1. はじめに
このモジュールはCSSの組版制御について説明します。 つまり、ソーステキストを整形し、行折返しされたテキストへ変換するCSSの機能です。 様々なCSSプロパティによって、大小文字変換、空白の折りたたみ、テキストの折返し、改行規則やハイフネーション、整列と両端揃え、間隔、 字下げなどを制御できます。
下線やアンダーライン、強調記号、 シャドウなどの テキスト装飾機能(以前はこのモジュールに含まれていました)は、 CSSテキスト装飾モジュールで定義されています。[CSS-TEXT-DECOR-3]
双方向および縦書きテキストは CSS書字モードモジュールで扱われています。[CSS-WRITING-MODES-4]。
世界中の様々な言語や書記体系の組版要件については、 国際化作業グループの言語対応インデックスに記載されています。[TYPOGRAPHY]
1.1. モジュール間の相互作用
このモジュールは、CSSテキスト装飾モジュールとともに、 Cascading Style Sheets Level 2 第16章で定義されていたテキスト関連機能を置き換え、拡張します。 [CSS-TEXT-DECOR-3] [CSS2]
以下に定義されている用語以外にも、 本仕様書で用いられる他の用語や概念は、 Cascading Style Sheets Level 2やCSS書字モードモジュールで定義されています。[CSS2]および[CSS-WRITING-MODES-4]。
1.2. 値の定義
この仕様書は、CSSプロパティ定義の慣例([CSS2])に従い、 値定義構文([CSS-VALUES-3])を使用しています。 この仕様で定義されていない値型は、CSS Values & Units [CSS-VALUES-3]で定義されています。 他のCSSモジュールとの組み合わせにより、これらの値型の定義が拡張される場合もあります。
各プロパティ定義で列挙されている値以外に、 この仕様で定義されているすべてのプロパティは CSS全域キーワードも値として受け付けます。 可読性のため、明示的には繰り返していません。
1.3. 言語と組版
著者は、最良の組版を得るために、コンテンツの言語タグを正確に指定してください。
多くの組版効果は言語的な文脈によって異なります。 言語や書記体系の慣習は、 改行、ハイフネーション、両端揃え、字形選択、 その他多くの組版効果に影響します。CSSでは、言語固有の組版調整は コンテンツ言語が既知(宣言されている)場合のみ適用されます。 したがって、 より高品質な組版には、著者が文書中のテキストの言語的文脈をUAに正しく伝える必要があります。
コンテンツ言語とは、 要素が宣言されている(人間の)言語を指し、 文書言語の規則に従います。 コンテンツ言語が不明である場合もあり得ます(例: タグ付けされていないコンテンツや、 言語タグ機能がない文書言語のコンテンツなどは コンテンツ言語が不明とみなされます)。
注: 著者はHTMLではグローバルlang属性、
XMLではユニバーサルxml:lang属性を使用して
コンテンツ言語を宣言できます。
HTMLのHTML要素のコンテンツ言語決定規則、
XML 1.0のXML要素のコンテンツ言語決定規則を参照してください。[HTML] [XML10]
要素が宣言されているコンテンツ言語は、 その要素で用いられている特定の書記体系(コンテンツ書記体系)も識別します。 文書言語が持つコンテンツ言語識別機能によって、 この情報は明示的または暗黙的に与えられます。 詳細は規定の付録F:コンテンツ書記体系の識別を参照してください。
注: いくつかの言語には複数の書記体系伝統があります。 また、言語が外国の書記体系に翻字される場合もあります。 そのような場合は、UAが適切に調整できるようサブタグを使用してください。
ko)はハングル(-Hang)、
漢字(-Hani)、
またはその組み合わせ(-Kore)で書かれます。
漢字のみで書かれた歴史的文書は単語間スペースを使用せず、
現代中国語に近い形式で整形されます。
つまり、組版の観点ではko-Haniはzh-Hantに近く、
ko(ko-Kore)とは異なります。
別の例として、日本語(ja)は通常、
ひらがな(-Hira)、カタカナ(-Kana)、漢字(-Hani)の組み合わせ(-Japn)で書かれます。
しかし、語学教材など特定用途ではラテン文字(-Latn)に“ローマ字化”されることもあり、
その場合は日本語ではなく英語に近い形式で整形されるべきです。
三例目として、現代モンゴル語は二つの書記体系で書かれます:
キリル文字(-Cyrl、モンゴル国で正式に使用)と
モンゴル文字(-Mong、中国内モンゴルで一般的)。
これらは整形要件が大きく異なり、
キリル文字はラテン・ギリシャ文字に近く、
モンゴル文字はアラビア・中国書記体系両方の慣習を継承しています。
1.4. 文字と文字種
組版の基本単位は文字です。 ただし、書記体系が必ずしも英語アルファベットのように単純でないため、 文字が何を指すかは文脈によって異なります。 例えば、ハングル(韓国語の書記体系)では、 各音節が四角い記号として表現され(例:한=Han)、 これが文字とみなされます。 しかし、この四角い記号は複数の音素(例:ㅎ=h, ㅏ=a, ㄴ=n)を表す文字で構成されており、 これらも文字とみなすことができます。
コンピュータでのテキスト符号化の基本単位も文字と呼ばれます。 符号化によっては、 一つの符号化文字が 音節全体の文字(例:한)、 個々の音素文字(例:ㅎ)、 あるいは 基本字形(例:ㅇ)と それを変化させる結合記号(例:発音を示す追加ストローク)など より小さい単位に対応する場合もあります。
さらに、一つの符号化文字は データストリーム上で1つ以上のバイトとして表現されます。 プログラミング環境ではバイト1個を文字と呼ぶ場合もあります。
したがって、文字という語は技術的に厳密さを要する場面ではかなり曖昧です。
テキストレイアウトにおいては、組版文字単位を基本単位とします。 テキストレイアウトの範囲内でも、 該当する文字単位は操作によって異なります。 例えば、タイ語のU+0E33 ำ THAI CHARACTER SARA AM を含む文字列では 行折返しと文字間隔調整で分割方法が異なります。 また、デーヴァナーガリーなどの合字の振る舞いは 使用するフォントに依存します。 組版文字は、 書記体系の単位(ラテンアルファベットの文字(ダイアクリティカルマーク含む)、ハングル音節、中国語表意文字、ミャンマー音節クラスタなど)で 特定の組版操作(行折返し、先頭文字効果、トラッキング、両端揃え、縦置き等)に関して分割できない単位を表します。
Unicode Standard Annex #29: Text Segmentationでは 書記素クラスタという単位が定義されており、これは組版文字に近いものです。 [UAX29] UAは 拡張書記素クラスタ(従来型クラスタではなく)をUAX29の定義に従って 組版文字単位の基礎として使用しなければなりません。 ただし、UAは組版の伝統に応じて定義を調整すべきであり、デフォルト規則が常に適切とは限らないため、 必要に応じて操作ごとに異なる調整が期待されます。
注: これらの調整規則はCSSの範囲外です。
- ミャンマー語やデーヴァナーガリーなどいくつかの書記体系では、 両端揃えや行折返しに用いる組版文字単位は音節全体であり、 1つ以上のUnicode書記素クラスタを含む場合があります。[UAX29]
-
タイ語やラオ語など別の書記体系では、
行折返しでは組版文字がUnicodeのデフォルト書記素クラスタと一致しますが、
文字間隔調整では
Unicode書記素クラスタより小さい単位が必要となり、
間隔挿入前に分解や代替処理が必要です。[UAX29]
例えば、タイ語「คำ」(U+0E04 + U+0E33)に正しく文字間隔を挿入するには U+0E33をU+0E4D + U+0E32に分解し、追加の文字間隔をU+0E32の前に挿入します: คํ า。
さらに複雑な例として「น้ำ」(U+0E19 + U+0E49 + U+0E33)では、 通常のタイ語字形処理でまずU+0E33をU+0E4D + U+0E32に分解し、 その後U+0E4DとU+0E49を入れ替え、U+0E19 + U+0E4D + U+0E49 + U+0E32となります。 ここでも追加の文字間隔はU+0E32の前に挿入します: นํ้ า。
- 縦組みでも調整が必要な場合があります。 例として、立て書きテキストの組版では チベット語のtsekやshad記号は直前の書記素クラスタとまとめて扱い、 独立した組版文字単位とはしません。[CSS-WRITING-MODES-4]
組版文字種単位(または本仕様書では文字種)は 組版文字単位のうち LetterまたはNumberUnicode一般カテゴリに属するものです。 組版文字単位のUnicodeプロパティの判定方法は付録E:文字とプロパティを参照してください。
組版文字単位が要素境界で分断された場合の描画特性は未定義です。 理想的には、各成分がそれぞれの要素のプロパティに従って整形されつつ 組版文字単位全体として正しい字形と配置を維持すべきですが、 部分ごとの整形差やフォント技術の限界によっては 常に可能とは限りません。 したがって、そのような組版文字単位は 境界のいずれかに属するか、両方に属する近似として描画される場合があります。 著者は書記素クラスタやリガチャを要素境界で分断すると 一貫性のない、または意図しない結果になる場合があることに注意してください。
1.5. テキスト処理
CSSはUnicodeを基盤としています。[UNICODE] UnicodeをサポートするUAは、Unicodeコア標準のすべての規範的要件に従う必要があり、 CSSで明示的に上書きされている場合を除きます。 Unicode以外のテキスト符号化モデルに基づいて実装されているUAであっても、 適切なマッピングと同等の挙動を仮定することで、同じテキスト処理要件を満たすことが求められます。
テキスト処理(空白処理、テキスト変換、改行など)の隣接関係を判定する目的、 そして本仕様全般において、 間に挟まるインラインボックスの境界やフロー外要素は 無視しなければなりません。 ただしテキスト字形処理については§ 7.3 要素境界をまたぐ字形調整を参照してください。
2. テキストの変換
2.1. 大文字・小文字変換: text-transform プロパティ
| 名前: | text-transform |
|---|---|
| 値: | none | [capitalize | uppercase | lowercase ] || full-width || full-size-kana |
| 初期値: | none |
| 適用対象: | text |
| 継承: | yes |
| パーセンテージ: | n/a |
| 算出値: | 指定されたキーワード |
| 正規化順序: | n/a |
| アニメーション型: | 離散 |
このプロパティはスタイリング目的でテキストを変換します。 元のコンテンツには影響せず、 プレーンテキストのコピー&ペースト操作の内容にも影響してはなりません。
著者はtext-transformを意味的な目的で頼ってはなりません。 正しい大文字・小文字や意味は ソース文書のテキストおよびマークアップに記述されるべきです。
値の意味は以下の通りです:
- none
- 何も変化しません。
- capitalize
- 各単語の最初の組版文字種単位が小文字の場合、タイトルケースに変換します。 それ以外の文字は影響を受けません。
- uppercase
- すべての文字種を大文字にします。
- lowercase
- すべての文字種を小文字にします。
- full-width
- すべての組版文字単位を全角形に変換します。 対応する全角形がない文字は、そのまま残ります。 この値は、ラテン文字や数字を表意文字のように組版する場合によく用いられます。
- full-size-kana
- すべての小かな文字を対応する大きいかなに変換します。 この値は主にルビ注記テキストで用いられ、 小さい文字サイズで可読性が下がるため、すべての小かなを大きいかなで表示したい場合に使われます。
abbr : lang ( ja) { text-transform : full-width; }
注: text-transformの目的は、 文書の意味を変更することなく見た目の文字変換を可能にすることです。 特にtext-transformによる変換は不可逆であり、 テキストの意味を歪める可能性があります。 アクセシビリティインターフェースは表示上の大文字・小文字を伝えたい場合もありますが、 変換後のテキストは文書の本来の意味を正確に表すものとは限りません。
section > p:first-of-type::first-line{ text-transform : uppercase; }
この効果はレイアウトによって改行位置が変わるため、ソース文書で指定することはできません。 また、大文字化は意味的な違いを反映するものではなく、段落の読解に影響を与える意図もないため、 プレゼンテーション層で指定すべきものです。
rt{ font-size : 50 % ; text-transform : full-size-kana; } :is ( h1, h2, h3, h4) rt{ text-transform : none; /* 大きい文字サイズでは解除 */ }
この変換によって小さい文字サイズでも見やすくなりますが、 テキスト自体は変形されているため、 読者は適切な箇所で小かなを頭の中で補う必要があります。 これはラテン語碑文で「U」がすべて「V」に見えるのと似ています。
例えば、次のソースにtext-transform: full-size-kanaを指定すると、 注記は「じゆう」(jiyū:「自由」の意味)と読まれることになりますが、 本来の「十」の正しい読み「じゅう」(jū:「十」の意味)とは異なります。
< ruby > 十< rt > じゅう</ ruby >
2.1.1. マッピング規則
capitalizeについて、何が「単語」と見なされるかはUA依存です。 境界判定には[UAX29]の利用が推奨されますが必須ではありません。 フロー外要素やインライン要素の境界は text-transformの単語境界を導入してはならず、 そうした境界は判定時に無視しなければなりません。
注: 著者はcapitalizeが 言語固有のタイトルケース規則(英語の冠詞スキップなど)に従うことを期待してはなりません。
UAはUnicode文字の完全な大文字・小文字マッピング(条件付き変換規則を含む)を The Unicode StandardのDefault Case Algorithms節に従って使用しなければなりません。[UNICODE] 要素のコンテンツ言語が 文書言語の規則に従い 既知の場合は、 該当する言語固有の規則も適用しなければなりません。 これには最小限として UnicodeのSpecialCasing.txtに記載されている言語固有規則が含まれます(限定されません)。
全角
および半角形の定義は
Unicode Standard Annex #11: East Asian
Widthに記載されています。[UAX11]
全角へのマッピングは
Unicode Standard Annex #44: Unicode Character
Databaseの
Decomposition_Mappingに<wide>または<narrow>タグが付与されたコードポイントにより定義されます。[UAX44]
<narrow>タグの場合は
コードポイントから分解先(<narrow>タグ除去)へ、
<wide>タグの場合は
分解先(<wide>タグ除去)から元のコードポイントへマッピングします。
小かなから大きいかなへのマッピングは 付録G: 小かなマッピングで定義されています。
2.1.2. 変換処理の順序
複数の値が指定され、複数の変換が必要な場合は、以下の順序で適用されます。
テキスト変換は§ 4.1.1 フェーズI: 折りたたみと変換の後、 § 4.1.2 フェーズII: トリミングと配置の前に行われます。 つまり、full-widthは 保持された空白内のみで スペース(U+0020)をU+3000表意スペースに変換します。
注: 付録A:テキスト処理の順序で定義されている通り、 テキスト変換は改行や他の書式処理に影響します。
3. 空白と折返し: white-spaceプロパティ
| 名前: | white-space |
|---|---|
| 値: | normal | pre | nowrap | pre-wrap | break-spaces | pre-line |
| 初期値: | normal |
| 適用対象: | text |
| 継承: | yes |
| パーセンテージ: | n/a |
| 算出値: | 指定されたキーワード |
| 正規化順序: | n/a |
| アニメーション型: | 離散 |
このプロパティは以下の2点を指定します:
値の意味は以下のとおりです。解釈は空白処理および改行規則に従います:
- normal
- この値はユーザーエージェントに空白の連続を1文字(または場合によってはゼロ文字)に折りたたむよう指示します。 行は許可されたソフト折返し機会で折り返されます。 これは現在の改行規則によって決定され、 インライン軸のオーバーフローを最小限にするためです。
- pre
- この値はユーザーエージェントが空白の連続を折りたたむことを防ぎます。セグメント区切り(改行など)は 強制改行として保持されます。 行は強制改行でのみ折り返されます。 コンテンツがブロックコンテナに収まらない場合はオーバーフローします。
- nowrap
- normalと同様に 空白を折りたたみますが、 preと同様に折返しは許可されません。
- pre-wrap
- preと同様に 空白を保持しますが、 normalと同様に折返しを許可します。
- break-spaces
-
振る舞いはpre-wrapと同一ですが、以下の点が異なります:
- 任意の保持された空白や他の空白区切りの連続は常に空間を取り、 行末でも同様です。
- ソフト折返し機会は すべての保持された空白文字および すべての他の空白区切り(隣接する空白間も含む)の後に存在します。
注: この値でも空白によるオーバーフローが完全に防げるわけではありません。 例えば、行の長さが短く、空白1文字すら収まらない場合はオーバーフローとなります。
- pre-line
- normalと同様に 連続する空白文字を折りたたみ、折返しを許可しますが、 ソース中のセグメント区切りは強制改行として保持されます。
空白が空白処理によって削除・折りたたまれなかった場合、 保持された空白と呼ばれます。
注: 場合によっては、保持された空白や 他の空白区切りは 行末でぶら下がりとなる場合があります。 これは内在サイズの測定に影響することがあります。
以下の参考表は、各種white-space値の動作をまとめたものです:
| 改行 | スペースとタブ | 折返し | 行末スペース | 行末他の空白区切り | |
|---|---|---|---|---|---|
| normal | 折りたたみ | 折りたたみ | 折返し | 削除 | ぶら下がり |
| pre | 保持 | 保持 | 折返しなし | 保持 | 折返しなし |
| nowrap | 折りたたみ | 折りたたみ | 折返しなし | 削除 | ぶら下がり |
| pre-wrap | 保持 | 保持 | 折返し | ぶら下がり | ぶら下がり |
| break-spaces | 保持 | 保持 | 折返し | 折返し | 折返し |
| pre-line | 保持 | 折りたたみ | 折返し | 削除 | ぶら下がり |
空白処理規則で空白がどのように折りたたまれるかの詳細を参照してください。
改行で折返し挙動の詳細を参照してください。
4. 空白処理と制御文字
文書のソーステキストには、最終レンダリングに直接関係しない書式が含まれていることがあります。 例えば、編集のしやすさのためセグメント(行)ごとに改行したり、 タブやスペースなどの空白文字で ソースコードをインデントする場合などです。 CSSの空白処理は、著者がこうした書式の解釈を制御できるようにします。 レンダリング時に保持するか、折りたたんで除去するかを選べます。 CSSの空白処理(white-spaceプロパティで制御)は 空白文字をレンダリング時のみ解釈し、 元の文書データには影響しません。
注: 文書言語によっては、
セグメントの区切りが特定の改行文字列(ラインフィードやCRLFペアなど)で分離されていたり、
SGMLのRECORD-STARTやRECORD-ENDトークンなど、他の方法で区切られている場合もあります。
CSS処理では、 各文書言語で定義された「セグメント区切り」や「改行文字列」―定義がなければ各ラインフィード(U+000A)― をセグメント区切りとして扱い、 white-spaceプロパティで指定された通りにレンダリング解釈します。
HTMLの場合、改行は DOM表現時にラインフィード(U+000A)へ正規化されるため、 HTML文書がDOMツリーとして表現される場合、 各ラインフィード(U+000A)がセグメント区切りとして扱われます。 [HTML] [DOM]
注: 一般的なCSS実装では、HTML自体が直接スタイルされることはほとんどありません。 代わりにDOMツリーへ変換され、それがスタイルされます。 HTMLとは異なり、 DOMはキャリッジリターン(U+000D)に特別な意味を与えないため、 それらはセグメント区切りとして扱われません。 HTMLパース以外の手段でDOMにキャリッジリターン(U+000D)が挿入された場合は、 以下の定義通りに処理されます。
注: 文書パーサはセグメント区切りの正規化だけでなく、 他の空白文字の折りたたみや マークアップ規則による空白処理なども行う場合があります。 CSS処理はパース後に行われるため、 これらの文字をスタイリング用に復元することはできません。 したがって、以下で指定される挙動の一部はこうした制約を受け、 UA依存となる場合があります。
注: 折りたたみ可能な空白のみで構成された匿名ブロックはレンダリングツリーから削除されます。 したがって、ブロックレベル要素の周囲にあるそのような空白は折りたたまれます。 CSS 2.1 § 9.2.2.1 匿名インラインボックスを参照してください。[CSS2]
制御文字(Unicodeカテゴリ Cc)―タブ(U+0009)、
ラインフィード(U+000A)、
キャリッジリターン(U+000D)、
およびセグメント区切りとなる並びを除く―は
UAがフォント内で可視でない場合は合成して可視グリフとして描画しなければならず、
その他の文字(Other Symbols(So)一般カテゴリ、
共通スクリプト)と同様に扱われます。
UAは制御文字専用のフォントグリフや
Control Picturesブロックの対応記号グリフ、
コードポイント値の視覚表現、
その他適切な可視グリフを利用できます。
Unicodeの規定通り、
サポートされないDefault_ignorable文字はテキストレンダリングで無視しなければなりません。[UNICODE]
キャリッジリターン(U+000D)はすべての面でスペース(U+0020)と同様に扱われます。
注: HTML文書では、
ソースコード中のキャリッジリターンはパース時にラインフィードへ変換されます
(HTML
§ 13.2.3.5 入力ストリームの前処理および改行の正規化の定義は
Infraを参照)ので、
CSSにはU+000Dキャリッジリターンとして現れません。[HTML]
[INFRA])
ただし、文字がエスケープシーケンス(
4.1. 空白処理規則
特に別途指定がない限り、 CSSの空白処理は 文書空白文字、すなわち スペース (U+0020)、タブ (U+0009)、およびセグメント区切りにのみ影響します。
注: 文書空白(文書内容の一部)と 構文空白(CSS構文の一部)として扱われる文字集合は必ずしも同じではありません。 しかし、両方にスペース (U+0020)、タブ (U+0009)、ラインフィード (U+000A) が含まれるため、 ほとんどの著者は違いに気付かないでしょう。
スペース (U+0020) やノーブレークスペース (U+00A0) 以外にも、 Unicodeではさらに複数の空白区切り文字が定義されています。[UNICODE] 本仕様では Unicodeの一般カテゴリZsに属し、 スペース (U+0020)・ノーブレークスペース (U+00A0) 以外の文字をまとめて その他の空白区切りと呼びます。
4.1.1. フェーズI:折りたたみと変換
各インライン
(匿名インラインも含む。
CSS 2.1 § 9.2.2.1 匿名インラインボックス
[CSS2]参照)
をインライン整形コンテキスト内で処理する際、
空白文字は
改行処理や
双方向再配置の前に
以下のように処理されます。
双方向整形文字
(Bidi_Controlプロパティを持つ文字 [UAX9])は
存在しないものとして無視します:
- white-spaceが normal、 nowrap、 pre-line のいずれかに設定されている場合、 空白文字は折りたたみ可能とみなされ、 次の手順で処理されます:
- white-spaceが pre、 pre-wrap、 break-spaces のいずれかに設定されている場合、 スペースの並びはノーブレークスペースの並びとして扱われます。 ただし、pre-wrapでは ソフト折返し機会が スペースやタブの並びの末尾に存在し、 break-spacesでは すべてのスペースとタブの後に ソフト折返し機会が存在します。
<ltr>A <rtl> B </rtl> C</ltr>ここで <ltr> 要素は左から右への埋め込み、
<rtl> 要素は右から左への埋め込みを表します。
white-spaceプロパティが
normal の場合、
空白処理モデルは次の結果になります:
こうしてA後・B後の2つのスペースが残り、 1つは左から右埋め込みレベルのA後、もう1つは右から左埋め込みレベルのB後に現れます。 テキストはUnicode双方向アルゴリズムに従って並べ替えられ、 最終的には次のようになります:
A BC
AとBの間には2つのスペースが現れ、 BとCの間にはスペースがありません。 これは、スペースを開始・終了タグの内側ではなく外側に置き、 可能な場合は明示的な埋め込みレベルよりも暗黙の双方向性に頼ることで回避できます。
4.1.2. フェーズII:トリミングと配置
この後、ブロック全体が描画されます。 インラインはレイアウトされ、 双方向再配置、 折返し(white-spaceプロパティで指定)を考慮してレイアウトします。 各行のレイアウト時:
- 行頭の折りたたみ可能スペースの並びは削除されます。
-
タブサイズが0の場合、
保持された
タブは描画されません。
それ以外の場合、各保持されたタブは
次の文字の開始端を次のタブストップに合わせて水平シフトとして描画されます。
この距離が0.5ch未満の場合は、次のタブストップが使われます。
タブストップは、
タブサイズの倍数の位置にあり、
保持されたタブの
最近傍のブロックコンテナ祖先の開始端から測ります。
タブサイズはtab-sizeプロパティで指定します。
注: Unicodeのタブ(U+0009)と双方向処理の規則も参照。[UAX9]
-
行末の折りたたみ可能スペースの並び、および
white-spaceプロパティが
normal、
nowrap、
pre-line
の場合は、末尾のU+1680 OGHAM SPACE MARKも削除されます。
注: Unicode Bidirectional AlgorithmのL1規則により、 双方向再配置前の行末にあった折りたたみ可能スペースは再配置後も行末に残ります。[UAX9] [CSS-WRITING-MODES-4]
-
さらに行末に空白、その他の空白区切り、
保持されたタブの並びが残っている場合(双方向再配置後):
- white-spaceが normal、 nowrap、 pre-line の場合、UAはこの並びを(無条件で)ぶら下げしなければなりません。
-
white-spaceが
pre-wrap
の場合、UAは(無条件で)この並びをぶら下げしなければなりませんが、
直後に強制改行がある場合は、
代わりに条件付きぶら下げを行います。
また、オーバーフローする場合は文字の進み幅を視覚的に折りたたんでも構いません。
注: 空白をぶら下げして折りたたまないことで、 テキスト選択や編集時に空白が見えるようになります。
-
white-spaceが
break-spaces
の場合、スペース、タブ、その他の空白区切りは他の可視文字と同様に扱われ、
ぶら下げも進み幅の折りたたみも行いません。
注: これらの文字は必ず空間を取り、 利用可能なスペースや改行制御によって オーバーフローまたは折返しが発生します。
p {
white-space : pre-wrap;
width : 5 ch ;
border : solid 1 px ;
font-family : monospace;
text-align : center;
}
< p > 0</ p >
上記サンプルは次のように描画されます:
最終行のスペースは 強制改行の前にあり、オーバーフローしないため、 ぶら下がりせず、中央揃えが意図通り働きます。
p {
white-space : pre-wrap;
width : 3 ch ;
border : solid 1 px ;
font-family : monospace;
}
< p > 0 0 0 0</ p >
上記サンプルは次のように描画されます:
0 0
0
もし p
を追加した場合、
次のようになります:
0 0
0
強制改行なしの行末の保持されたスペースはぶら下げされるため、 行揃え時に残りの行内容の配置に考慮されません。 右揃えの場合、こうしたスペースはオーバーフローし、 行内容が端と揃うのを妨げません。 一方、強制改行ありの行末空白は条件付きぶら下げとなり、 この例では最終行の空白がオーバーフローしないため、ぶら下がりせず行揃え時に考慮されます。
p {
white-space : pre-wrap;
width : 3 ch ;
border : solid 1 px ;
font-family : monospace;
}
< p > 0 0 0 0</ p >
0 0
最終行は最後の0の前で折返しされないのは、
条件付きぶら下げ文字が
行内容の収まり判定の際に考慮されないためです。
4.1.3. セグメント区切り変換規則
white-spaceがpre、pre-wrap、break-spaces、 またはpre-lineの場合、セグメント区切りは折りたたみ可能ではなく、代わりに保持されたラインフィード(U+000A)に変換されます。
その他のwhite-space値では、セグメント区切りは折りたたみ可能となり、以下のように折りたたまれます:
- まず、折りたたみ可能なセグメント区切りが別の折りたたみ可能なセグメント区切りの直後にあれば、削除されます。
- 次に、残ったセグメント区切りは 前後の文脈に応じてスペース(U+0020)に変換するか、削除されます。 この処理の規則はこのレベルではUA定義です。
Here is an English paragraph that is broken into multiple lines in the source code so that it can be more easily read and edited in a text editor.
Here is an English paragraph that is broken into multiple lines in the source code so that it can be more easily read and edited in a text editor.
中国語など単語区切りがない言語では、 行を「復元」する際に2つの行の間にスペースを挿入せずに結合します。
這個段落是那麼長,
在一行寫不行。最好
用三行寫。
這個段落是那麼長,在一行寫不行。最好用三行寫。
セグメント区切り変換規則では隣接する文脈を利用して、 セグメント区切りをスペースに変換するか、完全に除去するかを選択できます。
注: 歴史的に、HTMLやCSSはセグメント区切りを 無条件でスペースに変換してきました。 これにより、中国語などの言語でソース内改行ができない問題が生じていました。 そのため、UAのヒューリスティクスは、こうした言語への対応を強化しつつも、 セグメント区切りを除去する場面には慎重である必要があります。
4.2. タブ文字サイズ: tab-sizeプロパティ
| 名前: | tab-size |
|---|---|
| 値: | <number [0,∞]> | <length [0,∞]> |
| 初期値: | 8 |
| 適用対象: | text |
| 継承: | yes |
| パーセンテージ: | n/a |
| 算出値: | 指定された数値または絶対長 |
| 正規化順序: | n/a |
| アニメーション型: | 算出値型ごと |
このプロパティは、タブサイズを決定し、保持されたタブ文字(U+0009)の描画時に使用します。 <number>は、 最近傍の保持されたタブの ブロックコンテナ祖先のスペース文字(U+0020)の進み幅に対する倍率で指定します。 letter-spacingやword-spacingも含みます。 負の値は許可されません。
5. 改行と単語境界
インラインレベルの内容が行にレイアウトされる際、行ボックスをまたいで分割されます。 この分割を改行と呼びます。 明示的な改行制御(保持された改行文字など)や ブロックの開始・終了によって行が分割された場合は、強制改行となります。 内容の折返し(UAが内容を収めるために非強制的な改行を作成する場合)によって行が分割される場合は、 ソフト折返しとなります。 インラインレベルの内容を行に分割する処理を改行処理と呼びます。
折返しは許可された改行位置(ソフト折返し機会)でのみ行われます。 折返しが有効な場合(white-space参照)、 UAは行のオーバーフロー量を最小化するため、 ソフト折返し機会があればそこで折返しを行わなければなりません。
多くの書記体系では、 ハイフネーションがない場合、ソフト折返し機会は単語境界でのみ発生します。 多くの体系ではスペースや句読点で単語を明示的に区切り、 ソフト折返し機会はこれらの文字で判定できます。 しかし、タイ語、ラオ語、クメール語などの書記体系では 単語区切りとしてスペースや句読点を使いません。 U+200Bゼロ幅スペースが明示的な区切りとして使えるものの、 実際には一般的ではありません。 そのため、こうしたテキストでソフト折返し機会を正しく判定するには 辞書的リソースが必要です。
その他の書記体系では、ソフト折返し機会が単語境界ではなく正書法の音節境界に基づく場合もあります。 ジャワ語やバリ語など一部は、タイ語・ラオ語同様 区切り位置の解析が必要です。 中国語(日本語、イ語、時に韓国語も含む)などでは 各音節が1つの組版文字種単位に相当し、 改行規則により、特定の文字組み合わせ以外は任意の位置で改行できます。 また、これらの制限の厳密さは組版スタイルによって異なります。
CSSはソフト折返し機会の位置を完全には定義しませんが、 よくあるバリエーションを区別するための制御をいくつか提供します:
- line-breakプロパティは改行制限の厳密さを選択できます。
- word-breakプロパティは どの種類の文字を「単語」とみなして分割不可にするかを制御し、 CJK文字が非CJKテキストのように振る舞うか逆かを決定します。
- hyphensプロパティは ハイフネーションによる単語分割の可否を制御します。
- overflow-wrapプロパティは、 オーバーフローする分割不可文字列内で任意の位置で改行を許可します。
注: Unicode Standard Annex #14: Unicode Line Breaking Algorithmは Unicode全スクリプトの改行処理の基礎挙動を定義しており、 さらに調整が期待されます。[UAX14] 改行規則の詳細は 日本語については日本語組版処理の要件 [JLREQ]や日本語文書の組版方法 [JIS4051]、 中国語については中文排版需求 [CLREQ]や标点符号用法 [ZHMARK]を参照してください。 その他の言語については国際化作業グループの言語対応インデックスに情報があります。[TYPOGRAPHY] 他にも適切な参考文献の情報があればぜひご提案ください。
5.1. 改行の詳細
改行を判定する際:
- 改行処理と双方向テキストの相互作用は、CSS Writing Modes 4 § 2.4 双方向再配置アルゴリズムの適用およびUnicode双方向アルゴリズム(特に UAX9§3.4 Resolved Levelsの並べ替え)で定義されています。[CSS-WRITING-MODES-4] [UAX9]
-
保持されたセグメント区切り、およびwhite-space値に関係なく、
BKとNL改行クラスのUnicode文字は強制改行として扱われなければなりません。[UAX14]注: このような強制改行の双方向性への影響は、Unicode双方向アルゴリズムで定義されています。[UAX9]
- 明示的に別途定義されている場合(例:line-break: anywhereやoverflow-wrap: anywhere)を除き、
WJ、ZW、GL、ZWJのUnicode改行クラスで定義された改行挙動を遵守しなければなりません。[UAX14] - 書記体系で単語区切り以外の句読点で折返しを許可するUAは、改行ポイントの優先順位付けを推奨します。 (例えば、スラッシュ後の改行優先度がスペースより低い場合、“check /etc”は "/"と"e"の間で改行されません。) このような不自然な改行を避けつつ、適切な句読点で改行を許可することは、 特に狭い組み幅では均等な余白を得るために推奨されます。 UAはコンテナブロックの幅、テキストの言語、 line-break値、 などを用いて優先順位を付けることができます。 CSSはソフト折返し機会の優先順位付けは定義していません。 ただし、line-break: anywhereの下では、 word-break: break-all指定時は 単語区切りでの改行に基づかない挙動が明示的に要求されるため、優先順位付けは想定されず、禁止されています。
- フロー外要素やインライン要素の境界は、強制改行やソフト折返し機会を導入しません。
- Web互換性のため、 置換要素やその他のatomic inlineの前後には、隣接文字が改行抑制文字(U+00A0ノーブレークスペース含む)の場合でも ソフト折返し機会が存在します。 ただし、U+00A0ノーブレークスペース以外では Unicode GL, WJ, ZWJ改行クラスの隣接文字との間にはソフト折返し機会を設けてはなりません。[UAX14]
- 改行時に消える文字によるソフト折返し機会(例:U+0020スペース)の場合、 その文字を直接含むボックスのプロパティが改行挙動を制御します。 2文字またはatomic inline間で定義されるソフト折返し機会については、 2文字の最近傍共通祖先のwhite-spaceプロパティが改行を制御します。 どの要素のline-break、word-break、overflow-wrapプロパティが このような境界でのソフト折返し機会判定を制御するかはレベル3では未定義です。
- ボックスの最初または最後の文字の前後のソフト折返し機会では、改行は ボックスの直前/直後(マージン端)で発生し、内容間でボックスを分割しません。
- ルビ内や周辺の改行はCSS Ruby Annotation Layout 1 § 3.4 行をまたぐ改行で定義されています。[CSS-RUBY-1]
-
予期しないオーバーフローを防ぐため、
UAが必要な辞書的・正書法的解析を行えない(例:特定言語の辞書がない等)コンテンツ言語では、当該書記体系内の組版文字種単位のペア間にソフト折返し機会があるものと仮定しなければなりません。
注: この規定は、UAが文字列内で単語境界を見つけられない場合のみ発動するものではありません。 その文字列が分割不可の単語である可能性もあるためです。 例えば、UAがクメール文字(U+1780~U+17FF)の単語境界を判定できない場合に適用されます。
5.2. 文字種の改行規則: word-breakプロパティ
| 名前: | word-break |
|---|---|
| 値: | normal | keep-all | break-all | break-word |
| 初期値: | normal |
| 適用対象: | text |
| 継承: | yes |
| パーセンテージ: | n/a |
| 算出値: | 指定キーワード |
| 正規化順序: | n/a |
| アニメーション型: | 離散 |
このプロパティは文字種間でのソフト折返し機会、すなわちテキスト行を「通常」分割できる位置を指定します。
特に、隣接する組版文字種単位間に一般的なソフト折返し機会が存在するかどうかを制御します。
この目的に限り、非文字種の組版文字単位で
NU、AL、AI、
IDのUnicode改行クラスに該当するものは組版文字種単位として扱われます。[UAX14]
ソフト折返し機会の判定は、空白(およびその他の空白区切り)や句読点周りの規則には影響しません。
(句読点や小かなの判定はline-breakで制御します。)

他の例として、韓国語には2つの改行スタイルがあります: すべての韓国語音節間で改行(word-break: normal)、 または英語同様スペースでのみ改行(word-break: keep-all)。
각 줄의 마지막에 한글이 올 때 줄 나눔 기 준을 “글자” 또는 “어절” 단위로 한다。
각 줄의 마지막에 한글이 올 때 줄 나눔 기준을 “글자” 또는 “어절” 단위로 한다。
エチオピア文字にも2つの改行スタイルがあり、 単語区切りのみ改行(word separator)(word-break: normal)、 または単語内の任意の文字間で改行(word-break: break-all)が許可されます。
ተወልዱ፡ኵሉ፡ሰብእ፡ግዑዛን፡ወዕሩያን፡ በማዕረግ፡ወብሕግ።ቦሙ፡ኅሊና፡ወዐቅል፡ ወይትጌበሩ፡አሐዱ፡ምስለ፡አሀዱ፡ በመንፈሰ፡እኍና።
ተወልዱ፡ኵሉ፡ሰብእ፡ግዑዛን፡ወዕሩያን፡በማ ዕረግ፡ወብሕግ።ቦሙ፡ኅሊና፡ወዐቅል፡ወይትጌ በሩ፡አሐዱ፡ምስለ፡አሀዱ፡በመንፈሰ፡እኍና።
注: オーバーフロー時のみ追加の改行機会を有効化するには、overflow-wrapを参照してください。
値の意味は以下の通りです:
- normal
- 単語は慣習的な規則(上記参照)に従い分割されます。 韓国語(2つの挙動あり)は、連続したハングル/漢字間で改行可能です。 エチオピア文字(こちらも2つの挙動あり)は、単語内での改行は許可されません。
- break-all
-
“単語”内でも改行が許可されます:
具体的には、soft
wrap opportunities(normalで許可されるもの)に加え、
すべての組版文字種単位(および
NU(数字)、AL(アルファベット)、SA(東南アジア文字)の改行クラスに該当する組版文字単位)は、改行時にはID(表意文字)として扱われます。 ハイフネーションは適用されません。注: この値は句読点文字周りのsoft wrap opportunitiesの有無には影響しません。 任意の位置で改行を許可するにはline-break: anywhereを参照。
注: このオプションはエチオピア文字のもう一つの一般的な挙動にも有効です。 また、主にCJK文字が大半で短い非CJK部分がある場合など、 各行への分布を良くしたい状況でもよく使われます。
- keep-all
-
“単語”内での改行は禁止されます:
組版文字種単位間(または
NU、AL、AI、ID改行クラスに該当する組版文字単位間)の暗黙的なsoft wrap opportunitiesは抑制されます。 (line-break設定がanywhere以外の場合に限る) 辞書による分割機会がある場合を除き、その他はnormalと同等です。 このスタイルではCJK文字列は分割されません。注: これは韓国語のもう一つの一般的な挙動です(単語間にスペースを使う)。 また、CJK断片がスペース区切り言語に混在する場合にも有効です。
特定カテゴリの文字と同様の改行挙動を持つ記号も、同じように扱われます。
这是一些汉字 and some Latin و کمی خط عربی และตัวอย่างการเขียนภาษาไทย በጽሑፍ፡ማራዘሙን፡አንዳንድ፡
改行ポイントは以下のように判定されます(‘·’で示す):
- word-break: normal
-
这·是·一·些·汉·字·and·some·Latin·و·کمی·خط·عربی·และ·ตัวอย่าง·การเขียน·ภาษาไทย·በጽሑፍ፡·ማራዘሙን፡·አንዳንድ፡
- word-break: break-all
-
这·是·一·些·汉·字·a·n·d·s·o·m·e·L·a·t·i·n·و·ﮐ·ﻤ·ﻰ·ﺧ·ﻁ·ﻋ·ﺮ·ﺑ·ﻰ·แ·ล·ะ·ตั·ว·อ·ย่·า·ง·ก·า·ร·เ·ขี·ย·น·ภ·า·ษ·า·ไ·ท·ย·በ·ጽ·ሑ·ፍ፡·ማ·ራ·ዘ·ሙ·ን፡·አ·ን·ዳ·ን·ድ፡
- word-break: keep-all
-
这是一些汉字·and·some·Latin·و·کمی·خط·عربی·และ·ตัวอย่าง·การเขียน·ภาษาไทย·በጽሑፍ፡·ማራዘሙን፡·አንዳንድ፡
アラビア語等のシェーピング書記体系でbreak-allにより語内改行が許可される場合でも、文字は語が分割されていないかのように字形を組まなければなりません(§ 5.6 語内改行時の字形調整参照)。
レガシーコンテンツ互換のため、 word-breakプロパティは 非推奨のbreak-wordキーワードもサポートします。 指定時、この値はword-break: normalおよびoverflow-wrap: anywhereと同じ効果を持ちます。 overflow-wrapプロパティ値に関わらずです。
5.3. 改行厳密度: line-breakプロパティ
| 名前: | line-break |
|---|---|
| 値: | auto | loose | normal | strict | anywhere |
| 初期値: | auto |
| 適用対象: | text |
| 継承: | yes |
| パーセンテージ: | n/a |
| 算出値: | 指定キーワード |
| 正規化順序: | n/a |
| アニメーション型: | 離散 |
このプロパティは要素内で適用される改行規則の厳密度、特に折返しと句読点・記号の関係を指定します。 値の意味は以下の通りです:
- auto
- UAが適用する改行制限のセットを決定し、行の長さによって制限を変える場合があります。 例: 短い行ではより制限の少ない改行規則を使用。
- loose
- 最も制限の少ない改行規則でテキストを分割します。新聞など短い行でよく使われます。
- normal
- 最も一般的な改行規則でテキストを分割します。
- strict
- 最も厳格な改行規則でテキストを分割します。
- anywhere
-
すべての組版文字単位の前後、
句読点文字や保持された空白、
さらに語の途中でも、
改行禁止文字(Unicode
GL,WJ,ZWJクラス)や word-breakプロパティで導入された禁止を無視し、 ソフト折返し機会を設けます。[UAX14] 改行機会の優先順位付けは不可。 ハイフネーションは適用されません。注: この値は端末などでよく見られる改行規則を引き起こします。
注: anywhereは保持された空白が行末にある場合、 white-spaceがbreak-spacesの時のみ 次の行への折返しが許可されます。他の場合は:この値が保持された空白に影響する場合、 white-space: break-spacesでは 並びの最初のスペースの前での改行が許可されます。 (この効果はbreak-spaces単独では得られません。)
CSSはテキスト折返し規則の厳密度を4段階で区別します。 loose、normal、 strictの各キーワードで有効な規則はUA依存ですが、 言語慣習に従うべきです。 ただし、これら3つのキーワードについて本仕様は次を要求します:
-
次の改行はstrictで禁止され、
normalおよびlooseで許可されます:
- 日本語小かなやカタカナ・ひらがな長音記号(Unicode改行クラス
CJ)の前での改行。[UAX14]
- 日本語小かなやカタカナ・ひらがな長音記号(Unicode改行クラス
-
次の改行はnormalおよびlooseで、
書記体系が中国語または日本語の場合のみ許可され、それ以外は禁止:
- 特定のCJK風ハイフン文字の前: 〜 U+301C, ゠ U+30A0
-
次の改行はlooseで、
前の文字がUnicode改行クラス
ID(word-break: break-allでID扱いの場合も含む)である場合のみ許可され、それ以外は禁止:- ハイフンの前: ‐ U+2010, – U+2013
-
次の改行はnormalおよびstrictで禁止され、
looseで許可されます:
- くり返し記号の前: 々 U+3005, 〻 U+303B, ゝ U+309D, ゞ U+309E, ヽ U+30FD, ヾ U+30FE
- 分離不可文字間(例: ‥ U+2025, … U+2026、Unicode改行クラス
IN)。[UAX14]
-
次の改行はlooseで、
書記体系が
中国語または
日本語の場合のみ許可され、それ以外は禁止:
- 特定の中央配置句読点の前: ・ U+30FB, : U+FF1A, ; U+FF1B, ・ U+FF65, ‼ U+203C, ⁇ U+2047, ⁈ U+2048, ⁉ U+2049, ! U+FF01, ? U+FF1F
- 接尾辞の前: Unicode改行クラス
POかつ東アジア幅プロパティがAmbiguous,Fullwidth,Wide。[UAX11] - 接頭辞の後: Unicode改行クラス
PRかつ東アジア幅プロパティがAmbiguous,Fullwidth,Wide。[UAX11]
注: 上記要件はCJKテキストでのみ区別を生みます。 上記規則のみで追加規則がない実装では、line-breakはCJKコードポイントにしか影響せず、 書記体系が中国語または日本語でタグ付けされていない限り影響しません。 将来のレベルでは、他の書記体系や言語の要件が判明次第、追加の具体的規則が追加される可能性があります。
注: CSSWGは将来の版で出版用途の高度な改行制御が必要になる可能性を認識しています。
5.4. ハイフネーション: hyphensプロパティ
ハイフネーションは、通常は改行できない単語を制御された方法で分割し、段落のレイアウトを改善する技法です。 通常、音節や形態素の境界で単語を分割し、分割箇所を視覚的に示す(通常はハイフン U+2010 を挿入する)ことが多いです。 場合によっては、ハイフネーションによって単語の綴りが変化することもあります。 いずれにしても、ハイフネーションはレンダリング上の効果のみであり、 元の文書内容やテキスト選択・検索には影響しません。
| 言語 | 分割なし | 行区切り前 | 行区切り後 |
|---|---|---|---|
| 英語 | Unbroken | Un‐ | broken |
| オランダ語 | cafeetje | café‐ | tje |
| ハンガリー語 | Összeg | Ösz‐ | szeg |
| 中国語(拼音) | tú’àn | tú‐ | àn |
| àizēng‐fēnmíng | àizēng‐ | ‐fēnmíng | |
| ウイグル語 | ![[isolated DAL + isolated ALEF + initial MEEM +
medial YEH + final DAL +
isolated ALEF MAKSURA]](https://www.w3.org/TR/css-text-3/images/uyghur-unbroken.svg)
| ![[isolated DAL + isolated ALEF + initial MEEM +
final YEH + hyphen ]](https://www.w3.org/TR/css-text-3/images/uyghur-hyphenate-joined-before.svg)
| ![[ isolated DAL + isolated ALEF MAKSURA]](https://www.w3.org/TR/css-text-3/images/uyghur-hyphenate-joined-after.svg)
|
| クリー語 | ![[ᑲᓯᑕᓂᐘᓂᓂᐠ]
(CANADIAN SYLLABICS KA +
CANADIAN SYLLABICS SI +
CANADIAN SYLLABICS TA +
CANADIAN SYLLABICS NI +
CANADIAN SYLLABICS WEST-CREE WA +
CANADIAN SYLLABICS NI +
CANADIAN SYLLABICS NI +
CANADIAN SYLLABICS FINAL GRAVE)](https://www.w3.org/TR/css-text-3/images/cree.svg)
| ![[ᑲᓯᑕᓂ᐀]
(CANADIAN SYLLABICS KA +
CANADIAN SYLLABICS SI +
CANADIAN SYLLABICS TA +
CANADIAN SYLLABICS NI +
CANADIAN SYLLABICS HYPHEN)](https://www.w3.org/TR/css-text-3/images/cree-before.svg)
| ![[ᐘᓂᓂᐠ]
(CANADIAN SYLLABICS WEST-CREE WA +
CANADIAN SYLLABICS NI +
CANADIAN SYLLABICS NI +
CANADIAN SYLLABICS FINAL GRAVE)](https://www.w3.org/TR/css-text-3/images/cree-after.svg)
|
ハイフネーションは、行が有効なハイフネーション機会で区切られる時に発生します。 これは、単語内でハイフネーションが許可されている場所に存在するソフト折返し機会の一種です。 CSSではハイフネーション機会はhyphensプロパティで制御されます。 CSS Text Level 3ではハイフネーションの具体的規則は定義されませんが、 UAは改行位置の最適化や言語適合的なハイフネーションポイントの選択を強く推奨されます。
注: U+002D - HYPHEN-MINUSやU+2010 ‐ HYPHEN文字によるソフト折返し機会は ハイフネーション機会ではありません。 これらの文字は改行有無に関係なく常に表示されるため、分割の視覚的な印は生成されません。
ハイフネーション機会はmin-content内在サイズの計算時に考慮されます。
注: これにより、テーブル内の内容がオーバーフローせずハイフネーションされることが可能になり、 ドイツ語など長い単語の言語では特に重要です。
| 名前: | hyphens |
|---|---|
| 値: | none | manual | auto |
| 初期値: | manual |
| 適用対象: | text |
| 継承: | yes |
| パーセンテージ: | n/a |
| 算出値: | 指定キーワード |
| 正規化順序: | n/a |
| アニメーション型: | 離散 |
このプロパティは、テキスト行内でハイフネーションによって さらに多くのソフト折返し機会を許可するかどうかを制御します。 値の意味は以下の通りです:
- none
-
単語はハイフネーションされません。
単語内にハイフネーション機会が明示的にあっても、
分割されません。
注: これは、 U+002D - HYPHEN-MINUSやU+2010 ‐ HYPHENのような常に可視な文字による既存のソフト折返し機会を抑制しません。
- manual
-
単語は、単語内にハイフネーション機会を明示する文字がある場合のみ分割されます。
UAは適切な言語固有のハイフン文字を使用し、
自動ハイフネーションと同じ箇所で適切な綴り変更も適用すべきです。
Unicodeでは、U+00ADは条件付き「ソフトハイフン」、U+2010は無条件ハイフンです。 Unicode Standard Annex #14ではUnicode改行処理におけるソフトハイフンの役割について説明があります。[UAX14] HTMLでは ­はソフトハイフン文字を表し、ハイフネーション機会を示唆します。
ex
­ ample - auto
- 単語は、言語適合的なハイフネーションリソースにより自動的に判定されたハイフネーション機会、および条件付きハイフンによって明示された箇所で分割されます。 単語内に条件付きハイフン(­やU+00AD SOFT HYPHEN)が存在する場合は、 他の自動的なハイフネーション機会は無視され、 条件付きハイフン箇所で優先して分割されます。 ただし、その分割後でも1行に収まらない場合は、自動ハイフネーション機会も利用されます。
正しい自動ハイフネーションには、テキストの言語に適したハイフネーションリソースが必要です。 UAはコンテンツ言語が既知であり、かつ適切なハイフネーションリソースを持つ場合のみ自動ハイフネーションを適用しなければなりません。
UAは言語別ヒューリスティクスにより、特定の単語を自動ハイフネーションから除外することもできます。 例えば、UAが特定の大文字・句読点パターンに一致する単語(固有名詞など)を分割しないようにするなどです。 こうしたヒューリスティクスは仕様書で定義されません。 (言語によって大文字規則が異なるため、英語とドイツ語ではヒューリスティクスも異なります。)
hyphensプロパティの目的では、「単語」の定義はUA依存です。 ただし、インライン要素境界やフロー外要素は単語境界判定時に無視しなければなりません。
条件付きハイフン文字(U+00AD SOFT HYPHENなど)によるハイフネーション機会で表示されるグリフは、 その文字によって表現され、 適用されたプロパティに従いスタイルされます。
アラビア語などのシェーピング書記体系でハイフネーションによって語内改行が許可された場合でも、 文字は語が分割されていないかのように字形を組まなければなりません(§ 5.6 語内改行時の字形調整参照)。
![[isolated DAL + isolated ALEF + initial MEEM +
medial YEH + hyphen + line-break + final DAL +
isolated ALEF MAKSURA]](https://www.w3.org/TR/css-text-3/images/uyghur-hyphenate-joined.svg) のように表示され、
のように表示され、
![[isolated DAL + isolated ALEF + initial MEEM +
final YEH + hyphen + line-break + isolated DAL +
isolated ALEF MAKSURA]](https://www.w3.org/TR/css-text-3/images/uyghur-hyphenate-unjoined.svg) のようにはなりません。
のようにはなりません。
5.5. オーバーフロー折返し: overflow-wrap/word-wrapプロパティ
| 名前: | overflow-wrap, word-wrap |
|---|---|
| 値: | normal | break-word | anywhere |
| 初期値: | normal |
| 適用対象: | text |
| 継承: | yes |
| パーセンテージ: | n/a |
| 算出値: | 指定キーワード |
| 正規化順序: | n/a |
| アニメーション型: | 離散 |
このプロパティは、UAが本来許可されない行内のポイントで オーバーフロー防止のために改行できるかどうかを指定します。 つまり、改行不可の文字列が行ボックスに収まらない場合に効果を発揮します。 white-spaceが折返しを許可する場合のみ有効です。値の意味は以下の通りです:
- normal
- 行は許可された改行ポイントでのみ分割されます。 ただし、 word-break: keep-allによる制限は、 行内に他に許容できる改行ポイントがない場合、word-break: normalと同様に緩和されることがあります。
- anywhere
- 改行不可の文字列でも、行内に他に許容できる改行ポイントがない場合、任意の位置で分割できます。 シェーピング文字は語が分割されていないかのように字形調整され、 書記素クラスタは単一単位として維持されます。 改行ポイントにハイフン文字は挿入されません。 ソフト折返し機会 (anywhereによるもの)は min-content内在サイズの計算時に考慮されます。
- break-word
- anywhereと同様ですが、 ソフト折返し機会 (break-wordによるもの)は min-content内在サイズの計算時には考慮されません。
レガシー互換のため、UAはword-wrapを レガシー名エイリアス としてoverflow-wrapプロパティと同様に扱わなければなりません。
5.6. 語内改行時の字形調整
アラビア語などのシェーピング書記体系で、語内の非強制ソフト折返し機会(word-break: break-all、line-break: anywhere、overflow-wrap: break-word、overflow-wrap: anywhereなど、またはハイフネーション時) で改行する場合でも、文字は語が分割されていないかのように(接合形態を選択して)字形調整しなければなりません。
6. 整列と両端揃え
整列と両端揃えは、インライン内容が行ボックス内でどのように分布されるかを制御します。
6.1. テキストの整列: text-alignショートハンド
| 名前: | text-align |
|---|---|
| 値: | start | end | left | right | center | justify | match-parent | justify-all |
| 初期値: | start |
| 適用対象: | block containers |
| 継承: | yes |
| パーセンテージ: | 個別プロパティを参照 |
| 算出値: | 個別プロパティを参照 |
| アニメーション型: | 離散 |
| 正規化順序: | n/a |
このショートハンドプロパティは、text-align-allおよびtext-align-lastプロパティを設定し、 ブロック内のインラインレベル内容を 行ボックスのインライン軸に沿ってどのように整列させるかを指定します(内容が行ボックスを完全に満たさない場合)。 justify-allやmatch-parent以外の値は text-align-allに割り当てられ、 text-align-lastはautoにリセットされます。
値の意味は以下の通りです:
- start
- インラインレベル内容は行ボックスの開始端に整列されます。
- end
- インラインレベル内容は行ボックスの終了端に整列されます。
- left
- インラインレベル内容は行ボックスのline-left端に整列されます。 (縦書きモードでは、物理的な上端または下端になることもあり、 writing-modeによって決まります。)[CSS-WRITING-MODES-4]
- right
- インラインレベル内容は行ボックスのline-right端に整列されます。 (縦書きモードでは、物理的な上端または下端になることもあり、 writing-modeによって決まります。)[CSS-WRITING-MODES-4]
- center
- インラインレベル内容は行ボックス内で中央揃えされます。
- justify
- テキストはtext-justifyプロパティで指定された方法で両端揃えされ、 行ボックスを正確に満たすようにします。 text-align-lastで別途指定がない限り、 強制改行直前やブロック末尾の最終行はstart揃えになります。
- justify-all
- text-align-allおよびtext-align-last両方をjustifyに設定し、 最終行も強制的に両端揃えします。
- match-parent
-
この値はinherit(親の算出値を継承)と同じですが、
親から継承された値がstartやendの場合は
親のdirectionプロパティで解釈され、
算出値がleftまたはrightとなります。
ルート要素で指定した場合はstartになります。
text-alignショートハンドで指定した場合、 text-align-allおよびtext-align-last両方をmatch-parentに設定します。
テキストブロックは行ボックスのスタックです。 このプロパティは各行ボックス内のインラインレベルボックスが、 行ボックスの開始・終了側に対してどのように揃うかを指定します。 揃えはビューポートや包含ブロックとは関係ありません。
justifyの場合、 UAはテキストの調整によってインラインボックスを伸縮させることができます。 (text-justify参照。) 要素の空白が 折りたたみ可能でない場合、 UAは両端揃えのためにテキストを調整する必要はなく、 テキストに両端揃え機会がないものとして扱ってもよいです。 UAがテキスト調整を行う場合は、 タブストップが 空白処理規則に従って正しく揃うようにしなければなりません。
(両端揃え後も含めて)行ボックス内のインライン内容が収まらない場合、 内容は開始揃えとなり、 収まらない内容は行ボックスの終了端からオーバーフローします。
§ 8.3 双方向性と行ボックスで 行ボックスの開始端と終了端の判定方法について解説しています。
6.2. デフォルトのテキスト整列: text-align-all プロパティ
| 名前: | text-align-all |
|---|---|
| 値: | start | end | left | right | center | justify | match-parent |
| 初期値: | start |
| 適用対象: | ブロックコンテナ |
| 継承: | yes |
| パーセンテージ: | n/a |
| 算出値: | 指定キーワード。ただしmatch-parentは上記定義に従う |
| 正規化順序: | n/a |
| アニメーション型: | 離散 |
このプロパティはtext-alignのロングハンドであり、ショートハンドプロパティです。ブロックコンテナ内のインライン内容すべての行の整列を指定します。 ただし、最終行はauto以外のtext-align-last値で上書きされる場合があります。 値についてはtext-alignを参照してください。
著者はこのプロパティではなくtext-alignショートハンドの使用を推奨します。
6.3. 最終行の整列: text-align-last プロパティ
| 名前: | text-align-last |
|---|---|
| 値: | auto | start | end | left | right | center | justify | match-parent |
| 初期値: | auto |
| 適用対象: | ブロックコンテナ |
| 継承: | yes |
| パーセンテージ: | n/a |
| 算出値: | 指定キーワード。ただしmatch-parentは上記定義に従う |
| 正規化順序: | n/a |
| アニメーション型: | 離散 |
このプロパティは、ブロックの最終行や強制改行直前の行の整列方法を指定します。
autoが指定された場合、 対象行の内容はtext-align-allに従って整列されます。ただしtext-align-allがjustifyの場合は、開始揃え(start)となります。 その他の値はtext-alignの説明通りに解釈されます。
6.4. 両端揃え方法: text-justify プロパティ
| 名前: | text-justify |
|---|---|
| 値: | auto | none | inter-word | inter-character |
| 初期値: | auto |
| 適用対象: | テキスト |
| 継承: | yes |
| パーセンテージ: | n/a |
| 算出値: | 指定キーワード(ただしdistributeレガシー値は除く) |
| 正規化順序: | n/a |
| アニメーション型: | 離散 |
このプロパティは、行の整列がjustifyに設定された時に使われる両端揃え方法を選択します(text-align参照)。 このプロパティはテキストに適用されますが、 ブロックコンテナからそのインライン内容のルートインラインボックスに継承されます。 値は以下の通りです:
- auto
-
UAが両端揃えアルゴリズムを選択し、
パフォーマンスと十分な表示品質のバランスに基づいて決定します。
両端揃え規則は書記体系や言語によって異なるため、
UAは可能な限りテキストに適した両端揃えアルゴリズムを使うべきです。
例: UAはデフォルトで全書記体系に妥協した方法(主に単語区切りやCJK組版文字種単位間を拡張し、二次的に東南アジア組版文字種単位間も拡張)の両端揃え方法を使うことができます。 段落の言語が既知の場合は、 日本語なら日本語組版処理の要件([JLREQ])に従う、 アラビア語は草書的伸長、 ドイツ語はinter-wordを使うなど、 より言語に合わせた両端揃えも選択できます。

アラビア語の草書体両端揃え例(Tasmeemによる)。 英語同様、アラビア語も単語間の間隔調整で両端揃えできますが、 多くのスタイルでは文字自体をカリグラフィの技法で伸長・圧縮することで揃えます。 この例では、上段はkashidaやスワッシュ形で行を伸長し、 下段は特定文字のスタック型合字でやや圧縮しています。 伝統的なカリグラフィ技法を用いることで、流れや色を維持しつつ高品質な両端揃えが可能になりますが、 これは非常にスクリプト依存の効果です。 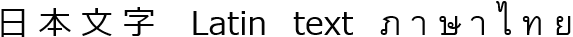
text-justify: autoの混合スクリプト例。 この解釈では、普遍的妥協法としてスペースやCJK・東南アジア文字間で拡張します。 実質的に、単語区切りやCJK文字のある行ではinter-word+inter-ideograph間隔を使い、 それ以外やスペースが広がりすぎる場合はinter-cluster挙動となります。 - none
-
両端揃えを無効化します。テキスト内に両端揃え機会はありません。
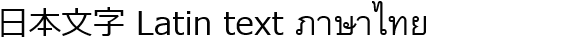
text-justify: noneの混合スクリプト例 注: この値はユーザースタイルシートで可読性やアクセシビリティ向上のために使われます。
- inter-word
-
両端揃えは単語区切りのみで間隔調整します
(実質的にword-spacingを行ごとに変化)。
英語や韓国語などスペースで単語区切りを行う言語で一般的です。

text-justify: inter-wordの混合スクリプト例 - inter-character
-
両端揃えは隣接する組版文字単位各ペア間で間隔調整します
(実質的にletter-spacingを行ごとに変化)。
この値は日本語など東アジア系システムで使われることがあります。
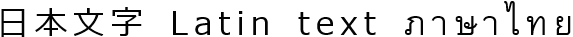
text-justify: inter-characterの混合スクリプト例 レガシー理由により、 UAは代替キーワードdistributeもサポートしなければならず、 これはinter-characterに算出され、 意味・挙動は完全に同一です。 UAはこれをレガシー値エイリアスとして扱っても構いません。
最適な両端揃えは言語依存のため、 著者はより良い結果のためにコンテンツに正しい言語タグを付与すべきです。
注: このCSSレベルのガイドラインは完全な両端揃えアルゴリズムを規定するものではありません。 あくまで完全なアルゴリズムが満たすべき最低要件の集合です。 要件を限定することで、UAは品質・速度・複雑さのバランスに応じたアルゴリズム選択の自由度を持てます。
6.4.1. テキストの拡張・圧縮
テキストを両端揃えする場合、 ユーザーエージェントは行内容の端と行ボックスの端の間に残ったスペースを取得し、 そのスペースを内容全体に分配して、内容が行ボックスをちょうど満たすようにします。 ユーザーエージェントは、逆に負のスペースを分配して、 通常の間隔条件下では収まらないほど多くの内容を行に載せることもできます。
両端揃え機会は、 両端揃えアルゴリズムがテキスト内の間隔を調整できるポイントです。 両端揃え機会は、単一の組版文字単位(単語区切りなど)、 または2つの組版文字単位が並んだ位置によって提供されます。 ソフト折返し機会の制御と同様に、 組版文字単位が両端揃え機会を提供するかどうかは、 親のtext-justify値で制御されます。 同様に、2つの連続する両端揃え機会が 2つの組版文字単位の間にあるかどうかは、 最近傍共通祖先のtext-justify値で決定されます。
両端揃えで分配されるスペースは、letter-spacingやword-spacingプロパティで定義される間隔に加えて分配されます。 この追加スペースが単語区切りの両端揃え機会に分配される場合は、 word-spacingと同じ規則で適用されます。 同様に、2つの両端揃え機会が組版文字単位間に分配される場合は、 letter-spacingと同じ規則で適用されるべきです。
両端揃えアルゴリズムは、両端揃え機会を複数の優先レベルに分割しても構いません。 1つのレベル内の両端揃え機会は、 どの組版文字単位によって生じたかに関わらず、同じ優先度で拡張・圧縮されます。 例えば、2つの漢字間や2つのラテン文字間の両端揃え機会が 同じレベル(inter-character両端揃えスタイルのように)で定義されていれば、 それがどちら由来でも区別されません。 このレベルでは、他の要素(フォントサイズ、letter-spacing、字形、行内位置など)が 行内の両端揃え機会へのスペース分配に影響するかどうかは定義されません。
UAは、任意の方法でテキストを両端揃えするために、 任意のリガチャの有効化・分割や、代替字形・字形圧縮などのフォント機能を利用しても構いません。 この挙動は本CSSレベルでは制御されません。 ただし、UAは必ず必要なリガチャの分割や、 複雑な書記体系の正しい字形化に必要な機能の無効化をしてはなりません。
行内に両端揃え機会があり、 テキスト整列がその行に完全両端揃え(justify)を指定していれば、 両端揃えされなければなりません。
6.4.2. 記号・句読点の扱い
両端揃え機会を判定する場合、 Unicodeの記号(S*)や句読点(P*)クラスの組版文字単位は、 一般に同じスクリプトの組版文字種単位と同等に扱われます (文字のスクリプトプロパティがCommonの場合は、主スクリプトの組版文字種単位として扱われます)。
ただし、組版の慣習によっては記号や句読点の両端揃えに追加規則がある場合もあります。 そのためUAは、特定文字の再分類や優先レベル追加を行い、 記号・句読点を含む両端揃え機会を調整しても構いません。
6.4.3. 拡張できないテキスト
行内内容が行ボックスの全幅まで伸長できない場合は、 text-align-lastプロパティで指定された通りに整列されなければなりません。 (text-align-lastがjustifyの場合は、center揃えとなります。)
6.4.4. 草書体書記体系
両端揃えによって、 アラビア語など草書体書記体系の 組版文字種単位同士の接合部分に隙間が生じてはなりません。 可能なら、UAはそうした組版文字種単位の並び内の両端揃え機会へのスペース分配を 草書体独自の伸長に変換してもよいですが、 それ以外は、両端揃え機会が草書体内のどのペアにもないものとみなさなければなりません(接合しているか否かに関わらず)。


一部のフォント設計では、タトウィール文字による両端揃えが可能です。 タトウィールベースの両端揃えを行うUAは、その使用規則を正しく処理しなければなりません。 タトウィール文字の正しい挿入は、文字の組み合わせ、単語内の位置、行内での位置などの文脈に依存することに注意してください。
6.4.5. auto両端揃えの最低要件
auto両端揃えについて、 本仕様は両端揃え機会のすべてや、 優先順位、複数レベルの両端揃え機会の相互作用などを定義しません。 ただし、次のことを要求します:
-
コンテンツ言語や隣接する記号・句読点の組版慣習で否定されない限り、
以下は各々両端揃え機会を提供します:
- 単語区切り
- いずれかのブロックスクリプトに属する組版文字単位と他の組版文字単位の境界
- いずれかのクラスタ型スクリプトに属する組版文字単位と他の組版文字単位の境界
- すべての文字種(ブロックスクリプトに属するもの)は同等に扱われ、 すべての文字種(クラスタ型スクリプトに属するもの)も同等に扱われます。 例えば、漢字同士の両端揃え機会と、漢字+ハングル文字の両端揃え機会は区別しません。
両端揃えの詳細は“Approaches to Full Justification”でも参照できます。ここでは書記体系・言語ごとにインデックスされており、 W3C国際化作業グループが管理しています。[JUSTIFY]
7. 行間・文字間
CSSはテキストの間隔制御手段として、 word-spacingプロパティと letter-spacingプロパティを提供しています。 これらはそれぞれ 単語区切りの周囲や 組版文字単位間の 追加スペースを指定します。
7.1. 単語間隔: word-spacing プロパティ
| 名前: | word-spacing |
|---|---|
| 値: | normal | <length> |
| 初期値: | normal |
| 適用対象: | テキスト |
| 継承: | yes |
| パーセンテージ: | N/A |
| 算出値: | 絶対長 |
| 正規化順序: | n/a |
| アニメーション型: | 算出値型ごと |
このプロパティは「単語」間の追加間隔を指定します。 値の解釈は以下の通りです:
- normal
- 追加間隔は適用されません。 算出値はゼロです。
- <length>
- フォントで定義された語間の本来の間隔に加えて追加の間隔を指定します。
追加間隔は、単語区切り文字ごと(空白処理規則適用後に残っていれば)に 適用されるべきであり、慣習がなければ文字の両側半分ずつ分配します。 負値も指定可能ですが、実装依存の制限がある場合があります。
単語区切り文字は、主な役割・一般的用途が単語区切りである組版文字単位です。 Unicodeでは(完全定義ではありませんが) スペース(U+0020)、 ノーブレークスペース(U+00A0)、 エチオピア語ワードスペース(U+1361)、 エーゲ語区切り(U+10100,U+10101)、 ウガリト語ワードディバイダー(U+1039F)、 フェニキア語ワードセパレータ(U+1091F)などが含まれます。[UNICODE]
注: 一般の句読点や固定幅スペース(U+3000, U+2000~U+200Aなど)は 単語区切り文字ではありません。 たとえ単語区切りとして使われることがあっても、主目的が単語区切りではないためです。
単語区切り文字がない場合や、 区切り文字が進み幅ゼロ(U+200Bゼロ幅スペースなど)の場合は、 UAは単語間の追加間隔を生成してはなりません。
7.2. トラッキング: letter-spacing プロパティ
| 名前: | letter-spacing |
|---|---|
| 値: | normal | <length> |
| 初期値: | normal |
| 適用対象: | インラインボックスおよびテキスト |
| 継承: | yes |
| パーセンテージ: | n/a |
| 算出値: | 絶対長 |
| 正規化順序: | n/a |
| アニメーション型: | 算出値型ごと |
このプロパティは隣接する組版文字単位間の追加間隔 (一般的にトラッキング)を指定します。 letter-spacingは双方向再配置後に適用され、 カーニングや word-spacingに加えて適用されます。[CSS-WRITING-MODES-4] [CSS-FONTS-3] 両端揃え規則によっては、 UAがさらに組版文字単位間の間隔を増減して 両端揃えを実現する場合があります。
値の意味は以下の通りです:
- normal
- 追加間隔は適用されません。算出値はゼロです。
- <length>
- 組版文字単位間に追加間隔を指定します。 負値も指定可能ですが、実装依存の制限がある場合があります。
レガシー理由により、
算出値がゼロのletter-spacingは
解決値(getComputedStyle()
の戻り値)はnormalとなります。
letter-spacingの観点では、 連続するatomic inline(画像やインラインブロックなど)は ひとつの組版文字単位として扱われます。
letter-spacingは行頭では適用してはなりません。 行末に適用されるかどうかは本レベルでは未定義です。
p{ letter-spacing : 1 em ; }
< p > abc</ p >
a b c
a b c
したがってUAは、本当に [RFC6919] 行末右端にletter-spacingを追加すべきではありません:
a b c
2つの組版文字単位間のletter-spacingは、 それら2つ組版文字単位を 内包する最も内側の要素に「属する」とみなします。 隣接する2つ組版文字単位間の 総letter-spacing(双方向再配置後)は、 それらの境界を含む最も内側の要素で指定・描画されます。 ただしUAは、要素境界でのletter-spacingを それぞれの組版文字単位に その包含要素の値として割り当てても構いません。
注: この二次的挙動はWeb互換性上許容されています。
p{ letter-spacing : 1 em ; }
< p > a< span > bb</ span > c</ p >
a b b c
a b b c
従って、指定したletter-spacing値は、 その要素に完全に含まれる文字間だけに影響すべきです:
p{ letter-spacing : 1 em ; } span{ letter-spacing : 2 em ; }
< p > a< span > bb</ span > c</ p >
a b b c
さらに、1文字のみの要素にletter-spacingを適用しても、 描画結果には影響しません:
p{ letter-spacing : 1 em ; } span{ letter-spacing : 2 em ; }
< p > a< span > b</ span > c</ p >
a b c
letter-spacingは双方向再配置後に挿入されるため、 下記の内側spanへのletter-spacingも効果がありません。 再配置後は "c" が "א" の隣にならないからです:
p{ letter-spacing : 1 em ; } span{ letter-spacing : 2 em ; }
<!-- abc followed by Hebrew letters alef (א), bet (ב) and gimel (ג) --> <!-- Reordering will display these in reverse order. --> < p > ab< span > cא</ span > בג</ p >
a b c א ב ג
letter-spacingは不可視のゼロ幅整形文字(Unicode Cfカテゴリ等)を無視します。 こうした文字が文書内に存在しないものとして間隔を加算しなければなりません。
2文字間の実効間隔がゼロでない場合(両端揃えや letter-spacingが非ゼロ値の場合)、 UAはオプションリガチャ(正しい字形化に必須でないもの)は適用すべきではありません。 ただし、低レベルfont-feature-settingsプロパティで指定されたリガチャや他のフォント機能はこの規則より優先されます。 CSS Fonts Module Level 3 § feature-precedence参照。
注: OpenTypeでは必須リガチャはrlig機能に紐付けられるべきとされています。
その他のリガチャはオプションとみなされます。
ただしUAやプラットフォームのヒューリスティックで、壊れたフォント対応として追加リガチャが適用される場合もあり、
本仕様ではこうした例外的挙動は定義・上書きしません。
7.2.1. 草書体書記体系
UAが可能であれば、 草書体書記体系に対して 配分する追加スペースをその文字列全体の草書的伸長(またはマイナス値の場合は圧縮)として変換し、 実質的に同じ合計拡張(または圧縮)となるようにしてletter spacingを適用してもよいです。 そうでない場合、 UAが草書体書記体系のテキストを 草書的接合を壊さずに拡張できない場合は、 その書記体系の組版文字種単位間に間隔を適用してはならず (letter-spacingの観点では各単語を1つの組版文字種単位として扱う)、 どちらも結果的に文字間隔はゼロとなりますが、 前者ではテキストを伸ばす感覚が保たれます。
| — | 元のテキスト | |
| BAD | すべての文字間に均等にスペースを分配。草書的接合が壊れていることに注意! | |
|---|---|---|
| OK | letter-spacing総量を組版的に適切な草書的伸長で分配。 結果のテキスト長は均等分配例と同じ。 | |
| OK | アラビア文字間でletter-spacingを抑制。 非アラビア文字(スペースなど)にはletter-spacingが適用されている点に注意。 | |
| BAD | 接合しない文字間だけletter-spacingを適用。 組版的な色彩が歪み、単語境界が分かりづらくなる。 |
注: テキストの正しい草書的伸長・圧縮は 書記体系、書体、言語、単語内・行内位置、実装の複雑さ、フォントの機能、カリグラフィの好みなどによって異なり、 場合によっては不可能なこともあります。 短縮リガチャ、スワッシュ字形、文脈形、伸長字形(U+0640 ـ ARABIC TATWEEL)や その他マイクロタイポグラフィを使うことが含まれる場合もあります。 これらの効果の詳細規則はCSSの範囲外です。 著者は、相互運用性のない結果を許容できない限り 草書体書記体系へのletter-spacingの適用を避けるべきです。
7.3. 要素境界をまたぐ字形調整
以下のいずれかが、2つの組版文字単位を分離するボックス境界で真の場合、 字形調整はインラインボックス境界で分断されなければなりません:
書式に実効変更がない場合、 または唯一の書式変更が字形に影響しない場合(text decorationの適用のみなど)は、 字形調整はインラインボックス境界で分断してはなりません。
それ以外の場合でも合理的かつ可能であれば、 字形調整はインラインボックス境界をまたいで分断しないべきです(フォント技術の制約に依存)。
合理的だが現実的でない例は、 両側20文字の文脈に応じて字形を選ぶフォントの場合で、 対象文字列の前後すべてのテキストを 書式変更をまたいで渡すのは複雑です。 UAはこうしたケースも処理できるかもしれませんが、 必須でも典型でもないので必須ではありません。
不可能な例は、 単語「and」の途中でフォントウェイトが変わる場合で、 フォントが「and」の3文字をリガチャでアンパサンド(&)に置き換える場合などです。
8. 行端処理
行端処理は、 行のインデント(text-indent)や 行頭・行末での内容の計測(hanging-punctuation)を制御します。
8.1. 最初の行のインデント: text-indentプロパティ
| 名前: | text-indent |
|---|---|
| 値: | [ <length-percentage> ] && hanging? && each-line? |
| 初期値: | 0 |
| 適用対象: | ブロックコンテナ |
| 継承: | yes |
| パーセンテージ: | ブロックコンテナ自身のインライン軸の内寸参照 |
| 算出値: | 算出された<length-percentage>値+指定キーワード |
| 正規化順序: | 定義に従う |
| アニメーション型: | 算出値型ごと |
このプロパティは、ブロック内インライン内容の行に適用するインデント量を指定します。 インデントは、行ボックスの開始端に適用されるマージンとして扱われます。
each-lineやhangingキーワードで 別途指定されない限り、 要素の最初の整形済み行のみが影響します。[CSS-PSEUDO-4] 例えば、匿名ブロックボックスの最初の行は、 親要素の最初の子である場合のみ影響します。
値の意味は以下の通りです:
- <length>
- インデント量を絶対長で指定します。
- <percentage>
-
インデント量をブロックコンテナ自身の論理幅のパーセンテージで指定します。
パーセンテージは内在サイズ寄与の計算時には0として扱い、 レイアウト時には常に通常通り解決されます。
注: これにより要素がオーバーフローすることがあります。 パーセンテージインデントと内在サイズを併用するのは推奨されません。
- each-line
- インデントは各ブロックコンテナの最初の行と 強制改行後の各行に適用されます(ソフト折返し後の行には適用されません)。
- hanging
- 影響する行を逆転します。
text-alignがstart、 text-indentが5emで、 左から右へのテキストかつfloatなしの場合、最初の行は5emだけ内側から始まります:
Since CSS1 it has been possible to indent the first line of a block element 5em by setting the 'text-indent' property to '5em'.
hangingキーワードを追加すると、 最初の行は端揃えになり、その他の行が5emインデントされます:
In CSS3 we can instead indent all other
lines of the block element by 5em
by setting the 'text-indent' property
to 'hanging 5em'.
For example, in the middle of
this paragraph is an equation,
which is centered:
x + y = z
The first line after the equation
is flush (else it would look like
we started a new paragraph).
ただし、詩やコードなどでは、折り返しが発生する各行をインデントするのが適切な場合もあります。 次の例ではtext-indentに3em hanging each-lineを指定し、 詩の3行目がソフトラップでブロック右端でぶら下げインデントされます:
In a short line of text There need be no wrapping, But when we go on and on and on and on, Sometimes a soft break Can help us stay on the page.
注: text-indentプロパティは継承されるため、 ブロック要素で指定した場合は子のinline-block要素にも影響します。 そのため、text-indent: 0を display: inline-block要素に明示するのがしばしば賢明です。
8.2. 行端のぶら下げグリフ
行の開始または終了端にあるグリフがぶら下げされる場合、 行内容のフィット・整列・両端揃えの計算には考慮されません。 行の整列や両端揃えによっては、 記号が行ボックス外に配置されることがあります。 ぶら下げグリフは、 内在サイズ(min-contentサイズや max-contentサイズ)や それに由来するサイズ計算時にも考慮されません。 (この計測とカーニングの相互作用は現状UA定義です。CSSWGは助言を歓迎します。)
ぶら下げグリフは、親のインラインボックス内に収まり、 両端揃えにも参加しますが、 行内に収まる内容量・両端揃えの伸縮量・行ボックス内での整列位置の計算時には 文字幅が無視されます。 実質的に、ぶら下げグリフの文字幅は、 影響を受ける親インラインボックスの 追加負のマージンとして再解釈され、 行のレイアウト自体は通常通り行われます。 はみ出したぶら下げグリフは、 通常インクオーバーフローとして扱われ、 不要なスクロールバーを防ぎますが、 UAは編集可能な場合や他の状況で スクロール可能なオーバーフローとして扱っても構いません。[CSS-OVERFLOW-3]
行末のグリフが 条件付きぶら下げとなる場合もあります: 両端揃え前に行内に収まらない場合のみぶら下げします。 行内容のフィット計算には考慮されませんが、 収まらない部分はぶら下げとみなされます。 条件付きぶら下げグリフは min-contentサイズや 派生サイズ計算時には無視されますが、 max-contentサイズや 派生サイズでは考慮されます。
ぶら下げ可能なグリフの端に インライン軸方向の非ゼロborderやpaddingがある場合、 ぶら下げは無効化されます。 例えば、インラインボックス末尾にpaddingがある場合、 文末のピリオドは行端でぶら下げされません。
複数の隣接グリフが同時にぶら下げされることもありますが、 ぶら下げできるグリフ数には制限(例:各端で最大1つの句読点のみぶら下げ可能など)を設けても構いません。
8.2.1. ぶら下げ句読点: hanging-punctuationプロパティ
| 名前: | hanging-punctuation |
|---|---|
| 値: | none | [ first || [ force-end | allow-end ] || last ] |
| 初期値: | none |
| 適用対象: | テキスト |
| 継承: | yes |
| パーセンテージ: | n/a |
| 算出値: | 指定キーワード |
| 正規化順序: | 定義順 |
| アニメーション型: | 離散 |
このプロパティは、句読点(もし存在すれば)がぶら下げされて行ボックス外(もしくはインデント部)に配置されるかどうかを、行頭・行末ごとに制御します。
注: ブロックコンテナのpaddingが不十分な場合、hanging-punctuationによりオーバーフローが発生することがあります。
値の意味は以下の通りです:
- none
- いかなる句読点もぶら下げされません。
- first
- 要素の最初の整形済み行の行頭にある括弧・引用符・全角スペースはぶら下げされます。 UnicodeカテゴリPs, Pf, Piの全文字、 ASCII引用符U+0027 '(APOSTROPHE)とU+0022 "(QUOTATION MARK)、 および全角スペースU+3000が対象です。
- last
- 要素の最終整形済み行の行末にある括弧・引用符はぶら下げされます。 UnicodeカテゴリPe, Pf, Piの全文字、 ASCII引用符U+0027 '(APOSTROPHE)とU+0022 "(QUOTATION MARK)が対象です。
- force-end
- 行末の終止符・コンマがぶら下げされます。
- allow-end
- 行末の終止符・コンマは条件付きぶら下げされます。
各行端でぶら下げできる句読点は最大1文字までです。
終止符・コンマでぶら下げ可能なものは以下を含みます:
| U+002C | , | コンマ |
| U+002E | . | ピリオド |
| U+060C | ، | アラビアコンマ |
| U+06D4 | ۔ | アラビアピリオド |
| U+3001 | 、 | 全角コンマ |
| U+3002 | 。 | 全角ピリオド |
| U+FF0C | , | 全角コンマ |
| U+FF0E | . | 全角ピリオド |
| U+FE50 | ﹐ | 小コンマ |
| U+FE51 | ﹑ | 小全角コンマ |
| U+FE52 | ﹒ | 小ピリオド |
| U+FF61 | 。 | 半角全角ピリオド |
| U+FF64 | 、 | 半角全角コンマ |
UAは他の文字も適宜追加しても構いません。
注: UAが他の文字を追加する場合は、作業部会へ通知をお願いします。

p{ text-align : justify; hanging-punctuation : allow-end; }

p{ text-align : justify; hanging-punctuation : force-end; }
allow-endでは1行目末尾の句読点はぶら下げされません(収まるため)。 一方force-endを使うと強制的にぶら下げされます。 両端揃え時はぶら下げ句読点を除外して行を測定するので、 行が拡張されると句読点が行外に押し出されます。
8.3. 双方向性と行ボックス
行ボックスの開始側と終了側は、 行ボックスのインライン基底方向によって決定されます。 通常は一致しますが、 インライン基底方向は 行ボックス自身のものであり、 包含ブロックや 双方向段落のものとは異なります。 行ボックスのインライン基底方向は、 text-align-all、 text-align-last、 text-indent、 hanging-punctuationなど、 内容の端に対する位置や整列に影響します。 インライン内容の書式や順序には影響せず、 (これはUnicode双方向アルゴリズムを CSS Writing Modesで適用することで制御されます [UAX9] [CSS-WRITING-MODES-4])。
ほとんどの場合、行ボックスのインライン基底方向は その包含ブロックの算出された directionで決まります。 ただし、包含ブロックがunicode-bidi: plaintextの場合[CSS-WRITING-MODES-4]:
- 双方向段落(行ボックスが属する、その内容を保持する段落)が 強い方向性を持つ場合、行ボックスのインライン基底方向はその方向になります。
- 行ボックスが空(atomic inlinesや改行以外の文字を含まない等)で強い方向性がない場合は、 直前の行ボックス(あれば)から継承し、 含むブロックの最初の行なら そのブロックのdirectionプロパティから決まります。 (この結果、RTL行ボックスの内容がLTR基底方向になることもあります。)
<block>が開始揃えの整形済みブロック(display:
block; white-space: pre; text-align: start)と仮定すると、
1行ごとに右揃え・左揃えが交互になります:
< block style = "unicode-bidi: plaintext" > français فارسی français فارسی français فارسی</ block >
< para style = "display: block; direction: rtl; unicode-bidi:plaintext" > “< quote style = "unicode-bidi:plaintext" > שלום!</ quote > ”, they said.</ para >
< textarea style = "direction: rtl; unicode-bidi:plaintext" > Hello!</ textarea >
unicode-bidi: plaintextのため、 "Hello!"はLTRで組版され(感嘆符は右端)、 左揃えになります。 含むブロックのRTLdirectionは無視されます。 空行もLTRになり、キャレットは左端に出現すべきです。 最初の空行は直前行がないため、包含ブロックのRTL方向を継承し右揃えになります。
付録A: テキスト処理の順序
この付録は規範的です。
以下はテキスト処理の順序を定義します。 (結果が同じレイアウトになる限り、実装はこの順序に拘束されません。)
- 空白処理パートI(折返し前)
- テキスト変換
- 縦組み合成 [CSS-WRITING-MODES-4]
- 文字方向 [CSS-WRITING-MODES-4]
- テキスト折返し(各行で適用):
- 両端揃え(グリフ選択・折返しにも影響し得るため、ステップに戻る場合あり)
- テキスト整列
付録B: プレーンテキストへの変換
この付録は規範的です(プレーンテキストへのコピー&ペースト操作時)。
CSSでレンダリングされた文書をプレーンテキスト形式に変換する際は、次のことが期待されます:
- text-transformプロパティは効果を持たない。
- § 4.1.1 フェーズI: 折りたたみと変換が適用され、 折りたたみ可能な空白が ブロックの先頭や 強制改行直後に連続する場合は 削除される。
付録C: UAデフォルトスタイルシート
この付録は参考です。HTMLのUAデフォルトスタイルシート実装の参考のためですが、 UA開発者は自由に無視や変更して構いません。
付録D: 書記体系と間隔
この付録は規範的です。
組版挙動は言語ごとに多少異なりますが、 書記体系ごとには大きく異なります。 この付録ではUnicode 6.0における代表的な書記体系について、 両端揃えや間隔挙動で分類します。 カテゴリの説明は記述的であり規定的ではありません。 判定基準は両端揃え機会の優先順位です。
- ブロックスクリプト
- CJKおよび拡張として全てのWide文字
(East Asian Width [UAX11])。
以下のUnicode書記体系が含まれます:
ボポモフォ、漢字、ハングル、ひらがな、カタカナ、イ語。
東アジア幅プロパティが
WideやFullwidthの文字も含みますが、Ambiguousは書記体系が中国語、 韓国語、 日本語の場合のみ含みます。 - クラスタ型スクリプト
- クラスタ型スクリプトは 離散的な単位を持ち、 単語境界のみで改行されますが、 可視の単語区切りは使いません。 主にスペースを伸ばして両端揃えしますが、 行間隔も柔軟に許容します。 このカテゴリには、以下のUnicode書記体系などが含まれます: クメール語、 ラオ語、 ミャンマー語、 新タイ・ルー語、 タイ・レー語、 タイ・タム語、 タイ・ベト語、 タイ語
- 草書体書記体系
-
草書体書記体系は、両端揃えやletter-spacingで
文字間に隙間を許さない。
以下のUnicode書記体系が該当:
アラビア語、
ハニフィ・ロヒンギャ語、
マンダイ語、
モンゴル語、
エヌコ語、
ファグス・パー語、
シリア語
注: ベースライン接続を持つインド系書記体系(デーバナーガリーやグジャラートなど)は草書体書記体系ではなく、 文字間の隙間を許容します。 インド組版要件参照。[ILREQ]
UAはUnicodeサポート更新時にこのリストも更新し、 未符号化の草書体書記体系も将来のUnicodeで扱えるようにし、 必要ならCSSWGへ本仕様の更新依頼をしてください。
付録E: 文字とプロパティ
この付録は規範的です。
Unicodeは、CSS組版で参照される4つの符号位置レベルのプロパティを定義しています:
- 東アジア幅プロパティ
- Unicode Standard Annex #11 [UAX11]で定義され、
Unicode Character Database [UAX44]で
East_Asian_Widthプロパティとして提供されています。 - 一般カテゴリ
- Unicode Standard Annex #44 [UAX44]で定義され、
Unicode Character Database [UAX44]で
General_Categoryプロパティとして提供されています。 - スクリプトプロパティ
- Unicode Standard Annex #24 [UAX24]で定義され、
Unicode Character Database [UAX44]で
Scriptプロパティとして提供されています。 (UAはこのマッピングにScriptExtensions.txtの割り当ても含めなければなりません。) - 縦書き方向プロパティ
- Unicode Standard Annex #50 [UAX50]で定義され、 Unicode Character Database [UAX44]で Vertical_Orientationプロパティとして提供されています。
Unicodeは個々の符号位置に対するプロパティを定義していますが、 CSS Textでは組版文字単位のプロパティを判定する必要がある場合もあります。 CSS Textの目的では、 組版文字単位のプロパティは、 その最初の書記素クラスタのベース文字によって与えられます(例外は2つ):
- 囲み記号(Enclosing Mark,Me)で Commonスクリプトになる書記素クラスタは、 Commonスクリプトの他の記号(So)とみなされます。 Unicodeプロパティは置換文字(U+FFFD)と同じものとします。
- スペース区切り(Zs)をベースとする書記素クラスタは、 修飾記号(Sk)とみなされます。 東アジア幅プロパティはベースに従い、 その他のプロパティは並びの最初の結合文字から取得します。
付録F: コンテンツの書記体系識別
この付録は規範的です。
ほとんどの言語には推奨書記体系がありますが、
複数を持つ言語もあり、
多くは他の書記体系に転写可能です。
例えば、ほとんどの言語に少なくとも1つラテン転写があり、
ラテン書記体系で記述できます。
転写テキストは通常、書記体系の組版慣習に従います。
例えば日本語の「ローマ字」や中国語のピンインはラテン文字と単語間スペースを用い、
ラテン系の改行・両端揃えルールに従います。
別の例として、歴史的な表意韓国語(ko-Hani)は単語間スペースを使わず、
現代韓国語ではなく中国語に近い組版が求められます。
HTMLや他の文書言語で言語識別にBCP47タグを使い
コンテンツ言語を宣言する場合、
著者はスクリプトサブタグで非標準書記体系の利用を明示できます。[BCP47] 例えば、ラテン書記体系で記述された非ラテン系言語には
-Latnスクリプトサブタグを追加できます(例:日本語ローマ字ならja-Latn)。
他の書記体系にも対応するサブタグがあり、
ISOのCode for the Representation of Names of ScriptsやISO15924スクリプトタグレジストリを参照してください。[ISO15924]
zh-Latn- 中国語(ラテン転写)
ko-Hani- 韓国語(漢字表記)
tr-Arab- トルコ語(アラビア書記体系)
mn-Cyrl- モンゴル語(キリル書記体系)
mn-Mong- モンゴル語(伝統的モンゴル書記体系)
ただし、BCP47スクリプトサブタグは
書記体系が明確に1つと紐付く言語には通常使われず(実際推奨されません)、
その書記体系は特別な指定がなければ暗黙的に推定されます。[BCP47] IANAは各言語の主な書記体系を
language subtag
registryのSuppress-Script欄で管理しています。
注: 言語タグ付けの詳細は 国際化ワーキンググループの 「HTMLとXMLの言語タグ」や 「言語タグの選び方」を参照してください。
書記体系が明示されていない場合、 UAは宣言されたコンテンツ言語の 最も一般的な書記体系を、 改行や両端揃えなど言語依存の組版挙動に使うべきです。 ただし、著者が別の書記体系を明示した場合はUAはそれを仮定してはなりません。 UAが特定言語・書記体系組み合わせの知識を持たない場合は、 宣言された書記体系の組版慣習(必要なら他言語の慣習を仮定)を使うべきで、 宣言言語の慣習を未指定書記体系に適用してはなりません。
言語と主書記体系の詳細な対応表は本書の範囲外です。 ただしUAは、少なくとも以下を仮定しなければなりません:
- コンテンツ言語が中国語で 書記体系が未指定の場合、 または任意のコンテンツ言語で 書記体系が Hant、Hans、Hani、Hanb、 BopoのISOスクリプトコードで指定された場合、 書記体系は中国語です。
- コンテンツ言語が日本語で 書記体系が未指定の場合、 または任意のコンテンツ言語で 書記体系が Jpan、Hrkt、Hira、 KanaのISOスクリプトコードで指定された場合、 書記体系は日本語です。
- コンテンツ言語が韓国語で 書記体系が未指定の場合、 または任意のコンテンツ言語で 書記体系が Kore、Hang、 JamoのISOスクリプトコードで指定された場合、 書記体系は韓国語です。
-
書記体系は
不明とみなされるのは、
コンテンツ言語自体が不明な場合か、
書記体系が明示的に不明と指定された場合のみです。
注: 書記体系情報が省略されているだけの場合で コンテンツ言語が宣言されているなら、 書記体系は暗黙的に推定され、不明ではありません。
付録G: 小書き仮名の対応表
この付録は規範的です。
| 小書き | 通常サイズ |
|---|---|
| ぁ U+3041 | あ U+3042 |
| ぃ U+3043 | い U+3044 |
| ぅ U+3045 | う U+3046 |
| ぇ U+3047 | え U+3048 |
| ぉ U+3049 | お U+304A |
| ゕ U+3095 | か U+304B |
| ゖ U+3096 | け U+3051 |
| 𛄲 U+1B132 | こ U+3053 |
| っ U+3063 | つ U+3064 |
| ゃ U+3083 | や U+3084 |
| ゅ U+3085 | ゆ U+3086 |
| ょ U+3087 | よ U+3088 |
| ゎ U+308E | わ U+308F |
| 𛅐 U+1B150 | ゐ U+3090 |
| 𛅑 U+1B151 | ゑ U+3091 |
| 𛅒 U+1B152 | を U+3092 |
| ァ U+30A1 | ア U+30A2 |
| ィ U+30A3 | イ U+30A4 |
| ゥ U+30A5 | ウ U+30A6 |
| ェ U+30A7 | エ U+30A8 |
| ォ U+30A9 | オ U+30AA |
| ヵ U+30F5 | カ U+30AB |
| ㇰ U+31F0 | ク U+30AF |
| ヶ U+30F6 | ケ U+30B1 |
| 𛅕 U+1B155 | コ U+30B3 |
| ㇱ U+31F1 | シ U+30B7 |
| ㇲ U+31F2 | ス U+30B9 |
| ッ U+30C3 | ツ U+30C4 |
| ㇳ U+31F3 | ト U+30C8 |
| ㇴ U+31F4 | ヌ U+30CC |
| ㇵ U+31F5 | ハ U+30CF |
| ㇶ U+31F6 | ヒ U+30D2 |
| ㇷ U+31F7 | フ U+30D5 |
| ㇸ U+31F8 | ヘ U+30D8 |
| ㇹ U+31F9 | ホ U+30DB |
| ㇺ U+31FA | ム U+30E0 |
| ャ U+30E3 | ヤ U+30E4 |
| ュ U+30E5 | ユ U+30E6 |
| ョ U+30E7 | ヨ U+30E8 |
| ㇻ U+31FB | ラ U+30E9 |
| ㇼ U+31FC | リ U+30EA |
| ㇽ U+31FD | ル U+30EB |
| ㇾ U+31FE | レ U+30EC |
| ㇿ U+31FF | ロ U+30ED |
| ヮ U+30EE | ワ U+30EF |
| 𛅤 U+1B164 | ヰ U+30F0 |
| 𛅥 U+1B165 | ヱ U+30F1 |
| 𛅦 U+1B166 | ヲ U+30F2 |
| 𛅧 U+1B167 | ン U+30F3 |
| ァ U+FF67 | ア U+FF71 |
| ィ U+FF68 | イ U+FF72 |
| ゥ U+FF69 | ウ U+FF73 |
| ェ U+FF6A | エ U+FF74 |
| ォ U+FF6B | オ U+FF75 |
| ッ U+FF6F | ツ U+FF82 |
| ャ U+FF6C | ヤ U+FF94 |
| ュ U+FF6D | ユ U+FF95 |
| ョ U+FF6E | ヨ U+FF96 |
プライバシーに関する考慮事項
この現行標準は、ユーザーがインストールしているハイフネーションおよび改行辞書を漏洩します。
セキュリティに関する考慮事項
この現行標準は新たなセキュリティ上の考慮事項を導入しません。
謝辞
この現行標準は以下の方々の協力なしには実現できませんでした: Addison Phillips, Aharon Lanin, Alan Stearns, Ambrose Li, Arnold Schrijver, Arye Gittelman, Ayman Aldahleh, Ben Errez, Bert Bos, Chris Lilley, Chris Pratley, Chris Thrasher, Chris Wilson, Dave Hyatt, David Baron, Emilio Cobos Álvarez, Eric LeVine, Etan Wexler, Frank Tang, Håkon Wium Lie, IM Mincheol, Ian Hickson, James Clark, Javier Fernandez, John Daggett, Jonathan Kew, Ken Lunde, Laurie Anna Edlund, Marcin Sawicki, Martin Dürst, Martin Heijdra, Masafumi Yabe, Masayasu Ishikawa, Michael Jochimsen, Michel Suignard, Mike Bemford, Myles Maxfield, Nat McCully, Paul Nelson, Rahul Sonnad, Richard Ishida, Shinyu Murakami, Stephen Deach, Steve Zilles, Takao Suzuki, Tantek Çelik, Xidorn Quan, Yaniv Feinberg.
変更点
最近の変更
以下の規範的な変更が 2023年9月版現行標準草案以降に加えられました:
-
text-align-lastの算出値行を修正しました。 (Issue 7331)
-
置換要素周りのソフト折返し機会の曖昧さを解消しました。 (Issue 9964)
2文字間の境界で定義されるソフト折返し機会 やatomic inlines間 の場合、 2文字の最近傍共通祖先のwhite-spaceプロパティが折返し制御します。
以下の規範的な変更が 2023年2月版現行標準草案以降に加えられました。
-
付録G:小書き仮名の対応表をUnicode 15.0に更新しました。 (Issue 8442)
-
NBSP以外のUnicode非調整可能改行制御はatomic inline規則より優先されることを明確化。 (Issue 8972)
Web互換性のため、 置換要素や他のatomic inlineの前後には ソフト折返し機会があります。 隣接する文字が通常抑制する場合でも
たとえば含めて U+00A0 NO-BREAK SPACEの前後にも機会が存在します。 ただし、U+00A0 NO-BREAK SPACE以外では、 Unicode GL, WJ, ZWJ改行クラスに属する文字とatomic inlineの間には ソフト折返し機会があってはなりません。[UAX14]
以下の規範的な変更が 2020年12月版現行標準草案以降に加えられました。
-
hanging-punctuation: firstで U+3000全角スペースのぶら下げを許可し、 プレーンテキストのインデント習慣に対応しました。 (Issue 2462)
-
distributeは inter-characterに算出されることを規定。 distributeは レガシー値エイリアスとして実装してもよい。 (Issue 6156, Issue 7322)
-
言語固有のハイフネーション規則は明示的なハイフネーション機会にも適用されることを明確化。 (Issue 5973)
単語内にハイフネーション機会を明示する文字がある場合のみ 単語がハイフネーションされます。 UAは適切な言語固有のハイフン文字を使用し、 同じ箇所で自動ハイフネーション時と同様に綴り変更も適用すべきです。
-
match-parentを ルート要素で指定した場合、 startに算出することを規定。 (Issue 6542)
-
text-transformに関する 著者向け助言を規範的な勧告としました。 (Issue 8279)
注: text-transformプロパティは表示層にのみ影響し、 セマンティックな目的の正しい大文字小文字は ソース文書に記述されるべきです。助言: 著者はtext-transform にセマンティックな目的を依存してはならず、 正しい大文字小文字や意味は ソース文書のテキストとマークアップで表現する必要があります。
その他、若干の編集上の修正が加えられています。
以前の変更
2020年・2019年の現行標準草案以前の変更点は 過去の変更一覧や 2013年〜2020年コメント一覧も参照してください。