はじめに
著者は、ユーザーエージェントにドキュメントツリーからではないコンテンツを描画させたい場合があります。 よくある例としては、番号付き見出しがあります。 著者は番号を明示的にマークアップしたくはなく、 それらをユーザーエージェントに自動生成させたいと考えています。 このような効果を実現するために、カウンターやマーカーが使われます。
同様に、著者は図のキャプションの前に「図」と表示したり、 第7章のタイトルの前に「第7章」と表示することもあるでしょう。
chapter{ counter-increment : chapter; } chapter > title::before{ content : "Chapter " counter ( chapter) "\A" ; }
他にも、要素を画像や他のマルチメディアコンテンツで置き換える効果がよく使われます。 すべてのユーザーエージェントがすべてのマルチメディア形式に対応しているわけではないため、 フォールバックの提供が必要となる場合もあります。
/* <logo>要素をサイトロゴに置き換え、UAがサポートする形式を使用 */ * logo{ content : url ( logo.mov ), url ( logo.mng ), url ( logo.png ), none; } /* <figure>要素を参照先のドキュメントで置き換え、 * alt属性があればその内容、なければ要素自身の内容で置き換え */ figure[ alt] { content : attr ( href url), attr ( alt); } figure:not ([ alt]) { content : attr ( href url), contents; }
値の定義
この仕様は、CSSプロパティ定義の慣例と、値定義構文に従います。 仕様で定義されていない値型は、CSS Values & Units [CSS-VALUES-3]で定義されています。 他のCSSモジュールとの組み合わせにより、これらの値型の定義が拡張されることがあります。
定義内で挙げられているプロパティ固有の値に加えて、 この仕様で定義されるすべてのプロパティは、 CSS全体で使えるキーワードもプロパティ値として受け入れます。 可読性のため、繰り返し明示はしていません。
1. コンテンツの挿入と置換: contentプロパティ
| 名前: | content |
|---|---|
| 値: | normal | none | [ <content-replacement> | <content-list> ] [/ [ <string> | <counter> | <attr()> ]+ ]? |
| 初期値: | normal |
| 適用対象: | すべての要素、ツリー順守疑似要素、ページマージンボックス |
| 継承: | no |
| パーセンテージ: | 該当なし |
| 算出値: | 下記の説明を参照 |
| 標準順序: | 構文通り |
| アニメーション型: | 離散型 |
テスト
- attr-case-sensitivity-001.html (ライブテスト) (ソース)
- attr-case-sensitivity-002.html (ライブテスト) (ソース)
- attr-case-sensitivity-003.html (ライブテスト) (ソース)
- computed-value.html (ライブテスト) (ソース)
- content-animation.html (ライブテスト) (ソース)
- content-no-interpolation.html (ライブテスト) (ソース)
- content-none-select-1.html (ライブテスト) (ソース)
- element-replacement-alt.html (ライブテスト) (ソース)
- element-replacement-display-contents.html (ライブテスト) (ソース)
- element-replacement-display-none.html (ライブテスト) (ソース)
- element-replacement-dynamic.html (ライブテスト) (ソース)
- element-replacement-gradient.html (ライブテスト) (ソース)
- element-replacement-image-alt.html (ライブテスト) (ソース)
- element-replacement.html (ライブテスト) (ソース)
- content-computed.html (ライブテスト) (ソース)
- content-counter-valid.html (ライブテスト) (ソース)
- content-invalid.html (ライブテスト) (ソース)
- content-valid.html (ライブテスト) (ソース)
ユーザーエージェントは、視覚的でないものを含むすべてのメディアでこのプロパティへの対応が期待されています。
contentプロパティは、要素や疑似要素の内部で描画される内容を制御します。
要素の場合は、 通常通り描画するか、 要素を画像(および関連する「altテキスト」)で置き換えることのみ指定できます。
疑似要素とマージンボックスの場合は、 より強力な制御が行えます。 要素自体の描画有無の制御や、 画像で置き換えたり、 任意のインラインコンテンツ(テキストや画像)への置き換えが可能です。
- normal
-
要素やページマージンボックスの場合、この値はcontentsに算出されます。
::beforeや::afterの場合は、noneに算出されます。
::marker、::placeholder、 そして::file-selector-buttonの場合は、 値そのもの(normal)に算出されます。
- none
-
要素の場合は、normalとして振る舞います。
疑似要素の場合、その疑似要素の生成を抑制し、 display: noneと同じように扱われます。
どちらの場合も、当該要素や疑似要素を発生元要素として持つ他の疑似要素生成は妨げません。
- <content-replacement>
-
同値:
<image>
要素や疑似要素を置換要素とし、 指定された<image>で満たします。 通常の内容は抑制され、 box生成されません。display: none扱いです。
もし<image>が不正な画像の場合、 幅・高さ0、透明黒で満たされた画像として扱います。
上記の不正な画像の挙動はChromeが採用しているものと同じです。 本当にこれでよいでしょうか? より良い挙動はあるでしょうか?
注: 置換要素は通常の要素と異なるレイアウト規則を持ちます。 (実質的にはHTMLの
img要素と同じになります。)注: 置換要素には::beforeや::after疑似要素は存在しません。 contentプロパティが内容全体を置換します。
この値は、 <content-list>として ::beforeや::afterで扱われてきました。 Web互換性の要求があると思われるので、これらの疑似要素には例外が必要かもしれません。[Issue #2889]
- <content-list>
-
要素の内容を、指定した値ごとに対応する複数の匿名インラインボックスに順番通り置換します。
通常の内容は抑制され、box生成されません。display:
none扱いです。
各値は、要素内容にインラインボックスとして寄与します。 <image>の場合は匿名インラインの置換要素、 その他の場合は匿名インラインテキスト列となります。
<image>が不正な画像を 表す場合、UAは以下のどちらかを行います:
本仕様ではUAがどちらを使うべきかは定めませんが、どちらか一方を一貫して使う必要があります。
注: <content-list>の値が単一の<image>である場合は、<content-replacement>として解釈されます。
- / [ <string> | <counter> | <attr()> ]+
- 要素の「altテキスト」を指定します。 詳細は§ 1.2 アクセシビリティ用代替テキストを参照ください。 省略された場合、 要素には「altテキスト」はありません。
::before{ content : "Chapter" counter ( chapter); content : "Chapter" counter ( chapter) /"Chapter" counter ( chapter); }
contentsキーワードをcontent()に置き換えるべきでしょうか?
1.1. 生成コンテンツのアクセシビリティ
生成されたコンテンツは検索可能で、選択可能であり、支援技術でも利用できるべきです。 contentプロパティは音声にも適用され、 生成コンテンツは音声出力時にもレンダリングされなければなりません。[CSS3-SPEECH]
1.2. アクセシビリティ用の代替テキスト
視覚メディア向けのコンテンツは、音声出力や非視覚的メディア向けに代替テキストが必要になることがあります。 contentプロパティは、スラッシュ(/)の後に <content-list>を指定した後、代替テキストを受け入れることができます。 代替テキストが提供されている場合は、 音声出力の際にその代替テキストを使用しなければなりません。
これにより、例えば装飾的テキストのみを音声出力で省略したい場合(代替テキストを空文字列にすることで)や、画像やアイコン、テキスト化された記号などにより読みやすい代替を著者が指定できるようになります。
.new::before{ content : url ( ./img/star.png ) /"New!" ; /* またはDOMのローカライズ属性: attr("data-alt") */ }
.expandable::before{ content : "\25BA" /"" ; /* または ► */ /* aria-expanded="false" がすでにDOMにあるため この疑似要素は装飾目的 */ }
2. 生成コンテンツ値: <content-list>型
<content-list>値はcontentで使用され、画像、文字列、カウンターの値、要素のテキスト値など、1つ以上の匿名インラインボックスで要素を満たすために使われます。 このセクションでは利用可能な内容種別を列挙します。
<content-list>の構文は以下の通りです:
<content-list> =[ <string> | <image> | <attr () > | contents | <quote> | <leader () > | <target> | <string () > | <content () > | <counter>] +
2.1. 基本文字列: <string> および<attr()> 値
- <string>
-
指定されたテキストで満たされた匿名インラインボックスを表します。
注: 空白文字は文字列リテラルと同じように処理され、 [CSS-TEXT-3]などで定義されたプロパティで制御されます。 特に、空白文字は文字列間でもまとめて折りたためます。 例えば content: "First " " Second"; の場合、デフォルトでは
"First Second" - <attr()>
-
attr()関数表記は、
指定した属性の値として格納されている文字列を表します。
引数はCSS修飾名(
qname)で、 属性名と(あれば)名前空間を示します。 詳しくは[CSS3-NAMESPACE]を参照。注: 属性セレクタと同様、 明示的な名前空間がない属性名はデフォルトの名前空間には関連付けられません。
2.2. 2D画像: <image> 値
- <image>
-
指定された<image>で満たされた匿名インラインの置換要素を表します。
<image>が 不正な画像の場合、 この値は何も表さなくなります。 (要素にインラインコンテンツは追加されず、この値は「スキップ」扱いとなります。)
CSS2.1では UAが不正な画像の場合に「壊れた画像」アイコンなどで代替することを明示的に許していました。 しかし、どのブラウザもこれを実際に行っていないようです。 この削除は問題ないでしょうか?
2.3. 要素コンテンツ: contentsキーワード
- contents
- 要素の子孫です。 これが1要素内で複数回使われることはできません (例えば子要素がプラグインやフォームコントロールの場合は複製できません)ので、 以下のように扱われます:
foo{ content : normal; } /* これは初期値 */ foo::after{ content : contents; }
...この場合, 要素のcontentプロパティはcontentsに算出され、::afterの疑似要素には内容がなく (noneと同等) なので表示されません。
foo{ content : none; } foo::after{ content : contents; }
この場合は、::after疑似要素にはfoo要素の内容が含まれます。
注: 1つのcontentプロパティ内で contentsを2回指定しても無意味ですが、これは構文エラーではありません。 2回目の指定はすでに利用済みのため効果がありません。 また::marker疑似要素で使っても構文エラーではありませんが、レンダリング段階でnone扱いとなります。
marker擬似要素についての記述は本当に必要か?旧仕様の遺産では?
2.4. 引用符
quotesプロパティ(引用符システムを定義します)と、
contentプロパティで使う
*-quote値を組み合わせることで、生成コンテンツとして対応する引用符を自動で挿入できます。
たとえばHTMLの
q
要素などが該当します。
2.4.1. 引用符システム: quotesプロパティ
| 名前: | quotes |
|---|---|
| 値: | auto | none | match-parent | [ <string> <string> ]+ |
| 初期値: | auto |
| 適用対象: | すべての要素 |
| 継承: | yes |
| パーセンテージ: | 該当なし |
| 算出値: | キーワード none 、キーワード auto 、 match-parent 、またはリスト(各項目は文字列のペア) |
| 標準順序: | 構文通り |
| アニメーション型: | 離散型 |
テスト
- quotes-001.html (ライブテスト) (ソース)
- quotes-002.html (ライブテスト) (ソース)
- quotes-003.html (ライブテスト) (ソース)
- quotes-004.html (ライブテスト) (ソース)
- quotes-005.html (ライブテスト) (ソース)
- quotes-006.html (ライブテスト) (ソース)
- quotes-007.html (ライブテスト) (ソース)
- quotes-008.html (ライブテスト) (ソース)
- quotes-009.html (ライブテスト) (ソース)
- quotes-010.html (ライブテスト) (ソース)
- quotes-011.html (ライブテスト) (ソース)
- quotes-012.html (ライブテスト) (ソース)
- quotes-013.html (ライブテスト) (ソース)
- quotes-014.html (ライブテスト) (ソース)
- quotes-015.html (ライブテスト) (ソース)
- quotes-016.html (ライブテスト) (ソース)
- quotes-017.html (ライブテスト) (ソース)
- quotes-018.html (ライブテスト) (ソース)
- quotes-019.html (ライブテスト) (ソース)
- quotes-020.html (ライブテスト) (ソース)
- quotes-021.html (ライブテスト) (ソース)
- quotes-022.html (ライブテスト) (ソース)
- quotes-023.html (ライブテスト) (ソース)
- quotes-024.html (ライブテスト) (ソース)
- quotes-025.html (ライブテスト) (ソース)
- quotes-026.html (ライブテスト) (ソース)
- quotes-027.html (ライブテスト) (ソース)
- quotes-028.html (ライブテスト) (ソース)
- quotes-029.html (ライブテスト) (ソース)
- quotes-030.html (ライブテスト) (ソース)
- quotes-031.html (ライブテスト) (ソース)
- quotes-032.html (ライブテスト) (ソース)
- quotes-033.html (ライブテスト) (ソース)
- quotes-034.html (ライブテスト) (ソース)
- quotes-first-letter-001.html (ライブ テスト) (ソース)
- quotes-first-letter-002.html (ライブ テスト) (ソース)
- quotes-first-letter-003.html (ライブ テスト) (ソース)
- quotes-first-letter-004.html (ライブ テスト) (ソース)
- quotes-first-letter-005.html (ライブ テスト) (ソース)
- quotes-first-line.html (ライブテスト) (ソース)
- quotes-lang-dynamic-001.html (ライブ テスト) (ソース)
ユーザーエージェントは視覚的でないメディアを含むすべてのメディアでこのプロパティをサポートすることが期待されています。
このプロパティは要素の引用符システムを指定し、 contentプロパティの open-quoteや close-quote値の挙動を定義します。 詳しくは§ 2.4.2 引用符の挿入: *-quoteキーワードを参照ください。 各値の意味は以下の通りです:
- none
- open-quoteとclose-quote値は contentプロパティ上で 引用符を生成せず、 それぞれno-open-quoteや no-close-quote と同じように振る舞います。
- auto
-
タイポグラフィ的に適切な引用符システムが、
親のコンテンツ言語(なければ要素自身の言語)に基づき
UAによって自動的に選択されます。
注: Unicode Common Locale Data Repository [CLDR]には タイポグラフィ的に適切な引用符に関する情報が掲載されています。 UAは他の情報源も利用できますが、 タイポグラフィの好みは多様性があり得るため、 Unicodeへの改善提案も歓迎されます。 (そうすればソフトウェア生態系全体の利益となります。)
- match-parent
-
親と同じ引用符システムを指定します。
通常これは親の算出値継承と同等ですが、
autoの場合は
親が用いたコンテンツ言語を使って解決されます。
ここには2つのアプローチがあり、現在は後者を仕様化しています: a) これは関連する文字列値に算出され、そのまま継承される。 b) この値はキーワード+言語コードとして継承され、 つまりautoだが言語は親から引き継ぐ。
- [ <string> <string> ]+
- 引用符システムは 指定された引用符ペア(開始と閉じ)リストとして定義されます。 最初のペアは最も外側の引用レベル、次のペアは埋め込みの次のレベル…というように表します。 ペア内では、 open-quote値は1つ目の <string>、 close-quoteは2つめに対応します。
2.4.2. 引用符の挿入: *-quoteキーワード
<quote> = open-quote | close-quote | no-open-quote | no-close-quote
- open-quote
- close-quote
- これらの値は、quotesプロパティで定義された適切な文字列に置換されます。 open-quoteの場合は引用の入れ子レベルが増加し、 close-quoteの場合は入れ子レベルが減少します。
- no-open-quote
- no-close-quote
- 何も挿入しません(noneと同様)。 ただしno-open-quoteは引用深度を増加、 no-close-quoteは減少します。
引用符は、open-quoteおよびclose-quote値を contentプロパティに指定することで、 ドキュメントの適切な場所に挿入できます。 open-quoteや close-quoteの出現ごとに、 引用符システムで定義された引用符文字列に置換されます。 これはquotesプロパティで指定され、 入れ子(引用深度)により決定します。
どの引用符ペアを使うかは引用の入れ子レベル (引用深度)によります。 これは、該当箇所までの生成テキスト内のopen-quoteの総数から、 それまでに出現したclose-quoteの総数を引いたものです。 深度0なら最初のペア、深度1なら2番目のペア…という具合です。 ペア数を深度が超えた場合は最後のペアが繰り返し使われます。
注: 引用深度は ドキュメントや書式構造の入れ子に依存しません。 また、カウンターの継承と同じく、 [DOM]内の「フラット化要素ツリー」で動作します。
close-quoteやno-close-quoteにより 引用深度が負になる場合はエラーとなり(レンダリング時に無視)、 深度は0のままで引用符は挿入されません (ただし、contentプロパティの他の値は挿入されます)。
以下のスタイルシートはblockquote内の各段落の前に開始引用符を挿入し、
最後の段落にのみ閉じ引用符を挿入します:
blockquote p::before{ content : open-quote} blockquote p::after{ content : no-close-quote} blockquote p:last-child::after{ content : close-quote}
対称性のためにno-open-quoteキーワードもあります。 これは何も挿入しませんが、引用深度を1増加させます。
注: 引用文が周囲の言語とは異なる場合、 引用符は引用文そのものの言語ではなく、周囲の言語に合わせたものを使うのが慣例です。
The device of the order of the garter is “Honi soit qui mal y pense.”
フランス語文中の英語:
Il disait: « Il faut mettre l’action en ‹ fast forward ›. »
例えば下記のようなスタイルシートでquotesプロパティを設定すれば、 open-quoteやclose-quoteが すべての要素で正しく機能します。 これらは英語・フランス語で構成される文書用。 追加言語ごとにルールが必要です。 親要素の言語ごとに適切な引用符を設定するためには子要素結合子(">")を使います:
:lang ( fr) > *{ quotes : "\00AB\2005" "\2005\00BB" "\2039\2005" "\2005\203A" } :lang ( en) > *{ quotes : "\201C" "\201D" "‘" "’" }
引用符はだれもが入力できる形でここに示しています。 直接入力できる場合は、次のように表示されます:
:lang ( fr) > *{ quotes : "« " " »" "‹ " " ›" } :lang ( en) > *{ quotes : "“" "”" "‘" "’" }
/* 2つの言語・2レベル用の引用符ペア指定 */ :lang ( en) > q{ quotes : '"' '"' "'" "'" } :lang ( no) > q{ quotes : "«" "»" "’" "’" } /* Q要素の内容前後に引用符挿入 */ q::before{ content : open-quote} q::after{ content : close-quote}
次のHTML片に適用すると:
<html lang="en" > <head> <title>Quotes</title> </head> <body> <p><q>Quote me!</q></p> </body> </html>
以下のような表示になります:
"Quote me!"
一方次のHTML片では:
<html lang="no" > <head> <title>Quotes</title> </head> <body> <p><q>Trøndere gråter når <q>Vinsjan på kaia</q> blir deklamert.</q></p> </body> </html>
このようになります:
«Trøndere gråter når ’Vinsjan på kaia’ blir deklamert.»
2.5. リーダー
リーダー(タブリーダーやドットリーダーとも呼ばれる)は、 水平方向にコンテンツを視覚的につなぐための繰り返しパターンです。 目次でタイトルとページ番号の間に最もよく使われます。 leader()関数を contentプロパティ値として使うことでCSSでリーダーが生成できます。 この関数は文字列(リーダー用パターン)を受け取り、パターンを繰返します。
2.5.1. leader()関数
- leader( <leader-type> )
- リーダーを挿入します。 詳しくはリーダーの節を参照ください。
leader () =leader ( <leader-type>) <leader-type> = dotted | solid | space | <string>
よく使うパターンを表す3つのキーワードがあります:
- dotted
- leader(".")と同等
- solid
- leader("_")と同等
- space
- leader(" ")と同等
- <string>
- 課題: 定義が必要です。
ol.toc a::after{ content : leader ( '.' ) target-counter ( attr ( href), page); } <h1>目次</h1> <ol class="toc" > <li><a href="#chapter1" >Loomings</a></li> <li><a href="#chapter2" >The Carpet-Bag</a></li> <li><a href="#chapter3" >The Spouter-Inn</a></li> </ol>
このような表示結果になります:
目次1 . Loomings.....................1 2 . The Carpet-Bag...............9 3 . The Spouter-Inn.............13
リーダーは後続コンテンツが右揃え(右端揃え)であることを前提にしているか?
2.5.2. リーダーの描画
リーダーの前のコンテンツ(「前コンテンツ」)、リーダー、リーダー後のコンテンツ(「後コンテンツ」)を含む行を考えます。 リーダーは次の規則に従います:
-
リーダー文字列は最低1回は完全に表示されなければなりません。
-
リーダーはできるだけ長くするべきです。
-
リーダー内の見える文字が可能なら縦に揃うべきです。
-
リーダー文字列内の改行文字は無視されねばなりません。
-
リーダー文字列内の空白は通常のCSS規則に従います。
-
リーダーは開始コンテンツと終了コンテンツの間だけに表示されます。
-
開始コンテンツや終了コンテンツが別行であっても、リーダー自体は1行だけに表示されます。
-
リーダーのみが1行に表示されることはありません。
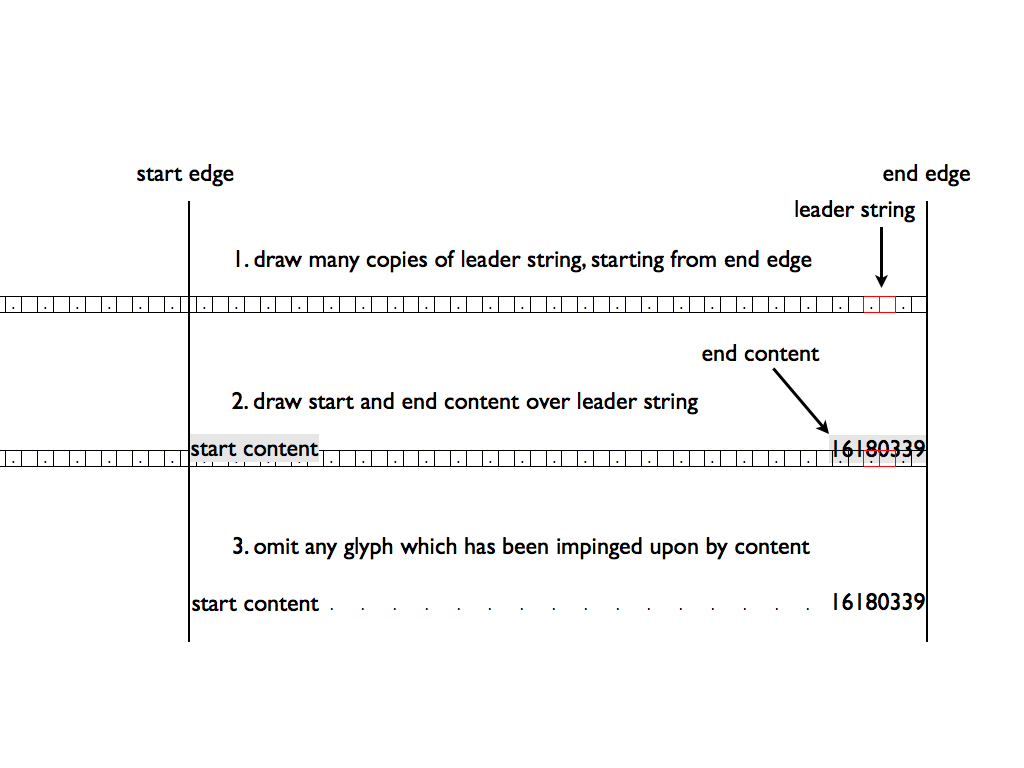
2.5.3. リーダー描画手順
-
前コンテンツをレイアウトし、その終了する行まで進めます。
BBBBBBBBBB BBB
-
リーダー文字列は1つ以上のグリフからなり、インラインボックスです。 リーダーはこれらのボックスが行末から行頭まで並ぶものです。 前後コンテンツが重ならない箇所だけ表示されます。 この行でリーダー文字列を行末から反復して並べ、行頭までできるだけ多く表示します。
BBBBBBBBBB ..........
-
リーダー上に前コンテンツおよび後コンテンツを重ね表示します。 前コンテンツや後コンテンツがリーダー文字列ボックスのグリフと重なる場合、 そのグリフは表示されません。
BBBBBBBBBB BBB....AAA
-
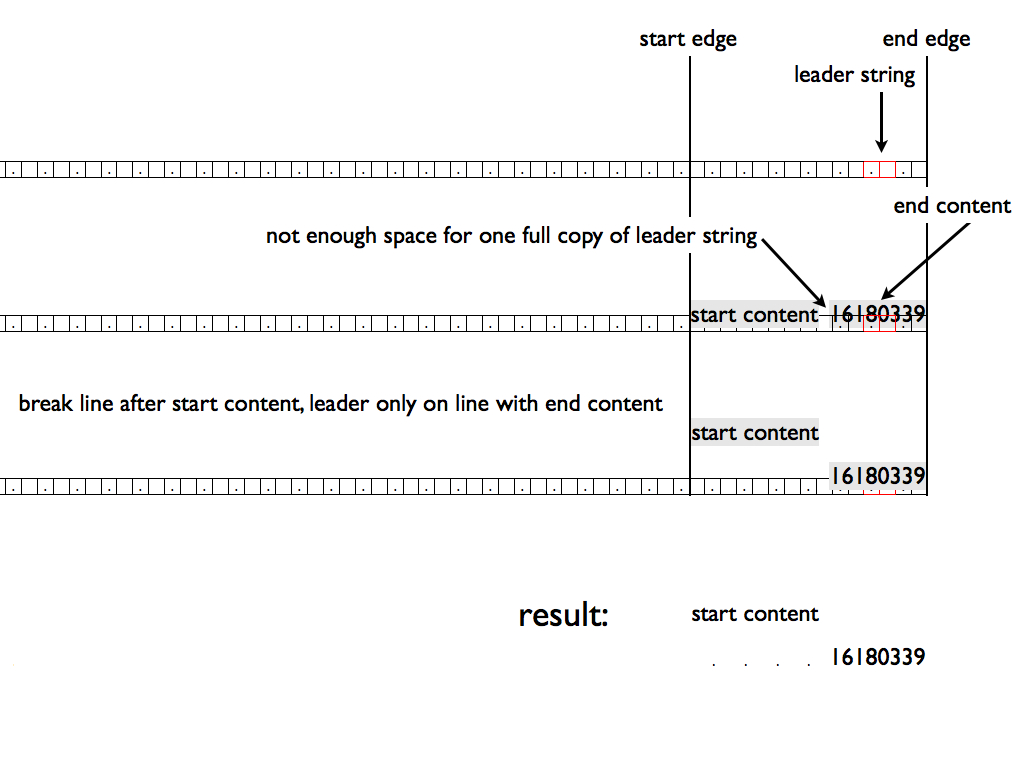
リーダー文字列が1回も完全には表示できない場合:
BBBBBBB BBBBBBA
前コンテンツの後に改行を挿入し、次の行にリーダーを表示し、 その上に後コンテンツを重ね、 完全に表示できないリーダー文字列は隠す。
BBBBBBB BBBBBB ......A
リーダーは表レイアウトと完全には合わない。どう修正すべきか?
2.6. 相互参照
多くのドキュメントには内部参照が含まれています:
contentプロパティ用に3つの新しい値があり、これらの種類の参照を自動生成できます:target-counter()、target-counters()、target-text()です。 これらはリンク先から取得した情報を表示します。
<target> = <target-counter () > | <target-counters () > | <target-text () >
詳細は以下のセクションを参照ください。
2.6.1. target-counter()関数
target-counter () =target-counter ( [ <string> | <url>] , <custom-ident>, <counter-style>?)
target-counter()関数は、指定した名前の最も内側のカウンターの値を取得します。 必須引数はターゲットのURLとカウンター名です。 結果の書式指定用にcounter-style引数を追加できます(省略可能)。
これらの関数は現在の文書内の場所を指すフラグメントURLのみ受け付けます。 フラグメントがない場合、参照先IDが存在しない場合、またはURLが外部文書を指す場合、 UAはそれをエラーとして扱う必要があります。
…これは"#chapter4_sec2" >ページで議論されます。
CSS:
a : :after{ content : target-counter ( attr ( href url), page) }
結果:
…これは137 ページで議論されます。
HTML:
<nav> <ol> <li class="frontmatter" ><a href="#pref_01" >序文</a></li> <li class="frontmatter" ><a href="#intr_01" >はじめに</a></li> <li class="bodymatter" ><a href="#chap_01" >第1章</a></li> </ol> </nav>
CSS:
.frontmatter a::after{ content : leader ( '.' ) target-counter ( attr ( href url), page, lower-roman) } .bodymatter a::after{ content : leader ( '.' ) target-counter ( attr ( href url), page, decimal) }
結果:
序文.............vii はじめに.........xi 第1章.............1
2.6.2. target-counters()関数
この関数は、リンク先のすべての指定カウンター値を取得し、各カウンター値の間に指定した文字列を挿入してフォーマット表示します。
target-counters () =target-counters ( [ <string> | <url>] , <custom-ident>, <string>, <counter-style>?)
2.6.3. target-text()関数
target-text()関数は、URLで参照される要素のテキスト値を取得します。 省略可能な第2引数で、取得する内容を指定でき、これはstring-setプロパティと同じ値です。
target-text () =target-text ( [ <string> | <url>] , [ content | before | after | first-letter] ?)
fantasaiによる簡易構文提案あり: https://lists.w3.org/Archives/Public/www-style/2012Feb/0745.html
…これは"#chapter_h1_1" >後で説明します。 a::after{ content : ", 「" target-text ( attr ( href url)) "」章で" ; }
結果:…これは後で説明します、「Loomings」章で。
2.7. 名前付き文字列
このセクションでは名前付き文字列について説明します。 これはカウンターのテキスト相当で、カウンターとは独立した名前空間になります。 名前付き文字列もカウンターと同じ入れ子規則に従います。 string-setプロパティは contentプロパティと似た値を受け取れ、カウンター値の抽出も可能です。
名前付き文字列は、メタデータを文書から抜き出してヘッダーやフッターに入れる便利な方法です。 例えばHTMLでは、ドキュメントのHEAD内にMETA要素があり、 名前付き文字列の値を設定できます。 属性セレクタと組み合わせることで強力なメカニズムになります:
meta[ author] { string-set : authorattr ( author); } head > title{ string-set : title contents; } @page :left{ @top { text-align : left; vertical-align : middle; content : string ( title); } } @page :right{ @top { text-align : right; vertical-align : middle; content : string ( author); } }
2.7.1. 名前付け: string-setプロパティ
| 名前: | string-set |
|---|---|
| 値: | none | [ <custom-ident> <string>+ ]# |
| 初期値: | none |
| 適用対象: | すべての要素、疑似要素には適用されません |
| 継承: | no |
| パーセンテージ: | N/A |
| 算出値: | キーワードnone、または各識別子+文字列値リストのリスト |
| 標準順序: | 構文通り |
| アニメーション型: | 離散型 |
ユーザーエージェントは視覚的でないものも含め全てのメディアでこのプロパティに対応することが期待されます。
string-setプロパティは要素のテキスト内容を名前付き文字列にコピーし、 変数として機能します。 この文字列値はstring()関数で取得できます。 ページごとに変数値が変わる場合があり、 string()関数の第2引数でどの値を使うか指定できます。
- none
- この要素は名前付き文字列を設定しません。
[ <custom-ident> <string>+] #-
要素は1つ以上の名前付き文字列を、リスト内の各コンマ区切りエントリにより確立します。
各エントリの<custom-ident>は文字列名です。 これに1つ以上の<string>値が続き、結合されて名前付き文字列の値となります。
要素がスタイル制御を持つ場合、 当該要素の子孫にはstring-setプロパティは効果を持ちません。
H1{ string-set : chapter contents; }
H1要素が現れた時、chapter文字列にその要素のテキスト内容が代入され、 以前の値は上書きされます。
2.7.2. 名前付き文字列の挿入: string()関数
string () =string ( <custom-ident>, [ first | start | last | first-except] ?)
string() 関数は、名前付き文字列の値をcontentプロパティ経由で文書に挿入するために使います。 この関数は1つ目の引数として文字列名が必要です。 ページ内で値が複数回変化する場合(文字列定義要素が複数現れる場合)、 省略可能な第2引数でどの値を使うか指定できます。
string()関数の第2引数は以下いずれかのキーワードです:
- first
- ページ内の最初の代入値を使用します。 ページ内に代入がない場合、entry valueが使われます。 第2引数を指定しない場合、これがデフォルト値です。
- start
- 要素がページで最初の要素なら、最初の代入値を使用。 そうでなければentry valueを使用します。 entry valueは、名前付き文字列がまだ現れていなければ空になることがあります。
- last
- 名前付き文字列のexit valueを使用します。
- first-except
- firstと同じですが、 代入されたページでは空文字列となります。
名前付き文字列の値は、要素の内容ボックスが初めて作成された時(display値がnoneでもボックスが作成されるはずなら)に代入されます。 ページのentry valueは前ページ終了時の代入値、 exit valueは当ページ終了時の代入値です。
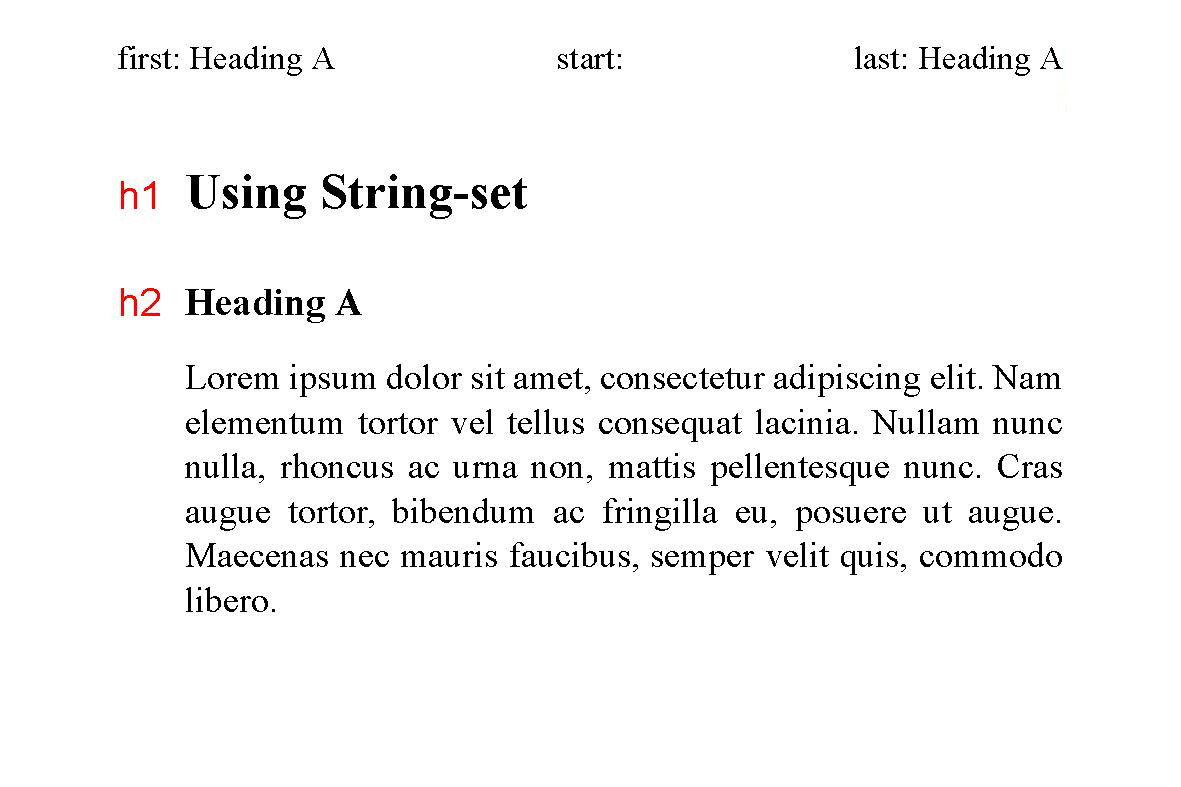
@page {
size: 15cm 10cm;
margin: 1.5cm;
@top-left { content: "first: " string(heading, first); }
@top-center { content: "start: " string(heading, start); }
@top-right { content: "last: " string(heading, last); }
}
h2 { string-set: heading content(); }
下記の図は、各ページの "heading" 文字列で first, start, last の代入値を示しています。


2.7.3. content() 関数
content () =content ( [ text | before | after | first-letter | marker] ?)
- text
- 要素の文字列値。 content() で値が指定されない場合、 text が指定されたものとして扱われます。
- before
- ::before 疑似要素の文字列値。
- after
- ::after 疑似要素の文字列値。
- first-letter
- ::first-letter 疑似要素に定義された要素の最初の文字。
- marker
- ::marker 疑似要素の文字列値。
<h1>Loomings</h1>
CSS:
h1 : :before{ content : 'Chapter ' counter ( chapter); } h1{ string-set : headercontent ( before) ':' content ( text); } h1::after{ content : '.' ; }
名前付き文字列 “header” の値は “Chapter 1: Loomings” になります。
<section title="Loomings" >
CSS:
section{ string-set : headerattr ( title) }
“header” 文字列の値は “Loomings” となります。
2.8. 自動カウンターと番号付け
CSS Lists 3 § 4 自動カウンターによる番号付け を参照してください。
3. ブックマーク
一部のドキュメント形式(PDFなど)では、ナビゲーション支援として ブックマーク が使用できます。 ブックマークはドキュメント要素へのリンク一覧と、リンク用ラベルテキスト、レベル値を提供します。 ブックマークには3つのプロパティがあります:bookmark-level、 bookmark-label、 bookmark-state。
ユーザーがブックマークを操作すると、UAはその参照点をユーザーに示す必要があります(フラグメントURLでその要素へ移動する場合と同様)。 この操作は :target 疑似クラスにも一致することになります。
要素が style containmentを持つ場合、 bookmark-level、 bookmark-label、 bookmark-state はその子孫には効果を持ちません。
3.1. ブックマーク設定: bookmark-level プロパティ
bookmark-levelプロパティはブックマークの生成有無とレベルを決定します。 このプロパティがない場合や値がnoneなら、 bookmark-labelやbookmark-stateの値に関係なく、ブックマークは生成されません。
| 名前: | bookmark-level |
|---|---|
| 値: | none | <integer [1,∞]> |
| 初期値: | none |
| 適用対象: | すべての要素 |
| 継承: | no |
| パーセンテージ: | N/A |
| 算出値: | キーワード none または 指定した整数値 |
| 標準順序: | 構文通り |
| アニメーション型: | 算出値型による |
- <integer [1,∞]>
- ブックマークのレベルを定義します。最上位は1(負および0は無効)。
- none
- ブックマークは生成されません。
section h1{ bookmark-level : 1 ; } section section h1{ bookmark-level : 2 ; } section section section h1{ bookmark-level : 3 ; }
注: ブックマークは厳密な階層構造にする必要はありません。
3.2. ブックマークラベル付け: bookmark-label プロパティ
| 名前: | bookmark-label |
|---|---|
| 値: | <content-list> |
| 初期値: | content(text) |
| 適用対象: | すべての要素 |
| 継承: | no |
| パーセンテージ: | N/A |
| 算出値: | 指定値 |
| 標準順序: | 構文通り |
| アニメーション型: | 離散型 |
- <content-list>
- <content-list> の定義は上記 string-set の節を参照。 <content-list> の値がブックマークラベルのテキスト内容になります。
<h1>Loomings</h1>
CSS:
h1{ bookmark-label : content ( text); bookmark-level : 1 ; }
ブックマークラベルは “Loomings” になります。
3.3. 初期ブックマーク切替状態: bookmark-state プロパティ
bookmark-stateは open または closed です。ユーザーはブックマーク状態を切り替え可能である必要があります。
| 名前: | bookmark-state |
|---|---|
| 値: | open | closed |
| 初期値: | open |
| 適用対象: | ブロックレベル要素 |
| 継承: | no |
| パーセンテージ: | N/A |
| 算出値: | 指定キーワード |
| 標準順序: | 構文通り |
| アニメーション型: | 離散型 |
- open
- 以降の高い bookmark-level のブックマークは全て表示され、同じレベルまたは低いbookmarkに到達するまで継続します。 以降のブックマークが closed の場合、そのブックマーク以降の表示も同じ判定になります。
- closed
- 以降の高い bookmark-level のブックマークは表示されません。同じレベルまたは低いbookmarkに到達するまで非表示です。
4. 変更点
2019年8月2日作業草案以降の主な変更は以下の通りです:
- auto が 親の content language を参照するようになりました(要素自身の content language ではなく)。 (Issue 5478)
- match-parent 値が quotes に追加されました。 (Issue 5478)
- quote depth のマイナス値を防ぐため余計な閉じ引用符を無視する挙動に変更([CSS2]と同じ)。 (Issue 2034)
- content: normal の算出値を ::placeholder や ::file-selector-button 用に定義。 (Issue 6124)
- 閉じ引用符の quote depth 計算オフバイワンバグ修正。 (Issue 2506)
- attr() の定義をインライン化([CSS-VALUES-4] から削除されたため)。
- Web Platform Testsカバレッジが追加されました。
- その他編集面のクリーンアップ。
過去の変更点は previous changes も参照。
謝辞
Stuart Ballard、 David Baron、 Bert Bos、Tantek Çelik、 James Craig から本仕様に役立つ貴重なご意見をいただきました。
プライバシーに関する注意事項
本仕様には新たなプライバシー面の懸念事項は報告されていません。
セキュリティに関する注意事項
本仕様には新たなセキュリティ面の懸念事項は報告されていません。