はじめに
これまでウェブ上のオーディオはかなり原始的であり、非常に最近までFlashやQuickTimeなどのプラグインを利用する必要がありました。HTML5で
audio
要素が導入されたことは非常に重要で、基本的なストリーミングオーディオ再生が可能になりました。しかし、より複雑なオーディオアプリケーションを扱うには十分なパワーがありません。高度なウェブベースのゲームやインタラクティブアプリケーションには、別のソリューションが必要です。本仕様の目標は、現代のゲームオーディオエンジンにある機能や、現代のデスクトップオーディオ制作アプリケーションで行われるミキシング、処理、フィルタリングのタスクの一部を含めることです。
APIは多様なユースケース[webaudio-usecases]を念頭に設計されています。理想的には、最適化されたC++エンジンをスクリプトで制御し、ブラウザで実行可能なあらゆるユースケースをサポートできるべきです。ただし、現代のデスクトップオーディオソフトウェアは非常に高度な機能を持ち、一部は本システムで構築するのが困難または不可能な場合もあります。AppleのLogic Audioはその一例で、外部MIDIコントローラ、任意のプラグインオーディオエフェクトやシンセサイザー、高度に最適化されたダイレクト・トゥ・ディスクのオーディオファイル読取/書込、緊密に統合されたタイムストレッチなどに対応しています。それでも、提案されているシステムはかなり多様な複雑なゲームやインタラクティブアプリケーション(音楽関連も含む)を十分にサポート可能です。そしてWebGLの高度なグラフィック機能と非常に良い補完関係になります。APIは後からさらに高度な機能を追加できるよう設計されています。
機能
APIがサポートする主な機能は以下の通りです:
-
モジュラー型ルーティングによるシンプルまたは複雑なミキシング/エフェクト構成。
-
内部処理に32ビット浮動小数点を使用する高ダイナミックレンジ。
-
サンプル精度のスケジュール済みサウンド再生と、低レイテンシによる、 ドラムマシンやシーケンサーなど非常に高いリズム精度が必要な音楽用途への対応。エフェクトの動的生成も含みます。
-
エンベロープやフェードイン/フェードアウト、グラニュラーエフェクト、フィルタースイープ、LFOなどのオーディオパラメータの自動化。
-
オーディオストリーム内のチャンネルを柔軟に扱い、分割・合成が可能。
-
audioやvideomedia elementからのオーディオソースの処理。 -
MediaStreamを用いたライブオーディオ入力の処理。取得にはgetUserMedia()を使用。 -
WebRTCとの統合
-
MediaStreamTrackAudioSourceNodeを使ってリモートピアから受信したオーディオの処理、[webrtc]。 -
MediaStreamAudioDestinationNodeを使って生成または処理されたオーディオストリームをリモートピアへ送信、[webrtc]。
-
-
スクリプトで直接 オーディオストリームの合成・処理。
-
空間化オーディオによる幅広い3Dゲームや没入型環境への対応:
-
パンニングモデル:equalpower、HRTF、パススルー
-
距離減衰
-
サウンドコーン
-
遮蔽・遮断
-
ソース/リスナーに基づく
-
-
幅広い線形エフェクト(特に高品質なルームエフェクト)に対応したコンボリューションエンジン。例えば:
-
小部屋/大部屋
-
大聖堂
-
コンサートホール
-
洞窟
-
トンネル
-
廊下
-
森
-
円形劇場
-
ドア越しの遠くの部屋の音
-
極端なフィルター
-
奇妙な逆再生効果
-
極端なコムフィルター効果
-
-
ミックス全体のコントロールや音質向上のためのダイナミクスコンプレッション
-
ローパス、ハイパスなどの一般的なフィルターに対応した効率的なバイカッドフィルター。
-
歪みや非線形効果のためのウェーブシェイピングエフェクト
-
オシレーター
モジュラー型ルーティング
モジュラー型ルーティングでは、異なるAudioNode
オブジェクト間で任意の接続が可能です。各ノードは入力や出力を持つことができます。
ソースノードは入力を持たず、出力は1つだけです。
デスティネーションノードは入力が1つで出力はありません。他のノード(フィルター等)はソースとデスティネーションの間に配置できます。開発者は、2つのオブジェクトを接続するときに低レベルのストリームフォーマット詳細を心配する必要はなく、適切に処理されます。
例えば、モノラルのオーディオストリームをステレオ入力に接続すれば、適切に左右チャンネルにミックスされます。
最も単純な場合、1つのソースを直接出力へルーティングできます。
すべてのルーティングは、AudioContext
内で、単一のAudioDestinationNode
によって行われます:
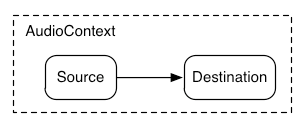
この単純なルーティングを図示すると、単一のサウンドを再生する簡単な例は以下の通りです:
const context= new AudioContext(); function playSound() { const source= context. createBufferSource(); source. buffer= dogBarkingBuffer; source. connect( context. destination); source. start( 0 ); }
より複雑な例として、3つのソースとコンボリューションリバーブのセンド、最終出力段にダイナミクスコンプレッサーを使ったルーティング例は以下です:
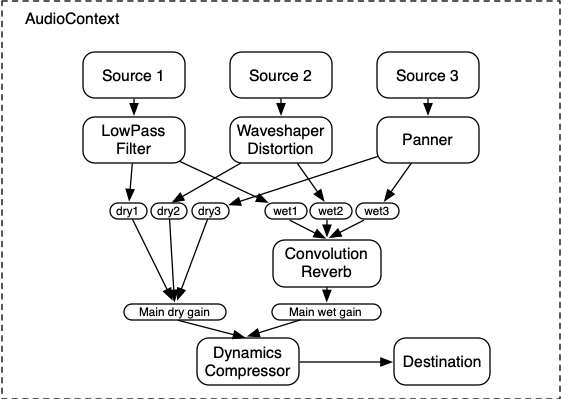
let context; let compressor; let reverb; let source1, source2, source3; let lowpassFilter; let waveShaper; let panner; let dry1, dry2, dry3; let wet1, wet2, wet3; let mainDry; let mainWet; function setupRoutingGraph() { context= new AudioContext(); // Create the effects nodes. lowpassFilter= context. createBiquadFilter(); waveShaper= context. createWaveShaper(); panner= context. createPanner(); compressor= context. createDynamicsCompressor(); reverb= context. createConvolver(); // Create main wet and dry. mainDry= context. createGain(); mainWet= context. createGain(); // Connect final compressor to final destination. compressor. connect( context. destination); // Connect main dry and wet to compressor. mainDry. connect( compressor); mainWet. connect( compressor); // Connect reverb to main wet. reverb. connect( mainWet); // Create a few sources. source1= context. createBufferSource(); source2= context. createBufferSource(); source3= context. createOscillator(); source1. buffer= manTalkingBuffer; source2. buffer= footstepsBuffer; source3. frequency. value= 440 ; // Connect source1 dry1= context. createGain(); wet1= context. createGain(); source1. connect( lowpassFilter); lowpassFilter. connect( dry1); lowpassFilter. connect( wet1); dry1. connect( mainDry); wet1. connect( reverb); // Connect source2 dry2= context. createGain(); wet2= context. createGain(); source2. connect( waveShaper); waveShaper. connect( dry2); waveShaper. connect( wet2); dry2. connect( mainDry); wet2. connect( reverb); // Connect source3 dry3= context. createGain(); wet3= context. createGain(); source3. connect( panner); panner. connect( dry3); panner. connect( wet3); dry3. connect( mainDry); wet3. connect( reverb); // Start the sources now. source1. start( 0 ); source2. start( 0 ); source3. start( 0 ); }
モジュラー型ルーティングでは、AudioNodeの出力を、
別のAudioParam
パラメータにルーティングして、異なるAudioNodeの挙動を制御することもできます。この場合、
ノードの出力は入力信号ではなく変調信号として機能します。
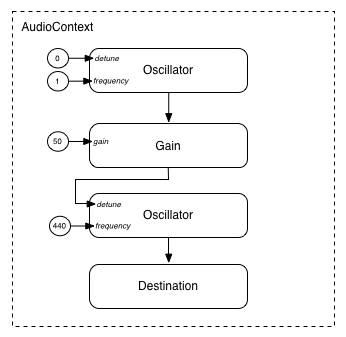
function setupRoutingGraph() { const context= new AudioContext(); // Create the low frequency oscillator that supplies the modulation signal const lfo= context. createOscillator(); lfo. frequency. value= 1.0 ; // Create the high frequency oscillator to be modulated const hfo= context. createOscillator(); hfo. frequency. value= 440.0 ; // Create a gain node whose gain determines the amplitude of the modulation signal const modulationGain= context. createGain(); modulationGain. gain. value= 50 ; // Configure the graph and start the oscillators lfo. connect( modulationGain); modulationGain. connect( hfo. detune); hfo. connect( context. destination); hfo. start( 0 ); lfo. start( 0 ); }
API概要
定義されるインターフェースは以下の通りです:
-
AudioContext インターフェースは、
AudioNode間の接続を表すオーディオ信号グラフを保持します。 -
AudioNodeインターフェースは、オーディオソース、オーディオ出力、中間処理モジュールを表します。AudioNodeはモジュラー方式で動的に接続可能です。AudioNodeはAudioContextの内部で存在します。 -
AnalyserNodeインターフェースは、音楽ビジュアライザーや他の可視化アプリケーション用のAudioNodeです。 -
AudioBufferインターフェースは、メモリ上のオーディオアセットを扱います。ワンショットサウンドや長いオーディオクリップを表現可能です。 -
AudioBufferSourceNodeインターフェースは、AudioNodeでAudioBufferからオーディオを生成します。 -
AudioDestinationNodeインターフェースは、すべてのレンダリングされたオーディオの最終出力先となるAudioNodeサブクラスです。 -
AudioParamインターフェースは、AudioNodeの音量など、個別の挙動を制御します。 -
AudioListenerインターフェースは、空間化のためのPannerNodeと連携します。 -
AudioWorkletインターフェースは、スクリプトで直接オーディオを処理するためのカスタムノードを生成するファクトリーです。 -
AudioWorkletGlobalScopeインターフェースは、AudioWorkletProcessorの処理スクリプトが実行されるコンテキストです。 -
AudioWorkletNodeインターフェースは、AudioWorkletProcessorで処理されるAudioNodeです。 -
AudioWorkletProcessorインターフェースは、オーディオワーカー内の単一ノードインスタンスを表します。 -
BiquadFilterNodeインターフェースは、以下のような一般的な低次数フィルターのAudioNodeです:-
ローパス
-
ハイパス
-
バンドパス
-
ローシェルフ
-
ハイシェルフ
-
ピーキング
-
ノッチ
-
オールパス
-
-
ChannelMergerNodeインターフェースは、複数のオーディオストリームのチャンネルを単一のストリームに合成するAudioNodeです。 -
ChannelSplitterNodeインターフェースは、ルーティンググラフ内のオーディオストリームの個々のチャンネルにアクセスするためのAudioNodeです。 -
ConstantSourceNodeインターフェースは、AudioNodeで名目上一定の出力値を生成し、AudioParamにより値の自動化を可能にします。 -
ConvolverNodeインターフェースは、コンサートホールなどのリアルタイム線形エフェクトを適用するAudioNodeです。 -
DynamicsCompressorNodeインターフェースは、ダイナミクスコンプレッションを行うAudioNodeです。 -
IIRFilterNodeインターフェースは、一般的なIIRフィルター用のAudioNodeです。 -
MediaElementAudioSourceNodeインターフェースは、AudioNodeで、audio、videoなどのメディア要素からのオーディオソースです。 -
MediaStreamAudioSourceNodeインターフェースは、AudioNodeで、MediaStream(ライブ入力やリモートピアなど)からのオーディオソースです。 -
MediaStreamTrackAudioSourceNodeインターフェースは、AudioNodeで、MediaStreamTrackからのオーディオソースです。 -
MediaStreamAudioDestinationNodeインターフェースは、AudioNodeで、リモートピアへ送信するMediaStreamへのオーディオ出力先です。 -
PannerNodeインターフェースは、3D空間でオーディオの空間化/位置指定を行うAudioNodeです。 -
PeriodicWaveインターフェースは、OscillatorNodeで使用するカスタム周期波形を指定します。 -
OscillatorNodeインターフェースは、周期波形を生成するAudioNodeです。 -
StereoPannerNodeインターフェースは、ステレオストリーム中のオーディオ入力のイコールパワー位置指定用AudioNodeです。 -
WaveShaperNodeインターフェースは、歪みや微妙なウォーミング効果のための非線形ウェーブシェイピングエフェクトを適用するAudioNodeです。
また、Web Audio APIから廃止予定であり現在は代替実装の経験を待っている機能もいくつか存在します:
-
ScriptProcessorNodeインターフェースは、スクリプトで直接オーディオを生成/処理するAudioNodeです。 -
AudioProcessingEventインターフェースは、ScriptProcessorNodeオブジェクトで使用されるイベント型です。
1. オーディオAPI
1.1.
BaseAudioContext
インターフェース
このインターフェースは、AudioNode
オブジェクト群とその接続を表します。任意の信号ルーティングをAudioDestinationNode
へ行うことができます。
ノードはコンテキストから生成され、相互接続されます。
BaseAudioContext
は直接インスタンス化されず、
代わりに具象インターフェースであるAudioContext
(リアルタイムレンダリング用)およびOfflineAudioContext
(オフラインレンダリング用)によって拡張されます。
BaseAudioContext
は内部スロット[[pending promises]]を持ち、これは初期状態では空の順序付きpromiseリストです。
各BaseAudioContext
は一意の
メディア要素イベントタスクソースを持ちます。
さらに、BaseAudioContext
は複数のプライベートスロット[[rendering thread state]]、
[[control thread state]]
を持ち、これらはAudioContextState
の値を取り、どちらも初期値は"suspended" です。また、プライベートスロット [[render quantum size]]は符号なし整数です。
enum {AudioContextState "suspended" ,"running" ,"closed" };
| 列挙値 | 説明 |
|---|---|
"suspended"
| このコンテキストは現在サスペンド状態です(コンテキスト時間は進行せず、オーディオハードウェアは電源切断・解放されている可能性があります)。 |
"running"
| オーディオが処理されています。 |
"closed"
| このコンテキストは解放され、オーディオ処理に使用できません。すべてのシステムオーディオリソースが解放されました。 |
enum {AudioContextRenderSizeCategory "default" ,"hardware" };
| 列挙型の説明 | |
|---|---|
"default"
| AudioContextのレンダリング量子サイズはデフォルト値128フレームです。 |
"hardware"
|
ユーザーエージェントが現在の構成に最適なレンダリング量子サイズを選択します。
注: これはホスト情報を公開し、フィンガープリントに利用される可能性があります。 |
callback DecodeErrorCallback =undefined (DOMException );error callback DecodeSuccessCallback =undefined (AudioBuffer ); [decodedData Exposed =Window ]interface BaseAudioContext :EventTarget {readonly attribute AudioDestinationNode destination ;readonly attribute float sampleRate ;readonly attribute double currentTime ;readonly attribute AudioListener listener ;readonly attribute AudioContextState state ;readonly attribute unsigned long renderQuantumSize ; [SameObject ,SecureContext ]readonly attribute AudioWorklet audioWorklet ;attribute EventHandler onstatechange ;AnalyserNode createAnalyser ();BiquadFilterNode createBiquadFilter ();AudioBuffer createBuffer (unsigned long ,numberOfChannels unsigned long ,length float );sampleRate AudioBufferSourceNode createBufferSource ();ChannelMergerNode createChannelMerger (optional unsigned long numberOfInputs = 6);ChannelSplitterNode createChannelSplitter (optional unsigned long numberOfOutputs = 6);ConstantSourceNode createConstantSource ();ConvolverNode createConvolver ();DelayNode createDelay (optional double maxDelayTime = 1.0);DynamicsCompressorNode createDynamicsCompressor ();GainNode createGain ();IIRFilterNode createIIRFilter (sequence <double >,feedforward sequence <double >);feedback OscillatorNode createOscillator ();PannerNode createPanner ();PeriodicWave createPeriodicWave (sequence <float >,real sequence <float >,imag optional PeriodicWaveConstraints = {});constraints ScriptProcessorNode createScriptProcessor (optional unsigned long bufferSize = 0,optional unsigned long numberOfInputChannels = 2,optional unsigned long numberOfOutputChannels = 2);StereoPannerNode createStereoPanner ();WaveShaperNode createWaveShaper ();Promise <AudioBuffer >decodeAudioData (ArrayBuffer ,audioData optional DecodeSuccessCallback ?,successCallback optional DecodeErrorCallback ?); };errorCallback
1.1.1. 属性
audioWorklet、 型: AudioWorklet、 読み取り専用-
Workletオブジェクトへのアクセスを許可し、AudioWorkletProcessorクラス定義を含むスクリプトを[HTML]およびAudioWorkletで定義されたアルゴリズムによりインポートできます。 currentTime、 型: double、読み取り専用-
これはコンテキストのレンダリンググラフで直近に処理されたオーディオブロックの最後のサンプルフレームに続くサンプルフレームの秒数です。レンダリンググラフがまだオーディオブロックを処理していない場合、
currentTimeの値は0です。currentTimeの時間座標系では、値0がグラフで最初に処理される最初のサンプルフレームに対応します。この座標系での経過時間は、BaseAudioContextにより生成されたオーディオストリームの経過時間に対応しますが、他のシステムクロックと同期しているとは限りません。(OfflineAudioContextでは、ストリームはデバイスで再生されないため、リアルタイムに近いものすらありません。)Web Audio APIのすべてのスケジュールされた時刻は
currentTimeの値を基準とします。BaseAudioContextが"running"状態のとき、 この属性の値は単調増加し、レンダリングスレッドにより均等な増分で更新され、レンダリング量子に対応します。したがって、runningなコンテキストではcurrentTimeはオーディオブロック処理に合わせて着実に増加し、常に次に処理されるオーディオブロックの開始時刻を表します。また、現在の状態でスケジュールされた変更が最も早く有効になる可能性のある時刻でもあります。currentTimeは返される前にコントロールスレッド上でアトミックに読み取られる必要があります。 destination、 型: AudioDestinationNode、読み取り専用-
1つの入力を持ち、すべてのオーディオの最終出力先を表す
AudioDestinationNodeです。通常は実際のオーディオハードウェアを表します。すべてのAudioNode(アクティブにオーディオをレンダリングしているもの)は直接または間接的にdestinationに接続されます。 listener、 型: AudioListener、 読み取り専用-
3D空間化に使用される
AudioListenerです。 onstatechange、 型: EventHandler-
AudioContextの状態が変化したとき(対応するpromiseが解決されたとき)、
BaseAudioContextにディスパッチされるイベント用のイベントハンドラを設定するためのプロパティです。イベント型はstatechangeです。Eventインターフェースを使うイベントがハンドラにディスパッチされ、AudioContextの状態を直接参照できます。新しく作成されたAudioContextは常にsuspended状態で開始し、状態が変化するたびにstatechangeイベントが発火されます。このイベントはcompleteイベントよりも前に発火されます。 sampleRate、 型: float、読み取り専用-
BaseAudioContextが処理するオーディオのサンプルレート(毎秒サンプルフレーム数)です。コンテキスト内のすべてのAudioNodeはこのレートで動作すると仮定されます。この仮定のもと、サンプルレート変換や「バリスピード」処理はリアルタイム処理ではサポートされません。 ナイキスト周波数はこのサンプルレート値の半分です。 state、 型: AudioContextState、読み取り専用-
BaseAudioContextの現在の状態を説明します。 この属性の取得は[[control thread state]]スロットの内容を返します。 renderQuantumSize、 型: unsigned long、読み取り専用-
この属性の取得は
[[render quantum size]]スロットの値を返します。
1.1.2. メソッド
createAnalyser()-
ファクトリメソッド。
AnalyserNodeを生成します。パラメータなし。返却型:AnalyserNode createBiquadFilter()-
ファクトリメソッド。
BiquadFilterNodeを生成し、代表的な二次フィルターのいずれかとして構成可能です。パラメータなし。返却型:BiquadFilterNode createBuffer(numberOfChannels, length, sampleRate)-
指定されたサイズのAudioBufferを生成します。バッファ内のオーディオデータはゼロ初期化(無音)されます。引数が負値、ゼロ、または規定範囲外の場合は、
NotSupportedError例外を必ず投げなければなりません。BaseAudioContext.createBuffer()メソッドの引数。 パラメータ 型 Nullable Optional 説明 numberOfChannelsunsigned long✘ ✘ バッファのチャンネル数を決定します。実装は少なくとも32チャンネルをサポートしなければなりません。 lengthunsigned long✘ ✘ バッファのサンプルフレーム数。最低でも1でなければなりません。 sampleRatefloat✘ ✘ バッファ内のリニアPCMオーディオデータのサンプルレート(毎秒サンプルフレーム数)。実装は少なくとも8000~96000の範囲をサポートしなければなりません。 返却型:AudioBuffer createBufferSource()-
ファクトリメソッド。
AudioBufferSourceNodeを生成します。パラメータなし。 createChannelMerger(numberOfInputs)-
ファクトリメソッド。
ChannelMergerNodeを生成します。IndexSizeErrorは、numberOfInputsが1未満、またはサポートされるチャンネル数を超える場合に必ず投げなければなりません。BaseAudioContext.createChannelMerger(numberOfInputs)メソッドの引数。 パラメータ 型 Nullable Optional 説明 numberOfInputsunsigned long✘ ✔ 入力数。最大32までサポート必須。省略時は 6が使用されます。返却型:ChannelMergerNode createChannelSplitter(numberOfOutputs)-
ファクトリメソッド。
ChannelSplitterNodeを生成します。IndexSizeErrorは、numberOfOutputsが1未満、またはサポートされるチャンネル数を超える場合に必ず投げなければなりません。BaseAudioContext.createChannelSplitter(numberOfOutputs)メソッドの引数。 パラメータ 型 Nullable Optional 説明 numberOfOutputsunsigned long✘ ✔ 出力数。最大32までサポート必須。省略時は 6が使用されます。返却型:ChannelSplitterNode createConstantSource()-
ファクトリメソッド。
ConstantSourceNodeを生成します。パラメータなし。返却型:ConstantSourceNode createConvolver()-
ファクトリメソッド。
ConvolverNodeを生成します。パラメータなし。返却型:ConvolverNode createDelay(maxDelayTime)-
ファクトリメソッド。
DelayNodeを生成します。初期デフォルトのディレイ時間は0秒です。BaseAudioContext.createDelay(maxDelayTime)メソッドの引数。 パラメータ 型 Nullable Optional 説明 maxDelayTimedouble✘ ✔ ディレイラインで許容される最大ディレイ時間(秒)。指定した場合、この値はゼロより大きく3分未満でなければならず、違反時は NotSupportedError例外を必ず投げなければなりません。省略時は1が使用されます。返却型:DelayNode createDynamicsCompressor()-
ファクトリメソッド。
DynamicsCompressorNodeを生成します。パラメータなし。 createGain()-
パラメータなし。返却型:
GainNode createIIRFilter(feedforward, feedback)-
BaseAudioContext.createIIRFilter()メソッドの引数。 パラメータ 型 Nullable Optional 説明 feedforwardsequence<double>✘ ✘ IIRフィルターの伝達関数のフィードフォワード(分子)係数の配列。最大長は20。すべての値がゼロの場合、 InvalidStateError必須で例外を投げます。NotSupportedError必須で、配列長が0または20超の場合に例外を投げます。feedbacksequence<double>✘ ✘ IIRフィルターの伝達関数のフィードバック(分母)係数の配列。最大長は20。配列の最初の要素が0の場合、 InvalidStateError必須で例外を投げます。NotSupportedError必須で、配列長が0または20超の場合に例外を投げます。返却型:IIRFilterNode createOscillator()-
ファクトリメソッド。
OscillatorNodeを生成します。パラメータなし。返却型:OscillatorNode createPanner()-
ファクトリメソッド。
PannerNodeを生成します。パラメータなし。返却型:PannerNode createPeriodicWave(real, imag, constraints)-
ファクトリメソッド。
PeriodicWaveを生成します。このメソッドを呼び出す際、以下の手順で実行します:-
realとimagの長さが一致しない場合、IndexSizeErrorを必ず投げます。 -
oを
PeriodicWaveOptions型の新しいオブジェクトとします。 -
oの
disableNormalization属性に、ファクトリメソッドに渡されたdisableNormalization属性の値をセットします。 -
新しい
PeriodicWavepを構築し、第一引数に本ファクトリメソッドが呼ばれたBaseAudioContextを、第二引数にoを渡します。 -
pを返します。
BaseAudioContext.createPeriodicWave()メソッドの引数。 パラメータ 型 Nullable Optional 説明 realsequence<float>✘ ✘ コサインパラメータの配列。詳細は realコンストラクタ引数の説明を参照。imagsequence<float>✘ ✘ サインパラメータの配列。詳細は imagコンストラクタ引数の説明を参照。constraintsPeriodicWaveConstraints✘ ✔ 指定しない場合、波形は正規化されます。指定した場合、 constraintsで与えられる値に従い正規化されます。返却型:PeriodicWave -
createScriptProcessor(bufferSize, numberOfInputChannels, numberOfOutputChannels)-
ファクトリメソッド。
ScriptProcessorNodeを生成します。このメソッドは非推奨であり、AudioWorkletNodeへの置き換えが予定されています。スクリプトによる直接音声処理用のScriptProcessorNodeを生成します。IndexSizeErrorは、bufferSizeやnumberOfInputChannelsやnumberOfOutputChannelsが有効範囲外の場合、必ず投げなければなりません。numberOfInputChannelsとnumberOfOutputChannelsの両方が0の場合は無効です。この場合はIndexSizeErrorを必ず投げなければなりません。BaseAudioContext.createScriptProcessor(bufferSize, numberOfInputChannels, numberOfOutputChannels)メソッドの引数。 パラメータ 型 Nullable Optional 説明 bufferSizeunsigned long✘ ✔ bufferSizeパラメータはバッファサイズ(サンプルフレーム単位)を決定します。指定しない場合や値が0の場合、実装側が最適なバッファサイズ(ノードの生存期間中はパワーオブ2で一定)を選択します。明示的に指定する場合は、256, 512, 1024, 2048, 4096, 8192, 16384いずれかでなければなりません。この値はaudioprocessイベントの発行頻度や、毎回処理するサンプルフレーム数を決定します。bufferSizeが小さいほどレイテンシが低くなります。値が大きいほど音切れやグリッチ回避に必要です。バッファサイズは指定せず実装に任せるのが推奨です。パワーオブ2以外の場合は、IndexSizeErrorを必ず投げなければなりません。numberOfInputChannelsunsigned long✘ ✔ ノード入力のチャンネル数。デフォルト値は2。最大32までサポート必須。 NotSupportedErrorをサポート外の場合は必ず投げなければなりません。numberOfOutputChannelsunsigned long✘ ✔ ノード出力のチャンネル数。デフォルト値は2。最大32までサポート必須。 NotSupportedErrorをサポート外の場合は必ず投げなければなりません。返却型:ScriptProcessorNode createStereoPanner()-
ファクトリメソッド。
StereoPannerNodeを生成します。パラメータなし。返却型:StereoPannerNode createWaveShaper()-
ファクトリメソッド。
WaveShaperNode(非線形歪み効果)を生成します。パラメータなし。返却型:WaveShaperNode decodeAudioData(audioData, successCallback, errorCallback)-
非同期的に、
ArrayBufferに格納されたオーディオファイルデータをデコードします。たとえばXMLHttpRequestのresponse属性でresponseTypeを"arraybuffer"に設定した後にロードしたArrayBufferなどが利用できます。オーディオファイルデータは、audio要素が対応する任意のフォーマットで構いません。decodeAudioData()に渡すバッファのcontent-typeは、[mimesniff]に記載されたスニッフィング手順で判定されます。主にpromiseのreturn値で扱いますが、コールバックパラメータはレガシー対応です。
破損ファイルについては作者への警告を推奨します(throwは後方互換性のため不可)。
注: 圧縮音声データのバイトストリームが破損していてもデコード可能な場合、実装は(例えば開発者ツールで)作者に警告することが推奨されます。decodeAudioDataが呼ばれた際、以下の手順をコントロールスレッドで実行する必要があります:-
thisの関連グローバルオブジェクトの関連付けられたDocumentが完全有効でない場合、"
InvalidStateError"DOMExceptionでrejectされたpromiseを返します。 -
promiseを新規生成。
-
-
promiseを
[[pending promises]]に追加。 -
audioDataArrayBufferをdetach。エラー時はstep 3へ。 -
デコード処理を他スレッドにキューイング。
-
-
それ以外の場合は以下のエラー処理:
-
errorを
DataCloneErrorとする。 -
promiseをerrorでrejectし、
[[pending promises]]から除去。 -
メディア要素タスクをキューイングし、
errorCallbackをerrorで呼び出す。
-
-
promiseを返す。
デコード処理を他スレッドにキューイングする場合、以下の手順をコントロールスレッド・レンダリングスレッド以外のデコードスレッドで実行する必要があります。注: 複数の
デコードスレッドが並列でdecodeAudioData処理可能。-
can decodeをtrueで初期化。
-
audioDataのMIMEタイプ判定。オーディオ・ビデオタイプパターン照合アルゴリズムがundefinedを返した場合、can decodeをfalseに。 -
can decodeがtrueなら、
audioDataをリニアPCMにデコード。失敗時はcan decodeをfalseに。 マルチトラックの場合は最初のトラックだけをデコード。注: より詳細なデコード制御が必要な場合は[WEBCODECS]を利用可能。
-
can decodeがfalseの場合、 メディア要素タスクをキューイングし、
-
errorを
DOMException(名前はEncodingError)に。-
promiseをerrorでrejectし、
[[pending promises]]から除去。
-
-
errorCallbackが存在する場合は、それをerrorで呼び出す。
-
-
それ以外の場合:
-
リザルト(デコード済みリニアPCM音声データ)を
BaseAudioContextのサンプルレートにリサンプル(異なる場合)。 -
-
リザルト(場合によりリサンプル済み)を含む
AudioBufferをbufferとする。 -
promiseをbufferでresolve。
-
successCallbackが存在する場合は、それをbufferで呼び出す。
-
-
BaseAudioContext.decodeAudioData()メソッドの引数。 パラメータ 型 Nullable Optional 説明 audioDataArrayBuffer✘ ✘ 圧縮音声データを含むArrayBuffer。 successCallbackDecodeSuccessCallback?✔ ✔ デコード終了時に呼ばれるコールバック関数。引数はデコード済みPCM音声データのAudioBuffer。 errorCallbackDecodeErrorCallback?✔ ✔ デコードエラー時に呼ばれるコールバック関数。 返却型:Promise<AudioBuffer> -
1.1.3. コールバック DecodeSuccessCallback()
のパラメータ
decodedData, 型AudioBuffer-
デコード済み音声データを含むAudioBufferです。
1.1.4. コールバック DecodeErrorCallback()
のパラメータ
error, 型DOMException-
デコード中に発生したエラーです。
1.1.5. ライフタイム
一度作成されたAudioContext
は、再生する音がなくなるか、ページが消えるまで音声の再生を続けます。
1.1.6. 内省やシリアル化プリミティブの欠如
Web Audio APIは発火して忘れる方式で音声ソースのスケジューリングを行います。つまり、ソースノードはAudioContext
のライフタイム中に各ノート用に生成され、グラフから明示的に削除されることはありません。これはシリアル化APIと互換性がなく、安定したノード集合がないためシリアル化できません。
さらに、内省APIがあると、コンテンツスクリプトがガベージコレクションの様子を観察できてしまいます。
1.1.7. BaseAudioContext
のサブクラスに関連するシステムリソース
サブクラスAudioContext
およびOfflineAudioContext
は高コストなオブジェクトと考えるべきです。これらのオブジェクトの作成は、ハイプライオリティなスレッドの生成や低レイテンシのシステムオーディオストリームの利用を伴い、エネルギー消費に影響します。通常、ドキュメント内で複数のAudioContext
を作成する必要はありません。
BaseAudioContext
サブクラスの構築や再開は、そのコンテキスト用のシステムリソースの取得を伴います。AudioContext
の場合、システムオーディオストリームの生成も必要です。これらの操作は、コンテキストが関連するオーディオグラフから出力の生成を開始するときに完了します。
さらに、ユーザーエージェントはAudioContext
の最大数を独自に定義でき、それを超えるAudioContext
の作成を試みると失敗し、NotSupportedErrorを投げます。
suspend
やclose
により、著者がスレッド、プロセス、オーディオストリームなどのシステムリソース解放を行えます。BaseAudioContext
のサスペンドは、実装が一部リソースを解放でき、resume
で後から再開可能です。AudioContext
のクローズは全リソースの解放を許可し、以後再利用や再開はできません。
注: 例えば、これはオーディオコールバックが定期的に発火するのを待ったり、ハードウェアが処理準備完了するのを待つことを含みます。
1.2. AudioContext
インターフェース
このインターフェースは、AudioDestinationNode
がリアルタイム出力デバイスにルーティングされ、ユーザーへ信号を出力するオーディオグラフを表します。ほとんどのユースケースでは、1文書につき1つのAudioContext
のみ使用されます。
enum {AudioContextLatencyCategory "balanced" ,"interactive" ,"playback" };
| 列挙値 | 説明 |
|---|---|
"balanced"
| オーディオ出力のレイテンシと消費電力のバランスを取る。 |
"interactive"
| グリッチを起こさず可能な限り低レイテンシでオーディオ出力を行う。これがデフォルト。 |
"playback"
| オーディオ出力のレイテンシよりも途切れのない持続的な再生を優先する。消費電力が最も低い。 |
enum {AudioSinkType "none" };
| 列挙値 | 説明 |
|---|---|
"none"
| オーディオグラフはオーディオ出力デバイスで再生せずに処理されます。 |
[Exposed =Window ]interface AudioContext :BaseAudioContext {constructor (optional AudioContextOptions contextOptions = {});readonly attribute double baseLatency ;readonly attribute double outputLatency ; [SecureContext ]readonly attribute (DOMString or AudioSinkInfo )sinkId ; [SecureContext ]readonly attribute AudioRenderCapacity renderCapacity ;attribute EventHandler onsinkchange ;attribute EventHandler onerror ;AudioTimestamp getOutputTimestamp ();Promise <undefined >resume ();Promise <undefined >suspend ();Promise <undefined >close (); [SecureContext ]Promise <undefined >((setSinkId DOMString or AudioSinkOptions ));sinkId MediaElementAudioSourceNode createMediaElementSource (HTMLMediaElement );mediaElement MediaStreamAudioSourceNode createMediaStreamSource (MediaStream );mediaStream MediaStreamTrackAudioSourceNode createMediaStreamTrackSource (MediaStreamTrack );mediaStreamTrack MediaStreamAudioDestinationNode createMediaStreamDestination (); };
AudioContext
が開始可能とは、ユーザーエージェントがコンテキスト状態を"suspended"
から
"running"へ遷移することを許可する場合を指します。
ユーザーエージェントはこの初回遷移を不許可にし、AudioContext
の関連グローバルオブジェクトがスティッキーアクティベーションを持つ場合のみ許可することがあります。
AudioContext
には以下の内部スロットがあります:
[[suspended by user]]-
コンテキストがユーザーコードによってサスペンドされているかを示す真偽値フラグです。 初期値は
falseです。 [[sink ID]]-
現在のオーディオ出力デバイスの識別子または情報を表す
DOMStringまたはAudioSinkInfoです。初期値は""(デフォルトのオーディオ出力デバイス)です。 [[pending resume promises]]
1.2.1. コンストラクター
AudioContext(contextOptions)-
現在の設定オブジェクトの関連グローバルオブジェクトの関連付けられたDocumentが完全有効でない場合は、 "
InvalidStateError" を投げて処理を中断します。AudioContextを作成する際、以下の手順を実行します:-
contextを新しい
AudioContextオブジェクトとして生成します。 -
contextの
[[control thread state]]をsuspendedに設定します。 -
contextの
[[rendering thread state]]をsuspendedに設定します。 -
messageChannelを新しい
MessageChannelとして生成します。 -
controlSidePortをmessageChannelの
port1属性値に設定します。 -
renderingSidePortをmessageChannelの
port2属性値に設定します。 -
serializedRenderingSidePortをStructuredSerializeWithTransfer(renderingSidePort, « renderingSidePort »)の結果とします。
-
audioWorkletのportをcontrolSidePortに設定します。 -
コントロールメッセージのキューイング を行い、AudioContextGlobalScopeにMessagePortをセットします。 引数はserializedRenderingSidePortです。
-
contextOptionsが指定されている場合、以下のサブ手順を実行します:-
sinkIdが指定されている場合、sinkIdをcontextOptions.の値として、以下のサブ手順を実行します:sinkId-
sinkIdと
[[sink ID]]の両方がDOMString型で、 かつ値が等しい場合はサブ手順を中断します。 -
sinkIdが
AudioSinkOptions型で、[[sink ID]]がAudioSinkInfo型で、 かつtypeの値が等しい場合はサブ手順を中断します。 -
validationResultをsink識別子の検証の返り値とします。
-
validationResultが
DOMException型の場合は、 validationResultで例外を投げてサブ手順を中断します。 -
sinkIdが
DOMString型の場合、[[sink ID]]をsinkIdに設定し、サブ手順を中断します。 -
sinkIdが
AudioSinkOptions型の場合、[[sink ID]]をtypeの値を使って新規作成したAudioSinkInfoインスタンスに設定します。
-
-
contextOptions.が指定されている場合は、latencyHintlatencyHintに記載された通り、contextの内部レイテンシを設定します。 -
contextOptions.が指定されている場合は、contextのsampleRatesampleRateをこの値に設定します。指定されていない場合は以下のサブ手順を実行します:-
sinkIdが空文字列、または
AudioSinkOptions型の場合は、 デフォルト出力デバイスのサンプルレートを使用し、サブ手順を中断します。 -
sinkIdが
DOMString型の場合は、 sinkIdで識別される出力デバイスのサンプルレートを使用し、サブ手順を中断します。
contextOptions.が出力デバイスのサンプルレートと異なる場合、ユーザーエージェントは必ず音声出力を出力デバイスのサンプルレートにリサンプルする必要があります。sampleRate注: リサンプリングが必要な場合、contextのレイテンシに大きく影響する場合があります。
-
-
-
contextを返します。
コントロールメッセージによる処理開始とは以下の手順です:-
documentを現在の設定オブジェクトの関連グローバルオブジェクトの関連付けられたDocumentとする。
-
[[sink ID]]に基づき、以下のオーディオ出力デバイス用にシステムリソースを取得する:-
空文字列ならデフォルトのオーディオ出力デバイス。
-
sinkIdで識別されるオーディオ出力デバイス。
-
リソース取得に失敗した場合は以下の手順:
-
documentが
"speaker-selection"という機能の利用を許可されていなければ、サブ手順を中断。 -
メディア要素タスクをキューイングして、
errorイベントをAudioContextに発火し、以下の手順を中断。
-
-
-
thisの
[[rendering thread state]]をrunningに設定。 -
メディア要素タスクをキューイングして、以下を実行:
-
state属性をAudioContextで"running"に設定。
-
注:
AudioContextを引数なしで構築しリソース取得に失敗した場合、ユーザーエージェントはオーディオ出力デバイスをエミュレートする機構で音声グラフをサイレントレンダリングする場合があります。コントロールメッセージでMessagePortをAudioWorkletGlobalScopeにセットする場合、以下の手順を レンダリングスレッドでserializedRenderingSidePortを使って実行します(current Realmに転送済)。-
deserializedPortをStructuredDeserialize(serializedRenderingSidePort, 現在のRealm)の結果とします。
-
portをdeserializedPortに設定します。
AudioContext.constructor(contextOptions) メソッドの引数。 パラメータ 型 Nullable Optional 説明 contextOptionsAudioContextOptions✘ ✔ AudioContextの構築方法を制御するユーザー指定オプション。 -
1.2.2. 属性
baseLatency、 型: double、読み取り専用-
これは
AudioContextがAudioDestinationNodeからオーディオサブシステムへ音声を渡す際に発生する処理レイテンシ(秒単位)を表します。他の処理による追加レイテンシ(AudioDestinationNode出力~オーディオハードウェア間)や、オーディオグラフ自体によるレイテンシは含みません。例えば、オーディオコンテキストが44.1kHzでデフォルトのレンダー量子サイズで動作し、
AudioDestinationNodeが内部でダブルバッファリングを実装し各レンダー量子毎に処理・出力できる場合、処理レイテンシは \((2\cdot128)/44100 = 5.805 \mathrm{ ms}\) 程度となります。 outputLatency、 型: double、読み取り専用-
オーディオ出力レイテンシの推定値(秒単位)。つまり、UAがホストシステムにバッファ再生を要求してから、バッファ内の最初のサンプルが実際にオーディオ出力デバイスで処理されるまでの間隔です。スピーカーやヘッドフォンなど、音響信号を生成するデバイスではこの時点はサンプルの音が出力されるタイミングです。
outputLatency属性値はプラットフォームや接続されているオーディオ出力デバイスのハードウェアに依存します。outputLatencyは、コンテキスト動作中や出力デバイスの変更時にも変化する場合があります。正確な同期が必要な場合はこの値を頻繁に取得するのが有効です。 renderCapacity、 型: AudioRenderCapacity、読み取り専用-
AudioContextに関連付けられたAudioRenderCapacityインスタンスを返します。 sinkId、 型:(DOMString or AudioSinkInfo)、読み取り専用-
[[sink ID]]内部スロットの値を返します。この属性は更新時にキャッシュされ、キャッシュ後は同じオブジェクトを返します。 onsinkchange、 型: EventHandler-
setSinkId()のイベントハンドラです。イベント型はsinkchangeで、出力デバイスの変更完了時に発火されます。注:
AudioContextの構築時の初回デバイス選択には発火されません。初期出力デバイスの準備確認にはstatechangeイベントが利用できます。 onerror、 型: EventHandler-
EventがAudioContextからディスパッチされたときのイベントハンドラです。 イベント型はerrorで、 以下の場合にUAがイベントを発火できます:-
選択したオーディオデバイスの初期化・有効化時に失敗した場合。
-
関連付けられたオーディオ出力デバイスが
AudioContext動作中に切断された場合。 -
OSからオーディオデバイスの異常が報告された場合。
-
1.2.3. メソッド
close()-
AudioContextを閉じて、使用中のシステムリソースを解放します。これによって すべてのAudioContext作成オブジェクトが自動的に解放されるわけではありませんが、AudioContextのcurrentTimeの進行を停止し、 音声データの処理を停止します。close が呼ばれたとき、次の手順を実行します:-
this の関連グローバルオブジェクトの関連付けられた Documentが完全有効でない場合、"
InvalidStateError" のDOMExceptionでrejectされた promiseを返します。 -
promise を新しい Promise とします。
-
AudioContext上の[[control thread state]]フラグがclosedの場合、InvalidStateErrorで promise を reject し、これらの手順を中断して promise を返します。 -
AudioContext上の[[control thread state]]フラグをclosedに設定します。 -
コントロールメッセージをキューイングして
AudioContextを閉じます。 -
promise を返します。
コントロールメッセージを実行してAudioContextを閉じるとは、 レンダリングスレッドで次の手順を実行することを意味します:-
システムリソースの解放を試みます。
-
[[rendering thread state]]をsuspendedに設定します。これによりレンダリングは停止します。 -
このコントロールメッセージがドキュメントのアンロードに対する反応として実行されている場合、 このアルゴリズムを中止します。
この場合、コントロールスレッドへ通知する必要はありません。 -
メディア要素タスクをキューイングして次の手順を実行します:
-
promise を resolve します。
-
AudioContextのstate属性がまだ "closed" でない場合:-
AudioContextのstate属性を "closed" に設定します。 -
メディア要素タスクをキューイングして、イベントを発火 名称
statechangeをAudioContextに対して行います。
-
-
AudioContextが閉じられると、 当該MediaStreamやHTMLMediaElementがAudioContextに接続されていた場合、その出力は無視されます。つまり、これらはスピーカーなどの出力デバイスに もはや出力を発生させません。挙動に柔軟性が必要な場合は、HTMLMediaElement.captureStream()の使用を検討してください。注:
AudioContextが閉じられた場合、実装はサスペンド時よりも積極的にリソースを解放することを選択できます。パラメータなし。 -
createMediaElementSource(mediaElement)-
MediaElementAudioSourceNodeを、 指定されたHTMLMediaElementから作成します。 このメソッド呼び出しの結果、当該HTMLMediaElementからの 音声再生は、AudioContextの処理グラフへと再ルーティングされます。AudioContext.createMediaElementSource() メソッドの引数。 パラメータ 型 Nullable Optional 説明 mediaElementHTMLMediaElement✘ ✘ 再ルーティングされるメディア要素。 createMediaStreamDestination()-
MediaStreamAudioDestinationNodeを作成します。パラメータなし。 createMediaStreamSource(mediaStream)-
MediaStreamAudioSourceNodeを作成します。AudioContext.createMediaStreamSource() メソッドの引数。 パラメータ 型 Nullable Optional 説明 mediaStreamMediaStream✘ ✘ ソースとして機能するメディアストリーム。 createMediaStreamTrackSource(mediaStreamTrack)-
MediaStreamTrackAudioSourceNodeを作成します。AudioContext.createMediaStreamTrackSource() メソッドの引数。 パラメータ 型 Nullable Optional 説明 mediaStreamTrackMediaStreamTrack✘ ✘ ソースとして機能する MediaStreamTrack。そのkind属性の値は"audio"と等しくなければならず、そうでない場合はInvalidStateError例外を必ず投げます。 getOutputTimestamp()-
新しい
AudioTimestampインスタンスを返します。 これはコンテキストに関する2つの関連するオーディオストリーム位置を含みます。contextTimeメンバーは、オーディオ出力デバイスによって現在レンダリングされているサンプルフレームの時刻(すなわち出力オーディオストリームの位置)を、 コンテキストのcurrentTimeと同じ単位および原点で保持します。performanceTimeメンバーは、保存されたcontextTimeに対応するサンプルフレームがオーディオ出力デバイスによってレンダリングされた時刻を、performance.now()([hr-time-3] 参照)と同じ単位および原点で推定した値を保持します。コンテキストのレンダリンググラフがまだオーディオブロックを処理していない場合、
getOutputTimestamp呼び出しは、両方のメンバーがゼロを含むAudioTimestampインスタンスを返します。コンテキストのレンダリンググラフがオーディオブロックの処理を開始した後は、
currentTime属性の値は常に、contextTimeの値(getOutputTimestampの呼び出しで取得)を上回ります。getOutputTimestampから返される値を利用して、やや先のコンテキスト時間に対するパフォーマンスタイムの推定値を得られます:function outputPerformanceTime( contextTime) { const timestamp= context. getOutputTimestamp(); const elapsedTime= contextTime- timestamp. contextTime; return timestamp. performanceTime+ elapsedTime* 1000 ; } 上の例では、推定の精度は引数の値が現在の出力オーディオストリーム位置にどれだけ近いかに依存します。与えた
contextTimeがtimestamp.contextTimeに近いほど、得られる推定の精度は高くなります。注: コンテキストの
currentTimeと、contextTime(getOutputTimestamp呼び出しで取得)の差は、 信頼できる出力レイテンシの推定とは見なせません。これはcurrentTimeが不均一な時間間隔で増分されうるためであり、代わりにoutputLatency属性を使用すべきです。パラメータなし。返却型:AudioTimestamp resume()-
サスペンドされている場合に、
AudioContextのcurrentTimeの進行を再開します。resume が呼ばれたとき、次の手順を実行します:-
this の関連グローバルオブジェクトの関連付けられた Documentが完全有効でない場合、"
InvalidStateError" のDOMExceptionでrejectされた promiseを返します。 -
promise を新しい Promise とします。
-
AudioContext上の[[control thread state]]がclosedの場合、InvalidStateErrorで promise を reject し、これらの手順を中断して promise を返します。 -
[[suspended by user]]をfalseに設定します。 -
contextが開始可能でない場合、promiseを
[[pending promises]]および[[pending resume promises]]に追加し、これらの手順を中止してpromiseを返します。 -
AudioContext上の[[control thread state]]をrunningに設定します。 -
コントロールメッセージをキューイングして
AudioContextの再開を行います。 -
promise を返します。
コントロールメッセージを実行してAudioContextを再開するとは、 レンダリングスレッドで次の手順を実行することを意味します:-
システムリソースの取得を試みます。
-
AudioContext上の[[rendering thread state]]をrunningに設定します。 -
オーディオグラフのレンダリングを開始します。
-
失敗した場合、 メディア要素タスクをキューイングして次の手順を実行します:
-
[[pending resume promises]]のすべての promise を順に reject し、その後[[pending resume promises]]をクリアします。 -
加えて、それらの promise を
[[pending promises]]から削除します。
-
-
メディア要素タスクをキューイングして次の手順を実行します:
-
[[pending resume promises]]のすべての promise を順に resolve します。 -
[[pending resume promises]]をクリアし、さらにそれらの promise を[[pending promises]]から削除します。 -
promise を resolve します。
-
AudioContextのstate属性がまだ "running" でない場合:-
AudioContextのstate属性を "running" に設定します。 -
メディア要素タスクをキューイングして、 イベントを発火 名称
statechangeをAudioContextに対して行います。
-
-
パラメータなし。 -
suspend()-
AudioContextのcurrentTimeの進行をサスペンドし、すでに処理済みの現在のコンテキスト処理ブロックが出力先へ再生されることを許可した後、システムがオーディオハードウェアに対する占有を解放できるようにします。 これはアプリケーションがしばらくの間AudioContextを必要としないことが分かっている場合に、 当該AudioContextに関連するシステムリソースの一時的な解放を行うのに有用です。promise はフレームバッファが空(ハードウェアへ引き渡された)になったときに解決され、 すでにコンテキストがsuspendedの場合は即座に(他の効果なしで)解決されます。コンテキストが閉じられている場合は promise は reject されます。suspend が呼ばれたとき、次の手順を実行します:-
this の関連グローバルオブジェクトの関連付けられた Documentが完全有効でない場合、"
InvalidStateError" のDOMExceptionでrejectされた promiseを返します。 -
promise を新しい Promise とします。
-
AudioContext上の[[control thread state]]がclosedの場合、InvalidStateErrorで promise を reject し、これらの手順を中断して promise を返します。 -
promise を
[[pending promises]]に追加します。 -
[[suspended by user]]をtrueに設定します。 -
AudioContext上の[[control thread state]]をsuspendedに設定します。 -
コントロールメッセージをキューイングして
AudioContextをサスペンドします。 -
promise を返します。
コントロールメッセージを実行してAudioContextをサスペンドするとは、 レンダリングスレッドで次の手順を実行することを意味します:-
システムリソースの解放を試みます。
-
AudioContext上の[[rendering thread state]]をsuspendedに設定します。 -
メディア要素タスクをキューイングして次の手順を実行します:
-
promise を resolve します。
-
AudioContextのstate属性がまだ "suspended" でない場合:-
AudioContextのstate属性を "suspended" に設定します。 -
メディア要素タスクをキューイングして、 イベントを発火 名称
statechangeをAudioContextに対して行います。
-
-
AudioContextがサスペンドされている間、MediaStreamの出力は無視されます。 つまり、メディアストリームのリアルタイム性によりデータは失われます。HTMLMediaElementも同様に、システムが再開されるまで出力は無視されます。AudioWorkletNodeとScriptProcessorNodeは、サスペンド中は処理ハンドラの呼び出しが行われなくなりますが、コンテキストの再開時に処理も再開します。AnalyserNodeのウィンドウ関数の観点では、 データは連続したストリームとみなされます。つまりresume()/suspend()はAnalyserNodeのデータストリーム中に無音を発生させません。 特に、AudioContextがサスペンドされているときにAnalyserNodeの関数を繰り返し呼び出すと、 同じデータを返さなければなりません。パラメータなし。 -
setSinkId((DOMString or AudioSinkOptions) sinkId)-
出力デバイスの識別子を設定します。このメソッドが呼び出されたとき、ユーザーエージェントは次の手順を実行しなければなりません:
-
sinkId をこのメソッドの第1引数とします。
-
sinkId が
[[sink ID]]と等しい場合、promise を返し、即座に resolve してこれらの手順を中断します。 -
validationResult を sink 識別子の検証(引数 sinkId)の戻り値とします。
-
validationResult が
nullでない場合、validationResult で reject された promise を返して、これらの手順を中断します。 -
p を新しい promise とします。
-
p と sinkId を伴うコントロールメッセージを送って、処理を開始します。
-
p を返します。
setSinkId()実行中に処理を開始するためにコントロールメッセージを送るとは、 次の手順を実行することを意味します:-
p をこのアルゴリズムに渡された promise とします。
-
sinkId をこのアルゴリズムに渡された sink 識別子とします。
-
sinkId と
[[sink ID]]の両方がDOMString型で、 かつ互いに等しい場合、 メディア要素タスクをキューイングして p を resolve し、これらの手順を中断します。 -
sinkId が
AudioSinkOptions型で、[[sink ID]]がAudioSinkInfo型であり、 さらに sinkId のtypeとtype([[sink ID]]内)が等しい場合、 メディア要素タスクをキューイングして p を resolve し、これらの手順を中断します。 -
wasRunning を true とします。
-
AudioContext上の[[rendering thread state]]が"suspended"の場合、wasRunning を false に設定します。 -
現在のレンダー量子の処理後にレンダラーを一時停止します。
-
システムリソースの解放を試みます。
-
wasRunning が true の場合:
-
AudioContext上の[[rendering thread state]]を"suspended"に設定します。 -
メディア要素タスクをキューイングして次の手順を実行します:
-
AudioContextのstate属性がまだ "suspended" でない場合:-
AudioContextのstate属性を "suspended" に設定します。 -
イベントを発火 名称
statechangeを、関連するAudioContextに対して行います。
-
-
-
-
[[sink ID]]に基づいて、レンダリングに使用する次のオーディオ出力デバイス用のシステムリソースを取得することを試みます:-
空文字列の場合はデフォルトのオーディオ出力デバイス。
-
[[sink ID]]で識別されるオーディオ出力デバイス。
失敗した場合、"
InvalidAccessError" で p を reject し、以降の手順を中断します。 -
-
メディア要素タスクをキューイングして次の手順を実行します:
-
sinkId が
DOMString型である場合、[[sink ID]]を sinkId に設定します。これらの手順を中断します。 -
sinkId が
AudioSinkOptions型で、[[sink ID]]がDOMString型である場合、[[sink ID]]を、sinkId のtypeの値で作成した新しいAudioSinkInfoインスタンスに設定します。 -
sinkId が
AudioSinkOptions型で、[[sink ID]]がAudioSinkInfo型である場合、type([[sink ID]]内)を sinkId のtypeの値に設定します。 -
p を resolve します。
-
イベントを発火 名称
sinkchangeを、関連するAudioContextに対して行います。
-
-
wasRunning が true の場合:
-
AudioContext上の[[rendering thread state]]を"running"に設定します。 -
メディア要素タスクをキューイングして次の手順を実行します:
-
AudioContextのstate属性がまだ "running" でない場合:-
AudioContextのstate属性を "running" に設定します。 -
イベントを発火 名称
statechangeを、関連するAudioContextに対して行います。
-
-
-
-
1.2.4.
sinkIdの検証
このアルゴリズムは、sinkIdを変更するために提供された情報を検証するために使用されます:
-
documentを、現在の設定オブジェクトの関連付けられたDocumentとします。
-
sinkIdArgをこのアルゴリズムに渡された値とします。
-
documentが
"speaker-selection"という機能の利用を許可されていない場合は、 名前が"NotAllowedError" の新しいDOMExceptionを返します。 -
sinkIdArgが
DOMString型であり、空文字列でない、またはenumerateDevices()の結果として識別されるオーディオ出力デバイスのいずれにも一致しない場合は、 名前が"NotFoundError" の新しいDOMExceptionを返します。 -
nullを返します。
1.2.5. AudioContextOptions
AudioContextOptions
辞書は、AudioContextのユーザー指定オプションを指定するために使用されます。
dictionary AudioContextOptions { (AudioContextLatencyCategory or double )latencyHint = "interactive";float sampleRate ; (DOMString or AudioSinkOptions )sinkId ; (AudioContextRenderSizeCategory or unsigned long )renderSizeHint = "default"; };
1.2.5.1. 辞書 AudioContextOptions
メンバー
latencyHint、 型:(AudioContextLatencyCategory or double)、デフォルトは"interactive"-
再生の種類を識別し、オーディオ出力レイテンシと消費電力のトレードオフに影響します。
latencyHintの推奨値はAudioContextLatencyCategoryの値ですが、細かい制御が必要な場合は秒数(double型)も指定可能です。ブラウザはこの数値を適切に解釈します。実際に使用されるレイテンシはbaseLatency属性で示されます。 sampleRate、 型: float-
作成される
AudioContextのsampleRateをこの値に設定します。サポートされる値はAudioBufferのサンプルレートと同じです。 指定したサンプルレートがサポートされていない場合はNotSupportedError例外を必ず投げなければなりません。sampleRateを指定しない場合、このAudioContext用の出力デバイスの推奨サンプルレートが使用されます。 sinkId、 型:(DOMString or AudioSinkOptions)-
オーディオ出力デバイスの識別子または関連情報。詳細は
sinkId参照。 renderSizeHint、 型:(AudioContextRenderSizeCategory or unsigned long)、デフォルトは"default"-
整数を指定した場合は特定のレンダー量子サイズを要求できます。何も指定しない場合や
"default"の場合はデフォルト(128フレーム)を使用します。"hardware"の場合はユーザーエージェントが最適なレンダー量子サイズを選択します。これはヒントであり、必ずしも反映されるとは限りません。
1.2.6.
AudioSinkOptions
AudioSinkOptions
辞書は、sinkId用のオプション指定に使用されます。
dictionary AudioSinkOptions {required AudioSinkType type ; };
1.2.6.1. 辞書 AudioSinkOptions
メンバー
type、 型: AudioSinkType-
デバイス種別を指定するための
AudioSinkTypeの値。
1.2.7. AudioSinkInfo
AudioSinkInfo
インターフェースは、sinkId経由で現在のオーディオ出力デバイス情報を取得するために使用されます。
[Exposed =Window ]interface AudioSinkInfo {readonly attribute AudioSinkType type ; };
1.2.7.1. 属性
type、 型: AudioSinkType、読み取り専用-
デバイス種別を表す
AudioSinkTypeの値。
1.2.8. AudioTimestamp
dictionary AudioTimestamp {double contextTime ;DOMHighResTimeStamp performanceTime ; };
1.2.8.1. 辞書 AudioTimestamp
メンバー
contextTime、 型: double-
BaseAudioContextの
currentTimeの時間座標系上の時点を表します。 performanceTime、 型: DOMHighResTimeStamp-
Performanceインターフェース実装の時間座標系上の時点を表します([hr-time-3]参照)。
1.2.9. AudioRenderCapacity
[Exposed =Window ]interface :AudioRenderCapacity EventTarget {undefined start (optional AudioRenderCapacityOptions = {});options undefined stop ();attribute EventHandler onupdate ; };
このインターフェースはAudioContext
のレンダリング性能指標を提供します。指標計算のため、レンダラーは負荷値をシステムレベルオーディオコールバックごとに収集します。
1.2.9.1. 属性
onupdate、 型: EventHandler-
このイベントハンドラのイベント型は
updateです。 ハンドラにディスパッチされるイベントはAudioRenderCapacityEventインターフェースを使用します。
1.2.9.2. メソッド
start(options)-
指標収集・分析を開始します。指定した更新間隔で
AudioRenderCapacityEventを使い、AudioRenderCapacityに対してupdateイベントを繰り返し発火します。 更新間隔はAudioRenderCapacityOptionsで指定します。 stop()-
指標収集・分析を停止します。また、
updateイベントのディスパッチも停止します。
1.2.10.
AudioRenderCapacityOptions
AudioRenderCapacityOptions
辞書は、AudioRenderCapacity用のユーザーオプション指定に利用できます。
dictionary {AudioRenderCapacityOptions double updateInterval = 1; };
1.2.10.1. 辞書 AudioRenderCapacityOptions
メンバー
updateInterval、 型: double、デフォルトは1-
AudioRenderCapacityEventのディスパッチ間隔(秒単位)。 負荷値はシステムレベルオーディオコールバックごとに計算され、指定された間隔期間中に複数の負荷値が収集されます。例えば、レンダラーが48kHzのサンプルレートで動作し、システムレベルオーディオコールバックのバッファサイズが192フレームの場合、1秒間隔で250個の負荷値が収集されます。指定値がシステムレベルオーディオコールバックの期間より小さい場合、
NotSupportedErrorが投げられます。
1.2.11. AudioRenderCapacityEvent
[Exposed =Window ]interface :AudioRenderCapacityEvent Event {(constructor DOMString ,type optional AudioRenderCapacityEventInit = {});eventInitDict readonly attribute double timestamp ;readonly attribute double averageLoad ;readonly attribute double peakLoad ;readonly attribute double underrunRatio ; };dictionary :AudioRenderCapacityEventInit EventInit {double = 0;timestamp double = 0;averageLoad double = 0;peakLoad double = 0; };underrunRatio
1.2.11.1. 属性
timestamp、 型: double、読み取り専用-
データ収集期間の開始時刻(関連
AudioContextのcurrentTime基準)。 averageLoad、 型: double、読み取り専用-
指定した更新間隔内で収集された負荷値の平均。精度は1/100単位まで。
peakLoad、 型: double、読み取り専用-
指定した更新間隔内で収集された負荷値の最大値。精度も1/100単位まで。
underrunRatio、 型: double、読み取り専用-
指定した更新間隔内において、バッファアンダーラン(負荷値が1.0を超えた場合)の回数とシステムレベルオーディオコールバック総数の比率。
\(u\) をバッファアンダーラン回数、\(N\) を指定した更新間隔内のシステムレベルオーディオコールバック総数とした場合、バッファアンダーラン比は以下の通り:
-
\(u\) = 0 の場合は 0.0。
-
それ以外の場合は \(u/N\) を計算し、最も近い100分位の天井値を取る。
-
1.3. OfflineAudioContext
インターフェース
OfflineAudioContext
は、BaseAudioContext
の特殊な型であり、レンダリングやミックスダウンを(リアルタイムより)高速に行うためのものです。オーディオハードウェアへはレンダリングせず、可能な限り高速にレンダリングを行い、レンダリング結果をAudioBufferとしてpromiseで返します。
[Exposed =Window ]interface OfflineAudioContext :BaseAudioContext {constructor (OfflineAudioContextOptions contextOptions );constructor (unsigned long numberOfChannels ,unsigned long length ,float sampleRate );Promise <AudioBuffer >startRendering ();Promise <undefined >resume ();Promise <undefined >suspend (double );suspendTime readonly attribute unsigned long length ;attribute EventHandler oncomplete ; };
1.3.1. コンストラクター
OfflineAudioContext(contextOptions)-
現在の設定オブジェクトの関連グローバルオブジェクトの関連付けられたDocumentが完全有効でない場合は、
cを新しいInvalidStateErrorを投げて処理を中断します。OfflineAudioContextオブジェクトとします。 cを以下のように初期化します:-
c上の
[[control thread state]]を"suspended"に設定します。 -
c上の
[[rendering thread state]]を"suspended"に設定します。 -
この
OfflineAudioContextの[[render quantum size]]をrenderSizeHintの値で決定します:-
値が
"default"または"hardware"の場合は、[[render quantum size]]プライベートスロットを128に設定します。 -
整数値を渡した場合は、ユーザーエージェントがこの値を反映するか決定し、
[[render quantum size]]プライベートスロットに設定します。
-
-
AudioDestinationNodeをcontextOptions.numberOfChannelsでchannelCountを設定して構築します。 -
messageChannelを新しい
MessageChannelとします。 -
controlSidePortをmessageChannelの
port1属性値にします。 -
renderingSidePortをmessageChannelの
port2属性値にします。 -
serializedRenderingSidePortをStructuredSerializeWithTransfer(renderingSidePort, « renderingSidePort »)の結果にします。
-
この
audioWorkletのport属性をcontrolSidePortに設定します。 -
コントロールメッセージのキューイングを行い、 AudioContextGlobalScopeにMessagePortをセットします。 引数はserializedRenderingSidePort。
OfflineAudioContext.constructor(contextOptions) メソッドの引数。 パラメータ 型 Nullable Optional 説明 contextOptionsこのコンテキストを構築するために必要な初期パラメータ。 -
OfflineAudioContext(numberOfChannels, length, sampleRate)-
OfflineAudioContextは AudioContext.createBuffer と同じ引数で構築可能です。いずれかの引数が負、ゼロ、あるいは規定範囲外の場合はNotSupportedError例外を必ず投げなければなりません。OfflineAudioContextは、以下の呼び出しと同じように構築されます:
new OfflineAudioContext({ numberOfChannels: numberOfChannels, length: length, sampleRate: sampleRate}) が呼ばれた場合と同等です。
OfflineAudioContext.constructor(numberOfChannels, length, sampleRate)メソッドの引数。 パラメータ 型 Nullable Optional 説明 numberOfChannelsunsigned long✘ ✘ バッファのチャンネル数を決定します。対応チャンネル数は createBuffer()参照。lengthunsigned long✘ ✘ バッファのサイズ(サンプルフレーム数)。 sampleRatefloat✘ ✘ バッファ内のリニアPCMオーディオデータのサンプルレート(秒間サンプルフレーム数)。有効な値は createBuffer()参照。
1.3.2. 属性
length、 型: unsigned long、読み取り専用-
バッファのサイズ(サンプルフレーム数)。これはコンストラクタの
lengthパラメータと同じ値です。 oncomplete、 型: EventHandler-
このイベントハンドラのイベント型は
completeです。ハンドラにディスパッチされるイベントはOfflineAudioCompletionEventインターフェースを使用します。これはOfflineAudioContext上で最後に発火されるイベントです。
1.3.3. メソッド
startRendering()-
現在の接続およびスケジュール済みの変更に基づいて、オーディオのレンダリングを開始します。
レンダリングされたオーディオデータを取得する主な方法はプロミスの返り値ですが、インスタンスはレガシー理由により
completeというイベントも発火します。[[rendering started]]は、このOfflineAudioContextの内部スロットである。 このスロットを false に初期化する。startRenderingが呼び出されたとき、以下の手順を コントロールスレッド で実行しなければならない:- this の 関連グローバルオブジェクト の 関連付けられた Document が 完全にアクティブ でない場合、プロミスを拒否して返す。理由は "
InvalidStateError"DOMExceptionである。 [[rendering started]]スロットがOfflineAudioContext上で true の場合、プロミスをInvalidStateErrorで拒否して返し、これらの手順を中断する。[[rendering started]]スロットをOfflineAudioContext上で true に設定する。- promise を新しいプロミスとして作成する。
AudioBufferを新規作成し、チャンネル数・長さ・サンプルレートはこのインスタンスのコンストラクタでcontextOptionsパラメータに渡されたnumberOfChannels・length・sampleRateと同じ値で設定する。 このバッファを内部スロット[[rendered buffer]]に割り当てる。- 前述の
AudioBufferコンストラクタ呼び出し中に例外が発生した場合、promise をその例外で拒否する。 - バッファが正常に構築された場合、オフラインレンダリングを開始する。
- promise を
[[pending promises]]に追加する。 - promise を返す。
オフラインレンダリングを開始 するには、以下の手順をこのために作成された レンダリングスレッド で実行しなければならない。- 現在の接続とスケジュール済みの変更に基づいて、
lengthサンプルフレーム分のオーディオを[[rendered buffer]]にレンダリングする。 - 各 レンダー量子
において、
suspendが必要か確認する。 - サスペンドされたコンテキストが再開された場合、バッファのレンダリングを続行する。
-
レンダリング完了後、メディア要素タスクをキューに追加し、以下の手順を実行する:
startRendering()で作成した promise を[[rendered buffer]]で解決する。- メディア要素タスクをキューに追加し、complete イベントを発火する。イベントは
OfflineAudioContext上で発火され、OfflineAudioCompletionEventを使い、renderedBufferプロパティを[[rendered buffer]]に設定する。
パラメータなし。返り値型:Promise<AudioBuffer> - this の 関連グローバルオブジェクト の 関連付けられた Document が 完全にアクティブ でない場合、プロミスを拒否して返す。理由は "
resume()-
OfflineAudioContextのcurrentTimeがサスペンドされている場合、その進行を再開します。resume が呼び出されたとき、以下の手順を実行する:-
this の 関連グローバルオブジェクト の 関連付けられた Document が 完全にアクティブ でない場合、プロミスを拒否して返す。理由は "
InvalidStateError"DOMExceptionである。 -
promise を新しい Promise として作成する。
-
次のいずれかの条件が true の場合、これらの手順を中断し promise を
InvalidStateErrorで拒否する:-
[[control thread state]]がOfflineAudioContext上でclosedである。 -
[[rendering started]]スロットがOfflineAudioContext上で false である。
-
-
[[control thread state]]フラグをOfflineAudioContext上でrunningに設定する。 -
promise を返す。
コントロールメッセージを実行してOfflineAudioContextを再開するには、以下の手順を レンダリングスレッド で実行する:-
[[rendering thread state]]をOfflineAudioContext上でrunningに設定する。 -
オーディオグラフのレンダリング を開始する。
-
失敗した場合は、メディア要素タスクをキューに追加し、promise を拒否して残りの手順を中断する。
-
メディア要素タスクをキューに追加して以下の手順を実行する:
-
promise を解決する。
-
state属性がOfflineAudioContext上で まだ "running" でない場合:-
state属性をOfflineAudioContext上で "running" に設定する。 -
メディア要素タスクをキューに追加し、statechange イベントを発火する。イベントは
OfflineAudioContext上で発火される。
-
-
パラメータなし。 -
suspend(suspendTime)-
指定した時間にオーディオコンテキストの時間進行のサスペンドをスケジュールし、プロミスを返します。これは
OfflineAudioContextのオーディオグラフを同期的に操作する際に一般的に便利です。サスペンドの最大精度は レンダー量子 のサイズであり、指定したサスペンド時間は最も近い レンダー量子 境界に切り上げられます。そのため、同じ量子化フレームで複数のサスペンドをスケジュールすることはできません。また、正確なサスペンドのためにはコンテキストが実行中でない間にスケジューリングするべきです。
OfflineAudioContext.suspend() メソッドの引数 パラメータ 型 Nullable Optional 説明 suspendTimedouble✘ ✘ 指定した時間でレンダリングのサスペンドをスケジュールします。時間は量子化され、レンダー量子のサイズに切り上げられます。量子化されたフレーム番号が - 負の値である場合
- 現在時刻以下である場合
- 合計レンダー期間以上である場合
- 同じ時間に他の suspend がスケジュールされている場合
InvalidStateErrorで拒否されます。
1.3.4. OfflineAudioContextOptions
これは OfflineAudioContext
の構築時に使用するオプションを指定します。
dictionary OfflineAudioContextOptions {unsigned long numberOfChannels = 1;required unsigned long length ;required float sampleRate ; (AudioContextRenderSizeCategory or unsigned long )renderSizeHint = "default"; };
1.3.4.1. 辞書 OfflineAudioContextOptions
のメンバー
length, 型 unsigned long-
レンダリングされた
AudioBufferのサンプルフレーム数です。 numberOfChannels, 型 unsigned long, デフォルト値は1-
この
OfflineAudioContextのチャンネル数です。 sampleRate, 型 float-
この
OfflineAudioContextのサンプルレートです。 renderSizeHint, 型(AudioContextRenderSizeCategory or unsigned long), デフォルト値は"default"-
この
OfflineAudioContextのレンダー量子サイズのヒントです。
1.3.5.
OfflineAudioCompletionEvent
インターフェース
これは Event
オブジェクトであり、レガシー理由により OfflineAudioContext
にディスパッチされます。
[Exposed =Window ]interface OfflineAudioCompletionEvent :Event {(constructor DOMString ,type OfflineAudioCompletionEventInit );eventInitDict readonly attribute AudioBuffer renderedBuffer ; };
1.3.5.1. 属性
renderedBuffer, 型 AudioBuffer, 読み取り専用-
レンダリングされたオーディオデータを含む
AudioBufferです。
1.3.5.2.
OfflineAudioCompletionEventInit
dictionary OfflineAudioCompletionEventInit :EventInit {required AudioBuffer renderedBuffer ; };
1.3.5.2.1. 辞書 OfflineAudioCompletionEventInit
のメンバー
renderedBuffer, 型 AudioBuffer-
イベントの
renderedBuffer属性に割り当てる値です。
1.4. AudioBuffer
インターフェース
このインターフェースはメモリ上のオーディオアセットを表します。1つ以上のチャンネルを持つことができ、各チャンネルは32ビット浮動小数点のリニアPCM値で、名目上の範囲は\([-1,1]\)ですが、値がこの範囲に制限されているわけではありません。通常、PCMデータの長さはかなり短い(たいてい1分未満)ことが期待されます。
より長い音声(音楽のサウンドトラックなど)には、audio要素やMediaElementAudioSourceNodeを用いたストリーミングを使用してください。
AudioBufferは
1つ以上のAudioContextで利用でき、
OfflineAudioContextとAudioContext間で共有できます。
AudioBufferには4つの内部スロットがあります:
[[number of channels]]-
この
AudioBufferのオーディオチャンネル数(unsigned long)。 [[length]]-
この
AudioBufferの各チャンネルの長さ(unsigned long)。 [[sample rate]]-
この
AudioBufferのサンプルレート(Hz、float)。 [[internal data]]-
オーディオサンプルデータを保持するデータブロック。
[Exposed =Window ]interface AudioBuffer {constructor (AudioBufferOptions );options readonly attribute float sampleRate ;readonly attribute unsigned long length ;readonly attribute double duration ;readonly attribute unsigned long numberOfChannels ;Float32Array getChannelData (unsigned long );channel undefined copyFromChannel (Float32Array ,destination unsigned long ,channelNumber optional unsigned long = 0);bufferOffset undefined copyToChannel (Float32Array ,source unsigned long ,channelNumber optional unsigned long = 0); };bufferOffset
1.4.1. コンストラクタ
AudioBuffer(options)-
-
optionsの値が名目上の範囲外の場合は、NotSupportedError例外を投げて以降の手順を中断します。 -
b を新しい
AudioBufferオブジェクトとして作成します。 -
コンストラクタに渡された
AudioBufferOptionsのnumberOfChannels,length,sampleRateの値を、それぞれ内部スロット[[number of channels]],[[length]],[[sample rate]]に割り当てます。 -
この
AudioBufferの内部スロット[[internal data]]をCreateByteDataBlock(の呼び出し結果に設定します。[[length]]*[[number of channels]])注:これは基礎となるストレージをゼロで初期化します。
-
b を返します。
AudioBuffer.constructor() メソッドの引数。 パラメータ 型 Nullable Optional 説明 optionsAudioBufferOptions✘ ✘ この AudioBufferのプロパティを決定するAudioBufferOptions。 -
1.4.2. 属性
duration, 型 double, 読み取り専用-
PCMオーディオデータの長さ(秒単位)。
これは
[[sample rate]]と[[length]]の値を使い、AudioBufferについて[[length]]を[[sample rate]]で割って算出します。 length, 型 unsigned long, 読み取り専用-
PCMオーディオデータの長さ(サンプルフレーム数)。これは
[[length]]の値を返す必要があります。 numberOfChannels, 型 unsigned long, 読み取り専用-
離散的なオーディオチャンネル数。この値は
[[number of channels]]の値を返す必要があります。 sampleRate, 型 float, 読み取り専用-
PCMオーディオデータのサンプルレート(1秒あたりのサンプル数)。この値は
[[sample rate]]の値を返す必要があります。
1.4.3. メソッド
copyFromChannel(destination, channelNumber, bufferOffset)-
copyFromChannel()メソッドは、指定されたチャンネルのAudioBufferからdestination配列へサンプルをコピーします。bufferをAudioBuffer(フレーム数\(N_b\))とし、destination配列の要素数を\(N_f\)、bufferOffsetの値を\(k\)とします。 コピーされるフレーム数は \(\max(0, \min(N_b - k, N_f))\)です。これが\(N_f\)未満の場合、残りのdestinationの要素は 変更されません。AudioBuffer.copyFromChannel() メソッドの引数。 パラメータ 型 Nullable Optional 説明 destinationFloat32Array✘ ✘ チャンネルデータがコピーされる配列。 channelNumberunsigned long✘ ✘ コピー元のチャンネルのインデックス。 channelNumberがAudioBufferの チャンネル数以上の場合、IndexSizeErrorを必ず投げる必要があります。bufferOffsetunsigned long✘ ✔ オプションのオフセット。デフォルトは0です。 AudioBufferのこのオフセットからdestinationへデータがコピーされます。返り値型:undefined copyToChannel(source, channelNumber, bufferOffset)-
copyToChannel()メソッドはsource配列から 指定されたチャンネルのAudioBufferへサンプルをコピーします。UnknownErrorは、sourceが バッファにコピーできない場合に投げられることがあります。bufferをAudioBuffer(フレーム数\(N_b\))、source配列の要素数を\(N_f\)、bufferOffsetの値を\(k\)とします。 コピーされるフレーム数は \(\max(0, \min(N_b - k, N_f))\)です。これが\(N_f\)未満の場合、残りのbufferの要素は変更されません。AudioBuffer.copyToChannel() メソッドの引数。 パラメータ 型 Nullable Optional 説明 sourceFloat32Array✘ ✘ チャンネルデータのコピー元となる配列。 channelNumberunsigned long✘ ✘ データをコピーするチャンネルのインデックス。 channelNumberがAudioBufferの チャンネル数以上の場合、IndexSizeErrorを必ず投げる必要があります。bufferOffsetunsigned long✘ ✔ オプションのオフセット。デフォルトは0です。 sourceのデータがAudioBufferのこのオフセットからコピーされます。返り値型:undefined getChannelData(channel)-
acquire the contentで記載されたルールに従い、書き込みを許可するか、 またはコピーを取得して、
[[internal data]]内のバイトを新しいFloat32Arrayで返します。UnknownErrorは、[[internal data]]や新しいFloat32Arrayが 作成できない場合に投げられることがあります。AudioBuffer.getChannelData() メソッドの引数。 パラメータ 型 Nullable Optional 説明 channelunsigned long✘ ✘ データ取得対象となるチャンネルを表すインデックス。0は最初のチャンネル。このインデックス値は [[number of channels]]未満でなければならず、 そうでなければIndexSizeError例外を必ず投げる必要があります。返り値型:Float32Array
注: copyToChannel()およびcopyFromChannel()は、
Float32Arrayで
より大きな配列の一部を埋めるために利用できます。AudioBufferのチャンネルから
データを読み出し、チャンク単位で処理する場合は、copyFromChannel()を
getChannelData()で
取得した配列を直接アクセスするより優先して使うべきです。不要なメモリ割り当てやコピーを回避できる場合があります。
内部操作acquire the
contents of an AudioBufferは、
AudioBufferの
内容がAPI実装で必要な場合に呼び出されます。この操作は呼び出し元に不変なチャンネルデータを返します。
AudioBufferでacquire the content操作が発生した場合、以下の手順を実行します:
-
AudioBufferのArrayBufferが detachedであれば、trueを返して手順を中断し、 呼び出し元に長さ0のチャンネルデータバッファを返す。 -
この
AudioBufferで 以前getChannelData()で返された配列のArrayBufferを Detachする。注:
AudioBufferはcreateBuffer()またはAudioBufferの コンストラクタでのみ作成されるため、これは例外を投げません。 -
それら
[[internal data]]の 基礎となるストレージを保持し、呼び出し元にその参照を返す。 -
データのコピーを含む
ArrayBufferをAudioBufferに アタッチし、次回getChannelData()呼び出し時に返す。
acquire the contents of an AudioBuffer操作は以下の場合に呼び出されます:
-
AudioBufferSourceNode.startが呼ばれたとき、ノードのbufferの 内容を取得します。 操作に失敗した場合、何も再生されません。 -
bufferがAudioBufferSourceNodeで セットされ、AudioBufferSourceNode.startが 以前に呼ばれている場合、セッターはAudioBufferの 内容を取得します。操作に失敗した場合、何も再生されません。 -
ConvolverNodeのbufferがAudioBufferに セットされたとき、AudioBufferの 内容を取得します。 -
AudioProcessingEventの ディスパッチが完了したときは、outputBufferの 内容を取得します。
注: copyToChannel()は
AudioBufferの
内容がAudioNodeに
acquire the
content of an AudioBufferで取得された場合、その内容を変更することはできません。
AudioNodeは
取得時点のデータを引き続き使用します。
1.4.4. AudioBufferOptions
これはAudioBufferの構築時に使用するオプションを指定します。
lengthと
sampleRateメンバーは
必須です。
dictionary AudioBufferOptions {unsigned long numberOfChannels = 1;required unsigned long length ;required float sampleRate ; };
1.4.4.1. 辞書 AudioBufferOptions
のメンバー
この辞書のメンバーに許可される値は制約されています。createBuffer()
を参照してください。
length, 型 unsigned long-
バッファのサンプルフレーム数。制約については
lengthを参照してください。 numberOfChannels, 型 unsigned long, デフォルト値は1-
バッファのチャンネル数。制約については
numberOfChannelsを参照してください。 sampleRate, 型 float-
バッファのサンプルレート(Hz)。制約については
sampleRateを参照してください。
1.5. AudioNode
インターフェース
AudioNodeは
AudioContext
の構成要素です。このインターフェースは
オーディオソース、オーディオ出力先、および中間処理モジュールを表します。これらのモジュールは相互に接続することで処理グラフを形成し、
オーディオハードウェアへのレンダリングを行います。各ノードは入力や出力を持つことができます。ソースノードは入力を持たず出力は1つです。フィルターなどのほとんどの処理ノードは入力1つ、出力1つとなります。各AudioNodeの
音声処理や合成の詳細は異なりますが、一般的にAudioNodeは
入力(ある場合)を処理し、出力(ある場合)用の音声を生成します。
各出力は1つ以上のチャンネルを持ちます。正確なチャンネル数は個々のAudioNodeの詳細によります。
出力は1つ以上のAudioNodeの
入力に接続できるため、ファンアウトがサポートされています。入力は最初は接続がありませんが、1つ以上のAudioNodeの
出力から接続されることができ、ファンインもサポートされています。connect()メソッドで
AudioNodeの
出力を別のAudioNodeの
入力に接続すると、その入力への接続が発生したと呼びます。
各AudioNodeの
入力は、任意の時点で特定のチャンネル数を持ちます。
このチャンネル数は、入力への接続状況に応じて変化します。入力に接続がない場合は、1チャンネル(無音)となります。
各入力について、AudioNodeは
その入力への全ての接続をミキシングします。
規定の要件や詳細については§ 4 チャンネルのアップミックス・ダウンミックスを参照してください。
入力の処理およびAudioNodeの
内部処理は、ノードに接続された出力があるかどうか、またそれらの出力が
AudioContextの
AudioDestinationNodeに
到達するかどうかに関わらず、AudioContextの
時間を基準に継続的に行われます。
[Exposed =Window ]interface AudioNode :EventTarget {AudioNode connect (AudioNode destinationNode ,optional unsigned long output = 0,optional unsigned long input = 0);undefined connect (AudioParam destinationParam ,optional unsigned long output = 0);undefined disconnect ();undefined disconnect (unsigned long output );undefined disconnect (AudioNode destinationNode );undefined disconnect (AudioNode destinationNode ,unsigned long output );undefined disconnect (AudioNode destinationNode ,unsigned long output ,unsigned long input );undefined disconnect (AudioParam destinationParam );undefined disconnect (AudioParam destinationParam ,unsigned long output );readonly attribute BaseAudioContext context ;readonly attribute unsigned long numberOfInputs ;readonly attribute unsigned long numberOfOutputs ;attribute unsigned long channelCount ;attribute ChannelCountMode channelCountMode ;attribute ChannelInterpretation channelInterpretation ; };
1.5.1. AudioNodeの生成
AudioNodeは
2つの方法で生成できます。1つはこのインターフェースのコンストラクタを利用する方法、もう1つはBaseAudioContext
または AudioContext上の
ファクトリメソッドを利用する方法です。
BaseAudioContextを
AudioNodeのコンストラクタの
第1引数として渡す場合、それは生成されるAudioNodeの
関連付けられたBaseAudioContextとなります。
同様に、ファクトリメソッドを利用した場合も、関連付けられた
BaseAudioContextは、そのファクトリメソッドを呼び出したBaseAudioContextです。
AudioNodeを
BaseAudioContext
c上のファクトリメソッドで生成するには、以下の手順を実行します。
-
nodeを型nの新しいオブジェクトとして生成する。
-
optionを、このファクトリメソッドに関連するインターフェースに関連付けられている オプション辞書型として用意する。
-
ファクトリメソッドに渡された各パラメータについて、同じ名前の辞書メンバーに値をセットする。
-
cとoptionを引数に、nのコンストラクタをnode上で呼び出す。
-
nodeを返す。
-
oの
BaseAudioContextをcontextに設定する。 -
このインターフェースの仕様に記載されたデフォルト値に従い、
numberOfInputs、numberOfOutputs、channelCount、channelCountMode、channelInterpretationの値を設定する。 -
dictの各メンバーについて、キーkと値vで以下の手順を実行する。手順実行時に例外が発生した場合は、 イテレーションを中断し、その例外をアルゴリズム(コンストラクタまたはファクトリメソッド)の呼び出し元へ伝播する。
-
kがこのインターフェース上の
AudioParam名である場合、 そのvalue属性にvをセットする。 -
それ以外の場合、kがこのインターフェース上の属性名であれば、関連するオブジェクトの属性値をvにセットする。
-
ファクトリメソッドの関連インターフェースは、 そのメソッドが返すオブジェクトのインターフェースです。インターフェースの関連オプションオブジェクトは、 そのインターフェースのコンストラクタに渡すことができるオプションオブジェクトです。
AudioNodeは
EventTargetであり、
[DOM]に記載されています。
つまりAudioNodeにも、
他のEventTarget同様に
イベントを配送できます。
enum {ChannelCountMode "max" ,"clamped-max" ,"explicit" };
ChannelCountModeは、
ノードのchannelCountや
channelInterpretation値と
組み合わせて
ノードの入力をどのようにミックスするかを制御するcomputedNumberOfChannelsを決定します。computedNumberOfChannelsの決定方法は以下に示します。
ミックス方法の詳細は§ 4 チャンネルのアップミックス・ダウンミックスを参照してください。
| 列挙値 | 説明 |
|---|---|
"max"
| computedNumberOfChannelsは
入力へのすべての接続のチャンネル数の最大値となります。このモードではchannelCountは無視されます。
|
"clamped-max"
| computedNumberOfChannelsは
"max"と同様に決定され、その後指定されたchannelCountの最大値にクランプされます。
|
"explicit"
| computedNumberOfChannelsは
channelCountで指定された値となります。
|
enum {ChannelInterpretation "speakers" ,"discrete" };
| 列挙値 | 説明 |
|---|---|
"speakers"
| アップミックス方程式やダウンミックス方程式を使用します。 チャンネル数が基本的なスピーカーレイアウトと一致しない場合は"discrete"にフォールバックします。 |
"discrete"
| チャンネルが尽きるまで埋めて残りはゼロでアップミックス。ダウンミックスは埋められるだけ埋めて残りは削除します。 |
1.5.2. AudioNodeのテイルタイム
AudioNodeには
テイルタイムが存在する場合があります。
これはAudioNodeに
サイレンスが入力されても、出力がサイレンスにならない場合があることを意味します。
AudioNodeは
入力の過去の値が将来の出力に影響を与えるような内部処理状態を持つ場合、非ゼロのテイルタイムを持ちます。
入力が非サイレンスからサイレンスに遷移した後も、計算されたテイルタイムの間非サイレンスな出力を生成し続ける場合があります。
1.5.3. AudioNodeのライフタイム
AudioNodeは、以下のいずれかの条件を満たす場合、レンダー量子中にアクティブ処理中となります。
-
AudioScheduledSourceNodeは、現在のレンダリング量子の一部でも再生中ならば、アクティブ処理中です。 -
MediaElementAudioSourceNodeは、対応するmediaElementが現在のレンダリング量子の一部でも再生中ならば、アクティブ処理中です。 -
MediaStreamAudioSourceNodeやMediaStreamTrackAudioSourceNodeは、関連付けられたMediaStreamTrackオブジェクトのreadyState属性が"live"、muted属性がfalse、enabled属性がtrueであるとき、アクティブ処理中です。 -
サイクル内の
DelayNodeは、現在のレンダー量子の出力サンプルの絶対値が\( 2^{-126} \)以上のときのみアクティブ処理中です。 -
ScriptProcessorNodeは、入力または出力が接続されているときアクティブ処理中です。 -
AudioWorkletNodeは、AudioWorkletProcessorの[[callable process]]がtrueを返し、かつアクティブソースフラグがtrueか、いずれかの入力に接続されているAudioNodeがアクティブ処理中の場合にアクティブ処理中です。 -
その他の
AudioNodeは、いずれかの入力に接続されたAudioNodeがアクティブ処理中のときアクティブ処理中となり、他のアクティブ処理中のAudioNodeから受け取った入力が出力に影響しなくなった場合にアクティブ処理中を終了します。
注: これはテイルタイムを持つAudioNodeも考慮しています。
アクティブ処理中でないAudioNodeは、サイレンス(無音)の1チャンネルのみを出力します。
1.5.4. 属性
channelCount, 型 unsigned long-
channelCountは、 ノードへの入力をアップミックス・ダウンミックスする際に使用されるチャンネル数です。デフォルト値は2ですが、特定ノードでは値が異なる場合があります。この属性は入力のないノードには効果がありません。この値が0または実装の最大チャンネル数を超えて設定された場合、NotSupportedError例外を必ず投げる必要があります。さらに、特定ノードにはチャンネル数の値に対する追加のchannelCount制約があります:
AudioDestinationNode-
このノードが
AudioContextかOfflineAudioContextの出力先かで挙動が異なります。AudioContext-
チャンネル数は1から
maxChannelCountまででなければなりません。この範囲外に設定しようとするとIndexSizeError例外を必ず投げる必要があります。 OfflineAudioContext-
チャンネル数は変更できません。値を変更しようとした場合は
InvalidStateError例外を必ず投げる必要があります。
AudioWorkletNodeChannelMergerNode-
チャンネル数は変更できません。値を変更しようとした場合は
InvalidStateError例外を必ず投げる必要があります。 ChannelSplitterNode-
チャンネル数は変更できません。値を変更しようとした場合は
InvalidStateError例外を必ず投げる必要があります。 ConvolverNode-
チャンネル数は2より大きくできません。2より大きい値に変更しようとした場合は
NotSupportedError例外を必ず投げる必要があります。 DynamicsCompressorNode-
チャンネル数は2より大きくできません。2より大きい値に変更しようとした場合は
NotSupportedError例外を必ず投げる必要があります。 PannerNode-
チャンネル数は2より大きくできません。2より大きい値に変更しようとした場合は
NotSupportedError例外を必ず投げる必要があります。 ScriptProcessorNode-
チャンネル数は変更できません。値を変更しようとした場合は
NotSupportedError例外を必ず投げる必要があります。 StereoPannerNode-
チャンネル数は2より大きくできません。2より大きい値に変更しようとした場合は
NotSupportedError例外を必ず投げる必要があります。
この属性については§ 4 チャンネルのアップミックス・ダウンミックスも参照してください。
channelCountMode, 型 ChannelCountMode-
channelCountModeは、ノードへの入力をアップミックス・ダウンミックスする際にチャンネル数をどのように決定するかを指定します。デフォルト値は"max"です。この属性は入力のないノードには効果がありません。さらに、特定ノードにはchannelCountMode値に対する追加のchannelCountMode制約があります:
AudioDestinationNode-
このノードが
OfflineAudioContextのdestinationノードである場合、channelCountModeは変更できません。値を変更しようとした場合はInvalidStateError例外を必ず投げる必要があります。 ChannelMergerNode-
channelCountModeは"
explicit"から変更できません。値を変更しようとした場合はInvalidStateError例外を必ず投げる必要があります。 ChannelSplitterNode-
channelCountModeは"
explicit"から変更できません。値を変更しようとした場合はInvalidStateError例外を必ず投げる必要があります。 ConvolverNode-
channelCountModeは"
max"に設定できません。"max"に設定しようとした場合はNotSupportedError例外を必ず投げる必要があります。 DynamicsCompressorNode-
channelCountModeは"
max"に設定できません。"max"に設定しようとした場合はNotSupportedError例外を必ず投げる必要があります。 PannerNode-
channelCountModeは"
max"に設定できません。"max"に設定しようとした場合はNotSupportedError例外を必ず投げる必要があります。 ScriptProcessorNode-
channelCountModeは"
explicit"から変更できません。値を変更しようとした場合はNotSupportedError例外を必ず投げる必要があります。 StereoPannerNode-
channelCountModeは"
max"に設定できません。"max"に設定しようとした場合はNotSupportedError例外を必ず投げる必要があります。
この属性については§ 4 チャンネルのアップミックス・ダウンミックスも参照してください。
channelInterpretation, 型 ChannelInterpretation-
channelInterpretationは、ノードへの入力をアップミックス・ダウンミックスする際に各チャンネルをどのように扱うかを指定します。デフォルト値は"speakers"です。この属性は入力のないノードには効果がありません。さらに、特定ノードにはchannelInterpretation値に対する追加のchannelInterpretation制約があります:
ChannelSplitterNode-
channelInterpretationは"
discrete"から変更できません。値を変更しようとした場合はInvalidStateError例外を必ず投げる必要があります。
この属性については§ 4 チャンネルのアップミックス・ダウンミックスも参照してください。
context, 型 BaseAudioContext, 読み取り専用-
この
AudioNodeを所有するBaseAudioContextです。 numberOfInputs, 型 unsigned long, 読み取り専用-
この
AudioNodeに入力される入力の数です。ソースノードの場合は0となります。多くのAudioNode型ではこの値は固定ですが、ChannelMergerNodeやAudioWorkletNodeのように可変な場合もあります。 numberOfOutputs, 型 unsigned long, 読み取り専用-
この
AudioNodeから出力される出力の数です。この値は一部のAudioNode型では固定ですが、ChannelSplitterNodeやAudioWorkletNodeのように可変な場合もあります。
1.5.5. メソッド
connect(destinationNode, output, input)-
特定ノードのある出力と、別の特定ノードのある入力との間には、1つの接続のみが可能です。同じ終端同士で複数回接続を試みても無視されます。
このメソッドは
destinationAudioNodeオブジェクトを返します。AudioNode.connect(destinationNode, output, input) メソッドの引数。 パラメータ 型 Nullable Optional 説明 destinationNodedestinationパラメータは接続先のAudioNodeです。もしdestinationパラメータが別のAudioContextで作成されたAudioNodeの場合は、InvalidAccessError例外を必ず投げる必要があります。つまり、AudioNodeはAudioContext間で共有できません。複数のAudioNodeを同じAudioNodeに接続することも可能です(チャンネルのアップミックス・ダウンミックス参照)。outputunsigned long✘ ✔ outputパラメータは、どのAudioNode出力から接続するかを示すインデックスです。このパラメータが範囲外の場合、IndexSizeError例外を必ず投げる必要があります。1つのAudioNode出力を複数の入力に接続することも可能(ファンアウト)。inputinputパラメータは接続先AudioNodeのどの入力かを示すインデックスです。このパラメータが範囲外の場合、IndexSizeError例外を必ず投げる必要があります。また、AudioNode同士を接続して、サイクル(一方がもう一方に接続し、さらに元のノードやそのAudioParamへ戻る接続)も作成できます。返り値型:AudioNode connect(destinationParam, output)-
AudioNodeをAudioParamに接続し、a-rate信号でパラメータ値を制御します。1つの
AudioNode出力を複数のAudioParamに接続することも可能(ファンアウト)。複数の
AudioNode出力を1つのAudioParamに接続することも可能(ファンイン)。AudioParamは、接続されたAudioNode出力からレンダリングされたオーディオデータを受け取り、モノラルでない場合はダウンミックスしてモノラル化し、他の出力とミックスし、さらに本来のパラメータ値(オーディオ接続がないときのvalue値とタイムライン変更)とも最終的にミックスします。モノラルへのダウンミックスは、
AudioNodeでchannelCount= 1、channelCountMode= "explicit"、channelInterpretation= "speakers"と同等です。特定ノードのある出力と、特定の
AudioParamとの間には1つの接続のみが可能です。同じ終端同士で複数回接続を試みても無視されます。AudioNode.connect(destinationParam, output) メソッドの引数。 パラメータ 型 Nullable Optional 説明 destinationParamAudioParam✘ ✘ destinationパラメータは接続先のAudioParamです。このメソッドはdestinationAudioParamオブジェクトを返しません。destinationParamが、 そのAudioNodeの作成元とは異なるBaseAudioContextに所属している場合は、InvalidAccessError例外を必ず投げる必要があります。outputunsigned long✘ ✔ outputパラメータはどのAudioNode出力から接続するかを示すインデックスです。このパラメータが範囲外の場合、IndexSizeError例外を必ず投げる必要があります。返り値型:undefined disconnect()-
AudioNodeからのすべての出力接続を切断します。パラメータなし。返り値型:undefined disconnect(output)-
指定した
AudioNodeの出力ひとつから、接続されているAudioNodeまたはAudioParamすべてを切断します。AudioNode.disconnect(output) メソッドの引数。 パラメータ 型 Nullable Optional 説明 outputunsigned long✘ ✘ 切断する AudioNodeの出力のインデックス。指定した出力からのすべての出力接続を切断します。このパラメータが範囲外の場合、IndexSizeError例外を必ず投げる必要があります。返り値型:undefined disconnect(destinationNode)-
指定した
AudioNodeへのすべての出力接続を切断します。AudioNode.disconnect(destinationNode) メソッドの引数。 パラメータ 型 Nullable Optional 説明 destinationNode切断対象の AudioNodeです。指定したdestinationNodeへのすべての出力接続を切断します。指定したdestinationNodeへの接続がない場合、InvalidAccessError例外を必ず投げる必要があります。返り値型:undefined disconnect(destinationNode, output)-
指定した
AudioNodeの特定の出力を、任意の入力からすべて切断します。AudioNode.disconnect(destinationNode, output) メソッドの引数。 パラメータ 型 Nullable Optional 説明 destinationNode切断対象の AudioNodeです。指定した出力からdestinationNodeへの接続がない場合、InvalidAccessError例外を必ず投げる必要があります。outputunsigned long✘ ✘ 切断する AudioNodeの出力のインデックス。このパラメータが範囲外の場合、IndexSizeError例外を必ず投げる必要があります。返り値型:undefined disconnect(destinationNode, output, input)-
指定した
AudioNodeの特定の出力から、指定した入力への接続のみを切断します。AudioNode.disconnect(destinationNode, output, input) メソッドの引数。 パラメータ 型 Nullable Optional 説明 destinationNode切断対象の AudioNodeです。指定した出力から指定した入力へのdestinationNodeへの接続がない場合、InvalidAccessError例外を必ず投げる必要があります。outputunsigned long✘ ✘ 切断する AudioNodeの出力のインデックス。このパラメータが範囲外の場合、IndexSizeError例外を必ず投げる必要があります。input切断する AudioNodeの入力のインデックス。このパラメータが範囲外の場合、IndexSizeError例外を必ず投げる必要があります。返り値型:undefined disconnect(destinationParam)-
指定した
AudioParamへのすべての出力接続を切断します。このAudioNodeのパラメータ値への寄与は、この操作が有効になった時点で0になります。パラメータの本来の値はこの操作で影響を受けません。AudioNode.disconnect(destinationParam) メソッドの引数。 パラメータ 型 Nullable Optional 説明 destinationParamAudioParam✘ ✘ 切断対象の AudioParamです。指定したdestinationParamへの接続がない場合、InvalidAccessError例外を必ず投げる必要があります。返り値型:undefined disconnect(destinationParam, output)-
指定した
AudioNodeの特定の出力から、指定したAudioParamへの接続のみを切断します。このAudioNodeのパラメータ値への寄与は、この操作が有効になった時点で0になります。パラメータの本来の値はこの操作で影響を受けません。AudioNode.disconnect(destinationParam, output) メソッドの引数。 パラメータ 型 Nullable Optional 説明 destinationParamAudioParam✘ ✘ 切断対象の AudioParamです。指定したdestinationParamへの接続がない場合、InvalidAccessError例外を必ず投げる必要があります。outputunsigned long✘ ✘ 切断する AudioNodeの出力のインデックス。このパラメータが範囲外の場合、IndexSizeError例外を必ず投げる必要があります。返り値型:undefined
1.5.6.
AudioNodeOptions
これはすべてのAudioNodeの構築時に使用できるオプションを指定します。
すべてのメンバーは省略可能ですが、各ノードで使用される具体的な値はノードごとに異なります。
dictionary AudioNodeOptions {unsigned long channelCount ;ChannelCountMode channelCountMode ;ChannelInterpretation channelInterpretation ; };
1.5.6.1. 辞書 AudioNodeOptions
のメンバー
channelCount, 型 unsigned long-
channelCount属性に指定する希望するチャンネル数。 channelCountMode, 型 ChannelCountMode-
channelCountMode属性に指定する希望するモード。 channelInterpretation, 型 ChannelInterpretation-
channelInterpretation属性に指定する希望するモード。
1.6. AudioParam
インターフェース
AudioParam
はAudioNodeの機能(たとえば音量)など個別の要素を制御します。
パラメータはvalue属性で即座に値を設定したり、値の変化を非常に正確なタイミング(AudioContextのcurrentTime属性の座標系)でスケジュールできます。これにより、エンベロープ・ボリュームフェード・LFO・フィルタスウィープ・グレインウィンドウ等、任意のタイムラインベースのオートメーションカーブが設定可能です。
また、AudioNodeの出力からのオーディオ信号をAudioParamに接続し、本来のパラメータ値と合算することもできます。
一部の合成・処理AudioNodeは、AudioParam属性を持ち、その値はオーディオサンプル毎に考慮される必要があります。他のAudioParamではサンプル精度が重要ではなく、値の変化はより粗くサンプリングされてもかまいません。各AudioParamは、a-rateパラメータ(サンプルごとに値を考慮する必要あり)か、k-rateパラメータかを指定します。
実装はブロック処理を使用し、各AudioNodeは1つのレンダー量子を処理します。
各レンダー量子ごとに、k-rateパラメータの値は最初のサンプルフレーム時点でサンプリングされ、その値がそのブロック全体で使用されます。a-rateパラメータはブロックの各サンプルフレームごとにサンプリングされます。
AudioParamによっては、automationRate属性で"a-rate"または"k-rate"に設定して制御できます。
個々のAudioParamの説明も参照してください。
各AudioParamはminValueとmaxValue属性を持ち、
これらがパラメータの単純名目範囲となります。実際には、パラメータ値は\([\mathrm{minValue},
\mathrm{maxValue}]\)にクランプされます。詳細は§ 1.6.3 値の算出参照。
多くのAudioParamでは、minValueとmaxValueは最大可能範囲に設定されることが想定されています。この場合、maxValueは最大正単精度浮動小数点値(3.4028235e38)に設定します。(ただしJavaScriptではIEEE-754倍精度のみ対応のため、3.4028234663852886e38と記述する必要があります。)同様にminValueは最小負単精度浮動小数点値(-3.4028235e38、JavaScriptでは-3.4028234663852886e38)に設定します。
AudioParamはゼロ個以上のオートメーションイベントのリストを保持します。各イベントは、そのイベントのオートメーションイベント時刻(AudioContextのcurrentTime座標系で)に関連して、
指定された時間範囲でパラメータ値の変化を指定します。イベントリストはオートメーションイベント時刻の昇順で管理されます。
特定のオートメーションイベントの挙動は、AudioContextの現在時刻や、イベントリスト内のこのイベントと隣接するイベントの時刻によって決まります。以下のオートメーションメソッドは、
メソッド固有の型のイベントをイベントリストに追加します:
-
setValueAtTime()-SetValue -
linearRampToValueAtTime()-LinearRampToValue -
exponentialRampToValueAtTime()-ExponentialRampToValue -
setTargetAtTime()-SetTarget -
setValueCurveAtTime()-SetValueCurve
これらのメソッドを呼び出す際の規則:
-
オートメーションイベント時刻は、現在のサンプルレートに量子化されません。カーブやランプの算出式はイベントスケジューリング時に与えられた厳密な数値時刻に適用されます。
-
既に同じ時刻に他のイベントがある場合、新しいイベントはそれらの直後、かつより後の時刻のイベントの前にリストされます。
-
setValueCurveAtTime()が時刻\(T\)、持続時間\(D\)で呼ばれた際、 \(T\)より大きく\(T+D\)より小さい時刻のイベントがある場合はNotSupportedError例外を必ず投げる必要があります。 つまり、他のイベントを含む時間区間に値カーブをスケジューリングすることはできませんが、他のイベントと同じ時刻には可能です。 -
同様に、区間\([T, T+D)\)(\(T\)はカーブの時刻、\(D\)は持続時間)に含まれる時刻で他の
オートメーションメソッドが呼ばれた場合、NotSupportedError例外を必ず投げる必要があります。
注: AudioParam属性は読み取り専用ですが、value属性のみ書き込み可能です。
AudioParamのオートメーションレートは、automationRate属性で以下の値のいずれかに設定できます。ただし、AudioParamによってはオートメーションレートの変更に制約があります。
enum {AutomationRate "a-rate" ,"k-rate" };
| 列挙値 | 説明 |
|---|---|
"a-rate"
| このAudioParamはa-rate処理用に設定されます。
|
"k-rate"
| このAudioParamはk-rate処理用に設定されます。
|
各AudioParamは内部スロット[[current value]]を持ち、
初期値はAudioParamのdefaultValueです。
[Exposed =Window ]interface AudioParam {attribute float value ;attribute AutomationRate automationRate ;readonly attribute float defaultValue ;readonly attribute float minValue ;readonly attribute float maxValue ;AudioParam setValueAtTime (float ,value double );startTime AudioParam linearRampToValueAtTime (float ,value double );endTime AudioParam exponentialRampToValueAtTime (float ,value double );endTime AudioParam setTargetAtTime (float ,target double ,startTime float );timeConstant AudioParam setValueCurveAtTime (sequence <float >,values double ,startTime double );duration AudioParam cancelScheduledValues (double );cancelTime AudioParam cancelAndHoldAtTime (double ); };cancelTime
1.6.1. 属性
automationRate, 型 AutomationRate-
AudioParamのオートメーションレート。 デフォルト値は各AudioParamごとに異なります。個別のAudioParamの説明を参照してください。一部のノードには追加のオートメーションレート制約があります:
AudioBufferSourceNode-
AudioParamのplaybackRateとdetuneは "k-rate"でなければなりません。 レートを"a-rate"に変更しようとした場合はInvalidStateErrorを必ず投げる必要があります。 DynamicsCompressorNode-
AudioParamのthreshold、knee、ratio、attack、releaseは"k-rate"でなければなりません。 レートを"a-rate"に変更しようとした場合はInvalidStateErrorを必ず投げる必要があります。 PannerNode-
panningModelが "HRTF"の場合、PannerNodeのいかなるAudioParamのautomationRateの設定は無視されます。 同様にAudioListenerのAudioParamのautomationRateの設定も無視されます。 この場合、AudioParamはautomationRateが "k-rate"に設定されたかのように振る舞います。
defaultValue, 型 float, 読み取り専用-
value属性の初期値。 maxValue, 型 float, 読み取り専用-
パラメータが取り得る名目上の最大値。
minValueとあわせて、このパラメータの名目範囲を形成します。 minValue, 型 float, 読み取り専用-
パラメータが取り得る名目上の最小値。
maxValueとあわせて、このパラメータの名目範囲を形成します。 value, 型 float-
パラメータの浮動小数点値。この属性は
defaultValueで初期化されます。この属性を取得すると、
[[current value]]スロットの内容を返します。値の算出アルゴリズムは§ 1.6.3 値の算出参照。この属性に値を設定すると、要求された値が
[[current value]]スロットに割り当てられ、setValueAtTime()メソッドが現在のAudioContextのcurrentTimeと[[current value]]で呼び出されます。setValueAtTime()で例外が投げられる場合、この属性の設定でも同じ例外が投げられます。
1.6.2. メソッド
cancelAndHoldAtTime(cancelTime)-
これは
cancelScheduledValues()と似ており、cancelTime以降の すべてのスケジュール済みパラメータ変更をキャンセルします。 ただし、加えて、cancelTime時点で 本来発生するはずだったオートメーション値が、その後他のオートメーションイベントが追加されるまで保持されます。オートメーションが動作中に、
cancelAndHoldAtTime()呼び出し後、cancelTime到達前に オートメーションが追加され得る場合のタイムラインの挙動は複雑です。cancelAndHoldAtTime()の 挙動は以下のアルゴリズムで規定されます。\(t_c\) をcancelTimeの値とする。 次の手順を実行します:-
\(E_1\) を、時刻 \(t_1\)(\(t_1 \le t_c\) を満たす最大の数)のイベント(存在する場合)とする。
-
\(E_2\) を、時刻 \(t_2\)(\(t_c \lt t_2\) を満たす最小の数)のイベント(存在する場合)とする。
-
\(E_2\) が存在する場合:
-
\(E_2\) がリニアまたは指数ランプの場合、
-
\(E_2\) を、同じ種類のランプとして、終了時刻を \(t_c\)、終了値を元のランプの時刻 \(t_c\) における値として書き換える。

-
ステップ5へ。
-
-
それ以外の場合はステップ4へ。
-
-
\(E_1\) が存在する場合:
-
\(E_1\) が
setTargetイベントの場合、-
暗黙的に、時刻 \(t_c\) に
setValueAtTimeイベント(値はsetTargetの \(t_c\) における値)を挿入する。
-
ステップ5へ。
-
-
\(E_1\) が開始時刻 \(t_3\)、期間 \(d\) の
setValueCurveの場合、-
\(t_c \gt t_3 + d\) ならステップ5へ。
-
それ以外の場合、
-
このイベントを、開始時刻 \(t_3\)、新しい期間 \(t_c-t_3\) の
setValueCurveイベントで置き換える。ただし、これは厳密な置換ではなく、元のカーブと同じ出力を生成するように自動化しなければならない。異なる期間で計算すると値曲線のサンプリング方法が変わり、異なる結果となるため。
-
ステップ5へ。
-
-
-
-
時刻 \(t_c\) より後のすべてのイベントを削除する。
イベントが追加されなければ、
cancelAndHoldAtTime()後のオートメーション値は、元のタイムラインが\(t_c\)時点で持つ値を以降保持します。AudioParam.cancelAndHoldAtTime() メソッドの引数。 パラメータ 型 Nullable Optional 説明 cancelTimedouble✘ ✘ この時刻以降のスケジュール済みパラメータ変更をキャンセルする時刻。 AudioContextのcurrentTime座標系の時刻。RangeErrorはcancelTimeが負の場合に必ず投げる必要があります。cancelTimeがcurrentTime未満の場合はcurrentTimeにクランプされます。返り値型:AudioParam -
cancelScheduledValues(cancelTime)-
cancelTime以降の すべてのスケジュール済みパラメータ変更をキャンセルします。 キャンセルは、イベントリストから対象イベントを削除することです。automation event timeがcancelTime未満の アクティブなオートメーションもキャンセルされ、元の値(オートメーション前の値)に即座に戻ります。cancelAndHoldAtTime()で 保持された値も、保持時刻がcancelTime以降の場合は削除されます。setValueCurveAtTime()の場合、 \(T_0\)と\(T_D\)をイベントのstartTime、durationとする。cancelTimeが \([T_0, T_0 + T_D]\)区間内にあれば、そのイベントはタイムラインから削除されます。AudioParam.cancelScheduledValues() メソッドの引数。 パラメータ 型 Nullable Optional 説明 cancelTimedouble✘ ✘ この時刻以降のスケジュール済みパラメータ変更をキャンセルする時刻。 AudioContextのcurrentTime座標系の時刻。RangeErrorはcancelTimeが負の場合に必ず投げる必要があります。cancelTimeがcurrentTime未満の場合はcurrentTimeにクランプされます。返り値型:AudioParam exponentialRampToValueAtTime(value, endTime)-
パラメータ値を、前回スケジュールされたパラメータ値から指定された値まで指数関数的に連続して変化させるようにスケジュールします。フィルターの周波数や再生速度を表すパラメータは、人間の音の知覚方法のため、指数関数的に変化させるのが最適です。
時間区間 \(T_0 \leq t < T_1\)(ここで \(T_0\) は前回イベントの時刻、\(T_1\) はこのメソッドに渡された
endTimeパラメータの値)における値は、以下のように計算されます:$$ v(t) = V_0 \left(\frac{V_1}{V_0}\right)^\frac{t - T_0}{T_1 - T_0} $$ここで \(V_0\) は時刻 \(T_0\) における値、\(V_1\) はこのメソッドに渡された
valueパラメータの値です。もし \(V_0\) と \(V_1\) の符号が異なる場合や、\(V_0\) がゼロの場合は、\(T_0 \le t \lt T_1\) の間は \(v(t) = V_0\) となります。このことは、0 への指数関数的ランプが不可能であることも意味します。適切なタイムコンスタントを選択した
setTargetAtTime()を使うことで良い近似が可能です。この ExponentialRampToValue イベントの後にイベントがなければ、\(t \geq T_1\) の間は \(v(t) = V_1\) となります。
このイベントの前にイベントがない場合、指数ランプは
setValueAtTime(value, currentTime)を呼び出したかのように動作します。ここでvalueは属性の現在値、currentTimeはcurrentTimeのコンテキストでexponentialRampToValueAtTime()が呼ばれた時点の値です。直前のイベントが
SetTargetイベントの場合、\(T_0\) および \(V_0\) はSetTargetオートメーションの現在時刻と値から選ばれます。すなわち、SetTargetイベントがまだ開始されていない場合、\(T_0\) はイベントの開始時刻、\(V_0\) はSetTargetイベント開始直前の値です。この場合、ExponentialRampToValueイベントは事実上SetTargetイベントを置き換えます。SetTargetイベントがすでに開始されている場合、\(T_0\) は現時点のコンテキスト時刻、\(V_0\) は時刻 \(T_0\) でのSetTargetオートメーション値です。どちらの場合も、オートメーションカーブは連続になります。AudioParam.exponentialRampToValueAtTime() メソッドの引数。 パラメータ 型 Nullable Optional 説明 valuefloat✘ ✘ 指定時刻に指数的に到達する値。 RangeErrorはこの値が0の場合必ず投げる必要があります。endTimedouble✘ ✘ AudioContextのcurrentTime座標系で 指定する指数ランプ終了時刻。RangeErrorはendTimeが負または有限でない場合必ず投げる必要があります。 endTimeがcurrentTime未満の場合はcurrentTimeにクランプされます。返り値型:AudioParam linearRampToValueAtTime(value, endTime)-
パラメータ値を前回スケジュール値から指定値へ、線形に連続変化するようスケジュールします。
時間区間 \(T_0 \leq t < T_1\)(ここで \(T_0\) は前回のイベントの時刻、\(T_1\) はこのメソッドに渡された
endTimeパラメータの値)における値は、以下のように計算されます:$$ v(t) = V_0 + (V_1 - V_0) \frac{t - T_0}{T_1 - T_0} $$\(V_0\):時刻\(T_0\)での値、\(V_1\):このメソッドの
value。このイベント以降にイベントがなければ \(t \geq T_1\) で値は\(V_1\)となる。
直前にイベントがなければ、
setValueAtTime(value, currentTime)を (value:現在値、currentTime:呼び出し時点のcontext currentTime)呼んだのと同様の挙動。直前が
SetTargetイベントなら、\(T_0\)、\(V_0\)はSetTargetオートメーションの現在時刻・値で決定。 そのイベント未開始なら開始時刻・開始直前値、開始済みなら現在時刻・現在値。どちらもオートメーションカーブは連続。AudioParam.linearRampToValueAtTime() メソッドの引数。 パラメータ 型 Nullable Optional 説明 valuefloat✘ ✘ 指定時刻に線形で到達する値。 endTimedouble✘ ✘ AudioContextのcurrentTime座標系で 指定するオートメーション終了時刻。RangeErrorはendTimeが負または有限でない場合必ず投げる必要があります。 endTimeがcurrentTime未満の場合はcurrentTimeにクランプされます。返り値型:AudioParam setTargetAtTime(target, startTime, timeConstant)-
指定時刻から指定時定数で目標値へ指数的に近づくようパラメータ値を変化させます。ADSRエンベロープのdecay/release部分などに有用です。値は即座に目標値になるのではなく、徐々に近づきます。
区間\(T_0 \leq t\)(\(T_0\):
startTime)での値は次式で算出:$$ v(t) = V_1 + (V_0 - V_1)\, e^{-\left(\frac{t - T_0}{\tau}\right)} $$\(V_0\):時刻\(T_0\)での初期値(
[[current value]])、 \(V_1\):target、 \(\tau\):timeConstant。このイベントの後に
LinearRampToValueやExponentialRampToValueイベントがある場合は、各メソッドの説明参照。 それ以外では、次イベント時刻でSetTargetイベントは終了。AudioParam.setTargetAtTime() メソッドの引数。 パラメータ 型 Nullable Optional 説明 targetfloat✘ ✘ 指定時刻からパラメータ値が目標値へ変化し始める値。 startTimedouble✘ ✘ 指数近似が始まる時刻。 AudioContextのcurrentTime座標系。RangeErrorはstartが負または有限でない場合必ず投げる必要があります。 startTimeがcurrentTime未満の場合はcurrentTimeにクランプされます。timeConstantfloat✘ ✘ 一次フィルター(指数近似)への時定数値。大きいほど遷移は遅くなる。値は非負でなければならず、そうでなければ RangeError例外を必ず投げる必要があります。 0の場合は即座に最終値へジャンプ。 timeConstantは1次線形連続時間不変系が入力ステップ応答で値\(1-1/e\)(約63.2%)に到達するのに必要な時間。返り値型:AudioParam setValueAtTime(value, startTime)-
指定時刻にパラメータ値を変更するようスケジュールします。
この
SetValueイベント以降にイベントがなければ、\(t \geq T_0\) で \(v(t) = V\)(\(T_0\):startTime、\(V\):value)と 常に一定。この
SetValueイベントの後に時刻 \(T_1\) の次のイベントがあり、そのイベントがLinearRampToValueやExponentialRampToValue型でない場合、\(T_0 \leq t < T_1\) の間は:$$ v(t) = V $$この区間も値は一定となり、ステップ関数的動作を作れます。
次イベントが
LinearRampToValueやExponentialRampToValueなら、各メソッド説明参照。AudioParam.setValueAtTime() メソッドの引数。 パラメータ 型 Nullable Optional 説明 valuefloat✘ ✘ 指定時刻に変更する値。 startTimedouble✘ ✘ パラメータが指定値に変化する時刻。 BaseAudioContextのcurrentTime座標系。RangeErrorはstartTimeが負または有限でない場合必ず投げる必要があります。 startTimeがcurrentTime未満の場合はcurrentTimeにクランプされます。返り値型:AudioParam setValueCurveAtTime(values, startTime, duration)-
指定した時刻から指定した時間まで、任意のパラメータ値の配列を設定します。値の数は、希望する時間に収まるようにスケールされます。
\(T_0\) を
startTime、 \(T_D\) をduration、 \(V\) をvalues配列、 そして \(N\) をvalues配列の長さとします。すると、時間区間 \(T_0 \le t < T_0 + T_D\) の間は、次のようになります:$$ \begin{align*} k &= \left\lfloor \frac{N - 1}{T_D}(t-T_0) \right\rfloor \\ \end{align*} $$値\(v(t)\)は\(V[k]\)と\(V[k+1]\)を線形補間して算出。
カーブ終了後(\(t \ge T_0 + T_D\))は、次のオートメーションイベントがあるまで値は最終値で固定。
内部的に、時刻\(T_0 + T_D\)で値\(V[N-1]\)で
setValueAtTime()が呼ばれ、 以降のオートメーションはこのカーブ終端値から始まります。AudioParam.setValueCurveAtTime() メソッドの引数。 パラメータ 型 Nullable Optional 説明 valuessequence<float>✘ ✘ パラメータ値カーブを表すfloat値の配列。指定時刻から指定持続時間だけ適用。呼び出し時に内部コピーが作られ、以降配列内容を変更しても AudioParamには影響しない。InvalidStateErrorは 配列長が2未満の場合必ず投げる必要があります。startTimedouble✘ ✘ 値カーブ適用開始時刻。 AudioContextのcurrentTime座標系。RangeErrorはstartTimeが負または有限でない場合必ず投げる必要があります。 startTimeがcurrentTime未満の場合はcurrentTimeにクランプされます。durationdouble✘ ✘ startTime以降、valuesに基づき値が算出される秒数。RangeErrorはdurationが正でない場合、または有限でない場合必ず投げる必要があります。返り値型:AudioParam
1.6.3. 値の計算
2種類のAudioParamがあり、単純パラメータと複合パラメータです。単純パラメータ(デフォルト)は、AudioNodeの最終的なオーディオ出力を計算するために単独で使われます。
複合パラメータは、他のAudioParamと組み合わせて値を計算し、その値が入力としてAudioNodeの出力を計算するために使われます。
computedValueは、最終的にオーディオDSPを制御する値であり、各レンダリング時間量子ごとにオーディオレンダリングスレッドによって計算されます。
AudioParamの値の計算は2つの部分から成り立ちます:
-
paramComputedValueは、最終的にオーディオDSPを制御する値であり、各レンダー量子ごとにオーディオレンダリングスレッドによって計算されます。
これらの値は次のように計算しなければなりません:
-
paramIntrinsicValueは、各時刻で計算されます。これは
value属性に直接設定された値、またはその時刻以前または同時の自動化イベントがあれば、それらのイベントから計算された値です。もし自動化イベントが特定の時間範囲から削除された場合、paramIntrinsicValueは前回の値のまま変更されず、value属性が直接設定されるか、その時間範囲に自動化イベントが追加されるまで維持されます。 -
[[current value]]を、このレンダー量子の開始時点におけるparamIntrinsicValueの値に設定します。 -
paramComputedValueは、paramIntrinsicValueの値と入力AudioParamバッファの値の合計です。合計が
NaNの場合は、defaultValueで置き換えます。 -
この
AudioParamが複合パラメータの場合、他のAudioParamとともに最終値を計算します。 -
computedValueをparamComputedValueに設定します。
computedValueの名目範囲は、このパラメータが実際に持つことができる最小値と最大値です。単純パラメータの場合、computedValueはそのパラメータの単純名目範囲にクランプされます。複合パラメータは、構成する各AudioParam値から計算された後、最終値がそれぞれの名目範囲にクランプされます。
自動化メソッドが使われる場合でも、クランプ処理は適用されます。ただし、自動化の計算自体はクランプされていないかのように行われ、出力に適用する時点でのみ上記のようにクランプされます。
N. p. setValueAtTime( 0 , 0 ); N. p. linearRampToValueAtTime( 4 , 1 ); N. p. linearRampToValueAtTime( 0 , 2 );
曲線の初期の傾きは4ですが、最大値1に達すると出力は一定となります。最後に、時刻2付近では傾きが-4となります。下図では、破線がクリッピングなしの場合の挙動、実線が名目範囲へのクリッピングによるAudioParamの実際の挙動を示しています。
1.6.4. AudioParam
自動化の例
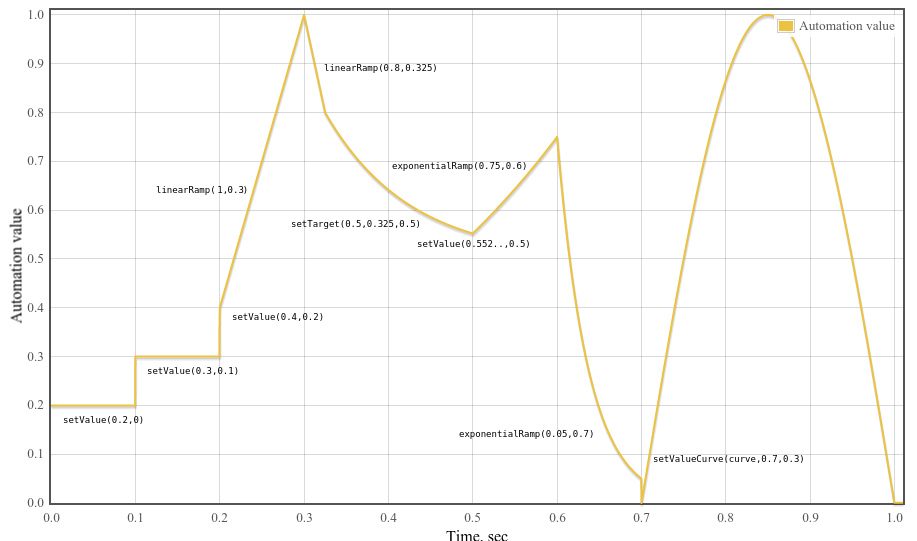
const curveLength= 44100 ; const curve= new Float32Array( curveLength); for ( const i= 0 ; i< curveLength; ++ i) curve[ i] = Math. sin( Math. PI* i/ curveLength); const t0= 0 ; const t1= 0.1 ; const t2= 0.2 ; const t3= 0.3 ; const t4= 0.325 ; const t5= 0.5 ; const t6= 0.6 ; const t7= 0.7 ; const t8= 1.0 ; const timeConstant= 0.1 ; param. setValueAtTime( 0.2 , t0); param. setValueAtTime( 0.3 , t1); param. setValueAtTime( 0.4 , t2); param. linearRampToValueAtTime( 1 , t3); param. linearRampToValueAtTime( 0.8 , t4); param. setTargetAtTime( .5 , t4, timeConstant); // t5時点でsetTargetAtTimeがどこにあるか計算し、 // 以下のexpが正しい位置から始まるようにジャンプ不連続を防ぐ。 // 仕様より、v(t) = 0.5 + (0.8 - 0.5)*exp(-(t-t4)/timeConstant) // よってv(t5) = 0.5 + (0.8 - 0.5)*exp(-(t5-t4)/timeConstant) param. setValueAtTime( 0.5 + ( 0.8 - 0.5 ) * Math. exp( - ( t5- t4) / timeConstant), t5); param. exponentialRampToValueAtTime( 0.75 , t6); param. exponentialRampToValueAtTime( 0.05 , t7); param. setValueCurveAtTime( curve, t7, t8- t7);
1.7. AudioScheduledSourceNode
インターフェース
このインターフェースは、AudioBufferSourceNode、ConstantSourceNode、OscillatorNodeなどのソースノードの共通機能を表します。
ソースが(start()を呼び出して)開始される前は、ソースノードは必ず無音(0)を出力しなければなりません。ソースが(stop()を呼び出して)停止された後も、ソースは必ず無音(0)を出力しなければなりません。
AudioScheduledSourceNodeは直接インスタンス化できず、ソースノード用の具体的なインターフェースによって拡張されます。
AudioScheduledSourceNodeは、その関連するBaseAudioContextのcurrentTimeがソースノードの開始時刻以上、停止時刻未満の場合に再生中と言います。
AudioScheduledSourceNodeは、内部的なブール型スロット[[source started]]を持ち、初期値はfalseです。
[Exposed =Window ]interface AudioScheduledSourceNode :AudioNode {attribute EventHandler onended ;undefined start (optional double when = 0);undefined stop (optional double when = 0); };
1.7.1. 属性
onended, 型 EventHandler-
endedイベントタイプのイベントハンドラを設定するためのプロパティです。このイベントはAudioScheduledSourceNodeノードタイプに送出されます。ソースノードが再生を停止した時(具体的なノードによって判断されます)、Eventインターフェースを使用したイベントがイベントハンドラへ送出されます。すべての
AudioScheduledSourceNodeで、endedイベントはstop()で決定された停止時刻に達した時に送出されます。AudioBufferSourceNodeの場合、durationに達した場合やbuffer全体が再生された場合にもイベントが送出されます。
1.7.2. メソッド
start(when)-
指定した時刻にサウンドを再生するようスケジュールします。
このメソッドが呼ばれた時、次の手順を実行します:-
この
AudioScheduledSourceNodeの内部スロット[[source started]]がtrueの場合、InvalidStateError例外を投げなければなりません。 -
下記のパラメータ制約により投げる必要があるエラーがないか確認します。ステップ中に例外が投げられた場合は手順を中断します。
-
この
AudioScheduledSourceNodeの内部スロット[[source started]]をtrueに設定します。 -
制御メッセージをキューイング して
AudioScheduledSourceNodeを開始します。パラメータ値をメッセージに含めます。 -
関連付けられた
AudioContextにレンダリングスレッドの実行開始のための制御メッセージを送信します。ただし、以下すべての条件が満たされた場合のみ:-
コンテキストの
[[control thread state]]が"suspended"である。 -
コンテキストが開始可能である。
-
[[suspended by user]]フラグがfalseである。
注意:この仕組みにより、
start()によって現在開始可能な状態だが、以前は開始が阻止されていたAudioContextを開始できる場合があります。 -
AudioScheduledSourceNode.start(when) メソッドの引数。 パラメータ 型 Nullable Optional 説明 whendouble✘ ✔ whenパラメータは、何秒後にサウンドを再生開始するかを示します。AudioContextのcurrentTime属性と同じ時間座標系です。AudioScheduledSourceNodeの発する信号が開始時刻に依存する場合、whenの値は常にサンプルフレーム単位で丸めず正確に使われます。0またはcurrentTimeより小さい値を指定した場合、即座に再生が開始されます。whenが負の場合はRangeError例外を投げなければなりません。戻り値の型:undefined -
stop(when)-
指定した時刻にサウンドの再生を停止するようスケジュールします。すでに
stopが呼ばれた後に再度呼び出された場合、最後の呼び出しのみが適用されます。以前の呼び出しによる停止時刻は、バッファが停止済みでない限り適用されません。バッファがすでに停止済みの場合、以降のstop呼び出しは効果がありません。停止時刻が開始時刻より先に到達した場合、サウンドは再生されません。このメソッドが呼ばれた時、次の手順を実行します:-
この
AudioScheduledSourceNodeの内部スロット[[source started]]がtrueでない場合、InvalidStateError例外を投げなければなりません。 -
下記のパラメータ制約により投げる必要があるエラーがないか確認します。
-
制御メッセージをキューイング して
AudioScheduledSourceNodeを停止します。パラメータ値をメッセージに含めます。
AudioScheduledSourceNode.stop(when) メソッドの引数。 パラメータ 型 Nullable Optional 説明 whendouble✘ ✔ whenパラメータは、何秒後にソースを停止するかを示します。AudioContextのcurrentTime属性と同じ時間座標系です。0またはcurrentTimeより小さい値を指定した場合、即座に停止します。whenが負の場合はRangeError例外を投げなければなりません。戻り値の型:undefined -
1.8. AnalyserNode
インターフェース
このインターフェースは、リアルタイムの周波数および時間領域解析情報を提供できるノードを表します。オーディオストリームは、入力から出力へ未処理のまま渡されます。
| プロパティ | 値 | 備考 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 1 | この出力は未接続でも構いません。 |
channelCount
| 2 | |
channelCountMode
| "max"
| |
channelInterpretation
| "speakers"
| |
| tail-time | なし |
[Exposed =Window ]interface AnalyserNode :AudioNode {constructor (BaseAudioContext ,context optional AnalyserOptions = {});options undefined getFloatFrequencyData (Float32Array );array undefined getByteFrequencyData (Uint8Array );array undefined getFloatTimeDomainData (Float32Array );array undefined getByteTimeDomainData (Uint8Array );array attribute unsigned long fftSize ;readonly attribute unsigned long frequencyBinCount ;attribute double minDecibels ;attribute double maxDecibels ;attribute double smoothingTimeConstant ; };
1.8.1. コンストラクター
AnalyserNode(context, options)-
このコンストラクターが
BaseAudioContextc と オプションオブジェクト option で呼び出された場合、ユーザーエージェントは AudioNodeの初期化 を this に対して context および options を引数にして行わなければなりません。AnalyserNode.constructor() メソッドの引数。 パラメータ 型 Nullable Optional 説明 contextBaseAudioContext✘ ✘ この新しい AnalyserNodeが 関連付けられるBaseAudioContext。optionsAnalyserOptions✘ ✔ この AnalyserNodeの初期パラメータ値(省略可能)。
1.8.2. 属性
fftSize, 型 unsigned long-
周波数領域解析に使われるFFTのサイズ(サンプルフレーム数)。この値は32から32768までの2のべき乗でなければならず、そうでない場合は
IndexSizeError例外を投げなければなりません。デフォルト値は2048です。 大きなFFTサイズは計算コストが高くなることがあります。fftSizeを別の値に変更した場合、 周波数データのスムージングに関連するすべての状態(getByteFrequencyData()およびgetFloatFrequencyData()) がリセットされます。つまり、previous block、\(\hat{X}_{-1}[k]\) は 時間方向のスムージングで全ての \(k\) に対して0に設定されます。fftSizeを増やすと、現在の時間領域データは過去のフレームも含むように拡張されます。これはAnalyserNodeが直近32768サンプルフレームを保持し、現在の時間領域データはそのうち最新のfftSize個となります。 frequencyBinCount, 型 unsigned long(読み取り専用)-
FFTサイズの半分の値。
maxDecibels, 型 double-
maxDecibelsはFFT解析データを符号なしバイト値に変換するためのスケーリング範囲の最大パワー値です。デフォルト値は-30です。この属性値がminDecibels以下に設定された場合、IndexSizeError例外を投げなければなりません。 minDecibels, 型 double-
minDecibelsはFFT解析データを符号なしバイト値に変換するためのスケーリング範囲の最小パワー値です。デフォルト値は-100です。この属性値がmaxDecibels以上に設定された場合、IndexSizeError例外を投げなければなりません。 smoothingTimeConstant, 型 double-
0から1の範囲の値で、0は直前の解析フレームとの時間平均化なしを表します。デフォルト値は0.8です。この属性値が0未満または1より大きい場合、
IndexSizeError例外を投げなければなりません。
1.8.3. メソッド
getByteFrequencyData(array)-
現在の周波数データをarrayに書き込みます。arrayのバイト長が
frequencyBinCount未満の場合、余分な要素は削除されます。arrayのバイト長がfrequencyBinCountより大きい場合、余分な要素は無視されます。周波数データの計算には直近のfftSizeフレームが使われます。同じレンダー量子内で
getByteFrequencyData()またはgetFloatFrequencyData()が複数回呼ばれた場合、現在の周波数データは同じデータで再計算されず、前回計算したデータが返されます。符号なしバイト配列に格納される値は次の方法で計算されます。\(Y[k]\)を現在の周波数データ(FFTウィンドウ処理と時間方向スムージング参照)とします。バイト値\(b[k]\)は、
$$ b[k] = \left\lfloor \frac{255}{\mbox{dB}_{max} - \mbox{dB}_{min}} \left(Y[k] - \mbox{dB}_{min}\right) \right\rfloor $$ここで\(\mbox{dB}_{min}\)は
minDecibels、\(\mbox{dB}_{max}\)はmaxDecibelsAnalyserNode.getByteFrequencyData() メソッドの引数。 パラメータ 型 Nullable Optional 説明 arrayUint8Array✘ ✘ このパラメータには周波数領域解析データがコピーされます。 戻り値の型:undefined getByteTimeDomainData(array)-
現在の時間領域データ(波形データ)をarrayに書き込みます。arrayのバイト長が
fftSize未満の場合、余分な要素は削除されます。arrayのバイト長がfftSizeより大きい場合、余分な要素は無視されます。バイトデータの計算には直近のfftSizeフレームが使われます。符号なしバイト配列に格納される値は次の方法で計算されます。\(x[k]\)を時間領域データとすると、バイト値\(b[k]\)は
$$ b[k] = \left\lfloor 128(1 + x[k]) \right\rfloor. $$\(b[k]\)が0から255の範囲外の場合は、その範囲にクリップされます。
AnalyserNode.getByteTimeDomainData() メソッドの引数。 パラメータ 型 Nullable Optional 説明 arrayUint8Array✘ ✘ このパラメータには時間領域サンプルデータがコピーされます。 戻り値の型:undefined getFloatFrequencyData(array)-
現在の周波数データをarrayに書き込みます。arrayの要素数が
frequencyBinCount未満の場合、余分な要素は削除されます。arrayの要素数がfrequencyBinCountより多い場合、余分な要素は無視されます。周波数データの計算には直近のfftSizeフレームが使われます。同じレンダー量子内で
getFloatFrequencyData()またはgetByteFrequencyData()が複数回呼ばれた場合、現在の周波数データは同じデータで再計算されず、前回計算したデータが返されます。周波数データはdB単位です。
AnalyserNode.getFloatFrequencyData() メソッドの引数。 パラメータ 型 Nullable Optional 説明 arrayFloat32Array✘ ✘ このパラメータには周波数領域解析データがコピーされます。 戻り値の型:undefined getFloatTimeDomainData(array)-
現在の時間領域データ(波形データ)をarrayに書き込みます。arrayの要素数が
fftSize未満の場合、余分な要素は削除されます。arrayの要素数がfftSizeより多い場合、余分な要素は無視されます。最も新しいfftSizeフレームが(ダウンミックス後)書き込まれます。AnalyserNode.getFloatTimeDomainData() メソッドの引数。 パラメータ 型 Nullable Optional 説明 arrayFloat32Array✘ ✘ このパラメータには時間領域サンプルデータがコピーされます。 戻り値の型:undefined
1.8.4.
AnalyserOptions
これはAnalyserNodeを構築する際に使用されるオプションを指定します。
すべてのメンバーは省略可能で、指定されていない場合は通常のデフォルト値が使われてノードが構築されます。
dictionary AnalyserOptions :AudioNodeOptions {unsigned long fftSize = 2048;double maxDecibels = -30;double minDecibels = -100;double smoothingTimeConstant = 0.8; };
1.8.4.1. 辞書 AnalyserOptions
のメンバー
fftSize, 型 unsigned long、デフォルト値2048-
周波数領域解析のためのFFTの初期サイズを指定します。
maxDecibels, 型 double、デフォルト値-30-
FFT解析時の最大パワー(dB)の初期値を指定します。
minDecibels, 型 double、デフォルト値-100-
FFT解析時の最小パワー(dB)の初期値を指定します。
smoothingTimeConstant, 型 double、デフォルト値0.8-
FFT解析時の初期スムージング定数を指定します。
1.8.5. 時間領域ダウンミックス
現在の時間領域データが計算される際、入力信号はchannelCount
が1、channelCountMode
が"max"、channelInterpretation
が"speakers"のように、ダウンミックスされてモノラルになります。
これはAnalyserNode自身の設定とは無関係です。ダウンミックス処理には直近のfftSizeフレームが使用されます。
1.8.6. FFTウィンドウ処理と時間方向スムージング
現在の周波数データを計算する際、以下の処理を行います:
-
現在の時間領域データを計算する。
-
Blackmanウィンドウを時間領域入力データに適用する。
-
フーリエ変換をウィンドウ処理済みの時間領域入力データに適用して、実数・虚数の周波数データを得る。
-
時間方向のスムージングを周波数領域データに適用する。
-
dB変換を行う。
以下において、\(N\)はこのfftSize属性の値とします。
$$
\begin{align*}
\alpha &= \mbox{0.16} \\ a_0 &= \frac{1-\alpha}{2} \\
a_1 &= \frac{1}{2} \\
a_2 &= \frac{\alpha}{2} \\
w[n] &= a_0 - a_1 \cos\frac{2\pi n}{N} + a_2 \cos\frac{4\pi n}{N}, \mbox{ for } n = 0, \ldots, N - 1
\end{align*}
$$
ウィンドウ処理後の信号\(\hat{x}[n]\)は
$$
\hat{x}[n] = x[n] w[n], \mbox{ for } n = 0, \ldots, N - 1
$$
$$
X[k] = \frac{1}{N} \sum_{n = 0}^{N - 1} \hat{x}[n]\, W^{-kn}_{N}
$$
ここで\(k = 0, \dots, N/2-1\)、\(W_N = e^{2\pi i/N}\)です。
-
\(\hat{X}_{-1}[k]\)は、前回ブロックに対するこの操作の結果です。前回ブロックは、前回の時間方向スムージング操作で計算されたバッファ、または初回の場合は\(N\)個のゼロからなる配列です。
-
\(\tau\)はこの
smoothingTimeConstant属性値とします。 -
\(X[k]\)は現在ブロックに対してフーリエ変換の適用で得られる値です。
スムージング後の値\(\hat{X}[k]\)は以下で計算されます:
$$
\hat{X}[k] = \tau\, \hat{X}_{-1}[k] + (1 - \tau)\, \left|X[k]\right|
$$
-
\(\hat{X}[k]\)が
NaN、正の無限大または負の無限大の場合、\(\hat{X}[k] = 0\)とします。
(\(k = 0, \ldots, N - 1\)まで)。
$$
Y[k] = 20\log_{10}\hat{X}[k]
$$
\(k = 0, \ldots, N-1\)まで。
この配列\(Y[k]\)は、getFloatFrequencyData()の出力配列にコピーされます。
getByteFrequencyData()の場合、\(Y[k]\)は
minDecibels
から
maxDecibelsminDecibels
が値0に、
maxDecibels
1.9. AudioBufferSourceNode
インターフェース
このインターフェースは、AudioBuffer
内のメモリー上のオーディオアセットからのオーディオソースを表します。
スケジューリングの柔軟性や精度が高く求められるオーディオアセットの再生に便利です。ネットワークやディスク上のアセットをサンプル精度で再生する必要がある場合は、AudioWorkletNodeを使って再生を実装してください。
start()
メソッドは再生開始タイミングのスケジュールに使用します。start()
メソッドは複数回発行することはできません。再生は、バッファのオーディオデータがすべて再生し終わったとき(loop
属性が false の場合)、または stop()
メソッドが呼ばれ指定時刻に達したときに自動的に停止します。詳細は start()
および stop()
の説明を参照してください。
| プロパティ | 値 | 備考 |
|---|---|---|
numberOfInputs
| 0 | |
numberOfOutputs
| 1 | |
channelCount
| 2 | |
channelCountMode
| "max"
| |
channelInterpretation
| "speakers"
| |
| tail-time | なし |
出力のチャンネル数は buffer
属性に指定された AudioBuffer のチャンネル数と同じになります。
ただし buffer
が null の場合は1チャンネルの無音となります。
さらに、バッファが複数チャンネルの場合、次のいずれかの条件が満たされた時点以降のレンダー量子の先頭で AudioBufferSourceNode
の出力は1チャンネルの無音に切り替わらなければなりません:
AudioBufferSourceNode
の 再生位置は、バッファの最初のサンプルフレームの時間座標に対する秒単位のオフセットを表す任意の値として定義されます。これらの値はノードの
playbackRate や detune
パラメータとは独立して扱われます。
一般に、再生位置はサブサンプル精度であり、必ずしもサンプルフレームの正確な位置を指す必要はありません。0からバッファの duration までの有効な値を持ちます。
playbackRate
と detune
属性は 複合パラメータを構成します。両者は組み合わせて computedPlaybackRate 値を決定します:
computedPlaybackRate(t) = playbackRate(t) * pow(2, detune(t) / 1200)
この 複合パラメータ の 名目範囲は \((-\infty, \infty)\) です。
AudioBufferSourceNode
は内部ブール型スロット [[buffer set]] を持ち、初期値は
false です。
[Exposed =Window ]interface AudioBufferSourceNode :AudioScheduledSourceNode {constructor (BaseAudioContext ,context optional AudioBufferSourceOptions = {});options attribute AudioBuffer ?buffer ;readonly attribute AudioParam playbackRate ;readonly attribute AudioParam detune ;attribute boolean loop ;attribute double loopStart ;attribute double loopEnd ;undefined start (optional double when = 0,optional double offset ,optional double duration ); };
1.9.1. コンストラクター
AudioBufferSourceNode(context, options)-
このコンストラクターが
BaseAudioContextc と オプションオブジェクト option で呼び出された場合、ユーザーエージェントは AudioNodeの初期化 を this に対して context および options を引数にして行わなければなりません。AudioBufferSourceNode.constructor() メソッドの引数。 パラメータ 型 Nullable Optional 説明 contextBaseAudioContext✘ ✘ この新しい AudioBufferSourceNodeが 関連付けられるBaseAudioContext。optionsAudioBufferSourceOptions✘ ✔ この AudioBufferSourceNodeの初期パラメータ値(省略可能)。
1.9.2. 属性
buffer, 型 AudioBuffer、 nullable-
再生するオーディオアセットを表します。
buffer属性を設定するには、以下の手順を実行します:-
new buffer を
AudioBufferまたはnullの値として、bufferに代入します。 -
new buffer が
nullでなく、かつ[[buffer set]]が true なら、InvalidStateErrorを投げて手順を中止します。 -
new buffer が
nullでない場合、[[buffer set]]を true に設定します。 -
new buffer を
buffer属性に代入します。
-
detune, 型 AudioParam(読み取り専用)-
オーディオストリームの再生速度を変調するための追加パラメータ(単位:セント)。このパラメータは
playbackRateと組み合わせた 複合パラメータ であり、computedPlaybackRate を形成します。パラメータ 値 備考 defaultValue0 minValue最小単精度float値 約 -3.4028235e38 maxValue最大単精度float値 約 3.4028235e38 automationRate" k-rate"自動化レート制約あり loop, 型 boolean-
loopStartおよびloopEndで指定された領域のオーディオデータをループ再生するかどうかを示します。デフォルト値はfalseです。 loopEnd, 型 double-
再生位置のオプション値で、loop属性が true の場合、ループ終了位置を指定します。この値はループの内容に含まれません。デフォルト値は0で、バッファの0からdurationまでのどの値でも設定できます。loopEndが0以下、またはバッファのdurationより大きい場合、ループはバッファの終端で終了します。 loopStart, 型 double-
再生位置のオプション値で、loop属性が true の場合、ループ開始位置を指定します。デフォルト値は0で、バッファの0からdurationまでのどの値でも設定できます。loopStartが0未満の場合は0から開始、バッファのdurationより大きい場合はバッファの終端から開始します。 playbackRate, 型 AudioParam(読み取り専用)-
オーディオストリームの再生速度。このパラメータは
detuneと組み合わせた 複合パラメータで、computedPlaybackRate を形成します。パラメータ 値 備考 defaultValue1 minValue最小単精度float値 約 -3.4028235e38 maxValue最大単精度float値 約 3.4028235e38 automationRate" k-rate"自動化レート制約あり
1.9.3. メソッド
start(when, offset, duration)-
指定した時刻にサウンドを再生するようスケジュールします。
このメソッドが呼ばれたとき、以下の手順を実行します:-
この
AudioBufferSourceNodeの内部スロット[[source started]]がtrueなら、InvalidStateError例外を投げなければなりません。 -
下記パラメータ制約によって投げる必要があるエラーがないか確認します。ステップ中に例外が発生した場合は手順を中断します。
-
この
AudioBufferSourceNodeの内部スロット[[source started]]をtrueに設定します。 -
制御メッセージをキューイング して
AudioBufferSourceNodeを開始します。パラメータ値をメッセージに含めます。 -
関連付けられた
AudioContextにレンダリングスレッドの実行開始のための制御メッセージを送信します。ただし、以下すべての条件が満たされた場合のみ:-
コンテキストの
[[control thread state]]がsuspendedである。 -
コンテキストが開始可能である。
-
[[suspended by user]]フラグがfalseである。
注意:この仕組みにより、
start()によって現在開始可能な状態だが、以前は開始が阻止されていたAudioContextを開始できる場合があります。 -
AudioBufferSourceNode.start(when, offset, duration)メソッドの引数。 パラメータ 型 Nullable Optional 説明 whendouble✘ ✔ whenパラメータは、何秒後にサウンドを再生開始するかを示します。AudioContextのcurrentTime属性と同じ時間座標系です。0またはcurrentTimeより小さい値の場合、即座に再生が開始されます。whenが負の場合はRangeError例外を投げなければなりません。offsetdouble✘ ✔ offsetパラメータは、再生開始位置(再生位置)を指定します。0の場合はバッファの先頭から再生します。offsetが負の場合はRangeError例外を投げなければなりません。offsetがloopEndより大きく、playbackRateが正または0、かつloopがtrueなら、loopEndから再生します。offsetがloopStartより大きく、playbackRateが負、かつloopがtrueなら、loopStartから再生します。offsetはstartTime到達時に[0,duration]にクランプされます。ここでdurationは、AudioBufferのduration属性の値です。durationdouble✘ ✔ durationパラメータは、再生するサウンドの長さ(バッファ内容として出力する合計秒数、ループも含む)を秒単位で指定します。playbackRateの影響とは独立しています。例えば、5秒のdurationにplaybackRateが0.5の場合は、バッファ内容5秒分を半速で再生し、実際の出力は10秒分となります。durationが負の場合はRangeError例外を投げなければなりません。戻り値の型:undefined -
1.9.4. AudioBufferSourceOptions
これはAudioBufferSourceNodeを構築する際に使用するオプションを指定します。
すべてのメンバーは省略可能で、指定されていない場合は通常のデフォルト値でノードが構築されます。
dictionary AudioBufferSourceOptions {AudioBuffer ?buffer ;float detune = 0;boolean loop =false ;double loopEnd = 0;double loopStart = 0;float playbackRate = 1; };
1.9.4.1. 辞書 AudioBufferSourceOptions
のメンバー
buffer, 型 AudioBuffer、 nullable-
再生するオーディオアセット。これは
bufferをbuffer属性に代入するのと同等です。AudioBufferSourceNodeの場合。 detune, 型 float、デフォルト値0-
detuneAudioParam の初期値。 loop, 型 boolean、デフォルト値false-
loop属性の初期値。 loopEnd, 型 double、デフォルト値0-
loopEnd属性の初期値。 loopStart, 型 double、デフォルト値0-
loopStart属性の初期値。 playbackRate, 型 float、デフォルト値1-
playbackRateAudioParam の初期値。
1.9.5. ループ再生
このセクションは規範的ではありません。規範的要件については 再生アルゴリズム を参照してください。
loop
属性を true に設定すると、バッファの loopStart
と loopEnd
で定義される範囲が一度でも再生された後は、無限にループ再生されます。loop
が true の間は、次のいずれかが発生するまでループ再生が続きます:
-
stop()が呼び出された場合 -
予約された停止時刻に到達した場合
-
start()のduration引数が指定された場合、そのdurationを超過した場合
ループ本体は loopStart
から loopEnd
の直前までの領域とみなされます。ループ領域の再生方向はノードの playbackRate の符号に従います。正の playbackRate の場合は loopStart
から loopEnd、
負の playbackRate の場合は loopEnd
から loopStart
へのループとなります。
ループ再生は start() の offset 引数の解釈には影響しません。再生は常に指定された offset
から開始し、ループ本体に到達した時点でループ再生が始まります。
有効なループ開始・終了位置は、下記アルゴリズムの通り、0からバッファ duration の範囲内でなければなりません。さらに、loopEnd
は loopStart
以上である必要があります。
これらを満たさない場合は、バッファ全体がループ対象となります。
ループ端点はサブサンプル精度です。端点がサンプルフレームの正確な位置でない場合や playbackRate が 1 でない場合、ループ区間の再生は端点を正しくつなぐように補間されます。
ループ関連プロパティはバッファ再生中に変更でき、通常は次のレンダー量子で反映されます。正確な動作は後続の規範的な再生アルゴリズムで定義されています。
loopStart
と loopEnd
のデフォルト値はどちらも 0 です。loopEnd
が 0 の場合はバッファの長さと同等なので、デフォルトでバッファ全体がループされます。
ループ端点の値はバッファのサンプルレートに基づく時間オフセットとして表されるため、これらの値はノードの playbackRate
パラメータの影響を受けません。再生中に playbackRate が動的に変化しても独立です。
1.9.6. AudioBuffer 内容の再生
この規範的なセクションでは、バッファ内容の再生について、再生が以下の複数要因の組み合わせで影響される事実を考慮した上で規定します:
-
サブサンプル精度で指定できる開始オフセット
-
再生中に動的に変化可能なサブサンプル精度のループポイント
-
再生速度とデチューンパラメータ(両者を組み合わせて有限の正負値となる computedPlaybackRate を生成)
AudioBufferSourceNode
から出力を生成する内部アルゴリズムは以下の原則に従います:
-
バッファのリサンプリングは UA が任意のタイミングで実施可能(効率や品質向上のため)
-
サブサンプル開始オフセットやループポイントはサンプルフレーム間で補間が必要
-
ループバッファの再生は、補間の影響を除き、ループ音声が連続してバッファ内に存在する非ループバッファの再生と同様に動作するべき
アルゴリズムの説明は以下の通りです:
let buffer; // このノードが使用する AudioBuffer let context; // このノードが使用する AudioContext // 以下の変数はノードの属性値と AudioParam の値を保持 // process() の各呼び出し前に k-rate 単位で更新される let loop; let detune; let loopStart; let loopEnd; let playbackRate; // ノードの再生パラメータ用変数 let start= 0 , offset= 0 , duration= Infinity ; // start() で設定 let stop= Infinity ; // stop() で設定 // ノード再生状態の管理用変数 let bufferTime= 0 , started= false , enteredLoop= false ; let bufferTimeElapsed= 0 ; let dt= 1 / context. sampleRate; // start メソッド呼び出し処理 function handleStart( when, pos, dur) { if ( arguments. length>= 1 ) { start= when; } offset= pos; if ( arguments. length>= 3 ) { duration= dur; } } // stop メソッド呼び出し処理 function handleStop( when) { if ( arguments. length>= 1 ) { stop= when; } else { stop= context. currentTime; } } // マルチチャンネル信号値の補間。サンプルフレームごとに配列で返す // サンプルフレームが正確な位置ならそのフレーム、そうでなければ UA の独自アルゴリズムで近傍補間 function playbackSignal( position) { /* この関数は buffer の再生信号関数で、再生位置から出力信号値(各チャンネル毎)を取得する |position| がバッファの正確なサンプルフレームならそのフレームを返す そうでなければ UA 独自の補間アルゴリズムで周辺フレームを計算 |position| が |loopEnd| 以上で、バッファに続きサンプルフレームがなければ、 |loopStart| からのフレーム列で補間する */ ... } // 1レンダー量子分のオーディオ生成。output配列にサンプルフレームを格納 function process( numberOfFrames) { let currentTime= context. currentTime; // 次のフレームのコンテキスト時刻 const output= []; // サンプルフレーム格納 // 再生速度に影響する2つの k-rate パラメータを合成 const computedPlaybackRate= playbackRate* Math. pow( 2 , detune/ 1200 ); // 有効なループ端点決定 let actualLoopStart, actualLoopEnd; if ( loop&& buffer!= null ) { if ( loopStart>= 0 && loopEnd> 0 && loopStart< loopEnd) { actualLoopStart= loopStart; actualLoopEnd= Math. min( loopEnd, buffer. duration); } else { actualLoopStart= 0 ; actualLoopEnd= buffer. duration; } } else { // loopフラグがfalseならループ状態記録解除 enteredLoop= false ; } // nullバッファの場合 if ( buffer== null ) { stop= currentTime; // 全時間出力0 } // 量子内サンプルフレームのレンダリング for ( let index= 0 ; index< numberOfFrames; index++ ) { // currentTime, bufferTimeElapsed が再生可能範囲か判定 if ( currentTime< start|| currentTime>= stop|| bufferTimeElapsed>= duration) { output. push( 0 ); // 無音 currentTime+= dt; continue ; } if ( ! started) { // バッファ再生開始記録と初期再生位置取得 if ( loop&& computedPlaybackRate>= 0 && offset>= actualLoopEnd) { offset= actualLoopEnd; } if ( computedPlaybackRate< 0 && loop&& offset< actualLoopStart) { offset= actualLoopStart; } bufferTime= offset; started= true ; } // ループ関連処理 if ( loop) { // ループ領域初回到達判定 if ( ! enteredLoop) { if ( offset< actualLoopEnd&& bufferTime>= actualLoopStart) { enteredLoop= true ; } if ( offset>= actualLoopEnd&& bufferTime< actualLoopEnd) { enteredLoop= true ; } } // 必要に応じてループ区間へラップ if ( enteredLoop) { while ( bufferTime>= actualLoopEnd) { bufferTime-= actualLoopEnd- actualLoopStart; } while ( bufferTime< actualLoopStart) { bufferTime+= actualLoopEnd- actualLoopStart; } } } if ( bufferTime>= 0 && bufferTime< buffer. duration) { output. push( playbackSignal( bufferTime)); } else { output. push( 0 ); // バッファ終端以降は無音 } bufferTime+= dt* computedPlaybackRate; bufferTimeElapsed+= dt* computedPlaybackRate; currentTime+= dt; } // 量子ループ終了 if ( currentTime>= stop) { // ノードの再生状態終了。process()の呼び出しは以降なし。出力チャンネル数を1に変更するスケジュール。 } return output; }
以下の非規範的な図は、さまざまな主要シナリオにおけるアルゴリズムの挙動を示します。バッファの動的リサンプリングは考慮していませんが、ループ位置の時刻が変更されない限り、再生結果には大きな違いはありません。すべての図で以下の表記規則を用います:
-
コンテキストのサンプルレートは 1000 Hz
-
AudioBuffer内容は最初のサンプルフレームが x 軸原点に表示される -
出力信号は、時刻
startのサンプルフレームが x 軸原点に表示される -
線形補間で描画(UA は他の補間手法でも可)
-
図内の
duration値はbufferの値であり、start()の引数ではない
次の図は、バッファの基本再生を示します。ループはバッファの最後のサンプルフレームで終了します:
AudioBufferSourceNode
基本再生 次の図は playbackRate
の補間を示し、バッファ内容を半速で再生した場合、出力の各サンプルフレームが補間されます。特に、ループ出力の最後のサンプルフレームはループ開始点を用いて補間されます:
AudioBufferSourceNode
playbackRate の補間 次の図はサンプルレート補間を示します。バッファのサンプルレートがコンテキストの半分(50%)となり、computed playback rate が 0.5 となる例です。結果の出力は前の例と同じですが理由が異なります。
AudioBufferSourceNode
サンプルレート補間 次の図はサブサンプルオフセット再生の例で、バッファ内のオフセットがちょうど半サンプルフレームから始まり、すべての出力フレームが補間されます:
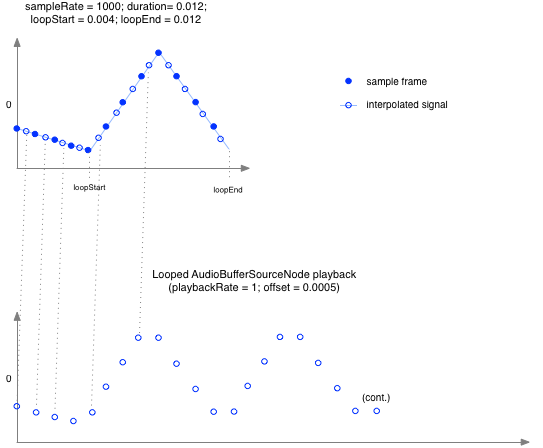
AudioBufferSourceNode
サブサンプルオフセット再生 次の図はサブサンプルループ再生の例で、ループ端点の分数フレームオフセットがバッファ内の補間点となる様子を示します。
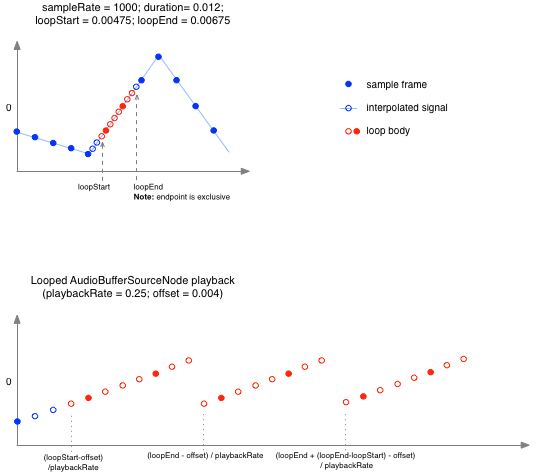
AudioBufferSourceNode
サブサンプルループ再生 1.10. AudioDestinationNode
インターフェース
これは最終的なオーディオ出力を表す AudioNode
であり、ユーザーが実際に聞くことになるノードです。しばしばスピーカーに接続されたオーディオ出力デバイスと見なすことができます。聞こえるようレンダリングされたすべてのオーディオは、このノードにルーティングされ、AudioContext
のルーティンググラフ上では「終端」ノードです。各 AudioContext
につき AudioDestinationNode は1つだけで、destination 属性から取得できます。
AudioDestinationNode
の出力は、入力を合計することで生成されます。これにより、例えば MediaStreamAudioDestinationNode
や MediaRecorder([mediastream-recording] 参照)などに AudioContext の出力をキャプチャできます。
AudioDestinationNode
は、AudioContext
または OfflineAudioContext
のいずれかの出力先となり、チャンネルプロパティはコンテキストによって異なります。
AudioContext
の場合、デフォルトは以下の通りです:
| プロパティ | 値 | 備考 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 1 | |
channelCount
| 2 | |
channelCountMode
| "explicit"
| |
channelInterpretation
| "speakers"
| |
| tail-time | なし |
channelCount
は maxChannelCount
以下の任意の値に設定できます。
IndexSizeError
例外は有効範囲外なら必ず投げなければなりません。 例えばオーディオハードウェアが8チャンネル出力対応なら、channelCount
を8に設定し、8チャンネル出力できます。
OfflineAudioContext
の場合、デフォルトは以下の通りです:
| プロパティ | 値 | 備考 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 1 | |
channelCount
| numberOfChannels | |
channelCountMode
| "explicit"
| |
channelInterpretation
| "speakers"
| |
| tail-time | なし |
ここで numberOfChannels は OfflineAudioContext
のコンストラクタで指定されたチャンネル数です。
この値は変更できません。NotSupportedError
例外は channelCount
を変更した場合に必ず投げなければなりません。
[Exposed =Window ]interface AudioDestinationNode :AudioNode {readonly attribute unsigned long maxChannelCount ; };
1.10.1. 属性
maxChannelCount, 型 unsigned long(読み取り専用)-
channelCount属性に設定できる最大チャンネル数です。オーディオハードウェア終端(通常ケース)を表すAudioDestinationNodeは、ハードウェアがマルチチャンネルの場合2チャンネル以上の出力も可能です。maxChannelCountはこのハードウェアがサポート可能な最大チャンネル数となります。
1.11. AudioListener
インターフェース
このインターフェースは、オーディオシーンを聴いている人の位置と向きを表します。すべての PannerNode
オブジェクトは、BaseAudioContext
の listener
を基準に空間化します。空間化についての詳細は § 6 空間化/パンニング を参照してください。
positionX、
positionY、
positionZ
パラメータは、リスナーの位置を3次元デカルト座標空間で表します。PannerNode
オブジェクトは、個々のオーディオソースとの相対位置をこの座標で空間化します。
forwardX、
forwardY、
forwardZ
パラメータは、3次元空間の方向ベクトルを表します。forwardベクトルとupベクトルの両方が、リスナーの向きを決定するのに使われます。簡単に言えば、forwardベクトルは人の鼻が向いている方向を、upベクトルは頭頂が向いている方向を示します。これら2つのベクトルは線形独立であることが期待されます。これらの値の規範的な解釈については、§ 6 空間化/パンニングを参照してください。
[Exposed =Window ]interface AudioListener {readonly attribute AudioParam positionX ;readonly attribute AudioParam positionY ;readonly attribute AudioParam positionZ ;readonly attribute AudioParam forwardX ;readonly attribute AudioParam forwardY ;readonly attribute AudioParam forwardZ ;readonly attribute AudioParam upX ;readonly attribute AudioParam upY ;readonly attribute AudioParam upZ ;undefined setPosition (float ,x float ,y float );z undefined setOrientation (float ,x float ,y float ,z float ,xUp float ,yUp float ); };zUp
1.11.1. 属性
forwardX, 型 AudioParam(読み取り専用)-
リスナーが3次元デカルト座標空間で向いている方向のx成分を設定します。
パラメータ 値 備考 defaultValue0 minValue最小単精度float値 約 -3.4028235e38 maxValue最大単精度float値 約 3.4028235e38 automationRate" a-rate" forwardY, 型 AudioParam(読み取り専用)-
リスナーが3次元デカルト座標空間で向いている方向のy成分を設定します。
パラメータ 値 備考 defaultValue0 minValue最小単精度float値 約 -3.4028235e38 maxValue最大単精度float値 約 3.4028235e38 automationRate" a-rate" forwardZ, 型 AudioParam(読み取り専用)-
リスナーが3次元デカルト座標空間で向いている方向のz成分を設定します。
パラメータ 値 備考 defaultValue-1 minValue最小単精度float値 約 -3.4028235e38 maxValue最大単精度float値 約 3.4028235e38 automationRate" a-rate" positionX, 型 AudioParam(読み取り専用)-
リスナーの3次元デカルト座標空間でのx位置を設定します。
パラメータ 値 備考 defaultValue0 minValue最小単精度float値 約 -3.4028235e38 maxValue最大単精度float値 約 3.4028235e38 automationRate" a-rate" positionY, 型 AudioParam(読み取り専用)-
リスナーの3次元デカルト座標空間でのy位置を設定します。
パラメータ 値 備考 defaultValue0 minValue最小単精度float値 約 -3.4028235e38 maxValue最大単精度float値 約 3.4028235e38 automationRate" a-rate" positionZ, 型 AudioParam(読み取り専用)-
リスナーの3次元デカルト座標空間でのz位置を設定します。
パラメータ 値 備考 defaultValue0 minValue最小単精度float値 約 -3.4028235e38 maxValue最大単精度float値 約 3.4028235e38 automationRate" a-rate" upX, 型 AudioParam(読み取り専用)-
リスナーが3次元デカルト座標空間で向いている上方向のx成分を設定します。
パラメータ 値 備考 defaultValue0 minValue最小単精度float値 約 -3.4028235e38 maxValue最大単精度float値 約 3.4028235e38 automationRate" a-rate" upY, 型 AudioParam(読み取り専用)-
リスナーが3次元デカルト座標空間で向いている上方向のy成分を設定します。
パラメータ 値 備考 defaultValue1 minValue最小単精度float値 約 -3.4028235e38 maxValue最大単精度float値 約 3.4028235e38 automationRate" a-rate" upZ, 型 AudioParam(読み取り専用)-
リスナーが3次元デカルト座標空間で向いている上方向のz成分を設定します。
パラメータ 値 備考 defaultValue0 minValue最小単精度float値 約 -3.4028235e38 maxValue最大単精度float値 約 3.4028235e38 automationRate" a-rate"
1.11.2. メソッド
setOrientation(x, y, z, xUp, yUp, zUp)-
このメソッドは非推奨です。これは
forwardX.value,forwardY.value,forwardZ.value,upX.value,upY.value,upZ.valueにそれぞれx,y,z,xUp,yUp,zUpの値を直接代入するのと同じです。したがって、もし
forwardX、forwardY、forwardZ、upX、upY、upZのAudioParamにsetValueCurveAtTime()でオートメーションカーブが設定されている場合、このメソッド呼び出し時にNotSupportedErrorを投げなければなりません。setOrientation()は、リスナーが3次元デカルト座標空間で向いている方向を指定します。forwardベクトルとupベクトルの両方が指定されます。簡単に言えば、forwardベクトルは人の鼻が向いている方向を、upベクトルは頭頂が向いている方向を表します。これら2つのベクトルは線形独立であることが期待されます。これらの値の規範的な解釈については § 6 空間化/パンニング を参照してください。x、y、zパラメータは3次元空間の forward方向ベクトルを表し、デフォルト値は (0,0,-1) です。xUp、yUp、zUpパラメータは3次元空間の up方向ベクトルを表し、デフォルト値は (0,1,0) です。AudioListener.setOrientation() メソッドの引数。 パラメータ 型 Nullable Optional 説明 xfloat✘ ✘ AudioListenerの forward x 方向yfloat✘ ✘ AudioListenerの forward y 方向zfloat✘ ✘ AudioListenerの forward z 方向xUpfloat✘ ✘ AudioListenerの up x 方向yUpfloat✘ ✘ AudioListenerの up y 方向zUpfloat✘ ✘ AudioListenerの up z 方向戻り値の型:undefined setPosition(x, y, z)-
このメソッドは非推奨です。これは
positionX.value,positionY.value,positionZ.valueにそれぞれx,y,zの値を直接代入するのと同じです。したがって、もしこの
AudioListenerのpositionX、positionY、positionZのAudioParamにsetValueCurveAtTime()でオートメーションカーブが設定されている場合、このメソッド呼び出し時にNotSupportedErrorを投げなければなりません。setPosition()は、リスナーの位置を3次元デカルト座標空間で設定します。PannerNodeオブジェクトは、各音源との相対位置をこの座標で空間化します。デフォルト値は (0,0,0) です。
AudioListener.setPosition() メソッドの引数。 パラメータ 型 Nullable Optional 説明 xfloat✘ ✘ AudioListenerの位置の x 座標yfloat✘ ✘ AudioListenerの位置の y 座標zfloat✘ ✘ AudioListenerの位置の z 座標
1.11.3. 処理
AudioListener
のパラメータは AudioNode
と接続でき、
同じグラフ内の PannerNode
の出力にも影響を与えるため、
ノード順序アルゴリズムは処理順序を計算するとき AudioListener
を考慮する必要があります。
このため、グラフ内のすべての PannerNode は
AudioListener
を入力にもつことになります。
1.12. AudioProcessingEvent
インターフェース - 非推奨
これは Event
オブジェクトであり、ScriptProcessorNode
ノードにディスパッチされます。ScriptProcessorNode が削除される際に一緒に削除され、代替の AudioWorkletNode
では異なる方法が使われます。
イベントハンドラは、inputBuffer属性から入力(存在する場合)のオーディオデータを取得して処理します。
処理結果のオーディオデータ(入力がなければ合成データ)は outputBuffer
に格納されます。
[Exposed =Window ]interface AudioProcessingEvent :Event {(constructor DOMString ,type AudioProcessingEventInit );eventInitDict readonly attribute double playbackTime ;readonly attribute AudioBuffer inputBuffer ;readonly attribute AudioBuffer outputBuffer ; };
1.12.1. 属性
inputBuffer, 型 AudioBuffer(読み取り専用)-
入力オーディオデータを含む AudioBuffer。createScriptProcessor() メソッドの
numberOfInputChannelsパラメータに等しいチャンネル数を持ちます。この AudioBuffer はaudioprocessイベントハンドラ関数のスコープ内のみ有効です。 このスコープ外では値は無意味です。 outputBuffer, 型 AudioBuffer(読み取り専用)-
出力オーディオデータを書き込む AudioBuffer。createScriptProcessor() メソッドの
numberOfOutputChannelsパラメータに等しいチャンネル数を持ちます。audioprocessイベントハンドラ関数のスコープ内で Script コードはこの AudioBuffer のチャンネルデータを表すFloat32Array配列を変更することが期待されます。スコープ外での変更は音声出力に影響しません。 playbackTime, 型 double(読み取り専用)-
オーディオが再生される時刻。
AudioContextのcurrentTimeと同じ時間座標系です。
1.12.2. AudioProcessingEventInit
dictionary AudioProcessingEventInit :EventInit {required double playbackTime ;required AudioBuffer inputBuffer ;required AudioBuffer outputBuffer ; };
1.12.2.1. 辞書 AudioProcessingEventInit
のメンバー
inputBuffer, 型 AudioBuffer-
イベントの
inputBuffer属性に代入する値。 outputBuffer, 型 AudioBuffer-
イベントの
outputBuffer属性に代入する値。 playbackTime, 型 double-
イベントの
playbackTime属性に代入する値。
1.13.
BiquadFilterNode
インターフェース
BiquadFilterNode
は、非常によく使われる低次数フィルタを実装するAudioNodeプロセッサです。
低次数フィルタは、基本的なトーンコントロール(ベース・ミッド・トレブル)、グラフィックイコライザー、さらに高度なフィルタなどの構成要素です。複数のBiquadFilterNodeフィルタを組み合わせて、より複雑なフィルタを構成できます。フィルタパラメータ(例:frequency)はフィルタスイープなどのために時間とともに変更できます。各BiquadFilterNodeは、以下のIDLで示される一般的なフィルタ型のいずれかに設定できます。デフォルトのフィルタ型は"lowpass"です。
frequency
とdetune
は複合パラメータを構成し、いずれもa-rateです。両者を組み合わせて、computedFrequency値を決定します:
computedFrequency(t) = frequency(t) * pow(2, detune(t) / 1200)
この複合パラメータの名目範囲は[0, ナイキスト周波数]です。
| プロパティ | 値 | 備考 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 1 | |
channelCount
| 2 | |
channelCountMode
| "max"
| |
channelInterpretation
| "speakers"
| |
| tail-time | あり | 入力がゼロでも非サイレントなオーディオ出力を継続します。IIRフィルタなので理論上は無限に出力しますが、実際には出力が十分ゼロに近づいた後、有限時間で打ち切ることができます。具体的な時間はフィルタ係数によります。 |
出力のチャンネル数は常に入力のチャンネル数と一致します。
enum {BiquadFilterType "lowpass" ,"highpass" ,"bandpass" ,"lowshelf" ,"highshelf" ,"peaking" ,"notch" ,"allpass" };
| 列挙値 | 説明 |
|---|---|
"lowpass"
|
ローパスフィルタは、カットオフ周波数以下の周波数を通過させ、カットオフ以上の周波数を減衰させます。12dB/octの標準2次共振ローパスフィルタを実装します。
|
"highpass"
|
ハイパスフィルタはローパスフィルタの逆で、カットオフ周波数以上の周波数を通過させ、以下を減衰させます。12dB/octの標準2次共振ハイパスフィルタを実装します。
|
"bandpass"
|
バンドパスフィルタは周波数帯域を通過させ、それ以外の周波数を減衰させます。2次バンドパスフィルタを実装します。
|
"lowshelf"
|
ローシェルフフィルタは全周波数を通過させますが、低周波数にブースト(または減衰)を加えます。2次ローシェルフフィルタを実装します。
|
"highshelf"
|
ハイシェルフフィルタはローシェルフの逆で、全周波数を通過させつつ高周波数にブーストを加えます。2次ハイシェルフフィルタを実装します。
|
"peaking"
|
ピーキングフィルタは全周波数を通過させますが、特定範囲にブースト(または減衰)を加えます。
|
"notch"
|
ノッチフィルタ(バンドストップまたはバンドリジェクション)はバンドパスフィルタの逆で、指定した周波数帯以外を通過させます。
|
"allpass"
|
オールパスフィルタは、すべての周波数を通過させつつ周波数間の位相関係を変化させます。2次オールパスフィルタを実装します。
|
BiquadFilterNodeのすべての属性はa-rateなAudioParamです。
[Exposed =Window ]interface BiquadFilterNode :AudioNode {(constructor BaseAudioContext ,context optional BiquadFilterOptions = {});options attribute BiquadFilterType type ;readonly attribute AudioParam frequency ;readonly attribute AudioParam detune ;readonly attribute AudioParam Q ;readonly attribute AudioParam gain ;undefined getFrequencyResponse (Float32Array ,frequencyHz Float32Array ,magResponse Float32Array ); };phaseResponse
1.13.1. コンストラクター
BiquadFilterNode(context, options)-
このコンストラクターが
BaseAudioContextc と オプションオブジェクト option で呼び出された場合、ユーザーエージェントは AudioNodeの初期化 を this に対して context および options を引数にして行わなければなりません。BiquadFilterNode.constructor() メソッドの引数。 パラメータ 型 Nullable Optional 説明 contextBaseAudioContext✘ ✘ この新しい BiquadFilterNodeが 関連付けられるBaseAudioContext。optionsBiquadFilterOptions✘ ✔ この BiquadFilterNodeの初期パラメータ値(省略可能)。
1.13.2. 属性
Q, 型 AudioParam(読み取り専用)-
フィルタの Q値。
lowpassおよびhighpassフィルタの場合は、Q値はdB単位で解釈されます。これらのフィルタの名目範囲は \([-Q_{lim}, Q_{lim}]\) で、\(Q_{lim}\) は \(10^{Q/20}\) がオーバーフローしない最大値です。これは約 \(770.63678\) です。bandpass、notch、allpass、peakingフィルタの場合は線形値です。値はフィルタの帯域幅に関係し、正の値であるべきです。名目範囲は \([0, 3.4028235e38]\) です(上限は 最大単精度float値)。lowshelfおよびhighshelfフィルタでは使用しません。パラメータ 値 備考 defaultValue1 minValue最小単精度float値 約 -3.4028235e38、ただしフィルタごとに実際の上限は上記参照 maxValue最大単精度float値 約 3.4028235e38、ただしフィルタごとに実際の上限は上記参照 automationRate" a-rate" detune, 型 AudioParam(読み取り専用)-
frequency用のデチューン値(単位: セント)。
複合パラメータであり、frequencyと組み合わせて computedFrequency を形成します。パラメータ 値 備考 defaultValue0 minValue\(\approx -153600\) maxValue\(\approx 153600\) この値はおよそ \(1200\ \log_2 \mathrm{FLT\_MAX}\) で、FLT_MAXは最大の float値です。automationRate" a-rate" frequency, 型 AudioParam(読み取り専用)-
この
BiquadFilterNodeが動作する周波数(Hz)。複合パラメータであり、detuneと組み合わせて computedFrequency を形成します。パラメータ 値 備考 defaultValue350 minValue0 maxValueナイキスト周波数 automationRate" a-rate" gain, 型 AudioParam(読み取り専用)-
フィルタのゲイン。値はdB単位です。ゲインは、
lowshelf、highshelf、peakingフィルタでのみ使用されます。パラメータ 値 備考 defaultValue0 minValue最小単精度float値 約 -3.4028235e38 maxValue\(\approx 1541\) この値はおよそ \(40\ \log_{10} \mathrm{FLT\_MAX}\) で、FLT_MAXは最大の float値です。automationRate" a-rate" type, 型 BiquadFilterType-
この
BiquadFilterNodeのフィルタ型。 デフォルト値は "lowpass" です。 他のパラメータの意味はtype属性値によって異なります。
1.13.3. メソッド
getFrequencyResponse(frequencyHz, magResponse, phaseResponse)-
各フィルタパラメータの
[[current value]]を用いて、指定した周波数の周波数応答を同期的に計算します。3つのパラメータはすべて同じ長さのFloat32Arrayでなければならず、そうでない場合はInvalidAccessErrorを投げなければなりません。返される周波数応答は、現在の処理ブロックの
AudioParamをサンプリングして計算されなければなりません。BiquadFilterNode.getFrequencyResponse() メソッドの引数。 パラメータ 型 Nullable Optional 説明 frequencyHzFloat32Array✘ ✘ このパラメータは応答値を計算する周波数(Hz)の配列を指定します。 magResponseFloat32Array✘ ✘ このパラメータは線形の振幅応答値を受け取る出力配列です。 frequencyHzの値が[0, sampleRate/2]の範囲外の場合、対応するmagResponseの値はNaNとなります。ここでsampleRateはsampleRateプロパティ値です。phaseResponseFloat32Array✘ ✘ このパラメータはラジアン単位の位相応答値を受け取る出力配列です。 frequencyHzの値が[0; sampleRate/2]範囲外の場合、対応するphaseResponseの値はNaNとなります。ここでsampleRateはsampleRateプロパティ値です。戻り値の型:undefined
1.13.4. BiquadFilterOptions
これはBiquadFilterNodeを構築する際に使用するオプションを指定します。
すべてのメンバーは省略可能で、指定されていない場合は通常のデフォルト値でノードが構築されます。
dictionary BiquadFilterOptions :AudioNodeOptions {BiquadFilterType type = "lowpass";float Q = 1;float detune = 0;float frequency = 350;float gain = 0; };
1.13.4.1. 辞書 BiquadFilterOptions
のメンバー
Q, 型 float(デフォルト値1)-
Qの初期値として指定したい値。 detune, 型 float(デフォルト値0)-
detuneの初期値として指定したい値。 frequency, 型 float(デフォルト値350)-
frequencyの初期値として指定したい値。 gain, 型 float(デフォルト値0)-
gainの初期値として指定したい値。 type, 型 BiquadFilterType(デフォルト値"lowpass")-
フィルタの初期型として指定したい値。
1.13.5. フィルタ特性
BiquadFilterNode
で利用可能なフィルタ型には複数の実装方法があり、それぞれ特性が大きく異なります。このセクションの式は、適合実装が実装しなければならないフィルタを規定します。これは各型の特性を決定し、Audio EQ
Cookbookの式を参考にしています。
BiquadFilterNode
は次の伝達関数でオーディオを処理します:
$$
H(z) = \frac{\frac{b_0}{a_0} + \frac{b_1}{a_0}z^{-1} + \frac{b_2}{a_0}z^{-2}}
{1+\frac{a_1}{a_0}z^{-1}+\frac{a_2}{a_0}z^{-2}}
$$
これは、時系列の式で表すと次の通りです:
$$
a_0 y(n) + a_1 y(n-1) + a_2 y(n-2) =
b_0 x(n) + b_1 x(n-1) + b_2 x(n-2)
$$
初期フィルタ状態は0です。
注意: 固定フィルタは安定ですが、AudioParam
のオートメーションを利用すると不安定なバイカッドフィルタを生成することも可能です。開発者はこれを管理する責任があります。
注意: UAはフィルタ状態でNaN値が発生した場合、警告を表示することがあります。これは通常、不安定なフィルタの兆候です。
上記伝達関数の係数(\(b_0, b_1, b_2, a_0, a_1, a_2\))はフィルタ型ごとに異なり、各型の係数計算には以下の中間変数が必要です。これはBiquadFilterNodeのAudioParamのcomputedValueに基づきます。
-
\(F_s\)はこの
AudioContextのsampleRate属性値。 -
\(f_0\)はcomputedFrequencyの値。
-
\(G\)は
gainAudioParamの値。 -
\(Q\)は
QAudioParamの値。 -
最後に、次を定義します:
$$ \begin{align*} A &= 10^{\frac{G}{40}} \\ \omega_0 &= 2\pi\frac{f_0}{F_s} \\ \alpha_Q &= \frac{\sin\omega_0}{2Q} \\ \alpha_{Q_{dB}} &= \frac{\sin\omega_0}{2 \cdot 10^{Q/20}} \\ S &= 1 \\ \alpha_S &= \frac{\sin\omega_0}{2}\sqrt{\left(A+\frac{1}{A}\right)\left(\frac{1}{S}-1\right)+2} \end{align*} $$
各フィルタ型ごとに、6つの係数(\(b_0, b_1, b_2, a_0, a_1, a_2\))は以下の通り:
- "
lowpass" -
$$ \begin{align*} b_0 &= \frac{1 - \cos\omega_0}{2} \\ b_1 &= 1 - \cos\omega_0 \\ b_2 &= \frac{1 - \cos\omega_0}{2} \\ a_0 &= 1 + \alpha_{Q_{dB}} \\ a_1 &= -2 \cos\omega_0 \\ a_2 &= 1 - \alpha_{Q_{dB}} \end{align*} $$ - "
highpass" -
$$ \begin{align*} b_0 &= \frac{1 + \cos\omega_0}{2} \\ b_1 &= -(1 + \cos\omega_0) \\ b_2 &= \frac{1 + \cos\omega_0}{2} \\ a_0 &= 1 + \alpha_{Q_{dB}} \\ a_1 &= -2 \cos\omega_0 \\ a_2 &= 1 - \alpha_{Q_{dB}} \end{align*} $$ - "
bandpass" -
$$ \begin{align*} b_0 &= \alpha_Q \\ b_1 &= 0 \\ b_2 &= -\alpha_Q \\ a_0 &= 1 + \alpha_Q \\ a_1 &= -2 \cos\omega_0 \\ a_2 &= 1 - \alpha_Q \end{align*} $$ - "
notch" -
$$ \begin{align*} b_0 &= 1 \\ b_1 &= -2\cos\omega_0 \\ b_2 &= 1 \\ a_0 &= 1 + \alpha_Q \\ a_1 &= -2 \cos\omega_0 \\ a_2 &= 1 - \alpha_Q \end{align*} $$ - "
allpass" -
$$ \begin{align*} b_0 &= 1 - \alpha_Q \\ b_1 &= -2\cos\omega_0 \\ b_2 &= 1 + \alpha_Q \\ a_0 &= 1 + \alpha_Q \\ a_1 &= -2 \cos\omega_0 \\ a_2 &= 1 - \alpha_Q \end{align*} $$ - "
peaking" -
$$ \begin{align*} b_0 &= 1 + \alpha_Q\, A \\ b_1 &= -2\cos\omega_0 \\ b_2 &= 1 - \alpha_Q\,A \\ a_0 &= 1 + \frac{\alpha_Q}{A} \\ a_1 &= -2 \cos\omega_0 \\ a_2 &= 1 - \frac{\alpha_Q}{A} \end{align*} $$ - "
lowshelf" -
$$ \begin{align*} b_0 &= A \left[ (A+1) - (A-1) \cos\omega_0 + 2 \alpha_S \sqrt{A})\right] \\ b_1 &= 2 A \left[ (A-1) - (A+1) \cos\omega_0 )\right] \\ b_2 &= A \left[ (A+1) - (A-1) \cos\omega_0 - 2 \alpha_S \sqrt{A}) \right] \\ a_0 &= (A+1) + (A-1) \cos\omega_0 + 2 \alpha_S \sqrt{A} \\ a_1 &= -2 \left[ (A-1) + (A+1) \cos\omega_0\right] \\ a_2 &= (A+1) + (A-1) \cos\omega_0 - 2 \alpha_S \sqrt{A}) \end{align*} $$ - "
highshelf" -
$$ \begin{align*} b_0 &= A\left[ (A+1) + (A-1)\cos\omega_0 + 2\alpha_S\sqrt{A} )\right] \\ b_1 &= -2A\left[ (A-1) + (A+1)\cos\omega_0 )\right] \\ b_2 &= A\left[ (A+1) + (A-1)\cos\omega_0 - 2\alpha_S\sqrt{A} )\right] \\ a_0 &= (A+1) - (A-1)\cos\omega_0 + 2\alpha_S\sqrt{A} \\ a_1 &= 2\left[ (A-1) - (A+1)\cos\omega_0\right] \\ a_2 &= (A+1) - (A-1)\cos\omega_0 - 2\alpha_S\sqrt{A} \end{align*} $$
1.14.
ChannelMergerNode
インターフェース
ChannelMergerNode
はより高度な用途向けであり、ChannelSplitterNodeと組み合わせて使われることが多いです。
| プロパティ | 値 | 備考 |
|---|---|---|
numberOfInputs
| 備考参照 | デフォルトは6ですが、ChannelMergerOptions、numberOfInputs
または createChannelMerger
で指定された値によって決まる。
|
numberOfOutputs
| 1 | |
channelCount
| 1 | channelCount 制約あり |
channelCountMode
| "explicit"
| channelCountMode 制約あり |
channelInterpretation
| "speakers"
| |
| tail-time | なし |
このインターフェースは複数のオーディオストリームからチャンネルを1つのオーディオストリームに合成するAudioNodeを表します。入力数は可変(デフォルト6)ですが、すべてが接続されている必要はありません。出力は1つで、いずれかの入力が能動処理中の場合、出力ストリームのチャンネル数は入力数と等しくなります。どの入力も能動処理中でない場合、出力は1チャンネルの無音になります。
複数の入力を1つのストリームに合成するには、各入力は指定されたミックスルールで1チャンネル(モノラル)にダウンミックスされます。未接続の入力も出力では1つの無音チャンネルとしてカウントされます。入力ストリームを変更しても出力チャンネルの順序には影響ありません。
ChannelMergerNode
に2つのステレオ入力が接続されている場合、1番目と2番目の入力はそれぞれモノラルにダウンミックスされた後、合成されます。出力は6チャンネルストリームとなり、最初の2チャンネルがそれぞれ最初の2つの(ダウンミックスされた)入力で埋められ、残りのチャンネルは無音になります。
またChannelMergerNode
は、5.1サラウンドなどのマルチチャンネルスピーカー配列用に複数のオーディオストリームを特定の順序で配置するのにも使えます。マージャはチャンネルの識別(左・右など)は解釈せず、入力された順番通りに単純にチャンネルを合成します。

[Exposed =Window ]interface ChannelMergerNode :AudioNode {constructor (BaseAudioContext ,context optional ChannelMergerOptions = {}); };options
1.14.1. コンストラクター
ChannelMergerNode(context, options)-
このコンストラクターが
BaseAudioContextc と オプションオブジェクト option で呼び出された場合、ユーザーエージェントは AudioNodeの初期化 を this に対して context および options を引数にして行わなければなりません。ChannelMergerNode.constructor() メソッドの引数。 パラメータ 型 Nullable Optional 説明 contextBaseAudioContext✘ ✘ この新しい ChannelMergerNodeが 関連付けられるBaseAudioContext。optionsChannelMergerOptions✘ ✔ この ChannelMergerNodeの初期パラメータ値(省略可能)。
1.14.2. ChannelMergerOptions
dictionary ChannelMergerOptions :AudioNodeOptions {unsigned long numberOfInputs = 6; };
1.14.2.1. 辞書 ChannelMergerOptions
のメンバー
numberOfInputs, 型 unsigned long(デフォルト値6)-
ChannelMergerNodeの入力数。値の制約についてはcreateChannelMerger()も参照。
1.15. ChannelSplitterNode
インターフェース
ChannelSplitterNode
はより高度な用途向けであり、ChannelMergerNodeと組み合わせて使われることが多いです。
| プロパティ | 値 | 備考 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 備考参照 | デフォルトは6ですが、ChannelSplitterOptions.numberOfOutputs
や createChannelSplitter、
numberOfOutputs
および ChannelSplitterOptions
の辞書
constructorで指定された値によって決まる。
|
channelCount
| numberOfOutputs
| channelCount 制約あり |
channelCountMode
| "explicit"
| channelCountMode 制約あり |
channelInterpretation
| "discrete"
| channelInterpretation 制約あり |
| tail-time | なし |
このインターフェースは、ルーティンググラフ内でオーディオストリームの個々のチャンネルにアクセスするAudioNodeを表します。入力は1つで、入力オーディオストリームのチャンネル数に等しい「アクティブ」出力を持ちます。例えば、ステレオ入力がChannelSplitterNodeに接続されていれば、アクティブ出力数は2(左チャンネルと右チャンネル)。出力は常に合計N個(numberOfOutputsパラメータで決定)あり、デフォルト値は指定されなければ6です。アクティブでない出力は無音となり、通常は何も接続されません。
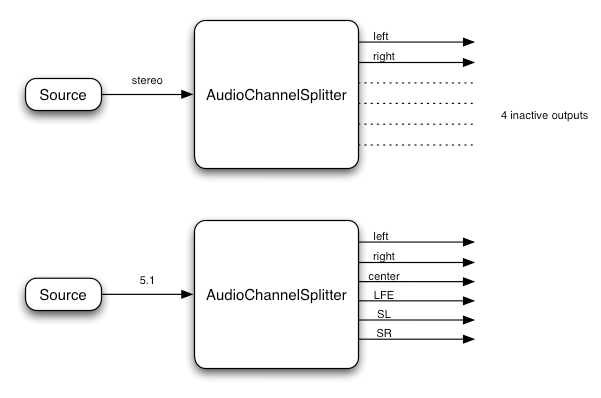
ChannelSplitterNode
の用途例として、各チャンネルの個別ゲイン制御が必要な「マトリックスミキシング」があります。
[Exposed =Window ]interface ChannelSplitterNode :AudioNode {constructor (BaseAudioContext ,context optional ChannelSplitterOptions = {}); };options
1.15.1. コンストラクター
ChannelSplitterNode(context, options)-
このコンストラクターが
BaseAudioContextc と オプションオブジェクト option で呼び出された場合、ユーザーエージェントは AudioNodeの初期化 を this に対して context および options を引数にして行わなければなりません。ChannelSplitterNode.constructor() メソッドの引数。 パラメータ 型 Nullable Optional 説明 contextBaseAudioContext✘ ✘ この新しい ChannelSplitterNodeが 関連付けられるBaseAudioContext。optionsChannelSplitterOptions✘ ✔ この ChannelSplitterNodeの初期パラメータ値(省略可能)。
1.15.2. ChannelSplitterOptions
dictionary ChannelSplitterOptions :AudioNodeOptions {unsigned long numberOfOutputs = 6; };
1.15.2.1. 辞書 ChannelSplitterOptions
のメンバー
numberOfOutputs, 型 unsigned long(デフォルト値6)-
ChannelSplitterNodeの出力数。値の制約についてはcreateChannelSplitter()も参照。
1.16.
ConstantSourceNode
インターフェース
このインターフェースは出力が名目上一定値となる定数オーディオソースを表します。一般的な定数ソースノードとして便利で、AudioParamのように構築可能なものとして
offset
を自動化したり、他のノードを接続して使うこともできます。
このノードの出力は1チャンネル(モノラル)です。
| プロパティ | 値 | 備考 |
|---|---|---|
numberOfInputs
| 0 | |
numberOfOutputs
| 1 | |
channelCount
| 2 | |
channelCountMode
| "max"
| |
channelInterpretation
| "speakers"
| |
| tail-time | なし |
[Exposed =Window ]interface ConstantSourceNode :AudioScheduledSourceNode {constructor (BaseAudioContext ,context optional ConstantSourceOptions = {});options readonly attribute AudioParam offset ; };
1.16.1. コンストラクター
ConstantSourceNode(context, options)-
このコンストラクターが
BaseAudioContextc と オプションオブジェクト option で呼び出された場合、ユーザーエージェントは AudioNodeの初期化 を this に対して context および options を引数にして行わなければなりません。ConstantSourceNode.constructor() メソッドの引数。 パラメータ 型 Nullable Optional 説明 contextBaseAudioContext✘ ✘ この新しい ConstantSourceNodeが 関連付けられるBaseAudioContext。optionsConstantSourceOptions✘ ✔ この ConstantSourceNodeの初期パラメータ値(省略可能)。
1.16.2. 属性
offset, 型 AudioParam(読み取り専用)-
ソースの定数値。
パラメータ 値 備考 defaultValue1 minValue最小単精度float値 約 -3.4028235e38 maxValue最大単精度float値 約 3.4028235e38 automationRate" a-rate"
1.16.3. ConstantSourceOptions
これは ConstantSourceNode
を構築する際に使用するオプションを指定します。
すべてのメンバーは省略可能で、指定されなければ通常のデフォルト値が使われます。
dictionary ConstantSourceOptions {float offset = 1; };
1.16.3.1. 辞書 ConstantSourceOptions
のメンバー
offset, 型 float(デフォルト値1)-
このノードの
offsetAudioParam の初期値。
1.17. ConvolverNode
インターフェース
このインターフェースは、インパルス応答を与えて線形畳み込み効果を適用する処理ノードを表します。
| プロパティ | 値 | 備考 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 1 | |
channelCount
| 2 | channelCount 制約あり |
channelCountMode
| "clamped-max"
| channelCountMode 制約あり |
channelInterpretation
| "speakers"
| |
| tail-time | あり | 入力がゼロでもbufferの長さ分、非サイレントなオーディオを出力し続けます。
|
このノードの入力はモノラル(1チャンネル)またはステレオ(2チャンネル)で、それ以上増やすことはできません。チャンネル数が多いノードからの接続は適切にダウンミックスされます。
このノードにはchannelCount 制約およびchannelCountMode 制約があります。これにより入力はモノラルまたはステレオに限定されます。
[Exposed =Window ]interface ConvolverNode :AudioNode {constructor (BaseAudioContext ,context optional ConvolverOptions = {});options attribute AudioBuffer ?buffer ;attribute boolean normalize ; };
1.17.1. コンストラクター
ConvolverNode(context, options)-
このコンストラクターが
BaseAudioContextcontext と オプションオブジェクト options で呼び出された場合、以下の手順を実行します:-
normalize属性をdisableNormalizationの値の反転に設定します。 -
もし
buffer存在するなら、buffer属性にその値を設定します。注意: bufferは
normalize属性の値により正規化されます。 -
o を新しい
AudioNodeOptions辞書とする。 -
もし
channelCountが options に存在するなら、同じ値で o のchannelCountを設定する。 -
もし
channelCountModeが options に存在するなら、同じ値で o のchannelCountModeを設定する。 -
もし
channelInterpretationが options に存在するなら、同じ値で o のchannelInterpretationを設定する。 -
AudioNodeの初期化 を this に対して c および o を引数として行う。
ConvolverNode.constructor() メソッドの引数。 パラメータ 型 Nullable Optional 説明 contextBaseAudioContext✘ ✘ この新しい ConvolverNodeが 関連付けられるBaseAudioContext。optionsConvolverOptions✘ ✔ この ConvolverNodeの初期パラメータ値(省略可能)。 -
1.17.2. 属性
buffer, 型 AudioBuffer(nullable)-
この属性を設定した時点で、
bufferとnormalize属性の状態を使って このインパルス応答に指定された正規化を適用したConvolverNodeを構成します。初期値はnullです。buffer attributeを設定する際、以下の 手順を同期的に 実行する:-
バッファの
number of channelsが 1, 2, 4 以外である場合、またはバッファのsample-rateがその associatedBaseAudioContextのsample-rateと異なる場合、NotSupportedErrorを投げなければならない。
注意: 新しいbufferを設定すると、オーディオにグリッチが発生する場合があります。好ましくない場合は、新たな
ConvolverNodeを作成し、古いものとクロスフェードすることを推奨します。注意:
ConvolverNodeは、入力チャンネルが1かつbufferが1チャンネルの場合のみモノラル出力となり、それ以外はステレオ出力です。特にbufferが4チャンネルかつ入力が2チャンネルの場合は、行列「真のステレオ」畳み込みを行います。規範的情報はチャンネル構成図参照。 -
normalize, 型 boolean-
bufferが設定された時、インパルス応答が等電力正規化でスケーリングされるかどうかを制御します。デフォルト値は
trueであり、様々なインパルス応答をロードした際により均一な出力レベルを得るためです。normalizeがfalseの場合、畳み込みはインパルス応答に前処理/スケーリングなしで行われます。この値の変更は、次にbuffer属性が設定されたときのみ有効になります。normalize属性がfalseのときbuffer属性を設定すると、ConvolverNodeはbufferに格納されたインパルス応答そのままの線形畳み込みを実行します。一方、
normalize属性がtrueのときbuffer属性を設定すると、ConvolverNodeはまずbuffer内のオーディオデータに対してスケーリングしたRMSパワー解析を行い、以下のアルゴリズムでnormalizationScaleを計算します:function calculateNormalizationScale( buffer) { const GainCalibration= 0.00125 ; const GainCalibrationSampleRate= 44100 ; const MinPower= 0.000125 ; // RMSパワーで正規化 const numberOfChannels= buffer. numberOfChannels; const length= buffer. length; let power= 0 ; for ( let i= 0 ; i< numberOfChannels; i++ ) { let channelPower= 0 ; const channelData= buffer. getChannelData( i); for ( let j= 0 ; j< length; j++ ) { const sample= channelData[ j]; channelPower+= sample* sample; } power+= channelPower; } power= Math. sqrt( power/ ( numberOfChannels* length)); // 過負荷防止 if ( ! isFinite( power) || isNaN( power) || power< MinPower) power= MinPower; let scale= 1 / power; // 未処理音声と知覚音量を同等にするためのキャリブレーション scale*= GainCalibration; // サンプルレートに依存したスケーリング if ( buffer. sampleRate) scale*= GainCalibrationSampleRate/ buffer. sampleRate; // 真のステレオ補正 if ( numberOfChannels== 4 ) scale*= 0.5 ; return scale; } 処理中、ConvolverNodeはこのnormalizationScale値を使い、インパルス応答(
bufferで表される)で入力を畳み込みした結果に乗算して最終出力を生成します。または、入力にnormalizationScaleを掛けたり、インパルス応答のバージョンに事前にnormalizationScaleを掛けたりするなど、数学的に等価な方法でも構いません。
1.17.3.
ConvolverOptions
これはConvolverNodeを構築する際に使用するオプションを指定します。
すべてのメンバーは省略可能で、指定されなければ通常のデフォルト値でノードが構築されます。
dictionary ConvolverOptions :AudioNodeOptions {AudioBuffer ?buffer ;boolean disableNormalization =false ; };
1.17.3.1. 辞書 ConvolverOptions
のメンバー
buffer, 型 AudioBuffer(nullable)-
ConvolverNodeに設定したいbuffer。bufferはdisableNormalizationの値によって正規化されます。 disableNormalization, 型 boolean(デフォルト値false)-
ConvolverNodeのnormalize属性の初期値の逆を指定します。
1.17.4. 入力・インパルス応答・出力のチャンネル構成
実装は ConvolverNode
のインパルス応答チャンネルについて、1または2チャンネル入力で様々なリバーブ効果を得るため、以下の構成をサポートしなければなりません。
下図の通り、単一チャンネルの畳み込みはモノラル入力、モノラルインパルス応答、モノラル出力で動作します。残りの図は、入力チャンネル数が1または2、bufferのチャンネル数が1・2・4の場合にサポートされるケースを示しています。
より複雑な任意のマトリックスを希望する開発者は、ChannelSplitterNode、
複数の単一チャンネルConvolverNode、
ChannelMergerNodeを利用できます。
このノードが能動処理中でない場合、出力は1チャンネルの無音となります。
注意: 下図は能動処理中時の出力を示します。
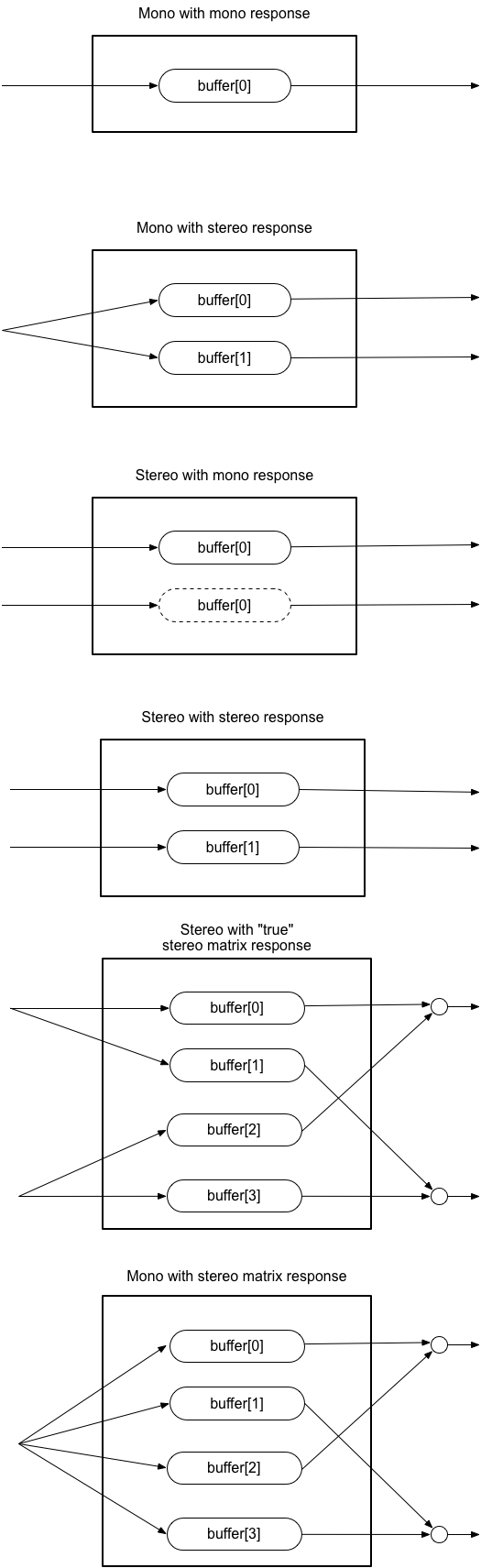
ConvolverNode
使用時の入力および出力チャンネル数の可能性を示す図 1.18. DelayNode
インターフェース
ディレイラインはオーディオアプリケーションの基本的な構成要素です。このインターフェースは入力と出力が1つずつのAudioNodeです。
| プロパティ | 値 | 備考 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 1 | |
channelCount
| 2 | |
channelCountMode
| "max"
| |
channelInterpretation
| "speakers"
| |
| tail-time | あり | maxDelayTimeまでゼロ入力でも非サイレント音声を出力
|
出力のチャンネル数は常に入力のチャンネル数と一致します。
入力オーディオ信号を一定時間遅延させます。具体的には、各時刻tで、入力信号input(t)、遅延時間delayTime(t)、出力信号output(t)に対して、output(t)
= input(t - delayTime(t))となります。デフォルトのdelayTimeは0秒(遅延なし)です。
DelayNodeの入力チャンネル数が変化した場合(出力チャンネル数も変化)、ノードの内部状態として未出力の遅延オーディオサンプルが残っていることがあります。このサンプルが以前と異なるチャンネル数で受信された場合は、内部の遅延ラインミックスが常に単一の現在のチャンネルレイアウトで行われるよう、アップミックスまたはダウンミックスを行って新しい入力と組み合わせなければなりません。
注意: 定義上、DelayNodeは遅延量と同等のオーディオ処理レイテンシを導入します。
[Exposed =Window ]interface DelayNode :AudioNode {constructor (BaseAudioContext ,context optional DelayOptions = {});options readonly attribute AudioParam delayTime ; };
1.18.1. コンストラクター
DelayNode(context, options)-
このコンストラクターが
BaseAudioContextc と オプションオブジェクト option で呼び出された場合、ユーザーエージェントは AudioNodeの初期化 を this に対して context および options を引数にして行わなければなりません。DelayNode.constructor() メソッドの引数。 パラメータ 型 Nullable Optional 説明 contextBaseAudioContext✘ ✘ この新しい DelayNodeが 関連付けられるBaseAudioContext。optionsDelayOptions✘ ✔ この DelayNodeの初期パラメータ値(省略可能)。
1.18.2. 属性
delayTime, 型 AudioParam(読み取り専用)-
適用する遅延量(秒)を表す
AudioParamオブジェクト。デフォルトvalueは0(遅延なし)。最小値は0、最大値はmaxDelayTime引数やDelayOptions辞書のmaxDelayTimeメンバーで決まります。DelayNodeがサイクルの一部なら、delayTime属性値はレンダー量子の最小値にクランプされます。パラメータ 値 備考 defaultValue0 minValue0 maxValuemaxDelayTimeautomationRate" a-rate"
1.18.3. DelayOptions
これは DelayNode
を構築する際に使用するオプションを指定します。すべてのメンバーは省略可能で、指定しない場合は通常のデフォルト値でノードが構築されます。
dictionary DelayOptions :AudioNodeOptions {double maxDelayTime = 1;double delayTime = 0; };
1.18.3.1. 辞書 DelayOptions
のメンバー
delayTime, 型 double(デフォルト値0)-
ノードの初期遅延時間。
maxDelayTime, 型 double(デフォルト値1)-
ノードの最大遅延時間。制約については
createDelay(maxDelayTime)参照。
1.18.4. 処理
DelayNode
は内部にdelayTime秒分のオーディオを保持するバッファを持っています。
DelayNodeの処理は、ディレイラインへの書き込みと読み取りの2つに分かれています。これは2つの内部AudioNode(著者には公開されず、ノード内部の動作説明のためだけに存在)によって行われます。どちらもDelayNodeから作成されます。
DelayNodeのDelayWriterを作成するとは、AudioNodeと同じインターフェースを持つオブジェクトを作成し、入力オーディオをDelayNodeの内部バッファに書き込むことを意味します。DelayNodeと同じ入力接続を持ちます。
DelayNodeのDelayReaderを作成するとは、AudioNodeと同じインターフェースを持つオブジェクトを作成し、DelayNodeの内部バッファからオーディオデータを読み取ることを意味します。DelayNodeと同じAudioNodeと接続されます。DelayReaderはソースノードです。
入力バッファを処理する際、DelayWriterはオーディオをDelayNodeの内部バッファに書き込まなければなりません。
出力バッファを生成する際、DelayReaderは対応するDelayWriterがdelayTime秒前に書き込んだオーディオと全く同じものを出力しなければなりません。
注意: これはチャンネル数の変更が遅延時間経過後に反映されることを意味します。
1.19. DynamicsCompressorNode
インターフェース
DynamicsCompressorNode
はダイナミクスコンプレッション効果を実装するAudioNodeプロセッサです。
ダイナミクスコンプレッションは音楽制作やゲームオーディオで非常に一般的に使われます。信号の最も大きい部分の音量を下げ、最も小さい部分の音量を上げます。全体的により大きく、豊かで迫力あるサウンドが実現できます。特に多数の個別サウンドを同時再生するゲームや音楽アプリで、全体の信号レベルを制御し、スピーカーへの音声出力でクリッピング(歪み)を防ぐために重要です。
| プロパティ | 値 | 備考 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 1 | |
channelCount
| 2 | channelCount 制約あり |
channelCountMode
| "clamped-max"
| channelCountMode 制約あり |
channelInterpretation
| "speakers"
| |
| tail-time | あり | このノードにはtail-timeがあり、ルックアヘッド遅延のためゼロ入力でも非サイレント音声を出力し続けます。 |
[Exposed =Window ]interface DynamicsCompressorNode :AudioNode {constructor (BaseAudioContext ,context optional DynamicsCompressorOptions = {});options readonly attribute AudioParam threshold ;readonly attribute AudioParam knee ;readonly attribute AudioParam ratio ;readonly attribute float reduction ;readonly attribute AudioParam attack ;readonly attribute AudioParam release ; };
1.19.1. コンストラクター
DynamicsCompressorNode(context, options)-
このコンストラクターが
BaseAudioContextc と オプションオブジェクト option で呼び出された場合、ユーザーエージェントは AudioNodeの初期化 を this に対して context および options を引数にして行わなければなりません。[[internal reduction]]はthisのプライベートスロットで、デシベル単位の浮動小数点数を保持します。[[internal reduction]]を0.0に設定します。DynamicsCompressorNode.constructor() メソッドの引数。 パラメータ 型 Nullable Optional 説明 contextBaseAudioContext✘ ✘ この新しい DynamicsCompressorNodeが 関連付けられるBaseAudioContext。optionsDynamicsCompressorOptions✘ ✔ この DynamicsCompressorNodeの初期パラメータ値(省略可能)。
1.19.2. 属性
attack, 型 AudioParam(読み取り専用)-
10dB分ゲインを下げるのにかかる時間(秒)。
パラメータ 値 備考 defaultValue.003 minValue0 maxValue1 automationRate" k-rate"automation rate 制約あり knee, 型 AudioParam(読み取り専用)-
しきい値を超えた範囲でカーブが「ratio」部分へスムーズに移行する区間を表すデシベル値。
パラメータ 値 備考 defaultValue30 minValue0 maxValue40 automationRate" k-rate"automation rate 制約あり ratio, 型 AudioParam(読み取り専用)-
出力が1dB変化する際、入力側のdB変化量。
パラメータ 値 備考 defaultValue12 minValue1 maxValue20 automationRate" k-rate"automation rate 制約あり reduction, 型 float(読み取り専用)-
メーター用の読み取り専用デシベル値で、コンプレッサーが信号に対して現在どれだけゲインリダクションを行っているかを表します。信号が供給されなければ値は0(ゲインリダクションなし)。この属性を読み取る際はプライベートスロット
[[internal reduction]]の値を返します。 release, 型 AudioParam(読み取り専用)-
10dB分ゲインを上げるのにかかる時間(秒)。
パラメータ 値 備考 defaultValue.25 minValue0 maxValue1 automationRate" k-rate"automation rate 制約あり threshold, 型 AudioParam(読み取り専用)-
コンプレッションが効果を発揮し始めるデシベル値。
パラメータ 値 備考 defaultValue-24 minValue-100 maxValue0 automationRate" k-rate"automation rate 制約あり
1.19.3. DynamicsCompressorOptions
これはDynamicsCompressorNodeを構築する際に使用するオプションを指定します。
すべてのメンバーは省略可能で、指定されなければ通常のデフォルト値でノードが構築されます。
dictionary DynamicsCompressorOptions :AudioNodeOptions {float attack = 0.003;float knee = 30;float ratio = 12;float release = 0.25;float threshold = -24; };
1.19.3.1. 辞書 DynamicsCompressorOptions
のメンバー
attack, 型 float(デフォルト値0.003)-
attackAudioParamの初期値。 knee, 型 float(デフォルト値30)-
kneeAudioParamの初期値。 ratio, 型 float(デフォルト値12)-
ratioAudioParamの初期値。 release, 型 float(デフォルト値0.25)-
releaseAudioParamの初期値。 threshold, 型 float(デフォルト値-24)-
thresholdAudioParamの初期値。
1.19.4. 処理
ダイナミクスコンプレッションには様々な実装方法があります。DynamicsCompressorNode
は以下の特徴を持つダイナミクスプロセッサを実装しています:
-
固定ルックアヘッド(つまり
DynamicsCompressorNodeは信号チェーンに固定レイテンシを追加する)。 -
アタック速度、リリース速度、しきい値、キーハードネス、レシオが設定可能。
-
サイドチェーンはサポートされません。
-
ゲインリダクションは
reductionプロパティ経由でDynamicsCompressorNodeから参照できます。 -
コンプレッションカーブは3つの部分から成ります:
-
第1部分は恒等関数:\(f(x) = x\)。
-
第2部分はソフトニー部で、単調増加関数でなければなりません。
-
第3部分は線形関数:\(f(x) = \frac{1}{ratio} \cdot x \)。
このカーブは連続かつ区分的微分可能で、入力レベルに基づく目標出力レベルを表します。
-
グラフ化するとこのようなカーブになります:

内部的には、DynamicsCompressorNode
は他のAudioNodeと特殊アルゴリズムの組み合わせでゲインリダクション値を計算します。
以下のAudioNodeグラフが内部で使われます。inputとoutputはそれぞれ入力・出力AudioNode、contextはこのDynamicsCompressorNode用のBaseAudioContext、そして特殊な
EnvelopeFollowerクラスがあり、AudioNodeのように振る舞います。説明は下記:
const delay = new DelayNode(context, {delayTime: 0.006});
const gain = new GainNode(context);
const compression = new EnvelopeFollower();
input.connect(delay).connect(gain).connect(output);
input.connect(compression).connect(gain.gain);

DynamicsCompressorNode処理アルゴリズムの一部として使われる内部AudioNodeグラフ
注意: これはプレディレイとリダクションゲインの適用を実装します。
以下のアルゴリズムは、入力信号に対してゲインリダクション値を生成するためのEnvelopeFollowerオブジェクトの処理内容です。EnvelopeFollowerは2つのスロットに浮動小数点値を保持し、呼び出し間で値が保存されます。
-
[[detector average]]は浮動小数点数で、初期値は0.0。 -
[[compressor gain]]は浮動小数点数で、初期値は1.0。
-
attackとreleaseは、それぞれ
attackとreleaseの値(k-rateパラメータ)を処理時点でサンプリングし、BaseAudioContextのサンプルレートを掛ける。 -
detector averageはスロット
[[detector average]]の値。 -
compressor gainはスロット
[[compressor gain]]の値。 -
レンダー量子内の各inputサンプルについて以下を実行:
-
inputの絶対値が0.0001未満ならattenuationは1.0。それ以外なら、絶対値をcompression curveに通した値をshaped inputとし、attenuationはshaped input÷絶対値。
-
attenuationがcompressor gainより大きければreleasingは
true、そうでなければfalse。 -
detector curveをattenuationに適用し、detector rateとする。
-
detector averageをattenuationから引き、その差にdetector rateを掛けて加算。
-
detector averageを最大1.0にクランプ。
-
envelope rateをattackとreleaseから計算。
-
releasingが
trueなら、compressor gainはcompressor gain×envelope rate(最大1.0にクランプ)。 -
releasingが
falseなら、gain increment=detector average−compressor gain。gain increment×envelope rateを加算。 -
reduction gain=compressor gain×makeup gain。
-
metering gain=reduction gainをデシベルに変換。
-
-
[[compressor gain]]にcompressor gainをセット。 -
[[detector average]]にdetector averageをセット。 -
アトミックに内部スロット
[[internal reduction]]にmetering gain値をセット。注意: このステップでメーター値はブロック処理終了時に1回更新されます。
メイクアップゲインは固定ゲインステージで、コンプレッサーのratio・knee・thresholdパラメータのみに依存し、入力信号には依存しません。目的は出力レベルを入力レベルと同等にすることです。
-
compression curveを1.0に適用し、full range gain。
-
full range makeup gain=full range gainの逆数。
-
full range makeup gainの0.6乗を返す。
-
エンベロープレートはcompressor gainとdetector averageの比から計算。
注意: アタック時はこの値は1以下、リリース時は必ず1より大きい。
-
アタックカーブは範囲\([0, 1]\)で連続かつ単調増加。カーブ形状は
attackで制御可。 -
リリースカーブは常に1より大きく、連続かつ単調減少。形状は
releaseで制御可。
この操作はcompressor gainとdetector averageの比に関数を適用した値を返します。
detector curveをアタック・リリース時の変化率に適用するとアダプティブリリースを実現できます。次の制約を満たす必要があります:
-
出力は\([0,1]\)の範囲。
-
関数は連続かつ単調増加。
注意: 例えば圧縮が強いほどリリースが速いアダプティブリリースや、アタックとリリースのカーブ形状が異なるコンプレッサーも許可されます。
-
threshold および knee に、
thresholdとkneeの値をそれぞれ割り当て、線形単位へ変換し、このブロックの処理時点でサンプリングする(k-rateパラメータとして)。 -
thresholdとkneeを、このブロックの処理時点(k-rateパラメータとして)でサンプリングし、その合計を計算する。 -
この合計値を knee end threshold とし、線形単位へ変換する。
-
この関数は、線形 threshold の値までは恒等写像となる(すなわち \(f(x) = x\))。
-
threshold から knee end threshold までの区間では、ユーザーエージェントはカーブ形状を選択できる。関数全体は単調増加かつ連続でなければならない。
注: knee が 0 の場合、
DynamicsCompressorNodeはハードニーコンプレッサーと呼ばれる。 -
この関数は threshold およびソフトニーより後は、ratio に基づき線形となる(すなわち \(f(x) = \frac{1}{ratio} \cdot x\))。
-
\(v = 0\)なら-1000を返す。
-
それ以外なら\( 20 \, \log_{10}{v} \)を返す。
1.20. GainNode
インターフェース
オーディオ信号のゲイン(増幅)を変更することは、オーディオアプリケーションにおいて基本的な操作です。
このインターフェースは入力・出力が1つずつのAudioNodeです:
| プロパティ | 値 | 備考 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 1 | |
channelCount
| 2 | |
channelCountMode
| "max"
| |
channelInterpretation
| "speakers"
| |
| tail-time | なし |
GainNodeの入力データ各チャンネル・各サンプルは、gain
AudioParamのcomputedValueで乗算されなければなりません。
[Exposed =Window ]interface GainNode :AudioNode {constructor (BaseAudioContext ,context optional GainOptions = {});options readonly attribute AudioParam gain ; };
1.20.1. コンストラクター
GainNode(context, options)-
このコンストラクターが
BaseAudioContextc と オプションオブジェクト option で呼び出された場合、ユーザーエージェントは AudioNodeの初期化 を this に対して context および options を引数にして行わなければなりません。GainNode.constructor() メソッドの引数。 パラメータ 型 Nullable Optional 説明 contextBaseAudioContext✘ ✘ この新しい GainNodeが 関連付けられるBaseAudioContext。optionsGainOptions✘ ✔ この GainNodeの初期パラメータ値(省略可能)。
1.20.2. 属性
gain, 型 AudioParam(読み取り専用)-
適用されるゲイン量を表します。
パラメータ 値 備考 defaultValue1 minValue最小単精度float値 約 -3.4028235e38 maxValue最大単精度float値 約 3.4028235e38 automationRate" a-rate"
1.20.3. GainOptions
これはGainNodeを構築する際に使用するオプションを指定します。すべてのメンバーは省略可能で、指定されなければ通常のデフォルト値でノードが構築されます。
dictionary GainOptions :AudioNodeOptions {float gain = 1.0; };
1.20.3.1. 辞書 GainOptions
のメンバー
gain, 型 float(デフォルト値1.0)-
このノードの
gainAudioParamの初期値。
1.21. IIRFilterNode
インターフェース
IIRFilterNode
は一般的なIIRフィルタを実装するAudioNodeプロセッサです。一般的には、以下の理由から高次フィルタの実装にはBiquadFilterNodeを使うのが良いです:
-
一般的に数値的な問題に対して安定しやすい
-
フィルタパラメータの自動化が可能
-
すべての偶数次IIRフィルタの生成に利用できる
ただし、奇数次フィルタは生成できないため、それらが必要な場合や自動化が不要な場合はIIRフィルタが適しています。
一度生成したフィルタ係数は変更できません。
| プロパティ | 値 | 備考 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 1 | |
channelCount
| 2 | |
channelCountMode
| "max"
| |
channelInterpretation
| "speakers"
| |
| tail-time | あり | ゼロ入力でも非サイレント音声を出力し続けます。IIRフィルタの性質上、理論的には無限に非ゼロ出力が続きますが、実際には十分ゼロに近づいた時点で終了できます。実際の長さは係数によります。 |
出力のチャンネル数は常に入力のチャンネル数と一致します。
[Exposed =Window ]interface IIRFilterNode :AudioNode {constructor (BaseAudioContext ,context IIRFilterOptions );options undefined getFrequencyResponse (Float32Array ,frequencyHz Float32Array ,magResponse Float32Array ); };phaseResponse
1.21.1. コンストラクター
IIRFilterNode(context, options)-
このコンストラクターが
BaseAudioContextc と オプションオブジェクト option で呼び出された場合、ユーザーエージェントは AudioNodeの初期化 を this に対して context および options を引数にして行わなければなりません。IIRFilterNode.constructor() メソッドの引数。 パラメータ 型 Nullable Optional 説明 contextBaseAudioContext✘ ✘ この新しい IIRFilterNodeが 関連付けられるBaseAudioContext。optionsIIRFilterOptions✘ ✘ この IIRFilterNodeの初期パラメータ値。
1.21.2. メソッド
getFrequencyResponse(frequencyHz, magResponse, phaseResponse)-
現在のフィルタパラメータ設定に基づき、指定した周波数の周波数応答を同期的に計算します。3つのパラメータはすべて同じ長さの
Float32Arrayでなければならず、そうでない場合はInvalidAccessErrorを投げなければなりません。IIRFilterNode.getFrequencyResponse() メソッドの引数。 パラメータ 型 Nullable Optional 説明 frequencyHzFloat32Array✘ ✘ 応答値を計算する周波数(Hz)の配列。 magResponseFloat32Array✘ ✘ 線形の振幅応答値を受け取る出力配列。 frequencyHzの値が[0, sampleRate/2]の範囲外の場合、対応するmagResponseの値はNaNとなります。ここでsampleRateはsampleRateプロパティ値です。phaseResponseFloat32Array✘ ✘ ラジアン単位の位相応答値を受け取る出力配列。 frequencyHzの値が[0; sampleRate/2]範囲外の場合、対応するphaseResponseの値はNaNとなります。ここでsampleRateはsampleRateプロパティ値です。戻り値の型:undefined
1.21.3.
IIRFilterOptions
IIRFilterOptions辞書はIIRFilterNodeのフィルタ係数指定に使います。
dictionary IIRFilterOptions :AudioNodeOptions {required sequence <double >feedforward ;required sequence <double >feedback ; };
1.21.3.1. 辞書 IIRFilterOptions
のメンバー
feedforward, 型 sequence<double>-
IIRFilterNodeのフィードフォワード係数。必須。その他の制約はfeedforward引数やcreateIIRFilter()参照。 feedback, 型 sequence<double>-
IIRFilterNodeのフィードバック係数。必須。その他の制約はfeedback引数やcreateIIRFilter()参照。
1.21.4. フィルタ定義
\(b_m\)をfeedforward係数、\(a_n\)をfeedback係数とし、これらはcreateIIRFilter()
やIIRFilterOptions辞書(constructor)で指定します。
このとき一般的なIIRフィルタの伝達関数は、
$$
H(z) = \frac{\sum_{m=0}^{M} b_m z^{-m}}{\sum_{n=0}^{N} a_n z^{-n}}
$$
ここで、\(M + 1\)はb配列の長さ、\(N + 1\)はa配列の長さです。係数\(a_0\)は0であってはなりません(feedback parameter参照)。
\(b_m\)のうち少なくとも1つは0であってはなりません(feedforward parameter参照)。
同等の時系列式は次の通りです:
$$
\sum_{k=0}^{N} a_k y(n-k) = \sum_{k=0}^{M} b_k x(n-k)
$$
初期フィルタ状態は全ゼロ状態です。
注意: UAはフィルタ状態にNaN値が生じた場合警告を出すことがあります。これは通常、不安定なフィルタの兆候です。
1.22.
MediaElementAudioSourceNode
インターフェース
このインターフェースは
audio
または
video
要素からのオーディオソースを表します。
| プロパティ | 値 | 備考 |
|---|---|---|
numberOfInputs
| 0 | |
numberOfOutputs
| 1 | |
| tail-time 参照 | なし |
出力のチャンネル数は、HTMLMediaElementが参照するメディアのチャンネル数に対応します。
したがって、メディア要素のsrc属性を変更すると、このノードの出力チャンネル数も変化することがあります。
HTMLMediaElementのサンプルレートが、関連付けられたAudioContextのサンプルレートと異なる場合、
HTMLMediaElementからの出力はコンテキストのsample rateに合わせてリサンプリングされなければなりません。
MediaElementAudioSourceNode
は、HTMLMediaElementを使って、
AudioContext
のcreateMediaElementSource()メソッドや、
MediaElementAudioSourceOptions辞書のmediaElementメンバーを使って
constructor経由で生成されます。
単一出力のチャンネル数は、HTMLMediaElement
がcreateMediaElementSource()の引数に渡された場合のオーディオチャンネル数と一致し、オーディオがない場合は1チャンネルとなります。
HTMLMediaElementは、
MediaElementAudioSourceNode生成後も
基本的には同様に動作しますが、再生されるオーディオは直接聞こえるのではなく、
MediaElementAudioSourceNodeがルーティンググラフを通じて接続されることで聞こえるようになります。
したがって、再生・一時停止・シーク・音量・src属性の変更など、HTMLMediaElementの挙動は、
MediaElementAudioSourceNodeなしの場合と同様に動作しなければなりません。
const mediaElement= document. getElementById( 'mediaElementID' ); const sourceNode= context. createMediaElementSource( mediaElement); sourceNode. connect( filterNode);
[Exposed =Window ]interface MediaElementAudioSourceNode :AudioNode {constructor (AudioContext ,context MediaElementAudioSourceOptions ); [options SameObject ]readonly attribute HTMLMediaElement mediaElement ; };
1.22.1. コンストラクター
MediaElementAudioSourceNode(context, options)-
-
AudioNodeの初期化を this に対して context および options を引数にして行う。
MediaElementAudioSourceNode.constructor() メソッドの引数。 パラメータ 型 Nullable Optional 説明 contextAudioContext✘ ✘ この新しい MediaElementAudioSourceNodeが 関連付けられるAudioContext。optionsMediaElementAudioSourceOptions✘ ✘ この MediaElementAudioSourceNodeの初期パラメータ値。 -
1.22.2. 属性
mediaElement, 型 HTMLMediaElement(読み取り専用)-
この
HTMLMediaElementは、このMediaElementAudioSourceNodeの構築時に使われます。
1.22.3.
MediaElementAudioSourceOptions
これはMediaElementAudioSourceNodeを構築する際に使用するオプションを指定します。
dictionary MediaElementAudioSourceOptions {required HTMLMediaElement mediaElement ; };
1.22.3.1. 辞書 MediaElementAudioSourceOptions
のメンバー
mediaElement, 型 HTMLMediaElement-
リルートされるメディア要素。必須項目です。
1.22.4. MediaElementAudioSourceNodeとクロスオリジンリソースのセキュリティ
HTMLMediaElement
はクロスオリジンリソースの再生を許可します。Web Audioでは、MediaElementAudioSourceNodeや
AudioWorkletNode、
ScriptProcessorNodeでサンプルを読み取ることができるため、
他オリジンのスクリプトが別オリジンのリソース内容を調べると情報漏洩が生じることがあります。
これを防ぐため、MediaElementAudioSourceNode
は、HTMLMediaElement
で作成された場合、該当リソースがfetch
algorithm [FETCH]によってCORS-cross-originとラベル付けされた場合、通常の出力の代わりに無音を出力しなければなりません。
1.23.
MediaStreamAudioDestinationNode
インターフェース
このインターフェースは MediaStream
を表すオーディオ出力先であり、MediaStreamTrack
の kind が "audio" となる1本のみを持ちます。この MediaStream
はノード生成時に作成され、stream
属性経由でアクセスできます。この stream は MediaStream
を getUserMedia()
で取得した場合と同様に利用でき、例えば RTCPeerConnection ([webrtc] 参照)
の addStream() メソッドでリモートピアに送信できます。
| プロパティ | 値 | 備考 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 0 | |
channelCount
| 2 | |
channelCountMode
| "explicit"
| |
channelInterpretation
| "speakers"
| |
| tail-time | なし |
入力のチャンネル数はデフォルトで2(ステレオ)です。
[Exposed =Window ]interface MediaStreamAudioDestinationNode :AudioNode {constructor (AudioContext ,context optional AudioNodeOptions = {});options readonly attribute MediaStream stream ; };
1.23.1. コンストラクター
MediaStreamAudioDestinationNode(context, options)-
-
AudioNodeの初期化を this に対して context および options を引数にして行う。
MediaStreamAudioDestinationNode.constructor() メソッドの引数。 パラメータ 型 Nullable Optional 説明 contextAudioContext✘ ✘ この新しい BaseAudioContextが 関連付けられるMediaStreamAudioDestinationNode。optionsAudioNodeOptions✘ ✔ この MediaStreamAudioDestinationNodeの初期パラメータ値(省略可能)。 -
1.23.2. 属性
stream, 型 MediaStream(読み取り専用)-
この
MediaStreamは、ノード自身と同じチャンネル数のMediaStreamTrackを1本だけ含み、そのkind属性は"audio"となります。
1.24. MediaStreamAudioSourceNode
インターフェース
このインターフェースは MediaStream
からのオーディオソースを表します。
| プロパティ | 値 | 備考 |
|---|---|---|
numberOfInputs
| 0 | |
numberOfOutputs
| 1 | |
| tail-time 参照 | なし |
出力チャンネル数は MediaStreamTrack
のチャンネル数に一致します。
MediaStreamTrack
が終了した場合、この AudioNode
は1チャンネルの無音を出力します。
MediaStreamTrack
のサンプルレートが
関連付けられた AudioContext
のサンプルレートと異なる場合は、
MediaStreamTrack
の出力はコンテキストの sample rate
に合わせてリサンプリングされます。
[Exposed =Window ]interface MediaStreamAudioSourceNode :AudioNode {constructor (AudioContext ,context MediaStreamAudioSourceOptions ); [options SameObject ]readonly attribute MediaStream mediaStream ; };
1.24.1. コンストラクター
MediaStreamAudioSourceNode(context, options)-
-
mediaStreamメンバーがoptionsにあり、MediaStreamにMediaStreamTrackが1本以上あり、 そのkind属性値が"audio"でなければInvalidStateErrorを投げて中断。 そうでなければ、この stream を inputStream とする。 -
tracks を inputStream の
MediaStreamTrackのうちkindが"audio"のもの全てのリストとする。 -
tracks の要素を
id属性で コードユニット値の並び順でソート。 -
AudioNodeの初期化を this に対して context および options を引数にして行う。
-
この
MediaStreamAudioSourceNodeの内部スロット[[input track]]に tracks の最初の要素をセットする。 これがこのノードの入力オーディオとなる。
構築後、コンストラクターに渡した
MediaStreamに変更があっても、このAudioNodeの出力には影響しません。スロット
[[input track]]はMediaStreamTrackへの参照保持用です。注意: コンストラクターで選ばれたトラックを
MediaStreamAudioSourceNodeからMediaStreamから削除しても、 入力は同じトラックから取得し続けます。注意: 出力トラックの選択仕様はレガシー理由で任意です。入力トラックを明示的に選びたい場合は
MediaStreamTrackAudioSourceNodeを利用してください。MediaStreamAudioSourceNode.constructor() メソッドの引数。 パラメータ 型 Nullable Optional 説明 contextAudioContext✘ ✘ この新しい AudioContextが 関連付けられる。optionsMediaStreamAudioSourceOptions✘ ✘ この MediaStreamAudioSourceNodeの初期パラメータ値。 -
1.24.2. 属性
mediaStream, 型 MediaStream(読み取り専用)-
この
MediaStreamは、このMediaStreamAudioSourceNodeの構築時に使われます。
1.24.3.
MediaStreamAudioSourceOptions
これは MediaStreamAudioSourceNode
を構築する際に使用するオプションを指定します。
dictionary MediaStreamAudioSourceOptions {required MediaStream mediaStream ; };
1.24.3.1. 辞書 MediaStreamAudioSourceOptions
のメンバー
mediaStream, 型 MediaStream-
ソースとなるメディアストリーム。必須項目です。
1.25.
MediaStreamTrackAudioSourceNode
インターフェース
このインターフェースは MediaStreamTrack
からのオーディオソースを表します。
| プロパティ | 値 | 備考 |
|---|---|---|
numberOfInputs
| 0 | |
numberOfOutputs
| 1 | |
| tail-time 参照 | なし |
出力チャンネル数は mediaStreamTrack
のチャンネル数に一致します。
MediaStreamTrack
のサンプルレートが
関連付けられた AudioContext
のサンプルレートと異なる場合、
mediaStreamTrack
の出力は
コンテキストの sample rate
に合わせてリサンプリングされます。
[Exposed =Window ]interface MediaStreamTrackAudioSourceNode :AudioNode {constructor (AudioContext ,context MediaStreamTrackAudioSourceOptions ); };options
1.25.1. コンストラクター
MediaStreamTrackAudioSourceNode(context, options)-
-
mediaStreamTrackのkind属性値が"audio"でなければInvalidStateErrorを投げて中断します。 -
AudioNodeの初期化を this に対して context および options を引数にして行う。
MediaStreamTrackAudioSourceNode.constructor() メソッドの引数。 パラメータ 型 Nullable Optional 説明 contextAudioContext✘ ✘ この新しい AudioContextが 関連付けられる。optionsMediaStreamTrackAudioSourceOptions✘ ✘ この MediaStreamTrackAudioSourceNodeの初期パラメータ値。 -
1.25.2. MediaStreamTrackAudioSourceOptions
これは MediaStreamTrackAudioSourceNode
を構築する際に使用するオプションを指定します。
必須です。
dictionary MediaStreamTrackAudioSourceOptions {required MediaStreamTrack mediaStreamTrack ; };
1.25.2.1. 辞書 MediaStreamTrackAudioSourceOptions
のメンバー
mediaStreamTrack, 型 MediaStreamTrack-
ソースとなるメディアストリームトラック。 この
MediaStreamTrackのkind属性値が"audio"でなければInvalidStateErrorを投げなければなりません。
1.26. OscillatorNode
インターフェース
OscillatorNode
は周期波形を生成するオーディオソースを表します。よく使われる波形をいくつか設定できるほか、PeriodicWave
オブジェクトを利用して任意の周期波形も設定可能です。
オシレーターは音響合成の基礎的な構成要素です。OscillatorNodeは start()
メソッドで指定した時刻から音を出し始めます。
数学的には、連続時間の周期波形は周波数領域で非常に高い(または無限に高い)周波数成分を持ち得ます。この波形を特定のサンプルレートで離散時間のデジタルオーディオ信号としてサンプリングする場合、高周波成分(ナイキスト周波数超)の情報をデジタル化前に捨てる(除去する)必要があります。これを行わない場合、エイリアシングが発生し、高周波成分(ナイキスト周波数超)が 低い周波数領域に折り返して鏡像として現れます。多くの場合、これは聴覚的に不快なアーティファクトを生じます。これはオーディオDSPの基本原理です。
このエイリアシングを回避するため、実装にはいくつか実用的な手法があります。どの手法でも、理想的な離散時間デジタルオーディオ信号は数学的に明確に定義されています。実装のトレードオフはCPU使用量と理想実現度(忠実度)のバランスです。
理想実現に配慮した実装が期待されますが、低価格なハードウェアでは低品質・低負荷な方式も許容されます。
frequency
と detune
は a-rate パラメータで、複合パラメータです。これらで computedOscFrequency値が決まります:
computedOscFrequency(t) = frequency(t) * pow(2, detune(t) / 1200)
OscillatorNodeの瞬時位相は、開始時刻を位相0とした computedOscFrequency の定積分です。公称範囲は [-ナイキスト周波数, ナイキスト周波数]です。
このノードの単一出力は1チャンネル(モノラル)となります。
| プロパティ | 値 | 備考 |
|---|---|---|
numberOfInputs
| 0 | |
numberOfOutputs
| 1 | |
channelCount
| 2 | |
channelCountMode
| "max"
| |
channelInterpretation
| "speakers"
| |
| tail-time | なし |
enum {OscillatorType "sine" ,"square" ,"sawtooth" ,"triangle" ,"custom" };
| 列挙値 | 説明 |
|---|---|
"sine"
| サイン波 |
"square"
| デューティ比0.5の矩形波 |
"sawtooth"
| ノコギリ波 |
"triangle"
| 三角波 |
"custom"
| カスタム周期波 |
[Exposed =Window ]interface OscillatorNode :AudioScheduledSourceNode {constructor (BaseAudioContext ,context optional OscillatorOptions = {});options attribute OscillatorType type ;readonly attribute AudioParam frequency ;readonly attribute AudioParam detune ;undefined setPeriodicWave (PeriodicWave ); };periodicWave
1.26.1. コンストラクター
OscillatorNode(context, options)-
このコンストラクターが
BaseAudioContextc と オプションオブジェクト option で呼び出された場合、ユーザーエージェントは AudioNodeの初期化 を this に対して context および options を引数にして行わなければなりません。OscillatorNode.constructor() メソッドの引数。 パラメータ 型 Nullable Optional 説明 contextBaseAudioContext✘ ✘ この新しい OscillatorNodeが 関連付けられるBaseAudioContext。optionsOscillatorOptions✘ ✔ この OscillatorNodeの初期パラメータ値(省略可能)。
1.26.2. 属性
detune, 型 AudioParam(読み取り専用)-
与えられた値(セント単位)分だけ
frequencyをオフセットします。デフォルト値は0。a-rateパラメータ。frequencyと共に 複合パラメータを形成し、computedOscFrequencyが得られます。下記の公称範囲により、このパラメータでfrequencyの全範囲をデチューンできます。パラメータ 値 備考 defaultValue0 minValue\(\approx -153600\) maxValue\(\approx 153600\) この値は \(1200\ \log_2 \mathrm{FLT\_MAX}\)(FLT_MAXは最大 float値)に相当automationRate" a-rate" frequency, 型 AudioParam(読み取り専用)-
周期波形の周波数(Hz)。デフォルト値は440。a-rateパラメータ。
detuneとともに 複合パラメータを形成し、computedOscFrequencyとなる。公称範囲は[-ナイキスト周波数, ナイキスト周波数]。パラメータ 値 備考 defaultValue440 minValue-ナイキスト周波数 maxValueナイキスト周波数 automationRate" a-rate" type, 型 OscillatorType-
周期波形の形状。直接設定できるのは"
custom"以外の定数値のみです。 これを行うとInvalidStateError例外を投げなければなりません。setPeriodicWave()メソッドでカスタム波形を設定可能で、その場合この属性は"custom"になります。 デフォルト値は"sine"です。 この属性を設定した際、オシレーターの位相は保存されなければなりません。
1.26.3. メソッド
setPeriodicWave(periodicWave)-
PeriodicWaveを指定して任意のカスタム周期波形を設定します。OscillatorNode.setPeriodicWave() メソッドの引数。 パラメータ 型 Nullable Optional 説明 periodicWavePeriodicWave✘ ✘ オシレーターで使用するカスタム波形 戻り値の型:undefined
1.26.4.
OscillatorOptions
これはOscillatorNodeを構築する際に使用するオプションを指定します。
すべてのメンバーは省略可能で、未指定の場合は通常のデフォルト値でオシレーターが構築されます。
dictionary OscillatorOptions :AudioNodeOptions {OscillatorType type = "sine";float frequency = 440;float detune = 0;PeriodicWave periodicWave ; };
1.26.4.1. 辞書 OscillatorOptions
のメンバー
detune, 型 float(デフォルト値0)-
OscillatorNodeの初期デチューン値。 frequency, 型 float(デフォルト値440)-
OscillatorNodeの初期周波数。 periodicWave, 型 PeriodicWave-
OscillatorNode用のPeriodicWave。 これを指定した場合、typeの値は無視され、 "custom"が指定されているものとして扱われます。 type, 型 OscillatorType(デフォルト値"sine")-
構築されるオシレーター種別。これを"custom"にして
periodicWaveを指定しない場合はInvalidStateError例外を投げなければなりません。periodicWaveを指定した場合、typeの値は無視され、 "custom"が設定されたものとして扱われます。
1.26.5. 基本波形の位相
各オシレーター種別の理想的な数学的波形を以下に定義します。要約すると、すべての波形は時刻0で正の傾きを持つ奇関数として数学的に定義されます。実際の波形はエイリアシング防止のため異なる場合があります。
オシレーターは、該当するフーリエ級数とdisableNormalization
をfalseにして生成したPeriodicWaveと同じ結果を出力しなければなりません。
- "
sine" -
サインオシレーターの波形:
$$ x(t) = \sin t $$ - "
square" -
矩形波オシレーターの波形:
$$ x(t) = \begin{cases} 1 & \mbox{for } 0≤ t < \pi \\ -1 & \mbox{for } -\pi < t < 0. \end{cases} $$この関数は奇関数で周期\(2\pi\)で全ての\(t\)に拡張されます。
- "
sawtooth" -
ノコギリ波オシレーターの波形(ランプ):
$$ x(t) = \frac{t}{\pi} \mbox{ for } -\pi < t ≤ \pi; $$この関数は奇関数で周期\(2\pi\)で全ての\(t\)に拡張されます。
- "
triangle" -
三角波オシレーターの波形:
$$ x(t) = \begin{cases} \frac{2}{\pi} t & \mbox{for } 0 ≤ t ≤ \frac{\pi}{2} \\ 1-\frac{2}{\pi} \left(t-\frac{\pi}{2}\right) & \mbox{for } \frac{\pi}{2} < t ≤ \pi. \end{cases} $$この関数は奇関数で周期\(2\pi\)で全ての\(t\)に拡張されます。
1.27. PannerNode
インターフェース
このインターフェースは、入力されたオーディオストリームを三次元空間内で位置/空間化する処理ノードを表します。空間化はBaseAudioContextのAudioListener
(listener属性)との関係で行われます。
| プロパティ | 値 | 備考 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 1 | |
channelCount
| 2 | channelCount制約あり |
channelCountMode
| "clamped-max"
| channelCountMode制約あり |
channelInterpretation
| "speakers"
| |
| tail-time | 場合による | panningModel
が"HRTF"の場合、頭部応答処理により無音入力でも非サイレント出力を生成します。それ以外はtail-timeはゼロです。
|
このノードの入力はモノラル(1ch)またはステレオ(2ch)で、増やすことはできません。チャンネル数が異なるノードからの接続は適切にアップ/ダウンミックスされます。
ノードが積極的に処理中の場合、出力はステレオ(2ch)に固定され、設定変更できません。非処理中は1chの無音となります。
PanningModelType
列挙型は空間化アルゴリズムの種類を決定します。デフォルトは"equalpower"です。
enum {PanningModelType "equalpower" ,"HRTF" };
| 列挙値 | 説明 |
|---|---|
"equalpower"
|
イコールパワー・パンニングを使ったシンプルかつ効率的な空間化アルゴリズム。
注意: このパンニングモデルでは、出力計算に使われる |
"HRTF"
|
人体計測インパルス応答の畳み込みを使った高品質空間化アルゴリズム。ステレオ出力を生成します。
注意: このパンニングモデルでは、出力計算に使われる |
有効オートメーションレートは、AudioParamがPannerNodeに属する場合、panningModelおよびautomationRateによって決定されます。panningModelが「HRTF」の場合、有効オートメーションレートは「k-rate」となり、automationRateの設定に依存しません。それ以外の場合、有効オートメーションレートはautomationRateの値となります。
DistanceModelType
列挙型は、リスナーから音源が離れるほど音量を減衰させる計算アルゴリズムの種類を決定します。デフォルトは"inverse"です。
以下の距離モデルの説明では、\(d\)はリスナーとパンナー間の距離、\(d_{ref}\)はrefDistance属性値、\(d_{max}\)はmaxDistance属性値、\(f\)はrolloffFactor属性値です。
enum {DistanceModelType "linear" ,"inverse" ,"exponential" };
| 列挙値 | 説明 |
|---|---|
"linear"
|
線形距離モデル。distanceGainは以下で計算:
$$
1 - f\ \frac{\max\left[\min\left(d, d’_{max}\right), d’_{ref}\right] - d’_{ref}}{d’_{max} - d’_{ref}}
$$
ここで\(d’_{ref} = \min\left(d_{ref}, d_{max}\right)\)、\(d’_{max} = \max\left(d_{ref}, d_{max}\right)\)。\(d’_{ref} = d’_{max}\)の場合、線形モデル値は\(1-f\)となる。 \(d\)は区間\(\left[d’_{ref},\, d’_{max}\right]\)にクランプ。 |
"inverse"
|
逆数距離モデル。distanceGainは以下で計算:
$$
\frac{d_{ref}}{d_{ref} + f\ \left[\max\left(d, d_{ref}\right) - d_{ref}\right]}
$$
\(d\)は区間\(\left[d_{ref},\, \infty\right)\)にクランプ。\n\(d_{ref} = 0\)の場合、モデル値は\(d\)や\(f\)の値に関わらず0になります。 |
"exponential"
|
指数距離モデル。distanceGainは以下で計算:
$$
\left[\frac{\max\left(d, d_{ref}\right)}{d_{ref}}\right]^{-f}
$$
\(d\)は区間\(\left[d_{ref},\, \infty\right)\)にクランプ。\n\(d_{ref} = 0\)の場合、値は\(d\)や\(f\)に関わらず0になります。 |
[Exposed =Window ]interface PannerNode :AudioNode {constructor (BaseAudioContext ,context optional PannerOptions = {});options attribute PanningModelType panningModel ;readonly attribute AudioParam positionX ;readonly attribute AudioParam positionY ;readonly attribute AudioParam positionZ ;readonly attribute AudioParam orientationX ;readonly attribute AudioParam orientationY ;readonly attribute AudioParam orientationZ ;attribute DistanceModelType distanceModel ;attribute double refDistance ;attribute double maxDistance ;attribute double rolloffFactor ;attribute double coneInnerAngle ;attribute double coneOuterAngle ;attribute double coneOuterGain ;undefined setPosition (float ,x float ,y float );z undefined setOrientation (float ,x float ,y float ); };z
1.27.1. コンストラクター
PannerNode(context, options)-
このコンストラクターが
BaseAudioContextc と オプションオブジェクト option で呼び出された場合、ユーザーエージェントは AudioNodeの初期化 を this に対して context および options を引数にして行わなければなりません。PannerNode.constructor() メソッドの引数。 パラメータ 型 Nullable Optional 説明 contextBaseAudioContext✘ ✘ この新しい PannerNodeが 関連付けられるBaseAudioContext。optionsPannerOptions✘ ✔ この PannerNodeの初期パラメータ値(省略可能)。
1.27.2. 属性
coneInnerAngle, 型 double-
指向性オーディオソース用で、音量減衰が起きない角度(度単位)。デフォルト値は360。角度が[0, 360]区間外の場合の動作は未定義。
coneOuterAngle, 型 double-
指向性オーディオソース用で、この角度(度単位)外では音量が
coneOuterGainで一定に減衰。デフォルト値は360。[0, 360]区間外の場合の動作は未定義。 coneOuterGain, 型 double-
指向性オーディオソース用で、
coneOuterAngle外でのゲイン値。デフォルト値は0。範囲[0, 1]の線形値。この範囲外ならInvalidStateErrorを投げなければならない。 distanceModel, 型 DistanceModelType-
この
PannerNodeで使用される距離モデル。デフォルトは"inverse"。 maxDistance, 型 double-
音源とリスナーの最大距離。この距離以降は音量減衰しない。デフォルト値は10000。0以下なら
RangeError例外を投げなければならない。 orientationX, 型 AudioParam(読み取り専用)-
音源が向いている方向ベクトルのx成分(3Dデカルト座標)
パラメータ 値 備考 defaultValue1 minValue最小単精度float値 約 -3.4028235e38 maxValue最大単精度float値 約 3.4028235e38 automationRate" a-rate"automation rate制約あり orientationY, 型 AudioParam(読み取り専用)-
音源が向いている方向ベクトルのy成分(3Dデカルト座標)
パラメータ 値 備考 defaultValue0 minValue最小単精度float値 約 -3.4028235e38 maxValue最大単精度float値 約 3.4028235e38 automationRate" a-rate"automation rate制約あり orientationZ, 型 AudioParam(読み取り専用)-
音源が向いている方向ベクトルのz成分(3Dデカルト座標)
パラメータ 値 備考 defaultValue0 minValue最小単精度float値 約 -3.4028235e38 maxValue最大単精度float値 約 3.4028235e38 automationRate" a-rate"automation rate制約あり panningModel, 型 PanningModelType-
この
PannerNodeで使用されるパンニングモデル。デフォルトは"equalpower"。 positionX, 型 AudioParam(読み取り専用)-
音源のx座標(3Dデカルト系)
パラメータ 値 備考 defaultValue0 minValue最小単精度float値 約 -3.4028235e38 maxValue最大単精度float値 約 3.4028235e38 automationRate" a-rate"automation rate制約あり positionY, 型 AudioParam(読み取り専用)-
音源のy座標(3Dデカルト系)
パラメータ 値 備考 defaultValue0 minValue最小単精度float値 約 -3.4028235e38 maxValue最大単精度float値 約 3.4028235e38 automationRate" a-rate"automation rate制約あり positionZ, 型 AudioParam(読み取り専用)-
音源のz座標(3Dデカルト系)
パラメータ 値 備考 defaultValue0 minValue最小単精度float値 約 -3.4028235e38 maxValue最大単精度float値 約 3.4028235e38 automationRate" a-rate"automation rate制約あり refDistance, 型 double-
音量減衰の基準距離。この距離未満では音量減衰しない。デフォルト値は1。負値なら
RangeError例外を投げなければならない。 rolloffFactor, 型 double-
音源がリスナーから離れるほど音量が減衰する速度。デフォルト値は1。負値なら
RangeError例外を投げなければならない。rolloffFactorの公称範囲はrolloffFactorが取りうる最小値と最大値を指定します。範囲外の値は、この範囲にクランプされます。公称範囲はdistanceModelに依存し、次の通りです:- "
linear" -
公称範囲は \([0, 1]\)。
- "
inverse" -
公称範囲は \([0, \infty)\)。
- "
exponential" -
公称範囲は \([0, \infty)\)。
クランプは距離計算処理時に行われます。属性値は設定された値をそのまま反映し、変更されません。
- "
1.27.3. メソッド
setOrientation(x, y, z)-
このメソッドは非推奨です。
orientationX.value、orientationY.value、orientationZ.value属性に、それぞれx、y、zパラメータを直接設定するのと同じです。従って、
orientationX、orientationY、orientationZのいずれかのAudioParamにsetValueCurveAtTime()で自動化カーブが設定されている場合、このメソッドを呼び出すとNotSupportedErrorを投げなければなりません。3次元デカルト座標系で音源が向いている方向を指定します。音の指向性(cone属性で制御)によっては、リスナーと反対方向を向いていると非常に小さくなるか完全に無音になります。
x, y, zパラメータは3D空間の方向ベクトルです。デフォルト値は(1,0,0)です。
PannerNode.setOrientation() メソッドの引数。 パラメータ 型 Nullable Optional 説明 xfloat✘ ✘ yfloat✘ ✘ zfloat✘ ✘ 戻り値の型:undefined setPosition(x, y, z)-
このメソッドは非推奨です。
positionX.value、positionY.value、positionZ.value属性に、それぞれx、y、zパラメータを直接設定するのと同じです。従って、
positionX、positionY、positionZのいずれかのAudioParamにsetValueCurveAtTime()で自動化カーブが設定されている場合、このメソッドを呼び出すとNotSupportedErrorを投げなければなりません。音源の位置を
listener属性に対して設定します。3次元デカルト座標系を使用します。x, y, zパラメータは3D空間の座標です。デフォルト値は(0,0,0)です。
PannerNode.setPosition() メソッドの引数。 パラメータ 型 Nullable Optional 説明 xfloat✘ ✘ yfloat✘ ✘ zfloat✘ ✘ 戻り値の型:undefined
1.27.4. PannerOptions
これはPannerNodeを構築する際に使用するオプションを指定します。すべてのメンバーは省略可能で、未指定の場合は通常のデフォルト値でノードが構築されます。
dictionary PannerOptions :AudioNodeOptions {PanningModelType panningModel = "equalpower";DistanceModelType distanceModel = "inverse";float positionX = 0;float positionY = 0;float positionZ = 0;float orientationX = 1;float orientationY = 0;float orientationZ = 0;double refDistance = 1;double maxDistance = 10000;double rolloffFactor = 1;double coneInnerAngle = 360;double coneOuterAngle = 360;double coneOuterGain = 0; };
1.27.4.1. 辞書 PannerOptions
のメンバー
coneInnerAngle, 型 double(デフォルト値360)-
ノードの
coneInnerAngle属性の初期値。 coneOuterAngle, 型 double(デフォルト値360)-
ノードの
coneOuterAngle属性の初期値。 coneOuterGain, 型 double(デフォルト値0)-
ノードの
coneOuterGain属性の初期値。 distanceModel, 型 DistanceModelType(デフォルト値"inverse")-
ノードで使用する距離モデル。
maxDistance, 型 double(デフォルト値10000)-
ノードの
maxDistance属性の初期値。 orientationX, 型 float(デフォルト値1)-
orientationXAudioParamの初期x成分値。 orientationY, 型 float(デフォルト値0)-
orientationYAudioParamの初期y成分値。 orientationZ, 型 float(デフォルト値0)-
orientationZAudioParamの初期z成分値。 panningModel, 型 PanningModelType(デフォルト値"equalpower")-
ノードで使用するパンニングモデル。
positionX, 型 float(デフォルト値0)-
positionXAudioParamの初期x座標値。 positionY, 型 float(デフォルト値0)-
positionYAudioParamの初期y座標値。 positionZ, 型 float(デフォルト値0)-
positionZAudioParamの初期z座標値。 refDistance, 型 double(デフォルト値1)-
ノードの
refDistance属性の初期値。 rolloffFactor, 型 double(デフォルト値1)-
ノードの
rolloffFactor属性の初期値。
1.27.5. チャンネル制限
StereoPannerNode
のチャンネル制限のセットは、
PannerNodeにも適用されます。
1.28. PeriodicWave
インターフェース
PeriodicWave
は、OscillatorNode
とともに使う任意の周期波形を表します。
適合実装は、PeriodicWave
を少なくとも8192要素までサポートしなければなりません。
[Exposed =Window ]interface PeriodicWave {constructor (BaseAudioContext ,context optional PeriodicWaveOptions = {}); };options
1.28.1. コンストラクター
PeriodicWave(context, options)-
-
p を新しい
PeriodicWaveオブジェクトとし、[[real]]と[[imag]]を型Float32Arrayの2つの内部スロット、[[normalize]]を内部スロットとする。 -
optionsを次のいずれかのケースに従って処理する:-
options.realとoptions.imagの両方が指定されている場合-
両者の長さが異なる、またはどちらかの長さが2未満の場合は、
IndexSizeErrorを投げてアルゴリズムを中断。 -
[[real]]と[[imag]]をoptions.realと同じ長さの新しい配列にセット。 -
options.realの要素全てを[[real]]に、options.imagの要素全てを[[imag]]にコピー。
-
-
options.realのみ指定されている場合-
options.realの長さが2未満なら、IndexSizeErrorを投げて中断。 -
[[real]]と[[imag]]をoptions.realと同じ長さの配列にセット。 -
options.realを[[real]]にコピーし、[[imag]]は全要素ゼロにする。
-
-
options.imagのみ指定されている場合-
options.imagの長さが2未満なら、IndexSizeErrorを投げて中断。 -
[[real]]と[[imag]]をoptions.imagと同じ長さの配列にセット。 -
options.imagを[[imag]]にコピーし、[[real]]は全要素ゼロにする。
-
-
それ以外の場合
注意: この
PeriodicWaveをOscillatorNodeに設定すると、組込タイプ "sine" と同等になる。
-
-
[[normalize]]をdisableNormalization属性の逆値に初期化。 -
p を返す。
PeriodicWave.constructor() メソッドの引数。 パラメータ 型 Nullable Optional 説明 contextBaseAudioContext✘ ✘ この新しい PeriodicWaveが 関連付けられるBaseAudioContext。AudioBufferとは異なり、PeriodicWaveはAudioContextやOfflineAudioContext間で共有できない。特定のBaseAudioContextに関連付けられる。optionsPeriodicWaveOptions✘ ✔ この PeriodicWaveの初期パラメータ値(省略可能)。 -
1.28.2. PeriodicWaveConstraints
PeriodicWaveConstraints
辞書は、波形が正規化される方法を指定するために使います。
dictionary PeriodicWaveConstraints {boolean disableNormalization =false ; };
1.28.2.1. 辞書 PeriodicWaveConstraints
のメンバー
disableNormalization, 型 boolean(デフォルト値false)-
周期波形を正規化するかどうか制御します。
trueなら波形は正規化されません。falseなら正規化されます。
1.28.3. PeriodicWaveOptions
PeriodicWaveOptions
辞書は波形の構築方法を指定します。real
または imag
片方のみ指定の場合、もう片方は同じ長さの全ゼロ配列として扱います(辞書メンバーの説明参照)。
両方未指定なら、OscillatorNode
の type
"sine"
と同等の PeriodicWaveが生成されます。
両方指定の場合、配列長が異なれば NotSupportedError
エラーを投げなければなりません。
dictionary PeriodicWaveOptions :PeriodicWaveConstraints {sequence <float >real ;sequence <float >imag ; };
1.28.3.1. 辞書 PeriodicWaveOptions
のメンバー
imag, 型 sequence<float>-
imagパラメータはsine項の配列を表します。最初の要素(インデックス0)はフーリエ級数では存在しません。2番目(インデックス1)が基本周波数、3番目が第一倍音...という意味です。 real, 型 sequence<float>-
realパラメータはcosine項の配列を表します。最初の要素(インデックス0)は周期波形のDCオフセット。2番目(インデックス1)が基本周波数、3番目が第一倍音...という意味です。
1.28.4. 波形生成
createPeriodicWave()
メソッドは PeriodicWave
のフーリエ係数を指定するための2つの配列を受け取ります。\(a\)、\(b\) をそれぞれ長さ \(L\) の [[real]]、[[imag]]配列とします。基本的な時系列波形
\(x(t)\) は次で計算できます:
$$
x(t) = \sum_{k=1}^{L-1} \left[a[k]\cos2\pi k t + b[k]\sin2\pi k t\right]
$$
これが基本(未正規化)波形です。
1.28.5. 波形の正規化
この PeriodicWave
の内部スロット [[normalize]]
が true(デフォルト)の場合、
前節で定義した波形を最大値1になるように正規化します。正規化方法は以下の通り。
次を考える:
$$
\tilde{x}(n) = \sum_{k=1}^{L-1} \left(a[k]\cos\frac{2\pi k n}{N} + b[k]\sin\frac{2\pi k n}{N}\right)
$$
ここで \(N\) は2の累乗です(\(\tilde{x}(n)\)は逆FFTを使って計算可能)。固定正規化係数 \(f\) は次で計算:
$$
f = \max_{n = 0, \ldots, N - 1} |\tilde{x}(n)|
$$
したがって、実際の正規化波形 \(\hat{x}(n)\) は:
$$
\hat{x}(n) = \frac{\tilde{x}(n)}{f}
$$
この固定正規化係数は生成されたすべての波形に適用しなければなりません。
1.28.6. オシレーター係数
組込オシレータータイプは PeriodicWave
オブジェクトで生成されます。参考までに各組込タイプについて
PeriodicWave
の係数を示します。デフォルト正規化なしで組込タイプを使いたい場合に役立ちます。
以下の説明では、createPeriodicWave()
の
実数係数配列 \(a\)、虚数係数配列 \(b\) を考えます。
すべての場合で \(a[n] = 0\)(波形が奇関数であるため)。また \(b[0] = 0\)です。したがって \(b[n]\) の \(n \ge 1\) のみ下記に指定します。
- "
sine" -
$$ b[n] = \begin{cases} 1 & \mbox{for } n = 1 \\ 0 & \mbox{otherwise} \end{cases} $$ - "
square" -
$$ b[n] = \frac{2}{n\pi}\left[1 - (-1)^n\right] $$ - "
sawtooth" -
$$ b[n] = (-1)^{n+1} \dfrac{2}{n\pi} $$ - "
triangle" -
$$ b[n] = \frac{8\sin\dfrac{n\pi}{2}}{(\pi n)^2} $$
1.29. ScriptProcessorNode
インターフェース - 非推奨
このインターフェースはAudioNodeであり、
スクリプトを使って直接オーディオの生成・処理・解析が可能です。このノード型は非推奨で、AudioWorkletNodeに置き換えられる予定です。
このテキストは、実装がこのノード型を削除するまで参考用としてのみ残っています。
| プロパティ | 値 | 備考 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 1 | |
channelCount
| numberOfInputChannels
| ノード生成時に指定したチャンネル数。channelCount制約あり。 |
channelCountMode
| "explicit"
| channelCountMode制約あり |
channelInterpretation
| "speakers"
| |
| tail-time | なし |
ScriptProcessorNode
は bufferSize
を指定して生成され、この値は次のいずれかでなければなりません:256,
512, 1024, 2048, 4096, 8192, 16384。この値は audioprocess
イベントが発行される頻度や、各呼び出しで処理すべきサンプルフレーム数を制御します。audioprocess
イベントは、ScriptProcessorNode
に入力または出力のいずれかが接続されている場合のみ発行されます。bufferSize
が小さいほど(数値が低いほど)レイテンシが低く(良好)なります。大きい値は音切れやグリッチ回避に必要です。createScriptProcessor()
の bufferSize 引数が未指定または0の場合、実装側で値を選択します。
numberOfInputChannels
および numberOfOutputChannels
は入力・出力チャンネル数を決定します。両方ともゼロは無効です。
[Exposed =Window ]interface ScriptProcessorNode :AudioNode {attribute EventHandler onaudioprocess ;readonly attribute long bufferSize ; };
1.29.1. 属性
bufferSize, 型 long(読み取り専用)-
audioprocessが発行されるたびに処理すべきバッファ(サンプルフレーム数)。合法値は(256, 512, 1024, 2048, 4096, 8192, 16384)。 onaudioprocess, 型 EventHandler-
audioprocessイベント型の イベントハンドラーを設定するためのプロパティ。イベントハンドラーに渡されるイベントはAudioProcessingEventインターフェースを使用します。
1.30.
StereoPannerNode
インターフェース
このインターフェースは、低コストなパンニングアルゴリズムを使って入力オーディオストリームをステレオイメージ内に定位する処理ノードを表します。このパンニング効果は、ステレオストリーム内のオーディオ要素の位置決めによく使われます。
| プロパティ | 値 | 備考 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 1 | |
channelCount
| 2 | channelCount制約あり |
channelCountMode
| "clamped-max"
| channelCountMode制約あり |
channelInterpretation
| "speakers"
| |
| tail-time | なし |
このノードの入力はステレオ(2チャンネル)で、増やすことはできません。チャンネル数が異なるノードからの接続は適切にアップ/ダウンミックスされます。
このノードの出力はステレオ(2チャンネル)に固定され、設定変更できません。
[Exposed =Window ]interface StereoPannerNode :AudioNode {constructor (BaseAudioContext ,context optional StereoPannerOptions = {});options readonly attribute AudioParam pan ; };
1.30.1. コンストラクター
StereoPannerNode(context, options)-
このコンストラクターが
BaseAudioContextc と オプションオブジェクト option で呼び出された場合、ユーザーエージェントは AudioNodeの初期化 を this に対して context および options を引数にして行わなければなりません。StereoPannerNode.constructor() メソッドの引数。 パラメータ 型 Nullable Optional 説明 contextBaseAudioContext✘ ✘ この新しい StereoPannerNodeが 関連付けられるBaseAudioContext。optionsStereoPannerOptions✘ ✔ この StereoPannerNodeの初期パラメータ値(省略可能)。
1.30.2. 属性
pan, 型 AudioParam(読み取り専用)-
出力ステレオイメージ内で入力の位置を表します。-1で完全左、+1で完全右。
パラメータ 値 備考 defaultValue0 minValue-1 maxValue1 automationRate" a-rate"
1.30.3. StereoPannerOptions
これはStereoPannerNodeを構築する際に使用するオプションを指定します。すべてのメンバーは省略可能で、未指定の場合は通常のデフォルト値でノードが構築されます。
dictionary StereoPannerOptions :AudioNodeOptions {float pan = 0; };
1.30.3.1. 辞書 StereoPannerOptions
のメンバー
pan, 型 float(デフォルト値0)-
panAudioParamの初期値。
1.30.4. チャンネル制限
処理が上記定義に制約されるため、StereoPannerNodeは
最大2チャンネルのミックス、必ず2チャンネルの出力に制限されます。ChannelSplitterNodeや、
GainNode等で中間処理し、
ChannelMergerNodeで再合成することで、
任意のパンニング・ミックス手法も実現可能です。
1.31. WaveShaperNode
インターフェース
WaveShaperNode
はAudioNodeプロセッサで、非線形ディストーション効果を実装します。
非線形ウェーブシェイピング・ディストーションは、繊細な非線形ウォーミングから、より顕著なディストーション効果まで幅広く使われます。任意の非線形シェイピングカーブを指定できます。
| プロパティ | 値 | 備考 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 1 | |
channelCount
| 2 | |
channelCountMode
| "max"
| |
channelInterpretation
| "speakers"
| |
| tail-time | 場合による | oversample
属性が"2x"または"4x"に設定されている場合のみ
tail-timeがあります。
実際のtail-timeの長さは実装依存です。
|
出力チャンネル数は常に入力チャンネル数と一致します。
enum {OverSampleType "none" ,"2x" ,"4x" };
| 列挙値 | 説明 |
|---|---|
"none"
| オーバーサンプリングしない |
"2x"
| 2倍にオーバーサンプリング |
"4x"
| 4倍にオーバーサンプリング |
[Exposed =Window ]interface WaveShaperNode :AudioNode {constructor (BaseAudioContext ,context optional WaveShaperOptions = {});options attribute Float32Array ?curve ;attribute OverSampleType oversample ; };
1.31.1. コンストラクター
WaveShaperNode(context, options)-
このコンストラクターが
BaseAudioContextc と オプションオブジェクト option で呼び出された場合、ユーザーエージェントは AudioNodeの初期化 を this に対して context および options を引数にして行わなければなりません。また、
[[curve set]]をこのWaveShaperNodeの内部スロットとし、初期値をfalseにする。optionsが指定され、curveが含まれていれば、[[curve set]]をtrueにする。WaveShaperNode.constructor() メソッドの引数。 パラメータ 型 Nullable Optional 説明 contextBaseAudioContext✘ ✘ この新しい WaveShaperNodeが 関連付けられるBaseAudioContext。optionsWaveShaperOptions✘ ✔ この WaveShaperNodeの初期パラメータ値(省略可能)。
1.31.2. 属性
curve, 型 Float32Array(nullable)-
ウェーブシェイピング効果で使われるシェイピングカーブ。入力信号は原則として範囲[-1, 1]内です。この範囲内の各入力サンプルはシェイピングカーブをインデックス指定で参照し、信号レベル0はカーブ配列の中央値(要素数が奇数の場合)、要素数が偶数の場合は中央2値の間で補間されます。-1未満は配列の最初の値、+1超は配列の最後の値となります。
実装は隣接するカーブ点間の線形補間を行わなければなりません。初期状態ではcurve属性はnullで、その場合WaveShaperNodeは入力をそのまま出力に渡します。
カーブ値は[-1; 1]区間で等間隔に配置されます。偶数要素の場合、信号ゼロの値は存在せず、奇数要素の場合はゼロの値が直接存在します。出力は次のアルゴリズムで決定。
-
入力サンプルを \(x\)、対応するノード出力を \(y\)、カーブ配列の \(k\) 番目要素を \(c_k\)、カーブ長を \(N\) とする。
-
次を計算:
$$ \begin{align*} v &= \frac{N-1}{2}(x + 1) \\ k &= \lfloor v \rfloor \\ f &= v - k \end{align*} $$ -
次で出力:
$$ \begin{align*} y &= \begin{cases} c_0 & v \lt 0 \\ c_{N-1} & v \ge N - 1 \\ (1-f)\,c_k + fc_{k+1} & \mathrm{otherwise} \end{cases} \end{align*} $$
InvalidStateErrorは、Float32Arrayのlengthが2未満の値でこの属性を設定したとき投げなければなりません。この属性が設定されると、WaveShaperNodeはカーブの内部コピーを作成します。したがって、属性設定に使った配列の内容を後で変更しても効果はありません。
curve属性を設定する手順:-
new curveを
Float32Arrayまたはnullとする。 -
new curveが
nullでなく、[[curve set]]がtrueなら、InvalidStateErrorを投げて手順中断。 -
new curveが
nullでなければ、[[curve set]]をtrueにする。 -
new curveをcurve属性に割り当てる。
注意: ゼロ入力で非ゼロ出力値となるカーブを使うと、入力未接続でもこのノードはDC信号を生成します。ノードを下流から切断するまで持続します。
-
oversample, 型 OverSampleType-
シェイピングカーブ適用時にどのオーバーサンプリング方式(有無)を使うか指定します。デフォルトは"
none"で、入力サンプルに直接カーブを適用します。"2x"や"4x"は エイリアシング抑制により処理品質向上のため使えます。"4x"が最も高品質。用途によってはオーバーサンプリング無しがシェイピングカーブ精度に有利。"2x"または"4x"の場合、次の手順を必ず実施:-
入力サンプルを
AudioContextのサンプルレートの2倍または4倍にアップサンプリング。 各レンダー量子ごとに2倍(2x)または4倍(4x)のサンプルを生成。 -
シェイピングカーブを適用。
-
結果を
AudioContextのサンプルレートにダウンサンプリング。先に処理したサンプルから、最終的に1レンダー量子分のサンプルを生成。
具体的なアップ/ダウンサンプリングフィルタは規定されておらず、音質(エイリアシング低減など)、レイテンシ、パフォーマンスに合わせて調整可能です。
注意: オーバーサンプリングを使うと、アップ/ダウンサンプリングフィルタの影響で処理レイテンシが増加します。レイテンシ量は実装ごとに異なります。
-
1.31.3.
WaveShaperOptions
これはWaveShaperNodeを構築する際に使用するオプションを指定します。すべてのメンバーは省略可能で、未指定の場合は通常のデフォルト値でノードが構築されます。
dictionary WaveShaperOptions :AudioNodeOptions {sequence <float >curve ;OverSampleType oversample = "none"; };
1.31.3.1. 辞書 WaveShaperOptions
のメンバー
curve, 型 sequence<float>-
ウェーブシェイピング効果用のシェイピングカーブ。
oversample, 型 OverSampleType(デフォルト値"none")-
シェイピングカーブ用に使うオーバーサンプリング方式。
1.32. AudioWorklet
インターフェイス
[Exposed =Window ,SecureContext ]interface AudioWorklet :Worklet {readonly attribute MessagePort port ; };
1.32.1. 属性
port, 型 MessagePort, readonly-
MessagePortはAudioWorkletGlobalScopeのポートに接続されます。注: この
portの"message"イベントにイベントリスナーを登録する開発者は、closeをMessageChannelのいずれかのエンド(AudioWorkletまたはAudioWorkletGlobalScope側)で呼び出し、リソースが収集されるようにしてください。
1.32.2. 概念
AudioWorklet
オブジェクトは、開発者がスクリプト(JavaScript や WebAssembly コードなど)を レンダリングスレッド 上でオーディオ処理するために提供し、カスタム AudioNode
をサポートします。
この処理機構は、オーディオグラフ内の他の組み込み AudioNode
とスクリプトコードの同期的な実行を保証します。
この仕組みを実現するために、対応するオブジェクトのペアを定義しなければなりません:AudioWorkletNode
と AudioWorkletProcessor
です。
前者は他の AudioNode
オブジェクトのようにメイングローバルスコープのインターフェイスを表し、後者は
AudioWorkletGlobalScope
という特別なスコープ内で内部オーディオ処理を実装します。

AudioWorkletNode
と AudioWorkletProcessor
各 BaseAudioContext
には、正確に1つの AudioWorklet
が存在します。
AudioWorklet
の
workletグローバルスコープ型は AudioWorkletGlobalScope
です。
AudioWorklet
の
worklet宛先型は "audioworklet" です。
addModule(moduleUrl)
メソッドでスクリプトをインポートすると、AudioWorkletProcessor
のクラス定義が
AudioWorkletGlobalScope
下に登録されます。
インポートしたクラスコンストラクターと、コンストラクターから生成されたアクティブインスタンス用の2種類の内部ストレージ領域があります。
AudioWorklet
には1つの内部スロットがあります:
-
node name to parameter descriptor map は、 node name to processor constructor map から同一セットの文字列キーに対応し、対応する parameterDescriptors 値が格納されているマップです。 この内部ストレージは、
registerProcessor()メソッドを レンダリングスレッド で呼び出した結果として埋められます。addModule()がコンテキストのaudioWorkletで返すプロミスの解決よりも前に、必ずストレージが完了します。
// bypass-processor.js スクリプトファイル、AudioWorkletGlobalScope上で実行 class BypassProcessorextends AudioWorkletProcessor{ process( inputs, outputs) { // 単一入力、単一チャンネル。 const input= inputs[ 0 ]; const output= outputs[ 0 ]; output[ 0 ]. set( input[ 0 ]); // アクティブな入力がある場合のみ処理。 return false ; } }; registerProcessor( 'bypass-processor' , BypassProcessor);
// メイングローバルスコープ const context= new AudioContext(); context. audioWorklet. addModule( 'bypass-processor.js' ). then(() => { const bypassNode= new AudioWorkletNode( context, 'bypass-processor' ); });
メイングローバルスコープで AudioWorkletNode
をインスタンス化する際、対応する AudioWorkletProcessor
も
AudioWorkletGlobalScope
で生成されます。これら2つのオブジェクトは § 2 処理モデル で述べる非同期メッセージパッシングによって通信します。
1.32.3. AudioWorkletGlobalScope
インターフェイス
この特別な実行コンテキストは、スクリプトによるオーディオデータの生成・処理・解析を、オーディオレンダリングスレッド上で直接可能にするために設計されています。
ユーザーが提供したスクリプトコードはこのスコープで評価され、1つ以上の AudioWorkletProcessor
のサブクラスを定義し、それらが
AudioWorkletNode
と1対1で関連する AudioWorkletProcessor
のインスタンス化に利用されます。
各 AudioContext
には、1つ以上の AudioWorkletNode
が含まれる場合、必ず1つの AudioWorkletGlobalScope
が存在します。
インポートされたスクリプトの実行は [HTML] で定義される UA
によって行われます。[HTML] のデフォルト指定を上書きし、
AudioWorkletGlobalScope
はユーザーエージェントによって
任意に終了されてはなりません。
AudioWorkletGlobalScope
には以下の内部スロットがあります:
-
node name to processor constructor map は processor name →
AudioWorkletProcessorConstructorインスタンスのキーと値のペアを保存するマップです。 初期状態では空で、registerProcessor()メソッドが呼び出されたときに埋められます。 -
pending processor construction data は、
AudioWorkletNodeコンストラクターによって生成された、一時的なデータを保存します。これは対応するAudioWorkletProcessorのインスタンス化のために使われます。pending processor construction data には以下の項目があります:-
node reference は 初期状態では空です。このストレージは
AudioWorkletNodeコンストラクターから転送されたAudioWorkletNode参照を格納します。 -
transferred port は 初期状態では空です。このストレージは
MessagePortのデシリアライズされた値で、AudioWorkletNodeコンストラクターから転送されたものです。
-
注: AudioWorkletGlobalScope
には、これらのインスタンス間で共有されるその他のデータやコードも含めることができます。例えば、複数のプロセッサが同じArrayBuffer(ウェーブテーブルやインパルス応答)を共有することも可能です。
注: AudioWorkletGlobalScope
は、1つの BaseAudioContext
と紐づき、そのコンテキスト用の単一オーディオレンダリングスレッドに関連します。これにより、同時スレッドでグローバルスコープコードが動作する際のデータ競合が防止されます。
callback =AudioWorkletProcessorConstructor AudioWorkletProcessor (object ); [options Global =(Worklet ,AudioWorklet ),Exposed =AudioWorklet ]interface AudioWorkletGlobalScope :WorkletGlobalScope {undefined registerProcessor (DOMString name ,AudioWorkletProcessorConstructor processorCtor );readonly attribute unsigned long long currentFrame ;readonly attribute double currentTime ;readonly attribute float sampleRate ;readonly attribute unsigned long renderQuantumSize ;readonly attribute MessagePort port ; };
1.32.3.1. 属性
currentFrame, 型 unsigned long long, readonly-
処理中のオーディオブロックの現在フレーム。これは、
[[current frame]]内部スロットの値と一致しなければなりません。該当するBaseAudioContextの値です。 currentTime, 型 double, readonly-
処理中のオーディオブロックのコンテキスト時間。この値は定義上、
BaseAudioContextのcurrentTime属性のうち、コントロールスレッドで最新観測可能な値と等しくなります。 sampleRate, 型 float, readonly-
関連付けられた
BaseAudioContextのサンプルレートです。 renderQuantumSize, 型 unsigned long, readonly-
関連付けられた
BaseAudioContextのプライベートスロット [[render quantum size]] の値です。 port, 型 MessagePort, readonly-
MessagePortはAudioWorkletのポートに接続されます。注: この
portの"message"イベントにイベントリスナーを登録する場合は、closeをMessageChannelのいずれかのエンド(AudioWorkletまたはAudioWorkletGlobalScope側)で呼び出し、リソースが収集されるようにしてください。
1.32.3.2. メソッド
registerProcessor(name, processorCtor)-
AudioWorkletProcessorから派生したクラスコンストラクターを登録します。registerProcessor(name, processorCtor)メソッドが呼び出されたとき、以下の手順を実行します。いずれかの段階で例外が発生した場合、残りの手順は中止されます。-
name が空文字列の場合、
NotSupportedErrorをスローします。 -
name が node name to processor constructor map に既にキーとして存在する場合、
NotSupportedErrorをスローします。 -
IsConstructor(argument=processorCtor)の結果がfalseの場合、TypeErrorをスローします。 -
prototypeをGet(O=processorCtor, P="prototype")の結果とします。 -
Type(argument=prototype)の結果がObjectでない場合、TypeErrorをスローします。 -
parameterDescriptorsValue を
Get(O=processorCtor, P="parameterDescriptors")の結果とします。 -
parameterDescriptorsValue が
undefinedでない場合、次の手順を実行します:-
parameterDescriptorSequence を 変換 により parameterDescriptorsValue から
sequence<AudioParamDescriptor>型のIDL値へ変換した結果とします。 -
paramNames を空の配列とします。
-
parameterDescriptorSequence の各 descriptor について:
-
paramName を descriptor 内の
nameメンバーの値とします。NotSupportedErrorをスローします、もし paramNames に既に paramName の値が含まれる場合。 -
paramName を paramNames 配列に追加します。
-
defaultValue を descriptor 内の
defaultValueメンバーの値とします。 -
minValue を descriptor 内の
minValueメンバーの値とします。 -
maxValue を descriptor 内の
maxValueメンバーの値とします。 -
もし minValue <= defaultValue <= maxValue 式が false なら、
InvalidStateErrorをスローします。
-
-
-
name → processorCtor のキーと値のペアを、関連する node name to processor constructor map に追加します。該当する
AudioWorkletGlobalScopeのものです。 -
media element task をキューして、name → parameterDescriptorSequence のキーと値のペアを 関連する node name to parameter descriptor map に追加します。該当する
BaseAudioContextのものです。
注: クラスコンストラクターの参照は一度だけ検索されるべきであり、登録後に動的に変更される機会はありません。
AudioWorkletGlobalScope.registerProcessor(name, processorCtor) メソッドの引数 パラメータ 型 Nullable Optional 説明 nameDOMString✘ ✘ 登録するクラスコンストラクターを表す文字列キー。このキーは AudioWorkletProcessorのコンストラクターをAudioWorkletNode構築時に検索するために使われます。processorCtorAudioWorkletProcessorConstructor✘ ✘ AudioWorkletProcessorから拡張されたクラスコンストラクターです。返却型:undefined -
1.32.3.3. AudioWorkletProcessor
のインスタンス化
AudioWorkletNode
の構築の最後に、
構造体である
プロセッサー構築データ がスレッド間転送のために準備されます。この 構造体 には以下の 項目が含まれます:
-
name:
DOMStringであり、ノード名とプロセッサーコンストラクタのマップで参照されます。 -
node:作成された
AudioWorkletNodeへの参照。 -
options:
AudioWorkletNodeOptionsをシリアライズしたものであり、AudioWorkletNodeのconstructorに渡されたものです。 -
port:
MessagePortをシリアライズしたものであり、AudioWorkletNodeのportとペアになっています。
転送されたデータが AudioWorkletGlobalScope
に到着すると、レンダリングスレッド
は以下のアルゴリズムを呼び出します:
-
constructionData を プロセッサー構築データ(制御スレッドから転送されたもの)とする。
-
processorName、nodeReference、serializedPort をそれぞれ constructionData の name、node、port とする。
-
serializedOptions を constructionData の options とする。
-
deserializedPort を StructuredDeserialize(serializedPort, 現在の Realm) の結果とする。
-
deserializedOptions を StructuredDeserialize(serializedOptions, 現在の Realm) の結果とする。
-
processorCtor を processorName をキーとして
AudioWorkletGlobalScopeの ノード名とプロセッサーコンストラクタのマップ から検索した結果とする。 -
nodeReference および deserializedPort をこの
AudioWorkletGlobalScopeの ノード参照 と 転送ポート にそれぞれ格納する。 -
コールバック関数の構築 を processorCtor から deserializedOptions を引数として行う。コールバック内で例外がスローされた場合は、タスクをキューし、制御スレッドに イベント名
processorerrorを nodeReference でErrorEventを用いて発火する。 -
pending processor construction data スロットを空にする。
1.32.4.
AudioWorkletNode
インターフェイス
このインターフェイスは、ユーザー定義の AudioNode
を表し、
制御スレッド上で動作します。
ユーザーは AudioWorkletNode
を BaseAudioContext
から作成でき、
このノードは他の組み込み AudioNode
と接続して
オーディオグラフを構成できます。
| プロパティ | 値 | 備考 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 1 | |
channelCount
| 2 | |
channelCountMode
| "max"
| |
channelInterpretation
| "speakers"
| |
| tail-time | 備考参照 | すべての tail-time はノード自身で処理されます |
すべての AudioWorkletProcessor
は アクティブソース フラグを持ち、初期値は
true です。このフラグにより、入力が接続されていない場合でもノードはメモリに保持され、オーディオ処理を行います。
すべての AudioWorkletNode
から投稿されたタスクは、関連付けられた BaseAudioContext
のタスクキューに投稿されます。
[Exposed =Window ]interface {AudioParamMap readonly maplike <DOMString ,AudioParam >; };
このインターフェイスは readonly maplike によって "entries", "forEach", "get", "has", "keys", "values",
@@iterator メソッドおよび "size" ゲッターを備えます。
[Exposed =Window ,SecureContext ]interface AudioWorkletNode :AudioNode {constructor (BaseAudioContext ,context DOMString ,name optional AudioWorkletNodeOptions = {});options readonly attribute AudioParamMap parameters ;readonly attribute MessagePort port ;attribute EventHandler onprocessorerror ; };
1.32.4.1. コンストラクター
AudioWorkletNode(context, name, options)-
AudioWorkletNode.constructor() メソッドの引数。 パラメーター 型 Nullable Optional 説明 contextBaseAudioContext✘ ✘ この新しい BaseAudioContextにAudioWorkletNodeが 関連付けられます。nameDOMString✘ ✘ この文字列は BaseAudioContextの ノード名からパラメータ記述子へのマップ のキーとなります。optionsAudioWorkletNodeOptions✘ ✔ この AudioWorkletNodeの初期パラメータ値(任意)。コンストラクターが呼び出されたとき、ユーザーエージェントは 制御スレッドで以下の手順を実行しなければなりません:
AudioWorkletNodeコンストラクターが context, nodeName, options で呼び出された場合:-
nodeName が
BaseAudioContextの ノード名からパラメータ記述子へのマップ にキーとして存在しない場合、InvalidStateError例外を投げてこれらの手順を中止する。 -
node を this の値とする。
-
AudioNode の初期化を node に context と options を引数として実行する。
-
入力、出力および出力チャンネルの設定 を node に options で行う。 例外が発生した場合は残りの手順を中止する。
-
messageChannel を新しい
MessageChannelとする。 -
nodePort を messageChannel の
port1属性の値とする。 -
processorPortOnThisSide を messageChannel の
port2属性の値とする。 -
serializedProcessorPort を StructuredSerializeWithTransfer(processorPortOnThisSide, « processorPortOnThisSide ») の結果とする。
-
Convert options 辞書を optionsObject に変換する。
-
serializedOptions を StructuredSerialize(optionsObject) の結果とする。
-
node の
portを nodePort に設定する。 -
parameterDescriptors を nodeName を ノード名からパラメータ記述子へのマップ から取得した結果とする:
-
audioParamMap を新しい
AudioParamMapオブジェクトとする。 -
parameterDescriptors の各 descriptor について:
-
paramName を
nameメンバーの値とする。 -
audioParam を新しい
AudioParamインスタンスとして、automationRate,defaultValue,minValue, およびmaxValueの値を descriptor の各メンバーの値と同じにする。 -
audioParamMap の entries に paramName → audioParam のペアを追加する。
-
-
parameterDataが options に存在する場合は、以下の手順を実行する:-
parameterData を
parameterDataの値とする。 -
parameterData の各 paramName → paramValue について:
-
audioParamMap に paramName のキーのエントリが存在する場合は、そのエントリを audioParamInMap とする。
-
audioParamInMap の
valueプロパティを paramValue に設定する。
-
-
-
node の
parametersを audioParamMap に設定する。
-
-
制御メッセージをキューに入れることで、対応する
AudioWorkletProcessorのコンストラクターを呼び出す。この際、プロセッサー構築データとして、nodeName、node、serializedOptions、serializedProcessorPortが渡される。
-
1.32.4.2. 属性
onprocessorerror, 型 EventHandler-
プロセッサの
constructor、processメソッド、 またはユーザー定義クラスメソッドから未処理の例外がスローされた場合、プロセッサは メディア要素タスクをキューし、イベントを発火して関連付けられたprocessorerrorイベントをAudioWorkletNodeで発生させ、ErrorEventを使用します。ErrorEventはmessage、filename、lineno、colno属性を制御スレッドで適切に作成・初期化されます。未処理の例外がスローされると、その後プロセッサは生涯にわたり無音を出力する点に注意してください。
parameters, 型 AudioParamMap, readonly-
parameters属性は、名前付きで関連付けられたAudioParamオブジェクトのコレクションです。この maplike オブジェクトは、AudioWorkletProcessorクラスのコンストラクターでAudioParamDescriptorのリストからインスタンス化時に生成されます。 port, 型 MessagePort, readonly-
すべての
AudioWorkletNodeにはportが関連付けられており、このMessagePortです。 このポートは 対応するAudioWorkletProcessorオブジェクトのポートと接続されており、AudioWorkletNodeとAudioWorkletProcessorの間で双方向通信が可能です。注: この
portの"message"イベントにイベントリスナーを登録する著者は、closeをMessageChannelのいずれか一方(AudioWorkletProcessorまたはAudioWorkletNode側)で呼び出し、リソースを回収できるようにしてください。
1.32.4.3. AudioWorkletNodeOptions
AudioWorkletNodeOptions
辞書は
AudioWorkletNode
のインスタンスの属性を初期化するために使用できます。
dictionary AudioWorkletNodeOptions :AudioNodeOptions {unsigned long numberOfInputs = 1;unsigned long numberOfOutputs = 1;sequence <unsigned long >outputChannelCount ;record <DOMString ,double >parameterData ;object processorOptions ; };
1.32.4.3.1. 辞書 AudioWorkletNodeOptions
のメンバー
numberOfInputs, 型 unsigned long、デフォルトは1-
これは
AudioNodeのnumberOfInputs属性の値を初期化するために使用されます。 numberOfOutputs, 型 unsigned long、デフォルトは1-
これは
AudioNodeのnumberOfOutputs属性の値を初期化するために使用されます。 outputChannelCount, 型sequence<unsigned long>-
この配列は各出力のチャンネル数を設定するために使用されます。
parameterData, 型 record<DOMString, double>-
これはユーザー定義のキーと値のペアのリストであり、
AudioParamのvalueをAudioWorkletNode内で名前が一致するものに初期設定するために使用されます。 processorOptions, 型 object-
これは
AudioWorkletNodeに紐付けられるAudioWorkletProcessorインスタンスのカスタムプロパティ初期化に使用できる任意のユーザー定義データです。
1.32.4.3.2. AudioWorkletNodeOptions
によるチャンネル設定
以下のアルゴリズムは AudioWorkletNodeOptions
で様々なチャンネル構成を設定する方法を示します。
-
node をこのアルゴリズムに与えられた
AudioWorkletNodeインスタンスとする。 -
numberOfInputsとnumberOfOutputsの両方が 0 の場合、NotSupportedErrorを投げて以降の手順を中止する。 -
outputChannelCountが 存在する場合、-
outputChannelCountのいずれかの値が 0 または実装の最大チャンネル数を超えている場合、NotSupportedErrorを投げて以降の手順を中止する。 -
outputChannelCountの長さがnumberOfOutputsと等しくない場合、IndexSizeErrorを投げて以降の手順を中止する。 -
numberOfInputsとnumberOfOutputsの両方が 1 の場合、 node の出力チャンネル数をoutputChannelCountの1つの値に設定する。 -
それ以外の場合は node の k 番目の出力チャンネル数を
outputChannelCount配列の k 番目の要素に設定し、return する。
-
-
outputChannelCountが 存在しない場合、-
numberOfInputsとnumberOfOutputsの両方が 1 の場合、 node の初期出力チャンネル数を 1 に設定し、return する。注: この場合、出力チャンネル数は 入力と
channelCountModeに基づいて、実行時に computedNumberOfChannels に動的に変更されます。 -
それ以外の場合は node の各出力チャンネル数を 1 に設定し、return する。
-
1.32.5. AudioWorkletProcessor
インターフェイス
このインターフェイスは、オーディオ レンダリングスレッド 上で動作する
オーディオ処理コードを表します。
AudioWorkletGlobalScope
内に存在し、クラス定義が実際のオーディオ処理を実現します。
AudioWorkletProcessor
の構築は AudioWorkletNode
の構築によってのみ発生することに注意してください。
[Exposed =AudioWorklet ]interface AudioWorkletProcessor {constructor ();readonly attribute MessagePort port ; };callback AudioWorkletProcessCallback =boolean (FrozenArray <FrozenArray <Float32Array >>,inputs FrozenArray <FrozenArray <Float32Array >>,outputs object );parameters
AudioWorkletProcessor
には2つの内部スロットがあります:
[[node reference]]-
関連付けられた
AudioWorkletNodeへの参照です。 [[callable process]]-
process() が呼び出し可能な関数かどうかを示す真偽値フラグです。
1.32.5.1. コンストラクター
AudioWorkletProcessor()-
AudioWorkletProcessorのコンストラクターが呼び出されるとき、 以下の手順が レンダリングスレッド上で実行されます。-
nodeReference を 現在の
AudioWorkletGlobalScopeの pending processor construction data から検索したノード参照とする。 スロットが空の場合はTypeError例外を投げる。 -
processor を this の値とする。
-
processor の
[[node reference]]に nodeReference を設定する。 -
processor の
[[callable process]]をtrueに設定する。 -
deserializedPort を pending processor construction data から検索した転送ポートとする。
-
processor の
portに deserializedPort を設定する。 -
pending processor construction data スロットを空にする。
-
1.32.5.2. 属性
port, 型 MessagePort, readonly-
すべての
AudioWorkletProcessorにはportが関連付けられており、これはMessagePortです。 このポートは 対応するAudioWorkletNodeオブジェクトのポートと接続されており、AudioWorkletNodeとAudioWorkletProcessorの間で双方向通信が可能です。注: この
portの"message"イベントにイベントリスナーを登録する著者は、closeをMessageChannelのいずれか一方(AudioWorkletProcessorまたはAudioWorkletNode側)で呼び出し、リソースを回収できるようにしてください。
1.32.5.3. コールバック AudioWorkletProcessCallback
ユーザーは AudioWorkletProcessor
を拡張してカスタムオーディオプロセッサーを定義できます。
サブクラスは AudioWorkletProcessCallback
である process()
を定義しなければならず、オーディオ処理アルゴリズムを実装し、静的プロパティ
parameterDescriptors
を持つことができ、これは
AudioParamDescriptor
のイテラブルです。
process() コールバック関数は グラフのレンダリングで指定された通りに扱われます。
AudioWorkletProcessor
に紐付けられた
AudioWorkletNode
のライフタイムを制御します。
このライフタイム方針は 組み込みノードで見られる様々な方式をサポートできます。例:
-
入力を変換し、接続された入力やスクリプト参照が存在する間のみアクティブなノード。 このようなノードは process() から
falseを返すべきであり、 接続された入力の有無によってAudioWorkletNodeが 積極的に処理中か決定できます。 -
入力を変換し、入力切断後も tail-time の間アクティブなノード。 この場合、process() は
inputsがゼロチャンネルのときも一定期間trueを返すべきです。 現在時刻はグローバルスコープのcurrentTimeから取得して tail-time の開始・終了を計測するか、 プロセッサの内部状態に応じて動的に算出できます。 -
出力のソースとなるノード(通常は寿命あり)。 このようなノードは process() から
trueを返し続け、 出力しなくなった時点で返さなくなります。
上記定義は process() 実装で戻り値がない場合(事実上
false とみなされる、
実効的な戻り値は falsy な undefined)は
入力がアクティブな時のみアクティブな AudioWorkletProcessor
には合理的な挙動であることを意味します。
下記例は AudioParam
を AudioWorkletProcessor
で定義・利用する方法を示します。
class MyProcessorextends AudioWorkletProcessor{ static get parameterDescriptors() { return [{ name: 'myParam' , defaultValue: 0.5 , minValue: 0 , maxValue: 1 , automationRate: "k-rate" }]; } process( inputs, outputs, parameters) { // 1つ目のinputとoutputを取得 const input= inputs[ 0 ]; const output= outputs[ 0 ]; const myParam= parameters. myParam; // 単純なアンプ処理。automationRateが"k-rate"なので各レンダー量子ごとに[0]のみ for ( let channel= 0 ; channel< output. length; ++ channel) { for ( let i= 0 ; i< output[ channel]. length; ++ i) { output[ channel][ i] = input[ channel][ i] * myParam[ 0 ]; } } } }
1.32.5.3.1.
コールバック AudioWorkletProcessCallback
のパラメーター
以下は AudioWorkletProcessCallback
関数のパラメーターの説明です。
一般に、inputs
および outputs
配列は呼び出し間で再利用され、メモリ割り当てが行われません。ただし、トポロジーが変化した場合(例えば、入力や出力のチャンネル数が変化した場合)、新しい配列が再割り当てされます。また、inputs
や outputs
のいずれかが転送された場合も新しい配列が再割り当てされます。
inputs型FrozenArray<FrozenArray<Float32Array>>-
ユーザーエージェントが提供する入力オーディオバッファ。
inputs[n][m]は \(n\) 番目の入力の \(m\) 番目のチャンネル用のFloat32Arrayです。入力数は構築時に固定ですが、チャンネル数は computedNumberOfChannels に基づき動的に変更できます。現在のレンダー量子において
AudioWorkletNodeの \(n\) 番目の入力に actively processing なAudioNodeが接続されていない場合、inputs[n]の内容は空配列となり、入力チャンネル数が 0 であることを示します。この場合のみinputs[n]の要素数が 0 になる可能性があります。 outputs型FrozenArray<FrozenArray<Float32Array>>-
ユーザーエージェントが消費するための出力オーディオバッファ。
outputs[n][m]は \(n\) 番目の出力の \(m\) 番目のチャンネル用のFloat32Arrayオブジェクトで、オーディオサンプルが格納されます。各Float32Arrayはゼロで初期化されています。ノードに出力が1つしかない場合、出力チャンネル数は computedNumberOfChannels と一致します。 parameters型object-
ordered map の name → parameterValues。
parameters["name"]は parameterValues を返し、これはFrozenArray<Float32Array> で、その name のAudioParamのオートメーション値です。各配列には computedValue が render quantum のすべてのフレーム分入っています。ただし、このレンダー量子内でオートメーションがスケジュールされていなければ、配列の長さは 1 で、その値は
AudioParamの定数値となる場合があります。このオブジェクトは以下の手順でフリーズされます。
-
parameter を ordered map の name とパラメータ値とする。
-
SetIntegrityLevel(parameter, frozen)
このフリーズされた ordered map は、アルゴリズムで計算されて
parameters引数に渡されます。注: このオブジェクトは変更できないため、 配列の長さが変わらない限り、連続した呼び出しで同じオブジェクトを使うことができます。
-
1.32.5.4. AudioParamDescriptor
AudioParamDescriptor
辞書は、
AudioParam
オブジェクトのプロパティを指定するために使用します。
このオブジェクトは AudioWorkletNode
で利用されます。
dictionary AudioParamDescriptor {required DOMString name ;float defaultValue = 0;float minValue = -3.4028235e38;float maxValue = 3.4028235e38;AutomationRate automationRate = "a-rate"; };
1.32.5.4.1. 辞書 AudioParamDescriptor
のメンバー
これらのメンバーの値には制約があります。詳細は AudioParamDescriptor の処理アルゴリズムを参照してください。
automationRate, 型 AutomationRate、デフォルトは"a-rate"-
デフォルトのオートメーションレートを表します。
defaultValue, 型 float、デフォルトは0-
パラメータのデフォルト値を表します。
maxValue, 型 float、デフォルトは3.4028235e38-
最大値を表します。
minValue, 型 float、デフォルトは-3.4028235e38-
最小値を表します。
name, 型 DOMString-
パラメータの名前を表します。
1.32.6. AudioWorklet のイベントシーケンス
以下の図は、AudioWorklet
に関して発生する理想化されたイベントシーケンスを示します:
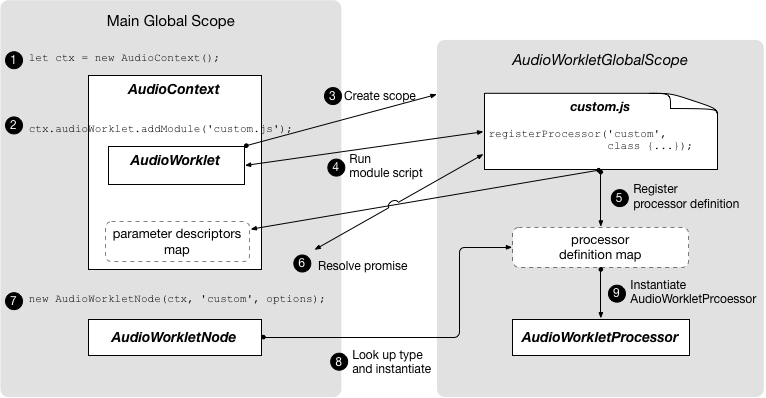
AudioWorklet
のシーケンス 図に示されている手順は、AudioContext
と
それに関連付けられる AudioWorkletGlobalScope
の作成、
さらに AudioWorkletNode
と
それに紐付く AudioWorkletProcessor
の作成に関する
一例のイベントシーケンスです。
-
AudioContextが作成される。 -
メインスコープで
context.audioWorkletにスクリプトモジュールの追加要求を行う。 -
まだ存在しない場合、新しい
AudioWorkletGlobalScopeが context に関連付けて作成される。これはAudioWorkletProcessorの クラス定義が評価されるグローバルスコープとなる。(以降の呼び出しでは、既存のスコープが利用される。) -
インポートされたスクリプトが新たに作成されたグローバルスコープで実行される。
-
インポートされたスクリプトの実行の一部として、
AudioWorkletProcessorが"custom"(上記図の例)というキーでAudioWorkletGlobalScope内に 登録される。これにより、グローバルスコープおよびAudioContextの両方でマップが更新される。 -
addModule()の promise が解決される。 -
メインスコープで、ユーザーが指定したキーとオプション辞書を使って
AudioWorkletNodeが作成される。 -
ノードの作成時、このキーを用いて正しい
AudioWorkletProcessorのサブクラスがインスタンス化用に検索される。 -
その
AudioWorkletProcessorサブクラスのインスタンスが、同じオプション辞書の構造化クローンでインスタンス化される。 このインスタンスは、先に作成されたAudioWorkletNodeとペアになる。
1.32.7. AudioWorklet の例
1.32.7.1. BitCrusher ノード
ビットクラッシングは、サンプル値の量子化(より低いビット深度のシミュレーション)と
時間解像度の量子化(より低いサンプルレートのシミュレーション)によって
オーディオストリームの品質を下げる仕組みです。
この例では、AudioParam(この場合は
a-rateとして扱う)を
AudioWorkletProcessor
内で利用する方法を示しています。
const context= new AudioContext(); context. audioWorklet. addModule( 'bitcrusher.js' ). then(() => { const osc= new OscillatorNode( context); const amp= new GainNode( context); // ワークレットノードを作成。'BitCrusher'は // bitcrusher.jsインポート時に登録された // AudioWorkletProcessor を識別する。optionsはAudioParamsを自動初期化。 const bitcrusher= new AudioWorkletNode( context, 'bitcrusher' , { parameterData: { bitDepth: 8 } }); osc. connect( bitcrusher). connect( amp). connect( context. destination); osc. start(); });
class Bitcrusher extends AudioWorkletProcessor {
...(コードは原文通り)...
注: AudioWorkletProcessor
クラスの定義で、著者が提供したコンストラクターが this 以外を返したり super() を正しく呼ばない場合は
InvalidStateError
がスローされます。
1.32.7.2. VUメーターノード
この簡易音量計の例は、
AudioWorkletNode
のサブクラスとして
ネイティブ AudioNode
のように振る舞うノードの作成方法を
さらに示します。
コンストラクターオプションを受け取り、
AudioWorkletNode
と
AudioWorkletProcessor
間の
スレッド間通信(非同期)をカプセル化します。
このノードは出力を使いません。
/* vumeter-node.js: Main global scope */ export default class VUMeterNodeextends AudioWorkletNode{ constructor ( context, updateIntervalInMS) { super ( context, 'vumeter' , { numberOfInputs: 1 , numberOfOutputs: 0 , channelCount: 1 , processorOptions: { updateIntervalInMS: updateIntervalInMS|| 16.67 } }); // States in AudioWorkletNode this . _updateIntervalInMS= updateIntervalInMS; this . _volume= 0 ; // Handles updated values from AudioWorkletProcessor this . port. onmessage= event=> { if ( event. data. volume) this . _volume= event. data. volume; } this . port. start(); } get updateInterval() { return this . _updateIntervalInMS; } set updateInterval( updateIntervalInMS) { this . _updateIntervalInMS= updateIntervalInMS; this . port. postMessage({ updateIntervalInMS: updateIntervalInMS}); } draw() { // Draws the VU meter based on the volume value // every |this._updateIntervalInMS| milliseconds. } };
/* vumeter-processor.js: AudioWorkletGlobalScope */ const SMOOTHING_FACTOR= 0.9 ; const MINIMUM_VALUE= 0.00001 ; registerProcessor( 'vumeter' , class extends AudioWorkletProcessor{ constructor ( options) { super (); this . _volume= 0 ; this . _updateIntervalInMS= options. processorOptions. updateIntervalInMS; this . _nextUpdateFrame= this . _updateIntervalInMS; this . port. onmessage= event=> { if ( event. data. updateIntervalInMS) this . _updateIntervalInMS= event. data. updateIntervalInMS; } } get intervalInFrames() { return this . _updateIntervalInMS/ 1000 * sampleRate; } process( inputs, outputs, parameters) { const input= inputs[ 0 ]; // Note that the input will be down-mixed to mono; however, if no inputs are // connected then zero channels will be passed in. if ( input. length> 0 ) { const samples= input[ 0 ]; let sum= 0 ; let rms= 0 ; // Calculated the squared-sum. for ( let i= 0 ; i< samples. length; ++ i) sum+= samples[ i] * samples[ i]; // Calculate the RMS level and update the volume. rms= Math. sqrt( sum/ samples. length); this . _volume= Math. max( rms, this . _volume* SMOOTHING_FACTOR); // Update and sync the volume property with the main thread. this . _nextUpdateFrame-= samples. length; if ( this . _nextUpdateFrame< 0 ) { this . _nextUpdateFrame+= this . intervalInFrames; this . port. postMessage({ volume: this . _volume}); } } // Keep on processing if the volume is above a threshold, so that // disconnecting inputs does not immediately cause the meter to stop // computing its smoothed value. return this . _volume>= MINIMUM_VALUE; } });
/* index.js: Main global scope, entry point */ import VUMeterNodefrom './vumeter-node.js' ; const context= new AudioContext(); context. audioWorklet. addModule( 'vumeter-processor.js' ). then(() => { const oscillator= new OscillatorNode( context); const vuMeterNode= new VUMeterNode( context, 25 ); oscillator. connect( vuMeterNode); oscillator. start(); function drawMeter() { vuMeterNode. draw(); requestAnimationFrame( drawMeter); } drawMeter(); });
2. 処理モデル
2.1. 背景
この節は規範的ではありません。
低遅延が要求されるリアルタイムオーディオシステムは多くの場合、コールバック関数を使って実装されます。オペレーティングシステムが、再生を途切れさせないためにさらにオーディオを計算する必要があるとき、プログラムを呼び戻します。理想的にはこのコールバックは高優先度のスレッド(しばしばシステム上で最も高い優先度)で呼び出されます。つまり、オーディオを扱うプログラムはこのコールバックからのみコードを実行します。スレッド境界を越えたり、レンダリングスレッドとコールバックの間にバッファリングを追加すると、当然ながら遅延が増えたり、システムのグリッチ耐性が低下します。
このため、Webプラットフォームで非同期処理を行う従来の方法であるイベントループはここでは機能しません。なぜなら、スレッドが継続的に実行されているわけではないからです。さらに、従来の実行コンテキスト(WindowやWorker)では不要かつ潜在的にブロッキングとなる多くの操作が可能になっており、許容できるパフォーマンスを得る上で好ましくありません。
また、Workerモデルではスクリプト実行コンテキストのために専用スレッドを作成する必要がありますが、全ての AudioNode
は通常同じ実行コンテキストを共有します。
注: この節は最終結果がどうあるべきかを規定するものであり、実装方法を規定するものではありません。特に、メッセージキューを使う代わりに、実装者はスレッド間で共有されるメモリを使っても構いません。ただし、メモリ操作が順序変更されない限りです。
2.2. 制御スレッドとレンダリングスレッド
Web Audio API は 制御スレッド と レンダリングスレッド を使って実装しなければなりません。
制御スレッド は AudioContext
がインスタンス化されるスレッドであり、著者がオーディオグラフを操作する、つまり BaseAudioContext
の操作を呼び出すスレッドです。レンダリングスレッド は、実際のオーディオ出力が計算されるスレッドであり、制御スレッド からの呼び出しに応じて動作します。AudioContext
の場合はリアルタイム・コールバックベースのオーディオスレッド、OfflineAudioContext
の場合は通常のスレッドになることがあります。
制御スレッド は [HTML] で説明されている従来のイベントループを使います。
レンダリングスレッド は、オーディオグラフのレンダリングのセクションで説明される特化したレンダリングループを使います。
制御スレッド から レンダリングスレッド への通信は 制御メッセージのパスで行われます。逆方向の通信は従来のイベントループタスクで行われます。
各 AudioContext
には、制御メッセージキューがひとつあり、これは 制御メッセージのリストで、レンダリングスレッド上で動作する操作です。
制御メッセージをキューするとは、BaseAudioContext
の 制御メッセージキューの末尾にメッセージを追加することです。
注: 例えば、source の start()
を正常に呼び出すと、関連する AudioBufferSourceNode
の 制御メッセージが 制御メッセージキュー に追加されます。
制御メッセージは 制御メッセージキューで 挿入時刻順に並びます。最も古いメッセージは 制御メッセージキューの先頭にあるものです。
-
QC を新しい空の 制御メッセージキューとする。
-
QA の 制御メッセージをすべて QC に移動する。
-
QB の 制御メッセージをすべて QA に移動する。
-
QC の 制御メッセージをすべて QB に移動する。
2.3. 非同期操作
AudioNode
のメソッド呼び出しは事実上非同期であり、2段階で行わなければなりません:同期部分と非同期部分です。各メソッドの一部は 制御スレッドで実行され(例えばパラメータが不正な場合に例外を投げる等)、一部は レンダリングスレッドで実行されます(例えば AudioParam
の値を変更するなど)。
AudioNode や
BaseAudioContext
の各操作の説明では、同期部分が ⌛ で示されています。それ以外の操作は 並列で実行されます([HTML] 参照)。
同期部分は 制御スレッドで即座に実行されます。失敗した場合はメソッド実行は中止され、例外が投げられることがあります。成功した場合は、レンダリングスレッドで実行する操作を符号化した 制御メッセージがこの レンダリングスレッドの 制御メッセージキュー にエンキューされます。
同期部分と非同期部分の順序は他のイベントとの関係でも必ず同じでなければなりません:操作 A と B があり、それぞれ同期・非同期部分 ASync・AAsync、BSync・BAsync がある場合、A が B より先に発生したら ASync は BSync より先に、AAsync は BAsync より先に実行されます。つまり、同期・非同期部分は順序が入れ替わることはありません。
2.4. オーディオグラフのレンダリング
オーディオグラフのレンダリングは、サンプルフレームのブロック単位で行われ、そのブロックサイズは BaseAudioContext
のライフタイム中一定です。
ブロック内のサンプルフレーム数を レンダー量子サイズと呼び、ブロック自体は レンダー量子と呼ばれます。初期値は128で、renderSizeHintを設定することで変更可能です。
あるスレッド上でアトミックに発生する操作は、他のスレッドで別のアトミック操作が実行中でない場合にのみ実行できます。
BaseAudioContext
G および 制御メッセージキュー
Q から
オーディオのブロックをレンダリングするアルゴリズムは複数ステップからなり、グラフのレンダリングのアルゴリズムで詳しく説明されます。
AudioContext
のレンダリングスレッドは
システムレベルのオーディオコールバックによって定期的に駆動されます。
各コールには システムレベルのオーディオコールバックバッファサイズ があり、
次のシステムレベルのオーディオコールバックまでに
計算を完了すべきサンプルフレーム数です(サイズは可変)。
各システムレベルのオーディオコールバックごとに
負荷値が計算されます。これは実行時間を
システムレベルのオーディオコールバックバッファサイズで割り、
さらに sampleRate
で割った値です。
理想的には負荷値が1.0未満となり、再生にかかる時間より短時間でレンダリングできていることを意味します。オーディオバッファアンダーランはこの負荷値が1.0を超えたときに発生します。すなわちリアルタイムに十分速くレンダリングできない状態です。
システムレベルのオーディオコールバックや負荷値の概念は
OfflineAudioContextには適用されません。
オーディオコールバックは制御メッセージキューのタスクとしてもキューされます。UAは、こうしたタスクを満たすためにレンダー量子を処理してバッファサイズを埋めるため、以下のアルゴリズムを実行しなければなりません。
制御メッセージキューに加え、各 AudioContext
には通常の
タスクキューがあり、これは制御スレッドからレンダリングスレッドへ投稿されるタスク専用で、
関連付けタスクキューと呼ばれます。各レンダー量子処理後には、processメソッド実行中にキューされたマイクロタスクを実行するための追加のマイクロタスクチェックポイントが実行されます。
AudioWorkletNode
から投稿されたすべてのタスクは、
関連付けられた BaseAudioContext
の関連付けタスクキューに投稿されます。
-
BaseAudioContextの内部スロット[[current frame]]を 0 に設定する。同時にcurrentTimeも 0 に設定する。
-
render result を
falseとする。 -
制御メッセージキュー を処理する。
-
Qrendering を空の 制御メッセージキューとする。アトミックに 入れ替え を Qrendering と現在の 制御メッセージキュー の間で行う。
-
Qrendering にメッセージがある間、次の手順を繰り返す:
-
-
BaseAudioContextの 関連付けタスクキューを処理する。-
task queue を
BaseAudioContextの 関連付けタスクキューとする。 -
task count を task queue 内のタスク数とする。
-
task count が 0 でない間、次の手順を繰り返す:
-
oldest task を task queue 内で最初に実行可能なタスクとし、task queue から削除する。
-
レンダリングループの現在実行中タスクを oldest task に設定する。
-
oldest task のステップを実行する。
-
レンダリングループの現在実行中タスクを
nullに戻す。 -
task count をデクリメントする。
-
マイクロタスクチェックポイントを行う。
-
-
-
レンダー量子を処理する。
-
[[rendering thread state]]がrunningでない場合はfalseを返す。 -
BaseAudioContextのAudioNodeの処理順を決定する。-
ordered node list を空の
AudioNodeとAudioListenerのリストとする。アルゴリズム終了時に順序付けされたリストとなる。 -
nodes をこの
BaseAudioContextで作成され、まだ生存しているすべてのノードの集合とする。 -
AudioListenerを nodes に追加する。 -
cycle breakers を空の
DelayNodeの集合とする。サイクルに含まれるDelayNodeを格納する。 -
nodes 内の各
AudioNodenode について:-
node がサイクルに含まれる
DelayNodeの場合、cycle breakers に追加し、nodes から削除する。
-
-
cycle breakers 内の各
DelayNodedelay について:-
delayWriter と delayReader をそれぞれ DelayWriter と DelayReader として nodes に追加し、delay のすべての入力・出力を切断する。
注: これによりサイクルが解消される。サイクルに含まれる
DelayNodeは、両端を独立して扱える。サイクル内の遅延ラインはレンダー量子未満にはできない。
-
-
nodes 内のすべての要素は未マーク状態とする。未マーク要素がある間、次の手順を繰り返す:
-
nodes の要素から node を選択する。
-
Visit node を実行する。
-
-
ordered node list の順序を逆にする。
-
-
AudioListenerのAudioParamの値をこのブロックで 計算する。 -
ordered node list 内の各
AudioNodeについて:-
この
AudioNodeの各AudioParamについて次の手順を実行:-
この
AudioParamにAudioNodeが接続されている場合、すべてのAudioNodeが 読み取り可能としたバッファ を 合計し、モノラルチャンネルに ダウンミックスし、このバッファを 入力AudioParamバッファとする。 -
この
AudioParamの値をこのブロックで 計算する。 -
この
AudioParamの[[current value]]スロットを § 1.6.3 値の計算に従って設定する 制御メッセージをキューする。
-
-
この
AudioNodeに入力が接続されている場合、すべてのAudioNodeの 読み取り可能としたバッファ を 合計し、入力チャンネル数に合わせて アップ/ダウンミックスする。得られたバッファを 入力バッファとする。 -
この
AudioNodeが ソースノード の場合は、オーディオブロックを計算し、読み取り可能とする。 -
この
AudioNodeがAudioWorkletNodeの場合は次のサブステップを実行:-
processor を
AudioWorkletNodeに関連付けられたAudioWorkletProcessorインスタンスとする。 -
O を processor に対応する ECMAScript オブジェクトとする。
-
processCallback を初期化されていない変数とする。
-
completion を初期化されていない変数とする。
-
スクリプトを実行する準備を 現在の設定オブジェクトで行う。
-
コールバックを実行する準備を 現在の設定オブジェクトで行う。
-
getResult を Get(O, "process") とする。
-
getResult が abrupt completion の場合、completion に getResult を設定し、return のラベルへジャンプする。
-
processCallback を getResult.[[Value]] に設定する。
-
! IsCallable(processCallback) が
falseの場合:-
completion に新しく作成した Completion {[[Type]]: throw, [[Value]]: 新しい TypeError オブジェクト, [[Target]]: 空} を設定する。
-
return のラベルへのジャンプ。
-
-
[[callable process]]をtrueに設定する。 -
以下のサブステップを実行:
-
args を
inputs、outputs、parametersからなる Web IDL 引数リストとする。 -
esArgs を args を ECMAScript 引数リストへ変換した結果とする。
-
callResult を Call(processCallback, O, esArgs) とする。この操作で オーディオブロックが計算される。正常終了時は
Float32Arrayのコピーされた要素を含むバッファが 読み取り可能とする。この呼び出し内で解決されたPromiseはAudioWorkletGlobalScopeのマイクロタスクキューにキューされる。 -
callResult が abrupt completion の場合は completion に callResult を設定し、return のラベルへジャンプ。
-
processor の active source フラグを ToBoolean(callResult.[[Value]]) に設定する。
-
-
Return: この時点で completion は ECMAScript completion 値となっている。
-
コールバック実行後の後処理を 現在の設定オブジェクトで行う。
-
スクリプト実行後の後処理を 現在の設定オブジェクトで行う。
-
completion が abrupt completion の場合:
-
[[callable process]]をfalseに設定する。 -
processor の active source フラグを
falseに設定する。 -
タスクをキューし、制御スレッドで processorerror イベントを発火し、関連付けられた
AudioWorkletNodeでErrorEventを使う。
-
-
-
-
この
AudioNodeが 出力ノード(destination node) の場合は、入力を記録する。
-
-
アトミックに次の手順を実行する:
-
[[current frame]]を レンダー量子サイズ分インクリメントする。 -
currentTimeを[[current frame]]をsampleRateで割った値に設定する。
-
-
render result を
trueに設定する。
-
-
render result を返す。
ミュート(Muting)とは、AudioNode の
出力が、このオーディオブロックのレンダリング中必ず無音になることを意味します。
バッファを読み取り可能にする(Making a
buffer
available for reading)とは、AudioNode の
バッファが、この AudioNode
に接続された
他の AudioNode から
安全に読み出せる状態にすることです。
注: 例えば、実装では新しいバッファを割り当てたり、未使用となった既存バッファを再利用するなど、より高度な機構を採用することもできます。
入力の記録(Recording the
input)とは、AudioNode の
入力データを将来利用するためにコピーすることです。
オーディオブロックの計算(Computing a block
of audio)とは、この AudioNode
のアルゴリズムを実行し、[[render quantum size]]
サンプルフレームを生成することです。
入力バッファの処理(Processing an
input buffer)とは、
AudioNode
のアルゴリズムを実行し、入力バッファと、この AudioNode の
AudioParam
の値を入力として用いることです。
2.5. AudioContext
でシステムオーディオリソースのエラーを扱う方法
AudioContext
audioContext は、オーディオシステムリソースのエラー発生時、レンダリングスレッドで次の手順を実行します。
-
audioContext の
[[rendering thread state]]がrunningである場合:-
システムリソースの解放を試みる。
-
audioContext の
[[rendering thread state]]をsuspendedに設定する。 -
メディア要素タスクをキューし、次の手順を実行する:
-
error イベントを audioContext で発火する。イベント名は
error。 -
audioContext の
[[suspended by user]]をfalseに設定する。 -
audioContext の
[[control thread state]]をsuspendedに設定する。
-
-
これらの手順を中止する。
-
-
audioContext の
[[rendering thread state]]がsuspendedである場合:-
メディア要素タスクをキューし、次の手順を実行する:
-
error イベントを audioContext で発火する。イベント名は
error。
-
-
注: システムオーディオリソースのエラーの例としては、AudioContext
のアクティブレンダリング中に外部またはワイヤレスのオーディオデバイスが切断される場合などが挙げられます。
2.6. ドキュメントのアンロード
BaseAudioContext
を使用するドキュメントに対して、追加の アンロード時クリーンアップ手順
が定義されています:
-
関連するグローバルオブジェクトがドキュメントの関連付けWindowと同じである
AudioContextおよびOfflineAudioContextの[[pending promises]]のすべての promise をInvalidStateErrorでrejectする。 -
すべての
decoding threadを停止する。 -
AudioContextまたはOfflineAudioContextに対してclose()を呼び出す 制御メッセージをキューする。
3. 動的ライフタイム
3.1. 背景
注: AudioContext
および AudioNode
のライフタイム特性の規範的な説明は AudioContextのライフタイムおよび AudioNodeのライフタイム で記載されています。
この節は規範的ではありません。
静的なルーティング構成の作成だけでなく、有限のライフタイムを持つ動的に割り当てられるボイスでカスタムエフェクトルーティングを行うことも可能であるべきです。本節では、このような短命なボイスを「ノート」と呼びます。多くのオーディオアプリケーションでノートの概念が使われており、例としてドラムマシン、シーケンサー、ゲーム中の多数のワンショットサウンドがあります。
従来のソフトウェアシンセサイザーでは、ノートは利用可能なリソースプールから動的に割り当て・解放されます。MIDIノートオンメッセージを受信するとノートが割り当てられ、サンプルデータの終端到達(非ループ)、エンベロープのサステインフェーズがゼロになる、MIDIノートオフメッセージでリリースフェーズに入る、などで再生終了時にノートが解放されます。MIDIノートオフの場合、リリースエンベロープフェーズが終了するまでノートはすぐには解放されません。常時多くのノートが再生されていても、ノート集合は新規ノートの追加と既存ノートの解放で絶えず変化します。
オーディオシステムは「ノート」イベントごとにルーティンググラフの該当部分を自動で解体します。「ノート」は AudioBufferSourceNode
で表現され、
他の処理ノードに直接接続できます。ノート再生終了時、contextは AudioBufferSourceNode
への参照を自動で解放し、
これにより接続されているノードへの参照も解放されます。これらのノードはグラフから自動で切断され、参照がなくなれば削除されます。グラフ内で長寿命かつ複数ボイスで共有するノードは明示的に管理できます。複雑そうですが、追加処理不要で自動的に行われます。
3.2. 例
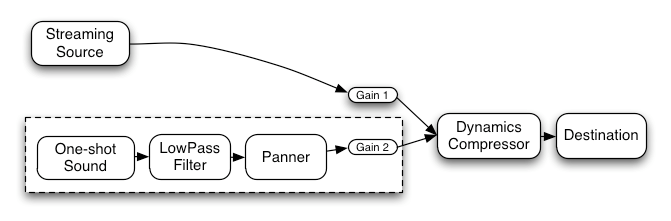
ローパスフィルター、パンナー、2つ目のゲインノードはワンショットサウンドから直接接続されています。再生終了時、contextが自動で(点線内の全て)を解放します。ワンショットサウンドや接続ノードへの参照がなければ直ちにグラフから削除・消去されます。ストリーミングソースはグローバル参照があり、明示的切断まで接続されたままです。JavaScriptでの例は以下の通りです:
let context= 0 ; let compressor= 0 ; let gainNode1= 0 ; let streamingAudioSource= 0 ; // 「長寿命」部分の初期セットアップ function setupAudioContext() { context= new AudioContext(); compressor= context. createDynamicsCompressor(); gainNode1= context. createGain(); // ストリーミングオーディオソースの作成 const audioElement= document. getElementById( 'audioTagID' ); streamingAudioSource= context. createMediaElementSource( audioElement); streamingAudioSource. connect( gainNode1); gainNode1. connect( compressor); compressor. connect( context. destination); } // 後でユーザー操作(通常はマウスやキーイベント)に応じて // ワンショットサウンドを再生できる function playSound() { const oneShotSound= context. createBufferSource(); oneShotSound. buffer= dogBarkingBuffer; // フィルター、パンナー、ゲインノード作成 const lowpass= context. createBiquadFilter(); const panner= context. createPanner(); const gainNode2= context. createGain(); // 接続 oneShotSound. connect( lowpass); lowpass. connect( panner); panner. connect( gainNode2); gainNode2. connect( compressor); // 今から0.75秒後に再生(即座に再生するには0を渡す) oneShotSound. start( context. currentTime+ 0.75 ); }
4. チャンネルのアップミックス・ダウンミックス
この節は現行標準です。
AudioNode の入力には、すべての接続されたチャンネルを合成する ミキシング規則 があります。簡単な例として、入力がモノラル出力とステレオ出力から接続されている場合、通常はモノラル接続がステレオにアップミックスされ、ステレオ接続と合算されます。しかし、もちろん全ての AudioNode の各入力に対して正確な ミキシング規則を定義することが重要です。すべての入力のデフォルトミキシング規則は、特にモノラル・ステレオストリームの非常に一般的なケースにおいて、細部を気にせずとも「とりあえず動く」よう選択されています。高度な用途、とくにマルチチャンネルの場合は規則を変更できます。
用語定義として、アップミックスは少ないチャンネル数のストリームを多いチャンネル数のストリームに変換する処理、ダウンミックスは多いチャンネル数のストリームを少ないチャンネル数のストリームに変換する処理です。
AudioNode
の入力は、接続されたすべての出力をミックスする必要があります。この過程で、任意のタイミングにおける実際の入力チャンネル数を表す内部値 computedNumberOfChannels
を計算します。
AudioNode
の入力について、実装は以下を行わなければなりません:
-
computedNumberOfChannels を計算する。
-
入力への各接続について:
-
ノードの
channelInterpretation属性で指定されたChannelInterpretation値に従い、接続を computedNumberOfChannels に アップミックス または ダウンミックス する。 -
他の接続(他のストリーム)と合算してミックスする。このとき、各接続でステップ1で アップミックスまたはダウンミックスされた対応チャンネルごとに単純加算する。
-
4.1. スピーカーチャンネルレイアウト
channelInterpretation
が
"speakers"
の場合、アップミックス および ダウンミックスは特定のチャンネルレイアウトについて定義されます。
モノラル(1チャンネル)、ステレオ(2チャンネル)、クアッド(4チャンネル)、5.1(6チャンネル)は必ずサポートされなければなりません。他のチャンネルレイアウトは現行標準の将来バージョンでサポートされる可能性があります。
4.2. チャンネル順序
チャンネル順序は以下の表で定義されます。個々のマルチチャンネルフォーマットは全ての中間チャンネルをサポートしない場合があります。実装は、下記で定義された順番でチャンネルを提供し、存在しないチャンネルはスキップしなければなりません。
| 順序 | ラベル | モノ | ステレオ | クアッド | 5.1 |
|---|---|---|---|---|---|
| 0 | SPEAKER_FRONT_LEFT | 0 | 0 | 0 | 0 |
| 1 | SPEAKER_FRONT_RIGHT | 1 | 1 | 1 | |
| 2 | SPEAKER_FRONT_CENTER | 2 | |||
| 3 | SPEAKER_LOW_FREQUENCY | 3 | |||
| 4 | SPEAKER_BACK_LEFT | 2 | 4 | ||
| 5 | SPEAKER_BACK_RIGHT | 3 | 5 | ||
| 6 | SPEAKER_FRONT_LEFT_OF_CENTER | ||||
| 7 | SPEAKER_FRONT_RIGHT_OF_CENTER | ||||
| 8 | SPEAKER_BACK_CENTER | ||||
| 9 | SPEAKER_SIDE_LEFT | ||||
| 10 | SPEAKER_SIDE_RIGHT | ||||
| 11 | SPEAKER_TOP_CENTER | ||||
| 12 | SPEAKER_TOP_FRONT_LEFT | ||||
| 13 | SPEAKER_TOP_FRONT_CENTER | ||||
| 14 | SPEAKER_TOP_FRONT_RIGHT | ||||
| 15 | SPEAKER_TOP_BACK_LEFT | ||||
| 16 | SPEAKER_TOP_BACK_CENTER | ||||
| 17 | SPEAKER_TOP_BACK_RIGHT |
4.3. テールタイムが入力・出力チャンネル数に与える影響
AudioNode が
非ゼロの テールタイム
を持ち、出力チャンネル数が入力チャンネル数に依存する場合、入力チャンネル数が変化した際は AudioNode の
テールタイム を考慮しなければなりません。
入力チャンネル数が減少した場合、出力チャンネル数の変更は、より多いチャンネル数で受け取った入力が出力に影響しなくなったタイミングで行わなければなりません。
入力チャンネル数が増加した場合、その挙動は AudioNode
の型によって異なります:
-
DelayNodeやDynamicsCompressorNodeの場合は、 より多くのチャンネル数で受け取った入力が出力に影響するタイミングで出力チャンネル数を増やさなければなりません。 -
その他の
AudioNodeで テールタイム を持つものは、即座に出力チャンネル数を増やさなければなりません。注:
ConvolverNodeの場合は、インパルス応答がモノラルの場合にのみ該当し、それ以外ではConvolverNodeは入力チャンネル数に関係なく常にステレオ出力となります。
注: 直感的には、これは処理中にステレオ情報が失われないようにするためです。複数の入力レンダー量子が異なるチャンネル数で出力レンダー量子に寄与する場合、出力レンダー量子のチャンネル数は入力レンダー量子のチャンネル数の上位集合となります。
4.4. スピーカーレイアウトのアップミックス
モノラルのアップミックス:
1 -> 2 : モノラルからステレオへのアップミックス
output.L = input;
output.R = input;
1 -> 4 : モノラルからクアッドへのアップミックス
output.L = input;
output.R = input;
output.SL = 0;
output.SR = 0;
1 -> 5.1 : モノラルから5.1へのアップミックス
output.L = 0;
output.R = 0;
output.C = input; // センターに入れる
output.LFE = 0;
output.SL = 0;
output.SR = 0;
ステレオのアップミックス:
2 -> 4 : ステレオからクアッドへのアップミックス
output.L = input.L;
output.R = input.R;
output.SL = 0;
output.SR = 0;
2 -> 5.1 : ステレオから5.1へのアップミックス
output.L = input.L;
output.R = input.R;
output.C = 0;
output.LFE = 0;
output.SL = 0;
output.SR = 0;
クアッドのアップミックス:
4 -> 5.1 : クアッドから5.1へのアップミックス
output.L = input.L;
output.R = input.R;
output.C = 0;
output.LFE = 0;
output.SL = input.SL;
output.SR = input.SR;
4.5. スピーカーレイアウトのダウンミックス
例えば、5.1ソース素材をステレオ再生する場合など、ダウンミックスが必要となります。
モノラルへのダウンミックス:
2 -> 1 : ステレオからモノラル
output = 0.5 * (input.L + input.R);
4 -> 1 : クアッドからモノラル
output = 0.25 * (input.L + input.R + input.SL + input.SR);
5.1 -> 1 : 5.1からモノラル
output = sqrt(0.5) * (input.L + input.R) + input.C + 0.5 * (input.SL + input.SR)
ステレオへのダウンミックス:
4 -> 2 : クアッドからステレオ
output.L = 0.5 * (input.L + input.SL);
output.R = 0.5 * (input.R + input.SR);
5.1 -> 2 : 5.1からステレオ
output.L = L + sqrt(0.5) * (input.C + input.SL)
output.R = R + sqrt(0.5) * (input.C + input.SR)
クアッドへのダウンミックス:
5.1 -> 4 : 5.1からクアッド
output.L = L + sqrt(0.5) * input.C
output.R = R + sqrt(0.5) * input.C
output.SL = input.SL
output.SR = input.SR
4.6. チャンネル規則の例
// Set gain node to explicit 2-channels (stereo). gain. channelCount= 2 ; gain. channelCountMode= "explicit" ; gain. channelInterpretation= "speakers" ; // Set "hardware output" to 4-channels for DJ-app with two stereo output busses. context. destination. channelCount= 4 ; context. destination. channelCountMode= "explicit" ; context. destination. channelInterpretation= "discrete" ; // Set "hardware output" to 8-channels for custom multi-channel speaker array // with custom matrix mixing. context. destination. channelCount= 8 ; context. destination. channelCountMode= "explicit" ; context. destination. channelInterpretation= "discrete" ; // Set "hardware output" to 5.1 to play an HTMLAudioElement. context. destination. channelCount= 6 ; context. destination. channelCountMode= "explicit" ; context. destination. channelInterpretation= "speakers" ; // Explicitly down-mix to mono. gain. channelCount= 1 ; gain. channelCountMode= "explicit" ; gain. channelInterpretation= "speakers" ;
5. オーディオ信号値
5.1. オーディオサンプルフォーマット
線形パルス符号変調(linear PCM)は、オーディオ値が定期的な間隔でサンプリングされ、連続する値間の量子化レベルが線形に均一なフォーマットを示します。
この仕様で信号値がスクリプトに公開される場合、それらは線形32ビット浮動小数点パルス符号変調フォーマット(線形32ビット float PCM)となっており、しばしば Float32Array
オブジェクトの形で提供されます。
5.2. レンダリング
任意のオーディオグラフの出力ノードにおける全てのオーディオ信号の範囲は、標準的に [-1, 1] です。この範囲外の信号値、または
NaN、正の無限大あるいは負の無限大となる値のオーディオ再生は、本仕様では定義されません。
6. 空間化・パンニング
6.1. 背景
現代の3Dゲームにおける一般的な機能要件は、複数のオーディオソースを3D空間で動的に空間化・移動できることです。例えば OpenAL にはこの機能があります。
PannerNode
を使うことで、オーディオストリームを
AudioListener
を基準に空間化または空間上の位置指定が可能です。
BaseAudioContext
には必ず1つの
AudioListener
が含まれます。
パナーとリスナーは共に、右手系のデカルト座標系を用いた3D空間上の位置を持ちます。座標系で使う単位(例:メートル、フィートなど)は定義されていません。これは、これら座標によって計算される効果が、特定の単位に依存せず不変であるためです。
PannerNode
オブジェクト(音源ストリームを表す)は、音が投射される方向を示す orientation ベクトルを持ちます。さらに、音の指向性を示す sound cone
を持ちます。例えば、音が全方位型(オムニディレクショナル)であれば、どの方向でも聞こえますが、より指向性がある場合はリスナーの方向を向いているときのみ聞こえます。
AudioListener
オブジェクト(人の耳を表す)は、forward および up ベクトルを持ち、人物が向いている方向を示します。
空間化用の座標系は、以下の図にデフォルト値とともに示されています。AudioListener
と PannerNode
の位置は、分かりやすくするためデフォルトから移動されています。

レンダリング中、PannerNode
は azimuth(方位角) と elevation(仰角) を計算します。これらの値は空間化効果をレンダリングするために内部的に利用されます。これらの値の利用方法の詳細は パンニングアルゴリズムのセクションを参照してください。
6.2. 方位角と仰角
以下のアルゴリズムは、PannerNode
の azimuth(方位角)および elevation(仰角)を計算するために必ず使用されなければなりません。実装は、以下の様々な AudioParam
が "a-rate"
か "k-rate"
かを適切に考慮しなければなりません。
// |context| を BaseAudioContext、|panner| を // context内で作成されたPannerNodeとする。 // ソース-リスナーのベクトルを計算する。 const listener= context. listener; const sourcePosition= new Vec3( panner. positionX. value, panner. positionY. value, panner. positionZ. value); const listenerPosition= new Vec3( listener. positionX. value, listener. positionY. value, listener. positionZ. value); const sourceListener= sourcePosition. diff( listenerPosition). normalize(); if ( sourceListener. magnitude== 0 ) { // ソースとリスナーが同一位置の場合の退化ケース処理。 azimuth= 0 ; elevation= 0 ; return ; } // 軸を整列。 const listenerForward= new Vec3( listener. forwardX. value, listener. forwardY. value, listener. forwardZ. value); const listenerUp= new Vec3( listener. upX. value, listener. upY. value, listener. upZ. value); const listenerRight= listenerForward. cross( listenerUp); if ( listenerRight. magnitude== 0 ) { // リスナーの「up」と「forward」ベクトルが線形従属の場合、 // 「right」が決定できないケースの処理 azimuth= 0 ; elevation= 0 ; return ; } // リスナーのright, forwardに垂直な単位ベクトルを決定する const listenerRightNorm= listenerRight. normalize(); const listenerForwardNorm= listenerForward. normalize(); const up= listenerRightNorm. cross( listenerForwardNorm); const upProjection= sourceListener. dot( up); const projectedSource= sourceListener. diff( up. scale( upProjection)). normalize(); azimuth= 180 * Math. acos( projectedSource. dot( listenerRightNorm)) / Math. PI; // ソースがリスナーの前方か後方かを判定。 const frontBack= projectedSource. dot( listenerForwardNorm); if ( frontBack< 0 ) azimuth= 360 - azimuth; // azimuthをリスナー「right」ベクトルではなく「forward」ベクトル基準に調整。 if (( azimuth>= 0 ) && ( azimuth<= 270 )) azimuth= 90 - azimuth; else azimuth= 450 - azimuth; elevation= 90 - 180 * Math. acos( sourceListener. dot( up)) / Math. PI; if ( elevation> 90 ) elevation= 180 - elevation; else if ( elevation< - 90 ) elevation= - 180 - elevation;
6.3. パンニングアルゴリズム
モノラル→ステレオおよびステレオ→ステレオのパンニングは必須です。モノラル→ステレオ処理は、すべての入力接続がモノラルの場合に使用されます。それ以外はステレオ→ステレオ処理が用いられます。
6.3.1. PannerNode「equalpower」パンニング
これは、基本的で合理的な結果を提供する、シンプルで比較的低コストなアルゴリズムです。
PannerNode
で panningModel
属性が
"equalpower"
に設定されている場合に使用されます。この場合elevation値は無視されます。アルゴリズムは
automationRate
で指定された適切なレートで必ず実装しなければなりません。
PannerNodeの
AudioParam
や
AudioListenerの
AudioParam
が
"a-rate"
の場合、a-rate処理を用いる必要があります。
-
この
AudioNodeが計算する各サンプルについて:-
azimuthは方位角と仰角のセクションで計算された値とする。
-
azimuth値を次のように [-90, 90] 範囲に収める:
// まず azimuth を [-180, 180] の範囲にクランプ。 azimuth= max( - 180 , azimuth); azimuth= min( 180 , azimuth); // 次に [-90, 90] の範囲にラップ。 if ( azimuth< - 90 ) azimuth= - 180 - azimuth; else if ( azimuth> 90 ) azimuth= 180 - azimuth; -
正規化値 x は、モノラル入力の場合 azimuth から次のように計算される:
x
= ( azimuth+ 90 ) / 180 ; ステレオ入力の場合:
if ( azimuth<= 0 ) { // -90 → 0 // azimuth値 [-90, 0] 度を [-90, 90] の範囲へ変換。 x= ( azimuth+ 90 ) / 90 ; } else { // 0 → 90 // azimuth値 [0, 90] 度を [-90, 90] の範囲へ変換。 x= azimuth/ 90 ; } -
左右のゲイン値は次のように計算:
gainL
= cos( x* Math. PI/ 2 ); gainR= sin( x* Math. PI/ 2 ); -
モノラル入力の場合、ステレオ出力は次のように計算:
outputL
= input* gainL; outputR= input* gainR; ステレオ入力の場合の出力:
if ( azimuth<= 0 ) { outputL= inputL+ inputR* gainL; outputR= inputR* gainR; } else { outputL= inputL* gainL; outputR= inputR+ inputL* gainR; } -
距離ゲインとコーンゲインを適用。距離の計算は距離効果、コーンゲインはサウンドコーン参照:
let distance= distance(); let distanceGain= distanceModel( distance); let totalGain= coneGain() * distanceGain(); outputL= totalGain* outputL; outputR= totalGain* outputR;
-
6.3.2. PannerNode「HRTF」パンニング(ステレオのみ)
これは様々な方位角・仰角で記録されたHRTF (頭部伝達関数)のインパルス応答セットを必要とします。実装には高効率な畳み込み関数が必要です。「equalpower」より計算コストは高いですが、より知覚的に空間化されたサウンドを提供します。
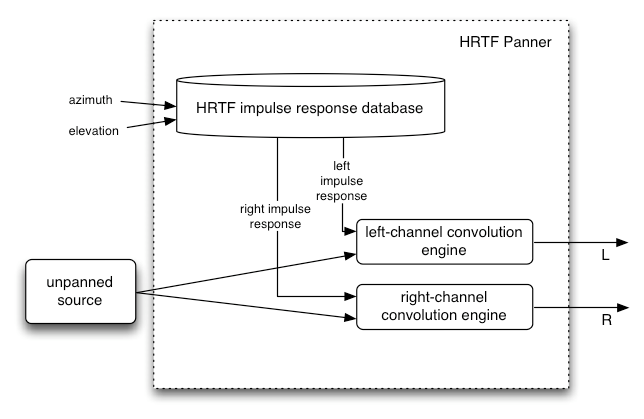
6.3.3. StereoPannerNode パンニング
StereoPannerNode
について、次のアルゴリズムが必ず実装されなければなりません。
-
この
AudioNodeが計算する各サンプルについて:-
panはこの
panAudioParamのcomputedValueとする。 -
panを [-1, 1] にクランプ:
pan
= max( - 1 , pan); pan= min( 1 , pan); -
pan値を正規化して [0, 1] の範囲にする。モノラル入力の場合:
x
= ( pan+ 1 ) / 2 ; ステレオ入力の場合:
if ( pan<= 0 ) x= pan+ 1 ; else x= pan; -
左右のゲイン値を次のように計算:
gainL
= cos( x* Math. PI/ 2 ); gainR= sin( x* Math. PI/ 2 ); -
モノラル入力の場合、ステレオ出力は次のように計算:
outputL
= input* gainL; outputR= input* gainR; ステレオ入力の場合の出力:
if ( pan<= 0 ) { outputL= inputL+ inputR* gainL; outputR= inputR* gainR; } else { outputL= inputL* gainL; outputR= inputR+ inputL* gainR; }
-
6.4. 距離効果
音源が近いほど音が大きくなり、遠いほど小さくなります。音量が距離によってどのように変化するかは、distanceModel
属性によって決まります。
オーディオレンダリング中、distance値はパナーとリスナーの位置から次のように計算されます:
function distance( panner) { const pannerPosition= new Vec3( panner. positionX. value, panner. positionY. value, panner. positionZ. value); const listener= context. listener; const listenerPosition= new Vec3( listener. positionX. value, listener. positionY. value, listener. positionZ. value); return pannerPosition. diff( listenerPosition). magnitude; }
distanceは、distanceModel
属性に応じてdistanceGainの計算に使われます。各距離モデルの計算方法はDistanceModelType
セクションを参照してください。
処理の一部として、PannerNode
は入力オーディオ信号にdistanceGainを掛けて、遠い音を小さく、近い音を大きくします。
6.5. サウンドコーン
リスナーと各音源は向いている方向を示すオリエンテーションベクトルを持ちます。各音源の投射特性は「内側コーン」と「外側コーン」で記述され、音源の方向ベクトルからのソース/リスナー角度に応じた音の強度を示します。つまり、音源がリスナーの正面を向いているときは音が大きく、軸から外れるほど小さくなります。音源は全方位型(オムニディレクショナル)にもできます。
次の図は音源のコーンとリスナーの関係を示します。図中で
coneInnerAngle
= 50coneOuterAngle
= 120

次のアルゴリズムは、音源(PannerNode)とリスナーを与えてコーン効果によるゲイン寄与を計算するために必ず使用されなければなりません:
function coneGain() { const sourceOrientation= new Vec3( source. orientationX, source. orientationY, source. orientationZ); if ( sourceOrientation. magnitude== 0 || (( source. coneInnerAngle== 360 ) && ( source. coneOuterAngle== 360 ))) return 1 ; // コーン指定なし - ゲイン1 // 正規化されたソース-リスナーベクトル const sourcePosition= new Vec3( panner. positionX. value, panner. positionY. value, panner. positionZ. value); const listenerPosition= new Vec3( listener. positionX. value, listener. positionY. value, listener. positionZ. value); const sourceToListener= sourcePosition. diff( listenerPosition). normalize(); const normalizedSourceOrientation= sourceOrientation. normalize(); // ソースのオリエンテーションベクトルとソース-リスナーベクトルの角度 const angle= 180 * Math. acos( sourceToListener. dot( normalizedSourceOrientation)) / Math. PI; const absAngle= Math. abs( angle); // ここで2で割る理由は、APIが全角度(半角度ではなく)を扱うため const absInnerAngle= Math. abs( source. coneInnerAngle) / 2 ; const absOuterAngle= Math. abs( source. coneOuterAngle) / 2 ; let gain= 1 ; if ( absAngle<= absInnerAngle) { // 減衰なし gain= 1 ; } else if ( absAngle>= absOuterAngle) { // 最大減衰 gain= source. coneOuterGain; } else { // 内側と外側のコーンの間 // inner → outer, xは0→1 const x= ( absAngle- absInnerAngle) / ( absOuterAngle- absInnerAngle); gain= ( 1 - x) + source. coneOuterGain* x; } return gain; }
7. パフォーマンス考慮事項
7.1. レイテンシ
ウェブアプリケーションでは、マウスやキーボードイベント(keydown、mousedownなど)と音が聞こえるまでの遅延時間が重要です。
この遅延時間はレイテンシと呼ばれ、複数の要因(入力デバイスのレイテンシ、内部バッファのレイテンシ、DSP処理のレイテンシ、出力デバイスのレイテンシ、ユーザーの耳とスピーカーの距離など)によって生じ、累積します。レイテンシが大きいほど、ユーザー体験は満足度が下がります。極端に大きい場合は音楽制作やゲームプレイが不可能になることもあります。中程度でもタイミングに影響し、音が遅れて聞こえたりゲームが反応しない印象を与えます。音楽アプリではリズムに、ゲームではプレイの精度に影響します。インタラクティブアプリでは、極端に低いアニメーションフレームレートと同様、体験を損ないます。用途によって許容されるレイテンシは3~6ミリ秒から25~50ミリ秒まで様々です。
実装は一般的に全体のレイテンシを最小化するよう努めます。
全体のレイテンシの最小化とともに、実装はAudioContext
のcurrentTimeとAudioProcessingEvent
のplaybackTimeの差も最小化しようとします。
ScriptProcessorNode
の廃止により、この考慮は今後重要性が下がります。
さらに、いくつかのAudioNode
はオーディオグラフの一部経路にレイテンシを追加する場合があります。具体的には:
-
AudioWorkletNodeは内部バッファを持つスクリプトを実行し、信号経路に遅延を加えることがあります。 -
DelayNodeは、制御された遅延時間を加える役割を持ちます。 -
BiquadFilterNodeやIIRFilterNodeのフィルタ設計は、因果フィルタ処理の結果として入力サンプルを遅延させます。 -
ConvolverNodeは、インパルスによって入力サンプルを畳み込み処理の結果遅延させます。 -
DynamicsCompressorNodeは先読みアルゴリズムを用いて信号経路に遅延を生じさせます。 -
MediaStreamAudioSourceNode、MediaStreamTrackAudioSourceNode、MediaStreamAudioDestinationNodeは、実装によっては内部バッファを追加し遅延を生じさせる場合があります。 -
ScriptProcessorNodeは制御スレッドとレンダリングスレッド間にバッファを持つことがあります。 -
WaveShaperNodeはオーバーサンプリング時、手法によって信号経路に遅延を生じさせます。
7.2. オーディオバッファコピー
acquire the content操作がAudioBuffer
に対して行われる際、通常チャンネルデータのコピーを行うことなく処理できます。特に、最後のステップは次回のgetChannelData()
呼び出し時に遅延実行すべきです。
すなわち、複数回連続してacquire the
contents操作を行い、間にgetChannelData()
を挟まない場合(例:同じAudioBufferSourceNode
で複数回再生)では、割り当てやコピーなしで実装可能です。
さらに実装は追加の最適化が可能です:
getChannelData()
がAudioBuffer
で呼び出されたとき、まだ新しいArrayBuffer
が割り当てられていないが、以前のacquire the
content操作の呼び出し元がAudioBuffer
のデータ使用を終了していれば、生データバッファを新しいAudioBuffer
に再利用でき、チャンネルデータの再割り当てやコピーを回避できます。
7.3. AudioParam遷移
value
属性を直接設定しても自動的なスムージングは行われませんが、特定のパラメータについては値を直接設定するよりも滑らかな遷移が望ましいです。
setTargetAtTime()
メソッドを低いtimeConstantとともに使うことで、滑らかな遷移を実現できます。
7.4. オーディオのグリッチ(音切れ)
オーディオのグリッチは、通常の連続したオーディオストリームが途切れることで発生し、大きなクリック音やポップ音となります。これはマルチメディアシステムにおける致命的な障害とされ、必ず回避しなければなりません。オーディオストリームをハードウェアへ届けるスレッドに問題が生じる(スレッドの優先度や時間制約が適切でないためのスケジューリングレイテンシなど)ことで発生する場合や、オーディオDSPがCPU速度に対してリアルタイム処理できる以上の負荷を要求している場合などが原因となります。
8. セキュリティとプライバシーの考慮事項
Self-Review Questionnaire: Security and Privacy § questionsに従い:
-
この仕様は個人識別可能情報を扱いますか?
Web Audio APIを使って聴力検査を行うことが可能であり、個人が聞き取れる周波数範囲(年齢とともに低下)を明らかにできます。ただし、これはユーザーの自覚的参加と同意なしには難しく、能動的な操作が必要です。
-
この仕様は高価値データを扱いますか?
いいえ。Web Audioでクレジットカード情報などは利用されません。Web Audioを使って音声データの処理や分析は可能ですが、ユーザーのマイクへのアクセスは
getUserMedia()による許可制です。 -
この仕様は、セッションをまたいでオリジンに新しい状態を導入しますか?
いいえ。AudioWorkletはセッションをまたいで保持されません。
-
この仕様は、永続的かつクロスオリジンな状態をWebに公開しますか?
はい。サポートされるオーディオサンプルレートや出力デバイスのチャンネル数が公開されます。
AudioContext参照。 -
この仕様は、オリジンが現在アクセスできない他のデータを公開しますか?
はい。利用可能な
AudioNodeに関する情報をWeb Audio APIが公開することにより、クライアントの特徴(例:オーディオハードウェアのサンプルレート)をページが取得可能です。さらに、AnalyserNodeやScriptProcessorNodeでタイミング情報を収集できます。これら情報はクライアントのフィンガープリント生成に用いられる可能性があります。Princeton CITPのWeb Transparency and Accountability Projectによる研究では、
DynamicsCompressorNodeやOscillatorNodeでクライアントからエントロピーを取得し、デバイスのフィンガープリント化が可能であると示されています。これは、異なる実装間のDSPアーキテクチャ、リサンプリング戦略や丸め処理の差異、コンパイラフラグやCPUアーキテクチャ(ARM vs. x86)による細かな、通常は可聴でない違いが原因です。しかし実際には、これにより得られる情報は(User Agent文字列など)より簡単な手段ですでに得られるものとほぼ同じです。「このブラウザXはプラットフォームY上で動作中」といった情報です。ただし追加的なフィンガープリント可能性を減らすため、各ノードの出力によるフィンガープリント化を抑制する措置をブラウザに求めます。
クロックスキューによるフィンガープリントについては、Steven J MurdochとSebastian Zanderによる記述があります。
getOutputTimestampで検出できる可能性があります。SkewベースのフィンガープリントはNakiblyらによるHTMLの例でも示されています。詳細はHigh Resolution Time § 10. Privacy Considerationsを参照してください。レイテンシによるフィンガープリントも可能です。これは
baseLatencyやoutputLatencyから推測できる場合があります。対策としてジッタ(ディザ)や量子化を加え、正確なスキューが誤って報告されるようにします。ただしほとんどのオーディオシステムは低レイテンシを目指しており、WebAudioで生成されるオーディオを他のオーディオ・ビデオソースや視覚的キューと同期させる必要があります(例:ゲームや音楽制作環境)。過剰なレイテンシは使い勝手を損ない、アクセシビリティの問題となることもあります。AudioContextのサンプルレートによるフィンガープリント化も可能です。これを最小化するために以下を推奨します:-
44.1kHzと48kHzがデフォルトレートとして許可され、システムは最適なものを選択します。(デバイスが44.1なら44.1を、96kHzなら48kHzなど、最も「互換性が高い」レートが選ばれます。)
-
デバイスがそれ以外のレートの場合も、システムはどちらかにリサンプリングすべきです(バッテリー消費増加の可能性あり)。(例:16kHzなら48kHzに変換されることが期待されます。)
-
ブラウザがネイティブレートの強制利用をユーザーが選択できるUI(例えばフラグ設定)を提供することが期待されますが、この設定はAPIで公開されません。
-
AudioContextのコンストラクタで明示的に異なるレートを要求できることも仕様に含まれています。通常は要求されたレートでレンダリングし、出力デバイスに合わせてアップ/ダウンサンプルします。ネイティブでサポートされていればそのまま出力されます。例えばMediaDevicesの機能をユーザー操作で取得し、高いレートがサポートされていればそれを利用できます。
AudioContextの出力チャンネル数によるフィンガープリント化も可能です。maxChannelCountは2(ステレオ)に設定することを推奨します。ステレオは最も一般的なチャンネル数です。 -
-
この仕様は新しいスクリプト実行やロード機構を導入しますか?
いいえ。[HTML]仕様で定義されたスクリプト実行方式を利用します。
-
この仕様はオリジンがユーザーの位置情報へアクセスすることを許可しますか?
いいえ。
-
この仕様はオリジンがユーザーのデバイス上のセンサーへアクセスすることを許可しますか?
直接は許可しません。本仕様では音声入力については定義されていませんが、クライアントのオーディオ入力やマイクへのアクセスには適切な方法でユーザーの許可が必要です。通常は
getUserMedia()API経由で行われます。さらに、Media Capture and Streams仕様のセキュリティ・プライバシー考慮事項にも注意が必要です。特に、環境音の分析や一意な音を再生することで、ユーザーの居場所(部屋単位や複数ユーザー・デバイスの同時滞在など)を特定できる場合があります。オーディオ出力・入力の両方にアクセスできれば、ブラウザ内の分離されたコンテキスト間で通信を行うことも可能です。
-
この仕様はオリジンがユーザーのローカル計算環境の側面にアクセスすることを許可しますか?
直接は許可しません。要求されたサンプルレートはすべてサポートされ、必要であればアップサンプリングされます。Media Capture and Streamsを使ってMediaTrackSupportedConstraintsで対応サンプルレートを調査することは可能ですが、明示的なユーザー同意が必要です。これも微弱なフィンガープリント化につながる可能性はありますが、実際にはほとんどの民生・業務用デバイスは44.1kHz(CD用)または48kHz(DAT用)の標準レートを使用しています。リソースが限られるデバイスは11kHz(音声品質)を、高級機器は88.2, 96, 192kHzもサポートすることがあります。
すべての実装に48kHzなど単一の共通レートへのアップサンプリングを義務付けると、CPU負荷増加以外に利点がなく、ハイエンド機器に低レートを強制するとWeb Audioがプロ用途に不向きとされてしまいます。
-
この仕様はオリジンが他のデバイスへアクセスすることを許可しますか?
通常は他のネットワークデバイスへのアクセスを許可しません(例外:録音スタジオのDanteネットワークデバイスなどは専用ネットワークを使用)。必然的にユーザーのオーディオ出力デバイス(複数の場合もあり)へのアクセスは許可されます。
音声や音による制御デバイスでは、Web Audio APIが他デバイスの制御に用いられる場合があります。また、音響機器が超音波帯に敏感な場合は、可聴外で制御できる可能性もあります。これはHTMLでも<audio>や<video>要素経由で同様に可能です。一般的なサンプリングレートでは設計上、可聴外帯域はほとんどありません:
人間の聴覚限界は通常20kHzとされます。44.1kHzサンプリングではナイキスト限界が22.05kHzとなり、20~22.05kHz間は急峻なロールオフフィルタで強力減衰されます。
48kHzサンプリングでも20~24kHz帯域で減衰されます(パスバンドでの位相歪みを避けやすい)。
-
この仕様はオリジンがユーザーエージェントのネイティブUIの制御を行うことを許可しますか?
UIに音声アシスタントやスクリーンリーダーなどのオーディオ要素がある場合、Web Audio APIを使ってネイティブUIの一部を模倣し、攻撃をローカルシステムイベントに見せかけることが可能です。これはHTMLの<audio>要素でも同様です。
-
この仕様は一時的な識別子をWebに公開しますか?
いいえ。
-
この仕様はファーストパーティとサードパーティのコンテキストで動作の違いを設けますか?
いいえ。
-
この仕様はユーザーエージェントの「シークレットモード」において動作を変更しますか?
変更しません。
-
この仕様はユーザーのローカルデバイスにデータを永続化しますか?
いいえ。
-
この仕様は「セキュリティの考慮事項」と「プライバシーの考慮事項」セクションを持っていますか?
はい(本セクションです)。
-
この仕様はデフォルトのセキュリティ特性をダウングレードできますか?
いいえ。
9. 要件とユースケース
[webaudio-usecases]を参照してください。
10. 仕様コードの共通定義
このセクションでは、本仕様で用いられるJavaScriptコードの共通関数およびクラスについて説明します。
// 3次元ベクトルクラス class Vec3{ // 3つの座標から生成 constructor ( x, y, z) { this . x= x; this . y= y; this . z= z; } // 他のベクトルとの内積 dot( v) { return ( this . x* v. x) + ( this . y* v. y) + ( this . z* v. z); } // 他のベクトルとの外積 cross( v) { return new Vec3(( this . y* v. z) - ( this . z* v. y), ( this . z* v. x) - ( this . x* v. z), ( this . x* v. y) - ( this . y* v. x)); } // 他のベクトルとの差分 diff( v) { return new Vec3( this . x- v. x, this . y- v. y, this . z- v. z); } // ベクトルの大きさ(ノルム) get magnitude() { return Math. sqrt( dot( this )); } // スカラー倍したベクトルのコピーを取得 scale( s) { return new Vec3( this . x* s, this . y* s, this . z* s); } // 正規化したベクトルのコピーを取得 normalize() { const m= magnitude; if ( m== 0 ) { return new Vec3( 0 , 0 , 0 ); } return scale( 1 / m); } }
11. 変更履歴
12. 謝辞
本仕様はW3CAudio Working Groupによる共同作業です。
ワーキンググループの現メンバーおよび元メンバー、仕様への貢献者(執筆時点、アルファベット順):
Adenot, Paul (Mozilla Foundation) - 仕様共同編集者;
Akhgari, Ehsan (Mozilla Foundation);
Becker, Steven (Microsoft Corporation);
Berkovitz, Joe (招待専門家、Noteflight/Hal Leonard所属) - WG共同議長(2013年9月~2017年12月);
Bossart, Pierre (Intel Corporation);
Borins, Myles (Google, Inc);
Buffa, Michel (NSAU);
Caceres, Marcos (招待専門家);
Cardoso, Gabriel (INRIA);
Carlson, Eric (Apple, Inc);
Chen, Bin (Baidu, Inc);
Choi, Hongchan (Google, Inc) - 仕様共同編集者;
Collichio, Lisa (Qualcomm);
Geelnard, Marcus (Opera Software);
Gehring, Todd (Dolby Laboratories);
Goode, Adam (Google, Inc);
Gregan, Matthew (Mozilla Foundation);
Hikawa, Kazuo (AMEI);
Hofmann, Bill (Dolby Laboratories);
Jägenstedt, Philip (Google, Inc);
Jeong, Paul Changjin (HTML5 Converged Technology Forum);
Kalliokoski, Jussi (招待専門家);
Lee, WonSuk (Electronics and Telecommunications Research Institute);
Kakishita, Masahiro (AMEI);
Kawai, Ryoya (AMEI);
Kostiainen, Anssi (Intel Corporation);
Lilley, Chris (W3Cスタッフ);
Lowis, Chris (招待専門家) - WG共同議長(2012年12月~2013年9月、BBC所属);
MacDonald, Alistair (W3C招待専門家) — WG共同議長(2011年3月~2012年7月);
Mandyam, Giridhar (Qualcomm Innovation Center, Inc);
Michel, Thierry (W3C/ERCIM);
Nair, Varun (Facebook);
Needham, Chris (BBC);
Noble, Jer (Apple, Inc);
O’Callahan, Robert(Mozilla Foundation);
Onumonu, Anthony (BBC);
Paradis, Matthew (BBC) - WG共同議長(2013年9月~現在);
Pozdnyakov, Mikhail (Intel Corporation);
Raman, T.V. (Google, Inc);
Rogers, Chris (Google, Inc);
Schepers, Doug (W3C/MIT);
Schmitz, Alexander (JS Foundation);
Shires, Glen (Google, Inc);
Smith, Jerry (Microsoft Corporation);
Smith, Michael (W3C/Keio);
Thereaux, Olivier (BBC);
Toy, Raymond (Google, Inc.) - WG共同議長(2017年12月~現在);
Toyoshima, Takashi (Google, Inc);
Troncy, Raphael (Institut Telecom);
Verdie, Jean-Charles (MStar Semiconductor, Inc.);
Wei, James (Intel Corporation);
Weitnauer, Michael (IRT);
Wilson, Chris (Google,Inc);
Zergaoui, Mohamed (INNOVIMAX)