1. イントロダクション
このセクションは非規範的です。
Web Speech APIは、ウェブ開発者がウェブブラウザ上で、標準的な音声認識ソフトウェアやスクリーンリーダーでは通常利用できない音声入力およびテキスト読み上げ出力機能を提供できるようにすることを目的としています。 本APIは基盤となる音声認識および合成の実装に依存しない設計であり、サーバー側およびクライアント/組み込み型の認識・合成の両方をサポートできます。 APIは一度きりの短い音声入力(ワンショット)と連続的な音声入力の両方を可能にするよう設計されています。 音声認識の結果は、各仮説に関する関連情報とともに、仮説のリストとしてウェブページに提供されます。
本仕様は、HTML Speech Incubator Group Final Reportで定義されたAPIのサブセットです。 当該レポートは仕様トラック文書ではないため完全に参考情報です。 そのレポートの全ての部分は本ドキュメントに関して参考情報と見なすことができ、本仕様に対する参考的背景を提供します。 本仕様はそのレポートの機能的に完全なサブセットです。 具体的には、このサブセットは基盤となるトランスポートプロトコル、HTMLマークアップへの提案的追加を除外しており、JavaScript APIの簡略化されたサブセットを定義しています。 このサブセットはIncubator Group Final Reportの大半のユースケースとサンプルコードをサポートします。 このサブセットは将来のマークアップ、API、または基盤トランスポートプロトコルの標準化を排除するものではなく、実際にIncubator Reportはそのような将来の作業のための可能なロードマップを定義しています。
2. ユースケース
このセクションは非規範的です。
本仕様は、Incubator Report のセクション4で定義された以下のユースケースをサポートします。
- 音声によるウェブ検索
- 音声コマンドインターフェース
- オープン対話の連続認識
- 表示可能なUIがない場合における音声UIの提供
- 音声活動検出
- 視覚フィードバックを提供するための合成の時間構造
- Hello World
- 音声翻訳
- 音声対応のメールクライアント
- ダイアログシステム
- マルチモーダルインタラクション
- 音声による経路案内
- マルチモーダルビデオゲーム
- マルチモーダル検索
APIを最小限に保つため、本仕様は以下のユースケースを直接サポートしません。 ただし、将来のAPI拡張としてこれを追加することを排除するものではなく、実際にIncubator reportはそのためのロードマップを提供しています。
- 再認識(Rerecognition)
3. セキュリティおよびプライバシーに関する考慮事項
-
ユーザーエージェントは、明示的かつ十分に情報提供されたユーザーの同意がある場合にのみ音声入力セッションを開始しなければなりません。
ユーザーの同意には、例えば次のようなものが含まれます:
- 音声入力を開始することが明らかなグラフィカルな表示を持つ可視の音声入力要素上でのユーザーのクリック。
start()の呼び出しの結果として表示される許可プロンプトを承認すること。- このウェブページに対して常に音声入力を許可するよう以前に与えられた同意。
-
ユーザーエージェントはオーディオが録音されているときにユーザーに明白な表示を与えなければなりません。
- グラフィカルなユーザーエージェントでは、これはウェブページからアクセスできないユーザーエージェントのクロームの一部として表示される必須の通知であってよいです。
例えばブラウザのクローム/アドレスバーの一部として点滅する録音アイコン、ステータスバーでの表示、可聴の通知、またはユーザーにとって関連かつアクセス可能なその他の何かが考えられます。
このUI要素はユーザーが録音を停止できるようにする必要があります。
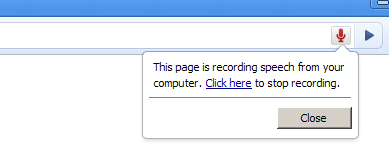
- 音声のみのユーザーエージェントでは、表示は例えば音声入力要素のラベルをシステムが話し、その後に短いビープ音を鳴らす形をとる場合があります。
- グラフィカルなユーザーエージェントでは、これはウェブページからアクセスできないユーザーエージェントのクロームの一部として表示される必須の通知であってよいです。
例えばブラウザのクローム/アドレスバーの一部として点滅する録音アイコン、ステータスバーでの表示、可聴の通知、またはユーザーにとって関連かつアクセス可能なその他の何かが考えられます。
このUI要素はユーザーが録音を停止できるようにする必要があります。
- ユーザーエージェントは、音声入力が初めて使用される際に、音声入力が何であるか、必要に応じて音声録音を無効にするためにプライバシー設定をどのように調整できるかをユーザーにより長い説明として提供してもよいです。
- フィンガープリンティングのリスクを軽減するため、ユーザーエージェントは
MediaStreamTrack上で音声認識を行う際に音声認識を個別最適化してはなりません(MUST NOT)。
3.1. 実装に関する考慮事項
このセクションは非規範的です。
- 音声でのパスワード入力はセキュリティの観点から問題を引き起こす可能性がありますが、パスワードを音声で入力するかどうかはユーザーの判断に委ねられます。
- 音声入力は潜在的にユーザーの盗聴に利用される可能性があります。 悪意のあるウェブページは、入力要素を隠す、または録音が停止したとユーザーに信じ込ませ続けるなどの手口を使って録音を継続する可能性があります。 また、入力要素を別のものに見せかけるようにスタイル設定してユーザーを騙してクリックさせることも考えられます。 ファイル入力要素のスタイリングの例は https://www.quirksmode.org/dom/inputfile.html に示されています。 上記の推奨は、そのような攻撃のリスクを減らすことを目的としています。
4. API の説明
このセクションは規範的です。
4.1. SpeechRecognition インターフェース
音声認識インターフェースは、特定の認識を制御するためのスクリプト可能なウェブAPIです。
用語「final result(最終結果)」はSpeechRecognitionResult
のうち isFinal
属性が true であるものを指します。
用語「interim result(暫定結果)」は SpeechRecognitionResult
のうち isFinal
属性が false であるものを指します。
SpeechRecognition
は以下の内部スロットを持ちます:
[[started]]-
音声認識が開始されたかどうかを表すブールフラグ。初期値は
falseです。
[[processLocally]]-
認識がローカルで実行されるべきかどうかを示すブールフラグ。初期値は
falseです。
[[phrases]]-
コンテキストバイアス用のフレーズのリストを表す
ObservableArrayのSpeechRecognitionPhraseオブジェクト。初期値は新しい空のObservableArrayです。
[SecureContext ,Exposed =Window ]interface :SpeechRecognition EventTarget {(); // recognition parametersconstructor attribute SpeechGrammarList grammars ;attribute DOMString lang ;attribute boolean continuous ;attribute boolean interimResults ;attribute unsigned long maxAlternatives ;attribute boolean processLocally ;attribute ObservableArray <SpeechRecognitionPhrase >phrases ; // methods to drive the speech interactionundefined start ();undefined start (MediaStreamTrack );audioTrack undefined stop ();undefined abort ();static Promise <AvailabilityStatus >available (SpeechRecognitionOptions );options static Promise <boolean >install (SpeechRecognitionOptions ); // event methodsoptions attribute EventHandler ;onaudiostart attribute EventHandler ;onsoundstart attribute EventHandler ;onspeechstart attribute EventHandler ;onspeechend attribute EventHandler ;onsoundend attribute EventHandler ;onaudioend attribute EventHandler ;onresult attribute EventHandler ;onnomatch attribute EventHandler ;onerror attribute EventHandler ;onstart attribute EventHandler ; };onend dictionary {SpeechRecognitionOptions required sequence <DOMString >;langs boolean =processLocally false ; };enum {SpeechRecognitionErrorCode "no-speech" ,"aborted" ,"audio-capture" ,"network" ,"not-allowed" ,"service-not-allowed" ,"language-not-supported" ,"phrases-not-supported" };enum {AvailabilityStatus "unavailable" ,"downloadable" ,"downloading" ,"available" }; [SecureContext ,Exposed =Window ]interface :SpeechRecognitionErrorEvent Event {(constructor DOMString ,type SpeechRecognitionErrorEventInit );eventInitDict readonly attribute SpeechRecognitionErrorCode error ;readonly attribute DOMString message ; };dictionary :SpeechRecognitionErrorEventInit EventInit {required SpeechRecognitionErrorCode ;error DOMString = ""; }; // Item in N-best list [message SecureContext ,Exposed =Window ]interface {SpeechRecognitionAlternative readonly attribute DOMString transcript ;readonly attribute float confidence ; }; // A complete one-shot simple response [SecureContext ,Exposed =Window ]interface {SpeechRecognitionResult readonly attribute unsigned long length ;getter SpeechRecognitionAlternative item (unsigned long );index readonly attribute boolean isFinal ; }; // A collection of responses (used in continuous mode) [SecureContext ,Exposed =Window ]interface {SpeechRecognitionResultList readonly attribute unsigned long length ;getter SpeechRecognitionResult item (unsigned long ); }; // A full response, which could be interim or final, part of a continuous response or not [index SecureContext ,Exposed =Window ]interface :SpeechRecognitionEvent Event {(constructor DOMString ,type SpeechRecognitionEventInit );eventInitDict readonly attribute unsigned long resultIndex ;readonly attribute SpeechRecognitionResultList results ; };dictionary :SpeechRecognitionEventInit EventInit {unsigned long = 0;resultIndex required SpeechRecognitionResultList ; }; // The object representing a speech grammar. This interface has been deprecated and exists in this spec for the sole purpose of maintaining backwards compatibility. [results Exposed =Window ]interface {SpeechGrammar attribute DOMString src ;attribute float weight ; }; // The object representing a speech grammar collection. This interface has been deprecated and exists in this spec for the sole purpose of maintaining backwards compatibility. [Exposed =Window ]interface {SpeechGrammarList ();constructor readonly attribute unsigned long length ;getter SpeechGrammar item (unsigned long );index undefined addFromURI (DOMString ,src optional float = 1.0);weight undefined addFromString (DOMString ,string optional float = 1.0); }; // The object representing a phrase for contextual biasing. [weight SecureContext ,Exposed =Window ]interface {SpeechRecognitionPhrase constructor (DOMString ,phrase optional float = 1.0);boost readonly attribute DOMString phrase ;readonly attribute float boost ; };
4.1.1. SpeechRecognition 属性
grammars属性, 型 SpeechGrammarList- grammars 属性は、この認識で有効な文法(SpeechGrammar オブジェクト)のコレクションを保持します。 この属性は動作せず、後方互換性維持のみの目的で仕様に存在します。
lang属性, 型 DOMString- この属性はリクエストの認識の言語を、正しい BCP 47 言語タグを使って設定します。[BCP47] 未設定の場合はスクリプトからも未設定のままですが、html ドキュメントのルート要素や継承階層の言語がデフォルトで使われます。 このデフォルト値は入力リクエストが認識サービスへの接続を開始する際に計算・適用されます。
continuous属性, 型 boolean- continuous 属性が false の場合、ユーザーエージェントは認識開始に対して最大1つの final result(単一ターンの対話等)しか返してはなりません。 continuous 属性が true の場合、ユーザーエージェントは認識開始に対し、連続する複数回の認識を表す0個以上の final result(ディクテーション等)を返します。 デフォルト値は false でなければなりません。この属性設定は interim results には影響しません。
interimResults属性, 型 boolean- interim result を返すかどうかを制御します。 true の場合、interim result が返されるべきです。 false の場合、interim result は返してはなりません。 デフォルト値は false でなければなりません。この属性設定は final result には影響しません。
maxAlternatives属性, 型 unsigned long- この属性は各 result あたり最大何件の
SpeechRecognitionAlternativeを返すか設定します。 デフォルト値は 1 です。 processLocally属性, 型 boolean- この属性が true なら、音声認識は必ずユーザー端末上で実行される必要があることを示します。 false の場合、ユーザーエージェントはローカルまたはリモート処理を選択できます。 デフォルト値は false です。
phrases属性, 型 ObservableArray<SpeechRecognitionPhrase>-
phrases属性は、コンテキストバイアス用に使うSpeechRecognitionPhraseオブジェクトのリストを提供します。これはObservableArray型で、JavaScript のArrayのように(例:push()など)変更可能です。- ゲッター手順は
[[phrases]]の値を返すことです。 - ゲッター手順は
グループはWebRTCがオーディオソースやリモート認識器の選択指定に使えるか検討しました。 詳しくは public-speech-api@w3.org のスレッド WebRTC、Web Audio API、および他の外部ソースとの連携 を参照してください。
4.1.2. SpeechRecognition メソッド
start()method-
デバイスのマイクから直接音声認識プロセスを開始します。
呼び出されたとき、以下の手順を実行します:
-
bool 型の変数 requestMicrophonePermission を
trueに設定します。 -
start session algorithm を requestMicrophonePermission とともに実行します。
-
start(methodMediaStreamTrackaudioTrack)-
MediaStreamTrackを使用して音声認識プロセスを開始します。 呼び出されたとき、以下の手順を実行します:-
audioTrack を最初の引数とします。
-
audioTrack の
kind属性が"audio"でない場合、InvalidStateErrorをスローしてこれらの手順を中止します。 -
audioTrack の
readyState属性が"live"でない場合、InvalidStateErrorをスローしてこれらの手順を中止します。 -
requestMicrophonePermission を
falseに設定します。 -
start session algorithm を requestMicrophonePermission とともに実行します。
-
stop()method- stop メソッドは、認識サービスに対してこれ以上オーディオの聴取を停止し、かつこの認識のために既に受信したオーディオのみを使用して結果を返すよう指示することを表します。 stop メソッドの典型的な使用例は、エンドユーザーが発話中のみ話す(例: トランシーバーのように)アプリケーションです。 エンドユーザーは話すときにスペースキーを押し続け、スペースダウン時に start 呼び出しが発生し、スペースキーを離すと stop メソッドが呼ばれてシステムがもはやユーザーを聞かないことを保証するかもしれません。 stop メソッドが呼ばれると、音声サービスは追加のオーディオを収集してはならず、ユーザーを聞き続けてはなりません。 音声サービスは、この認識のために既に収集したオーディオに基づいて認識結果(または nomatch)を返すことを試みなければなりません。 start が決して呼ばれていない、または end または error イベントが既に発火している、あるいは以前に stop が呼ばれたなどの理由で既に停止中または停止処理中のオブジェクトで stop が呼ばれた場合、ユーザーエージェントはその呼び出しを無視しなければなりません。
abort()method- abort メソッドは、直ちに聴取と認識を停止し、何の情報も返さずに処理を終了するよう要求するものです。 abort メソッドが呼ばれると、音声サービスは認識を停止しなければなりません。 ユーザーエージェントは、音声サービスがもはや接続されていないときに end イベントを発火しなければなりません。 start が決して呼ばれていない、または end または error イベントが既に発火している、あるいは以前に abort が呼ばれているなどの理由で既に停止中または中止処理中のオブジェクトで abort が呼ばれた場合、ユーザーエージェントはその呼び出しを無視しなければなりません。
available(methodSpeechRecognitionOptionsoptions)-
availableメソッドは、Promiseを返し、その Promise はAvailabilityStatusに解決され、引数で与えられたSpeechRecognitionOptionsに一致する認識の可用性を示します。 このメソッドへのアクセスは、ポリシー制御機能 "on-device-speech-recognition" の背後で制御されており、そのデフォルト許可リストは'self'です。呼び出されたとき、以下の手順を実行します:
-
promise を 新しい Promise とします。
-
availability algorithm を options と promise で実行します。例外が返されたら、それをスローしてこれらの手順を中止します。
-
promise を返します。
-
install(methodSpeechRecognitionOptionsoptions)-
installメソッドは、options.langsで指定された全ての言語のオンデバイス音声認識の言語パックをインストールしようと試みます。 このメソッドはPromiseを返し、その Promise はbooleanに解決されます。 指定された要求されたかつサポートされている言語の全てのインストール試行が成功した(またはすでにインストールされている)場合、Promise はtrueに解決されます。options.langsが空である場合、要求されたすべての言語がサポートされていない場合、またはサポートされている言語のインストール試行のいずれかが失敗した場合、Promise はfalseに解決されます。 このメソッドへのアクセスは、ポリシー制御機能 "on-device-speech-recognition" の背後で制御されており、そのデフォルト許可リストは'self'です。呼び出されたとき、以下の手順を実行します:
-
現在の設定オブジェクトの関連グローバルオブジェクトの関連ドキュメントが完全にアクティブでない場合、
InvalidStateErrorをスローしてこれらの手順を中止します。 -
options の
langsの任意の lang が有効な [BCP47] 言語タグでない場合、SyntaxErrorをスローしてこれらの手順を中止します。 -
options の
langsに含まれる任意の lang のオンデバイス音声認識言語パックがサポートされていない場合、解決済みのPromiseを false で返し、残りの手順をスキップします。 -
promise を新しい Promise とします。
-
options の各 lang について、オンデバイス音声認識言語パックのダウンロードを開始します。
注: ユーザーエージェントはオンデバイス音声認識言語パックのダウンロードに対してユーザーに明示的な許可を求めることができます。
-
関連グローバルオブジェクトのタスクキューにタスクをキューして、次の手順を実行します:
-
options の
langsで指定された全ての言語のダウンロードが成功したときに promise をtrueで解決し、そうでなければfalseで解決します。注: Promise が
falseに解決されることは失敗の具体的原因を示すものではありません。ユーザーエージェントは開発者ツールのコンソールメッセージで失敗の詳細情報を提供することが推奨されます。ただし、この詳細なエラー情報はスクリプトに公開されません。
-
-
promise を返します。
processLocallyはこのアルゴリズムでは使用されません。
-
4.1.3. AvailabilityStatus 列挙値
AvailabilityStatus
列挙は音声認識の利用可能性を示します。値は次の通りです:
"unavailable"- 指定された言語および処理設定について音声認識が利用できないことを示します。
processLocallyが options においてtrueの場合、この言語のオンデバイス認識がユーザーエージェントでサポートされていないことを意味します。processLocallyが options でfalseの場合、指定言語の少なくとも1つについてローカルおよびリモート認識のどちらも利用できないことを意味します。 "downloadable"- 指定された言語のオンデバイス音声認識がユーザーエージェントでサポートされているが、まだインストールされていないことを示します。
install()メソッドによってインストール可能です。このステータスは主にprocessLocallyが true の場合に該当します。 "downloading"- 指定された言語のオンデバイス音声認識が現在ダウンロード中であることを示します。このステータスは主に
processLocallyが true の場合に該当します。 "available"- すべての指定言語と与えられた処理設定について音声認識が利用可能であることを示します。
processLocallyが options で true の場合、オンデバイス認識がインストールされ利用可能であることを意味します。processLocallyが false の場合、(ローカルまたはリモート)認識が利用できることを意味します。
availability algorithm が options と promise で呼び出された場合、ユーザーエージェントは以下の手順を実行しなければなりません:
-
current settings object の relevant global object の associated Document が fully active でない場合、
InvalidStateErrorをスローし、以降の手順を中止します。 -
langs を
langsof optionsとします。 -
langs 内の任意の lang が有効な[BCP47] 言語タグでない場合、
SyntaxErrorをスローし、これらの手順を中止します。 -
processLocallyが options でfalseの場合:-
langs が空のシーケンスの場合、status を
unavailableとします。 -
それ以外で、すべての language in langs について認識(リモートも可)が利用可能な場合、status を
availableとします。 -
それ以外の場合、status を
unavailableとします。
-
-
processLocallyが options でtrueの場合:- langs が空の場合、status を
unavailableとします。 -
それ以外の場合:
- finalStatus を
availableとします。 -
langs 内の各 language について:
- currentLanguageStatus を設定します。
- language のオンデバイス音声認識がインストールされている場合、currentLanguageStatus に
availableを設定します。 - 現在ダウンロード中なら
downloadingを設定します。 - サポートはされているが未インストールなら
downloadableを設定します。 - サポートされていない場合は
unavailableを設定します。 - currentLanguageStatus が
[{{AvailabilityStatus/available}}, {{AvailabilityStatus/downloading}}, {{AvailabilityStatus/downloadable}}, {{AvailabilityStatus/unavailable}}]の順で finalStatus より後の場合、finalStatus を currentLanguageStatus に更新します。
- status を finalStatus にします。
- finalStatus を
- langs が空の場合、status を
-
queue a task を relevant global object の task queue に追加し、次のステップを実行します:
-
promise を status で解決します。
-
start session algorithm が requestMicrophonePermission で呼ばれた場合、ユーザーエージェントは次の手順を実行しなければなりません:
-
current settings object の relevant global object の associated Document が fully active でない場合、
InvalidStateErrorをスローし、以降の手順を中止します。 -
[[started]]がtrueかつ error イベントまたは end イベント が発火していない場合、InvalidStateErrorをスローし、これらの手順を中止します。 -
この
phrasesのlengthが 0 より大きく、かつユーザーエージェントがコンテキストバイアスをサポートしない場合:-
queue a task を実施し、fire an event(名前 error)を this で
SpeechRecognitionErrorEventを使いerror属性をphrases-not-supportedに初期化し、message属性を理由を示す実装依存の文字列で設定します。 -
これらの手順を中止します。
-
-
この
[[processLocally]]がtrueの場合:-
ユーザーエージェントがこの
langでローカル音声認識を利用不可と判定した場合、または他の理由でローカル処理要求を満たせない場合:-
queue a task を行い、fire an event(名前 error)を this で
SpeechRecognitionErrorEventを使いerror属性をservice-not-allowedで初期化し、message属性を理由を示す実装依存の文字列で設定します。 -
これらの手順を中止します。
-
-
-
[[started]]をtrueに設定します。 -
requestMicrophonePermission が
trueであり、request permission to use "microphone" が "denied" の場合:-
queue a task を実施し、fire an event(名前 error)を this で
SpeechRecognitionErrorEventを使いerror属性をnot-allowedで初期化し、message属性を理由を示す実装依存の文字列で設定します。 -
これらの手順を中止します。
-
-
認識のリッスンが正常に開始されたら、タスクキューに登録して fire an event(名前 start)を this で実行します。
4.1.4. SpeechRecognition イベント
音声認識イベントではDOM Level 2 イベントモデルが使用されます。 EventTarget インターフェースのメソッドを用いてイベントリスナーの登録を行います。 SpeechRecognition インターフェースにも各イベントタイプごとのシングルイベントハンドラ属性が含まれています。 これらのイベントはバブリングせず、キャンセルもできません。
これらの全イベントについて、DOM Level 2 Event インターフェースで定義されている timeStamp 属性は、イベントオブジェクトが表す実際の現実世界イベントの発生時刻の最良推定値に設定しなければなりません。 このタイムスタンプは、たとえリモート認識サービス等別マシンで発生したイベントの場合でも、ユーザーエージェントの時刻基準で表現しなければなりません(例:リモート speech endpointer の speechend イベント)。
以下で特に指定されていない限り、異なるイベントの発火順は未定義です。 例えば、クライアント側でオーディオ検出、サーバー側で音声検出を行っている場合、実装によっては audioend が speechstart より前や speechend より前に発火することもあります。
audiostartevent- ユーザーエージェントが音声の取得を開始したときに発火します。
soundstartevent- 何らかの音(音声の場合も含む)が検出されたときに発火します。 これはクライアントサイドのエネルギー検出器等により低遅延で発火しなければなりません。 audiostart イベントは soundstart より前に常に発火している必要があります。
speechstartevent- 音声認識に用いられる発話が始まったときに発火します。 audiostart イベントは speechstart より前に必ず発火している必要があります。
speechendevent- 音声認識に用いられる発話が終了したときに発火します。 speechstart イベントは speechend より前に必ず発火している必要があります。
soundendevent- 何らかの音がもはや検出されなくなった時に発火します。 これはクライアントサイドのエネルギー検出器等により低遅延で発火しなければなりません。 soundstart イベントの後に必ず発火している必要があります。
audioendevent- ユーザーエージェントによる音声取得が終了したときに発火します。 audiostart イベントの後に必ず発火している必要があります。
resultevent- 音声認識器が結果を返した際に発火します。
イベントは
SpeechRecognitionEventインターフェースを使用します。 audiostart イベントは result イベントより前に常に発火している必要があります。 nomatchevent- 認識器が信頼度閾値以上の認識仮説を持たない最終結果を返した際に発火します。
イベントは
SpeechRecognitionEventインターフェースを使用します。 イベント内のresults属性は信頼度閾値を下回る認識結果か、null かもしれません。audiostartイベントの後に必ず nomatch イベントは発火している必要があります。 errorevent- 音声認識エラーが発生したときに発火します。
イベントは
SpeechRecognitionErrorEventインターフェースを使用します。 startevent- 認識サービスが認識のために音声リッスンを開始したときに発火します。
endevent- サービスが切断されたときに発火します。 終了理由に関わらずセッションが終了した際に必ず生成される必要があります。
4.1.5. SpeechRecognitionErrorEvent
SpeechRecognitionErrorEvent
インターフェースは error イベント用に使用されます。
errorattribute, 型 SpeechRecognitionErrorCode, readonly-
errorCode は何が問題となったかを示す列挙値です。
その値は次の通りです:
"no-speech"- 音声が検出されませんでした。
"aborted"- 何らかの理由で音声入力が中断されました(例えばUIで入力キャンセルなど)。
"audio-capture"- 音声キャプチャに失敗しました。
"network"- 認識に必要なネットワーク通信が失敗しました。
"not-allowed"- ユーザーエージェントがセキュリティ・プライバシー・ユーザー設定等の理由で音声入力を許可しません。
"service-not-allowed"- ユーザーエージェントがウェブアプリケーションの要求した音声サービスは許可していませんが、別の音声サービスなら許可する可能性があります(ユーザーエージェントによる未対応またはセキュリティ・プライバシー・ユーザー設定などが理由)。
"language-not-supported"- 言語がサポートされていません。
"phrases-not-supported"- コンテキストバイアス用フレーズは音声認識モデルでサポートされていません。
messageattribute, 型 DOMString, readonly- メッセージ内容は実装依存です。 この属性は主にデバッグ目的であり、アプリケーションUIで直接利用すべきではありません。
4.1.6. SpeechRecognitionAlternative
SpeechRecognitionAlternative は、n-best リストで使用される応答の単純なビューを表します。
transcript属性, 型 DOMString, readonly- transcript 文字列は、ユーザーが発話した生のワードを表します。 連続認識の場合、連続する SpeechRecognitionResult を連結してセッションの正しいトランスクリプトになるよう、必要に応じて前後の空白を含めなければなりません。
confidence属性, 型 float, readonly-
confidence は、認識システムが認識が正しいとどれだけ確信しているかを 0~1 の間で数値的に推定した値です。
大きな値ほどシステムの自信が高いことを意味します。
グループは、confidence が認識エンジン非依存な方法で指定できるか、およびこの API がダイアログ API ではないため confidence threshold や nomatch を含めるべきかどうか議論しています。public-speech-api@w3.org の Confidence property スレッドを参照してください。
4.1.7. SpeechRecognitionResult
SpeechRecognitionResult オブジェクトは、連続認識の一部または非連続認識の完全な返却結果としての、単一のワンショット認識マッチを表します。
length属性, 型 unsigned long, readonly- long 属性は item 配列で何個の n-best alternative が表現されているかを示します。
item(index)getter- item getter は n-best 値の配列の index から SpeechRecognitionAlternative を返します。 index が length 以上の場合、これは null を返します。 ユーザーエージェントは length 属性が配列要素数になるよう保証しなければなりません。 ユーザーエージェントは、n-best リストが信頼度の降順(各要素は直前要素の confidence 以下)でソートされることを保証しなければなりません。
isFinal属性, 型 boolean, readonly- final boolean は、このインデックス値について音声サービスが返す最後の値であれば true に設定されなければなりません。 false の場合はこの値が暫定結果で、今後変更され得ることを表します。
4.1.8. SpeechRecognitionResultList
SpeechRecognitionResultList オブジェクトは認識結果のシーケンスを保持し、連続認識の完全な返却結果を表します。 非連続認識の場合は単一の値のみを持ちます。
length属性, 型 unsigned long, readonly- length 属性は item 配列にいくつ結果が入っているかを示します。
item(index)getter- item getter は result 値の配列の index から SpeechRecognitionResult を返します。 index が length 以上の場合、null を返します。 ユーザーエージェントは length 属性が配列要素数になるよう保証しなければなりません。
4.1.9. SpeechRecognitionEvent
SpeechRecognitionEvent は interim 結果または final 結果に変更があったとき毎回発火されるイベントです。
resultIndex属性, 型 unsigned long, readonly- resultIndex には "results" 配列で変更があった最小インデックスが設定されなければなりません。
results属性, 型 SpeechRecognitionResultList, readonly- このセッションの全ての現時点の認識結果配列。 具体的には全ての final 結果が返ったものに続き、全 interim 結果の現時点での最良仮説が続きます。 0以上の final 結果→0以上の interim 結果、という構成でなければなりません。 後続の SpeechRecognitionResultEvent で interim 結果は新しい interim 結果や final 結果で上書きか、(配列末尾かつ短縮で)削除されます。 final 結果は上書きも削除もされてはなりません。 resultIndex 未満のインデックスのすべての要素は最後の SpeechRecognitionResultEvent 発火時と同一でなければなりません。 resultIndex 以上のインデックスの要素はすべて新しい結果で上書きされます。 "results" 配列の長さは増減しても構いませんが、resultIndex 未満にはできません。 resultIndex が results.length と等しい場合は新しい結果は返りません。(例: interim 結果1つ以上削除のとき等)
4.1.10. SpeechRecognitionPhrase
SpeechRecognitionPhrase オブジェクトはコンテキストバイアス用のフレーズを表し、以下の内部スロットを持ちます:
[[phrase]]-
ブースト対象のテキスト文字列を表す
DOMString。初期値は null。 空値は許可されますが、音声認識モデルで無視されます。
[[boost]]-
このフレーズが音声認識モデル既知のものよりどれぐらいサイト的に確率高いと思うかの対数(自然対数相当)の float。 有効な boost 値は [0.0, 10.0] の float で、指定なし時は 1.0。 boost 0.0 はまったく強調されず、大きな値ほど登場確率が上がります。 boost 10.0 は極端に出やすい状態を意味し、めったに設定されるべきではありません。
SpeechRecognitionPhrase(phrase, boost)コンストラクタ-
このコンストラクタが呼ばれる際、下記手順を実行します:
-
boost が 0.0 未満または 10.0 を超える場合、
SyntaxErrorをスローして中止します。 -
phr を
SpeechRecognitionPhraseの新規オブジェクトとします。 -
phr.
[[phrase]]に phrase を設定します。 -
phr.
[[boost]]に boost を設定します。 -
phr を返します。
-
phrase属性, 型 DOMString, readonly- この属性は
[[phrase]]の値を返します。 boost属性, 型 float, readonly- この属性は
[[boost]]の値を返します。
4.1.11. SpeechGrammar
SpeechGrammar オブジェクトは文法のコンテナを表します。
文法サポートは廃止されており削除されています。grammar オブジェクトは後方互換目的のためスペック上残っていますが、音声認識には影響しません。
この構造は以下の属性を持ちます:
src属性, 型 DOMString- 必須 src 属性は grammar の URI です。
weight属性, 型 float- 任意の weight 属性は、この grammar に対して音声認識サービスが使用すべき重みを制御します。 デフォルトでは grammar のウエイトは 1 です。 値が大きいほどその grammar の重みが高く、小さいほど弱くなります。
4.1.12. SpeechGrammarList
SpeechGrammarList オブジェクトは SpeechGrammar オブジェクトの集合を表します。 この構造は次の属性を持ちます:
文法サポートは廃止されており削除されています。grammar オブジェクトは後方互換目的で仕様に残っていますが、音声認識には影響しません。
length属性, 型 unsigned long, readonly- length 属性は配列に現在いくつ grammar があるかを示します。
item(index)getter- item getter は grammar 配列の index から SpeechGrammar を返します。 ユーザーエージェントは length 属性が配列要素数であること、index の昇順が grammar の追加順と一致することを保証しなければなりません。
addFromURI(src, weight)メソッド- このメソッドは URI に基づいて grammar を grammar 配列に追加します。 grammar の URI は src パラメータで与えられます。 一部サービスでは URI で組み込み grammar をサポートする場合があります。 weight パラメータは他の grammar に対する本 grammar の重みを示します。
addFromString(string, weight)メソッド- このメソッドはテキストに基づいて grammar を grammar 配列に追加します。 grammar の内容は string パラメータで指定します。 この内容は SpeechGrammar オブジェクト作成時 data: URI へエンコードすべきです。 weight パラメータは他の grammar に対する重みを示します。
4.2. SpeechSynthesis インターフェース
SpeechSynthesis インターフェースはテキスト読み上げ出力を制御するスクリプト Web API です。
[Exposed =Window ]interface :SpeechSynthesis EventTarget {readonly attribute boolean pending ;readonly attribute boolean speaking ;readonly attribute boolean paused ;attribute EventHandler ;onvoiceschanged undefined speak (SpeechSynthesisUtterance );utterance undefined cancel ();undefined pause ();undefined resume ();sequence <SpeechSynthesisVoice >getVoices (); };partial interface Window { [SameObject ]readonly attribute SpeechSynthesis ; }; [speechSynthesis Exposed =Window ]interface :SpeechSynthesisUtterance EventTarget {(constructor optional DOMString );text attribute DOMString text ;attribute DOMString lang ;attribute SpeechSynthesisVoice ?voice ;attribute float volume ;attribute float rate ;attribute float pitch ;attribute EventHandler ;onstart attribute EventHandler ;onend attribute EventHandler ;onerror attribute EventHandler ;onpause attribute EventHandler ;onresume attribute EventHandler ;onmark attribute EventHandler ; }; [onboundary Exposed =Window ]interface :SpeechSynthesisEvent Event {(constructor DOMString ,type SpeechSynthesisEventInit );eventInitDict readonly attribute SpeechSynthesisUtterance utterance ;readonly attribute unsigned long charIndex ;readonly attribute unsigned long charLength ;readonly attribute float elapsedTime ;readonly attribute DOMString name ; };dictionary :SpeechSynthesisEventInit EventInit {required SpeechSynthesisUtterance ;utterance unsigned long = 0;charIndex unsigned long = 0;charLength float = 0;elapsedTime DOMString = ""; };name enum {SpeechSynthesisErrorCode "canceled" ,"interrupted" ,"audio-busy" ,"audio-hardware" ,"network" ,"synthesis-unavailable" ,"synthesis-failed" ,"language-unavailable" ,"voice-unavailable" ,"text-too-long" ,"invalid-argument" ,"not-allowed" , }; [Exposed =Window ]interface :SpeechSynthesisErrorEvent SpeechSynthesisEvent {(constructor DOMString ,type SpeechSynthesisErrorEventInit );eventInitDict readonly attribute SpeechSynthesisErrorCode error ; };dictionary :SpeechSynthesisErrorEventInit SpeechSynthesisEventInit {required SpeechSynthesisErrorCode ; }; [error Exposed =Window ]interface {SpeechSynthesisVoice readonly attribute DOMString voiceURI ;readonly attribute DOMString name ;readonly attribute DOMString lang ;readonly attribute boolean localService ;readonly attribute boolean default ; };
4.2.1. SpeechSynthesis 属性
pending属性, 型 boolean, 読み取り専用- この属性は、グローバル SpeechSynthesis インスタンスのキューにまだ読み上げが開始されていない発話が含まれている場合に true です。
speaking属性, 型 boolean, 読み取り専用- この属性は発話が再生中(読み上げが開始されておりまだ完了していない)の場合に true です。 これはグローバル SpeechSynthesis インスタンスが一時停止状態かどうかに関係ありません。
paused属性, 型 boolean, 読み取り専用- この属性はグローバル SpeechSynthesis インスタンスが一時停止状態のとき true です。 この状態はキューに何かがあるかどうかに依存しません。 新規ウィンドウのグローバル SpeechSynthesis インスタンスはデフォルトで非一時停止状態です。
4.2.2. SpeechSynthesis メソッド
speak(utterance)メソッド- このメソッドは、SpeechSynthesisUtterance オブジェクト utterance をグローバル SpeechSynthesis インスタンスのキュー末尾に追加します。 SpeechSynthesis インスタンスの一時停止状態を変更しません。 インスタンスが一時停止中ならそのままです。 一時停止中でなくキューに他の発話がないときはその発話がすぐに読み上げられ、キューに他の発話がある場合はその発話の後に再生されます。 このメソッド呼び出し後、対応する end または error イベントまでの間に SpeechSynthesisUtterance オブジェクトに変更を加えた場合、 その変更が実際の読み上げ内容に影響するかや、エラーになるかどうかは未定義です。 SpeechSynthesis オブジェクトは SpeechSynthesisUtterance オブジェクトの排他的な所有権を取得します。 別の SpeechSynthesis オブジェクトに同じ Utterance を渡すと例外になるべきです。 (例えば同一オリジンの2つのフレームが各々 SpeechSynthesis オブジェクトを持つ場合など)
cancel()メソッド- このメソッドはキュー内の全ての発話を削除します。 すでに発話中のものがある場合は直ちに再生が停止します。 このメソッドでグローバル SpeechSynthesis インスタンスの一時停止状態は変更されません。
pause()メソッド- このメソッドはグローバル SpeechSynthesis インスタンスを一時停止状態にします。 発話が再生中であれば途中で一時停止します。 (すでに一時停止状態のとき呼んでも何もしません。)
resume()メソッド- このメソッドはグローバル SpeechSynthesis インスタンスを非一時停止状態にします。 再生途中の発話があれば中断した箇所から再開し、なければキュー内の次の発話があればそれが再生されます。 (すでに非一時停止状態で呼んでも何もしません。)
getVoices()メソッド- このメソッドは利用可能な音声リストを返します。 どの音声が利用可能かはユーザーエージェント依存です。 利用可能な音声がない場合や、音声リストがまだ分かっていない(例:サーバー側合成で非同期の場合など)場合は、このメソッドは長さ0の SpeechSynthesisVoiceList を必ず返します。
4.2.3. SpeechSynthesis イベント
voiceschangedイベント- getVoices メソッドが返す SpeechSynthesisVoiceList の内容が変化した時に発火します。 例:サーバー側合成でリストが非同期的に決定されたとき、またはクライアント側音声をインストール/アンインストールしたとき等。
4.2.4. SpeechSynthesisUtterance 属性
text属性, 型 DOMString- この属性はこの発話で合成・読み上げすべきテキストを指定します。 プレーンテキストでも、完全な SSML 文書でも指定できます。 [SSML] SSML 非対応または一部対応のみのエンジンの場合、ユーザーエージェントやエンジンは未対応タグを除去してテキストを合成します。 テキストは最大32,767文字等、上限がある場合があります。
lang属性, 型 DOMString- この属性は、BCP 47 言語タグで発話の音声合成対象言語を指定します。 [BCP47] スクリプト上未設定のままだと、HTMLドキュメントルート要素やその継承階層の言語がデフォルト値として使われます。 このデフォルト値はリクエストの接続時に算出・使用されます。
voice属性, 型 SpeechSynthesisVoice, null 許容- この属性はウェブアプリが利用したい音声合成の声を指定します。
SpeechSynthesisUtteranceオブジェクト生成時はこの属性が null で初期化されなければなりません。speak()呼び出し時にこの属性がSpeechSynthesisVoiceリスト内の1つにセット済みなら、ユーザーエージェントはそれを使わなければなりません。 speak() 実行時に未設定または null なら、ユーザーエージェントはデフォルトの声を使わなければなりません。 デフォルトの声は現在の言語をサポートしている必要があり(lang参照)、 ローカルおよびリモートサービスのいずれでもありえます。また、ブラウザ設定等でエンドユーザー選択も反映されます。 volume属性, 型 float- この属性は発話の音量を指定します。 0 以上 1 以下で、0 が最小音量、1 が最大音量(デフォルト1)です。 SSML を利用している場合は prosody タグ値が優先されます。
rate属性, 型 float- この属性は発話の話速を指定します。 声固有のデフォルト話速を基準に相対的に指定します。 1 が通常話速(デフォルト値)、2 は2倍速、0.5 は半速です。 0.1未満または10超は使用禁止ですが、合成エンジンや声によって範囲はさらに狭まる場合があります(例:指定値が3以上でも実際には3倍より速く話せないなど)。 SSML の場合は prosody タグ値が優先されます。
pitch属性, 型 float- この属性は発話の音程を指定します。 0 以上 2 以下、0 が最低音、2 が最高音、1 が合成エンジンや声のデフォルト音程です。 合成エンジンや声によってはさらに制限されることがあります。 SSML を使った場合は prosody タグ値が優先されます。
4.2.5. SpeechSynthesisUtterance イベント
これら各イベントは SpeechSynthesisEvent
インターフェースを使う必要があります。
ただし error イベントのみ SpeechSynthesisErrorEvent
インターフェースを使う必要があります。
これらのイベントはバブルせず、キャンセル不可です。
startイベント- この発話の読み上げが開始したとき発火します。
endイベント- この発話の読み上げが完了したとき発火します。 このイベントが発火した場合は error イベントは発火してはなりません。
errorイベント- この発話の読み上げでエラーが発生した場合に発火します。 このイベントが発火した場合は end イベントは発火してはなりません。
pauseイベント- この発話が途中で一時停止したときに発火します。
resumeイベント- この発話が一時停止後に再開したときに発火します。 グローバル SpeechSynthesis インスタンスが一時停止状態の間に発話をキューに追加し、その後 resume を呼んでも resume イベントは発火せず、 この場合は utterance の start イベントが発火します。
markイベント- 発話が SSML の "mark" タグに達したときに発火します。 [SSML] 合成エンジンがこのイベントをサポートしている場合、ユーザーエージェントは発火しなければなりません。
boundaryイベント- 発話が単語または文境界に達したときに発火します。 合成エンジンがこのイベントをサポートしている場合、ユーザーエージェントは発火しなければなりません。
4.2.6. SpeechSynthesisEvent 属性
utterance属性, 型 SpeechSynthesisUtterance, 読み取り専用- この属性はこのイベントをトリガーした SpeechSynthesisUtterance を含みます。
charIndex属性, 型 unsigned long, 読み取り専用- この属性は合成エンジンの現発話位置に最も近い、元の発話文字列中のゼロ始まりの文字インデックスです。 charIndex が単語境界のどちら側か等は保証しませんが、charIndex より前はすでに再生済、charIndex より後は未再生です。 合成エンジンがサポートする場合、この値を返し、そうでなければ 0 を返さなければなりません。
charLength属性, 型 unsigned long, 読み取り専用- この属性は、このイベントに対応するテキスト(単語または文)の長さ(文字数)です。
この属性は、このイベントの
charIndexから始まる長さ(文字数)です。 合成エンジンがサポートまたは検出可能な場合はこの値、それ以外は 0 を必ず返します。 elapsedTime属性, 型 float, 読み取り専用- このイベントが発火した時点で、この発話の読み上げ開始からの経過時間(秒)です。 合成エンジンがサポートまたは検出可能な場合はこの値、それ以外は 0 を必ず返します。
name属性, 型 DOMString, 読み取り専用- mark イベント用では、これは SSML の mark 要素の name 属性としてマーカー名を示します。[SSML] boundary イベント用では、イベント原因の区切り種別:"word" または "sentence" です。 それ以外のイベントでは "" を返すべきです。
4.2.7. SpeechSynthesisErrorEvent 属性
SpeechSynthesisErrorEvent は SpeechSynthesisUtterance の error イベント用インターフェースです。
error属性, 型 SpeechSynthesisErrorCode, 読み取り専用-
errorCode は何が問題となったかを示す列挙値です。
値は次の通りです:
"canceled"- cancel メソッド呼び出しにより、SpeechSynthesisUtterance が再生前にキューから削除された。
"interrupted"- 再生中の SpeechSynthesisUtterance が cancel メソッド呼び出しで完了前に途中で中断された。
"audio-busy"- ユーザーエージェントがオーディオ出力デバイスにアクセスできず操作できない。 (例えば他アプリケーションを終了する等で修正可能な場合があります。)
"audio-hardware"- ユーザーエージェントがオーディオ出力デバイスを認識できず操作できない。 (例えばスピーカーの接続やシステム設定変更が必要な場合があります。)
"network"- 必要なネットワーク通信の失敗により操作できない。
"synthesis-unavailable"- 利用可能な合成エンジンがなく操作できない。 (例えばエンジンのインストールや設定が必要な場合があります。)
"synthesis-failed"- 合成エンジンがエラーを返し操作に失敗。
"language-unavailable"- SpeechSynthesisUtterance lang で指定した言語用の適切な声が利用できない。
"voice-unavailable"- SpeechSynthesisUtterance voice 属性で指定した声が利用できない。
"text-too-long"- SpeechSynthesisUtterance text 属性の内容が長すぎて合成できない。
"invalid-argument"- SpeechSynthesisUtterance rate, pitch, volume 属性の値が合成エンジンでサポートされていない。
"not-allowed"- 現在のコンテキストでユーザーエージェントまたはシステム側で合成が許可されていない。
4.2.8. SpeechSynthesisVoice 属性
voiceURI属性, 型 DOMString, 読み取り専用- voiceURI 属性はこの声の音声合成サービスの場所を含めて音声合成声を指定します。 voiceURI は汎用URIであり、URNあるいはユーザーエージェントがローカルサービスだと解釈できるURLなど、ローカルやリモートいずれのサービスも指し得ます。
name属性, 型 DOMString, 読み取り専用- この属性は声を表す人間可読名です。 すべての名前が一意とは保証されません。
lang属性, 型 DOMString, 読み取り専用- この属性は声の言語(BCP47 言語タグ)です。[BCP47]
localService属性, 型 boolean, 読み取り専用- ローカル音声合成エンジン由来の声なら true、リモート音声合成サービス由来なら false です。 (リモートだと遅延やコスト等が発生する、ローカルだと品質が下がる等の意味合いになる場合もありますが、必ずしもそうとは限りません。)
default属性, 型 boolean, 読み取り専用- この属性は1言語につき最大1つの声で true です。 言語ごとにデフォルトは異なる場合があります。 どれがデフォルトになるかはユーザーエージェント依存です。
5. 例
このセクションは非規範的です。
5.1. 音声認識の例
音声認識を利用して入力フィールドに記入し、ウェブ検索を実行します。
< script type = "text/javascript" > var recognition= new SpeechRecognition(); recognition. onresult= function ( event) { if ( event. results. length> 0 ) { q. value= event. results[ 0 ][ 0 ]. transcript; q. form. submit(); } } </ script > < form action = "https://www.example.com/search" > < input type = "search" id = "q" name = "q" size = 60 > < input type = "button" value = "話して入力" onclick = "recognition.start()" > </ form >
音声認識を利用してオプションリストに音声による選択肢(オルタナティブ結果)を入力します。
< script type = "text/javascript" > var recognition= new SpeechRecognition(); recognition. maxAlternatives= 10 ; recognition. onresult= function ( event) { if ( event. results. length> 0 ) { var result= event. results[ 0 ]; for ( var i= 0 ; i< result. length; ++ i) { var text= result[ i]. transcript; select. options[ i] = new Option( text, text); } } } function start() { select. options. length= 0 ; recognition. start(); } </ script > < select id = "select" ></ select > < button onclick = "start()" > 話して入力</ button >
連続的な音声認識を利用してテキストエリアを入力します。
< textarea id = "textarea" rows = 10 cols = 80 ></ textarea > < button id = "button" onclick = "toggleStartStop()" ></ button > < script type = "text/javascript" > var recognizing; var recognition= new SpeechRecognition(); recognition. continuous= true ; reset(); recognition. onend= reset; recognition. onresult= function ( event) { for ( var i= event. resultIndex; i< event. results. length; ++ i) { if ( event. results[ i]. isFinal) { textarea. value+= event. results[ i][ 0 ]. transcript; } } } function reset() { recognizing= false ; button. innerHTML= "話して入力" ; } function toggleStartStop() { if ( recognizing) { recognition. stop(); reset(); } else { recognition. start(); recognizing= true ; button. innerHTML= "停止" ; } } </ script >
連続的な音声認識を利用し、最終結果を黒、暫定結果をグレーで表示します。
< button id = "button" onclick = "toggleStartStop()" ></ button > < div style = "border:dotted;padding:10px" > < span id = "final_span" ></ span > < span id = "interim_span" style = "color:grey" ></ span > </ div > < script type = "text/javascript" > var recognizing; var recognition= new SpeechRecognition(); recognition. continuous= true ; recognition. interimResults= true ; reset(); recognition. onend= reset; recognition. onresult= function ( event) { var final = "" ; var interim= "" ; for ( var i= 0 ; i< event. results. length; ++ i) { if ( event. results[ i]. isFinal) { final += event. results[ i][ 0 ]. transcript; } else { interim+= event. results[ i][ 0 ]. transcript; } } final_span. innerHTML= final ; interim_span. innerHTML= interim; } function reset() { recognizing= false ; button. innerHTML= "話して入力" ; } function toggleStartStop() { if ( recognizing) { recognition. stop(); reset(); } else { recognition. start(); recognizing= true ; button. innerHTML= "停止" ; final_span. innerHTML= "" ; interim_span. innerHTML= "" ; } } </ script >
5.2. 音声合成の例
テキストの読み上げ。
< script type = "text/javascript" > speechSynthesis. speak( new SpeechSynthesisUtterance( 'Hello World' )); </ script >
属性やイベントを使った読み上げテキスト。
< script type = "text/javascript" > var u= new SpeechSynthesisUtterance(); u. text= 'Hello World' ; u. lang= 'en-US' ; u. rate= 1.2 ; u. onend= function ( event) { alert( '終了まで ' + event. elapsedTime+ ' 秒でした。' ); } speechSynthesis. speak( u); </ script >
謝辞
Adam Sobieski (Phoster) Björn Bringert (Google) Charles Pritchard Dominic Mazzoni (Google) Gerardo Capiel (Benetech) Jerry Carter Kagami Sascha Rosylight Marcos Cáceres (Mozilla) Nagesh Kharidi (Openstream) Olli Pettay (Mozilla) Peter Beverloo (Google) Raj Tumuluri (Openstream) Satish Sampath (Google)
また、HTML Speech Incubator Group のメンバーと、それが本仕様の基礎となった該当 Final Report。