1. はじめに
このモジュールはCSSの組版制御について説明します。 つまり、ソーステキストを整形し、行折返しされたテキストへと変換するCSSの機能です。 様々なCSSプロパティが、大文字小文字変換、空白の折畳み、テキストの折返し、行分割規則やハイフネーション、整列と均等割り付け、字間、 そしてインデントを制御します。 レベル3からの追加点については、レベル3以降の追加も参照してください。
下線やアンダーライン、圏点、 シャドウなどのテキスト装飾機能 (以前は本モジュールの一部でした)は CSSテキスト装飾モジュールで扱われます。[CSS-TEXT-DECOR-3]
双方向および縦書きテキストについては CSS書字方向モジュールで扱われます。[CSS-WRITING-MODES-4]。
世界中の様々な言語や書記体系の組版要件については、 Internationalization Working Groupの Language Enablement Indexにて 詳しく確認できます。[TYPOGRAPHY]
1.1. モジュール間の相互作用
このモジュールは、CSSテキスト装飾モジュール と共に、Cascading Style Sheets Level 2 第16章で定義されたテキストレベルの機能を拡張・置き換えます。 [CSS-TEXT-DECOR-3] [CSS2]
以下に定義される用語だけでなく、 この仕様で使用されている他の用語や概念は Cascading Style Sheets Level 2や CSS書字方向モジュールで定義されています。 [CSS2] および [CSS-WRITING-MODES-4]。
1.2. 値の定義
この仕様では、CSSプロパティ定義規約([CSS2])に従い、 値定義構文([CSS-VALUES-3])を使用しています。 この仕様で定義されていない値型はCSS Values & Units [CSS-VALUES-3]で定義されています。 他のCSSモジュールとの組み合わせにより、これらの値型の定義が拡張される場合があります。
プロパティ定義に記載されている値型以外にも、 この仕様で定義される全てのプロパティは CSS全体キーワードもプロパティ値として受け入れます。 可読性のため、これらは明示的には繰り返し記載していません。
1.3. 言語と組版
最適な組版動作のため、著者はコンテンツに正確な言語タグを付与するべきです。
多くの組版効果は言語的文脈によって異なります。 言語や書記体系の慣習は 行分割、ハイフネーション、均等割り付け、グリフ選択、 その他多くの組版効果に影響します。 CSSでは、言語特有の組版調整は コンテンツ言語が既知(宣言済み)の場合のみ適用されます。 そのため、より高品質な組版には、著者が文書内テキストの言語的文脈をUAに正しく伝えることが必要です。
コンテンツ言語とは、 要素が所属すると宣言されている(人間の)言語のことです。 文書言語の規則に従います。 コンテンツ言語が不明な場合もあります。 例えばタグ付けされていないコンテンツや、 言語タグ付け機構のない文書言語のコンテンツは、 コンテンツ言語が不明とみなされます。
注記: 著者はコンテンツ言語を、
HTMLではグローバルlang属性、
XMLではユニバーサルxml:lang属性で宣言できます。
HTML要素のコンテンツ言語決定規則(HTML)や
XML要素のコンテンツ言語決定規則(XML 1.0)も参照してください。
[HTML] [XML10]
コンテンツ言語に宣言された要素は、 その要素で用いられる特定の書記体系も識別します。 これをコンテンツ書記体系と呼びます。 文書言語による コンテンツ言語識別機構により、 この情報が明示または暗黙的に決定される場合があります。 規定の詳細は付録F: コンテンツ書記体系の識別を参照してください。
注記: 1つの言語に複数の書記体系伝統が存在する場合があります。 また、他言語の書記体系に翻字される場合もあります。 UAが適切に調整できるよう、著者はサブタグで明示してください。
ko)は
ハングル(-Hang)、
漢字(-Hani)、
またはその組み合わせ(-Kore)で書かれます。
漢字のみで書かれた歴史的文書では
単語間のスペースを使わず、
現代中国語に近い体裁で書式設定されます。
つまり、組版上は ko-Hani は zh-Hant に近い挙動をし、
ko(ko-Kore)とは異なります。
日本語(ja)は通常ひらがな(-Hira)、
カタカナ(-Kana)、漢字(-Hani)を組み合わせた(-Japn)形で書かれますが、
特殊な目的(語学教材など)ではラテン文字(-Latn)で「ローマ字化」される場合もあり、
その際は日本語ではなく英語風に書式設定するべきです。
現代モンゴル語は、
キリル文字(-Cyrl、モンゴル国の公式)と
モンゴル文字(-Mong、中国内モンゴルで一般的)の2つの書記体系で書かれます。
これらは組版要件が大きく異なり、
キリル文字はラテン語やギリシャ語に似た挙動をし、
モンゴル文字はアラビア語や中国語の書式慣習の影響を受けます。
1.4. 文字と文字種
組版の基本単位は文字です。 しかし、書記体系は単純な英語アルファベットとは限らず、 文字の意味は 用途により異なります。 例えばハングル(韓国語書記体系)では、 1つの正方形の音節表記(例: 한=Han)を 1文字とみなすこともできます。 しかし、実際は複数の音素を表す文字(例: ㅎ=h, ㅏ=a, ㄴ=n) から構成されており、これらもそれぞれ文字とみなすことができます。
任意のエンコーディングにおけるコンピュータテキストの基本単位も文字と呼ばれます。 エンコーディング次第で、 1つのエンコード文字が、 完全な合成音節文字(例: 한)、 個々の音素文字(例: ㅎ)、 あるいは 基本字形(例: ㅇ)や 変化記号(例:発音変化を示す追加ストローク)などのより小さな単位に対応する場合もあります。
さらに、1つのエンコード文字は データストリーム内で1バイト以上で表現されることがあり、 プログラミング環境では1バイトも文字と呼ばれる場合もあります。
したがって、技術的な精密さが必要な場面では文字という用語は非常に曖昧です。
テキストレイアウトにおいては、組版文字単位をテキストの基本単位とします。 テキストレイアウトの範囲でも、適用する文字単位は操作によって異なります。 例えば、行分割や字送りでは、 タイ文字U+0E33 ำ(THAI CHARACTER SARA AM)を含む文字列を分割する方法が異なりますし、 デーヴァナーガリーの合字子音の振る舞いはフォントによって異なる場合があります。 よって組版文字単位は 書記体系ごとの単位―ラテンアルファベットの文字(ダイアクリティカルマーク含む)、 ハングル音節、 漢字、 ミャンマー音節クラスターなど― 特定の組版操作(行分割、先頭文字効果、トラッキング、均等割り付け、縦組など)に対して不可分な単位です。
Unicode Standard Annex #29: Text Segmentation では組版文字単位に近い 書記素クラスタという単位が定義されています。 [UAX29] UAはUAX29で定義される 拡張書記素クラスタ(従来型ではなく)を 組版文字単位の基礎としなければなりません。 ただし、UAは組版慣習に合わせて定義を調整すべきであり― デフォルト規則が常に適切とは限らないため― 操作によっても調整が求められる場合があります。
注記: このような調整の規則はCSSの範囲外です。
- ミャンマー語やデーヴァナーガリーなど一部の書記体系では、 組版文字単位(均等割り付けや行分割)は 音節全体であり、 Unicodeの書記素クラスタを複数含む場合があります。[UAX29]
-
タイ語やラオ語など他の書記体系では、
行分割では組版文字がUnicodeの書記素クラスタと一致しますが、
字送りの場合は
Unicodeの書記素クラスタより
小さい単位が適切で、
分解や代替処理が必要になる場合があります。[UAX29]
例えば、タイ語「คำ」(U+0E04 + U+0E33)を字送り処理するには、 U+0E33をU+0E4D + U+0E32に分解し、 追加の字送りをU+0E32の前に挿入します: คํ า。
もう少し複雑な例では「น้ำ」(U+0E19 + U+0E49 + U+0E33)があります。 通常のタイ語形状処理ではU+0E33をU+0E4D + U+0E32に分解した後、U+0E4DをU+0E49と入れ替えて U+0E19 + U+0E4D + U+0E49 + U+0E32となります。 追加の字送りはU+0E32の前に挿入されます: นํ้ า。
- 縦組では調整が必要な場合もあります。 例えば直立テキストの組版では、 チベット語のtsekやshad記号は直前の書記素クラスタに結合され、 独立した組版文字単位として扱われません。[CSS-WRITING-MODES-4]
組版文字種単位(または本仕様の目的における文字種)は、 組版文字単位のうちLetterまたはNumber一般カテゴリに属するものです。 付録E: 文字とプロパティを参照し、 組版文字単位のUnicodeプロパティを判定してください。
要素境界で分割された組版文字単位のレンダリング特性は未定義です。 理想的には各部分がそれぞれの要素プロパティに従ってフォーマットされつつ、 組版文字単位全体として正しい形状・配置を維持すべきですが、 部分間のフォーマット差や使用フォント技術によっては 常に可能とは限りません。 このため、そのような組版文字単位は 境界のいずれか一方に属するか、両方に属する近似でレンダリングされる場合があります。 著者は書記素クラスタや合字を要素境界で分割すると 一貫性のない、または意図しない結果になる可能性があることに注意してください。
1.5. テキスト処理
CSSはUnicodeを基盤としています。[UNICODE] UnicodeをサポートするUAは、CSSで明示的に上書きされている場合を除き、Unicode Core Standardのすべての規範的要件を遵守しなければなりません。 Unicode以外のテキストエンコーディングモデルを基に実装されるUAも、適切なマッピングと類似の挙動を仮定することで、同じテキスト処理要件を満たすことが期待されます。
テキスト処理(空白処理、テキスト変換、行分割など)の隣接性判定、および本仕様全般においては、間に挟まるインラインボックス境界やフロー外要素は無視しなければなりません。 ただし、テキスト整形に関しては§ 8.7 要素境界をまたぐシェーピングを参照してください。
2. テキスト変形
2.1. 大文字小文字変換: text-transform プロパティ
| 名前: | text-transform |
|---|---|
| 値: | none | [capitalize | uppercase | lowercase ] || full-width || full-size-kana | math-auto |
| 初期値: | none |
| 適用対象: | text |
| 継承: | yes |
| パーセンテージ: | n/a |
| 算出値: | 指定キーワード |
| 正規順序: | n/a |
| アニメーション型: | 離散 |
このプロパティは、スタイル目的でテキストを変形します。 元のコンテンツには影響せず、プレーンテキストのコピー&ペースト操作にも影響してはなりません。
著者はtext-transformに意味的目的を依存してはなりません。 正しい大文字・小文字や意味は、ソース文書のテキストおよびマークアップに記述してください。
値の意味は以下の通りです:
- none
- 何も効果なし。
- capitalize
- 各単語の最初の組版文字種単位が小文字の場合、タイトルケースに変換します。他の文字には影響しません。
- uppercase
- すべての文字種を大文字にします。
- lowercase
- すべての文字種を小文字にします。
- full-width
- すべての組版文字単位を全角形にします。 対応する全角形が存在しない場合はそのままです。 この値は通常、ラテン文字や数字を漢字のように組版する場合に使われます。
- full-size-kana
- すべての小仮名を、同等の大仮名に変換します。 この値は主にルビ注釈テキストで使われ、小さなフォントサイズで可読性を補うために全ての小仮名を大きな仮名で描画したい場合に用いられます。
- math-auto
- MathML Core § 4.2 新しいtext-transform値を参照してください。
abbr : lang ( ja) { text-transform : full-width; }
注記: text-transformの目的は、 文書の意味に影響せずに、見た目上の大文字・小文字変換を可能にすることです。 特にtext-transformによる変換は情報損失を伴い、 テキストの意味が変化する可能性があります。 アクセシビリティの観点から見た目上の大小文字を伝える場合もありますが、 変形後のテキストが文書本来の意味を正確に表すとは限りません。
section > p:first-of-type::first-line{ text-transform : uppercase; }
この効果は、改行位置がレイアウトに依存するためソース文書に直接記述できません。 また、大文字化は意味的な区別を反映するものではなく、段落の読み方に影響を与える意図もないため、プレゼンテーション層でのみ使われます。
rt{ font-size : 50 % ; text-transform : full-size-kana; } :is ( h1, h2, h3, h4) rt{ text-transform : none; /* 大きな文字サイズでは解除 */ }
この変換により、小さい文字サイズでも仮名が見やすくなりますが、テキスト自体が歪められることに注意してください。 読者は適切な箇所で小仮名を頭の中で読み替える必要があります。これは、ラテン語碑文で全ての「U」が「V」に見える場合と似ています。
例えば、次のソースにtext-transform: full-size-kanaを適用すると、 注釈は「じゆう」(jiyū、「自由」の意味)と読まれますが、 本来「十」(じゅう、「十」の意味)の正しい読みと意味が失われます。
< ruby > 十< rt > じゅう</ ruby >
2.1.1. 変換ルール
capitalizeの場合、「単語」とみなす範囲はUA依存です。 判定には[UAX29]が推奨されていますが、必須ではありません。 フロー外要素やインライン要素境界はtext-transformの単語境界を導入してはならず、これらは単語境界判定時に無視します。
注記: 著者はcapitalizeによる 言語固有のタイトルケース規則(英語の冠詞除外など)への準拠を期待することはできません。
UAはUnicode文字の全てのケースマッピング(条件付き大文字・小文字規則含む)を、The Unicode StandardのDefault Case Algorithmsセクションで定義される通りに使用しなければなりません。[UNICODE] 要素のコンテンツ言語が、 文書言語規則に従い 既知の場合、適切な言語固有の規則も適用しなければなりません。 これには最低限、UnicodeのSpecialCasing.txtに記載された言語固有規則が含まれますが、これに限りません。
全角および半角形の定義は、
Unicode Standard Annex #11: East Asian
Widthに記載されています。[UAX11]
全角形へのマッピングは、Unicode Standard Annex #44: Unicode Character
Database内の
Decomposition_Mappingに<wide>や<narrow>タグが付与されている符号位置により定義されています。[UAX44]
<narrow>タグの場合は符号位置から分解(タグ除去)へのマッピング、<wide>タグの場合は分解(タグ除去)から元の符号位置へのマッピングとなります。
小仮名から大仮名へのマッピングは、付録G: 小仮名マッピングで定義されています。
2.2. 単語間の展開: word-space-transformプロパティ
| 名前: | word-space-transform |
|---|---|
| 値: | none | [ space | ideographic-space ] && auto-phrase? |
| 初期値: | none |
| 適用対象: | text |
| 継承: | yes |
| パーセンテージ: | N/A |
| 算出値: | 指定通り |
| 正規順序: | 文法通り |
| アニメーション型: | 離散 |
一部の言語や書記体系では、単語の区切り方にさまざまな方法があり、異なる区切り文字を使ったり、時には目に見える文字がない場合もあります。 このプロパティは、マークアップを変更せずに、著者がレンダリングスタイルを別のものに切り替えられるようにします。
- none
- このプロパティは何も効果を持ちません。
- space
- この要素の子展開可能区切りは、U+0020 SPACEに置換されます。
- ideographic-space
- この要素の子展開可能区切りは、U+3000 IDEOGRAPHIC SPACEに置換されます。
- auto-phrase
-
コンテンツ言語が既知であり、
UAがその言語の言語解析をサポートしている場合、
UAはフレーズ境界検出を行う必要があります。
単語区切り文字、その他スペース区切り、
またはU+200B ZERO WIDTH SPACEがその境界に既に存在しない場合、
UAは仮想展開可能区切りを挿入しなければなりません。
この値が省略された場合、 またはコンテンツ言語が不明の場合、 またはUAがその言語のフレーズ境界検出をサポートしていない場合、 仮想展開可能区切りはありません。
このプロパティの目的では、展開可能区切りは以下のいずれかです:
仮想展開可能区切りは、 UAがテキスト中で検出した構文上の境界であり、ソース文書に存在しない展開可能区切りを表します。 このプロパティ以外の効果はありません。
UAは展開可能区切りが強制改行の直前または直後(間のインラインボックス境界や、 関連するmargin/border/paddingは無視)にある場合、置換してはなりません。
注記: 仮想展開可能区切りはインラインボックス境界に参加する最も外側の要素に配置されるため、 インラインボックスの境界と仮想区切りが重なる場合、 親ボックスの使用値がword-space-transform: noneである場合、 その仮想展開可能区切りは展開されません。 親ボックスに配置されるためです。
text-transformと同様、このプロパティはスタイル目的でテキストを変形します。 元のコンテンツには影響せず、プレーンテキストのコピー&ペースト操作にも影響してはなりません。
大人向けの書籍とは異なり、日本の幼児向け書籍では、文章の区切りごとにスペースが入ることがあり、読みやすさを高めます。 ディスレクシアの方もこのスタイルの方が読みやすい傾向があります。
特別なスタイルがなければ、下記の文章は次のように表示されます。
< p > むかしむかし、< wbr > あるところに、< wbr > おじいさんと< wbr > おばあさんが< wbr > すんでいました。
むかしむかし、あるところに、おじいさんとおばあさんがすんでいました。
フレーズ区切りのスペースは、以下のCSSで実現できます。
p {
word-space-transform : ideographic-space;
}
むかしむかし、 あるところに、 おじいさんと おばあさんが すんでいました。
さらに一般的なバリエーションとして、許される改行位置をこれらのフレーズ境界のみに制限するものがあります。 同じマークアップでも、以下のCSSで簡単に実現できます。
p {
word-break : keep-all;
word-space-transform : ideographic-space;
}
むかしむかし、
ソースコードの可読性を高めるだけでなく、
U+200Bよりもwbr要素を使うことで
区切りをグループ分けすることもできます。
次の例では、
wbr要素が
単語区切りでは無印、
フレーズ区切りではclass p付きとなっています。
< p > らいしゅう< wbr > の< wbr > じゅぎょう< wbr > に< wbr class = p
> たいこ< wbr > と< wbr > ばち< wbr > を< wbr class = p
> もって< wbr > きて< wbr > ください。
このように、よく使われるフレーズ区切りのスペースだけでなく、 単語ごとのスペース(ディスレクシアの方が曖昧さを減らすため好む可能性が高い)、または フレーズ区切り+単語区切りの折返しなど、さまざまなバリエーションが可能です。
らいしゅう
p wbr.p {
word-space-transform : ideographic-space;
}
らいしゅう
p wbr {
word-space-transform : ideographic-space;
}
らいしゅう
p {
word-break : keep-all;
}
p wbr.p {
word-space-transform : ideographic-space;
}
らいしゅう
p {
word-break : keep-all;
}
p wbr {
word-space-transform : ideographic-space;
}
らいしゅう
2.3. 操作順序
複数の変形を適用する場合、次の順序で適用されます:
単語間スペース変形とテキスト変形は、§ 4.3.1 第I段階: 折畳みと変換の後、 § 4.3.2 第II段階: トリミングと配置の前に行われます。 つまり、full-widthは 保存された空白内でのみ スペース(U+0020)をU+3000 IDEOGRAPHIC SPACEに変換します。
注記: 付録A: テキスト処理の操作順序で定義されているように、 変形は行分割やその他の書式処理に影響します。
3. 空白と折返し: white-spaceプロパティ
| 名前: | white-space |
|---|---|
| 値: | normal | pre | pre-wrap | pre-line | <'white-space-collapse'> || <'text-wrap-mode'> || <'white-space-trim'> |
| 初期値: | normal |
| 適用対象: | text |
| 継承: | 個別プロパティ |
| パーセンテージ: | n/a |
| 算出値: | 指定キーワード |
| 正規順序: | n/a |
| アニメーション型: | 離散 |
このプロパティはwhite-space-collapse、text-wrap-mode、white-space-trimの略記です。 このプロパティは2点を指定します:
注記:この略記は継承可能・非継承プロパティ両方を組み合わせます。 問題がある場合はCSSWGへご連絡ください。
特に指定がない限り、省略されたロングハンドはその初期値に設定されます。
次の表は、略記の特別なキーワード値を 同等のロングハンド値に対応付ける規定のマッピングです。
| white-space | white-space-collapse | text-wrap-mode | white-space-trim |
|---|---|---|---|
| normal | collapse | wrap | none |
| pre | preserve | nowrap | none |
| pre-wrap | preserve | wrap | none |
| pre-line | preserve-breaks | wrap | none |
注記:場合によっては、保存された空白や他のスペース区切りが 行末でぶら下がりになることがあります。 これは内在サイズの計測に影響する場合があります。
次の参考表は、様々なwhite-space値の挙動をまとめたものです:
| 改行 | スペース・タブ | 折返し | 行末スペース | 行末他のスペース区切り | |
|---|---|---|---|---|---|
| normal | 折畳み | 折畳み | 折返し | 削除 | ぶら下がり |
| pre | 保持 | 保持 | 折返しなし | 保持 | 折返しなし |
| nowrap | 折畳み | 折畳み | 折返しなし | 削除 | ぶら下がり |
| pre-wrap | 保持 | 保持 | 折返し | ぶら下がり | ぶら下がり |
| break-spaces | 保持 | 保持 | 折返し | 折返し | 折返し |
| pre-line | 保持 | 折畳み | 折返し | 削除 | ぶら下がり |
4. 空白処理と制御文字
文書のソーステキストには、最終レンダリングに関係ない書式が含まれることがよくあります。 例えば、編集しやすいようにソースを区切って(行)分割したり、 空白文字としてインデント用のタブやスペースを追加するなどです。 CSSの空白処理により、著者はそのような書式の解釈を制御できます。 レンダリング時に保持するか、折畳んで削除するかを選択できます。 CSSの空白処理(white-space-collapse、 white-space-trimプロパティで制御)は、空白文字をレンダリング目的のみに解釈します。 元の文書データには影響しません。
注記:文書言語によっては、セグメントは特定の改行シーケンス(LFやCRLFなど)で区切られる場合や、
SGMLのRECORD-STARTやRECORD-ENDトークンなど、別の機構で区切られることもあります。
CSS処理においては、文書言語で定義された「セグメント区切り」または「改行シーケンス」、定義がなければテキスト内の各LF(U+000A)がセグメント区切りとみなされ、 white-spaceプロパティで指定された通りにレンダリング時解釈されます。
HTMLの場合、改行は 正規化され、DOMではLF(U+000A)で表現されます。 よって、HTML文書がDOMツリーとして表現される場合、各LF(U+000A)がセグメント区切りとみなされます。 [HTML] [DOM]
注記:多くのCSS実装では、HTML自体は直接スタイリングされません。 DOMツリーへと処理され、そこでスタイリングされます。 HTMLと異なり、DOMではキャリッジリターン(U+000D)に特別な意味はなく、セグメント区切りとして扱われません。 HTML以外の方法でDOMにキャリッジリターン(U+000D)が挿入された場合は、以下の定義通り扱われます。
注記:文書パーサはセグメント区切りの正規化だけでなく、 他のスペース文字の折畳みやマークアップ規則に従った空白処理も行う場合があります。 CSS処理はパース段階後に行われるため、 これらの文字をスタイリングのために復元することはできません。 したがって以下の挙動の一部はこの制限の影響を受け、UA依存の場合もあります。
注記:全てが折畳み可能な空白のみからなる匿名ブロックはレンダリングツリーから削除されます。 そのため、ブロック要素の周囲にあるそのような空白は折畳まれます。 詳細はCSS 2.1 §9.2.2.1 匿名インラインボックス参照。[CSS2]
制御文字(Unicodeカテゴリ
Cc)—タブ(U+0009)、LF(U+000A)、CR(U+000D)やセグメント区切りになるシーケンス以外—は、
UAがフォントに見えるグリフがなければ合成し、表示可能グリフとしてレンダリングしなければなりません。
その他はOther Symbols(So)一般カテゴリおよびCommonスクリプトと同様に扱います。
UAは制御文字専用フォントのグリフ、Control Picturesブロックの対応する記号グリフ、コードポイント値の可視表現、または他の方法で適切な可視グリフを生成しても構いません。
Unicodeの規定により、未対応Default_ignorable文字はテキストレンダリング時に無視されなければなりません。[UNICODE]
キャリッジリターン(U+000D)は、全ての点でスペース(U+0020)と同一に扱われます。
注記:HTML文書では、ソースコード中のキャリッジリターンは
パース段階で改行(LF)に変換されます
(HTML
§13.2.3.5 入力ストリームの前処理および改行の正規化定義参照。Infra)よってCSSにはU+000D CARRIAGE RETURNとして現れません。[HTML] [INFRA])
ただし、エスケープシーケンス(
4.1. 空白の折畳み: white-space-collapseプロパティ
このセクションは現在議論中であり、今後の草案で変更される可能性があります。
| 名前: | white-space-collapse |
|---|---|
| 値: | collapse | discard | preserve | preserve-breaks | preserve-spaces | break-spaces |
| 初期値: | collapse |
| 適用対象: | text |
| 継承: | yes |
| パーセンテージ: | n/a |
| 算出値: | 指定キーワード |
| 正規順序: | 文法通り |
| アニメーション型: | 離散 |
このプロパティは空白を折畳むかどうか、どのように折畳むかを指定します。 各値の意味は空白処理規則に従って解釈されます:
- collapse
- この値はUAに対して、空白の連続した並びを1文字(または場合によっては文字なし)に折畳むよう指示します。
- preserve
- この値はUAに対して、空白の連続した並びを折畳まないよう指示します。セグメント区切り(改行など)は強制改行として保持されます。
- preserve-breaks
- collapseと同様に、 連続する空白文字は折畳みますが、 ソース内のセグメント区切りは強制改行として保持されます。
- preserve-spaces
- この値はUAが空白の連続を折畳まないようにし、
タブやセグメント区切りをスペースに変換します。
(この値はSVGの
xml:space="preserve"の挙動を表現するために意図されています。) - break-spaces
-
挙動はpreserveと同じですが、以下の点が異なります:
注記: この値は空白によるオーバーフローを完全に防ぐことはできません。 例えば行の長さが非常に短く、スペース1文字すら入らない場合はオーバーフローが不可避です。
- discard
-
この値はUAに対して、要素内の全ての空白を「捨てる」よう指示します。
行分割機会は保持されるべきか?"hide"値が必要か? 行分割機会を保持するならば、word-space-transform値へ置換すべきかもしれません。
空白処理によって削除・折畳まれなかった空白は保存された空白と呼びます。
次のスタイルルールはMathMLの空白処理を実装します:
@namespace m "http://www.w3.org/1998/Math/MathML";
m|* {
white-space-collapse: discard;
}
m|mi, m|mn, m|mo, m|ms, m|mtext {
white-space-trim: discard-inner;
}
4.2. 空白のトリミング: white-space-trimプロパティ
| 名前: | white-space-trim |
|---|---|
| 値: | none | discard-before || discard-after || discard-inner |
| 初期値: | none |
| 適用対象: | インラインボックスおよびブロックコンテナ |
| 継承: | no |
| パーセンテージ: | n/a |
| 算出値: | 指定キーワード |
| 正規順序: | 文法通り |
| アニメーション型: | 離散 |
このプロパティは要素の先頭・末尾でトリミング動作を指定できます。 各値の意味は以下の通りです:
- discard-before
- この値はUAに対して、要素の直前の全ての折畳み可能な空白を折畳むよう指示します。
- discard-after
- この値はUAに対して、要素の直後の全ての折畳み可能な空白を折畳むよう指示します。
- discard-inner
- ブロックコンテナの場合、この値はUAに対して、要素の先頭から最初の非空白文字の直前までの最後のセグメント区切りを含めて全ての空白を除去し、 要素の末尾でも最後の非空白文字の後の最初のセグメント区切りから全ての空白を除去するよう指示します。 その他の要素では、先頭・末尾の全ての空白を除去します。
注記: 文書空白をwhite-space-trimで除去すると、テキスト内のソフト折返し機会の位置が変化します。
次のスタイルルールは、DT要素をソースで別行になっていてもカンマ区切りリストとしてレンダリングします:
dt { display: inline; }
dt + dt:before { content: ", "; white-space-trim: discard-before; }
次のスタイルルールは、整形済みブロックの開始/終了タグに隣接するソース書式空白を除去しますが、要素内容のインデントや途中の空白は除去しません:
pre { white-space: pre; white-space-trim: discard-inner; }
この結果、以下の2つのソースコードスニペットは:
< pre > some preformatted text</ pre >
< pre > some preformatted text</ pre >
some preformatted text
代わりにインライン要素に適用すると:
span { white-space: normal; white-space-trim: discard-inner; }
start[< span > some inline text</ span > ]end
start[< span > some inline text</ span > ]end
start[some inline text]end
white-space-trimの空白処理は、§4.3.1 第I段階: 折畳みと変換より前に行われます。
4.3. 空白処理規則
特に指定がない限り、 CSSにおける空白処理は 文書空白文字:スペース(U+0020)、タブ(U+0009)、およびセグメント区切りのみに影響します。
注記: 文書空白(文書内容の一部)として扱われる文字と CSS構文上の空白(CSSの文法の一部)として扱われる文字集合は必ずしも一致しません。 しかし、どちらにもスペース(U+0020)、タブ(U+0009)、改行(U+000A)が含まれるため、 多くの著者は違いに気づかないでしょう。
スペース(U+0020)とノーブレークスペース(U+00A0)の他にも、 Unicodeでは追加のスペース区切り文字がいくつか定義されています。[UNICODE] この仕様では、 Unicodeの一般カテゴリZsに属する文字のうち、 スペース(U+0020)とノーブレークスペース(U+00A0)以外を その他のスペース区切りと呼びます。
4.3.1. 第I段階: 折畳みと変換
注記: white-space-trimはこの段階より前に考慮されます。
各インライン
(匿名インラインも含む;
CSS 2.1 § 9.2.2.1
匿名インラインボックス[CSS2]参照)
がインライン整形コンテキスト内にある場合、空白文字は
行分割や
双方向並び替えの前に
以下のように処理されます。
双方向整形文字
(Bidi_Controlプロパティを持つ文字[UAX9])は無視して扱います:
- white-space-collapseが collapseまたはpreserve-breaksの場合、 空白文字は 折畳み可能とみなされ、 以下の手順で処理されます:
- white-space-collapseが preserve-spacesの場合、 各タブとセグメント区切りをスペースに変換する。
- white-space-collapseが preserveまたはpreserve-spacesの場合、 スペースの並びはノーブレークスペースの並びとして扱う。 ただし、ソフト折返し機会は 最大のスペース・タブ並びの末尾に生じる。 break-spacesの場合は、各スペースとタブの後にソフト折返し機会が生じる。
<ltr>A <rtl> B </rtl> C</ltr><ltr>要素は左から右への埋め込み、
<rtl>要素は右から左への埋め込みを表します。
white-spaceプロパティがnormalの場合、
空白処理モデルは以下の結果になります:
結果として2つのスペースが残り、 1つは左から右埋め込みレベルのAの後、 もう1つは右から左埋め込みレベルのBの後になります。 テキストはUnicode双方向アルゴリズムに従い並べ替えられ、 最終的には次のようになります:
A BC
AとBの間には2つのスペースがあり、 BとCの間にはスペースがありません。 この現象は、スペースを開始/終了タグ内ではなく要素外に配置し、 可能な限り暗黙的な双方向性に頼ることで回避できます。
4.3.2. 第II段階: トリミングと配置
その後、全体ブロックがレンダリングされます。 インラインは 双方向並び替えを考慮して配置され、 折返しはtext-wrap-modeやtext-wrap-styleプロパティで指定された通り行われます。 各行のレイアウト時:
- 行頭に並ぶ折畳み可能スペースは削除されます。
-
タブサイズが0の場合、保存された
タブはレンダリングされません。
それ以外の場合、各保存されたタブは、次のグリフの開始端が次のタブストップに揃うように水平方向にシフトして描画されます。
この距離が0.5ch未満なら、次のタブストップが使われます。タブストップは
タブサイズの整数倍の位置(保存されたタブの最近傍のブロックコンテナ祖先の内容端から)に現れます。
タブサイズはtab-sizeプロパティで与えられます。
注記:Unicodeのタブ(U+0009)と双方向性の関係規則も参照。[UAX9]
-
行末の折畳み可能スペースは削除され、
さらにcollapseまたはpreserve-breaksの
white-space-collapseプロパティを持つ
末尾のU+1680 OGHAM SPACE MARKも削除されます。
注記: Unicode双方向アルゴリズムのL1規則により、 行並び替え前の行末の折畳み可能スペースは並び替え後も行末に残ります。[UAX9] [CSS-WRITING-MODES-4]
-
行末に空白、その他のスペース区切り、
および保存されたタブの並びが残っている場合(双方向並び替え後[CSS-WRITING-MODES-4]):
- white-space-collapseが collapseまたはpreserve-breaksの場合、 UAはこの並びを(無条件で)ぶら下がりにする必要があります。
-
white-space-collapseがpreserveかつtext-wrap-modeがnowrapでない場合、
UAは(無条件で)この並びをぶら下がりにしなければなりません。
ただし後ろに強制改行が続く場合は、
条件付きぶら下がりにします。
また、オーバーフローする場合は文字送り幅を視覚的に折畳むこともできます。
注記: ぶら下がりを使うことで、選択・編集時に空白が見える利点があります。
-
white-space-collapseがbreak-spacesの場合、
スペース、タブ、その他のスペース区切りは
他の可視文字と同様に扱われます:
ぶら下がりにもならず送り幅も折畳まれません。
注記: このような文字はスペースを占有するため、 利用可能スペースや行分割制御に応じてオーバーフローするか折返しになります。
p {
white-space : pre-wrap;
width : 5 ch ;
border : solid 1 px ;
font-family : monospace;
text-align : center;
}
< p > 0</ p >
上記サンプルのレンダリング例:
最終スペースが強制改行前にあり、オーバーフローしないため ぶら下がらず、中央寄せも期待通り動作します。
p {
white-space : pre-wrap;
width : 3 ch ;
border : solid 1 px ;
font-family : monospace;
}
< p > 0 0 0 0</ p >
上記サンプルのレンダリング例:
0 0
0
p
を追加すると、次のようになります:
0 0
0
強制改行なしの行末スペースはぶら下がりとなり、 テキスト整列時に他の内容の配置に考慮されません。 右寄せの場合、これらスペースはオーバーフローし、 他の内容が端まで揃うのを妨げません。 一方、強制改行ありの行末空白は条件付きぶら下がりになり、 最終行末の空白はオーバーフローしない場合はぶら下がらず、整列時に考慮されます。
p {
white-space : pre-wrap;
width : 3 ch ;
border : solid 1 px ;
font-family : monospace;
}
< p > 0 0 0 0</ p >
0 0
最終行は最後の0の前で折返しされません。これは条件付きぶら下がり文字が
行内容の収まり判定の際に考慮されないためです。
4.3.3. セグメント区切り変換規則
white-space-collapseがcollapse以外の場合、セグメント区切りは折畳み可能ではありません。 collapseや preserve-spaces以外の値(これらはセグメント区切りをスペースに変換します)の場合、 セグメント区切りは保存された改行(U+000A)に変換されます。
white-space-collapseがcollapseの場合、セグメント区切りは折畳み可能となり、以下のように折畳まれます:
- まず、直前に別の折畳み可能なセグメント区切りがある場合、その折畳み可能なセグメント区切りは削除されます。
- 残ったセグメント区切りは、前後の文脈によってスペース(U+0020)に変換されるか削除されます。 この操作の規則は現行標準ではUA定義となっています。
Here is an English paragraph that is broken into multiple lines in the source code so that it can be more easily read and edited in a text editor.
Here is an English paragraph that is broken into multiple lines in the source code so that it can be more easily read and edited in a text editor.
中国語など単語区切りを持たない言語では、行の「分割解除」には、2行をスペースなしで連結する必要があります。
這個段落是那麼長,
在一行寫不行。最好
用三行寫。
這個段落是那麼長,在一行寫不行。最好用三行寫。
セグメント区切り変換規則は、前後の文脈を利用してセグメント区切りをスペースに変換したり、完全に排除したりできます。
注記: 歴史的に、HTMLとCSSはセグメント区切りを無条件にスペースに変換してきました。 これにより、中国語などの言語でコンテンツをソース内で改行できなくなっていました。 したがって、UAのヒューリスティクスは、こうした言語のサポート向上を目指しつつも、セグメント区切りの破棄箇所について慎重である必要があります。
4.4. タブ文字サイズ: tab-sizeプロパティ
| 名前: | tab-size |
|---|---|
| 値: | <number [0,∞]> | <length [0,∞]> |
| 初期値: | 8 |
| 適用対象: | text |
| 継承: | yes |
| パーセンテージ: | n/a |
| 算出値: | 指定された数値または絶対長さ |
| 正規順序: | n/a |
| アニメーション型: | 算出値型による |
このプロパティは、タブサイズ(U+0009)のレンダリング時の大きさを決定します。 <number>は、 最も近いブロックコンテナ祖先要素のスペース文字(U+0020)の送り幅の何倍かを表します。 関連するletter-spacingやword-spacingも含みます。 負の値は許可されません。
5. テキストの折返し
インラインレベルの内容が行に分割される際、内容は複数のラインボックスに分割されます。 この分割を改行と呼びます。 明示的な改行制御(保存された改行文字など)やブロックの始端・終端によって行が分割される場合、 強制改行となります。 内容の折返し(UAが内容を収めるために未強制の改行を作成する場合)による分割は、 ソフト折返しとなります。 インラインレベルの内容を行に分割する処理を改行処理と呼びます。
折返しは、許可された改行位置(ソフト折返し機会)でのみ行われます。 折返しが有効な場合(white-space参照)、 UAは行のオーバーフロー量を最小化するため、ソフト折返し機会で折返す必要があります(機会があれば)。
テキストが折返せる場所は改行規則と制御で管理されます。折返せるかどうかおよび行内に複数のソフト折返し機会の優先順位付けは text-wrap-mode、text-wrap-style、wrap-before、 wrap-after、 およびwrap-insideプロパティで制御されます。
5.1. 折返しの有無の決定: text-wrap-mode プロパティ
| 名前: | text-wrap-mode |
|---|---|
| 値: | wrap | nowrap |
| 初期値: | wrap |
| 適用対象: | text |
| 継承: | yes |
| パーセンテージ: | n/a |
| 算出値: | 指定キーワード |
| 正規順序: | 文法通り |
| アニメーション型: | 離散 |
このプロパティ名は暫定であり、CSSWGがより良い名前を検討中です。
注記: このプロパティはwhite-spaceおよびtext-wrapのロングハンドです。
このプロパティは、未強制ソフト折返し機会で行が折返せるかどうかを指定します。 可能な値:
- wrap
-
許可されたソフト折返し機会で内容を行分割できます。
現行の行分割規則によりインライン軸方向のオーバーフローを最小化します。
注記: § 5.6 行分割の詳細で ソフト折返し機会の規則や制約について詳しく説明しています。
- nowrap
- インラインレベル内容は行分割されず、内容がブロックコンテナに収まりきらない場合はオーバーフローします。
text-wrap-modeの値に関わらず、保存されたセグメント区切りや
UnicodeのBK、CR、LF、NLライン分割クラスを持つ文字は
強制改行として扱われなければなりません。[UAX14]
注記: こうした強制改行の双方向性への影響は Unicode双方向アルゴリズムで定義されています。[UAX9]
5.2. ボックス内の改行制御: wrap-insideプロパティ
| 名前: | wrap-inside |
|---|---|
| 値: | auto | avoid |
| 初期値: | auto |
| 適用対象: | インラインボックス |
| 継承: | no |
| パーセンテージ: | n/a |
| 算出値: | 指定キーワード |
| 正規順序: | 文法通り |
| アニメーション型: | 離散 |
- auto
- 許可された改行位置で、現行の行分割規則に従ってボックス内で行分割できます。
- avoid
-
ボックス内での行分割を抑制します。
UAは他に有効な改行位置がない場合のみ、ボックス内で分割できます。
テキストが分割される場合は、auto同様、行分割制限が適用されます。
avoid付きボックスが入れ子の場合、 UAが分割しなければならない時、内側より外側のボックスでの分割を優先します。
5.2.1. 'wrap-inside: avoid' を使ったフッター表示例
改行位置の優先順位は、意図したテキストグループ化を反映できます。
下記のルールを例にします:
footer { wrap-inside: avoid; }
venue { wrap-inside: avoid; }
date { wrap-inside: avoid; }
place { wrap-inside: avoid; }
および、次のマークアップ:
<footer> <venue>27th Internationalization and Unicode Conference</venue> • <date>April 7, 2005</date> • <place>Berlin, Germany</place> </footer>
ウィンドウ幅が狭い場合、フッターは次のように分割できます:
27th Internationalization and Unicode Conference • April 7, 2005 • Berlin, Germany
さらに狭い場合:
27th Internationalization and Unicode Conference • April 7, 2005 • Berlin, Germany
ただし、次のような分割にはなりません:
27th Internationalization and Unicode Conference • April 7, 2005 • Berlin, Germany
5.3. ボックス間の改行制御: wrap-before/wrap-afterプロパティ
| 名前: | wrap-before, wrap-after |
|---|---|
| 値: | auto | avoid | avoid-line | avoid-flex | line | flex |
| 初期値: | auto |
| 適用対象: | インラインレベルボックスおよびフレックスアイテム |
| 継承: | no |
| パーセンテージ: | n/a |
| 算出値: | 指定キーワード |
| 正規順序: | 文法通り |
| アニメーション型: | 離散 |
これらのプロパティは、行分割(およびフレックスライン分割[CSS3-FLEXBOX])における改行機会の修正を指定します。 可能な値:
- auto
- 現行の行分割規則に従い、ボックスの前後で許可された改行位置で行分割できます。
- avoid
- ボックスの直前/直後の行分割を抑制します。 UAは他に有効な改行位置がない場合のみ分割できます。 テキストが分割される場合は、auto同様に行分割制限が適用されます。
- avoid-line
- avoidと同じですが、行分割のみ適用。
- avoid-flex
- avoidと同じですが、フレックスライン分割のみ適用。
- line
- ボックスがインラインレベルボックスの場合、直前/直後で強制的に行分割します。
- flex
- ボックスがフレックスアイテムかつ複数行フレックスコンテナ内の場合、直前/直後で強制的にフレックスライン分割します。
インラインレベルボックスでの強制改行は、 親インラインボックスにも上方伝播し、 ブロックレベルボックスの強制改行が 同じ断片化コンテキスト内の親ブロックボックスに伝播するのと同じです。[CSS3-BREAK]
5.4. 折返し方法の選択: text-wrap-style プロパティ
| 名前: | text-wrap-style |
|---|---|
| 値: | auto | balance | stable | pretty |
| 初期値: | auto |
| 適用対象: | インライン整形コンテキストを確立するブロックコンテナ |
| 継承: | yes |
| パーセンテージ: | n/a |
| 算出値: | 指定キーワード |
| 正規順序: | 文法通り |
| アニメーション型: | 離散 |
折返しが許可されている場合 (text-wrap-mode参照)、 このプロパティは複数の折返し手法の選択を行い、レイアウトの速度・品質・スタイル・安定性のトレードオフを決定します。 どのソフト折返し機会が存在するかは変更せず、 UAがどれを選択するかの方法のみ変わります。 可能な値:
- auto
- どのソフト折返し機会で分割するかのアルゴリズムはUA定義です。 複数行を考慮して改行位置を決定してもよい(may)。 UAは速度優先のレイアウトを選んでもよい(may)。 UAはbalanceのように全ての行(最後の行も含む)を均等化してはならない(must not)。 この値はUA推奨(またはWeb互換性重視)アルゴリズムを選択します。
- balance
-
行分割は各行ボックスの残り(空)スペースをバランスよく分配するように選択されます。
autoよりバランスが取れる場合のみ。
この値は、text-wrapがautoのときと同じ行数になるよう、(5行以下の場合は変更しないことも含め)変更を避けるべきです。
注記: 行ボックスの高さは、同じ行に表示される内容が変わることで変化する場合があります。
残りスペースは、フロートやインライン内容を配置した後、テキストの均等割り付け前の余り部分を指し、 行ボックスは各行の残りスペースの平均からの標準偏差が減るようバランスされます(強制改行で終わる行も含む)。
強制改行で分断された行グループは個別に処理されます。 line-clampの影響を受ける場合は、まずクランプし、 残りの行をバランスします。
正確なアルゴリズムはUA定義です。
10行を超える場合は、UAはこの値をautoとして扱っても構いません。
- stable
- 改行位置決定時に後続行の内容を考慮しないべき(should not)ことを指定し、編集中でもカーソルより前の内容が安定します。 それ以外はautoと同等です。
- pretty
- UAは速度よりもより良いレイアウトを優先すべき(should)であり、複数行を考慮して改行位置を決定することが期待されます。 それ以外はautoと同等です。
注記: auto値は 通常Webブラウザの高速な従来型行分割(first-fit/greedyアルゴリズム)に該当し、最適でない結果になることも多いです。 UAはこのデフォルト値でより良い行分割アルゴリズムを試しても構いませんが、 最適化には時間がかかるので、より良い結果を求める場合はprettyでopt-inできます。 pretty値は本文に、 最終行が平均より短いことが期待される場合に、 balance値はタイトルやキャプションで、同じ長さの行が好まれる場合に、 stable値は編集可能な箇所やトグルされる可能性のあるセクション向けです。
- インデント以上の長さ
- X文字以上
- パーセンテージ
値空間例:match-indent | <length> | <percentage>(Xchはその用途例)。 または<integer>で文字数を直接数える案も。
テキストバランスとの関係は未定義。 以前の提案では同じプロパティとし(100%で完全バランス)という案もありました。
語単位制限の要望もあるが、語の長さに依存するため文字単位の方が良い。
5.5. 共同折返し制御: text-wrapショートハンドプロパティ
| 名前: | text-wrap |
|---|---|
| 値: | <'text-wrap-mode'> || <'text-wrap-style'> |
| 初期値: | wrap |
| 適用対象: | 個別プロパティ参照 |
| 継承: | 個別プロパティ参照 |
| パーセンテージ: | 個別プロパティ参照 |
| 算出値: | 個別プロパティ参照 |
| 正規順序: | 文法通り |
| アニメーション型: | 個別プロパティ参照 |
このプロパティはtext-wrap-modeおよび text-wrap-styleプロパティの略記です。 省略されたロングハンドはその初期値に設定されます。
5.6. 行分割の詳細
行分割(改行)の決定時:
- 行分割処理と双方向テキストの相互作用は、CSS Writing Modes 4 § 2.4 双方向並び替えアルゴリズムの適用およびUnicode双方向アルゴリズム(特にUAX9§3.4 解決済みレベルの並び替え)で定義されています。[CSS-WRITING-MODES-4] [UAX9]
- 明確に別途定義されていない限り
(例:line-break: anywhereやoverflow-wrap: anywhereなど)、
CM、SG、WJ、ZW、GL、ZWJのUnicode行分割クラスで定義された行分割動作を尊重しなければなりません。[UAX14] - 単語区切り以外の句読点で折返しを許可するUAは、書記体系が単語区切りを使う場合優先順位付けすべきです。 (例えば、スラッシュ後の改行優先度がスペースより低い場合、「check /etc」は"/"と"e"の間で改行されることはありません。) こうした不自然な改行を避ける配慮がされていれば、 単語区切り以外の適切な句読点での改行を許可するのは推奨されます。 これは特に狭い組幅で均一な余白に寄与します。 UAは親ブロックの幅、テキストの言語、line-break値などで優先順位を割り当てても構いませんが、 CSSはソフト折返し機会の優先順位付けを定義しません。 単語区切りの優先順位付けは、word-break: break-all指定時は期待されず(この値は区切りに依存しない改行動作を明示的に要求するため)、 line-break: anywhereでは禁止されます。
- フロー外要素やインライン要素の境界は、 フロー内で強制改行やソフト折返し機会を導入しません。
- Web互換性のため、各置換要素や他のアトミックインラインの前後には、 隣接する文字が通常それらを抑制する場合でもソフト折返し機会が生じます(U+00A0 ノーブレークスペースを含む)。 ただし、U+00A0以外は、 UnicodeのGL, WJ, ZWJ行分割クラスに属する文字が隣接している場合は、 ソフト折返し機会を設けてはなりません。[UAX14]
- 行分割時に改行で消える文字(例:U+0020 スペース)によるソフト折返し機会では、 その文字を直接含むボックスのプロパティが改行制御します。 2文字またはアトミックインラインの境界で定義される ソフト折返し機会では、 2文字の最近共通祖先のwhite-spaceプロパティが改行制御します。 どの要素のline-break、word-break、overflow-wrapプロパティが、その境界での ソフト折返し機会の判定を制御するかは現行標準では未定義です。
- ボックスの最初または最後の文字の前後のソフト折返し機会では、 改行はボックスの直前/直後(マージン端)で発生し、 ボックス内容の端との間で分割されません。
- ルビ周辺の行分割は、CSS Ruby Annotation Layout 1 § 3.4 行分割で定義されています。[CSS-RUBY-1]
- アラビア語などの書字体系で、単語内の未強制ソフト折返し機会で折返しする場合 (word-break: break-all、line-break: anywhere、overflow-wrap: break-word、overflow-wrap: anywhere等による分割、またはハイフネーション時)は、 文字は単語が分割されていないかのようにシェーピング(結合形選択)されなければなりません。
6. 行分割と単語境界
多くの書記体系では、ハイフネーションがない場合ソフト折返し機会は単語境界でのみ発生します。 多くの体系ではスペースや句読点で単語を明示的に区切り、 ソフト折返し機会はこれらの文字で判別できます。
タイ語、ラオ語、クメール語などの体系では、単語の区切りにスペースや句読点を用いません。 これらの体系ではゼロ幅スペース(U+200B)が明示的な単語区切りとして使えますが、 その慣習は一般的ではありません。 そのため、こうしたテキストでソフト折返し機会を正しく判定するには語彙リソースが必要です。
他の書記体系では、ソフト折返し機会は単語ではなく書記音節境界に基づきます。 これらの体系(特にジャワ語やバリ語などのブラーフミ系)は、分割機会の特定にテキスト分析が必要です。 SA行分割クラス文字を使う言語とは異なり、この分析はコンテンツ言語や(言語固有の)単語境界検出、語彙リソースを必要としません。
中国語(日本語、イ語、時に韓国語も含む)などでは、各音節が単一の組版文字種単位に対応し、 行分割規則は、特定の文字組み合わせ以外ならどこでも行分割を許可します。 また、これらの制限の厳密度は組版スタイルにより異なります。
CSSはソフト折返し機会の場所を完全には定義しませんが、 一般的なバリエーションを区別するための制御を提供します:
- line-breakプロパティで行分割制限の「厳密度」レベルを選択できます。
- word-breakプロパティで「単語」とみなす文字種を制御でき、CJK文字を非CJKテキスト同様に扱ったり、その逆にしたり、東南アジア言語で語検出を制御したり、単語をフレーズ単位でグループ化したりできます。
- hyphensプロパティで、ハイフネーション可能な書字体系で単語分割を許可するか制御できます。
- overflow-wrapプロパティで、通常分割できない文字列でもオーバーフロー時に分割を許可できます。
注記: Unicode Standard Annex #14: Unicode Line Breaking AlgorithmはUnicode全書体系の行分割の基準動作を定義しており、さらに調整されることが期待されます。[UAX14] 行分割の慣例については、日本語組版処理の要件 [JLREQ] や日本語文書の組版方法 [JIS4051](日本語)、中文排版需求 [CLREQ] や标点符号用法 [ZHMARK](中国語)なども参照してください。 また、Internationalization Working GroupのLanguage Enablement Indexも追加言語の情報を含みます。[TYPOGRAPHY] 追加で適切な参考文献の案内も歓迎します。
6.1. 文字の分割規則: word-breakプロパティ
| 名前: | word-break |
|---|---|
| 値: | normal | break-all | keep-all | manual | auto-phrase | break-word |
| 初期値: | normal |
| 適用対象: | text |
| 継承: | yes |
| パーセンテージ: | n/a |
| 算出値: | 指定キーワード |
| 正規順序: | n/a |
| アニメーション型: | 離散 |
このプロパティは「単語」内外のソフト折返し機会、つまりテキストを「通常」分割できる位置を指定します。 主に文字間の分割に注目し、ソフト折返し機会を空白や他のスペース区切りで発生させるかどうか(auto-phraseで抑制する場合あり)や、句読点周辺の分割規則は定義しません。 (句読点や小仮名の分割制御はline-break参照)
特にword-breakは、隣接する組版文字種単位間に通常ソフト折返し機会があるかを制御します。
この目的では非文字種の組版文字単位で
Unicode行分割クラスNU, AL, AI, IDに該当するものも
組版文字種単位として扱います。[UAX14]

また韓国語には2種類の改行スタイルがあり、どの2つのハングル・漢字間でも分割できる(word-break: normal)、あるいは英語のように主にスペースで分割(word-break: keep-all)があります。
각 줄의 마지막에 한글이 올 때 줄 나눔 기 준을 “글자” 또는 “어절” 단위로 한다。
각 줄의 마지막에 한글이 올 때 줄 나눔 기준을 “글자” 또는 “어절” 단위로 한다。
エチオピア文字も改行スタイルが2種あり、 単語区切りでのみ分割(word-break: normal)、 または単語内文字間でも分割(word-break: break-all)が可能です。
ተወልዱ፡ኵሉ፡ሰብእ፡ግዑዛን፡ወዕሩያን፡ በማዕረግ፡ወብሕግ።ቦሙ፡ኅሊና፡ወዐቅል፡ ወይትጌበሩ፡አሐዱ፡ምስለ፡አሀዱ፡ በመንፈሰ፡እኍና።
ተወልዱ፡ኵሉ፡ሰብእ፡ግዑዛን፡ወዕሩያን፡በማ ዕረግ፡ወብሕግ።ቦሙ፡ኅሊና፡ወዐቅል፡ወይትጌ በሩ፡አሐዱ፡ምስለ፡አሀዱ፡በመንፈሰ፡እኍና።
値の意味は以下の通りです:
- normal
-
単語は慣例に従って分割されます(上記参照)。
韓国語は2種の挙動があり、任意のハングル・漢字間で分割可能。
エチオピア文字は単語内分割不可。
一部書記体系では、慣例的なソフト折返し機会を得るために特別な処理が必要です(§ 6.1.1 分析的単語分割参照)。
- break-all
-
「単語」内分割も許可されます。
具体的には、soft
wrap opportunities(normalで許可されるもの)に加え、
全ての組版文字種単位(および
NU(数字)、AL(アルファベット)、SA(東南アジア系)行分割クラスの組版文字単位)は 行分割目的ではID(表意文字)として扱われます。 ハイフネーションは適用されません。注記: この値は句読点周辺のソフト折返し機会には影響しません。 任意位置で改行したい場合はline-break: anywhereを参照してください。
注記: このオプションはエチオピア文字のもう一つの一般的な挙動も有効にします。 またCJK文字が主で非CJK部分が短い場合など、各行でより均等な分布をしたいときに使われます。
- keep-all
-
「単語」内分割は禁止されます。
組版文字種単位(または
NU,AL,AI,IDクラスの組版文字単位)間の暗黙的ソフト折返し機会は抑制され、 つまりそのような文字ペア間の分割は禁止されます(line-breakがanywhere以外の場合)。 ただし§ 6.1.1.1 レキシカル分割による分割機会は除きます。 それ以外はnormalと同等です。 このスタイルではCJK文字の並びは分割されません。注記: これは韓国語のもう一つの一般的な挙動(単語間にスペースを使う)であり、 CJK混在テキスト(CJK断片が他言語に混じる場合)にも有効です。
- manual
-
normalと同様ですが、
§ 6.1.1.1 レキシカル分割は行いません。
具体的には、組版文字単位のうちクラスSAは、[UAX14]
クラスALとして扱われます(つまりline-breakがanywhere以外の場合、こうした文字ペア間にソフト折返し機会はありません)。
注記: この値はバリ語などの単語内音節分割とは無関係です。 (こうした体系の議論は§ 6.1.1.2 正書法的分割参照)
この値は keep-allベースでもよいし、 normalベースでもよい。 さらにこの挙動をkeep-allと統合する案もあり。
注記: 一部の東南アジア言語はUAによる自動判定が誤認されがちです。 word-break: normalだと、 言語固有ロジックが不適切に適用され、分割機会が誤配置されることがあります。例えば、タイ語以外にもタイ文字を使う言語が多く、 これらをタイ語扱いで分割すると不適切・混乱した結果になります。
この場合は、この値を使えばUA組み込みの単語境界検出をオフにし、 著者が手動で分割機会をマークアップして、適切な結果を得られます。
- auto-phrase
-
normalと同様ですが、
UAが言語固有の内容解析を行い、自然なフレーズ(複数単語のまとまり)を優先的に維持するよう指示します。
要素のコンテンツ言語が不明の場合、 またはUAがその言語のフレーズ境界検出を知らない場合は この値はnormalとして扱います。 それ以外の場合はUAはフレーズ境界検出し、各フレーズ内のソフト折返し機会を抑制するべきです。
コンテンツ言語やフレーズ境界検出の有無に関わらず、 ハイフネーション機会は hyphens: none指定時のように抑制されます。
注記: ある言語用の単語境界検出システムが、その言語の全方言に適切かは主観的であり、現行標準ではUAの裁量に委ねます。 検出がほとんど正しいならサポートとみなしてよい場合もありますが、 境界判定精度が低い言語や誤判定率が高い言語をサポートと主張するのは著者や利用者に不利益です。例えば、UAが広東語用の単語境界検出システムを持っていて、中国語全体には不適切な場合は、 auto-phraseは lang=yue・lang=zh-yue・lang=zh-HKなどには有効ですが、 lang=zhやlang=zh-Hantには効くべきでありません。一方、中国語全般に使える汎用検出システムをUAが持つ場合は、 auto-phraseは lang=zhに加え、lang=zh-yue、lang=zh-Hant-HK、lang=zh-Hans-SG、lang=zh-hakなどにも有効です。
特定カテゴリの文字と同じ行分割動作をする記号も、そのカテゴリの文字と同様に扱われます。
UAは、このプロパティのいかなる値においても、以下のソフト折返し機会を抑制してはなりません:
-
wbrHTML要素やU+200B ZERO WIDTH SPACEで導入されるもの -
line-breakプロパティで要求されるもの
注記: オーバーフロー時のみ追加分割機会を制御したい場合は、 overflow-wrap参照。
word-breakの効果は内在サイズ算出時に考慮されます。
这是一些汉字 and some Latin و کمی خط عربی และตัวอย่างการเขียนภาษาไทย በጽሑፍ፡ማራዘሙን፡አንዳንድ፡
分割位置は以下(‘·’で表示):
- word-break: normal
-
这·是·一·些·汉·字·and·some·Latin·و·کمی·خط·عربی·และ·ตัวอย่าง·การเขียน·ภาษาไทย·በጽሑፍ፡·ማራዘሙን፡·አንዳንድ፡
- word-break: break-all
-
这·是·一·些·汉·字·a·n·d·s·o·m·e·L·a·t·i·n·و·ﮐ·ﻤ·ﻰ·ﺧ·ﻁ·ﻋ·ﺮ·ﺑ·ﻰ·แ·ล·ะ·ตั·ว·อ·ย่·า·ง·ก·า·ร·เ·ขี·ย·น·ภ·า·ษ·า·ไ·ท·ย·በ·ጽ·ሑ·ፍ፡·ማ·ራ·ዘ·ሙ·ን፡·አ·ን·ዳ·ን·ድ፡
- word-break: keep-all
-
这是一些汉字·and·some·Latin·و·کمی·خط·عربی·และ·ตัวอย่าง·การเขียน·ภาษาไทย·በጽሑፍ፡·ማራዘሙን፡·አንዳንድ፡
アラビア語などのシェーピング書記体系で break-all指定で単語内分割が許可されても、 文字は単語が分割されていないかのようにシェーピングされます(分割されていない扱い)。
レガシーコンテンツとの互換性のため、 word-breakプロパティは 非推奨キーワードbreak-wordもサポートします。 指定すると、実際のword-break: normal値や overflow-wrap: anywhereと同じ効果になります(overflow-wrapプロパティ値に関わらず)。
6.1.1. 分析的単語分割
6.1.1.1. レキシカル単語分割
東南アジア言語に期待されるnormal挙動を実現するためには、 組版文字単位のうちUnicode行分割クラスSAは [UAX14]上、ALとして扱う必要があります。 ただしUAは、そのような文字列について内容解析を行い、 単語境界検出し、 各境界をソフト折返し機会として扱う必要があります。
様々な言語がSAクラス文字を使う書記体系で記述できるため、 コンテンツ言語が既知の場合、 UAはこの情報を解析に活用すべきです。
6.1.1.2. 正書法的分割
バリ語など、正書法音節に基づく行分割を行う書記体系では、 UAは内容解析し、正しいソフト折返し機会を挿入する箇所を特定しなければなりません。
注記:執筆時点では、Unicodeはこの解析方法を定義しておらず、 これらの書記体系の全ての文字をALクラスとして扱っています。 ただし、提案があり、 まだ最終化されていないものの参考になります。[L2-22-080R]
6.1.1.3. フォールバック分割
予期せぬオーバーフローを回避するため、 UAが必要なレキシカル・正書法解析(辞書がないなど)による行分割ができないコンテンツ言語がある場合、 SAクラス文字を使う言語でソフト折返し機会を その書記体系の組版文字種単位ペア間に仮定する必要があります。
注記:この規定は、UAが特定のテキストラン内で単語境界を見つけられないだけでは発動しません。 そのテキストランが本当に1語で分割不可な場合もあるためです。 この規定は、例えばUAがクメール語(U+1780~U+17FF)の単語境界判定方法を知らない場合などに適用されます。
6.1.2. フレーズ単位の行分割に関する利用者設定
UAは利用者設定に応じて auto-phraseで説明される言語固有の内容解析を有効にしても良いです。 この挙動を持つUAは、 宣言値としてword-breakにauto-phraseをユーザーオリジンで設定することでこれを実現しなければなりません。
注記:この機能が有効かどうかは、
getComputedStyle()で検出したり、
適切な場合は著者オリジンで上書きすることもできます。
6.2. 行分割の厳密度: line-breakプロパティ
| 名前: | line-break |
|---|---|
| 値: | auto | loose | normal | strict | anywhere |
| 初期値: | auto |
| 適用対象: | text |
| 継承: | yes |
| パーセンテージ: | n/a |
| 算出値: | 指定キーワード |
| 正規順序: | n/a |
| アニメーション型: | 離散 |
このプロパティは要素内で適用される行分割規則の厳密度、特に折返しが句読点や記号とどう相互作用するかを指定します。 値の意味は以下の通りです:
- auto
- UAが使用する行分割制限のセットを決定し、制限を行長によって変化させても良い(例:短い行ではより緩い規則を使う)。
- loose
- 最も制約の少ない行分割規則で分割します。新聞など短い行でよく使われます。
- normal
- 最も一般的な行分割規則で分割します。
- strict
- 最も厳格な行分割規則で分割します。
- anywhere
-
全ての組版文字単位の周囲で
ソフト折返し機会が生じます。
句読点や保存された空白、
単語内でも区切りを設け、
改行禁止文字(GL, WJ, ZWJ)やword-breakプロパティで強制される禁止も無視します。[UAX14] 区切り機会の優先付けは不可。
ハイフネーションは適用されません。
注記:この値は端末で一般的な行分割規則を発動します。
注記:この値は組版文字単位間のみ ソフト折返し機会を設け、単位内部では設けません。 よって
CMやSGクラスは尊重されます。[UAX14]注記: anywhereは 保存された空白が行末にある場合、 white-spaceがbreak-spacesのときだけ、 その空白を次行に折返せます。 それ以外の場合:この値が保存された空白に影響する場合、 white-space: break-spacesなら 空白並びの最初のスペース前で折返し可能になります(break-spaces単独では不可)。
CSSはテキスト折返し規則の厳密度に4段階を区別します。 loose、 normal、 strict それぞれの厳密度で有効な規則セットはUAに委ねられ、言語慣習に従うべきです。 ただし本仕様は以下を要求します:
-
strict分割で禁止、
normalやlooseで許可される分割:
- 日本語小仮名やカタカナ・ひらがな長音符(Unicode行分割クラスCJ)の前での分割。[UAX14]
-
normalやloose分割で、書記体系が中国語または日本語の場合のみ許可され、他は禁止される分割:
- CJKハイフン類(〜 U+301C、゠ U+30A0)の前での分割
-
loose分割で、
直前文字がUnicode行分割クラスID([UAX14]。word-break:
break-allでID扱いの場合も含む)の場合のみ許可され、他は禁止される分割:
- ハイフン(‐ U+2010、– U+2013)の前での分割
-
normalやstrict分割で禁止、
loose分割で許可される分割:
- 繰り返し記号(々 U+3005、〻 U+303B、ゝ U+309D、ゞ U+309E、ヽ U+30FD、ヾ U+30FE)の前
- 不可分文字(‥ U+2025、… U+2026など、Unicode行分割クラスIN)の間。[UAX14]
- loose分割で、 書記体系が中国語または日本語の場合のみ許可され、他は禁止される分割:
注記:上記要求はCJKテキストのみ違いを生じます。 これらのみ実装した場合、line-breakはCJKコードポイントにのみ影響し、書記体系が中国語や日本語タグでない限り他には影響しません。 今後のレベルでは他の書記体系や言語の要件が明らかになれば、追加の規則を定義する可能性があります。
-
U+0021(感嘆符、
!)と文字(Unicode一般カテゴリL)の間では改行機会を設けない。 これで"!important"の分割を防げます。 -
U+002F(スラッシュ、
/)と文字(Unicode一般カテゴリL)の間では改行機会を設けない。 これで日付"23/Jan/2024"の分割を防げます。 -
U+007C(縦棒、
|)と文字(Unicode一般カテゴリL)の間では改行機会を設けない。 -
U+002D(ハイフン
-)と数字(Unicode一般カテゴリNd)の間で、 ハイフンの直前が文字や数字(Unicode一般カテゴリLまたはNd)でない場合は改行機会を設けない。 これで数値"-13"直後での分割を防ぎ、 "ABCD-1234"や"1234-5678"(長いURL等)での分割は許可されます。
注記: CSSWGは将来版で、 高度出版要件を満たすためにより細かい行分割制御が必要となる可能性を認識しています。
6.3. ハイフネーション:単語内の形態素分割
6.3.1. ハイフネーション制御: hyphensプロパティ
ハイフネーションは、通常行分割できない単語を制御的に分割し、段落のレイアウトを改善する技法です。 通常は音節や形態素の境界で単語を分割し、その分割を視覚的に示します(多くの場合U+2010ハイフンを挿入)。 場合によっては分割後のスペルが変化することもあります。 いずれにせよ、ハイフネーションはレンダリング効果のみであり、 元の文書内容やテキスト選択・検索には影響してはなりません。
| 言語 | 分割無し | 分割前 | 分割後 |
|---|---|---|---|
| 英語 | Unbroken | Un‐ | broken |
| オランダ語 | cafeetje | café‐ | tje |
| ハンガリー語 | Összeg | Ösz‐ | szeg |
| 中国語(ピンイン) | tú’àn | tú‐ | àn |
| àizēng‐fēnmíng | àizēng‐ | ‐fēnmíng | |
| ウイグル語 | ![[isolated DAL + isolated ALEF + initial MEEM +
medial YEH + final DAL +
isolated ALEF MAKSURA]](https://www.w3.org/TR/css-text-4/images/uyghur-unbroken.svg)
| ![[isolated DAL + isolated ALEF + initial MEEM +
final YEH + hyphen ]](https://www.w3.org/TR/css-text-4/images/uyghur-hyphenate-joined-before.svg)
| ![[ isolated DAL + isolated ALEF MAKSURA]](https://www.w3.org/TR/css-text-4/images/uyghur-hyphenate-joined-after.svg)
|
| クリー語 | ![[ᑲᓯᑕᓂᐘᓂᓂᐠ]
(CANADIAN SYLLABICS KA +
CANADIAN SYLLABICS SI +
CANADIAN SYLLABICS TA +
CANADIAN SYLLABICS NI +
CANADIAN SYLLABICS WEST-CREE WA +
CANADIAN SYLLABICS NI +
CANADIAN SYLLABICS NI +
CANADIAN SYLLABICS FINAL GRAVE)](https://www.w3.org/TR/css-text-4/images/cree.svg)
| ![[ᑲᓯᑕᓂ᐀]
(CANADIAN SYLLABICS KA +
CANADIAN SYLLABICS SI +
CANADIAN SYLLABICS TA +
CANADIAN SYLLABICS NI +
CANADIAN SYLLABICS HYPHEN)](https://www.w3.org/TR/css-text-4/images/cree-before.svg)
| ![[ᐘᓂᓂᐠ]
(CANADIAN SYLLABICS WEST-CREE WA +
CANADIAN SYLLABICS NI +
CANADIAN SYLLABICS NI +
CANADIAN SYLLABICS FINAL GRAVE)](https://www.w3.org/TR/css-text-4/images/cree-after.svg)
|
ハイフネーションは、行分割が有効なハイフネーション機会で発生します。 これは単語内でハイフネーションが許可される場所で存在する ソフト折返し機会の一種です。 CSSではハイフネーション機会はhyphensプロパティで制御します。 CSS Text Level 3はハイフネーションの厳密な規則を定義しませんが、 UAは分割位置の選択を最適化し、言語に適したハイフネーション位置を選ぶことが強く推奨されます。
注記: U+002D HYPHEN-MINUSやU+2010 HYPHENによる ソフト折返し機会は ハイフネーション機会ではありません。 これらの文字は折返し位置に関わらず常に表示されるため、分割の視覚的指示が新たに作られるわけではありません。
ハイフネーション機会はmin-content内在サイズ算出時に考慮されます。
注記: この仕様により、テーブル内容をハイフネーションで折返し、親ブロックの外へオーバーフローするのを防げます。 ドイツ語など長い単語を持つ言語では特に重要です。
| 名前: | hyphens |
|---|---|
| 値: | none | manual | auto |
| 初期値: | manual |
| 適用対象: | text |
| 継承: | yes |
| パーセンテージ: | n/a |
| 算出値: | 指定キーワード |
| 正規順序: | n/a |
| アニメーション型: | 離散 |
このプロパティは、ハイフネーションによって、テキスト行内でより多くのソフト折返し機会を作るかどうかを制御します。 各値の意味は以下の通りです:
- none
-
単語のハイフネーションは行いません。
たとえ単語内にハイフネーション機会を明示する文字があってもハイフネートしません。
注記: これは、U+002D HYPHEN-MINUSやU+2010 HYPHENなど 常に表示される文字による既存のソフト折返し機会の抑制にはなりません。
- manual
-
単語内にハイフネーション機会を明示する文字がある場合のみハイフネートされます。
UAは適切な言語固有のハイフン文字を使い、分割位置が自動ハイフネーションの場合と同様のスペル変更も適用すべきです。
UnicodeではU+00ADは条件付き「ソフトハイフン」、U+2010は無条件ハイフンです。Unicode Standard Annex #14はUnicode行分割におけるソフトハイフンの役割を説明しています。[UAX14] HTMLでは ­がソフトハイフン文字を表し、これはハイフネーション機会を示唆します。
ex
­ ample - auto
- 単語は、言語に適したハイフネーションリソースで自動的に判定されたハイフネーション機会でも分割されます。条件付きハイフンによる機会以外にも分割可能です。 単語内に条件付きハイフン(­またはU+00AD SOFT HYPHEN)がある場合は、 他の自動ハイフネーション機会は無視し、条件付きハイフンを優先します。 ただし、条件付きハイフンでも分割後にさらに行に収まりきらない場合は、自動ハイフネーション機会も利用可能です。
正しい自動ハイフネーションには、テキスト言語に適したハイフネーションリソースが必要です。 よって、UAはコンテンツ言語が既知で、 かつ適切なハイフネーションリソースを持つ場合にのみ自動ハイフネートできます。
UAは言語毎に独自のヒューリスティクスで 特定の単語を自動ハイフネートから除外してもよいです。 例えば、UAは大文字・句読点パターンで固有名詞を除外しようとする場合があります。 こうしたヒューリスティクスは本仕様では定義されません。 (言語ごとにヒューリスティクスが異なる必要があります。英語とドイツ語では大文字慣習が大きく異なります。)
hyphensプロパティにおいて「単語」とみなす範囲はUA依存です。 ただし、インライン要素の境界やフロー外要素は単語境界判定時には無視されなければなりません。
条件付きハイフン文字(U+00ADなど)によるハイフネーション機会で表示されるグリフは、 その文字自体で表現され、それに適用されるプロパティでスタイリングされます。
アラビア語などのシェーピング書記体系でハイフネーションによって単語内分割が許可されても、 文字は単語が分割されていないかのようにシェーピングされなければなりません(分割されていない扱い)。
![[isolated DAL + isolated ALEF + initial MEEM +
medial YEH + hyphen + line-break + final DAL +
isolated ALEF MAKSURA]](https://www.w3.org/TR/css-text-4/images/uyghur-hyphenate-joined.svg) のように表示され、
のように表示され、
![[isolated DAL + isolated ALEF + initial MEEM +
final YEH + hyphen + line-break + isolated DAL +
isolated ALEF MAKSURA]](https://www.w3.org/TR/css-text-4/images/uyghur-hyphenate-unjoined.svg) のようにはなりません。
のようにはなりません。
6.3.2. ハイフン: hyphenate-character プロパティ
| 名前: | hyphenate-character |
|---|---|
| 値: | auto | <string> |
| 初期値: | auto |
| 適用対象: | text |
| 継承: | yes |
| パーセンテージ: | n/a |
| 算出値: | 指定キーワード |
| 正規順序: | 文法通り |
| アニメーション型: | 離散 |
このプロパティはハイフネーションされた単語の各部分の間に表示される文字列を指定します。 値の意味は以下の通りです:
- auto
- UAがコンテンツ言語の組版慣習に基づいて 適切な文字列を選択します。ハイフネーション辞書と同じ情報源を利用する場合もあります。
- <string>
-
ハイフネーション時に表示される文字列を指定します。
(この文字列の位置には影響しません。
UAはコンテンツ言語の組版慣習に従って挿入し、既定ではハイフネーション分割直前に挿入します。)
UAはused valueを
一定数の組版文字単位まで切り詰めてもよいですが、
組版文字単位の一部分のみを切り詰めてはなりません。
注記: 空文字列 "" の指定も有効であり、 UAはハイフネーション機会で可視のハイフン文字を挿入せずに分割します。
[lang]:lang(ojs) { hyphenate-character: "᐀" /* CANADIAN SYLLABICS HYPHEN (U+1400) */ }
注記:自動ハイフネーションによるハイフンもソフトハイフンによるハイフンも hyphenate-characterでレンダリングされます。
6.3.3. ハイフネーションサイズ制限: hyphenate-limit-zoneプロパティ
| 名前: | hyphenate-limit-zone |
|---|---|
| 値: | <length-percentage> |
| 初期値: | 0 |
| 適用対象: | ブロックコンテナ |
| 継承: | yes |
| パーセンテージ: | 行ボックスの長さ参照 |
| 算出値: | 算出<length-percentage>値 |
| 正規順序: | 文法通り |
| アニメーション型: | 算出値型による |
hyphenate-limit-zoneという名前で良いか?コメント・提案募集中。
このプロパティは行ボックス(均等割付前)に残してよい最大未充填スペースを指定します。 この制限を超えるとハイフネーションが発動し、次行の単語の一部を現在の行に引き戻します。
6.3.4. ハイフネーション文字数制限: hyphenate-limit-charsプロパティ
| 名前: | hyphenate-limit-chars |
|---|---|
| 値: | [ auto | <integer> ]{1,3} |
| 初期値: | auto |
| 適用対象: | text |
| 継承: | yes |
| パーセンテージ: | n/a |
| 算出値: | 3値(autoキーワードまたは整数) |
| 正規順序: | 文法通り |
| アニメーション型: | 算出値型による |
このプロパティはハイフネーションされる単語の最小文字数を指定します。 単語が、単語全体・ハイフン前・ハイフン後のいずれかについて必要な最小文字数を満たさない場合はハイフネートされません。 非間隔結合記号(Unicode General Category Mn)や単語内句読点(Unicode General Category P*)は最小文字数に含みません。
値を3つ指定した場合、1番目が単語全体の最小文字数、2番目がハイフネーション分割前の最小文字数、3番目が分割後の最小文字数です。 3番目が省略された場合は2番目と同じ値、2番目が省略された場合はautoになります。 auto値はUAが現在のレイアウトに応じて適応的に値を選択することを意味します。
注記: UAがより良い値を計算できない場合は、autoは前後2文字、単語全体5文字を意味することが推奨されます。
p { hyphenate-limit-chars: auto 3; }
6.3.5. ハイフネーション行制限: hyphenate-limit-lines・hyphenate-limit-lastプロパティ
| 名前: | hyphenate-limit-lines |
|---|---|
| 値: | no-limit | <integer> |
| 初期値: | no-limit |
| 適用対象: | ブロックコンテナ |
| 継承: | yes |
| パーセンテージ: | n/a |
| 算出値: | キーワードまたは整数 |
| 正規順序: | 文法通り |
| アニメーション型: | 算出値型による |
このプロパティは要素内で連続してハイフネーションされる行数の最大数を示します。 no-limit値は制限なしを意味します。
場合によっては、UAが指定値を守れないこともあります(overflow-wrap参照)。 こうした非常時の分割で生じるハイフネーションが近傍のハイフン位置に影響するかは未定義です。
| 名前: | hyphenate-limit-last |
|---|---|
| 値: | none | always | column | page | spread |
| 初期値: | none |
| 適用対象: | ブロックコンテナ |
| 継承: | yes |
| パーセンテージ: | n/a |
| 算出値: | 指定キーワード |
| 正規順序: | 文法通り |
| アニメーション型: | 離散 |
このプロパティは要素・段・ページ・見開き末尾でのハイフネーション動作を示します。 見開きは読者が同時に閲覧する2ページのセットです。 値の意味は以下の通りです:
- none
- 制限なし。
- always
- 要素の最終行、または要素内の段・ページ・見開き分割直前の最終行はハイフネートしない。
- column
- 要素内の段・ページ・見開き分割直前の最終行はハイフネートしない。
- page
- 要素内のページ・見開き分割直前の最終行はハイフネートしない。
- spread
- 要素内の見開き分割直前の最終行はハイフネートしない。
段落はhyphenate-limit-last: none指定時は 下記のように書式化されます:
This is just a simple example to show Antarc- tica.
'hyphenate-limit-last: always'の場合:
This is just a simple example to show Antarctica.
6.4. オーバーフロー折返し: overflow-wrap/word-wrapプロパティ
| 名前: | overflow-wrap, word-wrap |
|---|---|
| 値: | normal | break-word | anywhere |
| 初期値: | normal |
| 適用対象: | text |
| 継承: | yes |
| パーセンテージ: | n/a |
| 算出値: | 指定キーワード |
| 正規順序: | n/a |
| アニメーション型: | 離散 |
このプロパティは、UAが本来許可されない行内の分割位置でも、オーバーフロー回避のため分割を許可するかどうかを指定します。 分割不可の文字列が行ボックスに収まりきらない場合に有効です。 white-spaceが折返しを許可している時のみ効果があります。値:
- normal
-
行は許可された分割位置のみで分割されます。
ただし、word-break: keep-allによる制限は、
行内に他に許容可能な分割位置がない場合、word-break:
normal同様に緩和されます。
また、word-break: auto-phraseによる制限も、 行内に他に許容可能な分割位置がない場合は緩和されます:
- 特定フレーズ内のソフト折返し機会を抑制した結果、そのフレーズが空行でもオーバーフローする場合、 UAはそのフレーズ内でnormal同様の分割機会へフォールバックしなければなりません。
- それでもオーバーフローが防げない場合は、 行オーバーフローする各行でハイフネーション機会の抑制も解除しなければなりません。
- 中間案として、UAは多段階のフレーズ(個々の単語まで短縮など)を検出し、長いものがオーバーフローする場合は短いものにすることもできます。
ソフト折返し機会のうち word-break: keep-allやword-break: auto-phraseの制限緩和で得られるものは min-content内在サイズ算出時には考慮されません。
- anywhere
-
本来分割不可の文字の並びでも、行内に他に許容分割位置がなければ任意位置で分割可能です。
シェーピング文字は単語が分割されていないかのようにシェーピングされ、
グラフェムクラスタは一体として扱われます。
分割位置にハイフン文字は挿入されません。
ソフト折返し機会のうち
anywhereによるものは
min-content内在サイズ算出時に考慮されます。
word-break: auto-phraseの場合、 こうした追加ソフト折返し機会は overflow-wrap: normalによる制限緩和でもオーバーフロー防止できなかった場合のみ導入されます。
- break-word
- anywhereと同様ですが、 ソフト折返し機会のうち break-wordによるものは min-content内在サイズ算出時に考慮されません。
overflow-wrapにnone値を追加し、
keep-all'とauto-phrase''の制限緩和を
overflow-wrap: normalで許容する挙動をオプトアウトできるようにすべきか?
レガシー互換のため、UAはword-wrapを レガシー名エイリアスとして overflow-wrapプロパティと同じ扱いにしなければなりません。
7. 整列と均等割付
整列と均等割付はインライン内容が行ボックス内でどのように分布するかを制御します。
7.1. テキスト整列: text-alignショートハンド
| 名前: | text-align |
|---|---|
| 値: | start | end | left | right | center | <string> | justify | match-parent | justify-all |
| 初期値: | start |
| 適用対象: | ブロックコンテナ |
| 継承: | yes |
| パーセンテージ: | 個別プロパティ参照 |
| 算出値: | 個別プロパティ参照 |
| アニメーション型: | 離散 |
| 正規順序: | n/a |
このショートハンドプロパティは text-align-allと text-align-lastプロパティを設定し、 ブロックのインライン内容をインライン軸上で 行ボックスを完全に埋めない場合にどのように整列させるかを指定します。 justify-allや match-parent以外の値は text-align-allに割り当てられ、 text-align-lastはautoにリセットされます。
値の意味は以下の通りです:
- start
- インライン内容は行ボックスの開始端に整列されます。
- end
- インライン内容は行ボックスの終了端に整列されます。
- left
- インライン内容は行ボックスのline-left端に整列されます。 (縦書きモードでは、物理的な上端・下端いずれかになり、writing-modeによります。)[CSS-WRITING-MODES-4]
- right
- インライン内容は行ボックスのline-right端に整列されます。 (縦書きモードでは、物理的な上端・下端いずれかになり、writing-modeによります。)[CSS-WRITING-MODES-4]
- center
- インライン内容は行ボックス中央に配置されます。
- <string>
- 文字列は1文字でなければならず、そうでない場合は宣言は無効で無視されます。 テーブルセルに適用した場合、セル内容を整列させる整列文字を指定します。 詳細やキーワードとの組み合わせは下記参照。
- justify
- テキストはtext-justifyプロパティで指定された方法で均等割付され、 行ボックスをぴったり埋めます。 text-align-lastで別途指定がない限り、 強制改行前やブロック末尾の最終行はstart揃えとなります。
- justify-all
- text-align-allと text-align-last両方を justifyに設定し、 最終行も均等割付を強制します。
- match-parent
-
この値はinherit(親の算出値)と同じですが、
親から継承した値がstartや
endの時は
親のdirectionで解釈され、
left/right算出値となります。
ルート要素で指定時はstartになります。
text-alignショートハンドで指定時は text-align-allと text-align-last両方が match-parentに設定されます。
テキストブロックは行ボックスのスタックです。 このプロパティは各行ボックス内のインラインボックスが 行ボックスの開始端・終了端に対してどのように整列されるかを指定します。 整列はビューポートや包含ブロックに対するものではありません。
justifyの場合、 UAはインラインボックスをテキスト調整して伸縮できます。 (text-justify参照)。 要素の空白が 折畳み可能でない場合、 UAは均等割付のためにテキストを調整する義務はなく、代わりに 均等割付機会がないものとして扱ってもよいです。 テキスト調整する場合は、 タブストップが 空白処理規則通り揃うことを保証しなければなりません。
(均等割付後も含め)行ボックス内のインライン内容が長すぎて収まらない場合は 開始端揃えとなり、収まらない内容は行ボックスの終了端からオーバーフローします。
§ 9.3 双方向性と行ボックスで 行ボックスの開始端・終了端の判定詳細を参照してください。
7.2. テーブル列の文字基準整列
列内の複数セルで整列文字が指定されている場合、 その列の各セルの整列文字は単一の列方向軸上で中央揃えにされ、 列内の他のテキストもそれに合わせてシフトされます。 (セルごとに文字列が異なってもよいですが、通常は同じです。)
これは「整列文字の中心」を揃えるべきという意図か? そのように書かれているか不明だが、そうであるべきか、異なる挙動かを明記する必要がある。 特に異なるフォントで整列文字が現れる場合の挙動を記述すべき。 (最も重要なのは太字と通常の幅の違い等。) [フィードバック] [2016-02-02 10:00 AM Face-to-face議事録]
次のスタイルシート:
TD { text-align: "." center }
は次のHTMLテーブルのドル金額の列を:
<TABLE> <COL width="40"> <TR> <TH>Long distance calls <TR> <TD> $1.30 <TR> <TD> $2.50 <TR> <TD> $10.80 <TR> <TD> $111.01 <TR> <TD> $85. <TR> <TD> N/A <TR> <TD> $.05 <TR> <TD> $.06 </TABLE>
小数点で揃えます。テーブルは下記のように表示されるでしょう:
+---------------------+ | Long distance calls | +---------------------+ | $1.30 | | $2.50 | | $10.80 | | $111.01 | | $85. | | N/A | | $.05 | | $.06 | +---------------------+
<string> 値にキーワード値を併記可能です。 指定がない場合、デフォルトはrightです。 この値は以下の場合に使われます:
- 文字基準整列がテーブルセル以外のボックスに適用された場合。
- テキストが複数行に折返された場合(強制改行箇所以外)。
- 文字基準セルが複数列をまたぐ場合。 この場合、キーワード整列値に従い、どの列の軸で揃えるか決まります: leftなら最も左の列、 right・centerなら最も右の列、 startなら最も開始側の列、 endなら最も終了側の列。
- 列が十分広く、文字基準整列のみで内容位置が決まらない場合。 この場合、最初の整列文字指定セルのキーワード整列値に従い、 可能な限りその位置に内容をスライドさせて揃えます(列幅は変更しない)。 centerの場合、 UAは内容の端や軸自体の中心(可能な限り)や、内容の左右端の加重平均などで光学的中央揃えにしてもよいです。
注記: 文字基準整列のデフォルトは右揃えです。 これは多くの番号体系が右から左書記体系でも左から右で並ぶためで、 文字基準整列の主用途が数値整列だからです。
整列文字がテキスト中に複数現れる場合、最初の出現で整列します。 セルに整列文字が全くない場合、内容末尾に整列文字が挿入されたかのように整列します。
どのテキストを整列文字検索対象とするか明確化すべき。 インフローテキストのみか、セルで確立されるブロック整形コンテキスト内のインフロー子孫も含むのか? その場合、セルのtext-alignと一致する場合のみか? (一致は整列文字だけか、プロパティ全体か?)
内容末尾に整列文字を挿入した扱いと 文字中心整列の組み合わせは、列のいずれの行にも整列文字がない場合や、 行がmax-content幅でレイアウトされない場合、 行単独で終端側に空白が生じる可能性があり、望ましくないかもしれません。
内容末尾に整列文字を挿入する場合、 どのフォントが使われるべきか? (特に、整列文字が子ブロック内の場合、ブロック・セルどちらのフォントか? インライン内の強制改行位置ならインライン・ブロック・セルいずれのフォントか?)
文字基準整列はテーブルセル幅計算前に行われ、 自動幅計算が整列のため十分なスペースを残せるようにします。 列跨ぎセルが幅計算前/後いずれで整列参加するかは未定義です。 セル内容の幅制約で列全体で十分な整列ができない場合、結果の整列は未定義です。
文字整列がテーブル列やその中の全内容の min-content/max-content内在幅にどう影響するか正式定義すべき。 max-content幅は(整列文字中心揃えと仮定すると)3つの数値に分割: 整列文字なし幅、整列文字中心より開始側幅、終了側幅。 これは強制改行間の全テキスト区間に基づく。 min-content幅は、強制改行間区間でオプション改行があれば「整列文字なし幅」だけ寄与。 ただし、すべてのmin-content幅がこの方式か、強制改行間区間でオプション改行がなければ (実際に整列文字がある場合のみ?)開始側/終了側幅にも寄与すべきかは不明。 この選択は「最小合理サイズ」と「整列文字重視」のトレードオフ。 オプション改行許可の有無で挙動を切り替える案も。
列跨ぎセルの <string> のtext-alignによる内在幅寄与の正式定義も必要。 非跨ぎセルの内在幅決定の拡張であり、これも正式定義すべき。 寄与は整列する側(開始・終了)列の分割内在幅と、他の跨ぎ列の「整列文字なし幅」へ分割される。
7.3. デフォルトテキスト整列: text-align-all プロパティ
| 名前: | text-align-all |
|---|---|
| 値: | start | end | left | right | center | <string> | justify | match-parent |
| 初期値: | start |
| 適用対象: | ブロックコンテナ |
| 継承: | yes |
| パーセンテージ: | n/a |
| 算出値: | 指定キーワード(match-parentは前述通り算出) |
| 正規順序: | n/a |
| アニメーション型: | 離散 |
このtext-alignのロングハンドプロパティは、 ブロックコンテナ内のインライン内容の全行の整列を指定します( 最終行はauto以外のtext-align-lastで上書きされる場合を除く)。 値の詳細はtext-align参照。
著者はこのプロパティより text-alignショートハンドの利用を推奨します。
7.4. 最終行整列: text-align-last プロパティ
| 名前: | text-align-last |
|---|---|
| 値: | auto | start | end | left | right | center | justify | match-parent |
| 初期値: | auto |
| 適用対象: | ブロックコンテナ |
| 継承: | yes |
| パーセンテージ: | n/a |
| 算出値: | 指定キーワード(match-parentは前述通り算出) |
| 正規順序: | n/a |
| アニメーション型: | 離散 |
このプロパティはブロックの最終行や 強制改行直前の行の整列方法を示します。
auto指定時は、 該当行の内容はtext-align-allで整列されますが、 text-align-allが justifyのときは start揃えになります。 その他の値はtext-alignと同様に解釈されます。
7.5. 均等割付方法: text-justify プロパティ
| 名前: | text-justify |
|---|---|
| 値: | [ auto | none | inter-word | inter-character | ruby ] || no-compress |
| 初期値: | auto |
| 適用対象: | text |
| 継承: | yes |
| パーセンテージ: | n/a |
| 算出値: | 指定キーワード(distributeレガシー値を除く) |
| 正規順序: | n/a |
| アニメーション型: | 離散 |
このプロパティは、行の整列がjustify(text-align参照)に設定されたときに使用する均等割付方法を選択します。 プロパティはテキストに適用されますが、ブロックコンテナからそのインライン内容のルートインラインボックスに継承されます。 次の値を取ります:
- auto
-
UAがアルゴリズムを決定し、パフォーマンスと表示品質のバランスで選択します。
均等割付規則は書記体系や言語ごとに異なるため、
UAは可能ならテキストに適した均等割付アルゴリズムを使うべきです。
例えば、 UAはデフォルトで全書記体系に妥協した均等割付(主に単語区切り・CJK組版文字種単位間の拡張+東南アジア組版文字種単位間の拡張等)を使い、 段落の言語が分かる場合は、日本語組版処理の要件(日本語)[JLREQ]、 アラビア語はカリグラフィエロンゲーション、 ドイツ語はinter-word等、より言語特化の挙動も選択できます。

カリグラフィック均等割付のアラビア語例(Tasmeemレンダリング)。 英語同様、アラビア語も単語間スペース調整で均等割付できるが、多くのスタイルでは字形自体の伸長・圧縮(カシーダ・スウォッシュ形等)でも割付可能。 この例では、上行は伸長形・スウォッシュ形で行を埋め、下行は字符間の合字組み合わせでやや圧縮。 伝統的なカリグラフィ技術を用いることで、流れ・色調を保ちつつ高品位な均等割付が可能。 ただし、これは非常にスクリプト固有の効果です。 
text-justify: autoでの混合スクリプト例。 この解釈ではスペース・CJK・東南アジア文字間にも均等に余白を分配。 単語区切りやCJK文字のある行はinter-word+inter-ideograph方式、 それ以外やスペースが伸びすぎる場合はinter-cluster動作にフォールバック。 - none
-
均等割付を無効化(テキスト内に均等割付機会なし)。
text-justify: noneの混合スクリプト例 注記: この値はユーザースタイルシートで可読性やアクセシビリティ向上に使います。
- inter-word
-
単語区切りのみで余白調整
(事実上、行のword-spacing値を可変にする)。
この動作は英語・韓国語などスペースで単語を分ける言語で典型的。

text-justify: inter-wordの混合スクリプト例 - inter-character
-
隣接する組版文字単位ペア間で余白調整
(事実上、行のletter-spacing値を可変にする)。
この値は日本語など東アジア系で使われることがあります。
text-justify: inter-characterの混合スクリプト例 レガシー互換のため、 UAはキーワードdistributeもサポートし、 inter-character同等とする必要があります。 UAはこれをレガシー値エイリアスとして扱っても構いません。
- ruby
-
均等割付はauto同様だが、例外として:
注記: この値はルビ注記用の合理的なデフォルト整列用です。 [CSS-RUBY-1]参照。
- no-compress
-
text-spacing-trimや
text-autospaceで制御される余白は圧縮不可。
(この値がない場合、均等割付処理でこうした余白は行頭・行末以外圧縮され得る。)
注記:日本語では圧縮規則例が3.8均等割付にあり [JLREQ]参照。
このキーワードは以前text-spacingの一部だったが、 ここでより明示的な命名が必要かもしれない(例:U+0020も圧縮不可を含意)。[Issue #7079]
最適な均等割付は言語依存なので、 著者は最良の結果を得るためにコンテンツを正しく言語タグ付けすべきです。
注記: 現行標準のCSSガイドラインは 完全な均等割付アルゴリズムを記述しません。 これは完全なアルゴリズムが満たすべき最小要件のみを示します。 要件を絞ることでUAに品質・速度・複雑性など各自のニーズに合うアルゴリズム選択の自由度を与えます。
7.5.1. テキストの伸縮
均等割付時、UAは行内容の両端と行ボックス端の間の残りスペースを取り、 行内容全体に分配してちょうど行ボックスを埋めるようにします。 UAは、逆に負のスペース(余分な内容)を分配し、通常の間隔条件下より多くの内容を行に載せる場合もあります。
均等割付機会とは 均等割付アルゴリズムがテキスト内の余白を変更できる位置です。 均等割付機会は、単一の組版文字単位(単語区切りなど)や 2つの組版文字単位の並びで発生します。 ソフト折返し機会の制御同様、 組版文字単位が均等割付機会かどうかは親のtext-justify値で制御されます。 同様に、2つの連続する均等割付機会があるかどうかは 最近共通祖先のtext-justify値で決まります。
均等割付で分配される余白は、letter-spacingやword-spacingプロパティで定義される余白に追加されます。 この追加余白が単語区切りの均等割付機会に分配される場合はword-spacingと同じ規則で適用されます。 同様に、2つの均等割付機会間に分配される場合は letter-spacingと同じ規則で適用されるべきです。
均等割付アルゴリズムは均等割付機会を複数の優先レベルに分けてもよいです。 あるレベル内の均等割付機会は全て同じ優先で伸縮され、 その機会を作った組版文字単位に関係なく扱われます。 例えば、2つの漢字間の均等割付機会と 2つのラテン文字間の機会が同じレベル(inter-characterスタイル)なら、 由来が異なっても区別されません。 本レベルでは、他の要素(フォントサイズ、letter-spacing、グリフ形状、行内位置等)が 行内の均等割付機会への余白分配に影響するかは定義しません。
UAは、任意の方法でオプション合字を分割したり、代替グリフ・グリフ圧縮などのフォント機能を使って 均等割付を補助しても構いません。 この挙動は現行標準では制御されません。 ただし、UAは必須合字を分割したり、複雑スクリプトの正しい整形に必要な機能を無効化してはなりません。
行内に均等割付機会が存在し、 テキスト整列でその行が全面均等割付(justify)なら、 必ず均等割付されなければなりません。
7.5.2. 記号と句読点の扱い
均等割付機会の決定において、 Unicodeの記号(S*)および句読点(P*)クラスの組版文字単位は、一般的に同じ書記体系の組版文字種単位と同様に扱われます。 (文字のscript属性がCommonの場合は、支配的書記体系の組版文字種単位として扱う。)
ただし、組版慣習によって記号・句読点の均等割付には追加規則がある場合があります。 このためUAは特定文字の割当を変更したり、記号・句読点に関する均等割付機会の優先レベルを追加設定できます。
7.5.3. 伸ばせないテキスト
行ボックス幅いっぱいにインライン内容を伸ばせない場合は、 text-align-lastプロパティで指定されたように整列します。 (text-align-lastが justifyの場合は centerと同様に整列します。)
7.5.4. 筆記体スクリプト
均等割付では、アラビア語等の筆記体スクリプトの 組版文字種単位同士の連結部分に隙間を作ってはなりません。 UAが可能な場合は、こうした組版文字種単位列内の 均等割付機会へのスペース分配を筆記体の伸長形(カシーダ等)に変換してもよいです。 それ以外の場合は、筆記体スクリプト内の任意の組版文字種単位ペア間には 均等割付機会が存在しないと見なさなければなりません (連結有無に関わらず)。


一部フォント設計では、タトウィール文字による均等割付が可能です。 タトウィールを使うUAは、その使用規則を正しく扱う必要があります。 正しいタトウィール挿入には、文字組み合わせや単語内位置、行内位置等の文脈に依存します。
7.5.5. auto 均等割付の最低要件
auto均等割付について、 本仕様は均等割付機会の種類や優先順位、複数レベルの均等割付機会の相互作用を定義しません。 ただし、以下は要求します:
-
コンテンツ言語の組版慣習や隣接記号・句読点で否定されない限り、
以下の各項目は均等割付機会となります:
- 単語区切り
- ブロックスクリプトの組版文字単位と他の組版文字単位の境界
- クラスタ型スクリプトの組版文字単位と他の組版文字単位の境界
- 全てのブロックスクリプトに属する文字は同等に扱い、 全てのクラスタ型スクリプトに属する文字も同等に扱います。 例えば、漢字→漢字間、漢字→ハングル間の均等割付機会は区別しません。
均等割付についてのさらなる情報は“全文均等割付のアプローチ”を参照してください。 これは書記体系や言語ごとの索引を提供し、W3C Internationalization Working Groupが管理しています。[JUSTIFY]
7.6. テキストブロックのコンテナ内整列: text-group-alignプロパティ
| 名前: | text-group-align |
|---|---|
| 値: | none | start | end | left | right | center |
| 初期値: | none |
| 適用対象: | ブロックコンテナ |
| 継承: | no |
| パーセンテージ: | N/A |
| 算出値: | 指定キーワード |
| 正規順序: | 文法通り |
| アニメーション型: | 離散 |
このプロパティは、テキスト整列を維持しつつ、行ボックス群をグループとして整列させます。
グループ整列は、残余スペースが最も短い行ボックスを探し、 その分だけパディングを行ボックスの一方または両側に追加して内容のスペースを減らし、 残りスペース内でテキスト整列を適用します。 同じブロック整形コンテキスト内の全ての子孫in-flow行ボックスが、最短残余スペースの検索とパディング追加時に考慮されます。 独立整形コンテキストを確立する子孫の内容は除外されます。
このプロパティの派生型は継承され、 各ブロックコンテナごとに個別適用され、直下の行ボックスだけに影響します。 利便性は低いですが、実装は容易でしょう。
同じブロックコンテナ由来のフロートも 同じ量だけ移動するとCJK組版で特に整列が美しくなります。 この仕組みや祖先要素由来の侵入フロートとの相互作用は今後の課題です。
値の意味:
- none
- 通常のテキスト整列のみ。グループ整列は行いません。
- start
- インライン内容をグループ整列でインライン開始側に揃え、 各行ボックスのインライン終了側にパディングを追加します。
- end
- インライン内容をグループ整列でインライン終了側に揃え、 各行ボックスのインライン開始側にパディングを追加します。
- left
- インライン内容をグループ整列でline-left側に揃え、 各行ボックスのline-right側にパディングを追加します。
- right
- インライン内容をグループ整列でline-right側に揃え、 各行ボックスのline-left側にパディングを追加します。
- center
- インライン内容をグループ整列で中央揃えし、 各行ボックスの両側にパディング(半分ずつ)を追加します。
8. 行間・字間
CSSは通常のテキスト間隔制御を word-spacing、 letter-spacing、 line-paddingプロパティで提供します。 これらはそれぞれ 単語区切り周り、 組版文字単位間、 行頭・行末に追加スペースを指定します。 また、text-spacing-trimプロパティによる文脈的な間隔制御もあり、 CJK句読点の全角・半角設定を文脈依存で切り替えられます。 text-autospaceプロパティでは、 スクリプト切替や句読点周辺に自動で追加スペースを挿入できます。
8.1. 単語間隔: word-spacing プロパティ
| 名前: | word-spacing |
|---|---|
| 値: | normal | <length-percentage> |
| 初期値: | normal |
| 適用対象: | text |
| 継承: | yes |
| パーセンテージ: | 現在の要素の算出font-sizeを基準(例:1em) |
| 算出値: | 絶対長さおよび/またはパーセンテージ |
| 正規順序: | n/a |
| アニメーション型: | 算出値型による |
このプロパティは「単語」間の追加間隔を指定します。 値の解釈は以下の通りです:
- normal
- 追加間隔なし。算出値はゼロ。
- <length-percentage>
-
フォント定義の単語間隔に追加して余分なスペースを指定。
注記: パーセンテージはそのまま継承され、 現在の要素の算出font-sizeに対して解決されます。 (つまり適用テキストのサイズに相対的)
em単位は、継承元要素の算出font-sizeに対して絶対長さとして解決される点が異なります。
追加間隔は空白処理規則適用後に残る各単語区切りに適用され、組版慣習で特に指定がない限り、文字の両側半分ずつ分配されます。 負の値も可ですが、実装依存の制限がある場合もあります。
単語区切り文字は、主に単語を区切る用途・慣習を持つ組版文字単位です。 Unicodeでは(網羅的定義ではないが)スペース(U+0020)、ノーブレークスペース(U+00A0)、エチオピア語ワードスペース(U+1361)、 エーゲ海ワードセパレータ(U+10100,U+10101)、ウガリト語ワード区切り(U+1039F)、フェニキア語ワードセパレータ(U+1091F)などが該当します。[UNICODE]
注記: 一般的な句読点や固定幅スペース(U+3000、U+2000~U+200Aなど)は 単語区切り文字とはみなされません。 それらが結果的に単語を分けることが多くても、主目的が単語区切りでないためです。
単語区切り文字がない場合や、 区切り文字のアドバンス幅がゼロ(例:U+200Bゼロ幅スペース)の場合は、 UAは単語間に追加スペースを生成してはなりません。
8.2. トラッキング: letter-spacing プロパティ
| 名前: | letter-spacing |
|---|---|
| 値: | normal | <length-percentage> |
| 初期値: | normal |
| 適用対象: | インラインボックスおよびテキスト |
| 継承: | yes |
| パーセンテージ: | 現在の要素の算出font-size基準(例:1em) |
| 算出値: | 絶対長さおよび/またはパーセンテージ |
| 正規順序: | n/a |
| アニメーション型: | 算出値型による |
このプロパティは隣接する組版文字単位間の追加間隔 (一般にトラッキングと呼ばれる)を指定します。 letter-spacingは双方向並び替え後に適用され、 カーニングや word-spacingに追加されます。[CSS-WRITING-MODES-4] [CSS-FONTS-3] 均等割付規則によっては、 UAが組版文字単位間のスペースをさらに増減して 均等割付することもあります。
値の意味:
- normal
- 追加間隔なし。算出値はゼロ。
- <length-percentage>
-
組版文字単位間に追加スペースを指定。
負値も可ですが、実装依存の制限がある場合もあります。
注記: パーセンテージはそのまま継承され、 現在の要素の算出font-sizeに対して解決されます。 (つまり適用テキストのサイズに相対的)
em単位は、継承元要素の算出font-sizeに対して絶対長さとして解決される点が異なります。
レガシー互換として、
算出letter-spacingがゼロの場合、
resolved value(getComputedStyle()
戻り値)はnormalになります。
letter-spacingに関しては、 連続するアトミックインライン(画像やインラインブロックなど)は 1つの組版文字単位として扱われます。
letter-spacingは行頭には適用しません。 行末への適用は現行標準では未定義です。
p{ letter-spacing : 1 em ; }
< p > abc</ p >
a b c
a b c
UAは右端・末尾にletter-spacingを追加しては絶対ならない:[RFC6919]
a b c
2つの組版文字単位間のletter-spacingは、実質的にそれら両方を含む最も内側の要素に「属します」: 2つの隣接組版文字単位間のtotal letter-spacing(bidi並び替え後)は、 その境界を含む最内要素で指定・描画されます。 ただしUAは、要素境界でのletter-spacingをどちらか一方の組版文字単位に その要素の値で付加しても構いません。
注記: この挙動はWeb互換性のため本レベルで許容されます。
p{ letter-spacing : 1 em ; }
< p > a< span > bb</ span > c</ p >
a b b c
a b b c
したがって、指定したletter-spacingは、 その要素内で完全に含まれる文字間だけに効くべきです:
p{ letter-spacing : 1 em ; } span{ letter-spacing : 2 em ; }
< p > a< span > bb</ span > c</ p >
a b b c
さらに、1文字のみ含む要素にletter-spacingを指定しても 描画結果には影響しません:
p{ letter-spacing : 1 em ; } span{ letter-spacing : 2 em ; }
< p > a< span > b</ span > c</ p >
a b c
letter-spacingはRTL並び替え後に挿入されるため、 下記のような内側spanへのletter-spacingも、並び替え後に「c」が「א」に隣接しないので効果がありません:
p{ letter-spacing : 1 em ; } span{ letter-spacing : 2 em ; }
<!-- abcの後にヘブライ文字 alef (א), bet (ב), gimel (ג) --> <!-- 並び替えで逆順に表示される --> < p > ab< span > cא</ span > בג</ p >
a b c א ב ג
letter-spacingは不可視のゼロ幅書式文字(Unicode Cfカテゴリなど)を無視します。 こうした文字が文書に存在しないかのようにスペースを追加すべきです。
2文字間の実効スペースがゼロでない場合(均等割付や非ゼロletter-spacingなど)、 UAはオプション合字(基本的に正しい字形形成に必須でないもの)は適用すべきでありません。 ただし低レベルfont-feature-settingsプロパティで合字指定した場合はこのルールより優先されます。 CSS Fonts Module Level 3 § feature-precedence参照。
注記: OpenTypeでは必須合字はrlig機能として扱われます。
他の合字はオプション扱いです。
ただし、UAやプラットフォームのヒューリスティクスが壊れたフォント処理のため追加合字を適用する場合があり、
この仕様はそうした例外処理を定義・上書きしません。
8.2.1. 筆記体スクリプト
UAが可能な場合、 筆記体スクリプトにletter-spacingを適用する際、 その文字列への追加スペース全体を筆記体の伸長(負のトラッキング値なら圧縮)として変換し、 実質的に同じ総伸長(または圧縮)になるようにしてもよいです。 それができない場合、 UAが筆記体スクリプトのテキストを連結を壊さずに伸長できないなら、 そのスクリプトの組版文字種単位ペア間にスペースを適用してはなりません (letter-spacing上は単語全体を1つの組版文字種単位として扱う)。 どちらの場合もこうした文字間の実効スペースはゼロとなりますが、 前者はテキストを伸ばした印象を維持します。
| — | 元のテキスト | |
| BAD | 各文字間に均等にスペース分配。筆記体の連結が壊れていることに注意! | |
|---|---|---|
| OK | ∑letter-spacingを組版的に適切な筆記体伸長で分配。 結果のテキスト長は均等スペース例と等しい。 | |
| OK | アラビア文字間のletter-spacing抑制。 ただし非アラビア文字(スペース等)には適用されることに注意。 | |
| BAD | 非連結文字間だけletter-spacing適用。 組版の色が乱れ、単語境界が判別しにくくなります。 |
注記: テキストの筆記体伸長や圧縮の適切な処理は スクリプト、書体、言語、単語内・行内位置、実装の複雑さ、フォント機能、カリグラフィ嗜好などで異なり、 場合によっては全く不可能なこともあります。 短縮合字やスウォッシュ形、文脈形、U+0640 ـ ARABIC TATWEELなどの伸長字形、 その他マイクロタイポグラフィを使うこともあります。 これらの効果の規則は現行標準CSSでは定義されません。 著者は、互換性のない結果を許容できない限り、筆記体スクリプトにletter-spacingを適用すべきではありません。
8.3. 行頭/行末パディング: line-paddingプロパティ
| 名前: | line-padding |
|---|---|
| 値: | <length> |
| 初期値: | 0 |
| 適用対象: | インラインボックス |
| 継承: | yes |
| パーセンテージ: | N/A |
| 算出値: | 絶対長さ |
| 正規順序: | 文法通り |
| アニメーション型: | 算出値型による |
letter-spacingが 組版文字単位間の間隔を調整し 行頭・行末には適用されないのに対し、 このプロパティは行頭・行末のみに間隔を調整します。 追加スペースは、行ボックスの開始/終了に位置する最内側のインラインボックスの内容端と、 隣接するインラインレベル内容(テキストまたはatomic inline)の間に挿入されます。 この追加スペースは均等割付機会ではありません。
p { line-padding: 0.5em; line-height: 1; text-align: center }
span { background: black; color: white; }
em { background: green; color: white; }
<p><span>Here is <em>some text</em></span>
line-paddingによって各行の両端に0.5emのインライン背景が追加表示されます。 “some”と“text”間で改行される場合、 1行目は左が黒・右が緑、2行目は両端が緑になります。
Here is some
text
8.4. 自動文脈的スペース: text-autospace プロパティ
| 名前: | text-autospace |
|---|---|
| 値: | normal | <autospace> | auto |
| 初期値: | normal |
| 適用対象: | text |
| 継承: | yes |
| パーセンテージ: | N/A |
| 算出値: | 指定キーワード |
| 正規順序: | 文法通り |
| アニメーション型: | 離散 |
このプロパティは、同一インライン整形コンテキスト内の同一行で隣接する文字間のスペースを 文字クラスに基づく規則で制御します。 これによりスクリプト切替時や句読点周辺で自動調整が可能です。
値の定義:
<autospace> = no-autospace |
[ ideograph-alpha || ideograph-numeric || punctuation ]
|| [ insert | replace ]
- normal
- ideograph-alpha ideograph-numericと同じ挙動。
- no-autospace
- 自動スペース挿入なし。
- insert
-
指定スペースは、既に何らかのスペース文字(Unicode一般カテゴリ
Z)がなければ自動挿入。 - replace
-
指定スペースは、既にスペース
(U+0020)があっても自動挿入され、加えてスペース(U+0020)は削除されます。
他のスペース文字(Unicode一般カテゴリ
Z)は insert同様に自動スペースを抑制します。注記: U+0020など簡易入力スペースを正しいスペースに補正する用途。
- ideograph-alpha
- 表意文字と非表意文字アルファベット間に追加スペース挿入。 § 8.4.1 スクリプト間スペース参照。
- ideograph-numeric
- 表意文字と非表意数字間に追加スペース挿入。 § 8.4.1 スクリプト間スペース参照。
- punctuation
-
言語固有の組版慣習に従い、句読点周辺に自動でノーブレークスペースを挿入。
現行標準では、要素のコンテンツ言語がフランス語の場合、 狭ノーブレークスペース(U+202F)やノーブレークスペース(U+00A0)を フランス組版ガイドライン通り挿入します。 それ以外の言語では効果なし。 今後の仕様で他言語への自動スペース追加もありうる。
- auto
-
UAが組版品質の高いスペース挿入セットを選択。
実行環境ごとに値が異なる場合もあり。
注記: このスペース値はOSプラットフォーム慣習と一致する場合もしない場合もある。
このプロパティのスペースはword-spacingや letter-spacingと加算的に作用します。 letter-spacing値(あれば)によるスペースは text-autospaceで作られるスペースに加算されます。 word-spacingにも同様。
要素境界で追加スペース量は、その境界を含む最内要素が決定・描画します。
8.4.1. スクリプト間スペース
ideograph-alphaおよび ideograph-numeric値は、 特定文字クラス間で直接隣接する場合(間に非ゼロmargin・border・paddingや他の文字(引用符やスペース等)がない場合)に 境界へスペースを挿入します。 このキーワードで挿入されるスペース量はCJKアドバンス値の1/8、つまり0.125icです。
注記: 間隔慣習は様々ですが、値は1/4ic~1/8ic程度で、 金属活字時代は1/4icが多く、プロポーショナル組版では1/6ic以下が一般的です。 初期値normalでデフォルト挿入されるため、 CSSでは干渉を控えて1/8icを採用しています。 今後のモジュールで間隔量の制御が追加される可能性があります。
8.5. CJK句読点のスペース制御: text-spacing-trim プロパティ
| 名前: | text-spacing-trim |
|---|---|
| 値: | <spacing-trim> | auto |
| 初期値: | normal |
| 適用対象: | text |
| 継承: | yes |
| パーセンテージ: | N/A |
| 算出値: | 指定キーワード |
| 正規順序: | 文法通り |
| アニメーション型: | 離散 |
同一行かつ同一インライン整形コンテキスト内のCJK句読点周りのスペースを 文字クラス規則で制御し、位置や隣接文字に応じて半角・全角を自動切り替えできます。
値の定義:
<spacing-trim> = space-all | normal | space-first | trim-start | trim-both | trim-all
- space-all
- 全ての全角句読点は全角グリフ(スペースあり)で表示。
- normal
- 行頭の全角始まり句読点は全角グリフ(スペースあり)で表示。 行末の全角終わり句読点は半角グリフ(詰め)で表示(均等割付前に収まらない場合)、 そうでない場合は全角グリフ。 句読点間のスペースは下記の通り折り畳む。
- trim-both
- 行頭の全角始まり句読点は半角グリフ(詰め)で表示、 行末の全角終わり句読点も半角グリフ(詰め)で表示。 句読点間のスペースは下記の通り折り畳む。
- space-first
-
全角始まり句読点は
ブロックコンテナの最初の行および強制改行直後の行では全角グリフ(スペースあり)で表示。
それ以外はnormalと同じ。
この値は互換目的で存在します。
この値は既存の中国語・日本語コンテンツの整形調整用で、 trim-bothが組版的に適切でも、 既に先頭行にspace-all的表示を期待して作成されている場合に使う。
特に、UA間でhanging-punctuationの信頼性がないため、 既存コンテンツ(特にePub等)は段落字下げ代わりにU+3000の全角スペースを使い、 段落先頭に句読点が来て字下げぶら下げをしたいときはスペースを省略することで対応している。 trim-bothを先頭行に使うと 実質的な字下げが消え、段落最初の行の区別が失われてしまう。
このような全角スペースによる字下げは HTML/CSSの内容とスタイルの分離思想に反し、 hanging-punctuationやtext-indentで段落整形制御すべきである。 そうすれば文書の意味を保ちつつ、スタイルだけで自由に切り替え可能になる。 § 8.5.3 日本語段落先頭の慣習CSS参照。
さらに、行末の挙動は normalやtrim-start値に合わせており、 trim-both値とは異なり、 均等割付前に収まらない場合のみグリフを詰める。 組版改善効果は限定的だが、 space-allのレガシー挙動に近く 互換性懸念が少ない。
- trim-start
- 行頭の全角始まり句読点は半角グリフ(詰め)で表示。 他はnormalと同じ。
- trim-all
- 全角始まり句読点・全角終わり句読点・ 全角中点句読点を全て半角グリフで表示。 行中位置や隣接文字は問わない。
- auto
-
UAが組版品質の高いスペースセットを選択。
実行環境ごとに値が異なる場合もあり。
注記: このスペース値はOSプラットフォーム慣習と一致する場合もしない場合もある。
| 値 | 行頭詰め | 行末詰め | 隣接ペア詰め | 全箇所詰め |
|---|---|---|---|---|
| space-all | なし | |||
| normal | なし | 収まらない場合のみ | あり | なし |
| space-first | 最初の行を除きあり | |||
| trim-start | あり | |||
| trim-both | あり | |||
| trim-all | 全て詰め | |||
| auto | UA依存・プラットフォーム依存 | |||
8.5.1. 全角句読点のスペース折り畳み
全角文字は通常、標準漢字(例:水 U+6C34)と同じアドバンス幅を持つグリフですが、 多くの全角句読点グリフは全角デザイン空間の一部しか使用しません。 そのため、こうした句読点は常に全角で組まれるとは限りません。 text-spacing-trimの複数値で、 どのタイミングで半角(通常は漢字の半分幅)・全角で組むか制御できます。
指定通りにテキストを組むため、UAは次のいずれかを行う必要があります:
- グリフが全角で半角にすべき場合は余白部分をトリム(カーニング)する
- グリフが半角で全角にすべき場合は余白を追加する
UAは、フォントで実装されていればOpenType haltやvhal機能を使って
グリフのトリム処理をしてもよいです。
hwid機能や他の半角グリフ代替は使ってはなりません(形状が変わってしまうため)。
一部フォントは全角句読点にプロポーショナルグリフを使います。 グリフ形状で全角・半角を区別できない場合(フォント機能等がない場合)、 そのプロポーショナルグリフのアドバンス幅は 全角・半角両方と見なし、UAはスペース追加・削除をしてはなりません。
注記: 標準漢字のアドバンス幅は
OpenType ideoやidtpベースライン(反対の書字方向)や
水 U+6C34のアドバンス幅で判定可能。
(一部フォントは圧縮されて正方形でないため反対書字方向の値が必要)。
詳細はOpenType仕様参照。
水 U+6C34、卜 U+535C、一 U+4E00の幅が揃っていない場合は
プロポーショナル漢字フォントなので信頼できない。
一部フォントの全角句読点は余白が小さすぎてトリムできません。 UAは、グリフのバウンディングボックスやメトリクス、フォント機能で トリムが切断・衝突・過剰カーニングになると判断した場合、トリムしない選択もできます。
text-spacing-trimがtrim-all の場合、UAはこうした全角グリフの余白を文脈に関わらず必ず折り畳まなければなりません。 それ以外の場合、text-spacing-trimが space-all(またはフォントがプロポーショナル全角句読点)の場合を除き、 UAは下記のように行内隣接時のみ折り畳みます:
-
全角始まり句読点は、前の文字が次のいずれかなら半角で表示:
-
全角始まり句読点
-
全角中点句読点
-
U+3000(全角スペース)
-
同じかより大きいfont-sizeの全角終わり句読点
-
Unicode一般カテゴリ
Psの文字
それ以外は全角で表示。
-
-
全角終わり句読点は、次の文字がいずれかなら半角で表示:
-
全角終わり句読点
-
全角中点句読点
-
U+3000(全角スペース)
-
より大きいfont-sizeの全角始まり句読点
-
Unicode一般カテゴリ
Peの文字
それ以外は全角で表示。
-
| 組み合わせ | サンプルペア | 表示例 |
|---|---|---|
| 始まり—始まり | 〔+( | 〔( |
| 中点—始まり | ・+( | ・( |
| 終わり—始まり | 〕+( | 〕( |
| 全角スペース—始まり | +( | ( |
| 終わり—終わり | )+〕 | )〕 |
| 終わり—中点 | )+・ | )・ |
| 終わり—全角スペース | )+ | ) |
8.5.2. テキストスペース文字クラス
このプロパティの文脈では、以下の定義が適用されます:
クラスとUnicodeコードポイントは見直し中で、 Unicodeの新規追加文字に対応するため一部変更が必要です。[Issue #9503]
- 表意文字
- 以下の基底文字を持つ全ての組版文字単位を含みます。[CSS-TEXT-3]
- 非表意文字アルファベット
-
UnicodeのLetters [L*] とMark [M*] 一般カテゴリに属する全ての組版文字単位を含みます。ただし以下の場合は除外:
- 表意文字と定義されている場合。
- [UAX11]で東アジア全角(F)分類された場合。
- text-orientationプロパティ、 またはtext-combine-uprightプロパティで 縦書きで立て組みされる場合。
- 非表意数字
-
UnicodeのDecimal Digit Number [Nd] 一般カテゴリに属する全ての組版文字単位を含みます。ただし以下の場合は除外:
- [UAX11]で東アジア全角(F)分類された場合。
- text-orientationプロパティ、 またはtext-combine-uprightプロパティで 縦書きで立て組みされる場合。
- 全角始まり句読点
- CJK記号・句読点ブロック(U+3000–U+303F)内の、Unicodeカテゴリ
Psの始まり句読点、 または[UAX11]で東アジア全角(F)分類されたもの。 LEFT SINGLE QUOTATION MARK (U+2018)とLEFT DOUBLE QUOTATION MARK (U+201C)も含む。 トリム時は左側(横書き)または上側(縦書き)半分をカーニング。 - 全角終わり句読点
- CJK記号・句読点ブロック(U+3000–U+303F)内の、Unicodeカテゴリ
Peの終わり句読点、 または[UAX11]で東アジア全角(F)分類されたもの。 RIGHT SINGLE QUOTATION MARK (U+2019)とRIGHT DOUBLE QUOTATION MARK (U+201D)も含む。 全角コロン句読点や全角ドット句読点も含む可能性(下記参照)。 トリム時は右側(横書き)または下側(縦書き)半分をカーニング。 - 全角中点句読点
- MIDDLE DOT (U+00B7)、HYPHENATION POINT (U+2027)、カタカナ中点 (U+30FB)も含む。 全角コロン句読点や全角ドット句読点も含む可能性(下記参照)。
- 全角コロン句読点
- FULLWIDTH COLON (U+FF1A)とFULLWIDTH SEMICOLON (U+FF1B)を含む。
- 全角ドット句読点
- IDEOGRAPHIC COMMA (U+3001)、 IDEOGRAPHIC FULL STOP (U+3002)、 FULLWIDTH COMMA (U+FF0C)、 FULLWIDTH FULL STOP (U+FF0E)。
全角コロン句読点と全角ドット句読点を 全角終わり句読点とするか、 全角中点句読点とするかは グリフボックス内の描画位置によります。 句読点が中央なら中点句読点として扱い、 左側(横書き)や上側(縦書き)に描かれてもう一方が空白なら終わり句読点として扱い、必要に応じてトリムします。
UAは全角コロン句読点や全角ドット句読点を 全角終わり句読点または全角中点句読点のいずれかに分類しなければなりません。 言語慣習や書字方向(横書き/縦書き)、フォント情報を考慮して判定可能です。 必要に応じて任意のカテゴリに追加文字を加えても構いません。
| コロン句読点 | ドット句読点 | |
|---|---|---|
| 簡体字中国語(横書き) | 終わり | 終わり |
| 簡体字中国語(縦書き) | 終わり | 終わり |
| 繁体字中国語 | 中点 | 中点 |
| 韓国語 | 中点 | 終わり |
| 日本語 | 中点 | 終わり |
中国語フォントについては、標準慣習が必ずしも守られていないことがある点に留意。
8.5.3. CSSによる日本語段落先頭の慣習
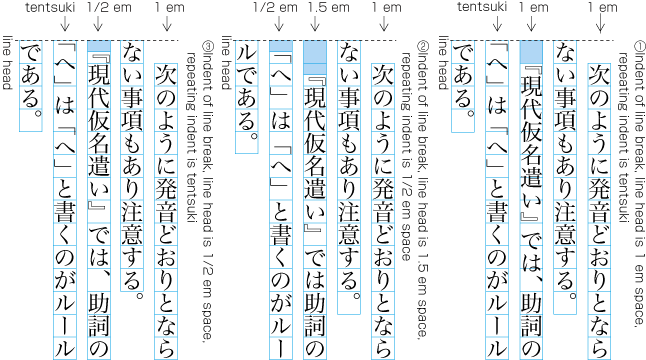
行頭の括弧の位置関係 [JLREQ]
UAスタイルシートがp { margin: 1em 0; }の場合、CSSで日本語組版方式は以下のルールで実現できます:
-
字下げ端・行頭両方に括弧を詰める(第一方式):
p { /* Flush alignment */ margin: 0; text-indent: 1em; text-spacing-trim: trim-both; } -
全行で括弧の全角スペースを維持(第二方式):
p { /* Fullwidth alignment */ margin: 0; text-indent: 1em; text-spacing-trim: space-all; } -
先頭行は字下げ内に括弧をぶら下げ、他の行は行頭に詰める(第三方式):
p { /* Hanging alignment */ margin: 0; text-indent: 1em; text-spacing-trim: trim-both; hanging-punctuation: first; }
8.6. 文字クラススペースのショートハンド: text-spacingプロパティ
| 名前: | text-spacing |
|---|---|
| 値: | none | auto | <spacing-trim> || <autospace> |
| 初期値: | 個別プロパティ参照 |
| 適用対象: | text |
| 継承: | yes |
| パーセンテージ: | N/A |
| 算出値: | 指定キーワード |
| アニメーション型: | 離散 |
| 正規順序: | 文法通り |
このプロパティはtext-spacing-trimとtext-autospaceを同時に設定するショートハンドです。 値の意味は次の通り:
- none
- 全てのtext-spacing機能をオフにします: text-spacing-trimをspace-allに、 text-autospaceをno-autospaceに設定。
- auto
- text-spacing-trimとtext-autospace両方をautoに設定します。
- <spacing-trim>
- text-spacing-trimを指定値に設定。 <autospace>値がなければ、 text-autospaceは初期値に設定。
- <autospace>
- text-autospaceを指定値に設定。 <spacing-trim>値がなければ、 text-spacing-trimは初期値に設定。
注記: normalは text-spacing-trimとtext-autospace両方の初期値なので、 text-spacing: normalは 両方を初期値にリセットします。
8.7. 要素境界をまたぐシェーピング
次のいずれかに該当する場合、 2つの組版文字単位の間のインラインボックス境界で テキストのシェーピングを分割しなければなりません:
- 2つの組版文字単位間のインライン軸に margin、 border、 padding のいずれかが非ゼロで区切られる場合
- vertical-alignがbaselineでない場合
- 境界が双方向分離境界の場合
書式変更が実際にない場合や、グリフ自体に影響しない変更(テキスト装飾など)のみなら、 インラインボックス境界でテキストシェーピングを分割してはなりません。
その他の場合でも、フォント技術の制約下で合理的・可能な場合は インラインボックス境界でシェーピングを分割すべきでありません。
境界越えで可能だが合理的でない例は、 グリフ選択に前後20文字の文脈が必要なフォントの場合で、 境界をまたいで前後のテキスト全体を渡すのは複雑です。 UAはこうしたケースに対応できるが、 現代の書記体系で本質的に必要なものではないため必須ではありません。
境界越えで不可能な例は、 単語"and"の途中でフォントウェイトが変わり、 "and"全体が合字でアンパサンド(&)になるフォントの場合です。
9. 端部効果
端部効果は、 ブロック内の行の字下げ(text-indent) や行頭・行末で内容の測定方法(hanging-punctuation)を制御します。
9.1. 1行目の字下げ: text-indentプロパティ
| 名前: | text-indent |
|---|---|
| 値: | [ <length-percentage> ] && hanging? && each-line? |
| 初期値: | 0 |
| 適用対象: | ブロックコンテナ |
| 継承: | yes |
| パーセンテージ: | ブロックコンテナ自身のインライン軸内寸法基準 |
| 算出値: | 算出<length-percentage>値+指定キーワード |
| 正規順序: | 文法通り |
| アニメーション型: | 算出値型による |
このプロパティはブロック内のインライン内容各行に適用される字下げを指定します。 字下げは行ボックスの開始端にmarginとして適用されます。
each-lineやhangingキーワードで 別途指定がない限り、 要素の最初に整形された行のみに適用されます。[CSS-PSEUDO-4] 例えば、匿名ブロックボックスの最初の行は、親要素の最初の子の場合のみ影響します。
値の意味:
- <length>
- 絶対長さで字下げ量を指定。
- <percentage>
-
ブロックコンテナ自身の論理幅に対する割合で字下げ量を指定。
パーセンテージは0として内在サイズ算出時に扱われますが、 レイアウト時は通常通り解決されます。
注記: この指定は要素のオーバーフローにつながる場合があります。 パーセンテージ字下げと内在サイズ算出の併用は非推奨です。
- each-line
- 字下げは各ブロックコンテナの1行目と、強制改行後の各行に適用されます(ソフト折返し後は適用されません)。
- hanging
- どの行が影響されるかを反転します。
左から右書き・フロートなしのテキストでtext-alignがstart、text-indentが5emなら、 最初の行は5em分字下げされて始まります:
CSS1から、'text-indent'プロパティ を'5em'に設定することで ブロック要素の最初の行を 5em字下げできます。
hangingキーワードを追加すると、 最初の行は詰め、他の行が5em字下げされます:
CSS3では
ブロック要素の他行を
'text-indent'プロパティで
'hanging 5em'と指定することで
5em字下げできます。
段落中ほどに
数式があり
中央揃えされている場合:
x + y = z
数式後の最初の行は字下げされず(新段落開始に見えないため)。
ただし(詩やコードなど)折返しで十分な長さになった各行に字下げしたい場合もある。 下記例ではtext-indentに3em hanging each-lineを指定し、 詩の3行目がソフト折返しで右端でぶら下げ字下げになります:
短い行なら 折返し不要ですが 長く続くと たまに ソフト改行で ページ内に収まります。
注記: text-indent プロパティは継承されるため、 ブロック要素に指定すると子のinline-block要素にも影響します。 そのためtext-indent: 0を display: inline-block指定要素にも付けるのが望ましい場合があります。
9.2. 行端のぶら下げグリフ
行の開始端や終了端にあるグリフがぶら下げされる場合、 行内容の収まり・整列・均等割付の測定には含まれません。 行の整列/均等割付によっては、記号が行ボックス外に配置されることがあります。 ぶら下げグリフは 内在サイズ(最小内容サイズ・ 最大内容サイズ)や、それに由来するサイズを計算する際にも無視されます。 (この測定とカーニングの関係は現時点でUA定義です。 CSSWGではこの点への助言を歓迎しています。)
ぶら下げグリフは親インラインボックス内に収まり、 テキスト均等割付にも参加しますが、 行にどれだけ内容が収まるか・均等割付で内容をどれだけ伸縮するか・内容の行ボックス内配置には 文字アドバンスが測定されません。 実質的には、ぶら下げグリフの文字アドバンスは 影響端に追加の負のmarginとして再解釈され、他は通常通りレイアウトされます。 溢れたぶら下げグリフは 通常インクオーバーフローとして扱い、 不要なスクロールバーを防ぎますが、 編集可能な場合やその他ユーザーに有用な場合は スクロール可能オーバーフローとして扱っても構いません。[CSS-OVERFLOW-3]
場合によっては、行末のグリフが 条件付きぶら下げ になることがあります: これは均等割付前に収まらない場合のみぶら下げされます。 行内容の収まり測定には含まれませんが、 収まらない部分だけがぶら下げとなります。 条件付きぶら下げグリフは 最小内容サイズやそれに由来するサイズ計算には無視されますが、 最大内容サイズには含まれます。
インライン軸の非ゼロボーダー・パディングが ぶら下げ可能グリフと行端の間にある場合、 グリフはぶら下げされません。 例えば、インラインボックスの終端にpaddingがある場合、 末尾のピリオドは行端でぶら下げされません。
隣接する複数グリフを同時にぶら下げできますが、 ぶら下げ可能数の制限も指定可能です (例:両端でぶら下げできる句読点は最大1文字など)。
9.2.1. ぶら下げ句読点: hanging-punctuationプロパティ
| 名前: | hanging-punctuation |
|---|---|
| 値: | none | [ first || [ force-end | allow-end ] || last ] |
| 初期値: | none |
| 適用対象: | text |
| 継承: | yes |
| パーセンテージ: | n/a |
| 算出値: | 指定キーワード |
| 正規順序: | 文法通り |
| アニメーション型: | 離散 |
このプロパティは、句読点がある場合にそれをぶら下げし、 行ボックス外(または字下げ内)に配置できるかを制御します。
注記: ブロックコンテナに十分なpaddingがない場合、 hanging-punctuationでオーバーフローが発生することがあります。
値の意味:
- none
- 句読点はぶら下げされません。
- first
- 要素の最初に整形された行の開始端にある 括弧・引用符・全角スペースはぶら下げされます。 これはUnicodeカテゴリPs, Pf, Piの全ての文字、 ASCII引用符U+0027 'アポストロフィ, U+0022 "引用符、 全角スペースU+3000に適用されます。
- last
- 要素の最後に整形された行の終了端にある括弧・引用符はぶら下げされます。 これはUnicodeカテゴリPe, Pf, Piの全ての文字、 ASCII引用符U+0027 'アポストロフィ, U+0022 "引用符に適用されます。
- force-end
- 行末の終止記号・カンマはぶら下げされます。
- allow-end
- 行末の終止記号・カンマは条件付きぶら下げされます。
行の両端でぶら下げできる句読点は最大1文字のみです。
終止記号・カンマでぶら下げ可能なのは以下:
| U+002C | , | COMMA |
| U+002E | . | FULL STOP |
| U+060C | ، | ARABIC COMMA |
| U+06D4 | ۔ | ARABIC FULL STOP |
| U+3001 | 、 | IDEOGRAPHIC COMMA |
| U+3002 | 。 | IDEOGRAPHIC FULL STOP |
| U+FF0C | , | FULLWIDTH COMMA |
| U+FF0E | . | FULLWIDTH FULL STOP |
| U+FE50 | ﹐ | SMALL COMMA |
| U+FE51 | ﹑ | SMALL IDEOGRAPHIC COMMA |
| U+FE52 | ﹒ | SMALL FULL STOP |
| U+FF61 | 。 | HALFWIDTH IDEOGRAPHIC FULL STOP |
| U+FF64 | 、 | HALFWIDTH IDEOGRAPHIC COMMA |
UAは必要に応じて他の文字も含めて構いません。
注記: UAが他の文字を含める場合、CSSワーキンググループに追加報告をお願いします。

p{ text-align : justify; hanging-punctuation : allow-end; }

p{ text-align : justify; hanging-punctuation : force-end; }
allow-endの場合、1行目の句読点はぶら下げされません(収まっているため)。 force-endの場合は強制的にぶら下げされます。 均等割付の測定はぶら下げ句読点を除外し、行が拡張されると句読点は行外に押し出されます。
9.3. 双方向性と行ボックス
start側とend側は 行ボックスのインライン基底方向で決まります。 通常は一致しますが、 インライン基底方向は行ボックスごとに独立しており、 インライン基底方向は包含ブロックや 双方向段落とは別です。 行ボックスのインライン基底方向は text-align-all、 text-align-last、 text-indent、 hanging-punctuationなどに影響し、 内容の位置・整列に関係します。 インライン内容の整形や順序には影響せず、 (これはUnicode双方向アルゴリズムと CSS Writing Modes [UAX9] [CSS-WRITING-MODES-4]で制御されます)。
多くの場合、行ボックスのインライン基底方向は 包含ブロックの 算出directionで決まります。 ただし、包含ブロックがunicode-bidi: plaintextの場合 [CSS-WRITING-MODES-4]:
- 双方向段落(行ボックスが含む内容の段落) に強い方向性がある場合、 行ボックスのインライン基底方向はその方向性に従う。
- 行ボックスが空の場合 (atomic inlineや文字(改行以外)を含まない)、 または強い方向性がない場合(弱・中立文字のみ)、 そのインライン基底方向は前の行ボックス(あれば)から継承、 それが最初の行ボックスなら包含ブロックのdirectionプロパティから決定。 (この結果、RTLの行ボックス内容がLTR基底方向になる場合もある。)
<block>がstart揃えの整形済みブロック
(display: block; white-space: pre; text-align: start)
だとすると、各行は交互に右揃えになります:
< block style = "unicode-bidi: plaintext" > français فارسی français فارسی français فارسی</ block >
< para style = "display: block; direction: rtl; unicode-bidi:plaintext" > “< quote style = "unicode-bidi:plaintext" > שלום!</ quote > ”, they said.</ para >
< textarea style = "direction: rtl; unicode-bidi:plaintext" > Hello!</ textarea >
unicode-bidi: plaintextのため、 “Hello!”はLTRで組まれ(感嘆符が右側)左揃え、 包含ブロックのRTLdirectionは無視されます。 これにより次の空行もLTRとなり、 その行のキャレットは左端に表示されます。 ただし、先頭の空行は前の行がないため、包含ブロックのRTL方向を継承し右揃えになります。
付録A: テキスト処理の操作順序
この付録は規定的です。
以下はテキスト処理の順序定義です。 (実装は結果レイアウトが同じならこの順序に拘束されません。)
- § 4.2 空白トリム: white-space-trimプロパティ
- 空白処理第I部(折返し前)
- § 2.2 単語間拡張: word-space-transformプロパティとテキスト変換
- text combination [CSS-WRITING-MODES-4]
- text orientation [CSS-WRITING-MODES-4]
- テキスト折返し(1行ごとに次を適用):
- 均等割付(グリフ選択・折返しに影響し得るため再度そのステップに戻る場合あり)
- テキスト整列
- テキストグループ整列
付録B: プレーンテキストへの変換
この付録はプレーンテキストコピー&ペースト操作時は規定的です。
CSSレンダリング文書をプレーンテキストに変換する際は、以下を期待:
- text-transformプロパティは効果なし。
- white-space-trimと§ 4.3.1 第I部: 折畳みと変形が適用され、 折畳み可能な空白が ブロックの先頭や 強制改行直後は削除される。
付録C: UAデフォルトスタイルシート
この付録は参考情報です。 UA開発者がHTMLのデフォルトスタイルシートを実装する際の参考ですが、 必ずしも従う必要はありません、自由に修正可能です。
/* option要素を揃えて表示 */ option{ text-align : match-parent; } /* textarea内の空白折畳み禁止 */ textarea{ white-space-collapse : preserve !important; } /* 整形済みテキストで文字グリッド維持 */ pre, code, kbd, samp, tt{ text-spacing : none; } /* pre整形ブロックへのぶら下げ句読点継承抑止 */ pre{ hanging-punctuation : none; }
付録D: スクリプトとスペース分類
この付録は規定的です。
組版挙動は言語によって多少異なりますが、書記体系によって大きく異なります。 この付録ではUnicode6.0のいくつかの一般的なスクリプトを 均等割付やスペース挙動で分類します。 カテゴリ記述は説明的であり規定的ではありません; 判定基準は均等割付機会の優先度です。
- ブロックスクリプト
- CJKおよびそれに準じる全てのWide文字
(East Asian Width [UAX11]参照)。
以下のUnicodeスクリプトが含まれます:
Bopomofo, Han, Hangul, Hiragana, Katakana, Yi。
East
Asian Width属性が
WideやFullwidthの文字も含みますが、Ambiguous文字は書記体系が中国語・韓国語・ 日本語の場合のみ含みます。 - クラスタ型スクリプト
- クラスタ型スクリプトは離散単位を持ち、単語境界でのみ分割されますが、 明示的な単語区切り文字は使いません。 スペース伸長を優先しますが、均等割付のため文字間スペースも許容します。 クラスタ型スクリプトには、次のUnicodeスクリプトが含まれます(ただし限定せず): Khmer, Lao, Myanmar, New Tai Lue, Tai Le, Tai Tham, Tai Viet, Thai
- 筆記体スクリプト
-
筆記体スクリプトは均等割付やletter-spacingで
文字間に隙間を入れません。
以下のUnicodeスクリプトが含まれます:
Arabic,
Hanifi Rohingya,
Mandaic,
Mongolian,
N’Ko,
Phags Pa,
Syriac
注記: インド系スクリプトのベースライン接続型(DevanagariやGujaratiなど)は筆記体スクリプトに含まれませんが、 文字間に隙間を入れます。 Indic Layout Requirements [ILREQ]参照。
UAはUnicode対応アップデート時にこのリストも更新し、 未符号化の新たな筆記体スクリプトも今後対応すべきです。 CSSWGへの仕様更新依頼も推奨します。
付録E: 文字とプロパティ
この付録は規定的です。
UnicodeはCSS組版で参照されるコードポイントレベルのプロパティを4つ定義しています:
- 東アジア幅プロパティ
- Unicode Standard Annex #11 [UAX11]で定義され、Unicode Character Database [UAX44]で
East_Asian_Widthプロパティとして与えられます。 - 一般カテゴリ
- Unicode Standard Annex #44 [UAX44]で定義され、Unicode Character Database [UAX44]で
General_Categoryプロパティとして与えられます。 - スクリプトプロパティ
- Unicode Standard Annex #24 [UAX24]で定義され、Unicode Character Database [UAX44]で
Scriptプロパティとして与えられます。 (UAはこのマッピングにScriptExtensions.txtの割当も含めなければなりません。) - 縦書き方向プロパティ
- Unicode Standard Annex #50 [UAX50]で定義され、Unicode Character Database [UAX44]でVertical_Orientationプロパティとして与えられます。
Unicodeは個々のコードポイントのプロパティを定義しますが、時に組版文字単位のプロパティ判定が必要です。 CSS Textの目的では、 組版文字単位のプロパティは 最初のグラフェムクラスターの基底文字で決定します。ただし例外が2つあります:
- CommonスクリプトのEnclosing Mark (
Me)で構成されたグラフェムクラスターは、CommonスクリプトのOther Symbols (So)とみなされ、Unicodeプロパティは置換文字(U+FFFD)と同様とします。 - 基底がSpace Separator (
Zs)のグラフェムクラスターはModifier Symbols (Sk)とみなし、East Asian Widthプロパティは基底に従い、他のプロパティは最初の結合文字に従います。
付録F: コンテンツ書記体系の識別
この付録は規定的です。
多くの言語には推奨書記体系がありますが、複数持つ場合や、他言語書記体系で転写される場合もあります。
例えば多くの言語はラテン文字転写(ローマ字)があり、ラテン書記体系で書けます。
転写文は通常、その書記体系の組版慣習を採用します:
例えば日本語ローマ字や中国語ピンインはラテン文字・単語間スペースを使い、ラテン系の改行・均等割付慣習に従います。
別例として、歴史的な表意韓国語(ko-Hani)は単語間スペースを使わず、中国語に近い組版が必要です(現代韓国語とは異なる)。
HTMLやその他文書言語で、言語識別にBCP47タグを使いコンテンツ言語を宣言する場合、
著者はスクリプトサブタグで異例の書記体系を区別・明示できます。[BCP47]
例えば、ラテン書記体系を使う場合-Latnサブタグを追加し、ja-Latn(日本語ローマ字表記)などとします。
他の書記体系用のサブタグもISOのCode for the Representation of Names of ScriptsやISO15924スクリプトタグレジストリにあります。[ISO15924]
zh-Latn- 中国語、ラテン文字転写。
ko-Hani- 韓国語、漢字(中国語表意文字)表記。
tr-Arab- トルコ語、アラビア文字表記。
mn-Cyrl- モンゴル語、キリル文字表記。
mn-Mong- モンゴル語、伝統的モンゴル文字表記。
ただしBCP47スクリプトサブタグは、特定書記体系と強く結びついた言語には一般に使われません(むしろ推奨されません)。
その場合は他指定がない限り当該書記体系が暗黙的に使われるとします。[BCP47] IANAはSuppress-Scriptフィールドで
各言語の最も一般的な書記体系をlanguage
subtag registryで管理しています。
注記: 言語タグについては国際化ワーキンググループ の “HTMLとXMLの言語タグ” や “言語タグの選択”も参照。
書記体系が明示されていない場合、 UAは宣言されたコンテンツ言語の最も一般的な書記体系を 行分割や均等割付など言語感知組版挙動に採用すべきです。 ただし著者が明示的に他の書記体系を宣言した場合はそれを優先します。 UAが特定言語+書記体系組み合わせについて知識がない場合は、 宣言された書記体系の組版慣習(必要なら他言語の慣習を流用)を使い、 宣言言語の暗黙的書記体系の慣習は使ってはなりません。
言語と最も一般的な書記体系の完全な対応表は本書範囲外です。 ただしUAは少なくとも以下を仮定すべきです:
- コンテンツ言語が中国語で、書記体系が未指定の場合、 または任意のコンテンツ言語で、書記体系にHant, Hans, Hani, Hanb, BopoのISOスクリプトコードが指定された場合、 書記体系は中国語書記体系とする。
- コンテンツ言語が日本語で、書記体系が未指定の場合、 または任意のコンテンツ言語で、書記体系にJpan, Hrkt, Hira, KanaのISOスクリプトコードが指定された場合、 書記体系は日本語書記体系とする。
- コンテンツ言語が韓国語で、書記体系が未指定の場合、 または任意のコンテンツ言語で、書記体系にKore, Hang, JamoのISOスクリプトコードが指定された場合、 書記体系は韓国語書記体系とする。
-
書記体系は
不明とみなされるのは、
コンテンツ言語自体が不明な場合、
あるいは明示的に不明書記体系を指定した場合のみ。
注記: 書記体系情報の単なる省略で コンテンツ言語が宣言されている場合は 書記体系が暗黙的に使われるのであり、不明ではありません。
付録G: 小書き仮名マッピング
この付録は規定的です。
| 小書き | 正書き |
|---|---|
| ぁ U+3041 | あ U+3042 |
| ぃ U+3043 | い U+3044 |
| ぅ U+3045 | う U+3046 |
| ぇ U+3047 | え U+3048 |
| ぉ U+3049 | お U+304A |
| ゕ U+3095 | か U+304B |
| ゖ U+3096 | け U+3051 |
| 𛄲 U+1B132 | こ U+3053 |
| っ U+3063 | つ U+3064 |
| ゃ U+3083 | や U+3084 |
| ゅ U+3085 | ゆ U+3086 |
| ょ U+3087 | よ U+3088 |
| ゎ U+308E | わ U+308F |
| 𛅐 U+1B150 | ゐ U+3090 |
| 𛅑 U+1B151 | ゑ U+3091 |
| 𛅒 U+1B152 | を U+3092 |
| ァ U+30A1 | ア U+30A2 |
| ィ U+30A3 | イ U+30A4 |
| ゥ U+30A5 | ウ U+30A6 |
| ェ U+30A7 | エ U+30A8 |
| ォ U+30A9 | オ U+30AA |
| ヵ U+30F5 | カ U+30AB |
| ㇰ U+31F0 | ク U+30AF |
| ヶ U+30F6 | ケ U+30B1 |
| 𛅕 U+1B155 | コ U+30B3 |
| ㇱ U+31F1 | シ U+30B7 |
| ㇲ U+31F2 | ス U+30B9 |
| ッ U+30C3 | ツ U+30C4 |
| ㇳ U+31F3 | ト U+30C8 |
| ㇴ U+31F4 | ヌ U+30CC |
| ㇵ U+31F5 | ハ U+30CF |
| ㇶ U+31F6 | ヒ U+30D2 |
| ㇷ U+31F7 | フ U+30D5 |
| ㇸ U+31F8 | ヘ U+30D8 |
| ㇹ U+31F9 | ホ U+30DB |
| ㇺ U+31FA | ム U+30E0 |
| ャ U+30E3 | ヤ U+30E4 |
| ュ U+30E5 | ユ U+30E6 |
| ョ U+30E7 | ヨ U+30E8 |
| ㇻ U+31FB | ラ U+30E9 |
| ㇼ U+31FC | リ U+30EA |
| ㇽ U+31FD | ル U+30EB |
| ㇾ U+31FE | レ U+30EC |
| ㇿ U+31FF | ロ U+30ED |
| ヮ U+30EE | ワ U+30EF |
| 𛅤 U+1B164 | ヰ U+30F0 |
| 𛅥 U+1B165 | ヱ U+30F1 |
| 𛅦 U+1B166 | ヲ U+30F2 |
| 𛅧 U+1B167 | ン U+30F3 |
| ァ U+FF67 | ア U+FF71 |
| ィ U+FF68 | イ U+FF72 |
| ゥ U+FF69 | ウ U+FF73 |
| ェ U+FF6A | エ U+FF74 |
| ォ U+FF6B | オ U+FF75 |
| ッ U+FF6F | ツ U+FF82 |
| ャ U+FF6C | ヤ U+FF94 |
| ュ U+FF6D | ユ U+FF95 |
| ョ U+FF6E | ヨ U+FF96 |
付録H: 単語・文節検出
この付録は規定的です。
本仕様の一部操作は自動的な単語境界検出または文節境界検出に依存します。
両操作は類似していて、 UAがテキスト言語解析を行い、言語固有の意味ある文字列を特定します。 違いは対象単位(単語または文節)です。
概念としては容易ですが、 多言語対応の厳密な定義は難しく、特に単語・文節の概念は曖昧です。 ただしこの文脈では:
-
単語とは、意味を持つ認識可能な単位で、1文字または複数文字・音節から成る場合もあります。
注記: この概念についてはWhat is a word?参照。
-
文節とは、1つ以上の単語が概念的または文法的単位としてまとまった短いグループで、句や文の構成要素となります。
注記: これはフランス語のphrase(英語のphraseではなく文の意味)とは異なります。 日本語では文節の概念に相当します。
検出された各単語・文節の開始・終了位置は単語境界や文節境界と呼びます。 単体では境界は不可視ですが、word-space-transformやword-breakなどのプロパティで可視化される場合があります。
単語・文節検出アルゴリズムと境界位置決定はUA依存で、 辞書ベースの語彙解析、句読点や区切り文字の特定、形態素解析、機械学習など様々な要素・手法を考慮できます。
ただし、以下の制約は必須です:
- UAは、1つの組版文字単位を構成する文字間に単語・文節境界を置いてはなりません。
- UAは、行分割クラスGL, WJ, ZWJを持つ文字に隣接して単語・文節境界を置いてはなりません。 それらで区切られる2つの単語・文節は1つとみなします。[UAX14]
-
単語・文節直後に以下の文字がある場合、それらを直前の単語・文節の一部とみなす必要があります:
- 単語区切り文字
- その他スペース区切り文字
- U+200Bゼロ幅スペース
-
句読点自体は文節になりません。隣接する単語・文節に適切に付属すべきです。 例:括弧・引用符は包含する文節の一部、カンマ・セミコロンは直前文節に添付、 U+00BF逆疑問符は直後単語に添付など。
ただし、顔文字やPerlスニペット等の非慣用句読点はUAがこの原則から逸脱する場合もあります。
- 単語・文節境界判定時はインラインボックス境界やアウトオブフロー要素を無視します。 ただし、単語や文節境界が インラインボックス境界と同位置にある場合は、 境界はそのインラインボックス境界に参加する最外側要素に挿入しなければなりません。
セキュリティの考慮事項
この現行標準は新しいセキュリティ上の考慮事項を導入しません。
プライバシーの考慮事項
この現行標準は利用者がインストールしたハイフネーションおよび改行辞書情報を漏洩します。
謝辞
この現行標準は以下の方々の協力がなければ実現しませんでした: Addison Phillips, Aharon Lanin, Alan Stearns, Ambrose Li, Arnold Schrijver, Arye Gittelman, Ayman Aldahleh, Ben Errez, Bert Bos, Chris Lilley, Chris Pratley, Chris Thrasher, Chris Wilson, Dave Hyatt, David Baron, Emilio Cobos Álvarez, Eric LeVine, Etan Wexler, Frank Tang, Håkon Wium Lie, IM Mincheol, Ian Hickson, James Clark, Javier Fernandez, John Daggett, Jonathan Kew, Ken Lunde, Laurie Anna Edlund, Marcin Sawicki, Martin Dürst, Martin Heijdra, Masafumi Yabe, Masayasu Ishikawa, Michael Jochimsen, Michel Suignard, Mike Bemford, Myles Maxfield, Nat McCully, Paul Nelson, Pierre-Anthony Lemieux, Rahul Sonnad, Randy Edmunds, Richard Ishida, Shinyu Murakami, Stephen Deach, Steve Zilles, Takao Suzuki, Tantek Çelik, Xidorn Quan, Yaniv Feinberg.
変更点
このドラフトは [CSS-TEXT-3] と同期されており、CSS Text 3 §
変更点を参照してください。
レベル4固有の変更は以下に記載します。
2024年2月19日作業草案以降の主な変更点:
-
text-spacing-trimのtrim-auto値をtrim-bothに名称変更。 (Issue 10161)
-
大量の行がある場合のtext-wrap-style: balanceの行変更不可要件を緩和。 (Issue 10186)
-
text-wrap-style: balanceとline-clampの相互作用を定義。(Issue 9310)
-
math-auto値をtext-transformに追加。 (Issue 5386)
2023年10月20日作業草案以降の主な変更点:
-
強制改行後の各行に text-spacing-trim: space-firstの定義記述を復元。 (Issue 9532)
-
normalをtext-spacing-trimの初期値に設定。 (Issue 9511)
-
space-firstの行末挙動を変更。 (Issue 9736)
-
space-firstが改行後にも適用されるよう変更。 (Issue 9532)
-
全角句読点の折り畳み詳細を明確化。 (Issue 9225)
-
pre要素がデフォルトでぶら下げ句読点を継承しないようUAスタイルルールを追加。 (Issue 9689)
2023年3月29日作業草案以降の主な変更点:
-
text-wrapプロパティを2つの新プロパティ text-wrap-modeと text-wrap-styleのショートハンドとし、 text-wrap-modeが text-wrapのロングハンドとなるよう変更。 white-spaceプロパティのロングハンドとして。
-
付録G: 小書き仮名マッピングをUnicode 15.0に更新。 (Issue 8442)
-
word-break: auto-phrase word-break: manual機能の設計変更 (以前のword-boundary-detectionプロパティ案から)、 auto-phrase値を word-space-transformに追加(依存不可になったため)。 関連メカニズムも更新。
-
word-boundary-expansionをword-space-transformに名称変更。 -
NBSP以外の非カスタマイズUnicode改行制御文字がアトミックインラインルールより優先されるよう変更。 (Issue 8972)
2023年3月1日作業草案以降の主な変更点:
-
white-spaceプロパティの複数ロングハンド翻訳完了:
-
break-spacesを white-space-collapseに追加し、 全てのショートハンド値をロングハンドで表現可能化 (Issue 8256)
-
全ロングハンドキーワードをwhite-spaceショートハンドに統合
-
関連記述を更新
-
-
text-space-collapseとtext-space-trimを white-space-collapseと white-space-trimに名称変更。 (Issue 8273)
2022年12月31日作業草案以降の主な変更点:
-
text-spacingを以下のように再設計:
-
space-firstを初期値化 (Issue 2462)
-
hanging-punctuationで 先頭の全角スペースをぶら下げ可能化(プレーンテキスト由来に対応)。 (Issue 2462)
-
no-compressを text-justifyへ移動(スペース制御より均等割付に関係するため)。 (Issue 7079)
-
文脈評価対象文字に
PeとPsカテゴリも追加。 (Issue 6091) -
text-space-collapseをwhite-space-collapseに戻す名称変更。 (Issue 8273)
2022年5月5日作業草案以降の主な変更点:
- ruby値をtext-justifyに追加。 (Issue 771 Issue 779)
- text-spacing: normalをtrim-endに変更(allow-endから)。 (Issue 7055)
- text-spacing: normalでideograph-alphaとideograph-numericも適用、 UAデフォルトスタイルシートで等幅コンテキストから除外、 非ゼロmargin/border/paddingでスペース挿入を抑制、 挿入スペース量は0.125icと定義。 (Issue 6950)
- text-align: match-parentをstartに算出するよう定義(root要素にて)。 (Issue 6542)
- distributeキーワードを レガシー値エイリアスとしても、 inter-characterとして算出しても良いと定義。 どちらでも後方互換性の観点で問題ないのでUAが容易な方を選択可能。 (Issue 7322)
- trim-inner値をwhite-space-trimの discard-innerに名称変更。 (Issue 448)
2019年作業草案以降の主な変更点:
- [CSS-TEXT-3]の全文統合。
- word-spacingおよびletter-spacingでパーセンテージ指定を可能にし、 現在のfont-sizeに相対的なサイズ指定を可能化。 (Issue 2165)
- UAルールで
textareaのスペース折畳みを防止する提案。 (Issue 6309)
レベル3以降の追加点
レベル4の新機能:
-
word-break: auto-phrase(改行時に文節を自動判定してまとまり保持)
-
word-space-transform(単語区切り変換)
-
white-spaceプロパティの複数ロングハンド分割:
-
white-space-trim(要素境界の余分な空白トリム)
-
text-wrap-mode(折返し有無制御)
-
text-wrap-styleとその balance・ stable・ pretty値
-
wrap-before、 wrap-after、 wrap-inside (改行禁止・強制制御。ページ分割用
break-*プロパティに類似) -
hyphenate-character(ハイフネーション文字の明示制御)
-
hyphenate-limit-zone、 hyphenate-limit-chars、 hyphenate-limit-lines、 hyphenate-limit-last (自動ハイフネーション制御強化)
-
<string>値をtext-alignで使用可能化(小数点揃え等)
-
text-group-alignで text-alignで整列された 行ボックス群をグループ整列可能化
-
line-paddingで行頭・行末のインラインボックス内にスペース挿入
-
text-spacingで句読点周辺やスクリプト切替時の自動スペース挿入