1. はじめに
1.1. ルビとは何か
この小節は規範的ではありません。
ルビとは、他のテキスト(「基底」と呼ばれる)のそばに配置され、そのテキストに関連する注釈や発音ガイドとして機能するテキスト列の一般的な名称です。
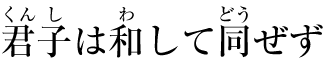
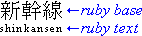
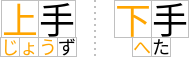
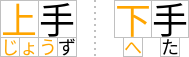
以下の図は、単純なケースとより複雑な構造の2つのルビの例を示しています。

日本語におけるルビの例(単純なケース)
日本語組版では、このケースを「対語ルビ」(日本語: 対語ルビ、すなわち単語ごとルビ)やグループルビと呼ぶことがあります。注釈全体が複数文字の単語(全体)に対応しているためです。

基底文字の上下に注釈テキストが付与された複雑なルビ
ひらがな注釈と対応する漢字基底文字の正しい対応関係を反映するため、基底レベルテキスト内の字送りが調整されていることに注目してください。 (これは上図の4番目の漢字の周辺で発生しており、3文字のふりがなが付いています。) 上記の例のような基底テキストの可変な字送りを避けるため、ひらがな注釈をマージ注釈としてスタイル指定することができ、これにより先ほどのグループルビのような見た目になります。 ただし、基底-注釈のペアリングはルビ構造で記録されているため、テキストが行をまたいで折り返された場合でも、注釈文字は対応する基底文字と正しくペアリングされたまま保持されます。
HTMLでは、ルビ構造およびそのマークアップの表現方法がRuby Markup Extension仕様で説明されています。 本モジュールでは、そのようなマークアップに対するCSSによるレンダリングモデルとルビレイアウトに関する書式制御について説明します。
ルビやその書式指定についてさらに詳しく知りたい場合は、「What is Ruby」記事[QA-RUBY]を参照してください。 日本語における主なルビの書式手法については、JIS X-4051 [JIS4051](日本語)や 「ルビおよび圏点」(日本語組版処理の要件 [JLREQ]、日本語・英語)に詳しくまとめられています。 Rules for Simple Placement of Japanese Ruby [SIMPLE-RUBY]も(英語)で日本語ルビ書式の一手法を解説しています。 「行間注記」(Requirements for Chinese Text Layout [CLREQ]、中国語・英語)には中国語組版での関連手法も記載されています。
1.2. モジュール間の関係
このモジュールは、CSS Level 2 [CSS2] のインラインボックスモデルを拡張してルビをサポートします。
このモジュール内のプロパティは、::first-line や ::first-letter 疑似要素には適用されません。 ただし、ruby-position は ::first-line を継承して 1行目のルビ注釈に影響を与えることができます。
1.3. 値の定義
本仕様は、CSSプロパティ定義の規約([CSS2])および 値定義構文([CSS-VALUES-3])に従っています。 本仕様で定義されていない値型は CSS Values & Units [CSS-VALUES-3] で定義されています。 他のCSSモジュールとの組み合わせにより、これらの値型の定義が拡張される場合があります。
プロパティごとの値に加え、本仕様で定義されるすべてのプロパティは CSS全域キーワードもプロパティ値として受け付けます。 可読性のため、ここでは繰り返し記載していません。
1.4. 図の表記規則
この小節は規範的ではありません。
東アジア組版における多くの表記規則は、表示される文字が全角(CJK)か半角(非CJK)かに依存します。 本文書に登場するいくつかの図では、次の凡例が使われています:

- テキスト中のn番目に位置する全角グリフ(例:漢字)。注釈の場合は通常50%の大きさになります。
- テキスト中のn番目に位置する半角グリフ(例:ローマ字)。
上記シンボルが図中で取る向きは、実際にユーザーエージェントで描画される際のグリフの向きと対応しています。 図中の各文字間の間隔は特に意味がない場合もありますが、意図的に変えている場合もあります。
2. ルビボックスモデル
CSSルビモデルは、 W3C HTML5 Rubyマークアップモデル および XHTML Ruby Annotation 勧告 [RUBY] に基づいています。 このモデルにおいて、ルビ構造は、 基底(注釈対象)テキストを表す1つ以上のルビ基底要素と、 注釈を表す1つ以上のレベルのルビ注釈要素から構成されます。 ルビの構造はテーブルの構造と似ており、 「行」(基底テキストレベル、各注釈レベル) および「列」(各ルビ基底とその対応するルビ注釈)があります。
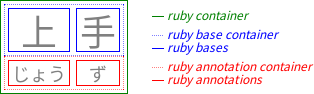
連続する基底とその連続する注釈のセットはルビセグメントとしてまとめられます。 ルビセグメント内では、ルビ注釈が複数のルビ基底にまたがることがあります。
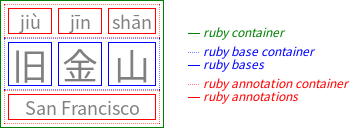
注記: HTMLでは、1つの<ruby>要素に複数のルビセグメントを含めることができます。
(XHTML Rubyモデルでは、1つの<ruby>要素には1つのルビセグメントしか含められません。)
2.1. ルビ用display 値
あらかじめルビ要素が定義されていない文書言語(XMLアプリケーション等)の場合は、著者が文書言語の要素をルビ要素にマッピングする必要があり、 これはdisplay プロパティで行います。
以下の新しいdisplay 値は、任意の要素にルビレイアウトの役割を割り当てます:
- ruby
- 要素がルビコンテナボックスを生成することを指定します。
(HTML/XHTMLの
<ruby>要素に対応します。) - ruby-base
- 要素がルビ基底ボックスを生成することを指定します。
(HTML/XHTMLの
<rb>要素に対応します。) - ruby-text
- 要素がルビ注釈ボックスを生成することを指定します。
(HTML/XHTMLの
<rt>要素に対応します。) - ruby-base-container
- 要素がルビ基底コンテナボックスを生成することを指定します。
(XHTMLの
<rbc>要素に対応。HTMLでは匿名ボックスとして生成されます。) - ruby-text-container
- 要素がルビ注釈コンテナボックスを生成することを指定します。
(HTML/XHTMLの
<rtc>要素に対応します。)
専用のルビマークアップをサポートする言語(HTMLなど)を使用する場合は、
任意の要素(<span>など)にルビ用display
値を適用するのではなく、正しいマークアップを使うべきです。
正しいマークアップを使うことで、スクリーンリーダーや非CSSレンダラーでもルビ構造を解釈できるようになります。
注記: 置換要素が display 値として ruby-base、ruby-text、ruby-base-container、 ruby-text-container を持つ場合は、 インラインレベルボックスとして扱われます。 (CSS Display 3 § 2.4 レイアウト内部displayタイプ:table-*およびruby-*キーワード参照) 置換要素が display 値として ruby または inline ruby を持つ場合は、 外部displayタイプに従って動作します。 (CSS Display 3 § 2.1 フローレイアウトの外部displayロール:block、inline、run-inキーワード参照。) (§ 2.1.2 非インラインルビも参照。)
2.1.1. ルビ整形コンテキスト
ルビコンテナは非原子的な インラインレベルボックスです。 通常のインラインボックス(CSS Inline Layout 3 § 2 インラインレイアウトモデル参照)と同じく、 行をまたぎ、 その包含ブロックは最も近いブロックコンテナ祖先です。 また、インラインボックスの内容がそのインラインボックス自身を含む同一のインライン整形コンテキストに参加するのと同様に、 ルビコンテナおよびその基底レベルの内容も そのルビコンテナ自身を含む同一のインライン整形コンテキストに参加します。
ただし、ルビコンテナは 注釈を格納するために、そのインライン整形コンテキストの区間に対してさらに構造を与える ルビ整形コンテキストを確立します。 注記: この整形コンテキストは独立した 整形コンテキストではありません。 ルビ基底、 ルビ注釈、 ルビ基底コンテナ、 ルビ注釈コンテナは 内部ルビボックスです。 内部テーブル要素と同様に、 ルビレイアウトで特定の役割を持ち、 それぞれのルビコンテナのルビ整形コンテキストに参加します。 ルビ整形コンテキストでの役割に加え、 ルビ基底は同時に ルビコンテナと同じ基底レベルのインライン整形コンテキストにも参加し、 ルビ注釈は ルビコンテナによって確立される注釈レベルのインライン整形コンテキストに参加します。
インラインボックスの内容と同様に、 包含ブロックは ルビコンテナ(およびすべての内部ルビボックス)の内容に対して ルビコンテナの包含ブロックです。 したがって、例えばfloatはルビコンテナの包含ブロックで止められ、 ルビボックスタイプのいずれにも影響しません。
2.1.2. 非インラインルビ
要素が内部display型としてrubyを持ち、 かつ外部display型が inline以外の場合、 2つのボックスが生成されます: 必要な外部display型の主ボックスと、 インラインレベルのルビコンテナです。 要素に指定されたすべてのプロパティは主ボックスに適用され (継承可能な場合はルビコンテナボックスにも継承されます)。 これにより、要素をブロックとしてスタイル指定しつつ、内部のルビ構造を正しく維持できます。
注記:要素を絶対配置またはfloatさせると、そのdisplay 値はブロックレベル同等に計算されます。 ([CSS-DISPLAY-3]や[CSS2] セクション9.7参照) 内部ルビdisplay型については、 そのdisplay値がblockに計算されます。
2.2. 匿名ルビボックス生成
CSSモデルでは、文書言語がこれらすべての構成要素に対応する要素を含む必要はありません。 欠落している構造部品は、テーブル正規化で使われるものと類似の匿名ボックス生成規則により補われます。[CSS2]
- ブロックレベルボックスのインライン化: ルビコンテナ、 ルビ基底コンテナ、 ルビ注釈コンテナ、 ルビ基底ボックス、 ルビ注釈ボックス に直接含まれるin-flowなブロックレベルボックスは、[CSS-DISPLAY-3]に従い 「インライン化」され、そのdisplay値も適切に計算され、 インラインレベルの内容のみを含むようになります。 例えば、displayプロパティがdisplay: blockのin-flow要素が display: ruby-textの親を持つ場合、 そのdisplay値はinline-blockに計算されます。
- 匿名ルビコンテナの生成: 連続した 不適切に包含されたルビ基底コンテナ、 ルビ注釈コンテナ、 ルビ基底、 ルビ注釈 (および間の空白)のいずれかの連続列は 匿名ルビコンテナでラップされます。 このステップにおいて:
-
誤った親を持つインラインレベル内容のラップ:
ルビコンテナまたは
ルビ基底コンテナの直下に連続するテキストやインラインレベルボックスは、匿名ルビ基底でラップされます。
同様に、ルビ注釈コンテナの直下に連続するテキストやインラインレベルボックスは匿名ルビ注釈でラップされます。
(この目的のため、誤った親を持つ内部テーブル要素はインラインレベル内容と見なされます。なぜなら、ルビボックスの親を持つため、最終的にインラインレベルのテーブルラッパーボックスでラップされるからです。)
ただし、このように構築された匿名ボックスが空白のみを含む場合は、 ルビ内空白と見なされ、下記のように破棄または保持されます。
- 先頭/末尾空白のトリム: ルビ内空白が親の唯一のin-flow子でなく、かつ ルビコンテナ、 ルビ注釈コンテナ、または ルビ基底コンテナの 最初または最後のin-flow子である場合は、display: noneのように削除されます。
-
レベル間空白の削除:
直前直後のin-flow兄弟ボックスが下表のパターンに一致するルビ内空白は
レベル間空白と見なされ、
display: noneのように削除されます。
前のボックス 次のボックス 任意 ルビ注釈コンテナ ルビ注釈以外 ルビ注釈 -
レベル内空白の解釈:
直前直後のin-flow兄弟ボックスが下表のパターンに一致するルビ内空白ボックスには下表のボックスタイプとサブタイプが割り当てられます:
上記で定義されたレベル内空白ボックスは ペアリングやレイアウトにおいて特別に扱われます。 下記を参照してください。前のボックス 次のボックス ボックスタイプ サブタイプ ルビ基底 ルビ基底 ルビ基底 基底間空白 ルビ注釈 ルビ注釈 ルビ注釈 注釈間空白 ルビ注釈 または ルビ注釈コンテナ ルビ基底 または ルビ基底コンテナ ルビ基底 セグメント間空白 ルビ基底 または ルビ基底コンテナ ルビ基底コンテナ ルビ基底コンテナ ルビ基底 または ルビ基底コンテナ -
改行の抑制:
ルビ注釈内のすべての強制改行を
(white-space値に関わらず)
CSS Text Level 3 § 4.1.2で定義される
セグメント分割の折り畳みに従って変換します。
この目的は、ルビ注釈内の改行を抑制してレイアウトモデルを簡略化することです。 あるいは、許容可能な挙動を定義することも考えられます。
- 匿名レベルコンテナの生成: ルビ基底と 基底間空白(ただしセグメント間空白でないもの)の連続列で ルビ基底コンテナの親でないものは匿名ルビ基底コンテナでラップされます。 同様に、ルビ注釈と 注釈間空白の連続列で ルビ注釈コンテナの親でないものは匿名ルビ注釈コンテナでラップされます。
すべてのルビレイアウト構造が正しく親付けされた時点で、 UAは基底と注釈の対応付けを開始できます。
注記: UAは内部構造としてこれらの匿名ボックス (や§ 2.3 注釈ペアリングの匿名空のレベル内空白ボックス)を生成する必要はありません。 ペアリングやレイアウトの挙動が それらが存在するかのように動作していれば十分です。
< ruby > ×< rbc > ×< rb ></ rb > ⬕< rb ></ rb > ×</ rbc > ☒< rtc > ×< rt ></ rt > ⬔< rt ></ rt > ×</ rtc > ◼< rbc > ×< rb ></ rb > …</ rtc > ×</ ruby >
ここで
-
× は先頭/末尾空白の破棄を表します
-
☒ はレベル間空白の破棄を表します
-
⬕ は基底間空白を表します
-
⬔ は注釈間空白を表します
-
◼ はセグメント間空白を表します
2.3. 注釈ペアリング
注釈のペアリングとは、 ルビ注釈とルビ基底を対応付ける処理です。 各ルビ注釈は1つ以上のルビ基底と対応付けられ、 それらの基底をスパンするといいます。 (ルビ注釈が複数の基底をスパンする場合、 それはスパン注釈と呼ばれます。)
ルビ基底は 各注釈レベルごとに1つのルビ注釈としか対応付けられません。 ただし、注釈レベルが複数ある場合は、 複数のルビ注釈と対応付けることができます。
ペアリングが完了すると、ルビカラムが定義されます。 各カラムは1つのルビ基底と それぞれの行間注釈注釈レベルごとに1つ(場合によっては空の匿名)のルビ注釈によって表されます(同じルビセグメント内)。
2.3.1. セグメントペアリングと注釈レベル
ルビ構造はルビセグメントに分割されます。 各セグメントは1つのルビ基底コンテナと、それに続く1つ以上のルビ注釈コンテナから成ります。 各ルビ注釈コンテナは 基底テキストに対する1つの注釈レベルを表し、 最初は第1レベル、2番目は第2レベル…となります。 ルビ基底コンテナは基底レベルを表します。 各セグメントのルビ基底コンテナは そのセグメント内のすべてのルビ注釈コンテナとペアになります。
異常ケースを扱うため、いくつかの空の匿名コンテナの存在が仮定されます:
- ルビコンテナの最初の子がルビ注釈コンテナである場合、 その前に匿名で空のルビ基底コンテナが存在するとみなされます。
- 同様に、ルビコンテナが 連続したルビ基底コンテナを含む場合、 その間には匿名の空のルビ注釈コンテナが存在するとみなされます。
セグメント間空白は実質的に独立したルビセグメントとみなされます。
2.3.2. ユニットペアリングとスパン注釈
ルビセグメント内では、 ルビ基底コンテナ内の各ルビ基底が そのルビセグメント内の各ルビ注釈コンテナの1つのルビ注釈とペアになります。
もしルビ注釈コンテナが ただ1つだけの匿名ルビ注釈を含む場合、 そのルビ注釈は、そのルビセグメント内の すべてのルビ基底とペアリングされ(すなわちスパンする)ことになります。
それ以外の場合、各ルビ注釈は 文書順でそのセグメント内対応するルビ基底とペアになります。 ルビ注釈コンテナ内のルビ注釈数が足りない場合は、 残りのルビ基底は ルビ注釈コンテナの末尾に挿入された匿名空注釈とペアになります。 ルビ基底が足りない場合は、 残りのルビ注釈は ルビ基底コンテナの末尾に挿入された匿名空基底とペアになります。
実装が明示的スパン付きルビマークアップ(例:XHTML Complex Ruby Annotations)をサポートする場合は、 スパン注釈と基底のペアリング規則を適切に調整する必要があります。
レベル内空白は 標準の注釈ペアリングには参加しません。 ただし、直近のルビ基底やルビ注釈がペアリングされている場合:
- 2つのルビ基底または 注釈 が他のレベルで対応するレベル内空白を挟んでいる場合、 それら対応するレベル内空白ボックスもペアリングされます。
- 1つのスパンするルビ注釈の場合、 レベル内空白もそのルビ注釈とペアリングされます。
- 2つのルビ基底または 注釈 間にレベル内空白がない場合は、 レベル内空白ボックスは その間に存在すると仮定される匿名空レベル内空白ボックスとペアリングされます。
|[ s p a n n i n g a n n o t a t i o n ]| |[ a1 ]|[ws]|[ a2 ]|[ ]|[ a3 ]|[ws]|[ a4 ]| |[ b1 ]|[ws]|[ b2 ]|[ws]|[ b3 ]|[ ]|[ b4 ]|
青い括弧([ ])は基底ボックス、 赤い括弧([ ])は注釈ボックス、 灰色の縦棒(|)はルビカラムの区切り、 [ws]はルビ内空白、 []は空の匿名基底または注釈(他レベルのレベル内空白に対応して自動生成されるもの)を表します。 ルビコンテナ、 基底コンテナ、 注釈コンテナは省略しています。
2.4. 注釈の非表示:visibility: collapse と自動非表示ルビ
ルビ注釈の visibilityが collapse の場合、その注釈は非表示注釈となります。 さらに、ルビ注釈のテキスト内容が基底と完全に一致する場合、 UAによって自動的に(自動非表示)になります。
となったルビ注釈は、 注釈ペアリングに影響しません。 ただし、は表示されず、レイアウトにも影響を与えませんが、 同じレベル内で隣接するルビ注釈ボックスの区切りとして作用し、 まるで異なるセグメントに属しているかのように、 の基底がルビ基底でなく途中のインライン要素であるかのように扱われます。
振り仮名(ふりがな)
したがって、次のようにマークアップされます:
< ruby > < rb > 振</ rb >< rb > り</ rb >< rb > 仮</ rb >< rb > 名</ rb > < rp > (</ rp >< rt > ふ</ rt >< rt > り</ rt >< rt > が</ rt >< rt > な</ rt >< rp > )</ rp > </ ruby >
しかしルビ表示時には「り」の注釈は非表示となるべきです。

振り仮名のひらがなルビ。「り」の上には注釈がありません(すでにひらがなだから)。
< ruby >< rb > 昆</ rb > 虫</ rb > 記< rt > こん</ rt class = easy > ちゅう</ rt > き</ ruby >

すべての文字に発音ガイドが必要な読者もいれば、 一部の読者には簡単な文字の注釈は非表示にした方が適切です。 visibility: collapse を適用すると非表示にできます:

の visibility: collapse の挙動は、 visibility: hiddenとは異なります。 hiddenは注釈を不可視にしますが、その分のスペースはレイアウト上残ります:

また、display: none とも異なります。visibility: collapse はペアリング関係を維持しますが、 display: none はボックスをツリーから完全に削除し、 以降の注釈のペアリングが崩れてしまいます:

computed value がruby-merge で 注釈コンテナにおいて merge の場合、は無効化されます。 値が auto の場合は、 ユーザーエージェントが非表示の可否を判断できますが、UAのレイアウトアルゴリズムが separate と同様の結果を生成する場合は を有効化することを推奨します。
の内容比較は、空白の折り畳み(white-space)やテキスト変換(text-transform)の前に行われ、
要素は無視され(ボックスの textContent のみを見る)、比較されます。
注記:将来のCSS Rubyレベルではの制御が追加される可能性がありますが、 本レベルでは常に強制されます。
2.5. 空白の折り畳み
§ 2.2 匿名ルビボックス生成で説明した通り、 ルビ構造内の空白は破棄されます:
< ruby > < rb > 東</ rb >< rb > 京</ rb > < rt > とう</ rt >< rt > きょう</ rt > < rtc >< rt > Tō</ rt >< rt > kyō</ rt ></ rtc > </ ruby >
ルビセグメント間、 ルビ基底間、 ルビ注釈間では 空白は破棄されず、 基底間空白、 注釈間空白、 セグメント間空白としてレンダリングで保持されます。 (上記レベル内空白の解釈参照)
< ruby > < rb > W</ rb >< rb > W</ rb >< rb > W</ rb > < rt > World</ rt > < rt > Wide</ rt > < rt > Web</ rt > </ ruby >
また、注釈付き空白も保持されます。例えば、
< ruby > < rb > Aerith</ rb >< rb > </ rb >< rb > Gainsborough</ rb > < rt > エアリス</ rt >< rt > ・</ rt >< rt > ゲインズブール</ rt > </ ruby >
破棄されなかった空白が折り畳み可能な場合は、 各行ボックス内で隣接するボックス間で 標準の空白処理ルール [CSS-TEXT-3]に従い折り畳まれます。 異なるルビセグメントや で区切られた注釈は隣接しているとはみなされません。 ただし、基底レベルの内容( 字間注釈を含む、これらは アトミックインラインとして扱われます)では隣接扱いとなります。 折り畳み可能空白が ルビセグメント間(セグメント間空白)に存在する場合、 文脈テキストは両側のルビ基底によって決まります。 (ソース文書上の空白両側のテキストではなく、間に行間注釈があっても基底が基準となります。)
< ruby > 屋< rt > おく</ rt > 内< rt > ない</ rt > 禁< rt > きん</ rt > 煙< rt > えん</ rt > </ ruby >
ただし、セグメント分割を含まない空白は完全には消えず、 次の例では1組目と2組目のルビの間に空白が表示されます:
< ruby > 屋< rt > おく</ rt > 内< rt > ない</ rt > 禁< rt > きん</ rt > 煙< rt > えん</ rt > </ ruby >
3. ルビのレイアウト
ルビ構造をレイアウトする際、 まず基底レベルは そのルビ基底が通常の インラインボックスであるかのように、 ルビコンテナを そのままインラインボックスとして包み込む形で行上に配置されます。
ルビコンテナ内に 字間注釈がある場合は、 基底レベル内に § 3.2 字間ルビレイアウトで詳細に述べる方法で配置されます。 その後、基底コンテナのサイズが決まり、 行間注釈が § 3.1 行間ルビレイアウトで説明される方法で配置されます。
他のCSSレイアウトモデルと同様、 相対位置指定や変形、その他のグラフィカル効果はボックスのレイアウト後に適用されます。
3.1. 行間ルビレイアウト
行間 のルビ注釈は まず同じインラインボックスであるかのように 同じインライン整形コンテキストに参加して配置され、 実質的に行ボックスをその注釈レベルごとに ルビコンテナ内で確立します。 注釈と基底は以下の説明に従って間隔を調整して互いに揃えられます。
3.1.1. インライン軸行間レイアウト
インライン軸において、行間ルビ注釈は、 ルビ基底ボックスに対して、 それぞれの注釈コンテナのruby-merge値に従い揃えられます。
ruby-mergeがseparateの場合、 各ルビカラムは そのカラム内で最も幅の広い内容(ルビ基底または ルビ注釈)に合わせて幅が決まります。 スパン注釈(実際にスパンする場合も ruby-merge: mergeでスパン扱いの場合も)において、 スパン注釈の内容がスパン先のカラム合計幅より広い場合は、 差分がスパンしたカラムに均等配分されます。 ルビセグメント内に 複数のスパン注釈がある場合は、 より少ない基底をスパンする注釈から順に追加スペースの分配を行い、 スパン数が多い注釈ほど後から分配されます。 各ルビ基底とルビ注釈は それぞれ自分のカラム幅にちょうど合うようにサイズ調整されます。
注記: 異なるレベルの複数注釈が同数の基底をスパンしつつ スパン範囲が重なってもぴったり一致しない場合、 追加スペースの分配は未定義です。 これはHTMLマークアップでは発生しませんが、 [RUBY]のように明示的スパンができるマークアップ言語では起こり得ます。
注釈コンテナで ruby-merge: auto の場合に いずれかのルビ注釈が 対応する基底より広い場合は、 そのルビ注釈は注釈コンテナ内で 自分のカラムをはみ出してもよいです。 この場合、はみ出し部分がどのようにカラム幅へ影響するかはUAに委ねられますが、 ルビセグメント全体が すべての内容を収める幅になることが条件です。
字間注釈はカラム間に挿入されます: これは両隣のカラムをスパンする注釈の計測には含まれますが、 いずれのカラムにも含まれず、 行間注釈の サイズや配置の影響は一切受けません。
各基底や 注釈ボックス内で、 内容がボックス幅より狭い場合の余白の分配方法は ruby-alignプロパティによって決まります。
青い括弧([ ])は基底ボックス、 赤い括弧([ ])は注釈ボックス、 灰色の縦棒(|)はルビカラムの区切りです。 ルビコンテナ、 基底コンテナ、 注釈コンテナは省略しています。
- 分離/非スパン:
-
|[ a1 ]|[ a2 ]|[annotation-3]| |[base 1]|[base 2]|[ base 3 ]|
各カラム内のボックスは、そのカラムで最も幅の広い ボックスに合わせて幅が決まります。 各ruby-align値に従い 基底ボックスや注釈ボックス内の余白が分配されます。
- スパン(短い):
-
|[ a1 ]|[ short span ]| |[base 1]|[base 2]|[base 3]|
スパン注釈がスパンする 基底の合計幅より短い場合は、 追加スペースの分配はありません。 スパン注釈内の余白は そのruby-align値に従い分配されます(非スパンと同様)。
- スパン(長い):
-
|[ a1 ]|[spanning annotation]| |[base 1]|[ base 2 ]|[ base 3 ]|
- マージ(短い):
-
|[merged annotation]| |[base 1]|[base 2]|[base 3]|
マージ注釈は スパン注釈と似ていますが、 余白の分配はruby-align値が 注釈コンテナに効きます(個々の注釈ボックスではなく)。
- 複数レベル+スパン注釈:
-
|[ a1 ]|[ annotation-2 ]|[ a3 ]| |[long annotation spanning all content]| |[ base 1 ]|[ base 2 ]|[ base 3 ]|
|[ xx ]|[annotation spanning bases]| |[ a1 ]|[ annotation-2 ]|[ a3 ]| |[base 1]|[ base 2 ]|[ base 3 ]|
複数の注釈レベルにまたがる2例では、 各カラムは その中で最も長い内容に合わせて幅が決まります。 スパン注釈がさらに長い場合は スパン先のカラム合計幅をさらに広げ、各カラムに均等に加算します。
- 複数レベル+複数スパン注釈:
-
|[ xx ]|[ annotation spanning bases ]| |[ a1 ]|[ annotation-2 ]|[ a3 ]| |[lengthy annotation spanning base content]| |[ base 1 ]|[ base 2 ]|[ base 3 ]|
複数のスパン注釈がある場合、 より少ない基底をスパンする注釈から先に処理します。 この例では緑の注釈(2基底スパン)が橙の注釈(3基底スパン)より先に処理されます。 順序が変わればスペース分配も変わります。
どのスパン注釈が どの余白に関与しているか分かりやすいよう、 各スパン注釈のテキスト色を、 追加スペースの背景色と合わせています。
3.1.2. ブロック軸行間レイアウト
これらのルビボックスに対して vertical-alignがどの程度影響するか定義する必要があります。 Issue 4987 を参照。
各基底コンテナは次の内容すべてを ちょうど収めるようにサイズと位置が決まります: そのルビ基底の margin ボックス全体、対応する字間注釈のルビ注釈 margin ボックス(存在する場合)、およびこのルビコンテナに従属して同じインライン整形コンテキストに参加する子孫の基底や注釈コンテナ。 (基底コンテナにin-flow内容がない場合は、 空のルビ基底が1つ入っているとしてサイズ・位置決定されます。)
各行間の注釈コンテナは そのルビ注釈の margin ボックス全体および、 このルビコンテナに従属して同じ注釈レベルのインライン整形コンテキストに参加する 基底や注釈コンテナをちょうど収めるようにサイズ・位置決定されます。 (注釈コンテナにin-flow内容がない場合は、空のルビ注釈1つ入っているとしてサイズ・位置決定されます。) これらの注釈コンテナは ruby-positionに応じて 対応する基底コンテナの上下どちらかにスペース無しで積み重なり、 ルビ注釈の基底とのブロック軸方向配置が決まります。
ブロック軸マージンは折り畳むべきか? そうすればレイアウトが堅牢になるが、インライン軸での挙動とは矛盾する。
3.2. 字間ルビレイアウト
字間注釈は特殊なレイアウトとなります。字間のルビ注釈ボックスは 基底レベルのレイアウトの一部として挿入・測定されます。 各ルビ注釈は、ペアとなるルビ基底の右側に挿入されます。 スパンする字間注釈は、スパンする基底の一番右の後ろに配置されます。 字間のルビ注釈は、以下に述べる例外を除き インラインブロックと同じようにレイアウトされます。
注記: inter-character の定義通り、 字間注釈は常に vertical-rl の writing-mode となり、 横書きのルビコンテナでのみ存在します。
各ルビ注釈は 対象となるルビ基底の直後、 (基底間空白やセグメント間空白の前)に配置されます。 もし同じルビ基底に複数の 字間ルビ注釈ボックスが並ぶ場合は、 それらのmargin ボックスは、スペースなしで右方向に(レベル順で)積み重ねられます。
もし自動高さのルビ注釈ボックスの 内容領域が、直後の内容ボックス(ルビ基底の)より低い場合、 注釈ボックスの内容ボックス高さは正確に基底と一致するよう拡大されます。
ルビ注釈ボックスの揃え方は、 ruby-alignプロパティによって決まります:
- ruby-align が start の場合、 ルビ注釈の 内容ボックス上端を ルビ基底の 内容ボックス上端に揃えます。
- それ以外の場合は、ルビ注釈の 内容ボックス中心を ルビ基底の 内容ボックス中心に垂直に揃えます。
字間注釈のルビ注釈コンテナボックスは、 その内容ボックスがルビ基底コンテナボックスと ちょうど一致するようにサイズ・配置されます。
注記: 字間の ルビ注釈コンテナボックスの サイズや位置はレイアウトに一切影響しません。 上記定義はプログラムによる問い合わせで決定的な結果を得るためのものです。
揃えやカラム幅決定(§ 3 ルビのレイアウト参照)の目的では、 字間の ルビ注釈は、 紐付く基底と同じカラムの一部とみなされず、 独自のカラムを形成するものとします。
3.3. ルビボックスのスタイル付け
ルビ基底とルビコンテナは インラインボックスとして扱われ、 特に規定がない限り、インラインボックスに適用可能なすべてのプロパティも同様に適用されます。 ただし、行基準シフト値 vertical-align (top、bottom)は無視され(ゼロとして扱う)必要があります。
特に規定がない限り、 インラインボックスに適用可能なすべてのプロパティは、 ルビ注釈にも同様に適用されますが、 line-heightは適用されません。 また、行基準シフト値 vertical-align(top、bottom)も無視され(ゼロとして扱う)必要があります。
margin、 padding、 borderプロパティ およびインラインボックスに適用されないプロパティは 基底コンテナや 注釈コンテナには適用されません。 さらに、line-heightは注釈コンテナには適用されません。
UAは ルビ基底コンテナボックスや ルビ注釈コンテナボックスに対し、 backgroundプロパティやoutlineプロパティなど ボックスの範囲を描画するプロパティをサポートする必要はありません。 UAはこれらのボックスを継承や内容レイアウト制御のための抽象概念として実装してもかまいません。
3.4. 行の折り返し
ルビコンテナ全体が行に収まらない場合、 すべてのレベルで同時に改行が許可されている箇所でルビを折り返してもよいです。 (行の折り返し詳細は CSS Text 3 § 5 行の折り返しと単語境界を参照。) ルビは通常、基底-注釈セットの間で折り返されますが、 行折り返し規則が許す場合、ルビ基底(および対応するルビ注釈ボックス)内部でも折り返されることがあります。
ルビが行をまたぐときは、ルビ注釈は必ず 対応するルビ基底と一緒に動きます。 ルビ基底と注釈の間、 あるいは字間注釈の場合であっても、 行途中で分断してはなりません。
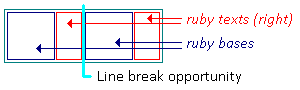
字間ルビの行折り返し位置
行折り返し後、 各断片は独立してレイアウトされ、 ルビ揃えも断片ごとに行われます。
3.4.1. 基底間の折り返し
通常、ルビ基底ボックスや ルビ注釈ボックスは 内部での改行を禁止するスタイルとなっており、強制改行も含みません。 (付録Aを参照。) この場合、ルビコンテナは 隣接するルビ基底間でのみ折り返すことができ、 そのルビ基底にスパンするルビ注釈が存在しない場合のみです。
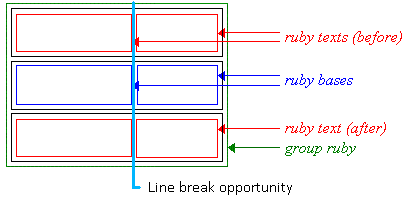
ルビの行折り返し位置
2つの隣接するルビ基底間でルビが折り返せるかどうかは、 基底テキストの通常の行折り返し規則で制御されます。 これはルビ基底が隣接するインラインボックスであるかのように判定されます。 (注釈は基底レベルの ソフトラップ判定時には無視されます。)
< ruby > 蝴< rt > hú</ rt > 蝶< rt > dié</ rt >
基底間空白は、ルビ基底間での行折り返し機会を評価する際に意味を持ちます。 インライン間の空白と同様に、 そこで行が折り返されると空白は折り畳まれます。 詳細はCSS Text 3 § 4.1 空白処理ルール参照。 同様に、注釈の空白も行折り返し時にトリムされます。
< ruby >< rb > one</ rb > < rb > two</ rb > < rt > 1</ rt > < rt > 2</ rt ></ ruby >
この場合、空白があるため "one" と "two" の間で行が折り返せます。 そこで行が折り返されると、その空白や "1" と "2" の間の空白は標準CSS空白処理規則により消えます。
3.4.2. 基底内での折り返し
長い基底テキストの場合、基底-注釈ペアの内部で行を折り返し可能にするのが適切なこともあります。 例えば、英文に日本語訳注釈を付けた場合、テキストの折り返しを許すことで段落内の行折り返しが自然になります。
仕様執筆者の妄想ではなく実際例であることを示すため、スキャン例を挿入すること。
ルビ基底内での行折り返しは、 white-spaceプロパティが ルビ基底とすべての並列注釈で許可されており、 かつ各基底/注釈ボックス内容内(先頭・末尾以外)に ソフトラップ機会がある場合のみです。 ルビ基底や注釈の断片間には構造的対応関係が無いため、 UAは任意の機会で改行してよいですが、 断片ごとの内容量を比例的に均等化するのが推奨されます。
字間注釈内では 行折り返し機会はありません。
3.5. 双方向(Bidi)並べ替え
Unicode双方向アルゴリズムは、異なる方向性の文字が同一段落内に混在した場合、 視覚的表示のため論理順テキストを並べ替えます。
ルビ注釈と対応するルビ基底の対応関係を保つため、 いくつかの制約を課す必要があります:
- ルビ基底や ルビ注釈の内容は連続していなければならない。
- ルビ注釈は 対応するルビ基底と一緒に並べ替えられなければならない。
- 単一のルビ注釈で スパンされるすべてのルビ基底は連続していなければならない。
これを実現するために、
-
すべての内部ルビボックスおよびルビコンテナに
強制的にBidiアイソレーションが適用されます:
normal および
embed の
unicode-bidi値は
isolate に、
bidi-overrideは
isolate-override に計算されます。
注記: これにより、暗黙的なBidi並べ替えは ルビ基底をまたいで動作しなくなるため、 著者はルビコンテナの direction指定が内容と一致していることを保証する必要があります。
- レイアウト時、ルビセグメントは ルビコンテナ内でそのdirectionプロパティに従い順序付けされます。
-
セグメント内では、ルビ基底や
ルビ注釈で
マージ注釈でないものは
セグメントのルビ基底コンテナの
directionプロパティで順序付けされます。
マージ注釈は
注釈コンテナの
directionで順序付けされ、
まるで注釈コンテナ内のインラインボックス列であるかのように扱われます。
注記: つまりdirectionプロパティは 注釈コンテナ の非マージ注釈の レイアウトには無視されますが、子要素へ継承し インライン基底方向に影響を与える場合があります。
他のインラインレベル内容と同じく、 内部ルビボックスのBidi並べ替えは 行折り返し後に行われ、論理順に従って内容が行に分割されます。
注記: もしruby-mergeが対象注釈コンテナで merge の場合に限り、 個々の注釈へのBidiアイソレーションを適用しないことで 一括処理できるようにしてもよいかもしれません。 ただし、この状況をサポートする需要がない限り 実装複雑化の正当性が薄いため、必要な事例がある方はCSS WGまでご連絡ください。
CSSにおける双方向テキストについてさらに詳しくは [CSS3-WRITING-MODES]を参照してください。
3.6. 行間隔
line-heightプロパティは、CSSにおける行間の間隔を制御します。 行内のインライン内容がline-heightより短い場合は、 内容の上下にハーフリーディングが追加されます(CSS Inline Layout 3 § 5 論理的高さと行間隔参照)。
行間の一貫した間隔を確保するため、 ルビ付き文書では通常、line-heightが ルビをテキスト行間に収めるのに十分な大きさになるようにします。 そのため、通常はルビ注釈コンテナやルビ注釈ボックスは 行内内容の高さの計測には寄与せず、 揃え(vertical-align参照)やline-heightの計算は ルビ基底コンテナのみを用いて行われます。これはあたかも通常のインラインであるかのように動作します。
ただし、line-heightがルビコンテナで指定されており、その値が 一番上のルビ注釈コンテナの上端と 一番下のルビ注釈コンテナの下端の間の距離よりも小さい場合は、 ルビ基底コンテナの適切な側に追加リーディングが加えられます。これにより、もし3行すべてに同じルビがあったとしても ルビコンテナ同士が重ならないようになります。
注記: これはルビ注釈が 行ボックス内に必ず収まることを保証するものではありません。 あくまですべての行の間隔が等しくかつルビ注釈の量や位置が等しい場合に オーバーラップを防ぐのに十分な余白が確保されるのみです。
著者は、ルビを考慮したline-heightやpaddingの指定に注意し、 特にブロックの先頭や末尾、または行内に 画像・インラインブロック・vertical-alignでシフトされた パラグラフのデフォルトフォントサイズより高いインライン要素がある場合には十分配慮してください。
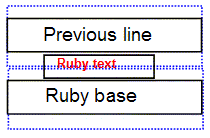
ルビ注釈はしばしば行からはみ出します。ルビ付き行の上や下の内容には ルビのための十分なスペースを確保してください。
注記: ルビが整列や行レイアウトにどう影響するかについての より詳細な制御はCSS Line Layout Module Level 3で導入予定です。 ただし現時点では探究段階であり、新機能の記述はまだ信頼性がありません。
4. ルビ書式プロパティ
以下のプロパティはルビの配置、テキスト分布、 揃えを制御するために導入されています。
4.1. ルビの配置:ruby-positionプロパティ
| 名前: | ruby-position |
|---|---|
| 値: | [ alternate || [ over | under ] ] | inter-character |
| 初期値: | alternate |
| 適用対象: | ルビ注釈コンテナ |
| 継承: | yes |
| 百分率: | n/a |
| 算出値: | 指定キーワード |
| 正規順序: | 文法順 |
| アニメーション型: | 離散 |
このプロパティはルビ注釈が基底に対してどこに配置されるかを制御します。 各値の意味は以下の通りです:
- alternate
-
複数の注釈レベルが
over と under で交互になります。
もし注釈コンテナがその注釈レベルで最初である場合や、 それ以前のすべてのレベルが字間の場合は、 alternate単独または overとの組み合わせは overと同様に動作し、 alternateと underの組み合わせは underと同様に動作します。
それ以外の場合、 直前の行間注釈が overであれば alternateは underと同じ動作をし、 逆も同様です。 (この場合、alternateを単独指定しても overまたは underと組み合わせても違いはありません。)
- over
-
ルビ注釈は基底の上側に表示されます。
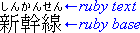
横書き日本語の基底の上にルビ
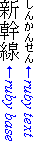
縦書き日本語の基底の右にルビ
- under
-
ルビ注釈は基底の下側に表示されます。
この設定は表意東アジア系文字の組版では比較的珍しく、教育用テキストなどで見られます。
横書き日本語の基底の下にルビ
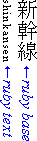
縦書き日本語の基底の左にルビ
- inter-character
-
親writing mode がルビコンテナで
縦書きの場合は、
overと同じ動作になります。
それ以外の場合、ルビ注釈は字間注釈となります。 注釈は横書きテキストの場合、基底の右側に表示されます。 このとき、このルビ注釈コンテナの 子ルビ注釈の writing-modeの算出値は vertical-rl となります。
注記: writing-modeの算出値は ルビ注釈コンテナ自身には影響しません。 これは、同一要素上の writing-mode、 display、 ruby-position の算出値間で循環依存を避けるためです。
この値は台湾などで使われる伝統的な中国語の特殊ケース向けです。 その文脈では(注音符号ルビ)は、 横組みでも基底文字の右側に縦に現れます:
伝統的中国語の“注音符号”ルビ(分かりやすく青で表示)横組みの場合
注記: 継承は要素ツリーに沿って行われるため ルビレイアウトで生成される匿名ボックスは考慮されません。 字間注釈を使う場合、 要素ベースのルビ注釈コンテナ・ 匿名ルビ注釈・ さらにその子孫要素を含む マークアップパターンは避ける必要があります。なぜなら、 その子孫はルビ注釈コンテナから writing-modeを継承し、 ルビ注釈の writing-mode 変更の影響を受けません。ruby
{ ruby-position : inter-character; } < ruby > base< rtc >< em > problematic</ em > annotation</ ruby > 上記のマークアップでは、“problematic annotation”全体をラップする匿名ルビ注釈ボックスが
<rtc>要素の子として生成されます。 それは注釈コンテナの ruby-positionが inter-character のため、 その writing-mode は vertical-rl となり、期待通りです。 しかし<em>要素は<rtc>のwriting-modeを直接継承し、 それはvertical-rlに強制されていません。この例では明示的なルビ注釈コンテナ要素は不要なので ルビ注釈要素を使えば問題は避けられます:
< ruby > base< rt >< em > problematic</ em > annotation</ ruby > 明示的なルビ注釈コンテナ要素が必要な場合でも ルビ注釈要素を合わせて使えば解決します:
< ruby > base< rtc >< rt >< em > problematic</ em > annotation</ ruby >
注釈コンテナで 字間注釈でないものは 行間注釈と呼ばれます。
複数のルビ注釈コンテナが 同じruby-positionを持つ場合、 それらは基底テキストから外側に積み重なります。
4.2. 注釈スペースの共有:ruby-mergeプロパティ
| 名前: | ruby-merge |
|---|---|
| 値: | separate | merge | auto |
| 初期値: | separate |
| 適用対象: | 行間ルビ注釈コンテナ |
| 継承: | yes |
| 百分率: | n/a |
| 算出値: | 指定キーワード |
| 正規順序: | 文法順 |
| アニメーション型: | 算出値型による |
このプロパティは、1つのルビコンテナボックス内に複数のルビ注釈ボックスがある場合、 各ペアを分離して表示するか、 注釈をマージしてグループとして表示するか、 または空間状況に応じて分離/合体のどちらにするかを制御します。
注記: 字間注釈は常に分離され、このプロパティは適用されません。
値の意味:
- separate
-
各ルビ注釈ボックスは
対応するカラム内(基底ボックスと同じ)で表示され、
隣接する基底と重ならないように配置されます。
このスタイルは[JLREQ]で「モノルビ」と呼ばれます。

ruby-merge: separate(中央揃え) - merge
-
同じ行・同じルビセグメント内の全ルビ注釈ボックスを
インラインボックスとして
注釈コンテナ内に連結し、
それらすべての基底ボックスにまたがる
単一の匿名ルビ注釈ボックスにまとめてレイアウトします。
1行で表示される場合、このスタイルは[JLREQ]における「グループルビ」と似ています。
ただし行をまたぐ場合は、ルビ注釈は必ず
対応するルビ基底と一緒に処理されます。
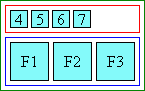
ruby-merge: merge(中央揃え) 2行とも両文字が同じ行内に収まる場合、 下記2行は同じように表示されます。< p >< ruby > 無常< rt > むじょう</ ruby > < p >< ruby style = "ruby-merge:merge" >< rb > 無< rb > 常< rt > む< rt > じょう</ ruby > ただし2つの基底が行をまたぐ場合は、2例目はruby-position: separateと同じように表示されます。
- auto
-
UAは任意のアルゴリズムで各ルビ注釈ボックスを対応する基底と合わせてレンダリングしてよいですが、
すべての注釈が基底上に収まる場合は
separateと同じになるようにし、
一部注釈が基底より広い場合は
基底間スペースを挿入しない形で
何らかの方法でスペースを共有させます。
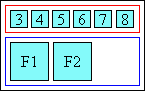
ruby-merge: auto(中央揃え) 注記: この挙動は複合語(熟語)ルビ向けです。 “What is ruby?”のJukugo Ruby参照。[QA-RUBY]この種のルビの表示には様々な慣習があります。 Simple Ruby PlacementのJukugo-ruby配置、 JLREQの熟語ルビの配置、 JISX4051の4.12.3(c) 熟語ルビの処理 など参照。
最も単純なものは、 すべての注釈が基底幅内に収まる場合はseparate、 そうでなければmergeで表示する方法です。
注記: テキストは、たとえマージされた場合でも ルビ注釈や 基底をまたいで 字形結合やリガチャを形成しません。 これはbidiアイソレーションによるものです。 § 3.5 双方向並べ替えおよび CSS Text 3 § 7.3 要素境界をまたぐ字形処理も参照。
4.3. ルビテキスト分布: ruby-align プロパティ
| 名前: | ruby-align |
|---|---|
| 値: | start | center | space-between | space-around |
| 初期値: | space-around |
| 適用対象: | ルビ基底、ルビ注釈、ルビ基底コンテナ、ルビ注釈コンテナ |
| 継承: | yes |
| 百分率: | n/a |
| 算出値: | 指定キーワード |
| 正規順序: | 文法順 |
| アニメーション型: | 算出値型による |
このプロパティは、各種ルビボックスの内容がそのボックスを正確に満たさない場合に、テキストをどのように分布させるかを指定します。 ruby-alignによって分配される空白は、字詰め(ジャスティフィケーション)による空白とは無関係かつ独立しています。
字間注釈の場合、このプロパティはボックス自体の配置にも影響します (§ 3.2 字間ルビレイアウト参照)。 それ以外の場合は、ボックス内の内容の配置のみに影響し、ボックス自体の大きさや位置には影響しません。
各値の意味は以下の通りです:
- start
-
ルビ内容がボックスの開始端に揃います。
「肩付きルビ」はこの start値に近いが、厳密には同じではありません。 特に基底をはみ出す場合の挙動は文脈によって異なることがあります。JLREQ参照。 また、これは縦書きでのみ使われ、JLTFでも特に重要とはされていません。 したがって、この値を肩付きルビに合わせて高度に調整する必要はないかもしれません。 startが他用途で必要なら残し、そうでなければ削除も検討?
- center
- ルビ内容がボックス内で中央揃えされます。
- space-between
- ルビ内容は通常のテキストジャスティフィケーション(text-justifyで定義)に従い分布しますが、 ジャスティフィケーション機会justification opportunitiesが無い場合は中央揃えされます。
- space-around
- space-betweenと同様ですが、 追加のjustification opportunityが存在し、 その空白がルビ内容の前後に半分ずつ分配されます。
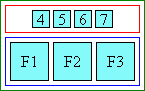
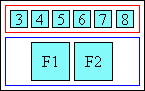
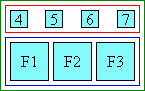
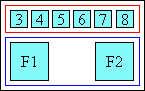
空白分布はtext-justifyで制御できます。[CSS-TEXT-3]
ルビ基底や ルビ注釈内の内容は、 ruby-merge: mergeによるスパンを除き、 そのボックス上のruby-alignの値で揃えられます。 マージ注釈内の内容は、 ルビ注釈コンテナ上の ruby-alignの値によって揃えられ、 個々のruby-alignや ルビ注釈上の値は無視されます。
マージ注釈によって ルビセグメント全体が広がった場合どうするか? 現仕様ではすべての基底がスパン扱いで広がるが、例えば複数基底を持つ基底コンテナ内テキストを中央揃えしたい場合に不都合。 代わりにruby-mergeを基底コンテナにも適用できるようにするか? ただしその場合、基底が複数注釈をスパンし得る(基底側がマージで注釈レベルがマージでない場合)・ あるいは基底をマージにしたら注釈レベルすべてマージ必須……など追加仕様要検討。
ruby-mergeが autoの場合の内容の揃え方はUA依存ですが、 すべての注釈が対応基底に収まる場合は ruby-merge: separateと同じでなければなりません。
4.4. ルビテキストの装飾
テキスト装飾は基底テキストから注釈へは伝播しません。
ルビの祖先にテキスト装飾が指定された場合、 ルビ基底コンテナ全体の内容領域に装飾が描画されます。 これには、長い注釈のために基底内容の両端に追加されたスペースも含まれます。 ルビ基底自身に装飾が指定された場合、 この追加スペースは装飾されません。これはボックス自体のpaddingが装飾対象外になるのと同様です。 [CSS3-TEXT-DECOR]
テキスト装飾はルビ基底コンテナやルビ注釈コンテナに直接指定することもできます。 その場合はコンテナ内のすべての基底または注釈に伝播し、またその間も装飾を連続して描画します。
ルビ注釈の位置は、基底テキストにオーバーラインやアンダーライン装飾が適用された際の衝突を回避するために 調整される場合があります。 フォントサイズやベースライン配置が一貫している基本的な場合は、 アンダーラインやオーバーラインは 基底レベルとその側の注釈の間に配置されます。
隣接する基底/注釈内容間での装飾描画 について要明確化。ボックスがカラム幅いっぱいか否かで変わる。
5. エッジ効果
5.1. ルビのはみ出し: ruby-overhangプロパティ
| 名前: | ruby-overhang |
|---|---|
| 値: | auto | none |
| 初期値: | auto |
| 適用対象: | ルビ注釈コンテナ |
| 継承: | yes |
| 百分率: | n/a |
| 算出値: | 指定キーワード |
| 正規順序: | 文法順 |
| アニメーション型: | 算出値型による |
ruby-overhangプロパティは ルビ注釈が ルビコンテナの外側の隣接テキストにはみ出して重なることを許可するかどうかを制御します。 各値の意味は以下の通りです:
- auto
-
ルビ注釈コンテナが対応するルビ基底コンテナより長い場合、
ルビ注釈コンテナは隣接ボックスにはみ出して重なることができます。
どの程度・どんな条件ではみ出すかはUAが決定します。
- none
- ルビ注釈コンテナは絶対にはみ出してはなりません。
ルビ注釈がはみ出し不可の場合、 ルビコンテナは 従来のインラインボックスのように振る舞い、 つまり自分自身の内容のみが境界内に描画され、隣接要素はボックス境界をまたぎません:
隣接テキストにはみ出し不可のシンプルなルビ
一方、ルビ注釈コンテナがはみ出し可の場合、 隣接内容はルビコンテナボックスと重なり、 ルビ注釈が 周囲のインラインレベル内容に部分的に重なることも許されます。 はみ出しは、隣接内容と ルビコンテナの注釈ボックスや 重なった基底内容との衝突を 起こさない範囲に限られます。
隣接テキストにはみ出し可のシンプルなルビ
注記: あるルビ基底に関するルビ注釈が別のルビ基底をはみ出してよいかは ruby-mergeで制御されます。
通常、基底や注釈の内容自体の揃え方は、はみ出しの許可有無に影響されません。 揃えや空白分布(ruby-align参照)は はみ出し許可と無関係に同じ方法で行われ、 はみ出し可能スペースの計算前に決定されます。 ただし、UAは空白分布や揃え決定時に許容されるはみ出しを考慮しても構いません。
はみ出しと揃えの相互作用については 場合によってはさらなる検討が必要かもしれません。
5.2. 行端揃え
行頭や行末に、ルビ基底より長いルビ注釈ボックスがある場合、 UAはそのルビ注釈の端を 基底の対応端に強制的に揃えてもよいです。 この種の揃えは[JLREQ]で説明されています。
本仕様レベルではこの挙動を制御する仕組みは提供しません。
行端揃え
付録A: サンプルスタイルシート
このセクションは参考情報です。
A.1 デフォルトUAスタイルシート
以下はHTMLおよびXHTMLルビマークアップをルビレイアウトとして描画するための、デフォルトUAスタイルシートの例です:
ruby{ display : ruby; } rp{ display : none; } rbc{ display : ruby-base-container; } rtc{ display : ruby-text-container; } rb{ display : ruby-base; white-space : nowrap; } rt{ display : ruby-text; } ruby, rb, rt, rbc, rtc{ unicode-bidi : isolate; } rtc, rt{ font-variant-east-asian : ruby; /* See [[CSS-FONTS-3]] */ text-justify: ruby; /* See [[CSS-TEXT-4]] */ text-emphasis: none; /* See [[CSS-TEXT-DECOR-3]] */ white-space: nowrap; line-height : 1 ; } rtc, :not ( rtc) > rt{ font-size : 50 % ; } rtc:lang ( zh-TW), :not ( rtc) > rt:lang ( zh-TW), rtc:lang ( zh-Hanb), :not ( rtc) > rt:lang ( zh-Hanb), { font-size : 30 % ; } /* bopomofo */
注記: 著者は上記のルールを使用しないでください。 ルビレイアウトをサポートするUAはこのスタイルをデフォルトで提供すべきです。
ユーザー制御の「最小フォントサイズ」機能を実装するUAは、ルビ注釈に対してはその最小値を縮小して適用することを検討してください。
A.2 ルビ注釈のインライン化
以下はHTMLおよびXHTMLルビマークアップをインライン注釈として描画するためのサンプルスタイルシートです:
ruby, rb, rt, rbc, rtc, rp{ display : inline; white-space : inherit; font : inherit; text-emphasis : inherit; }
A.3 括弧の自動生成
残念ながら、セレクタはテキストノードにマッチできないため、 CSSだけではHTML内の全てのルビマークアップパターンに対し 未括弧化ルビ注釈へ自動的かつ正確に括弧を追加することはできません。 (これはHTMLルビが、対応要素なしで生テキストからルビ基底を暗黙的に扱えるためです。)
しかし、<rb>や<rtc>が厳格に使われている場合は、以下のルールで
各注釈シーケンスの前後に括弧を追加できます:
/* <rtc> の前後に括弧 */ rtc::before{ content : "(" ; } rtc::after{ content : ")" ; } /* <rtc>でない最初の<rt>の前に括弧 */ rb + rt::before, rtc + rt::before{ content : "(" ; } /* <rtc>でない<rt>の後ろに括弧 */ rb ~ rt:last-child::after, rt + rb::before{ content : ")" ; } rt + rtc::before{ content : ")(" ; }
また、完全に交互型(adjacentなルビ注釈がない)
/* 各<rt>の前後に括弧 */ rt::before{ content : "(" ; } rt::after{ content : ")" ; }
6. 用語集
- ボポモフォ または 注音符号 (中国語: ㄅㄆㄇㄈ, 注音符號, 注音符号)
-
主に標準中国語(普通話)の発音記号として使われるために開発された文字および声調記号。 これらはルビ注釈(振り仮名)として用いられることが多いですが、必ずしもそれだけではありません。

中国語で音声補助の字間注釈として使われるボポモフォの例
ボポモフォ声調記号は、各ボポモフォ音節の末尾(メモリ上)に現れるスペース文字です。 通常は他のボポモフォ文字の右側や上側の別軌道に表示され、記号の位置は音節内の文字数によって異なります。 ただし、軽声記号(ニュートラルトーン)は、右側や上側ではなく、ボポモフォの前(同じ行)に配置されます。
注記: テキスト表示時の字形の相対配置や位置決め(ボポモフォ声調記号含む)はユーザーエージェントやフォントシステムの責任であり、ルビ注釈や通常のインライン内容であってもCSSルビレイアウトの役割ではありません。
ボポモフォ文字は
BopomofoUnicode スクリプト(U+3100–312F, U+31A0–31BFブロック)に属します。 ボポモフォ声調記号は U+02C9 (ˉ), U+02CA (ˊ), U+02C7 (ˇ), U+02CB (ˋ), U+02EA (˪), U+02EB (˫), U+02D9 (˙) です。 これらはCSS上「ボポモフォ文字」として扱います。 - 漢字(ハンジャ、韓国語: 漢字)
- 中国文字体系から借用・改変された表意文字を用いる韓国語表記体系の一部。 漢字(かんじ)も参照。
- ひらがな(日本語: 平仮名)
- 日本語の音節文字またはその一文字。 丸みを帯びた書体が特徴。 日本語表記体系の一部であり、 漢字やカタカナとともに使われる。 近年では、主に漢字が使えない・ふさわしくない場合の日本語単語や語尾・助詞の表記に用いられる。 カタカナも参照。
- 表意文字
- アルファベットや音節文字とは異なり、意味・語・語要素を表すための文字。 最も有名な表意文字体系は東アジア(中国・日本・韓国など)で用いられている。
- かな(日本語: 仮名)
- ひらがなとカタカナをまとめて指す総称。
- 漢字(日本語: 漢字)
- 日本語で使われる表意文字を指す日本語の用語。 日本語表記体系の一部であり、 ひらがな・カタカナとともに使われる。 ハンジャ(韓国漢字)も参照。
- カタカナ(日本語: 片仮名)
- 日本語の音節文字またはその一文字。 角ばった書体が特徴。 日本語表記体系の一部であり、 漢字やひらがなとともに使われる。 近年では主に外来語の表記に用いられる。 ひらがなも参照。
謝辞
この仕様の作成には、以下の方々のご協力が不可欠でした:
David Baron、 Robin Berjon、 Susanna Bowen、 Stephen Deach、 Martin Dürst、 Hideki Hiura (樋浦 秀樹)、 Masayasu Ishikawa (石川雅康)、 Taichi Kawabata、 Chris Pratley、 Xidorn Quan、 Takao Suzuki (鈴木 孝雄)、 Frank Yung-Fong Tang、 Chris Thrasher、 Masafumi Yabe (家辺勝文)、 Boris Zbarsky、 Steve Zilles。
特に、以前の編集者である Michel Suignard氏、Marcin Sawicki氏(Microsoft)、 Richard Ishida氏(W3C)に感謝します。
変更点
本節は過去の公開以降の変更点を記録しています。
2021年12月2日WD以降の変更点
- writing-mode の算出値調整を 字間注釈に対して ルビ注釈ボックスに適用するよう変更。
zh-HantをHTMLでfont-size: 30%を適用する条件に追加。- UAデフォルトスタイルシートに
text-justify: rubyを追加。 (Issue 771 Issue 779)
2020年4月29日WD以降の変更点
- alternate キーワードを ruby-position に追加し、初期値とした。
- ruby-merge の値 collapse を merge に名称変更。 (Issue 5004)
- visibility: collapse を、()と 同様に明示的に隠すものとして定義。 (Issue 5927)
- 各ルビdisplay型に適用されるプロパティをより明確に規定し、 ルビ・ルビ基底・ルビ注釈ボックスが他に規定がない限り通常のインラインボックスと 同様に振る舞うことを定義。 (Issue 4935, Issue 4936, Issue 4976, Issue 4979)
- § 3 ルビのレイアウトを大幅に刷新し、 行間注釈と字間注釈の定義と ruby-alignとの関係をより明確にした。 字間ルビはインラインブロックレイアウトをベースとし、 行間ルビとの相互作用も明確化。 行間ルビのインライン軸空間分布も スパン注釈に関してより厳密に定義(グリッドのmax-contentトラックモデルを参考)。
- 入れ子ルビの扱いを、ブロック軸サイズ決定時に子孫基底・注釈コンテナも考慮するようにして明確化。 (Issue 4986, Issue 4980)
- ruby-alignの動作をより厳密に定義。
- ルビのはみ出しが内容の整列に影響しないことを緩和し、隣接内容との衝突を防ぐ要件を追加。
- 双方向並べ替えとマージ注釈の関係を明確化。 (§ 3.5 双方向並べ替え)
- 全体的に規範的な記述を強化。
- はじめにや例などの情報的テキストを改善。
注記: 多数の未解決の課題が残っています。Disposition of Comments および GitHub上の新しい課題を参照。
2014年8月5日WD以降の変更点
- ruby-overhang: auto | none を復活し、基本的なはみ出し制御を追加。
- CSS Display Module に合わせてinlinificationを調整。
- ルビや強調符がアンダーライン・オーバーラインと衝突する場合、UAによるシフトを許可。
- ruby-merge の算出値が
collapseのとき自動非表示を無効化。 - デフォルトスタイルシートを微調整。
- テキスト装飾との相互作用の定義セクションを追加。
- ruby-position の right と left値は次レベルに持ち越し。
- ルビペアリング規則を
匿名注釈(
rtc直下の内容)にのみ適用するよう変更。 - 過剰な基底/注釈は自動生成の空匿名基底/注釈とペアリング。
- ruby-position を ::first-line に適用。 (Issue 2998)
- ルビボックスの包含ブロックが、他のインラインボックス同様、最も近いブロックコンテナとなることを明確化。
- 誤った親を持つ内部テーブル要素の扱いを明確化。
- ルビコンテナ、基底コンテナ、注釈コンテナの先頭・末尾空白をトリムし、ペアリング妨害を防止。
- 空の基底・注釈コンテナのレイアウト効果を定義。
- ルビ基底コンテナ・ルビ注釈コンテナ(ルビ基底やルビ注釈ではなく)へのmargin/padding/borderの無効化を明確化。
2013年9月19日WD以降の変更点
- 匿名ボックス生成規則および空白処理規則を全面的に書き直し、 匿名空白ボックスのペアリングを明確化。
- 入れ子ルビの扱いをペアリングから独立させた。 (今後はサイズ・レイアウトで扱う予定。)
- ルビ構造の双方向(Bidi)レイアウトを定義。
2011年6月30日WD以降の変更点
ruby-spanおよびrbspanへの言及を削除。- HTMLルビでは明示的スパンではなく暗黙的スパンを採用。 これにより、複雑な両側スパンの病的ケースは扱えませんが、現時点で要件はありません。 (XHTML複雑ルビをフルサポートする実装では、テーブルのセルスパンと同様 マークアップからスパンを暗黙的に推定可能です。 この制御をLevel 1で入れる必要はなさそうです。)
ruby-overhangとruby-align: line-endはLevel 2に持ち越し。- 複雑で高度な機能のため。UA定義挙動とし、許容例を示す形とする提案。
display: rpリクエストへの対応:display: noneを使用。- Internationalization WGで
rp要素のdisplay値リクエストがあったが、ルビ表示時に非表示にするにはdisplay: noneで十分。 - ruby-position値を text-emphasis-positionに合わせた。
- ただしinter-characterは維持。 ルビ位置をtext-emphasis-positionと揃える方が 横書き・縦書きの組み合わせに柔軟に対応できる。
- ruby-alignの未使用値を削除。
- left、right、endは不要。
- auto、distribute-letter、distribute-space を ruby-alignから削除し、 space-between と space-around で統一。
- autoは内容調査型だったが、
space-around と
標準ジャスティフィケーション規則だけで十分。
distribute-letter/distribute-spaceは
space-between、
space-aroundとした方が
[CSS-FLEXBOX-1]、
[CSS-ALIGN-3]等の分布キーワードと一貫し、
text-justify: distributeとの関連も避けられる。 - ruby-mergeプロパティ追加、熟語ルビ制御用。
- これは構造的効果ではなくスタイル効果。 旧モデルは構造的でマークアップ変更による対応を想定していたが、誤りだった。
- inline を ruby-position から削除。
- これは各種要素に
display: inlineを適用すればAppendix Aのように実現可能。 - デフォルトスタイルルール追加
- Internationalization WGの要望による。
- 匿名ボックス生成規則を策定
- 基底・注釈ペアリング明確化。 HTMLルビ全マークアップの組み合わせも扱えるはず。
- ルビのレイアウト定義
- 空間分布・空白処理・改行・行積み上げ等を詳細に規定。 bidiについてはopen issue。