1. インフラストラクチャ
この仕様はInfra Standardに依存しています。[INFRA]
2. はじめに
2.1. ユースケース
2.1.1. Webテキスト参照
テキストフラグメントの主なユースケースは、URLがWeb全体で正確なテキスト参照として機能することです。例えば、Wikipediaの参照はページから引用している正確なテキストにリンクできます。同様に、検索エンジンはページの先頭ではなく、ユーザーが探している答えがある場所へ誘導するURLを提供することができます。2.1.2. ユーザー共有
テキストディレクティブを使うことで、ブラウザはユーザーがテキスト選択部分でコンテキストメニューを開いたときに「ここへのURLをコピー」というオプションを実装できるかもしれません。ブラウザは選択したテキストを適切に指定したURLを生成し、そのURLの受信者に指定されたテキストが分かりやすく示されます。テキストフラグメントがなければ、ユーザーがページ内のテキストを共有したい時は、通常そのテキストをコピー&ペーストすることになりますが、その場合、受信者はページのコンテキストを失ってしまいます。2.2. リンクの有効期間
この仕様は、例えば実際のテキスト内容をURLのペイロードとして使用したり、フォールバックとして要素IDのフラグメントを許可することにより、テキストディレクティブリンクの有用な有効期間を最大化しようとしています。しかし、Web上のページはしばしば更新され、内容が変化します。そのため、このようなリンクは参照先のテキスト内容が目的のページから無くなってしまい「リンク切れ」を起こす場合があります。
この問題があってもテキストディレクティブリンクは有用です。ユーザー共有のユースケースでは、リンクは送信してから短期間のみ利用されることが多く、一時的なものです。参照やWebページのリンクのような長期間にわたって利用される場合でも、テキストディレクティブは通常のリンクに緩やかに劣化するので価値があります。また、古くなったテキストディレクティブがあることで、ユーザーがリンク作成者の意図やその後ページ内容が変わったことを理解する助けになります。
強固なテキストディレクティブリンクの作成方法については§ 4 テキストフラグメントディレクティブの生成を参照してください。
3. 説明
3.1. 指示
この仕様はユーザーエージェントがテキストの一致を「指示」する際に取るアクションを意図的に定義しません。ユーザーエージェントにより異なる体験やトレードオフが考えられます。可能なアクション例:
-
テキスト部分を視覚的に強調またはハイライトする
-
ページ移動時に自動的にその部分までスクロールする
-
該当テキスト部分でUAのページ内検索機能を起動する
-
「クリックしてテキスト部分へスクロール」通知の表示
-
該当テキスト部分がページ内に見つからない場合の通知の表示
3.2. 構文
テキストディレクティブは、フラグメントディレクティブ(§ 3.3 フラグメントディレクティブ参照)で次のフォーマットで指定されます:
#:~:text=[prefix-,]start[,end][,-suffix]
context |--match--| context
(角括弧はオプションパラメータを示します)
テキストパラメータは一致前にパーセントデコードされます。テキストパラメータ内のダッシュ(-)、アンパサンド(&)、カンマ(,)はテキストディレクティブ構文の一部と解釈されないようパーセントエンコードされます。
唯一必須のパラメータはstartです。startだけが指定された場合、その正確なテキストが最初に出現する箇所がターゲットテキストとなります。
endパラメータも指定された場合、テキストディレクティブはページ内のテキスト範囲を示します。ターゲット範囲はstartの最初の出現から、その後に現れるendの最初の出現までの範囲です。これはstartに全体のテキスト範囲を指定するのと同じですが、長いテキストディレクティブでURLが肥大化するのを防げます。
#:~:text=an%20example,text%20fragmentは、"an example"が最初に出現してから、続けて現れる"text
fragment"の最初までがターゲットテキストとなることを示します。
3.2.1. コンテキスト用語
他の2つのオプションパラメータはコンテキスト用語です。プレフィックスの後やサフィックスの前にダッシュ(-)を置くことで指定し、startやendパラメータと区別します。任意のオプションパラメータの組み合わせが可能です。
コンテキスト用語はターゲットテキストフラグメントを区別するために使います。コンテキスト用語はフラグメント直前(プレフィックス)や直後(サフィックス)のテキストを指定でき、空白も許容されます。
コンテキスト用語はターゲットテキストフラグメントには含まれず、視覚的にも指示されません。
#:~:text=this%20is-,an%20example,-text%20fragment は "this is an example text fragment" の "an
example" に一致しますが、"here is an example text" の "an example" には一致しません。
3.2.2. 双方向(BiDi)の考慮事項
URL文字列はASCIIエンコードなので、双方向テキストを組み込むサポートはありません。ただし、対象とするページ内容はLTR(左から右)、RTL(右から左)、あるいは両方(双方向/BiDi)となり得ます。このセクションは、仕様の規範的セクションで暗黙的に記述された挙動の直感的な説明を提供します。
テキストフラグメント内の各項目の文字は論理順序です。つまり、母語話者が読む順番(かつメモリ上の文字の格納順)です。
同様にprefixやstart用語は論理順で他の用語の前、suffixやendは論理順で後ろにあるテキストを特定します。
注:ユーザーエージェントは、表示時にURL文字列をUnicodeへ変換するなど、母語話者向けに視覚的な表示を工夫できますが、URLの文字列表現は純粋なASCIIのままです。
مِصر(エジプト、アラビア語)を、البحرين(バーレーン、アラビア語)が直前にある形で選択したい場合、まず各項目をパーセントエンコードします:
مِصر は "%D9%85%D8%B5%D8%B1" になります(注: UTF-8文字[0xD9,0x85]がアラビア語単語の最初(右端)の文字)。
البحرين は "%D8%A7%D9%84%D8%A8%D8%AD%D8%B1%D9%8A%D9%86" になります。
テキストフラグメントはこうなります:
:~:text=%D8%A7%D9%84%D8%A8%D8%AD%D8%B1%D9%8A%D9%86-,%D9%85%D8%B5%D8%B1
ブラウザのアドレスバーでは、自然なRTL方向で視覚的に表示され、ユーザーには次のように見えます:
:~:text=البحرين-,مِصر
3.3. フラグメントディレクティブ
既存のURLフラグメントの利用と互換性の問題を避けるため、この仕様ではフラグメントディレクティブという概念を導入します。これはURLフラグメントのうち、フラグメントディレクティブ区切り子の後ろの部分であり、区切り子が現れなければnullになり得ます。
フラグメントディレクティブ区切り子は":~:"という文字列、すなわち3連続するU+003A(:)、U+007E(~)、U+003A(:)のコードポイントです。
フラグメントディレクティブは解析され、ユーザーエージェントに何らかのアクションを実行するよう指示するディレクティブとして個別に処理されます。一つのフラグメントディレクティブ内に複数のディレクティブを記述できます。
ページ動作への影響を避けるため、著者のスクリプトとの相互作用を防ぐ目的でスクリプトからアクセス可能なAPIではこれを削除します。これにより、将来新たなディレクティブを追加してもWeb互換性リスクを回避できます。
3.3.1. フラグメントディレクティブの抽出
このセクションでは、フラグメントディレクティブがスクリプトから隠される仕組みと、それがHTML § 7.4 ナビゲーションとセッション履歴にどのように組み込まれるかについて説明します。
-
セッション履歴エントリに新しい「ディレクティブ状態」項目が含まれるようになりました
-
すべての新しいエントリは空値を持つディレクティブ状態で作成されます。新しいURLにフラグメントディレクティブが含まれていれば、それが状態値に書き込まれます(そうでなければnullのままです)。
-
フラグメントディレクティブを含む可能性のあるURLがセッション履歴エントリに書き込まれるたびに、URLからフラグメントディレクティブを抽出し、そのエントリのディレクティブ状態項目に格納します。ディレクティブを含む可能性があるのは次の4つのタイミングです:
-
通常のクロスドキュメントナビゲーションの「navigate」手順中
-
フラグメントベースの同一ドキュメントナビゲーションの「navigate to a fragment」手順中
-
pushState/replaceStateなどの同期更新時「URL and history update steps」
-
リダイレクト由来のURL用「create navigation params by fetching」手順中
-
-
フラグメントのみを変更し、新しいURLにディレクティブが指定されていない同一ドキュメントナビゲーションは、前のエントリのディレクティブ状態を引き継ぐ新しいエントリを作成します。
HTML § 7.4.1 セッション履歴でディレクティブ状態を定義します:
HTML § 7.4.1 セッション履歴へのモンキーパッチ:
ディレクティブ状態 は、セッション履歴エントリ作成時のフラグメントディレクティブの値を保持し、エントリを辿るたびにテキストハイライトなどのディレクティブを起動するために使用されます。次の内容を持ちます:
value:フラグメントディレクティブまたはnullのASCII文字列。初期値はnull。
ディレクティブ状態は、複数のセッション履歴エントリで共有される場合があります。
フラグメントディレクティブはURLから削除され、セッション履歴エントリにセットされる前にディレクティブ状態に格納されます。これにより、スクリプトAPIから見えなくなり、ページ動作に影響を与えずにディレクティブを指定できます。
ディレクティブは生の文字列ではなくディレクティブ状態オブジェクト内に格納されます。これは、同一のディレクティブ状態が複数の連続した履歴エントリで共有できるようにするためです。トラバース時、2つのエントリ間でディレクティブ状態が変化した場合のみ(=新規ハイライト等が必要な時)ディレクティブが処理されます。
セッション履歴エントリの定義に、次を追加します:
HTML § 7.4.1.1 セッション履歴エントリへのモンキーパッチ:
URLからフラグメントディレクティブ文字列を削除・返却するヘルパーアルゴリズムを追加します:
[HTML]へのモンキーパッチ:
このアルゴリズムはURLのフラグメントをフラグメントディレクティブ区切り子手前までにします。戻り値のフラグメントディレクティブは区切り子以降すべての文字を含み、区切り子自体は含みません。TODO: フラグメントが':~:'で終わる(空ディレクティブ)の場合、nullを返します。これは明示的ディレクティブ未指定扱い(既存を上書きしない)ですが、空文字列を返すべき? '#:~:'へのnavigate/pushStateで明示的にディレクティブやハイライトを解除できるよう配慮する案。フラグメントディレクティブを除去するには、URL url から、次の手順を実行する:
raw fragment に url のフラグメントを代入
fragment directive をnullにする
raw fragmentが非nullかつフラグメントディレクティブ区切り子を含む場合:
fragment directive を返す
以降の4つのモンキーパッチは、フラグメントディレクティブが含まれる可能性があるURLでセッション履歴エントリ作成時に、フラグメントディレクティブを除去してディレクティブ状態へ保存する点を修正します。
navigateの定義では:
HTML § 7.4.2.2 ナビゲーション開始へのモンキーパッチ:
ナビゲーブルなnavigableをURLurlにナビゲートするには...:
...
- navigableのongoing navigationをnavigationIdに設定
urlのスキームが"javascript"なら...
並列で次の手順を実行:
...
- urlがabout:blankならdocumentStateのoriginにinitiator originを設定
そうでなくabout:srcdocならdocumentStateのoriginにnavigableの親のアクティブドキュメントoriginを設定
historyEntryを新規セッション履歴エントリにし、そのURLをurl、document stateをdocumentStateに設定。- fragment directiveにフラグメントディレクティブを削除をurlで実行した結果を代入。
directive stateを新しいディレクティブ状態(valueにfragment directiveセット)として作成
historyEntryを新規セッション履歴エントリ(URLはurl、document stateはdocumentState、ディレクティブ状態はdirective state)に設定
navigationParamsをnullに設定
...
navigate to a fragmentの定義では:
HTML § 7.4.2.3.3 フラグメントナビゲーションへのモンキーパッチ:
ナビゲーブルnavigableでフラグメントにナビゲートするには...:
directive stateにnavigableのアクティブセッション履歴エントリのディレクティブ状態を代入
fragment directiveにフラグメントディレクティブを削除をurlで実行した結果を代入
fragment directiveがnullでなければ:
フラグメントのみ変更かつディレクティブ未指定なら、アクティブエントリのディレクティブ状態を再利用(=ハイライト維持)。historyEntryを新規セッション履歴エントリとして:
URL: url
document state: navigableのアクティブセッション履歴エントリのdocument state
scroll restoration mode: navigableのアクティブセッション履歴エントリのscroll restoration mode
ディレクティブ状態: directive state
historyHandlingが"replace"ならentryToReplaceをnavigableのアクティブセッション履歴エントリに、そうでなければnullに設定
...
URLと履歴更新手順の定義では:
HTML § 7.4.4 非フラグメント同期ナビゲーションへのモンキーパッチ:
Document documentでのURLと履歴更新手順は...:
navigableにdocumentのノードナビゲーブルを代入
activeEntryにnavigableのアクティブセッション履歴エントリを代入
fragment directiveにフラグメントディレクティブを削除をnewUrlで実行した結果を代入
historyEntryを新規セッション履歴エントリ(
documentのis initial about:blankがtrueならhistoryHandlingを"replace"にセット
historyHandlingが"push"なら:
そうでなく、fragment directiveがnullでなければ、historyEntryのディレクティブ状態のvalueにfragment directiveをセット
serializedDataがnullでなければ、history object stateをdocumentとnewEntryで復元
create navigation params by fetchingの定義では:
HTML § 7.4.5 セッション履歴エントリの充填へのモンキーパッチ:
session history entry entryでcreate navigation params by fetchingを行うには...:
これは並列実行であるassert
...
- currentURLにrequestのcurrent URLをセット
commitEarlyHintsをnullに
while (true):
requestのreserved clientがnullでなく、currentURLのorigin≠reserved clientの生成URLのoriginなら:
...
- currentURL = locationURL
fragment directiveにフラグメントディレクティブを削除をlocationURLで実行した結果を代入
entryのURLをcurrentURLにentryのURLをlocationURLに
locationURLのスキームがfetch schemeでなければ、initiator originをrequestのcurrent URLのoriginとした新規non-fetch scheme navigation paramsを返す
...
Documentは履歴エントリから生成されるため、そのURL
にはフラグメントディレクティブが含まれません。またwindowのLocation
オブジェクトはアクティブドキュメントのURL表現であり、全getterでディレクティブを除去したバージョンが返ります。
さらに、HashChangeEvent
はフラグメントの変更に応じて
セッション履歴エントリ間のURLの変化で発火しますが、ナビゲーションやトラバースでフラグメントディレクティブのみ変化した場合は
hashchangeは発火しません。
様々なエッジケースを明確化する例をいくつか示します。
window.location = "https://example.com#page1:~:hello"; console.log(window.location.href); // 'https://example.com#page1' console.log(window.location.hash); // '#page1'
初回ナビゲーションで新しいセッション履歴エントリが作成されます。エントリのURLはフラグメントディレクティブが除去され:"https://example.com#page1"、ディレクティブ状態の値は"hello"となります。ドキュメントがこのエントリから生成されるため、Web API経由のURLにはフラグメントディレクティブは含まれません。
location.hash = "page2"; console.log(location.href); // 'https://example.com#page2'
同一ドキュメント内でフラグメントだけが変更されました。これはnavigate to a fragment手順で新規履歴エントリ追加となりますが、フラグメントのみ変更であるため新エントリのディレクティブ状態は前エントリと同じ("bar")を参照します。
onhashchange = () => console.assert(false, "hashchange doesn’t fire."); location.hash = "page2:~:world"; console.log(location.href); // 'https://example.com#page2' onhashchange = null;
同一ドキュメントナビゲーションでフラグメントのみ変更したうえでディレクティブも含めた場合、明示的ディレクティブ指定なので新エントリは独自の(値が"fizz"の)ディレクティブ状態を持ちます。
この場合ページに見えるフラグメントは変わっていないためhashchangeは発火しません。hashchange判定は履歴エントリ間のディレクティブ除去済URLで行われるためです。
history.pushState("", "", "page3");
console.log(location.href); // 'https://example.com/page3'
pushStateによる同一ドキュメントの新規履歴エントリ作成。非フラグメントURLが変化しているためこのエントリのディレクティブ状態は独立し、値は現時点でnull。
URLオブジェクト:
let url = new URL('https://example.com#foo:~:bar');
console.log(url.href); // 'https://example.com#foo:~:bar'
console.log(url.hash); // '#foo:~:bar'
document.url = url;
console.log(document.url.href); // 'https://example.com#foo:~:bar'
console.log(document.url.hash); // '#foo:~:bar'
<a>や<area>要素の場合:
<a id='anchor' href="https://example.com#foo:~:bar">Anchor</a> <script> console.log(anchor.href); // 'https://example.com#foo:~:bar' console.log(anchor.hash); // '#foo:~:bar' </script>
3.3.2. ドキュメントへのディレクティブ適用
上記のセクションでは、フラグメントディレクティブがURLから分離され、セッション履歴エントリに保存される仕組みについて説明しました。
このセクションでは、ナビゲーションおよびトラバーサル時に履歴エントリのディレクティブ状態を利用し、セッション履歴エントリに関連付けられたディレクティブをDocumentへ適用するタイミングと方法を定義します。
DOM § 4.5 Interface Documentへのモンキーパッチ:
各ドキュメントは関連付けられた保留中テキストディレクティブを持ちます。これはnullまたはリスト(テキストディレクティブのリスト)で、初期値はnullです。
履歴ステップ適用のためのドキュメント更新の定義にて:
HTML § 7.4.6.2 ドキュメントの更新へのモンキーパッチ:
Document documentとセッション履歴エントリ entry ... を与えて履歴ステップ適用のためのドキュメントを更新する:
...
- document の history object の length を scriptHistoryLength に設定
documentsEntryChanged が true の場合:
oldURL に document の latest entry の URL を代入
document の保留中テキストディレクティブに、フラグメントディレクティブのパースの結果をセット。
document の latest entry を entry に設定
...
3.3.3. フラグメントディレクティブの文法
注: このセクションは規範的ではありません。
注: この文法は便宜のためのリファレンスです。厳密な構文解析手順は§ 3.4 テキストディレクティブセクションの手続きで命令的に規定されています。この文法とそちらの手順が異なる場合は、手順のほうが正となります。
FragmentDirectiveは"&"文字で分割された複数のディレクティブを含めることができます。現時点では複数のテキストディレクティブによってページ内で複数のテキストを指示できますが、将来他種類のディレクティブの拡張や併用も可能です。この拡張性のため、不明なディレクティブが含まれていてもパースに失敗しません。
文字列が有効なフラグメントディレクティブであるのは、次のEBNF(拡張バッカス・ナウア記法)生成規則に合致する場合です:
-
FragmentDirective::= -
(TextDirective | UnknownDirective) ("&" FragmentDirective)? -
TextDirective::= -
"text="CharacterString -
UnknownDirective::= -
CharacterString - TextDirective -
CharacterString::= -
(ExplicitChar | PercentEncodedByte)* -
ExplicitChar::= -
[a-zA-Z0-9] | "!" | "$" | "'" | "(" | ")" | "*" | "+" | "." | "/" | ":" | ";" | "=" | "?" | "@" | "_" | "~" | "," | "-"ExplicitCharは"&"以外の任意のURL code pointです。
TextDirectiveは次の生成規則を満たすとき有効と見なします:
ValidTextDirective::="text=" TextDirectiveParametersTextDirectiveParameters::=-
(TextDirectivePrefix ",")? TextDirectiveString ("," TextDirectiveString)? ("," TextDirectiveSuffix)? TextDirectivePrefix::=TextDirectiveString"-"TextDirectiveSuffix::="-"TextDirectiveStringTextDirectiveString::=(TextDirectiveExplicitChar | PercentEncodedByte)+TextDirectiveExplicitChar::=-
[a-zA-Z0-9] | "!" | "$" | "'" | "(" | ")" | "*" | "+" | "." | "/" | ":" | ";" | "=" | "?" | "@" | "_" | "~"TextDirectiveExplicitCharは"&""-""、","で使われている以外の全てのURL code point。テキストフラグメントが"&"や"-"や","を参照する場合はパーセントエンコードする必要があります。 PercentEncodedByte::="%" [a-zA-Z0-9][a-zA-Z0-9]
3.4. テキストディレクティブ
テキストディレクティブは、ユーザーに指示するためのテキスト範囲を示すディレクティブの一種です。構造体で、四つの文字列: start, end, prefix, suffix を持ちます。startはnull不可。他3つはnullでもよく、未指定時を示します。空文字列はどれにも許可されません。
各構成要素の意味や使い方は§ 3.2 構文を参照してください。
-
termがnullならnullを返す。
-
decoded bytes を percent-decoding term の結果とする。
-
decoded bytes にBOMなしのUTF-8デコードを実施して返す。
このアルゴリズムは単一のテキストディレクティブ値(例:"prefix-,foo,bar")を入力とし、その内容をディレクティブの構成要素(例:("prefix", "foo", "bar", null))に分割しようとします。各構成要素の意味や使い方は§ 3.2 構文を参照。
入力が不正ならnullを返します。正しければテキストディレクティブを返します。
-
prefix, suffix, start, end をすべてnullで初期化。
-
Assert: text directive value はASCII文字列で、フラグメントパーセントエンコードセットのコードポイントやU+0026 (&) を含まない。
-
tokensに厳密分割でtext directive valueをU+002C(,)区切りで分割したリストを代入。
-
tokens のサイズが1未満または4より大ならnullを返す。
-
tokensの最初の要素がU+002D(-)で終わる場合:
-
tokensの最後の要素がU+002D(-)で始まる場合:
-
tokensのサイズが2より大きければnullを返す。
-
startをtokensの最初の要素にする。
-
tokensの先頭を削除。
-
startが空文字列またはU+002D(-)を含む場合はnullを返す。
-
tokensが空でなければ:
-
endをtokensの最初の要素にする。
-
endが空文字列またはU+002D(-)を含む場合はnullを返す。
-
-
次を持つテキストディレクティブ新規作成し返す:
ASCII文字列 fragment directive に対し「フラグメントディレクティブのパース」は:
-
directivesに厳密分割でfragment directiveをU+0026 (&) 区切りで分割したリストを代入。
-
outputに空のテキストディレクティブリストを初期化。
-
-
directiveが"
text="で始まらない場合、スキップ。 -
text directive value にdirectiveの5文字目以降部分文字列を代入
注: 空文字列もありうる -
parsed text directiveにテキストディレクティブのパースの結果を代入
-
parsed text directiveがnullでなければoutputに追加
-
-
output を返す。
3.4.1. テキストディレクティブの呼び出し
このセクションでは、ドキュメントの保留中テキストディレクティブ内のテキストディレクティブがどのように処理・呼び出され、該当テキスト部分の指示が行われるかを説明します。
-
指示された部分処理モデルを修正し、保留中テキストディレクティブをrangeに変換し、指示される部分として返すようにします。
-
「フラグメントへのスクロール」を修正し、rangeベースの指示部分の場合のスクロールとドキュメントのtarget要素の設定を正しく行えるようにします。
-
保留中テキストディレクティブが現在のナビゲーション・トラバーサルのフラグメント検索が完了したらnullにリセットされることを保証します。
-
ユーザーエージェントがテキストディレクティブ検索を完了した場合は、通常フラグメントをフォールバックとして試行することを保証します。
indicated partにおいて、フラグメントでrangeを指示できるようにします。以下のように修正:
HTML § 7.4.6.3 フラグメントへのスクロールへのモンキーパッチ:
HTML文書documentについて、その指示部分を決定するための処理モデルは次の通り:
text directivesをdocumentの保留中テキストディレクティブとする。
text directivesがnullでない場合:
rangesリストをテキストディレクティブ呼び出し手順でdocumentとtext directivesから生成。
rangesが空でなければ:
firstRangeをrangesの最初の要素とする。
ranges内の各rangeを 実装依存の方法で視覚的に指示する。指示は著者スクリプトから観測不可でなければならない。§ 3.7 テキスト一致の指示を参照。
rangesの最初のrangeがスクロールされますが、全て指示は視覚的にユーザーに見せる必要があります。firstRangeをdocumentの指示部分としてセットし、return。
fragmentをdocumentのURLフラグメントとする。
fragmentが空文字列なら、特殊値「ドキュメント先頭」を返す。
potentialIndicatedElementをdocumentとfragmentをもとに求める。
...
フラグメント識別子へのスクロールにおいて、指示部分がrangeの場合や、force-load-at-topポリシー時のスクロール制御を記述。次のように修正:
HTML § 7.4.6.3 フラグメントへのスクロールへのモンキーパッチ:
documentの指示部分がnullなら、documentのtarget要素をnullに。
documentの指示部分が「ドキュメント先頭」なら:
documentのtarget要素をnullに。
documentでドキュメント先頭へスクロール。
return。
その他の場合:
アサーション: documentの指示部分はelementまたはrange。
scrollTargetをdocumentの指示部分とする。
targetをscrollTargetとする。
targetがrangeの場合:
アサート:targetはelement。
documentのtarget要素にtargetをセット。
ancestor details revealingアルゴリズムをtargetで実行。
ancestor hidden-until-found revealingアルゴリズムをtargetで実行。
revealingアルゴリズムの現状だとtargetが祖先またはドキュメントルートノードの場合うまくいかない場合がある。 #89 でcontain:style layoutブロックへの制限提案あり。blockPositionはscrollTargetがrangeなら"center"、それ以外は"start"。
テキストディレクティブへのスクロールはブロック方向で中央寄せスクロールとなる。targetを自動・start・nearestでスクロール。- scroll a target into viewのtargetは scrollTarget、behaviorは"auto"、blockはblockPosition、inlineは"nearest"で実行。
実装はテキストディレクティブから生成されたtargetの場合スクロールしないことも可能。
targetのfocusing stepsを実行(fallbackはDocumentのビューポート)。
逐次focusナビゲーションの開始点をtargetに移動。
次の2つのモンキーパッチは、ユーザーエージェントがフラグメント検索完了時に保留中テキストディレクティブをクリアすること、およびテキストディレクティブ検索パース終了時は非テキストディレクティブのフラグメントもサーチすることを保証します。
try to scroll to the fragmentの定義にて:
HTML § 7.4.6.3 フラグメントへのスクロールへのモンキーパッチ:
Document documentについて、try to scroll to the fragmentのパラレル手順は以下:
実装依存の時間だけwait(パフォーマンス配慮のためのUX最適化)。
documentのrelevant global objectでnavigation/traversal task sourceのグローバルタスクとして以下をキュー:
documentにparserが存在しないか、パース完了か、スクロール不要ならabort- ユーザーエージェントがスクロール不要と判断した場合
保留中テキストディレクティブをnullにセット
abort
documentにparserが存在しないかparserがstopなら:
保留中テキストディレクティブがnullでなければ:
保留中テキストディレクティブをnullに
フラグメント識別子へのスクロールをdocumentで実行
abort
documentでフラグメントへスクロールを実行。
ドキュメントの indicated part がまだ null の場合、ドキュメントのフラグメントへスクロールを試みる。それ以外の場合は、保留中のテキストディレクティブ を null に設定する。
navigate to a fragmentの定義では:
HTML § 7.4.2.3.3 フラグメントナビゲーションへのモンキーパッチ:
navigable navigableでフラグメントにナビゲートするには...:
...
- navigableのactive document, historyEntry, true, scriptHistoryIndex, scriptHistoryLengthで履歴ステップ適用のためのドキュメント更新を行う。
navigableのactive documentでフラグメントにスクロールする。
- navigableのactive documentの保留中テキストディレクティブをnullに
traversableをnavigableのtraversable navigableとする。
...
指示部分へのスクロールは「scroll to the fragment」から行われるものの1つにすぎない。名称と関連定義を「indicating a fragment」にリネーム:
HTML § 7.4.2.3.3 フラグメントナビゲーションへのモンキーパッチ:
HTML § 7.4.2.3.3 Fragment navigations およびその関連手順の名称を「indicating a fragment」(フラグメントの指示)にリネーム。
3.5. セキュリティとプライバシー
3.5.1. 動機
テキストディレクティブを実装する際は、オリジン間で情報漏えいに使われないよう注意が必要です。スクリプトはクロスオリジンのテキストディレクティブ付きURLにナビゲートできます。悪意のある者が、被害者ページでテキストフラグメントが発見されたかを検出できれば、ページ内テキストの有無を推測できてしまいます。
次節以降の処理モデルでは、この攻撃ベクトルを軽減できるように制限を設けています。要点をまとめると、テキストディレクティブは次の条件下でのみ許可されます:
-
トップレベルのnavigable(=iframe不可)
-
ユーザーアクションによるナビゲーション
-
ナビゲーションがクロスオリジンイニシエータの場合は、行き先がopener isolatedである必要がある(他のドキュメントからグローバルオブジェクト参照不可)
3.5.2. ナビゲーション時のスクロール
UAは一致したテキスト部分を自動スクロール表示できる場合があります。これはユーザーにとって便利ですが、実装UAはリスクに注意が必要です。
ナビゲーション時スクロールが通常のユーザースクロールと区別できる既知・未知の検出方法があります。
このような漏洩方法は、ターゲットページ特有の状況に依存し一般化は難しいです。テキストフラグメントの発動に更なる制限をつけることで、攻撃者の行動範囲はさらに狭くなります。ただし、UAごとにリスク受容性判断が異なる可能性があります。UAはこうしたリスクを考慮し、テキストフラグメントでの自動スクロール実施可否を判断して下さい。
準拠UAはナビゲーション時の自動スクロールをしない選択もできます。その場合はUIでユーザーがスクロール開始できる仕組み(「クリックしてスクロール」など)や、指示部分が下部ページに存在する旨の通知をすることも可能です。
上記例は状況次第でページ内容1ビット漏洩可能となることを示していますが、攻撃を繰り返して任意のページ内容抽出が行えないよう、ユーザーアクティベーション制限やブラウジングコンテキスト分離などが重要かつ必須です。
また、悪意ある利用も隠しにくくなります。グループ内唯一ならトップレベルコンテキスト(タブやウィンドウ)となるため。
UAが自動スクロール実施を選ぶ場合、ドキュメントがバックグラウンド(非アクティブタブ等)では一切スクロールしない必要があります。これにより、不正利用がユーザー可視となり、バックグラウンド自動化攻撃を防止します。
UAが自動スクロールを実施しない場合、テキストフラグメント有無に関わらず要素ID指定部分は必ずスクロールしてください。そうしないと要素IDがスクロールされたか否かで一致判別ができてしまいます。
3.5.3. 検索タイミング
ナイーブなテキスト検索アルゴリズムでは、一致/不一致時の実行時間差で情報漏えいの可能性があります。攻撃者がテキストディレクティブ呼び出しURLへ同期ナビゲートできれば、その実行時間からテキスト片の存在を推測可能です。
そのため、§ 3.6 テキストフラグメントへのナビゲーション手順の実行時間が一致の有無で変化しないように実装しなければなりません。
この仕様では、UAが達成する手法は問わず、多様な解法とトレードオフが存在します。例:UAはテキストディレクティブから範囲検索で一致が見つかってもツリー走査を継続したり、非同期タスクでドキュメント指示部分を設定するなど。
3.5.4. テキストフラグメントの制限
-
DocumentとRequestの両方にboolean型
text directive user activationを追加します。このフラグはユーザーアクティベーションによるナビゲートで生成されたドキュメントにセットされ、テキストディレクティブでスクロール時に消費されます。未消費の場合、外部へのナビゲーション要求に転送できます。以下の注記で説明される、リダイレクト経由ユーザーアクティベーション挙動を実装します。 -
ドキュメント、およびナビゲーションのユーザー関与・イニシエーターオリジン状態に基づき、一連のチェックを定義し、テキストディレクティブのスクロール許可可否を判定します。
-
「finalize a cross document navigation」や「navigate to a fragment steps」でスクロール許可を計算し、「scroll to the fragment」手順へ伝搬して、テキストディレクティブスクロール中断に利用します。
requestおよびDocumentの定義を修正し、新たなboolean型text directive user activationフィールドを含めます:
Monkeypatching [FETCH]:
requestには関連付けられたboolean型text directive user activation があり、初期値はfalse。
Monkeypatching [HTML]:
各Documentはtext directive user activation(boolean型、初期値はfalse)を持つ。
text directive user activationは、テキストフラグメントを一度だけアクティベート可能にするためのユーザー操作シグナルです。ドキュメント読み込み中、ユーザーアクティベーションによるナビゲート時のみtrueになり、クライアントサイドリダイレクトでも伝搬します。Documentのtext directive user activationがテキストフラグメントのアクティベートに使われなかった場合は、新しいナビゲーションrequestのtext directive user activationにもtrueがセットされます。これにより、一つのtext directive user activationがナビゲーションをまたいで引き継がれます。
どちらのDocumentのtext directive user activationも、requestのtext directive user activationも、使用された時点で常にfalseになる。これにより、一度のユーザーアクティベーションで複数のテキストフラグメントをアクティベートできなくなる。
この仕組みにより、多くのWebサイトで用いられる一般的なリダイレクト経由でもテキストフラグメントをアクティベートできます。これらのサイトはスクリプトで window.location をセットする200レスポンスで目的地にリダイレクトします。
本当のHTTP(
status 3xx)
リダイレクトとは異なり、そのような「クライアントサイド」リダイレクトではNaavがユーザー操作の結果かを伝搬できません。text directive user
activationは、この限定的な範囲のユーザーアクティベーションをそのようなナビゲーションで引き継ぐことを可能にします。プログラムでテキストフラグメントにナビゲート可能ですが、一度だけユーザー操作同様のアクティベートが許されます。text fragment user activationはここでリセットされるため以降は新たなユーザーアクションが必要です。
以下の図は、このフラグがクライアントサイドリダイレクトサービス経由で使われる例を示します:
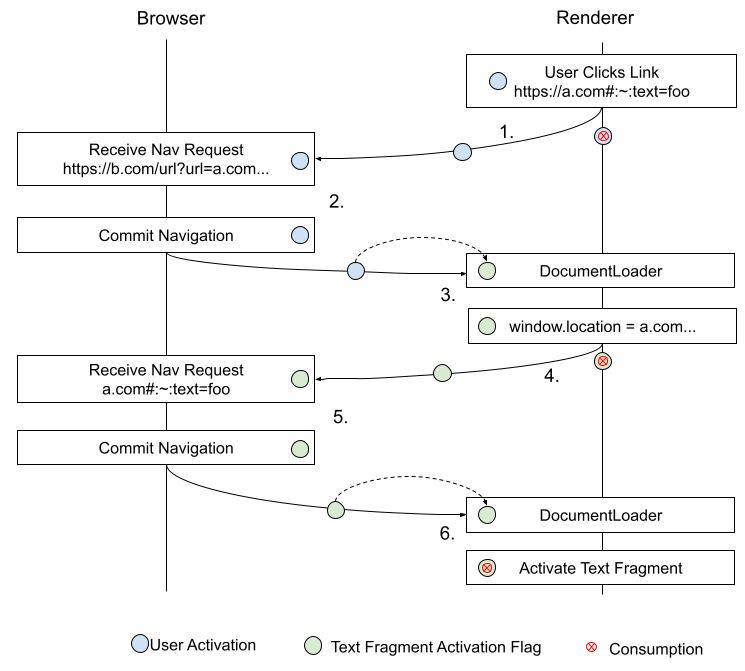
詳しくは redirects.md 参照。
create navigation params by fetching手順では、active documentのtext directive user activation値をrequestのtext directive user activationに伝搬します。
Monkeypatching [HTML]:
これは並列実行である
documentResourceをentryのdocument stateのresourceとする。
requestを新規requestとして作成:
- url
- entryのURL
- ...
- ...
- referrer policy
- entryのdocument stateのrequest referrer policy
- text directive user activation
- navigableのactive documentのtext directive user activation
navigableのactive documentのtext directive user activationをfalseに設定。
documentResourceがPOST resourceであれば:
...
navigation params定義にも新しいフィールドを含める:
Monkeypatching [HTML]:
- user involvement
- user navigation involvement値。
user involvement値をナビゲーションparams作成時にセット。特にcreate navigation params by fetchingのケースでは初期値true:
Monkeypatching [HTML]:
To create navigation params by fetching given ... user navigation involvement user involvement, ...
アサート:これは並列で実行されている。
...
- resultPolicyContainer を、response の URL、entry の document state の history policy container、sourceSnapshotParams の source policy container、null、および responsePolicyContainer からナビゲーションパラメータポリシーコンテナを決定した結果とする。
navigable の container が iframe であり、かつ response の timing allow passed フラグが立っている場合、container の pending resource-timing start time を null に設定する。
次の内容を持つ新しいナビゲーションパラメータを返す:
- id
- navigationId
- ...
- ...
- about base URL
- entry の document state の about base URL
- ユーザー関与
- user involvement
Documentオブジェクトの生成と初期化手順にてtext directive user activationフラグの計算と保存を行う:
Monkeypatching [HTML]:
link headersをdocument, navigationParamsのresponse, "pre-media"で処理。
navigationParamsのuser involvementが"
activation"navigationParamsのuser involvementが"
browser UI"navigationParamsのrequestのtext directive user activationがtrue
text directive user activationはコピーできないことが重要であり、ユーザーアクティベートされたナビゲートごとに1回のみテキストフラグメントがアクティベートできる。documentを返す。
text
directive allowing MIME typeは、MIME typeのessenceが"text/html"または"text/plain"であるもの。
注: scrolling to a fragmentで述べられているように、フラグメント処理は各MIME Typeごとに定義されています。したがってscroll to the fragmentでのテキストディレクティブスクロールはtext/htmlメディアタイプのみが対象。ただし実際にはブラウザはtext/plainにもHTML方式のフラグメント処理を適用することがあり、そのためtext/plainへのテキストディレクティブ適用許可が有用です。text/css, application/json, application/javascript等は明示的に除外され、XS-Search攻撃等への配慮です。
-
documentの保留中テキストディレクティブがnullまたは空ならfalseを返す。
-
is user involvedを次のいずれかでtrue、そうでなければfalseとする:documentのtext directive user activationがtrue、またはuser involvementが"
activation"または"browser UI" -
documentのtext directive user activationをfalseに。
-
documentのcontent typeがtext directive allowing MIME typeでなければfalse。
-
user involvementが"
browser UI"ならtrue。ナビゲーションがブラウザUIからのものなら常に許可、ユーザー起因でありページ/スクリプトがテキスト片を与えないため。
この項の意図はアプリ/ページがURL制御可能なケースと完全にユーザー側制御なケースを区別することにある。前者では、宛先が別のブラウジングコンテキストグループ(元ページがテキスト片と副作用を両方制御できない)でない限りテキストフラグメントのスクロールを防ぐ必要がある。UIによる「新しいウィンドウで開く」等、グレーなケースもある。
sec-fetch-siteも参照。
-
is user involvedがfalseならfalse。
-
documentのnode navigableにparentがあればfalse。
-
initiator originがnullでなく、documentのoriginがinitiator originとsame originならtrue。
-
documentのbrowsing contextのgroupのbrowsing context setが長さ1ならtrue。
つまりクロスオリジン要素/スクリプトからのナビゲートは、documentがnoopenerな場合のみ許可。ナビがスクリプトアクセス不可で別プロセスに分離可能な新規トップレベルbrowsing contextであること。 -
その他の場合false。
§ 3.4.1 テキストディレクティブの呼び出しですでに修正済みのscroll to the fragment手順にboolean型allow text directive scroll引数を追加:
Monkeypatching HTML § 7.4.6.3 フラグメントへのスクロール:
Document document、boolean allow text directive scroll引数で scroll to the fragmentを実行:
ドキュメントの indicated part が null の場合、ドキュメントの target element を null に設定する。
...
それ以外の場合:
アサート:ドキュメントの indicated part は要素、または range である。
...
- target が range の場合:
allow text directive scroll が false なら、return。
target を target の 最初の共通祖先(target の start node と end node)にする。
...
try to scroll to the fragmentを修正、boolean型allow text directive scrollを引数に持ち、手順2のタスク内容を差し替え:
Monkeypatching [HTML]:
Document documentとboolean allow text directive scroll でtry to scroll to the fragmentを並列実行:
実装依存の時間wait。
documentのrelevant global objectでnavigation/traversal task sourceのグローバルタスクとして以下:
documentにparserがない/停止済/ユーザーがスクロール希望でないならabort。
documentとallow text directive scrollでscroll to the fragmentを実行。
documentの指示部分がnullなら再度try to scroll to the fragment(allow text directive scroll)。
update document for history step application手順でもboolean allow text directive scrollを引数に持ち、scroll to a fragment時に利用:
Monkeypatching [HTML]:
Document document, session history entry entry, boolean doNotReactivate, 数値scriptHistoryLengthとIndex、entriesForNavigationAPI(任意)、boolean allow text directive scroll引数でupdate document for history step application手順:
documentIsNewはdocumentのlatest entryがnullならtrue。
...
- documentsEntryChangedがtrueの場合:
oldURL = documentのlatest entryのURL
...
documentIsNewがtrueなら:
documentとallow text directive scrollでtry to scroll to the fragment実行
apply the history stepアルゴリズムもboolean allow text directive scroll引数を持ち、update document for history step application へ渡す:
Monkeypatching [HTML]:
apply the history step handoff... boolean allow text directive scroll(デフォルトfalse)で呼び出し
completedChangeJobs が totalChangeJobs と等しくない間:
...
- navigation and traversal task source で、navigable の active window に対し次のステップを実行するグローバルタスクをキューする:
changingNavigableContinuation の update-only が false の場合:
...
navigable の targetEntry の履歴エントリをアクティブ化する。
updateDocument を次のアルゴリズムステップとする:targetEntry の document、targetEntry、changingNavigableContinuation の update-only、scriptHistoryLength、scriptHistoryIndex、entriesForNavigationAPI、および allow text directive scroll を指定して履歴ステップ適用のためのドキュメント更新を実行する。
targetEntry の document が displayedDocument と等しければ、updateDocument を実行する。
totalNonchangingJobs を nonchangingNavigablesThatStillNeedUpdates のサイズとする。
apply the push/replace history stepでもallow text directive scrollingをapply the history stepへ渡す:
Monkeypatching [HTML]:
apply the push/replace history step handoff... boolean allow text directive scroll(デフォルトfalse)で呼び出しapply the history step内でfalse, null, null, null, allow text directive scrollを渡し実行。
注: allow text directive scrollはトラバースやリロード時には意図的にセットされません。イニシエーターオリジンやユーザー関与のチェック回避や履歴スクロール状態優先のためです。テキストディレクティブはドキュメントの指示部分として使われるため、ハイライトは復元される。
finalize a cross-document navigationにuser involvement引数を渡し、allow text directive scrollingも計算・伝搬:
Monkeypatching [HTML]:
finalize a cross-document navigation handoff...user navigation involvement user involvement、...
...
- allow text directive scrollをテキストディレクティブがスクロール可能か判定で計算し、historyEntryのdocument, entryのdocument state, initiator origin, user involvement引数で渡す
apply the push/replace history step targetStep to traversable, with allow text directive scroll
navigateアルゴリズムにてuser involvementをfinalize a cross-document navigationへ伝播:
Monkeypatching [HTML]:
...
- . 並列で次の手順を実行する:
...
- . allowPOST を true、completionSteps を次の手順とし、navigable、"navigate"、sourceSnapshotParams、targetSnapshotParams、navigationId、navigationParams、cspNavigationType を指定して historyEntry のための履歴エントリの document を生成しようとする:
navigable、historyHandling、historyEntry、および userInvolvement を指定して、セッションクロスドキュメントナビゲーションを完了するためのセッション履歴トラバーサル手順を navigable の traversable に追加する。
Navigate to a fragmentアルゴリズムもinitiator originを引数にとり、 allow text directive scrollをフラグメントスクロール時に渡す:
Monkeypatching [HTML]:
navigate to a fragment handoff... navigable, URL, ..., userInvolvement, navigationAPIState, navigationId, origin initiator origin...
...
- navigableのactive document, historyEntry, true, ...などでupdate document for history step application
...
allow text directive scrollをcheck if a text directive can be scrolledで計算(active document, initiator origin, userInvolvement)
active document, allow text directive scrollでscroll to the fragment呼び出し
navigateアルゴリズムでfragment navigationする際にinitiator originを渡す:
Monkeypatching [HTML]:
navigation must be a replaceの判定(...)
次4条件がすべてtrueの場合:
documentResourceがnull
responseがnull
urlがnavigableのactive session history entryのURL(fragment除去)と等しい
urlのfragmentがnon-null
なら:
navigate to a fragment(navigable, url, historyHandling, userInvolvement, navigationAPIState, navigationId, initiatorOriginSnapshot)
navigation = navigableのactive windowのnavigation API
3.5.5. ロード時のスクロール制限
このセクションでは、新しいドキュメントの読み込み時に、テキストディレクティブなどを含むすべての種類のスクロールを防ぐために、force-load-at-top
ポリシーがどのように使用されるかを定義します。
force-load-at-top がナビゲーションAPIとどのように連携するかを決定する必要があります。[Issue
#WICG/scroll-to-text-fragment#242]
保存状態の復元ステップを修正し、スクロールの復元を抑制する新しいブールパラメーターを受け取るようにします:
Monkeypatching [HTML]:
セッション履歴エントリ entry , およびブール値 suppressScrolling から保存状態を復元するには:
entryのスクロール復元モードが "auto"、 suppressScrolling がfalse、かつentryのドキュメントの関連グローバルオブジェクトのナビゲーションAPIの ongoing navigation中の通常のスクロール復元抑制がfalseであれば、entryを指定してスクロール位置データを復元する。
...
履歴ステップ適用のためのドキュメント更新ステップを修正し、
force-load-at-top ポリシーを確認することで、新しいドキュメントで設定されていればスクロールを回避します。
Monkeypatching [HTML]:
...
- documentの履歴オブジェクトのlengthを scriptHistoryLength に設定する。
scrollingBlockedInNewDocument を ポリシー値の取得 を使って
force-load-at-topを document に対して取得した結果とする。documentsEntryChanged が true の場合、次を行う:
oldURL を document の latest entry の URL とする。
...
- documentIsNew が false の場合:
ナビゲーション、entry、"traverse" を指定して、同一ドキュメントナビゲーション用のナビゲーションAPIエントリを更新する。
popstate という名前のイベントを発火する...
entry および suppressScrolling をfalseにして保存状態を復元する。
oldURLのフラグメントが...でなければ
それ以外の場合、
Assert: entriesForNavigationAPI が与えられている。
entry および scrollingBlockedInNewDocument で保存状態を復元する。
ナビゲーション、entriesForNavigationAPI、entry を指定して新しいドキュメント用のナビゲーションAPIエントリを初期化する。
documentIsNew が true の場合、
scrollingBlockedInNewDocument がfalseであれば、ドキュメントのフラグメントへスクロールを試みる。
この時点でスクリプトが新たに生成された document 用に実行される場合がある。
それ以外で、documentsEntryChanged が false かつ doNotReactivate が false なら:
...
3.6. テキストフラグメントへのナビゲーション
-
commonAncestor を nodeA にする。
-
commonAncestor がnullでなく、かつshadow-including inclusive ancestor でない場合、commonAncestor を commonAncestor のshadow-including parent にする。
-
commonAncestor を返す。
-
node が shadow root の場合、 node の host を返す。
-
それ以外の場合、node の parent を返す。
3.6.1. ドキュメント内の範囲の特定
概略では、次のようなフラグメントディレクティブ文字列を受け取ります:
text=prefix-,foo&unknown&text=bar,baz
これを個々のテキストディレクティブに分けます:
text=prefix-,foo text=bar,baz
各テキストディレクティブごとに、ディレクティブ内の制限条件に一致するレンダリング済みテキストの最初のインスタンスをドキュメント内で検索します。 検索はそれぞれ独立しており、他にいくつディレクティブがあっても、また一致結果にかかわらず、同じ結果となります。
ディレクティブが文書内テキストと一致した場合、ドキュメント内の一致する部分を示すrangeを返します。テキストディレクティブの実行ステップがこのセクションで提供される上位APIです。 これらは、個々のディレクティブ毎のマッチングステップで一致したrangeの リスト を(ディレクティブ文字列に指定された順に)返します。
ディレクティブが一致しなかった場合、その戻り値リストにはアイテムを追加しません。
-
ranges を rangeリスト(初期値は空)にする。
-
各テキストディレクティブ directive について:
-
テキストディレクティブから範囲を探す を directive と document で実行した結果が null でなければ、それを ranges に追加 する。
-
-
ranges を返す。
end はnull可です。省略した場合「完全一致」検索となり、返される rangeはstart と完全一致する文字列となります。 end があれば「範囲検索」となり、返される rangeは start〜end で始まります。正規な条件に合致するテキスト部分を、 以下「matching text」と呼びます。
prefix とsuffixは両方またはいずれかがnull可で、その場合片側のコンテキストはチェックしません。例:prefixがnullなら前方のテキスト制約なしで一致。
:~:text=The quick,lazy dog次の例では一致しません
<div>The<div> </div>quick brown fox</div> <div>jumped over the lazy dog</div>
なぜなら "The quick" という開始文字列が同一かつ途切れないブロック内に登場しないからです。ドキュメント内の"The quick" は"The"と"quick"の間にブロック要素が挟まっています。
ただしこの例なら一致します:
<div>The quick brown fox</div> <div>jumped over the lazy dog</div>
-
searchRange を Range(開始:document, 0、終了:document の長さ)とする
-
searchRange がcollapsed でないかぎり:
-
potentialMatch を null に。
-
parsedValues のprefixが null でない場合:
-
prefixMatch を 範囲内文字列検索 を、 query parsedValues の prefix、 searchRange searchRange、wordStartBounded true、wordEndBounded false で実行した結果とする。
-
prefixMatch が null であれば null を返す。
-
searchRange のstart を prefixMatch の boundary point の後ろ after にセット
-
matchRange を Range(開始:prefixMatchのend、終了:searchRangeのend)とする。
-
matchRange がcollapsed なら null を返す。
この場合、prefixMatch のend 、またはその後の非空白場所がドキュメント末尾にあるときに発生します。 -
Assert: matchRange のstart node は
Textノード。matchRange の start は一致したprefixに続く次の非空白文字位置。 -
mustEndAtWordBoundary を、parsedValues のend が null でなければ true、suffixが null なら true、そうでなければfalse。
-
potentialMatch に 範囲内文字列検索を ( parsedValues のstart, matchRange, false, mustEndAtWordBoundary)で実行した結果をセット
-
potentialMatch が null なら null を返す。
-
potentialMatch のstart が matchRangeの start でなければ、次のループ を続ける。
この場合、一致するprefixは見つかりましたが、それに続くテキストが一致せず、ループを継続して次のprefix出現箇所を探します。
-
-
そうでなければ:
-
rangeEndSearchRange を Range(開始:potentialMatchのend、終了:searchRange のend)とする。
-
rangeEndSearchRange がcollapsedでないかぎり:
-
parsedValues のendがnullでなければ、
-
Assert: potentialMatchは非nullでcollapsedした範囲でなく、一致するテキスト範囲を表す。
-
parsedValues のsuffix がnullなら、potentialMatch を返す。
-
suffixRange を Range (開始:potentialMatch の end 、終了:searchRangeの end)とする。
-
suffixMatch を 範囲内文字列検索( parsedValues のsuffix, suffixRange, false, true) の結果
-
suffixMatch が null なら null を返す。
suffixが文書残りテキストに現れない場合、一致できない。 -
suffixMatch のstart が suffixRange の start なら potentialMatch を返す。
-
parsedValues のendがnullなら break;
これは一致がexactでsuffixが一致しなければ、ループを抜けて次の範囲検索に進む。範囲一致の場合はinner loopを続行。 -
rangeEndSearchRange のstart を potentialMatch の end
この場合、正しいrange startはみつかったがrange end が一致しない場合で、inner loop を継続する。
-
-
rangeEndSearchRange がcollapsedなら:
-
-
null を返す
-
range が collapsed(折りたたまれていない)間:
-
node を range の 開始ノードとする。
-
offset を range の 開始オフセットとする。
-
node が 検索不可部分木の一部である、または node が 可視テキストノード でない、または offset が node の 長さと等しければ:
-
range の 開始ノード を shadow-including tree順で次のノードに設定する。
-
range の 開始オフセット を 0 に設定する。
-
続ける。
-
-
node の 部分文字列データのオフセット offset から 6 文字分が文字列 " " に等しければ:
-
range の 開始オフセット に6を加算。
-
-
その他の場合、部分文字列データのオフセット offset から5文字分が文字列 " " に等しければ:
-
range の 開始オフセット に5を加算。
-
-
それ以外の場合:
-
このアルゴリズムの基本は、ブロック内の検索可能な全テキストノードをリストに収集し、それらを連結して検索し、ノードリストでオフセットを解釈して戻り値の範囲を作ること。
ブロックノードに到達するとリスト化を中断。例:
<div> a<em>b</em>c<div>d</div>e </div>
この場合は"abc"・"d"・"e"と分割して検索。
よって query は、ブロックレベルのコンテナ内で途切れのない連続したテキストのみに一致する。
-
searchRange が collapsed でない間:
-
curNode を searchRange の 開始ノード とする。
-
curNode が 検索不可部分木であれば:
-
searchRange の 開始ノード を、shadow-including tree順で curNode の shadow-including descendant でない次のノードに設定。
-
searchRange の 開始オフセット を 0 に設定。
-
続ける。
-
-
curNode が 可視テキストノード でなければ:
-
searchRange の 開始ノード を shadow-including tree順で次の doctype でないノードに設定する。
-
searchRange の 開始オフセット を 0 に設定。
-
続ける。
-
-
blockAncestor を 直近のブロック祖先 とする。
-
curNode が shadow-including descendant かつ 境界点 (curNode, 0) が searchRangeの終了より後でない間:
-
curNode が ブロックレベル表示を持つ場合、break。
-
curNode が 検索不可であれば:
-
curNode を、shadow-including tree順で curNode の shadow-including descendant でない次のノードに設定。
-
続ける。
-
-
curNode が 可視テキストノード であれば textNodeList に追加。
-
curNode をshadow-including tree順で次のノードに更新。
-
-
ノードリストから範囲を得る を引数 query, searchRange, textNodeList, wordStartBounded, wordEndBounded で実行し、結果が非nullならそれを返す。
-
curNode が null なら break。
-
Assert: curNode は searchRangeの開始ノードに続くノードである。
-
searchRange の start を (curNode, 0) に設定。
-
-
null を返す。
ノードは、検索不可 である条件: 要素であり、HTML名前空間内にあり、以下いずれかを満たすとき:
-
computed value(算出値)の display プロパティが none である。
-
そのノードが voidとしてシリアライズされるとき。
-
次の型のいずれかである場合:
HTMLIFrameElement、HTMLImageElement、HTMLMeterElement、HTMLObjectElement、HTMLProgressElement、HTMLStyleElement、HTMLScriptElement、HTMLVideoElement、HTMLAudioElement
ノードが 検索不可部分木 の一部となる条件は、自身または shadow-including ancestor が 検索不可 である場合です。
ノードが 可視テキストノード
と判定される条件は、Text
ノードであり、親要素の算出値による親要素の visibility プロパティが visible であり、描画されていることです。
ノードがブロックレベル表示を持つとは、 要素であり、 算出値による display プロパティが block、table、flow-root、grid、flex、list-item のいずれかであることです。
-
curNode を node にする。
-
curNode が null でない間:
-
curNode が
Textノードでなく、かつ ブロックレベル表示を持つ場合は curNode を返す。 -
それ以外は curNode を親ノードに更新。
-
-
単語開始境界必須なら “color orange” には一致しません。
-
単語終了境界必須なら “forest ranger” には一致しません。
詳細・他例は § 3.6.2 Word Boundaries を参照。
-
searchBuffer を nodes 内各要素の データ を 連結 して作る。
データはこの文脈では正確でなく、DOM上のテキストデータなので注意。本来は描画済みテキストを対象にし、その後DOMに戻す必要あり。[Issue #WICG/scroll-to-text-fragment#98]
-
searchStart を 0 に初期化。
-
nodes の先頭が searchRange の 開始ノードなら searchStart を searchRange の 開始オフセットに設定。
-
start/end を 境界点(null初期値)とする。
-
matchIndex をnullに初期化。
-
matchIndex がnullの間:
-
searchBuffer で文字列 queryString の最初の出現インデックス matchIndex を searchStart から探す。比較は 第一水準(大文字小文字・アクセント無視)で。
直感的には大文字小文字・濁点など無視の検索。 -
matchIndex がnullなら null を返す。
-
endIx を matchIndex + queryString の 長さとする。
endIx は一致文字列の末尾+1の位置。 -
start を 境界点として get boundary point at index matchIndex を nodes、isEnd=false で実行した結果に。
-
end を 境界点として get boundary point at index endIx を nodes、isEnd=true で実行した結果に。
-
wordStartBounded が true かつ matchIndex が 単語境界でない場合、または wordEndBounded が true かつ matchIndex+queryString の長さが 単語境界でない場合:
-
searchStart を matchIndex+1に。
-
matchIndex を nullに。
-
-
-
endInset を0に初期化。
-
nodes の末尾が searchRange の 終了ノードなら endInset を( searchRange の 終了ノード の 長さ − searchRange の 終了オフセット )に設定。
endInsetは最後のノードの逆方向のオフセット分。すなわち含まれない長さ。 -
matchIndex+queryString の 長さ が searchBuffer の長さ−endInset を超える場合、nullを返す。
範囲末尾をまたいだマッチは無効。
これは上記アルゴリズムで、連結文字列上のインデックスがどのノードに所属するか確定するための補助ルーチンです。
isEndは始端と終端を区別のため利用。終端インデックスは一致文字列の「次の位置」を指す。マッチがノード境界上なら、次ノード頭ではなく、そのノード末としてほしい。
3.6.2. 単語境界
単語境界は、[UAX29]およびUnicode Text Segmentation § Word_Boundariesで定義されます。Unicode Text Segmentation § Default_Word_Boundariesでは デフォルトの単語境界規則セットを規定していますが、仕様でも述べている通り、より高度なアルゴリズムをロケールに応じて使うべきです。
辞書ベースの単語境界判定は、単語区切り文字のないロケールでは特に注意が必要です。英語ではスペース(' ')で単語区切りですが、日本語には単語間を区切る文字がありません。そのような場合、かつアルファベットが100文字未満の場合、辞書には有効な1文字単語をアルファベットの20%以内に抑える必要があります。
ロケールとは、有効な文字列([BCP47]言語タグ)または空文字列です。空文字列は主言語が不明であることを示します。
部分文字列が単語境界で区切られているとは、文字列 text、ロケール startLocale と endLocale が与えられたとき、その最初の文字の位置が 単語境界であるかつ、末尾(最後の文字の直後の位置)が 単語境界である場合を指します。
数値 position が 単語境界であるのは、文字列 text、および ロケール locale が与えられたとき、localeに従い 単語境界が直前にある、または text の長さが0より大きく、positionが0 または text長と等しい場合を指します。
区切り記号(例: 半角スペース)がある言語では(ほぼ)簡単ですが、技術資料で扱う改行・ハイフネーション・引用符等の詳細な規定があります。
区切り記号のない言語(中・日・韓等)は辞書ベースで有効な単語を認識する必要があります。
テキストフラグメントの一致語句は、隣接する文脈語と連結したときに単語境界となるように制限されます。たとえば exact検索 prefix,start,suffix
では、"prefix+start+suffix"全体が単語境界で区切られているときのみマッチします。一方range検索
prefix,start,end,suffix
では、"prefix+start"と"end+suffix"の両方が単語境界である必要があります。
目的は、第三者が一致トークンの全体を既知であるケースのみ閲覧できること。start,endのrangeマッチで内側が単語境界でなければ、第三者が繰り返し一致探索してトークン復元を試行(例:"Balance: 123,456 $"なら
prefix="Balance: ", end="$" かつ start を1文字ずつ試す)できてしまう。
詳細はセキュリティレビュー文書 参照。
3.7. 一致したテキストの指示
UAは、try to scroll to the fragment の手順や他のメカニズムの一環として、テキストフラグメントをインビューにスクロールしても構いませんが、必ずしも一致箇所を表示する義務はありません。
UAはユーザに一致箇所を認識させるため、ハイコントラストなハイライトなど視覚的に強調して示すべきです。
UAはユーザーの操作で一致表示状態を解除し、強調を消す手段も提示すべきです。
その見た目やUI動作はUA依存です。ただし、オーサスクリプトで観測可能な手法(例:Documentのselection)によって表示してはなりません。そうするとコンテント抽出の攻撃ベクトルとなります。
UAは提供されたコンテキスト語句には視覚的強調を表示してはいけません。
強調はドキュメントの内容の一部ではないため、UAはユーザがページ内容と区別できる工夫も推奨されます。
3.7.1. UA機能のURL表示
UAは、ドキュメントURLを消費する様々な場所を提供します(window.locationのようなAPIを除く)。例としては、ロケーションバーで現在表示中ドキュメントのURLを見せたり、ブックマーク作成時のURLなどがあります。
ユーザの混乱を避けるため、こうしたURLにフラグメントディレクティブを含めるかどうかは統一すべきです。本節で推奨する標準動作例を示します。
ここでの推奨は統一的なユーザ体験を基準としますが、UA間相互運用性には影響せず厳密な適合要件ではありません。
細かい挙動は実装UAに委ねられ、デフォルト設定を変えたり抽出UIを出すのも可。例えばユーザがURL内のフラグメントディレクティブ公開を選べるようにも。
UX向上実験も許容されます。例えばテキストフラグメントが画面外にスクロールされた場合表示URLから省略してもよいでしょう。
原則として、URLはビジュアル指示(マーカー)が表示中のみフラグメントディレクティブを含めるべきです。マーカーが解除されたらURLからも同ディレクティブを除外すべきです。
URLがテキストフラグメントを含むが実際には一致しなかった場合、UAは公開URLからそれを省くこともできます。
ページ内にフラグメントが見つからないのは、リンク作成以降ページが変わったなどをユーザに示す有用な情報となります。
ただしブックマーク目的ではその情報はあまり役に立ちません。
よくある具体例は以下のとおりです。
3.7.1.1. ロケーションバー
ロケーションバーのURLには、マーカー表示中はテキストフラグメントを含めるべきです。マーカー解除時はロケーションバーのURLから同ディレクティブを消してください。
たとえ一致しなくても、ロケーションバーにはフラグメント情報を含めることが推奨されます。
3.7.1.2. ブックマーク
多くのUAは「ブックマーク」機能で現在ページへのリンクを保存できます。
新たに作成されたブックマークURLは、デフォルトで一致がありかつマーカー表示中であればフラグメントディレクティブを含めるべきです。
ブックマークからの遷移時は通常と同様、同ディレクティブを処理します。
3.7.1.3. 共有
一部UAはURL共有(他アプリ・メッセージ転送)機能を提供します。
この場合も、一致がありマーカーが未解除ならフラグメントディレクティブをURLに含めるべきです。
3.8. Document Policyとの統合
本仕様は Document Policy の設定点として
"force-load-at-top" という名前で定義します。型は boolean で、初期値
は falseです。
https://example.com#:~:text=foo に遷移、
example.comはレスポンスヘッダで
Document-Policy: force-load-at-topと返した場合、
ページロード時、"foo"を含む要素は indicated partとしてマークされ、target elementとなります。しかし "foo" はスクロール表示されません。
このポリシーによるフラグメント由来のスクロール抑制は、本書scroll to the fragmentアルゴリズム修正として§ 3.6 テキストフラグメントへのナビゲート内で規定されています。
履歴スクロール復元の抑制は、restore persisted state ステップの2の直後に下記処理を挿入することで規定します:
-
"force-load-at-top" 機能のDocument policy値を取得し、Documentについて trueなら、ユーザエージェントは Documentやそのスクロール可能領域のスクロール位置を復元してはならない。
3.9. 機能検出について
機能検出のため、新しいFragmentDirectiveインターフェイスを追加し、UAが対応していればdocument.fragmentDirectiveで公開する提案です。
[Exposed =Window ]interface { };FragmentDirective
このため Document
インターフェイスに fragmentDirective プロパティを追加します:
partial interface Document { [SameObject ]readonly attribute FragmentDirective ; };fragmentDirective
このオブジェクトは将来テキストフラグメントやその他ディレクティブに関する追加情報を提供する目的にも使えるでしょう。
4. テキストフラグメントディレクティブ生成
本節ではUAがテキストディレクティブ付きURLを自動生成する際の推奨を示します。必須仕様ではありませんが、生成URLの安定性・利便性を高める観点でまとめています。
4.1. 範囲一致より完全一致を優先
一致テキストは exact型(例: "text=foo%20bar%20baz")または range型(例: "text=foo,bar")いずれでも指定できます。
可能なら全体を1つの文字列として指定するほうが望ましいです。これにより遷移先ページが削除・変動しても意図したリンク先がURLから分かります。
The first recorded idea of using digital electronics for computing was the 1931 paper "The Use of Thyratrons for High Speed Automatic Counting of Physical Phenomena" by C. E. Wynn-Williams.
範囲指定の場合:
https://en.wikipedia.org/wiki/History_of_computing#:~:text=The%20first%20recorded,Williams
完全一致指定の場合:
範囲一致は安定性が低く、ページ途中に "The first recorded" が追加されると違う箇所がターゲットとなってしまいます。
また、範囲一致は意味的な価値も小さいです。当該文自体がなくなった場合、ユーザーは意図したターゲット文を知り得ません。exactタイプならUAやユーザーが「探しても出ない」旨明示できます。
範囲一致は引用テキストが非常に長く、全体をエンコードするとURLが極端に長大になる場合は有用です。
300文字未満のテキスト断片は完全一致を推奨、超える場合はrange型も可。
4.2. 文脈指定は必要時のみ
文脈指定はテキストディレクティブによるページ内断片の曖昧性解消に使えますが、構造変化などで 脆くなりやすいです。多くの場合、断片テキストは要素境界で始まったり終わることが多いので文脈側が隣接別要素に現れます。そのためページ構造の変更で文脈と一致断片が隣接しなくなりURLが無効になりがちです。
<div class="section">HEADER</div> <div class="content">Text to quote</div>
ディレクティブ例:
text=HEADER-,Text%20to%20quote
しかし、ページが [edit] リンクをヘッダー隣に追加した場合、このURLは壊れてしまいます。
断片テキストが十分長くユニークな場合、UAは無用な文脈語追加を避けるべきです。
文脈指定が必要な条件:
- UAが引用テキストが曖昧だと判定した場合
- 引用テキストが3語以下
4.3. フラグメントIDの要否判定
UAがテキストディレクティブ付きURLへ遷移時、テキストフラグメントが見つからなければ通常の要素IDフラグメントにフォールバックしてスクロールします。
これは、ページテキストが変化してテキストディレクティブが無効化された場合の保険として有用です。
The earliest known tool for use in computation is the Sumerian abacus
該当文が含まれるセクションを#で指定することで、文が消えてもユーザーを該当セクションに案内できます:
ただし、フォールバック先の要素IDが適切かどうか注意が必要です:
By the late 1960s, computer systems could perform symbolic algebraic manipulations
この時ページURLは https://en.wikipedia.org/wiki/History_of_computing#Early_computation ですが、フォールバックで#Early_computationを使うべきではありません。当該文が消えた場合、全く関係ない位置(#Early_computation)が開いてしまい混乱の元となります。
UAが妥当な要素IDフラグメントを自動判定できない場合、URLからフラグメントIDを除去するべきです: