベントループは、必ずしも実装上の スレッドに対応するとは限らない。たとえば、複数のウィンドウイベント ループを、単一のスレッド内で協調的にスケジュールできる。
ただし、[[CanBlock]] が true に設定されて割り当てられる各種ワーカーのエージェントについては、JavaScript 仕様が前進保証に関する要件を課しており、これは実質的に、 そのような場合にエージェントごとの専用スレッドを要求することに相当する。
イベントループは、1つ以上のタスクキューを持つ。タスクキューは、タスクの集合である。
タスクキューはキューではなく、集合である。これは、イベントループ処理モデルが、最初のタスクをデキューするのではなく、選択されたキューから最初の実行可能なタスクを取得するためである。
マイクロタスクキューはタスクキューではない。
タスクは、次のような処理を担うアルゴリズムをカプセル化する:
特定の EventTarget
オブジェクトに Event
オブジェクトをディスパッチする処理は、多くの場合、専用のタスクによって行われる。
すべてのイベントがタスクキューを使用してディスパッチされるわけではない。 多くのイベントは、他のタスクの実行中にディスパッチされる。
HTML パーサーが1つ以上のバイトを トークン化し、生成されたトークンを処理することは、通常は1つのタスクである。
コールバックの呼び出しは、多くの場合、専用のタスクによって行われる。
アルゴリズムがリソースをフェッチする際、 フェッチが非ブロッキング方式で行われる場合、リソースの一部または全部が利用可能になった後の リソース処理はタスクによって行われる。
一部の要素は、DOM 操作に応じて起動されるタスクを持つ。たとえば、その要素が文書に挿入された場合などである。
形式的には、タスクは、次のものを持つ構造体である:
Document。
ウィンドウイベントループ内にない
タスクの場合は null。
各タスクは、そのソースフィールドに従って、 特定のタスクソースから来たものとして定義される。 各イベントループについて、すべてのタスクソースは、特定のタスクキューに関連付けられなければならない。
本質的に、タスクソースは、 ユーザーエージェントが区別したい可能性のある、論理的に異なる種類のタスクを標準内で分離するために使用される。 タスクキューは、ユーザーエージェントが 特定のイベントループ内で タスクソースを統合するために使用する。
たとえば、ユーザーエージェントは、マウスおよびキーイベント用のタスクキューを1つ (これにはユーザー操作タスクソースを関連付ける)、 その他のすべてのタスクソースを関連付ける別のキューを1つ持つことができる。 そして、イベントループ処理モデルの最初の手順で与えられる 自由度を使用して、4分の3の頻度でキーボードおよびマウスイベントを他のタスクより優先し、 他のタスクキューを飢餓状態にすることなくインターフェイスの応答性を維持できる。 この構成でも、処理モデルは、ユーザーエージェントが1つのタスクソースからのイベントを順序を無視して処理することが 決してないように強制することに注意。
各イベントループは、タスクまたは null である現在実行中のタスクを持つ。初期値は null である。 これは再入を処理するために使用される。
各イベントループは、初期状態では空である、 マイクロタスクのキューであるマイクロタスクキューを持つ。 マイクロタスクとは、マイクロタスクをキューに追加するアルゴリズムを介して作成されたタスクを指す通称である。
各イベントループは、初期値が false である マイクロタスクチェックポイント実行中ブール値を持つ。 これは、マイクロタスクチェックポイントを実行する アルゴリズムの再入呼び出しを防ぐために使用される。
各ウィンドウイベントループは、
初期値が0に設定された DOMHighResTimeStamp
最後のレンダリング機会時刻を持つ。
各ウィンドウイベントループは、
初期値が0に設定された DOMHighResTimeStamp
最後のアイドル期間開始時刻を持つ。
ウィンドウイベントループ loop の同一ループウィンドウを取得するには、関連するエージェントのイベントループが loop であるすべての
Window オブジェクトを返す。
タスクソース source 上に、一連の手順 steps を実行するタスクをキューに追加するには、 任意でイベントループ event loop および文書 document が与えられたとき:
event loop が与えられていない場合、event loop を暗黙の イベントループに設定する。
document が与えられていない場合、document を暗黙の 文書に設定する。
task を新しいタスクとする。
task の手順を steps に設定する。
task のソースを source に設定する。
task の文書を document に設定する。
task のスクリプト評価環境設定 オブジェクト集合を空の集合に設定する。
queue を、event loop 上で source が関連付けられているタスクキューとする。
task を queue に付加する。
タスクをキューに追加する際にイベントループおよび文書を渡さないことは、 曖昧で不十分に規定された暗黙のイベントループおよび暗黙の 文書という概念に依存することを意味する。仕様の作者は、これらの値を常に渡すか、代わりに ラッパーアルゴリズムであるグローバルタスクをキューに追加するまたは要素タスクをキューに追加するを使用するべきである。 ラッパーアルゴリズムの使用が推奨される。
タスクソース source 上に、 グローバルオブジェクト global および一連の手順 steps を持つグローバルタスクをキューに追加するには:
event loop を、global の関連するエージェントのイベントループとする。
global が Window
オブジェクトである場合、document を global の関連付けられた Documentとし、
それ以外の場合は null とする。
source、event loop、 document、および steps が与えられたとき、タスクをキューに追加する。
タスクソース source 上に、 要素 element および一連の手順 steps を持つ要素タスクをキューに追加するには:
global を element の関連するグローバル オブジェクトとする。
source、global、および steps が与えられたとき、グローバルタスクをキューに追加する。
一連の手順 steps を実行するマイクロタスクをキューに追加するには、 任意で文書 document が与えられたとき:
eventLoop を、周囲の エージェントのイベントループとする。
document が与えられていない場合、document を暗黙の 文書に設定する。
microtask を新しいタスクとする。
microtask の手順を steps に設定する。
microtask のソースをマイクロタスクタスクソースに設定する。
microtask の文書を document に設定する。
microtask のスクリプト評価環境 設定オブジェクト集合を空の集合に設定する。
microtask を eventLoop のマイクロタスク キューにエンキューする。
マイクロタスクは、最初の実行中にイベントループを回す場合、通常のタスク キューへ移動される可能性がある。マイクロタスクのソース、文書、およびスクリプト評価環境設定 オブジェクト集合が参照されるのは、この場合だけである。これらはマイクロタスクチェックポイントを実行する アルゴリズムでは無視される。
タスクをキューに追加するときの暗黙のイベントループは、 呼び出し元アルゴリズムの文脈から推定できるイベントループである。ほとんどの仕様アルゴリズムは、 通常1つのエージェント、したがって1つのイベントループだけに関係するため、一般に曖昧さはない。 例外は、エージェント間通信を伴う、または規定するアルゴリズム (たとえば、ウィンドウとワーカー間)である。そのような場合、暗黙の イベントループという概念に依存してはならず、仕様はタスクをキューに追加する際にイベントループを明示的に指定しなければならない。
イベントループ event loop 上にタスクをキューに追加するときの暗黙の文書は、 次のように決定される:
event loop がウィンドウ イベントループでない場合、null を返す。
タスクが要素の文脈でキューに追加されている場合、要素のノード文書を返す。
タスクがスクリプトによって、またはスクリプトのために
キューに追加されている場合、スクリプトの設定オブジェクトのグローバルオブジェクトの関連付けられた
Documentを返す。
表明:前の条件のいずれかが true であるため、 この手順には決して到達しない。本当に?
暗黙のイベントループと暗黙の 文書は、どちらも曖昧に定義されており、遠隔作用が多い。特に暗黙の文書を削除することが 望まれている。issue #4980 を参照。
イベントループは、 存在する限り、次の手順を継続的に実行しなければならない:
oldestTask および taskStartTime を null とする。
イベントループに、 少なくとも1つの実行可能なタスクを持つタスクキューがある場合:
taskQueue を、実装定義の方法で選択した、そのようなタスクキューの1つとする。
マイクロタスクキューはタスク キューではないため、この手順では選択されないことを思い出すこと。ただし、マイクロタスクタスクソースが関連付けられたタスクキューは、 この手順で選択される可能性がある。その場合、次の手順で選択されるタスクは、元々はマイクロタスクであったが、イベントループを回す処理の一部として移動されたものである。
taskStartTime を安全でない共有現在時刻に設定する。
oldestTask を taskQueue 内の最初の実行可能なタスクに設定し、 それを taskQueue から削除する。
oldestTask の文書が null でない場合、 taskStartTime および oldestTask の文書が与えられたとき、タスク開始時刻を記録する。
イベントループの現在実行中の タスクを oldestTask に設定する。
oldestTask の手順を実行する。
taskEndTime を安全でない共有現在時刻とする。 [HRT]
oldestTask が null でない場合:
top-level browsing contexts を空の集合とする。
oldestTask のスクリプト評価 環境設定オブジェクト集合の各環境設定オブジェクト settingsについて:
global を settings のグローバルオブジェクトとする。
tlbc を global の閲覧 コンテキストのトップレベル閲覧 コンテキストとする。
tlbc が null でない場合、それを top-level browsing contexts に付加する。
taskStartTime、taskEndTime、 top-level browsing contexts、および oldestTask を渡して、長時間タスクを報告する。
oldestTask の文書が null でない場合、 taskEndTime および oldestTask の文書が与えられたとき、タスク終了時刻を記録する。
これがウィンドウイベント ループであり、このイベントループのタスクキューに実行可能なタスクがない場合:
このイベントループの最後の アイドル期間開始時刻を安全でない共有現在時刻に設定する。
computeDeadline を次の手順とする:
deadline を、このイベントループの最後のアイドル期間開始 時刻に50を加えたものとする。
将来50ミリ秒という上限は、人間の知覚しきい値内で新しいユーザー入力への 応答性を確保するためのものである。
hasPendingRenders を false とする。
このイベントループの同一ループウィンドウの各 windowInSameLoopについて:
windowInSameLoop のアニメーションフレーム コールバックのマップが空でない場合、またはユーザーエージェントが windowInSameLoop に保留中のレンダリング更新がある可能性があると判断する場合、 hasPendingRenders を true に設定する。
timerCallbackEstimates を、windowInSameLoop のアクティブタイマーの マップの値を取得した結果とする。
timerCallbackEstimates の各 timeoutDeadlineについて、 timeoutDeadline が deadline より小さい場合、 deadline を timeoutDeadline に設定する。
hasPendingRenders が true の場合:
nextRenderDeadline を、このイベントループの最後のレンダリング 機会時刻に、1000を現在のリフレッシュレートで除算した値を加えたものとする。
リフレッシュレートは、ハードウェアまたは実装に固有であり得る。リフレッシュレートが 60Hz の場合、nextRenderDeadline は最後の レンダリング機会時刻から約16.67ミリ秒後となる。
nextRenderDeadline が deadline より小さい場合、 nextRenderDeadline を返す。
deadline を返す。
このイベントループの同一ループウィンドウの各 winについて、次の手順を使用して win のアイドル期間開始アルゴリズムを実行する: computeDeadline を呼び出した結果を、win の関連する設定 オブジェクトのクロスオリジン 分離能力が与えられたときに粗くしたものを返す。[REQUESTIDLECALLBACK]
これがワーカーイベント ループである場合:
このイベントループのエージェントの単一のレルムのグローバルオブジェクトが、
サポートされている
DedicatedWorkerGlobalScope
であり、かつユーザーエージェントが、この時点でレンダリングを更新することが有益であると判断する場合:
now を、DedicatedWorkerGlobalScope
が与えられたときの現在の高分解能時刻とする。
[HRT]
その DedicatedWorkerGlobalScope
について、now をタイムスタンプとして渡し、アニメーションフレーム
コールバックを実行する。
その専用ワーカーのレンダリングを、現在の状態を反映するように更新する。
ウィンドウイベントループ内でレンダリングを更新する場合の注記と同様に、 ユーザーエージェントは専用ワーカー内のレンダリング頻度を決定できる。
イベントループのタスクキューにタスクがなく、かつ
WorkerGlobalScope
オブジェクトのclosingフラグが true の場合、
イベントループを破棄し、
これらの手順を中止して、以下のウェブワーカーの節で説明するワーカーを実行する手順を再開する。
ウィンドウイベントループ eventLoop は、存在する限り、次の処理も並列に実行しなければならない:
アクティブ文書の関連するエージェントのイベント ループが eventLoop である少なくとも1つのナビゲーブルに、 レンダリング機会が生じる可能性があるまで待つ。
eventLoop の最後のレンダリング機会時刻を安全でない 共有現在時刻に設定する。
レンダリング機会を持つ各 navigableについて、navigable のアクティブウィンドウが与えられたとき、 レンダリングタスクソース上に、 レンダリングを更新するためのグローバルタスクをキューに追加する:
これにより、レンダリングを更新する呼び出しが 重複する可能性がある。ただし、不要なレンダリングの手順に従えばレンダリングは不要であるため、 これらの呼び出しに観測可能な効果はない。実装は、このタスクがまだキューに追加されていない場合にのみ 追加するなど、さらなる最適化を導入できる。ただし、タスクに関連付けられた文書は、 タスクが処理される前に非アクティブになる可能性があることに注意。
frameTimestamp を eventLoop の最後のレンダリング機会 時刻とする。
docs を、関連するエージェントのイベント
ループが eventLoop であるすべての完全に
アクティブな Document
オブジェクトとし、次の条件を満たす限り任意に並べ替える:
文書 A および B が、同じ null でないコンテナー文書 C を持つ場合、リスト内の A と B の順序は、 C のノードツリー内にある、それぞれのナビゲーブル コンテナーのシャドウを含む ツリー順と一致しなければならない。
以下で docs を反復する手順では、各 Document は、
リスト内で見つかった順序で処理されなければならない。
レンダリング不能な文書をフィルターする:次のいずれかが true である
Document
オブジェクト doc を docs から削除する:
doc がレンダリングブロックされている。
doc の可視性状態が "hidden" である。
doc のレンダリングがビュー遷移のために抑制されている。
doc のノード ナビゲーブルが現在レンダリング 機会を持っていない。
並列に実行する手順で確認することに加えて、 ここでもレンダリング機会を確認する必要がある。これは、同じイベント ループを共有する一部の文書が、同時にはレンダリング機会を持たない可能性があるためである。
不要なレンダリング:次のすべてが true である Document オブジェクト
doc を docs から削除する:
ユーザーエージェントが、doc のノード ナビゲーブルのレンダリングを更新しても目に見える効果はないと判断する。かつ
doc のアニメーションフレーム コールバックのマップが空である。
ユーザーエージェントが、その他の理由でレンダリングの更新をスキップする方が望ましいと判断する
すべての Document
オブジェクトを docs から削除する。
レンダリング不能な文書をフィルターすると記された手順は、 ユーザーに新しい内容を提示できない場合に、ユーザーエージェントがレンダリングを更新することを防ぐ。
不要なレンダリングと記された手順は、描画すべき新しい内容がない場合に、 ユーザーエージェントがレンダリングを更新することを防ぐ。
この手順により、ユーザーエージェントは、その他の理由で以下の手順が実行されることを防げる。 たとえば、特定のタスクが互いに直後に実行され、 その間にマイクロタスクチェックポイント だけが挟まれるようにし、たとえばアニメーションフレームコールバック が挟まれないようにできる。具体的には、ユーザーエージェントは、途中にレンダリング更新を入れずに、 タイマーコールバックをまとめて実行したい場合がある。
docs の各 docについて、doc を表示する。
docs の各 docについて、そのノードナビゲーブルがトップレベルトラバーサブルである場合、 doc のautofocus 候補をフラッシュする。
docs の各 docについて、doc のリサイズ手順を実行する。 [CSSOMVIEW]
docs の各 docについて、doc のスクロール手順を実行する。 [CSSOMVIEW]
docs の各 docについて、doc のメディアクエリーを評価して変更を 報告する。[CSSOMVIEW]
docs の各 docについて、frameTimestamp および doc の関連するグローバルオブジェクトが 与えられたときの相対高分解能時刻をタイムスタンプとして渡し、 doc のアニメーションを更新してイベントを送信する。 [WEBANIMATIONS]
docs の各 docについて、doc の全画面手順を実行する。 [FULLSCREEN]
docs の各 docについて、ユーザーエージェントが CanvasRenderingContext2D
または OffscreenCanvasRenderingContext2D
である context に関連付けられたバッキングストレージが失われたことを検出した場合、
そのような各 context についてコンテキスト消失手順を実行しなければならない:
context が CanvasRenderingContext2D
である場合、canvas を context の canvas
属性の値とし、それ以外の場合は、context に関連付けられた
OffscreenCanvas
オブジェクトとする。
context のコンテキスト 消失を true に設定する。
context が与えられたとき、レンダリング コンテキストを既定の状態にリセットする。
shouldRestore を、cancelable
属性を true に初期化して、canvas に contextlost
という名前のイベントを発火した結果とする。
shouldRestore が false の場合、これらの手順を中止する。
context の属性を使用してバッキングストレージを作成し、 それを context に関連付けることにより、context の復元を試みる。 これに失敗した場合、これらの手順を中止する。
context のコンテキスト 消失を false に設定する。
canvas に contextrestored
という名前のイベントを発火する。
docs の各 docについて、frameTimestamp および doc の関連するグローバルオブジェクトが 与えられたときの相対高分解能時刻をタイムスタンプとして渡し、 doc のアニメーションフレーム コールバックを実行する。
unsafeStyleAndLayoutStartTime を安全でない共有現在 時刻とする。
docs の各 docについて:
resizeObserverDepth を0とする。
true の間:
doc のスタイルを再計算し、レイアウトを更新する。
hadInitialVisibleContentVisibilityDetermination を false とする。
'content-visibility' の'auto'使用値を持つ各要素 elementについて:
element のビューポートへの近接度が未決定であり、 かつユーザーに関連しない場合、 checkForInitialDetermination を true とする。それ以外の場合、 checkForInitialDetermination を false とする。
element のビューポートへの近接度を決定する。
checkForInitialDetermination が true であり、かつ element が 現在ユーザーに関連する場合、 hadInitialVisibleContentVisibilityDetermination を true に設定する。
hadInitialVisibleContentVisibilityDetermination が true の場合、 続行する。
この手順の意図は、直ちに有効になる初回のビューポート近接度判定を、 このループの前の手順で行われるスタイルおよびレイアウト計算に反映させることである。 初回以外の近接度判定は、次のレンダリング 機会に有効になる。[CSSCONTAIN]
doc について、深さ resizeObserverDepth のアクティブなリサイズ観測を収集する。
doc がアクティブなリサイズ観測を持つ場合:
resizeObserverDepth を、doc が与えられたときにアクティブなリサイズ 観測を配信した結果に設定する。
doc がスキップされたリサイズ観測を持つ場合、 doc が与えられたとき、リサイズループエラーを通知する。
docs の各 docについて、doc のフォーカス領域がフォーカス可能領域でない場合、 doc のビューポートについてフォーカス手順を実行し、 doc の関連するグローバルオブジェクトのナビゲーション APIの進行中のナビゲーション中に フォーカスが変更されたを false に設定する。
たとえば、要素に
属性が追加され、その要素がレンダリングされなくなった場合に起こり得る。
また、input
要素が無効化された場合にも起こり得る。
これは通常、blur イベントを発火し、
場合によっては change
イベントも発火する。
この非同期的な修正に加えて、文書のフォーカス領域が
削除された場合には、同期的な修正が行われる。
その修正では、blur または change
イベントは発火されない。
docs の各 docについて、doc の保留中の遷移操作を実行する。 [CSSVIEWTRANSITIONS]
docs の各 docについて、now および doc の関連するグローバルオブジェクトが 与えられたときの相対高分解能 時刻をタイムスタンプとして渡し、doc の交差観測更新手順を実行する。 [INTERSECTIONOBSERVER]
docs の各 docについて、unsafeStyleAndLayoutStartTime が 与えられたとき、doc のレンダリング時間を記録する。
docs の各 docについて、doc のペイントタイミングを記録する。
docs の各 docについて、現在の状態を反映するように、 doc およびそのノード ナビゲーブルのレンダリングまたはユーザーインターフェイスを更新する。
docs の各 docについて、doc が与えられたとき、最上位レイヤーからの削除を処理する。
ナビゲーブルは、 ハードウェアのリフレッシュレート制約およびパフォーマンス上の理由によるユーザーエージェントの スロットリングを考慮しつつ、ビューポート外の内容も提示可能と見なし、ユーザーエージェントが現在 そのナビゲーブルの内容をユーザーに提示できる場合、 レンダリング機会を持つ。
ナビゲーブルのレンダリング機会は、
ディスプレイのリフレッシュレートなどのハードウェア制約、およびページのパフォーマンスや、
そのアクティブ文書の可視性状態が
"visible" であるかどうかなどの要因に基づいて決定される。
レンダリング機会は通常、一定の間隔で発生する。
この仕様は、レンダリング機会を選択するための特定のモデルを義務付けない。 ただし、たとえばブラウザーが60Hzのリフレッシュレートを達成しようとしている場合、 レンダリング機会は最大でも60分の1秒ごと(約16.7ミリ秒)に発生する。 ブラウザーが、あるナビゲーブルがこの頻度を維持できないと判断した場合、 ときどきフレームを落とすのではなく、そのナビゲーブルについて、 より持続可能な毎秒30回のレンダリング機会に下げる可能性がある。同様に、ナビゲーブルが表示されていない場合、 ユーザーエージェントは、そのページを毎秒4回、またはさらに少ないレンダリング機会まで 大幅に低下させることを決定する可能性がある。
ユーザーエージェントがマイクロタスクチェックポイントを実行する場合:
イベントループのマイクロタスクチェックポイント実行中が true の場合、返す。
イベントループのマイクロタスクチェックポイント実行中を true に設定する。
oldestMicrotask を、イベントループのマイクロタスクキューからデキューした結果とする。
イベントループの現在実行中の タスクを oldestMicrotask に設定する。
oldestMicrotask を実行する。
これにはスクリプト化されたコールバックの呼び出しが含まれる可能性があり、 最終的にスクリプト実行後のクリーンアップをする 手順が呼び出される。その手順は、このマイクロタスク チェックポイントを実行するアルゴリズムを再び呼び出す。そのため、再入を防ぐためにマイクロタスクチェックポイント 実行中フラグを使用する。
担当イベント ループがこのイベントループである各環境設定オブジェクト settingsObjectについて、settingsObject のグローバルオブジェクトが 与えられたとき、拒否された Promise について通知する。
ClearKeptObjects() を実行する。
WeakRef.prototype.deref()
がオブジェクトを返す場合、そのオブジェクトは次のClearKeptObjects() 呼び出しまで生存状態に保たれ、
その後は再びガベージコレクションの対象となる。
イベントループのマイクロタスクチェックポイント実行中を false に設定する。
並列に実行されているアルゴリズムが安定状態を待つ場合、ユーザーエージェントは、次の手順を実行するマイクロタスクをキューに追加し、 その後実行を停止しなければならない(アルゴリズムの実行は、次の手順で説明するように、 マイクロタスクが実行されたときに再開される):
アルゴリズムの同期セクションを実行する。
アルゴリズムの手順で説明されているとおり、適切な場合はアルゴリズムの実行を並列に再開する。
同期セクション内の手順には⌛が付けられる。
条件 goal が満たされるまでイベントループを回すと記されたアルゴリズム手順は、 次のアルゴリズム手順を代入することと等価である:
task を、イベント ループの現在実行中の タスクとする。
task はマイクロタスクである可能性がある。
task source を task のソースとする。
old stack をJavaScript 実行コンテキスト スタックのコピーとする。
JavaScript 実行コンテキストスタックを空にする。
task がマイクロタスクである場合、 マイクロタスクチェックポイント実行中が true であるため、この手順は何もしない。
並列に:
条件 goal が満たされるまで待つ。
task source 上に、次を実行するタスクをキューに追加する:
JavaScript 実行コンテキストスタックを old stack で置き換える。
元のアルゴリズムで、このイベントループを回す処理の後に 現れる手順を実行する。
これにより task が再開される。
task を停止し、それを呼び出したアルゴリズムが再開できるようにする。
これにより、イベント ループの主要な手順集合、またはマイクロタスクチェックポイントを実行する アルゴリズムが続行される。
プログラミング言語の関数呼び出しと同様に動作する、この仕様および他の仕様の その他のアルゴリズムとは異なり、イベントループを回すは、 一連の手順および操作に展開することで、使用箇所での記述量とインデントを減らすマクロに近い。
次の手順を持つアルゴリズム:
何かを行う。
素晴らしいことが起こるまでイベントループを回す。
別の何かを行う。
は、「マクロ展開」後に次のようになる省略表現である:
何かを行う。
old stack をJavaScript 実行コンテキスト スタックのコピーとする。
JavaScript 実行コンテキストスタックを空にする。
並列に:
素晴らしいことが起こるまで待つ。
「何かを行う」が実行されたタスクソース上に、次を実行するタスクをキューに追加する:
JavaScript 実行コンテキストスタックを old stack で置き換える。
別の何かを行う。
次は、並列処理からキューに追加されたタスク内でイベントループを回す、 より完全な代入例である。イベントループを回すを使用する版:
並列に:
並列処理1を行う。
DOM 操作タスクソース上に、次を実行するタスクをキューに追加する:
タスク処理1を行う。
素晴らしいことが起こるまでイベント ループを回す。
タスク処理2を行う。
並列処理2を行う。
完全に展開した版:
並列に:
並列処理1を行う。
old stack を null とする。
DOM 操作タスクソース上に、 次を実行するタスクをキューに追加する:
タスク処理1を行う。
old stack をJavaScript 実行コンテキスト スタックのコピーに設定する。
JavaScript 実行コンテキストスタックを空にする。
素晴らしいことが起こるまで待つ。
DOM 操作タスクソース上に、 次を実行するタスクをキューに追加する:
JavaScript 実行コンテキストスタックを old stack で置き換える。
タスク処理2を行う。
並列処理2を行う。
この仕様の一部のアルゴリズムは、歴史的な理由から、条件 goal が満たされるまで、 タスクの実行中にユーザーエージェントが一時停止することを要求する。これは、次の手順を実行することを意味する:
global を現在のグローバルオブジェクトとする。
timeBeforePause を、global が与えられたときの現在の高分解能時刻とする。
必要な場合、現在の状態を反映するように、任意の Document または
ナビゲーブルの
レンダリングまたはユーザーインターフェイスを更新する。
条件 goal が満たされるまで待つ。ユーザーエージェントがタスクを 一時停止している間、対応するイベントループはそれ以上のタスクを実行してはならず、 現在実行中のタスク内のすべてのスクリプトはブロックしなければならない。 ただし、一時停止中であっても、ユーザーエージェントはユーザー入力に対する応答性を維持するべきである。 ただし、イベントループが何も行わないため、 その能力は低下する。
timeBeforePause から、global が与えられたときの現在の高分解能時刻までの継続時間が与えられたとき、一時停止時間を記録する。
一時停止は、 特に単一のイベントループが複数の文書で共有される場合に、 ユーザー体験を著しく損なう。ユーザーエージェントには、既存の内容との互換性を維持しながら 可能な範囲で、一時停止の代替手段を試すことが推奨される。 たとえば、イベントループを回すことや、 実行を一切中断せずに単に処理を続行することなどである。 ウェブ互換性のある、より影響の小さい代替手段が見つかった場合、この仕様は喜んで変更される。
それまでの間、実装者は、ユーザーエージェントが試す可能性のあるさまざまな代替手段により、 タスクおよびマイクロタスクのタイミングを含む、 イベントループの動作の微妙な側面が 変化し得ることを認識するべきである。実装は、一時停止操作が暗示する厳密な意味論に違反することに なったとしても、実験を続けるべきである。
次のタスクソースは、この仕様および他の仕様にある、 ほとんど 関連のない多数の機能によって使用される。
このタスクソースは、要素が文書に挿入されたときに 非ブロッキング方式で発生する処理など、DOM 操作に反応する機能に使用される。
このタスクソースは、 キーボードまたはマウス入力など、ユーザー操作に反応する機能に使用される。
ユーザー入力に応じて送信されるイベント(たとえば、click
イベント)は、ユーザー操作タスクソースを使用してキューに追加されたタスクを使用して発火しなければならない。
[UIEVENTS]
このタスクソースは、 ネットワーク活動に応じて起動する機能に使用される。
このタスクソースは、レンダリングを更新するためだけに 使用される。
イベントループと正しく相互作用する仕様を 記述することは難しい場合がある。 この仕様では並行処理モデルに依存しない用語を使用するため、さらに複雑になる。つまり、 「メインスレッド」や「バックグラウンドスレッド上」のような、より馴染みのあるモデル固有の用語ではなく、 「イベントループ」や「並列に」のような表現を使用する。
既定では、仕様のテキストは通常、イベントループ上で実行される。これは形式的なイベントループ処理モデルから導かれるものであり、 ほとんどのアルゴリズムは、最終的にはそこでキューに追加されたタスクまでたどることができる。
任意の JavaScript メソッドのアルゴリズム手順は、作者コードがそのメソッドを
呼び出すことによって起動される。そして作者コードは、通常はscript 処理モデルのどこかに由来する、
キューに追加されたタスクを介してのみ実行できる。
この出発点からの最も重要な指針は、仕様が実行する必要のある処理のうち、そうでなければイベント ループをブロックするものは、代わりにイベントループと並列に実行しなければならないということである。 これには、次の処理が含まれるが、これらに限定されない:
負荷の高い計算を実行すること。
ユーザー向けのプロンプトを表示すること。
外部システムの関与を必要とする可能性のある操作 (すなわち「プロセス外へ出る」操作)を実行すること。
次に複雑なのは、並列に実行されるアルゴリズムの節では、 特定のレルム、グローバルオブジェクト、または環境設定オブジェクトに関連付けられた オブジェクトを作成または操作してはならないことである。(より馴染みのある表現にすると、 バックグラウンドスレッドからメインスレッドの生成物に直接アクセスしてはならない。) そのような処理を行うと、アルゴリズム手順は JavaScript コードと並列に実行されているため、 JavaScript コードから観測可能なデータ競合が発生する。
同様に、並列に実行される手順から、 Web IDL の this 値にアクセスすることはできない。 これは、その手順を起動したアルゴリズムが this 値にアクセスできる場合でも同様である。
ただし、Infra の仕様レベルのデータ構造および値は、 レルムに依存しないため操作できる。これらは、特定の変換 (多くの場合、Web IDL を介した変換)が行われることなく、 JavaScript に直接公開されることはない。 [INFRA] [WEBIDL]
したがって、観測可能な JavaScript オブジェクトの世界に影響を与えるには、そのような操作を実行するグローバルタスクをキューに追加する必要がある。 これにより、手順はイベントループ上で発生する他の処理に対して、 適切に交互配置される。さらに、グローバルタスクをキューに追加する際にはタスクソースを選択しなければならない。 これによって、他の手順に対する手順の相対的な順序が決まる。どのタスクソースを使用すべきか不明な場合は、 最も適切と思われる汎用タスク ソースの1つを選択する。最後に、キューに追加されるタスクがどのグローバル オブジェクトに関連付けられるかを示さなければならない。これにより、そのグローバルオブジェクトが 非アクティブである場合、タスクは実行されない。
グローバルタスクをキューに追加するが基礎とする 基本プリミティブは、タスクをキューに追加するアルゴリズムである。 一般に、グローバルタスクをキューに追加する方が適切である。 これは、正しいイベント ループと、必要に応じて文書を自動的に選択するためである。 古い仕様では、暗黙のイベントループおよび暗黙の文書という概念と組み合わせてタスクをキューに追加するを 使用することが多いが、これは推奨されない。
以上をまとめると、非同期に処理を行う必要のある典型的なアルゴリズムのテンプレートを 次のように示すことができる:
イベントループ上にいる間に、 同期的な設定処理をすべて行う。これには、レルム固有の JavaScript 値を、レルムに依存しない 仕様レベルの値へ変換する処理が含まれる場合がある。
負荷が高い可能性のある一連の手順を並列に実行し、 レルムに依存しない値だけを操作して、レルムに依存しない結果を生成する。
指定されたタスク ソース上に、適切なグローバルオブジェクトが与えられたとき、 レルムに依存しない結果を、イベントループ上の観測可能な JavaScript オブジェクトの世界における観測可能な効果へ変換するグローバルタスクをキューに追加する。
次は、渡されたリストであるスカラー値文字列 input を URL として構文解析した後、 それらを「暗号化」するアルゴリズムである:
urls を空のリストとする。
input の各 stringについて反復する:
parsed を、string および現在の設定オブジェクトが与えられたときにURL をエンコーディング構文解析した結果とする。
parsed が失敗である場合、"SyntaxError" DOMException
で拒否された Promiseを返す。
serialized を、parsed にURL シリアライザーを適用した結果とする。
serialized を urls に付加する。
realm を現在のレルムとする。
p を新しい Promise とする。
次の手順を並列に実行する:
encryptedURLs を空のリストとする。
urls の各 urlについて反復する:
realm のグローバルオブジェクトが与えられたとき、 ネットワーク処理タスクソース上に、 次の手順を実行するグローバル タスクをキューに追加する:
array を、realm 内で encryptedURLs を JavaScript 配列に変換した結果とする。
p を array で解決する。
p を返す。
このアルゴリズムについて、次の点に注意:
並列に実行する手順へ進む前に、イベントループ上で URL の構文解析を先に行っている。構文解析は現在の 設定オブジェクトに依存し、並列に実行した後では、 そのオブジェクトは現在のものではなくなるため、これは必要である。
別の方法として、現在の設定 オブジェクトのAPI ベース URLへの参照を保存し、 並列に実行する手順中に使用することもできる。 これは同等である。ただし、この例のように、できるだけ多くの処理を先に行うことを推奨する。 正しい値を保存しようとすると、誤りが発生しやすい。たとえば、API ベース URLではなく、現在の設定オブジェクトだけを 保存していた場合、競合が発生する可能性があった。
最初の手順から並列に実行する手順へ、文字列のリストを暗黙に渡している。 リストと文字列は、どちらもレルムに依存しないため、これは問題ない。
「高負荷な計算」(入力 URL ごとに100ミリ秒待つ処理)を並列に実行する手順中に行うことで、 メインのイベントループをブロックしない。
観測可能な JavaScript オブジェクトである Promise は、並列に実行する手順中には作成も操作もされない。 p はその手順に入る前に作成され、その後、この目的のために明示的にキューに追加されたタスク中に操作される。
JavaScript 配列オブジェクトの作成も、キューに追加されたタスク中で行われる。 文脈から明らかではなくなっているため、どのレルム内に配列を作成するかも明示されている。
(最後の2点については、上記の Promise 解決パターンの微妙な点が現在も検討されている whatwg/webidl issue #135 および whatwg/webidl issue #371 も参照。)
もう1つ注意すべき点として、このアルゴリズムが sequence<USVString>
を取る Web IDL で規定された操作から呼び出された場合、作者が入力として提供したレルム固有の JavaScript オブジェクトから、
レルムに依存しない sequence<USVString>
Web IDL 型への自動変換が行われていた。これはその後、スカラー値文字列のリストとして扱われる。
したがって、仕様の構成によっては、並列に実行する準備を整える一連の処理全体において、
メインのイベントループ上で、
他の暗黙の手順も役割を果たしている可能性がある。
多くのオブジェクトには、イベントハンドラーを指定できる。これらは、指定されたオブジェクトに対する 非キャプチャのイベントリスナーとして機能する。 [DOM]
値。
null、コールバックオブジェクト、または内部の未加工な未コンパイルハンドラーの
いずれかである。EventHandler
コールバック関数型は、これがスクリプトにどのように公開されるかを説明する。初期状態では、イベントハンドラーの値を
null に設定しなければならない。
リスナー。 null、またはイベントハンドラー処理アルゴリズムを 実行する役割を担うイベントリスナーのいずれかである。初期状態では、イベントハンドラーのリスナーを null に設定しなければならない。
イベントハンドラーは、2つの方法で公開される。
1つ目の方法は、すべてのイベントハンドラーに共通する、イベントハンドラー IDL 属性としての公開である。
2つ目の方法は、イベントハンドラー内容
属性としての公開である。HTML 要素上のイベントハンドラー、および
Window オブジェクト上の
一部のイベントハンドラーは、この方法で公開される。
これら2つの方法のどちらでも、イベント
ハンドラーは名前を通して公開される。
この名前は、常に "on" で始まり、その後にハンドラーの対象となるイベントの名前が続く文字列である。
ほとんどの場合、イベントハンドラーを公開するオブジェクトは、
対応するイベントリスナーが追加されるオブジェクトと同じである。
ただし、body および
frameset 要素は、
存在する場合、その要素の Window オブジェクトに作用する複数のイベント
ハンドラーを公開する。どちらの場合も、イベント
ハンドラーが作用するオブジェクトを、そのイベントハンドラーのターゲットと呼ぶ。
イベントハンドラーが公開される EventTarget
オブジェクト eventTarget およびイベントハンドラー名
name が与えられたとき、イベントハンドラーのターゲットを決定するには、
次の手順を実行する:
name が WindowEventHandlers
インターフェイスミックスインの属性メンバーの名前でなく、かつWindow を反映する
body 要素イベントハンドラー集合に name が含まれない場合、eventTarget を返す。
eventTarget のノード文書がアクティブ 文書でない場合、null を返す。
これは、たとえば、このオブジェクトが対応する Window オブジェクトを持たない
body
要素である場合に起こり得る。
この確認は、ノード
文書のbody 要素ではない
body および
frameset 要素が
次の手順に進むことを必ずしも防がない。特に、アクティブ文書内で作成された
(たとえば document.createElement()
によって作成された)が接続されていない body 要素も、
それを通して公開される複数のイベントハンドラーのターゲットとして、
対応する Window
オブジェクトを持つ。
eventTarget のノード 文書の関連するグローバル オブジェクトを返す。
1つ以上のイベント
ハンドラーが指定された各 EventTarget
オブジェクトには、関連付けられたイベントハンドラーマップがある。これは、イベントハンドラーの名前を表す文字列からイベントハンドラーへのマップである。
1つ以上のイベント
ハンドラーが指定された EventTarget
オブジェクトが作成されたとき、そのイベント
ハンドラーマップは、そのオブジェクトをターゲットとする各イベント
ハンドラーについてエントリーを含むように
初期化しなければならない。また、それらのイベントハンドラーの項目を初期値に設定する。
イベントハンドラー マップのエントリーの順序は任意でよい。 マップを操作するどのアルゴリズムからも観測できない。
あるオブジェクト上で単に公開されているだけで、他のオブジェクトをターゲットとするイベント ハンドラーについては、そのオブジェクトのイベントハンドラー マップにエントリーは作成されない。
イベントハンドラー IDL 属性は、 特定のイベント ハンドラーのための IDL 属性である。IDL 属性の名前は、イベントハンドラーの名前と同じである。
名前が name であるイベントハンドラー IDL 属性の 取得子は、呼び出されたとき、次の手順を実行しなければならない:
eventTarget を、このオブジェクトおよび name が与えられたときにイベントハンドラーの ターゲットを決定した結果とする。
eventTarget が null の場合、null を返す。
eventTarget および name が与えられたときにイベントハンドラーの現在の値を 取得した結果を返す。
名前が name であるイベントハンドラー IDL 属性の 設定子は、呼び出されたとき、次の手順を実行しなければならない:
eventTarget を、このオブジェクトおよび name が与えられたときにイベント ハンドラーのターゲットを決定した結果とする。
eventTarget が null の場合、返す。
与えられた値が null の場合、eventTarget および name が与えられたとき、イベントハンドラーを非アクティブ化する。
それ以外の場合:
handlerMap を eventTarget のイベントハンドラー マップとする。
eventHandler を handlerMap[name] とする。
eventHandler の値を 与えられた値に設定する。
eventTarget および name が与えられたとき、イベントハンドラーをアクティブ化する。
一部のイベントハンドラー IDL 属性には、
追加の要件がある。特に、MessagePort オブジェクトの
onmessage
属性が該当する。
イベントハンドラー内容属性は、 特定のイベントハンドラーのための内容属性である。 内容属性の名前は、イベントハンドラーの名前と同じである。
イベントハンドラー内容属性は、 指定される場合、有効な JavaScript コードを含まなければならない。そのコードは構文解析されたとき、自動セミコロン挿入後に FunctionBody 生成規則と一致するものでなければならない。
次の属性変更 手順は、イベントハンドラー内容属性とイベントハンドラーを同期するために 使用される:[DOM]
namespace が null でない場合、または localName が element 上のイベントハンドラー内容属性の 名前でない場合、返す。
eventTarget を、element および localName が与えられたときにイベント ハンドラーのターゲットを決定した結果とする。
eventTarget が null の場合、返す。
value が null の場合、eventTarget および localName が与えられたとき、 イベントハンドラーを非アクティブ化する。
それ以外の場合:
element、"script attribute"、および value について実行されたとき、
要素の
インライン動作をコンテンツセキュリティポリシーによってブロックするべきか?
アルゴリズムが "Blocked" を返す場合、返す。
[CSP]
handlerMap を eventTarget のイベントハンドラー マップとする。
eventHandler を handlerMap[localName] とする。
location を、これらの手順の実行を起動したスクリプトの位置とする。
eventHandler の値を、内部の未加工な未コンパイルハンドラー value/location に設定する。
eventTarget および localName が与えられたとき、イベントハンドラーを アクティブ化する。
DOM 標準に従い、これらの手順は oldValue と value が同一である場合(属性を現在の値に設定する場合)にも実行されるが、 oldValue と value が両方とも null の場合 (現在存在しない属性を削除する場合)には実行されない。 [DOM]
EventTarget
オブジェクト eventTarget およびイベントハンドラーの名前である文字列
name が与えられたとき、イベントハンドラーを非アクティブ化するには、
次の手順を実行する:
handlerMap を eventTarget のイベントハンドラー マップとする。
eventHandler を handlerMap[name] とする。
eventHandler の値を null に設定する。
listener を eventHandler のリスナーとする。
listener が null でない場合、eventTarget および listener を使用してイベントリスナーを削除する。
eventHandler のリスナーを null に設定する。
EventTarget
オブジェクト eventTarget が与えられたとき、すべてのイベントリスナーおよびハンドラーを消去するには、
次の手順を実行する:
eventTarget に関連付けられたイベントハンドラーマップがある場合、 eventTarget に関連付けられたイベント ハンドラーマップの各 name → eventHandlerについて、 eventTarget および name が与えられたとき、イベントハンドラーを非アクティブ化する。
eventTarget が与えられたとき、すべてのイベントリスナーを削除する。
このアルゴリズムは、document.open()を
定義するために使用される。
EventTarget
オブジェクト eventTarget およびイベントハンドラーの名前である文字列
name が与えられたとき、イベントハンドラーをアクティブ化するには、
次の手順を実行する:
handlerMap を eventTarget のイベントハンドラー マップとする。
eventHandler を handlerMap[name] とする。
eventHandler のリスナーが null でない場合、返す。
callback を、eventTarget、name、およびその引数が与えられたときにイベントハンドラー処理
アルゴリズムの手順を実行する1引数の関数への参照を表す Web IDL EventListener
インスタンスを作成した結果とする。
EventListenerのコールバックコンテキストは任意でよい。
イベントハンドラー処理
アルゴリズムの手順には影響しない。[DOM]
コールバックは、イベントハンドラー自体では決してない。 すべてのイベントハンドラーは、最終的に同じコールバック、すなわち以下で定義するアルゴリズムを登録する。 このアルゴリズムは、適切なコードの呼び出しと、そのコードの戻り値の処理を担当する。
listener を、新しいイベント リスナーとする。その型は eventHandler に対応するイベントハンドラーイベント型であり、コールバックは callback である。
明確にすると、イベント
リスナーは、EventListenerとは異なる。
eventTarget および listener を使用してイベントリスナーを追加する。
eventHandler のリスナーを listener に設定する。
イベントリスナーの登録は、イベント ハンドラーの値が null でない値に設定されようとしており、 かつイベントハンドラーがまだ アクティブ化されていない場合にのみ行われる。リスナーは登録された順序で呼び出されるため、非アクティブ化が行われなかったと仮定すると、 特定のイベント型のイベントリスナーの順序は常に次のようになる:
イベントハンドラーの値が初めて null でない値に設定される前に、
addEventListener()
を使用して登録されたイベントリスナー
次に、現在設定されているコールバック(存在する場合)
最後に、イベントハンドラーの値が初めて null
でない値に設定された後に、
addEventListener()
を使用して登録されたイベントリスナー。
この例は、イベントリスナーが呼び出される順序を示す。この例のボタンをユーザーがクリックすると、 ページにはそれぞれ「ONE」、「TWO」、「THREE」、「FOUR」というテキストを持つ4つのアラートが表示される。
< button id = "test" > Start Demo</ button >
< script >
var button = document. getElementById( 'test' );
button. addEventListener( 'click' , function () { alert( 'ONE' ) }, false );
button. setAttribute( 'onclick' , "alert('NOT CALLED')" ); // event handler listener is registered here
button. addEventListener( 'click' , function () { alert( 'THREE' ) }, false );
button. onclick = function () { alert( 'TWO' ); };
button. addEventListener( 'click' , function () { alert( 'FOUR' ) }, false );
</ script > ただし、次の例では、イベントハンドラーは最初にアクティブ化された後、 後の時点で再びアクティブ化される前に非アクティブ化される (そのイベントリスナーも削除される)。ページには、「ONE」、「TWO」、「THREE」、「FOUR」、「FIVE」という 5つのアラートが、この順序で表示される。
< button id = "test" > Start Demo</ button >
< script >
var button = document. getElementById( 'test' );
button. addEventListener( 'click' , function () { alert( 'ONE' ) }, false );
button. setAttribute( 'onclick' , "alert('NOT CALLED')" ); // event handler is activated here
button. addEventListener( 'click' , function () { alert( 'TWO' ) }, false );
button. onclick = null ; // but deactivated here
button. addEventListener( 'click' , function () { alert( 'THREE' ) }, false );
button. onclick = function () { alert( 'FOUR' ); }; // and re-activated here
button. addEventListener( 'click' , function () { alert( 'FIVE' ) }, false );
</ script > イベントオブジェクトが実装するインターフェイスは、イベントハンドラーが起動されるかどうかに影響しない。
EventTarget
オブジェクト eventTarget、イベントハンドラーの名前を表す文字列
name、および Event
オブジェクト event に対するイベントハンドラー処理アルゴリズムは、次のとおりである:
eventTarget についてスクリプト処理が無効である場合、返す。
callback を、eventTarget および name が与えられたときにイベント ハンドラーの現在の値を取得した結果とする。
callback が null の場合、返す。
event が ErrorEvent
オブジェクトであり、
event の type
が "error" であり、
event の currentTarget
が WindowOrWorkerGlobalScope
ミックスインを実装する場合、special error event handling を true とする。
それ以外の場合、special error event handling を false とする。
Event
オブジェクト event を次のように処理する:
return value を、«
event の message、
event の
filename、
event の lineno、
event の colno、
event の error »、
"rethrow" を使用し、コールバック this 値を
event の currentTarget
に設定して、callback を呼び出した結果とする。
return value を、« event »、"rethrow" を使用し、
コールバック this 値を
event の currentTarget
に設定して、callback を呼び出した結果とする。
コールバックによって例外がスローされた場合、その例外は再スローされ、 これらの手順は終了する。例外はDOM イベントディスパッチロジックへ伝播し、 そこで報告される。
return value を次のように処理する:
BeforeUnloadEvent
オブジェクトであり、event の type
が "beforeunload"
である場合
この場合、イベントハンドラー
IDL 属性の型は OnBeforeUnloadEventHandler
となるため、return value は null または DOMString
のいずれかに型強制されている。
return value が null でない場合:
event のキャンセル済みフラグを設定する。
event の returnValue
属性の値が空文字列である場合、event の returnValue
属性の値を return value に設定する。
return value が true の場合、event のキャンセル済み フラグを設定する。
return value が false の場合、event のキャンセル済み フラグを設定する。
event の type
が "beforeunload"
であるが、event が BeforeUnloadEvent
オブジェクトではないために、この「それ以外の場合」の節に到達した場合、
return value は決して false にならない。このような場合、
return value は null または DOMString
のいずれかに型強制されているためである。
EventHandler
コールバック関数型は、イベントハンドラーに使用されるコールバックを表す。
Web IDL では次のように表される:
[LegacyTreatNonObjectAsNull ]
callback EventHandlerNonNull = any (Event event );
typedef EventHandlerNonNull ? EventHandler ;JavaScript では、すべての Function
オブジェクトがこのインターフェイスを実装する。
たとえば、次の文書フラグメント:
< body onload = "alert(this)" onclick = "alert(this)" > …では、文書が読み込まれたときに "[object Window]" と表示するアラートが発生し、
ユーザーがページ内の何かをクリックするたびに
"[object HTMLBodyElement]" と表示するアラートが発生する。
関数の戻り値は、イベントがキャンセルされるかどうかに影響する。上で説明したとおり、 戻り値が false の場合、イベントはキャンセルされる。
歴史的な理由により、プラットフォームには2つの例外がある:
グローバルオブジェクト上の onerror
ハンドラーでは、true を返すとイベントがキャンセルされる。
onbeforeunload
ハンドラーでは、null でも undefined でもない任意の値を返すとイベントがキャンセルされる。
歴史的な理由により、onerror
ハンドラーは、
異なる引数を持つ:
[LegacyTreatNonObjectAsNull ]
callback OnErrorEventHandlerNonNull = any ((Event or DOMString ) event , optional DOMString source , optional unsigned long lineno , optional unsigned long colno , optional any error );
typedef OnErrorEventHandlerNonNull ? OnErrorEventHandler ;window. onerror = ( message, source, lineno, colno, error) => { … }; 同様に、onbeforeunload
ハンドラーは、異なる戻り値を持つ:
[LegacyTreatNonObjectAsNull ]
callback OnBeforeUnloadEventHandlerNonNull = DOMString ? (Event event );
typedef OnBeforeUnloadEventHandlerNonNull ? OnBeforeUnloadEventHandler ;内部の未加工な未コンパイルハンドラーは、 次の情報を持つタプルである:
未コンパイルのスクリプト本体
エラーを報告する必要がある場合に使用する、スクリプト本体の生成元の位置
EventTarget
オブジェクト eventTarget およびイベントハンドラーの名前である文字列
name が与えられたとき、ユーザーエージェントがイベントハンドラーの現在の値を取得する場合、
次の手順を実行しなければならない:
handlerMap を eventTarget のイベントハンドラー マップとする。
eventHandler を handlerMap[name] とする。
eventHandler の値が内部の未加工な未コンパイルハンドラーである場合:
eventTarget が要素である場合、element を
eventTarget とし、document を element のノード
文書とする。それ以外の場合、eventTarget は Window オブジェクトであり、
element を null とし、document を eventTarget の関連付けられた
Documentとする。
document のアクティブなサンドボックス化フラグ集合に サンドボックス化されたスクリプト 閲覧コンテキストフラグが設定されている場合、null を返す。
body を eventHandler の値にある未コンパイルのスクリプト本体とする。
location を、eventHandler の値によって与えられる、 スクリプト本体が生成された位置とする。
element が null でなく、element がフォーム所有者を持つ場合、 form owner をそのフォーム所有者とする。 それ以外の場合、form owner を null とする。
settings object を document の関連する設定オブジェクトとする。
body を FunctionBody として構文解析できない場合、または構文解析によって早期エラーが検出された場合、次の下位手順を実行する:
eventHandler の値を null に設定する。
これはイベントハンドラーを非アクティブ化しない。 非アクティブ化では、イベントハンドラーのリスナーも (存在する場合)削除される。
syntaxError を、構文解析中のエラーを説明する、
settings object のレルムに関連付けられた
新しい SyntaxError
例外とする。これは、スクリプト本体が生成された location に基づくべきである。
settings object のグローバル オブジェクトについて、syntaxError による例外を報告する。
null を返す。
settings object のレルム実行コンテキストをJavaScript 実行コンテキストスタックに プッシュする。これが現在の実行中の JavaScript 実行コンテキストとなる。
これは、後続のOrdinaryFunctionCreate の呼び出しが正しいレルム内で行われるために必要である。
function を、次の引数を使用してOrdinaryFunctionCreate を呼び出した結果とする:
realm を settings object のレルムとする。
scope を realm.[[GlobalEnv]] とする。
eventHandler が要素のイベント ハンドラーである場合、scope をNewObjectEnvironment(document, true, scope) に設定する。
form owner が null でない場合、scope をNewObjectEnvironment(form owner, true, scope) に設定する。
element が null でない場合、scope をNewObjectEnvironment(element, true, scope) に設定する。
scope を返す。
settings object のレルム実行コンテキストをJavaScript 実行コンテキストスタックから削除する。
function.[[ScriptOrModule]] を null に設定する。
これは、作成された関数をスタック上の最も近いスクリプトに関連付けるという既定の動作が、 経路に依存する結果を引き起こす可能性があるために行われる。たとえば、 ユーザー操作によって最初に呼び出されたイベントハンドラーは、最終的に null の [[ScriptOrModule]] を持つことになる(その場合、このアルゴリズムが最初に呼び出されたとき、 アクティブ スクリプトが null であるため)。一方、スクリプトからイベントをディスパッチすることによって 最初に呼び出されたイベントハンドラーは、[[ScriptOrModule]] がそのスクリプトに設定される。
代わりに、[[ScriptOrModule]] は常に null に設定される。この方が直感的でもある。 イベントを最初にディスパッチしたスクリプトが、何らかの形でイベントハンドラーコードに責任を持つという考えは 疑わしい。
実際には、これは import()
を介した相対 URL の解決だけに影響する。これは関連付けられたスクリプトのベース URLを参照する。
[[ScriptOrModule]] を null にすることで、HostLoadImportedModule は、
現在の設定オブジェクトのAPI ベース URLに
フォールバックする。
eventHandler の値を、オブジェクト参照が
function であり、コールバックコンテキストが
settings object である Web IDL EventHandler
コールバック関数オブジェクトを作成した結果に設定する。
eventHandler の値を返す。
Document
オブジェクト、および Window
オブジェクトのイベントハンドラー
次に示すのは、すべてのHTML 要素が、イベント
ハンドラー内容属性およびイベントハンドラー
IDL 属性の両方としてサポートしなければならず、また、すべての Document
および Window
オブジェクトが、イベントハンドラー
IDL
属性としてサポートしなければならないイベントハンドラー
(および対応するイベントハンドラー
イベント型)である:
| イベントハンドラー | イベント ハンドラーイベント型 |
|---|---|
onabort
現在のすべてのエンジンでサポートされている。 Firefox9+Safari3.1+Chrome3+
Opera12.1+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ |
abort
|
onauxclick
Firefox53+SafariいいえChrome55+
Opera?Edge79+ Edge (Legacy)?Internet Explorerいいえ Firefox Android53+Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
auxclick
|
onbeforeinput |
beforeinput
|
onbeforematch |
beforematch
|
onbeforetoggle |
beforetoggle
|
oncancel
HTMLDialogElement/cancel_event 現在のすべてのエンジンでサポートされている。 Firefox98+Safari15.4+Chrome37+
Opera?Edge79+ Edge (Legacy)?Internet Explorerいいえ Firefox Android?Safari iOS?Chrome AndroidいいえWebView Android?Samsung Internet?Opera Android? |
cancel
|
oncanplay
HTMLMediaElement/canplay_event 現在のすべてのエンジンでサポートされている。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
canplay
|
oncanplaythrough
HTMLMediaElement/canplaythrough_event 現在のすべてのエンジンでサポートされている。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
canplaythrough
|
onchange
現在のすべてのエンジンでサポートされている。 Firefox1+Safari3+Chrome1+
Opera9+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android10.1+ |
change
|
onclick
現在のすべてのエンジンでサポートされている。 Firefox6+Safari3+Chrome1+
Opera11.6+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android6+Safari iOS1+Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ |
click
|
onclose |
close
|
oncommand |
command
|
oncontextlost |
contextlost
|
oncontextmenu |
contextmenu
|
oncontextrestored |
contextrestored
|
oncopy
現在のすべてのエンジンでサポートされている。 Firefox22+Safari3+Chrome1+
Opera12.1+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ |
copy
|
oncuechange
HTMLTrackElement/cuechange_event 現在のすべてのエンジンでサポートされている。 Firefox68+Safari10+Chrome32+
Opera19+Edge79+ Edge (Legacy)14+Internet Explorerいいえ Firefox Android?Safari iOS?Chrome Android?WebView Android4.4.3+Samsung Internet?Opera Android19+ |
cuechange
|
oncut
現在のすべてのエンジンでサポートされている。 Firefox22+Safari3+Chrome1+
Opera12.1+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ |
cut
|
ondblclick
現在のすべてのエンジンでサポートされている。 Firefox6+Safari3+Chrome1+
Opera11.6+Edge79+ Edge (Legacy)12+Internet Explorer8+ Firefox Android6+Safari iOS1+Chrome AndroidいいえWebView Android?Samsung Internet?Opera Android12.1+ |
dblclick
|
ondrag |
drag
|
ondragend |
dragend
|
ondragenter |
dragenter
|
ondragleave |
dragleave
|
ondragover |
dragover
|
ondragstart |
dragstart
|
ondrop |
drop
|
ondurationchange
HTMLMediaElement/durationchange_event 現在のすべてのエンジンでサポートされている。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
durationchange
|
onemptied
HTMLMediaElement/emptied_event 現在のすべてのエンジンでサポートされている。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
emptied
|
onended
現在のすべてのエンジンでサポートされている。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
ended
|
onformdata |
formdata
|
oninput
現在のすべてのエンジンでサポートされている。 Firefox6+Safari3.1+Chrome1+
Opera11.6+Edge79+ Edge (Legacy)いいえInternet Explorer🔰 9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android12+ |
input
|
oninvalid |
invalid
|
onkeydown
現在のすべてのエンジンでサポートされている。 Firefox6+Safari1.2+Chrome1+
Opera12.1+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ |
keydown
|
onkeypress |
keypress
|
onkeyup
現在のすべてのエンジンでサポートされている。 Firefox6+Safari1.2+Chrome1+
Opera12.1+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ |
keyup
|
onloadeddata
HTMLMediaElement/loadeddata_event 現在のすべてのエンジンでサポートされている。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
loadeddata
|
onloadedmetadata
HTMLMediaElement/loadedmetadata_event 現在のすべてのエンジンでサポートされている。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
loadedmetadata
|
onloadstart
HTMLMediaElement/loadstart_event 現在のすべてのエンジンでサポートされている。 Firefox6+Safari4+Chrome3+
Opera12.1+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ |
loadstart
|
onmousedown
現在のすべてのエンジンでサポートされている。 Firefox6+Safari4+Chrome2+
Opera11.6+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android37+Samsung Internet?Opera Android12.1+ |
mousedown
|
onmouseenter
現在のすべてのエンジンでサポートされている。 Firefox10+Safari7+Chrome30+
Opera?Edge79+ Edge (Legacy)12+Internet Explorer5.5+ Firefox Android?Safari iOS?Chrome Android?WebView Android37+Samsung Internet?Opera Android? |
mouseenter
|
onmouseleave
現在のすべてのエンジンでサポートされている。 Firefox10+Safari7+Chrome30+
Opera?Edge79+ Edge (Legacy)12+Internet Explorer5.5+ Firefox Android?Safari iOS?Chrome Android?WebView Android37+Samsung Internet?Opera Android? |
mouseleave
|
onmousemove
現在のすべてのエンジンでサポートされている。 Firefox6+Safari4+Chrome2+
Opera11.6+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android37+Samsung Internet?Opera Android12.1+ |
mousemove
|
onmouseout
現在のすべてのエンジンでサポートされている。 Firefox6+Safari1+Chrome1+
Opera12.1+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android37+Samsung Internet?Opera Android12.1+ |
mouseout
|
onmouseover
現在のすべてのエンジンでサポートされている。 Firefox6+Safari4+Chrome2+
Opera9.5+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android37+Samsung Internet?Opera Android10.1+ |
mouseover
|
onmouseup
現在のすべてのエンジンでサポートされている。 Firefox6+Safari4+Chrome2+
Opera11.6+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android37+Samsung Internet?Opera Android12.1+ |
mouseup
|
onpaste
現在のすべてのエンジンでサポートされている。 Firefox22+Safari3+Chrome1+
Opera12.1+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android12.1+ |
paste
|
onpause
現在のすべてのエンジンでサポートされている。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
pause
|
onplay
現在のすべてのエンジンでサポートされている。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
play
|
onplaying
HTMLMediaElement/playing_event 現在のすべてのエンジンでサポートされている。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
playing
|
onprogress
HTMLMediaElement/progress_event 現在のすべてのエンジンでサポートされている。 Firefox6+Safari3.1+Chrome3+
Opera12.1+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ |
progress
|
onratechange
HTMLMediaElement/ratechange_event 現在のすべてのエンジンでサポートされている。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
ratechange
|
onreset |
reset
|
onscrollend
Firefox109+SafariいいえChrome114+
Opera?Edge114+ Edge (Legacy)?Internet Explorerいいえ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? Firefox109+SafariいいえChrome114+
Opera?Edge114+ Edge (Legacy)?Internet Explorerいいえ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
scrollend
|
onsecuritypolicyviolation
Element/securitypolicyviolation_event 現在のすべてのエンジンでサポートされている。 Firefox63+Safari10+Chrome41+
Opera?Edge79+ Edge (Legacy)15+Internet Explorerいいえ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
securitypolicyviolation
|
onseeked
現在のすべてのエンジンでサポートされている。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
seeked
|
onseeking
HTMLMediaElement/seeking_event 現在のすべてのエンジンでサポートされている。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
seeking
|
onselect
現在のすべてのエンジンでサポートされている。 Firefox6+Safari1+Chrome1+
Opera12.1+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ HTMLTextAreaElement/select_event 現在のすべてのエンジンでサポートされている。 Firefox6+Safari1+Chrome1+
Opera12.1+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ |
select
|
onslotchange
HTMLSlotElement/slotchange_event 現在のすべてのエンジンでサポートされている。 Firefox63+Safari10.1+Chrome53+
Opera?Edge79+ Edge (Legacy)?Internet Explorerいいえ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
slotchange
|
onstalled
HTMLMediaElement/stalled_event 現在のすべてのエンジンでサポートされている。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
stalled
|
onsubmit
現在のすべてのエンジンでサポートされている。 Firefox1+Safari3+Chrome1+
Opera8+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS1+Chrome Android?WebView Android?Samsung Internet?Opera Android10.1+ |
submit
|
onsuspend
HTMLMediaElement/suspend_event 現在のすべてのエンジンでサポートされている。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
suspend
|
ontimeupdate
HTMLMediaElement/timeupdate_event 現在のすべてのエンジンでサポートされている。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
timeupdate
|
ontoggle |
toggle
|
onvolumechange
HTMLMediaElement/volumechange_event 現在のすべてのエンジンでサポートされている。 Firefox6+Safari3.1+Chrome3+
Opera12.1+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android12.1+ |
volumechange
|
onwaiting
HTMLMediaElement/waiting_event 現在のすべてのエンジンでサポートされている。 Firefox6+Safari3.1+Chrome3+
Opera12.1+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android12.1+ |
waiting
|
onwebkitanimationend |
webkitAnimationEnd
|
onwebkitanimationiteration |
webkitAnimationIteration
|
onwebkitanimationstart |
webkitAnimationStart
|
onwebkittransitionend |
webkitTransitionEnd
|
onwheel
現在のすべてのエンジンでサポートされている。 Firefox17+Safari7+Chrome31+
Opera?Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOSいいえChrome Android?WebView Android?Samsung Internet?Opera Android? |
wheel
|
次に示すのは、body
および frameset
要素を除くすべてのHTML 要素が、イベント
ハンドラー内容属性およびイベントハンドラー
IDL
属性の両方としてサポートしなければならず、すべての Document
オブジェクトが、イベントハンドラー
IDL 属性としてサポートしなければならず、さらにすべての Window
オブジェクトが、Window
オブジェクト自体のイベントハンドラー
IDL 属性としてサポートしなければならないイベントハンドラー
(および対応するイベントハンドラー
イベント型)である。また、対応するイベント
ハンドラー内容
属性およびイベントハンドラー
IDL 属性は、その Window
オブジェクトの関連付けられた
Documentによって所有される、すべての body
および frameset
要素上にも公開されなければならない:
| イベントハンドラー | イベント ハンドラーイベント型 |
|---|---|
onblur
現在のすべてのエンジンでサポートされている。 Firefox24+Safari3.1+Chrome1+
Opera11.6+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ 現在のすべてのエンジンでサポートされている。 Firefox6+Safari5.1+Chrome5+
Opera12.1+Edge79+ Edge (Legacy)12+Internet Explorer11 Firefox Android?Safari iOS?Chrome Android?WebView Android37+Samsung Internet?Opera Android12.1+ |
blur
|
onerror
現在のすべてのエンジンでサポートされている。 Firefox6+Safari5.1+Chrome10+
Opera?Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android37+Samsung Internet?Opera Android? |
error
|
onfocus
現在のすべてのエンジンでサポートされている。 Firefox24+Safari3.1+Chrome1+
Opera11.6+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ 現在のすべてのエンジンでサポートされている。 Firefox6+Safari5.1+Chrome5+
Opera12.1+Edge79+ Edge (Legacy)12+Internet Explorer11 Firefox Android?Safari iOS?Chrome Android?WebView Android37+Samsung Internet?Opera Android12.1+ |
focus
|
onload |
load
|
onresize |
resize
|
onscroll
現在のすべてのエンジンでサポートされている。 Firefox6+Safari2+Chrome1+
Opera11.6+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android12+ 現在のすべてのエンジンでサポートされている。 Firefox6+Safari1.3+Chrome1+
Opera12.1+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ |
scroll
|
次に示すのは、Window
オブジェクトが、Window
オブジェクト自体のイベントハンドラー
IDL 属性としてサポートしなければならないイベントハンドラー
(および対応するイベントハンドラー
イベント型)である。また、対応するイベント
ハンドラー内容
属性およびイベントハンドラー
IDL 属性は、その Window
オブジェクトの関連付けられた
Documentによって所有される、すべての body
および frameset
要素上にも公開されなければならない:
| イベントハンドラー | イベント ハンドラーイベント型 |
|---|---|
onafterprint
現在のすべてのエンジンでサポートされている。 Firefox6+Safari13+Chrome63+
Opera?Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
afterprint
|
onbeforeprint
現在のすべてのエンジンでサポートされている。 Firefox6+Safari13+Chrome63+
Opera?Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
beforeprint
|
onbeforeunload
現在のすべてのエンジンでサポートされている。 Firefox1+Safari3+Chrome1+
Opera12+Edge79+ Edge (Legacy)12+Internet Explorer4+ Firefox Android?Safari iOS1+Chrome Android?WebView Android?Samsung Internet?Opera Android12+ |
beforeunload
|
onhashchange
現在のすべてのエンジンでサポートされている。 Firefox3.6+Safari5+Chrome8+
Opera10.6+Edge79+ Edge (Legacy)12+Internet Explorer8+ Firefox Android?Safari iOS5+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
hashchange
|
onlanguagechange
現在のすべてのエンジンでサポートされている。 Firefox32+Safari10.1+Chrome37+
Opera?Edge79+ Edge (Legacy)?Internet Explorerいいえ Firefox Android4+Safari iOS?Chrome Android?WebView Android?Samsung Internet4.0+Opera Android? |
languagechange
|
onmessage
現在のすべてのエンジンでサポートされている。 Firefox9+Safari4+Chrome60+
Opera?Edge79+ Edge (Legacy)12+Internet Explorer8+ Firefox Android?Safari iOS4+Chrome Android?WebView Android?Samsung Internet?Opera Android47+ |
message
|
onmessageerror
現在のすべてのエンジンでサポートされている。 Firefox6+Safari3.1+Chrome3+
Opera11.6+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android?Samsung Internet?Opera Android12+ 現在のすべてのエンジンでサポートされている。 Firefox57+Safari16.4+Chrome60+
Opera?Edge79+ Edge (Legacy)18Internet Explorerいいえ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android47+ |
messageerror
|
onoffline
現在のすべてのエンジンでサポートされている。 Firefox9+Safari4+Chrome3+
Opera?Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android? |
offline
|
ononline
現在のすべてのエンジンでサポートされている。 Firefox9+Safari4+Chrome3+
Opera?Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android? |
online
|
onpageswap |
pageswap
|
onpagehide |
pagehide
|
onpagereveal |
pagereveal
|
onpageshow |
pageshow
|
onpopstate
現在のすべてのエンジンでサポートされている。 Firefox4+Safari5+Chrome5+
Opera11.5+Edge79+ Edge (Legacy)12+Internet Explorer10+ Firefox Android?Safari iOS?Chrome Android?WebView Android37+Samsung Internet?Opera Android11.5+ |
popstate
|
onrejectionhandled
現在のすべてのエンジンでサポートされている。 Firefox69+Safari11+Chrome49+
Opera?Edge79+ Edge (Legacy)?Internet Explorerいいえ Firefox Android?Safari iOS11.3+Chrome Android?WebView Android?Samsung Internet?Opera Android? |
rejectionhandled
|
onstorage
現在のすべてのエンジンでサポートされている。 Firefox45+Safari4+Chrome1+
Opera?Edge79+ Edge (Legacy)15+Internet Explorer9+ Firefox Android?Safari iOS4+Chrome Android?WebView Android37+Samsung Internet?Opera Android? |
storage
|
onunhandledrejection
Window/unhandledrejection_event 現在のすべてのエンジンでサポートされている。 Firefox69+Safari11+Chrome49+
Opera?Edge79+ Edge (Legacy)?Internet Explorerいいえ Firefox Android?Safari iOS11.3+Chrome Android?WebView Android?Samsung Internet?Opera Android? |
unhandledrejection
|
onunload
現在のすべてのエンジンでサポートされている。 Firefox1+Safari3+Chrome1+
Opera4+Edge79+ Edge (Legacy)12+Internet Explorer4+ Firefox Android?Safari iOS1+Chrome Android?WebView Android?Samsung Internet?Opera Android10.1+ |
unload
|
このイベントハンドラーの
リストは、WindowEventHandlers
インターフェイスミックスインを通して、イベントハンドラー
IDL
属性として具現化される。
次に示すのは、Document
オブジェクト上で、イベント
ハンドラー IDL 属性としてサポートしなければならないイベントハンドラー
(および対応するイベントハンドラー
イベント型)である:
| イベントハンドラー | イベント ハンドラーイベント型 |
|---|---|
onreadystatechange |
readystatechange
|
onvisibilitychange
Document/visibilitychange_event 現在のすべてのエンジンでサポートされている。 Firefox56+Safari14.1+Chrome62+
Opera49+Edge79+ Edge (Legacy)18Internet Explorer🔰 10+ Firefox Android?Safari iOS?Chrome Android?WebView Android62+Samsung Internet?Opera Android46+ |
visibilitychange
|
interface mixin GlobalEventHandlers {
attribute EventHandler onabort ;
attribute EventHandler onauxclick ;
attribute EventHandler onbeforeinput ;
attribute EventHandler onbeforematch ;
attribute EventHandler onbeforetoggle ;
attribute EventHandler onblur ;
attribute EventHandler oncancel ;
attribute EventHandler oncanplay ;
attribute EventHandler oncanplaythrough ;
attribute EventHandler onchange ;
attribute EventHandler onclick ;
attribute EventHandler onclose ;
attribute EventHandler oncommand ;
attribute EventHandler oncontextlost ;
attribute EventHandler oncontextmenu ;
attribute EventHandler oncontextrestored ;
attribute EventHandler oncopy ;
attribute EventHandler oncuechange ;
attribute EventHandler oncut ;
attribute EventHandler ondblclick ;
attribute EventHandler ondrag ;
attribute EventHandler ondragend ;
attribute EventHandler ondragenter ;
attribute EventHandler ondragleave ;
attribute EventHandler ondragover ;
attribute EventHandler ondragstart ;
attribute EventHandler ondrop ;
attribute EventHandler ondurationchange ;
attribute EventHandler onemptied ;
attribute EventHandler onended ;
attribute OnErrorEventHandler onerror ;
attribute EventHandler onfocus ;
attribute EventHandler onformdata ;
attribute EventHandler oninput ;
attribute EventHandler oninvalid ;
attribute EventHandler onkeydown ;
attribute EventHandler onkeypress ;
attribute EventHandler onkeyup ;
attribute EventHandler onload ;
attribute EventHandler onloadeddata ;
attribute EventHandler onloadedmetadata ;
attribute EventHandler onloadstart ;
attribute EventHandler onmousedown ;
[LegacyLenientThis ] attribute EventHandler onmouseenter ;
[LegacyLenientThis ] attribute EventHandler onmouseleave ;
attribute EventHandler onmousemove ;
attribute EventHandler onmouseout ;
attribute EventHandler onmouseover ;
attribute EventHandler onmouseup ;
attribute EventHandler onpaste ;
attribute EventHandler onpause ;
attribute EventHandler onplay ;
attribute EventHandler onplaying ;
attribute EventHandler onprogress ;
attribute EventHandler onratechange ;
attribute EventHandler onreset ;
attribute EventHandler onresize ;
attribute EventHandler onscroll ;
attribute EventHandler onscrollend ;
attribute EventHandler onsecuritypolicyviolation ;
attribute EventHandler onseeked ;
attribute EventHandler onseeking ;
attribute EventHandler onselect ;
attribute EventHandler onslotchange ;
attribute EventHandler onstalled ;
attribute EventHandler onsubmit ;
attribute EventHandler onsuspend ;
attribute EventHandler ontimeupdate ;
attribute EventHandler ontoggle ;
attribute EventHandler onvolumechange ;
attribute EventHandler onwaiting ;
attribute EventHandler onwebkitanimationend ;
attribute EventHandler onwebkitanimationiteration ;
attribute EventHandler onwebkitanimationstart ;
attribute EventHandler onwebkittransitionend ;
attribute EventHandler onwheel ;
};
interface mixin WindowEventHandlers {
attribute EventHandler onafterprint ;
attribute EventHandler onbeforeprint ;
attribute OnBeforeUnloadEventHandler onbeforeunload ;
attribute EventHandler onhashchange ;
attribute EventHandler onlanguagechange ;
attribute EventHandler onmessage ;
attribute EventHandler onmessageerror ;
attribute EventHandler onoffline ;
attribute EventHandler ononline ;
attribute EventHandler onpagehide ;
attribute EventHandler onpagereveal ;
attribute EventHandler onpageshow ;
attribute EventHandler onpageswap ;
attribute EventHandler onpopstate ;
attribute EventHandler onrejectionhandled ;
attribute EventHandler onstorage ;
attribute EventHandler onunhandledrejection ;
attribute EventHandler onunload ;
};特定の操作およびメソッドは、要素上でイベントを発火するものとして定義される。例えば、click()
メソッドは、HTMLElement インターフェース上で、その要素に
click
イベントを発火するものとして定義される。[POINTEREVENTS]
target において、任意の not trusted flag を伴って、 e という名前の合成ポインターイベントを発火するとは、 次の手順を実行することを意味する:
PointerEvent
を使用して
イベントを
作成した結果を
event とする。
event の type
属性を
e に初期化する。
event の bubbles
および cancelable
属性を true に初期化する。
event の composed フラグを設定する。
not trusted flag が設定されている場合、event の isTrusted
属性を false に初期化する。
event の ctrlKey、shiftKey、altKey、および
metaKey
属性を、キー入力デバイスが存在する場合はその現在の状態に従って初期化する(利用できないキーは
false とする)。
event の view
属性を、存在する場合は
target のノード
文書の Window オブジェクトに、存在しない場合は null
に初期化する。
event の getModifierState() メソッドは、キー入力デバイスの
現在の状態を適切に記述する値を返すものとする。
target において event を配送した 結果を返す。
target においてclick イベントを発火する
とは、target において click という名前の合成
ポインターイベントを発火することを意味する。
WindowOrWorkerGlobalScope
ミックスインWindowOrWorkerGlobalScope
ミックスインは、
Window および WorkerGlobalScope
オブジェクト上で公開される API に使用するためのものである。
他の標準は、適切な参照とともに、
partial
interface mixin WindowOrWorkerGlobalScope { … };
を使用してこれをさらに拡張することが推奨される。
typedef (DOMString or Function or TrustedScript ) TimerHandler ;
interface mixin WindowOrWorkerGlobalScope {
[Replaceable ] readonly attribute USVString origin ;
readonly attribute boolean isSecureContext ;
readonly attribute boolean crossOriginIsolated ;
undefined reportError (any e );
// base64 utility methods
DOMString btoa (DOMString data );
ByteString atob (DOMString data );
// timers
long setTimeout (TimerHandler handler , optional long timeout = 0, any ... arguments );
undefined clearTimeout (optional long id = 0);
long setInterval (TimerHandler handler , optional long timeout = 0, any ... arguments );
undefined clearInterval (optional long id = 0);
// microtask queuing
undefined queueMicrotask (VoidFunction callback );
// ImageBitmap
Promise <ImageBitmap > createImageBitmap (ImageBitmapSource image , optional ImageBitmapOptions options = {});
Promise <ImageBitmap > createImageBitmap (ImageBitmapSource image , long sx , long sy , long sw , long sh , optional ImageBitmapOptions options = {});
// structured cloning
any structuredClone (any value , optional StructuredSerializeOptions options = {});
};
Window includes WindowOrWorkerGlobalScope ;
WorkerGlobalScope includes WindowOrWorkerGlobalScope ;self.isSecureContext
現在のすべてのエンジンでサポートされています。
この大域オブジェクトが安全なコンテキストを表すかどうかを返す。 [SECURE-CONTEXTS]
self.origin
現在のすべてのエンジンでサポートされています。
文字列として直列化された大域オブジェクトのオリジンを返す。
self.crossOriginIsolated
現在のすべてのエンジンでサポートされています。
この大域で実行されるスクリプトが、オリジン間分離を必要とする API を使用できるかどうかを返す。
これは、`Cross-Origin-Opener-Policy`
および
`Cross-Origin-Embedder-Policy`
HTTP 応答ヘッダーと、"cross-origin-isolated"
機能に依存する。
開発者には、location.origin よりも self.origin を使用することが強く推奨される。前者は
環境のオリジンを
返し、
後者は環境の URL のオリジンを返す。https://stargate.example/ 上の文書で
次のスクリプトが実行される場合を想像してほしい:
var frame = document. createElement( "iframe" )
frame. onload = function () {
var frameWin = frame. contentWindow
console. log( frameWin. location. origin) // "null"
console. log( frameWin. origin) // "https://stargate.example"
}
document. body. appendChild( frame) self.origin は、より信頼性の高いセキュリティ指標である。
isSecureContext 取得子の手順は、
this の関連設定オブジェクトが安全なコンテキストである場合は
true を返し、そうでない場合は false を返すことである。
origin
取得子の手順は、this の
関連
設定オブジェクトのオリジンを直列化して返すことである。
crossOriginIsolated 取得子の手順は、
this の関連設定オブジェクトのオリジン間
分離
機能を返すことである。
WindowOrWorkerGlobalScope
ミックスインを実装する要素には、次の
オリジンを抽出する手順がある:
this の関連設定オブジェクトのオリジンが、入口 設定オブジェクトのオリジンと同一オリジンドメイン でない場合、null を返す。
this の関連設定オブジェクトの オリジンを返す。
これらのオブジェクトはオリジンをまたいでアクセスできる可能性があるため(例えば
WindowProxy を介して)、オリジンへの
アクセスを許可する前に、ここでセキュリティ検査を行う必要がある。
atob() および btoa() メソッドを使用すると、
開発者はコンテンツを Base64 符号化へ、または Base64 符号化から変換できる。
これらの API では、記憶を助けるため、"b" は "binary"、"a" は "ASCII" を表すものと考えることができる。ただし実際には、主として歴史的な理由により、これらの 関数の入力と出力はいずれも Unicode 文字列である。
result = self.btoa(data)
現在のすべてのエンジンでサポートされています。
U+0000 から U+00FF までの範囲の文字のみを含む Unicode 文字列形式の入力データを受け取る。 各文字はそれぞれ 0x00 から 0xFF までの値を持つバイナリバイトを表し、それを Base64 表現へ変換して返す。
入力文字列に範囲外の文字が含まれる場合、"InvalidCharacterError" DOMException
を投げる。
result = self.atob(data)
現在のすべてのエンジンでサポートされています。
Base64 で符号化されたバイナリデータを含む Unicode 文字列形式の入力データを受け取り、 それを復号し、対応するバイナリデータについて、それぞれ 0x00 から 0xFF までの値を持つ バイナリバイトを表す U+0000 から U+00FF までの範囲の文字で構成される文字列を 返す。
入力文字列が有効な Base64 データでない場合、"InvalidCharacterError" DOMException
を
投げる。
btoa(data) メソッドは、data に
コードポイントが U+00FF より大きい文字が含まれている場合、
"InvalidCharacterError" DOMException
を投げなければならない。そうでない場合、ユーザーエージェントは
data を、その第 n バイトが data の第 n
コードポイントの 8 ビット表現であるバイト列へ変換し、そのバイト列に
寛容な Base64 符号化を適用して、結果を
返さなければならない。
atob(data) メソッドの手順は次のとおりである:
data に対して寛容な Base64 復号を 実行した結果を decodedData とする。
decodedData が失敗である場合、
"InvalidCharacterError" DOMException
を投げる。
decodedData を返す。
文書へマークアップを動的に挿入するための API は構文解析器と相互作用するため、 その動作は、それらが HTML 文書(および HTML 構文解析器)とともに使用されるか、XML 文書(および XML 構文解析器)とともに使用されるかによって異なる。
Document オブジェクトは、動的マークアップ挿入時例外送出カウンターを持つ。
これは、トークン用の要素を作成するアルゴリズムとともに使用され、
カスタム
要素コンストラクターが構文解析器によって呼び出されたときに、
document.open()、document.close()、および
document.write()
を使用できないようにする。
このカウンターは、初期状態ではゼロに設定しなければならない。
document = document.open()
現在のすべてのエンジンでサポートされています。
Document が新しい
Document オブジェクトであるかのように、
以前のオブジェクトを再利用しつつ、その場で置換する。再利用されたオブジェクトが返される。
結果として得られる Document には
HTML 構文解析器が関連付けられ、document.write()
を使用して、
解析するデータを与えることができる。
Document
がまだ解析中である場合、このメソッドは効果を持たない。
Document が XML 文書である場合、
"InvalidStateError" DOMException
を投げる。
構文解析器が現在カスタム要素コンストラクターを実行している場合、
"InvalidStateError" DOMException
を投げる。
window = document.open(url, name, features)
window.open()
メソッドと同様に動作する。
Document オブジェクトは、アクティブな構文解析器が中止されたという真偽値を持つ。
これは、文書のアクティブな構文解析器が
中止された後に、スクリプトが document.open()
および document.write()
メソッドを(直接または間接に)
呼び出すことを防ぐために使用される。初期値は false である。
document を指定した場合の文書を開く手順は、次のとおりである:
document が XML 文書である場合、
"InvalidStateError" DOMException
を投げる。
document の動的マークアップ挿入時例外送出
カウンターが 0 より大きい場合、
"InvalidStateError"
DOMException
を投げる。
入口大域オブジェクトの関連付けられた
Document を entryDocument とする。
document のオリジン
が
entryDocument のオリジンと同一オリジンでない場合、
"SecurityError" DOMException
を投げる。
document がアクティブな 構文解析器を持ち、そのスクリプト 入れ子 レベルが 0 より大きい場合、document を返す。
これは基本的に、解析中に見つかったインラインスクリプト内から document.open() が
呼び出された場合には無視されるようにしつつ、タイマーコールバックやイベントハンドラーなどの
構文解析器以外のタスクから呼び出された場合には、引き続き効果を持つようにする。
同様に、document のunload カウンターが 0 より大きい場合、 document を返す。
これは基本的に、Document のアンロード中に、beforeunload、
pagehide、または unload イベント
ハンドラーから document.open() が
呼び出された場合に無視されるようにする。
document のアクティブな構文解析器が中止されたが true の場合、 document を返す。
これは特に、初回の解析中に限り、ナビゲーションが開始された後に
document.open() が
呼び出された場合、それを無視するようにする。詳細な背景については、課題 #4723を参照されたい。
document のノード ナビゲーション可能が非 null であり、 document のノード ナビゲーション可能の進行中の ナビゲーションが ナビゲーション IDである場合、document のノード ナビゲーション可能の読み込みを停止する。
document の各シャドウを含む包括的子孫 node について、 node を指定してすべてのイベントリスナーおよび ハンドラーを消去する。
document が、document の関連大域オブジェクトの関連付けられた
Documentである場合、document の関連
大域オブジェクトを指定して、すべてのイベントリスナーおよび
ハンドラーを消去する。
document 内を null ですべて 置換する。
document が完全に アクティブである場合:
entryDocument の URL の複製を newURL とする。
entryDocument が document でない場合、newURL の フラグメント を null に設定する。
document および newURL を使用して、URL と履歴を更新する手順を実行する。
document の初期 about:blank であるを
false に設定する。
document のiframe の読み込み進行中フラグが設定されている場合、 document のiframe の 読み込みを抑制するフラグを設定する。
document を非 quirks モードに設定する。
宣言的
シャドウルートを許可するが
document の宣言的
シャドウルートを許可するである HTML
構文解析器を作成し、document に関連付ける。これは
スクリプトによって作成された構文解析器である(つまり、document.open()
および document.close()
メソッドによって閉じることができ、字句解析器は
ファイル終端トークンを発行する前に、document.close()
の明示的な呼び出しを待つ)。符号化の信頼度は
無関係である。
document の現在の文書の
準備状態を更新し、"loading" にする。
これにより readystatechange
イベントが発火するが、前の手順で、それを観測できるすべてのイベントリスナーおよび
ハンドラーが消去されたため、実際には作者コードからイベントを観測できない。
document を返す。
文書を開く
手順は、Document が
読み込み後
タスクの準備ができているか、または完全に読み込まれているかどうかには影響しない。
open(unused1,
unused2) メソッドは、this を使用して
文書を開く
手順を実行した結果を返さなければならない。
unused1 および
unused2 引数は無視されるが、1 個または 2 個の引数を指定してこの関数を呼び出すコードが
引き続き動作できるように、IDL に残されている。これらは Web IDL の
オーバーロード解決アルゴリズムの規則により必要である。
これらの引数が存在しなければ、そのような呼び出しは TypeError
例外を投げることになる。whatwg/webidl 課題 #581では、
これらを削除できるようにアルゴリズムを変更することが検討されている。[WEBIDL]
open(url,
name, features) メソッドは、次の手順を実行しなければならない:
this が完全にアクティブでない場合、
"InvalidAccessError" DOMException
を投げる。
url、name、および features を使用して、 ウィンドウを開く手順を実行した結果を返す。
document.close()
現在のすべてのエンジンでサポートされています。
document.open()
メソッドによって開かれた入力ストリームを閉じる。
Document が XML 文書である場合、
"InvalidStateError" DOMException
を投げる。
構文解析器が現在カスタム要素コンストラクターを実行している場合、
"InvalidStateError" DOMException
を投げる。
close() メソッドは、
次の
手順を実行しなければならない:
this が XML 文書である場合、
"InvalidStateError" DOMException
を投げる。
this の動的マークアップ挿入時例外送出
カウンターが
0 より大きい場合、"InvalidStateError"
DOMException
を投げる。
this に関連付けられたスクリプトによって作成された構文解析器が 存在しない場合、 return する。
構文解析器の入力 ストリームの末尾に、明示的な "EOF" 文字を挿入する。
this の保留中の構文解析を阻害するスクリプトが null でない場合、 return する。
字句解析器を実行し、結果のトークンが発行されるたびにそれを処理し、字句解析器が 明示的な "EOF" 文字に到達するか、イベントループを回すときに停止する。
document.write()document.write(...text)
現在のすべてのエンジンでサポートされています。
一般に、指定された文字列を Document の入力ストリームへ追加する。
このメソッドの動作は非常に特異である。場合によっては、構文解析器の実行中に
このメソッドが HTML 構文解析器の状態へ影響し、
文書のソースと一致しない DOM が
生成されることがある(例えば、書き込まれた文字列が
"<plaintext>" または "<!--" である場合)。別の場合には、
document.open() が
呼び出されたかのように、呼び出しによって最初に現在のページが消去されることがある。さらに別の場合には、このメソッドが
単に無視されるか、例外を投げる。ユーザーエージェントには、このメソッドによって挿入された
script 要素を実行しないことが明示的に許可されている。さらに悪いことに、
このメソッドの正確な動作は、場合によってはネットワーク遅延に依存する可能性があり、デバッグが
非常に困難な障害を引き起こすことがある。これらすべての理由により、このメソッドの
使用は強く非推奨とされる。
XML 文書上で呼び出された場合、
"InvalidStateError" DOMException
を投げる。
構文解析器が現在カスタム要素コンストラクターを実行している場合、
"InvalidStateError" DOMException
を投げる。
このメソッドは、script
やイベントハンドラー
内容属性など、潜在的に危険な要素および属性を除去するための無害化を行わない。
Document オブジェクトは、破壊的な書き込みを無視するカウンターを持つ。これは、
script 要素の処理と
組み合わせて使用され、外部
スクリプトが document.write()
を使用し、
document.open() を暗黙的に呼び出して
文書を消去できないようにする。
このカウンターは、初期状態ではゼロに設定しなければならない。
Document オブジェクト document、
リスト text、真偽値 lineFeed、および文字列 sink を指定した場合の
文書を書き込む手順は、次のとおりである:
string を空文字列とする。
text が文字列を含む場合は isTrusted を false とし、それ以外の場合は true とする。
text の各 value について反復する:
value が TrustedHTML
オブジェクトである場合、
value に関連付けられたデータを
string に付加する。
それ以外の場合、value を string に付加する。
isTrusted が false である場合、TrustedHTML、
this
の関連大域
オブジェクト、string、sink、および "script" を使用して、
信頼型に
適合する文字列を取得するアルゴリズムを呼び出した結果を string に設定する。
lineFeed が true である場合、U+000A LINE FEED を string に付加する。
document が XML 文書である場合、
"InvalidStateError" DOMException
を投げる。
document の動的マークアップ挿入時例外送出
カウンターが
0 より大きい場合、"InvalidStateError"
DOMException
を投げる。
document のアクティブな構文解析器が中止されたが true の場合、 return する。
挿入点が未定義の場合:
document のunload カウンターが 0 より大きいか、 document の破壊的な書き込みを無視するカウンターが 0 より大きい場合、 return する。
document を使用して、文書を開く手順を実行する。
document の保留中の構文解析を阻害するスクリプトが null である場合、
HTML 構文解析器に string を
コードポイントごとに処理させ、結果のトークンが発行されるたびにそれを処理し、字句解析器が
挿入点に到達するか、木構築段階によって字句解析器の処理が中止されたときに停止させる(これは、
字句解析器によって script
終了タグトークンが
発行された場合に起こり得る)。
document.write()
メソッドが、
インラインで実行されるスクリプトから
呼び出された場合(すなわち、構文解析器が一連の
script
タグを解析したために実行された場合)、
これは構文解析器の再入
呼び出しである。構文解析器一時停止
フラグが設定されている場合、字句解析器の構文解析器一時停止
フラグ検査に従い、字句解析器は直ちに中止され、
HTML は解析されない。
document.writeln()document.writeln(...text)
現在のすべてのエンジンでサポートされています。
指定された文字列を Document の入力ストリームへ追加し、その後に改行
文字を追加する。必要な場合は、最初に open() メソッドを
暗黙的に呼び出す。
このメソッドの動作は非常に特異である。document.write()
と同じ理由により、
このメソッドの使用は強く非推奨とされる。
XML 文書上で呼び出された場合、
"InvalidStateError" DOMException
を投げる。
構文解析器が現在カスタム要素コンストラクターを実行している場合、
"InvalidStateError" DOMException
を投げる。
このメソッドは、script
やイベント
ハンドラー内容属性など、潜在的に危険な要素および属性を除去するための無害化を行わない。
document.writeln(...text) メソッドの手順は、
this、
text、true、および
"Document writeln" を使用して、文書を書き込む手順を実行することである。
現在のすべてのエンジンでサポートされています。
partial interface Element {
[CEReactions ] undefined setHTML (DOMString html , optional SetHTMLOptions options = {});
[CEReactions ] undefined setHTMLUnsafe ((TrustedHTML or DOMString ) html , optional SetHTMLUnsafeOptions options = {});
DOMString getHTML (optional GetHTMLOptions options = {});
[CEReactions ] attribute (TrustedHTML or [LegacyNullToEmptyString ] DOMString ) innerHTML ;
[CEReactions ] attribute (TrustedHTML or [LegacyNullToEmptyString ] DOMString ) outerHTML ;
[CEReactions ] undefined insertAdjacentHTML (DOMString position , (TrustedHTML or DOMString ) string );
};
partial interface ShadowRoot {
[CEReactions ] undefined setHTML (DOMString html , optional SetHTMLOptions options = {});
[CEReactions ] undefined setHTMLUnsafe ((TrustedHTML or DOMString ) html , optional SetHTMLUnsafeOptions options = {});
DOMString getHTML (optional GetHTMLOptions options = {});
[CEReactions ] attribute (TrustedHTML or [LegacyNullToEmptyString ] DOMString ) innerHTML ;
};
enum SanitizerPresets { " default " };
dictionary SetHTMLOptions {
(Sanitizer or SanitizerConfig or SanitizerPresets ) sanitizer = "default";
};
dictionary SetHTMLUnsafeOptions {
(Sanitizer or SanitizerConfig or SanitizerPresets ) sanitizer = {};
boolean runScripts = false ;
};
dictionary ParseHTMLUnsafeOptions {
(Sanitizer or SanitizerConfig or SanitizerPresets ) sanitizer = {};
};
dictionary GetHTMLOptions {
boolean serializableShadowRoots = false ;
sequence <ShadowRoot > shadowRoots = [];
};DOMParser インターフェースDOMParser インターフェースを使用すると、
作者は文字列を HTML または XML として解析し、新しい
Document オブジェクトを作成できる。
parser = new DOMParser()
現在のすべてのエンジンでサポートされています。
新しい DOMParser
オブジェクトを構築する。
document = parser.parseFromString(string, type)
現在のすべてのエンジンでサポートされています。
type に従って HTML または XML 構文解析器を使用して string を解析し、
結果の Document を返す。
type には、"text/html"
(HTML 構文解析器を呼び出す)、または "text/xml"、
"application/xml"、
"application/xhtml+xml"、
もしくは
"image/svg+xml" のいずれか
(XML 構文解析器を呼び出す)を指定できる。
XML 構文解析器では、string を解析できない場合、返される
Document に、結果として生じた
エラーを記述する要素が含まれる。
script
要素は解析中に評価されず、結果の
文書の符号化は常に
UTF-8 となることに注意されたい。文書の
URL は、
parser の関連大域オブジェクトから継承される。
type に上記以外の値を指定すると、TypeError
例外が
投げられる。
DOMParser が、構築した後に
parseFromString()
メソッドを呼び出す必要があるクラスとして設計されているのは、
不幸な歴史的遺物である。この機能を今日設計するなら、独立した関数になるだろう。HTML の解析には、
Document.parseHTMLUnsafe()
が現代的な代替手段である。
このメソッドは、script やイベント
ハンドラー内容属性など、潜在的に危険な要素および属性を除去するための無害化を行わない。
[Exposed =Window ]
interface DOMParser {
constructor ();
[NewObject ] Document parseFromString ((TrustedHTML or DOMString ) string , DOMParserSupportedType type );
};
enum DOMParserSupportedType {
" text/html " ,
" text/xml " ,
" application/xml " ,
" application/xhtml+xml " ,
" image/svg+xml "
};new DOMParser() コンストラクターの
手順は、何もしないことである。
parseFromString(string,
type) メソッドの手順は次のとおりである:
TrustedHTML、
this の関連大域
オブジェクト、string、"DOMParser parseFromString"、および
"script" を使用して、信頼型に
適合する文字列を取得するアルゴリズムを呼び出した結果を compliantString とする。
内容型が type であり、URL が
this の関連大域オブジェクトの関連付けられた
Documentの URL
である、新しい Document を document とする。
文書の符号化は、
既定値である UTF-8 のままとなる。特に、compliantString の
解析中に見つかった XML 宣言または
meta 要素は
いずれも効果を持たない。
type に応じて分岐する:
text/html"document および compliantString を指定して、文字列から HTML を解析する。
document は閲覧コンテキストを持たないため、スクリプト処理は無効化される。
document に関連付けられ、XML スクリプト処理対応が無効化された XML 構文解析器 parser を作成する。
parser を使用して compliantString を解析する。
前の手順によって XML 整形式性エラーまたは XML 名前空間整形式性 エラーが生じた場合:
document を返す。
Document
document および文字列 html を指定して、文字列から HTML
を解析するには:
document の型を
"html" に設定する。
宣言的 シャドウルートを許可するが、document の宣言的シャドウルートを許可する である、document に関連付けられた新しいHTML 構文解析器を parser とする。
parser を開始し、入力ストリームへ挿入されたすべての文字を消費するまで 実行させる。
これにより、文書のモードが変化することがある。
element.setHTML(html, options)
オプション options を指定して HTML 構文解析器で html を解析し、
element の子をその結果で置換する。element は
HTML 構文解析器へコンテキストを提供する。解析された断片は、options の
"sanitizer"
メンバーに基づいて無害化され、
安全でない内容が
除去される。
shadowRoot.setHTML(html, options)
オプション options を指定して HTML 構文解析器で html を解析し、
shadowRoot の子をその結果で置換する。shadowRoot のホストは、HTML 構文解析器へコンテキストを提供する。
解析された断片は、options の
"sanitizer"
メンバーに基づいて無害化され、安全でない
内容が除去される。
element.setHTMLUnsafe(html, options)
オプション options を指定して HTML 構文解析器で html を解析し、
element の子をその結果で置換する。element は
HTML 構文解析器へコンテキストを提供する。options 辞書に
"sanitizer"
メンバーが含まれる場合、解析された断片を element へ挿入する前に
無害化するために使用される。
options 辞書の "runScripts"
メンバーが true である場合、html に含まれるスクリプトは、
ノード木の更新直後に実行される。
shadowRoot.setHTMLUnsafe(html, options)
オプション options を指定して HTML 構文解析器で html を解析し、
shadowRoot の子をその結果で置換する。shadowRoot のホストは、HTML 構文解析器へコンテキストを提供する。
options 辞書に "sanitizer"
メンバーが含まれる場合、解析された断片を shadowRoot へ挿入する前に
無害化するために使用される。
options 辞書の "runScripts"
メンバーが true である場合、html に含まれるスクリプトは、
ノード木の更新直後に実行される。
doc = Document.parseHTML(html, options)
オプション options を指定して HTML 構文解析器で html を解析し、
結果を含む新しい Document を返す。
結果の文書は、options の "sanitizer"
メンバーに基づいて無害化され、安全でない
内容が除去される。
doc = Document.parseHTMLUnsafe(html, options)
オプション options を指定して HTML 構文解析器で html を解析し、
結果の Document を返す。
script
要素は解析中に評価されず、結果の
文書の符号化は常に
UTF-8 となることに注意されたい。文書の
URL は
about:blank となる。
options 辞書に "sanitizer"
メンバーが含まれる場合、結果の DOM を
無害化するために使用される。
Unsafe 接尾辞を持つメソッドは、script や
イベントハンドラー
内容属性など、潜在的に危険な要素および属性を除去するための
無害化を行わない。
Element
の
setHTML(html, options) メソッドの
手順は次のとおりである:
ShadowRoot
の
setHTML(html, options) メソッドの
手順は次のとおりである:
this、html、 options、および true を指定して、HTML を設定してフィルタリングする。
Element
の
setHTMLUnsafe(html, options)
メソッドの手順は次のとおりである:
TrustedHTML、
this の関連大域
オブジェクト、html、"Element setHTMLUnsafe"、および
"script" を使用して、信頼型に
適合する文字列を取得するアルゴリズムを呼び出した結果を compliantHTML とする。
this が template
要素である場合、this のテンプレート内容を target とし、
それ以外の場合は this とする。
target、compliantHTML、 options、および false を指定して、HTML を設定してフィルタリングする。
ShadowRoot
の
setHTMLUnsafe(html,
options) メソッドの手順は次のとおりである:
TrustedHTML、
this の関連大域
オブジェクト、html、"ShadowRoot setHTMLUnsafe"、および
"script" を使用して、信頼型に
適合する文字列を取得するアルゴリズムを呼び出した結果を compliantHTML とする。
this、compliantHTML、 options、および false を指定して、HTML を設定してフィルタリングする。
静的な parseHTML(html,
options) メソッドの手順は次のとおりである:
内容型が "text/html" である
新しい Document を
document とする。
document は閲覧コンテキストを持たないため、スクリプト処理は 無効化される。
document の宣言的シャドウルートを許可するを true に設定する。
document および html を指定して、文字列から HTML を 解析する。
options および true を使用して、オプションから無害化器のインスタンスを 取得するを呼び出した結果を sanitizer とする。
sanitizer および true を使用して、document 上で無害化するを呼び出す。
document を返す。
静的な parseHTMLUnsafe(html, options)
メソッドの手順は次のとおりである:
TrustedHTML、
this の関連大域
オブジェクト、html、"Document parseHTMLUnsafe"、および
"script" を使用して、信頼型に
適合する文字列を取得するアルゴリズムを呼び出した結果を compliantHTML とする。
内容型が "text/html" である
新しい Document を
document とする。
document は閲覧コンテキストを持たないため、スクリプト処理は 無効化される。
document の宣言的シャドウルートを許可するを true に設定する。
document および compliantHTML を指定して、文字列から HTML を 解析する。
options および false を使用して、オプションから無害化器のインスタンスを 取得するを呼び出した結果を sanitizer とする。
sanitizer および false を使用して、document 上で無害化するを呼び出す。
document を返す。
html = element.getHTML({ serializableShadowRoots, shadowRoots })
element を HTML へ直列化した結果を返す。element 内のシャドウルートは、指定されたオプションに従って 直列化される:
serializableShadowRoots
が true である場合、直列化可能と
マークされたすべてのシャドウルートが直列化される。
shadowRoots
配列が指定された場合、その配列で指定されたすべてのシャドウルートが、直列化可能と
マークされているかどうかにかかわらず直列化される。
どちらのオプションも指定されていない場合、シャドウルートは直列化されない。
html = shadowRoot.getHTML({ serializableShadowRoots, shadowRoots })
シャドウホストをコンテキスト要素として使用し、 shadowRoot を HTML へ直列化した結果を返す。shadowRoot 内のシャドウルートは、上記と同様に、指定された オプションに従って直列化される。
Element
の
getHTML(options) メソッドの手順は、
this、options["serializableShadowRoots"]、
および options["shadowRoots"]
を使用した
HTML 断片直列化アルゴリズムの
結果を返すことである。
ShadowRoot
の
getHTML(options) メソッドの手順は、
this、options["serializableShadowRoots"]、
および options["shadowRoots"]
を使用した
HTML 断片直列化
アルゴリズムの結果を返すことである。
innerHTML プロパティinnerHTML
プロパティには、
その仕様に関するさまざまな問題を記録した、DOM の構文解析および直列化の課題
追跡システムに未解決の課題が多数存在する。
element.innerHTML
要素の内容を表す HTML または XML の断片を返す。
XML 文書の場合、要素を XML へ直列化できなければ、"InvalidStateError"
DOMException
を投げる。
element.innerHTML = value
指定された文字列から解析したノードで、要素の内容を置換する。
XML 文書の場合、指定された文字列が整形式でなければ、"SyntaxError"
DOMException
を投げる。
shadowRoot.innerHTML
シャドウルートの内容を表す HTML の断片を返す。
shadowRoot.innerHTML = value
指定された文字列から解析したノードで、シャドウルートの内容を置換する。
これらのプロパティの設定子は、script やイベント
ハンドラー
内容属性など、潜在的に危険な要素および属性を除去するための無害化を行わない。
Element、
Document、または DocumentFragment
node と真偽値 require
well-formed を指定した場合の断片を直列化するアルゴリズムの手順は次のとおりである:
node のノード文書を context document とする。
context document が HTML 文書である場合、 node、false、および « » を使用した HTML 断片直列化アルゴリズムの 結果を返す。
require well-formed を指定した node の XML 直列化を 返す。
Element
または
DocumentFragment
target、文字列 markup、および任意の
構文解析器スクリプト処理モード
scriptingMode(既定値は 不活性)を指定した場合の断片を解析するアルゴリズムの手順は、次のとおりである:
target のノード文書が XML 文書である場合、target および markup を指定して XML 断片構文解析 アルゴリズムを呼び出した結果を返す。
target、markup、false、および scriptingMode を指定した HTML 断片構文解析アルゴリズムの 結果を返す。
Element
の
innerHTML
取得子の手順は、this
および true を使用して、断片を直列化するアルゴリズムの手順を
実行した結果を返すことである。
ShadowRoot
の
innerHTML 取得子の手順は、
this
および true を使用して、断片を直列化するアルゴリズムの手順を
実行した結果を返すことである。
Element
の
innerHTML
設定子の手順は
次のとおりである:
TrustedHTML、
this の関連大域
オブジェクト、指定された値、"Element innerHTML"、および "script" を使用して、
信頼型に
適合する文字列を取得するアルゴリズムを呼び出した結果を compliantString とする。
this を target とする。
target が template
要素である場合、target を
template
要素のテンプレート内容(DocumentFragment)
に設定する。
template
要素上で innerHTML
を
設定すると、その子ではなく、
テンプレート内容内のすべてのノードが置換される。
target および compliantString を使用して、断片を解析するアルゴリズムの 手順を呼び出した結果を fragment とする。
target 内を fragment ですべて 置換する。
ShadowRoot
の
innerHTML
設定子の
手順は次のとおりである:
TrustedHTML、
this の関連大域
オブジェクト、指定された値、"ShadowRoot innerHTML"、および "script" を使用して、
信頼型に
適合する文字列を取得するアルゴリズムを呼び出した結果を compliantString とする。
this および compliantString を使用して、断片を解析するアルゴリズムの 手順を呼び出した結果を fragment とする。
outerHTML プロパティouterHTML
プロパティには、
その仕様に関するさまざまな問題を記録した、DOM の構文解析および直列化の課題
追跡システムに未解決の課題が多数存在する。
element.outerHTML
要素およびその内容を表す HTML または XML の断片を返す。
XML 文書の場合、要素を XML へ直列化できなければ、"InvalidStateError"
DOMException
を投げる。
element.outerHTML = value
指定された文字列から解析したノードで要素を置換する。
XML 文書の場合、指定された文字列が整形式でなければ、"SyntaxError"
DOMException
を投げる。
要素の親が Document である場合、
"NoModificationAllowedError" DOMException
を投げる。
このプロパティの設定子は、script やイベント
ハンドラー内容
属性など、潜在的に危険な要素および属性を除去するための無害化を行わない。
Element
の
outerHTML
取得子の手順は次のとおりである:
唯一の子が this である架空のノードを element とする。
element および true を使用して、断片を直列化するアルゴリズムの手順を 実行した結果を返す。
Element
の
outerHTML
設定子の手順は
次のとおりである:
TrustedHTML、
this の関連大域
オブジェクト、指定された値、"Element outerHTML"、および "script" を使用して、
信頼型に
適合する文字列を取得するアルゴリズムを呼び出した結果を compliantString とする。
parent が null である場合、return する。残りの手順を実行したとしても、 作成されたノードへの参照を取得する方法がないためである。
parent が Document
である場合、
"NoModificationAllowedError" DOMException
を投げる。
parent が DocumentFragment
である場合、this の
ノード文書、"body"、および HTML
名前空間を指定して、要素を作成した
結果を parent に設定する。
parent および compliantString を指定して、断片を解析するアルゴリズムの 手順を呼び出した結果を fragment とする。
insertAdjacentHTML()
メソッドinsertAdjacentHTML()
メソッドには、その仕様に関するさまざまな問題を記録した、DOM の構文解析および直列化の課題追跡システムに未解決の課題が
多数存在する。
element.insertAdjacentHTML(position, string)
string を HTML または XML として解析し、結果のノードを、 position 引数で指定された次の位置にある木へ挿入する:
beforebegin"afterbegin"beforeend"afterend"引数に無効な値がある場合(例えば、XML 文書において、
指定された文字列が整形式でない場合)、"SyntaxError" DOMException
を投げる。
指定された位置が不可能である場合(例えば、Document のルート要素の後に
要素を挿入する場合)、"NoModificationAllowedError" DOMException
を投げる。
このメソッドは、script やイベントハンドラー内容属性など、
潜在的に危険な要素および属性を除去するための無害化を行わない。
Element
の
insertAdjacentHTML(position,
string) メソッドの手順は次のとおりである:
TrustedHTML、
this の関連大域
オブジェクト、string、"Element insertAdjacentHTML"、および
"script" を使用して、信頼型に
適合する文字列を取得するアルゴリズムを呼び出した結果を compliantString とする。
context を null とする。
このリストで最初に一致する項目を使用する:
beforebegin" と ASCII 大文字・小文字不区別で一致する場合afterend" と ASCII 大文字・小文字不区別で一致する場合context が null または Document である場合、
"NoModificationAllowedError" DOMException
を投げる。
afterbegin" と ASCII 大文字・小文字不区別で一致する場合beforeend" と ASCII 大文字・小文字不区別で一致する場合"SyntaxError" DOMException
を投げる。
context が Element
でないか、次のすべてが true である場合:
その場合、this のノード文書、
"body"、および HTML
名前空間を指定して、
要素を
作成した結果を context に設定する。
context および compliantString を使用して、断片を解析するアルゴリズムの 手順を呼び出した結果を fragment とする。
beforebegin" と ASCII 大文字・小文字不区別で一致する場合afterbegin" と ASCII 大文字・小文字不区別で一致する場合beforeend" と ASCII 大文字・小文字不区別で一致する場合afterend" と ASCII 大文字・小文字不区別で一致する場合他の直接的な Node
操作
API と同様に(また、innerHTML
とは異なり)、
insertAdjacentHTML()
には、template
要素に対する特別な処理は含まれない。ほとんどの場合、template
要素の子ノードを直接操作する代わりに、
templateEl.content.insertAdjacentHTML()
を使用することになる。
createContextualFragment()
メソッドcreateContextualFragment()
メソッドには、その仕様に関するさまざまな問題を記録した、DOM の構文解析および直列化の課題追跡システムに
未解決の課題が多数存在する。
docFragment = range.createContextualFragment(string)
range の始点ノードを、fragment が解析される
コンテキストとして使用し、マークアップ文字列 string から作成した DocumentFragment
を返す。
このメソッドは、script や
イベントハンドラー内容属性など、
潜在的に危険な要素および属性を除去するための無害化を行わない。
partial interface Range {
[CEReactions , NewObject ] DocumentFragment createContextualFragment ((TrustedHTML or DOMString ) string );
};Range
の
createContextualFragment(string)
メソッドの手順は次のとおりである:
TrustedHTML、
this の関連大域
オブジェクト、string、"Range createContextualFragment"、および
"script" を使用して、信頼型に
適合する文字列を取得するアルゴリズムを呼び出した結果を compliantString とする。
element を null とする。
それ以外で、node が Text
または
Comment
を実装する場合、
element を node の親
要素に設定する。
element が null であるか、次のすべてが true である場合:
その場合、this のノード文書、
"body"、および HTML
名前空間を指定して、
要素を
作成した結果を element に設定する。
element、compliantString、および断片を使用して、断片を解析するアルゴリズムの 手順を呼び出した結果を返す。
XMLSerializer インターフェースXMLSerializer インターフェースには、
その仕様に関するさまざまな問題を記録した、
DOM の構文解析および直列化の課題追跡システムに、
未解決の課題が多数存在する。DOM の構文解析および直列化の残りの部分は、
この仕様へ段階的に取り込まれる予定である。
xmlSerializer = new XMLSerializer()
新しい XMLSerializer
オブジェクトを構築する。
string = xmlSerializer.serializeToString(root)
root を XML へ直列化した結果を返す。
root を XML へ直列化できない場合、
"InvalidStateError" DOMException
を投げる。
XMLSerializer が、
構築した後にその serializeToString()
メソッドを呼び出す必要があるクラスとして設計されているのは、不幸な歴史的遺物である。この機能を
今日設計するなら、独立した関数になるだろう。
[Exposed =Window ]
interface XMLSerializer {
constructor ();
DOMString serializeToString (Node root );
};new XMLSerializer()
コンストラクターの手順は、何もしないことである。
serializeToString(root)
メソッドの手順は次のとおりである:
false を指定した root の XML 直列化を 返す。
この節は非規範的である。
ウェブアプリケーションでは、ユーザー生成コンテンツを描画するときや、クライアント側テンプレートを 使用するときなど、信頼されていない HTML 文字列を処理する必要があることが多い。これらの文字列を DOM へ 安全に挿入するには、DOM ベースのクロスサイトスクリプティング(XSS)攻撃を防ぐための慎重な無害化が必要である。
HTML の無害化は、HTML 文字列を安全に解析して無害化するためのネイティブな仕組みを提供する。 ユーザーエージェント自身の HTML 構文解析器を使用することにより、無害化された出力がブラウザーによる 内容の描画方法を正確に反映することを保証し、スクリプトの実行を防ぎ、スクリプト ガジェットなどの高度な攻撃を緩和する。
これらの API は、HTML を含む文字列を DOM 木へ解析し、利用者が指定した構成に従って 結果の木をフィルタリングする機能を提供する。メソッドには、主として「安全」と「安全でない」の 2 種類がある。
「安全」なメソッドは、スクリプトを実行するマークアップを生成しない。すなわち、 XSS に対して安全であることを意図している。「安全でない」メソッドは、指定された 構成に基づいて解析およびフィルタリングを行うが、既定では同じ安全性の保証を持たない。
Sanitizer インターフェース[Exposed =Window ]
interface Sanitizer {
constructor (optional (SanitizerConfig or SanitizerPresets ) configuration = "default");
// Query configuration:
SanitizerConfig get ();
// Modify a Sanitizer's lists and fields:
boolean allowElement (SanitizerElementWithAttributes element );
boolean removeElement (SanitizerElement element );
boolean replaceElementWithChildren (SanitizerElement element );
boolean allowProcessingInstruction (SanitizerPI pi );
boolean removeProcessingInstruction (SanitizerPI pi );
boolean allowAttribute (SanitizerAttribute attribute );
boolean removeAttribute (SanitizerAttribute attribute );
boolean setComments (boolean allow );
boolean setDataAttributes (boolean allow );
// Remove markup that executes script.
boolean removeUnsafe ();
};config = sanitizer.get()
無害化器の構成の複製を返す。
sanitizer.allowElement(element)
無害化器の構成が指定された要素を許可することを保証する。
sanitizer.removeElement(element)
無害化器の構成が指定された要素を阻止することを保証する。
sanitizer.replaceElementWithChildren(element)
指定された要素を除去し、その子 ノードは保持するように無害化器を構成する。
sanitizer.allowAttribute(attribute)
指定された属性を大域的に許可するように無害化器を構成する。
sanitizer.removeAttribute(attribute)
指定された属性を大域的に阻止するように無害化器を構成する。
sanitizer.allowProcessingInstruction(pi)
指定された処理命令を許可するように無害化器を構成する。
sanitizer.removeProcessingInstruction(pi)
指定された処理命令を阻止するように無害化器を構成する。
sanitizer.setComments(allow)
無害化器がコメントを保持するかどうかを設定する。
sanitizer.setDataAttributes(allow)
無害化器がカスタムデータ属性(例えば data-*)を保持するかどうかを設定する。
sanitizer.removeUnsafe()
安全でないと見なされる要素および属性を自動的に除去するように構成を変更する。
Sanitizer オブジェクトには、
SanitizerConfig である、
関連付けられた構成がある。
new
Sanitizer(configuration) コンストラクターの手順は次のとおりである:
configuration が SanitizerPresets の文字列である場合:
configuration を組み込みの安全な既定 構成に設定する。
辞書 configuration および真偽値
allowCommentsPIsAndDataAttributes を指定して、Sanitizer
sanitizer を構成するには:
真偽値 allowCommentsPIsAndDataAttributes を使用して、SanitizerConfig configuration の構成を正規化するには:
configuration["elements"]
と configuration["removeElements"]
のどちらも存在しない場合、
configuration["removeElements"]
を空のリストに設定する。
configuration["attributes"]
と configuration["removeAttributes"]
のどちらも存在しない場合、
configuration["removeAttributes"]
を空の
リストに設定する。
configuration["processingInstructions"]
と
configuration["removeProcessingInstructions"]
のどちらも存在しない場合:
allowCommentsPIsAndDataAttributes が true である場合、
configuration["removeProcessingInstructions"]
を空のリストに設定する。
それ以外の場合、configuration["processingInstructions"]
を空の
リストに設定する。
configuration["removeElements"]
が存在する場合、
configuration["removeElements"]
を、configuration["removeElements"]
を正規化した結果に設定する。
configuration["attributes"]
が存在する場合、
configuration["attributes"]
を、configuration["attributes"]
を正規化した結果に設定する。
configuration["removeAttributes"]
が存在する場合、
configuration["removeAttributes"]
を、configuration["removeAttributes"]
を正規化した結果に設定する。
configuration["replaceWithChildrenElements"]
が存在する場合、
configuration["replaceWithChildrenElements"]
を、configuration["replaceWithChildrenElements"]
を正規化した
結果に設定する。
configuration["processingInstructions"]
が存在する場合、
configuration["processingInstructions"]
を、configuration["processingInstructions"]
を正規化した
結果に設定する。
configuration["removeProcessingInstructions"]
が存在する場合、
configuration["removeProcessingInstructions"]
を、configuration["removeProcessingInstructions"]
を正規化した結果に設定する。
configuration["comments"]
が存在しない場合、
それを allowCommentsPIsAndDataAttributes に設定する。
configuration["attributes"]
が存在し、かつ
configuration["dataAttributes"]
が存在しない場合、
それを allowCommentsPIsAndDataAttributes に設定する。
list という無害化器リストを正規化するには:
list という処理命令リストを正規化する には:
SanitizerPI
pi を指定して、処理命令を正規化するには:
DOMString
または辞書 name と、既定の名前空間
defaultNamespace(既定値は null)を指定して、無害化器の名前を正規化するには:
SanitizerElement
element を指定して、無害化器の要素を正規化するには:
list という無害化器の要素リストを正規化するには:
リスト A および B の 正規化された共通部分を求めるには:
get() メソッドの
手順は次のとおりである:
get()
メソッドの外部では、
Sanitizer の要素および
属性の順序は観測できない。このメソッドの結果を明示的に並べ替えることにより、実装には、
例えば内部で順序なし集合を使用するなどの最適化を行う機会が与えられる。
config["elements"]
の各 element について反復する:
element["attributes"]
が存在する場合、
element["attributes"]
を、無害化器の項目を比較するを使用して
element["attributes"]
を並べ替えた
結果に設定する。
element["removeAttributes"]
が存在する場合、
element["removeAttributes"]
を、無害化器の項目を比較するを使用して
element["removeAttributes"]
を並べ替えた結果に設定する。
config["elements"]
を、無害化器の
項目を比較するを使用して
config["elements"]
を並べ替えた
結果に設定する。
それ以外の場合:
config["removeElements"]
を、無害化器の項目を比較するを使用して
config["removeElements"]
を並べ替えた結果に設定する。
config["replaceWithChildrenElements"]
が存在する場合、
config["replaceWithChildrenElements"]
を、無害化器の項目を比較するを使用して
config["replaceWithChildrenElements"]
を並べ替えた
結果に設定する。
config["processingInstructions"]
が存在する場合、
config["processingInstructions"]
を、piA["target"]
が piB["target"]
より
コード単位で小さいことを使用して、
config["processingInstructions"]
を並べ替えた結果に設定する。
それ以外の場合:
config["removeProcessingInstructions"]
を、piA["target"]
が piB["target"]
より
コード
単位で小さいことを使用して、
config["removeProcessingInstructions"]
を並べ替えた結果に設定する。
config["attributes"]
が存在する場合、
config["attributes"]
を、無害化器の
項目を比較するを指定して
config["attributes"]
を並べ替えた結果に設定する。
それ以外の場合:
config["removeAttributes"]
を、無害化器の項目を比較するを指定して
config["removeAttributes"]
を並べ替えた結果に設定する。
config を返す。
allowElement(element) メソッドの手順は
次のとおりである:
element を正規化した 結果を element に設定する。
configuration["elements"]
が存在する場合:
configuration["replaceWithChildrenElements"]
から element を除去した
結果を modified とする。
configuration["attributes"]
が存在する場合:
element["attributes"]
が存在する場合:
element["attributes"]
を、element["attributes"]
から集合を作成した
結果に設定する。
element["attributes"]
を、element["attributes"]
と
configuration["attributes"]
の差に設定する。
configuration["dataAttributes"]
が true である場合、element["attributes"]
から、item がカスタムデータ属性であるすべての項目
item を除去する。
element["removeAttributes"]
が存在する場合:
element["removeAttributes"]
を、element["removeAttributes"]
から集合を作成した結果に設定する。
element["removeAttributes"]
を、element["removeAttributes"]
と configuration["attributes"]
の共通部分に設定する。
それ以外の場合:
element["attributes"]
が存在する場合:
element["attributes"]
を、element["attributes"]
から集合を作成した結果に設定する。
element["attributes"]
を、element["attributes"]
と、既定値を
« » とした element["removeAttributes"]
の
差に設定する。
element["removeAttributes"]
を除去する。
element["attributes"]
を、element["attributes"]
と
configuration["removeAttributes"]
の差に設定する。
element["removeAttributes"]
が存在する場合:
element["removeAttributes"]
を、element["removeAttributes"]
から集合を作成した結果に設定する。
element["removeAttributes"]
を、element["removeAttributes"]
と configuration["removeAttributes"]
の差に設定する。
configuration["elements"]
のうち、name
メンバーが element の name
メンバーであり、namespace
メンバーが
element の namespace
メンバーである項目を currentElement とする。
element が currentElement と等しい場合、 modified を返す。
true を返す。
それ以外の場合:
element["attributes"]
が存在するか、既定値を
« » とした element["removeAttributes"]
が空でない場合、false を返す。
configuration["replaceWithChildrenElements"]
から element を除去した
結果を modified とする。
configuration["removeElements"]
が element を含まない場合、
modified を返す。
configuration["removeElements"]
から element を除去する。
true を返す。
replaceElementWithChildren(element)
メソッドの手順は次のとおりである:
element を正規化した結果を element に設定する。
組み込みの置換不可能な要素 リストが element を含む場合、false を返す。
configuration["elements"]
から element を除去した
結果を modified とする。
configuration["removeElements"]
から element を除去した結果が true である場合、
modified を true に設定する。
configuration["replaceWithChildrenElements"]
が element を含まない場合:
element を
configuration["replaceWithChildrenElements"]
へ付加する。
true を返す。
modified を返す。
allowAttribute(attribute) メソッドの
手順は次のとおりである:
attribute を正規化した結果を attribute に設定する。
configuration["attributes"]
が存在する場合:
configuration["dataAttributes"]
が true であり、
attribute がカスタムデータ属性である場合、false を返す。
configuration["attributes"]
が attribute を含む場合、false を返す。
configuration["elements"]
が存在する場合:
configuration["elements"]
内の各 element について反復する:
既定値を « » とした element["attributes"]
が attribute を含む場合、
element["attributes"]
から attribute を除去する。
attribute を
configuration["attributes"]
へ付加する。
true を返す。
それ以外の場合:
configuration["removeAttributes"]
が attribute を含まない場合、
false を返す。
configuration["removeAttributes"]
から attribute を除去する。
true を返す。
setComments(allow) メソッドの手順は
次のとおりである:
setDataAttributes(allow) メソッドの
手順は次のとおりである:
configuration["attributes"]
が存在しない場合、false を返す。
configuration["dataAttributes"]
が存在し、
allow と等しい場合、false を返す。
allow が true である場合:
configuration["elements"]
が存在する場合:
configuration["elements"]
の各 element について反復する:
element["attributes"]
が存在する場合、
element["attributes"]
から、item がカスタムデータ属性であるすべての項目
item を除去する。
configuration["attributes"]
から、item がカスタムデータ属性であるすべての項目
item を除去する。
configuration["dataAttributes"]
を allow に設定する。
true を返す。
allowProcessingInstruction(pi)
メソッドの手順は次のとおりである:
pi を正規化した結果を pi に設定する。
configuration["processingInstructions"]
が存在する場合:
configuration["processingInstructions"]
が pi を含む場合、false を返す。
pi を
configuration["processingInstructions"]
へ付加する。
true を返す。
それ以外の場合:
configuration["removeProcessingInstructions"]
が pi を含む場合:
configuration["removeProcessingInstructions"]
から pi を除去する。
true を返す。
false を返す。
removeProcessingInstruction(pi)
メソッドの手順は次のとおりである:
pi を正規化した結果を pi に設定する。
configuration["processingInstructions"]
が存在する場合:
configuration["processingInstructions"]
が pi を含む場合:
configuration["processingInstructions"]
から pi を除去する。
true を返す。
false を返す。
それ以外の場合:
configuration["removeProcessingInstructions"]
が pi を含む場合、false を返す。
pi を
configuration["removeProcessingInstructions"]
へ付加する。
true を返す。
removeUnsafe() メソッドの手順は、this の
構成から安全でないものを除去した
結果を返すことである。
dictionary SanitizerElementNamespace {
required DOMString name ;
DOMString ? _namespace = "http://www.w3.org/1999/xhtml";
};
// Used by "elements"
dictionary SanitizerElementNamespaceWithAttributes : SanitizerElementNamespace {
sequence <SanitizerAttribute > attributes ;
sequence <SanitizerAttribute > removeAttributes ;
};
dictionary SanitizerAttributeNamespace {
required DOMString name ;
DOMString ? _namespace = null ;
};
dictionary SanitizerProcessingInstruction {
required DOMString target ;
};
typedef (DOMString or SanitizerElementNamespace ) SanitizerElement ;
typedef (DOMString or SanitizerElementNamespaceWithAttributes ) SanitizerElementWithAttributes ;
typedef (DOMString or SanitizerProcessingInstruction ) SanitizerPI ;
typedef (DOMString or SanitizerAttributeNamespace ) SanitizerAttribute ;
dictionary SanitizerConfig {
sequence <SanitizerElementWithAttributes > elements ;
sequence <SanitizerElement > removeElements ;
sequence <SanitizerElement > replaceWithChildrenElements ;
sequence <SanitizerPI > processingInstructions ;
sequence <SanitizerPI > removeProcessingInstructions ;
sequence <SanitizerAttribute > attributes ;
sequence <SanitizerAttribute > removeAttributes ;
boolean comments ;
boolean dataAttributes ;
};SanitizerElementNamespace、
SanitizerAttributeNamespace、
SanitizerElementNamespaceWithAttributes、
および
SanitizerProcessingInstruction
辞書は、それらのすべてのメンバーが等しい場合に等しいと見なされる。
代わりに、等価性は Infra 仕様で定義されるべきである。課題 #664を参照。
この節は非規範的である。
構成は、開発者の目的に合わせて変更でき、また変更すべきである。選択肢としては、新しい
SanitizerConfig 辞書を
ゼロから記述する方法、変更用メソッドを使用して既存の
Sanitizer の構成を変更する方法、または既存の Sanitizer の
構成を辞書として get() し、
その辞書を変更した後、それを使用して新しい
Sanitizer を作成する方法がある。
空の構成は、setHTMLUnsafe()
のような「安全でない」メソッドで呼び出された場合、すべてを許可する。
構成「default」には、
組み込みの安全な既定構成が含まれる。
「安全な」無害化器メソッドと「安全でない」無害化器メソッドでは、既定値が異なることに注意。
すべての構成辞書が有効であるとは限らない。有効な構成は、冗長性(同じ要素を二度許可するよう指定することなど)や 矛盾(ある要素を除去すると同時に許可するよう指定することなど)を回避する。
構成が有効であるためには、いくつかの条件が満たされる必要がある:
大域許可リストと大域除去リストの混在:
elements
または removeElements
のいずれかは存在できるが、両方は存在できない。両方とも欠けている場合、これは removeElements
が空のリストであることと同等である。
attributes
または removeAttributes
のいずれかは存在できるが、両方は存在できない。
両方とも欠けている場合、これは removeAttributes
が空のリストであることと同等である。
dataAttributes
は概念的には attributes
許可リストの拡張である。
dataAttributes
メンバーは、attributes
リストが使用される場合にのみ許可される。
異なる大域リスト間の重複項目:
elements、
removeElements、
または replaceWithChildrenElements
の間に重複項目(すなわち同じ要素)は存在しない。
attributes
と removeAttributes
の間に重複項目(すなわち同じ属性)は存在しない。
同じ要素上での局所許可リストと局所除去リストの混在:
attributes
リストが存在する場合、同じ要素上では attributes
リストと removeAttributes
リストの両方、一方、またはいずれも存在しないことが許可される。
removeAttributes
リストが存在する場合、同じ要素上では attributes
リストと removeAttributes
リストのいずれか一方、またはいずれも存在しないことが許可されるが、両方は許可されない。
同じ要素上の重複項目:
同じ要素上の attributes
と removeAttributes
の間に重複項目は存在しない。
組み込みの置換不可能な要素リストにある要素は、
replaceWithChildrenElements
に現れない。これらの要素をその子で置換すると、再構文解析の問題や無効なノードツリーが生じる可能性があるためである。
elements
要素許可リストでは、特定の要素について属性を許可または除去することも指定できる。これは、特定の要素に適用される局所属性と
大域属性の両方を認識する、この標準の構造を反映することを意図している。
大域属性と局所属性は混在させられるが、ある属性が一方のリストでは許可され、もう一方では禁止されるような曖昧な構成は、
一般に無効であることに注意。
大域 attributes
|
大域 removeAttributes
|
|
|---|---|---|
局所 attributes
|
属性はいずれかのリストに一致すれば許可される。重複は許可されない。 | 属性は局所許可リストにある場合にのみ許可される。大域除去リストと局所許可リストの間に重複項目は許可されない。 大域除去リストはこの特定の要素に対しては機能しないが、局所許可リストを持たない他の要素には適用できることに注意。 |
局所 removeAttributes
|
属性は大域許可リストにあり、かつ局所除去リストにない場合に許可される。 局所除去リストは大域許可リストの部分集合でなければならない。 | 属性はいずれのリストにもない場合に許可される。大域除去リストと局所除去リストの間に重複項目は許可されない。 |
大域リストと要素ごとのリストの間では、ほとんどの場合重複が許可されない一方、 大域許可リストと要素ごとの除去リストの場合、後者が前者の部分集合でなければならないという非対称性に注意。 重複のみに焦点を当てた上表の抜粋は、次のとおりである:
大域 attributes
|
大域 removeAttributes
|
|
|---|---|---|
局所 attributes
|
重複は許可されない。 | 重複は許可されない。 |
局所 removeAttributes
|
局所除去リストは大域許可リストの部分集合でなければならない。 | 重複は許可されない。 |
dataAttributes
設定は、
カスタムデータ属性を許可する。
dataAttributes
を許可リストと見なせば、上記の規則は
カスタムデータ属性にも容易に拡張できる:
大域 attributes
と dataAttributes
が設定されている |
|
|---|---|
局所 attributes
|
すべてのカスタムデータ属性が許可される。 どのカスタムデータ属性も、 それが重複項目を意味するため、いかなる許可リストにも列挙できない。 |
局所 removeAttributes
|
カスタムデータ属性は、 局所除去リストに列挙されていない限り許可される。どのカスタムデータ属性も、 それが重複項目を意味するため、大域許可リストには列挙できない。 |
これらの規則を言葉で表すと、次のようになる:
大域リストと局所リストの重複および相互作用:
大域 attributes
許可リストが存在する場合、すべての要素の局所リストについて:
局所 attributes
許可リストが存在する場合、これらのリスト間に重複項目は存在できない。
局所 removeAttributes
除去リストが存在する場合、そのすべての項目は大域 attributes
許可リストにも列挙されている必要がある。
dataAttributes
が true の場合、どのカスタムデータ属性も、
いかなる許可リストにも列挙できない。
大域 removeAttributes
除去リストが存在する場合:
局所 attributes
許可リストが存在する場合、これらのリスト間に重複項目は存在できない。
局所 removeAttributes
除去リストが存在する場合、これらのリスト間に重複項目は存在できない。
局所 attributes
許可リストと局所 removeAttributes
除去リストの両方が存在することはできない。
dataAttributes
は false でなければならない。
Element
または
DocumentFragment
target、文字列 html、辞書 options、および真偽値
safe が与えられたとき、HTML を設定してフィルタリングするには:
target が Element
である場合は target を、それ以外の場合は target の
ホストを context とする。
表明:context は非 null である。
次のすべてが true である場合:
その場合、返る。
safe を与えて options から 無害化器を取得した結果を sanitizer とする。
scriptingMode を 不活性とする。
options["runScripts"]
が true である場合:
target、html、true、および scriptingMode を与えて HTML 断片構文解析アルゴリズムを 呼び出した結果を fragment とする。
fragment 内のスクリプトは、target に挿入された後にのみ実行される。
sanitizer と safe を与えて、 fragment を無害化する。
target 内を fragment ですべて置換する。
辞書 options と真偽値 safe から 無害化器のインスタンスを取得するには:
sanitizerSpec を「default」とする。
options["sanitizer"]
が存在する場合、sanitizerSpec を
options["sanitizer"]
に設定する。
表明:sanitizerSpec は
Sanitizer インスタンス、
SanitizerPresets メンバー、
または SanitizerConfig 辞書のいずれかである。
sanitizerSpec が文字列である場合:
sanitizerSpec を組み込みの安全な既定構成に設定する。
sanitizerSpec が辞書である場合:
sanitizerSpec を返す。
Node
node を、Sanitizer
sanitizer と真偽値 safe を用いて
無害化するには:
sanitizer の構成を configuration とする。
safe が true である場合、configuration から 安全でないものを除去する。
node、configuration、および safe を与えて、 内部無害化手順を実行する。
Node
node、SanitizerConfig
configuration、および真偽値
handleJavascriptNavigationUrls が与えられたとき、
内部無害化手順を実行するには:
表明:child は Text、
Comment、
Element、
ProcessingInstruction、
または DocumentType
ノードである。
child が DocumentType
または Text
ノードである場合、
継続する。
child が Comment
ノードである場合:
child が ProcessingInstruction
ノードである場合:
child の対象を piTarget とする。
configuration["processingInstructions"]
が存在する場合:
configuration["processingInstructions"]
が piTarget を含まない場合、
child を除去する。
それ以外の場合:
configuration["removeProcessingInstructions"]
が piTarget を含む場合、
child を除去する。
それ以外の場合:
child の局所名と名前空間を持つ SanitizerElementNamespace を elementName とする。
configuration["replaceWithChildrenElements"]
が存在し、かつ configuration["replaceWithChildrenElements"]
が elementName を含む場合:
それ以外の場合:
configuration["removeElements"]
が elementName を含む場合、
child を除去し、
継続する。
elementName["name"]
が「template」であり、
elementName["namespace"]
が HTML
名前空間である場合、
child のテンプレート内容、
configuration、および
handleJavascriptNavigationUrls を与えて、
内部無害化手順を実行する。
child がシャドウホストである場合、 child のシャドウルート、 configuration、および handleJavascriptNavigationUrls を与えて、 内部無害化手順を実行する。
elementWithLocalAttributes を «[ ]» とする。
configuration["elements"]
が存在し、かつ configuration["elements"]
が elementName を含む場合、
elementWithLocalAttributes を configuration["elements"][elementName]
に設定する。
child の属性リスト内の各 attribute について反復する:
attribute の局所名と名前空間を持つ SanitizerAttributeNamespace を attrName とする。
elementWithLocalAttributes["removeAttributes"]
が存在し、かつ
elementWithLocalAttributes["removeAttributes"]
が attrName を含む場合、
attribute を除去する。
それ以外で、configuration["attributes"]
が存在する場合:
configuration["attributes"]
が attrName を含まず、かつ
elementWithLocalAttributes["attributes"]
が既定値 « » を伴い、
attrName を含まず、さらに「data-」が
attribute の局所名のコード単位接頭辞でないか、
attribute の名前空間が null でないか、
configuration["dataAttributes"]
が true でない場合、
attribute を除去する。
それ以外の場合:
elementWithLocalAttributes["attributes"]
が存在し、かつ
elementWithLocalAttributes["attributes"]
が attrName を含まない場合、
attribute を除去する。
それ以外で、configuration["removeAttributes"]
が attrName を含む場合、
attribute を除去する。
handleJavascriptNavigationUrls が true である場合:
対 (elementName, attrName) が
組み込みのナビゲーション URL
属性リストの項目と一致し、かつ attribute が
javascript:
URL を含む場合、attribute を除去する。
child の名前空間が
MathML 名前空間であり、
attribute の局所名が「href」であり、
attribute の名前空間が null または
XLink 名前空間であり、かつ
attribute がjavascript: URL を含む場合、
attribute を除去する。
組み込みのアニメーション URL
属性リストが対 (elementName, attrName) を含み、かつ
attribute の値が「href」または
「xlink:href」である場合、attribute を除去する。
child、configuration、および handleJavascriptNavigationUrls を与えて、 内部無害化手順を実行する。
属性 attribute が
javascript:
URL を含むかどうかを判定するには:
attribute の値に対して基本 URL 構文解析器を実行した結果を url とする。
url が失敗である場合、false を返す。
url のスキームが
「javascript」である場合は true を、それ以外の場合は false を返す。
SanitizerConfig configuration から element を 除去するには:
element を、element を正規化した結果に設定する。
configuration["replaceWithChildrenElements"]
から element を除去した結果を modified
とする。
それ以外の場合:
configuration["removeElements"]
が element を含む場合、modified を返す。
element を configuration["removeElements"]
に付加する。
true を返す。
SanitizerConfig configuration から attribute を 除去するには:
attribute を、attribute を正規化した結果に設定する。
configuration["attributes"]
が存在する場合:
configuration["attributes"]
から attribute を除去した結果を
modified とする。
configuration["elements"]
が存在する場合:
configuration["elements"]
の各 element について反復する:
element["attributes"]
が既定値 « » を伴い、
attribute を含む場合:
modified を true に設定する。
element["attributes"]
から attribute を除去する。
element["removeAttributes"]
が既定値 « » を伴い、
attribute を含む場合:
表明:modified は true である。
element["removeAttributes"]
から attribute を除去する。
modified を返す。
それ以外の場合:
configuration["removeAttributes"]
が attribute を含む場合、false を返す。
configuration["elements"]
が存在する場合:
configuration["elements"]
内の各 element について反復する:
element["attributes"]
が既定値 « » を伴い、
attribute を含む場合、
element["attributes"]
から attribute を除去する。
element["removeAttributes"]
が既定値 « » を伴い、
attribute を含む場合、
element["removeAttributes"]
から attribute を除去する。
attribute を configuration["removeAttributes"]
に付加する。
true を返す。
SanitizerConfig configuration から 安全でないものを除去するには:
result を false とする。
組み込みの安全な基準構成["removeElements"]
内の各 element について反復する:
configuration から element を除去した結果が true である場合、result を true に設定する。
組み込みの安全な基準構成["removeAttributes"]
内の各 attribute について反復する:
configuration から attribute を除去した結果が true である場合、result を true に設定する。
イベントハンドラー内容属性である 各 attribute について反復する:
configuration から attribute を除去した結果が true である場合、result を true に設定する。
result を返す。
itemA と itemB という 無害化器の項目を比較するには:
SanitizerElementWithAttributes element を正規化するには:
element を正規化した結果を result とする。
element が辞書である場合:
element["attributes"]
が存在する場合、
result["attributes"]
を element["attributes"]
を正規化した結果に設定する。
element["removeAttributes"]
が存在する場合、
result["removeAttributes"]
を element["removeAttributes"]
を正規化した結果に設定する。
result["attributes"]
と result["removeAttributes"]
のいずれも存在しない場合、
result["removeAttributes"]
を空のリストに設定する。
result を返す。
正規化された SanitizerConfig config が有効かどうかを判定するには:
渡された構成には、以前に構成を正規化する手順が実行されていることが期待される。 ここでは、そのアルゴリズムによって成立することが保証されている条件を単に表明する。
表明:config["elements"]
が存在するか、
config["removeElements"]
が存在する。
config["elements"]
が存在し、かつ
config["removeElements"]
が存在する場合、false を返す。
表明:config["processingInstructions"]
または config["removeProcessingInstructions"]
のいずれかが存在する。
config["processingInstructions"]
が存在し、かつ config["removeProcessingInstructions"]
が存在する場合、false を返す。
表明:config["attributes"]
または config["removeAttributes"]
のいずれかが存在する。
config["attributes"]
が存在し、かつ config["removeAttributes"]
が存在する場合、false を返す。
表明:config 内のすべての SanitizerElementNamespaceWithAttributes、 SanitizerElementNamespace、 SanitizerProcessingInstruction、および SanitizerAttributeNamespace 項目は 正規化されている。すなわち、必要に応じて正規化が実行されている。
それ以外の場合:
config["removeElements"]
に重複がある場合、false を返す。
config["replaceWithChildrenElements"]
が存在し、かつ重複がある場合、false
を返す。
config["processingInstructions"]
が存在する場合:
config["processingInstructions"]
に重複がある場合、false を返す。
それ以外の場合:
config["removeProcessingInstructions"]
に重複がある場合、false を返す。
config["attributes"]
が存在する場合:
config["attributes"]
に重複がある場合、false を返す。
それ以外の場合:
config["removeAttributes"]
に重複がある場合、false を返す。
config["replaceWithChildrenElements"]
が存在する場合:
config["replaceWithChildrenElements"]
の各 element について反復する:
組み込みの置換不可能な要素リストが element を含む場合、false を返す。
config["elements"]
と config["replaceWithChildrenElements"]
の積集合が空でない場合、
false を返す。
それ以外の場合:
config["removeElements"]
と config["replaceWithChildrenElements"]
の積集合が空でない場合、
false を返す。
config["attributes"]
が存在する場合:
表明:config["dataAttributes"]
が存在する。
config["elements"]
の各 element について反復する:
element["attributes"]
が存在し、かつ
element["attributes"]
に重複がある場合、false を返す。
element["removeAttributes"]
が存在し、かつ
element["removeAttributes"]
に重複がある場合、false を返す。
config["attributes"]
と、既定値 « » を伴う
element["attributes"]
の積集合が空でない場合、
false を返す。
既定値 « » を伴う
element["removeAttributes"]
が config["attributes"]
の部分集合でない場合、false を返す。
config["dataAttributes"]
が true であり、かつ
element["attributes"]
がカスタムデータ属性を含む場合、
false を返す。
config["dataAttributes"]
が true であり、かつ
config["attributes"]
がカスタムデータ属性を含む場合、
false を返す。
それ以外の場合:
config["elements"]
の各 element について反復する:
element["attributes"]
が存在し、かつ
element["removeAttributes"]
が存在する場合、false を返す。
element["attributes"]
が存在し、かつ
element["attributes"]
に重複がある場合、false を返す。
element["removeAttributes"]
が存在し、かつ
element["removeAttributes"]
に重複がある場合、false を返す。
config["removeAttributes"]
と、既定値 « » を伴う
element["attributes"]
の積集合が空でない場合、
false を返す。
config["removeAttributes"]
と、既定値 « » を伴う
element["removeAttributes"]
の積集合が空でない場合、
false を返す。
config["dataAttributes"]
が存在する場合、false を返す。
true を返す。
要素の無害化カテゴリーは、次のいずれかである:
SanitizerConfig
に含まれる。setHTMLUnsafe()
または parseHTMLUnsafe()
によって保持され、
setHTML()、parseHTML()、
および removeUnsafe()
によって除去される。)
SanitizerConfig
に追加できる。
組み込みの安全な基準構成は
SanitizerConfig である。その
removeElements
リストは、個々の定義内で規範的に安全でないと示されるすべての HTML 要素、
廃止された frame 要素、ならびに
SVG
script 要素および
SVG use 要素からなり、その
removeAttributes
リストは空である。
イベントハンドラー内容属性は、安全な無害化の際に安全でないものを除去するアルゴリズムによって自動的に除去されるため、
実効的な基準構成は、それらが removeAttributes
リストに含まれているかのように動作する。
組み込みの安全な既定構成は、メンバーが次のように初期化される SanitizerConfig である:
processingInstructions
attributes
dirlangtitlealignment-baseline
baseline-shift
clip-path
clip-rule
color
color-interpolation
cursor
direction
display
displaystyle
dominant-baseline
fill
fill-opacity
fill-rule
font-family
font-size
font-size-adjust
font-stretch
font-style
font-variant
font-weight
letter-spacing
marker-end
marker-mid
marker-start
mathbackground
mathcolor
mathsize
opacity
paint-order
pointer-events
scriptlevel
shape-rendering
stop-color
stop-opacity
stroke
stroke-dasharray
stroke-dashoffset
stroke-linecap
stroke-linejoin
stroke-miterlimit
stroke-opacity
stroke-width
text-anchor
text-decoration
text-overflow
text-rendering
transform
transform-origin
unicode-bidi
vector-effect
visibility
white-space
word-spacing
writing-mode
comments
dataAttributes
elements
attributes
リストに含まれる。
次の表は、組み込みの安全な既定構成において
既定として分類される MathML
および SVG 要素を、
SanitizerElementNamespaceWithAttributes
辞書のリストとして列挙している。表の各行について、「要素」列は
name
メンバーに対応し、「名前空間」列は
namespace
メンバーに対応し、「許可される属性」列は
attributes
メンバーに対応する(列挙された各属性は、シーケンス内の
SanitizerAttribute として表される):
組み込みのナビゲーション URL 属性リストは、
規範的な定義内でナビゲーション URL 属性を持つと示された
すべての HTML 要素と、次の表に示される要素と属性の対に対応する。表の各行について、
要素は、「要素」列によって name
メンバーが与えられ、「要素の名前空間」列によって namespace
メンバーが与えられる
SanitizerElementNamespace に対応する。
属性は、「属性」列によって name
メンバーが与えられ、「属性の名前空間」列によって namespace
メンバーが与えられる
SanitizerAttributeNamespace に対応する:
| 要素 | 要素の名前空間 | 属性 | 属性の名前空間 |
|---|---|---|---|
a
|
SVG | href
|
名前空間なし |
a
|
SVG | href
|
XLink |
組み込みのアニメーション URL 属性リストは、
次の表で示される要素と属性の対のリストである。表の各行について、
要素は、「要素」列によって name
メンバーが与えられ、「要素の名前空間」列によって namespace
メンバーが与えられる
SanitizerElementNamespace に対応する。
属性は、「属性」列によって name
メンバーが与えられ、namespace
メンバーが null である
SanitizerAttributeNamespace に対応する:
| 要素 | 要素の名前空間 | 属性 |
|---|---|---|
animate
|
SVG | attributeName
|
animateTransform
|
SVG | attributeName
|
set
|
SVG | attributeName
|
組み込みの置換不可能な要素リストには、
子で置換してはならない要素が含まれる。置換すると、再構文解析の問題や無効なノードツリーが生じる可能性があるためである。
これは、次の表で表される
SanitizerElementNamespace
辞書のリストである。表の各行について、「要素」列は
name
メンバーに対応し、「要素の名前空間」列は
namespace
メンバーに対応する:
| 要素 | 要素の名前空間 |
|---|---|
html
|
HTML |
svg
|
SVG |
math
|
MathML |
この節は非規範的である。
Sanitizer API は、提供された HTML 内容を走査し、構成に従って要素と属性を除去することにより、
DOM ベースのクロスサイトスクリプティングを防止することを意図している。設計上、
setHTML()
および parseHTML()
メソッドは、提供された構成にかかわらず、スクリプトを実行できるマークアップを除去する。
これらのメソッドを通じてそのようなマークアップを保持できる構成が存在するなら、それはバグである。
ただし、Sanitizer API では防止できないセキュリティ上の問題もある。次の各節でそれらについて説明する。
この節は非規範的である。
Sanitizer API は DOM 内でのみ動作し、既存の
DocumentFragment
を走査してフィルタリングする機能を追加する。Sanitizer API は、サーバー側の反射型 XSS または格納型 XSS には対処しない。
この節は非規範的である。
DOM クロバーリングとは、悪意のある HTML が id
または name 属性を使用し、HTML 要素の children
プロパティなどの DOM プロパティを悪意のある内容によって隠蔽することで、
アプリケーションを混乱させる攻撃を指す。
Sanitizer API は既定では DOM クロバーリング攻撃から保護しないが、id
および name 属性を除去するよう構成できる。
この節は非規範的である。
スクリプトガジェットとは、攻撃者が一般的な JavaScript ライブラリーにある既存のアプリケーションコードを利用して、 自身のコードを実行させる手法である。これは多くの場合、無害に見えるコードまたは一見不活性な DOM ノードを注入し、 フレームワークだけにそれらを構文解析および解釈させ、その入力に基づいて JavaScript を実行させることで行われる。
Sanitizer API はこれらの攻撃を防止できない。その代わり、一般に未知の要素を明示的に許可することに加え、
テンプレート処理やフレームワーク固有のコードで一般的に使用される属性、要素、およびマークアップ、
たとえば data-* 属性、
slot 属性、
ならびに slot や
template
のような要素も明示的に許可することを、著者に要求している。
これらの制限は網羅的ではなく、著者には、使用する第三者ライブラリーにこのような動作がないか確認することが推奨される。
この節は非規範的である。
変異型 XSS(mXSS)とは、構文解析された DOM 構造がシリアル化して再度構文解析した後の構造と同じでない場合を悪用し、 シリアル化前に行われる無害化を回避する攻撃を指す。このような攻撃は、たとえば外来内容や誤って入れ子にされたタグで 構文解析の動作が変化することを利用して実行できる。
Sanitizer API が提供するのは、文字列をノードツリーへ変換する関数だけである。 文脈はすべての無害化関数によって暗黙的に提供される。setHTML() は現在の要素を使用し、Document.parseHTML() は新しい文書を作成する。 したがって、Sanitizer API は変異型 XSS の直接的な影響を受けない。
開発者が無害化されたノードツリーを、たとえば innerHTML
を通じて文字列として取得し、その後それを再び構文解析すると、変異型 XSS が発生する可能性がある。
この慣行は強く非推奨とされる。それでも文字列としての HTML の処理または受け渡しが必要な場合、
すべての文字列を信頼できないものと見なし、DOM に挿入するときに再び無害化する必要がある。
つまり、無害化した後にシリアル化された HTML ツリーは、もはや無害化済みとは見なせない。
mXSS のより完全な解説は [MXSS] にある。
setTimeout() および
setInterval()
メソッドを使用すると、著者はタイマーに基づくコールバックをスケジュールできる。
id = self.setTimeout(handler [, timeout [, ...arguments ] ])
現在のすべてのエンジンでサポートされている。
timeout ミリ秒後に handler を実行するタイムアウトをスケジュールする。 すべての arguments は、そのまま handler に渡される。
id = self.setTimeout(code [, timeout ])
timeout ミリ秒後に code をコンパイルして実行するタイムアウトをスケジュールする。
self.clearTimeout(id)
現在のすべてのエンジンでサポートされている。
id によって識別される、setTimeout()
または
setInterval()
で設定されたタイムアウトを取り消す。
id = self.setInterval(handler [, timeout [, ...arguments ] ])
現在のすべてのエンジンでサポートされている。
timeout ミリ秒ごとに handler を実行するタイムアウトをスケジュールする。 すべての arguments は、そのまま handler に渡される。
id = self.setInterval(code [, timeout ])
timeout ミリ秒ごとに code をコンパイルして実行するタイムアウトをスケジュールする。
self.clearInterval(id)
現在のすべてのエンジンでサポートされている。
id によって識別される、setInterval()
または
setTimeout()
で設定されたタイムアウトを取り消す。
タイマーは入れ子にできる。ただし、このように入れ子になったタイマーが五つに達した後は、 間隔が少なくとも 4 ミリ秒になるよう強制される。
この API は、タイマーが正確に予定どおり実行されることを保証しない。 CPU 負荷や他のタスクなどによる遅延が生じることは予想される。
WindowOrWorkerGlobalScope
ミックスインを実装するオブジェクトは、初期状態で空の順序付きマップである
setTimeout
および setInterval ID のマップを持つ。
このマップ内の各キーは、
setTimeout() または
setInterval()
呼び出しの戻り値に対応する正の整数である。各値は、オブジェクトのアクティブなタイマーのマップ内の
キーに対応する一意の内部値である。
setTimeout(handler, timeout,
...arguments) メソッドの手順は、
this、handler、timeout、
arguments、および false を与えてタイマー初期化手順を実行した結果を返すことである。
setInterval(handler, timeout,
...arguments) メソッドの手順は、
this、handler、timeout、
arguments、および true を与えてタイマー初期化手順を実行した結果を返すことである。
clearTimeout(id) および clearInterval(id) メソッドの手順は、
this のsetTimeout および
setInterval ID のマップ[id]
を除去することである。
clearTimeout() と
clearInterval() は
同じマップから項目を消去するため、どちらのメソッドも
setTimeout() または
setInterval()
によって作成されたタイマーを消去するために使用できる。
WindowOrWorkerGlobalScope
global、文字列または Function
または TrustedScript
handler、数値 timeout、リスト arguments、
真偽値 repeat、および任意選択で(かつ repeat が true の場合に限り)
数値 previousId が与えられたとき、
タイマー初期化手順を実行するには、
次の手順を実行する。これらは数値を返す。
global が WorkerGlobalScope
オブジェクトである場合は global を thisArg とし、
それ以外の場合は global に対応する WindowProxy を
thisArg とする。
previousId が与えられている場合は previousId を id とする。それ以外の場合は、0 より大きく、global の setTimeout および setInterval ID のマップに まだ存在しない 実装定義の整数を id とする。
周囲のエージェントのイベントループの現在実行中のタスクが このアルゴリズムによって作成されたタスクである場合、 タスクのタイマーの入れ子レベルを nesting level とする。それ以外の場合、nesting level を 0 とする。
タスクのタイマーの入れ子レベルは、
setTimeout() の
入れ子になった呼び出しと、setInterval()
によって作成される反復タイマーの両方に使用される。(実際には、この二つの任意の組み合わせにも使用される。)
つまり、これは特定のメソッドではなく、このアルゴリズムの入れ子になった呼び出しを表す。
timeout が 0 未満である場合、timeout を 0 に設定する。
nesting level が 5 より大きく、かつ timeout が 4 未満である場合、 timeout を 4 に設定する。
global の関連レルムを realm とする。
アクティブスクリプトを initiating script とする。
uniqueHandle を null とする。
次の下位手順を実行するタスクを task とする:
id が global のsetTimeout および setInterval ID のマップに 存在しない場合、 これらの手順を中止する。
global のsetTimeout および setInterval ID のマップ[id] が uniqueHandle と等しくない場合、これらの手順を中止する。
これは、clearTimeout() または
clearInterval()
の呼び出しによって ID が消去された後、後続の
setTimeout() または
setInterval()
の呼び出しによって再利用される場合に対応する。
global の関連設定オブジェクトを settings object とする。
settings object についてスクリプトが無効である場合、 これらの手順を中止する。
handler、settings object、および repeat を与えて、 タイマーハンドラーのタイミング情報を記録する。
handler が Function
である場合、arguments と「report」を与え、
コールバック this 値を
thisArg に設定して、handler を呼び出す。
それ以外の場合:
previousId が与えられていない場合:
global が Window オブジェクトである場合は
「Window」を、それ以外の場合は「WorkerGlobalScope」を
globalName とする。
repeat が true である場合は「setInterval」を、
それ以外の場合は「setTimeout」を methodName とする。
globalName、U+0020 SPACE、および methodName を連結したものを sink とする。
TrustedScript、
global、handler、sink、および
「script」を用いてTrusted Type
準拠文字列を取得する
アルゴリズムを呼び出した結果に handler を設定する。
表明:handler は文字列である。
EnsureCSPDoesNotBlockStringCompilation(realm, « », handler, handler, timer, « », handler) を実行する。 これが例外を送出した場合は、その例外を捕捉し、global について報告し、 これらの手順を中止する。
既定のスクリプト取得オプションを fetch options とする。
settings object のAPI ベース URLを base URL とする。
initiating script が null でない場合:
fetch options を、次のスクリプト取得オプションに設定する。
暗号学的ノンスは
initiating script の取得オプションの暗号学的ノンス、
完全性メタデータは空文字列、
構文解析器メタデータは
「not-parser-inserted」、
資格情報モードは
initiating script の取得オプションの資格情報モード、
リファラーポリシーは
initiating script の取得オプションのリファラーポリシー、
取得優先度は
「auto」である。
base URL を initiating script のベース URLに設定する。
これらの手順により、setTimeout() および
setInterval()
によって行われる文字列のコンパイルが、eval()
によって行われるものと同等に動作することが保証される。すなわち、import()
を介したモジュールスクリプトの取得は、どちらの文脈でも同じように動作する。
handler、settings object、base URL、および fetch options を与えて古典スクリプトを作成した結果を script とする。
古典スクリプト script を実行する。
id が global のsetTimeout および setInterval ID のマップに 存在しない場合、 これらの手順を中止する。
global のsetTimeout および setInterval ID のマップ[id] が uniqueHandle と等しくない場合、これらの手順を中止する。
handler 内の著者コードが
clearTimeout() または
clearInterval()
を呼び出すことにより、ID が除去されている可能性がある。
uniqueHandle が異ならないことを確認することで、消去された後の ID が後続の
setTimeout() または
setInterval()
呼び出しによって再利用される可能性に対処する。
repeat が true である場合、global、handler、 timeout、arguments、true、および id を与えて、 タイマー初期化手順を再び実行する。
それ以外の場合、global のsetTimeout および setInterval ID のマップ[id] を除去する。
nesting level を 1 増加させる。
task のタイマーの入れ子レベルを nesting level に設定する。
global を与えて、task を実行する大域タスクをキューに追加する アルゴリズム手順を completionStep とする。このタスクは タイマータスクソース上にキューされる。
global、「setTimeout/setInterval」、timeout、および
completionStep を与えてタイムアウト後に手順を実行した結果に
uniqueHandle を設定する。
global のsetTimeout および setInterval ID のマップ[id] を uniqueHandle に設定する。
id を返す。
Web IDL によって定義される引数変換(たとえば、最初の引数として渡されたオブジェクトの
toString() メソッドを呼び出すこと)は、このアルゴリズムが呼び出される前に、
Web IDL で定義されたアルゴリズム内で行われる。
たとえば、次のややばかげたコードを実行すると、ログには
「ONE TWO 」が含まれることになる:
var log = '' ;
function logger( s) { log += s + ' ' ; }
setTimeout({ toString: function () {
setTimeout( "logger('ONE')" , 100 );
return "logger('TWO')" ;
} }, 100 ); ユーザーインターフェイスを処理できなくなることを避けるため(また、CPU の占有を理由にブラウザーが スクリプトを終了することを避けるため)ブラウザーへ制御を戻しながら、数ミリ秒のタスクを遅延なく 連続して実行するには、処理を実行する前に次のタイマーをキューへ追加するだけでよい:
function doExpensiveWork() {
var done = false ;
// ...
// this part of the function takes up to five milliseconds
// set done to true if we're done
// ...
return done;
}
function rescheduleWork() {
var id = setTimeout( rescheduleWork, 0 ); // preschedule next iteration
if ( doExpensiveWork())
clearTimeout( id); // clear the timeout if we don't need it
}
function scheduleWork() {
setTimeout( rescheduleWork, 0 );
}
scheduleWork(); // queues a task to do lots of work WindowOrWorkerGlobalScope
ミックスインを実装するオブジェクトは、初期状態で空の順序付きマップである
アクティブなタイマーのマップを持つ。
このマップ内の各キーは、
タイマーを表す一意の内部値であり、各値は、
そのタイマーの満了時刻を表す
DOMHighResTimeStamp
である。
WindowOrWorkerGlobalScope
global、文字列 orderingIdentifier、数値 milliseconds、および
手順の集合 completionSteps が与えられたとき、
タイムアウト後に手順を実行するには、
次の手順を実行する。これらは一意の内部値を返す。
timerKey を新しい一意の内部値とする。
global を与えた現在の高分解能時刻を startTime とする。
global のアクティブなタイマーのマップ[timerKey] を startTime に milliseconds を加えた値に設定する。
次の手順を並行して実行する:
global が Window オブジェクトである場合、
global の関連付けられた
Documentが、
さらに milliseconds ミリ秒間(必ずしも連続している必要はない)
完全にアクティブになるまで待つ。
それ以外の場合、global は WorkerGlobalScope
オブジェクトである。ワーカーが一時停止していない状態で
milliseconds ミリ秒が経過するまで待つ(必ずしも連続している必要はない)。
同じ global と orderingIdentifier を持ち、 この呼び出しより前に開始され、その milliseconds がこの呼び出しの値以下である、 このアルゴリズムのすべての呼び出しが完了するまで待つ。
任意選択で、さらに実装定義の時間だけ待つ。
これは、端末の電力使用量を最適化するため、必要に応じてユーザーエージェントが タイムアウトに時間を上乗せできるようにすることを意図している。たとえば、一部のプロセッサーには タイマーの粒度が低下する低電力モードがある。そのようなプラットフォームでは、ユーザーエージェントは、 より正確で、それに伴って消費電力も高いモードをプロセッサーに使用させる代わりに、 このスケジュールに合わせてタイマーを遅くできる。
completionSteps を実行する。
global のアクティブなタイマーのマップ[timerKey] を除去する。
timerKey を返す。
タイムアウト後に手順を実行するは、
開発者が指定したタイムアウトの後、setTimeout()
と同様の方法で開発者提供のコードを実行する必要がある他の仕様によって使用されることを意図している。
(ただし、setTimeout()
が持つ入れ子およびクランプ動作は備えていない。)
そのような仕様は、他の仕様のタイムアウトに対する順序を制約せずに、
自身の仕様のタイムアウト内で順序を保証するための orderingIdentifier を選択できる。
現在のすべてのエンジンでサポートされている。
queueMicrotask(callback) メソッドは、
« » と「report」を用いて callback を呼び出すためのマイクロタスクをキューに追加しなければならない。
queueMicrotask()
メソッドを使用すると、著者はマイクロタスクキュー上にコールバックをスケジュールできる。
これにより、現在実行中のすべての同期 JavaScript の実行が完了して、次に
JavaScript 実行コンテキストスタックが空になったときに、
コードを実行できる。これは、たとえば setTimeout(f, 0)
を使用する場合とは異なり、イベントループへ制御を戻さない。
著者は、多数のマイクロタスクをスケジュールすると、多数の同期コードを実行する場合と同じパフォーマンス上の
欠点が生じることを認識すべきである。どちらも、レンダリングなどのブラウザー自身の処理を妨げる。
多くの場合、requestAnimationFrame()
または
requestIdleCallback()
の方が適切である。特に、次のレンダリングサイクルより前にコードを実行することが目的である場合、
それこそが requestAnimationFrame()
の目的である。
次の例から分かるように、queueMicrotask()
は、同期コードを並べ替え、キューに追加されたコードを、現在実行中の同期 JavaScript の実行が完了した直後へ
実質的に配置する仕組みとして捉えるのが最適である。
queueMicrotask()
を使用する最も一般的な理由は、情報を同期的に利用できる場合であっても、
不必要な遅延を生じさせずに一貫した順序を作ることである。
たとえば、以前に読み込んだデータの内部キャッシュも保持するカスタム要素が、
load イベントを発火する場合を考える。単純な実装は次のようになるだろう:
MyElement. prototype. loadData = function ( url) {
if ( this . _cache[ url]) {
this . _setData( this . _cache[ url]);
this . dispatchEvent( new Event( "load" ));
} else {
fetch( url). then( res => res. arrayBuffer()). then( data => {
this . _cache[ url] = data;
this . _setData( data);
this . dispatchEvent( new Event( "load" ));
});
}
}; しかし、この単純な実装には、利用者に一貫しない動作を経験させるという問題がある。 たとえば、次のようなコードは
element. addEventListener( "load" , () => console. log( "loaded" ));
console. log( "1" );
element. loadData();
console. log( "2" ); データを取得する必要がある場合には「1, 2, loaded」とログへ出力し、
データがすでにキャッシュされている場合には「1, loaded, 2」と出力する。同様に、
loadData() の呼び出し後にデータが要素へ設定されているかどうかも一貫しない。
一貫した順序を得るには、queueMicrotask()
を使用できる:
MyElement. prototype. loadData = function ( url) {
if ( this . _cache[ url]) {
queueMicrotask(() => {
this . _setData( this . _cache[ url]);
this . dispatchEvent( new Event( "load" ));
});
} else {
fetch( url). then( res => res. arrayBuffer()). then( data => {
this . _cache[ url] = data;
this . _setData( data);
this . dispatchEvent( new Event( "load" ));
});
}
}; キューに追加されたコードを、JavaScript 実行コンテキストスタックが 空になった後へ実質的に並べ替えることで、一貫した順序と要素状態の更新が保証される。
queueMicrotask()
のもう一つの興味深い用途は、複数の呼び出し元による、調整を必要としない処理の「バッチ化」を可能にすることである。
たとえば、できるだけ早くデータをどこかへ送信したい一方、容易に回避できる場合には複数のネットワーク要求を
行いたくないライブラリー関数を考える。このバランスを取る方法の一つは、次のようになる:
const queuedToSend = [];
function sendData( data) {
queuedToSend. push( data);
if ( queuedToSend. length === 1 ) {
queueMicrotask(() => {
const stringToSend = JSON. stringify( queuedToSend);
queuedToSend. length = 0 ;
fetch( "/endpoint" , stringToSend);
});
}
} この構成では、現在実行中の同期 JavaScript 内で行われる後続の複数の
sendData() 呼び出しが、一つの fetch()
呼び出しへまとめられるが、取得処理へ割り込むイベントループタスクは存在しない
(代わりに setTimeout()
を使用する同様のコードでは、そのような割り込みが発生していた)。
window.alert(message)
現在のすべてのエンジンでサポートされている。
与えられたメッセージを含むモーダル警告を表示し、ユーザーがそれを閉じるまで待つ。
result = window.confirm(message)
現在のすべてのエンジンでサポートされている。
与えられたメッセージを含むモーダルの OK/キャンセルプロンプトを表示し、 ユーザーが閉じるまで待つ。ユーザーが OK をクリックした場合は true を、 キャンセルをクリックした場合は false を返す。
result = window.prompt(message [, default])
現在のすべてのエンジンでサポートされている。
与えられたメッセージを含むモーダルのテキストコントロールプロンプトを表示し、 ユーザーが閉じるまで待って、ユーザーが入力した値を返す。 ユーザーがプロンプトをキャンセルした場合は、代わりに null を返す。 第 2 引数が存在する場合、与えられた値が既定値として使用される。
メディア要素がそのメディアデータを読み込む処理など、 タスクまたはマイクロタスクに依存するロジックは、 これらのメソッドが呼び出されている間停止する。
alert() および alert(message)
メソッドの手順は次のとおりである:
this について単純なダイアログを表示できない場合、返る。
メソッドが引数なしで呼び出された場合、message を空文字列とする。 それ以外の場合、メソッドの最初の引数を message とする。
message を、message を与えて改行を正規化した結果に設定する。
message を、message を任意選択で切り詰めた結果に設定する。
this、「alert」、および message を用いた
WebDriver BiDi ユーザープロンプトの開始を
userPromptHandler とする。
userPromptHandler が「none」である場合:
U+000A LF を改行として扱い、message をユーザーに表示する。
任意選択で、ユーザーがメッセージを確認するまで一時停止する。
this、「alert」、および true を用いて
WebDriver BiDi ユーザープロンプトの終了を呼び出す。
歴史的な理由により、このメソッドは任意選択の引数を使用せず、
二つのオーバーロードを使用して定義されている。実際上の影響として、
alert(undefined) は alert("undefined") として扱われるが、
alert() は alert("") として扱われる。
confirm(message)
メソッドの手順は次のとおりである:
this について単純なダイアログを表示できない場合、 false を返す。
message を、message を与えて改行を正規化した結果に設定する。
message を、message を任意選択で切り詰めた結果に設定する。
U+000A LF を改行として扱い、message をユーザーに表示して、 肯定または否定で応答するようユーザーに求める。
this、「confirm」、および message を用いた
WebDriver BiDi ユーザープロンプトの開始を
userPromptHandler とする。
accepted を false とする。
userPromptHandler が「none」である場合:
ユーザーが肯定または否定で応答するまで一時停止する。
ユーザーが肯定で応答した場合、accepted を true に設定する。
userPromptHandler が「accept」である場合、
accepted を true に設定する。
this、「confirm」、および accepted を用いて
WebDriver BiDi ユーザープロンプトの終了を呼び出す。
accepted を返す。
prompt(message,
default) メソッドの手順は次のとおりである:
this について単純なダイアログを表示できない場合、 null を返す。
message を、message を与えて改行を正規化した結果に設定する。
message を、message を任意選択で切り詰めた結果に設定する。
default を、default を任意選択で切り詰めた結果に設定する。
U+000A LF を改行として扱い、message をユーザーに表示して、 文字列値で応答するか中止するようユーザーに求める。応答の既定値には default によって与えられた値を使用しなければならない。
this、「prompt」、および message を用いた
WebDriver BiDi ユーザープロンプトの開始を
userPromptHandler とする。
result を null とする。
userPromptHandler が「none」である場合:
ユーザーの応答を待つ間、一時停止する。
ユーザーが中止しなかった場合、ユーザーが応答した文字列に result を設定する。
それ以外で、userPromptHandler が「accept」である場合、
result を空文字列に設定する。
this、「prompt」、
result が null である場合は false、それ以外の場合は true、および
result を用いて
WebDriver BiDi ユーザープロンプトの終了を呼び出す。
result を返す。
単純なダイアログ文字列 s を 任意選択で切り詰めるには、 s 自体または s から派生した、より短い文字列のいずれかを返す。 ユーザーエージェントは、s の省略された部分を表示するための UI を提供すべきではない。 それを提供すると、悪用者が「重要なセキュリティ警告!完全な詳細を表示するには『さらに表示』をクリックしてください!」 という形式のダイアログを容易に作成できるためである。
たとえば、ユーザーエージェントはメッセージの最初の 100 文字だけを表示したい場合がある。 または、文字列の中央を「…」で置換する場合もある。この種の変更は、不自然に大きく、 信頼できるように見えるシステムダイアログが悪用される可能性を制限するのに役立つ。
次のアルゴリズムが true を返す場合、Window window について
単純なダイアログを表示できない:
window の関連付けられた
Documentのアクティブなサンドボックス化フラグ集合に
サンドボックス化されたモーダルフラグが設定されている場合、
true を返す。
window の関連設定オブジェクトの生成元と、 window の関連設定オブジェクトの最上位生成元が同一オリジンドメインでない場合、true を返す。
任意選択で true を返す。(たとえば、ユーザーエージェントはすべてのモーダルダイアログを 無視する選択肢をユーザーに提供し、メソッドが呼び出されるたびにこの手順で中止する場合がある。)
false を返す。
現在のすべてのエンジンでサポートされている。
window.print()ページを印刷するようユーザーに促す。
print() メソッドの手順は次のとおりである:
this の関連付けられた Documentを
document とする。
document が完全にアクティブでない場合、返る。
document のunload カウンターが 0 より大きい場合、返る。
document が読み込み後タスクの準備ができている場合、 document について印刷手順を実行する。
それ以外の場合、document の 読み込み時に印刷フラグを設定する。
ユーザーが文書の物理的形態を取得する機会 (たとえば印刷物)、または物理的形態の表現(たとえば PDF)を要求した場合にも、 ユーザーエージェントは印刷手順を実行すべきである。
Document
document の印刷手順は次のとおりである:
ユーザーエージェントは、ユーザーにメッセージを表示するか、返るか、またはその両方を行ってもよい。
たとえば、キオスクブラウザーは print()
メソッドのすべての呼び出しを通知せずに無視できる。
たとえば、モバイル端末上のブラウザーは、近くにプリンターが存在しないことを検出し、 その旨を伝えるメッセージを表示した後で、「PDF として保存」する選択肢を引き続き提供できる。
document のアクティブなサンドボックス化フラグ集合に サンドボックス化されたモーダルフラグが設定されている場合、返る。
印刷ダイアログが Document のサンドボックスによって
ブロックされた場合、beforeprint イベントも
afterprint イベントも発火しない。
ユーザーエージェントは、document の関連大域オブジェクトと、その中にあるすべての子ナビゲータブルにおいて、
beforeprint
という名前のイベントを発火しなければならない。
ここで子だけに発火するのは正しくないように思われ、いくつかのタスクをキューへ 追加する必要もありそうである。課題 #5096を参照。
beforeprint
イベントは、たとえば文書が印刷された時刻を追加するなど、印刷物へ注釈を付けるために使用できる。
ユーザーエージェントは、document の物理的形態を取得する機会 (または物理的形態の表現を取得する機会)をユーザーに提供すべきである。 ユーザーエージェントは、返る前にユーザーが承諾または拒否するまで待ってもよい。 待つ場合、メソッドが待機している間、ユーザーエージェントは一時停止しなければならない。 ユーザーエージェントがこの時点で待たない場合でも、後に代替形態を作成するときには、 アルゴリズムのこの時点における関連文書の状態を使用しなければならない。
ユーザーエージェントは、document の関連大域オブジェクトと、その中にあるすべての子ナビゲータブルにおいて、
afterprint
という名前のイベントを発火しなければならない。
ここで子だけに発火するのは正しくないように思われ、いくつかのタスクをキューへ 追加する必要もありそうである。課題 #5096を参照。
afterprint
イベントは、以前のイベントで追加した注釈を元に戻すためや、印刷後の UI を表示するために使用できる。
たとえば、ページが住宅ローンの申請手順をユーザーに案内している場合、フォームなどを印刷した後、
スクリプトによって自動的に次の手順へ進められる。
Navigator オブジェクト現在のすべてのエンジンでサポートされている。
Navigator のインスタンスは、
ユーザーエージェント(クライアント)の識別情報と状態を表す。これは、さまざまな API が配置される
汎用的な大域オブジェクトとしても使用されてきたが、これを今後踏襲すべき先例とはしない。
代わりに、WindowOrWorkerGlobalScope
ミックスインまたは同等のものを使用する。
[Exposed =Window ]
interface Navigator {
// objects implementing this interface also implement the interfaces given below
};
Navigator includes NavigatorID ;
Navigator includes NavigatorLanguage ;
Navigator includes NavigatorOnLine ;
Navigator includes NavigatorContentUtils ;
Navigator includes NavigatorCookies ;
Navigator includes NavigatorPlugins ;
Navigator includes NavigatorConcurrentHardware ;これらのインターフェイスミックスインは、WorkerNavigator が
Navigator
インターフェイスの一部を再利用できるよう、個別に定義されている。
各 Window は、
Navigator オブジェクトである
関連付けられた Navigator を持つ。
Window オブジェクトの作成時に、
その関連付けられた
Navigatorは、
Window オブジェクトの関連レルム内に作成された新しい Navigator
オブジェクトに設定されなければならない。
現在のすべてのエンジンでサポートされている。
navigator および clientInformation
の取得子手順は、
this
の関連付けられた
Navigatorを返すことである。
interface mixin NavigatorID {
readonly attribute DOMString appCodeName ; // constant "Mozilla"
readonly attribute DOMString appName ; // constant "Netscape"
readonly attribute DOMString appVersion ;
readonly attribute DOMString platform ;
readonly attribute DOMString product ; // constant "Gecko"
[Exposed =Window ] readonly attribute DOMString productSub ;
readonly attribute DOMString userAgent ;
[Exposed =Window ] readonly attribute DOMString vendor ;
[Exposed =Window ] readonly attribute DOMString vendorSub ; // constant ""
};場合によっては、業界全体の最大限の努力にもかかわらず、ウェブブラウザーにバグや制限があり、 ウェブ著者がそれらを回避せざるを得ないことがある。
この節では、このような問題を回避するため、使用されているユーザーエージェントの種類を スクリプトから判定するために使用できる属性の集合を定義する。
ユーザーエージェントは、Chrome、Gecko、または WebKit のいずれかである ナビゲーター互換モードを持つ。
ナビゲーター互換モードは、
NavigatorID
ミックスインを、既存のウェブ内容と互換性があることが知られている属性値の組み合わせ、および
taintEnabled()
と oscpu
の有無に制約する。
クライアント検出は、既知の現行バージョンの検出だけに常に限定すべきである。 将来のバージョンと未知のバージョンは、常に完全に準拠していると想定すべきである。
self.navigator.appCodeName
文字列「Mozilla」を返す。
self.navigator.appName
文字列「Netscape」を返す。
self.navigator.appVersion
ブラウザーのバージョンを返す。
self.navigator.platform
プラットフォームの名前を返す。
self.navigator.product
文字列「Gecko」を返す。
window.navigator.productSub
文字列「20030107」または文字列「20100101」のいずれかを返す。
self.navigator.userAgent
現在のすべてのエンジンでサポートされている。
現在のすべてのエンジンでサポートされている。
完全な `User-Agent` ヘッダーを返す。
window.navigator.vendor
空文字列、文字列「Apple Computer, Inc.」、または
文字列「Google Inc.」のいずれかを返す。
window.navigator.vendorSub
空文字列を返す。
appCodeName の取得子手順は、
「Mozilla」を返すことである。
appName
の取得子手順は、
「Netscape」を返すことである。
appVersion の取得子手順は次のとおりである:
this の関連設定オブジェクトの環境の既定の
`User-Agent` 値を userAgent とする。
userAgent が `Mozilla/5.0 (` で始まらない場合、空文字列を返す。
userAgent を同型復号したもののうち、
「Mozilla/」接頭辞に続く部分文字列を trail とする。
trail を返す。
trail が「5.0 (Windows」で始まる場合、
「5.0 (Windows)」を返す。
それ以外の場合、trail の先頭から最初の U+003B (;) の直前までの接頭辞に、
文字 U+0029 RIGHT PARENTHESIS を連結して返す。たとえば、
「5.0 (Macintosh)」、「5.0 (Android 10)」、
または「5.0 (X11)」である。
platform
の取得子手順は、
ブラウザーが実行されているプラットフォームを表す文字列
(たとえば「MacIntel」、「Win32」、
「Linux x86_64」、「Linux armv81」)、
またはプライバシーと互換性のために、別のプラットフォームで一般的に返される文字列を返すことである。
product
の取得子手順は、
「Gecko」を返すことである。
productSub の取得子手順は、
次のリストから適切な文字列を返すことである:
文字列「20030107」。
文字列「20100101」。
userAgent の取得子手順は、
this
の関連設定オブジェクトの環境の既定の
`User-Agent` 値を返すことである。
vendor
の取得子手順は、
次のリストから適切な文字列を返すことである:
文字列「Google Inc.」。
空文字列。
文字列「Apple Computer, Inc.」。
vendorSub の取得子手順は、
空文字列を返すことである。
ナビゲーター互換モードが Gecko である場合、ユーザーエージェントは次の部分インターフェイスもサポートしなければならない:
partial interface mixin NavigatorID {
[Exposed =Window ] boolean taintEnabled (); // constant false
[Exposed =Window ] readonly attribute DOMString oscpu ;
};taintEnabled() メソッドは false を返さなければならない。
oscpu
属性の取得子は、
空文字列、またはブラウザーが実行されているプラットフォームを表す文字列、
たとえば「Windows NT 10.0; Win64; x64」、
「Linux
x86_64」のいずれかを返さなければならない。
![]() この API に含まれるユーザーごとに異なる情報は、ユーザーのプロファイリングに使用できる。
実際、このような情報が十分に利用できれば、ユーザーを一意に識別することさえ可能である。
このため、ユーザーエージェントの実装者には、この API に含める情報を可能な限り少なくすることが強く推奨される。
この API に含まれるユーザーごとに異なる情報は、ユーザーのプロファイリングに使用できる。
実際、このような情報が十分に利用できれば、ユーザーを一意に識別することさえ可能である。
このため、ユーザーエージェントの実装者には、この API に含める情報を可能な限り少なくすることが強く推奨される。
interface mixin NavigatorLanguage {
readonly attribute DOMString language ;
readonly attribute FrozenArray <DOMString > languages ;
};self.navigator.language
現在のすべてのエンジンでサポートされている。
現在のすべてのエンジンでサポートされている。
ユーザーの優先言語を表す言語タグを返す。
self.navigator.languages
現在のすべてのエンジンでサポートされている。
現在のすべてのエンジンでサポートされている。
ユーザーの優先言語を表す言語タグの配列を、最も優先される言語を先頭にして返す。
最も優先される言語は、navigator.language
によって返される言語である。
ユーザーエージェントによるユーザーの優先言語についての認識が変化すると、
Window または
WorkerGlobalScope
オブジェクトにおいて、languagechange
イベントが発火する。
language の取得子手順は次のとおりである:
languages の取得子手順は次のとおりである:
ユーザーエージェントが異なる値または異なる順序の値を返す必要が生じるか、 emulatedLanguage が更新されるまでは、同じオブジェクトを返さなければならない。
ユーザーエージェントが、Window または
WorkerGlobalScope
オブジェクト global の navigator.languages
属性に新しい言語タグの集合を返させる必要が生じるたびに、ユーザーエージェントは
global を与えて、DOM 操作タスクソース上に、
global において languagechange
という名前のイベントを発火する大域タスクをキューに追加しなければならず、
実際に新しい値を返す前に、そのタスクの実行が開始されるまで待たなければならない。
妥当と思われる言語を決定するため、 ユーザーエージェントは次の点を念頭に置くべきである:
en-US」という値が推奨される。
そのサービスのすべてのユーザーが同じ値を使用すれば、ユーザーを互いに区別できる可能性が低下する。
![]() さらなるフィンガープリンティングベクトルを導入しないようにするため、ユーザーエージェントは、
この関数で定義される API と HTTP `
さらなるフィンガープリンティングベクトルを導入しないようにするため、ユーザーエージェントは、
この関数で定義される API と HTTP `Accept-Language`
ヘッダーで同じリストを使用すべきである。
interface mixin NavigatorOnLine {
readonly attribute boolean onLine ;
};self.navigator.onLine
現在のすべてのエンジンでサポートされている。
現在のすべてのエンジンでサポートされている。
ユーザーエージェントが確実にオフライン(ネットワークから切断済み)である場合は false を返す。 ユーザーエージェントがオンラインである可能性がある場合は true を返す。
onLine
の取得子手順は、
this の関連設定オブジェクトについて
オフラインであるが false である場合は true を、
それ以外の場合は false を返すことである。
Window または
WorkerGlobalScope
global の navigator.onLine
属性によって返される値が true から false に変化した場合、ユーザーエージェントは
global を与えて、ネットワーキングタスクソース上に、
global において offline
という名前のイベントを発火する大域タスクをキューに追加しなければならない。
一方、Window または
WorkerGlobalScope
global の navigator.onLine
属性によって返される値が false から true に変化した場合、ユーザーエージェントは
global を与えて、ネットワーキングタスクソース上に、
Window または
WorkerGlobalScope
オブジェクトにおいて online
という名前のイベントを発火する大域タスクをキューに追加しなければならない。
この属性は本質的に信頼できない。コンピューターは、インターネットへアクセスできなくても ネットワークへ接続されていることがある。
この例では、ブラウザーがオンラインまたはオフラインになるのに応じてインジケーターが更新される。
<!DOCTYPE HTML>
< html lang = "en" >
< head >
< title > Online status</ title >
< script >
function updateIndicator() {
document. getElementById( 'indicator' ). textContent = navigator. onLine ? 'online' : 'offline' ;
}
</ script >
</ head >
< body onload = "updateIndicator()" ononline = "updateIndicator()" onoffline = "updateIndicator()" >
< p > The network is: < span id = "indicator" > (state unknown)</ span >
</ body >
</ html > registerProtocolHandler()
メソッドNavigator/registerProtocolHandler
interface mixin NavigatorContentUtils {
[SecureContext ] undefined registerProtocolHandler (DOMString scheme , USVString url );
[SecureContext ] undefined unregisterProtocolHandler (DOMString scheme , USVString url );
};window.navigator.registerProtocolHandler(scheme, url)
url にある scheme のハンドラーを登録します。たとえば、オンライン電話
メッセージングサービスは、それ自体を sms:
スキームのハンドラーとして登録でき、それによってユーザーがそのようなリンクをクリックした場合、その
ウェブサイトを使用する機会が与えられます。[SMS]
url 内の文字列「%s」は、処理対象コンテンツの URL を
挿入する場所を示すプレースホルダーとして使用されます。
ユーザーエージェントが登録をブロックした場合(たとえば「http」のハンドラーとして
登録しようとした場合に起こり得ます)、「SecurityError」 DOMException
をスローします。
url に文字列「%s」がない場合、「SyntaxError」 DOMException
をスローします。
window.navigator.unregisterProtocolHandler(scheme, url)
Navigator/unregisterProtocolHandler
1 つのエンジンでのみサポートされています。
引数で指定されたハンドラーの登録を解除します。
ユーザーエージェントが登録解除をブロックした場合(たとえば無効なスキームの場合に
起こり得ます)、「SecurityError」 DOMException
をスローします。
url に文字列「%s」がない場合、「SyntaxError」 DOMException
をスローします。
registerProtocolHandler(scheme,
url) メソッドの手順は次のとおりです:
(normalizedScheme, normalizedURLString) を、 scheme、url、および this の 関連する設定オブジェクトを用いて プロトコルハンドラーのパラメーターを正規化するを実行した結果とします。
並行して:normalizedScheme および normalizedURLString のプロトコルハンドラーを 登録します。ユーザーエージェントは、記載された制約の範囲内で任意の処理を行えます。たとえば ユーザーに確認し、サイトをハンドラーの候補リストに追加する、ハンドラーを既定にする、 または要求を取り消す機会をユーザーに提供できます。ユーザーエージェントは、情報を 暗黙に収集し、ユーザーにとって関連する場合にのみ提示することもできます。
ユーザーエージェントは、同じ要求をユーザーに繰り返し提示しないよう、どのサイトがハンドラーを 登録したか(ユーザーがその登録を拒否した場合も含む)を追跡するべきです。
this
の関連する大域オブジェクトの関連付けられた
Document の
registerProtocolHandler()
自動化
モードが「none」でない場合、ユーザーエージェントはまず、それが
自動化コンテキスト内にあることを検証するべきです(WebDriver のセキュリティに関する考慮事項を参照)。
その後、ユーザーエージェントは上記の情報伝達およびユーザー同意の取得を省略し、
registerProtocolHandler()
自動化
モードの値に基づいて、代わりに次の処理を行うべきです:
autoAccept」ユーザーが登録の詳細を確認し、要求を承認したものとして動作します。
autoReject」ユーザーが登録の詳細を確認し、要求を拒否したものとして動作します。
ユーザーエージェントが URL inputURL に対して このハンドラーを使用する場合:
inputURL と空文字列を与えて、 ユーザー名を設定します。
inputURL と空文字列を与えて、 パスワードを設定します。
inputURLString を、inputURL の 直列化とします。
encodedURL を、コンポーネントパーセントエンコードセットを使用して inputURLString に UTF-8 パーセントエンコードを実行した結果とします。
handlerURLString を normalizedURLString とします。
handlerURLString 内で最初に現れる「%s」を
encodedURL に置換します。
resultURL を、handlerURLString を 構文解析した結果とします。
ユーザーが https://example.com/ にあるサイトを訪問し、そのサイトが
次の呼び出しを行ったとします:
navigator. registerProtocolHandler( 'web+soup' , 'soup?url=%s' ) ……そして、それからずっと後に https://www.example.net/ を訪問中、
次のようなリンクをクリックしたとします:
< a href = "web+soup:chicken-kïwi" > Download our Chicken Kïwi soup!</ a > ……すると、UA は次の URL にナビゲートする可能性があります:
https://example.com/soup?url=web+soup:chicken-k%C3%AFwi
その後、このサイトはスープを使って通常行っている任意の処理(スープを合成して ユーザーに発送するなど)を行えます。
これは、ハンドラーがいつ使用されるかを定義するものではありません。ある程度までは、文書間をナビゲートするための処理モデルが関連するいくつかの事例を 定義していますが、一般にユーザーエージェントは、スキームをネイティブプラグインやヘルパーアプリケーションに 渡すことを検討する場面で、この情報を使用できます。
unregisterProtocolHandler(scheme,
url) メソッドの手順は次のとおりです:
(normalizedScheme, normalizedURLString) を、 scheme、url、および this の 関連する設定 オブジェクトを用いて、プロトコルハンドラーのパラメーターを正規化するを実行した結果とします。
並行して: normalizedScheme および normalizedURLString によって記述される ハンドラーの登録を解除します。
文字列 scheme、文字列 url、および 環境設定オブジェクト environment が与えられたとき、 プロトコルハンドラーのパラメーターを正規化するには、 次の手順を実行します:
scheme を、scheme を ASCII 小文字に 変換したものに設定します。
scheme がセーフリストに登録されたスキームでも、
「web+」で始まり、その後に 1 つ以上の
ASCII
小文字アルファベットが続く文字列でもない場合、「SecurityError」
DOMException
をスローします。
これは、scheme にコロンを含めると(「mailto:」のように)
スローされることを意味します。
次のスキームが、セーフリストに登録された スキームです:
bitcoinftpftpsgeoimircircsmagnetmailtomatrixmmsnewsnntpopenpgp4fprsftpsipsmssmstosshtelurnwebcalwtaixmppこのリストは変更される可能性があります。追加すべきスキームがある場合は、 フィードバックを送信してください。
url に「%s」が含まれていない場合、
「SyntaxError」 DOMException
をスローします。
urlRecord を、environment を基準として url を与えてURL をエンコーディング構文解析する結果とします。
urlRecord が失敗の場合、「SyntaxError」
DOMException
をスローします。
%s プレースホルダーが URL のホストまたはポート内にある場合、
必ずこの状況になります。
urlRecord のスキームが
HTTP(S) スキームでないか、または urlRecord の
オリジンが
environment のオリジンと
同一オリジンでない場合、
「SecurityError」 DOMException
をスローします。
表明:urlRecord を与えた
URL は潜在的に信頼できるか?の結果は
「Potentially Trustworthy」です。
プロトコルハンドラーのパラメーターを正規化するは セキュアコンテキスト内で 実行されるため、これは同一オリジン条件によって暗黙に保証されます。
(scheme, urlRecord) を返します。
urlRecord の
直列化は、
URL 内の有効なコンポーネントではない文字列「%s」を含むため、定義上
妥当な URL 文字列
にはなりません。
カスタムスキームハンドラーは、特にプライバシーに関する多くの懸念を生じさせる可能性があります。
すべてのウェブ利用の乗っ取り。 ユーザーエージェントは、 HTTP(S) スキームなど、 通常の動作に不可欠なスキームが第三者サイトを経由するように 再ルーティングされることを許可するべきではありません。そうすると、ユーザーの活動を容易に追跡でき、 セキュアな接続においてさえユーザー情報を収集できるようになります。
既定値の乗っ取り。 ユーザーエージェントは、既定値を自動的に変更しないことを 強く推奨されます。変更すると、ユーザーが予期していないリモートホストへデータを送信する可能性があるためです。 新しいハンドラーが自身を登録しても、それによってそのサイトが自動的に使用されるようになってはなりません。
登録スパム。 ユーザーエージェントは、サイトが多数のハンドラーを、
場合によっては複数のドメインから登録しようとする可能性を考慮するべきです(たとえば、それぞれ異なる
ドメインにあり、各ページが web+spam: のハンドラーを登録する一連のページを経由して
リダイレクトする場合です。このようにウェブブラウザーの他の機能を悪用する類似の手法は、
ポルノサイトで長年使用されてきました)。ユーザーエージェントは、ユーザーを保護しながら、
そのような敵対的な試みを適切に処理するべきです。
敵対的なハンドラーメタデータ。 ユーザーエージェントは、インターフェイスに 埋め込まれた文字列に対する典型的な攻撃から保護するべきです。たとえば、そのような文字列内の マークアップやエスケープ文字が実行されないこと、null バイトが適切に処理されること、 過度に長い文字列がクラッシュやバッファーオーバーランを引き起こさないことなどを保証するべきです。
個人データの漏洩。 ウェブページの作成者は、非公開とみなされる URL データを使用して カスタムスキームハンドラーを参照する場合があります。ハンドラーに対するユーザーの選択が組織内のページを 指しており、機密データが第三者に公開されないことを期待して、そのようにする場合があります。しかし、 ユーザーが外部サイトを指すハンドラーを登録している可能性があり、その第三者へのデータ漏洩につながります。 実装者は、特定のサブドメイン、コンテンツタイプ、またはスキームで管理者がカスタムハンドラーを 無効にできるようにすることを検討してもよいでしょう。
インターフェイスへの干渉。 ユーザーエージェントは、意図的に長い引数が メソッドに渡される場合に対処できるようにするべきです。たとえば、公開されるユーザーインターフェイスが 「承認」ボタンと「拒否」ボタンで構成され、「承認」へのバインディングにハンドラー名が含まれる場合、 長い名前によって「拒否」ボタンが画面外へ押し出されないようにすることが重要です。
各 Document は、
registerProtocolHandler() 自動化
モードを持ちます。その既定値は「none」ですが、
「autoAccept」
または「autoReject」
にすることもできます。
ユーザーエージェントの自動化およびウェブサイトのテストを目的として、この標準は
RPH 登録モードを設定する WebDriver
拡張
コマンドを定義します。このコマンドは、登録確認プロンプトダイアログをユーザーが承認または
拒否する動作を自動的にシミュレートするモードへ、Document を移行するよう
ユーザーエージェントに指示します。
| HTTP メソッド | URI テンプレート |
|---|---|
`POST`
|
/session/{session id}/custom-handlers/set-mode
|
リモートエンドの手順は次のとおりです:
parameters が JSON オブジェクトでない場合、 WebDriver エラーを、 WebDriver エラーコード 無効な引数とともに返します。
mode を、parameters から「mode」という名前の
プロパティを
取得した結果とします。
mode が「autoAccept」、
「autoReject」、
または「none」
のいずれでもない場合、WebDriver エラーを、
WebDriver エラーコード
無効な引数とともに返します。
document を、 現在の 閲覧コンテキストのアクティブな文書とします。
document のregisterProtocolHandler()
自動化
モードを mode に設定します。
データ null とともに成功を返します。
interface mixin NavigatorCookies {
readonly attribute boolean cookieEnabled ;
};window.navigator.cookieEnabled
現在のすべてのエンジンでサポートされています。
Cookie の設定が無視される場合は false を、それ以外の場合は true を返します。
cookieEnabled 属性は、ユーザーエージェントが
HTTP 状態管理メカニズムに従って Cookie を処理しようとする場合は true を、
Cookie の変更要求を無視する場合は false を返さなければなりません。[COOKIES]
window.navigator.pdfViewerEnabled
PDF ファイルへナビゲートしたときに、ユーザーエージェントがそのインライン表示を サポートする場合は true を、それ以外の場合は false を返します。後者の場合、PDF ファイルは 外部 ソフトウェアによって処理されます。
interface mixin NavigatorPlugins {
[SameObject ] readonly attribute PluginArray plugins ;
[SameObject ] readonly attribute MimeTypeArray mimeTypes ;
boolean javaEnabled ();
readonly attribute boolean pdfViewerEnabled ;
};
[Exposed =Window ,
LegacyUnenumerableNamedProperties ]
interface PluginArray {
undefined refresh ();
readonly attribute unsigned long length ;
getter Plugin ? item (unsigned long index );
getter Plugin ? namedItem (DOMString name );
};
[Exposed =Window ,
LegacyUnenumerableNamedProperties ]
interface MimeTypeArray {
readonly attribute unsigned long length ;
getter MimeType ? item (unsigned long index );
getter MimeType ? namedItem (DOMString name );
};
[Exposed =Window ,
LegacyUnenumerableNamedProperties ]
interface Plugin {
readonly attribute DOMString name ;
readonly attribute DOMString description ;
readonly attribute DOMString filename ;
readonly attribute unsigned long length ;
getter MimeType ? item (unsigned long index );
getter MimeType ? namedItem (DOMString name );
};
[Exposed =Window ]
interface MimeType {
readonly attribute DOMString type ;
readonly attribute DOMString description ;
readonly attribute DOMString suffixes ;
readonly attribute Plugin enabledPlugin ;
};現在では、PDF ビューアーのサポートは navigator.pdfViewerEnabled
によって検出できますが、歴史的な理由により、同じ機能を提供する複雑で相互に絡み合った
多数のインターフェイスがあり、レガシーコードはそれらに依存しています。この節では、
単純な現代版と複雑な歴史的版の両方を規定します。
![]() 各ユーザーエージェントは、値が
実装定義である(また、ユーザーの設定によって異なる場合がある)
PDF ビューアーをサポートしている論理値を持ちます。
各ユーザーエージェントは、値が
実装定義である(また、ユーザーの設定によって異なる場合がある)
PDF ビューアーをサポートしている論理値を持ちます。
この値は、ナビゲーションの 処理モデルにも影響します。
各 Window オブジェクトは、
PDF ビューアープラグインオブジェクトのリストを持ちます。
ユーザーエージェントのPDF ビューアーをサポートしているが
false の場合、これは空のリストです。それ以外の場合、これは 5 個の
Plugin オブジェクトを含むリストであり、
それらの名前はそれぞれ次のとおりです:
PDF Viewer」Chrome PDF Viewer」Chromium PDF Viewer」Microsoft Edge PDF Viewer」WebKit built-in PDF」上記リストの値は、PDF ビューアープラグイン名のリストを形成します。
これらの名前は、ウェブサイトが歴史的に検索してきたものについての証拠、
したがって既存コンテンツとの互換性を維持するためにユーザーエージェントが公開する必要があるものに
基づいて選択されました。これらはアルファベット順に並べられています。その後、
enabledPlugin
取得子が一般的なプラグイン名を指せるように、「PDF Viewer」という名前が
0 番目の位置に挿入されました。
各 Window オブジェクトは、
PDF ビューアー MIME タイプオブジェクトのリストを持ちます。
ユーザーエージェントのPDF ビューアーをサポートしているが
false の場合、これは空のリストです。それ以外の場合、これは 2 個の
MimeType オブジェクトを含むリストであり、
それらのタイプは
それぞれ次のとおりです:
application/pdf」text/pdf」上記リストの値は、PDF ビューアー MIME タイプのリストを形成します。
各 NavigatorPlugins
オブジェクトは、新しい PluginArray
であるプラグイン配列と、新しい
MimeTypeArray である
MIME タイプ配列を持ちます。
NavigatorPlugins
ミックスインの plugins 取得子の手順は、
this の
プラグイン配列を返すことです。
NavigatorPlugins
ミックスインの mimeTypes 取得子の手順は、
this の
MIME タイプ配列を返すことです。
NavigatorPlugins
ミックスインの javaEnabled() メソッドの手順は、false を返すことです。
現在のすべてのエンジンでサポートされています。
NavigatorPlugins
ミックスインの pdfViewerEnabled 取得子の手順は、ユーザーエージェントの
PDF ビューアーを
サポートしているを返すことです。
PluginArray インターフェイスは
名前付き
プロパティをサポートします。ユーザーエージェントのPDF
ビューアーをサポートしているが true の場合、
それらはPDF ビューアープラグイン名です。
それ以外の場合、それらは空のリストです。
PluginArray インターフェイスの
namedItem(name) メソッドの手順は次のとおりです:
それぞれの
this
の関連する大域オブジェクトの
PDF
ビューアープラグインオブジェクトに含まれる
Plugin
plugin について、plugin の名前が
name である場合、plugin を返します。
null を返します。
PluginArray インターフェイスは
インデックス付きプロパティをサポートします。
サポートされるプロパティインデックスは、
this の
関連する大域オブジェクトの
PDF ビューアープラグイン
オブジェクトのインデックスです。
PluginArray インターフェイスの
item(index) メソッドの手順は次のとおりです:
plugins を、this の関連する大域オブジェクトの PDF ビューアープラグイン オブジェクトとします。
index < plugins の サイズである場合、 plugins[index] を返します。
null を返します。
PluginArray インターフェイスの
length
取得子の手順は、this の
関連する大域オブジェクトの
PDF ビューアープラグイン
オブジェクトのサイズを返すことです。
PluginArray インターフェイスの
refresh()
メソッドの手順は、何もしないことです。
MimeTypeArray インターフェイスは
名前付き
プロパティをサポートします。ユーザーエージェントのPDF
ビューアーをサポートしているが true の場合、
それらはPDF ビューアー MIME タイプです。
それ以外の場合、それらは空のリストです。
MimeTypeArray
インターフェイスの namedItem(name) メソッドの手順は次のとおりです:
それぞれの
this
の関連する大域オブジェクトの
PDF ビューアー MIME
タイプ
オブジェクトに含まれる MimeType
mimeType について、
mimeType のタイプが
name である場合、mimeType を返します。
null を返します。
MimeTypeArray インターフェイスは
インデックス付きプロパティをサポートします。
サポートされるプロパティインデックスは、
this の
関連する大域オブジェクトの
PDF ビューアー MIME
タイプオブジェクトの
インデックスです。
MimeTypeArray インターフェイスの
item(index) メソッドの手順は次のとおりです:
mimeTypes を、this の関連する大域オブジェクトの PDF ビューアー MIME タイプオブジェクトとします。
index < mimeTypes の サイズである場合、 mimeTypes[index] を返します。
null を返します。
MimeTypeArray インターフェイスの
length 取得子の手順は、
this の
関連する大域オブジェクトの
PDF ビューアー MIME タイプ
オブジェクトのサイズを返すことです。
各 Plugin オブジェクトは、
オブジェクトの作成時に設定される名前を持ちます。
Plugin インターフェイスの
description
取得子の手順は、
「Portable Document Format」を返すことです。
Plugin インターフェイスの
filename 取得子の手順は、
「internal-pdf-viewer」を返すことです。
Plugin インターフェイスは
名前付き
プロパティをサポートします。ユーザーエージェントのPDF
ビューアーを
サポートしているが true の場合、それらはPDF
ビューアー MIME タイプです。
それ以外の場合、それらは空のリストです。
Plugin インターフェイスの
namedItem(name) メソッドの手順は次のとおりです:
それぞれの
this の関連する大域オブジェクトの
PDF ビューアー MIME
タイプ
オブジェクトに含まれる MimeType
mimeType について、
mimeType のタイプが
name である場合、mimeType を返します。
null を返します。
Plugin インターフェイスは
インデックス付きプロパティをサポートします。
サポートされるプロパティインデックスは、
this の
関連する大域
オブジェクトのPDF
ビューアー MIME タイプオブジェクトのインデックスです。
Plugin インターフェイスの
item(index)
メソッドの手順は次のとおりです:
mimeTypes を、this の関連する大域オブジェクトの PDF ビューアー MIME タイプオブジェクトとします。
index < mimeTypes の サイズである場合、 mimeTypes[index] を返します。
null を返します。
Plugin インターフェイスの
length 取得子の手順は、
this の
関連する大域
オブジェクトのPDF
ビューアー MIME タイプ
オブジェクトのサイズを返すことです。
各 MimeType オブジェクトは、
オブジェクトの作成時に設定されるタイプを持ちます。
MimeType インターフェイスの
description 取得子の手順は、
「Portable Document Format」を返すことです。
MimeType インターフェイスの
suffixes
取得子の手順は、
「pdf」を返すことです。
MimeType インターフェイスの
enabledPlugin 取得子の手順は、
this の
関連する大域
オブジェクトのPDF
ビューアープラグイン
オブジェクト[0](すなわち、一般的な「PDF Viewer」)を返すことです。
ImageData インターフェイス現在のすべてのエンジンでサポートされています。
typedef (Uint8ClampedArray or Float16Array ) ImageDataArray ;
enum ImageDataPixelFormat { " rgba-unorm8 " , " rgba-float16 " };
dictionary ImageDataSettings {
PredefinedColorSpace colorSpace ;
ImageDataPixelFormat pixelFormat = "rgba-unorm8";
};
[Exposed =(Window ,Worker ),
Serializable ]
interface ImageData {
constructor (unsigned long sw , unsigned long sh , optional ImageDataSettings settings = {});
constructor (ImageDataArray data , unsigned long sw , optional unsigned long sh , optional ImageDataSettings settings = {});
readonly attribute unsigned long width ;
readonly attribute unsigned long height ;
readonly attribute ImageDataArray data ;
readonly attribute ImageDataPixelFormat pixelFormat ;
readonly attribute PredefinedColorSpace colorSpace ;
};
ImageData オブジェクトは、
幅が
width 属性に等しく、高さが height
属性に等しい
長方形のビットマップを表します。このビットマップのピクセル値は、左上のピクセルを 0 として、
左から右へ、上から下へ行ごとの順序で
data 属性に格納されます。各ピクセルの色成分の順序および数値表現は、pixelFormat
属性によって決定されます。
ビットマップのピクセル値の色空間は、colorSpace
属性によって決定されます。
imageData = new ImageData(sw, sh [, settings])
現在のすべてのエンジンでサポートされています。
指定された寸法および settings によって示される色空間を持つ
ImageData オブジェクトを
返します。返されるオブジェクト内のすべてのピクセルは、透明な
黒です。
幅または高さの引数のいずれかが 0 である場合、
「IndexSizeError」 DOMException
をスローします。
imageData = new ImageData(data, sw [, sh [, settings ] ])
ImageDataArray
引数で提供されたデータを使用し、指定された寸法および settings によって示される色空間で
解釈された ImageData
オブジェクトを返します。
データのバイト長は、ピクセル当たりのバイト数と指定された幅の積の倍数である必要があります。 高さも指定されている場合、その長さは、ピクセル当たりのバイト数、幅、および高さの積と 正確に等しい必要があります。
指定されたデータと寸法を一貫して解釈できない場合、またはいずれかの寸法が 0 である場合、
「IndexSizeError」 DOMException
をスローします。
imageData.width
現在のすべてのエンジンでサポートされています。
imageData.height
現在のすべてのエンジンでサポートされています。
ImageData オブジェクト内の
データの実際の寸法をピクセル単位で返します。
imageData.data
現在のすべてのエンジンでサポートされています。
RGBA 順でデータを格納し、0 から 255 までの範囲の整数で構成される 1 次元配列を返します。
imageData.colorSpace
ピクセルの色空間を返します。
new ImageData(sw,
sh, settings) コンストラクターの手順は次のとおりです:
sw と sh の一方または両方が 0 である場合、
「IndexSizeError」 DOMException
をスローします。
new
ImageData(data, sw, sh, settings)
コンストラクターの手順は次のとおりです:
settings["pixelFormat"]
が
「rgba-unorm8」である場合は
bytesPerPixel を 4 とし、それ以外の場合は 8 とします。
length を、data のバッファーソースのバイト長とします。
length が bytesPerPixel の 0 でない整数倍でない場合、
「InvalidStateError」 DOMException
をスローします。
length を、length を bytesPerPixel で除算した値とします。
length が sw の整数倍でない場合、
「IndexSizeError」 DOMException
をスローします。
この段階では、長さが 0 より大きいことが保証されています(そうでなければ、 上記の 2 番目の手順でこの手順全体が中止されています)。したがって、sw が 0 の場合、 この手順は例外をスローして返ります。
height を、length を sw で除算した値とします。
sh が指定され、その値が height と等しくない場合、
「IndexSizeError」 DOMException
をスローします。
sw、sh、settings、および source を data に設定して、this を初期化します。
この手順は、this のデータを
data のコピーに設定するものではありません。
data として渡された実際の ImageDataArray
オブジェクトに設定します。
1 行当たりの正の整数のピクセル数 pixelsPerRow、正の整数の行数
rows、ImageDataSettings
settings、省略可能な
ImageDataArray
source、および省略可能な
PredefinedColorSpace
defaultColorSpace が与えられたとき、
imageData という ImageData
オブジェクトを初期化するには:
source が指定されている場合:
settings["pixelFormat"]
が「rgba-unorm8」に等しく、
source が Uint8ClampedArray
でない場合、「InvalidStateError」 DOMException
をスローします。
settings["pixelFormat"]
が「rgba-float16」であり、
source が Float16Array
でない場合、「InvalidStateError」 DOMException
をスローします。
imageData の data 属性を
source に初期化します。
それ以外の場合(source が指定されていない場合):
settings["pixelFormat"]
が「rgba-unorm8」である場合、
imageData の data
属性を、新しい Uint8ClampedArray
オブジェクトに初期化します。この Uint8ClampedArray
オブジェクトは、そのストレージに新しい
ArrayBuffer
を使用しなければならず、バイトオフセットは 0、バイト長はそのストレージのバイト単位の長さと
等しくなければなりません。ストレージの ArrayBuffer
は、4 × rows × pixelsPerRow バイトの
長さを持たなければなりません。
それ以外の場合、settings["pixelFormat"]
が「rgba-float16」である場合、
imageData の data
属性を、新しい Float16Array
オブジェクトに初期化します。この Float16Array
オブジェクトは、そのストレージに新しい
ArrayBuffer
を使用しなければならず、バイトオフセットは 0、バイト長はそのストレージのバイト単位の長さと
等しくなければなりません。ストレージの ArrayBuffer
は、8 × rows × pixelsPerRow バイトの
長さを持たなければなりません。
ストレージの ArrayBuffer
を割り当てられなかった場合、JavaScript によってスローされた RangeError
を再スローして、返ります。
imageData の width 属性を
pixelsPerRow に初期化します。
imageData の height 属性を
rows に初期化します。
imageData の
pixelFormat
属性を
settings["pixelFormat"] に初期化します。
settings["colorSpace"]
が存在する場合、imageData の
colorSpace 属性を
settings["colorSpace"] に初期化します。
それ以外の場合、defaultColorSpace が指定されていれば、imageData の
colorSpace
属性を defaultColorSpace に初期化します。
それ以外の場合、imageData の colorSpace
属性を「srgb」に初期化します。
ImageData オブジェクトは
シリアライズ可能なオブジェクトです。
value および serialized が与えられたとき、その
シリアライズの
手順は次のとおりです:
serialized.[[Width]] を、value の width
属性の値に設定します。
serialized.[[Height]] を、value の height
属性の値に設定します。
serialized.[[ColorSpace]] を、value の colorSpace
属性の値に設定します。
serialized.[[PixelFormat]] を、value の pixelFormat
属性の値に設定します。
serialized、value、および targetRealm が与えられたとき、その 逆シリアライズの 手順は次のとおりです:
value の width 属性を
serialized.[[Width]] に初期化します。
value の height
属性を
serialized.[[Height]] に初期化します。
value の colorSpace
属性を serialized.[[ColorSpace]] に初期化します。
value の pixelFormat
属性を serialized.[[PixelFormat]] に初期化します。
ImageDataPixelFormat
列挙型は、ImageData の
data
属性の型、および各ピクセルの色成分の配置と数値表現を指定するために使用されます。
「rgba-unorm8」値は、
ImageData の
data
属性が Uint8ClampedArray
型でなければならないことを示します。
各ピクセルの色成分は、赤、緑、青、アルファの順に連続する 4 つの要素へ格納されなければなりません。
各要素は、その成分の 8 ビット符号なし正規化値を表します。
「rgba-float16」値は、
ImageData の
data
属性が Float16Array 型でなければならないことを示します。
各ピクセルの色成分は、赤、緑、青、アルファの順に連続する 4 つの要素へ格納されなければなりません。
各要素は、その成分の値を表します。
ImageBitmap インターフェイス現在のすべてのエンジンでサポートされています。
[Exposed =(Window ,Worker ), Serializable , Transferable ]
interface ImageBitmap {
readonly attribute unsigned long width ;
readonly attribute unsigned long height ;
undefined close ();
};
typedef (CanvasImageSource or
Blob or
ImageData ) ImageBitmapSource ;
enum ImageOrientation { " from-image " , " flipY " };
enum PremultiplyAlpha { " none " , " premultiply " , " default " };
enum ColorSpaceConversion { " none " , " default " };
enum ResizeQuality { " pixelated " , " low " , " medium " , " high " };
dictionary ImageBitmapOptions {
ImageOrientation imageOrientation = "from-image";
PremultiplyAlpha premultiplyAlpha = "default";
ColorSpaceConversion colorSpaceConversion = "default";
[EnforceRange ] unsigned long resizeWidth ;
[EnforceRange ] unsigned long resizeHeight ;
ResizeQuality resizeQuality = "low";
};ImageBitmap オブジェクトは、
過度な遅延なくキャンバスへ描画できるビットマップ画像を表します。
どの程度の遅延を過度と判断するかは実装者に委ねられますが、一般に、 ビットマップを使用するためにネットワーク I/O、またはローカルディスク I/O さえ必要となる場合、 その遅延はおそらく過度です。一方、GPU またはシステム RAM からのブロッキング読み取りのみが 必要な場合、その遅延はおそらく許容できます。
promise = self.createImageBitmap(image [, options ])
現在のすべてのエンジンでサポートされています。
promise = self.createImageBitmap(image, sx, sy, sw, sh [, options ])
image を受け取り、新しい
ImageBitmap が
作成されたときに解決される Promise を返します。image には、img 要素、
SVG
image 要素、video 要素、
canvas 要素、
Blob
オブジェクト、ImageData
オブジェクト、または別の
ImageBitmap
オブジェクトを使用できます。
たとえば、提供された image データが実際には画像でないために
ImageBitmap
オブジェクトを構築できない場合、代わりに Promise は拒否されます。
sx、sy、sw、および sh 引数が指定された場合、 ソース画像は指定されたピクセルに切り取られ、元の画像に存在しないピクセルは 透明な黒に置き換えられます。これらの座標は、 CSS ピクセルではなく、 ソース画像のピクセル座標空間内のものです。
options が指定された場合、ImageBitmap オブジェクトの
ビットマップデータは、options に従って変更されます。たとえば、premultiplyAlpha
オプションが「premultiply」
に設定されている場合、ビットマップデータの
アルファ以外の色成分には、アルファ成分が事前に乗算されます。
ソース画像が妥当な状態でない場合(たとえば、正常に読み込まれていない
img
要素、[[Detached]] 内部スロットの値が
true である ImageBitmap
オブジェクト、
data
属性値の [[ViewedArrayBuffer]] 内部スロットがデタッチされている
ImageData オブジェクト、
またはデータをビットマップ画像として解釈できない Blob)
は、「InvalidStateError」
DOMException
で Promise を拒否します。
imageBitmap.close()
現在のすべてのエンジンでサポートされています。
imageBitmap の基礎となるビットマップデータを解放します。
imageBitmap.width
現在のすべてのエンジンでサポートされています。
imageBitmap.height
現在のすべてのエンジンでサポートされています。
[[Detached]] 内部スロットの値が
false である ImageBitmap
オブジェクトには、幅と高さを持つビットマップデータが
常に関連付けられています。ただし、このデータが破損している可能性はあります。
ImageBitmap オブジェクトの
メディアデータをエラーなく復号できる場合、それは完全に復号可能であるといいます。
ImageBitmap オブジェクトの
ビットマップには、異なるオリジンのコンテンツによってビットマップが
汚染されているかどうかを示すオリジンクリーンフラグがあります。
このフラグは最初に true に設定され、createImageBitmap()
の手順によって false に変更される場合があります。
ImageBitmap オブジェクトは、
シリアライズ可能なオブジェクトであり、
転送可能な
オブジェクトです。
value および serialized が与えられたとき、その シリアライズ手順は 次のとおりです:
value のオリジンクリーン
フラグが設定されていない場合、「DataCloneError」
DOMException
をスローします。
serialized.[[BitmapData]] を、value の ビットマップデータの コピーに設定します。
serialized、value、および targetRealm が与えられたとき、その 逆シリアライズ 手順は次のとおりです:
value のビットマップデータを serialized.[[BitmapData]] に設定します。
value および dataHolder が与えられたとき、その 転送手順は 次のとおりです:
value のオリジンクリーン
フラグが設定されていない場合、「DataCloneError」
DOMException
をスローします。
dataHolder.[[BitmapData]] を、value の ビットマップデータに設定します。
value のビットマップ データの設定を解除します。
dataHolder および value が与えられたとき、その 転送受信手順は 次のとおりです:
value のビットマップデータを dataHolder.[[BitmapData]] に設定します。
createImageBitmap メソッドは、 返される Promise を確定するためにビットマップ タスクソースを使用します。
createImageBitmap(image,
options) および createImageBitmap(image,
sx, sy, sw, sh, options) メソッドは、
呼び出されたとき、次の手順を実行しなければなりません:
sw または sh のいずれかが指定されており、その値が 0 である場合、
RangeError
で拒否された Promiseを返します。
options の resizeWidth
または options の
resizeHeight のいずれかが存在し、その値が 0 の場合、
「InvalidStateError」
DOMException
で拒否された Promiseを返します。
image 引数の
使用可能性を確認します。これが例外をスローするか、bad を返した場合、
「InvalidStateError」 DOMException
で拒否された Promiseを返します。
promise を新しい Promise とします。
imageBitmap を新しい ImageBitmap
オブジェクトとします。
image に応じて分岐します:
img
image
image のメディアデータに
固有寸法がなく
(たとえば、コンテンツサイズが指定されていないベクターグラフィック)、
options の resizeWidth
または options の resizeHeight
のいずれかが存在しない場合、「InvalidStateError」
DOMException
で拒否された Promiseを返します。
image のメディアデータに
固有寸法がない場合
(たとえば、コンテンツサイズが指定されていないベクターグラフィック)、
resizeWidth
および resizeHeight
オプションで指定されたサイズのビットマップへ描画するべきです。
imageBitmap のビットマップ データを、image のメディアデータのコピーを 書式設定を伴って ソース矩形に切り取ったものに設定します。これがアニメーション画像である場合、 imageBitmap のビットマップデータは、 アニメーションの既定画像(アニメーションがサポートされていないか無効である場合に使用するものとして 形式が定義している画像)のみから取得しなければならず、そのような画像がない場合は、 アニメーションの最初のフレームから取得しなければなりません。
image がオリジンクリーンでない場合、 imageBitmap のビットマップの オリジンクリーンフラグを false に設定します。
ビットマップタスクソースを使用して、 promise を imageBitmap で解決する 大域 タスクをキューに追加します。
video
image の networkState
属性が NETWORK_EMPTY
である場合、「InvalidStateError」
DOMException
で拒否された Promiseを返します。
imageBitmap のビットマップ データを、現在の再生位置にあるフレームを、 メディアリソースの 固有の 幅および固有の高さ (すなわち、アスペクト比の補正を適用した後)でコピーし、 書式設定を伴って ソース矩形に切り取ったものに設定します。
image がオリジンクリーンでない場合、 imageBitmap のビットマップの オリジンクリーンフラグを false に設定します。
ビットマップタスクソースを使用して、 promise を imageBitmap で解決する 大域 タスクをキューに追加します。
canvas
imageBitmap のビットマップ データを、image のビットマップデータの コピーを書式設定を伴って ソース矩形に切り取ったものに設定します。
imageBitmap のビットマップの オリジンクリーンフラグを、 image のビットマップの オリジンクリーンフラグと 同じ値に設定します。
ビットマップタスクソースを使用して、 promise を imageBitmap で解決する 大域 タスクをキューに追加します。
Blob
次の手順を並行して実行します:
imageData を、image のデータを読み取った結果とします。
オブジェクトの読み取り中にエラーが発生した場合、
ビットマップタスクソースを使用して、
promise を「InvalidStateError」 DOMException
で拒否する大域
タスクをキューに追加し、これらの手順を中止します。
imageData のファイル形式を決定するために、
画像スニッフィング規則を適用します。
このとき、image の MIME タイプ(image の type
属性によって与えられる)を正式なタイプとします。
imageData がサポートされる画像ファイル形式でない場合
(たとえば、まったく画像でない場合)、または画像の寸法を取得できないほど
imageData が致命的に破損している場合
(たとえば、固有サイズのないベクターグラフィック)、
ビットマップタスクソースを使用して、
promise を「InvalidStateError」 DOMException
で拒否する大域タスクをキューに追加し、
これらの手順を中止します。
imageBitmap のビットマップ データを、imageData を 書式設定を伴って ソース矩形に切り取ったものに設定します。これがアニメーション画像である場合、 imageBitmap のビットマップデータは、 アニメーションの既定画像(アニメーションがサポートされていないか無効である場合に使用するものとして 形式が定義している画像)のみから取得しなければならず、そのような画像がない場合は、 アニメーションの最初のフレームから取得しなければなりません。
ビットマップタスクソースを使用して、 promise を imageBitmap で解決する 大域 タスクをキューに追加します。
ImageData
buffer を、image の data
属性値の [[ViewedArrayBuffer]] 内部スロットとします。
IsDetachedBuffer(buffer) が true の場合、
「InvalidStateError」
DOMException
で拒否された Promiseを返します。
imageBitmap のビットマップ データを、image の画像データを 書式設定を伴って ソース矩形に切り取ったものに設定します。
ビットマップタスクソースを使用して、 promise を imageBitmap で解決する 大域 タスクをキューに追加します。
ImageBitmap
imageBitmap のビットマップ データを、image のビットマップデータの コピーを書式設定を伴って ソース矩形に切り取ったものに設定します。
imageBitmap のビットマップの オリジンクリーンフラグを、 image のビットマップの オリジンクリーンフラグと 同じ値に設定します。
ビットマップタスクソースを使用して、 promise を imageBitmap で解決する 大域 タスクをキューに追加します。
VideoFrame
imageBitmap のビットマップ データを、image の可視ピクセルデータのコピーを 書式設定を伴って ソース矩形に切り取ったものに設定します。
ビットマップタスクソースを使用して、 promise を imageBitmap で解決する 大域 タスクをキューに追加します。
promise を返します。
上記の手順により、ユーザーエージェントが ビットマップデータを 書式設定を伴ってソース矩形に切り取る必要がある場合、 ユーザーエージェントは次の手順を実行しなければなりません:
input を、変換されるビットマップ データとします。
sx、sy、sw、および sh が指定されている場合、 sourceRectangle を、その四隅が (sx, sy)、(sx+sw, sy)、(sx+sw, sy+sh)、(sx, sy+sh) である矩形とします。 それ以外の場合、sourceRectangle を、その四隅が (0, 0)、 (input の幅, 0)、(input の幅, input の高さ)、 (0, input の高さ) である矩形とします。
sw または sh のいずれかが負である場合、 この矩形の左上隅は (sx, sy) 点の左または上に位置します。
outputWidth を次のように決定します:
resizeWidth
メンバーが指定されている場合
resizeWidth
メンバーの値resizeWidth
メンバーが指定されていないが、resizeHeight
メンバーが指定されている場合
resizeHeight
メンバーの値を乗算し、sourceRectangle の高さで除算して、
最も近い整数へ切り上げた値resizeWidth
も resizeHeight
も指定されていない場合outputHeight を次のように決定します:
resizeHeight
メンバーが指定されている場合
resizeHeight
メンバーの値resizeHeight
メンバーが指定されていないが、resizeWidth
メンバーが指定されている場合
resizeWidth
メンバーの値を乗算し、sourceRectangle の幅で除算して、
最も近い整数へ切り上げた値resizeWidth
も resizeHeight
も指定されていない場合input を無限の透明な黒の格子平面上に配置します。 その左上隅が平面の原点となり、x 座標は右方向に増加し、 y 座標は下方向に増加するように配置し、input 画像データ内の 各ピクセルが平面の格子上の 1 セルを占めるようにします。
output を、sourceRectangle によって示される 平面上の矩形とします。
output を、outputWidth および
outputHeight によって指定されるサイズへ拡大縮小します。
ユーザーエージェントは、拡大縮小アルゴリズムの選択を導くために、
resizeQuality
オプションの値を使用するべきです。
options の imageOrientation メンバーの値が
「flipY」である場合、
ソースに画像方向メタデータ(EXIF メタデータなど)があればそれを無視して、
output を垂直方向に反転しなければなりません。[EXIF]
値が「from-image」である場合、
追加の手順は必要ありません。
以前は「none」という列挙値がありました。
これは「from-image」
に名前が変更されました。将来、
「none」
は異なる意味で再び追加されます。
image が img 要素または
Blob
オブジェクトである場合、val を options の
colorSpaceConversion メンバーの値とし、
次の副手順を実行します:
val が「default」である場合、
色空間変換の動作は実装固有であり、画像をキャンバスへ描画するために実装が使用する
既定の色空間に従って選択するべきです。
val が「none」である場合、
output は色空間変換を行わずに復号しなければなりません。
これは、画像復号アルゴリズムがソースデータに埋め込まれたカラープロファイルメタデータと
表示装置のカラープロファイルの両方を無視しなければならないことを意味します。
val を、options の premultiplyAlpha メンバーの値とし、
次の副手順を実行します:
output を返します。
close()
メソッドの手順は次のとおりです:
this の[[Detached]] 内部スロットの値を true に設定します。
this のビットマップ データの設定を解除します。
width
取得子の手順は次のとおりです:
this の[[Detached]] 内部スロットの値が true である場合、 0 を返します。
height
取得子の手順は次のとおりです:
this の[[Detached]] 内部スロットの値が true である場合、 0 を返します。
ResizeQuality
列挙型は、画像を拡大縮小するときに使用する補間品質の設定を表すために使用されます。
「pixelated」値は、対象サイズが元のサイズの
正確な倍数でない場合に画像が歪むことを避けるため、必要に応じてわずかな平滑化を行いながら、
元画像のピクセル化された外観を可能な限り維持して拡大縮小する設定を示します。
「pixelated」
を実装するには、各軸について個別に、まず固有サイズの整数倍のうち、対象サイズに最も近く、
かつ 0 より大きいものを決定します。最近傍法を使用してこの整数倍のサイズへ拡大縮小し、
次に双線形補間を使用して残りの部分を対象サイズまで拡大縮小します。
「low」値は、
低いレベルの画像補間品質の設定を示します。低品質の画像補間は、
より高い設定よりも計算効率が高い場合があります。
「medium」値は、
中程度のレベルの画像補間品質の設定を示します。
「high」値は、
高いレベルの画像補間品質の設定を示します。高品質の画像補間は、
より低い設定よりも多くの計算を必要とする場合があります。
双線形拡大縮小は、比較的高速で低品質な画像平滑化アルゴリズムの一例です。
バイキュービックまたは Lanczos 拡大縮小は、より高品質な出力を生成する画像拡大縮小アルゴリズムの
例です。この仕様は、上記で説明した「pixelated」
を除き、特定の補間アルゴリズムを使用することを要求しません。
この API を使用すると、スプライトシートを事前に切り分けて準備できます:
var sprites = {};
function loadMySprites() {
var image = new Image();
image. src = 'mysprites.png' ;
var resolver;
var promise = new Promise( function ( arg) { resolver = arg });
image. onload = function () {
resolver( Promise. all([
createImageBitmap( image, 0 , 0 , 40 , 40 ). then( function ( image) { sprites. person = image }),
createImageBitmap( image, 40 , 0 , 40 , 40 ). then( function ( image) { sprites. grass = image }),
createImageBitmap( image, 80 , 0 , 40 , 40 ). then( function ( image) { sprites. tree = image }),
createImageBitmap( image, 0 , 40 , 40 , 40 ). then( function ( image) { sprites. hut = image }),
createImageBitmap( image, 40 , 40 , 40 , 40 ). then( function ( image) { sprites. apple = image }),
createImageBitmap( image, 80 , 40 , 40 , 40 ). then( function ( image) { sprites. snake = image })
]));
};
return promise;
}
function runDemo() {
var canvas = document. querySelector( 'canvas#demo' );
var context = canvas. getContext( '2d' );
context. drawImage( sprites. tree, 30 , 10 );
context. drawImage( sprites. snake, 70 , 10 );
}
loadMySprites(). then( runDemo); 一部のオブジェクトには、AnimationFrameProvider
インターフェイスミックスインが含まれます。
callback FrameRequestCallback = undefined (DOMHighResTimeStamp time );
interface mixin AnimationFrameProvider {
unsigned long requestAnimationFrame (FrameRequestCallback callback );
undefined cancelAnimationFrame (unsigned long handle );
};
Window includes AnimationFrameProvider ;
DedicatedWorkerGlobalScope includes AnimationFrameProvider ;各 AnimationFrameProvider
オブジェクトは、プロバイダーの内部状態を格納する対象オブジェクトも持ちます。
これは次のように定義されます:
各対象オブジェクトは、 最初は空でなければならない有順序マップである アニメーションフレームコールバックのマップと、 最初は 0 でなければならない数値であるアニメーションフレームコールバック 識別子を持ちます。
AnimationFrameProvider
provider は、次のいずれかが true である場合、
サポートされているとみなされます:
現在のすべてのエンジンでサポートされています。
requestAnimationFrame(callback)
メソッドの手順は次のとおりです:
this がサポートされていない場合、
「NotSupportedError」 DOMException
をスローします。
target のアニメーションフレームコールバック識別子を 1 増加させ、その結果を handle とします。
callbacks を、target の アニメーションフレーム コールバックのマップとします。
callbacks[handle] を callback に 設定します。
handle を返します。
現在のすべてのエンジンでサポートされています。
cancelAnimationFrame(handle)
メソッドの手順は次のとおりです:
this
がサポートされていない場合、
「NotSupportedError」 DOMException
をスローします。
callbacks を、this の対象オブジェクトの アニメーションフレーム コールバックのマップとします。
callbacks[handle] を 削除します。
対象オブジェクト target に対して、タイムスタンプ now を用いて アニメーションフレームコールバックを実行するには:
ワーカー内では、canvas
要素から転送された OffscreenCanvas とともに
requestAnimationFrame()
を使用できます。まず、文書内で制御をワーカーへ転送します:
const offscreenCanvas = document. getElementById( "c" ). transferControlToOffscreen();
worker. postMessage( offscreenCanvas, [ offscreenCanvas]); 次に、ワーカー内で次のコードを使用すると、左から右へ移動する矩形が描画されます:
let ctx, pos = 0 ;
function draw( dt) {
ctx. clearRect( 0 , 0 , 100 , 100 );
ctx. fillRect( pos, 0 , 10 , 10 );
pos += 10 * dt;
requestAnimationFrame( draw);
}
self. onmessage = function ( ev) {
const transferredCanvas = ev. data;
ctx = transferredCanvas. getContext( "2d" );
draw();
}; WebSocket
インターフェイスは、以前ここで定義されていました。現在は WebSockets で定義されています。
[WEBSOCKETS]
MessageEvent インターフェイス現在のすべてのエンジンでサポートされています。
サーバー送信
イベント、文書間メッセージング、
チャンネルメッセージング、
ブロードキャストチャンネル、
および WebSockets のメッセージは、その message イベントに
MessageEvent
インターフェイスを使用します:[WEBSOCKETS]
[Exposed =(Window ,Worker ,AudioWorklet )]
interface MessageEvent : Event {
constructor (DOMString type , optional MessageEventInit eventInitDict = {});
readonly attribute any data ;
readonly attribute USVString origin ;
readonly attribute DOMString lastEventId ;
readonly attribute MessageEventSource ? source ;
readonly attribute FrozenArray <MessagePort > ports ;
undefined initMessageEvent (DOMString type , optional boolean bubbles = false , optional boolean cancelable = false , optional any data = null , optional USVString origin = "", optional DOMString lastEventId = "", optional MessageEventSource ? source = null , optional sequence <MessagePort > ports = []);
};
dictionary MessageEventInit : EventInit {
any data = null ;
USVString origin = "";
DOMString lastEventId = "";
MessageEventSource ? source = null ;
sequence <MessagePort > ports = [];
};
typedef (WindowProxy or MessagePort or ServiceWorker ) MessageEventSource ;各 MessageEvent は、
オリジン
(オリジン、文字列、または null)
を持ち、その初期値は null です。
event.data
現在のすべてのエンジンでサポートされています。
メッセージのデータを返します。
event.origin
現在のすべてのエンジンでサポートされています。
サーバー送信イベントおよび 文書間メッセージングについて、 メッセージのオリジンを返します。
event.lastEventId
現在のすべてのエンジンでサポートされています。
サーバー送信イベントについて、 最終イベント ID 文字列を返します。
event.source
現在のすべてのエンジンでサポートされています。
文書間
メッセージングについてはソースウィンドウの
WindowProxy を返し、
SharedWorkerGlobalScope
オブジェクトで発生する connect
イベントについては、接続される MessagePort を返します。
event.ports
現在のすべてのエンジンでサポートされています。
文書間
メッセージングおよびチャンネル
メッセージングについて、メッセージとともに送信された
MessagePort
配列を返します。
data
属性は、初期化された値を返さなければなりません。
これは送信されるメッセージを表します。
origin
属性は、
サーバー送信
イベントおよび文書間
メッセージングにおいて、メッセージを送信した文書の
オリジンを表します
(通常は文書のスキーム、ホスト名、およびポートですが、パスまたは
フラグメントは含みません)。
origin
取得子の手順は次のとおりです:
origin
属性が「初期化」されるとき(たとえば、MessageEvent の
コンストラクター内)、
初期化値はオブジェクトのオリジンへ格納されます。
MessageEvent
インターフェイスを実装するオブジェクトのオリジンを抽出する手順は、
this のオリジンが
オリジンである場合は
それを返し、それ以外の場合は null を返すことです。
lastEventId 属性は、
初期化された値を返さなければなりません。これはサーバー送信イベントにおいて、
イベントソースの最終イベント ID 文字列を
表します。
source
属性は、
初期化された値を返さなければなりません。これは文書間メッセージングにおいて、
メッセージの送信元となった Window オブジェクトの
閲覧コンテキストの
WindowProxy を表し、
共有ワーカーによって使用される
connect
イベントにおいて、新しく接続される
MessagePort を表します。
ports
属性は、初期化された値を返さなければなりません。これは文書間
メッセージングおよびチャンネル
メッセージングにおいて、送信される MessagePort
配列を表します。
initMessageEvent(type, bubbles,
cancelable, data, origin, lastEventId,
source, ports) メソッドは、同様の名前を持つ
initEvent()
メソッドに類似した方法でイベントを初期化しなければなりません。
[DOM]
さまざまな API(たとえば、WebSocket、
EventSource)は、
MessagePort API を
使用せず、その message イベントに
MessageEvent
インターフェイスを使用します。
現在のすべてのエンジンでサポートされています。
この節は非規範的です。
サーバーが HTTP 経由または専用のサーバープッシュプロトコルを使用してウェブページへデータを
プッシュできるようにするため、この仕様では EventSource
インターフェイスを導入します。
この API は、EventSource オブジェクトを
作成し、イベントリスナーを登録することで使用します。
var source = new EventSource( 'updates.cgi' );
source. onmessage = function ( event) {
alert( event. data);
}; サーバー側では、スクリプト(この場合は「updates.cgi」)が、text/event-stream
MIME タイプを使用して、次の形式でメッセージを送信します:
data: This is the first message. data: This is the second message, it data: has two lines. data: This is the third message.
作成者は、異なるイベントタイプを使用してイベントを分離できます。次は、「add」と「remove」という 2 つのイベントタイプを持つストリームです:
event: add data: 73857293 event: remove data: 2153 event: add data: 113411
このようなストリームを処理するスクリプトは次のようになります
(addHandler および removeHandler は、イベントという 1 つの引数を
受け取る関数です):
var source = new EventSource( 'updates.cgi' );
source. addEventListener( 'add' , addHandler, false );
source. addEventListener( 'remove' , removeHandler, false ); 既定のイベントタイプは「message」です。
イベントストリームは常に UTF-8 として復号されます。別の文字エンコーディングを指定する方法は ありません。
イベントストリームの要求は、通常の HTTP 要求と同様に HTTP 301 および 307 リダイレクトを 使用してリダイレクトできます。接続が閉じられた場合、クライアントは再接続します。 HTTP 204 No Content 応答コードを使用すると、再接続を停止するようクライアントへ指示できます。
XMLHttpRequest
または iframe を使用して
この API を模倣するのではなく、この API を使用することで、ユーザーエージェントの実装者と
ネットワーク事業者が事前に連携できる場合、ユーザーエージェントはネットワークリソースを
より効率的に使用できます。ほかの利点に加えて、携帯機器のバッテリー寿命を大幅に節約できる
場合があります。これについては、後述するコネクションレス
プッシュの節で詳しく説明します。
EventSource インターフェイス現在のすべてのエンジンでサポートされています。
[Exposed =(Window ,Worker )]
interface EventSource : EventTarget {
constructor (USVString url , optional EventSourceInit eventSourceInitDict = {});
readonly attribute USVString url ;
readonly attribute boolean withCredentials ;
// ready state
const unsigned short CONNECTING = 0;
const unsigned short OPEN = 1;
const unsigned short CLOSED = 2;
readonly attribute unsigned short readyState ;
// networking
attribute EventHandler onopen ;
attribute EventHandler onmessage ;
attribute EventHandler onerror ;
undefined close ();
};
dictionary EventSourceInit {
boolean withCredentials = false ;
};各 EventSource
オブジェクトには、次のものが関連付けられます:
URL (URL レコード)。構築時に設定されます。
要求。初期値は null でなければなりません。
ミリ秒単位の再接続時間。 初期値は実装定義の値でなければならず、 おそらく数秒程度です。
最終イベント ID 文字列。 初期値は空文字列でなければなりません。
URLを除き、
これらは現在 EventSource オブジェクト上に
公開されていません。
source = new EventSource(
url [, { withCredentials:
true } ])
現在のすべてのエンジンでサポートされています。
新しい EventSource
オブジェクトを作成します。
url は、イベントストリームを提供する URL を指定する文字列です。
withCredentials
を true に設定すると、url への接続要求の
資格情報モードが
「include」に設定されます。
source.close()
現在のすべてのエンジンでサポートされています。
この EventSource
オブジェクトに対して開始されたフェッチアルゴリズムの
すべてのインスタンスを中止し、readyState
属性を CLOSED
に設定します。
source.url
現在のすべてのエンジンでサポートされています。
イベントストリームを提供する URLを返します。
source.withCredentials
現在のすべてのエンジンでサポートされています。
イベントストリームを提供する
URLへの
接続要求の資格情報モードが
「include」に設定されている場合は true を、それ以外の場合は false を返します。
source.readyState
現在のすべてのエンジンでサポートされています。
この EventSource オブジェクトの
接続状態を返します。次に説明する値を取ることができます。
EventSource(url, eventSourceInitDict)
コンストラクターは、呼び出されたとき、次の手順を実行しなければなりません:
ev を新しい EventSource
オブジェクトとします。
settings を、ev の関連する設定オブジェクトとします。
urlRecord を、settings を基準として url を与え、 URL をエンコーディング構文解析した結果とします。
urlRecord が失敗である場合、「SyntaxError」
DOMException
をスローします。
ev のURLを urlRecord に設定します。
corsAttributeState を匿名とします。
eventSourceInitDict の withCredentials
メンバーの値が true である場合、corsAttributeState を
資格情報を
使用に設定し、ev の withCredentials
属性を true に設定します。
request を、urlRecord、空文字列、および corsAttributeState を与えて 潜在的 CORS 要求を作成した結果とします。
request のクライアントを settings に設定します。
ユーザーエージェントは、request の
ヘッダーリストに
(`Accept`,
`text/event-stream`)
を設定してもよいです。
request のキャッシュ
モードを「no-store」に設定します。
request の開始元
タイプを「other」に設定します。
ev の要求を request に設定します。
応答 res が与えられた processEventSourceEndOfBody を、 次の手順とします:res がネットワークエラーでない場合、 接続を再確立します。
processResponseEndOfBody を processEventSourceEndOfBody に設定し、processResponse を、 応答 res が与えられた次の手順に設定して、request を フェッチします:
res が中止されたネットワークエラーである場合、 接続を失敗させます。
それ以外の場合、res が ネットワークエラーであれば、 接続を再確立します。 ただし、ユーザーエージェントが再確立しても無駄であると認識している場合、 ユーザーエージェントは接続を失敗させてもよいです。
それ以外の場合、res の
ステータスが 200 でないか、
res の `Content-Type` が
`text/event-stream`
でない場合、接続を失敗させます。
ev を返します。
url
属性の取得子は、この
EventSource
オブジェクトのURLの
直列化を返さなければなりません。
withCredentials 属性は、
最後に初期化された値を返さなければなりません。オブジェクトが作成されたとき、
false に初期化されなければなりません。
readyState 属性は接続の状態を表します。
次の値を取ることができます:
CONNECTING(数値 0)OPEN(数値 1)
CLOSED(数値
2)close()
メソッドが呼び出されました。オブジェクトが作成されたとき、その readyState
は CONNECTING
(0) に設定されなければなりません。値がいつ変更されるかは、以下の接続処理規則で定義されます。
close()
メソッドは、この
EventSource
オブジェクトに対して開始されたフェッチアルゴリズムの
すべてのインスタンスを中止し、readyState
属性を CLOSED
に設定しなければなりません。
次に示すものは、EventSource
インターフェイスを実装するすべてのオブジェクトが、
イベントハンドラー IDL
属性として
サポートしなければならないイベントハンドラー
(および対応するイベントハンドラーイベントタイプ)です:
| イベントハンドラー | イベントハンドラー イベントタイプ |
|---|---|
onopen
現在のすべてのエンジンでサポートされています。 Firefox6+Safari5+Chrome6+
Opera12+Edge79+ Edge (Legacy)?Internet Explorerいいえ Firefox Android45+Safari iOS5+Chrome Android?WebView Android?Samsung Internet?Opera Android12+ |
open
|
onmessage
現在のすべてのエンジンでサポートされています。 Firefox6+Safari5+Chrome6+
Opera12+Edge79+ Edge (Legacy)?Internet Explorerいいえ Firefox Android45+Safari iOS5+Chrome Android?WebView Android?Samsung Internet?Opera Android12+ |
message
|
onerror
現在のすべてのエンジンでサポートされています。 Firefox6+Safari5+Chrome6+
Opera12+Edge79+ Edge (Legacy)?Internet Explorerいいえ Firefox Android45+Safari iOS5+Chrome Android?WebView Android?Samsung Internet?Opera Android12+ |
error
|
ユーザーエージェントが接続を通知する場合、
ユーザーエージェントは、readyState
属性が CLOSED
以外の値に設定されていれば、readyState
属性を OPEN に設定し、
EventSource オブジェクトで
open という名前の
イベントを発生させる
タスクをキューに
追加しなければなりません。
ユーザーエージェントが接続を再確立する場合、 ユーザーエージェントは次の手順を実行しなければなりません。これらの手順は タスクの一部としてではなく、 並行して実行されます。 (もちろん、これらがキューに追加するタスクは通常のタスクと同様に実行され、 それ自体が並行して実行されるわけではありません。)
次の手順を実行するタスクをキューに追加します:
readyState
属性が CLOSED
に設定されている場合、タスクを中止します。
readyState
属性を CONNECTING
に設定します。
EventSource オブジェクトで
error という名前の
イベントを発生させます。
イベントソースの再接続時間と等しい遅延だけ待機します。
任意でさらに待機します。特に、前回の試行が失敗した場合、ユーザーエージェントは、 すでに過負荷となっている可能性のあるサーバーへさらに負荷をかけることを避けるため、 指数バックオフ遅延を導入することがあります。また、オペレーティングシステムから ネットワーク接続がないと報告された場合、ユーザーエージェントは再試行する前に、 ネットワーク接続が回復したとオペレーティングシステムが通知するまで待機することがあります。
前述のタスクがまだ実行されていない場合、そのタスクが実行されるまで待機します。
次の手順を実行するタスクをキューに追加します:
EventSource
オブジェクトの readyState
属性が CONNECTING
に設定されていない場合、返ります。
request を、EventSource オブジェクトの
要求とします。
EventSource
オブジェクトの最終イベント ID 文字列が
空文字列でない場合:
lastEventIDValue を、EventSource
オブジェクトの最終イベント ID 文字列を
UTF-8 としてエンコードしたものとします。
request の
ヘッダーリストに
(`Last-Event-ID`,
lastEventIDValue) を
設定します。
request をフェッチし、応答が得られた場合、 この節の前述の説明に従ってその応答を処理します。
ユーザーエージェントが接続を失敗させる場合、
ユーザーエージェントは、readyState
属性が CLOSED
以外の値に設定されていれば、readyState
属性を CLOSED
に設定し、EventSource オブジェクトで
error という名前の
イベントを発生させる
タスクをキューに
追加しなければなりません。
ユーザーエージェントは一度接続を失敗させると、
再接続を試みることはありません。
EventSource
オブジェクトによってキューに追加されるすべての
タスクの
タスクソースは、
リモートイベント
タスクソースです。
Last-Event-ID` ヘッダーLast-Event-ID` HTTP 要求ヘッダーは、
ユーザーエージェントが接続を再確立するときに、
EventSource
オブジェクトの最終イベント ID
文字列をサーバーへ報告します。
値空間をより適切に定義するには、whatwg/html issue #7363 を参照してください。これは基本的に、U+0000 NULL、U+000A LF、または U+000D CR を 含まない、任意の UTF-8 エンコード文字列です。
このイベントストリーム形式のMIME タイプは text/event-stream です。
イベントストリーム形式は、次の ABNF の stream 生成規則によって記述され、
その文字集合は Unicode です。[ABNF]
stream = [ bom ] * event
event = * ( comment / field ) end-of-line
comment = colon * any-char end-of-line
field = 1* name-char [ colon [ space ] * any-char ] end-of-line
end-of-line = ( cr lf / cr / lf )
; characters
lf = %x000A ; U+000A LINE FEED (LF)
cr = %x000D ; U+000D CARRIAGE RETURN (CR)
space = %x0020 ; U+0020 SPACE
colon = %x003A ; U+003A COLON (:)
bom = %xFEFF ; U+FEFF BYTE ORDER MARK
name-char = %x0000-0009 / %x000B-000C / %x000E-0039 / %x003B-10FFFF
; a scalar value other than U+000A LINE FEED (LF), U+000D CARRIAGE RETURN (CR), or U+003A COLON (:)
any-char = %x0000-0009 / %x000B-000C / %x000E-10FFFF
; a scalar value other than U+000A LINE FEED (LF) or U+000D CARRIAGE RETURN (CR) この形式のイベントストリームは、常に UTF-8 としてエンコードされなければなりません。 [ENCODING]
行は、U+000D CARRIAGE RETURN U+000A LINE FEED(CRLF)の文字対、 単一の U+000A LINE FEED(LF)文字、または単一の U+000D CARRIAGE RETURN(CR)文字の いずれかで区切られなければなりません。
このようなリソースについてリモートサーバーへ確立される接続は長時間維持されることが 予想されるため、UA は適切なバッファリングが使用されるようにするべきです。特に、 単一の U+000A LINE FEED(LF)文字で終了すると定義された行による行バッファリングは安全ですが、 ブロックバッファリング、または異なる行末を想定した行バッファリングは、 イベントの送出を遅延させる可能性があります。
ストリームは、UTF-8 復号アルゴリズムを使用して復号されなければなりません。
UTF-8 復号アルゴリズムは、先頭に UTF-8 バイト順マーク (BOM)がある場合、その 1 つを除去します。
次に、すべてを行ごとに読み取ることでストリームを構文解析しなければなりません。 U+000D CARRIAGE RETURN U+000A LINE FEED(CRLF)の文字対、 U+000D CARRIAGE RETURN(CR)文字が前にない単一の U+000A LINE FEED(LF)文字、 および U+000A LINE FEED(LF)文字が後にない単一の U+000D CARRIAGE RETURN(CR)文字が、 行を終了できる方法となります。
ストリームを構文解析するとき、data バッファー、event type バッファー、および last event ID バッファーを関連付けなければなりません。 これらは空文字列に初期化されなければなりません。
行は受信された順序で、次のように処理されなければなりません:
以下で定義するように、イベントを送出します。
その行を無視します。
行の最初の U+003A COLON 文字(:)より前にある文字を収集し、 その文字列を field とします。
行の最初の U+003A COLON 文字(:)より後にある文字を収集し、 その文字列を value とします。value が U+0020 SPACE 文字で 始まる場合、その文字を value から削除します。
field をフィールド名、value をフィールド値として、 以下に説明する手順を使用してフィールドを処理します。
行全体をフィールド名、空文字列をフィールド値として、以下に説明する手順を使用して フィールドを処理します。
ファイルの終端に到達したら、保留中のデータをすべて破棄しなければなりません。 (ファイルがイベントの途中、すなわち最後の空行より前で終了した場合、 不完全なイベントは送出されません。)
フィールド名およびフィールド値が与えられたときに フィールドを処理する手順は、次のリストに示すようにフィールド名によって異なります。 フィールド名は大文字と小文字を変換せず、文字どおりに比較しなければなりません。
event type バッファーをフィールド値に設定します。
フィールド値を data バッファーへ追加し、次に単一の U+000A LINE FEED(LF)文字を data バッファーへ追加します。
フィールド値に U+0000 NULL が含まれていない場合、 last event ID バッファーをフィールド値に設定します。 それ以外の場合、フィールドを無視します。
フィールド値がASCII 数字のみで構成される場合、 フィールド値を 10 進数の整数として解釈し、イベントストリームの 再接続時間を その整数に設定します。それ以外の場合、フィールドを無視します。
フィールドを無視します。
ユーザーエージェントがイベントを送出する必要がある場合、 ユーザーエージェントは、そのユーザーエージェントに適した手順を使用して、 data バッファー、event type バッファー、および last event ID バッファーを処理しなければなりません。
ウェブブラウザーの場合、イベントを送出するための 適切な手順は次のとおりです:
イベントソースの最終イベント ID 文字列を、 last event ID バッファーの値に設定します。このバッファーはリセットされないため、 イベントソースの最終イベント ID 文字列は、次にサーバーによって設定されるまで、この値のままになります。
data バッファーが空文字列である場合、data バッファーおよび event type バッファーを空文字列に設定して、返ります。
data バッファーの最後の文字が U+000A LINE FEED(LF)文字である場合、 data バッファーから最後の文字を削除します。
event を、EventSource
オブジェクトの関連するレルムで、
MessageEvent を
使用してイベントを作成した結果とします。
event の type
属性を「message」に、
data
属性を data に、そのオリジンを
イベントストリームの最終 URL(すなわちリダイレクト後の URL)の
オリジンに、lastEventId
属性をイベントソースの最終イベント ID 文字列に
初期化します。
event type バッファーが空文字列以外の値を持つ場合、 新しく作成されたイベントのタイプを event type バッファーの値と等しくなるように変更します。
data バッファーおよび event type バッファーを 空文字列に設定します。
readyState
属性が CLOSED
以外の値に設定されていれば、新しく作成されたイベントを
EventSource
オブジェクトへ送出する
タスクをキューに追加します。
イベントに「id」フィールドがなくても、それ以前のイベントがイベントソースの
最終イベント ID 文字列を
設定していた場合、そのイベントの lastEventId
フィールドには、最後に確認された「id」フィールドの値が設定されます。
その他のユーザーエージェントの場合、イベントを送出するための 適切な手順は実装依存ですが、少なくとも返る前に data および event type バッファーを空文字列に設定しなければなりません。
次のイベントストリームの後に空行が続くとします:
data: YHOO data: +2 data: 10
……これにより、EventSource
オブジェクトで、
MessageEvent
インターフェイスを持つ message
イベントが
送出されます。イベントの data
属性には文字列「YHOO\n+2\n10」が格納されます
(「\n」は改行を表します)。
これは次のように使用できます:
var stocks = new EventSource( "https://stocks.example.com/ticker.php" );
stocks. onmessage = function ( event) {
var data = event. data. split( '\n' );
updateStocks( data[ 0 ], data[ 1 ], data[ 2 ]);
}; ……ここで updateStocks() は、次のように定義された関数です:
function updateStocks( symbol, delta, value) { ... } ……またはこれに類するものです。
次のストリームには 4 つのブロックが含まれます。最初のブロックにはコメントしかなく、
何も発生しません。2 番目のブロックには、それぞれ「data」と「id」という名前の
2 つのフィールドがあります。このブロックでは、データが「first event」のイベントが発生し、
最終イベント ID が「1」に設定されます。そのため、このブロックと次のブロックの間で接続が
切れた場合、値 `1` を持つ `Last-Event-ID`
ヘッダーがサーバーへ送信されます。3 番目のブロックは、データが「second event」の
イベントを発生させ、「id」フィールドも持ちますが、今回は値がありません。
これにより最終イベント ID が空文字列へリセットされます
(再接続が試みられる場合でも `Last-Event-ID`
ヘッダーが送信されなくなることを意味します)。最後に、最終ブロックはデータが
「 third event」(先頭に空白文字が 1 つあります)のイベントを発生させるだけです。
最後のブロックも空行で終了する必要があり、ストリームの終端だけでは最終イベントの送出を
起動するには不十分であることに注意してください。
: test stream data: first event id: 1 data:second event id data: third event
次のストリームは 2 つのイベントを発生させます:
data data data data:
最初のブロックは、データが空文字列に設定されたイベントを発生させます。 最終ブロックの後に空行が続いた場合も同様です。中央のブロックは、 データが単一の改行文字に設定されたイベントを発生させます。 最終ブロックは空行が後に続かないため破棄されます。
次のストリームは、同一の 2 つのイベントを発生させます:
data:test data: test
これは、コロンの後に空白がある場合、その空白が無視されるためです。
従来のプロキシサーバーは、場合によっては短いタイムアウトの後に HTTP 接続を切断することが 知られています。このようなプロキシサーバーに対処するため、作成者は約 15 秒ごとに コメント行(「:」文字で始まる行)を含めることができます。
イベントソース接続同士、または以前に提供された特定の文書とイベントソース接続を関連付けたい 作成者は、IP アドレスに依存する方法が機能しない場合があります。個々のクライアントが 複数の IP アドレスを持つ可能性があり(複数のプロキシサーバーを持つため)、 個々の IP アドレスが複数のクライアントを持つ可能性があるためです (プロキシサーバーを共有するため)。文書を提供するときに一意の識別子を含め、 接続を確立するときにその識別子を URL の一部として渡す方が適切です。
HTTP チャンク化は、特にタイミング要件を認識していない別の層によってチャンク化が 行われる場合、このプロトコルの信頼性へ予期しない悪影響を与える可能性があることにも、 作成者は注意してください。これが問題となる場合、イベントストリームを提供する際の チャンク化を無効にできます。
HTTP のサーバーごとの接続制限をサポートするクライアントでは、各ページが同じドメインへの
EventSource を持つサイトから
複数のページを開くと、問題が発生する場合があります。作成者は、接続ごとに一意のドメイン名を
使用するという比較的複雑な仕組みを使用するか、ページごとに EventSource
機能を
有効または無効にできるようにするか、共有ワーカーを使用して単一の
EventSource
オブジェクトを共有することで、この問題を回避できます。
特定の通信事業者に関連付けられた携帯端末上のブラウザーなど、管理された環境で動作する ユーザーエージェントは、接続の管理をネットワーク上のプロキシへ委託してもよいです。 このような状況では、適合性のためのユーザーエージェントには、端末のソフトウェアと ネットワークプロキシの両方が含まれるとみなされます。
たとえば、モバイル機器上のブラウザーは、接続を確立した後、対応するネットワーク上に いることを検出し、ネットワーク上のプロキシサーバーに接続の管理を引き継ぐよう 要求する場合があります。このような状況の時系列は次のようになります:
EventSource
コンストラクターで指定したリソースを要求します。EventSource
コンストラクターで指定したリソースを要求します
(場合によっては `Last-Event-ID` HTTP
ヘッダーなどを含みます)。これにより、総データ使用量を削減でき、その結果、大幅な電力節約につながる可能性があります。
この仕様で定義される既存の API および text/event-stream
ワイヤー形式を、上述したより分散的な方法で実装することに加えて、
その他の適用可能な仕様で定義された
イベントフレーミング形式もサポートしてよいです。この仕様は、それらを構文解析または
処理する方法を定義しません。
EventSource オブジェクトの
readyState
が CONNECTING
であり、そのオブジェクトに open、message、または error イベント用の
イベントリスナーが 1 つ以上登録されている間、EventSource
オブジェクトの
コンストラクターが呼び出された Window または WorkerGlobalScope
オブジェクトから、その EventSource オブジェクト自体への
強い参照が存在しなければなりません。
EventSource オブジェクトの
readyState
が OPEN
であり、そのオブジェクトに message または error イベント用の
イベントリスナーが 1 つ以上登録されている間、EventSource
オブジェクトの
コンストラクターが呼び出された Window または WorkerGlobalScope
オブジェクトから、その EventSource オブジェクト自体への
強い参照が存在しなければなりません。
EventSource オブジェクトによって
リモートイベント
タスクソースにキューへ追加されたタスクが存在する間、EventSource オブジェクトの
コンストラクターが呼び出された Window または
WorkerGlobalScope
オブジェクトから、その EventSource オブジェクトへの
強い参照が存在しなければなりません。
ユーザーエージェントが EventSource オブジェクトを
強制的に閉じる場合
(これは Document
オブジェクトが恒久的に消滅するときに発生します)、ユーザーエージェントは、この EventSource オブジェクトに
対して開始されたフェッチアルゴリズムのすべてのインスタンスを中止し、
readyState
属性を CLOSED
に設定しなければなりません。
EventSource オブジェクトが、
接続がまだ開いている間にガベージコレクションされた場合、ユーザーエージェントは、この
EventSource によって
開かれたフェッチアルゴリズムのすべてのインスタンスを
中止しなければなりません。
この節は非規範的です。
作成者がこの API を使用するコードをデバッグできるように、ユーザーエージェントは
EventSource オブジェクトと
それに関連するネットワーク接続について、詳細な診断情報を開発者コンソールで提供することを
強く推奨されます。
たとえば、ユーザーエージェントは、ページが作成したすべての EventSource
オブジェクトを表示するパネルを持つことができます。各オブジェクトについて、
コンストラクターの引数、ネットワークエラーが発生したかどうか、接続の CORS 状態、
その状態に至るまでにクライアントから送信され、サーバーから受信されたヘッダー、
受信したメッセージとその構文解析方法などを一覧表示できます。
イベント自体で提供できる情報がほとんど、またはまったくないため、error イベントが
発生するたびに、実装が詳細な情報を開発者コンソールへ報告することを特に推奨します。
現在のすべてのエンジンでサポートされています。
ウェブブラウザーは、セキュリティおよびプライバシー上の理由から、異なるドメインの文書が 相互に影響することを防止します。すなわち、クロスサイトスクリプティングは禁止されています。
これは重要なセキュリティ機能ですが、異なるドメインのページが敵対的でない場合でも、 それらのページ間の通信を妨げます。この節では、クロスサイトスクリプティング攻撃を 可能にしないよう設計された方法で、ソースドメインに関係なく文書同士が通信できる メッセージングシステムを導入します。
![]()
postMessage() API は、
追跡
ベクトルとして使用できます。
この節は非規範的です。
たとえば、文書 A が文書 B を含む iframe
要素を含み、
文書 A のスクリプトが文書 B の Window オブジェクトで postMessage() を
呼び出した場合、そのオブジェクトでメッセージイベントが発生し、そのイベントは文書 A の
Window から発生したものとして
マークされます。文書 A のスクリプトは次のようになります:
var o = document. getElementsByTagName( 'iframe' )[ 0 ];
o. contentWindow. postMessage( 'Hello world' , 'https://b.example.org/' ); 受信イベント用のイベントハンドラーを登録するため、スクリプトは
addEventListener()(または同様の仕組み)を使用します。たとえば、
文書 B のスクリプトは次のようになります:
window. addEventListener( 'message' , receiver, false );
function receiver( e) {
if ( e. origin == 'https://example.com' ) {
if ( e. data == 'Hello world' ) {
e. source. postMessage( 'Hello' , e. origin);
} else {
alert( e. data);
}
}
} このスクリプトは、まずドメインが予想されたドメインであることを確認し、次にメッセージを 調べます。そのメッセージをユーザーへ表示するか、最初にメッセージを送信した文書へ メッセージを送り返すことで応答します。
この API を使用する場合、敵対的な主体が自身の目的のために サイトを悪用することからユーザーを保護するため、特別な注意が必要です。
作成者は、メッセージを受信すると予想しているドメインからのメッセージのみを受け入れるよう、
origin
属性を確認するべきです。そうしなければ、作成者のメッセージ処理コードのバグが
敵対的なサイトによって悪用される可能性があります。
さらに、origin
属性を確認した後でも、作成者は対象のデータが予想された形式であることも確認するべきです。
そうしなければ、イベントのソースがクロスサイトスクリプティングの脆弱性を使用して攻撃された場合、
postMessage()
メソッドを使用して送信された情報を確認せずにさらに処理すると、攻撃が受信側へ
伝播する可能性があります。
機密情報を含むメッセージでは、作成者は targetOrigin 引数に ワイルドカードキーワード(*)を使用するべきではありません。そうしなければ、 メッセージが意図された受信者のみに配信されることを保証する方法がありません。
任意のオリジンからのメッセージを受け入れる作成者は、サービス拒否攻撃のリスクを 考慮することを推奨します。攻撃者は大量のメッセージを送信できます。受信ページが そのようなメッセージごとに高コストの計算を実行したり、ネットワークトラフィックを 送信させたりする場合、攻撃者のメッセージがサービス拒否攻撃へ増幅される可能性があります。 このような攻撃を非現実的なものにするため、作成者にはレート制限 (1 分当たり一定数のメッセージのみを受け入れること)の採用を推奨します。
この API の完全性は、あるオリジンのスクリプトが、別のオリジン
(同一でないオリジン)にあるオブジェクトへ、
任意のイベントを(dispatchEvent() などを使用して)送出できないことに基づきます。
実装者は、この機能の実装に特別な注意を払うことを推奨されます。 この機能を使用すると、通常はセキュリティ上の理由から禁止されている、あるドメインから 別のドメインへの情報送信が可能になります。また、UA は特定のプロパティへのアクセスを 許可し、その他のプロパティへのアクセスを許可しないよう注意する必要があります。
ユーザーエージェントには、単純なサイトをサービス拒否攻撃から保護するため、 異なるオリジン間のメッセージトラフィックに レート制限を設けることも推奨します。
window.postMessage(message [, options ])
現在のすべてのエンジンでサポートされています。
指定されたウィンドウへメッセージを送信します。メッセージには、入れ子になったオブジェクトや
配列などの構造化オブジェクトを使用でき、JavaScript の値(文字列、数値、Date
オブジェクトなど)を含めることができ、File、
Blob、
FileList、
および ArrayBuffer
オブジェクトなど、特定のデータオブジェクトも含めることができます。
options の transfer
メンバーに列挙されたオブジェクトは、単に複製されるのではなく転送されます。
これは、送信側ではそれらを使用できなくなることを意味します。
options の targetOrigin
メンバーを使用して、対象オリジンを指定できます。指定しない場合、既定値は
「/」です。この既定値では、メッセージの対象が同一オリジンのみに制限されます。
対象ウィンドウのオリジンが指定された対象オリジンと一致しない場合、
情報漏洩を避けるためにメッセージは破棄されます。オリジンに関係なく対象へ
メッセージを送信するには、対象オリジンを「*」に設定します。
transfer 配列に重複するオブジェクトが含まれる場合、または
message を複製できない場合、「DataCloneError」 DOMException
をスローします。
window.postMessage(message, targetOrigin [, transfer ])
これは、対象オリジンを引数として指定する postMessage()
の別形式です。window.postMessage(message, target, transfer) の呼び出しは、
window.postMessage(message, {targetOrigin,
transfer}) と同等です。
新しい Document へ
ナビゲートされた直後の閲覧コンテキストの
Window へメッセージを送信すると、
メッセージが意図された受信者へ届かない可能性があります。対象の閲覧コンテキスト内のスクリプトが、
メッセージ用のリスナーを設定するための時間を必要とするためです。したがって、たとえば、
新しく作成された子 iframe の
Window へメッセージを送信する状況では、
作成者は子 Document から親へ、
メッセージを受信する準備ができたことを通知するメッセージを送信し、親はこのメッセージを
待ってからメッセージの送信を開始することを推奨されます。
targetWindow、message、および options が与えられたときの ウィンドウメッセージ送信手順は次のとおりです:
targetRealm を、targetWindow の レルムとします。
incumbentSettings を現任設定オブジェクトとします。
targetOrigin を options["targetOrigin"]
とします。
targetOrigin が単一の U+002F SOLIDUS 文字(/)である場合、 targetOrigin を incumbentSettings の オリジンに設定します。
それ以外の場合、targetOrigin が単一の U+002A ASTERISK 文字(*)でなければ:
parsedURL を、targetOrigin に URL パーサーを実行した結果とします。
parsedURL が失敗である場合、「SyntaxError」
DOMException
をスローします。
targetOrigin を parsedURL の オリジンに設定します。
transfer を options["transfer"]
とします。
serializeWithTransferResult を StructuredSerializeWithTransfer(message, transfer) とします。すべての例外を再スローします。
targetWindow が与えられた 送信済みメッセージタスクソース上に、 次の手順を実行する大域タスクをキューに追加します:
targetOrigin 引数が文字どおり単一の U+002A ASTERISK 文字(*)でなく、
targetWindow の関連付けられた
Documentの
オリジンが
targetOrigin と同一オリジンでない場合、返ります。
origin を incumbentSettings の オリジンとします。
source を、incumbentSettings の
大域
オブジェクト(Window オブジェクト)に対応する
WindowProxy
オブジェクトとします。
deserializeRecord を StructuredDeserializeWithTransfer(serializeWithTransferResult, targetRealm) とします。
これが例外をスローした場合、その例外を捕捉し、MessageEvent を使用し、
そのオリジンを
origin に、source
属性を source に初期化して、targetWindow で messageerror
という名前のイベントを発生させ、返ります。
messageClone を deserializeRecord.[[Deserialized]] とします。
newPorts を、
deserializeRecord.[[TransferredValues]] 内に存在するすべての
MessagePort
オブジェクトから構成され、その相対的な順序を維持する新しい
凍結
配列とします。
MessageEvent を使用し、
そのオリジンを
origin に、source
属性を source に、data
属性を messageClone に、ports
属性を newPorts に初期化して、targetWindow で
message という名前の
イベントを発生させます。
Window インターフェイスの
postMessage(message,
options) メソッドの手順は、this、
message、および options を与えて
ウィンドウメッセージ送信
手順を実行することです。
Window インターフェイスの
postMessage(message, targetOrigin,
transfer) メソッドの手順は、this、
message、および «[ "targetOrigin"
→
targetOrigin, "transfer"
→ transfer ]» を与えて、ウィンドウメッセージ送信
手順を実行することです。
現行のすべてのエンジンでサポートされています。
Channel_Messaging_API/Using_channel_messaging
現行のすべてのエンジンでサポートされています。
この節は非規範的です。
独立したコード(例えば、異なる閲覧コンテキストで実行されるコード)が直接通信できるようにするため、作成者はチャネル メッセージングを使用できます。
この機構の通信チャネルは、両端にポートを備えた双方向パイプとして実装されます。一方のポートから送信されたメッセージはもう一方のポートへ配信され、その逆も同様です。メッセージは、実行中のタスクを中断またはブロックすることなく、DOMイベントとして 配信されます。
接続(2つの「もつれた」ポート)を作成するには、MessageChannel()
コンストラクターを呼び出します。
var channel = new MessageChannel(); 一方のポートをローカルポートとして保持し、もう一方のポートをリモートコードへ送信します。例えば、
postMessage()を使用します。
otherWindow. postMessage( 'hello' , 'https://example.com' , [ channel. port2]); メッセージを送信するには、ポートのpostMessage()
メソッドを使用します。
channel. port1. postMessage( 'hello' ); メッセージを受信するには、messageイベントを待ち受けます。
channel. port1. onmessage = handleMessage;
function handleMessage( event) {
// message is in event.data
// ...
} ポートで送信するデータには構造化データを使用できます。例えば、ここでは文字列の配列を
MessagePortで渡しています。
port1. postMessage([ 'hello' , 'world' ]); この節は非規範的です。
この例では、2つのJavaScriptライブラリーが
MessagePortを使用して相互に接続されます。これによりAPIを変更することなく、後からライブラリーを異なるフレーム内や
Workerオブジェクト内でホストできるようになります。
< script src = "contacts.js" ></ script > <!-- exposes a contacts object -->
< script src = "compose-mail.js" ></ script > <!-- exposes a composer object -->
< script >
var channel = new MessageChannel();
composer. addContactsProvider( channel. port1);
contacts. registerConsumer( channel. port2);
</ script > 「addContactsProvider()」関数の実装は、次のようになります。
function addContactsProvider( port) {
port. onmessage = function ( event) {
switch ( event. data. messageType) {
case 'search-result' : handleSearchResult( event. data. results); break ;
case 'search-done' : handleSearchDone(); break ;
case 'search-error' : handleSearchError( event. data. message); break ;
// ...
}
};
}; 別の方法として、次のように実装することもできます。
function addContactsProvider( port) {
port. addEventListener( 'message' , function ( event) {
if ( event. data. messageType == 'search-result' )
handleSearchResult( event. data. results);
});
port. addEventListener( 'message' , function ( event) {
if ( event. data. messageType == 'search-done' )
handleSearchDone();
});
port. addEventListener( 'message' , function ( event) {
if ( event. data. messageType == 'search-error' )
handleSearchError( event. data. message);
});
// ...
port. start();
}; 主な違いは、addEventListener()を使用する場合、
start()メソッドも
呼び出す必要があることです。onmessageを使用する場合は、
start()の呼び出しが
暗黙に行われます。
start()メソッドは、明示的に呼び出された場合でも、
(onmessageの設定によって)暗黙に呼び出された場合でも、
メッセージの流れを開始します。メッセージポートへ送信されたメッセージは当初一時停止されているため、スクリプトがハンドラーを設定する前に
メッセージが失われることはありません。
この節は非規範的です。
ポートは、制限された能力(オブジェクト能力モデルの意味における能力)をシステム内の他のアクターへ公開する方法とみなせます。これは、特定のオリジン内で単に便利なモデルとしてポートを使用する弱い能力システムにも、一方のオリジンproviderが、別のオリジンconsumerがproviderに変更を加えたり情報を取得したりするための唯一の機構としてポートを提供する強い能力モデルにもなり得ます。
例えば、ソーシャルウェブサイトが、一方のiframeにユーザーの電子メール連絡先プロバイダー(第2のオリジンにあるアドレス帳サイト)を埋め込み、もう一方の
iframeに
ゲーム(第3のオリジンからのもの)を埋め込む状況を考えてみます。外側のソーシャルサイトと第2の
iframe内のゲームは、最初のiframe内のいかなるものにもアクセスできません。
両者が行えるのは、次のことだけです。
iframeを新しいURLへナビゲートすること。例えば、同じ
URLでも異なるフラグメントを持つものへナビゲートし、
iframe内の
Windowに
hashchange
イベントを受信させること。
window.postMessage()
APIを使用して、
iframe内の
Windowへ
message
イベントを送信すること。
連絡先プロバイダーは、これらの方法、特に3番目の方法を使用して、他のオリジンからアクセスできる、ユーザーのアドレス帳を操作するためのAPIを提供できます。例えば、「add-contact Guillaume Tell
<tell@pomme.example.net>」というメッセージに応答し、指定された人物と電子メールアドレスをユーザーの
アドレス帳へ追加できます。
ウェブ上のどのサイトからでもユーザーの連絡先を操作できてしまうことを避けるため、連絡先 プロバイダーは、ソーシャルサイトなど、特定の信頼できるサイトだけにこれを許可できます。
ここで、ゲームがユーザーのアドレス帳へ連絡先を追加することを望み、ソーシャルサイトが自らに代わってゲームにそれを行わせることを許可するとします。これは実質的に、連絡先プロバイダーがソーシャルサイトに寄せていた信頼を「共有」することになります。これを行う方法はいくつかあります。最も単純なのは、ゲームサイトと連絡先サイトの間でメッセージを中継する方法です。しかし、この解決策にはいくつかの問題があります。ソーシャルサイトは、ゲームサイトが権限を濫用しないことを完全に信頼するか、許可したくない要求(複数の連絡先の追加、連絡先の読み取りや削除など)でないことを確認するために、各要求を検証しなければなりません。また、複数のゲームが同時に連絡先プロバイダーとやり取りする可能性がある場合には、さらなる複雑さも伴います。
しかし、メッセージチャネルとMessagePort
オブジェクトを使用すれば、これらの問題はすべて
解消できます。ゲームがソーシャルサイトに連絡先を追加したいと伝えたとき、ソーシャルサイトは連絡先プロバイダーに連絡先の追加そのものを依頼するのではなく、単一の連絡先を追加する能力を要求できます。連絡先プロバイダーは一対のMessagePort
オブジェクトを作成し、その一方をソーシャルサイトへ送り返します。ソーシャルサイトはそれをゲームへ転送します。これにより、ゲームと連絡先プロバイダーは直接接続され、連絡先プロバイダーは単一の「連絡先を追加」要求だけを受け入れ、それ以外は受け入れないようにできます。言い換えると、ゲームには単一の連絡先を追加する能力が付与されたことになります。
この節は非規範的です。
前節の例を引き続き使用し、特に連絡先プロバイダーについて考えてみます。
初期の実装では、サービスのiframe内で単純にXMLHttpRequest
オブジェクトを使用していたとしても、サービスの進化に伴い、単一の
WebSocket
接続を持つ共有ワーカーを代わりに使用することが望まれる場合があります。
初期設計でMessagePort
オブジェクトを使用して能力を付与していた場合、または単に複数の独立したセッションを同時に扱えるようにしていた場合でも、サービスの実装はAPIをまったく変更せずに、各iframe内でXMLHttpRequestを使用するモデルから、共有WebSocket
モデルへ切り替えることができます。サービスプロバイダー側のすべてのポートを共有ワーカーへ転送しても、APIの利用者には少しも影響しません。
現行のすべてのエンジンでサポートされています。
[Exposed =(Window ,Worker )]
interface MessageChannel {
constructor ();
readonly attribute MessagePort port1 ;
readonly attribute MessagePort port2 ;
};channel = new MessageChannel()
現行のすべてのエンジンでサポートされています。
2つの新しいMessagePort
オブジェクトを持つ、新しいMessageChannel
オブジェクトを返します。
channel.port1
現行のすべてのエンジンでサポートされています。
最初のMessagePort
オブジェクトを返します。
channel.port2
現行のすべてのエンジンでサポートされています。
2番目のMessagePort
オブジェクトを返します。
MessageChannelオブジェクトには、関連付けられた
ポート1と、関連付けられた
ポート2があります。どちらもMessagePortオブジェクトです。
new MessageChannel()コンストラクターの手順は
次のとおりです。
MessageEventTarget
ミックスイン
interface mixin MessageEventTarget {
attribute EventHandler onmessage ;
attribute EventHandler onmessageerror ;
};次に示すものは、MessageEventTarget
インターフェイスを実装するオブジェクトが、イベント
ハンドラーIDL属性としてサポートしなければならないイベントハンドラー
(およびそれらに対応するイベントハンドラーのイベント型)です。
| イベントハンドラー | イベント ハンドラーのイベント型 |
|---|---|
onmessage
現行のすべてのエンジンでサポートされています。 Firefox41+Safari5+Chrome2+
Opera10.6+Edge79+ Edge (Legacy)12+Internet Explorer10+ Firefox Android?Safari iOS?Chrome Android?WebView Android37+Samsung Internet?Opera Android11.5+ DedicatedWorkerGlobalScope/message_event 現行のすべてのエンジンでサポートされています。 Firefox3.5+Safari4+Chrome4+
Opera10.6+Edge79+ Edge (Legacy)12+Internet Explorer10+ Firefox Android?Safari iOS5+Chrome Android?WebView Android37+Samsung Internet?Opera Android11.5+ |
message
|
onmessageerror
MessagePort/messageerror_event 現行のすべてのエンジンでサポートされています。 Firefox57+Safari16.4+Chrome60+
Opera?Edge79+ Edge (Legacy)18Internet Explorer非対応 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android47+ DedicatedWorkerGlobalScope/messageerror_event 現行のすべてのエンジンでサポートされています。 Firefox57+Safari16.4+Chrome60+
Opera?Edge79+ Edge (Legacy)18Internet Explorer非対応 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android47+ |
messageerror
|
現行のすべてのエンジンでサポートされています。
各チャネルには2つのメッセージポートがあります。一方のポートを通じて送信されたデータは、もう一方のポートで受信され、 その逆も同様です。
[Exposed =(Window ,Worker ,AudioWorklet ), Transferable ]
interface MessagePort : EventTarget {
undefined postMessage (any message , sequence <object > transfer );
undefined postMessage (any message , optional StructuredSerializeOptions options = {});
undefined start ();
undefined close ();
// event handlers
attribute EventHandler onclose ;
};
MessagePort includes MessageEventTarget ;
dictionary StructuredSerializeOptions {
sequence <object > transfer = [];
};port.postMessage(message [, transfer])
現行のすべてのエンジンでサポートされています。
port.postMessage(message [, { transfer }])
チャネルを通じてメッセージを送信します。transferに列挙されたオブジェクトは、単に複製されるのではなく 転送されます。つまり、それらは送信側では使用できなくなります。
transferに重複するオブジェクトまたはportが含まれている場合、あるいは
messageを複製できなかった場合は、「DataCloneError」DOMExceptionを
スローします。
port.start()
現行のすべてのエンジンでサポートされています。
ポートで受信したメッセージの配送を開始します。
port.close()
現行のすべてのエンジンでサポートされています。
ポートを切断し、アクティブでない状態にします。
各MessagePortオブジェクトには、メッセージイベントターゲット(
MessageEventTarget)があり、そこへ
messageイベントおよびmessageerrorイベントが配送されます。
特に指定されていない限り、既定ではMessagePort
オブジェクト自体になります。
各MessagePortオブジェクトは、別のオブジェクトと
もつれさせることができます(対称関係です)。
各MessagePortオブジェクトには、ポート
メッセージキューと呼ばれるタスクソースもあり、初期状態では空です。ポート
メッセージキューは有効または無効にでき、初期状態では無効です。一度有効にすると、ポートを再び無効にすることはできません(ただし、
キュー内のメッセージを別のキューへ移動したり、完全に削除したりすることはでき、これはほぼ同じ効果を持ちます)。
MessagePortには、移送済みフラグもあり、初期値は
falseでなければなりません。
ポートのポートメッセージキューが
有効な場合、イベントループはそれを
自身のタスクソースの1つとして使用しなければなりません。ポートの関連する
大域オブジェクトがWindowである場合、そのポートメッセージキューにキューされるすべてのタスクは、ポートの関連する大域オブジェクトの関連付けられた
Documentに関連付けられなければなりません。
文書が完全にアクティブであっても、 すべてのイベントリスナーが完全にアクティブではない文書のコンテキストで 作成された場合、それらの文書が再び完全にアクティブになるまで、メッセージは受信されません。
各イベントループには、未移送
ポート
メッセージキューと呼ばれるタスクソースがあります。これは仮想的なタスクソースです。すなわち、移送済みフラグがfalseで、ポートメッセージキューが有効であり、その関連するエージェントのイベントループが当該イベントループである各
MessagePortの各ポートメッセージキューにあるタスクを、それぞれのタスクソースへ追加された順序で含むかのように動作しなければなりません。未移送ポートメッセージ
キューからタスクが取り除かれる場合、代わりにそのポートメッセージキューから取り除かなければなりません。
MessagePortの移送済みフラグがfalseの場合、そのポート
メッセージキューは、イベントループの目的では無視しなければなりません。(代わりに
未移送ポートメッセージ
キューが使用されます。)
移送済みフラグは、
ポート、その対となるポート、またはその複製元のオブジェクトが転送されるか、すでに転送されている場合にtrueへ設定されます。
MessagePortの
移送済みフラグがtrueの場合、そのポートメッセージキューは、
いかなる未移送ポートメッセージ
キューにも影響されない、第一級のタスクソースとして動作します。
ユーザーエージェントが2つのMessagePortオブジェクトをもつれさせる場合、次の手順を実行しなければなりません。
いずれかのポートがすでにもつれている場合、そのポートと、それがもつれていたポートとのもつれを解きます。
以前にもつれていた2つのポートが、ある
MessageChannelオブジェクトの2つのポートであった場合、その
MessageChannelオブジェクトは、もはや
実際のチャネルを表しません。そのオブジェクト内の2つのポートは、もはやもつれていません。
もつれさせる2つのポートを関連付け、新しいチャネルの2つの部分を形成するようにします。
(このチャネルを表すMessageChannel
オブジェクトは存在しません。)
この手順を経た2つのポートAとBは、もつれているといいます。一方はもう一方と もつれており、その逆も同様です。
この仕様ではこの処理を瞬時に行われるものとして記述していますが、 実装ではメッセージの受け渡しを通じて実装される可能性が高いでしょう。すべてのアルゴリズムと同様に、 重要なのは、最終結果がブラックボックスとして見た場合に仕様と区別できないこと「だけ」です。
MessagePort
initiatorPortがもつれの解除を開始するとき、もつれを解く手順は次のとおりです。
otherPortを、initiatorPortがもつれていたMessagePortとします。
表明:otherPortは存在します。
initiatorPortとotherPortのもつれを解き、両者が互いにもつれたり、 関連付けられたりしていない状態にします。
otherPortで、closeという名前のイベントを発火します。
ポートが明示的に閉じられていない場合でも、closeイベントは発火します。
このイベントが配送されるのは、次の場合です。
close()
メソッドが呼び出された場合。Documentが破棄された場合。または、MessagePortがガベージ
コレクションされた場合。initiatorPortが明示的に閉鎖を引き起こしたか、そのDocumentが存在しなくなったか、または上記のようにすでに
ガベージコレクションされているため、イベントはotherPortでのみ配送します。
MessagePort
オブジェクトは転送可能
オブジェクトです。valueおよび
dataHolderが与えられたときの転送手順は、次のとおりです。
valueの移送済み フラグをtrueに設定します。
dataHolder.[[PortMessageQueue]]を、valueのポートメッセージ キューに設定します。
valueが別のポートremotePortともつれている場合:
remotePortの移送済み フラグをtrueに設定します。
dataHolder.[[RemotePort]]をremotePortに設定します。
それ以外の場合、dataHolder.[[RemotePort]]をnullに設定します。
dataHolderおよびvalueが与えられたときの、それらの転送受信 手順は、次のとおりです。
valueの移送済み フラグをtrueに設定します。
dataHolder.[[PortMessageQueue]]内にあり、messageイベントを発火するすべてのタスクがあれば、それらを
valueのポートメッセージキューへ移動します。このとき、valueの
ポートメッセージキューは初期の
無効状態のままにします。また、valueの関連する大域オブジェクトが
Windowである場合、移動したタスクを、valueの関連する大域オブジェクトの
関連付けられた
Documentに関連付けます。
dataHolder.[[RemotePort]]がnullでない場合、dataHolder.[[RemotePort]]と valueをもつれさせます。(これにより、dataHolder.[[RemotePort]]と、 転送された元のポートとのもつれが解かれます。)
sourcePort、targetPort、messageおよびoptionsが与えられたときの メッセージポートのメッセージ送信手順は、次のとおりです。
transferをoptions["transfer"]とします。
transferがsourcePortを含む場合、「DataCloneError」DOMExceptionを
スローします。
doomedをfalseとします。
targetPortがnullでなく、かつtransferがtargetPortを含む場合、doomedをtrueに設定し、ターゲットポートが 自分自身へ送信されたため通信チャネルが失われたことを、任意で開発者コンソールへ報告します。
serializeWithTransferResultを StructuredSerializeWithTransfer(message, transfer)とします。すべての例外を再スローします。
targetPortがnullの場合、またはdoomedがtrueの場合は、返ります。
次の手順を実行するタスクを、 targetPortのポート メッセージキューへ追加します。
finalTargetPortを、そのタスクが現在自身を見いだすポートメッセージ
キューを持つMessagePortとします。
targetPort自体が転送され、そのすべてのタスクも一緒に移動された場合、 これはtargetPortとは異なる可能性があります。
messageEventTargetをfinalTargetPortのメッセージイベント ターゲットとします。
targetRealmをfinalTargetPortの関連するレルムとします。
deserializeRecordを StructuredDeserializeWithTransfer(serializeWithTransferResult, targetRealm)とします。
これが例外をスローした場合は、その例外をキャッチし、messageEventTargetで
messageerrorという名前のイベントを発火します。
その際、MessageEventを使用し、その後返ります。
messageCloneをdeserializeRecord.[[Deserialized]]とします。
newPortsを、deserializeRecord.[[TransferredValues]]内にあるすべての
MessagePortオブジェクトがあれば、
それらの相対的な順序を維持して構成される新しい凍結配列とします。
messageEventTargetで、messageという名前のイベントを発火します。その際、
MessageEventを使用し、data属性を
messageCloneに、ports属性を
newPortsに初期化します。
postMessage(message,
options)メソッドの手順は、次のとおりです。
targetPortを、存在する場合はthisがもつれているポートとし、 それ以外の場合はnullとします。
this、 targetPort、messageおよびoptionsを渡して、メッセージ ポートのメッセージ送信手順を実行します。
postMessage(message,
transfer)メソッドの手順は、次のとおりです。
targetPortを、存在する場合はthisがもつれているポートとし、 それ以外の場合はnullとします。
optionsを«[「transfer」
→ transfer
]»とします。
this、targetPort、messageおよびoptionsを渡して、メッセージポートのメッセージ送信手順を実行します。
start()
メソッドの手順は、thisのポートメッセージキューがまだ有効でなければ、それを有効にすることです。
close()
メソッドの手順は、次のとおりです。
thisの[[Detached]]内部スロットの値をtrueに設定します。
次に示すものは、MessagePortインターフェイスを実装するすべてのオブジェクトが、
イベントハンドラーIDL
属性としてサポートしなければならないイベントハンドラー(およびそれらに対応するイベントハンドラーのイベント
型)です。
| イベントハンドラー | イベントハンドラーのイベント 型 |
|---|---|
onclose |
close
|
MessagePortオブジェクトの
onmessage
IDL属性が初めて設定されたとき、start()メソッドが
呼び出されたかのように、ポートのポートメッセージキューを有効にしなければなりません。
MessagePortオブジェクト
oがガベージコレクションされるとき、oがもつれている場合、ユーザーエージェントは
oのもつれを解かなければなりません。
MessagePortオブジェクト
oがもつれており、messageまたはmessageerror
イベントリスナーが登録されている場合、ユーザーエージェントは、oがもつれている
MessagePortオブジェクトが
oへの強参照を持つかのように動作しなければなりません。
さらに、MessagePort
オブジェクトは、そのオブジェクト上で配送されるイベントを参照するタスクがタスクキュー内に存在している間、または
MessagePortオブジェクトのポートメッセージキューが有効で
空でない間は、ガベージコレクションされてはなりません。
したがって、メッセージポートを受信してイベントリスナーを指定した後、そのポートを忘れても、 そのイベントリスナーがメッセージを受信できる限り、チャネルは維持されます。
もちろん、これがチャネルの両側で発生した場合、両方のポートは互いへの強参照を持っていても 実行中のコードから到達できないため、ガベージコレクションされる可能性があります。ただし、 メッセージポートに保留中のメッセージがある場合、そのポートはガベージコレクションされません。
作成者には、MessagePort
オブジェクトのもつれを解いて、そのリソースを回収できるようにするため、それらを明示的に閉じることを強く推奨します。多数の
MessagePortオブジェクトを作成し、
閉じずに破棄すると、ガベージコレクションは必ずしも直ちに実行されないため、一時的なメモリー使用量が多くなる可能性があります。特に、
ガベージコレクションにプロセス間の調整が必要となる可能性のあるMessagePortでは顕著です。
現行のすべてのエンジンでサポートされています。
現行のすべてのエンジンでサポートされています。
同じユーザーが同じユーザーエージェントを使用して開いた、単一のオリジン上のページは、互いに無関係な異なる閲覧コンテキストにあっても、 「こちらでユーザーがログインしたので、資格情報をもう一度確認してください」のような通知を相互に送信する必要がある場合があります。
共有状態のロック管理、サーバーと複数のローカルクライアント間におけるリソースの同期管理、リモートホストとの
WebSocket
接続の共有など、複雑な場合には、共有ワーカーが最も適切な解決策です。
一方、共有ワーカーが不合理なほど大きなオーバーヘッドとなる単純な場合には、作成者はこの節で説明する 単純なチャネルベースのブロードキャスト機構を使用できます。
[Exposed =(Window ,Worker )]
interface BroadcastChannel : EventTarget {
constructor (DOMString name );
readonly attribute DOMString name ;
undefined postMessage (any message );
undefined close ();
attribute EventHandler onmessage ;
attribute EventHandler onmessageerror ;
};broadcastChannel = new BroadcastChannel(name)
BroadcastChannel/BroadcastChannel
現行のすべてのエンジンでサポートされています。
指定されたチャネル名のメッセージを送受信できる、新しいBroadcastChannel
オブジェクトを返します。
broadcastChannel.name
現行のすべてのエンジンでサポートされています。
チャネル名(コンストラクターへ渡されたもの)を返します。
broadcastChannel.postMessage(message)
現行のすべてのエンジンでサポートされています。
このチャネル用に設定された他のBroadcastChannel
オブジェクトへ、指定されたメッセージを送信します。メッセージには、入れ子になったオブジェクトや配列などの
構造化オブジェクトを使用できます。
broadcastChannel.close()
現行のすべてのエンジンでサポートされています。
BroadcastChannel
オブジェクトを閉じ、ガベージコレクションできる状態にします。
BroadcastChannel
オブジェクトには、チャネル名と閉鎖
フラグがあります。
BroadcastChannel
オブジェクトの関連する大域オブジェクトが次のいずれかである場合、そのオブジェクトは
メッセージング適格であるといいます。
関連付けられた
Documentが完全にアクティブである
Windowオブジェクト。または、
closingフラグがfalseであり、
中断可能ではないWorkerGlobalScope
オブジェクト。
postMessage(message)メソッドの
手順は、次のとおりです。
thisの閉鎖フラグが
trueの場合、「InvalidStateError」DOMExceptionを
スローします。
serializedをStructuredSerialize(message)とします。 すべての例外を再スローします。
sourceOriginを、thisの関連する設定オブジェクトの オリジンとします。
sourceStorageKeyを、thisの関連する設定 オブジェクトを使用してストレージ以外の目的のストレージキーを取得する処理を実行した結果とします。
destinationsを、次の基準に合致するBroadcastChannel
オブジェクトのリストとします。
それらがメッセージング適格であること。
それらの関連する設定オブジェクトを使用してストレージ以外の目的のストレージキーを取得する処理を実行した結果が、 sourceStorageKeyと等しいこと。
destinationsからsourceを削除します。
destinationsを、関連するエージェントが同じであるすべてのBroadcastChannel
オブジェクトについて、作成順、古いものを先頭として並ぶようにソートします。(これは完全な順序を定義するものではありません。
この制約の範囲内で、ユーザーエージェントは任意の実装定義の方法でリストをソートできます。)
destinations内の各destinationについて、destinationの関連する大域オブジェクトを指定して、 DOM操作タスクソースに、 次の手順を実行する大域タスクをキューします。
destinationの閉鎖 フラグがtrueの場合、これらの手順を中止します。
targetRealmをdestinationの関連するレルムとします。
dataをStructuredDeserialize(serialized, targetRealm)とします。
これが例外をスローした場合は、その例外をキャッチし、destinationで
messageerror
という名前のイベントを発火します。その際、
MessageEventを使用し、
そのオリジンを
sourceOriginに初期化した後、これらの手順を中止します。
destinationで、message
という名前のイベントを発火します。その際、
MessageEventを使用し、data
属性をdataに、そのオリジンを
sourceOriginに初期化します。
閉鎖フラグがfalseであるBroadcastChannel
オブジェクトに、messageまたはmessageerror
イベントのイベントリスナーが登録されている間は、その
BroadcastChannel
オブジェクトの関連する大域オブジェクトから
BroadcastChannel
オブジェクト自体への強参照が存在しなければなりません。
作成者には、BroadcastChannel
オブジェクトが不要になったとき、ガベージコレクションできるようにするため、それらを明示的に閉じることを強く推奨します。多数の
BroadcastChannel
オブジェクトを作成し、イベントリスナーを残したまま閉じずに破棄すると、見かけ上のメモリーリークにつながる可能性があります。
オブジェクトはイベントリスナーを持つ限り(またはそのページやワーカーが閉じられるまで)存続し続けるためです。
次に示すものは、BroadcastChannel
インターフェイスを実装するすべてのオブジェクトが、イベントハンドラーIDL属性として
サポートしなければならないイベントハンドラー(およびそれらに対応するイベントハンドラーのイベント型)です。
| イベントハンドラー | イベントハンドラーのイベント型 |
|---|---|
onmessage
BroadcastChannel/message_event 現行のすべてのエンジンでサポートされています。 Firefox38+Safari15.4+Chrome54+
Opera?Edge79+ Edge (Legacy)?Internet Explorer非対応 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
message
|
onmessageerror
BroadcastChannel/messageerror_event 現行のすべてのエンジンでサポートされています。 Firefox57+Safari15.4+Chrome60+
Opera?Edge79+ Edge (Legacy)?Internet Explorer非対応 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android47+ |
messageerror
|
同じサイトの別のタブからユーザーがログアウトした場合でも、そのことをページが把握したいとします。
var authChannel = new BroadcastChannel( 'auth' );
authChannel. onmessage = function ( event) {
if ( event. data == 'logout' )
showLogout();
}
function logoutRequested() {
// called when the user asks us to log them out
doLogout();
showLogout();
authChannel. postMessage( 'logout' );
}
function doLogout() {
// actually log the user out (e.g. clearing cookies)
// ...
}
function showLogout() {
// update the UI to indicate we're logged out
// ...
} 現行のすべてのエンジンでサポートされています。
この節は非規範的です。
この仕様は、ユーザーインターフェイスのスクリプトとは独立して、バックグラウンドでスクリプトを実行するための APIを定義します。
これにより、クリックやその他のユーザー操作に応答するスクリプトによって中断されない長時間実行スクリプトを使用でき、 またページの応答性を維持するために処理を譲ることなく、長いタスクを実行できます。
ワーカー(本仕様では、これらのバックグラウンドスクリプトをこのように呼びます)は比較的重量級であり、 大量に使用することを意図していません。例えば、400万画素の画像の各画素につき1つのワーカーを起動するのは 適切ではありません。以下の例では、ワーカーの適切な用途をいくつか示します。
一般に、ワーカーは長期間存続し、起動時の性能コストが高く、インスタンスごとのメモリーコストも 高いことが想定されています。
この節は非規範的です。
ワーカーにはさまざまな用途があります。以下の各小節では、そのさまざまな使用例を示します。
この節は非規範的です。
ワーカーの最も単純な用途は、ユーザーインターフェイスを中断せずに、計算コストの 高いタスクを実行することです。
この例では、メイン文書がワーカーを生成して素朴な方法で素数を計算し、 最後に見つかった素数を順次表示します。
メインページは次のとおりです。
<!DOCTYPE HTML>
< html lang = "en" >
< head >
< meta charset = "utf-8" >
< title > Worker example: One-core computation</ title >
</ head >
< body >
< p > The highest prime number discovered so far is: < output id = "result" ></ output ></ p >
< script >
var worker = new Worker( 'worker.js' );
worker. onmessage = function ( event) {
document. getElementById( 'result' ). textContent = event. data;
};
</ script >
</ body >
</ html >
Worker()
コンストラクターを呼び出すとワーカーが作成され、そのワーカーを表す
Workerオブジェクトが返されます。
このオブジェクトは、ワーカーとの通信に使用されます。
そのオブジェクトのonmessage
イベントハンドラーにより、コードはワーカーからメッセージを受信できます。
ワーカー自体は次のとおりです。
var n = 1 ;
search: while ( true ) {
n += 1 ;
for ( var i = 2 ; i <= Math. sqrt( n); i += 1 )
if ( n % i == 0 )
continue search;
// found a prime!
postMessage( n);
}
このコードの大部分は、最適化されていない単純な素数探索です。素数が見つかったとき、
postMessage()
メソッドを使用して、ページへメッセージを送り返します。
この節は非規範的です。
これまでのすべての例では、古典
スクリプトを実行するワーカーを示してきました。代わりに、通常の利点を持つモジュール
スクリプトを使用してワーカーをインスタンス化できます。その利点には、JavaScriptの
import文を使用して他のモジュールをインポートできること、既定で厳格モードになること、および
トップレベル宣言によってワーカーの大域スコープが汚染されないことがあります。
import文を使用できるため、モジュールワーカー内ではimportScripts()
メソッドは自動的に失敗します。
この例では、メイン文書がワーカーを使用し、メインスレッド外で画像を操作します。 使用するフィルターは別のモジュールからインポートします。
メインページは次のとおりです。
<!DOCTYPE html>
< html lang = "en" >
< meta charset = "utf-8" >
< title > Worker example: image decoding</ title >
< p >
< label >
Type an image URL to decode
< input type = "url" id = "image-url" list = "image-list" >
< datalist id = "image-list" >
< option value = "https://html.spec.whatwg.org/images/drawImage.png" >
< option value = "https://html.spec.whatwg.org/images/robots.jpeg" >
< option value = "https://html.spec.whatwg.org/images/arcTo2.png" >
</ datalist >
</ label >
</ p >
< p >
< label >
Choose a filter to apply
< select id = "filter" >
< option value = "none" > none</ option >
< option value = "grayscale" > grayscale</ option >
< option value = "brighten" > brighten by 20%</ option >
</ select >
</ label >
</ p >
< div id = "output" ></ div >
< script type = "module" >
const worker = new Worker( "worker.js" , { type: "module" });
worker. onmessage = receiveFromWorker;
const url = document. querySelector( "#image-url" );
const filter = document. querySelector( "#filter" );
const output = document. querySelector( "#output" );
url. oninput = updateImage;
filter. oninput = sendToWorker;
let imageData, context;
function updateImage() {
const img = new Image();
img. src = url. value;
img. onload = () => {
const canvas = document. createElement( "canvas" );
canvas. width = img. width;
canvas. height = img. height;
context = canvas. getContext( "2d" );
context. drawImage( img, 0 , 0 );
imageData = context. getImageData( 0 , 0 , canvas. width, canvas. height);
sendToWorker();
output. replaceChildren( canvas);
};
}
function sendToWorker() {
worker. postMessage({ imageData, filter: filter. value });
}
function receiveFromWorker( e) {
context. putImageData( e. data, 0 , 0 );
}
</ script >
ワーカーファイルは次のようになります。
import * as filters from "./filters.js" ;
self. onmessage = e => {
const { imageData, filter } = e. data;
filters[ filter]( imageData);
self. postMessage( imageData, [ imageData. data. buffer]);
};
これはfilters.jsファイルをインポートします。
export function none() {}
export function grayscale({ data: d }) {
for ( let i = 0 ; i < d. length; i += 4 ) {
const [ r, g, b] = [ d[ i], d[ i + 1 ], d[ i + 2 ]];
// CIE luminance for the RGB
// The human eye is bad at seeing red and blue, so we de-emphasize them.
d[ i] = d[ i + 1 ] = d[ i + 2 ] = 0.2126 * r + 0.7152 * g + 0.0722 * b;
}
};
export function brighten({ data: d }) {
for ( let i = 0 ; i < d. length; ++ i) {
d[ i] *= 1.2 ;
}
};
現行のすべてのエンジンでサポートされています。
この節は非規範的です。
この節では、Hello Worldの例を使用して共有ワーカーを紹介します。各ワーカーは複数の接続を持つことができるため、 共有ワーカーでは少し異なるAPIを使用します。
最初の例では、ワーカーへ接続する方法と、接続されたときにワーカーからページへメッセージを 送り返す方法を示します。受信したメッセージはログに表示されます。
HTMLページは次のとおりです。
<!DOCTYPE HTML>
< html lang = "en" >
< meta charset = "utf-8" >
< title > Shared workers: demo 1</ title >
< pre id = "log" > Log:</ pre >
< script >
var worker = new SharedWorker( 'test.js' );
var log = document. getElementById( 'log' );
worker. port. onmessage = function ( e) { // note: not worker.onmessage!
log. textContent += '\n' + e. data;
}
</ script >
JavaScriptワーカーは次のとおりです。
onconnect = function ( e) {
var port = e. ports[ 0 ];
port. postMessage( 'Hello World!' );
}
2番目の例では、最初の例に2つの変更を加えています。第一に、イベントハンドラーIDL属性の代わりに
addEventListener()を使用してメッセージを受信します。第二に、ワーカーへ
メッセージを送信し、それに応じてワーカーから別のメッセージを送り返させます。受信したメッセージは、
再びログに表示されます。
HTMLページは次のとおりです。
<!DOCTYPE HTML>
< html lang = "en" >
< meta charset = "utf-8" >
< title > Shared workers: demo 2</ title >
< pre id = "log" > Log:</ pre >
< script >
var worker = new SharedWorker( 'test.js' );
var log = document. getElementById( 'log' );
worker. port. addEventListener( 'message' , function ( e) {
log. textContent += '\n' + e. data;
}, false );
worker. port. start(); // note: need this when using addEventListener
worker. port. postMessage( 'ping' );
</ script >
JavaScriptワーカーは次のとおりです。
onconnect = function ( e) {
var port = e. ports[ 0 ];
port. postMessage( 'Hello World!' );
port. onmessage = function ( e) {
port. postMessage( 'pong' ); // not e.ports[0].postMessage!
// e.target.postMessage('pong'); would work also
}
}
最後に、2つのページを同じワーカーへ接続する方法を示すように例を拡張します。この場合、2番目のページは
最初のページのiframe内にあるだけですが、
同じ原則は、別のトップレベル
トラバーサブルにある、まったく独立したページにも適用できます。
外側のHTMLページは次のとおりです。
<!DOCTYPE HTML>
< html lang = "en" >
< meta charset = "utf-8" >
< title > Shared workers: demo 3</ title >
< pre id = "log" > Log:</ pre >
< script >
var worker = new SharedWorker( 'test.js' );
var log = document. getElementById( 'log' );
worker. port. addEventListener( 'message' , function ( e) {
log. textContent += '\n' + e. data;
}, false );
worker. port. start();
worker. port. postMessage( 'ping' );
</ script >
< iframe src = "inner.html" ></ iframe >
内側のHTMLページは次のとおりです。
<!DOCTYPE HTML>
< html lang = "en" >
< meta charset = "utf-8" >
< title > Shared workers: demo 3 inner frame</ title >
< pre id = log > Inner log:</ pre >
< script >
var worker = new SharedWorker( 'test.js' );
var log = document. getElementById( 'log' );
worker. port. onmessage = function ( e) {
log. textContent += '\n' + e. data;
}
</ script >
JavaScriptワーカーは次のとおりです。
var count = 0 ;
onconnect = function ( e) {
count += 1 ;
var port = e. ports[ 0 ];
port. postMessage( 'Hello World! You are connection #' + count);
port. onmessage = function ( e) {
port. postMessage( 'pong' );
}
}
この節は非規範的です。
この例では、すべて同じ地図を表示する複数のウィンドウ(ビューアー)を開くことができます。 すべてのウィンドウは同じ地図情報を共有し、単一のワーカーがすべてのビューアーを調整します。 各ビューアーは独立して移動できますが、いずれかのビューアーが地図上のデータを設定すると、すべてのビューアーが 更新されます。
メインページ自体は特に興味深いものではなく、単にビューアーを開く方法を提供します。
<!DOCTYPE HTML>
< html lang = "en" >
< head >
< meta charset = "utf-8" >
< title > Workers example: Multiviewer</ title >
< script >
function openViewer() {
window. open( 'viewer.html' );
}
</ script >
</ head >
< body >
< p >< button type = button onclick = "openViewer()" > Open a new
viewer</ button ></ p >
< p > Each viewer opens in a new window. You can have as many viewers
as you like, they all view the same data.</ p >
</ body >
</ html >
ビューアーは、より複雑です。
<!DOCTYPE HTML>
< html lang = "en" >
< head >
< meta charset = "utf-8" >
< title > Workers example: Multiviewer viewer</ title >
< script >
var worker = new SharedWorker( 'worker.js' , 'core' );
// CONFIGURATION
function configure( event) {
if ( event. data. substr( 0 , 4 ) != 'cfg ' ) return ;
var name = event. data. substr( 4 ). split( ' ' , 1 )[ 0 ];
// update display to mention our name is name
document. getElementsByTagName( 'h1' )[ 0 ]. textContent += ' ' + name;
// no longer need this listener
worker. port. removeEventListener( 'message' , configure, false );
}
worker. port. addEventListener( 'message' , configure, false );
// MAP
function paintMap( event) {
if ( event. data. substr( 0 , 4 ) != 'map ' ) return ;
var data = event. data. substr( 4 ). split( ',' );
// display tiles data[0] .. data[8]
var canvas = document. getElementById( 'map' );
var context = canvas. getContext( '2d' );
for ( var y = 0 ; y < 3 ; y += 1 ) {
for ( var x = 0 ; x < 3 ; x += 1 ) {
var tile = data[ y * 3 + x];
if ( tile == '0' )
context. fillStyle = 'green' ;
else
context. fillStyle = 'maroon' ;
context. fillRect( x * 50 , y * 50 , 50 , 50 );
}
}
}
worker. port. addEventListener( 'message' , paintMap, false );
// PUBLIC CHAT
function updatePublicChat( event) {
if ( event. data. substr( 0 , 4 ) != 'txt ' ) return ;
var name = event. data. substr( 4 ). split( ' ' , 1 )[ 0 ];
var message = event. data. substr( 4 + name. length + 1 );
// display "<name> message" in public chat
var public = document. getElementById( 'public' );
var p = document. createElement( 'p' );
var n = document. createElement( 'button' );
n. textContent = '<' + name + '> ' ;
n. onclick = function () { worker. port. postMessage( 'msg ' + name); };
p. appendChild( n);
var m = document. createElement( 'span' );
m. textContent = message;
p. appendChild( m);
public. appendChild( p);
}
worker. port. addEventListener( 'message' , updatePublicChat, false );
// PRIVATE CHAT
function startPrivateChat( event) {
if ( event. data. substr( 0 , 4 ) != 'msg ' ) return ;
var name = event. data. substr( 4 ). split( ' ' , 1 )[ 0 ];
var port = event. ports[ 0 ];
// display a private chat UI
var ul = document. getElementById( 'private' );
var li = document. createElement( 'li' );
var h3 = document. createElement( 'h3' );
h3. textContent = 'Private chat with ' + name;
li. appendChild( h3);
var div = document. createElement( 'div' );
var addMessage = function ( name, message) {
var p = document. createElement( 'p' );
var n = document. createElement( 'strong' );
n. textContent = '<' + name + '> ' ;
p. appendChild( n);
var t = document. createElement( 'span' );
t. textContent = message;
p. appendChild( t);
div. appendChild( p);
};
port. onmessage = function ( event) {
addMessage( name, event. data);
};
li. appendChild( div);
var form = document. createElement( 'form' );
var p = document. createElement( 'p' );
var input = document. createElement( 'input' );
input. size = 50 ;
p. appendChild( input);
p. appendChild( document. createTextNode( ' ' ));
var button = document. createElement( 'button' );
button. textContent = 'Post' ;
p. appendChild( button);
form. onsubmit = function () {
port. postMessage( input. value);
addMessage( 'me' , input. value);
input. value = '' ;
return false ;
};
form. appendChild( p);
li. appendChild( form);
ul. appendChild( li);
}
worker. port. addEventListener( 'message' , startPrivateChat, false );
worker. port. start();
</ script >
</ head >
< body >
< h1 > Viewer</ h1 >
< h2 > Map</ h2 >
< p >< canvas id = "map" height = 150 width = 150 ></ canvas ></ p >
< p >
< button type = button onclick = "worker.port.postMessage('mov left')" > Left</ button >
< button type = button onclick = "worker.port.postMessage('mov up')" > Up</ button >
< button type = button onclick = "worker.port.postMessage('mov down')" > Down</ button >
< button type = button onclick = "worker.port.postMessage('mov right')" > Right</ button >
< button type = button onclick = "worker.port.postMessage('set 0')" > Set 0</ button >
< button type = button onclick = "worker.port.postMessage('set 1')" > Set 1</ button >
</ p >
< h2 > Public Chat</ h2 >
< div id = "public" ></ div >
< form onsubmit = "worker.port.postMessage('txt ' + message.value); message.value = ''; return false;" >
< p >
< input type = "text" name = "message" size = "50" >
< button > Post</ button >
</ p >
</ form >
< h2 > Private Chat</ h2 >
< ul id = "private" ></ ul >
</ body >
</ html >
ビューアーの記述方法について、注目すべき重要な点がいくつかあります。
複数のリスナー。単一のメッセージ処理関数を使用する代わりに、このコードでは複数の イベントリスナーを取り付け、各リスナーがメッセージと関係するかどうかを迅速に確認します。この例では大きな違いはありませんが、 複数の作成者が単一のポートを使用してワーカーと通信しながら共同作業する場合、すべての変更を単一のイベント処理関数へ 加える必要がなくなり、独立したコードを使用できます。
この方法でイベントリスナーを登録すると、この例のconfigure()メソッドで行っているように、
使用を終えた特定のリスナーの登録を解除することもできます。
最後に、ワーカーは次のとおりです。
var nextName = 0 ;
function getNextName() {
// this could use more friendly names
// but for now just return a number
return nextName++ ;
}
var map = [
[ 0 , 0 , 0 , 0 , 0 , 0 , 0 ],
[ 1 , 1 , 0 , 1 , 0 , 1 , 1 ],
[ 0 , 1 , 0 , 1 , 0 , 0 , 0 ],
[ 0 , 1 , 0 , 1 , 0 , 1 , 1 ],
[ 0 , 0 , 0 , 1 , 0 , 0 , 0 ],
[ 1 , 0 , 0 , 1 , 1 , 1 , 1 ],
[ 1 , 1 , 0 , 1 , 1 , 0 , 1 ],
];
function wrapX( x) {
if ( x < 0 ) return wrapX( x + map[ 0 ]. length);
if ( x >= map[ 0 ]. length) return wrapX( x - map[ 0 ]. length);
return x;
}
function wrapY( y) {
if ( y < 0 ) return wrapY( y + map. length);
if ( y >= map[ 0 ]. length) return wrapY( y - map. length);
return y;
}
function wrap( val, min, max) {
if ( val < min)
return val + ( max- min) + 1 ;
if ( val > max)
return val - ( max- min) - 1 ;
return val;
}
function sendMapData( viewer) {
var data = '' ;
for ( var y = viewer. y- 1 ; y <= viewer. y+ 1 ; y += 1 ) {
for ( var x = viewer. x- 1 ; x <= viewer. x+ 1 ; x += 1 ) {
if ( data != '' )
data += ',' ;
data += map[ wrap( y, 0 , map[ 0 ]. length- 1 )][ wrap( x, 0 , map. length- 1 )];
}
}
viewer. port. postMessage( 'map ' + data);
}
var viewers = {};
onconnect = function ( event) {
var name = getNextName();
event. ports[ 0 ]. _data = { port: event. ports[ 0 ], name: name, x: 0 , y: 0 , };
viewers[ name] = event. ports[ 0 ]. _data;
event. ports[ 0 ]. postMessage( 'cfg ' + name);
event. ports[ 0 ]. onmessage = getMessage;
sendMapData( event. ports[ 0 ]. _data);
};
function getMessage( event) {
switch ( event. data. substr( 0 , 4 )) {
case 'mov ' :
var direction = event. data. substr( 4 );
var dx = 0 ;
var dy = 0 ;
switch ( direction) {
case 'up' : dy = - 1 ; break ;
case 'down' : dy = 1 ; break ;
case 'left' : dx = - 1 ; break ;
case 'right' : dx = 1 ; break ;
}
event. target. _data. x = wrapX( event. target. _data. x + dx);
event. target. _data. y = wrapY( event. target. _data. y + dy);
sendMapData( event. target. _data);
break ;
case 'set ' :
var value = event. data. substr( 4 );
map[ event. target. _data. y][ event. target. _data. x] = value;
for ( var viewer in viewers)
sendMapData( viewers[ viewer]);
break ;
case 'txt ' :
var name = event. target. _data. name;
var message = event. data. substr( 4 );
for ( var viewer in viewers)
viewers[ viewer]. port. postMessage( 'txt ' + name + ' ' + message);
break ;
case 'msg ' :
var party1 = event. target. _data;
var party2 = viewers[ event. data. substr( 4 ). split( ' ' , 1 )[ 0 ]];
if ( party2) {
var channel = new MessageChannel();
party1. port. postMessage( 'msg ' + party2. name, [ channel. port1]);
party2. port. postMessage( 'msg ' + party1. name, [ channel. port2]);
}
break ;
}
}
複数のページへの接続。このスクリプトは、複数の接続を待ち受けるためにonconnect
イベントリスナーを使用します。
直接チャネル。ワーカーが、あるビューアーから別のビューアーを指定する「msg」メッセージを 受信すると、両者の間に直接接続を設定します。これにより、ワーカーがすべてのメッセージを中継しなくても、 2つのビューアーが直接通信できます。
この節は非規範的です。
マルチコアCPUが普及するにつれ、計算コストの高いタスクを複数のワーカーへ分割することが、 より高い性能を得る方法の1つとなっています。この例では、1から10,000,000までの各数値に対して実行する必要がある、 計算コストの高いタスクを10個のサブワーカーへ割り当てます。
メインページは次のとおりで、単に結果を報告します。
<!DOCTYPE HTML>
< html lang = "en" >
< head >
< meta charset = "utf-8" >
< title > Worker example: Multicore computation</ title >
</ head >
< body >
< p > Result: < output id = "result" ></ output ></ p >
< script >
var worker = new Worker( 'worker.js' );
worker. onmessage = function ( event) {
document. getElementById( 'result' ). textContent = event. data;
};
</ script >
</ body >
</ html >
ワーカー自体は次のとおりです。
// settings
var num_workers = 10 ;
var items_per_worker = 1000000 ;
// start the workers
var result = 0 ;
var pending_workers = num_workers;
for ( var i = 0 ; i < num_workers; i += 1 ) {
var worker = new Worker( 'core.js' );
worker. postMessage( i * items_per_worker);
worker. postMessage(( i+ 1 ) * items_per_worker);
worker. onmessage = storeResult;
}
// handle the results
function storeResult( event) {
result += 1 * event. data;
pending_workers -= 1 ;
if ( pending_workers <= 0 )
postMessage( result); // finished!
}
このコードは、サブワーカーを起動するループと、すべてのサブワーカーから応答が返るのを待つ ハンドラーで構成されています。
サブワーカーは次のように実装します。
var start;
onmessage = getStart;
function getStart( event) {
start = 1 * event. data;
onmessage = getEnd;
}
var end;
function getEnd( event) {
end = 1 * event. data;
onmessage = null ;
work();
}
function work() {
var result = 0 ;
for ( var i = start; i < end; i += 1 ) {
// perform some complex calculation here
result += 1 ;
}
postMessage( result);
close();
}
サブワーカーは2つのイベントで2つの数値を受信し、そのように指定された数値範囲について計算を実行してから、 結果を親へ報告します。
この節は非規範的です。
次の3つのタスクを提供する暗号ライブラリーが利用可能になっているとします。
ライブラリー自体は次のとおりです。
function handleMessage( e) {
if ( e. data == "genkeys" )
genkeys( e. ports[ 0 ]);
else if ( e. data == "encrypt" )
encrypt( e. ports[ 0 ]);
else if ( e. data == "decrypt" )
decrypt( e. ports[ 0 ]);
}
function genkeys( p) {
var keys = _generateKeyPair();
p. postMessage( keys[ 0 ]);
p. postMessage( keys[ 1 ]);
}
function encrypt( p) {
var key, state = 0 ;
p. onmessage = function ( e) {
if ( state == 0 ) {
key = e. data;
state = 1 ;
} else {
p. postMessage( _encrypt( key, e. data));
}
};
}
function decrypt( p) {
var key, state = 0 ;
p. onmessage = function ( e) {
if ( state == 0 ) {
key = e. data;
state = 1 ;
} else {
p. postMessage( _decrypt( key, e. data));
}
};
}
// support being used as a shared worker as well as a dedicated worker
if ( 'onmessage' in this ) // dedicated worker
onmessage = handleMessage;
else // shared worker
onconnect = function ( e) { e. port. onmessage = handleMessage; }
// the "crypto" functions:
function _generateKeyPair() {
return [ Math. random(), Math. random()];
}
function _encrypt( k, s) {
return 'encrypted-' + k + ' ' + s;
}
function _decrypt( k, s) {
return s. substr( s. indexOf( ' ' ) + 1 );
}
ここでの暗号関数は単なるスタブであり、実際の暗号処理を行わないことに注意してください。
このライブラリーは次のように使用できます。
<!DOCTYPE HTML>
< html lang = "en" >
< head >
< meta charset = "utf-8" >
< title > Worker example: Crypto library</ title >
< script >
const cryptoLib = new Worker( 'libcrypto-v1.js' ); // or could use 'libcrypto-v2.js'
function startConversation( source, message) {
const messageChannel = new MessageChannel();
source. postMessage( message, [ messageChannel. port2]);
return messageChannel. port1;
}
function getKeys() {
let state = 0 ;
startConversation( cryptoLib, "genkeys" ). onmessage = function ( e) {
if ( state === 0 )
document. getElementById( 'public' ). value = e. data;
else if ( state === 1 )
document. getElementById( 'private' ). value = e. data;
state += 1 ;
};
}
function enc() {
const port = startConversation( cryptoLib, "encrypt" );
port. postMessage( document. getElementById( 'public' ). value);
port. postMessage( document. getElementById( 'input' ). value);
port. onmessage = function ( e) {
document. getElementById( 'input' ). value = e. data;
port. close();
};
}
function dec() {
const port = startConversation( cryptoLib, "decrypt" );
port. postMessage( document. getElementById( 'private' ). value);
port. postMessage( document. getElementById( 'input' ). value);
port. onmessage = function ( e) {
document. getElementById( 'input' ). value = e. data;
port. close();
};
}
</ script >
< style >
textarea { display : block ; }
</ style >
</ head >
< body onload = "getKeys()" >
< fieldset >
< legend > Keys</ legend >
< p >< label > Public Key: < textarea id = "public" ></ textarea ></ label ></ p >
< p >< label > Private Key: < textarea id = "private" ></ textarea ></ label ></ p >
</ fieldset >
< p >< label > Input: < textarea id = "input" ></ textarea ></ label ></ p >
< p >< button onclick = "enc()" > Encrypt</ button > < button onclick = "dec()" > Decrypt</ button ></ p >
</ body >
</ html >
ただし、後のバージョンのAPIでは、すべての暗号処理をサブワーカーへ委ねることが望まれる場合があります。 これは次のように行えます。
function handleMessage( e) {
if ( e. data == "genkeys" )
genkeys( e. ports[ 0 ]);
else if ( e. data == "encrypt" )
encrypt( e. ports[ 0 ]);
else if ( e. data == "decrypt" )
decrypt( e. ports[ 0 ]);
}
function genkeys( p) {
var generator = new Worker( 'libcrypto-v2-generator.js' );
generator. postMessage( '' , [ p]);
}
function encrypt( p) {
p. onmessage = function ( e) {
var key = e. data;
var encryptor = new Worker( 'libcrypto-v2-encryptor.js' );
encryptor. postMessage( key, [ p]);
};
}
function encrypt( p) {
p. onmessage = function ( e) {
var key = e. data;
var decryptor = new Worker( 'libcrypto-v2-decryptor.js' );
decryptor. postMessage( key, [ p]);
};
}
// support being used as a shared worker as well as a dedicated worker
if ( 'onmessage' in this ) // dedicated worker
onmessage = handleMessage;
else // shared worker
onconnect = function ( e) { e. ports[ 0 ]. onmessage = handleMessage };
小さなサブワーカーは次のようになります。
鍵ペアを生成する場合:
onmessage = function ( e) {
var k = _generateKeyPair();
e. ports[ 0 ]. postMessage( k[ 0 ]);
e. ports[ 0 ]. postMessage( k[ 1 ]);
close();
}
function _generateKeyPair() {
return [ Math. random(), Math. random()];
}
暗号化する場合:
onmessage = function ( e) {
var key = e. data;
e. ports[ 0 ]. onmessage = function ( e) {
var s = e. data;
postMessage( _encrypt( key, s));
}
}
function _encrypt( k, s) {
return 'encrypted-' + k + ' ' + s;
}
復号する場合:
onmessage = function ( e) {
var key = e. data;
e. ports[ 0 ]. onmessage = function ( e) {
var s = e. data;
postMessage( _decrypt( key, s));
}
}
function _decrypt( k, s) {
return s. substr( s. indexOf( ' ' ) + 1 );
}
APIの利用者は、この処理が行われていることを知る必要さえありません。APIは変更されていません。 ライブラリーはメッセージチャネルを使用してデータを受け取っていても、APIを変更することなく処理を サブワーカーへ委譲できます。
この節は非規範的です。
ワーカーを作成するには、JavaScriptファイルのURLが必要です。Worker()コンストラクターは、そのファイルのURLを唯一の
引数として呼び出されます。これによりワーカーが作成され、返されます。
var worker = new Worker( 'helper.js' ); ワーカースクリプトを、デフォルトのクラシックスクリプトではなくモジュールスクリプトとして解釈させる場合は、 少し異なるシグネチャを使用する必要があります。
var worker = new Worker( 'helper.mjs' , { type: "module" }); この節は非規範的です。
専用ワーカーは内部でMessagePortオブジェクトを
使用するため、構造化データの送信、バイナリーデータの転送、ほかのポートの転送など、
すべて同じ機能をサポートします。
専用ワーカーからメッセージを受信するには、Workerオブジェクトのonmessage
イベントハンドラーIDL属性を使用します。
worker. onmessage = function ( event) { ... }; addEventListener()
メソッドも使用できます。
専用ワーカーが使用する暗黙的なMessagePortでは、
作成時にそのポートメッセージキューが暗黙的に有効化されるため、Workerインターフェイスには、MessagePort
インターフェイスのstart()
メソッドに相当するものはありません。
ワーカーにデータを送信するには、postMessage()
メソッドを使用します。この通信チャネルでは構造化データを送信できます。ArrayBuffer
オブジェクトを(複製するのではなく転送することによって)効率的に送信するには、第2引数の配列にそれらを列挙します。
worker. postMessage({
operation: 'find-edges' ,
input: buffer, // an ArrayBuffer object
threshold: 0.6 ,
}, [ buffer]); ワーカー内でメッセージを受信するには、onmessage
イベントハンドラーIDL属性を使用します。
onmessage = function ( event) { ... }; ここでも、addEventListener()
メソッドも使用できます。
いずれの場合も、データはイベントオブジェクトのdata
属性で提供されます。
メッセージを送り返す場合も、postMessage()を使用します。
これは同じ方法で構造化データをサポートします。
postMessage( event. data. input, [ event. data. input]); // transfer the buffer back 現行のすべてのエンジンでサポートされています。
この節は非規範的です。
共有ワーカーは、その作成に使用されたスクリプトのURLと、オプションの明示的な名前によって識別されます。 名前を使用すると、特定の共有ワーカーの複数のインスタンスを起動できます。
共有ワーカーの適用範囲はオリジンによって定まります。同じ名前を使用する 異なる2つのサイトが衝突することはありません。ただし、あるページが同じサイトの別のページと 同じ共有ワーカー名を異なるスクリプトURLで使用しようとすると、失敗します。
共有ワーカーは、SharedWorker()
コンストラクターを使用して作成します。このコンストラクターは、第1引数として使用するスクリプトのURLを取り、
存在する場合は第2引数としてワーカーの名前を取ります。
var worker = new SharedWorker( 'service.js' ); 共有ワーカーとの通信は、明示的なMessagePortオブジェクトを使用して行います。SharedWorker()コンストラクターが返す
オブジェクトは、そのport属性にポートへの参照を保持します。
worker. port. onmessage = function ( event) { ... };
worker. port. postMessage( 'some message' );
worker. port. postMessage({ foo: 'structured' , bar: [ 'data' , 'also' , 'possible' ]}); 共有ワーカー内では、ワーカーの新しいクライアントはconnect
イベントを使用して通知されます。新しいクライアントのポートは、
イベントオブジェクトのsource属性によって提供されます。
onconnect = function ( event) {
var newPort = event. source;
// set up a listener
newPort. onmessage = function ( event) { ... };
// send a message back to the port
newPort. postMessage( 'ready!' ); // can also send structured data, of course
}; この標準では、専用ワーカーと共有ワーカーという2種類のワーカーを定義します。専用 ワーカーは、作成されるとその作成者にリンクされますが、メッセージポートを使用すれば、 専用ワーカーから複数のほかの閲覧コンテキストまたはワーカーと通信できます。一方、共有ワーカーには 名前が付けられ、作成された後は、同じオリジンで実行されている任意のスクリプトが そのワーカーへの参照を取得して通信できます。Service Workersでは、 第3の種類を定義しています。[SW]
グローバルスコープは、ワーカーの「内部」である。
WorkerGlobalScope 共通インターフェイス現在のすべてのエンジンでサポートされている。
[Exposed =Worker ]
interface WorkerGlobalScope : EventTarget {
readonly attribute WorkerGlobalScope self ;
readonly attribute WorkerLocation location ;
readonly attribute WorkerNavigator navigator ;
undefined importScripts ((TrustedScriptURL or USVString )... urls );
attribute OnErrorEventHandler onerror ;
attribute EventHandler onlanguagechange ;
attribute EventHandler onoffline ;
attribute EventHandler ononline ;
attribute EventHandler onrejectionhandled ;
attribute EventHandler onunhandledrejection ;
};WorkerGlobalScope
は、DedicatedWorkerGlobalScope、
SharedWorkerGlobalScope、
および ServiceWorkerGlobalScopeを含む、特定の種類のワーカーグローバル
スコープオブジェクトの基底クラスとして機能する。
WorkerGlobalScope
オブジェクトには、関連付けられた所有者集合(
Documentおよび WorkerGlobalScope
オブジェクトの集合)がある。これは
初期状態では空であり、ワーカーが作成または取得されたときに設定される。
単一の所有者ではなく集合であるのは、
SharedWorkerGlobalScope
オブジェクトに対応するためである。
WorkerGlobalScope
オブジェクトには、関連付けられたタイプ(「classic」または「module」)がある。これは作成時に設定される。
WorkerGlobalScope
オブジェクトには、関連付けられたURL(null またはURL)がある。これは初期状態では
null である。
WorkerGlobalScope
オブジェクトには、関連付けられた名前(文字列)がある。これは作成時に設定される。
名前は、WorkerGlobalScopeの各サブクラスで異なる
意味を持つことができる。
DedicatedWorkerGlobalScope
インスタンスでは、単に開発者が指定した名前であり、主に
デバッグ目的で役立つ。SharedWorkerGlobalScope
インスタンスでは、SharedWorker()
コンストラクターを介して共通の共有ワーカーへの参照を取得できる。ServiceWorkerGlobalScope
オブジェクトでは意味をなさない(そのため、JavaScript API を
通じてまったく公開されない)。
WorkerGlobalScope
オブジェクトには、関連付けられたポリシーコンテナ(ポリシー
コンテナ)がある。これは初期状態では新しいポリシーコンテナである。
WorkerGlobalScope
オブジェクトには、関連付けられた埋め込み元ポリシー(埋め込み元
ポリシー)がある。
WorkerGlobalScope
オブジェクトには、関連付けられたモジュールマップがある。これはモジュールマップであり、
初期状態では空である。
WorkerGlobalScope
オブジェクトには、関連付けられたオリジン間分離
機能のブール値がある。これは初期状態では false である。
workerGlobal.self
現在のすべてのエンジンでサポートされている。
workerGlobal.location
現在のすべてのエンジンでサポートされている。
WorkerLocation
オブジェクトを返す。workerGlobal.navigator
現在のすべてのエンジンでサポートされている。
WorkerNavigator
オブジェクトを返す。workerGlobal.importScripts(...urls)
WorkerGlobalScope/importScripts
現在のすべてのエンジンでサポートされている。
self属性は、
WorkerGlobalScope
オブジェクト自体を返さなければならない。
location属性は、
関連付けられたWorkerGlobalScope
オブジェクトが
当該 WorkerGlobalScope
オブジェクトである WorkerLocation
オブジェクトを返さなければならない。
WorkerLocation
オブジェクトは
WorkerGlobalScope
オブジェクトの後に作成されるが、スクリプトから観測できないため、
これは問題ではない。
以下は、WorkerGlobalScope
インターフェイスを実装するオブジェクトが、
イベントハンドラー IDL 属性として
サポートしなければならないイベント
ハンドラー(および対応するイベントハンドラーイベントタイプ)である:
| イベントハンドラー | イベントハンドラーイベントタイプ |
|---|---|
onerror
現在のすべてのエンジンでサポートされている。 Firefox3.5+Safari4+Chrome4+
Opera11.5+Edge79+ Edge (Legacy)12+Internet Explorer10+ Firefox Android?Safari iOS5+Chrome Android?WebView Android?Samsung Internet?Opera Android? |
error
|
onlanguagechange
WorkerGlobalScope/languagechange_event 現在のすべてのエンジンでサポートされている。 Firefox74+Safari4+Chrome4+
Opera11.5+Edge79+ Edge (Legacy)?Internet Explorer非対応 Firefox Android?Safari iOS5+Chrome Android?WebView Android37+Samsung Internet?Opera Android? |
languagechange
|
onoffline
WorkerGlobalScope/offline_event Firefox29+Safari8+Chrome非対応
Opera?Edge非対応 Edge (Legacy)?Internet Explorer非対応 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
offline
|
ononline
WorkerGlobalScope/online_event Firefox29+Safari8+Chrome非対応
Opera?Edge非対応 Edge (Legacy)?Internet Explorer非対応 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
online
|
onrejectionhandled |
rejectionhandled
|
onunhandledrejection |
unhandledrejection
|
DedicatedWorkerGlobalScope
インターフェイス現在のすべてのエンジンでサポートされている。
[Global =(Worker ,DedicatedWorker ),Exposed =DedicatedWorker ]
interface DedicatedWorkerGlobalScope : WorkerGlobalScope {
[Replaceable ] readonly attribute DOMString name ;
undefined postMessage (any message , sequence ><object > transfer );
undefined postMessage (any message , optional StructuredSerializeOptions options = {});
undefined close ();
};
DedicatedWorkerGlobalScope includes MessageEventTarget ;DedicatedWorkerGlobalScope
オブジェクトには、関連付けられた内部ポート(
MessagePort)がある。
このポートは、ワーカーが作成されたときに設定されるチャネルの一部であるが、
公開されない。このオブジェクトは、DedicatedWorkerGlobalScope
オブジェクトより前にガベージコレクションされてはならない。
dedicatedWorkerGlobal.name
DedicatedWorkerGlobalScope/name
現在のすべてのエンジンでサポートされている。
dedicatedWorkerGlobalの名前、
すなわち
Worker
コンストラクターに与えられた値を返す。主にデバッグに役立つ。
dedicatedWorkerGlobal.postMessage(message [, transfer ])
DedicatedWorkerGlobalScope/postMessage
現在のすべてのエンジンでサポートされている。
dedicatedWorkerGlobal.postMessage(message [, { transfer } ])
messageを複製し、dedicatedWorkerGlobalに関連付けられた
Worker
オブジェクトへ送信する。transferは、複製する代わりに
転送するオブジェクトのリストとして渡すことができる。
dedicatedWorkerGlobal.close()
DedicatedWorkerGlobalScope/close
現在のすべてのエンジンでサポートされている。
dedicatedWorkerGlobalを中止する。
DedicatedWorkerGlobalScope
オブジェクトのpostMessage(message,
transfer)およびpostMessage(message,
options)メソッドは、
呼び出されたときに、同じ引数を使用してポート上の対応する postMessage(message, transfer)
および postMessage(message,
options)を直ちに呼び出し、同じ戻り
値を返したかのように動作する。
workerGlobalが与えられたとき、ワーカーを閉じるには、次の 手順を実行する:
workerGlobalの関連するエージェントのイベント ループのタスク キューに追加されたすべてのタスクを破棄する。
workerGlobalの終了中 フラグを true に設定する。(これにより、それ以降のタスクがキューに入れられることを防ぐ。)
SharedWorkerGlobalScope
インターフェイス現在のすべてのエンジンでサポートされている。
[Global =(Worker ,SharedWorker ),Exposed =SharedWorker ]
interface SharedWorkerGlobalScope : WorkerGlobalScope {
[Replaceable ] readonly attribute DOMString name ;
undefined close ();
attribute EventHandler onconnect ;
};共有ワーカーは、各
接続について、SharedWorkerGlobalScope
オブジェクト上の connect
イベントを通じてメッセージポートを受信する。
sharedWorkerGlobal.name
現在のすべてのエンジンでサポートされている。
sharedWorkerGlobalの名前、すなわち
SharedWorker
コンストラクターに与えられた値を返す。複数の SharedWorker
オブジェクトは、同じ
名前を再利用することにより、同じ共有ワーカー(および SharedWorkerGlobalScope)に対応できる。
sharedWorkerGlobal.close()
現在のすべてのエンジンでサポートされている。
sharedWorkerGlobalを中止する。
nameの取得子手順は、
thisの名前を返すことである。その
値は、
SharedWorker
コンストラクターを使用してワーカーへの参照を取得するために使用できる名前を
表す。
以下は、SharedWorkerGlobalScope
インターフェイスを実装するオブジェクトが、
イベントハンドラー IDL
属性としてサポートしなければならないイベントハンドラー(および
対応するイベントハンドラーイベント
タイプ)である:
| イベントハンドラー | イベントハンドラーイベント タイプ |
|---|---|
onconnect
SharedWorkerGlobalScope/connect_event 現在のすべてのエンジンでサポートされている。 Firefox29+Safari16+Chrome4+
Opera10.6+Edge79+ Edge (Legacy)?Internet Explorer非対応 Firefox Android?Safari iOS16+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
connect
|
ワーカーイベントループのタスクキューには、タスクとして、イベント、コールバック、およびネットワーク処理のみが含まれます。 これらのワーカーイベントループは、ワーカーを実行するアルゴリズムによって作成されます。
各WorkerGlobalScope
オブジェクトには、終了中フラグがあります。このフラグは最初は
falseでなければなりませんが、後述する処理モデル節のアルゴリズムによってtrueに設定されることがあります。
WorkerGlobalScopeの終了中フラグが
trueに設定されると、イベント
ループのタスクキューは、それ以降に
追加されるすべてのタスクを破棄しなければなりません
(すでにキューにあるタスクは、別途指定されている場合を除いて影響を受けません)。実質的に、終了中フラグが
trueになると、タイマーの発火は停止し、保留中のすべてのバックグラウンド処理に関する通知は破棄される、という具合です。
ワーカーは、メッセージチャネルとそのMessagePort
オブジェクトを通じて、ほかのワーカーおよびWindowと通信します。
各WorkerGlobalScope
オブジェクトworker global scopeには、ワーカーのポートのリストがあります。このリストは、別のポートと絡み合っており、そのうち
1つ(ただし1つだけ)のポートがworker global scopeによって所有されている、すべてのMessagePortオブジェクトで構成されます。
専用ワーカーの場合、このリストには暗黙的なMessagePortが含まれます。
ワーカーを作成または取得するときに環境設定
オブジェクトoが指定された場合、追加する関連所有者は、
oによって指定されたグローバル
オブジェクトの型に応じて決まります。oのグローバルオブジェクトがWorkerGlobalScope
オブジェクトである場合(すなわち、入れ子になった専用ワーカーを作成している場合)、関連所有者はその
グローバルオブジェクトです。それ以外の場合、oのグローバル
オブジェクトはWindowオブジェクトであり、
関連所有者はそのWindowに関連付けられた
Documentです。
ユーザーエージェントには、読み込み間共有ワーカー タイムアウトという、短い時間を表す実装定義の値があります。これは、読み込み中のページが共有ワーカーに 再び接続する可能性に備えて、そのページの読み込み中にユーザーエージェントが共有ワーカーの存続を許可する期間を表します。 この値を0より大きく設定すると、ユーザーがサイト内のページ間を移動するときに、そのサイトが使用する 共有ワーカーを再起動するコストをユーザーエージェントが回避できます。
読み込み間共有ワーカータイムアウトの 一般的な値は5秒程度です。
ユーザーエージェントには、延長存続期間 共有ワーカータイムアウトという、ある時間を表す実装定義の値があります。これは、ウェブ開発者が存続期間の延長を要求した 共有ワーカーについて、そのすべての所有者が 消滅した後も、ユーザーエージェントが存続して処理を行うことを許可する期間を表します。ユーザーエージェントは、 サービスワーカーがクライアントなしで 存続できる最長期間と等しい値を選択するべきであり、その期間より長い値を選択してはなりません。
延長存続期間共有ワーカータイムアウトの 一般的な値は、ユーザーに表示される表現を持たないオリジンが実行するバックグラウンド処理に関する 実装固有の方針に応じて、10秒から5分までの範囲になり得ます。
WorkerGlobalScope
globalは、次のアルゴリズムがtrueを返す場合、延長存続期間中です。
globalがSharedWorkerGlobalScopeでない場合、
falseを返します。
globalの延長された存続期間がfalseの場合、 falseを返します。
globalの所有者集合が空であるものの、空になってからユーザーエージェントの延長存続期間共有ワーカー タイムアウトより短い時間しか経過していない場合、trueを返します。
globalの所有者集合の各ownerについて、次を実行します。
ownerがDocumentであり、ownerが
非完全
アクティブになってからの時間が、ユーザーエージェントの延長存続期間共有ワーカー
タイムアウトより短い場合、trueを返します。
ownerが延長存続期間中のWorkerGlobalScope
である場合、trueを返します。
falseを返します。
WorkerGlobalScope
globalは、次のアルゴリズムがtrueを返す場合、アクティブに必要です。
WorkerGlobalScope
globalは、次のアルゴリズムがtrueを返す場合、保護されています。
globalがアクティブに必要でない場合、 falseを返します。
globalが延長 存続期間中の場合、trueを返します。
globalがSharedWorkerGlobalScopeである場合、
trueを返します。
globalに未処理のタイマー、データベーストランザクション、またはネットワーク 接続がある場合、trueを返します。
falseを返します。
WorkerGlobalScope
globalは、次のアルゴリズムがtrueを返す場合、許容されます。
globalが延長 存続期間中の場合、trueを返します。
次のすべてがtrueである場合:
globalがSharedWorkerGlobalScopeである。
globalの所有者集合が空になってから、ユーザーエージェントの読み込み間共有ワーカー タイムアウト以下の時間しか経過していない。かつ、
ユーザーエージェントに、アクティブな文書が完全に 読み込まれていないナビゲータブルがある。
その場合、trueを返します。
falseを返します。
これらの用語の間には、次の関係が成り立ちます。
延長存続期間中であるすべてのWorkerGlobalScopeは、
アクティブに
必要であり、保護されており、許容されます。
アクティブに
必要であるか、または保護されているすべてのWorkerGlobalScopeは、許容されます。
保護されているすべてのWorkerGlobalScopeは、アクティブに必要です。
ただし、その逆が常に成り立つとは限りません。
WorkerGlobalScopeは、
完全にアクティブな所有者のために計算を実行中であるものの未処理の非同期処理がなく、対応するWorkerオブジェクトがガベージコレクションされた
専用ワーカーである場合、アクティブに
必要でありながら、保護されていないことがあります。ガベージコレクションによって、ポートの集合が空になるため、
保護されなくなります。しかし、そのイベントループは、まだ所有者集合を空にするところまで処理を譲っていないため、
依然としてアクティブに必要です。
WorkerGlobalScopeは、
所有者の推移的集合内のすべてのDocumentがbfcache内にある場合、または現在の所有者がなく、読み込み間共有ワーカータイムアウトの間
存続させられているSharedWorkerGlobalScope
である場合、許容されていながら、保護されておらず、アクティブに必要でもないことがあります。
WorkerGlobalScope
globalは、次のアルゴリズムがtrueを返す場合、一時停止可能です。
これらの概念は、仕様内のほかの規範的要件で次のように使用されます。
ワーカーは、保護されている状態ではなくなってから、許容されている状態ではなくなるまでの間に、孤立したものとして閉じられます。
閉じられた後も実行を続けているワーカーは、アクティブに 必要ではなくなった時点で、ユーザーエージェントの裁量により終了させることができます。
ワーカーは、一時停止可能かどうかに基づいて、一時停止または一時停止解除されます。
ユーザーエージェントが、WorkerまたはSharedWorkerオブジェクト
worker、URL url、環境
設定オブジェクト outside settings、MessagePort
outside port、およびWorkerOptions辞書
optionsを持つスクリプトについてワーカーを実行するとき、次の手順を実行しなければなりません。
workerがSharedWorker
オブジェクトである場合はis sharedをtrueとし、それ以外の場合はfalseとします。
ownerを、outside settingsを指定したときの追加する関連所有者とします。
unsafeWorkerCreationTimeを、安全でない共有現在 時刻とします。
agentを、outside settingsとis sharedを指定して専用/共有ワーカー エージェントを取得した結果とします。残りの手順はそのエージェント内で実行します。
realm execution contextを、agentと次のカスタマイズを指定して新しいレルムを作成した 結果とします。
グローバルオブジェクトについて、is sharedがtrueの場合は、新しいSharedWorkerGlobalScope
オブジェクトを作成します。それ以外の場合は、新しいDedicatedWorkerGlobalScope
オブジェクトを作成します。
worker global scopeを、realm execution contextのRealmコンポーネントのグローバル オブジェクトとします。
これは、前の手順で作成されたDedicatedWorkerGlobalScope
またはSharedWorkerGlobalScope
オブジェクトです。
realm execution context、outside settings、および unsafeWorkerCreationTimeを使用してワーカー環境 設定オブジェクトを設定し、その結果をinside settingsとします。
is sharedがtrueの場合:
worker global scopeのコンストラクターのストレージ キーを、 outside settingsを与えてストレージ以外の目的のためのストレージキーを 取得するを実行した結果に 設定する。
worker global scopeのコンストラクター URLを urlに設定する。
worker global scopeの資格情報を
options["credentials"]に設定する。
worker global scopeの延長された存続期間を
options["extendedLifetime"]に設定する。
is sharedがtrueの場合はdestinationを「sharedworker」とし、
それ以外の場合は「worker」とします。
options["type"]に
応じて切り替え、scriptを取得します。
classic"module"credentialsメンバーの値、およびinside settingsを指定し、
onCompleteおよびperformFetchを後述のように設定して、モジュールワーカースクリプトグラフを取得します。
どちらの場合も、request、isTopLevel、およびprocessCustomFetchResponseを指定したときの performFetchを、次の取得実行フックとします。
isTopLevelがfalseの場合、processResponseConsumeBodyを processCustomFetchResponseに設定してrequestを取得し、 これらの手順を中止します。
processResponseConsumeBodyを、 応答 responseと、null、失敗、またはバイト列bodyBytesを指定した次の手順に設定して、 requestを取得します。
worker global scope、response、およびinside settingsを指定して、ワーカーグローバルスコープの ポリシーコンテナーを初期化します。
worker global scopeに対して実行したときに、グローバルオブジェクトのCSP初期化を
実行するアルゴリズムが「Blocked」を返した場合、responseをネットワーク
エラーに設定します。[CSP]
worker global scopeの埋め込み元ポリシーの値がオリジン間分離と互換性があり、
かつis sharedがtrueの場合、agentのエージェント
クラスターのオリジン間分離
モードを「logical」
または「concrete」に
設定します。どちらを選択するかは実装定義です。
これは本来、エージェントクラスターの作成時に設定されるべきですが、そのためには この節の再設計が必要です。
worker global scope、outside settings、およびresponseを使用してグローバルオブジェクトの 埋め込み元ポリシーを検査した結果がfalseの場合、responseをネットワーク エラーに設定します。
agentのエージェント
クラスターのオリジン間分離モードが
「concrete」である場合は
worker global scopeのオリジン間
分離機能をtrueに設定します。
is sharedがfalseであり、ownerのオリジン間 分離機能がfalseの場合、worker global scopeのオリジン間 分離機能をfalseに設定します。
is sharedがfalseであり、responseのURLの
スキームが
「data」である場合、worker global scopeのオリジン間
分離機能をfalseに設定します。
これは、一般的なワーカー、とりわけ(所有者とはオリジンが異なる)data:
URLワーカーが権限ポリシーのコンテキストでどのように扱われるかを解明するまでの間の、
現時点での保守的なデフォルトです。詳細については、w3c/webappsec-permissions-policy
issue #207を参照してください。
responseとbodyBytesを指定して processCustomFetchResponseを実行します。
どちらの場合も、scriptを指定したonCompleteを、次の手順とします。
scriptがnullであるか、scriptの再スローするエラーがnullでない場合:
workerの関連するグローバルオブジェクトを指定し、DOM操作タスクソース上にグローバル
タスクをキューに追加して、workerでerrorという名前の
イベントを発火させます。
inside settingsについて環境破棄手順を実行します。
これらの手順を中止します。
workerをworker global scopeに関連付けます。
inside portを、inside settingsのレルム内の新しいMessagePortオブジェクトとします。
is sharedがfalseの場合:
inside portのメッセージイベントターゲットをworker global scopeに設定します。
worker global scopeの内部ポートをinside portに設定します。
outside portとinside portを絡み合わせます。
新しいWorkerLocationオブジェクトを
作成し、worker global scopeに関連付けます。
孤立したワーカーを閉じる:worker global scopeの監視を開始し、worker global scopeが保護されている状態ではなくなった時点より前ではなく、許容されている状態では なくなった時点より後でもない時点で、その終了中フラグがtrueに設定されるようにします。
ワーカーを一時停止する:worker global scopeの監視を開始し、worker global scopeの終了中フラグがfalseで、かつ一時停止可能であるときは、 終了中フラグがtrueに切り替わるか、worker global scopeが一時停止可能ではなくなるまで、 ユーザーエージェントがworker global scope内のスクリプトの実行を一時停止するようにします。
inside settingsの実行準備完了フラグを設定します。
scriptがクラシックスクリプトである場合は、scriptというクラシック スクリプトを実行します。それ以外の場合、それはモジュール スクリプトであり、scriptというモジュールスクリプトを実行します。
値を返す場合や例外によって失敗する場合という通常の可能性に加え、これは後述するワーカーを終了する アルゴリズムによって途中で中止されることがあります。
outside portのポートメッセージキューを有効化します。
is sharedがfalseの場合、ワーカーの暗黙的なポートのポートメッセージキューを 有効化します。
is sharedがtrueの場合、worker global scopeを指定してDOM
操作タスクソース上にグローバルタスクをキューに追加し、worker
global scopeで、data属性を
空文字列で初期化し、ports属性を
inside portを含む新しい凍結
配列で初期化し、source属性を
inside portで初期化したMessageEventを使用して、
connectという
名前のイベントを発火させます。
関連付けられたサービスワーカークライアントが
worker global scopeの関連する設定オブジェクトであるServiceWorkerContainer
オブジェクトのクライアント
メッセージキューを有効化します。
イベントループ:inside settingsによって指定された責任を持つ イベントループを、それが破棄されるまで実行します。
イベントループによって実行されるタスクによるイベントの処理またはコールバックの実行は、 後述するワーカーを終了するアルゴリズムによって途中で中止されることがあります。
ワーカー処理モデルは、イベントループが破棄されるまでこの手順に留まります。 イベントループは、イベントループ処理モデルで説明されているとおり、終了中 フラグがtrueに設定された後に破棄されます。
worker global scopeのアクティブな タイマーのマップを消去します。
ワーカーのポートのリストにあるすべてのポートの 絡み合わせを解除します。
ユーザーエージェントがワーカーを終了するとき、 ワーカーのメインループ(上記で定義した「ワーカーを実行する」処理モデル)と並列に、次の手順を実行しなければなりません。
ワーカーのWorkerGlobalScope
オブジェクトの終了中フラグをtrueに設定します。
WorkerGlobalScope
オブジェクトの関連するエージェントのイベントループのタスク
キューにキューイングされたタスクがある場合、それらを処理せずに破棄します。
ワーカー内で現在実行されているスクリプトを中止します。
ワーカーのWorkerGlobalScope
オブジェクトが実際にはDedicatedWorkerGlobalScope
オブジェクトである場合(すなわち、ワーカーが専用ワーカーである場合)、ワーカーの暗黙的なポートと
絡み合っているポートのポートメッセージ
キューを空にします。
ワーカーがアクティブに必要ではなくなり、その終了中フラグがtrueに設定された後も ワーカーが実行を続ける場合、ユーザーエージェントはワーカーを終了する アルゴリズムを呼び出してもよいものとします。
ワーカーのいずれかのスクリプトで捕捉されない実行時スクリプトエラーが発生したとき、そのエラーが
以前のスクリプトエラーの処理中に発生したものでない場合、ユーザーエージェントはワーカーのWorkerGlobalScope
オブジェクトについて、そのエラーを報告します。
AbstractWorkerミックスイン
interface mixin AbstractWorker {
attribute EventHandler onerror ;
};以下は、AbstractWorkerインターフェイスを
実装するオブジェクトが、イベントハンドラー
IDL属性としてサポートしなければならないイベントハンドラー(および対応するイベントハンドラーのイベント型)です。
| イベントハンドラー | イベントハンドラーの イベント型 |
|---|---|
onerror
現行のすべてのエンジンでサポートされています。 Firefox44+Safari11.1+Chrome40+
Opera?Edge79+ Edge (Legacy)17+Internet Explorer非対応 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? 現行のすべてのエンジンでサポートされています。 Firefox29+Safari16+Chrome5+
Opera10.6+Edge79+ Edge (Legacy)?Internet Explorer非対応 Firefox Android33+Safari iOS16+Chrome Android非対応WebView Android?Samsung Internet4.0–5.0Opera Android11–14 現行のすべてのエンジンでサポートされています。 Firefox3.5+Safari4+Chrome4+
Opera10.6+Edge79+ Edge (Legacy)12+Internet Explorer10+ Firefox Android?Safari iOS5+Chrome Android?WebView Android?Samsung Internet?Opera Android11+ |
error
|
JavaScript 実行 コンテキストexecution context、環境設定オブジェクト outside settings、および数値unsafeWorkerCreationTimeを指定して、ワーカー環境設定オブジェクトを設定するには、次の手順を実行します。
realmを、execution contextのRealmコンポーネントの値とします。
worker global scopeを、realmのグローバルオブジェクトとします。
worker global scopeのURLのスキームが「data」である場合は、
originを一意の不透明なオリジンとし、それ以外の場合は
outside settingsのオリジンとします。
settings objectを、アルゴリズムが次のように定義される新しい環境設定オブジェクトとします。
execution contextを返します。
worker global scopeのモジュールマップを返します。
worker global scopeのURLを返します。
originを返します。
outside settingsのサイトをまたぐ 祖先を持つがtrueの場合、trueを返します。
falseを返します。
worker global scopeのポリシーコンテナーを返します。
worker global scopeのオリジン間 分離機能を返します。
worker global scopeのオリジン間 分離機能を使用してunsafeWorkerCreationTimeを粗粒度化した結果を返します。
settings objectのIDを新しい一意の不透明な文字列に、作成URLを worker global scopeのURLに、トップレベル作成URLを nullに、ターゲット閲覧コンテキストを nullに、アクティブなサービスワーカーを nullに設定します。
worker global scopeがDedicatedWorkerGlobalScope
オブジェクトである場合、settings objectのトップレベルオリジンをoutside
settingsのトップレベルオリジンに設定します。
それ以外の場合、settings objectのトップレベルオリジンを実装定義の値に設定します。
これを適切に定義するための最新情報については、クライアント側 ストレージパーティショニングを参照してください。
realmの[[HostDefined]]フィールドをsettings objectに設定します。
settings objectを返します。
Workerインターフェイス
現行のすべてのエンジンでサポートされています。
[Exposed =(Window ,DedicatedWorker ,SharedWorker )]
interface Worker : EventTarget {
constructor ((TrustedScriptURL or USVString ) scriptURL , optional WorkerOptions options = {});
undefined terminate ();
undefined postMessage (any message , sequence <object > transfer );
undefined postMessage (any message , optional StructuredSerializeOptions options = {});
};
dictionary WorkerOptions {
DOMString name = "";
WorkerType type = "classic";
RequestCredentials credentials = "same-origin"; // credentials is only used if type is "module"
};
enum WorkerType { "classic" , "module" };
Worker includes AbstractWorker ;
Worker includes MessageEventTarget ;worker = new Worker(scriptURL [, options ])
現行のすべてのエンジンでサポートされています。
新しいWorkerオブジェクトを返します。
scriptURLはバックグラウンドで取得および実行され、新しいグローバル環境が作成されます。
workerはその環境との通信チャネルを表します。
optionsには、次の値を含められます。
typeを
「module」に設定すると、scriptURLから新しい
グローバル環境をJavaScriptモジュールとして読み込めます。
credentialsを
使用すると、scriptURLを取得する方法を指定できますが、これはtypeが
「module」に設定されている場合に限られます。
worker.terminate()
現行のすべてのエンジンでサポートされています。
worker.postMessage(message [, transfer ])
現行のすべてのエンジンでサポートされています。
worker.postMessage(message [, { transfer } ])
messageを複製し、workerのグローバル環境に送信します。 transferには、複製する代わりに転送するオブジェクトのリストを渡せます。
各Workerオブジェクトには、
関連付けられた外部ポート(MessagePort)があります。
このポートはワーカーの作成時に設定されるチャネルの一部ですが、公開されません。このオブジェクトは、Workerオブジェクトより先に
ガベージコレクションされてはなりません。
WorkerオブジェクトのpostMessage(message, transfer)
およびpostMessage(message,
options)メソッドは、呼び出されたときに、thisの外部ポート上で、同じ引数を使用して対応するpostMessage(message, transfer)
およびpostMessage(message,
options)を直ちに呼び出し、同じ戻り値を返したかのように動作します。
postMessage()
メソッドの第1引数には構造化データを指定できます。
worker. postMessage({ opcode: 'activate' , device: 1938 , parameters: [ 23 , 102 ]}); new Worker(scriptURL,
options)コンストラクターの手順は次のとおりです。
compliantScriptURLを、TrustedScriptURL、thisの関連するグローバル
オブジェクト、scriptURL、「Worker constructor」、および
「script」を使用してTrusted Type準拠文字列を取得するアルゴリズムを
呼び出した結果とします。
outsideSettingsを、thisの関連する設定 オブジェクトとします。
workerURLを、outsideSettingsを基準として compliantScriptURLを指定し、URLをエンコーディング解析した 結果とします。
blob: URLを含む、任意の同一オリジンURLを使用できます。data:
URLも使用できますが、これは不透明なオリジンを持つワーカーを作成します。
workerURLが失敗である場合、「SyntaxError」DOMExceptionをスローします。
outsidePortを、outsideSettingsのレルム内の新しいMessagePortとします。
outsidePortのメッセージイベントターゲットをthisに設定します。
workerをthisとします。
次の手順を並列に実行します。
worker、workerURL、outsideSettings、 outsidePort、およびoptionsを指定してワーカーを実行します。
SharedWorkerインターフェイス
現行のすべてのエンジンでサポートされています。
[Exposed =Window ]
interface SharedWorker : EventTarget {
constructor ((TrustedScriptURL or USVString ) scriptURL , optional (DOMString or SharedWorkerOptions ) options = {});
readonly attribute MessagePort port ;
};
SharedWorker includes AbstractWorker ;
dictionary SharedWorkerOptions : WorkerOptions {
boolean extendedLifetime = false ;
};sharedWorker = new SharedWorker(scriptURL [, name ])
現行のすべてのエンジンでサポートされています。
新しいSharedWorker
オブジェクトを返します。scriptURLはバックグラウンドで取得および実行され、
新しいグローバル環境が作成されます。sharedWorkerはその環境との通信チャネルを表します。
nameを使用すると、そのグローバル環境の名前を定義できます。
sharedWorker = new SharedWorker(scriptURL [, options ])
新しいSharedWorker
オブジェクトを返します。scriptURLはバックグラウンドで取得および実行され、
新しいグローバル環境が作成されます。sharedWorkerはその環境との通信チャネルを表します。
optionsには、次の値を含められます。
typeを
「module」に設定すると、scriptURLから新しいグローバル環境を
JavaScriptモジュールとして読み込めます。
credentialsを
使用すると、scriptURLを取得する方法を指定できますが、これはtypeが
「module」に設定されている場合に限られます。
extendedLifetimeを
設定すると、新しく作成されたグローバル環境に、そのすべての所有者が
消滅した後も処理を実行するための追加時間を与えるよう要求できます。これは、たとえばページの
アンロード後に非同期処理を実行する場合に役立ちます。
同じコンストラクター
URLおよび名前を持つ
既存の共有ワーカーと、optionsのtype、
credentials、
またはextendedLifetimeの
値が一致しない共有ワーカーを構築しようとすると、返されたsharedWorkerでerror
イベントが発火し、既存の共有ワーカーには接続されないことに注意してください。
sharedWorker.port
現行のすべてのエンジンでサポートされています。
グローバル環境との通信に使用できる、sharedWorkerのMessagePort
オブジェクトを返します。
ユーザーエージェントには、新しい並列 キューを開始した結果である、関連付けられた共有ワーカーマネージャーがあります。
簡単にするため、各ユーザーエージェントには単一の共有ワーカーマネージャーがあります。 実装はオリジンごとに1つ使用することもできます。 これは観察可能な違いを生じさせず、より高い並行性を実現できます。
各SharedWorkerには、
オブジェクトの作成時に設定されるMessagePortである
ポートがあります。
new
SharedWorker(scriptURL, options)コンストラクターの手順は次のとおりです。
compliantScriptURLを、TrustedScriptURL、thisの関連するグローバル
オブジェクト、scriptURL、「SharedWorker constructor」、および
「script」を使用してTrusted Type準拠文字列を取得するアルゴリズムを
呼び出した結果とします。
optionsがDOMStringである場合、
optionsを、name
メンバーをoptionsの値に設定し、そのほかのメンバーをデフォルト値に設定した新しいWorkerOptions
辞書に設定します。
outsideSettingsを、thisの関連する設定 オブジェクトとします。
urlRecordを、outsideSettingsを基準として compliantScriptURLを指定し、URLをエンコーディング解析した 結果とします。
blob: URLを含む、任意の同一オリジンURLを使用できます。data:
URLも使用できますが、これは不透明なオリジンを持つワーカーを作成します。
urlRecordが失敗である場合、「SyntaxError」DOMExceptionをスローします。
outsidePortを、outsideSettingsのレルム内の新しいMessagePortとします。
outsideSettingsがセキュア コンテキストである場合はcallerIsSecureContextをtrueとし、それ以外の場合はfalseとします。
outsideStorageKeyを、outsideSettingsを指定してストレージ以外の目的の ストレージキーを取得した結果とします。
workerをthisとします。
次の手順を共有ワーカーマネージャーにキューに追加します。
workerGlobalScopeをnullとします。
すべてのSharedWorkerGlobalScope
オブジェクトのリスト内の各scopeについて、次を実行します。
次のすべてが true である場合:
name"]に等しい、
その場合:
workerGlobalScopeをscopeに設定する。
中断する。
data:
URL は不透明なオリジンを持つワーカーを作成するため、
そのようなワーカー自身のストレージキーが
使用された場合、そのワーカーが一致することは
決してない。代わりに、コンストラクター
ストレージ
キー(作成環境から導出される)とコンストラクター
URLが比較されるため、
同じ data:
URL を、あるストレージ
キー内で使用して、同じ SharedWorkerGlobalScope
オブジェクトに到達できるが、
ストレージキー
制限を回避するためには使用できない。
workerGlobalScopeがnullでないものの、workerGlobalScopeが表すワーカーと、 設定オブジェクトがoutsideSettingsであるスクリプトとの間の通信を 許可しないようユーザーエージェントが構成されている場合、workerGlobalScopeをnullに設定します。
たとえば、ユーザーエージェントには、特定のトップレベル トラバーサブルをほかのすべてのページから分離する開発モードを設けることができ、その開発モード内の スクリプトが、通常のブラウザーモードで実行されている共有ワーカーへ接続することを阻止できます。
workerGlobalScopeがnullでなく、次のいずれかがtrueである場合:
workerGlobalScopeの資格情報が
options["credentials"]と
等しくない。または、
workerGlobalScopeの延長された
存続期間がoptions["extendedLifetime"]と
等しくない。
その場合:
workerの関連するグローバル
オブジェクトを指定して、DOM操作
タスクソース上にグローバルタスクを
キューに追加し、workerでerrorという
名前のイベントを発火させます。
これらの手順を中止します。
workerGlobalScopeがnullでない場合:
insideSettingsを、workerGlobalScopeの関連する 設定オブジェクトとします。
insideSettingsがセキュア コンテキストである場合はworkerIsSecureContextをtrueとし、それ以外の場合はfalseとします。
workerIsSecureContextがcallerIsSecureContextでない場合:
workerの関連するグローバル
オブジェクトを指定して、DOM
操作タスクソース上にグローバルタスクを
キューに追加し、workerでerrorという
名前のイベントを発火させます。
これらの手順を中止します。
workerをworkerGlobalScopeに関連付けます。
insidePortを、insideSettingsのレルム内の新しいMessagePortとします。
outsidePortとinsidePortを絡み合わせます。
workerGlobalScopeを指定して、DOM操作
タスクソース上にグローバルタスクを
キューに追加し、data
属性を空文字列で初期化し、ports
属性をinsidePortだけを含む新しい凍結
配列で初期化し、source
属性をinsidePortで初期化したMessageEventを
使用して、workerGlobalScopeでconnectという
名前のイベントを発火させます。
outsideSettingsを指定したときの追加する関連所有者を、 workerGlobalScopeの所有者 集合に付加します。
それ以外の場合は、worker、urlRecord、outsideSettings、 outsidePort、およびoptionsを指定して、並列にワーカーを実行します。
interface mixin NavigatorConcurrentHardware {
readonly attribute unsigned long long hardwareConcurrency ;
};self.navigator.hardwareConcurrency
ユーザーエージェントが利用できる可能性のある論理プロセッサーの数を返します。
![]()
navigator.hardwareConcurrency属性の取得は、
1からユーザーエージェントが利用できる可能性のある論理プロセッサー数までの数値を返さなければなりません。
これを判断できない場合、取得は1を返さなければなりません。
ユーザーエージェントは、利用可能な論理プロセッサー数を公開する方向で判断するべきであり、 ユーザーエージェント固有の制限(作成できるワーカー数の制限など)がある場合、または ユーザーエージェントがフィンガープリンティングの可能性を制限しようとする場合に限り、 より小さい値を使用するべきです。
importScripts(...urls)
メソッドの手順は次のとおりです。
urlStringsを« »とします。
urlsの各urlについて、次を実行します。
TrustedScriptURL、thisの関連するグローバル
オブジェクト、url、「WorkerGlobalScope importScripts」、および
「script」を使用してTrusted Type準拠文字列を取得するアルゴリズムを
呼び出した結果をurlStringsに付加します。
thisと urlStringsを指定して、ワーカーグローバルスコープへ スクリプトをインポートします。
WorkerGlobalScope
オブジェクトworker global scope、リストであるスカラー値文字列urls、およびオプションの取得実行フック
performFetchを指定して、ワーカーグローバルスコープへスクリプトをインポートするには、次の手順を実行します。
settings objectを現在の設定オブジェクトとします。
urlsが空の場合、戻ります。
urlRecordsを« »とします。
urlsの各urlについて:
urlRecordを、settings objectを基準としてurlを指定し、URLをエンコーディング解析した結果とします。
urlRecordが失敗である場合、「SyntaxError」DOMExceptionをスローします。
urlRecordをurlRecordsに付加します。
urlRecordsの各urlRecordについて:
urlRecordとsettings objectを指定し、 提供されている場合はperformFetchを引き渡して、クラシックワーカーへ インポートされるスクリプトを取得します。これが成功した場合、その結果をscriptとします。 それ以外の場合、例外を再スローします。
エラーを再スローをtrueに設定して、scriptというクラシックスクリプトを実行します。
scriptは、戻る、解析に失敗する、例外を捕捉できない、または上記で定義されたワーカーを終了するアルゴリズムによって途中で中止されるまで実行されます。
例外がスローされた場合、またはスクリプトが途中で中止された場合、 これらの手順をすべて中止し、例外または中止の処理を、呼び出し元のスクリプトによって引き続き行わせます。
Service Workersは、独自の取得実行 フックを使用してこのアルゴリズムを実行する仕様の一例です。[SW]
WorkerNavigator インターフェイスすべての現行エンジンでサポートされています。
WorkerGlobalScope インターフェイスの navigator 属性は、ユーザーエージェント
(クライアント)の識別情報および状態を表す
WorkerNavigator
インターフェイスのインスタンスを返さなければならない:
[Exposed =Worker ]
interface WorkerNavigator {};
WorkerNavigator includes NavigatorID ;
WorkerNavigator includes NavigatorLanguage ;
WorkerNavigator includes NavigatorOnLine ;
WorkerNavigator includes NavigatorConcurrentHardware ;WorkerLocation インターフェイスすべての現行エンジンでサポートされています。
すべての現行エンジンでサポートされています。
[Exposed =Worker ]
interface WorkerLocation {
stringifier readonly attribute USVString href ;
readonly attribute USVString origin ;
readonly attribute USVString protocol ;
readonly attribute USVString host ;
readonly attribute USVString hostname ;
readonly attribute USVString port ;
readonly attribute USVString pathname ;
readonly attribute USVString search ;
readonly attribute USVString hash ;
};WorkerLocation オブジェクトには、
関連付けられた WorkerGlobalScope オブジェクト
(WorkerGlobalScope
オブジェクト)がある。
すべての現行エンジンでサポートされています。
href
取得子の手順は、this
の
WorkerGlobalScope
オブジェクトの URLをシリアライズして返すことである。
すべての現行エンジンでサポートされています。
origin 取得子の手順は、this の WorkerGlobalScope オブジェクトの
URLのオリジンをシリアライズして返すことである。
すべての現行エンジンでサポートされています。
protocol 取得子の手順は、
this の WorkerGlobalScope オブジェクトの
URLのスキームに「:」を続けて返すことである。
すべての現行エンジンでサポートされています。
host
取得子の手順は次のとおりである:
すべての現行エンジンでサポートされています。
hostname 取得子の手順は次のとおりである:
host を、this の WorkerGlobalScope オブジェクトの
URLのホストとする。
host が null の場合、空文字列を返す。
host をシリアライズして返す。
すべての現行エンジンでサポートされています。
port
取得子の手順は次のとおりである:
port を、this の WorkerGlobalScope オブジェクトの
URLのポートとする。
port が null の場合、空文字列を返す。
port をシリアライズして返す。
すべての現行エンジンでサポートされています。
pathname 取得子の手順は、this のWorkerGlobalScope オブジェクトの
URLをURL パスシリアライズした結果を返すことである。
すべての現行エンジンでサポートされています。
search 取得子の手順は次のとおりである:
query を、this の WorkerGlobalScope オブジェクトの
URLのクエリーとする。
query が null または空文字列のいずれかである場合、空文字列を返す。
「?」に query を続けて返す。
すべての現行エンジンでサポートされています。
hash
取得子の手順は次のとおりである:
fragment を、this の WorkerGlobalScope オブジェクトの
URLのフラグメントとする。
fragment が null または空文字列のいずれかである場合、空文字列を返す。
「#」に fragment を続けて返す。
この節は非規範的である。
ワークレットは、特定の実装モデルを要求することなく、メインの JavaScript 実行環境から 独立してスクリプトを実行するために使用できる仕様基盤の一部である。
ここで規定するワークレット基盤を、ウェブ開発者が直接使用することはできない。代わりに、 他の仕様がこの基盤を利用し、ブラウザー実装パイプラインの特定部分での実行に特化した、 直接使用可能なワークレット型を作成する。
この節は非規範的である。
レンダリング、または音声出力などの実装パイプラインのその他の慎重な扱いを要する部分に
拡張ポイントを設けることは難しい。Window で利用可能な API への完全なアクセス権を持つ拡張ポイントを
設ける場合、エンジンは、それらのフェーズの途中で起こり得ることについて従来維持してきた
前提を放棄する必要がある。たとえば、レイアウトフェーズ中、レンダリングエンジンは DOM が
変更されないものと想定している。
さらに、Window 環境内に
拡張ポイントを定義すると、ユーザーエージェントは Window オブジェクトと同じ
スレッドで処理を実行するよう制限される。(実装が、スレッドセーフな API を可能にする
複雑でオーバーヘッドの大きい基盤と、スレッド結合の保証を追加する場合を除く。)
ワークレットは、ユーザーエージェントが現在依存している保証を維持しながら、拡張ポイントを
実現できるよう設計されている。これは、WorkletGlobalScope
のサブクラスに基づく、新しいグローバル環境を通じて行われる。
ワークレットはウェブワーカーに似ている。ただし、次の点が異なる:
スレッドに依存しない。すなわち、各ワーカーのように専用の別スレッドで実行されるようには 設計されていない。実装は、メインスレッドを含め、任意の場所でワークレットを実行できる。
並列処理のため、グローバルスコープの重複したインスタンスを複数作成できる。
イベントベースの API を使用しない。代わりに、クラスがグローバルスコープに登録され、 そのメソッドがユーザーエージェントによって呼び出される。
グローバルスコープで利用できる API の範囲が縮小されている。
グローバルオブジェクトの 生存期間は他の仕様によって定義され、多くの場合、実装定義の方法で定義される。
ワークレットには比較的大きなオーバーヘッドがあるため、控えめに使用するのが最善である。
このため、特定の WorkletGlobalScope は、
複数の個別スクリプト間で共有されることが想定されている。(これは、単一の Window
が複数の個別スクリプト間で
共有される方法に似ている。)
ワークレットは、さまざまなユースケースに対応する汎用技術である。CSS Painting API で定義されるものなど、一部のワークレットは、ステートレスで冪等かつ短時間で完了する計算を 対象とした拡張ポイントを提供し、これには次の二つの節で説明する特別な考慮事項がある。 Web Audio API で定義されるものなど、その他のワークレットは、ステートフルで長時間 実行される処理に使用される。[CSSPAINT] [WEBAUDIO]
ワークレットを使用する一部の仕様は、ユーザーエージェントが処理を複数のスレッド間で 並列化したり、必要に応じて処理をスレッド間で移動したりできるようにすることを意図している。 これらの仕様では、ユーザーエージェントは、ウェブ開発者が提供するクラスのメソッドを 実装定義の順序で呼び出すことがある。
そのため、相互運用性の問題を防ぐため、そのような WorkletGlobalScope に
クラスを登録する作者は、コードを冪等にするべきである。すなわち、クラスのメソッドまたは
メソッド群は、特定の入力が与えられた場合に同じ出力を生成するべきである。
この仕様は、作者が冪等な方法でコードを記述するよう促すため、次の手法を使用する:
グローバルオブジェクトへの参照は利用できない(すなわち、WorkletGlobalScope
には self に
相当するものがない)。
ワークレットが最初に規定された時点ではこれが意図されていたが、
globalThis の導入により、現在では当てはまらなくなっている。詳細な議論については
issue #6059 を参照。
コードはモジュールスクリプトとして
読み込まれるため、コードは厳格モードで実行され、グローバルプロキシを参照する共有
this は存在しない。
これらの制限を組み合わせることで、二つの異なるスクリプトがグローバルオブジェクトのプロパティを使用して状態を 共有することを防ぎやすくなる。
さらに、ワークレットを使用し、実装定義の動作を許可することを意図する仕様は、 次の要件に従わなければならない:
ユーザーエージェントが、Worklet ごとに常に少なくとも二つの WorkletGlobalScope
インスタンスを持ち、クラスのメソッドまたはメソッド群を特定の WorkletGlobalScope
インスタンスにランダムに割り当てることを要求しなければならない。これらの仕様は、
メモリーに制約がある場合の適用除外を設けてもよい。
これらの仕様は、ユーザーエージェントが、その WorkletGlobalScope
サブクラスのインスタンスをいつでも作成および破棄できるようにしなければならない。
ワークレットを使用する一部の仕様では、ユーザーエージェントの状態に基づいて、ウェブ開発者が 提供するクラスのメソッドを呼び出すことができる。スレッド間の並行性を高めるため、 ユーザーエージェントは、将来起こり得る状態に基づいてメソッドを投機的に呼び出してもよい。
これらの仕様では、ユーザーエージェントは、そのようなメソッドをいつでも、またユーザー エージェントの現在の状態に対応するものだけでなく、任意の引数を使用して呼び出すことがある。 このような投機的評価の結果は直ちには表示されないが、ユーザーエージェントの状態が投機された 状態と一致した場合に使用できるよう、キャッシュできる。これにより、ユーザーエージェントと ワークレットスレッド間の並行性を高めることができる。
そのため、ユーザーエージェント間の相互運用性リスクを防ぐため、そのような WorkletGlobalScope に
クラスを登録する作者は、コードをステートレスにするべきである。すなわち、メソッドの呼び出しが
及ぼす唯一の効果はその結果であるべきであり、変更可能な状態の更新などの副作用を生じさせる
べきではない。
コードの冪等性を促すものと同じ手法が、作者にステートレスな コードを記述することも促す。
この節は非規範的である。
これらの例では、架空のワークレットを使用する。Window オブジェクトは二つの
Worklet インスタンスを提供し、
それぞれが独自の FakeWorkletGlobalScope
の集合内でコードを実行する:
partial interface Window {
[SameObject , SecureContext ] readonly attribute Worklet fakeWorklet1 ;
[SameObject , SecureContext ] readonly attribute Worklet fakeWorklet2 ;
};各 Window には、架空のワークレット
1 および 架空のワークレット
2 という二つの Worklet インスタンスがある。これらはいずれも、ワークレット
グローバルスコープ型が FakeWorkletGlobalScope
に設定され、ワークレット
宛先型が「fakeworklet」に設定されている。ユーザーエージェントは、
ワークレットごとに少なくとも二つの FakeWorkletGlobalScope
インスタンスを作成するべきである。
「fakeworklet」は、実際には Fetch における有効な宛先ではない。
しかし、これは実際のワークレットが一般に、そのワークレット型に固有の宛先を持つことを示している。
[FETCH]
fakeWorklet1 取得子の手順は、
this の架空のワークレット 1を返すことである。
fakeWorklet2 取得子の手順は、
this の架空のワークレット 2を返すことである。
[Global =(Worklet ,FakeWorklet ),
Exposed =FakeWorklet ,
SecureContext ]
interface FakeWorkletGlobalScope : WorkletGlobalScope {
undefined registerFake (DOMString type , Function classConstructor );
};各 FakeWorkletGlobalScope
には、登録済みクラスコンストラクターマップがある。
これは順序付きマップであり、初期状態では空である。
registerFake(type, classConstructor) メソッドの
手順は、this
の登録済みクラスコンストラクター
マップ[type]を classConstructor に設定することである。
この節は非規範的である。
架空のワークレット 1に スクリプトを読み込むため、ウェブ開発者は次のように記述する:
window. fakeWorklet1. addModule( 'script1.mjs' );
window. fakeWorklet1. addModule( 'script2.mjs' ); どちらのスクリプトが先にフェッチを完了して実行されるかは、ネットワークのタイミングに
依存することに注意すること。script1.mjs と script2.mjs のどちらが
先になることもあり得る。ワークレットに読み込むことを意図した適切に記述されたスクリプトが、
投機的評価に備えるための提案に従っている場合、
通常これは問題にならない。
スクリプトが正常に実行され、いくつかのワークレットに読み込まれた後にのみタスクを 実行したい場合、ウェブ開発者は次のように記述できる:
Promise. all([
window. fakeWorklet1. addModule( 'script1.mjs' ),
window. fakeWorklet2. addModule( 'script2.mjs' )
]). then(() => {
// Do something which relies on those scripts being loaded.
}); スクリプトの読み込みに関するもう一つの重要な点は、コードの
冪等性に関する節で説明したように、読み込まれたスクリプトは、Worklet ごとに複数の
WorkletGlobalScope
内で実行され得ることである。特に、前述の架空のワークレット 1および架空のワークレット 2の仕様は、
これを要求している。そこで、次のようなシナリオを考える:
// script.mjs
console. log( "Hello from a FakeWorkletGlobalScope!" ); // app.mjs
window. fakeWorklet1. addModule( "script.mjs" ); この場合、ユーザーエージェントのコンソールには、次のような出力が表示される可能性がある:
[fakeWorklet1#1] Hello from a FakeWorkletGlobalScope!
[fakeWorklet1#4] Hello from a FakeWorkletGlobalScope!
[fakeWorklet1#2] Hello from a FakeWorkletGlobalScope!
[fakeWorklet1#3] Hello from a FakeWorkletGlobalScope!ユーザーエージェントが、ある時点で FakeWorkletGlobalScope
の三番目のインスタンスを終了して再起動することを決定した場合、その時点でコンソールには再び
[fakeWorklet1#3] Hello from a FakeWorkletGlobalScope! と表示される。
この節は非規範的である。
架空のワークレットについてウェブ開発者が意図する用途の一つが、非常に複雑なブール否定の 処理をカスタマイズできるようにすることだとする。開発者は、そのカスタマイズを次のように 登録できる:
// script.mjs
registerFake( 'negation-processor' , class {
process( arg) {
return ! arg;
}
}); // app.mjs
window. fakeWorklet1. addModule( "script.mjs" ); このように登録されたクラスを利用するため、架空のワークレットの仕様では、Worklet
worklet が与えられたときの、true の反対を求めるアルゴリズムを定義できる:
任意で、worklet 用のワークレットグローバルスコープを 作成する。
classConstructor を、workletGlobalScope の登録済みクラス
コンストラクターマップ["negation-processor"]とする。
classInstance を、引数なしで classConstructor を構築した結果とする。
function を、Get(classInstance,
"process")とする。例外があれば再スローする。
callback を « true » および「rethrow」で呼び出し、コールバック this 値を
classInstance に設定した結果を返す。
別の、おそらくより優れた仕様アーキテクチャは、登録時に registerFake() メソッドの手順の一部として、
「process」プロパティを取り出し、それを Function に変換するものである。
WorkletGlobalScope のサブクラスは、
特定の Worklet に読み込まれたコードを
実行できるグローバルオブジェクトを
作成するために使用される。
[Exposed =Worklet , SecureContext ]
interface WorkletGlobalScope {};他の仕様は、WorkletGlobalScope を
サブクラス化し、クラスを登録するための API と、そのワークレット型に固有のその他の API を
追加することを意図している。
各 WorkletGlobalScope
には、関連付けられた モジュールマップがある。
これはモジュールマップであり、
初期状態では空である。
この節は非規範的である。
各 WorkletGlobalScope
は、それに対応するイベントループを持つ、独自のワークレット
エージェントに含まれる。ただし実際には、これらのエージェントおよびイベントループの
実装は、他のほとんどのものとは異なることが想定されている。
理論上、実装は各 WorkletGlobalScope
インスタンスごとに個別のスレッドを使用でき、この程度の並列性を実現するにはエージェントを
使用するのが最適であるため、各 WorkletGlobalScope
に対してワークレット
エージェントが存在する。ただし、それらの [[CanBlock]] 値は false であるため、
エージェントとスレッドが一対一であるという要件はない。これにより実装は、類似オリジンウィンドウエージェント
のスレッド(「メインスレッド」)など、[[CanBlock]] が false である他のエージェントのコードを
実行するスレッドを含む、任意のスレッド上でワークレットに読み込まれたスクリプトを自由に
実行できる。これを、[[CanBlock]] の値が true であるため、実質的に専用のオペレーティング
システムスレッドを割り当てる必要がある専用ワーカーエージェントと比較されたい。
ワークレットのイベントループも
多少特殊である。これらは、addModule()
に関連付けられたタスク、
ユーザーエージェントが作者定義のメソッドを呼び出すタスク、およびマイクロタスクにのみ使用される。したがって、
イベントループ処理モデルでは、すべてのイベントループが
継続的に実行されると規定されているものの、実装は、作者が提供したメソッドを単に呼び出し、その処理によってマイクロタスクチェックポイントを
実行するという、より単純な方策を使用して、観測可能な結果が同等になるようにできる。
Worklet
worklet のためにワークレットグローバルスコープを作成するには:
outsideSettings を、worklet の関連設定 オブジェクトとする。
agent を、outsideSettings が与えられたときにワークレットエージェントを 取得する結果とする。残りの手順をそのエージェント内で実行する。
realmExecutionContext を、agent および次のカスタマイズが 与えられたときに新しいレルムを作成する結果とする:
グローバルオブジェクトについては、worklet のワークレット グローバルスコープ型によって指定される型の新しいオブジェクトを作成する。
workletGlobalScope を、realmExecutionContext の Realm コンポーネントの グローバル オブジェクトとする。
insideSettings を、realmExecutionContext および outsideSettings が与えられたときにワークレット 環境設定オブジェクトを設定する結果とする。
pendingAddedModules を、worklet の追加済みモジュール リストの複製とする。
runNextAddedModule を、次の手順とする:
pendingAddedModules が空でない場合:
moduleURL を、pendingAddedModules からデキューする結果とする。
moduleURL、insideSettings、worklet のワークレット宛先型、どの資格情報モード?、insideSettings、worklet の モジュールレスポンスマップ、 および script が与えられたときの次の手順を使用して、ワークレットスクリプトグラフを フェッチする:
これは、worklet のモジュールレスポンスマップの レスポンスを再利用するだけなので、実際には ネットワークリクエストを実行しない。この手順の主な目的は、そのレスポンスから、新しい workletGlobalScope 固有のモジュール スクリプトを作成することである。
表明:worklet のモジュールレスポンス マップへ最初に moduleURL が追加されたとき、フェッチが成功し、 ソーステキストの構文解析も正常に完了しているため、script は null ではない。
script が与えられたときにモジュールスクリプトを 実行する。
runNextAddedModule を実行する。
workletGlobalScope を、outsideSettings のグローバル
オブジェクトの関連付けられた
Documentのワークレット
グローバルスコープに付加する。
workletGlobalScope を、worklet のグローバル スコープに付加する。
insideSettings によって指定される担当イベントループを実行する。
runNextAddedModule を実行する。
WorkletGlobalScope
workletGlobalScope が与えられたときにワークレットグローバルスコープを終了するには:
eventLoop が現在実行中の タスクを完了するまで待つ。
eventLoop を破棄する。
workletGlobalScope を自身のグローバルスコープに
含む Worklet のグローバルスコープから、
workletGlobalScope を削除する。
workletGlobalScope を自身のワークレットグローバル
スコープに含む Document のワークレットグローバルスコープから、
workletGlobalScope を削除する。
JavaScript 実行コンテキスト executionContext および環境設定 オブジェクト outsideSettings が与えられたときに、ワークレット環境設定オブジェクトを設定するには:
origin を、一意な不透明 オリジンとする。
inheritedAPIBaseURL を、outsideSettings のAPI ベース URLとする。
inheritedPolicyContainer を、outsideSettings のポリシーコンテナーの複製とする。
realm を、executionContext の Realm コンポーネントの値とする。
workletGlobalScope を、realm のグローバルオブジェクトとする。
settingsObject を、次のようにアルゴリズムが定義される新しい環境設定オブジェクトとする:
executionContext を返す。
workletGlobalScope のモジュールマップを返す。
inheritedAPIBaseURL を返す。
ワーカーや単一のリソースから派生するその他のグローバルとは異なり、
ワークレットには主要リソースがない。代わりに、それぞれ独自の URL を持つ複数の
スクリプトが、worklet.addModule()
を介してグローバルスコープに読み込まれる。そのため、このAPI
ベース URLは、他のグローバルのものとは
かなり異なる。ただし、これまでのところ、ワークレットコードで利用可能な API は
API ベース URLを使用しないため、
これは問題にならない。
origin を返す。
true を返す。
inheritedPolicyContainer を返す。
TODO を返す。
settingsObject のIDを新しい一意な不透明文字列に、 作成 URLを inheritedAPIBaseURL に、最上位作成 URLを null に、最上位 オリジンを outsideSettings の最上位オリジンに、対象閲覧コンテキストを null に、そしてアクティブサービスワーカーを null に設定する。
realm の [[HostDefined]] フィールドを settingsObject に設定する。
settingsObject を返す。
Worklet クラスすべての現行エンジンでサポートされています。
Worklet クラスは、関連付けられた
WorkletGlobalScopeに
モジュールスクリプトを追加する機能を提供する。その後、ユーザーエージェントは
WorkletGlobalScopeに
登録されたクラスを作成し、そのメソッドを呼び出すことができる。
[Exposed =Window , SecureContext ]
interface Worklet {
[NewObject ] Promise <undefined > addModule (USVString moduleURL , optional WorkletOptions options = {});
};
dictionary WorkletOptions {
RequestCredentials credentials = "same-origin";
};Worklet インスタンスを作成する仕様は、
特定のインスタンスについて次のものを指定しなければならない:
そのワークレットグローバルスコープ型。
これは、WorkletGlobalScopeから
継承する Web IDL 型でなければならない。および
そのワークレット宛先型。 これは宛先でなければならず、スクリプトの フェッチ時に使用される。
await worklet.addModule(moduleURL[, { credentials }])
すべての現行エンジンでサポートされています。
moduleURL によって指定されるモジュールスクリプトを、worklet のすべての グローバルスコープに読み込んで実行する。 ワークレット型によっては、この処理の一部として追加のグローバルスコープを作成することも できる。返される promise は、スクリプトがすべてのグローバルスコープに正常に読み込まれ、 実行された時点で履行される。
credentials
オプションを資格情報モードに設定して、
スクリプトのフェッチ処理を変更できる。既定値は「same-origin」である。
スクリプトまたはその依存関係のフェッチに失敗すると、返される promise は
「AbortError」 DOMException で拒否される。
スクリプトまたはその依存関係の構文解析中にエラーが発生すると、返される promise は
構文解析中に生成された例外で拒否される。
Worklet には、グローバルスコープのリストがある。このリストには、Worklet のワークレット
グローバルスコープ型のインスタンスが含まれる。これは初期状態では空である。
Worklet には、追加済みモジュール
リストがある。これは、URL のリストであり、初期状態では空である。
このリストへのアクセスはスレッドセーフであるべきである。
Worklet には、モジュール
レスポンスマップがある。これは、URL から「fetching」、
またはレスポンスと、null、失敗、もしくはレスポンス本体を表すバイト
シーケンスのいずれかで構成されるタプルへの順序付きマップである。このマップは初期状態では空であり、
これへのアクセスはスレッドセーフであるべきである。
追加済み
モジュールリストおよびモジュールレスポンスマップは、
異なる時点で作成された WorkletGlobalScopeで、
同じソーステキストに基づく同等のモジュール
スクリプトが実行されることを保証するために存在する。これにより、追加の WorkletGlobalScopeの
作成が作者に対して透過的になる。
実際には、ユーザーエージェントがスレッドセーフなプログラミング手法を使用して、
これらのデータ構造やそれらを参照するアルゴリズムを実装することは想定されていない。
代わりに、addModule() が
呼び出されたとき、ユーザーエージェントはメインスレッドでモジュールグラフをフェッチし、
フェッチされたソーステキスト(すなわち、モジュールレスポンスマップに含まれる
重要なデータ)を、WorkletGlobalScopeを
持つ各スレッドへ送信できる。
その後、ユーザーエージェントが特定の Worklet のために、新しい WorkletGlobalScopeを
作成するとき、フェッチされたソーステキストの
マップとエントリーポイントのリストを、メインスレッドから新しい WorkletGlobalScopeを
含むスレッドへ送信するだけでよい。
addModule(moduleURL,
options) メソッドの手順は次のとおりである:
outsideSettings を、this の関連設定オブジェクトとする。
moduleURLRecord を、outsideSettings を基準として moduleURL が与えられたときにURL をエンコーディング解析する結果とする。
moduleURLRecord が失敗である場合、「SyntaxError」 DOMException で拒否された promiseを返す。
promise を新しい promise とする。
workletInstance を、this とする。
次の手順を並行して実行する:
workletInstance のグローバル スコープが空である場合:
workletInstance が与えられたときにワークレットグローバルスコープを 作成する。
任意で、対象となる特定のワークレットおよびその仕様に応じて、 workletInstance が与えられたときに追加のグローバルスコープインスタンスを作成する。
先へ進む前に、ワークレット エージェント内で行われるものを含め、すべての作成処理の手順が完了するまで待つ。
addedSuccessfully を false とする。
workletInstance のグローバル
スコープの各 workletGlobalScope について、反復し、workletGlobalScope
が与えられたときに
ネットワーキングタスクソース上でグローバルタスクを
キューする。そのタスクでは、moduleURLRecord、
outsideSettings、workletInstance のワークレット宛先
型、options["credentials"]、
workletGlobalScope の関連設定
オブジェクト、workletInstance のモジュールレスポンスマップ、
および script が与えられたときの次の手順を使用して、ワークレットスクリプトグラフをフェッチする:
これらのフェッチのうち、実際にネットワークリクエストを実行するのは
最初のものだけである。他の WorkletGlobalScope
用のものは、workletInstance のモジュールレスポンスマップのレスポンスを再利用する。
script が null である場合:
workletInstance の関連グローバルオブジェクトが 与えられたときに、ネットワーキングタスクソース上で グローバルタスクをキューする。 そのタスクで次の手順を実行する:
pendingTasks が −1 でない場合:
pendingTasks を −1 に設定する。
promise を「AbortError」
DOMException で
拒否する。
これらの手順を中止する。
script の再スローする エラーが null でない場合:
workletInstance の関連グローバルオブジェクトが 与えられたときに、ネットワーキングタスクソース上で グローバルタスクをキューする。 そのタスクで次の手順を実行する:
pendingTasks が −1 でない場合:
pendingTasks を −1 に設定する。
promise を、script の再スローするエラーで 拒否する。
これらの手順を中止する。
addedSuccessfully が false である場合:
moduleURLRecord を、workletInstance の追加済み モジュールリストに付加する。
addedSuccessfully を true に設定する。
script が与えられたときにモジュールスクリプトを実行する。
workletInstance の関連グローバルオブジェクトが 与えられたときに、ネットワーキングタスク ソース上でグローバルタスクをキューする。 そのタスクで次の手順を実行する:
pendingTasks が −1 でない場合:
pendingTasks を pendingTasks − 1 に設定する。
pendingTasks が 0 である場合、promise を解決する。
promise を返す。
Worklet の生存期間について、
特別な考慮事項はない。それは、Window
など、自身が属するオブジェクトに結び付けられている。
各 Document には、ワークレット
グローバルスコープがある。これは WorkletGlobalScope の集合であり、初期状態では空である。
WorkletGlobalScope の
生存期間は、少なくとも、それをワークレットグローバル
スコープに含む Document に結び付けられている。特に、その Document を破棄すると、対応する
WorkletGlobalScope は終了され、
ガベージコレクションの対象になり得る。
さらに、対応するワークレット型を定義する仕様に別段の定めがない限り、ユーザーエージェントは
いつでも、特定の WorkletGlobalScope を終了してもよい。たとえば、ワークレットエージェントのイベントループに
キューされたタスクがない場合、
ユーザーエージェントにワークレットを利用する予定の保留中の処理がない場合、またはユーザー
エージェントが無限ループや、課された時間制限を超えるコールバックなどの異常な処理を検出した場合、
それらを終了することがある。
最後に、特定のワークレット型の仕様は、特定のワークレット型について、いつ WorkletGlobalScope を作成するかについて、
より具体的な詳細を規定できる。たとえば、例のように、
ワークレットコードを呼び出す特定の処理中にそれらを作成することがある。
すべての現行エンジンでサポートされています。
この節は非規範的である。
この仕様は、クライアント側に名前と値の組を保存するための、HTTP セッションクッキーに似た、 相互に関連する二つの仕組みを導入する。[COOKIES]
一つ目は、ユーザーが一つのトランザクションを実行している一方で、異なるウィンドウで同時に 複数のトランザクションを実行する可能性がある状況を対象として設計されている。
クッキーは、この場合をうまく扱えない。たとえば、ユーザーが同じサイトを使用して、異なる 二つのウィンドウで航空券を購入している場合がある。サイトが、ユーザーがどの航空券を購入中かを 追跡するためにクッキーを使用していると、ユーザーが両方のウィンドウでページ間を移動するにつれ、 現在購入中の航空券が一方のウィンドウからもう一方へ「漏れ」、ユーザーが気付かないまま同じ便の 航空券を二枚購入する可能性がある。
これに対処するため、この仕様は sessionStorage 取得子を
導入する。サイトはセッションストレージにデータを追加でき、そのウィンドウで開かれた同じサイトの
任意のページからそのデータにアクセスできる。
たとえば、ページには、ユーザーが保険を希望することを示すためにチェックする チェックボックスを置くことができる:
< label >
< input type = "checkbox" onchange = "sessionStorage.insurance = checked ? 'true' : ''" >
この旅行に保険を付けたい。
</ label > 後のページでは、ユーザーがチェックボックスをチェックしたかどうかをスクリプトから確認できる:
if ( sessionStorage. insurance) { ... } ユーザーがサイト上で複数のウィンドウを開いている場合、それぞれがセッションストレージ オブジェクトの独自のコピーを持つ。
二つ目のストレージ機構は、複数のウィンドウにまたがり、現在のセッションを越えて持続する ストレージを対象として設計されている。特に、ウェブアプリケーションは、パフォーマンス上の理由から、 ユーザーが作成した文書全体やユーザーのメールボックスなど、数メガバイトのユーザーデータを クライアント側に保存したい場合がある。
この場合も、クッキーはリクエストのたびに送信されるため、うまく扱えない。
localStorage 取得子は、
ページのローカルストレージ領域にアクセスするために使用される。
example.com のサイトは、ページの末尾に次のものを置くことで、ユーザーがそのページを 読み込んだ回数を表示できる:
< p >
このページを
< span id = "count" > 数え切れないほど</ span >
回閲覧しました。
</ p >
< script >
if ( ! localStorage. pageLoadCount)
localStorage. pageLoadCount = 0 ;
localStorage. pageLoadCount = parseInt( localStorage. pageLoadCount) + 1 ;
document. getElementById( 'count' ). textContent = localStorage. pageLoadCount;
</ script > 各サイトには、それぞれ個別のストレージ領域がある。
localStorage
取得子は、
共有状態へのアクセスを提供する。この仕様は、マルチプロセスのユーザーエージェントにおける
他のエージェントクラスターとの相互作用を定義しておらず、作者にはロック機構が存在しないものと
想定することが推奨される。たとえば、サイトはキーの値を読み取り、その値を増加させてから
書き戻し、新しい値をセッションの一意な識別子として使用しようとする場合がある。サイトがこれを
異なる二つのブラウザーウィンドウで同時に二回行うと、両方のセッションに同じ「一意な」識別子を
使用することになり、深刻な影響をもたらす可能性がある。
すべての現行エンジンでサポートされています。
Storage インターフェイス[Exposed =Window ]
interface Storage {
readonly attribute unsigned long length ;
DOMString ? key (unsigned long index );
getter DOMString ? getItem (DOMString key );
setter undefined setItem (DOMString key , DOMString value );
deleter undefined removeItem (DOMString key );
undefined clear ();
};storage.length
すべての現行エンジンでサポートされています。
キーと値の組の数を返す。
storage.key (n)
すべての現行エンジンでサポートされています。
n 番目のキーの名前を返す。n がキーと値の組の数以上である場合は null を返す。
value = storage.getItem (key)
すべての現行エンジンでサポートされています。
value = storage[key]指定された key に現在関連付けられている値を返す。指定された key が存在しない場合は null を返す。
storage.setItem (key, value)
すべての現行エンジンでサポートされています。
storage[key] = valuekey によって識別される組の値を value に設定する。以前 key に対応するキーと値の組が存在しなかった場合は、新しい組を作成する。
新しい値を設定できなかった場合、QuotaExceededError をスローする。
(たとえば、ユーザーがそのサイトのストレージを無効にしている場合や、クォータを超過した場合、
設定に失敗することがある。)
storage.removeItem (key)
すべての現行エンジンでサポートされています。
delete
storage[key]
指定された key を持つキーと値の組が存在する場合、その組を削除する。
storage.clear()
すべての現行エンジンでサポートされています。
キーと値の組が存在する場合、それらをすべて削除する。
Storage オブジェクトには、
次のものが関連付けられている:
local」または「session」。
残念ながら、反復順序は定義されておらず、ほとんどの変更時に変化する可能性がある。
key、oldValue、および newValue が与えられたときに、Storage オブジェクト
storage をブロードキャストするには、次の手順を
実行する:
thisDocument を、storage の関連グローバルオブジェクトの関連付けられた
Documentとする。
remoteStorages を、storage を除く、次の条件を満たすすべての Storage オブジェクトとする:
さらに、型が「session」である場合は、
その関連設定オブジェクトの関連付けられた
Documentのノードナビゲータブルのトラバーサブルナビゲータブルが、
thisDocument のノードナビゲータブルのトラバーサブル
ナビゲータブルであるもの。
remoteStorages の各 remoteStorage について反復する:remoteStorage の関連グローバルオブジェクトが与えられたときに、
DOM
操作タスクソース上でグローバルタスクを
キューする。そのタスクでは、StorageEvent を使用し、
key を key で、oldValue を oldValue で、newValue を newValue で、url を
url で、そして storageArea を remoteStorage で初期化して、
remoteStorage の関連グローバル
オブジェクトで、storage という名前のイベントを発火する。
結果として生じるタスクに関連付けられた Document オブジェクトは、
必ずしも完全にアクティブではないが、
そのようなオブジェクト上で発火されたイベントは、Document
が再び完全にアクティブになるまで、
イベントループによって無視される。
key(index)
メソッドの手順は次のとおりである:
Storage オブジェクト
storage 上のサポートされるプロパティ名は、storage のマップに対してキーを取得する処理を実行した結果である。
setItem(key,
value) メソッドの手順は次のとおりである:
oldValue を null とする。
reorder を true とする。
value を保存できない場合、QuotaExceededError をスローする。
this を、key、oldValue、および value とともにブロードキャストする。
removeItem(key) メソッドの手順は次のとおりである:
clear() メソッドの
手順は次のとおりである:
sessionStorage
取得子interface mixin WindowSessionStorage {
readonly attribute Storage sessionStorage ;
};
Window includes WindowSessionStorage ;window.sessionStorage
すべての現行エンジンでサポートされています。
その window のオリジンのセッションストレージ領域に関連付けられた
Storage
オブジェクトを返す。
Document のオリジンが
不透明オリジンである場合、
またはリクエストがポリシー決定に違反する場合(たとえば、ユーザーエージェントがページによる
データの永続化を許可しないよう設定されている場合)、「SecurityError」 DOMException をスローする。
Document オブジェクトには、
関連付けられた セッションストレージホルダーがある。これは
null または Storage オブジェクトである。初期値は null である。
![]()
sessionStorage 取得子の手順は次のとおりである:
this の関連付けられた
Documentのセッションストレージホルダーが
null でない場合、this の関連付けられた
Documentのセッションストレージホルダーを返す。
map を、this の関連設定オブジェクトおよび
「sessionStorage」を使用して、セッションストレージボトルマップを
取得する処理を実行した結果とする。
map が失敗である場合、「SecurityError」
DOMException をスローする。
this の関連付けられた
Documentのセッションストレージホルダーを
storage に設定する。
storage を返す。
新しい補助閲覧コンテキストおよび 文書を作成した後、セッションストレージはコピーされる。
localStorage 取得子interface mixin WindowLocalStorage {
readonly attribute Storage localStorage ;
};
Window includes WindowLocalStorage ;window.localStorage
すべての現行エンジンでサポートされています。
window のオリジンのローカルストレージ領域に関連付けられた
Storage
オブジェクトを返す。
Document のオリジンが
不透明オリジンである場合、
またはリクエストがポリシー決定に違反する場合(たとえば、ユーザーエージェントがページによる
データの永続化を許可しないよう設定されている場合)、「SecurityError」 DOMException をスローする。
Document オブジェクトには、
関連付けられた ローカルストレージホルダーがある。これは null
または Storage
オブジェクトである。初期値は null である。
![]()
localStorage 取得子の手順は次のとおりである:
this の関連付けられた
Documentのローカルストレージホルダーが
null でない場合、this の関連付けられた
Documentのローカルストレージホルダーを返す。
map を、this の関連設定オブジェクトおよび
「localStorage」を使用して、ローカルストレージボトルマップを取得する
処理を実行した結果とする。
map が失敗である場合、「SecurityError」
DOMException をスローする。
this の関連付けられた
Documentのローカルストレージホルダーを
storage に設定する。
storage を返す。
StorageEvent インターフェイスすべての現行エンジンでサポートされています。
[Exposed =Window ]
interface StorageEvent : Event {
constructor (DOMString type , optional StorageEventInit eventInitDict = {});
readonly attribute DOMString ? key ;
readonly attribute DOMString ? oldValue ;
readonly attribute DOMString ? newValue ;
readonly attribute USVString url ;
readonly attribute Storage ? storageArea ;
undefined initStorageEvent (DOMString type , optional boolean bubbles = false , optional boolean cancelable = false , optional DOMString ? key = null , optional DOMString ? oldValue = null , optional DOMString ? newValue = null , optional USVString url = "", optional Storage ? storageArea = null );
};
dictionary StorageEventInit : EventInit {
DOMString ? key = null ;
DOMString ? oldValue = null ;
DOMString ? newValue = null ;
USVString url = "";
Storage ? storageArea = null ;
};event.key変更されるストレージ項目のキーを返す。
event.oldValue
値が変更されるストレージ項目のキーに対応する以前の値を返す。
event.newValue
値が変更されるストレージ項目のキーに対応する新しい値を返す。
event.urlストレージ項目が変更された文書のURL を返す。
event.storageArea
影響を受けた Storage オブジェクトを返す。
key、
oldValue、
newValue、
url、および
storageArea
属性は、それぞれが初期化された値を返さなければならない。
initStorageEvent(type, bubbles,
cancelable, key, oldValue, newValue, url,
storageArea) メソッドは、同様の名前を持つ initEvent() メソッドと同様の方法で
イベントを初期化しなければならない。[DOM]
第三者広告主(または複数のサイトにコンテンツを配信できる任意の主体)は、ローカルストレージ 領域に保存した一意な識別子を使用して、複数のセッションにわたってユーザーを追跡し、ユーザーの 関心に関するプロファイルを構築して、高度にターゲットを絞った広告を可能にすることができる。 ユーザーの実際の身元を認識しているサイト(たとえば、認証済み資格情報を要求する電子商取引 サイト)と組み合わせると、純粋に匿名のウェブ利用しか存在しない世界よりも高い精度で、 抑圧的な集団が個人を標的にできる可能性がある。
ユーザー追跡のリスクを軽減するために使用できる手法はいくつかある:
ユーザーエージェントは、localStorage
オブジェクトへのアクセスを、最上位トラバーサブルのアクティブ文書のドメインをオリジンとするスクリプトに
制限してもよい。たとえば、iframe 内で実行される
他のドメインのページによる API へのアクセスを拒否できる。
ユーザーエージェントは、ユーザーが設定できる方法などにより、一定期間後に保存データを 自動的に削除してもよい。
たとえば、ユーザーエージェントは、第三者のローカルストレージ領域をセッション限定 ストレージとして扱い、ユーザーがそれにアクセスできるすべてのナビゲータブルを閉じた時点でデータを削除するよう設定できる。
こうすると、サイトがユーザーを追跡できる能力を制限できる。サイトが複数のセッションに わたってユーザーを追跡できるのは、ユーザーがサイト自体に対して認証を行った場合 (たとえば、購入を行ったりサービスにログインしたりした場合)だけになるためである。
ただし、これは長期ストレージ機構としての API の有用性も低下させる。また、ユーザーが データの有効期限切れによる影響を十分に理解していない場合、ユーザーのデータを危険に さらす可能性もある。
ユーザーがローカルストレージ領域に保存されたデータを消去せず、クッキーだけを消去して プライバシーを保護しようとした場合、サイトは二つの機能を互いの冗長バックアップとして 使用することで、その試みを無効にできる。ユーザーエージェントは、この可能性をユーザーが 理解し、すべての永続ストレージ機能のデータを同時に削除できるよう支援する形で、それらを 消去するためのインターフェイスを提示するべきである。[COOKIES]
ユーザーエージェントは、サイトがセッションストレージ領域へ制限なくアクセスすることを 許可する一方、ローカルストレージ領域へのアクセスにはユーザーの許可を要求してもよい。
ユーザーエージェントは、データの保存を引き起こした第三者オリジンのコンテンツを含んでいた サイトのオリジンを記録してもよい。
この情報を使用して、現在永続ストレージにあるデータの表示を提示すれば、永続ストレージの どの部分を削除するかについて、ユーザーが十分な情報に基づいて判断できるようになる。 ブロックリスト(「このデータを削除し、このドメインが今後データを保存することを禁止する」) と組み合わせることで、ユーザーは永続ストレージの使用を信頼するサイトに限定できる。
ユーザーエージェントは、ユーザーが永続ストレージのドメインブロックリストを共有できるように してもよい。
これにより、コミュニティーが協力してプライバシーを保護できる。
これらの提案は、この API をユーザー追跡に単純に使用することを防ぐが、それを完全に 阻止するものではない。単一のドメイン内では、サイトはセッション中にユーザーを追跡し続けることが でき、その後、サイトが取得した識別情報(氏名、クレジットカード番号、住所)とともに、これらの 情報すべてを第三者へ渡すことができる。第三者が複数のサイトと協力してそのような情報を取得すれば、 依然としてプロファイルを作成できる。
しかし、ユーザー追跡は、ユーザーエージェントからの協力が一切なくても、ある程度は可能である。 たとえば URL 内のセッション識別子を使用できる。この手法は、無害な目的ですでに一般的に使用 されているが、ユーザー追跡用に容易に転用できる(遡及的な転用さえ可能である)。その後、 訪問者の IP アドレスおよびその他のユーザー固有データ(たとえば、ユーザーエージェントヘッダーや 構成設定)を使用して別々のセッションを一貫したユーザープロファイルに統合し、この情報を 他のサイトと共有できる。
ユーザーエージェントは、永続的に保存されたデータを潜在的に機密性の高いものとして扱うべきである。 電子メール、カレンダーの予定、健康記録、またはその他の機密文書がこの機構に保存される可能性は 十分にある。
このため、ユーザーエージェントは、データを削除するときに、基盤となるストレージからも速やかに 削除されるようにするべきである。
DNS スプーフィング攻撃の可能性があるため、特定のドメインに属すると主張するホストが、 実際にそのドメインのものであることを保証することはできない。これを軽減するため、ページは TLS を使用できる。TLS を使用するページは、ユーザー、ユーザーの代理として動作する ソフトウェア、および同じドメインのものであることを識別する証明書を持つ、TLS を使用する その他のページだけが、そのストレージ領域にアクセスできることを確信できる。
一つのホスト名を共有する異なる作者、たとえば現在は廃止された
geocities.com 上でコンテンツをホストしていたユーザーは、全員が一つの
ローカルストレージオブジェクトを共有する。パス名によってアクセスを制限する機能はない。
したがって、共有ホスト上の作者には、これらの機能を使用しないことが強く推奨される。
他の作者がデータを読み取り、上書きすることは容易だからである。
パス制限機能が利用可能になったとしても、通常の DOM スクリプティング セキュリティモデルにより、この保護を回避して任意のパスからデータへアクセスすることは 容易である。
これらの永続ストレージ機能を実装する際の二つの主要なリスクは、悪意のあるサイトが 他のドメインから情報を読み取れるようにすることと、悪意のあるサイトが書き込んだ情報を 他のドメインから読み取れるようにすることである。
第三者サイトが、そのドメインから読み取られることを想定していないデータを読み取れるようにすると、 情報漏洩が発生する。たとえば、あるドメインにあるユーザーの買い物のほしい物リストが、 別のドメインによるターゲット広告に使用される可能性がある。また、ワードプロセッシングサイトに 保存された、ユーザーが作業中の機密文書が、競合企業のサイトによって調べられる可能性がある。
第三者サイトが他のドメインの永続ストレージへデータを書き込めるようにすると、同様に危険な 情報スプーフィングが発生する可能性がある。たとえば、悪意のあるサイトがユーザーの ほしい物リストに項目を追加したり、ユーザーのセッション識別子を既知の ID に設定し、 その悪意のあるサイトが被害サイト上でのユーザーの操作を追跡するために使用したりする可能性がある。
したがって、ユーザーのセキュリティのためには、この仕様で説明されるオリジンモデルに厳密に従うことが重要である。
この節では、HTML MIME タイプでラベル付けされたリソースの規則のみを説明する。XML リソースの規則については、 以下の「XML 構文」という節で説明する。
この節は、文書、オーサリングツール、およびマークアップ生成器にのみ適用される。 特に、適合性チェッカーには適用されない。適合性チェッカーは、次の節 (「HTML 文書の構文解析」)で示される要件を使用しなければならない。
文書は、指定された順序で、次の部分から構成されなければならない:
上記の各種コンテンツについては、次のいくつかの節で説明する。
さらに、文字エンコーディング宣言をシリアライズする方法には、 その主題に関する節で説明されるいくつかの制限がある。
html 要素の前、
html 要素の先頭、および
head 要素の前にあるASCII 空白は、文書の構文解析時に破棄される。html 要素の後にあるASCII 空白は、body 要素の末尾にあるかのように
構文解析される。したがって、文書要素の周囲にあるASCII
空白は、往復変換で維持されない。
DOCTYPE の後、文書要素の前にある各コメントの後、html
要素の開始タグの後
(そのタグが省略されていない場合)、
および html 要素内で
head 要素の前にある
各コメントの後には、改行を挿入することが提案される。
HTML 構文内の多くの文字列(たとえば、要素およびその属性の名前)は、大文字と小文字を 区別しないが、これはASCII 大文字および ASCII 小文字についてのみである。便宜上、この節では これを単に「大文字と小文字を区別しない」と呼ぶ。
DOCTYPE は、 必須の前置きである。
DOCTYPE は、歴史的な理由により必須である。省略すると、ブラウザーは一部の仕様と 互換性のない別のレンダリングモードを使用する傾向がある。文書に DOCTYPE を含めることで、 ブラウザーが関連仕様に従うために最大限努力することが保証される。
DOCTYPE は、次の構成要素をこの順序で含まなければならない:
<!DOCTYPE」とASCII
大文字・小文字を区別せず一致する文字列。html」とASCII
大文字・小文字を区別せず一致する文字列。言い換えると、大文字と小文字を区別しない <!DOCTYPE html> である。
短い DOCTYPE「<!DOCTYPE html>」を含む HTML マークアップを出力できない
HTML 生成器のために、DOCTYPE レガシー文字列を
DOCTYPE 内(上記で定義された位置)に挿入してもよい。この文字列は、次のものから
構成されなければならない:
SYSTEM」とASCII
大文字・小文字を区別せず一致する文字列。about:legacy-compat」。言い換えると、<!DOCTYPE html SYSTEM "about:legacy-compat"> または
<!DOCTYPE html SYSTEM 'about:legacy-compat'> であり、単一引用符または
二重引用符で囲まれた部分を除き、大文字と小文字を区別しない。
DOCTYPE レガシー文字列は、 より短い文字列を出力できないシステムから文書が生成される場合を除き、使用するべきではない。
要素には、空要素、template 要素、生テキスト要素、エスケープ可能な
生テキスト要素、外来要素、および
通常要素という、六つの異なる種類がある。
area, base, br, col, embed,
hr, img, input, link, meta,
source, track, wbr
template 要素templatescript, styletextarea, titleタグは、マークアップ内で要素の開始と終了を区切るために使用される。 生テキスト要素、エスケープ可能な 生テキスト要素、および通常要素には、開始位置を示す開始タグと、終了位置を示す終了タグがある。一部の通常要素の開始タグおよび終了タグは、以下の省略可能なタグに関する節で 説明するように、省略できる。省略できないものは、省略してはならない。 空要素には開始タグのみがあり、空要素に終了タグを指定してはならない。 外来要素には、開始タグと終了タグの 両方があるか、自己終了としてマークされた開始タグがなければならない。後者の場合、終了タグを 持ってはならない。
要素の内容は、 開始タグの直後(開始タグは特定の場合に暗黙となることがある)と、終了タグの直前 (終了タグも同様に、特定の場合に暗黙となることがある)との間に置かなければ ならない。各要素で許可される正確な内容は、この仕様で前述した、その要素のコンテンツモデルによって決まる。 要素は、そのコンテンツモデルによって許可されないコンテンツを含んではならない。ただし、 それらのコンテンツモデルによって内容に課される制限に加えて、五種類の要素には追加の 構文上の要件がある。
空要素は内容を持つことができない (終了タグがないため、開始タグと終了タグの間にコンテンツを置くことができない)。
template 要素はテンプレート内容を持つことができるが、
そのテンプレート内容は
template 要素自体の
子ではない。代わりに、template の内容が
メインの Document に干渉することを
避けるため、閲覧コンテキストを
持たない別の Document に関連付けられた
DocumentFragment に保存される。
template 要素のテンプレート内容のマークアップは、
他の要素と同様に、template 要素の開始タグの直後と、template 要素の
終了タグの直前に置かれ、任意のテキスト、
文字参照、要素、およびコメントから構成してもよい。ただし、
テキストには U+003C LESS-THAN SIGN 文字(<)または曖昧なアンパサンドを含めてはならない。
生テキスト要素はテキストを持つことができるが、これには 以下で説明する制限がある。
エスケープ可能な生テキスト要素はテキストおよび文字参照を持つことができるが、テキストには曖昧なアンパサンドを含めてはならない。また、 以下で説明するさらなる制限もある。
開始タグが自己終了としてマークされた外来要素は、内容を持つことができない (繰り返しになるが、終了タグがないため、開始タグと終了タグの間にコンテンツを置くことが できない)。開始タグが自己終了としてマークされていない外来要素は、テキスト、文字参照、CDATA セクション、その他の要素、およびコメントを持つことができる。ただし、テキストには U+003C LESS-THAN SIGN 文字(<)または曖昧なアンパサンドを含めてはならない。
HTML 構文は、外来要素においても、名前空間宣言をサポートしない。
たとえば、次の HTML 断片を考える:
< p >
< svg >
< metadata >
<!-- this is invalid -->
< cdr:license xmlns:cdr = "https://www.example.com/cdr/metadata" name = "MIT" />
</ metadata >
</ svg >
</ p > 最も内側の要素 cdr:license は、実際には SVG 名前空間に属する。
「xmlns:cdr」属性は(XML とは異なり)効果を持たないためである。実際、
上の断片内のコメントが示すように、この断片は適合していない。これは、SVG 2 が
SVG 名前空間に「cdr:license」という名前の要素を定義していないためである。
通常要素は、テキスト、文字参照、その他の要素、およびコメントを持つことができる。ただし、テキストには U+003C LESS-THAN SIGN 文字(<)または曖昧なアンパサンドを含めてはならない。一部の通常要素には、コンテンツモデルによる 制限およびこの段落で説明した制限に加えて、保持を許可されるコンテンツについてさらに多くの制限がある。それらの制限については以下で説明する。
タグには、要素の名前を示すタグ名が含まれる。すべての HTML 要素の名前には、ASCII 英数字だけが使用される。HTML 構文では、 外来要素のタグ名を含め、 タグ名は、小文字に変換したときに要素のタグ名と一致する限り、任意の大文字と小文字の組み合わせで 記述してもよい。タグ名は大文字と小文字を区別しない。
開始タグは、次の形式でなければならない:
終了タグは、次の形式でなければならない:
要素の属性は、その要素の開始タグ内に表現される。
属性には名前と値がある。属性名は、制御文字、U+0020 SPACE、U+0022(")、U+0027(')、U+003E(>)、 U+002F(/)、U+003D(=)、および非文字以外の一つ以上の文字から 構成されなければならない。HTML 構文では、外来要素の属性名を含め、属性名はASCII 小文字とASCII 大文字を任意に組み合わせて記述してもよい。
属性値は、テキストと文字参照の組み合わせである。ただし、テキストには曖昧なアンパサンドを含めることができないという 追加の制限がある。
属性は、四つの異なる方法で指定できる:
属性名だけを記述する。 値は暗黙的に空文字列となる。
次の例では、disabled 属性が
空属性構文で指定されている:
< input disabled > 空属性構文を使用する属性の後に別の属性を置く場合、二つの間を区切るASCII 空白がなければならない。
属性名、ゼロ個以上の ASCII 空白、一つの U+003D EQUALS SIGN 文字、ゼロ個以上の ASCII 空白、そして属性値をこの順序で記述する。属性値は、上記の 属性値に関する要件に加えて、リテラルのASCII 空白、U+0022 QUOTATION MARK 文字(")、 U+0027 APOSTROPHE 文字(')、U+003D EQUALS SIGN 文字(=)、U+003C LESS-THAN SIGN 文字 (<)、U+003E GREATER-THAN SIGN 文字(>)、または U+0060 GRAVE ACCENT 文字(`)を 含んではならず、空文字列であってはならない。
次の例では、value 属性が
引用符なし属性値構文で指定されている:
< input value = yes > 引用符なし属性構文を使用する属性の後に別の属性、または上記の開始タグ構文の手順 6 で許可される 任意の U+002F SOLIDUS 文字(/)を置く場合、二つの間を区切るASCII 空白がなければならない。
属性名、ゼロ個以上の ASCII 空白、一つの U+003D EQUALS SIGN 文字、ゼロ個以上の ASCII 空白、一つの U+0027 APOSTROPHE 文字(')、 属性値、そして 二つ目の U+0027 APOSTROPHE 文字(')をこの順序で記述する。属性値は、上記の属性値に関する 要件に加えて、リテラルの U+0027 APOSTROPHE 文字(')を含んではならない。
次の例では、type 属性が
単一引用符付き属性値構文で指定されている:
< input type = 'checkbox' > 単一引用符付き属性構文を使用する属性の後に別の属性を置く場合、二つの間を区切るASCII 空白がなければならない。
属性名、ゼロ個以上の ASCII 空白、一つの U+003D EQUALS SIGN 文字、ゼロ個以上の ASCII 空白、一つの U+0022 QUOTATION MARK 文字(")、 属性値、そして 二つ目の U+0022 QUOTATION MARK 文字(")をこの順序で記述する。属性値は、上記の属性値に 関する要件に加えて、リテラルの U+0022 QUOTATION MARK 文字(")を含んではならない。
次の例では、name
属性が二重引用符付き属性値構文で指定されている:
< input name = "be evil" > 二重引用符付き属性構文を使用する属性の後に別の属性を置く場合、二つの間を区切るASCII 空白がなければならない。
同じ開始タグ内に、名前が互いにASCII 大文字・小文字を区別せず一致する二つ以上の属性があってはならない。
外来要素が、次の表の行の 一番目および二番目のセルに示されるローカル名と名前空間を持つ名前空間付き属性の一つを持つ場合、 同じ行の三番目のセルに示される名前を使用して記述しなければならない。
| ローカル名 | 名前空間 | 属性名 |
|---|---|---|
actuate |
XLink 名前空間 | xlink:actuate
|
arcrole |
XLink 名前空間 | xlink:arcrole
|
href |
XLink 名前空間 | xlink:href
|
role |
XLink 名前空間 | xlink:role
|
show |
XLink 名前空間 | xlink:show
|
title |
XLink 名前空間 | xlink:title
|
type |
XLink 名前空間 | xlink:type
|
lang |
XML 名前空間 | xml:lang
|
space |
XML 名前空間 | xml:space
|
xmlns |
XMLNS 名前空間 | xmlns
|
xlink |
XMLNS 名前空間 | xmlns:xlink
|
その他の名前空間付き属性は、HTML の構文で表現することができない。
上の表にある属性が適合するかどうかは、他の仕様(たとえば SVG 2 および MathML)によって定義される。この節では、属性が HTML 構文を使用して シリアライズされる場合の構文規則のみを説明する。
特定のタグは省略できる。
以下で説明する状況で要素の開始タグを省略しても、その要素が存在しないという意味には
ならない。その要素は暗黙に存在し、依然としてそこにある。たとえば、マークアップ内のどこにも
<html> という文字列が現れない場合でも、HTML 文書には常にルートとなる
html 要素がある。
html 要素内の
最初のものがコメントでない場合、その html 要素の開始タグを省略してもよい。
たとえば、次の場合は「<html>」タグを削除してもよい:
<!DOCTYPE HTML>
< html >
< head >
< title > こんにちは</ title >
</ head >
< body >
< p > この例へようこそ。</ p >
</ body >
</ html > そうすると、文書は次のようになる:
<!DOCTYPE HTML>
< head >
< title > こんにちは</ title >
</ head >
< body >
< p > この例へようこそ。</ p >
</ body >
</ html > これはまったく同じ DOM を持つ。特に、文書 要素の周囲の空白は構文解析器によって無視されることに注意すること。次の例も、 まったく同じ DOM を持つ:
<!DOCTYPE HTML> < head >
< title > こんにちは</ title >
</ head >
< body >
< p > この例へようこそ。</ p >
</ body >
</ html > ただし、次の例では、開始タグを削除するとコメントが html
要素の前へ移動する:
<!DOCTYPE HTML>
< html >
<!-- where is this comment in the DOM? -->
< head >
< title > こんにちは</ title >
</ head >
< body >
< p > この例へようこそ。</ p >
</ body >
</ html > タグを削除すると、文書は実際には次と同じものになる:
<!DOCTYPE HTML>
<!-- where is this comment in the DOM? -->
< html >
< head >
< title > こんにちは</ title >
</ head >
< body >
< p > この例へようこそ。</ p >
</ body >
</ html > タグの直後にコメントがある場合に限ってタグを削除できないのは、このためである。 そこにコメントがある状態でタグを削除すると、文書の構文解析結果のツリーが変化する。 もちろん、コメントの位置が重要でない場合は、最初からコメントが開始タグの前へ移動されたかの ように、タグを省略できる。
html 要素の直後に
コメントがない場合、その
html 要素の終了タグを省略してもよい。
head 要素が空である場合、
または head 要素内の
最初のものが要素である場合、その要素の開始タグを省略してもよい。
head 要素の直後に
ASCII 空白またはコメントがない場合、その head 要素の終了タグを省略してもよい。
body 要素が空である場合、
または body 要素内の
最初のものがASCII 空白でもコメントでもない場合、その要素の開始タグを省略してもよい。
ただし、body 要素内の
最初のものが meta、
noscript、
link、script、style、または template 要素である場合を除く。
body 要素の直後に
コメントがない場合、その
body 要素の終了タグを省略してもよい。
上の例では、head 要素の開始タグと終了タグ、
および body 要素の
開始タグは、空白に囲まれているため省略できないことに注意すること:
<!DOCTYPE HTML>
< html >
< head >
< title > こんにちは</ title >
</ head >
< body >
< p > この例へようこそ。</ p >
</ body >
</ html > (body および
html 要素の
終了タグは問題なく省略できる。それらの後にある空白は、いずれにしても body 要素内へ
構文解析されるためである。)
ただし、通常は空白が問題になることはない。まず、重要でない空白を削除すると:
<!DOCTYPE HTML> < html >< head >< title > こんにちは</ title ></ head >< body >< p > この例へようこそ。</ p ></ body ></ html > その後、DOM に影響を与えることなく、複数のタグを省略できる:
<!DOCTYPE HTML> < title > こんにちは</ title >< p > この例へようこそ。</ p > その時点で、一部の空白を戻すこともできる:
<!DOCTYPE HTML>
< title > こんにちは</ title >
< p > この例へようこそ。</ p > これは、省略されたタグを構文解析器によって暗黙に置かれる位置へ表示した、次の文書と
等価である。この結果として生じる唯一の空白テキストノードは、head 要素の末尾にある
改行である:
<!DOCTYPE HTML>
< html >< head > < title > こんにちは</ title >
</ head >< body > < p > この例へようこそ。</ p > </ body ></ html > li 要素の直後に別の
li 要素がある場合、
または親要素内にそれ以上のコンテンツがない場合、その li 要素の終了タグを省略してもよい。
dt 要素の直後に別の
dt 要素または
dd 要素がある場合、
その dt 要素の終了タグを省略してもよい。
dd 要素の直後に別の
dd 要素または
dt 要素がある場合、
または親要素内にそれ以上のコンテンツがない場合、その dd 要素の終了タグを省略してもよい。
p 要素の直後に
address、article、
aside、blockquote、details、dialog、
div、dl、fieldset、figcaption、
figure、footer、form、h1、
h2、
h3、
h4、
h5、
h6、
header、
hgroup、hr、main、menu、nav、
ol、p、pre、search、section、
table、または ul 要素がある場合、その
p 要素の終了タグを省略してもよい。または、
親要素内にそれ以上のコンテンツがなく、親要素が a、audio、del、ins、map、
noscript、または
video 要素ではない
HTML 要素、あるいは自律型カスタム要素である場合も、省略してよい。
したがって、先の例をさらに簡略化できる:
<!DOCTYPE HTML> < title > こんにちは</ title >< p > この例へようこそ。rt 要素の直後に
rt または rp 要素がある場合、
または親要素内にそれ以上のコンテンツがない場合、その rt 要素の終了タグを省略してもよい。
rp 要素の直後に
rt または rp 要素がある場合、
または親要素内にそれ以上のコンテンツがない場合、その rp 要素の終了タグを省略してもよい。
optgroup 要素の
直後に別の optgroup 要素がある場合、
直後に hr 要素がある場合、
または親要素内にそれ以上のコンテンツがない場合、その optgroup 要素の終了タグを省略してもよい。
option 要素の直後に
別の option 要素が
ある場合、直後に optgroup
要素がある場合、
直後に hr 要素がある場合、
または親要素内にそれ以上のコンテンツがない場合、その option 要素の終了タグを省略してもよい。
colgroup 要素内の
最初のものが col 要素であり、
その要素の直前に、終了タグが
省略された別の colgroup 要素がない場合、
その colgroup 要素の
開始タグを省略してもよい。
(要素が空の場合は省略できない。)
colgroup 要素の
直後にASCII 空白またはコメントがない場合、その colgroup 要素の終了タグを省略してもよい。
caption 要素の
直後にASCII 空白またはコメントがない場合、その caption 要素の終了タグを省略してもよい。
thead 要素の直後に
tbody または
tfoot 要素がある場合、
その thead 要素の終了タグを省略してもよい。
tbody 要素内の
最初のものが tr 要素であり、
その要素の直前に、終了タグが
省略された tbody、
thead、または
tfoot 要素がない場合、
その tbody 要素の
開始タグを省略してもよい。
(要素が空の場合は省略できない。)
tbody 要素の直後に
別の tbody または
tfoot 要素がある場合、
または親要素内にそれ以上のコンテンツがない場合、その tbody 要素の終了タグを省略してもよい。
親要素内にそれ以上のコンテンツがない場合、tfoot
要素の終了タグを省略してもよい。
tr 要素の直後に別の
tr 要素がある場合、
または親要素内にそれ以上のコンテンツがない場合、その tr 要素の終了タグを省略してもよい。
td 要素の直後に
td または th 要素がある場合、
または親要素内にそれ以上のコンテンツがない場合、その td 要素の終了タグを省略してもよい。
th 要素の直後に
td または th 要素がある場合、
または親要素内にそれ以上のコンテンツがない場合、その th 要素の終了タグを省略してもよい。
これらの表関連タグをすべて省略できるため、表のマークアップを大幅に簡潔にできる。
次の例を考える:
< table >
< caption > 37547 TEE 電動式鉄道車両の列車機能(略称)</ caption >
< colgroup >< col >< col >< col ></ colgroup >
< thead >
< tr >
< th > 機能</ th >
< th > 制御装置</ th >
< th > 中央ステーション</ th >
</ tr >
</ thead >
< tbody >
< tr >
< td > 前照灯</ td >
< td > ✔</ td >
< td > ✔</ td >
</ tr >
< tr >
< td > 室内灯</ td >
< td > ✔</ td >
< td > ✔</ td >
</ tr >
< tr >
< td > 電気機関車の運転音</ td >
< td > ✔</ td >
< td > ✔</ td >
</ tr >
< tr >
< td > 運転室照明</ td >
< td ></ td >
< td > ✔</ td >
</ tr >
< tr >
< td > 駅案内放送 — スイス</ td >
< td ></ td >
< td > ✔</ td >
</ tr >
</ tbody >
</ table > 多少の空白の違いを除けば、まったく同じ表を次のようにマークアップできる:
< table >
< caption > 37547 TEE 電動式鉄道車両の列車機能(略称)
< colgroup >< col >< col >< col >
< thead >
< tr >
< th > 機能
< th > 制御装置
< th > 中央ステーション
< tbody >
< tr >
< td > 前照灯
< td > ✔
< td > ✔
< tr >
< td > 室内灯
< td > ✔
< td > ✔
< tr >
< td > 電気機関車の運転音
< td > ✔
< td > ✔
< tr >
< td > 運転室照明
< td >
< td > ✔
< tr >
< td > 駅案内放送 — スイス
< td >
< td > ✔
</ table > この方法ではセルが占める空間が大幅に少なくなるため、各行を一行に置くことでさらに簡潔にできる:
< table >
< caption > 37547 TEE 電動式鉄道車両の列車機能(略称)
< colgroup >< col >< col >< col >
< thead >
< tr > < th > 機能 < th > 制御装置 < th > 中央ステーション
< tbody >
< tr > < td > 前照灯 < td > ✔ < td > ✔
< tr > < td > 室内灯 < td > ✔ < td > ✔
< tr > < td > 電気機関車の運転音 < td > ✔ < td > ✔
< tr > < td > 運転室照明 < td > < td > ✔
< tr > < td > 駅案内放送 — スイス < td > < td > ✔
</ table > DOM レベルでのこれらの表の唯一の違いは、いずれにしても意味論的には中立な空白の 正確な位置だけである。
ただし、属性を一つでも持つ開始タグは、決して省略してはならない。
すべての空白を削除し、その後すべての省略可能なタグを削除した先の例へ戻る:
<!DOCTYPE HTML> < title > こんにちは</ title >< p > この例へようこそ。この例の body 要素に
class 属性が必要であり、html 要素に lang 属性が必要である場合、
マークアップは次のようにしなければならない:
<!DOCTYPE HTML> < html lang = "en" >< title > こんにちは</ title >< body class = "demo" >< p > この例へようこそ。この節では、文書が適合しており、特にコンテンツモデルへの違反がないことを前提とする。この仕様で 説明するコンテンツモデルに 適合しない文書で、この節で説明する方法によってタグを省略すると、予期しない DOM の差異が 生じる可能性が高い(コンテンツモデルは、部分的にはこれを回避するために設計されている)。
歴史的な理由により、特定の要素には、そのコンテンツモデルによって与えられる制限を 超える追加の制限がある。
table 要素は、
この仕様で説明されるコンテンツモデルによれば、技術的には table 要素内で
許可されているにもかかわらず、tr 要素を含んではならない。
(マークアップ内で tr 要素が table 内に置かれた場合、
実際にはその前に tbody 開始タグが暗黙に挿入される。)
pre および textarea 要素の
開始タグの直後には、一つの
改行を置いてもよい。
これは要素の処理には影響しない。要素の内容自体が改行で始まる場合、それ以外では任意である改行を含めなければならない
(そうしないと、内容の先頭の改行が任意の改行として扱われ、無視されるためである)。
生テキスト要素およびエスケープ可能な生テキスト要素内の
テキストには、文字列「</」(U+003C LESS-THAN SIGN、U+002F SOLIDUS)に続いて、
要素のタグ名と大文字・小文字を区別せず一致する文字があり、その後に U+0009 CHARACTER TABULATION
(タブ)、U+000A LINE FEED(LF)、U+000C FORM FEED(FF)、U+000D CARRIAGE RETURN(CR)、
U+0020 SPACE、U+003E GREATER-THAN SIGN(>)、または U+002F SOLIDUS(/)のいずれかが続く
文字列を含めてはならない。
テキストは、要素、属性値、およびコメント内で許可される。 他の節で説明するように、テキストを置く場所に応じて、テキスト内で許可されるものと 許可されないものに追加の制約が課される。
HTML における改行は、U+000D CARRIAGE RETURN(CR)文字、 U+000A LINE FEED(LF)文字、またはこの順序の U+000D CARRIAGE RETURN(CR)文字と U+000A LINE FEED(LF)文字の組として表現できる。
文字参照が許可される場所では、 U+000A LINE FEED(LF)文字の文字参照(ただし U+000D CARRIAGE RETURN(CR)文字ではない)も 改行を表す。
他の節で説明される特定の場合、テキストには文字参照を 混在させてもよい。これらは、通常ならテキスト内へ合法的に含めることができない文字を エスケープするために使用できる。
文字参照は U+0026 AMPERSAND 文字(&)で始まらなければならない。その後には、 次の三種類の文字参照のいずれかが続く:
上で説明した数値文字参照形式は、U+000D CR、非文字、および制御文字のうちASCII 空白ではないものを除く、任意のコードポイントを 参照することが許可される。
曖昧なアンパサンドとは、 U+0026 AMPERSAND 文字(&)に一つ以上のASCII 英数字が続き、その後に U+003B SEMICOLON 文字(;)が続くものの、それらの文字が名前付き文字参照の節に示される いずれの名前とも一致しないものである。
CDATA セクションは、次の構成要素をこの順序で 含まなければならない:
<![CDATA[」。]]>」を含めてはならないという追加の制限がある。]]>」。CDATA セクションは、外来コンテンツ(MathML または SVG)内でのみ使用できる。この例では、
CDATA セクションを使用して、MathML
ms 要素の内容をエスケープしている:
< p > 文字列を数値に加算できるが、これにより数値は文字列化される:</ p >
< math >
< ms > <![CDATA[x<y]]> </ ms >
< mo > +</ mo >
< mn > 3</ mn >
< mo > =</ mo >
< ms > <![CDATA[x<y3]]> </ ms >
</ math > コメントは、次の形式でなければならない:
<!--」。>」または文字列「->」で始まってはならず、
文字列「<!--」、「-->」、または
「--!>」を含んではならず、文字列「<!-」で
終わってはならないという追加の制限がある。-->」。テキストは、
<!--My favorite operators are > and
<!--> のように、文字列「<!」で終わることが許可される。
処理命令は、文書内の、追加の処理を行う位置を示す。
処理命令は、次の形式でなければならない:
対象は、ASCII
英数字、
U+002D(-)、および U+005F(_)コードポイントで構成される。これはASCII 英字または
U+005F(_)で始まらなければならず、
「xml」または「xml-stylesheet」とASCII
大文字・小文字を区別せず一致してはならない。
データはテキストである。ただし、テキストには U+003E(>)を 含めてはならず、U+003F(?)で終わってはならないという追加の制限がある。
HTML 構文における処理命令には、XML における処理命令との間に、いくつかの 注目すべき違いがある:[XML]
この節は、ユーザーエージェント、データマイニングツール、および適合性チェッカーにのみ 適用される。
XML 文書を DOM ツリーへ構文解析するための規則については、次の 「XML 構文」という節で扱う。
ユーザーエージェントは、text/html
リソースから DOM ツリーを生成するため、この節で説明する構文解析規則を使用しなければならない。
これらの規則を合わせて、HTML 構文解析器と呼ぶ。
この仕様で説明する HTML 構文は SGML および XML によく似ているが、独自の構文解析規則を持つ 別個の言語である。
HTML の以前の一部のバージョン(特に HTML2 から HTML4)は SGML に基づき、SGML の 構文解析規則を使用していた。しかし、HTML 文書に対する真の SGML 構文解析を実装した ウェブブラウザーは、ほとんど(あるいはまったく)存在しなかった。HTML を SGML アプリケーションとして厳密に扱った唯一のユーザーエージェントは、歴史的には バリデーターであった。バリデーターが文書は一つの表現を持つと主張する一方、広く配備された ウェブブラウザーが相互運用可能に異なる表現を実装するという、その結果生じた混乱は、 数十年分の生産性を浪費してきた。したがって、このバージョンの HTML は非 SGML の基盤へ戻る。
適合性チェッカーに関して、リソースがHTML 構文であると判断された場合、それはHTML 文書である。
用語の節で述べたように、
名前空間を明示的に指定しない要素型への参照は、常にHTML
名前空間内の要素を参照する。たとえば、仕様が
「menu 要素」と述べる場合、
それはローカル名「menu」、名前空間「http://www.w3.org/1999/xhtml」、
およびインターフェイス HTMLMenuElement を持つ要素である。可能な場合、そのような要素への
参照には、その定義へのハイパーリンクが付けられる。

HTML 構文解析処理への入力は、コードポイントの
ストリームから構成される。これはトークン化段階を通過し、その後にツリー構築段階を
通過する。出力は Document オブジェクトである。
スクリプティングをサポートしない実装は、実際に DOM の
Document
オブジェクトを作成する必要はないが、そのような場合でも、DOM ツリーは仕様の残りの部分の
モデルとして使用される。
一般的な場合、トークン化段階で扱われるデータはネットワークから取得されるが、
ユーザーエージェント内で実行されるスクリプトから、たとえば document.write() API を使用して取得されることもある。
トークン化段階およびツリー構築段階には、一組の状態しか存在しないが、 ツリー構築段階は再入可能である。これは、ツリー構築段階が一つのトークンを処理している間に トークン化処理が再開され、最初のトークンの処理が完了する前に、追加のトークンが発行され 処理される可能性があることを意味する。
次の例では、ツリー構築段階は、「script」終了タグトークンを処理している間に 「p」開始タグトークンを処理するよう呼び出される:
...
< script >
document. write( '<p>' );
</ script >
...これらの場合を処理するため、構文解析器にはスクリプト入れ子レベル があり、初期値をゼロに設定しなければならない。また、構文解析器一時停止フラグがあり、初期値を false に設定しなければならない。
この仕様は、HTML 文書が構文的に正しいかどうかにかかわらず、その構文解析規則を定義する。 構文解析アルゴリズム内の特定の箇所は、構文解析エラーであるとされる。構文解析エラーに対する エラー処理は明確に定義されている(それがこの仕様全体で説明される処理規則である)が、 ユーザーエージェントは HTML 文書を構文解析している間、この仕様で説明される規則を適用したくない 最初の構文解析エラーで、 構文解析器を中止してもよい。
適合性チェッカーは、文書内に一つ以上の構文解析エラー条件が存在する場合、少なくとも一つの 構文解析エラー条件をユーザーへ報告しなければならず、文書内に構文解析エラー条件が存在しない場合、 構文解析エラー条件を報告してはならない。文書内に複数の構文解析エラー条件が存在する場合、 適合性チェッカーは複数の構文解析エラー条件を報告してもよい。
構文解析エラーは、HTML の構文に関するエラーだけである。 構文解析エラーの確認に加えて、適合性チェッカーは、文書がこの仕様で説明されるその他すべての 適合要件に従っていることも検証する。
一部の構文解析エラーには、以下の表で示される専用コードがあり、適合性チェッカーは 報告時にそれらを使用するべきである。
以下の表のエラー説明は非規範的である。
| コード | 説明 |
|---|---|
| abrupt-closing-of-empty-comment |
このエラーは、構文解析器が U+003E(>)コードポイントによって突然閉じられる空のコメント
(すなわち、 |
| abrupt-doctype-public-identifier |
このエラーは、構文解析器がDOCTYPE 公開識別子内で U+003E(>)コードポイントに遭遇した場合
(たとえば、 |
| abrupt-doctype-system-identifier |
このエラーは、構文解析器がDOCTYPE システム識別子内で
U+003E(>)コードポイントに遭遇した場合
(たとえば、 |
| absence-of-digits-in-numeric-character-reference |
このエラーは、構文解析器が数字を一つも含まない数値文字参照(たとえば、 |
| cdata-in-html-content |
このエラーは、構文解析器が外来コンテンツ(SVG または MathML)の外部でCDATA
セクションに遭遇した場合に
発生する。構文解析器は、そのような CDATA セクションを、先頭の
「 |
| character-reference-outside-unicode-range |
このエラーは、構文解析器が有効な Unicode 範囲を超えるコードポイントを参照する数値文字参照に遭遇した場合に 発生する。構文解析器は、そのような文字参照を U+FFFD REPLACEMENT CHARACTER に解決する。 |
| control-character-in-input-stream |
このエラーは、入力ストリームに、 ASCII 空白でも U+0000 NULL でもない制御コードポイントが含まれる場合に発生する。そのような コードポイントはそのまま構文解析され、通常、構文解析規則によって追加の制限が 適用されない場所では DOM 内に入る。 |
| control-character-reference |
このエラーは、構文解析器が、ASCII 空白ではないか、U+000D CARRIAGE RETURN である 制御コードポイントを参照する数値文字参照に遭遇した場合に発生する。構文解析器は、 数値文字参照終了状態に従って 置換される C1 制御文字参照を除き、そのような文字参照をそのまま解決する。 |
| disallowed-processing-instruction-target |
このエラーは、構文解析器が「 |
| duplicate-attribute |
このエラーは、構文解析器が、同じ名前の属性をすでに持つタグ内で属性に遭遇した場合に発生する。 構文解析器は、その属性の重複するすべての出現を無視する。 |
| end-tag-with-attributes |
このエラーは、構文解析器が属性を持つ終了タグに遭遇した場合に発生する。終了タグ内の属性は 無視され、DOM 内には入らない。 |
| end-tag-with-trailing-solidus |
このエラーは、構文解析器が、閉じる U+003E(>)コードポイントの直前に
U+002F(/)コードポイントを持つ終了タグ
(たとえば、 |
| eof-before-tag-name |
このエラーは、タグ名が期待される場所で構文解析器が入力ストリームの終端に
遭遇した場合に発生する。この場合、構文解析器は開始タグの先頭(すなわち
|
| eof-in-cdata |
このエラーは、構文解析器がCDATA セクション内で入力ストリームの終端に 遭遇した場合に発生する。構文解析器は、そのような CDATA セクションを、入力ストリームの 終端の直前で閉じられたかのように扱う。 |
| eof-in-comment |
このエラーは、構文解析器がコメント内で入力ストリームの終端に 遭遇した場合に発生する。構文解析器は、そのようなコメントを、入力ストリームの終端の 直前で閉じられたかのように扱う。 |
| eof-in-doctype |
このエラーは、構文解析器がDOCTYPE 内で入力ストリームの終端に遭遇した場合に
発生する。この場合、DOCTYPE が文書の前置きとして正しく配置されていれば、
構文解析器は |
| eof-in-processing-instruction |
このエラーは、構文解析器が処理命令内
(たとえば、 |
| eof-in-script-html-comment-like-text |
このエラーは、構文解析器が
|
| eof-in-tag |
このエラーは、構文解析器が開始タグまたは終了タグ内
(たとえば、 |
| incorrectly-closed-comment |
このエラーは、構文解析器が「 |
| incorrectly-opened-comment |
このエラーは、構文解析器が、直後に二つの U+002D(-)コードポイントが続かず、
DOCTYPE またはCDATA セクションの先頭でもない
「 このエラーの考えられる原因の一つは、HTML 内で XML マークアップ宣言
(たとえば、 |
| invalid-character-sequence-after-doctype-name |
このエラーは、構文解析器がDOCTYPE
名の後に、「 |
| invalid-first-character-of-processing-instruction-target |
このエラーは、処理命令の対象の最初のコードポイントが 期待される場所で、構文解析器がASCII 英字でも U+005F(_)でもないコードポイントに遭遇した場合に発生する。 先行する U+003F(?)および、その後の U+003E(>)(存在する場合)まで、または 入力ストリームの終端までの すべての内容は、コメントとして扱われる。 |
| invalid-first-character-of-tag-name |
このエラーは、開始タグ名または終了タグ名の最初のコードポイントが期待される場所で、 構文解析器がASCII 英字ではないコードポイントに遭遇した場合に発生する。開始タグが 期待されていた場合、そのコードポイントと先行する U+003C(<)はテキストコンテンツとして 扱われ、その後のすべての内容はマークアップとして扱われる。一方、終了タグが期待されていた 場合、そのコードポイントおよび、その後の U+003E(>)コードポイント (存在する場合)まで、または入力ストリームの終端までのすべての内容は、 コメントとして扱われる。 タグ名の最初のコードポイントはASCII 英字に制限されるが、後続の位置ではASCII 数字を含む広範なコードポイントが許可される。 |
| invalid-processing-instruction-target |
このエラーは、処理命令の対象が期待される場所で、 構文解析器がASCII 英数字、U+002D(-)、または U+005F(_)ではないコードポイントに遭遇した場合に発生する。 先行する U+003F(?)および、その後の U+003E(>)(存在する場合)まで、または 入力ストリームの終端までの すべての内容は、コメントとして扱われる。 |
| missing-attribute-value |
このエラーは、属性値が期待される場所で、
構文解析器が U+003E(>)コードポイントに遭遇した場合
(たとえば、 |
| missing-doctype-name |
このエラーは、構文解析器が名前を欠くDOCTYPE
(たとえば、 |
| missing-doctype-public-identifier |
このエラーは、DOCTYPE 公開識別子の先頭が期待される場所で、
構文解析器が U+003E(>)コードポイントに遭遇した場合
(たとえば、 |
| missing-doctype-system-identifier |
このエラーは、DOCTYPE システム識別子の先頭が期待される場所で、
構文解析器が U+003E(>)コードポイントに遭遇した場合
(たとえば、 |
| missing-end-tag-name |
このエラーは、終了タグ名が期待される場所で、構文解析器が
U+003E(>)コードポイント、すなわち
|
| missing-quote-before-doctype-public-identifier |
このエラーは、構文解析器が引用符の前置されていないDOCTYPE 公開識別子
(たとえば、 |
| missing-quote-before-doctype-system-identifier |
このエラーは、構文解析器が引用符の前置されていないDOCTYPE システム識別子
(たとえば、 |
| missing-semicolon-after-character-reference |
このエラーは、構文解析器が U+003B(;)コードポイントで終了していない文字参照に遭遇した場合に 発生する。構文解析器は、その文字参照が U+003B(;)コードポイントで終了している場合と 同じように動作する。 ほとんどの名前付き文字参照には、終端の U+003B(;)コードポイントが必要である。これを必要としないものは、 特定の曖昧な状況では、より長い名前付き文字参照として解決される可能性がある。 たとえば、 |
| missing-whitespace-after-doctype-public-keyword |
このエラーは、構文解析器が「 |
| missing-whitespace-after-doctype-system-keyword |
このエラーは、構文解析器が「 |
| missing-whitespace-before-doctype-name |
このエラーは、構文解析器が「 |
| missing-whitespace-between-attributes |
このエラーは、構文解析器がASCII 空白で区切られていない属性
(たとえば、 |
| missing-whitespace-between-doctype-public-and-system-identifiers |
このエラーは、構文解析器が公開識別子とシステム識別子がASCII 空白で区切られていないDOCTYPEに遭遇した場合に 発生する。この場合、構文解析器は ASCII 空白が存在するかのように動作する。 |
| nested-comment |
このエラーは、構文解析器が入れ子になったコメント
(たとえば、 |
| noncharacter-character-reference |
このエラーは、構文解析器が非文字を参照する数値文字参照に遭遇した場合に発生する。構文解析器は、 そのような文字参照をそのまま解決する。 |
| noncharacter-in-input-stream |
このエラーは、入力ストリームに非文字が含まれる場合に発生する。そのようなコードポイントはそのまま構文解析され、通常、 構文解析規則によって追加の制限が適用されない場所では DOM 内に入る。 |
| non-void-html-element-start-tag-with-trailing-solidus |
このエラーは、構文解析器が、空要素の一覧に含まれず、外来コンテンツの一部でもない (すなわち SVG または MathML 要素ではない)要素について、閉じる U+003E(>) コードポイントの直前に U+002F(/)コードポイントを持つ開始タグに遭遇した場合に 発生する。構文解析器は、U+002F(/)が存在しないかのように動作する。 開始タグ名の末尾にある U+002F(/)は、自己終了タグを指定するために 外来コンテンツでのみ使用できる。(自己終了タグは HTML には存在しない。)空要素でも 許可されるが、この場合は何の効果もない。 |
| null-character-reference |
このエラーは、構文解析器が U+0000 NULL コードポイントを参照する数値文字参照に遭遇した場合に 発生する。構文解析器は、そのような文字参照を U+FFFD REPLACEMENT CHARACTER に解決する。 |
| surrogate-character-reference |
このエラーは、構文解析器がサロゲートを参照する数値文字参照に遭遇した場合に 発生する。構文解析器は、そのような文字参照を U+FFFD REPLACEMENT CHARACTER に解決する。 |
| surrogate-in-input-stream |
このエラーは、入力ストリームにサロゲートが含まれる場合に発生する。そのようなコードポイントはそのまま構文解析され、通常、 構文解析規則によって追加の制限が適用されない場所では DOM 内に入る。 サロゲートは、 |
| unexpected-character-after-doctype-system-identifier |
このエラーは、構文解析器がDOCTYPE システム識別子の後で、ASCII 空白または閉じる U+003E(>)以外のコードポイントに 遭遇した場合に発生する。構文解析器は、それらのコードポイントを無視する。 |
| unexpected-character-in-attribute-name |
このエラーは、構文解析器が属性名内で U+0022(")、U+0027(')、 または U+003C(<)コードポイントに遭遇した場合に発生する。 構文解析器は、そのようなコードポイントを属性名に含める。 このエラーを引き起こすコードポイントは通常、別の構文構造の一部であり、 属性名の周辺にある誤入力の兆候である可能性がある。 |
| unexpected-character-in-unquoted-attribute-value |
このエラーは、構文解析器が引用符なしの属性値内で U+0022(")、U+0027(')、 U+003C(<)、U+003D(=)、または U+0060(`)コードポイントに遭遇した場合に発生する。 構文解析器は、そのようなコードポイントを属性値に含める。 このエラーを引き起こすコードポイントは通常、別の構文構造の一部であり、 属性値の周辺にある誤入力の兆候である可能性がある。 U+0060(`)がこのエラーを引き起こすコードポイントの一覧に含まれているのは、 一部のレガシーユーザーエージェントがこれを引用符として扱うためである。 たとえば、次のマークアップを考える: U+0027(')コードポイントが誤った位置にあるため、構文解析器は
「 |
| unexpected-equals-sign-before-attribute-name |
このエラーは、構文解析器が属性名の前で U+003D(=)コードポイントに遭遇した場合に発生する。この場合、 構文解析器は U+003D(=)を属性名の最初のコードポイントとして扱う。 このエラーの一般的な原因は、属性名の書き忘れである。 たとえば、次のマークアップを考える: 属性名を忘れたため、構文解析器はこのマークアップを二つの属性、すなわち
値「 |
| unexpected-null-character |
このエラーは、構文解析器が特定の位置で入力ストリーム内の U+0000 NULL コードポイントに遭遇した場合に発生する。一般に、 そのようなコードポイントは無視されるか、セキュリティ上の理由により U+FFFD REPLACEMENT CHARACTER に置き換えられる。 |
| unexpected-solidus-in-tag |
このエラーは、構文解析器が、引用符付き属性値の一部ではなく、かつタグ内で
U+003E(>)コードポイントが直後に続かない U+002F(/)コードポイント
(たとえば、 |
| unknown-named-character-reference |
トークン化段階への入力を構成するコードポイントのストリームは、最初はユーザーエージェントに バイトのストリームとして認識される(通常はネットワークまたはローカルファイルシステムから 取得される)。バイトは、特定の文字エンコーディングに従って実際の文字を符号化しており、 ユーザーエージェントはその文字エンコーディングを使用してバイトを文字へ復号する。
XML 文書について、ユーザーエージェントが文字エンコーディングを決定するために 使用することを要求されるアルゴリズムは、XML で規定されている。この節は XML 文書には適用されない。[XML]
通常、文字エンコーディングを決定するために、以下で定義するエンコーディング スニッフィングアルゴリズムが使用される。
文字エンコーディングが与えられたとき、入力バイトストリームおよび文字エンコーディングを 復号に渡すことにより、 入力バイトストリーム内のバイトを トークナイザーの入力 ストリーム用の文字へ変換しなければならない。
先頭のバイト順マーク(BOM)がある場合、文字エンコーディング引数は無視され、 BOM 自体も読み飛ばされる。
元のバイトストリーム内にある、Encoding 標準に適合しないバイトまたはバイト列 (たとえば、UTF-8 入力バイトストリーム内の無効な UTF-8 バイト列)は、適合性チェッカーが 報告することを期待されるエラーである。[ENCODING]
復号器アルゴリズムは、無効な入力を処理する方法を説明している。 セキュリティ上の理由により、これらの規則に厳密に従うことが不可欠である。無効なバイト列の 処理方法に差異があると、特にスクリプト注入の脆弱性(「XSS」)などの問題が発生する可能性がある。
HTML 構文解析器が入力バイトストリームを復号するとき、文字エンコーディングおよび確信度を使用する。確信度は、暫定的、 確実、または無関係のいずれかである。使用されるエンコーディング、および そのエンコーディングに対する確信度が暫定的か確実かは、構文解析中に使用され、エンコーディングを変更するかどうかを決定する。 たとえば、構文解析器が Unicode ストリームを処理していて、文字エンコーディングをまったく 使用する必要がないため、エンコーディングが不要である場合、確信度は 無関係となる。
一部のアルゴリズムは、バイトを入力バイトストリームへ追加する代わりに、 文字を入力 ストリームへ直接追加することによって、構文解析器へ入力を供給する。
HTML 構文解析器が既知の確定エンコーディングを持つ入力バイトストリームを処理する場合、 文字エンコーディングはそのエンコーディングであり、確信度は 確実である。
場合によっては、文書の構文解析前にエンコーディングを明確に決定することが現実的でないことがある。 このため、この仕様は、任意の事前走査を伴う二段階の仕組みを提供する。実装は、以下で説明するように、 文書の構文解析を開始する前に、利用可能なバイトに対して簡略化された構文解析アルゴリズムを 適用することが許可される。その後、この事前構文解析およびその他の帯域外メタデータから導出された 暫定的なエンコーディングを使用して、実際の構文解析器が開始される。文書の読み込み中に、 ユーザーエージェントがこの情報と競合する文字エンコーディング宣言を発見した場合、 実際のエンコーディングを使用して文書を構文解析するため、構文解析器を再び呼び出すことができる。
ユーザーエージェントは、最初のパスで文書を復号する際に使用する 文字エンコーディングを決定するため、エンコーディング スニッフィングアルゴリズムと呼ばれる次のアルゴリズムを使用しなければならない。 このアルゴリズムは、ユーザーエージェントが利用できる任意の帯域外メタデータ (たとえば、文書のContent-Type メタデータ)および それまでに利用可能なすべてのバイトを入力として受け取り、文字エンコーディングと、 暫定的または確実のいずれかである確信度を返す。
BOM スニッフィングの結果がエンコーディングである場合、 そのエンコーディングを確信度 確実とともに返す。
復号アルゴリズム自体も、 バイト順マークの存在に基づいて使用するエンコーディングを変更するが、このアルゴリズムでも BOM をスニッフィングし、正しい文書の文字エンコーディングおよび確信度を設定する。
ユーザーが、特定のエンコーディングによって文書の文字エンコーディングを上書きするよう ユーザーエージェントへ明示的に指示した場合、任意で、そのエンコーディングを確信度 確実とともに返す。
通常、ユーザーエージェントは、そのようなユーザーの要求をセッション間で記憶し、
場合によっては iframe 内の文書にも適用する。
ユーザーエージェントは、この手順またはこのアルゴリズム内の後の任意の手順で、 リソースのより多くのバイトが利用可能になるまで待ってもよい。たとえば、 ユーザーエージェントは 500 ミリ秒または 1024 バイトの、いずれか早い方まで待つことがある。 一般に、エンコーディングを見つけるためにソースを事前構文解析すると、エンコーディング情報を 発見したときに構文解析に使用したデータ構造を破棄する必要性が減るため、パフォーマンスが 向上する。ただし、エンコーディングを決定するためのデータを取得するために ユーザーエージェントが長時間遅延すると、その遅延のコストが事前構文解析による パフォーマンス向上を上回る可能性がある。
文字エンコーディング宣言に関する作者向け適合要件では、それらが 最初の 1024 バイト内にのみ現れるよう制限している。 したがって、ユーザーエージェントには、以下の事前走査アルゴリズムを (これらの手順によって呼び出されるように)最初の 1024 バイトに対して使用し、 それを超えて処理を停滞させないことが推奨される。
トランスポート層が文字エンコーディングを指定しており、それがサポートされている場合、 そのエンコーディングを確信度 確実とともに返す。
任意で、ユーザーエージェントがそれ以上のバイトを走査することは効率的でないと判断した 時点を終了 条件として、エンコーディングを 決定するためにバイトストリームを事前走査する。ユーザーエージェントには、 最初の 1024 バイトのみを事前走査することが推奨される。ユーザーエージェントは、 いずれのバイトを走査することも効率的でないと判断してもよく、その場合、 これらの下位手順はすべて省略される。
前述のアルゴリズムは、文字エンコーディングまたは失敗のいずれかを返す。 文字エンコーディングを返した場合、同じエンコーディングを確信度 暫定的とともに返す。
このアルゴリズムが実行されているHTML 構文解析器が、コンテナー
文書が null でない Document
d に関連付けられている場合:
parentDocument を、d のコンテナー文書とする。
parentDocument のオリジンが、d のオリジンと同一オリジンであり、 parentDocument の文字エンコーディングがUTF-16BE/LEでない場合、 parentDocument の文字エンコーディングを、確信度 暫定的とともに返す。
それ以外で、たとえば前回そのページを訪問した際のエンコーディングに基づくなど、 ユーザーエージェントがこのページで使用される可能性の高いエンコーディングに関する情報を 持っている場合、そのエンコーディングを確信度 暫定的とともに返す。
ユーザーエージェントは、データストリームに頻度分析またはその他のアルゴリズムを適用して、 文字エンコーディングを自動検出しようとしてもよい。そのようなアルゴリズムは、 リソースの内容以外の情報(リソースのアドレスを含む)を使用してもよい。 自動検出によって文字エンコーディングの決定に成功し、そのエンコーディングが サポートされるエンコーディングである場合、そのエンコーディングを確信度 暫定的とともに返す。[UNIVCHARDET]
ネットワーク経由で取得されたリソースのエンコーディングを自動検出しようとする ことは、本質的に相互運用不能なヒューリスティックを伴うため、一般に推奨されない。 HTML 文書の前置きに基づいてエンコーディングを検出しようとすることは、HTML マークアップが 通常 ASCII 文字のみを使用し、HTML 文書がテキストコンテンツではなく大量のマークアップから 始まる傾向があるため、特に難しい。
UTF-8 エンコーディングには、非常に検出しやすいビットパターンがある。 ローカルファイルシステム内のファイルに、UTF-8 パターンと一致する 0x7F より大きな値の バイトが含まれている場合、そのファイルは UTF-8 である可能性が非常に高い。一方、 一致しないバイト列を含む文書は、UTF-8 ではない可能性が非常に高い。 ユーザーエージェントが前置きだけでなくファイル全体を調べられる場合、UTF-8 に限定した 検出は特に効果的になり得る。[PPUTF8] [UTF8DET]
それ以外の場合、実装定義またはユーザー指定の既定の 文字エンコーディングを、確信度 暫定的とともに返す。
制御された環境、または文書のエンコーディングを指定できる環境
(たとえば、新しいネットワークでの専用使用を意図したユーザーエージェント)では、
包括的な UTF-8 エンコーディングが推奨される。
その他の環境では、既定のエンコーディングは通常、ユーザーのロケール (ユーザーが頻繁に訪問する可能性が高いページの言語、したがって多くの場合は エンコーディングの近似)に依存する。次の表は、レガシーコンテンツとの互換性のため、 ユーザーのロケールに基づく推奨既定値を示す。ロケールは BCP 47 言語タグによって識別される。 [BCP47] [ENCODING]
| ロケール言語 | 推奨される既定のエンコーディング | |
|---|---|---|
| ar | アラビア語 | windows-1256 |
| az | アゼルバイジャン語 | windows-1254 |
| ba | バシキール語 | windows-1251 |
| be | ベラルーシ語 | windows-1251 |
| bg | ブルガリア語 | windows-1251 |
| cs | チェコ語 | windows-1250 |
| el | ギリシャ語 | ISO-8859-7 |
| et | エストニア語 | windows-1257 |
| fa | ペルシア語 | windows-1256 |
| he | ヘブライ語 | windows-1255 |
| hr | クロアチア語 | windows-1250 |
| hu | ハンガリー語 | ISO-8859-2 |
| ja | 日本語 | Shift_JIS |
| kk | カザフ語 | windows-1251 |
| ko | 韓国語 | EUC-KR |
| ku | クルド語 | windows-1254 |
| ky | キルギス語 | windows-1251 |
| lt | リトアニア語 | windows-1257 |
| lv | ラトビア語 | windows-1257 |
| mk | マケドニア語 | windows-1251 |
| pl | ポーランド語 | ISO-8859-2 |
| ru | ロシア語 | windows-1251 |
| sah | ヤクート語 | windows-1251 |
| sk | スロバキア語 | windows-1250 |
| sl | スロベニア語 | ISO-8859-2 |
| sr | セルビア語 | windows-1251 |
| tg | タジク語 | windows-1251 |
| th | タイ語 | windows-874 |
| tr | トルコ語 | windows-1254 |
| tt | タタール語 | windows-1251 |
| uk | ウクライナ語 | windows-1251 |
| vi | ベトナム語 | windows-1258 |
| zh-Hans, zh-CN, zh-SG | 中国語(簡体字) | GBK |
| zh-Hant, zh-HK, zh-MO, zh-TW | 中国語(繁体字) | Big5 |
| その他すべてのロケール | windows-1252 | |
この表の内容は、Windows、Chrome、および Firefox の 既定値の共通部分から導出されている。
文書の文字エンコーディングは、 ユーザーエージェントが返された値を使用して入力バイトストリーム用の復号器を選択するのと同時に、 このアルゴリズムから返された値へ直ちに設定されなければならない。
アルゴリズムが、定義された終了条件を 与えて、ユーザーエージェントにエンコーディングを決定するためにバイトストリームを事前走査することを 要求する場合、次の手順を実行しなければならない。これらの手順の途中 (このアルゴリズムによって呼び出される属性を取得する アルゴリズムの実行中を含む)で、ユーザーエージェントがバイトを使い果たす (すなわち、以下の最初の手順で作成された position ポインターが、 それまでに取得されたバイトストリームの終端を越える)か、end condition に 到達した場合、エンコーディングを 決定するためにバイトストリームを事前走査するアルゴリズムを中止し、エンコーディングを 決定するためにバイトストリームを事前走査するアルゴリズムが適用されたものと同じ バイトに対してXML エンコーディングを取得するを適用した結果を返す。それ以外の場合、これらの手順は 文字エンコーディングを返す。
position を、入力バイトストリーム内のバイトを指すポインターとし、 初期状態では最初のバイトを指すようにする。
UTF-16 XML 宣言を事前走査する:position が次を指している場合:
UTF-16LE を返す。
UTF-16BE を返す。
歴史的な理由により、この接頭辞は XML の附属書 Fにあるものより 2 バイト長く、エンコーディング名は検査されない。
ループ:position が次を指している場合:
<!--」)で始まるバイト列position ポインターを、二つの 0x2D バイトが直前にあり (すなわち ASCII の「-->」列の終端にあり)、検出された 0x3C バイトより後にある 最初の 0x3E バイトを指すよう進める。(二つの 0x2D バイトは、「<!--」列内のものと 同じであってもよい。)
position ポインターを、次の 0x09、0x0A、0x0C、0x0D、 0x20、または 0x2F バイト(上で一致した文字列内のもの)を指すよう進める。
attribute list を文字列の空のリストとする。
got pragma を false とする。
need pragma を null とする。
charset を null 値とする(このアルゴリズムの目的では、 認識されないエンコーディングまたは空文字列とは異なる)。
属性:属性を 取得することにより、属性とその値を取得する。属性をスニッフィングできなかった場合、 以下の処理とラベル付けされた手順へ進む。
属性の名前がすでに attribute list 内にある場合、 属性とラベル付けされた手順へ戻る。
属性の名前を attribute list へ追加する。
該当する場合、次のリストから適切な手順を実行する:
http-equiv」である場合属性の値が「content-type」である場合、
got pragma を true に設定する。
content」である場合属性の値を構文解析する文字列として与えて、meta
要素から文字エンコーディングを抽出するアルゴリズムを適用する。
文字エンコーディングが返され、charset がまだ null に設定されている場合、
charset を返されたエンコーディングとし、need
pragma を true に設定する。
charset」である場合charset を、属性の値からエンコーディングを取得する結果とし、 need pragma を false に設定する。
属性とラベル付けされた手順へ戻る。
処理:need pragma が null である場合、以下の 次のバイトとラベル付けされた手順へ進む。
need pragma が true であるが、got pragma が false である場合、以下の次のバイトとラベル付けされた手順へ進む。
charset が失敗である場合、以下の次の バイトとラベル付けされた手順へ進む。
charset がUTF-16BE/LEである場合、 charset をUTF-8に設定する。
charset がx-user-definedである場合、 charset をwindows-1252に設定する。
charset を返す。
position ポインターを、次の 0x09(HT)、0x0A(LF)、 0x0C(FF)、0x0D(CR)、0x20(SP)、または 0x3E(>)バイトを指すよう進める。
それ以上の属性が見つからなくなるまで、繰り返し属性を 取得する。その後、以下の次のバイトとラベル付けされた手順へ進む。
<!」)で始まるバイト列</」)で始まるバイト列<?」)で始まるバイト列position ポインターを、検出された 0x3C バイトより後にある 最初の 0x3E バイト(>)を指すよう進める。
そのバイトに対して何もしない。
エンコーディングを 決定するためにバイトストリームを事前走査するアルゴリズムが属性を取得するよう指示した場合、 次を行うことを意味する:
position にあるバイトが 0x09(HT)、0x0A(LF)、0x0C(FF)、 0x0D(CR)、0x20(SP)、または 0x2F(/)のいずれかである場合、 position を次のバイトへ進め、この手順を再び行う。
position にあるバイトが 0x3E(>)である場合、属性を取得する アルゴリズムを中止する。属性は存在しない。
それ以外の場合、position にあるバイトは属性名の先頭である。 attribute name および attribute value を空文字列とする。
position にあるバイトを次のように処理する:
position を次のバイトへ進め、前の手順へ戻る。
空白:position にあるバイトが 0x09(HT)、0x0A(LF)、 0x0C(FF)、0x0D(CR)、または 0x20(SP)のいずれかである場合、 position を次のバイトへ進め、この手順を繰り返す。
position にあるバイトが 0x3D(=)でない場合、属性を取得する アルゴリズムを中止する。属性の名前は attribute name の値であり、 その値は空文字列である。
position を 0x3D(=)バイトの後まで進める。
値:position にあるバイトが 0x09(HT)、0x0A(LF)、 0x0C(FF)、0x0D(CR)、または 0x20(SP)のいずれかである場合、 position を次のバイトへ進め、この手順を繰り返す。
position にあるバイトを次のように処理する:
position にあるバイトを次のように処理する:
position を次のバイトへ進め、前の手順へ戻る。
エンコーディングを 決定するためにバイトストリームを事前走査するアルゴリズムが、 エンコーディングを返さずに中止された場合、XML エンコーディングを取得するとは、 次を行うことを意味する。
text/html
内であっても、
XML 宣言に似た構文を探すことは、既存のコンテンツとの互換性のために必要である。
encodingPosition を、ストリームの先頭を指すポインターとする。
encodingPosition がバイト列 0x3C、0x3F、0x78、0x6D、0x6C
(「<?xml」)の先頭を指していない場合、失敗を返す。
xmlDeclarationEnd を、入力バイトストリーム内で 0x3E(>)である 次のバイトを指すポインターとする。そのようなバイトがない場合、失敗を返す。
encodingPosition を、現在の encodingPosition 以降にある
バイト部分列 0x65、0x6E、0x63、0x6F、0x64、0x69、0x6E、0x67
(「encoding」)の最初の出現位置に設定する。そのようなバイト列がない場合、
失敗を返す。
encodingPosition を 0x67(g)バイトの後まで進める。
encodingPosition にあるバイトが 0x20 以下である間 (すなわち、ASCII 空白または制御文字である間)、encodingPosition を 次のバイトへ進める。
encodingPosition にあるバイトが 0x3D(=)でない場合、失敗を返す。
encodingPosition を次のバイトへ進める。
encodingPosition にあるバイトが 0x20 以下である間 (すなわち、ASCII 空白または制御文字である間)、encodingPosition を 次のバイトへ進める。
quoteMark を、encodingPosition にあるバイトとする。
quoteMark が 0x22(")または 0x27(')のいずれでもない場合、失敗を返す。
encodingPosition を次のバイトへ進める。
encodingEndPosition を、encodingPosition 以降にある quoteMark の次の出現位置とする。quoteMark が再び出現しない場合、 失敗を返す。
potentialEncoding を、encodingPosition(含む)と encodingEndPosition(含まない)の間のバイト列とする。
potentialEncoding に、バイト値が 0x20 以下であるバイトが一つ以上 含まれる場合、失敗を返す。
encoding を、potentialEncoding を同型復号したものが与えられたときにエンコーディングを取得する結果とする。
encoding がUTF-16BE/LEである場合、それをUTF-8へ変更する。
encoding を返す。
相互運用性のため、ユーザーエージェントは、上で説明したものと異なる結果を返す 事前走査アルゴリズムを使用するべきではない。(ただし、使用する場合は、少なくともそのことを 知らせてほしい。そうすれば、このアルゴリズムを改善し、すべての人に利益をもたらすことが できる……。)
ユーザーエージェントは、Encoding で定義されるエンコーディングをサポートしなければ ならない。これには、次のものが含まれるが、これらに限定されない: UTF-8、 ISO-8859-2、 ISO-8859-7、 ISO-8859-8、 windows-874、 windows-1250、 windows-1251、 windows-1252、 windows-1254、 windows-1255、 windows-1256、 windows-1257、 windows-1258、 GBK、 Big5、 ISO-2022-JP、 Shift_JIS、 EUC-KR、 UTF-16BE、 UTF-16LE、 UTF-16BE/LE、および x-user-defined。 ユーザーエージェントは、その他のエンコーディングをサポートしてはならない。
上記は、たとえば CESU-8、UTF-7、BOCU-1、SCSU、EBCDIC、および UTF-32 の サポートを禁止する。この仕様のアルゴリズムは、禁止されたエンコーディングをサポートしようとは 一切していない。したがって、禁止されたエンコーディングをサポートまたは使用すると、 予期しない動作が生じる。 [CESU8] [UTF7] [BOCU1] [SCSU]
構文解析器がユーザーエージェントにエンコーディングを変更する よう要求した場合、次の手順を実行しなければならない。これは、上で説明したエンコーディング スニッフィングアルゴリズムが文字エンコーディングを見つけられなかった場合、または ファイルの実際のエンコーディングではない文字エンコーディングを見つけた場合に発生することがある。
入力ストリームの解釈にすでに使用されているエンコーディングがUTF-16BE/LEである場合、確信度を 確実に設定して返る。新しいエンコーディングは無視される。それが同じ エンコーディング以外のものであれば、明らかに誤っているためである。
新しいエンコーディングがUTF-16BE/LEである場合、それをUTF-8へ変更する。
新しいエンコーディングがx-user-definedである場合、それをwindows-1252へ変更する。
新しいエンコーディングが、入力ストリームの解釈にすでに使用されているエンコーディングと 同一または等価である場合、確信度を 確実に設定して返る。これは、ファイル内で見つかったエンコーディング情報が、エンコーディング スニッフィングアルゴリズムによって決定されたエンコーディングと一致する場合、および 前の節で説明したエンコーディングスニッフィングアルゴリズムが正しいエンコーディングを 見つけられなかったことを最初のパスで発見した後、構文解析器を二回目に通過する場合に発生する。
現在の復号器によって変換された最後のバイトまでのすべてのバイトが、現在の エンコーディングと新しいエンコーディングの両方で同じ Unicode 解釈を持ち、かつ ユーザーエージェントが変換器の動的な変更をサポートしている場合、ユーザーエージェントは エンコーディング用の新しい変換器へ動的に変更してもよい。文書の文字エンコーディングおよび 入力ストリームの変換に使用するエンコーディングを新しいエンコーディングに設定し、確信度を 確実に設定して返る。
それ以外の場合、historyHandling を「replace」に設定し、その他の入力は同じままにして、
navigate アルゴリズムを
再起動する。ただし今回は、エンコーディング
スニッフィングアルゴリズムを省略し、代わりにエンコーディングを新しいエンコーディングに、
確信度を
確実に設定する。可能な場合、これは実際にネットワーク層へ接続せずに行うべきである
(バイトはメモリーから再構文解析するべきである)。これは、たとえば文書がキャッシュ不可と
マークされている場合でも同様である。それが不可能で、ネットワーク層へ接続すると
`GET` 以外のメソッドを使用するリクエストを繰り返すことになる場合は、
代わりに確信度を
確実に設定し、新しいエンコーディングを無視する。リソースは誤って解釈される。
ユーザーエージェントは、アプリケーション開発を支援するため、この状況をユーザーへ
通知してもよい。
このアルゴリズムは、新しいエンコーディングが meta 要素上で宣言されていることが判明した場合にのみ呼び出される。
入力ストリームは、入力バイト ストリームが復号される際にそこへ追加される文字、または入力ストリームを直接操作する 各種 API から追加される文字で構成される。
サロゲートの出現はすべて、surrogate-in-input-stream 構文解析エラーである。非文字の出現はすべて、noncharacter-in-input-stream 構文解析エラーであり、制御文字のうち、ASCII 空白および U+0000 NULL 文字以外の出現はすべて、control-character-in-input-stream 構文解析エラーである。
U+0000 NULL 文字の処理は、その文字が見つかった場所によって異なり、 構文解析の後の段階で行われる。それらは無視されるか、セキュリティ上の理由により U+FFFD REPLACEMENT CHARACTER に置き換えられる。この処理は、必然的にトークン化段階と ツリー構築段階の両方に分散している。
トークン化段階の前に、 入力ストリームは改行を正規化することによって前処理されなければならない。 したがって、HTML DOM 内の改行は U+000A LF 文字で表され、トークン化段階への入力には U+000D CR 文字が決して存在しない。
次の入力文字とは、入力ストリーム内で、まだ消費されて おらず、この節の要件によって明示的に無視されてもいない最初の文字である。初期状態では、 次の入力文字は入力内の最初の文字である。 現在の入力文字とは、最後に消費された文字である。
挿入位置とは、document.write() を使用して挿入されるコンテンツが実際に
挿入される位置(ある文字の直前、または入力ストリームの終端の直前)である。挿入位置は、
その直後の文字の位置に対する相対位置であり、入力ストリーム内の絶対オフセットではない。
初期状態では、挿入位置は未定義である。
以下の表にある「EOF」文字は、入力ストリームの終端を表す概念上の文字である。
構文解析器がスクリプトによって作成された構文解析器で
ある場合、document.close() メソッドによって挿入された明示的な「EOF」文字が消費されたときに、入力ストリームの終端へ
到達する。それ以外の場合、「EOF」文字はストリーム内の実際の文字ではなく、後続の文字が
それ以上存在しないことを意味する。
挿入モードは、木構築段階の主要な動作を制御する状態変数である。
トークンを外部 コンテンツ内で構文解析するための規則は、挿入 モードではない。木 構築 ディスパッチャーは、現在の挿入モードとは独立してこれらを選択し、これらが 使用されている間、挿入モードは変更されない。
初期状態では、挿入モードは「初期」である。構文解析の 過程で、「html の前」、「head の前」、「head 内」、「head noscript 内」、「head の後」、 「body 内」、「テキスト」、「table 内」、「table テキスト内」、「caption 内」、「column group 内」、「table body 内」、「row 内」、「cell 内」、「template 内」、 「body の後」、「frameset 内」、「frameset の後」、「body の後の後」、および 「frameset の後の後」へ変更され得る。これは、 木構築段階で説明されている。挿入 モードは、トークンの処理方法に影響する。
これらのモードのうちいくつか、すなわち「head 内」、「body 内」、および「table 内」は、他のモードがさまざまな時点でこれらに処理を委ねるという点で特別である。以下の アルゴリズムが、ユーザーエージェントは「m 挿入モードの 規則を使用して」何かを行うものとするとき、mがこれらのモードのいずれかである場合、ユーザーエージェントは mの挿入モードの節で説明されている規則を使用しなければならないが、 m内の規則自体が 挿入モードを新しい値へ切り替えない限り、 挿入モードを変更してはならない。
挿入モードが「テキスト」または 「table テキスト内」に切り替えられると、元の挿入 モードも設定される。これは、木構築段階が 戻る挿入モードである。
同様に、入れ子になった template
要素を構文解析するために、template 挿入
モードのスタックが使用される。これは初期状態では空である。現在の template
挿入モードは、
template
挿入モードのスタックに最後に追加された
挿入モードである。以下の節のアルゴリズムは、挿入モードをこのスタックへプッシュする。これは、
指定された挿入モードをスタックへ追加することを意味する。また、挿入モードを
スタックからポップする。これは、最後に追加された挿入モードを
スタックから削除しなければならないことを意味する。
以下の手順が UA に挿入モードを適切に リセットするよう要求する場合、UA は次の手順に従わなければならない:
lastを false とする。
nodeを、開いている 要素のスタック内の最後のノードとする。
ループ:nodeが開いている要素のスタック内の最初のノードである場合、 lastを true に設定し、パーサーがHTML フラグメント 構文解析アルゴリズム(フラグメントの場合)の一部として作成された場合は、 nodeを、そのアルゴリズムに渡されたコンテキスト要素に設定する。
nodeが td
または th 要素であり、
lastが
false である場合、挿入モードを
「セル
内」に切り替え、返る。
nodeが tbody、thead、または
tfoot 要素である場合、
挿入モードを「テーブル本体内」に切り替え、返る。
nodeが template 要素である場合、
挿入モードを現在の
template 挿入モードに切り替え、
返る。
nodeが head
要素であり、
lastが
false である場合、挿入モードを
「head
内」に切り替え、返る。
nodeが frameset
要素である場合、
挿入モードを「frameset 内」に切り替え、
返る。(フラグメントの場合)
nodeが html
要素である場合、次の
下位手順を実行する:
head
要素ポインターが null である場合、
挿入モードを「head
の前」に切り替え、
返る。(フラグメントの場合)
それ以外の場合、head
要素ポインターは null ではないため、
挿入モードを「head
の後」に切り替え、
返る。
lastが true である場合、挿入モードを「body 内」に切り替え、返る。(フラグメント の場合)
nodeを、開いている要素のスタック内でnodeの直前にあるノードとする。
ループとラベル付けされた手順に戻る。
初期状態では、開いている要素のスタックは空である。 スタックは下方向へ伸びる。スタックの最上位ノードはスタックへ最初に追加されたノードであり、 スタックの最下位ノードはスタックへ最後に追加されたノードである。ただし、誤って入れ子にされたタグの処理の一部として、スタックが ランダムアクセス方式で操作される場合を除く。
「html の前」挿入モードは、html 文書要素を作成し、その後それをスタックへ追加する。
断片の場合、開いている要素のスタックは、そのアルゴリズムの一部として作成される
html 要素を含むよう初期化される。(断片の場合、「html の前」挿入モードは省略される。)
html ノードは、どのように作成された場合でも、スタックの
最上位ノードである。構文解析器が終了するときにのみ、スタックからポップされる。
現在のノードとは、この開いている 要素のスタック内の最下位ノードである。
調整済み現在ノードとは、構文解析器がHTML 断片構文解析アルゴリズムの 一部として作成され、かつ開いている要素のスタックに 要素が一つしかない場合(断片の場合)は、コンテキスト要素である。それ以外の場合、調整済み現在ノードは現在のノードである。
現在のノードが開いている 要素のスタックから削除されたとき、現在のノードのノード文書が与えられたときに、内部リソースリンクを処理する。
開いている要素のスタック内の要素は、 次のカテゴリーに分類される:
次の要素には、さまざまな程度の特殊な構文解析規則がある:HTML の
address、
applet、area、article、
aside、base、basefont、bgsound、
blockquote、
body、br、button、
caption、
center、col、colgroup、
dd、details、dir、div、dl、
dt、embed、fieldset、
figcaption、
figure、footer、form、frame、
frameset、h1、
h2、
h3、
h4、
h5、
h6、
head、header、hgroup、
hr、html、iframe、
img、input、keygen、li、link、
listing、main、marquee、menu、
meta、nav、noembed、noframes、
noscript、
object、ol、p、
param、plaintext、pre、script、
search、section、select、source、
style、summary、table、tbody、
td、template、
textarea、
tfoot、
th、thead、title、tr、track、
ul、wbr、xmp;MathML
mi、
MathML mo、MathML mn、MathML
ms、MathML
mtext、およびMathML
annotation-xml;ならびにSVG foreignObject、SVG
desc、およびSVG
title。
image 開始タグトークンはツリービルダーによって処理されるが、
これは要素ではないため、この一覧には含まれない。これは img
要素へ変換される。
次の HTML 要素は、アクティブな書式設定
要素のリストへ入るものである:a、b、big、code、
em、font、i、nobr、s、
small、strike、strong、tt、および
u。
HTML 文書の構文解析中に見つかるその他すべての要素。
通常、特殊要素の開始タグトークンおよび終了タグトークンは
個別に処理される一方、通常要素のトークンは「その他の開始タグ」および
「その他の終了タグ」の節へ入り、ツリービルダーの一部は、開いている要素のスタック内の
特定の要素が特殊カテゴリーに属するかを確認する。ただし、
一部の要素(たとえば option 要素)は、開始タグまたは終了タグトークンが
個別に処理されるにもかかわらず、依然として特殊カテゴリーには属さない。これにより、
その他の場所では通常の処理を受ける。
開いている 要素のスタックは、次のアルゴリズムが一致状態で終了するとき、要素型のリスト list から構成される特定のスコープ内に 要素 target node を持つとされる:
node を現在のノード (スタックの最下位ノード)に初期化する。
node が target node である場合、一致状態で終了する。
それ以外で、node が list 内の要素型の一つである場合、 失敗状態で終了する。
それ以外の場合、node を開いている
要素のスタック内の前のエントリーに設定し、手順 2 へ戻る。
(スタックの最上位、すなわち html 要素へ到達した場合、ループは必ず前の手順で
終了するため、これは決して失敗しない。)
開いている 要素のスタックは、次の要素型から構成される特定のスコープ内に その要素を持つ場合、特定の要素をスコープ内に持つと される:
開いている 要素のスタックは、次の要素型から構成される特定のスコープ内に その要素を持つ場合、特定の要素を リスト項目スコープ内に持つとされる:
olul開いている 要素のスタックは、次の要素型から構成される特定のスコープ内に その要素を持つ場合、特定の要素を button スコープ内に持つとされる:
button開いている 要素のスタックは、次の要素型から構成される特定のスコープ内に その要素を持つ場合、特定の要素を table スコープ内に持つとされる:
開いている要素のスタック内の要素が、
いつでも Document ツリー内の新しい位置へ移動されたり、ツリーから削除されたりしても、
何も起こらない。特に、この状況ではスタックは変更されない。これにより、DOM 内に存在しなくなった
ノードへコンテンツが追加されるなど、さまざまな奇妙な影響が生じる可能性がある。
一部の場合(すなわち、誤って入れ子にされた書式設定 要素を閉じる場合)、スタックはランダムアクセス方式で操作される。
初期状態では、アクティブな書式設定要素のリストは 空である。これは、誤って入れ子にされた書式設定要素タグを処理するために使用される。
このリストには、書式設定カテゴリーの要素、およびマーカーが含まれる。
マーカーは、applet、
object、
marquee、
template、
td、
th、および caption 要素へ入るときに挿入され、書式設定が applet、object、marquee、template、td、th、および caption 要素の内部へ「漏れる」ことを防ぐために使用される。
さらに、アクティブな書式設定 要素のリスト内の各要素は、それが作成されたトークンに関連付けられる。これにより、 必要に応じてそのトークン用に追加の要素を作成できる。
以下の手順が UA に、要素 element をアクティブな書式設定 要素のリストへプッシュするよう要求する場合、UA は次の手順を実行しなければならない:
最後のマーカーがある場合は その後、またはマーカーがない場合は リスト全体の中に、element と同じタグ名、名前空間、および属性を持つ要素が すでに三つある場合、そのような要素のうち最も早く追加されたものをアクティブな書式設定 要素のリストから削除する。この目的では、属性は構文解析器によって要素が作成された時点の 状態で比較しなければならない。二つの要素の構文解析済み属性をすべて組にでき、各組の二つの 属性が同一の名前、名前空間、および値を持つ場合、その二つの要素は同じ属性を持つ (属性の順序は問わない)。
これはノアの箱舟条項である。ただし、一族あたり二つではなく三つである。
element をアクティブな書式設定 要素のリストへ追加する。
以下の手順が UA にアクティブな書式設定要素を 再構築するよう要求する場合、UA は次の手順を実行しなければならない:
アクティブな書式設定 要素のリストにエントリーがない場合、再構築するものはないため、このアルゴリズムを停止する。
アクティブな書式設定 要素のリストの最後の(最後に追加された)エントリーがマーカーである場合、 または開いている要素のスタックにも 含まれる要素である場合、再構築するものはないため、このアルゴリズムを停止する。
entry を、アクティブな書式設定 要素のリスト内の最後の(最後に追加された)要素とする。
巻き戻し:アクティブな書式設定 要素のリスト内で entry より前にエントリーがない場合、作成と ラベル付けされた手順へ進む。
entry を、アクティブな書式設定 要素のリスト内で entry より一つ前のエントリーとする。
entry がマーカーでも、開いている 要素のスタックにも含まれる要素でもない場合、巻き戻しとラベル付けされた 手順へ進む。
前進:entry を、アクティブな書式設定 要素のリスト内で entry より一つ後の要素とする。
作成:要素 entry が作成されたトークン用のHTML 要素を挿入することで、 new element を取得する。
リスト内の entry のエントリーを、new element のエントリーで置き換える。
アクティブな書式設定 要素のリスト内の new element のエントリーがリストの最後のエントリーでない場合、 前進とラベル付けされた手順へ戻る。
これは、現在の body、セル、または caption のうち最も新しいものの中で開かれ、 明示的に閉じられていないすべての書式設定要素を再び開く効果を持つ。
この仕様の記述方法では、アクティブな書式設定 要素のリストは常に、最も早く追加された要素を先頭、最も遅く追加された要素を末尾とする 時系列順の要素で構成される(もちろん、上のアルゴリズムの手順 7 から 10 が実行されている間を除く)。
以下の手順が UA に最後のマーカーまで アクティブな書式設定要素のリストを消去するよう要求する場合、UA は次の手順を 実行しなければならない:
entry を、アクティブな 書式設定要素のリスト内の最後の(最後に追加された)エントリーとする。
entry をアクティブな 書式設定要素のリストから削除する。
手順 1 へ進む。
初期状態では、head 要素ポインターおよび
form 要素ポインターはいずれも null である。
head 要素が
暗黙的または明示的に構文解析されると、head
要素ポインターはこのノードを
指すよう設定される。
form 要素
ポインターは、最後に開かれ、終了タグがまだ検出されていない form 要素を指す。
これは歴史的な理由により、著しく不正なマークアップでもフォームコントロールをフォームに
関連付けるために使用される。template 要素内では無視される。
ルート挿入対象。これは null または DocumentFragment である
(初期値は null)。
真偽値の 宣言的シャドウルートを許可する (初期値は false)。
スクリプティングモード。これは構文解析器スクリプティングモードである。
構文解析器スクリプティングモードは、次のいずれかである:
async
および defer 属性を尊重し、古典スクリプトに遭遇したときは構文解析器を
ブロックする。noscript 要素は代替コンテンツを表すことができる。async および
defer 属性は無視される。このモードは createContextualFragment() によって使用される。
frameset-ok フラグは、構文解析器が作成されたときに 「ok」に設定される。特定のトークンが検出された後は「not ok」に設定される。
実装は、HTML をトークン化するために次の状態機械を使用したかのように動作しなければならない。 状態機械はデータ状態から開始しなければならない。 ほとんどの状態は一つの文字を消費する。その文字はさまざまな副作用を持つことがあり、状態機械を 新しい状態へ切り替えて現在の入力文字を再消費するか、新しい状態へ切り替えて次の文字を消費するか、 同じ状態のまま次の文字を消費する。一部の状態はより複雑な動作を持ち、別の状態へ切り替える前に 複数の文字を消費することがある。場合によっては、トークナイザーの状態がツリー構築段階によって 変更されることもある。
ある状態が、一致した文字を指定された状態で再消費するよう 指示した場合、その状態へ切り替えるが、その状態が次の入力文字を消費しようとするとき、代わりに 現在の入力文字を 与えることを意味する。
特定の状態の正確な動作は、挿入モードおよび開いている要素のスタックに依存する。 特定の状態は進行状況を追跡するために一時バッファーも 使用し、文字参照状態は、呼び出し元の状態へ戻るために 復帰状態を使用する。
トークン化手順の出力は、次のトークンのうちゼロ個以上の列である:DOCTYPE、開始タグ、 終了タグ、コメント、文字、ファイル終端。DOCTYPE トークンには、名前、公開識別子、 システム識別子、および強制互換モードフラグがある。 DOCTYPE トークンが作成されると、その名前、公開識別子、およびシステム識別子は欠落として マークされなければならない(これは空文字列とは異なる状態である)。また、強制互換モードフラグは オフに設定されなければならない(もう一つの状態はオンである)。 開始タグおよび終了タグトークンには、タグ名、自己終了フラグ、および属性のリストがあり、各属性には名前と値がある。 開始タグまたは終了タグトークンが作成されると、その自己終了フラグは設定解除されなければならず (もう一つの状態は設定済みである)、属性リストは空でなければならない。 コメントおよび文字トークンにはデータがある。
トークンが発行されると、それは直ちにツリー構築段階によって処理されなければならない。
ツリー構築段階はトークン化段階の状態へ影響を与えることができ、ストリームへ追加の文字を
挿入することもできる。(たとえば、script 要素により
スクリプトが実行され、動的マークアップ挿入 API を使用して、
トークン化中のストリームへ文字が挿入されることがある。)
トークンの作成と発行は別々の動作である。開始タグトークンへ構文解析される文字を 処理している途中でファイルが予期せず終了した場合など、トークンが作成されたものの暗黙に 破棄される(発行されない)ことがある。
開始タグトークンが、その自己終了フラグを設定した状態で発行され、 ツリー構築段階で処理される際にそのフラグが確認されなかった場合、これはnon-void-html-element-start-tag-with-trailing-solidus 構文解析エラーである。
属性を持つ終了タグトークンが発行された場合、これはend-tag-with-attributes 構文解析 エラーである。
終了タグトークンが、その自己終了フラグを設定した状態で発行された場合、これはend-tag-with-trailing-solidus 構文解析エラーである。
適切な終了タグトークンとは、タグ名が、 このトークナイザーから最後に発行された開始タグのタグ名と一致する終了タグトークンである。 開始タグがこのトークナイザーから一つも発行されていない場合、適切な終了タグトークンは存在しない。
文字参照は、復帰状態が属性値(二重引用符)状態、属性値(単一引用符)状態、または属性値(引用符なし) 状態のいずれかである場合、属性の一部として消費されたとされる。
ある状態が文字参照として消費された コードポイントをフラッシュするよう指示した場合、一時 バッファー内の各コードポイントについて、バッファーへ追加された順序で、 文字参照が属性の一部として消費された場合はバッファー内の コードポイントを現在の属性の値へ付加し、それ以外の場合はコードポイントを文字トークンとして 発行しなければならないことを意味する。
一時バッファーをコメントへ変換するには、
「?」と、一時バッファー内のコードポイントを、
バッファーへ追加された順序で連結したものをデータとするコメントトークンを作成する。
これは、処理命令の対象が無効であることが判明し、代わりに偽コメントとして 扱われる場合に使用される。
トークナイザーの各手順の前に、ユーザーエージェントはまず構文解析器一時停止フラグを 確認しなければならない。それが true である場合、トークナイザーは、入れ子になった トークナイザー呼び出しの処理をすべて中止し、呼び出し元へ制御を戻さなければならない。
トークナイザー状態機械は、次の下位節で定義される状態から構成される。
次の入力文字を消費する:
次の入力文字を消費する:
次の入力文字を消費する:
次の入力文字を消費する:
次の入力文字を消費する:
次の入力文字を消費する:
次の入力 文字を消費する:
次の入力文字を消費する:
次の入力文字を消費する:
次の入力文字を消費する:
次の入力 文字を消費する:
次の入力 文字を消費する:
次の入力 文字を消費する:
次の入力 文字を消費する:
次の入力文字を消費する:
次の入力文字を消費する:
次の入力文字を消費する:
次の入力文字を消費する:
次の 入力文字を消費する:
次の入力文字を消費する:
次の入力文字を消費する:
次の 入力文字を消費する:
次の入力文字を消費する:
次の 入力文字を消費する:
次の 入力文字を消費する:
次の 入力文字を消費する:
script」である場合、スクリプトデータ二重
エスケープ済み状態へ切り替える。それ以外の場合、スクリプトデータ
エスケープ済み状態へ切り替える。現在の入力
文字を文字トークンとして発行する。
次の入力 文字を消費する:
次の 入力文字を消費する:
次の入力文字を消費する:
次の入力文字を消費する:
次の 入力文字を消費する:
script」である場合、スクリプトデータ
エスケープ済み状態へ切り替える。それ以外の場合、スクリプトデータ二重
エスケープ済み状態へ切り替える。現在の入力
文字を文字トークンとして発行する。次の入力 文字を消費する:
次の入力 文字を消費する:
ユーザーエージェントが属性名状態を離れるとき(該当する場合、タグトークンを発行する前)、 完成した属性の名前を同じトークン上の他の属性と比較しなければならない。同じ名前を持つ属性が すでにトークン上にある場合、これはduplicate-attribute 構文解析エラーであり、 新しい属性をトークンから削除しなければならない。
このように属性がトークンから削除された場合、その属性およびそれに関連付けられる値は、 存在する場合でも、その後構文解析器によって使用されることはなく、実質的に破棄される。 ただし、この方法で属性を削除しても、トークナイザーにおける「現在の属性」としての状態は変化しない。
次の入力 文字を消費する:
次の入力 文字を消費する:
次の 入力文字を消費する:
次の 入力文字を消費する:
次の入力 文字を消費する:
次の 入力文字を消費する:
次の入力 文字を消費する:
次の入力 文字を消費する:
次の数文字が以下である場合:
DOCTYPE」とASCII
大文字・小文字を区別せず一致するもの[CDATA[」[CDATA[」であるコメントトークンを作成する。偽コメント
状態へ切り替える。次の入力 文字を消費する:
次の入力 文字を消費する:
次の入力文字を消費する:
次の入力 文字を消費する:
次の 入力文字を消費する:
次の 入力文字を消費する:
次の入力文字を消費する:
次の入力 文字を消費する:
次の入力文字を消費する:
次の入力 文字を消費する:
次の入力文字を消費する:
次の入力 文字を消費する:
次の入力 文字を消費する:
次の入力 文字を消費する:
現在の入力文字から始まる六文字が
「PUBLIC」とASCII
大文字・小文字を区別せず一致する場合、その文字を消費してDOCTYPE public キーワードの後状態へ
切り替える。
それ以外で、現在の入力文字から始まる六文字が
「SYSTEM」とASCII
大文字・小文字を区別せず一致する場合、その文字を消費してDOCTYPE system キーワードの後状態へ
切り替える。
それ以外の場合、これはinvalid-character-sequence-after-doctype-name 構文解析エラーである。 現在の DOCTYPE トークンの強制互換モード フラグをオンに設定する。偽 DOCTYPE 状態で再消費する。
次の 入力文字を消費する:
次の 入力文字を消費する:
次の入力文字を消費する:
次の入力文字を消費する:
次の 入力文字を消費する:
次の入力文字を消費する:
次の入力 文字を消費する:
次の入力 文字を消費する:
次の入力文字を消費する:
次の入力文字を消費する:
次の入力文字を消費する:
次の入力 文字を消費する:
次の入力 文字を消費する:
U+0000 NULL 文字は、CDATA セクションが出現し得る唯一の場所である 外部 コンテンツ 内でトークンを構文解析するための規則の一部として、木構築段階で処理される。
次の入力 文字を消費する:
次の入力 文字を消費する:
次の 入力文字を消費する:
次の 入力文字を消費する:
target を、一時バッファー内のコード ポイントを、バッファーへ追加された順序で連結したものとする。
target が「xml」または「xml-stylesheet」とASCII
大文字・小文字を区別せず一致する場合:
それ以外の場合:
対象が target で、データが空文字列である処理命令トークンを作成する。
処理命令対象の後 状態で再消費する。
次の入力文字を消費する:
次の 入力文字を消費する:
次の入力文字を消費する:
一時 バッファーを空文字列に設定する。U+0026 AMPERSAND(&)文字を一時 バッファーへ付加する。次の入力文字を消費する:
消費される文字が名前付き文字参照表の最初の列にある 識別子の一つとなる範囲で、可能な限り多くの文字を消費する。各文字を消費したときに一時 バッファーへ付加する。
文字参照が属性の一部として 消費されたものであり、最後に一致した文字が U+003B SEMICOLON 文字(;)でなく、 次の入力 文字が U+003D EQUALS SIGN 文字(=)またはASCII 英数字のいずれかである場合、 歴史的な理由により、文字参照として 消費されたコードポイントをフラッシュし、復帰状態へ切り替える。
それ以外の場合:
最後に一致した文字が U+003B SEMICOLON 文字(;)でない場合、これはmissing-semicolon-after-character-reference 構文解析エラーである。
一時バッファーを空文字列に設定する。文字参照名に対応する 一つまたは二つの文字(名前付き文字参照表の 二番目の列に示されるもの)を一時バッファーへ付加する。
マークアップの属性外に文字列 I'm ¬it; I
tell you が含まれる場合、文字参照は「not」として構文解析され、I'm ¬it;
I tell you となる(これは構文解析エラーである)。一方、マークアップが I'm
∉ I tell you である場合、文字参照は「notin;」として構文解析され、
I'm ∉ I tell you となる(構文解析エラーは発生しない)。
ただし、文字列 I'm ¬it; I tell you が属性内に含まれる場合、
文字参照は構文解析されず、文字列はそのまま維持される(構文解析エラーも発生しない)。
次の入力 文字を消費する:
文字参照コードを ゼロ (0) に設定する。
次の 入力文字を消費する:
次の入力文字を消費する:
次の 入力文字を消費する:
次の 入力文字を消費する:
文字参照コードを確認する:
数値が 0x00 である場合、これはnull-character-reference 構文解析 エラーである。文字参照コードを 0xFFFD に設定する。
数値が 0x10FFFF より大きい場合、これはcharacter-reference-outside-unicode-range 構文解析エラーである。 文字参照 コードを 0xFFFD に設定する。
数値がサロゲートである場合、これはsurrogate-character-reference 構文解析エラーである。 文字参照 コードを 0xFFFD に設定する。
数値が非文字である場合、これは noncharacter-character-reference 構文解析エラーである。
数値が 0x0D であるか、または制御文字であってASCII 空白ではない場合、これはcontrol-character-reference 構文解析エラーである。 数値が次の表の最初の列にある数値の一つである場合、その数値が最初の列にある行を見つけ、 文字参照コードを、その行の二番目の列にある数値へ 設定する。
| 数値 | コードポイント | |
|---|---|---|
| 0x80 | 0x20AC | EURO SIGN(€) |
| 0x82 | 0x201A | SINGLE LOW-9 QUOTATION MARK(‚) |
| 0x83 | 0x0192 | LATIN SMALL LETTER F WITH HOOK(ƒ) |
| 0x84 | 0x201E | DOUBLE LOW-9 QUOTATION MARK(„) |
| 0x85 | 0x2026 | HORIZONTAL ELLIPSIS(…) |
| 0x86 | 0x2020 | DAGGER(†) |
| 0x87 | 0x2021 | DOUBLE DAGGER(‡) |
| 0x88 | 0x02C6 | MODIFIER LETTER CIRCUMFLEX ACCENT(ˆ) |
| 0x89 | 0x2030 | PER MILLE SIGN(‰) |
| 0x8A | 0x0160 | LATIN CAPITAL LETTER S WITH CARON(Š) |
| 0x8B | 0x2039 | SINGLE LEFT-POINTING ANGLE QUOTATION MARK(‹) |
| 0x8C | 0x0152 | LATIN CAPITAL LIGATURE OE(Œ) |
| 0x8E | 0x017D | LATIN CAPITAL LETTER Z WITH CARON(Ž) |
| 0x91 | 0x2018 | LEFT SINGLE QUOTATION MARK(‘) |
| 0x92 | 0x2019 | RIGHT SINGLE QUOTATION MARK(’) |
| 0x93 | 0x201C | LEFT DOUBLE QUOTATION MARK(“) |
| 0x94 | 0x201D | RIGHT DOUBLE QUOTATION MARK(”) |
| 0x95 | 0x2022 | BULLET(•) |
| 0x96 | 0x2013 | EN DASH(–) |
| 0x97 | 0x2014 | EM DASH(—) |
| 0x98 | 0x02DC | SMALL TILDE(˜) |
| 0x99 | 0x2122 | TRADE MARK SIGN(™) |
| 0x9A | 0x0161 | LATIN SMALL LETTER S WITH CARON(š) |
| 0x9B | 0x203A | SINGLE RIGHT-POINTING ANGLE QUOTATION MARK(›) |
| 0x9C | 0x0153 | LATIN SMALL LIGATURE OE(œ) |
| 0x9E | 0x017E | LATIN SMALL LETTER Z WITH CARON(ž) |
| 0x9F | 0x0178 | LATIN CAPITAL LETTER Y WITH DIAERESIS(Ÿ) |
一時 バッファーを空文字列に設定する。文字参照コードと等しいコードポイントを一時 バッファーへ付加する。文字参照として 消費されたコードポイントをフラッシュする。復帰状態へ切り替える。
ツリー構築段階への入力は、トークン化段階からのトークン列である。構文解析器が
作成されると、ツリー構築段階は DOM Document オブジェクトに関連付けられる。
この段階の「出力」は、その文書の DOM ツリーを動的に変更または拡張することで構成される。
この仕様は、対話型ユーザーエージェントが、ユーザーに利用可能となるようにいつ Document をレンダリングしなければ
ならないか、またはいつユーザー入力の受け付けを開始しなければならないかを定義しない。
各トークンがトークナイザーから発行されるたびに、ユーザーエージェントは、ツリー構築ディスパッチャーと呼ばれる次の一覧から、 適切な手順に従わなければならない:
annotation-xml 要素であり、トークンがタグ名「svg」の開始タグである場合次のトークンとは、ツリー 構築ディスパッチャーによって、これから処理されようとしているトークンである (そのトークンが後で単に無視される場合も含む)。
ノードがMathML テキスト統合点であるとは、 次の要素の一つである場合をいう:
mi 要素mo 要素mn 要素ms 要素mtext 要素ノードがHTML 統合点であるとは、 次の要素の一つである場合をいう:
annotation-xml 要素であり、その開始タグトークンが、
名前が「encoding」で、値が「text/html」とASCII
大文字・小文字を区別せず一致する属性を持っていたものannotation-xml 要素であり、その開始タグトークンが、
名前が「encoding」で、値が「application/xhtml+xml」とASCII
大文字・小文字を区別せず一致する属性を持っていたものforeignObject 要素desc 要素title 要素問題のノードが、HTML 断片 構文解析アルゴリズムへ渡されたコンテキスト要素である場合、その要素の開始タグトークンは、 そのHTML 断片構文解析アルゴリズム中に作成された 「偽の」トークンである。
以下で言及されるタグ名のすべてが、この仕様に適合するタグ名であるとは限らない。 多くはレガシーコンテンツを処理するために含まれている。これらも、実装が適合性を主張するために 実装しなければならないアルゴリズムの一部を形成する。
以下で説明するアルゴリズムは、生成される DOM ツリーの深さ、タグ名、属性名、
属性値、Text ノードなどの長さに制限を
設けない。実装者には任意の制限を
避けることが推奨されるが、実際上の事情により、ユーザーエージェントが入れ子の深さへ
制約を課さざるを得ない可能性が高いことは認識されている。
構文解析器がトークンを処理している間、里親処理を有効または 無効にできる。これは次のアルゴリズムへ影響する。
ノードを挿入する適切な位置とは、 任意で特定の上書き対象を使用して、次の手順を実行することで返される要素内の位置である:
上書き対象が指定されている場合、target を 上書き対象とする。
それ以外の場合、target を現在のノードとする。
次の一覧から最初に一致する手順を使用して、adjusted insertion location を決定する:
table、
tbody、tfoot、
thead、または
tr 要素である場合
里親処理は、コンテンツが表内で誤って入れ子にされている場合に行われる。
次の下位手順を実行する:
last template を、存在する場合は開いている
要素のスタック内の最後の template 要素とする。
last table を、存在する場合は開いている
要素のスタック内の最後の table 要素とする。
last template が存在し、かつ last table が存在しないか、 存在しても last template が開いている 要素のスタック内で last table より下 (より最近に追加された位置)にある場合、adjusted insertion location を last template のテンプレート内容内の、 最後の子の後(子がある場合)とし、これらの手順を中止する。
last table が存在しない場合、adjusted insertion
location を開いている要素のスタック内の
最初の要素(html 要素)内の、最後の子の後(子がある場合)とし、
これらの手順を中止する。
(断片の場合)
last table が親ノードを持つ場合、adjusted insertion location を last table の親ノード内の、last table の直前とし、 これらの手順を中止する。
previous element を、開いている 要素のスタック内で last table の直上にある要素とする。
adjusted insertion location を previous element 内の、最後の子の後(子がある場合)とする。
これらの手順が必要となる理由の一つは、要素、特にこの場合の table 要素が、構文解析器によって挿入された後に
スクリプトによって DOM 内の別の場所へ移動されたり、DOM から完全に削除されたりする
可能性があるためである。
adjusted insertion location を target 内の、 最後の子の後(子がある場合)とする。
adjusted insertion location が template 要素内にある場合、代わりにそれを
template 要素のテンプレート内容内の、
最後の子の後(子がある場合)とする。
adjusted insertion location を返す。
トークン token、文字列 namespace、および Node オブジェクト
intendedParent が与えられたとき、トークン用の要素を作成するには:
アクティブな投機的 HTML 構文解析器が null でない場合、namespace、token のタグ名、 および token の属性が与えられたときに投機的モック要素を作成する結果を 返す。
それ以外の場合、任意で namespace、token のタグ名、および token の属性が与えられたときに投機的モック要素を作成する。
結果は使用されない。この手順により、非投機的構文解析から投機的フェッチを開始できる。 この時点でもフェッチが投機的なのは、たとえば要素が挿入されるまでに intendedParent が文書から削除される可能性があるためである。
document を、intendedParent のノード文書とする。
localName を token のタグ名とする。
is を、存在する場合は token 内の「is」属性の値とし、
それ以外の場合は null とする。
registry を、intendedParent が与えられたときにカスタム要素レジストリーを 検索する結果とする。
definition を、registry、namespace、 localName、および is が与えられたときにカスタム要素定義を検索する 結果とする。
definition が null でなく、かつ構文解析器がHTML 断片構文解析アルゴリズムの 一部として作成されていない場合、willExecuteScript を true とする。それ以外の場合は false とする。
willExecuteScript が true である場合:
document の動的マークアップ挿入時 スローカウンターを増加させる。
新しい要素キューを document の関連 エージェントのカスタム要素リアクション スタックへプッシュする。
element を、document、localName、 namespace、null、is、willExecuteScript、および registry が与えられたときに要素を作成する結果とする。
willExecuteScript が true である場合、これによりカスタム要素 コンストラクターが実行される。ただし、動的マークアップ挿入時 スローカウンターを増加させているため、これによって新しい文字がトークナイザーへ挿入される ことも、文書が消去されることもない。
指定されたトークン内の各属性を element へ付加する。
これにより、attributeChangedCallback 用のカスタム要素コールバック
リアクションをキューすることがあり、そのリアクションは直ちに
(次の手順で)実行される可能性がある。
is 属性はカスタマイズされた組み込み要素の作成を制御するが、
関連するカスタム要素コンストラクターの
実行中には存在しない。この手順で、その他すべての属性とともに付加される。
willExecuteScript が true である場合:
queue を、document の関連 エージェントのカスタム要素リアクション スタックからポップした結果とする。(これは上でプッシュされたものと同じ要素キューとなる。)
queue 内のカスタム要素リアクションを 呼び出す。
document の動的マークアップ挿入時 スローカウンターを減少させる。
element が、値が要素の名前空間と厳密に同じでない xmlns 属性を
XMLNS
名前空間内に持つ場合、これは構文解析エラーである。同様に、
element がXMLNS 名前空間内に
xmlns:xlink 属性を持ち、
その値がXLink 名前空間でない場合、これは構文解析エラーである。
element がリセット可能要素であり、 フォーム関連カスタム要素でない場合、 そのリセットアルゴリズムを呼び出す。 (これにより、要素の属性に基づいて、要素の値およびチェック状態が初期化される。)
element がフォーム関連要素であり、
フォーム関連カスタム要素ではなく、
form
要素ポインターが null でなく、開いている要素のスタック上に
template 要素がなく、element が列挙対象でないか、
form 属性を持たず、かつ intendedParent がform 要素
ポインターによって指される要素と同じツリー内にある場合、element をform 要素
ポインターによって指される form 要素へ関連付け、
element の構文解析器挿入済みフラグを設定する。
element を返す。
任意の挿入位置 insertionLocation(既定値は null)を使用して調整済み挿入位置を計算するには:
insertionLocation が null である場合、overrideTarget を null とする。 それ以外の場合、insertionLocation が含まれるノードとする。
adjustedInsertionLocation を、overrideTarget が与えられたときのノードを挿入する 適切な位置とする。
adjustedInsertionLocation が含まれるノードが開いている要素のスタック内の 最初の要素であり、構文解析器のルート挿入 対象が null でない場合、adjustedInsertionLocation を構文解析器の ルート挿入対象内の、 最後の子の後(子がある場合)に設定する。
adjustedInsertionLocation を返す。
要素 element を使用して、調整済み挿入位置に要素を挿入するには:
insertionLocation を調整済み挿入位置とする。
insertionLocation へ element を挿入できない場合、 これらの手順を中止する。
構文解析器がHTML 断片構文解析 アルゴリズムの一部として作成されていない場合、新しい要素キューを element の 関連エージェントのカスタム要素リアクション スタックへプッシュする。
element を insertionLocation へ挿入する。
構文解析器がHTML 断片構文解析 アルゴリズムの一部として作成されていない場合、element の関連エージェントのカスタム要素リアクション スタックから要素キューをポップし、そのキュー内のカスタム要素リアクションを 呼び出す。
調整済み挿入位置がそれ以上の要素を
受け入れられない場合、たとえば、すでに要素の子を持つ Document である場合、
element は破棄される。
トークン token、文字列 namespace、および真偽値 onlyAddToElementStack が与えられたとき、外来要素を挿入するには:
adjustedInsertionLocation をノードを挿入する 適切な位置とする。
element を、token、namespace、および adjustedInsertionLocation が含まれる要素が与えられたときにトークン用の要素を作成する 結果とする。
onlyAddToElementStack が false である場合、element を使用して調整済み 挿入位置に要素を挿入する。
element を開いている要素のスタックへ プッシュし、新しい現在のノードとする。
element を返す。
以下の手順がユーザーエージェントに、トークンのMathML 属性を調整するよう要求する場合、
トークンが definitionurl という名前の属性を持つなら、その名前を
definitionURL へ変更する(大文字と小文字の違いに注意)。
以下の手順がユーザーエージェントに、トークンのSVG 属性を調整するよう要求する場合、 トークン上の各属性について、その属性名が次の表の最初の列にあるものの一つであるなら、 属性名を二番目の列の対応するセルに示される名前へ変更する。 (これにより、すべて小文字ではない SVG 属性の大文字と小文字が修正される。)
| トークン上の属性名 | 要素上の属性名 |
|---|---|
attributename |
attributeName
|
attributetype |
attributeType
|
basefrequency |
baseFrequency
|
baseprofile |
baseProfile
|
calcmode |
calcMode
|
clippathunits |
clipPathUnits
|
diffuseconstant |
diffuseConstant
|
edgemode |
edgeMode
|
filterunits |
filterUnits
|
glyphref |
glyphRef
|
gradienttransform |
gradientTransform
|
gradientunits |
gradientUnits
|
kernelmatrix |
kernelMatrix
|
kernelunitlength |
kernelUnitLength
|
keypoints |
keyPoints
|
keysplines |
keySplines
|
keytimes |
keyTimes
|
lengthadjust |
lengthAdjust
|
limitingconeangle |
limitingConeAngle
|
markerheight |
markerHeight
|
markerunits |
markerUnits
|
markerwidth |
markerWidth
|
maskcontentunits |
maskContentUnits
|
maskunits |
maskUnits
|
numoctaves |
numOctaves
|
pathlength |
pathLength
|
patterncontentunits |
patternContentUnits
|
patterntransform |
patternTransform
|
patternunits |
patternUnits
|
pointsatx |
pointsAtX
|
pointsaty |
pointsAtY
|
pointsatz |
pointsAtZ
|
preservealpha |
preserveAlpha
|
preserveaspectratio |
preserveAspectRatio
|
primitiveunits |
primitiveUnits
|
refx |
refX
|
refy |
refY
|
repeatcount |
repeatCount
|
repeatdur |
repeatDur
|
requiredextensions |
requiredExtensions
|
requiredfeatures |
requiredFeatures
|
specularconstant |
specularConstant
|
specularexponent |
specularExponent
|
spreadmethod |
spreadMethod
|
startoffset |
startOffset
|
stddeviation |
stdDeviation
|
stitchtiles |
stitchTiles
|
surfacescale |
surfaceScale
|
systemlanguage |
systemLanguage
|
tablevalues |
tableValues
|
targetx |
targetX
|
targety |
targetY
|
textlength |
textLength
|
viewbox |
viewBox
|
viewtarget |
viewTarget
|
xchannelselector |
xChannelSelector
|
ychannelselector |
yChannelSelector
|
zoomandpan |
zoomAndPan
|
以下の手順がユーザーエージェントに、トークンの外来属性を調整するよう要求する場合、
トークン上の属性のいずれかが次の表の最初の列に示される文字列と一致するなら、
その属性を名前空間付き属性とする。その接頭辞は二番目の列の対応するセルに示される文字列、
ローカル名は三番目の列の対応するセルに示される文字列、名前空間は四番目の列の対応するセルに
示される名前空間とする。(これにより、名前空間付き属性、特にXML 名前空間内の
lang 属性の使用が修正される。)
| 属性名 | 接頭辞 | ローカル名 | 名前空間 |
|---|---|---|---|
xlink:actuate |
xlink |
actuate |
XLink 名前空間 |
xlink:arcrole |
xlink |
arcrole |
XLink 名前空間 |
xlink:href |
xlink |
href |
XLink 名前空間 |
xlink:role |
xlink |
role |
XLink 名前空間 |
xlink:show |
xlink |
show |
XLink 名前空間 |
xlink:title |
xlink |
title |
XLink 名前空間 |
xlink:type |
xlink |
type |
XLink 名前空間 |
xml:lang |
xml |
lang |
XML 名前空間 |
xml:space |
xml |
space |
XML 名前空間 |
xmlns |
(なし) | xmlns |
XMLNS 名前空間 |
xmlns:xlink |
xmlns |
xlink |
XMLNS 名前空間 |
以下の手順が、トークンの処理中にユーザーエージェントへ文字を挿入するよう要求する場合、ユーザーエージェントは 次の手順を実行しなければならない:
data を、このアルゴリズムへ渡された文字、または文字が明示的に 指定されていない場合は、処理中の文字トークンの文字とする。
insertionLocation を調整済み挿入位置とする。
insertionLocation が Document ノード内にある場合、返る。
insertionLocation の直前に Text ノードがある場合、
data をその Text ノードのデータへ付加する。
それ以外の場合、textを、insertionLocationが存在する要素のノード文書 および dataを与えてテキスト ノードを作成した結果とし、textを insertionLocationに挿入する。
以下は、パーサーへの入力例と、それらによって生成される Text
ノードの対応する数であり、スクリプトを実行するユーザーエージェントを前提とする。
| 入力 | Text
ノードの数
|
|---|---|
|
文書内の 1 つの Text
ノードで、「AB」を含む。
|
|
3 つの Text
ノード。スクリプトの前の「A」、スクリプトの内容、およびスクリプトの後の「BC」(パーサーは、スクリプトによって作成された
Text
ノードに追加する)。
|
|
文書内の隣接する 2 つの Text
ノードで、「A」と「BC」を含む。
|
|
table の前にある 1 つの Text
ノードで、「ABCD」を含む。(これはフォスターペアレンティングによって生じる。)
|
|
table の前にある 1 つの Text
ノードで、「A B C」(A-空白-B-空白-C)を含む。(これはフォスターペアレンティングによって生じる。)
|
|
table の前にある 1 つの Text
ノードで、「A BC」(A-空白-B-C)を含み、table 内(tbodyの子として)に
1 つの Text
ノードがあり、
1 つの空白文字を含む。(文字でないトークンによって非空白文字から分離された空白文字は、
それらの他のトークンが後で無視される場合でも、フォスター
ペアレンティングの影響を受けない。)
|
以下の手順が、コメントトークンの処理中にユーザーエージェントへコメントを挿入するよう要求する場合、任意の挿入位置 insertionLocation(既定値は null)を使用して、ユーザーエージェントは 次の手順を実行しなければならない:
dataを、処理されているコメントトークンで 与えられたデータとする。
insertionLocationを、insertionLocationを与えた調整済み挿入位置に 設定する。
commentを、insertionLocationが存在するノードのノード文書 および dataを与えてコメント ノードを作成した結果とする。
commentをinsertionLocationに挿入する。
以下の手順が、処理命令トークンを処理している間に、オプションの挿入位置 insertionLocation(既定値は null)を用いて、ユーザーエージェントに処理 命令を挿入することを要求する場合、ユーザーエージェントは次の手順を実行しなければならない:
targetを、処理されている処理命令トークンで 与えられたターゲットとする。
dataを、処理されている処理命令トークンで 与えられたデータとする。
insertionLocationを、insertionLocationを与えた調整済み挿入位置に 設定する。
piを、insertionLocationが存在する ノードのノード文書、target、および dataを与えて処理命令ノードを作成した結果とする。
piをinsertionLocationに挿入する。
汎用生テキスト要素構文解析アルゴリズムおよび 汎用 RCDATA 要素 構文解析アルゴリズムは、次の手順から構成される。これらのアルゴリズムは常に 開始タグトークンへの応答として呼び出される。
そのトークン用のHTML 要素を 挿入する。
呼び出されたアルゴリズムが汎用生テキスト 要素構文解析 アルゴリズムである場合、トークナイザーをRAWTEXT 状態へ切り替える。 それ以外の場合、呼び出されたアルゴリズムは汎用 RCDATA 要素 構文解析アルゴリズムであるため、トークナイザーを RCDATA 状態へ 切り替える。
以下の手順が UA に暗黙の終了タグを生成するよう要求する場合、
現在のノードが dd 要素、dt 要素、
li 要素、optgroup 要素、option 要素、
p 要素、rb 要素、rp 要素、rt 要素、または rtc 要素である間、
UA は現在のノードを
開いている
要素のスタックからポップしなければならない。
ある手順が UA に暗黙の終了タグを生成するよう要求しつつ、その処理から除外する要素を 列挙している場合、UA は、その要素が上の一覧にないものとして上記の手順を実行しなければならない。
以下の手順が UA にすべての暗黙の終了タグを
徹底的に生成するよう要求する場合、現在の
ノードが caption 要素、
colgroup 要素、dd 要素、dt 要素、
li 要素、optgroup 要素、option 要素、
p 要素、rb 要素、rp 要素、rt 要素、rtc 要素、tbody 要素、td 要素、
tfoot 要素、th 要素、thead 要素、または
tr 要素である間、UA は現在のノードを
開いている
要素のスタックからポップしなければならない。
Document オブジェクトには、
関連付けられた構文解析器はモードフラグを変更できない
フラグ(真偽値)がある。初期値は false である。
ユーザーエージェントが「初期」挿入モードの規則を適用する場合、 ユーザーエージェントはトークンを次のように処理しなければならない:
トークンを無視する。
DOCTYPE トークンの名前が「html」でないか、トークンの公開
識別子が欠落していないか、またはトークンのシステム識別子が欠落しておらず、かつ
「about:legacy-compat」でもない場合、
構文解析エラーがある。
doctypeを、Document
ノード、DOCTYPE トークンで与えられた名前(名前が
欠落していた場合は空文字列)、DOCTYPE トークンで与えられた公開識別子(公開識別子が
欠落していた場合は空文字列)、および
DOCTYPE トークンで与えられたシステム識別子(システム識別子が欠落していた場合は空文字列)を与えて文書型を
作成した結果とする。次に、
doctypeを Document
ノードに付加する。
これにより、DocumentType
ノードが、
Document オブジェクトの
doctype
属性の値として返されることも保証される。
次に、文書がiframe
srcdoc 文書でなく、パーサーが
モードフラグを変更できないが false であり、かつ DOCTYPE トークンが
次の一覧の条件のいずれかに一致する場合、Documentを互換モードに設定する:
html」でない。 -//W3O//DTD W3 HTML Strict 3.0//EN//」に設定されている。 -/W3C/DTD HTML 4.0 Transitional/EN」に設定されている。 HTML」に設定されている。 http://www.ibm.com/data/dtd/v11/ibmxhtml1-transitional.dtd」に設定されている。 +//Silmaril//dtd html Pro v0r11 19970101//」で始まる。 -//AS//DTD HTML 3.0 asWedit + extensions//」で始まる。 -//AdvaSoft Ltd//DTD HTML 3.0 asWedit + extensions//」で始まる。
-//IETF//DTD HTML 2.0 Level 1//」で始まる。 -//IETF//DTD HTML 2.0 Level 2//」で始まる。 -//IETF//DTD HTML 2.0 Strict Level 1//」で始まる。 -//IETF//DTD HTML 2.0 Strict Level 2//」で始まる。 -//IETF//DTD HTML 2.0 Strict//」で始まる。 -//IETF//DTD HTML 2.0//」で始まる。 -//IETF//DTD HTML 2.1E//」で始まる。 -//IETF//DTD HTML 3.0//」で始まる。 -//IETF//DTD HTML 3.2 Final//」で始まる。 -//IETF//DTD HTML 3.2//」で始まる。 -//IETF//DTD HTML 3//」で始まる。 -//IETF//DTD HTML Level 0//」で始まる。 -//IETF//DTD HTML Level 1//」で始まる。 -//IETF//DTD HTML Level 2//」で始まる。 -//IETF//DTD HTML Level 3//」で始まる。 -//IETF//DTD HTML Strict Level 0//」で始まる。 -//IETF//DTD HTML Strict Level 1//」で始まる。 -//IETF//DTD HTML Strict Level 2//」で始まる。 -//IETF//DTD HTML Strict Level 3//」で始まる。 -//IETF//DTD HTML Strict//」で始まる。 -//IETF//DTD HTML//」で始まる。 -//Metrius//DTD Metrius Presentational//」で始まる。 -//Microsoft//DTD Internet Explorer 2.0 HTML Strict//」で始まる。
-//Microsoft//DTD Internet Explorer 2.0 HTML//」で始まる。 -//Microsoft//DTD Internet Explorer 2.0 Tables//」で始まる。 -//Microsoft//DTD Internet Explorer 3.0 HTML Strict//」で始まる。
-//Microsoft//DTD Internet Explorer 3.0 HTML//」で始まる。 -//Microsoft//DTD Internet Explorer 3.0 Tables//」で始まる。 -//Netscape Comm. Corp.//DTD HTML//」で始まる。 -//Netscape Comm. Corp.//DTD Strict HTML//」で始まる。 -//O'Reilly and Associates//DTD HTML 2.0//」で始まる。 -//O'Reilly and Associates//DTD HTML Extended 1.0//」で始まる。
-//O'Reilly and Associates//DTD HTML Extended Relaxed 1.0//」で始まる。 -//SQ//DTD HTML 2.0 HoTMetaL + extensions//」で始まる。 -//SoftQuad Software//DTD HoTMetaL PRO 6.0::19990601::extensions to HTML 4.0//」で始まる。 -//SoftQuad//DTD HoTMetaL PRO 4.0::19971010::extensions to HTML 4.0//」で始まる。 -//Spyglass//DTD HTML 2.0 Extended//」で始まる。 -//Sun Microsystems Corp.//DTD HotJava HTML//」で始まる。 -//Sun Microsystems Corp.//DTD HotJava Strict HTML//」で始まる。
-//W3C//DTD HTML 3 1995-03-24//」で始まる。 -//W3C//DTD HTML 3.2 Draft//」で始まる。 -//W3C//DTD HTML 3.2 Final//」で始まる。 -//W3C//DTD HTML 3.2//」で始まる。 -//W3C//DTD HTML 3.2S Draft//」で始まる。 -//W3C//DTD HTML 4.0 Frameset//」で始まる。 -//W3C//DTD HTML 4.0 Transitional//」で始まる。 -//W3C//DTD HTML Experimental 19960712//」で始まる。 -//W3C//DTD HTML Experimental 970421//」で始まる。 -//W3C//DTD W3 HTML//」で始まる。 -//W3O//DTD W3 HTML 3.0//」で始まる。 -//WebTechs//DTD Mozilla HTML 2.0//」で始まる。 -//WebTechs//DTD Mozilla HTML//」で始まる。 -//W3C//DTD HTML 4.01 Frameset//」で始まる。 -//W3C//DTD HTML 4.01 Transitional//」で始まる。 それ以外の場合、文書がiframe srcdoc
文書でなく、パーサーが
モードフラグを変更できないが false であり、かつ DOCTYPE トークンが
次の一覧の条件のいずれかに一致する場合、Documentを限定互換モードに設定する:
-//W3C//DTD XHTML 1.0 Frameset//」で始まる。 -//W3C//DTD XHTML 1.0 Transitional//」で始まる。 -//W3C//DTD HTML 4.01 Frameset//」で始まる。 -//W3C//DTD HTML 4.01 Transitional//」で始まる。 システム識別子および公開識別子の文字列は、上記の一覧で与えられた値と ASCII 大文字・小文字を区別しない方法で比較しなければならない。値が 空文字列であるシステム識別子は、上記の条件の目的上、欠落しているとは見なされない。
文書がiframe srcdoc
文書でない場合、これは構文解析
エラーである。パーサーがモードフラグを変更できない
が false である場合、
Documentを互換モードに設定する。
ユーザーエージェントが「html の前」挿入モードの規則を適用する場合、 ユーザーエージェントはトークンを次のように処理しなければならない:
構文解析エラー。 そのトークンを無視する。
そのトークンを無視する。
Document を意図された親として、HTML
名前空間内にそのトークン用の要素を作成する。
それを Document オブジェクトへ付加する。この要素を開いている要素のスタックへ入れる。
以下の「その他の場合」の項目で説明されるように動作する。
構文解析エラー。 そのトークンを無視する。
ノード文書が Document オブジェクトである html 要素を作成する。それを Document オブジェクトへ付加する。この要素を開いている
要素のスタックへ入れる。
文書要素は、たとえばスクリプトによって Document オブジェクトから削除されることがある。そのような場合でも
特別なことは何も起こらず、次の節で説明するように、コンテンツは引き続きノードへ付加される。
ユーザーエージェントが「head の前」挿入モードの規則を適用する場合、 ユーザーエージェントはトークンを次のように処理しなければならない:
そのトークンを無視する。
構文解析エラー。 そのトークンを無視する。
そのトークン用のHTML 要素を挿入する。
head
要素ポインターを、
新しく作成された head 要素へ設定する。
以下の「その他の場合」の項目で説明されるように動作する。
構文解析エラー。 そのトークンを無視する。
属性を持たない「head」開始タグトークン用のHTML 要素を挿入する。
head
要素ポインターを、
新しく作成された head 要素へ設定する。
現在のトークンを再処理する。
ユーザーエージェントが「head 内」挿入モードの規則を適用する場合、 ユーザーエージェントはトークンを次のように処理しなければならない:
構文解析エラー。 そのトークンを無視する。
そのトークン用のHTML 要素を挿入する。 直ちに現在の ノードを開いている 要素のスタックからポップする。
設定されている場合、トークンの自己終了フラグを確認する。
そのトークン用のHTML 要素を挿入する。直ちに現在の ノードを開いている 要素のスタックからポップする。
設定されている場合、トークンの自己終了フラグを確認する。
アクティブな投機的 HTML 構文解析器が null である場合:
要素が charset 属性を持ち、その値からエンコーディングを取得する結果がエンコーディングとなり、かつ確信度が現在
暫定的である場合、結果のエンコーディングへエンコーディングを変更する。
それ以外で、要素が、値が「Content-Type」とASCII 大文字・小文字を区別せず一致する
http-equiv 属性を持ち、要素が content 属性を持ち、その属性の値へmeta
要素から文字エンコーディングを抽出するアルゴリズムを適用した結果がエンコーディングとなり、かつ確信度が現在
暫定的である場合、抽出されたエンコーディングへエンコーディングを変更する。
投機的 HTML 構文解析器は、 実装の複雑さを軽減するため、文字エンコーディング宣言を投機的に適用しない。
そのトークン用のHTML 要素を挿入する。
挿入モードを「head noscript 内」へ切り替える。
次の手順を実行する:
adjustedInsertionLocation をノードを挿入する 適切な位置とする。
adjustedInsertionLocation が含まれる要素を意図された親として、HTML 名前空間内にそのトークン用の要素を作成する。
スクリプティングモードが断片でない場合、
要素の構文解析器文書を Document に設定する。
断片
スクリプティングモードは、構文解析器によって挿入されたスクリプトを、
構文解析器によって挿入されていないものとして扱う。これにより、たとえば
createContextualFragment() によって
作成された断片を適用するときにスクリプトを実行できる。
要素の強制 asyncを false に設定する。
これにより、スクリプトが外部スクリプトである場合、スクリプト内の
document.write() 呼び出しが、他の多くの場合のように
文書を消去するのではなく、インラインで実行されることが保証される。また、終了タグが
検出されるまでスクリプトが実行されることも防止される。
構文解析器のスクリプティングモードが不活性である場合、script 要素のすでに開始済みを true に設定する。
(断片の場合)
構文解析器が document.write() または document.writeln() メソッドによって呼び出された場合、
任意で script 要素のすでに開始済みを true に設定する。
(たとえば、ユーザーエージェントはこの条項を使用して、低速なネットワーク状況下、
またはページの読み込みにすでに長時間かかっている場合に、document.write() によって挿入されたクロスオリジンスクリプトの実行を防止できる。)
新しく作成した要素を、adjustedInsertionLocation が与えられたときの調整済み挿入位置へ挿入する。
要素を開いている要素のスタックへプッシュし、 新しい現在のノードとする。
トークナイザーをスクリプトデータ状態へ切り替える。
現在のノード
(これは head 要素となる)を開いている
要素のスタックからポップする。
以下の「その他の場合」の項目で説明されるように動作する。
次の手順を実行する:
templateStartTag を開始タグとする。
アクティブな書式設定要素の リストの末尾にマーカーを挿入する。
frameset-ok フラグを 「not ok」に設定する。
挿入モードを「template 内」へ切り替える。
「template 内」をtemplate 挿入モードのスタックへ プッシュし、新しい現在の template 挿入モードとする。
adjustedInsertionLocation をノードを挿入する 適切な位置とする。
intendedParent を、adjustedInsertionLocation が含まれる要素とする。
document を、intendedParent のノード 文書とする。
次のいずれかが false である場合:
shadowrootmode がなし状態でない。その場合、そのトークン用のHTML 要素を挿入する。
それ以外の場合:
declarativeShadowHostElement を調整済み現在 ノードとする。
template を、templateStartTag、HTML 名前空間、および true が与えられたときに外来要素を挿入する結果とする。
mode を、templateStartTag の shadowrootmode 属性の値とする。
slotAssignment を「named」とする。
templateStartTag の shadowrootslotassignment 属性が
手動状態である場合、
slotAssignment を「manual」に設定する。
templateStartTag が shadowrootclonable 属性を持つ場合、
clonable を true とする。それ以外の場合は false とする。
templateStartTag が shadowrootserializable 属性を持つ場合、
serializable を true とする。それ以外の場合は false とする。
templateStartTag が shadowrootdelegatesfocus 属性を持つ場合、
delegatesFocus を true とする。それ以外の場合は false とする。
declarativeShadowHostElement がシャドウ ホストである場合、template を使用して調整済み挿入位置に 要素を挿入する。
それ以外の場合:
templateStartTag が shadowrootcustomelementregistry
属性を持つ場合、registry を null とする。それ以外の場合、
declarativeShadowHostElement のノード文書のカスタム要素レジストリーとする。
declarativeShadowHostElement、mode、 clonable、serializable、delegatesFocus、 slotAssignment、および registry を使用してシャドウルートを付加する。
例外がスローされた場合、それを捕捉して次を行う:
template を使用して調整済み 挿入位置に要素を挿入する。
ユーザーエージェントは、開発者コンソールへエラーを報告してもよい。
返る。
shadow を、declarativeShadowHostElement のシャドウルートとする。
shadow の宣言的を true に設定する。
template のテンプレート内容を shadow に設定する。
shadow の要素内部から利用可能を true に 設定する。
templateStartTag が shadowrootcustomelementregistry
属性を持つ場合、shadow のカスタム要素レジストリーを null のまま
保つを true に設定する。
開いている要素のスタック上に template 要素がない場合、これは構文解析エラーである。そのトークンを無視する。
それ以外の場合、次の手順を実行する:
template 要素がスタックからポップされるまで、
開いている要素のスタックから
要素をポップする。
現在の template 挿入モードを template 挿入モードのスタックからポップする。
構文解析エラー。 そのトークンを無視する。
現在のノード
(これは head 要素となる)を開いている
要素のスタックからポップする。
そのトークンを再処理する。
ユーザーエージェントが「head noscript 内」挿入モードの規則を適用する場合、ユーザーエージェントは トークンを次のように処理しなければならない:
構文解析エラー。 そのトークンを無視する。
現在のノード
(これは noscript
要素となる)を
開いている要素のスタックからポップする。
新しい現在のノードは
head 要素と
なる。
以下の「その他の場合」の項目で説明されるように動作する。
構文解析エラー。 そのトークンを無視する。
現在のノード
(これは noscript
要素となる)を
開いている要素のスタックからポップする。
新しい現在のノードは
head 要素と
なる。
そのトークンを再処理する。
ユーザーエージェントが「head の後」挿入モードの規則を適用する場合、 ユーザーエージェントはトークンを次のように処理しなければならない:
構文解析エラー。 そのトークンを無視する。
そのトークン用のHTML 要素を挿入する。
frameset-ok フラグを 「not ok」に設定する。
そのトークン用のHTML 要素を挿入する。
挿入モードを「frameset 内」へ切り替える。
head
要素ポインターが指す
ノードを開いている要素のスタックへプッシュする。
「head 内」挿入モードの規則を使用してトークンを処理する。
head
要素ポインターが指す
ノードを開いている要素のスタックから
削除する。(この時点では現在のノードでない可能性がある。)
この時点で、head 要素ポインターが
null であることはない。
以下の「その他の場合」の項目で説明されるように動作する。
構文解析エラー。 そのトークンを無視する。
属性を持たない「body」開始タグトークン用のHTML 要素を挿入する。
現在のトークンを再処理する。
ユーザーエージェントが「body 内」挿入モードの規則を 適用する場合、ユーザーエージェントはトークンを次のように処理しなければならない:
構文解析エラー。 そのトークンを無視する。
存在する場合、アクティブな書式設定要素を 再構築する。
存在する場合、アクティブな書式設定要素を 再構築する。
frameset-ok フラグを 「not ok」に設定する。
構文解析エラー。 そのトークンを無視する。
開いている要素のスタック上に template 要素が
ある場合、そのトークンを無視する。
それ以外の場合、トークン上の各属性について、その属性が開いている要素のスタック内の最上位要素に すでに存在するかどうかを確認する。存在しない場合、その属性および対応する値をその要素へ 追加する。
開いている要素のスタックにノードが一つしか
ない場合、または開いている要素のスタック内の二番目の要素が
body 要素でない
場合、または開いている要素のスタック上に
template
要素がある場合、そのトークンを無視する。
(断片の場合、またはスタック上に
template
要素がある場合)
それ以外の場合、frameset-ok
フラグを「not ok」に設定する。次に、トークン上の各属性について、その属性が開いている要素のスタック内の
body 要素
(二番目の要素)にすでに存在するかどうかを確認し、存在しない場合、その属性および対応する値を
その要素へ追加する。
開いている要素のスタックにノードが一つしか
ない場合、または開いている要素のスタック内の二番目の要素が
body 要素でない
場合、そのトークンを無視する。(断片の場合、またはスタック上に
template
要素がある場合)
frameset-ok フラグが 「not ok」に設定されている場合、そのトークンを無視する。
それ以外の場合、次の手順を実行する:
開いている要素のスタック内の二番目の要素に 親ノードがある場合、その親ノードから二番目の要素を削除する。
開いている要素のスタックの最下位から、
現在のノードからルートの
html 要素の
直前までのすべてのノードをポップする。
そのトークン用のHTML 要素を挿入する。
挿入モードを「frameset 内」へ切り替える。
template 挿入モードのスタックが 空でない場合、「template 内」挿入モードの規則を使用してトークンを処理する。
それ以外の場合、次の手順に従う:
開いている要素のスタックがスコープ内に body
要素を持たない
場合、これは構文解析エラーである。
そのトークンを無視する。
それ以外で、開いている要素のスタック内に、
dd 要素、dt 要素、li 要素、optgroup 要素、
option 要素、
p 要素、rb 要素、rp 要素、rt 要素、rtc 要素、tbody 要素、td 要素、tfoot 要素、th 要素、thead 要素、tr 要素、body 要素、または
html 要素の
いずれでもないノードがある場合、これは構文解析エラーである。
開いている要素のスタックがスコープ内に body
要素を持たない
場合、これは
構文解析エラーである。
そのトークンを無視する。
それ以外で、開いている要素のスタック内に、
dd 要素、dt 要素、li 要素、optgroup 要素、
option 要素、
p 要素、rb 要素、rp 要素、rt 要素、rtc 要素、tbody 要素、td 要素、tfoot 要素、th 要素、thead 要素、tr 要素、body 要素、または
html 要素の
いずれでもないノードがある場合、これは構文解析エラーである。
そのトークンを再処理する。
開いている要素のスタックがbutton スコープ内に
p 要素を持つ場合、p
要素を閉じる。
そのトークン用のHTML 要素を挿入する。
開いている要素のスタックがbutton
スコープ内に
p 要素を持つ場合、p
要素を閉じる。
現在のノードが、タグ名が 「h1」、「h2」、「h3」、「h4」、「h5」、または「h6」のいずれかであるHTML 要素である場合、これは 構文解析 エラーである。現在のノードを開いている要素のスタックからポップする。
そのトークン用のHTML 要素を挿入する。
開いている要素のスタックがbutton
スコープ内に
p 要素を持つ場合、p
要素を閉じる。
そのトークン用のHTML 要素を挿入する。
次のトークンが
U+000A LINE FEED(LF)の文字トークンである場合、そのトークンを無視して次のトークンへ進む。
(pre ブロックの
先頭にある改行は、オーサリング上の便宜のため無視される。)
frameset-ok フラグを 「not ok」に設定する。
form
要素ポインターが null でなく、かつ開いている要素のスタック上に
template
要素がない場合、これは構文解析エラーである。そのトークンを無視する。
それ以外の場合:
そのトークン用のHTML
要素を挿入する。また、開いている要素のスタック上に
template
要素がない場合、form
要素ポインターを、
作成された要素を指すよう設定する。
次の手順を実行する:
frameset-ok フラグを 「not ok」に設定する。
node を現在の ノード(スタックの最下位ノード)に初期化する。
ループ:node が li 要素である場合、
次の下位手順を実行する:
li 要素を
除いて暗黙の終了タグを生成する。
li 要素が
スタックからポップされるまで、開いている要素のスタックから
要素をポップする。
以下の完了とラベル付けされた手順へ進む。
node が特殊カテゴリーに属するが、
address、
div、または
p 要素ではない
場合、以下の完了とラベル付けされた手順へ進む。
それ以外の場合、node を開いている 要素のスタック内の前のエントリーに設定し、ループとラベル付けされた手順へ戻る。
最後に、そのトークン用のHTML 要素を挿入する。
次の手順を実行する:
frameset-ok フラグを 「not ok」に設定する。
node を現在の ノード(スタックの最下位ノード)に初期化する。
ループ:node が dd 要素である場合、
次の下位手順を実行する:
dd 要素を
除いて暗黙の終了タグを生成する。
dd 要素が
スタックからポップされるまで、開いている要素のスタックから
要素をポップする。
以下の完了とラベル付けされた手順へ進む。
node が dt
要素である場合、
次の下位手順を実行する:
dt 要素を
除いて暗黙の終了タグを生成する。
dt 要素が
スタックからポップされるまで、開いている要素のスタックから
要素をポップする。
以下の完了とラベル付けされた手順へ進む。
node が特殊カテゴリーに属するが、
address、
div、または
p 要素ではない
場合、以下の完了とラベル付けされた手順へ進む。
それ以外の場合、node を開いている 要素のスタック内の前のエントリーに設定し、ループとラベル付けされた手順へ戻る。
最後に、そのトークン用のHTML 要素を挿入する。
開いている要素のスタックがbutton
スコープ内に
p 要素を持つ場合、p
要素を閉じる。
そのトークン用のHTML 要素を挿入する。
トークナイザーをPLAINTEXT 状態へ切り替える。
タグ名が「plaintext」である開始タグが検出されると、それ以降のすべての
トークンは文字トークン(および最後のファイル終端トークン)となる。トークナイザーを
PLAINTEXT 状態から切り替える方法がないためである。
ただし、ツリービルダーは既存の挿入モードのままであるため、それらの文字トークンを処理する
間にアクティブな書式設定要素を
再構築する可能性がある。これは、構文解析器が plaintext 要素内へ
その他の要素を挿入できることを意味する。
開いている要素のスタックがスコープ内に
button 要素を持つ場合、次の下位手順を実行する:
button 要素がスタックからポップされるまで、
開いている要素のスタックから
要素をポップする。
存在する場合、アクティブな書式設定要素を 再構築する。
そのトークン用のHTML 要素を挿入する。
frameset-ok フラグを 「not ok」に設定する。
開いている要素のスタックが、 トークンと同じタグ名を持つHTML 要素をスコープ内に持たない場合、これは構文解析 エラーである。そのトークンを無視する。
それ以外の場合、次の手順を実行する:
トークンと同じタグ名を持つHTML 要素がスタックからポップされるまで、 開いている要素のスタックから 要素をポップする。
開いている要素のスタック上に
template
要素がない場合、次の下位手順を実行する:
node を、form
要素ポインターが設定されている要素、または要素へ設定されていない場合は null とする。
form
要素ポインターを null に設定する。
node が null であるか、または開いている要素のスタックが node をスコープ内に持たない場合、これは 構文解析エラーである。 返って、そのトークンを無視する。
node を開いている要素のスタックから削除する。
開いている要素のスタック上に template 要素が
ある場合、代わりに次の下位手順を実行する:
開いている要素のスタックがスコープ内に
form 要素を持たない場合、これは構文解析
エラーである。返って、そのトークンを無視する。
form 要素が
スタックからポップされるまで、開いている要素のスタックから
要素をポップする。
開いている要素のスタックがbutton
スコープ内に
p 要素を持たない場合、これは構文解析
エラーである。属性を持たない「p」開始タグトークン用のHTML 要素を挿入する。
開いている要素のスタックがリスト項目スコープ内に
li 要素を持たない場合、これは構文解析
エラーである。そのトークンを無視する。
それ以外の場合、次の手順を実行する:
li 要素を
除いて暗黙の終了タグを生成する。
li 要素が
スタックからポップされるまで、開いている要素のスタックから
要素をポップする。
開いている要素のスタックが、 トークンと同じタグ名を持つHTML 要素をスコープ内に持たない場合、これは構文解析 エラーである。そのトークンを無視する。
それ以外の場合、次の手順を実行する:
トークンと同じタグ名を持つHTML 要素を除いて暗黙の終了タグを生成する。
トークンと同じタグ名を持つHTML 要素がスタックからポップされるまで、 開いている要素のスタックから 要素をポップする。
開いている要素のスタックが、 タグ名が「h1」、「h2」、「h3」、「h4」、「h5」、または「h6」のいずれかであるHTML 要素をスコープ内に持たない場合、これは 構文解析エラーである。 そのトークンを無視する。
それ以外の場合、次の手順を実行する:
タグ名が「h1」、「h2」、「h3」、「h4」、「h5」、または「h6」のいずれかであるHTML 要素が スタックからポップされるまで、開いている要素のスタックから 要素をポップする。
深呼吸してから、以下の「その他の終了タグ」の項目で説明されるように動作する。
アクティブな書式設定要素のリストが、
リストの末尾とリスト内の最後のマーカーとの間
(リスト内にマーカーがない場合はリストの先頭との間)に
a 要素を含む場合、
これは構文解析
エラーである。そのトークンに対して養子縁組機関アルゴリズムを実行し、
その要素をアクティブな書式設定要素のリスト
および開いている要素のスタックから削除する。
ただし、養子縁組機関アルゴリズムがすでに削除していた
場合を除く(要素がtable
スコープ内にない場合など、
削除されていない可能性がある)。
不適合なストリーム
<a href="a">a<table><a href="b">b</table>x では、
二番目の a 要素が
検出された時点で最初の要素が閉じられ、「x」文字は「a」ではなく「b」へのリンク内に入る。
これは、外側の a 要素が table スコープ内にない
(つまり、表の先頭に通常の </a> 終了タグがあっても外側の a 要素を閉じない)
にもかかわらず起こる。その結果、二つの
a 要素は間接的に
互いの内部へ入れ子になる。不適合なマークアップは、構文解析時に不適合な DOM を生じることが多い。
存在する場合、アクティブな書式設定要素を 再構築する。
そのトークン用のHTML 要素を挿入する。その要素をアクティブな書式設定要素の リストへプッシュする。
存在する場合、アクティブな書式設定要素を 再構築する。
そのトークン用のHTML 要素を挿入する。その要素をアクティブな書式設定要素の リストへプッシュする。
存在する場合、アクティブな書式設定要素を 再構築する。
開いている要素のスタックがスコープ内に
nobr 要素を持つ場合、これは構文解析エラーである。そのトークンに対して
養子縁組機関アルゴリズムを実行し、
その後、存在する場合は再びアクティブな書式設定要素を
再構築する。
そのトークン用のHTML 要素を挿入する。その要素をアクティブな書式設定要素の リストへプッシュする。
そのトークンに対して養子縁組機関アルゴリズムを実行する。
存在する場合、アクティブな書式設定要素を 再構築する。
そのトークン用のHTML 要素を挿入する。
アクティブな書式設定要素の リストの末尾にマーカーを挿入する。
frameset-ok フラグを 「not ok」に設定する。
開いている要素のスタックが、 トークンと同じタグ名を持つHTML 要素をスコープ内に持たない場合、これは構文解析 エラーである。そのトークンを無視する。
それ以外の場合、次の手順を実行する:
トークンと同じタグ名を持つHTML 要素がスタックからポップされるまで、 開いている要素のスタックから 要素をポップする。
Document が互換モードに設定されておらず、かつ
開いている要素のスタックがbutton
スコープ内に
p 要素を持つ場合、p
要素を閉じる。
そのトークン用のHTML 要素を挿入する。
frameset-ok フラグを 「not ok」に設定する。
構文解析エラー。トークンから 属性を削除し、次の項目で説明されるように動作する。すなわち、実際には終了タグトークンであるが、 属性を持たない「br」開始タグトークンであるかのように動作する。
存在する場合、アクティブな書式設定要素を 再構築する。
そのトークン用のHTML 要素を挿入する。直ちに現在の ノードを開いている要素のスタックからポップする。
設定されている場合、トークンの自己終了 フラグを確認する。
frameset-ok フラグを 「not ok」に設定する。
構文解析器がHTML 断片構文解析アルゴリズムの
一部として作成され(断片の場合)、そのアルゴリズムへ渡されたコンテキスト要素が select 要素である場合:
そのトークンを無視する。
返る。
開いている要素のスタックがスコープ内に
select 要素を持つ場合:
select 要素がスタックからポップされるまで、
開いている要素のスタックから
要素をポップする。
存在する場合、アクティブな書式設定要素を 再構築する。
そのトークン用のHTML 要素を挿入する。直ちに現在の ノードを開いている要素のスタックからポップする。
設定されている場合、トークンの自己終了 フラグを確認する。
トークンが「type」という名前の属性を持たない場合、または持つが、その属性の値が
「hidden」とASCII
大文字・小文字を区別せず一致しない場合、frameset-ok
フラグを「not ok」に設定する。
そのトークン用のHTML 要素を挿入する。直ちに現在の ノードを開いている要素のスタックからポップする。
設定されている場合、トークンの自己終了 フラグを確認する。
開いている要素のスタックがbutton
スコープ内に
p 要素を持つ場合、p
要素を閉じる。
開いている要素のスタックがスコープ内に
select 要素を持つ場合:
開いている要素のスタックがスコープ内に
option 要素を持つか、またはスコープ内に
optgroup 要素を持つ場合、これは構文解析
エラーである。
そのトークン用のHTML 要素を挿入する。直ちに現在の ノードを開いている要素のスタックからポップする。
設定されている場合、トークンの自己終了 フラグを確認する。
frameset-ok フラグを 「not ok」に設定する。
構文解析エラー。トークンのタグ名を 「img」へ変更し、再処理する。(理由は聞かないこと。)
次の手順を実行する:
そのトークン用のHTML 要素を挿入する。
次のトークンが
U+000A LINE FEED(LF)の文字トークンである場合、そのトークンを無視して次のトークンへ進む。
(textarea 要素の先頭にある改行は、
オーサリング上の便宜のため無視される。)
トークナイザーをRCDATA 状態へ切り替える。
frameset-ok フラグを 「not ok」に設定する。
開いている要素のスタックがbutton
スコープ内に
p 要素を持つ場合、p
要素を閉じる。
存在する場合、アクティブな書式設定要素を 再構築する。
frameset-ok フラグを 「not ok」に設定する。
frameset-ok フラグを 「not ok」に設定する。
構文解析器がHTML 断片構文解析アルゴリズムの
一部として作成され(断片の場合)、そのアルゴリズムへ渡されたコンテキスト要素が select 要素である場合:
そのトークンを無視する。
それ以外で、開いている要素のスタックがスコープ内に select 要素を持つ
場合:
そのトークンを無視する。
select 要素がスタックからポップされるまで、
開いている要素のスタックから
要素をポップする。
それ以外の場合:
存在する場合、アクティブな書式設定要素を 再構築する。
そのトークン用のHTML 要素を挿入する。
frameset-ok フラグを 「not ok」に設定する。
開いている要素のスタックがスコープ内に
select 要素を持つ場合:
optgroup 要素を除いて暗黙の終了タグを生成する。
開いている要素のスタックがスコープ内に
option 要素を持つ場合、これは構文解析エラーである。
それ以外の場合:
現在のノードが
option
要素である場合、現在のノードを開いている要素のスタックからポップする。
存在する場合、アクティブな書式設定要素を 再構築する。
そのトークン用のHTML 要素を挿入する。
開いている要素のスタックがスコープ内に
select 要素を持つ場合:
開いている要素のスタックがスコープ内に
option 要素を持つか、またはスコープ内に
optgroup 要素を持つ場合、これは構文解析
エラーである。
それ以外で、現在のノードが
option 要素で
ある場合、現在のノードを開いている要素のスタックからポップする。
存在する場合、アクティブな書式設定要素を 再構築する。
そのトークン用のHTML 要素を挿入する。
開いている要素のスタックがスコープ内に
ruby 要素を持つ場合、暗黙の終了タグを生成する。その後、
現在のノードが ruby 要素でない場合、
これは構文解析エラーである。
そのトークン用のHTML 要素を挿入する。
開いている要素のスタックがスコープ内に
ruby 要素を持つ場合、rtc 要素を除いて暗黙の終了タグを生成する。その後、
現在のノードが
rtc 要素または ruby 要素の
いずれでもない場合、これは構文解析エラーである。
そのトークン用のHTML 要素を挿入する。
存在する場合、アクティブな書式設定要素を 再構築する。
トークンのMathML 属性を調整する。(これにより、すべて小文字ではない MathML 属性の大文字と小文字が 修正される。)
トークンの外来 属性を調整する。(これにより、名前空間付き属性、特に XLink の使用が修正される。)
MathML 名前空間および false を使用して、そのトークン用の外来要素を挿入する。
トークンの自己終了 フラグが設定されている場合、現在のノードを 開いている要素のスタックからポップし、 トークンの自己終了フラグを確認する。
存在する場合、アクティブな書式設定要素を 再構築する。
トークンのSVG 属性を調整する。 (これにより、すべて小文字ではない SVG 属性の大文字と小文字が修正される。)
トークンの外来 属性を調整する。(これにより、名前空間付き属性、特に SVG 内の XLink の使用が修正される。)
SVG 名前空間および false を使用して、そのトークン用の外来要素を挿入する。
トークンの自己終了フラグが設定されている場合、現在のノードを 開いている要素のスタックからポップし、 トークンの自己終了フラグを確認する。
構文解析エラー。 そのトークンを無視する。
存在する場合、アクティブな書式設定要素を 再構築する。
そのトークン用のHTML 要素を挿入する。
この要素は通常要素となる。ただし一つの例外がある。
スクリプティングモードが無効である場合、noscript 要素と
なることもある。
次の手順を実行する:
node を現在のノード(スタックの最下位ノード)に 初期化する。
ループ:node がトークンと同じタグ名を持つHTML 要素である場合:
トークンと同じタグ名を持つHTML 要素を除いて暗黙の終了タグを生成する。
現在のノードから node まで、 node を含むすべてのノードをポップし、これらの手順を停止する。
node を開いている 要素のスタック内の前のエントリーに設定する。
ループとラベル付けされた手順へ戻る。
上記の手順がユーザーエージェントにp 要素を閉じるよう
要求する場合、ユーザーエージェントは次の手順を実行しなければならない:
p 要素を除いて暗黙の終了タグを生成する。
p 要素が
スタックからポップされるまで、開いている要素のスタックから
要素をポップする。
唯一の引数として、アルゴリズムが実行される対象のトークン token を取る養子縁組機関アルゴリズムは、 次の手順から構成される:
subject を token のタグ名とする。
現在のノードが、 タグ名が subject であるHTML 要素であり、かつ現在のノードがアクティブな書式設定要素のリスト内に ない場合、現在のノードを開いている要素のスタックからポップして返る。
outerLoopCounter を 0 とする。
無限に繰り返す:
outerLoopCounter が 8 以上である場合、返る。
outerLoopCounter を 1 増加させる。
formattingElement を、アクティブな 書式設定要素のリスト内で、次を満たす最後の要素とする:
そのような要素がない場合、上記の「その他の終了タグ」の項目で説明されるように動作して 返る。
formattingElement が開いている要素のスタック内にない場合、 これは構文解析エラーである。その要素をリストから 削除して返る。
formattingElement が開いている要素のスタック内にあるが、 その要素がスコープ内にない場合、これは 構文解析エラーである。返る。
furthestBlock を、開いている 要素のスタック内で、formattingElement より下にあり、かつ特殊カテゴリーに属する要素のうち、 最上位のノードとする。存在しない場合もある。
furthestBlock が存在しない場合、UA はまず開いている要素のスタックの最下位から、 現在のノードから formattingElement まで、formattingElement を含むすべてのノードを ポップし、次に formattingElement をアクティブな書式設定要素のリスト から削除し、最後に返らなければならない。
commonAncestor を、開いている要素のスタック内で formattingElement の直上にある要素とする。
ブックマークに、アクティブな 書式設定要素のリスト内における formattingElement の位置を、 リスト内の両隣の要素を基準として記録させる。
node および lastNode を furthestBlock とする。
innerLoopCounter を 0 とする。
無限に繰り返す:
innerLoopCounter を 1 増加させる。
node を、開いている要素のスタック内で node の直上にある要素とする。または、node が開いている要素のスタック内に なくなっている場合(たとえば、このアルゴリズムによって削除されたため)、 node が削除される前に開いている要素のスタック内で node の直上にあった要素とする。
node が formattingElement である場合、中断する。
innerLoopCounter が 3 より大きく、かつ node が アクティブな書式設定 要素のリスト内にある場合、node を アクティブな書式設定 要素のリストから削除する。
node がアクティブな 書式設定要素のリスト内にない場合、node を開いている 要素のスタックから削除し、継続する。
要素 node が作成されたトークン用の要素を作成する。 HTML 名前空間内で、 commonAncestor を意図された親とする。アクティブな書式設定 要素のリスト内の node のエントリーを新しい要素のエントリーで置き換え、 開いている要素のスタック内の node のエントリーを新しい要素のエントリーで置き換え、 node を新しい要素とする。
lastNode が furthestBlock である場合、前述のブックマークを アクティブな書式設定 要素のリスト内で新しい node の直後へ移動する。
lastNode を node へ付加する。
lastNode を node に設定する。
insertionLocation を、存在する場合は commonAncestor の最後の子の後とする。
前の手順で最終的に得られた lastNode を、insertionLocation が 与えられたときの調整済み挿入位置へ挿入する。
formattingElement が作成されたトークン用の要素を作成する。 HTML 名前空間内で、 furthestBlock を意図された親とする。
furthestBlock のすべての子ノードを取り出し、最後の手順で作成した要素へ 付加する。
その新しい要素を furthestBlock へ付加する。
formattingElement をアクティブな書式設定 要素のリストから削除し、前述のブックマークの位置へ新しい要素をアクティブな書式設定 要素のリストへ挿入する。
formattingElement を開いている 要素のスタックから削除し、スタック内の furthestBlock の位置の直下へ 新しい要素を開いている要素のスタックへ挿入する。
このアルゴリズムの名前「養子縁組機関アルゴリズム」は、要素の親を変更させる方法に 由来し、誤って入れ子にされたコンテンツを処理するためのその他の可能なアルゴリズムと対照をなす。
ユーザーエージェントが「テキスト」挿入モードの規則を適用する場合、ユーザーエージェントは トークンを次のように処理しなければならない:
これは U+0000 NULL 文字には決してなり得ない。トークナイザーはそれらを U+FFFD REPLACEMENT CHARACTER 文字へ変換する。
現在のノードが script 要素である
場合、そのすでに
開始済みを true に設定する。
現在のノードを開いている要素の スタックからポップする。
アクティブな投機的 HTML 構文解析器が null であり、かつJavaScript 実行 コンテキストスタックが空である場合、マイクロタスクチェックポイントを実行する。
script を現在の
ノード(これは
script 要素と
なる)とする。
現在のノードを開いている要素の スタックからポップする。
old insertion point を現在の 挿入位置と同じ値とする。挿入位置を次の 入力文字の直前とする。
構文解析器のスクリプト 入れ子レベルを一つ増加させる。
アクティブな投機的 HTML 構文解析器が null である場合、script であるscript 要素を準備する。これにより、 スクリプトが実行され、その結果新しい文字がトークナイザーへ挿入される可能性があり、 またトークナイザーがさらに多くのトークンを出力し、その結果構文解析器が 再入的に呼び出される可能性がある。
構文解析器のスクリプト入れ子レベルを一つ減少させる。 構文解析器のスクリプト 入れ子レベルがゼロである場合、構文解析器一時停止フラグを false に設定する。
挿入位置を old insertion point の値とする。(言い換えると、挿入位置を以前の値へ復元する。 この値は「未定義」である可能性がある。)
この段階で、保留中の構文解析ブロッキング スクリプトが null でない場合:
構文解析器一時停止 フラグを true に設定し、トークナイザーの入れ子になった呼び出しの処理をすべて中止して、 呼び出し元へ制御を戻す。(呼び出し元が「外側」のツリー構築段階へ戻ると、 トークン化が再開される。)
この特定の構文解析器のツリー構築段階は、たとえば document.write() の呼び出しから、再入的に呼び出されている。
保留中の構文解析ブロッキング スクリプトが null でない間:
the script を保留中の構文解析ブロッキング スクリプトとする。
保留中の構文解析ブロッキング スクリプトを null に設定する。
この HTML 構文解析器のインスタンスについて投機的 HTML 構文解析器を開始する。
このHTML 構文解析器の インスタンスについてトークナイザーをブロックし、イベントループがトークナイザーを呼び出すタスクを実行しないようにする。
構文解析器の Document がスクリプトをブロックしている
スタイルシートを持つか、または the script の構文解析器によって実行される準備ができて
いるが false である場合、構文解析器の Document がスクリプトをブロックしている
スタイルシートを持たなくなり、かつ the script の構文解析器によって実行される準備が
できているが true になるまで、イベントループを回す。
その間にこの構文解析器が中止されている場合、返る。
これは、たとえばイベントループを回す
アルゴリズムの実行中に、Document が破棄されるか、
または document.open() メソッドが Document 上で呼び出された場合に起こり得る。
この HTML 構文解析器のインスタンスについて投機的 HTML 構文解析器を停止する。
このHTML 構文解析器の インスタンスについてトークナイザーのブロックを解除し、トークナイザーを呼び出すタスクを再び実行できるようにする。
構文解析器のスクリプト入れ子レベルを一つ増加させる (この手順の前はゼロであるべきなので、これにより一になる)。
the script であるscript 要素を実行する。
構文解析器のスクリプト入れ子レベルを一つ減少させる。 構文解析器のスクリプト入れ子 レベルがゼロである場合(この時点では常にそうであるべきである)、構文解析器一時停止 フラグを false に設定する。
挿入位置を再び 未定義とする。
現在のノードを開いている要素の スタックからポップする。
ユーザーエージェントが「table 内」挿入モードの規則を 適用する場合、ユーザーエージェントはトークンを次のように処理しなければならない:
table、tbody、template、tfoot、thead、または tr 要素である場合の
文字トークン
保留中の table 文字 トークンを空のトークンリストとする。
挿入モードを「table テキスト内」へ切り替え、そのトークンを再処理する。
構文解析エラー。 そのトークンを無視する。
スタックを table コンテキストまで 消去する。(下記参照。)
アクティブな書式設定要素の リストの末尾にマーカーを挿入する。
そのトークン用のHTML 要素を挿入し、 挿入モードを「caption 内」へ切り替える。
スタックを table コンテキストまで 消去する。(下記参照。)
そのトークン用のHTML 要素を挿入し、挿入モードを「列 グループ内」へ切り替える。
スタックを table コンテキストまで 消去する。(下記参照。)
属性を持たない「colgroup」開始タグトークン用のHTML 要素を挿入し、 挿入モードを「列 グループ内」へ切り替える。
現在のトークンを再処理する。
スタックを table コンテキストまで 消去する。(下記参照。)
そのトークン用のHTML 要素を挿入し、挿入モードを「table 本体内」へ切り替える。
スタックを table コンテキストまで 消去する。(下記参照。)
属性を持たない「tbody」開始タグトークン用のHTML 要素を挿入し、 挿入モードを「table 本体内」へ切り替える。
現在のトークンを再処理する。
開いている要素のスタックがtable スコープ内に
table 要素を持たない場合、そのトークンを無視する。
それ以外の場合:
table 要素がスタックからポップされるまで、
このスタックから要素をポップする。
そのトークンを再処理する。
開いている要素のスタックがtable スコープ内に
table 要素を持たない場合、これは構文解析
エラーである。そのトークンを無視する。
それ以外の場合:
table 要素がスタックからポップされるまで、
このスタックから要素をポップする。
構文解析エラー。 そのトークンを無視する。
トークンが「type」という名前の属性を持たない場合、または持つが、その属性の値が
「hidden」とASCII
大文字・小文字を区別せず一致しない場合、
以下の「その他の場合」の項目で説明されるように動作する。
それ以外の場合:
そのトークン用のHTML 要素を挿入する。
その input 要素を開いている要素の
スタックからポップする。
設定されている場合、トークンの自己終了 フラグを確認する。
開いている要素のスタック上に template 要素が
ある場合、またはform 要素
ポインターが null でない場合、そのトークンを無視する。
それ以外の場合:
そのトークン用のHTML
要素を挿入し、form 要素ポインターを
作成された要素を指すよう設定する。
その form 要素を開いている要素の
スタックからポップする。
構文解析エラー。里親処理を有効にし、 「body 内」挿入モードの規則を使用してトークンを処理し、その後 里親処理を無効にする。
上記の手順が UA にスタックを table コンテキストまで
消去するよう要求する場合、UA は、現在の
ノードが table、
template、
または
html 要素でない間、
開いている
要素のスタックから要素をポップしなければならない。
これは、table スコープ内に要素を持つ手順で使用される要素の一覧と同じである。
この処理の後で現在のノードが html 要素であるのは、
断片の場合である。
ユーザーエージェントが「table テキスト内」挿入モードの規則を適用する場合、ユーザーエージェントは トークンを次のように処理しなければならない:
構文解析エラー。 そのトークンを無視する。
文字トークンを保留中の table 文字トークンリストへ付加する。
保留中の table 文字トークンリスト内のトークンのいずれかが、ASCII 空白でない文字トークンである場合、これは構文解析エラーである。 「table 内」挿入モードの「その他の場合」の項目で示される規則を使用して、保留中の table 文字トークンリスト内の 文字トークンを再処理する。
それ以外の場合、保留中の table 文字トークンリストで示される 文字を挿入する。
ユーザーエージェントが「caption 内」挿入モードの規則を 適用する場合、ユーザーエージェントはトークンを次のように処理しなければならない:
開いている要素のスタックがtable スコープ内に
caption 要素を持たない場合、これは構文解析
エラーである。そのトークンを無視する。(断片の場合)
それ以外の場合:
caption 要素がスタックからポップされるまで、
このスタックから要素をポップする。
開いている要素のスタックがtable
スコープ内に
caption 要素を持たない場合、これは構文解析
エラーである。そのトークンを無視する。(断片の場合)
それ以外の場合:
caption 要素がスタックからポップされるまで、
このスタックから要素をポップする。
そのトークンを再処理する。
構文解析エラー。 そのトークンを無視する。
ユーザーエージェントが「列グループ内」挿入モードの規則を適用する場合、ユーザーエージェントは トークンを次のように処理しなければならない:
構文解析エラー。 そのトークンを無視する。
そのトークン用のHTML 要素を挿入する。直ちに現在の ノードを開いている要素のスタックからポップする。
設定されている場合、トークンの自己終了 フラグを確認する。
現在のノードが
colgroup 要素でない場合、これは
構文解析エラーである。
そのトークンを無視する。
それ以外の場合、現在のノードを開いている要素のスタックからポップする。 挿入モードを「table 内」へ切り替える。
構文解析エラー。 そのトークンを無視する。
現在のノードが
colgroup 要素でない場合、これは
構文解析エラーである。
そのトークンを無視する。
それ以外の場合、現在のノードを開いている要素のスタックからポップする。
そのトークンを再処理する。
ユーザーエージェントが「table 本体内」挿入モードの規則を適用する場合、ユーザーエージェントは トークンを次のように処理しなければならない:
スタックを table 本体 コンテキストまで消去する。(下記参照。)
そのトークン用のHTML 要素を挿入し、 挿入モードを「行内」へ切り替える。
スタックを table 本体 コンテキストまで消去する。(下記参照。)
属性を持たない「tr」開始タグトークン用のHTML 要素を挿入し、 挿入モードを「行内」へ切り替える。
現在のトークンを再処理する。
開いている要素のスタックが、 トークンと同じタグ名を持つHTML 要素をtable スコープ内に持たない場合、 これは構文解析エラーである。 そのトークンを無視する。
それ以外の場合:
スタックを table 本体 コンテキストまで消去する。(下記参照。)
現在のノードを開いている要素のスタックからポップする。 挿入モードを「table 内」へ切り替える。
開いている要素のスタックがtable スコープ内に
tbody、thead、または
tfoot 要素を持たない場合、これは構文解析エラーである。
そのトークンを無視する。
それ以外の場合:
スタックを table 本体 コンテキストまで消去する。(下記参照。)
現在のノードを開いている要素のスタックからポップする。 挿入モードを「table 内」へ切り替える。
そのトークンを再処理する。
構文解析エラー。 そのトークンを無視する。
上記の手順が UA にスタックを
table 本体コンテキストまで消去するよう要求する場合、
UA は、現在の
ノードが tbody、
tfoot、thead、template、または
html 要素でない間、
開いている要素のスタックから
要素をポップしなければならない。
この処理の後で現在のノードが html 要素であるのは、
断片の場合である。
ユーザーエージェントが「行内」挿入モードの規則を適用する場合、ユーザーエージェントは トークンを次のように処理しなければならない:
スタックを table 行 コンテキストまで消去する。(下記参照。)
そのトークン用のHTML 要素を挿入し、 挿入モードを「セル内」へ切り替える。
アクティブな書式設定要素の リストの末尾にマーカーを挿入する。
開いている要素のスタックがtable スコープ内に
tr 要素を持たない場合、これは構文解析エラーである。
そのトークンを無視する。
それ以外の場合:
スタックを table 行 コンテキストまで消去する。(下記参照。)
現在のノード
(これは tr 要素となる)を
開いている要素のスタックからポップする。
挿入モードを「table 本体内」へ切り替える。
開いている要素のスタックがtable スコープ内に
tr 要素を持たない場合、これは構文解析エラーである。
そのトークンを無視する。
それ以外の場合:
スタックを table 行 コンテキストまで消去する。(下記参照。)
現在のノード
(これは tr 要素となる)を
開いている要素のスタックからポップする。
挿入モードを「table 本体内」へ切り替える。
そのトークンを再処理する。
開いている要素のスタックが、 トークンと同じタグ名を持つHTML 要素をtable スコープ内に持たない場合、 これは構文解析エラーである。 そのトークンを無視する。
開いている要素のスタックがtable スコープ内に
tr 要素を持たない場合、そのトークンを無視する。
それ以外の場合:
スタックを table 行 コンテキストまで消去する。(下記参照。)
現在のノード
(これは tr 要素となる)を
開いている要素のスタックからポップする。
挿入モードを「table 本体内」へ切り替える。
そのトークンを再処理する。
構文解析エラー。 そのトークンを無視する。
上記の手順が UA にスタックを table 行
コンテキストまで消去するよう要求する場合、
UA は、現在の
ノードが tr、
template、または
html 要素でない間、
開いている要素のスタックから要素をポップしなければ
ならない。
この処理の後で現在のノードが html 要素であるのは、
断片の場合である。
ユーザーエージェントが「セル内」挿入モードの規則を適用する場合、ユーザーエージェントは トークンを次のように処理しなければならない:
開いている要素のスタックが、 トークンと同じタグ名を持つHTML 要素をtable スコープ内に持たない場合、これは 構文解析 エラーである。そのトークンを無視する。
それ以外の場合:
トークンと同じタグ名を持つHTML 要素がスタックからポップされるまで、 開いている要素のスタックから 要素をポップする。
表明:開いている要素のスタックはtable スコープ内に
td または th 要素を持つ。
セルを閉じ(下記参照)、 そのトークンを再処理する。
構文解析エラー。 そのトークンを無視する。
開いている要素のスタックが、 トークンと同じタグ名を持つHTML 要素をtable スコープ内に持たない場合、これは 構文解析 エラーである。そのトークンを無視する。
それ以外の場合、セルを閉じ(下記参照)、 そのトークンを再処理する。
上記の手順がセルを閉じるよう指示する場合、 次のアルゴリズムを実行することを意味する:
td
要素または th 要素がスタックからポップされるまで、開いている要素の
スタックから要素をポップする。
開いている要素のスタックは、
td 要素と
th 要素の両方を同時に
table
スコープ内に持つことはできず、
またセルを閉じるアルゴリズムが
呼び出されるときに、そのどちらも持たないこともできない。
ユーザーエージェントが「template 内」挿入モードの規則を 適用する場合、ユーザーエージェントはトークンを次のように処理しなければならない:
現在の template 挿入モードをtemplate 挿入モードのスタックからポップする。
「table 内」をtemplate 挿入モードのスタックへプッシュし、新しい現在の template 挿入 モードとする。
現在の template 挿入モードを template 挿入モードのスタックからポップする。
「列グループ内」を template 挿入モードのスタックへ プッシュし、新しい現在の template 挿入モードとする。
現在の template 挿入モードを template 挿入モードのスタックからポップする。
「table 本体内」をtemplate 挿入モードのスタックへプッシュし、新しい現在の template 挿入 モードとする。
現在の template 挿入モードを template 挿入モードのスタックからポップする。
「行内」をtemplate 挿入モードのスタックへプッシュし、新しい現在の template 挿入モードとする。
現在の template 挿入モードを template 挿入モードのスタックからポップする。
「body 内」をtemplate 挿入モードのスタックへプッシュし、新しい現在の template 挿入モードとする。
構文解析エラー。 そのトークンを無視する。
開いている要素のスタック上に
template 要素がない場合、
構文解析を停止する。(断片の場合)
それ以外の場合、これは構文解析エラーである。
template 要素がスタックからポップされるまで、開いている要素のスタックから
要素をポップする。
最後の マーカーまでアクティブな書式設定要素のリストを消去する。
現在の template 挿入モードを template 挿入モードのスタックからポップする。
そのトークンを再処理する。
ユーザーエージェントが「body の後」挿入モードの規則を適用する場合、ユーザーエージェントは トークンを次のように処理しなければならない:
開いている要素のスタック内の最初の要素
(html 要素)の最後の子としてコメントを挿入する。
開いている要素のスタック内の最初の要素
(html 要素)の最後の子として処理命令を挿入する。
構文解析エラー。 そのトークンを無視する。
構文解析器がHTML 断片構文解析アルゴリズムの 一部として作成された場合、これは構文解析エラーである。そのトークンを無視する。(断片の場合)
ユーザーエージェントが「frameset 内」挿入モードの規則を 適用する場合、ユーザーエージェントはトークンを次のように処理しなければならない:
構文解析エラー。 そのトークンを無視する。
そのトークン用のHTML 要素を挿入する。
現在のノードがルートの
html 要素である
場合、これは
構文解析エラーである。
そのトークンを無視する。(断片の場合)
それ以外の場合、現在のノードを開いている要素のスタックからポップする。
構文解析器がHTML 断片構文解析アルゴリズムの
一部として作成されておらず(断片の場合)、かつ現在のノードが
frameset 要素でなくなった
場合、挿入モードを「frameset
の後」へ切り替える。
そのトークン用のHTML 要素を挿入する。直ちに現在の ノードを開いている要素のスタックからポップする。
設定されている場合、トークンの自己終了 フラグを確認する。
現在のノードがルートの
html 要素でない場合、これは
構文解析エラーである。
構文解析エラー。 そのトークンを無視する。
ユーザーエージェントが「frameset の後」挿入モードの規則を適用する場合、ユーザーエージェントは トークンを次のように処理しなければならない:
構文解析エラー。 そのトークンを無視する。
挿入モードを 「frameset の後の後」へ 切り替える。
構文解析エラー。 そのトークンを無視する。
ユーザーエージェントが「body の後の後」挿入モードの規則を 適用する場合、ユーザーエージェントはトークンを次のように処理しなければならない:
ユーザーエージェントが「frameset の後の後」 挿入モードの規則を 適用する場合、ユーザーエージェントはトークンを次のように処理しなければならない:
構文解析エラー。 そのトークンを無視する。
ユーザーエージェントが外来コンテンツ内のトークンを構文解析する規則を適用する場合、 ユーザーエージェントはトークンを次のように処理しなければならない:
frameset-ok フラグを 「not ok」に設定する。
構文解析エラー。 そのトークンを無視する。
現在のノードがMathML テキスト統合点でも、 HTML 統合点でも、HTML 名前空間内の要素でもない間、開いている要素のスタックから 要素をポップする。
HTML コンテンツにおける現在の挿入モードに対応する節で示される規則に従って、 トークンを再処理する。
調整済み現在ノードがMathML 名前空間内の要素である場合、トークンのMathML 属性を調整する。 (これにより、すべて小文字ではない MathML 属性の大文字と小文字が修正される。)
調整済み現在ノードがSVG 名前空間内の要素であり、かつトークンのタグ名が 次の表の最初の列にあるものの一つである場合、タグ名を二番目の列の対応するセルに示される 名前へ変更する。(これにより、すべて小文字ではない SVG 要素の大文字と小文字が修正される。)
| タグ名 | 要素名 |
|---|---|
altglyph |
altGlyph
|
altglyphdef |
altGlyphDef
|
altglyphitem |
altGlyphItem
|
animatecolor |
animateColor
|
animatemotion |
animateMotion
|
animatetransform |
animateTransform
|
clippath |
clipPath
|
feblend |
feBlend
|
fecolormatrix |
feColorMatrix
|
fecomponenttransfer |
feComponentTransfer
|
fecomposite |
feComposite
|
feconvolvematrix |
feConvolveMatrix
|
fediffuselighting |
feDiffuseLighting
|
fedisplacementmap |
feDisplacementMap
|
fedistantlight |
feDistantLight
|
fedropshadow |
feDropShadow
|
feflood |
feFlood
|
fefunca |
feFuncA
|
fefuncb |
feFuncB
|
fefuncg |
feFuncG
|
fefuncr |
feFuncR
|
fegaussianblur |
feGaussianBlur
|
feimage |
feImage
|
femerge |
feMerge
|
femergenode |
feMergeNode
|
femorphology |
feMorphology
|
feoffset |
feOffset
|
fepointlight |
fePointLight
|
fespecularlighting |
feSpecularLighting
|
fespotlight |
feSpotLight
|
fetile |
feTile
|
feturbulence |
feTurbulence
|
foreignobject |
foreignObject
|
glyphref |
glyphRef
|
lineargradient |
linearGradient
|
radialgradient |
radialGradient
|
textpath |
textPath
|
調整済み現在ノードがSVG 名前空間内の要素である場合、トークンのSVG 属性を調整する。 (これにより、すべて小文字ではない SVG 属性の大文字と小文字が修正される。)
トークンの外来属性を調整する。 (これにより、名前空間付き属性、特に SVG 内の XLink の使用が修正される。)
調整済み現在ノードの名前空間および false を使用して、そのトークン用の外来要素を挿入する。
トークンの自己終了フラグが設定されている場合、次の一覧から適切な 手順を実行する:
script 要素である場合の、タグ名が「script」である終了タグ現在のノードを開いている要素のスタックからポップする。
old insertion point を現在の 挿入位置と同じ値とする。挿入位置を次の 入力文字の直前とする。
構文解析器のスクリプト入れ子レベルを一つ増加させる。構文解析器一時停止 フラグを true に設定する。
アクティブな投機的 HTML 構文解析器が
null であり、かつユーザーエージェントが SVG をサポートしている場合、
SVG の規則に従ってSVG
script 要素を処理する。[SVG]
これにより新しい文字が トークナイザーへ挿入される場合でも、構文解析器一時停止フラグが true であるため、 構文解析器は再入的に実行されない。
構文解析器のスクリプト入れ子レベルを一つ減少させる。 構文解析器のスクリプト 入れ子レベルがゼロである場合、構文解析器一時停止フラグを false に設定する。
挿入位置を old insertion point の値とする。(言い換えると、挿入位置を以前の値へ復元する。 この値は「未定義」である可能性がある。)
次の手順を実行する:
node を現在のノード(スタックの最下位ノード)に 初期化する。
node のタグ名をASCII 小文字へ変換したものが、 トークンのタグ名と同じでない場合、これは構文解析エラーである。
ループ:node が開いている 要素のスタック内の最上位要素である場合、返る。(断片の場合)
node のタグ名をASCII 小文字へ変換したものが、 トークンのタグ名と同じである場合、node がスタックからポップされるまで開いている要素のスタックから 要素をポップし、その後返る。
node を開いている 要素のスタック内の前のエントリーに設定する。
node がHTML 名前空間内の要素でない場合、ループとラベル付けされた手順へ戻る。
それ以外の場合、HTML コンテンツにおける現在の挿入モードに対応する節で示される規則に従って、 トークンを処理する。
Document/DOMContentLoaded_event
すべての現行エンジンでサポート。
すべての現行エンジンでサポート。
ユーザーエージェントが文書の構文解析を停止すると、 ユーザーエージェントは次の手順を実行しなければならない:
アクティブな投機的 HTML 構文解析器が null でない場合、 投機的 HTML 構文解析器を停止して返る。
挿入位置を未定義に設定する。
現在の文書の準備状態を更新して
「interactive」にする。
開いている要素のスタックからすべてのノードを ポップする。
文書の構文解析が 完了したときに実行されるスクリプトのリストが空でない間:
文書の
構文解析が完了したときに実行されるスクリプトのリスト内の最初の script の構文解析器によって実行される準備ができているが
true に設定され、かつ構文解析器の Document がスクリプトをブロックしている
スタイルシートを持たなくなるまで、イベントループを回す。
文書の
構文解析が完了したときに実行されるスクリプトのリスト内の最初の script であるscript 要素を実行する。
最初の script 要素を文書の
構文解析が完了したときに実行されるスクリプトのリストから削除する
(すなわち、リストの最初のエントリーをシフトして取り出す)。
Document の関連グローバルオブジェクトが与えられたとき、DOM 操作タスクソース上にグローバルタスクをキューし、
次の下位手順を実行する:
Document の読み込みタイミング情報のDOM content loaded
イベント開始時刻を、Document の関連グローバルオブジェクトが与えられたときの現在の高解像度時刻に設定する。
Document
オブジェクトで、bubbles 属性を true に
初期化して、DOMContentLoaded という名前のイベントを発火する。
Document の読み込みタイミング情報のDOM content loaded
イベント終了時刻を、Document の関連グローバルオブジェクトが与えられたときの現在の高解像度時刻に設定する。
関連付けられたサービスワーカークライアントが
Document オブジェクトの関連設定オブジェクトである ServiceWorkerContainer
オブジェクトのクライアントメッセージキューを有効にする。
Document の閲覧コンテキストと、
新しいWebDriver BiDi
ナビゲーション状態を使用して、WebDriver BiDi DOM content loadedを
呼び出す。新しいナビゲーション状態のidは
Document オブジェクトのWebDriver BiDi
用の読み込み中
ナビゲーション ID、状態は「pending」、
url は Document オブジェクトのURL とする。
可能な限り早く実行される スクリプトの集合と可能な限り早く順番に 実行されるスクリプトのリストが空になるまで、イベントループを回す。
Document 内でload
イベントを遅延させるものが何もなくなるまで、イベントループを回す。
Document の関連グローバルオブジェクトが与えられたとき、DOM 操作タスクソース上にグローバルタスクをキューし、次の手順を実行する:
現在の文書の準備状態を更新して
「complete」にする。
window を Document の関連グローバルオブジェクトとする。
Document の読み込みタイミング情報のload イベント開始時刻を、
window が与えられたときの現在の高解像度時刻に設定する。
Document の閲覧コンテキストと、新しいWebDriver BiDi
ナビゲーション状態を使用して、WebDriver BiDi load completeを呼び出す。
新しいナビゲーション状態のidは
Document オブジェクトのWebDriver BiDi
用の読み込み中
ナビゲーション ID、状態は「complete」、
url は Document オブジェクトのURL とする。
Document オブジェクトのWebDriver BiDi
用の読み込み中
ナビゲーション IDを null に設定する。
Document の読み込みタイミング情報のload イベント終了時刻を、
window が与えられたときの現在の高解像度時刻に設定する。
window で false を使用し、pageshow という名前のページ遷移イベントを発火する。
Document の読み込み時に印刷フラグが設定されている場合、印刷手順を実行する。
Document は、これで読み込み後タスクの準備ができた。
ユーザーエージェントが構文解析器を中止する場合、 次の手順を実行しなければならない:
入力ストリーム内の保留中のコンテンツをすべて 破棄し、将来そこへ追加されるはずだったコンテンツもすべて破棄する。
この HTML 構文解析器の投機的 HTML 構文解析器を停止する。
現在の文書の準備状態を更新して
「interactive」にする。
開いている要素のスタックからすべてのノードを ポップする。
現在の文書の準備状態を更新して
「complete」にする。
ユーザーエージェントは、この節で説明する最適化を実装してもよい。これは、HTML 構文解析器が 保留中の構文解析ブロッキング スクリプトのフェッチおよび実行を待っている間、または通常の構文解析中にトークン用の要素が作成される時点で、 HTML マークアップ内に宣言されたリソースを投機的にフェッチするものである。 この最適化は詳細には定義されていないが、相互運用性のために考慮すべき規則がいくつかある。
各HTML 構文解析器は、アクティブな投機的 HTML 構文解析器を持つことが できる。初期値は null である。
投機的 HTML 構文解析器は、いくつかの例外を除き、 通常の HTML 構文解析器と同様に動作しなければならない(たとえば、ツリービルダーの規則が適用される):
通常の HTML 構文解析器の状態および文書自体に影響を与えてはならない。
たとえば、通常の HTML 構文解析器の次の入力文字または開いている要素のスタックは、投機的 HTML 構文解析器の影響を受けない。
HTML 構文解析器の入力バイトストリームへプッシュされたバイトは、 投機的 HTML 構文解析器の入力バイトストリームへもプッシュしなければ ならない。ストリームからのバイトの読み取りは独立していなければならない。
投機的構文解析の結果は、主として一連の投機的フェッチである。どの種類のリソースを 投機的にフェッチするかは実装定義であるが、ユーザーエージェントは、 HTML 構文解析器をブロックしているスクリプトが何もしないと仮定した場合に、通常の HTML 構文解析器では フェッチされないリソースを投機的にフェッチしてはならない。
同じマークアップが投機的 HTML 構文解析器で複数回検出され、 その後通常の HTML 構文解析器でも検出される可能性がある。重複したフェッチはキャッシュ規則によって 防止されることが期待されるが、それらの規則はまだ完全には規定されていない。
投機的モック要素 element の投機的フェッチは、次の規則に従わなければならない:
これらの一部は、投機的に検出された場合でも、文書へ「実際に」適用すべきだろうか?
投機的 HTML 構文解析器が次の要素の いずれかに遭遇した場合、その要素が後続の投機的フェッチへ与える影響について処理されたかのように 動作する。
base 要素。meta 要素であり、その http-equiv 属性がコンテンツ
セキュリティポリシー状態にあるもの。meta 要素であり、その name 属性が
「referrer」とASCII 大文字・小文字を区別せず一致するもの。
meta 要素であり、その name 属性が
「viewport」とASCII 大文字・小文字を区別せず一致するもの。
(これは、メディアクエリーリストが環境と一致するかどうかに影響し得る。)
[CSSDEVICEADAPT]
url を、element が通常どおり処理された場合にフェッチするURLとする。そのようなURLが存在しない場合、または空文字列である場合、何もしない。 それ以外で、url がすでに投機的フェッチ URL のリストに ある場合、何もしない。それ以外の場合、要素が通常どおり処理されたかのように url をフェッチし、url を投機的フェッチ URL のリストへ 追加する。
各 Document は投機的フェッチ URL のリストを持つ。これはリストであり、URLを含み、初期状態では空である。
HTML 構文解析器のインスタンス parser について投機的 HTML 構文解析器を開始するには:
任意で、返る。
この手順により、ユーザーエージェントは投機的 HTML 構文解析を使用しないことを 選択できる。
parser のアクティブな投機的 HTML 構文解析器が null でない場合、parser の投機的 HTML 構文解析器を停止する。
これは document.write() が別の構文解析器ブロッキングスクリプトを
書き込んだ場合に起こり得る。簡潔にするため、この仕様では常に投機的構文解析を再起動するが、
最終結果が同等である限り、ユーザーエージェントはより効率的な方法を実装できる。
speculativeParser を、parser と同じ状態を持つ新しい投機的 HTML 構文解析器とする。
speculativeDoc を、parser の
Document の新しい同型表現とし、すべての要素を代わりに投機的モック要素とする。
speculativeParser に
speculativeDoc へ構文解析させる。
parser のアクティブな投機的 HTML 構文解析器を speculativeParser に設定する。
HTML 構文解析器のインスタンス parser について投機的 HTML 構文解析器を停止するには:
speculativeParser を parser のアクティブな投機的 HTML 構文解析器とする。
speculativeParser が null である場合、返る。
speculativeParser の入力 ストリーム内の保留中のコンテンツをすべて破棄し、将来そこへ追加されるはずだった コンテンツもすべて破棄する。
parser のアクティブな投機的 HTML 構文解析器を null に設定する。
投機的 HTML 構文解析器は、通常の要素の代わりに投機的モック要素を作成する。 ツリービルダーが通常要素に対して行う DOM 操作は、投機的モック要素に対しても適切に動作することが 期待される。
namespace、tagName、および attributes が与えられたとき、 投機的モック要素を作成するには:
ツリービルダーが template 要素のテンプレート内容へ要素を挿入するよう指示したとき、
それが投機的モック要素であり、かつ
template
要素のテンプレート内容が
ShadowRoot
ノードでない場合、代わりに何もしない。非宣言的シャドウルートの template
要素内で投機的に検出された URL は、それ自体がテンプレートである可能性があり、
投機的にフェッチしてはならない。
アプリケーションが HTML
構文解析器を XML パイプラインと組み合わせて使用する場合、構築された DOM が、ある種の微妙な
点で XML ツールチェーンと互換性を持たない可能性がある。たとえば、XML ツールチェーンは
xmlns という名前の属性を表現できない場合がある。これは、その属性が XML の名前空間構文と
競合するためである。また、HTML
構文解析器が生成するデータの中には、
DOM 自体には含まれないものもある。この節では、これらの問題を処理するための規則をいくつか
規定する。
使用されている XML API が DOCTYPE をサポートしない場合、ツールは DOCTYPE を完全に破棄してもよい。
XML API が、名前空間を持たず「xmlns」という名前の属性、名前が
「xmlns:」で始まる属性、または
XMLNS 名前空間内の
属性をサポートしない場合、ツールはそのような属性を破棄してもよい。
ツールは、適切な動作に必要な任意の名前空間宣言を出力に注釈として付加してもよい。
使用されている XML API が要素および属性のローカル名に使用できる文字を制限する場合、 ツールは、API がサポートしないすべての要素および属性のローカル名を、許可される名前の集合へ マッピングしてもよい。これは、サポートされていない各文字を、大文字の U と、その文字の コードポイントを 16 進数で表した 6 桁の数字に置き換えることで行う。記号には数字 0~9 および 大文字 A~F を数値の昇順で使用する。
たとえば、要素名 foo<bar は、HTML 構文解析器によって出力され得るが、
正当な HTML 要素名でも整形式の XML 要素名でもない。この名前は
fooU00003Cbar に変換される。この名前は整形式の XML 要素名である
(ただし、依然として HTML では決して正当ではない)。
別の例として、属性 xlink:href を考える。
MathML 要素で使用される場合、これは調整された後、接頭辞
「xlink」とローカル名「href」を持つ属性になる。しかし、HTML 要素で
使用される場合、接頭辞を持たず、ローカル名が「xlink:href」である属性になる。
これは有効な NCName ではないため、XML API に受け入れられない可能性がある。そのため、
「xlinkU00003Ahref」へ変換されることがある。
この変換で得られる名前は、HTML 構文解析器によって生成される属性と 衝突することがないという便利な性質を持つ。構文解析器によって生成される名前はすべて小文字であるか、 外来属性を調整するアルゴリズムの 表に列挙されているものだからである。
XML API が、コメント内に連続する二つの U+002D HYPHEN-MINUS 文字(--)を含むことを制限する場合、 ツールは、そのような問題のある文字の間に一つの U+0020 SPACE 文字を挿入してもよい。
XML API が、コメントの末尾を U+002D HYPHEN-MINUS 文字(-)とすることを制限する場合、 ツールは、そのようなコメントの末尾に一つの U+0020 SPACE 文字を挿入してもよい。
XML API が文字データ、属性値、またはコメント内で許可される文字を制限する場合、 ツールは任意の U+000C FORM FEED(FF)文字を U+0020 SPACE 文字へ置き換え、その他の XML 文字ではないリテラル文字を U+FFFD REPLACEMENT CHARACTER へ置き換えてもよい。
ツールに帯域外情報を伝達する方法がない場合、ツールは次の情報を破棄してもよい:
form
要素の祖先ではないフォームとの関連付け(構文解析器におけるform 要素ポインターの
使用)template
要素のテンプレート内容。この節で許可される変更は、HTML
構文解析器の規則が適用された後に行われる。たとえば、
<a::> 開始タグは </a::> 終了タグによって閉じられ、
</aU00003AU00003A> 終了タグによって閉じられることはない。これは、
ユーザーエージェントが上記の規則を使用し、その開始タグについて、DOM 内に
aU00003AU00003A という名前の実際の要素を生成する場合でも同様である。
この節は非規範的である。
この節では、いくつかの誤ったマークアップを検討し、HTML 構文解析器が これらの場合をどのように処理するかを説明する。
この節は非規範的である。
誤ったマークアップの例として最も頻繁に議論されるものは、次のとおりである:
< p > 1< b > 2< i > 3</ b > 4</ i > 5</ p > このマークアップの構文解析は「3」までは単純である。この時点で、DOM は次のようになる:
ここで、開いている要素のスタックには五つの要素がある:
html、
body、p、b、および i である。アクティブな
書式設定要素のリストには二つだけがある:b
および i である。挿入
モードは「body 内」である。
タグ名が「b」である終了タグトークンを受け取ると、「養子縁組機関アルゴリズム」が呼び出される。これは単純な場合であり、
formattingElement は b 要素で、
furthest block は存在しない。そのため、開いている要素のスタックには、
最終的に三つの要素だけが残る:html、
body、および
p である。一方、
アクティブな書式設定要素のリストには
一つだけが残る:i
である。この時点では DOM ツリーは変更されていない。
次のトークンは文字(「4」)であり、アクティブな書式設定要素の
再構築を引き起こす。この場合は i
要素だけである。そのため、
「4」の Text ノード用に、新しい i 要素が作成される。
「i」の終了タグトークンも受け取られ、「5」の Text ノードが挿入された後、DOM は次のように
なる:
この節は非規範的である。
前のものと似た場合は、次のとおりである:
< b > 1< p > 2</ b > 3</ p > ここでの構文解析は「2」までは単純である:
興味深い部分は、タグ名が「b」である終了タグトークンが構文解析されるときである。
そのトークンが検出される前、開いている要素のスタックには四つの要素がある:
html、body、b、および p である。アクティブな
書式設定要素のリストには一つだけがある:b
である。挿入モードは
「body 内」である。
タグ名が「b」である終了タグトークンを受け取ると、前の例と同様に
「養子縁組機関アルゴリズム」が呼び出される。しかし、この場合は
furthest block が存在する。それは p 要素である。
したがって、今回は養子縁組機関アルゴリズムが省略されない。
common ancestor は body 要素である。
概念的な「ブックマーク」が、アクティブな書式設定要素のリスト内の
b の位置を示すが、
このリストには要素が一つしかないため、ブックマークは大きな影響を持たない。
アルゴリズムが進むにつれて、node は最終的に書式設定要素
(b)に設定され、
last node は最終的に furthest block
(p)に設定される。
last node は common ancestor へ付加(移動)され、 DOM は次のようになる:
新しい b 要素が
作成され、p 要素の
子がそこへ移動される:
最後に、新しい b
要素が p 要素へ
付加され、DOM は次のようになる:
b 要素は、
アクティブな書式設定要素のリストと
開いている要素のスタックから削除される。
そのため、「3」が構文解析されると、これは p
要素へ付加される:
この節は非規範的である。
表におけるエラー処理は、歴史的な理由により、特に奇妙である。たとえば、次のマークアップを 考える:
< table > < b > < tr >< td > aaa</ td ></ tr > bbb</ table > ccc強調表示された b 要素の開始タグを、このように表の直下に置くことは許可されていない。
構文解析器は、この場合を、その要素を表の前に配置することで処理する。
(これは里親処理と
呼ばれる。)これは、table 要素の開始タグが検出された直後の DOM ツリーを
調べることで確認できる:
……そして、b 要素の開始タグが検出された直後は次のようになる:
この時点で、開いている要素のスタックには、
html、body、table、および
b の各要素が
この順序で存在する(生成された DOM ツリーとは一致しない)。アクティブな書式設定要素のリストには
b 要素だけがあり、
挿入モードは「table 内」である。
tr 開始タグにより、
b 要素が
スタックからポップされ、tbody 開始タグが暗黙に生成される。その後、tbody および
tr 要素は
比較的単純な方法で処理され、構文解析器は「table
本体内」および「行内」挿入モードを
通過する。その後、DOM は次のようになる:
ここで、開いている要素のスタックには、html、
body、table、tbody、および
tr 要素がある。
アクティブな
書式設定要素のリストには、依然として b 要素があり、
挿入モードは「行内」である。
td 要素の
開始タグトークンは、td 要素をツリーに配置した後、マーカーをアクティブな
書式設定要素のリストへ配置する(また、「セル内」挿入モードへも切り替える)。
マーカーがあるため、「aaa」の文字トークンが
検出されても、結果となる Text ノードを保持する b 要素は作成されない:
終了タグは単純な方法で処理される。それらを処理した後、開いている
要素のスタックには、html、body、
table、および
tbody 要素が
ある。アクティブな書式設定要素のリストには
依然として b 要素がある(マーカーは「td」終了タグトークンによって
削除されている)。また、挿入モードは「table 本体内」である。
こうして「bbb」の文字トークンが検出される。これらにより、「table テキスト内」挿入モードが使用される
(元の
挿入モードは「table
本体内」に設定される)。
文字トークンが収集され、次のトークン(table 要素の
終了タグ)が検出されると、それらはグループとして処理される。すべてが空白ではないため、
「table 内」挿入モードの
「その他の場合」の規則に従って処理される。この規則は、里親処理を使用しつつ、「body 内」挿入モードへ処理を委ねる。
アクティブな書式設定要素が
再構築されると、b 要素が作成され、里親処理され、その後「bbb」の Text ノードがそこへ付加される:
開いている要素のスタックには、html、
body、table、tbody、および
新しい b がある(これも生成されたツリーとは一致しないことに注意)。
アクティブな書式設定要素のリストには
新しい b 要素があり、挿入モードは依然として「table 本体内」である。
文字トークンが「bbb」ではなく、ASCII 空白だけで
あった場合、そのASCII 空白は単に tbody 要素へ
付加される。
最後に、table は「table」終了タグによって閉じられる。これにより、
開いている要素のスタックから、
table 要素までのすべてのノードが、その要素を含めてポップされる。
しかし、アクティブな書式設定要素のリストには
影響しないため、表の後の「ccc」の文字トークンにより、さらに別の b 要素が、
今度は表の後に作成される:
この節は非規範的である。
次のマークアップを考える。この例では、これは URL
https://example.com/inner を持つ文書であり、URL
https://example.com/outer を持つ別の文書内の iframe の内容としてレンダリングされるものと仮定する:
< div id = a >
< script >
var div = document. getElementById( 'a' );
parent. document. body. appendChild( div);
</ script >
< script >
alert( document. URL);
</ script >
</ div >
< script >
alert( document. URL);
</ script > 最初の「script」終了タグまで、スクリプトが構文解析される前の結果は比較的単純である:
しかし、スクリプトが構文解析された後、div 要素と、その子である script 要素は消えている:
この時点で、それらは前述した外側の閲覧
コンテキストの Document 内にある。しかし、開いている要素のスタックは
依然として div 要素を含んでいる。
したがって、二番目の script 要素が構文解析されると、それは外側の
Document オブジェクト内に挿入される。
構文解析器が作成された対象とは異なる Document 内へ構文解析されたものは実行されないため、
最初のアラートは表示されない。
div 要素の終了タグが構文解析されると、div 要素がスタックからポップされる。そのため、次の script 要素は内側の Document 内に配置される:
このスクリプトは実行され、「https://example.com/inner」というアラートが表示される。
この節は非規範的である。
前の節の例をさらに詳しく考え、二番目の script 要素が外部スクリプト(すなわち、src 属性を持つもの)である場合を考える。この要素は作成時に
構文解析器の Document 内になかったため、その外部スクリプトはダウンロードすらされない。
script 要素が src 属性を持ち、通常どおり構文解析器の Document 内へ構文解析されたが、外部スクリプトのダウンロード中に
その要素が別の文書へ移動された場合、スクリプトのダウンロードは継続されるが、実行はされない。
一般に、script 要素を複数の Document 間で移動することは、好ましくない慣行と見なされる。
この節は非規範的である。
次のマークアップは、入れ子にされた書式設定要素(b
など)が
収集され、それを含む要素が閉じられた後も引き続き適用される一方で、過剰な重複は破棄される
様子を示す。
<!DOCTYPE html>
< p >< b class = x >< b class = x >< b >< b class = x >< b class = x >< b > X
< p > X
< p >< b >< b class = x >< b > X
< p ></ b ></ b ></ b ></ b ></ b ></ b > X結果となる DOM ツリーは次のとおりである:
htmlhtml
マークアップ内の二番目の p 要素には明示的な b 要素がないが、
結果となる DOM では、各種の書式設定要素が最大三つずつ(この場合、class 属性を持つ三つの
b 要素と、
装飾のない二つの b 要素)その要素の「X」の前に再構築されることに注意。
また、これは最後の段落では、アクティブな書式設定要素のリストを
完全に消去するために、b 終了タグが六つだけ必要であることも意味する。この時点までに
b 開始タグが
九つ検出されているにもかかわらずである。
次の手順は、HTML フラグメント
シリアライズアルゴリズムを構成する。このアルゴリズムは、the node と呼ばれる
DOM Element、Document、または DocumentFragment、
真偽値 serializableShadowRoots、および
sequence<ShadowRoot> shadowRoots を入力として取り、文字列を返す。
このアルゴリズムは、シリアライズされるノード自体ではなく、そのノードの 子をシリアライズする。
the node が空としてシリアライズされる場合、 空文字列を返す。
s を文字列とし、空文字列に初期化する。
the node が template 要素である場合、代わりに
the node をその template 要素のテンプレート内容(DocumentFragment
ノード)とする。
current node がシャドウホストである場合:
shadow を current node のシャドウルートとする。
次のいずれかが true である場合:
serializableShadowRoots が true であり、かつ shadow の シリアライズ可能が true である。または
shadowRoots が shadow を含む。
その場合:
「<template shadowrootmode="」を付加する。
shadow のモードが
「open」である場合、「open」を付加する。
それ以外の場合、「closed」を付加する。
U+0022(")を付加する。
shadow のフォーカスを委譲するが設定されている場合、
「 shadowrootdelegatesfocus=""」を付加する。
shadow のシリアライズ可能が設定されている場合、
「 shadowrootserializable=""」を付加する。
shadow のスロット割り当てが「manual」である場合、
「 shadowrootslotassignment="manual"」を付加する。
shadow のクローン可能が設定されている場合、
「 shadowrootclonable=""」を付加する。
shouldAppendRegistryAttribute を、次の手順を実行した結果とする:
documentRegistry を、shadow のノード文書のカスタム要素レジストリーとする。
shadowRegistry を、shadow のカスタム要素レジストリーとする。
documentRegistry が null であり、かつ shadowRegistry が null である場合、false を返す。
documentRegistry がグローバルカスタム要素 レジストリーであり、かつ shadowRegistry がグローバルカスタム要素 レジストリーである場合、false を返す。
true を返す。
shouldAppendRegistryAttribute が true である場合、
「 shadowrootcustomelementregistry=""」を付加する。
U+003E(>)を付加する。
shadow、serializableShadowRoots、および shadowRoots を使用してHTML フラグメント シリアライズアルゴリズムを実行した値を付加する (したがって、その要素についてこのアルゴリズムへ再帰する)。
「</template>」を付加する。
the node の各子ノードについて、ツリー順に次の手順を実行する:
current node を、処理中の子ノードとする。
次の一覧から適切な文字列を s へ付加する:
Element である場合
current node がHTML 名前空間、MathML 名前空間、またはSVG 名前空間内の要素である場合、 tagname を current node のローカル名とする。それ以外の場合、 tagname を current node の修飾名とする。
U+003C(<)と、それに続けて tagname を付加する。
HTML 構文解析器または
createElement() によって
作成されたHTML 要素では、
tagname は小文字になる。
current node のis 値が null でなく、かつ
要素の属性リスト内に is 属性がない場合、「 is="」と、それに続けて
current node のis 値を
属性モードで下記の説明に従ってエスケープしたもの、
および U+0022(")を付加する。
要素が持つ各属性について、U+0020 SPACE、下記の説明に従った属性の
シリアライズ名、「="」、属性の値を
属性モードで下記の説明に従ってエスケープしたもの、
および U+0022(")を付加する。
前の段落における属性のシリアライズ名は、 次のように決定しなければならない:
属性のシリアライズ名は、属性のローカル名である。
HTML
構文解析器または setAttribute() によって
設定されたHTML 要素上の属性では、
ローカル名は小文字になる。
属性のシリアライズ名は、「xml:」と、それに続く属性のローカル名である。
xmlns である場合
属性のシリアライズ名は「xmlns」である。
xmlns でない場合
属性のシリアライズ名は、「xmlns:」と、それに続く属性のローカル名である。
属性のシリアライズ名は、「xlink:」と、それに続く属性のローカル名である。
属性のシリアライズ名は、属性の修飾名である。
属性の正確な順序は実装定義であり、元のマークアップで属性が 指定された順序などの要因に依存する場合があるが、並べ替え順序は安定していなければならない。 すなわち、このアルゴリズムを連続して呼び出した場合、要素の属性は同じ順序で シリアライズされなければならない。
U+003E(>)を付加する。
current node が空としてシリアライズされる場合、 この時点で次の子ノードへ継続する。
current node、serializableShadowRoots、および
shadowRoots を使用してHTML フラグメント
シリアライズアルゴリズムを実行した値
(したがって、そのノードについてこのアルゴリズムへ再帰する)と、それに続けて
「</」、tagname、および U+003E(>)を付加する。
Text ノードである場合current node の親が style、script、xmp、iframe、noembed、
noframes、または plaintext 要素である場合、または
current node の親が noscript 要素であり、かつそのノードについて
スクリプト処理が有効である場合、
current node のデータの値をそのまま付加する。
それ以外の場合、current node のデータの値を、下記の説明に従ってエスケープして付加する。
Comment である場合
「<!--」と、それに続けて current node のデータの値、および
「-->」を付加する。
ProcessingInstruction
である場合
「<?」と、それに続けて current node の対象の値、U+0020 SPACE、
current node のデータの値、および
「?>」を付加する。
DocumentType である場合
「<!DOCTYPE 」と、それに続けて current node の名前の値、および U+003E(>)を付加する。
s を返す。
このアルゴリズムの出力を HTML 構文解析器で構文解析しても、 元のツリー構造が復元されない可能性がある。シリアライズして再構文解析する手順を往復しても 復元されないツリー構造は、HTML 構文解析器自体によって生成されることもあるが、 そのような場合は通常、不適合である。
たとえば、textarea 要素へ Comment ノードを付加し、
それをシリアライズしてから出力を再構文解析すると、コメントはテキストコントロール内に
表示されることになる。同様に、DOM 操作の結果として、要素が「-->」を含む
コメントを持つ場合、その要素をシリアライズした結果を構文解析すると、コメントはその位置で
切り詰められ、コメントの残りはマークアップとして解釈される。その他の例として、script 要素に「</script>」という
テキスト文字列を持つ Text ノードを含ませる場合や、
p 要素に
ul 要素を
含ませる場合がある(ul 要素の開始タグは、p の終了タグを
暗黙に生成するためである)。
これはクロスサイトスクリプティング攻撃を可能にすることがある。その例として、ユーザーが
フォントファミリー名を入力でき、それを DOM を介して CSS の style ブロックへ挿入し、その後 innerHTML IDL 属性を使用して、その style 要素の HTML シリアライズを取得するページがある。
ユーザーがフォントファミリー名として
「</style><script>attack</script>」を入力した場合、innerHTML は、別のコンテキストで構文解析すると
script ノードを含むマークアップを返す。元の DOM には
script ノードが存在しなかったにもかかわらずである。
たとえば、次のマークアップを考える:
< form id = "outer" >< div ></ form >< form id = "inner" >< input > これは次のように構文解析される:
input 要素は、内側の form 要素へ関連付けられる。ここで、このツリー構造を
シリアライズして再構文解析すると、<form
id="inner"> 開始タグは無視されるため、input 要素は、代わりに外側の form 要素へ関連付けられる。
< html >< head ></ head >< body >< form id = "outer" >< div > < form id = "inner" > < input ></ form ></ div ></ form ></ body ></ html > 別の例として、次のマークアップを考える:
< a >< table >< a > これは次のように構文解析される:
すなわち、二番目の a 要素が里親処理されるため、a 要素は入れ子になる。シリアライズと再構文解析を往復した後は、
a 要素と table 要素はすべて兄弟になる。二番目の
<a> 開始タグが最初の a 要素を暗黙に閉じるためである。
< html >< head ></ head >< body >< a > < a > </ a >< table ></ table ></ a ></ body ></ html > 歴史的な理由により、このアルゴリズムは pre、textarea、または listing 要素内の先頭の
U+000A(LF)文字を往復変換しない。ただし、最初の二つの場合には、往復変換されるマークアップが
適合していることもある。HTML 構文解析器は構文解析中にそのような文字を
破棄するが、このアルゴリズムは余分な U+000A(LF)文字をシリアライズしない。
たとえば、次のマークアップを考える:
< pre >
Hello.</ pre > この文書が最初に構文解析されると、pre 要素の子テキスト内容は、一つの改行文字で始まる。
シリアライズと再構文解析を往復した後、pre 要素の子テキスト内容は、単に「Hello.」となる。
カスタマイズされた
組み込み要素の作成を通知する際の is 属性の特殊な役割、
すなわち構文解析された HTML が要素のis 値を設定するための仕組みを提供するという
役割のため、シリアライズ中はこの属性を特別扱いする。これにより、要素のis 値が、
シリアライズと構文解析の往復を通じて保持される。
構文解析器を介してカスタマイズされた組み込み要素を
作成する場合、開発者は is 属性を直接使用する。このような場合、シリアライズと構文解析の
往復は正しく機能する。
< script >
window. SuperP = class extends HTMLParagraphElement {};
customElements. define( "super-p" , SuperP, { extends : "p" });
</ script >
< div id = "container" >< p is = "super-p" > Superb!</ p ></ div >
< script >
console. log( container. innerHTML); // <p is="super-p">
container. innerHTML = container. innerHTML;
console. log( container. innerHTML); // <p is="super-p">
console. assert( container. firstChild instanceof SuperP);
</ script > しかし、カスタマイズされた組み込み要素を、そのコンストラクターまたは createElement() を介して
作成する場合、is 属性は追加されない。代わりに、カスタム要素機構が使用する
is 値が、属性を仲介せずに設定される。
< script >
container. innerHTML = "" ;
const p = document. createElement( "p" , { is: "super-p" });
container. appendChild( p);
// The is attribute is not present in the DOM:
console. assert( ! p. hasAttribute( "is" ));
// But the element is still a super-p:
console. assert( p instanceof SuperP);
</ script > シリアライズと構文解析の往復が引き続き機能することを保証するため、シリアライズ処理は
要素のis 値を、is 属性として明示的に
書き出す:
< script >
console. log( container. innerHTML); // <p is="super-p">
container. innerHTML = container. innerHTML;
console. log( container. innerHTML); // <p is="super-p">
console. assert( container. firstChild instanceof SuperP);
</ script > 文字列をエスケープすることは (上記のアルゴリズムにおいて)、次の手順を実行することからなる:
「&」文字の各出現を「&」へ置き換える。
U+00A0 NO-BREAK SPACE 文字の各出現を「 」へ置き換える。
「<」文字の各出現を
「<」へ置き換える。
「>」文字の各出現を
「>」へ置き換える。
アルゴリズムが属性モードで呼び出された場合、「"」文字の各出現を
「"」へ置き換える。
Element または
DocumentFragment
target、文字列 input、任意の真偽値
allowDeclarativeShadowRoots(既定値は false)、および任意の構文解析器スクリプト
モード scriptingMode(既定値は不活性)が与えられたとき、
HTML フラグメント構文解析アルゴリズムは
次の手順である。この手順は DocumentFragment を返す。
HTML 構文解析器の節にあるアルゴリズム内で 断片の場合と記された部分は、このアルゴリズムのために構文解析器が 作成された場合にのみ発生する部分である。アルゴリズムには情報提供のみを目的としてそのような 表示が付けられており、規範的な効力はない。構文解析器がこのアルゴリズムを処理する目的で 作成されたものでない場合でも、断片の場合として記述された条件が発生し得るなら、 それは仕様の誤りである。
target が Element である場合、
context を
target とする。それ以外の場合、target のホストとする。
それ以外で、contextDocument が限定互換モードである場合、
document のモードを
「limited-quirks」に設定する。
宣言的シャドウルートを許可するが allowDeclarativeShadowRoots である新しいHTML 構文解析器を作成し、 document へ関連付ける。
contextDocument のスクリプト処理が無効である場合、 scriptingMode を無効に設定する。
構文解析器のスクリプティングモードを scriptingMode に設定する。
context に応じて、HTML 構文解析器の トークン化段階の状態を次のように設定する:
titletextarea
stylexmpiframenoembednoframesscriptnoscript
plaintext性能上の理由から、エラーを報告せず、この仕様で説明される実際の状態機械を 直接使用する実装は、上の一覧で RAWTEXT 状態およびスクリプトデータ状態が言及される箇所で、 代わりに PLAINTEXT 状態を使用できる。構文解析エラーに関する規則を除けば、それらは同等である。 断片の場合には適切な終了タグトークンが存在しない一方、 PLAINTEXT 状態では状態遷移がはるかに少ないためである。
root を、document、「html」、HTML
名前空間、null、null、false、および
target が与えられたときにカスタム要素レジストリーを
検索する結果を使用して、要素を作成する結果とする。
root を document へ付加する。
HTML 構文解析器の開いている要素のスタックが、 単一の要素 root だけを含むように設定する。
fragmentを、文書 フラグメントを作成した結果とする。これは、targetのノード 文書が与えられたものである。
構文解析器のルート挿入対象を fragment に設定する。
context が template 要素である場合、「template 内」をtemplate 挿入モードのスタックへ
プッシュし、新しい現在の template
挿入モードとする。
名前が context のローカル名であり、属性が context の属性である開始タグトークンを作成する。
この開始タグトークンを context の開始タグトークンとする。たとえば、 それがHTML 統合点であるかどうかを 判定する目的で使用する。
構文解析器の挿入モードを 適切にリセットする。
構文解析器は、このアルゴリズムの一部として context 要素を参照する。
HTML 構文解析器のform
要素ポインターを、
context に最も近い form 要素であるノードへ設定する
(祖先チェーンをまっすぐ上へたどり、要素自体が form 要素である場合はその要素も含める)。
そのような要素が存在する場合に限る。(そのような form 要素がない場合、form 要素ポインターは
初期値である null のままとなる。)
input を、作成したばかりのHTML 構文解析器の入力ストリームへ配置する。エンコーディングの 確信度は無関係である。
HTML 構文解析器を開始し、入力ストリームへ 挿入したすべての文字を消費するまで実行させる。
fragment を返す。
この表は、HTML がサポートする文字参照の名前と、それらが参照するコードポイントを 列挙する。前の各節からこの表が参照される。
レガシー互換性のため、多くのコードポイントが複数の文字参照名を持つことは 意図的である。たとえば、末尾のセミコロンを持つものと持たないものの両方や、大文字小文字が 異なるものが存在する。
| 名前 | 文字 | グリフ |
|---|---|---|
Aacute; |
U+000C1 | Á |
Aacute |
U+000C1 | Á |
aacute; |
U+000E1 | á |
aacute |
U+000E1 | á |
Abreve; |
U+00102 | Ă |
abreve; |
U+00103 | ă |
ac; |
U+0223E | ∾ |
acd; |
U+0223F | ∿ |
acE; |
U+0223E U+00333 | ∾̳ |
Acirc; |
U+000C2 | Â |
Acirc |
U+000C2 | Â |
acirc; |
U+000E2 | â |
acirc |
U+000E2 | â |
acute; |
U+000B4 | ´ |
acute |
U+000B4 | ´ |
Acy; |
U+00410 | А |
acy; |
U+00430 | а |
AElig; |
U+000C6 | Æ |
AElig |
U+000C6 | Æ |
aelig; |
U+000E6 | æ |
aelig |
U+000E6 | æ |
af; |
U+02061 | |
Afr; |
U+1D504 | 𝔄 |
afr; |
U+1D51E | 𝔞 |
Agrave; |
U+000C0 | À |
Agrave |
U+000C0 | À |
agrave; |
U+000E0 | à |
agrave |
U+000E0 | à |
alefsym; |
U+02135 | ℵ |
aleph; |
U+02135 | ℵ |
Alpha; |
U+00391 | Α |
alpha; |
U+003B1 | α |
Amacr; |
U+00100 | Ā |
amacr; |
U+00101 | ā |
amalg; |
U+02A3F | ⨿ |
AMP; |
U+00026 | & |
AMP |
U+00026 | & |
amp; |
U+00026 | & |
amp |
U+00026 | & |
And; |
U+02A53 | ⩓ |
and; |
U+02227 | ∧ |
andand; |
U+02A55 | ⩕ |
andd; |
U+02A5C | ⩜ |
andslope; |
U+02A58 | ⩘ |
andv; |
U+02A5A | ⩚ |
ang; |
U+02220 | ∠ |
ange; |
U+029A4 | ⦤ |
angle; |
U+02220 | ∠ |
angmsd; |
U+02221 | ∡ |
angmsdaa; |
U+029A8 | ⦨ |
angmsdab; |
U+029A9 | ⦩ |
angmsdac; |
U+029AA | ⦪ |
angmsdad; |
U+029AB | ⦫ |
angmsdae; |
U+029AC | ⦬ |
angmsdaf; |
U+029AD | ⦭ |
angmsdag; |
U+029AE | ⦮ |
angmsdah; |
U+029AF | ⦯ |
angrt; |
U+0221F | ∟ |
angrtvb; |
U+022BE | ⊾ |
angrtvbd; |
U+0299D | ⦝ |
angsph; |
U+02222 | ∢ |
angst; |
U+000C5 | Å |
angzarr; |
U+0237C | ⍼ |
Aogon; |
U+00104 | Ą |
aogon; |
U+00105 | ą |
Aopf; |
U+1D538 | 𝔸 |
aopf; |
U+1D552 | 𝕒 |
ap; |
U+02248 | ≈ |
apacir; |
U+02A6F | ⩯ |
apE; |
U+02A70 | ⩰ |
ape; |
U+0224A | ≊ |
apid; |
U+0224B | ≋ |
apos; |
U+00027 | ' |
ApplyFunction; |
U+02061 | |
approx; |
U+02248 | ≈ |
approxeq; |
U+0224A | ≊ |
Aring; |
U+000C5 | Å |
Aring |
U+000C5 | Å |
aring; |
U+000E5 | å |
aring |
U+000E5 | å |
Ascr; |
U+1D49C | 𝒜 |
ascr; |
U+1D4B6 | 𝒶 |
Assign; |
U+02254 | ≔ |
ast; |
U+0002A | * |
asymp; |
U+02248 | ≈ |
asympeq; |
U+0224D | ≍ |
Atilde; |
U+000C3 | Ã |
Atilde |
U+000C3 | Ã |
atilde; |
U+000E3 | ã |
atilde |
U+000E3 | ã |
Auml; |
U+000C4 | Ä |
Auml |
U+000C4 | Ä |
auml; |
U+000E4 | ä |
auml |
U+000E4 | ä |
awconint; |
U+02233 | ∳ |
awint; |
U+02A11 | ⨑ |
backcong; |
U+0224C | ≌ |
backepsilon; |
U+003F6 | ϶ |
backprime; |
U+02035 | ‵ |
backsim; |
U+0223D | ∽ |
backsimeq; |
U+022CD | ⋍ |
Backslash; |
U+02216 | ∖ |
Barv; |
U+02AE7 | ⫧ |
barvee; |
U+022BD | ⊽ |
Barwed; |
U+02306 | ⌆ |
barwed; |
U+02305 | ⌅ |
barwedge; |
U+02305 | ⌅ |
bbrk; |
U+023B5 | ⎵ |
bbrktbrk; |
U+023B6 | ⎶ |
bcong; |
U+0224C | ≌ |
Bcy; |
U+00411 | Б |
bcy; |
U+00431 | б |
bdquo; |
U+0201E | „ |
becaus; |
U+02235 | ∵ |
Because; |
U+02235 | ∵ |
because; |
U+02235 | ∵ |
bemptyv; |
U+029B0 | ⦰ |
bepsi; |
U+003F6 | ϶ |
bernou; |
U+0212C | ℬ |
Bernoullis; |
U+0212C | ℬ |
Beta; |
U+00392 | Β |
beta; |
U+003B2 | β |
beth; |
U+02136 | ℶ |
between; |
U+0226C | ≬ |
Bfr; |
U+1D505 | 𝔅 |
bfr; |
U+1D51F | 𝔟 |
bigcap; |
U+022C2 | ⋂ |
bigcirc; |
U+025EF | ◯ |
bigcup; |
U+022C3 | ⋃ |
bigodot; |
U+02A00 | ⨀ |
bigoplus; |
U+02A01 | ⨁ |
bigotimes; |
U+02A02 | ⨂ |
bigsqcup; |
U+02A06 | ⨆ |
bigstar; |
U+02605 | ★ |
bigtriangledown; |
U+025BD | ▽ |
bigtriangleup; |
U+025B3 | △ |
biguplus; |
U+02A04 | ⨄ |
bigvee; |
U+022C1 | ⋁ |
bigwedge; |
U+022C0 | ⋀ |
bkarow; |
U+0290D | ⤍ |
blacklozenge; |
U+029EB | ⧫ |
blacksquare; |
U+025AA | ▪ |
blacktriangle; |
U+025B4 | ▴ |
blacktriangledown; |
U+025BE | ▾ |
blacktriangleleft; |
U+025C2 | ◂ |
blacktriangleright; |
U+025B8 | ▸ |
blank; |
U+02423 | ␣ |
blk12; |
U+02592 | ▒ |
blk14; |
U+02591 | ░ |
blk34; |
U+02593 | ▓ |
block; |
U+02588 | █ |
bne; |
U+0003D U+020E5 | =⃥ |
bnequiv; |
U+02261 U+020E5 | ≡⃥ |
bNot; |
U+02AED | ⫭ |
bnot; |
U+02310 | ⌐ |
Bopf; |
U+1D539 | 𝔹 |
bopf; |
U+1D553 | 𝕓 |
bot; |
U+022A5 | ⊥ |
bottom; |
U+022A5 | ⊥ |
bowtie; |
U+022C8 | ⋈ |
boxbox; |
U+029C9 | ⧉ |
boxDL; |
U+02557 | ╗ |
boxDl; |
U+02556 | ╖ |
boxdL; |
U+02555 | ╕ |
boxdl; |
U+02510 | ┐ |
boxDR; |
U+02554 | ╔ |
boxDr; |
U+02553 | ╓ |
boxdR; |
U+02552 | ╒ |
boxdr; |
U+0250C | ┌ |
boxH; |
U+02550 | ═ |
boxh; |
U+02500 | ─ |
boxHD; |
U+02566 | ╦ |
boxHd; |
U+02564 | ╤ |
boxhD; |
U+02565 | ╥ |
boxhd; |
U+0252C | ┬ |
boxHU; |
U+02569 | ╩ |
boxHu; |
U+02567 | ╧ |
boxhU; |
U+02568 | ╨ |
boxhu; |
U+02534 | ┴ |
boxminus; |
U+0229F | ⊟ |
boxplus; |
U+0229E | ⊞ |
boxtimes; |
U+022A0 | ⊠ |
boxUL; |
U+0255D | ╝ |
boxUl; |
U+0255C | ╜ |
boxuL; |
U+0255B | ╛ |
boxul; |
U+02518 | ┘ |
boxUR; |
U+0255A | ╚ |
boxUr; |
U+02559 | ╙ |
boxuR; |
U+02558 | ╘ |
boxur; |
U+02514 | └ |
boxV; |
U+02551 | ║ |
boxv; |
U+02502 | │ |
boxVH; |
U+0256C | ╬ |
boxVh; |
U+0256B | ╫ |
boxvH; |
U+0256A | ╪ |
boxvh; |
U+0253C | ┼ |
boxVL; |
U+02563 | ╣ |
boxVl; |
U+02562 | ╢ |
boxvL; |
U+02561 | ╡ |
boxvl; |
U+02524 | ┤ |
boxVR; |
U+02560 | ╠ |
boxVr; |
U+0255F | ╟ |
boxvR; |
U+0255E | ╞ |
boxvr; |
U+0251C | ├ |
bprime; |
U+02035 | ‵ |
Breve; |
U+002D8 | ˘ |
breve; |
U+002D8 | ˘ |
brvbar; |
U+000A6 | ¦ |
brvbar |
U+000A6 | ¦ |
Bscr; |
U+0212C | ℬ |
bscr; |
U+1D4B7 | 𝒷 |
bsemi; |
U+0204F | ⁏ |
bsim; |
U+0223D | ∽ |
bsime; |
U+022CD | ⋍ |
bsol; |
U+0005C | \ |
bsolb; |
U+029C5 | ⧅ |
bsolhsub; |
U+027C8 | ⟈ |
bull; |
U+02022 | • |
bullet; |
U+02022 | • |
bump; |
U+0224E | ≎ |
bumpE; |
U+02AAE | ⪮ |
bumpe; |
U+0224F | ≏ |
Bumpeq; |
U+0224E | ≎ |
bumpeq; |
U+0224F | ≏ |
Cacute; |
U+00106 | Ć |
cacute; |
U+00107 | ć |
Cap; |
U+022D2 | ⋒ |
cap; |
U+02229 | ∩ |
capand; |
U+02A44 | ⩄ |
capbrcup; |
U+02A49 | ⩉ |
capcap; |
U+02A4B | ⩋ |
capcup; |
U+02A47 | ⩇ |
capdot; |
U+02A40 | ⩀ |
CapitalDifferentialD; |
U+02145 | ⅅ |
caps; |
U+02229 U+0FE00 | ∩︀ |
caret; |
U+02041 | ⁁ |
caron; |
U+002C7 | ˇ |
Cayleys; |
U+0212D | ℭ |
ccaps; |
U+02A4D | ⩍ |
Ccaron; |
U+0010C | Č |
ccaron; |
U+0010D | č |
Ccedil; |
U+000C7 | Ç |
Ccedil |
U+000C7 | Ç |
ccedil; |
U+000E7 | ç |
ccedil |
U+000E7 | ç |
Ccirc; |
U+00108 | Ĉ |
ccirc; |
U+00109 | ĉ |
Cconint; |
U+02230 | ∰ |
ccups; |
U+02A4C | ⩌ |
ccupssm; |
U+02A50 | ⩐ |
Cdot; |
U+0010A | Ċ |
cdot; |
U+0010B | ċ |
cedil; |
U+000B8 | ¸ |
cedil |
U+000B8 | ¸ |
Cedilla; |
U+000B8 | ¸ |
cemptyv; |
U+029B2 | ⦲ |
cent; |
U+000A2 | ¢ |
cent |
U+000A2 | ¢ |
CenterDot; |
U+000B7 | · |
centerdot; |
U+000B7 | · |
Cfr; |
U+0212D | ℭ |
cfr; |
U+1D520 | 𝔠 |
CHcy; |
U+00427 | Ч |
chcy; |
U+00447 | ч |
check; |
U+02713 | ✓ |
checkmark; |
U+02713 | ✓ |
Chi; |
U+003A7 | Χ |
chi; |
U+003C7 | χ |
cir; |
U+025CB | ○ |
circ; |
U+002C6 | ˆ |
circeq; |
U+02257 | ≗ |
circlearrowleft; |
U+021BA | ↺ |
circlearrowright; |
U+021BB | ↻ |
circledast; |
U+0229B | ⊛ |
circledcirc; |
U+0229A | ⊚ |
circleddash; |
U+0229D | ⊝ |
CircleDot; |
U+02299 | ⊙ |
circledR; |
U+000AE | ® |
circledS; |
U+024C8 | Ⓢ |
CircleMinus; |
U+02296 | ⊖ |
CirclePlus; |
U+02295 | ⊕ |
CircleTimes; |
U+02297 | ⊗ |
cirE; |
U+029C3 | ⧃ |
cire; |
U+02257 | ≗ |
cirfnint; |
U+02A10 | ⨐ |
cirmid; |
U+02AEF | ⫯ |
cirscir; |
U+029C2 | ⧂ |
ClockwiseContourIntegral; |
U+02232 | ∲ |
CloseCurlyDoubleQuote; |
U+0201D | ” |
CloseCurlyQuote; |
U+02019 | ’ |
clubs; |
U+02663 | ♣ |
clubsuit; |
U+02663 | ♣ |
Colon; |
U+02237 | ∷ |
colon; |
U+0003A | : |
Colone; |
U+02A74 | ⩴ |
colone; |
U+02254 | ≔ |
coloneq; |
U+02254 | ≔ |
comma; |
U+0002C | , |
commat; |
U+00040 | @ |
comp; |
U+02201 | ∁ |
compfn; |
U+02218 | ∘ |
complement; |
U+02201 | ∁ |
complexes; |
U+02102 | ℂ |
cong; |
U+02245 | ≅ |
congdot; |
U+02A6D | ⩭ |
Congruent; |
U+02261 | ≡ |
Conint; |
U+0222F | ∯ |
conint; |
U+0222E | ∮ |
ContourIntegral; |
U+0222E | ∮ |
Copf; |
U+02102 | ℂ |
copf; |
U+1D554 | 𝕔 |
coprod; |
U+02210 | ∐ |
Coproduct; |
U+02210 | ∐ |
COPY; |
U+000A9 | © |
COPY |
U+000A9 | © |
copy; |
U+000A9 | © |
copy |
U+000A9 | © |
copysr; |
U+02117 | ℗ |
CounterClockwiseContourIntegral; |
U+02233 | ∳ |
crarr; |
U+021B5 | ↵ |
Cross; |
U+02A2F | ⨯ |
cross; |
U+02717 | ✗ |
Cscr; |
U+1D49E | 𝒞 |
cscr; |
U+1D4B8 | 𝒸 |
csub; |
U+02ACF | ⫏ |
csube; |
U+02AD1 | ⫑ |
csup; |
U+02AD0 | ⫐ |
csupe; |
U+02AD2 | ⫒ |
ctdot; |
U+022EF | ⋯ |
cudarrl; |
U+02938 | ⤸ |
cudarrr; |
U+02935 | ⤵ |
cuepr; |
U+022DE | ⋞ |
cuesc; |
U+022DF | ⋟ |
cularr; |
U+021B6 | ↶ |
cularrp; |
U+0293D | ⤽ |
Cup; |
U+022D3 | ⋓ |
cup; |
U+0222A | ∪ |
cupbrcap; |
U+02A48 | ⩈ |
CupCap; |
U+0224D | ≍ |
cupcap; |
U+02A46 | ⩆ |
cupcup; |
U+02A4A | ⩊ |
cupdot; |
U+0228D | ⊍ |
cupor; |
U+02A45 | ⩅ |
cups; |
U+0222A U+0FE00 | ∪︀ |
curarr; |
U+021B7 | ↷ |
curarrm; |
U+0293C | ⤼ |
curlyeqprec; |
U+022DE | ⋞ |
curlyeqsucc; |
U+022DF | ⋟ |
curlyvee; |
U+022CE | ⋎ |
curlywedge; |
U+022CF | ⋏ |
curren; |
U+000A4 | ¤ |
curren |
U+000A4 | ¤ |
curvearrowleft; |
U+021B6 | ↶ |
curvearrowright; |
U+021B7 | ↷ |
cuvee; |
U+022CE | ⋎ |
cuwed; |
U+022CF | ⋏ |
cwconint; |
U+02232 | ∲ |
cwint; |
U+02231 | ∱ |
cylcty; |
U+0232D | ⌭ |
Dagger; |
U+02021 | ‡ |
dagger; |
U+02020 | † |
daleth; |
U+02138 | ℸ |
Darr; |
U+021A1 | ↡ |
dArr; |
U+021D3 | ⇓ |
darr; |
U+02193 | ↓ |
dash; |
U+02010 | ‐ |
Dashv; |
U+02AE4 | ⫤ |
dashv; |
U+022A3 | ⊣ |
dbkarow; |
U+0290F | ⤏ |
dblac; |
U+002DD | ˝ |
Dcaron; |
U+0010E | Ď |
dcaron; |
U+0010F | ď |
Dcy; |
U+00414 | Д |
dcy; |
U+00434 | д |
DD; |
U+02145 | ⅅ |
dd; |
U+02146 | ⅆ |
ddagger; |
U+02021 | ‡ |
ddarr; |
U+021CA | ⇊ |
DDotrahd; |
U+02911 | ⤑ |
ddotseq; |
U+02A77 | ⩷ |
deg; |
U+000B0 | ° |
deg |
U+000B0 | ° |
Del; |
U+02207 | ∇ |
Delta; |
U+00394 | Δ |
delta; |
U+003B4 | δ |
demptyv; |
U+029B1 | ⦱ |
dfisht; |
U+0297F | ⥿ |
Dfr; |
U+1D507 | 𝔇 |
dfr; |
U+1D521 | 𝔡 |
dHar; |
U+02965 | ⥥ |
dharl; |
U+021C3 | ⇃ |
dharr; |
U+021C2 | ⇂ |
DiacriticalAcute; |
U+000B4 | ´ |
DiacriticalDot; |
U+002D9 | ˙ |
DiacriticalDoubleAcute; |
U+002DD | ˝ |
DiacriticalGrave; |
U+00060 | ` |
DiacriticalTilde; |
U+002DC | ˜ |
diam; |
U+022C4 | ⋄ |
Diamond; |
U+022C4 | ⋄ |
diamond; |
U+022C4 | ⋄ |
diamondsuit; |
U+02666 | ♦ |
diams; |
U+02666 | ♦ |
die; |
U+000A8 | ¨ |
DifferentialD; |
U+02146 | ⅆ |
digamma; |
U+003DD | ϝ |
disin; |
U+022F2 | ⋲ |
div; |
U+000F7 | ÷ |
divide; |
U+000F7 | ÷ |
divide |
U+000F7 | ÷ |
divideontimes; |
U+022C7 | ⋇ |
divonx; |
U+022C7 | ⋇ |
DJcy; |
U+00402 | Ђ |
djcy; |
U+00452 | ђ |
dlcorn; |
U+0231E | ⌞ |
dlcrop; |
U+0230D | ⌍ |
dollar; |
U+00024 | $ |
Dopf; |
U+1D53B | 𝔻 |
dopf; |
U+1D555 | 𝕕 |
Dot; |
U+000A8 | ¨ |
dot; |
U+002D9 | ˙ |
DotDot; |
U+020DC | ◌⃜ |
doteq; |
U+02250 | ≐ |
doteqdot; |
U+02251 | ≑ |
DotEqual; |
U+02250 | ≐ |
dotminus; |
U+02238 | ∸ |
dotplus; |
U+02214 | ∔ |
dotsquare; |
U+022A1 | ⊡ |
doublebarwedge; |
U+02306 | ⌆ |
DoubleContourIntegral; |
U+0222F | ∯ |
DoubleDot; |
U+000A8 | ¨ |
DoubleDownArrow; |
U+021D3 | ⇓ |
DoubleLeftArrow; |
U+021D0 | ⇐ |
DoubleLeftRightArrow; |
U+021D4 | ⇔ |
DoubleLeftTee; |
U+02AE4 | ⫤ |
DoubleLongLeftArrow; |
U+027F8 | ⟸ |
DoubleLongLeftRightArrow; |
U+027FA | ⟺ |
DoubleLongRightArrow; |
U+027F9 | ⟹ |
DoubleRightArrow; |
U+021D2 | ⇒ |
DoubleRightTee; |
U+022A8 | ⊨ |
DoubleUpArrow; |
U+021D1 | ⇑ |
DoubleUpDownArrow; |
U+021D5 | ⇕ |
DoubleVerticalBar; |
U+02225 | ∥ |
DownArrow; |
U+02193 | ↓ |
Downarrow; |
U+021D3 | ⇓ |
downarrow; |
U+02193 | ↓ |
DownArrowBar; |
U+02913 | ⤓ |
DownArrowUpArrow; |
U+021F5 | ⇵ |
DownBreve; |
U+00311 | ◌̑ |
downdownarrows; |
U+021CA | ⇊ |
downharpoonleft; |
U+021C3 | ⇃ |
downharpoonright; |
U+021C2 | ⇂ |
DownLeftRightVector; |
U+02950 | ⥐ |
DownLeftTeeVector; |
U+0295E | ⥞ |
DownLeftVector; |
U+021BD | ↽ |
DownLeftVectorBar; |
U+02956 | ⥖ |
DownRightTeeVector; |
U+0295F | ⥟ |
DownRightVector; |
U+021C1 | ⇁ |
DownRightVectorBar; |
U+02957 | ⥗ |
DownTee; |
U+022A4 | ⊤ |
DownTeeArrow; |
U+021A7 | ↧ |
drbkarow; |
U+02910 | ⤐ |
drcorn; |
U+0231F | ⌟ |
drcrop; |
U+0230C | ⌌ |
Dscr; |
U+1D49F | 𝒟 |
dscr; |
U+1D4B9 | 𝒹 |
DScy; |
U+00405 | Ѕ |
dscy; |
U+00455 | ѕ |
dsol; |
U+029F6 | ⧶ |
Dstrok; |
U+00110 | Đ |
dstrok; |
U+00111 | đ |
dtdot; |
U+022F1 | ⋱ |
dtri; |
U+025BF | ▿ |
dtrif; |
U+025BE | ▾ |
duarr; |
U+021F5 | ⇵ |
duhar; |
U+0296F | ⥯ |
dwangle; |
U+029A6 | ⦦ |
DZcy; |
U+0040F | Џ |
dzcy; |
U+0045F | џ |
dzigrarr; |
U+027FF | ⟿ |
Eacute; |
U+000C9 | É |
Eacute |
U+000C9 | É |
eacute; |
U+000E9 | é |
eacute |
U+000E9 | é |
easter; |
U+02A6E | ⩮ |
Ecaron; |
U+0011A | Ě |
ecaron; |
U+0011B | ě |
ecir; |
U+02256 | ≖ |
Ecirc; |
U+000CA | Ê |
Ecirc |
U+000CA | Ê |
ecirc; |
U+000EA | ê |
ecirc |
U+000EA | ê |
ecolon; |
U+02255 | ≕ |
Ecy; |
U+0042D | Э |
ecy; |
U+0044D | э |
eDDot; |
U+02A77 | ⩷ |
Edot; |
U+00116 | Ė |
eDot; |
U+02251 | ≑ |
edot; |
U+00117 | ė |
ee; |
U+02147 | ⅇ |
efDot; |
U+02252 | ≒ |
Efr; |
U+1D508 | 𝔈 |
efr; |
U+1D522 | 𝔢 |
eg; |
U+02A9A | ⪚ |
Egrave; |
U+000C8 | È |
Egrave |
U+000C8 | È |
egrave; |
U+000E8 | è |
egrave |
U+000E8 | è |
egs; |
U+02A96 | ⪖ |
egsdot; |
U+02A98 | ⪘ |
el; |
U+02A99 | ⪙ |
Element; |
U+02208 | ∈ |
elinters; |
U+023E7 | ⏧ |
ell; |
U+02113 | ℓ |
els; |
U+02A95 | ⪕ |
elsdot; |
U+02A97 | ⪗ |
Emacr; |
U+00112 | Ē |
emacr; |
U+00113 | ē |
empty; |
U+02205 | ∅ |
emptyset; |
U+02205 | ∅ |
EmptySmallSquare; |
U+025FB | ◻ |
emptyv; |
U+02205 | ∅ |
EmptyVerySmallSquare; |
U+025AB | ▫ |
emsp; |
U+02003 | |
emsp13; |
U+02004 | |
emsp14; |
U+02005 | |
ENG; |
U+0014A | Ŋ |
eng; |
U+0014B | ŋ |
ensp; |
U+02002 | |
Eogon; |
U+00118 | Ę |
eogon; |
U+00119 | ę |
Eopf; |
U+1D53C | 𝔼 |
eopf; |
U+1D556 | 𝕖 |
epar; |
U+022D5 | ⋕ |
eparsl; |
U+029E3 | ⧣ |
eplus; |
U+02A71 | ⩱ |
epsi; |
U+003B5 | ε |
Epsilon; |
U+00395 | Ε |
epsilon; |
U+003B5 | ε |
epsiv; |
U+003F5 | ϵ |
eqcirc; |
U+02256 | ≖ |
eqcolon; |
U+02255 | ≕ |
eqsim; |
U+02242 | ≂ |
eqslantgtr; |
U+02A96 | ⪖ |
eqslantless; |
U+02A95 | ⪕ |
Equal; |
U+02A75 | ⩵ |
equals; |
U+0003D | = |
EqualTilde; |
U+02242 | ≂ |
equest; |
U+0225F | ≟ |
Equilibrium; |
U+021CC | ⇌ |
equiv; |
U+02261 | ≡ |
equivDD; |
U+02A78 | ⩸ |
eqvparsl; |
U+029E5 | ⧥ |
erarr; |
U+02971 | ⥱ |
erDot; |
U+02253 | ≓ |
Escr; |
U+02130 | ℰ |
escr; |
U+0212F | ℯ |
esdot; |
U+02250 | ≐ |
Esim; |
U+02A73 | ⩳ |
esim; |
U+02242 | ≂ |
Eta; |
U+00397 | Η |
eta; |
U+003B7 | η |
ETH; |
U+000D0 | Ð |
ETH |
U+000D0 | Ð |
eth; |
U+000F0 | ð |
eth |
U+000F0 | ð |
Euml; |
U+000CB | Ë |
Euml |
U+000CB | Ë |
euml; |
U+000EB | ë |
euml |
U+000EB | ë |
euro; |
U+020AC | € |
excl; |
U+00021 | ! |
exist; |
U+02203 | ∃ |
Exists; |
U+02203 | ∃ |
expectation; |
U+02130 | ℰ |
ExponentialE; |
U+02147 | ⅇ |
exponentiale; |
U+02147 | ⅇ |
fallingdotseq; |
U+02252 | ≒ |
Fcy; |
U+00424 | Ф |
fcy; |
U+00444 | ф |
female; |
U+02640 | ♀ |
ffilig; |
U+0FB03 | ffi |
fflig; |
U+0FB00 | ff |
ffllig; |
U+0FB04 | ffl |
Ffr; |
U+1D509 | 𝔉 |
ffr; |
U+1D523 | 𝔣 |
filig; |
U+0FB01 | fi |
FilledSmallSquare; |
U+025FC | ◼ |
FilledVerySmallSquare; |
U+025AA | ▪ |
fjlig; |
U+00066 U+0006A | fj |
flat; |
U+0266D | ♭ |
fllig; |
U+0FB02 | fl |
fltns; |
U+025B1 | ▱ |
fnof; |
U+00192 | ƒ |
Fopf; |
U+1D53D | 𝔽 |
fopf; |
U+1D557 | 𝕗 |
ForAll; |
U+02200 | ∀ |
forall; |
U+02200 | ∀ |
fork; |
U+022D4 | ⋔ |
forkv; |
U+02AD9 | ⫙ |
Fouriertrf; |
U+02131 | ℱ |
fpartint; |
U+02A0D | ⨍ |
frac12; |
U+000BD | ½ |
frac12 |
U+000BD | ½ |
frac13; |
U+02153 | ⅓ |
frac14; |
U+000BC | ¼ |
frac14 |
U+000BC | ¼ |
frac15; |
U+02155 | ⅕ |
frac16; |
U+02159 | ⅙ |
frac18; |
U+0215B | ⅛ |
frac23; |
U+02154 | ⅔ |
frac25; |
U+02156 | ⅖ |
frac34; |
U+000BE | ¾ |
frac34 |
U+000BE | ¾ |
frac35; |
U+02157 | ⅗ |
frac38; |
U+0215C | ⅜ |
frac45; |
U+02158 | ⅘ |
frac56; |
U+0215A | ⅚ |
frac58; |
U+0215D | ⅝ |
frac78; |
U+0215E | ⅞ |
frasl; |
U+02044 | ⁄ |
frown; |
U+02322 | ⌢ |
Fscr; |
U+02131 | ℱ |
fscr; |
U+1D4BB | 𝒻 |
gacute; |
U+001F5 | ǵ |
Gamma; |
U+00393 | Γ |
gamma; |
U+003B3 | γ |
Gammad; |
U+003DC | Ϝ |
gammad; |
U+003DD | ϝ |
gap; |
U+02A86 | ⪆ |
Gbreve; |
U+0011E | Ğ |
gbreve; |
U+0011F | ğ |
Gcedil; |
U+00122 | Ģ |
Gcirc; |
U+0011C | Ĝ |
gcirc; |
U+0011D | ĝ |
Gcy; |
U+00413 | Г |
gcy; |
U+00433 | г |
Gdot; |
U+00120 | Ġ |
gdot; |
U+00121 | ġ |
gE; |
U+02267 | ≧ |
ge; |
U+02265 | ≥ |
gEl; |
U+02A8C | ⪌ |
gel; |
U+022DB | ⋛ |
geq; |
U+02265 | ≥ |
geqq; |
U+02267 | ≧ |
geqslant; |
U+02A7E | ⩾ |
ges; |
U+02A7E | ⩾ |
gescc; |
U+02AA9 | ⪩ |
gesdot; |
U+02A80 | ⪀ |
gesdoto; |
U+02A82 | ⪂ |
gesdotol; |
U+02A84 | ⪄ |
gesl; |
U+022DB U+0FE00 | ⋛︀ |
gesles; |
U+02A94 | ⪔ |
Gfr; |
U+1D50A | 𝔊 |
gfr; |
U+1D524 | 𝔤 |
Gg; |
U+022D9 | ⋙ |
gg; |
U+0226B | ≫ |
ggg; |
U+022D9 | ⋙ |
gimel; |
U+02137 | ℷ |
GJcy; |
U+00403 | Ѓ |
gjcy; |
U+00453 | ѓ |
gl; |
U+02277 | ≷ |
gla; |
U+02AA5 | ⪥ |
glE; |
U+02A92 | ⪒ |
glj; |
U+02AA4 | ⪤ |
gnap; |
U+02A8A | ⪊ |
gnapprox; |
U+02A8A | ⪊ |
gnE; |
U+02269 | ≩ |
gne; |
U+02A88 | ⪈ |
gneq; |
U+02A88 | ⪈ |
gneqq; |
U+02269 | ≩ |
gnsim; |
U+022E7 | ⋧ |
Gopf; |
U+1D53E | 𝔾 |
gopf; |
U+1D558 | 𝕘 |
grave; |
U+00060 | ` |
GreaterEqual; |
U+02265 | ≥ |
GreaterEqualLess; |
U+022DB | ⋛ |
GreaterFullEqual; |
U+02267 | ≧ |
GreaterGreater; |
U+02AA2 | ⪢ |
GreaterLess; |
U+02277 | ≷ |
GreaterSlantEqual; |
U+02A7E | ⩾ |
GreaterTilde; |
U+02273 | ≳ |
Gscr; |
U+1D4A2 | 𝒢 |
gscr; |
U+0210A | ℊ |
gsim; |
U+02273 | ≳ |
gsime; |
U+02A8E | ⪎ |
gsiml; |
U+02A90 | ⪐ |
GT; |
U+0003E | > |
GT |
U+0003E | > |
Gt; |
U+0226B | ≫ |
gt; |
U+0003E | > |
gt |
U+0003E | > |
gtcc; |
U+02AA7 | ⪧ |
gtcir; |
U+02A7A | ⩺ |
gtdot; |
U+022D7 | ⋗ |
gtlPar; |
U+02995 | ⦕ |
gtquest; |
U+02A7C | ⩼ |
gtrapprox; |
U+02A86 | ⪆ |
gtrarr; |
U+02978 | ⥸ |
gtrdot; |
U+022D7 | ⋗ |
gtreqless; |
U+022DB | ⋛ |
gtreqqless; |
U+02A8C | ⪌ |
gtrless; |
U+02277 | ≷ |
gtrsim; |
U+02273 | ≳ |
gvertneqq; |
U+02269 U+0FE00 | ≩︀ |
gvnE; |
U+02269 U+0FE00 | ≩︀ |
Hacek; |
U+002C7 | ˇ |
hairsp; |
U+0200A | |
half; |
U+000BD | ½ |
hamilt; |
U+0210B | ℋ |
HARDcy; |
U+0042A | Ъ |
hardcy; |
U+0044A | ъ |
hArr; |
U+021D4 | ⇔ |
harr; |
U+02194 | ↔ |
harrcir; |
U+02948 | ⥈ |
harrw; |
U+021AD | ↭ |
Hat; |
U+0005E | ^ |
hbar; |
U+0210F | ℏ |
Hcirc; |
U+00124 | Ĥ |
hcirc; |
U+00125 | ĥ |
hearts; |
U+02665 | ♥ |
heartsuit; |
U+02665 | ♥ |
hellip; |
U+02026 | … |
hercon; |
U+022B9 | ⊹ |
Hfr; |
U+0210C | ℌ |
hfr; |
U+1D525 | 𝔥 |
HilbertSpace; |
U+0210B | ℋ |
hksearow; |
U+02925 | ⤥ |
hkswarow; |
U+02926 | ⤦ |
hoarr; |
U+021FF | ⇿ |
homtht; |
U+0223B | ∻ |
hookleftarrow; |
U+021A9 | ↩ |
hookrightarrow; |
U+021AA | ↪ |
Hopf; |
U+0210D | ℍ |
hopf; |
U+1D559 | 𝕙 |
horbar; |
U+02015 | ― |
HorizontalLine; |
U+02500 | ─ |
Hscr; |
U+0210B | ℋ |
hscr; |
U+1D4BD | 𝒽 |
hslash; |
U+0210F | ℏ |
Hstrok; |
U+00126 | Ħ |
hstrok; |
U+00127 | ħ |
HumpDownHump; |
U+0224E | ≎ |
HumpEqual; |
U+0224F | ≏ |
hybull; |
U+02043 | ⁃ |
hyphen; |
U+02010 | ‐ |
Iacute; |
U+000CD | Í |
Iacute |
U+000CD | Í |
iacute; |
U+000ED | í |
iacute |
U+000ED | í |
ic; |
U+02063 | |
Icirc; |
U+000CE | Î |
Icirc |
U+000CE | Î |
icirc; |
U+000EE | î |
icirc |
U+000EE | î |
Icy; |
U+00418 | И |
icy; |
U+00438 | и |
Idot; |
U+00130 | İ |
IEcy; |
U+00415 | Е |
iecy; |
U+00435 | е |
iexcl; |
U+000A1 | ¡ |
iexcl |
U+000A1 | ¡ |
iff; |
U+021D4 | ⇔ |
Ifr; |
U+02111 | ℑ |
ifr; |
U+1D526 | 𝔦 |
Igrave; |
U+000CC | Ì |
Igrave |
U+000CC | Ì |
igrave; |
U+000EC | ì |
igrave |
U+000EC | ì |
ii; |
U+02148 | ⅈ |
iiiint; |
U+02A0C | ⨌ |
iiint; |
U+0222D | ∭ |
iinfin; |
U+029DC | ⧜ |
iiota; |
U+02129 | ℩ |
IJlig; |
U+00132 | IJ |
ijlig; |
U+00133 | ij |
Im; |
U+02111 | ℑ |
Imacr; |
U+0012A | Ī |
imacr; |
U+0012B | ī |
image; |
U+02111 | ℑ |
ImaginaryI; |
U+02148 | ⅈ |
imagline; |
U+02110 | ℐ |
imagpart; |
U+02111 | ℑ |
imath; |
U+00131 | ı |
imof; |
U+022B7 | ⊷ |
imped; |
U+001B5 | Ƶ |
Implies; |
U+021D2 | ⇒ |
in; |
U+02208 | ∈ |
incare; |
U+02105 | ℅ |
infin; |
U+0221E | ∞ |
infintie; |
U+029DD | ⧝ |
inodot; |
U+00131 | ı |
Int; |
U+0222C | ∬ |
int; |
U+0222B | ∫ |
intcal; |
U+022BA | ⊺ |
integers; |
U+02124 | ℤ |
Integral; |
U+0222B | ∫ |
intercal; |
U+022BA | ⊺ |
Intersection; |
U+022C2 | ⋂ |
intlarhk; |
U+02A17 | ⨗ |
intprod; |
U+02A3C | ⨼ |
InvisibleComma; |
U+02063 | |
InvisibleTimes; |
U+02062 | |
IOcy; |
U+00401 | Ё |
iocy; |
U+00451 | ё |
Iogon; |
U+0012E | Į |
iogon; |
U+0012F | į |
Iopf; |
U+1D540 | 𝕀 |
iopf; |
U+1D55A | 𝕚 |
Iota; |
U+00399 | Ι |
iota; |
U+003B9 | ι |
iprod; |
U+02A3C | ⨼ |
iquest; |
U+000BF | ¿ |
iquest |
U+000BF | ¿ |
Iscr; |
U+02110 | ℐ |
iscr; |
U+1D4BE | 𝒾 |
isin; |
U+02208 | ∈ |
isindot; |
U+022F5 | ⋵ |
isinE; |
U+022F9 | ⋹ |
isins; |
U+022F4 | ⋴ |
isinsv; |
U+022F3 | ⋳ |
isinv; |
U+02208 | ∈ |
it; |
U+02062 | |
Itilde; |
U+00128 | Ĩ |
itilde; |
U+00129 | ĩ |
Iukcy; |
U+00406 | І |
iukcy; |
U+00456 | і |
Iuml; |
U+000CF | Ï |
Iuml |
U+000CF | Ï |
iuml; |
U+000EF | ï |
iuml |
U+000EF | ï |
Jcirc; |
U+00134 | Ĵ |
jcirc; |
U+00135 | ĵ |
Jcy; |
U+00419 | Й |
jcy; |
U+00439 | й |
Jfr; |
U+1D50D | 𝔍 |
jfr; |
U+1D527 | 𝔧 |
jmath; |
U+00237 | ȷ |
Jopf; |
U+1D541 | 𝕁 |
jopf; |
U+1D55B | 𝕛 |
Jscr; |
U+1D4A5 | 𝒥 |
jscr; |
U+1D4BF | 𝒿 |
Jsercy; |
U+00408 | Ј |
jsercy; |
U+00458 | ј |
Jukcy; |
U+00404 | Є |
jukcy; |
U+00454 | є |
Kappa; |
U+0039A | Κ |
kappa; |
U+003BA | κ |
kappav; |
U+003F0 | ϰ |
Kcedil; |
U+00136 | Ķ |
kcedil; |
U+00137 | ķ |
Kcy; |
U+0041A | К |
kcy; |
U+0043A | к |
Kfr; |
U+1D50E | 𝔎 |
kfr; |
U+1D528 | 𝔨 |
kgreen; |
U+00138 | ĸ |
KHcy; |
U+00425 | Х |
khcy; |
U+00445 | х |
KJcy; |
U+0040C | Ќ |
kjcy; |
U+0045C | ќ |
Kopf; |
U+1D542 | 𝕂 |
kopf; |
U+1D55C | 𝕜 |
Kscr; |
U+1D4A6 | 𝒦 |
kscr; |
U+1D4C0 | 𝓀 |
lAarr; |
U+021DA | ⇚ |
Lacute; |
U+00139 | Ĺ |
lacute; |
U+0013A | ĺ |
laemptyv; |
U+029B4 | ⦴ |
lagran; |
U+02112 | ℒ |
Lambda; |
U+0039B | Λ |
lambda; |
U+003BB | λ |
Lang; |
U+027EA | ⟪ |
lang; |
U+027E8 | ⟨ |
langd; |
U+02991 | ⦑ |
langle; |
U+027E8 | ⟨ |
lap; |
U+02A85 | ⪅ |
Laplacetrf; |
U+02112 | ℒ |
laquo; |
U+000AB | « |
laquo |
U+000AB | « |
Larr; |
U+0219E | ↞ |
lArr; |
U+021D0 | ⇐ |
larr; |
U+02190 | ← |
larrb; |
U+021E4 | ⇤ |
larrbfs; |
U+0291F | ⤟ |
larrfs; |
U+0291D | ⤝ |
larrhk; |
U+021A9 | ↩ |
larrlp; |
U+021AB | ↫ |
larrpl; |
U+02939 | ⤹ |
larrsim; |
U+02973 | ⥳ |
larrtl; |
U+021A2 | ↢ |
lat; |
U+02AAB | ⪫ |
lAtail; |
U+0291B | ⤛ |
latail; |
U+02919 | ⤙ |
late; |
U+02AAD | ⪭ |
lates; |
U+02AAD U+0FE00 | ⪭︀ |
lBarr; |
U+0290E | ⤎ |
lbarr; |
U+0290C | ⤌ |
lbbrk; |
U+02772 | ❲ |
lbrace; |
U+0007B | { |
lbrack; |
U+0005B | [ |
lbrke; |
U+0298B | ⦋ |
lbrksld; |
U+0298F | ⦏ |
lbrkslu; |
U+0298D | ⦍ |
Lcaron; |
U+0013D | Ľ |
lcaron; |
U+0013E | ľ |
Lcedil; |
U+0013B | Ļ |
lcedil; |
U+0013C | ļ |
lceil; |
U+02308 | ⌈ |
lcub; |
U+0007B | { |
Lcy; |
U+0041B | Л |
lcy; |
U+0043B | л |
ldca; |
U+02936 | ⤶ |
ldquo; |
U+0201C | “ |
ldquor; |
U+0201E | „ |
ldrdhar; |
U+02967 | ⥧ |
ldrushar; |
U+0294B | ⥋ |
ldsh; |
U+021B2 | ↲ |
lE; |
U+02266 | ≦ |
le; |
U+02264 | ≤ |
LeftAngleBracket; |
U+027E8 | ⟨ |
LeftArrow; |
U+02190 | ← |
Leftarrow; |
U+021D0 | ⇐ |
leftarrow; |
U+02190 | ← |
LeftArrowBar; |
U+021E4 | ⇤ |
LeftArrowRightArrow; |
U+021C6 | ⇆ |
leftarrowtail; |
U+021A2 | ↢ |
LeftCeiling; |
U+02308 | ⌈ |
LeftDoubleBracket; |
U+027E6 | ⟦ |
LeftDownTeeVector; |
U+02961 | ⥡ |
LeftDownVector; |
U+021C3 | ⇃ |
LeftDownVectorBar; |
U+02959 | ⥙ |
LeftFloor; |
U+0230A | ⌊ |
leftharpoondown; |
U+021BD | ↽ |
leftharpoonup; |
U+021BC | ↼ |
leftleftarrows; |
U+021C7 | ⇇ |
LeftRightArrow; |
U+02194 | ↔ |
Leftrightarrow; |
U+021D4 | ⇔ |
leftrightarrow; |
U+02194 | ↔ |
leftrightarrows; |
U+021C6 | ⇆ |
leftrightharpoons; |
U+021CB | ⇋ |
leftrightsquigarrow; |
U+021AD | ↭ |
LeftRightVector; |
U+0294E | ⥎ |
LeftTee; |
U+022A3 | ⊣ |
LeftTeeArrow; |
U+021A4 | ↤ |
LeftTeeVector; |
U+0295A | ⥚ |
leftthreetimes; |
U+022CB | ⋋ |
LeftTriangle; |
U+022B2 | ⊲ |
LeftTriangleBar; |
U+029CF | ⧏ |
LeftTriangleEqual; |
U+022B4 | ⊴ |
LeftUpDownVector; |
U+02951 | ⥑ |
LeftUpTeeVector; |
U+02960 | ⥠ |
LeftUpVector; |
U+021BF | ↿ |
LeftUpVectorBar; |
U+02958 | ⥘ |
LeftVector; |
U+021BC | ↼ |
LeftVectorBar; |
U+02952 | ⥒ |
lEg; |
U+02A8B | ⪋ |
leg; |
U+022DA | ⋚ |
leq; |
U+02264 | ≤ |
leqq; |
U+02266 | ≦ |
leqslant; |
U+02A7D | ⩽ |
les; |
U+02A7D | ⩽ |
lescc; |
U+02AA8 | ⪨ |
lesdot; |
U+02A7F | ⩿ |
lesdoto; |
U+02A81 | ⪁ |
lesdotor; |
U+02A83 | ⪃ |
lesg; |
U+022DA U+0FE00 | ⋚︀ |
lesges; |
U+02A93 | ⪓ |
lessapprox; |
U+02A85 | ⪅ |
lessdot; |
U+022D6 | ⋖ |
lesseqgtr; |
U+022DA | ⋚ |
lesseqqgtr; |
U+02A8B | ⪋ |
LessEqualGreater; |
U+022DA | ⋚ |
LessFullEqual; |
U+02266 | ≦ |
LessGreater; |
U+02276 | ≶ |
lessgtr; |
U+02276 | ≶ |
LessLess; |
U+02AA1 | ⪡ |
lesssim; |
U+02272 | ≲ |
LessSlantEqual; |
U+02A7D | ⩽ |
LessTilde; |
U+02272 | ≲ |
lfisht; |
U+0297C | ⥼ |
lfloor; |
U+0230A | ⌊ |
Lfr; |
U+1D50F | 𝔏 |
lfr; |
U+1D529 | 𝔩 |
lg; |
U+02276 | ≶ |
lgE; |
U+02A91 | ⪑ |
lHar; |
U+02962 | ⥢ |
lhard; |
U+021BD | ↽ |
lharu; |
U+021BC | ↼ |
lharul; |
U+0296A | ⥪ |
lhblk; |
U+02584 | ▄ |
LJcy; |
U+00409 | Љ |
ljcy; |
U+00459 | љ |
Ll; |
U+022D8 | ⋘ |
ll; |
U+0226A | ≪ |
llarr; |
U+021C7 | ⇇ |
llcorner; |
U+0231E | ⌞ |
Lleftarrow; |
U+021DA | ⇚ |
llhard; |
U+0296B | ⥫ |
lltri; |
U+025FA | ◺ |
Lmidot; |
U+0013F | Ŀ |
lmidot; |
U+00140 | ŀ |
lmoust; |
U+023B0 | ⎰ |
lmoustache; |
U+023B0 | ⎰ |
lnap; |
U+02A89 | ⪉ |
lnapprox; |
U+02A89 | ⪉ |
lnE; |
U+02268 | ≨ |
lne; |
U+02A87 | ⪇ |
lneq; |
U+02A87 | ⪇ |
lneqq; |
U+02268 | ≨ |
lnsim; |
U+022E6 | ⋦ |
loang; |
U+027EC | ⟬ |
loarr; |
U+021FD | ⇽ |
lobrk; |
U+027E6 | ⟦ |
LongLeftArrow; |
U+027F5 | ⟵ |
Longleftarrow; |
U+027F8 | ⟸ |
longleftarrow; |
U+027F5 | ⟵ |
LongLeftRightArrow; |
U+027F7 | ⟷ |
Longleftrightarrow; |
U+027FA | ⟺ |
longleftrightarrow; |
U+027F7 | ⟷ |
longmapsto; |
U+027FC | ⟼ |
LongRightArrow; |
U+027F6 | ⟶ |
Longrightarrow; |
U+027F9 | ⟹ |
longrightarrow; |
U+027F6 | ⟶ |
looparrowleft; |
U+021AB | ↫ |
looparrowright; |
U+021AC | ↬ |
lopar; |
U+02985 | ⦅ |
Lopf; |
U+1D543 | 𝕃 |
lopf; |
U+1D55D | 𝕝 |
loplus; |
U+02A2D | ⨭ |
lotimes; |
U+02A34 | ⨴ |
lowast; |
U+02217 | ∗ |
lowbar; |
U+0005F | _ |
LowerLeftArrow; |
U+02199 | ↙ |
LowerRightArrow; |
U+02198 | ↘ |
loz; |
U+025CA | ◊ |
lozenge; |
U+025CA | ◊ |
lozf; |
U+029EB | ⧫ |
lpar; |
U+00028 | ( |
lparlt; |
U+02993 | ⦓ |
lrarr; |
U+021C6 | ⇆ |
lrcorner; |
U+0231F | ⌟ |
lrhar; |
U+021CB | ⇋ |
lrhard; |
U+0296D | ⥭ |
lrm; |
U+0200E | |
lrtri; |
U+022BF | ⊿ |
lsaquo; |
U+02039 | ‹ |
Lscr; |
U+02112 | ℒ |
lscr; |
U+1D4C1 | 𝓁 |
Lsh; |
U+021B0 | ↰ |
lsh; |
U+021B0 | ↰ |
lsim; |
U+02272 | ≲ |
lsime; |
U+02A8D | ⪍ |
lsimg; |
U+02A8F | ⪏ |
lsqb; |
U+0005B | [ |
lsquo; |
U+02018 | ‘ |
lsquor; |
U+0201A | ‚ |
Lstrok; |
U+00141 | Ł |
lstrok; |
U+00142 | ł |
LT; |
U+0003C | < |
LT |
U+0003C | < |
Lt; |
U+0226A | ≪ |
lt; |
U+0003C | < |
lt |
U+0003C | < |
ltcc; |
U+02AA6 | ⪦ |
ltcir; |
U+02A79 | ⩹ |
ltdot; |
U+022D6 | ⋖ |
lthree; |
U+022CB | ⋋ |
ltimes; |
U+022C9 | ⋉ |
ltlarr; |
U+02976 | ⥶ |
ltquest; |
U+02A7B | ⩻ |
ltri; |
U+025C3 | ◃ |
ltrie; |
U+022B4 | ⊴ |
ltrif; |
U+025C2 | ◂ |
ltrPar; |
U+02996 | ⦖ |
lurdshar; |
U+0294A | ⥊ |
luruhar; |
U+02966 | ⥦ |
lvertneqq; |
U+02268 U+0FE00 | ≨︀ |
lvnE; |
U+02268 U+0FE00 | ≨︀ |
macr; |
U+000AF | ¯ |
macr |
U+000AF | ¯ |
male; |
U+02642 | ♂ |
malt; |
U+02720 | ✠ |
maltese; |
U+02720 | ✠ |
Map; |
U+02905 | ⤅ |
map; |
U+021A6 | ↦ |
mapsto; |
U+021A6 | ↦ |
mapstodown; |
U+021A7 | ↧ |
mapstoleft; |
U+021A4 | ↤ |
mapstoup; |
U+021A5 | ↥ |
marker; |
U+025AE | ▮ |
mcomma; |
U+02A29 | ⨩ |
Mcy; |
U+0041C | М |
mcy; |
U+0043C | м |
mdash; |
U+02014 | — |
mDDot; |
U+0223A | ∺ |
measuredangle; |
U+02221 | ∡ |
MediumSpace; |
U+0205F | |
Mellintrf; |
U+02133 | ℳ |
Mfr; |
U+1D510 | 𝔐 |
mfr; |
U+1D52A | 𝔪 |
mho; |
U+02127 | ℧ |
micro; |
U+000B5 | µ |
micro |
U+000B5 | µ |
mid; |
U+02223 | ∣ |
midast; |
U+0002A | * |
midcir; |
U+02AF0 | ⫰ |
middot; |
U+000B7 | · |
middot |
U+000B7 | · |
minus; |
U+02212 | − |
minusb; |
U+0229F | ⊟ |
minusd; |
U+02238 | ∸ |
minusdu; |
U+02A2A | ⨪ |
MinusPlus; |
U+02213 | ∓ |
mlcp; |
U+02ADB | ⫛ |
mldr; |
U+02026 | … |
mnplus; |
U+02213 | ∓ |
models; |
U+022A7 | ⊧ |
Mopf; |
U+1D544 | 𝕄 |
mopf; |
U+1D55E | 𝕞 |
mp; |
U+02213 | ∓ |
Mscr; |
U+02133 | ℳ |
mscr; |
U+1D4C2 | 𝓂 |
mstpos; |
U+0223E | ∾ |
Mu; |
U+0039C | Μ |
mu; |
U+003BC | μ |
multimap; |
U+022B8 | ⊸ |
mumap; |
U+022B8 | ⊸ |
nabla; |
U+02207 | ∇ |
Nacute; |
U+00143 | Ń |
nacute; |
U+00144 | ń |
nang; |
U+02220 U+020D2 | ∠⃒ |
nap; |
U+02249 | ≉ |
napE; |
U+02A70 U+00338 | ⩰̸ |
napid; |
U+0224B U+00338 | ≋̸ |
napos; |
U+00149 | ʼn |
napprox; |
U+02249 | ≉ |
natur; |
U+0266E | ♮ |
natural; |
U+0266E | ♮ |
naturals; |
U+02115 | ℕ |
nbsp; |
U+000A0 | |
nbsp |
U+000A0 | |
nbump; |
U+0224E U+00338 | ≎̸ |
nbumpe; |
U+0224F U+00338 | ≏̸ |
ncap; |
U+02A43 | ⩃ |
Ncaron; |
U+00147 | Ň |
ncaron; |
U+00148 | ň |
Ncedil; |
U+00145 | Ņ |
ncedil; |
U+00146 | ņ |
ncong; |
U+02247 | ≇ |
ncongdot; |
U+02A6D U+00338 | ⩭̸ |
ncup; |
U+02A42 | ⩂ |
Ncy; |
U+0041D | Н |
ncy; |
U+0043D | н |
ndash; |
U+02013 | – |
ne; |
U+02260 | ≠ |
nearhk; |
U+02924 | ⤤ |
neArr; |
U+021D7 | ⇗ |
nearr; |
U+02197 | ↗ |
nearrow; |
U+02197 | ↗ |
nedot; |
U+02250 U+00338 | ≐̸ |
NegativeMediumSpace; |
U+0200B | |
NegativeThickSpace; |
U+0200B | |
NegativeThinSpace; |
U+0200B | |
NegativeVeryThinSpace; |
U+0200B | |
nequiv; |
U+02262 | ≢ |
nesear; |
U+02928 | ⤨ |
nesim; |
U+02242 U+00338 | ≂̸ |
NestedGreaterGreater; |
U+0226B | ≫ |
NestedLessLess; |
U+0226A | ≪ |
NewLine; |
U+0000A | ␊ |
nexist; |
U+02204 | ∄ |
nexists; |
U+02204 | ∄ |
Nfr; |
U+1D511 | 𝔑 |
nfr; |
U+1D52B | 𝔫 |
ngE; |
U+02267 U+00338 | ≧̸ |
nge; |
U+02271 | ≱ |
ngeq; |
U+02271 | ≱ |
ngeqq; |
U+02267 U+00338 | ≧̸ |
ngeqslant; |
U+02A7E U+00338 | ⩾̸ |
nges; |
U+02A7E U+00338 | ⩾̸ |
nGg; |
U+022D9 U+00338 | ⋙̸ |
ngsim; |
U+02275 | ≵ |
nGt; |
U+0226B U+020D2 | ≫⃒ |
ngt; |
U+0226F | ≯ |
ngtr; |
U+0226F | ≯ |
nGtv; |
U+0226B U+00338 | ≫̸ |
nhArr; |
U+021CE | ⇎ |
nharr; |
U+021AE | ↮ |
nhpar; |
U+02AF2 | ⫲ |
ni; |
U+0220B | ∋ |
nis; |
U+022FC | ⋼ |
nisd; |
U+022FA | ⋺ |
niv; |
U+0220B | ∋ |
NJcy; |
U+0040A | Њ |
njcy; |
U+0045A | њ |
nlArr; |
U+021CD | ⇍ |
nlarr; |
U+0219A | ↚ |
nldr; |
U+02025 | ‥ |
nlE; |
U+02266 U+00338 | ≦̸ |
nle; |
U+02270 | ≰ |
nLeftarrow; |
U+021CD | ⇍ |
nleftarrow; |
U+0219A | ↚ |
nLeftrightarrow; |
U+021CE | ⇎ |
nleftrightarrow; |
U+021AE | ↮ |
nleq; |
U+02270 | ≰ |
nleqq; |
U+02266 U+00338 | ≦̸ |
nleqslant; |
U+02A7D U+00338 | ⩽̸ |
nles; |
U+02A7D U+00338 | ⩽̸ |
nless; |
U+0226E | ≮ |
nLl; |
U+022D8 U+00338 | ⋘̸ |
nlsim; |
U+02274 | ≴ |
nLt; |
U+0226A U+020D2 | ≪⃒ |
nlt; |
U+0226E | ≮ |
nltri; |
U+022EA | ⋪ |
nltrie; |
U+022EC | ⋬ |
nLtv; |
U+0226A U+00338 | ≪̸ |
nmid; |
U+02224 | ∤ |
NoBreak; |
U+02060 | |
NonBreakingSpace; |
U+000A0 | |
Nopf; |
U+02115 | ℕ |
nopf; |
U+1D55F | 𝕟 |
Not; |
U+02AEC | ⫬ |
not; |
U+000AC | ¬ |
not |
U+000AC | ¬ |
NotCongruent; |
U+02262 | ≢ |
NotCupCap; |
U+0226D | ≭ |
NotDoubleVerticalBar; |
U+02226 | ∦ |
NotElement; |
U+02209 | ∉ |
NotEqual; |
U+02260 | ≠ |
NotEqualTilde; |
U+02242 U+00338 | ≂̸ |
NotExists; |
U+02204 | ∄ |
NotGreater; |
U+0226F | ≯ |
NotGreaterEqual; |
U+02271 | ≱ |
NotGreaterFullEqual; |
U+02267 U+00338 | ≧̸ |
NotGreaterGreater; |
U+0226B U+00338 | ≫̸ |
NotGreaterLess; |
U+02279 | ≹ |
NotGreaterSlantEqual; |
U+02A7E U+00338 | ⩾̸ |
NotGreaterTilde; |
U+02275 | ≵ |
NotHumpDownHump; |
U+0224E U+00338 | ≎̸ |
NotHumpEqual; |
U+0224F U+00338 | ≏̸ |
notin; |
U+02209 | ∉ |
notindot; |
U+022F5 U+00338 | ⋵̸ |
notinE; |
U+022F9 U+00338 | ⋹̸ |
notinva; |
U+02209 | ∉ |
notinvb; |
U+022F7 | ⋷ |
notinvc; |
U+022F6 | ⋶ |
NotLeftTriangle; |
U+022EA | ⋪ |
NotLeftTriangleBar; |
U+029CF U+00338 | ⧏̸ |
NotLeftTriangleEqual; |
U+022EC | ⋬ |
NotLess; |
U+0226E | ≮ |
NotLessEqual; |
U+02270 | ≰ |
NotLessGreater; |
U+02278 | ≸ |
NotLessLess; |
U+0226A U+00338 | ≪̸ |
NotLessSlantEqual; |
U+02A7D U+00338 | ⩽̸ |
NotLessTilde; |
U+02274 | ≴ |
NotNestedGreaterGreater; |
U+02AA2 U+00338 | ⪢̸ |
NotNestedLessLess; |
U+02AA1 U+00338 | ⪡̸ |
notni; |
U+0220C | ∌ |
notniva; |
U+0220C | ∌ |
notnivb; |
U+022FE | ⋾ |
notnivc; |
U+022FD | ⋽ |
NotPrecedes; |
U+02280 | ⊀ |
NotPrecedesEqual; |
U+02AAF U+00338 | ⪯̸ |
NotPrecedesSlantEqual; |
U+022E0 | ⋠ |
NotReverseElement; |
U+0220C | ∌ |
NotRightTriangle; |
U+022EB | ⋫ |
NotRightTriangleBar; |
U+029D0 U+00338 | ⧐̸ |
NotRightTriangleEqual; |
U+022ED | ⋭ |
NotSquareSubset; |
U+0228F U+00338 | ⊏̸ |
NotSquareSubsetEqual; |
U+022E2 | ⋢ |
NotSquareSuperset; |
U+02290 U+00338 | ⊐̸ |
NotSquareSupersetEqual; |
U+022E3 | ⋣ |
NotSubset; |
U+02282 U+020D2 | ⊂⃒ |
NotSubsetEqual; |
U+02288 | ⊈ |
NotSucceeds; |
U+02281 | ⊁ |
NotSucceedsEqual; |
U+02AB0 U+00338 | ⪰̸ |
NotSucceedsSlantEqual; |
U+022E1 | ⋡ |
NotSucceedsTilde; |
U+0227F U+00338 | ≿̸ |
NotSuperset; |
U+02283 U+020D2 | ⊃⃒ |
NotSupersetEqual; |
U+02289 | ⊉ |
NotTilde; |
U+02241 | ≁ |
NotTildeEqual; |
U+02244 | ≄ |
NotTildeFullEqual; |
U+02247 | ≇ |
NotTildeTilde; |
U+02249 | ≉ |
NotVerticalBar; |
U+02224 | ∤ |
npar; |
U+02226 | ∦ |
nparallel; |
U+02226 | ∦ |
nparsl; |
U+02AFD U+020E5 | ⫽⃥ |
npart; |
U+02202 U+00338 | ∂̸ |
npolint; |
U+02A14 | ⨔ |
npr; |
U+02280 | ⊀ |
nprcue; |
U+022E0 | ⋠ |
npre; |
U+02AAF U+00338 | ⪯̸ |
nprec; |
U+02280 | ⊀ |
npreceq; |
U+02AAF U+00338 | ⪯̸ |
nrArr; |
U+021CF | ⇏ |
nrarr; |
U+0219B | ↛ |
nrarrc; |
U+02933 U+00338 | ⤳̸ |
nrarrw; |
U+0219D U+00338 | ↝̸ |
nRightarrow; |
U+021CF | ⇏ |
nrightarrow; |
U+0219B | ↛ |
nrtri; |
U+022EB | ⋫ |
nrtrie; |
U+022ED | ⋭ |
nsc; |
U+02281 | ⊁ |
nsccue; |
U+022E1 | ⋡ |
nsce; |
U+02AB0 U+00338 | ⪰̸ |
Nscr; |
U+1D4A9 | 𝒩 |
nscr; |
U+1D4C3 | 𝓃 |
nshortmid; |
U+02224 | ∤ |
nshortparallel; |
U+02226 | ∦ |
nsim; |
U+02241 | ≁ |
nsime; |
U+02244 | ≄ |
nsimeq; |
U+02244 | ≄ |
nsmid; |
U+02224 | ∤ |
nspar; |
U+02226 | ∦ |
nsqsube; |
U+022E2 | ⋢ |
nsqsupe; |
U+022E3 | ⋣ |
nsub; |
U+02284 | ⊄ |
nsubE; |
U+02AC5 U+00338 | ⫅̸ |
nsube; |
U+02288 | ⊈ |
nsubset; |
U+02282 U+020D2 | ⊂⃒ |
nsubseteq; |
U+02288 | ⊈ |
nsubseteqq; |
U+02AC5 U+00338 | ⫅̸ |
nsucc; |
U+02281 | ⊁ |
nsucceq; |
U+02AB0 U+00338 | ⪰̸ |
nsup; |
U+02285 | ⊅ |
nsupE; |
U+02AC6 U+00338 | ⫆̸ |
nsupe; |
U+02289 | ⊉ |
nsupset; |
U+02283 U+020D2 | ⊃⃒ |
nsupseteq; |
U+02289 | ⊉ |
nsupseteqq; |
U+02AC6 U+00338 | ⫆̸ |
ntgl; |
U+02279 | ≹ |
Ntilde; |
U+000D1 | Ñ |
Ntilde |
U+000D1 | Ñ |
ntilde; |
U+000F1 | ñ |
ntilde |
U+000F1 | ñ |
ntlg; |
U+02278 | ≸ |
ntriangleleft; |
U+022EA | ⋪ |
ntrianglelefteq; |
U+022EC | ⋬ |
ntriangleright; |
U+022EB | ⋫ |
ntrianglerighteq; |
U+022ED | ⋭ |
Nu; |
U+0039D | Ν |
nu; |
U+003BD | ν |
num; |
U+00023 | # |
numero; |
U+02116 | № |
numsp; |
U+02007 | |
nvap; |
U+0224D U+020D2 | ≍⃒ |
nVDash; |
U+022AF | ⊯ |
nVdash; |
U+022AE | ⊮ |
nvDash; |
U+022AD | ⊭ |
nvdash; |
U+022AC | ⊬ |
nvge; |
U+02265 U+020D2 | ≥⃒ |
nvgt; |
U+0003E U+020D2 | >⃒ |
nvHarr; |
U+02904 | ⤄ |
nvinfin; |
U+029DE | ⧞ |
nvlArr; |
U+02902 | ⤂ |
nvle; |
U+02264 U+020D2 | ≤⃒ |
nvlt; |
U+0003C U+020D2 | <⃒ |
nvltrie; |
U+022B4 U+020D2 | ⊴⃒ |
nvrArr; |
U+02903 | ⤃ |
nvrtrie; |
U+022B5 U+020D2 | ⊵⃒ |
nvsim; |
U+0223C U+020D2 | ∼⃒ |
nwarhk; |
U+02923 | ⤣ |
nwArr; |
U+021D6 | ⇖ |
nwarr; |
U+02196 | ↖ |
nwarrow; |
U+02196 | ↖ |
nwnear; |
U+02927 | ⤧ |
Oacute; |
U+000D3 | Ó |
Oacute |
U+000D3 | Ó |
oacute; |
U+000F3 | ó |
oacute |
U+000F3 | ó |
oast; |
U+0229B | ⊛ |
ocir; |
U+0229A | ⊚ |
Ocirc; |
U+000D4 | Ô |
Ocirc |
U+000D4 | Ô |
ocirc; |
U+000F4 | ô |
ocirc |
U+000F4 | ô |
Ocy; |
U+0041E | О |
ocy; |
U+0043E | о |
odash; |
U+0229D | ⊝ |
Odblac; |
U+00150 | Ő |
odblac; |
U+00151 | ő |
odiv; |
U+02A38 | ⨸ |
odot; |
U+02299 | ⊙ |
odsold; |
U+029BC | ⦼ |
OElig; |
U+00152 | Π|
oelig; |
U+00153 | œ |
ofcir; |
U+029BF | ⦿ |
Ofr; |
U+1D512 | 𝔒 |
ofr; |
U+1D52C | 𝔬 |
ogon; |
U+002DB | ˛ |
Ograve; |
U+000D2 | Ò |
Ograve |
U+000D2 | Ò |
ograve; |
U+000F2 | ò |
ograve |
U+000F2 | ò |
ogt; |
U+029C1 | ⧁ |
ohbar; |
U+029B5 | ⦵ |
ohm; |
U+003A9 | Ω |
oint; |
U+0222E | ∮ |
olarr; |
U+021BA | ↺ |
olcir; |
U+029BE | ⦾ |
olcross; |
U+029BB | ⦻ |
oline; |
U+0203E | ‾ |
olt; |
U+029C0 | ⧀ |
Omacr; |
U+0014C | Ō |
omacr; |
U+0014D | ō |
Omega; |
U+003A9 | Ω |
omega; |
U+003C9 | ω |
Omicron; |
U+0039F | Ο |
omicron; |
U+003BF | ο |
omid; |
U+029B6 | ⦶ |
ominus; |
U+02296 | ⊖ |
Oopf; |
U+1D546 | 𝕆 |
oopf; |
U+1D560 | 𝕠 |
opar; |
U+029B7 | ⦷ |
OpenCurlyDoubleQuote; |
U+0201C | “ |
OpenCurlyQuote; |
U+02018 | ‘ |
operp; |
U+029B9 | ⦹ |
oplus; |
U+02295 | ⊕ |
Or; |
U+02A54 | ⩔ |
or; |
U+02228 | ∨ |
orarr; |
U+021BB | ↻ |
ord; |
U+02A5D | ⩝ |
order; |
U+02134 | ℴ |
orderof; |
U+02134 | ℴ |
ordf; |
U+000AA | ª |
ordf |
U+000AA | ª |
ordm; |
U+000BA | º |
ordm |
U+000BA | º |
origof; |
U+022B6 | ⊶ |
oror; |
U+02A56 | ⩖ |
orslope; |
U+02A57 | ⩗ |
orv; |
U+02A5B | ⩛ |
oS; |
U+024C8 | Ⓢ |
Oscr; |
U+1D4AA | 𝒪 |
oscr; |
U+02134 | ℴ |
Oslash; |
U+000D8 | Ø |
Oslash |
U+000D8 | Ø |
oslash; |
U+000F8 | ø |
oslash |
U+000F8 | ø |
osol; |
U+02298 | ⊘ |
Otilde; |
U+000D5 | Õ |
Otilde |
U+000D5 | Õ |
otilde; |
U+000F5 | õ |
otilde |
U+000F5 | õ |
Otimes; |
U+02A37 | ⨷ |
otimes; |
U+02297 | ⊗ |
otimesas; |
U+02A36 | ⨶ |
Ouml; |
U+000D6 | Ö |
Ouml |
U+000D6 | Ö |
ouml; |
U+000F6 | ö |
ouml |
U+000F6 | ö |
ovbar; |
U+0233D | ⌽ |
OverBar; |
U+0203E | ‾ |
OverBrace; |
U+023DE | ⏞ |
OverBracket; |
U+023B4 | ⎴ |
OverParenthesis; |
U+023DC | ⏜ |
par; |
U+02225 | ∥ |
para; |
U+000B6 | ¶ |
para |
U+000B6 | ¶ |
parallel; |
U+02225 | ∥ |
parsim; |
U+02AF3 | ⫳ |
parsl; |
U+02AFD | ⫽ |
part; |
U+02202 | ∂ |
PartialD; |
U+02202 | ∂ |
Pcy; |
U+0041F | П |
pcy; |
U+0043F | п |
percnt; |
U+00025 | % |
period; |
U+0002E | . |
permil; |
U+02030 | ‰ |
perp; |
U+022A5 | ⊥ |
pertenk; |
U+02031 | ‱ |
Pfr; |
U+1D513 | 𝔓 |
pfr; |
U+1D52D | 𝔭 |
Phi; |
U+003A6 | Φ |
phi; |
U+003C6 | φ |
phiv; |
U+003D5 | ϕ |
phmmat; |
U+02133 | ℳ |
phone; |
U+0260E | ☎ |
Pi; |
U+003A0 | Π |
pi; |
U+003C0 | π |
pitchfork; |
U+022D4 | ⋔ |
piv; |
U+003D6 | ϖ |
planck; |
U+0210F | ℏ |
planckh; |
U+0210E | ℎ |
plankv; |
U+0210F | ℏ |
plus; |
U+0002B | + |
plusacir; |
U+02A23 | ⨣ |
plusb; |
U+0229E | ⊞ |
pluscir; |
U+02A22 | ⨢ |
plusdo; |
U+02214 | ∔ |
plusdu; |
U+02A25 | ⨥ |
pluse; |
U+02A72 | ⩲ |
PlusMinus; |
U+000B1 | ± |
plusmn; |
U+000B1 | ± |
plusmn |
U+000B1 | ± |
plussim; |
U+02A26 | ⨦ |
plustwo; |
U+02A27 | ⨧ |
pm; |
U+000B1 | ± |
Poincareplane; |
U+0210C | ℌ |
pointint; |
U+02A15 | ⨕ |
Popf; |
U+02119 | ℙ |
popf; |
U+1D561 | 𝕡 |
pound; |
U+000A3 | £ |
pound |
U+000A3 | £ |
Pr; |
U+02ABB | ⪻ |
pr; |
U+0227A | ≺ |
prap; |
U+02AB7 | ⪷ |
prcue; |
U+0227C | ≼ |
prE; |
U+02AB3 | ⪳ |
pre; |
U+02AAF | ⪯ |
prec; |
U+0227A | ≺ |
precapprox; |
U+02AB7 | ⪷ |
preccurlyeq; |
U+0227C | ≼ |
Precedes; |
U+0227A | ≺ |
PrecedesEqual; |
U+02AAF | ⪯ |
PrecedesSlantEqual; |
U+0227C | ≼ |
PrecedesTilde; |
U+0227E | ≾ |
preceq; |
U+02AAF | ⪯ |
precnapprox; |
U+02AB9 | ⪹ |
precneqq; |
U+02AB5 | ⪵ |
precnsim; |
U+022E8 | ⋨ |
precsim; |
U+0227E | ≾ |
Prime; |
U+02033 | ″ |
prime; |
U+02032 | ′ |
primes; |
U+02119 | ℙ |
prnap; |
U+02AB9 | ⪹ |
prnE; |
U+02AB5 | ⪵ |
prnsim; |
U+022E8 | ⋨ |
prod; |
U+0220F | ∏ |
Product; |
U+0220F | ∏ |
profalar; |
U+0232E | ⌮ |
profline; |
U+02312 | ⌒ |
profsurf; |
U+02313 | ⌓ |
prop; |
U+0221D | ∝ |
Proportion; |
U+02237 | ∷ |
Proportional; |
U+0221D | ∝ |
propto; |
U+0221D | ∝ |
prsim; |
U+0227E | ≾ |
prurel; |
U+022B0 | ⊰ |
Pscr; |
U+1D4AB | 𝒫 |
pscr; |
U+1D4C5 | 𝓅 |
Psi; |
U+003A8 | Ψ |
psi; |
U+003C8 | ψ |
puncsp; |
U+02008 | |
Qfr; |
U+1D514 | 𝔔 |
qfr; |
U+1D52E | 𝔮 |
qint; |
U+02A0C | ⨌ |
Qopf; |
U+0211A | ℚ |
qopf; |
U+1D562 | 𝕢 |
qprime; |
U+02057 | ⁗ |
Qscr; |
U+1D4AC | 𝒬 |
qscr; |
U+1D4C6 | 𝓆 |
quaternions; |
U+0210D | ℍ |
quatint; |
U+02A16 | ⨖ |
quest; |
U+0003F | ? |
questeq; |
U+0225F | ≟ |
QUOT; |
U+00022 | " |
QUOT |
U+00022 | " |
quot; |
U+00022 | " |
quot |
U+00022 | " |
rAarr; |
U+021DB | ⇛ |
race; |
U+0223D U+00331 | ∽̱ |
Racute; |
U+00154 | Ŕ |
racute; |
U+00155 | ŕ |
radic; |
U+0221A | √ |
raemptyv; |
U+029B3 | ⦳ |
Rang; |
U+027EB | ⟫ |
rang; |
U+027E9 | ⟩ |
rangd; |
U+02992 | ⦒ |
range; |
U+029A5 | ⦥ |
rangle; |
U+027E9 | ⟩ |
raquo; |
U+000BB | » |
raquo |
U+000BB | » |
Rarr; |
U+021A0 | ↠ |
rArr; |
U+021D2 | ⇒ |
rarr; |
U+02192 | → |
rarrap; |
U+02975 | ⥵ |
rarrb; |
U+021E5 | ⇥ |
rarrbfs; |
U+02920 | ⤠ |
rarrc; |
U+02933 | ⤳ |
rarrfs; |
U+0291E | ⤞ |
rarrhk; |
U+021AA | ↪ |
rarrlp; |
U+021AC | ↬ |
rarrpl; |
U+02945 | ⥅ |
rarrsim; |
U+02974 | ⥴ |
Rarrtl; |
U+02916 | ⤖ |
rarrtl; |
U+021A3 | ↣ |
rarrw; |
U+0219D | ↝ |
rAtail; |
U+0291C | ⤜ |
ratail; |
U+0291A | ⤚ |
ratio; |
U+02236 | ∶ |
rationals; |
U+0211A | ℚ |
RBarr; |
U+02910 | ⤐ |
rBarr; |
U+0290F | ⤏ |
rbarr; |
U+0290D | ⤍ |
rbbrk; |
U+02773 | ❳ |
rbrace; |
U+0007D | } |
rbrack; |
U+0005D | ] |
rbrke; |
U+0298C | ⦌ |
rbrksld; |
U+0298E | ⦎ |
rbrkslu; |
U+02990 | ⦐ |
Rcaron; |
U+00158 | Ř |
rcaron; |
U+00159 | ř |
Rcedil; |
U+00156 | Ŗ |
rcedil; |
U+00157 | ŗ |
rceil; |
U+02309 | ⌉ |
rcub; |
U+0007D | } |
Rcy; |
U+00420 | Р |
rcy; |
U+00440 | р |
rdca; |
U+02937 | ⤷ |
rdldhar; |
U+02969 | ⥩ |
rdquo; |
U+0201D | ” |
rdquor; |
U+0201D | ” |
rdsh; |
U+021B3 | ↳ |
Re; |
U+0211C | ℜ |
real; |
U+0211C | ℜ |
realine; |
U+0211B | ℛ |
realpart; |
U+0211C | ℜ |
reals; |
U+0211D | ℝ |
rect; |
U+025AD | ▭ |
REG; |
U+000AE | ® |
REG |
U+000AE | ® |
reg; |
U+000AE | ® |
reg |
U+000AE | ® |
ReverseElement; |
U+0220B | ∋ |
ReverseEquilibrium; |
U+021CB | ⇋ |
ReverseUpEquilibrium; |
U+0296F | ⥯ |
rfisht; |
U+0297D | ⥽ |
rfloor; |
U+0230B | ⌋ |
Rfr; |
U+0211C | ℜ |
rfr; |
U+1D52F | 𝔯 |
rHar; |
U+02964 | ⥤ |
rhard; |
U+021C1 | ⇁ |
rharu; |
U+021C0 | ⇀ |
rharul; |
U+0296C | ⥬ |
Rho; |
U+003A1 | Ρ |
rho; |
U+003C1 | ρ |
rhov; |
U+003F1 | ϱ |
RightAngleBracket; |
U+027E9 | ⟩ |
RightArrow; |
U+02192 | → |
Rightarrow; |
U+021D2 | ⇒ |
rightarrow; |
U+02192 | → |
RightArrowBar; |
U+021E5 | ⇥ |
RightArrowLeftArrow; |
U+021C4 | ⇄ |
rightarrowtail; |
U+021A3 | ↣ |
RightCeiling; |
U+02309 | ⌉ |
RightDoubleBracket; |
U+027E7 | ⟧ |
RightDownTeeVector; |
U+0295D | ⥝ |
RightDownVector; |
U+021C2 | ⇂ |
RightDownVectorBar; |
U+02955 | ⥕ |
RightFloor; |
U+0230B | ⌋ |
rightharpoondown; |
U+021C1 | ⇁ |
rightharpoonup; |
U+021C0 | ⇀ |
rightleftarrows; |
U+021C4 | ⇄ |
rightleftharpoons; |
U+021CC | ⇌ |
rightrightarrows; |
U+021C9 | ⇉ |
rightsquigarrow; |
U+0219D | ↝ |
RightTee; |
U+022A2 | ⊢ |
RightTeeArrow; |
U+021A6 | ↦ |
RightTeeVector; |
U+0295B | ⥛ |
rightthreetimes; |
U+022CC | ⋌ |
RightTriangle; |
U+022B3 | ⊳ |
RightTriangleBar; |
U+029D0 | ⧐ |
RightTriangleEqual; |
U+022B5 | ⊵ |
RightUpDownVector; |
U+0294F | ⥏ |
RightUpTeeVector; |
U+0295C | ⥜ |
RightUpVector; |
U+021BE | ↾ |
RightUpVectorBar; |
U+02954 | ⥔ |
RightVector; |
U+021C0 | ⇀ |
RightVectorBar; |
U+02953 | ⥓ |
ring; |
U+002DA | ˚ |
risingdotseq; |
U+02253 | ≓ |
rlarr; |
U+021C4 | ⇄ |
rlhar; |
U+021CC | ⇌ |
rlm; |
U+0200F | |
rmoust; |
U+023B1 | ⎱ |
rmoustache; |
U+023B1 | ⎱ |
rnmid; |
U+02AEE | ⫮ |
roang; |
U+027ED | ⟭ |
roarr; |
U+021FE | ⇾ |
robrk; |
U+027E7 | ⟧ |
ropar; |
U+02986 | ⦆ |
Ropf; |
U+0211D | ℝ |
ropf; |
U+1D563 | 𝕣 |
roplus; |
U+02A2E | ⨮ |
rotimes; |
U+02A35 | ⨵ |
RoundImplies; |
U+02970 | ⥰ |
rpar; |
U+00029 | ) |
rpargt; |
U+02994 | ⦔ |
rppolint; |
U+02A12 | ⨒ |
rrarr; |
U+021C9 | ⇉ |
Rrightarrow; |
U+021DB | ⇛ |
rsaquo; |
U+0203A | › |
Rscr; |
U+0211B | ℛ |
rscr; |
U+1D4C7 | 𝓇 |
Rsh; |
U+021B1 | ↱ |
rsh; |
U+021B1 | ↱ |
rsqb; |
U+0005D | ] |
rsquo; |
U+02019 | ’ |
rsquor; |
U+02019 | ’ |
rthree; |
U+022CC | ⋌ |
rtimes; |
U+022CA | ⋊ |
rtri; |
U+025B9 | ▹ |
rtrie; |
U+022B5 | ⊵ |
rtrif; |
U+025B8 | ▸ |
rtriltri; |
U+029CE | ⧎ |
RuleDelayed; |
U+029F4 | ⧴ |
ruluhar; |
U+02968 | ⥨ |
rx; |
U+0211E | ℞ |
Sacute; |
U+0015A | Ś |
sacute; |
U+0015B | ś |
sbquo; |
U+0201A | ‚ |
Sc; |
U+02ABC | ⪼ |
sc; |
U+0227B | ≻ |
scap; |
U+02AB8 | ⪸ |
Scaron; |
U+00160 | Š |
scaron; |
U+00161 | š |
sccue; |
U+0227D | ≽ |
scE; |
U+02AB4 | ⪴ |
sce; |
U+02AB0 | ⪰ |
Scedil; |
U+0015E | Ş |
scedil; |
U+0015F | ş |
Scirc; |
U+0015C | Ŝ |
scirc; |
U+0015D | ŝ |
scnap; |
U+02ABA | ⪺ |
scnE; |
U+02AB6 | ⪶ |
scnsim; |
U+022E9 | ⋩ |
scpolint; |
U+02A13 | ⨓ |
scsim; |
U+0227F | ≿ |
Scy; |
U+00421 | С |
scy; |
U+00441 | с |
sdot; |
U+022C5 | ⋅ |
sdotb; |
U+022A1 | ⊡ |
sdote; |
U+02A66 | ⩦ |
searhk; |
U+02925 | ⤥ |
seArr; |
U+021D8 | ⇘ |
searr; |
U+02198 | ↘ |
searrow; |
U+02198 | ↘ |
sect; |
U+000A7 | § |
sect |
U+000A7 | § |
semi; |
U+0003B | ; |
seswar; |
U+02929 | ⤩ |
setminus; |
U+02216 | ∖ |
setmn; |
U+02216 | ∖ |
sext; |
U+02736 | ✶ |
Sfr; |
U+1D516 | 𝔖 |
sfr; |
U+1D530 | 𝔰 |
sfrown; |
U+02322 | ⌢ |
sharp; |
U+0266F | ♯ |
SHCHcy; |
U+00429 | Щ |
shchcy; |
U+00449 | щ |
SHcy; |
U+00428 | Ш |
shcy; |
U+00448 | ш |
ShortDownArrow; |
U+02193 | ↓ |
ShortLeftArrow; |
U+02190 | ← |
shortmid; |
U+02223 | ∣ |
shortparallel; |
U+02225 | ∥ |
ShortRightArrow; |
U+02192 | → |
ShortUpArrow; |
U+02191 | ↑ |
shy; |
U+000AD | |
shy |
U+000AD | |
Sigma; |
U+003A3 | Σ |
sigma; |
U+003C3 | σ |
sigmaf; |
U+003C2 | ς |
sigmav; |
U+003C2 | ς |
sim; |
U+0223C | ∼ |
simdot; |
U+02A6A | ⩪ |
sime; |
U+02243 | ≃ |
simeq; |
U+02243 | ≃ |
simg; |
U+02A9E | ⪞ |
simgE; |
U+02AA0 | ⪠ |
siml; |
U+02A9D | ⪝ |
simlE; |
U+02A9F | ⪟ |
simne; |
U+02246 | ≆ |
simplus; |
U+02A24 | ⨤ |
simrarr; |
U+02972 | ⥲ |
slarr; |
U+02190 | ← |
SmallCircle; |
U+02218 | ∘ |
smallsetminus; |
U+02216 | ∖ |
smashp; |
U+02A33 | ⨳ |
smeparsl; |
U+029E4 | ⧤ |
smid; |
U+02223 | ∣ |
smile; |
U+02323 | ⌣ |
smt; |
U+02AAA | ⪪ |
smte; |
U+02AAC | ⪬ |
smtes; |
U+02AAC U+0FE00 | ⪬︀ |
SOFTcy; |
U+0042C | Ь |
softcy; |
U+0044C | ь |
sol; |
U+0002F | / |
solb; |
U+029C4 | ⧄ |
solbar; |
U+0233F | ⌿ |
Sopf; |
U+1D54A | 𝕊 |
sopf; |
U+1D564 | 𝕤 |
spades; |
U+02660 | ♠ |
spadesuit; |
U+02660 | ♠ |
spar; |
U+02225 | ∥ |
sqcap; |
U+02293 | ⊓ |
sqcaps; |
U+02293 U+0FE00 | ⊓︀ |
sqcup; |
U+02294 | ⊔ |
sqcups; |
U+02294 U+0FE00 | ⊔︀ |
Sqrt; |
U+0221A | √ |
sqsub; |
U+0228F | ⊏ |
sqsube; |
U+02291 | ⊑ |
sqsubset; |
U+0228F | ⊏ |
sqsubseteq; |
U+02291 | ⊑ |
sqsup; |
U+02290 | ⊐ |
sqsupe; |
U+02292 | ⊒ |
sqsupset; |
U+02290 | ⊐ |
sqsupseteq; |
U+02292 | ⊒ |
squ; |
U+025A1 | □ |
Square; |
U+025A1 | □ |
square; |
U+025A1 | □ |
SquareIntersection; |
U+02293 | ⊓ |
SquareSubset; |
U+0228F | ⊏ |
SquareSubsetEqual; |
U+02291 | ⊑ |
SquareSuperset; |
U+02290 | ⊐ |
SquareSupersetEqual; |
U+02292 | ⊒ |
SquareUnion; |
U+02294 | ⊔ |
squarf; |
U+025AA | ▪ |
squf; |
U+025AA | ▪ |
srarr; |
U+02192 | → |
Sscr; |
U+1D4AE | 𝒮 |
sscr; |
U+1D4C8 | 𝓈 |
ssetmn; |
U+02216 | ∖ |
ssmile; |
U+02323 | ⌣ |
sstarf; |
U+022C6 | ⋆ |
Star; |
U+022C6 | ⋆ |
star; |
U+02606 | ☆ |
starf; |
U+02605 | ★ |
straightepsilon; |
U+003F5 | ϵ |
straightphi; |
U+003D5 | ϕ |
strns; |
U+000AF | ¯ |
Sub; |
U+022D0 | ⋐ |
sub; |
U+02282 | ⊂ |
subdot; |
U+02ABD | ⪽ |
subE; |
U+02AC5 | ⫅ |
sube; |
U+02286 | ⊆ |
subedot; |
U+02AC3 | ⫃ |
submult; |
U+02AC1 | ⫁ |
subnE; |
U+02ACB | ⫋ |
subne; |
U+0228A | ⊊ |
subplus; |
U+02ABF | ⪿ |
subrarr; |
U+02979 | ⥹ |
Subset; |
U+022D0 | ⋐ |
subset; |
U+02282 | ⊂ |
subseteq; |
U+02286 | ⊆ |
subseteqq; |
U+02AC5 | ⫅ |
SubsetEqual; |
U+02286 | ⊆ |
subsetneq; |
U+0228A | ⊊ |
subsetneqq; |
U+02ACB | ⫋ |
subsim; |
U+02AC7 | ⫇ |
subsub; |
U+02AD5 | ⫕ |
subsup; |
U+02AD3 | ⫓ |
succ; |
U+0227B | ≻ |
succapprox; |
U+02AB8 | ⪸ |
succcurlyeq; |
U+0227D | ≽ |
Succeeds; |
U+0227B | ≻ |
SucceedsEqual; |
U+02AB0 | ⪰ |
SucceedsSlantEqual; |
U+0227D | ≽ |
SucceedsTilde; |
U+0227F | ≿ |
succeq; |
U+02AB0 | ⪰ |
succnapprox; |
U+02ABA | ⪺ |
succneqq; |
U+02AB6 | ⪶ |
succnsim; |
U+022E9 | ⋩ |
succsim; |
U+0227F | ≿ |
SuchThat; |
U+0220B | ∋ |
Sum; |
U+02211 | ∑ |
sum; |
U+02211 | ∑ |
sung; |
U+0266A | ♪ |
Sup; |
U+022D1 | ⋑ |
sup; |
U+02283 | ⊃ |
sup1; |
U+000B9 | ¹ |
sup1 |
U+000B9 | ¹ |
sup2; |
U+000B2 | ² |
sup2 |
U+000B2 | ² |
sup3; |
U+000B3 | ³ |
sup3 |
U+000B3 | ³ |
supdot; |
U+02ABE | ⪾ |
supdsub; |
U+02AD8 | ⫘ |
supE; |
U+02AC6 | ⫆ |
supe; |
U+02287 | ⊇ |
supedot; |
U+02AC4 | ⫄ |
Superset; |
U+02283 | ⊃ |
SupersetEqual; |
U+02287 | ⊇ |
suphsol; |
U+027C9 | ⟉ |
suphsub; |
U+02AD7 | ⫗ |
suplarr; |
U+0297B | ⥻ |
supmult; |
U+02AC2 | ⫂ |
supnE; |
U+02ACC | ⫌ |
supne; |
U+0228B | ⊋ |
supplus; |
U+02AC0 | ⫀ |
Supset; |
U+022D1 | ⋑ |
supset; |
U+02283 | ⊃ |
supseteq; |
U+02287 | ⊇ |
supseteqq; |
U+02AC6 | ⫆ |
supsetneq; |
U+0228B | ⊋ |
supsetneqq; |
U+02ACC | ⫌ |
supsim; |
U+02AC8 | ⫈ |
supsub; |
U+02AD4 | ⫔ |
supsup; |
U+02AD6 | ⫖ |
swarhk; |
U+02926 | ⤦ |
swArr; |
U+021D9 | ⇙ |
swarr; |
U+02199 | ↙ |
swarrow; |
U+02199 | ↙ |
swnwar; |
U+0292A | ⤪ |
szlig; |
U+000DF | ß |
szlig |
U+000DF | ß |
Tab; |
U+00009 | ␉ |
target; |
U+02316 | ⌖ |
Tau; |
U+003A4 | Τ |
tau; |
U+003C4 | τ |
tbrk; |
U+023B4 | ⎴ |
Tcaron; |
U+00164 | Ť |
tcaron; |
U+00165 | ť |
Tcedil; |
U+00162 | Ţ |
tcedil; |
U+00163 | ţ |
Tcy; |
U+00422 | Т |
tcy; |
U+00442 | т |
tdot; |
U+020DB | ◌⃛ |
telrec; |
U+02315 | ⌕ |
Tfr; |
U+1D517 | 𝔗 |
tfr; |
U+1D531 | 𝔱 |
there4; |
U+02234 | ∴ |
Therefore; |
U+02234 | ∴ |
therefore; |
U+02234 | ∴ |
Theta; |
U+00398 | Θ |
theta; |
U+003B8 | θ |
thetasym; |
U+003D1 | ϑ |
thetav; |
U+003D1 | ϑ |
thickapprox; |
U+02248 | ≈ |
thicksim; |
U+0223C | ∼ |
ThickSpace; |
U+0205F U+0200A | |
thinsp; |
U+02009 | |
ThinSpace; |
U+02009 | |
thkap; |
U+02248 | ≈ |
thksim; |
U+0223C | ∼ |
THORN; |
U+000DE | Þ |
THORN |
U+000DE | Þ |
thorn; |
U+000FE | þ |
thorn |
U+000FE | þ |
Tilde; |
U+0223C | ∼ |
tilde; |
U+002DC | ˜ |
TildeEqual; |
U+02243 | ≃ |
TildeFullEqual; |
U+02245 | ≅ |
TildeTilde; |
U+02248 | ≈ |
times; |
U+000D7 | × |
times |
U+000D7 | × |
timesb; |
U+022A0 | ⊠ |
timesbar; |
U+02A31 | ⨱ |
timesd; |
U+02A30 | ⨰ |
tint; |
U+0222D | ∭ |
toea; |
U+02928 | ⤨ |
top; |
U+022A4 | ⊤ |
topbot; |
U+02336 | ⌶ |
topcir; |
U+02AF1 | ⫱ |
Topf; |
U+1D54B | 𝕋 |
topf; |
U+1D565 | 𝕥 |
topfork; |
U+02ADA | ⫚ |
tosa; |
U+02929 | ⤩ |
tprime; |
U+02034 | ‴ |
TRADE; |
U+02122 | ™ |
trade; |
U+02122 | ™ |
triangle; |
U+025B5 | ▵ |
triangledown; |
U+025BF | ▿ |
triangleleft; |
U+025C3 | ◃ |
trianglelefteq; |
U+022B4 | ⊴ |
triangleq; |
U+0225C | ≜ |
triangleright; |
U+025B9 | ▹ |
trianglerighteq; |
U+022B5 | ⊵ |
tridot; |
U+025EC | ◬ |
trie; |
U+0225C | ≜ |
triminus; |
U+02A3A | ⨺ |
TripleDot; |
U+020DB | ◌⃛ |
triplus; |
U+02A39 | ⨹ |
trisb; |
U+029CD | ⧍ |
tritime; |
U+02A3B | ⨻ |
trpezium; |
U+023E2 | ⏢ |
Tscr; |
U+1D4AF | 𝒯 |
tscr; |
U+1D4C9 | 𝓉 |
TScy; |
U+00426 | Ц |
tscy; |
U+00446 | ц |
TSHcy; |
U+0040B | Ћ |
tshcy; |
U+0045B | ћ |
Tstrok; |
U+00166 | Ŧ |
tstrok; |
U+00167 | ŧ |
twixt; |
U+0226C | ≬ |
twoheadleftarrow; |
U+0219E | ↞ |
twoheadrightarrow; |
U+021A0 | ↠ |
Uacute; |
U+000DA | Ú |
Uacute |
U+000DA | Ú |
uacute; |
U+000FA | ú |
uacute |
U+000FA | ú |
Uarr; |
U+0219F | ↟ |
uArr; |
U+021D1 | ⇑ |
uarr; |
U+02191 | ↑ |
Uarrocir; |
U+02949 | ⥉ |
Ubrcy; |
U+0040E | Ў |
ubrcy; |
U+0045E | ў |
Ubreve; |
U+0016C | Ŭ |
ubreve; |
U+0016D | ŭ |
Ucirc; |
U+000DB | Û |
Ucirc |
U+000DB | Û |
ucirc; |
U+000FB | û |
ucirc |
U+000FB | û |
Ucy; |
U+00423 | У |
ucy; |
U+00443 | у |
udarr; |
U+021C5 | ⇅ |
Udblac; |
U+00170 | Ű |
udblac; |
U+00171 | ű |
udhar; |
U+0296E | ⥮ |
ufisht; |
U+0297E | ⥾ |
Ufr; |
U+1D518 | 𝔘 |
ufr; |
U+1D532 | 𝔲 |
Ugrave; |
U+000D9 | Ù |
Ugrave |
U+000D9 | Ù |
ugrave; |
U+000F9 | ù |
ugrave |
U+000F9 | ù |
uHar; |
U+02963 | ⥣ |
uharl; |
U+021BF | ↿ |
uharr; |
U+021BE | ↾ |
uhblk; |
U+02580 | ▀ |
ulcorn; |
U+0231C | ⌜ |
ulcorner; |
U+0231C | ⌜ |
ulcrop; |
U+0230F | ⌏ |
ultri; |
U+025F8 | ◸ |
Umacr; |
U+0016A | Ū |
umacr; |
U+0016B | ū |
uml; |
U+000A8 | ¨ |
uml |
U+000A8 | ¨ |
UnderBar; |
U+0005F | _ |
UnderBrace; |
U+023DF | ⏟ |
UnderBracket; |
U+023B5 | ⎵ |
UnderParenthesis; |
U+023DD | ⏝ |
Union; |
U+022C3 | ⋃ |
UnionPlus; |
U+0228E | ⊎ |
Uogon; |
U+00172 | Ų |
uogon; |
U+00173 | ų |
Uopf; |
U+1D54C | 𝕌 |
uopf; |
U+1D566 | 𝕦 |
UpArrow; |
U+02191 | ↑ |
Uparrow; |
U+021D1 | ⇑ |
uparrow; |
U+02191 | ↑ |
UpArrowBar; |
U+02912 | ⤒ |
UpArrowDownArrow; |
U+021C5 | ⇅ |
UpDownArrow; |
U+02195 | ↕ |
Updownarrow; |
U+021D5 | ⇕ |
updownarrow; |
U+02195 | ↕ |
UpEquilibrium; |
U+0296E | ⥮ |
upharpoonleft; |
U+021BF | ↿ |
upharpoonright; |
U+021BE | ↾ |
uplus; |
U+0228E | ⊎ |
UpperLeftArrow; |
U+02196 | ↖ |
UpperRightArrow; |
U+02197 | ↗ |
Upsi; |
U+003D2 | ϒ |
upsi; |
U+003C5 | υ |
upsih; |
U+003D2 | ϒ |
Upsilon; |
U+003A5 | Υ |
upsilon; |
U+003C5 | υ |
UpTee; |
U+022A5 | ⊥ |
UpTeeArrow; |
U+021A5 | ↥ |
upuparrows; |
U+021C8 | ⇈ |
urcorn; |
U+0231D | ⌝ |
urcorner; |
U+0231D | ⌝ |
urcrop; |
U+0230E | ⌎ |
Uring; |
U+0016E | Ů |
uring; |
U+0016F | ů |
urtri; |
U+025F9 | ◹ |
Uscr; |
U+1D4B0 | 𝒰 |
uscr; |
U+1D4CA | 𝓊 |
utdot; |
U+022F0 | ⋰ |
Utilde; |
U+00168 | Ũ |
utilde; |
U+00169 | ũ |
utri; |
U+025B5 | ▵ |
utrif; |
U+025B4 | ▴ |
uuarr; |
U+021C8 | ⇈ |
Uuml; |
U+000DC | Ü |
Uuml |
U+000DC | Ü |
uuml; |
U+000FC | ü |
uuml |
U+000FC | ü |
uwangle; |
U+029A7 | ⦧ |
vangrt; |
U+0299C | ⦜ |
varepsilon; |
U+003F5 | ϵ |
varkappa; |
U+003F0 | ϰ |
varnothing; |
U+02205 | ∅ |
varphi; |
U+003D5 | ϕ |
varpi; |
U+003D6 | ϖ |
varpropto; |
U+0221D | ∝ |
vArr; |
U+021D5 | ⇕ |
varr; |
U+02195 | ↕ |
varrho; |
U+003F1 | ϱ |
varsigma; |
U+003C2 | ς |
varsubsetneq; |
U+0228A U+0FE00 | ⊊︀ |
varsubsetneqq; |
U+02ACB U+0FE00 | ⫋︀ |
varsupsetneq; |
U+0228B U+0FE00 | ⊋︀ |
varsupsetneqq; |
U+02ACC U+0FE00 | ⫌︀ |
vartheta; |
U+003D1 | ϑ |
vartriangleleft; |
U+022B2 | ⊲ |
vartriangleright; |
U+022B3 | ⊳ |
Vbar; |
U+02AEB | ⫫ |
vBar; |
U+02AE8 | ⫨ |
vBarv; |
U+02AE9 | ⫩ |
Vcy; |
U+00412 | В |
vcy; |
U+00432 | в |
VDash; |
U+022AB | ⊫ |
Vdash; |
U+022A9 | ⊩ |
vDash; |
U+022A8 | ⊨ |
vdash; |
U+022A2 | ⊢ |
Vdashl; |
U+02AE6 | ⫦ |
Vee; |
U+022C1 | ⋁ |
vee; |
U+02228 | ∨ |
veebar; |
U+022BB | ⊻ |
veeeq; |
U+0225A | ≚ |
vellip; |
U+022EE | ⋮ |
Verbar; |
U+02016 | ‖ |
verbar; |
U+0007C | | |
Vert; |
U+02016 | ‖ |
vert; |
U+0007C | | |
VerticalBar; |
U+02223 | ∣ |
VerticalLine; |
U+0007C | | |
VerticalSeparator; |
U+02758 | ❘ |
VerticalTilde; |
U+02240 | ≀ |
VeryThinSpace; |
U+0200A | |
Vfr; |
U+1D519 | 𝔙 |
vfr; |
U+1D533 | 𝔳 |
vltri; |
U+022B2 | ⊲ |
vnsub; |
U+02282 U+020D2 | ⊂⃒ |
vnsup; |
U+02283 U+020D2 | ⊃⃒ |
Vopf; |
U+1D54D | 𝕍 |
vopf; |
U+1D567 | 𝕧 |
vprop; |
U+0221D | ∝ |
vrtri; |
U+022B3 | ⊳ |
Vscr; |
U+1D4B1 | 𝒱 |
vscr; |
U+1D4CB | 𝓋 |
vsubnE; |
U+02ACB U+0FE00 | ⫋︀ |
vsubne; |
U+0228A U+0FE00 | ⊊︀ |
vsupnE; |
U+02ACC U+0FE00 | ⫌︀ |
vsupne; |
U+0228B U+0FE00 | ⊋︀ |
Vvdash; |
U+022AA | ⊪ |
vzigzag; |
U+0299A | ⦚ |
Wcirc; |
U+00174 | Ŵ |
wcirc; |
U+00175 | ŵ |
wedbar; |
U+02A5F | ⩟ |
Wedge; |
U+022C0 | ⋀ |
wedge; |
U+02227 | ∧ |
wedgeq; |
U+02259 | ≙ |
weierp; |
U+02118 | ℘ |
Wfr; |
U+1D51A | 𝔚 |
wfr; |
U+1D534 | 𝔴 |
Wopf; |
U+1D54E | 𝕎 |
wopf; |
U+1D568 | 𝕨 |
wp; |
U+02118 | ℘ |
wr; |
U+02240 | ≀ |
wreath; |
U+02240 | ≀ |
Wscr; |
U+1D4B2 | 𝒲 |
wscr; |
U+1D4CC | 𝓌 |
xcap; |
U+022C2 | ⋂ |
xcirc; |
U+025EF | ◯ |
xcup; |
U+022C3 | ⋃ |
xdtri; |
U+025BD | ▽ |
Xfr; |
U+1D51B | 𝔛 |
xfr; |
U+1D535 | 𝔵 |
xhArr; |
U+027FA | ⟺ |
xharr; |
U+027F7 | ⟷ |
Xi; |
U+0039E | Ξ |
xi; |
U+003BE | ξ |
xlArr; |
U+027F8 | ⟸ |
xlarr; |
U+027F5 | ⟵ |
xmap; |
U+027FC | ⟼ |
xnis; |
U+022FB | ⋻ |
xodot; |
U+02A00 | ⨀ |
Xopf; |
U+1D54F | 𝕏 |
xopf; |
U+1D569 | 𝕩 |
xoplus; |
U+02A01 | ⨁ |
xotime; |
U+02A02 | ⨂ |
xrArr; |
U+027F9 | ⟹ |
xrarr; |
U+027F6 | ⟶ |
Xscr; |
U+1D4B3 | 𝒳 |
xscr; |
U+1D4CD | 𝓍 |
xsqcup; |
U+02A06 | ⨆ |
xuplus; |
U+02A04 | ⨄ |
xutri; |
U+025B3 | △ |
xvee; |
U+022C1 | ⋁ |
xwedge; |
U+022C0 | ⋀ |
Yacute; |
U+000DD | Ý |
Yacute |
U+000DD | Ý |
yacute; |
U+000FD | ý |
yacute |
U+000FD | ý |
YAcy; |
U+0042F | Я |
yacy; |
U+0044F | я |
Ycirc; |
U+00176 | Ŷ |
ycirc; |
U+00177 | ŷ |
Ycy; |
U+0042B | Ы |
ycy; |
U+0044B | ы |
yen; |
U+000A5 | ¥ |
yen |
U+000A5 | ¥ |
Yfr; |
U+1D51C | 𝔜 |
yfr; |
U+1D536 | 𝔶 |
YIcy; |
U+00407 | Ї |
yicy; |
U+00457 | ї |
Yopf; |
U+1D550 | 𝕐 |
yopf; |
U+1D56A | 𝕪 |
Yscr; |
U+1D4B4 | 𝒴 |
yscr; |
U+1D4CE | 𝓎 |
YUcy; |
U+0042E | Ю |
yucy; |
U+0044E | ю |
Yuml; |
U+00178 | Ÿ |
yuml; |
U+000FF | ÿ |
yuml |
U+000FF | ÿ |
Zacute; |
U+00179 | Ź |
zacute; |
U+0017A | ź |
Zcaron; |
U+0017D | Ž |
zcaron; |
U+0017E | ž |
Zcy; |
U+00417 | З |
zcy; |
U+00437 | з |
Zdot; |
U+0017B | Ż |
zdot; |
U+0017C | ż |
zeetrf; |
U+02128 | ℨ |
ZeroWidthSpace; |
U+0200B | |
Zeta; |
U+00396 | Ζ |
zeta; |
U+003B6 | ζ |
Zfr; |
U+02128 | ℨ |
zfr; |
U+1D537 | 𝔷 |
ZHcy; |
U+00416 | Ж |
zhcy; |
U+00436 | ж |
zigrarr; |
U+021DD | ⇝ |
Zopf; |
U+02124 | ℤ |
zopf; |
U+1D56B | 𝕫 |
Zscr; |
U+1D4B5 | 𝒵 |
zscr; |
U+1D4CF | 𝓏 |
zwj; |
U+0200D | |
zwnj; |
U+0200C | |
このデータは、JSON ファイルとしても利用できる。
上に表示されているグリフは非規範的である。上に列挙されている文字の正式な定義については Unicode を参照すること。
文字参照名は XML Entity Definitions for Characters に由来するが、規範的と見なされるのは上記のみである。[XMLENTITY]
この一覧は静的であり、今後 拡張または変更されることはない。
すべての現行エンジンでサポートされている。
この節では XML リソースの規則のみを説明する。
text/html リソースの規則については、
上の「HTML
構文」という節で説明している。
XML 構文の使用は推奨されない。
その理由には、XML 構文解析器がバイトまたは文字の文字列を Document
オブジェクトへどのように
マッピングしなければならないかを定義する仕様が存在しないことや、XML 構文が実質的に保守されて
いないことが含まれる。つまり、たとえそのような機能がHTML 構文へ追加された場合でも、今後 XML 構文へさらなる機能が
追加されることはないと予想されている。
HTML の XML 構文は、以前は「XHTML」と呼ばれていたが、この仕様ではその用語を 使用しない(理由の一つは、MathML および SVG の HTML 構文についてそのような用語が使用されて いないためである)。
XML の構文は XML および Namespaces in XML で定義されている。[XML] [XMLNS]
この仕様は、XML 自体について定義されているものを超える構文レベルの要件を定義しない。
XML 文書は、必要に応じて DOCTYPE を含んでもよいが、この仕様へ適合するために
必須ではない。この仕様は公開識別子またはシステム識別子を定義せず、正式な DTD も提供しない。
XML によれば、XML プロセッサーが DOCTYPE で参照される外部 DTD
サブセットを処理することは保証されない。これは、たとえば XML 文書内の文字について実体参照を使用することは、それらが外部ファイルで
定義されている場合には安全でないことを意味する(<、
>、&、
"、および ' を除く)。
この節では、特に HTML との相互作用を重点的に扱いながら、XML と DOM の関係を説明する。
この仕様におけるXML 構文解析器とは、
XML で示される規則に従ってバイトまたは文字の文字列を
Document オブジェクトへ
マッピングする構造である。
執筆時点では、そのような規則は実際には存在しない。
XML 構文解析器は、作成時に Document オブジェクトへ
関連付けられるか、暗黙に一つ作成する。
次に、この Document には、
XML、Namespaces
in XML、および DOM で定義される、構文解析器へ渡された入力のツリー構造を表す
DOM ノードを配置しなければならない。要素を表す DOM ノードを作成する場合、適切な要素インターフェイスが
作成され、カスタム要素が正しく
設定されることを保証するため、トークン用の要素を作成するアルゴリズム、
または適切な XML データ構造を操作する同等のものを使用しなければならない。
XML 構文解析器が Document のツリーに対して
実行する操作について、ユーザーエージェントは、要素が文書へ挿入された場合や属性が設定された場合に
何が起こるかに関するこの仕様の規則を発火させるように、要素と属性がそれぞれ個別に付加および
設定されたかのように動作しなければならない。また、DOM のミューテーションオブザーバーに関する要件により、
ミューテーションオブザーバーは発火する。
[XML] [XMLNS] [DOM] [UIEVENTS]
要素の開始タグが構文解析されてから、その要素の終了タグが構文解析されるか、または構文解析器が 整形式性エラーを検出するまでの間、ユーザーエージェントは、その要素が開いている 要素のスタック内にあるかのように動作しなければならない。
これは、さまざまな要素が、開いている要素のスタックから ポップされた後にのみ特定の処理を開始するために使用される。
この仕様は、外部実体を取得する際にユーザーエージェントが使用すべき次の追加情報を提供する。 次の一覧に示される公開識別子はすべて、 このリンクによって指定される URLに対応する。(この URL は、名前付き文字参照の節に列挙される名前の実体 宣言を含む DTD である。)[XML]
-//W3C//DTD XHTML 1.0 Transitional//EN-//W3C//DTD XHTML 1.1//EN-//W3C//DTD XHTML 1.0 Strict//EN-//W3C//DTD XHTML 1.0 Frameset//EN-//W3C//DTD XHTML Basic 1.0//EN-//W3C//DTD XHTML 1.1 plus MathML 2.0//EN-//W3C//DTD XHTML 1.1 plus MathML 2.0 plus SVG 1.1//EN-//W3C//DTD MathML 2.0//EN-//WAPFORUM//DTD XHTML Mobile 1.0//EN-//WAPFORUM//DTD XHTML Mobile 1.1//EN-//WAPFORUM//DTD XHTML Mobile 1.2//ENさらに、ユーザーエージェントは、上記の公開識別子のいずれかが使用された場合には、 上記の外部実体の内容を取得しようとすべきであり、それ以外の外部実体の内容を取得しようと すべきではない。
これは厳密には XML の意図的な違反では ないが、XML の要件の精神には反する。これは、外部サブセットの処理にネットワークアクセスを 必要とせず、すべてのユーザーエージェントが相互運用可能な方法で実体を処理することを望むためである。 [XML]
XML 構文解析器は、XML スクリプティングサポートが 有効またはXML スクリプティングサポートが無効の 状態で呼び出すことができる。別途指定されている場合を除き、XML 構文解析器は XML スクリプティングサポートが有効な状態で呼び出される。
XML スクリプティング
サポートが
有効なXML 構文解析器が script 要素を
作成する場合、その構文解析器
文書を設定し、その強制
asyncを false に設定しなければならない。
構文解析器がXML
フラグメント構文解析アルゴリズムの
一部として作成された場合、要素のすでに開始済みを true
に設定しなければならない。
その後、要素の終了タグが構文解析された場合、ユーザーエージェントはマイクロタスクチェックポイントを実行し、
その後 script 要素を準備しなければならない。
これにより保留中の構文解析ブロッキングスクリプトが
存在することになった場合、ユーザーエージェントは
次の手順を実行しなければならない:
構文解析器の Document がスクリプトをブロックしている
スタイルシートを持たなくなり、かつ保留中の構文解析ブロッキング
スクリプトの構文解析器によって実行される準備が
できているが true になるまで、イベントループを回す。
保留中の構文解析ブロッキング スクリプトによって指定されるscript 要素を実行する。
保留中の構文解析ブロッキングスクリプトを null に設定する。
document.write() API は
XML 文書では利用できないため、HTML 構文解析器にある複雑さの多くは、
XML 構文解析器では必要ない。
XML 構文解析器のXML スクリプティングサポートが無効である場合、 これらは一切行われない。
XML 構文解析器がノードを
template 要素へ
付加しようとする場合、代わりにそのノードを template 要素の
テンプレート内容(DocumentFragment
ノード)へ付加しなければならない。
これは XML の意図的な違反である。
残念ながら、XML は template の
処理に必要な方法では正式に拡張可能でない。
[XML]
この仕様の一部のアルゴリズムは、文字を一つずつ構文解析器へ少しずつ 与える。そのような場合、XML 構文解析器は、それらすべての文字を 連結した単一の文字列に直面した場合と同様に動作しなければならない。
XML 構文解析器が入力の終端へ 到達した場合、HTML 構文解析器と同じ規則に従って、構文解析を 停止しなければならない。XML 構文解析器は中止することもでき、その場合も HTML 構文解析器と 同じ方法で行わなければならない。
適合性チェッカーの目的では、リソースがXML 構文であると判定された場合、それはXML 文書である。
Document または
Element
ノードに対するXML フラグメントシリアライズ
アルゴリズムは、そのノードを表す XML フラグメントを返すか、例外をスローする。
Document の場合、
以下のエラーケースのいずれも該当しなければ、アルゴリズムは文書実体の形式の文字列を返さなければならない。
Element
の場合、
以下のエラーケースのいずれも該当しなければ、アルゴリズムは内部一般
構文解析対象実体の形式の文字列を返さなければならない。
どちらの場合も、返される文字列は XML 名前空間整形式でなければならず、そのノードのすべての関連する子ノードをツリー順に同型シリアライズしたものでなければならない。
ユーザーエージェントは、シリアライズ内の接頭辞および名前空間宣言を調整してもよい
(実際、XML 名前空間整形式を得るため、一部の場合にはそうせざるを得ないことがある)。
ユーザーエージェントは、DOM 内の Text
ノードを表すために、通常のテキストと文字参照を組み合わせて使用してもよい。
ノードの関連する子ノードは、次の規則に従って適用されるものである:
Element
の場合、
シリアライズ内の要素のいずれかが名前空間を持たないなら、それらの要素に対して有効範囲内の
既定の名前空間を空文字列として明示的に宣言しなければならない。(これは Document の場合には適用されない。)
[XML]
[XMLNS]
この節の目的では、名前空間宣言を持たない要素からなり、その内容が内部一般構文解析対象実体である 文書自体が XML 名前空間整形式となる場合、その内部一般構文解析対象実体は XML 名前空間整形式であると 見なされる。
シリアライズされる DOM サブツリー内に次のエラーケースのいずれかが見つかった場合、
アルゴリズムは文字列を返す代わりに"InvalidStateError" DOMException
をスローしなければならない:
Document ノード。PubidChar 生成規則に一致しない文字を含む外部サブセット公開識別子を持つ
DocumentType
ノード。[XML]
Char 生成規則に一致しない文字を含む外部サブセットシステム識別子を持つ
DocumentType
ノード。[XML]
Name
生成規則に一致しないローカル名を持つノード。[XML]xmlns」である Attr
ノード。[XMLNS]Element
ノード。Char 生成規則に一致しない文字を含む Attr
ノード、Text
ノード、Comment
ノード、または
ProcessingInstruction
ノード。[XML]
Comment
ノード。xml」とASCII
大文字・小文字を区別せず一致する ProcessingInstruction
ノード。ProcessingInstruction
ノード。?>」を含む ProcessingInstruction
ノード。DOM をシリアライズ不能にする方法はこれらだけである。DOM はその他のすべての
XML 制約を強制する。たとえば、二つの要素を Document
ノードへ
付加しようとすると、"HierarchyRequestError" DOMException
がスローされる。
Element
または
DocumentFragment
ノード target および文字列 input が与えられたとき、XML
フラグメント構文解析アルゴリズムは次の手順を
実行する。この手順は DocumentFragment
を返す。
context を、target が Element
である場合は
target とし、それ以外の場合は target のホストとする。
新しいXML 構文解析器を作成する。
作成したばかりの構文解析器へ、context の開始タグに対応する文字列を与える。その際、 DOM 内のその要素で有効範囲内にあるすべての名前空間接頭辞と、DOM 内のその要素で有効範囲内にある 既定の名前空間(存在する場合)を宣言する。
要素に対する DOM の lookupNamespaceURI() メソッドが、その接頭辞について
null でない値を返す場合、その名前空間接頭辞は有効範囲内にある。
既定の名前空間は、要素に対する DOM の isDefaultNamespace() メソッドが
true を返す名前空間である。
DOCTYPE は構文解析器へ渡されないため、外部サブセットは
参照されず、したがって実体は認識されない。
作成したばかりの構文解析器へ文字列 input を与える。
XML 整形式性エラーまたは XML 名前空間整形式性エラーがある場合、
"SyntaxError" DOMException
をスローする。
結果となる Document の文書要素が兄弟ノードを持つ場合、
"SyntaxError"
DOMException
をスローする。
fragmentを、文書 フラグメントを作成した結果とする。これは、contextのノード 文書を与えたものである。
fragment を返す。
ユーザーエージェントは、HTML 文書を特定の方法で提示することを要求されない。しかし、この 節では、従った場合に文書の作者が意図した体験に近いユーザー体験をもたらす可能性が高い、 HTML 文書のレンダリングに関する一連の提案を示す。この節の規範性に関する混乱を避けるため、 「must」は使用していない。代わりに、この体験をもたらす動作を示すため「期待される」という用語を 使用する。推奨される既定のレンダリングをサポートするものとして指定された ユーザーエージェントの適合性について、この節の「期待される」という用語は 「must」と同じ適合性上の意味を持つ。
この節の提案は、一般に CSS の用語で表現される。ユーザーエージェントは、 CSS をサポートするか、この節で示される CSS 規則を他の提示機構の近似表現へ変換することが 期待される。
これに反するスタイル層の規則(たとえば作者スタイルシート)がない場合、ユーザーエージェントは、 この仕様で説明される要素が表す意味を ユーザーへ伝えるように、その要素をレンダリングすることが期待される。
この節の提案は一般に、解像度が 96dpi 以上の視覚的出力媒体を想定しているが、HTML は 複数の媒体へ適用されることを意図している(HTML は媒体非依存の言語である)。 ユーザーエージェントの実装者には、この節の提案を対象媒体へ適合させることが推奨される。
要素に関連付けられた CSS レイアウトボックス、SVG レイアウトボックス、または他のスタイル言語に おける同等のものがある場合、その要素はレンダリングされている。
単に画面外にあることは、その要素がレンダリングされて いないことを意味しない。 属性が存在することは、通常その要素がレンダリングされていないことを意味するが、 スタイルシートによって上書きされる可能性がある。
完全にアクティブな状態は、 要素がレンダリングされているかどうかに 影響しない。文書が完全にアクティブでなく、 ユーザーにまったく表示されていない場合でも、その中の要素は「レンダリングされている」と 見なされ得る。
要素がレンダリングされており、 その関連付けられた CSS レイアウトボックスがビューポートと交差する場合、 その要素はビューポートと交差すると言う。
レンダリングされている 状態と同様に、完全に アクティブでない文書内の要素もビューポートと交差することがある。ビューポートは 文書間で共有されず、常にユーザーへ表示されるとは限らないため、完全にアクティブでない文書内の要素も、その文書に 関連付けられたビューポートと交差することがある。
この仕様は、交差がテストされる正確なタイミングを定義しないが、そのタイミングは Intersection Observer API のものと一致させることが提案される。[INTERSECTIONOBSERVER]
要素がレンダリングされていないが、 CSS の 'display: contents'、または他のスタイル言語における同等のものの結果として、 その子(存在する場合)がレンダリングされ得る場合、その要素は レンダリングを子へ委譲している。 [CSSDISPLAY]
作者レベルの CSS スタイルシートを尊重しないユーザーエージェントも、それでもこの仕様と 関連する CSS および Unicode 仕様に整合する方法で、この節に示される CSS 規則を適用したかのように 動作することが期待される。 [CSS] [UNICODE] [BIDI]
これは特に、'display'、 'unicode-bidi'、および 'direction' プロパティに関する問題で重要である。
これらの小節で示される CSS 規則は、別途指定されている場合を除き、HTML 要素を含むすべての 文書について、ユーザーエージェントレベルのスタイルシートの既定値の一部として使用されることが 期待される。
一部の規則は、CSS カスケードにおける作者レベルで詳細度がゼロの表示上のヒント部分を対象としている。 これらは表示上のヒントとして明示的に示される。
以下の文章で、要素 element 上の属性 attribute が ピクセル長プロパティ(または複数のプロパティ)properties へ対応付けられると記されている場合、 element に属性 attribute が設定され、その属性値を非負整数を 構文解析する規則を使用して構文解析してもエラーが生成されないなら、ユーザーエージェントは、 構文解析された値を properties に対する表示上の ヒントのピクセル長として使用することが期待されることを意味する。
以下の文章で、要素 element 上の属性 attribute が 寸法プロパティ(または複数のプロパティ)properties へ対応付けられると記されている場合、 element に属性 attribute が設定され、その属性値を寸法値を 構文解析する規則を使用して構文解析してもエラーが生成されないなら、ユーザーエージェントは、 構文解析された寸法を properties に対する表示上のヒントの値として 使用することが期待されることを意味する。 寸法が長さである場合、値はピクセル長として与えられ、寸法がパーセンテージである場合、 値はパーセンテージとして与えられる。
以下の文章で、要素 element 上の属性 attribute が 寸法プロパティ(ゼロを無視)(または複数のプロパティ)properties へ対応付けられると記されている場合、 element に属性 attribute が設定され、その属性値をゼロでない 寸法値を構文解析する規則を使用して構文解析してもエラーが生成されないなら、 ユーザーエージェントは、構文解析された寸法を properties に対する表示上の ヒントの値として使用することが期待されることを意味する。 寸法が長さである場合、値はピクセル長として与えられ、寸法がパーセンテージである場合、 値はパーセンテージとして与えられる。
以下の文章で、要素 element 上の属性の組 w および h が
aspect-ratio プロパティへ対応付けられると
記されている場合、element が属性 w および h の両方を持ち、
それらの属性値を非負整数を
構文解析する規則を使用して構文解析しても、どちらにもエラーが生成されないなら、
ユーザーエージェントは、構文解析された整数を
'aspect-ratio'
プロパティに対する auto w /
h という形式の表示上のヒントとして
使用することが期待されることを意味する。
以下の文章で、要素 element 上の属性の組 w および h が
寸法規則を使用して aspect-ratio プロパティへ対応付けられると
記されている場合、element が属性 w および h の両方を持ち、
それらの属性値を寸法値を
構文解析する規則を使用して構文解析しても、どちらにもエラーが生成されず、
パーセンテージも返されないなら、ユーザーエージェントは、構文解析された寸法を
'aspect-ratio'
プロパティに対する auto w /
h という形式の表示上のヒントとして
使用することが期待されることを意味する。
ユーザーエージェントがノードの子孫を整列する場合、
ユーザーエージェントは、'margin-inline-start' および 'margin-inline-end' プロパティの両方の算出値が
'auto' 以外であり、制約過多で、その二つのマージンのうち一つの使用値が
より大きい値へ強制され、かつ自身には適用可能な align 属性がない子孫だけを
整列することが期待される。
複数の要素が特定の子孫を整列する場合、
最も深く入れ子にされたそのような要素が他の要素を上書きすることが期待される。
整列される要素は、その行の左側および行の右側のマージンの使用値を、それに応じて設定することによって整列されることが
期待される。
[CSSLOGICAL] [CSSWM]
@namespace "http://www.w3.org/1999/xhtml" ;
area, base, basefont, datalist, head, link, meta, noembed,
noframes, param, rp, script, style, template, title {
display : none;
}
{
display : none;
}
[hidden=until-found i]:not(embed) {
content-visibility : hidden;
}
embed[hidden] { display : inline; height : 0 ; width : 0 ; }
input[type=hidden i] { display : none !important; }
@media (scripting) {
noscript { display: none !important; }
}@namespace "http://www.w3.org/1999/xhtml" ;
html, body { display : block; } 下の表の各プロパティについて、body 要素が与えられたとき、
存在する最初の属性が body 要素上のピクセル長プロパティへ対応付けられる。
プロパティに対する属性が一つも見つからない場合、または見つかった属性の値を正常に
構文解析できない場合、代わりにそのプロパティへ既定値 8px を使用することが期待される。
| プロパティ | 参照元 |
|---|---|
| 'margin-top', 'margin-bottom' | body 要素の marginheight 属性
|
body 要素の topmargin 属性
|
|
body 要素のコンテナーフレーム要素の
marginheight 属性
|
|
| 'margin-left', 'margin-right' | body 要素の marginwidth 属性
|
body 要素の leftmargin 属性
|
|
body 要素のコンテナーフレーム要素の
marginwidth 属性
|
body 要素のノード文書のノード
ナビゲータブルが子ナビゲータブルであり、そのナビゲータブルのコンテナーが frame または iframe 要素である場合、
body 要素の
コンテナーフレーム要素は、その frame または
iframe 要素である。
それ以外の場合、コンテナーフレーム要素は存在しない。
上記の要件は、ページが、たとえば iframe を使用して、
別のページ(別のオリジンのものを含む)の
マージンを変更できることを意味する。これは、場合によっては、ページが作者の意図とは異なる方法で
レンダリングされる状況を攻撃者が作り出し、フィッシングやその他の方法でユーザーを欺くことを
可能にする可能性があるため、潜在的なセキュリティリスクである。
Document のノードナビゲータブルが子ナビゲータブルである場合、そのナビゲータブルのコンテナーのコンテンツ
ボックス内に収まるように配置およびサイズ設定されることが期待される。
コンテナーがレンダリングされていない場合、
ナビゲータブルは、幅および高さがゼロのビューポートを
持つことが期待される。
Document のノードナビゲータブルが子ナビゲータブルであり、そのナビゲータブルのコンテナーが
frame または iframe 要素であり、その要素が
scrolling 属性を持ち、その属性値が文字列「off」、
「noscroll」、または「no」とASCII
大文字・小文字を区別せず一致する場合、
ユーザーエージェントは、そのビューポートへ
適用される'overflow' プロパティにかかわらず、Document のノードナビゲータブルのビューポートに
スクロールバーが表示されないようにすることが期待される。
body 要素の background 属性が
空でない値へ設定された場合、新しい値を要素のノード文書を基準としてエンコーディングを考慮して構文解析および
シリアライズすることが期待される。
それが失敗を返さない場合、ユーザーエージェントは、その属性を要素の'background-image' プロパティを返された値へ設定する表示上のヒントとして
扱うことが期待される。
body 要素の bgcolor 属性が
設定された場合、新しい値を従来の色値を構文解析する規則を使用して
構文解析することが期待される。
それが失敗を返さない場合、ユーザーエージェントは、その属性を要素の'background-color' プロパティを
結果の色へ設定する表示上のヒントとして扱うことが期待される。
body 要素が text 属性を持つ場合、その値を従来の色値を構文解析する
規則を使用して構文解析することが期待される。それが失敗を返さない場合、
ユーザーエージェントは、その属性を要素の'color' プロパティを結果の色へ設定する表示上の
ヒントとして扱うことが期待される。
body 要素が link 属性を持つ場合、その値を従来の色値を構文解析する
規則を使用して構文解析することが期待される。それが失敗を返さない場合、
ユーザーエージェントは、その属性を、Document 内で :link 疑似クラスに
一致するすべての要素の'color' プロパティを結果の色へ設定する表示上のヒントとして
扱うことが期待される。
body 要素が vlink 属性を持つ場合、
その値を従来の色値を構文解析する
規則を使用して構文解析することが期待される。それが失敗を返さない場合、
ユーザーエージェントは、その属性を、Document 内で :visited 疑似クラスに
一致するすべての要素の'color' プロパティを結果の色へ設定する表示上の
ヒントとして扱うことが期待される。
body 要素が alink 属性を持つ場合、
その値を従来の色値を構文解析する
規則を使用して構文解析することが期待される。それが失敗を返さない場合、
ユーザーエージェントは、その属性を、Document 内で
:active 疑似クラスと、
:link 疑似クラスまたは :visited 疑似クラスの
いずれかに一致するすべての要素の'color' プロパティを結果の色へ設定する表示上の
ヒントとして扱うことが期待される。
@namespace "http://www.w3.org/1999/xhtml" ;
address, blockquote, center, dialog, div, figure, figcaption, footer, form,
header, hr, legend, listing, main, p, plaintext, pre, search, xmp {
display : block;
}
blockquote, figure, listing, p, plaintext, pre, xmp {
margin-block : 1 em ;
}
blockquote, figure { margin-inline : 40 px ; }
address { font-style : italic; }
listing, plaintext, pre, xmp {
font-family : monospace; white-space : pre;
}
dialog:not([open]) { display : none; }
dialog {
position : absolute;
inset-inline-start : 0 ; inset-inline-end : 0 ;
width : fit-content;
height : fit-content;
margin : auto;
border : solid;
padding : 1 em ;
background-color : Canvas;
color : CanvasText;
}
dialog:modal {
position : fixed;
overflow : auto;
inset-block : 0 ;
max-width : calc ( 100 % - 6 px - 2 em );
max-height : calc ( 100 % - 6 px - 2 em );
}
dialog::backdrop {
background : rgba ( 0 , 0 , 0 , 0.1 );
}
[popover]:not(:popover-open):not(dialog[open]) {
display : none;
}
dialog:popover-open {
display : block;
}
[popover] {
position : fixed;
inset : 0 ;
width : fit-content;
height : fit-content;
margin : auto;
border : solid;
padding : 0.25 em ;
overflow : auto;
color : CanvasText;
background-color : Canvas;
}
:popover-open::backdrop {
position : fixed;
inset : 0 ;
pointer-events : none !important;
background-color: transparent;
}
slot {
display: contents;
}次の規則も、表示上のヒントとして適用されることが期待される:
@namespace "http://www.w3.org/1999/xhtml" ;
pre[wrap] { white-space : pre-wrap; } @namespace "http://www.w3.org/1999/xhtml" ;
form { margin-block-end : 1 em ; } center 要素、および div 要素が、その値が文字列
「center」または文字列「middle」のいずれかとASCII
大文字・小文字を区別せず一致する align 属性を持つ場合、その要素は、自身の内部のテキストを中央揃えにし、
'text-align'
プロパティが表示上のヒントで 'center'
に設定されているかのように
動作し、かつ子孫を中央へ整列することが期待される。
div 要素が、
その値が文字列「left」とASCII
大文字・小文字を区別せず一致する align 属性を持つ場合、その要素は、自身の内部のテキストを左揃えにし、
'text-align' プロパティが表示上のヒントで 'left' に設定されているかのように動作し、
かつ子孫を左へ整列することが期待される。
div 要素が、
その値が文字列「right」とASCII
大文字・小文字を区別せず一致する align 属性を持つ場合、その要素は、自身の内部のテキストを右揃えにし、
'text-align' プロパティが表示上のヒントで 'right' に設定されているかのように動作し、
かつ子孫を右へ整列することが期待される。
div 要素が、
その値が文字列「justify」とASCII
大文字・小文字を区別せず一致する align 属性を持つ場合、その要素は、自身の内部のテキストを両端揃えにし、
'text-align' プロパティが表示上のヒントで 'justify' に設定されているかのように
動作し、かつ子孫を左へ整列することが期待される。
@namespace "http://www.w3.org/1999/xhtml" ;
cite, dfn, em, i, var { font-style : italic; }
b, strong { font-weight : bolder; }
code, kbd, samp, tt { font-family : monospace; }
big { font-size : larger; }
small { font-size : smaller; }
sub { vertical-align : sub; }
sup { vertical-align : super; }
sub, sup { line-height : normal; font-size : smaller; }
ruby { display : ruby; }
rt { display : ruby-text; }
:link { color : #0000EE; }
:visited { color : #551A8B; }
:link:active, :visited:active { color : #FF0000; }
:link, :visited { text-decoration : underline; cursor : pointer; }
:focus-visible { outline : auto; }
mark { background : yellow; color : black; } /* this color is just a suggestion and can be changed based on implementation feedback */
abbr[title], acronym[title] { text-decoration : dotted underline; }
ins, u { text-decoration : underline; }
del, s, strike { text-decoration : line-through; }
q::before { content : open-quote; }
q::after { content : close-quote; }
br { display-outside : newline; } /* this also has bidi implications */
nobr { white-space : nowrap; }
wbr { display-outside : break-opportunity; } /* this also has bidi implications */
nobr wbr { white-space : normal; } 次の規則も、表示上のヒントとして適用されることが期待される:
@namespace "http://www.w3.org/1999/xhtml" ;
br[clear=left i] { clear : left; }
br[clear=right i] { clear : right; }
br[clear=all i], br[clear=both i] { clear : both; } CSS ruby モデルの目的では、ruby
要素の子のうち、
rt または rp 要素でない連続した子は、
'display' プロパティの値が'ruby-base'
である匿名ボックスで包まれることが期待される。
[CSSRUBY]
ルビの特定の部分に複数の注釈がある場合、片側へのルビ注釈の積み重なりを最小化するように、 注釈を基底テキストの両側へ分配すべきである。
可能になった時点で、前の要件は CSS ruby の用語で表現されるよう更新される。
(現在、CSS ruby は、入れ子にされた ruby
要素や、
この意味を表現する方法である複数の連続する rt
要素を処理しない。)
正しいルビレンダリングをサポートしないユーザーエージェントは、rp 要素がない場合、
rt 要素のテキストの
周囲に括弧をレンダリングすることが期待される。
ユーザーエージェントは、clear 属性を持つ br 要素をレンダリングするため、
インライン要素上で'clear' プロパティを、CSS のこの効果に関する
非規範的な注記で説明される方法に従ってサポートすることが期待される。
'color' プロパティの初期値は黒であることが期待される。 'background-color' プロパティの初期値は 'transparent' であることが期待される。キャンバスの背景は白であることが期待される。
font 要素が color
属性を持つ場合、その値を従来の色値を
構文解析する規則を使用して構文解析することが期待される。それが失敗を返さない場合、
ユーザーエージェントは、その属性を要素の'color'
プロパティを結果の色へ設定する表示上のヒントとして
扱うことが期待される。
font 要素が face
属性を持つ場合、ユーザーエージェントは、その属性を要素の
'font-family' プロパティを属性値へ設定する表示上の
ヒントとして扱うことが期待される。
font 要素が size
属性を持つ場合、ユーザーエージェントは、その属性を要素の
'font-size' プロパティを設定する表示上のヒントとして
扱うため、従来のフォントサイズを構文解析する規則と
呼ばれる次の手順を使用することが期待される:
input を属性値とする。
position を input 内へのポインターとし、初期状態では文字列の 先頭を指すものとする。
position が与えられた input 内でASCII 空白を読み飛ばす。
position が input の終端を過ぎている場合、表示上のヒントは存在しない。返る。
position の文字が U+002B PLUS SIGN 文字 (+) である場合、 mode を relative-plus とし、position を次の文字へ進める。 それ以外で、position の文字が U+002D HYPHEN-MINUS 文字 (-) である場合、 mode を relative-minus とし、position を次の文字へ進める。 それ以外の場合、mode を absolute とする。
position が与えられた input から、ASCII 数字であるコードポイント列を収集し、 digits を結果の列とする。
digits が空文字列である場合、表示上のヒントは存在しない。返る。
digits を 10 進整数として解釈する。value を結果の数値とする。
mode が relative-plus である場合、value を 3 増加させる。 mode が relative-minus である場合、value を 3 から value を減算した結果とする。
value が 7 より大きい場合、7 とする。
value が 1 より小さい場合、1 とする。
次の表に従い、'font-size' プロパティを value の値に対応するキーワードへ設定する:
| value | 'font-size' キーワード |
|---|---|
| 1 | 'x-small' |
| 2 | 'small' |
| 3 | 'medium' |
| 4 | 'large' |
| 5 | 'x-large' |
| 6 | 'xx-large' |
| 7 | 'xxx-large' |
@namespace "http://www.w3.org/1999/xhtml" ;
[dir]:dir(ltr), bdi:dir(ltr), input[type=tel i]:dir(ltr) { direction : ltr; }
[dir]:dir(rtl), bdi:dir(rtl) { direction : rtl; }
address, blockquote, center, div, figure, figcaption, footer, form, header, hr,
legend, listing, main, p, plaintext, pre, summary, xmp, article, aside,
:heading, hgroup, nav, search, section, table, caption, colgroup, col, thead,
tbody, tfoot, tr, td, th, dir, dd, dl, dt, menu, ol, ul, li, bdi, output,
[dir=ltr i], [dir=rtl i], [dir=auto i] {
unicode-bidi : isolate;
}
bdo, bdo[dir] { unicode-bidi : isolate-override; }
input[dir=auto i]:is([type=search i], [type=tel i], [type=url i],
[type=email i]), textarea[dir=auto i], pre[dir=auto i] {
unicode-bidi : plaintext;
}
/* see prose for input elements whose type attribute is in the Text state */
/* the rules setting the 'content' property on br and wbr elements also has bidi implications */ input 要素の dir 属性がauto 状態であり、その type 属性がText 状態である場合、
ユーザーエージェントは、'unicode-bidi' プロパティを 'plaintext' へ設定する
ユーザーエージェントレベルのスタイルシート規則を持つかのように動作することが期待される。
入力フィールド(すなわち textarea
要素、および
input 要素の
type 属性がText、Search、
Telephone、URL、
またはEmail 状態である場合)は、要素の
'direction' プロパティと一致する方向性を持つ編集ユーザーインターフェイスを
提示することが期待される。
文書の文字エンコーディングがISO-8859-8である場合、 上記の規則に続いて、次の規則も追加で適用されることが期待される:[ENCODING]
@namespace "http://www.w3.org/1999/xhtml" ;
address, blockquote, center, div, figure, figcaption, footer, form, header, hr,
legend, listing, main, p, plaintext, pre, summary, xmp, article, aside,
:heading, hgroup, nav, search, section, table, caption, colgroup, col, thead,
tbody, tfoot, tr, td, th, dir, dd, dl, dt, menu, ol, ul, li, [dir=ltr i],
[dir=rtl i], [dir=auto i], *|* {
unicode-bidi : bidi-override;
}
input:not([type=submit i]):not([type=reset i]):not([type=button i]),
textarea {
unicode-bidi : normal;
} @namespace "http://www.w3.org/1999/xhtml" ;
article, aside, :heading, hgroup, nav, section {
display : block;
}
:heading { font-weight : bold; }
:heading(1) { margin-block : 0.67 em ; font-size : 2.00 em ; }
:heading(2) { margin-block : 0.83 em ; font-size : 1.50 em ; }
:heading(3) { margin-block : 1.00 em ; font-size : 1.17 em ; }
:heading(4) { margin-block : 1.33 em ; font-size : 1.00 em ; }
:heading(5) { margin-block : 1.67 em ; font-size : 0.83 em ; }
:heading(6, 7, 8, 9) {
font-size : 0.67 em ;
margin-block : 2.33 em ;
}
@namespace "http://www.w3.org/1999/xhtml" ;
dir, dd, dl, dt, menu, ol, ul { display : block; }
li { display : list-item; text-align : match-parent; }
dir, dl, menu, ol, ul { margin-block : 1 em ; }
:is(dir, dl, menu, ol, ul) :is(dir, dl, menu, ol, ul) {
margin-block : 0 ;
}
dd { margin-inline-start : 40 px ; }
dir, menu, ol, ul { padding-inline-start : 40 px ; }
ol, ul, menu { counter-reset : list-item; }
ol { list-style-type : decimal; }
dir, menu, ul {
list-style-type : disc;
}
:is(dir, menu, ol, ul) :is(dir, menu, ul) {
list-style-type : circle;
}
:is(dir, menu, ol, ul) :is(dir, menu, ol, ul) :is(dir, menu, ul) {
list-style-type : square;
} 次の規則も、表示上のヒントとして適用されることが期待される:
@namespace "http://www.w3.org/1999/xhtml" ;
ol[type="1"], li[type="1"] { list-style-type : decimal; }
ol[type=a s], li[type=a s] { list-style-type : lower-alpha; }
ol[type=A s], li[type=A s] { list-style-type : upper-alpha; }
ol[type=i s], li[type=i s] { list-style-type : lower-roman; }
ol[type=I s], li[type=I s] { list-style-type : upper-roman; }
ul[type=none i], li[type=none i] { list-style-type : none; }
ul[type=disc i], li[type=disc i] { list-style-type : disc; }
ul[type=circle i], li[type=circle i] { list-style-type : circle; }
ul[type=square i], li[type=square i] { list-style-type : square; } @namespace "http://www.w3.org/1999/xhtml" ;
li { list-style-position : inside; }
li :is(dir, menu, ol, ul) { list-style-position : outside; }
:is(dir, menu, ol, ul) :is(dir, menu, ol, ul, li) { list-style-position : unset; } li 要素をレンダリングする場合、
CSS を使用しないユーザーエージェントは、リスト項目マーカー内のカウンターをレンダリングするために
li 要素の序数値を使用することが期待される。
CSS ユーザーエージェントについて、リスト項目のレンダリングの一部は CSS Lists 仕様で 定義される。さらに、次の属性の対応付けが適用されることが期待される: [CSSLISTS]
li 要素が value 属性を持ち、その属性値を整数を構文解析する規則を
使用して構文解析してもエラーが生成されない場合、ユーザーエージェントは、構文解析された値
value を、'counter-set' プロパティに対する list-item
value という形式の表示上のヒントとして使用することが期待される。
ol 要素が start 属性または reversed 属性、あるいはその両方を
持つ場合、ユーザーエージェントは、それらの属性を'counter-reset' プロパティに対する表示上のヒントとして扱うため、
次の手順を使用することが期待される:
value を null とする。
要素が start 属性を
持つ場合、value を、その属性値を整数を構文解析する規則を使用して構文解析した
結果に設定する。
要素が reversed
属性を持つ場合:
value が整数である場合、value を 1 増加させ、
reversed(list-item) value を返す。
それ以外の場合、reversed(list-item) を返す。
start
属性が存在しなかったか、その値の構文解析でエラーが発生した。
それ以外の場合:
value が整数である場合、value を 1 減少させ、
list-item value を返す。
それ以外の場合、表示上のヒントは存在しない。
@namespace "http://www.w3.org/1999/xhtml" ;
table { display : table; }
caption { display : table-caption; }
colgroup, colgroup[hidden] { display : table-column-group; }
col, col[hidden] { display : table-column; }
thead, thead[hidden] { display : table-header-group; }
tbody, tbody[hidden] { display : table-row-group; }
tfoot, tfoot[hidden] { display : table-footer-group; }
tr, tr[hidden] { display : table-row; }
td, th { display : table-cell; }
colgroup[hidden], col[hidden], thead[hidden], tbody[hidden],
tfoot[hidden], tr[hidden] {
visibility : collapse;
}
table {
box-sizing : border-box;
border-spacing : 2 px ;
border-collapse : separate;
text-indent : initial;
}
td, th { padding : 1 px ; }
th { font-weight : bold; }
caption { text-align : center; }
thead, tbody, tfoot, table > tr { vertical-align : middle; }
tr, td, th { vertical-align : inherit; }
thead, tbody, tfoot, tr { border-color : inherit; }
table[rules=none i], table[rules=groups i], table[rules=rows i],
table[rules=cols i], table[rules=all i], table[frame=void i],
table[frame=above i], table[frame=below i], table[frame=hsides i],
table[frame=lhs i], table[frame=rhs i], table[frame=vsides i],
table[frame=box i], table[frame=border i],
table[rules=none i] > tr > td, table[rules=none i] > tr > th,
table[rules=groups i] > tr > td, table[rules=groups i] > tr > th,
table[rules=rows i] > tr > td, table[rules=rows i] > tr > th,
table[rules=cols i] > tr > td, table[rules=cols i] > tr > th,
table[rules=all i] > tr > td, table[rules=all i] > tr > th,
table[rules=none i] > thead > tr > td, table[rules=none i] > thead > tr > th,
table[rules=groups i] > thead > tr > td, table[rules=groups i] > thead > tr > th,
table[rules=rows i] > thead > tr > td, table[rules=rows i] > thead > tr > th,
table[rules=cols i] > thead > tr > td, table[rules=cols i] > thead > tr > th,
table[rules=all i] > thead > tr > td, table[rules=all i] > thead > tr > th,
table[rules=none i] > tbody > tr > td, table[rules=none i] > tbody > tr > th,
table[rules=groups i] > tbody > tr > td, table[rules=groups i] > tbody > tr > th,
table[rules=rows i] > tbody > tr > td, table[rules=rows i] > tbody > tr > th,
table[rules=cols i] > tbody > tr > td, table[rules=cols i] > tbody > tr > th,
table[rules=all i] > tbody > tr > td, table[rules=all i] > tbody > tr > th,
table[rules=none i] > tfoot > tr > td, table[rules=none i] > tfoot > tr > th,
table[rules=groups i] > tfoot > tr > td, table[rules=groups i] > tfoot > tr > th,
table[rules=rows i] > tfoot > tr > td, table[rules=rows i] > tfoot > tr > th,
table[rules=cols i] > tfoot > tr > td, table[rules=cols i] > tfoot > tr > th,
table[rules=all i] > tfoot > tr > td, table[rules=all i] > tfoot > tr > th {
border-color : black;
} 次の規則も、表示上のヒントとして適用されることが期待される:
@namespace "http://www.w3.org/1999/xhtml" ;
table[align=left i] { float : left; }
table[align=right i] { float : right; }
table[align=center i] { margin-inline : auto; }
thead[align=absmiddle i], tbody[align=absmiddle i], tfoot[align=absmiddle i],
tr[align=absmiddle i], td[align=absmiddle i], th[align=absmiddle i] {
text-align : center;
}
caption[align=bottom i] { caption-side : bottom; }
p[align=left i], h1[align=left i], h2[align=left i], h3[align=left i],
h4[align=left i], h5[align=left i], h6[align=left i] {
text-align : left;
}
p[align=right i], h1[align=right i], h2[align=right i], h3[align=right i],
h4[align=right i], h5[align=right i], h6[align=right i] {
text-align : right;
}
p[align=center i], h1[align=center i], h2[align=center i], h3[align=center i],
h4[align=center i], h5[align=center i], h6[align=center i] {
text-align : center;
}
p[align=justify i], h1[align=justify i], h2[align=justify i], h3[align=justify i],
h4[align=justify i], h5[align=justify i], h6[align=justify i] {
text-align : justify;
}
thead[valign=top i], tbody[valign=top i], tfoot[valign=top i],
tr[valign=top i], td[valign=top i], th[valign=top i] {
vertical-align : top;
}
thead[valign=middle i], tbody[valign=middle i], tfoot[valign=middle i],
tr[valign=middle i], td[valign=middle i], th[valign=middle i] {
vertical-align : middle;
}
thead[valign=bottom i], tbody[valign=bottom i], tfoot[valign=bottom i],
tr[valign=bottom i], td[valign=bottom i], th[valign=bottom i] {
vertical-align : bottom;
}
thead[valign=baseline i], tbody[valign=baseline i], tfoot[valign=baseline i],
tr[valign=baseline i], td[valign=baseline i], th[valign=baseline i] {
vertical-align : baseline;
}
td[nowrap], th[nowrap] { white-space : nowrap; }
table[rules=none i], table[rules=groups i], table[rules=rows i],
table[rules=cols i], table[rules=all i] {
border-style : hidden;
border-collapse : collapse;
}
table[border] { border-style : outset; } /* border がゼロと等価でない場合のみ */
table[frame=void i] { border-style : hidden; }
table[frame=above i] { border-style : outset hidden hidden hidden; }
table[frame=below i] { border-style : hidden hidden outset hidden; }
table[frame=hsides i] { border-style : outset hidden outset hidden; }
table[frame=lhs i] { border-style : hidden hidden hidden outset; }
table[frame=rhs i] { border-style : hidden outset hidden hidden; }
table[frame=vsides i] { border-style : hidden outset; }
table[frame=box i], table[frame=border i] { border-style : outset; }
table[border] > tr > td, table[border] > tr > th,
table[border] > thead > tr > td, table[border] > thead > tr > th,
table[border] > tbody > tr > td, table[border] > tbody > tr > th,
table[border] > tfoot > tr > td, table[border] > tfoot > tr > th {
/* border がゼロと等価でない場合のみ */
border-width : 1 px ;
border-style : inset;
}
table[rules=none i] > tr > td, table[rules=none i] > tr > th,
table[rules=none i] > thead > tr > td, table[rules=none i] > thead > tr > th,
table[rules=none i] > tbody > tr > td, table[rules=none i] > tbody > tr > th,
table[rules=none i] > tfoot > tr > td, table[rules=none i] > tfoot > tr > th,
table[rules=groups i] > tr > td, table[rules=groups i] > tr > th,
table[rules=groups i] > thead > tr > td, table[rules=groups i] > thead > tr > th,
table[rules=groups i] > tbody > tr > td, table[rules=groups i] > tbody > tr > th,
table[rules=groups i] > tfoot > tr > td, table[rules=groups i] > tfoot > tr > th,
table[rules=rows i] > tr > td, table[rules=rows i] > tr > th,
table[rules=rows i] > thead > tr > td, table[rules=rows i] > thead > tr > th,
table[rules=rows i] > tbody > tr > td, table[rules=rows i] > tbody > tr > th,
table[rules=rows i] > tfoot > tr > td, table[rules=rows i] > tfoot > tr > th {
border-width : 1 px ;
border-style : none;
}
table[rules=cols i] > tr > td, table[rules=cols i] > tr > th,
table[rules=cols i] > thead > tr > td, table[rules=cols i] > thead > tr > th,
table[rules=cols i] > tbody > tr > td, table[rules=cols i] > tbody > tr > th,
table[rules=cols i] > tfoot > tr > td, table[rules=cols i] > tfoot > tr > th {
border-width : 1 px ;
border-block-style : none;
border-inline-style : solid;
}
table[rules=all i] > tr > td, table[rules=all i] > tr > th,
table[rules=all i] > thead > tr > td, table[rules=all i] > thead > tr > th,
table[rules=all i] > tbody > tr > td, table[rules=all i] > tbody > tr > th,
table[rules=all i] > tfoot > tr > td, table[rules=all i] > tfoot > tr > th {
border-width : 1 px ;
border-style : solid;
}
table[rules=groups i] > colgroup {
border-inline-width : 1 px ;
border-inline-style : solid;
}
table[rules=groups i] > thead,
table[rules=groups i] > tbody,
table[rules=groups i] > tfoot {
border-block-width : 1 px ;
border-block-style : solid;
}
table[rules=rows i] > tr, table[rules=rows i] > thead > tr,
table[rules=rows i] > tbody > tr, table[rules=rows i] > tfoot > tr {
border-block-width : 1 px ;
border-block-style : solid;
} @namespace "http://www.w3.org/1999/xhtml" ;
table {
font-weight : initial;
font-style : initial;
font-variant : initial;
font-size : initial;
line-height : initial;
white-space : initial;
text-align : initial;
} CSS 表モデルの目的では、col 要素は、その span 属性が指定する回数だけ存在するかのように扱われることが
期待される。
CSS 表モデルの目的では、colgroup 要素が
col 要素を含まない場合、
その span 属性が指定する数だけ、そのような子を持つかのように
扱われることが期待される。
CSS 表モデルの目的では、td および th 要素上の colspan 属性と
rowspan 属性は、
行および列にまたがるセルに関する特別な知識を提供することが期待される。
@namespace "http://www.w3.org/1999/xhtml" ;
:is(table, thead, tbody, tfoot, tr) > form { display : none !important; }table 要素の cellspacing 属性は、
要素上の'border-spacing' ピクセル長
プロパティへ対応付けられる。
table 要素の cellpadding 属性は、
table 要素に対応する表内に対応するセルを持つすべての td および
th 要素の
'padding-top'、'padding-right'、
'padding-bottom'、および 'padding-left'
ピクセル長
プロパティへ対応付けられる。
table 要素の height 属性は、table 要素上の'height' 寸法プロパティへ対応付けられる。
table 要素の width 属性は、table 要素上の
'width' 寸法プロパティへ対応付けられる
(ゼロを無視)。
col 要素の width 属性は、col 要素上の'width' 寸法プロパティへ対応付けられる。
thead、tbody、および tfoot 要素の height 属性は、要素上の
'height' 寸法プロパティへ対応付けられる。
tr 要素の height 属性は、tr 要素上の'height' 寸法プロパティへ対応付けられる。
td および th 要素の height 属性は、要素上の
'height' 寸法プロパティへ対応付けられる
(ゼロを無視)。
td および th 要素の width 属性は、要素上の
'width' 寸法プロパティへ対応付けられる
(ゼロを無視)。
thead、tbody、tfoot、tr、
td、および th 要素が、その値が文字列
「center」または文字列「middle」のいずれかとASCII
大文字・小文字を区別せず一致する
align 属性を持つ場合、その要素は、自身の内部のテキストを中央揃えにし、
'text-align' プロパティが表示上のヒントで 'center' に設定されているかのように
動作し、かつ子孫を中央へ整列することが期待される。
thead、tbody、tfoot、tr、
td、および th 要素が、その値が文字列
「left」とASCII
大文字・小文字を区別せず一致する
align 属性を持つ場合、その要素は、自身の内部のテキストを左揃えにし、
'text-align' プロパティが表示上のヒントで 'left' に設定されているかのように動作し、
かつ子孫を左へ整列することが期待される。
thead、tbody、tfoot、tr、
td、および th 要素が、その値が文字列
「right」とASCII
大文字・小文字を区別せず一致する
align 属性を持つ場合、その要素は、自身の内部のテキストを右揃えにし、
'text-align' プロパティが表示上のヒントで 'right' に設定されているかのように動作し、
かつ子孫を右へ整列することが期待される。
thead、tbody、tfoot、tr、
td、および th 要素が、その値が文字列
「justify」とASCII
大文字・小文字を区別せず一致する
align 属性を持つ場合、その要素は、自身の内部のテキストを両端揃えにし、
'text-align' プロパティが表示上のヒントで 'justify' に設定されているかのように
動作し、かつ子孫を左へ整列することが期待される。
ユーザーエージェントは、親ノードの算出値において、'text-align'
プロパティが初期値である th 要素に一致し、
'text-align' プロパティを 'center' へ設定する単一の宣言だけから
宣言ブロックが構成される規則を、ユーザーエージェントスタイルシートに持つことが期待される。
table、thead、tbody、tfoot、
tr、td、または th 要素の background 属性が空でない値へ
設定された場合、新しい値を要素のノード文書を基準としてエンコーディングを考慮して構文解析および
シリアライズすることが期待される。
それが失敗を返さない場合、ユーザーエージェントは、その属性を要素の'background-image' プロパティを返された値へ設定する表示上のヒントとして
扱うことが期待される。
table、thead、tbody、tfoot、
tr、td、または th 要素が bgcolor
属性を持つ場合、新しい値を従来の色値を構文解析する規則を使用して
構文解析することが期待される。
それが失敗を返さない場合、ユーザーエージェントは、その属性を要素の'background-color' プロパティを結果の色へ設定する表示上のヒントとして
扱うことが期待される。
table 要素が bordercolor 属性を
持つ場合、その値を従来の色値を構文解析する
規則を使用して構文解析することが期待される。それが失敗を返さない場合、
ユーザーエージェントは、その属性を要素の'border-top-color'、
'border-right-color'、'border-bottom-color'、および
'border-left-color' プロパティを結果の色へ設定する表示上のヒントとして
扱うことが期待される。
table 要素の border 属性は、
要素上の'border-top-width'、'border-right-width'、
'border-bottom-width'、および 'border-left-width' ピクセル長プロパティへ対応付けられる。
属性が存在するが、その属性値を非負整数を構文解析する規則を使用して
構文解析するとエラーが生成される場合、代わりにそのプロパティへ既定値 1px を使用することが
期待される。
上の CSS ブロックで「border がゼロと等価でない場合のみ」と
記された規則は、その規則のセレクターで言及される border
属性が存在するだけでなく、
非負整数を構文解析する規則を使用して
構文解析したとき、値がゼロ以外であるか、エラーが生成される場合にのみ適用されることが期待される。
互換モードでは、nowrap 属性を持つが、
ゼロでない寸法値を構文解析する規則を
使用して構文解析したとき、その値が長さである
(エラーでもパーセンテージとして分類される数値でもない)width
属性も持つ
td 要素または th 要素は、上の CSS ブロックで
'nowrap' へ設定する規則を上書きして、要素の'white-space'
プロパティを 'normal' へ設定する表示上のヒントを持つことが期待される。
ノードが要素間空白でないテキストノードであるか、 要素ノードである場合、そのノードは実質的である。
ノードが実質的なノードを含まない要素である場合、 そのノードは空白である。
既定のマージンを持つ要素は、次の要素である:
blockquote、
dir、dl、
h1、
h2、
h3、
h4、
h5、
h6、
listing、menu、ol、
p、plaintext、pre、ul、xmp。
互換モードでは、body、td、または th 要素の子であり、
先行する実質的な兄弟を持たない既定のマージンを持つ要素は、
その'margin-block-start' プロパティをゼロへ設定する
ユーザーエージェントレベルのスタイルシート規則を持つことが期待される。
互換モードでは、body、td、または th 要素の子であり、
先行する実質的な兄弟を持たず、かつ
空白である既定のマージンを持つ要素は、
その'margin-block-end' プロパティもゼロへ設定する
ユーザーエージェントレベルのスタイルシート規則を持つことが期待される。
互換モードでは、td または th 要素の子であり、
後続の実質的な兄弟を持たず、かつ
空白である既定のマージンを持つ要素は、
その'margin-block-start' プロパティをゼロへ設定する
ユーザーエージェントレベルのスタイルシート規則を持つことが期待される。
互換モードでは、td または th 要素の子であり、後続の実質的な兄弟を持たない p 要素は、その
'margin-block-end' プロパティをゼロへ設定する
ユーザーエージェントレベルのスタイルシート規則を持つことが期待される。
@namespace "http://www.w3.org/1999/xhtml" ;
input, button, textarea {
letter-spacing : initial;
word-spacing : initial;
line-height : initial;
}
input, select, button, textarea {
text-transform : initial;
text-indent : initial;
text-shadow : initial;
appearance : auto;
}
input:not([type=range i], [type=checkbox i], [type=radio i]) {
overflow : clip !important;
overflow-clip-margin: 0 !important;
}
input[type=image i] {
overflow-clip-margin: content-box !important;
}
input, select, textarea {
text-align: initial;
}
:autofill {
field-sizing: fixed !important;
}
input:is([type=reset i], [type=button i], [type=submit i]), button {
text-align: center;
}
input, button {
display: inline-block;
}
input[type=hidden i], input[type=file i], input[type=image i] {
appearance: none;
}
input:is([type=radio i], [type=checkbox i], [type=reset i], [type=button i],
[type=submit i], [type=color i], [type=search i]), select, button {
box-sizing: border-box;
}
textarea { white-space: pre-wrap; }@namespace "http://www.w3.org/1999/xhtml" ;
input:not([type=image i]), textarea { box-sizing : border-box; } 各種類のフォームコントロールは、コントロールの外観と操作感を説明する「ウィジェット」の節でも説明される。
type 属性が 状態でも
Image Button
状態でもなく、かつ
レンダリングされている input 要素は、次のように
動作することが期待される:
内部表示型は常に 'flow-root' である。
hr 要素@namespace "http://www.w3.org/1999/xhtml" ;
hr {
color : gray;
border-style : inset;
border-width : 1 px ;
margin-block : 0.5 em ;
margin-inline : auto;
overflow : hidden;
} 次の規則も、表示上のヒントとして適用されることが期待される:
@namespace "http://www.w3.org/1999/xhtml" ;
hr[align=left i] { margin-left : 0 ; margin-right : auto; }
hr[align=right i] { margin-left : auto; margin-right : 0 ; }
hr[align=center i] { margin-left : auto; margin-right : auto; }
hr[color], hr[noshade] { border-style : solid; } hr 要素が color 属性または noshade 属性のいずれかを持ち、
さらに size 属性も持ち、
その属性値を非負整数を構文解析する規則を使用して
構文解析してもエラーが生成されない場合、ユーザーエージェントは、構文解析された値を 2 で
除算した値を、要素上の'border-top-width'、
'border-right-width'、'border-bottom-width'、および
'border-left-width' プロパティに対する表示上のヒントの
ピクセル長として使用することが期待される。
それ以外で、hr 要素が color 属性も noshade 属性も持たないが、
size 属性を持ち、その属性値を
非負整数を構文解析する規則を使用して
構文解析してもエラーが生成されない場合、構文解析された値が 1 なら、ユーザーエージェントは、
その属性を要素の'border-bottom-width' を 0 へ設定する表示上のヒントとして
使用することが期待される。
それ以外で、構文解析された値が 1 より大きい場合、ユーザーエージェントは、構文解析された値から
2 を減算した値を、要素上の'height' プロパティに対する表示上のヒントの
ピクセル長として使用することが期待される。
hr 要素上の width 属性は、要素上の
'width' 寸法プロパティへ対応付けられる。
hr 要素が color 属性を持つ場合、その値を
従来の色値を構文解析する規則を
使用して構文解析することが期待される。それが失敗を返さない場合、
ユーザーエージェントは、その属性を要素の'color' プロパティを結果の色へ設定する表示上のヒントとして
扱うことが期待される。
fieldset および
legend
要素
@namespace "http://www.w3.org/1999/xhtml" ;
fieldset {
display : block;
margin-inline : 2 px ;
border : groove 2 px ThreeDFace;
padding-block : 0.35 em 0.625 em ;
padding-inline : 0.75 em ;
min-inline-size : min-content;
}
legend {
padding-inline : 2 px ;
}
legend[align=left i] {
justify-self : left;
}
legend[align=center i] {
justify-self : center;
}
legend[align=right i] {
justify-self : right;
} fieldset
要素がCSS ボックスを
生成する場合、次のように動作することが期待される:
要素は新しいブロック整形 コンテキストを確立することが期待される。
'display' プロパティは、次のように動作することが期待される:
これは算出値を変更しない。
要素のボックスが次の一覧の条件に一致する子ボックスを持つ場合、最初のそのような 子ボックスが 'fieldset' 要素のレンダリングされた凡例となる:
legend
要素である。要素がレンダリングされた凡例を持つ場合、 fieldset の書字モードを使用して次のように定義される長方形の背後には、境界線を描画しないことが 期待される:
長方形のブロック始端辺は、静的位置にあるレンダリングされた凡例の
マージン長方形のブロック始端辺(変形を無視)と、fieldset
の境界線のブロック始端外辺のうち、小さい方である。
長方形のブロック終端辺は、静的位置にあるレンダリングされた凡例の
マージン長方形のブロック終端辺(変形を無視)と、fieldset
の境界線のブロック終端外辺のうち、大きい方である。
長方形のインライン始端辺は、静的位置にあるレンダリングされた凡例の
境界長方形のインライン始端辺(変形を無視)と、fieldset
の境界線のインライン始端外辺のうち、小さい方である。
長方形のインライン終端辺は、静的位置にあるレンダリングされた凡例の
境界長方形のインライン終端辺(変形を無視)と、fieldset
の境界線のインライン終端外辺のうち、大きい方である。
ブロック始端側で要素の境界線に割り当てられる空間は、要素の'border-block-start-width' または
fieldset
のブロックフロー方向におけるレンダリングされた凡例の
マージンボックスサイズのうち、大きい方であることが期待される。
使用される'block-size'を計算する目的で、算出された 'block-size' が 'auto' でない場合、レンダリングされた 凡例のマージンボックスのうち、存在する場合に境界線を越えてはみ出す部分へ割り当てられた 空間を、'block-size' から減算することが期待される。コンテンツボックスの ブロックサイズが負になる場合、代わりにコンテンツボックスのブロックサイズを 0 とする。
要素がレンダリングされた凡例を持つ場合、 その要素が最初の子ボックスとなることが期待される。
匿名 fieldset コンテンツ
ボックスは、レンダリングされた凡例の後に
現れることが期待され、fieldset
要素の内容('::before' および '::after' 疑似要素を含む)から、存在する場合のレンダリングされた凡例を除いたものを
含むことが期待される。
'padding-top'、'padding-right'、 'padding-bottom'、および 'padding-left' プロパティの使用値は、ゼロであることが期待される。
最小コンテンツインラインサイズを計算する目的では、レンダリングされた凡例の 最小コンテンツインラインサイズと、匿名 fieldset コンテンツ ボックスの最小コンテンツインラインサイズのうち、大きい方を使用する。
最大コンテンツインラインサイズを計算する目的では、レンダリングされた凡例の 最大コンテンツインラインサイズと、匿名 fieldset コンテンツ ボックスの最大コンテンツインラインサイズのうち、大きい方を使用する。
fieldset
要素のレンダリングされた凡例が存在する場合、
次のように動作することが期待される:
要素は、その内容のために新しい整形コンテキストを確立することが期待される。 この整形コンテキストの型は、通常どおり、その 'display' 値によって決定される。
'display' プロパティは、その算出値がブロック化されたかのように 動作することが期待される。
これは算出値を変更しない。
'inline-size' の算出値が 'auto' である場合、使用値は内容に合わせたインラインサイズとなる。
要素は、ブロックに対して通常行われるように、インライン方向へ配置されることが期待される (たとえば、マージンおよび'justify-self' プロパティを考慮する)。
要素のボックスは、算出されたインラインパディングを使用したかのように、fieldset
のインラインコンテンツサイズによってインライン方向へ制約されることが期待される。
たとえば、fieldset
に 50px のパディングが指定されている場合、レンダリングされた凡例は、fieldset
の境界線から 50px 内側に配置される。そのパディングはさらに、fieldset
要素自体ではなく、匿名 fieldset コンテンツ
ボックスへ適用される。
要素は、その境界ボックスが fieldset
要素のブロック始端側の境界線上で中央に配置されるよう、ブロックフロー方向へ配置されることが
期待される。
fieldset
要素の匿名 fieldset コンテンツボックスは、
次のように動作することが期待される:
次のプロパティは、fieldset
要素から継承されることが期待される:
'block-size' プロパティは '100%' へ設定されることが期待される。
パーセンテージパディングを計算する目的では、そのパディングが fieldset
要素について計算されたかのように動作する。
次の要素は、置換
要素になり得る:audio、canvas、embed、iframe、
img、input、object、および video。
embed、
iframe、および
video 要素は、
期待される。置換
要素として扱われることが。
埋め込み
コンテンツを表す canvas
要素は、
期待される。置換
要素として扱われることが。そのような
要素の内容は、存在する場合は要素のビットマップであり、そうでない場合は、要素と同じ透明な
黒のビットマップであり、
要素と同じ自然な
寸法を持つ。その他の canvas
要素は、
期待される。レンダリングモデルにおける通常の要素として
扱われることが。
画像、プラグイン、またはその
コンテンツナビゲータブルを
表す object
要素は、期待される。置換
要素として扱われることが。その他の object
要素は、期待される。レンダリングモデルにおける
通常の要素として扱われることが。
audio
要素は、ユーザーインターフェイスを公開している場合、期待される。高さが約 1 行であり、
ユーザーエージェントのユーザーインターフェイス機能を公開するために必要な幅を持つ置換
要素として扱われることが。audio 要素が
ユーザーインターフェイスを公開していない場合、
ユーザーエージェントには、
期待される。CSS 規則にかかわらず、その「display」プロパティの算出値を「none」に強制することが。
video 要素が
ユーザーインターフェイスを公開しているかどうかは、
レンダリングの大きさに影響することは期待されない。コントロールには、レイアウト変更を生じさせずに
ページ内容の上に重ねて表示されることが期待されるほか、ユーザーが必要としないときには
消えることが期待される。
video 要素が
ポスターフレームまたは動画フレームを表す場合、そのポスターフレーム
または動画フレームには、そのポスターフレームまたは動画フレームの縦横比を維持しつつ、
video
要素自体より高くも幅広くもならない最大の大きさでレンダリングされることが期待されるほか、
video
要素内で中央に配置されることが期待される。
字幕またはキャプションには、関連するレンダリング規則で定義されるとおり、それらの
video
要素の真上に直接重ねて表示されることが期待される。WebVTT の場合、それらは
WebVTT
テキストトラックの表示を更新する規則である。[WEBVTT]
ユーザーエージェントが video 要素について
ユーザー
インターフェイスを公開し始めたとき、ユーザーエージェントは、video 要素の
テキストトラックのリスト
にある、表示中であり、
かつテキストトラックの種類が
subtitles
または captions
のいずれかである各テキスト
トラックについて、テキストトラックの
レンダリングを更新する規則を実行するべきである(たとえば、WebVTT に基づくテキスト
トラックの場合は、WebVTT
テキスト
トラックの表示を更新する規則)。[WEBVTT]
video および canvas
要素の大きさを変更しても、
動画の再生が中断されたり、キャンバスが消去されたりすることはない。
次の CSS 規則が適用されることが期待される:
@namespace "http://www.w3.org/1999/xhtml" ;
iframe { border : 2 px inset; }
video { object-fit : contain; } ユーザーエージェントには、img 要素および、
type 属性が
画像ボタン状態にある
input 要素を、
次の一覧のうち最初に適用可能な規則に従ってレンダリングすることが期待される:
input 要素については、その要素が
ボタンであることを示すため、ボタンのように
表示されることが期待される。
img 要素であり、
ユーザーエージェントがこれが変更されると予想していない場合img 要素であり、
ユーザーエージェントがこれが変更されると予想していない場合input
要素であり、ユーザーエージェントがこれが変更されると予想していない場合上記のアイコンには、ほとんどのテキストを乱さず、かつ容易にクリックできる程度に比較的小さいことが期待される。 たとえば視覚的環境では、アイコンは 16 ピクセル×16 ピクセルの正方形、または画像が拡大縮小可能なら 1em×1em とすることができる。音声環境では、アイコンを短いビープ音にすることができる。アイコンは、 ユーザーエージェントが画像について提供する任意の選択肢にアクセスするために使用できることを ユーザーに示すことを意図しており、適切な場合には、ユーザーが実際の画像と対話した場合に 表示されるコンテキストメニューへのアクセスを提供することが期待される。
同じ絶対 URLおよび同じ 画像データを持つすべてのアニメーション画像には、グループとして同じタイムラインに同期して レンダリングされることが期待される。その タイムラインは、グループへの最も古い追加時点から開始する。
言い換えると、同じ絶対 URLおよび アニメーション画像データを持つ 2 番目の画像が文書へ挿入された場合、その画像は、 最初の画像によって現在表示されているアニメーション周期内の位置へ移動する。
ユーザーエージェントが、アニメーション画像を表示している img
要素について
アニメーションを再開するとき、その img 要素のノード文書内で、同じ絶対 URLおよび
同じ画像データを持つすべてのアニメーション画像には、アニメーションを最初から再開することが
期待される。
次の CSS 規則が適用されることが期待される:
@namespace "http://www.w3.org/1999/xhtml" ;
img:is([sizes="auto" i], [sizes^="auto," i]) {
contain : size !important;
contain-intrinsic-size: 300px 150px;
}Document が
互換モードにある場合、次の CSS 規則が適用されることが期待される:
@namespace "http://www.w3.org/1999/xhtml" ;
img[align=left i] { margin-right : 3 px ; }
img[align=right i] { margin-left : 3 px ; } 次の CSS 規則が、表示上の ヒントとして適用されることが期待される:
@namespace "http://www.w3.org/1999/xhtml" ;
embed[align=left i], iframe[align=left i], img[align=left i],
input[type=image i][align=left i], object[align=left i] {
float : left;
}
embed[align=right i], iframe[align=right i], img[align=right i],
input[type=image i][align=right i], object[align=right i] {
float : right;
}
embed[align=top i], iframe[align=top i], img[align=top i],
input[type=image i][align=top i], object[align=top i] {
vertical-align : top;
}
embed[align=baseline i], iframe[align=baseline i], img[align=baseline i],
input[type=image i][align=baseline i], object[align=baseline i] {
vertical-align : baseline;
}
embed[align=texttop i], iframe[align=texttop i], img[align=texttop i],
input[type=image i][align=texttop i], object[align=texttop i] {
vertical-align : text-top;
}
embed[align=absmiddle i], iframe[align=absmiddle i], img[align=absmiddle i],
input[type=image i][align=absmiddle i], object[align=absmiddle i],
embed[align=abscenter i], iframe[align=abscenter i], img[align=abscenter i],
input[type=image i][align=abscenter i], object[align=abscenter i] {
vertical-align : middle;
}
embed[align=bottom i], iframe[align=bottom i], img[align=bottom i],
input[type=image i][align=bottom i], object[align=bottom i] {
vertical-align : bottom;
} embed、
iframe、
img、
または object
要素、あるいは type
属性が画像ボタン状態にある input
要素に、その値が文字列「center」または文字列「middle」とASCII
大文字・小文字を区別しない一致となる
align 属性がある場合、ユーザー
エージェントには、要素の「vertical-align」プロパティが、
要素の垂直方向の中央を親要素のベースラインに揃える値に設定されたかのように動作することが
期待される。
embed、
img、
または object
要素、および type
属性が画像
ボタン状態にある input
要素の hspace 属性は、要素上の寸法プロパティ 「margin-left」 および
「margin-right」
へ対応付けられる。
embed、
img、
または object
要素、および type
属性が画像
ボタン状態にある input
要素の vspace 属性は、要素上の寸法プロパティ 「margin-top」 および 「margin-bottom」へ対応付けられる。
iframe
要素に frameborder
属性があり、その値を整数の構文解析規則を使用して
構文解析した結果が 0 またはエラーである場合、ユーザーエージェントには、要素の
「border-top-width」、「border-right-width」、
「border-bottom-width」、および 「border-left-width」プロパティを 0 に設定する表示上の
ヒントを持つことが期待される。
img
要素、object
要素、または
type
属性が画像ボタン状態にある input
要素に border 属性があり、その値を非負整数の
構文解析規則を使用して構文解析した結果、0 より大きい数値であることが判明した場合、ユーザーエージェントには、
構文解析された値を 8 個の表示上のヒントに使用することが
期待される。そのうち 4 個は、
構文解析された値をピクセル長として、要素の「border-top-width」、
「border-right-width」、「border-bottom-width」、および
「border-left-width」プロパティに設定し、残りの 4 個は、要素の
「border-top-style」、「border-right-style」、
「border-bottom-style」、および 「border-left-style」プロパティを値
「solid」に設定する。
width 属性および
height
属性は、img
要素の寸法属性
ソース上で、img
要素の寸法プロパティ
「width」および 「height」へそれぞれ対応付けられる。同様に、
これらは img 要素の
aspect-ratio
プロパティへも対応付けられる(寸法規則を使用)。
embed、
iframe、
object、
および video
要素、ならびに type
属性が画像ボタン状態にあり、
画像を表すか、最終的に画像を表すことをユーザーが期待する input
要素上の width 属性および
height 属性は、要素上の寸法プロパティ
「width」および 「height」へそれぞれ対応付けられる。
width
属性および
height
属性は、img
および video
要素、ならびに type
属性が画像
ボタン状態にある input
要素上のaspect-ratio
プロパティへ対応付けられる(寸法規則を使用)。
width
属性および height
属性は、canvas
要素上のaspect-ratio
プロパティへ対応付けられる。
イメージマップ上の図形には、CSS カスケードの目的上、
元の area 要素とは独立した
要素として動作し、偶然同じスタイル規則に一致するものの、img または
object
要素から継承することが期待される。
レンダリングの目的では、「cursor」プロパティだけが 図形に何らかの効果を持つことが期待される。
したがって、たとえば area
要素に、「cursor」プロパティを「help」に設定する style 属性がある場合、
ユーザーがその図形を指し示すと、カーソルはヘルプカーソルへ変化する。
同様に、area 要素に、その
「cursor」プロパティを「inherit」に設定する CSS 規則がある場合
(または、「cursor」
プロパティを設定する規則が要素にまったく一致しない場合)、図形のカーソルは、
img または object 要素から継承され、
イメージマップの area 要素の親からは継承されない。
CSS 基本ユーザーインターフェイス仕様は、ネイティブ外観を持ち得る要素をウィジェットと呼び、「appearance」 プロパティに応じて、そのネイティブ 外観を使用するかどうかを定義する。その論理はさらに、各要素が退化可能な ウィジェットまたは退化不可能な ウィジェットのどちらに分類されるかに依存する。この節では、HTML においてどの要素が これらの概念に一致するか、それらのネイティブ 外観が何であるか、およびそれらの退化した状態またはプリミティブ 外観の特殊性を定義する。 [CSSUI]
次の要素は、CSS の 「appearance」プロパティの目的上、ネイティブ 外観を持ち得る。
いくつかのウィジェットは、そのレンダリングが 「writing-mode」 CSS プロパティによって制御される。これらのウィジェットの目的上、次の定義を用いる。
横書きモードとは、コントロールの「writing-mode」 プロパティを解決した結果、算出値が「horizontal-tb」になる場合である。
縦書きモードとは、コントロールの「writing-mode」プロパティを解決した結果、 算出値が「vertical-rl」、「vertical-lr」、「sideways-rl」、 または「sideways-lr」のいずれかになる場合である。
要素がボタンレイアウトを使用する場合、 それは退化可能なウィジェットであり、そのネイティブ外観はボタンの外観である。
ボタンレイアウトは次のとおりである:
要素には、その内容のために新しい整形コンテキストを確立することが期待される。 この整形コンテキストの型は、通常どおり、その 「display」値によって決まる。
要素が絶対配置されている場合、 CSS 視覚整形モデルの目的上、その要素が置換 要素であるかのように動作する。[CSS]
「inline-size」の算出値が「auto」である場合、 使用値はfit-content インラインサイズである。
「align-self」プロパティの「normal」キーワードの目的上、 要素が置換要素であるかのように動作する。
要素が input
要素である場合、または button
要素であり、
かつその 「display」の
算出値が「inline-grid」、「grid」、「inline-flex」、
または「flex」ではない場合、要素のボックスは、次の動作を持つ子の 匿名ボタン内容
ボックスを持つ:
このボックスは、ブロックレベルのブロック コンテナーであり、新しいブロック整形コンテキストを確立する(すなわち、「display」は 「flow-root」である)。
ボックスが水平方向の軸でオーバーフローしない場合、水平に中央揃えされる。
ボックスが垂直方向の軸でオーバーフローしない場合、垂直に中央揃えされる。
それ以外の場合、匿名ボタン内容ボックスは存在しない。
プリミティブ 外観を定義する必要がある。
button 要素button 要素が
CSS ボックスを生成する場合、ボタンを描写し、ボタンレイアウトを使用することが
期待される。その匿名ボタン
内容ボックスの内容(匿名ボタン
内容ボックスがある場合)は、そうでなければ要素のボックスが持つことになる子ボックスである。
details および
summary
要素
@namespace "http://www.w3.org/1999/xhtml" ;
details, summary {
display : block;
}
details > summary:first-of-type {
display : list-item;
counter-increment : list-item 0 ;
list-style : disclosure-closed inside;
}
details[open] > summary:first-of-type {
list-style-type : disclosure-open;
} details
要素には、3 個の子要素を持つ内部シャドウ
ツリーがあることが期待される:
最初の子要素は、details
要素の最初の summary
要素の子が存在する場合に、それを受け取ることが期待される slot である。
この要素には、既定の要約と呼ばれる単一の子 summary
要素があり、そのテキスト内容は実装定義である(おそらくロケール固有でもある)。
2 番目の子要素は、details
要素の残りの子孫が存在する場合に、それらを受け取ることが期待される slot である。
この要素には内容がない。
この要素には、「::details-content」 擬似要素に一致することが期待される。
details
要素に open
属性がない場合、この要素には、その style
属性を「display: block; content-visibility: hidden;」に設定することが期待される。open
属性がある場合、style 属性には
「display: block;」に設定されることが期待される。
スロットはシャドウツリー内に隠されているため、この style 属性は
作者のコードから直接は見えない。ただし、その影響は見える。特に、
display: none などの代わりに content-visibility: hidden を
選択することは、レイアウト情報を問い合わせるさまざまな API の結果に影響する。
3 番目の子要素は、既定の要約について次のスタイルを持つ link または
style
要素のいずれかである:
:host summary {
display : list-item;
counter-increment : list-item 0 ;
list-style : disclosure-closed inside;
}
:host([open]) summary {
list-style-type : disclosure-open;
} 他の 2 個に対するこの子要素の相対位置は観測できない。 これは、実装が兄弟に対して異なる順序でこれを配置してもよいことを意味する。 実装は、要素ではない機構を使用してスタイルをシャドウツリーへ関連付けてもよい。
このシャドウツリーの構造は、details
要素の子および「::details-content」擬似要素が
CSS スタイルに応答する方法を通じて観測できる。
input
要素
type
属性が、
Text、
Telephone、URL、または
Email 状態にある input
要素は、退化可能なウィジェットである。
その
ネイティブ
外観には、1 行のテキストコントロールを描写する
「inline-block」
ボックスとしてレンダリングされることが期待される。
type
属性が、
Search
状態にある input
要素は、退化可能なウィジェットである。
そのネイティブ
外観には、1 行のテキストコントロールを描写する
「inline-block」
ボックスとしてレンダリングされることが期待される。要素の「appearance」
プロパティの算出
値が 「textfield」ではない場合、
それが検索フィールドであることを示す固有のスタイルを持ってもよい。
type
属性が、
Password 状態にある input
要素は、退化可能な
ウィジェットである。そのネイティブ
外観には、データ入力を隠す 1 行のテキストコントロールを描写する
「inline-block」
ボックスとしてレンダリングされることが期待される。
type
属性が上記の状態のいずれかにある input
要素について、「line-height」プロパティの使用値は、
「line-height: normal」の使用値となる値以上の長さ値でなければならない。
使用値は、 実際のキーワード「normal」にはならない。また、この 規則は算出値には影響しない。
これらのテキストコントロールがテキスト選択を提供する場合、ユーザーが現在の
選択を変更したとき、ユーザーエージェントには、input
要素を与えて、ユーザー操作タスクソース上で
要素タスクをキューに入れ、
要素において select
という名前のイベントを発火し、bubbles
属性を true に初期化することが期待される。
type
属性が上記の状態のいずれかにある input
要素は、既定の優先サイズを持つ要素であり、ユーザー
エージェントには、「field-sizing」 CSS
プロパティを要素に適用することが期待される。ユーザーエージェントには、その
内在サイズのインラインサイズを
次の手順で決定することが期待される:
要素上の「field-sizing」プロパティの算出
値が「content」である場合、インラインサイズは、
要素が表示するテキストによって決定される。テキストは、
値、または
placeholder
属性で指定される短いヒントのいずれかである。ユーザーエージェントは、
インライン
サイズにテキストキャレットの大きさを考慮してもよい。
要素に size
属性があり、その属性値を非負整数の
構文解析規則を使用して構文解析しても
エラーが生成されない場合、属性の値に文字幅を
ピクセルへ変換するアルゴリズムを適用して得られた値を返す。
それ以外の場合、数値 20 に文字幅を ピクセルへ 変換するアルゴリズムを適用して得られた値を返す。
文字幅をピクセルへ変換するアルゴリズムは、 (size-1)×avg + maxを返す。 ここで size は変換する文字幅、avg はアルゴリズムの実行対象となる要素の 基本フォントの平均文字幅(ピクセル単位)、max は同じフォントの最大文字幅(同じく ピクセル単位)である。(要素の「letter-spacing」プロパティは結果に影響しない。)
これらのテキストコントロールには、スクロール コンテナーであり、インライン軸ではスクロールを サポートするが、ブロック 軸ではサポートしないことが期待される。
ネイティブ 外観およびプリミティブ 外観を詳しく定義する必要がある。
input
要素
type
属性が
Date 状態にある input
要素は、日付コントロールを描写する
「inline-block」
ボックスとしてレンダリングされることが期待される
退化可能なウィジェットである。
type
属性が
Month 状態にある input
要素は、月コントロールを描写する
「inline-block」
ボックスとしてレンダリングされることが期待される
退化可能なウィジェットである。
type
属性が
Week 状態にある input
要素は、週コントロールを描写する
「inline-block」
ボックスとしてレンダリングされることが期待される
退化可能なウィジェットである。
type
属性が
Time 状態にある input
要素は、時刻コントロールを描写する
「inline-block」
ボックスとしてレンダリングされることが期待される
退化可能なウィジェットである。
type
属性が
ローカルの日付と
時刻状態にある input
要素は、ローカルの日付と時刻のコントロールを描写する
「inline-block」
ボックスとしてレンダリングされることが期待される
退化可能なウィジェットである。
type
属性が
Number 状態にある input
要素は、数値
コントロールを描写する
「inline-block」
ボックスとしてレンダリングされることが期待される
退化可能なウィジェットである。
type
属性が
Number 状態にある input
要素は、既定の優先サイズを持つ要素であり、ユーザーエージェントには
「field-sizing」 CSS
プロパティを要素に適用することが期待される。内在サイズのブロックサイズは
高さがおよそ 1 行である。要素上の「field-sizing」プロパティの算出値が
「content」である場合、
内在サイズのインラインサイズには、
現在の値を表示するために必要な程度の
幅であることが期待される。
それ以外の場合、内在サイズのインラインサイズには、
可能な最も幅広い値を表示するために必要な程度の幅であることが期待される。
type
属性が、
Date、
Month、
Week、Time、
またはローカルの日付
と時刻状態にある input
要素には、高さがおよそ 1 行であり、可能な最も幅広い値を表示するために必要な程度の幅であることが
期待される。
ネイティブ 外観およびプリミティブ 外観を詳しく定義する必要がある。
input 要素type 属性が
Range
状態にある input
要素は、退化不可能な
ウィジェットである。そのネイティブ
外観には、スライダーコントロールを描写する
「inline-block」
ボックスとしてレンダリングされることが期待される。
このコントロールが横書きモードを持つ場合、 コントロールには水平スライダーであることが期待される。その 「direction」 プロパティの算出値が 「rtl」である場合、最小値は右側にあり、それ以外の場合は左側にある。このコントロールが縦書きモードを持つ場合、 垂直スライダーであることが期待される。その 「direction」 プロパティの算出値が 「rtl」である場合、最小値は下側にあり、それ以外の場合は上側にある。
list
属性によって提供される事前定義済みの推奨値には、スライダー上の目盛りとして表示され、
スライダーがそこへスナップできることが期待される。
プリミティブ 外観を詳しく定義する必要がある。
input 要素type 属性が
Color
状態にある input
要素には、作動すると、色を変更できるカラーピッカー(たとえばカラーホイールまたは
カラーパレット)をユーザーに提供するカラーウェルを描写することが期待される。要素がCSS
ボックスを生成する場合、ボタンレイアウトを使用し、
匿名ボタン内容ボックスに
子ボックスを持たないことが期待される。匿名ボタン内容ボックスには、
「background-color」プロパティを要素の値に設定する表示上のヒントを持つことが期待される。
list
属性によって提供される事前定義済みの推奨値には、カラーウェル自体ではなく、
カラーピッカーインターフェイス内に表示されることが期待される。
ネイティブ 外観およびプリミティブ 外観を詳しく定義する必要がある。
input
要素type
属性が
Checkbox 状態にある
input
要素は、ラベルのない単一のチェックボックスコントロールを含む
「inline-block」
ボックスとしてレンダリングされることが期待される
退化不可能な
ウィジェットである。
ネイティブ 外観およびプリミティブ 外観を詳しく定義する必要がある。
type
属性が
Radio Button
状態にある input
要素は、ラベルのない単一のラジオボタンコントロールを含む
「inline-block」
ボックスとしてレンダリングされることが期待される
退化不可能な
ウィジェットである。
ネイティブ 外観およびプリミティブ 外観を詳しく定義する必要がある。
input
要素
type
属性が
ファイルアップロード状態にある
input
要素がCSS
ボックスを生成する場合、選択されたファイルが
存在する場合はそのファイル名を示す一連のテキストと、それに続く、作動するとユーザーに
選択を変更できるファイルピッカーを提供するボタンを含む
「inline-block」
ボックスとしてレンダリングされることが期待される。ボタンには、ボタンレイアウトを使用し、
「::file-selector-button」擬似要素に一致することが期待される。その匿名ボタン
内容ボックスの内容には、「ファイルを選択」などの実装定義の
(場合によってはロケール固有の)テキストであることが期待される。
ユーザーエージェントは、type
属性が
ファイルアップロード状態にある
input
要素を既定の優先サイズを持つ要素として扱ってもよく、
ユーザーエージェントは「field-sizing」 CSS
プロパティを要素に適用してもよい。要素上の「field-sizing」
プロパティの算出値が
「content」である場合、要素の内在サイズには、
「::file-selector-button」擬似要素および選択されたファイル名などの
内容に依存することが期待される。
input 要素input
要素で、その type
属性が
Submit Button、Reset
Button、または Button 状態にあり、CSS ボックスを生成する場合、ボタンを描画してボタンレイアウトを使用することが
期待される。また、匿名ボタンコンテンツボックスの内容は、
存在する場合には要素の value
属性の
テキストであり、存在しない場合には、要素の type 属性から
実装定義の(おそらくロケール固有の)方法で導出された
テキストであることが期待される。
marquee 要素@namespace "http://www.w3.org/1999/xhtml" ;
marquee {
display : inline-block;
text-align : initial;
overflow : hidden !important;
}marquee
要素は、オンである間、
次のように、その属性に従ってアニメーション表示されることが期待される:
behavior
属性が
scroll
状態にある場合
下記で定義される direction
属性で示される方向へ要素の内容をスライドさせ、marquee の
始端側の外側から開始し、内側の終端側と同じ位置で終了させる。
たとえば、direction
属性がleft(既定値)である場合、
内容は、その左端が marquee のコンテンツ領域の右端より外側にある状態から開始し、
内容の左端が marquee のコンテンツ領域の左内端と同じ位置になるまでスライドする。
アニメーションが終了すると、ユーザーエージェントはmarquee の現在のループインデックスを 増加させることが期待される。その後も要素がオンである場合、ユーザーエージェントは アニメーションを再開することが期待される。
behavior
属性が
slide 状態にある場合
下記で定義される direction
属性で示される方向へ要素の内容をスライドさせ、marquee の
始端側の外側から開始し、marquee の
終端側の外側で終了させる。
たとえば、direction
属性がleft(既定値)である場合、
内容は、その左端が marquee のコンテンツ領域の右端より外側にある状態から開始し、
内容の右端が marquee のコンテンツ領域の左内端と同じ位置になるまでスライドする。
アニメーションが終了すると、ユーザーエージェントはmarquee の現在のループインデックスを 増加させることが期待される。その後も要素がオンである場合、ユーザーエージェントは アニメーションを再開することが期待される。
behavior
属性が
alternate 状態にある場合
marquee
の現在のループインデックスが
偶数(またはゼロ)である場合、下記で定義される direction
属性で示される方向へ要素の内容をスライドさせ、marquee の
始端側と同じ位置から開始し、marquee の
終端側と同じ位置で終了させる。
marquee
の現在のループインデックスが
奇数である場合、下記で定義される direction
属性で示される方向とは反対方向へ要素の内容をスライドさせ、marquee の
終端側と同じ位置から開始し、marquee の
始端側と同じ位置で終了させる。
たとえば、direction
属性がleft(既定値)である場合、
内容は、その右端が marquee のコンテンツ領域の右内端と同じ位置にある状態から開始し、
内容の左端が marquee のコンテンツ領域の左内端と同じ位置になるまでスライドする。
アニメーションが終了すると、ユーザーエージェントはmarquee の現在のループインデックスを 増加させることが期待される。その後も要素がオンである場合、ユーザーエージェントは アニメーションを継続することが期待される。
direction
属性は、次の表に示す意味を持つ:
direction
属性の状態
|
アニメーションの方向 | 始端辺 | 終端辺 | 反対方向 |
|---|---|---|---|---|
| left | ← 右から左 | 右 | 左 | → 左から右 |
| right | → 左から右 | 左 | 右 | ← 右から左 |
| up | ↑ 上(下から上) | 下 | 上 | ↓ 下(上から下) |
| down | ↓ 下(上から下) | 上 | 下 | ↑ 上(下から上) |
いずれの場合も、アニメーションは、各フレーム間にmarquee の スクロール間隔で与えられる遅延があり、各フレームで内容がmarquee のスクロール 距離で与えられる距離以下だけ移動するように進行するべきである。
marquee
要素が bgcolor 属性を持つ場合、その値を従来の色値を構文解析する
規則を使用して構文解析することが期待される。それが失敗を返さない場合、
ユーザーエージェントは、その属性を要素の'background-color' プロパティを結果の色へ設定する表示上のヒントとして
扱うことが期待される。
marquee 要素上の
width および height 属性は、それぞれ要素上の'width' および 'height' 寸法
プロパティへ対応付けられる。
marquee 要素の vspace 属性は、要素上の'margin-top' および 'margin-bottom' 寸法
プロパティへ対応付けられる。marquee 要素の
hspace 属性は、要素上の'margin-left' および
'margin-right' 寸法
プロパティへ対応付けられる。
meter 要素@namespace "http://www.w3.org/1999/xhtml" ;
meter { appearance : auto; } meter 要素は
退化可能ウィジェットである。そのネイティブな
外観は、'block-size' が '1em'、'inline-size' が '5em'、'vertical-align' が '-0.2em' で、その内容がゲージを描画する'inline-block' ボックスとしてレンダリングされることが期待される。
この要素が横書きモードを持つ場合、描画は 水平ゲージとなることが期待される。その'direction' プロパティの算出値が 'rtl' である場合、最小値は右側にあり、 それ以外の場合は左側にある。この要素が縦書きモードを持つ場合、垂直ゲージを描画することが 期待される。その'direction' プロパティの算出値が 'rtl' である場合、最小値は下側にあり、 それ以外の場合は上側にある。
ユーザーエージェントは、存在する場合にはプラットフォームのゲージの慣例と整合する表示を 使用することが期待される。
ゲージに何を描画しなければならないかに関する要件は、meter 要素の定義に
含まれている。
プリミティブな 外観を詳しく説明する必要がある。
progress 要素@namespace "http://www.w3.org/1999/xhtml" ;
progress { appearance : auto; } progress 要素は、退化可能ウィジェットである。その
ネイティブな外観は、'block-size'
が '1em'、'inline-size' が '10em'、'vertical-align' が '-0.2em' である'inline-block' ボックスとしてレンダリングされることが期待される。
 この
要素が横書きモードを持つ場合、要素は水平
プログレスバーとして描画されることが期待される。この要素上の'direction' プロパティの算出値が 'rtl'
である場合、始端は右側、終端は左側にあり、
それ以外の場合、始端は左側、終端は右側にある。この要素が
縦書きモードを持つ場合、垂直
プログレスバーとして描画されることが期待される。この要素上の'direction' プロパティの算出値が 'rtl'
である場合、始端は下側、終端は上側にあり、
それ以外の場合、始端は上側、終端は下側にある。
この
要素が横書きモードを持つ場合、要素は水平
プログレスバーとして描画されることが期待される。この要素上の'direction' プロパティの算出値が 'rtl'
である場合、始端は右側、終端は左側にあり、
それ以外の場合、始端は左側、終端は右側にある。この要素が
縦書きモードを持つ場合、垂直
プログレスバーとして描画されることが期待される。この要素上の'direction' プロパティの算出値が 'rtl'
である場合、始端は下側、終端は上側にあり、
それ以外の場合、始端は上側、終端は下側にある。
ユーザーエージェントは、プログレスバーに関するプラットフォームの慣例と整合する表示を 使用することが期待される。 特に、ユーザーエージェントは、確定プログレスバーと不確定プログレスバーに異なる表示を 使用することが期待される。ユーザーエージェントは、 要素の寸法に基づいて表示を変化させることも期待される。
プログレスバーが確定しているか不確定であるかを判定する方法、および確定
プログレスバーがどの進捗を示すかに関する要件は、progress 要素の定義に含まれている。
プリミティブな 外観を詳しく説明する必要がある。
select 要素select 要素は、
既定の優先サイズを持つ要素であり、
ユーザーエージェントは select
要素へ'field-sizing' CSS プロパティを適用することが期待される。
select 要素は、
その属性に応じて、リストボックスまたは
ドロップダウンボックスの
いずれかである。
select 要素で、
multiple
属性が存在するものは、その表示サイズが 1
より大きい場合、複数選択のリスト
ボックスとしてレンダリングされることが期待される。select 要素が
multiple
属性を持ち、表示サイズが 1 である場合、プラットフォームが
サポートしていれば複数選択のドロップダウンボックスとしてレンダリングしてもよく、
それ以外の場合は複数選択のリストボックスとしてレンダリングしてもよい。
select 要素で、
multiple
属性が存在しないものは、その表示サイズが 1
である場合、単一選択のドロップダウン
ボックスとして、表示サイズが 1
より大きい場合、単一選択のリストボックスとしてレンダリングされることが
期待される。
要素がリストボックスとしてレンダリングされる場合、
その要素は退化可能ウィジェットであり、'inline-block'
ボックスとしてレンダリングされることが期待される。その内在サイズのインライン
サイズは、select の
ラベルの幅にスクロールバーの幅を加えたものである。その内在
サイズのブロックサイズは、次の手順によって決定される:
要素上の'field-sizing' プロパティの算出値が'content' である場合、すべての項目の行を収容するために 必要な高さを返す。
size 属性が
存在しないか、有効な値を持たない場合、四行を収容するために必要な高さを返す。
それ以外の場合、要素の表示サイズで与えられる数の項目の行を 収容するために必要な高さを返す。
ドロップダウンボックスとして
レンダリングされる select 要素は、
'inline-block' ボックスとしてレンダリングされることが期待される。その内在サイズのインライン
サイズは、select の
ラベルの幅である。要素上の'field-sizing' プロパティの算出
値が'content' である場合、内在サイズのインラインサイズは、表示されるテキストに依存する。表示される
テキストは通常、選択状態が true
に設定された option のラベルである。
要素がドロップダウンボックスとしてレンダリングされる場合、
その要素は退化可能
ウィジェットである。退化した状態での外観、および要素の'appearance'
プロパティの算出値が
'menulist-button'
である場合の外観は、「ドロップダウンボタン」を含むドロップダウンボックスの外観であるが、
ホストオペレーティングシステムのネイティブコントロールを使用してレンダリングされるとは限らない。
この状態では、'color'、'background-color'、および 'border' などの CSS
プロパティを無視するべきではない(要素をそのネイティブな外観に従ってレンダリングする場合には、
一般に無視することが許可されている)。
いずれの場合も(リストボックスまたはドロップダウンボックス)、
要素の項目は、その選択肢の
リストであることが期待される。要素の optgroup 要素の子は、適用可能な場合に選択肢グループの見出しを提供する。
ドロップダウンボックスとして
レンダリングされる select 要素は、
ネイティブな
外観およびプリミティブな
外観に加えて、基本外観をサポートする。
select 要素で、
multiple
属性を持たないドロップダウンボックスとして、またはリストボックスとしてレンダリングされるものは、
ネイティブな外観およびプリミティブな
外観に加えて、基本外観をサポートする。
select 要素の
select ポップオーバーは、基本
外観およびネイティブな
外観をサポートする。select ポップオーバーは、関連付けられた
select が基本外観でレンダリングされている場合に限り、基本外観でレンダリングできる。
select がドロップダウンボックスとして基本
外観でレンダリングされる場合、次の要素を含むシャドウツリーでレンダリングされることが期待される:
select ボタンスロット。これは slot 要素である。
select の
シャドウルートへ最初の子として付加される。select の
最初の子要素が button
である場合、
その最初の子要素を受け取ることが期待される。
select フォールバックボタンテキスト。これは div 要素である。
select ボタンスロットへ付加される。
select ポップオーバー。これは div 要素である。これは、
select ボタン
スロットの後に、2 番目の子として
select のシャドウルートへ追加される。指定された
引数が select である場合、select 要素の「::picker」擬似要素は、
select ポップオーバーである。
select ポップオーバースロット。これは slot 要素である。
select ポップオーバーへ付加される。select の
すべての子ノードのうち、select
ボタンスロットが受け取る最初の子 button を
除くものを受け取ることが期待される。
基本外観はスタイルを算出することによって決定されるため、
外観を切り替えるときにこの DOM 構造を交換することはできない。実装は、select が
ドロップダウンボックスとして
レンダリングされる場合、常に基本外観の DOM 構造を含め、レンダリングするかどうかを制御するため、
それをレイアウトツリーへ含めるか除外するかを選択できる。
select ポップオーバーは、select 要素とは
別個に基本外観を選択している場合に限りレンダリングされる。
それ以外の場合、ネイティブピッカーが使用される。
select が
リストボックスとして基本
外観でレンダリングされる場合、select リストボックス
スロットを含むシャドウツリーでレンダリングされることが期待される。これは slot 要素である。
select リストボックス
スロットは、select
のシャドウルートへ最初の子として付加される。
select リストボックススロットは、select 要素の
すべての子を受け取ることが期待される。
select ポップオーバーの暗黙的アンカー要素は、関連付けられた select 要素である。
select 要素が
ネイティブな
外観または
プリミティブな外観でレンダリングされている場合、または
select 要素が
リストボックスとしてレンダリングされている場合、
'::picker' 疑似要素および
'::picker-icon' 疑似要素は適用されない。
'::picker' 疑似要素は、ネイティブな 外観またはプリミティブな 外観を持つ場合、レンダリングされない。
'::checkmark' 疑似要素は、基本外観でレンダリングされている option 要素にのみ
適用される。
optgroup
要素は、少なくとも一つの slot
要素を持つ内部シャドウツリーを持つ。
optgroup
要素は、最も近い祖先 select の内容が基本外観で
レンダリングされている場合、基本外観で
レンダリングされる。その祖先は最も近い祖先
selectである。
optgroup
要素が基本外観で
レンダリングされていない場合、その要素のラベルと子を表示することでレンダリングされることが
期待される。
optgroup
要素が基本外観で
レンダリングされている場合、次の要素を含むシャドウ
ツリーでレンダリングされることが期待される:
optgroup 凡例スロット。これは slot 要素である。
optgroup のシャドウルートへ最初の子として付加される。optgroup の
最初の子要素が legend 要素である
場合、その最初の子要素を受け取ることが期待される。
optgroup ラベル要素。これは div 要素である。
optgroup 凡例スロットへ付加される。
optgroup の
label 属性の
値、または属性が存在しない場合は空文字列をデータとする Text ノードを含むことが期待される。
optgroup 内容スロット。これは slot 要素である。
optgroup のシャドウルートへ、optgroup 凡例
スロットの後に付加される。optgroup
要素の残りのすべての子ノードを受け取ることが期待される。
select 要素
select が与えられたとき、select
の内容が
基本外観でレンダリングされているかどうかを判定するには:
select がドロップダウンボックスとして基本
外観でレンダリングされ、そのselect
ポップオーバーも基本
外観でレンダリングされ、かつ select が multiple
属性を持たない場合、true を返す。
false を返す。
option 要素は、
slot 要素を持つ
内部シャドウツリーを持つ。
option 要素は、
最も近い祖先
selectを持ち、そのselect の
内容が基本
外観でレンダリングされている場合、基本
外観でレンダリングされる。
option が
最も近い祖先
selectを持たない場合、その子をレンダリングすることが期待される。
それ以外で、option 要素が
基本外観で
レンダリングされていない場合、option と true を
指定してoption テキストを収集する結果を表示することで
レンダリングされることが期待される。
それ以外の場合、次の要素を含むシャドウツリーでレンダリングされることが期待される:
option 内容スロット。これは slot 要素である。
option のシャドウルートへ最初の子として付加される。
option
要素が、値が空文字列でない label
属性を持つ場合、
option 内容スロットは、どのノードも
受け取らないことが期待される。それ以外の場合、option 要素の
すべての子ノードを受け取ることが期待される。
option 内容スロットがどの要素も受け取らない場合、option ラベル要素がフォールバック内容として レンダリングされる。
option ラベル要素。これは span 要素である。
option 内容
スロットへ付加される。option の label 属性の値を
データとする Text ノードを含むことが期待される。
一つ以上の子 hr 要素からなる各連続する
兄弟の列は、単一の区切りとしてレンダリングしてもよい。
select のラベルの幅は、最も幅広い
optgroup
をレンダリングするために必要な幅と、要素の選択肢の
リスト内の最も幅広い option 要素
(存在する場合はそのインデントを含む)をレンダリングするために必要な幅のうち、広い方である。
select が
multiple
属性を持ち、ドロップダウンボックスとしてレンダリングされている場合、
幅は、任意の組み合わせの option
が
選択された状態で select 内に
レンダリングされるテキストを収容できる十分な広さも持つべきである。
select のラベルの幅には
multiple
のための余裕がある。これは、一部の実装が複数の選択肢が選択されていることを表すため、
「2 selected」のような特別なテキストを使用するためである。この場合、select は個々の option に加えて
「2 selected」をレンダリングできる十分な幅を持つ必要がある。
select 要素が
プレースホルダーラベル
選択肢を含む場合、ユーザーエージェントは、その option を、
コントロールの有効な選択肢ではなくラベルであることが伝わる方法でレンダリングすることが期待される。これには、ユーザーがプレースホルダーラベル
選択肢を明示的に選択できないようにすることが含まれ得る。プレースホルダーラベル
選択肢の選択状態が
true である場合、
現在有効な選択肢が選択されていないことを示す方法でコントロールが表示されることが期待される。
ユーザーエージェントは、select
内の
ラベルを、ラベルがページの一部として表示されている場合でもメニューコントロール内に表示されている
場合でも、配置が一貫する方法でレンダリングすることが期待される。
ネイティブな 外観およびプリミティブな 外観を詳しく説明する必要がある。
@namespace "http://www.w3.org/1999/xhtml" ;
option {
display : block;
}
optgroup {
display : block;
font-weight : bolder;
} 次のスタイルは、select 要素が
ネイティブな
外観またはプリミティブな
外観でレンダリングされている場合に適用されることが期待される:
@namespace "http://www.w3.org/1999/xhtml" ;
select {
letter-spacing : initial;
word-spacing : initial;
line-height : initial;
} 次のスタイルは、select 要素が
ドロップダウンボックスとしてネイティブな外観または
プリミティブな外観でレンダリングされている場合に
適用されることが期待される:
@namespace "http://www.w3.org/1999/xhtml" ;
select {
display : inline-block;
} 次のスタイルは、select 要素が
基本外観でレンダリングされている場合に適用されることが期待される:
@namespace "http://www.w3.org/1999/xhtml" ;
select {
background-color : transparent;
border : 1 px solid currentColor;
user-select : none;
box-sizing : border-box;
}
select option:enabled:hover {
background-color : color-mix ( currentColor 10 % , transparent);
}
select option:enabled:active {
background-color : color-mix ( currentColor 20 % , transparent);
}
select option:disabled {
color : color-mix ( currentColor 50 % , transparent);
}
select option {
min-inline-size : 24 px ;
min-block-size : max ( 24 px , 1 lh );
padding-inline : 0.5 em ;
padding-block-end : 0 ;
display : flex;
align-items : center;
gap : 0.5 em ;
white-space : nowrap;
}
select option::checkmark {
content : '\2713' / '' ;
}
select option:not(:checked)::checkmark {
visibility : hidden;
}
select optgroup {
display : block;
font-weight : bolder;
}
select optgroup option {
font-weight : normal;
}
select optgroup legend {
padding-inline : 0.5 em ;
min-block-size : 1 lh ;
} 次のスタイルは、select 要素が
ドロップダウンボックスとして基本外観でレンダリングされている場合に適用されることが期待される:
@namespace "http://www.w3.org/1999/xhtml" ;
select {
border-radius : 0.5 em ;
padding-block : 0.25 em ;
padding-inline : 0.5 em ;
min-block-size : calc-size ( auto, max ( size, 24 px , 1 lh ));
min-inline-size : calc-size ( auto, max ( size, 24 px ));
display : inline-flex;
gap : 0.5 em ;
border-radius : 0.5 em ;
field-sizing : content !important;
}
select > button:first-child {
all: unset;
display: contents;
}
select:enabled:hover {
background-color: color-mix(currentColor 10%, transparent);
}
select:enabled:active {
background-color: color-mix(currentColor 20%, transparent);
}
select:disabled {
color: color-mix(currentColor 50%, transparent);
}
::picker(select) {
box-sizing: border-box;
border: 1px solid;
padding: 0;
color: CanvasText;
background-color: Canvas;
margin: 0;
inset: auto;
min-inline-size: anchor-size(self-inline);
max-block-size: stretch;
overflow: auto;
position-area: self-block-end span-self-inline-end;
position-try-order: most-block-size;
position-try-fallbacks:
self-block-start span-self-inline-end,
self-block-end span-self-inline-start,
self-block-start span-self-inline-start;
}
select::picker-icon {
content: counter(fake-counter-name, disclosure-open);
display: block;
margin-inline-start: auto;
}次のスタイルは、select 要素が
リストボックスとして基本外観でレンダリングされている場合に適用されることが期待される:
@namespace "http://www.w3.org/1999/xhtml" ;
select {
overflow : auto;
display : inline-block;
block-size : calc ( max ( 24 px , 1 lh ) * attr(size type(<integer>), 4));
}次のスタイルは、optgroup ラベル 要素へ適用されることが期待される:
padding-inline: 0.5em
min-block-size: 1lh
textarea 要素textarea 要素は、複数行テキストコントロールを描画する'inline-block' ボックスとしてレンダリングされることが期待される退化可能ウィジェットである。この複数行テキストコントロールが
選択を提供する場合、ユーザーが現在の選択を変更すると、ユーザーエージェントは、textarea
要素を指定して、ユーザー
操作タスクソース上に要素タスクをキューし、bubbles 属性を true に初期化して、
要素で select という名前のイベントを発火することが期待される。
textarea 要素は、既定の優先サイズを持つ要素であり、
ユーザーエージェントは textarea
要素へ'field-sizing' CSS プロパティを適用することが期待される。
要素上の'field-sizing' プロパティの算出値が'content' である場合、内在サイズは、要素が表示するテキストから決定される。その
テキストは、生の値または placeholder 属性で指定される短いヒントのいずれかである。
ユーザーエージェントは、内在サイズにテキストキャレットのサイズを考慮してもよい。
それ以外の場合、その内在サイズは、textarea の実効幅および
textarea の実効
高さ(下記で定義)から算出される。
textarea 要素のtextarea の実効幅は、
size×avg + sbw である。ここで
size は要素の文字幅、
avg は要素の主要フォントの平均文字幅(CSS ピクセル単位)、sbw はスクロールバーの幅
(CSS
ピクセル単位)である。
(要素の'letter-spacing' プロパティは結果へ影響しない。)
ユーザーエージェントは、textarea
要素へ'white-space' CSS プロパティを適用することが期待される。歴史的な理由により、
要素が、その値が文字列「off」とASCII
大文字・小文字を区別せず一致する wrap 属性を
持つ場合、ユーザーエージェントは、その属性を要素の'white-space'
プロパティを 'pre' へ設定する表示上のヒントとして扱うことが期待される。
ネイティブな 外観およびプリミティブな 外観を詳しく説明する必要がある。
ユーザーエージェントは、frameset 要素を、ビューポートと同じ高さおよび幅を持ち、次のレイアウトアルゴリズムに
従って面がレンダリングされるボックスとしてレンダリングすることが期待される:
cols および rows 変数は、数値と単位からなるゼロ個以上の組の リストであり、単位は percentage、relative、および absolute のいずれかである。
存在する場合、要素の cols 属性の値を寸法のリストを構文解析する規則を
使用して構文解析する。
cols をその結果とし、そのような属性が存在しない場合は空のリストとする。
存在する場合、要素の rows 属性の値を寸法のリストを
構文解析する規則を使用して構文解析する。
rows をその結果とし、そのような属性が存在しない場合は空のリストとする。
cols または rows のうち、数値がゼロで単位が relative である項目について、その項目の数値を一に変更する。
cols に項目がない場合、値 1 と単位 relative からなる単一の 項目を cols へ追加する。
rows に項目がない場合、値 1 と単位 relative からなる単一の 項目を rows へ追加する。
cols を入力リストとして使用し、frameset がレンダリングされる
面の幅をCSS
ピクセル単位の入力寸法として使用して、下記で定義される寸法のリストを
ピクセル値のリストへ変換するアルゴリズムを呼び出す。sized cols を結果の
リストとする。
rows を入力リストとして使用し、frameset がレンダリングされる
面の高さをCSS
ピクセル単位の入力寸法として使用して、下記で定義される寸法のリストを
ピクセル値のリストへ変換するアルゴリズムを呼び出す。sized rows を結果の
リストとする。
面を w×h 個の長方形のグリッドへ分割する。ここで w は sized cols の項目数、h は sized rows の項目数である。
グリッド内の各列の幅を、sized cols リスト内の対応する項目と同じ数のCSS ピクセルになるように設定する。
グリッド内の各行の高さを、sized rows リスト内の対応する項目と同じ数のCSS ピクセルになるように設定する。
children を、アルゴリズムが呼び出された frameset 要素の子である frame および frameset 要素のリストとする。
前の手順で作成した長方形のグリッドの各行について、上から下へ、次の下位手順を実行する:
行内の各長方形について、左から右へ、次の下位手順を実行する:
children に要素が残っている場合、リストの最初の要素を取り出し、 その長方形へ割り当てる。
これが frameset 要素である場合、
その長方形を面として、frameset 要素について
frameset
レイアウトアルゴリズム全体を再帰的に実行する。
それ以外の場合、これは frame 要素である。そのコンテンツ
ナビゲータブルを、長方形に収まるよう配置およびサイズ設定してレンダリングする。
children に要素が残っている場合、children から最初の要素を 削除する。
frameset 要素が境界線を持つ場合、要素のフレーム境界線の色を使用して、
長方形の周囲へ外側の境界線一式を描画する。
各長方形について、その長方形へ要素が割り当てられ、その要素が境界線を持つ場合、要素の フレーム境界線の 色を使用して、その長方形の周囲へ内側の境界線一式を描画する。
noresize 属性を持つ frame
要素へ割り当てられた
長方形と接していない各(可視の)境界線について(さらに入れ子になった frameset 要素内の長方形を
含む)、ユーザーエージェントは、入れ子になった frameset
グリッドの比率を
維持しながら、ユーザーが境界線を移動して内部の長方形をサイズ変更できるようにすることが期待される。
frameset または frame 要素は、次のアルゴリズムが
true を返す場合に境界線を持つ:
要素が frameborder 属性を持ち、その値が空文字列でなく、最初の文字が
U+0031 DIGIT ONE (1) 文字、U+0079 LATIN SMALL LETTER Y 文字 (y)、または U+0059
LATIN CAPITAL LETTER Y 文字 (Y) のいずれかである場合、true を返す。
それ以外で、要素が frameborder 属性を持つ場合、false を返す。
それ以外で、要素の親要素が frameset
要素である場合、
その要素が境界線を持つなら true を返し、
持たないなら false を返す。
それ以外の場合、true を返す。
frameset または frame 要素のフレーム境界線の色は、次のアルゴリズムから得られる色である:
要素が bordercolor 属性を持ち、その属性値へ従来の色値を構文解析する
規則を適用しても失敗を返さない場合、そのように得られた色を返す。
それ以外で、要素の親要素が frameset
要素である場合、
その要素のフレーム
境界線の色を返す。
それ以外の場合、gray を返す。
寸法のリストを ピクセル値のリストへ変換するアルゴリズムは、次の手順からなる:
input list を、アルゴリズムへ渡された数値と単位のリストとする。
output list を、input list と同じ長さで、すべてがゼロである 数値のリストとする。
output list の項目は、input list 内で同じ位置にある項目に対応する。
input dimension を、アルゴリズムへ渡されたサイズとする。
total percentage を、input list 内で単位が percentage であるすべての数値の合計とする。
total relative を、input list 内で単位が relative であるすべての数値の合計とする。
total absolute を、input list 内で単位が absolute であるすべての数値の合計とする。
remaining space を input dimension の値とする。
total absolute が remaining space より大きい場合、 input list 内で単位が absolute である各項目について、 output list 内の対応する値を、input list 内の項目の数値に remaining space を乗算し、total absolute で除算した値に設定する。 その後、remaining space をゼロに設定する。
それ以外の場合、input list 内で単位が absolute である各項目について、 output list 内の対応する値を、input list 内の項目の数値に設定する。 その後、remaining space から total absolute を減算する。
total percentage に input dimension を乗算して 100 で除算した値が remaining space より大きい場合、input list 内で単位が percentage である各項目について、output list 内の対応する値を、 input list 内の項目の数値に remaining space を乗算し、 total percentage で除算した値に設定する。その後、remaining space を ゼロに設定する。
それ以外の場合、input list 内で単位が percentage である各項目について、 output list 内の対応する値を、input list 内の項目の数値に input dimension を乗算し、100 で除算した値に設定する。その後、 remaining space から、total percentage に input dimension を乗算し、100 で除算した値を減算する。
input list 内で単位が relative である各項目について、 output list 内の対応する値を、input list 内の項目の数値に remaining space を乗算し、total relative で除算した値に設定する。
output list を返す。
フレーム幅に整数値を使用するユーザーエージェント(サブピクセル精度でフレームをレイアウトできる ユーザーエージェントとは対照的)は、余りを、最初に単位が relative である最後の項目へ、 次に単位が percentage である各項目へ等しく(比例ではなく)、次に単位が absolute である各項目へ等しく(比例ではなく)、最後に、それ以外のすべてが失敗した場合は 最後の項目へ分配することが期待される。
frameset 親を持たない frame 要素の内容は、透明な黒としてレンダリングされることが期待される。この場合、ユーザーエージェントは、そのコンテンツナビゲータブルをレンダリングしないことが期待され、そのコンテンツナビゲータブルは、幅および高さがゼロのビューポートを持つことが期待される。
ユーザーエージェントは、後続のナビゲーションにどのナビゲータブルを使用するかなど、ハイパーリンクの作動およびフォーム送信の 側面をユーザーが制御できるようにすることが期待される。
ユーザーエージェントは、ハイパーリンクおよびフォームの ナビゲーションを起動する前に、 その行き先をユーザーが確認できるようにすることが期待される。
ユーザーエージェントは、ハイパーリンクにハイパーリンク監査が含まれているかどうかを ユーザーへ通知し、そのような監査の一環として接続されるドメインを、少なくともユーザーへ 知らせることが期待される。
ユーザーエージェントは、q、
blockquote、
ins、および del 要素上の
cite 属性によって示される URL へナビゲータブルをナビゲートできるようにしてもよい。
ユーザーエージェントは、前述のように、
link
要素によって作成されたハイパーリンクを、そのユーザーインターフェイスに
表示してもよい。
title 属性ユーザーエージェントは、ユーザーの要求に応じて要素の補足情報を公開し、そのような情報が 存在することをユーザーに認識させることが期待される。
ユーザーがポインティングデバイスを使用できる対話型グラフィカルシステムでは、 これはツールチップの形式を取ることができる。ユーザーがポインティングデバイスを使用できない場合、 ユーザーエージェントは、たとえば要素をフォーカス可能領域にして、現在フォーカスされている要素の補足 情報を常に表示するか、ユーザーが画面上を移動するときに、タッチデバイス上でユーザーの指の 下にある要素の補足 情報を表示するなど、他の何らかの方法で内容を利用可能にすることが期待される。
U+000A LINE FEED (LF) 文字は、ツールチップ内で改行を生じさせることが期待される。U+0009 CHARACTER TABULATION (tab) 文字は、次のグリフを次のタブ位置に揃えるゼロでない水平方向の移動としてレンダリングされることが 期待される。タブ位置は、 U+0020 SPACE 文字の幅の 8 倍の整数倍となる位置に置かれる。
たとえば、視覚的ユーザーエージェントは、title
属性を持つ要素をフォーカス可能にし、title 属性を持つフォーカスされた要素が、フォーカスを
持つ間、その要素の下にツールチップを表示するようにできる。これにより、ユーザーは文書内を
タブ移動して、すべての補足テキストを見つけられる。
別の例として、スクリーンリーダーは、ツールチップを持つ要素を読み上げるときに音声による 合図を提供し、合図が再生された最後のツールチップを読み上げるための対応するキーを提供できる。
現在のテキスト編集キャレット(すなわち、存在する場合、空であり、かつ編集ホスト内にあるアクティブ 範囲)は、CSS レンダリングモデルの目的では、キャレットの垂直寸法とゼロの幅を持つ インライン置換要素のように動作することが期待される。
これは、空のブロック内にもキャレットを置くことができ、キャレットがそのような 要素内にある場合、要素を通じてマージンが 相殺されることを防ぐことを意味する。
ユーザーエージェントは、ユーザーインターフェイスに公開されるテキストの Unicode の意味を 尊重することが期待される。たとえば、ダイアログ、 タイトルバー、ポップアップメニュー、およびツールチップに表示されるテキストで双方向アルゴリズムを サポートする。要素の内容から得られたテキストは、そのテキストを取得した要素の方向性を尊重する方法で レンダリングされることが期待される。属性から得られたテキストは、 属性の方向性を 尊重する方法でレンダリングされることが期待される。
次のマークアップを考える。これはプログラミング言語を尋ねるヘブライ語のテキストを持ち、 言語名の一部に含まれる句読点のため、それらの言語名のテキストでは左から右の方向が重要である:
< p dir = "rtl" lang = "he" >
< label >
בחר שפת תכנות:
< select >
< option dir = "ltr" > C++</ option >
< option dir = "ltr" > C#</ option >
< option dir = "ltr" > FreePascal</ option >
< option dir = "ltr" > F#</ option >
</ select >
</ label >
</ p > select
要素がドロップダウンボックスとしてレンダリングされた場合、正しいレンダリングでは、
ドロップダウン内と現在の選択を表示するボックス内の両方で、句読点が同じになることを保証する。

属性の方向性は、次の例が示すように、属性および要素の dir 属性に依存する。
次のマークアップを考える:
< table >
< tr >
< th abbr = "(א" dir = ltr > A
< th abbr = "(א" dir = rtl > A
< th abbr = "(א" dir = auto > A
</ table > abbr 属性が、たとえばツールチップまたは他のユーザーインターフェイスで
レンダリングされる場合、最初のものは左括弧(方向が 'ltr' であるため)、二番目のものは右括弧
(方向が 'rtl' であるため)、三番目のものは右括弧(方向が属性値から 'rtl' と
判定されるため)を持つ。
しかし、属性が方向性対応 属性でなかった場合、結果は異なる:
< table >
< tr >
< th data-abbr = "(א" dir = ltr > A
< th data-abbr = "(א" dir = rtl > A
< th data-abbr = "(א" dir = auto > A
</ table > この場合、ユーザーエージェントがユーザーインターフェイス(たとえばデバッグ環境)に
data-abbr 属性を公開すると、最後の場合は左括弧でレンダリングされる。
これは、方向が要素の内容から決定されるためである。
スクリプトによって提供される文字列(たとえば window.alert() の
引数)は、表示時に、双方向アルゴリズムで定義される一つ以上の独立した双方向アルゴリズムの段落の
集合として扱われることが期待される。これには、たとえば
U+000A LINE FEED (LF) 文字の段落分割動作のサポートが含まれる。双方向アルゴリズムにおける
そのようなテキストの段落レベルを決定する目的では、この仕様は規則 P2 および P3 に対する
上位レベルの上書きを提供しない。[BIDI]
必要な場合、作者は、特定の段落を Unicode の U+200E LEFT-TO-RIGHT MARK または U+200F RIGHT-TO-LEFT MARK 文字で開始することにより、その段落の特定の方向を強制できる。
したがって、次のスクリプト:
alert( '\u05DC\u05DE\u05D3 HTML \u05D4\u05D9\u05D5\u05DD!' ) ...は、ユーザーエージェントインターフェイスの言語、ページの方向、またはその要素の いずれかの方向にかかわらず、常に 「למד LMTH היום!」 (「דמל HTML םויה!」ではない)と読めるメッセージになる。
より複雑な例として、次のスクリプトを考える:
/* Warning: this script does not handle right-to-left scripts correctly */
var s;
if ( s = prompt( 'What is your name?' )) {
alert( s + '! Ok, Fred, ' + s + ', and Wilma will get the car.' );
} ユーザーが「Kitty」と入力すると、ユーザーエージェントは「Kitty! Ok, Fred, Kitty, and Wilma will get the car.」と通知する。しかし、ユーザーが「لا أفهم」と入力すると、双方向アルゴリズムは段落の方向が右から左であると 判定するため、出力は次の意図しない混乱したものになる:「لا أفهم! derF ,kO, لا أفهم, rac eht teg lliw amliW dna.」
ユーザーが提供したテキスト(または方向が不明な他のテキスト)で始まる通知を左から右へ レンダリングするよう強制するには、文字列の先頭に U+200E LEFT-TO-RIGHT MARK 文字を付けることが できる:
var s;
if ( s = prompt( 'What is your name?' )) {
alert( ' \u200E ' + s + '! Ok, Fred, ' + s + ', and Wilma will get the car.' );
} ユーザーエージェントは、Document の物理的な形態を
取得する(または物理的な形態の表現を取得する)機会をユーザーが要求できるようにすることが
期待される。たとえば、ページを印刷するか
PDF 形式へ変換するオプションを選択することである。[PDF]
ユーザーが実際に Document の物理的な
形態を取得する(または物理的な形態の表現を取得する)場合、ユーザーエージェントは
印刷媒体向けに Document の新しいレンダリングを作成することが期待される。
HTML ユーザーエージェントは、特定の状況で、組み込みの知識を持たない語彙を使用する HTML 以外の文書をレンダリングすることがある。この節では、ユーザーエージェントがそのような 文書をある程度有用な方法で処理するための方法を規定する。
Document がスタイルなし文書である間、
ユーザーエージェントはスタイルなし文書ビューを
レンダリングすることが期待される。
Document は、次の条件に
一致する間、スタイルなし文書である:
Document に作者
スタイルシートがない(HTTP ヘッダー、処理命令、link のような
要素、style のようなインライン要素、またはその他の仕組みによって
参照されているかどうかを問わない)。
Document 内のどの要素も表示上のヒントを持たない。
Document 内のどの要素もstyle
属性を持たない。
Document 内のどの要素も、
次の名前空間のいずれにも属さない:HTML 名前空間、SVG 名前空間、MathML 名前空間。
Document に、ビューポート以外のフォーカス可能領域(たとえば XLink によるもの)がない。
Document にハイパーリンク(たとえば XLink によるもの)が
ない。
Document を関連付けられた
Documentとして持つ Window
オブジェクトであるスクリプトが存在しない。
Document 内のどの要素も、
登録されたイベントリスナーを持たない。
スタイルなし文書ビューとは、DOM が CSS に従って
レンダリングされず(このコンテキストでは適用可能なスタイルがないため、単なるテキストの壁に
なってしまう)、代わりに開発者にとって有用な方法でレンダリングされるビューである。これは、
Document オブジェクトの
ソースだけを、必要に応じて構文強調表示付きで表示すること、DOM ツリーだけを表示すること、
または単にページがスタイル付き文書ではないというメッセージを表示することで構成できる。
Document がスタイルなし文書でなくなった場合、上記の条件は
適用されなくなり、したがってこれらの要件に従うユーザーエージェントは通常の CSS レンダリングへ
切り替える。
この節に列挙された機能は、適合性チェッカーで警告を発生させる。
作者は、img 要素に
border 属性を指定するべきではない。属性が存在する場合、その値は
文字列「0」でなければならない。代わりに CSS を使用するべきである。
作者は、script
要素に charset
属性を指定するべきではない。属性が存在する場合、その値は「utf-8」とASCII
大文字・小文字を区別せず一致しなければならない。
(この標準内の他の箇所で要求されるとおり、UTF-8 で符号化された文書では、これは効果を持たない。)
作者は、script
要素に language 属性を指定するべきではない。属性が存在する場合、その値は
文字列「JavaScript」とASCII
大文字・小文字を区別せず一致し、さらに type 属性が
省略されているか、その値が文字列「text/javascript」とASCII
大文字・小文字を区別せず一致しなければならない。
代わりに、この属性を完全に省略するべきである(値が「JavaScript」の場合、効果を
持たない)。または、type
属性を
使用して置き換えるべきである。
作者は、script
要素上の type
属性に、空文字列またはJavaScript MIME タイプの
エッセンス一致となる値を指定するべきではない。代わりに、同じ効果を持つ属性の省略を行うべきである。
作者は、style 要素に type 属性を
指定するべきではない。属性が存在する場合、その値は「text/css」とASCII
大文字・小文字を区別せず一致しなければならない。
作者は、a 要素に name 属性を指定する
べきではない。属性が存在する場合、その値は空文字列であってはならず、要素自身のID(存在する場合)以外の、要素のツリー内にあるいずれかのIDの値と等しくてもならず、要素のツリー内にある他の a 要素上の
いずれかの name 属性の値と等しくてもならない。この属性が存在し、要素にID がある場合、属性の値は要素のID と等しくなければならない。この言語の以前の版では、
この属性は URL 内のフラグメントの候補となる対象を指定する方法として
意図されていた。代わりに id
属性を
使用するべきである。
作者は、この仕様の他の箇所で反対の要件があるにもかかわらず、その type 属性が
Number
状態にある input
要素に
maxlength
および size 属性を指定するべきではないが、指定してもよい。それでもこれらの
属性を使用する妥当な理由の一つは、type="number" を持つ input
要素をサポートしない古いユーザーエージェントでも、有用な幅でテキストコントロールをレンダリング
できるようにするためである。
HTML4 Transitional 文書からこの仕様で定義される言語への移行を容易にし、 ごく限られた状況でのみ許可される特定の機能の使用を抑制するため、文書内で次の機能が使用された場合、 適合性チェッカーはユーザーへ警告しなければならない。これらは一般に、効果を持たない古い廃止済み 機能であり、誤りである可能性が高いもの(通常の適合性エラー)と、単なる痕跡的なマークアップ、 または通常ではなく推奨されない慣行(これらの警告)を区別するためだけに許可される。
次の機能は、上記のように分類しなければならない:
script
要素上に、その値が「utf-8」とASCII
大文字・小文字を区別せず一致する charset 属性が存在すること。
script
要素上に、その値が文字列「JavaScript」とASCII
大文字・小文字を区別せず一致する language 属性が存在し、かつ type 属性が存在しないか、存在してその値が文字列
「text/javascript」とASCII
大文字・小文字を区別せず一致すること。
script
要素上に、その値がJavaScript MIME タイプのエッセンス
一致となる type 属性が存在すること。
style
要素上に、その値が「text/css」と
ASCII
大文字・小文字を区別せず一致する type 属性が存在すること。
適合性チェッカーは、適合性エラーがなく、これらの廃止された機能も一つもないページと、 適合性エラーはないが、これらの廃止された機能の一部を持つページとを区別しなければならない。
たとえば、バリデーターは一部のページを「Valid HTML」、他のページを 「Valid HTML with warnings」と報告できる。
次の一覧にある要素は完全に廃止されており、作者は使用してはならない:
appletacronym代わりに abbr を使用する。
bgsound代わりに audio を使用する。
dir代わりに ul を使用する。
frameframesetnoframes代わりに iframe と
CSS を
使用するか、サーバー側インクルードを使用して、さまざまな不変部分を統合した完全なページを
生成する。
isindex代わりに、明示的な form とテキストコントロールの
組み合わせを使用する。
keygen企業のデバイス管理の用途には、デバイス上のネイティブ管理機能を使用する。
証明書登録の用途には、Web Cryptography API を使用して証明書の鍵ペアを生成し、 証明書と鍵をエクスポートしてユーザーが手動でインストールできるようにする。[WEBCRYPTO]
listingmenuitemカスタムコンテキストメニューを実装するには、スクリプトを使用して contextmenu
イベントを処理する。
nextid代わりに GUID を使用する。
noembedparamplaintext代わりに「text/plain」
MIME タイプを使用する。
rbrtcstrikexmp代わりに pre と code を使用し、
「<」および「&」文字をそれぞれ
「<」および「&」としてエスケープする。
basefontbigblinkcenterfontmarqueemulticolnobrspacertt代わりに適切な要素または CSS を使用する。
tt 要素をキーボード入力の
マークアップに使用していた場合は、kbd
要素を検討する。
変数には var 要素、
コンピューターコードには code
要素、
コンピューター出力には
samp 要素を
検討する。
同様に、big 要素を見出しを示すために
使用している場合は、h1
要素の使用を検討する。重要な一節をマークアップするために使用している場合は、
strong
要素の使用を検討する。参照目的でテキストを強調するために使用している場合は、mark 要素の使用を
検討する。
例を含むその他の提案については、テキストレベル意味論の使用法の概要も 参照すること。
次の属性は廃止されており(要素自体は依然として言語の一部である)、作者は使用してはならない:
a 要素上の
charset
link 要素上の
charset
代わりに、リンク先リソース上で HTTP の「Content-Type」ヘッダーを
使用する。
script
要素上の charset
(前の節で述べた場合を除く)
属性を省略する。文書とスクリプトはどちらもUTF-8 を使用することが
要求されるため、文書から継承する script 要素で
それを指定することは冗長である。
a 要素上の
coords
a 要素上の
shape
a 要素上の
methods
link 要素上の
methods
代わりに HTTP OPTIONS 機能を使用する。
a 要素上の
name
(前の節で述べた場合を除く)
embed 要素上の
name
img 要素上の
name
option 要素上の
name
代わりに id 属性を使用する。
a 要素上の
rev
link 要素上の
rev
代わりに、反対の用語を指定した rel 属性を
使用する。(たとえば rev="made" の代わりに rel="author" を使用する。)
a 要素上の
urn
link 要素上の
urn
代わりに href 属性を
使用して、優先される永続的識別子を指定する。
form 要素上の
accept
area
要素上の hreflang
area 要素上の
type
これらの属性は有用なことを何も行わず、歴史的な理由から、area 要素上には
対応する IDL 属性もない。完全に省略する。
area 要素上の
nohref
head 要素上の
profile
不要である。完全に省略する。
html 要素上の
manifest
代わりに Service Worker を使用する。[SW]
html 要素上の
version
不要である。完全に省略する。
input 要素上の
ismap
不要である。完全に省略する。その type
属性が
Image
Button 状態にあるすべての input 要素は、
サーバー側イメージマップとして処理される。
input 要素上の
usemap
object
要素上の usemap
イメージマップには img 要素を使用する。
iframe
要素上の longdesc
img 要素上の
longdesc
説明へリンクするには通常の a 要素を使用するか、画像の場合は、画像から画像の説明へのリンクを
提供するためにイメージマップを使用する。
img 要素上の
lowsrc
二つの別々の画像を使用する代わりに、src
属性で指定された
プログレッシブ JPEG 画像を使用する。
link 要素上の
target
不要である。完全に省略する。
menu 要素上の
type
カスタムコンテキストメニューを実装するには、スクリプトを使用して contextmenu
イベントを処理する。ツールバーメニューでは、属性を省略する。
menu 要素上の
label
contextmenuonshowカスタムコンテキストメニューを実装するには、スクリプトを使用して contextmenu
イベントを処理する。
meta 要素上の
scheme
フィールドごとに一つのスキームだけを使用するか、スキーム宣言を値の一部にする。
object
要素上の archive
object
要素上の classid
object 要素上の
code
object
要素上の codebase
object
要素上の codetype
object
要素上の declare
リソースを再利用するたびに、object 要素を
完全に繰り返す。
object
要素上の standby
リンク先リソースが高速に、または少なくとも段階的に読み込まれるよう最適化する。
object
要素上の typemustmatch信頼できないリソースを持つ object 要素の
使用を避ける。
script
要素上の language
(前の節で述べた場合を除く)
script 要素上の
event
script 要素上の
for
イベントリスナーを登録するには DOM イベントの仕組みを使用する。[DOM]
style 要素上の
type
(前の節で述べた場合を除く)
table 要素上の
datapagesize
不要である。完全に省略する。
table
要素上の summary
代わりに、table の節で
示される表を説明するための技法のいずれかを使用する。
td 要素上の
abbr
曖昧でなく簡潔な方法で始まるテキストを使用し、その後に、より詳しいテキストを含める。
title 属性も、
より詳細なテキストを含め、セルの内容を簡潔にするために有用となり得る。見出しである場合は、
abbr 属性を持つ
th を使用する。
td および th 要素上の
axis
td 要素上の
scope
見出しセルには th 要素を使用する。
a、button、div、frame、iframe、img、input、label、legend、marquee、object、option、select、span、table、および textarea 要素上の
datasrc
a、button、div、fieldset、frame、iframe、img、input、label、legend、marquee、object、select、span、および textarea 要素上の
datafld
button、div、input、label、legend、marquee、object、option、select、span、および table 要素上の
dataformatas
ページを動的に構築するには、スクリプトおよび XMLHttpRequest のような仕組みを
使用する。[XHR]
dropzonebody 要素上の
alink
body 要素上の
bgcolor
body 要素上の
bottommargin
body 要素上の
leftmargin
body 要素上の
link
body 要素上の
marginheight
body 要素上の
marginwidth
body 要素上の
rightmargin
body 要素上の
text
body 要素上の
topmargin
body 要素上の
vlink
br 要素上の
clear
caption
要素上の align
col 要素上の
align
col 要素上の
char
col 要素上の
charoff
col 要素上の
valign
col 要素上の
width
div 要素上の
align
dl 要素上の
compact
embed 要素上の
align
embed 要素上の
hspace
embed 要素上の
vspace
hr 要素上の
align
hr 要素上の
color
hr 要素上の
noshade
hr 要素上の
size
hr 要素上の
width
h1—h6
要素上の aligniframe 要素上の
align
iframe 要素上の
allowtransparency
iframe 要素上の
frameborder
iframe 要素上の
framespacing
iframe
要素上の hspace
iframe 要素上の
marginheight
iframe 要素上の
marginwidth
iframe
要素上の scrollingiframe
要素上の vspace
input 要素上の
align
input 要素上の
border
input 要素上の
hspace
input 要素上の
vspace
img 要素上の
align
img 要素上の
border
(前の節で述べた場合を除く)
img 要素上の
hspace
img 要素上の
vspace
legend 要素上の
align
li 要素上の
type
menu 要素上の
compact
object 要素上の
align
object
要素上の border
object
要素上の hspace
object
要素上の vspace
ol 要素上の
compact
p 要素上の
align
pre 要素上の
width
table 要素上の
align
table
要素上の bgcolor
table 要素上の
border
table 要素上の
bordercolor
table 要素上の
cellpadding
table 要素上の
cellspacing
table 要素上の
frame
table 要素上の
height
table 要素上の
rules
table 要素上の
width
tbody、thead、および tfoot 要素上の
align
tbody、thead、および tfoot 要素上の
char
tbody、thead、および tfoot 要素上の
charoff
thead、tbody、および tfoot 要素上の
height
tbody、thead、および tfoot 要素上の
valign
td および th 要素上の
align
td および th 要素上の
bgcolor
td および th 要素上の
char
td および th 要素上の
charoff
td および th 要素上の
height
td および th 要素上の
nowrap
td および th 要素上の
valign
td および th 要素上の
width
tr 要素上の
align
tr 要素上の
bgcolor
tr 要素上の
char
tr 要素上の
charoff
tr 要素上の
height
tr 要素上の
valign
ul 要素上の
compact
ul 要素上の
type
body、table、thead、tbody、tfoot、tr、td、および th 要素上の
background
代わりに CSS を使用する。
marquee
要素
marquee 要素は、
内容をアニメーション化する表示用要素である。CSS
トランジションおよびアニメーションの方が適切な仕組みである。[CSSANIMATIONS] [CSSTRANSITIONS]
marquee 要素は
HTMLMarqueeElement インターフェイスを実装しなければならない。
[Exposed =Window ]
interface HTMLMarqueeElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute DOMString behavior ;
[CEReactions , Reflect ] attribute DOMString bgColor ;
[CEReactions , Reflect ] attribute DOMString direction ;
[CEReactions , Reflect ] attribute DOMString height ;
[CEReactions , Reflect ] attribute unsigned long hspace ;
[CEReactions ] attribute long loop ;
[CEReactions , Reflect , ReflectDefault=6] attribute unsigned long scrollAmount ;
[CEReactions , Reflect , ReflectDefault=85] attribute unsigned long scrollDelay ;
[CEReactions , Reflect ] attribute boolean trueSpeed ;
[CEReactions , Reflect ] attribute unsigned long vspace ;
[CEReactions , Reflect ] attribute DOMString width ;
undefined start ();
undefined stop ();
};marquee 要素は
オンまたはオフにできる。
作成時にはオンである。
marquee 要素上の behavior 内容属性は、
次のキーワードと状態(すべて非適合)を持つ列挙属性である:
| キーワード | 状態 |
|---|---|
scroll
|
scroll |
slide
|
slide |
alternate
|
alternate |
marquee 要素上の direction 内容属性は、次のキーワードと状態
(すべて非適合)を持つ列挙
属性である:
| キーワード | 状態 |
|---|---|
left
|
left |
right
|
right |
up
|
up |
down
|
down |
marquee 要素上の truespeed 内容属性は、ブール属性である。
marquee 要素は
marquee のスクロール間隔を持ち、これは次のように取得される:
要素が scrolldelay 属性を持ち、その値を非負整数を構文解析する規則を
使用して構文解析してもエラーが返されない場合、delay を構文解析された値とする。
それ以外の場合、delay を 85 とする。
要素が truespeed 属性を持たず、delay の値が
60 より小さい場合、代わりに delay を 60 とする。
marquee のスクロール 間隔は、ミリ秒として解釈される delay である。
marquee 要素はmarquee のスクロール距離を持つ。要素が
scrollamount 属性を持ち、その値を非負整数を構文解析する規則を
使用して構文解析してもエラーが返されない場合、これは構文解析された値をCSS ピクセルとして解釈したものであり、
それ以外の場合は 6 CSS
ピクセルである。
marquee 要素はmarquee のループ回数を持つ。要素が loop 属性を持ち、その値を整数を構文解析する規則を使用して構文解析しても
エラーまたは 1 より小さい数値が返されない場合、これは構文解析された値であり、それ以外の場合は
−1 である。
loop
IDL 属性は、取得時には要素のmarquee
のループ回数を返さなければならない。
設定時には、新しい値が要素のmarquee
のループ回数と異なり、かつ
ゼロより大きいか −1 と等しい場合、要素の loop 内容属性を
(必要なら追加して)新しい値を表す妥当な整数へ設定しなければならない。
(その他の値は無視される。)
marquee 要素は、marquee
の現在のループインデックスも持ち、要素の作成時には
ゼロである。
レンダリング層は、ときどきmarquee の現在のループインデックスを 増加させる。これにより、次の手順を実行しなければならない:
marquee のループ回数が −1 である場合、戻る。
marquee の現在のループインデックスを 1 増加させる。
marquee の
現在のループインデックスが、要素のmarquee
のループ回数以上になった場合、
marquee 要素をオフにする。
frameset 要素は、
フレームを使用する文書においてbody 要素として動作する。
frameset 要素は、HTMLFrameSetElement
インターフェイスを実装しなければならない。
[Exposed =Window ]
interface HTMLFrameSetElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute DOMString cols ;
[CEReactions , Reflect ] attribute DOMString rows ;
};
HTMLFrameSetElement includes WindowEventHandlers ;frameset 要素は、Window オブジェクトの多数のイベントハンドラーをイベントハンドラー内容
属性として公開する。また、それらのイベントハンドラー
IDL 属性も反映する。
frameset 要素上で公開される、Window を反映する body 要素の
イベントハンドラー集合によって名前が指定される Window オブジェクトのイベントハンドラーは、通常HTML 要素がサポートする同名の汎用イベントハンドラーを置き換える。
frame 要素は、iframe 要素と同様のコンテンツナビゲータブルを持つが、
frameset 要素内でレンダリングされる。
insertedNode が与えられたときの frame のHTML 要素挿入手順は、次のとおりである:
insertedNode が文書ツリー内にない場合、戻る。
insertedNode のために新しい子ナビゲータブルを作成する。
initialInsertion を true に設定して、
insertedNode のframe 属性を処理する。
removedNode が与えられたときの frame のHTML
要素削除手順は、removedNode を指定して
子ナビゲータブルを破棄する
ことである。
null でないコンテンツナビゲータブルを持つ frame 要素の src 属性が設定、変更、
または削除されるたびに、ユーザーエージェントはframe 属性を処理しなければならない。
要素 element のframe 属性を
処理するには、オプションのブール値 initialInsertion とともに:
element および initialInsertion を指定して、iframe および
frame 要素の共有属性処理手順を実行した結果を url とする。
url が null である場合、戻る。
url が about:blank
に一致し、
initialInsertion が true である場合:
element、url、空文字列、および initialInsertion を指定して、
iframe または
frame を
ナビゲートする。
frame 要素は、load イベントを遅延させる可能性がある。
frame 要素は、HTMLFrameElement
インターフェイスを実装しなければならない。
[Exposed =Window ]
interface HTMLFrameElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute DOMString name ;
[CEReactions , Reflect ] attribute DOMString scrolling ;
[CEReactions , ReflectURL ] attribute USVString src ;
[CEReactions , Reflect ] attribute DOMString frameBorder ;
[CEReactions , ReflectURL ] attribute USVString longDesc ;
[CEReactions , Reflect ] attribute boolean noResize ;
readonly attribute Document ? contentDocument ;
readonly attribute WindowProxy ? contentWindow ;
[CEReactions , Reflect ] attribute [LegacyNullToEmptyString ] DOMString marginHeight ;
[CEReactions , Reflect ] attribute [LegacyNullToEmptyString ] DOMString marginWidth ;
};contentWindow の取得手順は、this のコンテンツウィンドウを返すことである。
ユーザーエージェントは、意味論およびレンダリングの目的で、acronym 要素を
abbr 要素と同等の方法で扱わなければならない。
partial interface HTMLAnchorElement {
[CEReactions , Reflect ] attribute DOMString coords ;
[CEReactions , Reflect ] attribute DOMString charset ;
[CEReactions , Reflect ] attribute DOMString name ;
[CEReactions , Reflect ] attribute DOMString rev ;
[CEReactions , Reflect ] attribute DOMString shape ;
};partial interface HTMLAreaElement {
[CEReactions , Reflect ] attribute boolean noHref ;
};partial interface HTMLBodyElement {
[CEReactions , Reflect ] attribute [LegacyNullToEmptyString ] DOMString text ;
[CEReactions , Reflect ] attribute [LegacyNullToEmptyString ] DOMString link ;
[CEReactions , Reflect ] attribute [LegacyNullToEmptyString ] DOMString vLink ;
[CEReactions , Reflect ] attribute [LegacyNullToEmptyString ] DOMString aLink ;
[CEReactions , Reflect ] attribute [LegacyNullToEmptyString ] DOMString bgColor ;
[CEReactions , Reflect ] attribute DOMString background ;
};background
IDL 属性は、歴史的な理由により ReflectURL または USVString を使用しない。
partial interface HTMLBRElement {
[CEReactions , Reflect ] attribute DOMString clear ;
};partial interface HTMLTableCaptionElement {
[CEReactions , Reflect ] attribute DOMString align ;
};partial interface HTMLTableColElement {
[CEReactions , Reflect ] attribute DOMString align ;
[CEReactions , Reflect="char"] attribute DOMString ch ;
[CEReactions , Reflect="charoff"] attribute DOMString chOff ;
[CEReactions , Reflect ] attribute DOMString vAlign ;
[CEReactions , Reflect ] attribute DOMString width ;
};ユーザーエージェントは、意味論およびレンダリングの目的で、dir 要素を
ul
要素と同等の方法で扱わなければならない。
dir 要素は、HTMLDirectoryElement インターフェイスを実装しなければならない。
[Exposed =Window ]
interface HTMLDirectoryElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute boolean compact ;
};partial interface HTMLDivElement {
[CEReactions , Reflect ] attribute DOMString align ;
};partial interface HTMLDListElement {
[CEReactions , Reflect ] attribute boolean compact ;
};partial interface HTMLEmbedElement {
[CEReactions , Reflect ] attribute DOMString align ;
[CEReactions , Reflect ] attribute DOMString name ;
};font 要素は、HTMLFontElement インターフェイスを実装しなければならない。
[Exposed =Window ]
interface HTMLFontElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute [LegacyNullToEmptyString ] DOMString color ;
[CEReactions , Reflect ] attribute DOMString face ;
[CEReactions , Reflect ] attribute DOMString size ;
};partial interface HTMLHeadingElement {
[CEReactions , Reflect ] attribute DOMString align ;
};head 要素(HTMLHeadElement インターフェイスを持つ)上の profile IDL 属性は、意図的に省略されている。
適用可能な別の仕様によって
要求されない限り、実装はしたがってこの属性をサポートしない。(これは以前の版の
DOM で定義されていたため、ここで言及している。)
partial interface HTMLHRElement {
[CEReactions , Reflect ] attribute DOMString align ;
[CEReactions , Reflect ] attribute DOMString color ;
[CEReactions , Reflect ] attribute boolean noShade ;
[CEReactions , Reflect ] attribute DOMString size ;
[CEReactions , Reflect ] attribute DOMString width ;
};partial interface HTMLHtmlElement {
[CEReactions , Reflect ] attribute DOMString version ;
};partial interface HTMLIFrameElement {
[CEReactions , Reflect ] attribute DOMString align ;
[CEReactions , Reflect ] attribute DOMString scrolling ;
[CEReactions , Reflect ] attribute DOMString frameBorder ;
[CEReactions , ReflectURL ] attribute USVString longDesc ;
[CEReactions , Reflect ] attribute [LegacyNullToEmptyString ] DOMString marginHeight ;
[CEReactions , Reflect ] attribute [LegacyNullToEmptyString ] DOMString marginWidth ;
};partial interface HTMLImageElement {
[CEReactions , Reflect ] attribute DOMString name ;
[CEReactions , ReflectURL ] attribute USVString lowsrc ;
[CEReactions , Reflect ] attribute DOMString align ;
[CEReactions , Reflect ] attribute unsigned long hspace ;
[CEReactions , Reflect ] attribute unsigned long vspace ;
[CEReactions , ReflectURL ] attribute USVString longDesc ;
[CEReactions , Reflect ] attribute [LegacyNullToEmptyString ] DOMString border ;
};partial interface HTMLInputElement {
[CEReactions , Reflect ] attribute DOMString align ;
[CEReactions , Reflect ] attribute DOMString useMap ;
};partial interface HTMLLegendElement {
[CEReactions , Reflect ] attribute DOMString align ;
};partial interface HTMLLIElement {
[CEReactions , Reflect ] attribute DOMString type ;
};partial interface HTMLLinkElement {
[CEReactions , Reflect ] attribute DOMString charset ;
[CEReactions , Reflect ] attribute DOMString rev ;
[CEReactions , Reflect ] attribute DOMString target ;
};ユーザーエージェントは、意味論およびレンダリングの目的で、listing 要素を pre
要素と同等の方法で扱わなければならない。
partial interface HTMLMenuElement {
[CEReactions , Reflect ] attribute boolean compact ;
};partial interface HTMLMetaElement {
[CEReactions , Reflect ] attribute DOMString scheme ;
};ユーザーエージェントは、scheme 内容
属性を、
meta 要素の
name 内容
属性の拡張として扱ってもよい。これは、meta 要素を
処理する際に、その name
属性の値が、ユーザーエージェントによって scheme
属性をサポートするものとして認識されている場合に限る。
ユーザーエージェントには、scheme 属性を無視し、代わりにメタデータ名へ与えられた値を、
scheme 属性の予想される各値に対して指定されたかのように
処理することが推奨される。
たとえば、ユーザーエージェントが、値「eGMS.subject.keyword」を持つ name 属性を持つ meta 要素に対して動作し、scheme 属性がこのメタデータ名とともに使用されることを
認識している場合、scheme 属性を考慮し、それを name 属性の拡張であるかのように動作できる。したがって、
次の二つの meta 要素は、異なる二つのメタデータ名へ値を与える要素として
扱うことができる。一つは「eGMS.subject.keyword」と「LGCL」の組み合わせで構成され、もう一つは
「eGMS.subject.keyword」と「ORLY」の組み合わせで構成される:
<!-- this markup is invalid -->
< meta name = "eGMS.subject.keyword" scheme = "LGCL" content = "Abandoned vehicles" >
< meta name = "eGMS.subject.keyword" scheme = "ORLY" content = "Mah car: kthxbye" > しかし、このマークアップに対して推奨される処理は、次と同等になる:
< meta name = "eGMS.subject.keyword" content = "Abandoned vehicles" >
< meta name = "eGMS.subject.keyword" content = "Mah car: kthxbye" > すべての現行エンジンでサポートされている。
partial interface HTMLObjectElement {
[CEReactions , Reflect ] attribute DOMString align ;
[CEReactions , Reflect ] attribute DOMString archive ;
[CEReactions , Reflect ] attribute DOMString code ;
[CEReactions , Reflect ] attribute boolean declare ;
[CEReactions , Reflect ] attribute unsigned long hspace ;
[CEReactions , Reflect ] attribute DOMString standby ;
[CEReactions , Reflect ] attribute unsigned long vspace ;
[CEReactions , ReflectURL ] attribute DOMString codeBase ;
[CEReactions , Reflect ] attribute DOMString codeType ;
[CEReactions , Reflect ] attribute DOMString useMap ;
[CEReactions , Reflect ] attribute [LegacyNullToEmptyString ] DOMString border ;
};partial interface HTMLOListElement {
[CEReactions , Reflect ] attribute boolean compact ;
};partial interface HTMLParagraphElement {
[CEReactions , Reflect ] attribute DOMString align ;
};param 要素は、HTMLParamElement インターフェイスを実装しなければならない。
[Exposed =Window ]
interface HTMLParamElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute DOMString name ;
[CEReactions , Reflect ] attribute DOMString value ;
[CEReactions , Reflect ] attribute DOMString type ;
[CEReactions , Reflect ] attribute DOMString valueType ;
};ユーザーエージェントは、意味論およびレンダリングの目的で、plaintext 要素を
pre 要素と同等の方法で扱わなければならない。
(ただし、構文解析器はこの要素に対して特別な動作を持つ。)
partial interface HTMLPreElement {
[CEReactions , Reflect ] attribute long width ;
};partial interface HTMLStyleElement {
[CEReactions , Reflect ] attribute DOMString type ;
};partial interface HTMLScriptElement {
[CEReactions , Reflect ] attribute DOMString charset ;
[CEReactions , Reflect ] attribute DOMString event ;
[CEReactions , Reflect="for"] attribute DOMString htmlFor ;
};partial interface HTMLTableElement {
[CEReactions , Reflect ] attribute DOMString align ;
[CEReactions , Reflect ] attribute DOMString border ;
[CEReactions , Reflect ] attribute DOMString frame ;
[CEReactions , Reflect ] attribute DOMString rules ;
[CEReactions , Reflect ] attribute DOMString summary ;
[CEReactions , Reflect ] attribute DOMString width ;
[CEReactions , Reflect ] attribute [LegacyNullToEmptyString ] DOMString bgColor ;
[CEReactions , Reflect ] attribute [LegacyNullToEmptyString ] DOMString cellPadding ;
[CEReactions , Reflect ] attribute [LegacyNullToEmptyString ] DOMString cellSpacing ;
};partial interface HTMLTableSectionElement {
[CEReactions , Reflect ] attribute DOMString align ;
[CEReactions , Reflect="char"] attribute DOMString ch ;
[CEReactions , Reflect="charoff"] attribute DOMString chOff ;
[CEReactions , Reflect ] attribute DOMString vAlign ;
};partial interface HTMLTableCellElement {
[CEReactions , Reflect ] attribute DOMString align ;
[CEReactions , Reflect ] attribute DOMString axis ;
[CEReactions , Reflect ] attribute DOMString height ;
[CEReactions , Reflect ] attribute DOMString width ;
[CEReactions , Reflect="char"] attribute DOMString ch ;
[CEReactions , Reflect="charoff"] attribute DOMString chOff ;
[CEReactions , Reflect ] attribute boolean noWrap ;
[CEReactions , Reflect ] attribute DOMString vAlign ;
[CEReactions , Reflect ] attribute [LegacyNullToEmptyString ] DOMString bgColor ;
};partial interface HTMLTableRowElement {
[CEReactions , Reflect ] attribute DOMString align ;
[CEReactions , Reflect="char"] attribute DOMString ch ;
[CEReactions , Reflect="charoff"] attribute DOMString chOff ;
[CEReactions , Reflect ] attribute DOMString vAlign ;
[CEReactions , Reflect ] attribute [LegacyNullToEmptyString ] DOMString bgColor ;
};partial interface HTMLUListElement {
[CEReactions , Reflect ] attribute boolean compact ;
[CEReactions , Reflect ] attribute DOMString type ;
};ユーザーエージェントは、意味論およびレンダリングの目的で、xmp 要素を
pre 要素と同等の方法で扱わなければならない。
(ただし、構文解析器はこの要素に対して特別な動作を持つ。)
partial interface Document {
[CEReactions ] attribute [LegacyNullToEmptyString ] DOMString fgColor ;
[CEReactions ] attribute [LegacyNullToEmptyString ] DOMString linkColor ;
[CEReactions ] attribute [LegacyNullToEmptyString ] DOMString vlinkColor ;
[CEReactions ] attribute [LegacyNullToEmptyString ] DOMString alinkColor ;
[CEReactions ] attribute [LegacyNullToEmptyString ] DOMString bgColor ;
[SameObject ] readonly attribute HTMLCollection anchors ;
[SameObject ] readonly attribute HTMLCollection applets ;
undefined clear ();
undefined captureEvents ();
undefined releaseEvents ();
[SameObject ] readonly attribute HTMLAllCollection all ;
};次の表の最初の列に列挙された Document
オブジェクトの
属性は、body 要素が frameset 要素ではなく
body 要素である場合、同じ行の二番目の列の対応するセルで
指定された名前を持つ、body
要素上の内容属性を反映しなければならない。
body
要素が存在しない場合、またはそれが frameset 要素である場合、属性は代わりに取得時に空文字列を返し、
設定時には何も行わなければならない。
| IDL 属性 | 内容属性 |
|---|---|
fgColor
|
text
|
linkColor
|
link
|
vlinkColor
|
vlink
|
alinkColor
|
alink
|
bgColor
|
bgcolor
|
anchors
属性は、Document ノードを
ルートとし、name 属性を持つ a 要素だけに
一致するフィルターを持つ HTMLCollection を返さなければならない。
applets
属性は、Document ノードを
ルートとし、何にも一致しないフィルターを持つ HTMLCollection を返さなければならない。
(これは歴史的な理由により存在する。)
clear()、captureEvents()、および releaseEvents() メソッドは何も行ってはならない。
all 属性は、Document ノードを
ルートとし、すべての要素に一致するフィルターを持つ HTMLAllCollection を返さなければならない。
partial interface Window {
undefined captureEvents ();
undefined releaseEvents ();
[Replaceable , SameObject ] readonly attribute External external ;
};captureEvents() および releaseEvents() メソッドは何も行ってはならない。
[Exposed =Window ]
interface External {
undefined AddSearchProvider ();
undefined IsSearchProviderInstalled ();
};AddSearchProvider() および IsSearchProviderInstalled() メソッドは、
何も行ってはならない。
text/htmlこの登録はコミュニティレビュー用であり、レビュー、承認、および IANA への登録のために IESG へ提出される。
charsetcharset パラメーターは、文書内のバイトオーダーマーク(BOM)以外の文字エンコーディング宣言を上書きして、文書の文字エンコーディングを指定するために
提供してもよい。パラメーターの値は、文字列「utf-8」とASCII 大文字・小文字を区別せず一致しなければならない。
[ENCODING]
HTML 文書に適用されるセキュリティ上の考慮事項については、小説一冊分にもなるほど多くの 内容が書かれている。その多くはこの文書に列挙されており、詳細についてはそちらを参照されたい。 ただし、いくつかの一般的な懸念はここで言及するに値する:
HTML はスクリプト化された言語であり、多数の API を持つ(その一部はこの文書で説明される)。 スクリプトは、情報漏洩、認証情報漏洩、クロスサイトスクリプティング攻撃、 クロスサイトリクエストフォージェリ、およびその他多数の問題の潜在的リスクへユーザーを さらす可能性がある。この仕様の設計は、正しく実装されれば安全となることを意図しているが、 完全な実装は大規模な作業であり、他のソフトウェアと同様に、ユーザーエージェントには セキュリティバグが存在する可能性が高い。
スクリプティングがなくても、HTML には、歴史的な理由から旧来のコンテンツとの広範な互換性の
ために必要とされる一方で、ユーザーを不都合なセキュリティ問題へさらす特定の機能がある。
特に、img 要素は、
他のいくつかの機能と組み合わせることで、インターネット上のユーザーの位置からポートスキャンを
実行する方法として使用できる。これにより、攻撃者が他の方法では判定できないローカルネットワークの
トポロジーが公開される可能性がある。
HTML は、「同一オリジンポリシー」と呼ばれることのある区画化方式に依存する。 ほとんどの場合、オリジンは、 同じホストから、同じポート上で、同じプロトコルを使用して配信されるすべてのページから構成される。
したがって、サイトの一部を構成する信頼できないコンテンツは、そのサイト上の機密コンテンツとは 異なるオリジンでホストされることを 保証することが極めて重要である。信頼できないコンテンツは、同じオリジン上の他のページを容易に 偽装し、そのオリジンからデータを読み取り、そのオリジン内でスクリプトを実行させ、 固有のトークンによってクロスサイトリクエストフォージェリ攻撃から保護されている場合でも そのオリジンへのフォームおよびそのオリジンからのフォームを送信し、そのオリジンへ公開された サードパーティーリソースまたはそのオリジンへ付与された権利を利用できる。
html」および「htm」は一般的に、
ただし決して排他的ではなく、HTML 文書の拡張子として使用される。TEXTtext/html リソースで使用されるフラグメントは、対応する Document の示された部分を参照するか、
ページ内スクリプトへ状態情報を提供する。
multipart/x-mixed-replaceこの登録はコミュニティレビュー用であり、レビュー、承認、および IANA への登録のために IESG へ提出される。
boundary(RFC2046 で定義)[RFC2046]
multipart/x-mixed-replace
リソースのサブリソースは、text/html のように
無視できないセキュリティ上の影響を持つタイプを含め、任意のタイプになり得る。
multipart/mixed と同じである。[RFC2046]
multipart/x-mixed-replace
リソースを一意に識別できるバイト列は存在しない。multipart/x-mixed-replace
リソースで使用されるフラグメントは、その本文部分で使用されるタイプによって
定義されるとおり、各本文部分へ適用される。
application/xhtml+xmlこの登録はコミュニティレビュー用であり、レビュー、承認、および IANA への登録のために IESG へ提出される。
application/xml と同じ
[RFC7303]
application/xml と同じ
[RFC7303]
application/xml と同じ
[RFC7303]
application/xml と同じ
[RFC7303]
application/xml と同じ
[RFC7303]
application/xhtml+xml
タイプを付与することは、そのリソースがHTML 名前空間に由来する文書要素を持つ可能性が高い XML 文書であることを表明する。
したがって、関連する仕様は XML、Namespaces in
XML、およびこの仕様である。[XML] [XMLNS]application/xml と同じ
[RFC7303]
application/xml と同じ
[RFC7303]
xhtml」および「xht」は、HTML
名前空間に由来する文書要素を持つ XML
リソースの拡張子として
使用されることがある。TEXTapplication/xhtml+xml
リソースで使用されるフラグメントは、他の任意のXML MIME タイプと同じ意味論を持つ。[RFC7303]
text/pingこの登録はコミュニティレビュー用であり、レビュー、承認、および IANA への登録のために IESG へ提出される。
charsetcharset パラメーターを提供してもよい。パラメーターの値は
「utf-8」でなければならない。このパラメーターは何の目的も果たさず、
旧来のサーバーとの互換性のためだけに許可される。
ハイパーリンク監査の文脈で説明された方法だけで 使用される場合、このタイプは新しいセキュリティ上の懸念をもたらさない。
text/ping リソースは常に、
4 バイト 0x50 0x49 0x4E 0x47(「PING」)から構成される。ping 属性の
処理の一部として生成される HTTP POST リクエストでのみ使用することを意図している。text/ping リソースでは、フラグメントは意味を持たない。
application/microdata+json
この登録はコミュニティレビュー用であり、レビュー、承認、および IANA への登録のために IESG へ提出される。
application/json
と同じ
[JSON]
application/json
と同じ
[JSON]
application/json
と同じ
[JSON]
application/json
と同じ
[JSON]
application/microdata+json
タイプを付与することは、そのリソースが「items」という単一のエントリを持つ
オブジェクトからなる JSON テキストであることを表明する。そのエントリはエントリの配列からなり、
各エントリは、値が文字列である「id」というエントリ、値が別の文字列である
「type」というエントリ、および値がオブジェクトである
「properties」というエントリを持つオブジェクトからなる。
そのオブジェクトの各エントリの値は、オブジェクトまたは文字列の配列からなり、
オブジェクトは前述の「items」エントリ内のオブジェクトと同じ形式である。
したがって、関連する仕様は JSON およびこの仕様である。[JSON]
HTML の microdata 機能で使用することを意図したデータを転送するアプリケーション、 特にドラッグアンドドロップの文脈におけるものが、このタイプの主要なアプリケーションクラスである。
application/json
と同じ
[JSON]
application/json
と同じ
[JSON]
application/json
と同じ
[JSON]
application/microdata+json
リソースで使用されるフラグメントは、application/json
で使用される場合と同じ意味論を持つ
(すなわち、執筆時点では、まったく意味論を持たない)。
[JSON]
application/speculationrules+json
この登録はコミュニティレビュー用であり、レビュー、承認、および IANA への登録のために IESG へ提出される。
application/json
と同じ
[JSON]
application/json
と同じ
[JSON]
application/json
と同じ
[JSON]
application/json
と同じ
[JSON]
application/microdata+json
タイプを付与することは、そのリソースが投機ルールセットの
オーサリング要件に従う JSON テキストであることを表明する。したがって、関連する仕様は
JSON およびこの仕様である。[JSON]
ウェブブラウザー。
application/json
と同じ
[JSON]
application/json
と同じ
[JSON]
application/json
と同じ
[JSON]
application/speculationrules+json
リソースで使用されるフラグメントは、application/json
で使用される場合と同じ意味論を持つ
(すなわち、執筆時点では、まったく意味論を持たない)。
[JSON]
text/event-streamこの登録はコミュニティレビュー用であり、レビュー、承認、および IANA への登録のために IESG へ提出される。
charsetcharset パラメーターを指定してもよい。パラメーターの値は
「utf-8」でなければならない。このパラメーターは何の目的も果たさず、
旧来のサーバーとの互換性のためだけに許可される。
イベントストリームを利用するコンテンツのオリジンとは異なるオリジンからのイベント ストリームは、情報漏洩を引き起こす可能性がある。これを回避するため、ユーザーエージェントには CORS の意味論を適用することが要求される。[FETCH]
イベントストリームはユーザーエージェントを圧倒する可能性がある。ユーザーエージェントは、 イベントストリームからの過剰な情報によってローカルリソースが枯渇することを回避するため、 適切な制限を適用することが期待される。
サーバーがクライアントを急速に再接続させる状況が発生した場合、サーバーが圧倒される可能性が ある。サーバーは容量の問題を示すために 5xx ステータスコードを使用するべきである。これにより、 適合するクライアントが自動的に再接続することを防止できる。
text/event-stream リソースでは、フラグメントは意味を持たない。
web+ スキーム接頭辞この節では、IANA URI スキームレジストリで使用するための規約を説明する。この節自体は、 特定のスキームを登録しない。[RFC7595]
web+」で始まり、その後に a~z の範囲の
1 文字以上の英字が続くスキーム。
web+」スキームは、該当する場合に UTF-8 エンコーディングを
使用するべきである。web+」スキームのハンドラーを登録できる。
したがって、これらのスキームを、HTTP などの中核的なプラットフォーム機能となることを意図した
機能に使用してはならない。同様に、そのようなスキームは、ユーザー名、パスワード、個人情報、
または機密プロジェクト名などの機密情報を URL に保存してはならない。
次の節では、適合する要素および機能のみを扱う。
この節は非規範的である。
セル内のアスタリスク(*)は、実際の規則が上の表に示されたものより 複雑であることを示す。
†「親」列のカテゴリーは、それ自体がそのカテゴリーに属する要素ではなく、
内容モデルに指定されたカテゴリーを列挙する親を指す。たとえば、a
要素の「親」列には
「フレージング」と記載されているため、内容モデルに「フレージング」カテゴリーを含む任意の要素が
a 要素の親になり得る。
「フロー」カテゴリーはすべての「フレージング」要素を含むため、th 要素は
a 要素の親になり得る。
この節は非規範的である。
この節は非規範的である。
| 属性 | 要素 | 説明 | 値 |
|---|---|---|---|
abbr
|
th
|
他のコンテキストでセルを参照するときに見出しセルに使用する代替ラベル | テキスト* |
accept
|
input
|
ファイルアップロードコントロールで予想される ファイルタイプのヒント | パラメーターを持たない妥当な MIME タイプ文字列、または
audio/*、video/*、もしくは image/* からなる、コンマ区切り
トークンの集合*
|
accept-charset
|
form
|
フォーム送信に使用する 文字エンコーディング | 「UTF-8」とのASCII
大文字・小文字を区別しない一致
|
accesskey
|
HTML 要素 | 要素を作動またはフォーカスするためのキーボードショートカット | 互いに同一ではなく、 それぞれ長さが一つのコードポイントである、一意な空白区切りトークンの 順序付き集合 |
action
|
form
|
フォーム送信に使用するURL | 空白で囲まれている可能性のある 妥当な空でない URL |
allow
|
iframe
|
iframe の内容に
適用する権限
ポリシー
|
直列化された権限ポリシー |
allowfullscreen
|
iframe
|
iframe の内容に
requestFullscreen()
の使用を許可するかどうか
|
ブール属性 |
alpha
|
input
|
色のアルファ成分の設定を許可する | ブール属性 |
alt
|
area;
img;
input
|
画像が利用できない場合に使用する代替テキスト | テキスト* |
as
|
link
|
プリロード要求の宛先(rel="preload" および rel="modulepreload"
の場合)
|
rel="preload" の場合はプリロード宛先、rel="modulepreload"
の場合はモジュールプリロード宛先
|
async
|
script
|
取得中にブロックせず、利用可能になったときにスクリプトを実行する | ブール属性 |
autocapitalize
|
HTML 要素 | 推奨される自動大文字化の動作(対応する入力方式の場合) | 「on」;
「off」;
「none」;
「sentences」;
「words」;
「characters」
|
autocomplete
|
form
|
フォーム内のコントロールに対する自動入力機能の既定設定 | 「on」; 「off」
|
autocomplete
|
input;
select;
textarea
|
フォーム自動入力機能のヒント | 自動入力フィールド名および関連する トークン* |
autocorrect
|
HTML 要素 | 推奨される自動修正の動作(対応する入力方式の場合) | 「on」;
「off」;
空文字列
|
autofocus
|
HTML 要素 | ページが読み込まれたときに要素を自動的にフォーカスする | ブール属性 |
autoplay
|
audio;
video
|
ページが読み込まれたときにメディアリソースを自動的に開始できることを示すヒント | ブール属性 |
blocking
|
link;
script;
style
|
要素がレンダリングをブロックする可能性があるかどうか | 一意な空白区切りトークンの 順序なし集合* |
charset
|
meta
|
文字 エンコーディング宣言 | 「utf-8」
|
checked
|
input
|
コントロールがチェックされているかどうか | ブール属性 |
cite
|
blockquote;
del;
ins;
q
|
引用元または編集に関する詳細情報へのリンク | 空白で囲まれている可能性のある 妥当な URL |
class
|
HTML 要素 | 要素が属するクラス | 空白区切り トークンの集合 |
closedby
|
dialog
|
ダイアログを閉じるユーザー操作 | 「any」;
「closerequest」;
「none」;
|
color
|
link
|
サイトのアイコンをカスタマイズするときに使用する色(rel="mask-icon"
の場合)
|
CSS <color> |
colorspace
|
input
|
直列化された色の色空間 | 「limited-srgb」;
「display-p3」
|
cols
|
textarea
|
一行あたりの最大文字数 | 0 より大きい妥当な非負整数 |
colspan
|
td;
th
|
セルがまたがる列数 | 0 より大きい妥当な非負整数 |
command
|
button
|
対象要素へ実行するアクションを示す。 | 「toggle-popover」;
「show-popover」;
「hide-popover」;
「close」;
「request-close」;
「show-modal」;
カスタムコマンド
キーワード
|
commandfor
|
button
|
呼び出す別の要素を対象とする。 | ID* |
content
|
meta
|
要素の値 | テキスト* |
contenteditable
|
HTML 要素 | 要素が編集可能かどうか | 「true」;
「false」;
「plaintext-only」;
空文字列
|
controls
|
audio;
video
img;
|
ユーザーエージェントのコントロールを表示する | ブール属性 |
coords
|
area
|
イメージマップ内に作成する図形の座標 | 妥当な浮動小数点数のリスト* |
crossorigin
|
audio;
img;
link;
script;
video
|
要素がオリジン間要求を処理する方法 | 「anonymous」;
「use-credentials」;
空文字列
|
data
|
object
|
リソースのアドレス | 空白で囲まれている可能性のある 妥当な空でない URL |
datetime
|
del;
ins
|
変更の日付およびオプションの時刻 | オプションの時刻を持つ妥当な日付文字列 |
datetime
|
time
|
機械可読な値 | 妥当な月文字列、 妥当な日付文字列、 妥当な年なし日付 文字列、 妥当な時刻文字列、 妥当な ローカル日時文字列、 妥当な タイムゾーンオフセット文字列、 妥当な グローバル日時文字列、 妥当な週文字列、 妥当な非負 整数、または 妥当な期間文字列 |
decoding
|
img
|
表示のためにこの画像を処理するときに使用するデコードのヒント | 「sync」;
「async」;
「auto」
|
default
|
track
|
より適切なテキストトラックがない場合に トラックを有効にする | ブール属性 |
defer
|
script
|
スクリプトの実行を遅延する | ブール属性 |
dir
|
HTML 要素 | 要素のテキストの方向性 | 「ltr」; 「rtl」; 「auto」
|
dir
|
bdo
|
要素のテキストの方向性 | 「ltr」; 「rtl」
|
dirname
|
input;
textarea
|
フォーム送信で要素の方向性を送信するために使用するフォームコントロールの名前 | テキスト* |
disabled
|
button;
input;
optgroup;
option;
select;
textarea;
フォーム関連カスタム要素
|
フォームコントロールが無効かどうか | ブール属性 |
disabled
|
fieldset
|
legend 内のものを
除き、子孫のフォームコントロールが無効かどうか
|
ブール属性 |
disabled
|
link
|
リンクが無効かどうか | ブール属性 |
download
|
a;
area
|
リソースへナビゲートする代わりにダウンロードするかどうか、およびその場合のファイル名 | テキスト |
draggable
|
HTML 要素 | 要素がドラッグ可能かどうか | 「true」; 「false」
|
enctype
|
form
|
フォーム送信に使用するエントリリストのエンコーディングタイプ | 「application/x-www-form-urlencoded」;
「multipart/form-data」;
「text/plain」
|
enterkeyhint
|
HTML 要素 | Enter キーのアクションを選択するためのヒント | 「enter」;
「done」;
「go」;
「next」;
「previous」;
「search」;
「send」
|
fetchpriority
|
img;
link;
script
|
要素によって開始されるフェッチの優先度を設定する | 「auto」;
「high」;
「low」
|
for
|
label
|
ラベルをフォームコントロールに関連付ける | ID* |
for
|
output
|
出力の計算元となったコントロールを指定する | ID からなる一意な空白区切りトークンの 順序なし集合* |
form
|
button;
fieldset;
input;
object;
output;
select;
textarea;
フォーム関連カスタム要素
|
要素を form 要素に関連付ける
|
ID* |
formaction
|
button;
input
|
フォーム送信に使用するURL | 空白で囲まれている可能性のある 妥当な空でない URL |
formenctype
|
button;
input
|
フォーム送信に使用するエントリリストのエンコーディングタイプ | 「application/x-www-form-urlencoded」;
「multipart/form-data」;
「text/plain」
|
formmethod
|
button;
input
|
フォーム送信に使用する形式 | 「get」;
「post」;
「dialog」
|
formnovalidate
|
button;
input
|
フォーム送信で フォームコントロールの検証を回避する | ブール属性 |
formtarget
|
button;
input
|
フォーム送信のためのナビゲータブル | 妥当なナビゲータブルターゲット名または キーワード |
headers
|
td;
th
|
このセルの見出しセル | ID からなる一意な空白区切りトークンの 順序なし集合* |
headingoffset
|
HTML 要素 | 子孫の見出しレベルをオフセットする | 0 以上 8 以下の妥当な非負整数 |
headingreset
|
HTML 要素 | 見出しオフセットの計算が、この属性を持つ要素を越えてたどることを防ぐ | ブール属性 |
height
|
canvas;
embed;
iframe;
img;
input;
object;
source(picture 内);
video
|
垂直方向の寸法 | 妥当な非負 整数 |
hidden
|
要素が関連するかどうか | 「」; 「」; 空文字列 | |
high
|
meter
|
高い範囲の下限 | 妥当な 浮動小数点数* |
href
|
a;
area
|
ハイパーリンクのアドレス | 空白で囲まれている可能性のある 妥当な URL |
href
|
link
|
ハイパーリンクのアドレス | 空白で囲まれている可能性のある 妥当な空でない URL |
href
|
base
|
文書の基底 URL | 空白で囲まれている可能性のある 妥当な URL |
hreflang
|
a;
link
|
リンク先リソースの言語 | 妥当な BCP 47 言語タグ |
http-equiv
|
meta
|
プラグマ指令 | 「content-type」;
「default-style」;
「refresh」;
「x-ua-compatible」;
「content-security-policy」
|
id
|
HTML 要素 | 要素のID | テキスト* |
imagesizes
|
link
|
異なるページレイアウトに対する画像サイズ(rel="preload" の場合)
|
妥当なソースサイズの リスト |
imagesrcset
|
link
|
高解像度ディスプレイや小型モニターなど、異なる状況で使用する画像(rel="preload" の場合)
|
画像候補文字列の コンマ区切りリスト |
inert
|
HTML 要素 | 要素が不活性かどうか。 | ブール属性 |
inputmode
|
HTML 要素 | 入力方式を選択するためのヒント | 「none」;
「text」;
「tel」;
「email」;
「url」;
「numeric」;
「decimal」;
「search」
|
integrity
|
link;
script
|
サブリソース完全性の検査で使用される完全性メタデータ [SRI] | テキスト |
is
|
HTML 要素 | カスタマイズされた 組み込み要素を作成する | 定義されたカスタマイズされた組み込み要素の妥当なカスタム要素名 |
ismap
|
img
|
画像がサーバー側イメージマップかどうか | ブール属性 |
itemid
|
HTML 要素 | microdata 項目のグローバル識別子 | 空白で囲まれている可能性のある 妥当な URL |
itemprop
|
HTML 要素 | microdata 項目のプロパティ名 | 妥当な絶対 URL、定義済みプロパティ名、 またはテキストからなる一意な空白区切りトークンの 順序なし集合* |
itemref
|
HTML 要素 | 参照される要素 | ID からなる一意な空白区切りトークンの 順序なし集合* |
itemscope
|
HTML 要素 | microdata 項目を導入する | ブール属性 |
itemtype
|
HTML 要素 | microdata 項目の項目タイプ | 妥当な絶対 URLからなる一意な空白区切りトークンの 順序なし集合* |
kind
|
track
|
テキストトラックのタイプ | 「subtitles」;
「captions」;
「descriptions」;
「chapters」;
「metadata」
|
label
|
optgroup;
option;
track
|
ユーザーに表示されるラベル | テキスト |
lang
|
HTML 要素 | 要素の言語 | 妥当な BCP 47 言語タグまたは空文字列 |
list
|
input
|
自動補完の選択肢のリスト | ID* |
loading
|
iframe;
img;
audio;
video
|
読み込みの遅延を決定するときに使用される | 「lazy」;
「eager」
|
loop
|
audio;
video
|
メディアリソースを ループするかどうか | ブール属性 |
low
|
meter
|
低い範囲の上限 | 妥当な浮動小数点数* |
max
|
input
|
最大値 | 場合による* |
max
|
meter;
progress
|
範囲の上限 | 妥当な浮動小数点数* |
maxlength
|
input;
textarea
|
値の最大長さ | 妥当な非負整数 |
media
|
link;
meta;
source;
style
|
適用可能なメディア | 妥当なメディアクエリーの リスト |
method
|
form
|
フォーム送信に使用する形式 | 「get」;
「post」;
「dialog」
|
min
|
input
|
最小値 | 場合による* |
min
|
meter
|
範囲の下限 | 妥当な浮動小数点数* |
minlength
|
input;
textarea
|
値の最小長さ | 妥当な非負整数 |
multiple
|
input;
select
|
複数の値を許可するかどうか | ブール属性 |
muted
|
audio;
video
|
既定でメディアリソースを ミュートするかどうか | ブール属性 |
name
|
button;
fieldset;
input;
output;
select;
textarea;
フォーム関連カスタム要素
|
フォーム送信および form.elements API で
使用する要素の名前
|
テキスト* |
name
|
details
|
相互排他的な details 要素の
グループ名
|
テキスト* |
name
|
form
|
document.forms API で
使用するフォームの名前
|
テキスト* |
name
|
iframe;
object
|
コンテンツナビゲータブルの名前 | 妥当なナビゲータブルターゲット名または キーワード |
name
|
map
|
usemap 属性から
参照するイメージマップの名前
|
テキスト* |
name
|
meta
|
メタデータ名 | テキスト* |
name
|
slot
|
シャドウツリーのスロット名 | テキスト |
nomodule
|
script
|
モジュールスクリプトをサポートするユーザーエージェントでの 実行を防ぐ | ブール属性 |
nonce
|
HTML 要素 | コンテンツセキュリティポリシーの検査で使用される暗号学的 nonce [CSP] | テキスト |
novalidate
|
form
|
フォーム送信で フォームコントロールの検証を回避する | ブール属性 |
open
|
details
|
詳細が表示されているかどうか | ブール属性 |
open
|
dialog
|
ダイアログボックスが表示されているかどうか | ブール属性 |
optimum
|
meter
|
ゲージ内の最適値 | 妥当な浮動小数点数* |
pattern
|
input
|
フォームコントロールの値が一致すべきパターン | JavaScript の Pattern 生成規則に 一致する正規表現 |
ping
|
a;
area
|
ping するURL | 妥当な空でない URLからなる空白区切り トークンの集合 |
placeholder
|
input;
textarea
|
フォームコントロール内に配置されるユーザー可視のラベル | テキスト* |
playsinline
|
video
|
ユーザーエージェントに、要素の再生領域内で動画コンテンツを表示するよう促す | ブール属性 |
popover
|
HTML 要素 | 要素をポップオーバー要素にする | 「auto」;
「manual」;
「hint」;
空文字列
|
popovertarget
|
button;
input
|
切り替え、表示、または非表示にするポップオーバー要素を対象とする | ID* |
popovertargetaction
|
button;
input
|
対象のポップオーバー要素を切り替えるか、表示するか、非表示にするかを示す | 「toggle」;
「show」;
「hide」
|
poster
|
video
|
動画再生前に表示するポスターフレーム | 空白で囲まれている可能性のある 妥当な空でない URL |
preload
|
audio;
video
|
メディア リソースが必要とする可能性が高いバッファリング量のヒント | 「none」;
「metadata」;
「auto」;
空文字列
|
readonly
|
input;
textarea
|
ユーザーによる値の編集を許可するかどうか | ブール属性 |
readonly
|
フォーム関連カスタム要素 | willValidate
およびカスタム要素の作者が追加した動作に影響する
|
ブール属性 |
referrerpolicy
|
a;
area;
iframe;
img;
link;
script
|
要素によって開始されるフェッチのリファラーポリシー | リファラーポリシー |
rel
|
a;
area
|
ハイパーリンクを含む文書内の位置と宛先リソースとの関係 | 一意な空白区切りトークンの 順序なし集合* |
rel
|
link
|
ハイパーリンクを含む文書と宛先リソースとの関係 | 一意な空白区切りトークンの 順序なし集合* |
required
|
input;
select;
textarea
|
フォーム送信にコントロールが必須かどうか | ブール属性 |
reversed
|
ol
|
リストを逆順に番号付けする | ブール属性 |
rows
|
textarea
|
表示する行数 | 0 より大きい妥当な非負整数 |
rowspan
|
td;
th
|
セルがまたがる行数 | 妥当な非負整数 |
sandbox
|
iframe
|
入れ子のコンテンツに対するセキュリティ規則 | 次のものからなる、ASCII
大文字・小文字を区別しない一意な空白区切りトークンの
順序なし集合
|
scope
|
th
|
見出しセルがどのセルに適用されるかを指定する | 「row」;
「col」;
「rowgroup」;
「colgroup」
|
selected
|
option
|
選択肢が既定で選択されているかどうか | ブール属性 |
shadowrootclonable
|
template
|
宣言的シャドウルート上の複製可能を設定する | ブール属性 |
shadowrootcustomelementregistry
|
template
|
宣言的シャドウルートがカスタム要素レジストリを使用することを示せるようにする | ブール属性 |
shadowrootdelegatesfocus
|
template
|
宣言的シャドウルート上のフォーカス委譲を設定する | ブール属性 |
shadowrootmode
|
template
|
ストリーミング宣言的シャドウルートを有効にする | 「open」;
「closed」
|
shadowrootserializable
|
template
|
宣言的シャドウルート上の直列化可能を設定する | ブール属性 |
shadowrootslotassignment
|
template
|
宣言的シャドウルート上のスロット 割り当てを設定する | 「named」;
「manual」
|
shape
|
area
|
イメージマップ内に作成する図形の種類 | 「circle」;
「default」;
「poly」;
「rect」
|
size
|
input;
select
|
コントロールのサイズ | 0 より大きい妥当な非負整数 |
sizes
|
link
|
アイコンのサイズ(rel="icon" の場合)
|
サイズからなる、ASCII 大文字・小文字を区別しない一意な空白区切りトークンの 順序なし集合* |
sizes
|
img;
source
|
異なるページレイアウトに対する画像サイズ | 妥当なソースサイズのリスト |
slot
|
HTML 要素 | 要素が希望するスロット | テキスト |
span
|
col;
colgroup
|
要素がまたがる列数 | 0 より大きい妥当な非負整数 |
spellcheck
|
HTML 要素 | 要素の綴りおよび文法を検査するかどうか | 「true」;
「false」;
空文字列
|
src
|
audio;
embed;
iframe;
img;
input;
script;
source(video または audio 内);
track;
video
|
リソースのアドレス | 空白で囲まれている可能性のある 妥当な空でない URL |
srcdoc
|
iframe
|
iframe 内に
レンダリングする文書
|
iframe
srcdoc 文書のソース*
|
srclang
|
track
|
テキストトラックの言語 | 妥当な BCP 47 言語タグ |
srcset
|
img;
source
|
高解像度ディスプレイや小型モニターなど、異なる状況で使用する画像 | 画像候補文字列のコンマ区切りリスト |
start
|
ol
|
リストの開始値 | 妥当な整数 |
step
|
input
|
フォームコントロールの値が一致すべき粒度 | 0 より大きい妥当な浮動小数点数、または「any」
|
style
|
HTML 要素 | 表示および書式設定の指示 | CSS 宣言* |
tabindex
|
HTML 要素 | 要素がフォーカス可能かつ順次フォーカス可能かどうか、 および順次フォーカスナビゲーションのための要素の相対順序 | 妥当な整数 |
target
|
a;
area
|
ハイパーリンクのナビゲーションのためのナビゲータブル | 妥当なナビゲータブルターゲット名または キーワード |
target
|
base
|
ハイパーリンクのナビゲーションおよびフォーム送信のための既定のナビゲータブル | 妥当なナビゲータブルターゲット名または キーワード |
target
|
form
|
フォーム送信のためのナビゲータブル | 妥当なナビゲータブルターゲット名または キーワード |
title
|
HTML 要素 | 要素の補足情報 | テキスト |
title
|
abbr;
dfn
|
略語の完全な用語または展開形 | テキスト |
title
|
input
|
パターンの説明(pattern
属性とともに
使用する場合)
|
テキスト |
title
|
link
|
リンクのタイトル | テキスト |
title
|
link;
style
|
CSS スタイルシートセット名 | テキスト |
translate
|
HTML 要素 | ページのローカライズ時に要素を翻訳するかどうか | 「yes」; 「no」; 空文字列
|
type
|
a;
link
|
参照されるリソースのタイプのヒント | 妥当な MIME タイプ文字列 |
type
|
button
|
ボタンのタイプ | 「submit」;
「reset」;
「button」
|
type
|
embed;
object;
source
|
埋め込みリソースのタイプ | 妥当な MIME タイプ文字列 |
type
|
input
|
フォームコントロールのタイプ | input タイプキーワード
|
type
|
ol
|
リストマーカーの種類 | 「1」;
「a」;
「A」;
「i」;
「I」
|
type
|
script
|
スクリプトのタイプ | 「module」; 「importmap」; 「speculationrules」; JavaScript MIME タイプのエッセンス一致ではない
妥当な MIME タイプ文字列
|
usemap
|
img
|
使用するイメージマップの名前 | 妥当なハッシュ名 参照* |
value
|
button;
option
|
フォーム送信に使用する値 | テキスト |
value
|
data
|
機械可読な値 | テキスト* |
value
|
input
|
フォームコントロールの値 | 場合による* |
value
|
li
|
リスト項目の序数値 | 妥当な整数 |
value
|
meter;
progress
|
要素の現在値 | 妥当な浮動小数点数 |
width
|
canvas;
embed;
iframe;
img;
input;
object;
source(picture 内);
video
|
水平方向の寸法 | 妥当な非負整数 |
wrap
|
textarea
|
フォーム送信のためにフォームコントロールの値を 折り返す方法 | 「soft」;
「hard」
|
writingsuggestions
|
HTML 要素 | 要素が文章作成の提案を提供できるかどうか。 | 「true」;
「false」;
空文字列
|
セル内のアスタリスク(*)は、実際の規則が上の表に示されたものより 複雑であることを示す。
すべての現行エンジンでサポートされている。
すべての現行エンジンでサポートされている。
すべての現行エンジンでサポートされている。
すべての現行エンジンでサポートされている。
すべての現行エンジンでサポートされている。
すべての現行エンジンでサポートされている。
すべての現行エンジンでサポートされている。
本节是非规范性的。
本节是非规范性的。
AudioTrackAudioTrackListBarPropBeforeUnloadEventBroadcastChannelCanvasGradientCanvasPatternCanvasRenderingContext2D
CloseWatcherCommandEventCustomElementRegistryCustomStateSetDOMParserDOMStringListDOMStringMapDataTransferDataTransferItemDataTransferItemList
DedicatedWorkerGlobalScope
Document,部分接口 1 2DragEventElement,
部分接口
ElementInternalsErrorEventEventSourceExternalFormDataEventHTMLAllCollectionHTMLAnchorElement,部分接口HTMLAreaElement,部分接口HTMLAudioElementHTMLBRElement,部分接口HTMLBaseElementHTMLBodyElement,部分接口HTMLButtonElementHTMLCanvasElementHTMLDListElement,部分接口HTMLDataElementHTMLDataListElementHTMLDetailsElementHTMLDialogElementHTMLDirectoryElement
HTMLDivElement,部分接口HTMLElementHTMLEmbedElement,部分接口HTMLFieldSetElementHTMLFontElementHTMLFormControlsCollection
HTMLFormElementHTMLFrameElementHTMLFrameSetElementHTMLHRElement,部分接口HTMLHeadElementHTMLHeadingElement,部分接口HTMLHtmlElement,部分接口HTMLIFrameElement,部分接口HTMLImageElement,部分接口HTMLInputElement,部分接口HTMLLIElement,部分接口HTMLLabelElementHTMLLegendElement,部分接口HTMLLinkElement,部分接口HTMLMapElementHTMLMarqueeElementHTMLMediaElementHTMLMenuElement,部分接口HTMLMetaElement,部分接口HTMLMeterElementHTMLModElementHTMLOListElement,部分接口HTMLObjectElement,部分接口HTMLOptGroupElementHTMLOptionElementHTMLOptionsCollectionHTMLOutputElementHTMLParagraphElement,
部分接口
HTMLParamElementHTMLPictureElementHTMLPreElement,部分接口HTMLProgressElementHTMLQuoteElementHTMLScriptElement,部分接口HTMLSelectElementHTMLSelectedContentElement
HTMLSlotElementHTMLSourceElementHTMLSpanElementHTMLStyleElement,部分接口HTMLTableCaptionElement,
部分接口
HTMLTableCellElement,
部分接口
HTMLTableColElement,部分接口HTMLTableElement,部分接口HTMLTableRowElement,部分接口HTMLTableSectionElement,
部分接口
HTMLTemplateElementHTMLTextAreaElementHTMLTimeElementHTMLTitleElementHTMLTrackElementHTMLUListElement,部分接口HTMLUnknownElementHTMLVideoElementHashChangeEventHistoryImageBitmapImageBitmapRenderingContext
ImageDataLocationMediaErrorMessageChannelMessageEventMessagePortMimeTypeMimeTypeArrayNavigateEventNavigationNavigationActivation
NavigationCurrentEntryChangeEvent
NavigationDestinationNavigationHistoryEntry
NavigationPrecommitController
NavigationTransition
Navigator,部分接口NotRestoredReasonDetails
NotRestoredReasonsOffscreenCanvasOffscreenCanvasRenderingContext2D
OriginPageRevealEventPageSwapEventPageTransitionEventPath2DPluginPluginArrayPopStateEventPromiseRejectionEventRadioNodeListRange,
部分接口
SanitizerShadowRoot,
部分接口
SharedWorkerSharedWorkerGlobalScope
StorageStorageEventSubmitEventTextMetricsTextTrackTextTrackCueTextTrackCueListTextTrackListTimeRangesToggleEventTrackEventUserActivationValidityStateVideoTrackVideoTrackListVisibilityStateEntry
Window,部分接口WorkerWorkerGlobalScopeWorkerLocationWorkerNavigatorWorkletWorkletGlobalScopeXMLSerializer本节是非规范性的。
下表列出了本规范触发的事件,但不包括已在媒体元素事件和 拖放事件中定义的事件。
| 事件 | 接口 | 相关目标 | 描述 |
|---|---|---|---|
DOMContentLoaded
所有当前引擎均支持。 Firefox1+Safari3.1+Chrome1+
Opera9+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android37+Samsung Internet?Opera Android10.1+ |
Event
|
Document
|
解析器完成后,在 Document 上触发
|
afterprint
所有当前引擎均支持。 Firefox6+Safari13+Chrome63+
Opera?Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
Event
|
Window
|
打印后在 Window 上触发
|
beforeprint
所有当前引擎均支持。 Firefox6+Safari13+Chrome63+
Opera?Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
Event
|
Window
|
打印前在 Window 上触发
|
beforematch
仅一个引擎支持。 Firefox否Safari否Chrome102+
Opera否Edge102+ Edge(旧版)?Internet Explorer否 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
Event
|
元素 | 在具有 属性的元素显示之前,于这些元素上触发。 |
beforetoggle
HTMLElement/beforetoggle_event 所有当前引擎均支持。 Firefox🔰
114+Safari预览版+Chrome114+
Opera?Edge114+ Edge(旧版)?Internet Explorer否 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
ToggleEvent
|
元素 | 当具有 popover
属性的元素在显示状态与隐藏状态之间转换时,于该元素上触发
|
beforeunload
所有当前引擎均支持。 Firefox1+Safari3+Chrome1+
Opera12+Edge79+ Edge(旧版)12+Internet Explorer4+ Firefox Android?Safari iOS1+Chrome Android?WebView Android?Samsung Internet?Opera Android12+ |
BeforeUnloadEvent
|
Window
|
当页面即将卸载时,在 Window 上触发,
以便页面在需要时显示警告提示
|
blur
|
Event
|
Window、元素
|
当节点不再获得焦点时,在节点上触发 |
cancel
HTMLDialogElement/cancel_event 所有当前引擎均支持。 Firefox98+Safari15.4+Chrome37+
Opera?Edge79+ Edge(旧版)?Internet Explorer否 Firefox Android?Safari iOS?Chrome Android否WebView Android?Samsung Internet?Opera Android? |
Event
|
CloseWatcher、dialog 元素、input 元素
|
当 CloseWatcher 对象或
dialog 元素收到
关闭请求时,或者当其 type 属性处于文件状态的 input 元素中用户未更改其选择时触发
|
change
所有当前引擎均支持。 Firefox1+Safari3+Chrome1+
Opera9+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android10.1+ |
Event
|
表单控件 | 当用户确认值更改时,在控件上触发(另请参阅 input
事件)
|
click
|
PointerEvent
|
元素 | 通常是鼠标事件;当通过非指针输入设备(例如键盘)激活元素时,也会在运行元素的激活行为之前,于该元素上以合成方式触发 |
close
所有当前引擎均支持。 Firefox98+Safari15.4+Chrome37+
Opera?Edge79+ Edge(旧版)?Internet Explorer否 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
Event
|
CloseWatcher、dialog 元素、MessagePort
|
当 CloseWatcher 对象或
dialog 元素通过
关闭请求或 Web 开发者代码关闭时触发,
或者当 MessagePort 对象被解除纠缠时触发
|
command
|
CommandEvent
|
元素 | 当元素通过 commandfor
属性处理用户调用时,
在该元素上触发。
|
connect
SharedWorkerGlobalScope/connect_event 所有当前引擎均支持。 Firefox29+Safari16+Chrome4+
Opera10.6+Edge79+ Edge(旧版)?Internet Explorer否 Firefox Android?Safari iOS16+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
MessageEvent
|
SharedWorkerGlobalScope
|
当新客户端连接时,在共享工作者的全局作用域上触发 |
contextlost
HTMLCanvasElement/webglcontextlost_event 仅一个引擎支持。 Firefox否Safari否Chrome98+
Opera?Edge98+ Edge(旧版)?Internet Explorer否 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
Event
|
canvas 元素、OffscreenCanvas 对象
|
当对应的 CanvasRenderingContext2D
或 OffscreenCanvasRenderingContext2D
丢失时触发
|
contextrestored
HTMLCanvasElement/contextrestored_event 仅一个引擎支持。 Firefox否Safari否Chrome98+
Opera?Edge98+ Edge(旧版)?Internet Explorer否 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
Event
|
canvas 元素、OffscreenCanvas 对象
|
当对应的 CanvasRenderingContext2D
或 OffscreenCanvasRenderingContext2D
在丢失后恢复时触发
|
currententrychange
|
NavigationCurrentEntryChangeEvent
|
Navigation
|
当 navigation.currentEntry
发生更改时触发
|
dispose
|
Event
|
NavigationHistoryEntry
|
当与 NavigationHistoryEntry
对应的会话历史记录条目
被永久从会话历史记录中移除,且无法再遍历到该条目时触发
|
error
所有当前引擎均支持。 Firefox6+Safari5+Chrome6+
Opera12+Edge79+ Edge(旧版)?Internet Explorer否 Firefox Android45+Safari iOS5+Chrome Android?WebView Android?Samsung Internet?Opera Android12+ 所有当前引擎均支持。 Firefox6+Safari5.1+Chrome10+
Opera?Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android37+Samsung Internet?Opera Android? |
Event
或 ErrorEvent
|
全局作用域对象、Worker 对象、元素、
与网络相关的对象
|
发生意外错误时触发(例如网络错误、脚本错误、解码错误) |
focus
|
Event
|
Window、元素
|
当节点获得焦点时,在节点上触发 |
formdata
HTMLFormElement/formdata_event 所有当前引擎均支持。 Firefox72+Safari15+Chrome77+
Opera?Edge79+ Edge(旧版)?Internet Explorer否 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
FormDataEvent
|
form 元素
|
当 form 元素
构造条目列表时,
在该元素上触发
|
hashchange
所有当前引擎均支持。 Firefox3.6+Safari5+Chrome8+
Opera10.6+Edge79+ Edge(旧版)12+Internet Explorer8+ Firefox Android?Safari iOS5+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
HashChangeEvent
|
Window
|
当文档 URL 的片段部分发生更改时,在 Window 上触发
|
input
|
Event
|
元素 | 当用户更改 contenteditable
元素的内容,
或更改表单控件的值时触发。对于表单控件,另请参阅 change 事件。
|
invalid
HTMLInputElement/invalid_event 所有当前引擎均支持。 Firefox4+Safari5+Chrome10+
Opera10+Edge79+ Edge(旧版)12+Internet Explorer10+ Firefox Android64+Safari iOS5+Chrome Android?WebView Android4+Samsung Internet4.0+Opera Android12+ |
Event
|
表单控件 | 在表单验证期间,如果控件不满足其约束条件,则在该控件上触发 |
languagechange
所有当前引擎均支持。 Firefox32+Safari10.1+Chrome37+
Opera?Edge79+ Edge(旧版)?Internet Explorer否 Firefox Android4+Safari iOS?Chrome Android?WebView Android?Samsung Internet4.0+Opera Android? WorkerGlobalScope/languagechange_event 所有当前引擎均支持。 Firefox74+Safari4+Chrome4+
Opera11.5+Edge79+ Edge(旧版)?Internet Explorer否 Firefox Android?Safari iOS5+Chrome Android?WebView Android37+Samsung Internet?Opera Android? |
Event
|
全局作用域对象 | 当用户的首选语言发生更改时,在全局作用域对象上触发 |
load
|
Event
|
Window、元素
|
当文档完成加载时,在 Window 上触发;
当包含资源的元素(例如 img、embed)中的资源完成加载时,
在该元素上触发
|
message
BroadcastChannel/message_event 所有当前引擎均支持。 Firefox38+Safari15.4+Chrome54+
Opera?Edge79+ Edge(旧版)?Internet Explorer否 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? DedicatedWorkerGlobalScope/message_event 所有当前引擎均支持。 Firefox3.5+Safari4+Chrome4+
Opera10.6+Edge79+ Edge(旧版)12+Internet Explorer10+ Firefox Android?Safari iOS5+Chrome Android?WebView Android37+Samsung Internet?Opera Android11.5+ 所有当前引擎均支持。 Firefox6+Safari5+Chrome6+
Opera12+Edge79+ Edge(旧版)?Internet Explorer否 Firefox Android45+Safari iOS5+Chrome Android?WebView Android?Samsung Internet?Opera Android12+ 所有当前引擎均支持。 Firefox41+Safari5+Chrome2+
Opera10.6+Edge79+ Edge(旧版)12+Internet Explorer10+ Firefox Android?Safari iOS?Chrome Android?WebView Android37+Samsung Internet?Opera Android11.5+ 所有当前引擎均支持。 Firefox9+Safari4+Chrome60+
Opera?Edge79+ Edge(旧版)12+Internet Explorer8+ Firefox Android?Safari iOS4+Chrome Android?WebView Android?Samsung Internet?Opera Android47+ 所有当前引擎均支持。 Firefox3.5+Safari4+Chrome4+
Opera10.6+Edge79+ Edge(旧版)12+Internet Explorer10+ Firefox Android?Safari iOS5+Chrome Android?WebView Android?Samsung Internet?Opera Android11.5+ |
MessageEvent
|
Window、EventSource、MessagePort、BroadcastChannel、DedicatedWorkerGlobalScope、
Worker、ServiceWorkerContainer
|
当对象接收到消息时,在该对象上触发 |
messageerror
BroadcastChannel/messageerror_event 所有当前引擎均支持。 Firefox57+Safari15.4+Chrome60+
Opera?Edge79+ Edge(旧版)?Internet Explorer否 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android47+ DedicatedWorkerGlobalScope/messageerror_event 所有当前引擎均支持。 Firefox57+Safari16.4+Chrome60+
Opera?Edge79+ Edge(旧版)18Internet Explorer否 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android47+ MessagePort/messageerror_event 所有当前引擎均支持。 Firefox57+Safari16.4+Chrome60+
Opera?Edge79+ Edge(旧版)18Internet Explorer否 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android47+ 所有当前引擎均支持。 Firefox57+Safari16.4+Chrome60+
Opera?Edge79+ Edge(旧版)18Internet Explorer否 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android47+ 所有当前引擎均支持。 Firefox57+Safari16.4+Chrome60+
Opera?Edge79+ Edge(旧版)18Internet Explorer否 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android47+ |
MessageEvent
|
Window、MessagePort、BroadcastChannel、DedicatedWorkerGlobalScope、
Worker、ServiceWorkerContainer
|
当对象接收到无法反序列化的消息时,在该对象上触发 |
navigate
|
NavigateEvent
|
Navigation
|
在可导航对象导航、重新加载、遍历或以其他方式更改其 URL 之前触发 |
navigateerror
|
ErrorEvent
|
Navigation
|
当导航未成功完成时触发 |
navigatesuccess
|
Event
|
Navigation
|
当导航成功完成时触发 |
offline
所有当前引擎均支持。 Firefox9+Safari4+Chrome3+
Opera?Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android? |
Event
|
全局作用域对象 | 当网络连接失败时,在全局作用域对象上触发 |
online
所有当前引擎均支持。 Firefox9+Safari4+Chrome3+
Opera?Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android? |
Event
|
全局作用域对象 | 当网络连接恢复时,在全局作用域对象上触发 |
open
所有当前引擎均支持。 Firefox6+Safari5+Chrome6+
Opera12+Edge79+ Edge(旧版)?Internet Explorer否 Firefox Android45+Safari iOS5+Chrome Android?WebView Android?Samsung Internet?Opera Android12+ |
Event
|
EventSource
|
建立连接时,在 EventSource
对象上触发
|
pageswap
|
PageSwapEvent
|
Window
|
因导航导致文档即将卸载之前,在 Window 上触发。
|
pagehide
所有当前引擎均支持。 Firefox6+Safari5+Chrome3+
Opera?Edge79+ Edge(旧版)12+Internet Explorer11 Firefox Android?Safari iOS?Chrome Android?WebView Android37+Samsung Internet?Opera Android? |
PageTransitionEvent
|
Window
|
当页面的会话历史记录条目不再是活动条目时,在 Window 上触发
|
pagereveal
|
PageRevealEvent
|
Window
|
当页面在初始化或重新激活后首次开始渲染时,在 Window 上触发
|
pageshow
所有当前引擎均支持。 Firefox6+Safari5+Chrome3+
Opera?Edge79+ Edge(旧版)12+Internet Explorer11 Firefox Android?Safari iOS?Chrome Android?WebView Android37+Samsung Internet?Opera Android? |
PageTransitionEvent
|
Window
|
当页面的会话历史记录条目
成为活动条目时,在
Window 上触发
|
pointercancel
|
PointerEvent
|
元素和 Text
节点
|
当用户尝试启动拖放操作时,在源节点上触发 |
popstate
所有当前引擎均支持。 Firefox4+Safari5+Chrome5+
Opera11.5+Edge79+ Edge(旧版)12+Internet Explorer10+ Firefox Android?Safari iOS?Chrome Android?WebView Android37+Samsung Internet?Opera Android11.5+ |
PopStateEvent
|
Window
|
在某些会话历史记录遍历
情况下,于 Window 上触发
|
readystatechange
Document/readystatechange_event 所有当前引擎均支持。 Firefox4+Safari5.1+Chrome9+
Opera12.1+Edge79+ Edge(旧版)12+Internet Explorer4+ Firefox Android?Safari iOS?Chrome Android?WebView Android37+Samsung Internet?Opera Android12.1+ |
Event
|
Document
|
当 Document 完成解析时触发,
并在其所有子资源完成加载时再次触发
|
rejectionhandled
|
PromiseRejectionEvent
|
全局作用域对象 | 当先前未处理的 promise 拒绝变为已处理时,在全局作用域对象上触发 |
reset
所有当前引擎均支持。 Firefox6+Safari3+Chrome1+
Opera12.1+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS1+Chrome Android?WebView Android37+Samsung Internet?Opera Android12.1+ |
Event
|
form 元素
|
当 form 元素被重置时,在该元素上触发
|
select
所有当前引擎均支持。 Firefox6+Safari1+Chrome1+
Opera12.1+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ HTMLTextAreaElement/select_event 所有当前引擎均支持。 Firefox6+Safari1+Chrome1+
Opera12.1+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ |
Event
|
表单控件 | 当表单控件的文本选区被调整时(无论是通过 API 还是由用户调整),在该控件上触发 |
storage
所有当前引擎均支持。 Firefox45+Safari4+Chrome1+
Opera?Edge79+ Edge(旧版)15+Internet Explorer9+ Firefox Android?Safari iOS4+Chrome Android?WebView Android37+Samsung Internet?Opera Android? |
StorageEvent
|
Window
|
当对应的 localStorage 或 sessionStorage 存储区域发生更改时,
在 Window 上触发
|
submit
所有当前引擎均支持。 Firefox1+Safari3+Chrome1+
Opera8+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS1+Chrome Android?WebView Android?Samsung Internet?Opera Android10.1+ |
SubmitEvent
|
form 元素
|
当 form 元素被提交时,在该元素上触发
|
toggle
HTMLDetailsElement/toggle_event 所有当前引擎均支持。 Firefox49+Safari10.1+Chrome36+
Opera?Edge79+ Edge(旧版)?Internet Explorer否 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? 所有当前引擎均支持。 Firefox🔰
114+Safari预览版+Chrome114+
Opera?Edge114+ Edge(旧版)?Internet Explorer否 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
ToggleEvent
|
details 和弹出框元素
|
当 details
元素打开或关闭时,在该元素上触发;当具有
popover 属性的元素
在显示状态与隐藏状态之间转换时,在该元素上触发
|
unhandledrejection
Window/unhandledrejection_event 所有当前引擎均支持。 Firefox69+Safari11+Chrome49+
Opera?Edge79+ Edge(旧版)?Internet Explorer否 Firefox Android?Safari iOS11.3+Chrome Android?WebView Android?Samsung Internet?Opera Android? |
PromiseRejectionEvent
|
全局作用域对象 | 当 promise 拒绝未被处理时,在全局作用域对象上触发 |
unload
所有当前引擎均支持。 Firefox1+Safari3+Chrome1+
Opera4+Edge79+ Edge(旧版)12+Internet Explorer4+ Firefox Android?Safari iOS1+Chrome Android?WebView Android?Samsung Internet?Opera Android10.1+ |
Event
|
Window
|
当页面即将离开时,在 Window
对象上触发
|
visibilitychange
Document/visibilitychange_event 所有当前引擎均支持。 Firefox56+Safari14.1+Chrome62+
Opera49+Edge79+ Edge(旧版)18Internet Explorer🔰 10+ Firefox Android?Safari iOS?Chrome Android?WebView Android62+Samsung Internet?Opera Android46+ |
Event
|
Document
|
当页面对用户变为可见或隐藏时,在 Document 对象上触发
|
本节是非规范性的。
本规范定义了以下 HTTP 请求标头:
Last-Event-ID`Ping-From`Ping-To`本规范定义了以下 HTTP 响应标头:
Cross-Origin-Embedder-Policy`
Cross-Origin-Embedder-Policy-Report-Only`
Cross-Origin-Opener-Policy`
Cross-Origin-Opener-Policy-Report-Only`
Origin-Agent-Cluster`
Refresh`X-Frame-Options`この節は非規範的である。
この仕様では、次の MIME タイプに言及する:
application/atom+xmlapplication/jsonapplication/octet-stream
application/microdata+json
application/rss+xmlapplication/wasmapplication/x-www-form-urlencoded
application/xhtml+xml
application/xmlimage/gifimage/jpegimage/pngimage/svg+xmlmultipart/form-datamultipart/mixedmultipart/x-mixed-replace
text/csstext/event-streamtext/javascripttext/jsontext/plaintext/htmltext/pingtext/uri-listtext/vcardtext/vtttext/xmlvideo/mp4
video/mpeg「非規範的」と記されていない限り、すべての参考文献は規範的である。
XMLHttpRequest, A. van Kesteren. WHATWG.
HTML を発明し、それなしにはこれらのいずれも存在しなかった Tim Berners-Lee に感謝する。
また、 Aankhen, Aaqa Ishtyaq, Aaron Boodman, Aaron Leventhal, Aaron Krajeski, Abhishek Ghaskata, Abhishek Gupta, Adam Barth, Alexandra Borovova, Adam de Boor, Adam Hepton, Adam Klein, Adam Rice, Adam Roben, Addison Phillips, Adele Peterson, Adrian Bateman, Adrian Roselli, Adrian Sutton, Agustín Fernández, Aharon (Vladimir) Lanin, Ajai Tirumali, Ajay Poshak, Akash Balenalli, Akatsuki Kitamura, Alan Jeffrey, Alan Plum, Alastair Campbell, Alejandro G. Castro, Alex Bishop, Alex Nicolaou, Alex Nozdriukhin, Alex Rousskov, Alex Soncodi, Alexander Farkas, Alexander J. Vincent, Alexander Kalenik, Alexandre Dieulot, Alexandre Morgaut, Alexey Feldgendler, Алексей Проскуряков (Alexey Proskuryakov), Alexey Shvayka, Alexis Deveria, Alfred Agrell, Ali Juma, Alice Boxhall, Alice Wonder, Allan Clements, Allen Wirfs-Brock, Alex Komoroske, Alex Russell, Alphan Chen, Aman Ansari, Ami Fischman, Amos Jeffries, Amos Lim, Anders Carlsson, André Bargull, André E. Veltstra, Andrea Rendine, Andreas, Andreas Deuschlinger, Andreas Farre, Andreas Kling, Andrei Popescu, Andres Gomez, Andres Rios, Andreu Botella, Andrew Barfield, Andrew Clover, Andrew Gove, Andrew Grieve, Andrew Kaster, Andrew Macpherson, Andrew Oakley, Andrew Paseltiner, Andrew Simons, Andrew Smith, Andrew W. Hagen, Andrew Williams, Andrey V. Lukyanov, Andry Rendy, Andy Davies, Andy Earnshaw, Andy Heydon, Andy Paicu, Andy Palay, Anjana Vakil, Ankur Kaushal, Anna Belle Leiserson, Anna Sidwell, Anthony Boyd, Anthony Bryan, Anthony Hickson, Anthony Ramine, Anthony Ricaud, Anton Vayvod, Antonio Sartori, Antti Koivisto, Arfat Salman, Arkadiusz Michalski, Arne Thomassen, Aron Spohr, Arphen Lin, Arthur Hemery, Arthur Sonzogni, Arthur Stolyar, Arun Patole, Aryeh Gregor, Asanka Herath, Asbjørn Ulsberg, Ashley Gullen, Ashley Sheridan, Asumu Takikawa, Atsushi Takayama, Attila Haraszti, Aurelien Levy, Ave Wrigley, Avi Drissman, Axel Dahmen, 방성범 (Bang Seongbeom), Barry Pollard, Ben Boyle, Ben Godfrey, Ben Golightly, Ben Kelly, Ben Lerner, Ben Leslie, Ben Meadowcroft, Ben Millard, Benjamin Carl Wiley Sittler, Benjamin Hawkes-Lewis, Benjamin VanderSloot, Benji Bilheimer, Benoit Ren, Bert Bos, Bijan Parsia, Bil Corry, Bill Mason, Bill McCoy, Billy Wong, Billy Woods, Bjartur Thorlacius, Björn Höhrmann, Blake Frantz, Bob Lund, Bob Owen, Bobby Holley, Boris Zbarsky, Brad Fults, Brad Neuberg, Brad Spencer, Bradley Meck, Brady Eidson, Brandon Jones, Brendan Eich, Brenton Simpson, Brett Wilson, Brett Zamir, Brian Birtles, Brian Blakely, Brian Campbell, Brian Korver, Brian Kuhn, Brian M. Dube, Brian Ryner, Brian Smith, Brian Wilson, Bryan Sullivan, Bruce Bailey, Bruce D'Arcus, Bruce Lawson, Bruce Miller, Bugs Nash, C. Scott Ananian, C. Williams, Cameron McCormack, Cameron Zemek, Cao Yipeng, Carlos Amengual, Carlos Gabriel Cardona, Carlos Ibarra López, Carlos Perelló Marín, Carolyn MacLeod, Casey Leask, Cătălin Badea, Cătălin Mariș, Cem Turesoy, ceving, Chao Cai, 윤석찬 (Channy Yun), Charl van Niekerk, Charlene Wright, Charles Iliya Krempeaux, Charles McCathie Nevile, Charlie Reis, 白丞祐 (Cheng-You Bai), Chris Apers, Chris Cressman, Chris Dumez, Chris Evans, Chris Harrelson, Chris Markiewicz, Chris Morgan, Chris Morris, Chris Nardi, Chris Needham, Chris Pearce, Chris Peterson, Chris Rebert, Chris Weber, Chris Wilson, Christian Biesinger, Christian Johansen, Christian Schmidt, Christoph Päper, Christophe Dumez, Christopher Aillon, Christopher Cameron, Christopher Ferris, Chriswa, Clark Buehler, Cole Robison, Colin Fine, Collin Jackson, Conrad Crawford, Corey Farwell, Corprew Reed, Craig Cockburn, Csaba Gabor, Csaba Marton, Cynthia Shelly, Cyrille Tuzi, Daksh Shah, Dan Callahan, Dan Yoder, Dane Foster, Daniel Barclay, Daniel Bratell, Daniel Brooks, Daniel Brumbaugh Keeney, Daniel Buchner, Daniel Cheng, Daniel Clark, Daniel Davis, Daniel Ehrenberg, Daniel Ethridge, Daniel Glazman, Daniel Holbert, Daniel Peng, Daniel Schattenkirchner, Daniel Spång, Daniel Steinberg, Daniel Tan, Daniel Trebbien, Daniel Vogelheim, Danny Sullivan, Daphne Preston-Kendal, Darien Maillet Valentine, Darin Adler, Darin Fisher, Darxus, Dave Camp, Dave Cramer, Dave Hodder, Dave Lampton, Dave Singer, Dave Tapuska, Dave Townsend, David Baron, David Bloom, David Bokan, David Bruant, David Carlisle, David E. Cleary, David Egan Evans, David Fink, David Flanagan, David Gerard, David Grogan, David Hale, David Håsäther, David Hyatt, David I. Lehn, David John Burrowes, David Matja, David Remahl, David Resseguie, David Smith, David Storey, David Vest, David Woolley, David Zbarsky, Dave Methvin, DeWitt Clinton, Dean Edridge, Dean Edwards, Dean Jackson, Debanjana Sarkar, Debi Orton, Delan Azabani, Derek Featherstone, Derek Guenther, Devarshi Pant, Devdatta, Devin Mullins, Devin Rousso, Di Zhang, Diego Ferreiro Val, Diego González Zúñiga, Diego Ponce de León, Dimitri Glazkov, Dimitry Golubovsky, Dirk Pranke, Dirk Schulze, Dirkjan Ochtman, Divya Manian, Dmitry Lazutkin, Dmitry Titov, dolphinling, Dominic Cooney, Dominique Hazaël-Massieux, Don Brutzman, Donovan Glover, Doron Rosenberg, Doug Kramer, Doug Simpkinson, Drew Wilson, Edgar Chen, Edmund Lai, Eduard Pascual, Eduardo Vela, Edward Welbourne, Edward Z. Yang, Eemeli Aro, Ehsan Akhgari, Ehsan Karamad, Eira Monstad, Eitan Adler, Eli Friedman, Eli Grey, Eliot Graff, Elisabeth Robson, Elizabeth Castro, Elliott Sprehn, Elliotte Harold, Emilio Cobos Álvarez, Emily Stark, Eric Carlson, Eric Casler, Eric Lawrence, Eric Portis, Eric Rescorla, Eric Semling, Eric Shepherd, Eric Willigers, Erik Arvidsson, Erik Charlebois, Erik Rose, 栗本 英理子 (Eriko Kurimoto), espretto, Evan Jacobs, Evan Martin, Evan Prodromou, Evan Stade, Evert, Evgeny Kapun, ExE-Boss, Ezequiel Garzón, fantasai, Félix Sanz, Felix Sasaki, Fernando Altomare Serboncini, Forbes Lindesay, Francesco Schwarz, Francis Brosnan Blazquez, Franck 'Shift' Quélain, François Marier, Frank Barchard, Frank Liberato, Franklin Shirley, Frederik Braun, Fredrik Söderquist, 鵜飼文敏 (Fumitoshi Ukai), Futomi Hatano, Gavin Carothers, Gavin Kistner, Gareth Rees, Garrett Smith, Gary Blackwood, Gary Kacmarcik, Gary Katsevman, Geoff Richards, Geoffrey Garen, Georg Neis, George Lund, Gianmarco Armellin, Giovanni Campagna, Giuseppe Pascale, Glenn Adams, Glenn Maynard, Graham Klyne, Greg Botten, Greg Houston, Greg Wilkins, Gregg Tavares, Gregory J. Rosmaita, Gregory Terzian, Grey, guest271314, Guilherme Johansson Tramontina, Guy Bedford, Gytis Jakutonis, Håkon Wium Lie, Habib Virji, Hajime Morrita, Hallvord Reiar Michaelsen Steen, Hanna Laakso, Hans S. Tømmerhalt, Hans Stimer, Harald Alvestrand, Hayato Ito, 何志翔 (HE Zhixiang), Henri Sivonen, Henrik Lied, Henrik Lievonen, Henry Lewis, Henry Mason, Henry Story, Hermann Donfack Zeufack, 中川博貴 (Hiroki Nakagawa), Hiroshige Hayashizaki, Hiroyuki USHITO, Hitoshi Yoshida, Hongchan Choi, 王华 (Hua Wang), Hugh Bellamy, Hugh Guiney, Hugh Winkler, Ian Bicking, Ian Clelland, Ian Davis, Ian Fette, Ian Henderson, Ian Kilpatrick, Ibrahim Ahmed, Ido Green, Ignacio Javier, Igor Oliveira, 安次嶺 一功 (Ikko Ashimine), Ilya Grigorik, Ingvar Stepanyan, isonmad, Iurii Kucherov, Ivan Enderlin, Ivan Nikulin, Ivan Panchenko, Ivo Emanuel Gonçalves, J. King, J.C. Jones, Jackson Ray Hamilton, Jacob Davies, Jacques Distler, Jake Archibald, Jake Verbaten, Jakub Vrána, Jakub Łopuszański, Jakub Wilk, James Browning, James Craig, James Graham, James Greene, James Justin Harrell, James Kozianski, James M Snell, James Perrett, James Robinson, Jamie Liu, Jamie Lokier, Jamie Mansfield, Jan Kühle, Jan Miksovsky, Janice Shiu, Janusz Majnert, Jan-Ivar Bruaroey, Jan-Klaas Kollhof, Jared Jacobs, Jason Duell, Jason Kersey, Jason Lustig, Jason Orendorff, Jason White, Jasper Bryant-Greene, Jasper St. Pierre, Jatinder Mann, Jay Henry Kao, Jayson Chen, Jean-Yves Avenard, Jed Hartman, Jeff Balogh, Jeff Cutsinger, Jeff Gilbert, Jeff "=JeffH" Hodges, Jeff Schiller, Jeff Walden, Jeffrey Yasskin, Jeffrey Zeldman, 胡慧鋒 (Jennifer Braithwaite), Jellybean Stonerfish, Jennifer Apacible, Jens Bannmann, Jens Fendler, Jens Oliver Meiert, Jens Widell, Jer Noble, Jeremey Hustman, Jeremy Keith, Jeremy Orlow, Jeremy Roman, Jeroen van der Meer, Jerry Smith, Jesse Renée Beach, Jessica Jong, jfkthame, Jian Li, Jihye Hong, Jim Jewett, Jim Ley, Jim Meehan, Jim Michaels, Jin Dongxun (金东勋, 金東勳, 김동훈), Jinho Bang, Jinjiang (勾三股四), Jirka Kosek, Jjgod Jiang, Joaquim Medeiros, João Eiras, Jochen Eisinger, Joe Clark, Joe Gregorio, Joel Spolsky, Joel Verhagen, Joey Arhar, Johan Herland, Johanna Herman, John Boyer, John Bussjaeger, John Carpenter, John Daggett, John Fallows, John Foliot, John Harding, John Keiser, John Law, John Musgrave, John Snyders, John Stockton, John-Mark Bell, Johnny Stenback, Jon Coppeard, Jon Ferraiolo, Jon Gibbins, Jon Jensen, Jon Perlow, Jonas Sicking, Jonathan Cook, Jonathan Kew, Jonathan Neal, Jonathan Oddy, Jonathan Rees, Jonathan Watt, Jonathan Worent, Jonny Axelsson, Joram Schrijver, Jordan Tucker, Jorgen Horstink, Joris van der Wel, Jorunn Danielsen Newth, Joseph Kesselman, Joseph Mansfield, Joseph Pecoraro, Josh Aas, Josh Hart, Josh Juran, Josh Levenberg, Josh Matthews, Joshua Bell, Joshua Chen, Joshua Randall, Juan Olvera, Juanmi Huertas, Jukka K. Korpela, Jules Clément-Ripoche, Julian Reschke, Julio Lopez, 小勝 純 (Jun Kokatsu), Jun Yang (harttle), Jungkee Song, Jürgen Jeka, Justin Lebar, Justin Novosad, Justin Rogers, Justin Schuh, Justin Sinclair, Juuso Lapinlampi, Ka-Sing Chou, Kagami Sascha Rosylight, Kai Hendry, Kamishetty Sreeja, 呂康豪 (KangHao Lu), Karl Dubost, Karl Tomlinson, Kartik Arora, Kartikaya Gupta, Kathy Walton, 河童エクマ(Kawarabe Ecma) Keith Cirkel, Keith Rollin, Keith Yeung, Kelly Ford, Kelly Norton, Ken Russell, Kenji Baheux, Kevin Babbitt, Kevin Benson, Kevin Cole, Kevin Gadd, Kevin McNee, Kevin Venkiteswaran, Khushal Sagar, Kinuko Yasuda, Koji Ishii, Kornél Pál, Kornel Lesinski, 上野 康平 (UENO, Kouhei), Kris Northfield, Kristian Spangsege, Kristof Zelechovski, Krzysztof Maczyński, 黒澤剛志 (Kurosawa Takeshi), Kurt Catti-Schmidt, Kyle Barnhart, Kyle Hofmann, Kyle Huey, Léonard Bouchet, Léonie Watson, Lachlan Hunt, Larry Masinter, Larry Page, Lars Gunther, Lars Solberg, Laura Carlson, Laura Granka, Laura L. Carlson, Laura Wisewell, Laurens Holst, Lawrence Forooghian, Lee Kowalkowski, Leif Halvard Silli, Leif Kornstaedt, Lenny Domnitser, Leonard Rosenthol, Leons Petrazickis, Liviu Tinta, Lobotom Dysmon, Logan, Logan Moore, Lorenz Ackermann, Loune, Luca Casonato, Lucas Gadani, Łukasz Pilorz, Luke Kenneth Casson Leighton, Luke Warlow, Luke Wilde, Maciej Stachowiak, Magne Andersson, Magnus Kristiansen, Maik Merten, Majid Valipour, Maksim Sadym, Malcolm Rowe, Manish Goregaokar, Manish Tripathi, Manuel Martinez-Almeida, Manuel Rego Casasnovas, Marc Hoyois, Marc-André Choquette, Marc-André Lafortune, Marco Zehe, Marcus Bointon, Marcus Otterström, Marijn Kruisselbrink, Mark Amery, Mark Birbeck, Mark Davis, Mark Green, Mark Miller, Mark Nottingham, Mark Pilgrim, Mark Rogers, Mark Rowe, Mark Schenk, Mark Vickers, Mark Wilton-Jones, Markus Cadonau, Markus Stange, Martijn van der Ven, Martijn Wargers, Martin Atkins, Martin Chaov, Martin Dürst, Martin Honnen, Martin Janecke, Martin Kutschker, Martin Nilsson, Martin Robinson, Martin Thomson, Masataka Yakura, Masatoshi Kimura, Mason Freed, Mason Mize, Mathias Bynens, Mathieu Henri, Matias Larsson, Matt Brubeck, Matt Di Pasquale, Matt Falkenhagen, Matt Giuca, Matt Harding, Matt Schmidt, Matt Wright, Matthew Gaudet, Matthew Gregan, Matthew Mastracci, Matthew Noorenberghe, Matthew Raymond, Matthew Thomas, Matthew Tylee Atkinson, Mattias Waldau, Max Romantschuk, Maxim Tsoy, Mayeul Cantan, Menachem Salomon, Menno van Slooten, Micah Dubinko, Micah Nerren, Michael 'Ratt' Iannarelli, Michael A. Nachbaur, Michael A. Puls II, Michael Carter, Michael Daskalov, Michael Day, Michael Dyck, Michael Enright, Michael Ficarra, Michael Gratton, Michael Kohler, Michael McKelvey, Michael Nordman, Michael Powers, Michael Rakowski, Michael(tm) Smith, Michael Walmsley, Michal Zalewski, Michel Buffa, Michel Fortin, Michelangelo De Simone, Michiel van der Blonk, Miguel Casas-Sanchez, Mihai Şucan, Mihai Parparita, Mike Brown, Mike Dierken, Mike Dixon, Mike Hearn, Mike Pennisi, Mike Schinkel, Mike Shaver, Mikko Rantalainen, Mingye Wang, Mirko Brodesser, Mohamed Zergaoui, Mohammad Al Houssami, Mohammad Reza Zakerinasab, Momdo Nakamura, Morten Stenshorne, Mounir Lamouri, Ms2ger, mtrootyy, 邱慕安 (Mu-An Chiou), Mukilan Thiyagarajan, Mustaq Ahmed, Myles Borins, Nadia Heninger, Nate Chapin, NARUSE Yui, Navid Zolghadr, Neil Deakin, Neil Rashbrook, Neil Soiffer, Nereida Rondon, networkException, Nicholas Shanks, Nicholas Stimpson, Nicholas Zakas, Nickolay Ponomarev, Nicolas Gallagher, Nicolas Pena Moreno, Nicolò Ribaudo, Nidhi Jaju, Nigel Megitt, Nikki Bee, Niklas Gögge, Nina Satragno, Noah Mendelsohn, Noah Slater, Noam Rosenthal, Noel Gordon, Nolan Waite, NoozNooz42, Norbert Lindenberg, Oisín Nolan, Ojan Vafai, Olaf Hoffmann, Olav Junker Kjær, Oldřich Vetešník, Oli Studholme, Oliver Hunt, Oliver Rigby, Olivia (Xiaoni) Lai, Olivier Gendrin, Olli Pettay, Ondřej Žára, Ori Avtalion, Oriol Brufau, oSand, Pablo Flouret, Patrick Dark, Patrick Garies, Patrick H. Lauke, Patrik Persson, Paul Adenot, Paul Lewis, Paul Norman, Per-Erik Brodin, 一丝 (percyley), Perry Smith, Peter Beverloo, Peter Karlsson, Peter Kasting, Peter Moulder, Peter Occil, Peter Stark, Peter Van der Beken, Peter van der Zee, Peter-Paul Koch, Phil Pickering, Philip Ahlberg, Philip Brembeck, Philip Taylor, Philip TAYLOR, Philippe De Ryck, Pierre-Arnaud Allumé, Pierre-Marie Dartus, Pierre-Yves Gérardy, Piers Wombwell, Pooja Sanklecha, Prashant Hiremath, Prashanth Chandra, Prateek Rungta, Pravir Gupta, Prayag Verma, Psychpsyo, 李普君 (Pujun Li), Rachid Finge, Rafael Weinstein, Rafał Miłecki, Rahim Abdi, Rahul Purohit, Raj Doshi, Rajas Moonka, Rakina Zata Amni, Ralf Stoltze, Ralph Giles, Rebecca Star, Remci Mizkur, Remco, Remy Sharp, Rene Saarsoo, Rene Stach, Ric Hardacre, Rich Clark, Rich Doughty, Richa Rupela, Richard Gibson, Richard Ishida, Richard Torres, Ricky Mondello, Rigo Wenning, Rikkert Koppes, Rimantas Liubertas, Riona Macnamara, River Champeimont, Rob Buis, Rob Ennals, Rob Jellinghaus, Rob S, Rob Smith, Robert Blaut, Robert Collins, Robert Hogan, Robert Kieffer, Robert Linder, Robert Millan, Robert O'Callahan, Robert Sayre, Robin Berjon, Robin Schaufler, Rodger Combs, Roland Steiner, Roma Matusevich, Romain Deltour, Roman Ivanov, Roy Fielding, Rune Lillesveen, Russell Bicknell, Ruud Steltenpool, Ryan King, Ryan Landay, Ryan Sleevi, Ryo Kajiwara, Ryo Kato, Ryosuke Niwa, S. Mike Dierken, Salvatore Loreto, Sam Atkins, Sam Dutton, Sam Kuper, Sam Ruby, Sam Sneddon, Sam Weinig, Samikshya Chand, Samuel Bronson, Samy Kamkar, Sander van Lambalgen, Sanjoy Pal, Sanket Joshi, Sarah Gebauer, Sarven Capadisli, Satrujit Behera, Sayan Sivakumaran, Schalk Neethling, Scott Beardsley, Scott González, Scott Hess, Scott Jehl, Scott Miles, Scott O'Hara, Sean B. Palmer, Sean Feng, Sean Fraser, Sean Hayes, Sean Hogan, Sean Knapp, Sebastian Markbåge, Sebastian Schnitzenbaumer, Sendil Kumar N, Seth Call, Seth Dillingham, Shannon Booth, Shannon Moeller, Shanti Rao, Shaun Inman, Shiino Yuki, 贺师俊 (HE Shi-Jun), Shiki Okasaka, Shivani Sharma, shreyateeza, Shubheksha Jalan, Sidak Singh Aulakh, Sierk Bornemann, Sigbjørn Finne, Sigbjørn Vik, Silver Ghost, Silvia Pfeiffer, Šime Vidas, Simon Fraser, Simon Montagu, Simon Sapin, Yu Han, Simon Spiegel, Simon Wülker, Siye Liu, skeww, Smylers, Srirama Chandra Sekhar Mogali, Stanton McCandlish, stasoid, Stefan Håkansson, Stefan Haustein, Stefan Santesson, Stefan Schumacher, Ştefan Vargyas, Stefan Weiss, Steffen Meschkat, Stephen Chenney, Stephen Ma, Stephen Stewart, Stephen White, Steve Comstock, Steve Faulkner, Steve Fink, Steve Orvell, Steve Runyon, Steven Bennett, Steven Bingler, Steven Garrity, Steven Tate, Stewart Brodie, Stuart Ballard, Stuart Langridge, Stuart Parmenter, Subramanian Peruvemba, Sudhanshu Jaiswal, sudokus999, Sunava Dutta, Surma, Susan Borgrink, Susan Lesch, Sylvain Pasche, T.J. Crowder, Tab Atkins-Bittner, Taiju Tsuiki, Takashi Toyoshima, Takayoshi Kochi, Takeshi Yoshino, Tantek Çelik, 田村健人 (Kent TAMURA), Tawanda Moyo, Taylor Hunt, Ted Mielczarek, Terence Eden, Terrence Wood, Tetsuharu OHZEKI, Theresa O'Connor, Thijs van der Vossen, Thomas Broyer, Thomas Koetter, Thomas O'Connor, Tim Altman, Tim Dresser, Tim Flynn, Tim Johansson, Tim Nguyen, Tim Perry, Tim van der Lippe, TJ VanToll, Tobias Schneider, Tobie Langel, Toby Inkster, Todd Moody, Tom Baker, Tom Pike, Tom Schuster, Tom ten Thij, Tomasz Jakut, Tomek Wytrębowicz, Tommy Thorsen, Tony Ross, Tooru Fujisawa, Toru Kobayashi, Traian Captan, Travis Leithead, Trevor Rowbotham, Trevor Saunders, Trey Eckels, triple-underscore, Tristan Fraipont, Tristan Parisot, 保呂 毅 (Tsuyoshi Horo), Tyler Close, Valentin Gosu, Vardhan Gupta, Vas Sudanagunta, Veli Şenol, Victor Carbune, Victor Costan, Vipul Snehadeep Chawathe, Vitya Muhachev, Vlad Levin, Vladimir Katardjiev, Vladimir Vukićević, Vyacheslav Aristov, voracity, Walter Steiner, Wakaba, Wayne Carr, Wayne Pollock, Wellington Fernando de Macedo, Wenson Hsieh, Weston Ruter, Wilhelm Joys Andersen, Will Levine, Will Ray, William Chen, William Swanson, Willy Martin Aguirre Rodriguez, Wladimir Palant, Wojciech Mach, Wolfram Kriesing, Xan Gregg, xenotheme, XhmikosR, Xida Chen, Xidorn Quan, Xue Fuqiao, Yang Chen, Yao Xiao, Yash Handa, Yay295, Ye-Kui Wang, Yehuda Katz, Yi Xu, Yi-An Huang, Yngve Nysaeter Pettersen, Yoav Weiss, Yoel Hawa, Yonathan Randolph, Yu Huojiang, Yuki Okushi, Yury Delendik, 平野裕 (Yutaka Hirano), Yuzo Fujishima, 西條柚 (Yuzu Saijo), Zhenbin Xu, 张智强 (Zhiqiang Zhang), Zoltan Herczeg, Zyachel, および Øistein E. Andersen に、 長年にわたってこの仕様の変更につながった、大小さまざまな有益なコメントを寄せてくれたことに 感謝する。
また、ブログ、公開メーリングリスト、またはフォーラムに HTML について投稿したすべての人々、 すなわち さまざまな W3C HTML WG リストおよびさまざまな WHATWG リストへのすべての貢献者にも感謝する。
Safari における canvas の最初の実装を作成し、そこから
canvas 機能が設計された Richard Williamson に特に感謝する。
イベントベースのドラッグ&ドロップ機構、contenteditable、
および Windows Internet Explorer ブラウザーによって最初に広く展開されたその他の機能を
最初に実装した Microsoft の従業員にも特に感謝する。
壊れた養子縁組機関アルゴリズムの実装を考案し、 構文解析の節で使用する前に編集者がリバースエンジニアリングして修正しなければならなかった David Hyatt に、特別な感謝と 10,000 ドルを贈る。
microdata 機能を設計するための指針として、その誤りを使用することを許可してくれた microdata ユーザビリティ調査の参加者に感謝する。
仕様で使用される例に着想を与えた多くの情報源に感謝する。
いくつかのアイデアを提供した Microsoft のブログコミュニティ、着想を与えた W3C ウェブアプリケーションおよび複合文書ワークショップの参加者、#mrt クルー、#mrt.no クルー、#whatwg クルー、ならびにアイデアと支援を提供した Pillar と Hedral にも感謝する。
仕様の PDF 版を生成した Igor Zhbanov に感謝する。
picture 要素および関連機能を開発した
RICG に特に感謝する。特に Adrian Bateman、
Bruce Lawson、David Newton、Ilya Grigorik、John Schoenick、Leon de Rijke、Mat Marquis、Marcos
Cáceres、Tab Atkins、Theresa O'Connor、および Yoav Weiss の貢献に感謝する。
カスタム要素機能を育成した WPWG に特に感謝する。特に、XBL 仕様を通じて 影響を与えた David Hyatt と Ian Hickson、カスタム要素仕様の最初の草案を作成した Dimitri Glazkov、 および Alex Komoroske, Alex Russell, Andres Rios, Boris Zbarsky, Brian Kardell, Daniel Buchner, Dominic Cooney, Erik Arvidsson, Elliott Sprehn, Hajime Morrita, Hayato Ito, Jan Miksovsky, Jonas Sicking, Olli Pettay, Rafael Weinstein, Roland Steiner, Ryosuke Niwa, Scott Miles, Steve Faulkner, Steve Orvell, Tab Atkins, Theresa O'Connor, Tim Perry, and William Chen の貢献に感謝する。
Worklet を開発した CSSWG に特に感謝する。特に、元の Worklet 仕様の 編集者としての Ian Kilpatrick の作業に感謝する。
投機的読み込み機能を育成したWICG に特に感謝する。特に、元の投機ルールおよび プリフェッチ仕様の編集者としての Jeremy Roman の作業に感謝する。
Sanitizer API を育成した WICG に特に感謝する。特に、元の Sanitizer API 仕様の編集者としての Frederik Braun、Mario Heiderich、Daniel Vogelheim、および Tom Schuster の 作業に感謝する。
2003 年から約 10 年間、この標準はほぼすべて Ian Hickson (Google、ian@hixie.ch)によって 執筆された。
2015 年以降、編集者グループは拡大した。現在は Anne van Kesteren(Apple、annevk@annevk.nl)、 Domenic Denicola(Google、d@domenic.me) Dominic Farolino(Google、domfarolino@gmail.com)、 Philip Jägenstedt(Google、philip@foolip.org)、および Simon Pieters(Mozilla、zcorpan@gmail.com)によって保守されている。
The image in the introduction is based on a photo by Wonderlane. (CC BY 2.0)
The image of the wolf in the embedded content introduction is based on a photo by Barry O'Neill. (Public domain)
The image of the kettlebell swing in the embedded content introduction is based on a photo by kokkarina. (CC0 1.0)
The Blue Robot Player sprite used in the canvas demo is based on a work by JohnColburn. (CC BY-SA 3.0)
The photograph of robot 148 climbing the tower at the FIRST Robotics Competition 2013 Silicon Valley Regional is based on a work by Lenore Edman. (CC BY 2.0)
The diagram showing how async and defer impact script loading is based on a
similar diagram from a
blog post by Peter Beverloo.
(CC0 1.0)
The image decoding demo used to demonstrate module-based workers draws on some example code from a tutorial by Ilmari Heikkinen. (CC BY 3.0)
The <flag-icon> example was inspired by a custom element by Steven
Skelton. (MIT)
Part of the revision history of the
picture element and related features
can be found in the ResponsiveImagesCG/picture-element
repository, which is available under the W3C Software and
Document License.
Part of the revision history of the theme-color metadata name can be found in the whatwg/meta-theme-color
repository, which is available under CC0.
Part of the revision history of the custom elements feature can be found in the w3c/webcomponents repository, which
is available under the W3C Software and
Document License.
Part of the revision history of the innerText getter and setter can be found in the rocallahan/innerText-spec
repository, which is available under CC0.
Part of the revision history of the worklets feature can be found in the w3c/css-houdini-drafts
repository, which is available under the W3C Software and
Document License.
Part of the revision history of the import
maps feature can be found in the WICG/import-maps
repository, which is available under the W3C Software and
Document License.
Part of the revision history of the navigation API feature can be found in the WICG/navigation-api
repository, which is available under the W3C Software and
Document License.
Part of the revision history of the Close requests and close watchers section can be
found in the WICG/close-watcher
repository, which is available under the W3C Software and
Document License.
Part of the revision history of the Speculative loading section can be
found in the WICG/nav-speculation
repository, which is available under the W3C Software and
Document License.
Copyright © WHATWG (Apple, Google, Mozilla, Microsoft). This work is licensed under a Creative Commons Attribution 4.0 International License. To the extent portions of it are incorporated into source code, such portions in the source code are licensed under the BSD 3-Clause License instead.
This is the Living Standard. Those interested in the patent-review version should view the Living Standard Review Draft.
{kind=link}